

خلاصه
بلایای اخیر، مانند زلزله 2010 هائیتی، توجه را به نقش بالقوه شهروندان به عنوان تولیدکنندگان فعال اطلاعات جلب کرده است. شهروندان با استفاده از دستگاههای آگاه از موقعیت مکانی مانند تلفنهای هوشمند برای جمعآوری اطلاعات جغرافیایی در قالب متن، عکس یا ویدیو با برچسبگذاری جغرافیایی و اشتراکگذاری این اطلاعات از طریق رسانههای اجتماعی آنلاین مانند توییتر، اطلاعات جغرافیایی داوطلبانه (VGI) را ایجاد میکنند. برای استفاده موثر از این اطلاعات برای مدیریت بلایا، ما یک چارچوب VGI برای کشف VGI ایجاد کردیم. این چارچوب از چهار جزء تشکیل شده است: (1) یک ماژول کارگزاری VGI برای ارائه یک رابط سرویس استاندارد برای بازیابی VGI از منابع متعدد بر اساس پارامترهای مکانی، زمانی و معنایی. (ii) یک جزء کنترل کیفیت VGI، که از فیلتر معنایی و تکنیک های ارجاع متقابل برای ارزیابی VGI استفاده می کند. (iii) یک ماژول ناشر VGI، که از یک مکانیسم تحویل مبتنی بر خدمات برای انتشار VGI استفاده میکند، و (iv) یک مؤلفه کشف VGI برای مکانیابی، مرور، و پرسوجو متادیتا درباره مجموعه دادههای VGI موجود. در یک مطالعه موردی، ما از استراتژی FOSS (نرمافزار منبع باز و رایگان)، استانداردها/مشخصات باز و دادههای آزاد/باز برای نشان دادن کاربرد چارچوب استفاده کردیم. ما نشان میدهیم که این چارچوب میتواند کشف دادهها را برای مدیریت بلایا تسهیل کند. افزودن معیارهای کیفیت و یک منبع مجزا از بحران مربوطه VGI به کاربران اجازه میدهد تا انتخابهای سیاستی آگاهانهای داشته باشند که میتواند جان انسانها را نجات دهد، نیازهای اولیه بشردوستانه را زودتر برآورده کند و شاید آسیبهای زیستمحیطی و اقتصادی را محدود کند. که از یک مکانیسم تحویل مبتنی بر خدمات برای انتشار VGI استفاده میکند و (iv) یک مؤلفه کشف VGI برای مکانیابی، مرور، و پرسوجو متادیتا درباره مجموعه دادههای VGI موجود. در یک مطالعه موردی، ما از استراتژی FOSS (نرمافزار منبع باز و رایگان)، استانداردها/مشخصات باز و دادههای آزاد/باز برای نشان دادن کاربرد چارچوب استفاده کردیم. ما نشان میدهیم که این چارچوب میتواند کشف دادهها را برای مدیریت بلایا تسهیل کند. افزودن معیارهای کیفیت و یک منبع مجزا از بحران مربوطه VGI به کاربران اجازه میدهد تا انتخابهای سیاستی آگاهانهای داشته باشند که میتواند جان انسانها را نجات دهد، نیازهای اولیه بشردوستانه را زودتر برآورده کند و شاید آسیبهای زیستمحیطی و اقتصادی را محدود کند. که از یک مکانیسم تحویل مبتنی بر خدمات برای انتشار VGI استفاده میکند و (iv) یک مؤلفه کشف VGI برای مکانیابی، مرور، و پرسوجو متادیتا درباره مجموعه دادههای VGI موجود. در یک مطالعه موردی، ما از استراتژی FOSS (نرمافزار منبع باز و رایگان)، استانداردها/مشخصات باز و دادههای آزاد/باز برای نشان دادن کاربرد چارچوب استفاده کردیم. ما نشان میدهیم که این چارچوب میتواند کشف دادهها را برای مدیریت بلایا تسهیل کند. افزودن معیارهای کیفیت و یک منبع مجزا از بحران مربوطه VGI به کاربران اجازه میدهد تا انتخابهای سیاستی آگاهانهای داشته باشند که میتواند جان انسانها را نجات دهد، نیازهای اولیه بشردوستانه را زودتر برآورده کند و شاید آسیبهای زیستمحیطی و اقتصادی را محدود کند. در یک مطالعه موردی، ما از استراتژی FOSS (نرمافزار منبع باز و رایگان)، استانداردها/مشخصات باز و دادههای آزاد/باز برای نشان دادن کاربرد چارچوب استفاده کردیم. ما نشان میدهیم که این چارچوب میتواند کشف دادهها را برای مدیریت بلایا تسهیل کند. افزودن معیارهای کیفیت و یک منبع مجزا از بحران مربوطه VGI به کاربران اجازه میدهد تا انتخابهای سیاستی آگاهانهای داشته باشند که میتواند جان انسانها را نجات دهد، نیازهای اولیه بشردوستانه را زودتر برآورده کند و شاید آسیبهای زیستمحیطی و اقتصادی را محدود کند. در یک مطالعه موردی، ما از استراتژی FOSS (نرمافزار منبع باز و رایگان)، استانداردها/مشخصات باز و دادههای آزاد/باز برای نشان دادن کاربرد چارچوب استفاده کردیم. ما نشان میدهیم که این چارچوب میتواند کشف دادهها را برای مدیریت بلایا تسهیل کند. افزودن معیارهای کیفیت و یک منبع مجزا از بحران مربوطه VGI به کاربران اجازه میدهد تا انتخابهای سیاستی آگاهانهای داشته باشند که میتواند جان انسانها را نجات دهد، نیازهای اولیه بشردوستانه را زودتر برآورده کند و شاید آسیبهای زیستمحیطی و اقتصادی را محدود کند.
کلید واژه ها:
مدیریت بلایا ؛ اطلاعات جغرافیایی داوطلبانه کشف محتوا ؛ ارزیابی کیفیت ؛ قابلیت همکاری
1. معرفی
به اشتراک گذاری اطلاعات به روز و دقیق یک استراتژی موثر برای بهبود فعالیت های مدیریت بلایا است [ 1 ]. به اشتراک گذاری اطلاعات نقش مهمی در افزایش آگاهی موقعیتی، ارائه کمک به افراد آسیب دیده از بحران، و کمک به توسعه طرح های کاهش ایفا می کند [ 2 ، 3 ]. پلتفرمهای مدیریت بلایا با ارائه ابزارهای (آنلاین) که امکان جمعآوری، تجزیه و تحلیل و توزیع اطلاعات مکانی، زمانی و موضوعی را فراهم میکند، این توانایی را دارند که این استراتژی را تقویت کنند. چنین پلتفرمهایی باید قادر به مدیریت دادههای بحران ورودی، تجسم اطلاعات و توسعه سناریوهای آینده باشند، که در حالت ایدهآل، به کاهش اثرات منفی بیشتر فاجعه کمک میکند [ 4 ].]. به این ترتیب، این سیستمها این پتانسیل را دارند که تخریب، ضرر اقتصادی و مرگی را که در غیر این صورت ممکن است از یک رویداد فاجعهآمیز ناشی شود، به حداقل برسانند. به عنوان مثال، Ushahidi ( http://www.ushahidi.com/ ) به طور گسترده برای کمک به مردم برای یافتن و استفاده از اطلاعات بحرانی اضطراری در موقعیتهای مختلف، از بحرانهای سیاسی [ 5 ] تا بلایای طبیعی [ 6 ] استفاده شده است.
برای ایجاد چنین پلتفرم هایی، باید به برخی از چالش های مدیریت داده پرداخته شود. به عنوان مثال، یک وضعیت اضطراری می تواند به سرعت در طول یک رویداد فاجعه به دلیل وقوع حوادث پس از فاجعه (به عنوان مثال، قطع برق، بسته شدن جاده ها و پل ها، و غیره ) و پیشرفت عملیات واکنش به بلایا (به عنوان مثال، استقرار خدمه اضطراری) تغییر کند. ). از این رو، این سیستم ها باید بتوانند به طور منظم، اگر نه به طور مداوم، اطلاعات به روز بحران را از منابع مختلف جمع آوری و به اشتراک بگذارند. چنین اطلاعاتی باید شامل داده های تولید شده توسط شهروندان (در زمان واقعی) باشد که توسط سرویس های وب 2.0 ( به عنوان مثال ، وب سایت های شبکه های اجتماعی) از افرادی که از موقعیت های دشوار گزارش می دهند/در مورد آن ها گزارش می دهند، ارائه می شود، زیرا زمان محدودی برای به روز رسانی مخازن داده های رسمی وجود دارد [ 7 ]]. ایجاد اطلاعات جغرافیایی توسط مردم با استفاده از روشهای مشارکتی مبتنی بر وب 2.0، اطلاعات جغرافیایی داوطلبانه (VGI) نامگذاری شده است [ 8 ].
اگرچه چندین نمونه موفق از VGI وجود دارد که برای پاسخ اضطراری استفاده می شود [ 9 ]، اما هنوز مکانیسم های کارآمد قابل همکاری برای کشف، دسترسی و استفاده از VGI توسط پلت فرم های مدیریت بلایا وجود ندارد. به عنوان مثال، خدمات وب 2.0 دسترسی به VGI را از طریق رابط های برنامه نویسی برنامه های کاربردی مختلف (API) و رمزگذاری داده ها فراهم می کند. این امر میتواند دسترسی و بازیابی دادهها را برای برنامههای سرویس گیرنده دشوار کند، زیرا آنها نیاز به پیادهسازی APIهای مختلف و درک رمزگذاری دادههای خاص دارند تا بتوانند به دادهها از سرویسهای مختلف Web 2.0 دسترسی پیدا کرده و بازیابی کنند [ 10 ].]. علاوه بر این، این پلتفرمها باید بتوانند دادههای ناهمگن (جغرافیایی) با انواع و کیفیتهای مختلف را از منابع مختلف، به عنوان مثال، دادههای VGI از سرویسهای وب 2.0 و دادههای معتبر از زیرساختهای دادههای مکانی (SDI) یکپارچه کنند. ادغام و استفاده از داده های VGI همراه با داده های معتبر موجود به ابزارهای کنترل کیفیت برای درک بهتر عدم قطعیت و کامل بودن مجموعه داده های VGI نیاز دارد. همچنین به مکانیسمهای استانداردسازی برای غلبه بر ناهمگونی در توصیف دادهها و قالبهای داده نیاز دارد. نکته دیگر این است که تأیید اطلاعات ارائه شده توسط داوطلبان از یک منبع خاص دشوار است. مثلث بندی، یعنی بررسی متقاطع، چندین منبع VGI ممکن است به نتایجی با سطح بالاتری از اعتبار و اطمینان منجر شود [ 11 ]].
هدف اصلی این مقاله ارائه چارچوبی برای استفاده موثر از محتوای تولید شده توسط کاربر در پلتفرمهای مدیریت بلایا برای فعال کردن روشهای ایجاد و توزیع دادههای پایین به بالا است. این به نوبه خود از ادغام داده های معتبر SDI و VGI پشتیبانی می کند. ما ابتدا وضعیت فعلی پلتفرمهای مدیریت بلایا را تحلیل میکنیم و چالشهای مربوط به دادهها را از دیدگاه فنی ارزیابی میکنیم. سپس چارچوبی برای کشف و استفاده از VGI در پلتفرمهای مدیریت بلایا ایجاد میکنیم که از چهار جزء تشکیل شده است: (1) یک ماژول کارگزاری VGI برای ارائه یک رابط سرویس استاندارد برای بازیابی VGI از منابع متعدد بر اساس جستجوی مکانی، زمانی و کیفی. مولفه های؛ (ب) یک جزء کنترل کیفیت VGI برای ارزیابی ارتباط مکانی و زمانی و اعتبار VGI. (iii) یک ماژول ناشر VGI، که از مکانیزم تحویل مبتنی بر خدمات برای انتشار VGI استفاده می کند. و (IV) یک مؤلفه کشف VGI، که به عنوان یک سرویس کاتالوگ برای یافتن، مرور، و پرس و جو متادیتا در مورد مجموعه داده های VGI موجود عمل می کند. اولین مجموعه از معیارهای کیفیت که ممکن است برای ارزیابی VGI استفاده شود، پیشنهاد شده است. سپس معماری فنی یک پیاده سازی نمونه اولیه را ارائه می کنیم و این نمونه اولیه را با داده های رسانه های اجتماعی جمع آوری شده در طول طوفان هاگوپیت آزمایش می کنیم.به عنوان مثال ، Typhoon Ruby)، که در دسامبر 2014 فیلیپین را درنوردید. در نهایت، ما نمونه اولیه را با توجه به ویژگیهای فنی، مانند انعطافپذیری پلت فرم و قابلیت حمل، و مجموعه اولیه معیارهای کیفیت با توجه به مطالعات موردی اجتماعی ارزیابی و مورد بحث قرار میدهیم. داده های رسانه ای
2. آثار قبلی
اجزای زیرساخت اطلاعات و ارتباطات، بلوک های سازنده سیستم های مدیریت بلایا هستند. بسیاری از سیستمها در دهه گذشته توسعه یافتهاند – در حال حرکت از سیستمهای سنتی مبتنی بر تلفن، رادیو و تلویزیون به سمت پلتفرمهای مبتنی بر وب مدرن [ 11 ]. در اوایل دهه 2000، بلایا، مانند حملات تروریستی 11 سپتامبر و طوفان کاترینا در ایالات متحده، نشان داد که سیستم های مدیریت بلایای سنتی در توانایی خود برای پاسخگویی به اشتراک گذاری اطلاعات در سطح جامعه و نیازهای ارتباطی همه ذینفعان محدود هستند، به عنوان مثال، مقامات قضایی، پاسخ دهندگان اضطراری و شهروندان [ 12]. در مقایسه با اینترنت، میزان اطلاعات منتشر شده توسط تلفن، رادیو یا تلویزیون محدود است و سیستم ها بر جریان اطلاعات یک جهته تمرکز می کنند. این سطح تعامل ممکن را محدود می کند [ 13 ]. از این رو، نیاز به پلتفرم هایی وجود دارد که بتواند ارتباطات چند به چند را فراهم کند و مکانیسم های به اشتراک گذاری اطلاعات موثری را ارائه دهد که مدیریت بلایا را به جای ممانعت، تسهیل کند.
در طول دهه گذشته، رویکردهای مختلفی برای طراحی و توسعه سیستم های مدیریت بلایا مورد بررسی قرار گرفته است. ما می توانیم این آثار را به سه نسل گروه بندی کنیم: نسل اول سیستم هایی را پوشش می دهد که بر اساس اصول SDI طراحی شده اند [ 14 ]. زیرساخت داده های مکانی [ 15 ] چارچوب امیدوارکننده ای را برای تسهیل و هماهنگی تبادل و به اشتراک گذاری داده های مکانی در سیستم های مدیریت بلایا ارائه می دهد که منجر به بهبود کیفیت تصمیم گیری و افزایش کارایی فعالیت های مدیریت بلایا می شود [ 1 ، 16 ، 17 ، 18 ].]. چندین پیاده سازی از چارچوب های SDI برای مدیریت بلایا در مطالعات موردی مختلف آزمایش شده است، مانند سناریوهای (1-i) تخلیه پس از تهدید بمب [ 19 ]، (1-ii) ارزیابی خطر آتش سوزی وحشی [ 20 ] و هشدار سیل. سیستم [ 21 ]. برای توضیح فنی این سیستم ها به جدول 1 مراجعه کنید .

جدول 1. مقایسه پلتفرم های مدیریت بلایا مبتنی بر وب.
اگرچه SDI به اشتراک گذاری و مدیریت داده ها را تسهیل می کند، پیاده سازی SDI از یک رویکرد از بالا به پایین پیروی می کند که در نظر نمی گیرد که کاربران غیر نهادی ممکن است داده ها را به شیوه ای مشارکتی مشارکت دهند [ 27 ]. این منجر به پارادایم ارائه-مصرف می شود، که در آن فقط ارائه دهندگان رسمی داده مانند آژانس های نقشه برداری ملی یا محیط زیست مجاز به جمع آوری، استقرار و نگهداری منابع هستند [ 23 ]]. علاوه بر این، ارائهدهندگان رسمی دادهها چرخههای بهروزرسانی و انتشار دقیقی دارند که ممکن است دسترسی به اطلاعات بهموقع، بهویژه در هنگام فاجعه را مختل کند. به عنوان مثال، در هائیتی، اگرچه پایگاههای اطلاعاتی GIS (سیستم اطلاعات جغرافیایی) در دسترس بود، اما فاقد اطلاعات حیاتی و بهروز پس از زلزله بود که تلاشهای نجات و بازیابی را در روزهای اول پس از زلزله پیچیده کرد. در مورد هائیتی، تصاویر ماهوارهای با کیفیت بالا از هائیتی پس از زلزله جمعآوری شد و در عرض 24 ساعت پس از فاجعه توسط ارائهدهندگان محتوای تجاری تجاری مانند DigitalGlobe در دسترس قرار گرفت. با این حال، همانطور که توسط Zook و همکاران گزارش شده است. [ 6]، هنوز نیاز به پردازش تصاویر برای استخراج اطلاعات مفید (به عنوان مثال، ردیابی جاده ها و ساختمان ها) و انجام تجزیه و تحلیل های مورد نیاز (به عنوان مثال، تجزیه و تحلیل ارزیابی آسیب) وجود داشت. پلتفرم های مبتنی بر SDI نیز تمایل دارند از یک مکانیسم استقرار پیچیده استفاده کنند، که می تواند مشارکت شهروندان را در طول جمع آوری داده ها و استقرار منابع مختل کند [ 23 ]. با این حال، در طول رویداد هائیتی، یک جامعه داوطلب توانست به سرعت یک زیرساخت اطلاعاتی ایجاد کند که امکان جمعآوری و توزیع دادههای مشترک را با استفاده از ابزارها و خدمات منبع باز و رایگان مانند OpenStreetMap ( http://www.openstreetmap.org/ میکند)) و اوشهیدی. این رویکرد ابزارهای مناسبی را در دستان مردم نگران قرار داد که قادر به افزایش آگاهی موقعیت بودند که در نهایت فعالیتهای واکنش اضطراری را تسهیل میکرد [ 6 ].
زلزله 2010 هائیتی نقشی را که اینترنت می تواند در یک محیط مشارکتی داشته باشد، برجسته کرده است [ 6 ]، که در آن مردم نه تنها محتوا مصرف می کنند، بلکه محتوای جدید نیز تولید می کنند [ 28 ]. ایده «شهروندان بهعنوان حسگر» [ 8 ] بر این پتانسیل تأکید میکند که شهروندان باید تولیدکنندگان اطلاعات فعالی باشند که میتوانند اطلاعات بهموقع و مقرونبهصرفه (به عنوان مثال ، VGI) در حمایت از فعالیتهای مدیریت بلایا ارائه کنند [ 8 ، 29 ].]. علاوه بر این، مردم محلی اغلب نسبت به جمعآوریکنندگان دادههای معتبر سنتی، آگاهی بیشتری از آنچه در زمین در طول یک فاجعه اتفاق میافتد، دارند. این دانش محلی باید برای تکمیل دانش علمی معتبر استفاده شود [ 30 ]. متعاقباً، نسل دوم پلتفرمهای مدیریت بلایا، VGI را در مرکز سیستم مدیریت قرار میدهد.
استفاده از VGI در مدیریت بلایا چهار مزیت اصلی دارد: (1) زمان مورد نیاز برای جمع آوری اطلاعات بحران را به طور قابل توجهی کاهش می دهد [ 3 ]. (ii) اغلب دقت قابل مقایسه ای با منابع معتبر دارد [ 31 ]. (iii) به روز رسانی و نرخ تجدید آن به طور کلی بسیار سریع است، به ویژه برای منطقه آسیب دیده [ 32 ]. و (IV) از آنجایی که دادهها باز و آزادانه در دسترس هستند، پلتفرمهای مدیریت بحران مختلف، شاید سازمانهای مختلف بتوانند بدون محدودیت آنها را کشف، پردازش و منتشر کنند [ 11 ]. چندین کار تحقیقاتی استفاده موفقیت آمیز از پلتفرم های VGI محور در رویدادهایی مانند (2-i) خشونت پس از انتخابات 2008 در کنیا را گزارش کرده اند [ 5 ]]، (2-ii) آتش سوزی جنگل 2009 در اطراف مارسی، فرانسه [ 22 ]، و (2-iii) زلزله 2010 هائیتی [ 6 ].
همانطور که توسط De Longueville و همکاران بیان شده است. [ 29 ]، VGI یک منبع غنی و مکمل اطلاعات برای SDI ها، به ویژه در زمینه مدیریت بلایا است. بنابراین، نسل سوم سیستم های مدیریت بلایا در نهایت قصد دارد VGI را در SDI ادغام کند. در اینجا، نقش کاربر در SDI از یک گیرنده غیرفعال داده به یک «تولیدکننده» فعال تغییر میکند [ 33 ]. در این زمینه، Genovese & Roche [ 34 ] در مورد نقاط قوت، ضعف، فرصت ها و تهدیدات VGI برای بهبود SDI در زمینه جهانی شمال در مقابل جنوب بحث می کنند ( یعنی توسعه یافته در مقابل.کشورهای در حال توسعه). تحقیقات آنها نشان می دهد که اگرچه بودجه قابل توجهی به ایجاد SDI در کشورهای توسعه یافته اختصاص داده شده است، هنوز مسائلی وجود دارد که مانع یکپارچه سازی VGI-SDI می شود. به عنوان مثال، یک نقطه ضعف، توانایی کاربران در درک کیفیت و اعتبار VGI است. بنابراین، گنجاندن VGI در SDI های رسمی ممکن است تهدیدی برای یکپارچگی داده ها باشد و ابزارهایی برای ارزیابی کیفیت مورد نیاز است.
Genovese & Roche [ 34 ] اقتصاد را به عنوان یک عامل محدود کننده در مورد توسعه زیرساخت SDI، به ویژه در کشورهای در حال توسعه، شناسایی می کنند. آنها همچنین تاکید می کنند که به نظر می رسد پوشش نقشه SDI یکنواخت نیست: مناطق شهری تمایل به پوشش کامل تری نسبت به مناطق روستایی دارند. برای رفع این اشکالات ممکن است فرصت هایی برای استفاده از VGI برای پر کردن حفره های داده های مکانی اداری موجود در SDI وجود داشته باشد. آثار (3-i) دیاز و همکاران. [ 23 ] و (3-ii) Shade et al. [ 24 ] در مورد جنبه های مختلف ادغام VGI با داده های معتبر (رسمی) تحت یک الگوی SDI بحث کنید.
جدول 1 پلتفرم های برجسته مدیریت بلایای مبتنی بر وب را فهرست می کند و آنها را بر اساس عملکرد و زیرساخت های توانمند آنها توصیف می کند. این یک فهرست جامع نیست، زیرا هدف ما ارائه یک مرور کوتاه از، به نظر ما، کارهای قابل توجه اخیر است.
زیرساختهای فعال : از نظر زیرساختهای فعال، شبکه جهانی وب کانال ارتباطی زیربنایی برای همه پلتفرمها است، اگرچه برخی از آنها از رسانههای ارتباطی اضافی مانند پیام کوتاه و وبسایتهای شبکههای اجتماعی استفاده میکنند (به عنوان مثال، نسل 2 و 3). از دیدگاه معماری سیستم، بیشتر پلتفرم های مدیریت بلایای آنلاین با استفاده از معماری سرویس گیرنده-سرور توسعه داده شده اند. با این حال، نمونه های اولیه توسعه یافته توسط Mazzetti و همکاران. [ 20 ] و دیاز و همکاران. [ 23 ] بر اساس معماری سرویس گرا (SOA) پیاده سازی شدند.
استفاده از SOA برای برنامه های مدیریت بلایای آنلاین به سه دلیل مفید است. اول، SOA از یک رویکرد “داده به عنوان سرویس” (DaaS) [ 35 ] پشتیبانی می کند، که یک راه حل تعاملی برای دسترسی به داده های ذخیره شده در مکان های مختلف، همانطور که معمولا در مورد داده های مورد نیاز برای مدیریت بلایا وجود دارد، ارائه می دهد. دوم، پذیرش SOA منجر به معماری میشود که توابع را قادر میسازد بر اساس مکانیزم «نرمافزار بهعنوان سرویس» (SaaS) [ 36 ] با استفاده از استانداردهای ارتباطی رایج ارائه شوند. به این ترتیب، عملکردهای مدیریت و تجزیه و تحلیل داده های بلایا را می توان برای کاربران در مکان های مختلف با سطوح دسترسی متفاوت فراهم کرد. همچنین استقرار توزیع شده عملکرد را امکان پذیر می کند به طوری که پردازش توزیع شده می تواند در زمان های با تقاضای بالا به کار گرفته شود [ 37 ]]. سوم، یک رویکرد توسعه مبتنی بر SOA، تولید سیستمهایی را امکانپذیر میسازد که میتوانند با الزامات و فناوریهای در حال تغییر سازگار شوند. نگهداری از اینها آسانتر است و امکان درمان مداوم دادهها و عملکرد را فراهم میکند [ 38 ].
در یک رویکرد مبتنی بر SOA، یک استراتژی طراحی سرویس (DaaS و SaaS) برای حفظ تعادل مناسب بین معیارهای متعدد مانند انعطافپذیری، قابلیت استفاده مجدد و عملکرد ضروری است [ 39 ، 40 ]. برای دستیابی به این هدف و داشتن خدماتی متناسب با موارد استفاده کاربردی خاص، لازم است الگوها و اصول طراحی معماری مختلف مانند الگوی کنترل گردش کار، الگوی تعامل داده ها و الگوی ارتباط در نظر گرفته شود [ 41 ].]. این الگوها (1) مدیریت و اجرای یک گردش کار از خدمات، (2) انتقال داده بین خدمات در یک گردش کار یا بین یک مشتری و یک زنجیره خدمات، و (iii) مکانیسم های تبادل پیام بین خدمات یا بین یک مشتری را کنترل می کنند. و خدمات (برای بحث مفصل رجوع کنید به پورعزیزی و همکاران [ 25 ]).
از نظر استقرار، بیشتر پلتفرمهای بررسیشده میتوانند در یک محیط محاسبات محلی، شبکهای یا ابری مستقر شوند (برای تفاوتها، به یادداشتهای جدول 1 مراجعه کنید). با توجه به انطباق با استاندارد و قابلیت همکاری، همه پلت فرم ها بر اساس دستورالعمل های SDI (به عنوان مثال، استانداردهای OGC (کنسرسیوم فضایی باز)) به جز سیستم های نسل 2، که از رویکردهای سازگار با W3C برای توسعه پلت فرم پیروی می کردند، توسعه یافتند. بیشتر پلتفرمها از دادههای معتبر به عنوان منبع اصلی اطلاعات استفاده میکنند، در حالی که برخی از آنها از جریانهای داده بلادرنگ مانند VGI پشتیبانی میکنند.
توابع پلتفرم : همه پلتفرمها از کشف و دسترسی به دادههای (مکانی) پشتیبانی میکنند. برای انجام این کار، بیشتر از روشهای مبتنی بر استاندارد استفاده میکنند، اما برخی از روشهای موقت غیراستاندارد ، به عنوان مثال، سیستمهای نسل 2 استفاده میکنند. پلتفرم Okolloh [ 5 ] Ushahidi به کاربران اجازه می دهد تا اطلاعات را با استفاده از مولفه جغرافیایی Ushahidi یا با ارسال پیام های متنی تلفن همراه (SMS) جستجو و مشارکت دهند. دی لونگویل و همکاران [ 22 ] از API توییتر ( https://dev.twitter.com/ ) برای جستجو و بازیابی اطلاعات مربوط به بحران (به عنوان مثال ، توییتها) و اسکریپتهای خزنده وب برای فیلتر کردن و طبقهبندی محتوا استفاده کرد. زوک و همکاران [ 6] زیرساختی مبتنی بر ابزارها و خدمات منبع باز و رایگان را توصیف کرد که در زلزله 2010 هائیتی مورد استفاده قرار گرفت و شامل OpenStreetMap، Ushahidi و GeoCommons ( http://geocommons.com/ ) برای پشتیبانی از فعالیت های واکنش اضطراری بود. همه سیستم ها یک پورتال جغرافیایی برای داوطلبان برای مشارکت و گزارش اطلاعات بحران فراهم کردند، در حالی که Ushahidi و GeoCommons همچنین داده ها را از منابع خارجی مانند پیام کوتاه و وب سایت های شبکه های اجتماعی (به عنوان مثال، توییتر) واکشی کردند.
هنوز مکانیسمهای مؤثر، انعطافپذیر و قابل همکاری برای کشف VGI وجود ندارد. به عنوان مثال، رویکردهای اخیر از معیارهای مکانی، زمانی و متنی (مثلاً نوع فاجعه) برای جستجو و بازیابی VGI استفاده کردند [ 10 ، 24 ، 42 ]. با این حال، کیفیت داده ها در نظر گرفته نمی شود، که از دیدگاه ما، باید در هنگام جستجوی محتوا در وب باشد. این نیاز، برای مثال، از وجود محتوای هرزنامه و مغرضانه پدید می آید [ 43 ، 44 ]. بنابراین، نیاز به توسعه مکانیزمی برای کشف وجود دارد که پارامترهای مرتبط با کیفیت را هنگام جستجوی VGI، به ویژه هنگام در نظر گرفتن ادغام VGI-SDI در نظر بگیرد.
ارزیابی کیفیت داده ها : به جز سیستم های نسل 1، همه پلتفرم ها قادر به مدیریت VGI تولید شده توسط شهروندان هستند. با این حال، عملکرد کنترل کیفیت خودکار تنها در دو پلتفرم از هشت پلتفرم جدول 1 پیاده سازی شده است . پوزر و درانش [ 45 ] دو رویکرد کلی را برای ارزیابی کیفیت VGI مورد بحث قرار دادند: کیفیت به عنوان دقت، و کیفیت به عنوان اعتبار. مفهوم اول سطح شباهت بین داده های تولید شده و پدیده های دنیای واقعی را که توصیف می کند اندازه گیری می کند. این رویکرد عمدتاً توسط ارائه دهندگان داده استفاده می شود [ 45]. مفهوم دوم، که اغلب در زمینه وب 2.0 به کار می رود، به اعتبار داده ها، به ویژه داده های تولید شده توسط کاربران (غیر متخصص) اشاره دارد. در حالی که دقت یک ویژگی عینی است، اعتبار ذهنی است، و تمایل دارد به رتبهبندی کاربران به اعتبار سایر کاربران و اطلاعاتی که آنها ارائه کردهاند تکیه کند [ 46 ].
پوزر و درانش [ 45 ] رویکردهای ارزیابی کیفیت متفاوتی را برای مراحل مختلف چرخه مدیریت بلایا، به عنوان مثال ، برای کاهش، آمادگی، واکنش و بازیابی پیشنهاد میکنند. آنها پیشنهاد می کنند از رویکرد کیفیت به عنوان اعتبار در مراحل کاهش و آمادگی استفاده شود، جایی که مشارکت مداوم شهروندان وجود دارد. آنها سپس استفاده از رویکرد کیفیت به عنوان دقت را در مرحله واکنش پیشنهاد می کنند، جایی که نیاز به جمع آوری اطلاعات واقعی در مورد بحران برای تعیین تأثیر آن وجود دارد. نمونه هایی از ارزیابی کیفیت به دنبال یکی از دو رویکرد کلی توسط چندین نویسنده ارائه شده است (به Fan, Zipf, Fu, & Neis [ 47 ], Bishr & Mantelas [ 48 ], Bishr & Kuhn [ 49 ] مراجعه کنید.]، Goodchild & Li [ 50 ]، Schade و همکاران. [ 24 ]، دی لونگویل و همکاران. [ 22 ]) و در زیر مورد بحث قرار می گیرند.
Fan، Zipf، Fu و Neis [ 47 ] کیفیت دادههای ردپای ساختمان را در OpenStreetMap برای مونیخ، آلمان بر اساس رویکرد کیفیت به عنوان دقت ارزیابی کردند. آنها در کار خود از کامل بودن، دقت معنایی، دقت موقعیت و صحت شکل به عنوان معیارهای ارزیابی کیفیت استفاده کردند. بر اساس رویکرد کیفیت به عنوان اعتبار، Bishr & Mantelas [ 48 ] و Bishr & Kuhn [ 49 ] مدل اعتماد و شهرت را برای ارزیابی کیفیت VGI پیشنهاد کردند. آنها یک مدل محاسباتی ساختند که زمینه مکانی-زمانی را برای برنامه ریزی شهری [ 48 ] و کاربردهای مدیریت کیفیت آب [ 49 ] در نظر می گیرد.
یکی دیگر از رویکردهای ارزیابی کیفیت پیشنهاد شده توسط Goodchild & Li [ 50 ] بر استفاده از رویهها برای کنترل و ارتقای کیفیت در حین جمعآوری و گردآوری دادههای مکانی تأکید داشت. این شبیه به فرآیندهای تضمین کیفیت است که توسط آژانس های نقشه برداری سنتی استفاده می شود. این روش به مکانیسم هایی برای تولید معیارهای کیفیت برای داده های تولید شده و مکانیسم هایی برای ارزیابی VGI در برابر منابع مرجع معتبر نیاز دارد.
در نهایت، Shade و همکاران. [ 24 ] یک مکانیسم اعتبار سنجی متقابل برای غلبه بر چالش اعتبار VGI پیشنهاد کرد. ایده اصلی در کار آنها این بود که VGI را از منابع متعددی مانند Twitter، Flickr، OpenStreetMap و غیره جمعآوری کنند و این دادههای VGI را برای تعیین ارتباط آنها در یک زمینه مشخص پردازش کنند. در میان تکنیکهای اعتبارسنجی، اعتبارسنجی متقاطع k -fold یک رویکرد رایج برای تأیید و اعتبارسنجی VGI است [ 7 ، 51 ، 52 ].
علاوه بر این، تجزیه و تحلیل مکانی-زمانی برای ارزیابی کیفیت VGI استفاده شده است. برای مثال، De Longueville و همکاران. [ 22 ] اطلاعات مکانی را از VGI استخراج کرد، مانند مکان مشارکت کنندگان و نام مکان ها برای ارزیابی ارتباط محتوا با آتش سوزی جنگل های 2009 در اطراف مارسی، فرانسه. آنها سپس یک تحلیل زمانی برای تخمین دقت زمانی محتوا در مقایسه با رویداد واقعی انجام دادند. Ostermann & Spinsanti [ 53] استفاده از تجزیه و تحلیل فضایی برای تعیین همبستگی بین اطلاعات مکانی پیوست شده به محتوا (به عنوان مثال، توییت های دارای برچسب جغرافیایی)، استخراج شده از محتوا (به عنوان مثال، نام مکان های کدگذاری شده جغرافیایی) و مرتبط با نمایه های مشارکت کنندگان (به عنوان مثال، موقعیت مکانی کاربر) توصیه می شود. ). سپس میتوان از این اطلاعات برای رتبهبندی محتوا بر اساس فاصله مکان مشارکتکننده تا محل رویداد و ارزیابی اعتبار VGI استفاده کرد.
توزیع داده ها : از نظر انتشار VGI، تعدادی راه حل ایجاد شده است که در جدول 1 فهرست شده است. همه پلتفرمهای مبتنی بر SDI (نسل 1) از انتشار دادههای مبتنی بر خدمات استاندارد با استفاده از WMS (سرویس نقشه وب) OGC [ 54 ] پشتیبانی میکنند. در مقابل، سیستمهای نسل 2 مبتنی بر VGI، دادهها را با استفاده از رویکردهای موقت ، به عنوان مثال ، غیر استاندارد، توزیع میکنند، برای مثال، با استفاده از قالب داده باز مانند JSON. دو نمونه نسل 3 نیز از رویکردهای مبتنی بر خدمات استفاده می کنند.
پلت فرم نسل 3 توسط دیاز و همکاران. [ 23 ] از خدمات OGC مانند WFS (Web Feature Service) [ 55 ]، WMS و WCS (Web Coverage Service) [ 56 ] برای انتشار VGI استفاده می کند. اگرچه این رویکرد به اشتراک گذاری اطلاعات تولید شده توسط کاربر را تسهیل می کند، اما بعد زمانی VGI را که در فعالیت های مدیریت بلایا بسیار مهم است، پوشش نمی دهد. این موضوع توسط پلتفرم نسل 3 دیگر توسط Schade et al. [ 24 ]. آنها رویکرد جدیدی را برای مدیریت داده های VGI پیشنهاد می کنند که VGI Sensing نامیده می شود، که از چارچوب OGC SWE (Sensor Web Enablement) [ 57 ] برای انتشار VGI استفاده می کند. به عنوان بخشی از OGC’s Interoperability Testbed-10 (OWS-10)، Bröringو همکاران [ 58 ] همچنین چارچوبی را برای ادغام VGI در SDI از طریق استفاده از استانداردهای SWE و WFS OGC بررسی کرد. با این حال، این پلتفرمها از انتشار اطلاعات با کیفیت پشتیبانی نمیکنند، که یک نگرانی عمده بهویژه در زمینه یکپارچهسازی VGI-SDI [ 59 ] است. در حالی که کورنفورد و همکاران. [ 60 ] و Devaraju و همکاران. [ 61 ] نشان می دهد که چگونه چارچوب SWE OGC و مشخصات UncertML [ 62 ]] می تواند برای ارائه اطلاعات با کیفیت (به عنوان مثال، عدم قطعیت) در مورد مشاهدات حسگر مورد استفاده قرار گیرد، در حال حاضر هیچ رویکرد تعاملی برای انتشار داده های VGI وجود ندارد که نیاز به ابزارهای ارزیابی کیفیت داده یکپارچه را برطرف کند.
در نتیجه، هدف ما پرداختن به محدودیتهای پلتفرم مدیریت بلایای مبتنی بر وب است که قبلاً توسعه داده شده بود: (1) ایجاد یک الگوی اشتراکگذاری داده ترکیبی که از روشهای ایجاد و توزیع دادهها از بالا به پایین و پایین به بالا پشتیبانی میکند. و (ii) یک معماری سیستم انعطاف پذیر که از قابلیت همکاری و توسعه پذیری از طریق انطباق استاندارد و مدولارسازی پشتیبانی می کند.
3. چارچوب VGI
همانطور که در بالا توضیح داده شد، هدف ما ارائه یک رویکرد موثر و قابل همکاری برای کشف، کنترل کیفیت و انتشار VGI است. برای هدایت توسعه پلت فرم، مجموعهای از ویژگیها/نیازمندیهای کیفیت پلتفرم و اهداف تجاری را شناسایی کردیم [ 63 ، 64 ]. الزامات با توجه به اهمیت آنها برای مدیریت بلایا اولویت بندی شدند و به صورت گرافیکی در پیوست یافت می شوند . علاوه بر استفاده از الزامات در فرآیند طراحی چارچوب، آنها همچنین برای ارزیابی پیامدهای تصمیمات معماری، و شناسایی محدودیت ها/خطرات معماری سیستم مفید بودند [ 65 ].
در مرحله طراحی چارچوب/پلتفرم، اولویت اول به ویژگی های کیفی زیر داده شد: (الف) مقیاس پذیری/توسعه پذیری، (ب) سیستم/استانداردهای باز، و (ج) قابلیت همکاری. این ویژگیها تضمین میکنند که سیستمهای ساخته شده با استفاده از چارچوب VGI به طور موثر با هم کار میکنند و مجموعهای از خدمات توسعهیافته با استفاده از این چارچوب منسجم خواهند بود و در عین حال به مسائل مدیریت بلایای قانونی مانند اشتراکگذاری اطلاعات بحران میپردازند. اولویتهای طراحی ثانویه عبارت بودند از: (د) عملکرد، (ه) انعطافپذیری، (و) یکپارچگی، (ز) امنیت، (ح) سهولت در نصب، (1) سهولت استفاده، و (j) قابلیت حمل. این معیارها بر قابلیت و کیفیت سیستم تمرکز دارند. علاوه بر این، اولویتهای سطح پایین دیگری نیز وجود دارد، مانند (k) توسعه توزیع شده و (l) سهولت در تعمیر،ضمیمه ) که در حالت ایده آل باید برای دستیابی به تمام اهداف تجاری ارضا شود. در بخشهای بعدی، به طراحی مفهومی چارچوب، معماری فنی و جزئیات پیادهسازی میپردازیم.
3.1. طراحی مفهومی
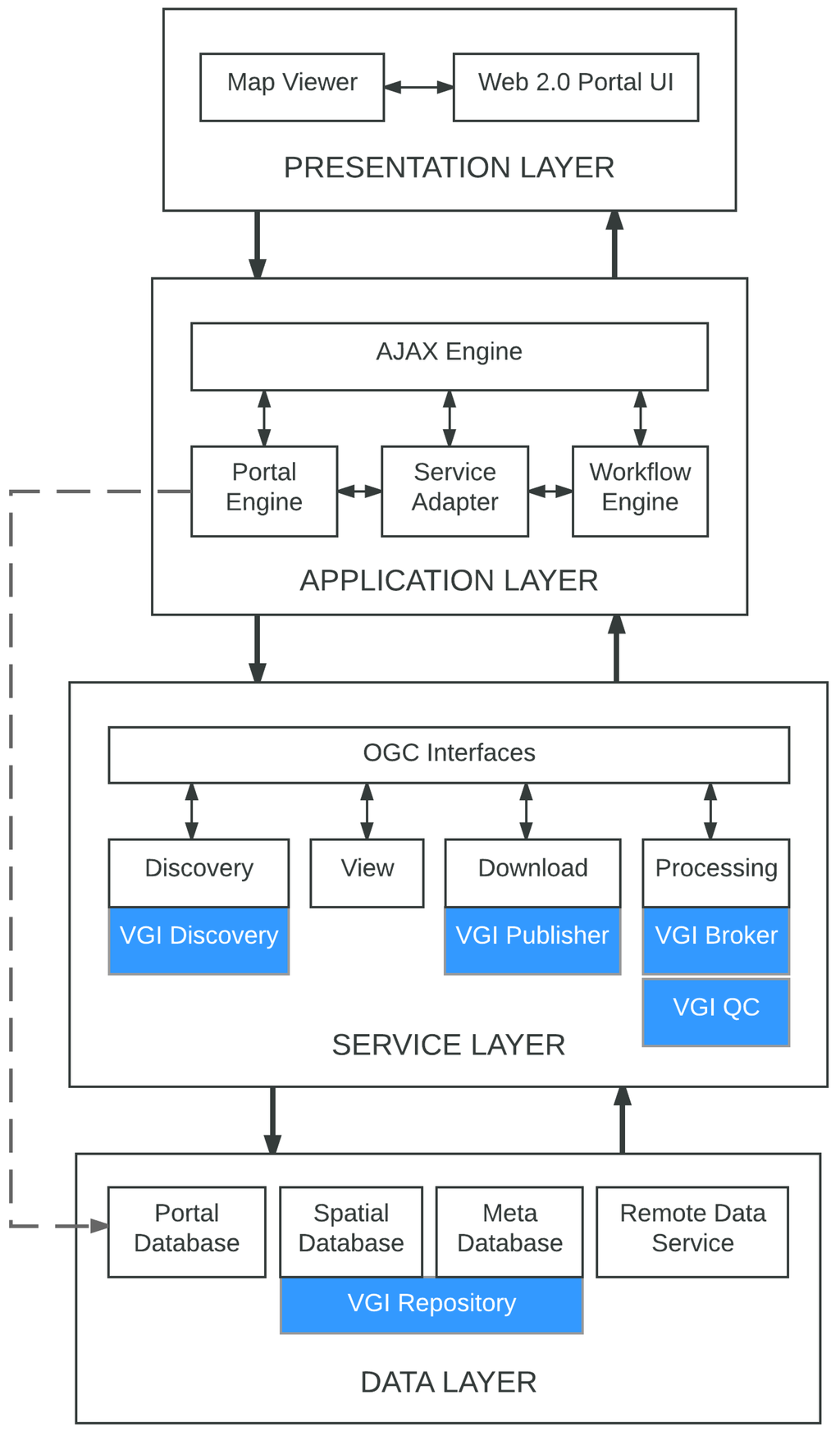
شکل 1 نمای کلی مفهومی چارچوب VGI را نشان می دهد که بر اساس الزامات عملکردی و معماری مورد بحث در بالا توسعه داده شده است. کارگزار VGI، VGI QC (کنترل کیفیت)، VGI Discovery، و VGI Publisher بلوک های سازنده چارچوب پیشنهادی هستند.
شکل 1. گردش کار مفهومی برای کشف، ارزیابی و انتشار VGI.
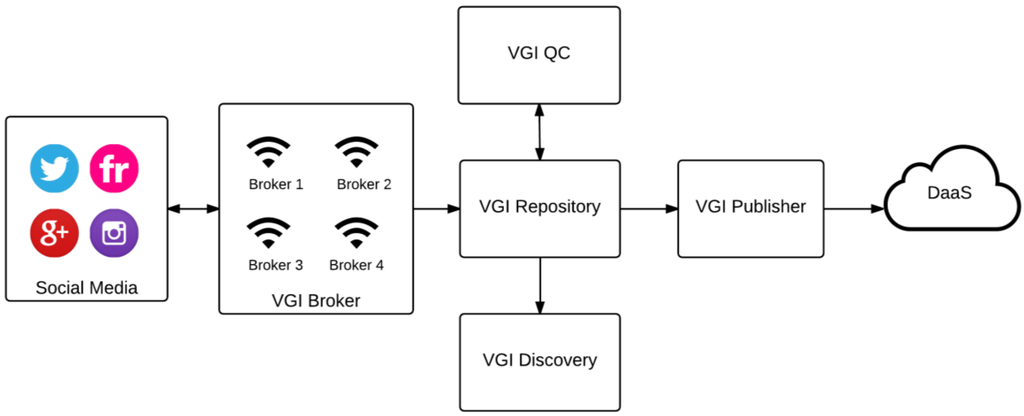
VGI Broker یک رابط خدماتی برای یافتن و جمعبندی محتوای تولید شده توسط کاربر از پلتفرمهای مختلف رسانههای اجتماعی ارائه میکند. بسیاری از پلتفرمهای رسانههای اجتماعی APIهای عمومی را در اختیار مشتریان قرار میدهند تا با استفاده از سیستم پیام درخواست-پاسخ خاص خود با آنها تعامل داشته باشند. اگرچه آنها معمولاً رابطهای مبتنی بر REST (انتقال وضعیت REpresentational) را اتخاذ میکنند و از فرمتهای داده محبوب (به عنوان مثال، JSON یا XML) پشتیبانی میکنند، هیچ توضیح یکسانی از رابطهای سرویس و رمزگذاری دادهها وجود ندارد [ 10 ]]. از این رو، ماژول VGI Broker کاربر پلتفرم را به API های مختلف متصل می کند و امکان بازیابی داده ها را از چندین پلتفرم رسانه اجتماعی از طریق یک رابط سرویس واحد فراهم می کند. این یک پرس و جو را به چندین پرس و جو مبتنی بر API ترجمه می کند و فرمت های مختلف داده درخواست-پاسخ را مدیریت می کند. سپس داده های بازیابی شده بر اساس مدل های داده طراحی شده برای هر پلتفرم (مثلاً توییتر، فلیکر و غیره ) در مخزن VGI ذخیره می شود .
ذخیره دادههای VGI در مخزن به ماژول VGI QC اجازه میدهد تا بررسیهای کنترل کیفیت دادهها را انجام دهد و ابردادههای مرتبط با کیفیت را که در مخزن VGI ذخیره میشوند تولید کند. این یک گام بسیار مهم است، به ویژه در زمینه مدیریت بلایا، که در آن VGI به طور بالقوه می تواند همراه با داده های معتبر برای تصمیم گیری استفاده شود. همچنین بازیابی داده های مبتنی بر کیفیت را که در پلتفرم های رسانه های اجتماعی فعلی وجود ندارد، امکان پذیر می کند. ماژول VGI QC رویه های کنترل کیفیت را در چارچوب پیشنهادی مدیریت می کند.
ماژول VGI Publisher یک سرویس داده است که VGI ارزیابی شده با کیفیت را بر اساس رویکرد DaaS منتشر می کند. همچنین به مشتریان اجازه می دهد تا به VGI بر اساس پارامترهای مکانی-زمانی و کیفیت به روشی تعاملی دسترسی داشته باشند و آن را بازیابی کنند. این بدان معناست که برخلاف پلتفرمهای رسانههای اجتماعی که پارادایمهای درخواست-پاسخ متفاوتی دارند، VGI Publisher یک رابط واحد و یک رمزگذاری داده مشترک برای انتشار دادهها ارائه میکند.
در نهایت، ماژول VGI Discovery به عنوان یک سرویس کاتالوگ برای کشف، مرور، و پرس و جو متادیتا در مورد مجموعه داده های VGI موجود عمل می کند. گزینه های جستجوی مبتنی بر کیفیت را به مشتریان ارائه می دهد. جستجو یک سند فراداده را باز می گرداند که شامل اطلاعاتی درباره داده ها مانند زمان، مکان و کیفیت و همچنین پیوندی به خود داده است.
3.2. معیارهای ارزیابی کیفیت
بر اساس رویکردهای ارزیابی کیفیت ارائه شده و مورد بحث در بالا (نگاه کنید به [ 7 ، 29 ، 53 ، 66 ، 67 ، 68 ])، ما پنج معیار را برای ارزیابی کیفیت داده های VGI و به دست آوردن امتیازات کیفیت داده اتخاذ کرده ایم. توجه داریم که با این مجموعه از معیارها، ما در تلاش برای تعریف ارزیابی کیفیت ناقص نیستیم. در عوض، معیارها به عنوان یک مجموعه آزمایش اولیه برای ارزیابی عملکرد کلی چارچوب پیشنهادی با استفاده از Typhoon Ruby به عنوان مطالعه موردی (در ادامه توضیح داده شد) استفاده میشود.
(1) نزدیکی موقعیتی : معادله (1) برای محاسبه امتیاز نزدیکی موقعیتی (PNS) استفاده می شود، که در آن Δ د∆دفاصله (بر حسب کیلومتر) بین هر مشارکت (مثلاً یک توییت) و مرکز همه مشارکتها (مثلاً همه توییتها) برای یک بافت معین است که میتواند به عنوان مرکز میانگین با استفاده از رابطه (2) محاسبه شود. متذکر می شویم که روش های متعددی برای تخمین یک مرکز، میانگین حسابی، میانگین وزنی، مرکز حداقل فاصله، مرکز بیشترین شدت و غیره وجود دارد. برای سادگی، از میانگین حسابی برای این کار به عنوان نقطه شروع اولیه استفاده کرده ایم.
( k > Δ d→ پناس= 1 ) ∧ ( k < Δ d→ پناس= k1Δ د)(ک>∆د→پناس=1)∧(ک<∆د→پناس=ک1∆د)
ایکس¯¯¯=∑i = 1nایکسمنn،Y¯¯¯=∑i = 1nyمنnایکس¯=∑من=1�ایکسمن�،�¯=∑من=1��من�
k یک اسکالر است که با انحراف فاصله استاندارد مجموعه مشارکت ها تعریف می شود. از رابطه (3) برای محاسبه معادل دو بعدی انحراف فاصله استاندارد استفاده می شود که d i فاصله بین هر نقطه i و مرکز میانگین و n تعداد کل نقاط است. در اصل، این مدل وزن بیشتری به مشارکتهای نزدیک به مرکز مجموعه مشارکتها میدهد.
k =∑i = 1n(دمن)2n – 2–––––––––⎷ک=∑من=1�(دمن)2�–2
(2) نزدیکی زمانی : تاریخ و زمان ایجاد هر مشارکت (به عنوان مثال، یک توییت) با زمان رویداد (یا پایان رویداد، در صورت وجود مدت زمان) مقایسه میشود تا تعداد روزهایی که رویداد واقعاً رخ داده است، مشخص شود. ( Δ t∆تی). از معادله (4) برای محاسبه امتیاز نزدیکی زمانی (TNS) استفاده می شود. مانند ( Δ t∆تی) افزایش می یابد، TNS کاهش می یابد.
( Δ t < 1 → Tناس= 1 ) ∧ ( Δ t > 1 → Tناس=1Δ t)(∆تی<1→تیناس=1)∧(∆تی>1→تیناس=1∆تی)
(3) تشابه معنایی : هر مشارکت (به عنوان مثال، یک توییت) با یک فرهنگ لغت از پیش تعریف شده از کلمات مرتبط با فاجعه مقایسه می شود و سپس از معادله (5) برای محاسبه امتیاز تشابه معنایی (SSS) استفاده می شود، که در آن N i برابر است. تعداد کلمات فرهنگ لغت که در یک مشارکت ظاهر می شوند و M تعداد کلمات موجود در فرهنگ لغت است.
اساساس=نمنماساساس=نمنم
(4) ارجاع متقابل : وسعت فضایی به شکل یک مستطیل حداقل مرزی موازی محور (MBR) از همه مشارکتها برای هر پلتفرم رسانه اجتماعی (مثلاً مجموعه دادههای توییتر) محاسبه میشود. پس از آن، عملیات نقطه در چند ضلعی برای هر مشارکت (به عنوان مثال، یک توییت) در هر MBR مجموعه داده اجتماعی (به عنوان مثال، مجموعه داده توییتر) انجام می شود. سپس از معادله (6) برای محاسبه امتیاز ارجاع متقابل (CRS) استفاده می شود، که در آن N i تعداد کادرهای مرزی است که یک سهم در آن قرار می گیرد و M است.تعداد کل جعبههای محدود/جریانهای رسانهای است. توجه می کنیم که گستره فضایی از نظر مشارکت رسانه های اجتماعی یک مفهوم مبهم است. ما در اینجا از آن به عنوان معیار نزدیکی استفاده می کنیم. ما همچنین توجه می کنیم که راه های زیادی برای نشان دادن نزدیکی وجود دارد. برای سادگی، نزدیکی را به این معنا انتخاب کردهایم که «چیزی نزدیکترین است اگر در تقاطع همه MBRهای مشارکتی قرار گیرد».
سیآر اس=نمنمسیآراس=نمنم
(5) اعتبار : مجموعهای از عوامل اعتبار تعریف شد و حداکثر مقدار هر عامل در همه مشارکتها (مثلاً همه توییتها) برای هر پلتفرم رسانه اجتماعی (مثلا توییتر) برای یک رویداد خاص (مثلاً Typhoon) محاسبه میشود. روبی) ( M). به عنوان مثال، توئیتر API به مشتری اجازه می دهد تا تعدادی از عوامل اعتبار را برای هر توییت جمع آوری کند. آنها عبارتند از: تأیید توییتر (یک حساب توییتر تأیید شده به طور رسمی هویت شخص یا شرکت صاحب حساب را تأیید می کند)، تعداد فالوورهای توییتر (تعداد دنبال کنندگان این حساب در حال حاضر؛ با فالوورهای بیشتر، حساب توییتر بیشتر به دست می آورد. توجه، در نتیجه محبوبیت آن افزایش می یابد)، چند بار توییت «مورد علاقه» قرار گرفته است (تقریباً چند بار یک توییت مورد علاقه کاربران توییتر قرار گرفته است؛ برگزیده شدن یک توییت نشان می دهد که کاربر یک توییت خاص را پسندیده است) و تعداد بازتوییت ( تعداد دفعاتی که این توییت بازنشر شده است؛ ریتوییت به معنای ارسال مجدد یا ارسال پیام در توییتر است). سپس از رابطه (7) (الف) برای محاسبه امتیاز اعتبار برای هر عامل استفاده می شود.CS i )، که در آن N ij مقدار هر عامل i برای سهم j است و M i حداکثر مقدار هر عامل در همه سهم های j است. نمره کل اعتبار (CS) با استفاده از رابطه (7) (ب) محاسبه می شود. n تعداد عواملی است که برای ارزیابی اعتبار استفاده می شود.
( الف ) جاسمن=نمن جممن، ( ب ) جاس=∑i = 1nسیاسمن/ n(آ)سیاسمن=نمن�ممن،(ب)سیاس=∑من=1�سیاسمن/�
در پیادهسازی/مطالعه موردی خود، از عوامل اعتبار زیر استفاده میکنیم: برای توییتر، (i) تأیید (توئیتر). (ii) تعداد فالوورهای توییتر. (iii) چند بار توییت “مورد علاقه” و (iv) بازتوییت شده است. برای فلیکر، ما از تعداد دفعاتی که یک عکس “مشاهده شده” به عنوان جانشین اعتبار استفاده می کنیم. برای Google Plus، تعداد دفعاتی را که یک پست «اشتراکگذاری مجدد»، «پاسخ» یا «بهعلاوه» شده است، ارزیابی کردیم (یک «plus-one» یا «+1» نشان میدهد که یک کاربر پست خاصی را پسندیده است. در گوگل پلاس). برای اینستاگرام، علاوه بر تعداد فالوورهای یک کاربر اینستاگرام، تعداد دفعاتی که یک عکس/فیلم «لایک» و «کامنت» شده است، ارزیابی کردیم.
امتیاز کیفیت : در نهایت، ماژول QC VGI یک نمره کیفیت کل (QS) را برای هر مشارکت (به عنوان مثال، یک توییت)، جمعآوری امتیازهای کیفیت فردی ( n ) محاسبهشده برای هر متریک محاسبه میکند (معادله (8)). جمع بندی ضروری است زیرا امتیازات فردی می تواند صفر باشد. به عنوان مثال، امتیاز نزدیکی موقعیتی صفر است زمانی که یک مشارکت بدون مرجع مکانی (به عنوان مثال ، مختصات) باشد.
Q S= پناسمن+ تیناسمن+ اساساسمن+ سیآراسمن+ سیاسمنساس=پناسمن+تیناسمن+اساساسمن+سیآراسمن+سیاسمن
همه نمرات کیفیت مقادیر بین صفر تا پنج را برمیگردانند که صفر نشاندهنده کیفیت نسبتاً پایین و پنج نشاندهنده سهم نسبتاً با کیفیت برای مدیریت بلایا است.
کنترل کیفیت بهعنوان یک فرآیند تکراری انجام میشود و بنابراین، با افزودن دادههای بیشتری به مخزن VGI، امتیازات کیفیت در طول زمان تغییر خواهد کرد. برای فعال کردن پرس و جوهای مبتنی بر کیفیت، تمام امتیازهای کیفیت (به عنوان مثال ، PNS، TNS، SSS، CRS، CS، و QS) برای هر مشارکت در مخزن VGI ذخیره میشوند.
3.3. معماری فنی
شکل 2 یک معماری مرجع معمولی را با اجزای چارچوب VGI نشان می دهد. نتیجه یک پلت فرم مدیریت بلایای قابل دسترس، انعطاف پذیر و قابل نگهداری است. این یک معماری لایهای است که از رویکردهای طراحی و تحویل SOA، اصول SDI و فناوریهای وب 2.0 استفاده میکند. این شامل چهار لایه ماژول، از جمله یک لایه ارائه، یک لایه برنامه، یک لایه سرویس و یک لایه داده است. این معماری از معماری سیستم e -Planning پیشنهاد شده توسط پورعزیزی و همکاران اقتباس شده است. [ 25 ]. همانطور که در شکل 2 نشان داده شده است، اجزای چارچوب VGI به عنوان انواع سرویس SDI مستقر در لایه سرویس طبقه بندی می شوند. از این رو، در ادامه، تنها به مؤلفه های لایه سرویس می پردازیم و به پورعزیزی و همکاران مراجعه می کنیم. [ 25 ] برای توضیح سایر لایهها.
لایه سرویس شامل مجموعهای از سرویسهای وب است که قابلیتهایی را برای جستجو، دسترسی و تجزیه و تحلیل دادههای مکانی، از جمله مجموعه دادههای معتبر و VGI ارائه میکند. سرویسهای وب بر اساس انواع سرویس SDI گروهبندی میشوند: (i) سرویس کشف (به عنوان مثال، OGC CSW [ 69 ]) برای جستجو و دسترسی به دادهها و خدمات مکانی موجود. (ب) سرویس دانلود (به عنوان مثال، WFS یا WCS) برای دسترسی به داده های مکانی در سطح ویژگی های جغرافیایی در قالب های برداری مانند GML، KML، یا GeoJSON. (iii) مشاهده سرویس (مانند WMS یا WMTS [ 70 ]) برای تجسم داده ها به شکل نقشه. و (IV) خدمات پردازش (به عنوان مثال، WPS [ 71 ]) برای اجرای مدل های آماری و جغرافیایی محاسباتی.

شکل 2. یک معماری مرجع شامل اجزای چارچوب پیشنهادی VGI.
ماژول VGI Broker به عنوان یک سرویس پردازش توسعه داده شده است. این با استفاده از استاندارد WPS پیادهسازی میشود، و بر اساس تعداد کارگزاران، از چندین نمونه خدمات (به عنوان مثال ، یک نمونه WPS برای هر کارگزار) تشکیل شده است. هر نمونه WPS به طور مستقل برای جستجو در یک پلت فرم رسانه اجتماعی برای یافتن، بازیابی و ذخیره داده های VGI در مخزن VGI اجرا می شود.
VGI QC نیز به عنوان مجموعه ای از نمونه های WPS پیاده سازی شده است. برای هر یک از پنج معیار کیفیت بالا ( به عنوان مثال ، PNS، TNS، SSS، CRS، و CS)، ما یک نمونه سرویس را پیادهسازی کردیم. یک نمونه خدمات دیگر برای محاسبه امتیاز کلی کیفیت استفاده می شود (QS، به بخش 3.1 مراجعه کنید ). پنج نمونه خدمات متریک کیفیت را می توان به صورت جداگانه یا موازی اجرا کرد زیرا ترتیب اجرای سرویس انعطاف پذیر است.
VGI Publisher به عنوان یک سرویس دانلود توسعه یافته است. ما چارچوب SWE OGC را برای انتشار VGI ارزیابی شده با کیفیت به عنوان یک سرویس پذیرفته ایم. بنابراین، ما رابط استاندارد سرویس مشاهده حسگر (SOS) [ 72 ] و مدل داده مشاهدات و اندازهگیریها (O&M) [ 73 ] را گسترش دادهایم تا توزیع VGI را همراه با معیارهای کیفیت فعال کنیم. این به مشتریان اجازه می دهد تا داده های VGI را بر اساس پارامترهای مکانی-زمانی و معیارهای مرتبط با کیفیت بازیابی کنند.
در نهایت، VGI Discovery به عنوان یک سرویس اکتشافی برای انتشار ابرداده در مورد داده های VGI موجود توسعه داده شده است. ما مشخصات OGC OpenSearch Geo and Time Extensions (OSGTE) [ 74 ] را برای توسعه VGI Discovery به عنوان یک سرویس وب استاندارد که مجموعه داده های VGI ( به عنوان مثال ، داده های VGI منتشر شده توسط VGI Publisher) را بر اساس پارامترهای جستجوی مکانی، زمانی و کیفی برمی گرداند، پذیرفته ایم. به یک مشتری
4. چارچوب VGI در عمل
برای نشان دادن نحوه عملکرد چارچوب VGI و ارزیابی عملکرد آن، دادههای آب و هوا و رسانههای اجتماعی مربوط به Typhoon Ruby [ 75 ] را مطالعه کردیم. در بخشهای بعدی، رویداد فاجعه و جزئیات پیادهسازی چارچوب VGI را به طور خلاصه شرح میدهیم و سپس نتایج آزمایشهای انجامشده را مورد بحث قرار میدهیم.
4.1. مطالعه موردی
طوفان روبی یک طوفان فاجعه بار بود که به عنوان شدیدترین طوفان استوایی سال 2014 رتبه بندی شد [ 76 ، 77 ]. در طول طوفان، 18 نفر جان خود را از دست دادند و خسارت قابل توجهی به اموال و زیرساخت های خصوصی و عمومی (114 میلیون دلار آمریکا) وارد شد [ 78 ]. طوفان در 4 دسامبر 2014 وارد فیلیپین شد، اولین بار در 6 دسامبر 2014 بر فراز سامر شرقی با سرعت باد به حداکثر سرعت 175 کیلومتر در ساعت (کیلومتر در ساعت) رسید و در 10 دسامبر 2014 به عنوان یک طوفان گرمسیری از کشور خارج شد. [ 79 ].
ما محتوای تولید شده توسط کاربر را از توییتر، فلیکر، گوگل پلاس و اینستاگرام با استفاده از VGI Broker بین 4 تا 17 دسامبر 2014 بر اساس مجموعه ای از پارامترهای جستجوی از پیش تعریف شده، هشتگ ها و کلمات کلیدی جمع آوری کردیم ( جدول 2 را ببینید ). چهار کارگزار با استفاده از API Python پلتفرم های رسانه های اجتماعی با استفاده از درخواست های HTTP GET/POST پیاده سازی شدند. سپس کارگزارها با استفاده از GeoServer WPS پیچیده شدند و به عنوان مجموعه ای از نمونه های استاندارد WPS در معرض دید قرار گرفتند. ما یک مدل داده برای هر مجموعه داده رسانه های اجتماعی طراحی کردیم و چهار پایگاه داده PostgreSQL/PostGIS را برای ذخیره و مدیریت جریان داده های دریافتی مستقر کردیم. جدول 2APIهای پایتون مورد استفاده برای توسعه بروکرها و پارامترهای جستجوی مورد استفاده برای فراخوانی آنها را فهرست می کند. لازم به ذکر است که پارامترهای جستجو از طریق بررسی اولیه جریان عمومی هر پلتفرم رسانه های اجتماعی برای یافتن نمونه ای مرتبط از داده ها با نویز نسبتاً کمی انتخاب شدند.
جدول 2. API های پایتون برای توسعه VGI Broker و پارامترهای جستجو استفاده می شود.
پس از جمع آوری داده ها، پردازش QC VGI انجام شد. ماشین حساب های امتیاز کیفیت به عنوان برنامه های کاربردی پایتون قابل دسترسی به وب (HTTP GET/POST) پیاده سازی شدند. بنابراین، عملکرد متریک کیفیت با استفاده از کتابخانه های پایتون توسعه داده شد. سپس ماشینحسابهای امتیاز کیفیت با استفاده از چارچوب GeoServer WPS پیچیده و به عنوان نمونههای استاندارد WPS در معرض دید قرار گرفتند. توابع فضایی PostGIS برای انجام محاسبات هندسی، مانند محاسبه فاصله بین جفت نقاط و آزمون های نقطه در چندضلعی (برای متریک ارجاع متقابل) استفاده شد.
VGI Discovery و VGI Publisher به عنوان نقاط پایانی سرویس توسعه داده شدند. برای توسعه VGI Discovery، از کتابخانههای pycsw ( http://pycsw.org/ ) استفاده و گسترش دادیم تا انتشار و کشف با کیفیت را فعال کنیم. برای ناشر VGI، ما از سرور SOS 52°North ( http://52north.org/communities/sensorweb/sos/index.html ) استفاده کردیم تا دسترسی و بازیابی داده ها را بر اساس ویژگی های کیفیت فعال کنیم.
4.2. نتایج
در این بخش، ویژگیهای مشارکت از هر مجموعه داده را شرح میدهیم و نتایج را برای نمرات کنترل کیفیت ارائه میکنیم. برای ارائه ساده تر، مقادیر پنج امتیاز کیفیت در سطوح 1 تا 4 طبقه بندی شدند که به ترتیب مقادیر بین 0.00 و 0.25، 0.25 و 0.50، 0.50 و 0.75، و 0.75 و 1.00 را نشان می دهند. به طور مشابه، مقادیر QS، از 0 تا 5، به عنوان سطح 1 تا سطح 5 طبقه بندی شدند، که مربوط به مقادیر بین 0 و 5 با مقدار گامی 1 است. در نتیجه، سطح با ارزش بالاتر (امتیاز) مربوط به مشارکت با کیفیت بالاتر ، که با توجه به مدلهای متریک استفاده شده، فرض میشود که کاربرد بهتری برای مدیریت بلایا دارد.
نزدیکی موقعیتی: ما حدود 117300 مشارکت را از چهار منبع داده مختلف، توییتر، فلیکر، گوگل پلاس، و اینستاگرام جمعآوری کردیم که به تایفون روبی اشاره میکردند [ 75 ]. از این مشارکت ها، تنها 2440 (~2%) با اطلاعات مختصات (موقعیت) برچسب جغرافیایی شدند. در جدول 3ما تعداد مشارکتها را برای هر امتیاز نزدیکی موقعیتی (PNS) با توجه به منبع آنها نشان میدهیم. مشارکت های سطح 1 PNS ارجاع جغرافیایی نداشتند. به نظر می رسد که برای این مطالعه موردی، ما تنها دو مشارکت جغرافیایی ارجاع شده از هر دو فلیکر و گوگل پلاس داشتیم. از این رو، گوگل پلاس کمترین نسبت محتوای دارای برچسب جغرافیایی (2 از 935 ~ 0.2٪) را ارائه کرد، پس از آن توییتر (440 از 110249 ~ 0.3٪)، سپس فلیکر (2 از 66 ~ 3.0٪) با اینستاگرام قرار گرفت. ارائه نسبت قابل توجهی بیشتر از مشارکت های دارای برچسب جغرافیایی (1996 از 6022 ~ 33.1٪). آزمون 2 نمونه ای برای برابری نسبت ها انجام شد که نشان دهنده تفاوت معنادار بین دو نسبت بود (χ2= 30 , 051 , d . f . = 1 , p ≪ 0.001 )(�2=30،051،د.f.=1،پ≪0.001). سه تا از جریانهای داده، توییتر، فلیکر و گوگل پلاس، با هم ترکیب شدند، زیرا هر دو فلیکر و گوگل پلاس کمتر از پنج مشارکت با مختصات ارائه کردند که میتواند منجر به یک راهحل غیرقابل اعتماد شود. همچنین تفاوت معنی داری بین نسبت های شمارش برای آن خدمات وجود نداشت. نسبت بیشتر مشارکتهای اینستاگرام با برچسب جغرافیایی را میتوان تا حدی با این واقعیت توضیح داد که کاربران اینستاگرام فقط میتوانند عکسها و ویدیوها را از طریق تلفن همراه خود منتشر کنند، به این ترتیب اینستاگرام ممکن است اطلاعات مکانی را از آدرس GPS یا IP کاربران استنتاج کند. شکل 3 توزیع فضایی داده های بازیابی شده از رسانه های اجتماعی را نشان می دهد.
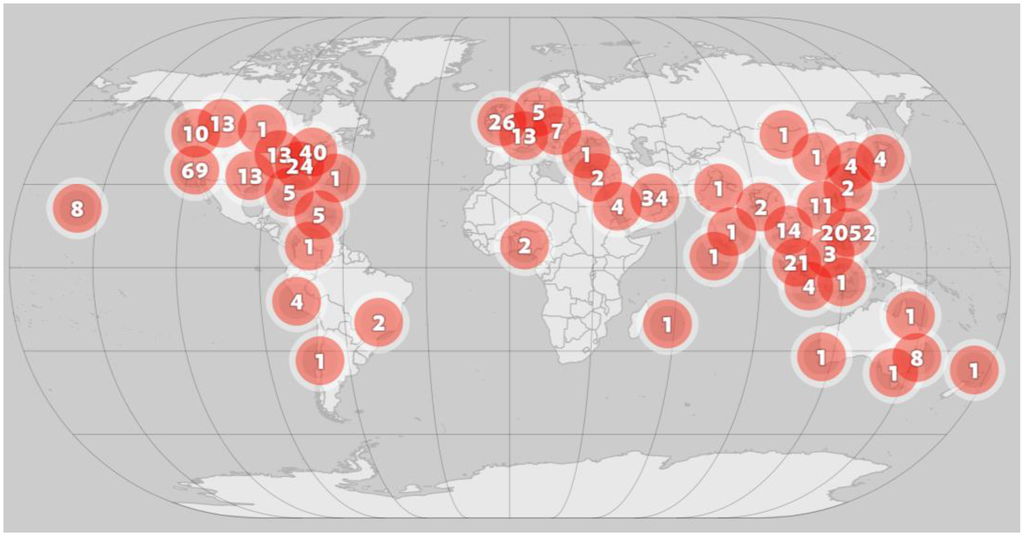
شکل 3. توزیع فضایی محتوای رسانه های اجتماعی. هر حلقه نشان دهنده تعداد معینی از مشارکت های رسانه های اجتماعی است.
جدول 3. شمارش مقادیر امتیاز نزدیکی موقعیتی (PNS) برای هر جریان رسانه.
نزدیکی زمانی : در طول دوره جمعآوری دادهها، فیدهای رسانههای اجتماعی با نرخ متوسط 2129 مشارکت در روز جریان داشتند. همانطور که در شکل 4 نشان داده شده است ، از مشارکت های جمع آوری شده، بیشتر آنها بین 4 دسامبر 2014 و 10 دسامبر 2014، زمانی که خود رویداد در فیلیپین رخ داد، منتشر شد. از شکل 4 مشهود است که در حالی که ما قبل از ورود طوفان به فیلیپین دادهها را جمعآوری کردیم، در زمان استقرار VGI Broker، حجم قابل توجهی از مشارکتها در توییتر و غیره ایجاد شده بود.
ارزیابی نزدیکی زمانی نشان میدهد که بیش از 76 درصد از همه مشارکتها در طول رویداد پخش شد، که بالاترین امتیاز نزدیکی زمانی را به خود اختصاص دادند ( یعنی سطح 4). مشارکت های سطح 1 همه چند روز قبل یا بعد از رویداد منتشر شدند. از میان چهار جریان مشارکتکننده، فلیکر با 98.5 درصد، بالاترین نسبت مشارکتهای سطح 4 TNS را داشت، پس از آن اینستاگرام با 82.4 درصد، سپس توییتر با 76.6 درصد و در نهایت گوگل پلاس با 56.9 درصد ( جدول 4 را ببینید ). مقایسه زوجی نسبت ها نشان می دهد که تفاوت قابل توجهی در عملکرد زمانی همه جریان های رسانه های اجتماعی وجود دارد. χ2= 331.6 ، df = 3 ، p ≪ 0.001.�2=331.6،df=3،پ≪0.001.برای مثال، عکسها و ویدئوهای اینستاگرام عمدتاً در طول این رویداد پست میشد، در حالی که مشارکتهای توییتر نیز قبل از طوفان به عنوان هشدار و سپس پس از توفان به عنوان پیامهای امیدوارکننده برای آسیبدیدگان منتشر شد.

شکل 4. پویایی زمانی مشارکت کاربران در رسانه های اجتماعی.
تشابه معنایی : متداولترین هشتگها/کلمات کلیدی مورد استفاده (تعیین شده پس از رویداد) برای توصیف رویداد عبارتند از : rubyph ، hagupit ، typhoonruby ، typhoonhagupit ، و philippines . با این حال، به منظور جمعآوری دادهها در زمان واقعی، از یک فرهنگ لغت مرجع از واژههای مرتبط با بحران در تاریخ 4 دسامبر 2014 استفاده کردیم که شامل چهار کلمه کلیدی تایفون ، یاقوت ، هاگوپیت ، و فیلیپین برای انجام ارزیابی تشابه معنایی است. مشارکت های طبقه بندی شده به عنوان سطح 1 در جدول 5با تعداد کمی از کلمات مرجع دقیقا مطابقت داشت—آنها در واقع دارای تطابق جزئی هشتگ/کلمه کلیدی بودند، زیرا برای ورود به پایگاه داده رویداد ضروری بود. مشارکتهای سطح 2 حداقل یک تطابق با کلمه مرجع داشتند.
جدول 4. شمارش مقادیر امتیاز نزدیکی زمانی (TNS) برای هر مجموعه داده.
جدول 5. شمارش مقادیر امتیاز شباهت معنایی (SSS) هر مجموعه داده.
محتوای Google Plus از نظر معنایی بسیار شبیه به فرهنگ لغت مرجع بود زیرا 100٪ از داده های جمع آوری شده به عنوان سطح 3 یا 4 طبقه بندی شده بودند. با این حال، این به طور قابل توجهی بیشتر از مشارکت برای داده های بازیابی شده از Flickr نیست (98.5٪ به سطح 3 یا دست یافتند. 4). به طور کلی، یک آزمون 4 نمونه ای برای برابری نسبت ها به همراه مقایسه زوجی نشان می دهد که تفاوت معناداری در کیفیت معنایی مشارکت بین چهار جریان رسانه های اجتماعی وجود ندارد. χ2= 4 , 384 , d . f . = 3 ، p ≪ 0.001�2=4،384، د.f.=3، پ≪0.001. دادههای توییتر حاوی برچسبهای کافی از فرهنگ لغت مرجع برای رسیدن به سطح 3 یا 4 در 27٪ مواقع بود، در حالی که اینستاگرام در 3.7٪ مواقع این کار را انجام داد.
ارجاع متقابل: فرآیند ارجاع متقابل بر مولفه فضایی مشارکتها متمرکز بود، و اندازهگیری چند بار هر مشارکت در MBR هر جریان رسانههای اجتماعی بود. مشارکتهایی که به سطح 1 اختصاص داده شدهاند، یا هیچ مرجع فضایی نداشتند یا در جعبهای محدود به غیر از خودشان قرار نمیگرفتند. همانطور که از مقایسه زوجی نسبتها مشاهده میشود، نشان میدهد که مشارکتهای اینستاگرام به احتمال زیاد در تقاطع جغرافیایی منابع داده رسانههای اجتماعی یا نزدیک آن است.
جدول 6 و مشارکت های کمی (~0.1٪) در کادر محدود حداقل دو مجموعه داده دیگر قرار داشتند. تنها 684 توییت وجود داشت که در MBR دو مجموعه داده دیگر قرار داشتند. هیچ مشارکتی در تقاطع همه MBBها سقوط نکرد. یک آزمون 3 نمونه ای برای برابری نسبت ها گزارش می دهد که تفاوت قابل توجهی در ارجاع متقابل در چهار جریان رسانه های اجتماعی با χ2= 26 ، 554 ، د . f . = 2 ، p ≪ 0.001.�2=26،554،د.f.=2،پ≪0.001.در این آزمایش، فلیکر و گوگل پلاس مانند سطوح 2 تا 4 با هم ترکیب شدند تا اطمینان حاصل شود که χ2�2تقریب درست خواهد بود مقایسه زوجی نسبتها نشان میدهد که مشارکتهای اینستاگرام به احتمال زیاد در محدوده یا نزدیک تقاطع جغرافیایی منابع داده رسانههای اجتماعی است.
جدول 6. شمارش مقادیر امتیاز ارجاع متقابل (CRS) هر مجموعه داده.
اعتبار : با توجه به ویژگیهای مختلف پلتفرمهای رسانههای اجتماعی (مثلاً مدل داده)، ما مجموعهای از عوامل متفاوت را برای ارزیابی اعتبار برای هر جریان رسانهای انتخاب کردیم که در بالا توضیح داده شد. بسته به منبع رسانه، مشارکتهای سطح 1 هیچ اشتراکگذاری، لایک، مشارکتکننده یا دنبالکنندهای نخواهد داشت. همانطور که در جدول 7 نشان داده شده است، تعداد کمی از مشارکت ها نمره اعتبار بالایی را کسب کردند. یک آزمون 2 نمونه ای برای برابری نسبت ها گزارش می دهد که تفاوت قابل توجهی در اعتبار در بین چهار جریان رسانه های اجتماعی وجود دارد. χ2= 111.4 ، د . f . = 1 ، p ≪ 0.001�2=111.4،د.f.=1،پ≪0.001. در این آزمایش، فلیکر، گوگل پلاس و اینستاگرام و سطوح 2 تا 4 با هم ترکیب شدند تا اطمینان حاصل شود که χ2�2تقریب درست خواهد بود داده ها نشان می دهد که توییتر اطلاعات معتبرتری ارائه می دهد.
جدول 7. شمارش مقادیر امتیاز اعتبار (CS) هر مجموعه داده.
امتیاز کلی : جدول 8 خلاصه ای از محاسبات نمره کیفیت نهایی را برای هر مجموعه داده ارائه می دهد. با توجه به دادهها، بیشتر محتوای منتشر شده در خدمات رسانههای اجتماعی در سطوح 2 و 3 قرار داشتند. در واقع، مشارکتهای بدون هیچ مرجع جغرافیایی فقط میتوانند به سطح کیفی 3 برسند. یک آزمون 4 نمونهای برای برابری نسبتها همراه با مقایسه زوجی نشان میدهد که تفاوتهای قابلتوجهی در کیفیت هر جریان داده رسانههای اجتماعی با χ2= 22 , 003 , d . f . = 3 ، p ≪ 0.001�2=22،003،د.f.=3،پ≪0.001. در این آزمون، سطوح 3 تا 5 با هم ترکیب شدند تا اطمینان حاصل شود که χ2�2تقریب درست خواهد بود ما با احتیاط اعلام می کنیم که با توجه به داده ها، نتایج ما نشان می دهد که Flickr با 72.7٪ از داده ها در سطح 3 یا بالاتر، بالاترین کیفیت داده ها را ارائه می دهد، پس از آن اینستاگرام (30.6٪)، گوگل پلاس (19.2٪) و توییتر با 0.9 درصد
جدول 8. شمارش مقادیر امتیاز کیفیت کل (QS) هر مجموعه داده.
5. ارزیابی و بحث
ارزیابی و بحث درباره این اثر بر اساس دو موضوع موجود در اثر تقسیم شده است. ابتدا چارچوب VGI را بر حسب اهداف چارچوب تعیین شده در بخش 3 ارزیابی می کنیم . این با ارزیابی مدل ارزیابی کیفیت و معیارها دنبال می شود.
5.1. ارزیابی چارچوب فنی
برای ارزیابی چارچوب پیشنهادی، استفاده از معیارهای کمی و کیفی برای تأیید اینکه آیا طراحی سیستم با موفقیت نیازهای کاربران را برآورده میکند و ارزیابی عملکرد آن در شرایط مختلف مفید است [ 80 ]. در این بخش به معیارهای کیفی می پردازیم. یک ارزیابی کمی، که ممکن است، برای مثال، به عملکرد محاسباتی قابلیتهای جستجو و ذخیرهسازی چارچوب، و تجزیه و تحلیل کامل جریانهای رسانهای، تمرکز کار آینده باشد.
برای پیاده سازی معماری، به دو دلیل از استراتژی FOSS (نرم افزار رایگان و متن باز) استفاده کردیم. اول، هزینه بالقوه مورد نیاز برای پیاده سازی، اصلاح یا سفارشی سازی سیستم را به حداقل می رساند. دوم، پذیرش رایگان پلتفرم توسط سازمانهایی که مسئولیتهای مدیریت بلایا را بر عهده دارند، تسهیل میکند [ 81 ، 82 ]. با توجه به ویژگی های معماری می توان گفت:
- (من)
-
چارچوب پیشنهادی از استانداردهای فضایی باز و شبکه جهانی وب ( به عنوان مثال ، OGC و W3C) پیروی می کند، که تعاملات ماشین-ماشین و انسان-ماشین را به شیوه ای متقابل تسهیل می کند.
- (II)
-
این به توسعه دهندگان اجازه می دهد تا اجزای سیستم ( به عنوان مثال ، خدمات) را با استفاده از فناوری ها و ابزارهای مختلف (به عنوان مثال، FOSS یا اختصاصی) طراحی و بسازند.
- (iii)
-
این معماری از یک رویکرد توسعه مبتنی بر خدمات پشتیبانی میکند که انعطافپذیری لازم برای اجازه دادن به تغییرات یا سفارشیسازی سیستم را فراهم میکند. و
- (IV)
-
این یک راه حل استقرار انعطاف پذیر را ارائه می دهد که در آن اجزای سیستم را می توان به راحتی به سیستم های موجود “وصل کرد” و امکان استقرار در محیط های محلی و توزیع شده (مثلاً ابر) را فراهم می کند.
در نتیجه، با توجه به الزامات ویژگی اولیه کیفیت و اهداف تجاری [ 63 ، 64 ] که توسعه سیستم را هدایت کردند (به پیوست مراجعه کنید )، نتیجه میگیریم که ویژگیهای کیفیت مانند مقیاسپذیری/توسعهپذیری، سیستمها/استانداردهای باز و قابلیت همکاری (از لحاظ نظری) همگی در چارچوب پیشنهادی اولویتهای ثانویه انعطافپذیری، یکپارچگی، سهولت نصب و عملکرد از طریق اتخاذ «بهترین شیوهها» در طول فرآیند طراحی در سیستم ایجاد شدهاند. اولویت های سطح پایین تر مانند قابل حمل بودن و سهولت تعمیر نیز برآورده شده اند ( جدول 9 را ببینید ).
با این حال، همانطور که اشاره شد، هنوز نیاز به ارزیابی چارچوب از نظر عملکرد فنی عملی، مقیاس پذیری و قابلیت استفاده وجود دارد. این امر برای درک نحوه واکنش سیستم در عملیات اضطراری واقعی ضروری است تا اطمینان حاصل شود که اپراتورهای سیستم قادر به استفاده مناسب از چارچوب VGI هستند. همچنین نیاز به مطالعه مکانیسمهایی وجود دارد که یکپارچهسازی چارچوب VGI را در جریانهای کاری اطلاعات و تصمیمگیری موجود (سازمانی) ممکن میسازد. این امر ادغام منابع داده بیشتر (به عنوان مثال ، داده های معتبر و تولید شده توسط کاربر) را در پلت فرم تسهیل می کند، که متعاقباً امکان اصلاح روش های کنترل کیفیت را برای دستیابی به نتایج واقعی تر فراهم می کند.
جدول 9. الزامات ویژگی کیفیت و اهداف تجاری که توسط چارچوب VGI مورد توجه قرار گرفته است.
5.2. ارزیابی معیارهای کنترل کیفیت
چندین کار الزامات کیفی دادههای مکانی را برای ایجاد دادههای مکانی معتبر و سازمانی، مانند دادههای جمعآوریشده توسط آژانسهای نقشهبرداری ملی بررسی کردهاند [ 83 ، 84 ، 85 ، 86 ]. نمونه هایی از این استانداردهای کیفیت مربوط به «نسب»، «دقت موقعیتی»، «دقت ویژگی»، «سازگاری منطقی»، «کامل بودن» و «دقت زمانی» است. اگرچه برخی از این معیارهای کیفیت ممکن است مستقل از یک برنامه کاربردی خاص به نظر برسند، اما باید با توجه به زمینه خاص استفاده از داده ها (یا نقشه) تعریف شوند تا اطمینان حاصل شود که داده ها برای هدف مناسب هستند [ 87 ].
تناسب اندام برای هدف یک مسئله حیاتی برای تضمین کیفیت VGI است [ 87 ]، که به موجب آن VGI رویکرد متفاوتی را برای ارزیابی کیفیت می طلبد. این تفاوت از (1) رویه های مختلف انجام شده برای تولید داده های معتبر و VGI، (2) ماهیت اجتماعی و فنی سیستم های VGI، و (3) ناهمگونی VGI ( برای بحث مفصل به [ 87 ] مراجعه کنید) پدیدار می شود. بنابراین، چندین رویکرد توسط محققان برای پر کردن این شکاف پیشنهاد شده است، از جمله رویکردهای «جمع سپاری»، «اجتماعی»، «جغرافیایی»، «دامنه»، «مشاهده ابزاری» و «فرایند محور» [ 50 ، 87 ]. این رویکردها لزوماً به صورت مجزا برای یک مورد خاص مورد استفاده قرار نمی گیرند، بلکه برای برنامه های کاربردی دنیای واقعی ترکیب می شوند.87 ]. به عنوان مثال، در این مطالعه، ما از سه رویکرد برای اطمینان از اینکه تضمین کیفیت متناسب با هدف مدیریت فاجعه است استفاده کردیم: (الف) «جمعسپاری» برای ارزیابی رتبهبندی کاربران و اندازهگیری کیفیت مشارکت (مثلاً بازتوییتها). (ب) تجزیه و تحلیل “جغرافیایی” برای ارزیابی کیفیت فضایی اطلاعات. و (ج) تجزیه و تحلیل “دامنه” برای اطمینان از ارتباط اطلاعات با یک زمینه خاص (به عنوان مثال، تایفون روبی). در نتیجه، نزدیکی موقعیتی و ارجاع متقابل رویکردهای تحلیل «جغرافیایی» هستند، نزدیکی زمانی و ارزیابی شباهت معنایی را می توان رویکردهای «دامنه» در نظر گرفت، و اعتبار یک رویکرد «انبوه سپاری» است.
مجموعه فعلی معیارهای ارزیابی کیفیت باید به عنوان یک مجموعه آزمایشی در نظر گرفته شود که هدف اصلی آن نشان دادن کاربرد معماری پیشنهادی برای بازیابی داده های VGI مبتنی بر کیفیت است. با این حال، مطالعه موردی ما همچنین به ما اجازه میدهد تا معیارها را ارزیابی کنیم و تشخیص دهیم کدام یک ممکن است کار کنند و کدام یک نیاز به کار مجدد یا اصلاح دارند.
نزدیکی موقعیتی : اگرچه فیلیپین مرکز بحران بود، اما حجم قابل توجهی از دادهها از سایر نقاط جهان جریان داشت ( شکل 3 را ببینید ). رسانههای اجتماعی از این مشارکتها به عنوان پاسخی به یک «رویداد سایبری» یاد میکنند [ 88 ]. این بدان معنی است که آنها گزارش هایی از خود بحران نیستند، بلکه واکنش هایی به پوشش آن در رسانه های اجتماعی هستند. بنابراین، چنین مشارکتهایی باید نمرات نزدیکی موقعیتی کمتری دریافت کنند، زیرا ممکن است تأثیر منفی بر تلاشها برای بومیسازی بحران با استفاده از فیدهای رسانههای اجتماعی داشته باشند [ 88 ]]. به عنوان مثال، مرکز میانگین همه مشارکتهای توییتر در دریای عرب (65.66996 درجه شرقی، 19.57687 درجه شمالی)، 750 کیلومتری شرق بمبئی، هند قرار دارد که حدود 6000 کیلومتر با مرکز بحران فاصله دارد.
مشارکتهای اینستاگرام بهطور قابلتوجهی فشردهتر از مشارکتهای توییتر هستند، و با نسبت مشارکتهای سطح 4 به 30.2 درصد به زمان طوفان واقعی نزدیکتر هستند. یک آزمون 2 نمونه ای برای برابری نسبت ها نشان می دهد که اینستاگرام نسبت به طور قابل توجهی بالاتری از مشارکت ها را تولید می کند که در نزدیکی یکدیگر قرار گرفته اند. (χ2= 34 ، 35 ، د . f . = 1 , p ≪ 0.001 )(�2=34،35،د.f.=1،پ≪0.001). برای دقت آماری، توییتر، گوگل پلاس و فلیکر برای اطمینان از اینکه χ2�2تقریب درست خواهد بود، همانطور که سطوح 1 تا 3 در هر گروه بندی درست بود. این که مشارکتهای اینستاگرام به تایفون واقعی نزدیکتر هستند، ممکن است به این دلیل باشد که مشارکتهای اینستاگرام عموماً حاوی عکسها و ویدیوهای مرتبط با تایفون هستند، نه پیامهای متنی مانند توییتر. از این رو، مشارکتکنندگان اینستاگرام به احتمال زیاد عکسها یا ویدیوها را در مجاورت رویداد ایجاد کردهاند، در حالی که مشارکتهای دیگر در واقع میتوانند از هر نقطه از جهان ایجاد شوند. این همچنین در دادههای ما دیده میشود که در آن نمرات نزدیکی اینستاگرام دارای نسبت بالاتری از امتیازات سطح 3 و 4 نسبت به سایر جریانهای رسانهای است ( جدول 3 و جدول 4 را ببینید).
با این حال، ما با دو مشکل روبرو هستیم: اول، اعمال این معیار برای رویدادهایی با پاسخ جهانی دشوار است، زیرا این منابع داده توسط سیستم مختصاتی که برای ذخیره موقعیت جغرافیایی استفاده میشود، سوگیری میکنند و ممکن است به خوبی جغرافیایی (حساب) ایجاد کنند. مراکزی که از بحران دور هستند. معیارهای دیگر، مانند مرکز میانگین فاصله، یا مرکز شدت، ممکن است مناسب تر باشند. دوم، مشارکتهای Google Plus و Flickr با ارجاع مکانی بسیار کم است. مطلوب است که هر جریان رسانه ای تعداد قابل توجهی از مشارکت های جغرافیایی ارجاع شده برای معیارهای نزدیکی و ارجاع متقابل داشته باشد. یکی از دلایل داشتن تعداد کمی از ویژگیهای برچسبگذاریشده جغرافیایی این است که ما فقط از اطلاعات فضایی صریح پیوست شده به مشارکتها استفاده میکنیم ( یعنیمختصات جغرافیایی). با این حال، تکنیکهای بازیابی اطلاعات جغرافیایی [ 89 ] باید در کار آینده در نظر گرفته شوند تا اطلاعات مکانی ضمنی (مثلاً نام مکان یا POI) که در متن تعبیه شده است استخراج شود، یا برای بازیابی اطلاعات مکان از نمایههای کاربران برای غنیسازی مولفه فضایی. از مشارکت های کاربر
نزدیکی زمانی : یکی از دلایل داشتن مشارکتهایی با امتیاز نزدیکی زمانی پایین این است که ما نظارت بر رویداد را دو روز قبل از وقوع طوفان در فیلیپین آغاز کردیم و جمعآوری دادهها را تا پس از خروج از کشور ادامه دادیم. این بدان معنی است که مجموعه داده ها شامل مشارکت رسانه های اجتماعی از مراحل مختلف فاجعه، آمادگی از طریق واکنش و سپس بازیابی است. تفاوت در الگوهای زمانی، همانطور که در شکل 4 مشاهده می شود، ممکن است دو دلیل متفاوت داشته باشد: (1) زیرا مشارکت کنندگان ترجیح می دهند از خدمات رسانه های اجتماعی مختلف در طول مراحل مختلف یک رویداد استفاده کنند. و (ii) به دلیل الگوهای توزیع مکانی متفاوت هر یک از مجموعه داده های رسانه های اجتماعی به دلیل پاسخ های جهانی به “رویداد سایبری”. این نکته اخیر نشان می دهد که متریک باید با نمرات نزدیکی موقعیتی ترکیب شود تا مرکز مکانی-زمانی یا مرکز متحرک یک رویداد شناسایی شود. با این حال، یک سوال اضافی که باید در نظر گرفته شود این است که چه بازه زمانی باید برای محاسبه بهترین امتیازها استفاده شود. در مطالعه موردی خود، دادههای واجد شرایط را بر حسب «روز» از پایان رویداد داریم. به نظر می رسید این واحد زمانی به اندازه کافی کار می کند زیرا طوفان با توجه به گستردگی فضایی منطقه رویداد به آرامی در حال حرکت بود. با این حال، انواع دیگر رویدادها، مانند زلزله یا تصادف،
تشابه معنایی : ارزیابی شباهت معنایی نشان میدهد که مشارکتهای Google Plus در 99 درصد موارد حاوی همه برچسبهای مرجع فرهنگ لغت است. این ممکن است به دلیل نحوه عملکرد Google Plus به عنوان یک وب سایت شبکه اجتماعی باشد. در مقایسه با توییتر، یک سرویس میکروبلاگینگ با محدودیت 140 کاراکتر، اینستاگرام و فلیکر، هر دو سرویس اشتراکگذاری عکس/فیلم، گوگل پلاس به کاربران اجازه میدهد محتوای متنی کوتاه و متوسط را مستقیماً در جریان خود پست کنند و محتوا را به اشتراک بگذارند. به عنوان مثال، عکسها، ویدیوها یا مقالات خبری) از وبسایتهای شخص ثالث. از این رو، با توجه به انواع محتوا و حجم کلمه در هر مشارکت، ممکن است گوگل با محاسبه شباهت معنایی مورد استفاده قرار گیرد. این نشان دهنده نیاز به سنجش مشارکت برای هر جریان رسانه اجتماعی و همچنین برای هر نوع رسانه (تصویر، متن،و غیره ).
مسئله ای که با داده های فعلی مشاهده کردیم این است که گاهی اوقات کلماتی شبیه به کلمات مرجع در پیام وجود دارد اما با املای متفاوت یا نادرست. در نتیجه، ممکن است یک رویکرد تطبیق کلمه متفاوت معرفی شود که شباهت را با استفاده از فاصله مبتنی بر کاراکتر اندازهگیری میکند، برای مثال، مانند فاصله همینگ [ 90 ]. چالش دیگر تفسیر زبانها و اصطلاحات مختلف در مشارکتها است، که وقتی فاجعهای در یک کشور چند زبانه اتفاق میافتد یا جایی که مردم از اصطلاحات بومی و جایگزین برای توصیف یک رویداد استفاده میکنند بسیار مهم است [ 91 ]. یک رویکرد امیدوارکننده برای به حداقل رساندن این موضوع، استفاده از فرهنگ لغت دادهای است که زبانها یا اصطلاحات مختلف را در یک زمینه خاص پوشش میدهد، شبیه به CrisisLex پیشنهاد شده توسط Olteanu.و همکاران [ 92 ].
ارجاع متقابل : نگاهی به جدول 3 و جدول 6، به نظر می رسد که گوگل و فلیکر هر کدام تنها دو مشارکت دارند و هر دو امتیاز بالایی دارند، زیرا این مشارکت های ارجاع شده جغرافیایی هستند. این نگرانی در مورد چگونگی تعریف مفهوم نزدیکی ایجاد می کند. ما استفاده از MBR را انتخاب کردیم، اما با مشارکتهای جهانی در رسانههای اجتماعی، توییتر و اینستاگرام، این ممکن است ارزش کمی داشته باشد. بهعلاوه، اگر دادههای کمی از جریان رسانههای اجتماعی انتخاب شده به دست آمده باشد، جعبههای مرزی ممکن است به طور بالقوه بسیار کوچک باشند (در مورد ما Flickr و Google Plus)، یا در یک مکان جغرافیایی متفاوت از مکان رویداد. با کمال تعجب، و با توجه به جعبه های محدود گوگل و فلیکر کوچک، ما هنوز به نتایج “معقول” رسیدیم. با این حال، ما فکر میکنیم که این متریک را میتوان با یک متریک مبتنی بر چگالی، به عنوان مثال، یک بیضی انحراف استاندارد، 95% MBR (حداقل مستطیل مرزی) بهبود داد یا جایگزین کرد.93 ]).
اعتبار : این معیار نسبتاً ساده است و ما را قادر میسازد تا هر سهم را با همتایانش بسنجیم. با این حال، جالب است که مشاهده کنید که تعداد بسیار کمی از مشارکت ها دارای سطح اعتبار سه یا بالاتر هستند. این نشاندهنده دو چیز است: یا معیارهای اعتبار بیش از حد نیاز دارند، و ممکن است توسعه اعتبار مدنی در چارچوب یک بحران به دلیل اثرات باند واگن [ 94 ] دشوار باشد، یا ساختار شبکه سلسله مراتبی رسانه (به عنوان مثال ، مرکزیت شبکه و اتصال [ 94]). 95 ]) توزیع مساوی تری از مشارکت ها را بین سطوح اعتبار اجازه نمی دهد. مشکلی که ما مشاهده کردیم، مربوط به محاسبه نمره کیفیت کل، این است که حداکثر امتیازات اعتبار (به عنوان مثال، نه سطوح) برای زیرمجموعه های داده های مرجع جغرافیایی به 0.25 رسید و نه 1.0 که بسیار مطلوب بود. به طور مشابه، محتوای هرزنامه و مغرضانه چالش دیگری در هنگام تجزیه و تحلیل اعتبار محتوای رسانه های اجتماعی است [ 96 ]. از این رو، نیاز به بررسی روشهای تشخیص هرزنامه و متعاقباً بهبود الگوریتم ارزیابی اعتبار وجود دارد.
مجموع QS; ارزیابی نمرات کیفیت کلی با این مجموعه اولیه از معیارهای (تصفیه نشده) و برای این مطالعه موردی خاص به دلیل مشکلات ذکر شده در بالا تا حدودی دشوار است: به نظر می رسد نزدیکی موقعیتی و ارجاع متقابل اگر یک مجموعه داده جهانی باشد، کاربرد محدودی دارد. . ثانیاً، اطلاعات مکان دارای دو وزن است زیرا ما دو معیار وابسته به مکان داریم، که منجر به این محدودیت میشود که مشارکتهای بدون هیچ مرجع مکانی حداکثر میتوانند امتیاز 3 را داشته باشند. سوم، نمرات اعتبار پایین است، با حداکثر امتیاز 0.25 برای زیرمجموعه مشارکت های مکانی ارجاع داده شده است. بنابراین اساساً اعتبار به حساب نمی آید. این مسئله شایستگی نسبی هر معیار را در رابطه با یک بحران مطرح میکند: آیا باید همه معیارها به طور مساوی وزن شوند، یا برخی از آنها ارزش بیشتری در رابطه با بحران دارند؟ اگر این مورد است،برای مثال، 97 ] لازم است.
در نتیجه این سه موضوع، بالاترین رتبهبندی مشارکتهای توییتر و اینستاگرام همچنان حاوی سر و صدای زیادی است و شاید تنها نیمی از مشارکتها را بتوان آموزنده دانست ( جدول 10 ، جدول 11 ، جدول 12 و جدول 13 را ببینید). علاوه بر این، تعدادی از نتایج گزارش شده ممکن است تحت تأثیر اختلاف در حجم نمونه قرار گیرند. این سؤال را مطرح میکند که 96575 توییتی که QC سطح 2 یا 3 را در مقابل 64 مشارکت Flickr یا Google Plus 935 به دست آوردهاند، چقدر ارزش دارد. برای این منظور، هر معیاری که استفاده میشود باید قبل از اینکه به طور گسترده مورد استفاده قرار گیرد (از لحاظ کیفی) اعتبارسنجی شود. به تصویب رسید.
جدول 10. نمونه ای از مشارکت های توییتر با بالاترین نمره کیفیت کل.
جدول 11. نمونه ای از مشارکت های گوگل پلاس با بالاترین نمره کیفیت کل.
با این حال، پیادهسازی معیارها نشان داده است که خود گردش کار، از بازیابی دادههای VGI تا ارزیابی کیفیت دادهها، طبق طراحی کار میکند. فقط مجموعه معیارهای کیفیت نیاز به اصلاح و آزمایش بیشتر با مجموعه دادههای رویداد مختلف دارد. ما انتظار داریم که رویدادهای اضافی ویژگیهای مکانی و زمانی متفاوتی داشته باشند که ارزیابی و درک بهتر همبستگی متریک و قابلیت استفاده را ممکن میسازد.
جدول 12. نمونه ای از مشارکت های فلیکر * با بالاترین نمره کیفیت کل.
جدول 13. نمونه ای از مشارکت های اینستاگرام * با بالاترین نمره کیفیت کل.
6. نتیجه گیری
در این مقاله، ما یک چارچوب VGI برای کشف و استفاده از محتوای تولید شده توسط کاربر در زمینه مدیریت بلایا معرفی کردیم. ما الزامات کاربردی و معماری را برای توسعه چارچوب در نظر گرفتیم. ما همچنین نشان دادهایم که پیروی از استانداردها و مشخصات باز، پیروی از استراتژی FOSS و استفاده از رویکرد توسعه مبتنی بر خدمات، عوامل کلیدی برای ساخت یک پلتفرم نمونه اولیه بودند. در نتیجه، این پلتفرم قابلیت همکاری را ممکن میسازد و از نظر یکپارچهسازی اجزا برای پلتفرمهای جدید یا موجود مدیریت بلایا انعطافپذیر است. اگرچه این سیستم برای موارد استفاده خاص از تایفون روبی مورد استفاده قرار گرفت، چارچوب پیشنهادی را می توان به راحتی برای پشتیبانی از انواع دیگر حوادث فاجعه منطبق کرد.
نتایج مطالعه موردی در مورد تایفون روبی تفاوت بین مشارکتهای چهار جریان رسانهای را برجسته میکند. این تفاوت ها شامل انواع مختلف رسانه (متن، تصاویر و غیره )، الگوهای مشارکت زمانی متفاوت و اطلاعات اعتبار متفاوت است. با این حال، به دلیل عدم مشارکت جغرافیایی ارجاع شده، هیچ اظهارنظر قطعی نمی توان در مورد تفاوت در الگوهای مشارکت فضایی ارائه داد. برای این نوع رویداد، یک طوفان، اینستاگرام در مقایسه با فلیکر و گوگل پلاس منبع اطلاعاتی امیدوارکننده ای به نظر می رسد. با این حال، با توجه به تفاوتهایی که در بالا ذکر شد، این جریانهای رسانهای به احتمال زیاد باید به شکل مکمل استفاده شوند.
بحث ما در مورد ارزیابی متریک نیز متنوع بوده است و نشان میدهد که نیاز به توسعه الگوریتمها و مدلهای پیچیدهتری برای معیارهای کیفیت برای یک رویداد از نوع طوفان وجود دارد. بنابراین، بررسی بیشتر معیارها به مجموعه دادههای رویداد مختلف برای ارزیابی گزینههای پارامترسازی مدل و استحکام نیاز دارد.
نیاز به ارزیابی مداوم چارچوب و پلت فرم از نظر جنبه های فنی و قابلیت استفاده برای اطمینان از کارایی و اثربخشی پلت فرم در برآوردن نیازهای کاربران در هنگام فاجعه وجود دارد. بهویژه، اگر کمکهای رتبهبندی شده با کیفیت بالا واقعاً برای مدیریت بلایا مفید باشد، باید تأیید شود. این امر تا حدی می تواند با ارزیابی منابع رسمی اطلاعات مانند روزنامه ها یا وب سایت های پاسخگویی به بلایای تحت مدیریت دولت محقق شود. به عنوان مثال، دولت فیلیپین یک وب سایت ( http://www.gov.ph/crisis-response/typhoon-ruby/ ) راه اندازی کرد تا مردم را از طوفان روبی مطلع کند. ما این وظایف را در تحقیقات آینده خود بررسی خواهیم کرد.
محدودیت هایی برای استفاده از پلتفرم پیشنهادی به عنوان ابزاری برای مدیریت بلایا وجود دارد. به عنوان مثال، افرادی که در مناطق دور افتاده و کمتر توسعه یافته زندگی می کنند ممکن است دسترسی محدودی به اینترنت و وب سایت های شبکه های اجتماعی مانند توییتر داشته باشند. علاوه بر این، برخی از وبسایتهای شبکههای اجتماعی مانند توییتر دارای محدودیتهای API هستند، مانند محدودیتهای نرخ API ( https://dev.twitter.com/rest/public/rate-limiting ) یا دانلود دادههای تاریخی محدود (مثلاً API جستجوی توییتر). فهرست شامل 6 تا 9 روز توییت ( https://dev.twitter.com/rest/public/search))، که مانع از دسترسی به داده ها در طول یک رویداد فاجعه می شود. همچنین سانسور اینترنتی، که ممکن است توسط دولتها، سازمانهای خصوصی یا گروهی از مردم برای کنترل آنچه میتوان در اینترنت به آن دسترسی داشت، منتشر کرد یا مشاهده کرد [ 13 ، 98 ، 99 ] اعمال شود، میتواند مانع پذیرش فاجعه مبتنی بر VGI شود. پلتفرم های مدیریتی با این حال، قبل از پرداختن به این موارد خاص، چالش دستیابی به حمایت سیاسی برای ادغام پلت فرم های مدیریت بلایا از پایین به بالا در استراتژی های مدیریت اضطراری وجود دارد. حریم خصوصی، حقوق مالکیت معنوی، و مالکیت داده ها و حق چاپ نمونه هایی از مسائل بحث برانگیز در این زمینه هستند [ 100 ، 101 ]]. برای رسیدگی به این مسائل، سازمانهای دولتی باید چارچوبهای قانونی و سیاستی را که در حال حاضر مدیریت SDI را تسهیل میکنند، مجددا ارزیابی کرده و شاید آنها را تطبیق دهند تا بتوان آنها را برای یکپارچهسازی و مدیریت VGI با دادههای معتبر گسترش داد.
ضمیمه
منابع
- منصوریان، ع. رجبی فرد، ع. Valadan Zoej، MJ; Williamson, I. استفاده از SDI و سیستم مبتنی بر وب برای تسهیل مدیریت بلایا. محاسبه کنید. Geosci. 2006 ، 32 ، 303-315. [ Google Scholar ] [ CrossRef ]
- زلاتانوا، اس. Fabbri، AG Geo-ICT برای مدیریت ریسک و بلایا. در فناوری زمین فضایی و نقش مکان در علم ; Scholten, PHJ, van de Velde, DR, van Manen, N., Eds. Springer: آمستردام، هلند، 2009; صص 239-266. [ Google Scholar ]
- شولز، آ. Paulheim, H. Mashups برای حوزه مدیریت اضطراری. در Semantic Mashups ; Endres-Niggemeyer، B.، Ed. Springer: برلین، آلمان، 2013; ص 237-260. [ Google Scholar ]
- لی، دی. زنگ، ال. چن، ن. شان، جی. لیو، ال. فن، ی. لی، دبلیو. طراحی چارچوبی برای سیستمهای کاهش بلایای ملی چین (CNDRSS). بین المللی جی دیجیت. زمین 2014 ، 7 ، 68-87. [ Google Scholar ] [ CrossRef ]
- Okolloh، O. Ushahidi، یا “شهادت”: ابزارهای وب 2.0 برای جمع سپاری اطلاعات بحران. شرکت کنید. فرا گرفتن. اقدام 2009 ، 59 ، 65-70. [ Google Scholar ]
- زوک، م. گراهام، ام. شلتون، تی. گورمن، اس. داوطلبانه اطلاعات جغرافیایی و جمع سپاری امداد رسانی به بلایا: مطالعه موردی زلزله هائیتی. پزشکی جهانی سیاست سلامت 2010 ، 2 ، 7-33. [ Google Scholar ] [ CrossRef ]
- اسپینسانتی، ال. Ostermann, F. تجزیه و تحلیل خودکار زمینه جغرافیایی برای اطلاعات داوطلبانه. Appl. Geogr. 2013 ، 43 ، 36-44. [ Google Scholar ] [ CrossRef ]
- Goodchild، MF Citizens به عنوان حسگر: دنیای جغرافیای داوطلبانه. ژئوژورنال 2007 ، 69 ، 211-221. [ Google Scholar ] [ CrossRef ]
- دوک، KN; Vu، T.-T. پلتفرمهای منبع باز Ban، Y. Ushahidi و Sahana Eden برای کمک به امدادرسانی در بلایا: اجزاء و قابلیتهای جغرافیایی. در Geoinformation برای تصمیمات آگاهانه ; یادداشت های سخنرانی در اطلاعات جغرافیایی و نقشه برداری. رحمان، AA، Boguslawski، P.، Anton، F.، Said، MN، Omar، KM، Eds. Springer: آمستردام، هلند، 2014; صص 163-174. [ Google Scholar ]
- دیاز، ال. گرانل، سی. هوئرتا، جی. Gould, M. Web 2.0 Broker: یک سرویس مبتنی بر استانداردها برای جستجوی مکانی-زمانی اطلاعات جمع آوری شده. Appl. Geogr. 2012 ، 35 ، 448-459. [ Google Scholar ] [ CrossRef ]
- روشه، اس. پروپک-زیمرمن، ای. Mericskay، B. GeoWeb و مدیریت بحران: مسائل و دیدگاههای اطلاعات جغرافیایی داوطلبانه. جئوژورنال 2013 ، 78 ، 21-40. [ Google Scholar ] [ CrossRef ]
- جیگر، پی تی. اشنایدرمن، بی. Fleischmann، KR; پریس، جی. Qu، Y. فی وو، پی. شبکههای پاسخ جامعه: دولت الکترونیک، شبکههای اجتماعی و مدیریت موثر اضطراری. مخابرات سیاست 2007 ، 31 ، 592-604. [ Google Scholar ] [ CrossRef ]
- هوانگ، سی.-م. چان، ای. Hyder، AA Web 2.0 و شبکه های اجتماعی اینترنتی: ابزار جدیدی برای مدیریت بلایا؟—درس هایی از تایوان. BMC Med. Inf. تصمیم می گیرد. ماک 2010 . [ Google Scholar ] [ CrossRef ]
- انجمن جهانی زیرساخت داده های مکانی کتاب آشپزی زیرساخت داده های مکانی ; انجمن زیرساخت دادههای مکانی جهانی: Orono، ME، ایالات متحده آمریکا، 2009. [ Google Scholar ]
- گرانل، سی. گولد، ام. منسو، Á.M. برنابه، Á.B. زیرساخت های داده های مکانی در کتابچه راهنمای تحقیقات ژئوانفورماتیک ; کریمی، ح.ا.، ویرایش. هرشی: نیویورک، نیویورک، ایالات متحده آمریکا، 2009; صص 36-41. [ Google Scholar ]
- آنونی، ا. برنارد، ال. داگلاس، جی. گرین وود، جی. لایز، آی. لوید، ام. صابور، ز. ساسن، ع.-م. سرانو، جی.-جی. Usländer، T. Orchestra: توسعه یک معماری باز یکپارچه برای برنامه های کاربردی مدیریت ریسک. در اطلاعات جغرافیایی برای مدیریت بلایا ; van Oosterom، PDP، Zlatanova، DS، Fendel، EM، Eds. Springer: برلین، آلمان، 2005; صص 1-17. [ Google Scholar ]
- مولینا، م. Bayarri, S. یک سیستم چند ملیتی مبتنی بر SDI برای تسهیل مدیریت ریسک بلایا در جامعه آند. محاسبه کنید. Geosci. 2011 ، 37 ، 1501-1510. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- جولیانی، جی. Peduzzi, P. The PREVIEW Global Risk Data Platform: یک ژئوپورتال برای ارائه و به اشتراک گذاری داده های جهانی در مورد خطرات طبیعی. نات سیستم خطرات زمین. علمی 2011 ، 11 ، 53-66. [ Google Scholar ] [ CrossRef ]
- ویزر، آ. Zipf، A. سازماندهی وب سرویس خدمات وب OGC برای مدیریت بلایا. در راه حل های ژئوماتیک برای مدیریت بلایا ; Li، APJ، Zlatanova، APS، Fabbri، PAG، Eds. Springer: برلین، آلمان، 2007; صص 239-254. [ Google Scholar ]
- مازتی، پی. ناتیوی، س. آنجلینی، وی. ورلاتو، ام. Fiorucci, P. پلت فرم شبکه ای برای زیرساخت الکترونیکی حفاظت مدنی اروپا: سناریوی استفاده از آتش سوزی های جنگلی. علوم زمین آگاه کردن. 2009 ، 2 ، 53-62. [ Google Scholar ] [ CrossRef ]
- آگوستو، ای. دالماسو، اس. پاسکوالی، پ. Terzo، O. Ithaca سیستم هشدار سیل در سراسر جهان: چارچوب وب. Appl. Geomat. 2011 ، 3 ، 83-89. [ Google Scholar ] [ CrossRef ]
- دی لونگویل، بی. اسمیت، آر.اس. Luraschi، G. “OMG، از اینجا، من می توانم شعله های آتش را ببینم!”: یک مورد استفاده از شبکه های اجتماعی مبتنی بر مکان معدن برای به دست آوردن داده های مکانی-زمانی در مورد آتش سوزی های جنگلی. در مجموعه مقالات کارگاه بین المللی 2009 در مورد شبکه های اجتماعی مبتنی بر مکان، سیاتل، WA، ایالات متحده آمریکا، 4-6 نوامبر 2009.
- دیاز، ال. گرانل، سی. گولد، ام. Huerta, J. مدیریت اطلاعات تولید شده توسط کاربر در زیرساخت های سایبری جغرافیایی. ژنرال آینده. محاسبه کنید. سیستم 2011 ، 27 ، 304-314. [ Google Scholar ] [ CrossRef ]
- Shade، S. دیاز، ال. اوسترمن، اف. اسپینسانتی، ال. لوراشی، جی. کاکس، اس. نونیز، م. De Longueville، B. سنجش وقایع بحران مبتنی بر شهروند: فعال سازی وب حسگر برای اطلاعات جغرافیایی داوطلبانه. Appl. Geomat. 2013 ، 5 ، 3-18. [ Google Scholar ] [ CrossRef ]
- پورعزیزی، من; اشتاینیگر، اس. هانتر، AJS معماری سرویس گرا برای فعال کردن برنامه ریزی مشارکتی: یک پلت فرم برنامه ریزی الکترونیکی. بین المللی جی. جئوگر. Inf. علمی 2015 ، 1-30. [ Google Scholar ] [ CrossRef ]
- فاستر، آی. ژائو، ی. رایکو، آی. لو، اس. محاسبات ابری و محاسبات شبکه ای 360 درجه مقایسه شده است. در مجموعه مقالات کارگاه آموزشی محیط های محاسباتی شبکه ای 2008، آستین، تگزاس، ایالات متحده آمریکا، 16 نوامبر 2008; صص 1-10.
- بجار، ر. Latre، MA; نوگراس-ایسو، جی. مورو مدرانو، روابط عمومی؛ Zarazaga-Soria، FJ یک سبک معماری برای زیرساخت های داده های مکانی. بین المللی جی. جئوگر. Inf. علمی 2009 ، 23 ، 271-294. [ Google Scholar ] [ CrossRef ]
- باگ، جی. گرانل، سی. فونت، O.; هوئرتا، جی. Painho، M. ارزیابی مشارکت عمومی فناوریهای GIS و Web 2.0 در برنامهریزی شهری در Canela، برزیل. شهرها 2010 ، 27 ، 172-181. [ Google Scholar ] [ CrossRef ]
- دی لونگویل، بی. آنونی، ا. Shade، S. استلندر، ن. Whitmore، C. سیستم عصبی زمین دیجیتال برای رویدادهای بحرانی: فعال کردن وب حسگر در زمان واقعی اطلاعات جغرافیایی داوطلبانه. بین المللی جی دیجیت. زمین 2010 ، 3 ، 242-259. [ Google Scholar ] [ CrossRef ]
- McCall, M. آیا GIS مشارکتی می تواند برنامه ریزی در سطح محلی را تقویت کند؟ پیشنهادات برای تمرین بهتر ؛ Universiti Teknologi Malaysia: Johor، مالزی، 2004. [ Google Scholar ]
- لی، ال. Goodchild، MF نقش شبکه های اجتماعی در مدیریت اضطراری: یک دستور کار تحقیقاتی. بین المللی J. Inf. سیستم مدیریت واکنش به بحران 2010 ، 2 ، 48-58. [ Google Scholar ] [ CrossRef ]
- مونی، پی. Corcoran, P. آیا OpenStreetMap نقشی در برنامه های کاربردی زمین دیجیتال دارد؟ بین المللی جی دیجیت. زمین 2014 ، 7 ، 534-553. [ Google Scholar ] [ CrossRef ]
- بوداتوکی، NR; بروس، بی. Nedovic-Budic، Z. مفهوم سازی مجدد نقش کاربر زیرساخت داده های مکانی. ژئوژورنال 2008 ، 72 ، 149-160. [ Google Scholar ] [ CrossRef ]
- جنووز، ای. Roche، S. پتانسیل VGI به عنوان منبعی برای SDIs در زمینه شمال/جنوب. Geomatica 2010 ، 64 ، 439-450. [ Google Scholar ]
- اولسون، JA Data به عنوان یک سرویس: آیا ما در ابرها هستیم؟ J. Map Geogr. Libr 2009 ، 6 ، 76-78. [ Google Scholar ] [ CrossRef ]
- وی دونگ، سی. Qing-zhan، Z. تحقیق در مورد حالت خدمات GIS مبتنی بر SaaS. در مجموعه مقالات دومین کنفرانس بین المللی علوم و مهندسی اطلاعات (ICISE)، هانگژو، چین، 4 تا 6 دسامبر 2010. صص 6812–6814.
- کاسترونوا، AM; گودال، جی ال. مدل Elag، MM به عنوان خدمات وب با استفاده از استاندارد خدمات پردازش وب کنسرسیوم فضایی باز (OGC) (WPS). محیط زیست مدل. نرم افزار 2013 ، 41 ، 72-83. [ Google Scholar ] [ CrossRef ]
- شاهین، ک. Gumusay، MU خدمات وب مبتنی بر معماری سرویس گرا (SOA) برای سیستم های اطلاعات جغرافیایی. در مجموعه مقالات بیست و یکمین آرشیو بین المللی ISPRS فتوگرامتری، سنجش از دور، و علوم اطلاعات فضایی، پکن، چین، 3 تا 11 ژوئیه 2008.
- گرانل، سی. دیاز، ال. Gould، M. برنامه های کاربردی سرویس گرا برای مدل های محیطی: خدمات مکانی قابل استفاده مجدد. محیط زیست مدل. نرم افزار 2010 ، 25 ، 182-198. [ Google Scholar ] [ CrossRef ]
- هاسن، آر. اسنوک، م. Lemahieu، W. Poelmans, S. در مورد تعریف دانه بندی خدمات و تأثیر معماری آن. در مهندسی سیستم های اطلاعات پیشرفته ; یادداشت های سخنرانی در علوم کامپیوتر; Bellahsène, Z., Léonard, M., Eds. Springer: برلین، آلمان، 2008; جلد 5074، صص 375–389. [ Google Scholar ]
- فریس-کریستنسن، آ. لوچی، آر. لوتز، ام. Ostländer، N. معماری های زنجیره ای خدمات برای برنامه های کاربردی که پردازش اطلاعات جغرافیایی توزیع شده را اجرا می کنند. بین المللی جی. جئوگر. Inf. علمی 2009 ، 23 ، 561-580. [ Google Scholar ] [ CrossRef ]
- آرکائینی، پ. بوردوگنا، جی. Sterlacchini، S. جستجوی انعطاف پذیر اطلاعات جغرافیایی داوطلبانه برای مدیریت ریسک . آتلانتیس پرس: پاریس، فرانسه، 2013. [ Google Scholar ]
- برین، اس. Page, L. آناتومی یک موتور جستجوی وب فرامتنی در مقیاس بزرگ. محاسبه کنید. شبکه سیستم ISDN 1998 ، 30 ، 107-117. [ Google Scholar ] [ CrossRef ]
- Mandl, T. پیاده سازی و ارزیابی یک موتور جستجوی مبتنی بر کیفیت. در مجموعه مقالات هفدهمین کنفرانس ابرمتن و ابررسانه (HYPERTEXT’06)، اودنسه، دانمارک، 22 تا 25 اوت 2006.
- پوزر، ک. Dransch، D. اطلاعات جغرافیایی داوطلبانه برای مدیریت بلایا با کاربرد برای برآورد سریع خسارت سیل. Geomatica 2010 ، 64 ، 89-98. [ Google Scholar ]
- Flanagin، AJ; Metzger, MJ اعتبار اطلاعات جغرافیایی داوطلبانه. جئوژورنال 2008 ، 72 ، 137-148. [ Google Scholar ] [ CrossRef ]
- فن، اچ. Zipf، A.; فو، س. Neis, P. ارزیابی کیفیت برای ایجاد داده های ردپایی در OpenStreetMap. بین المللی جی. جئوگر. Inf. علمی 2014 ، 28 ، 700-719. [ Google Scholar ] [ CrossRef ]
- بیشر، م. Mantelas، L. یک مدل اعتماد و شهرت برای فیلتر کردن و طبقه بندی دانش در مورد رشد شهری. جئوژورنال 2008 ، 72 ، 229-237. [ Google Scholar ] [ CrossRef ]
- بیشر، م. مدل های اعتماد و شهرت کوهن، دبلیو برای ارزیابی کیفیت مشاهدات حسگر انسانی. در نظریه اطلاعات مکانی ; یادداشت های سخنرانی در علوم کامپیوتر; Tenbrink, T., Stell, J., Galton, A., Wood, Z., Eds. Springer: آمستردام، هلند، 2013; صص 53-73. [ Google Scholar ]
- Goodchild، MF; Li, L. اطمینان از کیفیت اطلاعات جغرافیایی داوطلبانه. تف کردن آمار 2012 ، 1 ، 110-120. [ Google Scholar ] [ CrossRef ]
- بدنار، ت. Salathé، M. اعتبارسنجی مدلهای تشخیص بیماری با استفاده از توییتر. در مجموعه مقالات بیست و دومین کنفرانس بین المللی در مورد همنشین وب جهانی (WWW’13 Companion)، ریودوژانیرو، برزیل، 13 تا 17 مه 2013.
- آچرکار، اچ. گانده، ا. لازاروس، ر. یو، S.-H. لیو، بی. پیشبینی روند آنفولانزا با استفاده از دادههای توییتر. در مجموعه مقالات کنفرانس IEEE 2011 در کارگاه های آموزشی ارتباطات کامپیوتری (INFOCOM WKSHPS)، شانگهای، چین، 10-15 آوریل 2011.
- Ostermann، FO; Spinsanti، L. یک گردش کار مفهومی برای ارزیابی خودکار کیفیت اطلاعات جغرافیایی داوطلبانه برای مدیریت بحران. در مجموعه مقالات کنفرانس AGILE 2011، اوترخت، هلند، 7 تا 13 اوت 2011.
- خدمات نقشه وب در دسترس آنلاین: portal.opengeospatial.org/files/?artifact_id=5316 (در 1 فوریه 2014 قابل دسترسی است).
- مشخصات پیاده سازی سرویس ویژگی های وب. در دسترس به صورت آنلاین: https://portal.opengeospatial.org/files/?artifact_id=8339 (در 16 ژوئیه 2014 قابل دسترسی است).
- ایوانز، سرویس پوشش وب JD (WCS). در دسترس آنلاین: portal.opengeospatial.org/files/?artifact_id=3837 (در 3 آوریل 2014 قابل دسترسی است).
- بوتس، ام. پرسیوال، جی. رید، سی. فعال سازی وب حسگر دیویدسون، J. OGC : نمای کلی و معماری سطح بالا. در شبکه های ژئوسنسور ؛ Nittel, S., Labrinidis, A., Stefanidis, A., Eds. Springer: برلین، آلمان، 2008; جلد 4540، صص 175–190. [ Google Scholar ]
- برورینگ، آ. جیرکا، س. ریکه، ام. Pross, B. OGC® Testbed-10 CCI VGI Engineering Report 2014 ; کنسرسیوم فضایی باز: نیویورک، نیویورک، ایالات متحده آمریکا.
- الوود، اس. اطلاعات جغرافیایی داوطلبانه: مسیرهای تحقیقاتی آینده با انگیزه GIS انتقادی، مشارکتی و فمینیستی. جئوژورنال 2008 ، 72 ، 173-183. [ Google Scholar ] [ CrossRef ]
- کورنفورد، دی. ویلیامز، ام. Bastin, L. Uncertainty Enabled Sensor Observation Services ; مجمع عمومی EGU: وین، اتریش، 2010; جلد 12، ص. 9082. [ Google Scholar ]
- دوراجو، ع. کانکل، آر. سورگ، ج. بوگنا، اچ. Vereecken، H. فعال کردن کنترل کیفیت مشاهدات وب حسگر. در مجموعه مقالات سومین کنفرانس بین المللی شبکه های حسگر (SENSORNETS 2014)، لیسبون، پرتغال، 7 تا 9 ژانویه 2014.
- ویلیامز، ام. کورنفورد، دی. باستین، ال. Pebesma، E. زبان نشانه گذاری عدم قطعیت (UnCertML). در دسترس آنلاین: https://portal.opengeospatial.org/files/?artifact_id=33234. (دسترسی در 20 مه 2015).
- بارباچی، MR; الیسون، RJ; Lattanze، AJ; استافورد، JA; Weinstock، CB; چوب، WG کیفیت ویژگی کارگاه آموزشی (QAWs) ; موسسه مهندسی نرم افزار، دانشگاه کارنگی ملون: پیتسبورگ، پنسیلوانیا، 2003. [ Google Scholar ]
- کازمان، ر. Bass, L. دسته بندی اهداف تجاری برای معماری نرم افزار ; موسسه مهندسی نرم افزار، دانشگاه کارنگی ملون: پیتسبورگ، پنسیلوانیا، 2005. [ Google Scholar ]
- کازمان، ر. گاگلیاردی، م. Wood, W. تجزیه و تحلیل معماری نرم افزار مقیاس پذیر. جی. سیست. نرم افزار 2012 ، 85 ، 1511-1519. [ Google Scholar ] [ CrossRef ]
- اسپینسانتی، ال. Ostermann, F. اعتبارسنجی و ارزیابی ارتباط اطلاعات جغرافیایی داوطلبانه در مورد آتش سوزی جنگل. در مجموعه مقالات دومین کارگاه بین المللی اعتبار سنجی محصولات اطلاعات جغرافیایی برای مدیریت بحران، ایسپرا، ایتالیا، 11 تا 13 اکتبر 2010.
- بیمونته، اس. بوسلما، او. ماچابرت، او. سلامی، س. یک رویکرد جدید فضایی OLAP برای تجزیه و تحلیل اطلاعات جغرافیایی داوطلبانه. محاسبه کنید. محیط زیست سیستم شهری 2014 ، 48 ، 111-123. [ Google Scholar ] [ CrossRef ]
- میک، اس. جکسون، ام جی؛ Leibovici، DG چارچوبی انعطافپذیر برای ارزیابی کیفیت دادههای جمعسپاری ؛ AGILE Digital Editions: Castellón، اسپانیا، 2014. [ Google Scholar ]
- نبرت، دی. وایتساید، ا. Vretanos، P. مشخصات خدمات کاتالوگ OpenGIS®. در دسترس آنلاین: portal.opengeospatial.org/files/?artifact_id=20555 (در 21 فوریه 2014 دسترسی پیدا کرد).
- ماسو، جی. پوماکیس، ک. جولیا، N. استاندارد اجرای خدمات کاشی نقشه وب OpenGIS®. در دسترس آنلاین: http://www.opengeospatial.org/standards/wmts (در 1 ژوئن 2014 قابل دسترسی است).
- Schut, P. OpenGIS Web Processing Service. در دسترس آنلاین: portal.opengeospatial.org/files/?artifact_id=28772&version=2 (در تاریخ 10 اوت 2014 قابل دسترسی است).
- Na، A. کشیش، خدمات مشاهده سنسور M. در دسترس به صورت آنلاین: http://portal.opengeospatial.org/files/?artifact_id=12846 (در 2 ژوئیه 2014 قابل دسترسی است).
- مشاهدات و اندازهگیریها – پیادهسازی XML. در دسترس آنلاین: http://portal.opengeospatial.org/files/?artifact_id=41510 (در 11 سپتامبر 2014 قابل دسترسی است).
- Gonçalves، P. OGC® OpenSearch Geo and Time Extensions. در دسترس آنلاین: https://portal.opengeospatial.org/files/?artifact_id=56866 (در 26 آوریل 2014 قابل دسترسی است).
- الیس، آر. گری، ام. هزاران نفر به دلیل طوفان هاگوپیت فیلیپین را تخلیه کردند. در دسترس آنلاین: http://www.cnn.com/2014/12/06/world/asia/philippines-typhoon-hagupit-ruby/index.html (دسترسی در 9 فوریه 2015).
- رایس، دی. سوپر تایفون هاگوپیت فیلیپین را هدف گرفته است. در دسترس آنلاین: http://www.usatoday.com/story/weather/2014/12/03/super-typhoon-hagupit-philippines/19849821/ (دسترسی در 9 فوریه 2015).
- Typhoon Hagupit 2014. موجود به صورت آنلاین: http://en.wikipedia.org/w/index.php?title=Typhoon_Hagupit_(2014)&oldid=644324125 (در 27 ژانویه 2015 قابل دسترسی است).
- Pama, A. SitRep شماره 27 دوباره اثرات طوفان “Ruby” (هاگوپیت) ; شورای ملی مدیریت و کاهش خطر بلایا: شهر کوئزون، فیلیپین، 2014. پ. 42. [ Google Scholar ]
- روزنامه رسمی. هشدار طوفان گرمسیری: طوفان استوایی یاقوت سرخ ; دفتر ملی چاپ: شهر کوئزون، فیلیپین، 2014.
- موروگسان، اس. دشپنده، ی. هانسن، اس. Ginige، A. مهندسی وب: یک رشته جدید برای توسعه سیستم های مبتنی بر وب. در مهندسی وب ؛ Murugesan, S., Deshpande, Y., Eds.; Springer: برلین، 2001; صص 3-13. [ Google Scholar ]
- کوریون، پ. سیلوا، سی دی; van de Walle, B. نرم افزار منبع باز برای مدیریت بلایا. اشتراک. ACM 2007 ، 50 ، 61-65. [ Google Scholar ] [ CrossRef ]
- اشتاینیگر، اس. Hunter، AJS نقشه نرم افزار GIS رایگان و منبع باز 2012 – راهنمای تسهیل تحقیق، توسعه و پذیرش. محاسبه کنید. محیط زیست سیستم شهری 2013 ، 39 ، 136-150. [ Google Scholar ] [ CrossRef ]
- دیویلر، آر. Jeansoulin، R. کیفیت داده های فضایی: مفاهیم. در مبانی کیفیت داده های مکانی ; Devillers, R., Jeansoulin, R., Eds. ISTE: دهلی نو، هند، 2006; صص 31-42. [ Google Scholar ]
- گوپتیل، SC; موریسون، JL عناصر کیفیت داده های مکانی ; الزویر: آمستردام، هلند، 2013. [ Google Scholar ]
- ون اورت، پی. کیفیت داده های مکانی: از توصیف تا کاربرد . دانشگاه Wageningen: Wageningen، هلند، 2006. [ Google Scholar ]
- شی، دبلیو. فیشر، پی. Goodchild، MF کیفیت داده های مکانی ; CRC Press: Boca Raton، FL، USA، 2003. [ Google Scholar ]
- هاکلی، ام. اطلاعات جغرافیایی داوطلبانه، تضمین کیفیت. بین المللی دایره Geogr. مردم محیط زمین. تکنولوژی 2015 ، در دست چاپ. [ Google Scholar ]
- کروکس، آ. کرویتورو، آ. استفانیدیس، ا. Radzikowski، J. #زلزله: توییتر به عنوان یک سیستم حسگر توزیع شده. ترانس. GIS 2013 ، 17 ، 124-147. [ Google Scholar ]
- پوروز، آر. جونز، سی. بازیابی اطلاعات جغرافیایی. مشخصات SIGSPATIAL 2011 ، 3 ، 2-4. [ Google Scholar ] [ CrossRef ]
- لی، ام. چن، ایکس. لی، ایکس. ما، بی. ویتانی، PMB معیار تشابه. IEEE Trans. Inf. نظریه 2004 ، 50 ، 3250-3264. [ Google Scholar ] [ CrossRef ]
- چان، CK; واسردانی، م. Winter, S. استفاده از توییتر برای شناسایی نام رویدادهای مرتبط با یک مکان. جی. اسپات. علمی 2014 ، 59 ، 137-155. [ Google Scholar ] [ CrossRef ]
- اولتئانو، ا. کاستیو، سی. دیاز، اف. Vieweg, S. CrisisLex: واژگانی برای جمع آوری و فیلتر کردن ارتباطات میکروبلاگ در بحران ها. در مجموعه مقالات هشتمین کنفرانس بین المللی AAAI در وبلاگ ها و رسانه های اجتماعی، ان آربور، ML، ایالات متحده، 1 تا 4 ژوئن 2014.
- اشتاینیگر، اس. Hunter، AJS یک تخمینگر چگالی هسته مبتنی بر خط برای بازیابی توزیعهای استفاده و محدودههای خانگی از مسیرهای حرکت GPS. Ecol. آگاه کردن. 2013 ، 13 ، 1-8. [ Google Scholar ] [ CrossRef ]
- Moe، WW; Schweidel, DA Online نظرات محصول: بروز، ارزیابی و تکامل. علامت گذاری. علمی 2012 ، 31 ، 372-386. [ Google Scholar ] [ CrossRef ]
- رومرو، دی.ام. میدر، بی. کلینبرگ، جی. تفاوت در مکانیک انتشار اطلاعات در موضوعات: اصطلاحات، هشتگ های سیاسی، و سرایت پیچیده در توییتر. در مجموعه مقالات بیستمین کنفرانس بین المللی وب جهانی، حیدرآباد، هند، 28 مارس تا 1 آوریل 2011.
- گوا، دی. چن، سی. شناسایی کاربران غیر شخصی و هرزنامه در شبکه توییتر دارای برچسب جغرافیایی. ترانس. GIS 2014 ، 18 ، 370-384. [ Google Scholar ] [ CrossRef ]
- ساعتی، TL فرآیند تحلیل سلسله مراتبی ; McGraw-Hill: نیویورک، نیویورک، ایالات متحده آمریکا، 1980. [ Google Scholar ]
- لایتوری، م. Kodrich، K. جامعه پاسخگویی به بلایا آنلاین: افراد به عنوان حسگرهای بلایای بزرگ با استفاده از GIS اینترنتی. Sensors 2008 , 8 , 3037-3055. [ Google Scholar ] [ CrossRef ]
- شانکار، کی. باد، آب و وای فای: روندهای جدید در انفورماتیک جامعه و مدیریت بلایا. Inf. Soc. 2008 ، 24 ، 116-120. [ Google Scholar ] [ CrossRef ]
- راک، ع. کلمن، دی. Nichols, S. مسئولیت حقوقی مربوط به اطلاعات جغرافیایی داوطلبانه مربوط به کانادا است. در زمینه توانمندسازی فضایی دولت، صنعت و شهروندان: دیدگاههای تحقیق و توسعه ؛ رجبی فرد، ع.، کلمن، د.، ویرایش. GSD I Association Press: Needham، MA، ایالات متحده آمریکا، 2012; صص 25-142. [ Google Scholar ]
- هو، اس. رجبی فرد، ع. یادگیری از جمعیت: نقش اطلاعات جغرافیایی داوطلبانه در تحقق جامعه توانمند فضایی. در مجموعه مقالات کنفرانس جهانی GSDI 12: تحقق جوامع توانمند فضایی، سنگاپور، 19 تا 22 اکتبر 2010.
© 2015 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر