

خلاصه
شناسایی موقعیت مکانی با دقت بالا اساس آگاهی از موقعیت مکانی و خدمات مکان است. با این حال، به دلیل تأثیر از دست دادن سیگنال GPS، رانش داده ها و دسترسی مکرر به داده های مسیر منفرد، کارایی و دقت الگوریتم های موجود دارای کاستی هایی است. بنابراین، ما یک رویکرد خوشهبندی دو مرحلهای برای استخراج مکان افراد با توجه به دادههای مسیر GPS آنها پیشنهاد میکنیم. در ابتدا، ما سه نوع مختلف نقطه توقف را تعریف کردیم. در مرحله دوم، ما این نقاط را از داده های مسیر با استفاده از الگوریتم خوشه بندی مکانی-زمانی بر اساس زمان و فاصله استخراج کردیم. نتایج تجربی نشان میدهد که الگوریتم خوشهبندی مکانی-زمانی بهتر از الگوریتمهای استخراج سنتی عمل میکند. میتواند از مشکلات ناشی از دسترسی مکرر جلوگیری کند و اثرات از دست دادن سیگنال GPS و جابجایی دادهها را به میزان قابل توجهی کاهش دهد. در نهایت، یک الگوریتم خوشهبندی بهبودیافته مبتنی بر جستجوی سریع و شناسایی قلههای چگالی برای کشف مکانهای مسیر اعمال شد. در مقایسه با الگوریتم های موجود، روش ما عملکرد و دقت بهتری را نشان می دهد.
کلید واژه ها:
داده های مسیر GPS ; داده کاوی ; الگوریتم خوشه بندی ; موقعیت مکانی شخصی
1. معرفی
با محبوبیت پایانه های تلفن همراه هوشمند، داده های مسیر روزانه شخصی بیشتر و بیشتری ثبت می شود. چگونگی استخراج سریع و دقیق اطلاعات مفید از این دادههای مسیر به منظور ارائه خدمات مکان شخصیسازی شده، دغدغه اصلی محاسبات آگاه از مکان است. از طریق تجزیه و تحلیل حجم زیادی از داده ها، گونزالس و همکاران. [ 1 ] دریافتند که مسیرهای انسانی درجه بالایی از نظم زمانی و مکانی را نشان می دهند. یک کاربر به مکان های شناخته شده خاصی دسترسی فرکانس بالایی دارد، به این معنی که مکان اطلاعات کلیدی برای داده های مسیر است. موقعیت مکانی شخصی جزء حیاتی خدمات مبتنی بر مکان است [ 2]. با شناسایی دقیق مکان فردی از داده های مسیر، می توان برنامه های کاربردی آگاه از مکان را هوشمندتر کرد [ 3 ]. به عنوان مثال، ناوبر می تواند کاربر را با مکان های شخصی راهنمایی کند [ 4 ]. همچنین، سیستم توصیهگر مبتنی بر مکان میتواند اطلاعات مربوط به موقعیت مکانی افراد را فشار دهد [ 5 ]. یک سیستم پیشبینی مکان همچنین میتواند مقصد بعدی یک فرد را با توجه به موقعیت فعلیاش حدس بزند [ 6 ]، و یک سیستم پرس و جو فضایی میتواند اطلاعات زمینهای [ 7 ] و غیره را ارائه دهد.
مجموعه ای غنی از تحقیقات در مورد چگونگی کشف مکان شخصی از داده های مسیر وجود دارد. برای دادههای مسیر بیسیم بیسیم، مانند دادههای مبتنی بر شبکههای بیسیم یا برجهای سلولی، برخی از ویژگیهای چراغ (به عنوان مثال، اطلاعات نقطه دسترسی یا نرخ پاسخ سیگنال) ممکن است به عنوان اثر انگشت برای شناسایی مکان در آینده ثبت شوند [8 ] ، 9 ]. در مقایسه با موقعیتیابی GSM یا Wi-Fi، GPS دقیقتر است [ 10]. بنابراین، ما در این مقاله بر روی پردازش داده های مسیر GPS تمرکز می کنیم. یکی از ویژگی های داده های مسیر منفرد این است که مکرراً به همان نقطه مرجع دسترسی پیدا می کند. در همین حال، تحت تأثیر فناوری GPS موجود، داده های مسیر از دو اشکال رنج می برند: اول، ناپیوستگی ناشی از از دست دادن سیگنال GPS. دوم، رانش داده ناشی از سایر عوامل محیطی. این مشکلات تأثیر قابل توجهی بر الگوریتم های استخراج مکان دارند. الگوریتمهای موجود بیشتر بر اساس ویژگیهای زمانی و مکانی دادههای مسیر هستند و یا در ترکیب با دادههای موضوعی به منظور یافتن مکان هستند. این الگوریتم ها مزایای خود را دارند، اما در برخورد با مشکلات ذکر شده در بالا، کمبودهایی وجود دارد.
مستقیم ترین راه، خوشه بندی نقاط GPS بر اساس چگالی نقطه است. برای مثال، Schuessler & Axhausen [ 11 ] از آستانه چگالی برای شناسایی مکان ها استفاده کردند. اشبروک و استارنر [ 12 ] از تغییری از الگوریتم خوشهبندی K-Means برای یادگیری مکانها از دادههای مسیر استفاده کردند. ژو و همکاران [ 13 ] الگوریتم DJ-Cluster را بر اساس DBSCAN (خوشه بندی فضایی مبتنی بر چگالی برنامه های کاربردی با نویز) پیشنهاد کرد [ 14]] به منظور تشخیص مکان. این الگوریتمها ظرفیت پردازشی را برای نقاط با از دست دادن سیگنال و جابجایی دادهها، به ویژه از دست دادن سیگنال ناشی از یک بلوک ساختمان، فراهم نمیکنند. آنها فقط موقعیت مکانی را بدون توجه به ویژگی زمانی در نظر می گیرند. بنابراین، این الگوریتمها فقط برای نقاطی با سیگنال قوی مناسب هستند.
برای حل مشکلات ناشی از از دست دادن داده ها، اشبروک و استارنر [ 15 ] پیشنهاد کردند که ابتدا نقاط از دست رفته را شناسایی کنند. سپس، آنها از الگوریتم بهبود یافته K-Means برای خوشه بندی نقاط از دست رفته به منظور تشکیل مکان ها استفاده کردند. از آنجایی که الگوریتم K-Means به نویز حساس است و رویکرد تنها نقاط از دست رفته را تشخیص می دهد، عملکرد ضعیفی دارد. بنابراین الگوریتم های بیشتری مکان را بر اساس ویژگی های زمانی و مکانی انتخاب می کنند. برای مثال، Du & Aultman-Hall [ 16 ] نقاط متوالی GPS با سرعت کمتر را به عنوان مکان در نظر گرفتند. کانگ و همکاران [ 17] یک الگوریتم خوشه بندی مبتنی بر زمان پیشنهاد کرد. الگوریتم این نقاط را که نزدیک به یکدیگر هستند و فاصله زمانی را که بیشتر از آستانه در مکان ها است، می گیرد. الگوریتم SMOT [ 18 ] تجزیه و تحلیلی را بر اساس تلاقی داده های مسیر و توقف های نامزد انجام داد، که در آن نقاط همپوشانی و پایدار به عنوان مکان در نظر گرفته شدند. پالما و همکاران [ 19] الگوریتم CB-SMoT را بر اساس مطالعات قبلی پیشنهاد کرد. الگوریتم داده ها را با پارامترهای Eps (رادیوم خوشه) و حداقل زمان بر اساس الگوریتم DBSCAN خوشه بندی کرد. سپس، تقاطع آن خوشه ها را تجزیه و تحلیل کرد و نامزد متوقف می شود. این الگوریتم ها تا حدودی می توانند از مشکلات ناشی از از دست دادن داده ها جلوگیری کنند. با این حال، با توجه به تاثیر رانش داده ها، این الگوریتم ها مستعد مثبت کاذب هستند. این الگوریتم ها مشکل دسترسی مکرر به یک مکان را نیز در نظر نمی گیرند. در نتیجه هر مکانی که توسط این الگوریتم ها استخراج شده باشد به عنوان مکان جدید در نظر گرفته می شود.
بنابراین، یک الگوریتم خوشهبندی سلسله مراتبی برای استخراج مکان اعمال شد. یوان و همکاران [ 20 ] رویکردی را پیشنهاد کرد که ابتدا دادههای مسیر را به بخشهایی تقسیم کرد و سپس نقاط پایانی بخشها را به مکانها خوشهبندی کرد. اگرچه الگوریتم بر مشکل دسترسی مکرر غلبه می کند، اما به دلیل تأثیر از دست دادن سیگنال و رانش داده، نتیجه ایده آل نیست. مهمتر از آن، نقاط پایانی بخش ها تنها نقطه عطف اصلی مسیر را نشان می دهند. برای کاهش این اشکالات، Lv و همکاران. [ 3] از یک الگوریتم مبتنی بر زمان برای به دست آوردن نقاط بازدید استفاده کرد که سپس توسط یک الگوریتم DBSCAN بهبودیافته برای تشکیل مکانهای فیزیکی خوشهبندی شدند. آزمایش ها به نتایج خوبی رسیده اند، اما الگوریتم مشکلاتی نیز دارد. اول، تحت تأثیر رانش داده، یک نقطه بازدید به راحتی به چند خوشه کوچک تقسیم می شود. در نتیجه، دقت و نرخ فراخوان الگوریتم تحت تأثیر تقسیم بندی قرار می گیرد. دوم، الگوریتم DBSCAN به پارامترهای [ 21 ] بسیار حساس است و پیچیدگی زمانی نسبتاً بالایی دارد. برای پردازش حجم زیادی از داده ها به عنوان بخشی از داده کاوی مسیری مناسب نیست.
با چنین نگرانیهایی در مورد الگوریتمهای استفاده شده قبلی، ما یک رویکرد خوشهبندی دو مرحلهای را برای استخراج مکانهای شخصی از دادههای مسیر GPS فردی پیشنهاد میکنیم. ابتدا نقاط توقف احتمالی را با استفاده از الگوریتم خوشه بندی مکانی – زمانی استخراج کردیم. با توجه به ویژگیهای دادههای مسیر منفرد، این مقاله سه نوع مختلف نقطه توقف را ارائه میکند که در بین آنها نوع اول در الگوریتم موجود در نظر گرفته نشده است. الگوریتم خوشه بندی مکانی-زمانی می تواند تا حد زیادی از مشکلات از دست دادن سیگنال و رانش داده جلوگیری کند. همچنین می تواند تأثیر تقسیم بندی موجود در ادبیات را کاهش دهد [ 3]. سپس، یک الگوریتم خوشهبندی سریع بهبود یافته برای خوشهبندی نقاط توقف در مکانها اتخاذ میشود. می تواند کارایی و دقت را تا حد زیادی بهبود بخشد. در نهایت، آزمایشهای متضاد را برای تأیید امکانسنجی و اثربخشی رویکرد طراحی کردیم.
2. استخراج مکان
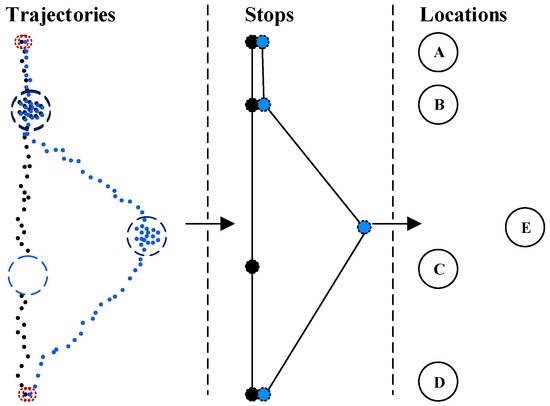
همانطور که در شکل 1 نشان داده شده است، یک مسیر از نقاط GPS به ترتیب زمانی تشکیل شده است و مسیرهای مختلف در زندگی روزمره مجموعه داده را تشکیل می دهند. با در نظر گرفتن ویژگیهای یک مسیر منفرد، رویکرد ما یک خوشهبندی مکانی-زمانی بر اساس زمان و مسافت را برای شناسایی نقاط توقف از مجموعه داده اتخاذ میکند (جزئیات بیشتر در بخش 2.1)، سپس مکانها را از این نقاط توقف بر اساس یک خوشهبندی بهبودیافته استخراج میکند. جستجوی سریع و شناسایی پیک های چگالی (جزئیات بیشتر در بخش 2.2 ).
تعریف 1. نقطه GPS : یک نقطه GPS یک گروه ویژگی است. P = (lng، lat، alt، d، t، v، ماهواره ها، HDOP) طول، عرض جغرافیایی، ارتفاع، تاریخ، زمان، سرعت و تعداد ماهواره های ردیابی شده و رقت موقعیت دقیق را نشان می دهد .
تعریف 2. مسیر : یک مسیر، فهرستی از نقاط GPS بر اساس سریال زمانی آنها، T = {P 0 , P 1 , …, P n } است که در آن t 0 < t 1 < … < t n و i = 0، 1، …، n. معمولاً یک مسیر شامل نقاط GPS است که در یک روز جمع آوری می شوند .
تعریف 3. نقطه توقف : یک نقطه توقف مخفف یک مکان بازدید شده است که در آن شخص در شروع t وارد شده و در پایان t ترک شده است ، SP = {P m ، P m+1 ، …، Pn } = (lng، lat، نوع , t start , t end , (lng, lat) نشان دهنده مختصات میانگین نقاط و نوع نشان دهنده نوع نقطه توقف است. این به دو پارامتر بستگی دارد، آستانه زمانی δt و آستانه فاصله δd ( جزئیات بیشتر در بخش 2.1 ) .
تعریف 4. Location Point : یک نقطه موقعیت مکانی به معنای مکانی است که شخص اغلب از آن بازدید می کند، LP = {SP i , …, SP j , …, SP k }. این از نتایج یک الگوریتم خوشه بندی نقطه توقف (جزئیات بیشتر در بخش 2.2 ) می آید .
2.1. استخراج نقاط توقف
همانطور که در بالا ذکر شد، به دلیل تأثیر از دست دادن سیگنال GPS و رانش داده، اکثر الگوریتم های فعلی استخراج نقاط توقف دارای کاستی هایی هستند. برای مقابله با این مشکل، ما یک خوشه بندی مکانی-زمانی جدید بر اساس زمان و مسافت پیشنهاد می کنیم که به اختصار TDBC است. الگوریتم زمانی که نقاط توقف را استخراج می کند، سازگاری بهتری برای مسیر فردی دارد.
در این مقاله سه نوع مختلف نقطه توقف را تعریف می کنیم.
نوع اول از نقطه شروع یا پایان هر آهنگ می آید. جمعآوری دادههای مسیر از مکانی شروع میشود که فرد از آنجا خارج میشود (مثلاً صبح از خانه خارج میشود تا به محل کارش برود) و برای مدت طولانی بدون سیگنال در موقعیتی به پایان میرسد (مثلاً بعد از کار در عصر به خانه میرسد). با این حال، با در نظر گرفتن وقوع گاه به گاه اکتساب داده ها، یک مسیر ممکن است به عوامل دیگری مانند باتری کم یا عامل ساخت دست بشر ختم شود. بنابراین، همه نقاط شروع یا پایان اولین نوع نقطه توقف نیستند. فقط نقاطی که مجاور یکدیگر هستند نوع اول در نظر گرفته می شوند (نوع I، به عنوان مثال، نقطه a در شکل 2 ). نقطه توقف نوع I دارای دو نقطه در T = ( P 0 , P 1 , …,Pn ) ، که در آن فاصله ( P 0 ، Pn ) < δd .
هنگامی که شخصی برای مدت طولانی بدون از دست دادن سیگنال در یک مکان می ماند، نقاط مسیر نوع دوم را تشکیل می دهند (نوع II، به عنوان مثال، نقطه b در شکل 2 ). الگوریتم ما به دو پارامتر بستگی دارد، آستانه زمانی δt و آستانه فاصله δd . نقطه توقف نوع II لیستی از نقاط متوالی GPS است، SP = { P m , P m+1 , …, P n } که در آن ∀ m ≤ i ≤ n , فاصله(( lng , lat , P i ) < δ دو | P n . t – P m . t | > δ t .
نوع سوم منطقه ای است که سیگنال برای مدت طولانی به دلیل موانع، ساختمان ها یا مشکلات تجهیزات و غیره از دست می رود (نوع III، به عنوان مثال، نقطه c در شکل 2 ). به این دو پارامتر نیز نیاز دارد. یک نقطه توقف نوع III دارای دو نقطه متوالی GPS SP = { P m , P m+1 } است که در آن فاصله ( P m , P m + 1 ) < δ d و | P m+1 . t – P m . t | > δ t .
همانطور که در الگوریتم 1 نشان داده شده است، ما یک روش خوشه بندی مکانی-زمانی، که TDBC نام دارد، برای استخراج نقاط توقف از مسیر منفرد اتخاذ می کنیم. TDBC یک مسیر T ، آستانه زمانی δt و آستانه فاصله δ d را به عنوان شرایط ورودی می گیرد. Cluster و Previous C خوشه فعلی و خوشه قبلی هستند که برای مقابله با نقطه توقف نوع دوم استفاده می شوند.
TDBC نقاط GPS را در امتداد محور زمانی برای هر مسیر جداگانه پردازش می کند. با توجه به تعریف نوع، TDBC این نقاط را که مطابق با الزامات تعریف هستند، به عنوان نقاط توقف می گیرد و آنها را در مجموعه SP قرار می دهد (نوع I، خط 2؛ نوع II، خط 6؛ نوع III، خط 10).
اگر فاصله بین مرکز خوشه و نقطه P i بیشتر از δd باشد ، و مدت زمان کمتر از δ t باشد ، TDBC خوشه را نادیده نمی گیرد ، اما رابطه بین خوشه و C قبلی را بررسی می کند (همانطور که در نشان داده شده است . بررسی عملکرد ). این استراتژی می تواند به طور موثر از مشکل جلوگیری کند، مانند زمانی که یک نقطه توقف به چندین خوشه تقسیم می شود، که ممکن است از دقت دستگاه GPS یا جابجایی داده ها ناشی شود.
| الگوریتم 1. استخراج نقطه توقف (TDBC) | ||
| ورودی: مسیر T ، آستانه زمانی δ t ، آستانه فاصله δ d | ||
| خروجی: مجموعه ای از نقاط توقف SP | ||
| 1: | خوشه = ∅; C= قبلی ∅; | |
| 2: | اگر اولین یا آخرین نقطه از نوع I باشد ، SP .add(the point); | // نوع I |
| 3: | برای هر نقطه P i در T انجام دهید | |
| 4: | اگر فاصله( Cluster , P i ) < δ d سپس P i را در Cluster قرار دهید . ادامه هید؛ | |
| 5: | اگر فاصله( خوشه , P i ) > δ d و مدت زمان ( خوشه ) > δ t | |
| 6: | SP .add( Cluster ); ادامه هید؛ | // نوع دوم |
| 7: | اگر فاصله( خوشه , P i ) > δ d و مدت زمان ( خوشه ) < δ t | |
| 8: | چک ( خوشه , C قبلی ) ; ادامه هید؛ | |
| 9: | اگر فاصله ( P i-1 , P i ) < δ d و مدت زمان ( P i-1 , P i ) > δ t | |
| 10: | SP .add({ P i-1 , P i }); ادامه هید؛ | // نوع III |
| 11: | اگر فاصله( P i-1 , P i ) > δ d و مدت زمان ( P i-1 , P i ) > δ t سپس ignore(); | |
| 12: | بازگشت SP ; | |
| بررسی عملکرد ( خوشه ، خوشه قبلی ){ | ||
| اگر (فاصله زمانی ( خوشه , قبلی ) < δ t و فاصله ( خوشه , قبلی ) < δ d ) سپس | ||
| Previous = ادغام ( Cluster , Previous ); | ||
| اگر Previous از نوع II است ، SP .add( Previous ); | ||
| else قبلی = خوشه ;} | ||
| تابع SP .add( Cluster ){ | ||
| اگر (فاصله( خوشه، نقطه توقف قبلی در SP ) < δ ) سپس | ||
| Previous = ادغام( Cluster, Previous ) ; | ||
| دیگری Cluster را در SP قرار دهید . قبلی = خوشه; } | ||
تابع SP .add ( Cluster ) در الگوریتم به این معنی است که تابع Cluster را به عنوان نقطه توقف در نظر گرفته و مجموعه SP را قرار می دهد . با این حال، این عملیات انجام نمی شود تا زمانی که تابع بررسی کند که آیا خوشه می تواند با نقطه توقف قبلی ادغام شود یا خیر . در صورت برآورده شدن شرط، دو خوشه با هم ادغام می شوند، در غیر این صورت تابع یک نقطه توقف جدید در مجموعه SP قرار می دهد.. هدف این تابع ادغام نقاط توقفی است که دارای همسایه های فضایی و روابط زمانی پیوسته با یکدیگر هستند. یک نقطه توقف که برای مدت طولانی در محدوده معینی باقی می ماند، با این روش به چند قسمت تقسیم نمی شود. بنابراین، می تواند دقت استخراج نقاط توقف را بهبود بخشد.
همانطور که از توضیحات بالا مشخص است، TDBC تمام نقاط GPS را تنها یک بار بررسی می کند. بنابراین، پیچیدگی زمانی TDBC O(n) است . این توانایی عالی برای رسیدگی به نقاط متوالی GPS با جابجایی داده ها (به عنوان مثال، ماندن در یک ساختمان نیمه بسته) دارد و از مشکلات ناکارآمد ناشی از تقسیم بندی یک نقطه توقف جلوگیری می کند.
2.2. استخراج مکان ها
نقطه موقعیت مکانی به این معنی است که شخصی مرتباً از آن مکان بازدید می کند. اطلاعات موقعیت مکانی شخصی یک جزء حیاتی در زمینه آگاهی از موقعیت مکانی، پیشبینی موقعیت مکانی، توصیههای اجتماعی و غیره است. برای شناسایی موقعیت مکانی افراد به طور قابل توجهی متفاوت است. همانطور که در بخش 2.1 ذکر شد ، الگوریتم TDBC برای استخراج نقاط توقف از یک مسیر طراحی شده است. اما فرد بارها و بارها از یک مکان در زمان متفاوت بازدید می کند و به دلیل عدم دقت احتمالی تجهیزات جی پی اس، لازم است نقاط توقف را برای به دست آوردن نقاط مکان، خوشه بندی کرد.
2.2.1. خوشه بندی با جستجوی سریع و یافتن اوج چگالی
در حال حاضر، بسیاری از الگوریتمهای خوشهبندی برای مسئله قابل اجرا هستند. ادبیات رویکردی مبتنی بر خوشه بندی با جستجوی سریع و شناسایی پیک های چگالی [ 22 ] پیشنهاد کرده است. الگوریتم بسیار کارآمد است. فرض میکند که مراکز خوشهای در فاصله نسبتاً زیادی از نقاطی که چگالی بالاتری دارند، و همچنین مراکزی که توسط نقاطی که چگالی کمتری دارند احاطه شدهاند، قرار دارند. این فرض به خوبی با ویژگی های توزیع داده یک نقطه توقف مطابقت دارد. به طور کلی، نقاط توقف مختلف در یک مکان از یکدیگر دور نیستند و مکان های مختلف به هم نزدیک نیستند.
تعریف 5. چگالی : چگالی ρ i نقطه SP i تعداد نقاطی است که فاصله بین نقطه SP j و SP i کمتر از δ d است که به صورت معادله (1) تعریف شده است.
ρمن=∑jf(دمنj–δد)
که اگر x ≤ 0، f(x) = 1، در غیر این صورت f(x) = 0. d ij به معنای فاصله بین SP j و SP i است . وقتی i = j، d ij = 0 .
تعریف 6. همسایه : همسایه N i = {SP j , …, SP k , …, SP l } نقطه SP i مجموعه ای از نقاط توقف را نشان می دهد که به موجب آن فاصله بین نقطه توقف فعلی SP i و سایر نقاط کمتر است. از δ d .
جریان الگوریتم به شرح زیر است:
مرحله 1، چگالی و همسایه را برای هر نقطه محاسبه کنید، و نقاط باید به ترتیب نزولی بر اساس چگالی فهرست شوند.
مرحله 2، حداقل فاصله بین نقطه و سایر نقاط با چگالی محلی بالاتر را محاسبه کنید، معادله (2).
δمن=دقیقه(دمنj)j:ρj>ρمن.
اگر چگالی حداکثر باشد، فاصله به صورت δi = max( d ij ) تعریف می شود. بنابراین، برای مراکز خوشه، مقدار δ i آشکارا بزرگتر از همسایگان است.
مرحله 3، λ i = ρ i δ i را برای هر نقطه محاسبه کنید و نتایج را به ترتیب کاهشی مرتب کنید. این نقاط که دارای λi نسبتاً بزرگتر هستند ، مراکز خوشه هستند.
مرحله 4، با توجه به مقدار چگالی به ترتیب نزولی، نقاط غیر مرکزی را به نزدیکترین همسایه با چگالی بالاتر اختصاص دهید.
در مقایسه با الگوریتمهای تکراری بهینهشده، میتواند با دقت و سرعت خوشههایی از اشکال دلخواه را پیدا کند. پس از یافتن مراکز خوشه، انتساب خوشه در یک مرحله انجام می شود. می توان آن را به خوبی برای استخراج مکان ها از نقاط توقف به کار برد.
2.2.2. تفسیر مسئله و بهبود الگوریتم
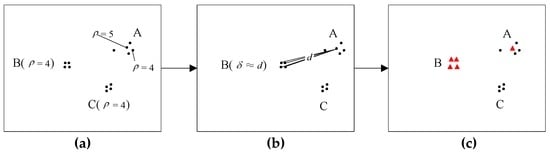
خوشهبندی با انجام جستجوی سریع و شناسایی پیکهای چگالی، برای خوشهبندی نقاط پراکنده نامنظم مناسب است. تعداد نقاطی که چگالی یکسانی دارند قابل توجه نیست. هنگامی که مراکز خوشه مشخص می شوند، الگوریتم به طور قابل توجهی تحت تأثیر قرار نمی گیرد. با این حال، این مورد برای داده های مسیر نیست، نقاط توقف مختلف در یک مکان از یکدیگر دور نیستند، و نقاط توقف بسیاری با چگالی یکسان دارند. اگر از الگوریتم بدون هیچ پیشرفتی استفاده کنیم، تعداد زیادی از مراکز خوشه خطا انتخاب می شود. همانطور که در شکل 3 نشان داده شده است، سه مکان A، B و C وجود دارد که یک نفر به ترتیب 5 بار، 4 بار و 4 بار از آنها بازدید کرده است. مطابق مرحله 2، مقدار فاصله چهار نقطه توقف در B تقریباً برابر با d است ، در شکل 3 b. در نهایت، در شکل 3 ج ، چهار نقطه توقف به عنوان مراکز انتخاب شده اند که آشکارا اشتباه هستند . مثلث قرمز نشان دهنده مرکز خوشه است.
برای حل مشکل مربوط به همان چگالی که در بالا ذکر شد، می توان چگالی را با مراحل زیر تنظیم کرد. الگوریتم نقاط توقف را که به ترتیب نزولی بر اساس چگالی مرتب شده اند به عنوان شرط ورودی می گیرد. a نشان دهنده چگالی جریان است .
- (1)
-
a = حداکثر( ρ).
- (2)
-
نقاط با چگالی یکسان a را بیرون بیاورید و هر نقطه را با مراحل 3 و 4 زیر پردازش کنید.
- (3)
-
برای نقطه SP i با چگالی a ، چگالی هر نقطه را در همسایه N i بررسی کنید . اگر نقطه ای در N i وجود دارد که چگالی آن بیشتر از a است ، نقطه SP i را نادیده بگیرید ، در غیر این صورت آن را در مجموعه S قرار دهید . ρ= a ).
- (4)
-
برای هر نقطه با چگالی a در همسایه N i ، مراحل 3 و 4 را تکرار کنید تا تمام نقاط با چگالی a پردازش شوند و مجموعه S را تشکیل دهید . ρ= a ) = { SP i ، …، SP j ، …، SP k }.
- (5)
-
برای هر نقطه از مجموعه S ، رابطه همسایه را با یکدیگر بررسی کنید. اگر دو نقطه همسایه هستند، آنها را در یک زیر مجموعه SB j قرار دهید . سپس مجموعه S = { SB 1 , …, SB m }, SB j = { SP l , …, SP k } را تشکیل دهید که حاوی m زیر مجموعه است. برای هر زیر مجموعه، نقاط مجاور یکدیگر هستند و چگالی یکسانی دارند .
- (6)
-
برای هر زیر مجموعه SB i ، یک نقطه را به طور تصادفی انتخاب کنید و چگالی آن را برابر ρ i = a + i /( m +1) کنید.
- (7)
-
a = a – 1، مراحل 2 تا 7 را تکرار کنید. اگر a = 1 باشد، الگوریتم خاتمه می یابد.
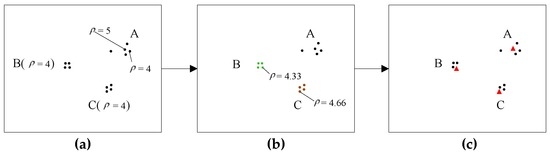
شکل 4 کل فرآیند تنظیم چگالی را نشان می دهد. در شکل 4 الف، نقطه ای با چگالی 4 در A وجود دارد، اما در همسایه نقطه، نقطه ای با چگالی 5 وجود دارد. بنابراین، نقطه را نادیده می گیریم. در شکل 4 ب، نقاط B و C دو زیرمجموعه را تشکیل می دهند و طبق فرآیند فوق به دو نقطه یک مقدار چگالی جدید داده می شود. در شکل 4 ج، مراکز خوشه با چگالی جدید انتخاب شده اند.
ویژگی نقاط توقف را در نظر بگیرید: نقاط توقف با مقدار چگالی برابر با 1 نشان می دهد که فرد دارای یک رکورد دسترسی واحد است. آن نقطه توقف یک خوشه است. بنابراین، زمانی که الگوریتم خوشهبندی با جستجوی سریع و شناسایی پیکهای چگالی، حداقل فاصله را در مرحله 2 محاسبه میکند، اگر چگالی حداکثر یا 1 باشد، فاصله باید به صورت δi = max (d ij ) ثبت شود .
3. بخش تجربی
3.1. اکتساب داده ها
به منظور بررسی اثربخشی الگوریتم پیشنهادی ما، از 30 داوطلب دعوت کردیم تا مسیرهای GPS خود را در زندگی روزمره خود جمع آوری کنند. آزمایش به مدت یک ماه به طول انجامید. همه داوطلبان شرکت کننده در این آزمایش دانش آموزان و معلمان دانشگاه ووهان هستند. اپلیکیشن جمعآوری دادهها در تلفنهای هوشمند داوطلبان که شامل اندروید یا iOS بود، نصب شد. برای اطمینان از صحت داده ها، HOLUX GPSlim236 به عنوان سیگنال GPS دریافت کننده دستگاه گرفته شد و از طریق بلوتوث به تلفن هوشمند متصل شد. بنابراین، GPS تنها GNSS در آزمایش ما است. از آنجایی که HOLUX GPSlim236 داده ها را یک بار در ثانیه به روز می کند، برای کاهش داده های اضافی، برنامه می تواند فاصله نمونه برداری را بر اساس سرعت موبایل تنظیم کند. کوتاه ترین فاصله کمتر از 5 ثانیه نیست.
در طول جمعآوری دادههای مسیر، هیچ محدودیت یا مداخله دستی برای داوطلبان ایجاد نکردیم. از داوطلبان خواسته شد تا دستگاه GPS را در نور روز اجرا کنند تا برنامه تا حد امکان در پس زمینه اجرا شود و دستگاه در شب شارژ شد. داده های بیشتری توسط برنامه جمع آوری شد تا زندگی روزمره داوطلبان را منعکس کند. داده های مسیر در حافظه یک تلفن هوشمند در مقیاس زمانی روزانه ذخیره می شد. این برنامه نه تنها می تواند به طور خودکار اطلاعات آهنگ را ضبط کند، بلکه می تواند مکان را به صورت دستی علامت گذاری کند. داوطلبان مجبور به ثبت مکان نشدند. هنگامی که داوطلب به مکانی یا در طول دوره نقل مکان کرد، داوطلب باید مختصات و زمان فعلی را از طریق برنامه ثبت کند، به این معنی که داوطلب یک رکورد از مکان ایجاد کرده است. هر مکان ثبت شده دارای یک ویژگی نوع است. در برنامه، پنج نوع برای داوطلبان وجود داشت: خانه یا خوابگاه، دفتر یا کلاس درس، رستوران، سرگرمی (مانند مکان دیدنی، سینما و غیره) و خدمات عمومی (به عنوان مثال، بیمارستان، ایستگاه اتوبوس و غیره). . در این مقاله مکان ثبت شده را به صورت تعریف کردیمRL = ( lng ، lat ، type ، t )، که نشان دهنده طول جغرافیایی، عرض جغرافیایی، نوع مکان و زمان یک مکان ثبت شده است. در همان زمان، اگر داوطلبان چندین بار مکانها را در یک مکان ثبت کنند، برنامه به داوطلبان اجازه میدهد مکانهای ضبط شده را انتخاب کرده و آنها را با هم گروهبندی کنند. مکانهای ثبتشده عمدتاً برای تأیید الگوریتم استخراج نقطه توقف و گروهها برای الگوریتم خوشهبندی مکان استفاده میشوند.
در طول کل آزمایش، ما داده های مسیر 23 داوطلب را جمع آوری کردیم. یازده نفر از آنها مکان های زیادی را ثبت کردند. داده های به دست آمده در جدول 1 ، مجموعه داده 1 نشان داده شده است، شامل داده های 11 داوطلب در طول 20 روز است. داده های مسیر نسبتا کامل است. مجموعه داده های 2 و 3 از مجموعه داده 1 انتخاب می شوند.
3.2. پیش پردازش
به دلیل تأثیر از دست دادن سیگنال GPS و رانش داده، تعدادی از نقاط پرت در داده های مسیر در طول اکتساب داده وجود دارد. بنابراین، داده ها باید پاک شوند. با توجه به این پارامترها که منعکس کننده کیفیت سیگنال GPS مانند ارتفاع، تعداد ماهواره های ردیابی شده، HDOP و سرعت هستند، داده های خام را می توان فیلتر کرد. ووهان در دشت جیانگهان واقع شده است و میانگین ارتفاع آن زیر 50 متر از سطح دریا است. منطقه اکتساب داده عمدتاً در دانشگاه ووهان متمرکز شده است. با توجه به دقت موقعیت یابی عمودی GPS، آستانه ارتفاع 100 متر تنظیم شده است. این نقاط پرت که ناشی از ناهنجاری داده های ارتفاع هستند، می توانند از طریق آزمایش فیلتر شوند. این مقاله بر اساس نتایج تحقیقات استوفر [ 5]. در الگوریتم پیش پردازش، تعداد ماهواره های ردیابی شده روی 3 و HDOP روی 5 تنظیم می شود تا نقاط رانش بزرگ داده حذف شود. با در نظر گرفتن عادات مختلف سفر داوطلبان، آستانه سرعت به عنوان یک مقدار ثابت پیکربندی نشده است. برای داده های هر داوطلب، یک نمونه تصادفی از داده های مسیر برای تعیین آستانه سرعت با معیار Pauta δ v = استفاده می شود.μ+ 3 σ.
هدف از الگوریتم 2 فیلتر کردن مقادیر پرت از داده های خام است. برای هر نقطه GPS در داده های مسیر، سرعت نقطه برابر است با فاصله بین نقطه و نقطه بعدی تقسیم بر مدت زمان. این به این دلیل است که در دادههای خام برخی نقاط پرت متوالی وجود دارد در حالی که پارامترهای فیلتر استاندارد هستند، درست مانند ناحیه A در شکل 5 a. خطوط زرد و قرمز نشان دهنده مسیرهای مختلف GPS است که در مسیرهای مختلف جمع آوری شده است. در مجموع، 13.14 درصد از داده های خام پس از پیش پردازش فیلتر شدند. حتی اگر هنوز در دادههای باقیمانده مقادیر پرت وجود دارد، میتوانیم با استفاده از بافر نقطهای تأثیر این نقاط پرت را کاهش دهیم.
| الگوریتم 2 . پیش پردازش | |
| ورودی: مسیر T ، آستانه سرعت δ v ، آستانه ارتفاع δ alt ، آستانه ماهواره δ ماهواره ، آستانه HDOP δ hdop | |
| خروجی: T بدون نقاط پرت | |
| 1: | نقطه قبلی = P 0 ; |
| 2: | برای هر نقطه P i در T انجام دهید |
| 3: | v i = فاصله( نقطه قبلی , P i ) / مدت زمان ( نقطه قبلی , P i ) ; |
| 4: | اگر v i > δ v یا P i . alt > δ alt یا P i . ماهواره < δ ماهواره یا P i . HDOP > δ hdop سپس |
| 5: | P i را از T حذف کنید . |
| 6: | else نقطه قبلی = P i ; |
| 7: | بازگشت T ; |
3.3. مولفه های
قبل از تایید الگوریتم، باید پارامترهای الگوریتم را انتخاب کنیم. همانطور که در بالا ذکر کردیم، دو پارامتر وجود دارد: آستانه زمانی و آستانه فاصله.
در الگوریتم TDBC، پارامتر آستانه زمانی δ t تعداد خوشه ها را تعیین می کند، زیرا الگوریتم یک خوشه را تنها زمانی به عنوان نقطه توقف در نظر می گیرد که مدت زمان خوشه بیش از δ t باشد . اگر δ t خیلی بزرگ باشد، این خوشه ها که مدت زمان نسبتاً کوتاهی دارند، نادیده گرفته می شوند. در غیر این صورت این خوشه ها به عنوان نقاط توقف در نظر گرفته شده و در مجموعه به هم متصل می شوند.
پارامتر آستانه فاصله δ d اندازه خوشه ها را تعیین می کند. برای هر نقطه، الگوریتم فاصله بین نقطه و مرکز خوشه فعلی را محاسبه می کند. نقطه فقط زمانی به خوشه جاری می پیوندد که فاصله کمتر از δ d باشد . تنظیم بیشتر δ d منجر به ادغام خوشه ها می شود که در مجاورت یکدیگر قرار دارند. تنظیم کمتر δ d خوشه های کوچک تری می دهد که ممکن است به عنوان نویز در نظر گرفته شود. به دلیل عدم دقت تجهیزات GPS، حتی اگر فرد برای مدت طولانی در یک مکان بماند، داده های GPS نمی تواند یکسان باشد. اگر δ tکمتر از سطح دقت است، الگوریتم برخی از خوشه های بخش بندی شده را از یک دوره طولانی در طول یک بازدید تولید می کند. این خوشه ها ممکن است نادیده گرفته شوند زیرا مدت زمان برای پوشش δ t کافی نیست .
در همین حال، آستانه فاصله تأثیراتی بر الگوریتم خوشه بندی مکان دارد. مکان فردی یک مفهوم ذهنی است که با توجه به مقیاس های مختلف تعاریف متفاوتی دارد. با توجه به کاربرد مکان (به عنوان مثال، ناوبری و توصیه کننده مبتنی بر مکان)، مکان باید بر اساس سطح ساختمان باشد. بنابراین، مقدار آستانه فاصله نباید خیلی زیاد باشد.
به منظور یافتن محدوده مناسب پارامترها، این مقاله مجموعه داده 2 را به عنوان داده های تجربی انتخاب می کند که شامل چهار مسیر حرکت داوطلب در یک روز است. نمودارهای شکل 6 تعداد نقاط توقف استخراج شده از مجموعه داده 2 را برای فاصله ها و آستانه های زمانی مختلف نشان می دهد.
از نمودارها، میتوانیم مشاهده کنیم که منحنیها به شدت کاهش مییابند وقتی δ t از 0 ثانیه به 300 ثانیه افزایش مییابد. آستانه زمانی کوتاه δ t ، منجر به تعدادی خوشه با مدت زمان کوتاه می شود که به عنوان نقاط توقف در نظر گرفته می شوند. وقتی δ t > 300 ثانیه، منحنی ها صاف می شوند، که نشان می دهد تأثیر آستانه زمانی به وضوح ضعیف شده است. در ضمن، برای آستانه های مسافتی مختلف، هر چه آستانه زمانی بیشتر باشد، تعداد نقاط توقف مشابه تر است. بنابراین، آستانه زمانی δ t باید از [300، 800] ثانیه انتخاب شود.
در مقایسه با سایر آستانه های فاصله، منحنی ها با δd = 20 متر با سرعت بیشتری کاهش می یابند. دلیل این امر این است که δ d نزدیک به دقت تجهیزات GPS است (دقت HOLUX GPSlim236 5-25 متر است). وقتی δ d = 200 متر، منحنی ها برای تشخیص نقاط توقف، به ویژه برای سطح ساختمان مکان ها، خیلی صاف هستند. هنگامی که δ d = 125 متر، منحنی ها مشابه 200 متر هستند، به این معنی که آستانه فاصله بزرگ است. برای این آستانه های فاصله، مانند 50 متر و 100 متر، منحنی ها دارای یک نقطه زانو واضح هستند. بنابراین آستانه فاصله δ d باید از (20125) متر انتخاب شود.
برای تخمین بیشتر پارامترهای TDBC، این مقاله از دقت ( P )، یادآوری ( R ) و F1-Measure ( F ) به عنوان معیارهای قضاوت استفاده میکند. مکان های ثبت شده که توسط داوطلبان ثبت شده است به عنوان نمونه مرجع در نظر گرفته می شود.
تعریف 7. مطابقت: ∀ نقطه توقف SP i = (lng i ، lat i ، نوع i ، t i شروع ، t i پایان )، ∃یک مکان ثبت شده RL j = (lng j ، lat j ، نوع j ، t j )، جایی که t i شروع می شود < t j < t i پایان و فاصله (SP i , RL j ) < δ d . همانطور که در شکل 7 نشان داده شده است ، یک نقطه مطابق به این معنی است که نقطه ثبت شده RL 1 در طول نقطه توقف SP 1 ثبت شده است.و فاصله بین SP 1 و RL 1 کمتر از آستانه فاصله است .
نرخ دقت نسبت نقاط توقف است که با مکان های ثبت شده مطابقت دارد، معادله (3). در حالی که p + مخفف تعداد نقاط توقف منطبق است، p − اینطور نیست. نرخ فراخوان نسبت مکان های ثبت شده است که با نقاط توقف مطابقت دارند، معادله (4). r + مخفف تعداد مکان های ثبت شده مطابقت شده است، در حالی که r – اینطور نیست.
پ=پ+پ++پ–
آر=r+r++r–
ما از مجموعه داده 1 به عنوان داده آزمایش استفاده کردیم که شامل داده های مسیر حرکت 11 داوطلب و مکان های ثبت شده آنها است. آنها به طور متوسط هفت مکان ثبت شده در روز را علامت گذاری کردند. شکل 8نمودارهای دقت و فراخوانی برای فاصله ها و آستانه های زمانی مختلف است. هنگامی که دقت افزایش می یابد، فراخوان کاهش می یابد. در کل، میزان دقت معقول حدود 0.8 و نرخ فراخوان حدود 0.7 است. دلیل احتمالی این امر این است که مکان های ثبت شده دقیق نیستند. به عنوان مثال، سه بازدید توسط A، B و C در طول یک روز انجام شد و مدت زمان آن 10، 15 و 30 دقیقه بود. با این حال، زمانی که داوطلب مکان را ثبت کرد، یک بازدید را در B و دو بازدید را در C ثبت کرد. بنابراین، دقت Matched تحت تأثیر قرار خواهد گرفت.
وقتی آستانه فاصله δ d یکسان است، نرخ دقت با افزایش آستانه زمانی δ t افزایش می یابد . این بدان معناست که نقاط توقف با مدت زمان طولانی که توسط TDBC تشخیص داده شده است، فقط توسط داوطلبان ثبت شده است. که با وضعیت واقعی همخوانی دارد. هر چه یک داوطلب بیشتر بماند، احتمال بیشتری برای ثبت یک مکان ثبت شده وجود دارد. در همین حال، نرخ فراخوان کاهش می یابد، به این معنی که تعداد نقاط توقف کاهش می یابد و بسیاری از نقاط توقف شناسایی نمی شوند.
هنگامی که آستانه زمانی δ t یکسان است، هر دو میزان دقت و یادآوری با افزایش آستانه فاصله δd افزایش مییابند . با این حال، زمانی که δd از 60 متر فراتر رفت، دقت و نرخ فراخوان به طور قابل توجهی بهبود نمییابد، که نشان میدهد که پارامتر فاصله خیلی کوچک یا خیلی زیاد مناسب نیست و δd = 60 متر نقطه عطف است. برای انتخاب پارامترهای مناسب، F1-Measure بیشتر مورد بررسی قرار می گیرد.
F1-Measure یک شاخص ارزیابی جامع بر اساس دقت و نرخ فراخوان است.
اف=2×پ×آرپ+آر
شکل 9 نمودار F1-Measure برای فاصله ها و آستانه های زمانی مختلف است. وقتی δ d بیش از 60 متر باشد، اندازه گیری F1 ثابت می ماند. وقتی δd = 60 متر و δ t = 500 ثانیه، F1-Measure به حداکثر افزایش می یابد . نرخ دقت 0.81 و نرخ فراخوان 0.68 است.
3.4. آزمایش استخراج نقطه توقف
در ادامه، دو گروه آزمایش برای مقایسه TDBC با چهار الگوریتم دیگر، K-Medoids، DJ-Cluster [13]، CB -SMoT [ 19 ] و خوشه بندی مبتنی بر زمان [ 3 ] طراحی شد. آزمایش اول از Dataset 1 که دارای حجم زیادی از داده ها است برای مقایسه عملکرد الگوریتم ها استفاده کرد. آزمایش دوم از Dataset 3 برای مقایسه مزایا و معایب الگوریتمهای مختلف در شرایط خاص استفاده کرد.
نتایج آزمایش اول در جدول 2 آمده است . پارامترهای TDBC با بحث در بخش 3.3 تعیین می شوند، در حالی که چهار الگوریتم دیگر پارامترها را با توجه به مقدار بهینه Precision، Recall و F1-Measure انتخاب کردند. برای CB-SMoT، ما فقط اولین مرحله را برای رسیدن به توقف های بالقوه بدون عملیات پیگیری تکمیل کردیم. از جدول، k-medoids، DJ-Cluster و CB-SMoT نسبت به دو الگوریتم دیگر به دلیل محاسبات پیچیدهشان زمانبرتر هستند. کارایی TDBC شبیه به زمان مبتنی است و هر دو دارای راندمان خوشهبندی بالایی هستند. از نظر دقت، TDBC و DJ-Cluster بیش از 0.8 هستند که به طور قابل توجهی بزرگتر از سه الگوریتم دیگر است. از نظر فراخوانی، در مقایسه با سایرین، TDBC اندکی بهبود یافته است. بنابراین، با وعده اطمینان از بهره وری زمانی، عملکرد TDBC به طور قابل توجهی بهبود یافت.
درمان از دست دادن سیگنال GPS و رانش داده تا حد زیادی دقت الگوریتم را بهبود می بخشد. با توجه به تشخیص نقاط توقف نوع I، نرخ فراخوان درجه ای از بهبود را نشان داد. همانطور که از جدول 2 می بینیم ، نرخ فراخوان در کل زیاد نیست. ما پس از آزمایش یک بازدید مجدد انجام دادیم و متوجه شدیم که بسیاری از داوطلبان مکانهای ثبتشده را بهطور دقیق ثبت نکردهاند. برای مثال، داوطلبان ممکن است مکانها را قبل از رسیدن یا پس از ترک مکانها ثبت کنند، یا مکان را به طور مکرر علامتگذاری کنند. این عوامل ممکن است بر دقت تطبیق تأثیر بگذارد و نرخ فراخوان را در الگوریتمهای مختلف کاهش دهد.
شکل 10نشان دهنده نتایج استخراج نقطه توقف TDBC برای انواع مختلف از مجموعه داده 1 است. نمودار سمت چپ نسبت انواع مختلف و سمت راست دقت انواع مختلف است. از نمودارها، میتوان دید که نسبت نوع III 0.52 و دقت آن 0.88 است، که نشان میدهد TDBC نرخ تشخیص بالاتری برای نقاط توقفی دارد که سیگنال برای مدت طولانی از بین رفته است. نرخ بالای دقت به این معنی است که داوطلبان تمایل بیشتری به ثبت مکان ثبت شده در ساختمان دارند که با واقعیت مطابقت دارد. با توجه به اینکه اکثر داوطلبان دانشجو هستند، نقاط توقف آنها بیشتر در این ساختمان ها مانند ساختمان های آموزشی، آزمایشگاه ها، خوابگاه های دانشجویی، کتابخانه ها و … است. ، و دقت 0.79 است. این نشان می دهد که دستگاه GPS سیگنال را با رانش داده های کوتاه برد در ساختمان نیمه بسته دریافت کرده است که مطابق با داده های خام است. هم نسبت نوع I و هم دقت بالا نیست، به این معنی که داوطلبان مختلف عادت های مختلف تور داشتند و مکان های نسبتا کمی را در موقعیت اولیه یک مسیر ثبت کردند.
جدول 3 نتیجه آزمایش دوم از مجموعه داده 3 است که فقط شامل داده های مسیر یک روز از یک داوطلب است. ما می دانیم که داوطلب در آن روز برای گردش رفت و 9 مکان را ضبط کرد. پارامترهای سایر الگوریتمها روی همان مقدار آزمایش اول تنظیم شدهاند، با این تفاوت که K-Medoids روی 9 تنظیم شده است.
همانطور که در جدول 3 نشان داده شده است ، نتایج خوشه بندی الگوریتم های مختلف به طور کلی مطابق با نتایج آزمایش اول است. دقت DJ-Cluster و فراخوانی TDBC بالاترین میزان است.
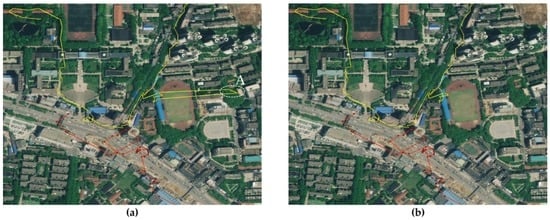
نتایج مقایسه بین TDBC و چهار الگوریتم در شکل 11 نشان داده شده است . پنج مکان ثبت شده در ناحیه قابل مشاهده وجود دارد. TDBC به درستی پنج نقطه را پیدا کرد و دو نقطه دیگر را که توسط داوطلب ثبت نشد استخراج کرد. نقاط A و E در شکل 11 a. تجزیه و تحلیل نشان می دهد که نقطه A یک کشتی است و داوطلب در آنجا توقف کرد و منتظر ماند تا از رودخانه یانگ تسه عبور کند. نقطه E یک توقف در خیابان تنقلات است. داوطلب هیچ یک از دو نقطه را ثبت نکرده بود. بنابراین، TDBC معقول است. نقطه B در شکل 11 b توقفی است که برای مدت طولانی از دست دادن سیگنال را تجربه کرده است. نقطه C در شکل 11d توقفی است که دارای نقاط با رانش داده با برد کوتاه است و نقطه D در شکل 11 d یک توقف دایره ای است.
شکل 11 a نتیجه K-Medoids است که سه نقطه توقف را به دقت استخراج کرده است. از آنجایی که الگوریتم به نقاط اولیه حساس است، نقاط اولیه مختلف ممکن است نتایج متفاوتی داشته باشند. در این مقاله، زمانهای اصلی را برای نقاط اولیه تصادفی مختلف آزمایش کردهایم. برخی از نقاط، به عنوان مثال، نقطه F در شکل 11 a، هنوز اجتناب ناپذیر بود. بدیهی است که این نقاط نقطه توقف معقولی نیستند. در این میان، زمان مشخصه مهم داده های مسیر است و توسط K-Medoids در نظر گرفته نمی شود. با توجه به پیچیدگی و دقت زمانی، عملکرد TDBC البته بهتر از K-Medoids است.
شکل 11 b نتیجه DJ-Cluster است. نقاط توقف یافت شده محله های متراکم نقاط GPS هستند و داوطلب فقط در این مکان ها وارد شده است. از آنجایی که ماهیت DJ-Cluster یک الگوریتم خوشهبندی مبتنی بر چگالی است، برای نقاط GPS که در یک منطقه در زمانهای مختلف ثبت میشوند، DJ-Cluster آنها را با هم در یک خوشه ادغام میکند و خوشه را به عنوان نقطه توقف بدون آن میگیرد. با توجه به تاثیر زمان اگرچه نتایج معقول نیستند، اما اگر زمان را در نظر نگیریم، دقت DJ-Cluster بسیار بالاست. در عین حال، الگوریتم دارای عیوب طبیعی برای این نقاط توقف است، که شامل از دست دادن سیگنال برای یک دوره طولانی است، به عنوان مثال، نقطه B در شکل 11 b، و دارای یک مسیر دایره ای با چگالی کمتر، به عنوان مثال، نقطه D درشکل 11 ب. به همین دلیل است که فراخوان کم است.
شکل 11 c نتیجه CB-SMoT است. با توجه به تاثیر زمان، ماهیت CB-SMoT بر اساس سرعت متوسط برای یافتن نقطه توقف است. بنابراین، الگوریتم می تواند این نقاط توقف را که برای مدت طولانی بیرون می مانند یا سیگنال از دست می دهند، تشخیص دهد، به عنوان مثال، نقطه B در شکل 11 c. دقیقاً به دلیل این ویژگی است که الگوریتم به راحتی در اتصالات جاده یا ترافیک به عنوان نقاط توقف در نظر گرفته می شود، به عنوان مثال، نقطه G در شکل 11 c. همچنین قابلیت نقطه توقف دایره ای وجود ندارد. بنابراین، دقت CB-SMoT بالا نیست.
شکل 11 d نتایج مبتنی بر زمان را نشان می دهد که دقت بالاتری دارند. از آنجایی که الگوریتم تأثیر زمان را در نظر می گیرد و اقدامات درمانی مربوطه را برای از دست دادن سیگنال دارد، این نقاط توقف که از دست دادن سیگنال دارند به درستی شناسایی می شوند، به عنوان مثال، نقطه B در شکل 11 d. با این حال، الگوریتم این مکانها را که دارای رانش داده یا ناحیه دایرهای هستند به چندین نقطه توقف، مانند نقاط C و D در شکل 11 تقسیم میکند.د هر دو نقطه به دو بخش تقسیم می شوند. این می تواند منجر به افزایش تعداد کل نقاط توقف و کاهش دقت نتایج مبتنی بر زمان شود. در همین حال، فراخوانی الگوریتم خوشهبندی مبتنی بر زمان محدود است، زیرا تقسیمبندی، خوشههای کوچک بیشتری را ایجاد میکند، که ممکن است با الزامات نقطه توقف مطابقت نداشته باشد و این خوشهها نادیده گرفته میشوند.
3.5. آزمایش استخراج مکان
خوشهبندی بهبودیافته با جستجوی سریع و شناسایی پیکهای چگالی در این تحقیق، نقاط توقف را در مکانهایی از مجموعه داده 1 خوشهبندی کرد. در مقایسه با الگوریتمهای موجود در ادبیات [ 15 ، 17 ]، خوشهبندی مبتنی بر چگالی عملکرد بهتری دارد، که پیشنهاد شد. در ادبیات [ 3 ]. بنابراین، الگوریتم بهبود یافته ما با الگوریتم مبتنی بر چگالی مقایسه خواهد شد.
همانطور که در شکل 12 نشان داده شده است ، درست به این معنی است که هر یک از نقاط توقف به خوبی با مکان ثبت شده در همان گروه مطابقت دارد. باطل یعنی برعکس . Merged نشان دهنده مطابقت یا عدم تطابق نقاط توقف با مکان های ثبت شده از گروه های مختلف است . The Lost مخفف مکان های ثبت شده از همان گروه است که امتیاز منطبق ندارد. Divided مخفف مکان های ضبط شده است که با نقاط توقف از خوشه های مختلف مطابقت دارند . دقت نسبت خوشه های صحیح و فراخوانی نسبت صحیح استگروه ها. شاخص های ارزیابی شامل زمان سپری شده الگوریتم، نرخ نادرست ( FR )، نرخ ادغام شده ( MR )، نرخ از دست رفته ( LR )، نرخ تقسیم شده ( DR )، دقت ( P )، یادآوری ( R ) و F1-Measure است.
جدول 4 مقایسه بین الگوریتم ما و خوشه بندی مبتنی بر چگالی است. پارامترهای هر دو الگوریتم روی 60 متر تنظیم شده است. در مقایسه با روش مبتنی بر چگالی، الگوریتم بهبود یافته ما دارای مزایای مشخصی در کارایی است و نرخ ادغام کمتر و نرخ تقسیم بالاتری دارد . این به این دلیل است که الگوریتم بهبودیافته ما مکانهای نزدیک به یکدیگر را ادغام نمیکند، در حالی که الگوریتم مبتنی بر چگالی این کار را انجام میدهد. همانطور که در شکل 13 نشان داده شده است، رویکرد مبتنی بر چگالی مکان های B و C را تشخیص نمی دهد، اما آنها را با هم ادغام می کند. به همین دلیل است که دقت الگوریتم ما بالاتر است. علاوه بر این، نرخ نادرست، نرخ از دست رفته و یادآوری در دو الگوریتم مشابه یکدیگر هستند. هر دوی آنها نرخ از دست دادن بالاتر و یادآوری کمتری دارند. این به این دلیل است که نرخ فراخوان کلی الگوریتم ها همانطور که در بخش 3.4 بحث کردیم کم است . از کل دیدگاه، تحت پیش نیاز اطمینان از دقت و نرخ فراخوان، الگوریتم بهبود یافته ما عملکرد و کارایی بالاتری دارد.
4. نتیجه گیری و کار آینده
در این مقاله، ما یک رویکرد خوشهبندی دو مرحلهای را برای استخراج مکانهای شخصی از دادههای مسیر GPS فردی پیشنهاد کردیم. ابتدا سه نوع نقطه توقف توسط الگوریتم TDBC تعریف و استخراج می شود. سپس، روش خوشهبندی بهبودیافته که جستجوی سریع انجام داد و پیکهای چگالی را پیدا کرد برای استخراج مکانها از این نقاط توقف استفاده شد. آزمایشهای گستردهای برای تأیید عملکرد الگوریتم انجام شد. نتایج کارایی روش پیشنهادی را نشان می دهد. بدیهی است که از نظر کارایی و عملکرد، TDBC از الگوریتم استخراج نقاط توقف موجود بهتر عمل می کند. رویکرد جدید ما میتواند تأثیر از دست دادن سیگنال GPS و جابجایی دادهها را به میزان قابل توجهی کاهش دهد و مکانهای منحصربهفرد مانند مناطق دایرهای را تشخیص دهد. در همین حال، خوشهبندی بهبود یافته با جستجوی سریع و شناسایی قلههای چگالی برای کشف مکانهای مسیر اعمال شد. این رویکرد عملکرد بهتری را نسبت به الگوریتمهای خوشهبندی مکان موجود نشان میدهد.
با این حال، رویکرد پیشنهادی به برخی پارامترهای قبلی نیاز دارد. در این مقاله پارامترهایی برای استخراج مکان های سطح ساختمان تهیه شد. اگرچه روشی که برای یافتن پارامترهای بهینه استفاده شد ارائه شد، اما خودکار نبود. در رویکرد پیشنهادی ما، زمانی که مراکز خوشهای در مرحله 3 انتخاب میشوند، مداخله دستی ضروری است. در عین حال، تجزیه و تحلیل اطلاعات معنایی و شناسایی عادات شخصی برای این مکانها، کار اساسی برای پیشبینی مسیر و مکان، توصیه دوستان اجتماعی، خدمات مکانیابی شخصیسازیشده را تشکیل میدهد. و غیره این موضوعات مورد توجه ما در مطالعات آینده خواهد بود.
منابع
- گونزالس، ام سی؛ هیدالگو، کالیفرنیا؛ Barabási، AL درک الگوهای تحرک فردی انسان. طبیعت 2008 ، 453 ، 779-782. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- هریسون، اس. Dourish, P. Replace-ing space: نقش مکان و فضا در سیستم های مشارکتی. در مجموعه مقالات کنفرانس ACM 1996 در مورد کار تعاونی با پشتیبانی رایانه، بوستون، MA، ایالات متحده آمریکا، 16-20 نوامبر 1996.
- Lv، M. چن، ال. خو، ز. لی، ی. چن، جی. کشف مکانهای معنایی شخصی مبتنی بر دادهکاوی مسیر. محاسبات عصبی 2016 ، 173 ، 1142-1153. [ Google Scholar ] [ CrossRef ]
- یو، ی. کیم، جی. شین، ک. جو، سیستم توصیه GS با استفاده از هستی شناسی مبتنی بر مکان در اینترنت بی سیم: نمونه ای از هوش جمعی با استفاده از برنامه های کاربردی ‘mashup’. سیستم خبره Appl. 2009 ، 36 ، 11675-11681. [ Google Scholar ] [ CrossRef ]
- استوفر، روابط عمومی؛ جیانگ، کیو. FitzGerald, C. پردازش داده های GPS از نظرسنجی های سفر. در مجموعه مقالات دومین کنفرانس بین المللی مبانی رفتاری مدل های یکپارچه کاربری زمین و حمل و نقل: چارچوب ها، مدل ها و کاربردها، تورنتو، ON، کانادا، 12-15 ژوئن 2005.
- چن، ال. Lv، M. Chen, G. سیستمی برای پیش بینی مقصد و مسیر آینده بر اساس استخراج مسیر. اوباش فراگیر. محاسبه کنید. 2010 ، 6 ، 657-676. [ Google Scholar ] [ CrossRef ]
- ژانگ، جی. زو، ام. پاپادیاس، دی. تائو، ی. پرس و جوهای فضایی مبتنی بر مکان لی، DL. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 2003 در مدیریت داده ها، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 10-12 ژوئن 2003.
- کیم، دی اچ. هایتاور، جی. گوویندان، ر. استرین، دی. کشف مکانهای معنایی معنادار از چراغهای RF فراگیر. در مجموعه مقالات یازدهمین کنفرانس بین المللی در محاسبات همه جا حاضر، اورلاندو، فلوریدا، ایالات متحده آمریکا، 30 سپتامبر تا 3 اکتبر 2009.
- هایتاور، جی. Consolvo، S. لامارکا، آ. اسمیت، آی. هیوز، جی. یادگیری و شناخت مکان هایی که می رویم. In Proceedings of the Ubicomp 2005: Ubiquitous Computing، توکیو، ژاپن، 11-14 سپتامبر 2005.
- پیک، جی. کیم، جی. Govindan، R. موقعیت یابی مبتنی بر GPS سازگار با نرخ کارآمد برای تلفن های هوشمند. در مجموعه مقالات هشتمین کنفرانس بین المللی سیستم های تلفن همراه، برنامه ها و خدمات، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 15 تا 18 ژوئن 2010.
- شوسلر، ن. Axhausen، K. پردازش داده های خام از سیستم های موقعیت یابی جهانی بدون اطلاعات اضافی. ترانسپ Res. ضبط J. Transp. Res. هیئت 2009 . [ Google Scholar ] [ CrossRef ]
- اشبروک، دی. Starner, T. یادگیری مکان های مهم و پیش بینی حرکت کاربر با GPS. در مجموعه مقالات ششمین سمپوزیوم بین المللی، وین، اتریش، 21-23 آوریل 2002.
- ژو، سی. فرانکوفسکی، دی. لودفورد، پی. شکر، س. تروین، ال. کشف مکانهای معنادار شخصی: یک رویکرد خوشهبندی تعاملی. ACM Trans. Inf. سیستم (TOIS) 2007 . [ Google Scholar ] [ CrossRef ]
- استر، ام. کریگل، اچ.-پی. ساندر، جی. Xu, X. یک الگوریتم مبتنی بر چگالی برای کشف خوشه ها در پایگاه داده های فضایی بزرگ با نویز. در مجموعه مقالات دومین کنفرانس بین المللی کشف دانش و داده کاوی، پورتلند، OR، ایالات متحده آمریکا، 2 تا 4 اوت 1996.
- اشبروک، دی. Starner, T. استفاده از GPS برای یادگیری مکانهای مهم و پیشبینی حرکت بین کاربران متعدد. پارس محاسبات همه جا حاضر. 2003 ، 7 ، 275-286. [ Google Scholar ] [ CrossRef ]
- دو، ج. Aultman-Hall, L. افزایش دقت اطلاعات نرخ سفر از مجموعه دادههای سفر چند روزه GPS غیرفعال: مسائل شناسایی خودکار پایان سفر. ترانسپ Res. بخش A سیاست سیاست. 2007 ، 41 ، 220-232. [ Google Scholar ] [ CrossRef ]
- کانگ، جی اچ. ولبورن، دبلیو. استوارت، بی. Borriello, G. استخراج مکان ها از آثار مکان. در مجموعه مقالات دومین کارگاه بین المللی ACM در مورد برنامه ها و خدمات تلفن همراه بی سیم در نقاط اتصال WLAN، فیلادلفیا، PA، ایالات متحده آمریکا، 1 اکتبر 2004.
- آلوارس، لو. بوگورنی، وی. کویجپرز، بی. de Macedo، JAF; مولانز، بی. Vaisman, A. مدلی برای غنی سازی مسیرها با اطلاعات جغرافیایی معنایی. در مجموعه مقالات پانزدهمین سمپوزیوم بین المللی سالانه ACM در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سیاتل، WA، ایالات متحده آمریکا، 7-9 نوامبر 2007.
- پالما، AT; بوگورنی، وی. کویجپرز، بی. Alvares, LO یک رویکرد مبتنی بر خوشهبندی برای کشف مکانهای جالب در مسیرها. در مجموعه مقالات سمپوزیوم ACM 2008 در محاسبات کاربردی، سئارا، برزیل، 16 تا 20 مارس 2008.
- یوان، اچ. کیان، ی. یانگ، آر. تحقیق در مورد شخصیسازی مبتنی بر مسیر GPS و استخراج مسیر. سیستم مهندس عمل تئوری. 2015 ، 35 ، 1276-1282. [ Google Scholar ]
- Zaïane، OR; حفره کوچک.؛ لی، CH; Wang، W. در مورد تجزیه و تحلیل خوشه بندی داده ها: مقیاس پذیری، محدودیت ها، و اعتبار. در مجموعه مقالات کنفرانس اقیانوس آرام-آسیا در مورد کشف دانش و داده کاوی، تایپه، تایوان، 6-8 مه 2002.
- رودریگز، آ. Laio، A. خوشه بندی با جستجوی سریع و یافتن قله های چگالی. Science 2014 ، 344 ، 1492-1496. [ Google Scholar ] [ CrossRef ] [ PubMed ]
شکل 1. نمودار جریان استخراج مکان.

شکل 2. انواع مختلف نقاط توقف. ( الف ) نوع I. ( ب ) نوع II. ( ج ) نوع III.
شکل 3. نمونه ای از مراکز خوشه بندی اشتباه. ( الف ) نقاط اولیه؛ ( ب ) برای هر نقطه، حداقل فاصله را محاسبه کنید. ( ج ) مراکز اشتباه را انتخاب کنید.
شکل 4. نمونه ای از تنظیم چگالی. ( الف ) نقاط اولیه؛ ( ب ) برای نقاطی که چگالی یکسان دارند، چگالی را دوباره محاسبه کنید. ( ج ) مراکز را انتخاب کنید.
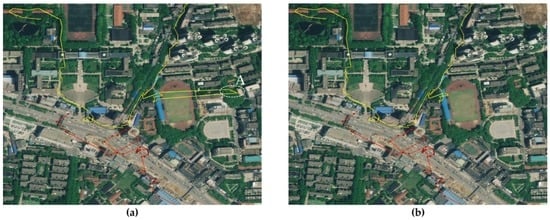
شکل 5. ( الف ) داده های خام. ( ب ) داده های فیلتر شده.

شکل 6. تعداد نقاط توقف یافت شده برای فاصله ها و آستانه های زمانی مختلف. ( الف ) نتایج داوطلب A. ( ب ) داوطلب B; ( ج ) داوطلب C; ( د ) داوطلب D.
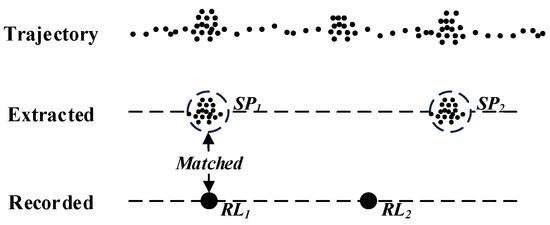
شکل 7. نمونه ای از نقطه منطبق.
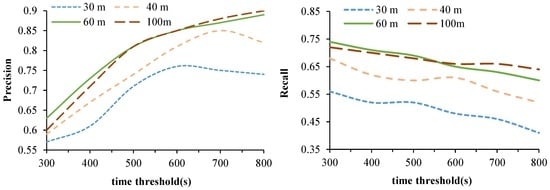
شکل 8. دقت و فراخوانی برای فاصله و آستانه زمانی مختلف.
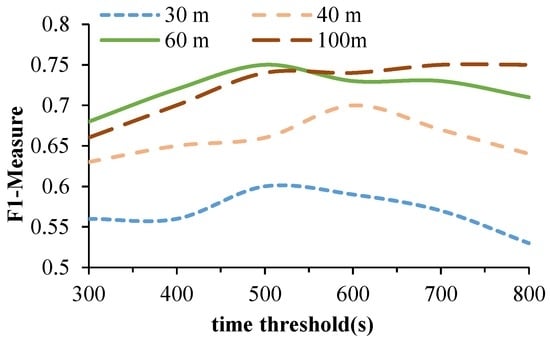
شکل 9. F1-Measure برای فاصله ها و آستانه های زمانی مختلف.
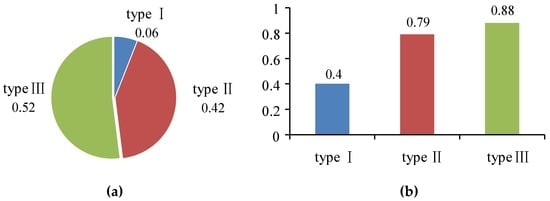
شکل 10. جزئیات انواع مختلف خوشه. الف ) نسبت انواع مختلف ؛ ( ب ) دقت انواع مختلف.

شکل 11. نتایج در مقایسه با سایر الگوریتم ها. ( الف ) K-Medoids; ( ب ) DJ-Cluster; ( ج ) CB-SMoT; ( د ) خوشه بندی مبتنی بر زمان.

شکل 12. نمونه ای از معیارهای ارزیابی.

شکل 13. نمونه ای از خوشه بندی برای دو الگوریتم.

جدول 1. جزئیات مجموعه داده های مختلف.
جدول 2. نتایج الگوریتم های مختلف خوشه برای مجموعه داده 1.
جدول 3. نتایج الگوریتم های مختلف خوشه برای مجموعه داده 3.
جدول 4. مقایسه با الگوریتم مبتنی بر چگالی.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر