1. معرفی
بارش یکی از اجزای اصلی هواشناسی با تنوع زیاد است. در تحقیقات آب و هواشناسی، برآورد بارش یک پارامتر مرجع کلیدی است که اطلاعات ارزشمندی را برای برنامه ریزی اقتصادی و اجتماعی فراهم می کند. این اطلاعات می تواند از جان و دارایی افراد محافظت کند. تخمین سنتی بارش بر اساس دادههای مشاهده درجا است. داده های جمع آوری شده با استفاده از شبکه های مشاهده ای توزیع شده در حوضه های زهکشی با استفاده از روش میانگین وزنی [ 1 ]، یک روش هموارسازی یا درونیابی [ 2 ]، و/یا یک روش آماری تنظیم شده جغرافیایی [ 3] پردازش می شوند.]. چنین فرآیندهایی برای به دست آوردن مقادیر اولیه بسیاری از مدل های هیدرولوژیکی استفاده می شود. توزیع زمانی-مکانی بارش در استان شانشی و شمال غربی چین با استفاده از داده های بارش روزانه ایستگاه های هواشناسی بر اساس تحلیل رگرسیون خطی و روش تحلیل موجک مورد مطالعه قرار گرفت [ 4 ، 5 ]. با این حال، ایستگاههای رصد سطحی در چین عمدتاً در جنوب شرقی و مرکزی چین توزیع شدهاند، در حالی که توزیع فضایی ایستگاهها در مناطق دیگر نسبتاً پراکنده است. روش های ارزیابی برای رتبه بندی و ترتیب طوفان های باران روزانه در هر ایستگاه برای این نوع منطقه توسط چنگ و همکاران توسعه داده شد. [ 6]. با توجه به تنوع فضایی واضح بارش، بارش تجمعی در هر منطقه آماری می تواند به طور قابل توجهی متفاوت باشد. علاوه بر این، توزیع بارندگی ممکن است بسیار ناهمگن باشد و تخمینهای بارندگی منطقه که درونیابی میشوند، عدم قطعیت بیشتری نسبت به آنهایی که با استفاده از شبکههای رصدی تعیین میشوند، دارند.
در سال های اخیر، دانشمندان تلاش های قابل توجهی برای استفاده از تصاویر ماهواره ای با پوشش جهانی برای تخمین بارش انجام داده اند. مأموریت اندازهگیری باران گرمسیری (TRMM) یک پروژه مشترک است که توسط سازمان ملی هوانوردی و فضایی (NASA) و آژانس اکتشافات هوافضای ژاپن (JAXA) در سال 1997 راهاندازی شد و دادههای فراوانی از بارندگیهای استوایی جهانی را ارائه میدهد [7 ، 8 ، 9 ] . در این مقاله، محصول 3B43 (نسخه 7) تجزیه و تحلیل بارش چندماهواره 3 ساعته TRMM (TMPA) به عنوان هدف آزمایش انتخاب شد. TMPA به طور مستقیم در مطالعات مختلف آب و هواشناسی استفاده شده است [ 10 ، 11]. با این حال، وضوح فضایی TMPA برای مطالعات مربوط به ناهمگنی هواشناسی یا هیدرولوژیکی کمتر از رضایت بخش است [ 12 ]. وضوح پایین تخمین مبتنی بر ماهواره، کاربرد آب و هواشناسی آن را محدود می کند. با این وجود، TMPA به دلیل تأخیر زمانی، نمونه برداری زمانی با کیفیت بالا و پوشش جهانی گسترده، داده های ارزشمندی را برای استفاده در چنین برنامه هایی فراهم می کند. ادغام دادههای TMPA و مشاهده سطحی حداقل دو مزیت دارد: (1) خطاهای دو نوع تخمین بارندگی مستقل هستند و (2) در مناطقی که ایستگاههای مشاهده سطحی پراکنده هستند، توزیعهای بارش ساخته شده توسط TMPA میتواند یک مرجع مهم
در پایان قرن بیستم، روش آمار فضایی در الگوریتمهای تخمین بارندگی معرفی شد که ترکیبی از رصدهای ماهوارهای و سطحی را ممکن میسازد. با این حال، این رویکرد منوط به بهبود مستمر است. پلوف و همکاران [ 13 ] چهار تکنیک درونیابی فضایی را مقایسه کرد: وزن دهی معکوس فاصله، خطوط با صفحه نازک، کریجینگ معمولی و کریجینگ بیزی. نتایج آنها نشان داد که کریجینگ بیزی برای بارندگی کم در سریلانکا بهترین عملکرد را دارد. ژانگ و همکاران [ 14] روشی را برای تخمین میانگین بارندگی منطقه ای (AMR) با استفاده از مدل تخمین بیماری منطقه مبتنی بر بیمارستان سنتینل (B-SHADE)، مشاهدات مغشوش باران سنج و داده های TRMM در مناطق دورافتاده با توزیع پراکنده و ناهموار باران سنج ارائه کرد. نتایج نشان داد که B-SHADE کمترین سوگیری برآورد را نشان میدهد. چی و همکاران [ 15] تخمین ناپارامتری یک توزیع اختلاط را با به حداقل رساندن فاصله درجه دوم بین توزیع تجربی و توزیع مخلوط در نظر گرفت، که هر دو با استفاده از توابع هسته هموار شدند. مطالعات تجربی نشان داد که برآوردگرهای چگالی مبتنی بر مخلوط جدید از نظر میانگین مجذور خطای ادغام شده برای تقریباً همه توزیعهای مورد مطالعه در نتیجه کاهش بایاس قابلتوجه ارائه شده توسط مدلهای مخلوط ناپارامتری و هموارسازی مضاعف، از برآوردگرهای چگالی مبتنی بر هسته محبوب عملکرد بهتری داشتند. شائو و همکاران [ 16] یک روش هموارسازی دوگانه برای استخراج مقادیر بارندگی در اندازه شبکه کوچک بر اساس مشاهدات گیج ارائه کرد. آنها از یک تبدیل تجربی برای تثبیت باقیمانده ها استفاده کردند و به راحتی توانستند با استفاده از روش بوت استرپینگ، بارش را افزایش دهند.
هدف از مطالعه لانگ و همکاران. [ 17 ] قرار بود یک چارچوب ادغام دادههای ماهواره و بارانسنج ارائه دهد که برای طراحیهای با وضوح درشت و دادههای پراکنده سازگار شده بود. در این چارچوب، یک روش کاهش مقیاس فضایی آماری بر اساس روابط بین بارش، ویژگیهای توپوگرافی، و شرایط آب و هوایی برای کاهش مقیاس بارش روزانه 0.25 به دست آمده از محصول بارش TMPA استفاده شد. تکنیک ادغام ناپارامتری هموارسازی هسته دوگانه، که برای طراحی پراکنده داده اقتباس شده بود، با روش بهینهسازی جهانی تکامل پیچیده ترکیبی برای ادغام TRMM کاهشیافته و بارندگی اندازهگیری شده با حداقل خطای اعتبار متقابل ترکیب شد. نرینی و همکاران [ 18] دو روش ادغام دادههای ناپارامتری بارندگی را با دو روش زمینآماری برای بهینهسازی عملکرد آبوهواشناسی یک محصول بارش ماهوارهای بر روی حوضه آبخیز آند استوایی در مقیاس متوسط در پرو مقایسه کرد. نتایج با استفاده از روشهای زیر مورد ارزیابی قرار گرفت: (1) یک روش اعتبارسنجی متقابل و (2) یک تجزیه و تحلیل تعادل آب حوضه و مدلسازی هیدرولوژیکی. آنها دریافتند که روش هموارسازی دو هستهای بیشترین پیشرفت را نسبت به محصول اصلی ماهوارهای در اعتبارسنجی متقاطع و ارزیابی هیدرولوژیکی ارائه میدهد. بنابراین، یک رویکرد سیستماتیک برای انتخاب تکنیکی برای ادغام دادههای باران سنج ماهوارهای بر اساس ویژگیهای داده پیشنهاد شد.
دادههای بارندگی مبتنی بر ماهواره توسط Pfeifroth و همکاران آنالیز شد. [ 19 ] در غرب آفریقا، منطقه ای با تنوع روزانه قابل توجه. اینگبریگتسن و همکاران [ 20 ] جنبههای تخمینهای مختلف را با استفاده از یک مدل فضایی غیر ثابت بیزی از بارش سالانه بر اساس مشاهدات چندین سال بررسی کرد. این مدل حاوی تکرارهایی از میدانهای فضایی بود که دقت تخمینها را افزایش داد و آنها را نسبت به مقادیر قبلی کمتر حساس کرد. آنها داده های بارش از جنوب نروژ را تجزیه و تحلیل کردند و ویژگی های آماری مدل تکراری را در یک مطالعه شبیه سازی بررسی کردند. مطالعه ای در استرالیا [ 21] روش های زمین آماری انتخاب شده را برای تخمین نقشه های بارش روزانه در سراسر استرالیا ارزیابی کرد. این مطالعه تغییرات مشکل پشتیبانی و تناوب مکانی دادههای بارندگی روزانه را با ترکیب دادههای ماهواره و گیج بررسی کرد. رگرسیون وزندار جغرافیایی (GWR) [ 22 ] برای تخمین توزیع فضایی خطای محصول TRMM با استفاده از ارتفاع و طول و عرض جغرافیایی به عنوان متغیرهای مستقل استفاده شد. یک مدل بارندگی با ترکیب اندازهگیریهای بارندگی زمینی و ماهوارهای توسعه داده شد و دقت مدل با استفاده از روش اعتبارسنجی متقاطع بر اساس اندازهگیریهای بارندگی سنج تأیید شد. نتایج مطالعه از چین [ 23] نشان داد که در مقایسه با TMPA، بازیابیهای چندماهوارهای یکپارچه برای اندازهگیری بارش جهانی (GPM)، که به آن IMERG گفته میشود، به طور قابلتوجهی دقت تخمین بارش را در منطقه سین کیانگ و در فلات چینگهای-تبت بهبود بخشید. با این حال، اکثر محصولات IMERG در این مناطق غیرقابل اعتماد هستند.
گوتوی و همکاران [ 24 ] یک مرور کلی به روز از نحوه حل مشکل داده های مکانی ناسازگار ارائه کرد. Kyriakidis [ 25 ] یک روش زمین آماری مبتنی بر تغییرات در تفکیک فضایی ارائه کرد که در آن مدلهای ساختار کوواریانس منطقه به منطقه و منطقه به نقطه برای محاسبه و به دست آوردن دادههای مساحت و برای پیشبینی در یک نقطه مورد نظر اتخاذ میشوند. . پان و همکاران [ 26 ] و گائو و همکاران. [ 27] روش درونیابی بهینه را برای آزمایش همجوشی بر اساس داده های رصدی ماهواره ای و سطحی اتخاذ کرد و به نتایج مشابهی رسید، یعنی اینکه محصول ذوب شده دقت تخمین بارش را به میزان قابل توجهی بهبود بخشید و دامنه تخمین را برای منعکس کردن اطلاعات بارش برای سکوها در مقیاس های مختلف گسترش داد. . شن و همکاران [ 28] کیفیت محصول ذوب شده را ارزیابی کرد و نشانه هایی یافت که محصول ذوب شده از نظر ارزش بارش و توزیع فضایی با استفاده موثر از مزایای مربوط به مشاهدات سطحی و بارش های ماهواره ای منطقی تر شد. این روش همجوشی میانگین انحراف و خطای ریشه میانگین مربع را کاهش داد و کیفیت محصول را بیشتر بهبود بخشید و مزیت خاصی را در نظارت کمی بر بارشهای سنگین ارائه داد. مقاله حاضر یک روش آماری جدید را پیشنهاد میکند که دادههای TMPA و مشاهدات سطحی را ترکیب میکند. هنگامی که انحرافات داده های TMPA وجود دارد و هیچ فرضیه فضایی نسبتاً قوی وجود ندارد، این روش همچنان می تواند یک چارچوب آماری ناپارامتریک بسیار رضایت بخش ایجاد کند و به اصلاح متناوب و درون یابی فضایی عالی دست یابد.
2. منطقه مطالعه و داده های تجربی
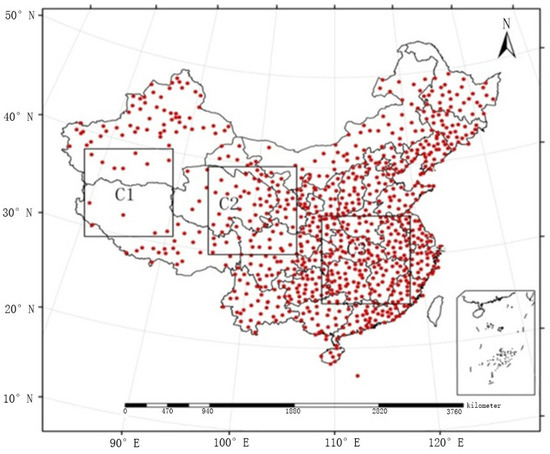
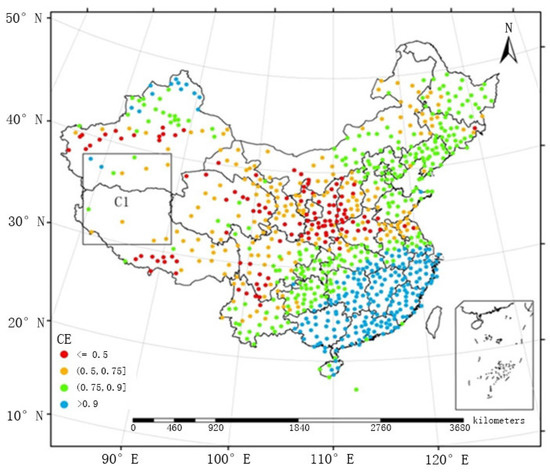
در این مقاله، دادههای ایستگاه هواشناسی خودکار از شبکه سامانه خدمات اشتراکگذاری دادههای هواشناسی چین استخراج شد و توسط مرکز ملی اطلاعات هواشناسی (NMIC) در فایلهای دادههای ارزش روزانه تهیه شد. این شبکه شامل 839 ایستگاه است که بازه زمانی 2005 تا 2010 را پوشش می دهد. با توجه به توپوگرافی پیچیده چین، توزیع فضایی شبکه ملی پلویومترها در ایستگاه های هواشناسی خودکار ناهموار است (یعنی در شرق متراکم و در منطقه پراکنده است. غرب). بنابراین، ارزیابی کیفیت روش همجوشی در مناطق با تراکم های مختلف ضروری است. سه اندازه مساوی از مناطق شبکه با توجه به منطقه آزمایشی، یعنی منطقه C1 در غرب (جایی که 12 ایستگاه عمدتاً پراکنده وجود دارد) انتخاب شدند.شکل 1 . داده های ایستگاه هواشناسی خودکار در C1، C2، و C3 با محصول بارش TMPA ترکیب شدند و نتایج آنها به ترتیب به عنوان “C1″، “C2” و “C3” برچسب گذاری شدند. اثرات همجوشی تحت سه تراکم شبکه منطقه ای مورد آزمایش قرار گرفت.
TMPA، محصول ویرایش هفتم TRMM که برای داده های ماهواره ای پذیرفته شده است، به عنوان محصولی با بالاترین دقت در میان محصولات بارش TRMM شناخته شده است. داده های تجزیه و تحلیل بارش به دست آمده در هر 3 ساعت توسط TMPA ابتدا در داده های بارش روزانه و سپس به داده های بارش ماهانه انباشته شد. محصول بارش TMPA اتخاذ شده در این مقاله از 2005 تا 2010 از نظر فاصله زمانی و از 10 درجه شمالی تا 50 درجه عرض شمالی متغیر بود.
3. روش برای یکپارچه سازی محصولات بارش ماهواره ای
روش پیشنهادی در این مقاله برای تخمین بارش با ادغام دادههای مکانی مختلف استفاده میشود و از تئوری جذب دادهها مشتق شده است. یکسان سازی داده ها شامل پردازش منابع مختلف داده است تا بتوان محصولات نهایی را یکپارچه کرد. در پیشبینی عددی آب و هوا، جذب دادهها در ابتدا فرآیندی در نظر گرفته میشود که برای ارائه زمینههای اولیه برای پیشبینی عددی توزیعهای مکانی و زمانی دادههای مشاهداتی استفاده میشود. کلید این روش در محاسبه تفاوت بین داده های منطقه و داده های نقطه ای نهفته است. روش درون یابی اتخاذ شده در این مقاله، هموارسازی هسته است که برخلاف روش کریجینگ، به فرضیه ثابت بودن بستگی ندارد و در شرایطی که فرضیه آماری جغرافیایی شکست خورده است، قابل اعمال است، یعنی: زمانی که داده های جغرافیایی درگیر در تجزیه و تحلیل آماری جغرافیا، مرتبط یا همبسته، ناهمگن هستند و با فرضیات تصادفی تحلیل آماری عمومی مطابقت ندارند. علاوه بر این، دو موضوع مربوط به روش همجوشی مبتنی بر خطای باقیمانده مورد بحث قرار میگیرد: (1) استفاده از TMPA اصلی به عنوان زمینه پسزمینه مشکلساز است. بنابراین، پیش پردازش داده های منطقه ضروری است. (2) روش صاف کردن هسته معمولی، پس از بهبود، می تواند بیان بصری و کارایی تخمین را در یک منطقه پراکنده بهبود بخشد. (1) استفاده از TMPA اصلی به عنوان زمینه پس زمینه مشکل ساز است. بنابراین، پیش پردازش داده های منطقه ضروری است. (2) روش صاف کردن هسته معمولی، پس از بهبود، می تواند بیان بصری و کارایی تخمین را در یک منطقه پراکنده بهبود بخشد. (1) استفاده از TMPA اصلی به عنوان زمینه پس زمینه مشکل ساز است. بنابراین، پیش پردازش داده های منطقه ضروری است. (2) روش صاف کردن هسته معمولی، پس از بهبود، می تواند بیان بصری و کارایی تخمین را در یک منطقه پراکنده بهبود بخشد.
3.1. اصل تلفیق داده های ناپارامتریک مبتنی بر خطای باقیمانده
در حالی که کلید تحلیل مبتنی بر خطای باقیمانده در محاسبه تفاوتهای بین میدان پسزمینه و مقادیر مشاهدهشده نهفته است، روش همجوشی ناپارامتریک مبتنی بر خطای باقیمانده با هدف حل میانگین وزنی خطاهای باقیمانده با توجه به فاصله بین نقاط مشاهده است. فیلد تخمین از طریق ترکیب فیلد خطای باقیمانده با فیلد پس زمینه به دست می آید. بنابراین، میدان تخمین از طریق تنظیم دادههای مشاهده مجاور به دست میآید و اگر دادههای مشاهده محلی وجود نداشته باشد، فیلد پسزمینه حفظ میشود.
روابط بین میدان پسزمینه X B ، میدان مشاهده X O ، و خطای باقیمانده D را میتوان با سیستم معادلات زیر بیان کرد:
که e B و e O به ترتیب نشان دهنده خطای پس زمینه و خطای مشاهده هستند و X T نشان دهنده میدان واقعی است. فرض بر این است که X B در هر نقطه از S شناخته شده است ، که یک مجموعه نقطه 2 بعدی است، در حالی که X O را می توان در نقاط مشاهده حل کرد.
که در آن N تعداد نقاط مشاهده است.
همچنین فرض می شود که خطای پس زمینه e B شرایط را برآورده می کند
و
که در آن μ B نمی تواند 0 باشد و در فضا متفاوت خواهد بود.
اگرچه مفروضات مستقلی وجود دارد، خطای پسزمینه دو پیکسل مجاور دادههای شطرنجی به طور کلی مرتبط است. در مقایسه با مدلی که خطای همبسته در آن دقیق تر است، نقض فرض استقلال می تواند منجر به واریانس تخمین بزرگتر شود. با این حال، انحراف هنوز نزدیک به صفر است. اگر همبستگی قوی وجود داشته باشد، به دست آوردن تخمین عدم قطعیت دشوارتر است. این مورد در این مطالعه در نظر گرفته نشده است. در مطالعات آتی، این فرض استقلال خطای پسزمینه و محاسبه عدم قطعیت را در نظر میگیرد.
در مقابل خطای پس زمینه، خطای اندازه گیری به عنوان نویز گاوسی سفید در نظر گرفته می شود و به صورت بیان می شود.
و
نویز سفید گاوسی نوعی خطای تصادفی است که از توزیع نرمال پیروی می کند. خطای تصادفی خطای ناشی از عدم قطعیت اندازه گیری از جمله خطای انسانی است.
با توجه به معادلات (1)-(3)، مدل ناپارامتریک برای بیان میدان خطای باقیمانده استفاده می شود، همانطور که با فرمول زیر نشان داده شده است:
معادله (9) نشان می دهد که میدان خطای باقیمانده برابر است با اختلاف بین خطای پس زمینه و خطای مشاهده. فیلد تخمین X M میتواند مدل ناپارامتری مبتنی بر خطای باقیمانده را برای تخمین بپذیرد، همانطور که با فرمول زیر نشان داده شده است:
در غیر این صورت،
کجا ||…|| فاصله اندازه گیری شده است. تابع هسته دارای سه شرط است
که در آن h یک عدد مثبت است و به آن پهنای باند می گویند. مدل ناپارامتری از تابع هسته برای تخصیص وزن ها بر اساس فواصل بین نقاط مشاهده محیطی استفاده می کند.
اتخاذ روش همجوشی ناپارامتریک مبتنی بر خطای باقیمانده شامل سه مرحله است: (1) محاسبه خطای باقیمانده در نقطه مشاهده با استفاده از رابطه (10). (2) روش هموارسازی هسته را برای تخمین خطای پسزمینه تولید شده توسط خطای باقیمانده با استفاده از معادلات (20) و (21) اتخاذ کنید. و (iii) با استفاده از معادله (12) فیلد تخمینی یا زمینه موثر پس زمینه را با توجه به خطای پس زمینه تخمین زده استخراج کنید.
3.2. تنظیم فیلد پس زمینه
روش توصیف شده در این مقاله با معادلات (10)-(12) ارائه شده است و هدف آن ترکیب داده های شطرنجی و داده های نقطه ای است. بنابراین، تعریف واضح زمینه پس زمینه ضروری است. با توجه به اینکه “همجوشی مستقیم” [ 29 ] انحرافات قابل توجهی در مرز صفحه ایجاد می کند (یعنی مرز بین دو مجموعه داده شطرنجی پیوسته TMPA) و باعث ناپیوستگی در زمینه زمینه می شود، این مقاله روش “همجوشی هموار” را برای کاهش انحرافات مرزی معرفی می کند. ناشی از ادغام داده های شطرنجی و داده های نقطه ای است. ایده اصلی روش استفاده از میانگین متحرک TMPA برای تولید یک میدان هموار و اتخاذ میدان کمکی به عنوان میدان پس زمینه معادلات (10)-(12) است. پنجره مورد استفاده توسط میانگین متحرک اندازه یک پیکسل در مجموعه داده شطرنجی TMPA است.S i ( i = 1، 2، 3، 4) چهار پیکسل شطرنجی TMPA حاوی میانگین متحرک s را نشان می دهد. A i ( i = 1، 2، 3، 4) نشان دهنده ناحیه تقاطع بین S i و پنجره متحرک است، همانطور که در شکل 2 نشان داده شده است .
علاوه بر این، T ( sj ) تخمین بارش TMPA را برای رستر S i نشان می دهد . TMPA صاف شده در s با فرمول [ 30 ] زیر ارائه می شود:
3.3. الگوریتم دو صاف کردن
هموارسازی هسته (معادله (11)) را می توان برای تخمین موثر انتظارات میدان خطای پس زمینه به کار برد، و شرایط آن با میدان خطای باقیمانده در شرایطی که نقاط مشاهده به طور متراکم توزیع شده اند، برآورده می شود. با این حال، عملکرد هموارسازی هسته معمولی به اندازه کافی پایدار نیست، به ویژه به این دلیل که نمی تواند انتظارات واقعی را به خوبی منعکس کند، زمانی که نقاط مشاهده به طور پراکنده توزیع می شوند. به طور دقیق تر، میانگین شرطی خطاهای پس زمینه با استفاده از رابطه (11) حل می شود، به عنوان مثال،
که از آن می توان دریافت که
اگر و فقط اگر حداقل یک S i در شعاع پهنای باند h از S وجود داشته باشد . با فرض اینکه فقط یک نقطه مشاهده در محدوده نمونه ها قرار می گیرد، خطای پس زمینه تخمینی در خارج از شعاع پهنای باند مشاهده شده صفر خواهد بود، اما در شعاع پهنای باند مشاهده شده تفاوت قابل توجهی خواهد داشت و در نتیجه تخمین بارش ناپیوسته می شود. در مناطق دورافتاده چین، توزیع مکانی پلویومترهای ایستگاههای هواشناسی خودکار بسیار کم است و در بسیاری از مناطق ایستگاههای آبوهوای خودکار وجود ندارد. بنابراین، با اتخاذ تکنیک صاف کردن دوگانه [ 31]، این مطالعه نشان داد که تخمین هموارسازی دوگانه بر روی سطوح همه مناطق صاف است، که اطمینان حاصل میکند که تخمین میدان پسزمینه به اندازه کافی صاف بوده و میتواند با فرضیه صافی میدان پسزمینه پایه برآورده کند. متعاقباً از روش همجوشی معادله (11) به عنوان هموارسازی منفرد یاد شد.
تخمین هموارسازی مضاعف بر اساس فرآیند زیر است: اول، دادههای شبه مشاهده جدید از طریق درونیابی خشن اضافه میشوند. دوم، مقدار تخمین زده شده از داده های شبه مشاهداتی که از طریق درونیابی به دست آمده و داده های اصلی به دست می آید. بنابراین، تخمین هموارسازی دوگانه را می توان به دو مرحله تقسیم کرد [ 30 ].
(1) داده های اصلی D(si) را به شبه داده های شطرنجی شده با اندازه شطرنجی L تبدیل کنید.
(2) فیلد خطای پس زمینه را از مجموعه داده توسعه یافته، از جمله داده های اصلی و شبه داده ها، تخمین بزنید.
به عنوان یک مقدار تجربی، پهنای باند h 1 در این مقاله h 1 = 0.3 تنظیم شد . پهنای باند h2 از طریق اعتبارسنجی متقابل تعیین شد. K مقدار شبه داده است. تابع هسته K 1 تابع هسته گاوسی و تابع هسته K 2 هسته Epanechnikov را پذیرفته است. برای اطمینان از کفایت دادههای توسعهیافته، اندازه شطرنجی L شبه دادهها باید شرایط αL < h 2 را داشته باشد ، جایی که α > 1 است. طبق گفته Goudenhoofd و همکاران. [ 29 ]، پارامتر α روی 1.2 و حداقل مقدار h 2 تنظیم شد.0.3 بود. اندازه شطرنجی L شبه داده های تولید شده 0.25 درجه بود که برابر با وضوح TMPA است.
3.4. روش فیوژن تخمین بارش
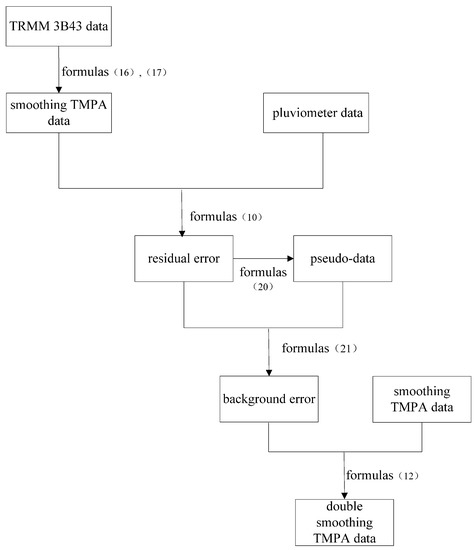
ابتدا، داده های TMPA با هموارسازی داده های بارش پذیرفته شده برای ماهواره TRMM 3B43 با استفاده از معادلات (1) و (2) تولید می شوند. دوم، میدان خطای باقیمانده D(si) با کم کردن دادههای مشاهدات پلویومتر بر اساس دادههای TMPA با استفاده از معادله (10) ایجاد میشود. سوم، شبه داده ها بر اساس میدان خطای باقیمانده با استفاده از رابطه (20) محاسبه می شوند. سپس مجموعه داده ها با توجه به قسمت خطای باقیمانده و شبه داده گسترش یافته و با استفاده از رابطه (21) فیلد خطای پس زمینه ایجاد می شود. در نهایت، فیلد تخمین X M (Si) با کم کردن فیلد خطای پسزمینه از فیلد پسزمینه با استفاده از رابطه (12) تشکیل میشود. این فرآیند در شکل 3 نشان داده شده است .
4. نتایج تجربی
میانگین انحرافات ( AD )، خطاهای ریشه میانگین مربع (RMSE) و ضرایب همبستگی (CC) روش همجوشی تحت سه تراکم شبکه منطقه ای مختلف در چین برای جولای 2009 در جدول 1 ارائه شده است .
با افزایش تراکم توزیع پلویومترها، میانگین انحرافات و خطاهای ریشه میانگین مربع دو محصول همجوشی کاهش یافت که با افزایش همبستگی فضایی همراه بود.
در منطقه C1، جایی که پلویومترها به طور پراکنده توزیع شدهاند، روش همجوشی پیشنهادی در این مقاله (که به عنوان FMP نامیده میشود) میانگین انحراف 0.082- میلیمتر بر ساعت، خطای ریشه میانگین مربع 1.960 میلیمتر در ساعت و یک همبستگی را به همراه داشت. ضریب 0.455. در منطقه C2، جایی که پلویومترها توزیع متوسطی دارند، خطای تخمین کاهش یافت. میانگین انحراف و خطای ریشه میانگین مربع به ترتیب به 0.058- میلی متر در ساعت و 1.833 میلی متر در ساعت کاهش یافت و ضریب همبستگی به 0.701 افزایش یافت. در منطقه C3، جایی که پلویومترها به طور متراکم توزیع شده اند، میانگین انحراف و خطای ریشه میانگین مربع بیشتر کاهش یافت و ضریب همبستگی به 0.722 رسید.
روش فیوژن پیشنهاد شده توسط شن و همکاران. [ 28 ] به عنوان FMS نامیده می شود. در مقاله آنها، محصول بارش ادغام شده در چین در ساعت، 0.1 درجه عرض جغرافیایی، و 0.1 درجه طول جغرافیایی تفکیک زمانی-مکانی از طریق یک الگوریتم ادغام دو مرحله ای با استفاده از تابع چگالی احتمال (PDF) و درون یابی بهینه (OI) مبتنی بر توسعه داده شد. در مورد بارش ساعتی مشاهده شده در ایستگاه های هواشناسی خودکار در چین و بازیابی شده از داده های ماهواره ای CMORPH (تکنیک ماشین حساب برنامه ریزی شده کارتی MORPHing).
در مقایسه با FMS، FMP هیچ گونه نوسان قابل توجهی در تخمین بارش نشان نداد و میتوانست برآورد کلی پایدارتری را محقق کند. در منطقه C1، با پذیرش FMP، میانگین انحراف از 0.121- میلی متر در ساعت به 0.082- میلی متر در ساعت بهبود یافت و ضریب همبستگی از 0.309 به 0.455 افزایش یافت، که نشان می دهد می تواند تخمین بارش را در مناطق به شدت بهبود بخشد. که در آن پلویومترها به طور پراکنده در چین توزیع می شوند. در منطقه C2، دو روش همجوشی از نظر تخمین بارش سازگار بودند. در منطقه C3، FMS از نظر تخمین بارندگی نسبت به FMP برتری داشت، که نشان میدهد بهتر است FMS در مناطقی که ایستگاهها پراکنده هستند اتخاذ شود.
ضریب کارایی ( CE ) رایج ترین شاخص ارزیابی کارایی در مدل های هیدرولوژیکی است. بدون واحد است و به کسری از واریانس توضیح داده شده توسط یک مدل اشاره دارد.
این مقاله CE را برای مقایسه تجربی بیشتر دو روش همجوشی از نظر بازده مدل در منطقه پراکنده C1 معرفی کرد. مقایسه دو روش همجوشی از نظر ضریب راندمان در ژوئیه 2009 در شکل 4 ارائه شده است که نشان می دهد تمام نقاط (مقدار نسبت CE) بالای خط 1:1 قرار گرفته اند که نشان می دهد روش اتخاذ شده توسط محور y از محوری که توسط محور x اتخاذ شده بود برتر بود . بنابراین، آزمایش ثابت کرد که اتخاذ FMP در مناطق پراکنده موثرتر خواهد بود.
برای نشان دادن واضح تر اینکه FMP در مناطقی که پلویومترها به طور پراکنده هستند دقیق تر است، این مقاله به طور مقایسه ای شاخص های آماری دو روش همجوشی را تحت درجه های مختلف بارش تجزیه و تحلیل کرد و نتایج همجوشی را تحت این درجه ها آزمایش کرد. با توجه به شدت بارش (IP)، بارش ساعتی را می توان به پنج درجه تقسیم کرد: <1.0 میلی متر، 1.0-2.5 میلی متر، 2.5-8.0 میلی متر، 8.0-16.0 میلی متر، و >16.0 میلی متر. جدول 2نشان می دهد که میانگین انحراف و انحراف نسبی (RD) FMS از مثبت به منفی متفاوت است. این تنوع نشان میدهد که میزان بارش در سطح پایین کمتر از 1.0 میلیمتر در ساعت بیشازحد برآورد شده است، در حالی که بارش حداقل 1.0 میلیمتر در ساعت دستکم گرفته شده است، و نشان میدهد که انحراف به تدریج با افزایش شدت بارش افزایش مییابد. پس از تصویب FMP، میدان بارش هنوز تا حدودی انحرافاتی را در برآوردهای بارش نشان می دهد. با این حال، مقادیر مطلق میانگین انحراف، انحراف نسبی، و ریشه میانگین مربعات خطا در همان درجه به طور قابل توجهی در مقایسه با موارد تحت FMS کاهش یافت. به طور خاص، پس از تصویب FMP، بهبود در نتایج زمانی که نرخ بارندگی بالای 8.0 میلیمتر در ساعت بود، بسیار قابل توجه بود. به ویژه زمانی که شدت بارش از 16 فراتر رفت. 0 میلی متر در ساعت، انحراف نسبی از -30.967٪ قبلی به -14.461٪ کاهش یافت. بنابراین، نتایج دقیق تری را می توان برای شدت بارندگی بیشتر به دست آورد.
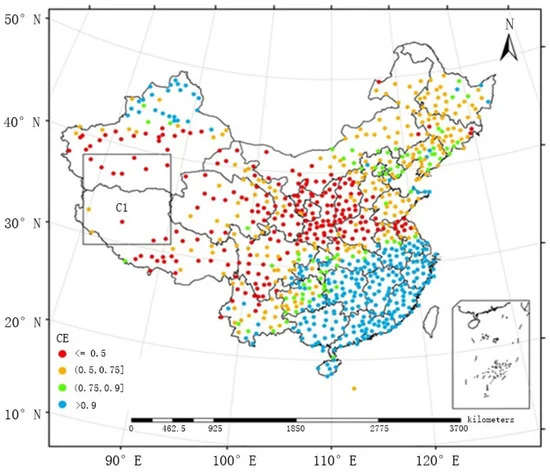
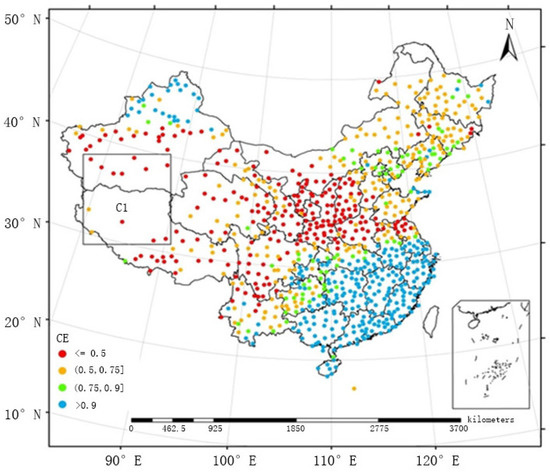
بخش زیر اثربخشی مدل ها را به عنوان تابعی از توزیع فضایی پلویومترها مورد بحث و مقایسه قرار می دهد. توزیع فضایی ضرایب کارایی به دست آمده توسط FMS و FMP بین ماه می و سپتامبر از سال 2005 تا 2010 به ترتیب در شکل 5 و شکل 6 ارائه شده است. در برخی از مناطق دورافتاده چین، پلویومترها به صورت پراکنده توزیع شده اند (به عنوان مثال، منطقه C1 در شکل 5 و شکل 6و FMS نتوانست بارش را به خوبی تخمین بزند. بنابراین، ضرایب کارایی به طور کلی زیر 0.5 بود. پس از پذیرش FMP، ضرایب راندمان در محدوده 0.5 و 0.9 کاهش یافت و حتی در برخی موارد از 0.9 نیز فراتر رفت، که نشان داد اتخاذ FMP در مناطقی که پلویومترها به طور پراکنده هستند، دقیق تر و موثرتر خواهد بود.
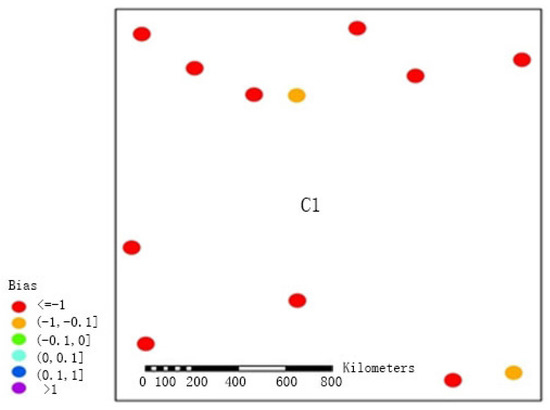
برای نشان دادن بیشتر اینکه FMP به نتایج دقیق تری برای تخمین بارندگی در مناطقی که پلویومترها پراکنده هستند، دست می یابد، ما انحراف بین تخمین های بارش به دست آمده با استفاده از دو روش و مشاهدات بارش به دست آمده در ایستگاه های منطقه C1 بین ماه های مه و سپتامبر را محاسبه کردیم. از 2005 تا 2010 (نتایج را در شکل 7 و شکل 8 ببینید). هر دو روش بارش را در منطقه غربی پراکنده، که ممکن است با توزیع پراکنده پلویومترها و همرفت اتمسفر محلی توضیح داده شود، دست کم گرفتند. سوگیری های به دست آمده توسط FMS عمدتاً در محدوده <-1 متمرکز شده بودند، و بایاس های تنها دو ایستگاه بین -1 و -0.1 بود. پس از پذیرش الگوریتم هموارسازی دوگانه این مقاله برای پردازش (FMP)، سوگیری ها عموماً در محدوده 1- تا 0.1- (پنج ایستگاه) و محدوده 0.1- تا 0 (شش ایستگاه) قرار گرفتند و فقط یک ایستگاه دارای بایاس در محدوده 0 تا 0.1 بود. این بهبود به طور کامل نشان داد که در مناطق پراکنده، الگوریتم هموارسازی دوگانه میتواند به طور موثرتری خطاها را کاهش دهد و رویدادهای بارش را به طور رضایتبخشتری منعکس کند.
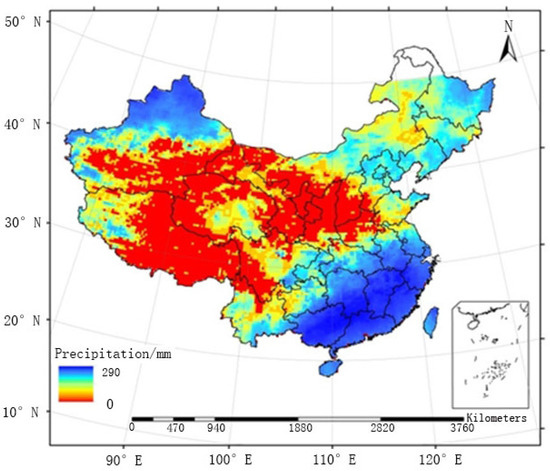
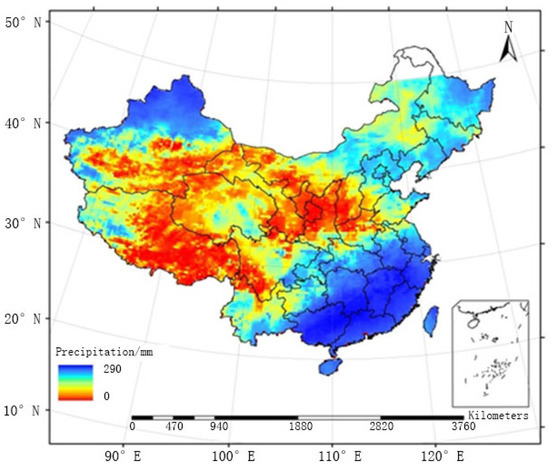
نقشه شطرنجی میانگین میدان بارندگی ماهانه تولید شده توسط FMS و آنچه که توسط FMP بین ماه مه و سپتامبر از سال 2005 تا 2010 تولید شده است، به ترتیب در شکل 9 و شکل 10 ارائه شده است . دو روش از نظر توزیع کلی میدان بارش مشابه بودند و رویدادهای بارشی بزرگ عمدتاً در مناطق جنوب شرقی متمرکز بودند. توزیع بارندگی تولید شده توسط FMS نسبتاً ناهمگن بود، به ویژه در مناطقی که ایستگاه های مشاهده سطحی به طور پراکنده توزیع شده اند (به عنوان مثال، منطقه C1). FMP، روشی که در این مقاله پیشنهاد شده است، یک پردازش هموارسازی دوگانه را برای مناطق پراکنده اتخاذ کرد و دقت میدان بارش را بهبود بخشید، که صافتر است، همانطور که در زیر نشان داده شده است.
5. نتیجه گیری ها
برای پرداختن به موضوع توزیع پراکنده ایستگاه های هواشناسی خودکار در مناطق غربی چین، الگوریتم هموارسازی دوگانه در این مقاله اتخاذ شده است. دادههای نقطهای بارش، همانطور که توسط پلویومترها مشاهده میشود، و دادههای شطرنجی بارش از TMPA در مجموعهای از نقاط گسسته ادغام میشوند و دو مجموعه داده را به نوع جدیدی از مجموعه دادههای بهبودیافته تبدیل میکنند. علاوه بر این، روش هموارسازی برای اصلاح ناپیوستگی ها قبل از ذوب شدن TMPA اتخاذ می شود. نتایج تجربی نشان میدهد که در مقایسه با روش شن و همکاران، الگوریتم هموارسازی دوگانه از نظر بزرگی و توزیع فضایی بارش منطقیتر و مؤثرتر است. یعنی در مناطقی که پلویومترها پراکنده هستند، تغییر در میانگین انحراف و خطای ریشه میانگین مربع با زمان ناچیز است. الگوریتم هموارسازی دوگانه می تواند بارش های سنگین را با دقت بیشتری تخمین بزند. روش تخمین بارش این مقاله با دیدگاهی نسبت به تفاوتهای فردی پیشنهاد شده است. هدف تحقیق بعدی، معرفی متغیرهای بیشتر در زمینه زمینه برای بهبود بیشتر کارایی برآورد است.






بدون نظر