

خلاصه
سیستم های تشخیص خودکار نشانه ها ; نقاط دیدنی ; برجسته معنایی ; محلی بودن شبکه های اجتماعی آنلاین ؛ اشتراک گذاری موقعیت اجتماعی ؛ مسیریابی
چکیده گرافیکی
1. معرفی
2. انسان راه یابی
2.1. تعریف راه یابی انسانی
-
جهت گیری ( یعنی آگاهی از موقعیت نسبی خود در مقایسه با مقصد نهایی).
-
انتخاب مسیر ( یعنی تعیین مسیر برای رسیدن به مقصد نهایی).
-
کنترل مسیر ( یعنی دنبال کردن مسیری که قبلا ایجاد شده است).
-
شناخت مقصد ( یعنی فهمیدن اینکه به مقصد نهایی رسیده ایم).
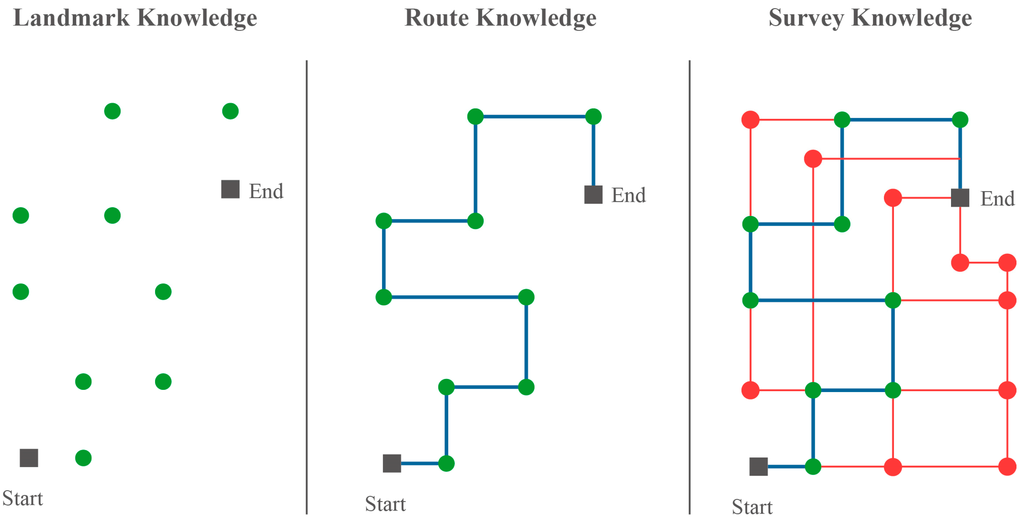
2.2. دانش فضایی انسان
2.3. کمک به راهیابی
3. به سمت تشخیص خودکار نشانه ها
3.1. برجستگی نشانهها و سیستمهای تشخیص خودکار نشانهها
3.1.1. مدل رسمی نقطه عطفی

3.1.2. سیستم های تشخیص نقطه عطف خودکار


3.2. چالش ها و مسائل مربوط به ALDS
-
اول از همه، ALDS ها بیشتر بر ویژگی های بصری و ساختاری ساختمان ها تمرکز می کنند در حالی که معنای معنایی آنها نیز بسیار مهم است ( جدول 1 را ببینید). علاوه بر این، رویکردهای سنتی منحصراً مبتنی بر ویژگیهای ثابت و عینی (به عنوان مثال، ارتفاع ساختمانها) هستند. ویژگی های پویا و ذهنی مانند تعداد بازدیدکنندگان نیز باید در نظر گرفته شود. ما هیچ راه حلی را شناسایی نکردیم که چنین ویژگی های پویا را در نظر بگیرد.
-
از آنجایی که ارزیابی وزندهی واقعی دشوار است، رویکردهای سنتی وزندهی یکنواخت را برای ویژگیهای هر شی اعمال میکنند. همانطور که گفته شد، وینتر و همکاران. [ 42 ] دنبالهای برای کار خود در زمینه ناوبری ارائه میدهند. علاوه بر این، داکهام و همکاران. [ 52 ] وزن قابل تنظیم را اعمال می کنند زیرا اندازه گیری نقطه عطف آنها وابسته به مسیر است.
-
جدا از چند راه حل (به عنوان مثال، [ 53 ])، تنها ساختمان ها در نظر گرفته می شوند. انواع دیگر اشیاء، مانند درختان، نادیده گرفته می شوند. با این حال، ساختمانها تنها موردی نیستند که میتوانند بهعنوان نقاط عطفی برای ناوبری عمل کنند [ 37 ]. حتی اگر داکهام و همکاران. تصدیق می کنند که اشیاء غیر از ساختمان ها باید در نظر گرفته شوند، راه حل آنها از این قاعده عدول نمی کند [ 52 ].
-
راهحلهای سنتی فقط بر نقاط عطف واقع در نقاط انتخاب یا نقاط انتخاب بالقوه تمرکز میکنند. با این حال، نقاط در مسیر و خارج از مسیر نیز در ناوبری بسیار مهم هستند [ 30 ]. ما باید بیان کنیم که Core LNM توسعه یافته شامل انتخاب نقاط عطف خارج از نقاط تصمیم است.
3.3. پتانسیل Crowdsourcing برای تشخیص خودکار نشانهها
4. مجموعه داده های اشتراک گذاری موقعیت مکانی اجتماعی به عنوان منبع اطلاعاتی قابل اعتماد برای اندازه گیری برجستگی معنایی شاخص
4.1. چرا از داده های اشتراک گذاری موقعیت مکانی اجتماعی برای اندازه گیری برجستگی معنایی شاخص استفاده کنیم؟
4.1.1. یک شاخص مرتبط از معنای جمعی و فردی مکان ها
4.1.2. دادههای اشتراکگذاری موقعیت مکانی اجتماعی نماینده روزمرگی شهرها هستند
4.1.3. پایگاههای داده مکان ایجاد شده توسط کاربر برای اندازهگیری برجستگی معنایی شاخص مناسب هستند
-
اول از همه، کاربران شبکههای اجتماعی آنلاین با افزودن (یا عدم) مکانها، نوعی «فیلتر معنایی» را اعمال میکنند. در واقع، وجود یک مکان در داخل یک UGPD به وضوح نشان دهنده علایق کاربران است. به عبارت دیگر، حضور در مقابل عدم وجود یک مکان معین، یک شاخص معنایی جهانی را تشکیل میدهد که میتواند با شاخصهای محلی اضافی ، مانند تعداد ورود، نظرات یا نکات منتشر شده از آن مکان ترکیب شود.
-
ثانیاً، برخلاف دادههای موقعیت مکانی، اعلام حضور همیشه با مکانی مرتبط است که مختصات جغرافیایی آن در یک پایگاه داده ذخیره میشود. این اصل یکنواختی موقعیت را تضمین می کند. به عنوان مثال، به استثنای توییتهای دارای برچسب جغرافیایی ارسال شده از Foursquare، دو توییت منتشر شده از یک مکان ممکن است مختصات جغرافیایی متفاوتی داشته باشند، بسته به دقت دستگاه تلفن همراهی که از آن پست شدهاند.
-
ثالثاً، دادههای SLS به ما امکان میدهد هر مکان را بر اساس فعالیتهای ورود به جلسه در طول روز و شب (به ویژه برای ورود به Swarm) دستهبندی کنیم. بنابراین، این داده ها همچنین می توانند برای بهبود تشخیص نشانه های معنایی برای دوره شبانه استفاده شوند.
-
در نهایت، شبکه های اجتماعی آنلاین مزیت ارائه طیف گسترده ای از دسته بندی مکان ها را ارائه می دهند. برخلاف رویکردهای سنتی که بر انتخاب ساختمانها بهعنوان نامزدهای شاخص متمرکز است، یک پلتفرم مانند Foursquare به چندین نوع اشیاء، از جمله موارد طبیعی (به عنوان مثال، باغ یا حتی کوهها) دسترسی میدهد که میتوانند بهعنوان نشانهها نیز عمل کنند. با این حال، ما باید اذعان کنیم که بخش بزرگی از UGPD ها اساساً از ساختمان ها تشکیل شده اند.
4.1.4. ردپای روزانه به جا مانده توسط کاربران رسانه های اجتماعی می تواند برای بهبود تشخیص نقطه عطف مبتنی بر زمینه ناوبری استفاده شود
4.2. چگونه می توان برجستگی معنایی شاخص را از طریق جریان های داده SLS اندازه گیری کرد؟
4.2.1. منحصر به فرد بودن مکان ها
که در آن، UNQ = امتیاز منحصر به فرد، p = مکان، C = دسته مکان.
جایی که، Uنسm i n�نسمترمن�= حداقل امتیاز در بین تمام امتیازات منحصر به فرد، Uنسm a x�نسمترآایکس= حداکثر امتیاز در بین تمام نمرات منحصر به فرد.
4.2.2. فعالیت های جغرافیایی اجتماعی مکان ها
که در آن، GSA = امتیاز فعالیت جغرافیایی اجتماعی، p = مکان، Swr = ازدحام، TP = نکات، LK = پسندیدن، USR = کاربرانی که یک یا چند اعلام حضور از p منتشر کردهاند .
که در آن، fb = فیس بوک، CK = اعلام حضور ، LK = لایک، TA = صحبت کردن در مورد تعداد.
جایی که، جی اسآm i nجیاسآمترمن�= حداقل امتیاز در بین تمام نمرات فعالیت های جغرافیایی، جی اسآm a xجیاسآمترآایکس= حداکثر امتیاز در بین تمام نمرات فعالیت های جغرافیایی.
4.2.3. برجستگی معنایی شاخص
5. تشخیص نشانه معنایی مبتنی بر داده های جغرافیایی
5.1. نشانه های معنایی معروف جهان
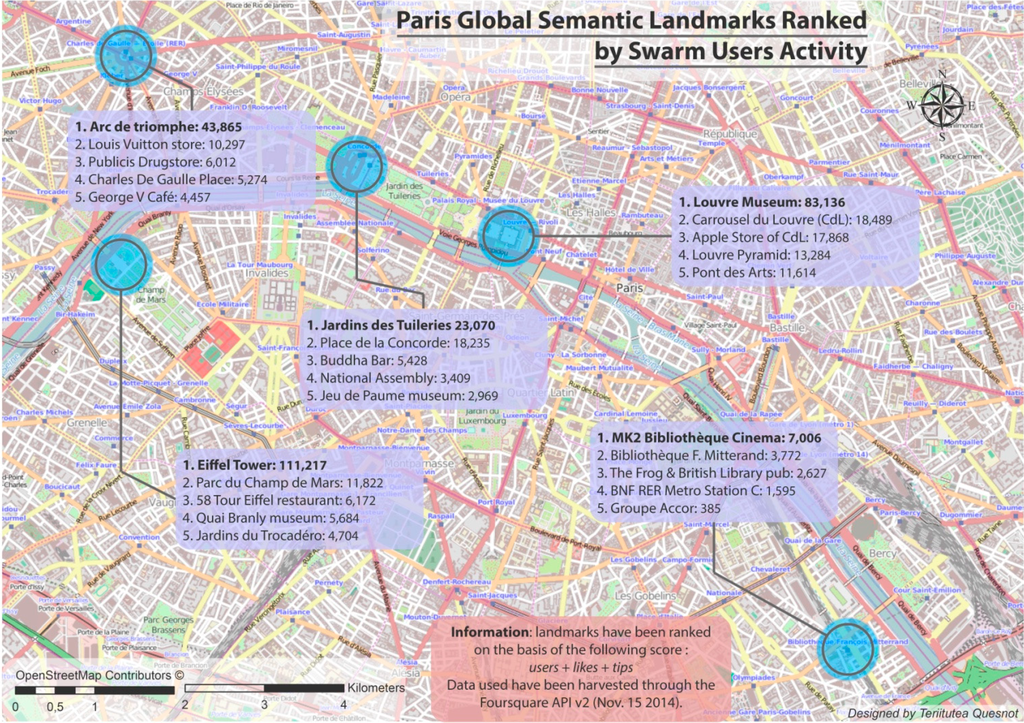
5.2. نشانه های جهانی معنایی در سراسر شهر پاریس
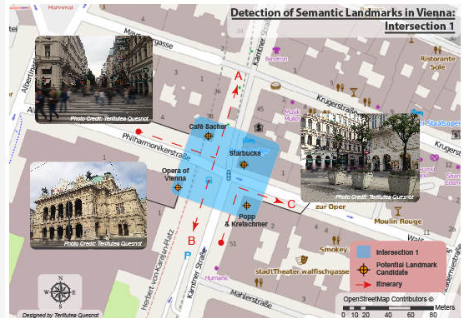
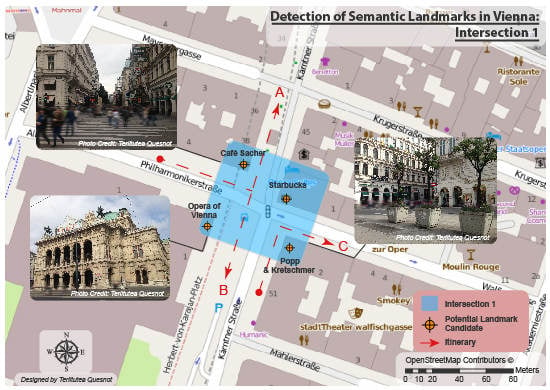
5.3. شناسایی نقاط دیدنی در خیابان های وین (اتریش)
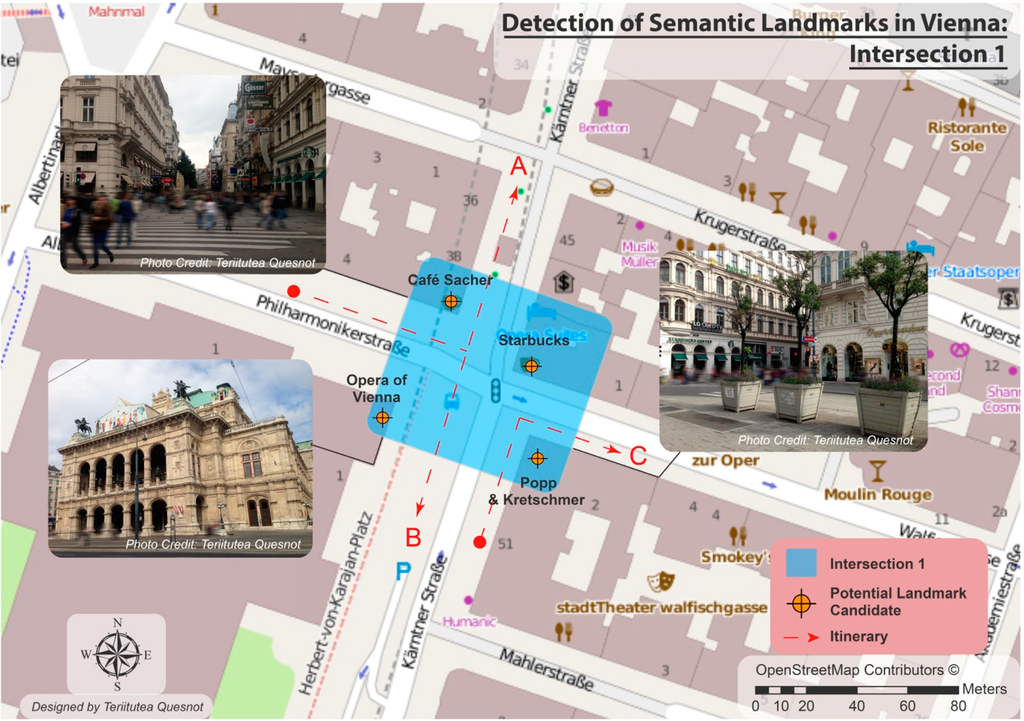



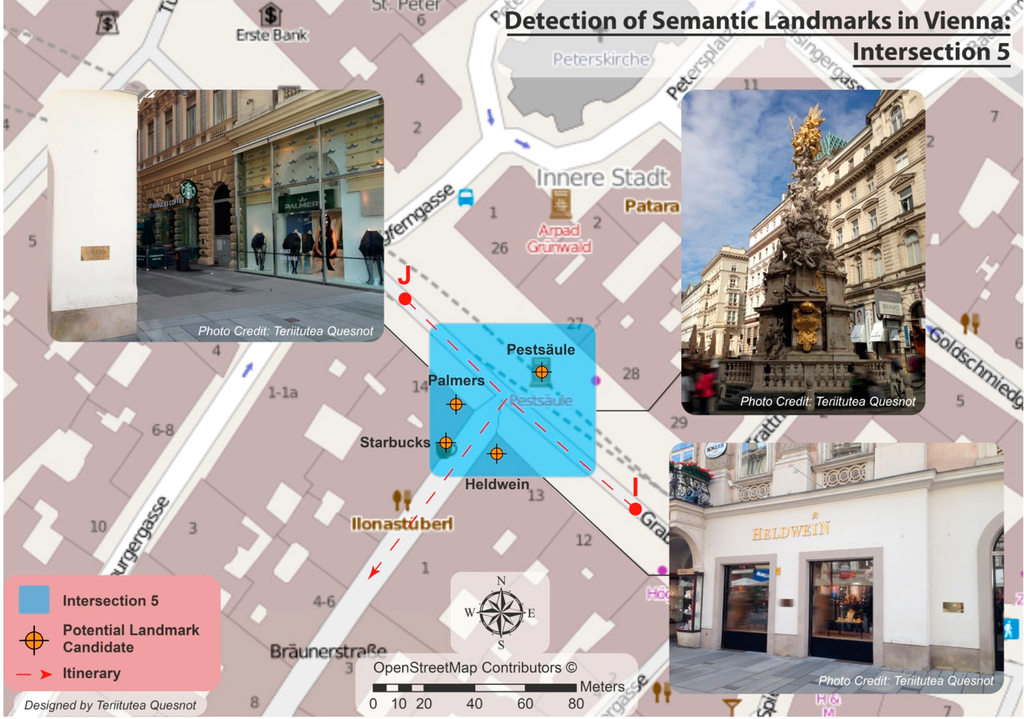
5.4. بحث و چشم انداز
6. نتیجه گیری
منابع
- کالابرس، اف. کولونا، ام. لوویسولو، پی. پاراتا، دی. Ratti, C. نظارت بر شهری در زمان واقعی با استفاده از تلفن های همراه: مطالعه موردی در رم. IEEE Trans. هوشمند ترانسپ سیستم 2011 ، 12 ، 141-151. [ Google Scholar ] [ CrossRef ]
- کالابرس، اف. کلوکل، ک. Ratti, C. Wikicity: ابزارهای حساس به مکان در زمان واقعی برای شهر. هندب Res. اطلاعات شهری 2008 ، 390-413. [ Google Scholar ]
- کالابرس، اف. پریرا، اف سی؛ دی لورنزو، جی. لیو، ال. راتی، سی. جغرافیای ذائقه: تحلیل تحرک تلفن همراه و رویدادهای اجتماعی. محاسبات فراگیر 2010 . [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- راتی، سی. سوتسوک، ا. هوانگ، اس. Pailer، R. مناظر موبایل: Graz در زمان واقعی. در خدمات مبتنی بر مکان و تله کارتوگرافی ; Springer: New York, NY, USA, 2007; ص 433-444. [ Google Scholar ]
- راتی، سی. ویلیامز، اس. فرانسوی، دی. Pulselli، R. مناظر موبایل: استفاده از داده های مکان از تلفن های همراه برای تجزیه و تحلیل شهری. محیط زیست طرح. B 2006 , 33 , 727-748. [ Google Scholar ] [ CrossRef ]
- ریدز، جی. کالابرس، اف. سوتسوک، ا. راتی، سی. سرشماری سلولی: کاوش در جمع آوری داده های شهری. محاسبات فراگیر IEEE 2007 ، 6 ، 30-38. [ Google Scholar ] [ CrossRef ]
- Goodchild، MF Citizens به عنوان حسگر: دنیای جغرافیای داوطلبانه. Geo J. 2007 , 69 , 211-221. [ Google Scholar ]
- اکسنر، جی. همسلی، جی. آزمایشگاه نظارت شهری: مزایا و پتانسیل جدید برای برنامه ریزی شهری از طریق استفاده از سنجش شهری، ژئو و موبایل وب. در مجموعه مقالات Real CORP; مرکز صلاحیت برنامه ریزی شهری و منطقه ای: اسن، آلمان، 2011; صص 1087–1096. [ Google Scholar ]
- کرامپتون، جی. گراهام، ام. پورتویس، ا. شلتون، تی. استفنز، ام. ویلسون، مگاوات؛ Zook، AM فراتر از برچسب جغرافیایی: قرار دادن “داده های بزرگ” و استفاده از پتانسیل geoweb. کارتوگر. Geogr. Inf. علمی 2013 ، 40 ، 130-139. [ Google Scholar ]
- تانگ، KP; لین، جی. هنگ، جی. Siewiorek، DP; Sadeh, N. بازاندیشی اشتراکگذاری مکان: بررسی مفاهیم اشتراکگذاری مکان مبتنی بر اجتماعی در مقابل هدفمحور. در مجموعه مقالات UbiComp 2010، کپنهاگ، دانمارک، 26-29 سپتامبر 2010.
- تاچر، جی. زندگی بر روی دود: ردپای دیجیتال، بخار داده ها، و محدودیت های داده های بزرگ فضایی. بین المللی J. Commun. 2014 ، 8 ، 1765-1783. [ Google Scholar ]
- گیفینگر، آر. فرتنر، سی. کرامار، اچ. کالاسک، آر. پیچلر-میلانوویچ، ن. Meijers، E. شهرهای هوشمند: رتبه بندی شهرهای متوسط اروپا، مرکز علوم منطقه ای (SRF) ; دانشگاه صنعتی وین: وین، اتریش، 2007. [ Google Scholar ]
- چورابی، ح. نام، تی. واکر، اس. گیل-گارسیا، جی آر. ملولی، س. ناهون، ک. پاردو، تی. Scholl, HJ درک شهرهای هوشمند: یک چارچوب یکپارچه. در مجموعه مقالات چهل و پنجمین کنفرانس بین المللی هاوایی در علوم سیستم، مائوئی، HI، ایالات متحده آمریکا، 4 تا 7 ژانویه 2012.
- Batty, M. The New Science of Cities ; انتشارات MIT: کمبریج، MA، ایالات متحده آمریکا، 2013. [ Google Scholar ]
- روشه، اس. علم اطلاعات جغرافیایی I: چرا یک شهر هوشمند باید از نظر فضایی فعال شود؟ برنامه هوم Geogr. 2013 . [ Google Scholar ] [ CrossRef ]
- فار، AC؛ کلاینشمیت، تی. یارلاگادا، پ. منگرسن، K. Wayfinding: یک مفهوم ساده، یک فرآیند پیچیده. حمل و نقل. Rev. 2012 , 32 , 715-743. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لینچ، کی . تصویر شهر . مطبوعات MIT: کمبریج، بریتانیا، 1960. [ Google Scholar ]
- Downs, RM; Stea، D. نقشه های شناختی و رفتار فضایی: فرآیند و محصول. در تصویر و محیط ; Stea, D., Downs, RM, Eds. Aldine Publishing: Chigao, IL, USA, 1973; صص 8-26. [ Google Scholar ]
- نقشه های راهیابی و شناختی گولج، RG Human. در رفتار راه یابی: نقشه برداری شناختی و سایر فرآیندهای فضایی . گولج، آر جی، اد. انتشارات دانشگاه جان هاپکینز: بالتیمور، MD، ایالات متحده آمریکا، 1999; صص 5-45. [ Google Scholar ]
- مونتلو، DR; Raubal, M. توابع و کاربردهای شناخت فضایی. در APA Handbook of Spatial Cognition ; Waller, D., Nadel, L., Eds. انجمن روانشناسی آمریکا: واشنگتن دی سی، ایالات متحده آمریکا، 2013; صص 555-591. [ Google Scholar ]
- دیویس، سی. لی، سی. آلبرشت، جی. درک انسان از فضا. در تعامل با فناوری های جغرافیایی ; هاکلی، MM، اد. John Wiley & Sons Ltd.: Chichester، UK، 2010; صص 19-35. [ Google Scholar ]
- کیچین، آر. Blades, M. The Cognition of Geographic Space ; Tauris: لندن، انگلستان، 2002. [ Google Scholar ]
- سیگل، AW; White, SH توسعه بازنمایی های فضایی محیط های در مقیاس بزرگ. در پیشرفت در رشد و رفتار کودک ; ریس، WH، اد. انتشارات آکادمیک: نیویورک، نیویورک، ایالات متحده آمریکا، 1975. [ Google Scholar ]
- ایشیکاوا، تی. ناکامورا، U. انتخاب نقطه عطف در محیط: روابط با ویژگی های شی و حس جهت. تف کردن شناخت. محاسبه کنید. 2012 ، 12 ، 1-22. [ Google Scholar ]
- شرودر، سی جی; Mackaness، WA; Gittings، BM دادن مسیرهای “درست”: الزامات سیستم های ناوبری عابر پیاده. ترانس. GIS 2011 ، 15 ، 419-438. [ Google Scholar ] [ CrossRef ]
- Montello, DR چارچوبی جدید برای درک اکتساب دانش فضایی در محیط های بزرگ مقیاس. در استدلال مکانی و زمانی در سیستم های اطلاعات جغرافیایی ; Egenhofer, MJ, Golledge, RG, Eds. انتشارات دانشگاه آکسفورد: نیویورک، نیویورک، ایالات متحده آمریکا، 1998; صص 143-154. [ Google Scholar ]
- دنیس، م. فرناندز، جی. پردازش نشانهها در جهتهای مسیر. در بازنمایی فضا در شناخت: روابط متقابل رفتار، زبان و مدلهای رسمی ؛ تنبرینک، تی.، وینر، جی.، کلارامونت، سی.، ویرایش. انتشارات دانشگاه آکسفورد: آکسفورد، انگلستان، 2013; صص 42-55. [ Google Scholar ]
- دنیس، م. Michon، PE; تام، الف. کمک به مسیریابی عابر پیاده در محیطهای شهری: چرا ارجاع به نقاط دیدنی در جهتدهی بسیار مهم است. در شناخت فضایی کاربردی: از پژوهش تا فناوری شناختی . آلن، جی ال، اد. Lawrence Erlbaum: Mahwah, NJ, USA, 2007; صص 25-51. [ Google Scholar ]
- دانیل، M.-P. دنیس، ام. توصیفات فضایی به عنوان کمک های ناوبری: تحلیل شناختی جهت های مسیر. Kognitionswissenschaft 1998 ، 7 ، 45-52. [ Google Scholar ] [ CrossRef ]
- لاولیس، KL; هگارتی، م. Montello, DR عناصر جهت مسیر خوب در محیط های آشنا و ناآشنا. در نظریه اطلاعات مکانی ; Freksa, C., Mark, D., Eds. Springer: برلین، آلمان، 1999; جلد 1661، ص 65–82. [ Google Scholar ]
- دنیس، م. پازاگلیا، اف. کورنولدی، سی. برتولو، L. گفتمان فضایی و ناوبری: تحلیلی از جهت های مسیر در شهر ونیز. Appl. شناخت. روانی 1999 ، 13 ، 145-174. [ Google Scholar ] [ CrossRef ]
- دنیس، ام. توصیف مسیرها: رویکردی شناختی برای تولید گفتمان فضایی. Cah روانی شناخت. 1997 ، 16 ، 409-458. [ Google Scholar ]
- Michon، PE; دنیس، ام. چه زمانی و چرا به نشانه های بصری در جهت دادن اشاره می کنیم؟ در نظریه اطلاعات مکانی ; Goos, G., Hartmanis, J., van Leeuwen, J., Eds. Springer: برلین، آلمان، 2001; جلد 2205، ص 292–305. [ Google Scholar ]
- تام، آ. دنیس، ام. با اشاره به اطلاعات نشانه یا خیابان در جهت مسیر: چه تفاوتی دارد؟ در نظریه اطلاعات مکانی ; Kuhn, W., Worboys, MF, Timpf, S., Eds.; Springer: برلین، آلمان، 2003; جلد 2825، صص 362–374. [ Google Scholar ]
- دانیل، M.-P. تام، آ. منقی، ای. دنیس، ام. آزمایش ارزش جهت های مسیر از طریق عملکرد ناوبری. تف کردن شناخت. محاسبه کنید. 2003 ، 3 ، 269-289. [ Google Scholar ]
- دانیل، M.-P. دنیس، ام. تولید جهتهای مسیر: بررسی شرایطی که به اختصار در گفتمان فضایی کمک میکند. Appl. شناخت. روانی 2004 ، 18 ، 57-75. [ Google Scholar ] [ CrossRef ]
- گولج، آر جی. دوگرتی، وی. بل، اس. کسب دانش فضایی: پیمایش در مقابل دانش مبتنی بر مسیر در محیطهای ناآشنا. ان دانشیار صبح. Geogr. 1995 ، 85 ، 134-158. [ Google Scholar ]
- غم ها، من. هیرتل، SC ماهیت مکان های دیدنی برای فضاهای واقعی و الکترونیکی. در نظریه اطلاعات مکانی مبانی شناختی و محاسباتی علم اطلاعات جغرافیایی ; Springer: هایدلبرگ، آلمان، 1999; صص 37-50. [ Google Scholar ]
- راوبال، م. Winter, S. غنیسازی دستورالعملهای راهیابی با مکانهای دیدنی محلی. در علم اطلاعات جغرافیایی ; Egenhofer, MJ, Mark, DM, Eds. Springer: برلین، آلمان، 2002; جلد 2478، ص 243-259. [ Google Scholar ]
- ناثگر، سی. زمستان، اس. Raubal, M. انتخاب ویژگی های برجسته برای مسیرهای مسیر. تف کردن شناخت. محاسبه کنید. 2004 ، 4 ، 113-136. [ Google Scholar ]
- Winter, S. مسیر انتخاب تطبیقی از ویژگی های برجسته. در نظریه اطلاعات مکانی ; Kuhn, W., Worboys, MF, Timpf, S., Eds.; Springer: هایدلبرگ، آلمان، 2003; جلد 2825، ص 349–361. [ Google Scholar ]
- زمستان، اس. راوبال، م. Nothegger, C. تمرکز بر معیارهای برجسته برای راهیابی. در خدمات تلفن همراه مبتنی بر نقشه ؛ Springer: هایدلبرگ، آلمان، 2005; صص 125-139. [ Google Scholar ]
- کلیپل، ا. زمستان، S. برجستگی ساختاری نشانهها برای مسیرهای مسیر. در نظریه اطلاعات مکانی ; Cohn، AG، Mark، DM، Eds. Springer: Ellicottville, NY, USA, 2005; جلد 3693، صص 347–362. [ Google Scholar ]
- صادقیان، پ. Kantardzic، M. نسل جدید سیستم های خودکار تشخیص نقطه عطف: چالش ها و دستورالعمل ها. تف کردن شناخت. محاسبه کنید. 2008 ، 8 ، 252-287. [ Google Scholar ]
- الیاس، ب. استخراج نشانه ها با روش های داده کاوی. در نظریه اطلاعات مکانی ; Kuhn, W., Worboys, MF, Timpf, S., Eds.; Springer: برلین، آلمان، 2003; جلد 2825، صص 398–412. [ Google Scholar ]
- زمستان، اس. تومکو، م. الیاس، بی. سستر، ام. سلسله مراتب شاخص در زمینه. محیط زیست طرح. B 2008 , 35 , 381-398. [ Google Scholar ] [ CrossRef ]
- Tomko، M. مطالعه موردی – ارزیابی توزیع فضایی منابع وب برای خدمات ناوبری. در مجموعه مقالات چهارمین کارگاه بین المللی در وب و سیستم های اطلاعات جغرافیایی بی سیم W2GIS04، کویانگ، کره، 26-27 نوامبر 2004.
- تزوکا، تی. Tanaka، K. استخراج نقطه عطف: یک رویکرد وب کاوی. در نظریه اطلاعات مکانی ; Springer: هایدلبرگ، آلمان، 2005; جلد 3693، صص 379–396. [ Google Scholar ]
- Caduff، D.; Timpf, S. عنکبوت نقطه عطف: معرف دانش نقطه عطفی برای کارهای راهیابی. در مجموعه مقالات سمپوزیوم بهار AAAI: استدلال با نمودارهای ذهنی و بیرونی: مدلسازی محاسباتی و کمک فضایی، پالو آلتو، کالیفرنیا، ایالات متحده آمریکا، 23 تا 25 مارس 2005. صص 30-35.
- الیاس، بی. Sester، M. ترکیب نشانهها با معیارهای کیفیت در روشهای مسیریابی. در علم اطلاعات جغرافیایی 2006 ; Raubal, M., Miller, HJ, Frank, AU, Goodchild, MF, Eds. Springer: برلین، آلمان، 2006; جلد 4197، ص 65–80. [ Google Scholar ]
- ریشتر، KF; کلیپل، الف. قبل یا بعد: حروف اضافه در سیستم های فضایی محدود. در شناخت فضایی V ; Barkowsky, T., Knauff, M., Ligozat, G., Montello, DR, Eds. Springer: برلین، آلمان، 2007; جلد 4387، صص 453–469. [ Google Scholar ]
- داکهام، ام. زمستان، اس. رابینسون، ام. از جمله نشانهها در دستورالعملهای مسیریابی. J. Locat. سرویس مبتنی بر 2010 ، 4 ، 28-52. [ Google Scholar ] [ CrossRef ]
- کلیپل، ا. هانسن، اس. ریشتر، KF; زمستان، S. دانه بندی شهری – یک ساختار داده برای مسیرهای ارگونومیک شناختی. Geoinformatica 2009 ، 13 ، 223-247. [ Google Scholar ] [ CrossRef ]
- هیرتل، طراحی جغرافیایی SC: شناخت فضایی و علم اطلاعات جغرافیایی ; Morgan & Claypool Publishers: San Rafael, CA, USA, 2011. [ Google Scholar ]
- ریشتر، KF چشم اندازها و چالش های نقاط عطف در خدمات ناوبری. در جنبه های شناختی و زبانی فضای جغرافیایی ; Raubal, M., Mark, DM, Frank, AU, Eds. Springer: هایدلبرگ، آلمان، 2013; صص 83-97. [ Google Scholar ]
- ریشتر، KF; Winter, S. برداشت محتوای تولید شده توسط کاربر برای اطلاعات مکانی معنایی: مورد نشانهها در OpenStreetMap. در مجموعه مقالات کنفرانس دوسالانه نقشه برداری و علوم فضایی، ولینگتون، نیوزلند، 21 تا 25 نوامبر 2011. صص 75-86.
- فرانک، AU; Raubal, M. آموزش GIS امروز: از علم GI تا مهندسی GI. URISA J. 2001 ، 13 ، 5-10. [ Google Scholar ]
- ترانت، جی. مطالعه برچسبگذاری اجتماعی و عامیانه: بررسی و چارچوب. جی دیجیت. اطلاعات 2009، 10، ص. شماره 1. در دسترس آنلاین: https://journals.tdl.org/jodi/index.php/jodi/article/view/269/278 (دسترسی در 24 ژوئن 2014).
- کراندال، دی. بکستروم، ال. هاتنلوچر، دی. عکس های کلینبرگ، جی. نقشه برداری از جهان. در مجموعه مقالات هجدهمین کنفرانس بین المللی وب جهانی، مادرید، اسپانیایی، 20-24 آوریل 2009.
- هیل، اچ. ودانتهام، آر. کوئلار، جی. لیو، ا. گلفاند، ن. گرززچوک، آر. Borriello, G. پیمایش عابر پیاده مبتنی بر مکان دیدنی از مجموعه عکسهای دارای برچسب جغرافیایی. در مجموعه مقالات هفتمین کنفرانس بین المللی چند رسانه ای موبایل و همه جا حاضر، Umea، سوئد، 3-5 دسامبر 2008. صص 145-152.
- شلیدر، سی. ماتیاس، سی. عکاسی از یک شهر: تحلیلی از مفاهیم مکان بر اساس انتخاب های فضایی. تف کردن شناخت. محاسبه کنید. 2009 ، 9 ، 212-228. [ Google Scholar ]
- جردن، KO; شپتیکین، آی. گروتر، بی. Vatterrott, H. شناسایی نشانه های ساختاری در یک پارک با استفاده از داده های حرکتی جمع آوری شده در یک بازی مبتنی بر مکان. در مجموعه مقالات SIGSPATIAL COMP’13، اورلاندو، فلوریدا، ایالات متحده آمریکا، 5 تا 8 نوامبر 2013.
- شوارتز، آر. نعمان، م. نقشه های ذهنی جمعی و فردی شهر در جریان های آگاهی اجتماعی. در مجموعه مقالات کارگاه GeoHCI در CHI 2013، پاریس، فرانسه، 27-28 آوریل 2013.
- الوود، اس. Goodchild، MF; Sui، چشم انداز DS برای تحقیقات VGI و پارادایم چهارم در حال ظهور. در جمع سپاری دانش جغرافیایی ; Sui، DS، Elwood، S.، Goodchild، MF، Eds. Springer Netherlands: Dordrecht, The Netherlands, 2013; صص 361-375. [ Google Scholar ]
- لوی، جی. لوسو، ام. اسپیس. در Dictionnaire de la Géographie et de L’espace des Sociétés ; بلین: پاریس، فرانسه، 2003; صص 325-333. [ Google Scholar ]
- Lussault, M. Lʼhomme Spatial: la Construction Sociale de L’espace Humain ; Seuil: پاریس، فرانسه، 2007. [ Google Scholar ]
- بارخوس، ال. براون، بی. بل، م. هال، م. شروود، اس. چالمرز، ام. از آگاهی تا پاسخگو: اشتراکگذاری مکان در گروههای اجتماعی، CHI’08 . انتشارات ACM: فلورانس، ایتالیا، 2008. [ Google Scholar ]
- کرامر، اچ. رست، م. Holmquist، LE انجام چک-این: شیوه های در حال ظهور، هنجارها و “تضادها” در اشتراک گذاری مکان با استفاده از چهار مربع. در مجموعه مقالات موبایل HCI 2011، استکهلم، سوئد، 30 اوت تا 2 سپتامبر 2011.
- Evans, L. خدمات مبتنی بر مکان: دگرگونی تجربه فضا. J. Locat. سرویس مبتنی بر 2011 ، 5 ، 242-260. [ Google Scholar ] [ CrossRef ]
- لیندکویست، جی. کرنشاو، جی. ویز، جی. هنگ، جی. زیمرمن، جی. من شهردار خانهام هستم: بررسی اینکه چرا مردم از چهار ضلعی استفاده میکنند—یک برنامه اشتراکگذاری مکان مبتنی بر اجتماعی. در مجموعه مقالات کنفرانس عوامل انسانی در سیستم های محاسباتی (CHI-11)، ونکوور، BC، کانادا، 7-12 مه 2011.
- رست، م. بارخوس، ال. کرامر، اچ. براون، ب. بازنمایی و ارتباطات: چالشها در تفسیر مجموعه دادههای بزرگ رسانههای اجتماعی. در مجموعه مقالات CSCW ’13، سن آنتونیو، تگزاس، ایالات متحده آمریکا، 23 تا 27 فوریه 2013.
- نولاس، ا. اسکلاتو، اس. ماسکولو، سی. پونتیل، ام. مطالعه تجربی الگوهای فعالیت کاربر جغرافیایی در Foursquare. در مجموعه مقالات پنجمین کنفرانس بین المللی AAAI در وبلاگ ها و رسانه های اجتماعی، بارسلون، اسپانیا، 17 تا 21 ژوئیه 2011.
- کلی، ام جی تخیلات شهری نوظهور رسانه های جغرافیایی اجتماعی. Geo J. 2013 ، 78 ، 181-203. [ Google Scholar ]
- باوا-کاویا، الف. حس شهری: استفاده از داده های شبکه اجتماعی مبتنی بر مکان در تحلیل شهری. در مجموعه مقالات نهمین کنفرانس بین المللی محاسبات فراگیر، کارگاه آموزشی کاربردهای فراگیر شهری (PURBA)، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 12 ژوئن 2011.
- کرنشاو، جی. شوارتز، آر. هنگ، جی. Sadeh, N. پروژه زندگی: استفاده از رسانه های اجتماعی برای درک پویایی یک شهر. در مجموعه مقالات ششمین کنفرانس بین المللی AAAI در مورد وبلاگ ها و رسانه های اجتماعی (ICWSM-12)، دوبلین، بریتانیا، 4 تا 7 ژوئن 2012.
- کرنشاو، جی. یانو، تی. دیدن خانه ای دور از خانه: تقطیر محله های اولیه از داده های اتفاقی با مدل سازی موضوع پنهان. در مجموعه مقالات کارگاه NIPS در مورد علوم اجتماعی محاسباتی و حکمت جمعیت، ویستلر، کانادا، 10 دسامبر 2010.
- پرئوتیوک-پیترو، دی. کرنشاو، جی. یانو، تی. بررسی اقدامات شباهت شهر به شهر مبتنی بر مکان. در مجموعه مقالات UrbComp 13، شیکاگو، IL، ایالات متحده آمریکا، 11-14 اوت 2013. انتشارات ACM: شیکاگو، IL، ایالات متحده آمریکا، 2013. [ Google Scholar ]
- زادروزنی، پ. Kodali, R. تجزیه و تحلیل چهار مربع چک کردن. در تجزیه و تحلیل داده های بزرگ با استفاده از Splunk ; Apress: نیویورک، نیویورک، ایالات متحده آمریکا، 2013; صص 231-253. [ Google Scholar ]
- ریشتر، KF; Winter, S. Landmark: GIScience for Intelligent Services ; Springer: Cham، Switzerland، 2014. [ Google Scholar ]
© 2014 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر