1. معرفی
تجزیه و تحلیل چند مقیاسی هم در بینایی انسان و هم در بینایی کامپیوتری بسیار مهم است [ 1 ، 2 ، 3 ، 4 ، 5 ، 6 ]. این تا حدی به این دلیل است که ویژگی های مهم ممکن است در طیف وسیعی از مقیاس ها، بسته به فاصله تا ناظر یا دوربین، وجود داشته باشد. از نظر مفهومی، تجزیه و تحلیل چند مقیاسی تصویر را بر روی یک فضای با ابعاد بالاتر یا پشته ای از تصاویر ترسیم می کند. پس مشکل شناسایی مهم ترین یا برجسته ترین ویژگی ها در این فضای مقیاس است [ 5 ، 7 ، 8 ].
روشهای چند مقیاسی مبتنی بر فیلترهای مورفولوژیکی متصل [ 1 ، 2 ، 9 ، 10 ، 11 ] در انواع مختلف در کاربردهای سنجش از راه دور، هم در پردازش چند باندی و هم در تصاویر در مقیاس خاکستری (معمولاً پانکروماتیک) مفید بودهاند. در مورد اول، درختان آلفا [ 12 ] یا سایر سلسله مراتب پارتیشن بیشتر مورد استفاده قرار می گیرند [ 13 ، 14 ]، در حالی که در روش دوم مبتنی بر بازسازی یا فیلترهای ویژگی رایج ترین است. محبوبترین این روشها در مقیاس خاکستری، نمایههای مورفولوژیکی دیفرانسیل (DMPs) [ 7 ، 8 ]، نمایههای ناحیه متفاوت [ 15] هستند.، 16 ]، و تعمیم آنها نمایه های ویژگی متفاوت (DAPs) [ 17 ، 18 ].
در این مقاله، ما بر روی این روشهای اخیر در مقیاس خاکستری تمرکز خواهیم کرد و پیشرفتهای اخیر در این زمینه، به ویژه، انطباق الگوریتمها برای محاسبه موازی نمایشهای چند مقیاسی را مرور خواهیم کرد. علاوه بر این، تعدادی بهبود در الگوریتمهای موجود معرفی میکنیم و عملکرد محاسباتی و بار حافظه این روشها را با هم مقایسه میکنیم. یک عامل مشترک که قابلیت استفاده هر دو DMP و DAP را محدود می کند، فقدان ابزار کارآمد برای مدیریت حجم عظیم داده های ورودی است. بار حافظه و زمان محاسبه روش های تکراری استاندارد به صورت خطی با توجه به اندازه تصویر ورودی و تعداد مقیاس های استفاده شده افزایش می یابد [ 8 ، 16 ].
DMPs [ 7 ، 8] مجموعه ای از فضاهای ترازوی کلاه بالایی هستند که بر اساس بازشوها با بازسازی هستند. به طور سنتی، آنها را می توان با انجام یک سری فرسایش با مجموعه ای از عناصر ساختاری (SEs)، محاسبه بازسازی ژئودزیکی از هر یک از این تصاویر نشانگر، و در نهایت در نظر گرفتن تفاوت بین بازسازی های متوالی، که در آن بازسازی کوچکترین، محاسبه کرد. SE از نسخه اصلی کم می شود. بنابراین، پشتهای از تصاویر به دست میآید که نشاندهنده فضایی در مقیاس بالاست، که هر یک جزئیات روشن از یک محدوده عرض معین را ذخیره میکند، که توسط عرض SE استفاده میشود. برای به دست آوردن جزئیات تاریک، پس از وارونه کردن تصویر ورودی، فرآیند مشابهی انجام می شود. DMP ها طیف وسیعی از کاربردها در زمینه علوم زمین و سیاره شناسی، علوم کامپیوتر، مهندسی، فیزیک و نجوم و ریاضیات دارند. در زمینه سنجش از دور، آنها بیشتر برای مرحله استخراج ویژگی تصویر و فیلتر کردن یا اهداف انتخاب اطلاعات تصویر مبتنی بر دانش استفاده می شوند. خروجی DMP ها معمولاً به عنوان ورودی فرآیندهای طبقه بندی نظارت شده یا بدون نظارت استفاده می شود. محاسبه DMP ها به روش کلاسیک شامل چندین عملیات بازسازی است که هزینه بر است. که در [8 ، نشان داده شد که فرآیند را می توان با (i) استفاده از یک Max-Tree [ 19 ] برای محاسبه تمام بازسازی ها در یک پاس واحد، و (ii) استفاده از پردازش موازی بر اساس الگوریتم در [ 20 ] تسریع کرد. .
نمایه های ویژگی دیفرانسیل [ 15 ، 17 ، 21 ] تعمیم DMP ها بر اساس فیلترهای ویژگی متصل [ 22 ] هستند. به جای یک سری از بازشوها، از یک سری فیلترهای ویژگی استفاده می شود که گرانولومتری اندازه یا شکل را تشکیل می دهند [ 23 ، 24 ]. باز هم، تفاوت بین تصاویر فیلتر شده متوالی برای ایجاد یک پشته از تصاویر حاوی کلاس های اندازه یا شکل مختلف از جزئیات گرفته می شود، و دوباره، این دسته از تصاویر معمولاً در یک تصویر چند باندی خلاصه می شوند. نمونهای از مجموعههای DAP در سطح مقطع فضای باز کردن سطح کلاه بالا و فضای بسته شدن فضای مقیاس کلاه پایین در شکل 1 نشان داده شده است..
کاربردهای DAP ها متفاوت است و نمونه های معمولی طبقه بندی صحنه [ 18 ، 25 ]، تقسیم بندی تصویر [ 26 ، 27 ]، خصوصیات الگوی شهری [ 28 ، 29 ، 30 ، 31 ، 32 ] و تجسم سکونتگاه انسانی [ 33 ] است. توجه داشته باشید که هر دو DAP و DMP را می توان به صورت متناوب به عنوان مجموعه ای از تصاویر در مقیاس های مختلف یا به عنوان یک تصویر برداری در نظر گرفت که در آن هر پیکسل با بردار مقادیر مربوط به پاسخ در هر نوار فیلتر مورفولوژیکی نشان داده می شود.
CSL یک مدل کلی مناسب برای نمایش فشرده طرحواره تجزیه تصویر چند مقیاسی، از جمله DMPs و DAP است. این شامل سه لایه شطرنجی است که از تجزیه چند مقیاسی تصویر به دست آمده است. مقیاس مشخصه (C)، برجستگی (S) و سطح بندی (L). اجزای اصلی CSL (C, S) ابتدا در [ 34 ] معرفی شدند که از یک طرح طبقهبندی ساخته شده با یک طبقهبندیکننده نظارت عصبی از اجزای متصل به تصویر (که مناطق یا اشیاء نیز نامیده میشوند) و ویژگیهای آنها ساخته شدهاند. متعاقبا، آنها در [ 7 ، 35 ] برای اهداف تقسیم بندی کلی تصویر ارائه شدند . در [ 36]، مفهوم DMP با نام “باز شدن نهایی” دوباره معرفی شد و همان عناصر C، S از DMP با نام پارامترهای حداکثر باقیمانده v و اندازه q از دهانه منتهی به این باقیمانده ارائه شد. با نامگذاری اخیر، آنها برای تقسیم بندی مناطق متن در تصاویر دیجیتال در [ 37 ] و وظایف تشخیص شکل در [ 38 ] اعمال شده اند . در [ 33 ، 39]، طرح CSL با معرفی صریح توصیفگر تراز (L) تکمیل شد و برای کاهش ابعاد و هزینه ذخیرهسازی/تخصیص حافظه تجزیه چند مقیاسی تصویر اعمال شد. به طور خاص، نیاز به انجام وظایف پردازش تصویر بدون نظارت گسترده در یک رویکرد بدون مدل آماری، به عنوان مثال ، اجتناب از خوشهبندی بر اساس توزیع آماری ویژگیهای DMP/DAP، مورد توجه قرار گرفت. داده های تصویری تجزیه شده و توصیف شده توسط طرحواره CSL می تواند برای استخراج و انتخاب اطلاعات تصویر مبتنی بر دانش [ 39 ، 40 ]، طبقه بندی نظارت شده و بدون نظارت [ 41 ، 42 ، 43 ، 44] استفاده شود.] و اهداف تجسم [ 39 ، 45 ].
در مورد DAPها مانند DMPها، مشکلات مربوط به بار حافظه و زمان محاسبه را می توان با استفاده از Max-Trees و Min-Trees دوگانه آنها برطرف کرد [ 19 ]. یکی از مشکلات کلیدی نیاز به ذخیره کل فضای مقیاس یا فیلد برداری است که از تعداد تصاویری که مقیاس وجود دارد تشکیل شده است. در مورد DMP، این امر اجتناب ناپذیر است، زیرا تصاویر نشانگر برای هر مقیاس مورد نیاز است. از این نشانگرها می توان برای ذخیره خود فیلد برداری DMP مانند [ 8 ] استفاده مجدد کرد. در مورد DAP، اگر تنها چیزی که نیاز داریم خلاصه ای مانند نمایش CSL باشد، می توان از این امر اجتناب کرد. گسترش کار بر روی محاسبه سریع گرانولومتری های متصل و طیف های الگو در [ 24 ]، در [ 16 ]، طرحی پیشنهاد شد که به عنوانتجزیه منطقه صفت . به گره های درختی بسته به مقدار ویژگی مولفه تصویری که با آن مرتبط است، یک برچسب منطقه منحصر به فرد اختصاص داده می شود. سازماندهی گره های درختی در مناطق نیازمند یک عبور واحد از ساختار درختی است و حداقل وابستگی به طول امضا دارد. این طرح روش یک گذر نامیده می شود . مقایسه عملکرد در برابر سایر روش های تکراری در [ 16 ] ارائه شده است.
جدای از برچسب گذاری ناحیه، روش یک گذر را می توان برای محاسبه مجموعه ای از ویژگی هایی که مدل CSL را تشکیل می دهند، اعمال کرد [ 33 ]. فیلد برداری DAP، به عنوان مثال ، مجموعه ای از DAP ها که کل تصویر ورودی را به حساب می آورند، با نگاشت هر جزء تصویر به صفحه DAP مربوطه استخراج می شود. دو برابر تعداد آستانههای مشخصهای که تجزیه را تعیین میکنند، وجود دارد. مدل به طور مستقیم از دو ساختار داده مبتنی بر درخت و بدون نیاز به صادرات فیلدهای برداری DMP/DAP محاسبه می شود.
با تکیه بر روشی موازی برای محاسبه ساختار Max-Tree بر روی پلتفرم های حافظه مشترک، در این مقاله، یک نسخه همزمان جدید از روش یک پاس ارائه شده است. این الگوریتم بر اساس الگوریتم همزمان برای پروفایلهای مورفولوژیکی دیفرانسیل [ 8 ] است، که به نوبه خود، بر اساس الگوریتم موازی حافظه مشترک برای درختهای مؤلفه از [ 20] بود.]. ما الگوریتم موجود برای DMP را با DAP تطبیق میدهیم و این را بیشتر توسعه میدهیم تا الگوریتمی تولید کنیم که کل میدان برداری را محاسبه نمیکند، بلکه فقط دادههای مورد نیاز برای محاسبه مدل CSL را محاسبه میکند. دومی هم سریعتر و هم از نظر حافظه کارآمدتر است. این کد می تواند تصاویر را تا 4 گیگاپیکسل کنترل کند، محدودیت اعمال شده توسط GeoTIFF، و پردازش روی یک ماشین 64 هسته ای سرعت بیش از 3.5 گیگاپیکسل در دقیقه را نشان می دهد. بسط دادن به حجمهای بزرگتر فقط به استفاده از فهرستبندی 64 بیتی به جای 32 بیتی آرایههای مورد استفاده، و البته فرمت ورودی متفاوت نیاز دارد.
ساختار این مقاله بدین شرح است. بخش 2 یک نمای کلی از فیلترهای مشخصه متصل، پروفایل های ویژگی دیفرانسیل و مدل CSL ارائه می دهد. در بخش 3 ، ساختار Max-Tree مجدداً مورد بررسی قرار می گیرد و پس از آن شرح مختصری از روش یک گذر ارائه می شود. الگوریتم همزمان پیشنهادی برای محاسبه DAPها و باندهای CSL در بخش 4 ارائه شده است . مجموعه ای از آزمایش های زمان بندی بر روی تصاویر ماهواره ای با وضوح بسیار بالا در بخش 5 آمده است . بحث و تحلیل نتایج تجربی در بخش 6 و خلاصه ای از کار همراه با نتیجه گیری در بخش 7 ارائه شده است .
2. پس زمینه
2.1. فیلترهای ویژگی
فیلترهای ویژگی [ 22 ] فیلترهای مورفولوژیکی هستند که برای حفظ یا حذف ساختارهای تصویر متصل بر اساس ویژگی ها یا ویژگی های آنها طراحی شده اند . این ویژگیها میتوانند هر چیزی باشند، از اندازههای ساده مانند مساحت [ 46 ] تا اعداد شکل [ 23 ، 24 ] تا بردارهای ویژگی. در حالت باینری، آنها به سادگی تمام اجزای پیش زمینه یا پس زمینه متصل را بر اساس یک معیار انتخاب، بر اساس مقادیر ویژگی و برخی از مرزهای تصمیم حذف می کنند.
اجازه دهید E دامنه تعریف یک تصویر در مقیاس خاکستری باشد [ خطای پردازش ریاضی ]�:�→آر، و اجازه دهید محتوای اطلاعاتی f در مجموعه ای از مناطق مسطح [ 11 ] سازماندهی شود که اتحاد آنها برابر با E است . یک منطقه مسطح F مجموعه ای متصل از حداکثر وسعت است. از پیکسل های ایزوتون تشکیل شده است که در مسیر به هم متصل هستند. با توجه به یک نکته [ خطای پردازش ریاضی ]ایکس∈�، F به طور رسمی به صورت زیر تعریف می شود:
که در آن [ خطای پردازش ریاضی ]�(ایکس⇝�)نشان دهنده مسیری از x به y است . مجموعه مناطق مسطح تصویر پارتیشنی از E را تشکیل می دهد . برای معرفی مفهوم نظم با توجه به شدت تصویر، نوع کلی تری از مؤلفه تعریف شده است. یک جزء اوج که با یک نقطه مشخص شده است [ خطای پردازش ریاضی ]ایکس∈�در سطح h توسط:
جزء قله ای که با یک منطقه مسطح منطبق است حداکثر منطقه ای نامیده می شود.
فیلترهای متصل اپراتورهای متصل را در نظر می گیرند که به جای پیکسل های مجزا به اجزای پیک دسترسی دارند. به طور خاص، فیلترهای مشخصه در مقیاس خاکستری [ 22 ] تبدیلهای تصویری هستند که محتوای اطلاعاتی را با حذف مؤلفههای پیک که در یک معیار ویژگی شکست میخورند، کاهش میدهند. فیلترهای ویژگی فاقد قدرت هستند، به عنوان مثال، تکرار مجدد اپراتور نتیجه را بیشتر تغییر نمی دهد. فیلترهای ویژگی عملگرهای حفظ لبه هستند و میتوانند بر اساس ترتیب شدتی که با آن پیکربندی شدهاند و ویژگیهای مشخصهای که استفاده میکنند دستهبندی شوند. فیلتری که اجزای روشن را بهعنوان اطلاعات پیشزمینه در مقابل پسزمینه تاریک رفتار میکند، بهعنوان نشان داده میشود [ خطای پردازش ریاضی ]��آو در صورتی که معیار در حال افزایش یا نازک شدن باشد، باز شدن صفت نامیده می شود. در مقابل، فیلتری که اجزای تاریک را به عنوان اطلاعات پیشزمینه در مقابل پسزمینهای روشن در نظر میگیرد، به عنوان نشان داده میشود [ خطای پردازش ریاضی ]��آو اگر معیار در حال افزایش باشد یا در غیر این صورت ضخیم شدن صفت نامیده می شود. عبارت A نوع صفت و λ آستانه صفت را مشخص می کند.
2.2. نمایه های ویژگی های دیفرانسیل و مدل CSL
یک جفت فیلتر ویژگی دوگانه را در نظر بگیرید [ خطای پردازش ریاضی ](��آ،��آ)و یک بردار آستانه صفت [ خطای پردازش ریاضی ]�→=[�من]با [ خطای پردازش ریاضی ]من∈[0،1،2،…،من–1]و [ خطای پردازش ریاضی ]�0=0. برای هر فیلتر، اجازه دهید [ خطای پردازش ریاضی ]ΔΠیک نمایه دیفرانسیل باشد که به آن یک امتیاز داده می شود [ خطای پردازش ریاضی ]ایکس∈�به صورت زیر تعریف شده است:
برای فیلتر [ خطای پردازش ریاضی ]��آ، و
برای [ خطای پردازش ریاضی ]��آ. هر نمایه یک بردار پاسخ مرتبط با x است . [ خطای پردازش ریاضی ]ΔΠ(��آ)مثبت نامیده می شود و [ خطای پردازش ریاضی ]ΔΠ(��آ)بردار پاسخ منفی به ترتیب. الحاق این دو که با ⊔ مشخص می شود، a است [ خطای پردازش ریاضی ]2×(من–1)بردار طولانی، به نام مشخصات ویژگی دیفرانسیل [ 17 ] x :
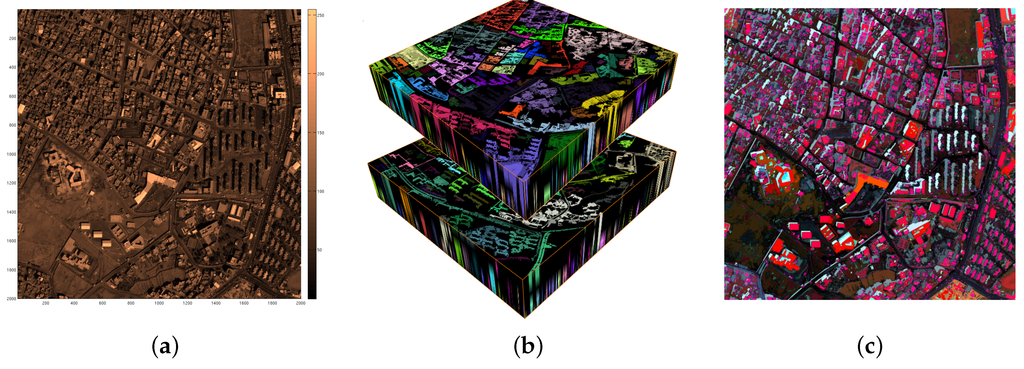
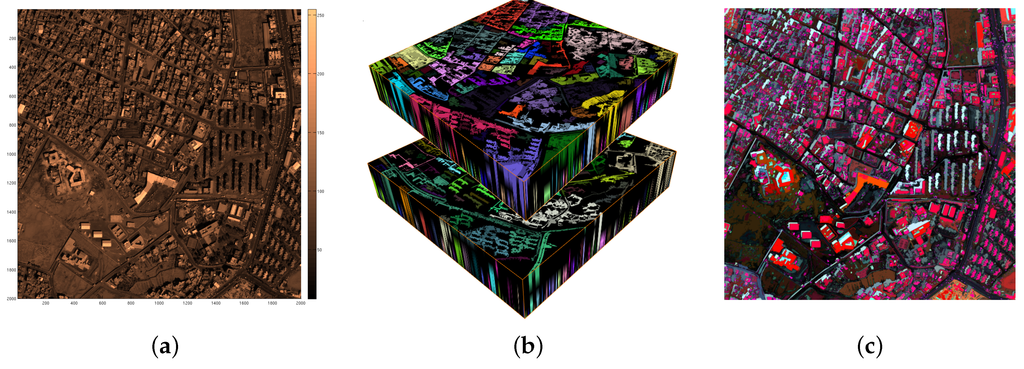
مجموعه DAPهای محاسبه شده از دامنه کامل تعریف تصویر، میدان برداری DAP نامیده می شود. یک نمونه i از یک میدان برداری DAP یک تصویر متفاوت با توجه به عملگر داده شده است و صفحه DAP نامیده می شود. شکل 2 یک مثال را نشان می دهد. تصویر (الف) بخش مسکونی شهر صنعا در یمن را نشان می دهد. این یک تصویر پانکروماتیک Quickbird در سال 2009 ©DigitalGlobe, Inc.، با وضوح فضایی 0.6 متر در طرح نقشه رنگی است. تصویر (ب) فیلد برداری DAP را نشان می دهد که از (a) محاسبه شده است. تجسم در (ب) از برچسبهای رنگی اجزای متصل سه بعدی استفاده میکند. ولوم بالا که در (ب) تنظیم شده است، فضای باز شدن ترازو کلاه بالایی را نشان میدهد و مجموعه حجم پایینتر، فضای ترازو کلاه پایین را نشان میدهد.
مقادیر شدید یک ورودی در هر یک از دو بردار پاسخ 0 و است [ خطای پردازش ریاضی ]ساعتحداکثربا دومی مقدار حداکثر شدت تصویر. یک نکته را در نظر بگیرید [ خطای پردازش ریاضی ]ایکس∈�و اجازه دهید [ خطای پردازش ریاضی ]دساعت̌��Λبالاترین مقدار در بردار پاسخ مثبت DAP باشد [ خطای پردازش ریاضی ](ایکس)، یعنی :
که در مقیاس i داده شده است . توجه داشته باشید که i ممکن است لزوما منحصر به فرد نباشد، به عنوان مثال ، پاسخ مشابهی را می توان در مقیاس های دیگر نیز مشاهده کرد. با این حال، از آنجایی که مرتبط ترین اطلاعات تجزیه در صفحات مرتبط با مقیاس های کوچکتر وجود دارد، پارامتر:
شناسایی می شود. به این معنا که، [ خطای پردازش ریاضی ]من^��Λکوچکترین مقیاسی است که در آن بردار پاسخ مثبت از [ خطای پردازش ریاضی ]DAP(ایکس)حداکثر پاسخ را ثبت می کند. پارامتر مقیاس معادل برای بردار پاسخ منفی به طور مشابه تعریف می شود:
آنها به ترتیب به عنوان ویژگی باز و بسته شدن چند مقیاسی شناخته می شوند . MOC و MCC.
طرح برچسب گذاری زیر را بر اساس ماکزیمم دو بردار پاسخ در نظر بگیرید:
-
محدب، اگر [ خطای پردازش ریاضی ]دساعت̌��Λ(ایکس)>دساعت̌��Λ(ایکس)،
-
مقعر، اگر [ خطای پردازش ریاضی ]دساعت̌��Λ(ایکس)<دساعت̌��Λ(ایکس)،
-
مسطح، اگر [ خطای پردازش ریاضی ]دساعت̌��Λ(ایکس)=دساعت̌��Λ(ایکس).
این تاکسونومی معادل آنهایی است که بر اساس تجزیههای مورفولوژیکی و پروفیل مساحتی به ترتیب در [ 7 ] و [ 16 ] پیشنهاد شدهاند. مجموعه ای از برچسب ها به عنوان انحنای محلی سطح تابع سطح خاکستری نامیده می شود، جایی که مقدار مشخصه دامنه فضایی محلی را تعیین می کند.
یک طرح تقسیم بندی چند باندی بصری به این صورت است:
این طرح تقسیم بندی چند سطحی را می توان با جایگزین کردن پارامتر مقیاس با یک سطح خاکستری ثابت به یک تقسیم بندی سه باندی ساده تر کرد.
مقیاس برنده از مقایسه در معادله (9) به عنوان مقیاس مشخصه یا به سادگی مشخصه C نامیده می شود . پاسخ مرتبط با مقیاس برنده، برجسته بودن S نامیده می شود و با نشان داده می شود [ خطای پردازش ریاضی ]دساعت¯. این دو، که با سطح L پیکسل x پس از تکرار فیلتر مشخصه مربوطه در مقیاس مرجع i ، که با ħ نشان داده میشود، تکمیل میشوند ، سه باند مدل CSL را تشکیل میدهند [ 33 ]. دومی یک مدل مخلوط غیر خطی است که برای نمایش فشرده اطلاعات تصویر چند مقیاسی استفاده می شود تا برای طبقه بندی و سایر اهداف تحلیلی استفاده شود. نمونه ای از CSL مورد استفاده برای مصورسازی در شکل 2 c نشان داده شده است. محاسبه شده از a.
2.3. تجزیه منطقه صفت
فیلترهای مشخصه که روی یک تصویر در مقیاس خاکستری عمل میکنند، دوگانگی ایجاد میکنند، یعنی محتوای تصویر را در دو مجموعه از مؤلفهها جدا میکنند – اجزایی که معیار مشخصه را برآورده میکنند و آنهایی که آن را رعایت نمیکنند. گسترش این برای آستانه های ویژگی های متعدد، مفهوم تجزیه منطقه ویژگی را به وجود می آورد . هر منطقه گروهی از اجزای اوج با مقادیر مشخصه در محدوده از پیش تعیین شده است.
اجازه دهید [ خطای پردازش ریاضی ]Γ�Λو [ خطای پردازش ریاضی ]Φ�Λهمتای باینری باشد [ خطای پردازش ریاضی ]��Λو [ خطای پردازش ریاضی ]��Λبه ترتیب، و تجزیه آستانه f [ 47 ] را در نظر بگیرید. هر آستانه تعیین شده است [ خطای پردازش ریاضی ]تیساعت(�)، با [ خطای پردازش ریاضی ]ساعت∈{ساعتمترمن�،…،ساعتمترآایکس}، حاوی [ خطای پردازش ریاضی ]ک∈کساعت�اجزای اوج [ خطای پردازش ریاضی ]پکساعتو برای هر پیکسل [ خطای پردازش ریاضی ]ایکس∈�تابع مشخصه χ از [ خطای پردازش ریاضی ]تیساعت(�)از رابطه زیر بدست می آید:
تعریف 1.
منطقه ویژگی [ خطای پردازش ریاضی ]ز�آ،�بآ از یک نقشه برداری [ خطای پردازش ریاضی ]�:�→ز، با دو آستانه مشخصه محدود شده است [ خطای پردازش ریاضی ]�آ و [ خطای پردازش ریاضی ]�ب به طوری که [ خطای پردازش ریاضی ]�آ<�ب، توسط:
به طور خلاصه، شدت هر نقطه x از حوزه تصویر، که یک جزء را در یک منطقه مشخص می کند [ خطای پردازش ریاضی ]ز�آ،�بآمی توان با مقداردهی اولیه آن به صفر و به روز رسانی آن با افزودن مقدار 1 برای هر سطح که در آن، [ خطای پردازش ریاضی ]ایکس∈پکساعتدر تفاوت بین دو فیلتر ویژگی غیر صفر است [ خطای پردازش ریاضی ]Γ�آآ، [ خطای پردازش ریاضی ]Γ�بآ. همان تجزیه برای اپراتور تعریف شده است [ خطای پردازش ریاضی ]Φ�آ. عملگر ناحیه مشخصه یک عملگر متصل است و تجزیه مبتنی بر ویژگی را همانطور که در [ 16 ] توضیح داده شد ایجاد می کند، به عنوان مثال ، هر دو منطقه با هم همپوشانی ندارند و تجزیه منحصر به فرد است.
2.4. DMP در مقابل DAP
DMP یک مورد خاص از یک DAP است، همانطور که فیلترهای بازسازی یک مورد خاص از فیلترهای ویژگی هستند. با جایگزینی فیلترهای ویژگی عمومی در DAP با بازسازی های مجموعه ای از نشانگرها، DMP را به دست می آوریم. مجموعه نشانگرها جایگزین مجموعه آستانههای صفت میشوند، و اینجاست که تفاوت مهمی از نظر محاسبات وجود دارد، همانطور که در بخشهای بعدی بحث خواهد شد. نکته کلیدی این است که خود نشانگرها باید به عنوان پشته ای از تصاویر در حافظه ذخیره شوند. همانطور که نشان داده شد [ 8 ]، می توانیم از این فضا برای ذخیره ابتدا پشته تصاویر بازسازی شده و در نهایت DMP خروجی استفاده مجدد کنیم. سپس می توان دومی را به یک MOC یا MCC پردازش کرد. اگرچه الگوریتم در [ 8 ] بسیار کارآمد است، ما یک روش تک پاسی و اقتصادهای بیشتر را برای افزایش عملکرد بیشتر بررسی خواهیم کرد.
3. الگوریتم Max-Tree و روش یک گذر
یک روش کارآمد برای محاسبه میدان برداری DAP و مدل CSL در [ 16 ] ارائه شده است. برای محاسبه تجزیه ناحیه صفت که در بخش قبل بحث شد، بر ترکیبی از ساختارهای نمایش تصویر Max-Tree و Min-Tree [ 19 ] متکی است.
Max-Tree یک تصویر f درختی است که سلسله مراتب گره مربوط به تودرتوی اجزای پیک f است . هر گره [ خطای پردازش ریاضی ]نکساعتبا سطح h و شاخص آن k نشان داده می شود و مربوط به مجموعه ای از مناطق مسطح [ 11 ] است که برای آنها یک نگاشت منحصر به فرد به یک جزء اوج منفرد وجود دارد:
“برگ” درخت با حداکثر منطقه ای f مطابقت دارد و ریشه آن در پایین ترین سطح خاکستری ساختار تعریف شده است که مجموعه پیکسل های پس زمینه را نشان می دهد.
در پیاده سازی فعلی، مانند [ 20 ]، هر پیکسل با یک گره Max-Tree نشان داده می شود که در آرایه ای به اندازه تصویر ذخیره می شود. همه گره ها حاوی یک مرجع والد هستند که به صورت یک عدد صحیح بدون علامت 32 بیتی نمایش داده می شود. یک فیلد بولی معتبر نشان می دهد که آیا یک گره پردازش شده است یا خیر. در مورد کلی فیلترهای ویژگی، هر گره حاوی یک اشاره گر به مجموعه ای از متغیرهای ویژگی کمکی است که از پیکسل های عضو آن در طول ساخت درخت به روز می شوند [ 48 ]. در مورد فیلترهای ناحیه، حافظه با استفاده از یک ذخیره می شود ناحیه ذخیره می شودفیلد، همچنین به عنوان یک عدد صحیح بدون علامت 32 بیتی نشان داده می شود. مساحت یک جزء قله با جمع مساحت فرزندان آن با مساحت کل مناطق مسطح آن محاسبه می شود. در هر جزء پیک، یک پیکسل به عنوان نماینده یا عنصر متعارف انتخاب می شود. ما این پیکسل را ریشه سطح می نامیم . همه پیکسل های یک جزء پیک، به جز ریشه سطح به ریشه سطح اشاره می کنند. ریشه سطح خود به یک پیکسل در مؤلفه پیک والد اشاره می کند. ریشه درخت به یک ریشه جهانی ⊥ اشاره می کند.
Max-Tree با استفاده از یک الگوریتم سلسله مراتبی، عمق اول، سیل پرکننده معرفی شده توسط Salembier و همکاران محاسبه می شود. [ 19 ]. روش های جایگزین در [ 49 ، 50 ، 51 ، 52 ] ارائه شد . روش بازگشتی مورد بحث در [ 19 ] ساخت درخت را از محاسبه صفات و فیلتر واقعی جدا می کند. این معماری بهویژه در برنامههایی که نیاز به فیلتر تعاملی یا چند نمونه فیلتر دارند، مورد استقبال قرار میگیرد. توجه داشته باشید که Min-Tree یک نمایش معادل Max-Tree از تصویر ورودی معکوس است.
روش یک گذر برای محاسبه مناطق ویژگی در هر یک از دو درخت در [ 16 ] ارائه شد. فهرست شبه کد را می توان در همان مقاله یافت. روشها از رویکرد مشابهی برای توابع فیلتر شرح داده شده در [ 19 ، 48 ] پیروی میکنند. مناطق مشخصه مستقل از مسیرهای ریشه مختلف هستند و با یک عدد صحیح منحصر به فرد مربوط به منطقه شناسایی می شوند. [ خطای پردازش ریاضی ]�بآدرس در [ خطای پردازش ریاضی ]�→بردار:
به عبارت دیگر، عضو ID منطقه هر گره به آدرس پایین ترین آستانه مشخصه تنظیم می شود [ خطای پردازش ریاضی ]�→که مؤلفه پیک مورد مطالعه معیار ویژگی را رد می کند. هنگامی که تصویر به مناطق مشخصه خود تجزیه می شود، دو نمونه از فیلد DAP که هر کدام یک مجموعه حجم ( I – 1) × ImageSize هستند ، می توانند با بازدید از هر پیکسل I -1 بار، یعنی یک بار برای هر ناحیه استخراج شوند. منطقه
4. یک روش همزمان یک پاس
در این بخش، ما مطالعه میکنیم که چگونه روش فوق را میتوان برای محاسبه همزمان نمایه ویژگی دیفرانسیل تطبیق داد. ما ابتدا روی مورد افزایش صفات تمرکز می کنیم، و به طور خاص، این مورد که ویژگی مساحت هر جزء است. دو مورد را می توان از هم جدا کرد: (1) محاسبه صریح میدان برداری DAP، و (ب) محاسبه مستقیم MOC، و با دوگانگی، MCC.
4.1. محاسبات موازی DAP
برخلاف DMP، ما مجبور نیستیم هیچ تصویر نشانگری را محاسبه کنیم. ما به سادگی به یک Max-Tree با ویژگی های مناسب برای همه گره ها نیاز داریم. برای ذخیره خروجی به آرایه ای از تصاویر عددی نیاز داریم . یک آرایه لامبدا حاوی مرزهای کلاس مقیاس به عنوان ورودی مورد نیاز است. به جای فیلتر کردن تصویر در هر سطح به طور صریح، و محاسبه تفاوت در مقیاس های متوالی، ما به مشکل به روشی مشابه با [ 8 ] برخورد می کنیم. یک مرحله فیلتر، کل DAP را محاسبه می کند. الگوریتم در الگوریتم 1 نشان داده شده است.
هر فرآیند یا رشته p بخش V p اختصاص داده شده به آن را اسکن می کند. هر پیکسلی که گره مربوطه برای آن هنوز معتبر علامت گذاری نشده باشد پردازش می شود. با شروع از کوچکترین مقیاس، الگوریتم مسیر ریشه را دنبال می کند تا زمانی که ریشه جهانی یا یک گره معتبر را پیدا کند یا گرهی با مساحت بزرگتر از مقیاس فعلی پیدا کند. این کار را برای همه مقیاس ها انجام می دهد، مکان گره را در یک آرایه ws و سطح خاکستری مربوطه را در یک آرایه val ذخیره می کند . پس از پردازش همه مقیاسها، یک گذر دوم در امتداد مسیر ریشه انجام میشود و تمام مقادیر آرایه DAP را به مقادیر صحیح برای همه پیکسلهای بخش V p تنظیم میکند. تنظیم میکند .
پس از این عبور ، هر برش از آرایه حاوی باز شدن ناحیه برای مقیاس مناسب λi است که در کد شبه با لامبدا [ i ] نشان داده شده است. آنچه باقی می ماند محاسبه تفاوت بین برش های متوالی برای به دست آوردن DAP نهایی است.
نقطه ضعف این روش این است که هم استفاده از حافظه و هم مقیاس زمانی محاسباتی به صورت خطی با تعداد مقیاس ها انجام می شود. این برای تعداد زیادی از مقیاس ها ممنوع می شود.
4.2. محاسبات مستقیم MOC
مانند الگوریتم قبلی، فرض می کنیم که Max-Tree با تمام اطلاعات ویژگی ها در جای خود محاسبه شده است. محاسبه MOC به طور مستقیم می تواند بدون نیاز به ذخیره سازی یک فیلد برداری DAP انجام شود. در عوض، ما فقط بردار DAP را برای هر مقیاس، ذخیره شده در تصویر outDH ، به همراه مقیاس مربوطه، ذخیره شده در تصویر outScale ، و سطح خاکستری اصلی در آن مقیاس برای هر پیکسل در تصویر، ذخیره شده در تصویر outOrig محاسبه می کنیم. . برای محاسبه این، هر گره Max-Tree را با فیلدهای maxDH تجهیز می کنیم و هر دو را از نوع سطح خاکستری مقیاس می کنیم (کاراکتر بدون علامت در مورد ما). مانند قبل، آرایه لامبدا مرزهای کلاس مقیاس را ذخیره می کند.
| الگوریتم 1 مرحله فیلتر الگوریتم موازی مشخصات دیفرانسیل (DAP) |
|
رویه MaxTreeMakeDAP ( Vp : Section ;
var node : Max-Tree ; var out : DAP ;
lambda : integer [ numscales ])
برای همه v ∈ Vp اگر گره [ v ] نیست انجام دهید .
معتبر پس از آن w := v ;
برای همه مقیاس ها من ترتیب افزایشی انجام می دهم در حالی که Par ( w ) ≠ ⊥ ⋀ نه
گره [ w ]. گره ⋀ معتبر [ w ]. area < lambda [ i ] do w := Par ( w );
پایان ;
ws [ i ] := w ; (∗ ذخیره موقت برای هر مقیاس ∗)
اگر گره [ w ]. پس از آن برای همه مقیاسها معتبر است j ≥ i do (∗ گره فیلتر شده یافت شد ∗)
val [ j
] := خروجی [ j ][ w ];
پایان ;
other if گره [ w ]. ناحیه ≥ lambda [ i ] سپس (∗ w فیلتر می شود ∗)
val [ i ] := out [ i ][ w ];
else (∗ lambda [ i ] خیلی بزرگ ∗)
val [ j ] := 0;
پایان ;
پایان ;
پایان;
پایان ;
u := v ;
برای همه مقیاس ها مرتبه افزایشی i تکرار کنید اگر u ∈ Vp سپس برای همه مقیاس ها j < i انجام می دهم [ j ][ u ] := f [ u ]; پایان ;
برای همه مقیاس ها j ≥ i انجام می دهم [ j ] [ u ] := val [ j ]; پایان ;
گره [
u ]. معتبر := درست ;
پایان ;
u := گره [ u ]. پدر و
مادر تا زمانی که u = ws [ i ];
پایان ;
اگر u ∈ Vp سپس (∗ پردازش ws [ numscales − 1] ∗ )
برای همه مقیاسها j < i do out [ j ][ u ] := f [ u ]; پایان;
گره [ u ]. معتبر := درست ;
پایان ;
پایان ;
پایان ;
|
|
در اولین نسخه از الگوریتم، ما از فیلد ناحیه برای ذخیره کلاس مقیاس (به عنوان یک عدد صحیح) استفاده مجدد کردیم. این الگوریتم در دو مرحله (پس از ساخت درخت) کار کرد. در مرحله اول، ما به سادگی کلاس مقیاس را برای هر ریشه سطح در درخت محاسبه می کنیم. این را می توان به طور کامل به موازات انجام داد، زیرا تصمیم گیری محلی است. پس از این، درخت تقریباً به همان روشی که روش اصلی یک گذر بود، طی شد.
برخی از آزمایشهای اولیه نشان داد که فاز اول این رویکرد دو پاسی بهطور شگفتانگیزی از نظر افزایش سرعت ناکارآمد بود و تنها 16 تا 18 برابر محاسبات سریعتر را روی 64 گره انجام داد. دلیل این امر به احتمال زیاد این است که یک فاز بسیار کوتاه با موانع در دو طرف است. این بدان معنی است که عدم تعادل بار و هزینه های همگام سازی تأثیر زیادی دارد. بنابراین ما یک نسخه یک گذر را پیاده سازی کردیم. در اینجا، ما نیاز به معرفی یک فیلد مقیاس در درخت داریم، و اگرچه این البته از نظر حافظه پرهزینهتر است، اما یک مزیت مهم دارد، زیرا دادههای ناحیه بازنویسی نمیشوند. این بدان معناست که در صورت نیاز، میتوانیم MOCها را با تنظیمات پارامترهای مختلف از یک درخت دوباره محاسبه کنیم.
الگوریتم یک گذر برای محاسبه MOC در الگوریتم 2 و الگوریتم 3 ارائه شده است. الگوریتم دوم به سادگی بخش تصویر اختصاص داده شده به فرآیند را اسکن می کند و NodeSetMOC را از الگوریتم 2 برای هر گره ای که هنوز معتبر نیست فراخوانی می کند. این بررسی می کند که آیا گره فعلی ریشه سطح است یا خیر، و اگر چنین است، مقیاس و سطح خاکستری تضاد را با والد آن محاسبه می کند. سپس، بررسی میکند که آیا مقیاس حداکثر است یا خیر، که نشان میدهد که گره فعلی دارای ناحیه خارج از محدوده مورد نظر است و پارامترهای MOC آن بر روی شرایط «خارج از محدوده» تنظیم شدهاند. هیچ صعود دیگری لازم نیست زیرا همه اجداد باید مناطق بزرگتری داشته باشند.
| الگوریتم 2 مراحل فیلتر مشخصه باز شدن چند مقیاسی موازی (MOC) |
|
رویه NodeSetMOC ( Vp : بخش ؛ گره var : Max-Tree ؛ جریان : عدد صحیح ؛
var maxDH ، curScale : grayval ؛ var outDH ، outScale ،
outOrig : آرایه [0، ...، N -1] پیکسل ، عدد لامبدا : inte [ عدد مقیاس ])؛
مقیاس var ، DH : گریوال ;
اگر IsLevelRoot ( گره [ جریان ]) سپس (∗ مقیاس محاسبه و DH برای گرههای فعلی ∗)
مقیاس := FindScale ( گره [ جریان ]، لامبدا ). DH := getDH ( گره [ جریان ])؛
پایان ;
اگر IsLevelRoot ( گره [ فعلی ]) و scale = numscales ، (∗ در محدوده خارج از مقیاس ∗ مقداردهی اولیه کنید)
maxScale := numscales ; maxDH := 0; curDH := 0;
maxOrig := 0; curScale := numscales ;
else
والد = گره [ جریان ]. پدر و
مادر اگر نه گره [ والد ]. پس از آن معتبر است (∗ برای تنظیم صحیح مقادیر والد به بازگشت بروید ∗)
NodeSetMOC ( Vp ، node ، والد ، maxDH ،
curScale ، outDH, outScale , outOrig , lambda );
else (∗ اگر والد معتبر است، مقادیر مربوطه را کپی کنید ∗)
maxScale := outScale [ والد ]; maxDH := outDH [ والد ]; maxOrig := outOrig [ والد ];
curScale := گره [ والد ]. مقیاس ; curDH := گره [ والد ]. curDH ;
پایان
اگر IsLevelRoot ( گره [ فعلی ]) سپس (∗ اگر ریشه سطح داشته باشم، برخی چیزها ممکن است تغییر کنند ∗)
اگر scale = curScale سپس (∗ کلاس مقیاس یکسان: CurDH پیکسل فعلی را اضافه کنید ∗)
curDH = curDH + curDH ;
else (∗ تغییر کلاس مقیاس، مقیاس فعلی به روز رسانی و DH ∗)
curDH = DH ; curScale = مقیاس ;
پایان ;
اگر curDH ≥ maxDH باشد پس (∗ اگر curDH به روز شده بالاتر یا برابر با حداکثر DH یافت شده به روز رسانی maxDH، maxScale و outOrig ∗ باشد)
maxDH := curDH ; maxScale := مقیاس ;
outOrig = gval [ جریان ];
پایان ;
پایان ;
پایان ;
اگر جریان ∈ Vp باشد سپس (∗ اطلاعات را ذخیره کنید ∗)
OutScale [ current ] := maxScale ; outDH [ جریان ] := maxDH ;
outOrig[ فعلی ] := maxOrig ; گره [ جاری ]. مقیاس := curScale ;
گره [ جاری ]. curDH := curDH ; گره [ جاری ]. معتبر := پایان واقعی
;
پایان ;
|
|
| الگوریتم 3 مرحله نهایی فیلتر MOC موازی |
|
روش MaxTreeComputeMOC ( Vp : بخش ؛
var outDH ، outScale ،
outOrig : آرایه [0، ...، N -1] پیکسل ،
لامبدا : عدد صحیح [ Numscales ]).
var curScale , maxScale , maxDH , curDH , maxOrig : grayval ;
برای همه v ∈ Vp اگر
نه گره [ v]. معتبر سپس
NodeSetMOC ( Vp ، v ،
curDH ، maxDH ،
maxScale ، maxOrig ،
curScale ، outDH ،
outScale ، outOrig ، lambda );
پایان ;
پایان ;
پایان ;
|
|
در غیر این صورت، والد را جستجو می کنیم و بررسی می کنیم که آیا معتبر است یا خیر. اگر نه، NodeSetMOC به صورت بازگشتی برای والد فراخوانی می شود. در غیر این صورت، داده های والد کپی می شوند (از آنجا که معتبر هستند). اکنون مقادیر صحیح MOC مسیر ریشه تا والد گره فعلی را داریم. اگر گره فعلی یک ریشه سطح باشد، بررسی می کنیم که آیا مقیاس آن با مقدار والد ذخیره شده در curScale یکسان است یا خیر . اگر چنین است، مقدار کنتراست curDH باید با کنتراست گره فعلی، ذخیره شده در DH افزایش یابد . اگر مقیاس ها یکسان نباشند، مقیاس فعلی و کنتراست به مقیاس های گره فعلی به روز می شوند.
پس از این، بررسی می کنیم که آیا کنتراست فعلی curDH بزرگتر یا مساوی با حداکثر کنتراست maxDH m است یا خیر، و اگر چنین است، maxDH ، maxScale و outOrig به روز می شوند (به ترتیب مربوط به بخش های C، S و L MOC هستند. ).
در نهایت، اگر گره فعلی در بخش خصوصی پردازشگر Vp تصویر باشد، پارامترها در فیلدهای گره و در خروجی MOC نوشته میشوند. این رویکرد به این معنی است که مقادیر مقیاس ممکن است چندین بار توسط رشتههای مختلف محاسبه شوند، اما این واقعیت با از دست دادن یک مانع جبران میشود.
5. آزمایشات
این الگوریتم در C پیادهسازی شد و روی سرور محاسباتی Dell R815 با 4 پردازنده Opteron با 16 هسته آزمایش شد. در مجموع 512 گیگابایت رم نصب شده است. کد منبع در http://www.cs.rug.nl/~michael/ParMaxTree/ موجود است . مجموعه دادهها شامل یک تصویر پانکروماتیک Quickbird از صنعا، یمن، توسط DigitalGlobe, Inc.، دو تصویر پانکروماتیک پس از زلزله از هائیتی، توسط Google، و یک تصویر ماهوارهای پانکروماتیک از یک فرودگاه بود. همه تصاویر کپی شده و کاشی شده بودند تا به اندازه کلی تصویر بین 3.4 تا 3.9 گیگاپیکسل دست یابند. برای مشخصات تصویر، جدول 1 را ببینید .
5.1. محاسبه همزمان CSL
در همه موارد، زمانبندی در رشتههای 1، 2، 4، 8، 12، 16، 24، 32، 48، 64، 128 و 256 انجام شد. در کار قبلی، ما مشاهده کرده بودیم که فاز ساخت Max-Tree در واقع می تواند سرعت بیشتری داشته باشد اگر رشته های بیشتری نسبت به هسته ها استفاده شود، به دلیل کاهش thrashing حافظه پنهان [ 20 ]. از آنجایی که انتظار می رفت محاسبات CSL تحت سلطه فاز درخت سازی باشد، می خواستیم تاثیر این اثر را بدانیم.
در مورد CSL برنامه نهایی ساختار زیر را دارد:
- (1)
-
تصویر را بخوانید و یک کپی معکوس از تصویر ایجاد کنید
- (2)
-
ساخت Max-Tree از تصویر اصلی
- (3)
-
MOC را محاسبه کنید
- (4)
-
ساخت Min-Tree از تصویر معکوس
- (5)
-
ساخت MCC
- (6)
-
MOC و MCC را با CSL نهایی ترکیب کنید
- (7)
-
خروجی را بنویسید
برنامه تقسیمبندی مدل CSL موازی 24 بار در هر زمان اجرا شد و کوتاهترین زمان نشاندهنده عملکرد الگوریتم در غیاب تداخل توسط برنامههای دیگر در نظر گرفته شد. در نتایج زمانبندی، زمانهای Min-Tree و Max-Tree را به یک زمانبندی درختسازی اضافه کردیم، و به همین ترتیب برای زمانهای MOC و MCC.
آزمایشها در سه تنظیمات پارامتر مورد استفاده در موارد عملی اجرا شدند. دو تنظیم با مقیاس حداکثر 16.7 × 10 6 m 2 ، با مقیاس های 12 و 32 استفاده شد. آخرین تنظیم دارای 64 مقیاس و حداکثر مقیاس مساحت 16، 384 متر مربع بود . مشخص شد که این تنظیمات تاثیر قابل توجهی بر عملکرد الگوریتم ها ندارند. در ادامه به زمان بندی دوم با حداکثر تعداد مقیاس می پردازیم.
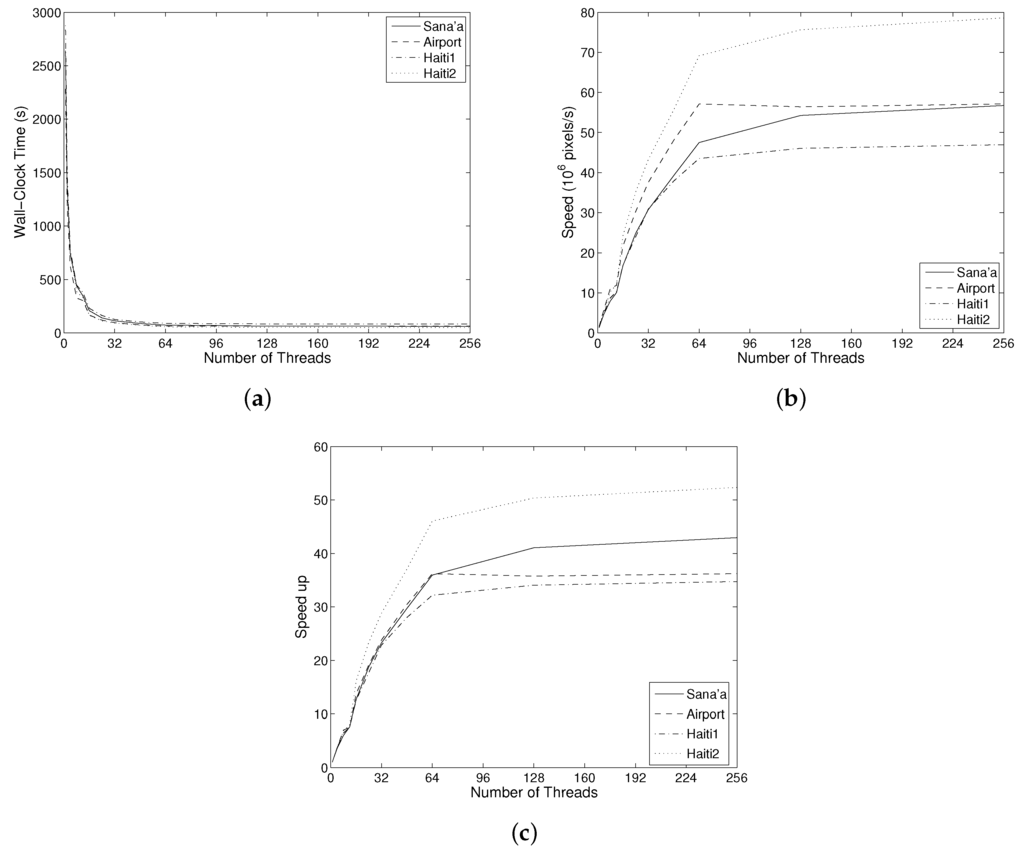
شکل 3 عملکرد الگوریتم را از نظر زمان ساعت دیواری، سرعت بر حسب میلیون ها پیکسل در ثانیه و افزایش سرعت نشان می دهد. کل زمانهای محاسباتی از میانگین 2609 ثانیه در 1 رشته، به 70.8 ثانیه در 64 رشته، و کاهش بیشتر به 64.4 ثانیه در 256 متغیر بود. مورد دوم به دلیل کاهش کوبیدن حافظه پنهان در طول فاز ساخت Max-Tree است [ 20 ] . میانگین سرعت برای فرآیند کامل 36.85 در 64 رشته و 40.51 در 256 رشته است.
شکل 3 b سرعت محاسباتی را بر حسب میلیون ها پیکسل در ثانیه نشان می دهد. این برای تفاوت در زمان پردازش به دلیل تفاوت در اندازه تصویر کالیبره می شود. با وجود این اصلاح، تفاوت های کاملاً قابل توجهی مشاهده می شود. در حداکثر عملکرد، سرعت پردازش از 46.96 مگاپیکسل در ثانیه تا 78.58 مگاپیکسل در ثانیه، با میانگین 59.85 مگاپیکسل در ثانیه، در حالی که سرعت از 34.74 تا 52.36 متغیر است. این تفاوت ها عمدتاً از پیچیدگی های مختلف تصویر ناشی می شود. Haiti1 فقط شامل مناطق ساخته شده است، به این معنی که Max-Tree شامل گره های بسیار بیشتری است. هائیتی 2 شامل بخش های بزرگی از مناطق روستایی و برخی مناطق سیاه گسترده است که هیچ داده ای در دسترس نبود. این Max-Tree را ساده می کند. تصاویر صنعا و فرودگاه بیشتر ترکیبی هستند.
ساخت Max-Tree با استفاده از الگوریتم از [ 20 ]، از میانگین 1912 ثانیه در یک رشته، به 46.4 ثانیه در 64 رشته، و بیشتر به 38.8 ثانیه در 256 نخ، بیشترین زمان را برد. فاز MOC-MCC به طور متوسط روی یک رشته 576.75 ثانیه طول کشید که در 64 رشته به 18.7 ثانیه کاهش یافت و در 256 رشته به 21.0 ثانیه افزایش یافت. ترکیب اطلاعات MOC و MCC در بخشبندی نهایی مدل CSL ارزانترین است که بهطور متوسط روی یک هسته 105.7 ثانیه هزینه دارد، بهطور متوسط برای 64 هسته به 2.25 ثانیه کاهش مییابد، بدون تغییر قابل توجهی فراتر از آن.
همانطور که در شکل 4 مشاهده می شود، تفاوت های قابل توجهی در افزایش سرعت بین فازها وجود دارد . فاز ساختمان به طور متوسط بالاترین سرعت را دارد، اما همچنین بیشترین تغییرات را دارد که از 33.05 برای Haiti1 تا 53.67 برای Haiti2 در 64 رشته، با میانگین 42.22 متغیر است. فراتر از 64 رشته، افزایش بیشتری در سرعت وجود دارد، و 256 رشته سرعت افزایش از 38.80 برای Haiti1 تا 64.49 برای Haiti2، با میانگین 50.67 متغیر است.
میانگین سرعت فاز MOC-MCC بسیار کمتر است و به طور متوسط در 64 رشته به 30.92 می رسد، بدون افزایش قابل توجهی فراتر از آن. مرحله نهایی سرعت بسیار خوبی دارد، به طور متوسط 47.07 در 64 موضوع.
برای مقایسه، اجرای الگوریتم موازی برای پروفایلهای مورفولوژی دیفرانسیل روی تصویر 3.8 گیگاپیکسلی Sana’a، با استفاده از تنها هفت مقیاس، در یک دستگاه، و روی یک هسته، زمان ساعت دیواری 5 ساعت و 9 دقیقه و 6.7 ثانیه بود که به 8 دقیقه 33.7 ثانیه یا افزایش سرعت 36.1 روی 64 هسته. حدود نیمی از زمان ساعت دیواری توسط محاسبه نشانگرها اشغال می شود، که با محاسبه فرسایش توسط دیسک های اقلیدسی دقیق توسط الگوریتم [ 53 ] انجام می شود. هنگام استفاده از مربع SE با همان الگوریتم، استفاده از حافظه به طور چشمگیری کاهش می یابد و زمان ساعت دیواری برای 7 مقیاس به 4 ساعت و 10 دقیقه و 46.8 ثانیه و 6 دقیقه و 19.5 ثانیه برای 64 هسته یا سرعت 39.6 کاهش می یابد.
الگوریتم تقسیمبندی مدل CSL دارای پیچیدگی حافظه O ( N + Ns )، با N تعداد پیکسلها و Ns تعداد مقیاسها است. زیرا N s << N این در عمل به O ( N ) تبدیل می شود. آنچه مشاهده می کنیم این است که حداکثر تخصیص حافظه 24 برابر اندازه داده های تصویر است، حداقل برای ویژگی area. سایر ویژگی ها به حافظه بیشتری نیاز دارند، مانند استفاده از اعداد صحیح 64 بیتی برای محاسبات ناحیه و آدرس دهی پیکسل، همانطور که در تصاویر فراتر از 4 Gpixel مورد نیاز است. در این صورت، ما به 32 برابر اندازه داده نیاز داریم.
در مقابل، محاسبه تقسیمبندی مدل CSL از DAP به صراحت دارای پیچیدگی حافظه O ( NN s ) است که برای Ns بزرگ غیرممکن میشود . در حالت 64 مقیاس بالا، استفاده از حافظه تا 164 برابر اندازه تصویر افزایش می یابد (زیرا دو آرایه به اندازه 64 Nباید ذخیره شود). ما چند آزمایش بر روی تصاویر کوچک انجام دادیم که نشان داد محاسبات میدان برداری DAP در 64 مقیاس بیش از 10 برابر کندتر از تقسیمبندی مدل CSL است. در تصویر 870 مگاپیکسلی اصلی Sana’a، محاسبه DAP 177.25 ثانیه در 64 رشته طول کشید، در حالی که با استفاده از تقسیمبندی مستقیم مدل CSL، 15.42 ثانیه طول کشید. حتی برای 12 مقیاس، تفاوت ضریب دو تا سه است. در مورد تصویر 870 مگاپیکسلی Sana’a، محاسبه DAP 39.61 ثانیه طول کشید، در حالی که تقسیم بندی مدل CSL 15.43 ثانیه طول کشید.
برای DMP، وضعیت شبیه به محاسبات صریح DAP از نظر استفاده از حافظه است. پشته ای از تصاویر N ابتدا برای ذخیره نشانگرها استفاده می شود. سپس این نشانگرها به تصاویر بازسازی شده تبدیل می شوند و پس از آن از تفاضل پیکسلی برای به دست آوردن فیلد برداری DMP (ذخیره شده در همان مکان) استفاده می شود. سپس این فیلد DMP باید به یک بخش بندی نهایی CSL تبدیل شود. بار محاسباتی معمولاً بیشتر است، به دلیل نیاز به فرسایش Ns ، هر یک از حداقل O ( N ) پیچیدگی زمانی O ( NNs ) را ایجاد می کند. اگر تغییر ناپذیری چرخش مورد نیاز باشد، این به راحتی به O ( NN) افزایش می یابدs R max ) پیچیدگی زمانی، با Rmax حداکثر شعاع SE های مورد استفاده. این مرحله اولیه بسیار پرهزینه تر از استفاده از ناحیه به عنوان ویژگی در DAP است که پیچیدگی زمانی ثابتی در هر پیکسل دارد. برای ویژگی های پیچیده تر از مساحت، بار حافظه افزایش می یابد. هنگام استفاده از ممان های مرتبه بالاتر، ذخیره سازی در هر گره maxtree تقریباً به صورت O ( M 2 )، با M ترتیب لحظه استفاده می شود، و زمان محاسبه به طور مشابه افزایش می یابد. از آنجایی که تعداد گرهها میتواند با تعداد پیکسلها برابر باشد، پیچیدگی حافظه در بدترین حالت محاسبات صریح DAP به O ( N ( N s + M میشود2 )). برای محاسبه مستقیم CSL، به O ( NM 2 ) تبدیل می شود، بنابراین دوباره، وابستگی به تعداد مقیاس ها حذف می شود.
برای نشان دادن شدت مشکل، لازم به ذکر است که با وجود اینکه سرور ما با حداکثر 512 گیگابایت رم نصب شده بود، مجموعه داده های بزرگ به دلیل محدودیت حافظه نمی توانند در مقیاس 64 اجرا شوند.
6. بحث
نتایج نشان میدهد که محاسبه موازی تقسیمبندی مدل CSL را میتوان با استفاده از الگوریتم پیشنهادی بسیار کارآمد انجام داد. سرعت متوسط کلی نزدیک به 60 مگاپیکسل در ثانیه، یا 3.59 گیگاپیکسل در دقیقه، حتی برای 64 مقیاس در تقسیم بندی مدل CSL به دست می آید. این بدان معنی است که پردازش معمولی این تصاویر بسیار بزرگ در سرورهای محاسباتی نسبتاً استاندارد و همچنین ایستگاه های کاری پیشرفته امکان پذیر می شود. علاوه بر این، اگر Max-Tree یک بار ساخته شود، می توان آن را ذخیره کرد، و تقسیم بندی های مختلف مدل CSL را می توان با پارامترهای مقیاس متفاوت ایجاد کرد. برای تصاویر با اندازه های استفاده شده در اینجا، این زمان بین 14.09 و 26.62 ثانیه طول می کشد. در حالی که این دقیقاً یک پاسخ در زمان واقعی نیست، اما بسیار سریع است. این مراحل بعدی الگوریتم دارای پیچیدگی زمانی خطی هستند،
جالب است که فاز MOC-MCC الگوریتم کمترین سرعت را دارد و به نظر می رسد به حدود 32 محدود می شود. ما در نظر گرفتیم که آیا این ممکن است به این دلیل باشد که برخی از ریاضیات ممیز شناور در این مرحله استفاده شده است. سرور R815 ممکن است 64 هسته داشته باشد، اما اینها تنها 32 واحد ممیز شناور را بین خود به اشتراک می گذارند. ما کد ممیز شناور را با ریاضی اعداد صحیح جایگزین کردیم اما فقط کمی افزایش سرعت به دست آوردیم. بنابراین، ما حدس زدیم که این واقعیت که مقیاس های مساحت یک گره معین ممکن است چندین بار محاسبه شود، مشکل است. با این حال، نسخه قبلی مقیاس منطقه را برای هر گره به صورت موازی محاسبه کرد و سپس از نتایج در یک فاز MOC-MCC کمی سادهتر استفاده کرد. در این مورد، فاز MOC-MCC سریعتر نبود: 20.37 ثانیه برای تصویر 3.48 گیگاپیکسلی Sana’a، در مقابل .20.22 ثانیه، زمانی که مقیاس های منطقه در فاز MOC-MCC گنجانده شده است. این تفاوت قابل توجه نیست و نشان می دهد که این راه حل نیست. با قرار دادن محاسبات مقیاس در فاز MOC-MCC، یک مانع برداشته شد و عملکرد کلی تا حد زیادی افزایش یافت. برای تصویر 3.48 گیگاپیکسلی Sana’a، زمان ساعت دیواری در 256 رشته از 73.11 ثانیه به 61.37 ثانیه کاهش یافت.
بنابراین منطقی به نظر می رسد که هزینه اصلی در پیمودن موازی Max-Tree باشد، با چندین رشته که چندین بار مسیرهای ریشه یکسان را طی می کنند. افزودن محاسبات اضافی به ازای هر گره بازدید شده تنها تأثیر بسیار جزئی بر زمان ساعت دیواری یا افزایش سرعت دارد. بنابراین، متوجه میشویم که فاز نسبتاً پیچیده MOC-MCC فقط کمی بیشتر از یک مرحله فیلتر کردن یک باز شدن منطقه هزینه دارد. این پیامدهای زیادی برای سرعت به دست آمده توسط الگوریتم پیشنهادی دارد، کاملا جدا از موازی به دست آمده.
در مقایسه، انجام یک مرحله فیلتر یک ناحیه روی یک Max-Tree از پیش محاسبه شده از این تصاویر بزرگ تقریباً 3 تا 5 ثانیه طول می کشد که عمدتاً به محتوای تصویر بستگی دارد. برای 64 مقیاس، این به معنای 128 مرحله فیلتر است که به مقداری بین 384 و 640 ثانیه می رسد، با فرض اینکه به دلیل مشکلات همگام سازی کاهش سرعت نداشته باشد. با الگوریتم جدید، این محدوده تقریباً 14 تا 27 ثانیه (حدود 25 برابر سریعتر) بدون توجه به تعداد مقیاسها است.
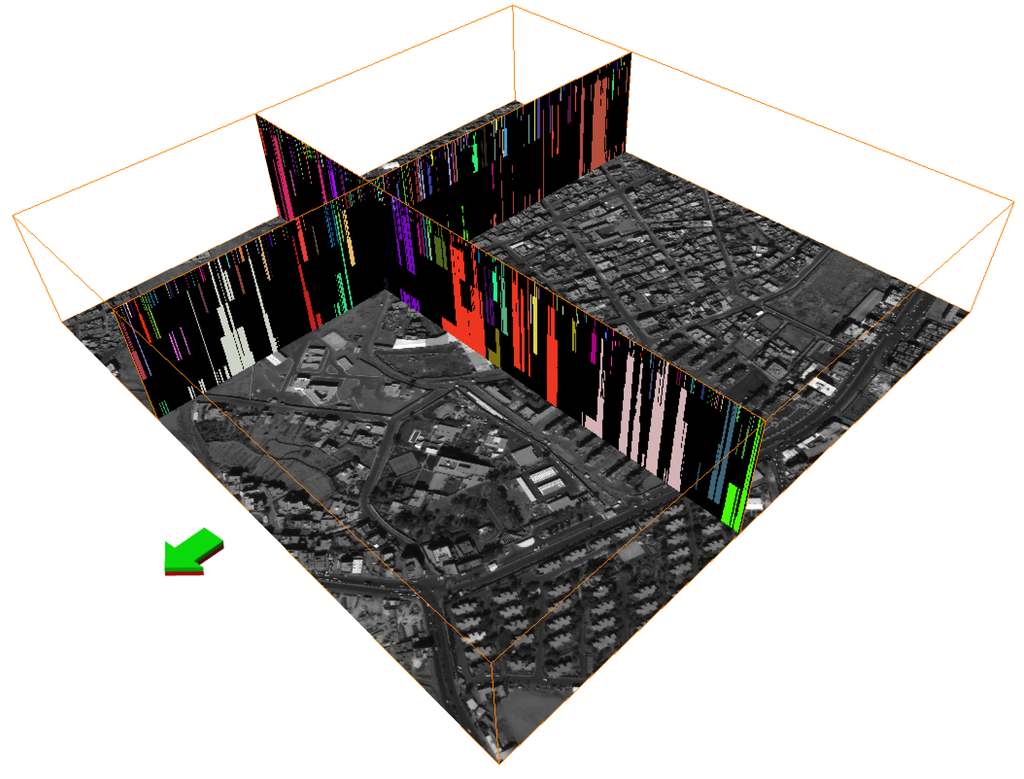
گونهای از این استراتژی موازیسازی برای الگوریتم Max-Tree و محاسبات CSL در پلتفرم دادههای بزرگ مکانی (GBDX) DigitalGlobe ( http://www.digitalglobe.com/) میزبانی میشود.) برای محاسبه لایههای CSL خام هر تصویر در صف قبل از طبقهبندی رادیومتری. این یک سرویس استخراج ردپای ساختمان است که در فضای ابری کار میکند و میتواند برای پردازش تمام تصاویر چندطیفی WorldView دو و سه DigitalGlobe در زمان واقعی بهینه شود. گردش کار مربوطه سه گانه CSL را محاسبه می کند که به گونه ای پیکربندی شده است که مرتبط ترین/توصیفی ترین ساختارهای تصویر را در مقایسه با فیلد برداری کامل DAP داشته باشد. اینها به نوبه خود، می توانند با استفاده از ویژگی های رادیومتریک در مرحله فرا فرآیند به طور موثر طبقه بندی شوند و عناصر نویز احتمالی حذف شوند. کارایی در این مورد در نتیجه کاهش تعداد نمونه های آزمایشی (ساختارهای CSL غالب) است. یک مثال در شکل 5 نشان داده شده است. تصویر (الف) نمای RGB از یک مجموعه داده چند طیفی هشت بانده را نشان می دهد که شهر برست، فرانسه و اطراف آن را پوشش می دهد. این یک تصویر WorldView 2 © DigitalGlobe, Inc (وستمینستر، CO، ایالات متحده آمریکا)، در 1.6 متر است. تفکیک فضایی پس از تصحیح ارتو و جبران جوی (14 bpp عمق داده). این تصویر در 15 اکتبر 2014 به دست آمد و مساحت کل 313 کیلومتر مربع را پوشش می دهد . تصویر (ب) تقسیم بندی CSL مربوطه را به دنبال روش های پالایش عنصر طبیعی نشان می دهد. بخش بندی تمام سازه های ساخته شده را مستقل از اندازه، ساختار یا ویژگی های رادیومتری هدف قرار می دهد. تصویر (ج) نمای بزرگنمایی مرکز شهر در شمال بندر آن را نشان می دهد. این گردش کار فقط از MOC ها استفاده می کند ( به عنوان مثال.، یک سازه Max-Tree به تنهایی) به لطف یک روش ترکیبی جدید باند که مجموعه داده های 8 باندی WorldView 2 یا 3 را با اتمسفر جبران شده به لایه های خاکستری کاهش می دهد که به طور انحصاری واکنش قوی به مصالح ساختمانی نشان می دهد.
7. نتیجه گیری
در این مقاله، ما یک الگوریتم جدید برای حافظه کارآمد، مشترک، محاسبات موازی تقسیمبندی مدل CSL و نمایه CSL تصاویر در محدوده گیگاپیکسلی، علاوه بر چندین پیشرفت در DMP موجود، تقسیمبندی چند مقیاسی (MSLS) ارائه کردهایم. و الگوریتم های DAP الگوریتم CSL را می توان با هر ویژگی افزایشی، با گنجاندن مدیریت داده های کمکی شرح داده شده در [ 20 ] تطبیق داد. یکی از این گسترشها به طیفهای الگوی دوبعدی قبلاً با استفاده از مساحت و عدم فشردگی به عنوان ویژگی ارائه شده است [ 54]. ویژگی های پیچیده تر بر زمان ساخت Max-Tree و استفاده از حافظه تأثیر می گذارد، اما بر زمان تقسیم بندی مدل MOC-MCC و CSL تأثیر نمی گذارد. ویژگی های غیر فزاینده نیاز به تغییرات متعددی دارند که ما قصد داریم در کارهای آینده به آنها بپردازیم. برای طیف های الگو، ویژگی های غیر افزایشی مشکلی ایجاد نمی کنند.
در مقایسه با هر دو DMP و DAP، رویکرد تقسیمبندی مدل CSL مزیت سرعت آشکاری دارد، بهویژه در تعداد زیادی مقیاس. علاوه بر این، استفاده از حافظه در روش جدید بسیار کمتر از روش DMP است، و اجازه می دهد تصاویر بسیار بزرگتری در همان حافظه پردازش شوند. مهمتر از همه، نیاز به حافظه مستقل از تعداد مقیاس های استفاده شده است.
الگوریتم فعلی تنها به دلیل استفاده از اعداد صحیح 32 بیتی به 4 گیگاپیکسل محدود شده است. تغییر یک اعلان واحد به اعداد صحیح 64 بیتی آن را برای هر اندازه تصویری که در حافظه قرار می گیرد مناسب می کند. ما در حال حاضر کد خود را به حافظه توزیع شده گسترش می دهیم و در آینده نزدیک پردازش تصاویر تراپاکسل را هدف داریم. محدودیت دیگر، وضوح سطح خاکستری است. الگوریتم فعلی تا حدود 16 بیت در هر پیکسل مناسب است. فراتر از آن، الگوریتم موازی [ 20] که این بر اساس آن است، دیگر به طور موثر کار نمی کند، به دلیل این واقعیت که هزینه محاسباتی الگوریتم اتصال به صورت خطی با تعداد سطوح خاکستری مقیاس می شود. کار بر روی الگوریتمهای موازی در حال انجام است تا هر تعداد از سطوح خاکستری را به طور موثر مدیریت کند. در نهایت، الگوریتم فعلی یک الگوریتم حافظه مشترک است که حد بالایی را برای حداکثر اندازه تصویر در نظر میگیرد، زیرا اندازه حافظه در ماشینهای حافظه مشترک معمولاً محدود است. کار بر روی الگوریتم های حافظه توزیع شده در حال انجام است.
نتایج این مقاله در حال حاضر امکان پردازش سریع مجموعههای دادههای گسترده را تحت محدودیتهای زمانی محدود میدهد، مانند مواردی که ممکن است در برنامههایی که از مدیریت بحران پشتیبانی میکنند، برای آمادگی در برابر بلایا و تلاشهای امدادی یا زمانی که تغییرات سریع در زمین رخ میدهد، مورد نیاز باشد. سرور تک رک ما میتوانست حدود 5 تراپیکسل داده را در یک روز پردازش کند، مشروط بر اینکه مراقب باشیم ورودی/خروجی گلوگاهی ایجاد نکند. این را می توان با تنظیم دقیق خط لوله پردازش به دست آورد. الگوریتم جدید همچنین امکان پردازش یکپارچه مناطق را در مقیاس کل شهرها فراهم می کند. حرکت به محاسبات توزیع شده به ما امکان می دهد پردازش یکپارچه را در مقیاس کشورها یا حتی جهان انجام دهیم.





بدون نظر