

چکیده
:
روشهای انجمنی برای رتبهبندی تصاویر مبتنی بر محتوا بر اساس معناشناسی به دلیل شباهت مدلهای تولید شده به مدلهای درک انسانی جذاب هستند. اگرچه آنها تمایل به بازگشت نتایجی دارند که توسط تحلیلگران تصویر بهتر درک می شوند، القای این مدل ها به دلیل عواملی که بر پیچیدگی آموزش تأثیر می گذارند دشوار است، مانند همزیستی الگوهای بصری در تصاویر مشابه، بیش از حد برازش یا کم تناسب بودن و معنایی. تفاوت های بازنمایی در بین تحلیلگران تصویر این مقاله روشی را برای کاهش پیچیدگی رتبهبندی تصاویر ماهوارهای برای روشهای انجمنی پیشنهاد میکند. رویکرد ما از عملیات ژنتیکی برای ارائه مدلهای سریعتر و دقیقتر برای رتبهبندی بر اساس معنایی با استفاده از ویژگیهای سطح پایین استفاده میکند. دقت افزوده شده با کاهش احتمال رسیدن به حداقل های محلی یا بیش از حد مناسب ارائه می شود. آزمایشها نشان میدهند که با استفاده از بهینهسازی ژنتیکی، روشهای تداعی بهتر یا در سطوح مشابه به عنوان روشهای گروهی پیشرفته برای رتبهبندی عمل میکنند. میانگین دقت متوسط (MAP) رتبهبندی براساس معنایی 14 درصد نسبت به روشهای انجمنی مشابهی که از تکنیکهای بهینهسازی دیگر استفاده میکنند در حالی که اندازه کوچکتر را برای هر مدل معنایی حفظ میکنند، بهبود یافت.
کلید واژه ها:
رتبه بندی تصاویر مبتنی بر محتوا ؛ داده کاوی ; رتبه بندی ; ژنتیکی ؛ تصاویر ماهواره ای ; انجمنی
1. مقدمه
ارزیابی تصاویر مکانی به دلیل ابعاد بالای داده های مکانی و همزیستی الگوهای بصری مرتبط با معناشناسی چندگانه در تصاویر چالش برانگیز است [ 1 ]. همانطور که سرعت جمع آوری تصاویر به طور تصاعدی رشد می کند، استخراج دستی دانش از تصاویر مکانی به منظور ارائه اطلاعات متمرکز برای تصمیم گیری برای تحلیلگران تصویر بسیار دشوار می شود. این امر نیاز به تجزیه و تحلیل و ارزیابی خودکار داده های سنجش از دور را ضروری می کند. رویکردهای سنتی دادهها، مانند روشهای آماری، محدودیتهایی از نظر مفروضات توزیعی و محدودیتهایی در ورودی دادهها دارند که ممکن است آنها را از تجزیه و تحلیل روابط ناشناخته و غیرمنتظره در تصاویر مکانی بازدارد [ 2 ].]. سایر روشهای سنتی دادهکاوی مانند شبکههای عصبی مصنوعی و الگوریتمهای ژنتیک (GA) دارای ویژگی جعبه سیاه هستند که استفاده از قوانین استخراجشده را برای سایر موارد برای کاربران دشوار میکند [ 3 ]. علاوه بر این، مقادیر دادهها تنها در زمینه حوزه مکانی و وجود تفاسیر معنایی متعدد برای یک تصویر [ 4 ، 5 ] معنا پیدا میکنند، که استفاده از روشهای سنتی تحلیل دادهها را برای تصاویر دشوار میکند. بنابراین، رویکردهای جدیدی که ویژگیهای منحصربهفرد دادههای تصویر را در نظر میگیرند، برای الگوهای استخراج از تصاویر پدید آمدهاند.
در بازیابی تصویر مبتنی بر محتوا، تصاویر با محتوای بصری خود مانند رنگ و شکل نمایه می شوند. با این حال، این ویژگی های سطح پایین نمی توانند به درستی معنای تصویر سطح بالا را در ذهن کاربر ثبت کنند. بنابراین، مطالعات اخیر بر روی بازیابی تصویر مبتنی بر محتوا بر کاهش شکاف معنایی بین ویژگیهای سطح پایین و معناشناسی انسانی سطح بالا با ساخت مدلهای معنایی که میتوانند برای پیشبینی استفاده شوند، تمرکز دارند. بررسی جامع مدلهای معنایی مختلف در [ 6 ] ارائه شده است] که در آن روشهایی برای کاهش شکاف معنایی شامل استفاده از هستیشناسی شی برای تعریف مفاهیم، استفاده از روشهای یادگیری ماشین برای مرتبط کردن ویژگیهای سطح پایین با معنایی کاربران، معرفی بازخورد مرتبط برای یادگیری اهداف کاربران، تولید یک الگوی معنایی برای ترسیم ویژگیهای سطح پایین است. به مفاهیم سطح بالا و ترکیب محتوای بصری و متنی برای بازیابی تصاویر وب.
تحقیقات اخیر در حوزه ژئوفضایی راه حل های عمیق متنوعی را ارائه کرده است [ 7 ، 8 ، 9 ، 10 ، 11 ، 12 ، 13 ، 14 ، 15 ، 16 ، 17 ، 18 ]، برای نشان دادن دانش جغرافیایی پیچیده و اغلب همپوشانی و برای کمک به تحلیلگران تصویر در تولید فراداده های خاص دامنه ضروری. تحقیق در [ 7] چارچوبی را برای مدل سازی و بازیابی تصویر با استفاده از روابط فضایی جهت دار بین اشیا توصیف می کند. روشهای بازیابی تصویر مبتنی بر محتوا (CBIR) برای رتبهبندی تصاویر ماهوارهای با استفاده از ارتباطات احتمالی بین ویژگیهای سطح پایین و معنایی مورد علاقه [ 8 ] استفاده شد. محققان در [ 9 ، 10 ، 13 ] از روشهای نیمه نظارتی تخصیص دیریکله پنهان (LDA) برای حاشیهنویسی تصاویر با کلاسهای معنایی استفاده میکنند. هر دو روش نظارت شده و بدون نظارت در چارچوب I 3 KR [ 11 ] ترکیب شده اند تا قابلیت های جستجوی تصویر را با استفاده از اطلاعات معنایی و مبتنی بر محتوا افزایش دهند. تحقیقات در [ 12 ، 15] به طور موثر تصاویر را با استفاده از ساختارهای نمایه سازی در فضای ویژگی بازیابی می کند. کاربرد نقشه های خودسازماندهی برای تجزیه و تحلیل ساختارهای دست ساز در تصاویر چند طیفی در [ 14 ] بررسی شده است. تحقیق در [ 16 ] ادغام یک سیستم مبتنی بر محتوای چندوجهی را با روش های پیچیده پرس و جو در مورد شکل، روابط چند شیء، و معناشناسی پیشنهاد می کند، در حالی که تحقیق در [ 17 ] به طور خودکار تغییرات در تصاویر جغرافیایی را شناسایی می کند و خوشه بندی را اعمال می کند. تکنیک هایی برای سازماندهی تغییرات الگوی بصری رویکرد در [ 18] از دانش هستی شناسی و شبکه های عصبی مصنوعی برای ساخت مدل های معنایی الگوهای بصری با استفاده از ویژگی های تصویری سطح پایین و توصیفی استفاده می کند. از این مدل ها می توان برای اندازه گیری شباهت معنایی بین اشیاء تصویر استفاده کرد. برای بررسی عمیق داده کاوی مکانی و کشف دانش، خواننده به [ 3 ] هدایت می شود.
در میان راهحلهای پیشنهادی، ارتباط بین ویژگیهای سطح پایین و الگوهای بصری با استفاده از تکنیکهای داده کاوی [ 8 ، 19 ] ایجاد میشود و بینش قابلخوانایی بیشتری در مورد ساختار مدلهای تولید شده برای انسان ارائه میکند. هر قانون تداعی یک قانون تصمیم ایجاد می کند که در آن مجموعه ای از ویژگی های سطح پایین به عنوان مقدم و یک معنایی منحصر به فرد به عنوان نتیجه قاعده تصمیم انتخاب می شوند. سپس قوانین تداعی برای ارتباط آنها با الگوهای بصری سطح بالا ارزیابی و رتبه بندی می شوند. الگوریتمهای مختلفی برای کاوی قوانین تداعی فضایی پیشنهاد شدهاند. در میان آنها، الگوریتم های Apriori و AprioriTid [ 20] برای ایجاد قوانین کارآمد و فیلتر کردن قوانینی که پیش پا افتاده یا رایج هستند، پیشرفت های قابل توجهی انجام داده اند. یکی از چالشهای موجود در این زمینه، سربار محاسباتی مرتبط با محمولات فضایی مختلف به منظور استخراج قوانین ارتباط از مجموعه دادههای بزرگ است. رویکردی که قوانین تداعی را با استفاده از تکنیک های داده کاوی فازی استخراج می کند در [ 21 ] برای مقابله با عدم قطعیت موجود در داده های مکانی پیشنهاد شده است. در [ 22 ]، نقشه های خودسازماندهی برای بررسی اینکه آیا تصاویر ماهواره ای، و سپس قوانین انجمن وابسته به زمان، با استفاده از الگوریتم Apriori استخراج شده اند یا خیر، استفاده می شود. برای بررسی عمیق استخراج طبقهبندی انجمنی و کاوی قوانین انجمنی فضایی، خواننده به [ 23 ] هدایت میشود.
روش انتخاب ویژگی از تصاویر اصلی خام، گام مهمی در بهبود عملکرد روشهای استخراج قانون انجمنی است. این فرآیند با حذف ویژگیهای نامربوط و زائد، ابعاد و پیچیدگی دادههای تصویر خام را کاهش میدهد. اندازهگیری شباهت/عدم شباهت بین مجموعه انتخاب شده از ویژگیهای سطح پایین و معناشناسی سطح بالا، اثربخشی مدلهای انجمنی را تعیین میکند. یک مشکل مهم در کشف دانش مکانی، انتخاب استراتژیهای بهینهسازی است که میتواند در یک فضای ویژگی اعمال شود. یافتن یک راه حل منحصر به فرد در یک فضای ویژگی با ابعاد بالا که حاوی مقدار زیادی از متغیرهای پیوسته است، یک کار چالش برانگیز است. به طور خاص، در کاوی تداعی فضایی،24 ]. الگوریتمهای انتخاب ویژگی تلاش میکنند تا پیچیدگی فضای ویژگی را با حذف ویژگیهای نامربوط [ 25 ] با استفاده از روشهای فیلتر یا بستهبندی کاهش دهند. الگوریتمهای انتخاب ویژگی Brute-force نیز از نظر محاسباتی گران هستند، در حالی که الگوریتمهای انتخاب ویژگی اخیراً پیشنهاد شده ماهیت طمعآمیز دارند و ممکن است عملکرد پایینتری داشته باشند. سایر الگوریتمهای تصمیمگیری حریصانه [ 26 ، 27 ] تلاش میکنند تا پیچیدگی مسئله را کاهش دهند، اما ممکن است در راهحلهای حداکثر محلی و غیربهینه به دام افتاده باشند. برای غلبه بر این مشکل، از مدلهای انجمنی افزایشی استفاده میشود که قانون ارتباط تازه کشفشده تنها در صورتی به مدل اضافه میشود که ارتباط قاعده با مدل معنایی بیشتر از یک آستانه از پیش تعریفشده باشد [ 9 ]]. به عنوان مثال در [ 8 ، 28 ] مدلهای افزودنی با الگوریتمهایی مانند الگوریتم انتخاب شناور متوالی به جلو (SFFS) ترکیب شدند، که تا زمانی که تابع هدف نتایج بهتری را برمیگرداند، تعدادی گام به عقب را اعمال میکند. انتخاب ویژگی از طریق قوانین تداعی نیز در [ 29 ] برای کاهش ابعاد بردارهای ویژگی به کار گرفته شده است.
الگوریتمهای تکاملی روشهای بهینهسازی خود تطبیقی هستند که جستجوی سراسری را در فضای راهحل انجام میدهند. آنها در مقایسه با الگوریتمهای تصمیمگیری حریصانه [ 30 ] تمایل دارند با تعاملات ویژگیها بهتر عمل کنند . الگوریتم های ژنتیک (GAs) [ 31 ، 32] فضای محلول های کاندید در ساختار کروموزوم را مدل کنید که در آن موفقیت هر کروموزوم با یک تابع تناسب ارزیابی می شود. بهترین راهحل یا رضایتبخشترین راهحل مبتنی بر روشهای انتخاب طبیعی است که ویژگیهای موفق موجود در مجموعهای از مدلهای تولید شده قبلی را با انتخاب، متقاطع و جهش ترکیب میکند. از آنجایی که دانش در مورد فضای جستجو در طول فرآیند جستجو انباشته میشود، GAs میتواند با حرکت تطبیقی فضای راهحل برای نزدیک شدن به یک بهینه جهانی، تلههای حداکثر محلی را حذف کند. GA ها در حوزه های مختلف داده کاوی مکانی اعمال می شوند. در [ 33 ]، برنامه نویسی تکاملی برای طبقه بندی تصاویر چند طیفی با استفاده از ترکیب غیر خطی معیارهای طیفی و بافت استفاده می شود. تحقیق در [ 34] از گازهای گازی برای بهینه سازی درون یابی داده های آلودگی هوا استفاده می کند در حالی که تحقیق در [ 2 ] برای GAها برای طبقه بندی پوشش زمین با استفاده از شکل جسم موجود در تصویر اعمال می شود. در [ 35 ]، یک روش خوشه بندی فضایی مبتنی بر GAs و k-medoids برای رسیدگی به خوشه بندی فضایی با محدودیت های مانع پیشنهاد شده است. تحقیق در [ 36 ] از GA برای کشف قوانین ارتباطی برای داده کاوی تصویر استفاده می کند. در [ 37 ]، یک الگوریتم بهینه سازی چند هدفه برای جستجوی تعدادی از توابع هدف متضاد برای یافتن راه حل پارتو بهینه برای طبقه بندی پیکسل استفاده می شود.
GA همچنین برای انتخاب ویژگی در وظایف بازیابی تصویر استفاده شده است. در [ 38 ]، الگوریتم انتخاب ویژگی مبتنی بر GA برای انتخاب مجموعه ای از ویژگی های متمایز برای تصاویر ماهواره ای استفاده می شود. شاخص تفکیک پذیری به عنوان تابع تناسب برای ارزیابی زیرمجموعه های ویژگی استفاده می شود و اثربخشی الگوریتم بر روی یک طبقه بندی شبکه عصبی آزمایش می شود. در [ 39 ]، توابع ارزیابی رتبه بندی به عنوان توابع تناسب در انتخاب ویژگی مبتنی بر GA برای جستجوی بهترین مجموعه ویژگی پیشنهاد شده است. در [ 40 ]، روش انتخاب ویژگی شامل یک انتخاب ویژگی مبتنی بر فیلتر با استفاده از الگوریتم ژنتیک برای بهبود تخمین بارش از یک تصویر سنجش از راه دور است.
در این مقاله، ما کار در [ 41 ] را برای کشف روش های ژنتیکی حالت پایدار [ 42 ] گسترش می دهیم.] برای بهینه سازی مدل های انجمنی برای رتبه بندی مناطق تصویر جغرافیایی بر اساس پوشش زمین. هدف ما ارائه یک روش تداعی برای نگاشت معناشناسی به الگوهای بصری در تصاویر دامنه خاص است. این روشها به دلیل اینکه میتوانند به راحتی توسط متخصصان تفسیر شوند، جذاب هستند که در نهایت میتوان از آنها در روشهای آموزشی متخصص استفاده کرد. در رویکردهای قبلی، ما از تکنیکهای استخراج قانون انجمن Apriori برای تعیین اولیه زیرفضاهای ویژگی استفاده کردهایم. با این حال، ثابت شد که آموزش پیچیده است و بسیاری از روشهای مورد استفاده برای کاهش پیچیدگی، محدودکننده بوده و مستقیماً بر کیفیت شوخی تأثیر میگذارد. بنابراین، در رویکرد جدید تنها از روشهای ژنتیکی برای تولید، انتخاب و تنظیم دقیق نگاشتهای بین فضاهای ویژگی و معناشناسی استفاده میکنیم. حوزه اصلی این مقاله ارزیابی این است که آیا روشهای ژنتیکی برای استخراج قوانین انجمنی منجر به عملکردی بهتر یا مشابه با عملکرد سایر تکنیکهای پیشرفته میشوند. ما دو مدل از الگوریتم ژنتیک را برای تولید فرزندان بررسی کردیم. GA نسلی (GA استاندارد) و GA حالت پایدار و استفاده از بعدی را انتخاب کرد. در GA استاندارد، عملگرهای ژنتیکی کل نسل قدیم را با جمعیت تازه بهار جایگزین میکنند، در حالی که در GA حالت پایدار، جمعیت بهطور تدریجی جایگزین میشود به طوری که یک عضو جدید به جمعیت جدید وارد میشود. یک استراتژی جایگزینی تعیین می کند که کدام یک از اعضای جمعیت با فرزندان جدید جایگزین می شوند [ GA نسلی (GA استاندارد) و GA حالت پایدار و استفاده از بعدی را انتخاب کرد. در GA استاندارد، عملگرهای ژنتیکی کل نسل قدیم را با جمعیت تازه بهار جایگزین میکنند، در حالی که در GA حالت پایدار، جمعیت بهطور تدریجی جایگزین میشود به طوری که یک عضو جدید به جمعیت جدید وارد میشود. یک استراتژی جایگزینی تعیین می کند که کدام یک از اعضای جمعیت با فرزندان جدید جایگزین می شوند [ GA نسلی (GA استاندارد) و GA حالت پایدار و استفاده از بعدی را انتخاب کرد. در GA استاندارد، عملگرهای ژنتیکی کل نسل قدیم را با جمعیت تازه بهار جایگزین میکنند، در حالی که در GA حالت پایدار، جمعیت بهطور تدریجی جایگزین میشود به طوری که یک عضو جدید به جمعیت جدید وارد میشود. یک استراتژی جایگزینی تعیین می کند که کدام یک از اعضای جمعیت با فرزندان جدید جایگزین می شوند [43 ]. هر ارتباط بین یک ویژگی و پوشش زمین مورد علاقه به عنوان یک اگزون k -bit مدلسازی میشود که حاوی اطلاعاتی در مورد ویژگیها و ویژگیهای زیرفضای ویژگی مورد استفاده است. تازگی رویکرد ما استفاده از عملیات ژنتیکی در هر دو سطح ویژگی و زیرفضا است. ما تناسب مدلها را در جمعیتهای ژنتیکی با استفاده از MAP ارزیابی میکنیم و آن را با الگوریتم بهینهسازی SFFS مورد استفاده در [ 8 ] مقایسه و مقایسه میکنیم. این مقاله به شرح زیر سازماندهی شده است: در بخش 2 روش مورد استفاده برای پیاده سازی الگوریتم های ژنتیک را معرفی می کنیم، نتایج تجربی را در بخش 3 ارائه می کنیم و سپس مقاله را در بخش 4 به پایان می رسانیم .
2. روش شناسی
در این بخش روش خود را برای رتبهبندی مناطق تصاویر ماهوارهای با استفاده از عملیات ژنتیکی ارائه میکنیم. برای هر تصویر در پایگاه داده یک فضای ویژگی F ایجاد می کنیم . ویژگی کلیدی الگوریتم این است که ما از مجموعهای از قوانین ارتباط بین زیرفضاهای ویژگی و معنایی در فضای معنایی S برای رتبهبندی تصاویر بر اساس معنایی استفاده میکنیم. هر مجموعه ای از تداعی ها با استفاده از عملیات ژنتیکی در دو سطح ایجاد و تکامل می یابد: سطح ویژگی و زیرفضا. در سطح ویژگی، مجموعه ویژگیهای مورد استفاده برای شناسایی قوانین مرتبط را تغییر میدهیم، در حالی که در سطح زیرفضا، منطقه را برای مجموعه ویژگیهای مشابهی که در رتبهبندی استفاده میشود، تغییر میدهیم. به عنوان مثال، برای یک فضای 38 بعدی، 2 38 وجود داردترکیبی از ویژگی های منحصر به فرد با استفاده از عملیات ژنتیکی، ما به طور تصادفی ترکیبی از ویژگی ها را با استفاده از روش هایی مانند جهش متقاطع، کوچک، ثابت یا رشد، انتخاب و تکامل می دهیم. هنگامی که ترکیبی از ویژگیها انتخاب میشود، بهطور تصادفی زیرفضاهای ویژگیها را که توسط توابع احتمالی سیگموئید مدلسازی شدهاند، تولید و تکامل میدهیم. علاوه بر این، مجموعهای از فضاهای ویژگی به صورت افزودنی برای مدلسازی همبستگی با معنایی مورد علاقه استفاده میشوند. برای ارزیابی اینکه کدام زیرفضا مرتبطتر است، عملیات ژنتیکی را نیز در این سطح اعمال میکنیم.
2.1. عملکرد تناسب اندام
تابع تناسب برای هر مدل معنایی توسط الگوریتم بهینهسازی استفاده میشود تا مشخص کند کدام ترکیبی از قوانین تداعی ارتباط بین زیرفضاهای ویژگی و معنایی مورد علاقه را بهتر مدلسازی میکند. در مطالعه خود، ما از MAP برای تعیین ارتباط هر زیرفضای ویژگی استفاده می کنیم، مجموعه ای از تداعی ها که یک مدل معنایی را تشکیل می دهند. با این حال، از آنجایی که هر مدل معنایی مجموعهای از تداعیها است، با مقادیر مرتبط غیرصفر متعدد، تابع تناسب به صورت زیر اعمال میشود: هر قانون تداعی منطقه فضای ویژگی را در معنایی مورد علاقه ترسیم میکند. 




تابع g یک توزیع احتمالی سیگموئید دوتایی نامتقارن است ( L— چپ و R— راست) که ارتباط یک اندازه گیری را با ς معنایی مدل می کند . هر نیم سیگموئید توسط دو پارامتر کنترل می شود: (الف) مرکز ( ، ) و (ب) عرض ( ، ) در حالی که wg وزن مربوط به بازیابی شده توسط g است . هر توزیع احتمال با استفاده از ارزیابیهای مرتبط ارائه شده توسط تحلیلگران تصویر شکل میگیرد، که ما آن را به عنوان اطلاعات معنایی واقعی برای هر معنایی مورد علاقه در نظر گرفتیم. برای جزئیات این تابع نگاشت، خواننده به [ 8 ].




 ].
]. ارتباط یک تصویر ι با یک ς معنایی با ارتباط مقادیر ویژگی تصویر در ناحیه فضای ویژگی Θ تعیین می شود :
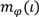

جایی که وزنی از زیرفضای ویژگی Θ است که ارتباط آن را در نگاشت F به ς تعیین می کند. علاوه بر این، برای هر ς معنایی یک مدل معنایی ایجاد می کنیم که به عنوان مجموعه ای از نگاشت زیرفضاهای Θ از F در فضای معنایی S تعریف شده است :
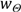


ارتباط کلی یک تصویر ι با اندازهگیری ویژگی ، با یک ς معنایی با مرتبسازی مقادیر مربوط (عملکرد رتبه) اندازهگیریهای ویژگی تصویر به هر زیرفضای ویژگی به ترتیب نزولی محاسبه میشود و سپس محاسبه میشود:



در این معادله، بهعنوان میانگین وزنی تمام مقادیر ارتباط سیگموئیدی انجمنها در مدل معنایی محاسبه میشود. ما این میانگین را انتخاب کردهایم زیرا میخواهیم بر مرتبطترین ارتباط تأکید کنیم و در عین حال بر ارتباط کمتر مرتبط که فقط تأثیر حاشیهای دارند، تأکید نکنیم.
در نهایت، برای هر یک از آزمایشها، تابع تناسب را بهعنوان نقشه رتبهبندی محاسبه میکنیم، که یک مقیاس کلی از دقت (چه تعداد از تصاویر بازیابی شده در جستجوی معنایی واقعاً مرتبط هستند) در تمام سطوح یادآوری برای هر مدل ارائه میکند. برای بیش از یک فضای ویژگی F. اندازه گیری MAP در زیر نشان داده شده است:

در این فرمول مجموعه ای از تصاویر j رتبه بندی شده از بالا تا k امین تصویر است.

2.2. رمزگذاری
هر تابع عضویت تولید شده یک اگزون ε در نظر گرفته می شود و به عنوان یک رشته اعشاری برای دنباله ( φ , , , , ) با استفاده از مجموع 20 رقم اعشاری کدگذاری می شود. ویژگی φ به عنوان شاخص ویژگی در فضای ویژگی با استفاده از چهار رقم اعشاری ثبت میشود، در حالی که برای هر یک از پارامترهای سیگموئید، مهمترین چهار رقم را بعد از نقطه اعشار که پس از فرآیند عادیسازی بهدست آمده ذخیره میکنیم . برای خوانایی مقاله، یک توالی ژنتیکی را در قسمتهای کوچکتر میشکنیم و هر گروه چهار رقمی را با متناوب کردن متنهای ایتالیک و پررنگ برجسته میکنیم. به عنوان مثال، بیش از یک ویژگی F 1 به صورت کدگذاری می شود
 ε = 0001 0100 0500 6240 0100 .
ε = 0001 0100 0500 6240 0100 .یک ژن مجموعهای از اگزونهای پیوندی است و توسط توالی کدگذاری میشود که در آن η تعداد اگزونهای موجود در ژن است و نشاندهنده ارتباط عضویت کامل مجاز توسط ژن است. به عنوان مثال، ژنی را در نظر بگیرید که دارای دو اگزون و حاوی دو اگزون در فضای ویژگی دو بعدی { F 1, F 2} است. هر اگزون معادل توابع سیگموئید زیر است: و . این ژن 0002 7210 0001 8870 0150 9980 0010 0002 0100 0500 6240 0100 رمزگذاری شده است . برای این ژن، هر نقطه در ویژگی &فضای فرعی F 1 ∈ [0.887, 0.998] ˄ F 2 ∈ [0.01، 0.624] دارای ارتباط 0.721 = Θ است در حالی که نقاط مشخصه خارج از این ناحیه ارتباط کمتری دارند که توسط توابع سیگموئید دیکته می شود.






 1 ∈ [0.887, 0.998] ˄ F 2 ∈ [0.01، 0.624] دارای ارتباط 0.721 = Θ است در حالی که نقاط مشخصه خارج از این ناحیه ارتباط کمتری دارند که توسط توابع سیگموئید دیکته می شود.
1 ∈ [0.887, 0.998] ˄ F 2 ∈ [0.01، 0.624] دارای ارتباط 0.721 = Θ است در حالی که نقاط مشخصه خارج از این ناحیه ارتباط کمتری دارند که توسط توابع سیگموئید دیکته می شود.کروموزوم χ مجموعهای از ژنهای جداکننده است که میتوانند با استفاده از تابع جمع شوند و به عنوان ترکیبی از ژنهای سازنده χ = ( ) کدگذاری میشوند. به عنوان مثال، در نظر بگیرید که ما یک کروموزوم با دو ژن داریم: = 0002 7210 0001 8870 0150 9980 0010 0002 0100 0500 6240 0100 ، که در پاراگراف قبلی توضیح داده شد، که در پاراگراف قبلی توضیح داده شد، که در پاراگراف قبلی توضیح داده شد : 18001 تا 1801 = 1801 . بیش از ویژگی F 1 و با . این کروموزوم χ = 0002 7210 0001 8870 0150 9980 0010 0002 0100 0500 6240 0100 0001 2018 0001 66070 0001 8818 کدگذاری شده است . هر کروموزوم یک منطقه سفارشی شده از فضای ویژگی را نشان می دهد. هدف روش شناسی ما شناسایی منطقه بهینه است که می تواند کیفیت رتبه بندی را برای یک معنایی به حداکثر برساند. این مجموعه از تداعی ها یک مدل معنایی برای آن معنایی تشکیل می دهد و برای رتبه بندی تصاویر جدید و بدون برچسبی که به پایگاه داده اضافه می شوند استفاده می شود.



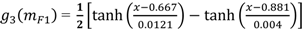
 . این کروموزوم χ = 0002 7210 0001 8870 0150 9980 0010 0002 0100 0500 6240 0100 0001 2018 0001 66070 0001 8818 کدگذاری شده است . هر کروموزوم یک منطقه سفارشی شده از فضای ویژگی را نشان می دهد. هدف روش شناسی ما شناسایی منطقه بهینه است که می تواند کیفیت رتبه بندی را برای یک معنایی به حداکثر برساند. این مجموعه از تداعی ها یک مدل معنایی برای آن معنایی تشکیل می دهد و برای رتبه بندی تصاویر جدید و بدون برچسبی که به پایگاه داده اضافه می شوند استفاده می شود.
. این کروموزوم χ = 0002 7210 0001 8870 0150 9980 0010 0002 0100 0500 6240 0100 0001 2018 0001 66070 0001 8818 کدگذاری شده است . هر کروموزوم یک منطقه سفارشی شده از فضای ویژگی را نشان می دهد. هدف روش شناسی ما شناسایی منطقه بهینه است که می تواند کیفیت رتبه بندی را برای یک معنایی به حداکثر برساند. این مجموعه از تداعی ها یک مدل معنایی برای آن معنایی تشکیل می دهد و برای رتبه بندی تصاویر جدید و بدون برچسبی که به پایگاه داده اضافه می شوند استفاده می شود.در نهایت، یک جمعیت مجموعهای از کروموزومها (χ1 ، … ،χn ) است که برای توضیح ارتباط بین یک فضای ویژگی و یک معنایی با هم رقابت میکنند، در حالی که یک ماده ژنتیکی مجموعهای از کروموزومها است که بالاترین عملکرد را در مدلسازی تمام موارد نشان میدهد. معناشناسی مورد علاقه
2.3. عملیات ژنتیکی
ما عملیات ژنتیکی را در سه سطح اگزون، ژن و کروموزوم انجام می دهیم. در زیر عملیات ژنتیکی انجام شده بر روی هر جمعیت را برمی شمریم که در شکل 1 در یک فضای ویژگی دوبعدی ساده شده متشکل از کشش ناحیه محدب جسم ( F 1) و چولگی جهت ( F 2) مثال زده شده است. در این شکل، محور عمودی، ویژگی مربوط به یک معنایی مورد علاقه است.
شکل 1. مثالی از دنباله ای از عملیات ژنتیکی: ( الف ) تصادفی. ( ب ) تغییر اگزون لامبدا 1. ( ج ) تغییر اگزون لامبدا 2; ( د ) جهش رشد ژن. ( ه ) جهش مربوط به ژن. ( f ) جهش ثابت ژن. ( g ) تلاقی ژن با جایگزینی اگزون دوم در (e) با اگزون اول در (a). ( h ) جهش کوچک شدن ژن; ( من ) جهش رشد کروموزوم. ( j ) جهش ثابت کروموزوم. ( k ) کروموزوم با اولین ژن در (d) تلاقی می کند. ( l ) جهش کوچک شدن کروموزوم.
نسل تصادفی کروموزوم: اولین جمعیت از نسل کاملاً تصادفی کروموزوم ها استفاده می کند. تعداد ژن ها در هر کروموزوم به طور تصادفی بین سه تا دوازده انتخاب می شود، در حالی که هر ژن حداکثر دارای پنج اگزون است. محدوده ژنها در یک اگزون بهطور تجربی توسط آزمایشهای ما نشان داده شد که توسط مدل انجمنی بازگردانده میشوند، در حالی که ما میخواهیم تعداد اگزونها را در یک مدل حفظ کنیم تا ماهیت جعبه سفید مدلهای معنایی خود را حفظ کنیم. شکل 1 (a) ارتباط فضای ویژگی را هنگام استفاده از یک کروموزوم تصادفی تولید شده با یک ژن، یک اگزون در F 2 و با کد 0001 6510 0002 1012 3410 0200 0513 نشان می دهد . این معادل تابع سیگموئید است .
 .
.Exon Shift پارامتر λ 1 : این عملیات با تغییر تصادفی و تا ± 5٪ ، تغییراتی را به فاصله ویژگی حداکثر ارتباط اضافه می کند . شکل 1 (ب) ارتباط فضای ویژگی را هنگام تبدیل ژنتیکی 0001 6510 0002 1012 3410 0200 0513 به 0001 6510 000 2 3763 4586 0200 0513 نشان می دهد . این معادل یک تابع سیگموئید جدید با تغییرات در نسل قبلی و بیش از آن است.

Exon Shift از پارامتر λ 2 : این عملیات با تغییر تصادفی و تا 5±٪ ، به فاصله ویژگی حداکثر ارتباط تغییر میدهد. شکل 1 (ج) ارتباط فضای ویژگی را هنگام تبدیل ژنتیکی 0001 6510 0002 1012 3410 0200 0513 به 0001 6510 0002 3763 4586 2130 0500 نشان می دهد. این معادل یک تابع سیگموئید جدید با تغییرات در نسل قبلی و نسبت به نسل قبلی است.
جهش رشد ژن : این عمل یک اگزون جدید را به یک ژن انتخاب شده در کروموزوم به طور تصادفی اضافه می کند. شکل 1 (د) ارتباط فضای ویژگی را هنگام اضافه کردن اگزون با کد 0001 2001 6011 0100 0055 در ویژگی F 1 به ژن در کروموزوم موجود نشان می دهد. کد ژنتیکی جدید کروموزوم 0002 6510 0002 3763 4586 2130 0500 0001 2001 6011 0100 0055 است. این معادل یک کروموزوم با ارتباط Θ = 0.651 و و است.


جهش مربوط به ژن : این عمل با تغییر تصادفی وزن یک ژن در کروموزوم، تغییراتی را به ژن اضافه می کند. شکل 1 (e) ارتباط فضای ویژگی را هنگام افزایش ارتباط از 0.651 به 0.9999 نشان می دهد. کد ژنتیکی جدید کروموزوم 0002 9999 0002 3763 4586 2130 0500 0001 2001 6011 0100 0055 است.

جهش ثابت ژن : این عمل جایگزین یک اگزون در یک ژن به طور تصادفی انتخاب شده می شود. انتخاب اگزون جدید با یک عملیات تصادفی انجام می شود. شکل 1 (f) ارتباط فضای ویژگی را پس از جایگزینی اگزون 0002 3763 4586 2130 0500 با 0001 5160 7613 0501 0500 نشان می دهد. اگزون جدید معادل . کد نهایی کروموزوم 0002 9999 0001 5160 7613 0501 0500 0001 2001 6011 0100 0055 است.

Gene Cross Over : این عملیات زیرمجموعه اگزون ها را بین دو ژن انتخاب شده به طور تصادفی تغییر می دهد. هر زیرمجموعه اگزونهایی که باید سوئیچ شوند نیز به صورت تصادفی انتخاب می شوند. شکل 1 (g) ارتباط فضای ویژگی را پس از جایگزینی اگزون دوم در ژن 0001 2001 6011 0100 0055 با اگزون از اولین جهش تصادفی 0002 1012 3410 0200 0513 نشان می دهد . کد نهایی کروموزوم 0002 9999 0001 5160 7613 0501 0500 0002 1012 3410 0200 0513 است.
جهش کوچک شدن ژن : این عملیات یک اگزون را در یک ژن به طور تصادفی انتخاب شده حذف می کند. انتخاب اگزونی که باید حذف شود با یک عملیات تصادفی انجام می شود. شکل 1 (h) ارتباط فضای ویژگی را پس از حذف اگزون 0002 1012 3410 0200 0513 از ژن شرح داده شده در بالا نشان می دهد. کد نهایی کروموزوم 0001 9999 0001 5160 7613 0501 0500 است.
جهش رشد کروموزوم : این عمل یک ژن را به یک کروموزوم انتخاب شده به طور تصادفی با احتمالی که مستقیماً با ارتباط کروموزوم متناسب است، اضافه می کند. ژن جدید به صورت تصادفی تولید می شود. شکل 1 (i) ارتباط فضای ویژگی را پس از افزودن یک ژن جدید با دو اگزون نشان می دهد: 0001 1210 4100 0200 0500 و 0002 6200 8522 0300 0050 و وزن = 0.712. ژن جدید اضافه شده دارای کد: 0002 7120 0001 1210 4100 0200 0500 0002 6200 8522 0300 0050 است. در حالی که کد نهایی کروموزوم 0001 9999 0001 5160 7613 0501 0500 0002 7120 0001 1210 4100 0200 0500 0002 62003002 6200 3002 است .
در حالی که کد نهایی کروموزوم 0001 9999 0001 5160 7613 0501 0500 0002 7120 0001 1210 4100 0200 0500 0002 62003002 6200 3002 است .جهش ثابت کروموزوم : این عمل به طور تصادفی یک کروموزوم را انتخاب می کند و ویژگی مرتبط با یکی از ژن های آن را تغییر می دهد. شکل 1 (j) ارتباط فضای ویژگی را پس از تغییر ویژگی اولین ژن از F 1 به F 2 با کد حاصل نشان می دهد: 0002 9999 0002 5160 7613 0501 0500 . کروموزوم جدید دارای کد 0001 9999 0002 5160 7613 0501 0500 0002 7120 0001 1210 4100 0200 0500 0002 6200 8502 0050 .
کروموزوم متقاطع : این عملیات زیر مجموعههای ژنها را بین دو کروموزوم انتخاب شده بهطور تصادفی تغییر میدهد. هر زیرمجموعه ای از ژن هایی که قرار است تعویض شوند نیز به صورت تصادفی انتخاب می شوند. شکل 1 (k) ارتباط فضای ویژگی را پس از تعویض اولین ژن کروموزوم در شکل 1 (د) با اولین ژن در کروموزوم توصیف شده قبلی نشان می دهد. کد نهایی کروموزوم 0002 6510 0002 3763 4586 2130 0500 0001 2001 6011 0100 0055 0002 7120 0001 1210 2002 1210 2002 0002 3763 0050 .
جهش کوچک شدن کروموزوم : این عمل یک ژن را از کروموزوم با هدف کاهش پیچیدگی توالی DNA حذف می کند. احتمال این عمل با ارتباط هر کروموزوم نسبت معکوس دارد. شکل 1 (l) ارتباط فضای ویژگی را پس از حذف ژن دوم از کروموزوم نشان می دهد. کد نهایی کروموزوم 0002 6510 0002 3763 4586 2130 05 00 0001 2001 6011 0100 0055 است.
تولید مثل کروموزوم : این عمل یک کپی دقیق از یک کروموزوم می سازد و آن را به توالی DNA جدید اضافه می کند. انتخاب کروموزومهای مورد استفاده در عملیات ژنتیکی با استفاده از الگوریتم انتخاب چرخ رولت [ 44 ] تعیین میشود، که شانس انتخاب را متناسب با تناسب هر مدل معنایی در جامعه اختصاص میدهد.
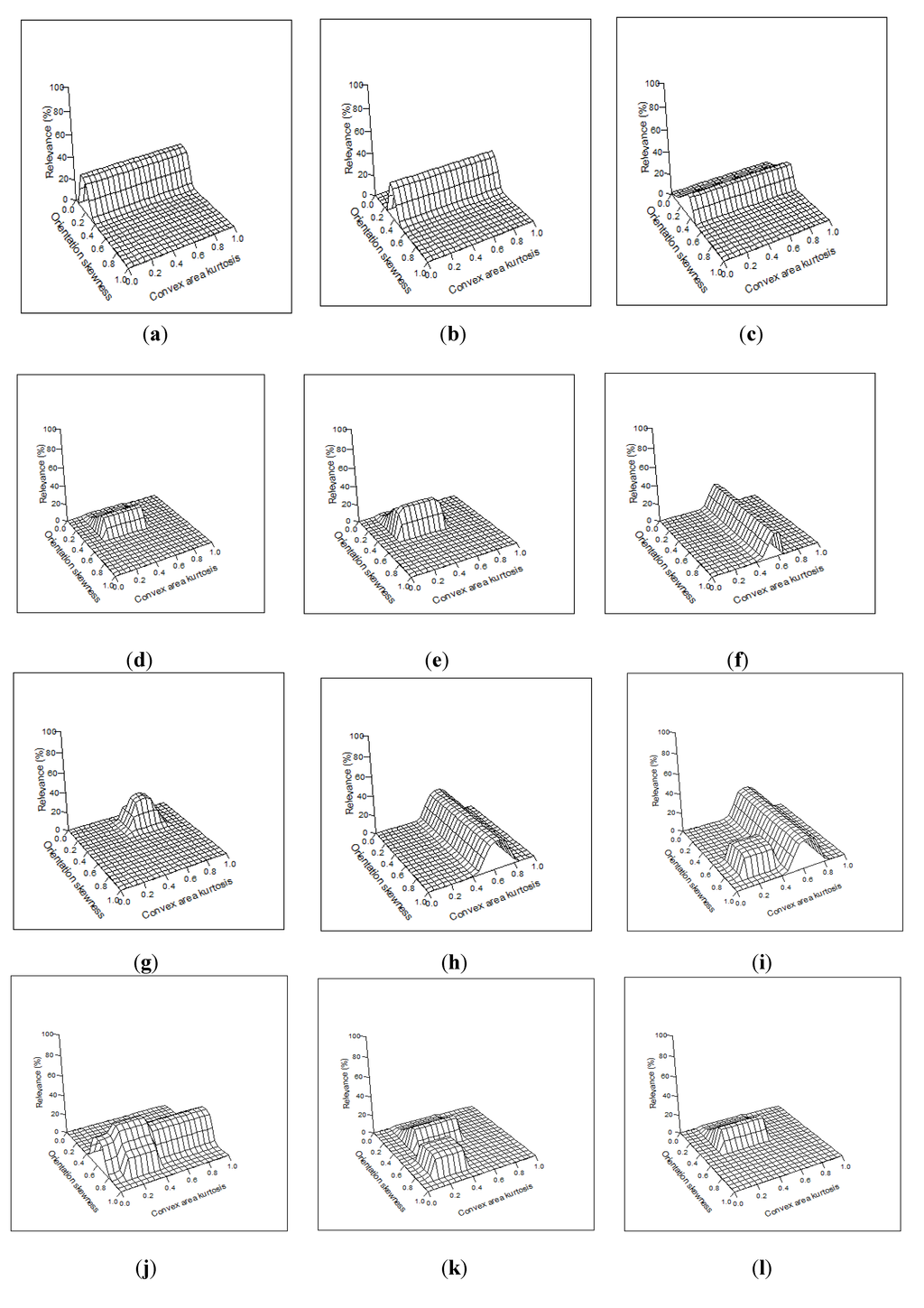
شکل 2. فلوچارت برای تولید یک مدل معنایی با استفاده از عملیات ژنتیکی.
شکل 2 فلوچارت برای تولید یک مدل معنایی با استفاده از عملیات ژنتیکی را نشان می دهد. پارامترهای ورودی برای این فرآیند یک مجموعه آموزشی حاوی ویژگی های تصویری است که توسط تحلیلگران تصویر با یک یا چند معناشناسی برچسب گذاری شده است. . این الگوریتم همچنین پارامترهای زیر را بهعنوان ورودی میگیرد: تعداد کروموزومها در هر نسل از جمعیت، حداکثر تعداد نسلها (تکرار) که الگوریتم اجرا میکند، و آستانهای در کیفیت رتبهبندی که الگوریتم برای آن خاتمه مییابد. الگوریتم با جمعیتی شروع می شود که در آن هر کروموزوم، ژن و اگزون به طور تصادفی تولید شده است. سپس کیفیت رتبه بندی با استفاده از اندازه گیری MAP ارزیابی شده و در رابطه (6) نشان داده شده است. سپس کروموزوم های برتر به عنوان والدین کروموزوم های نسل بعدی انتخاب می شوند که با استفاده از عملیات ژنتیکی توضیح داده شده در بخش 2.3 تولید می شود.. در نهایت، هنگامی که معیار خاتمه برآورده شد – یا کیفیت رتبه بندی کروموزوم برتر از آستانه از پیش تعیین شده فراتر رفت یا حداکثر تعداد تکرارها تکمیل شد – الگوریتم برازش ترین کروموزوم را برمی گرداند. این کروموزوم به یک مدل معنایی تبدیل می شود که برای رتبه بندی تصاویر جدید و بدون برچسب استفاده می شود.
. این الگوریتم همچنین پارامترهای زیر را بهعنوان ورودی میگیرد: تعداد کروموزومها در هر نسل از جمعیت، حداکثر تعداد نسلها (تکرار) که الگوریتم اجرا میکند، و آستانهای در کیفیت رتبهبندی که الگوریتم برای آن خاتمه مییابد. الگوریتم با جمعیتی شروع می شود که در آن هر کروموزوم، ژن و اگزون به طور تصادفی تولید شده است. سپس کیفیت رتبه بندی با استفاده از اندازه گیری MAP ارزیابی شده و در رابطه (6) نشان داده شده است. سپس کروموزوم های برتر به عنوان والدین کروموزوم های نسل بعدی انتخاب می شوند که با استفاده از عملیات ژنتیکی توضیح داده شده در بخش 2.3 تولید می شود.. در نهایت، هنگامی که معیار خاتمه برآورده شد – یا کیفیت رتبه بندی کروموزوم برتر از آستانه از پیش تعیین شده فراتر رفت یا حداکثر تعداد تکرارها تکمیل شد – الگوریتم برازش ترین کروموزوم را برمی گرداند. این کروموزوم به یک مدل معنایی تبدیل می شود که برای رتبه بندی تصاویر جدید و بدون برچسب استفاده می شود.3. ارزیابی
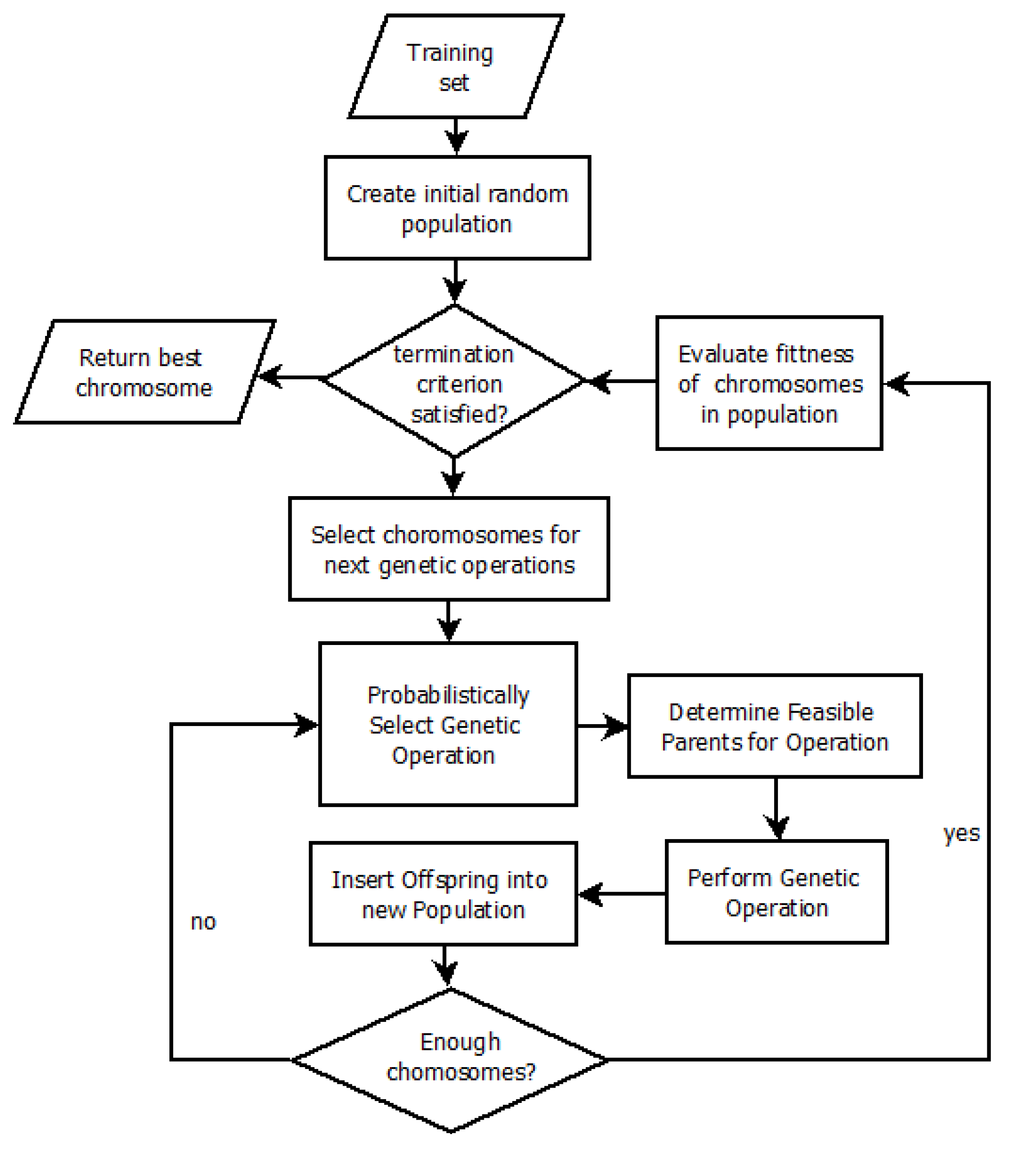
ما سه آزمایش را برای ارزیابی ارتباط استفاده از روشهای بهینهسازی ژنتیکی برای رتبهبندی تصاویر بر اساس معناشناسی طراحی کردیم: (1) عملکرد رویکرد پیشنهادی را در تعداد زیادی از عملیات ژنتیکی ارزیابی میکنیم. (2) ما یک ارزیابی مقایسه ای عمیق از Associative & SFFS و رویکرد پیشنهادی (Associative & Genetic) انجام می دهیم. و (3) ما عملکرد روش پیشنهادی را با شش روش دیگر مقایسه می کنیم. برای هر آزمایش ما از روش نشان داده شده در شکل 3 پیروی کردیم : ابتدا داده های اصلی با استفاده از یک استراتژی طبقه بندی شده به ده زیر مجموعه تقسیم شدند [ 45 ]] برای اطمینان از اینکه هر کلاس معنایی به طور متناسب در هر فولد نمایش داده می شود. سپس، با استفاده از رویکرد تکرار ده برابری، دادهها به آزمونهایی که شامل زیرمجموعهای متفاوت برای هر فولد بود و آموزش حاوی تاهای باقیمانده تفکیک شدند. سپس مدلهای رتبهبندی بر روی دادههای آموزشی ساخته شد و بر اساس دادههای آزمایشی مورد ارزیابی قرار گرفت. این رویکرد با Associative & SFFS متفاوت است زیرا دومی از روش زیر استفاده می کند: (1) از الگوریتم Apriori برای تولید تعداد زیادی زیرفضاهای ویژگی نامزد استفاده کنید. (2) تداعی های ایجاد شده را با میانگین هارمونیک اطمینان و پشتیبانی مرتب کنید. (3) مدل سیگموئید پارامتری را با استفاده از روش حداقل مربع با استفاده از توزیع داده ها در زیر فضای ویژگی ایجاد کنید. و (4) با افزودن و اعمال مکرر روش های SFFS به بهترین مدل کاندید، مدل های معنایی کاندید را تولید کنید.
برای آزمایشات خود از دو مجموعه داده استفاده کردیم: تصاویر ماهواره ای WROC 2010 از ویسکانسین [ 46 ] و ماهواره چند طیفی UCI Statlog Landsat [ 47 ]]. تصاویر ماهواره ای WROC 2010 شامل 18 کاشی تصویر GeoTIFF 3 باندی با ابعاد 15678 × 11105 پیکسل است که در بهار 2010 جمع آوری شد. برای هر کاشی، یک الگوریتم استخراج ویژگی اعمال شد که شامل موارد زیر میشود: برای رنگ، ویژگیها را از کانال خاکستری، R، G، B، H، S، V و همچنین بافت رنگ استخراج میکنیم. برای بافت، خودهمبستگی، کنتراست، همبستگی، انرژی، آنتروپی، گشتاور اختلاف معکوس و همگنی را استخراج می کنیم. برای اجسام، میانگین خاکستری، مساحت، مرکز، کادر محدود، طول محور اصلی و فرعی، خروج از مرکز، جهت، ناحیه محدب، ناحیه پر، عدد اویلر، قطر معادل، جامد، محیط و همخوانی فاز را استخراج میکنیم. ما استخراج ویژگی را با استفاده از جعبه ابزار پردازش تصویر از MatLab انجام می دهیم. برای هر یک از این ویژگی ها به طور متوسط، چارک، انحراف معیار، چولگی و کشیدگی محاسبه شد که منجر به یک بردار ویژگی 292 برای هر کاشی شد. علاوه بر این، ما تعدادی از 100 کاشی را انتخاب کردیم که با یک یا چند برچسب ازمنطقه شهری (L100)، کشاورزی (L110)، علفزار (L150)، جنگل (L160)، آبهای آزاد (L200)، تالاب (L210)، بایر ( L240 )، بوته زار ( L250 ). در این زیرمجموعه، تعدادی از 72 کاشی با دو معنیشناسی برچسبگذاری شدند: همپوشانی بیثمر ( L240 ) با کشاورزی (L110) در 26 کاشی، با Grassland (L150) در 4 کاشی، با جنگل (L160) در 5 کاشی، و با تالاب . (L210) در 4 کاشی. همچنین، بوته زار ( L250 ) با Grassland (L150) در 4 کاشی و با جنگل همپوشانی دارد.(L160) در 29 کاشی. مجموعه داده دوم، مجموعه داده های ماهواره چند طیفی UCI Statlog Landsat است که شامل 6435 تصویر ماهواره ای است که با یکی از شش نوع مختلف خاک برچسب گذاری شده است: خاک قرمز (L1)، محصول پنبه (L2)، خاک خاکستری (L3)، خاکستری مرطوب . خاک (L4)، خاک با کلش گیاهی (L5)، یا خاک خاکستری بسیار مرطوب(L7). برای هر تصویر، یک فضای ویژگی 36 بعدی با ویژگی مربوط به 9 مقدار شدت یک ناحیه 3 × 3 پیکسل (با مناطق همپوشانی) در دو باند طیفی مرئی و دو باند طیفی مادون قرمز نزدیک استخراج شد. مدلهای معنایی بر روی یک مجموعه آموزشی بهطور تصادفی انتخاب شدند که شامل 90 درصد دادهها است، در حالی که آزمایش بر روی 10 درصد باقیمانده دادهها انجام شد.
شکل 3. فلوچارت برای تنظیمات آزمایشی.
3.1. ارزیابی عمیق عملیات ژنتیکی در روش پیشنهادی
برای روش پیشنهادی، هر عمل ژنتیکی که بر روی جمعیت ژنتیکی انجام شده است را ثبت کرده ایم. این منجر به تعداد 90000 عملیات ژنتیکی برای آزمایشها روی مجموعه دادههای UCI Statlog Landsat و 120000 عملیات ژنتیکی برای آزمایشها روی مجموعه دادههای WROC شد. درصد برای هر عملیات جداگانه انجام شده در شکل 4 نشان داده شده است . برای مثال، عملیات متقاطع 57 درصد از تمام عملیاتهایی را تشکیل میدهد که به طور مساوی روی جهشهای کروموزوم و ژن توزیع شدهاند. با توجه به تصادفی بودن عملیات ژنتیکی، ما حداقل تغییرات صدک را برای آزمایشها روی دو مجموعه داده مشاهده کردیم.
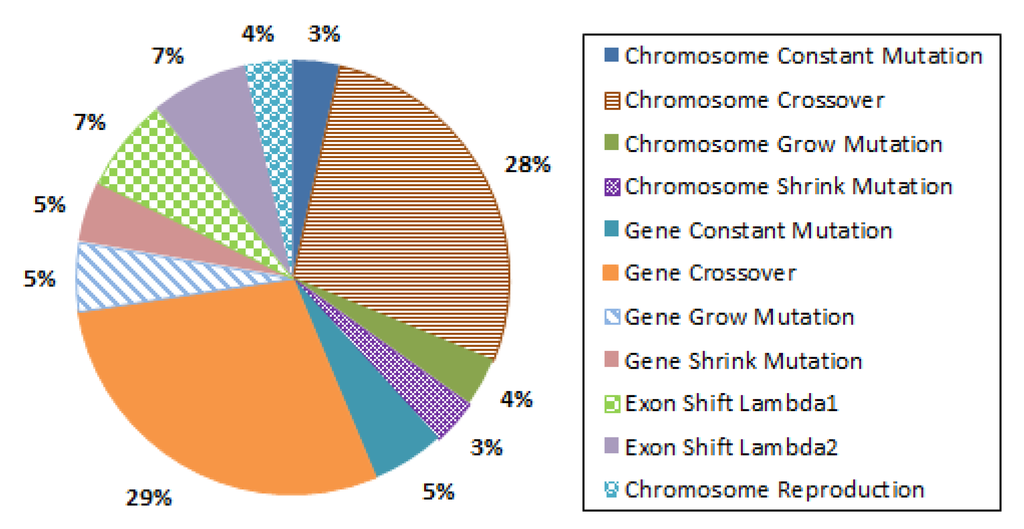
شکل 4. عملیات ژنتیکی به عنوان درصد در هنگام رتبه بندی تصاویر بر اساس معناشناسی انجام می شود.
ما همچنین عملیات ژنتیکی را ثبت کردهایم که منجر به بهترین عملکرد کروموزوم برای هر جمعیت جهشیافته برای هر ترکیب داده-مجموعه-معنای تا شد. از 21000 جمعیت جهش یافته، تنها 6491 مدل بهتر با 3517 و 2974 جمعیت برای مجموعه داده های UCI Statlog Landsat و WROC یا نرخ موفقیت جهش ژنتیکی 30.9 درصد را برگرداندند. شکل 5درصد عملیاتی را نشان می دهد که مدل های معنایی بهبود یافته را برمی گرداند. برای مثال، این شکل نشان میدهد که جهشهای متقاطع کلی کمتر از حد متوسط برای بهبود مدلهای معنایی کمک میکنند. آنها بهترین مدل ها را به ترتیب در 44 درصد و 34 درصد برای مجموعه داده های UCI Statlog Landsat و مجموعه داده های WROC برگرداندند. از سوی دیگر، جابهجایی اگزونها به ترتیب با درصدهای 22 و 33 درصد موفقترین در بهبود مدلهای معنایی بودند، اگرچه تنها 14 درصد از کل عملیات ژنتیکی را تشکیل میدادند. همچنین خاطرنشان می شود که کمترین احتمال بهبود مدل هایی با درصدهای کمتر از 0.5 درصد است.

شکل 5. عملیات ژنتیکی مربوطه به عنوان درصد هنگام رتبه بندی تصاویر بر اساس معناشناسی در ( الف ) مجموعه داده UCI Statlog Landsat و ( ب ) مجموعه داده های WROC.
3.2. ارزیابی عمیق روش های انجمنی برای رتبه بندی
برای ارزیابی تفاوت بین دو روش انجمنی (Associative & SFFS و Associative & Genetic) ما اندازه گیری MAP را در هر تکرار برای مجموعه داده آموزشی و آزمایشی ثبت کرده ایم. در این آزمایش، هر مدل تولید شده یک تکرار در نظر گرفته می شود. به عنوان مثال، روش Associative و Genetic با جمعیت 10 کروموزوم و 150 نسل، 1500 تکرار ایجاد می کند. در هر تکرار یک کروموزوم/مدل معنایی جدید ارزیابی می شود. به طور مشابه، برای روش Associative & SFFS، یک تکرار جدید با افزودن یک ارتباط جدید به مدل ایجاد میشود. شکل 6 ، شکل 7هنگام رتبهبندی تصاویر از مجموعه دادههای WROC برای Associative & SFFS و Associative & Genetic، محدوده MAP را نشان میدهد. نتایج مجموعه داده های UCI Statlog Landsat به دلیل کمبود فضا حذف شدند، اما از نظر رفتار مشابه هستند. به عنوان مثال، در شکل 6، در تکرار 1250 میانگین MAP برگردانده شده با روش Associative & SFFS در مجموعه آموزشی 72.33٪ و 59.99٪ در مجموعه تست بود. این نشان می دهد که به طور متوسط روش Associative & SFFS مدل را با داده های آموزشی به میزان 12.32 درصد اضافه می کند. برای همان تکرار، مقدار MAP بین 49.94٪ و 98.54٪ در مجموعه آموزشی و بین 30.81٪ و 87.71٪ برای مجموعه تست متغیر بود. همچنین، این شکل نشان میدهد که 150 تکرار آخر که MAP بهتری روی مجموعه آموزشی تولید کردهاند، مدل را بیش از حد برازش دادهاند، زیرا آنها MAP را در مجموعه آزمایشی 0.4٪ کاهش دادهاند.
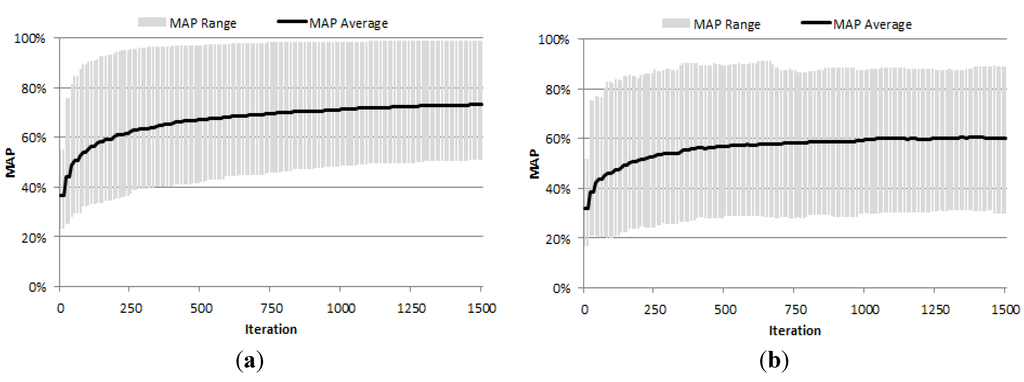
شکل 6. محدوده MAP بر اساس تکرار برای ( a ) آموزش و ( b ) مجموعه داده های آزمایشی هنگام رتبه بندی تصاویر از مجموعه داده WROC با استفاده از Associative & SFFS.

شکل 7. محدوده MAP بر اساس تکرار برای ( a ) آموزش و ( b ) مجموعه داده های آزمایشی هنگام رتبه بندی تصاویر از مجموعه داده WROC با استفاده از Associative & Genetic.
شکل 7 نتایج مشابهی را برای روش Associative & Genetic نشان می دهد. در تکرار 1250 میانگین MAP برگشتی با این روش به ترتیب 78.06% و 72.34% در مجموعه آموزش و تست بود. این نشان می دهد که به طور متوسط روش Associative & Genetic مدل را به طور متوسط 5.72٪ به داده های آموزشی اضافه می کند که کمتر از نیمی از تغییرات اندازه گیری شده برای Associative & SFFS است. به طور مشابه، دامنه مقادیر MAP نسبت به روش Associative و SFFS با مقادیر بین 53.09٪ و 98.86٪ برای مجموعه آموزشی و 44.45٪ و 97.27٪ برای مجموعه تست، کوچکتر بود. برای همان تکرار، مقدار MAP بین 49.94٪ و 98.54٪ در مجموعه آموزشی و بین 30.81٪ و 87.71٪ برای مجموعه تست متغیر بود.
نتایج در این شکلها نشان میدهد که مزایای روش Associative و Genetic به دو صورت است: (الف) مدلهای آموزشدیده بهتر که میانگین MAP بالاتری را در دادههای آموزشی به دست میآورند و (ب) بیش از حد برازش مدلها با دادههای آموزشی. برای ارزیابی بیشتر دلایل برازش روشهای Associative و SFFS، ما همچنین تعداد قوانین را در مدلهای معنایی تولید شده توسط دو روش ثبت کردیم. نتایج این آزمایش در شکل 8 برای مجموعه داده های UCI Statlog Landsat و در شکل 9 برای مجموعه داده های WROC نشان داده شده است. به عنوان مثال، در شکل 8(الف)، میانگین تعداد قوانین در یک مدل معنایی تولید شده توسط Associative و SFFS در تکرار 1250 در مجموعه داده UCI Statlog Landsat 65.25٪ با حداقل و حداکثر 27 و 1224 قانون است. برای همان تکرار و مجموعه داده، روش Associative & Genetic به طور متوسط 12.85 قانون با حداقل و حداکثر 4 و 18 قانون را برگرداند. این نشان میدهد که مزیت روش پیشنهادی نسبت به Associative & SFFS توسط مدلهای صرفهجویی [ 48 ] آن ارائه میشود که بهطور متوسط، پنج برابر اندازه کوچکتر هستند.

شکل 8. محدوده شمارش قوانین بر اساس تصاویر رتبه بندی تکراری با استفاده از روش Associative & SFFS در ( a ) UCI Statlog Landsat و ( b ) مجموعه داده های WROX.

شکل 9. محدوده شمارش قوانین بر اساس تصاویر رتبه بندی تکراری با استفاده از روش Associative & Genetic در ( الف ) UCI Statlog Landsat و ( ب ) مجموعه داده های WROX.
3.3. مطالعه تطبیقی رتبه بندی عملکرد
برای این آزمایش، ما هفت آزمایش رتبهبندی ده برابری را طراحی کردیم: (1) انجمن افزایشی همراه با SFFS [ 8 ]، (2) رتبهبندی گروهی با استفاده از شبکههای عصبی مصنوعی (ANN) [ 49 ] با AdaBoost [ 50 ]، (3) رتبه بندی گروه با استفاده از درخت تصمیم C4.5 (C4.5) [ 27 ] با AdaBoost، (4) درختان مدل لجستیک [ 51 ]، (5) رتبه بندی گروه با استفاده از TreeRank با هسته SVM [ 52 ]، (6) رتبه بندی گروه با استفاده از جنگل درختی با هسته SVM [ 52 ] و (7) رتبه بندی انجمنی افزودنی همراه با عملیات ژنتیکی همانطور که در بخش 2 توضیح داده شد . همه این آزمایش ها در محیط آماری R [ 53 ] اجرا شد]. برای آزمایشهای (2) تا (6) از بستههای موجود در R استفاده کردهایم. برای آزمایشهای (1) و (7) از 1500 مرحله بهینهسازی استفاده کردهایم. داده ها با استفاده از الگوریتم Boruta [ 54 ] برای انتخاب متغیر پیش پردازش شدند.
شکل 10مقایسه ای از هفت روش برای رتبه بندی تصاویر در دو مجموعه داده توصیف شده در بالا با استفاده از میانگین میانگین دقت (MAP) رتبه بندی را نشان می دهد. هنگام رتبهبندی تصاویر از مجموعه دادههای UCI Statlog Landsat، روش پیشنهادی بهترین نتایج را با میانگین MAP 87.93٪ و به دنبال آن LMT با MAP 86.11٪ به دست آورد. هر دو روش انحراف استاندارد پایین 2.49% برای روش Associative & Genetic و 3.44% برای LMT را نشان دادند. عملکرد پایین توسط ANN و Adaboost – که مستعد بیش از حد برازش است – و SVM & TreeRank – که یک روش غیر گروهی است – به ترتیب با میانگین MAP 66.01٪ و 71.79٪ بازگشت داده شد. این دو روش همچنین انحراف استاندارد بالاتری از MAP را به ترتیب با 6.56% و 6.61% نشان دادند. هنگام رتبهبندی تصاویر از مجموعه دادههای WROC، روش پیشنهادی بهترین نتایج را با میانگین MAP 73 بازیابی کرد. 30٪ در کنار SVM & TreeForest با نقشه 74.26٪. با این حال، روش پیشنهادی انحراف استاندارد کمی کمتر را در 9.55٪ در مقایسه با 10.29٪ برای SVM & TreeForest نشان داد. LMT برای این مجموعه داده پس از C4.5 و Adaboost در رتبه چهارم قرار گرفت. مشابه نتایج قبلی، عملکرد پایین توسط ANN & Adaboost، Associative & SFFS، و SVM & TreeRank به ترتیب با میانگین MAP 59.06٪، 60.12٪ و 60.47٪ بازگردانده شد.
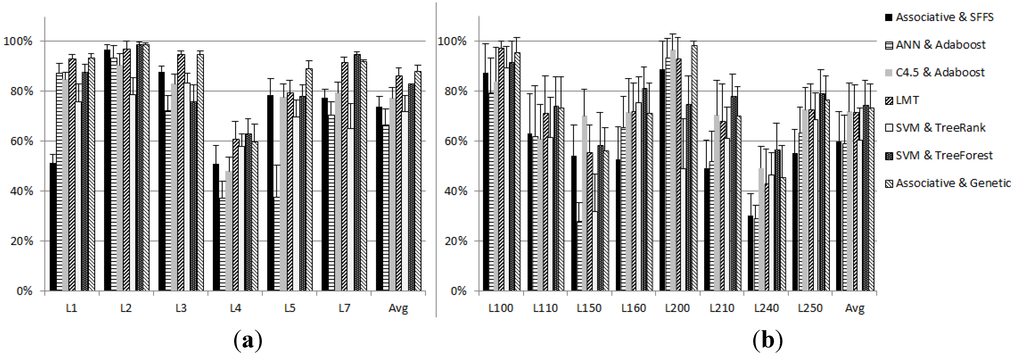
شکل 10. نتایج MAP برای آزمایشهای مقایسهای برای رتبهبندی تصاویر بر اساس معناشناسی با استفاده از روشهای رتبهبندی مختلف در ( الف ) مجموعه دادههای UCI Statlog Landsat و ( ب ) مجموعه دادههای WROC.
هنگام بررسی نتایج MAP برای هر برچسب معنایی، ما تغییرات گسترده ای را در عملکرد مشاهده می کنیم. برای مثال، روش Associative & SFFS هنگام رتبهبندی خاک قرمز معنایی (L1) در مجموعه دادههای UCI Statlog Landsat، MAP 51.25% را برمیگرداند. این 24.65٪ کمتر از روش بعدی (SVM & TreeRank) است. در همان مجموعه داده، روش ANN و Adaboost MAP بسیار کم را برای خاک خاکستری مرطوب (L4) و خاک با کلش گیاهی (L5) با مقادیر MAP 37.40٪ و 37.80٪ نشان می دهد. ANN & Adabost همچنین عملکرد پایینی را برای Grassland (L150) و Barren ارائه کردند(L240) معنای مجموعه داده های WROC با مقادیر MAP 27.92٪ و 29.15٪ به ترتیب. تغییرات در روشهای با عملکرد برتر نیز مشاهده میشود: روش پیشنهادی هنگام رتبهبندی پنج معنایی در بین دو مجموعه داده بهترین است، در حالی که SVM و TreeRank هنگام رتبهبندی نه معنایی در بین دو مجموعه داده بهترین هستند. با این حال، به طور متوسط، روش پیشنهادی بهترین نتایج را در بین دو مجموعه داده با میانگین 80.61٪، به دنبال LMT با 78.85٪ و SVM & TreeForest با 78.69٪ به دست آورد. این رفتار سازگارتر روش پیشنهادی را با احتمال کمتر برازش/زیاد برازش نشان میدهد.
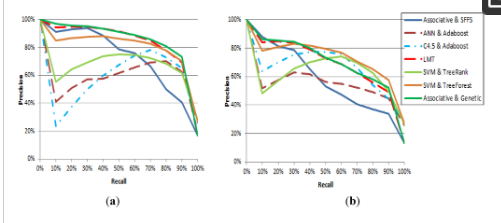
برای تجزیه و تحلیل عمیق تر از دقت نتایج رتبه بندی شده، معیارهای دقیق و یادآوری را ارائه می دهیم. دقت اندازه گیری می کند که چه تعداد از تصاویر بازیابی شده در جستجوی معنایی واقعاً مرتبط هستند، در حالی که یادآوری اندازه گیری می کند که چه تعداد از تصاویر مرتبط با معنایی هدف واقعاً بازیابی شده اند. شکل 11معیارهای فراخوان دقیق درون یابی شده را برای هفت روش رتبه بندی نشان می دهد. به عنوان مثال، هنگام رتبهبندی تصاویر از مجموعه دادههای UCI Statlog Landsat، روش پیشنهادی به طور متوسط دقت 95.47% را هنگام فراخوانی 20% از تصاویر مربوطه برمیگرداند. برای همان مجموعه داده ها و سطح فراخوان، LMT 94.76٪ بازده در حالی که SVM & TreeForest بازده 86.61٪. نتایج روی مجموعه دادههای WROC نشان میدهد که روش پیشنهادی بهترین دقت را در نرخهای فراخوان پایینتر از 30 درصد برمیگرداند اما در سطوح بالاتر فراخوان بدتر عمل میکند. به عنوان مثال، در مجموعه دادههای WROC و فراخوانی 60%، روش Associative & Genetic با دقت 68.81% پس از SVM & TreeForest، C4.5 و Adaboost، و SVM & TreeRank با دقت 77.09% در رتبه چهارم قرار میگیرد. به ترتیب 75.85 درصد و 74.01 درصد. این روند برای روش Associative & SFFS نیز مشاهده میشود که سه عملکرد برتر برای فراخوانهای کمتر از 20 درصد است اما در سطوح بالاتر کاهش عملکرد را نشان میدهد. Associative & SFFS، Associative & Genetic، و LMT کمترین سطوح دقت را در 100% یادآوری نشان میدهند که به این واقعیت اشاره دارد که این روشها نمیتوانند کل جهان ویژگی را پوشش دهند و در نتیجه برخی از تصاویر را رتبهبندی نمیکنند. این نشان می دهد که برخی از مشکلات بیش از حد مدل های ایجاد شده با استفاده از این روش ها که برای روش هایی مانند SVM & TreeForest، SVM & TreeRank یا C4.5 و Adaboost کمتر مشهود هستند. و LMT کمترین سطوح دقت را در یادآوری 100% نشان میدهند که به این واقعیت اشاره دارد که این روشها نمیتوانند کل جهان ویژگی را پوشش دهند، و در نتیجه برخی از تصاویر را رتبهبندی نمیکنند. این نشان می دهد که برخی از مشکلات بیش از حد مدل های ایجاد شده با استفاده از این روش ها که برای روش هایی مانند SVM & TreeForest، SVM & TreeRank یا C4.5 و Adaboost کمتر مشهود هستند. و LMT کمترین سطوح دقت را در یادآوری 100% نشان میدهند که به این واقعیت اشاره دارد که این روشها نمیتوانند کل جهان ویژگی را پوشش دهند، و در نتیجه برخی از تصاویر را رتبهبندی نمیکنند. این نشان می دهد که برخی از مشکلات بیش از حد مدل های ایجاد شده با استفاده از این روش ها که برای روش هایی مانند SVM & TreeForest، SVM & TreeRank یا C4.5 و Adaboost کمتر مشهود هستند.
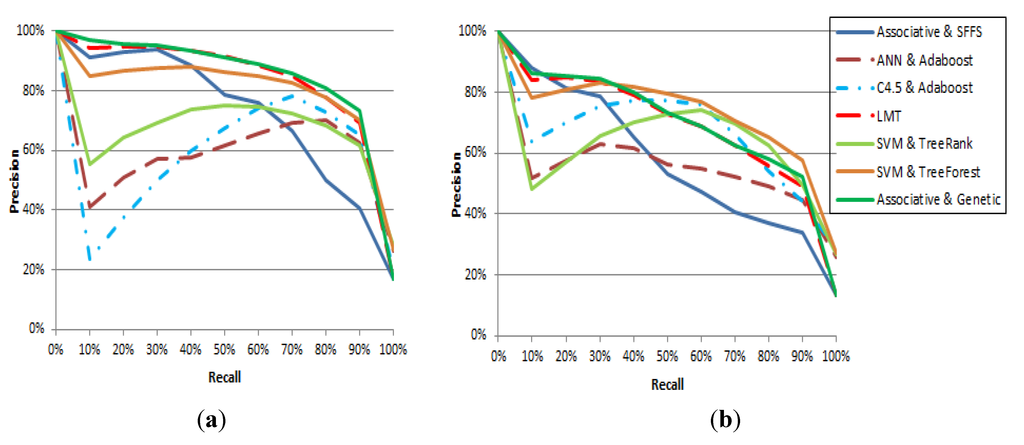
شکل 11. میانگین نتایج فراخوان دقیق برای آزمایشهای مقایسهای برای رتبهبندی تصاویر بر اساس معناشناسی با استفاده از هفت روش رتبهبندی مختلف در ( الف ) مجموعه دادههای UCI Statlog Landsat و ( ب ) مجموعه دادههای WROC.
به طور کلی، نتیجه گیری ما برای این آزمایش این است که چندین دلیل وجود دارد که باعث ایجاد تغییرات در عملکرد روش هایی می شود که ما تحلیل کردیم. به عنوان مثال، Associative & SFFS قادر است تنها آن دسته از تصاویری را رتبه بندی کند که الگوریتم Apriori برای آنها پیوندهای قوی را برگرداند و کاهش دقت در مقادیر فراخوان بالا نشان می دهد که برخی از تصاویر وجود دارند که در هیچ زیرفضای ویژگی تولید شده نگاشت نشده اند. الگوریتم SVM & TreeRank تنها الگوریتمی است که از روشهای گروهی استفاده نمیکند و احتمالاً بیش از حد برازش میکند. مشاهده می کنیم که کیفیت رتبه بندی به طور قابل توجهی افزایش می یابد، زمانی که رویه های گروه جایگزین TreeRank شوند. برازش بیش از حد احتمالاً دلیل عملکرد ضعیف است که توسط ANN و AdaBoost بازگردانده شده است که به شدت به ویژگی شبکه عصبی در حالی که C4 بستگی دارد.
4. نتیجه گیری و کار آینده
ما یک رویکرد برای تولید مدلهای انجمنی برای رتبهبندی مناطق تصویر ماهوارهای بر اساس پوشش زمین ایجاد کردهایم. نتایج مطالعات تطبیقی ما نشان میدهد که روش پیشنهادی عملکرد بهتری دارد یا عملکردی مشابه با روشهای دیگر مجموعه دارد. روش ما از روشهای ژنتیکی برای بازگرداندن دقت بهتر در دادههای آزمایشنشده جدید استفاده میکند، در حالی که با کاهش حداقلهای محلی موجود در مدلهای افزایشی، از برازش بیش از حد جلوگیری میکند. به طور کلی نتایج ما نشان می دهد که روش ژنتیکی قوانین ارتباط بهتری را سریعتر از روش افزایشی موجود کشف کرد. این نشان میدهد که روشهای تداعی جایگزینهای امیدوارکنندهای برای الگوهای بصری موجود در تصاویر ارائه میدهند، اگرچه آنها مستعد بیش از حد برازش هستند. کلید موفقیت آنها یک روش یادگیری کافی است که بتواند از حداقل های محلی جلوگیری کند. رویکردهای انجمنی قبلی از الگوریتمهای استخراج قانون انجمن برای شناسایی فضاهای ویژگی مربوطه استفاده میکنند، اما از اندازهگیری ناکافی مربوط به قوانین انجمن، مانند پشتیبانی و اطمینان رنج میبرند، که برای رتبهبندی مسائل بهینه نیستند. اگرچه آزمایشهای ما در مقایسه با سایر روشهای پیشرفته، شواهد روشنی از برتری روش پیشنهادی ارائه نکرد، اما درک آسان ماهیت مدلهای تولید شده، برای تحقیقات آینده در زمینههایی مانند تخصص و تخصص مفید است. آموزش تحلیلگران تصویر مدلهای ژنتیکی همچنین دارای مزیت انتخاب تصادفی و آزمایش زیرفضاهای ویژگی جدید هستند که منجر به مدلهای بهتر در زمان کوتاهتر میشود. اگرچه به طور خاص اندازه گیری نشده است، اما زمان آموزش یک جزء مهم در هر الگوریتم رتبه بندی است. مانند هر روش گروه دیگری، آموزش روش پیشنهادی متناسب با اندازه مجموعه آموزشی، تعداد قوانین در یک مدل معنایی و تعداد تکرارها است. این یک پیشرفت نسبت به روشهای SFFS است که کاهش تعداد قوانین در یک مدل نیازمند پیچیدگی درجه دوم تعداد قوانین است.
کار آینده ما شامل یک ارزیابی جامع تر در مورد روش های مختلف تصویر و مجموعه های معنایی است، به ویژه برای مجموعه داده هایی که الگوهای بصری همپوشانی را نشان می دهند و رتبه بندی آنها دشوارتر است. به طور خاص در مورد عملیات ژنتیکی، ما قصد داریم ترکیب بهتری از عملیات ژنتیکی را ارزیابی کنیم که عملکرد را بیشتر بهبود بخشد. ما همچنین می خواهیم به زمان آموزش بپردازیم، که یک نقص شناخته شده در روش های گروهی است. رتبهبندی تصاویر متقابل منطقهای نیز حوزهای برای تحقیقات آینده است، زیرا روشهای رتبهبندی برای دادههای مناطق مختلف جهان، دقت کمتری را نشان میدهند.
منابع
- داتکو، ام. سیدل، ک. مفاهیم انسان محور برای کاوش و درک تصاویر رصد زمین. IEEE Trans. Geosci. Remote Sens. 2005 ، 43 ، 601-609. [ Google Scholar ] [ CrossRef ]
- Tseng، M.-H.; چن، اس.-جی. هوانگ، جی.-اچ. شن، ام.-ای. یک رویکرد مبتنی بر قانون الگوریتم ژنتیک برای طبقهبندی پوشش زمین ISPRS J. Photogramm. 2008 ، 63 ، 202-212. [ Google Scholar ] [ CrossRef ]
- منیس، جی. گوو، دی. داده کاوی فضایی و کشف دانش جغرافیایی – مقدمه. محاسبه کنید. محیط زیست سیستم شهری 2009 ، 33 ، 403-408. [ Google Scholar ] [ CrossRef ]
- داتکو، ام. سیدل، ک. کاوی اطلاعات تصویر: کاوش محتوای تصویر در آرشیوهای بزرگ. در مجموعه مقالات کنفرانس هوافضای IEEE 2000، Big Sky، MT، ایالات متحده آمریکا، 18-25 مارس 2000. جلد 3، ص 253-264.
- هسو، دبلیو. لی، ام ال. ژانگ، جی. تصویر کاوی: روندها و تحولات. جی. اینتل. Inf. سیستم 2002 ، 19 ، 7-23. [ Google Scholar ] [ CrossRef ]
- لیو، ی. ژانگ، دی. لو، جی. ما، W.-Y. بررسی بازیابی تصویر مبتنی بر محتوا با معناشناسی سطح بالا. تشخیص الگو 2007 ، 40 ، 262-282. [ Google Scholar ]
- آکسوی، اس. Cinbis، R. تصویر کاوی با استفاده از محدودیت های فضایی جهت دار. IEEE Geosci. سنسور از راه دور Lett. 2010 ، 7 ، 33-37. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بارب، ا. شیو، سی.- آر. مدلسازی بصری- معنایی در بازیابی اطلاعات مکانی مبتنی بر محتوا با استفاده از تکنیکهای کاوی انجمنی. IEEE Geosci. سنسور از راه دور Lett. 2010 ، 7 ، 38-42. [ Google Scholar ] [ CrossRef ]
- بلانچارت، پ. Datcu، M. یک الگوریتم نیمه نظارت شده برای حاشیه نویسی خودکار و کشف ساختارهای ناشناخته در پایگاه داده های تصاویر ماهواره ای. IEEE J. انتخاب کنید. موضوعات کاربردی رصد زمین. Remote Sens. 2010 ، 3 ، 698-717. [ Google Scholar ] [ CrossRef ]
- براتاسانو، دی. ندلکو، آی. Datcu، M. پل زدن شکاف معنایی برای حاشیه نویسی تصاویر ماهواره ای و برنامه های نقشه برداری خودکار. IEEE J. انتخاب کنید. موضوعات کاربردی رصد زمین. Remote Sens. 2011 ، 4 ، 193-204. [ Google Scholar ] [ CrossRef ]
- دوربا، اس. کینگ، آر. چارچوب فعال معناشناسی برای کشف دانش از آرشیو داده های رصد زمین. IEEE Trans. Geosci. Remote Sens. 2005 ، 43 ، 2563-2572. [ Google Scholar ] [ CrossRef ]
- کلاریچ، م. اسکات، جی. شیو، سی.- آر. بازیابی مبتنی بر محتوای چند شیء چند شاخصه. IEEE Trans. Geosci. Remote Sens. 2012 , 50 , 4036–4049. [ Google Scholar ] [ CrossRef ]
- لینو، م. مایتر، اچ. Datcu، M. حاشیه نویسی معنایی تصاویر ماهواره ای با استفاده از تخصیص دیریکله نهفته. IEEE Geosci. سنسور از راه دور Lett. 2010 ، 7 ، 28-32. [ Google Scholar ] [ CrossRef ]
- مولینیر، ام. لاکسونن، جی. Hame، T. تشخیص ساختارهای دستساز و تغییرات در تصاویر ماهوارهای با یک سیستم بازیابی اطلاعات مبتنی بر محتوا که بر روی نقشههای خود سازماندهی شده است. IEEE Trans. Geosci. Remote Sens. 2007 , 45 , 861-874. [ Google Scholar ] [ CrossRef ]
- اسکات، جی. کلاریچ، م. دیویس، سی. شیو، سی.- آر. درخت بیت مپ متعادل با آنتروپی برای بازیابی اشیاء مبتنی بر شکل از پایگاه داده های تصاویر ماهواره ای در مقیاس بزرگ. IEEE Trans. Geosci. Remote Sens. 2011 ، 49 ، 1603-1616. [ Google Scholar ] [ CrossRef ]
- شیو، سی.-ر. کلاریچ، م. اسکات، جی جی; بارب، ع. دیویس، CH; Palaniappan، K. GeoIRIS: بازیابی اطلاعات مکانی و سیستم نمایه سازی – محتوا کاوی، مدل سازی معناشناسی، و پرس و جوهای پیچیده. IEEE Trans. Geosci. Remote Sens. 2007 , 45 , 839-852. [ Google Scholar ] [ CrossRef ]
- Sjahputera، O. اسکات، جی. کلایول، بی. کلاریچ، م. هادسون، ن. کلر، جی. دیویس، سی. خوشه بندی تغییرات شناسایی شده در تصاویر ماهواره ای با وضوح بالا با استفاده از یک الگوریتم تراکم رقابتی تثبیت شده. IEEE Trans. Geosci. Remote Sens. 2011 , 49 , 4687–4703. [ Google Scholar ] [ CrossRef ]
- لی، دبلیو. راسکین، آر. Goodchild، M. سنجش تشابه معنایی مبتنی بر دانش کاوی: یک رویکرد شبکه عصبی مصنوعی. بین المللی جی. جئوگر. Inf. علمی 2012 ، 26 ، 1415-1435. [ Google Scholar ] [ CrossRef ]
- آگراوال، آر. ایمیلینسکی، تی. سوامی، الف. قوانین انجمن معدن بین مجموعه ای از آیتم ها در پایگاه های داده بزرگ. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD در سال 1993 در مدیریت داده ها (SIGMOD ’93)، واشنگتن، دی سی، ایالات متحده آمریکا، 26-28 مه 1993. ص 207-216.
- آگراوال، آر. Srikant، R. الگوریتم های سریع برای قوانین انجمن معدن در پایگاه های داده بزرگ. در مجموعه مقالات بیستمین کنفرانس بین المللی پایگاه های داده بسیار بزرگ (VLDB ’94)، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 12 تا 15 سپتامبر 1994. ص 487-499.
- لدنر، آر. پتری، FE; Cobb، MA فازی رویکردهایی را برای داده کاوی مکانی قوانین تداعی مجموعه ای تنظیم کرد. ترانس. GIS 2003 ، 7 ، 123-138. [ Google Scholar ]
- هوانگ، ی. چانگ، تی. Kao, L. استفاده از استراتژی SOM فازی برای بازیابی تصاویر ماهواره ای و استخراج اطلاعات. جی. سیست. سایبرن. Inf. 2008 ، 6 ، 56-61. [ Google Scholar ]
- ثبتاه، اف. بررسی معادن طبقه بندی انجمنی. بدانید. مهندس Rev. 2007 , 22 , 37-65. [ Google Scholar ] [ CrossRef ]
- هستی، تی. طبشیرانی، ر. Friedman, J. The Elements of Statistical Learning, Ser ; Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2009. [ Google Scholar ]
- بلوم، آل. Langley, P. انتخاب ویژگی ها و مثال های مرتبط در یادگیری ماشین. آرتیف. هوشمند 1997 ، 97 ، 245-271. [ Google Scholar ] [ CrossRef ]
- لی، دبلیو. هان، جی. Pei, J. CMAR: طبقهبندی دقیق و کارآمد بر اساس قوانین انجمنهای چندگانه. در مجموعه مقالات کنفرانس بین المللی IEEE در مورد داده کاوی (ICDM 2001)، سن خوزه، کالیفرنیا، ایالات متحده آمریکا، 29 نوامبر تا 2 دسامبر 2001. صص 369-376.
- Quinlan, J. بهبود استفاده از ویژگی های پیوسته در C4.5. جی آرتیف. هوشمند Res. 1996 ، 4 ، 77-90. [ Google Scholar ]
- پودیل، پ. نووویکووا، جی. کیتلر، جی. روش های جستجوی شناور در انتخاب ویژگی. تشخیص الگو Lett. 1994 ، 15 ، 1119-1125. [ Google Scholar ] [ CrossRef ]
- ریبیرو، MX؛ بوگاتی، PH; ترینا، سی، جونیور؛ مارکز، PMA; رزا، NA; Traina، AJM پشتیبانی از بازیابی تصویر مبتنی بر محتوا و سیستمهای تشخیص به کمک رایانه با تکنیکهای مبتنی بر قوانین مرتبط. دانستن داده ها مهندس 2009 ، 68 ، 1370-1382. [ Google Scholar ] [ CrossRef ]
- Freitas، A. مروری بر الگوریتم های تکاملی برای داده کاوی. در کتاب داده کاوی و کشف دانش ; Maimon, O., Rokach, L., Eds. Springer: New York, NY, USA, 2010; صص 371-400. [ Google Scholar ]
- گلدبرگ، الگوریتمهای ژنتیک DE در جستجو، بهینهسازی و یادگیری ماشین ، ویرایش اول. Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1989. [ Google Scholar ]
- هالند، سازگاری JH در سیستمهای طبیعی و مصنوعی: تحلیل مقدماتی با کاربردهای زیستشناسی، کنترل و هوش مصنوعی . انتشارات MIT: کمبریج، MA، ایالات متحده آمریکا، 1992. [ Google Scholar ]
- مامان، اچ. ایسون، جی. Kuszmaul, J. ارزیابی استفاده از اطلاعات طیفی و بافتی توسط یک الگوریتم تکاملی برای طبقه بندی تصاویر چند طیفی. محاسبه کنید. محیط زیست سیستم شهری 2009 ، 33 ، 463-471. [ Google Scholar ] [ CrossRef ]
- شاد، ر. مسگری، ام اس; آبکار، ع. شاد، الف. پیش بینی آلودگی هوا با استفاده از کریجینگ عضویت خطی ژنتیکی فازی در GIS. محاسبه کنید. محیط زیست سیستم شهری 2009 ، 33 ، 472-481. [ Google Scholar ]
- ژانگ، ایکس. وانگ، جی. وو، اف. فن، ز. Li، X. یک خوشه بندی فضایی جدید با محدودیت های موانع بر اساس الگوریتم های ژنتیک و k-Medoids. در مجموعه مقالات ششمین کنفرانس بین المللی طراحی و کاربردهای سیستم های هوشمند (ISDA ’06)، واشنگتن، دی سی، ایالات متحده آمریکا، 16-18 اکتبر 2006. جلد 1، ص 605–610.
- گائو، ال. دای، اس. ژنگ، اس. Yan, G. استفاده از الگوریتم ژنتیک برای بهینه سازی داده کاوی در یک پایگاه داده تصویر. در مجموعه مقالات چهارمین کنفرانس بین المللی سیستم های فازی و کشف دانش (FSKD 2007)، هایکو، هاینان، چین، 24-27 اوت 2007. جلد 3، ص 721–723.
- Bandyopadhyay، S.; Maulik، U. Mukhopadhyay، A. خوشه بندی ژنتیکی چند هدفه برای طبقه بندی پیکسل در تصاویر سنجش از دور. IEEE Trans. Geosci. Remote Sens. 2007 , 45 , 1506-1511. [ Google Scholar ] [ CrossRef ]
- دی استفانو، سی. فونتانلا، اف. Marrocco, C. الگوریتم انتخاب ویژگی مبتنی بر GA برای تصاویر سنجش از دور. در مجموعه مقالات کنفرانس 2008 در مورد کاربردهای محاسبات تکاملی (Evo’08)، ناپل، ایتالیا، 26 مارس 2008. Springer-Verlag: برلین/هایدلبرگ، آلمان؛ ص 285-294.
- داسیلوا، اس.اف. ریبیرو، MX؛ باتیستا نتو، جیدز; ترینا، سی، جونیور؛ Traina، AJM بهبود کیفیت رتبه بندی بازیابی تصویر پزشکی با استفاده از روش انتخاب ویژگی ژنتیکی. تصمیم می گیرد. سیستم پشتیبانی 2011 ، 51 ، 810-820. [ Google Scholar ] [ CrossRef ]
- محروقی، م. یونان، ن. آنانتارج، وی. آنستوس، ج. یاراحمدیان، س. در مورد استفاده از تکنیک انتخاب ویژگی مبتنی بر فیلتر الگوریتم ژنتیک برای تخمین بارش ماهواره ای. IEEE Geosci. سنسور از راه دور Lett. 2012 ، 9 ، 963-967. [ Google Scholar ] [ CrossRef ]
- بارب، ع. روشهای ژنتیکی Barb، CS برای رتبهبندی معنایی انجمنی مناطق تصویر Landsat بر اساس پوشش زمین. در مجموعه مقالات کارگاه آموزشی کاوی اطلاعات تصویری، Oberpfaffenhofen، آلمان، 24-26 اکتبر 2012; آژانس فضایی اروپا و کمیسیون های تحقیقات مشترک: Oberpfaffenhofen، آلمان. صص 102-105.
- Syswerda, G. A Study of Reproduction in Generational and Staady-state Genetic Algorithms. در مجموعه اولین کارگاه آموزشی مبانی الگوریتم های ژنتیک، پردیس بلومینگتون، IN، ایالات متحده آمریکا، 15-18 ژوئیه 1990. صص 94-101.
- واوک، ف. فوگارتی، تی. مقایسه الگوریتمهای ژنتیک حالت پایدار و نسلی برای استفاده در محیطهای غیر ساکن. در مجموعه مقالات کنفرانس بین المللی IEEE در محاسبات تکاملی، ناگویا، ژاپن، 20-22 مه 1996. صص 192-195.
- Davis, L. Handbook of Genetic Algorithms ; ون نوستراند راینهولد: نیویورک، نیویورک، ایالات متحده آمریکا، 1991. [ Google Scholar ]
- شووه، جی. Tillé، Y. یک الگوریتم سریع برای نمونه برداری متعادل. محاسبه کنید. آمار 2006 ، 21 ، 53-62. [ Google Scholar ] [ CrossRef ]
- کنسرسیوم ارتفوتوگرافی منطقه ای ویسکانسین (WROC). 2012. در دسترس آنلاین: http://www.ncwrpc.org/WROC/ (در 1 اوت 2012 قابل دسترسی است).
- آسونسیون، آ. Newman، DJ UCI Machine Learning Repository. 2007. در دسترس آنلاین: http://www.ics.uci.edu/∼mlearn/MLRepository.html (در 1 مارس 2012 قابل دسترسی است).
- Sober, E. مشکل سادگی چیست؟ Zellner, A., Keuzenkamp, H., McAleer, M., Eds. انتشارات دانشگاه کمبریج: کمبریج، انگلستان، 2002. [ Google Scholar ]
- Bishop, C. Neural Networks for Pattern Recognition , 1st ed; انتشارات دانشگاه آکسفورد: نیویورک، نیویورک، ایالات متحده آمریکا، 1996. [ Google Scholar ]
- فروند، ی. Schapire، R. یک تعمیم نظری تصمیم گیری از یادگیری آنلاین و یک کاربرد برای تقویت. جی. کامپیوتر. سیستم علمی 1997 ، 55 ، 119-139. [ Google Scholar ] [ CrossRef ]
- لندور، ن. هال، م. فرانک، ای. درختان مدل لجستیک. ماخ فرا گرفتن. 2005 ، 59 ، 161-205. [ Google Scholar ] [ CrossRef ]
- کلمنکن، اس. Vayatis، N. روش های رتبه بندی مبتنی بر درخت. IEEE Trans. Inf. نظریه 2009 ، 55 ، 4316-4336. [ Google Scholar ] [ CrossRef ]
- تیم اصلی توسعه R. R: زبان و محیطی برای محاسبات آماری، R Foundation for Statistical Computing ; وین، اتریش، 2011. در دسترس آنلاین: http://www.R-project.org (در 1 نوامبر 2012 قابل دسترسی است).
- Kursa، MB; Rudnicki، WR انتخاب ویژگی با بسته Boruta. J. Stat. نرم افزار 2010 ، 36 ، 1-13. [ Google Scholar ]
© 2013 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/3.0/) توزیع شده است.
بدون نظر