

خلاصه
(1) زمینه: با توجه به ظهور اطلاعات جغرافیایی داوطلبانه (VGI)، مجموعه داده های بزرگی از نقاط مورد علاقه (POI) تولید شده توسط کاربر در حال حاضر در دسترس هستند. با این حال، مانند تمام VGI، عدم اطمینان در مورد کیفیت داده و تناسب استفاده وجود دارد. در حال حاضر، وظیفه ارزیابی تناسب برای استفاده از POI به کاربر داده واگذار شده است، بدون اینکه چارچوب راهنمایی در دسترس باشد، به همین دلیل است که این تحقیق یک رویکرد عمومی برای انتخاب اقدامات مناسب برای ارزیابی تناسب برای استفاده از POI جمعسپاری شده پیشنهاد میکند. وظایف مختلف (2) روشها: POI به مفهوم سطح بالاتر ژئواتمها به منظور شناسایی و تمایز دو عملکرد اساسی آنها یعنی ارجاع جغرافیایی و ارجاع به شی مرتبط است. سپس برای هر یک از این توابع، معیارهای مناسب کیفیت موضعی و موضوعی بر اساس شاخص های کیفی موجود توسعه می یابد. (3) نتایج: موارد استفاده معمولی از POI با توجه به استفاده آنها از دو عملکرد اساسی POI ارزیابی میشوند و اقدامات مناسب برای تناسب اندام برای استفاده تخصیص داده میشوند. روش کلی در یک مثال عملی مختصر نشان داده شده است. (4) نتیجهگیری: این تحقیق به موضوع تناسب برای استفاده از POI در سطح مفهومی بالاتر با ارتباط آن با مفاهیم اساسیتر نمایش اطلاعات جغرافیایی میپردازد. انتظار می رود که نتایج به کاربران مجموعه داده های POI جمع سپاری شده در تعیین روش مناسب برای ارزیابی تناسب برای استفاده کمک کند. و اقدامات مناسبی را برای تناسب اندام برای استفاده تخصیص داد. روش کلی در یک مثال عملی مختصر نشان داده شده است. (4) نتیجهگیری: این تحقیق به موضوع تناسب برای استفاده از POI در سطح مفهومی بالاتر با ارتباط آن با مفاهیم اساسیتر نمایش اطلاعات جغرافیایی میپردازد. انتظار می رود که نتایج به کاربران مجموعه داده های POI جمع سپاری شده در تعیین روش مناسب برای ارزیابی تناسب برای استفاده کمک کند. و اقدامات مناسبی را برای تناسب اندام برای استفاده تخصیص داد. روش کلی در یک مثال عملی مختصر نشان داده شده است. (4) نتیجهگیری: این تحقیق به موضوع تناسب برای استفاده از POI در سطح مفهومی بالاتر با ارتباط آن با مفاهیم اساسیتر نمایش اطلاعات جغرافیایی میپردازد. انتظار می رود که نتایج به کاربران مجموعه داده های POI جمع سپاری شده در تعیین روش مناسب برای ارزیابی تناسب برای استفاده کمک کند.
کلید واژه ها:
VGI _ کیفیت داده ها ؛ نقاط مورد علاقه ؛ تناسب اندام برای استفاده
1. معرفی
نقاط مورد علاقه (POI) ویژگیهای صفر بعدی هستند که به مکانهای خاص یا موجودیتهای دنیای واقعی در فضای جغرافیایی، مانند مکانهای تاریخی، مکانهای دیدنی، خدمات عمومی، مغازهها، رستورانها یا بارها اشاره میکنند [1 ] . POI با ارائه یک منبع داده اصلی برای چندین سرویس مبتنی بر وب و برنامه های کاربردی تجاری جغرافیایی، توسط شرکت هایی مانند Garmin، Facebook یا Yelp، اغلب از طریق جمع سپاری، برای اهداف مختلف، از جمله ناوبری و مسیریابی، ارائه توصیه های فضایی، جمع آوری می شود. یا امکان به اشتراک گذاری اطلاعات مبتنی بر موقعیت مکانی مانند بررسی مکان، ورود به جلسه، یا عکس های دارای برچسب جغرافیایی به کاربران را می دهد. در یک زمینه تحقیقاتی، POI برای استفاده های اضافی از جمله تجزیه و تحلیل پراکندگی جمعیت [ 2 ]، فعالیت اجتماعی شهری در شهر [2] قرار می گیرد.3 ، یا مکان درک شده از مرکز شهر [ 4 ].
در مقایسه با دادههای مکانی سنتی، همانطور که توسط فروشندگان تجاری یا مقامات ارائه میشود، اطلاعات جغرافیایی داوطلبانه (VGI) به روشهای مناسبی برای ارزیابی کیفیت دادهها نیاز دارد، این واقعیت به دلیل عدم آموزش و ناهمگن بودن مشارکتکنندگان آن، فقدان رسمی است. مشخصات و اثرات بالقوه عوامل اجتماعی [ 5 ، 6 ، 7 ، 8 ]. از آنجایی که در این زمینه، تضمین کیفیت در بهترین حالت چالش برانگیز است [ 6 ]، می توان استدلال کرد که وظیفه ارزیابی کیفیت تا حدودی از تولیدکننده به استفاده کنندگان داده ها منتقل شده است، که ملزم به ارزیابی مناسب بودن آن با توجه به داده ها هستند. انگیزه خاص، یا مناسب بودن آن برای استفاده [ 9]. با توجه به سازمان بین المللی استاندارد (ISO)، کیفیت اطلاعات جغرافیایی باید به طور کلی با مناسب بودن آن با اشاره به «نیازها یا الزامات کاربردی خاص» [ 10 ] (ص. 1) مرتبط باشد. ارتباط چنین اقدامات وابسته به وظیفه مناسب برای استفاده با این واقعیت که اخیراً، کنسرسیوم فضایی باز (OGC) استانداردهای نامزدی را برای جمع آوری تجربیات کاربر با مجموعه داده ها و ارائه آنها به عنوان ابرداده پیشنهاد کرده است [11]، بیشتر تاکید می شود . بر این اساس، ارزیابی کیفی یک مجموعه داده جغرافیایی-فضایی نباید مستقل از استفاده مورد نظر آن اتفاق بیفتد، بلکه باید ارتباط نزدیکی با مناسب بودن مورد انتظار آن برای این هدف خاص داشته باشد [ 12] .]. در حالی که مناسب بودن داده های OpenStreetMap (OSM) با توجه به وظایف کاربردی خاص مانند ناوبری [ 13 ، 14 ]، بازسازی ساختمان سه بعدی از ردپای ساختمان [ 15 ]، یا نقشه برداری و تحلیل مربوط به دوچرخه [ 16 ] تحلیل شده است. تا جایی که ما می دانیم، در حال حاضر مطالعه ای وجود ندارد که به صراحت تناسب استفاده از مجموعه داده های POI را ارزیابی کند.
بنابراین، در حالی که POI به شدت برای اهداف پژوهشی و کاربردی مورد استفاده قرار می گیرد، هنوز کمبود دانش در رابطه با ویژگی های کلی مرتبط با کیفیت این مجموعه داده ها و همچنین روش های بالقوه برای ارزیابی تناسب آنها برای استفاده وجود دارد. اگر چه در درجه اول بر روی POI تمرکز نمی شود، اما به طور کلی بر روی VGI تمرکز می شود، برای مثال، [ 12 ] به صراحت برای فعالیت های تحقیقاتی آینده “توسعه یک چارچوب سیستماتیک که روش ها و اقداماتی را برای ارزیابی تناسب برای هدف هر نوع VGI ارائه می دهد” توصیه کرده است. 12] (ص 21). بنابراین، به عنوان اولین گام در این جهت، این کار بر POI جمعسپاری شده تمرکز میکند و یک رویکرد کلی برای ارزیابی تناسب آنها برای استفاده در مورد وظایف مختلف پیشنهاد میکند. با این چارچوب، هدف ما این است که به کاربران مجموعه داده POI کمک کنیم تا از طیفی از معیارهای کیفیت موجود و روشهای ارزیابی، آنهایی را انتخاب کنند که برای ارزیابی تناسب آن برای استفاده با توجه به مورد خاص یا کار کاربردی آنها مناسب است. برای این کار، از آنجایی که POI به عنوان یکی از راه های ممکن برای نشان دادن موجودیت های جغرافیایی در سیستم های اطلاعات جغرافیایی (GIS) عمل می کند، ما به موضوع نمایش اطلاعات جغرافیایی مبتنی بر POI در سطح مفهومی بالاتری با ارتباط دادن POI به مفهوم اساسی جغرافیا نزدیک می شویم. اتم های پیشنهاد شده توسط [ 17]. این به ما امکان میدهد که ارجاع جغرافیایی و ارجاع به شی را به عنوان دو عملکرد اساسی POI شناسایی و متمایز کنیم، همانطور که در ادامه بحث میکنیم، هر کدام به معیارهای کیفیت خاصی نیاز دارند. با تمرکز بر دقت موقعیتی و موضوعی، و بر اساس تحقیقات قبلی در مورد کیفیت داده ها، ما مجموعه ای از روش های مطابق را پیشنهاد می کنیم. این برای کاربران داده مرتبط است، زیرا، همانطور که ما استدلال می کنیم، برای ارزیابی تناسب استفاده از POI برای یک مورد خاص، لازم است یکی از دو عملکرد POI اساسی که در وظیفه مربوطه را انتخاب کنید و معیارهای کیفی را انتخاب کنید. این در یک مثال عملی نشان داده شده است.
ساختار این مقاله به شرح زیر است: ابتدا، بر اساس بررسی مختصری از ادبیات مربوطه، راههای بالقوه برای ارزیابی کیفیت دادههای POI شناسایی میشوند. سپس، رویکرد ما نسبت به ارزیابی تناسب برای استفاده از دادههای POI توضیح داده شده و در یک مثال عملی نشان داده میشود. در نهایت، کار ما مورد بحث و نتیجه گیری قرار می گیرد.
2. روش های ارزیابی کیفیت POI
مطالعات متعددی وجود دارد که در آنها کیفیت VGI، در بیشتر موارد با تمرکز قوی بر OSM، مورد بررسی قرار گرفت (به عنوان مثال، [ 18 ، 19 ، 20 ]). برای بسیاری از این موارد، جهت گیری به سمت ویژگی های داده مربوطه توسط مجموعه ای از معیارهای کیفی ارائه شده است که توسط ISO تعریف شده است: کامل بودن، سازگاری منطقی، دقت موقعیتی، کیفیت زمانی، دقت موضوعی، و قابلیت استفاده [10 ] . با توجه به این واقعیت که این لیست در زمینه داده های جغرافیایی به طور کلی توسعه یافته است، با این حال، اعتبار آن برای VGI نیز به چالش کشیده شده است [5]، با رویکردهای جایگزین که تاکید بیشتری بر قابل اعتماد بودن و اعتبار اطلاعات تولید شده دارند [ 21 ،22 ].
با توجه به کار قبلی در مورد ارزیابی کیفیت داده های جغرافیایی-مکانی، دو رویکرد اساسی را می توان بسته به اینکه داده ها با یک مجموعه داده مرجع مقایسه شده است، که فرض می شود از بالاترین استانداردهای کیفیت برخوردار است و بنابراین به عنوان حقیقت پایه استفاده می شود یا خیر، متمایز کرد. در حالت اول، یک ارزیابی بیرونی انجام میشود، در حالی که نوع دوم ارزیابی کیفیت درونی نامیده میشود، و بر مجموعهای از ویژگیهای دادهای که به عنوان شاخصهای کیفیت عمل میکنند، مانند نسبت نمونهگیری یا چگالی برچسب [23]، زمانی متکی است . توسعه مجموعه داده [ 24 ]، اما همچنین ویژگی های جمعیتی یا اجتماعی-اقتصادی منطقه جغرافیایی خاص مورد علاقه (به عنوان مثال، [ 25 ]). در یک مطالعه اخیر، [ 18] یک چارچوب مفهومی برای ارزیابی کیفیت ذاتی VGI ارائه می کند.
در این کار، تمرکز بر رویکردهای بیرونی برای ارزیابی کیفیت است. هنگام ارتباط دادههای جمعسپاری شده به یک مجموعه داده مرجع، که در بیشتر موارد از منابع معتبر یا تجاری به دست آمدهاند، برای هر معیار کیفیت ISO، روشهای ارزیابی متعددی پیشنهاد شدهاند. بنابراین، برای مثال، کامل بودن داده ها را می توان با مقایسه تعداد کل ویژگی ها در هر دو مجموعه داده [ 26 ] یا استخراج یک شاخص کامل بودن بر اساس تعداد ویژگی های ارائه شده در هر دو مجموعه داده در رابطه با تعداد کل آنها [ 27 ] ارزیابی کرد. همچنین چندین روش بالقوه برای ارزیابی سازگاری منطقی مجموعه دادههای جمعآوریشده، مانند بررسی توپولوژی [ 28] وجود دارد.]، با این حال، این جنبه بیشتر با کیفیت ذاتی یک مجموعه داده مرتبط است. شاخصهای معمولی برای دقت موقعیتی عبارتند از فواصل اقلیدسی بین نقاط همارجاع (به عنوان مثال، [ 26 ، 27 ])، انحراف فاصله در محور X و Y [ 29 ]، یا ارزیابی اینکه آیا، و در مورد ویژگیهای خط یا چندضلعی. چه مقدار از یک ویژگی از یک مجموعه داده جمعسپاری در یک منطقه بافر خاص محاسبه شده حول یک ویژگی مرجع قرار دارد (به عنوان مثال، [ 20 , 30)]). دقت زمانی میتواند به واقعی بودن دادهها مرتبط باشد، اما، مشابه سازگاری منطقی، با توجه به ارزیابیهای کیفیت ذاتی نیز مرتبطتر است. در نهایت، دقت موضوعی با استخراج درصد طبقهبندی صحیح ویژگیها (به عنوان مثال، [ 15 ، 29 ])، فاصله لونشتاین که شباهت رشتهها را بیان میکند (مثلا [ 26 ])، یا تعداد ویژگیهایی که دارای مشخصه هستند، بررسی میشود. صفات [ 15 ، 30 ].
در گذشته، چندین مطالعه به طور خاص بر روی ارزیابی کیفیت مجموعه دادههای POI متمرکز شدهاند یا حداقل شامل ارزیابی میشوند. به عنوان مثال، در [ 26 ]، POI از OSM با IGN BD topo مقایسه می شود، و دقت موقعیتی (روش فاصله اقلیدسی)، دقت معنایی (فاصله لونشتاین و فرکانس صفت) و جریان (ارزیابی داخلی فرکانس به روز رسانی) ارزیابی می شود. [ 30 ] در مورد کاری گزارش می دهد که از داده های Teleatlas به عنوان حقیقت پایه برای مقایسه با OSM POI استفاده می کند و بر دقت موقعیت (روش بافر) و کامل بودن (مقایسه تعداد ویژگی ها در هر سلول شطرنجی) تمرکز دارد. [ 31] دقت موقعیتی عکسهای برچسبگذاریشده جغرافیایی از فلیکر و پانورامیو را با ارزیابی فاصله اقلیدسی تا موقعیتی که به احتمال زیاد تصویر از آنجا گرفته شده است را بررسی میکند. [ 27 ] POI بهدستآمده از Navteq و Yelp را با یک مجموعه داده مرجع ترکیب میکند که دادههای OSM با آن مقایسه میشوند، و بر روی موقعیت (روش فاصله اقلیدسی) و دقت معنایی (فاصله Levenshtein)، و همچنین کامل بودن (شاخص کامل بودن) تمرکز میکند.
مطالعات ذکر شده، کیفیت داده ها را به عنوان درجه شباهت به حقیقت زمین، همانطور که توسط یک مجموعه داده مرجع نشان داده می شود، عملیاتی می کند. بنابراین، این کار همچنین به جریان متفاوتی از تحقیقات مربوط میشود که بر کیفیت دادهها به خودی خود تمرکز نمیکند، بلکه بر ارزیابی شباهت POI بهدستآمده از مجموعه دادههای مختلف برای اهداف ترکیب یا ادغام دادهها تمرکز دارد. این بیشتر با هدف شناسایی POI مشترک انجام می شود، که نشان دهنده همان موجودیت واقعی است و بنابراین باید از آنها اجتناب شود یا در یک پایگاه داده POI یکپارچه تطبیق داده شود. [ 1برای مثال، از تئوری مجموعه فازی برای شناسایی و ادغام POI مشترک بر اساس شباهت نحوی آنها با توجه به نام، تناظر مکانی با توجه به مقیاسی که در آن دیجیتالی شدهاند و نزدیکی معنایی دسته اختصاص داده شده استفاده میکند. مثال دیگری توسط [ 32 ] ارائه شده است، که الگوریتم تطبیق خود را بر اساس فاصله اقلیدسی، شباهت نام و شباهت وب سایت دو POI قرار می دهد. [ 33 ] POI بهدستآمده از سایتهای شبکههای اجتماعی مختلف را با مقایسه فاصله جغرافیایی آنها و همچنین شباهت رشتهای ویژگیهای معنایی انتخاب شده مطابقت میدهد. با هدف توسعه یک سیستم کمکی برای ویرایش داده ها، [ 34] شباهت POI را در OSM بر اساس تاریخچه تغییر تگ های مربوطه محاسبه کنید. جدای از POI، کارهایی با تمرکز بر تطبیق ژئواشیاء مشترک از انواع هندسه خطی (به عنوان مثال [ 35 ، 36 ، 37 ]) یا چند ضلعی (مثلا [ 15 ، 38 ]) انجام شده است. در یک ارزیابی ترکیبی از اقدامات کنترل کیفیت و تلفیق دادهها از منابع مختلف VGI، [ 7 ] بیان میکند که در عمل، این دو مرحله اغلب در هم تنیده شدهاند، که به گفته نویسندگان، امکان ارزیابی مناسب بودن برای استفاده را محدود میکند. چنین داده هایی
3. تعریف Fitness-for-Use برای POI
همانطور که قبلاً ذکر شد، کیفیت یک مجموعه داده جغرافیایی باید بر حسب تناسب آن برای استفاده ارزیابی شود [ 9 ]. با این حال، تا جایی که ما می دانیم، در حال حاضر هیچ کار بر روی مورد خاص ارزیابی تناسب برای استفاده از مجموعه داده های POI وجود ندارد. بنابراین، در حال حاضر، یک کاربر آینده نگر از مجموعه داده های POI با طیف گسترده ای از معیارهای کیفی و روش های ارزیابی موجود، همانطور که در فصل قبل ارائه شد، مواجه است و باید یک استراتژی مناسب و مختص کار را برای ارزیابی تناسب ایجاد کند. برای استفاده از مجموعه داده بدون هیچ گونه کمک یا دستورالعملی که بتوان به آن مراجعه کرد. بر این اساس، همانطور که قبلاً بیان شد، توسعه یک چارچوب جهت گیری متناظر به عنوان یک نیاز تحقیقاتی مبرم شناسایی شده است [ 12]]. بنابراین، در این فصل، یک رویکرد کلی برای تعریف تناسب برای استفاده از دادههای POI ارائه شده است. برای این، بر اساس یک مفهوم رسمی از POI، ما ابتدا ارجاع جغرافیایی و ارجاع به شی را به عنوان دو عملکرد اصلی POI شناسایی و متمایز می کنیم. در مرحله دوم، ما بیشتر استدلال میکنیم که هر وظیفهای که شامل استفاده از POI میشود، یکی از این دو تابع را فراخوانی میکند، و بر این اساس نیاز به روشهای متفاوتی برای ارزیابی تناسب برای استفاده مجموعه داده دارد. در نتیجه، ما شاخصهای کیفیت مناسبی را برای هر یک از این عملکردها ایجاد میکنیم، که سپس به موارد استفاده معمول دادههای POI مربوط میشوند.
3.1. دو کارکردی POI
هدف از POI توصیف “موقعیت ها یا موجودیت های جغرافیایی در مکان های جغرافیایی” [ 1 ] (ص. 2) بیان شده است. در حالی که این بیانیه قبلاً به یک دوگانگی عملکردی خاص اشاره می کند، منطقی است که به مفهوم POI به روشی رسمی تر نزدیک شویم.
در کار خود بر روی پاکسازی خودکار پایگاههای اطلاعاتی POI، [ 1 ] یک تعریف اساسی از POI ارائه میکنند: «یک نقطه مورد علاقه (یا POI) بهطور بدیهی به عنوان بخشی از داده درک میشود که یک موجود جغرافیایی را در دنیای واقعی که مدلسازی شده است، توصیف میکند. توسط E ” [ 1 ] (ص 6). با E ، در این مورد، نویسندگان به جهان مناسبی از ویژگیهای یک موجودیت اشاره میکنند که برای دستیابی به یک مرجع موفق بین POI و موجودیت واقعی، باید با جهان O POI POI مربوطه از طریق یک پیوند مرتبط شود . تابع سطحی ρ : O POI → E . جهان O POIبه طور معمول مرکب است و بنابراین از جهان های غیر مرکب تشکیل شده است O POI = U 1 × U 2 × … × U n . به عنوان مثال، اینها می توانند شامل کلاس های زیر با برچسب های مربوطه باشند: نام ( U 1 )، عرض جغرافیایی ( U 2 )، طول جغرافیایی ( U 3 )، و دسته ( U 4 ). در این مورد، U 2 و U 3 را می توان به طور منطقی با هم گروه بندی کرد زیرا در ترکیب آنها این را ارائه می دهندمحل POI [ 1 ]. بنابراین، رابطه ارجاع بین POI و موجودیت دنیای واقعی از طریق جهانهای متناظر آن و مقادیر مربوطه برقرار میشود، به عنوان مثال، نام = ” کلیسای جامع سنت پل” ، عرض جغرافیایی = 51.51382 ، طول جغرافیایی = 0.09850- و دسته = ” محل عبادت”. ‘، که باید با ویژگیهای موجود در دنیای واقعی مطابقت داشته باشد، یا به عبارت دیگر، جهان مرکب آن E .
همانطور که در مقدمه بیان شد، POI برای نشان دادن اطلاعات جغرافیایی عمل می کند، و بنابراین، می تواند با مفهوم انتزاعی تر زمین اتم ها مرتبط باشد [ 17 ]. با هدف ارائه یک نظریه کلی از بازنمایی جغرافیایی مبتنی بر GIS، ژئواتمها به عنوان اتمهای اولیه انتزاعی معرفی شدهاند که هم زمینههای میدانهای پیوسته و هم اشیاء گسسته را تشکیل میدهند. بر این اساس، یک ژئواتم به عنوان «ارتباط بین یک مکان نقطه در فضا-زمان و یک ویژگی تعریف شده است. ما یک ژئواتم را به صورت یک تاپل <x, Z, z(x)> می نویسیم که در آن x یک نقطه در فضا-زمان را مشخص می کند، Z یک ویژگی را مشخص می کند و z(x) مقدار خاص ویژگی را در آن نقطه تعریف می کند. [ 17] (ص 243). بر اساس این شکل کاهش یافته و اتمی اطلاعات جغرافیایی، اشیاء یا میدان های سطح بالاتر را می توان ساخت. بنابراین، با توجه به اشیاء گسسته، در حالی که یک شی نقطه ای فقط از یک ژئواتم تشکیل شده است، اجسام خطی و چند ضلعی را می توان به عنوان تجمعی از اتم های جغرافیایی که مقادیر مشترک و مشخصی برای ویژگی های خاص دارند، مانند name = ‘ St. کلیسای جامع پل ‘ [ 17 ].
بنابراین، یک ژئواتم دارای عملکرد دوگانه است. از یک طرف، هدف اساسی آن مرتبط کردن یک مکان خاص با یک ویژگی خاص است. در این مرحله، نیاز خاصی به ارتباط این ویژگی با هر نوع شیء جغرافیایی فوق اردینیتی وجود ندارد. با این حال، از سوی دیگر، یک تابع صرفشناختی مشتق شده نیز وجود دارد که بخشی از یک شیء جغرافیایی سطح بالاتر است.
ما استدلال می کنیم که همان توابع برای POI اعمال می شود. معمولاً یک POI به یک موجودیت واقعی مانند یک ساختمان یا یک مکان اشاره دارد که میتواند در یک GIS به عنوان یک شیء جغرافیایی سطح بالاتر، به عنوان مثال، یک ویژگی چند ضلعی نشان داده شود. در این زمینه، POI را می توان به عنوان یک مدل کاهش یافته از شی ژئو شی اصلی، یک ژئواتم انتخاب شده که به عنوان نماینده از مجموعه بزرگتر ژئواتم ها انتخاب شده است که این شی ژئو شی خاص را تشکیل می دهند، درک کرد. بنابراین، برای مثال، اگر یک ساختمان دنیای واقعی به عنوان یک چند ضلعی ردپای نمایش داده شود، این نمایش میتواند بیشتر به یکی از ژئواتمهای آن تقلیل یابد، برای مثال اتمهایی که دقیقاً در مرکز هندسی چند ضلعی قرار دارد. با این حال، مکان دقیق ژئواتم انتخاب شده ضروری نیست،نام یا یک شناسه بدون ابهام دیگر، به عنوان مثال در روزنامه انجام می شود، که معمولاً یک جفت مختصات مجزا را با نام مکان و در صورت وجود، اطلاعات اضافی مرتبط می کند. به عبارت دیگر، تابع سطحی ρ: O POI → E که بین جهانهای مرکب POI و موجودیت دنیای واقعی نقشهبرداری میکند، به تناظر بین جهانهایی مانند name = ‘St. کلیسای جامع پل ، و نه لزوما مکان . در ادامه، این تابع به عنوان تابع مرجع شی POI نامیده می شود.
با این حال، مشابه یک ژئواتم، یک POI در درجه اول ارتباط یک مکان خاص با یک ویژگی است. ما از این به عنوان تابع ارجاع جغرافیایی یک POI یاد می کنیم. بنابراین، از یک سو، ممکن است که یک POI مستقل از یک شیء جغرافیایی مافوق باشد، به عنوان مثال، در مورد یک POI که نمایانگر یک دیدگاه مناسب در مسیر پیاده روی است، و بنابراین صرفاً اطلاعاتی را ارائه می دهد که در این مکان خاص، دید ملک = بالا. از سوی دیگر، در چندین مورد استفاده از آنها، POI که در واقع به یک شی جغرافیایی خاص و موجودیت واقعی مطابق با آن اشاره می کنند، به تابع مرجع جغرافیایی خود کاهش می یابند، به عنوان مثال هنگام شمارش تعداد POI در یک منطقه مطالعه، محاسبه سطوح چگالی POI یا محاسبه کوتاه ترین مسیر برای یک POI. در چنین مواردی، تمرکز به وضوح بر روی اطلاعات مکانی POI قرار می گیرد، در حالی که ارتباط معنایی با یک موجودیت واقعی خاص از اهمیت کمتری برخوردار است. بنابراین، با توجه به عملکرد ارجاع جغرافیایی آن، عملکرد یک POI به جای نام یا دسته بندی ، به طول و عرض جغرافیایی جهان که مکان آن را مشخص می کند، بستگی دارد .
3.2. معیارهای کیفیت وابسته به عملکرد برای POI
پس از شناسایی این دو عملکرد اساسی POI، ما بیشتر استدلال میکنیم که هنگام ارزیابی تناسب آنها برای استفاده، لازم است مشخص شود که کدام عملکرد اساسی در کار خاص مورد توجه قرار میگیرد. به عنوان مثال، چندین مطالعه وجود دارد که توزیع فضایی POI را در ترکیب با اطلاعات تخصیص یافته آنها، به ویژه طبقه بندی اختصاص داده شده، برای استنتاج سایر ویژگی های محیطی، مانند برآورد جمعیت [2]، کاربری زمین شهری [32]، اندازه اشتغال تجزیه و تحلیل می کند . [ 39 ]، مراکز اجتماعی در شهر [ 3 ]، یا مرزهای درک شده مرکز شهر [ 4]]. در چنین زمینههایی، همانطور که قبلاً گفته شد، ارجاع به یک شیء خاص در دنیای واقعی اهمیت کمتری دارد، بلکه مکان و تا حدی پایینتر، دسته یک POI است که کیفیت نتایج دریافتی را تعیین میکند. بنابراین، برای مثال، برای دریافت نتایج دقیق هنگام طبقهبندی یک منطقه در یک شهر به عنوان یک منطقه خرید بر اساس دستهبندی POI جمعسپاری واقع در محدوده آن، دقت موقعیتی بالایی از ویژگیهای نقطه درگیر مورد نیاز است. در غیر این صورت، POI واقع در حاشیه منطقه می تواند به اشتباه به مناطق همسایه اختصاص داده شود. علاوه بر این، POI باید به درستی به عنوان دسته = فروشگاه طبقه بندی شود. با این حال، مهم این واقعیت است که عدم اطمینان در مورد اینکه یک POI دقیقاً به کدام فروشگاه اشاره می کند، در این مورد هیچ تأثیری بر نتایج تجزیه و تحلیل نخواهد داشت. بنابراین، به منظور ارزیابی تناسب استفاده از یک مجموعه داده POI برای این منظور یا موارد مشابه، یک کاربر آینده نگر داده باید به جای ارجاع به شی، بر معیارهای کیفیت و روش های ارزیابی مربوط به تابع ارجاع جغرافیایی تمرکز کند. تابع.
با این حال، موارد استفاده از POI نیز وجود دارد که تابع دوم را فراخوانی می کند، و بنابراین نیاز به یک ارجاع معنایی بدون ابهام به یک شی در دنیای واقعی خاص دارد، به عنوان مثال در زمینه ورود در مکان های متمایز (مانند فیس بوک). قرار دادن نظرات (به عنوان مثال، Yelp)، یا مکان سیستم های توصیه [ 40]. در اینجا، مکان دقیق یک POI حیاتی نیست، تا زمانی که در یک فاصله آستانه قابل قبول از مکان واقعی قرار دارد، با این حال، یک ارجاع بدون ابهام به یک موجودیت واقعی خاص باید ارائه شود، معمولاً با استفاده از یک نام مکان یا ویژگی دیگری که به عنوان یک شناسه عمل می کند. برای مثال، اگر مشتری از یک سرویس مبتنی بر وب استفاده میکند تا رتبهبندی را به یک POI نشان دهد که نشاندهنده رستورانی است که قبلاً بازدید کرده است، لازم است که POI بدون ابهام به موجودیت واقعی واقعی مراجعه کند، زیرا در غیر این صورت، رتبه را می توان به اشتباه به یک موسسه همسایه نسبت داد. همچنین در این مورد این سوال مطرح است که چگونه یک معیار آستانه فاصله مناسب را می توان تعیین کرد. جدا از ساده ترین حالت تعریف ذهنی یک مقدار مطلق، به عنوان مثال، 50 متر، یک استراتژی دیگر می تواند شامل استفاده از فواصل نسبی باشد که به اندازه واقعی شیء نمایش داده شده در دنیای واقعی بستگی دارد. بنابراین، برای مثال، انحراف 50 متری باید در مورد یک POI که به یک رستوران کوچک به جای یک استادیوم فوتبال یا فرودگاه اشاره دارد، بهطور جدیتر ارزیابی شود. علاوه بر این، مقادیر آستانه قابل قبول می تواند با الگوهای فضایی معمولی POI دسته های مشابه مرتبط باشد. بر این اساس، برای مثال، در حالی که معمولاً کافهها را میتوان نزدیکتر به یکدیگر یافت، ایستگاههای پلیس عمداً به شیوهای پراکندهتر واقع شدهاند، که به نوبه خود اجازه میدهد تا عدم دقت موقعیت بالاتر از POI مربوطه همچنان قابل قبول باشد. در نهایت، جدای از اندازهگیریهای فاصله اقلیدسی، روابط توپولوژیکی را نباید نادیده گرفت، مانند POI همارجاعی که عبارتند از:
از این رو، در واقع نیاز به شاخص های کیفیت مناسب وجود دارد که به صراحت تفاوت بین تابع ارجاع جغرافیایی را در مقابل تابع مرجع شی POI ذکر می کند. از نظر ما، از معیارهای کیفیت تعریف شده توسط ISO، کامل بودن، سازگاری منطقی و کیفیت زمانی بر تناسب استفاده از مجموعه داده POI در سطح مفهومی بالاتر تأثیر میگذارد، به این معنی که مشکلات مرتبط با کیفیت به همان اندازه بر تناسب آن تأثیر میگذارند. بدون توجه به عملکرد POI مورد نظر، استفاده کنید. بنابراین، برای رجوع به موارد نمونه ای که قبلاً استفاده شده بود، استفاده از مجموعه داده POI ناقص بر نتایج یک روش طبقه بندی کاربری زمین تأثیر منفی می گذارد، به دلیل، به عنوان مثال، گم شدن اشیاء طبقه = فروشگاه .در یک منطقه، اما به همان اندازه سودمندی عملی یک سرویس بررسی مکان را کاهش می دهد. همانطور که نشان داده شد، با این حال، مسائل کیفی با توجه به دقت موقعیتی و موضوعی در واقع می توانند در اثر آنها بسته به وظیفه مربوطه متفاوت باشند و بنابراین، باید به شیوه ای خاص و در نهایت کارکرد خاص مورد توجه قرار گیرند. . به همین دلیل، آنها برای رویکرد ما جذابیت خاصی دارند.
با توجه به عملکرد ارجاع جغرافیایی یک POI، تأکید به وضوح بر دقت موقعیت و مکان مطلق آن است. بنابراین، یک روش مناسب برای ارزیابی کیفیت، محاسبه انحراف، به عنوان مثال، بر حسب فاصله اقلیدسی، از محل مرجع صحیح است (به عنوان مثال، [ 27 ، 35]]). با وجود تمرکز بر موقعیت، نمی توان از دقت موضوعی به طور کامل غافل شد. در عوض، صحت همه صفات معنایی باید ارائه شود، اما هیچ تفاوتی بین آنها وجود ندارد. بنابراین، از آنجایی که ارجاع به یک موجودیت واقعی خاص در اینجا اهمیت ثانویه دارد، همانطور که در مثالی از یک کار طبقه بندی کاربری زمین مبتنی بر POI نشان داده شده است، هیچ تمایز اجباری بین شناسه ها وجود ندارد، مانند نام جهان و ویژگی های دیگر مانند دسته POI . با این حال، ممکن است جهان های خاصی از اهمیت نسبی بالاتری برخوردار باشند، مانند دسته بندیدر مثال مورد استفاده، اما این بسیار مختص کار مربوطه است. بر این اساس، به طور کلی، دقت تمام ویژگی های POI را می توان به طور مساوی ارزیابی کرد، به عنوان مثال با محاسبه فاصله معنایی آنها تا مجموعه داده مرجع مربوطه با استفاده از هستی شناسی های واژگانی مانند WordNet [41] یا با محاسبه فاصله لونشتاین (مثلاً [ 26 ]).
در مقابل، تابع ارجاع به شی اساساً به دقت مکان دقیق بستگی ندارد، بلکه بیشتر به امکان استنباط ارجاع بدون ابهام به یک موجودیت واقعی از جهان مرکب POI بستگی دارد، همانطور که در مورد بحث شد. نمونه ای از خدمات رتبه بندی مکان مبتنی بر وب. بنابراین، دقت موقعیتی کافی است اگر POI در مجموعه ژئواتمهایی قرار گیرد که ژئو شی فوقالعاده را تشکیل میدهند، به عنوان مثال، ردپای رستوران مربوطه، اما به فاصله اقلیدسی تا مرجع بستگی ندارد. مکان، به عنوان مثال، مرکز جسم. بنابراین، یک روش ارزیابی کیفیت مناسب شامل آزمایش این رابطه توپولوژیکی از طریق یک عملیات متقاطع با ژئو شی مربوطه، به عنوان مثال، ردپای ساختمان است.ویژگی name با مقدار دقیقی که کیفیت آن را می توان با محاسبه فاصله Levenshtein آزمایش کرد. با این حال، اگر نامی ارائه نشده باشد ، در صورت دقت موقعیتی بالا و عدم وجود اطلاعات معنایی متناقض، می توان تا حدی به یک موجودیت واقعی خاص اشاره کرد. به عنوان مثال، اگر یک POI فاقد یک ویژگی نام باشد ، اما در محل دقیق یک رستوران قرار داشته باشد و به طور دقیق به عنوان دسته = رستوران برچسب گذاری شده باشد ، مکانمیتواند تا حدودی نقش شناسه شی را بر عهده بگیرد، با این حال، با عدم قطعیت باقیمانده، زیرا برای مثال میتوان تصور کرد که در واقع، POI به رستوران دیگری اشاره میکند که قبلاً قبل از بسته شدن در همان مکان بود . بر این اساس، در صورت عدم ارائه نام ، می توان با محاسبه فاصله معنایی از طریق WordNet یا فاصله Levenstein و با استفاده از یکی از روش های پیشنهادی برای محاسبه فاصله قابل قبول، صحت معنایی ویژگی های باقی مانده و همچنین دقت موقعیتی را به طور مناسب ارزیابی کرد. آستانه پیشنهادی قبلا
4. یک برنامه کاربردی برای POI که از فیس بوک به دست آمده است
برای اهداف توضیحی، مفهوم توسعهیافته برای مثال فرضی محققی به کار میرود که هدفش استفاده از مجموعه دادههای POI جمعسپاری شده برای دو هدف متفاوت است و اکنون با چالش ارزیابی تناسب آن برای استفاده مواجه است. در مثال ساده ما، مجموعه داده POI تنها از یک ویژگی نقطه تشکیل شده است، یعنی نمایش POI فیس بوک از کلیسای جامع سنت پل در لندن، که از طریق Graph API فیس بوک به دست آمده است. از آنجایی که یک مجموعه داده مرجع همیشه برای ارزیابی کیفیت بیرونی مورد نیاز است، POI مشترک از Factual، یک فروشنده تجاری مجموعه داده های POI تضمین شده با کیفیت، گرفته شده است. با این حال، به طور کلی، هنگام انتخاب منابع دادههای حقیقت زمینی مناسب، باید این واقعیت را تصدیق کرد که امروزه، فرض سنتی مجموعه داده های معتبر یا تجاری که کیفیت بالاتری نسبت به VGI دارند دیگر کاملا قابل اعتماد نیست. بنابراین، مجموعه داده های مرجع باید با دقت و در زمینه خاص مطالعه موردی خاص انتخاب شوند، چالشی که، با این حال، ذاتی روش های ارزیابی کیفیت بیرونی به طور کلی است و بنابراین، از دامنه این کار فراتر می رود.
شکل 1 POI موقعیت جغرافیایی هر دو منبع داده را همراه با ویژگی های موضوعی آنها نشان می دهد. مشاهده میشود که تفاوتهایی هم از نظر مکان و هم از نظر اطلاعات موضوعی منتسب به POI وجود دارد، یا با استفاده از اصطلاحات ارائه شده توسط [ 1 ]، تابع سطحی ρ: O POI → E که مرجع بین POI و واقعی را ایجاد میکند. – موجودیت جهان در مورد جهان ها متفاوت است O POI = U 1 × U 2 × … × U n . بنابراین، یک انحراف واضح را می توان از نظر مکان کیهان ، و واریانس های جزئی طبقه بندی اختصاص داده شده مشاهده کرد.برچسب ها. با این حال، جدا از مقادیر متفاوت ویژگیهای مشترک، تغییراتی نیز با اشاره به جهانهای تشکیلدهنده O POI وجود دارد . بنابراین، در حالی که فیس بوک اطلاعات عمومی و درباره ویژگی های اضافی را ارائه می دهد ، Factual اطلاعات مربوط به مکان بیشتری را در رابطه با منطقه یا محله و همچنین حقایق دیگری مانند ساعات کار ارائه می دهد .
در سناریوی اول، هدف محقق ما ارزیابی مناسب بودن برای استفاده از نمایش POI فیس بوک از کلیسای جامع سنت پل به منظور توسعه یک سیستم مبتنی بر وب است که امکان ثبت نام در مکان ها را فراهم می کند. مطابق با مفهوم پیشنهادی ما، در اولین گام، او باید مشخص کند که مورد استفاده مورد نظر کدام یک از دو عملکرد اساسی POI را فراخوانی میکند. با توجه به این واقعیت که ثبت نام در یک مکان مستلزم وجود یک ارجاع معنایی بدون ابهام بین POI و موجودیت واقعی خاص است، در این مورد به وضوح تابع مرجع شی است. این بینش اطلاعاتی را فراهم می کند که برای مرحله بعدی، یعنی انتخاب روش های ارزیابی کیفیت مناسب، ضروری است. بنابراین، در مورد خاص ارجاع به شی، باید ارزیابی شود که رابطه ارجاع بین POI و موجودیت واقعی با توجه به POI فیس بوک در مقایسه با داده های به دست آمده از Factual، که در نقش خود به عنوان یک مجموعه داده مرجع، از بالاترین سطح در نظر گرفته می شود، چقدر خوب است. کیفیت بنابراین، با توجه به دقت موقعیت، همانطور که بحث شد، باید آزمایش شود که آیا جفت مختصات x، y از POI فیس بوک واجد شرایط بودن آن برای عضوی از مجموعه اتم های جغرافیایی است که جغرافیای فوق مختصات را تشکیل می دهند. شی، بنابراین، رد پای چند ضلعی کلیسای جامع سنت پل. بر این اساس، یک مجموعه داده مرجع دوم در اینجا مورد نیاز است که در این مورد، می توان آن را از Ordnance Survey به دست آورد. با یک عملیات تقاطع ساده، محقق ما می تواند بررسی کند که آیا POI فیس بوک از نظر فضایی با ردپای کلیسای جامع سنت پل تلاقی می کند یا خیر. در این صورت، true را برمی گرداند. با توجه به دقت معنایی، یک شناسه بدون ابهام برای ایجاد مرجع بین POI و شی دنیای واقعی مورد نیاز است. بنابراین، اگر الفویژگی name ارائه شده است، همانطور که در اینجا وجود دارد، از طریق محاسبه فاصله Levenshtein با نام مربوط به مجموعه داده مرجع مقایسه می شود ، که به دلیل عدم وجود اشتباهات املایی، 0 را در اینجا برمی گرداند. با توجه به تابع ارجاع به شی، بنابراین، سایر ویژگی ها مورد نیاز نیست، و به دلیل دقت مکانی و موضوعی کامل، محقق ما بالاترین مقدار ممکن را دریافت می کند، به عنوان مثال 1، برای بیان تناسب استفاده از مجموعه داده فیس بوک به منظور توسعه یک سیستم بررسی مکان.
با این حال، در سناریوی دوم، هدف کاربر داده ما این است که مجموعه داده POI یکسان را برای هدفی متفاوت، یعنی تجزیه و تحلیل توزیع فضایی انواع مختلف POI در لندن، مستقر کند. در اینجا، همانطور که بحث شد، ارجاع به یک موجودیت خاص در دنیای واقعی، به عنوان مثال، کلیسای جامع سنت پل، مرتبط نیست، بلکه دقت اطلاعات مکان و بنابراین تابع ارجاع جغرافیایی است که تعیین کننده تناسب برای استفاده مجموعه داده بنابراین، دقت موقعیت باید بر حسب انحراف دقیق نسبت به موقعیت مرجع مشترک آن در مجموعه داده مرجع ارزیابی شود. بنابراین یک روش مناسب برای ارزیابی کیفیت، محاسبه انحراف بر حسب فاصله اقلیدسی است. بر این اساس، در مثال ما، انحراف تقریباً 36 متری بین POI فیسبوک و فکتوال برای St. کلیسای جامع پل محاسبه می شود، مقداری که سپس می تواند به یک شاخص کیفیت نرمال شده ترجمه شود که دقت موقعیت را بیان می کند. با توجه به دقت موضوعی در زمینه تابع ارجاع جغرافیایی POI، همانطور که گفته شد، تفاوتی بین ویژگی های معنایی وجود ندارد، که به این دلیل است که از آنجایی که ارجاع به یک واقعی خاص است. – موجودیت جهانی بی ربط است،جهان نام در مقایسه با سایر صفات از اهمیت یکسانی برخوردار است. بنابراین، همه صفات معنایی را می توان به روشی جزئی از نظر شباهت معنایی آنها مقایسه کرد. برای ویژگی هایی مانند نام ، آدرس ، شماره تلفن ، وب سایت یا آدرس ایمیل ، فاصله Levensthein را می توان استفاده کرد، در حالی که مقادیر تخصیص داده شده برای دسته ، به عنوان مثال، به طور مناسب تری از طریق محاسبه فاصله معنایی WordNet مقایسه می شوند [ 41] .]. در مورد ما، به دلیل عدم وجود اشتباهات املایی و وجود برچسبهای دستهبندی تا حد زیادی متناظر، بالاترین مقدار شاخص کیفیت برای دقت معنایی توسط محقق ما نسبت داده میشود. این واقعیت که تعداد متفاوتی از جهان های سازنده O POI = U 1 × U 2 × … × U n در فیس بوک در مقابل مجموعه داده واقعی وجود دارد، در اینجا نادیده گرفته شده است، اما برای مثال می توان با مقایسه ساده کل آنها اشاره کرد. در هر دو مجموعه داده شمارش شود.
بنابراین، با پیروی از رویکرد عمومی ما، و در نتیجه تحلیلهای قبلی، محقق ما متوجه میشود که تناسب استفاده از مجموعه داده فیسبوک برای موارد استفاده که به تابع ارجاع به شی آن مربوط میشود، نسبتاً بالاتر است تا به جغرافیای آن. تابع ارجاع، واقعیتی که ناشی از روش متفاوت محاسبه دقت موقعیت در این مثال خاص است. بنابراین، مجموعه داده برای توسعه یک سیستم بررسی مکان بهتر است تا برای تجزیه و تحلیل توزیع فضایی POI در منطقه مورد مطالعه.
5. بحث
علیرغم ویژگی اکتشافی آن، کاربرد نمونه قبلی سودمندی عملی رویکرد پیشنهادی ما را نشان میدهد. بنابراین، نشان داده شد که چگونه، با پیروی از استراتژی ابتدا شناسایی یکی از دو تابع اصلی POI مربوطه، و سپس انتخاب روشهای ارزیابی کیفیت مناسب، به کاربر یک مجموعه داده POI در ارزیابی تناسب آن برای استفاده کمک میشود. به وظایف مختلف در واقع، مجموعه داده استفاده شده در مثال با توجه به تناسب استفاده از آن برای دو سناریو استفاده متفاوت ارزیابی شد، در مورد ما به مقادیر نسبتاً بالاتری برای مورد مربوط به تابع ارجاع به شی نسبت به موقعیت جغرافیایی منجر شد. تابع ارجاع جدا از ارائه اطلاعات در مورد کیفیت مجموعه داده POI با توجه به موارد استفاده خاص، همانطور که نشان داده شده است، چارچوب ما همچنین میتواند برای مقایسه POI بهدستآمده از منابع مختلف برای مناسب بودن بسته به مورد استفاده خاص مورد نظر، و راهنمایی انتخاب مناسبترین جایگزین استفاده شود. این به ویژه برای مجموعه داده های POI مفید است که، همانطور که در این مقاله بحث کردیم، از یک طرف اغلب نتیجه جمع سپاری هستند و بنابراین مستعد مسائل مربوط به کیفیت داده ها هستند، و از طرف دیگر برای طیف گسترده ای از داده ها استفاده می شود. وظایف
با چارچوب کمکی پیشنهاد شده در این مقاله، ما یک استراتژی روشن برای شناسایی یک روش مناسب برای ارزیابی تناسب برای استفاده از مجموعه دادههای POI ارائه میکنیم که مبتنی بر ارتباط معیارهای کیفیت موقعیتی و موضوعی مختلف و همچنین روشهای ارزیابی مناسب آنها است. به عنوان مثال، محاسبه انحراف فاصله اقلیدسی یا فاصله معنایی صفات، به دو تابع اصلی POI، ارجاع جغرافیایی و ارجاع به شی. این موارد به نوبه خود به موارد استفاده مربوطه برای مجموعه داده های POI مانند خدمات بررسی مکان مبتنی بر وب یا محاسبات تراکم POI مربوط می شوند. بدون رویکرد سیستماتیک ما، کاربران مجموعه داده های POI ملزم به ایجاد یک جریان کاری برای ارزیابی تناسب برای استفاده بدون هیچ گونه کمکی هستند. و به طور مستقیم مورد استفاده خاص خود را به معیارهای کیفیت مناسب و روش های ارزیابی مرتبط می کند. با این حال، به نظر ما، این خطر انتخاب های دلخواه و غیربهینه را تا حد زیادی افزایش می دهد و همچنین قابلیت مقایسه مطالعاتی را که مناسب بودن برای استفاده و نتایج آنها را ارزیابی می کنند، کاهش می دهد. بنابراین، اگر هیچ ارتباط انگیزشی واضحی بین مورد استفاده داده شده از یک سو و معیارهای کیفی انتخاب شده و روشهای ارزیابی از سوی دیگر وجود نداشته باشد، توضیح اینکه چرا به عنوان مثال، تمرکز بر موضعی و نه موضوعی قرار گرفته است دشوار است. دقت برای ارزیابی تناسب برای استفاده، و اینکه کدام عوامل دقیق باعث انتخاب روشهای ارزیابی کیفیت خاص میشوند. در عین حال، رویکردهای مختلف برای ارزیابی تناسب برای استفاده از POI برای یک کار ممکن است از نظر روش اعمال شده متفاوت باشد و بنابراین، فقط تا حدی قابل مقایسه باشد با دنبال کردن توالی مراحل همانطور که در اینجا پیشنهاد شد، که از یک مورد استفاده خاص از طریق تابع POI مربوطه به معیارهای کیفیت مناسب و روشهای ارزیابی منتهی میشود، میتوان از چنین مشکلاتی اجتناب کرد، زیرا انتخاب دومی به وضوح انگیزه دارد و مستقیماً به هم مرتبط است. به وظیفه مربوطه و کاملاً شفاف.
جدا از ارائه راهنمایی برای انتخاب یک استراتژی مناسب برای ارزیابی تناسب استفاده، همانطور که در بالا ذکر شد، مفهوم پیشنهادی میتواند به فرآیند جمعسپاری برای خود تولید داده نیز کمک کند. بنابراین، اگر هدف اولیه یک مجموعه داده POI ایجاد شده قبل از فرآیند جمعآوری دادهها شناخته شده بود، میتوان اقدامات کنترل کیفیت ویژه کار را به روشی مشابه، یعنی ابتدا شناسایی تابع POI مربوطه، و سپس قرار دادن بر اساس آن، توسعه داد. تمرکز بر یک یا آن شاخص برای دقت موضوعی یا موقعیتی.
با این حال، با توجه به مراحل اولیه این تحقیق، هنوز چندین محدودیت در رویکرد ما وجود دارد. بنابراین، اعتبار روش پیشنهادی ما برای ارزیابی تناسب برای استفاده هنوز با مجموعه دادههای بزرگتر و موارد استفاده واقعی ارزیابی نشده است. ممکن است در عمل به استفاده از شاخص های کیفیت پیچیده تری نیاز باشد. علاوه بر این، اگرچه ما راههای بالقوه استخراج آستانهها را برای انحراف موقعیت قابل تحمل ترسیم کردیم، انتخاب مقادیر مناسب قطعاً چالش برانگیز است و ممکن است تا حد معینی از مقایسه مورد نظر روشهای مختلف که قبلا ذکر شد، بکاهد. یکی دیگر از مسائل مهم، فرض سادهسازی ما است که موارد استفاده به وضوح به یکی از دو عملکرد اصلی POI میپردازد، در حالی که نمونههای متعددی را ذکر کردهایم که در واقع چنین است. در عمل موارد استفاده ای نیز وجود دارد که به ترکیبی از ارجاع جغرافیایی و ارجاع به شی نیاز دارد، به عنوان مثال، پیمایش به یک POI خاص، که به یک رویکرد ترکیبی برای ارزیابی تناسب برای استفاده نیاز دارد. به طور کلی، یک مرور جامع تر از موارد استفاده بالقوه ارزشمند خواهد بود.
6. نتیجه گیری
انگیزه این کار عدم تطابق بین استفاده مکرر از POI جمعسپاری شده برای اهداف تجاری و پژوهش محور از یک سو و فقدان کار بر روی ارزیابی مناسب بودن برای استفاده از چنین مجموعههای داده از سوی دیگر بود. قبل از پیشزمینه مشکلات مرتبط با کیفیت VGI به طور کلی، اما با تمرکز خاص بر POI جمعسپاری، این تحقیق به نیاز تحقیق به یک چارچوب سیستماتیک برای کمک به کاربران داده در انتخاب معیارها و روشهای کیفیت برای ارزیابی تناسب برای هدف کمک میکند. بر اساس نزدیکی مفهومی مفاهیم POI و ژئواتمها، ما در مورد عملکرد دوگانه POI، یعنی ارجاع جغرافیایی در مقابل ارجاع به شی، نظریهپردازی کردیم و استدلال کردیم که به منظور ارزیابی مناسب بودن برای استفاده از POI مجموعه داده ها،
از دیدگاه هر کاربر داده، مزیتهای بالقوه از افزایش مقایسه روشها برای ارزیابی تناسب استفاده و نتایج آنها و همچنین دستورالعمل مفیدی که برای فرآیند انتخاب شاخصهای کیفیت ارائه میشود ناشی میشود. به صورت شفاف علاوه بر این، به نظر ما، کار ما به افزایش پتانسیل مجموعه دادههای POI جمعسپاری شده بهعنوان یک منبع داده با ارزش برای کاربردهای مختلف در حوزه جغرافیایی-فضایی کمک میکند. بنابراین، انتظار میرود چارچوب پیشنهادی به دستیابی به درک عمیقتری از مسائل مربوط به کیفیت POI جمعسپاری، به عنوان مثال در رابطه با مشکلات معمولی مرتبط با کیفیت، تفاوتهای کیفی بین منابع مختلف دادههای POI، یا موارد استفاده بالقوه که برای POI جمعسپاری شده است، کمک کند. کم و بیش مناسب هستند. به علاوه،
کار اولیه ما امکاناتی را برای کارهای آینده باز می کند، مانند تجزیه و تحلیل مقایسه ای POI به دست آمده از منابع داده های مختلف، به عنوان مثال، Facebook، Foursquare یا OSM، با توجه به تناسب نسبی آنها برای استفاده در مورد موارد استفاده مختلف. چنین تحلیل هایی اطلاعات مفیدی را برای کاربران داده های آینده فراهم می کند. علاوه بر این، می توان یک چارچوب جامع برای ارزیابی تناسب اندام برای استفاده برای انواع مختلف موارد استفاده معمولی که شامل POI است، ایجاد کرد. این احتمالاً می تواند به عنوان یک سیستم کمکی خودکار اجرا شود که از تصمیم گیری بین مجموعه داده های مختلف POI پشتیبانی می کند. با این حال، یک پیش نیاز برای این امر شامل آزمایش و اعتبار سنجی مفهوم ما با مجموعه داده بزرگی از POI جمعسپاری شده و مقایسه انتقادی نتایج با سایر رویکردهای موجود برای ارزیابی کیفیت دادههای جغرافیایی-مکانی است.
منابع
- دی تره، جی. ون بریتسوم، دی. مت، تی. Bronselaer, A. پاکسازی خودکار پایگاه های داده POI. در مسائل کیفیت در مدیریت اطلاعات وب ; Springer: برلین، آلمان؛ هایدلبرگ، آلمان، 2013; صص 55-91. [ Google Scholar ]
- باکیالله، م. لیانگ، اس. مبشری، ع. ارسنجانی، ج. Zipf، A. نگاشت جمعیت با وضوح خوب با استفاده از نقاط مورد علاقه OpenStreetMap. بین المللی جی. جئوگر. Inf. علمی 2014 ، 28 ، 1940-1963. [ Google Scholar ] [ CrossRef ]
- باوا-کاویا، الف. حس شهری: استفاده از داده های شبکه اجتماعی مبتنی بر مکان در تحلیل شهری. در مجموعه مقالات کارگاه برنامه های کاربردی شهری فراگیر (PURBA) 2011، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 12 ژوئن 2011.
- هوانگ، اچ. گارتنر، جی. Turdean, T. رسانه های اجتماعی به عنوان منبعی برای مطالعه درک و شناخت افراد از محیط ها. Mitteilungen der Österreichischen Geographischen Gesellschaft 2013 ، 155 ، 291-302. [ Google Scholar ] [ CrossRef ]
- آنتونیو، وی. Skopeliti، A. اندازه گیری ها و شاخص های کیفیت VGI: یک مرور کلی. ISPRS Ann. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2015 ، II-3/W5 ، 345-351. [ Google Scholar ] [ CrossRef ]
- Fonte, CC; باستین، ال. فودی، جی. کلنبرگر، تی. کرل، ن. مونی، پی. اولتئانو-ریموند، A.-M. کنترل کیفیت L. VGI را ببینید. ISPRS Ann. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2015 ، II-3/W5 ، 317-324. [ Google Scholar ] [ CrossRef ]
- Leibovici، DG; ایوانز، بی. هاجز، سی. ویمن، اس. میک، اس. راسر، جی. جکسون، ام. در مورد تضمین کیفیت داده ها و درهم تنیدگی در جمع سپاری برای مطالعات زیست محیطی. ISPRS Ann. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2015 ، II-3/W5 ، 195-202. [ Google Scholar ] [ CrossRef ]
- رویک، او. هوسر، اس. شبکه های اجتماعی مبتنی بر مکان – تعریف، وضعیت فعلی هنر و دستور کار تحقیقاتی. ترانس. GIS 2013 ، 17 ، 763-784. [ Google Scholar ] [ CrossRef ]
- Veregin، H. پارامترهای کیفیت داده. در سیستم های اطلاعات جغرافیایی: اصول و مسائل فنی ، ویرایش دوم. جان وایلی و پسران: نیوجرسی، ایالات متحده آمریکا، 2005; صص 177-189. [ Google Scholar ]
- سازمان بین المللی استاندارد (ISO). ISO/TC 211 19157: اطلاعات جغرافیایی—کیفیت داده ها . شماره ISO 19157:2013; ISO: ژنو، سوئیس، 2013. [ Google Scholar ]
- کنسرسیوم فضایی باز (OGC). OG C به دنبال اظهار نظر عمومی در مورد مدل مفهومی بازخورد کاربر مکانیکی نامزد و استاندارد رمزگذاری xml است. بیانیه مطبوعاتی 2016. در دسترس به صورت آنلاین: http://www.opengeospatial.org/pressroom/pressreleases/2356 (در 20 ژوئیه 2016 قابل دسترسی است).
- سناراتنه، اچ. مبشری، ع. علی، ال. کاپینری، سی. هاکلی، ام. مروری بر روشهای داوطلبانه ارزیابی کیفیت اطلاعات جغرافیایی. بین المللی جی. جئوگر. Inf. علمی 2016 . [ Google Scholar ] [ CrossRef ]
- موندزچ، جی. Sester, M. تجزیه و تحلیل کیفیت داده های OSM بر اساس نیازهای برنامه. Cartographica 2011 ، 46 ، 115-125. [ Google Scholar ] [ CrossRef ]
- ژانگ، ایکس. Tinghua، A. چگونه جاده ها را در OpenStreetMap مدل کنیم؟ روشی برای ارزیابی تناسب استفاده از شبکه برای ناوبری. در پیشرفت در مدیریت و تجزیه و تحلیل داده های مکانی ؛ Springer: برلین، آلمان؛ هایدلبرگ، آلمان، 2015; صص 143-162. [ Google Scholar ]
- فن، اچ. Zipf، A.; فو، س. Neis, P. ارزیابی کیفیت برای ایجاد داده های ردپایی در OpenStreetMap. بین المللی جی. جئوگر. Inf. علمی 2014 ، 28 ، 700-719. [ Google Scholar ] [ CrossRef ]
- هوچمیر، اچ. زیلسترا، دی. Neis، P. ارزیابی کامل ویژگیهای مسیر دوچرخه و مسیر در نقشه خیابان باز برای ایالات متحده. ترانس. GIS 2015 ، 19 ، 63-81. [ Google Scholar ] [ CrossRef ]
- گودچایلد، م. یوان، م. Cova، TJ به سوی یک نظریه عمومی نمایش جغرافیایی در GIS. بین المللی جی. جئوگر. Inf. علمی 2007 ، 21 ، 239-260. [ Google Scholar ] [ CrossRef ]
- بالاتوره، آ. Zipf، A. چارچوب کیفیت مفهومی برای اطلاعات جغرافیایی داوطلبانه. در مجموعه مقالات دوازدهمین کنفرانس بین المللی نظریه اطلاعات فضایی، COSIT 2015، سانتافه، NM، ایالات متحده آمریکا، 12-16 اکتبر 2015.
- دورن، اچ. تورنروس، تی. Zipf، A. ارزیابی کیفیت VGI با استفاده از دادههای معتبر – مقایسه با دادههای کاربری زمین در جنوب آلمان. بین المللی J. Geo-Inf. 2015 ، 4 ، 1657-1671. [ Google Scholar ] [ CrossRef ]
- Haklay, M. اطلاعات جغرافیایی داوطلبانه چقدر خوب است؟ مطالعه تطبیقی مجموعه داده های نظرسنجی OpenStreetMap و مهمات. محیط زیست طرح. B 2010 , 37 , 682-703. [ Google Scholar ] [ CrossRef ]
- بیشر، م. Mantelas، L. یک مدل اعتماد و شهرت برای فیلتر کردن و طبقه بندی دانش در مورد رشد شهری. جئوژورنال 2008 ، 72 ، 229-237. [ Google Scholar ] [ CrossRef ]
- فلاناژین، ا. متزگر، ام. اعتبار اطلاعات جغرافیایی داوطلبانه. جئوژورنال 2008 ، 72 ، 137-148. [ Google Scholar ] [ CrossRef ]
- مونی، پی. کورکوران، پ. Winstanley، AC به سمت معیارهای کیفیت برای OpenStreetMap. در مجموعه مقالات هجدهمین کنفرانس بین المللی SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی 2010، سن خوزه، کالیفرنیا، ایالات متحده آمریکا، 2 تا 5 نوامبر 2010.
- بارون، سی. نیس، پ. Zipf، A. چارچوبی جامع برای تحلیل کیفی OpenStreetMap ذاتی. ترانس. GIS 2014 ، 18 ، 877-895. [ Google Scholar ] [ CrossRef ]
- زیلسترا، دی. Zipf، A. مطالعه مقایسه ای داده های جغرافیایی اختصاصی و اطلاعات جغرافیایی داوطلبانه برای آلمان. در مجموعه مقالات سیزدهمین کنفرانس بین المللی AGILE در علم اطلاعات جغرافیایی، گیماراس، پرتغال، 11-14 مه 2010.
- گیرس، جی اف. Touya, G. عناصر ارزیابی کیفیت داده های OpenStreetMap فرانسه. ترانس. GIS 2010 ، 14 ، 435-459. [ Google Scholar ] [ CrossRef ]
- مشهدی، ع. کواترون، جی. Capra, L. تاثیر جامعه بر اطلاعات جغرافیایی داوطلبانه: مورد OpenStreetMap. در OpenStreetMap در GIScience ; انتشارات بین المللی Springer: چم، سوئیس، 2015; صص 125-141. [ Google Scholar ]
- کورکوران، پ. مونی، پی. Winstanley، A. تعمیم سازگار توپولوژیکی OpenStreetMap. در مجموعه مقالات GISRUK 2010: GIS Research UK 18 کنفرانس سالانه، لندن، انگلستان، 14-16 آوریل 2010.
- استارک، اچ.-جی. ارزیابی کیفیت اطلاعات جغرافیایی داوطلبانه با استفاده از خدمات نقشه وب باز در OpenAdresses. در مجموعه مقالات GI_Forum 2011، سالزبورگ، اتریش، 5-8 ژوئیه 2011.
- ارسنجانی، ج. بارون، سی. باکیالله، م. Helbich، M. ارزیابی کیفیت مشارکت کنندگان OpenStreetMap همراه با مشارکت آنها. در مجموعه مقالات کنفرانس بین المللی AGILE 2013 در علم اطلاعات جغرافیایی، لوون، بلژیک، 14-17 مه 2013.
- هوچمیر، اچ. Zielstra, D. دقت موقعیتی تصاویر فلیکر و پانورامیو در اروپا. در مجموعه مقالات GI_Forum 2012، سالزبورگ، اتریش، 3 تا 6 ژوئیه 2012.
- جیانگ، اس. آلوز، آ. رودریگز، اف. فریرا، جی.، جونیور. Pereira، FC داده های نقطه مورد علاقه استخراج از شبکه های اجتماعی برای طبقه بندی و تفکیک کاربری زمین شهری. محاسبه کنید. محیط زیست سیستم شهری 2015 ، 53 ، 36-46. [ Google Scholar ] [ CrossRef ]
- شفلر، تی. شیرو، آر. Lehmann, P. تطبیق نقاط مورد علاقه از سایت های مختلف شبکه های اجتماعی. در KI 2012: Advances in Artificial Intelligence 2012 ; Springer: برلین، آلمان، 2012; ص 245-248. [ Google Scholar ]
- مولیگان، سی. یانوویچ، ک. بله، م. لی، دبلیو.-سی. تحلیل تعامل مکانی- معنایی نقاط مورد علاقه در اطلاعات جغرافیایی داوطلبانه. در نظریه اطلاعات مکانی 2011 ; Springer: برلین، آلمان، 2011; صص 350-370. [ Google Scholar ]
- آناند، اس. مورلی، جی. جیانگ، دبلیو. دو، اچ. جکسون، ام. هارت، جی. وقتی دنیاها با هم برخورد می کنند: ترکیب بررسی مهمات و داده های نقشه خیابان باز. در مجموعه مقالات انجمن ژئوجامعه اطلاعات جغرافیایی کنفرانس 2010، لندن، انگلستان، 30 ژوئن 2010.
- لودویگ، آی. ووس، ا. Krause-Traudes، M. مقایسه شبکه های خیابانی Navteq و OSM در آلمان. In Advancing Geoinformation Science for a Changing World 2011 ; Springer: برلین، آلمان، 2011; صص 65-84. [ Google Scholar ]
- یانگ، بی. ژانگ، ی. Luan، X. یک رویکرد آرامش احتمالی برای تطبیق شبکه های جاده ای. بین المللی جی. جئوگر. Inf. علمی 2013 ، 27 ، 319-338. [ Google Scholar ] [ CrossRef ]
- دو، اچ. آلچینا، ن. جکسون، ام. هارت، جی. روشی برای تطبیق داده های مکانی با منبع جمعیتی و معتبر. ترانس. GIS 2016 . [ Google Scholar ] [ CrossRef ]
- رودریگز، اف. آلوز، آ. پولیشیوک، ای. جیانگ، اس. فریرا، جی. Pereira، FC برآورد اندازه اشتغال تفکیک شده از نقاط مورد علاقه و داده های سرشماری: از استخراج وب تا پیاده سازی و تجسم مدل. بین المللی J. Adv. هوشمند سیستم 2013 ، 6 ، 41-52. [ Google Scholar ]
- برجانی، ب. Strufe, T. یک سیستم توصیه برای نقاط در شبکه های اجتماعی آنلاین مبتنی بر مکان. در مجموعه مقالات چهارمین کارگاه آموزشی سیستم های شبکه های اجتماعی SNS’11، سالزبورگ، اتریش، 10 آوریل 2011.
- دانشگاه پرینستون. درباره WordNet در دسترس آنلاین: http://wordnet.princeton.edu (در 20 ژوئیه 2016 در دسترس است).
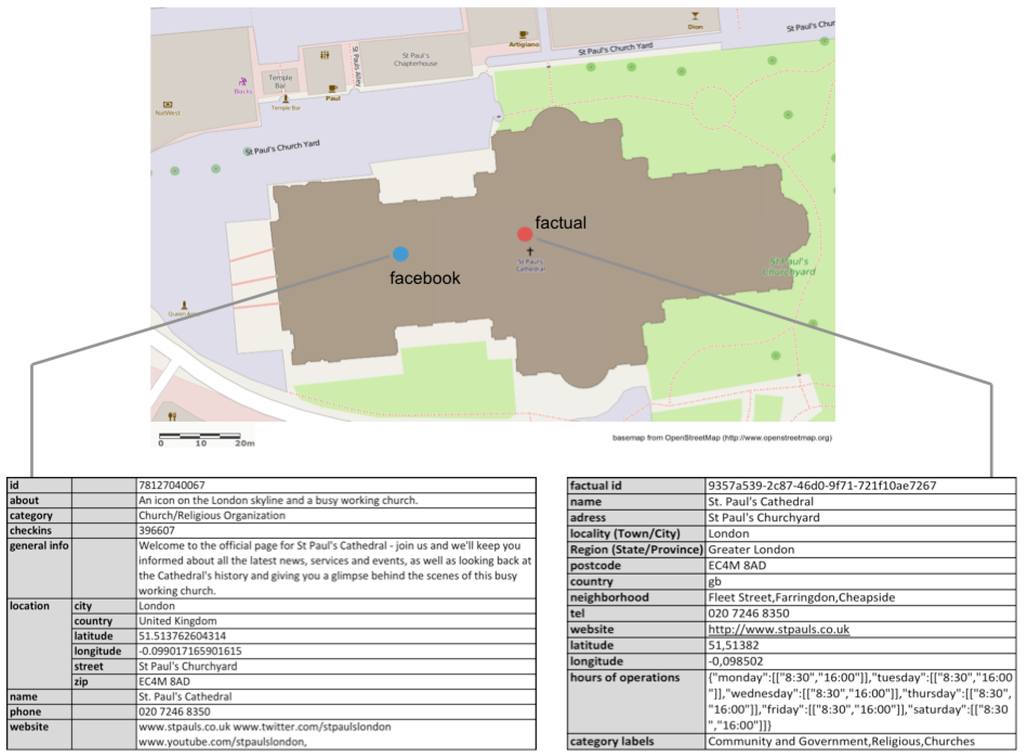
شکل 1. ارجاعات مشترک POI از Facebook و Factual.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر