1. معرفی
دادههای جمعسپاری، به عنوان مثال ، اطلاعات جغرافیایی داوطلبانه (VGI) [ 1 ، 2 ، 3 ]، ابزار امیدوارکنندهای برای جمعآوری دادههای مرزی [ 4 ] است. در حال حاضر، VGI به عنوان منبع جایگزین اطلاعات جغرافیایی حرفه ای عمل کرده است. از آنجایی که VGI اطلاعات گسترده و به موقع ارائه می دهد و رایگان است، در بسیاری از حوزه ها، به عنوان مثال، حمل و نقل، امداد رسانی اضطراری، مدیریت بلایا، ناوبری، و غیره استفاده شده است [ 5 ، 6 ، 7 ، 8 ، 9 ، 10 ].
در حالی که دادههای مکانی-زمانی سنتی بر اساس مشخصات استاندارد توسط متخصصان جمعآوری و به روز میشوند و کیفیت دادهها از طریق رویههای کنترل کیفیت دقیق و مشخصات پیادهسازی تضمین میشود، یک حالت یک موجودیت تنها یک نسخه در یک پایگاه داده جغرافیایی سنتی دارد و کیفیت همه آنها اشیاء به طور معمول یکنواخت هستند. VGI به طور خود به خود توسط شهروندانی که اکثر آنها حرفه ای نیستند جمع آوری می شود [ 1 ، 11]]. بلکه ممکن است یک حالت یک موجودیت چندین بار توسط چندین داوطلب ویرایش شود و چندین نسخه در پایگاه داده VGI داشته باشد و کیفیت هر نسخه ممکن است متفاوت باشد. بنابراین، مشکلات جدیدی در محیط های VGI ایجاد می شود. چون چندین نسخه از یک موجودیت وجود دارد، کدام نسخه بهترین است؟ چگونه می توان بهترین اشیاء چند نسخه را انتخاب کرد؟
چندین محقق با مقایسه دادههای جمعسپاری با دادههای معتبر، بر ارزیابی کیفیت کلی مجموعههای داده VGI، به عنوان مثال، کامل بودن دادهها، دقت موقعیتی و غیره تمرکز کردهاند [ 12 ]. با این حال، چنین روش هایی را نمی توان برای ارزیابی کیفیت ویژگی های منفرد در پایگاه داده VGI استفاده کرد [ 13 ]. در حل چنین مشکلاتی، برخی از محققان کیفیت VGI را بر اساس اعتماد و منشأ آن ارزیابی کرده اند [ 14 ]. برای مثال، بیشر و مانتلاس مفهوم «اعتماد اطلاعات» را معرفی کردند که با موفقیت برای ارزیابی اعتماد دادههای رشد شهری به کار گرفته شده است. اعتماد یک شی جغرافیایی با استفاده از مکانیزم رتبه بندی [ 14 ] محاسبه شد. کسلر و همکاراناز اعتماد به عنوان معیاری برای سنجش کیفیت VGI استفاده کرد و اعتماد یک شی جغرافیایی بر اساس تاریخچه ویرایش سیستم VGI آن تعیین شد [ 13 ]. نویسندگان به این نتیجه رسیدند که اطلاعات مربوط به اعتماد در یک سیستم VGI ضروری است.
در محیط های VGI، اعتماد هر نسخه ممکن است متفاوت باشد و معمولاً تحت تأثیر شهرت مشارکت کنندگان درگیر است. شهرت هر مشارکت کننده نیز ممکن است متفاوت باشد. شهرت یک مشارکت کننده تحت تأثیر درجه حرفه ای بودن صداقت، نگرش ها و غیره او قرار می گیرد . بنابراین در یک سیستم VGI، اطلاعات مربوط به اعتماد، یعنی نسخه، وضعیت، اعتماد نسخه، شهرت مشارکت کننده و غیره باید تعیین شود.
در مدلهای VGI موجود، بهعنوان مثال OpenStreetMap (OSM)، Google Map Maker، Wikimapia، در حالی که برخی از اطلاعات مشارکتکننده نشان داده میشوند، اطلاعات مربوط به اعتماد، بهعنوان مثال، اعتماد نسخه، شهرت مشارکتکننده و غیره مستقیماً نشان داده نمیشوند . بنابراین، از سیستمهای VGI موجود، نمیتوان بهترین نسخه یک موجودیت را تعیین کرد.
بر اساس مشاهدات فوق، یک مدل VGI مکانی-زمانی با در نظر گرفتن اطلاعات مربوط به اعتماد در این مقاله ارائه شده است. در این مدل، اشیاء جغرافیایی، حالت های شی و نسخه های حالت به عنوان سه سطح عنصر مختلف استفاده می شوند. هر شی ممکن است چندین حالت داشته باشد و هر حالت ممکن است یک یا چند نسخه نیز داشته باشد. رویدادهای جغرافیایی و ویرایش نیز متمایز هستند. در حالی که یک رویداد جغرافیایی ممکن است باعث تغییر در وضعیت یک یا چند شی جغرافیایی شود، یک رویداد ویرایشی علت تغییر در یک نسخه در پایگاه داده است. تمام نسخه های اشیاء VGI در مدل ما ذخیره می شوند. شهرت مشارکت کننده و اعتماد نسخه شیء VGI قابل محاسبه، ذخیره و دسترسی است. برای اطمینان از سازگاری داده های مورد استفاده در طول عملیات پویا، به عنوان مثال، ایجاد، اصلاح و حذف شی،و غیره ، مجموعه ای از عملیات مربوط به اعتماد و قوانین پیوند آنها در این مقاله ارائه شده است.
این مقاله به هفت بخش تقسیم شده است. کارهای مرتبط در بخش 2 ارائه شده است . سپس، در بخش 3 ، ویژگی های VGI را با مقایسه آن با اطلاعات جغرافیایی سنتی مورد بحث قرار می دهیم. یک مدل VGI مکانی-زمانی مبتنی بر اطلاعات مربوط به اعتماد در بخش 4 پیشنهاد شده است . عملیات مربوط به اعتماد و پیوندهای آنها در بخش 5 مورد بحث قرار گرفته است . روش تجربی و نتایج تجزیه و تحلیل در بخش 6 ارائه شده است . در نهایت، بخش 7 خلاصه ای را ارائه می دهد و بحث را به پایان می رساند.
2. کارهای مرتبط
VGI یک موضوع بحث برانگیز در تحقیقات GIS در دهه گذشته بوده است [ 10 ]. چندین محقق کاربردهای VGI [ 7 ، 15 ، 16 ]، کیفیت و قابلیت اطمینان داده ها [ 11 ، 12 ، 13 ، 17 ، 18 ، 19 ]، روش های پردازش و تمیز کردن داده ها [ 20 ، 21 ]، سازماندهی داده ها و سیستم های مدیریت [ 22 ] را بررسی کرده اند. ] و غیرهبا این حال، کارهای مرتبط مطالعه ما عمدتاً شامل مدلهای دادههای مکانی-زمانی، رویکردهای ارزیابی کیفیت شی VGI و روشهای سازماندهی دادههای VGI است. ما در این بخش درباره کارهای مرتبط با این سه موضوع بحث می کنیم.
2.1. مدل داده های مکانی-زمانی
در طول چند دهه گذشته، ده ها مدل داده مکانی-زمانی ایجاد شده است. مدل های موجود را می توان بر اساس حوزه های تمرکزشان به چهار دسته تقسیم کرد. اولین دسته از مدلها بر ثبت حالات اشیاء جغرافیایی تمرکز دارند و شامل مدل عکس فوری [ 23 ]، حالت پایه با مدل اصلاحی [ 23 ]، مدل دادههای ترکیبی فضا-زمان [ 24 ] و مدل مکعب فضا-زمان [ 24 ] است. . دسته دوم مدلها بر فرآیندهای تغییر شی و روابط علّی بین رویدادها تمرکز میکنند و شامل مدلهای دادهای رویداد-حالت-زمانی [ 25 ، 26 ]، مدلهای نسخهسازی مبتنی بر رویداد [ 27 ]، و مدلهای علت و معلولی مبتنی بر رویداد [27] است.28 ]. دسته سوم مدل ها بر توصیف اشیاء و روابط مکانی-زمانی تمرکز دارد و شامل مدل های داده های مکانی-زمانی شی گرا [ 29 ، 30 ]، مدل سه دامنه ای [ 31 ]، مدل نمودار تاریخچه [ 32 ]، و مدل رابطه موجودیت مکانی-زمانی [ 33 ]. دسته چهارم مدلها بر مدلسازی اجسام متحرک تمرکز دارند و شامل مدلهای دادههای اجسام متحرک میشوند [ 34 , 35]. هر یک از مدلهای دادههای مکانی-زمانی فوقالذکر ویژگیهای منحصر به فردی را ارائه میکنند. با این حال، این مدل ها در درجه اول بر روی اطلاعات جغرافیایی حرفه ای سنتی تمرکز می کنند و شهرت مشارکت کننده و اعتماد هر شی جغرافیایی را در نظر نمی گیرند. بنابراین، این مدلها نمیتوانند به این سؤال پاسخ دهند: «کدام نسخه برای حالت شی با چند نسخه بهترین است؟»
2.2. ارزیابی کیفیت VGI
تلاش های زیادی برای بررسی کیفیت VGI صورت گرفته است. روش های ارزیابی کیفیت VGI را می توان به طور کلی به سه دسته تقسیم کرد. برای دسته اول، کیفیت VGI با مقایسه VGI با داده های حرفه ای مربوطه ارزیابی می شود. برای مثال، دادههای OpenStreetMap (OSM) توسط محققان مختلف از طریق مقایسه با دادههای حرفهای مربوطه، به عنوان مثال، انگلستان [ 11 ]، آلمان [ 36 ، 37 ، 38 ]، فرانسه [ 39 ]، ایران [ 12 ] و غیره ارزیابی شدهاند .برای دسته دوم، کیفیت VGI بر اساس تاریخچه آن ارزیابی می شود و نه از طریق مقایسه با داده های مرجع. برای مثال، تمام دادههای OSM و نسخههای تاریخی آنها در یک تاریخچه کامل OSM ذخیره میشوند [ 40 ]. بارون و همکاران یک چارچوب جامع برای ارزیابی کیفیت ذاتی داده های OSM [ 41 ] پیشنهاد کرد. بگین و همکاران همچنین ابزاری برای ارزیابی کامل بودن VGI بر اساس رفتارهای مشارکت کننده پیشنهاد کرد [ 42 ]. برای دسته سوم، اعتماد به عنوان پروکسی کیفیت VGI استفاده می شود. به عنوان مثال، بیشر و همکاران. یک مدل اعتماد رسمی و شهرت برای فیلتر کردن و استخراج اطلاعات با کیفیت بالا در مورد رفتارهای رشد شهری از سوی بازیگران (افراد) پیشنهاد کرد.14 ]; کسلر و همکاران از اعتماد به عنوان معیاری برای سنجش کیفیت VGI استفاده کرد و قابلیت اعتماد VGI را بر اساس پنج شاخص، یعنی مشارکتکنندگان، نسخهها، تأییدیهها، اصلاحات و بازبینیهای VGI اندازهگیری کرد [ 13 ]. D’Antonio و همکاران. یک مدل اعتبار داده و شهرت کاربر ارائه کرد که به موجب آن اعتماد VGI بر اساس اثرات مستقیم، غیرمستقیم و زمانی ارزیابی شد و به موجب آن شهرت کاربر را میتوان بر اساس ارزش اعتماد اشیاء ایجاد شده توسط کاربر محاسبه کرد [43 ] . با این حال، روش های موجود ارزیابی کیفیت VGI نمی تواند هر نسخه از تمام اشیاء VGI را پوشش دهد.
2.3. سازمان داده VGI
از آنجایی که VGI برنامه محور است، تنها تعداد کمی از محققین روش های سازماندهی VGI را مطالعه کرده اند، به عنوان مثال، Qian و همکاران. Zoom Quadtree را برای پشتیبانی از نمایش چندگانه داده های VGI طراحی کرد [ 44 ]. تعداد کمی از محققان خواص ویژه VGI را توصیف کرده اند. از سوی دیگر، سیستم های VGI روش های سازمانی را برای مدیریت داده های جمع سپاری توسعه داده اند.
OpenStreetMap (OSM) یکی از محبوب ترین و موفق ترین پروژه های VGI بوده است. از PostgreSQL برای ذخیره داده های برداری و ویژگی استفاده می کند. سه داده اولیه برای نمایش اطلاعات جغرافیایی استفاده می شود، به عنوان مثال، گره ها، راه ها و روابط. فقط گره ها طول و عرض جغرافیایی را ذخیره می کنند. OSM به طور جداگانه داده های فعلی و تاریخی را ذخیره می کند. در OSM خدمات مرور نقشه و به روز رسانی داده ها نیز مجزا هستند. با این حال، OSM قابلیت اعتماد کاربر و شی را پردازش نمی کند. داده های اولیه در Google Map Maker شامل علامت مکان، خطوط و چند ضلعی است. Map Maker اطلاعات توپولوژیکی را ذخیره نمیکند و ویژگیهای اضافه شده توسط کاربران باید قبل از استفاده در برنامههای Google Map تأیید شوند. هنگامی که یک کاربر مشارکت های موفق متعددی را انجام می دهد، ویرایش های وی با دقت کمتری نظارت می شود و ممکن است بلافاصله روی نقشه منتشر شود [ 45]]. Wikimapia یک نقشه وب تعاملی را با یک سیستم ویکی ارجاع شده جغرافیایی ترکیب می کند. کاربر می تواند موارد جدید اضافه کند یا می تواند موارد را در یک لایه Wikimapia ویرایش کند. هنگامی که یک شی ایجاد میشود، از مشارکتکننده دعوت میشود تا دسته آن را مشخص کند، توضیحات متنی اضافه کند و عکسهای مربوطه را آپلود کند. Wikimapia تاریخچه ویرایش همه کاربران را ذخیره می کند و به آنها امتیاز می دهد. کاربران سطح بالا به ابزارهای ویرایش دسترسی بیشتری یافته اند و با محدودیت های کمتری در فعالیت های ویرایش مواجه هستند [ 46 ]. هم Google Map Maker و هم Wikimapia از مفهوم شهرت کاربر به جای مفهوم اعتماد به شی استفاده می کنند. با این حال، این سیستم ها اطلاعات مربوط به اعتماد را مدیریت نمی کنند.
از تحلیلهای فوق، نتیجه میگیریم که در حالی که چندین محقق گزارش کردهاند که اطلاعات مربوط به اعتماد برای کنترل کیفیت VGI ضروری است، در مدلهای سنتی دادههای مکانی-زمانی حرفهای و سیستمهای VGI موجود، شهرت کاربر و قابلیت اعتماد شی مورد نظارت قرار نمیگیرد. بنابراین، روشهای موجود نمیتوانند به سؤال ارائهشده در بخش 1 پاسخ دهند ، یعنی «کدام نسخه برای یک حالت خاص بهترین است؟» بر اساس این مشاهدات، ما یک مدل VGI فضایی-زمانی پیشنهاد میکنیم که اطلاعات مربوط به اعتماد را در نظر میگیرد.
3. ویژگی های سازمان داده VGI
از آنجایی که داوطلبان متعددی در سیستمهای VGI مشارکت میکنند، میتوان مقدار زیادی از دادههای جغرافیایی را در مدت زمان کوتاهی جمعآوری کرد [ 1 ]. داده های مکانی-زمانی VGI مزایای اصلی زیر را ارائه می دهند، به عنوان مثال ، زمان واقعی، انتقال سریع، اطلاعات غنی و هزینه کم [ 11 ، 47 ]. با این حال، اکثر شهروندان حرفه ای نیستند و به طور تصادفی در سراسر جهان توزیع می شوند [ 39 ]، که باعث می شود VGI منجر به مسائل کیفی زیر شود، به عنوان مثال، کیفیت ناهمگن، افزونگی، و ناقص بودن [ 41 ، 47]]. برای حل چنین مسائل کیفی، جنبههای سازماندهی دادههای VGI از طریق مقایسه با دادههای مکانی-زمانی سنتی در این بخش تحلیل میشوند.
3.1. وضعیت ها، نسخه ها و رویدادهای VGI
یک حالت “با عدم وجود تغییر مشخص می شود” [ 48 ]. از منظر فضایی، حالت به وضعیت (شامل موقعیت، هندسه، ویژگیها و غیره ) یک موجود جغرافیایی در دنیای واقعی در یک زمان معین اطلاق میشود [ 30 ]، و به تغییراتی مربوط میشود که میتواند در طول عمر رخ دهد. یک موجودیت [ 49 ]. در طول عمر یک موجودیت، چنین تغییراتی می تواند در نتیجه علل طبیعی یا مصنوعی ایجاد شود. برای مثال، در زمان t 1 ، شیء حالت A s 1 است . A در دنیای واقعی (مثلاً موقعیت یا شکل آن) در زمان t 2 تغییر کرد . سپس حالت A تغییر کرد و حالت آن به حالت s 2 تطبیق داده شد. طبق فرهنگ لغت کمبریج، نسخه «شکل خاصی از چیزی است که با سایر اشکال همان چیز متفاوت است» [ 50 ]. در حوزه علم اطلاعات، یک نسخه برای ذخیره حالات مختلف یک موجودیت معین در یک پایگاه داده استفاده می شود [ 51 ]. به عبارت دیگر، یک نسخه بازتاب پایگاه داده وضعیت یک موجودیت است. مکانیسمهای نسخهسازی پایگاه داده (به عنوان مثال، نسخهسازی در سطح رابطه و چند سطحی) برای ردیابی تحول وضعیت یک شی در طول زمان استفاده میشوند [52] و معمولاً برای مدیریت تکامل دادههای ارجاعشده جغرافیایی در GIS [ 24] استفاده میشوند.]. حالت ها و نسخه های VGI همان معانی را دارند که در سناریوهای سنتی انجام می دهند. با این حال، روابط آنها در VGI تا حدودی با موارد سنتی متفاوت است. در یک سیستم مکانی-زمانی سنتی، زمانی که وضعیت یک شی درگیر تغییر می کند، برای تضمین ارز داده های مکانی در پایگاه داده، وضعیت فعلی شی باید به عنوان نسخه فعلی به روز شود و نسخه قبلی تبدیل به تاریخچه می شود. نسخه [ 53 ]. بنابراین، به روز رسانی شی تنها زمانی رخ می دهد که وضعیت یک شی تغییر کرده باشد. در این مورد، یک نسخه از پایگاه داده تنها با یک وضعیت شی در دنیای واقعی مطابقت دارد، یعنی یک رابطه 1:1 بین حالت ها و نسخه ها وجود دارد.
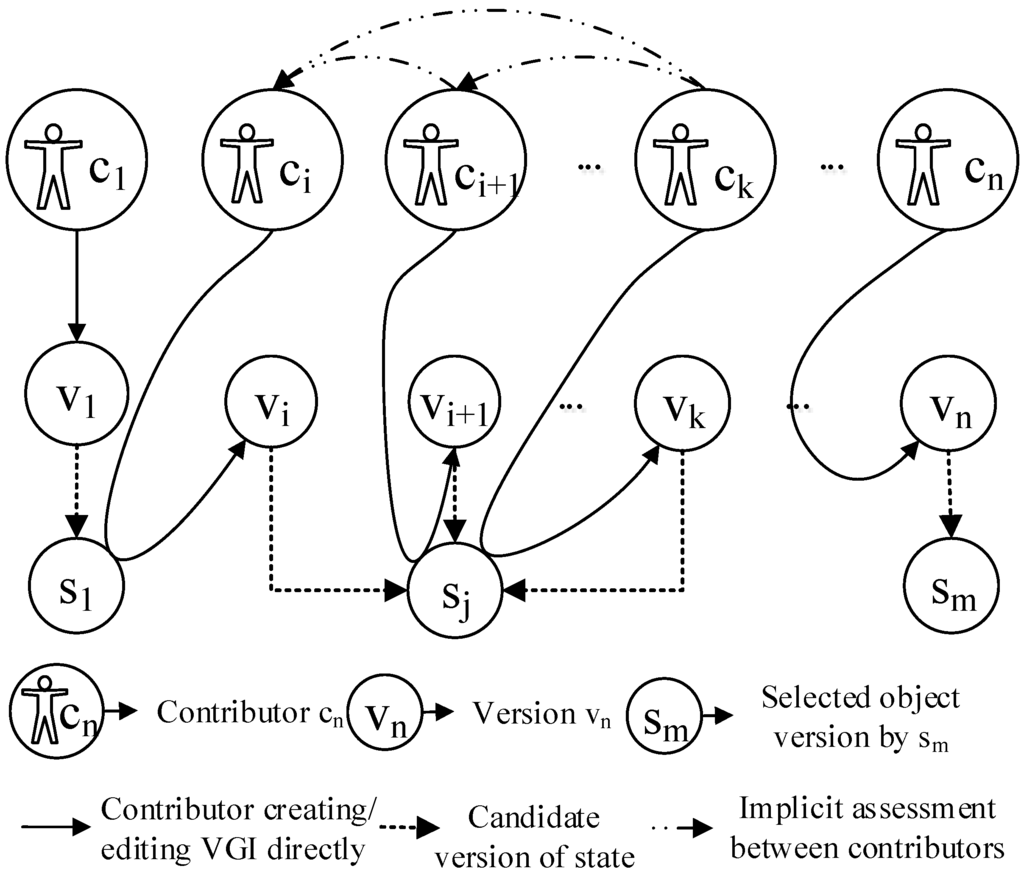
همانطور که در بخش اول این مقاله اشاره شد، در یک زمینه VGI، یک وضعیت یک موجودیت ممکن است چندین بار توسط چندین داوطلب ویرایش شود تا کیفیت داده ها را بهبود بخشد یا دیدگاه های شناختی مختلف را پشتیبانی کند. شکل 1 توضیح می دهد که چگونه چندین کاربر می توانند در ویرایش شی A شرکت کنند. شی A حاوی m (m ≥ 1) حالت است و هر حالت ممکن است چندین نسخه داشته باشد. برای مثال، حالت s j چندین نسخه دارد، یعنی v i ، v i+1 ، ⋯، v k . مشارکت کننده c 1 اولین نسخه v 1 از حالت s 1 را ارائه می کند . مشارکت کننده c i اولین نسخه v را مشارکت می دهدمن از حالت s j ; کاربر c i+1 نسخه v i+ 1 را با ویرایش نسخه v i تولید می کند . کاربر c k نسخه انتخابی حالت s j را ویرایش می کند و نسخه v k را تولید می کند . و Contributor c n نسخه انتخابی حالت s m را ویرایش می کند و نسخه v m را تولید می کند . از تجزیه و تحلیل ارائه شده در شکل 1، نتیجه می گیریم که دو دلیل اصلی برای به روز رسانی اشیاء در VGI وجود دارد: در حالت اول، تغییر در وضعیت یک شی از یک رویداد جغرافیایی واقعی (به عنوان مثال، زلزله، سیل یا طرح توسعه) ناشی می شود. این نوع رویداد منجر به انتقال بین حالتها [ 48 ] میشود و همیشه منجر به تولید نسخه جدیدی از یک حالت جدید از وضعیت موجود قبلی میشود [ 49]]؛ دلیل دوم برای به روز رسانی شی، بهبود کیفیت VGI (نه ناشی از یک رویداد جغرافیایی) است، و در چنین مواردی، وضعیت یک موجود جغرافیایی مربوطه در دنیای واقعی تغییر نمی کند. این نوع رویداد را می توان به عنوان رویداد غیرجغرافیایی نیز مشاهده کرد. در مدل ما، هر فرآیند به روز رسانی شی به یک پایگاه داده GIS، شامل دو دلیل توضیح داده شده در بالا، به یک رویداد تعلق دارد. برای پشتیبانی از مقایسه با رویدادهای جغرافیایی، از این رویداد به عنوان یک رویداد ویرایشی یاد می کنیم. یک رویداد ویرایش زمانی رخ می دهد که پایگاه داده به روز می شود. رویدادهای جغرافیایی و رویدادهای غیرجغرافیایی باعث ایجاد رویدادهای ویرایش می شوند. به عنوان مثال، هنگامی که وضعیت جسم A در اثر زلزله تغییر می کند، یک رویداد جغرافیایی به نام زلزله مستند می شود. سپس، یک نسخه جدید از A در یک پایگاه داده GIS به روز می شود و یک رویداد ویرایش ایجاد می کند. اگر حالت جسم B تغییر نکند، یک کاربر آن را تغییر می دهد و یک نسخه جدید تولید می کند. در این مورد، هیچ رویداد جغرافیایی مستند نیست، اما یک رویداد ویرایش است. که درشکل 1 ، تغییر از حالت s 1 به حالت s j در حالت اول رخ می دهد، یعنی به روز رسانی ناشی از یک رویداد جغرافیایی. وضعیت واقعی نسخههای v i ، v i+1 ، ⋯،v k با sj مطابقت دارد و یک بهروزرسانی توسط مشارکتکنندگان از طریق عملیات ویرایش برای بهبود کیفیت داده یا ارائه دیدگاه دیگری انجام میشود. در این حالت، state یک رابطه 1:m با نسخه ارائه می دهد. بنابراین، لازم است هر دو اطلاعات وضعیت و نسخه در پایگاه داده در این زمینه VGI ذخیره شوند.
شکل 1. روابط بین مشارکت کنندگان، نسخه های شی و درجات اعتماد با استفاده از یک فرآیند تکاملی ساده یک شی جغرافیایی به عنوان مثال.
بنابراین، در یک سیستم VGI، مفاهیم حالتها، نسخهها و رویدادها مانند سیستمهای سنتی است. با این حال، روابط آنها تغییر می کند، به عنوان مثال ، بر خلاف یک نسخه مربوط به یک حالت در موارد سنتی، حالت های یک موجودیت در یک سیستم VGI ممکن است چندین نسخه داشته باشد. در حالی که در سیستمهای سنتی، بهروزرسانیها فقط به دلیل رویدادهای جغرافیایی انجام میشوند، در سیستمهای VGI، بهروزرسانیها میتوانند به دلیل رویدادهای جغرافیایی یا غیرجغرافیایی انجام شوند. بنابراین، شناسایی روابط ویژه بین حالت ها، نسخه ها و رویدادها در سیستم های VGI ضروری است.
3.2. اعتماد و اعتبار VGI
چندین مطالعه در مورد اعتماد و شهرت VGI بحث کرده اند. مونی و همکاران تاریخچه ویرایش اشیاء OpenStreetMap را بررسی کرد و به این نتیجه رسید که نسخه نهایی یک شی VGI همیشه بهترین نسخه نیست [ 54 ]. به عنوان مثال، حالت s j در شکل 1 دارای n نسخه است. آخرین نسخه v n ممکن است بهترین نسخه حالت نباشد. بنابراین، انتخاب اشیاء VGI هنوز یک موضوع بحث برانگیز است. با این حال، معیارهای کیفیت سنتی (به عنوان مثال، اصل و نسب، دقت، سازگاری و کامل بودن) بر اساس نظریه احتمال است. نمی توان کیفیت هر نسخه شی را با این معیار ارزیابی کرد زیرا برای محیط های VGI امکان پذیر نیست [ 11 , 14]. بسیاری از محققان بر این باورند که درجه اعتماد یک شی می تواند به عنوان معیاری برای سنجش کیفیت VGI استفاده شود [ 13 ، 14 ]. اعتماد را می توان به عنوان “شرط بندی در مورد اقدامات احتمالی آینده دیگران” [ 55 ] تعریف کرد. همچنین میتوان آن را بهعنوان اعتماد به شخص یا چیزی در نظر گرفت که فرد با آن در تعامل است [ 56 ]. بشر و همکاران این اصل را با موفقیت در سناریوهای VGI اعمال کرده اند [ 14 ]. بنابراین، اگر بتوانیم درجات اعتماد را برای هر نسخه از هر وضعیت شی تعیین کنیم، نسخه با بالاترین درجه اعتماد را می توان بهترین نسخه (یا انتخاب شده) از وضعیت شی مربوطه در نظر گرفت. بشر و همکارانپیشنهاد کرد که اعتماد بین یک مصرف کننده و یک موجودیت اطلاعاتی VGI “با واسطه اعتماد بین فردی بین مبتکر VGI و مصرف کننده VGI انجام می شود” [ 57 ]، و شهرت مشارکت کننده عامل اصلی است که بر قابل اعتماد بودن یک شی VGI تأثیر می گذارد. کسلر و همکاران قابلیت اطمینان VGI را با ردیابی فرآیندهای ویرایش VGI ارزیابی کرد [ 58 ]. بر اساس عوامل پیشنهادی بیشر و کسلر و همکاران. ، قابل اعتماد بودن VGI را می توان بر اساس شهرت مشارکت کنندگان و فرآیندهای ویرایش ارزیابی کرد. بنابراین، قابل اعتماد بودن VGI را می توان به صورت زیر تعریف کرد.
در یک سناریوی VGI، قابل اعتماد بودن یک نسخه شی مبتنی بر درک ذهنی از قابلیت اعتماد است که از اطلاعات مربوط به فرآیند ویرایش تاریخی اشیاء مربوطه استنتاج می شود. بنابراین، عواملی که بر قابل اعتماد بودن نسخه شی تأثیر میگذارند، عمدتاً شامل فرآیند ویرایش و شهرت همه مشارکتکنندگان درگیر در فرآیند ویرایش است.
بسیاری از محققان بر این باورند که شهرت مشارکت کنندگان نقش مهمی در ارزیابی قابلیت اعتماد یک شی ایفا می کند [ 13 ، 14 ] و روش های مختلف ارزیابی را مورد بحث قرار داده اند. در محیطهای سرویسمحور، شهرت یک نماینده «تجمیع توصیههای همه نمایندگیهای پیشنهادی شخص ثالث» است [ 56 ]. با اشاره به محیط های VGI، Keßler و همکاران. استدلال کرد که شهرت کاربر را می توان با “چگونگی برخورد با ویژگی های ویرایش شده توسط جامعه پس از آن (به عنوان مثال، با نگاه کردن به بازبینی ها) ارزیابی کرد، که به طور بالقوه بر اساس دانش محلی مربوطه آنها وزن داده می شود [13 ] . ون اکسل و همکاراناستدلال کرد که شهرت کاربر به “دانش، تجربه و شناخت محلی” یک فرد مرتبط است [ 59 ].
مانند محیطهای سرویسمحور آنلاین، شهرت مشارکتکننده VGI معمولاً تحت تأثیر شهرت اولیه و اعتبار ارزیابی ناشی از مشارکتهای انجامشده به یک سیستم است. شهرت اولیه معمولاً به “ارزش های شهرت برای شرکت کنندگان یا تازه واردان” اشاره دارد [ 60 ]. هنگامی که کاربر در ابتدا در یک سیستم ثبت نام می کند، هیچ کمکی به سیستم نکرده است. بنابراین، شهرت او را نمی توان با آنچه که او کمک کرده است ارزیابی کرد. بنابراین، شهرت اولیه معمولاً توسط صحت و یکپارچگی اطلاعات ثبت نام، به عنوان مثال، هویت، ایمیل، نام واقعی، تحصیلات و غیره تعیین می شود.هنگامی که یک کاربر یک شی VGI را به یک سیستم کمک می کند و هنگامی که دیگران مشارکت او را ارزیابی می کنند، شهرت ارزیابی او به دست می آید. برخلاف سیستم تجارت الکترونیک، کاربران دوست دارند کالاها را با استفاده از کلمات یا از طریق رتبه بندی مستقیم ارزیابی کنند. در سیستم های VGI، کاربران معمولاً اشیاء را از طریق عملیات ویرایش بدون ارزیابی مستقیم، به حالت قابل قبول تغییر می دهند. به نظر ما، این نوع عملیات ویرایش – یعنی عملیات ویرایش به این دلیل اتفاق نمیافتد که وضعیت یک موجودیت تغییر کرده است، بلکه برای بهبود کیفیت یک شی – میتوان به عنوان ارزیابی ضمنی اشاره کرد. به عنوان مثال، در شکل 1 ، حالت s j شیء A دارای چندین نسخه است. در واقع، در طول عمر ایالت ایالت s j، وضعیت موجودیت به خودی خود تغییر نمی کند و در عوض تغییراتی در یک حالت برای بهبود کیفیت شی انجام می شود. بعلاوه، شباهتهای بین نسخهها نشاندهنده پشتیبانی از کمکهای دومی به نسخه قبلی است، بهعنوان مثال ، درجه تشابه بالا مربوط به درجه بیشتری از پشتیبانی است و بالعکس. بنابراین، در سیستم های VGI، ارزیابی های شهرت مشارکت کننده در میان کاربران را می توان به دو دسته تقسیم کرد، یعنی ارزیابی صریح و ضمنی. ارزیابی صریح به مکانیزم رتبهبندی مشابه آنچه در سیستم کسب و کار الکترونیکی استفاده میشود، اشاره دارد، به عنوان مثال ، یک کاربر یا محصول (یک شیء جغرافیایی در VGI) مستقیماً توسط دیگران رتبهبندی میشود. ارزیابی ضمنی به ارزیابی عملیات ویرایش اشاره دارد.
بنابراین، در یک سناریوی VGI، شهرت یک مشارکت کننده ترکیبی از شهرت اولیه و ارزیابی او است. برای مشارکت کنندگان جدید، شهرت اولیه از اطلاعات ثبت نام نقش کلیدی دارد. برای سایر مشارکتکنندگان، اعتبار ارزیابی نقش مهمی را ایفا میکند زیرا مشارکتهای بیشتری را انجام میدهند.
از تجزیه و تحلیل فوق، می توان نتیجه گرفت که اشیاء جغرافیایی، حالت های شی و رویدادهای جغرافیایی (دلیل تغییر وضعیت شی یا شی) بین VGI و داده های GIS حرفه ای مشترک هستند. مشارکتکنندهها، نسخههای حالت، شهرت مشارکتکننده، رویدادهای ویرایش و اعتماد نسخههای شی عناصر مرتبط با اعتماد اضافی هستند که در محیطهای VGI یافت میشوند. از آنجایی که این عناصر باید در سیستم های VGI نشان داده شوند، مدلی که این عناصر را در نظر می گیرد در بخش بعدی مورد بحث قرار می گیرد.
4. مدل فضایی-زمانی شامل اطلاعات مربوط به اعتماد
همانطور که در بخش 3 اشاره شد، عناصر سیستم های VGI شامل اشیاء جغرافیایی، وضعیت های شی، رویدادهای جغرافیایی، مشارکت کنندگان، نسخه های حالت، شهرت مشارکت کننده، رویدادهای ویرایش، قابلیت اعتماد نسخه شی و غیره است . این عناصر و روابط آنها باید نشان داده شود. از آنجایی که زبان مدل سازی یکپارچه (UML) یک استاندارد صنعتی در حوزه زبان مدل سازی تجسم بوده و به طور گسترده در برنامه نویسی شی گرا استفاده شده است، در اینجا برای توصیف مدل ما استفاده می شود. با توجه به تجزیه و تحلیل فوق، مدل مکانی-زمانی ما که ویژگیهای مرتبط با اعتماد را در بر میگیرد، عمدتاً شامل کلاس شی جغرافیایی ( GeoObject )، کلاس حالت شی ( State )، کلاس Version ،کلاس اعتماد ، کلاس Contributor ، کلاس تجربه مشارکت کننده ( UserExpRep )، کلاس اعتبار اولیه ( InitRep )، کلاس Reputation ، کلاس رویداد جغرافیایی ( GeoEvent ) و کلاس رویداد ویرایش ( EditEvent ). نمودار ساده UML برای مدل ما در شکل 2 نشان داده شده است .
شکل 2. نمودار UML (زبان مدلسازی یکپارچه) مدل فضایی-زمانی VGI که اطلاعات مربوط به اعتماد را در نظر می گیرد.
کلاس شی جغرافیایی ( GeoObject ) برای توصیف اشیاء جغرافیایی استفاده می شود و جزء اصلی مدل مکانی-زمانی است. اشیاء GO اشیاء این کلاس هستند. اشیاء GO کل طول عمر خود را در یک سیستم VGI توصیف می کنند و طول عمر آنها با بازه زمانی نمایش داده می شود ( ST ، ET ). یک شی GO باید طبقه بندی داشته باشد که به کد طبقه بندی برای توصیف لایه های مختلف نقشه (مثلاً آب، حمل و نقل، پوشش گیاهی، منطقه مسکونی و غیره ) اشاره دارد. این ویژگی برای ادغام داده های جمع سپاری و جغرافیایی حرفه ای مفید است و با C نشان داده می شود.بنابراین، فیلدهای داده کلاس GeoObject را می توان به صورت تاپل ( C, ST, ET ) توصیف کرد. یک شی GO توسط یک مشارکت کننده اضافه می شود و دارای یک یا چند حالت است. کلاس GeoObject شامل سه زیر کلاس (نقطه، خط و چند ضلعی) است و عملیات آن عمدتاً شامل addGeoObjects (افزودن اشیا)، deleteGeoObjects (حذف اشیاء)، getGeoObjects (پرس و جو از اشیاء جغرافیایی) و moveInventory است . از جمله این عملیات، deleteGeoObject استتابع عمدتا برای حذف یک شی خطا استفاده می شود. بسته به الگوهای فرکانس استفاده از دادههای مکانی، دادههای قدیمیتر معمولاً کمتر مورد استفاده قرار میگیرند و باید برای بهبود کارایی سیستم (مثلاً ذخیرهسازی و بازیابی) به یک موجودی منتقل شوند، و تابع moveInventory به حرکت دادهها از یک پایگاه داده موجود به یک پایگاه داده اشاره دارد. موجودی تاریخی
کلاس وضعیت شی ( State ) به یک عکس فوری از یک شی جغرافیایی در یک بازه زمانی معین اشاره دارد. STA شیء این کلاس است . یک شی STA کل طول عمر خود را در یک سیستم VGI توصیف می کند که با یک بازه زمانی نمایش داده می شود ( ST ، ET ). یک شی STA دارای یک یا چند نسخه است ، باید یک شماره حالت ( SN ) و یک ویژگی SV داشته باشد که نشاندهنده بهترین نسخه یا نسخه انتخابی یک وضعیت شی است و برای بازیابی سریع نسخه متناظر از یک وضعیت استفاده میشود. بنابراین، فیلدهای داده کلاس State را می توان از تاپل ها توصیف کرد (SN، SV، ST، ET ). یک شی STA توسط یک مشارکت کننده ایجاد می شود و یک یا چند نسخه دارد و عملیات آن عمدتاً شامل موارد زیر است: addStates (اضافه کردن حالت ها)، getStates (حالت های درخواست)، deleteStates (حالت های حذف) و moveInventory .
کلاس نسخه شی ( Version ) به یک عکس فوری از یک شی در زمان مشخصی اشاره دارد و توسط یک داوطلب اضافه می شود. یک VER یک شی از این کلاس است. یک شی VER شامل اعضای داده به عنوان ویژگی های فضایی ( S )، زمان شروع ( ST )، زمان پایان ( ET )، شماره نسخه ( VN ) و غیره است. فیلدهای کلاس Version را می توان با تاپل ها ( VN, S توصیف کرد ). ، ST، ET، C )، که در آن C نشان دهنده اعتبار یک VER استشی، که اعتبار، شهرت مشارکت کننده و عناصر کیفیت سنتی (دقت موقعیتی، دقت ویژگی، ثبات منطقی، کامل بودن و اصل و نسب) یک نسخه شی را به حساب می آورد. اگرچه عناصر کیفیت سنتی یک نسخه شی خارج از محدوده این مقاله است، این موضوع نیاز به بحث بیشتری دارد. یک شی VER توسط یک مشارکتکننده اضافه میشود و شامل ویژگیهای ویژگی و درجه اعتماد است، و یک یا چند شی VER متعلق به یک شیء حالت ( State )، یک رویداد جغرافیایی ( GeoEvent ) و یک رویداد ویرایش ( EditEvent ) است. به دلیل مکانیسم ارزیابی ضمنی، یک شی VER نیز با یک ارزیابی مرتبط استکلاس عملیات کلاس Version عمدتاً شامل موارد زیر است: addVersion/deleteVersion/getVersion (افزودن/حذف/پرسش اشیاء VER )، getTrust (اعتماد یک شی VER ) و moveInventory .
کلاس Trust به اطلاعات اعتماد و نسخه های شی اشاره دارد. یک TRU یک شی از این کلاس است. یک شی TRU برای محاسبه و ذخیره ارزش اعتماد یک نسخه شی استفاده می شود و بنابراین بخشی از یک شی VER را تشکیل می دهد. بنابراین یک شی TRU شامل اعضای داده زیر است: درجه اعتماد ( V )، مقدار ارزیابی ( AV )، نسبت ویرایش بین نسخه فعلی ( VID ) و نسخه قبلی ( EP )، و درجه اعتماد نسخه قبلی ( PVT) ). فیلدهای کلاس Trust را می توان از تاپل ها تعیین کرد ( PVT، EP، AV، V). عملیات کلاس Trust عمدتا شامل موارد زیر است: ComputeEditRatio (نسبت ویرایش محاسباتی)، getTrust (اعتماد یک نسخه)، getPreVerTrust (قابل اعتماد بودن نسخه قبلی یک شی)، updateTrust (به روز رسانی قابل اعتماد بودن یک نسخه)، getContributorRep (شهرت مشارکت کننده)، computeTrust (اعتماد محاسباتی)، و moveInventory .
کلاس Contributor نقش مهمی در مدل VGI فضایی-زمانی ایفا می کند زیرا برای توصیف اطلاعات حساب داوطلبانه استفاده می شود . یک USER یک شی از این کلاس است. یک شی USER برای توصیف اطلاعات ثبت نام استفاده می شود و شامل اعضای داده به عنوان نام کاربری ( نام )، رمز عبور ( PWD ) و زمان ثبت نام برای داوطلبان ( RT ) است. یک شی USER دارای شهرت است و با اشیاء Version و UserExpRep مرتبط است و فیلدهای داده آن را می توان با تاپل زیر ( Name, PWD, RT, isB, isC ) توصیف کرد.isB و isC متغیرهای بولی هستند که به ترتیب نشان می دهند که آیا یک حساب به طور موقت مسدود یا لغو شده است. عملیات کلاس Contributor عمدتاً شامل موارد زیر است: addContributor (افزودن کاربر)، cancelContributor (لغو کاربر)، blockContributor (مسدود کردن کاربر) و queryContributor (پرسش کاربر).
کلاس تجربه مشارکتکننده ( UserExpRep ) برای توصیف اعتبار ارزیابی مشارکتکننده استفاده میشود. یک UER، یک شی از این کلاس، بخشی از یک شی REP را تشکیل می دهد و شامل یک یا چند شیء Assess است . یک شی UER شامل اعضای داده زیر است: مشارکت ها ( NC )، تعداد اشیاء ویرایش شده توسط دیگران ( NE )، تعداد اشیاء حذف شده توسط دیگران ( ND )، ارزش شهرت تجربه کاربر ( V ) و زمان به روز رسانی ( T ). بنابراین، فیلدهای کلاس UserExpRep را می توان از یک تاپل توصیف کرد ( NC، NE، ND، T، V). عملیات کلاس UserExpRep عمدتا شامل موارد زیر است: computeUEP (محاسبه اعتبار ارزیابی کاربر)، getUEP (بازیابی اعتبار ارزیابی کاربر) و updateUEP (به روز رسانی اعتبار ارزیابی کاربر).
کلاس ارزیابی کاربر ( Assess ) برای توصیف اطلاعات ارزیابی مشارکت کننده استفاده می شود. بخشی از کلاس UserExpRep را تشکیل می دهد . یک AS یک شی از این کلاس است. یک شی AS اعضای داده را به عنوان اشیاء جغرافیایی ( GO )، انواع اشیاء جغرافیایی ( GT )، انواع ارزیابی ( AT )، زمانهای ارزیابی ( T ) و مقادیر ( V ) توصیف میکند. بنابراین، فیلدهای کلاس Assess را می توان از یک تاپل توصیف کرد ( GO، GT، AT، T، V )، که در آن AT شامل دو ویژگی است: ارزیابی صریح و ضمنی. عملیات ارزیابیکلاس عمدتاً شامل موارد زیر است: addAssess (افزودن ارزیابی)، getAssess (بازیابی ارزیابی)، deleteAssess (حذف ارزیابی)، و moveInventory . عملیات deleteAssess برای از بین بردن اثرات ارزیابی بیهوده استفاده می شود.
کلاس شهرت اولیه ( InitRep ) به اطلاعات اولیه مربوط به شهرت در مورد داوطلبان و متعلق به Reputation اشاره دارد . یک IR یک شی از این کلاس است. یک شی IR شامل اعضای داده مانند موارد زیر است: تلفن همراه ( تلفن )، ایمیل ( ایمیل )، نام واقعی ( TNAME )، شناسه هویت ( IID )، وضعیت آموزش ( TRA )، ارزش شهرت اولیه ( V )، و زمان به روز رسانی ( T ). بنابراین، فیلدهای کلاس InitRep را می توان از یک تاپل توصیف کرد ( ایمیل، تلفن، TName، IID، TRA، RegInfo، Validate، V، T )، که در آن RegInfo اطلاعات دیگر کاربر را نشان میدهد، مانند رشته یا تحصیلات یک مشارکتکننده (برای سادهتر کردن تاپل، بسیاری از ورودیهای اطلاعات کاربر با این فیلد نشان داده میشوند). Validate به معنای اعتبارسنجی اطلاعات هویت، ایمیل و مخاطبین تلفن همراه و غیره است. عملیات کلاس InitRep عمدتاً شامل موارد زیر است: addInitRep/updateInitRep/getInitRep (افزودن/بهروزرسانی/پرسش اعتبار اولیه)، validateUserInfo (تأیید اعتبار اطلاعات داوطلب) ، ComputeInitRep (محاسبه و به روز رسانی شهرت اولیه یک مشارکت کننده).
کلاس Reputation برای توصیف اطلاعات مربوط به شهرت یک مشارکت کننده استفاده می شود. یک REP یک شی از این کلاس است. اشیاء REP بخشی از کلاس Contributor را تشکیل می دهند و شامل اشیاء IR و UER می شوند. آنها شامل اعضای داده مرتبط با شهرت هستند، مانند شهرت ( R )، زمان شروع ( ST ) و زمان پایان ( ET ). بنابراین، فیلدهای کلاس Reputation را می توان از یک تاپل ( R, ST, ET ) توصیف کرد. عملیات کلاس Reputation عمدتاً شامل موارد زیر است: addReputation(افزودن شهرت)، updateReputation (به روز رسانی شهرت)، و getReputation (پرسش اعتبار).
کلاس رویداد جغرافیایی ( GeoEvent ) به رویدادهایی اشاره دارد که در دنیای واقعی رخ می دهند. یک رویداد جغرافیایی باعث ایجاد چندین رویداد ویرایشی می شود. یک شی GE باید یک شی VER داشته باشد و توسط یک مشارکت کننده گزارش شود. این شامل اعضای داده مانند موارد زیر است: نام رویدادهای جغرافیایی ( نام )، انواع رویداد ( نوع )، توضیحات رویداد ( جزئیات )، و زمان رویداد ( T ). بنابراین، فیلدهای کلاس GeoEvent را می توان از یک تاپل توصیف کرد ( Name, Type, Detail, T ). عملیات کلاس GeoEvent عمدتا شامل موارد زیر است: addEvent/modifyEvent/getEvent(افزودن/تغییر/پرسش یک رویداد) و moveInventory .
کلاس رویداد ویرایش ( EditEvent ) برای توصیف اطلاعات مربوط به رویداد ویرایش استفاده می شود. چنین اتفاقاتی در دنیای اطلاعات رخ می دهد و نه در دنیای واقعی. یک EE یک شی از این کلاس است. یک شی EE باید یک شی VER داشته باشد و توسط یک مشارکت کننده آغاز می شود. چنین اشیایی به اشیاء GE نیز مرتبط هستند و شامل اعضای داده مانند موارد زیر می شوند: نوع رویداد ( نوع ) و زمان رویداد ( T ). بنابراین، فیلدهای کلاس EditEvent را می توان از یک تاپل ( Type, T ) توصیف کرد. عملیات کلاس EditEvent عمدتاً شامل موارد زیر است:addEvent/modifyEvent/getEvent (افزودن/تغییر/پرسش یک رویداد) و moveInventory .
5. عملیات مرتبط با اعتماد و روابط پیوندی آنها
قابل اعتماد بودن یک شی VGI و شهرت مشارکت کننده در تعامل هستند. از یک طرف، شهرت یک مشارکت کننده به طور قابل توجهی بر درجه اعتماد یک شی که او کمک می کند تأثیر می گذارد. از سوی دیگر، فرآیند اصلاح یک شی بر شهرت مشارکت کننده تأثیر می گذارد. برای ثابت نگه داشتن تمام داده های مربوط به اعتماد، در این بخش، عملیات مربوط به اعتماد و روابط بین این عملیات ها را مورد بحث قرار می دهیم و مجموعه ای از قوانین عملیات پیوند ارائه شده است.
5.1. عملیات مرتبط با اعتماد
همانطور که در بخش 4 اشاره شد ، دو عملیات اصلی مرتبط با اعتماد در مدل ما گنجانده شده است: عملیات شهرت مربوط به کاربر و عملیات اعتماد مرتبط با شی. عملیات شهرت مرتبط با کاربر عمدتاً شامل موارد زیر است: افزودن/بهروزرسانی/بهدست آوردن عملیات اعتبار اولیه ( adInitRep / updateInitRep / getInitRep ) و اعتبارسنجی عملیات اطلاعات مشارکتکننده ( validateUserInfo ) کلاس InitRep . محاسبه/بهروزرسانی/بهروزرسانی عملیات شهرت تجربه کاربر ( computueUEP / getUEP / updateUEP ) از کلاس UserExpRep; و افزودن/به روز رسانی/به دست آوردن عملیات شهرت ( addReputation / updateReputation / getReputation ) از کلاس Reputation . عملیات اعتماد مرتبط با شی عمدتاً عبارتند از: محاسبات/به روز رسانی/به دست آوردن عملیات درجه اعتماد ( computeTrust / updateTrust / getTrust ) از کلاس Trust . تعاریف و توضیحات این عملیات در جدول 1 نشان داده شده است .
جدول 1. عملیات مربوط به اعتماد.
5.2. قوانین پیوند عملیات مربوط به اعتماد
در مدل فضایی-زمانی VGI که اطلاعات مربوط به اعتماد را در نظر می گیرد، روابط بین قابلیت اعتماد شی، شهرت کاربر و فرآیندهای ویرایش پیچیده است. برای حفظ ثبات داده های مربوط به اعتماد، لازم است قوانین پیوند مربوطه طراحی شود. فرض بر این است که شی جغرافیایی A دارای n نسخه است (n یک عدد صحیح و بزرگتر از 0 است) که بر اساس زمان های تولید شده آنها به عنوان v 1 , v 2 , v 3 , ⋯, v n نامیده می شود. نسخه v i (1 < i ≤ n) c i است . عملیات پیوند شهرت یک مشارکت کننده و قابل اعتماد بودن یک نسخه به شرح زیر تحلیل می شود.
5.2.1. عملیات پیوند اعتبارات مشارکت کننده
تغییر در شهرت مشارکت کننده عمدتاً ناشی از چهار فرآیند زیر است:
- (1)
-
هنگامی که یک کاربر به یک سیستم VGI اضافه می شود و اطلاعات ثبت نام خود را تأیید می کند، یک شی IR و یک شی REP باید اضافه شود.
- (2)
-
هنگامی که اطلاعات ثبت نام کاربر تغییر می کند، شهرت اولیه و شهرت کاربر باید به روز شود.
- (3)
-
هنگامی که یک کاربر توسط کاربر دیگری ارزیابی می شود، شهرت ارزیابی و شهرت کاربر نیز باید به روز شود.
- (4)
-
اگر برخی از ارزیابیهای کاربر لغو شد، شهرت ارزیابی و شهرت کاربر باید بهروزرسانی شود.
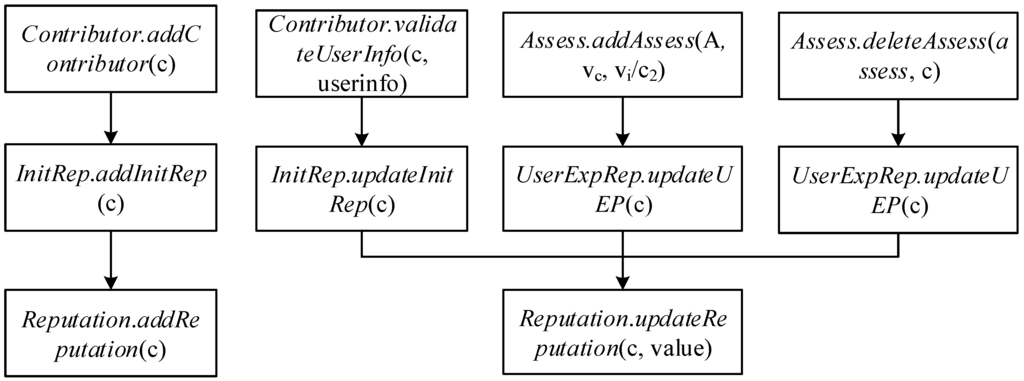
این چهار مورد به طور رسمی توسط چهار قانون پیوند (قوانین 1 تا 4)، که در شکل 3 نشان داده شده است، توصیف می شوند .
قانون 1 : مشارکت کننده IF . addContributor ( c ) سپس InitRep . addInitRep ( c ) AND Reputation . addReputation ( c ). هنگامی که مشارکت کننده c وارد سیستم VGI می شود، یک شی REP و یک شی IR باید برای کاربر c اضافه شود . این قانون در قسمت سمت چپ شکل 3 نشان داده شده است .
قانون 2 : IF Contributor.validateUserInfo ( c ، اطلاعات کاربری) سپس InitRep . updateInitRep ( c ) AND Reputation . updateReputation (c، مقدار). اگر اطلاعات ثبت نام مشارکت کننده c اضافه یا تأیید شود، شهرت کاربر باید به روز شود. این قانون در قسمت سمت راست شکل 3 نشان داده شده است .
قانون 3 : اگر ارزیابی کنید . addAssess (A، v c ، v i /c 2 ) سپس UserExpRep . updateUEP ( c ) AND Reputation . updateReputation ( c ، مقدار). نسخه v c نسخه ای از شی A است که توسط کاربر c اضافه شده است . هنگامی که کاربر c یک ارزیابی ضمنی (توسط v i ) یا صریح (توسط مشارکت کننده c 2 ) از دیگران دریافت می کند، شهرت ارزیابی و شهرت کاربر باید به روز شود. این قانون در قسمت سمت راست نشان داده شده استشکل 3 .
قانون 4 : اگر ارزیابی کنید . deleteAssess ( ارزیابی , ج ) سپس UserExpRep . updateUEP ( c ) AND Reputation . updateReputation ( c ، مقدار). هنگامی که ارزیابی ( ارزیابی ) کاربر c لغو شد، شهرت ارزیابی و شهرت کاربر باید به روز شود. این قانون در قسمت سمت راست شکل 3 نشان داده شده است .
شکل 3. عملیات پیوند شهرت یک مشارکت کننده.
5.2.2. عملیات پیوند افزودن یک نسخه شی
هنگامی که نسخه v i شی A توسط کاربر اضافه می شود، اشیاء رویداد مربوطه (یک رویداد جغرافیایی یا رویداد ویرایش یا هر دو) باید ابتدا اضافه شوند. اگر نسخه v i اولین نسخه شی A است، اشیاء GO و STA مربوطه باید اضافه شوند و درجه اعتماد v i باید به روز شود. هنگامی که یک شماره نسخه بزرگتر از 1 است و زمانی که رویداد یک رویداد غیرجغرافیایی است، یک شی UER باید اضافه شود و شهرت کاربر و قابل اعتماد بودن نسخه شی باید به روز شود. در غیر این صورت، STA و TRUاشیاء باید به روز شوند. عملیات پیوند افزودن یک نسخه در قوانین 5 تا 9 مشخص شده است که در شکل 4 نشان داده شده است .
قانون 5 : نسخه IF . addVersion (v i ) AND isGeoEvent = true THEN GeoEvent . addEvent ()، EditEvent . addEvent () ELSE GeoEvent . addEvent (). هنگامی که کاربر c i یک نسخه v i از هر شی A را اضافه می کند و اگر نوع رویداد یک رویداد جغرافیایی باشد، اشیاء GE و EE باید اضافه شوند. در غیر این صورت، یک شی GE باید اضافه شود.
قانون 6 : نسخه IF . addVersion (A, v i ) و i = 1 سپس GeoObject . addGeoObject (A), State . addState (s 1 ), Reputation . UpdateReputation (c j , value), Trust . updateTrust (v 1 , Reputation . getReputation (c i )). اگر مشارکت کننده c i یک نسخه جدید v 1 (نسخه اول) یک شی جغرافیایی A را اضافه کند، عملیات پیوند در مدل شامل افزودن یکشی GO ، اضافه کردن یک شی STA ، به روز رسانی شهرت کاربر همه مشارکت کنندگان c j که به طور ضمنی توسط v i ارزیابی می شوند ، و تنظیم درجه اعتماد نسخه.
قانون 7 : نسخه IF . addVersion (A, v i ) AND i > 1 AND isGeoEvent = true THEN State . addState ( نسخه . getVersionState (v i ) + 1)، Trust . updateTrust (v i , Reputation . GetReputation (c i )) (0 < j < i). هنگامی که یک نسخه شی اصلاح می شود و نوع رویداد درگیر یک رویداد جغرافیایی است، یک شی STA جدید باید اضافه شود.
قانون 8 : نسخه IF . addVersion (A, v i ) و i > 1 AND isGeoEvent = false سپس ارزیابی کنید . addAssess (A, v k , v i ) (k < i AND سvک=سvمنس�ک=س�من). هنگامی که یک نسخه شی اصلاح می شود و رویداد درگیر یک رویداد غیرجغرافیایی است، نسخه v i باید تمام نسخه های قبلی v k از همان وضعیت شی را ارزیابی کند.
قانون 9 : IF UserExpRep . updateUEP (c) THEN Reputation . به روز رسانی شهرت (ج) و اعتماد . updateTrust (v، مقدار). هنگامی که اعتبار ارزیابی کاربر c به روز می شود، شهرت او باید به روز شود. درجه اعتماد تمامی نسخه های نهایی اضافه شده توسط کاربر c i نیز باید به روز شود.
شکل 4. عملیات پیوند افزودن یک نسخه شی.
6. آزمایش و تجزیه و تحلیل
از مدلها و قوانینی که در بالا توضیح داده شد، ما یک سیستم نمونه اولیه را طراحی و پیادهسازی کردیم تا امکانسنجی و اثربخشی مدل خود را تأیید کنیم. سیستم نمونه اولیه با استفاده از Visual Studio 2010 و PostgreSQL 9.4 توسعه داده شد. داده های مکانی با استفاده از ArcGIS Engine 10 مدیریت شدند.
از آنجایی که جمعآوری مقادیر زیادی از دادههای جمعسپاری زمانبر است (میتواند چندین سال طول بکشد)، از مجموعه دادههای تخلیه تاریخی استخراجشده از OpenStreetMap (OSM، دادهها قابل دانلود هستند) در آزمایشهای ما استفاده شد [40 ]]. مجموعه داده شامل تاریخچه ویرایش همه اشیاء جغرافیایی است. در آزمایشات ما از داده های تاریخی برلین و پاکستان استفاده شد. در میان آنها، داده های تاریخی برای برلین از 28 ژانویه 2006 تا 15 فوریه 2013 جمع آوری شد. این داده ها شامل 4238401 نقطه، 554872 خط و 469080 چند ضلعی است که توسط 4842 داوطلب اضافه شده است. اکثر داوطلبان غیرحرفه ای هستند. داده های تاریخی برای پاکستان از 26 می 2007 تا 12 دسامبر 2014 جمع آوری شد. این داده ها شامل 2,005,806 نقطه، 195,765 خط و 34,326 چند ضلعی است که توسط 790 داوطلب اضافه شده است. از آنجایی که داده های OSM در قالب XML بودند، ابتدا داده ها را با برنامه نویسی به پایگاه داده خود وارد کردیم. در مقابل، داده های برلین پیچیده تر از پاکستان است، به ویژه در مورد داده های چند ضلعی. همانطور که سایر محققان دریافتند،47 ]. شهری در اروپا (برلین) بیش از شش برابر بیشتر از یک کشور در حال توسعه (پاکستان) داوطلب دارد. برای دادههای پاکستان، دادههای خط ظاهراً فراوانتر از دادههای چند ضلعی هستند، که نشان میدهد داوطلبان در پاکستان تمایل دارند به جای مشارکت در ویژگیهای جزئی شهر، مانند ساختمانها، ویژگیهای اصلی خط، مانند جادهها و رودخانهها را مشارکت دهند. داده های برلین نیز بیشتر از پاکستان تغییر کرده است. علاوه بر این، برلین شامل 431،724 شی، پاکستان شامل 118،313 شی (شامل چند ضلعی و چند خط)، و اشیایی که تنها یک نسخه دارند، به ترتیب 65.80٪ و 50.99٪ از داده های پاکستان و برلین را تشکیل می دهند. به طور خاص، اشیاء چند ضلعی 83.88٪ از کل داده های پاکستان را تشکیل می دهند. تنها تقریباً 16.12٪ از تمام اشیاء چند ضلعی پاکستان تا کنون اصلاح شده اند.
در آزمایشهای ما، شهرت یک کاربر تجمیع شهرت اولیه و اعتبار ارزیابی او بود. اگر شهرت کاربر c R ( c ) باشد ، از معادله زیر استفاده می شود.
که در آن R 0 ( c ) شهرت اولیه کاربر c است که با کامل بودن اطلاعات ثبت نام کاربر و اعتبار هویت وی محاسبه می شود. از آنجایی که به دست آوردن اطلاعات ثبت نام در مشارکت کنندگان OSM دشوار است، در آزمایشات ما در نظر گرفته نمی شود. e ثابت اویلر است. m نشان دهنده زمان ارزیابی است. M ثابت یک عدد طبیعی است که وزن R 0 ( c ) و R e ( c ) را تنظیم می کند. R e ( ج) شهرت ارزیابی است که از میانگین وزنی تمام یا بخشی از ارزیابی های مشارکت کننده محاسبه می شود. ارزیابی به دو دسته تقسیم می شود، یعنی ارزیابی صریح و ارزیابی ضمنی. در میان آنها، ارزیابی صریح ارزش صریح هر ارزیابی را نشان می دهد و تعیین آن آسان است. تعیین یک ارزیابی ضمنی دشوار است زیرا هیچ ارزش صریحی برای هر ارزیابی وجود ندارد. در آزمایشات ما، با استفاده از رابطه (2) محاسبه شده است.
جایی که R ( c j ) شهرت کاربر c j زمانی است که وی سهم v i کاربر c i را ارزیابی می کند . c ∈ [0,1] یک متغیر ثابت است که برای تعیین درجه ای که شهرت یک ارزیاب بر قابلیت اعتماد ارزیابی او تأثیر می گذارد استفاده می شود. VS(v i , vj ) نشان دهنده شباهت نسخه بین نسخه های v i و v j است و نشان دهنده ارزش ارزیابی شده نسخه های v j تا v i است.. سطوح بالاتر شباهت بین دو نسخه با ارزش ارزیابی بالاتر مطابقت دارد و بالعکس. سطوح شباهت نسخه را می توان از روی هندسی و شباهت های ویژگی بین نسخه های مختلف محاسبه کرد.
اگر قابل اعتماد بودن v i یک شی T ( v i ) باشد و اگر شماره نسخه i مقدار 1 را بگیرد، درجه اعتماد نسخه شیء شهرت مشارکت کننده است. در غیر این صورت، اگر i بزرگتر از 1 باشد، درجه اعتماد نسخه v i بر اساس درجه اعتماد نسخه قبلی v k ( k کمتر از i )، شهرت مشارکت کننده v i و نسبت های اصلاح بین نسخه های v i تعیین می شود. و v k. درجه اعتماد نسخه v i یک شی با استفاده از رابطه (3) محاسبه می شود.
که در آن R ( c i ) نشان دهنده شهرت کاربر c i است که نسخه v i را ایجاد کرده است . T ( v k ) نشان دهنده درجه اعتماد نسخه v k است . حداکثر ( T ( v k )، R ( c i )) حداکثر T ( v k ) و R ( c i ) است. EP ( v i ، v K) نشان دهنده درجه تغییر بین v i و vk است ، که در آن 0 ≤ EP ( v i ، v K ) ≤ 1، 1 – EP ( v i ، v K ) را می توان به عنوان یک جزء ویرایش نشده نشان داد. EP ( v i , v K ) با شباهت نسخه نسبت معکوس دارد. نسبتهای کمتر اصلاح مربوط به درجات بالاتر شباهت نسخه است و بالعکس.
دادههای برلین و پاکستان بر اساس مدل VGI فضایی-زمانی سازماندهی شدند. در دادههای تاریخی OSM، هیچ سابقهای مبنی بر اینکه چرا یک مشارکتکننده یک شی یا وضعیت تغییر شی VGI را تغییر داده، وجود ندارد. بنابراین، این که آیا وضعیت یک جسم تغییر کرده است یا خیر، معلوم نیست. در مدل ما، اگر یک نسخه و نسخه قبلی آن از یک حالت باشند، مدل یک ارزیابی ضمنی از نسخه قبلی انجام خواهد داد. در غیر این صورت، ارزیابی ضمنی نادیده گرفته خواهد شد. به طور کلی، فاصله زمانی باریکتر بین دو نسخه نشاندهنده احتمال بالاتری است که وضعیت یک شی تغییر نکرده است (اصلاحی مربوط به یک رویداد غیر جغرافیایی). در غیر این صورت، وضعیت جسم تغییر کرده است (اصلاحی مربوط به یک رویداد جغرافیایی). بنابراین، در آزمایشات ما، هنگامی که فاصله زمانی بین دو نسخه بزرگتر از یک آستانه بود، نسخه دوم به حالت جدیدی نسبت داده می شد. در غیر این صورت، هر دو نسخه به یک حالت اختصاص داده شدند. از آنجایی که دادههای OSM شامل هیچ ارزیابی صریحی نمیشود، ارزیابیهای انجامشده بین کاربران از طریق ارزیابی ضمنی محاسبه شد. چنین مقادیری بر اساس شباهت بین نسخه ها تعیین شد (معادله (2)). از زمان تولید همه نسخهها در OSM، اعتبار همه مشارکتکنندگان شرکتکننده و درجه اعتماد همه نسخههای شی محاسبه شد. به عنوان مثال، هر نسخه از یک شی جغرافیایی (شیء ارزیابی های انجام شده بین کاربران از طریق ارزیابی ضمنی محاسبه شد. چنین مقادیری بر اساس شباهت بین نسخه ها تعیین شد (معادله (2)). از زمان تولید همه نسخهها در OSM، اعتبار همه مشارکتکنندگان شرکتکننده و درجه اعتماد همه نسخههای شی محاسبه شد. به عنوان مثال، هر نسخه از یک شی جغرافیایی (شیء ارزیابی های انجام شده بین کاربران از طریق ارزیابی ضمنی محاسبه شد. چنین مقادیری بر اساس شباهت بین نسخه ها تعیین شد (معادله (2)). از زمان تولید همه نسخهها در OSM، اعتبار همه مشارکتکنندگان شرکتکننده و درجه اعتماد همه نسخههای شی محاسبه شد. به عنوان مثال، هر نسخه از یک شی جغرافیایی (شیءشناسه 73533774 است) در شکل 5 نشان داده شده است . شی یک ساختمان است و دارای سه نسخه است. اجازه دهید چگونگی تعیین قابل اعتماد بودن این شی و اعتبار مشارکت کنندگان آن را در طول فرآیند ویرایش آن تجزیه و تحلیل کنیم. ابتدا، نسخه v 1 شیء توسط مشارکت کننده ای به نام “ceyockey” اضافه شد که شهرت او در آن زمان 0.828 بود. درجه اعتماد نسخه v 1 شهرت مشارکت کننده آن است (مقدار 0.828). سپس نسخه v 2 توسط کاربر دیگری به نام “MMDawood” اضافه شد که شهرت آن در آن زمان 0.856 بود. درجه شباهت نسخه بین v 2 و v 1 0.843 بود. ارزیابی ضمنی از v 2 تا v 1با استفاده از رابطه (2) (تنظیم c = 1) انجام شد و مقدار 0.820 به دست آمد. شهرت کاربر “ceyockey” بر اساس ارزیابی های وی به روز شد و شهرت وی اندکی آسیب دید. مقدار اعتماد v 2 مطابق با معادله (3) 0.856 است. در نهایت، نسخه v 3 توسط کاربر “landfahrer” اضافه شد که شهرت آن در آن زمان 0.8735 بود. ارزیابی ضمنی برای v 3 تا v 2 و برای v 3 تا v 1با استفاده از رابطه (2)، مقادیر 0.884 و 0.821 به دست آمد. شهرت کاربران “ceyockey” و “MMDawood” بر اساس ارزیابی آنها به روز شد. شهرت “MMDawood” پس از ارائه یک ارزیابی بهتر بهبود یافت. در نهایت، مقدار اعتماد 0.874 برای v 3 با استفاده از رابطه (3) محاسبه شد.
پس از محاسبه اعتبار شی و شهرت مشارکتکننده، اطلاعات مربوط به هر شیء و داوطلب پرس و جو و مشاهده شد. همانطور که در شکل 5 نشان داده شده است، اطلاعات مربوط به اعتماد در هر نسخه از شی 73,533,774 بازیابی شد. نقوش هندسی هر نسخه که در یک تصویر ماهواره ای روی هم قرار گرفته اند، در سمت راست شکل نیز دیده می شود. اطلاعات آماری در مورد مشارکتکنندگان هر نسخه قابل بازیابی است و تمام اطلاعات مشارکتکننده (به عنوان مثال، نام، شهرت و تعداد مشارکتها) برای شی در بخش سمت راست پایین شکل نشان داده شده است. همانطور که در سمت چپ شکل نشان داده شده است، تمام حالت ها و نسخه های شی را می توان آزادانه برای مشاهده در پنجره سمت راست انتخاب کرد. علاوه بر این، ما همچنین میتوانیم بهترین نسخه یک حالت را با استفاده از رابط انسان و رایانه تعیین کنیم.
نتایج تجربی نشان میدهد که اعتبار یک شی و شهرت مشارکتکننده را میتوان به طور موثر با استفاده از مدل VGI ما ذخیره و مدیریت کرد. برخلاف مدل سنتی دادههای مکانی-زمانی، مدل ما اطلاعات مربوط به اعتماد را ارائه و ذخیره میکند (به عنوان مثال، مشارکتکنندگان، شهرت مشارکتکننده اولیه، ارزیابیهای مشارکتکننده، و شهرت مشارکتکننده). در میان این ویژگیها، ارزیابی مشارکتکنندگان یکی از عوامل اصلی است که نیاز به دسترسی به بودجه اضافی دارد. در مدل ما، تمام فیلدهای UERاشیاء (بیان کننده ارزیابی های مشارکت کننده، از جمله کلیدهای اصلی و خارجی) عددی هستند و برای ذخیره رکوردها تنها به 40 بایت نیاز دارند. یعنی 1,000,000 رکورد باید تقریباً 38.15 مگابایت فضای ذخیره سازی را اشغال کند. برای داده های تاریخی OSM برای برلین، 489386 رکورد (نسخه های چند ضلعی) 196.22 مگابایت در پایگاه داده را اشغال می کنند. یعنی 1,000,000 رکورد باید تقریباً 400.95 مگابایت فضای ذخیره سازی را اشغال کند. اگر نسبت بین مقدار شی و رکوردهای ارزیابی 1:1 باشد، نسبت داده بین رکوردهای ارزیابی و اشیاء چند ضلعی تقریباً 9.51٪ خواهد بود. با توجه به اینکه اطلاعات دیگری در مدل داده گنجانده شده است، داده های افزایشی (اطلاعات مربوط به اعتماد) باید کوچکتر از آن باشد. بنابراین، هنگام استفاده از مدل ما، مجموعه بزرگتری از داده ها قابل کنترل است. دادههای مکانی در مدل ما با ارجاع به دادههای OSM ذخیره میشوند تا از قابلیت استفاده و کاربرد مدل ما اطمینان حاصل شود. با توجه به سرعت سیستم نمونه اولیه خود، آزمایشهایی را روی یک رایانه شخصی انجام دادیم (Intel Core i5 3.0 هرتز، 8 G، ویندوز 7 حرفهای 64 بیت). از آنجایی که محاسبات مربوط به اعتماد شامل محاسبات هندسی می شود، اشیاء چند ضلعی یا چند خطی با نسخه ها و گره های بیشتر به عنوان اشیاء تجربی بهتر عمل می کنند. بنابراین، یک شی جغرافیایی برگرفته از OSM (ID: 4317997) برای آزمایش استفاده شد. شی دارای 11 نسخه است و هر نسخه به طور متوسط دارای 87 گره است. در آزمایشهای ما، 27 دور محاسبات مربوط به اعتماد و عملیات پایگاه داده انجام شد (هر نسخه سه نسخه قبلی (در صورت وجود) را در آزمایشها ارزیابی کرد). هر یک از 27 دور به طور متوسط 1.073 ثانیه طول کشید. به طور متوسط، هر دور از محاسبات مربوط به اعتماد و عملیات پایگاه داده 0.0397 ثانیه طول می کشد. این سرعت پردازش برای رایانه های شخصی قابل قبول است و ارزش بهبود بیشتر را دارد.
شکل 5. یک شی جغرافیایی VGI و اطلاعات مشارکت کننده مربوطه.
7. نتیجه گیری و بحث
VGI به عنوان منبع جایگزین داده های مکانی اهمیت فزاینده ای پیدا می کند [ 4 ]. با این حال، عدم قطعیت از نظر کیفیت آن، استفاده از آن را در کاربردهای مرتبط با GIS محدود کرده است [ 12 ]. بسیاری از محققان موافق هستند که شهرت مشارکت کنندگان به طور قابل توجهی بر کیفیت VGI تأثیر می گذارد [ 13 , 61]. با این حال، مطالعات کمی برای توسعه یک مدل VGI فضایی-زمانی با در نظر گرفتن شهرت مشارکتکننده و قابلیت اعتماد شی تلاش کردهاند. در همین حال، در محیط های VGI، وضعیت یک شی ممکن است یک یا چند نسخه داشته باشد. بنابراین، راه هایی برای انتخاب سریع بهترین نسخه های حالت ها باید فرموله شود. ما یک مدل VGI بر اساس اطلاعات مربوط به اعتماد ارائه می کنیم که به طور موثر اطلاعات مربوطه را ذخیره و مدیریت می کند. در این مدل، یک شی جغرافیایی با مکانیزم سه لایه “Object-State-Version” نشان داده می شود. هر حالت با بهترین نسخه خود برای جستجوی سریع عکس های فوری مربوطه مرتبط است. به نوبه خود، مسائل مربوط به وجود نسخه های متعدد VGI را می توان تا حدی به طور موثرتری مدیریت کرد. داده های VGI مربوط به اعتماد از فرآیندهای مشارکت اشیاء درگیر تشکیل می شوند. شهرت مشارکتکننده از شهرت اولیه و اعتبار ارزیابی تشکیل شده است، و ارزیابیهای بین کاربران ممکن است شامل ارزیابیهای صریح و ارزیابی ضمنی یا فقط یکی از آنها باشد. به نوبه خود، شهرت همه مشارکت کنندگان قابل محاسبه است. عملیات مربوط به اعتماد و روابط آنها در مدل نیز مورد تجزیه و تحلیل قرار گرفت و 9 قانون پیوند بین عملیات مربوط به اعتماد برای حفظ ثبات دادههای اعتماد و شهرت یافت شد. در نهایت، یک سیستم آزمایشی نمونه اولیه برای تایید اثربخشی مدل ارائه شده در این مقاله پیادهسازی شد. عملیات مربوط به اعتماد و روابط آنها در مدل نیز مورد تجزیه و تحلیل قرار گرفت و 9 قانون پیوند بین عملیات مربوط به اعتماد برای حفظ ثبات دادههای اعتماد و شهرت یافت شد. در نهایت، یک سیستم آزمایشی نمونه اولیه برای تایید اثربخشی مدل ارائه شده در این مقاله پیادهسازی شد. عملیات مربوط به اعتماد و روابط آنها در مدل نیز مورد تجزیه و تحلیل قرار گرفت و 9 قانون پیوند بین عملیات مربوط به اعتماد برای حفظ ثبات دادههای اعتماد و شهرت یافت شد. در نهایت، یک سیستم آزمایشی نمونه اولیه برای تایید اثربخشی مدل ارائه شده در این مقاله پیادهسازی شد.
لازم به ذکر است که با توجه به مکانیسم های مدل ما، قبل از استفاده در یک سیستم VGI واقعی، باید برخی از الزامات اساسی برآورده شود.
- (1)
-
اطلاعات مربوط به تمام نسخههای ویژگی بیان میکند که داوطلبان به مدل VGI اضافه کردهاند، باید ثبت شوند. اطلاعات مربوط به یک نسخه باید شامل مشارکت کننده، ویژگی هندسه، ویژگی ها، زمان تولید و غیره باشد. اطلاعات را می توان به طور صریح یا ضمنی ذخیره کرد.
- (2)
-
سیستم ها باید اطلاعات ثبت نام داوطلبان را ذخیره کنند. این اطلاعات برای محاسبه شهرت اولیه یک مشارکت کننده کلیدی است. هنگامی که ثبت نشده باشد، اعتبار اولیه قابل محاسبه نیست و دقت شهرت کاربر تحت تأثیر قرار می گیرد (به ویژه زمانی که مشارکت کنندگان ارزیابی های کمی انجام داده اند).
در این مقاله، ما بر مدلسازی اطلاعات مربوط به اعتماد در محیطهای VGI تمرکز میکنیم. جمع آوری چنین اطلاعاتی، به عنوان مثال، شهرت اولیه و اطلاعات رتبه بندی صریح، برای طراحی و اجرای سیستم های VGI با استفاده از مدل ارائه شده ضروری است. به نظر ما، از اطلاعات چند دیدگاهی می توان برای ارزیابی ترکیبی کیفیت اشیاء جمع سپاری استفاده کرد. علاوه بر این، چنین اطلاعاتی می توانند در مقابل یکدیگر اعتبارسنجی شوند. بنابراین، کیفیت اشیاء VGI را میتوان با ذخیرهسازی و اعتبارسنجی اطلاعات ثبت، با ارائه مکانیسمهایی که به افراد امکان میدهد رتبهبندی مشارکتکنندگان مختلف (یا اشیاء VGI) را بگذارند و با اجازه دادن به مشارکتکنندگان برای آپلود اطلاعات فراداده با کیفیت، بهطور منطقی کنترل شود.
روش های مختلف محاسبه درجه اعتماد اشیاء VGI هنوز برای بررسی بیشتر باز است. در آزمایش ما، شهرت کاربر به عنوان تجمیع شهرت اولیه و ارزیابی تعریف شد. شهرت اولیه از اطلاعات ثبت و اعتبار ارزیابی بر اساس شباهتهای بین نسخههای همان ایالت و موجودیت مشابه محاسبه میشود. قابل اعتماد بودن شی VGI بر اساس شهرت مشارکت کننده و نسبت مشارکت کننده مربوطه تعیین می شود. ما دریافتیم که کیفیت شی VGI با درجه اعتماد اشیاء VGI همبستگی مثبت دارد. با این حال، عوامل دیگر، به عنوان مثال، زمان باقی مانده نسخه ( به عنوان مثال، اگر یک شی در منطقه ای که چندین به روز رسانی را تجربه کرده است یکسان بماند، باید کیفیت بالایی داشته باشد و مشارکت کننده آن می تواند به سطح بالاتری از قابلیت اطمینان دست یابد، سازگاری توپولوژیکی (به عنوان مثال، یک شی VGI بدون تداخل توپولوژیکی معمولاً قابل اعتمادتر است و برعکس)، و غیره ، بر محاسبه قابلیت اعتماد شی VGI تأثیر میگذارند. چنین موضوعاتی خارج از محدوده تحقیق حاضر است.
در نتیجه، اگرچه ما یک مدل VGI فضایی-زمانی را با در نظر گرفتن شهرت مشارکتکننده و قابلیت اعتماد شی در این مقاله ارائه کردیم، به این معنی نیست که حفظ آخرین ویژگی ایجاد شده توسط یک مشارکتکننده قابل اعتمادتر همیشه بهتر است. محاسبه قابلیت اعتماد شی VGI هنوز یک موضوع باز است. بنابراین، ابزارهای موثر محاسبه قابلیت اعتماد شی و شهرت کاربر در مطالعات آینده مورد بررسی قرار خواهند گرفت.






بدون نظر