

خلاصه
تحقیقات بهعنوان یک شرکت دیجیتال چالشهای جدیدی را ایجاد کرده است که اغلب به آنها پرداخته نشده است تا از تداوم، شفافیت و مسئولیتپذیری اطمینان حاصل شود. یک سوء تفاهم رایج وجود دارد که میتوان در مرحله بعد از چرخه تحقیقاتی را در نظر گرفت یا به او تفویض کرد یا اینکه به دلیل کمبود ابزار کارآمد، بسیار سنگین یا بسیار گران است. این باعث ایجاد شکافی بین عمل تحقیق و نیازهای مراقبتی می شود. ما استدلال میکنیم که اگر متصدیان حمایت جذابی را که مناسب نیازهای پژوهشی است ارائه دهند و اگر محققان به طور مداوم کار خود را بر اساس مفاهیم عمومی به طور مداوم از ابتدا مدیریت کنند، میتوان این شکاف را کاهش داد. یک مطالعه موردی نسبتاً منحصر به فرد درازمدت نشان میدهد که چگونه چنین مفاهیمی به اجرای عملی یک عمل تحقیقاتی به طور عمدی با استفاده از ابزارهای حداقلی برای بایگانی پایدار و مستقل از سال 1989 کمک کردهاند. این مقاله مفاهیم زیربنایی سه فعالیت تحقیقاتی اصلی را ترسیم میکند. (i) مدیریت داده های تحقیق، (2) مدیریت مرجع به عنوان بخشی از انتشارات علمی، و (iii) پیشبرد نظریه ها از طریق مدل سازی و شبیه سازی. این مفاهیم نشان دهنده بهترین روش تحقیق قابل انتقال جهانی است، در حالی که جزئیات فنی آشکارا مستعد تغییر مداوم هستند. ما امیدواریم که محققان را تحریک کند تا تحقیقات را به طور مشابه مدیریت کنند و متصدیان به درک بهتری از چالشهای سرپرستی که عمل تحقیقاتی با آن مواجه است، دست یابند. این مقاله مفاهیم زیربنای سه فعالیت اصلی تحقیقاتی را ترسیم می کند. (i) مدیریت داده های تحقیق، (2) مدیریت مرجع به عنوان بخشی از انتشارات علمی، و (iii) پیشبرد نظریه ها از طریق مدل سازی و شبیه سازی. این مفاهیم نشان دهنده بهترین روش تحقیق قابل انتقال جهانی است، در حالی که جزئیات فنی آشکارا مستعد تغییر مداوم هستند. ما امیدواریم که محققان را تحریک کند تا تحقیقات را به طور مشابه مدیریت کنند و متصدیان به درک بهتری از چالشهای سرپرستی که عمل تحقیقاتی با آن مواجه است، دست یابند. این مقاله مفاهیم زیربنای سه فعالیت اصلی تحقیقاتی را ترسیم می کند. (i) مدیریت داده های تحقیق، (2) مدیریت مرجع به عنوان بخشی از انتشارات علمی، و (iii) پیشبرد نظریه ها از طریق مدل سازی و شبیه سازی. این مفاهیم نشان دهنده بهترین روش تحقیق قابل انتقال جهانی است، در حالی که جزئیات فنی آشکارا مستعد تغییر مداوم هستند. ما امیدواریم که محققان را تحریک کند تا تحقیقات را به طور مشابه مدیریت کنند و متصدیان به درک بهتری از چالشهای سرپرستی که عمل تحقیقاتی با آن مواجه است، دست یابند. در حالی که جزئیات فنی آشکارا مستعد تغییر مداوم هستند. ما امیدواریم که محققان را تحریک کند تا تحقیقات را به طور مشابه مدیریت کنند و متصدیان به درک بهتری از چالشهای سرپرستی که عمل تحقیقاتی با آن مواجه است، دست یابند. در حالی که جزئیات فنی آشکارا مستعد تغییر مداوم هستند. ما امیدواریم که محققان را تحریک کند تا تحقیقات را به طور مشابه مدیریت کنند و متصدیان به درک بهتری از چالشهای سرپرستی که عمل تحقیقاتی با آن مواجه است، دست یابند.
کلید واژه ها:
شکاف سرپرستی ; مدیریت داده های تحقیق ; مدیریت داده های دیجیتال ; حفظ داده ها ؛ مدیریت چرخه عمر داده ; تئوری مدیریت چرخه حیات ; آرشیو کردن بهترین تمرین
1. معرفی
جوامع امروزی انتظار دارند که علم به صورت تجمعی کار کند، به عنوان مثال، [ 1 ، 2 ، 3 ، 4 ]. در حالی که تحقیقات بیشتر و بیشتری با استفاده از ابزارهای دیجیتال انجام می شود و برخی از فعالیت های اصلی آن در حال حاضر به طور کامل دیجیتالی شده است، خطر افزایش اختلاف بین انتظارات جامعه و آنچه محققان و مؤسسات سرپرستی واقعاً انجام می دهند وجود دارد.
ما مدیریت را به عنوان مدیریت هر نوع داده در طول چرخه عمر آن درک می کنیم تا از حفظ ارزش آن در طول زمان و در دسترس بودن آن برای استفاده مجدد اطمینان حاصل کنیم. این دیدگاه چرخه عمر داده به مدیریت چرخه حیات داده ها و سایر رکوردهای اطلاعاتی که توسط آرشیوها استفاده می شود، برمی گردد [ 5 ، 6 ]. این مقاله استدلال می کند که نظارت بر خروجی علمی به طور سنتی سنگ بنای پیشرفت در علم بوده است.
برای هدف این مقاله، مدیریت دادههای پژوهشی شامل تمام فعالیتهایی است که توسط یک فرد یا گروهی از محققان برای سازماندهی، توصیف، ساختار و ذخیره دادههایی که تولید، جمعآوری یا استفاده میکنند انجام میشود. این شامل برخورد با داده هایی است که به طور منظم مورد استفاده قرار می گیرند، به عنوان مثال، در طول عمر یک پروژه تحقیقاتی و تا انتشار نتایج و حفظ آنها برای استفاده مجدد در آینده فراتر از محدوده پروژه اصلی گسترش می یابد. در نتیجه، ما مدیریت ادبیات تحقیق شامل تمام متا داده های مرتبط را به عنوان بخشی جدایی ناپذیر از مدیریت داده های تحقیق در نظر می گیریم، اگرچه این دسته اطلاعات اغلب به عنوان خود داده های تحقیق درک نمی شود. به طور مشابه، در مدیریت داده های پژوهشی، ما تحقیقات تئوری گرا را شامل می شود که اغلب از مدل های پیچیده و شبیه سازی استفاده می کند.
یک محرک مهم برای این مقاله، بازنشستگی قریب الوقوع رئیس گروه بوم شناسی سیستم های زمینی در ETH زوریخ بود. تحقیقات آن گروه، تا حدی، بر روی دادههای صحرایی طولانی مدت و منحصربهفرد حاصل از یک پروژه تحقیقاتی بزرگ در مورد پویایی جمعیت پروانه جوانه کاج اروپایی حلقوی در کوههای آلپ اروپایی بوده است، به عنوان مثال، [7 ] . نمونههای صحرایی غیرزیستی و زیستی با ماهیت ناهمگن قابلتوجهی از سال 1949 با استفاده از فناوریهای پیشرفته مدرن جمعآوری شدهاند [ 8]]. این فناوریها شامل استفاده از امکانات محاسباتی متمرکز و کارتهای پانچ برای ذخیره و وارد کردن دادهها برای هر تحلیلی است که بسیار متفاوت از فناوریهای امروزی است. تجربه به وضوح نشان می دهد که چگونه تغییرات چالش برانگیز در فناوری برای تحقیقات طولانی مدت کلیدی برای درک واقعی بسیاری از پدیده های محیطی، به ویژه در مقیاس بزرگ است، به عنوان مثال، [ 9 ]. هنگامی که مرکز محاسبات رها شد ، یک پایگاه داده پیچیده [ 10 ] شامل داده های واقعی به طور کامل از بین رفت. فقط داده های خام را می توان نجات داد. در نتیجه رویکردهای جدید و قوی تری جستجو شد و این تجربه به شکل قابل توجهی در شکل گیری تکنیک بایگانی شرح داده شده در بخش 2 کمک کرد .
به عنوان مؤسسات متولی، تیم مدیریت دیجیتال کتابخانه ETH و آرشیو دانشگاه ETH زوریخ اخیراً در مورد انتقال پیشنهادی آرشیو فوق به دامنه عمومی همانطور که در شکل 1 نشان داده شده است، بحث کردند . هنگام بازنشستگی اساتید، آرشیو دانشگاه اغلب با الزامات جمع آوری داده ها مواجه می شود. روشی که گروه بومشناسی سیستمهای زمینی آرشیو خود را سازماندهی کرده و در طول سالها از آن مراقبت میکرد، بسیار خوب فکر شده بود. همانطور که در زیر توضیح داده شد، اصولی را که می توان در مدل مرجع OAIS (جوانتر) نیز یافت، به عنوان مثال، [ 11 ] گنجاند و بنابراین منبع امیدوارکننده ای برای انتقال داده ها به آرشیو داده های ETH در آینده و انتشار آنها ارائه کرد.
تفاوت اصلی رویکرد گروه بومشناسی سیستمهای زمینی در مقایسه با رویکردهای گروههای دیگر، استفاده از هیچ سیستم فنی پیچیدهای نیست – هیچکدام وجود ندارد – بلکه این واقعیت است که این گروه در مسئولیت خود به عنوان محقق، آنچه را که برای دستیابی به آن نیاز داشتند، در نظر گرفته است. اصول و قواعدی که باید به این شیوه ها پایبند بوده و آنها را اجرا کنند. اینکه چگونه دقیقاً بایگانی انجام شد و چه تصمیماتی گرفته شد، همه الزامات نظری را برآورده نمی کند و ممکن است به راحتی برای گروه های دیگر مناسب نباشد. با این حال، ما این مورد را به دلایل زیر به عنوان مطالعه موردی انتخاب کردیم: (1) بایگانی به طور قابل توجهی عمر طولانی دارد، در سال 1989 شروع به کار کرد. (ii) ما می خواستیم بدانیم که چگونه آرشیو از بسیاری از تغییرات تکنولوژیک جان سالم به در برد. (iii) ما میخواستیم ارزش انجام ساده کاری را که زمانی که راهحلهای بهتری در دسترس نیست یا نمیتوان از عهده آنها برآمد، ممکن است را بررسی کنیم. (IV) ما همچنین به یک رویکرد مینیمالیستی علاقه مند بودیم، که شایستگی ابتکارات بزرگ گردآوری داده ها یا سودمندی راه حل های جامع سرپرستی یا دیگر آرشیوهای داده پیچیده تر را به چالش می کشد. (v) در نهایت میخواهیم نقشی را که محققان بازی میکنند و اینکه چگونه میتوانند یا باید در غلبه بر چالشهای ناشی از تغییرات تکنولوژیکی که درمان را به طور کلی در معرض خطر قرار میدهند، کمک کنند را بررسی کنیم.
هر چه فعالیتهای علمی دیجیتالیتر شوند، بهطور کلی، مدیریت بیشتر از شکنندگی دادههای دیجیتالی و بهطور خاص از فرسایش نرمافزار رنج میبرد، به عنوان مثال، [ 12 ، 13 ، 14 ، 15 ]. به نظر میرسد که اختلاف ممکن است آنقدر زیاد شود که اصلاً امکان رسیدگی وجود ندارد [ 11 ، 13 ، 16 ، 17 ، 18 ، 19 ]، برای مثال به این دلیل که بسیار پرهزینه است. ما این اختلاف بین عملکرد واقعی تحقیق و نیازهای حفظ محتوای تحقیق را “شکاف مراقبت” می نامیم، همچنین ببینید [ 20]]. ما استدلال میکنیم که این شکاف مراقبتی کاملاً حیاتی است، زیرا نتایج تحقیقات را در معرض خطر زودگذر شدن قرار میدهد، که مطالعه موردی ما آن را برجسته میکند. در دسترس بودن (تداوم) نتایج تحقیقات، با این حال، یک پیش نیاز شناخته شده برای پیشرفت علمی، به اشتراک گذاری داده ها در داخل و بین پروژه ها و به طور کلی علم باز است، به عنوان مثال، [15 ، 21 ] .
شکاف کیوریشن چندین دیدگاه دارد: دیدگاه اول، خود کیوریشن است. نیاز به مدیریت دیجیتال به خوبی پذیرفته شده است [ 22 ] و بسیاری از موسسات مانند دانشگاه ها، آژانس های تامین مالی، و موسسات اختصاصی از بخش خصوصی یا در سطح دولتی تلاش های قابل توجهی را برای آن انجام می دهند، به عنوان مثال، [ 16 ، 23 ، 24 ، 25 ] , 26 , 27 , 28 , 29 , 30 , 31 ]. ابتکارات و مراکز شایستگی مانند مرکز مدیریت دیجیتال ( www.dcc.ac.uk )، DataONE ( www.dataone.org، PANGEA ( 36.www.pangaea.de )، ANDS (سرویس داده ملی استرالیا، ands.org.au ) و تعدادی دیگر با موفقیت برای ایجاد خدمات و بهترین شیوه ها کار کرده اند. با این حال، در بسیاری از مناطق و حوزههای موضوعی، این تلاشها اغلب تنها به اقلیتی از محققان میرسند. علاوه بر این، خود درمان در حال حاضر با ابهامات زیادی مواجه است، نه کمترین به دلیل هزینه های ناشناخته [ 16 ، 17 ، 23 ، 32 ، 33 ، 34 ]، به علاوه چندین مانع و مشکلات دیگر [ 6 ، 18 ، 20 ، 22 ، 35 ،]. همچنین یک تعامل مشکل ساز با Open Data وجود دارد. در رشتههایی با سنت کمی مبادله داده، به سختی انگیزهای برای مدیریت دادههای خود به گونهای وجود دارد که اشتراکگذاری را تسهیل کند، مثلاً [21، 34 ، 37 ] ، چه رسد به اشتراک گذاری فوری. هنگامی که به درستی مدیریت می شود، ممکن است تلاش بیشتری برای اشتراک گذاری داده ها انجام شود یا حتی ممکن است غیرممکن شود.
این منجر به دیدگاه دوم، عمل تحقیق واقعی می شود. چگونه دادهها و گردشهای کاری مدیریت میشوند، بهویژه در رابطه با دیجیتالیسازی، از جمله هر جریان کاری که شامل دادههای دیجیتالی است؟
برخی از محققان و سایر ذینفعان استدلال کرده اند که فقدان ابزارها و زیرساخت های موجود مانع از گزینش داده های دیجیتال می شود [ 26 ]. بسیاری استدلال می کنند که وضعیت بهتر است با آموزش بیشتر و بهتر متخصصان و محققان، تسهیل درک متقابل [ 38 ، 39 ، 40 ، 41 ] بهبود یابد و تعداد کمی نیز خواستار آموزش هدفمند پژوهشگران فردی با توجه به گزینش داده های دیجیتال هستند، به عنوان مثال. ، [ 37 ، 42 ]. برخی از محققان درخواست حمایت بهتری از جمله حمایت از موسسات داخلی خود و همچنین از زیرساخت های ملی یا بین المللی دارند. 19]]. دیگران برای ارائه چنین حمایتی تلاش کردهاند و در حال حاضر جامعه فعالی از کتابداران، بایگانیها و کارشناسان اطلاعاتی مشابه، مشغول تهیه وسایل لازم هستند، به عنوان مثال، [ 16 , 23 , 24 , 25 , 26 , 27 , 28 , 29 , 30 , 31]. اما آیا این برای کاهش شکاف به ظاهر در حال گسترش کافی است؟ با تعداد فزاینده ای از ابتکارات و موسسات درگیر در مدیریت داده های تحقیقاتی، می توان انتظار داشت که این شکاف بسته شود. تجربه ما، از جمله از مطالعه موردی ما، این انتظار را به سوال تبدیل می کند. سرعت توسعه در خود تحقیق در حال حاضر به قدری سریع است که به نظر می رسد اطمینان حاصل نشده باشد.
محققان خود با چالشهایی مواجه هستند، انگیزههای خاصی دارند و در یک محیط خاص کار میکنند. همه این عوامل باید به خوبی درک شوند تا به مسائل مربوط به پردازش داده های دیجیتال به طور مناسب پرداخته شود، به عنوان مثال، [ 21 ، 43]]. علاوه بر این، توجه به این نکته مهم است که چالشها به طور قابل ملاحظهای در بین انواع خروجیهای پژوهشی متفاوت است، به عنوان مثال خروجی ممکن است به شکل دادههای خام یا پردازش شده، یا مدلها در مقابل خروجیهای تعریفشده و بهطور گستردهای با حمایت نهادی مانند انتشارات علمی باشد. مقالات مجلات علمی به روش استاندارد شده با هدف تبدیل شدن به بخشی از رکورد رسمی منتشر شده علم ایجاد می شوند. انتظار می رود آثار منتشر شده در دراز مدت در دسترس باقی بمانند و این در مورد نشریات الکترونیکی نیز صادق است. با این حال، نشریات الکترونیکی با چالشهای اضافی خاصی از نظر کسب، استفاده، به عنوان مثال، [ 35 ، 44 ، 45 ]، و حفظ، به عنوان مثال، [ 46] مواجه هستند.]. با این وجود، ما معتقدیم که مؤسسات حافظه مانند کتابخانهها در موقعیت معقولی هستند که میتوانند نظارت بر محتوای خوب تعریف شده مانند نشریات علمی را بدون در نظر گرفتن شکل آنها تضمین کنند، حتی اگر آن را تنها پس از پایان تولید آن به دست آورند.
با این حال، این مورد برای داده های تحقیق و دانش تحقیق، از جمله مدل های بزرگ و پیچیده، که معمولاً به طور رسمی منتشر نمی شوند، صادق نیست. امروزه آنها در بهترین حالت به شکل مواد تکمیلی در دسترس هستند، اما حتی در آن زمان نیز معمولاً از نظر نگهداری آنها مراقبت کمی صورت می گیرد. بسیاری از ناشران هر گونه مسئولیتی را در قبال خوانایی و قابل استفاده بودن مطالب تکمیلی فاش می کنند در حالی که نویسندگان معتقدند آن را ایمن می کنند، تنها به این دلیل که در وب سایت ناشر ذخیره شده است.
برای اشیاء دیجیتالی کمتر رسمی مانند، که اکثریت دادههای تحقیقاتی امروزی را تشکیل میدهند، ما استدلال میکنیم که بین پیشنهادات ارائهشده توسط کارشناسان سرپرستی و آنچه که اکثر محققان در حال حاضر انجام میدهند، اختلاف نظر مهمی وجود دارد . ، که حتی ممکن است در حال گسترش باشد. دلایل زیر احتمالاً به این روند تاسف بار کمک می کنند:
-
مسئله این نیست که آموزشها و ابزارهای موجود از مدیریت دادههای پژوهش پشتیبانی نمیکنند، به عنوان مثال، [ 47 ]، بلکه مسئله این نیست که تا زمانی که آنها راه خود را به محققان پیدا کنند، ممکن است قبلاً به سمت روشهای پیچیدهتر رفته باشند که به ابزارهای دیگری نیاز دارند. بنابراین ممکن است به جای تلاش برای همگام شدن با سرعت تغییرات تکنولوژیک، تمرکز بر مفاهیم بسیار اساسی مستقل از ابزارهای خاص ضروری باشد.
-
متصدیان اغلب درک دقیقی از عملکرد واقعی پژوهش ندارند و در نتیجه خطر نادیده گرفتن جامعه پژوهشی در فعالیت روزانه خود را دارند و بالعکس، برای جلوگیری از موانعی که پس از پایان پروژههای تحقیقاتی دیگر نمیتوان بر آنها فائق آمد، به درک متقابل خوبی نیاز است. ، [ 21 ، 42 ، 43 ].
-
شیوههای پژوهشی به شدت به روشها، سنتها و استانداردهای یک جامعه پژوهشی خاص بستگی دارد، و تأثیر «خارجیها» مانند متصدیان را محدود میکند.
-
محققان با یک محیط رقابتی روبرو هستند و اغلب انگیزه های کمی برای مدیریت داده های تحقیقاتی و سایر فعالیت های تحقیقاتی خود، از جمله همکاری بین محققان، به گونه ای که از درمان حمایت می کند، دارند.
-
مجموع هزینهها (زمان، منابع) مدیریت ممکن است مانع از گزینش دادههای دیجیتال شود و حتی بهشدت زیاد شود.
پاسخهای احتمالی سازمانی به این روندها شامل شروع تلاشها برای به حداقل رساندن هزینه کل گردآوری دادههای دیجیتال از نظر زمان و منابع صرف شده توسط همه درگیر و اصلاح محیطهای تحقیقاتی به سمت افزایش کیفیت دادهها و نتایج پژوهش از نظر «قابلیت درمانپذیری» آنها است. “. با این حال، چنین اصلاحاتی به آهستگی پیشرفت میکنند، بهویژه در مقایسه با نرخهای فعلی که دیجیتالیسازی در حال پیشرفت است.
ما استدلال می کنیم که درک بهتر از مسائل توسط جوامع درگیر می تواند فورا کمک کند. در این مقاله راه حل های عملی آماده ارائه می کنیم. با این حال، آنها مستلزم این هستند که به جای نادیده گرفتن نیازهای مراقبتی به خوبی رسیدگی شود. در اینجا ما از مطالعه موردی خود تجربهای را به دست میآوریم که بیش از سه دهه تلاش مدیریت دادههای تحقیقاتی را شامل میشود، از جمله یک مفهوم ساده بایگانی، همانطور که توسط گروه تحقیقاتی بومشناسی سیستمهای زمینی در ETH زوریخ توسعه و دنبال شد.
در این مقاله، ابتدا آرشیو و سپس مفاهیم اساسی را که توسط آن واحد پژوهشی توسعه و به کار گرفته شده است، با تمرکز بر آن بخشهایی از پژوهش که در هر نوع تحقیق رایج است، از علوم طبیعی گرفته تا علوم اجتماعی و علوم انسانی، تشریح میکنیم. ما فعالیتهای تحقیقاتی زیر را مورد بحث قرار میدهیم که هر کدام در بخش خاص خود مورد بررسی قرار میگیرند: (1) مدیریت دادههای تحقیق، (2) انتشار، از جمله مدیریت مرجع، (iii) مدیریت تئوریها، به ویژه همانطور که در مدلها محصور شدهاند. پس از یک تعریف محدود از داده های تحقیق، ممکن است تعجب آور باشد که همزمان در مورد ادبیات و مدیریت مرجع بحث شود. با این حال، ادبیات و مدیریت مرجع باید به عنوان بخشی جدایی ناپذیر از فرآیند تحقیق در نظر گرفته شود که کیفیت تحقیق را بهبود می بخشد. چالش اینجا کمتر بلند مدت است، بلکه مدیریت کارآمد اعضای یک گروه و پروژه های موازی یا متوالی آنهاست. مفاهیم به شیوه ای گویا و در عین حال با جزئیات کافی ارائه شده اند، به عنوان مثال، با توضیح چگونگی استفاده از ابزارهای معمول در دسترس برای آسان کردن مفاهیم – تا حدی کاملاً پیچیده – برای درک آسان تر. برخی از جزئیات فنی که ممکن است برای برخی از خوانندگان جالب باشد در ضمیمه ها (یکی برای هر فعالیت تحقیقی مورد بحث) آمده است. سپس در مورد برخی از درسهای آموختهشده از تجربیات توصیفشده و معنای آن در وضعیت فعلی شکاف در حال گسترش بحث میکنیم. ما امیدواریم که این امر باعث پیشرفت در همه جوامع درگیر، از جمله محققان، متصدیان و سازندگان ابزار شود. مفاهیم به شیوه ای گویا و در عین حال با جزئیات کافی ارائه شده اند، به عنوان مثال، با توضیح چگونگی استفاده از ابزارهای رایج در دسترس برای آسان کردن مفاهیم – تا حدی کاملاً پیچیده – برای درک آسان تر. برخی از جزئیات فنی که ممکن است برای برخی از خوانندگان جالب باشد در ضمیمه ها (یکی برای هر فعالیت تحقیقی مورد بحث) آمده است. سپس در مورد برخی از درسهای آموختهشده از تجربیات توصیفشده و معنای آن در وضعیت فعلی شکاف در حال گسترش بحث میکنیم. ما امیدواریم که این امر باعث پیشرفت در همه جوامع درگیر، از جمله محققان، متصدیان و سازندگان ابزار شود. مفاهیم به شیوه ای گویا و در عین حال با جزئیات کافی ارائه شده اند، به عنوان مثال، با توضیح چگونگی استفاده از ابزارهای رایج در دسترس برای آسان کردن مفاهیم – تا حدی کاملاً پیچیده – برای درک آسان تر. برخی از جزئیات فنی که ممکن است برای برخی از خوانندگان جالب باشد در ضمیمه ها (یکی برای هر فعالیت تحقیقی مورد بحث) آمده است. سپس درباره برخی از درسهای آموختهشده از تجربیات توصیفشده و معنای آن در وضعیت فعلی شکاف در حال گسترش بحث میکنیم. ما امیدواریم که این امر باعث پیشرفت در همه جوامع درگیر، از جمله محققان، متصدیان و سازندگان ابزار شود. برخی از جزئیات فنی که ممکن است برای برخی از خوانندگان جالب باشد در ضمیمه ها (یکی برای هر فعالیت تحقیقی مورد بحث) آمده است. سپس درباره برخی از درسهای آموختهشده از تجربیات توصیفشده و معنای آن در وضعیت فعلی شکاف در حال گسترش بحث میکنیم. ما امیدواریم که این امر باعث پیشرفت در همه جوامع درگیر، از جمله محققان، متصدیان و سازندگان ابزار شود. برخی از جزئیات فنی که ممکن است برای برخی از خوانندگان جالب باشد در ضمیمه ها (یکی برای هر فعالیت تحقیقی مورد بحث) آمده است. سپس در مورد برخی از درسهای آموختهشده از تجربیات توصیفشده و معنای آن در وضعیت فعلی شکاف در حال گسترش بحث میکنیم. ما امیدواریم که این امر باعث پیشرفت در همه جوامع درگیر، از جمله محققان، متصدیان و سازندگان ابزار شود.
2. مفهوم آرشیو عمدی مینیمالیست
برای چندین سال، مقررات ETH زوریخ تصریح کرده است که تمام دادهها و مدلهای ایجاد شده در حین استخدام در ETH زوریخ متعلق به مؤسسه است و نه به نویسندگان فردی، به استثنای حق غیرقابل مذاکره آنها به عنوان خالق. سیاست های تحقیقاتی ETH زوریخ همچنین بیان می کند که تمام تحقیقات باید قابل ردیابی باشند تا از شفافیت کامل و انجام صحیح اطمینان حاصل شود. بنابراین مدتی است که بایگانی برای هر محقق شاغل در ETH زوریخ یک وظیفه بوده است. با این حال، سیاستها این را به محققین اصلی واگذار میکنند که الزامات را بر اساس رویه رایج در حوزه خود تعریف کنند و با وسایلی که مناسب میدانند به آنها رسیدگی کنند. این منجر به استفاده از طیف گسترده ای از رویکردها، معمولاً در سطح گروه های تحقیقاتی می شود. اگرچه هیچ نمای کلی قابل اعتماد یا به روزی از این راه حل ها وجود ندارد، تجربه نویسندگانی که در کتابخانه ETH کار میکنند، نشان میدهد که صرفاً ذخیرهسازی ساختارهای پوشه بدون نظر یا تصاویر دیسک غیرمعمول نیست، بهویژه زمانی که دادهها به عنوان بخشی از تحقیقات بلندمدت در نظر گرفته نمیشوند. راهحلهای پیچیدهتری نیز وجود دارد، اما آنها قاعده نیستند و مدیریت آنها در طول نسلهای دانشجوی دکترا میتواند یک چالش باشد. گرچه قبلاً در سال 1988 تشکیل شده بود و بنابراین احتمالاً قبل از اجرایی شدن بیشتر الزامات ذکر شده در بالا، گروه بومشناسی سیستمهای زمینی با چالشهای خاصی در مدیریت تحقیقات خود مواجه بود (همچنین رجوع کنید به راهحلهای پیچیدهتری نیز وجود دارد، اما آنها قانون نیستند و مدیریت آنها بر نسلهای دانشجویان دکترا میتواند چالشبرانگیز باشد. گرچه قبلاً در سال 1988 تشکیل شده بود و بنابراین احتمالاً قبل از اجرایی شدن بیشتر الزامات ذکر شده در بالا، گروه بومشناسی سیستمهای زمینی با چالشهای خاصی در مدیریت تحقیقات خود مواجه بود (همچنین رجوع کنید به راهحلهای پیچیدهتری نیز وجود دارد، اما آنها قانون نیستند و مدیریت آنها بر نسلهای دانشجویان دکترا میتواند چالشبرانگیز باشد. گرچه قبلاً در سال 1988 تشکیل شده بود و بنابراین احتمالاً قبل از اجرایی شدن بیشتر الزامات ذکر شده در بالا، گروه بومشناسی سیستمهای زمینی با چالشهای خاصی در مدیریت تحقیقات خود مواجه بود (همچنین رجوع کنید بهبخش 1 ).
تحقیقات بین رشته ای آن به شدت به مدل های شبیه سازی پیچیده و منابع داده متنوع بستگی داشت. تجارب قبلی رهبر از پیشگامی در این زمینه در دهه 1970 با استفاده از امکانات محاسباتی متمرکز، نیاز به مدیریت قوی داده های تحقیقاتی را نشان داد که بتواند به آرامی از انتقال سریع فناوری های اطلاعاتی تجربه شده در دهه 1980 جان سالم به در ببرد. به عنوان مثال، [ 48 ].
فوریترین نیاز به مدیریت دادهها از این واقعیت ناشی میشد که این گروه تحقیقات میدانی را دنبال کرد، به عنوان مثال ، پروژه پروانه جوانه کاج اروپایی را ادامه داد، که با اندازهگیریهای میدانی گسترده در امتداد کل کوههای آلپ اروپایی در سال 1949 آغاز شد [ 7 ، 8 ]. از همان ابتدا، این پروژه به طور مداوم به دنبال استفاده از مدرن ترین فن آوری های آن زمان، از جمله محاسبات بود. در طول تحقیق، داده های جمع آوری شده در بسیاری از رسانه ها از جمله کارت های پانچ، نوار کاغذی، نوارهای قرقره مغناطیسی و غیره ذخیره شدند.امکانات محاسباتی و ذخیره سازی هنوز در دهه 1970 و اوایل دهه 1980 بسیار محدود بود. با این وجود، یکی از نویسندگان، همراه با همکاران و متخصصان پایگاه داده، یک پایگاه داده پیشرفته در اواخر دهه 1970 برای نگهداری انواع داده های تحقیقاتی پروانه غنچه کاج اروپایی از مزرعه و آزمایشگاه ایجاد کردند (LAWIDAT as یک پایگاه داده DDLDML-INFOSYS، [ 8 ، 10 ]). هدف اطمینان از ذخیره طولانی مدت تمام داده ها و ورود مداوم داده ها به محض جمع آوری نمونه ها بود. همچنین با هدف بهبود کیفیت داده ها از نظر سازگاری، بررسی خطای فوری، و ورود متا داده ها، به منظور دسترسی آسان به داده ها برای تجزیه و تحلیل و مدل سازی برای همه محققان درگیر، و امکان تجزیه و تحلیل داده ها جامع تر بود.
با این حال، این راه حل پایگاه داده از نظر نیاز به نیروی انسانی آن چندان پایدار نبود. زمانی که مرکز محاسبات ETH زوریخ در اواخر دهه 1980 متروک شد، انتقال آن سیستم پایگاه داده به یک میزبان مدرن بسیار پرهزینه شده بود. فرسایش نرم افزار همچنین بازیابی همه داده ها را به صورت منظم غیرممکن کرده بود و داده های گرانبها عمدتاً فقط در شکل خام خود قابل نجات هستند.
این تجربه در تصمیم گیری برای جستجوی یک سیستم جدید که عمدا حداقلی بود، در عین حال که اقتصاد و پایداری را تضمین می کرد، تأثیر گذاشت. رویکرد به حداقل رساندن وابستگیها به فناوریهای پیچیدهای بود که نیاز به تعمیر و نگهداری پرهزینه دارند و در عین حال دادهها را بر اساس برخی از اصول بنیادی مدیریت میکردند که یک سیستم قابل مقایسه با عملکردهای یک سیستم پایگاه داده را تشکیل میدهند.
آرشیو اکولوژی سیستم های حاصل در سال 1990 بر اساس مفهوم زیر ساخته شد.
-
خودکنترلی هدف اصلی اطمینان از استفاده طولانی مدت از داده ها برای تحقیقاتی بود که طی دهه ها انجام شده است. بایگانی همچنین نیاز به مستقل بودن داشت، یعنی نه تنها دادههای مشاهدهای و اندازهگیری (دادههای تحقیق به معنای محدود)، بلکه همه نرمافزارهای درگیر مانند مدلها، برنامهها و سیستمهای عامل بایگانی شدند. حتی سخت افزار در مواقع لزوم حفظ می شد. با محدود کردن دسترسی به آرشیو برای گروه تحقیقاتی، از مسائل مربوط به کپی رایت در تضاد با خودکنترلی اجتناب شد.
-
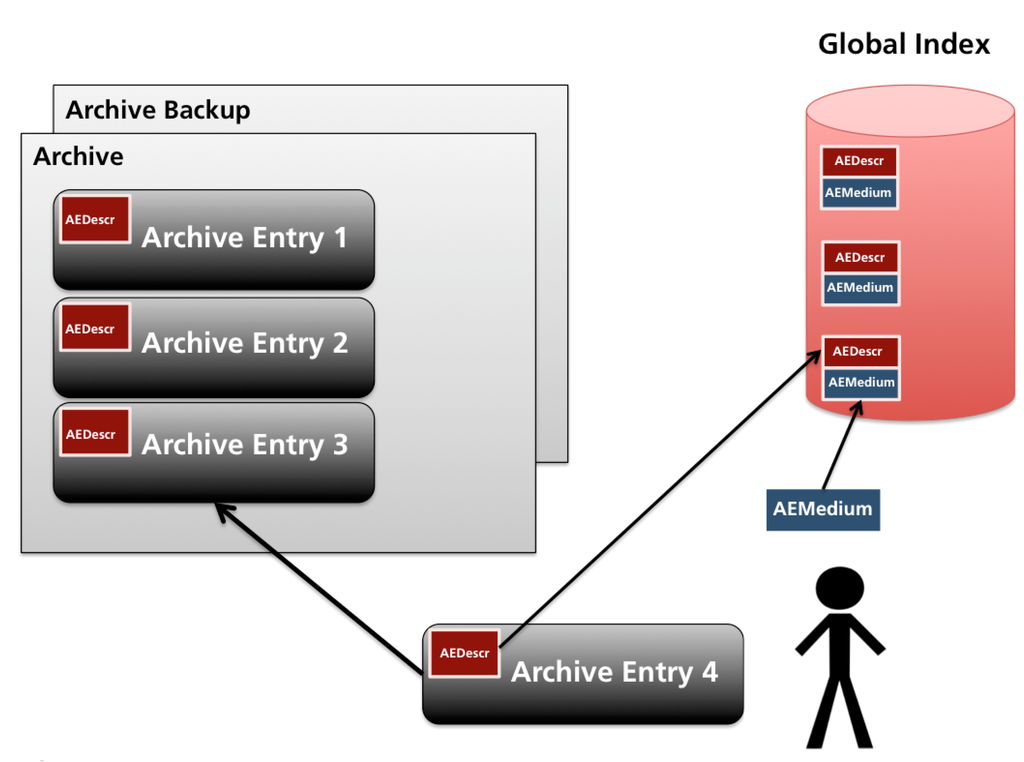
ورودیهای بایگانی در پایان هر پروژه یا یک مرحله پروژه کاملاً تعریف شده، باید یک ورودی بایگانی ایجاد میشد ( شکل 1 ، AEDescr). یک پروژه تحقیقاتی تنها پس از تکمیل آخرین ورودی آرشیو آن، واقعاً پایان یافته در نظر گرفته شد. هر ورودی با یک توضیح همراه است و با عنوان منحصر به فرد جهانی شناسایی می شود و بخشی از آرشیو را تشکیل می دهد. بنابراین، همه متا دادههای بایگانی میتوانند در هر زمان از بایگانی بازسازی شوند، و همچنین به خودکنترلی بایگانی کمک میکند.
-
داده های متا متا داده ها به بخش توصیف کننده و بخش رسانه تقسیم شدند ( شکل 1 ، AEDescr در مقابل AEMedium؛ نمونه های گویا در ضمیمه A.1 ، شکل A1 در مقابل شکل A2) ، جایی که دومی ها خارج از بایگانی نگهداری می شدند تا در طول تعمیر و نگهداری منظم به روز شوند، به عنوان مثال، زیرا رسانه های ذخیره سازی قدیمی می شوند و نیاز به کپی دارند. ورودیهای بایگانی فقط اضافه شدند و به هیچ وجه اجازه تغییر نداشتند، صرف نظر از اینکه آیا رسانه ذخیرهسازی اصولاً اجازه بازنویسی یا حذف را میدهد. به روز رسانی یک ورودی بایگانی باید با بایگانی مجدد نسخه به روز شده انجام شود. در نهایت از نرم افزار پایگاه داده به صورت هدفمند استفاده نشد. تمام این انتخابهای طراحی برای به حداقل رساندن نگهداری بایگانی انجام شد.
-
فرمت ها همه متا داده ها فقط در فایل های متنی ساده کدگذاری شده ASCII ذخیره می شدند، در حالی که داده های واقعی معمولاً در قالب های اصلی بایگانی می شدند. با این حال، بیشتر بخشهای حیاتی، به عنوان مثال، متن پایاننامه، بهطور اضافی بهعنوان rtf، بهعلاوه فایلهای متنی، یا صفحهگستردههای حاوی دادههای گرانبها، دوباره بهصورت اضافی، مانند SYLK، بهعلاوه فایلهای متنی، بایگانی شدند (برای جزئیات به پیوست A.1 مراجعه کنید ) .
-
رسانه ذخیرهسازی دسترسی به ورودیهای آرشیو منفرد به سیستم فایل در حال استفاده بستگی دارد که بسته به رسانه ذخیرهسازی ممکن است از استانداردها پیروی کند یا نه. به عنوان مثال، دیسک های مغناطیسی-اپتیکال، که به دلیل عمر طولانی مورد انتظارشان 50 سال مورد علاقه بودند، به طور عملی با پلت فرم کامپیوتری مورد استفاده در آن زمان قالب بندی شدند، که احتمالاً نیاز به نگهداری بایگانی در مقطعی از زمان با انتقال ورودی های تحت تأثیر به رسانه های جدید دارند. سی دی ها یا دی وی دی ها بر اساس استانداردهای ISO رایت شدند.
-
دسترسی و استفاده برای تسهیل بازیابی، یک فهرست جهانی ( شکل 1 ، استوانه قرمز)، به عنوان مثال ، مجموعه ای جهانی از توضیحات ورودی بایگانی، به طور اضافی در خارج از بایگانی بر روی یک سرور فایل مرکزی ذخیره شد که هر محققی می توانست به آن دسترسی داشته باشد. در این فایل متنی ASCII، تمام توضیحات ورودی بایگانی، که با توضیحات رسانههای آنها گسترش یافتهاند، به ترتیب زمانی جمعآوری شدهاند. جستجوی یک ورودی آرشیو خاص به قابلیت های جستجوی یک ویرایشگر متن یا یک ابزار خط فرمان مانند grep بستگی دارد . از آنجایی که نقش اصلی بایگانی بومشناسی سیستمها فعال کردن استفاده داخلی از دادهها برای اهداف تحقیقاتی بود، دسترسی فقط به اعضای تیم تحقیقاتی محدود شد.
جزئیات بیشتر در مورد ویژگیهای خاص این بایگانی، از جمله نمونههایی از متا دادهها، گردشهای کاری برای آمادهسازی مدخلهای بایگانی بهعلاوه قوانین استفاده شده برای دسترسی و نگهداری، در پیوست A.1 موجود است .
3. مدیریت داده های تحقیق
تمام مدیریت داده های تحقیقاتی توسط خود محققین در طول یک پروژه تحقیقاتی را می توان به عنوان مراحل یک پیوستار با توجه به حفظ و نگهداری، همانطور که توسط Treloar و Harboe-Ree [ 49 ] بحث شده و در شکل 2 نشان داده شده است، درک کرد .
اینکه چگونه می توان داده ها را در طول زمان حفظ کرد و آیا می توان از آنها دوباره استفاده کرد تا حد زیادی به اقدامات انجام شده در زمان تولید داده بستگی دارد. این وابستگی در مواردی که سرپرستی به مؤسسات تخصصی واگذار میشود، که اغلب فقط در «انتهای خط لوله» تولید دادهها وارد عمل میشوند، آشکارتر میشود. جای تعجب نیست که تأثیر چنین نهادهایی نسبتاً محدود است. در بهترین حالت میتوان از طریق سیاستها، دستورالعملها و آموزش، تأثیر مستقیم کمتری توسط متصدیان به دست آورد. مسائلی که مرتباً با آن مواجه میشوید مربوط به مفقود شدن دادههای متا و اسناد زمینه، اطلاعات از دست رفته در قالبهای فایل (ویژگیها، وابستگیها، نرمافزارهای مرتبط)، فایلهای داده از دست رفته یا خراب، و اطلاعات گمشده یا نامشخص در مورد جنبههای قانونی (حق دسترسی و استفاده از دادهها، و همچنین). به عنوان حقوق شخص ثالث)، به عنوان مثال،13 ، 26 ].
از آنجایی که معمولاً بین شروع تولید یا جمعآوری دادهها و تصمیمگیری برای انتشار و حفظ دادهها یک فاصله زمانی چند ساله (یا حتی دههها) وجود دارد، این خطر وجود دارد که این مسائل در زمان ارائه اطلاعات توجه لازم را دریافت نکنند. شکاف ها هنوز هم می توانند به راحتی بسته شوند.
با این حال، اطلاعات مورد نیاز برای شناسایی، بازیابی، تفسیر و استفاده از دادهها، البته برای هر بررسی معنادار بسیار مهم است. اطلاعاتی که باید جمع آوری شود در حالی که شناسایی و بازیابی هنوز امکان پذیر است، شامل اطلاعات مربوط به وابستگی ها و ویژگی های فنی، توصیف رویه ها و ابزارها، اطلاعات قانونی در مواردی که استفاده محدود است، و مستندات کامل زمینه علمی، به ویژه نظریه ها، مدل ها و مدل های اساسی است. ، الگوریتم ها و انتشارات. هر چند این ممکن است پیش پا افتاده باشد، تجربه ما نشان می دهد که موارد زیر اغلب فراموش می شوند: بیشتر این اطلاعات را فقط خود محققان می توانند ارائه دهند، به ویژه هر اطلاعاتی که برای تسهیل استفاده مجدد علمی از داده ها در آینده مورد نیاز است. روابط ممکن است کاملا نامتقارن باشند، به عنوان مثال، قانون 5 از [42 ]، برای مثال، در حالی که یک محقق ممکن است رابطه بین یک نشریه علمی و دادههای زیربنایی را واضح و ایمن بداند، از زمان انتشار، تجربه ما نشان میدهد که در طول یک بررسی دیرهنگام، اغلب غیرممکن است که آن دادهها را به انتشاراتی که آن منتشر شده است، متصل کنیم. مورد استفاده قرار گرفت، مگر اینکه محقق ارجاع صریح به دادهها و همه انتشارات مرتبط اضافه کرده باشد (این رابطه n:n به ندرت به درستی مدیریت میشود، مگر اینکه جنبههای مراقبت از همان ابتدا در نظر گرفته شود و نظارت شود).
چند اصل برای مدیریت مجموعه داده ها نه تنها توسط متصدیان، بلکه توسط محققان نیز باید رعایت شود.
در مرحله اول، باید داده ها را با کیفیت آنها، یعنی خام در مقابل پردازش شده، متمایز کرد. ممکن است وسوسه انگیز باشد که داده های خام را به عنوان یک کاندید آسان برای وظایف سرپرستی در نظر بگیریم زیرا تغییرات وابسته به ابزار بیشتری را که نیاز به مستندسازی دارند، متحمل نشده است. متأسفانه، این به ندرت معنیدار است، زیرا کیفیت دادههای خام معمولاً از استفاده از آنها جلوگیری میکند، زیرا دادهها باید ابتدا بررسی شوند و احتمالاً تغییر شکل دهند، که بهتر است توسط تولیدکننده انجام شود.
ثانیاً، دادههای پردازششده محصول بهکارگیری رویهها یا الگوریتمها برای دادههای خام یا کمتر پردازششده را نشان میدهند. اگرچه این ممکن است بیاهمیت به نظر برسد، اما اغلب نادیده گرفته میشود، اما پیامدهایی با توجه به مستندات چنین پردازشی به وجود میآیند. مبادله یا استفاده مجدد از داده ها، به عنوان مثال، در حین ضمیمه کردن برخی از داده های خام جدید، غیرممکن، بی معنی و یا از نظر علمی غیرممکن می شود، مگر اینکه به خوبی مستند شده باشد (به بهترین وجه با آرشیو کردن توضیحات دقیق رویه های مورد استفاده و حتی بهتر با گنجاندن خود برنامه های مورد استفاده). بسیار مشکوک
ثالثاً نوع اطلاعات مورد نیاز برای چنین اهدافی به طور جامع در مدل مرجع برای یک سیستم اطلاعات بایگانی باز (OAIS) [ 11 ] توضیح داده شده است (متن کامل عمدتاً با استاندارد ISO 14721:2012 [ 51 ] یکسان است). در آن مدل هر مجموعه داده ای را می توان ابتدا به عنوان یک Data Object مشاهده کرد. این مدل تاکید می کند که یک شی داده صرف تنها زمانی می تواند ارائه شود یا به طور معناداری مورد استفاده قرار گیرد که با اطلاعات نمایش مناسب همراه باشد (صص 2-4، [ 11 ]). اگر فقط شی داده در دسترس باشد، رندر کار نمی کند و شی اطلاعات مورد نظر غیرقابل دسترسی باقی می ماند ( شکل 3)، بالا) و بایگانی ارزش تلاش را ندارد. شیء داده و اطلاعات نمایش، شیء محتوا را با هم تشکیل میدهند، که سپس میتواند برای به دست آوردن شی اطلاعات مورد نظر پردازش شود ( شکل 3 ، پایین).
اطلاعات بازنمایی باید کل زنجیره وابستگیهایی را که یک Data Object به آنها تکیه میکند، به ویژه نرمافزار خاص مورد نیاز برای رندر کردن و استفاده از آن، سیستمعاملی که چنین نرمافزاری به آن متکی است، و حتی سختافزار مورد نیاز برای اجرای سیستمعامل را پوشش دهد. در اصل، Representation Information باید نرمافزار و سیستمعاملها را در نسخه دقیق موجود در آن زمان برای بایگانی به عنوان بخشی از Content Object بسته بندی کند.
از آنجایی که این یک رویکرد بسیار زائد خواهد بود، جمعآوری قابل اعتماد این ابزارها در یک مخزن مشترک مفیدتر و کارآمدتر خواهد بود و بنابراین فقط باید آنها را مستند کرده و به طور مداوم در اطلاعات نمایندگی ارجاع دهیم. در حالی که این رویکرد منابع مشترک از قبل می تواند در سطح گروه های تحقیقاتی اجرا شود، به دلایل کارآمدی ترجیح داده می شود که این امر در سطح کل موسسات یا حتی جوامع بین المللی با حمایت متولیان نهادی سازماندهی شود. با این حال، حمایت نهادی فعلی برای چنین رویکردهایی حداقل است.
خوشبختانه، هر چه جامعه علمی معینی بهتر تعریف شود – و بنابراین معمولاً از نظر تخصصی یکنواخت تر باشد، دانش رایج، از جمله ابزارهای مورد استفاده، بیشتر می تواند گسترش یابد. پس انداز قابل توجهی با حذف گسترده اطلاعات بازنمایی جامع از بایگانی ممکن می شود. با دانستن اینکه همه اجزای مورد نیاز برای رندرینگ به طور قابل اعتماد توسط انجمن در جاهای دیگر مدیریت می شوند، تنها ارجاع به آن استانداردها کافی است.
بعد دیگری که در این زمینه باید در نظر گرفته شود، دوره زمانی است که یک شی محتوا باید به طور کامل قابل استفاده باقی بماند. هرچه این مدت کوتاه تر باشد، می توان فرضیات بیشتری در مورد در دسترس بودن نرم افزار در خارج از خود آرشیو ایجاد کرد.
مهم نیست که در نهایت چگونه به این موضوع پرداخته شود، بدیهی است که با توجه به این واقعیت که هر عنصر از زنجیره باید یک شی داده در نظر گرفته شود، همیشه نمیتوان زنجیره کامل وابستگیها را به معنایی کاملاً بدون ابهام مستند کرد. حق خود. محدودیت های فنی و منابع این را غیرممکن می کند.
یک رویکرد عمل گرایانه برای پرداختن به این مسائل، اتخاذ حداقل اقدامات سازمانی در سطح یک گروه تحقیقاتی است. در آن سطح، وابستگیهای حیاتی دادهها و پردازش آنها، به عنوان مثال، نیازمندیهای ابزار خاص، بهترین شناخته شدهاند. مفهوم ساده بایگانی از آرشیو بومشناسی سیستمها ( بخش 2 ) از چنین رویکردی با پشتیبانی از ارجاع متقابل و فهرست وابستگی ورودیهای بایگانی پیروی میکند ( شکل A1)). برخی از مؤلفههای اغلب مشترک، مانند سیستمهای عامل، برنامههای کاربردی، و ابزارهای خاص رشته، بهطور جداگانه با ورودیهای مختلف بایگانی شدند، که نه تنها افزونگی را کاهش میدهد و تلاشهای بایگانی را به حداقل میرساند، بلکه به طور قابل توجهی خودکنترلی بایگانی را از نظر قابلیت استفاده مجدد افزایش میدهد. از داده های بایگانی شده مطالعه موردی ما نشان میدهد که شبیهسازهای سختافزاری امروزی همراه با ابزارهای قدیمی بازیابیشده از آرشیو، از دادهها، ابزارها و مدلها بهطور شگفتآوری طولانیمدت پشتیبانی میکنند و در نتیجه اثرات مخرب فرسایش نرمافزار را بهطور قابلتوجهی کاهش میدهند.
یکی دیگر از عناصر مهم رویکرد اتخاذ شده در گروه بومشناسی سیستمهای زمینی، پردازش سریع دادههای خام و آوردن آنها به شکلی بود که حاوی حداقل دادههای متا باشد که استفاده مجدد را تسهیل میکند. این امر آرشیو چنین مجموعههای دادهای را در هر زمان ممکن میسازد، زیرا در شکل پردازش شده، مخزن ممکن است حداقل ارجاعاتی به موجودیتها، به عنوان مثال، ابزارها، گزارشها، یا انتشارات موجود در سایر ورودیهای آرشیو، که حاوی اطلاعات بازنمایی مورد نیاز است را داشته باشد (همچنین رجوع کنید به بخش 2 ، شکل 1 ).
برای این منظور از چارچوب های داده استفاده شد، یک فرمت ذخیره سازی داده، که در میان بسیاری از مزایای دیگر، توانایی ذخیره داده های پردازش شده همراه با متا داده ها را ارائه می دهد (شکل 4، جزئیات در ضمیمه A.1 ؛ چارچوب های داده در درجه اول توسعه داده شدند. برای اهداف مدلسازی و شبیه سازی همانطور که در بخش 5 بحث شد ). سایر قالبها میتوانند با رزرو بخشهای جداگانه، به عنوان مثال، در ابتدا یا انتهای یک فایل داده بزرگ، برای نگهداری متا داده، اهداف مشابهی را انجام دهند. با این حال، سایر قالبها ممکن است محدودیتهای قابلتوجهی در مقایسه با چارچوبهای داده نوشته شده به زبان LL(1) داشته باشند، به عنوان مثال، [ 52 ] که از عملکرد کل سیستم پایگاه داده پشتیبانی میکند.
ذخیره سازی متا داده ها با هم در همان فایلی که خود داده ها هستند، پردازش را تسهیل می کند. سپس اطلاعات رندر ممکن است به طور کامل در متا داده ها ( شکل 4 ، پایین) یا حداقل ارجاع داده شوند ( شکل 4 ، بالا). در مورد دوم، شی اطلاعات تنها در صورتی قابل ارائه است که هم مرجع و هم ورودی های آرشیو ارجاع شده در دسترس باشند ( به بخش 2 و ضمیمه A.1 مراجعه کنید ).
منشاء مطالعه موردی مورد بحث در این مقاله به طور قابل توجهی پیش از ایجاد مدل OAIS است. در حالی که مدل OAIS و ابزارهای پیچیده مرتبط با آن کمبود داشتند، مفاهیم واضح این کمبود را جبران کرد و رویکرد آرشیو با قدرت قابل مقایسه با مدل OAIS را تقویت کرد. ما استدلال میکنیم که این تجربه باید امروز بهعنوان تشویقی برای انجام کارهایی که هماکنون انجام میشود درک شود، بهجای اینکه مدیریت دادهها را تسهیل کند تا به آیندهای نامشخص در حالی که منتظر یک راهحل فنی جامع یا خدمات ایدهآل هستیم، به تعویق بیفتد. خدماتی که به طور مطلوب برای کاربر مناسب هستند، ممکن است هرگز تکامل نیابند یا بسیار دیر باشد و زمانی که نیازهای تحقیقاتی کنونی در مقطعی در آینده در نهایت مطابقت داشته باشند، ممکن است قبلا رشد کرده یا تغییر کرده باشند.
4. مدیریت انتشارات و ادبیات
4.1. انتشارات علمی
فرآیند انتشار یک محصول تعریف شده را در قالب یک نشریه رسمی تولید می کند، اما از نظر علمی و کیوریتوری، این فقط نوک کوه یخ را تشکیل می دهد. انتشار رسمی نتایج بسیاری از تحقیقات اساسی را به شکل عمدی فشرده ارائه می کند در حالی که بیشتر داده ها و مواد مورد استفاده واقعاً منتشر نشده باقی می مانند.
در بهترین حالت، داده ها و مطالب جمع آوری شده تا حدی در مطالب تکمیلی مقاله در دسترس قرار می گیرند. با این حال، کیفیت این مطالب اغلب کاملاً مشکوک است، برای مثال، بسیاری از ناشران مطالب تکمیلی را فقط بر اساس آن ارائه میدهند و مسئولیتی در قبال محتوا و خوانایی به نویسندگان محول میکنند، در حالی که هیچ استانداردی برای چنین مطالبی اعمال نمیکنند. علاوه بر این، مشاهده میکنیم که نویسندگان با ارائه مطالب تکمیلی که فقط با نرمافزار اختصاصی قابل دسترسی است، فرسایش نرمافزار را دستکم میگیرند، به طوری که در هر زمانی که مقاله اصلی هنوز قابل خواندن است، مطالب تکمیلی غیرقابل خواندن شود.
خوشبختانه، سرمایهگذاران و سردبیران مجلات بیشتر و بیشتری برای انتشار آزاد تحقیقات با بودجه عمومی تلاش میکنند. با این حال، حتی اگر این کار به طور گسترده انجام شود، هنوز داده های منتشر نشده زیادی وجود خواهد داشت که باید طبق آنچه ما آن را عمل علمی خوب می نامیم حفظ شوند.
برای هر دو هدف – در دسترس قرار دادن دادههای مرتبط در اختیار دیگران و نگهداری آنها به دلایل مسئولیتپذیری – تجربه مطالعه موردی ما نشان میدهد که ممکن است مفید باشد که هر نشریه را به تنهایی یک پروژه در نظر بگیریم. بر اساس این مفهوم، در پایان هر پروژه بایگانی می آید ( به بخش 2 و پیوست A.1 مراجعه کنید ). بایگانی یک نشریه بر اساس اصل بسته بندی تمام داده ها، مدل ها و ابزارهایی است که برای ایجاد نشریه استفاده شده است، از جمله، به عنوان مثال، اسکریپت هایی که برای پردازش داده ها و/یا ایجاد گرافیک مورد نیاز بودند. بنابراین، اصول راهنما مانند نحوه رسیدگی به داده های تحقیق است که در بخش قبل ارائه شد (به بخش 3 مراجعه کنید ).
4.2. مدیریت ادبیات
بخش زیر صرفاً به داده های ادبی می پردازد (متا داده های کتابشناختی و متون کامل) و عمداً داده های تحقیق را که در جاهای دیگر درمان شده اند حذف می کند ( بخش 3 ). با این حال، بهطور قابلتوجهی، مقالات دادهها روز به روز رایجتر میشوند و بدین وسیله تمایز ما را محو میکنند.
مدیریت ادبیات که به این روش درک میشود، کل فرآیند تحقیق را در بر میگیرد، از خواندن اطلاعات پیشزمینه تا تولید خودکار فهرست مرجع در حین تألیف نشریات، در حالی که همیشه شامل بخش قابلتوجهی شخصی برای هر محقق است، به عنوان مثال، [53 ]]. بنابراین باید به عنوان بخشی همه جا حاضر و جدایی ناپذیر از مدیریت داده های پژوهشی در نظر گرفته شود، همانطور که ما آن را برای هدف این مقاله تعریف می کنیم. از آنجایی که محققان به طور معمول چندین هزار مرجع و مقاله را در طول حرفه خود جمع آوری می کنند، یک مدیریت کارآمد تنها در صورتی سودآور است که این اطلاعات را از نظر اقتصادی در پروژه های تحقیقاتی، نشریات، رزومه های پژوهشگران و وب سایت به علاوه به اشتراک گذاری آن با همکاران، همتایان و همکارها مدیریت کند. نویسندگان در داخل و خارج از پروژه های تحقیقاتی در حال انجام.
مدیریت خوب ادبیات هنوز یک چالش است، زیرا برخلاف آنچه بسیاری تصور میکنند، روندهای فعلی کمک چندانی به کاهش شکاف سرپرستی نمیکنند. این موضوع نیز نمونهای است که نشان میدهد شکاف سرپرستی نه تنها بر عهده بخش پژوهشی است، بلکه نیازمند پیشرفتهایی از سوی علم کتابداری و اطلاعرسانی و کلیه خدمات و ابزارهای مرتبط با آن است. کل چرخه زندگی دادههای ادبیات چالشهای قابلتوجهی را برای دانشمندان در تحقیقات روزانهشان ایجاد میکند، و برای پیشرفت واقعی در کاهش شکاف مراقبت، باید به خوبی درک شود.
دلایل متعددی وجود دارد که چرا ما نیز در این زمینه شکاف داریم. در اینجا به چند مورد اشاره می کنیم: (i) محققان معمولاً از چندین ابزار مختلف برای نوشتن مقالات استفاده می کنند (مثلاً مایکروسافت ورد، ) و استفاده از چندین ابزار مدیر مرجع (EndNote، Mendeley، و غیره) ضروری است .  (ابزارهای مدیریت مرجع فهرست شده در اینجا به طور خودسرانه فهرست شده و مورد بحث قرار گرفته اند و هیچ حمایت یا انتقادی از هیچ یک از این محصولات در نظر گرفته نشده است. ما در اینجا فقط چند مورد از محبوب ترین آنها را به عنوان نماینده بسیاری دیگر فهرست کرده ایم.)). (ii) استفاده از چنین ابزارهایی ممکن است توسط ناشران تجویز شود یا توسط یک تیم نویسنده تصمیم گرفته شود و بنابراین خارج از کنترل کامل محقق فردی است. (iii) بسیاری از محبوب ترین ابزارهای مدیریت مرجع امروزی با نقض اصول نظریه پایگاه داده (فقدان کلید پایگاه داده اولیه، به عنوان مثال، EndNote، Mendeley) یا در نظر گرفتن اساساً محقق به عنوان یک پایگاه داده مستحکم، مبتنی نیستند. فقط نویسنده یک مقاله (مثلاً EndNote) یا با داشتن مقررات ناکافی برای واردات، صادرات، و به روز رسانی مطمئن سوابق (مثلاً مندلی)، چه رسد به بررسی داده های مربوطه. (IV) مخازن متا داده های کم و بیش رقیب برای انتشارات علمی توسط بسیاری از خدمات عمدتا مبتنی بر اینترنت ارائه می شوند. آنها معمولاً از هر محقق جلوتر هستند و دلایل اقتصادی استفاده مناسب از چنین خدماتی را ضروری می کند. با این حال، این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه. آنها معمولاً از هر محقق جلوتر هستند و دلایل اقتصادی استفاده مناسب از چنین خدماتی را ضروری می کند. با این حال، این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه. آنها معمولاً از هر محقق جلوتر هستند و دلایل اقتصادی استفاده مناسب از چنین خدماتی را ضروری می کند. با این حال، این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه. این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه. این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه.
(ابزارهای مدیریت مرجع فهرست شده در اینجا به طور خودسرانه فهرست شده و مورد بحث قرار گرفته اند و هیچ حمایت یا انتقادی از هیچ یک از این محصولات در نظر گرفته نشده است. ما در اینجا فقط چند مورد از محبوب ترین آنها را به عنوان نماینده بسیاری دیگر فهرست کرده ایم.)). (ii) استفاده از چنین ابزارهایی ممکن است توسط ناشران تجویز شود یا توسط یک تیم نویسنده تصمیم گرفته شود و بنابراین خارج از کنترل کامل محقق فردی است. (iii) بسیاری از محبوب ترین ابزارهای مدیریت مرجع امروزی با نقض اصول نظریه پایگاه داده (فقدان کلید پایگاه داده اولیه، به عنوان مثال، EndNote، Mendeley) یا در نظر گرفتن اساساً محقق به عنوان یک پایگاه داده مستحکم، مبتنی نیستند. فقط نویسنده یک مقاله (مثلاً EndNote) یا با داشتن مقررات ناکافی برای واردات، صادرات، و به روز رسانی مطمئن سوابق (مثلاً مندلی)، چه رسد به بررسی داده های مربوطه. (IV) مخازن متا داده های کم و بیش رقیب برای انتشارات علمی توسط بسیاری از خدمات عمدتا مبتنی بر اینترنت ارائه می شوند. آنها معمولاً از هر محقق جلوتر هستند و دلایل اقتصادی استفاده مناسب از چنین خدماتی را ضروری می کند. با این حال، این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه. آنها معمولاً از هر محقق جلوتر هستند و دلایل اقتصادی استفاده مناسب از چنین خدماتی را ضروری می کند. با این حال، این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه. آنها معمولاً از هر محقق جلوتر هستند و دلایل اقتصادی استفاده مناسب از چنین خدماتی را ضروری می کند. با این حال، این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه. این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه. این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه.

 (ابزارهای مدیریت مرجع فهرست شده در اینجا به طور خودسرانه فهرست شده و مورد بحث قرار گرفته اند و هیچ حمایت یا انتقادی از هیچ یک از این محصولات در نظر گرفته نشده است. ما در اینجا فقط چند مورد از محبوب ترین آنها را به عنوان نماینده بسیاری دیگر فهرست کرده ایم.)). (ii) استفاده از چنین ابزارهایی ممکن است توسط ناشران تجویز شود یا توسط یک تیم نویسنده تصمیم گرفته شود و بنابراین خارج از کنترل کامل محقق فردی است. (iii) بسیاری از محبوب ترین ابزارهای مدیریت مرجع امروزی با نقض اصول نظریه پایگاه داده (فقدان کلید پایگاه داده اولیه، به عنوان مثال، EndNote، Mendeley) یا در نظر گرفتن اساساً محقق به عنوان یک پایگاه داده مستحکم، مبتنی نیستند. فقط نویسنده یک مقاله (مثلاً EndNote) یا با داشتن مقررات ناکافی برای واردات، صادرات، و به روز رسانی مطمئن سوابق (مثلاً مندلی)، چه رسد به بررسی داده های مربوطه. (IV) مخازن متا داده های کم و بیش رقیب برای انتشارات علمی توسط بسیاری از خدمات عمدتا مبتنی بر اینترنت ارائه می شوند. آنها معمولاً از هر محقق جلوتر هستند و دلایل اقتصادی استفاده مناسب از چنین خدماتی را ضروری می کند. با این حال، این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه. آنها معمولاً از هر محقق جلوتر هستند و دلایل اقتصادی استفاده مناسب از چنین خدماتی را ضروری می کند. با این حال، این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه. آنها معمولاً از هر محقق جلوتر هستند و دلایل اقتصادی استفاده مناسب از چنین خدماتی را ضروری می کند. با این حال، این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه. این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه. این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه.
(ابزارهای مدیریت مرجع فهرست شده در اینجا به طور خودسرانه فهرست شده و مورد بحث قرار گرفته اند و هیچ حمایت یا انتقادی از هیچ یک از این محصولات در نظر گرفته نشده است. ما در اینجا فقط چند مورد از محبوب ترین آنها را به عنوان نماینده بسیاری دیگر فهرست کرده ایم.)). (ii) استفاده از چنین ابزارهایی ممکن است توسط ناشران تجویز شود یا توسط یک تیم نویسنده تصمیم گرفته شود و بنابراین خارج از کنترل کامل محقق فردی است. (iii) بسیاری از محبوب ترین ابزارهای مدیریت مرجع امروزی با نقض اصول نظریه پایگاه داده (فقدان کلید پایگاه داده اولیه، به عنوان مثال، EndNote، Mendeley) یا در نظر گرفتن اساساً محقق به عنوان یک پایگاه داده مستحکم، مبتنی نیستند. فقط نویسنده یک مقاله (مثلاً EndNote) یا با داشتن مقررات ناکافی برای واردات، صادرات، و به روز رسانی مطمئن سوابق (مثلاً مندلی)، چه رسد به بررسی داده های مربوطه. (IV) مخازن متا داده های کم و بیش رقیب برای انتشارات علمی توسط بسیاری از خدمات عمدتا مبتنی بر اینترنت ارائه می شوند. آنها معمولاً از هر محقق جلوتر هستند و دلایل اقتصادی استفاده مناسب از چنین خدماتی را ضروری می کند. با این حال، این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه. آنها معمولاً از هر محقق جلوتر هستند و دلایل اقتصادی استفاده مناسب از چنین خدماتی را ضروری می کند. با این حال، این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه. آنها معمولاً از هر محقق جلوتر هستند و دلایل اقتصادی استفاده مناسب از چنین خدماتی را ضروری می کند. با این حال، این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه. این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه. این سرویسها اغلب از تکنیکهای اختصاصی استفاده میکنند که از استفاده انعطافپذیر و استفاده مجدد از متا دادههای درگیر در شرایطی که چندین تکنیک نوشتن به محقق تحمیل میشود، جلوگیری میکند. به طور خلاصه، هیچ راه حلی برای همه موجود نیست و بعید به نظر می رسد در آینده قابل پیش بینی باشد. در نتیجه، محققان باید به طور مداوم تکنیکهای نوشتن خود را تطبیق دهند و به انعطافپذیری نیاز دارند که عموماً بسیار فراتر از آن چیزی است که توسط هر یک از خدمات امروزی ارائه میشود، چه رسد به ابزارهای نرمافزاری مربوطه.در اینجا ما سیستمی را توصیف می کنیم که با موفقیت در گروه بوم شناسی سیستم های زمینی در ETH زوریخ در تلاش برای رسیدگی به چنین مسائلی پیاده سازی و استفاده شده است. این سیستم تکامل یافته و از تغییرات تکنولوژیکی متعددی جان سالم به در برده است و نزدیک به سه دهه است که مورد استفاده روزانه قرار گرفته است. این می تواند به عنوان یک مدل موفق از نحوه اجرای مدیریت ادبیات قوی در یک گروه تحقیقاتی و چگونگی غلبه بر برخی از چالش های فوق الذکر عملی عمل کند.
اهداف سیستم پیشنهادی در اینجا بر اساس اصول طراحی زیر بنا شده است. در حالی که سعی می شود مجموعه ادبیات را بین اعضای تیم تحقیقاتی به اشتراک بگذارد، به هر یک از اعضای تیم باید حداکثر آزادی برای حفظ یک مجموعه بسیار شخصی داده شود. در حالی که برخی این اهداف را گسترش دهنده اهداف متضاد می دانند، قوانین و توضیحات طراحی زیر باید انتخاب های انجام شده را قابل درک کند.
سیستم ادبیات پیشنهادی برای مجموعه های شخصی نشریات در شکل 5 نشان داده شده است . این سیستم از به اشتراک گذاری متا داده های کتابشناختی و متون کامل انتشارات، احتمالاً مشروح، در یک تیم از محققان پشتیبانی می کند، در حالی که مالکیت شخصی اولیه مجموعه توسط هر یک از محققین شرکت کننده را حفظ می کند .
این سیستم چه محقق x به اینترنت متصل باشد چه نباشد کار می کند و یکپارچگی داده ها را حفظ می کند، علیرغم پیچیدگی توپولوژی آن که از توزیع متا داده های کتابشناختی و متون کامل انتشارات بر روی چندین کاربر و چندین دستگاه پشتیبانی می کند (همچنین رجوع کنید به ضمیمه A.2 ). این به پژوهشگر منفرد احساس کار با یک مجموعه ادبیات شخصی را در همه زمان ها می دهد، در حالی که از همکاری حمایت می کند، از جمله با به اشتراک گذاری حداقل متا داده ها در مورد ادبیات مورد استفاده در تیم.
علاوه بر این و بسیار مهمتر، این سیستم نه تنها از مدیریت متا داده ها، بلکه از نگهداری مجموعه انتشارات شخصی، به عنوان مثال، در قالب مجموعه ای از فایل های PDF، خواندن آن انتشارات، به علاوه حاشیه نویسی آن انتشارات، پشتیبانی می کند (به پیوست مراجعه کنید . A.2 برای جزئیات فنی در مورد تکنیک ها و ابزار واقعی مورد استفاده). این مفهوم تلاش می کند تا سیستم را تا حد امکان از دیدگاه هر محقق جذاب کند، بنابراین احتمال استفاده از آن را به طور قابل توجهی افزایش می دهد، همانطور که تجربه نزدیک به سه دهه به طور مشخص تأیید می کند.
سوابق متا داده حاوی منابع کتابشناختی هر اثر علمی تنها از طریق پایگاه داده مرکزی بین کاربران تیم تحقیق مبادله می شود. L i t Ce n t r a l�منتیسیه�تی�آل(توپولوژی ستاره مانند). این اتفاق با همگام سازی رکوردهای مالک از طریق L i t Ce n t r a l�منتیسیه�تی�آلبه پایگاه داده های شخصی کاربر دیگر، به عنوان مثال، از L i T MYآ�منتیم�آهمانطور که توسط محقق a to استفاده می شودL i T MYب�منتیم�بهمانطور که توسط محقق ب استفاده شده است . فرض بر این است که این امر به صورت ناهمزمان اتفاق می افتد، یعنی هر زمان که یکی از محققین درگیر x به پایگاه داده مرکزی متصل شود. L i t Ce n t r a l�منتیسیه�تی�آل.
سازگاری بین محققان با مرتبط کردن مجوزهای خاص به سوابق تضمین می شود. محقق منفرد، به عنوان مثال، a ، دارای مجوز نوشتن (سبز) در تمام سوابق خود است، اما فقط تا زمانی که این سوابق در دستگاهی متعلق به آن کاربر باشد. توجه داشته باشید، دامنههای A ، B ، … مختص کاربر هستند (رابطه 1:1)، اما محدود به دستگاه نیستند، به طوری که یک محقق میتواند هر تعداد دستگاه را که دوست دارد استفاده کند (شکل 5 این را برای دامنه A با رایانه لوحی و یک رایانه نشان میدهد. تلفن هوشمند، برای دامنه Bبا لپ تاپ و تلفن هوشمند). هر رکورد همیشه تنها در اختیار یک محقق است (رابطه 1:1) و باید دارای یک کلید منحصر به فرد جهانی باشد که به یک کار علمی خاص (رابطه 1:1) ارجاع دهد تا ثبات را در سراسر سیستم همیشه تضمین کند. متأسفانه، این ویژگی جایی است که اکثر راه حل های امروزی، به عنوان مثال، مبتنی بر ابر (مانند، مندلی)، اساساً شکست می خورند.
برای اهداف توضیحی در شکل 5 از کلیدهایی استفاده می شود که شامل یک عدد و حرفی است که نشان دهنده صاحب رکورد، یعنی محقق x است . هر گونه تکراری از رکوردهای متا داده (رابطه 1:n) ممکن است در سراسر تیم تحقیقاتی توزیع شود، با این حال، فقط با مجوزهای فقط خواندنی (در شکل 5 ، اگر کپی رکورد در دامنه ای غیر از رکورد قرار داشته باشد، بخش ها قرمز رنگ می شوند. مالک).
اگر کلید شامل صاحب رکورد نیز باشد، هر کلیدی که در هر دامنه X اختصاص داده شده و در آن دامنه X منحصر به فرد است ، به طور خودکار در سطح جهانی نیز منحصر به فرد است. این امر تخصیص مستقل کلیدها را تا حد زیادی تسهیل میکند، اما با این مضرات وجود افزونگی در کل سیستم همراه است، زیرا به چندین محقق اجازه میدهد تا کلیدهای متفاوتی را به یک کار علمی مشابه اختصاص دهند.
با این حال، همانطور که تجربه ما نشان می دهد، تکنیک هایی برای به حداقل رساندن خطر چنین افزونگی وجود دارد، به عنوان مثال، با داشتن ابزار مناسب برای بررسی وجود سابقه ای که قبلاً به یک کار علمی خاص ارجاع می دهد. با گسترش شناسه های دیجیتالی اشیاء، می توان این عیب را بیشتر برطرف کرد. شکل 6 قوانین مربوطه را نشان می دهد که باید هنگام وارد کردن رکوردهای جدید به سیستم رعایت شود. با این حال، توجه داشته باشید، اصل طراحی پیشنهاد شده در اینجا استفاده از چنین امکاناتی را برای هر شرکت کننده جذاب می کند، زیرا حجم کاری کاربران را کاهش می دهد و آنها را قادر می سازد تا صرفاً یک رکورد را به اشتراک بگذارند به جای اینکه وارد مشکل ورود مجدد به آن شوند.
هر گونه به روز رسانی احتمالی داده های اصلی هر رکورد متعلق به کاربر x ، کپی مربوطه را در آن بازنویسی می کند L i t Ce n t r a l�منتیسیه�تی�آلبه محض اینکه محقق x او را همگام کرد L i T MYایکس�منتیم�ایکسبا پایگاه داده مرکزی و در عین حال ادغام هرگونه داده غیر اصلی مانند حاشیه نویسی های شخصی از همه کاربران رکورد.
هر کاربر دیگری، مثلاً کاربر y ، که احتمالاً از برخی از آن رکوردها نیز استفاده می کند، به محض اینکه خود را همگام سازی کرد، کپی های خود را در دامنه Y بازنویسی می کند.L i T MYy�منتیم��با پایگاه داده مرکزی L i t Ce n t r a l�منتیسیه�تی�آل. این بدان معنی است که همگام سازی ناهمزمان داده ها در بین نسخه های مختلف همیشه از رکورد اصلی در سیستم مالک یک طرفه است و باید در سراسر سیستم به دستگاه های دیگر در آن دامنه ها منتشر شود، تنها زمانی که کاربران به پایگاه داده مرکزی دسترسی دارند. L i t Ce n t r a l�منتیسیه�تی�آل. باز هم، این کنترل کامل را به همه شرکتکنندگان در هنگام به اشتراکگذاری دادههای کتابشناختی و متون کامل میدهد، در حالی که تکنیکهای لازم را ساده نگه میدارد و از سازگاری دادهها در همه زمانها اطمینان میدهد.
تجربه تقریباً سه دهه ای، پیاده سازی این مفهوم با استفاده از اجزای مختلف ابزارهای پرکاربرد مانند EndNote و از جمله در نگارش آثار علمی با استفاده از مایکروسافت آفیس ورد یا . – به ویژه تحقیقات مشترک – از بسیاری جهات. قابل ذکر است که انتظار می رود این سیستم آزمایش شده با زمان از استفاده از ابزارهای موجود به شیوه ای عملی و انعطاف پذیر پشتیبانی کند. این به محقق فردی امکان میدهد تا ابزارها را به سرعت تغییر دهد، و در صورت نیاز، زمانی که همکاری تغییر میکند یا صرفاً زمانی که مجله علمی دیگری استفاده از ابزارهای خاص دیگر را به محقق تحمیل میکند (مثلاً Word vs. ). اگر ابزارها به طور دائمی تغییر کنند یا ابزارهای دیگری نیاز به گنجاندن داشته باشند، سیستم می تواند به طور مشترک تکامل یابد و حتی تا حدی کاستی ها و کاستی های بسیاری را که برنامه های کاربردی محبوب امروزی در حفظ ثبات نشان می دهند، جبران کند.
 ). اگر ابزارها به طور دائمی تغییر کنند یا ابزارهای دیگری نیاز به گنجاندن داشته باشند، سیستم می تواند به طور مشترک تکامل یابد و حتی تا حدی کاستی ها و کاستی های بسیاری را که برنامه های کاربردی محبوب امروزی در حفظ ثبات نشان می دهند، جبران کند.
). اگر ابزارها به طور دائمی تغییر کنند یا ابزارهای دیگری نیاز به گنجاندن داشته باشند، سیستم می تواند به طور مشترک تکامل یابد و حتی تا حدی کاستی ها و کاستی های بسیاری را که برنامه های کاربردی محبوب امروزی در حفظ ثبات نشان می دهند، جبران کند.با این حال، این سیستم بدون معایب نیست. به عنوان مثال، هر محقق x اصولاً فقط باید همیشه یک نسخه اصلی متناظر با یک نشریه خاص در دامنه X خود داشته باشد . استثنائات الزامات فوق را فقط باید به طور موقت تحمل کرد، به عنوان مثال ، در هنگام ورود به یک نشریه جدید و در یک وضعیت گذرا از سیستم (به عنوان مثال، شکل 6 ). با این حال، این الزام تنها می تواند توسط رشته محقق x “اجرا شود” ، که خطر واقعی ناسازگاری را ایجاد می کند، علیرغم اینکه کاملاً در حوزه واحد X باقی می ماند که فقط توسط محقق واحد x کنترل می شود.. این محدودیت تا حد زیادی به دلیل ماهیت عملگرایانه مفهوم ما است، به عنوان مثال ، اجازه می دهیم ابزارهای محبوب، علیرغم ایراداتشان، ترکیب شوند، یعنی برای همکاری با ابزارهای رقابتی طراحی نشده اند.
مجبور شدن با تغییر تحقیقات مشترک برای استفاده، به عنوان مثال، چندین “مدیران مرجع” نیز پیچیدگی را اضافه می کند، مانع دیگری که ممکن است توسط محققان به عنوان یک عامل بازدارنده قابل توجه برای پایبندی به مفهوم ما درک شود. با این حال، شرط فوق حیاتی است، نباید آرام شود، و مستلزم نظم و انضباط دقیق از محقق x است تا از هرگونه میانبر صرفاً با بهروزرسانی رکوردهای سبز اجتناب کند، و هرگز به موارد نارنجی ( نگاه کنید به شکل 5 )، صرف نظر از اینکه در کجا کمبود برخی از متا دادهها وجود دارد. به عنوان مثال، یک اشتباه تایپی، شناسایی شد. رکوردهای سبز به روز شده باید با انتقال رکوردهای سبز به روز شده از مرکز در دامنه X منتشر شوندL i T MYایکس�منتیم�ایکسبه هر پایگاه داده دیگری که گزیده ای خاص از رکوردهای نارنجی را ذخیره می کند. خطر ناهماهنگی را می توان مجدداً با ارائه ابزارهای انتقال مناسب که می توانند به طور مؤثر چنین انتشاراتی را به راحتی انجام دهند به حداقل رساند ( پیوست A.2 ، شکل A4 و شکل A5 ).
علیرغم معایب خاصی که با رویکرد ما و کمبودهای متعدد «مدیران مرجع» امروزی به وجود میآید، رجوع کنید به. پیوست A.2 برای جزئیات)، که مفید نیستند، ما توانستهایم راهحلهای عملگرایانه و در عین حال بسیار موفقی را توسعه دهیم. ما فقط نیاز به پیروی از مفاهیم روشنی داشتیم که پایه و اساس حیاتی را برای تضمین ثبات در سیستم و در نتیجه قابلیت اطمینان ( شکل 5 و شکل 6 )، یکی از مرتبطترین عناصر برای کاربرپسندی، فراهم میکردند.
علاوه بر این، به نظر میرسد که مفهوم ما نیز تا حد زیادی با انگیزهها و انگیزههای پژوهشگر منطبق باشد – بهویژه با حمایت از استفاده شخصی – در حالی که با این وجود از همکاری و اشتراک دادههای ادبیات حمایت میکند. طراحی مفهومی ما ( شکل 5 و شکل 6 ) برای اجتناب از مسائل و به حداقل رساندن خطرات ناسازگاری ضروری به نظر می رسد. همچنین میتوان آن را مستقل از ابزارهای خاص تعمیم داد تا زمانی که شرایط زیر برآورده شود:
-
هر شرکتکننده را میتوان بهصورت جهانی بهصورت منحصربهفرد نشانداد (مثلاً با استفاده از شناسایی منحصربهفرد محقق ORCID).
-
هر نشریه همچنین به طور جهانی به طور منحصر به فرد با یک کلید اصلی (به عنوان مثال، DOI) در سیستم پایگاه داده توزیع شده مشخص می شود که مالک را نیز شناسایی می کند.
-
همه فایلها، بهعنوان مثال، فایلهای PDF مرتبط با یک نشریه معین، به گونهای نامگذاری میشوند که نام فایل حاوی کلید اصلی باشد یا اجازه میدهد تا کلید اصلی مشتق شود.
یک سرور ثبت مرکزی نیاز اول را حتی برای تعداد بسیار زیادی از محققین برآورده می کند. برای شرط دوم، یک کاندید خوب برای کلید اصلی ساختن کلیدهای اصلی از DOI (شناسه شی دیجیتال) پرکاربرد کار علمی مرجع مرتبط با شناسه کاربر به عنوان نتیجه الزام یک خواهد بود (فرض می کنیم که همه آثار درگیر دارای DOI هستند) . شرط سه در ساده ترین شکل خود با استفاده از کلید اصلی برای نام فایل، ناشی از برآورده کردن نیاز دو است.
با این حال، نسل فعلی DOI از کاراکترهایی استفاده می کند که از نظر فنی در تضاد قابل توجهی با سیستم های فایل امروزی و طرح های کدگذاری «مدیران مرجع» هستند. همراه با این واقعیت که همه نشریات به دور از اختصاص یک DOI منحصر به فرد در سطح جهانی، همه اینها مخالف راه حل کلی ساده و ساده است. بازنگری قابلتوجهی در طرحها و ابزارهای نرمافزاری که بهطور گسترده مورد استفاده قرار میگیرند مورد نیاز است تا هر سه نیاز را به خوبی برآورده کنند، تا پس از آن، به عنوان مثال، یک سیستم مبتنی بر ابر با راحتی بیشتر از آنچه سیستم ما در حال حاضر میتواند انجام دهد، ارائه شود.
در نهایت، در حالی که هر سیستم پایگاه داده حرفه ای برای انجام وظایف مورد نیاز مناسب است و در اصل می تواند از سیستم ما پشتیبانی کند، استناد به منابع در حالی که تالیف نشریات به هیچ وجه توسط آنها پشتیبانی نمی شود. آنچه که مورد نیاز است عملکرد دومی است که به نقاط قوت معمول “مدیران مرجع” تعلق دارد. با این حال، دومی دارای ضعف های قابل توجهی از نظر عملکرد پایگاه داده است، استدلال دیگری که به وضوح برای راه حلی مشابه آنچه ارائه کردیم صحبت می کند.
به نظر می رسد که اکثر «مدیران مرجع» امروزی در انجام کارکردهای بنیادی پایگاه داده آنگونه که واقعاً مورد نیاز است کوتاهی می کنند و/یا با تأمین نیازهای تحقیقی واقعی همانطور که در ابتدا توضیح داده شد، کمک بسیار کمی به بهبود وضعیت می کنند. رویکرد ما، با این حال، به تمام مسائل مربوطه پرداخت. این کارکرد یک سیستم پایگاه داده کاملاً پیشرفته را ارائه میکند، از جمله وارد کردن و صادر کردن از و به دیگر سیستمهای پایگاه داده و/یا «مدیران مرجع»، به علاوه استفاده از «مدیران مرجع» محبوب که میتواند به نویسندگان در استناد به آثار و تولید کتابشناسی کمک کند. . بنابراین، سیستم ما به طور قابلتوجهی به حفظ سرمایهگذاری قابل توجهی که هر محقق فردی ممکن است در حین خواندن، حاشیهنویسی، ارجاع، و مشارکت در ادبیات علمی به شیوهای سیستماتیک انجام دهد، کمک میکند. این کلید برای هر گونه اصلاح آن سرمایه گذاری است، که خطر از بین رفتن کامل آن را دارد، که ما گمان می کنیم معمولاً چنین است. همچنین بسیار قابل توجه است که چگونه بسیاری از نرمافزارها و ابزارهای مبتنی بر کتابداری و علم اطلاعات، به ویژه محبوبترین آنها، در رسیدگی به همه این مسائل کوتاهی میکنند. تنها در صورتی میتوان این شکاف را کاهش داد که ابزارسازان وضعیت واقعی را که محققان امروزی باید در آن کار کنند و با ادبیات علمی کار میکنند، درک کنند.
5. نظریه و مدل ها
نظریه های علمی و توسعه آنها خارج از حوصله این مقاله است. با این حال، ملاحظات کمی وجود دارد. اولین انتشارات علمی تا حد زیادی تئوری ها، از جمله زمینه آنها را در بر می گیرند، در حالی که تمام ظرافت ها را حفظ می کنند و با کمترین خطر از نظر مراقبت روبرو هستند همانطور که در بخش 4.2 بحث شد.. با این حال، این مورد در مورد شاخههای رو به رشد علم که در آن از مدلها، بهویژه مدلهای شبیهسازی پیچیده، برای گرفتن و محصور کردن درک نظری استفاده میشود، صادق نیست. آنها نیاز به توجه ویژه ای دارند تا توسعه نظریه را تضعیف نکنند اگر وابستگی دومی احتمالاً افزایش یابد در حالی که مدل اولی، مدل های شبیه سازی، که معمولاً به فناوری های محاسباتی کاملاً پیچیده وابسته هستند، به ویژه توسط فرسایش نرم افزار تهدید می شوند. چالشهای پیشرو نیز باید در این زمینه برطرف شود.
تمایز بین مدلهای نظری که توسط برخی مدلهای پایه نامیده میشوند، مهم است، به عنوان مثال، [ 54 ]، که بیانگر یک نظریه علمی است که در تلاش برای توضیح و/یا توصیف پدیدهای از جهان قابل مشاهده است که به عنوان «واقعیت» تعبیر میشود ( شکل 7 ، بیضی قهوهای ) و مدل های ساده شده، پارامتری شده یا یکپارچه، به عنوان مثال، [ 55 ، 56 ، 57 ، 58 ]، مدل های شبیه سازی ( شکل 7 )، که به طور معمول بسیاری از جنبه های سیستم واقعی را جمع می کنند. در حالی که مدل های قبلی معمولاً در دست نوشته های علمی منتشر می شوند، مدل های شبیه سازی به ندرت به طور کامل در دسترس عموم قرار می گیرند.
مدلها و دادههای مورد نیاز برای اجرا، تجزیه و تحلیل و اعتبارسنجی مدلهای اولی آشکارا به طور پیچیدهای به هم مرتبط هستند (همچنین به شکل 7 مراجعه کنید ). با این حال، تجربه ما نشان داد که اگر دادههای مدل از ساختارهای ریاضی موجود در یک مدل جدا شوند، چندین مزیت به وجود میآیند. یکی این است که دادههای یکسان میتوانند به زیبایی برای چندین مدل مدل استفاده شوند، به عنوان مثال، هنگام آزمایش فرضیههای نظری جایگزین که هر کدام در یک مدل مدل متفاوت با معادلات ریاضی جایگزین محصور شدهاند، مفید باشد. مزیت دیگر این است که مجموعههای مختلفی از پارامترها را میتوان برای یک مدل ریاضی به کار برد، به عنوان مثال، در طول شبیهسازیهای مجموعه برای تقلید تصادفی، تحلیل حساسیت یا زمانی که یک مدل، مثلاً یک مدل پوشش گیاهی، در میان قارهها جابجا میشود، مفید باشد.
برای این منظور، چارچوبهای داده توسط گروه بومشناسی سیستمهای زمینی در یک پروژه فرعی از پروژه RAMSES (کمکهای پژوهشی برای مدلسازی و شبیهسازی سیستمهای محیطی، [58]، www.sysecol.ethz.ch/ramses/ ) ، بر اساس توسعه داده شد. نظریه سیستم های ویمور و زیگلر [ 56 ، 57 ]. اینها همان چارچوب های داده ای هستند که قبلاً ذکر شد ( بخش 3 ) در زمینه ذخیره داده های متا همراه با داده های اصلی. قاب های داده صرفاً فایل های متنی هستند که می توانند آزادانه با استفاده از یک نحو خاص LL(1) قالب بندی شوند، به عنوان مثال، [ 52 ]، نحو DTF (به پیوست A.3 ، شکل A7 مراجعه کنید.) و با هر ابزاری که محقق ترجیح می دهد ایجاد و ویرایش می شوند. فریم های داده می توانند مجموعه داده های بزرگ و پیچیده ای را شامل شوند، نه تنها برای داده های مدل، بلکه برای نگهداری مشاهدات بزرگ (به بخش 3 مراجعه کنید ). این امکان پذیر است زیرا آنها می توانند هر تعداد فایل را از طریق مراجع فایل در بر گیرند ( پیوست A.3 ، شکل A7 را ببینید ) بدین ترتیب یک پایگاه داده کامل را تشکیل می دهند، اما به لطف فیلتر کردن و سایر تکنیک های شتاب، بازیابی کارآمدی را ارائه می دهند.
جداسازی خصوصیات مدل ریاضی (مثلاً شکل 8 ) از داده ها (مثلاً شکل 9 ) از بسیاری جهات قدرتمند است. همانطور که در بالا گفته شد برای شبیه سازان انعطاف پذیری ارائه می دهد، زیرا ترکیب رایگان n فریم داده با مدل های مشابه یا m با استفاده از چارچوب داده مشابه، امکان تعریف بسیاری از آنها را فراهم می کند، به عنوان مثال ، n × m�×مترآزمایش های شبیه سازی، به عنوان مثال، [ 59 ]. از آنجایی که نیاز کمی به بایگانی وجود دارد، در عین حال، کاریابی را تسهیل می کند n × m�×متربار مدل به علاوه داده، احتمالاً حاوی تعداد زیادی افزونگی است، اما فقط n قاب داده به اضافه کد برنامه های تعریف مدل m را بایگانی می کند .
چنین رویکردی برای مدل ریاضی عمداً ساده برای رشد لجستیک، DESS (مشخصات سیستم معادلات دیفرانسیل) نشان داده شده است. ایکس˙( t ) = a x ( t ) – b x( تی )2ایکس˙(تی)=آایکس(تی)–بایکس(تی)2( شکل 8 ).
برای هر شبیه سازی، آن مدل به مقادیر پارامتر (val) از جمله محدودیت های دامنه آنها (min، max) به اضافه واحدها و سایر داده ها مانند شرایط اولیه نیاز دارد. چارچوب داده نشان داده شده در شکل 9 این را برای پارامترهای مدل معادله لجستیک نشان می دهد.
جدا نگهداشتن دادهها از مدلهای ریاضی نه تنها مزایای فوقالذکر را ارائه میکند، به عنوان مثال، از نظر انعطافپذیری برای آزمایشهای شبیهسازی، بلکه مزایای قابلتوجهی را از نظر حفظ چنین تلاشهایی ارائه میدهد. بهویژه، اعتبارسنجی مدلسازی و شبیهسازی یک بار بایگانی و بازیابی شده را برای استفاده مجدد امکانپذیر میکند.
اگر یک ورودی مرجع خاص، مجدداً به شکل قابهای داده اختصاصی ذخیره شود (ورودی مرجع در شکل 7 )، و نتایج شبیهسازی مربوطه که رفتار مدل را تحت این شرایط نشان میدهند، مجدداً به عنوان خروجی مرجع کنار گذاشته شوند ( شکل 7 )، یک مجموعه آزمایشی برای استفاده مجدد از مدل ایجاد شده است. با توجه به این رویکرد، هر مدل باید همراه باشد (i) با ورودی مرجع خود متشکل از قاب های داده که آزمایش شبیه سازی خاصی را برای آزمایش تعریف می کند («ورودی مرجع» آبی تیره در شکل 7) و (2) خروجی مرجع ، یعنی شبیه سازی به عنوان مثال، در یک فایل به اصطلاح ذخیره («خروجی مرجع» آبی تیره در شکل 7). اگر همراه با کد مدل شبیهسازی آرشیو شود («مدل شبیهسازی» آبی تیره در شکل 7 )، هر گونه فعالسازی مجدد مدل را میتوان ابتدا با تولید مجدد خروجی مرجع و مقایسه آن با خروجی مرجع مورد انتظار همانطور که در آرشیو موجود است، آزمایش کرد. این تضمین میکند که محققی که کار روی آن مدل را در زمان بعدی بر روی یک ماشین و راهاندازی دیگر انتخاب میکند، میتواند ابتدا چنین آزمایشی را قبل از استفاده از مدل برای تحقیقات جدید انجام دهد.
این محقق را قادر می سازد تا از کیفیت بالای شی اطلاعات اطمینان حاصل کند، در حالی که تنها چند نتیجه شبیه سازی را بایگانی می کند (به بخش 3 ، شکل 3 مراجعه کنید ). در مواردی که نتایج شبیهسازی بسیار بزرگ است، به عنوان مثال، معمولاً برای نتایج پرهزینه از مدلهای آب و هوایی، این ممکن است به طور قابلتوجهی اندازه آرشیو را بدون به خطر انداختن تکرارپذیری کاهش دهد.
در اینجا چهار مورد قابل تفکیک است. آنها از ترکیب اجراهای شبیهسازی ارزان در مقابل پرهزینه به دلیل زمانهای طولانی شبیهسازی و/یا نیاز به کامپیوترهای فوقالعاده و ارزانقیمت ناشی میشوند.بایگانی پر هزینه به دلیل حجم داده ها اگر هم اندازه آرشیو کوچک باشد و هم آزمایش های شبیه سازی ارزان باشند، هیچ چالشی وجود ندارد. با این حال، رویکرد ما در دو موردی که اندازه آرشیو بزرگ یک چالش است، مزایای بزرگی ارائه میکند، اما ارائه تنظیمات شبیهسازی از جمله نتایج شبیهسازی آن را میتوان به راحتی انجام داد، یا زمانی که آزمایشهای شبیهسازی پرهزینه نتایج شبیهسازی با اندازه نسبتاً کوچک تولید میکنند. . این رویکرد تنها زمانی به محدودیتهای خود میرسد که هم نتایج شبیهسازی بزرگ به دست میآید و هم اجرای مجدد شبیهسازیها بسیار پرهزینه است، به عنوان مثال، موردی برای مدلهای گردش عمومی که در تحقیقات آب و هوایی استفاده میشود. روشی که برای ایجاد تعادل بین تعداد نتایج شبیه سازی وارد بایگانی می شود، باید بر اساس یک مورد به مورد تصمیم گیری شود. هنوز،
6. بحث و نتیجه گیری کلی
تنظیم دادههای دیجیتالی نیازمند اقدامات مناسب در مدیریت دادهها و تحقیقات است، به طور ایدهآل درست از ابتدای ایجاد داده، یعنی قبل از انجام تمام تحقیقات با استفاده از آن دادهها. چنین اقداماتی را تنها میتوان توسط خود محققانی که دادههایشان، وابستگیهای بین آنها و ابزارهای مورد نیاز را میدانند، و روابط بین دادهها، مدلها و نظریهها را کاملاً درک میکنند، بهعنوان مثال رجوع کنید به [13، 18، 37 ، 42 ] ، اجرا شود .
محققین برای انجام وظیفه خود نیاز به حمایت دارند که می تواند در قالب جریان های کاری ساختارمندتر ارائه شود. این به آنها اجازه می دهد تا تحقیقات بهتری را به طور کارآمدتر انجام دهند و در عین حال بررسی را تسهیل کنند. ما این را مدیریت داده های تحقیق ساختاریافته می نامیم، به عنوان مثال، [ 29 ] را نیز ببینید. این موضوع در محیطهای ترکیبی پیچیدهای که امروزه هنوز داریم، که بخشی از کار بهطور کامل دیجیتالیشده انجام میشود، اهمیت ویژهای دارد، در حالی که بخشهای دیگر، هر چند در حال کاهش هستند، سنتیتر باقی میمانند، یعنی « مبتنی بر کاغذ». بنابراین، اگر تحقیق و همچنین سرپرستی بتوانند از رویکردهایی که در اینجا پیشنهاد میکنیم سود ببرند، به نظر میرسد که در واقع یک موقعیت برد-برد خواهیم داشت.
با این حال، به دلیل این بینشها، شکاف فعلی در حال گسترش نه از بین میرود و نه محدود میشود و متصدیان نهادی مانند آرشیو دادهها و کتابخانهها با چالشهای قابلتوجهی هنگام تلاش برای به عهده گرفتن مسئولیت بر اساس مدل OAIS، به عنوان مثال، [33] مواجه میشوند . در بخش بعدی به برخی از دلایلی که ما را وادار می کند انتظار داشته باشیم که شکاف curation همچنان با ما باقی بماند و اینکه چرا رویکردهای پیشنهادی شرح داده شده در این مقاله نمی توانند بر شکاف curation به طور کامل غلبه کنند، بحث می کنیم.
ابزارهای ضعیف گاهی اوقات به عنوان بهانه ای برای فقدان مدیریت داده های تحقیق و سایر اقدامات برای ایجاد یک عمل تحقیقاتی ساختاریافته تر استفاده می شوند که باعث تسهیل در مدیریت می شود. برخی از تلاش ها برای رفع این نیاز انجام شده است، به عنوان مثال، [ 60 ]. ابزارهای پیچیده، اگر واقعاً در دسترس باشند، مطمئناً می توانند مدیریت و مدیریت داده ها را پشتیبانی و تسهیل کنند. اگر توسعهدهندگان نرمافزار تلاش کنند تا محققان را بهتر درک کنند و ابزارهای مناسبتری را در دسترس قرار دهند، ما نیز مانند دیگران انتظار داریم که وضعیت بهبود یابد، به عنوان مثال، [ 42]]. با این حال، باید ترسید که این کافی نباشد، زیرا انگیزه های اقتصادی ممکن است برای مشتریان محدود و بسیار متنوع محقق بسیار کم باشد، و/یا اینکه تحقیقات به سرعت پیشرفت کند که رسیدن کامل به آن برای همیشه بعید است.
از سوی دیگر توجه به این نکته نیز حائز اهمیت است که ابزارها، صرف نظر از اینکه چقدر به کمال نزدیک هستند، هرگز نمی توانند مفاهیم ضعیف را در مورد آنچه باید به دست آورد و کدام عوامل باید در تحقیق در نظر گرفته شوند، جبران کنند. همانطور که در این مقاله به طور گسترده نشان داده شده است، مفاهیم خوب طراحی شده را می توان حتی با منابع محدود و با ابزارهایی با قدرت محدود با ترکیب ابزارها بر اساس مفاهیم جامع، فراگیر و مهمتر از همه استوار و فکری پیاده سازی کرد. نتیجهای که از طریق ترکیبهای هوشمندانه به دست میآید بسیار بیشتر از آن چیزی است که از اجزای سازنده به تنهایی انتظار میرود. با این حال، چنین مفاهیمی گسترده نیستند، یا به دلایل مشابهی که به طور کلی به چالش کشیده می شود، اعتبار آنها به چالش کشیده می شود.
خوشبختانه، همانطور که مطالعه موردی نشان داد، شکاف درمان حداقل می تواند کاهش یابد. موفقیت قابل توجهی از نظر مدیریت به ویژه در زمینههای عمدهای به دست آمد که در آن چالشها در حال حاضر بزرگ هستند، اما برای تحقیقات در بسیاری از رشتهها بسیار مرتبط هستند، به عنوان مثال، برای (i) مدیریت داده، (ii) مدیریت ادبیات، و (iii) پیشرفت تئوری در زمینه ها با استفاده از مدل های پیچیده
رویکرد عملگرایانه استفاده بهینه از ابزارها و تکنیکهایی که در حال حاضر در دسترس است، همانطور که در اینجا پیشنهاد میکنیم، احتمالاً به دلایل زیادی که برخی از آنها در بالا ذکر شد، با ما باقی خواهد ماند. مورد دیگر که احتمالاً کاملاً مرتبط است، این است که محققان امروزی خود را با بسیاری از محیطهای تحقیقاتی متنوع و تا حدی ناسازگار میبینند که باید پیوسته با آنها سازگار شوند. مفاهیم انتزاعی، یعنی کلی و در عین حال جامع و قوی را می توان با این وجود به کار برد، زیرا آنها کمی به ابزارهای خاص و ویژگی های خاص آنها بستگی دارند. به همین دلیل است که ما استدلال میکنیم که برای کاهش شکاف سرپرستی، تمرکز قوی بر کاربرد عمومی و سازماندهی کار قبل از هر چیز بر اساس اصول کلی به جای راهحلهای خاص، کلیدی است، به عنوان مثال، [29 ] .
مطالعه موردی ما این را به طرز چشمگیری برای مدیریت ادبیات نشان می دهد ( بخش 4.2) که در آن ابزارهای کافی به ویژه در سال های قبل تا حد زیادی از دست رفته بودند. به دلیل ماهیت قوی و عمومی، این رویکرد با در دسترس قرار گرفتن ابزارهای جدید و/یا بهتر قابل گسترش بود و میتوانست گسترش یابد. همانطور که مدیریت ادبیات به طور خاص نیز نشان داد، ما هنوز با نیازهای واقعی محققین فاصله داریم و ابزارهای قوی تری برای تسهیل شیوه های تحقیقاتی مورد نیاز است، زیرا آنها به خوبی طراحی شده اند، از تبادل داده ها به طور انعطاف پذیر پشتیبانی می کنند، و در غیر این صورت به خوبی مناسب هستند. وضعیت امروز محقق البته اگر برخی از اصول ارائه شده، به عنوان مثال، جداسازی داده ها از مدل ها، از یک رشته به رشته دیگر منتقل شود، به محققان کمک بیشتری می شود. این رویکرد ما را زیر سوال نمی برد،
درسهای زیر را نیز میتوان از مطالعه موردی ما آموخت: بایگانی به خوبی زنده ماند و از سال 1989 تا به امروز به طور بینقصی به هدف خود عمل کرده است، بدین ترتیب از چندین تغییر تکنولوژیکی مانند تغییرات پلت فرم رایانه، بسیاری از تغییرات سیستم عامل و برنامه بدون نقص و بدون نیاز به حفظ است. هر گونه تعمیر و نگهداری اضافی به دلیل آن تغییرات. بنابراین به نظر میرسد که رویکرد مینیمالیستی نقش مهمی در این موفقیت داشته است و بر ارزش انجام کارهای ممکن تأکید میکند در حالی که راهحلهای بهتری در دسترس نیستند یا نمیتوان از پس آن برآمد. در این زمینه، شایان ذکر است که هر رویکرد کمتر مینیمالیستی در مراحل اولیه پروژه بلندمدت قبل از آرشیو ارائه شده در اینجا شکست خورده و باعث از دست دادن داده های حیاتی شده است، اما هنوز حل نشده است، در حالی که تلاش هایی برای نجات تا حد امکان انجام می شود، به عنوان مثال،
این تجربه همچنین تا حدودی به چالش می کشد یا حداقل باعث ایجاد برخی ملاحظات نسبت به شایستگی ابتکارات به اشتراک گذاری داده های بزرگ و همکاری می شود، به عنوان مثال، TERENO (رصدخانه های محیطی زمینی، teodoor.icg.kfa-juelich.de ، به عنوان مثال، [ 61 ]) یا TERN (زمینی) شبکه تحقیقات اکوسیستم، www.tern.org.au) ، جایی که هنوز باید نشان داده شود که (1) تلاش های چتر هماهنگ کننده بدون توجه به تغییرات تکنولوژیکی یا سازمانی بر مبنای طولانی مدت خواهد بود و می تواند حفظ شود و/یا (2) اینکه مشارکت های فردی می توانند دسترسی به داده های خود را به طور کامل حفظ کنند. یک پایه دائمی برای ذکر یک مثال کاملاً چشمگیر، تجربه ما، با مشارکت در شبکه مشابه LEMA (فعالیت مدلسازی بلندمدت اکوسیستم) پروژه GCTE (تغییر جهانی و اکوسیستمهای زمینی) IGBP (برنامه بینالمللی ژئوسفر-بیوسفر: مطالعه تغییر جهانی، به عنوان مثال، [ 62 ]، برای URL مراجعه کنید به [ 63 ])، نشان می دهد که خطرات فوق واقعی هستند، زیرا شبکه LEMA اکنون ناپدید شده است، به عنوان مثال، [ 64]]، علیرغم اینکه سنگ بنای مهم GCTE در نظر گرفته شده است، به عنوان مثال، [ 62 ]. در نهایت درسی که باید از این و تلاشهای مشابه آموخته شود، به عنوان مثال، [ 34 ] این است که مشارکت محققان برای موفقیت بسیار مهم است، مشابه فرض اولیه ما و یافتههای دیگران [ 18 ، 29 ، 37 ، 42 ، 47 ] .
در نهایت، یکی دیگر از پیش نیازهای اساسی برای موفقیت در کاهش شکاف سرپرستی، به ویژه در درازمدت، تعهد روشن از سوی رهبر گروه تحقیقاتی است، از جمله مهارتهایی برای اطمینان از اینکه همه اعضای کارکنان با ساختاردهی کار خود مطابق با مفاهیم مورد توافق مطابقت دارند.
با این حال، یک عمل تحقیقاتی بهبود یافته تنها مراحل اولیه چرخه حیات داده های تحقیق را پوشش می دهد. تلاشها در عمل تحقیقاتی باید با پاسخهای سازمانی بیشتر تکمیل شود [ 26 ، 29 ، 30 ]. دانشگاهها، سرمایهگذاران و مجلات نیز میتوانند نقش مهمی را ایفا کنند، به عنوان مثال، با تعیین انگیزههای مناسب برای یک عمل تحقیقاتی بهبود یافته از نظر سرپرستی، به عنوان مثال، [ 17 ، 19 ، 25 ، 28 ]. به طور قابلتوجه، اجرای دقیقتر یا گسترش دامنه دستورالعملهای موجود، ممکن است باعث پیشرفت شود، بهعنوان مثال، با اعمال دستورالعملهای انتشار موجود برای مطالب پشتیبانی به جای سپردن تمام مسئولیتها به نویسندگان.
علاوه بر این، دانشگاه ها، کتابخانه ها، بایگانی ها و مراکز داده باید تلاش های خود را برای رفع شکاف سرپرستی ادامه داده و تقویت کنند. ابتدا با ادامه حمایت و آموزش محققان. این همچنین مستلزم درک کاملی از نحوه کار محققان و چالش هایی است که باید با آنها روبرو شوند. ثانیاً، خدمات نگهداری داده ها، که مطمئناً پس از خروج داده های تحقیق از حوزه فردی محقق وارد عمل می شوند، باید بهبود و تقویت شوند. اگر متصدیان نیز نقش خود را در اینجا انجام دهند، یک رویکرد یکپارچه ممکن است به طور قابل توجهی سریعتر نتیجه دهد.
به طور کلی، با توجه به ملاحظاتی که در اینجا توضیح داده شد، نه تنها کیفیت ها در همه بخش های درگیر از طریق برد-برد متقابل افزایش می یابد، بلکه حرکت به سمت دسترسی آزاد به نتایج علمی نیز ممکن است پرورش یابد. حداقل در نتیجه به حداقل رساندن تلاش های اضافی مورد نیاز برای در دسترس قرار دادن اطلاعات به خوبی سازماندهی شده است. مطمئناً، تلاشهای انجام شده توسط جامعه پژوهشی و سرپرستی، در جهتهایی که در اینجا پیشنهاد میشود، به کاهش شکاف سرپرستی کمک میکند، و شاید حتی آن را در نهایت ناپدید میکند. گرایش به دیجیتالی شدن بیشتر ممکن است حتی به غلبه بر شکاف سرپرستی به جای کمک به آن کمک کند، همانطور که امروزه اغلب اتفاق می افتد.
از نظر چشم انداز آینده چنین تلاش هایی، موضوع پایداری دیجیتال در اینجا قابل ذکر است. حرکت به سمت خارجی سازی هزینه ها در درازمدت عدم تعادل ایجاد می کند. جامعه باید از نیاز به پایداری دیجیتال آگاه باشد، جایی که داده های تحقیقاتی مربوطه به طور ایمن برای نسل های آینده ذخیره می شود، به راحتی در دسترس است و توسط متخصصان نظارت می شود، به عنوان مثال، [ 15 ، 22 ]. همه اینها فقط از درخواست ما برای رویکردی عملگرایانه پشتیبانی می کند، مشابه آنچه که «تحقیق محض» سعی در انجام آن دارد.
پایداری دیجیتال نه تنها به معنای حفظ پایدار داده ها، تضمین بعد اجتماعی پایداری است، بلکه پایداری اقتصادی و زیست محیطی را نیز در بر می گیرد. مدیریت و حفظ داده های پژوهشی بیشتر و با ساختار بهتر می تواند به پیشرفت علمی کمک کند. به عنوان مثال می تواند به محققان کمک کند تا از تکرار ناخواسته تحقیقاتی که قبلاً نمی دانستند انجام شده است اجتناب کنند، شاید به این دلیل که آنها صرفاً به جزئیات آن تحقیق دسترسی نداشتند. این امر به نوبه خود باعث صرفه جویی در بودجه، صرفه جویی در زمان و منابع طبیعی مورد استفاده برای انجام تحقیقات می شود و شاید از این طریق حتی به طور کلی به پایداری کمک کند.
پیوست اول
پیوست A.1. جزئیات در مورد مفهوم آرشیو گروه اکولوژی سیستم های زمینی
مفهوم بایگانی مینیمالیستی همانطور که در بخش 2 معرفی شد نیاز به شرح ورودی بایگانی برای هر ورودی بایگانی دارد (AEDescr، قرمز، شکل 1 ). این متا داده ها باید در قالب یک فایل متنی ASCII جداگانه ارائه شوند و باید دقیقاً قبل از بایگانی به ورودی بایگانی اضافه شوند تا اطمینان حاصل شود که در صورت لزوم بازسازی متا داده از خود آرشیو امکان پذیر است. شکل A1 نشان میدهد که بایگانیکننده، معمولاً نویسنده، باید چه متا دادههایی را برای یک ورودی بایگانی با عنوان “Easy ModelWorks <= 1.3r2” ارائه دهد.
برای اینکه بتواند یک ورودی بایگانی را پیدا کند به اطلاعاتی در مورد رسانه (AEMedium، آبی، شکل 1 ) نیز نیاز دارد که در حال حاضر روی آن ذخیره شده است ( شکل A2 ). این یک فایل متنی ASCII جداگانه است که نباید به خود ورودی بایگانی اضافه شود، زیرا احتمالاً به دلیل نگهداری بایگانی تغییر می کند، به عنوان مثال، اگر یک ورودی بایگانی از یک رسانه قدیمی و قدیمی به یک رسانه جدید منتقل شود. این جداسازی به محتوای بایگانی اجازه می دهد تا بدون توجه به تغییرات در رسانه ذخیره سازی، همیشه ثابت نگه داشته شود ( شکل 1 ).
به منظور استانداردسازی ایجاد و نگهداری مدخلهای آرشیو، دستورالعملهای دستورالعمل، پژوهشگران را از طریق ایجاد یک ورودی بایگانی و متا دادههای آن راهنمایی میکند. راهنماهای دیگر به کاربران نحوه جستجو و بازیابی ورودیهای آرشیو و نحوه نگهداری آرشیو را آموزش میدهند.

شکل A1. نمونه ای از توضیحات ورودی بایگانی (به رنگ قرمز در شکل 1 نشان داده شده است ).

شکل A2. نمونه ای از توضیحات رسانه برای همان ورودی بایگانی که در شکل A1 توضیح داده شده است . چنین توضیحات رسانه ای در شکل 1 به رنگ آبی نشان داده شده است .
گردش کار برای یک ورودی جدید بایگانی:
- (1)
-
در مورد ورودی برنامه ریزی شده با عضو گروه مسئول بایگانی و همچنین رهبر گروه در صورت لزوم بحث کنید. آیا لحظه مناسب است، چه چیزی باید گنجانده شود، چه چیزی در جای دیگری بایگانی شد یا خواهد شد؟
- (2)
-
با انتقال و آماده سازی تمام عناصر برای بایگانی در یک پوشه واحد و همچنین با مرتب سازی و حذف فایل های منسوخ یا اضافی، ورودی بایگانی را آماده کنید.این مرحله بسیار مهم است زیرا جایی است که فایلهای حیاتی احتمالاً به فرمتهای فایل با طول عمر بیشتر تبدیل میشوند (مثلاً اسناد Word -> rtf، متن یا صفحات گسترده -> فایلهای SYLK). علیرغم اصل اجتناب از افزونگی، افزونگی دومی عمدی است زیرا باید به حداکثر استفاده طولانی مدت از آرشیو کمک کند. برای این منظور باید کپی های اضافی از اسناد مهمی که حاوی اطلاعات کمتری نسبت به اصل خود هستند، ذخیره شوند، به عنوان مثال، با ذخیره اجباری یک سند Word در قالب یک فایل متنی ساده که بدین وسیله تمام اطلاعات قالب بندی از بین می رود. بنابراین یک مقاله علمی، اگر، به عنوان مثال، با Word نوشته شده باشد، سه بار در ورودی آرشیو ذخیره می شود: (i) فایل Word باینری (doc/docx)، (ii) rtf (فایل متنی با اطلاعات قالب بندی)، (iii) فایل متنی ساده (فایل متنی بدون هیچ گونه اطلاعات قالب بندی). در نهایت برای اطمینان از استفاده مجدد، به عنوان مثال به منظور نوشتن اشتباه یا ادامه تحقیق، تمام فایل های اصلی اصلی که در تهیه شکل ها یا جداول استفاده می شوند، به عنوان مثال، رویه های آماری مانند اسکریپت های R، در آرشیو یک مقاله علمی، علی رغم اینکه انتشار دومی مثلا در صورت استفاده، تمام فایل های مورد نیاز به عنوان ورودی برای حروفچینی کامل، علاوه بر PDF منتشر شده، به شکل اصلی خود وارد آرشیو می شوند. ورودی بایگانی تنها زمانی آماده در نظر گرفته می شود که رویه هایی مانند حروفچینی را بتوان با استفاده از فایل های موجود در بایگانی انجام داد. بخشهای مشترک، بهعنوان مثال، نرمافزار مدلسازی و شبیهسازی، که توسط بسیاری از محققین به اشتراک گذاشته شده است را میتوان کنار گذاشت، اما چنین وابستگیهایی باید در تیم تحقیقاتی مورد بحث قرار گیرند تا اطمینان حاصل شود که آرشیو موازی آنها تضمین میشود.
- (3)
-
داده های متا، به عنوان مثال ، توضیحات ورودی بایگانی را برای ورودی بایگانی ایجاد کنید ( شکل A1 ). هر ورودی باید حاوی اطلاعاتی در مورد عنوان پروژه، نسخه، فهرست قطعات، نویسندگان، توضیحات محتوا، مدیریت (که همچنین شامل نرم افزار و/یا سخت افزار لازم برای خواندن داده ها) باشد، نکات کلی، اینکه آیا پروژه بخشی است یا خیر. از یک پروژه فرعی است و دارای هرگونه ارجاع متقابل، آرشیو و تاریخ ایجاد است.
- (4)
-
توضیحات ورودی بایگانی ( شکل A1 ) را به خود ورودی آرشیو اضافه کنید. به صورت اختیاری – مخصوصاً در مورد ورودیهای بایگانی بزرگ و پیچیده مفید است – به عنوان آخرین مرحله که بر محتوای آرشیو تأثیر میگذارد، میتوان از برخی ابزارهای فهرستبندی فایل برای اسکن کل ورودی بایگانی و افزودن یک قسمت فهرست فایل مفصل و جامع به ورودی بایگانی استفاده کرد. دوباره در قالب یک فایل متنی
- (5)
-
در مورد نوع و تعداد رسانه ذخیره سازی مورد نیاز تصمیم بگیرید ، به عنوان مثال، دیسک های مغناطیسی نوری (MO)، سی دی یا دی وی دی، که معمولاً با اندازه ورودی بایگانی تعیین می شود. از دیسکهایی استفاده کنید، بهعنوان مثال، دیسکهای MO، که قبلاً استفاده شدهاند، اگر هنوز پر نشدهاند و ورودی روی آن قرار میگیرد. اگر ورودی بایگانی بیش از حد بزرگ است که روی یک دیسک قرار نگیرد (رابطه n:n) از چندین دیسک، به عنوان مثال، DVD استفاده کنید.
- (6)
-
شرح رسانه را در ورودی بایگانی در فایل متنی کوچک جداگانه بنویسید. این متا داده ها رسانه ذخیره سازی، مکان و نام رسانه را توصیف می کنند ( شکل A2 ).
- (7)
-
ورودی بایگانی را دو بار در بایگانی ذخیره کنید . هنگامی که مراحل فوق برای رضایت همتا مسئول بایگانی تکمیل شد، ورودی بایگانی آماده را با کپی کردن دوبار کل شاخه سیستم فایل در رسانه ذخیره سازی هدف ذخیره کنید. هر دو کپی باید یکسان باشند و روی یک رسانه مانند دیسک MO، CD یا DVD ساخته شده باشند.
- (8)
-
توضیحات ورودی بایگانی را به فهرست جهانی ذخیره شده در سرور فایل مرکزی اضافه کنید ( شکل 1 ).
- (9)
-
شرح رسانه ورودی بایگانی را به فهرست جهانی ذخیره شده در سرور فایل مرکزی اضافه کنید. نمایه جهانی اکنون حاوی تمام داده های متا است که امکان دسترسی به هر ورودی بایگانی را فراهم می کند ( شکل 1 ).
- (10)
-
به صورت اختیاری شرح رسانه مدخل را در یک نمایه رسانه ای جداگانه و همچنین در مرکز ذخیره شده ذخیره کنید که همه رسانه های بایگانی موجود را جدول بندی می کند. آن شاخص حیاتی نیست (در شکل 1 نشان داده نشده است ) و فقط به بایگانیگر اطلاع میدهد که تعمیرات دورهای انجام شود، بهعنوان مثال ، با افزایش سن رسانهها، کدام بخشهای آرشیو باید در رسانههای جدید کپی شود و کدام توضیحات رسانهها نیاز به بهروزرسانی دارند.
- (11)
-
در نهایت، رسانه های آرشیو ، به عنوان مثال، دو دیسک MO، دو سی دی، یا دو دی وی دی، را در دو مکان جداگانه، به عنوان مثال، در یک گاوصندوق و یک کابینت بایگانی در یک ساختمان دیگر ذخیره کنید.
امنیت و حفظ طولانی مدت بایگانی با چندین اقدام تضمین شد: اول با استفاده از یک ایمن ضد بلایا (آتش، آب، رادیواکتیویته، پالس الکترومغناطیسی). ثانیا با ذخیره یک نسخه دوم از کل بایگانی در مکان دیگری. ثالثاً نگهداری پیشگیرانه بایگانی دورهای، با استفاده از نمایه رسانه ذخیرهسازی جداگانه، خوانایی را با انتقال ورودیهای آرشیو به رسانههای جدید به دلیل پیری رسانه و/یا تغییرات پلت فرم آنها تضمین میکند (به دنبال فواصل بازرسی/کپی رعایت میشود: پنج سال برای DVD و دیسکهای فلاپی، ده سال سال برای سی دی ها و دیسک های MO). چهارم، هر گونه از دست رفتن داده های متا که در خارج از بایگانی نگهداری می شود، به عنوان مثال در اثر آتش سوزی شاخص جهانی، بایگانی را به خطر نمی اندازد، زیرا مستقل است.، تمام متا داده ها، از جمله اطلاعات رسانه ذخیره سازی، می توانند از خود آرشیو بازسازی شوند، البته دومی نسبتاً پر زحمت است.
دسترسی به کارمندان عادی و قبلی محدود شده بود، در حالی که دادههای شخصی نیاز به مجوز اضافی خاص دارد، به عنوان مثال، از رهبر یا معاون آن، برای محافظت از حریم خصوصی دادههای شخصی احتمالاً درگیر. این رویکرد شامل Private و Shared است، اما نه دامنه عمومی همانطور که در شکل 2 نشان داده شده است .
گردش کار بازیابی از سه مرحله تشکیل شده است: (1) جستجو برای یک ورودی در فهرست جهانی، (2) اطمینان از داشتن حقوق دسترسی، و (iii) کپی کردن ورودی بایگانی مورد نیاز از رسانه بایگانی در رایانه ای که در حال حاضر استفاده می شود. سیستم. از کاربران آرشیو خواسته شد که هدف بازیابی را روشن کنند، اینکه آیا داده ها برای اهداف فقط خواندنی بازیابی شده اند یا برای ادامه تحقیق. در مورد قبلی، کاربران مجبور بودند کپی بازیابی شده را پس از استفاده حذف کنند تا از بایگانی مجدد تصادفی جلوگیری کنند. در مورد استفاده مجدد برای تحقیقات جدید، کاربران باید مطمئن می شدند که داده ها فقط در صورت اصلاح واقعی دوباره بایگانی می شوند.
ضمیمه A.2. مدیریت مرجع
این یک پیاده سازی مشخص از مفهوم مدیریت ادبیات ارائه شده در بخش 4.2 را توصیف می کند . برای اجرای سیستم مدیریت ادبیات پیشنهادی، باید برخی از اصول طراحی اساسی رعایت شود. در میان آنها به اصطلاح انواع مرجع هستند ( شکل A3 ).

شکل A3. انواع مراجع مورد استفاده در سیستم مدیریت ادبیات پیشنهادی شامل L i t Ce n t r a l�منتیسیه�تی�آلو شاخه های شخصی آن L i T MYایکس�منتیم�ایکس( ر.ک. شکل 5 ) با استفاده از FileMaker ( : انواع ورودی؛ EndNote : انواع مرجع؛ مندلی : نوع و غیره ) اجرا شده است. در ستون دوم توضیحاتی در مورد نوع مرجع و کاربرد آن ارائه شده است. رنگها همراه با دنباله اولویتها را مشخص میکنند (بالا سبز بالاتر، پایینترین قرمز) که در مواردی که چندین احتمال وجود دارد، باید از انواع مرجع استفاده شود.
ارجاعات باید به طور جامع تعریف شوند و در میان همه ابزارهای پشتیبانی شده، به ویژه «مدیرهای مرجع» خاص مانند BibDesk یا EndNote یا Mendeley مبتنی بر نقشهبرداری شوند . کاری به دور از بی اهمیت بودن. مجموعه ای که در شکل A3 نشان داده شده است چندین سال است که با موفقیت مورد استفاده قرار گرفته است و تمام نیازها را برآورده می کند. با این حال، بیشتر برای دانشمندان علوم طبیعی هدف قرار گرفته است و ممکن است به اندازه کافی از دانشمندان علوم اجتماعی و دانشمندان علوم انسانی حمایت نکند. بهویژه، این مجموعه احتمالاً نیاز به تمدید دارد تا به خوبی به دانشمندان حقوقی خدمت کند. با این حال، و مهمتر از آن، شکل A3 انواع مرجعی را پیشنهاد میکند که معمولاً استفاده میشوند، اما به طور شگفتانگیزی در برخی از مدیران مرجع محبوبتر (مانند مندلی) فاقد آن هستند. از جمله آنها انواع مرجع هستند Eدمن d e dB o o k�دمنتیهدب��ک، منn Eدمن d e dB o o kمن��دمنتیهدب��ک، یا منn Pr o c e e dمن n gسمن�پ��جههدمن��س، که در صورت عدم وجود و در نتیجه مخلوط کردن، به عنوان مثال، B o o kب��کبا Eدمن d e dB o o k�دمنتیهدب��ک، از تولید یک فهرست مناسب و بدون ابهام از مراجع جلوگیری کنید که، به عنوان مثال، به وضوح بین ویراستاران و نویسندگان تمایز قائل شود.
انواع مرجعی را پیشنهاد میکند که معمولاً استفاده میشوند، اما به طور شگفتانگیزی در برخی از مدیران مرجع محبوبتر (مانند مندلی) فاقد آن هستند. از جمله آنها انواع مرجع هستند Eدمن d e dB o o k�دمنتیهدب��ک، منn Eدمن d e dB o o kمن��دمنتیهدب��ک، یا منn Pr o c e e dمن n gسمن�پ��جههدمن��س، که در صورت عدم وجود و در نتیجه مخلوط کردن، به عنوان مثال، B o o kب��کبا Eدمن d e dB o o k�دمنتیهدب��ک، از تولید یک فهرست مناسب و بدون ابهام از مراجع جلوگیری کنید که، به عنوان مثال، به وضوح بین ویراستاران و نویسندگان تمایز قائل شود.شکل A3 همچنین نحوه استفاده از این انواع مرجع را توصیه می کند، به ویژه زمانی که محقق ممکن است در مورد استفاده از آن شک داشته باشد یا به راهنمایی روشن نیاز دارد. به عنوان مثال: یک شماره ویژه از یک مجله علمی حاوی مجموعه مقالات یک کنفرانس را می توان با استفاده از نوع مرجع مقالات ویرایش شده ، کتاب ویرایش شده ، یا مجموعه مقالات استناد کرد . سپس میتوان به مقالهای که در چنین جلساتی منتشر شده است، با استفاده از نوع مرجع مقاله مجله ، در کتاب ویرایش شده یا در مجموعه مقالات استناد کرد . این جدول توصیه می کند که مقالات ویرایش شده را به کتاب یا مجموعه مقالات ویرایش شده ترجیح دهید و به مقاله مجله ترجیح دهیددردر کتاب ویرایش شده یا بیش از آن در مجموعه مقالات . انتظار می رود این اولویت ها به خوانندگان و کتابداران کمک کند تا آثار ذکر شده را پیدا کنند و از اشتباه رایج استفاده از ظاهر فیزیکی یک اثر، به عنوان مثال، کتاب بودن، به عنوان مبنایی برای تصمیم گیری برای استفاده از نوع مرجع جلوگیری کنند.
مفهوم پیشنهادی مستلزم انتقال آزادانه سوابق در میان ابزارهای درگیر مانند پایگاه داده FileMaker با اهمیت محوری در حوزه هر محقق، کتابشناسی های EndNote خاص پروژه ، به عنوان مثال، هنگام نوشتن مقاله با مایکروسافت ورد ، و فایل های خاص پروژه، به عنوان مثال، هنگام نوشتن مقالات با . پایگاه داده مرکزی که تمام رکوردهای متعلق به یک کاربر را ذخیره می کند، فقط پایگاه داده FileMaker است (سوابق سبز، شکل 5 ). هر گونه ذخیرهسازی خاص پروژه از نسخههای فقط خواندنی در کتابشناسیهای EndNote یا فایلهای BibDesk (سوابق نارنجی، شکل 5) ) شامل یک زیر مجموعه گزیده از رکوردها است. هر گونه به روز رسانی رکوردهای سبز نیاز به انتقال مجدد از FileMaker به فایل های خاص پروژه EndNote یا فایل های BibDesk دارد ، و هر رکورد نارنجی رنگی که احتمالاً در آنجا ذخیره شده است را بازنویسی کنید ( به شکل A4 و شکل A5 مراجعه کنید ).
) شامل یک زیر مجموعه گزیده از رکوردها است. هر گونه به روز رسانی رکوردهای سبز نیاز به انتقال مجدد از FileMaker به فایل های خاص پروژه EndNote یا فایل های BibDesk دارد ، و هر رکورد نارنجی رنگی که احتمالاً در آنجا ذخیره شده است را بازنویسی کنید ( به شکل A4 و شکل A5 مراجعه کنید ). 
شکل A4. سوابق را بین پایگاه داده Filemaker LiteratureMY و کتابشناسی EndNote پروژه خاص EndNoteMY منتقل کنید ( شکل 5 را نیز ببینید ). انتقال در هر دو جهت امکان پذیر است، در حالی که انتقال از EndNote به FileMaker فقط در هنگام ورود رکوردهای جدید استفاده می شود. استفاده از هر ابزار میانی مانند ویرایشگر متن متن باز مبتنی بر tcl AlphaX کاملاً خودکار است و نیازی به دخالت کاربر ندارد.
مفاهیم انتقال همچنین امکان استفاده از چندین دستگاه را فراهم می کند ( شکل 5 ). اینکه محقق x از بیش از یک دستگاه استفاده کند، مثلاً یک لپتاپ و یک تبلت، کاملاً تصمیم x است. مشخصاً همگام سازی رکوردها در بین چندین دستگاه متعلق به یک شخص x نیز تنها مسئولیت شخصی محقق x است . در اینجا ( شکل 5 ) از نظر مفهومی فرض میکنیم که وقتی یک شخص از چندین دستگاه استفاده میکند، این اساساً به معنای تکراری شدن دامنه A در چندین دستگاه است، که در آن مسئولیت محقق فردی است که مطمئن شود او فقط با نسخه اصلی کار میکند. هر نقطه از زمان
خوشبختانه ابزارهای موجود در حال حاضر گزینه هایی را ارائه می دهند، به عنوان مثال، از طریق به اصطلاح ابری، برای همگام سازی متا داده های کتابشناختی و متون کامل در بین دستگاه های شخصی. با این حال، در موارد نقص فنی یا غیرقابل اعتماد بودن تکنیکهای همگامسازی خودکار، از لحاظ فنی، همگامسازی دستی ساده از یک دستگاه اصلی اختصاصی به دستگاه دیگر، به عنوان مثال، با استفاده از یک ابزار همگامسازی کلاسیک در سطح فایل (چنین ابزارهایی که برای این منظور مفید هستند نیز ارائه میشوند. به عنوان “نرم افزار رایگان” www.sysecol.ethz.ch/people/afischli/software توسط یکی از نویسندگان)، همچنین می تواند به غلبه بر کاستی های متعدد امروزی خدمات ابری در حال حاضر در بازار کمک کند. باز هم، سیستم پیشنهادی ما در اینجا انعطاف پذیری کامل را ارائه می دهد.
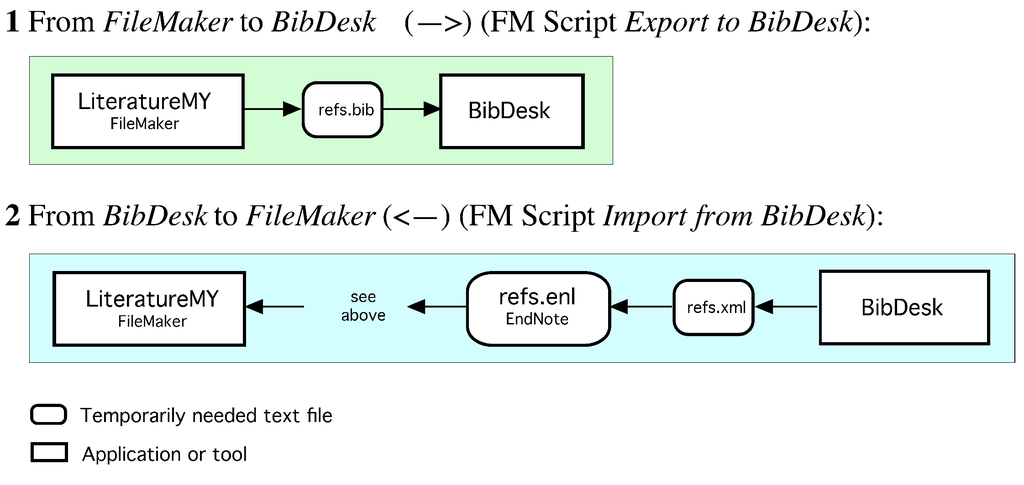
شکل A5. سوابق را بین پایگاه داده Filemaker LiteratureMY و یک فایل خاص پروژه BibDesk منتقل کنید (همچنین به شکل 5 مراجعه کنید ؛ BibDesk یک مدیر منبع باز همه کاره و قدرتمند برای فایل ها است). انتقال در هر دو جهت امکان پذیر است، در حالی که انتقال از BibDesk به FileMaker فقط در هنگام ورود رکوردهای جدید استفاده می شود. استفاده از هر ابزار میانی مانند EndNote یا ویرایشگر متن منبع باز مبتنی بر tcl AlphaX کاملاً خودکار است و نیازی به دخالت کاربر ندارد ( شکل A4 را ببینید ).

شکل A6. نگاشت انواع مرجع بین سیستم های درگیر، به عنوان مثال ، پایگاه داده Filemaker LiteratureMY ، EndNote ، و .
انتقال رکوردها ( شکل A4 و شکل A5 ) البته نیاز به نگاشت انواع مرجع ( شکل A3 ) از یک مکان ذخیره سازی به مکان دیگر دارد. شکل A6 نگاشت بین FileMaker ، EndNote و .
ضمیمه A.3. مدل سازی و شبیه سازی
چارچوب های داده، به عنوان مثال، [ 59 ] توسط گروه بوم شناسی سیستم های زمینی در چارچوب داعش (نرم افزار پیاده سازی سیستم های یکپارچه، www.sysecol.ethz.ch/ramses/layer/ISIS ) در قیاس با مفهوم نظری سیستم توسعه داده شد. فریم های تجربی، به عنوان مثال، [ 54 ]. قابهای داده به دادهها اجازه میدهند که در فرمت آزاد روی فایلهای متنی ساده ذخیره شوند و در یک نحو خاص DTF نوشته شوند ( شکل A7 ). نحو DTF LL(1) است، به عنوان مثال، با توضیحات مختصر [ 52 ] برای تجزیه آسان تر و کارآمد و اجازه می دهد تا داده های متا را در هر جایی تزریق کنند، و ذخیره داده ها را بسیار بصری برای درک می کند (به عنوان مثال، شکل 4 و شکل 9 ).

شکل A7. تعریف توسعه یافته Backus-Naur از نحو DTF مورد استفاده در ISIS (نرم افزار پیاده سازی سیستم های یکپارچه) برای ذخیره داده ها در قالب به اصطلاح Data Frames. دومی توسط گروه اکولوژی سیستم های زمینی توسعه داده شد. نحو DTF LL(1) [ 52 ] است و به عنوان مثال، ذخیره سازی داده های چند فایلی انعطاف پذیر و دسترسی تصادفی کارآمد را در زمان اجرا امکان پذیر می کند، به عنوان مثال، زمانی که داده ها توسط برنامه های تعریف مدل قابل دسترسی هستند، به عنوان مثال، [58] (به عنوان مثال ، شکل 4 ، شکل 8 و شکل 9 ).
برای بازیابی کارآمد و ذخیره سازی مدولار، می توان داده ها را به شیوه ای توزیع شده با استفاده از منابع فایل شرطی ذخیره کرد (به ساختار FileReference مراجعه کنید، به عنوان مثال، FILE = “~/DataBases/TemperatureObs/CH1887-1921.DTF؛ USE IF FILTER = 1880”). یک قاب داده باید به طور کامل در یک فایل ذخیره شود، در حالی که یک فایل ممکن است حاوی n قاب داده باشد (به عنوان مثال، شکل 4 ). اگر در طول بازیابی با تعاریف چندگانه قاب داده با همان شناسه مواجه شد، فقط داده های آخرین خوانده شده در واقع قابل دسترسی هستند، در حالی که مراجع فایل دایره ای اسکن شاخه درگیر را با بسته شدن دایره لغو می کنند.
بازیابی اطلاعات ذخیره شده توسط Data Frames از طریق تعاریف به اصطلاح ارزش انجام می شود. چارچوب داده ها امکان دسترسی تصادفی به داده ها را از طریق یک شناسه فراهم می کند و توالی ذخیره سازی را از توالی استفاده جدا می کند. این جداسازی همچنین امکان دسترسی به دادهها را در زمان اجرا از درون برنامههای تعریف مدل [ 58 ] فراهم میکند و یک محیط شبیهسازی بسیار انعطافپذیر و از لحاظ نظری سالم را فراهم میکند. با استفاده از چارچوب داده از شکل 4 ، شناسه ای که نشان دهنده نام علمی گونه درختی صنوبر نقره ای اروپایی است، “ForClim.Aalb.Scientific_name” (تعریف مقدار اسکالر) خواهد بود در حالی که بردار اندازه های سطل از تمام سایت های موجود با شناسه نشان داده می شود. “ForClim.Bucketsize” یا شناسه های همه سایت ها توسط “ForClim.SiteID” (تعریف مقدار برداری).
فریم های داده تنها چهار نوع داده ابتدایی را می شناسند: اعداد حقیقی و صحیح، رشته ها و شناسه ها. اعداد را می توان با هر دقتی ارائه کرد و نحوه کنترل واقعی آنها به پلت فرم بستگی دارد. اگر یک بایگانی قدیمی در پلتفرمی متفاوت از جایی که در ابتدا بایگانی شده است دوباره استفاده شود، ممکن است مشکلات عددی در هنگام تبدیل به فرمتهای باینری ایجاد شود. اگر کارایی مورد توجه خاصی باشد، البته می توان Data Frame ها را قبل از استفاده پردازش کرد و داده ها را به طور موقت به شکل باینری ذخیره کرد. آن ابزارهای مورد نیاز برای تولید مخازن باینری البته باید بایگانی شوند.
منابع
- Bunge, M. Scientific Research I: The Search for System ; مطالعات در روش مبانی و فلسفه علم; Springer: برلین، آلمان، 1967. [ Google Scholar ]
- Bunge, M. Scientific Research II: The Search for Truth ; مطالعات در روش مبانی و فلسفه علم; Springer: برلین، آلمان، 1967. [ Google Scholar ]
- پوپر، KR حدس و گمان ها و ابطال ها: رشد دانش علمی . Routledge & Kegan Paul: نیویورک، نیویورک، ایالات متحده آمریکا، 1963. [ Google Scholar ]
- پوپر، ک. دانش عینی: یک رویکرد تکاملی . Clarendon Press: آکسفورد، بریتانیا، 1972. [ Google Scholar ]
- Pearce-Moses, R. A Glossary of Archival and Records Terminology ; انجمن آرشیوداران آمریکا (SAA): شیکاگو، IL، ایالات متحده آمریکا، 2005. [ Google Scholar ]
- وایت، ا. ایوب، دی. گیلز، اس. لاوری، اس. چالش های سرپرستی در یک گروه تصویربرداری عصبی. بین المللی جی دیجیت. Curation 2008 , 3 , 171-181. [ Google Scholar ] [ CrossRef ]
- بالتنسوایلر، دبلیو. Fischlin، A. پروانه جوانه کاج اروپایی در کوه های آلپ. در دینامیک جمعیت حشرات جنگلی: الگوها، علل، پیامدها . بریمن، AA، اد. Plenum Publishing Corporation: نیویورک، نیویورک، ایالات متحده آمریکا، 1988; جلد 1، ص 331-351. [ Google Scholar ]
- بالتنسوایلر، دبلیو. Fischlin، A. در مورد روش های تجزیه و تحلیل اکوسیستم ها: درس هایی از تجزیه و تحلیل سیستم های جنگلی-حشره ای. Ecol. گل میخ. 1987 ، 61 ، 401-415. [ Google Scholar ]
- فیشلین، ا. Baltensweiler, W. تجزیه و تحلیل سیستم سیستم پروانه جوانه کاج اروپایی. بخش اول: رابطه پروانه جوانه کاج اروپایی و کاج اروپایی. میت شویز. Ent. Ges. 1979 ، 52 ، 273-289. [ Google Scholar ]
- روچتی، ج. فیشلین، ا. Strässler، E. DDLDML. Hilfsprogramm für PASCAL Programmierer zur Definition und Verwaltung von INFOSYS-Datenfiles (MANUAL) ; Institut für Phytomedizin ETHZ (vormals Entomologisches Institut ETHZ): زوریخ، سوئیس، 1978. [ Google Scholar ]
- کمیته مشورتی سیستم های داده های فضایی و دبیرخانه (CCSDS). مدل مرجع برای یک سیستم اطلاعات بایگانی باز (OAIS)—عمل توصیه شده ؛ CCSDS: واشنگتن، دی سی، ایالات متحده آمریکا، 2012. [ Google Scholar ]
- آندره، PQC؛ بسر، اچ. الکینگتون، ن. گرت، جی. گلدنی، اچ. هدستروم، ام. هیرتل، پی بی. هانتر، ک. کلی، آر. کرش، دی. و همکاران حفظ اطلاعات دیجیتال: گزارش کارگروه آرشیو اطلاعات دیجیتال . کمیسیون حفظ و دسترسی و گروه کتابخانه های تحقیقاتی (RLG): نیویورک، نیویورک، ایالات متحده آمریکا، 1996. [ Google Scholar ]
- نایت، جی. پنوک، ام. داده های بدون معنی: ایجاد ویژگی های مهم تحقیقات دیجیتال. بین المللی جی دیجیت. Curation 2009 , 4 , 159-174. [ Google Scholar ] [ CrossRef ]
- هسو، ال. مارتین، RL; مک الروی، بی. لیتوین میلر، ک. کیم، دبلیو. مدیریت دادهها، اشتراکگذاری و استفاده مجدد در ژئومورفولوژی تجربی: چالشها، استراتژیها و فرصتهای علمی ژئومورفولوژی 2015 ، 244 ، 180-189. [ Google Scholar ] [ CrossRef ]
- استافورد، N. علم در عصر دیجیتال. Nature 2010 ، 467 ، S19–S21. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- بیگری، ن. لاووی، بی. Woolard, M. ایمن نگه داشتن داده های تحقیق 2 ; JISC: سالزبری، بریتانیا، 2010. [ Google Scholar ]
- بیگری، ن. Chruszcz, J.; لاووی، بی. ایمن نگه داشتن داده های تحقیقاتی: مدل هزینه و راهنمایی برای دانشگاه های بریتانیا . JISC: سالزبری، انگلستان، آوریل 2008. [ Google Scholar ]
- غفلت خوش خیم Deridder، JL: توسعه قایق های نجات برای محتوای دیجیتال. Inf. تکنولوژی Libr 2011 ، 30 ، 71-74. [ Google Scholar ] [ CrossRef ]
- کویپرس، تی. ون در هوون، جی. بینش در مورد حفظ دیجیتالی خروجی تحقیقات در اروپا: گزارش نظرسنجی PARSE-Insight D3.6 ; پروژه PARSE.Insight—دسترسی دائمی به سوابق علم در اروپا: Didcot، انگلستان، 2010. [ Google Scholar ]
- والر، ام. Sharpe, R. Mind the Gap-Assessing Digital Preservation Needs in the UK ; ائتلاف حفظ دیجیتال (DPC): یورک، بریتانیا، 2006. [ Google Scholar ]
- نلسون، بی. اشتراک گذاری داده ها: بایگانی خالی. طبیعت 2009 ، 461 ، 160-163. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Pryor, G. (Ed.) Managing Research Data ; Facet Publishing: لندن، انگلستان، 2012.
- آیریس، پ. دیویس، آر. مک لئود، آر. میائو، آر. شنتون، اچ. Wheatley، P. گزارش نهایی پروژه LIFE2 . گزارش نهایی (22/08/08); JISC، کتابخانه بریتانیا، کالج دانشگاه لندن، LIBER: لندن، انگلستان، 2008. [ Google Scholar ]
- برتون، ا. Groenewegen، D.; عشق، سی. ترلوار، ا. Wilkinson, R. در دسترس قرار دادن داده های تحقیقاتی در استرالیا. IEEE Intell. سیستم 2012 ، 27 ، 40-43. [ Google Scholar ] [ CrossRef ]
- دیویدسون، جی. جونز، اس. مولوی، ال. Kejser، UB روش خوب در حال ظهور در مدیریت داده های تحقیقاتی و اطلاعات تحقیقاتی در دانشگاه های بریتانیا. Proecedia Comput. علمی 2014 ، 33 ، 215-222. [ Google Scholar ] [ CrossRef ]
- کویپرس، تی. ون در هوون، جی. بینش در مورد حفظ دیجیتالی خروجی تحقیقات در اروپا: گزارش نظرسنجی PARSE-Insight . گزارش بینش D3.4; پروژه PARSE.Insight—دسترسی دائمی به سوابق علم در اروپا: Didcot، انگلستان، 2009. [ Google Scholar ]
- نوروت، اچ. استراتمن، اس. اوسبالد، ا. شفل، آر. کلمپ، جی. Ludwig, J. (Eds.) مدیریت دیجیتال داده های تحقیقاتی – تجربیات یک مطالعه پایه در آلمان ; Verlag Werner Hülsbusch: Glückstadt، آلمان، 2013.
- OpenAIRE. برگههای اطلاعات OpenAIRE Horizon2020: آزمایشی دادههای تحقیقاتی باز در Horizon 2020. 2015. در دسترس آنلاین: www.openaire.eu/or-data-pilot-factsheet (در 3 ژوئن 2016 قابل دسترسی است).
- پریور، جی. جونز، اس. کالینز، ای. Whyte, A. (Eds.) ارائه خدمات مدیریت داده های پژوهشی: مبانی عملکرد خوب . Facet Publishing: لندن، انگلستان، 2014.
- تنوپیر، سی. توس، بی. Allard، S. کتابخانه های آکادمیک و خدمات داده های تحقیقاتی: رویه ها و برنامه های فعلی برای آینده . انجمن کتابخانههای کالج و تحقیقات (ACRL): شیکاگو، IL، ایالات متحده آمریکا، 2012. [ Google Scholar ]
- تنوپیر، سی. Sandusky، RJ; آلارد، اس. توس، ب. خدمات مدیریت داده های پژوهشی در کتابخانه های پژوهشی دانشگاهی و ادراکات کتابداران. Libr Inf. علمی Res. 2014 ، 36 ، 84-90. [ Google Scholar ] [ CrossRef ]
- Palaiologk، AS; Economides، AA; Tjalsma، HD; Sesink، LB یک مدل هزینهیابی مبتنی بر فعالیت برای حفظ و انتشار طولانیمدت دادههای تحقیقات دیجیتال: مورد DANS. بین المللی جی دیجیت. Libr 2012 ، 12 ، 195-214. [ Google Scholar ] [ CrossRef ]
- کجسر، UB; نیلسن، AB; Thirifays، A. مدل هزینه برای حفظ دیجیتال: هزینه مهاجرت دیجیتال. بین المللی جی دیجیت. Curation 2011 , 6 , 255-267. [ Google Scholar ] [ CrossRef ]
- کارلسون، دی. درس به اشتراک گذاری. طبیعت 2011 ، 469 ، 293-293. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Björk، BC; هدلاند، تی. یک مدل رسمی از فرآیند انتشار علمی. اطلاعات آنلاین Rev. 2004 , 28 , 8-21. [ Google Scholar ] [ CrossRef ]
- توماس، ا. کمپبل، LM؛ بارکر، پی. هاکسی، ام. (ویرایشگاه) Into the Wild: Technology for Open Educational Resources ; دانشگاه بولتون: بولتون، انگلستان، 2012.
- ون دن آیندن، وی. Bishop, L. Sowing the Seed: مشوق ها و انگیزه ها برای به اشتراک گذاری داده های تحقیقاتی، دیدگاه محقق . آرشیو دادههای بریتانیا، دانشگاه اسکس: اسکس، بریتانیا، 2014. [ Google Scholar ]
- چو، اچ. روش های تحقیق در علم کتابداری و اطلاع رسانی: تحلیل محتوا. Libr Inf. علمی Res. 2015 ، 37 ، 36-41. [ Google Scholar ] [ CrossRef ]
- تامارو، AM; کازاروسا، وی. مدیریت داده های تحقیق در برنامه درسی: یک رویکرد بین رشته ای. Proecedia Comput. علمی 2014 ، 38 ، 138-142. [ Google Scholar ] [ CrossRef ]
- جونز، اس. چگونه یک برنامه مدیریت داده و اشتراک گذاری ایجاد کنیم . DCC چگونه به راهنمای. مرکز مدیریت دیجیتال (DCC): ادینبورگ، اسکاتلند، 2011. [ Google Scholar ]
- وربان، ای. کاکس، AM خرده فرهنگهای شغلی، مبارزه قضایی و فضای سوم: نظریهپردازی پاسخهای خدمات حرفهای به مدیریت دادههای پژوهشی. J. Acad. Libr 2014 ، 40 ، 211-219. [ Google Scholar ] [ CrossRef ]
- گودمن، ا. پپه، آ. مسدود کننده، AW؛ بورگمن، CL; کرانمر، ک. کراساس، ام. دی استفانو، آر. گیل، ی. گروت، پ. هدستروم، ام. و همکاران ده قانون ساده برای مراقبت و تغذیه از داده های علمی. محاسبات PLoS. Biol. 2014 ، 10 ، e1003542. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- فاستر، NF; Gibbons، S. درک اعضای هیئت علمی برای بهبود جذب محتوا برای مخازن سازمانی. D-Lib Mag. 2005 ، 11 ، 1-12. [ Google Scholar ] [ CrossRef ]
- تنوپیر، سی. King, DW کاربرد و ارزش مجلات علمی: گذشته، حال و آینده. سریال های 2001 ، 14 ، 113-120. [ Google Scholar ] [ CrossRef ]
- تنوپیر، سی. کینگ، DW; اسپنسر، جی. وو، ال. تغییرات در الگوهای جستجوی مقاله و خواندن دانشگاهیان: چه چیزی تفاوت را ایجاد می کند؟ Libr Inf. علمی Res. 2009 ، 31 ، 139-148. [ Google Scholar ] [ CrossRef ]
- مورو، تی. بیگری، ن. جونز، ام. Chruszcz, J. A Comparative Study of E-Journal Archiving Solutions ; کمیته مشترک سیستم های اطلاعاتی (JISC): بریستول، انگلستان، 2008. [ Google Scholar ]
- Sutter، RD; Wainscott، SB; Boetsch, JR; پالمر، سی جی; Rugg, DJ راهنمای عملی برای ادغام مدیریت داده ها در پروژه های بلندمدت نظارت بر محیط زیست. Wildl. Soc. گاو نر 2015 ، 39 ، 451-463. [ Google Scholar ] [ CrossRef ]
- والدراپ، ام ام منشا محاسبات شخصی. علمی صبح. 2001 ، 285 ، 84-91. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ترلوار، ا. Harboe-Ree, C. مدیریت داده و پیوستار سرپرستی: چگونه تجربه موناش روابط مخزن را اطلاع رسانی می کند. در مجموعه مقالات چهاردهمین انجمن ویکتوریا برای اتوماسیون کتابخانه، کنفرانس و نمایشگاه، ملبورن، VIC، استرالیا، 5-7 فوریه 2008.
- Treloar, A. Private Research, Shared Research, Publication, and the Boundary Transitions, Version 1.4.3, 19 Mar 2012. موجود آنلاین: andrew.treloar.net (در 8 ژوئن 2016 قابل دسترسی است).
- CCSDS. سیستمهای انتقال اطلاعات و دادههای فضایی—سیستم اطلاعات بایگانی باز (OAIS)—مدل مرجع ; ISO 14721:2012; کمیته مشورتی برای سیستم های داده های فضایی و سازمان بین المللی استاندارد (ISO): ژنو، سوئیس، 2012. [ Google Scholar ]
- Bongulielmi، AP; Cellier، FE در مورد سودمندی گرامرهای قطعی برای زبان های شبیه سازی. ACM SIGSIM Simul. دایجست 1984 ، 15 ، 14-36. [ Google Scholar ] [ CrossRef ]
- زومشتاین، پی. Stöhr, M. Zur Nachnutzung von bibliographischen Katalog- und Normdaten für die persönliche Literaturverwaltung und Wissensorganisation. ABI Tech. 2015 ، 35 ، 210-221. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- زایگلر، BP پنج عنصر. در نظریه مدلسازی و شبیه سازی ، ویرایش اول. رابرت، ای.، اد. Krieger Publishing Company Inc.: Malabar, FL, USA, 1976; ص 27-49. [ Google Scholar ]
- زیگلر، بی پی مدلسازی چند فرمالیسم چندسطحی: یک نمونه اکوسیستم. در اکولوژی سیستم های نظری ; Halfon, E., Ed. مطبوعات آکادمیک: نیویورک، نیویورک، ایالات متحده آمریکا، 1979; صص 17-54. [ Google Scholar ]
- زایگلر، نظریه مدل سازی و شبیه سازی BP ، ویرایش اول. رابرت، ای.، اد. Krieger Publishing Company Inc.: Malabar, FL, USA, 1976. [ Google Scholar ]
- وای مور، نظریه سیستم های AW. در کتابچه راهنمای مهندسی نرم افزار ; Vick, CR, Ramamoorthy, CV, Eds. شرکت Van Nostrand Reinhold: نیویورک، نیویورک، ایالات متحده آمریکا، 1984; صص 119-133. [ Google Scholar ]
- Fischlin، A. مدل سازی تعاملی و شبیه سازی سیستم های محیطی در ایستگاه های کاری. در تجزیه و تحلیل سیستم های پویا در پزشکی، زیست شناسی و اکولوژی ؛ Möller, DPF, Richter, O., Eds. Springer: برلین، آلمان، 1991; جلد 275، صص 131–145. [ Google Scholar ]
- Nemecek، T. نقش رفتار شته در اپیدمیولوژی ویروس Y سیب زمینی: یک مطالعه شبیه سازی . دیس. ETH شماره 10086; موسسه فناوری فدرال سوئیس: زوریخ، سوئیس، 1993. [ Google Scholar ]
- آندرولاکیس، س. سگک، AM; اتکینسون، آی. Groenewegen، D.; نیکلاس، ن. ترلوار، ا. Beitz، A. ARCHER – ابزارهای تحقیق الکترونیکی برای مدیریت داده های تحقیق. بین المللی جی دیجیت. Curation 2009 , 4 , 22-33. [ Google Scholar ] [ CrossRef ]
- کانکل، آر. سورگ، ج. کلدیتز، او. رینک، ک. کلمپ، جی. گاشه، آر. Neidl, F. TEODOOR – یک زیرساخت داده مکانی برای داده های رصد زمینی. در مجموعه مقالات دهمین کنفرانس بین المللی IEEE 2013 در مورد شبکه، سنجش و کنترل (ICNSC)، Evry، فرانسه، 10-12 آوریل 2013. ص 242-245.
- استفن، WL; واکر، BH; اینگرام، تغییر جهانی JSI و اکوسیستم های زمینی: برنامه عملیاتی . گزارش تغییرات جهانی شماره 21; برنامه بین المللی ژئوسفر-زیست کره (IGBP): استکهلم، سوئد، 1992. [ Google Scholar ]
- GCTE – تغییرات جهانی و اکوسیستم های زمینی. موجود به صورت آنلاین: www.igbp.net/researchprojects/igbpcoreprojectsphaseone/globalchangeandterrestrialecosystems.4.1b8ae20512db692f2a680009018.html (در 3 ژوئن 2016 قابل دسترسی است).
- Seitzinger، SP; گافنی، او. براسور، جی. برودگیت، دبلیو. سیایس، پی. کلاوسن، ام. اریسمن، جی دبلیو. کیفر، تی. لانسلوت، سی. راهبان، PS; و همکاران برنامه بین المللی ژئوسفر-زیست کره و علم سیستم زمین: سه دهه تکامل مشترک Anthropocene 2015 ، 12 ، 3-16. [ Google Scholar ] [ CrossRef ]
شکل 1. سازمان آرشیو گروه بومشناسی سیستمهای زمینی با دو مخزن یکسان (مستطیل سمت چپ) در دو ساختمان مختلف که هر کدام شامل مجموعهای یکسان از مدخلهای بایگانی (خاکستری) است. در هر ورودی بایگانی (AE، خاکستری) متا داده ها حاوی توضیحات ورودی مربوطه بایگانی (AEDescr، قرمز) مشخص شده است. برای هر ورودی بایگانی، دومی (قرمز) نیز به صورت اضافی در یک فهرست جهانی که در یک سرور مرکزی (سیلندر) قرار دارد برای اهداف دسترسی همراه با توضیحات رسانه مربوطه (AEMedium، آبی) ذخیره میشود. همه فایلهای متا داده (قرمز، آبی)، از جمله فهرست جهانی، عمداً فقط فایلهای متنی ساده ASCII هستند (نمونههایی در ضمیمه شکل A1 و شکل A2 ، برای توضیحات بیشتر به متن مراجعه کنید).

شکل 2. انتقال بین حوزه های curation در طول چرخه عمر داده های تحقیق، بر اساس شکل Data Curation Continuum توسط Andrew Treloar [ 50 ].

شکل 3. اطلاعات موجود در یک Content Object تنها زمانی قابل دسترسی است که هم خود شیء داده و هم هر گونه اطلاعات نمایشی که بر آن تکیه دارد در دسترس باشد.
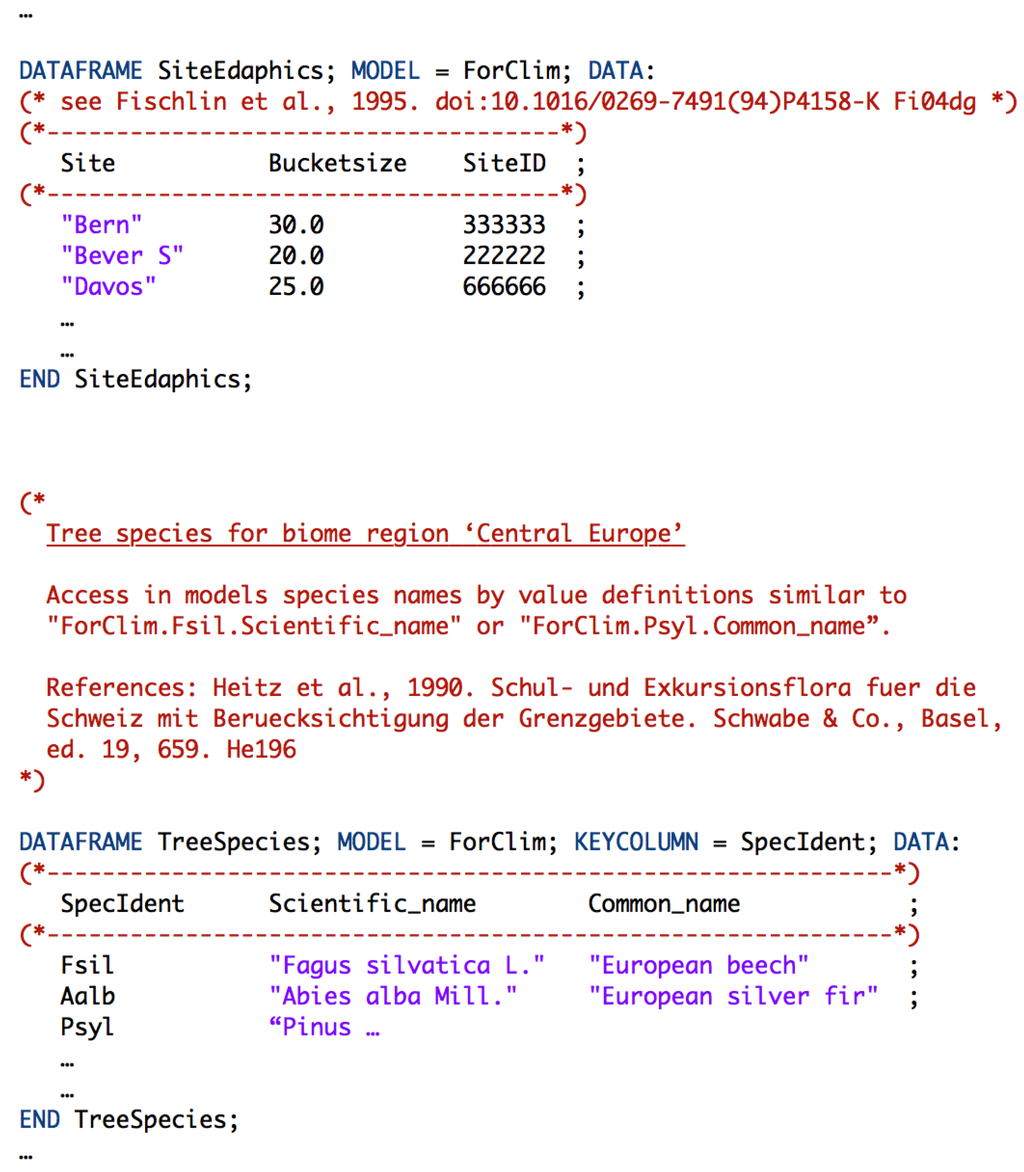
شکل 4. نمونه ای از داده های ذخیره شده به عنوان قاب های داده ای به دنبال دستور DTF ( به شکل A7 در پیوست A.3 مراجعه کنید ). نحو DTF اجازه می دهد تا داده های متا را وارد کنید و در هر جایی از فایل به عنوان نظر مداخله کنید. اینها میتوانند برای افزودن حداقل متا داده به دادههای واقعی ( بالا )، یعنی صرفا ارجاع دادن به سایر مؤلفههای حیاتی با ارزش بایگانی، مانند انتشار جداگانه به آرشیو ( ر.ک. بخش 4.1 )، یا به جای اسناد طولانی و مستقل استفاده شوند. پایین ).

شکل 5. اشتراک گذاری از طریق پایگاه داده مرکزی L i t Ce n t r a l�منتیسیه�تی�آلداده های متا در مجموعه های انتشارات شخصی ( L i T MYآ�منتیم�آ، L i T MYب�منتیم�ب…) در میان محققین a , b , … متعلق به همان تیم تحقیقاتی. سابقه ارجاع به یک کار علمی، به عنوان مثال، یک مقاله مجله، می تواند در چندین نسخه توزیع شده در سراسر سیستم وجود داشته باشد. با این حال، فقط رکوردهای سبز رنگ اصلی هستند و دارای مجوز نوشتن هستند، در حالی که هر کپی اضافی که خارج از سیستم پایگاه داده شخصی استفاده می شود. L i T MYآ�منتیم�آهمانطور که توسط محقق a استفاده می شود، یک کپی فقط خواندنی است (رنگ قرمز اگر در حوزه محقق دیگری باشد، نارنجی اگر در دامنه خود محقق به عنوان گزیده ای برای یک پروژه خاص مانند پروژه کاغذی استفاده شود). برای خواندن راحت، هر محققی معمولاً رکوردها را همیشه به یک مخزن اسناد شخصی، معمولاً یک مخزن PDF، پیوند میدهد، در حالی که احتمالاً از چندین دستگاه در دامنه شخصی استفاده میکند، مثلاً دامنه A (در اینجا فرض میکنیم که دستگاهها میتوانند به خوبی در دامنه مربوطه همگام شوند) برای توضیحات بیشتر به متن مراجعه کنید).

شکل 6. نمودار جریانی که قوانین ساده ای را نشان می دهد که محقق x باید هنگام افزودن آثار علمی جدید به سیستم پیشنهادی در اینجا رعایت کند ( شکل 5 را ببینید ). در اینجا فرض بر این است که این کار در دامنه A از محقق a (به اختصار “AF”) با استفاده از برنامه منبع باز BibDesk و برای L i t A F�منتیآافپایگاه داده FileMaker (برای توضیحات بیشتر به متن مراجعه کنید).
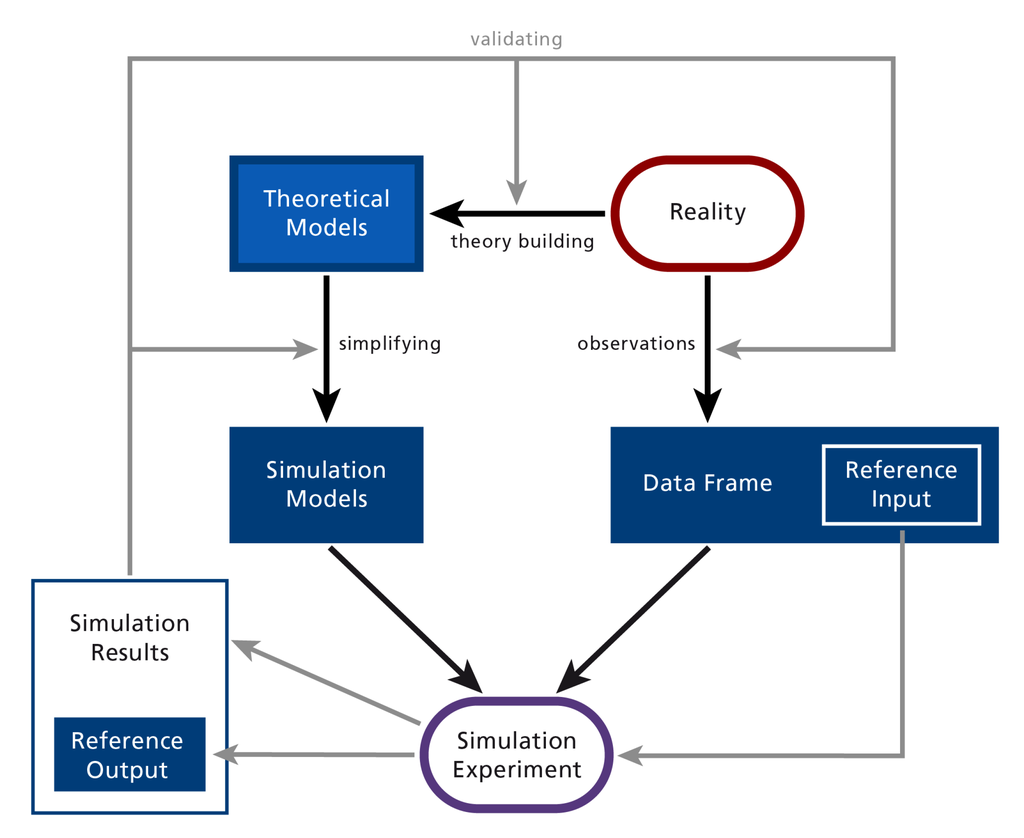
شکل 7. چرخه تحقیق ساخت تئوری شامل توسعه مدل، آزمایش های شبیه سازی، و تجزیه و تحلیل داده ها با پالایش گام به گام. جعبههای آبی نشاندهنده موجودیتهایی هستند – شامل دادهها و مدلهایی – که باید به منظور مدیریت معنیدار آرشیو شوند، به عنوان مثال، استفاده مجدد از مدلها. اگر بهدرستی بایگانی شوند، مدلها میتوانند نتایج شبیهسازی را که بایگانی نشدهاند، مجدداً محاسبه کنند، مثلاً به دلیل اندازه. برای آزمایش فعالسازی مجدد یک مدل، بایگانی باید دادههای مورد نیاز برای آزمایشهای شبیهسازی ویژه را نیز نگهداری کند که تلاش میکنند خروجی مرجع نیز بایگانیشده را بازتولید کنند و بدین وسیله از قابلیت استفاده مجدد مدل مطمئن اطمینان حاصل شود (متن را ببینید).

شکل 8. نمونه ای از یک مدل شبیه سازی برای یک مدل ریاضی ساده، به عنوان مثال ، معادله رشد لجستیک ایکس˙( t ) = a x ( t ) – b x( تی )2ایکس˙(تی)=آایکس(تی)–بایکس(تی)2، با استفاده از Data Frames ( شکل 9 ) برای نیازهای داده خود. چنین رویکردی مزایای قرار گرفتن در مدل شبیهسازی بسیار نزدیک به شکل ریاضی مدل نظری ( شکل 7 ) را ارائه میکند، در حالی که به طور همزمان انعطافپذیری را ارائه میدهد و کارکرد را تسهیل میکند.

شکل 9. نمونه ای از یک چارچوب داده استفاده شده در مدل سازی معادله لجستیک ( شکل 8 ) که پارامترهای مدل r و K را ارائه می دهد . این جداسازی داده ها از مدل، انعطاف پذیری را برای شبیه ساز ارائه می دهد (به متن مراجعه کنید).
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر