1. معرفی
ارائه اطلاعات مکانی-زمانی پوشش زمین به طور فزاینده ای برای بوم شناسی چشم انداز و نظارت بر محیط زیست مهم می شود. به عنوان مثال، داشتن اطلاعات دقیق در مورد پویایی پوشش زمین به منظور کمی سازی میزان و میزان تغییر پوشش زمین و توسعه مدل هایی برای مرتبط کردن فرآیندهای محرک تغییر با تغییرات چشم انداز مشاهده شده ضروری است. مطالعات موردی مرتبط از حوضه مدیترانه شمالی، کوههای آلپ اروپایی و مغولستان داخلی را میتوان در Millington و همکارانش یافت. [ 1 ]، رادرفورد و همکاران. [ 2 ] و وو و همکاران. [ 3 ] به ترتیب.
اطلاعات مکانی-زمانی پوشش زمین ممکن است از استفاده ترکیبی از دادههای پیمایش میدانی و تصاویر سنجش از راه دور از طریق تکنیکهای آماری و دیگر روشهای تحلیل الگو به صورت نیمه خودکار بهدست آید. فولر و همکاران [ 4 ] مسائل مربوط به تشخیص، اندازه گیری و توصیف تغییرات چشم انداز را با سنجش از دور و ابزارهای دیگر مورد بررسی قرار داد، در حالی که چن و همکاران. [ 5 ] یک استراتژی موثر و عملی را برای نقشه برداری عملیاتی پوشش زمین جهانی در وضوح 30 متر توصیف کرد. اطلاعات پوشش زمین را می توان به صورت نقشه های طبقه بندی شده (یا نقشه های کلاس منطقه) [ 6 ]، یا توسط چند ضلعی در قالب برداری یا بلوک های پیوسته سلول های شبکه در قالب شطرنجی نشان داد.
در حالی که پوشش زمین اغلب ایستا یا پایدار است، اطلاعات در مورد پویایی پوشش زمین نیز اغلب مصرف می شود. نتایج تشخیص تغییر شامل نقشههای باینری تغییرات و انواع بدون تغییر و نقشههای طبقهبندی شده که کلاسهای تغییر خاص «از به» را نشان میدهند. در اینجا مورد اخیر را به عنوان دسته بندی تغییر می خوانیم که بدون ایجاد سردرگمی می توان آن را مترادف تشخیص تغییر در نظر گرفت. واضح است که طبقهبندی در اینجا به دستهبندی هر دو نوع پوشش استاتیک و متغیر اشاره دارد و بنابراین به جای طبقهبندی تغییر در این مقاله استفاده میشود، مگر اینکه خلاف آن ذکر شود.
با این حال، اطلاعات پوشش زمین ناقص است، زیرا مستقیماً قابل اندازهگیری نیست، بلکه از فرآیندهای تفسیری و پیشبینیکننده ناشی میشود که در معرض ذهنیت، عدم دقت و پیچیدگی ذاتی هستند. لچنر و همکاران [ 7 ] فوریت پرداختن به عدم قطعیت فضایی در نقشه های طبقه بندی را به عنوان روش استاندارد در بوم شناسی منظر نشان داد. کنگالتون و همکاران [ 8 ] نیاز به تعاریف روشن و یکسان از طرح طبقه بندی در نقشه برداری جهانی پوشش زمین را برجسته کرد. بنابراین، توصیف و تجزیه و تحلیل دقت در اطلاعات پوشش زمین بسیار مهم است تا مشتقات و نتایج تجزیه و تحلیل بر اساس چنین اطلاعات ناقصی از نظر قابلیت تکرار علمی و قابلیت استفاده عملی مورد بررسی دقیق قرار گیرند. اولوفسون و همکاران [ 9] مجموعهای از توصیههای «عمل خوب» را برای طراحی و اجرای ارزیابی دقت برای نقشههای تغییر و تخمین مناطق طبقات مختلف بر اساس دادههای نمونه مرجع به پزشکان ارائه کرد.
مسائل مربوط به دقت مربوط به متریک ها، توصیف، انتشار و مدیریت دقت در اطلاعات پوشش زمین است. در این مقاله، ما بر توصیف دقت تمرکز می کنیم. دقت در نقشه های طبقه بندی شده را می توان با استفاده از باندهای خطای اپسیلون برای موقعیت مرزی و ماتریس های سردرگمی برای برچسب زدن توصیف کرد. اگرچه نوارهای اپسیلون برای توصیف عدم دقت مرز مفید هستند، آنها به عنوان محصولات جانبی عدم قطعیت در طبقه بندی در نظر گرفته می شوند. بنابراین در این مقاله به آنها پرداخته نخواهد شد. تمرکز در اینجا دقت طبقه بندی است. معیارهای آماری دقت در پوشش زمین و سایر اطلاعات طبقهبندی شده عمدتاً احتمالی هستند (یعنی درصد پیکسلهای به درستی طبقهبندی شده (PCC) و دقت کاربر در هر کلاس). چنین معیارهای آماری دقت دلالت بر مجموعههای واضح در تعریف و برچسبگذاری کلاس دارد، اگرچه مجموعههای فازی [10 ] ممکن است برای اندازه گیری و نشان دادن عدم قطعیت، به ویژه در مورد کلاس های ذاتا مبهم، مانند اکوتون ها، استفاده شود.
اندازهگیریهای دقت حاصل از ماتریسهای خطا معمولاً جهانی هستند (مثلاً PCCها و ضرایب توافق کاپا) یا طبقهبندیشده (مثلاً دقت کاربر برای کلاسهای جداگانه) [9، 11]، بدون تأیید تغییرات مکانی در دقت طبقهبندی، که مشخص است . همانطور که توسط Foody [ 12 ] نشان داده شده است، از نظر فضایی متنوع باشد . این مقاله به دنبال کمی کردن دقت طبقهبندی محلی در زمینه طبقهبندی تغییرات است. پیشبینیهای مکانی خاص دقت طبقهبندی اطلاعاتی در مورد تغییرات مکانی دقت ارائه میکند و میتواند از تحلیل اکتشافی و تشخیصی عوامل مؤثر بر دقت طبقهبندی پشتیبانی کند.
به طور کلی، بسته به در دسترس بودن و تنوع داده های منبع و ابرداده، دو نوع رویکرد گسترده برای تعیین کمیت دقت محلی در اطلاعات تغییر پوشش زمین وجود دارد، که می تواند علاوه بر نقشه های مورد آزمایش، برای کمک به توصیف دقت استفاده شود. یکی از رویکردهای تولیدکنندگان است که با استفاده از آن معیارهای دقت از دادههای منبع مختلف درگیر در تولید اطلاعات پوشش زمین، از جمله تصاویر چند تاریخ، نمونههای آموزشی و آزمایشی، دادههای جانبی و نقشههای مشتقشده طبقهبندی و طبقهبندی تغییر به دست میآیند. مورد دیگر رویکردهای کاربران است که در آن دادههای موجود برای ارزیابی دقت به سختی بیشتر از نمونههای اعتبارسنجی خاص (برای ارزیابی دقت) و نقشههایی است که باید ارزیابی شوند. برای سابق،13 ]، حداکثر احتمالات پسینی (به عنوان جایگزین معیارهای دقت طبقه بندی استفاده می شود) [ 14 ، 15 ] و نمونه برداری مجدد (که می تواند احتمالات طبقه بندی اشتباه را بر اساس نمونه های آموزشی و کریجینگ ترسیم کند) [ 16 ]. این مقاله استراتژی دومی را به شرح زیر گسترش می دهد.
برای رویکردهای کاربران، روشهایی مبتنی بر درونیابی و تحلیل رگرسیون وجود دارد. در مرحله اول، درون یابی ممکن است برای پیش بینی احتمالات طبقه بندی صحیح در مکان های نمونه برداری نشده، با توجه به مجموعه ای از داده های اعتبار سنجی انجام شود. برای این منظور، کریجینگ اندیکاتور، نوعی روش درونیابی زمین آماری، میتواند بر اساس نمونههای اعتبارسنجی و تبدیل شاخص آنها برای تولید سطوح احتمالی مورد استفاده قرار گیرد. به عنوان مثال، کریجینگ برای نگاشت احتمال طبقه بندی اشتباه توسط استیل و همکاران به کار گرفته شد. [ 16]. واضح است که کریجینگ ابزار ارزشمندی برای نقشهبرداری دقت طبقهبندی محلی خواهد بود، زیرا وابستگی فضایی گنجانده شده است، با معیارهای عدم قطعیت در پیشبینیهایی که به عنوان واریانس کریجینگ به دست میآیند. چنین اطلاعات عدم قطعیت مفید خواهد بود، همانطور که بعداً بحث خواهیم کرد. ثانیاً، رگرسیون لجستیک بر اساس شاخصهای الگوی منظر و سایر متغیرهای توضیحی (متغیرهای کمکی) برای تخمین احتمالات طبقهبندی (نادرست) پیشنهاد شده است، همانطور که توسط محققان از جمله اسمیت و همکاران توصیف شده است. [ 17 ]، اسمیت و همکاران. [ 18 ] و اورت و همکاران. [ 19 ]. مشخص شد که مشخصههای خاص چشمانداز، مانند ناهمگونی بالای پوشش زمین و اندازه کوچک وصله، منجر به طبقهبندی پیکسلها میشود (در نتیجه دقت پایینتر) [ 17 ،18 ، 19 ]. واضح است که هم رگرسیون کریجینگ و هم رگرسیون لجستیک ممکن است برای تعیین کمیت مکان خاص دقت در طبقهبندی تغییرات مورد بررسی قرار گیرند.
این مقاله به دنبال ادغام رویکردهای کاربرانی است که قبلاً ذکر شد با ترکیب رگرسیون و کریجینگ برای پیشبینی دقت در زمینه تشخیص تغییر. این کار با پیشبینی معیارهای دقت احتمالی محلی مبتنی بر رگرسیون لجستیک و به دنبال آن کریجینگ برای استخراج تصحیحات احتمالات رگرسیون بر اساس باقیماندههای رگرسیون ارزیابی شده در نمونههای اعتبارسنجی انجام میشود. در ترکیب لجستیک-رگرسیون-کریجینگ، رگرسیون لجستیک با کاوش و استفاده از اطلاعات منتقل شده از طریق تغییرات کمکی بین طبقه بندی (نادرستی) مشاهده شده و الگوهای محلی رخدادهای کلاس در نقشه مورد ارزیابی کار می کند، در حالی که کریجینگ به دنبال استخراج اطلاعات اضافی موجود در همبستگی فضایی است. باقیمانده های رگرسیون
برخی تحقیقات در مورد استفاده از رگرسیون لجستیک برای استخراج تخمینهای احتمالی دقت در زمینه تشخیص تغییر با بررسی روابط بین وقوع تشخیص تغییر اشتباه و متغیرهای کمکی مختلف، از جمله تخمینهای دقت طبقهبندی تک تاریخ، دادههای طیفی، مکانهای مکانی و ویژگیهای منظر، وجود دارد. همانطور که در Burnicki [ 20 ] گزارش شده است. به ندرت هیچ تحقیقی در مورد استفاده مستقیم از الگوهای محلی تغییر پوشش زمین در نقشه وجود دارد که به عنوان متغیرهای کمکی برای پیشبینی دقت بر اساس رگرسیون لجستیک در زمینه ابردادههای محدود ارزیابی میشوند، چه رسد به آن تلاشهای تحقیقاتی که همبستگی فضایی را از طریق ترکیبی بررسی میکنند .لجستیک-رگرسیون-کریجینگ برای پیش بینی های دقت بهبود یافته. در کریجینگ با باقیمانده رگرسیون، باید روشن کنیم که چگونه متغیرهای منطقهای غیر ثابت، مانند وقوع طبقهبندی (نادرست) باید به کار گرفته شوند. اینها انگیزه مهمی برای مقاله فراهم می کند و نشان دهنده تازگی اصلی آن است.
مهم است که بدانیم معیارهای دقت حاصل از رگرسیون و کریجینگ فقط تقریبی هستند، مشروط به نمونه های اعتبارسنجی (تعداد، توزیع و دقت آنها)، اعتبار رگرسیون (انتخاب مدل و دقت متغیرهای کمکی) و وجود و مدیریت همبستگی فضایی در فضایی. داده های باینری بنابراین، مهم است که مشخص کنیم که اندازهگیریهای دقت تخمینی چقدر از پیشبینیها به دست میآیند. این را می توان با کمی کردن عدم قطعیت ، همانطور که با واریانس یا ریشه دوم آن، خطای استاندارد (SE)، در دقت های محلی پیش بینی شده اندازه گیری می شود، انجام داد . سپس میتوانیم از چنین اطلاعاتی برای شناسایی مکانهایی استفاده کنیم که نمونههای اضافی ممکن است به طور بهینه برای کاهش عدم قطعیت در پیشبینیهای دقت، و ایجاد تطبیقپذیر قرار گیرند.استراتژیهای نمونهگیری برای جمعآوری تدریجی دادههای اعتبارسنجی، با توجه به نمونههای اعتبارسنجی موجود، بودجه برای نمونهگیری اضافی و دقت مورد نیاز در پیشبینیها. در این مقاله، مقادیر واریانس در پیشبینیهای رگرسیون و کریجینگ باقیمانده برآورد و ترکیب میشوند تا عدم قطعیت در مورد پیشبینیهای دقت محلی را نشان دهد.
به طور خلاصه، عمده ترین کمک های این مقاله عبارتند از:
- (1)
-
ترویج یک استراتژی کاربر محور برای توصیف دقت محلی در اطلاعات تغییر پوشش زمین از طریق رگرسیون لجستیک ترکیبی و کریجینگ بر اساس نمونه های اعتبارسنجی و الگوهای مقیاس محلی وقوع کلاس در نقشه های مورد ارزیابی.
- (2)
-
بررسی متغیرهای کمکی قابل توجهی که برای پیشبینی دقت محلی با رگرسیون لجستیک استفاده میشوند، در حالی که روشهای لجستیک-رگرسیون-کریجینگ (با یا بدون درمان همبستگی فضایی در رگرسیون لجستیک) برای استفاده انعطافپذیر آنها در کاربردها بسته به محدوده و قدرت همبستگی فضایی در مقایسه میشوند. طبقه بندی های (غیر) صحیح را مشاهده کرد.
- (3)
-
بررسی اثربخشی نمونهگیری تطبیقی بر اساس خطاهای استاندارد محاسبهشده پیشبینیهای دقت برای افزایش کارایی نمونهگیری و افزایش دقت پیشبینی.
در بخش 2 ، ابتدا زمین آمارهای شاخص را برای پیشبینی دقتهای محلی شرح میدهیم. این با توصیفی از رگرسیون لجستیک دنبال میشود که توسط آن احتمالات دستهبندی صحیح تغییرات پیشبینی میشود. ترکیبی لجستیک-رگرسیون-کریجینگ توصیف شده است، که در آن همبستگی فضایی در دادههای باینری مربوط به طبقهبندی (نادرست) برای تخمین ضرایب رگرسیون و پارامترهای واریوگرام تطبیق داده میشود. روشهای تخمین SE نیز همراه با روشهای مختلف پیشبینی دقت شرح داده شدهاند. بخش 3 یک مطالعه تجربی را با هدف آزمایش روش های جایگزین برای پیش بینی دقت با استفاده از داده های نمونه جمع آوری شده در منطقه مورد مطالعه توصیف می کند. بخش 4مقاله را با چند خلاصه و چشم انداز به پایان خواهد رساند.
2. روش ها
2.1. شاخص زمین آمار
وابستگی فضایی مشخصه بسیاری از توزیع های جغرافیایی است، مانند انواع پوشش زمین و انتقال. طبقهبندی اشتباه و دستهبندی تغییر اشتباه ناشی از تصاویر سنجش از راه دور نیز احتمالاً از نظر فضایی همبستگی دارند. در زمینآمار، چنین توزیعهای همبسته فضایی به عنوان متغیرهای منطقهای توصیف و مدلسازی میشوند [ 21 ، 22 ]. علاوه بر این، ما میتوانیم مجموعهای از متغیرهای تصادفی { Z ( x 1 ), …, Z ( x n )} ( x ∈ A , A که دامنه مشکل است) یک فیلد تصادفی (RF) نام ببریم، اگر n مکان { x 1 باشد, …, x n | x ∈ A } برای گسسته کردن دامنه مشکل A استفاده می شود . در یک مکان خاص x ، Z ( x ) یک متغیر تصادفی (RV) است. بدون ایجاد سردرگمی، ممکن است RF { Z ( x ), x ∈ A } را به سادگی با Z نشان دهیم . برای تمایز بهتر RFهای بازه/نسبتی از RFهای اسمی/ترتیبی، ما اغلب دومی (به عنوان مثال، پوشش زمین و سایر میدانهای اسمی [ 6 ]) را به عنوان C در مقابل Z برای اولی نشان می دهیم. یک فیلد اسمی Cمقادیر را در یک سری از برچسبهای کلاس میگیرد و میگوید {1، 2، …، K }، اگر K نشاندهنده تعداد کلاسهایی باشد که در دامنه A ممکن است . معمولاً یک RF اسکالر با حروف بزرگ، مثلاً C ، با حروف کوچک c برای تحقق (مقادیر) آن نشان داده میشود.
از آنجایی که تمرکز این مقاله بر روی صحت/نادرستی باینری در داده های طبقه بندی شده است (یعنی انواع تغییر پوشش زمین)، ما نیاز به بحث در مورد زمین آمار شاخص [ 21 ] داریم. در زیر، متغیرهای اندیکاتور و واریوگرام ها را به اختصار توضیح می دهیم. برای متغیر مقوله ای C ( x )، متغیر شاخص I ( x ) را می توان به طور کلی بر روی یک دامنه A تعریف کرد :
جایی که سی( x )�(�)و سی^( x )�^(�)نشان دهنده انواع تغییرات واقعی و پیش بینی شده پوشش زمین، به ترتیب، در مکان x ( x ∈ A�∈�). معادله (1) بیان می کند که اگر x به درستی طبقه بندی شود I ( x ) 1 است و در غیر این صورت 0 است. این اساساً یک کدگذاری باینری از طبقه بندی (نادرست) مکان های نمونه برداری شده است.
بر اساس تئوری متغیرهای منطقه ای، یک مدل داده های زمین آماری برای I ( x ) در x به گونه ای است که I ( x ) مجموع میانگین قطعی است. π�و باقیمانده تصادفی ε ( x )�(�):
اگر نمونه گیری اعتبارسنجی به درستی انجام شود، ممکن است ادعا کنیم که اندازه گیری PCC محاسبه شده از یک ماتریس سردرگمی، تخمین خوبی از مولفه ثابت و قطعی است. π�، مانند π�= E [ I ( x )] = prob { I ( x )} = 1.
با فرض ایستایی مرتبه دوم (که در بخش 2.3 مجدداً بررسی خواهیم کرد ) در RF I ، تابع کوواریانس فضایی، cov I ( h )، برای مکان هایی که با تاخیر h از هم جدا شده اند به صورت زیر تعریف می شود:
برای ایکسس–ایکسس“= ساعت�s−��′=ℎ، جایی که RF I ، جزء قطعی آن است π�و باقیمانده تصادفی ε�در رابطه (2) تعریف می شوند. یک مدل واریوگرام γمن( h )��(ℎ)مربوط به مدل کوواریانس می باشد covمن( h )cov�(ℎ)از طريق: γمن( h ) =covمن( 0 ) –covمن( h ) =covمن( 0 ) ( 1 −ρمن( س ) )��(ℎ)=cov�(0)−cov�(ℎ)=cov�(0)(1−��(ℎ))، جایی که covمن( 0 )cov�(0)واریانس (آستانه) RF I و استρمن( h )��(ℎ)همبستگی برای I است . توجه داشته باشید که زیرنویسها در نمادهای بالا ممکن است بدون از دست دادن وضوح حذف شوند زیرا به طور ضمنی به RF I اشاره میکنند ، مگر اینکه خلاف آن ذکر شده باشد.
با مدلهای واریوگرام یا کوواریانس برازش مناسب از دادههای تجربی، پیشبینی زمینآماری (که معمولاً به عنوان کریجینگ شناخته میشود) RF I در مکانهای نمونهگیری نشده ممکن است انجام شود. به طور کلی کریجینگ بهترین تخمین خطی را ارائه می دهد من^(ایکس0)�^(�0)برای مقدار مجهول I در مکان های نمونه برداری نشده x 0 ، که با اطمینان از بی طرفی و حداقل پراکندگی برآوردگر تعیین می شود. کریجینگ ساده (نشانگر) ممکن است زمانی انجام شود که یک میانگین ثابت باشد π�بیش از A شناخته شده است. به طور خاص، این را می توان به صورت زیر نوشت:
جایی که من^(ایکس0)�^(�0)و من (ایکسس)�(��)مقدار پیشبینیشده را به ترتیب در x 0 و مقدار داده را در x s ارائه کنید و λ ( xs ) وزن تخصیص داده شده به مکان داده xs را نشان میدهد . واریانس کریجینگ، به عنوان معیار عدم قطعیت در پیشبینی p {سی^(ایکس0) = سی(ایکس0) }�{�^(�0)=�(�0)}مشروط به داده های موجود، محاسبه می شود:
جایی که var ( I) =covمن( 0 )var(�)=cov�(0)نمایانگر آستانه واریوگرام RF I است.
با این حال، اغلب این مورد است که دقت طبقه بندی بر اساس مکان متفاوت است، به طوری که π�در رابطه (2) با ابزارهای محلی بهتر تعریف شده است π ( x )�(�)( x∈A )، که مشخص شد تا حدی به شاخصهای شکل منظره در محله متمرکز در مکانهای مورد ارزیابی مربوط میشوند [ 19 ، 20 ] . بنابراین، ما باید برای تجزیه و تحلیل زمین آماری RF I و پیشبینی آن در مکانهای نمونهبرداری نشده، ابزارهای محلی را به درستی تجویز کنیم، با معادله (2) که به صورت زیر نوشته میشود:
جایی که π ( x )�(�)و ε ( x )�(�)به ترتیب میانگین محلی و باقیمانده I در x را نشان دهید .
روشهایی برای ترکیب برخی متغیرهای کمکی مرتبط برای تخمین میانگینهای محلی وجود دارد π ( x )�(�)، همانطور که در معادله (6) تجویز شده است. در زمین آمار خطی، کریجینگ جهانی به شرایطی اشاره دارد که در آن وسایل محلی تابع مختصات فضایی هستند، در حالی که کریجینگ با رانش خارجی از توابع یک RF کمکی به عنوان وسیله تعریف شده محلی استفاده می کند، همانطور که توسط Hengl و همکارانش بحث شده است. [ 22 ]. برای اندیکاتور RF I ، نمیتوانیم کریجینگ جهانی را مستقیماً اعمال کنیم، اما ممکن است رگرسیون لجستیک را برای پیشبینی بررسی کنیم. π ( x )�(�)در معادله (6) بر اساس متغیرهای کمکی مربوطه، همانطور که در بخش بعدی نشان داده شده است.
2.2. رگرسیون لجستیک
به عنوان نوعی رویکرد مدلسازی خطی تعمیمیافته، رگرسیون لجستیک یک تکنیک کمی است که میتواند متغیرهای باینری وابسته (مثلاً طبقهبندیهای (در) صحیح) را با متغیرهای کمکی ثبتشده خاص مرتبط کند. تحقیقات گذشته نشان داده است که برچسبهای کلاس، ناهمگنی، اندازه وصله و تسلط بر منظر متغیرهای کمکی مهمی برای پیشبینی دقتهای محلی هستند، همانطور که در اسمیت و همکاران توضیح داده شد. [ 17 ]، اسمیت و همکاران. [ 18 ] و اورت و همکاران. [ 19]. در اینجا، برخی از شاخصهای شکل چشمانداز را که به خوبی تحقیق شدهاند، تطبیق میدهیم و آنها را در مقیاس محلی (برچسبهای پیکسل مرکزی بهعلاوه همسایگی 4 کانونی 3 در 3 پیکسل) اندازهگیری میکنیم تا با هدف پژوهشی مقاله در تعیین کمیت دقت محلی مطابقت داشته باشند. دلایل اساسی این است که متغیرهای کمکی کمیسازیشده در مقیاس کانونی با متغیر وابسته مورد تجزیه و تحلیل مطابقت بیشتری دارند، زیرا شاخصهایی که طبقهبندی (نادرست) در پیکسلهای منفرد را ثبت میکنند، میتوانند در یک همسایگی کانونی بهتر از فاصله دورتر و به دلیل روابط دقت-الگو اطلاعرسانی شوند. ممکن است به صورت خطی در مقیاس ها قابل انتقال نباشد.
ما استفاده از فرکانسهای وقوع کلاس تغییر در همسایگی کانونی را بهعنوان متغیرهای کمکی نامزد برای تحلیل رگرسیون پیشنهاد میکنیم، در حالی که شاخصهای الگوی ناهمگنی و تسلط را میتوان از آنها استخراج کرد. رخدادهای کلاس در پیکسل x با بردار احتمال کلاس p ( x ) در همسایگی کانونی نشان داده می شود: p ( x ) = ( p 1 ( x )، p 2 ( x )، …، p K -1 ( x )) T ، که در آن زیرنویس های 1، 2، ..، K -1 نشان دهنده برچسب های کلاس است، pk ( x ) نسبت پیکسلها در همسایگی کانونی 3 در 3 متعلق به کلاس k ، با بالانویس T نشاندهنده جابجایی و با فرض اینکه کل کلاسهای کاندید در نظر گرفته شده است. فقط باید K – 1 از آنها را مشخص کنیم، زیرا یک افزونگی وجود دارد: p K ( x ) = 1 – ∑K−1k=1pk(x)∑�=1�−1��(�).
چندین معیار مقیاس کانونی الگوهای رخداد کلاس را می توان از بردار احتمال p که در بالا تعریف شد به دست آورد. ناهمگنی کانونی ( HET ) ناهمگنی همسایگی کانونی را در اطراف هر سلول اندازه میگیرد و برابر با تعداد کلاسهای موجود در همسایگی کانونی متمرکز در پیکسل مورد تجزیه و تحلیل است. مقدار ناهمگنی 1 نشان می دهد که پیکسل مرکزی در یک بلوک همگن از پیکسل ها قرار دارد، در حالی که هر مقدار بیشتر از 1 نشان می دهد که پیکسل در یک لبه وصله یا در مرزهای کلاس قرار داشته است. اندازه بلوک به عنوان تعداد پیکسلهای به هم پیوسته از همان کلاس پیکسل مرکزی در حال تجزیه و تحلیل تعریف میشود، که میزان تکه تکه شدن بلوک محلی را اندازهگیری میکند و خلوص کلاس را در یک همسایگی کانونی منعکس میکند.L 10 B. _ ثالثاً، ما تسلط منظر ( DMG ) را محدود می کنیم، که به مقیاس چشم انداز در Oort و همکاران اشاره دارد. [ 19 ]، به یک همسایگی کانونی، آن را به عنوان تفاوت بین لگاریتم ناهمگنی و آنتروپی رخدادهای کلاس در همسایگی کانونی تعریف می کند:
که در آن p k احتمالات حاشیه ای کلاس های فردی k در همسایگی کانونی است.
متغیرهای کمکی نامزدی که قبلا ذکر شد به عنوان بردار F به طول 1 + Q > 1 نشان داده می شوند: F ( x ) = ( F 0 ( x ) = 1, F 1 ( x ), …, F Q ( x )) T , که در آن Q تعداد کل متغیرهای کمکی استفاده شده است، به جز ثابت 1. برای مثال، ممکن است F 1 = HET و F 2 = DMG و غیره داشته باشیم. مکان یاب x ممکن است همراه با آن مشخص شود یا نباشد.F بدون از دست دادن وضوح در متن زیر است.
برای نشانگر RF { I ( x )، x∈ A } که در بخش فرعی قبلی توضیح داده شد، میانگینهای محلی آن از طریق مدلهای لاجیت به بردارهای F ، مجموعهای از متغیرهای کمکی (مثلاً شاخصهای الگوی رخدادهای کلاس محلی) مرتبط است . به عبارت دیگر، احتمال طبقه بندی صحیح در یک مکان (مثلاً پیکسل x )، π ( x ) = p r o b { I( x ) = 1 }�(�)=����{�(�)=1}، از طریق مجموعه ای از ضرایب مربوطه به F ( x ) بستگی دارد،β =(β0،β1، ⋯ ،βس)تی�=(�0,�1,⋯,�Q)T. شانس ورود به سیستم، به نام logit (که نشان داده شده است) از π ( x )�(�)، به طور خطی با متغیرهای کمکی F ( x ) = (1, F 1 ( x ), …, F Q ( x )) T در مکان x مرتبط هستند :
تخمین بردار ضرایب β �، β^�^را میتوان با روش نیوتن-رافسون یا از طریق حداقل مربعات وزندهی مجدد تکراری با شکل خطی تابع پیوند لاجیت برای دادههای نمونه، همانطور که در Agresti [23] توضیح داده شد، بدست آورد . سیستم معادلات عبارت است از:
جایی که W =DتیV– 1D�=���−1�، η∗= η +D– 1(i−π)�*=�+�−1(�−�)، با بردارها η∗�*، η�، iمنو π �بردار ستون بودن η∗�*، η�، منمنو π�در مکانهای نمونه (فرض کنید n مکان نمونهگیری شده وجود دارد ؛ این بردارها هر کدام n طول دارند ). اینجا، ماتریس D =dمن یک جی[πس( 1- _πس) ]�=دمنآ�[�س(1–�س)]و با فرض استقلال در مجموعه RV ها (نمایش داده شده توسط I ) در مکان های نمونه برداری شده، ماتریس واریانس و کوواریانس V به صورت زیر مشخص می شود:
که در آن زیرنویس s مکان های x s .، s = 1، …، n را نشان می دهد ، با n تعداد مکان های نمونه در تحلیل رگرسیون. یک فرآیند تکرار شونده از حداقل مربعات راه حلی را ارائه می دهد β�. جزئیات بیشتر را می توان در Agresti [ 23 ] و Gotway و همکاران یافت . [ 24 ]. در محدوده فرآیند تکراری، β^�^به تخمین ماکزیمم احتمال همگرا می شود که ماتریس واریانس و کوواریانس آن به صورت زیر بدست می آید:
همانطور که در Agresti [ 23 ] توضیح داده شده است.
با β^�^تخمین زده می شود، ما می توانیم محاسبه کنیم η^(ایکس0)�^(ایکس0)برای یک مکان نمونه برداری نشده x 0 با استفاده از (8). سپس، می توانیم پیش بینی کنیم π^(ایکس0)�^(ایکس0)بر اساس معکوس معادله (8):
بدیهی است که مجموعههای مختلف متغیرهای کمکی F منجر به مدلهای لاجیت متفاوتی میشوند که به مسئله آزمون اهمیت در مورد انتخاب متغیرهای کمکی برای تحلیل رگرسیون اشاره میکند. برای انتخاب مدل، آمار انحراف وجود دارد:
جایی که il��نشان دهنده متغیر دو جمله ای برای تنظیم l-امین متغیرهای کمکی است، l=1, ⋯,nl�=1, ⋯,��(با nl��حداکثر تعداد تنظیمات برای بردارهای F ) و π^l�^�نشان دهنده برآورد مدل مربوط به probability (il=1|Fl)probability (��=1|��). تفاوت در مقادیر انحراف برای مدلها برای آزمایش اثر ترکیب متغیرهای کمکی اضافی مورد استفاده قرار گرفت. این تفاوت به دنبال توزیع کای دو با درجه آزادی ( df ) برابر با تفاوت در تعداد متغیرهای کمکی مورد استفاده در مدل پایه و مدل جایگزین است، همانطور که در Agresti [ 23 ] توضیح داده شده است. اهمیت آماری در سطح معنی داری معینی، مثلاً 0.05 قضاوت می شود.
مانند واریانس کریجینگ نشان داده شده در معادله (5)، ما همچنین می توانیم واریانس (یا خطای استاندارد SE =) را محاسبه کنیم. variance−−−−−−−√variance) که در π^(x)�^(�)پیش بینی شده از رگرسیون لجستیک واریانس در پیش بینی های رگرسیون لجستیک را می توان به صورت زیر محاسبه کرد. برای مقادیر تخمینی لاجیت مطابق با رابطه (8)، واریانس آن برابر است با:
جایی که cov(β^)cov(�^)با استفاده از رابطه (11) محاسبه می شود. واریانس برای احتمالات پیش بینی شده π^(x0)�^(�0)سپس می توان با روش دلتا به دست آورد، همانطور که در Agresti [ 23 ] نشان داده شده است. به طور خاص، واریانس در π(x0)�(�0)از واریانس محاسبه می شود η(x0)�(�0)استفاده كردن:
جایی که π“( η )�′(�)به صورت (با اشاره به معادله (12)) ارزیابی می شود:
واریانس در π^(ایکس0)�^(�0)را می توان با جایگزینی محاسبه کرد η^(ایکس0)�^(�0)و π^(ایکس0)�^(�0)برای η (ایکس0)�(�0)و π (ایکس0)�(�0)، به ترتیب.
2.3. ادغام رگرسیون لجستیک و کریجینگ در حالی که همبستگی فضایی را تطبیق می دهد
واریانس RF I و ماتریس کوواریانس V (برای مجموعه ای از مکان های نمونه برداری شده) که در رابطه (10) نشان داده شده است، به عنوان داده های باینری، مورب فرض می شود. من (ایکسس)�(��)s = 1، …، n } که در آنجا دخیل هستند، غیر همبسته در نظر گرفته می شوند. با این حال، (نا)درستی در طبقه بندی تغییرات (به نمایندگی از RF I) اغلب از نظر فضایی همبسته است، و مدیریت صحیح آن برای تخمین دقت محلی و خطاهای موضعی آنها در زمینه رگرسیون لجستیک مهم است. استراتژی ترویج شده در این مقاله نوعی رگرسیون-کریجینگ است که برای طبقهبندی تغییرات (نادرست) ثبت دادههای باینری طراحی شده است: رگرسیون لجستیک برای احتمالات محلی طبقهبندی (نادرست) بر روی متغیرهای کمکی خاص انجام میشود، با کریجینگ ساده برای باقیماندههای رگرسیون اعمال میشود. به طور خاص، پس از تعیین میانگین های محلی از طریق تجزیه و تحلیل رگرسیون، باقیمانده ها به باقیمانده های استاندارد تبدیل می شوند تا مدل سازی واریوگرام و اجرای کریجینگ تسهیل شود. مقادیر باقیمانده کریگ شده و برآوردهای واریانس آنها به فضای داده اصلی تبدیل می شوند. پیش بینی های محلی تصحیح شده RF Iمجموع میانگین های محلی رگرسیون و باقیمانده های کریگ شده خواهد بود، در حالی که واریانس در پیش بینی های تصحیح شده نیز مجموع واریانس ها در میانگین های پیش بینی شده و باقیمانده های پیش بینی شده خواهد بود. در هر دو رگرسیون لجستیک و کریجینگ، همبستگی فضایی با مدلسازی واریوگرام مناسب از طریق باقیماندههای استاندارد شده سازگار میشود. برای بخش رگرسیون، V در معادله (10) را می توان به صورت تکراری با مدل سازی واریوگرام بر اساس باقیمانده های استاندارد شده مشخص کرد. ما مراحل را در زیر شرح می دهیم.
برای رگرسیون لجستیک با دادههای باینری فضایی، مدلسازی واریوگرام باید در ترکیب با مشخصات میانگینهای غیر ثابت در نظر گرفته شود. در واقع، وقتی π ( x )�(�)نشان دهنده میانگین محلی از نظر مکانی متفاوت است، همانطور که در معادله (6)، واریانس نشان داده شده است ε ( x )�(�)غیر ثابت خواهد بود، و در نتیجه، ما نمی توانیم مدل سازی کنیم ε ( x )�(�)به عنوان یک RF ثابت [ 25 ]. در بخش 2.1 ، ثابت بودن در RF I در نظر گرفته شد، که کل حوزه مشکل را به عنوان یک کل در نظر گرفت و موارد طبقه بندی (نادرست) را در سراسر حوزه مشکل A به گونه ای مشاهده کرد که گویی تحقق یک RV I ( x ) در هر مکان خاص است. x در A (به دلیل فرض ثابت بودن در مورد RF I ).
محاسبه باقیمانده های استاندارد شده امکان پذیر است:
جایی که می توانیم جایگزین کنیم π(x)�(�)با π^(x)�^(�)برای بدست آوردن e^(x)�^(�)(یعنی نسخه تخمینی e(x)�(�)). با باقیماندههای استاندارد شده، میتوانیم واریوگرامهای آنها مانند cov e ( h ) و در نتیجه همبستگیها را مدلسازی کنیم.ρe(h)��(ℎ)، که سپس می تواند برای بدست آوردن ماتریس واریانس و کوواریانس V از RF I مورد سوء استفاده قرار گیرد (برخلاف معادله (10)):
که در آن:
که در آن n تعداد مکان های نمونه برداری شده است همانطور که در رابطه (10) و ρe(xs,xs′)��(��,��′)همبستگی بین مکان های داده را نشان می دهد xs��و xs′��′، که از باقیمانده های استاندارد شده، همانطور که در رابطه (17) نشان داده شده است، به دست می آید.
با داده های باینری همبسته فضایی، ضرایب رگرسیون β�و پارامترهای همبستگی α�(به عنوان مثال، محدوده، قطعه و آستانه توصیف واریوگرام) را می توان با استفاده از رویکردهای معادله تخمین تعمیم یافته (GEE) تخمین زد [ 26 ، 27 ]. آنها رویه های تکرار شونده هستند که بین برآوردهای به روز رسانی متناوب می شوند β�و کسانی که از α�، تا همگرایی. یک چالش در انطباق روش GEE برای تجزیه و تحلیل داده های مکانی، انتخاب یک ساختار همبستگی معقول است، زیرا برخی از ساختارهای همبستگی مفروض پشتیبانی شده در سیستم های نرم افزاری موجود GEE برای داده های مکانی طراحی نشده اند. در عمل، میتوانیم بهطور مکرر تخمینها را بهروزرسانی کنیم β�بر اساس پارامترهای مدل واریوگرام بهروزرسانیشده تکراری، مانند [ 24 ].
با حل ضرایب رگرسیون β�و پارامترهای همبستگی α�(بنابراین، R و V در معادله (18)) که در بالا به دست آمد، اندازه گیری های دقت محلی را می توان از اعمال بردار ضریب به دست آورد. β^�^به معادله (12). همانطور که در رگرسیون لجستیک مرسوم، میتوانیم روش دلتا (معادله (15)) را برای محاسبه واریانس در احتمالات پیشبینیشده طبقهبندی صحیح در مکانهای جداگانه اعمال کنیم.
پس از استخراج معیارهای دقت محلی و واریانس مرتبط با رگرسیون لجستیک، باقیمانده های رگرسیون را می توان از طریق کریجینگ در مکان های نمونه برداری نشده متراکم کرد. با توجه به وسایل محلی غیر ثابت π(x)�(�)و واریانس ها π(x)(1−π(x))�(�)(1−�(�))، اما نمی توانیم کریجینگ را با باقیمانده ها انجام دهیم { ε(x)�(�)} به طور مستقیم. در عوض، کریجینگ ساده را با استفاده از معادله (4) در فضای باقیمانده های استاندارد شده { e ( x )} انجام می دهیم. ما باید از مدل واریوگرام برازش برای e استفاده کنیم ، ρe(h)��(ℎ)، برای محاسبه عناصر ماتریس واریانس و کوواریانس بین مکان های داده x s ( s = 1, …, n ): Re(n,n)=(ρe(xs,xs′))��(�,�)=(��(��,��′)). عناصر بردار کوواریانس بین مکانی که باید پیش بینی شود (یعنی x 0 ) و مکان های داده x s ( s = 1, …, n ) را می توان به طور مشابه محاسبه کرد: Re(0,n)=(ρ(x0,x1),⋯,ρ(x0,xn))آره(0،�)=(�(ایکس0،ایکس1)،⋯،�(ایکس0،ایکس�)). واریانس در e^(x0)ه^(ایکس0)را می توان با استفاده از رابطه (5) محاسبه کرد، اما در فضای باقیمانده های استاندارد شده { e ( x )} و با sill = cov ( h = 0) = 1. باقیمانده های کریگ شده e ( x 0 ) (با معادله (5)) سپس به عقب تبدیل می شوند ε(x0)�(ایکس0)از طریق وارونگی معادله (17):
واریانس در ε^(x0)�^(ایکس0)به صورت زیر محاسبه می شود:
باقیماندههای کریگد در مکانهای نمونهبرداری نشده به عنوان اصلاحاتی برای پیشبینیهای رگرسیون دقتهای محلی استفاده میشوند. به طور خاص، پیشبینی I در یک پیکسل بدون نمونه x 0 ، p^(x0)�^(�0)، با افزودن باقیمانده پیش بینی شده انجام شد ε^(x0)�^(�0)(با استفاده از معادله (19)) برای پیش بینی رگرسیون π^(x0)�^(�0):
که در آن میانگین محلی با استفاده از رابطه (12) اما با β^�^، که باید از رویه هایی به دست آید که می توانند همبستگی فضایی را از طریق ماتریس V انجام دهند (معادله (18)). مقدار SE در اندازه گیری دقت تصحیح شده p^(x0)�^(�0)است:
جایی که var[π^(x0)]var[�^(�0)]و var[ε^(x0)]var[�^(�0)]به ترتیب با استفاده از معادلات (15) و (20) محاسبه می شوند
3. آزمایشات
3.1. حوزه مطالعه و مجموعه داده ها
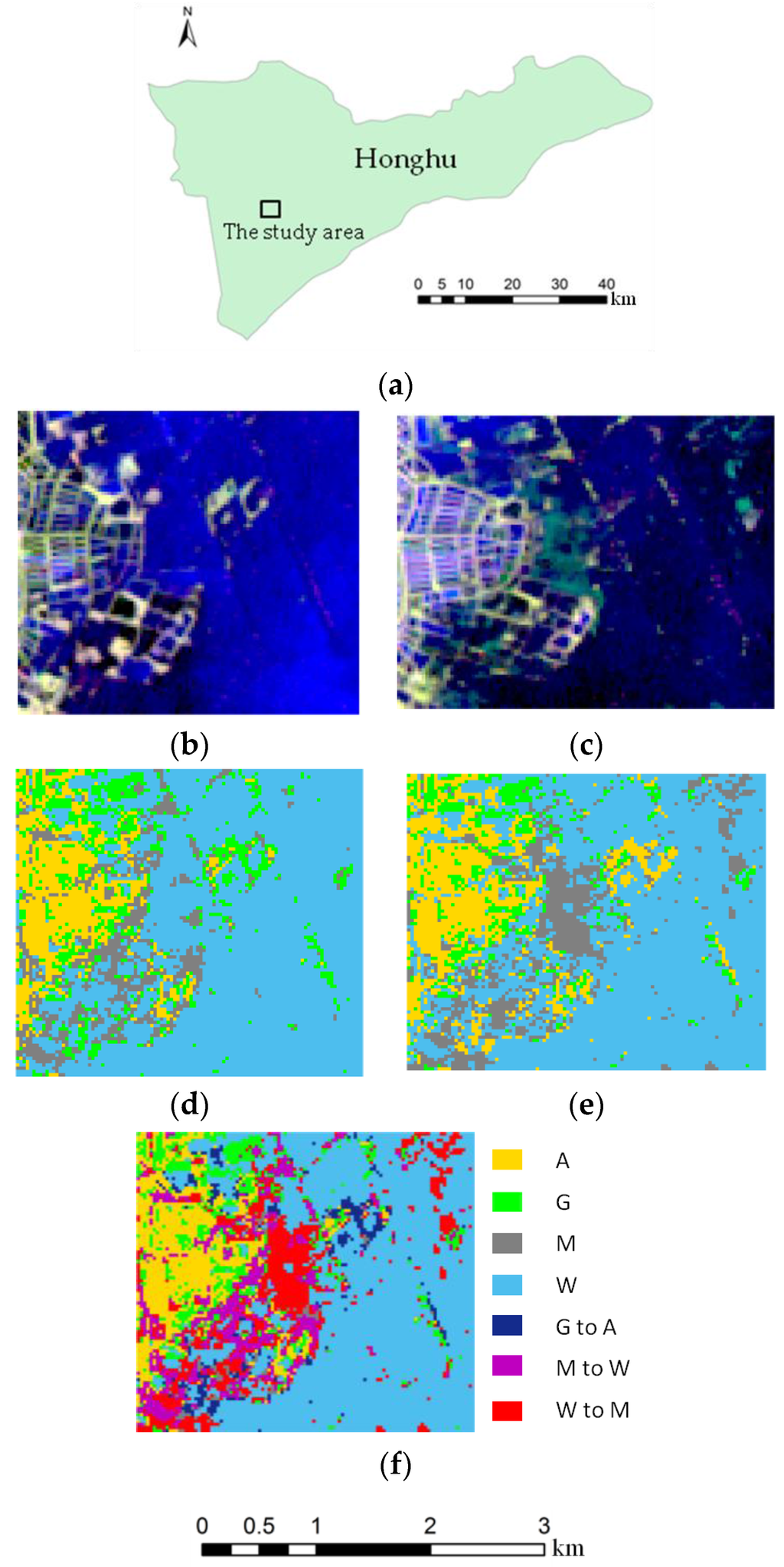
شهرداری هونگهو، استان هوبی، چین، که در شکل 1 الف نشان داده شده است، در شمال میانی رودخانه یانگ تسه و جنوب شرقی دشت جیانگگان واقع شده است. پهنای N Latitude را در بر می گیرد 29∘39′–30∘12′29∘39′–30∘12′و طول جغرافیایی E 113∘07′–114∘05′113∘07′–114∘05“، از آب و هوای نیمه گرمسیری مرطوب موسمی برخوردار است و دارای مناطق پست با ارتفاعات عمدتاً در محدوده 23 تا 28 متر از سطح متوسط دریا است. حدود 30 درصد از کل مناطق آن را آبهایی تشکیل میدهند که شبکهای متراکم از رودخانهها، نهرها، دریاچهها و قناتها را در بر میگیرد (جالب است که هر دو “hu” در “Honghu” و “Hu” در “Hubei” به معنای دریاچهها در چینی هستند). بارندگی بیشتر در بهار و تابستان رخ می دهد و در نتیجه سیلاب های مکرر رخ می دهد.
از نظر تاریخی، زمین های زراعی و آب منابع اصلی زمین هونگو هستند. از سال 2011، حدود 40٪ تا 60٪ بارندگی کمتری در بخش میانی و پایین دست رودخانه یانگ تسه وجود داشت. هونگهو با خطر خشک شدن دریاچه ها مواجه شد. تغییرات قابل توجهی در انواع پوشش زمین در آنجا به دلیل احیا و کشت بیش از حد و وضعیت جمعیت بیشتر و زمین کمتر، مانند انتقال از آب به زمین های مختلط و از پوشش گیاهی طبیعی (مثلاً علفزار) به زمین های زراعی، وجود داشت که نشان دهنده اکولوژیک است. و تخریب محیط زیست با اجرای اقدامات حفاظتی دریاچه از طریق تشویق به احیای اراضی، بهبود بهره برداری از منابع زمین و توسعه منابع آبی از سال 1391 تا 1394، پوشش اراضی مختلط که قبلاً استفاده نشده بود، به تدریج به بدنه های آبی و تالاب ها بازگردانده شد.
دو تصویر زیر صحنه Landsat ETM+ از شهرداری هونگهو، که در 17 می 2012 (زمان 1) و 8 آگوست 2013 (زمان 2) به ترتیب با باندهای 1 تا 5 و 7 با وضوح 30 متر پرواز کردند، برای استخراج تغییر پوشش زمین استفاده شد. اطلاعات تصاویر ترکیبی برای تصاویر زیر صحنه 2012 و 2013 Landsat ETM+ با استفاده از باندهای 5، 4 و 3 به ترتیب در شکل 1 b,c نشان داده شده است. منطقه مطالعه مستطیلی، که در شکل 1 الف مشخص شده است، 9964 پیکسل (94 ردیف در 106 ستون) را در بر می گیرد که هر کدام به اندازه 30 متر در 30 متر است.
با توجه به ویژگی های فوق الذکر منطقه مورد مطالعه (و کاربری زمین در آن) و وضوح فضایی محدود تصاویر ماهواره ای استفاده شده، برای مطالعات پوشش زمین محلی و پویایی آن، ما یک طرح طبقه بندی چهار طبقه را اتخاذ کردیم: زمین زراعی، زمین چمن، آب و خاک مخلوط نوع پوشش زمین مختلط شامل اراضی متروکه است و ممکن است ترکیبی از انواع پوشش زمین نامزد را نشان دهد، که تشخیص آنها به تنهایی از روی داده های تصاویر ماهواره ای آسان نیست. نوع بدنههای آبی شامل تالابها میشود و بنابراین احتمالاً ترکیبی از تالابها با زیستگاههای در حال رشد و تودههای آبی است.
در تشخیص تغییر بر اساس مقایسه پس از طبقهبندی، تصاویر Times 1 و 2 به طور جداگانه طبقهبندی شدند و نقشههای طبقهبندی را برای Times 1 و 2 ایجاد کردند، همانطور که در شکل 1 d,e نشان داده شده است . سپس نقشه های طبقه بندی برای ایجاد یک نقشه تغییر با اطلاعات تغییر “از به” خاص مقایسه شدند. یک نقشه تغییر پوشش زمین با 16 ترکیب ممکن از اطلاعات تغییر “از به” را می توان برای یک طرح طبقه بندی چهار طبقه تک تاریخی مشتق کرد: زراعی، چمن، مخلوط و آب. از آنجایی که برخی دستههای تغییر غیرمحتمل و غیرمحتمل وجود دارد، ما فقط 7 دسته را در نقشه نهایی تغییر پوشش زمین، از جمله 4 طبقه بدون تغییر یا پایدار و 3 کلاس تغییر، همانطور که در شکل 1 f نشان داده شده است، حفظ کردیم .
3 طبقه تغییر نشان داده شده در شکل 1 f عبارتند از: زمین چمن به زمین قابل کشت، پوشش زمین مختلط به آب و بدنه آبی به پوشش زمین مختلط. توضیحات برای این تغییرات عبارتند از: (1) برخی از علفزارها به دلیل افزایش تقاضا برای کشاورزی (به دلیل فشار برای تغذیه مردم در زمین های کشاورزی محدود) به زمین قابل کشت تبدیل شدند. (2) به دلیل کاهش بارندگی در طول دوره، بخش هایی از دریاچه ها شروع به خشک شدن کردند که منجر به افزایش پوشش مخلوط زمین شد. و (3) بازسازی زیست محیطی منجر به برخی از آب های بازسازی شده از زمین های مختلط قبلاً رها شده شد.
داده های مرجع مربوط به داده های تصویر از ترکیبی از بازدیدهای میدانی و تفسیر عکس بر اساس تصاویر با وضوح بالا (فضایی) جمع آوری شد. انواع پوشش مرجع برای سایتهای نمونه در سال 2013 در چندین تاریخ در اکتبر 2013 بررسی شدند، در حالی که موارد مربوط به سال 2012 با استفاده از تفسیر عکس بر اساس تصاویر با وضوح بالا که در مجاورت زمانی زیر مجموعه تصویر ETM+ 2012 در نظر گرفته میشوند تأیید شدند. تفسیر عکس با بررسی های میدانی و دانش محلی برای اطمینان از دقت معقول در داده های مرجع به دست آمده کمک شد. برچسبگذاری کلاس همه مکانهای نمونه، اعم از انواع پوشش تکتاریخ یا انواع تغییرات دوزمانی، دوبار بررسی شد و اگر برچسبگذاری مشکوک بود، آنها حذف شدند.
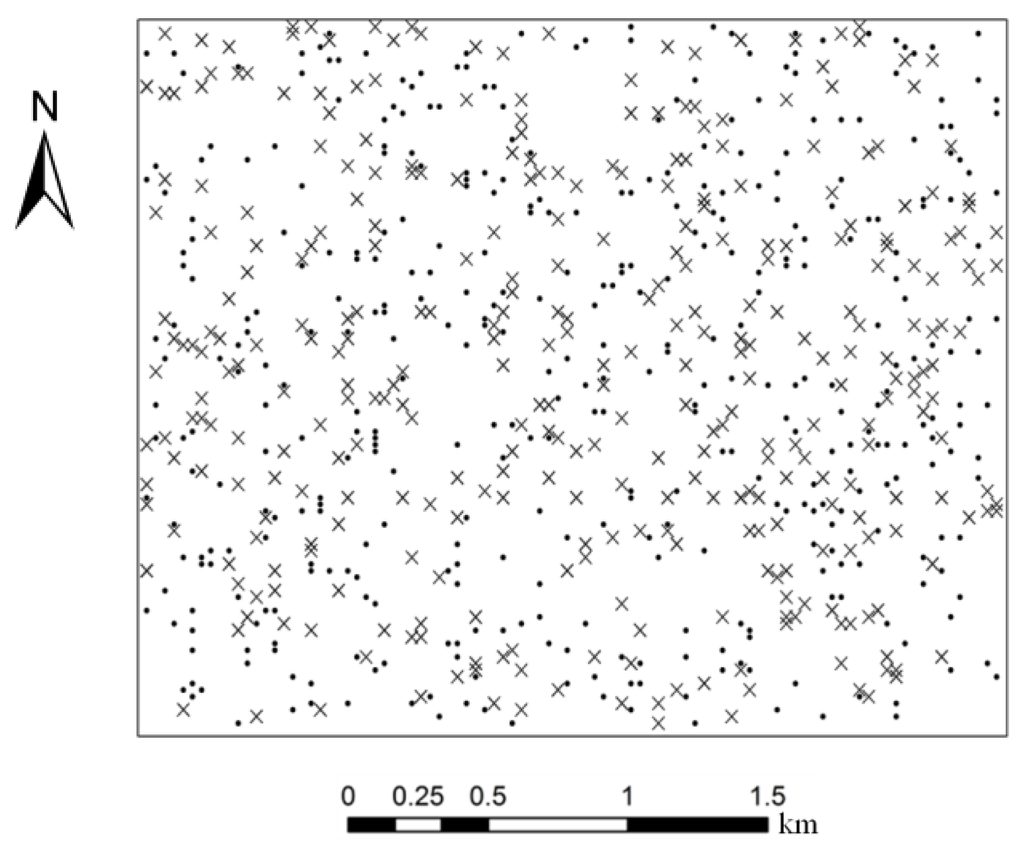
ما باید از اصول آماری مربوط به نمونهبرداری فضایی [ 28 ] برای جمعآوری نمونههای مرجع پیروی کنیم که به ترتیب برای ساخت مدلها و اعتبارسنجی مدلهای ساخته شده (برای پیشبینی دقت محلی) استفاده میشوند. مجموعه نمونه های قبلی نمونه های آموزشی نامیده می شدند و نمونه های دوم نمونه های آزمایشی (که برای مقایسه روش های جایگزین بودند و در بخش 3.3 مورد بررسی قرار خواهند گرفت.، مطابق با سنت در طبقه بندی تصاویر سنجش از دور. برای جمعآوری نمونههای آموزشی و آزمایشی، نمونهگیری با استفاده از طبقهبندی طبقاتی انجام شد که هر طبقه نقشه با نسبت ثابت یا در تعداد حداقل در مورد طبقات اقلیت نمونهبرداری شد. ما 25 را به عنوان حداقل تعداد نمونه برای طبقات اقلیت (مثلاً نوع پوشش مختلط) تعیین کردیم که به ترتیب 400 و 350 نمونه برای آموزش و آزمایش به دست آوردیم. تعداد نمونه ها برای کلاس های جداگانه در جدول 1 نشان داده شده است ، در حالی که توزیع آنها در شکل 2 نشان داده شده است .
آزمون تصادفی بودن مکانهای نمونه بر اساس «ابزار آمار فضایی» در سیستم نرمافزار ArcGIS انجام شد. با استفاده از ماژول “تجزیه و تحلیل الگوها”، آزمون Z برای تعیین اینکه آیا میانگین فاصله تا نزدیکترین همسایگان تفاوت معنی داری با میانگین فاصله تصادفی دارد یا خیر، استفاده شد. نمرات Z به ترتیب 72/0 و 85/0 برای نمونه های آموزشی و آزمایشی به دست آمد که به ترتیب با مقادیر p 46/0 و 39/0 مطابقت دارد. بنابراین، فرض صفر پذیرفته می شود که الگوی دو مجموعه نمونه تصادفی در سطح معنی داری 0.05 = α است.
مجموعه ای از 215 نمونه اضافی وجود داشت که برای آزمایش اثربخشی نمونه گیری تطبیقی با مکان یابی تعدادی از نمونه های آموزشی بیشتر (مثلا 30) با توجه به SE های ارزیابی شده در مکان های نمونه نامزد استفاده شد. این مجموعه از 215 نمونه کنار گذاشته شد، زیرا نمونهگیری به اصطلاح تطبیقی با نمونهگیری تصادفی جایگزین مقایسه شد که به استخر بزرگتری برای تصادفی بودن در مکانهای نمونه نیاز دارد. ما این را در بخش 3.2 توضیح خواهیم داد .
3.2. نتایج
بر اساس نمونه های آموزشی، ماتریس خطا را ساختیم. همانطور که در جدول 2 نشان داده شده است، برای استخراج PCC و دقت کاربران برای کلاس های فردی خلاصه شده است .
کریجینگ ساده برای پیشبینی احتمالات طبقهبندی صحیح در مکانهای نمونهگیری نشده از نمونههای آموزشی استفاده شد. همانطور که در جدول 2 نشان داده شده است ، میانگین جهانی RF I که صحت طبقه بندی را نشان می دهد، به عنوان اندازه گیری PCC تخمین زده شده از نمونه های آموزشی در نظر گرفته شد . مدل واریوگرام برای RF I با داده های نشانگر نصب شد که (نادرستی) در تشخیص تغییر را به عنوان 1/0 کدگذاری کرد. سطح احتمالات طبقه بندی صحیح در هر پیکسل در شکل 3 نشان داده شده استالف، جایی که آشکار است که احتمالات پیشبینیشده بیشتر شبیه مقادیر نمونهگیری شده در نزدیکی مکانهای نمونهبرداری شده هستند، در حالی که به دلیل دامنه تأثیر نسبتاً کوتاه نشاندادهشده توسط مدل واریوگرام (مناسب با دادههای آموزشی نشانگر) و ماهیت سادهتر، در جاهای دیگر یکنواخت به نظر میرسند. کریجینگ همانطور که فهمیده شد، پیشبینیهای کریجینگ ساده، مقدار متوسط شناخته شده در مکانهایی است که هیچ دادهای نمونه در شعاع جستجوی مشخصشده نیست یا دادههای نمونه فراتر از محدوده تأثیر است. محدوده واریوگرام برای مجموعه دادهها در اینجا 2 پیکسل بود، با شعاع جستجو برابر با پارامتر محدوده تنظیم شده است. 6967 مکان نمونهگیری نشده وجود داشت (یعنی پیکسلهایی که باید پیشبینی شوند)، که فراتر از محدوده تأثیر دادههای نمونه بودند و از این رو، مقدار میانگین را که 73.25٪ است، همانطور که در جدول 1 نشان داده شده است، اختصاص دادند .. در نتیجه، ظاهر یکنواختی از احتمالات پیشبینیشده در اکثر مکانهای نمونهگیری نشده وجود داشت، همانطور که در شکل 3 الف نشان داده شده است، اگرچه تنوع محلی در مقادیر پیشبینیشده را میتوان به وضوح با یک نسخه بزرگشده درست از شکل 3 a (یا بزرگنمایی در کپی نرمافزار آن مشاهده کرد. ). واریانس کریجینگ نیز محاسبه شد و سطحی را ایجاد کرد که SE ها (ریشه دوم واریانس کریجینگ) را در مکان های جداگانه نشان می دهد، همانطور که در شکل 4 a نشان داده شده است، که ظاهر معمولی واریانس کریجینگ را نشان می دهد: SE ها با فاصله بیشتر از مکان های نمونه گیری افزایش می یابند.
برای رگرسیون لجستیک، کلاس تغییر پوشش زمین ( کلاس )، اندازه مجاورت بلوک ( L 10 B )، ناهمگنی ( HET )، تسلط ( DMG) و بردار احتمال وقوع کلاس در همسایگی کانونی ( PROB = ( p 1 ( x )، p 2 ( x )،…، p6 ( x )) T ) به عنوان متغیرهای کمکی در ترکیبهای مختلف ( همانطور که در جدول 3 نشان داده شده است ) برای پیشبینی احتمالات هر پیکسل طبقهبندی صحیح تغییرات استفاده شد . کلاستوسط 6 متغیر باینری کدگذاری شد تا وجود یکی از 7 کلاس را نشان دهد (زیرا یک افزونگی در کدگذاری کلاس ها وجود دارد). PROB احتمالات کلاس های جداگانه را در همسایگی کانونی هر پیکسل نشان می دهد (توجه داشته باشید که یک افزونگی در احتمالات 7 کلاس ممکن وجود دارد زیرا مجموع آنها برابر با 1.0 است). مدل های آزمایش شده در جدول 3 نشان داده شده است . اعداد مدل نشان می دهد که چند مجموعه از متغیرهای کمکی (علاوه بر رهگیری). β0�0) برای رگرسیون لجستیک استفاده می شود: مدل های 1a تا 1e به ترتیب اثرات کلاس ، L 10 B ، HET ، DMG و PROB را بر دقت طبقه بندی تغییرات در نظر می گیرند. مدلهای 2a تا 2d به ترتیب اثرات L 10 B ، HET ، DMG و PROB را در خود جای میدهند ، زمانی که کلاس قبلاً در نظر گرفته شده باشد. مدلهای 3a تا 3c به ترتیب اثرات L 10 B ، HET و PROB را در هنگام کلاس توضیح میدهند.و DMG در حال حاضر گنجانیده شده اند. مدلهای 4a و 4b به دنبال تعیین کمیت اثرات همه L 10 B و HET هستند ، زمانی که کلاس ، DMG و PROB قبلاً گنجانده شدهاند. به عبارت دیگر، افزودن L 10 B یا HET به مدل 3c، مدل 4a یا 4b را ایجاد می کند، همانطور که در جدول 3 نشان داده شده است .
یک روش جامع انتخاب مدل برای یافتن مدل حاوی بیشترین تعداد متغیرهای توضیحی معنیدار (در 0.01 = α) استفاده شد. در هر مرحله از روش، اهمیت افزودن یک متغیر کمکی به یک مدل مورد آزمایش قرار گرفت. تفاوت بین انحرافات دو مدل به شرح زیر است χ2df�df2توزیع، که در آن df تعداد متغیرهای کمکی اضافی به آنهایی است که توسط دو مدل مشترک است. آ χ2�2بنابراین -test می تواند برای آزمایش اینکه آیا افزودن این متغیرهای df به مدل به طور قابل توجهی برازش مدل را بهبود می بخشد استفاده شود.
جدول 4 آزمایش اهمیت را در مورد بهبود برازش مدل ها با افزودن یک متغیر کمکی اضافی (یا مجموعه ای از متغیرهای کمکی، مانند کلاس و PROB ) F +1 نشان می دهد . همانطور که در جدول 4 نشان داده شده است ، تمام مجموعه های متغیرهای کمکی در سطح معنی دار بودند α�= 0.01. تأثیر شاخصهای الگوی محلی ( L 10 B ، HET ، DMG و PROB ) نسبتاً کوچک، اما معنیدار بود (در α�= 0.01) اگر مدل حاوی کلاس باشد ، که نشان می دهد بخشی از تأثیر این متغیرها قبلاً توسط کلاس محاسبه شده است . DMG مهم ترین در بود α�= 0.01 اگر کلاس قبلاً در مدل بود. بنابراین، تجزیه و تحلیل با کلاس و DMG ادامه یافت . افزودن L 10 B یا HET به یک مدل حاوی کلاس و DMG در 0.01 = α معنی دار نبود. افزودن PROB به مدلی با کلاس و DMG (مدل 3c) در آن معنادار بود α�= 0.1. در نهایت، آزمایش شد که افزودن به مدل 3c متغیر کمکی L 10 B یا HET به طور قابل توجهی (در α = 0.1 یا 0.01) تناسب را بهبود نمی بخشد. بنابراین مدل 3c (1& Class & DMG & PROB ) مدلی بود که دارای بیشترین تعداد متغیرهای کمکی معنیدار بود.
با انتخاب مدل 3c (1& Class & DMG & PROB ) با استفاده از آزمون معناداری همانطور که در بالا ذکر شد، رگرسیون لجستیک با استفاده از این مدل برای پیشبینی سطح پیکسل دقت طبقهبندی انجام شد. یک سطح احتمال با فرض استقلال فضایی در نمونه های دوتایی طبقه بندی (نادرست) ایجاد شد، همانطور که در شکل 3 ب نشان داده شده است. علاوه بر این، SE ها در پیش بینی های لجستیک با استفاده از معادله (15)، با نقشه حاصل از SE ها در شکل 4 ب محاسبه شدند.
همانطور که در بخش 2.3 توضیح داده شد ، داده های باینری که نشان دهنده صحت (نادرستی) در طبقه بندی تغییرات هستند، اغلب از نظر فضایی همبستگی دارند. یک چالش در رگرسیون لجستیک که شامل دادههای باینری همبسته فضایی است، مدلسازی وابستگی فضایی در دادههای پاسخ باینری در حالی که تخمین ضرایب رگرسیون β است. برای این کار، یک روش تکراری برای تخمین ضرایب مدل لجستیک و پارامترهای واریوگرام از طریق باقیماندههای استاندارد شده انجام شد. پس از همگرایی تخمین های پارامترهای مدل واریوگرام و ضرایب مدل لجستیک، مقادیر پارامتر مدل واریوگرام را به دست آوردیم (همانطور که در جدول 5 نشان داده شده است.، مجموعه نهایی مقادیر پارامترها) و ضرایب مدل لجستیک β’s. β برای پیشبینی دقت سطح پیکسل طبقهبندی تغییرات با وابستگی فضایی استفاده شد. علاوه بر این، خطاهای استاندارد را می توان با استفاده از رابطه (15) تخمین زد. دقت های پیش بینی شده و SE های مرتبط به ترتیب در شکل 3 c و شکل 4 c نشان داده شده است. تفاوت بین نتایج بهدستآمده از رگرسیون لجستیک با همبستگی فضایی تطبیقشده و نتایج بدون از نظر احتمالات پیشبینیشده و خطاهای پیشبینی به سختی قابل درک است. دلیل آن این است که محدوده همبستگی فضایی فقط در مقیاس حدود 3 پیکسل است که بسیار کمتر از میانگین فاصله بین مکان های نمونه برداری شده است.
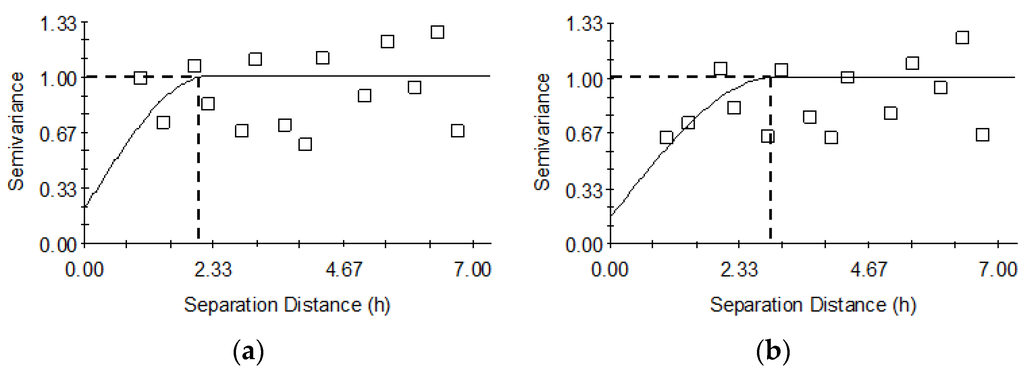
پس از رگرسیون لجستیک، باقیماندههای رگرسیون لجستیک در پیکسلهای نمونه برای تخمین اصلاحات پیشبینیهای رگرسیون از طریق کریجینگ ساده استفاده شد و سپس به پیشبینیهای رگرسیون اضافه شد (یعنی میانگینهای محلی، π^(x)�^(�)) برای به دست آوردن اندازه گیری های احتمالی تصحیح شده دقت طبقه بندی برای پیکسل های منفرد. معادلات (21) و (22) به ترتیب فرمولهایی بودند که برای محاسبه احتمالات تصحیح شده طبقهبندی صحیح و خطاهای استاندارد مربوطه استفاده میشدند. برای کریجینگ باقیمانده های رگرسیون، دو رویکرد اجرا شد: یکی بدون در نظر گرفتن همبستگی فضایی در رگرسیون لجستیک ( جدول 5 ، مجموعه اولیه مقادیر پارامتر واریوگرام) و دیگری با در نظر گرفتن همبستگی فضایی در آن، همانطور که در بخش 2.3 نشان داده شده است ( جدول را ببینید). 5 ، مجموعه نهایی مقادیر پارامتر واریوگرام همانطور که قبلا ذکر شد). برای کمک به تفسیر نتایج، شکل 5a پارامترهای مدل واریوگرام را بدون همبستگی فضایی در رگرسیون لجستیک نشان میدهد (مرتبط با مجموعه اولیه پارامترها در جدول 5 )، در حالی که شکل 5 b پارامترهای مدل واریوگرام را نشان میدهد که به طور تکراری با پارامترهای رگرسیون لجستیک که همبستگی فضایی در نظر گرفته شده است (مربوط به مجموعه نهایی پارامترها در جدول 5 ). رکاب های نشان داده شده در شکل 5a،b، که مجموع واریانسهای ساختاری و ناگت هستند، روی 1.0 تنظیم شد زیرا باقیماندههای استاندارد شده برای محاسبه واریوگرامهای تجربی استفاده شد. نتایج با اولی به معنای ارائه یک خط پایه برای دومی بود که به دلیل تکرار در تخمین پارامتر و مدلسازی واریوگرام، از نظر محاسباتی گرانتر است.
برای اولی، نقشه ای که احتمالات تصحیح شده طبقه بندی تغییرات صحیح و SE ها را در معیارهای احتمالی اصلاح شده به تصویر می کشد به ترتیب در شکل 3 d و شکل 4 d نشان داده شده است. برای دومی، نقشه هایی که احتمالات تصحیح شده و SE های آنها را نشان می دهند به ترتیب در شکل 3 e و شکل 4 e نشان داده شده است. جای تعجب نیست، نتایج نشان داده شده به صورت جفت (یعنی شکل 3 b,c و شکل 3d ,e) هیچ تفاوت ظاهری را نشان نمی دهد. این تفسیر بصری با نتایج آزمایش در بخش فرعی بعدی پشتیبانی خواهد شد.
پس از انجام آزمایشهایی درباره متغیرهای کمکی معنیدار برای رگرسیون لجستیک و مزایای لجستیک-رگرسیون-کریجینگ (با یا بدون درمان کامل همبستگی فضایی در تخمین پارامترهای مدل واریوگرام و ضرایب رگرسیون) در برابر رگرسیون یا کریجینگ به تنهایی، به اثرات نمونهگیری تطبیقی با معیارهای عدم قطعیت (به عنوان مثال، SE) در پیشبینیهای دقت محلی فعلی (بر اساس دادههای نمونه آموزشی موجود) هدایت میشود. برای آزمایش اثربخشی نمونهگیری تطبیقی (به این دلیل برچسبگذاری شده است که نمونههای بیشتر بر اساس SE در پیشبینیهای دقت موجود انتخاب میشوند)، ما از مجموعه ۲۱۵ نمونه اضافی به عنوان جامعه برای دریافت نمونههای آموزشی بیشتر استفاده کردیم. نمونه گیری تطبیقی در واقع بر اساس نتایج به دست آمده توسط لجستیک-رگرسیون-کریجینگ با یا بدون درمان کاملتر همبستگی فضایی انجام شد. ما 30 نمونه آموزش بیشتر را انتخاب کردیم که SE آنها به طور قابل توجهی بزرگتر از بقیه در مجموعه 215 نمونه بود. برای مقایسه با نمونهگیری تطبیقی که در اینجا دنبال میشود، ما همچنین از نمونهگیری تصادفی طبقهای (بدون توجه به SE) بر اساس همان مجموعه 215 نمونه اضافی برای به دست آوردن 30 نمونه آموزشی تصادفی استفاده کردیم. دو رویکرد نمونهگیری و دو مجموعه از نتایج لجستیک-رگرسیون-کریجینگ قبلی منجر به چهار مجموعه دیگر از نتایج شد. این چهار نتیجه پیش بینی در نشان داده شده است ما همچنین از نمونهگیری تصادفی طبقهای (بدون در نظر گرفتن SE) بر اساس همان مجموعه 215 نمونه اضافی برای به دست آوردن 30 نمونه آموزشی تصادفی استفاده کردیم. دو رویکرد نمونهگیری و دو مجموعه از نتایج لجستیک-رگرسیون-کریجینگ قبلی منجر به چهار مجموعه دیگر از نتایج شد. این چهار نتیجه پیش بینی در نشان داده شده است ما همچنین از نمونهگیری تصادفی طبقهای (بدون در نظر گرفتن SE) بر اساس همان مجموعه 215 نمونه اضافی برای به دست آوردن 30 نمونه آموزشی تصادفی استفاده کردیم. دو رویکرد نمونهگیری و دو مجموعه از نتایج لجستیک-رگرسیون-کریجینگ قبلی منجر به چهار مجموعه دیگر از نتایج شد. این چهار نتیجه پیش بینی در نشان داده شده استشکل 3 f تا شکل 3 i، در حالی که نقشه های مربوط به آنها از SE ها در شکل 4 f تا شکل 4 i نشان داده شده است. واضح است که SE های نشان داده شده در شکل 4 f,g و شکل 4h ,i به ترتیب کاهش جزئی را در مقایسه با شکل 4 d,e نشان می دهند.
3.3. آزمایش کردن
عملکرد 9 روش مختلف که قبلا برای پیش بینی دقت شرح داده شد را می توان با مقایسه مقادیر پیش بینی شده ارزیابی کرد. p^(xj)�^(��)با مشاهدات واقعی i(xj)�(��)در 350 مکان نمونه آزمایشی با استفاده از چهار معیار زیر: میانگین خطا ( ME )، میانگین خطای مطلق ( MAE )، ریشه میانگین مربع خطا ( RMSE ) و مجموع مربعات ( R2SS���2). آنها به صورت زیر محاسبه می شوند:
که در آن n t تعداد نمونه های آزمایشی و p¯�¯میانگین مقادیر مشاهده شده است. همانطور که در ادبیات توصیه شده است، R2SS���2نسبت تغییرات توضیح داده شده را با رگرسیون لجستیک اندازه گیری می کند [ 29 ]. از آنجایی که پیشبینیهای احتمالات طبقهبندی (نادرست) را میتوان به دادههای شاخص در آستانه 0.5 تبدیل کرد، ما همچنین میتوانیم معیارهای PCC را برای ارزیابی دقت پیشبینیها محاسبه کنیم. این معیارها برای 9 روش پیشبینی، همانطور که در جدول 6 ارائه شده است، محاسبه شد . نتایج برای مدل صفر، که 73.25% (تخمین PCC از جدول 2 ) را به عنوان پیشبینی دقت برای همه پیکسلها اختصاص میدهد، به عنوان خط پایه برای روشهای نشاندادهشده در جدول 6 استفاده میشود .
همانطور که از جدول 6 مشاهده می شود ، همه روش ها مقادیر ME منفی را ثبت می کنند (یعنی ME <0). این نشان میدهد که همه روشهای پیشبینی مورد استفاده در اینجا دقت در طبقهبندی تغییرات را بیش از حد تخمین زدهاند (به عنوان مقادیر مشاهدهشده < مقادیر پیشبینیشده). به دلیل عدم تعصب در کریجینگ، مقدار ME پیشبینیهای کریجینگ نشانگر نزدیکترین مقدار به 0 است.
همانطور که در جدول 6 نشان داده شده است ، تمایل به عملکرد بهتر وجود دارد، همانطور که با کاهش MAE و RMSE نشان داده شده است ، اما افزایش PCCs و R2SS���2برای روش های نشان داده شده از بالا به پایین در ردیف های جدول 6 . به طور خاص، همانطور که در جدول 6 نشان داده شده است، کریجینگ اندیکاتور در پیش بینی دقت های محلی بدترین است، در حالی که همبستگی فضایی تطبیق دهنده لجستیک-رگرسیون-کریجینگ بهترین بود. توجه داشته باشید که مدل صفر، که یک خط پایه را برای سایر روشهای آزمایش شده تعیین میکند، بدتر از سایر روشهای آزمایش شده بود، همانطور که در جدول 6 نشان داده شده است .
با این حال، در مقایسه با اجرای جایگزین بدون در نظر گرفتن همبستگی فضایی، تنها دستاوردهای اندکی در دقت به دست آمده است. این همچنین در مورد رگرسیون لجستیک با همبستگی فضایی در مقابل رگرسیون بدون در نظر گرفته شده صادق است. بنابراین، مبادله بین هزینه محاسبات و افزایش دقت در دقت پیشبینی مهم است. کاربران نقشه باید تصمیم بگیرند که آیا هزینه اضافی مربوط به رگرسیون-کریجینگ با دستاوردهای اندک در دقت پیشبینی قابل توجیه است یا خیر.
لازم به ذکر است که نمونه های مرجع کافی همیشه برای اطمینان از دقت معقول در پیش بینی ها (در مورد دقت طبقه بندی محلی) با روش های آزمایش شده در اینجا بدون توجه به پیچیدگی آنها مهم هستند. با توجه به حجم نمونه خاص، طراحی نمونه برای پیش بینی بهینه مهم خواهد بود. همانطور که قبلاً ذکر شد، نقشههای SEs نشاندادهشده در شکل 4 میتوانند برای مکانیابی نمونههای آموزشی تراکم برای تسهیل توسعه استراتژیهای نمونهگیری برای توصیف دقیق و در عین حال کارآمد دقت طبقهبندی استفاده شوند، زیرا نمونهبرداری از زمین اغلب گران است. ما نتایج (نشان داده شده در شکلهای فرعی (f) تا (i)) را که با افزودن نمونههای آموزشی اضافی (حالتهای تطبیقی و تصادفی)، با استفاده از همان نمونههای آزمایشی به دست آمد، آزمایش کردیم. آمار تست در جدول 6 آمده استبلوک پایین ردیف های مربوط به اثرات نمونه های آموزشی اضافی. آنها نشان می دهند که نمونه گیری تطبیقی برای نمونه های آموزشی اضافی مقرون به صرفه تر از نمونه گیری تصادفی است. به عنوان مثال، برای مورد ترکیب لجستیک-رگرسیون-کریجینگ با درمان همبستگی فضایی در رگرسیون، 7.5 درصد نمونه های آموزشی بیشتر منجر به حدود 8.8 درصد و 57.3 درصد افزایش در دقت پیش بینی، همانطور که توسط PCCs و اندازه گیری شد. R2SS���2، به ترتیب. در مقایسه، برای نمونهگیری تصادفی، همان افزایش در حجم نمونه آموزشی تنها منجر به افزایش 2.0% و 27.5% در دقت پیشبینی شد، همانطور که توسط PCCs و اندازهگیری شد. R2SS���2به ترتیب روابط بین نمونهگیری تطبیقی مبتنی بر عدم قطعیت و عملکردهای پیشبینی باید بیشتر مورد مطالعه قرار گیرد، اگرچه این خارج از محدوده این مقاله است.
3.4. بحث
روشهای پیشنهادی برای نقشهبرداری دقتهای محلی در نقشههای تغییر پوشش زمین را میتوان در ترکیب با کار بر روی پایش و مدلسازی دینامیک منظر، مانند آنچه که توسط Millington و همکارانش توضیح داده شد، بهطور مفید مورد بررسی قرار داد. [ 1 ] و رادرفورد و همکاران. [ 2 ]، و تلاش های پژوهشی مرتبط [ 28 ، 30 ، 31 ، 32 ]. اول، نتایج حاصل از نقشههای تغییرات پیشبینیشده با استفاده از روشهای توسعهیافته در [ 1 ، 2] را می توان با توجه به دقت محلی آنها با استفاده از روش های پیشنهادی در این مقاله ارزیابی کرد. این اطلاعات مفیدی در مورد تغییرات محلی دقت در تغییرات پیشبینیشده ارائه میکند، که به نوبه خود برای بهبود عملکرد مدل ارزشمند است. ثانیا، دقت نقشه های تغییر پیش بینی شده با استفاده از مدل های توسعه یافته در [ 1 ، 2] نه تنها تابع عملکردهای مدل هستند، بلکه همچنین به دقت مجموعه داده های ورودی که به عنوان متغیرهای کمکی در مدل سازی استفاده می شوند، بستگی دارد. اگر نقشههای طبقهبندی دیگری بهعنوان لایههای نقشه کمکی گنجانده شوند، میتوان روشهای پیشنهادی در این مقاله را برای تعیین کمیت دقتهای محلی آنها به کار برد که میتواند همراه با اطلاعات مربوط به دقت در انواع دیگر نقشههای ورودی برای تجزیه و تحلیل عدم دقت از ورودی استفاده شود. از طریق فرآیند مدل سازی، به خروجی. ثالثاً، عدم دقت در دادههای مرجع، بعد دیگری از مسائل مربوط به دقت است که در اینجا در این مقاله و در ادبیات مرتبط، مانند Wickham et al. [ 30]. ناقص بودن داده های مرجع باید بررسی شود تا تصویر واضح تری از عدم دقت در جمع آوری و پردازش اطلاعات پوشش زمین و در زمینه گسترده تر مدل سازی پویایی منظر داشته باشیم. چهارم، موضوع مقیاس مطرح شده در ادبیات، مانند Millington و همکاران. [ 1 ]، ژانگ و همکاران. [ 15 ] و پونتیوس و همکاران. [ 31 ]، باید برای توسعه بیشتر روشهای پیشنهاد شده در این مقاله در نظر گرفته شود، با توجه به اینکه روشهای پیشنهادی برای کار در مقیاس محلی (دقیق کانونی) طراحی شدهاند و ممکن است به صورت خطی به مقیاسهای درشتتر ترجمه نشوند، همانطور که بحث شد. قبلا در بخش 2.2. پنجم، همانطور که بونتمپس و همکاران اشاره کردند، باید از محدودیتهای مقایسه نقشه تکتاریخ بین سالها آگاه باشیم. [ 32 ]، و تجزیه و تحلیل سریهای زمانی را در نظارت بر تغییر منظر و مدلسازی دینامیک ترویج میکند، به دنبال محاسبه وابستگی زمانی و فنولوژی در تحلیل و مدلسازی دادهها. در نهایت، طراحی نمونهگیری [ 28 ] برای توصیف دقیق، بهویژه برای تحلیل تغییر و مدلسازی دینامیک، ضروری است، مهم نیست که روشهای رگرسیون، کریجینگ و سایر روشها چقدر پیچیده میشوند. استراتژی نمونه گیری تطبیقی که در این مقاله به طور مقدماتی توسعه و آزمایش شده است باید برای حل مسئله در مقیاس بزرگ و در تنظیمات عملیاتی بیشتر مورد بررسی قرار گیرد.
روشهای آزمایششده در این مقاله برای پیشبینی دقت طبقهبندی محلی مناسب هستند، که، با این حال، نمیتوانند مستقیماً برای محاسبه دقت در محصولات مشتق یا تجزیه و تحلیلها، مانند روشهایی که برای بومشناسی چشمانداز استفاده میشوند، استفاده شوند، مگر اینکه بخواهیم استقلال را در بین RVهایی که طبقهبندی را نشان میدهند، فرض کنیم. در) صحت در مکان های فردی. برای انطباق با وابستگی فضایی موجود در بین این RV ها، شبیه سازی زمین آماری باید اعمال شود [ 33 ]. به عنوان مثال، رویکردهای شبیه سازی برای: (1) تعیین دقت محلی در درشت و مبتنی بر شی [ 34] مورد نیاز است.] نقشههای تغییر پوشش زمین بر اساس نقشههای با وضوح بهتر، زیرا پیکسلهای همسایه در نقشههای با وضوح خوب احتمالاً از نظر طبقهبندی نادرست از نظر فضایی همبستگی دارند. (2) کمی سازی دقیق SE ها در دقت های محلی پیش بینی شده، به ویژه زمانی که نرمال بودن را نمی توان برای نمونه های کوچک داده های باینری فرض کرد. (3) انتشار خطا در تخمینهای مساحتی که احتمالاً شامل شمارش تعداد پیکسلهای متعلق به کلاسهای خاص میشود، جایی که پیکسلهای نزدیک را نمیتوان مستقل فرض کرد. و (4) مدلسازی اکولوژیکی و سناریوهای کاربردی که در آن نقشههای تغییر پوشش زمین بخشی از دادههای ورودی است. اینها موضوعاتی را برای تحقیقات بیشتر تشکیل می دهند.






بدون نظر