1. معرفی
در سالهای اخیر، دستگاههای GPS کوچک (سیستم موقعیتیابی جهانی) به طور گستردهتری در زندگی روزمره مورد استفاده قرار گرفتهاند و مقادیر زیادی از دادههای مسیر هدف را میتوان به راحتی ثبت کرد. به عنوان مثال، مسیرهای فعالیت روزانه افراد را می توان با تجهیزات GPS اتومبیل و تلفن های همراه مجهز به GPS ثبت کرد. یک مسیر متداول از زندگی روزمره یک فرد در شکل 1 نشان داده شده است. اطلاعات مفیدی را می توان از این مسیرها استخراج کرد و از آنها برای بهره مندی از زندگی روزمره استفاده کرد. در نتیجه، بسیاری از خدمات مبتنی بر مکان، مانند سیستمهای توصیهگر مبتنی بر موقعیت و سیستمهای پیشبینی مقصد، توجه روزافزونی را از سوی کاربران و توسعهدهندگان به خود جلب میکنند. دغدغه اصلی کاربردهای مبتنی بر مکان این است که چگونه معنای معنایی یک مسیر را درک کنیم، و نه صرفاً در نظر گرفتن مسیر به عنوان ترکیبی از نقاط ثبت شده. کار در مرجع [ 1] یک مدل مفهومی برای ارائه مسیرها با حاشیه نویسی معنایی پیشنهاد کرد که به فرد اجازه می دهد اطلاعات معنایی مانند حرکت و توقف را به بخش های خاصی از مسیرها اختصاص دهد. توقف در مسیرها نشان دهنده بخش های مسیر مربوط به اقامت فرد در مکان های خاص است. حرکات مربوط به بخش های مسیری است که توسط حرکت یک هدف بین مکان های توقف ایجاد می شود.
مکانهای توقف در یک مسیر، بخشی ضروری از برنامههای کاربردی مختلف هستند، مانند خدمات پیشبینی هدف، خدمات ناوبری، و توصیههای عمومی یا شخصیشده. در این مقاله، مسئله چگونگی استخراج مکان های توقف از مسیرها، تشخیص توقف نامیده می شود. در ادبیات، مدل های زیادی برای تقسیم یک مسیر به قطعات توقف و قطعات متحرک پیشنهاد شده است. تحقیقات در مورد تشخیص توقف را می توان به دو دسته روش های استاتیک و روش های دینامیکی تقسیم کرد. موقعیت های مهم از قبل برای تکنیک های استاتیک تعریف شده است [ 2 ، 3]، در حالی که هیچ دانش قبلی در مورد توقف برای یک رویکرد پویا ارائه نشده است. اخیراً، چندین مقاله راه حل دینامیکی را با در نظر گرفتن جنبه های مختلف ویژگی های تحرک، مانند ویژگی های سرعت، مورد مطالعه قرار داده اند. به طور معمول، الگوریتم های خوشه بندی عمومی، که قادر به خوشه بندی مکان های توقف فرد با اختصاص محدودیت های مختلف به ویژگی های مختلف هستند، در راه حل پویا اتخاذ می شوند.
به طور کلی، اکثر روش های خوشه بندی موجود در تشخیص توقف از اشکالات مربوطه رنج می برند. اول، ارزش مشخصههای رایج در این روشهای خوشهبندی، مانند سرعت، هنگام برخورد با یک مسیر واقعی، به شدت در نوسان است. ما یک تحلیل کیفی در مورد ویژگی سرعت در بخش 3 ارائه می دهیم. علاوه بر این، این مشکل منجر به دومین دسته از اشکالات میشود، یعنی در بیشتر موارد، الگوریتمها باید پارامترهایی را به صورت دستی برای ویژگیهای مختلف تنظیم کنند، که به دلیل نوسانهایی که در بالا توضیح داده شد، کار دشواری برای کاربران است. در نهایت، بیشتر الگوریتمهای مبتنی بر خوشهبندی، تعداد نقاط GPS در یک فاصله معین را به عنوان اندازهگیری چگالی میگیرند. در نتیجه، این روش ها ویژگی های متوالی را نادیده می گیرند و نتایج این کارها به طور چشمگیری تحت تأثیر پارامترهای فاصله قرار می گیرد. علاوه بر این، زمانی که چندین ویژگی با هم در نظر گرفته شوند، این بدتر خواهد بود، زیرا کاربران باید به ترتیب برای هر ویژگی یک پارامتر را مشخص کنند.
در این مقاله، با در نظر گرفتن جنبههایی که در بالا توضیح داده شد، یک روش جدید، جامع و ترکیبی اندازهگیری چگالی مبتنی بر ویژگی ایجاد کردیم. در روش خود، مفهوم جدیدی را برای توانایی حرکت تعریف میکنیم و نظریه میدان داده را که در مرجع [ 4 ] پیشنهاد شده است، برای اندازهگیری چگالی در اطراف یک نقطه GPS اعمال میکنیم. مفهوم جدید توانایی حرکت با دادن وزن وابسته به توانایی حرکت به چگالی در نظر گرفته می شود. در کار ما، آستانه چگالی به طور خودکار هنگام محاسبه نقاط اصلی تعیین می شود. پس از آن، از روش اندازهگیری چگالی خود برای بهبود الگوریتم اصلی DBSCAN (خوشهبندی فضایی مبتنی بر چگالی برنامهها با نویز) استفاده میکنیم.
بقیه مقاله ما به شرح زیر سازماندهی شده است. برخی از الگوریتم های رایج تشخیص توقف در بخش 2 ارائه شده است . در بخش 3 ، ما تعاریف برخی از مفاهیم اساسی، به عنوان مثال، تعاریف دقیق از مسیر GPS و توقف ها را ارائه می دهیم. پس از توصیف الگوریتم DBSCAN بهبود یافته خود در بخش 4 ، روش خود را با مجموعه داده های واقعی هم از نظر امکان سنجی و هم از نظر کارایی با مقایسه آن با چهار الگوریتم دیگر در بخش 5 تأیید می کنیم . ما کار خود را در بخش 6 به پایان می رسانیم .
2. آثار مرتبط
در این بخش، بررسی الگوریتمهای خوشهبندی توصیف یا تحلیل شده در ادبیات ارائه میکنیم. برای استخراج مکان های توقف در مسیرهای GPS می توان از روش های مختلفی استفاده کرد. به طور کلی روش های تشخیص توقف را می توان در دو دسته روش های استاتیک و روش های دینامیکی خلاصه کرد. در تکنیک های استاتیک [ 2 ، 3]، موقعیت های مهم مانند پمپ بنزین ها از قبل تعریف شده است. هنگام استخراج توقف از مسیرها، اگر اهداف وارد یک منطقه از پیش تعریف شده شوند و مدت اقامت از آستانه مدت زمان بیشتر شود، این منطقه از قبل تعریف شده به عنوان محل توقف در مسیر در نظر گرفته می شود. اشکال اصلی الگوریتم های استاتیک این است که کاربران باید مکان های مورد علاقه خود را مشخص کنند. در نتیجه، اگر از قبل توسط کاربران ارائه نشده باشند، برخی از مکان های توقف جالب و شخصی سازی شده پیدا نمی شوند.
در مورد رویکردهای پویا، هیچ دانش قبلی در مورد توقف ها داده نشده است و مکان های توقف شخصی را می توان کشف کرد. منابع متعدد از ادبیات راه حل پویا را با در نظر گرفتن جنبه های مختلف ویژگی های تحرک مورد مطالعه قرار داده اند [ 5 ، 6 ، 7 ، 8 ، 9 ، 10 ]. تنها با در نظر گرفتن ویژگیهای فضایی، چندین الگوریتم خوشهبندی کلاسیک برای استخراج توقفها از یک مسیر معرفی شدهاند. یک مدل پیشبینیکننده، بر اساس موقعیتهای توقف خودکار شناساییشده، در مرجع [ 11] پیشنهاد شده است]، و نویسندگان تنوعی از روشهای سنتی K-Means را برای شناسایی مکانهای توقف اتخاذ کردند. انتخاب مقدار پارامتر K و مرکز خوشه بندی اولیه مسئله اصلی است و مستقیماً بر نتایج نهایی تأثیر می گذارد. الگوریتم DBSCAN [ 12 ] در مرجع [ 13 ] برای استخراج مکان های مهم استفاده شده است. در مرجع [ 14 ]، یک الگوریتم DBSCAN اصلاحشده، DJ-Cluster (الگوریتم خوشهبندی مبتنی بر چگالی و پیوند)، برای شناسایی مکانهای معنادار شخصی پیشنهاد شده است. این الگوریتمهای خوشهبندی مبتنی بر چگالی میتوانند بر بسیاری از محدودیتهای رویکرد K-Means غلبه کنند [ 15]]؛ با این حال، آنها فقط ابعاد مکانی را در نظر می گیرند و ویژگی های ترتیبی زمانی نادیده گرفته می شوند.
در مقایسه با الگوریتمهایی که در بالا توضیح داده شد، بسیاری از مطالعات ویژگیهای مکانی و زمانی را در نظر گرفتهاند. روشهای مشتق متفاوت روش DBSCAN، با مشخصه ترتیبی زمانی در نظر گرفته شده است، توسط بسیاری از محققین به منظور استخراج موقعیتهای توقف [ 5 ، 6 ، 14 ، 16 ، 17 ] اتخاذ شده است. در مرجع [ 5 ]، یک الگوریتم DBSCAN بهبود یافته با درمان شکاف برای تشخیص اپیزودهای توقف در یک مسیر پیشنهاد شد. الگوریتم CB-SMoT (ایستها و حرکتهای مسیرهای مبتنی بر خوشه) در مرجع [ 6] پیشنهاد شد.] برای استخراج توقف های شناخته شده و ناشناخته. همانطور که سرعت زمانی و ویژگیهای مکانی را در نظر میگیرد، CB-SMoT یک الگوریتم خوشهبندی مبتنی بر چگالی است. در جزئیات، خوشهها با ارزیابی نقاط نمونه مسیر با سرعت کمتری نسبت به آستانه سرعت تولید میشوند. علاوه بر این، یکی از پارامترهای اصلی در مرجع [ 6 ]، یعنی Eps (آستانه فاصله معینی که اطراف آن نقاط به عنوان همسایه در نظر گرفته می شوند)، با استفاده از یک تابع چندک به دست می آید. همانطور که در مرجع [ 16 ] توضیح داده شد، تابع quantile در مرجع [ 6 ] همیشه در تخمین مقدار مناسب برای پارامتر Eps کار نمی کند و تعیین آستانه مناسب برای پارامتر را دشوار می کند. روش پیشنهادی در مرجع [16 ] الگوریتم CB-SMoT را با پیشنهاد جایگزینی برای محاسبه پارامتر Eps بهبود میبخشد، اما هنوز محاسبه آن دشوار است زیرا تشخیص بخش کم سرعت و سرعت بالا به کاربران بستگی دارد. علاوه بر این، با اختصاص آستانه های مختلف به ویژگی های مختلف، برخی از رویکردهای خوشه بندی پیشنهاد شده است [ 18 ، 19 ، 20 ، 21 ]. به خصوص، اطلاعات از ماهواره ها در الگوریتم TDBC (یک روش خوشه بندی مکانی-زمانی که برای استخراج نقاط توقف از مسیر منفرد استفاده می شود) معرفی شده است [ 21 ]. علاوه بر این، یک الگوریتم خوشهبندی مبتنی بر زمان در مرجع [ 18] پیشنهاد شد] و هم آستانه فاصله خوشه بندی و هم آستانه زمانی مورد نیاز است.
روش های ذکر شده در بالا می توانند عملکرد مطلوبی را در برخی شرایط به دست آورند. با این حال، این روش ها نیز معایب خود را دارند. اکثر این روش ها نیاز به اختصاص مقادیر آستانه مناسب برای هر پارامتر دارند. هنگام محاسبه چگالی نقاط GPS، اکثر الگوریتمهای مبتنی بر خوشهبندی، تعداد نقاط GPS را در یک فاصله معین، بدون در نظر گرفتن ویژگیهای تبعی آنها، در نظر میگیرند. در این مقاله، چگالی نقاط GPS با استفاده از نقاط مجاور بر روی مسیر محاسبه خواهد شد، اما نه از نقاط فضایی کلی. ابتدا مفهوم جدید قابلیت حرکت را تعریف می کنیم. با بهترین دانش نویسندگان، ویژگی توانایی حرکت برای اولین بار در تشخیص توقف ارائه شد. پس از آن، با ترکیب نظریه میدان داده، ارائه شده در مرجع [ 4]، و مفهوم جدید ما از توانایی حرکت، یک روش جدید، جامع، مبتنی بر ویژگی ترکیبی و اندازهگیری چگالی ایجاد میکنیم. در روش ما، آستانه چگالی به طور خودکار هنگام محاسبه نقاط هسته تعیین می شود. در نهایت، ما از روش اندازهگیری چگالی خود برای بهبود الگوریتم اصلی DBSCAN استفاده میکنیم.
3. مفاهیم اساسی
در این بخش، ما تعاریف مسیر GPS، توقف و حرکت را بر اساس تعاریف کلی در مرجع [ 1 ] نشان می دهیم. این تعاریف در ادامه این مقاله استفاده خواهد شد. این تعاریف با توجه به کاربرد خاص مورد مطالعه در این مقاله ارائه شده است. به عنوان مثال، ارتفاع در این مقاله در نظر گرفته نشده است زیرا تغییرات کمی در ارتفاع در مناطق شهری وجود دارد.
تعریف 1.
مسیر GPS: مسیر GPS لیستی از نقاط داده GPS است { پ0= (ایکس0،y0،تی0)�0=(�0,�0,�0)، پ1= (ایکس1،y1،تی1) ، … _پn= (ایکسn،yn،تیn)�1=(�1,�1,�1),…,��=(��,��,��)}، جایی که ∀ i ∈ [ 1 , n ]∀�∈[1,�]، پمن= (ایکسمن،yمن،تیمن)��=(��,��,��)و تیمن<تیمن + 1��<��+1، و ایکسمن��، yمن��و تیمن��به ترتیب طول، عرض جغرافیایی و مهر زمان را نشان می دهند.
ایستگاهها مکانهای قابل توجهی از مسیر GPS را نشان میدهند که هدف در آن زمان کمتری را صرف کرده است و اساساً با چگالی بالاتر نقاط GPS. یک حرکت نشان دهنده مسیر بین توقف ها است و مجهز به چگالی کمتری از نقاط GPS است. در مرجع [ 1 ]، Spaccapietra برخی از ویژگی های آنها را تعریف کرد.
تعریف 2.
توقف: توقف بخشی از یک مسیر است و ویژگی ها به شرح زیر است: (1) کاربر به صراحت این قسمت از مسیر را برای نشان دادن یک توقف تعریف کرده است. (ii) وسعت زمانی یک بازه زمانی غیر خالی است. (iii) جسم در حال حرکت تا آنجا که به نمای کاربردی این مسیر مربوط می شود حرکت نمی کند. و (IV) همه توقفها در یک مسیر به طور موقت از هم جدا هستند، یعنی وسعت زمانی دو توقف همیشه از هم جدا هستند.
تعریف 3.
حرکت: یک حرکت بخشی از یک مسیر است، به این صورت که: (1) آن قسمت با دو انتهای مشخص می شود که یا دو توقف متوالی را نشان می دهد، یا تیb e gمن n������و اولین توقف، یا آخرین توقف و تیe n d����، یا [ تیb e gمن n������، تیe n d����] (موردی که مسیری توقف ندارد). (ii) وسعت زمانی [ تیb e gمن n������، تیe n d����] یک بازه زمانی غیر خالی است. (iii) محدوده فضایی یک مسیر برای [ تیb e gمن n������، تیe n d����] بازه یک خط مکانی-زمانی (نه یک نقطه) است که توسط مسیر مشخص می شود، جایی که تیb e gمن n������نقطه ابتدایی مسیر است و تمایل نقطه پایانی است .
تعریف 4.
فاصله: فاصله بین دو نقطه < پn،پمتر��,��> با :
جایی که R نشان دهنده شعاع زمین است ( R = 6371 km _ �=6371 �متر) l aتیn�آ��و l aتیمترلآتیمترنشان دهنده عرض های جغرافیایی پnپ�و پمترپمتر، به ترتیب؛ به همین ترتیب، l gتیnل�تی�و l gتیمترل�تیمترنشان دهنده طول جغرافیایی
تعریف 5.
فاصله منحنی مسیر: فاصله منحنی یک بخش زیر مسیر، t r ajn m�����متر، که از دنباله ای از نقاط تشکیل شده است {پn،پn + 1, … ,پمتر}{��,��+1,…,��}، و با نشان داده می شود
تعریف 6.
فاصله مستقیم مسیر: فاصله مستقیم بخش زیر مسیر t r ajn m= {پn،پn + 1, … ,پمتر}تی�آ��متر={پ�،پ�+1،…،پمتر}مساوی فاصله بین نقطه اول و آخرین نقطه در مسیر فرعی است و با :
به طور کلی، هنگامی که یک هدف در یک منطقه توقف می ماند، فاصله مستقیم مسیر متناظر بسیار کمتر از فاصله منحنی مسیر است. برعکس، زمانی که هدف بین مناطق توقف حرکت می کند، فاصله مستقیم مسیر مربوطه نزدیک به فاصله منحنی مسیر خواهد بود. با در نظر گرفتن این موضوع، ما مفهوم جدید خود را از توانایی حرکت پیشنهاد می کنیم.
تعریف 7.
توانایی حرکت: توانایی حرکت یک بخش زیر مسیر t r ajn m= {پn،پn + 1, … ,پمتر}تی�آ��متر={پ�،پ�+1،…،پمتر}با نشان داده می شود:
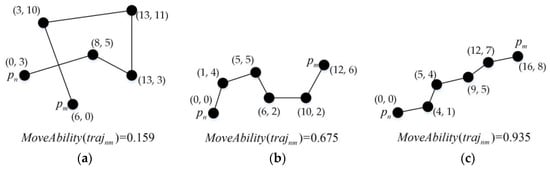
شکل 2 مفهوم توانایی حرکت را نشان می دهد. در شکل سه مسیر فرعی وجود دارد که هر کدام شامل شش نقطه است. در جزئیات، مختصات هر نقطه، طول و عرض جغرافیایی مکانی را در دنیای واقعی نشان می دهد. علاوه بر این، برای سادگی، از فاصله اقلیدسی در این تصویر برای محاسبه ویژگی های توانایی حرکت استفاده شده است. این سه زیرمسیر مسیرهای واقعی مربوط به موقعیت های مختلف را نشان می دهند: شکل 2 a فعالیت در یک توقف را نشان می دهد. شکل 2 ب حرکت در جاده های منحنی را نشان می دهد. شکل 2 c نشان دهنده یک حرکت خطی در واقعیت است. مقایسه توانایی حرکت هر یک از مسیرهای فرعی در شکل 2، نتایج با استدلال ما که در بالا توضیح داده شد مطابقت دارد.
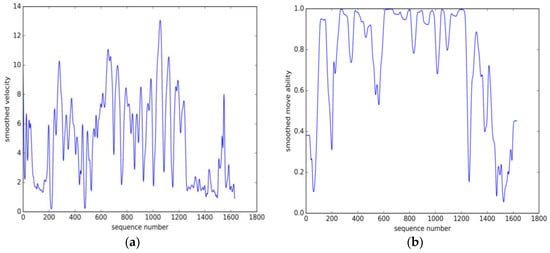
علاوه بر این، متوجه شدیم که مفهوم جدید ما از توانایی حرکت برای تشخیص قسمتهای حرکت و توقف مناسبتر است. مقایسه کیفی بین ویژگی سرعت و توانایی حرکت انجام شد. با در نظر گرفتن یک مسیر واقعی به عنوان مثال، منحنی سرعت پس از هموارسازی گاوسی در شکل 3 الف نشان داده شده است. منحنی سرعت نشان میدهد که سرعت اجسام متحرک میتواند بهطور چشمگیری تغییر کند و بخشهای کوتاه و کمسرعت زیادی در قطعات پرسرعت وجود دارد که ممکن است ناشی از کند شدن کوتاه در حرکت باشد. در مقایسه، منحنی توانایی حرکت پایدارتر و تبعیض آمیزتر است. منحنی توانایی حرکت هموار، با استفاده از همان هسته گاوسی، در شکل 3 نشان داده شده است.ب به خصوص، مقدار کمی برای توانایی حرکت تنها زمانی به دست می آید که هدف در حرکت در اطراف یک منطقه خاص، که احتمالاً یک منطقه توقف است، باقی بماند. علاوه بر این، حتی یک مسیر فرعی با سرعت کم نیز ممکن است به توانایی حرکت بالایی دست یابد. به عنوان مثال، هنگامی که یک هدف تقریباً خطی با سرعت کم حرکت می کند، این می تواند به حذف برخی از توقف های ساختگی مانند ترافیک کوتاه مدت کمک کند.
4. روش شناسی
اساس رویکرد ما این است که قسمت توقف یک مسیر باید دارای توانایی حرکت کمتر و چگالی بیشتر نقاط GPS باشد. بنابراین، پیدا کردن یک روش مناسب برای تخمین چگالی زمانی که توانایی حرکت در نظر گرفته میشود، معنادار است. مخصوصاً هنگام برخورد با شکاف های طولانی مدت در یک مسیر، هیچ درمان خاصی انجام نمی شود. این شکافها در مسیر ممکن است به دلیل بسیاری از چیزها ایجاد شوند، مانند تمام شدن شارژر GPS. این نامناسب است که فرض کنیم یک هدف در همان مکان باقی می ماند. در روش ما، چگالی نقطه مسیر در نظر اولیه است و شکاف های زمانی کوتاه در مسیرها تأثیر کمی بر نتایج دارد.
به دنبال استدلال شرح داده شده در بالا، ما یک روش جامع، مبتنی بر ویژگی ترکیبی، روش اندازهگیری چگالی را پیشنهاد میکنیم. علاوه بر این، ما الگوریتم اصلی DBSCAN را با استفاده از روش اندازهگیری چگالی خودمان بهبود میدهیم.
4.1. تابع چگالی
DBSCAN [ 12 ] یک روش کلاسیک خوشه بندی مبتنی بر چگالی است. چگالی یک نقطه جریان با تعداد نقاط در فاصله معینی از نقطه فعلی اندازه گیری می شود. در کار خود، با در نظر گرفتن مفهوم جدید خود از توانایی حرکت، روشی را برای اندازه گیری چگالی با معرفی میدان داده پیشنهاد شده توسط لی و همکاران پیشنهاد می کنیم. [ 4 ]. با توجه به میدان داده، هر نقطه مسیر یک تاثیر تعاملی از نقاط دیگر دریافت خواهد کرد. بدون از دست دادن کلیت، تأثیر بین نقاط را با استفاده از یک تابع گاوسی که دارای خواص ریاضی قابل قبولی است، تخمین زدیم و معادله به صورت زیر نشان داده شده است:
جایی که پمن��(i = 1، …، n ) یک نقطه مسیر را نشان می دهد، دمن ج���برابر فاصله بین پمن�منو پjپ�، و σ1�1نشان دهنده انحراف معیار است.
در کار خود، ما جمع بندی تاثیر مجموعه ای از نکات قبل و بعد را در نظر می گیریم پکپکبه عنوان جایگزینی برای چگالی تعداد این نقاط مجاور به عنوان پارامتر ورودی Nap ارائه می شود . علاوه بر این، مفهوم جدید خود از توانایی حرکت را با ضرب تابع وزن مربوط به توانایی حرکت در نظر می گیریم. چگالی نهایی نقاط به صورت زیر محاسبه می شود:
جایی که مآمن���نشان دهنده توانایی حرکت مسیر فرعی است که با نقاط مجاور که در بالا توضیح داده شد نشان داده می شود. σمآ���نشان دهنده انحراف استاندارد تابع وزن و adj(i) نشان دهنده نقاط مجاور قبل و بعد است. پمن��و سایر پارامترها مانند معادله (5) هستند.
4.2. DBSCAN بهبود یافته است
در روش ما، بیشتر مفاهیم DBSCAN همان تعریف اصلی است [ 12 ]. به جای استفاده از حداقل تعداد نقاط برای تعریف نقطه مرکزی، نقطه اصلی را به صورت زیر تعریف می کنیم:
تعریف 8.
نقطه مرکزی: یک نقطه مسیر پمن= (ایکسمن،yمن،تیمن)��=(��,��,��)یک مسیر با توجه به MinDensity نقطه مرکزی نامیده می شود، اگر φ (پمن) > مi n D e n s i t y�(��)>����������، جایی که MinDensity آستانه چگالی را نشان می دهد .
در مقاله ما، برای یافتن مقدار مناسب برای MinDensity ، مانند روش کمی در کار یوان [ 22 ]، “نقطه آرنج” را به عنوان آستانه در نظر می گیریم. “نقطه زانو” به نقطه ای با حداکثر انحنا اشاره دارد و معمولاً نقطه برش دو حالت را نشان می دهد. در روش ما، یک روش محاسبه انحنا، KD (تکنیکی برای تخمین انحنا روی منحنیها) انحنای [ 23 ]، برای تعیین «نقطه زانو» استفاده میشود. با گرفتن سه امتیاز متوالی، {پمن – 1، پمن،پمن + 1}{پمن–1، پمن،پمن+1}به عنوان مثال، انحنای KD مربوطه به صورت زیر محاسبه می شود:
جایی که γمن= ∠ (پمن – 1پمن، پمن + 1پمن)�من=∠(پمن–1پمن، پمن+1پمن)و η= ( |پمن – 1پمن| + |پمن + 1پمن| )�=(|پمن–1پمن|+|پمن+1پمن|)/2.
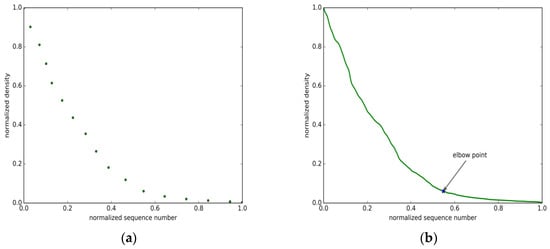
علاوه بر این، توالی چگالی در عمل به طور مکرر در نوسان است و به اندازه کافی صاف نیست و محاسبه “نقطه آرنج” را دشوار می کند. برای به دست آوردن نقطه آرنج دقیق، منحنی چگالی را با یک هسته گاوسی صاف می کنیم. پس از آن، با در نظر گرفتن مختصات افقی و عمودی به یک اندازه مهم، یک روش نرمال سازی برای نرمال کردن دنباله چگالی اتخاذ می شود. علاوه بر این، منحنی چگالی را با نمونهبرداری با فاصله طولی معین گسسته میکنیم و محاسبه «نقطه زانو» را آسانتر میکنیم. با در نظر گرفتن یک آهنگ در مجموعه داده واقعی ما به عنوان مثال، دنباله چگالی اصلی غیر هموار در شکل 4 a نشان داده شده است. توالی چگالی پس از صاف کردن در شکل 4 نشان داده شده استب. شکل ها نشان می دهد که در واقع نوسانات و شکاف هایی در دنباله وجود دارد. در الگوریتم ما، دنباله چگالی نرمال شده، پس از نمونه برداری با فاصله طولی Δl = 0.1 _Δل=0.1، در شکل 5 الف نشان داده شده است. ستاره در شکل 5 b به “نقطه آرنج” نهایی در دنباله چگالی نرمال شده اشاره دارد که با یک فلش سیاه نشان داده شده است.
در نهایت، یک مرحله ادغام در الگوریتم DBSCAN بهبود یافته ما معرفی شده است. در جزئیات، دو توقف متوالی با موقعیت جغرافیایی یکسان و یک فاصله زمانی کوتاه ادغام می شوند. این با زندگی واقعی مطابقت دارد، زیرا مردم همیشه در مناطق خاصی حرکت می کنند و در نتیجه چندین ایستگاه کوچک مکانی-زمانی مشابه در همان منطقه ظاهر می شوند. در آزمایشات ما، اگر فاصله بین آنها کمتر از 200 متر و فاصله زمانی کمتر از یک ساعت باشد، دو توقف متوالی با هم ادغام می شوند.
در مقایسه با الگوریتم اصلی DBSCAN، روش ما شامل دو اصلاح اصلی برای خوشهبندی در مسیرهای منفرد است: (من) با پیشنهاد مفهوم جدید توانایی حرکت و معرفی تئوری میدان داده، یک روش اندازهگیری جدید برای چگالی پیشنهاد میکنیم. علاوه بر این، ما چندین نکته را قبل و بعد از آن می گیریم پمنپمندر نظر گرفتن برای اندازه گیری تراکم محلی. (2) با معرفی روش کمی از یوان [ 22 ]، روش ما می تواند به طور خودکار مقدار مناسبی را برای آستانه چگالی انتخاب کند.
5. نتایج تجربی
در این بخش، الگوریتم DBSCAN بهبود یافته خود را از طریق آزمایشهایی بر روی مجموعه دادههای مسیر واقعی تأیید میکنیم. آزمایشهای مقایسهای بین روش ما و دو الگوریتم کلاسیک خوشهبندی مبتنی بر چگالی انجام شد. در بخش های بعدی، ابتدا مجموعه داده ها را مورد بحث قرار می دهیم و سپس نتایج تجربی مربوطه نشان داده می شود.
5.1. توضیحات مجموعه داده ها
در این مقاله، ما از مجموعه داده Geolife و مجموعه داده های جمع آوری شده خود برای انجام آزمایش های خود استفاده می کنیم. مجموعه داده Geolife توسط Microsoft Research Asia در طول پروژه Geolife آنها جمع آوری شد. مسیرهای 182 کاربر را از آوریل 2007 تا آگوست 2012 نشان می دهد. در مجموع، این مجموعه داده شامل 17621 مسیر است. هر مسیر در این مجموعه داده متشکل از دنباله ای از نقاط زمانی، مرتب و دارای مهر زمانی است. هر نقطه حاوی اطلاعات مختصات جغرافیایی است، مانند طول جغرافیایی، عرض جغرافیایی و ارتفاع. علاوه بر این، بیش از 90٪ از این مسیرها در یک نمایش متراکم، یعنی هر 5-10 متر یا 1-5 ثانیه در هر نقطه ثبت شدند.
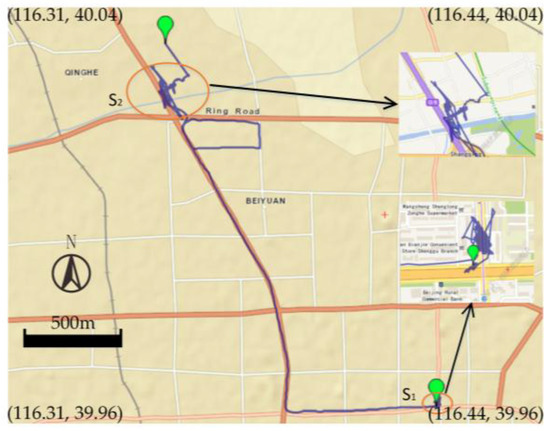
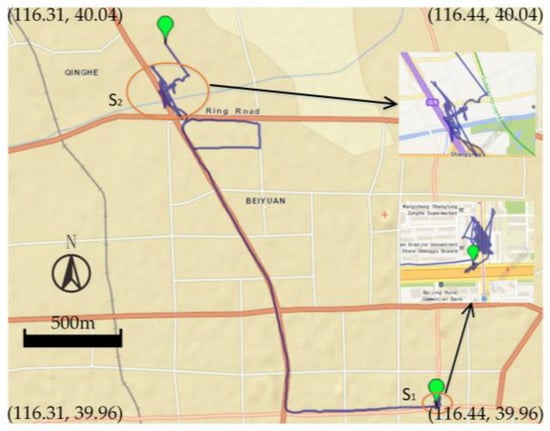
در آزمایش ما، یک ابزار نرم افزاری بر اساس API های نقشه های بینگ، که یک سرویس نقشه برداری وب ارائه شده توسط مایکروسافت است، توسعه یافت. بر اساس این نرم افزار، صدها مسیر توسط گروهی از دستیاران پژوهشی مورد بازرسی بصری قرار گرفت. در طول این کار، مناطق با تراکم بالا و مدت زمان طولانی به عنوان توقف نامگذاری شدند. یک مسیر واقعی برچسبگذاری شده در مجموعه داده ما در شکل 6 نشان داده شده استاس1اس1و اس2اس2نشان دهنده دو ایستگاه با توجه به اینکه بخش های مسیر کوتاه زیادی در مجموعه داده Geolife وجود دارد، مسیرهای انتخاب شده برای آزمایش ما باید به اندازه کافی طولانی باشد تا مطمئن شود که در مسیرها واقعاً توقف وجود دارد. در نهایت، به منظور تأیید الگوریتم خود، از 100 مسیر نشاندار استفاده کردیم که از مجموعه داده Geolife انتخاب شدهاند و بیش از 50 کاربر را پوشش میدهند. به طور دقیق، مسیرهای منتخب ما روزانه توسط داوطلبان ثبت می شد و شامل روش های مختلف حمل و نقل، مانند پیاده روی و دوچرخه سواری است. علاوه بر این، تمام مسیرها مسیر شهری بودند.
مجموعه داده دوم در آزمایشات ما توسط تیم ما از زندگی روزمره و با استفاده از تلفن همراه جمع آوری شد. در مجموع، این مجموعه داده شامل مسیرهای تیم ما به مدت یک ماه بود و هر 2 ثانیه در هر نقطه ثبت می شد. تمام توقف ها در این مسیرها با جزئیات ثبت شد. در آزمایشهای ما، 14 مسیر از این مجموعه داده برای تأیید اثربخشی الگوریتم جدید ما انتخاب شد.
5.2. برآورد پارامتر
در الگوریتم DBSCAN بهبود یافته ما، همانطور که در رابطه (6) نشان داده شده است، سه پارامتر برای تعیین مدل محاسبه چگالی وجود دارد. اینها عبارتند از Nap (تعداد نقاط مجاور)، σ1�1و σمآ�مآ. به منظور یافتن مقدار مناسب برای این پارامترها، ما از دادههای مسیر واقعی در مجموعه داده خود برای انجام آزمایشهای شبیهسازی برای هر پارامتر استفاده کردیم. نتایج برآورد این سه پارامتر در شکل 7 نشان داده شده است .
در الگوریتم DBSCAN بهبود یافته ما، پارامتر σمآ�مآوزن اختصاص داده شده به توانایی های حرکتی مختلف را تعیین می کند. همانطور که قبلاً توضیح داده شد، هنگامی که هدف در یک منطقه می ماند، مسیرهای فرعی حاصل از توانایی حرکت کمتری برخوردار هستند. هنگامی که هدف از یک منطقه به منطقه دیگر حرکت می کند، مسیرهای فرعی حاصل توانایی حرکت بیشتری دارند. شکل 7 a تغییرات وزن توانایی حرکت با پارامتر را نشان می دهد σمآ�مآ. وزن بالا باید به نقطه ای با توانایی حرکت کم و وزن کم به نقطه ای با توانایی حرکت بالا داده شود. پارامتر پیدا کردیم σمآ= 0.5�مآ=0.5مطلوب باشد زیرا ارزش یک وزن دارای توزیع زیادی است، بدون اینکه باعث تمایز جدی دو مرحله ای شود.
پارامتر σ1�1تاثیر تعاملی بین نقاط مسیر را تعیین می کند. در الگوریتم ما، از مجموع تاثیرات از نقاط مجاور برای اندازه گیری چگالی در اطراف یک نقطه مسیر مشخص استفاده می شود. در این میان هر نقطه از نقاط نزدیکتر ضربه قوی تری و از نقاط دورتر ضربه ضعیف تری دریافت می کند. یک تنظیم کمتر از σ1�1منجر به دریافت ضربه ضعیف تر از نقاط دورتر می شود. چه زمانی σ1�1مقدار بسیار کمی داده می شود، نقاط مسیر تنها از نقاط نزدیکتر تأثیر مؤثری دریافت می کنند.
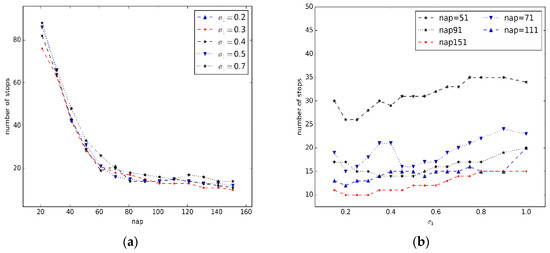
پارامتر Nap تعداد نقاط مجاور در نظر گرفته شده در محاسبات چگالی ما را نشان می دهد. هنگامی که به پارامتر Nap مقدار خیلی کوچک داده می شود، چگالی توسط چند نقطه مجاور تعیین می شود و در نتیجه استحکام کمتری در برابر نویز ایجاد می شود. علاوه بر این، Nap بر اندازه خوشه ها تأثیر دارد. از آنجایی که افراد همیشه در مقیاس کوچک حرکت میکنند، حتی زمانی که در یک منطقه توقف خاص میمانند، برای مثال دانشآموزان هنگام انجام فعالیتهایی در زمین بازی از مکانی به مکان دیگر حرکت میکنند، مقدار تنظیمی بسیار کوچک برای پارامتر Nap باعث کاهش اندازه خوشهها میشود . و یک منطقه توقف بزرگتر را به چندین ایستگاه کوچکتر تقسیم کنید. با این حال، مقدار تنظیمی برای Nap بسیار بزرگ استتشخیص توقف های کوچکتر را دشوار می کند، زیرا تغییرات کوچک محلی توانایی حرکت هموار می شود.
به منظور یافتن مقدار مناسب برای سه پارامتر در الگوریتم خود، پنج بخش مسیر را از مجموعه داده Geolife برای انجام آزمایشهای شبیهسازی برای هر پارامتر انتخاب کردیم. با مشاهده تعداد کل توقف های شناسایی شده برای ترکیب های مختلف پارامترها، محدوده مناسب مقادیر برای هر پارامتر تعیین شد. مرحله ادغام در الگوریتم ما در آزمایشهای شبیهسازی حذف شد، زیرا توقفهای کوچکی که نزدیک به یکدیگر هستند ممکن است ادغام شوند. شکل 7b تعداد توقف های کشف شده برای مقادیر مختلف پارامتر را نشان می دهد σمآ�مآ. برای هر منحنی در شکل 7 ب، پارامتر Nap و پارامتر σ1�1روی یک مقدار ثابت تنظیم می شوند. از نمودار شکل 7 ب، می بینیم که منحنی به طور چشمگیری کاهش می یابد σمآ�مآکمتر از 0.5 است. از سوی دیگر، زمانی که مقدار پارامتر σمآ�مآبزرگتر از 0.5 است، منحنی تمایل به پایداری دارد. بنابراین، مقدار پارامتر σمآ�مآدر آزمایش ها کمتر از 0.5 تنظیم شد.
به همین ترتیب، با این فرض که σمآ= 0.5�مآ=0.5، تعداد توقف های شناسایی شده با مقادیر مختلف برای Nap و σ1�1به ترتیب در شکل 8 a,b نشان داده شده است. شکل 8 الف نشان می دهد که تعداد توقف های شناسایی شده به شدت کاهش می یابد تا اینکه نa p > 50نآپ>50. هنگامی که مقدار Nap بزرگتر از 50 تنظیم می شود، منحنی ها تمایل به پایداری دارند. تغییر در تعداد توقف های شناسایی شده با مقادیر مختلف برای σ1�1در شکل 8 ب نشان داده شده است . نمودار نشان می دهد که تعداد توقف های شناسایی شده به آرامی با افزایش در افزایش می یابد σ1�1. در آزمایشهای ما، مقدار Nap بیشتر از 50 تنظیم شد. در مورد پارامتر σ1�1با توجه به اینکه مقدار نباید خیلی کوچک باشد، پارامتر را به صورت تنظیم می کنیم σ1> 0.3�1>0.3.
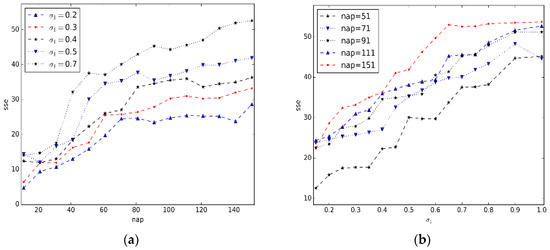
در این مقاله، با استفاده از یک بخش مسیر انتخاب شده از مجموعه داده Geo-life، مقادیر پارامترهای Nap و Nap را بیشتر تخمین زدیم.σ1�1با مشاهده sse (مجموع مجذور خطا). همانطور که در مرجع [ 24 ] توضیح داده شد، sse یک ارزیابی از پارتیشن بندی مکان های شناسایی شده است. هر چه مقدار sse کوچکتر باشد، خوشه ها بهتر هستند. به خصوص زمانی که تعداد توقف ها بسیار زیاد می شود، sse تمایل به بسیار کوچک دارد. با این حال، این به معنای نتیجه خوبی برای خوشه بندی نیست.
به منظور تخمین مقادیر پارامترهای Nap و σ1�1، پارامتر σمآ�مآروی یک مقدار ثابت تنظیم شده است ( σمآ= 0.5�مآ=0.5). شکل 9 a تغییرات sse را با رشد Nap نشان می دهد . وقتی sse کوچک استنa p < 50نآپ<50و وقتی بزرگ می شود نa p > 50نآپ>50. بنابراین مقدار پارامتر Nap به صورت تنظیم شد نa p > 50نآپ>50در آزمایشات ما شکل 9 ب تغییرات sse را با رشد نشان می دهدσ1�1. ما می توانیم دریابیم که بزرگتر σ1�1است، هر چه sse بزرگتر می شود. این با استدلال ما مطابقت دارد σ1�1نباید خیلی کوچک تنظیم شود.
5.3. ارزیابی اثربخشی
به منظور تأیید امکانسنجی الگوریتم خود، روش خود را با چهار الگوریتم تشخیص توقف دیگر، الگوریتم CB-SMoT [ 6 ]، الگوریتم DBSCAN، الگوریتم DJ-Cluster [ 14 ] و خوشهبندی مبتنی بر زمان [ 18 ] مقایسه کردیم. ، با استفاده از مجموعه داده عمومی و مجموعه داده جمع آوری شده خودمان. در این مقاله، ما الگوریتم خود را با استفاده از همان روش آزمایشی شرح داده شده در مرجع [ 25 ]، که از همان مجموعه داده Geolife نیز استفاده میکرد، تأیید میکنیم. در آزمایشات ما، محاسبه دقت و یادآوری به شرح زیر است:
علاوه بر این، همانطور که در مرجع [ 25 ] توضیح داده شد، میانگین وزنی هارمونیک دقت و یادآوری، افاندازه گرفتنافاندازه گرفتن، به صورت زیر محاسبه می شود:
در آزمایش اول، ما یک آزمایش مقایسهای را روی 100 مسیر نشاندار انجام دادیم که از مجموعه دادههای عمومی Geolife انتخاب شدند. علاوه بر این، به منظور بررسی اثرات تجربی ترکیبهای مختلف پارامترها، آزمایش را با ترکیبهای مختلف پارامترها برای الگوریتم DBSCAN بهبود یافته خود اجرا کردیم. به طور مفصل، تمام پارامترهای روش ما با توجه به بحث در بخش 5.2 انتخاب شدند . در آزمایشات ما، پارامتر σمآ= 0.5�مآ=0.5و بدون تغییر باقی ماند.
جدول 1 نتایج تجربی الگوریتم ما را با استفاده از ترکیبات مختلف پارامترها نشان می دهد. نتایج نشان می دهد که الگوریتم ما بهترین عملکرد را زمانی دارد σ1= 0.3�1=0.3و Nap =51 در مجموعه داده ما. علاوه بر این، متوجه شدیم که دقت با افزایش پارامتر Nap افزایش مییابد ، اما فراخوان کاهش مییابد. دلیل اصلی این امر این است که وقتی Nap بزرگتر شد، تغییرات محلی چگالی هموار شد. در نتیجه، فقط توقف هایی با مدت زمان طولانی تر در الگوریتم ما یافت می شود. در همان زمان، برخی از استاپ های جعلی با افزایش Nap کنار گذاشته می شوند.
با توجه به چهار الگوریتم دیگر، ما چندین آزمایش را با استفاده از ترکیبات مختلف پارامترهای مربوطه اجرا کردیم. با در نظر گرفتن مقدار بهینه سه اندازه گیری یعنی دقت، فراخوان و افاندازه گرفتنافاندازه گرفتن، t ترکیب بهینه پارامترها برای اجرای آزمایشهای مقایسهای با استفاده از الگوریتم بهبودیافته انتخاب شدند. با توجه به الگوریتم CB-SMoT، از آنجایی که محاسبه با استفاده از تابع کمیت نامناسب است، همانطور که در مرجع [ 16 ] توضیح داده شد، مقدار Eps هنگام محاسبه ترکیب بهینه پارامترها به صورت دستی تنظیم شد.
جدول 2 نتایج تجربی الگوریتم ما و چهار الگوریتم خوشه بندی دیگر را با استفاده از مجموعه داده Geolife نشان می دهد. همانطور که در جدول 2 مشاهده می شود ، روش DBSCAN بهبود یافته بهتر از چهار الگوریتم دیگر در مجموعه داده های دنیای واقعی کار می کند.
در این مقاله متوجه شدیم که الگوریتم CB-SMoT قادر به مقابله با استاپ های جعلی نیست. به عنوان مثال، برخی از نقاط متحرک با سرعت کمتر، مانند عبور از چهارراه، به عنوان توقف توسط CB-SMoT شناسایی می شوند. دلیل اصلی این امر این است که الگوریتم CB-SMoT وابسته به سرعت است و بنابراین، قطعات کوتاه سرعت آهسته منجر به توقف های جعلی می شود. در مورد الگوریتم DBSCAN، در مقایسه با روش ما، اشکال اصلی این است که فقط اطلاعات چگالی مکانی را در نظر می گیرد. برخی از تقاطعهای یک جاده، که اغلب توسط کاربر بازدید میشود، بهعنوان توقف شناسایی میشوند. الگوریتم DJ-Cluster اصلاحی از روش اصلی DBSCAN است. با این حال، هنوز فقط اطلاعات مکانی را در نظر می گیرد. روش خوشه بندی مبتنی بر زمان به آستانه زمانی حساس است. در این مقاله، ما مفهوم جدید خود را از توانایی حرکت اعمال کردیم، به جای سرعت، برای تشخیص توقف. این دلیل مهمی است که روش ما موثرتر از بقیه است.
به منظور تأیید بیشتر امکانسنجی الگوریتم ما، و کاهش تأثیر دادههای برچسبگذاری شده مصنوعی بر آزمایش، آزمایش دوم با استفاده از مجموعه دادههای خود ما انجام شد که توسط نویسندگان جمعآوری شد. به طور دقیق، مجموعه داده شامل 14 بخش مسیر بود و توقف در هر مسیر ثبت شد. همانند آزمایش اول، پس از تعدادی آزمایش با ترکیب های مختلف پارامترهای مربوطه، پارامترهای بهینه مورد استفاده انتخاب شدند. در نهایت، توقف های شناسایی شده را با اطلاعات توقف ثبت شده مطابقت دادیم. نتایج تجربی در جدول 3 نشان داده شده است ، و مطابق با نتایج تجربی مجموعه داده Geolife برچسب گذاری شده است. الگوریتم DBSCAN بهبود یافته ما بهتر از چهار الگوریتم دیگر برای تشخیص توقف کار کرد.
به طور کلی، روش ما و چهار الگوریتم خوشه بندی دیگر را می توان برای تشخیص توقف در سناریوهای مربوطه استفاده کرد. CB-SMoT برای تشخیص برخی از توقف های بسیار کوچک، مانند ترافیک کوتاه، در صورتی که توقف های جعلی حیاتی نباشند، قابل استفاده است. مسیر ترافیک گرچه سرعت نسبتاً پایینی دارد، اما معمولاً یک حرکت خطی است. روش ما این پارازیتها را به عنوان توقف تشخیص نمیدهد، زیرا قابلیت حرکت مربوط به این بخشها نسبتاً بزرگ است. در مورد الگوریتمهای DBSCAN و DJ-Cluster، هر دو روش فقط اطلاعات مکانی را در نظر میگیرند و میتوانند اکثر مکانهایی را با تراکم نقاط مسیر بالاتر، به عنوان مثال، موقعیتهایی که توسط یک سوژه مرتباً بازدید میشوند، شناسایی کنند. روش خوشه بندی مبتنی بر زمان برای برخورد با مسیرهایی با فرکانس ثبت ناپایدار مناسب است. با در نظر گرفتن اطلاعات مکانی و زمانی، الگوریتم ما برای شناسایی توقف های فعالیتی که مدت زمان بیشتری دارند، بهتر عمل می کند. معمولاً کاربران فقط به این توقف های فعالیت علاقه دارند. علاوه بر این، روش ما برای توقفهای جعلی، مانند ترافیک، قویتر است.
5.4. ارزیابی کارایی
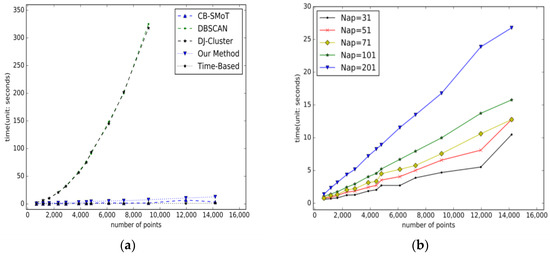
در این مقاله، ما همچنین ارزیابی کارایی محاسباتی الگوریتم DBSCAN بهبود یافته خود را انجام دادیم. ما الگوریتمها، روش خود و چهار روش دیگر را روی مجموعهای از مسیرها با تعداد نقاط مسیر متفاوت اجرا کردیم. زمان اجرای این آزمایش مقایسه ای برای ارزیابی کارایی ثبت شد. شکل 10 الف کارایی روش های مختلف را نشان می دهد. همانطور که از شکل 10 می بینیمa، منحنی های مربوط به هر دو الگوریتم DBSCAN و DJ-Cluster به شدت افزایش می یابد. این نشان می دهد که الگوریتم های DBSCAN و DJ-Cluster برای برخورد با مسیرهای طولانی مناسب نیستند. در مورد سه روش دیگر، کارایی محاسباتی الگوریتمها تقریباً خطی است. علاوه بر این، شکاف در کارایی بین این سه روش به اندازه ای کوچک است که قابل چشم پوشی باشد.
هر دو روش DBSCAN بهبود یافته و الگوریتم CB-SMoT روش های مشتق شده از الگوریتم DBSCAN هستند. تفاوت اصلی بین این روش های مشتق در نحوه تعریف یک نقطه اصلی است که منجر به تفاوت در پیچیدگی می شود. محاسبه فاصله بین تمام جفت نقاط مسیر در روش سنتی DBSCAN برای انتخاب نقاط اصلی مورد نیاز است. بنابراین، پیچیدگی روش DBSCAN است ای (n2)�(�2). با این حال، در روش ما و در الگوریتم CB-SMoT، فاصله تنها تا بخشی از نقاط مسیر برای تعیین اینکه آیا یک نقطه یک نقطه اصلی است یا خیر، ضروری است که منجر به پیچیدگی می شود. O ( n )�(�). در جزئیات بیشتر، پیچیدگی این الگوریتم ها متناسب با تعداد دفعاتی است که فاصله بین جفت نقطه محاسبه می شود. در روش ما، پارامتر Nap تعداد نقاط مجاور را نشان می دهد و به تعداد دفعاتی که فاصله بین جفت نقاط محاسبه می شود مربوط می شود. شکل 10 ب تأثیر پارامتر Nap را بر بازده محاسباتی نشان می دهد. نتایج نشان میدهد که یک مقدار بیشتر برای Nap منجر به زمان اجرای طولانیتر میشود که با تحلیلهای قبلی ما سازگار است.
6. نتیجه گیری
در این مقاله ابتدا مفهوم جدید توانایی حرکتی را ارائه کردیم. با معرفی تئوری میدان داده به منظور محاسبه چگالی نقاط مسیر، ما یک روش جدید، جامع، مبتنی بر ویژگی ترکیبی، روش اندازهگیری چگالی را برای بهبود روش اصلی DBSCAN پیشنهاد کردیم. در روش DBSCAN بهبود یافته ما، توانایی حرکت با دادن وزن بیشتر به توانایی حرکت پایینتر در نظر گرفته شد. علاوه بر این، آستانه چگالی را می توان به طور خودکار تعیین کرد. در آزمایشها، روش خود را با چهار الگوریتم خوشهبندی دیگر، CB-SMoT، DBSCAN، DJ-Cluster و خوشهبندی مبتنی بر زمان مقایسه کردیم. نتایج تجربی نشان میدهد که روش ما بهتر از روشهای سنتی کار میکند و امکانسنجی روش ما را نشان میدهد.





بدون نظر