

چکیده
ارزیابی کیفیت و دقت مشارکتهای داوطلبانه اطلاعات جغرافیایی (VGI) و در نتیجه کاربرد نهایی دادههای VGI، بحثهای زیادی را در جامعه جغرافیایی ایجاد کرده است. تحقیقات محدود تا به امروز بر روی داده های VGI از ویژگی های خطی متمرکز شده است و نشان داده است که خطا در داده ها به طور ناهمگن توزیع شده است. برخی استدلال کردهاند که دادههای تولید شده توسط مشارکتکنندگان متعدد، محصول دقیقتری نسبت به یک فرد تولید میکند و برخی تحقیقات در مورد ابتکارات با منبع جمعی نشان دادهاند که این درست است، اگرچه تحقیقات در مورد VGI نادرتر است. این مقاله روشی را برای کمیسازی کامل و دقت یک زیرمجموعه انتخابی از مجموعه دادههای نقطهای مرتبط با زیرساخت از دادههای جغرافیایی داوطلبانه در یک منطقه بزرگ شهری با استفاده از مجموعه دادههای ملی مکانی به عنوان معیار مرجع با دو مجموعه داده از داوطلبان مورد استفاده به عنوان مجموعه دادههای آزمایشی پیشنهاد میکند. نتایج این مطالعه مزایای گنجاندن کنترل کیفیت در فرآیند جمعآوری دادههای داوطلبانه را نشان میدهد.
کلید واژه ها:
اطلاعات جغرافیایی داوطلبانه (VGI) ؛ OpenStreetMap ; کیفیت ؛ خطا ؛ نقطه
1. مقدمه
پیشرفتها در فناوری ارتباطات و در دسترس بودن اطلاعات تأثیر قابلتوجهی بر حوزه جغرافیا دارد زیرا عموم مردم را قادر میسازد تا محصولات مکانی را برای مصرف انبوه در اینترنت تولید کنند [ 1 ، 2 ]. با ادامه پیشرفت فناوری (به عنوان مثال، افزایش قابلیتهای محاسباتی و مکانیابی دستگاههای دستی) و دسترسی به اینترنت توسط شهروندان بیشتری، انتظار میرود میزان دادههای مکانی تولید شده توسط شهروندان بدون آموزش رسمی جغرافیایی به سرعت افزایش یابد [ 3 ]. بنابراین، اطلاعات جغرافیایی داوطلبانه (VGI) [ 4] عموم مردم را وارد قلمرو توابع تولید نقشه می کند که به طور سنتی برای آژانس های رسمی محفوظ است. با تبدیل شدن همه انسانها به مشارکتکنندگان بالقوه اطلاعات مکانی [ 4 ]، این روند تأثیر زیادی بر جامعه مکانی دارد.
VGI توسعه وب 2.0 را دنبال می کند که در آن کاربران در مکان های بیشتری و اغلب بیشتر مشارکت می کنند [ 5 ]. یکی دیگر از عبارت های توصیفی مهم «انبوه سپاری» است که VGI را در شرایط تجاری توصیف می کند، منابع و تکالیف کاری را که توسط هاو پیشنهاد شده است پیوند می دهد [ 6 ]. جمع سپاری تعاریف زیادی در رابطه با توسعه داده های مکانی دارد. برابهام رویکرد را به عنوان استفاده از داوطلبان آنلاین برای حل یک نیاز تولید داخلی قبلی یک تجارت یا آژانس توصیف می کند [ 7 ]. Heipke پیشنهاد کرد که اصطلاح Crowdsourcing برای توصیف اکتساب داده توسط گروه های بزرگ و متنوعی از مردم با استفاده از فناوری های وب استفاده شود [ 8 ]. استفانیدیس و همکارانجمع سپاری متمایز از جمع آوری، و VGI از اطلاعات جغرافیایی محیطی (AGI) [ 9 ]. در اولی، یک وظیفه صریح به جمعیت ارائه میشود، و مشارکتهای آنها بخشی از این وظیفه است، در حالی که در دومی، اطلاعات گستردهتر ارائهشده توسط جمعیت (به عنوان مثال، از طریق مشارکتهای رسانههای اجتماعی) برای برداشت محتوای مرتبط با فضای جغرافیایی استخراج میشود. . هاروی استدلال میکند که جمعسپاری هم شامل دادههایی است که «داوطلبانه» و هم دادههایی «مشارکتشده» است، و این نشان میدهد که دادههای ارائهشده نشاندهنده اطلاعاتی است که بدون آگاهی فوری و تصمیم صریح فردی که از فناوری تلفن همراه استفاده میکند جمعآوری شده است. نماینده اطلاعاتی است که به صراحت ارائه شده است [ 10].
تمرکز این مقاله بر روی VGI جمعسپاری شده (بهجای AGI)، و به طور خاص بر دقت چنین اطلاعاتی است. اشاره شده است که مشارکت عمومی در نقشهبرداری جغرافیایی در وب به گروههای شهروند اجازه داده است تا نقشهبرداری و زمینه دانش محلی ارائه کنند که پروژه نقشهبرداری را بهطور قابل توجهی پیشرفت میدهد. با این حال، دیگران خاطرنشان کردهاند که ویژگیهای اطلاعات نسبت به گزارشهای سنتی جمعآوری دادههای علمی دقیقتر است، که میتواند بر محتوای ویژگی و اسناد تأثیر بگذارد [ 11 ، 12 ]. دادههای داوطلبانه معمولاً با اطلاعات کمی یا بدون اطلاعات در مورد استانداردهای نقشهبرداری، روشهای کنترل کیفیت و به طور کلی فراداده ارائه میشوند [ 13 ]]. درک و اندازهگیری کیفیت دادههای اطلاعات ارائهشده توسط داوطلبانی که ممکن است برنامهها و/یا سوگیریهای گزارشنشده داشته باشند، امروز یک مشکل مهم در جغرافیا است [ 14 ]. یک گام به سوی درک کیفیت دادههای بالقوه دادههای داوطلبانه، کمی کردن ویژگیهای کیفی کلیدی برای دادههای مکانی است که به طور منطقی میتوان انتظار داشت در مجموعه دادههای ارائهشده گنجانده شود، و سپس برای مقایسه آن ویژگیها با منابع مرجع دادهها برای تعیین کمیت کیفیت دادهها استفاده شود. .
ارزیابی دقت اطلاعات جغرافیایی داوطلبانه موضوع کار قبلی بوده است، اما این کار تقریباً به طور انحصاری بر دقت و کامل بودن ویژگیهای خطی مانند جادهها و مسیرهای پیادهروی با تمرکز بر تجزیه و تحلیل گرهها یا نقاطی که چنین ویژگیهایی را شامل میشوند، تمرکز کرده است. 15 ، 16 ، 17 ]. نشان داده شده است که خطاهای VGI تصادفی نیستند، و همانطور که Feick و Roche اشاره می کنند، در سراسر حوزه های فضایی و موضوعی رخ می دهد که داده هایی را به دست می دهد که باید قبل از استفاده عملیاتی ارزیابی شوند [ 15 ، 16 ، 17 ، 18 ].
با توجه به دقت ویژگی نقطهای، تلاشها تا به امروز عمدتاً بر تقاطعهای جادهها متمرکز شدهاند [ 15 ]، و دقت سایر ویژگیهایی را که معمولاً به عنوان نقاط در مجموعه دادههای VGI نشان داده میشوند، ارزیابی نکردهاند. نمونه ای از چنین ویژگی هایی، نقاط مورد علاقه (POI) در OpenStreetMap (OSM) است [ 15 ، 19 ]]. به منظور پر کردن این شکاف و گسترش وضعیت دانش فعلی، در این مطالعه به ویژگیهای نقطهای نشاندهنده مدارس میپردازیم و مسائل مربوط به دقت، یعنی کامل بودن و دقت (خطای فضایی) را ارزیابی میکنیم. ما برای مطالعه خود داده های VGI را در ایالات متحده (ایالات متحده) در نظر می گیریم، جایی که منابع ارائه شده توسط دولت به راحتی در دسترس هستند. با این حال، مفاهیم ارائه شده در این مطالعه برای هر منطقه جغرافیایی یا مجموعه داده قابل استفاده است.
مقاله بصورت زیر مرتب شده است. در بخش 2 ، ملاحظات مربوط به دقت VGI را مورد بحث قرار می دهیم. در بخش 3 ، ما یک روش شناسی و مطالعه موردی برای ارزیابی دقت داده های نقطه جمعی ارائه می کنیم. مطالعه موردی شامل سه مجموعه داده و نتایج این مطالعه است که در بخش 4 ارائه شده است و هدف آن ارائه درک بهتری از کامل بودن و دقت مجموعه دادههای داوطلبانه مختلف است. ما با خلاصه و چشم انداز خود در بخش 5 نتیجه می گیریم .
2. ملاحظات دقت و کامل بودن اطلاعات جغرافیایی داوطلبانه
گودچایلد اظهار داشت که «همه دادههای مکانی بدون استثنا از دقت مکانی محدودی برخوردار هستند» و با این حال، صحت دادههای مکانی امروزه، تقریباً 20 سال پس از اظهار نظر گودچایلد، یک نگرانی مهم باقی مانده است [ 20 ]. این نگرانی در حال حاضر بیشتر از گذشته با استفاده گسترده از فناوری های جدید برای نقشه برداری در سراسر اینترنت [ 21 ] است که هم چالش ها و هم فرصت هایی را برای انتشار اطلاعات جغرافیایی ارائه می دهد [ 22 ]. علاوه بر این، محققان چگونگی کمی کردن ارزش مشارکتها را از منظر اجتماعی و همچنین ارزیابی کیفیت و قابلیت استفاده خود دادههای مکانی ارائه شده در نظر گرفتهاند [ 23 ، 24 ، 25 ،26 ]. Feick و Roche اشاره میکنند که تولید دادههای VGI ذاتاً فاقد نظارت حرفهای است، از استانداردهای کیفیت تعیینشده پیروی نمیکند و تحت تأثیر ناهمگونی ذاتی VGI در ابعاد موضوعی، رسانهای و فضایی قرار میگیرد [ 18 ]. این مسائل بر کاربرد کاربردی استفاده از VGI به عنوان جایگزین یا مکمل برای مجموعه دادههای «معتبر»، که ممکن است از منابع تجاری یا دولتی در دسترس باشد، تأثیر میگذارد [ 12 ، 27 ، 28 ].
در حالی که کیفیت داده ها از زمان تعریف GIScience در مرکز دستور کار تحقیقاتی قرار گرفته است، گودچایلد و هانتر بحثی را در مورد روش مقایسه دو مجموعه داده ارائه کردند که به موجب آن منبع آزمایش شده داده با منبع مرجع داده مقایسه می شود [ 29 ، 30 ] . فرض بر این است که مجموعه داده مرجع نشان دهنده حقیقت پایه است در حالی که مجموعه داده آزمایشی با مجموعه داده مرجع اندازه گیری می شود. مقایسه بین مجموعه داده ها در ادبیات رایج است. با این حال، روشهای این مقاله برای مقایسه ویژگیهای نقطهای طراحی شدهاند [ 30 ، 31 ، 32 ، 33 ]. روش های ذکر شده در بخش 3این مقاله رویکرد مقایسه خطی Haklay [ 15 ] را تکمیل میکند و آن را برای کاربرد در ویژگیهای نقطهای گسترش میدهد. سپس نحوه محاسبه کامل بودن و دقت چنین داده هایی را نشان خواهیم داد.
با توجه به ماهیت موقت رویکردهای VGI، کامل بودن به اندازه دقت در ارزیابی کیفیت اطلاعات ارائه شده مهم است. هاکلی و دیگران کامل بودن داده های VGI را به عنوان معیاری از طول کل بخش های جاده در VGI در مقایسه با داده های مرجع اندازه گیری کردند [ 15 ، 16 ، 17 ]. براسل و همکاران اشاره کرد که مفهوم کامل بودن رابطه بین اشیاء در یک مجموعه داده و جهان همه اشیا (دنیای واقعی) را توصیف می کند و می تواند به ارزیابی کامل بودن اسناد و فراداده بسط داده شود [ 34]. Devillers و Jeansoulin تعریف کامل بودن را بسط دادند تا شامل ارزیابی خطاهای “حذف” و “کمیسیون” برای مجموعه داده هایی شود که واقعیت را کمتر یا بیش از حد نشان می دهند [ 32 ]. بنابراین، آگاهی از تعداد (واقعی) ویژگیهای موجود در یک منطقه مورد مطالعه، یک عامل کلیدی هنگام ارزیابی کامل بودن مشارکت داوطلبانه دادههای مکانی برای آن منطقه است، اما ارزیابی کامل بودن فراداده یا اسناد در این مطالعه گنجانده نشده است.
گودچایلد و هانتر روشی برای کمی سازی دقت مکانی با استفاده از روش های آماری سنتی مانند خطای میانگین مربعات ریشه (RMSE) و خطای استاندارد برای توصیف خطای مکانی ویژگی های نقطه ای [ 30 ] مورد بررسی قرار دادند. البکری و فیربرین دقت فضایی بین VGI و داده های دولتی را بررسی کردند و دریافتند که RMSE برای VGI بسیار بالا است [ 35 ]. این نویسندگان این خطاها را به روشهای رایج مورد استفاده توسط گردآورندگان داده VGI نسبت میدهند که اغلب از ابزارهای کم دقت مانند واحدهای GPS شخصی و خدمات تصویرسازی تجاری استفاده میکنند. Zielstra و Zipf تفاوت های بین VGI و منابع داده تجاری را در آلمان بررسی کردند و خاطرنشان کردند که کیفیت VGI به طور قابل توجهی با افزایش فاصله از هسته شهری کاهش می یابد [ 17 ]].
دراموند دقت موقعیتی را به عنوان توصیف “نزدیک” موجودیت دنیای واقعی در یک سیستم مختصات مناسب به موقعیت واقعی آن موجودیت تعریف کرد [ 36 ]. با این حال، در برخورد با ویژگیهای نقطهای که نمایانگر ویژگیهای منطقهای هستند، یک ابهام ذاتی در شناسایی یک مکان واحد برای نشان دادن چنین ویژگی وجود دارد. بر این اساس، دقت چنین ویژگیهایی تحتتاثیر این است که چگونه یک مشارکتکننده میتواند یک ویژگی منطقهای را به یک مکان واحد تقطیر کند و چگونه این عملیات میتواند در طیفی از مشارکتکنندگان مختلف انجام شود. بنابراین، دقت چنین ویژگیهایی نه تنها تحت تأثیر اندازهگیری (که تحت تأثیر مقیاس، دقت و دقت است)، بلکه تحت تأثیر تفسیر مشارکتکننده از مکان نماینده مناسب ویژگی قرار میگیرد [ 37 ]، 38 ]. این ابهام یا ابهام، همانطور که توسط Worboys و Duckham مورد بحث قرار گرفت، بر مفهوم سنتی اندازهگیریهای دقت تأثیر میگذارد [ 39 ]. این مقاله نشان میدهد که ابهام نمایشی در مجموعه دادههای VGI ذاتی است، و ارزیابی دقت موقعیتی دادههای ارائهشده درک درستی از قابلیت اطمینان و تنوع نتایج گزارششده را ارائه میدهد. علاوه بر این، درک پیشرفته از دقت موقعیتی به ارزیابی کیفیت کلی داده های ارائه شده به عنوان یک منبع داده بالقوه برای استفاده توسط آژانس های نقشه برداری و محققان کمک می کند.
تحقیق ما روند ارزیابی کامل و دقت را ادامه میدهد، اما مفهوم کامل بودن را به مقایسه ویژگیهای نقطهای منفرد که ویژگیهای ناحیه را نشان میدهند، گسترش میدهد و دقت را به طور کلی ارزیابی میکند. به دلیل ابهام ذاتی مکانهای POI، ما تحلیل خود را بر مفهوم ساختمان مدرسه یا وسعت محوطه مدرسه استوار میکنیم تا نتایج عددی را با مقادیر واقعی مرتبط کنیم.
3. مواد و روشها
بحث ارائه شده در اینجا به چند بخش تقسیم می شود. ما در بخش 3.1 با معرفی منطقه مورد مطالعه و مجموعه داده هایی که در ادامه این مقاله استفاده خواهد شد، شروع می کنیم. بعد، در بخش 3.2 ، دلیل توسعه روش خود را ارائه خواهیم کرد. به دنبال آن، در بخش 3.3 ، در مورد مسائل پردازش داده بحث می کنیم. این با ارائه روش های خودکار، در بخش 3.4 ، و روش های دستی، در بخش 3.5 ، که بخشی از روش ما هستند، دنبال می شود. در نهایت، در بخش 3.6 ، آمار خلاصه ای را ارائه می کنیم که به تحلیل بعدی برای کامل بودن و دقت کمک می کند.
3.1. مطالعه موردی
همانطور که در بخش قبل نشان داده شد، کیفیت داده های مکانی یک نگرانی مداوم است. با این حال، ایده هایی برای مقایسه مجموعه داده های مرجع و آزمون با یکدیگر ارائه شده است. کمیسازی کامل و دقت به کاربران دادهها امکان میدهد تا کاربرد دادهها را بهتر درک کنند، اما مستلزم آن است که مجموعه دادههای مرجع و آزمایشی در دسترس باشند. خوشبختانه، برخی از کارهای اخیر در ایالات متحده داده هایی را تولید کرده است که برای این تحلیل ها مناسب است. این تحقیق از سه منبع داده شامل یک منبع مرجع ارائه شده توسط دولت و دو منبع مختلف تست VGI استفاده می کند.
داده های مرجع بر اساس اطلاعات لیست مدارس دولتی و خصوصی وزارت آموزش است. از طرف دولت فدرال، از آزمایشگاه ملی اوک ریج (ORNL) خواسته شد تا دقت موقعیت مکانی دادههای وزارت آموزش و پرورش را با استفاده از روشهای تکرارپذیر بهبود بخشد. داده های ORNL با اطلاعات آدرس جغرافیایی برای مدارس ایجاد شد [ 40 ]. مجموعه داده بهدستآمده بهطور گسترده در سراسر دولت فدرال بهعنوان پایگاه دادهای در سطح ملی قطعی از مکان و اطلاعات ویژگیها برای مدارس دولتی و خصوصی در ایالات متحده استفاده میشود. علاوه بر این مجموعه داده مرجع، از دو مجموعه داده آزمایشی نیز در این مطالعه موردی استفاده شده است.
اولین مجموعه داده تست VGI شامل مکان های مدرسه از لایه POI OSM است. لایه POI هر ویژگی خاص را به عنوان یک گره نشان میدهد و ممکن است شامل: کلیساها، مدارس، تالارهای شهر، ساختمانهای متمایز، دفاتر پست، مغازهها، میخانهها و جاذبههای توریستی باشد که توسط سایت ویکی OSM [ 41 ] اشاره شده است. Over et al. نشان می دهد که کلید اولیه در OSM برای این گره ها “آمادگی” است، که به دسته هایی تقسیم می شود، از جمله: اقامت، غذا خوردن، آموزش، لذت، سلامت، پول، پست، امکانات عمومی و حمل و نقل، مغازه ها و ترافیک [ 42 ].]. از ویکی OSM ارجاع شده در بالا، دستورالعمل هایی به مشارکت کنندگان ارائه می شود تا در صورت امکان مدارس را به عنوان مناطق شناسایی کنند. با این حال، هنگامی که مرزهای منطقه ناشناخته است، به مشارکت کننده دستور داده می شود که یک گره را در وسط منطقه قرار دهد تا مجموعه مدرسه را نشان دهد. از آنجایی که هیچ محدودیتی برای مشارکت کنندگان OSM در مورد مکان ترجیحی یک مکان نماینده اعمال نمی شود، باید انتظار داشت که تغییرات قابل توجهی در مکان واقعی نقطه وجود داشته باشد، خواه سهم از GPS شخصی، تلفن هوشمند یا آنلاین با استفاده از دیجیتالی سازی سربالا با تصاویر نامشخص ایجاد شده باشد. دقت. ما از مجموعه داده OSM برای ارائه یک ارزیابی مستقیم از دقت ویژگی نقطه در مشارکت های VGI استفاده خواهیم کرد.
ما همچنین از یک مجموعه داده آزمایشی دوم استفاده میکنیم که محصول پروژه مشارکتی نقشه خیابان باز (OSMCP) – فاز دوم سازمان زمینشناسی ایالات متحده (USGS) است [ 43 ]. OSMCP یک نوع ترکیبی از VGI را نشان میدهد که نظارت محدودی را بر فرآیند VGI معرفی میکند: دادهها از طریق فرآیندهای VGI جمعآوری میشوند، توسط داوطلبان ویرایش میشوند و یک آژانس دولتی (در این مورد USGS) بازخورد کنترل کیفیت را به داوطلبان ارائه میدهد. در تلاش برای بهبود دقت کلی محصولات خود. USGS دستورالعمل هایی را به داوطلبان ارائه کرد و به آنها دستور داد که ویژگی ها را در مرکز ساختمانی که آنها نمایندگی می کنند قرار دهند [ 44 ]]؛ با این حال، روش جمعآوری دادههای OSMCP شامل بازدید از هیچ سایتی نمیشود، بلکه بر تحقیقات آنلاین همراه با دیجیتالیسازی با استفاده از تصاویر ارائه شده به کاربران تکیه میکند. انگیزه پشت تلاش OSMCP تمایل USGS برای استفاده از چنین داده های VGI به عنوان مکمل مجموعه داده های رسمی خود و ترکیب نتایج OSMCP در نقشه ملی است [ 43 ].
مهم است که تشخیص داده شود که یکی از منابع احتمالی ناسازگاری بین مجموعه داده ها، استفاده از طرح های طبقه بندی ویژگی های مختلف بین هر یک از منابع داده است. داده های ORNL و OSMCP نشان دهنده آموزش ابتدایی و متوسطه در ایالات متحده است [ 44 ، 45 ، 46 ]. داده های OSM شامل همان تعریف برای مدارس است. با این حال، کلمه “مهدکودک” در OSM برای نشان دادن امکانات مراقبت روزانه استفاده می شود، در حالی که در OSMCP و ORNL، سال اول مدرسه ابتدایی را نشان می دهد و در نتیجه، برخی از مدارس ممکن است به طور متناقضی در OSM برچسب گذاری شوند [ 47 ].]. یک بررسی گذرا از دادههای OSM برای منطقه مورد مطالعه هیچ موردی را نشان نداد که در آن «مهدکودک» زمانی که مدرسه ابتدایی در نظر گرفته شده بود استفاده میشد. در تحقیق برای این مقاله، ما به این اختلاف اشاره کردیم. با این حال، بر اساس همپوشانی اساسی بین این تعاریف، ما احساس نمی کنیم که این تفاوت ها به شدت بر نتایج تأثیر می گذارد.
OSMCP بر جمع آوری داده ها (ویژگی های نقطه ای) برای ساختارهای انتخاب شده که شبیه به POI از OSM هستند، متمرکز شد. اگرچه در مورد OSMCP، جمعآوری دادهها توسط یک گروه منتخب از 85 داوطلب غیرمتخصص دانشجوی کالج انجام شد، و فرآیند نیز تحت یک فرآیند کنترل کیفیت تکراری اما محدود توسط داوطلبان و USGS قرار گرفت [ 43 ، 48 ]]. بنابراین OSMCP به دو دلیل می تواند به عنوان یک تلاش VGI ترکیبی در نظر گرفته شود. ابتدا، همانطور که در بالا ذکر کردیم، مفهوم نظارت جزئی را به VGI معرفی می کند. دوم، با گروه نسبتاً کوچکی از داوطلبان دانشجوی کالج که جمعآوری دادهها را انجام میدهند، به جای مشارکت «گروههای بزرگ و متنوع مردم» که هایپکه به عنوان یک الگوی مشارکت نماینده در نظر میگرفت، شبیه تلاشهای جمعسپاری متمرکز مانند Ushahidi است [ 8 ، 49 ]. .
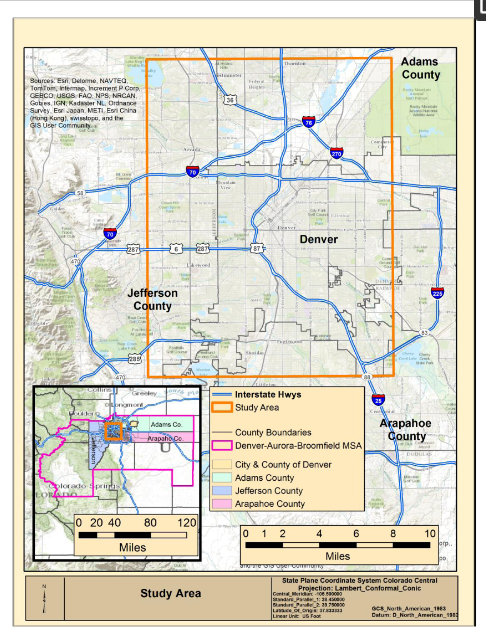
منطقه مورد مطالعه برای مقایسه ارائه شده در اینجا توسط ردپای داده های OSMCP دیکته می شود زیرا هر دو داده ORNL و OSM شامل کل ایالات متحده است. منطقه مورد مطالعه OSMCP به طور کامل در منطقه آماری کلانشهر کلرادو دنور-آرورا-برومفیلد (MSA) قرار دارد که توسط اداره سرشماری [ 50 ] تعریف شده است. منطقه مورد مطالعه درصد زیادی از شهر و شهرستان دنور، از جمله مرکز شهر دنور را پوشش میدهد، و به بخشهایی از شهرستانهای آراپاهو، جفرسون و آدامز اطراف گسترش مییابد که در شکل 1 نشان داده شده است.، و تقریباً 228.5 مایل مربع را در بر می گیرد. منطقه مورد مطالعه عمدتاً شامل محلههای تجاری، صنعتی و مسکونی است که معمولاً در مناطق شهری یافت میشوند و جمعیتی کمتر از 1100000 نفر یا تقریباً 43 درصد از کل جمعیت MSA 2.54 میلیونی را شامل میشود.
در حالی که دادههای ORNL با استفاده از روشها و استانداردهای از پیش تجویز شده [ 40 ] تولید شدهاند، بعید است که کامل باشد. با این حال، گودچایلد استفاده از داده های منبع مرجع ناقص را با اشاره به این نکته تأیید می کند که بسیاری از کاربران مایلند به منابع داده ای که رایج هستند، بدون توجه به روش هایی که ممکن است تحت آن توسعه یافته اند، اعتبار قائل شوند [ 4 ]]. در حالی که بعید به نظر می رسد کامل باشد، داده های ORNL به دلیل روش های جمع آوری مورد استفاده، احتمالاً سازگارتر از مجموعه داده های OSM یا OSMCP هستند. با این حال، روشهای بهروزرسانی دادههای ORNL کند هستند و برخی مدارس، بهویژه مدارسی که به تازگی افتتاح شده یا اخیراً بسته شدهاند، بعید است که در دادههای ORNL منعکس شوند. دیگران نشان داده اند که چگونه VGI به دلیل واحد پولی که دارند نسبت به منابعی مانند ORNL در هنگام بلایا مناسب تر است [ 51 ]. ماتیاس و همکاران به این نکته اشاره کنید که دادههایی مانند OSM که از طریق متدولوژیهای VGI جمعآوری میشوند، اغلب در فضایی شبیه به بازی انجام میشوند، زیرا کاربران هر زمان و به نحوی که دوست دارند با نظارت کم یا بدون نظارت مشارکت میکنند و در نتیجه ایده ویرایش خود را ترویج نمیکنند. 52]. در مقابل، OSMCP با گنجاندن ویراستاران از داوطلبان دانشجو و USGS در یک محیط ترکیبی [ 53 ]، به موضوع اشارهشده در بالا پرداخت و به مشارکتکنندگان و ویراستاران داوطلب دستورالعملهایی در رابطه با مکان نماینده مناسب برای هر ویژگی ارائه کرد. یکی از اهداف بیان شده OSMCP دستیابی به درک بهتری از کیفیت و کمیت داده های تولید شده توسط داوطلبان با اجرای مرحله کیفیت دو مرحله ای پس از جمع آوری داده ها بود [ 48 ].]. روش مورد استفاده برای توسعه داده های OSMCP شامل یک مرحله ویرایش بود که شامل شرایطی بود که به کاربران اجازه می داد رکوردهایی را اضافه کنند که در مجموعه داده مرجع شناسایی نشده بودند. همانطور که قبلاً بحث شد، روش بیان شده در این مقاله از داده های ORNL به عنوان یک مجموعه داده مرجع استفاده می کند زیرا بهترین روش موجود از سوی دولت فدرال است. با این حال، نویسندگان اذعان می کنند که به دلیل تفسیر مشارکت کننده همانطور که در بالا بحث شد، اختلاف بین مجموعه داده ها وجود خواهد داشت. رکوردهایی که در مجموعه داده های آزمایشی شناسایی شده اند اما در مجموعه داده مرجع وجود ندارند برای اندازه گیری های کامل مفید هستند زیرا کاستی های احتمالی مجموعه داده مرجع را برجسته می کنند.

شکل 1. منطقه مطالعه.
3.2. بنیاد و پایه
کمی کردن جنبههای کیفی مدارس در OSMCP، با گستره فضایی نسبتاً محدود و مجموعه مشارکتکنندگان محدود آن در مقایسه با دادههای OSM معادل، فرصتی منحصربهفرد برای ارزیابی این سوال ارائه میدهد: آیا کنترلهای کیفیت ایجاد شده توسط USGS به طور قابل اندازهگیری کامل بودن و بهبود را بهبود میبخشد. دقت مشارکت های داوطلبانه؟ علاوه بر این، آیا سوگیریهای فضایی ذکر شده در دادههای OSM بین ویژگیهای خطی و ویژگیهای نقطهای که در این مطالعه بر روی آنها متمرکز شدهاند همخوانی دارند [ 15 ]]؟ اگر چنین است، آیا سوگیری ها در داده های OSM و OSMCP وجود دارد؟ یافتههای این مطالعه میتواند توسط محققان دیگر در طول اجرای پروژههای VGI دیگر به کار گرفته شود تا بتوانند هرگونه سوگیری که ممکن است در دادههایی که با استفاده از روشهای جمعآوری دادههای VGI جمعآوری شدهاند را کاهش دهند.
جدول 1 تعداد کل مدارس در منطقه مورد مطالعه را برای هر منبع داده نشان می دهد. در حالی که تعداد کل مدارس در سه منبع به طور منطقی نزدیک است، مهم است که توجه داشته باشید دادههای ORNL و OSMCP فقط مدارس فعال را نشان میدهند در حالی که دادههای OSM شامل تقریباً 12٪ مدارس تاریخی است که احتمالاً دیگر وجود ندارند و بنابراین مطابقت ندارند. مدارس در ORNL یا OSMCP. بررسی محدود دادههای OSM خام نشان داد که اکثر رکوردها از سیستم اطلاعات نامهای جغرافیایی USGS (GNIS) مشتق شدهاند که شامل نقاط دیدنی تاریخی است. داده های GNIS به احتمال زیاد به صورت انبوه در OSM آپلود شده است و کاربران سوابق تاریخی را حذف نکرده اند.

جدول 1. تعداد مدارس بر اساس منبع داده.
به دنبال کار هاکلی، نتایج نشان داده شده در جدول 1 نشان می دهد که این مجموعه داده ها مشابه هستند [ 15 ]. با این حال، یک ارزیابی عمیق تر از مدارس نشان داد که تنها 281 مدرسه در هر سه مجموعه داده مشترک هستند که نشان می دهد که تعداد ویژگی های ساده ممکن است دقت یا کامل بودن فضایی را به اندازه کافی ارزیابی نکند.
شکل 2 بخشی از منطقه مورد مطالعه را نشان می دهد که شامل 33 مدرسه از سه مجموعه داده است: 11 OSM; 12 OSMCP; و 10 ORNL به ترتیب. بررسی شکل 2نشان می دهد که همبستگی فضایی بسیار خوبی بین سه منبع داده برای هفت مکان وجود دارد که هر منبع داده نشان دهنده حضور یک مدرسه است. با این حال، این بررسی همچنین امکان شناسایی دو مدرسه مرجع ORNL را فراهم میکند که مدرسه OSMCP یا OSM در نزدیکی آنها ندارند (دایره سیاه). علاوه بر این، سه ناحیه وجود دارد که هر دو مدرسه OSMCP و OSM نشان داده شدهاند، اما مدرسه ORNL مرتبط نیست (الماسهای سیاه)، و یک مکان وجود دارد که دادههای ORNL و OSMCP بدون مدرسه OSM مرتبط (مثلث سیاه) مرتبط هستند. در نهایت، دو مکان (مربع سیاه) وجود دارد که تنها یک منبع داده نشان دهنده وجود مدرسه است، یکی از OSM و دیگری از منبع داده OSMCP. ارزیابی بصری بالا به وضوح نشان می دهد که در حالی که تعداد مشابهی از مدارس در منطقه مورد مطالعه وجود دارد،جدول 1 ، تنوع فضایی نشان می دهد که ارزیابی دقیق منابع داده برای درک شباهت ها و تفاوت های بین مجموعه داده ها مورد نیاز است. ارزیابی فوق فقط به «ارتباط» فضایی ویژگیها نگاه میکند و به انتساب خاص مرتبط با آن مکانها نمیپردازد.
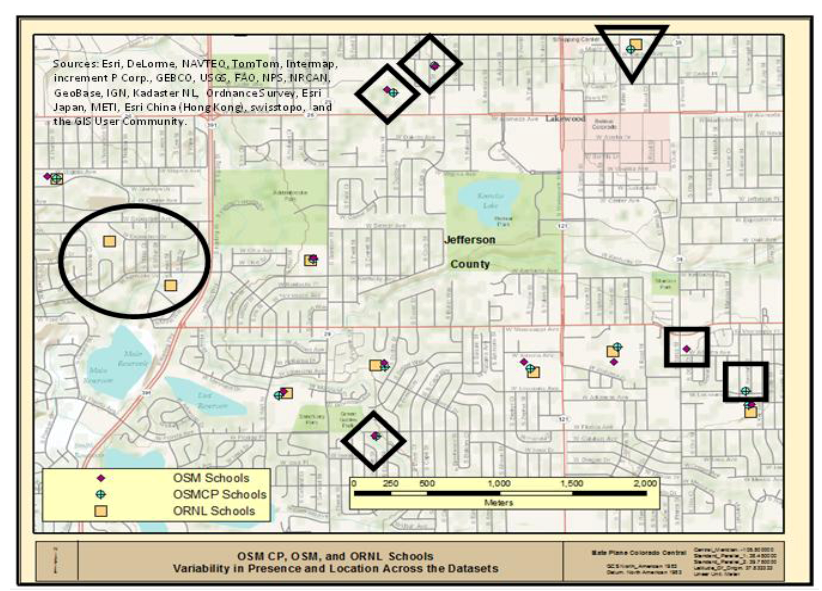
شکل 2. مقایسه داده های OSM، OSMCP و ORNL.
شکل 3مکانهای ویژگی ORNL، OSMCP و OSM را برای مجاورت کالج اولیه جنوب غربی در منطقه مورد مطالعه به تصویر میکشد و نمونهای را ارائه میکند که در آن اثرات تغییرپذیری فضایی که در بالا مورد بحث قرار گرفت، و همچنین تنوع در اسناد، مقایسه دادههای تأثیر. تنها یک مدرسه در مجموعه داده مرجع ORNL در مجاورت شناسایی شده است. مکان ORNL با یک مربع قهوهای مایل به زرد نشان داده می شود و چندین صد متر در شرق مکان های OSMCP و OSM قرار دارد. دادههای OSMCP چهار مدرسه مجزا را نشان میدهد (آکادمی سامیت؛ کالج اولیه جنوب غربی؛ کالج لورتو هایتس؛ و کالج کلرادو هایتس از شمال به جنوب) در همان مدرسه که به نظر میرسد، در حالی که دادههای OSM سه مدرسه را نشان میدهند (دانشگاه Teikyo Loretto Heights؛ Loretto). کالج هایتس؛ و کالج اولیه جنوب غربی، از شمال غرب به شرق).
شکل 3 مفهوم ابهام فضایی را در مجموعه دادههای مورد بحث در بالا نشان میدهد و نشان میدهد که مفهوم سنتی دقت جغرافیایی احتمالاً یک هدف غیرضروری در هنگام بررسی دادههای ویژگی نقطه جمعسپاری است. استفاده از هر یک از منابع برای کالج اولیه جنوب غربی، امکان پیمایش به دارایی مدرسه را فراهم میکند، اگرچه مکان ویژگی نقطه OSMCP از نظر بصری دقیقتر به نظر میرسد به این صورت که روی یک ساختمان واقعی میافتد در حالی که مکان OSM در محوطه مدرسه است و مکان ORNL نقشهبرداری شده است. به یک خط مرکزی جاده، دورتر از ساختمان های مدرسه و به طور کامل خارج از محوطه دانشگاه.
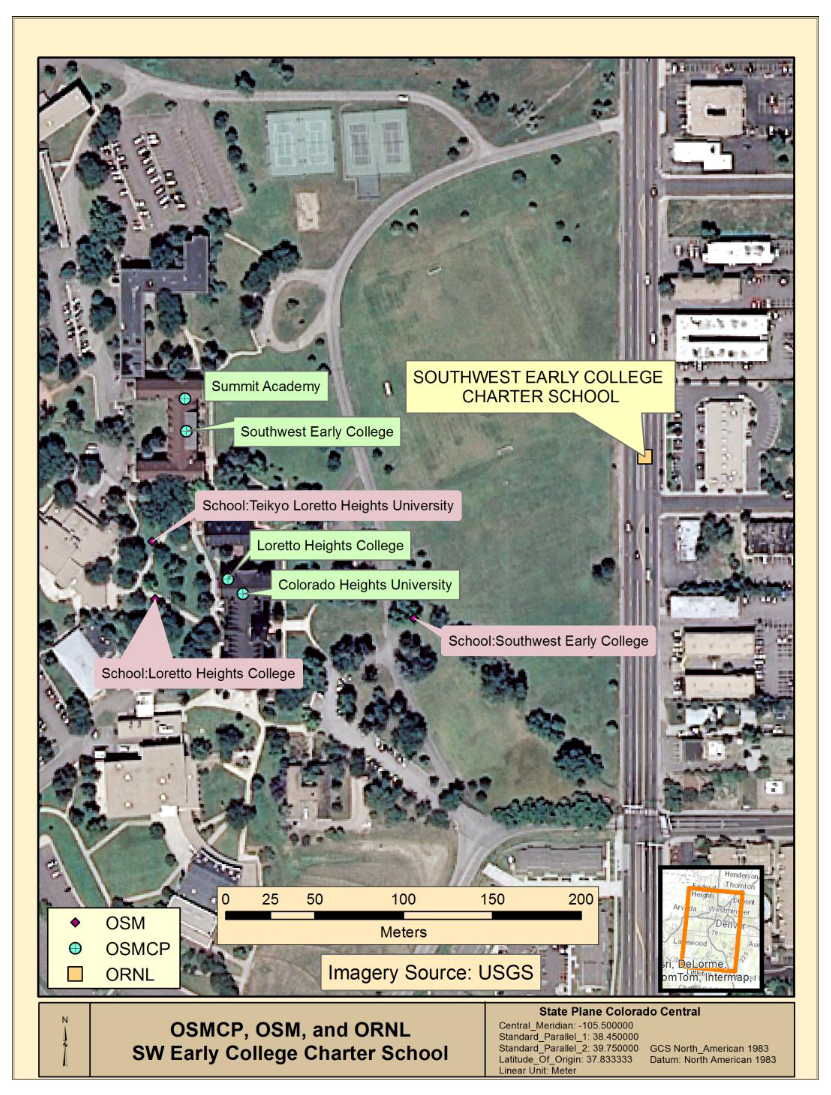
شکل 3. مکان های مختلف شناسایی شده کالج اولیه جنوب غربی.
بر اساس ارزیابیهای محدود ارائهشده در بالا، و بحث در مورد تفاوتهای منبع و منبع، واضح است که برای ارزیابی کیفیت دادههای آزمون VGI در مقایسه با دادههای مرجع، یک مقایسه سیستماتیک مجموعه دادهها مورد نیاز است. بخش زیر آن رویکرد سیستماتیک را تشریح می کند.
3.3. آماده سازی داده ها
دادههای ORNL در قالب فایل شکل پیشبینیشده در WGS84 ارائه شد، اما مجدداً در سیستم Central State Plane کلرادو پیشبینی شد. سپس داده ها در مرز منطقه مورد مطالعه OSMCP برش داده شد و 402 مکان مدرسه در منطقه مورد مطالعه به دست آمد.
داده های OSM از اینترنت دانلود شد [ 54]. دادهها در 13 دسامبر 2011 دانلود شدند و دادههای OSM را در 16 نوامبر 2011 نشان دادند. دادههای OSM نقاط مورد علاقه، ارائه شده در قالب فایل شکل پیشبینی شده در WGS84، استخراج شد و سپس در مرز منطقه مورد مطالعه OSMCP برش داده شد و 4285 امتیاز به دست آورد. . انتساب داده از چهار ویژگی تشکیل شده است: FID، Shape، Category و Name. به طور قابل توجهی، برای این مطالعه، ویژگی “Name” ترکیبی از تابع و نام است. به عنوان مثال، “مکان عبادت: کلیسای باپتیست اپل وود”، “رستوران: کباب ماهی استخوانی”، “کافه: برادران انیشتین”، “میخانه: میخانه و کباب خیابان بیکر” و “مدرسه: مدرسه دره آلپاین”. 4285 نقطه مورد علاقه OSM برای استخراج سوابق از جمله عبارت “مدرسه” پرس و جو شد: بازده 406 مدرسه در منطقه مورد مطالعه. یکی از نگرانیهای این روش استخراج این است که برای برچسبگذاری مناسب مدارس به کمککننده داده OSM متکی است. با این حال، برای این تحقیق، ما تلاشی برای شناسایی نهادهایی که دارای برچسب نامناسب برای جستجوی مدارس گمشده بودند، نکردیم. سپس داده ها در سیستم هواپیمای مرکزی کلرادو پیش بینی شد. متأسفانه آدرس در داده های استخراج شده OSM گنجانده نشده است و در نتیجه فقط می توان از نام ها برای مقایسه داده ها استفاده کرد. همانطور که در بالا توضیح داده شد، از داده های GNIS برای آپلود انبوه داده های مدارس در OSM استفاده شد و داده های GNIS شامل اطلاعات آدرس نمی شود. آدرس در داده های استخراج شده OSM گنجانده نشده است و در نتیجه فقط می توان از نام ها برای مقایسه داده ها استفاده کرد. همانطور که در بالا توضیح داده شد، از داده های GNIS برای آپلود انبوه داده های مدارس در OSM استفاده شد و داده های GNIS شامل اطلاعات آدرس نمی شود. آدرس در داده های استخراج شده OSM گنجانده نشده است و در نتیجه فقط می توان از نام ها برای مقایسه داده ها استفاده کرد. همانطور که در بالا توضیح داده شد، از داده های GNIS برای آپلود انبوه داده های مدارس در OSM استفاده شد و داده های GNIS شامل اطلاعات آدرس نمی شود.
داده های OSMCP ارائه شده توسط USGS با منطقه مورد مطالعه محدود می شود. با این حال، شامل دادههایی فراتر از آموزش است، بنابراین مدارس از مجموعه داده کلی با استفاده از ویژگی به نام FType (نوع ویژگی) استخراج شدند که 412 مدرسه را به دست آورد [ 55 ]. دادههای OSMCP در سیستم هواپیمای مرکزی کلرادو پیشبینی شد. پس از آن، رویه های مشخص شده در بخش 3.4 ، بخش 3.5 برای هر مقایسه یک مجموعه داده آزمایشی با یک مجموعه داده مرجع تکرار شد.
3.4. روش های خودکار
تطبیق خودکار مجموعه داده ها با استفاده از چهار روش مختلف در هر یک از فیلدهای نام و آدرس از ویژگی های مجموعه داده انجام شد. فرآیند تطبیق خودکار با تأیید اینکه مرجع مکانی هر مجموعه داده یکسان است و در واحدهایی که برای اندازهگیری خطای فضایی بین دو ویژگی مفید هستند، شروع میشود. برای مثال، دادههای WGS84 بعید است که نتایج تطبیقی مفیدی را به همراه داشته باشد، زیرا اندازهگیریهای فاصله بر حسب درجه هستند، در حالی که یک پیشبینی بر اساس فوت یا متر میتواند اندازهگیری فاصله مفیدتری را به همراه داشته باشد. سپس، یک پیوست فضایی از مجموعه داده آزمایشی به مجموعه داده مرجع انجام میشود (با استفاده از ابزار Join فضایی در جعبه ابزار تجزیه و تحلیل ArcGIS™) زیرا محتملترین تطابق برای هر رکورد، نزدیکترین رکورد فیزیکی است و پیوند مکانی نزدیکترین رکورد را شناسایی میکند. رکورد.
قبل از شروع تجزیه و تحلیل بیشتر، یک ویژگی به نام “MatchMethod” به جدول ویژگی های مجموعه داده متصل اضافه می شود. این ویژگی توسط یک اسکریپت پر شده است که توسط نویسندگان به عنوان بخشی از این تحقیق با استفاده از زبان برنامه نویسی Python در محیط ArcGIS™ توسعه یافته است. مقادیر معتبر برای MatchMethod از 0 تا 11 همانطور که در جدول 2 نشان داده شده است. اسکریپت در میان رکوردها به دنبال مطابقت بین مجموعه داده مرجع و آزمایشی حرکت می کند و MatchMethod مورد استفاده را ثبت می کند. در ابتدا، همه رکوردها دارای مقدار MatchMethod 0 هستند که نشان می دهد رکوردها هنوز ارزیابی نشده اند. مقادیر MatchMethod 1 تا 5 مطابق با “name” هستند که چهار مورد اول خودکار هستند و با پیشوند “AN” نشان داده می شوند. مقادیر MatchMethod از 6 تا 10 منعکس کننده مقادیر MatchMethod از 1 تا 5 در تابع هستند با این تفاوت که از فیلد آدرس برای یافتن یک تطابق به جای فیلد نام استفاده می شود. روش های خودکار مبتنی بر آدرس با پیشوند “AA” نشان داده می شوند. همانطور که قبلاً بحث شد، دادههای OSM شامل اطلاعات آدرس نمیشدند، بنابراین روشهای “AA” نتایجی را در آن مقایسه خاص به همراه نداشتند، اما آنها در اینجا گنجانده شدهاند، زیرا الگوریتم زمانی که در دسترس باشد، اطلاعات آدرس را تحت تاثیر قرار میدهد.
جدول 2. مقادیر مورد استفاده برای پیگیری تطابق رکورد.
در ابتدا، الگوریتم تلاش می کند تا تطابق کامل بین مجموعه داده آزمون و مرجع را شناسایی کند. نزدیکترین رکورد آزمایشی به هر رکورد مرجع با استفاده از یک اتصال فضایی همانطور که در بالا توضیح داده شد شناسایی شد. مطابقت کامل نزدیکترین رکوردها با پسوند “C” در جدول 2 نشان داده شده است. اگر نزدیکترین رکورد مطابقت دقیق با مجموعه داده مرجع پیدا نشد، آنگاه الگوریتم رکوردهای آزمایش را بررسی می کند تا مطابقت دقیق دیگری را در مجموعه داده آزمایشی شناسایی کند. اگر یکی پیدا شد، آنگاه مطابقت با پسوند “O” در جدول 2 نشان داده می شود . نمونه هایی از مقادیر AN-C و AN-O MatchMethod در شکل 4 (a,b) نشان داده شده است.
مقادیر MatchMethod که با «DC» و «DO» ختم میشوند از کتابخانه Python™ difflib برای شناسایی شباهتها در مقادیر ویژگیها استفاده میکنند. روش difflib بر اساس الگوریتم تطبیق الگو است که در اواخر دهه 1980 توسط راتکلیف و اوبرهلپ [ 56 ] توسعه یافت. دو روش ذکر شده در جدول 2که از پسوند “DC” استفاده می کند، نزدیکترین رکورد آزمون به هر رکورد مرجع را با استفاده از کلاس SequenceMatcher و روش نسبت برای یافتن یک مطابقت بررسی می کند. روش ratio هنگام مقایسه دو مقدار، مقداری بین 0 (بدون تطابق) و 1 (تطابق کامل) برمیگرداند. روشهای تطبیق الگوی پیادهسازی شده در Python™ در این تحلیل استفاده میشوند، زیرا برای اهداف ما سریع و مؤثر هستند و نتیجهای را ارائه میدهند، نسبتی که میتواند به سرعت تفسیر شود. در اصل، این روش تعداد کاراکترهای منطبق بین دو رشته را می شمارد و آن عدد را بر تعداد کل کاراکترهای دو رشته تقسیم می کند و نتیجه را به عنوان یک مقدار (نسبت) برمی گرداند که سپس می تواند با حداقل مقدار مقایسه شود تا تعیین شود. آیا یک تطابق مناسب شناسایی شده است. از طریق آزمون و خطا، حداقل نسبت های مناسب برای تطبیق ویژگی های نام و آدرس مشخص شد. این مقادیر نسبت با تمرکز بر به حداقل رساندن مثبت کاذب انتخاب شدند. به طور مشابه، روش های ازجدول 2 که پسوند “DO” دارد از روش get_close_matches برای یافتن نزدیکترین تطابق بین رکورد مرجع و تمام رکوردهای آزمایشی استفاده می کند. متد get_close_matches یک لیست مرتب شده از موارد نزدیک را برمی گرداند. اسکریپت توسعه یافته برای این مقاله، بالاترین مقدار تطابق را انتخاب می کند و آن مقدار را با حداقل نسبت قابل قبول مقایسه می کند تا تعیین کند که آیا رکورد مطابقت دارد یا خیر. نمونه هایی از مقادیر AN-DC و AN-DO MatchMethod در شکل 4 (c,d) نشان داده شده است.
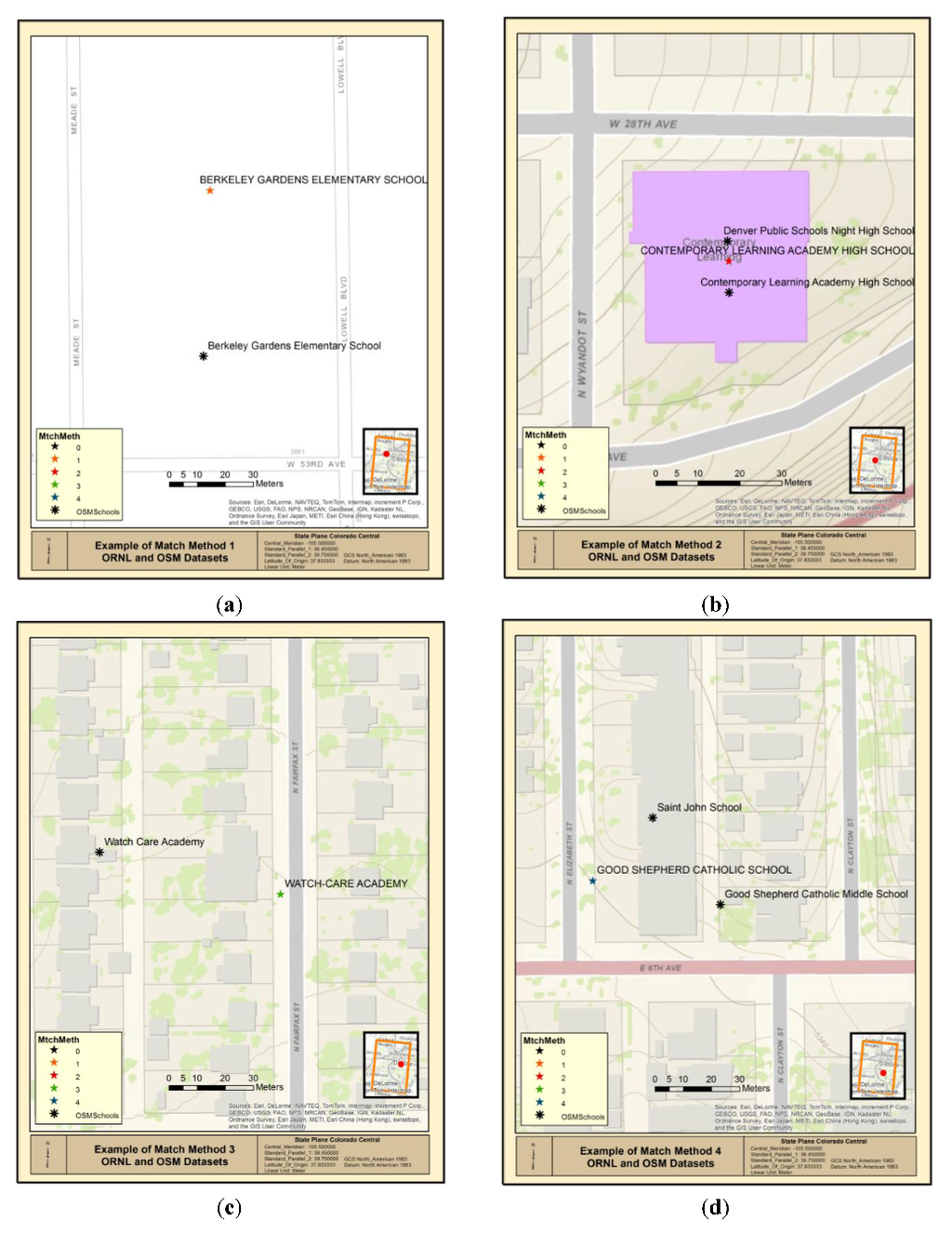
شکل 4. ( الف ) مقدار MatchMethod AN-C بین داده های ORNL و OSM. ( ب ) مقدار MatchMethod AN-O بین داده های ORNL و OSM. ( ج ) مقدار MatchMethod AN-DC بین داده های ORNL و OSM. ( د ) مقدار MatchMethod AN-DO بین داده های ORNL و OSM.
پس از تکمیل روش های خودکار، یک مدرسه، دبیرستان شهر آدامز، بیش از 3000 متر تفاوت بین مجموعه داده مرجع و آزمون مشاهده شد. بررسی اطلاعات مدرسه از منابع آنلاین نشان داد که ساختمانهای اصلی مدرسه (که در دادههای ORNL نشان داده شدهاند) پس از توسعه دادههای ORNL بسته شدهاند و مدرسه جدیدی با همین نام در مکان دیگری ساخته شده است (در هر دو نشان داده شده است). داده های OSMCP و OSM) [ 57 ]. بنابراین، این مکتب از تحلیل بیشتر دقت حذف شد.
3.5. روش های دستی
مقادیر 5 و 10 MatchMethod روش های تطبیق دستی هستند. روش های خودکار ما قادر به مقابله با این موارد نیستند. بنابراین، کاربر باید به صورت دستی سوابق غیرقابل تطبیق را که پس از فرآیندهای خودکار باقی میمانند، بررسی کند تا تعیین کند که آیا مطابقت بالقوه از دست رفته است یا خیر. در مفهوم، کاربر هر دو مجموعه داده مرجع و آزمایشی را به همراه برچسب های آنها در یک سیستم اطلاعات جغرافیایی (GIS) نمایش می دهد. سپس کاربر تمام رکوردهایی را که هنوز مطابقت ندارند بررسی می کند (به عنوان مثال، آنها مقدار MatchMethod 0 را حفظ می کنند، تا مشخص شود که آیا یک تطابق وجود دارد یا خیر. اگر رکوردی با نام مشابه به عنوان یک تطابق شناسایی شود، کاربر مقدار MatchMethod را به 5 بهروزرسانی میکند، فاصله بین دو ویژگی را اندازهگیری میکند و سپس فیلدهای فاصله، نام و آدرس را برای مطابقت با رکورد منطبق بهروزرسانی میکند. . در موارد نادر، روشهای خودکار با دو رکورد مطابقت ندارند، زیرا نام و/یا آدرسهای آنها برای الگوریتم تطبیق الگو بسیار متفاوت است. با این حال، در طول فرآیند دستی، کاربر می تواند این دو رکورد را به عنوان یک تطابق شناسایی کند. یکی از نمونههای تطبیق دستی «Escuela Tlatelolco Centro de Estudios» و «Escuela Tlatelolco» است که روشهای تطبیق خودکار به دلیل تفاوت در طول رکوردهای مربوطه نتوانستند این دو رکورد را شناسایی کنند. برای اینکه الگوریتم تطبیق الگو این رکوردها را به عنوان یک تطابق شناسایی کند، حداقل نسبت باید آنقدر پایین تنظیم شود که بسیاری از تطابقات نادرست برای سایر ویژگی ها ایجاد شود و همانطور که قبلاً گفته شد، حداقل مقادیر برای به حداقل رساندن اشتباه انتخاب شدند. مسابقات. نسبتی که تشابه این دو رشته را توصیف می کند 0.65 است که بسیار کمتر از حداقل نسبت 0.83 است که از طریق آزمون و خطا ایجاد شده است. خوشبختانه، موارد بسیار کمی از رکوردهای از دست رفته، مانند موردی که در بالا نشان داده شد، در طی فرآیند تطبیق دستی کشف شد که تصمیم برای تنظیم نسبت های بالاتر برای جلوگیری از تطابق های نادرست را تایید کرد. حداقل مقادیر برای به حداقل رساندن تطابقات نادرست انتخاب شدند. نسبتی که تشابه این دو رشته را توصیف می کند 0.65 است که بسیار کمتر از حداقل نسبت 0.83 است که از طریق آزمون و خطا ایجاد شده است. خوشبختانه، موارد بسیار کمی از رکوردهای از دست رفته، مانند موردی که در بالا نشان داده شد، در طی فرآیند تطبیق دستی کشف شد که تصمیم برای تنظیم نسبت های بالاتر برای جلوگیری از تطابق های نادرست را تایید کرد. حداقل مقادیر برای به حداقل رساندن تطابقات نادرست انتخاب شدند. نسبتی که تشابه این دو رشته را توصیف می کند 0.65 است که بسیار کمتر از حداقل نسبت 0.83 است که از طریق آزمون و خطا ایجاد شده است. خوشبختانه، موارد بسیار کمی از رکوردهای از دست رفته، مانند موردی که در بالا نشان داده شد، در طی فرآیند تطبیق دستی کشف شد که تصمیم برای تنظیم نسبت های بالاتر برای جلوگیری از تطابق های نادرست را تایید کرد.
یک فرآیند بسیار مشابه به دنبال یک رکورد مجاور با یک آدرس مشابه دنبال میشود، به جز اینکه کاربر مقدار MatchMethod را به 10 بهروزرسانی میکند و سپس فاصله، نام و آدرس را بهروزرسانی میکند. اگر هیچ تطابقی از طریق ابزار دستی یافت نشد، کاربر مقدار MatchMethod را به 11 بهروزرسانی میکند که نشان میدهد هیچ مطابقتی پیدا نشد. کاربر فرآیند را تکرار می کند تا زمانی که هیچ رکوردی با مقدار MatchMethod 0 باقی نماند و فرآیند تطبیق را تکمیل می کند.
3.6. محاسبه آمار خلاصه
همانطور که در بالا ذکر شد، هنگامی که مطابقت ها شناسایی شدند، قبل از انجام تجزیه و تحلیل، یک مرحله پردازش اضافی مورد نیاز است. فرآیند نهایی در تجزیه و تحلیل شامل محاسبه تقاطع، اتحاد و مکمل است. سپس می توان از این مقادیر در محاسبه دقت و کامل بودن استفاده کرد [ 58 ].
مجموعه داده تقاطع (آزمون مرجع ∩) شامل تمام رکوردهایی است که در هر دو مجموعه داده وجود دارد. رکوردها با انتخاب رکوردهایی که دارای مقدار MatchMethod 1-10 در مجموعه داده متصل هستند، شناسایی می شوند.
مجموعه داده تست مکمل مرجع (مرجع/آزمون) شامل آن دسته از رکوردهایی است که در مجموعه داده مرجع هستند، اما در مجموعه داده تست نیستند. برای شناسایی این رکوردها، رکوردهایی با مقدار MatchMethod 11 از مجموعه داده های متصل انتخاب می شوند.
مجموعه داده مرجع مکمل تست (آزمون/مرجع) شامل آن دسته از رکوردهایی است که در مجموعه داده تست هستند، اما در مجموعه داده مرجع نیستند. روش شناسایی این رکوردها کمی ساده تر از روش قبلی است. دلیل پیچیدگی اضافه شده این است که مجموعه داده پیوست شده شامل تمام رکوردهای مجموعه داده تست نمی شود، بلکه فقط آن دسته از رکوردهایی را شامل می شود که مطابقت دارند. به منظور تعیین اینکه کدام رکوردهای آزمایشی در مجموعه داده متصل نیستند، دو مجموعه داده با استفاده از اتصال جدول بر روی ویژگی ها با استفاده از یک شناسه منحصر به فرد در مجموعه داده آزمایشی مقایسه شدند و سپس همه رکوردهای متصل نشده استخراج شدند، زیرا در مجموعه داده پیوست شده شناسایی نشدند.
اتحادیه (آزمون مرجع) نشان دهنده تمام رکوردهایی است که در مجموعه داده مرجع یا تست هستند. مجموعه دادههای متقاطع و متمم که قبلاً توضیح داده شد برای استخراج اتحادیه ادغام شدند.
محاسبه این چهار پارامتر، محاسبات کامل و دقت را تسهیل میکند، که در ادامه این مقاله ارائه خواهد شد.
4. نتایج
از بحث قبلی، جدول 1 تعداد کل مدارس در منطقه مورد مطالعه را برای هر مجموعه داده ارائه می دهد و شباهت های بین دو مجموعه داده را صرفاً بر اساس تعداد رکوردها نشان می دهد. در حالی که هاکلی از تعداد رکورد بخشهای جاده به عنوان جایگزینی برای کامل بودن استفاده کرد، بحث قبلی نشان میدهد که چگونه مقایسه تعداد خالص برای توصیف تفاوتهای بین مجموعه دادههای دو نقطه کافی نیست [ 15 ]. نتیجه روش موجود در این مقاله است که این تفاوتها را به روشی قویتر کمّی میکند.
جدول 3تفکیک انواع هر تطابق را ارائه می دهد که با استفاده از تکنیک های تطبیق خودکار و دستی هنگام مقایسه مجموعه داده های ORNL با OSMCP و مجموعه داده های ORNL به OSM شناسایی شده اند تا مشخص شود آیا روش های ذکر شده در این مقاله با هدف انجام می شوند یا خیر. قابل تکرار و قابل اعتماد برای مقایسه ORNL با OSMCP، تقریباً 82٪ از رکوردها با استفاده از الگوریتم خودکار مطابقت داده شدند در حالی که کمتر از 7٪ با استفاده از روش های دستی با تقریباً 11٪ بی همتا مطابقت داشتند. برای مقایسه ORNL با OSM، درصد تطبیق تا حدودی کمتر بود، زیرا دادههای OSM مورد استفاده در تجزیه و تحلیل حاوی اطلاعات آدرس نبودند. تقریباً 56٪ از رکوردها با استفاده از الگوریتم خودکار مطابقت داشتند در حالی که تقریباً 15٪ با استفاده از روش های دستی با بیش از یک چهارم (28٪) بی همتا مطابقت داشتند.
جدول 3. نتایج تطبیق برای ORNL و OSMCP.
این تحلیلهای تعداد روشهای تطبیق نشان میدهد که روشهای خودکار در تطبیق اکثر رکوردها به صورت خودکار موفق بودهاند، حتی اگر مجموعه دادهها با استفاده از استانداردهای متفاوت یا وجود نداشته باشند. درصد رکوردهایی که با استفاده از روشهای دستی شناسایی شدند، حتی زمانی که تعداد رکوردهای بیهمتا بالا بود، نسبتاً پایین بود. این موفقیتها در تطبیق خودکار، تکرارپذیری روش مورد استفاده را تضمین میکند و اعتباری برای روش فراهم میکند. گام بعدی استفاده از این نتایج برای شروع ارزیابی تفاوت بین مجموعه داده ها است.
در ادامه بحث قبلی، با بررسی نتایج روشهای تطبیق خودکار و دستی، جدول 4 خلاصهای از شمارشهایی را ارائه میکند که از هر یک از محاسبات تقاطع، تکمیل و اتحاد بهدست آمدهاند. همانطور که انتظار می رود، تعداد Union و Complement برای مقایسه OSM بالاتر است، زیرا نرخ تطابق کمتر ناشی از عدم وجود اطلاعات آدرس است. با این حال، همانطور که در مورد مقایسه تعداد رکوردها وجود دارد، صرفاً مقایسه تعداد بین این مقایسه ها هنگام تلاش برای درک معنای نتایج کافی نیست.
جدول 4. خلاصه تعداد رکوردها برای تطبیق داده ها.
4.1. کامل بودن
ارزیابی کامل بودن دادههای ارائهشده، درک درستی از قابلیت اطمینان نتایج گزارششده را فراهم میکند و امکان ارزیابی سودمندی دادههای ارائهشده بهعنوان منبع دادههای بالقوه برای استفاده آژانسهای نقشهبرداری و محققان را فراهم میکند. پژوهش حاضر در ارزیابی کامل بودن، مسائل حذف و کمیسیون در پایگاه داده را مورد توجه قرار می دهد. براسل و همکاران تمرکز بر ارزیابی اینکه آیا اشیاء موجود در پایگاه داده همه نمونه های موجودیت را در دنیای واقعی نشان می دهند [ 34 ]. کامل بودن تفاوت بین دنیای واقعی و پایگاه داده را به عنوان درصدی از کل ساختارهای فیزیکی در منطقه مورد مطالعه توصیف می کند.
با استفاده از Brassel et al. با رویکرد تعیین درجه کامل بودن، این مطالعه داده های آزمون (OSMCP و OSM) را با داده های مرجع (ORNL) مقایسه کرد [ 34 ]. همانطور که در جدول 3 نشان داده شده است ، مقایسه داده های ORNL و OSMCP نشان داد که در مجموع 89 درصد از رکوردها مطابقت دارند. از این تعداد، 82٪ به طور خودکار مطابقت داده شدند در حالی که 7٪ باقیمانده به صورت دستی مطابقت داده شدند که نشان می دهد الگوریتم تطبیق خودکار موفقیت آمیز است.
جدول 3 همچنین مقایسه داده های ORNL و OSM را خلاصه می کند. در حالی که نرخ تطابق برای این مقایسه به طور قابل توجهی کمتر بود و تنها 71٪ از کل رکوردها مطابقت داشتند، نرخ تطابق دستی بیش از دو برابر بیشتر بود و 15٪ با نرخ مسابقه خودکار به 56٪ کاهش یافت. با توجه به عملکرد نسبتا ضعیف برای کامل بودن، کاربرد داده های OSM به عنوان منبع نگاشت جایگزین در منطقه مورد مطالعه مشکوک است. با این حال، داده های OSMCP، که تقریباً 9 مدرسه از هر 10 مدرسه را شامل می شد، نشان دهنده بهبود قابل توجهی نسبت به نتایج OSM بدون محدودیت در بیش از 7 مدرسه از هر 10 مدرسه بود.
تجزیه و تحلیلها نشان داد که تلاشهای OSM و OSMCP مدارسی را که در دادههای ORNL نبودند، بهدست آوردند. همانطور که در جدول 3 نشان داده شده است، 28 درصد از مدارس OSM در پایان تجزیه و تحلیل ها بی همتا باقی ماندند در حالی که 11 درصد از سوابق OSMCP بی همتا باقی ماندند . تجزیه و تحلیل های داخل این مقاله این مسائل را بیشتر بررسی نکردند تا مشخص کنند آیا این رکوردهای بی همتا مدارسی را که در مجموعه داده مرجع وجود ندارند شناسایی می کنند یا اینکه آیا مجموعه داده های آزمایشی رکوردهایی را ثبت می کنند که طبق تعریف رایج در بخش 3.1 در بالا توضیح داده شده است. تجزیه و تحلیل بیشتر از رکوردهای بی همتا برای مطالعه ماهیت آنها برای ارزیابی کیفیت مجموعه داده مرجع مورد نیاز است.
4.2. دقت
در حالی که معیار کامل بودن با مقایسه رکوردهای منطبق و نامطلوب ارزیابی می شود، دقت فقط آن دسته از رکوردهایی را بررسی می کند که مطابق قبلی در تقاطع شناسایی شده اند.
انتظار می رود که دقت کلی داده های OSMCP با توجه به رویه های کنترل کیفیت که بخشی از پروژه بودند بالا باشد. با این حال، مهم است که دقت داده ها را کمی کنید زیرا این یک عنصر اساسی در تجزیه و تحلیل جغرافیایی است. مقایسه دقت در میان مجموعههای داده از منابع مختلف مستلزم درک دقیق استانداردهای مورد استفاده برای قرار دادن ویژگی در هر منبع است. همانطور که در بالا ذکر شد، دادههای ORNL بر تطبیق آدرس با خط مرکزی خیابان متمرکز بود. پارامترهای مجموعه OSMCP به مشارکت کنندگان دستور می دهد تا ویژگی های مدرسه را در مرکز ساختمان قرار دهند. OSM به مشارکتکنندگان دستور میدهد تا ویژگیهای منطقه را برای مجتمعهای مدرسه ایجاد کنند، اما اگر مرز مجتمع به درستی مشخص نشده باشد، به مشارکتکننده دستور داده میشود که یک مکان را در وسط مجتمع تخمین بزند. مهم است که بدانیم که مرتبط کردن یک نقطه برای ویژگیهای مورد مطالعه در این کار ممکن است بسته به ویژگیهای یک ویژگی خاص و تفسیر توسط مشارکتکننده، منجر به درجات مختلفی از ابهام شود. در غیاب یک روش مشترک، برخی از تفاوت های موقعیتی بین هر دو مجموعه داده ممکن است رخ دهد. این موضوع که چگونه مشارکتکنندگان ویژگیهای منطقهای را به مکانهای نقطهای کاهش میدهند، موضوعی پیچیده است، و به این ترتیب خارج از محدوده این مقاله است [38 ].
خطای مکانی برای هر مسابقه ارزیابی شده و نتایج در جدول 5 آمده است. در حالی که حداقل خطا در هر دو مقایسه دو متر بود، حداکثر خطا برای داده های OSM تقریباً چهار برابر حداکثر خطا برای OSMCP بود. هم میانگین و هم انحراف استاندارد برای داده های OSM بالاتر بود و دومی نشان می دهد که خطا در داده های OSM بیشتر از OSMCP متفاوت است. علاوه بر این، میانه داده های OSM کمتر از میانگین است که نشان دهنده کج بودن داده ها است. این نتایج از مفهوم ناهمگونی خطا که قبلاً برای شبکه های جاده ای OSM توضیح داده شده بود حمایت می کند [ 15 ، 16 ، 17 ].
جدول 5. خطای مکانی برای مدارس همسان.
از آنجایی که خطا بین دو مجموعه داده بسیار متفاوت بود، تلاش بیشتری برای بررسی ماهیت توزیع خطا انجام شد. همانطور که قبلاً بحث شد، VGI هیچ مکانیسم رسمی برای اجرای استانداردهای جمع آوری داده ها ندارد و بنابراین برخی از کاربران ممکن است تصمیم بگیرند که ویژگی مدرسه را در جایی از ساختمان قرار دهند در حالی که برخی دیگر ممکن است تصمیم بگیرند که ویژگی مدرسه را در خیابان مجاور ساختمان قرار دهند. در نتیجه این عدم قطعیت در محل قرارگیری ویژگی، مقداری خطا انتظار می رود. همانطور که در جدول 5 مشاهده می شود، در حالی که در انتهای پایین طیف قرار داریدیک خطای دو متری می تواند نویز در نظر گرفته شود، در بیش از 1800 متر، ارتفاع بالا یک خطای واقعی در نظر گرفته می شود. جایی در بین این دو مقدار، خطا باعث جهش از نویز به خطای واقعی می شود. در تلاش برای ارزیابی مکانی که این پرش وجود دارد، دو آستانه شناسایی شد. با توجه به ابهام ذاتی تعریف مکان برای مدارس، ما آستانه هایی را انتخاب کردیم که بر اساس ماهیت فیزیکی عناصر ارائه شده در مقابل مبتنی بر آستانه ها بر اساس خود نتایج است.
آستانه ها به ترتیب در 30 و 150 متر مشخص شده اند. مقدار 30 متر (30 متر) با توجه به اندازه ساختمان مدرسه انتخاب شد. اگر مدرسه ای مربعی با مساحت 40000 فوت مربع بود که برای یک مدرسه راهنمایی 500 دانش آموز با دو طبقه معمولی است، نیمی از یک ضلع تقریباً 30 متر و در نتیجه هر دو نقطه در 30 متر خواهد بود. می توان یکدیگر را در وسط و لبه ساختمان تصور کرد [ 59 ]. به طور مشابه، مکان های مدرسه به طور ایده آل حدود 25 هکتار برای مدارس راهنمایی با جمعیت 500 دانش آموز [ 60 ] است.]. نیمی از یک ضلع یک زمین مربع 25 هکتاری کمی بیش از 150 متر است و بنابراین دو نقطه که در فاصله 150 متری از یکدیگر قرار دارند هنوز در ملک مدرسه هستند. بنابراین 30 متر برای نشان دادن دقت “ساختمان” و 150 متر برای نشان دادن دقت “پردیس” استفاده می شود. با استفاده از این دو آستانه، جدول 6 برای نشان دادن توزیع خطا در مجموعه داده های آزمایشی در این آستانه ها ایجاد شد.
جدول 6. درصد مدارس دارای خطای مکانی در هر آستانه.
با استفاده از اطلاعات جدول 6 ، درصد مدارس همسان در 150 متر (مجموع) برای هر دو OSMCP و OSM را می توان 96% نشان داد. با این حال، در سطح 30 متر، OSMCP قادر به مطابقت با 46٪ از رکوردها در حالی که OSM تنها 31٪ مطابقت دارد. این نتایج نشان میدهد که هر یک از مجموعهدادهها به همان اندازه قادر خواهند بود کاربر را به ملک مدرسه برسانند، همانطور که با درصد مشابهی از رکوردهای زیر آستانه 150 متر نشان داده شده است. با این حال، داده های OSMCP دارای پتانسیل بیشتری برای شناسایی ساختمان مدرسه است، همانطور که با درصد بالاتر آن با خطای کمتر از 30 متر نشان داده شده است. با این حال، اگر تمام داده های ORNL از مثال ارائه شده در شکل 3 پیروی کنند، جایی که ORNL آدرس را در خیابان ترسیم می کند در حالی که داده های OSM و OSMCP یک مکان را در دارایی ترسیم می کنند، در این صورت فقط آستانه 150 متر مناسب است و بنابراین آستانه بزرگتر معتبر است.
یک ارزیابی اضافی به منظور ارزیابی دقت OSM در مقابل OSMCP انجام شد. در این ارزیابی نهایی، خطای فضایی برای تطابق از هر دو مجموعه داده با یکدیگر مقایسه شد تا مشخص شود که کدام یک بیشتر نزدیکتر است. همه مدارس ORNL توسط مشارکت کنندگان OSM و OSMCP پیدا نشدند. از 402 مدرسه ORNL، 281 مدرسه وجود داشت که با هر دو OSMCP و OSM مطابقت داشتند. یک روش ساده برای تعیین دقت نسبی این است که فاصله OSM تا ORNL را از فاصله OSMCP تا ORNL برای هر یک از مدارسی که یک تطابق داشتند کم کنیم. با استفاده از این روش، یک مقدار منفی نشان می دهد که مکان OSM نسبت به مکان OSMCP به مکان ORNL نزدیکتر است. جدول 7نمونه ای از نحوه مقایسه تفاوت فاصله برای مدارس تطبیق بین ORNL-OSM (A) و ORNL-OSMCP (B) ارائه می دهد.
جدول 7. نمونه گیری داده ها از تفاوت فاصله برای مدارس همسان.
نتایج خلاصه تجزیه و تحلیل نمونه بالا برای تمام 281 مدرسه در جدول 8 آمده است. از 281 مدرسه مشابه، مدارس OSMCP برای 58٪ مدارس نزدیکتر بودند. با این حال، OSMCP نیز بیشترین تفاوت (224 متر) را دارد. جالب توجه است، میانگین فاصله OSMCP و OSM و انحراف استاندارد تقریباً یکسان بود و دادههای OSM دارای خطای متوسط کمی بالاتر برای مدارس همسان بود.
جدول 8. مقایسه دقت برای مدارس همسان.
5. بحث و نتیجه گیری
همانطور که VGI در حال افزایش محبوبیت است، منجر به تولید حجم زیادی از داده های مکانی می شود که به طور بالقوه می توانند منابع داده سنتی “معتبر” را تکمیل و تقویت کنند. برای استفاده از این پتانسیل، ما به درک بهتری از کیفیت مشارکت های VGI، به ویژه دقت و کامل بودن آنها نیاز داریم. این موضوع در حال حاضر مهمتر است، زیرا جمعآوری دادههای VGI به طور فزایندهای شامل داوطلبانی میشود که آموزش جغرافیایی کمی دارند یا بدون آموزش جغرافیایی هستند و دادههای جغرافیایی را تولید میکنند. در نتیجه، نیاز به مطالعه بیشتر ویژگی های کیفی VGI وجود دارد.
این مقاله وضعیت فعلی دانش در مورد این موضوع را با تمرکز بر کامل بودن و دقت ویژگیهای نقطهای در دادههای VGI گسترش میدهد. این مکمل مطالعات قبلی است که دقت ویژگیهای خطی را در VGI ارزیابی میکردند تا درک کلی ما از مسائل مربوط به کیفیت را بهبود بخشند. تجزیه و تحلیل ما نشان داد که مقایسه شمارش ساده بین مجموعه دادههای دو نقطه برای مشخص کردن تفاوتهای بین این دو مجموعه داده کافی نیست، زیرا آنها وجود خطاهای حذفی و کمیسیون را تشخیص نمیدهند. در نتیجه، برای شناسایی و طبقه بندی اختلافات بین دو (یا چند) مجموعه داده، به تحلیل قوی تری نیاز است. به طور خاص، ما یک رویکرد نیمه خودکار را برای تطبیق رکوردهای متناظر بین دو مجموعه داده معرفی کردیم و اثربخشی آن را نشان دادیم. تجزیه و تحلیل ما دو مجموعه داده تست VGI را با یک مجموعه داده مرجع مقایسه کرد و تفاوت های آنها را تجزیه و تحلیل کرد. ما همچنین ویژگیهای یک نوع ترکیبی VGI (OSMCP) را مورد بحث قرار دادیم که به موجب آن یک آژانس دولتی بازخورد کنترل کیفیت را به داوطلبان ارائه میدهد و تأثیر آن را بر دقت کلی محصول VGI ارزیابی کردیم. مشاهدات ما نشان می دهد که به نظر می رسد دقت اضافه شده در مقایسه با داده های OSM، هم کامل بودن و هم دقت را بهبود می بخشد.
تجزیه و تحلیل کامل بودن نشان داد که داده های OSMCP نزدیک به 90٪ از رکوردها در پایگاه داده مرجع ORNL را ضبط می کند، در حالی که داده های OSM تقریبا 70٪ از این رکوردها را ضبط می کند. نتیجه کامل کمتر مشاهدهشده در دادههای OSM را میتوان به دو عامل نسبت داد: دادههای OSM شامل اطلاعات آدرس نمیشوند، و روشهای جمعآوری به کار رفته برای دادههای OSM شامل فرآیندهای کنترل کیفیت رسمی اجرا شده در روشهای جمعآوری برای OSMCP نمیشوند. در نهایت، 70 مدرسه OSMCP (357) بیشتر از مدارس OSM (287) با مجموعه داده مرجع مطابقت داشتند.
روندهای مشابهی با توجه به دقت موقعیتی شناسایی شد، که نشان دهنده خطای فضایی بین مکانهای دو مجموعه داده است، با دادههای OSMCP که به نظر میرسد دقیقتر از OSM هستند. هر دو OSM و OSMCP در 96٪ مواقع در 150 متر از مجموعه داده مرجع قرار داشتند. با این حال، OSMCP در 30 متر بیشتر (46٪ از زمان) از OSM (31٪) بود. به طور کلی، 59٪ از مدارس OSMCP در مقایسه با همتایان OSM خود به ورودی های مرجع ORNL خود نزدیکتر بودند. این نتایج علاوه بر ارائه تخمینی برای دقت و کامل بودن، نشان میدهد که OSMCP بهتر از OSM عمل میکند.
این مقاله به موضوعی پرداخته است که تاکنون در جامعه ما به صورت گذرا مورد مطالعه قرار گرفته است. از طریق این کار، ما با توضیح روشی برای مقایسه دو مجموعه از ویژگی های نقطه، درک خود را به این موضوعات گسترش داده ایم. به طور خاص، ما نشان دادهایم که چگونه میتوان از این روش برای مقایسه منابع داده مرجع و VGI (تست) استفاده کرد. ما معتقدیم که این گام مهمی در درک کیفیت VGI در رابطه با سایر منابع داده است.
از آنجایی که VGI هم از نظر مشارکت و هم از نظر دامنه در حال تکامل است، درک بهتر کیفیت آن، پارامترهایی که بر آن تأثیر میگذارند و شیوههایی که برای تولید آن استفاده میشود، به افزایش کاربرد محصولات آن برای تجزیه و تحلیل جغرافیایی کمک میکند. بر اساس این کار اولیه، چندین زمینه کار آینده باید بررسی شود. مشارکت کنندگان بدون محدودیت (و آموزش ندیده) همیشه درک مشترکی از تعریف “چیستی” یک ویژگی یا “کجا” باید قرار گیرد ندارند و تأثیر ابهام بر کیفیت داده درک نشده است. نتیجه ابهام می تواند کاهش در کاربرد VGI برای تصمیم گیری باشد. با این حال، این اثرات مورد مطالعه قرار نگرفته است. در نهایت، نیاز به بهبود روشهای ارزیابی دادههایی است که در حال حاضر به عنوان «معتبر» برچسبگذاری شدهاند، زیرا همانطور که در این تحقیق نشان دادیم،
منابع
- رعنا، س. Joliveau, T. NeoGeography: گسترش جغرافیای جریان اصلی برای همه که توسط همه ساخته شده است؟ J. سرویس مبتنی بر مکان. 2009 ، 3 ، 75-81. [ Google Scholar ] [ CrossRef ]
- تولوچ، دی. شاپیرو، تی. تقاطع دسترسی به داده ها و مشارکت عمومی: تأثیر بر موفقیت کاربران GIS. URISA J. 2003 ، 15 ، 55-60. [ Google Scholar ]
- مونی، پی. کورکوران، پ. Winstanley، A. Towards Quality Metrics for OpenStreetMap. در مجموعه مقالات هجدهمین کنفرانس بین المللی SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سن خوزه، کالیفرنیا، ایالات متحده آمریکا، 2 تا 5 نوامبر 2010. صص 514-517.
- Goodchild، M. شهروندان به عنوان حسگرها: دنیای جغرافیای داوطلبانه. ژئوژورنال 2007 ، 69 ، 211-221. [ Google Scholar ] [ CrossRef ]
- هادسون اسمیت، ا. کروکس، آ. گیبین، م. میلتون، آر. Batty، M. NeoGeography و Web 2.0: مفاهیم، ابزارها و کاربردها. J. سرویس مبتنی بر مکان. 2009 ، 3 ، 118-145. [ Google Scholar ] [ CrossRef ]
- هاو، جی. ظهور جمع سپاری. مجله وایرد 2006 ، 14 ، 161-165. [ Google Scholar ]
- برابهام، دی سی جمع سپاری به عنوان مدلی برای حل مسئله: مقدمه و موارد. همگرایی. بین المللی J. Res. فناوری رسانه جدید 2008 ، 14 ، 75-90. [ Google Scholar ] [ CrossRef ]
- هیپک، سی. دادههای جغرافیایی جمعسپاری. ISPRS J. Photogramm. 2010 ، 65 ، 550-557. [ Google Scholar ] [ CrossRef ]
- استفانیدیس، ا. کروکس، آ. Radzikowski، J. برداشت اطلاعات مکانی محیطی از فیدهای رسانه های اجتماعی. جئوژورنال 2013 ، 78 ، 319-338. [ Google Scholar ] [ CrossRef ]
- هاروی، اف. داوطلب شدن یا مشارکت در اطلاعات مکانی؟ به سوی حقیقت در برچسبگذاری برای اطلاعات جغرافیایی جمعسپاری شده. در جمع سپاری دانش جغرافیایی: اطلاعات جغرافیایی داوطلبانه (VGI) در تئوری و عمل . Springer Science + Business Media: دوردخت، هلند، 2013; صص 31-42. [ Google Scholar ]
- هال، جی. چیپنیوک، آر. فیک، ر. لیهی، م. Deparday، V. تولید اطلاعات جغرافیایی مبتنی بر جامعه با استفاده از نرم افزار منبع باز و وب 2.0. بین المللی جی. جئوگر. Inf. علمی 2010 ، 24 ، 761-781. [ Google Scholar ] [ CrossRef ]
- الوود، اس. گودچایلد، م. Sui, D. چشم انداز تحقیقات VGI و پارادایم چهارم در حال ظهور. در جمع سپاری دانش جغرافیایی: اطلاعات جغرافیایی داوطلبانه (VGI) در تئوری و عمل . Springer Science + Business Media: دوردخت، هلند، 2013; صص 361-375. [ Google Scholar ]
- فلاناژین، ا. متزگر، ام. اعتبار اطلاعات جغرافیایی داوطلبانه. جئوژورنال 2008 ، 72 ، 137-148. [ Google Scholar ] [ CrossRef ]
- نیس، پ. Zipf، A. تجزیه و تحلیل فعالیت مشارکت کننده یک پروژه داوطلبانه اطلاعات جغرافیایی – مورد OpenStreetMap. ISPRS Int. J. Geo-Inf. 2012 ، 1 ، 146-165. [ Google Scholar ] [ CrossRef ]
- Haklay, M. اطلاعات جغرافیایی داوطلبانه چقدر خوب است؟ مطالعه مقایسه ای مجموعه داده های نظرسنجی OpenStreetMap و Ordnance. محیط زیست طرح. B طرح. طراحی 2010 ، 37 ، 682-703. [ Google Scholar ] [ CrossRef ]
- Girres, J.-F. Touya, G. ارزیابی کیفیت مجموعه داده OpenStreetMap فرانسه. ترانس. GIS 2010 ، 14 ، 435-459. [ Google Scholar ] [ CrossRef ]
- زیلسترا، دی. Zipf، A. مطالعه مقایسه ای ژئوداده اختصاصی و اطلاعات جغرافیایی داوطلبانه برای آلمان. در مجموعه مقالات سیزدهمین کنفرانس بین المللی AGILE در علم اطلاعات جغرافیایی، گیماراس، پرتغال، 10-14 مه 2010. جلد 2010، صص 1-15.
- فیک، ر. Roche, S. درک ارزش VGI. در جمع سپاری دانش جغرافیایی: اطلاعات جغرافیایی داوطلبانه (VGI) در تئوری و عمل . Springer Science + Business Media: دوردخت، هلند، 2013; صص 15-30. [ Google Scholar ]
- هاکلی، م. Weber, P. OpenStreetMap: نقشه های خیابانی تولید شده توسط کاربر. محاسبات فراگیر IEEE 2008 ، 7 ، 12-18. [ Google Scholar ] [ CrossRef ]
- Goodchild، مدل های داده MF و کیفیت داده: مشکلات و چشم اندازها. در مدلسازی محیطی با GIS ; انتشارات دانشگاه آکسفورد: نیویورک، نیویورک، ایالات متحده آمریکا، 1993; صص 94-103. [ Google Scholar ]
- هاکلی، م. سینگلتون، ا. پارکر، سی. نقشه برداری وب 2.0: جغرافیای جدید GeoWeb. Geogr. Compass 2008 , 2 , 2011-2039. [ Google Scholar ]
- فیک، ر. Roche, S. ارزش گذاری اطلاعات جغرافیایی داوطلبانه (VGI): فرصت ها و چالش های ناشی از شیوه جدید استفاده و تولید GI. در مجموعه مقالات دومین کارگاه GEOValue، هامبورگ، آلمان، 30 سپتامبر تا 2 اکتبر 2010. دانشگاه هافن سیتی: هامبورگ، آلمان، 2010; صص 75-79. [ Google Scholar ]
- الوود، اس. اطلاعات جغرافیایی داوطلبانه: مسیرهای تحقیقاتی آینده با انگیزه GIS انتقادی، مشارکتی و فمینیستی. جئوژورنال 2008 ، 72 ، 173-183. [ Google Scholar ] [ CrossRef ]
- الوود، اس. علم اطلاعات جغرافیایی: تحقیقات در حال ظهور در مورد پیامدهای اجتماعی وب جغرافیایی. Prog. هوم Geogr. 2009 ، 34 ، 349-357. [ Google Scholar ] [ CrossRef ]
- سیبر، آر. سیستم های اطلاعات جغرافیایی مشارکت عمومی: بررسی ادبیات و چارچوب. ان دانشیار صبح. Geogr. 2006 ، 96 ، 491-507. [ Google Scholar ]
- کوپر، ا. کوتزی، اس. کاچمارک، آی. کوری، دی. ایوانیاک، ع. چالش های کیفیت در اطلاعات جغرافیایی داوطلبانه کوبیک، تی. در مجموعه مقالات کنفرانس AfricaGEO 2011، کیپ تاون، آفریقای جنوبی، 31 مه تا 2 ژوئن، 2011. AfricaGEO: کیپ تاون، آفریقای جنوبی، 2011; پ. 13. [ Google Scholar ]
- Haklay، M. Citizen Science و داوطلبانه اطلاعات جغرافیایی: بررسی اجمالی و گونه شناسی مشارکت. در جمع سپاری دانش جغرافیایی: اطلاعات جغرافیایی داوطلبانه (VGI) در تئوری و عمل . Springer Science + Business Media: دوردخت، هلند، 2013; صص 105-124. [ Google Scholar ]
- کلمن، دی. مشارکتهای بالقوه و چالشهای VGI برای برنامههای نقشهبرداری پایه توپوگرافی معمولی. در جمع سپاری دانش جغرافیایی: اطلاعات جغرافیایی داوطلبانه (VGI) در تئوری و عمل . Springer Science + Business Media: دوردخت، هلند، 2013; ص 245-264. [ Google Scholar ]
- Goodchild، MF علم اطلاعات جغرافیایی. بین المللی جی. جئوگر. Inf. سیستم 1992 ، 6 ، 31-45. [ Google Scholar ] [ CrossRef ]
- Goodchild، MF; Hunter، GJ یک اندازه گیری دقت موقعیتی ساده برای ویژگی های خطی. بین المللی جی. جئوگر. Inf. علمی 1997 ، 11 ، 299-306. [ Google Scholar ]
- کریسمن، ن. مؤلفه خطا در داده های مکانی. در سیستم های اطلاعات جغرافیایی و علوم ; Longley, P., Goodchild, M., Maguire, D., Rhind, D., Eds. جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 1991; جلد 1، صص 165–174. [ Google Scholar ]
- دیویلر، آر. Jeansoulin, R. (Eds.) Fundamentals of Spatial Data Quality ; ISTE: لندن، انگلستان، 2006.
- هاکلی، م. بسیوکا، اس. آنتونیو، وی. Ather، A. برای نقشه برداری خوب یک منطقه به چند داوطلب نیاز است؟ اعتبار قانون لینوس برای اطلاعات جغرافیایی داوطلبانه کارتوگر. J. 2010 , 47 , 315-322. [ Google Scholar ] [ CrossRef ]
- براسل، ک. بوچر، اف. استفان، ای. Vckovski، A. کامل بودن. در عناصر کیفیت داده های مکانی ; الزویر: آکسفورد، بریتانیا، 1995; صص 81-108. [ Google Scholar ]
- البکری، م. Fairbairn، D. ارزیابی دقت داده های “انبوه سپاری” و ادغام آن با مجموعه داده های فضایی رسمی. در مجموعه مقالات نهمین سمپوزیوم بین المللی ارزیابی دقت فضایی در منابع طبیعی و علوم محیطی، لستر، بریتانیا، 20 تا 23 ژوئیه 2010. صص 317-320. در دسترس آنلاین: http://www.spatial-accuracy.org/system/files/img-X06165606_0.pdf (در 23 مه 2012 قابل دسترسی است).
- دراموند، جی. دقت موقعیت. در عناصر کیفیت داده های مکانی ; الزویر: آکسفورد، بریتانیا، 1995; صص 31-58. [ Google Scholar ]
- Weng، Q. سنجش از دور و یکپارچه سازی GIS، نظریه ها، روش ها و کاربردها. McGraw Hill: نیویورک، نیویورک، ایالات متحده آمریکا، 2010. [ Google Scholar ]
- لانگلی، پی. گودچایلد، م. مگوایر، دی. Rhind، D. سیستم های اطلاعات جغرافیایی و علوم ، ویرایش 3. جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2011. [ Google Scholar ]
- وربویز، م. Duckham, M. GIS A Computing Perspective , 2nd ed.; تیلور فرانسیس: لندن، بریتانیا، 2004. [ Google Scholar ]
- EPA. دروازه مجموعه داده های محیطی . در دسترس آنلاین: http://edg.epa.gov/metadata/catalog/search/resource/details.page?uuid=%7B794F5D6E-5347-41ED-9594-DCE122FFC419%7D (در 28 نوامبر 2012 قابل دسترسی است).
- نقاط مورد علاقه – OpenStreetMap Wiki . در دسترس آنلاین: http://wiki.openstreetmap.org/wiki/Points_of_interest (در 3 مه 2013 قابل دسترسی است).
- بیش از، م. شیلینگ، آ. نوبائر، اس. Zipf، A. تولید مدل های شهر سه بعدی مبتنی بر وب از OpenStreetMap: وضعیت فعلی در آلمان. Comp. محیط زیست سیستم شهری 2010 ، 34 ، 496-507. [ Google Scholar ] [ CrossRef ]
- پور، BS; گرگ، EB; کوریس، EM; والتر، جی ال. Matthews، GD Structures جمع آوری داده ها برای نقشه ملی با استفاده از اطلاعات جغرافیایی داوطلبانه . 2012، ص. 34. در دسترس آنلاین: http://pubs.usgs.gov/of/2012/1209 (در 12 فوریه 2013 قابل دسترسی است).
- مروری بر ویژگی های ساختار . در دسترس آنلاین: http://navigator.er.usgs.gov/help/vgistructures_userguide.html (در 3 مه 2013 قابل دسترسی است).
- نظرسنجی دانشگاه خصوصی (PSS)—نمای کلی . در دسترس آنلاین: http://nces.ed.gov/surveys/pss/ (در 4 مه 2013 قابل دسترسی است).
- هسته مشترک داده ها (CCD) – CCD چیست؟ در دسترس آنلاین: http://nces.ed.gov/ccd/aboutCCD.asp (در 3 مه 2013 قابل دسترسی است).
- OpenStreetMap Wik—Schools . در دسترس آنلاین: http://wiki.openstreetmap.org/wiki/Tag:amenity%3Dschool (در 1 مه 2013 قابل دسترسی است).
- گرگ، EB; متیوز، جی دی. مک نینچ، ک. پور، نمونه اولیه مشارکتی BS OpenStreetMap، فاز 1 . گزارش پرونده باز سازمان زمین شناسی ایالات متحده 2011–1136; سازمان زمین شناسی ایالات متحده: Reston، VA، ایالات متحده آمریکا، 2011; پ. 23. در دسترس آنلاین: http://pubs.usgs.gov/of/2011/1136/ (در 25 ژوئیه 2012 قابل دسترسی است).
- Ushahidi: نرم افزار منبع باز برای جمع آوری اطلاعات، تجسم و نقشه برداری تعاملی. در دسترس آنلاین: http://www.ushahidi.com/ (دسترسی در 18 فوریه 2013).
- تعاریف جغرافیایی اداره سرشماری ایالات متحده در دسترس آنلاین: http://www.census.gov/geo/www/geo_defn.html#CensusTract (در 27 ژوئیه 2012 قابل دسترسی است).
- زوک، م. گراهام، ام. شلتون، تی. Gorman, S. داوطلبانه اطلاعات جغرافیایی و جمع سپاری امداد رسانی به بلایا: مطالعه موردی زلزله هائیتی. پزشکی جهانی سیاست سلامت 2010 ، 2 ، 6-32. [ Google Scholar ]
- ماتیاس، اس. ماتیاس، سی. میطرایی، ح. کوماتا، م. کیفر، پ. Schlieder, C. طراحی بازی های موبایل مبتنی بر مکان: مطالعه موردی CityExplorer. در Digital Cityscapes: Merging Digital and Urban Playspaces ; Peter Lang Publishers: New York, NY, USA, 2009; ص 187-203. [ Google Scholar ]
- گرگ، EB; پور، BS; کارو، هنگ کنگ؛ متیوز، مجموعه داده های نقشه داوطلبانه GD در USGS. جیول آمریکا برگه اطلاعات نظرسنجی 2011-3103; سازمان زمین شناسی ایالات متحده: Reston، VA، ایالات متحده آمریکا، 2011; پ. 2. در دسترس آنلاین: http://pubs.usgs.gov/fs/2011/3103/ (در 25 ژوئیه 2012 قابل دسترسی است). [ Google Scholar ]
- دانلودهای CloudMade در دسترس آنلاین: http://downloads.cloudmade.com/americas/northern_america/united_states/colorado#downloads_breadcrumbs (در 12 فوریه 2013 قابل دسترسی است).
- Wolf, EB Re: یادداشتها/اقدامات از Call Today. 3 نوامبر 2011. [ Google Scholar ]
- 7.4. Difflib–Helpers for Computing Deltas– Python v2.7.3 Documentation . در دسترس آنلاین: http://docs.python.org/2/library/difflib.html (در 29 نوامبر 2012 قابل دسترسی است).
- دبیرستان Whaley، M. Old Adams City باید بازسازی شود. دنور پست . 15 دسامبر 2012. در دسترس آنلاین: http://www.denverpost.com/news/ci_22196962/old-adams-city-high-school-be-renovated (در 12 فوریه 2013 قابل دسترسی است).
- والپول، آر. مایرز، آر. احتمال و آمار برای مهندسان و دانشمندان ، ویرایش دوم. McMillan Publishing Co.: New York, NY, USA, 1978. [ Google Scholar ]
- Abramson, P. Hard Economy Hits Construction Planning . ص 2-8. در دسترس آنلاین: http://www.peterli.com/spm/pdfs/SPM-2009-02-SUPPLEMENT.pdf (در 12 فوریه 2013 قابل دسترسی است).
- Weihs, J. اندازه سایت مدرسه—چند هکتار لازم است؟ Issuetrak، شورای بین المللی برنامه ریزان تسهیلات آموزشی: اسکاتسدیل، AZ، ایالات متحده آمریکا، 2003; پ. 7. در دسترس آنلاین: http://media.cefpi.org/issuetraks/issuetrak0903.pdf (در 12 فوریه 2013 قابل دسترسی است).
© 2013 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/3.0/) توزیع شده است.
بدون نظر