1. معرفی
به لطف پیشرفت در فناوری ارتباطات از راه دور و معرفی دستگاه های ارتباطی قابل حمل، اخیراً استفاده از اطلاعات جغرافیایی فراتر از رایانه های رومیزی گسترش یافته و شامل دستگاه های تلفن همراه نیز شده است. با این حال، ویژگیهای حرکتی هیجانانگیز که همراه با چنین فناوریهایی هستند، چالشهایی را نیز از نظر استفاده از اطلاعات جغرافیایی به همراه آوردهاند. از یک طرف، کاربران تلفن همراه معمولاً در میانه کارها یا فعالیت های خاصی مانند راه رفتن یا یافتن راه هستند و بنابراین نمی توانند به اندازه کاربران دسکتاپ وقت خود را صرف خیره شدن به صفحه نمایش خود و مطالعه کنند. از سوی دیگر، این محیط جدید و پویا موبایل تاثیر زیادی بر رفتار کاربران دارد. به عنوان مثال، یک کاربر ممکن است به انواع مختلف جاذبه های گردشگری در زمان های مختلف علاقه مند باشد (به عنوان مثال،
بنابراین، سیستم های بازیابی اطلاعات جغرافیایی برای کاربران تلفن همراه باید بتوانند زمینه استفاده را درک کنند تا ارتباط متنی اطلاعات جغرافیایی را ارزیابی کنند. با در نظر گرفتن زمینه استفاده، مانند مکان، کار و زمان، می توان هم منابع محاسباتی و هم منابع ذهنی کاربران را ذخیره کرد و ادراک اطلاعات را افزایش داد.
با این حال، به دلیل ماهیت ناهمگن و پویای زمینه، جمع آوری زمینه استفاده آسان نیست. معمولاً، چنین اطلاعاتی یا با درخواست صریح از کاربر برای پر کردن فرم یا پاسخ دادن به سؤالات خاص، یا با جمعآوری ضمنی دادههای شناسایی شده توسط حسگرهایی مانند GPS جمعآوری میشود [ 1 ]]. با این حال، این رویکردها پرهزینه و دست و پا گیر هستند. در نتیجه، اطلاعات جغرافیایی داوطلبانه (VGI) مانند شبکه های اجتماعی مبتنی بر مکان (LBSN) امکان دیگری را فراهم می کند. علیرغم عدم تمایل عمومی کاربران به پر کردن فرمها، آنها تمایل دارند اطلاعات بیشتری درباره تجربیات، علایق و احساسات خود در وب ارائه دهند و این اطلاعات به طور بالقوه شامل اطلاعات متنی فراوانی است. از این رو می توان الگوهای تحرک متنی را از این مجموعه داده ها مشاهده کرد و بنابراین ارتباط را ارزیابی کرد و اطلاعات جغرافیایی را به شیوه ای هدفمندتر و آگاهانه تر بازیابی کرد.
هدف اصلی این مقاله این است که نشان دهد چگونه میتوان تأثیر ویژگیهای زمینهای بر الگوهای تحرک را با استفاده از مجموعه داده LBSN شناسایی کرد و رویکردی را برای زمینهسازی فرآیند ارزیابی ارتباط بر اساس این تأثیرات پیشنهاد کرد. بقیه این مقاله به شرح زیر سازماندهی شده است. ابتدا، یک مرور مختصر از کار مرتبط در مورد ارزیابیهای مرتبط جغرافیایی و اطلاعات جغرافیایی داوطلبانه در بخش 2 ارائه خواهد شد . پس از آن، بخش 3 زمینه را بر اساس دامنه تحقیق تعریف میکند، مجموعه دادههای کاری را معرفی میکند، و الگوهای تحرک زیربنایی مرتبط با عوامل زمینه زمانی و مکانی را نشان میدهد. بخش 4 رویکردی را برای زمینه سازی فرآیند ارزیابی ارتباط جغرافیایی پیشنهاد می کند که در آن هر دوارتباط پیشینی و زمینهای با استفاده از تأثیرات شناساییشده در بخش 3 به هم مرتبط میشوند . سپس این رویکرد با استفاده از آزمایشها تأیید میشود و پس از آن بحث در مورد نتایج و محدودیتها در همان بخش انجام میشود. بخش آخر مطالعه را به پایان میرساند و چشماندازی برای تحقیقات آتی ارائه میدهد.
2. کارهای مرتبط
قبل از مصرف توسط کاربران تلفن همراه، حجم عظیمی از اطلاعات جغرافیایی باید به طور مداوم بر اساس ارتباط آن با زمینه خاص فیلتر شود. در این راستا، ارزیابی ارتباط اطلاعات جغرافیایی با در نظر گرفتن زمینه استفاده ضروری است. بنابراین، بخش اول این بخش به بررسی کار مرتبط در ارزیابی ارتباط جغرافیایی می پردازد. از آنجایی که این مطالعه عمدتاً بر یک مجموعه داده LBSN متکی است، بخش دوم این بخش، تحقیقاتی را که بر روی اطلاعات جغرافیایی داوطلبانه انجام شده است، با تمرکز ویژه بر LBSN ها خلاصه می کند.
2.1. ارزیابی ارتباط جغرافیایی
مفهوم ارتباط از رشته بازیابی اطلاعات (IR) برای حداقل 40 سال [ 2 ] سرچشمه می گیرد، و در آن مرکزی بوده است، به موجب آن اسناد بر اساس شباهت آنها به متن پرس و جو رتبه بندی، فیلتر و بازیابی می شوند. با توسعه دستگاه های تلفن همراه، مدل های بازیابی اطلاعات اکنون به دنبال راه های شخصی تر برای کشف و ارائه توصیه های مرتبط در فضای تلفن همراه هستند. مفهوم ارتباط متعاقباً در زمینه ارتباط جغرافیایی (GR) [ 3 ، 4 ] توسعه یافت تا به تطبیق مدلهای موجود با محیط تلفن همراه کمک کند.
اگرچه اکثر سیستمهای موجود تصمیمات بازیابی خود را صرفاً بر اساس پرسشها و جمعآوری اسناد استوار میکنند، اما ثابت شده است که اطلاعات زمینهای با توجه به بازیابی اطلاعات و دسترسی مفید است [ 5 ]. مکان به عنوان مهمترین و شاید تنها معیار برای تعیین ارتباط جغرافیایی در نظر گرفته می شود [ 6 ]. رایشنباخر و همکاران [ 7]، با این حال، استدلال میکند که مکان و مفاهیم فضایی ساده (مثلاً بافرهای اطراف موقعیت کاربر) که فیلتر اطلاعات باینری را فراهم میکنند، وقتی به تنهایی استفاده میشوند، کافی نیستند. در این راستا، آنها یک چارچوب مفهومی را پیشنهاد کردند که برای ارزیابی ارتباط جغرافیایی از طریق انتزاع فاصله استفاده میشود، که به موجب آن میتوان فواصل مکانی و غیرمکانی، مانند فاصلههای مفهومی و معنایی را به تصویر کشید. با تکیه بر این دانش، De Sabbata و Reichenbacher [ 8 ] یک مدل احتمالی ایجاد کردند که مقدار فاصله را برای هر بعد محاسبه میکند و متعاقباً، شباهت بین بافت کاربر و اشیاء جغرافیایی را محاسبه میکند. در مطالعه بعدی خود، De Sabbata و Reichenbacher [ 9] معیارهای موجود را گسترش داد و مجموعه ای از 29 معیار را برای ارزیابی ارتباط ایجاد کرد.
مشکلات با رویکردهای موجود دو جانبه است. اول، اگرچه محققان به اهمیت زمینه توجه کرده اند، جمع آوری اطلاعات زمینه ای آسان نیست. همانطور که قبلا ذکر شد، زمینه ها معمولا از ورودی های کاربر و با استفاده از حسگرها جمع آوری می شوند. اطلاعات جمع آوری شده از ورودی کاربر می تواند چند وجهی باشد، اما نیاز به همکاری کاربر دارد. بهعلاوه، بهروز نگهداشتن دادهها دشوار است و هیچ دینامیک مکانی و زمانی را نشان نمیدهد. از سوی دیگر، زمینه های شناسایی شده توسط حسگرها می توانند در زمان واقعی باشند. با این حال، انواع زمینه جمعآوریشده ممکن است محدود باشد، و استفاده از حسگرها همیشه ارزان و راحت نیست. ثانیاً، هنگامی که اطلاعات زمینه ای جمع آوری شد، سیستم مورد استفاده نیاز به اعمال قوانین دارد تا بداند چگونه به زمینه های مختلف پاسخ دهد.
بنابراین، این مقاله سعی دارد با کمک تکنیک های داده کاوی این مشکلات را دور بزند. بر اساس سوابق تاریخی کاربران در LBSN ها، الگوهای تحرک متنی را می توان کشف کرد، به این معنی که ارتباط اطلاعات جغرافیایی را می توان به روشی آگاه از زمینه ارزیابی کرد.
3. درک زمینه
در این بخش، ابتدا مفهوم زمینه را در محدوده تحقیق خود تعریف می کنیم و سپس مجموعه داده های کاری را معرفی می کنیم، یعنی داده های چک در چهار ضلعی. بخش آخر این بخش با استفاده از تکنیکهای آماری، تأثیرات بافت بر الگوهای تحرک را بررسی میکند.
3.1. تعریف
مفهوم زمینه در گذشته از منظرهای مختلفی از جمله زبان شناسی، تجارت الکترونیک، تبلیغات و محاسبات سیار مورد توجه قرار گرفته است. بنابراین، استفاده از زمینه از تعاریف مختلفی استخراج شده است، که هر یک تا حد زیادی به یک دامنه کاربردی خاص وابسته است. برای مثال، زمینه در زبانشناسی چارچوبی را پیشنهاد میکند که یک رویداد کانونی را احاطه میکند [ 27 ]، مانند محیط فرهنگی، وضعیت گفتار و مفروضات پیشزمینه مشترک، در حالی که برای سیستمهای محاسباتی سیار، محققان معمولاً به این نتیجه میرسند که مکان، زمان، ویژگیهای کاربر، شرایط فیزیکی (نور، سطح سر و صدا، آب و هوا و محیط اطراف، و غیره ) عناصر بافت معمولی را تشکیل می دهند [ 28 ، 29 ]]. همانطور که توسط گارسیا، دورانتی و گودوین [ 27 ] اشاره شد، «این اصطلاح به معنای چیزهای کاملاً متفاوتی در پارادایمهای تحقیق جایگزین است، و در واقع حتی در سنتهای خاص به نظر میرسد که بیشتر با عمل موقعیتیافته، با استفاده از مفهوم برای کار با تحلیلهای خاص تعریف میشود. چالش ها و مسائل.”
ارتباط یک بخش از اطلاعات جغرافیایی برای یک کاربر تلفن همراه را نمی توان به درستی درک کرد مگر اینکه چارچوب زمینه ای مرتبط را که تصمیم گیری در آن جاسازی شده است در نظر گرفت. عوامل متعددی در این قاب دخیل هستند، مانند موقعیت مکانی، روحیه یا وظیفه کاربر و همراهی یا عدم همراهی او. در این مقاله، ما بر روی دو مورد از مهمترین عوامل زمینه ای تمرکز خواهیم کرد:
- (1)
-
زمانی. کاربران تمایل دارند الگوهای تحرک معمولی در دوره های زمانی مختلف داشته باشند. بافت زمانی را می توان در مقیاس های مختلف در نظر گرفت، مانند فصل، روزهای هفته، ساعات در روز و غیره. در این مقاله از آخرین مقیاس یعنی ساعت های یک روز استفاده می کنیم.
- (2)
-
فضایی. محققان تأیید کردهاند که مناطق شهری معمولاً دارای پیکربندیهای عملکردی متفاوتی هستند، مانند مسکونی، آموزشی و تجاری، که معمولاً بر رفتار کاربر تأثیر میگذارند [ 30 ]. در این مقاله، چنین تأثیراتی را در مناطق پستی اداری مشاهده خواهیم کرد.
در اینجا لازم به ذکر است که اگرچه این دو عامل جنبه های جالب و حیاتی استفاده از تلفن همراه را نشان می دهند، اما همه جنبه ها را شامل نمی شوند. همیشه میتوان عوامل بیشتری را در نظر گرفت. با این حال، گنجاندن همه چیز عاقلانه نیست. دو عامل گنجانده شده در این مقاله برای نشان دادن رویکرد ما به کار می روند و این رویکرد به راحتی می تواند برای ادغام عوامل زمینه ای بیشتر گسترش یابد.
3.2. Foursquare: نمونه ای از شبکه های اجتماعی مبتنی بر مکان
قبل از حرکت به جزئیات، مجموعه داده های چهار ضلعی که در این مقاله به آن اشاره شده است در اینجا به اختصار معرفی می شود.
امروزه، کاربران موبایل تمایل دارند تجربیات و علایق خود را در وب از طریق برنامه های کاربردی داده های رسانه ای غنی مانند Foursquare به اشتراک بگذارند. Foursquare با بیش از 50 میلیون کاربر و بیش از 6 میلیارد بررسی تا آگوست 2014، یکی از محبوب ترین LBSN ها است. یکی از مهمترین ویژگیهایی که Foursquare را از سایر سرویسهای اشتراکگذاری مکان متمایز میکند، این است که به جای بهروزرسانی خودکار و مداوم مکانهای جغرافیایی، مبتنی بر مکانهای نامگذاری و طبقهبندی معنایی است [ 31 ]. Foursquare همچنین یک سلسله مراتب [ 32 ] را برای طبقه بندی مکان ارائه می دهد که شامل 10 دسته سطح اول و بیش از 400 دسته سطح دوم است.
هر بار که کاربر در یک مکان حضور پیدا می کند، یک شیء ورود در پایگاه داده ایجاد می شود که نمایه کاربر (شامل شناسه، نام، جنسیت، عکس، دوستان و شهر محل اقامت)، نمایه محل برگزاری را پوشش می دهد. (شناسه، نام، دسته، مکان و آمار به روز شده)، و همچنین نمایه رویداد ورود (مهر زمان، مکان، پیام های متنی پیوست شده و نظرات در مورد محل برگزاری). بر اساس رابط برنامه نویسی کاربردی (API) که توسط Foursquare استفاده می شود، استخراج پروفایل های محل برگزاری نسبتا آسان است. به جز شناسه و جنسیت، نمایه یک کاربر متأسفانه برای غیر دوستان قابل مشاهده نیست تا از حریم خصوصی کاربر محافظت شود. خط مشی دسترسی در مورد نمایه های رویدادهای ورود کمی پیچیده تر است. اگر اعلام حضورها به فیدهای عمومی مانند توییتر ارسال شود، با امضای Foursquare قابل دسترسی هستند. در غیر این صورت،
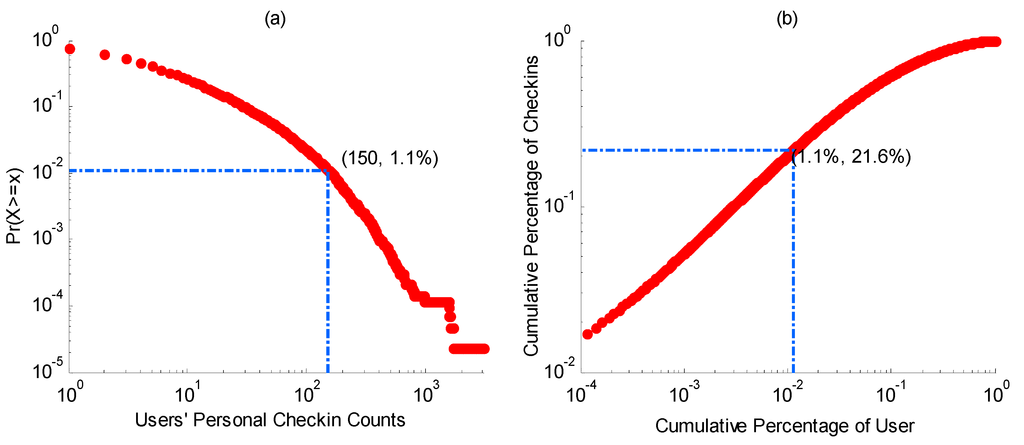
بر اساس این خط مشی حفاظت از حریم خصوصی، در این مقاله یک زیرمجموعه عمومی و ناشناس از اعلام حضورهای چهار ضلعی از شهر نیویورک در طی 150 روز از 1 فوریه تا 30 ژوئن 2014 استخراج می شود. مجموعه داده شامل 42,045 کاربر است که 566,420 اعلام حضور در این سایت ایجاد کرده اند. محدوده مکانی و زمانی مشخص شده است. آمار نشان می دهد که تنها 1.1 درصد از همه کاربران به طور متوسط حداقل یک ورود در روز دارند (به عنوان مثال ، 150 ورود در طی 150 روز؛ شکل 1 a را ببینید)، و این 1.1 درصد از کاربران، 21.6 درصد از کل را ایجاد می کند. سوابق ثبت نام ( شکل 1 را ببینیدب). علاوه بر این، طبق دادههای ما، حدود 10٪ از کل افزایش در پایگاه داده Foursquare که در مجموعه داده ما نشان داده شده است، نشان میدهد که تقریباً 10٪ از کل بررسیهای Foursquare از طریق فیدهای توییتر منتشر میشود و بنابراین برای بررسی عمومی باز است.
شکل 1. تابع توزیع تجمعی (CDF) تعداد ورودهای شخصی کاربر ( a ) و مشارکت انباشته کاربران در مجموعه داده ورود ( b ).
3.3. افشای تأثیرات متنی بر کاربران تلفن همراه
ارزش چنین اطلاعات داوطلبانه ای از دیدگاه ما در این فرضیه نهفته است که داده ها می توانند حاوی برخی زمینه های استفاده پنهان باشند که در غیر این صورت به دست آوردن آنها دشوار یا پرهزینه است. یک رویداد اعلام حضور که توسط کاربر انجام میشود، ناگزیر اطلاعات متنی مربوط به آن اعلام حضور خاص را نشان میدهد، و یک سری اعلام حضور میتواند به توصیف الگوی تحرک متنی و/یا علایق شخصی کاربر کمک کند. به عنوان مثال، هر شیء ثبت ورود، یک رکورد بلادرنگ از موقعیت خالق رویداد است. بنابراین، حاوی اطلاعات صریح در مورد وضعیت کاربر است [ 28] و زمینه در طول رویداد ورود. همچنین ممکن است به معنای کاری باشد که کاربر انجام میداد (مثلاً غذا خوردن)، برای مثال، اگر ورود به رستوران در زمان شام انجام شود. کاربر همچنین ممکن است چندین کلمه را در این رکورد ارسال کند، که ممکن است نشان دهنده حال و هوای او باشد، با چه کسی همراه است، و نظر او را در مورد مکان، در این مورد رستوران، نشان دهد. علاوه بر این، پس از تجزیه و تحلیل بررسیهای انجامشده توسط یک کاربر در طی چندین ماه، ممکن است بتوان تعیین کرد که کاربر چه نوع غذایی را ترجیح میدهد و آیا هر جمعه عصر به باشگاه میرود یا خیر. به طور کلی، با استفاده از تکنیکهای داده کاوی، میتوانیم تعداد زیادی از اطلاعات متنی ضمنی را نسبتاً آسان جمعآوری کنیم.
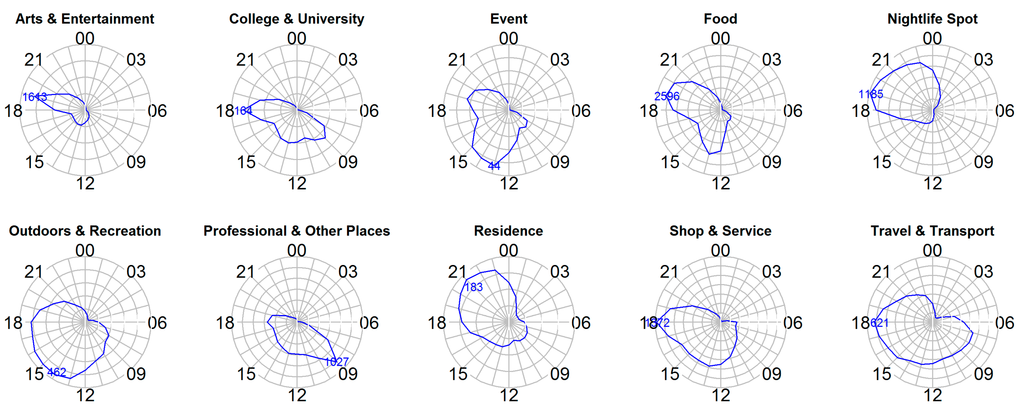
برای تعیین تأثیر عوامل زمانی، توزیع دستههای ورود کاربر در یک دوره 24 ساعته در شکل 2 نشان داده شده است.. هر دایره میانگین ساعتی تعداد اعلام حضور برای هر دسته را به هم متصل می کند و تفاوت های حاصل در شکل دایره ها علایق متغیر افراد را نسبت به انواع مختلف اطلاعات جغرافیایی در اسلات ساعتی خاص نشان می دهد. به عنوان مثال، “غذا” دارای دو اوج متمایز است، در ساعت 1 بعد از ظهر (کوتاه تر) و 7 بعد از ظهر (طولانی تر)، که با رفتار عادی غذا خوردن انسان سازگار است. دستههایی مانند «دانشگاه و دانشگاه»، «مکانهای حرفهای و دیگر» و «فروشگاه و خدمات» نمایههای محدب قابل توجهی در طول روز دارند، در حالی که «نقطه زندگی شبانه» و «محل اقامت» در شب به اوج خود میرسند. این مشاهدات با درک کلی ما از رفتار روزانه ساکنان شهر منطبق است و نشان میدهد که عوامل زمانی تأثیر قابلتوجهی بر ترجیحات کاربران تلفن همراه برای انواع مختلف اطلاعات جغرافیایی دارند. بدین ترتیب،
شکل 2. رفتارهای ورود کاربران در ساعت و در یک دوره 24 ساعته برای هر دسته.
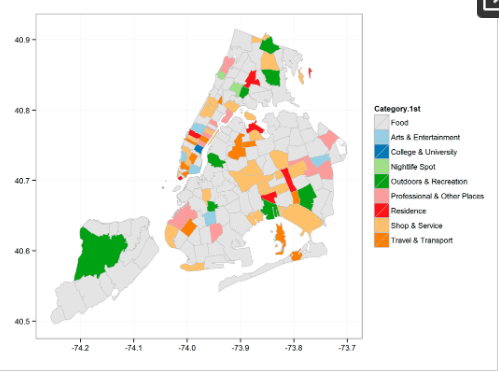
برای نشان دادن اولویتهای طبقهبندی مبتنی بر فضای کاربران تلفن همراه، شکل 3 رده غالب را در هر منطقه پستی اداری شهر نیویورک بر اساس اعلام حضور کاربران نشان میدهد.
شکل 3. دینامیک تنظیمات عملکردی در شهر نیویورک.
علیرغم تسلط دسته «غذا» در کل مجموعه داده ورود، نقشه نشان میدهد که کاربران علایق یکسانی را در زمینههای فضایی ابراز نمیکنند، زیرا مناطق شهری مختلف معمولاً دارای تنظیمات عملکرد متفاوتی هستند. به عنوان مثال، مناطق اطراف جزیره کوچک (به عنوان مثال ، کانال عریض در خلیج جامائیکا) معمولاً تحت سلطه «سفر و حمل و نقل» و «بازی و تفریح» هستند، در حالی که مناطق مرکز شهر (به عنوان مثال ، منهتن) عملکرد بسیار پیچیده تری را نشان می دهند. پیکربندی تقریباً تمام دسته بندی های ممکن را پوشش می دهد. با این حال، هنوز هم می توان مناطق اصلی غذا خوردن، خرید و آموزش را در این منطقه جامع مرکز شهر تشخیص داد.
فراتر از همه شک، بافت فضایی فقط بر ترجیحات کاربران برای یک دسته واحد که اعتقاد بر این است که غالب ترین دسته باشد، تأثیر نمی گذارد. علاوه بر این دسته غالب، هر منطقه پستی دارای عملکردهای مکمل دیگری نیز به میزان متفاوتی است. بنابراین، بافت فضایی را می توان با استفاده از توزیع احتمال همه مقوله های سازنده در یک منطقه فضایی معین بهتر نشان داد.
4. زمینه ارزیابی ارتباط جغرافیایی
تا این مرحله، برای بهبود نمایش گرافیکی، تنها از 10 دسته بندی سطح اول استفاده می شود. همانطور که قبلاً گفته شد، Foursquare از سلسله مراتب دسته برای سازماندهی مکان های خود استفاده می کند، و همین تجزیه و تحلیل را می توان با دسته های سطح بالاتر انجام داد تا یک نمایه پویایی کاربر دقیق در زمینه های مختلف ایجاد شود. در این بخش، دسته سطح دوم که شامل 383 زیرمجموعه در مجموعه داده های شهر نیویورک است، مستقر می شود.
در بخش 4.1 و بخش 4.2 ، ما رویکردی را پیشنهاد میکنیم که برای زمینهسازی ارزیابی ارتباط جغرافیایی مورد استفاده قرار گیرد، با بخش 4.1 که فرآیند زمینهسازی را توضیح میدهد. در حالی که این فرآیند بر اساس دو نوع زمینه، یعنی زمانی و مکانی توضیح داده میشود، فرآیند بافتسازی میتواند به راحتی برای ادغام انواع بافتهای بیشتر گسترش یابد. بخش 4.2 الگوهای جهانی را از الگوهای فردی متمایز می کند و رویکرد مورد استفاده برای ادغام هر دو الگو را برای موارد استفاده مختلف توضیح می دهد. بخش 4.3 روش پیشنهادی را بر اساس همان مجموعه داده چک در چهار ضلعی که در هنگام استفاده از 383 زیرمجموعه استفاده میشود، تأیید میکند.
4.1. زمینه سازی
مسئله تحقیق برای این مطالعه را می توان به گونه ای فرمول بندی کرد که سطح ارتباط نوع خاصی از اطلاعات جغرافیایی را با کاربر مورد نظر تعیین کند و هم بافت زمانی (ساعت از روز) و هم بافت مکانی (کد پستی) را در نظر بگیرد.
بر اساس این فرضیه که بافت زمانی مستقل از بافت مکانی است (رویداد T = i ، مستقل از رویداد S = j است)، احتمال اینکه یک مقوله خاص ( C = k ) به کاربر تحت بافت زمانی مربوط باشد T = i و زمینه فضایی S = j باید باشد:
توزیع احتمال مشترک مشروط Pr ( T= من ، اس= j | سی= k )Pr(�=�,�=�|�=�)برای ما ناشناخته است، اما انتظارات آن را می توان با توجه به توزیع جدول احتمالی به صورت زیر نوشت:
از این رو،
جایی که Pr ( C= k | تی= من )Pr(سی=ک|تی=من)و Pr ( C= k | اس= j )Pr(سی=ک|اس=�)می توان امتیازهای مربوط را بر اساس عوامل زمانی و مکانی و مخرج در نظر گرفت. Pr ( C= k )Pr(سی=ک)را می توان به عنوان یک امتیاز مرتبط پیشینی در نظر گرفت.
معادله (3) را می توان به صورت زیر نیز نوشت:
بنابراین معادلات را می توان به طور شهودی اینگونه تفسیر کرد: “انتظار احتمالی کاربرانی که در دسته بندی بررسی می کنند ککبا توجه به تأثیرات متنی زمان و مکان، تأثیر متقابل احتمال جهانی پیشینی است.
با توجه به گستردگی این مقاله، تنها زمینه های مکانی و زمانی در نظر گرفته شده است. با این حال، معادله (3) به راحتی می تواند به N زمینه مستقل به صورت زیر گسترش یابد:
جایی که {fمن}{�من}مجموعه ای از عوامل زمینه ای است و Pr ( C= k |fمن)Pr(سی=ک|�من)نشاندهنده ارتباط یک مقوله خاص ( C = k ) است که توسط یک عامل زمینهای زمینهسازی شده است fمن�من.
4.2. الگوهای جهانی و فردی
تجزیه و تحلیل مجموعه داده ورود به سیستم ارائه شده در شکل 1نشان می دهد که تنها 1.1٪ از همه کاربران به طور متوسط بیش از یک ورود در روز ایجاد می کنند، در حالی که ورودهای این 1.1٪ کاربر 21.6٪ از کل مجموعه داده را تشکیل می دهند. این نشان می دهد که ما تعداد بسیار کمی از کاربران با سابقه فردی غنی داریم. اکثر آنها داده های فردی کمی در دسترس دارند. اگر چه تاریخچه فردی یک شخص بدون شک زمانی که مایل به نمایه سازی الگوهای فردی است ارزشمند است، دانش جهانی جمع آوری شده از گروه بزرگی از کاربران به ویژه زمانی مفید خواهد بود که چنین کاربرانی دارای سابقه محدود یا حتی بدون سابقه باشند. بنابراین، رویکرد ما هم از الگوهای فردی ایجاد شده توسط کاربران خاص و هم از الگوهای جهانی ایجاد شده توسط همه کاربران در یک گروه استفاده خواهد کرد. سپس تمام امتیازات مربوطه را می توان به صورت جفت محاسبه کرد.
بنابراین، امتیاز ارتباط زمانی متنی شده است Pr ( C= k | تی= من )Pr(سی=ک|تی=من)مورد نیاز در معادله (3) برای یک کاربر هدف u را می توان برای هر دو نسخه کلی و تکی به صورت زیر محاسبه کرد:
که در آن Φ(شرط) و Φ u (شرط) تعداد کل ورودها، تحت شرایطی که در پرانتزها مشخص شده است، به ترتیب توسط همه کاربران و یک کاربر واحد u انجام شده است.
به طور مشابه، برای امتیاز ارتباط فضایی Pr ( C= k | اس= j )Pr(سی=ک|اس=�)در رابطه (3) داریم:
و برای امتیاز مربوط به پیشینیPr ( C= k )Pr(سی=ک)در معادله (3):
در نتیجه، معادله (3) همراه با معادله (6) تا معادله (8) امتیاز کلی مربوط به زمینه را برای اطلاعات جغرافیایی متعلق به دسته ( C = k ) می دهد.
4.3. نتایج تجربی
بر اساس ارتباط ارزیابیشده، فهرستی از بالاترین امتیازهای مرتبط را میتوان برای پیشبینی ارتباط نوع خاصی از اطلاعات جغرافیایی در زمینههای زمانی و مکانی داده شده ایجاد کرد. سپس لیست را می توان با بازدیدهای واقعی کاربر مقایسه کرد تا عملکرد رویکرد ما را تأیید کند.
این آزمایش با تقسیم کل مجموعه داده 5 ماهه به یک مجموعه داده یادگیری (چهار ماه اول شامل 471061 رکورد) و یک مجموعه داده مرجع (ماه گذشته شامل 95359 رکورد) تنظیم شده است. الگوهای کلی و فردی از مجموعه داده های یادگیری مورد مطالعه قرار می گیرند و الگوهای مورد مطالعه برای پیش بینی 95359 رکورد استفاده می شوند. سپس پیشبینیها با بازدیدهای واقعی انجام شده در مجموعه داده مرجع مقایسه میشوند. برای مقایسه، هر رکورد چهار گروه از پیش بینی ها را ایجاد می کند:
-
گروه 1: الگوهای کلی را از مجموعه داده های یادگیری بیاموزید و رکوردی را که باید پیش بینی شود ، بدون زمینه پیش بینی کنید.
-
گروه 2: الگوهای فردی را از مجموعه داده های یادگیری یاد بگیرید و بدون زمینه پیش بینی کنید .
-
گروه 3: الگوهای کلی را از مجموعه داده های یادگیری یاد بگیرید و با یک زمینه پیش بینی کنید .
-
گروه 4: الگوهای فردی را از مجموعه داده های یادگیری یاد بگیرید و با یک زمینه پیش بینی کنید .
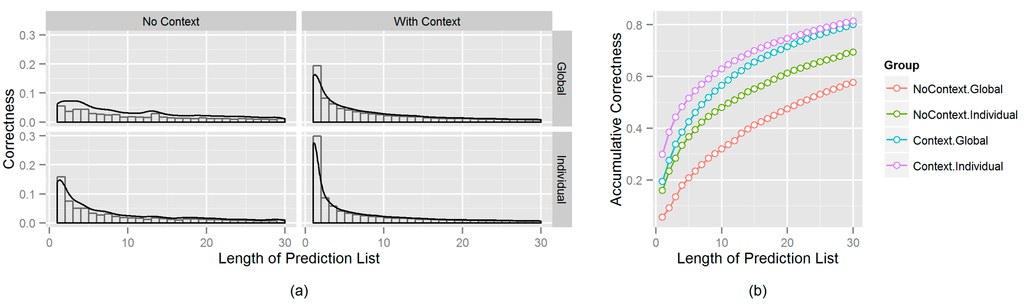
نتایج در شکل 4 نشان داده شده است. محور x طول لیست پیش بینی مورد نیاز برای به دست آوردن پیش بینی صحیح را نشان می دهد.
شکل 4 a نشان میدهد که با طول پیشبینی 1 (در اولین تلاش)، گروه 4 (پایین-راست در شکل 4 a) پیشبینیهای درستی را برای 30 درصد از کل 95359 الگوی فردی و اطلاعات زمینهای آموخته شده ارائه میکند. در همین حال، برای گروه 3 (بالا سمت راست در شکل 4 الف)، الگوهای جهانی آموخته شده و اطلاعات متنی نیز کاملاً دقیق هستند، با سطح تقریبی 20٪ صحت در اولین تلاش. در مقابل، سطوح عملکرد بدون در نظر گرفتن اطلاعات زمینهای حدود 15 درصد برای هر دو مورد کلی و فردی کمتر است. شکل 4b همین نتایج را برای صحت انباشته نشان می دهد. این نشان می دهد که برای مثال برای دستیابی به 50% صحت، چهار گروه باید به ترتیب 22، 11، 7 و فقط 4 بار تلاش کنند. از این رو، شکل 4 اهمیت در نظر گرفتن اطلاعات زمینه ای را هنگام ارزیابی ارتباط نشان می دهد.
شکل 4. مقایسه صحت پیش بینی بین گروه ها در مقیاس مستقل ( a ) و تجمعی ( b ).
علاوه بر این، شکل همچنین قدرت خرد جمعی را به عنوان بخشی از الگوی جهانی نشان می دهد. مطالعات تحقیقاتی متعدد در مورد سیستم های پیش بینی یا توصیه شخصی شده [ 15 ، 33 ، 34] نشان می دهد که چون کاربران ترجیحات شخصی را بر اطلاعات جغرافیایی اولویت می دهند، پیش بینی های غیرشخصی (آنهایی که اطلاعات فردی ندارند) بسیار کمتر از پیش بینی های شخصی قابل اعتماد هستند. در مورد دادههای ورود و استفاده از الگوریتم ما، این عبارت زمانی که هیچ اطلاعات زمینهای استفاده نمیشود صادق است (گروه 1)، اما زمانی که اطلاعات متنی گنجانده شده است (گروه 3) درست نیست. در واقع، گروه 3 (الگوی جهانی با زمینه ها) از گروه 2 (دانش فردی بدون هیچ زمینه ای) بهتر عمل می کند و به سرعت به گروه 4 (دانش و زمینه های فردی) می رسد ( شکل 4 را ببینید).ب). این یافته در بررسی تحقیقات آتی مورد توجه ویژهای قرار خواهد گرفت، زیرا مجموعه دادههای ورود و همچنین سایر مجموعههای داده رسانههای اجتماعی اغلب بسیار پراکنده هستند تا تضمین کنند که اطلاعات فردی در دسترس خواهد بود (به ویژه با محدودیتهایی که در زمینههای خاص اعمال میشود). توجه داشته باشید که حتی محاسبات الگوی فردی نیز در صورت لزوم از الگوهای کلی استفاده می کنند (به معادلات (6) – (8) مراجعه کنید). شکل 4 نشان می دهد که اطلاعات جهانی متنی می تواند برای فرآیند ارزیابی ارتباط، و به ویژه در میان کاربران غیرفعال، بسیار مفید باشد.
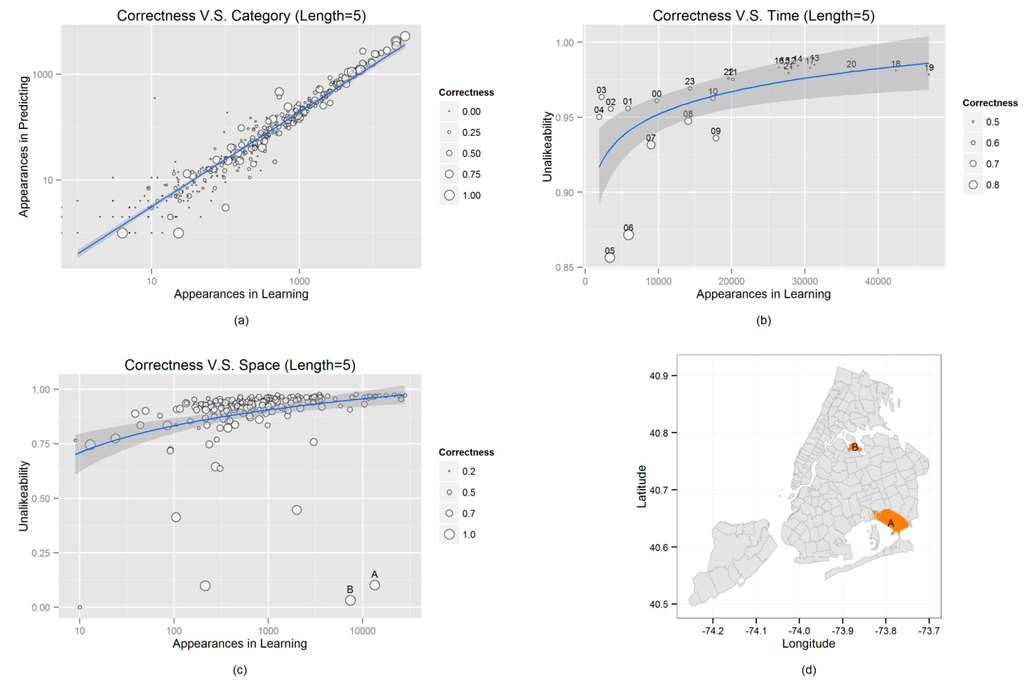
شکل 5 بیشتر روابط بین صحت (گروه 4، با طول پیش بینی ذکر شده به عنوان 5)، هدف پیش بینی (دسته) و دو زمینه (زمان و مکان) را نشان می دهد.
شکل 5 الف نشان می دهد که رویکرد پیشنهادی هم برخی از مقوله های غیر معمول و هم محبوبیت کلی دسته ها را حفظ می کند (روابط خطی بین تعداد دفعاتی که یک دسته در داده های یادگیری و در پیش بینی ها ظاهر می شود). با این حال، الگوریتم صحت بهتری را در میان دستههای محبوبتر به دست میدهد، زیرا نقاط بزرگتر عمدتاً در گوشه سمت راست بالا توزیع میشوند.
شکل 5 b,c روابط بین صحت، تعداد ظاهر شدن ( به عنوان مثال ، تعداد ورودها) در داده های یادگیری و “ناشابه نبودن” مرتبط با یک زمینه زمانی یا مکانی خاص را نشان می دهد. مشابه نبودن یک مفهوم قیاسی از تنوع است. در حالی که تنوع میزان تفاوت مشاهدات با میانگین دادههای کمی را اندازهگیری میکند، unalikeability اندازهگیری میکند که چقدر مشاهدات با یکدیگر برای دادههای کیفی متفاوت هستند [ 35 ]. ضریب عدم شباهت به دنبال تحقیق کادار و پری که متغیر بودن دادههای طبقهبندی را اندازهگیری میکند، پیادهسازی میشود [ 35 ].]. این شاخص در مقیاسی از 0 تا 1 تغییر می کند. ضریب عدم شباهت 0 به این معنی است که همه مشاهدات یکسان هستند، در حالی که ضریب بالاتر نشان دهنده مشاهدات غیرمشابه بیشتر است.
شکل 5. روابط بین صحت و دسته بندی ورود ( a )، زمان ( b ) و مکان ( c ) به ترتیب. نمودار فرعی ( d ) دو نقطه پرت را در قطعه فرعی (c) در فضای جغرافیایی واقعی ترسیم کرد.
اگرچه ادراک شهودی نشان میدهد که تعداد بیشتری از دادههای یادگیری سطح بهتری از صحت را به همراه خواهد داشت، شکل 5 b,c خلاف این را نشان میدهد، با بیشتر نقاط بزرگتر در سمت چپ محور x قرار دارند. دلیل این امر پس از ترسیم غیرمشابه بودن این حباب ها در برابر محور y آشکار می شود. سپس هر دو شکل یک رابطه ورود به سیستم خطی را نشان میدهند که نشان میدهد تعداد بازدیدهای بیشتر ضریب عدم مشابهت بیشتری دارند، که به این معنی است که فعالیتهای انسانی در شرایط زمانی یا مکانی فعالتر تمایل به ناهمگونی بیشتری دارد. به عنوان مثال، در شکل 5ب، درست در بعدازظهر (1 تا 5 بعدازظهر) علیرغم وجود حجم زیادی از داده های یادگیری کم است، زیرا افراد در آن زمان رفتارهای کاملاً متنوعی (مثلاً کار کردن، خرید کردن، غذا خوردن و مسافرت) نشان می دهند. در مقابل، صحت در صبح (5 تا 6 صبح) با مقدار بسیار کمتری از دادههای یادگیری بسیار بالاتر است، زیرا فعالیتهایی که میتوان در چنین زمانی انجام داد، بهعنوان مثال، فقط در سفر محدود هستند.
علاوه بر این، از شکل 5 ج، این پدیده همچنین به شکل کمتر قابل توجهی برای بافت فضایی وجود دارد، با نقاط بزرگتر عمدتا در سمت چپ دنباله اصلی، و با نقاط کوچکتر در سمت راست. با این حال، چندین نقطه پرت قابل توجه وجود دارد. گوشه سمت راست پایین نمودار دارای چندین نقطه است (با علامت A و B مشخص شده است) که تعداد نسبتاً زیادی از ورودها را نشان می دهد، اما عدم مشابهت بسیار کم را نشان می دهد. در نتیجه، این نقاط بزرگ هستند و از صحت بالایی برخوردارند. پس از ترسیم دو نقطه پرت بر روی نقشه ( شکل 5 د را ببینید)، دلیل بلافاصله آشکار می شود. منطقه A شامل فرودگاه بین المللی جان اف کندی است، در حالی که منطقه B شامل فرودگاه لاگواردیا، دو فرودگاه شلوغ در ایالات متحده است [ 36 ]]. از این رو، فعالیتهای انسانی در این دو منطقه به شدت فعال هستند (تعداد ورود زیاد) اما همگن (ناشابهناپذیری کم) و بنابراین سطح صحت برای هر دو منطقه بسیار بالا است.
5. نتیجه گیری و کار آینده
در محیط تلفن همراه، فیلتر کردن حجم وسیعی از اطلاعات جغرافیایی که بر اساس ارتباط جغرافیایی آن با کاربران وجود دارد، قبل از انجام فعالیتهای مصرف بسیار مهم است، زیرا کاربران تلفن همراه معمولاً چندین کار را همزمان انجام میدهند و بنابراین باید اطلاعات جغرافیایی را درک کنند. به آنها ارائه شود و بر اساس این اطلاعات در مدت زمان کوتاه تصمیم گیری کنند. هر گونه ارزیابی مربوط به اطلاعات جغرافیایی مستلزم درک جامعی از زمینه استفاده و استفاده از مکانیزم جامع برای انطباق با این زمینه است. ماهیت پویا و ناهمگون زمینه چالش های بزرگی را در این زمینه به همراه دارد.
ابزارهای نوظهور LSBN نمونه ای از اطلاعات جغرافیایی داوطلبانه هستند و در صورت تمایل به حل مشکل فیلتر اطلاعات گزینه جدیدی را ارائه می دهند. اعتقاد بر این است که یک رویداد اعلام حضور مبتنی بر مکان که توسط کاربر ایجاد میشود، در زمینههای خاصی اتفاق میافتد، مواردی که میتوانند در مجموعه دادهها تا حد خاصی شناسایی شوند. علاوه بر این، با مشاهده یک سری از تاریخچه های ورود، می توان الگوهای تحرک مشخص شده خاصی را کشف کرد، بنابراین فرآیند ارزیابی ارتباط را هدایت می کند.
این مقاله با در نظر گرفتن دو عامل زمینه ای، یعنی عوامل زمانی و مکانی، این فرضیه را نشان می دهد. تجزیه و تحلیل مجموعه داده 150 روزه بررسی چهار ضلعی برای شهر نیویورک الگوهای تحرک جالبی را نشان می دهد که تحت تأثیر دو عامل کلیدی قرار می گیرند، این عوامل زمانی و مکانی است. این مقاله سپس رویکردی را برای ارزیابی ارتباط اطلاعات جغرافیایی، با استفاده از یک الگوریتم برای پیوند دادن امتیاز مربوط به پیشینی با امتیاز مربوط به زمینه، و با استفاده از تأثیرات عوامل زمانی و مکانی شناساییشده بر الگوهای تحرک پیشنهاد میکند. نتیجه متنی در آزمایش بهتر از پیشینی عمل می کندیکی، استفاده از الگوهای جهانی آموخته شده یا الگوهای فردی، و این نتیجه مزایای در نظر گرفتن عوامل زمینه ای را هنگام ارزیابی ارتباط اطلاعات جغرافیایی برای کاربران تلفن همراه ثابت می کند. رویکرد پیشنهادی همچنین اثربخشی استفاده از خرد جمعی را که در الگوهای جهانی در هنگام ارزیابی ارتباط برای کاربران جدید یافت میشود، و زمانی که هیچ دانش فردی وجود ندارد، اثبات میکند.
اگرچه بحث در این مقاله به دو عامل زمینهای محدود میشود، رویکرد پیشنهادی به راحتی میتواند برای پوشش عوامل بیشتری از این قبیل گسترش یابد، تا زمانی که این عوامل مستقل از یکدیگر در نظر گرفته شوند. با این حال، هر گونه فرض استقلال همیشه راضی نمی شود، زیرا تمایل به تعامل بین عوامل زمینه ای مختلف وجود دارد. به عنوان مثال، آب و هوا و خلق و خوی هر دو عوامل زمینه ای هستند و خلق و خو ممکن است تحت تأثیر آب و هوا باشد. برای عوامل زمینهای که باید تعاملات در نظر گرفته شود، رویکرد پیشنهادی میتواند بیشتر بهبود یابد و این بخشی جداییناپذیر از تلاشهای تحقیقاتی آینده ما خواهد بود.



بدون نظر