1. معرفی
نقشه های دیجیتال یا نقشه های الکترونیکی آنلاین، اجزای اصلی سیستم های اطلاعات جغرافیایی وب مدرن (GIS) هستند. با پشتیبانی از پایگاههای اطلاعات موضوعی مختلف، سری نقشههای مبتنی بر وب را میتوان با مقیاسهای مختلف برای موضوعات جغرافیایی متعدد، مانند خیابانها، ترافیک، سیاست و پدیدههای کشاورزی ارائه کرد. چارچوب خدمات نقشه وب را می توان به عنوان یک چارچوب محاسباتی برای ادغام سخت افزار، الگوریتم، نرم افزار، شبکه و داده های مکانی در نظر گرفت. با رشد سریع منابع مختلف دادههای مکانی شبکهای، مانند اطلاعات جغرافیایی داوطلبانه در شبکههای اجتماعی، دادههای بلادرنگ بهدستآمده از شبکههای حسگر و مقادیر زیادی از دادههای رصد زمین از ماهوارهها، زیرساخت های خدمات نقشه الکترونیکی مبتنی بر وب با چالش بزرگ سازماندهی و استراتژی های پردازش برای حجم عظیم داده های مکانی و پیچیدگی ذاتی آن مواجه شده اند. این امر منجر به دنبال کردن معماریهای محاسباتی با کارایی بالا و الگوریتمهای پیچیده برای دستیابی به ذخیرهسازی دادههای نقشه مقیاسپذیر و پردازش سریع شده است.
در حال حاضر اکثر سیستم های خدمات نقشه مانند گوگل مپ، یاهو! Maps، Bing Maps و OpenStreetMap عمدتاً بر روی مدلهای نقشه کاشی برداری ساخته شدهاند، که در آن مجموعهای از تصاویر نقشه که از پیش تولید شده یا به صورت پویا از دادههای GIS بردار هستند از طریق یک مرورگر وب به درخواستکننده تحویل داده میشوند. برای تسهیل تجسم در وضوح های مختلف و تجزیه و تحلیل فضایی مبتنی بر نقشه، کل نقشه برداری باید قبل از تولید کاشی به تکه های زیادی با الگوریتم های کلیپ خاص تقسیم شود. کاشی های نقشه یا به اصطلاح کاشی های کاشی، واحدهای اساسی یک سطح کاشی خاص هستند و با سطح بزرگنمایی، ردیف و ستون مربوطه مشخص می شوند. سازههای ذخیرهسازی کاشیهای زیادی وجود دارد، و ساختار هرمی کاشی مبتنی بر مدل سطح جزئیات (LOD) به دلیل کارایی آن برای ارائه تصاویر نقشه بزرگ و زمانبندی سریع کاشی مشهور است.
اندازه کاشیها در سازههای هرم کاشی به سرعت در حال رشد است و تعداد کاربرانی که دسترسی همزمان دارند نیز در حال افزایش است زیرا برنامههای جغرافیایی اجتماعی توسط افراد بیشتری استفاده میشود. با این حال، استراتژیهای سنتی ذخیرهسازی و مدیریت کاشی، معماریهای کامپیوتری با کارایی بالا (HPC) و پایگاههای داده تجاری رابطهای نمیتوانند به راحتی اهداف پیشپردازش، یکپارچهسازی، کاوش، زمانبندی و تجسم کاشیهای کلان داده را محقق کنند. هنگامی که حجم دادههای کاشی و تعداد جلسات همزمان افزایش مییابد، این مدلهای مدیریت کلاسیک ویژگیهای سرعت خواندن و نوشتن آهسته، ظرفیت ذخیرهسازی محدود، مقیاسپذیری ضعیف و هزینه ساخت و نگهداری بالا را نشان میدهند. از این رو، در چنین محیط داده های جغرافیایی بزرگ، توسعه مکانیسمهای مؤثری که عملیات سریع کاشی را تسهیل میکند به یک نیاز کلیدی تبدیل میشود. مسائل فنی باید برای پیاده سازی ترکیبی از داده های کاشی برداری توزیع شده و پردازش جغرافیایی توزیع شده با استفاده از یک سیستم نرم افزاری مورد توجه قرار گیرد.
ما بیشتر بر روی اکتشاف روشهای مدیریت دادههای کاشی برداری عظیم تمرکز میکنیم، به ویژه بر روی یک چارچوب محاسباتی مقیاسپذیر همهکاره که هم ذخیرهسازی کاشی توزیع شده و هم پردازش کاشی برداری موازی (تولید کاشی و بازیابی سریع) را فراهم میکند. چارچوب پیوند بین مدل سازماندهی داده نقشه شبکه و عملیات فضایی مرتبط با این مدل توزیع شده را تشکیل می دهد. در مطالعات اخیر، مکانیسمهای مبتنی بر ابر، مانند ذخیرهسازی نه تنها SQL (NoSQL) و الگوی برنامهنویسی MapReduce، به تدریج توسط بسیاری از محققان در زمینه geocomputing برای کشف روشهای جدید برای پردازش دادههای فضایی با حجم بالا مورد استفاده قرار گرفتهاند. تعداد چارچوبهای ژئومحاسبات ابری افزایش یافته است، و آنها در نقاط اصلی مطالعات خود متفاوت هستند. مثلا، برخی از محققان بر ابزارهای ذخیره سازی توزیع شده برای ذخیره سازی کاشی تأکید کردند، در حالی که مطالعات دیگر بر روی پردازش داده های فضایی مبتنی بر MapReduce در برابر یک پلت فرم خاص دسته محور و با تأخیر بالا مانند Apache Hadoop متمرکز شدند. با نیاز به یک رویکرد سیستماتیک برای برآوردن ذخیرهسازی انبوه و پردازش موازی سریع برای دادههای کاشی بزرگ، نحوه ادغام یک مدل داده نقشه مقیاسپذیر با قابلیتهای عملیاتی سریع، به یک هدف حیاتی برای محاسبات کاشی مبتنی بر ابر تبدیل میشود.
اهداف این مقاله بر دو جنبه متمرکز است. ابتدا، ما یک مدل ذخیرهسازی داده کاشی جدید را بر اساس یک نوع پارادایم NoSQL پیشنهاد میکنیم: ذخیرهسازی ستونمحور گسترده. این مدل دادههای کاشی عظیم را در میان گرههای داده مقیاسپذیر توزیع میکند و در عین حال سازگاری جهانی را حفظ میکند و امکان مدیریت مؤثر دادههای کاشی خاص را فراهم میکند. دوم، بر اساس مدل داده کاشی ما، یک چارچوب الگوریتم موازی برای تولید سریع کاشی های برداری و پرس و جو با استفاده از مدل برنامه نویسی MapReduce ارائه شد. ما همچنین چارچوب الگوریتم جدید را در یک سرویس نقشه کاشیشده بهعنوان جزئی از نمونه اولیه سرویس نقشه برداری اطلاعات زمینشناسی واقعی گنجاندهایم و عملکرد آن را با روشهای دیگر زیرساخت داده کاشی NoSQL خود ارزیابی میکنیم. در ادامه مقاله، ما به طور متوالی کاربردهای روش محاسبات مبتنی بر ابر را معرفی می کنیم. مانند Hadoop، NoSQL و MapReduce در پردازش داده های جغرافیایی بزرگ. این با تصویری از تولید کاشی نقشه برداری توسعه یافته و الگوریتم مکان یابی، آماده سازی برای مدل داده کاشی مبتنی بر NoSQL دنبال می شود. در مرحله بعد، مدلهای دسترسی به ذخیرهسازی کاشی نقشه برداری را ترسیم میکنیم و نحوه نگاشت دادههای کاشی را در فروشگاههای ستون خانواده NoSQL نشان میدهیم. برش موازی نقشه کاشی و چارچوب پرس و جو مبتنی بر MapReduce به تفصیل مورد بحث قرار گرفته است. ما همچنین بخشی را به شرح و بسط تولید کاشی موازی و الگوریتم پرس و جو ایستا/دینامیک اختصاص می دهیم. پس از شرح تحویل الگوریتم عملیات کاشی موازی به عنوان یک سرویس GIS، ما یک سری آزمایش های مقایسه ای را برای ارزیابی عملکرد آن انجام می دهیم. در پایان با چند نکته پایانی پایان می دهیم. این با تصویری از تولید کاشی نقشه برداری توسعه یافته و الگوریتم مکان یابی، آماده سازی برای مدل داده کاشی مبتنی بر NoSQL دنبال می شود. در مرحله بعد، مدلهای دسترسی به ذخیرهسازی کاشی نقشه برداری را ترسیم میکنیم و نحوه نگاشت دادههای کاشی را در فروشگاههای ستون خانواده NoSQL نشان میدهیم. برش موازی نقشه کاشی و چارچوب پرس و جو مبتنی بر MapReduce به تفصیل مورد بحث قرار گرفته است. ما همچنین بخشی را به شرح و بسط تولید کاشی موازی و الگوریتم پرس و جو ایستا/دینامیک اختصاص می دهیم. پس از شرح تحویل الگوریتم عملیات کاشی موازی به عنوان یک سرویس GIS، ما یک سری آزمایش های مقایسه ای را برای ارزیابی عملکرد آن انجام می دهیم. در پایان با چند نکته پایانی پایان می دهیم. این با تصویری از تولید کاشی نقشه برداری توسعه یافته و الگوریتم مکان یابی، آماده سازی برای مدل داده کاشی مبتنی بر NoSQL دنبال می شود. در مرحله بعد، مدلهای دسترسی به ذخیرهسازی کاشی نقشه برداری را ترسیم میکنیم و نحوه نگاشت دادههای کاشی را در فروشگاههای ستون خانواده NoSQL نشان میدهیم. برش موازی نقشه کاشی و چارچوب پرس و جو مبتنی بر MapReduce به تفصیل مورد بحث قرار گرفته است. ما همچنین بخشی را به شرح و بسط تولید کاشی موازی و الگوریتم پرس و جو ایستا/دینامیک اختصاص می دهیم. پس از شرح تحویل الگوریتم عملیات کاشی موازی به عنوان یک سرویس GIS، ما یک سری آزمایش های مقایسه ای را برای ارزیابی عملکرد آن انجام می دهیم. در پایان با چند نکته پایانی پایان می دهیم. در مرحله بعد، مدلهای دسترسی به ذخیرهسازی کاشی نقشه برداری را ترسیم میکنیم و نحوه نگاشت دادههای کاشی را در فروشگاههای ستون خانواده NoSQL نشان میدهیم. برش موازی نقشه کاشی و چارچوب پرس و جو مبتنی بر MapReduce به تفصیل مورد بحث قرار گرفته است. ما همچنین بخشی را به شرح و بسط تولید کاشی موازی و الگوریتم پرس و جو ایستا/دینامیک اختصاص می دهیم. پس از شرح تحویل الگوریتم عملیات کاشی موازی به عنوان یک سرویس GIS، ما یک سری آزمایش های مقایسه ای را برای ارزیابی عملکرد آن انجام می دهیم. در پایان با چند نکته پایانی پایان می دهیم. در مرحله بعد، مدلهای دسترسی به ذخیرهسازی کاشی نقشه برداری را ترسیم میکنیم و نحوه نگاشت دادههای کاشی را در فروشگاههای ستون خانواده NoSQL نشان میدهیم. برش موازی نقشه کاشی و چارچوب پرس و جو مبتنی بر MapReduce به تفصیل مورد بحث قرار گرفته است. ما همچنین بخشی را به شرح و بسط تولید کاشی موازی و الگوریتم پرس و جو ایستا/دینامیک اختصاص می دهیم. پس از شرح تحویل الگوریتم عملیات کاشی موازی به عنوان یک سرویس GIS، ما یک سری آزمایش های مقایسه ای را برای ارزیابی عملکرد آن انجام می دهیم. در پایان با چند نکته پایانی پایان می دهیم. ما همچنین بخشی را به شرح و بسط تولید کاشی موازی و الگوریتم پرس و جو ایستا/دینامیک اختصاص می دهیم. پس از شرح تحویل الگوریتم عملیات کاشی موازی به عنوان یک سرویس GIS، ما یک سری آزمایش های مقایسه ای را برای ارزیابی عملکرد آن انجام می دهیم. در پایان با چند نکته پایانی پایان می دهیم. ما همچنین بخشی را به شرح و بسط تولید کاشی موازی و الگوریتم پرس و جو ایستا/دینامیک اختصاص می دهیم. پس از شرح تحویل الگوریتم عملیات کاشی موازی به عنوان یک سرویس GIS، ما یک سری آزمایش های مقایسه ای را برای ارزیابی عملکرد آن انجام می دهیم. در پایان با چند نکته پایانی پایان می دهیم.
2. کارهای مرتبط
2.1. پردازش داده های بزرگ جغرافیایی مبتنی بر ابر
هدف اصلی کار ما تلاش برای ادغام مکانیزم های محاسبات ابری مناسب بر اساس استانداردهای باز با مدیریت گسترده داده های اطلاعات مکانی، به ویژه مدیریت داده های کاشی نقشه برداری است. در حوزه جغرافیایی، پیشرفت هایی به سمت پیاده سازی یک معماری محاسباتی داده های جغرافیایی بزرگ عملیاتی شده است. بخشی از تحقیق بر روی مدلهای ژئوپردازش مبتنی بر وب برای اشتراکگذاری و محاسبات دادههای مکانی توزیع شده متمرکز شده است [ 1 ، 2 ، 3 ، 4 ]، و برخی از مطالعات مبتنی بر CyberGIS [ 5 ، 6] را بررسی کردهاند.] روشهایی برای رسیدگی به مشکلات جغرافیایی فشرده و مشترک محاسباتی با بهرهبرداری از زیرساختهای HPC، مانند شبکههای محاسباتی و خوشههای موازی [ 7 ، 8 ، 9 ]، به ویژه بر ادغام اجزای خاص CyberGIS، میانافزار فضایی و محاسبات و منابع ارتباطی با کارایی بالا. برای تحقیقات زمین فضایی [ 10 ، 11 ].
رایانش ابری در حال تبدیل شدن به یک راه حل برجسته تر برای محاسبات داده های جغرافیایی بزرگ پیچیده است. این ذخیرهسازی مقیاسپذیر را برای مدیریت و سازماندهی دادههای مکانی بهطور پیوسته در حال افزایش فراهم میکند، و قابلیت پردازش آن را بهطور کشسانی به محاسبات موازی داده با یک الگوی مؤثر برای ادغام بسیاری از منابع ژئومحاسباتی ناهمگن تغییر میدهد [ 12 ، 13 ]. تا کنون، پیشرفتهای ژئومحاسباتی مبتنی بر ابر شامل پرداختن به شدت دادهها، محاسبات، دسترسی همزمان و الگوهای مکانی و زمانی است [ 14 ]. تا به امروز، ادغام روش های پیشرفته پردازش کلان داده ها و سناریوهای عملی ژئومحاسبات جغرافیایی هنوز در مراحل اولیه است و یک زمینه تحقیقاتی بسیار فعال است.
2.2. Hadoop و Big Geo-Data Processing
Hadoop یک اکوسیستم نرم افزاری معتبر برای پردازش داده های گسترده در یک محیط ابری است. به عنوان یک نوع منبع باز پلتفرم پردازش داده های بزرگ گوگل، هدف اصلی آن ارائه قابلیت ذخیره سازی مقیاس پذیر با هزینه های سخت افزاری کمتر، ادغام موثر هر گونه منابع محاسباتی ناهمگن برای محاسبات مشارکتی، و یک سرویس ابری بسیار در دسترس در بالای خوشه های به هم پیوسته آزاد است. .
به عنوان مؤلفه اصلی، سیستم فایل توزیعشده Hadoop (HDFS)، که بر روی خوشههای مقیاسپذیر متشکل از سختافزار ارزان قیمت اجرا میشود، میتواند قابلیتهای ذخیرهسازی مجموعه داده بزرگ (معمولاً در محدوده گیگابایت تا TB) را با پهنای باند بالا و دسترسی به دادههای سیستم فایل جریانی فراهم کند. مشخصات. بر این اساس، می تواند محاسبات فشرده بر روی داده های عظیم را بر اساس این ایده که “محاسبات متحرک ارزان تر از داده های متحرک است” سرعت بخشد. با اتخاذ یک معماری master/slave، گره اصلی HDFS، که اغلب NameNode نامیده میشود، ابرداده فایل جهانی را حفظ میکند و مسئول توزیع دادهها و همچنین دسترسی به بلوکهای داده خاص است، در حالی که بردهها (DataNodes، که معمولاً گرههای محاسباتی نیز نامیده میشوند) آنها را مدیریت میکنند. منطقه داده خود اختصاص داده شده توسط گره اصلی، انجام ایجاد بلوک داده، اصلاح، عملیات حذف و تکرار صادر شده از NameNode. بر اساس این ویژگی های پیشرفته سیستم فایل توزیع شده، HDFS نیاز به دسترسی همزمان در مقیاس بزرگ و با کارایی بالا را برآورده می کند و به تدریج به پایه ای از محاسبات ابری برای ذخیره سازی و مدیریت داده های بزرگ تبدیل شده است.
یکی دیگر از اجزای اصلی Hadoop MapReduce است [ 15] چارچوب پردازش داده موازی. مدل MapReduce که بر روی یک خوشه Hadoop ساخته شده است، می تواند یک کار پردازش متوالی را به دو مرحله اجرای وظایف فرعی تقسیم کند – Map و Reduce. در مرحله نقشه، یک محاسبات مشخص شده توسط مشتری برای هر واحد رکورد (که توسط جفتهای کلید/مقدار منحصر به فرد مشخص میشود) از مجموعه داده ورودی اعمال میشود. دوره اجرا از چندین نمونه از محاسبات تشکیل شده است و این برنامه های نمونه به صورت موازی اجرا می شوند. خروجی این محاسبات – همه مقادیر میانی – بلافاصله توسط محاسبات مشخص شده توسط مشتری دیگر در مرحله Reduce جمع می شود (با همان شناسه کلید ادغام می شود). یکی از مهمترین مزایای MapReduce این است که انتزاعی را ارائه می دهد که بسیاری از جزئیات سطح سیستم را از مشتری پنهان می کند. بر خلاف سایر چارچوب های محاسباتی موازی،
Hadoop MapReduce پیاده سازی منبع باز مدل برنامه نویسی و چارچوب اجرایی است که بر روی HDFS ساخته شده است. در این چارچوب، گره ارسال کار (معمولا NameNode) JobTracker را اجرا میکند، که نقطه تماس مدیریت مشتریانی است که میخواهند یک کار MapReduce موازی را اجرا کنند. ورودی یک کار MapReduce از داده های ذخیره شده در سیستم فایل توزیع شده یا پایگاه های داده رابطه ای MPP (پردازش انبوه موازی) موجود می آید و خروجی به سیستم فایل توزیع شده یا پایگاه داده های رابطه ای بازگردانده می شود. هر سیستم دیگری که انتزاعات مناسب را برآورده کند می تواند به عنوان منبع داده یا سینک عمل کند. در مرحله Map، JobTracker برنامه های MapReduce را دریافت می کند که شامل بخش های کد برای Mappers و Reducer با پارامترهای پیکربندی داده است. با تولید جفتهای کلید/مقدار میانی، ورودی را به مشکلات فرعی کوچکتر تقسیم میکند، و آنها را در هر گره TaskTracker (معمولا DataNodes) در خوشه برای حل مشکلات فرعی توزیع میکند، در حالی که رویه Reduce همه مقادیر میانی مرتبط با یک کلید را ادغام میکند و نتایج نهایی را به گره JobTracker برمی گرداند. در طول کل فرآیند، JobTracker همچنین پیشرفت کارهای MapReduce در حال اجرا را نظارت می کند و مسئول هماهنگی اجرای Mappers و Reducer است. تا به امروز، علاوه بر Hadoop، بسیاری از برنامهها و پیادهسازیهای پارادایم MapReduce نیز وجود دارد، به عنوان مثال، به طور خاص برای پردازندههای چند هستهای، برای GPU (واحد پردازش گرافیک)، و برای معماری پایگاهداده NoSQL هدفگذاری شدهاند. و آنها را در هر گره TaskTracker (معمولا DataNodes) در خوشه توزیع می کند تا مشکلات فرعی را حل کند، در حالی که رویه Reduce تمام مقادیر میانی مرتبط با همان کلید را ادغام می کند و نتایج نهایی را به گره JobTracker برمی گرداند. در طول کل فرآیند، JobTracker همچنین پیشرفت کارهای MapReduce در حال اجرا را نظارت می کند و مسئول هماهنگی اجرای Mappers و Reducer است. تا به امروز، علاوه بر Hadoop، بسیاری از برنامهها و پیادهسازیهای پارادایم MapReduce نیز وجود دارد، به عنوان مثال، به طور خاص برای پردازندههای چند هستهای، برای GPU (واحد پردازش گرافیک)، و برای معماری پایگاهداده NoSQL هدفگذاری شدهاند. و آنها را در هر گره TaskTracker (معمولا DataNodes) در خوشه توزیع می کند تا مشکلات فرعی را حل کند، در حالی که رویه Reduce تمام مقادیر میانی مرتبط با همان کلید را ادغام می کند و نتایج نهایی را به گره JobTracker برمی گرداند. در طول کل فرآیند، JobTracker همچنین پیشرفت کارهای MapReduce در حال اجرا را نظارت می کند و مسئول هماهنگی اجرای Mappers و Reducer است. تا به امروز، علاوه بر Hadoop، بسیاری از برنامهها و پیادهسازیهای پارادایم MapReduce نیز وجود دارد، به عنوان مثال، به طور خاص برای پردازندههای چند هستهای، برای GPU (واحد پردازش گرافیک)، و برای معماری پایگاهداده NoSQL هدفگذاری شدهاند. در حالی که رویه Reduce تمام مقادیر میانی مرتبط با یک کلید را ادغام می کند و نتایج نهایی را به گره JobTracker برمی گرداند. در طول کل فرآیند، JobTracker همچنین پیشرفت کارهای MapReduce در حال اجرا را نظارت می کند و مسئول هماهنگی اجرای Mappers و Reducer است. تا به امروز، علاوه بر Hadoop، بسیاری از برنامهها و پیادهسازیهای پارادایم MapReduce نیز وجود دارد، به عنوان مثال، به طور خاص برای پردازندههای چند هستهای، برای GPU (واحد پردازش گرافیک)، و برای معماری پایگاهداده NoSQL هدفگذاری شدهاند. در حالی که رویه Reduce تمام مقادیر میانی مرتبط با یک کلید را ادغام می کند و نتایج نهایی را به گره JobTracker برمی گرداند. در طول کل فرآیند، JobTracker همچنین پیشرفت کارهای MapReduce در حال اجرا را نظارت می کند و مسئول هماهنگی اجرای Mappers و Reducer است. تا به امروز، علاوه بر Hadoop، بسیاری از برنامهها و پیادهسازیهای پارادایم MapReduce نیز وجود دارد، به عنوان مثال، به طور خاص برای پردازندههای چند هستهای، برای GPU (واحد پردازش گرافیک)، و برای معماری پایگاهداده NoSQL هدفگذاری شدهاند.
از آنجا که Hadoop یک سیستم فایل توزیعشده و یک چارچوب محاسباتی مقیاسپذیر را با پارتیشنبندی فرآیندهای محاسباتی در بسیاری از گرههای محاسباتی فراهم میکند، برای رسیدگی به چالشهای کلان داده بهتر است و به طور گسترده در سناریوهای پردازش و تحلیل دادههای جغرافیایی بزرگ مورد استفاده قرار گرفته است [ 16 ، 17 ، 18 ] .
2.3. نه تنها SQL (NoSQL) -Enabled Big Data Management
ظهور پایگاههای داده NoSQL () با تقاضای فوری برای روشهای جدید برای مدیریت دادههای با حجم بیشتر همراه بود، که کاوش در ساخت پلتفرمهای پردازش داده عظیم را از طریق خوشههای توزیعشده از سرورهای کالایی را مجبور کرد. علاوه بر پلتفرم پردازش زیربنایی، مدل داده باید به ساخت برنامههای کاربردی بالایی که برای ذخیرهسازی سریع دادهها و محاسبات موازی مناسبتر هستند، توجه داشته باشد، که مدل رابطهای دارای محدودیتهایی مانند عدم تطابق امپدانس است [19] .] و این واقعیت که تاپلهای رابطهای از ساختارهای ارزشی پیچیده پشتیبانی نمیکنند و غیره. به طور کلی، پایگاههای داده NoSQL به تعدادی از پایگاههای داده غیررابطهای اخیر اشاره دارد که بدون طرحواره هستند و روی خوشهها مقیاسپذیرتر هستند و مکانیسمهای انعطافپذیرتری برای معامله کردن دارند. سازگاری سنتی برای سایر خواص مفید، مانند افزایش عملکرد، مقیاس پذیری بهتر و سهولت توسعه برنامه و غیره.
در حال حاضر، چندین نوع اصلی پایگاه داده NoSQL وجود دارد:
-
مدل دادههای کلید/مقدار: این ذخیرهسازی NoSQL به سادگی به عنوان یک جدول هش یا یک تاپل رابطهای با دو ویژگی – یک کلید و مقدار متناظر آن – در نظر گرفته میشود و تمام دسترسی به پایگاه داده از طریق کلید اصلی است. از آنجایی که ذخیرهسازی کلید-مقدار همیشه از دسترسی کلید اصلی استفاده میکند، عموماً عملکرد بسیار خوبی دارد و به راحتی میتوان آن را مقیاسبندی کرد. پیادهسازی معمولی مدل دادههای کلید/مقدار، پایگاههای اطلاعاتی توزیعشده در حافظه، مانند Memcached DB، Redis، Riak و Berkeley DB است.
-
مدل دادههای سند: این مدل NoSQL محتویات سند را در قسمت مقدار مدل Key/Value بر اساس انواع XML، JSON و BSON ذخیره میکند. میتوان آن را بهعنوان ذخیرهسازی کلید-مقدار شناسایی کرد، که در آن مقدار خود توصیف میشود. با یک مدل سند، میتوانیم بهجای کل محتویات، بخشی از سند را بهسرعت پرسوجو کنیم، و فهرستهای داده را میتوان بر روی محتوای موجودیت سند ایجاد کرد. برخی از پیادهسازیهای محبوب مدل دادههای سند MongoDB، CouchDB و RavenDB هستند.
-
مدل داده های ستون-خانواده: ذخیره سازی ستون-خانواده را می توان یک مدل کلی-مقدار کلی در نظر گرفت. تنها بخش ویژه این است که مقدار از چندین ستون-خانواده تشکیل شده است که هر کدام یک ساختار داده Map هستند. در این ساختار نقشه، هر ستون باید بخشی از یک خانواده ستون باشد، و ستون به عنوان واحد اصلی برای دسترسی عمل می کند با این فرض که داده های یک خانواده ستون خاص معمولاً با هم قابل دسترسی هستند. HBase به عنوان یک کلون منبع باز Bigtable گوگل، یک پیادهسازی چند بعدی پراکنده، توزیعشده و مداوم از مدل ستون-خانواده است که توسط کلید ردیف، کلید ستون و مهر زمانی نمایهسازی شده و اغلب به عنوان منبع ورودی و ذخیره MapReduce استفاده میشود. خروجی دیگر پایگاههای دادههای خانواده ستونی معروف Cassandra، Amazon DynamoDB و Hypertable هستند.
-
مدل داده های گراف: مدل داده های گراف بر روابط بین موجودیت های ذخیره شده تمرکز می کند و به گونه ای طراحی شده است که به ما امکان می دهد الگوهای معناداری بین گره های موجودیت پیدا کنیم. مدل دادههای نمودار میتواند روابط چندسطحی بین موجودیتهای دامنه را برای چیزهایی مانند دسته، مسیر، درختهای زمانی، درختهای چهارگانه برای نمایهسازی فضایی، یا لیستهای پیوندی برای دسترسی مرتب شده نشان دهد. برخی از نمونه های معرف Neo4J، FlockDB و OrientDB هستند.
بر اساس مقیاسپذیری خوب، قابلیت پردازش همزمان در مقیاس بزرگ و مدل موازی MapReduce پایگاههای داده NoSQL، برخی تحقیقات اولیه در جهت کاوش در ذخیرهسازی و پردازش دادههای مکانی توزیع شده انجام شده است [20 ، 21 ، 22 ، 23 ، 24 ] .
3. مسائل طراحی
با توسعه سریع اینترنت، سرویس کاشی نقشه بیشتر و بیشتر مورد استفاده قرار می گیرد و تعداد زیادی از کاربران ممکن است همزمان به این سرویس دسترسی داشته باشند. این فشار پردازش سرور را ایجاد میکند، بنابراین استفاده از فناوریهای محاسباتی با کارایی بالا برای بهینهسازی مدیریت دادههای کاشی نقشه و دسترسی به انتخاب طبیعی تبدیل میشود. رویکردهای مدیریت دادههای کاشی سرویسهای کاشی نقشه اصلی فعلی، مانند Google Maps، Bing Maps، Baidu Map، و غیره، هنوز جعبههای سیاه هستند و برای جهان خارج شناخته شده نیستند. بنابراین، با توجه به مزایای فوقالعاده ذخیرهسازی نوظهور NoSQL و چارچوب محاسباتی موازی MapReduce، ما سعی میکنیم فناوریهای کلیدی استفاده از پایگاههای داده NoSQL برای مدیریت دادههای کاشی نقشه، از جمله روشهای برش سریع کاشی و رویکردهای جستجوی کاشی در زمان واقعی را بررسی کنیم. . به خصوص، ما از پایگاه داده های منبع باز NoSQL به جای محصولات تجاری برای دستیابی به مدیریت کارآمد داده های کاشی نقشه استفاده می کنیم. هدف این مقاله ارائه یک چارچوب فنی کمهزینه، مؤثر و شفاف مبتنی بر NoSQL همراه با رویکردهای کلیدی برای خوانندگانی است که باید خدمات کاشی نقشه خود را بسازند.
سرویس کاشی نقشه ای که ما پیش بینی کرده ایم از دو نوع سناریو کاربردی تشکیل شده است:
- (1)
-
کاربر به یک لایه علاقه مند است و درخواست های پرس و جو و تجسم را ارسال می کند. در این حالت، دادههای کاشی تک لایه در تعداد زیادی عکس از قبل در سمت سرور ذخیره میشوند. از این رو، هنگامی که درخواست پرس و جو می رسد، سرور مجموعه تصویر کاشی مربوطه را با توجه به محدوده پرس و جو برمی گرداند. به تولید کاشی از قبل، بریدن کاشی استاتیک نیز گفته می شود .
- (2)
-
کاربر به تعدادی لایه علاقه مند است و درخواست های پرس و جو و تجسم را ارسال می کند. در این حالت، به دلیل اینکه لایههای درخواستی کاربر را نمیتوان از قبل پیشبینی کرد، دادههای کاشی چند لایه به صورت پویا بر اساس مدل Tile Pyramid و پارامترهای تعریفشده توسط کاربر، تنها پس از رسیدن درخواستهای پرس و جو تولید میشوند. در این مرحله، چندین لایه روی هم قرار می گیرند و با هم رندر می شوند و به عنوان مجموعه ای از تصاویر کاشی بازگردانده می شوند. تولید کاشی در زمان اجرا را برش پویا نیز می گویند . علاوه بر این، کاشی های بریده شده به صورت پویا در پایگاه داده ذخیره می شوند. از این رو، هنگامی که یک درخواست مشابه در دفعه بعد وارد می شود، نتیجه را می توان مستقیماً بدون برش پویا برگرداند.
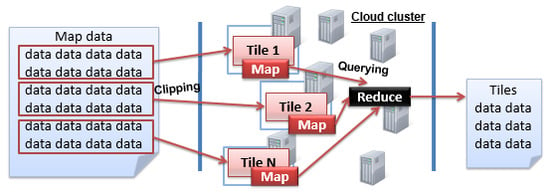
مطابق با دو سناریوی فوق، پایگاه داده NoSQL، با فضای ذخیره سازی توزیع شده و چارچوب محاسباتی موازی (یعنی چارچوب MapReduce)، به طور کامل نیازهای برش کاشی و پرس و جو نقشه را برآورده می کند. یک مثال معمولی، همانطور که در شکل 1 نشان داده شده است، نشان می دهد که چگونه فضای ذخیره سازی توزیع شده و چارچوب MapReduce در پردازش داده ها با هم کار می کنند. در مرحله اول، یک خوشه متشکل از چندین گره کامپیوتری وجود دارد. سپس، در سطح ذخیره سازی توزیع شده، داده ها به چندین بلوک تقسیم می شوند و به طور جداگانه در گره های مختلف ذخیره می شوند. بنابراین، هنگامی که یک درخواست یا درخواست پردازش ارسال می شود، چندین کار نقشه موازی مرتبط با بلوک های داده تنظیم می شود. پس از اتمام وظایف نقشه موازی، وظیفه کاهش برای به دست آوردن نتیجه محاسباتی نهایی با ادغام نتایج موقت خروجی توسط فاز نقشه انجام می شود. علاوه بر این، چارچوب MapReduce TaskTracker را روی هر گره در حال اجرا برای مدیریت و ردیابی نقشه یا کاهش کار تنظیم میکند، و JobTracker برای کل مسائل کنترلی MapReduce ساخته شده است.
از طریق وظایف نقشه همزمان، دادههای نقشه را میتوان به سرعت در کاشیها برش داد و در فضای ذخیرهسازی NoSQL توزیع کرد و همچنین از طریق چارچوب MapReduce میتوان به درخواستهای کاشی در زمان واقعی دست یافت. علاوه بر این، چهار نوع مدل ذخیرهسازی NoSQL شامل کلید-مقدار، سند، ستون و نمودار وجود دارد. پایگاه داده کلید-مقدار مانند Redis اغلب مبتنی بر حافظه است، اما حجم عظیم داده های کاشی نقشه اغلب بسیار بیشتر از مقدار حافظه است. پایگاه داده گراف برای مدیریت داده های نوع گراف استفاده می شود. پایگاه داده اسناد مانند MongoDB اغلب برای مدیریت داده های نیمه ساختار یافته (به عنوان مثال، داده های کاربران رسانه های اجتماعی) استفاده می شود. پایگاه داده ستون به طور فیزیکی داده ها را مطابق با ستون ذخیره می کند و بنابراین به نرخ فشرده سازی داده بهتری در مقایسه با ذخیره سازی ردیف دست می یابد. به خصوص، استفاده از پایگاه داده ستونی برای ذخیره فیزیکی داده های کاشی در کنار هم برای بهبود کارایی I/O در پردازش پرس و جو ضروری است. بنابراین، ما از HBase، محبوبترین پایگاه داده ستون منبع باز، برای ذخیره دادههای عظیم نقشه استفاده میکنیم، و چارچوب MapReduce داخلی HBase برای دستیابی به برش نقشه مؤثر و جستجوی کاشی در زمان واقعی استفاده میشود.
علاوه بر این، در مورد خدمات کاشی نقشه، کاشیهای مجاور فضایی اغلب قابل دسترسی هستند و با هم به کاربر بازگردانده میشوند، بنابراین کاشیهای مجاور با سطح یکسان باید تا حد امکان در یک سرور یا سرورهای مجاور در محیط کلاستر HBase ذخیره شوند. این از دسترسی به داده های بین سرورها جلوگیری می کند/کاهش می دهد و در نتیجه کارایی را بهبود می بخشد. در عین حال، تحت مدل ذخیرهسازی ستونی HBase، کاشیها نیز در سطح ذخیرهسازی فیزیکی کنار هم قرار میگیرند که به طور قابلتوجهی بازده ورودی/خروجی را بهبود میبخشد و بنابراین نیازهای دسترسی بلادرنگ را بهتر برآورده میکند.
4. روش تولید و مکان یابی کاشی مبتنی بر برداری
4.1. روش های اساسی
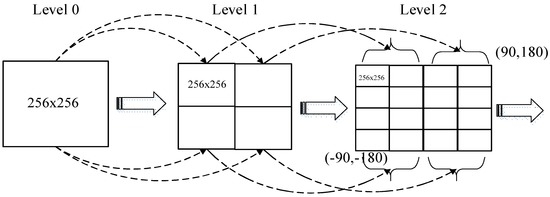
نقشه های کاشی معمولاً از مدل هرم کاشی با ساختار شاخص کاشی چهاردرخت (همانطور که در شکل 2 نشان داده شده است ) برای سازماندهی داده ها استفاده می کنند. به عنوان یک مدل سلسله مراتبی از بالا به پایین برای وضوح متغیر، بسیاری از ارائه دهندگان خدمات نقشه مانند Google Maps، Bing Maps و ArcGIS Online از آن برای سازماندهی کاشی های نقشه بزرگ خود استفاده می کنند.
در مدل Tile Pyramid، هر اندازه کاشی روی 256 × 256 پیکسل ثابت می شود و سطح اندازه نقشه را تعیین می کند. در پایین ترین سطح جزئیات (سطح 0)، نقشه جهانی 256 × 256 پیکسل است. با افزایش سطح، اندازه نقشه، از جمله عرض و ارتفاع، با ضریب 2 × 2 افزایش می یابد: سطح 1 512 × 512 پیکسل، سطح 2 1024 × 1024 پیکسل، سطح 3 2048 × 2048 پیکسل و غیره است. . به طور کلی، اندازه نقشه (بر حسب پیکسل) را می توان به صورت معادله (1) محاسبه کرد:
همانطور که در شکل 1 نشان داده شده است ، یک مجموعه داده برداری را می توان در نقشه های چند سطحی با استفاده از یک استراتژی زیربخش بازگشتی چهار درختی سازماندهی کرد. سپس، هر کاشی (که توسط یک بلوک مستطیل شکل نشان داده می شود) از یک سطح خاص را می توان برش داد و به عنوان بخشی از نقشه کاشی در یک تصویر رندر کرد. برای دادههای کاشی نقشه، میتوانیم از T = { level , row , col } سه گانه برای شناسایی آن استفاده کنیم، جایی که سطح نشان دهنده سطح وضوح کاشی است که با سطح 0 شروع میشود. ردیف و سرنگمختصات سطر و مختصات ستون کاشی مربوطه را به ترتیب در سطح فعلی نشان دهید. بدیهی است که لایه کاشی سطح N (N > 0) نتیجه متوالی بریده شده از سطح کاشی N-1 است. به عنوان مثال، سطح کاشی 1 نتیجه بریده شده بیشتر از سطح 0 است. سطرها و ستونهای سطح 0 که به نصف تقسیم شدهاند، در مجموع چهار کاشی به دست میآیند و مختصات ردیف و مختصات ستونها را میتوان به سادگی از 0 تا 1 شمارهگذاری کرد. پس از آن، گوشه سمت چپ بالای نقشه کاشی قابل شناسایی است. توسط کاشی سهگانه {1، 0، 0}. به همین ترتیب، تولید کاشی سطح 2 بر اساس کاشی های سطح 1 است و هر کاشی به طور مساوی به چهار قسمت تقسیم می شود، یعنی ردیف ها و ستون ها به چهار قسمت مساوی تقسیم شدند که در مجموع 16 کاشی به دست آمد. سپس، نقشه کاشی سطح q می تواند سطرها و ستون های آن را به طور مساوی به 2 تقسیم کندبخش q ، در نهایت منجر به در مجموع 4 کاشی q پس از عملیات رندر می شود. با استفاده از این روش، میتوانیم شناسایی سهگانه را برای هر کاشی در هر سطح با دقت استخراج کنیم.
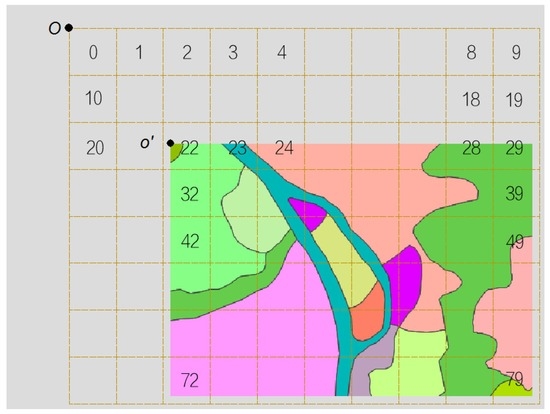
در کاربرد یک سرویس نقشه عظیم کاشی، یک نقشه کاشی با سطح پوشش بسیار بزرگ اغلب از بسیاری از نقشه های فرعی تولید می شود. از این رو، پارتیشنهای کاشی مختلف بریده شده توسط یک مجموعه داده بردار فرعی باید در زمینه یک نقشه کاشی بزرگتر شناسایی شوند. کلید الگوریتم مکانیابی کاشی نقشه نحوه محاسبه مجموعه شناسه کاشی تحت پوشش منطقه پرس و جو است. اسناد زیر نقشههای مختلف میتوانند محدودههای متناقضی داشته باشند، که منجر به تفاوتهایی در قاعده کدگذاری شده در ردیف و ستون در حافظه پنهان کاشی ایجاد شده توسط عملیات برش برای هر سند نقشه میشود. برای انجام عملیات مکان یابی کاشی یکنواخت جهانی در کاربردهای عملی، باید مبدا را برای شبکه جهانی کاشی نقشه بزرگ و شبکه کاشی محلی نقشه فرعی مشخص کنیم. در شکل 3، روش های مکان یابی کاشی برای نقشه چین، که به عنوان مثال استفاده می شود، دوره بازیابی کاشی را در یک محدوده نقشه برداری بزرگ نشان می دهد. در این مثال، قبل از شروع به ارائه دادههای کاشی برای زیر دامنه، ابتدا باید مبدا O را برای شبکه نقشه جهانی تعیین کنیم. در اینجا مختصات جغرافیایی گوشه سمت چپ بالای محدوده جغرافیایی چین را به عنوان مبدا شبکه جهانی تعیین می کنیم و همچنین نسبت نمایش را برای هر سطح و ارتفاع و عرض واحد کاشی را مشخص می کنیم. سپس، هم اندازه شبکه هر سطح خاص و هم تعداد سطر و ستون تحت پوشش شبکه جهانی را می توان تعیین کرد. منطقه زیر نقشه در شکل 3به شبکه ای که دارای هشت سطر و ده ستون است تقسیم می شود. هنگامی که برخی از مناطق محلی در این محدوده نیاز به برش دادن به کاشیها داشته باشند، میتوانیم به سرعت شناسههای شبکه مربوطه را در همان سطح شبکه پوشش جهانی پیدا کنیم. نقطه O در شکل 3 مبدا منطقه محلی یک نقشه فرعی را در نقشه جهانی نشان می دهد و در شبکه کاشی کشور در همان سطح شماره 22 دارد. با استفاده از این روش، میتوانیم از مختصات جغرافیایی برای محاسبه سطح کاشی مربوطه و منطقه پوشش در سطح برای درخواستهای پرس و جو کاشی استفاده کنیم و سپس به راحتی شناسههای کاشی تحت پوشش این محدوده جغرافیایی را محاسبه کنیم. کاشی های برداری نقشه های بزرگ، مانند نمونه نقشه چین در شکل 3را می توان به صورت موازی برش داد و با استفاده از این استراتژی تولید کاشی به صورت توزیع شده مستقر شد.
4.2. الگوریتم گسترش دامنه برش کاشی
از آنجا که اسناد نقشه برای برش اغلب در یک الگوی شکل نامنظم هستند، تولید کاشی ها بر اساس محدوده نقشه باعث می شود که نتایج برش با محدوده کاشی تعریف شده توسط مدل هرم کاشی ناسازگار باشد. به عبارت دیگر، محدوده نقشه اصلی باید گسترش یابد تا فقط تعداد صحیحی از عناوین را پوشش دهد. بنابراین، ما یک الگوریتم گسترش دامنه را برای گسترش دامنه اصلی نقشه ارائه میکنیم و محدوده گسترش یافته را به عنوان محدوده برش در نظر میگیریم.
یک الگوریتم گسترش دامنه در درجه اول به تنظیم مناسب محدوده داده واقعی با قوانین خاصی مطابق با هدف کلیپ برای رسیدگی آسان به آن اشاره دارد. به طور کلی، اجازه دهید ناحیه گیره نامنظم به یک ناحیه مستطیلی (مستطیل یا مربع) گسترش یابد، اندازه ارتفاع و عرض ناحیه را به اندازه واحد شبکه کاشی تغییر دهید، و سپس دامنه گسترش یافته را به عنوان محدوده برش جدید تنظیم کنید.
برای سادگی، در مطالعه خود، سند نقشه را به شکل مربعی قبل از تولید داده کاشی گسترش می دهیم. این روش در درجه اول پایین سمت چپ را به عنوان مبدأ محدوده اصلی تعیین می کند، از چپ به راست و از پایین به بالا گسترش می یابد. محدوده اصلی طبق این قانون به یک منطقه برش جدید گسترش می یابد. سپس، پردازش داده های برداری برای تولید کاشی های نقشه هر سطح توسط مدل رشد نمایی در این زمینه افزایش می یابد.
فرض کنید که محدوده اصلی به صورت {( x0 min , y0 min ), ( x0 max , y0 max )} بیان می شود، محدوده گسترش یافته به صورت {( x min , y min ), ( x max , y max )} نشان داده می شود، و ارتفاع و عرض واحد شبکه کاشی به ترتیب با ارتفاع و عرض نشان داده می شود .
اجازه دهید rate0 = ( y 0 max − y 0 min )/( x 0 max − x 0 min ); بدین ترتیب،
- (1)
-
وقتی rate0 > ارتفاع / عرض ، سپس y max = y0 max ، ( y0 max − y0 min )/=( x max − x0 min ) = ( Height / Width )، و نقشه کاشی به صورت افقی به سمت چپ گسترش می یابد، همانطور که در نشان داده شده است. شکل 4 .
- (2)
-
در شکل 5 ، اگر rate0 = ارتفاع / عرض ، به عنوان مثال، x max = x0 max ، y max = y0 max ، پس نقشه کاشی نیازی به بسط ندارد.
- (3)
-
اگر rate0 < ارتفاع / عرض , آنگاه x max = x0 max , ( y max − y0 min )/( x max − x min ) = Height / Width , و نقشه کاشی به صورت عمودی به بالا در شکل 6 گسترش می یابد .
5. مدل دسترسی کاشی ذخیرهسازی نقشه برداری مبتنی بر NoSQL
هرم نقشه کاشی، به عنوان یک مدل سلسله مراتبی با وضوح متغیر، دارای بسیاری از ویژگی های عالی است، مانند ظرفیت ذخیره سازی عظیم و مکانیزم به روز رسانی پویا. با استفاده از نقشه کاشی برداری جهان به عنوان مثال، تعداد کل کاشی های سطح زوم 1 تا 20 تقریباً 3 × 10 12 است.. در این سناریوی داده های عظیم، رویکرد مدیریت مبتنی بر پایگاه داده رابطه و فایل سیستم، که برای ذخیره سازی و پردازش کاشی های متعدد مناسب نیست، به طور جدی روی ذخیره سازی و اقدامات بازیابی داده ها، با محاسبه آهسته و سرعت به روز رسانی، تأثیر می گذارد. پایگاه های داده NoSQL از ذخیره سازی انبوه داده و پرس و جوهای بسیار همزمان با مقیاس پذیری بهتر و سایر ویژگی های عالی پشتیبانی می کنند. علاوه بر این، برخی از انواع NoSQL، مانند HBase، که بر روی یک سیستم فایل توزیع شده ساخته میشوند، همچنین مکانیزم ذخیرهسازی قابل تحمل، کپی و مقیاسپذیر را ارائه میکنند و برای پردازش مقادیر زیادی از رکوردهای داده کاشی مناسب هستند. بنابراین، ما در اینجا استفاده از روشهای NoSQL را برای ایجاد یک مدل مدیریت ذخیرهسازی توزیعشده برای دادههای عظیم نقشه کاشی در نظر میگیریم.
5.1. مدل ذخیره سازی توزیع شده بر اساس ستون-خانواده
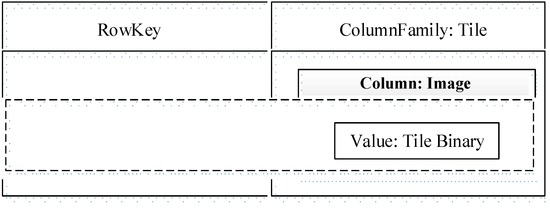
در مطالعات ما، دادههای کاشی نقشه، که از یک مجموعه داده برداری بریده شدهاند، با استفاده از یک مدل ستون-خانواده NoSQL مشابه BigTable Google ذخیره میشوند. در HBase، یک جدول از یک سری ردیف تشکیل شده است که از یک RowKey و تعدادی ColumnFamilies تشکیل شده است . RowKey کلید اصلی جدول است و رکوردهای جدول بر اساس RowKey مرتب شده اند . یک ColumnFamily می تواند از هر تعداد ستون تشکیل شده باشد ، یعنی ColumnFamily از بسط پویا بدون نیاز به از پیش تعریف کردن تعداد و نوع ستون پشتیبانی می کند .
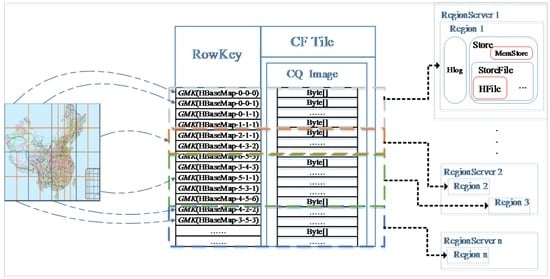
< map name, level, row, column, reverse timestamp > گزینه ای برای طراحی RowKey است، اما در این مورد کلید ردیف رشته ای با طول متغیر است و باید از جداکننده ها برای اتصال عناصر جدا شده استفاده کرد. یک جایگزین استفاده از الگوریتم هش مانند MD5 برای به دست آوردن یک کلید ردیف با طول ثابت است. با استفاده از “ MD5 (Map_Name) MD5 (سطح) MD5 (ردیف) MD5 (Col) + مهر زمانی معکوسبه عنوان RowKey، دو مزیت وجود دارد: (1) RowKey با طول ثابت می تواند به HBase کمک کند تا عملکرد خواندن و نوشتن را بهتر پیش بینی کند. (2) معمولاً انتظار می رود RowKey به طور مساوی توزیع شود. روش مبتنی بر MD5 این هدف را ممکن می سازد. از آنجا که بلوک های داده به طور خودکار توسط کلیدهای ردیف در HBase بر روی سرورهای منطقه توزیع می شوند، کلیدهای توزیع شده به طور مساوی می توانند از مشکل نوشتن نقاط داغ جلوگیری کنند و بنابراین از تمرکز بار در بخش کوچکی از سرورهای منطقه جلوگیری کنند.
همانطور که در شکل 7 نشان داده شده است ، RowKey برای شناسایی جهانی یک شی کاشی خاص استفاده می شود، که در ابتدا از شناسه سند نقشه، سطح کاشی، شماره ردیف و شماره ستون تشکیل شده است. علاوه بر این، برای تسهیل بهروزرسانی مکرر و مکانیابی سریع، یک مهر زمانی معکوس برای هر اقدام بهروزرسانی داده نیز به عنوان یکی از مؤلفههای RowKey در نظر گرفته میشود تا اطمینان حاصل شود که آخرین نسخه دادههای کاشی بهروزرسانی شده بهطور خودکار در بالای جدول دادههای کاشی مرتب میشود. این اجازه می دهد تا آخرین نسخه کاشی بیشترین اولویت دسترسی را در یک جلسه زمان بندی پرس و جو داشته باشد. بر این اساس، از روش محاسبه مقادیر MD5 16 بیتی (الگوریتم Message-Digest 5) هر فیلد استفاده می کنیم و سپس آنها را با هم ترکیب می کنیم تا RowKey را بدست آوریم .(یعنی تابع GMK همانطور که در شکل 8 نشان داده شده است ). در ذخیره سازی ستون-خانواده، ساختار تک ستون-خانواده را اتخاذ می کنیم – فقط یک ستون خانواده، کاشی و یک ستون، تصویر برای سرعت بخشیدن به دسترسی به داده ها و در عین حال اجتناب از هزینه عملکرد ستون گسترده. مقدار Image داده های باینری نقشه مربوط به این واحد کاشی است.
بر این اساس، ما یک مدل ذخیرهسازی توزیعشده کاشی مبتنی بر خوشه NoSQL را پیشنهاد میکنیم: همانطور که در شکل 8 نشان داده شده است، در فرآیند برش، سطوح مختلف دادههای کاشی سند نقشه، RowKey محاسبهشده مربوطه را تولید میکنند ، یعنی شناسه کاشی. ، طبق روش GMK (یعنی ” MD5 (Name_Name) MD5 (سطح) MD5 (ردیف) MD5 (Col) + معکوس برچسب زمانی “). سپس بلوکهای داده کاشی در رکوردهای جدول ستون NoSQL ذخیره میشوند و رکوردهای مختلف با توجه به استراتژی پارتیشنبندی به گرههای منطقه مختلف اختصاص مییابد. اینجا، منطقهبه عنصر اساسی در دسترس بودن و توزیع برای جدول کاشی اشاره دارد و از پارتیشن های رکورد برای خانواده ستون ها تشکیل شده است . به طور معمول، پایگاههای داده NoSQL مبتنی بر ستون مانند HBase به ذخیرهسازی مقیاسپذیر دادههای انبوه و توزیع متوازن دادهها از طریق بخشهای مختلف منطقه دست مییابند، و ویژگیهایی مانند مکانیسمهای MemStore و HLog میتوانند کارایی بالا برای خواندن و نوشتن دادههای کاشی و قابلیت اطمینان بالای دادهها را تضمین کنند.
هنگام پرس و جو و به دست آوردن نقشه های کاشی با الگوهای دسترسی مختلف، ابتدا باید RowKey نقشه کاشی مورد دسترسی با توجه به شناسه سند نقشه برداری، سطح داده های کاشی و شماره سطر و ستون تعیین شود. این پارامترها برای ایجاد یک RowKey مبتنی بر هش به تابع GMK منتقل میشوند . سپس، RowKeys نقشه کاشی مورد بررسی به گره اصلی در خوشه NoSQL ارسال می شود. گره اصلی که ابرداده های کاشی جهانی را حفظ می کند، اطلاعات دریافتی را پردازش می کند و به سرعت مسیر گره داده هدف را که کاشی ها در آن ذخیره می شوند، برمی گرداند. پس از آن، درخواست کننده کاشی می تواند با دسترسی مستقیم به گره داده از طریق، داده های کاشی مورد نظر را به دست آوردتطبیق RowKey . این مکانیزم مدیریتی میتواند به طور موثری حجم کاری افزایش یافته را از طریق همزمانی بالا کاهش دهد و همچنین میتواند کارایی ذخیرهسازی و دسترسی به دادههای نقشه کاشی را بهبود بخشد.
5.2. برش موازی نقشه کاشی و چارچوب پرس و جو بر اساس MapReduce
بر اساس مدل ذخیرهسازی دادههای کاشی NoSQL توزیعشده، ما چارچوبی را پیشنهاد میکنیم که مبتنی بر MapReduce برای برش موازی و زمانبندی سریع کاشیهای نقشه است. هدف این چارچوب بهبود کارایی دسترسی به داده های انبوه کاشی است. همانطور که در شکل 9 نشان داده شده است، پایین چارچوب یک خوشه ذخیره سازی NoSQL است (به عنوان مثال، یک پایگاه داده HBase)، که در میان آن هاست های منطقه متعدد به عنوان گره های داده برای ذخیره داده های نقشه کاشی توزیع شده استفاده می شود، و رکوردهای کاشی های مختلف را در فروشگاه های ستون-خانواده (که از این پس به آنها اشاره می شود) استفاده می شود. به عنوان TCFS، به عنوان مثال، HTable از HBase) با توجه به مدل داده کاشی ما. مجموعههای رکورد در TCFS به چند پارتیشن مستقل تقسیم میشوند – مناطق کاشی، با توجه به ظرفیت واحد منطقه – و در گرههای داده مختلف که مناطق مربوطه به آنها اختصاص داده شده است، ذخیره میشوند. سرویس هماهنگی NoSQL (مانند ZooKeeper) مناطق داده کاشی را در میان گره های داده مختلف همگام می کند، رابطه نگاشت بین مجموعه داده های کاشی جهانی و هر قسمت در گره های داده را حفظ می کند و از یکپارچگی منطقی مجموعه داده های کاشی جهانی اطمینان حاصل می کند. گره اصلی تخصیص و زمانبندی یکپارچه منابع ذخیرهسازی دادههای کاشی را بر روی گرههای داده مختلف با توجه به مناطق انجام میدهد. مزیت این است که دسترسی به داده های کاشی نقشه های متعدد به طور مستقیم توسط گره های داده توزیع شده مربوطه انجام می شود. علاوه بر این، مکانیسم تکراری افزونگی داده که توسط سیستم فایل توزیع شده (به عنوان مثال، HDFS) پشتیبانی می شود، قابلیت اطمینان داده های کاشی را تضمین می کند. بر اساس این چارچوب، ما به روشهای تولید موازی و بازیابی کاشیهای نقشه برداری با استفاده از مدل MapReduce پی بردیم. مکانیسم تکراری افزونگی داده که توسط سیستم فایل توزیع شده (به عنوان مثال، HDFS) پشتیبانی می شود، قابلیت اطمینان داده های کاشی را تضمین می کند. بر اساس این چارچوب، ما به روشهای تولید موازی و بازیابی کاشیهای نقشه برداری با استفاده از مدل MapReduce پی بردیم. مکانیسم تکراری افزونگی داده که توسط سیستم فایل توزیع شده (به عنوان مثال، HDFS) پشتیبانی می شود، قابلیت اطمینان داده های کاشی را تضمین می کند. بر اساس این چارچوب، ما به روشهای تولید موازی و بازیابی کاشیهای نقشه برداری با استفاده از مدل MapReduce پی بردیم.
5.3. الگوریتم برش موازی نقشه کاشی
عملیات گیره کاشی نقشه به طور کلی با توجه به سناریوهای مختلف برنامه به دو دسته کلیپ استاتیک و کلیپ پویا تقسیم می شود. برش کاشی استاتیک عمدتاً به پیش تولید یک نقشه کاشی قبل از دسترسی کاربر به داده ها و توزیع نقشه کاشی در بین پایگاه های داده کاشی یا برخی از انواع سیستم های فایل اشاره دارد. در حال حاضر، روش مدیریت اصلی برش استاتیک استفاده از مکانیزم پردازش متوالی یا روش محاسبات چند فرآیندی است و هر دو بر اساس گرههای مستقل هستند. با این حال، گسترش قابلیت های محاسباتی به طور جدی توسط ظرفیت سخت افزاری یک کامپیوتر مستقل محدود می شود، به ویژه زمانی که یک نقشه برداری از اسناد فرعی زیادی تشکیل شده باشد یا یک سند نقشه حاوی تعداد زیادی سطح باشد. در چنین مواردی، کلیپ کردن نقشه ها اغلب زمان زیادی می برد، گاهی اوقات حتی ساعت ها.
در چارچوب ما، با استفاده از مدل پردازش داده توزیعشده MapReduce، یک الگوریتم موازی برای اجرای عملیات تولید کاشی ارائه میشود (به مراحل C1 تا C5 در شکل 9 مراجعه کنید) : یک کلاینت یک کار کلیپ ارسال میکند و منبع محاسباتی را آپلود میکند – مجموعه اسناد نقشه، که شامل چندین سند نقشه برداری و اطلاعات پیکربندی کار (اندازه کاشی: ارتفاع / عرض کاشی ، حداکثر سطح کاشی: حداکثر سطح و غیره) تا نقطه پایانی اجرای کار است. JobTracker ، گره زمانبندی کار در چارچوب MapReduce، وظیفه را میپذیرد و سپس آن را به گرههای مختلف اجرای کار اختصاص میدهد – TaskTracker . TaskTrackerبه طور خودکار منابع محاسباتی مناسب را از مخزن منابع وظیفه برای اجرای موازی وظایف فرعی دانلود می کند. ابتدا، نمونه های Mapper برای انجام محاسبات Map ساخته می شوند . همانطور که در شکل 10 نشان داده شده است ، فرآیند اصلی الگوریتم نقشه به صورت زیر توضیح داده شده است: t نشان دهنده یک واحد کاشی در سطح مشخصی از سند نقشه داده شده است. تابع clip محاسبه تولید کاشی را برای هر t انجام می دهد تا داده های کاشی مربوطه را خروجی کند که سپس در یک جدول رکورد TCFS (یعنی جدول HBase) قرار می گیرد . نتیجه محاسباتی هر وظیفه نقشه یک شی کلید/مقدار است و با یک شماره دسترسی رکورد کاشی (به عنوان مثال rk) شناسایی می شود) سپس، تمام کلیدهای rk برای مرحله بعدی اجرای Reduce به چارچوب MapReduce فرستاده می شوند . در مرحله Reduce، TaskTracker هنگام دریافت درخواست اجرای وظایف فرعی، عملیات Reduce را انجام میدهد و ادغام موازی بر روی شمارههای دسترسی کاشی که نشاندهنده واحدهای کاشی هستند که طبق اسناد نقشه برداری مختلف با موفقیت به دست آمدهاند، انجام میشود . مجموعه نتایج نهایی پس از ادغام به مشتری بازگردانده می شود. در کل فرآیند، از طریق اجرای دو مرحله Map و Reduce ، چارچوب MapReduce کار محاسباتی موازی را برای دادههای کاشی نقشه با حجم بالا انجام میدهد.
در مورد جزئیات اجرای عملکرد کلیپ، عملکرد رندر توسط MapGIS K9، یکی از محبوب ترین نرم افزارهای پلت فرم GIS در چین ارائه شده است. دستور نمونه اولیه تابع رندر MapGIS به صورت زیر فهرست شده است:
رندر خالی (لایه های<List> لایه ها، توصیفگرهای SLD<List>، دامنه GeoEnvelope، Rectangle png_size، String output_path) ;
که در آن لایهها نمایانگر چندین سند نقشه هستند که میتوان آنها را مشخص کرد، توصیفگرها فایلهای SLD مربوطه (بهعنوان مثال، هر سند نقشه فایل SLD خود را دارد)، دامنه نشاندهنده مستطیل جغرافیایی برای رندر نقشه، png_size نشاندهنده اندازه تصویر PNG خروجی مورد نظر است. و به عنوان اندازه واحد کاشی 256 × 256 در تابع کلیپ ثابت می شود، output_path مسیر فایل خروجی را برای تصویر رندر شده نشان می دهد.
از آنجایی که تابع clip پارامترهایی مانند اسناد نقشه مرتبط با فایل های SLD، سطح ، xtile (شاخص کاشی در محور x ) و ytile (شاخص کاشی در محور y ) را منتقل می کند، از معادلات (2)-(4) زیر برای تبدیل سطح استفاده می شود . xtile و ytile به مستطیل جغرافیایی شامل محدوده طول و عرض جغرافیایی. پس از این تبدیلها، تابع رندر میتواند توسط تابع کلیپ فراخوانی شود و بنابراین تصویر کاشی میتواند به درستی رندر شود. به عنوان مثال، مستطیل جغرافیایی کاشی ( سطح = 1، xtile= 0، ytile = 0) به صورت ( طول جغرافیایی (2 1 ، 0) عرض جغرافیایی (2 1 ، 0)، طول جغرافیایی (2 1 ، 1) عرض جغرافیایی (2 1 ، 1)) = (-180° 85.05°، 0) محاسبه می شود . درجه 0).
به شیوه ای پویا، مجموعه داده های برداری نیازی به پردازش قبلی ندارند. در عوض، نقشه کاشی مربوطه به صورت پویا با توجه به سطح بزرگنمایی نقشه، محدوده پرس و جو و غیره، تنها زمانی که کاربران به کاشی های نقشه برداری دسترسی دارند، تولید می شود و سپس کاشی های نقشه تولید شده در جدول ذخیره NoSQL TCFS ذخیره می شوند. تفاوت اصلی با تولید کاشی استاتیک در این است که دادههای کاشی به صورت پویا تولید و بارگذاری میشوند که کاربران به طور مداوم به یک سری کاشی در سطوح مختلف نقشه یا چندین کاشی غیر مجاور یا برخی مناطق خاص دسترسی داشته باشند، بدون استفاده از کاشیهای تولید شده از قبل. از آنجایی که داده های نقشه نیازی به پیش پردازش ندارند، این روش انعطاف پذیرتر و راحت تر است و باعث صرفه جویی در فضای ذخیره سازی در سمت سرور می شود. با این حال، حالت پردازش کار به تولید کاشی در زمان واقعی نیاز دارد، بنابراین الگوریتم پردازش پس زمینه باید پیچیدگی زمانی کمی داشته باشد. در حال حاضر، اکثر پیاده سازی های پویا برش کاشی نیز بر اساس ساختار شاخص چهار درختی است. هنگامی که کاربران به طور تصادفی به یک قطعه کاشی یا چندین کاشی از یک منطقه دسترسی پیدا می کنند، می توانند ابتدا بررسی کنند که آیا داده های درخواستی در مجموعه داده های کاشی وجود دارد یا خیر. در غیر این صورت، عملیات برش کاشی بر روی داده های نقشه برداری با استفاده از الگوریتم های کلیپ نقشه مبتنی بر چهار درخت انجام می شود. سناریوی نشان داده شده در سپس عملیات برش کاشی بر روی داده های نقشه برداری با استفاده از الگوریتم های کلیپ نقشه مبتنی بر چهار درخت انجام می شود. سناریوی نشان داده شده در سپس عملیات برش کاشی بر روی داده های نقشه برداری با استفاده از الگوریتم های کلیپ نقشه مبتنی بر چهار درخت انجام می شود. سناریوی نشان داده شده درشکل 11 یک نمودار پارتیشن نقشه کاشی مبتنی بر چهاردرخت در یک جلسه درخواست پویا است، که در آن مکان جغرافیایی متناظر این نقشه کاشی، شهر ووهان چین است.
در چارچوب الگوریتم پردازش کاشی مبتنی بر NoSQL که ما پیشنهاد کردهایم، یک روش برش پویا موازی بر اساس مدل MapReduce نیز در نظر گرفته شده است. مراحل الگوریتم (D1 تا D6) در شکل 10 نشان داده شده است . اصل اساسی هر واحد محاسباتی تقریباً مشابه برش کاشی ایستا است – ورودی ها سطح کاشی و محدوده نقشه تولید شده با مجموعه اسناد نقشه به صورت پویا هستند. پس از اینکه وظایف و منابع محاسباتی مرتبط به پایان اجرا، JobTracker چارچوب الگوریتم MapReduce ارسال شد، به هر پایان اجرای زیرکار، یعنی TaskTracker ، اطلاع میدهد تا سند نقشه مربوطه خود را واکشی کند.و منابع تخصیص یافته؛ هر TaskTracker یک نمونه شی Mapper برای اجرای روش Map می سازد ، همانطور که در شکل 12 نشان داده شده است ، و تابع tiles مجموعه های شی کاشی را با استفاده از گستره فضایی m در سطح l از شی سند نقشه d ایجاد می کند . برای هر شی کاشی t در کاشی ، باینری کاشی را از جدول ثبت جهانی کاشی NoSQL بدست آورید. اگر مقدار آن خالی است، تابع clip را فراخوانی کنید تا بلافاصله شی t تولید شود. نتایج محاسبات در جدول داده کاشی و شماره دسترسی آن ذخیره می شودrk به عنوان یک شی کپسوله می شود که می تواند در مراحل Reduce پردازش شود. اگر مقدار خالی نباشد، نشان می دهد که داده های کاشی قبلاً تولید شده اند. سپس، شماره رکورد را در اشیاء Key/Value بسته بندی کنید و آنها را به مراحل کاهش ارسال کنید . مکانیسم اجرای دوره Reduce در زیرکارها شبیه به پردازش static tile است و پایان TaskTracker شروع به کاهش می کند.اجرای عملیات زمانی که اشیاء واجد شرایط دریافت می شوند. واحدهای کاشی که با موفقیت بریده شده اند و آنهایی که قبلاً در پایگاه داده کاشی وجود دارند، طبق اسناد نقشه برداری مختلف به موازات یکدیگر ادغام می شوند و مجموعه نتایج نهایی پس از کاهش به درخواست کننده بازگردانده می شود.
5.4. جستجوی موازی نقشه کاشی
الگوریتم پرس و جوی موازی نقشه کاشی ( شکل 13 را ببینید)، که عمدتاً با استفاده از پارادایم محاسباتی MapReduce پیاده سازی شده است، بازیابی موازی اشیاء کاشی را در مدل ذخیره سازی کاشی NoSQL ما به ارمغان می آورد. ورودی این الگوریتم مجموعه شرایط پرس و جو است Q = { c | c = < d , l , m >}، که در آن c سه گانه از سه شرط پرس و جو تشکیل شده است: d ، l و m که به ترتیب نشان دهنده شی سند نقشه، سطح زوم و پوشش است. اجرای زیرکار به پایان می رسد (یعنی TaskTracker) اشیاء پرس و جو را از مجموعه مجموعه Q بدست آورید و سپس منابع محاسباتی را دانلود کنید و به سرعت جدول کاشی را اسکن کنید و یک زیرمجموعه شی کاشی مطابق با شی پرس و جو ایجاد کنید. برای هر شی پرس و جو t در زیر مجموعه، RowKey مرتبط در جدول داده های کاشی جهانی به دست می آید و سپس در واحدهای محاسباتی که در فاز Reduce با توجه به سطح پرس و جو انجام می شود، بسته بندی می شود. تابع EMIT این واحدها را به زمانبندی کار MapReduce (یعنی JobTracker ) ارسال می کند. شایان ذکر است که اگر نتیجه query null باشد، تابع EMIT مقدار شی صادر شده را صفر می کند. فرآیند الگوریتم در Reduceمرحله شبیه به برش کاشی پویا است: ایجاد یک تاپل با توجه به سند نقشه و سطح پرس و جو، ادغام نتایج پرس و جو، و برگرداندن نتیجه نهایی به درخواست کننده.
6. آزمایشات
برای ارزیابی عملکرد مدلی که در بخش قبلی پیشنهاد کردهایم در یک محیط واقعی، یک محیط آزمایشی را با استفاده از شبکه اطلاعات زمینشناسی چین (که از این پس به عنوان شبکه CGS-Grid نامیده میشود) راهاندازی کردیم و یک نمونه اولیه تأیید ایجاد کردیم. بر این اساس ما یک سری آزمایشات را انجام دادیم. این آزمایشها عمدتاً چارچوب ما را با مدل سنتی مقایسه میکنند، که مکانیزم حافظه پنهان کاشی محلی و مدل مدیریت مبتنی بر سیستم فایل توزیع شده را از نظر کارایی و عملکرد ذخیرهسازی کاشی اتخاذ میکند.
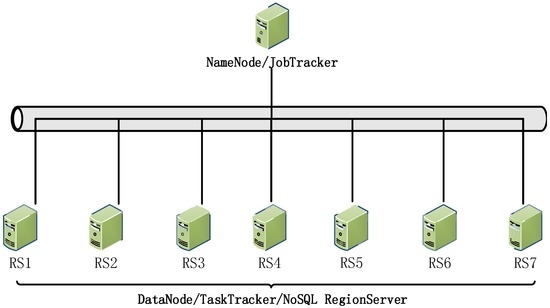
سیستم نمونه آزمایشی ما بر روی مرکز داده کاشی CGS-Grid ساخته شده است، معماری سیستمی که در شکل 14 نشان داده شده است . عمدتاً از یک خوشه داده کاشی با 8 سرور NoSQL تشکیل شده است که گره های داده از طریق اترنت گیگابیتی به یکدیگر متصل می شوند. هر پایان محاسباتی با یک پردازنده 2.8 گیگاهرتزی دو هسته ای اینتل، 4 گیگابایت حافظه 1066 مگاهرتزی DDR3 ECC و 1 ترابایت فضای ذخیره سازی دیسک پیکربندی شده است که سیستم عامل CentOS Linux 5.8 64 بیتی را اجرا می کند. یکی از این گرههای NoSQL بهعنوان یک کنترلکننده ذخیرهسازی کاشی توزیعشده و زمانبندی کار استفاده میشود (یعنی NameNode و JobTracker در شکل 14 )، در حالی که هفت گره دیگر برای ذخیرهسازی دادهها و اجرای کار انتخاب شدهاند (یعنی DataNode وTaskTracker در شکل 14 ). خوشه کاشی از پلتفرم Hadoop 1.1.2 و پایگاه داده HBase 0.96 NoSQL استفاده می کند که فروشگاه های NoSQL توزیع شده را ارائه می دهد. برای تسهیل مقایسه بین روش خود و سایر روشها، ما همچنین یک رایانه با کارایی بالا را آماده کردیم که با استفاده از مدل کلاسیک، سرویس کاشیکاری مستقل را ارائه میدهد و پیکربندی آن به شرح زیر است: 24 پردازنده دو هستهای اینتل 2.8 گیگاهرتز، 64 پردازنده حافظه گیگابایت و شبکه فضای ذخیره سازی مبتنی بر کانال فیبر (FC SAN) با ظرفیت ذخیره سازی 50 ترابایت. در این آزمایشها، ما از مجموعه دادههای عمومی یکپارچه سازمان زمینشناسی چین [ 25] استفاده کردیم] که شامل 110 سند نقشه برداری (شامل موضوعات ژئوفیزیکی، ژئوشیمیایی و بسیاری دیگر از موضوعات بررسی زمین شناسی می باشد). اندازه مجموعه داده های برداری بیش از 300 گیگابایت است و حداکثر سطح کاشی های مبتنی بر مدل LOD به 25 می رسد. برش نقشه کاشی و توابع جستجو در سرویس های GIS آرامش بخش مطابق با چارچوب های پردازش مختلف، از جمله GIS مستقل مبتنی بر HPC پیچیده می شود. سرویس کاشی، سیستم پردازش کاشی توزیع شده مبتنی بر Hadoop (HDFS) و چارچوب الگوریتم پردازش کاشی ما بر اساس MapReduce و NoSQL.
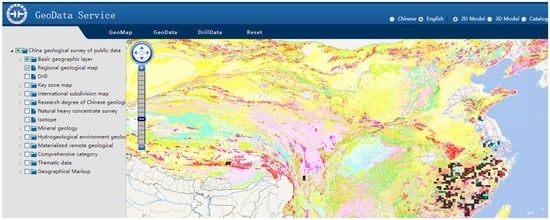
با استفاده از خدمات کاشی ذکر شده در بالا، یک سرویس گیرنده نقشه وب (نگاه کنید به شکل 15 ) برای ارائه خدمات نقشه زمین شناسی مناسب برای سه مدل مختلف ذخیره سازی و مدیریت داده های کاشی ایجاد شده است. بر این اساس، ما گروهی از آزمایشها را برای مقایسه قابلیتهای پردازش موازی و مقیاسپذیری بین روش مبتنی بر NoSQL و سایر الگوهای پردازش رایج انجام دادیم. دو آزمایش اول برای ارزیابی قابلیتهای پردازش پرس و جو کاشی موازی چارچوب الگوریتم ما استفاده میشوند، در حالی که دو آزمایش دوم برای ارزیابی عملکرد موازی برش کاشی استفاده میشوند.
6.1. توضیحات داده ها
آزمایش ما بر اساس مجموعه داده های واقعی پلت فرم خدمات اطلاعات سازمان زمین شناسی چین [ 25 ] است. مجموعه داده ها در 39 دسته اصلی طبقه بندی می شوند و شامل 247 مجموعه داده زمین شناسی موضوعی (همانطور که در جدول 1 نشان داده شده است)، از جمله نقشه های برداری زمین شناسی چند مقیاسی از ده پایگاه داده مهم زمین شناسی فضایی چین (شامل نقشه های زمین شناسی 1:200000 و 1:500000). ، نقشه زمین شناسی هیدرولوژیکی 1:200000، نقشه ژئوشیمیایی 1:200000، ذخایر معدنی، معدن سنگین طبیعی، توزیع ایزوتوپ، نقشه زمین شناسی محیطی 1:500،000 و پایگاه های اطلاعاتی اکتشافات زمین شناسی) و ده ها مجموعه داده های موضوعی بررسی زمین شناسی. حجم مجموعه داده ها به حدود 1 ترابایت رسیده است [ 26 ] و همچنان به طور مداوم در حال گسترش است.
6.2. آزمایش 1 – همزمانی
آزمایش اول عملکرد دسترسی به داده کاشی روش مبتنی بر حافظه پنهان فایل مستقل، روش مبتنی بر سیستم فایل توزیع شده (Hadoop HDFS) و چارچوب مدیریتی مبتنی بر NoSQL پیشنهادی ما را برای پردازش دادههای نقشه کاشی مقایسه کرد.
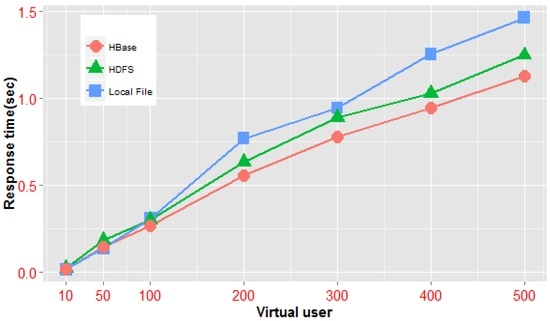
در این آزمایشها، ما عمدتاً از همان مجموعههای نقشه کاشی استفاده کردیم (مجموعه نقشه ژئوشیمیایی چین، در مقیاس 1:200000، شامل 32 سند نقشه است؛ اندازه دادههای برداری مجموعه تقریباً 20 گیگابایت است، و فایلهای کاشی تولید شده توسط عملیات برش مستقل، با اندازه 46.3 گیگابایت، در یک HPC مستقل، یک خوشه Hadoop و چارچوب خوشه NoSQL که در بالا ذکر شد استفاده میشود) و آزمایشهای عملکردی روی سه الگوی دسترسی انجام شده است. علاوه بر این، سوئیچ کپی HDFS در طول آزمایش بسته شد. الگوی اول دسترسی به یک کاشی نقشه خاص بر اساس سه گانه شناسایی شی کاشی است، و آزمایش مربوطه واحد کاشی منفرد را در ردیف 0، ستون 0 سطح 0 به عنوان منطقه هدف قرار می دهد. حالت دوم با استفاده از شرایط محدوده مستطیل به چندین نقشه کاشی در یک سطح دسترسی پیدا می کند. و دامنه دسترسی در آزمایش کل چهار کاشی نقشه سطح 1 را پوشش می دهد. روش سوم، دسترسی به نقشههای کاشی متعددی است که از چندین سطح با توجه به محدوده مستطیل عبور میکنند، و در آزمایش، ما از 21 کاشی که سطح 0 تا سطح 2 را پوشش میدهند به عنوان هدف پرس و جو استفاده کردیم. میانگین زمان دسترسی اسناد کاشی نقشه برداری چندگانه در سه معماری تحت کاربران و مدلهای دسترسی مختلف تحلیل میشود. نتایج تجربی در نشان داده شده است میانگین زمان دسترسی اسناد کاشی نقشه برداری چندگانه در سه معماری تحت کاربران و مدلهای دسترسی مختلف تحلیل میشود. نتایج تجربی در نشان داده شده است میانگین زمان دسترسی اسناد کاشی نقشه برداری چندگانه در سه معماری تحت کاربران و مدلهای دسترسی مختلف تحلیل میشود. نتایج تجربی در نشان داده شده استجدول 2 .
از شکل 16 ، شکل 17 و شکل 18، می بینیم که وقتی یک پرس و جو همزمان در مقیاس کوچک باشد، سیستم مستقل به طور قابل توجهی کارآمدتر از معماری توزیع شده است. در صورتی که تعداد درخواستهای همزمان کمتر از 50 باشد – چه درخواستهای همزمان یک واحد تک کاشی یا درخواستهای چند کاشی در یک سطح – میانگین زمانهای پاسخ معماری توزیعشده عموماً کمتر از زمانهای پاسخ سرور مستقل است. معماری. با این وجود، کارایی چارچوب مبتنی بر NoSQL ما بیشتر از معماری سیستم فایل توزیع شده است. بدیهی است که در این سناریو، هزینه ارتباطات شبکه زیربنایی معماری توزیع شده نسبت بیشتری از کل زمان اجرا است. و هزینه زمانی زمانبندی بلوکهای داده در چندین گره سیستم فایل توزیعشده بیشتر از بازیابی کاشی موازی با استفاده از مدل MapReduce در چارچوب پردازش کاشی ما است. با این حال، زمانی که جلسات همزمان به بیش از 100 برسد، میانگین زمان دسترسی به دادههای کاشی در محیط توزیعشده کمتر از حالت حافظه پنهان محلی است. این نشان می دهد که مقیاس همزمان دارای یک مقدار آستانه مشخص است و هنگامی که به آستانه رسید، افزایش تدریجی کاربران مجازی، پیچیدگی پرس و جو کاشی (به عنوان مثال، از پرس و جوهای ساده در همان سطح تا پرس و جوهایی که چندین سطح را پوشش می دهند) یا کل تعداد کاشی هایی که باید پرس و جو شوند باعث می شود کارایی پرس و جو انبوه در محیط توزیع شده بسیار بیشتر از مکانیسم کش فایل محلی باشد. علاوه بر این، تحت حالت های مختلف پرس و جوهای همزمان، چارچوب موازی مبتنی بر NoSQL عملکرد بهتری نسبت به چارچوب مبتنی بر سیستم فایل توزیع شده دارد. همه موارد فوق نشان می دهد که مدل پردازش موازی مبتنی بر NoSQL ما برای پردازش سریع داده در سناریوهای کاشی نقشه با همزمانی بالا و حجم زیاد مناسب است.
6.3. آزمایش 2 – مقیاس پذیری
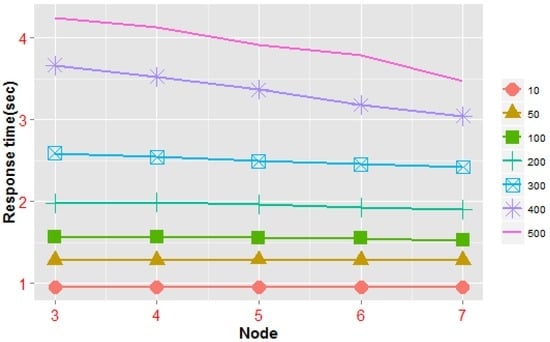
علاوه بر تعداد جلسات همزمان و روشهای دسترسی به دادههای کاشی، قابلیتهای پردازش پرسوجو نقشه کاشی نیز به تعداد گرههای شرکتکننده در پردازش موازی بستگی دارد، بهویژه در سناریوهای کاربردی نقشه کاشی برداری در مقیاس بزرگ. آزمایش 2 عمدتاً برای بررسی رابطه زمان پاسخ درخواست های پرس و جو و تعداد گره های پردازش معماری NoSQL تحت شرایط پرس و جو یکسان استفاده می شود. در این آزمایش، از نقشه برداری زمین شناسی چین در مقیاس 1:200000 استفاده کردیم (اندازه داده های برداری 7 گیگابایت است، 17 سطح کاشی با استفاده از چارچوب NoSQL تولید می شود و ظرفیت جدول رکورد کاشی NoSQL به آن می رسد. تقریباً 17.3 گیگابایت). ما به تدریج تعداد گره های خوشه ای را یکی یکی افزایش می دهیم. از سه گره در ابتدا تا هفت گره. هر بار که یک گره اضافه می شود، یک متعادل کننده داده توزیع داده های کاشی جهانی را در جدول NoSQL در همه موارد متعادل می کند.میزبان های منطقه ، که می توانند تعادل بار بهتری را ایجاد کنند و مقیاس پذیری ذخیره سازی را بهبود بخشند. قوانین تولید اشیاء پرس و جو به شرح زیر است: برای هر پرس و جو، یک واحد کاشی از هر سطح از سطح 3 تا سطح 17 به طور تصادفی انتخاب می شود تا یک مجموعه اشیاء پرس و جو در سطح متقابل (که شامل 15 کاشی است) ایجاد شود. ما آزمایش را تحت جلسات مختلف دسترسی همزمان با اشیاء پرس و جو انجام دادیم و میانگین زمان پاسخ چارچوب را ثبت کردیم. نتایج در جدول 3 نشان داده شده است .
داده های تجربی در جدول 3 را می توان به صورت نمودار خطی بیان کرد ( شکل 19) همانطور که می بینیم، زمانی که تعداد جلسات همزمان کمتر از 100 باشد، میانگین زمان پاسخ یک پرس و جو به طور قابل توجهی تحت تاثیر افزایش اعضای گره قرار نمی گیرد. با این حال، هنگامی که تعداد کاربران مجازی به 100 می رسد، هرچه تعداد گره های بیشتری در پردازش شرکت داشته باشیم، چارچوب ما سریعتر به پرس و جو پاسخ می دهد. در سناریوهای وظایف پرس و جوی همزمان در مقیاس کوچک، اثر بهبود کارایی پردازش با افزایش تعداد گرههای NoSQL آشکار نیست. دلیل این امر این است که شتاب موازی به دست آمده با افزایش گره های پردازش تا حدی با افزایش همزمان هزینه ارتباطات شبکه جبران می شود. هنگامی که مقیاس پرس و جو همزمان به یک آستانه خاص افزایش می یابد (به عنوان مثال، 200 کاربر در شکل 19)، سربار ارتباط مستقیماً توسط گرههای جدید افزایش مییابد در مقایسه با قابلیتهای شتاب پردازش موازی که توسط توسعه ایجاد میشود، ناچیز میشود. نتایج تجربی نشان دادهاند که با افزایش مناسب گرههای پردازش، میتوانیم وظایف پرس و جو را برای به حداقل رساندن بار روی هر گره پردازشی توزیع کنیم و در نتیجه تعداد قابل پشتیبانی وظایف پرس و جو کاشی موازی را افزایش دهیم. همه اینها می تواند به طور موثری قابلیت های پردازش موازی چارچوب محاسباتی NoSQL ما را گسترش دهد.
اجازه دهید u تعداد جلسات همزمان آغاز شده توسط یک تراکنش پرس و جو کاشی را نشان دهید، و اجازه دهید S تعداد کاشی ها در وظایف پرس و جو باشد. S را می توان به صورت زیر تعریف کرد:
که در آن n i نشان دهنده تعداد کاشی های درخواست شده توسط جلسه I است. برای چارچوب مبتنی بر NoSQL ما با گرههای پردازشی N (که در آن هر گره دارای یک هسته پردازشگر است)، میانگین زمان پاسخدهی عملیات پرسوجو Tr بهطور کلی به صورت زیر ارائه میشود:
که در آن t میانگین زمان پرس و جو یک شی کاشی منفرد در جدول NoSQL با استفاده از مدل ذخیره داده ما است (در مدل ما، RowKey یک رکورد کاشی طوری طراحی شده است که مطابق با شماره ردیف و ستون هر واحد کاشی تولید شود، بنابراین از اسکن کامل جدول هنگام انجام عملیات پرس و جو)، و p نشان دهنده میانگین زمان عملیات ادغام در نتایج پرس و جو است، در حالی که m و r به ترتیب تعداد کارهای Map و Reduce را در یک گره منفرد نشان می دهند. علاوه بر این، cm و cr متغیرهای تصادفی هستند که از توزیع های نمایی با پارامتر λ تبعیت می کنند .m و λ r به ترتیب. آنها به سربار زمانی ناشی از عوامل عدم قطعیت، مانند تأخیر ارتباط، آدرس دهی دیسک و مشتریان مشغول هنگام انجام هر عملیات Map یا Reduce اشاره دارند .
بدیهی است که زمان اجرا Tr عمدتاً با کاربران همزمان، تعداد کل کاشی ها، زمان اجرای برنامه پرس و جو و زمان ارتباط شبکه متناسب است و با تعداد گره های درگیر در محاسبه رابطه معکوس دارد. هنگامی که مقیاس S کوچک است، با افزایش N ، مقیاس کاهش Tr معنی دار نیست، اما زمانی که مقیاس S به سطح معینی می رسد ، مانند رشد مداوم N ، تأثیر بر مقیاس کاهش T. rآشکارتر است. در نتیجه، چارچوب مدیریت کاشی توزیع شده ما برای سناریوهای کاربردی با همزمانی بالا و حجم زیادی از پردازش داده مناسب است. در این سناریوها، افزایش تعداد گره های پردازش موازی می تواند به طور موثری کارایی پرس و جوهای عظیم کاشی را بهبود بخشد. علاوه بر این، برای اینکه زمانبندی کاشی تا حد امکان کارآمد باشد، باید روشی را برای بهبود پیکربندی سختافزاری مانند افزایش پهنای باند آداپتور شبکه و تعداد هسته پردازندهها و غیره اتخاذ کنیم.
6.4. آزمایش 3 – عملکرد برش استاتیک
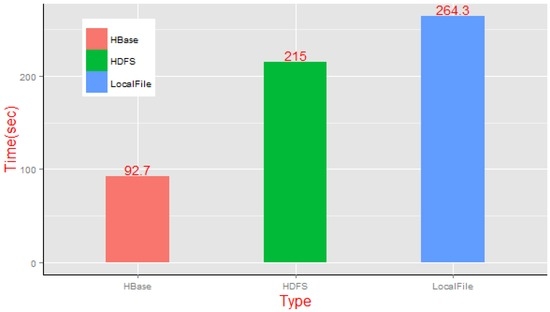
آزمایش 3 عملکرد محاسباتی سه معماری مختلف برش کاشی ایستا را مقایسه کرد – یک سرور سنتی با کارایی بالا، سیستم پردازش مبتنی بر فایل توزیع شده و چارچوب موازی مبتنی بر NoSQL ما. در آزمایش، ما همان مجموعه داده های برداری را انتخاب کردیم که در آزمایش 2، 0 تا 6 سطح کاشی را برای مجموع 981 واحد نقشه کاشی از طریق عملیات برش استاتیک درخواست شده توسط مشتری ایجاد کردیم.
بر اساس بستن سوئیچ تابع ماکت HDFS، میانگین زمان اجرای برش استاتیک حالت تک سرور و حالت محاسبات توزیع شده را مقایسه کردیم و نتایج در شکل 20 نشان داده شده است.نشان می دهد که روش کش فایل محلی بیشترین زمان را برای پردازش صرف می کند (264.3 ثانیه)، در حالی که چارچوب NoSQL مبتنی بر نمودار MapReduce دارای مزایای آشکار (92.7 ثانیه) در کارایی است. ما به وضوح میبینیم که میانگین زمان تکمیل تراکنش انجام وظیفه برش MapReduce بر اساس چارچوب HDFS کمی سریعتر از مدل متمرکز است، اما مزایای آن آشکار نیست. دلیل این امر این است که هزینه های دسترسی به داده های متقاطع که توسط فایل های کاشی افزایش یافته در پردازش ایجاد می شود را نباید نادیده گرفت. با این حال، چارچوب NoSQL ما با الگوریتمهای موازی MapReduce برای برش کاشی استاتیک روی مجموعه داده برداری کارآمدتر است.
6.5. آزمایش 4 – عملکرد برش پویا
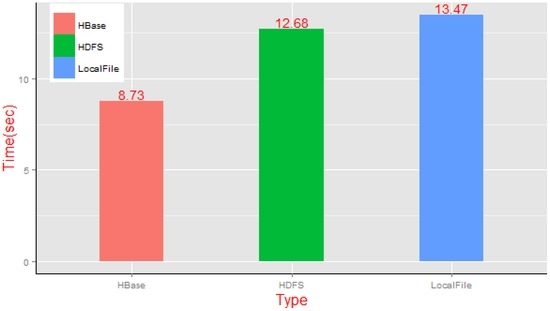
آزمایش 4 زمان تکمیل کار یک تراکنش با برش پویا را با روش سنتی یک سرور با کارایی بالا، روش پردازش سیستم فایل توزیع شده Hadoop و رویکرد پیشنهادی ما، یعنی تولید کاشی پویا با استفاده از یک خوشه NoSQL مقایسه کرد. با استفاده از مجموعه دادههای واقعی مشابه آزمایشهای 2 و 3، ما درخواستهای برش پویا را برای دادههای نقشه برداری زمینشناسی چین در سه محیط معماری انجام میدهیم. با توجه به قانون یک کاشی در هر سطح، ما به ده کاشی درخواست کردیم که به طور تصادفی از سطوح 3 تا 12 مجموعه نقشه برداری انتخاب شدند و سپس زمان تکمیل کار برش پویا آنها را همانطور که در شکل 21 نشان داده شده است، تجزیه و تحلیل کردیم .
اجرای سه روش فوق در آزمایشهای ما برای ویژگیهای برش پویا نسبت به روشهای استاتیک مربوطه زمانبرتر است. در مورد درخواستهای همزمان در مقیاس کوچک، تفاوت میانگین زمان مصرف شده برای برش پویا بین معماری تک پردازشی و معماری توزیعشده HDFS هنگام تولید 10 کاشی تصادفی کمتر بود. زمان اجرا به ترتیب 13.47 و 12.68 ثانیه بود. علاوه بر این، علاوه بر هزینه عملیات برش کاشی، عملیات ذخیره سازی داده های کاشی تولید شده در زمان واقعی، مقدار معینی از زمان را نیز به همراه داشت، به ویژه در مورد فعال کردن عملکرد کپی سیستم فایل HDFS (مصرف زمان HDFS). روش حتی بیشتر از مکانیسم مستقل بود). با این حال،
7. نتیجه گیری و کار آینده
این مقاله یک روش پردازش موازی برای دادههای کاشی برداری معرفی کرده است که میتواند برای عملیات برش و ذخیرهسازی کاشیهای داده عظیم در سناریوهای خدمات نقشه با همزمانی بالا اعمال شود. یک مدل ذخیرهسازی داده کاشی توزیعشده مبتنی بر خانواده برای موارد ساخت، دستکاری، بازیابی و به اشتراک گذاری دادههای کاشی در مقیاس بزرگ در یک خوشه NoSQL توسعه داده شد. این مدل داده نیاز حیاتی به پشتیبانی از راندمان ذخیره سازی بالا، توانایی مقیاس بندی سریع و توزیع متعادل داده را برطرف می کند.
برای بهبود کارایی پردازش یک نقشه کاشی کاری شده در مدل داده NoSQL، ما یک چارچوب الگوریتمی برای انجام عملیات برش و پرس و جو توزیع شده روی کاشی های برداری عظیم طراحی کردیم. این چارچوب از برش کاشی استاتیک و پویا در حالت موازی برای مدل ذخیره سازی NoSQL ما پشتیبانی می کند و همچنین بازیابی سریع مجموعه داده کاشی در مقیاس بزرگ را با استفاده از الگوی برنامه نویسی MapReduce در NoSQL پیاده سازی می کند. برای این منظور، ما همچنین چارچوب پردازش موازی را در یک محیط وب سرویس با کارایی بالا، که بر اساس شبکه اطلاعات زمینشناسی چین ایجاد شده است، تعبیه کردهایم تا نمونه اولیه خدمات نقشه کاشیشده را توسعه دهیم که میتواند خدمات برش و نقشه را برای بزرگها ارائه کند. داده های برداری
روش پردازش مبتنی بر NoSQL ما برای دادههای کاشی برداری، یک تلاش اولیه برای توسعه ابزاری مؤثر برای مقابله با حجم عظیم فضای ذخیرهسازی و مشکلات محاسباتی در Cloud است. ذخیره سازی توزیع شده، دسترسی و یک مدل پردازش سریع برای داده های کاشی سه بعدی با حجم بالا، به ویژه کاوش در افزایش کارایی و اثربخشی برش موازی، پرس و جو و تجزیه و تحلیل جغرافیایی، یکی از تاکیدات تحقیقاتی بعدی ما خواهد بود. علاوه بر این، ما امیدواریم که با سایر محققان برای کشف ساختارهای شاخص برای داده های فضایی با ابعاد بالا در چارچوب NoSQL، یک الگوریتم پرس و جو داده پیچیده برای داده های مکانی-زمانی عظیم با استفاده از مدل برنامه نویسی MapReduce، همکاری کنیم.














بدون نظر