

خلاصه
درونیابی مکانی-زمانی ; ناهمگونی ؛ کوواریانس مکانی-زمانی ; خوشه بندی
1. معرفی
2. درون یابی مکانی- زمانی: کارهای مرتبط و استراتژی ما
2.1. کار مرتبط
2.2. تحلیل انتقادی کار موجود و استراتژی ما
- (آ)
-
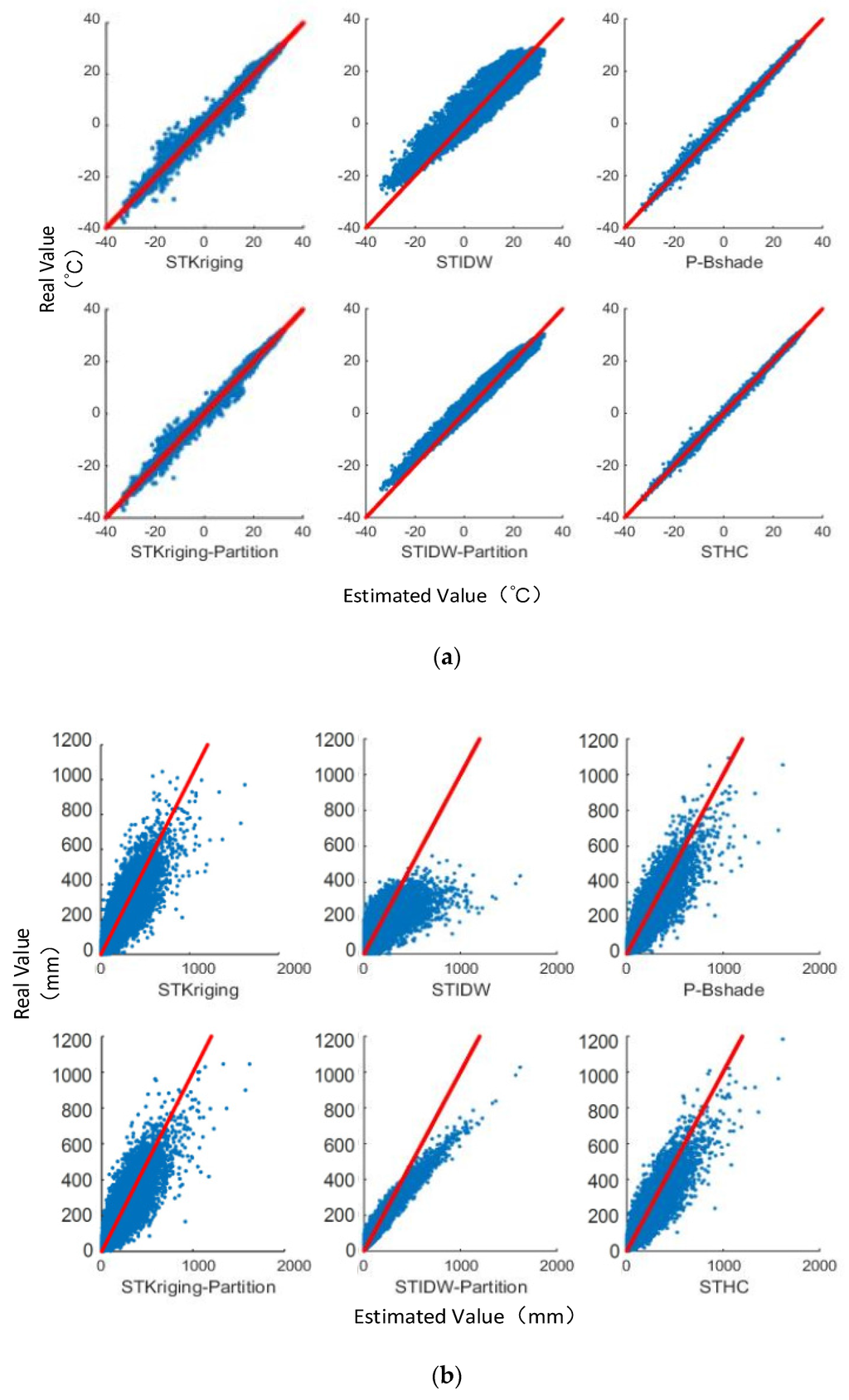
در حال حاضر، دادههای گمشده در مجموعه دادههای مکانی-زمانی عمدتاً با استفاده از روشهای درونیابی فضایی – به عنوان مثال، مدلهای رگرسیون فضایی، SRT، IDW، کریجینگ، و P-Bshade برآورد میشوند. بی توجهی به بعد زمانی منجر به از دست رفتن اطلاعات ارزشمند در برآورد داده های از دست رفته می شود. و
- (ب)
-
اگرچه چند روش درونیابی مکانی-زمانی در حال حاضر برای تخمین داده های از دست رفته در دسترس هستند – به عنوان مثال، STIDW و کریجینگ مکانی-زمانی – ناهمگنی (به عنوان مثال، عدم ایستایی مرتبه دوم) داده های مکانی-زمانی باید بیشتر مورد توجه قرار گیرد [ 35 ].
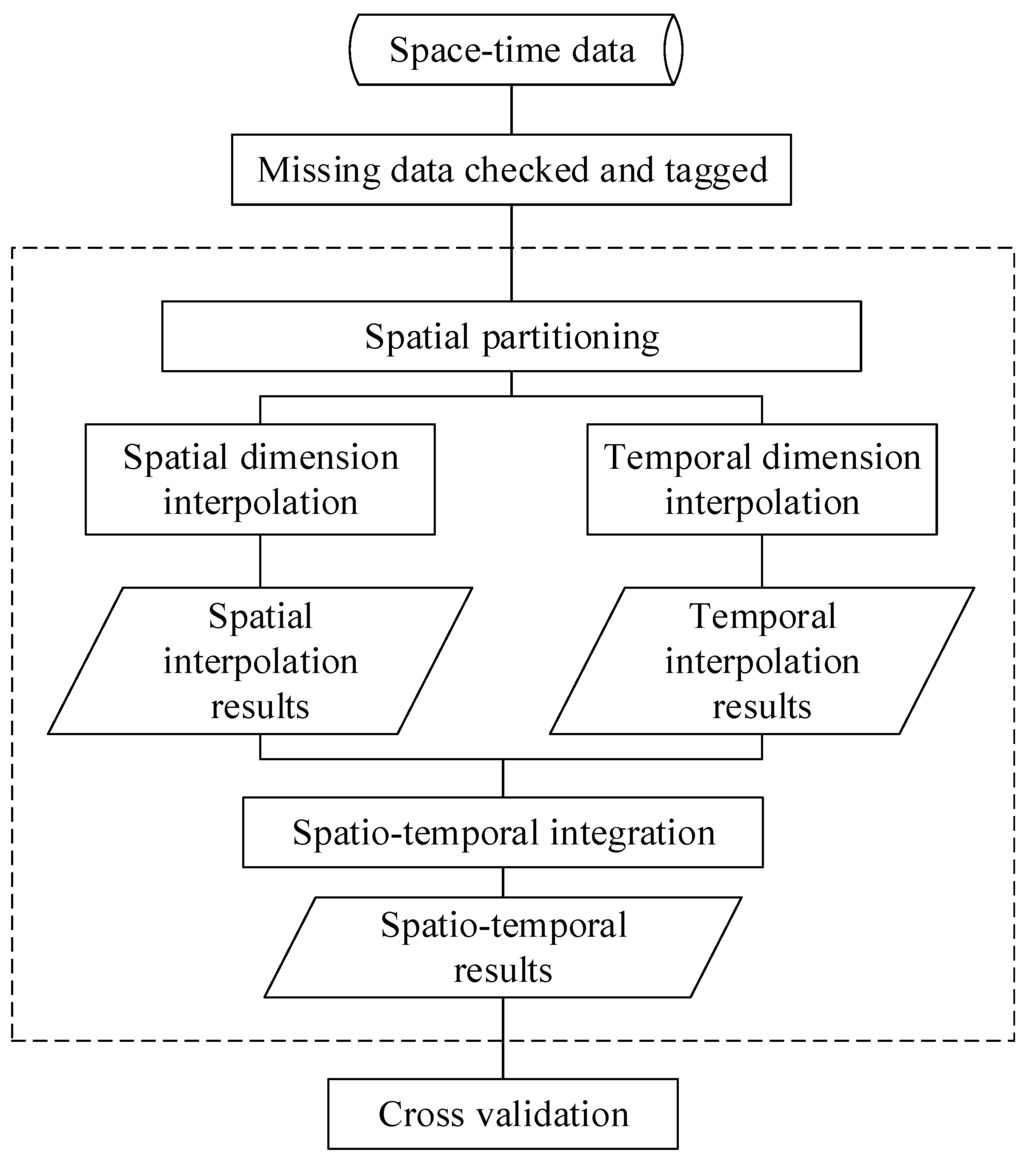
3. روش درونیابی ترکیبی برای داده های مکانی-زمانی ناهمگن
3.1. توابع کوواریانس ناهمگن برای مدیریت ناهمگونی فضا-زمان
که در آن k تعداد مناطق است، n i تعداد اشیاء در ناحیه i است، x ij مقدار ویژگی j امین شی در ناحیه i است، وایکس¯منمیانگین مقدار مشخصه ناحیه i است .
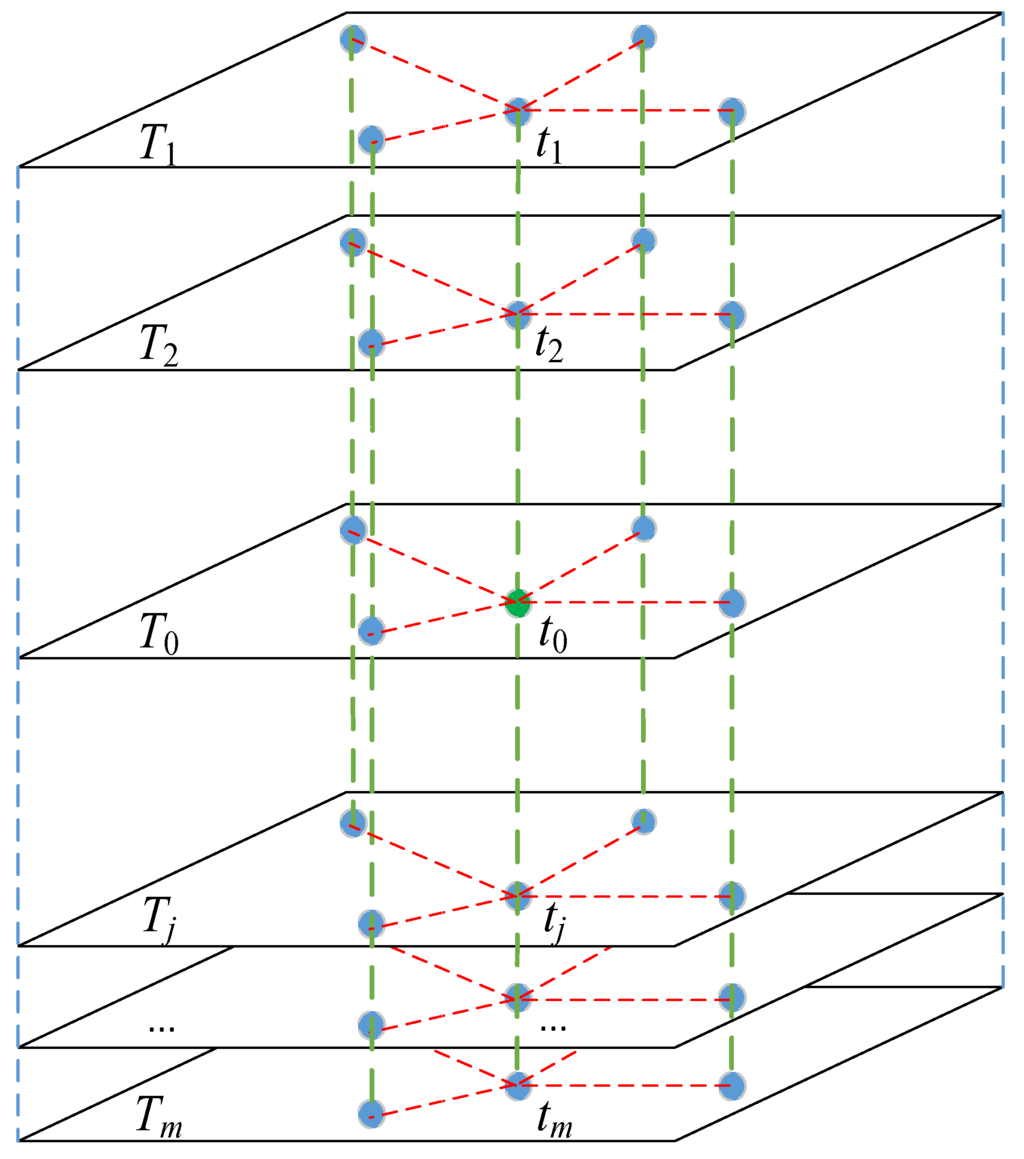
که در آن t j نشان دهنده j مین همسایه زمانی رکورد از دست رفته t 0 در بعد زمانی است و φ j نشان دهنده وزن سهم مربوطه t j است . رکوردهای گم شده را می توان با استفاده از معادله (2) توسط سایر رکوردهای ایستگاه های مشاهده گمشده محاسبه کرد. برای اطمینان از آن تی^0تخمین بی طرفانه برای رکوردهای از دست رفته است، رابطه زیر باید برآورده شود:
که در آن t 0 مقدار واقعی مقدار گم شده را نشان می دهد، E ( t 0 ) نشان دهنده انتظار آماری t 0 در بعد زمانی است. با جایگزینی معادله (2) به معادله (3)، معادله (4) را می توان به صورت زیر بازنویسی کرد:
که در آن υ یک ضریب لاگرانژ است. علاوه بر این، میتوانیم وزن φ j را بر اساس رابطه (7) محاسبه کنیم و تخمین دادههای نمونهبرداری نشده را بر اساس رابطه (2) بدست آوریم.
جایی که y i نشان دهنده رکورد مشاهده شده در ایستگاه i در همان لایه مقدار گمشده y 0 است ، w i نشان دهنده وزن سهم مربوطه y i است ، و y^0به عنوان یک تخمین بی طرفانه برای مقدار گمشده y 0 تعریف می شود . مشابه معادلات (6) و (7)، واریانس خطای برآورد حداقل شده در بعد فضایی را می توان به صورت زیر نشان داد:
که در آن μ ضریب لاگرانژ است. علاوه بر این، می توانیم وزن w i را بر اساس رابطه (9) محاسبه کنیم و بر اساس رابطه (8) تخمین مقادیر گمشده را بدست آوریم.
3.2. تخمین دادههای مفقود مکانی-زمانی با ترکیب اطلاعات مکانی و زمانی
که در آن υ نیز ضریب لاگرانژ است، سی(تیj،تیj‘)کوواریانس بین لایه زمانی j و لایه زمانی j است که بر اساس رکوردهای منطقه k i محاسبه می شود و اشیاء جفتی برای محاسبه سی(تیj،تیj“)به عنوان رکورد در k i با همان مکان شناسایی می شوند. سی(تیj،تی0)کوواریانس بین لایه زمانی j و لایه زمانی T 0 با مقادیر از دست رفته است. محاسبه از سی(تیj،تی0)شبیه به آن است سی(تیj،تیj“); با این حال، تنها رکوردهای مشاهده شده برای محاسبه کوواریانس درگیر هستند. a j نشان دهنده یک نسبت بین لایه زمانی T j و لایه زمانی T 0 با مقادیر گم شده است (محاسبه شده با معادله (5)).
جایی که μ نشان دهنده ضریب لاگرانژ است، سی(yمن،yمن“)در سمت چپ معادله (11) کوواریانس بین ایستگاه i و ایستگاه i’ است که بر اساس سری زمانی این دو ایستگاه محاسبه می شود. سی(yمن،y0)در سمت راست معادله (11) کوواریانس بین ایستگاه i و ایستگاه با مقدار گم شده است که بر اساس سری زمانی مشاهده شده این دو ایستگاه محاسبه می شود. b i نشان دهنده یک نسبت بین ایستگاه i و ایستگاه با مقدار گم شده است، محاسبه شده توسط E ( y i )/ E ( y 0 )، که در آن E ( y i ) نشان دهنده مقدار میانگین سری زمانی در ایستگاه i است . ماتریس متشکل از وزن سهم w i را می توان با رابطه (11) محاسبه کرد.
جایی که i عدد ایستگاه، j عدد سری زمانی، A وزن در بعد مکانی، و B آن در بعد زمانی ( A + B = 1) است. در این تحقیق وزن ها در ابعاد مکانی و زمانی با توجه به ضریب همبستگی به صورت زیر محاسبه می شوند:
که در آن n تعداد همسایگان مکانی و m نشان دهنده تعداد همسایه های زمانی است. R ( y i , y 0 ) نشان دهنده همبستگی بین مقدار گمشده و همسایگان فضایی آن است که با ضریب همبستگی بین سری زمانی مشاهده شده ایستگاه i و ایستگاه با مقدار گمشده y 0 اندازهگیری میشود . R ( tj , t 0 ) نشان دهنده همبستگی بین مقدار گمشده و همسایگان زمانی آن است که با ضریب همبستگی بین لایه زمانی T 0 و اندازه گیری می شود .T j بر اساس منطقه k i ( t j ∈ k i , t 0 ∈ k i ) محاسبه می شود. از معادله (13)، می توان دریافت که اگر مقدار گمشده با همسایگان مکانی آن (همسایه های زمانی) همبستگی بیشتری داشته باشد. بنابراین وزن در بعد مکانی (بعد زمانی) سنگین خواهد بود. پس از اینکه وزن ها در ابعاد مکانی و زمانی با حل معادله (13) محاسبه شد، نتایج تخمین نهایی داده های از دست رفته را می توان با معادله (12) به دست آورد.
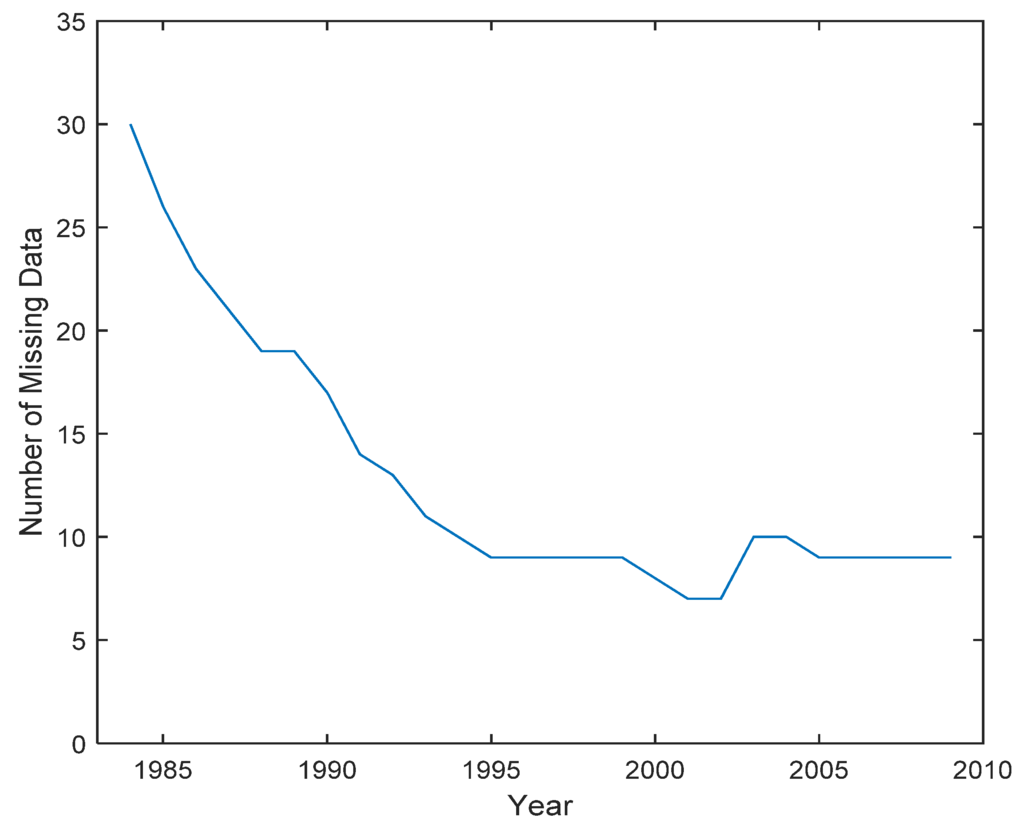
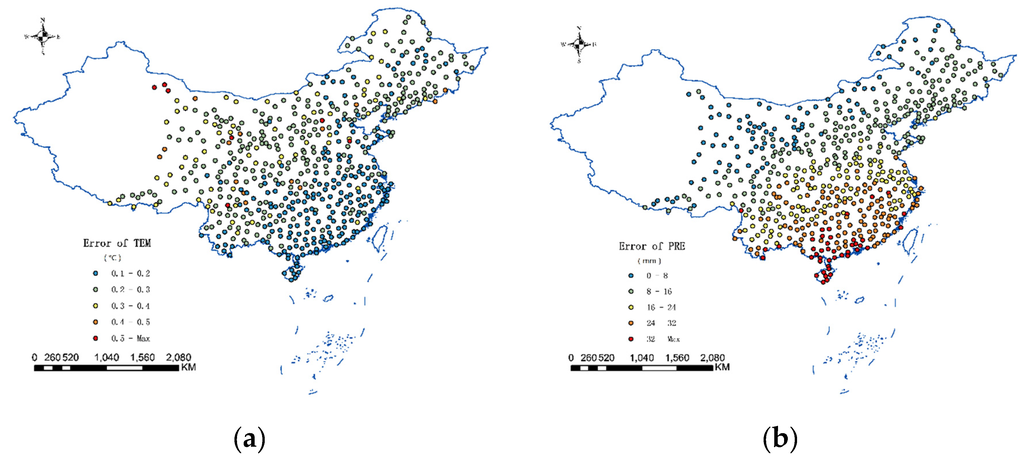
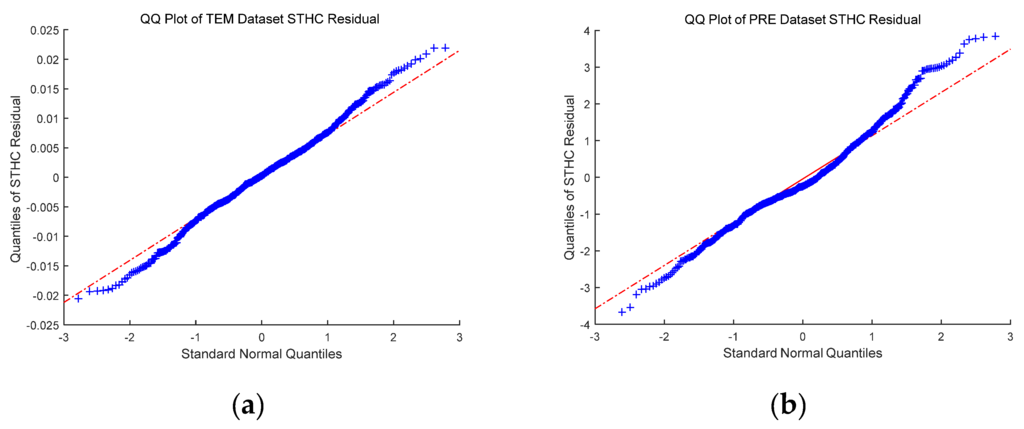
4. آزمایش ها و تجزیه و تحلیل نتایج
5. نتیجه گیری ها
منابع
- سیمپسون، جی. Wu, Y. دقت و تلاش درونیابی و نمونه برداری: آیا GIS می تواند به کاهش هزینه های میدانی کمک کند؟ ISPRS Int. J. Geo-Inf. 2014 ، 3 ، 1317-1333. [ Google Scholar ] [ CrossRef ]
- سیمولو، سی. برونتی، ام. موگری، م. Nanni, T. بهبود برآورد مقادیر از دست رفته در سری های بارش روزانه با رویکرد حفظ تابع چگالی احتمال. بین المللی جی.کلیماتول. 2010 ، 30 ، 1564-1576. [ Google Scholar ] [ CrossRef ]
- کورتارلی، ام. لیائو، جی. اوگاشاوارا، آی. لورنتستی، جی. Stech، J. ارزیابی روشهای درونیابی فضایی برای نقشهبرداری عمقسنجی یک مخزن هیدروالکتریک آمازون برای کمک به تصمیمگیری برای مدیریت آب. ISPRS Int. J. Geo-Inf. 2015 ، 4 ، 220-235. [ Google Scholar ] [ CrossRef ]
- تانگ، وای؛ قاسم، AHM; ابوباکار، SH مطالعات مقایسه ای روش های مختلف درمان داده های گمشده-تجربه مالزی. اتمس. Res. 1996 ، 42 ، 247-262. [ Google Scholar ] [ CrossRef ]
- Xu، C.-D. وانگ، J.-F. هو، ام جی; لی، Q. درون یابی داده های دمایی از دست رفته در ایستگاه های هواشناسی با استفاده از P-BSHADE. جی. کلیم. 2013 ، 26 ، 7452-7463. [ Google Scholar ] [ CrossRef ]
- د سزار، ال. مایرز، دی. پوسا، دی. برآورد و مدلسازی ساختارهای همبستگی فضا-زمان. آمار احتمالا. Lett. 2001 ، 51 ، 9-14. [ Google Scholar ] [ CrossRef ]
- کیریاکیدیس، PC; مجله، مدلهای فضا-زمان زمینآماری AG: مروری. ریاضی. جئول 1999 ، 31 ، 651-684. [ Google Scholar ] [ CrossRef ]
- کلیبردا، م. تادیچ، نماینده مجلس؛ هنگل، تی. لوکوویچ، جی. Bajat، B. مجموعه داده های جهانی هواشناسی در دسترس عموم: منابع، نمایش، و قابلیت استفاده برای تجزیه و تحلیل مکانی-زمانی. در دسترس آنلاین: http://dailymeteo.org/content/publicly-available-global-meteorological-data-sets-sources-representation-and-usability (دسترسی در 30 نوامبر 2015).
- وانگ، جی. خو، سی. هو، م. لی، کیو. یان، ز. ژائو، پی. جونز، P. برآورد جدیدی از سری ناهنجاری دمای چین و ارزیابی عدم قطعیت در 1900-2006. جی. ژئوفیس. پاسخ: اتمس. 2014 ، 119 ، 1-9. [ Google Scholar ] [ CrossRef ]
- دی یاکو، اس. مایرز، دی. پوزا، دی. واریوگرامهای فضا-زمان و فرمی کاربردی برای اندازهگیری کل آلودگی هوا. محاسبه کنید. آمار داده آنال. 2002 ، 41 ، 311-328. [ Google Scholar ] [ CrossRef ]
- لی، ال. Revesz, P. روش های درونیابی برای داده های جغرافیایی مکانی-زمانی. محاسبه کنید. محیط زیست سیستم شهری 2004 ، 28 ، 201-227. [ Google Scholar ] [ CrossRef ]
- هوانگ، بی. وو، بی. Barry, M. رگرسیون وزندار جغرافیایی و زمانی برای مدلسازی تغییرات فضا-زمان در قیمت خانه. بین المللی جی. جئوگر. Inf. علمی 2010 ، 24 ، 383-401. [ Google Scholar ] [ CrossRef ]
- Cressie، NAC Statistics for Spatial Data ; Wiley: Hoboken، NJ، ایالات متحده، 1993. [ Google Scholar ]
- Dutilleul، PRL ناهمگنی مکانی-زمانی: مفاهیم و تحلیلها . انتشارات دانشگاه کمبریج: کمبریج، بریتانیا، 2011. [ Google Scholar ]
- Goovaerts, P. Geostatistics for Natural Resources Evaluation ; انتشارات دانشگاه آکسفورد: آکسفورد، انگلستان، 1997. [ Google Scholar ]
- آنسلین، ال. برا، AK; فلوراکس، آر. Yoon, MJ تست های تشخیصی ساده برای وابستگی فضایی. Reg. علمی اقتصاد شهری 1996 ، 26 ، 77-104. [ Google Scholar ] [ CrossRef ]
- فاثرینگهام، اس. چارلتون، ام. براندون، سی. رگرسیون وزندار جغرافیایی: یک تکامل طبیعی روش بسط برای تجزیه و تحلیل دادههای مکانی. محیط زیست طرح. 1998 ، 30 ، 1905-1927 . [ Google Scholar ] [ CrossRef ]
- اردوغان، اس. مدلسازی توزیع فضایی خطای DEM با رگرسیون وزندار جغرافیایی: یک مطالعه تجربی. محاسبه کنید. Geosci. 2010 ، 36 ، 34-43. [ Google Scholar ] [ CrossRef ]
- لو، بی. چارلتون، ام. هریس، پی. Fotheringham، AS رگرسیون وزنی جغرافیایی با متریک فاصله غیر اقلیدسی: مطالعه موردی با استفاده از داده های قیمت خانه لذت بخش. بین المللی جی. جئوگر. Inf. علمی 2014 ، 28 ، 660-681. [ Google Scholar ] [ CrossRef ]
- هابارد، KG; گدارد، اس. سورنسن، WD; ولز، ن. Osugi، NN اجرای رویه های تضمین کیفیت برای یک سیستم اطلاعات آب و هوایی کاربردی. J. Atmos. اقیانوس. تکنولوژی 2005 ، 22 ، 105-112. [ Google Scholar ] [ CrossRef ]
- هابارد، KG; شما، J. تحلیل حساسیت تضمین کیفیت با استفاده از رویکرد رگرسیون فضایی – مطالعه موردی حداکثر / حداقل دمای هوا. J. Atmos. اقیانوس. تکنولوژی 2005 ، 22 ، 1520-1530. [ Google Scholar ] [ CrossRef ]
- Bartier، PM; درونیابی چند متغیره کلر، CP برای ترکیب داده های سطح موضوعی با استفاده از وزن دهی معکوس فاصله (IDW). محاسبه کنید. Geosci. 1996 ، 22 ، 795-799. [ Google Scholar ] [ CrossRef ]
- لو، جی. Wong، DW یک تکنیک درونیابی فضایی وزن دهی با فاصله معکوس تطبیقی. محاسبه کنید. Geosci. 2008 ، 34 ، 1044-1055. [ Google Scholar ] [ CrossRef ]
- رینولدز، KM; Madden، LV تجزیه و تحلیل اپیدمی ها با استفاده از همبستگی مکانی-زمانی. Phytopathology 1988 ، 78 ، 240-246. [ Google Scholar ] [ CrossRef ]
- فرر، آر. جنتون، ام جی; Nychka، D. کاهش کوواریانس برای درونیابی مجموعه داده های فضایی بزرگ. جی. کامپیوتر. نمودار. آمار 2006 ، 15 ، 502-523. [ Google Scholar ] [ CrossRef ]
- Pardo-Iguzquiza، E. Chica-Olmo، M. Geostatistics با مدل semivariogram مادر: کتابخانه ای از برنامه های کامپیوتری برای استنتاج، کریجینگ و شبیه سازی. محاسبه کنید. Geosci. 2008 ، 34 ، 1073-1079. [ Google Scholar ] [ CrossRef ]
- پسکوئر، ال. کورتس، آ. Pons, X. درون یابی کریجینگ معمولی موازی با اتصالات واریوگرام خودکار. محاسبه کنید. Geosci. 2011 ، 37 ، 464-473. [ Google Scholar ] [ CrossRef ]
- باتاچارجی، اس. میترا، پ. Ghosh, SK درونیابی فضایی برای پیشبینی ویژگیهای گمشده در GIS با استفاده از کریجینگ معنایی. IEEE Trans. Geosci. Remote Sens. 2014 , 52 , 4771–4780. [ Google Scholar ] [ CrossRef ]
- Ma، C. توابع کوواریانس فضایی-زمانی تولید شده توسط مخلوط. ریاضی. جئول 2002 ، 34 ، 965-975. [ Google Scholar ] [ CrossRef ]
- Ma، C. تحولات اخیر در ساخت مدل های کوواریانس مکانی-زمانی. استوکاست. محیط زیست Res. ارزیابی ریسک 2008 ، 22 ، 39-47. [ Google Scholar ] [ CrossRef ]
- دی یاکو، اس. مایرز، دی. پوسا، دی. تحلیل فضا-زمان با استفاده از یک مدل حاصل جمع کلی. آمار احتمالا. Lett. 2001 ، 52 ، 21-28. [ Google Scholar ] [ CrossRef ]
- دی یاکو، اس. مایرز، دی. پوسا، دی. مدلهای کوواریانس فضا-زمان غیرقابل تفکیک: برخی خانوادههای پارامتری. ریاضی. جئول 2002 ، 34 ، 23-42. [ Google Scholar ] [ CrossRef ]
- د سزار، ال. مایرز، دی. پوسا، دی. کوواریانس حاصل-مجموع برای مدلسازی فضا-زمان: یک کاربرد محیطی. Environmetrics 2001 ، 12 ، 11-23. [ Google Scholar ] [ CrossRef ]
- هو، M.-G. وانگ، J.-F. ژائو، ی. Jia, L. بهترین ابزار تخمین بی طرفانه خطی مبتنی بر B-SHADE برای نمونه های بایاس. محیط زیست مدل. نرم افزار 2013 ، 48 ، 93-97. [ Google Scholar ] [ CrossRef ]
- وانگ، J.-F. لی، X.-H.; کریستاکوس، جی. لیائو، Y.-L. ژانگ، تی. گو، ایکس. ژنگ، X.-Y. ارزیابی خطر سلامت مبتنی بر آشکارسازهای جغرافیایی و کاربرد آن در مطالعه نقص لوله عصبی منطقه هشون، چین. بین المللی جی. جئوگر. Inf. علمی 2010 ، 24 ، 107-127. [ Google Scholar ] [ CrossRef ]
- Guo, D. منطقهبندی با خوشهبندی و پارتیشنبندی تجمعی به صورت پویا محدود (REDCAP). بین المللی جی. جئوگر. Inf. علمی 2008 ، 22 ، 801-823. [ Google Scholar ] [ CrossRef ]
- کوپفر، جی. گائو، پی. Guo، D. منطقهبندی معیارهای الگوی جنگل برای قاره ایالات متحده با استفاده از خوشهبندی و تقسیمبندی محدود مجاورت. Ecol. Inf. 2012 ، 9 ، 11-18. [ Google Scholar ] [ CrossRef ]
- پلتیه، بی. دوتیلول، پی. لاروک، جی. Fyles، JW Coregionalization تجزیه و تحلیل با رانش برای ارزیابی چند مقیاسی روابط فضایی بین متغیرهای اکولوژیکی 1. برآورد رانش و اجزای تصادفی. محیط زیست Ecol. آمار 2009 ، 16 ، 439-466. [ Google Scholar ] [ CrossRef ]
- Kohavi, R. مطالعه اعتبار متقاطع و بوت استرپ برای تخمین دقت و انتخاب مدل. در مجموعه مقالات چهاردهمین کنفرانس مشترک بین المللی در مورد مصنوعی، مونترال، QC، کانادا، 20-25 اوت 1995; صص 1137–1145.





© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons by Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر