

خلاصه
با توسعه سریع فناوری اکتساب داده های تلفن همراه، حجم داده های مکانی موجود با سرعت فزاینده ای در حال رشد است. پردازش بیدرنگ دادههای مکانی بزرگ به یک مرز تحقیقاتی در زمینه سیستمهای اطلاعات جغرافیایی (GIS) تبدیل شده است. برای مقابله با این داده های بسیار پویا، هدف ما کاهش پیچیدگی زمانی به روز رسانی داده ها با اصلاح شاخص فضایی سنتی است. با این حال، الگوریتمها و ساختار دادههای موجود بر اساس گرههای کاری تکی هستند که قادر به مدیریت اعداد بالا و نرخ بهروزرسانی اشیاء متحرک نیستند. در این مقاله، ما یک شاخص فضایی توزیع شده بر اساس طوفان Apache، یک سیستم محاسباتی زمان واقعی توزیع شده منبع باز ارائه می کنیم. با استفاده از این رویکرد، ما محدوده و کارایی پرس و جو K-نزدیکترین همسایه (KNN) چهار شاخص فضایی را در یک مجموعه داده منفرد مقایسه می کنیم و روشی برای انجام اتصالات فضایی بین دو مجموعه داده متحرک معرفی می کنیم. به طور خاص، ما یک نمایه توزیع شده ثانویه برای جستارهای اتصال فضایی بر اساس شاخص پارتیشن شبکه می سازیم. در نهایت، مجموعهای از آزمایشها برای کشف عواملی که بر عملکرد شاخص توزیعشده تأثیر میگذارند و امکانسنجی شاخص توزیع پیشنهادی بر اساس طوفان ارائه میشوند. به عنوان یک برنامه کاربردی دنیای واقعی، این رویکرد در یک سیستم اطلاعاتی ادغام شده است که پشتیبانی تصمیم گیری ترافیک در زمان واقعی را فراهم می کند. ما یک نمایه توزیع شده ثانویه برای پرس و جوهای پیوستن فضایی بر اساس شاخص پارتیشن شبکه می سازیم. در نهایت، مجموعهای از آزمایشها برای کشف عواملی که بر عملکرد شاخص توزیعشده تأثیر میگذارند و امکانسنجی شاخص توزیع پیشنهادی بر اساس طوفان ارائه میشوند. به عنوان یک برنامه کاربردی دنیای واقعی، این رویکرد در یک سیستم اطلاعاتی ادغام شده است که پشتیبانی تصمیم گیری ترافیک در زمان واقعی را فراهم می کند. ما یک نمایه توزیع شده ثانویه برای پرس و جوهای پیوستن فضایی بر اساس شاخص پارتیشن شبکه می سازیم. در نهایت، مجموعهای از آزمایشها برای کشف عواملی که بر عملکرد شاخص توزیعشده تأثیر میگذارند و امکانسنجی شاخص توزیع پیشنهادی بر اساس طوفان ارائه میشوند. به عنوان یک برنامه کاربردی دنیای واقعی، این رویکرد در یک سیستم اطلاعاتی ادغام شده است که پشتیبانی تصمیم گیری ترافیک در زمان واقعی را فراهم می کند.
کلید واژه ها:
زمان واقعی ؛ پرس و جو فضایی ; اجسام متحرک ؛ طوفان آپاچی
1. معرفی
فن آوری های پیشرفته برای سنجش و محاسبات منجر به ایجاد مجموعه داده های عظیم متشکل از مسیر حرکت افراد و وسایل نقلیه شده است. توسعه تلفن های همراه و سایر دستگاه های GPS دستی و همچنین استفاده گسترده از خدمات مبتنی بر مکان (LBS) به کسب اطلاعات مکانی مربوط به اشیاء متحرک کمک کرده است. درک و تجزیه و تحلیل داده های در مقیاس بزرگ و پیچیده که اجسام متحرک را منعکس می کنند برای بهبود کیفیت زندگی و محیط های ساخته شده بسیار مهم است. به عنوان یکی از شاخههای مهم حوزه سیستمهای اطلاعات جغرافیایی (GIS)، فناوری GIS بلادرنگ به مطالعه جمعآوری، ادغام، مدیریت و تجزیه و تحلیل جریانهای دادههای مکانی در زمینههای بلادرنگ، مانند واکنش اضطراری و بلایا اختصاص دارد. نظارت بر.
دانشمندان در این حوزه نیاز به ذخیره، مدیریت، پرس و جو و تجسم حجم زیادی از داده های جریان پویا برای انجام وظایف اکتشافی و تحلیلی دارند. با این حال، آنها به دلیل کمبود قدرت محاسباتی کافی برای حمایت از مطالعات مبتنی بر داده های بزرگ با چالش های عظیمی روبرو هستند. پلتفرمی مورد نیاز است که پایگاههای داده مسیر مقیاسپذیر را با تجسم بصری و تعاملی و منابع محاسباتی سطح بالا یکپارچه کند [ 1]]. فقدان چنین ابزارهایی که به صراحت از تجزیه و تحلیل بصری تعاملی پشتیبانی می کنند، مانع از پیشرفت در استفاده کامل از داده های مسیری می شود که در دسترس هستند. برای دستیابی به این هدف، یک روش جستجوی فضایی سریع و قوی مورد نیاز است. یک شاخص فضایی مناسب برای اجسام متحرک می تواند برای کاهش زمان مصرف شده برای پرس و جوهای فضایی استفاده شود. با این حال، افزایش الزامات دقت و مقادیر فزاینده دادههای شی متحرک باعث افزایش متناظر در فراوانی بهروزرسانیهای دادههای مکانی میشود، در نتیجه چالشهای قابلتوجهی برای ایجاد نمایههای مکانی و اجرای بیدرنگ پرسوجوهای مکانی ایجاد میکند.
برای رفع این مشکل، فناوری های ابری به عنوان راه حلی جدید در حال ظهور هستند. به عنوان مثال، Hadoop MapReduce می تواند برای بهبود کارایی تحلیل همپوشانی چند ضلعی در برنامه های کاربردی داده های بزرگ فضایی (SBD) با ساخت یک شاخص فضایی شبکه ای استفاده شود [ 2 ]. S. شما و همکاران. روشی را با استفاده از یک چارچوب محاسباتی توزیع شده مبتنی بر حافظه برای رسیدگی به مشکل عملیات اتصال فضایی پیشنهاد کرد، زیرا نتایج محاسبات میانی Hadoop باید روی هارد دیسک ذخیره شود، که کارایی تحلیلی را به دلیل هزینه ورودی/خروجی بیش از حد دیسک کاهش میدهد [3 ]]. اگرچه این فناوریهای ابری مزایای محاسبات با کارایی بالا برای برنامههای GIS مبتنی بر SBD استاتیک را ارائه میدهند، اما برای مقابله با دادههای فضایی بسیار پویا به یک رویکرد جدید برای محاسبات ابری نیاز است.
تفاوت عمده بین داده های ایستا و داده های پویا این است که اولی در یک سیستم فایل توزیع شده به شکل بلوک های داده ذخیره می شود، در حالی که دومی از یک دستگاه حسگر خارجی با کمک میان افزار پیام گرا توزیع شده (DMOM) پخش می شود. سه تایی در مقایسه با SBD استاتیک، که مشکلات مربوطه عمدتاً بر روی مقدار داده متمرکز است، مشکلاتی که باید برای رسیدگی به دادههای پویا حل شوند، عمدتاً به بهروزرسانی سریع دادهها مربوط میشوند. داده هایی که به سرعت در حال تغییر هستند به عنوان داده های سریع شناخته می شوند [ 4 ].
برای ایجاد پایههای تجزیه و تحلیل بصری مؤثر مجموعه دادههای مسیر، این دستنوشته روشی را برای ایجاد یک شاخص فضایی توزیعشده بر روی یک چارچوب محاسبات ابری منبع باز، یعنی طوفان آپاچی، که نقش مهمی در آمار ترافیک بازی میکند، ارائه میکند [5 ] . و تشخیص ناهنجاری شبکه [ 6]. بر اساس این فناوری، ما پرس و جوی مکانی در زمان واقعی داده های سریع مکانی (SFD)، از جمله پرس و جو محدوده، پرس و جو KNN، و جست و جوی اتصال مکانی را انجام می دهیم. به طور خاص، ما یک نمایه ثانویه بر اساس شاخص پارتیشن شبکه ای برای پرس و جوهای پیوستن فضایی می سازیم. با توجه به نتایج تجربی، متوجه میشویم که استفاده از ساختار چهاردرختی برای شاخص ثانویه بهترین عملکرد را در محاسبات فضایی دارد. رویکرد پیشنهادی قابلیت مدیریت داده در مقیاس بزرگ و پشتیبانی از انواع مختلف پرس و جو را با استفاده از پلتفرمهای رایانش ابری ارائه میدهد. این تحقیق به جامعه تحقیقاتی کمک می کند تا مطالعات مرتبط با تحرک را به روشی کارآمدتر و سازنده تر انجام دهند.
به طور خلاصه، عمده ترین مطالب این مقاله به شرح زیر است:
-
ما یک شاخص توزیع شده بر اساس توپولوژی طوفان برای اجسام متحرک پیشنهاد می کنیم و سپس پرس و جوهای محدوده و پرس و جوهای KNN پیوسته (CKNN) را با استفاده از این شاخص توزیع شده پیاده سازی می کنیم. به این ترتیب، فشار ناشی از بهروزرسانی جریانهای داده در گرههای مستقل کاهش مییابد و بهروزرسانی بلادرنگ برای اجسام متحرک قابل تحقق است.
-
ما یک الگوریتم اتصال فضایی با استفاده از Storm برای جریان های جسم متحرک طراحی می کنیم. آزمایشها نشان میدهند که یک شاخص مبتنی بر چهاردرخت بهعنوان شاخص ثانویه برای پرسوجو و بهروزرسانی توزیعشده عملکرد بهتری از انواع دیگر دارد.
ادامه مقاله به شرح زیر تدوین شده است. بخش 2 پیشینه فناوری و کارهای مرتبط، از جمله پارادایم برنامه نویسی توپولوژی طوفان و شاخص های فضایی برای اجسام متحرک را بررسی می کند. در بخش 3 ، ما تنظیم مسئله را توصیف می کنیم، و معنایی انواع مختلف پرس و جوهای فضایی، مطابق با ویژگی های مجموعه داده های مکانی، به طور رسمی ارائه می شود. بخش 4 دو نوع رویکرد پرس و جو فضایی را بر اساس طوفان آپاچی پیشنهاد می کند. بخش 5 چندین مجموعه آزمایش را گزارش می دهد که برای کشف عوامل احتمالی مؤثر بر شاخص فضایی توزیع شده انجام شده است. بخش 6نتیجه گیری مطالعه و کاربردهای بالقوه این تحقیق را تشریح می کند.
2. کار و پیشینه مرتبط
2.1. کار مرتبط
2.1.1. شاخص فضایی برای اجسام متحرک
بسیاری از مطالعات قبلی پیشنهاد کردهاند که اصلاحات در شاخص فضایی سنتی میتواند به مقابله با ذخیرهسازی تغییر دادههای مکانی سیار کمک کند [ 7 ، 8 ]. با توجه به محتوای تحقیق و نوع دادههای مکانی، شاخصهای پیشنهادی را میتوان به دو نوع اصلی [ 9 ] طبقهبندی کرد: 1. شاخصهای فضایی برای ذخیرهسازی مسیر اجسام متحرک. اطلاعات زمانی و مکانی حرکت اجسام را می توان با گسترش ساختار داده های مکانی سنتی در بعد زمانی بیان کرد [ 10 ، 11 ، 12]. این شاخص ها بر اساس این فرضیه ساخته شده اند که همه داده ها از قبل ذخیره شده اند. در نتیجه، نمایههای فضایی که به این دسته تعلق دارند، مانند MV3R-tree، STR-Tree، و TB-Tree، هنوز برای جستجوهای فضایی بهینه شدهاند. 2. شاخص های فضایی برای ذخیره موقعیت های فعلی یا آینده نزدیک اجسام متحرک. برخی از مطالعات بر کاهش تعداد بهروزرسانیها با توصیف موقعیتهای اجسام متحرک بر حسب توابع خطی متمرکز شدهاند و تنها زمانی که مکان واقعی یک نقطه از مقدار نشاندادهشده توسط تابع با یک تابع فاصله میگیرد، فرآیندها را در پایگاههای اطلاعاتی مکانی-زمانی بهروزرسانی میکنند. آستانه خطای معین [ 13 ، 14 ، 15]. مطالعات دیگر نقاطی را بر اساس گزارشهای دورهای از آخرین موقعیت یک شی در مُهرهای زمانی جداگانه از تجهیزات جانبی در نظر گرفتهاند [ 9 ، 16 ، 17 ]. این مطالعات نشان دهنده تلاش هایی برای بهبود کارایی به روز رسانی داده ها برای انطباق با تغییرات مکرر در داده های پویا است.
علاوه بر این، پردازندههای چند هستهای، واحدهای پردازش گرافیکی (GPU) و سایر فنآوریهای موازی برای بهبود بهروزرسانی شاخص فضایی و کارایی پرسوجو برای محاسبات در افزایش مقدار داده به کار گرفته شدهاند [18 ، 19 ، 20 ] .
2.1.2. U-Grid و P-Grid
U-Grid (شبکه یکنواخت) یکی از انواع شاخص فضایی کارآمد به روز رسانی است که در یک رشته از حافظه اصلی به ویژه برای اجسام متحرک کار می کند. همانطور که در شکل 1 نشان داده شده است، U-Grid فضا را به شبکه های یکنواخت تقسیم می کند و هر سلول شبکه در آرایه یک اشاره گر به لیست پیوندی از سطل ها را ذخیره می کند که حاوی داده های شی [ 21 ] است. علاوه بر این، یک شاخص ثانویه را نیز ذخیره میکند که مستقیماً به موجودیتهای موجود در شبکه اشاره میکند، در یک جدول. هنگامی که داده ها به صورت محلی به روز می شوند، ایندکس به صورت پایین به بالا تازه می شود [ 22 ] که کارایی به روز رسانی را بهبود می بخشد. P-Grid (شبکه موازی)، روشی برای محاسبات فضایی موازی بر روی رشته های متعدد و کنترل همزمان، نیز برای بهبود عملکرد پیشنهاد شده است [ 18 ،23 ].
U-Grid و P-Grid به ترتیب اجرای ساختار داده و الگوریتم شاخص فضایی داده تلفن همراه را در حافظه اصلی و عملکرد پرس و جو و به روز رسانی فضایی با استفاده از multithreading روی پردازنده های چند هسته ای را امکان پذیر می کنند. با این حال، یک گره منفرد قادر به برآورده کردن الزامات این رویکردها در صورت مواجهه با افزایش تعداد داده های مکانی و افزایش فرکانس به روز رسانی به دلیل الزامات دقت بالاتر نیست.
2.1.3. پرس و جو فضایی در بستر توزیع شده
اخیراً، بسیاری از پلتفرمهای توزیعشده در برنامههای GIS برای بهبود پرسوجوی فضایی روی دادههای فضایی عظیم استفاده شدهاند [ 24 ]. Hadoop متداول ترین پلت فرم توزیع شده برای رسیدگی به پرس و جوهای فضایی است. در [ 25 و 26 ]، نویسندگان پرس و جوهای پیوستن فضایی و جستارهای پیوستن KNN را با استفاده از MapReduce پیاده سازی کردند. افسین آکدوگان و همکاران. کارایی پرس و جوهای موازی را با ساختن یک نمودار ورونوی توزیع شده به عنوان یک شاخص فضایی مسطح بهبود بخشید [ 27 ]. VegaGiStore یک معماری پردازش داده “شاخص سازی + MapReduce” را برای ارائه پردازش پرس و جوی فضایی کارآمد بر روی SBD و چندین پرس و جوی همزمان کاربر پیاده سازی می کند [ 28]]. علاوه بر این، بسیاری از پلتفرمهای پردازش فضایی مبتنی بر Hadoop، مانند Hadoop-GIS [ 29 ] و SpatialHadoop [ 30 ] پیشنهاد شدهاند. Hadoop-GIS برای پارتیشن بندی فضایی، پردازش موازی مبتنی بر پارتیشن بر روی MapReduce با استفاده از موتور جستجوی فضایی بلادرنگ (RESQUE) و نمایه سازی فضایی چند سطحی بهینه شده است. SpatialHadoop از یک زبان فضایی ساده سطح بالا، یک ساختار شاخص فضایی دو سطحی، اجزای فضایی اساسی ساخته شده در لایه MapReduce و سه عملیات فضایی اساسی: پرس و جوهای محدوده، پرس و جوهای KNN و اتصالات فضایی استفاده می کند. این پلتفرم ها ثابت کرده اند که ابزار قدرتمند GIS برای پرس و جوی فضایی هستند.
فراتر از موارد فوق، با توسعه پلتفرمهای محاسباتی حافظه توزیعشده کارآمد، تحقیقات بر روی افزایش کارآیی کوئریهای پیوستن فضایی با کمک Apache Spark متمرکز شده است. SpatialSpark [ 3 ] اتصالات فضایی مبتنی بر پارتیشن را با استفاده از Spark پیادهسازی میکند، که نسبت به رویکرد قبلی جهانیتر و کارآمدتر است. GeoSpark [ 31 ]، که از سه لایه اصلی تشکیل شده است – یک لایه اسپارک آپاچی، یک لایه RDD فضایی و یک لایه پردازش پرس و جو فضایی – Apache Spark RDD معمولی را برای پشتیبانی از اشیاء هندسی و مکانی با پارتیشن بندی و نمایه سازی داده ها گسترش می دهد. علاوه بر این، SparkGIS [ 32 ] و Simba [ 33] همچنین از پرس و جوی فضایی با کارایی بالا در SBD با کمک Apache Spark پشتیبانی می کند. با این حال، دادههای مکانی که توسط پلتفرمهای توزیعشده GIS فعلی مدیریت میشوند، دادههای استاتیک آفلاین هستند که روی هارد دیسک یا HDFS ذخیره میشوند. به دلیل تغییر سریع ماهیت دادههای تلفن همراه آنلاین، پیامهای بهروزرسانی ممکن است در هر زمانی از یک پایانه ارسال شوند. در نتیجه، ما نمی توانیم این داده ها را از قبل در چنین رسانه هایی ذخیره کنیم. در نتیجه، چارچوب پردازش دسته ای توزیع شده سنتی قابل اجرا نیست و باید یک رویکرد محاسبات ابری جدید ایجاد شود.
2.2. پیشینه فن آوری
2.2.1. چارچوب پردازش جریان توزیع شده
از سال 2010، زمانی که پلتفرم پردازش جریان توزیع شده منبع باز S4 توسط یاهو منتشر شد، پلتفرم های بسیاری مشابه اما دارای ویژگی های متفاوتی پیشنهاد شده اند. در میان آنها، Apache Storm، Yahoo S4، SparkStreaming و Samza نمونه هایی نماینده هستند. هر کدام ویژگی های خاص خود را دارند و تفاوت های اصلی بین آنها در جدول 1 خلاصه شده است .
Apache Storm به دلایل زیر برای استفاده در کار ما نسبت به سایر پلتفرمهای پخش توزیعشده انتخاب شد: (1) Spark Streaming به دادههای جریان به روشی میکرو دستهای آدرسدهی میکند. این دادههای جریانی بلادرنگ را در ریز دستههایی که از طریق برش زمانی ایجاد میشوند مدیریت میکند و پردازش جریان را به پردازش دستهای برشهای زمانی تبدیل میکند. در مقابل، طوفان دادهها را به صورت چند تایی مدیریت میکند، که برای بهروزرسانی مکرر دادههای تلفن همراه مناسبتر است. (2) در سمزا، هر مرحله در گردش کار یک موجودیت مستقل است و آن موجودیت ها با استفاده از کافکا به هم متصل می شوند. در طوفان، تمام مراحل توسط یک سیستم داخلی به هم متصل میشوند که منجر به تأخیر بسیار کمتری میشود و نیازمندیهای جستجوی بلادرنگ برای اجسام متحرک را برآورده میکند. (3) در مقایسه با S4، Storm قابلیت اطمینان بالاتر و یک روش مسیریابی انعطاف پذیرتر را ارائه می دهد.
به طور خلاصه، پرس و جو فضایی بلادرنگ برای اجسام متحرک به یک پلت فرم پردازش رویداد با سرعت بالا نیاز دارد که امکان محاسبات افزایشی را فراهم می کند. در نتیجه، Storm به دلیل ویژگیهای تاخیر کم، قابلیت اطمینان بالا و بلوغ، برای اهداف ما مناسبتر است.
2.2.2. پارادایم برنامه نویسی توپولوژی طوفان
توپولوژی یک گردش کار است که کل یک کار را در Storm توصیف می کند. توپولوژی طوفان یک گراف توپولوژی جهت دار است که شامل تعدادی مولفه از جمله دهانه ها و پیچ ها می شود [ 34 ]. دهانه واحدی است که جریان داده را تولید می کند و پیچ واحدی برای پردازش جریان داده است. هر تاپلی که توسط یک دهانه ایجاد می شود به روشی خاص به یک پیچ جریان می یابد. هر پیچ همچنین یک تاپل را به پیچ بعدی در یک گروه بندی مشخص می فرستد تا زمانی که تاپل در حافظه پایدار ذخیره شود.
Apache Storm راه های متعددی را برای گروه بندی جریان های داده ارائه می دهد. سه نوع اصلی گروه بندی در بحث ما در نظر گرفته می شود: ShuffleGrouping، FieldsGrouping و AllGrouping. هنگامی که جریان ها از طریق ShuffleGrouping گروه بندی می شوند، هر تاپل به طور تصادفی به یک نمونه پیچ ارسال می شود. FieldGrouping نوع دیگری از گروه بندی جریان است که در آن تاپل ها بر اساس یک فیلد خاص به نمونه های پیچ منتشر می شوند. جریان هایی که در این زمینه دارای ارزش یکسانی هستند تضمین شده است که به همان نمونه پیچ جریان می یابند. آخرین روش گروهبندی جریانی که روی آن تمرکز میکنیم AllGrouping است. در این روش، تمام تاپل ها در هر نمونه پیچ کپی شده و سپس به صورت موازی پردازش می شوند.
همه فرآیندها منابع مستقلی دارند که در یک توپولوژی Storm به هر گره توزیع می شوند. هر نمونه پیچ در هر زمان فقط یک تاپل را پردازش می کند، مگر اینکه نمونه پیچ خود رشته هایی ایجاد کند. به همین دلیل، یک برنامه Storm در شرایط عادی از نظر موضوعی ایمن است. قابل ذکر است که توپولوژی تراکنش Storm می تواند ترتیب محاسبات ارسالی را تضمین کند. با این حال، اگر پردازش آن با شکست مواجه شود، یک تاپل دوباره ارسال خواهد شد. برای ساده کردن مشکل، این مقاله چنین سناریوهایی را در نظر نمی گیرد.
3. تنظیم مسئله و اطلاعات معنایی
3.1. تنظیم مشکل
بر اساس ویژگی های اکثریت قریب به اتفاق سناریوهای کاربردی، ما اجسام متحرک را به عنوان نقاط گسسته در دو بعدی در نظر می گیریم | X | * | Y | فضا. | X | (| Y |) تعداد موقعیت های مختلف در بعد افقی (عمودی) را نشان می دهد. شاخص فضایی نقاطی را ذخیره می کند که هر کدام شامل یک ID و یک مقدار P ذخیره می شود ( X , Y ) که اطلاعات موقعیت مکانی شی متحرک مربوطه را نشان می دهد. هنگامی که فاصله بین موقعیت ذخیره شده و موقعیت واقعی بیشتر از تحمل Δ (Dist ( ذخیره P ( X 1, Y 1 ), P actua l ( X 2 , Y 2 )) > Δ Tolerance , که در آن Δ Tolerance فاصله تحمل است)، نقطه یک پیام به روز رسانی ( OID , Xold , Yold , Xnew , Ynew ) ارسال می کند که نشان دهنده حرکت نقطه از مکان ( Xold ، Yold ) به مکان ( Xnew ، Ynew )، به سرور مرکزی [ 35]. بر اساس این فرض، اگر هیچ پیام بهروزرسانی جدیدی ارسال نشده باشد، ایندکس در حال اجرا در سرور را بهعنوان جدیدترین داده بهروزرسانی شده در نظر میگیریم. تمام پرس و جوهای فضایی که در این مقاله مورد بحث قرار می دهیم بر اساس این شاخص هستند. اطلاعات مکانی هر جسم متحرک را می توان با یک تاپل 8 بایتی [ 36 ] نشان داد. بنابراین، کمتر از 8 گیگابایت فضای ذخیره سازی برای یک شاخص فضایی برای اجسام متحرک 100 متر مورد نیاز است، یعنی می توان از یک رایانه شخصی معمولی استفاده کرد. با این حال، سرعت به روز رسانی این داده های مکانی پویا ممکن است به 1 متر بر ثانیه یا حتی بیشتر برسد.
3.2. اطلاعات معنایی
پرس و جوهای فضایی را می توان به دو دسته طبقه بندی کرد. یکی از پرس و جوهای فضایی در یک مجموعه داده واحد تشکیل شده است. برای مثال پرس و جوهای محدوده و پرس و جوهای KNN در این دسته گنجانده شده اند. دسته دیگر شامل پرس و جوهای فضایی بین دو مجموعه داده است که روابط فضایی را در هر یک از مجموعه داده ها نادیده می گیرد، مانند اتصالات فضایی.
تعریف 1.
پرس و جوی محدوده: فرض کنید مجموعه معینی از نقاط متحرک وجود دارد که با O نمایش داده می شود و F(O) ویژگی های فضایی O را نشان می دهد. فرآیند بدست آوردن O’ به عنوان زیر مجموعه ای از O در محدوده ویژگی فضایی (F(O’ .min > F(Range).min ∩ F(O’).max < F(Range).max) به عنوان یک جستجوی محدوده تعریف می شود [ 19 ، 37 ، 38 ] .
تعریف 2.
پرس و جو KNN: فرض کنید مجموعه ای از نقاط متحرک وجود دارد که با O نشان داده شده و یک نقطه پرس و جو q مشخص شده است. یک پرس و جو KNN به فرآیند بدست آوردن زیرمجموعه ای از O اشاره دارد که شرایط زیر را برآورده می کند: 1. |O’|=K. 2. برای هر نقطه P خارج از O’ و هر نقطه P در داخل O’، فاصله بین P بیرون و q بزرگتر از فاصله بین P in و q است ( ∀ o ∈ (O-O’)، فاصله F (q,o > Max{F dist (q,o’)|o’ ∈ O’}) [ 17 ].
تعریف 3.
پرس و جو پیوستن فضایی محدوده: فرض کنید که دو مجموعه داده شده از نقاط متحرک، L و R وجود دارد. یک پرس و جو اتصال مکانی یک جفت نقطه P L ∈ L و نقطه P R ∈ R است که نابرابری F dist را برآورده می کند . P L , P R ) < d که در آن F dist (P L , P R ) به فاصله اقلیدسی بین P L و P R اشاره دارد و d ثابتی است که به نام فاصله اتصال (JD) شناخته می شود. اگر نتیجه پرس و جو برای برآوردن P L , P R ∈ نیز مورد نیاز باشدRange، سپس پرس و جو را پرس و جو پیوستن فضایی محدوده [ 39 , 40 , 41 ] می نامند .
تعریف 4.
پرس و جوی پیوسته: برخلاف پرس و جوهای فضایی ایستا، پرس و جوهای پیوسته [ 42 ، 43 ] را می توان به سه نوع دسته بندی کرد – پرس و جوهای متحرک روی اشیاء ثابت، پرس و جوهای ثابت روی اشیاء متحرک و پرس و جوهای متحرک روی اشیاء متحرک [ 44 ] . در تحقیق خود، ما نتیجه یک پرس و جو پیوسته را به عنوان یک سری عکس های فوری پیوسته از مجموعه ای از نتایج در نظر می گیریم که بر اساس موقعیت مکانی دائماً در حال تغییر اجسام متحرک مورد نظر محاسبه می شود. یعنی q’ = (I t1 (a 1 )، I t2 (a 2 )، …، I tn (a n ))، جایی که من ti (ai ) عکس فوری از مجموعه نتایج بدست آمده بر اساس شرط a i در زمان t i را نشان می دهد .
برای پرس و جوهای محدوده و جستارهای پیوستن فضایی محدوده همانطور که در بالا تعریف شد، یک محدوده مستطیلی متداول ترین نوع شرط پرس و جو است. بنابراین پیام بهروزرسانی مربوطه یک تاپلی به شکل ( X min ، Y min ، X max ، Y max ) است.
4. ساختار و الگوریتم های داده های مکانی در توپولوژی طوفان
4.1. الگوریتم توپولوژی طوفان برای یک مجموعه داده واحد
مفهوم کلی ایجاد توپولوژی طوفان برای یک مجموعه داده منفرد دارای سه مرحله است: 1. داده های مکانی بر اساس فیلد ID از طریق FieldsGrouping گروه بندی می شوند. 2. شاخص های توزیع شده در هر نمونه پیچ ایجاد می شوند و نتایج محلی با استفاده از الگوریتم پرس و جو فضایی حافظه اصلی به دست می آیند. 3. پس از خلاصه شدن نتایج محلی، نتیجه کلی برای مجموعه داده یکپارچه می شود.
همانطور که در شکل 2 نشان داده شده است، دو جزء خروجی وجود دارد، خروجی پرس و جو و خروجی به روز رسانی، که در آن جریان های داده در توپولوژی تولید می شوند. Update Spout به MOM خارجی متصل می شود و پیام های به روز رسانی را از دستگاه های تلفن همراه خارجی در زمان واقعی دریافت می کند. به این ترتیب اطلاعات مکانی به توپولوژی Storm در قالب یک جریان تاپل برای عملیات داده ارسال می شود. Query Spout کوئری های پیوسته را به چند تاپل تبدیل می کند که به شکل یک جریان وارد توپولوژی می شوند و یک پرس و جوی فضایی توزیع شده را انجام می دهد. در شکل 2، انتقال داده ها از Update Spout با خطوط چین نشان داده می شود زیرا پیام های به روز رسانی از طریق FieldsGrouping در خوشه ها گروه بندی می شوند. برای همه پیام های به روز رسانی مربوط به نقاط مکانی برای یک شناسه خاص، یک نمونه پیچ منحصر به فرد برای پذیرش آنها وجود دارد. در مقابل، انتقال دادهها از Query Spout با خطوط یکپارچه نشان داده میشود، زیرا پیامهای پرس و جو از طریق AllGrouping در هر نمونه پیچ الگوریتم اشیاء متحرک (MOAB) کپی میشوند. در ابتدا، MOAB ها دسته ای از مجریان با ساختار داده یکسان هستند که به طور تصادفی به هر گره کاری اختصاص داده می شوند. ساختار داده در هر پیچ نشان دهنده پارتیشنی از شاخص فضایی است که با شناسه نقطه جدا شده است و مقادیر نقطه محلی مربوطه را ذخیره می کند. این پیچ ها هسته کل توپولوژی هستند زیرا تمام عملیات به روز رسانی و پرس و جو در این پیچ ها به صورت موازی اجرا می شوند. هنگامی که وارد توپولوژی می شود، یک پیام چندگانه ارزیابی می شود تا مشخص شود که آیا یک پیام به روز رسانی است یا یک پیام پرس و جو. سپس بسته به نوع پیام، عملیات Query یا Update انجام می شود. یک نمونه MOAB پیاده سازی الگوریتم برای حرکت اجسام در حافظه اصلی است و به منابع قابل توجهی برای محاسبات فشرده آن نیاز دارد. سپس یک پیچ تجمیع نتیجه، راه حل کلی را از طریق تجمیع و محاسبه مجموعه نتایج از هر پارتیشن به دست می آورد. تاپل ها را از MOAB ها از طریق FieldsGrouping بر اساس فیلد QueryID بدست می آورد. سپس یک پرس و جوی محدوده فقط نیاز به اضافه کردن نتایج از هر پارتیشن مربوطه دارد.17 ]. در ابتدا، TopK برای هر پارتیشن محاسبه می شود. هنگامی که یک MOAB یک پیام به روز رسانی دریافت می کند، با توجه به تاپل به دست آمده و فاصله بحرانی محلی، مشخص می شود که آیا عملیات انبساط یا انقباض مورد نیاز است. اگر یک فاصله بحرانی محلی جدید ایجاد شود، مقایسه های بیشتر با فاصله بحرانی جهانی در پیچ تجمع نتایج انجام می شود.
از توپولوژی بالا، میتوانیم ببینیم که برای پرسوجوهای فضایی در یک مجموعه داده واحد، ساختار داده از یک مجری واحد به چندین مجری در یک یا چند گره کاری توزیع میشود. پیامهای بهروزرسانی برای اطلاعات مکانی بر اساس شناسههای نقطهای به این مجریها تخصیص مییابد، در نتیجه فشار بهروزرسانیهای مکرر و محاسبات و تحلیلهای بیدرنگ تعداد زیادی از اشیاء متحرک را کاهش میدهد. با این حال، برای تجزیه و تحلیل فضایی دو یا چند مجموعه داده، گروههای جریان مبتنی بر شناسه نقطه نمیتوانند تضمین کنند که نقاط همبسته فضایی به همان MOAB جریان مییابند. بنابراین، ما معمولاً پارتیشنهای شاخص فضایی را به عنوان پایه گروهبندی جریان ایجاد میکنیم.
4.2. اتصالات فضایی برای اجسام متحرک در توپولوژی طوفان
در این بخش، نحوه ساخت یک شاخص توزیع شده در توپولوژی طوفان برای پرس و جوهای پیوستن فضایی محدوده در اشیاء متحرک را شرح می دهیم. همانطور که در بالا ذکر شد، داده ها را نمی توان با شناسه نقطه در این مورد گروه بندی کرد. اگر شاخصی در دسترس نباشد، باید محاسبات زوجی برای نقاط دو مجموعه داده انجام شود. برای بهبود کارایی محاسباتی، یک شاخص شبکه برای پارتیشن بندی داده ها ساخته شده است. توپولوژی Storm برای اتصالات فضایی در شکل 3 نشان داده شده است .
4.2.1. ساختار داده ها
برای اجسام متحرک، فرکانس به روز رسانی داده ها معمولاً بسیار بیشتر از فرکانس پرس و جو است. استفاده از ساختار درختی برای سازماندهی داده ها، پیچیدگی زمانی فرآیند به روز رسانی را افزایش می دهد. در برخی موارد خاص، کل ساختار درخت، از پایین به بالا تغییر می کند. در نتیجه، یک شاخص شبکه یکنواخت یا شاخص شبکه سلسله مراتبی برای پارتیشن بندی فضایی طراحی شده است [ 21 ].
مشابه U-Grid، شاخص فضایی شبکه توزیع شده پیشنهادی از دو بخش تشکیل شده است. شاخص پارتیشن شبکه به عنوان شاخص اولیه استفاده می شود و تمام نقاط در هر سلول بیشتر در نمونه های پیچ مختلف ذخیره می شوند، همانطور که توسط یک شاخص ثانویه نشان داده شده است.
از آنجایی که نمونه های مختلف یک پیچ نمی توانند با یکدیگر ارتباط برقرار کنند، هر سلول نه تنها تمام نقاط آن سلول را ذخیره می کند، بلکه نقاط مربوط به آن سلول را نیز ذخیره می کند. همانطور که در شکل 4 نشان داده شده است ، کوتاه ترین فاصله بین یک نقطه P و یک سلول C با DistMin (P, C) نشان داده شده است . هنگامی که نقطه در سلول شبکه وجود دارد، DistMin (P, C) = 0. وسوسه انگیز است که نتیجه بگیریم که DistMin (P, C) فاصله عمودی از لبه سلول یا فاصله خطی از یکی از رئوس سلول است. وقتی DistMin (P, C) < JD، سلول و نقطه از نظر فضایی همبستگی دارند. تمام سلول هایی که از نظر فضایی با یک نقطه مشخص همبستگی دارند به عنوان سلول های آسیب دیده (ACs) آن نقطه تعریف می شوند. دایره ای با شعاع JD و نقطه P به عنوان مرکز آن به عنوان دایره بحرانی (CC) P تعریف می شود . از آنجایی که یک نقطه در نزدیکی یک راس سلول ممکن است چندین AC داشته باشد، کپی این نقاط در چندین سلول مختلف ذخیره می شود.
همانطور که در شکل 5 نشان داده شده است ، ساختار داده در هر سلول شبکه از دو مجموعه شاخص ثانویه و یک جدول نتیجه تشکیل شده است. شاخصهای ثانویه برای سازماندهی جداگانه دادههای مکانی از دو مجموعه داده استفاده میشوند. مجموعه نتایج (RS) برای ذخیره نتایج اتصال فضایی استفاده می شود. اگر شاخص ثانویه یک درخت R باشد، کل ساختار داده به عنوان D-Rtree (درخت R توزیع شده) نامیده می شود. به طور مشابه، شاخص های ثانویه بر اساس جدول هش و ساختارهای چهار درختی با D-HashTable و D-QuadTree مطابقت دارند. اگر RS یک آرایه دو بعدی است، A [Lm][Rn]دو نشانگر به دو نهاد، یکی از هر یک از دو شاخص ثانویه را نشان می دهد. یک مقدار تهی در این آرایه دو بعدی نشان می دهد که دو نقطه مربوط به شاخص ها با یک رابطه پیوستگی فضایی مطابقت ندارند. با بهره گیری از آرایه دو بعدی، می توانیم موجودیت های نقطه ای با پیچیدگی زمانی O(1) را هدایت کنیم. با این حال، در عمل، با توجه به اینکه تنها بخش کوچکی از تمام جفتهای نقاط از دو مجموعه داده در یک سلول یک رابطه پیوستگی فضایی را برآورده میکند، انتظار میرود که بروز بالای مقادیر صفر در آرایه دو بعدی منجر به اتلاف ذخیرهسازی شود. . بنابراین، یک جدول عنصر برای جایگزینی آرایه دوبعدی زمانی که تعداد کمی جفت تاپل اتصال فضایی وجود دارد، پیشنهاد میشود. برای یک جفت معین، هم OIDهای آنها و هم نشانگرهای آنها در یک ردیف از جدول عنصر ذخیره می شود.M*N ) که در آن M و N تعداد نقاط به هم پیوسته فضایی از هر یک از دو لایه هستند. هنگامی که M و N بیش از حد بزرگ نیستند، این ساختار داده می تواند به طور موثر فضای ذخیره سازی مورد نیاز را کاهش دهد و در عین حال کارایی پرس و جو قابل قبولی را حفظ کند.
4.2.2. بولت پارتیشن را به روز کنید
فرآیند به روز رسانی داده ها با استفاده از شاخص توزیع شده پیشنهادی توسط دو پیچ انجام می شود – پیچ پارتیشن به روز رسانی و پیچ شاخص فضایی توزیع شده. Update Spout پیام های به روز رسانی داده ها را به صورت چند تایی از فرم ( Id, OldX, OldY, newX, newY به بولت پارتیشن به روز رسانی ارسال می کند.) که حاوی اطلاعات مختصات قبل و بعد از به روز رسانی است. مشابه عملیات بهروزرسانی محلی و غیرمحلی در U-Grid، شاخص فضایی توزیعشده پیشنهادی دارای عملیات معادل بهروزرسانیهای AC معادل و متناقض است. هنگامی که سلول های آسیب دیده یک نقطه دقیقاً قبل و بعد از به روز رسانی نقطه برابر باشند، به روز رسانی یک به روز رسانی AC معادل است. در غیر این صورت، به روز رسانی یک به روز رسانی متناقض AC است. بولت پارتیشن Update نوع به روز رسانی را بر اساس تاپل ورودی قضاوت می کند. اگر یک بهروزرسانی AC معادل باشد، بولت پارتیشن Update فقط باید تاپلهایی را منتشر کند که شامل شناسه سلولی محاسبهشده، عملیات بهروزرسانی و موجودیت نقطهای به پیچ شاخص فضایی از طریق FieldsGrouping بر اساس فیلد CellId باشد. اگر بهروزرسانی متناقض AC است، پیچ شاخص فضایی باید ACهای مختلف را قبل و بعد از بهروزرسانی مقایسه کند.
| الگوریتم 1: UpdatePartBolt (Tuple UpdateMessage) | |
| 1. | OldCC←GetOldCC(JoinDistance, UpdateMessage.OldPoint) |
| 2. | NewCC←GetOldCC(JoinDistance, UpdateMessage.NewPoint) |
| 3. | OldACList←GetOldACList(شبکه، oldCC) |
| 4. | NewACList←GetNewACList(شبکه، newCC) |
| 5. | Foreach Cell در OldACList |
| 6. | اگر سلول در NewACList باشد |
| 7. | انتشار (CellId، UpdateOperation، Point) |
| 8. | دیگر |
| 9. | انتشار (CellId، DeleteOperation، Point) |
| 10. | پایان اگر-پس |
| 11. | end-foreach |
| 12. | سپس foreach Cell در NewACList |
| 13. | اگر در OldACList نیست پس |
| 14. | انتشار (CellID، DeleteOperation، Point) |
| 15. | پایان اگر-پس |
| 16. | end-foreach |
4.2.3. Query Partition Bolt
الگوریتم Query Partition Bolt نسبتا ساده است. ابتدا وسعت مستطیل پرس و جو به دست می آید و سلول های مربوطه (که توسط مستطیل پرس و جو قطع شده یا محتوی هستند) محاسبه می شوند. سپس، پیچ پارتیشن Query، CellIDها و روابط فضایی مربوطه (SR) را با مستطیل پرس و جو به پیچ شاخص فضایی توزیع شده از طریق FieldsGrouping بر اساس فیلد CellId منتشر می کند.
| الگوریتم 2: QueryPartBolt (Tuple QueryMessage) | |
| 1. | AffectQueryCellList←CalculateByRange(QueryMessage.Range) |
| 2. | Foreach Cell در AffectQueryCellList |
| 3. | اگر سلول Partial Covered توسط Range باشد |
| 4. | انتشار (CellID، SR: Intersect) |
| 5. | پایان اگر |
| 6. | اگر سلول TotalCovered توسط Range پس |
| 7. | انتشار (CellID، SR:Contain) |
| 8. | پایان اگر |
| 9. | end-foreach |
4.2.4. پیچ شاخص فضایی توزیع شده
پیچ شاخص فضایی توزیع شده هسته اصلی این توپولوژی برای پرس و جوهای اتصال فضایی است. این بر اساس مفهوم اجرای مشترک جهانی [ 45 ، 46 ] عمل می کند، و جریان های تولید شده توسط Query Partition Bolt و Update Partition Bolt در این پیچ جمع می شوند. ساختارهای داده، از جمله سلولهای مختلف با شاخصهای ثانویه مربوطه و جداول نتیجه اتصال فضایی، در یک جدول عنصر با یک شاخص هش در نمونههای پیچ ذخیره میشوند. تمام ساختارهای داده فوق در حافظه اجرا می شوند. در نتیجه، بازده پرس و جو داده و به روز رسانی نسبتاً بالا است زیرا هیچ عملیات I/O درگیر نیست.
یک به روز رسانی داده های شاخص توزیع شده در واقع از سه فرآیند [ 44 ] تشکیل شده است: 1. عملیات افزودن، به روز رسانی یا حذف را در نمایه های ثانویه که نقطه به روز رسانی در آن ذخیره می شود، انجام دهید. 2. عملیات پرس و جو را بر روی سایر شاخص های ثانویه انجام دهید. 3. نتایج پیوستن فضایی را به روز کنید. از توضیحات بالا می توان دریافت که هم کارایی به روز رسانی و هم کارایی پرس و جو باید با توجه به شاخص های ثانویه در نظر گرفته شود. همانطور که توسط مقایسه تجربی ارائه شده در بخش 5 نشان داده شده است، هنگامی که یک چهار درخت به عنوان شاخص ثانویه استفاده می شود، از شاخص های ثانویه بر اساس جدول هش و ساختارهای R-tree بهتر عمل می کند. برای یک تاپل کوئری معین، باید سلول های مربوطه را با توجه به شناسه تاپل تعیین کنیم. اگر یک سلول توسط مستطیل پرس و جو وجود داشته باشد، آنگاه همه جفت ها در RS به صورت چند تایی به پیچ بعدی گسیل می شوند. اگر یک سلول با مستطیل پرس و جو تقاطع پیدا کند، برای تعیین اینکه آیا یک جفت گسیل شده است یا خیر، قضاوت بیشتری لازم است.
| الگوریتم 3: SpatialIndexBolt (پیام چندگانه) | |
| 1. | Cell←FindCellByID(Message.CellId) |
| 2. | اگر از QueryPartBolt پیام دهید ، سپس |
| 3. | اگر Message.SR = حاوی آنگاه باشد |
| 4. | Foreach Pair در Cell.RS |
| 5. | جفت منتشر می کند |
| 6. | end-foreach |
| 7. | پایان اگر-پس |
| 8. | اگر Message.SR = متقاطع شود |
| 9. | Foreach Pair در Cell.RS |
| 10. | اگر Pair.Point1∈Message.Range& Pair.Point2∈Message.Range |
| 11. | جفت منتشر می کند |
| 12. | پایان اگر-پس |
| 13. | end-foreach |
| 14. | اگر از UpdatePartBolt پیام دهید ، سپس |
| 15. | foreach SpatialIndex در سلول.SI |
| 16. | اگر Message.Point∈SpatialIndex سپس |
| 17. | SpatialIndex.Operate(Message.Point، Message.Operate) |
| 18. | دیگر |
| 19. | PairList←SpatialIndex(Message.Point، JoinDistance) |
| 20. | به روز رسانی Cell.RS توسط PairList |
| 21. | پایان اگر-پس |
| 22. | end-foreach |
| 23. | پایان اگر-پس |
4.2.5. پیچ تجمع نتایج
در Results Aggregation Bolt، نتایج کلی نهایی از نتایج هر پرس و جوی شاخص توزیع شده جمع می شود. از آنجایی که چندین نسخه از موجودیتهای نقطهای که در نزدیکی رئوس شبکه قرار دارند ذخیره میشوند، جفتهای تکراری باید در این پیچ حذف شوند.
5. مطالعه تجربی
در این بخش، آزمایش هایی را با استفاده از توپولوژی شرح داده شده در بالا ارائه می کنیم و نتایج عملکرد آن را از نظر به روز رسانی داده ها و پرس و جو تجزیه و تحلیل می کنیم. در بخش 5.1 ، محیط نرمافزار و سختافزار، حجم کار و سایر آمادهسازیهای مربوط به آزمایشها را شرح میدهیم. از آزمایش های ارائه شده در بخش 5.2 ، مطالعه 1 آزمایشی است که برای بررسی طراحی شاخص توزیع شده برای یک مجموعه داده منفرد انجام شده است. U-Grid، UR-tree، R-tree و Grid انتخاب شدند و این آزمایش برای مقایسه کارایی آنها در پرس و جو و به روز رسانی فضایی با تعداد مختلف فرآیندهای Storm worker انجام شد. مطالعات 2 تا 4 آزمایشهای پرس و جو پیوستن فضایی دامنهای هستند که در آنها D-Rtree، D-HashTable و D-QuadTree به عنوان شاخص توزیعشده انتخاب شدند.
5.1. تنظیمات آزمایشی و بارهای کاری
تمام آزمایش ها با استفاده از هفت سرور به عنوان گره های کاری انجام شد که هر کدام دارای یک CPU 6 هسته ای Intel Xeon(R) 2.6 گیگاهرتز با 24 رشته سخت افزاری و 8 گیگابایت رم بودند. هر هفت گره از یک سیستم عامل لینوکس 64 بیتی (Suse Enterprise Server SP2) با آپاچی کافکا، یک سیستم پیام رسانی انتشار/اشتراک منبع باز توزیع شده، استفاده کردند که به عنوان DMOM خدمت می کند. سه تا از گره ها همچنین دارای Apache ZooKeeper برای هماهنگ کردن سیستم های توزیع شده بودند.
بارهای کاری توسط یک نسخه اصلاح شده از یک مولد ردیابی شی متحرک مبتنی بر شبکه منبع باز بر اساس الگوریتم برینخوف [ 47 ] تولید شد. داده های شبکه از استان جیانگ سو، چین به دست آمده است ( شکل 6 و شکل 7 را ببینید). در آزمایش تک مجموعه ای، 1 میلیون نقطه پویا با سرعت به روز رسانی 0.7 متر بر ثانیه به کافکا فرستاده شد و فوران طوفان تاپل ها را از کافکا به توپولوژی طوفان کشید. چهار شاخص ذکر شده در بالا با توجه به عملکرد آنها برای پرس و جوهای دامنه پیوسته، پرس و جوهای CKNN و نرخ به روز رسانی مقایسه شدند. در آزمایشهای پیوستن فضایی، نسبتهای بهروزرسانی فضایی را برای تعداد سلولهای شبکه و تعداد متفاوت اجسام متحرک مقایسه کردیم. برای پرس و جوهای پیوستن فضایی محدوده، به جای استفاده از تاپل های پرس و جو خالص، تاپل های به روز رسانی و تاپل های پرس و جو را در نسبت های مختلف به عنوان ورودی توپولوژی Storm مخلوط کردیم. برای این حجم های کاری، جستجوهایی با دامنه های مختلف انجام شد. جدول 2پارامترهای بارهای کاری را برای پرس و جوهای فضایی تک مجموعه ای نشان می دهد. بارهای کاری برای جستارهای اتصال فضایی محدوده شامل دو مجموعه از اشیاء متحرک تولید شده با استفاده از پارامترهای مشابه ارائه شده در جدول 3 می باشد . زمان آماده سازی در نتایج هیچ آزمایشی لحاظ نشده است.
5.2. نتایج تجربی
● مطالعه 1: تأثیر موازی پیچ طوفان بر پرس و جوهای فضایی برای یک مجموعه داده منفرد
در شکل 8 الف، بازده به روز رسانی شاخص ها در مقابل تعداد پیچ های موازی ترسیم شده است. شکل 8 b,c کارایی پرس و جوهای محدوده و CKNN را به ترتیب نشان می دهد. از شکل 8 الف، می توان نتیجه گرفت که هر چهار شاخص روند افزایش نرخ به روز رسانی را با درجه موازی فزاینده نشان می دهند. با این حال، هنگامی که شاخص اشباع شد، کارایی به روز رسانی دیگر افزایش نمی یابد و حتی شروع به کاهش می کند. این به این دلیل است که تعداد فرآیندهای به روز رسانی مختلف که وارد گره های کاری مختلف می شوند با افزایش موازی کاری افزایش می یابد و انتقال اطلاعات بین گره های کاری به زمان قابل توجهی نیاز دارد. شکل 8b,c نشان می دهد که افزایش موازی تأثیر نسبتاً کمی بر عملکرد پرس و جو فضایی دارد. افزایش موازی، تعداد اجسام متحرک را در هر اجراکننده پیچ شاخص فضایی توزیع شده کاهش می دهد و در عین حال ارتباطات بین گره ای بیشتری را ایجاد می کند. در نتیجه، اینکه افزایش درجه موازی تأثیر مثبت یا منفی دارد بستگی به این دارد که کدام عامل غالب باشد.
سه آزمایش زیر عوامل بالقوه مؤثر بر عملکرد اتصال فضایی را نشان می دهد. مطالعات 2 و 3 عملکرد به روز رسانی شاخص فضایی توزیع شده پیشنهادی را برای تعداد مختلف سلول های شبکه در دوره های زمانی مختلف بررسی می کنند. مطالعه 4 به این موضوع می پردازد که چگونه درصد تاپل های پرس و جو در حجم کاری بر توان عملیاتی کل کوئری های پیوستن فضایی تأثیر می گذارد. برای اطمینان از قابلیت اطمینان، حجم کاری وارد شده به کافکا برای آزمایشهای مختلف دقیقاً یکسان بود. نرخ بار ورودی 0.7 متر بر ثانیه بود که به اندازه کافی سریع بود تا اطمینان حاصل شود که سرعت خواندن داده ها به گلوگاه تبدیل نمی شود.
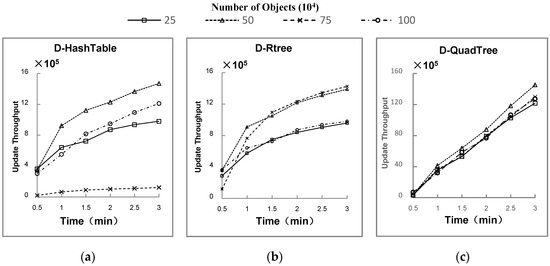
● مطالعه 2: تأثیر تعداد اجسام متحرک بر عملکرد اتصال فضایی
از شکل 9 a-c، میتوان نتیجه گرفت که کارایی بهروزرسانی D-Quadtree به طور قابلتوجهی بالاتر از شاخصهای دیگر است. به طور کلی، نرخ به روز رسانی سه شاخص در طول زمان، در ابتدا به سرعت و سپس به تدریج افزایش می یابد. از آنجا که نمایه ثانویه در ابتدا هیچ داده ای را ذخیره نمی کند، مرحله پرس و جو فرآیند به روز رسانی پیوستن فضایی در بخش 4.2 شرح داده شده است.در ابتدا زمان کمتری مصرف می کند. با این حال، با ذخیره شدن مقدار فزاینده ای از داده ها در شاخص ثانویه، کارایی به روز رسانی کاهش می یابد. تعداد اجسام متحرک تأثیر کمی بر شاخص D-Quadtree و تأثیر بیشتری بر D-Hashtable دارد. هنگامی که تعداد اشیاء 1 متر است، راندمان به روز رسانی بسیار کند است. برای D-Rtree، بازده به روز رسانی در ابتدا سریع است و سپس با افزایش تعداد اشیا کند می شود. زمانی که تعداد اشیاء 50 تا 75 متر باشد، سرعت بهروزرسانی سریعترین است.
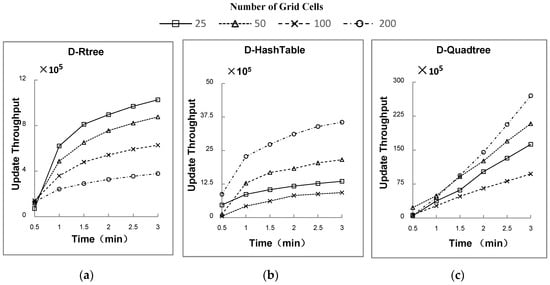
● مطالعه 3: تأثیر تعداد سلول های شبکه بر عملکرد اتصال فضایی
تأثیر تعداد سلولهای شبکه بر عملکرد اتصال فضایی دو ویژگی اصلی دارد: (الف) برای یک نقطه خاص، تعداد سلولهایی که شبکه به آنها تقسیم میشود و تعداد AC به طور مستقیم با هم مرتبط هستند. شبکه پارتیشن بندی شده به AC های بیشتری منجر می شود که تکرار نقاط را افزایش می دهد و کارایی به روز رسانی را کاهش می دهد. (ب) یک شبکه با پارتیشن های بزرگتر منجر به عدم تعادل در تعداد اجسام متحرک در سلول های شبکه مختلف می شود. سلول ها در مناطق متراکم تر از شبکه جاده ها نقاط بیشتری را ذخیره می کنند. همانطور که شکل 10 a-c نشان می دهد، برای D-Rtree، اولین عامل غالب است، در حالی که برای D-HashTable، عامل دوم غالب است. هر دو عامل بر روی D-Quadtree تاثیر دارند.
● مطالعه 4: تأثیر اندازه محدوده پرس و جو بر عملکرد اتصال فضایی
شکل 11 a-c نشان می دهد که افزایش نسبت پیام به روز رسانی/پرس و جو باعث افزایش در مجموع خروجی اتصال فضایی، به ویژه برای D-Quadtree و D-HashTable می شود. این نشان می دهد که فرآیند پرس و جو تاخیر کمتری نسبت به فرآیند به روز رسانی دارد. علاوه بر این، اندازه محدوده پرس و جو بزرگتر تأثیر کوچکتر اما همچنین مثبتی بر توان عملیاتی دارد. این به این دلیل است که Storm یک پیام پرس و جو برای هر نمونه پیچ ارسال می کند. وقتی دامنه پرس و جو زیاد باشد، تعداد مجریان فعال بیشتر می شود.
6. نتیجه گیری و کاربردها
تحرک افراد و وسایل نقلیه در حال حرکت عنصر اساسی جامعه بشری است. بررسی الگوها و روند حرکت انسان و وسیله نقلیه می تواند درک پویایی های منطقه ای و شهری را ارتقا دهد و نیروهای محرک اجتماعی-اقتصادی اساسی در کار را آشکار کند [ 1]]. در این مقاله، ما شاخصهای فضایی توزیعشده را برای ذخیرهسازی SFD با تغییر سریع برای اجسام متحرک بر اساس طوفان آپاچی توسعه میدهیم. به طور خاص، دو راه حل مختلف پیشنهاد شده است، یکی برای پرس و جوهای فضایی در یک مجموعه داده واحد و دیگری برای پرس و جوهای پیوستن فضایی محدوده بین دو مجموعه داده. چندین عامل که ممکن است بر کارایی شاخص توزیع شده تأثیر بگذارد از طریق آزمایشها مورد بررسی قرار گرفت. آزمایشها نشان میدهند که یک شاخص چهار درختی بدون در نظر گرفتن تعداد اشیاء متحرک، تعداد پارتیشنهای شبکه یا اندازه محدوده پرس و جو، کارایی محاسباتی بهتری را ارائه میدهد. برای چنین ارزیابی، ما باید نه تنها کارایی پرس و جو بلکه کارایی به روز رسانی شاخص ثانویه را نیز در نظر بگیریم. یک شاخص چهاردرختی بهترین عملکرد را به دلایل زیر نشان می دهد: 1. عملیات افزودن و حذف در یک درخت R ممکن است منجر به ادغام یا تقسیم گره های برگ شود. در برخی موارد خاص، ارتفاع درخت افزایش یا کاهش می یابد که منجر به راندمان پایین در به روز رسانی درخت R می شود. 2. یک پرس و جو فضایی باید از طریق همه عناصر در جدول هش تکرار شود. در نتیجه، کارایی پرس و جو مکانی یک شاخص جدول هش نسبتاً پایین است. در مقایسه با این دو ساختار شاخص، ساختار چهاردرختی کارایی محاسباتی بهتری را هم در عملیات پرس و جو و هم در عملیات بهروزرسانی ارائه میدهد و در نتیجه عملکرد بهتری را نشان میدهد. کارایی پرس و جو مکانی شاخص جدول هش نسبتاً پایین است. در مقایسه با این دو ساختار شاخص، ساختار چهاردرختی کارایی محاسباتی بهتری را هم در عملیات پرس و جو و هم در عملیات بهروزرسانی ارائه میدهد و در نتیجه عملکرد بهتری را نشان میدهد. کارایی پرس و جو مکانی شاخص جدول هش نسبتاً پایین است. در مقایسه با این دو ساختار شاخص، ساختار چهاردرختی کارایی محاسباتی بهتری را هم در عملیات پرس و جو و هم در عملیات بهروزرسانی ارائه میدهد و در نتیجه عملکرد بهتری را نشان میدهد.
از نظر تئوری، برای تغییر سریعتر داده های مکانی، می توانیم تعداد گره های کاری را افزایش دهیم تا منابع محاسباتی بیشتری ارائه کنیم. با این حال، زمانی که تمام نقاط سینماتیکی به یک پارتیشن شبکه تخصیص داده شوند، هر پیام تاپلی به یک مجری منفرد ارسال می شود. بنابراین، در آینده، نحوه رسیدگی به بارهای کاری بیش از حد در روش پیشنهادی مبتنی بر طوفان را بررسی خواهیم کرد. علاوه بر این، چارچوبهای پخش توزیعشده در حال ظهور، مانند Apache Flink، حیاتی قوی و چشمانداز توسعه عالی را نشان میدهند (به ویژه، Apache Flink توان عملیاتی بسیار بهتری نسبت به Apache Storm با تأخیر نسبتاً کم ارائه میدهد). کار تحقیقاتی آینده ما بر مقایسه این چارچوب ها با Storm و انتخاب بهترین پلت فرم های توزیع شده برای برنامه های GIS متمرکز خواهد بود.
این رویکرد پرس و جو مکانی یک جزء مهم سمت سرور در سیستم اطلاعات وب ما برای نظارت بر ترافیک در زمان واقعی است. این سیستم با موفقیت برای نظارت بر ترافیک و برنامه ریزی وسایل نقلیه اعمال شده است و پشتیبانی تصمیم گیری ترافیکی را برای دولت فراهم می کند ( شکل 12 را ببینید ). ابزار ما کاوش آسان داده های مسیر بزرگ را تسهیل کرده است. روش توسعهیافته با کمک به محققان در مقابله با چالشهای ناشی از دادههای بزرگ، پیشرفتها را در طیف گستردهای از کاربردها ممکن میسازد.
منابع
- هوانگ، ایکس. ژائو، ی. یانگ، جی. ژانگ، سی. مک.؛ Ye, X. TrajGraph: یک رویکرد تحلیل بصری مبتنی بر نمودار برای مطالعه مرکزیت شبکه شهری با استفاده از داده های مسیر تاکسی. Vis. محاسبه کنید. نمودار. 2016 ، 22 ، 160-169. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- وانگ، ی. لیو، ز. لیائو، اچ. بهبود عملکرد محاسبات همپوشانی چند ضلعی GIS با MapReduce برای پردازش داده های بزرگ فضایی. خوشه. محاسبه کنید. 2015 ، 18 ، 507-516. [ Google Scholar ] [ CrossRef ]
- شما، SJ; Zhang، LG پردازش درخواست پیوستن فضایی در مقیاس بزرگ در ابر. در مجموعه مقالات کنفرانس بین المللی IEEE در کارگاه های مهندسی داده، سئول، کره، 13 تا 17 آوریل 2015.
- داده های سریع: مرحله بعدی پس از داده های بزرگ. در دسترس آنلاین: http://www.infoworld.com/article/2608040 (در 13 سپتامبر 2016 قابل دسترسی است).
- Stojanović، DN; Turanjanin, J. پردازش مسیرهای بزرگ و جریان های داده توییتر با استفاده از Apache STORM. در مجموعه مقالات دوازدهمین کنفرانس بین المللی مخابرات در ماهواره، کابل و خدمات رادیویی مدرن (TELSIKS)، نیش، صربستان، 14 تا 17 اکتبر 2015.
- ژائو، اس. چندراشکار، م. Lee, Y. سیستم تشخیص ناهنجاری شبکه در زمان واقعی با استفاده از یادگیری ماشین. در مجموعه مقالات یازدهمین کنفرانس بین المللی طراحی شبکه های ارتباطی قابل اعتماد، کانزاس سیتی، MO، ایالات متحده آمریکا، 24-27 مارس 2015.
- Iwerks، GS; صامت، ح. اسمیت، KP Maintenance K-nn و جستارهای پیوستن فضایی در نقاط متحرک پیوسته. ACM Trans. سیستم پایگاه داده 2006 ، 31 ، 485-536. [ Google Scholar ] [ CrossRef ]
- Park, K. جستجوی دادههای مکانی مقیاسپذیر کارآمد برای سرویسهای تلفن همراه آگاه از مکان. J. Inf. علمی مهندس 2015 ، 31 ، 165-178. [ Google Scholar ]
- کوون، دی. لی، اس. نمایه سازی موقعیت فعلی اجسام متحرک با استفاده از درخت R به روز رسانی تنبل. در مجموعه مقالات سومین کنفرانس بین المللی مدیریت داده های تلفن همراه، سنگاپور، سنگاپور، 8-10 ژانویه 2002.
- Pfoser، D.; جنسن، CS; تئودوریدیس، ی. رویکردهای رمانی به نمایه سازی مسیرهای جسم متحرک. در مجموعه مقالات بیست و ششمین کنفرانس VLDB، قاهره، مصر، 10-14 سپتامبر 2000.
- خو، جی. روده، RH; ژنگ، ی. TM-RTree یک نمایه در مورد اشیاء متحرک عمومی برای جستجوهای محدوده. Geoinformatica 2015 ، 19 ، 487-524. [ Google Scholar ] [ CrossRef ]
- تائو، ی. پاپادیاس، دی. Sun, J. درخت TPR: یک روش دسترسی مکانی-زمانی بهینه برای پرس و جوهای پیش بینی. در مجموعه مقالات بیست و نهمین کنفرانس بین المللی پایگاه های داده بسیار بزرگ، برلین، آلمان، 9 تا 12 سپتامبر 2003.
- تائو، ی. Papadiasa, D. MV3R-Tree: A Spatio-Temporal Access Method for Timestamp and Interval Queries Dept ; دانشگاه هنگ کنگ: هنگ کنگ، چین، 2000. [ Google Scholar ]
- جنسن، CS; لین، دی. Ooi، BC جستجو و به روز رسانی کارآمد B ± درختی نمایه سازی اشیاء متحرک. در مجموعه مقالات 30 کنفرانس VLDB، تورنتو، ON، کانادا، 31 اوت تا 3 سپتامبر 2004.
- شلتنیس، اس. جنس، CS; لوتنگر، ST نمایه سازی موقعیت اجسام متحرک پیوسته. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD در مدیریت داده ها، نیویورک، نیویورک، ایالات متحده آمریکا، 16-18 می 2000.
- چن، ن. باید؛ چن، جی. نمایه سازی تطبیقی اجسام متحرک با فرکانس های به روز رسانی بسیار متغیر. جی. کامپیوتر. علمی تکنولوژی 2008 ، 23 ، 998-1014. [ Google Scholar ] [ CrossRef ]
- وو، دبلیو. Tan, K. ISEE: نظارت مستمر K نزدیکترین همسایه بر روی اجسام متحرک. در مجموعه مقالات نوزدهمین کنفرانس بین المللی مدیریت پایگاه داده های علمی و آماری، Banff، AB، کانادا، 9-11 ژوئیه 2007.
- Šidlauskas، D.; راس، کالیفرنیا؛ Jensen، CS نمایه سازی موازی در سطح موضوع بارهای کاری شی متحرک فشرده به روز رسانی. در مجموعه مقالات دوازدهمین سمپوزیوم بین المللی پایگاه های داده مکانی و زمانی، مینیاپولیس، MN، ایالات متحده، 24-26 اوت 2011.
- دنگ، ز. وو، ایکس. Wang, L. پردازش موازی پرس و جوهای پیوسته پویا در جریان جریان داده. IEEE Trans. توزیع موازی سیستم 2015 ، 82 ، 834-846. [ Google Scholar ] [ CrossRef ]
- شیونگ، دی. استراتژیهای سنگ مرمر، DF برای تجزیه و تحلیل فضایی بلادرنگ با استفاده از رایانههای SIMD موازی گسترده: برنامهای برای تحلیل جریان ترافیک شهری. بین المللی جی. جئوگر. Inf. سیستم 1996 ، 10 ، 769-789. [ Google Scholar ] [ CrossRef ]
- Šidlauskas، D.; شلتنیس، اس. جنسن، درختان CS یا شبکهها؟ نمایه سازی اجسام متحرک در حافظه اصلی در مجموعه مقالات هفدهمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سیاتل، WA، ایالات متحده آمریکا، 4-6 نوامبر 2009.
- لی، ام ال. هسو، دبلیو. Jense، CS پشتیبانی از بهروزرسانیهای مکرر در R-trees: رویکردی از پایین به بالا. در مجموعه مقالات بیست و نهمین کنفرانس بین المللی پایگاه های داده بسیار بزرگ، برلین، آلمان، 12 تا 13 سپتامبر 2003.
- Šidlauskas، D. شلتنیس، اس. جنسن، CS پردازش به روز رسانی شدید شی متحرک و بارهای کاری پرس و جو در حافظه اصلی. VLDB J. 2014 ، 23 ، 817-841. [ Google Scholar ] [ CrossRef ]
- شما، اس. ژانگ، جی. Le, G. پردازش پرس و جو فضایی در ابر: تجزیه و تحلیل انتخاب های طراحی و مقایسه عملکرد. در مجموعه مقالات کنفرانس بین المللی کارگاه های پردازش موازی، پکن، چین، 16 تا 19 اوت 2015.
- ژانگ، اس. هان، جی. Liu, Z. SJMR: پیوستن فضایی موازی با MapReduce در خوشهها. در مجموعه مقالات کنفرانس بین المللی IEEE در مورد محاسبات خوشه ای و کارگاه ها، نیواورلئان، لس آنجلس، ایالات متحده آمریکا، 31 اوت تا 4 سپتامبر 2009.
- لو، دبلیو. شن، ی. Chen, S. پردازش کارآمد k نزدیکترین همسایه با استفاده از MapReduce. Proc. VLDB Enddow. 2012 . [ Google Scholar ] [ CrossRef ]
- آکدوگان، ا. Demiryurek، U. بناییکشانی، ف. شهابی، سی. پردازش پرس و جوهای مکانی مبتنی بر ورونوی با MapReduce. در مجموعه مقالات دومین کنفرانس بین المللی IEEE در زمینه فناوری و علم رایانش ابری، ایندیاناپولیس، ایندیانا، IN، ایالات متحده آمریکا، 15-19 نوامبر 2010.
- ژونگ، YQ؛ هان، JZ; Zhang، TY به سمت پردازش پرس و جو فضایی موازی برای داده های فضایی بزرگ. در مجموعه مقالات سمپوزیوم پردازش موازی و توزیع شده کارگاه ها و انجمن دکتری، شانگهای، چین، 21 تا 25 مه 2012.
- آجی، ع. وانگ، اف. Vo, H. Hadoop-GIS: یک سیستم ذخیره سازی داده های مکانی با کارایی بالا بر روی MapReduce. Proc. VLDB Enddow. 2013 . [ Google Scholar ] [ CrossRef ]
- الدوی، ا. Mokbel، MF نمایش SpatialHadoop: یک چارچوب MapReduce کارآمد برای دادههای مکانی. Proc. VLDB Enddow. 2013 . [ Google Scholar ] [ CrossRef ]
- یو، جی. وو، جی. Sarwat، M. نمایشی از GeoSpark: یک چارچوب محاسباتی خوشه ای برای پردازش داده های فضایی بزرگ. در مجموعه مقالات کنفرانس بین المللی IEEE در مهندسی داده، هلسینکی، فنلاند، 16-25 مه 2016.
- بیگ، اف. مهروترا، م. Wang, F. SparkGIS: مقایسه و ارزیابی کارآمد نتایج الگوریتم در مطالعات تجزیه و تحلیل تصویر بافتی. در کارگاه های آموزشی VLDB ؛ Big-O(Q) و DMAH: Waikoloa، HI، USA، 2015; صص 134-146. [ Google Scholar ]
- زی، دی. لی، اف. لی، جی. سیمبا: کارآمد در تجزیه و تحلیل فضایی حافظه. در مجموعه مقالات کنفرانس بین المللی مدیریت داده ها در سال 2016، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 26 ژوئن تا 1 ژوئیه 2016.
- آلن، ST; یانکوفسکی، م. پاتیرانا، ص. مفاهیم اولیه طوفان. In Storm Applied: Strategies for Real-Time Event Processing ; انتشارات منینگ: جزیره پناهگاه، نیویورک، ایالات متحده آمریکا، 2015; ص 17-29. [ Google Scholar ]
- موراتیدیس، ک. پاپادیاس، دی. Hadjieleftheriou، M. پارتیشن بندی مفهومی: یک روش کارآمد برای نظارت مداوم نزدیکترین همسایه. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD در مدیریت داده ها، نیویورک، ایالات متحده آمریکا، 13-16 ژوئن 2005.
- دیتریچ، جی. بلونسچی، ال. Salles, MA Movies: نمایه سازی اجسام متحرک با عکسبرداری از تصاویر شاخص. Geoinformatica 2011 ، 15 ، 727-767. [ Google Scholar ] [ CrossRef ]
- بنتلی، جی ال. فریدمن، JH ساختارهای داده برای جستجوی محدوده. کامپیوتر ACM. Surv. 1979 ، 11 ، 397-409. [ Google Scholar ] [ CrossRef ]
- وانگ، اچ. Zimmermann, R. پردازش پرس و جوهای محدوده مبتنی بر مکان پیوسته بر روی اجسام متحرک در شبکه های جاده ای. IEEE Trans. دانستن مهندسی داده 2011 ، 23 ، 1065-1078. [ Google Scholar ] [ CrossRef ]
- توحید، ف. هاینس، تی. Ailamaki، A. Thermal-join: یک اتصال فضایی مقیاس پذیر برای بارهای کاری پویا. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD در مدیریت داده ها، ملبورن، استرالیا، 9 تا 16 ژوئیه 2015.
- کورال، ا. تورس، ام. Vassilakopoulos، M. پردازش پیوند پیش بینی بین مناطق و جسم متحرک. در مجموعه مقالات دوازدهمین کنفرانس اروپای شرقی، پوری، فنلاند، 5 تا 9 سپتامبر 2008.
- بخش، جی دی. او، ز. Zhang, R. تقاطع پیوسته بلادرنگ با استفاده از واحدهای پردازش گرافیکی به مجموعههای بزرگی از اجسام متحرک میپیوندد. VLDB J. 2014 ، 23 ، 965-985. [ Google Scholar ] [ CrossRef ]
- کلاشینکف، دی وی؛ پرابهاکار، اس. Hamrusch, SE ارزیابی حافظه اصلی پرس و جوهای نظارت بر روی اشیاء متحرک. توزیع کنید. پایگاه های داده موازی 2004 ، 15 ، 117-135. [ Google Scholar ] [ CrossRef ]
- گدیک، بی. Liu, L. MobiEyes: پردازش توزیع شده پرس و جوهای متحرک پیوسته روی اشیاء متحرک در یک سیستم تلفن همراه. در پیشرفت در فناوری پایگاه داده-EDBT 2004 ; Springer: Philadelphia, PA, USA, 2004; جلد 2992، صص 67-87. [ Google Scholar ]
- ژانگ، آر. Qi، JZ; Lin, D. یک الگوریتم بسیار بهینه برای پیوستن پرس و جوهای تقاطع پیوسته بر روی اشیاء متحرک. VLDB J. 2012 ، 21 ، 561-586. [ Google Scholar ] [ CrossRef ]
- موکبل، MF; Xiong، X. Aref, WG PLACE: یک پردازشگر پرس و جو برای مدیریت جریان های داده های مکانی-زمانی بلادرنگ. در مجموعه مقالات سی امین کنفرانس بین المللی پایگاه های داده بسیار بزرگ، تورنتو، ON، کانادا، 29 اوت تا 3 سپتامبر 2004.
- Xiong، XP؛ موکبل، MF; عارف، WG SEA-CNN: پردازش مقیاس پذیر جستارهای پیوسته k-نزدیکترین همسایه در پایگاه داده های مکانی-زمانی. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی مهندسی داده، توکیو، ژاپن، 5 تا 8 آوریل 2005.
- Brinkhoff, T. چارچوبی برای تولید اشیاء متحرک مبتنی بر شبکه. Geoinformatica 2002 ، 6 ، 153-180. [ Google Scholar ] [ CrossRef ]
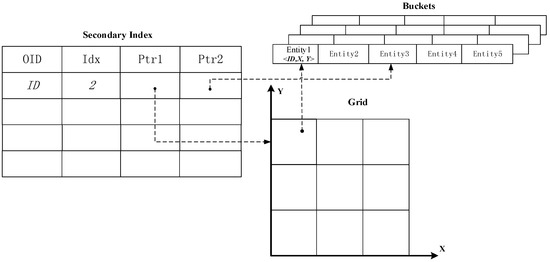
شکل 1. شاخص U-Grid.
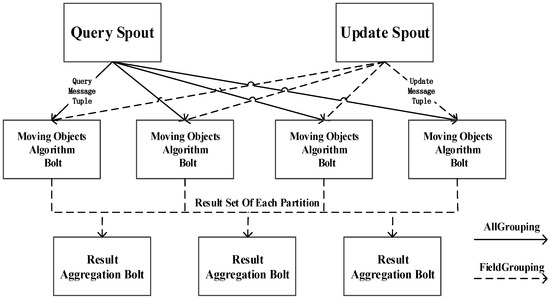
شکل 2. توپولوژی طوفان برای یک مجموعه داده منفرد.

شکل 3. توپولوژی طوفان برای اتصالات فضایی.

شکل 4. پارتیشن بندی سلول های شبکه ای.
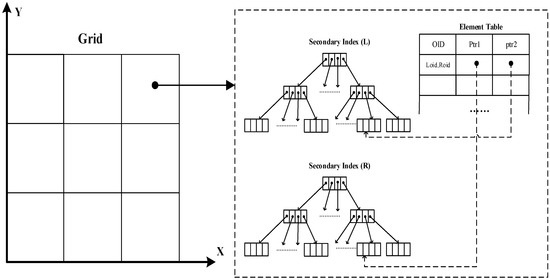
شکل 5. شاخص توزیع شده.
شکل 6. شبکه جاده ای در استان جیانگ سو.
شکل 7. اجسام متحرک در شبکه راه.

شکل 8. عملکرد یک مجموعه داده با درجات مختلف موازی. ( الف ) نرخ به روز رسانی شاخص فضایی. ( ب ) نرخ پرس و جو از پرس و جو محدوده; ( ج ) نرخ پرس و جو از پرس و جو KNN.
شکل 9. اثر تعداد اشیاء بر توان عملیاتی به روز رسانی اتصال فضایی. ( الف ) به روز رسانی توان عملیاتی D-Hahtable. ( ب ) توان عملیاتی به روز رسانی D-Rtree. ( ج ) توان عملیاتی به روز رسانی D-Quadtree.
شکل 10. تأثیر بر توان عملیاتی به روز رسانی اندازه های مختلف پارتیشن در طول زمان. ( الف ) به روز رسانی توان عملیاتی D-Rtree. ( ب ) توان عملیاتی به روز رسانی D-Hahtable. ( ج ) توان عملیاتی به روز رسانی D-Quadtree.

شکل 11. اثرات اندازه های مختلف محدوده پرس و جو برای نسبت های مختلف پرس و جو تحت یک حجم کاری مختلط. منطقه جستجو به صورت تصادفی مکانی قابل دسترسی است. ( الف ) به روز رسانی و عملیات پرس و جو از D-Hahtable. ( ب ) به روز رسانی و عملیات پرس و جو از D-Quadtree. ( ج ) به روز رسانی و عملیات پرس و جو از D-Rtree.

شکل 12. رابط وب سیستم نظارت بر ترافیک بلادرنگ ما، که تصویری از اجسام متحرک را نشان می دهد که هر دقیقه به روز می شوند، در حالی که شاخص فضایی هر ثانیه به روز می شود. ( الف ) نظارت بر ترافیک در زمان واقعی؛ ( ب ) جستجوی نزدیکترین همسایه.

جدول 1. مقایسه چارچوب های پردازش جریان توزیع شده.
جدول 2. پیکربندی بار کاری برای پرس و جوهای فضایی تک مجموعه داده.
جدول 3. پیکربندی بار کاری برای پرس و جوهای پیوستن فضایی محدوده.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر