

خلاصه
چندوجهی نیاز به یکپارچه سازی داده های ناهمگن حمل و نقل برای ساختن یک دید وسیع از شبکه حمل و نقل دارد. بسیاری از خدمات حمل و نقل جدید در حالی که از شبکه های قبلی جدا شده اند در حال ظهور هستند. این باعث می شود که آنها منابع داده خود را بر اساس اصول داده های پیوندی در وب منتشر کنند تا دیده شوند. علاقه ما استفاده از این داده ها برای ایجاد یک شبکه حمل و نقل گسترده است که این خدمات جدید را به خدمات موجود پیوند می دهد. مشکلات اصلی که در این مقاله به آنها می پردازیم در دسته بندی های تطبیق خودکار طرحواره و پیوند داده ها قرار می گیرند. ما رویکردی را پیشنهاد میکنیم که از خدمات وب به عنوان واسطهها برای کمک به شناسایی خودکار ویژگیهای مکانی و نقشهبرداری آنها بین دو طرحواره مختلف استفاده میکند. از سوی دیگر،
کلید واژه ها:
داده های حمل و نقل ؛ پیوند داده ها ؛ تطبیق خودکار طرحواره
1. معرفی
چندوجهی نیاز به یکپارچه سازی داده های ناهمگن حمل و نقل برای ساختن یک دید وسیع از شبکه حمل و نقل دارد. حوزه حمل و نقل با خدمات جدیدی که به سرعت در حال رشد هستند تا در رفت و آمد یا سفر روزانه مسافران شرکت کنند، به طور مداوم در حال توسعه است، به عنوان مثال، جمع آوری خودرو ( https://www.blablacar.fr/ )، اشتراک گذاری خودرو ( https://www. deways.com/ یا https://www.drivy.com/ ) و به اشتراک گذاری دوچرخه ( https://www.velib.fr). مشکل این است که این سرویس ها در نمایش داده ها متفاوت هستند و استاندارد خاصی برای رعایت آنها وجود ندارد. این منجر به این می شود که افراد به صورت دستی سفرهای فرعی مختلف را از منابع مختلف (وب سایت ها یا برنامه ها) ترکیب می کنند تا سفرهای بهینه و متناسب با نیازهای خود ایجاد کنند. چنین کاری مستلزم آن است که کاربران علاوه بر کار پیچیده یافتن پیوندهای بین یک سیستم و سیستم دیگر، از خدمات اطراف خود کاملاً آگاه باشند. این امر نیاز به یکپارچه سازی داده های حمل و نقل متعدد به منظور ارائه یک نمای کلی از شبکه را افزایش می دهد. فعال کردن چنین راه حلی برای هر شرکت مستلزم شناسایی سرویس های نزدیک و یافتن راه هایی برای ادغام آنها است، که کاری تکراری و خسته کننده است، به خصوص زمانی که به صورت دستی انجام شود. این اپراتورها را به راه حل های مجزا محدود می کند، که باید درک کنند، هر منبع داده مرتبط را ترجمه و ادغام کنید. اگرچه این کار پیچیده است، اما با در نظر گرفتن تکامل داده های یکپارچه و لزوم حفظ آنها و به روز نگه داشتن آنها، پیچیده تر می شود. برخی از رویکردها به سمت ایجاد یک مخزن عمومی برای ادغام داده های حمل و نقل عمومی حرکت کرده اند (Google Transit (http://maps.google.com/landing/transit/index.html ), Syndicat des transports d’ile-de-France (STIF) ( http://www.stif.info )); با این حال، آنها هنوز مجموعه دادههای بسیار در حال تکامل را در نظر نمیگیرند، مانند اشتراکگذاری خودرو، اشتراک دوچرخه، استخر خودرو، و غیره. چنین خدماتی بسیار پویا هستند و همیشه مفهوم توقف حمل و نقل ثابت را ندارند.
هدف ما یافتن راه ساده ای برای اپراتورها برای شناسایی خدمات حمل و نقل نزدیک با ارائه یک پورتال اتصال است که به فرد امکان می دهد ارتباطات بین یک منبع داده حمل و نقل را با منابع دیگر شناسایی کند. در این اثر از دو منظر به این مسئله می پردازیم. اولین مورد در سطح طرحواره است و ادغام خودکار مجموعه داده ها با طرحواره های مختلف را هدف قرار می دهد. مورد دوم در سطح نمونه است و کشف روابط حمل و نقل بین موجودیت های مختلف پراکنده بین مجموعه داده ها را هدف قرار می دهد. ما یک نمایش سبک وزن همگن از اتصالات حمل و نقل (نقاط انتقال از یک ایستگاه به ایستگاه دیگر) و ابزاری برای کشف آنها به شیوه ای انعطاف پذیر و سفارشی پیشنهاد می کنیم. با این نمایندگی، ما می توانیم انواع مختلف خدمات حمل و نقل را بدون توجه به نوع یا خدماتی که ارائه می دهند به هم مرتبط کنیم. تمام سیستمهای حملونقل باید بدانند این است که چگونه این اتصالات نوری را مدیریت کنند و از آنها برای ارتباط با دنیای بیرون استفاده کنند، که بسیار سادهتر از مدیریت دادههای ناهمگن و حفظ آنهاست.
در این مقاله، دو مشکل اصلی از هر دو زمینه را بررسی میکنیم: تطبیق خودکار طرحواره و پیوند دادهها.
1.1. تطبیق طرحواره
هدف تطبیق/نقشهبرداری خودکار طرحواره، پیشنهاد روشی خودکار برای کشف قوانین تطبیق بین مجموعههای داده است. با این حال، حوزه حمل و نقل دارای ویژگی های خاصی است که رویکردهای موجود نمی توانند از عهده آن برآیند. دادههای حملونقل حاوی ویژگیهای مکانی هستند که در قالبها و ساختارهای مختلف نشان داده میشوند. یک مثال ساده که باید در نظر گرفته شود این است که چگونه یک آدرس را می توان در منابع مختلف مدل کرد. شکل 1 سه نمایش متفاوت برای یک آدرس دنیای واقعی را نشان می دهد.
شکل 1 a مدلی را نشان می دهد که ویژگی های Street1، Street2، Zip-code، City و Country را برای نشان دادن یک آدرس ترکیب می کند. شکل 1 b آدرس را به صورت ترکیبی از مقادیر طول و عرض جغرافیایی نشان می دهد، در حالی که شکل 1 c نهایی یک نمایش WKT ( http://www.opengeospatial.org/standards/wkt-crs ) (متن معروف) از همان موجودیت
به منظور تشخیص نگاشت بین نمایشهای مختلف، رویکردهای موجود از تطبیقهای منفرد یا ترکیبی استفاده میکنند که بر روی سطوح طرحواره و/یا نمونه با استفاده از تکنیکهای مختلف کار میکنند، بهعنوان مثال، زبانشناختی، مبتنی بر محدودیت، مبتنی بر نوع داده، و غیره. با این حال، ریاضیات عملگرهای مبتنی بر استفاده برای تعریف شباهت بین روابط به تنهایی برای تشخیص روابط پیچیده در داده های حمل و نقل مناسب نیستند. برای مثال، هیچ راهی برای فهمیدن اینکه ترکیبی از خیابان1، خیابان2، کد پستی، شهر و کشور همان ترکیبی از طول و عرض جغرافیایی بین دو مجموعه داده با استفاده از برخی توابع ریاضی است، وجود ندارد. این مشکل این سوال را مطرح میکند که چگونه میتوانیم به طور خودکار بازنماییهای مختلف ویژگیهای مکانی را بین دو طرحواره شناسایی و نقشهبرداری کنیم.
این واقعیت که هر مجموعه داده حمل و نقل ممکن است شامل نمونه های متفاوتی باشد یک چالش است زیرا ما نمی توانیم برای دانستن نگاشت طرحواره به تکنیک های تطبیق نمونه اولیه تکیه کنیم. علاوه بر این، تنها تکیه بر ویژگی های دیگر، مانند نام ستون ها یا انواع مقادیر، ممکن است به خودی خود کافی نباشد. برای مقابله با این مشکل، ما یک رویکرد مبتنی بر نمونه را برای شناسایی ویژگیهای مکانی برای نقاط انتقال انتقال با استفاده از سرویسهای وب جغرافیایی معرفی میکنیم.
1.2. پیوند داده ها
فعال کردن راه حل یکپارچه سازی حمل و نقل مستلزم دسترسی به منابع حمل و نقل است که می تواند از داده های باز به دست آید [ 1 ، 2 ]، که محبوبیت زیادی پیدا کرده است و اپراتورهای حمل و نقل متعددی از آن برای انتشار داده های خود در وب استفاده می کنند تا بتوانند دید بازار خود را افزایش دهند ( http://opendata.paris.fr/page/home/ ، http://www.strasbourg.eu/ma-situation/professionnel/open-data/donnees/mobilite-transport-open-data ، http://www.uitp.org/tags/open-data). بسیاری از راه حل ها از این برای ارائه داده های غنی برای برنامه های کاربردی شهر هوشمند سود برده اند. آنها از تکنیکهای دادههای پیوندی و ابزارهای پیوند دادهها برای ارائه اطلاعات گسترده مرتبط با درخواستهای مشخصات حملونقل و مسافر استفاده میکنند [ 3 ، 4]]. این تکنیک ها به تشخیص هم ارزی بین موجودیت ها برای ایجاد پیوند بین منابع داده می پردازند. این ممکن است به غنی سازی داده ها در مورد موجودیت ها کمک کند. با این حال، این همیشه در داده های حمل و نقل کافی نیست. روابط پیچیده بیشتری برای منعکس کردن ماهیت ارتباطات حمل و نقل مورد نیاز است. فراتر از معادل سازی یا sameAslinks، ما علاقه مند به یافتن ارتباط بین منابع داده حمل و نقل بر اساس ویژگی های مکانی داده ها هستیم که دسترسی بین شبکه های حمل و نقل مختلف را نشان می دهد. علاوه بر این، با استفاده از ابزارهای داده شده، با دو محدودیت اصلی روبرو هستیم. اولین مورد محدودیت به مجموعه ای از توابع از پیش تعریف شده برای ترکیب قوانین پیوند است که به دلیل عدم انعطاف سیستم های موجود در تعریف توابع سفارشی است. برای مثال، برای محاسبه اطلاعاتی مانند نزدیکی دو نقطه حمل و نقل (ایستگاه اتوبوس، ایستگاه قطار و غیره)، نمیتوانیم توابع سفارشی را برای محاسبه مسافت پیادهروی، مسافت رانندگی و غیره تعریف کنیم. کاربر مجبور است کد را وارد کند (اگر موجود) و مستقیماً آن را اصلاح کنید. محدودیت دوم نمایش خروجی تولید شده است. حمایت از روابط پیچیده نیازمند الگوهای خروجی پیچیده تری است. به عنوان مثال، فرض کنید بین دو نقطه حمل و نقل ارتباطی برقرار شده است. ابزارهای موجود می توانند خروجی (BusStop1 nextTo TrainStation132) را ارائه دهند که اطلاعاتی در مورد وقوع این رابطه نمی دهد. آنها در کنار یکدیگر قرار دارند، اما چقدر به هم نزدیک هستند و از چه روش هایی می توانیم استفاده کنیم و غیره؟ ایستگاه قطار و غیره)، نمیتوانیم توابع سفارشی را برای محاسبه مسافتهای پیادهروی، مسافتهای رانندگی و غیره تعریف کنیم. کاربر مجبور است کد را (در صورت وجود) کند و مستقیماً آن را تغییر دهد. محدودیت دوم نمایش خروجی تولید شده است. حمایت از روابط پیچیده نیازمند الگوهای خروجی پیچیده تری است. به عنوان مثال، فرض کنید بین دو نقطه حمل و نقل ارتباطی برقرار شده است. ابزارهای موجود می توانند خروجی (BusStop1 nextTo TrainStation132) را ارائه دهند که اطلاعاتی در مورد وقوع این رابطه نمی دهد. آنها در کنار یکدیگر قرار دارند، اما چقدر به هم نزدیک هستند و از چه روش هایی می توانیم استفاده کنیم و غیره؟ ایستگاه قطار و غیره)، نمیتوانیم توابع سفارشی را برای محاسبه مسافتهای پیادهروی، مسافتهای رانندگی و غیره تعریف کنیم. کاربر مجبور است کد را (در صورت وجود) کند و مستقیماً آن را تغییر دهد. محدودیت دوم نمایش خروجی تولید شده است. حمایت از روابط پیچیده نیازمند الگوهای خروجی پیچیده تری است. به عنوان مثال، فرض کنید بین دو نقطه حمل و نقل ارتباطی برقرار شده است. ابزارهای موجود می توانند خروجی (BusStop1 nextTo TrainStation132) را ارائه دهند که اطلاعاتی در مورد وقوع این رابطه نمی دهد. آنها در کنار یکدیگر قرار دارند، اما چقدر به هم نزدیک هستند و از چه روش هایی می توانیم استفاده کنیم و غیره؟ کاربر مجبور است کد را (در صورت موجود بودن) کند و مستقیماً آن را تغییر دهد. محدودیت دوم نمایش خروجی تولید شده است. حمایت از روابط پیچیده نیازمند الگوهای خروجی پیچیده تری است. به عنوان مثال، فرض کنید بین دو نقطه حمل و نقل ارتباطی برقرار شده است. ابزارهای موجود می توانند خروجی (BusStop1 nextTo TrainStation132) را ارائه دهند که اطلاعاتی در مورد وقوع این رابطه نمی دهد. آنها در کنار یکدیگر قرار دارند، اما چقدر به هم نزدیک هستند و از چه روش هایی می توانیم استفاده کنیم و غیره؟ کاربر مجبور است کد را (در صورت موجود بودن) کند و مستقیماً آن را تغییر دهد. محدودیت دوم نمایش خروجی تولید شده است. حمایت از روابط پیچیده نیازمند الگوهای خروجی پیچیده تری است. به عنوان مثال، فرض کنید بین دو نقطه حمل و نقل ارتباطی برقرار شده است. ابزارهای موجود می توانند خروجی (BusStop1 nextTo TrainStation132) را ارائه دهند که اطلاعاتی در مورد وقوع این رابطه نمی دهد. آنها در کنار یکدیگر قرار دارند، اما چقدر به هم نزدیک هستند و از چه روش هایی می توانیم استفاده کنیم و غیره؟ فرض کنید بین دو نقطه حمل و نقل ارتباط برقرار شده است. ابزارهای موجود می توانند خروجی (BusStop1 nextTo TrainStation132) را ارائه دهند که اطلاعاتی در مورد وقوع این رابطه نمی دهد. آنها در کنار یکدیگر قرار دارند، اما چقدر به هم نزدیک هستند و از چه روش هایی می توانیم استفاده کنیم و غیره؟ فرض کنید بین دو نقطه حمل و نقل ارتباط برقرار شده است. ابزارهای موجود می توانند خروجی (BusStop1 nextTo TrainStation132) را ارائه دهند که اطلاعاتی در مورد وقوع این رابطه نمی دهد. آنها در کنار یکدیگر قرار دارند، اما چقدر به هم نزدیک هستند و از چه روش هایی می توانیم استفاده کنیم و غیره؟
ساختار این مقاله به صورت زیر است: در بخش 2 ، ما کار پسزمینه و کار مرتبط را به هر دو حوزه تطبیق خودکار طرحواره و پیوند دادهها ارائه میکنیم. سپس مشارکت های ما در بخش 3 و بخش 4 ارائه شده است . بخش 3 رویکرد تطبیق خودکار طرحواره ما را برای مجموعه داده های حمل و نقل مورد بحث قرار می دهد. بخش 4 روش منعطف و قابل تنظیم ما برای ایجاد اتصالات حمل و نقل برای مجموعه داده های انتقال داده باز را مورد بحث قرار می دهد. بعداً، هر دو رویکرد با یک سناریوی موردی واقعی ارائه شده در بخش 5 آزمایش میشوند . در نهایت، کار خود را به پایان میرسانیم و برخی از دیدگاهها را در بخش 6 مورد بحث قرار میدهیم .
2. وضعیت هنر
2.1. تطبیق خودکار طرحواره
تطبیق خودکار طرحواره یکی از رویکردهای حل ناهمگونی طرحواره است. ابزار و تکنیک های لازم برای دسترسی یکنواخت به داده ها را فراهم می کند.
بر اساس [ 5 ، 6 ، 7 ]، یک عنصر نگاشت پنج تایی است: ( من د، ای ، ه“, n , R ) (مند، ه، ه“، �، آر)جایی که:
-
id یک شناسه منحصر به فرد عنصر نگاشت داده شده است
-
e و e ‘ به ترتیب موجودیت های اولین طرحواره/هستی شناسی هستند
-
n یک معیار اطمینان است که مطابقت بین موجودیتهای e و e را دارد .
-
R رابطه ای است (به عنوان مثال، هم ارزی، کلی تر، ناپیوستگی، همپوشانی) بین موجودیت های e و e ‘
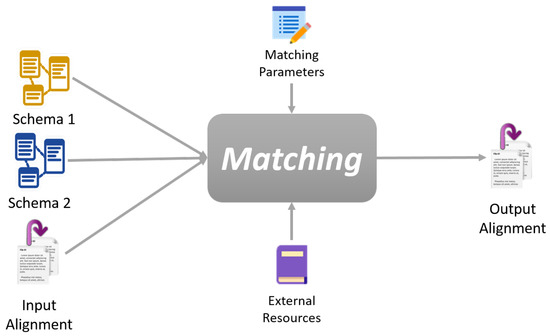
عملیات تطبیق یک تراز (مجموعه ای از عناصر نگاشت) را برای یک جفت طرحواره، با پارامترهای اختیاری اضافی، مانند: تراز ورودی، پارامترهای تطبیق (وزن، آستانه) و منابع خارجی (مثلاً اصطلاحنامه) تعیین می کند. شکل 2 را ببینید .
دامنه تطبیق طرحواره خودکار توسط چندین جامعه علوم کامپیوتر مورد مطالعه قرار گرفته است و توسط بسیاری از برنامه ها استفاده شده است [ 8 ]. بسیاری از نظرسنجی های جالب [ 7 ، 9 ، 10 ، 11 ، 12 ، 13 ] و معیارها [ 14 ، 15 ] در چند سال گذشته ارائه شده اند. در اینجا، آخرین رویکردهای مربوط به تطبیق خودکار طرحواره به طور کلی و رویکردهای خاص دادههای مکانی را بیان میکنیم.
در [ 9 ]، نویسندگان رویکردهای تطبیق طرحواره عمومی را نشان می دهند که داده های مکانی را در نظر نمی گیرند. آنها عمدتاً از تکنیک های مبتنی بر رشته استفاده می کنند، مانند N-grams در [ 16 ]، الحاق رشته های فرعی [ 17 ] یا مبتنی بر الگو [ 18 ]. این تکنیک ها به خوبی برای تطبیق جغرافیایی مناسب نیستند زیرا تطابق جغرافیایی نیاز به مقایسه بیش از شباهت های رشته ای دارد و ویژگی های آنها نمی توانند مقادیر خود را با الگوها توصیف کنند [ 19 ].
در حوزه هوش مصنوعی، SEMINTsystem [ 20 ] از یک راه حل شبکه عصبی برای تعیین نگاشت 1:1 با یادگیری متا داده ها و مقادیر داده ویژگی ها استفاده می کند. در [ 21 ]، نویسندگان دانش را از قطعات هستی شناسی دامنه و فریم های داده برای تشخیص نگاشت طرحواره 1:n اعمال می کنند. این تکنیکها با دادههای مکانی مناسب نیستند زیرا الگوها در تشخیص ویژگیها کافی نیستند. علاوه بر این، ویژگی ها می توانند الگوهای متا داده یا ارزش داده مشابهی را به اشتراک بگذارند در حالی که کاملاً متفاوت هستند، به عنوان مثال، شهر و شهرستان.
در حوزه جغرافیایی، رویکردهای تطبیق طرح واره عمدتاً بر دانش خارجی، مانند هستیشناسیهای دامنه و روزنامهها یا نمونههای داده برای هدایت کار تطبیق تکیه میکنند. براونر و همکاران [ 22 ] یک رویکرد مبتنی بر نمونه را برای مطابقت با طرحواره های صادراتی سرویس های وب پایگاه داده جغرافیایی پیشنهاد می کند. آنها فرض می کنند که سرویس های وب به خوبی توصیف شده اند تا ورودی و خروجی آنها مشخص باشد. یک فرمولساز پرس و جو از سرویسهای وب WS1 و WS2 سؤال میکندبر اساس مجموعه ای از نمونه های جهانی که بر اساس یک طرح کلی تعریف شده اند. سپس نتایج با نمونه های جهانی مقایسه می شود تا شباهت بین طرح کلی و طرح وب سرویس پیدا شود. این رویکرد در مواردی که پایگاههای داده نمونههای مشابهی را به اشتراک میگذارند، ساده و مؤثر است. در غیر این صورت، نوع داده های مختلف یا نمایش ساختاری احتمالی بین طرحواره های ورودی را در نظر نمی گیرد.
در [ 23 ]، نویسندگان پیشنهاد میکنند که از پایگاههای داده مرجع جغرافیایی برای تطبیق و تجسم دادههای موضوعی توسط مراجع فضایی ناهمگن استفاده شود. آنها ارجاعات موضوعی متفاوتی را با استفاده از پایگاههای داده مرجع جغرافیایی به عنوان منابع دانش پسزمینه به یک مجموعه دادههای جغرافیایی مرجع متصل میکنند. سپس آنها معادل یا سایر روابط را از روابط لنگر استخراج می کنند. این رویکرد مستلزم دانستن طرحواره ها از قبل است.
نویسندگان در [ 24 ] رویکرد تطبیقی دیگری را پیشنهاد کردند که پرس و جوهای کیفی را در پایگاه های داده مکانی ترجمه می کند. آنها پرس و جوهایی مانند سمت چپ، راست، نزدیک، بالا و غیره را بررسی می کنند. پرس و جوها به SQL ترجمه می شوند و با یک برنامه مشاوره سفر به نام مشاور گردشگری برمن ارزیابی می شوند.
رسیدگی به پرس و جوهای مکانی نیز توسط [ 25 ] در سیستم OnGIS آنها مورد هدف قرار گرفت، جایی که آنها تکنیک های واسطه ای را برای پاسخ دادن به پرس و جوهای فضایی پیچیده کاربر پیشنهاد می کنند.
در [ 26 ]، نویسندگان یک تکنیک تطبیق خودکار را برای ایجاد پیوندهایی بین اشیاء در مجموعه دادههای مختلف که همان پدیده دنیای واقعی را مدل میکنند، پیشنهاد کردند. آنها ابتدا گره ها را بر اساس برخی معیارهای فاصله، سپس جاده ها را بر اساس الگوریتم کوتاه ترین مسیر مطابقت می دهند.
نویسندگان در [ 27 ] از یک نمودار رابطه ای ویژگی برای نشان دادن الگوی اشیاء مکانی استفاده می کنند. سپس از آرامش احتمالی برای یافتن تطابق بهینه اشیاء در میان طرحوارههای دادههای جغرافیایی مختلف استفاده میشود. محدودیت چنین رویکردی این است که در موردی که دو نمایش متفاوت بین مجموعه داده ها وجود داشته باشد، کار نمی کند. علاوه بر این، آنها فقط از نام ها و مقادیر مشخصه ها برای اندازه گیری شباهت استفاده می کنند که در همه موارد دقیق نیست.
در [ 28 ]، نویسندگان یک رویکرد تطبیق نمونه مقیاس پذیر به نام VMI را پیشنهاد کردند. این به طور خودکار با ایجاد مجموعه ای از قوانین مبتنی بر شاخص معکوس برای بدست آوردن نامزدهای تطبیق اولیه، پیوندهایی بین نمونه های هستی شناسی ایجاد می کند. سپس مقادیر ویژگی های سفارشی شده توسط کاربر برای حذف بیشتر تطابقات نادرست استفاده می شود. در نهایت، شباهت ها به عنوان فواصل برداری یکپارچه محاسبه می شوند و نتایج تطبیق استخراج می شوند.
روند فعلی در تطابق طرحواره اکنون بیشتر بر ترکیب تطبیقکنندهها به جای ایجاد موارد جدید متمرکز شده است. بیشتر رویکردهای اخیر بر مشکل طرحوارههای مقیاس بزرگ و نحوه مدیریت کارآمد آنها تمرکز دارند. پشتیبانی زیادی برای ترازهای n:m وجود ندارد. در غیر این صورت، سیستم ها بیشتر بر روی 1:1 تمرکز می کنند. ارزیابیها در [ 29 ، 30 ] نشان میدهد که در مورد تطبیق مجموعههای دادههای مکانی، مانند DBpedia و Geonames، ابزارهای موجود برای نمایشهای جغرافیایی ساده، مانند (طول و عرض جغرافیایی، طول جغرافیایی)، کارآمد هستند، در حالی که با موارد پیچیدهتر شکست میخورند.
حوزه حمل و نقل به نگاشت های غنی تر و مناسب تری نیاز دارد که با مفاهیم آن مرتبط تر باشد. الگوهای جغرافیایی هنوز در سیستمهای فعلی یافت نمیشوند و تطبیقهای موجود توانایی تطبیق برخی طرحوارههای حملونقل پیچیده را ندارند.
2.2. پیوند داده ها
هدف از پیوند دادهها کشف موجودیتهایی است که یک شی را بر روی منابع داده RDF مجزا به صورت نیمه خودکار نشان میدهند [ 31 ]. هدف این است که موارد مشابه را به منظور اتصال منابع داده پیوند دهیم. نظرسنجی ارائه شده در [ 32 ] پیوند داده ها را با جزئیات بیشتری توصیف می کند و ویژگی های محبوب ترین رویکردها را برجسته می کند.
پیوند داده های حمل و نقل می تواند برای کشف روابط بین نهادهای حمل و نقل استفاده شود. این روابط توصیف میکنند که چگونه موجودیتها از نظر معنایی با یکدیگر مرتبط هستند، به عنوان مثال، نزدیک، قابل دسترس، قابل دسترسی در (زمان) و غیره. ارائه این روابط دید بهتری از دادهها را ممکن میسازد و خدمات دقیقتری را ممکن میسازد. ابزارهای موجود روابط هم ارزی (sameAs) را بر اساس معیارهای شباهت فاصله (رشته، جغرافیایی، عددی و غیره) تشخیص می دهند.
راه حل های زیادی برای پشتیبانی از پیوند و انتشار داده ها ارائه شده است [ 33 ، 34 ]. آنها ابزارهای لازم را برای تبدیل، پیوند، انتشار و جستجوی داده های استخراج شده از منابع مختلف با فرمت های مختلف فراهم می کنند. نمونه ای از رویکرد انتشار داده GeomRDF [ 35 ] است. این ابزاری است که به کاربران کمک می کند تا داده های مکانی را از فرمت های سنتی GIS به مدل RDF تبدیل کنند. با توجه به پیوند دادهها، Silk [ 36 ] راههای آسانی را برای افزودن مجموعههای داده، پیکربندی قوانین پیوند، استفاده از پیوندهای مرجع و پیکربندی خروجی برای ایجاد پیوند بین مجموعههای داده ارائه میکند. پیوند داده های مکانی با استفاده از برخی توابع فاصله ریاضی، به عنوان مثال، فاصله اقلیدسی انجام می شود. آهک [ 37] توابع فاصله جغرافیایی بهتری را نسبت به Silk ارائه می دهد (به عنوان مثال، orthodromic، Hausdorff، Frechet، و غیره)، که آن را برای مجموعه داده های جغرافیایی مناسب تر می کند. GNAT [ 38 ] بر روی مجموعه داده های موسیقی کار می کند و بر اساس الگوریتم تجمیع شباهت برای تشخیص روابط بر اساس همسایگان منبع در یک نمودار است. ODD-Linker [ 39 ] یک چارچوب قابل توسعه برای پیوند داده های رابطه ای با لینک های با کیفیت بالا پیشنهاد کرد. قوانین پیوند در LinQLlanguage بیان می شود که بعداً برای مقایسه و شناسایی پیوندها به پرس و جوهای SQL ترجمه می شود. RKB-CRS (سیستم تفکیک مرجع مشترک) [ 40 ] یک معماری برای مدیریت معادلهای یکسان شناسه منبع (URI) در وب دادهها با استفاده از خدمات مرجع ثابت است. RDF-AI [ 41] یک معماری تطبیق داده و ادغام مبتنی بر شباهت رشته ها با استفاده از یک منبع خارجی (WordNet) است.
با استفاده از اطلاعات ارائه شده در [ 32 ]، میتوانیم راهحلهای به هم پیوسته موجود را با ویژگیهایشان خلاصه کنیم و آنها را با رویکرد خود مقایسه کنیم، همانطور که در جدول 1 نشان داده شده است .
لینکهای تعریفشده توسط کاربر که توسط رویکردهای موجود ارائه میشوند، در واقع همان پیوندهایی هستند که برای مطابقت با ترجیحات کاربر تغییر نام دادهاند، برخلاف رویکرد ما، که در آن ساختار پیچیدهای دارند که توسط کاربر مشخص شده است.
رویکردهای دیگر، مانند BLOOMS [ 29 ] و STROMA [ 42 ]، پیوندهایی با معنایی متفاوت به عنوان sameAs ارائه میکنند. BLOOMS از ویکیپدیا بهعنوان دانش پسزمینه برای تشخیص روابط معنایی بین کلاسهای داده باز مرتبط استفاده میکند. روابط معنایی مشتق شده عبارتند از owl:subClassOf و owl:equivalentClass. STROMA مکاتبات is-a و مرتبط با آن را که با ایجاد بخشی از روابط ارائه می شود، گسترش می دهد.
تجزیه و تحلیل رویکردهای کشف پیوند موجود نشان می دهد که آنها برای تطبیق هم ارزی مناسب تر هستند. آنها توابع و تجمیع هایی را برای تشخیص sameAs، بخشی از یا subClassrelationship ها ارائه می کنند. این رویکردها ممکن است در برخی موارد برای دادههای مکانی مناسب باشند (پروژه GeoKnow [ 43 ] و LinkedGeoData [ 44]])، اما برای داده های حمل و نقل کافی نیستند. راه حل های به هم پیوسته باید ویژگی های مکانی و زمانی داده های حمل و نقل را علاوه بر وضعیت بلادرنگ در نظر بگیرند. در نظر بگیرید که ما می خواهیم دو منبع داده حمل و نقل را با هدف کشف چگونگی رسیدن به یک ایستگاه از ایستگاه دیگر به یکدیگر متصل کنیم. انجام این کار با ابزارهای موجود ما را به تشخیص هم ارزی به دلیل توابع ارائه شده و فرمت خروجی محدود می کند. آنچه مورد نیاز است، یک راه معرف و معنایی تر برای اتصال این منابع [ 45 ] است که نشان می دهد چگونه می توان آنها را از نقطه نظر حمل و نقل متصل کرد.
به عنوان یک نتیجه، خروجی یک فرآیند پیوندی عمدتاً بر شناسایی مجموعه ای از پیوندهای owl:sameAs متمرکز است. با این حال، ما باید اطلاعات بیشتری در پیوندهای تولید شده داشته باشیم تا بتوانیم پس پردازش و تجزیه و تحلیل بهتری داشته باشیم و هزینه های محاسبه مجدد را کاهش دهیم (به عنوان مثال، شامل اطلاعاتی در مورد وضعیت اتصال و فاصله بین دو نهاد متصل در پیوندهای حمل و نقل).
3. تطبیق خودکار برای مجموعه داده های حمل و نقل
نمونههای دادههای حملونقل همیشه به اشیاء دنیای واقعی اشاره میکنند، به عنوان مثال، ایستگاههای دوچرخه، ایستگاههای اتوبوس یا قطار، و غیره. ما با بازنمایی های مختلف این اطلاعات روبرو هستیم. هدف ما بررسی راهی برای شناسایی و تطبیق خودکار اطلاعات مکانی در مجموعه دادههای حملونقل با وجود ناهمگونی آنهاست.
خدمات کدگذاری جغرافیایی ( https://developers.google.com/maps/documentation/geocoding/intr ، http://dev.virtualearth.net/REST/v1/Locations/ ، http://cloudmade.com/documentation/geocoding/ , http://www.mapquestapi.com/geocoding/ , https://developer.yahoo.com/boss/placefinder/ ) ابزاری برای تبدیل توضیحات یک مکان (نام مکان، مختصات و غیره) فراهم می کند. به مکانی بر روی سطح زمین از طریق توابع geocoding و معکوس geocoding. آنها به عنوان یک موتور جستجو کار می کنند که در آن خروجی شامل تمام اطلاعات ممکن در مورد مکان داده های درخواست شده است.
ما معتقدیم که بهرهبرداری از این خدمات میتواند فرآیند تطبیق را در شناسایی خودکار ویژگیهای مکانی در مجموعه دادهها هدایت کند. ایده به طور کلی به شرح زیر است: ابتدا ما یک سرویس وب geocoding/reverse-geocoding را با نمونه های موجود پرس و جو می کنیم تا قوانین تطبیق بین نمونه های مورد بررسی و پاسخ سرویس وب را پیدا کنیم. طرح وب سرویس باید از قبل شناخته شده باشد، بنابراین تطبیق بین نمونه درخواست شده و نمونه وب سرویس اطلاعاتی در مورد طرح واره نمونه درخواست شده به ما می دهد. این ما را قادر می سازد تا روابط پیچیده بین دو نمایش متفاوت را با استفاده از وب سرویس به عنوان میانجی تشخیص دهیم. منابع داده ابتدا به میانجی نگاشت می شوند، سپس با اطلاعات شناخته شده قبلی در مورد ساختار میانجی، ما می توانیم قوانین تطبیق مورد نیاز را تشخیص دهیم. با توجه به اینکه می دانیم وب سرویس چگونه تعریف می شود، می توانیم تشخیص دهیمروابط n تا m بین طرحواره ها.
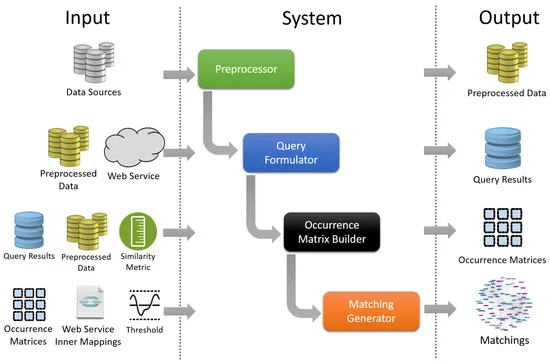
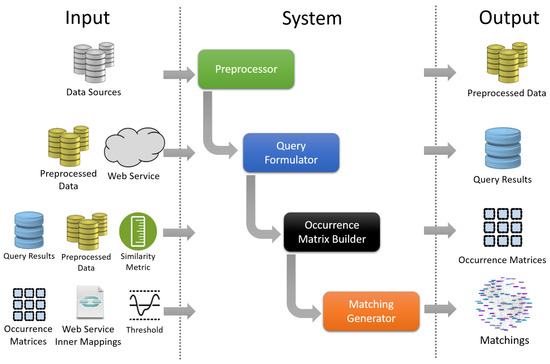
سیستم ما از چهار جزء تشکیل شده است که عبارتند از: انتخاب وب سرویس و فرمول پرس و جو، ساخت ماتریس همزمان و در نهایت، تولید کننده قوانین تطبیق. یک مرحله پیش پردازش قبل از رویکرد ما به منظور یکسان سازی بازنمایی ساختار در هر منبع داده و انجام برخی فیلترها و/یا اصلاحات انجام می شود. در اینجا به دلیل سادگی از فرمت CSV استفاده می کنیم. علاوه بر این، از آنجایی که برخی از ستونها به تنهایی نمیتوانند ورودی معنیداری را برای جستجوی وب سرویس ارائه دهند، پیش پردازش میتواند برخی ترکیب تصادفی/تقسیم ستونها را به عنوان دادههای اضافی انجام دهد که ممکن است نتایج جستجوی سرویس وب را بهبود بخشد، به عنوان مثال، ترکیب نام خیابان با نام شهر برای بدست آوردن نتایج دقیق تر از وب سرویس. این ترکیب به صورت خودکار و کورکورانه بدون هیچ گونه اطلاعات قبلی در مورد طرح داده انجام می شود. توجه داریم که حتی زمانی که قالب یکسان است، نمایش ممکن است کاملاً متفاوت باشد. به عنوان مثال، هر دو فایل با فرمت CSV هستند، اما هر کدام آدرس ها را متفاوت نشان می دهند.شکل 3 یک نمای کلی از سیستم ما را نشان می دهد.
3.1. فرمول پرس و جو مبتنی بر وب سرویس
یک وب سرویس به عنوان واسطه ای است که منابع داده را نقشه برداری می کند. ما میتوانیم قالبها و بازنماییهای بیشتری را با توجه به یک طرح وب سرویس غنیتر شناسایی کنیم. بنابراین، لازم است یک سرویس وب ارائه شود که حاوی نمایشهای کافی از آدرسها برای پوشش هر قالب احتمالی باشد. علاوه بر تعریف سرویس، دانش نحوه نگاشت عناصر در وب سرویس ها نیز باید تعریف شود. به عنوان مثال، اگر یک وب سرویس شامل طول جغرافیایی، عرض جغرافیایی و نمایش WKT از یک آدرس باشد، باید مشخص کنیم که ترکیبی از طول و عرض جغرافیایی می تواند در WKT نمایش داده شود و بالعکس. این اطلاعات بهعنوان «قوانین نقشهبرداری داخلی» یک وب سرویس ذخیره میشوند که بعداً در کار تطبیق استفاده میشوند.
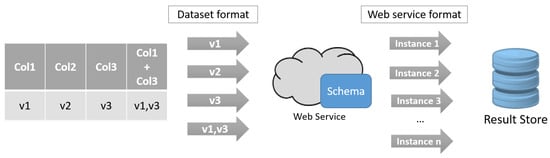
هدف یک فرمولساز پرس و جو این است که سرویس وب انتخاب شده را با نمونههای موجود با هدف دستیابی به اطلاعات غنیتر پرس و جو کند. این مرحله روی هر مجموعه داده جداگانه انجام می شود. فرمول ساز پرس و جو یک پرس و جو ایجاد می کند و آن را به وب سرویس می فرستد. درخواستهای جداگانه برای هر ستون در یک ردیف همانطور که در شکل 4 نشان داده شده است یا با تقسیم تصادفی/ترکیب ستونهایی که قبلاً در مرحله پیشپردازش انجام شده بود، صادر میشوند، به عنوان مثال، ستون چهارم در شکل 4 نتیجه پیشپردازش فایل با ترکیب ستونهای 1 و 3. توجه داشته باشید که Col1، Col2، Col3 نشان دهنده هر نام ستون هستند در حالی که v1، v2، v3 هر مقدار ممکن را نشان می دهند. نتایج وب سرویس توسط ستون های مورد نظر گروه بندی شده و در یک مخزن برای کارهای بعدی ذخیره می شود.
3.2. ساخت ماتریس همزمانی
در اینجا، ما از نتایج وب سرویس و نمونههای مجموعه داده برای ساختن یک ماتریس همزمانی استفاده میکنیم. ماتریس همزمانی ماتریسی از n * m ردیف است که n و m به ترتیب تعداد ستونهای مجموعه داده و طرح وب سرویس هستند. هر موجودیت در این ماتریس با تعداد دفعات یک عنصر مطابقت دارد آمن جآمن�به طور همزمان در ستون i از طرح مجموعه داده و ستون j از طرح نتایج وب سرویس ظاهر می شود.
مقایسه عنصر از طریق یک متریک شباهت [ 46 ، 47 ] انجام می شود که در آن هر بار که یک شباهت تشخیص داده می شود، مقدار متناظر در ماتریس یک افزایش می یابد. هر چه این مقدار بیشتر باشد، احتمال انطباق این دو ستون با یکدیگر بیشتر است. نمونه ای از موارد قبل در شکل 5 نشان داده شده استبا عناصر قرمز رنگ نشان دهنده اتفاقات رایج است. ما دو طرحواره را می بینیم که یکی نمایانگر طرح داده و دیگری طرحواره وب سرویس است. در طرح مجموعه داده، یک خیابان با نام و کد پستی آن که با کلمات انگلیسی نوشته شده است نشان داده می شود، در حالی که در طرح وب سرویس با مجموعه {Voie، CodeP و Ville} نشان داده می شود که مخفف {Street، Postal Code و City است. } در فرانسه. ماتریس همزمانی، ستونهای هر دو طرحواره را بهعنوان ردیف و ستون آرایه فهرست میکند و هر عنصر در ماتریس نشاندهنده تعداد دفعاتی است که همان مقدار در ترکیب سطر/ستون ظاهر میشود. به عنوان مثال، می بینیم که ستون های “Voie” و “Street Name” دو مقدار مشترک دارند که عبارتند از “Rue Edme Bouchardon” و “Rue des Chantiers”. برای محاسبه ماتریس، ابتدا روی هر ردیف در مجموعه داده تکرار می کنیم و مقدار هر ستون را با مقادیر ستون هر سطر در نتایج وب سرویس مقایسه می کنیم. اگر شباهت بین مقادیر از یک آستانه فراتر رود، مقدار در شاخص سطر/ستون خاص در ماتریس افزایش مییابد، به عنوان مثال، اگر مقدار Street Name مشابه مقدار Rue باشد، سلول مربوط به ستون Street Name و ردیف Rue افزایش یافته است.
یک ماتریس همزمانی برای هر مخزن ایجاد می شود که در آن یک مخزن نتایج پرس و جو مقادیر نمونه هر ستون را نشان می دهد. از آنجایی که ما چندین ماتریس همزمان داریم، آنها را با یک ماتریس تجمیع ترکیب می کنیم تا شباهت را به حداکثر برسانیم. این ماتریس نمای کلی در مورد چگونگی ارتباط ستون های هر مجموعه داده با طرح وب سرویس بر اساس همه پرس و جوها را نشان می دهد.
3.3. تطبیق قوانین تولید
ماتریسهای همرویداد محاسبهشده قواعد تطبیق احتمالی بین منابع داده و سرویس وب را جمعآوری میکنند و به نوبه خود به تولید قوانین تطبیق بین طرحوارههایشان کمک میکنند. در اینجا، ما روی هر ردیف تکرار می کنیم و بالاترین مقدار را انتخاب می کنیم. سپس، در صورتی که تعداد تکرارها از آستانه از پیش تعریف شده بیشتر باشد، تطبیق بین سطر/ستون مربوطه ایجاد می کنیم.
پس از انجام تطابق بین هر مجموعه داده و وب سرویس، ما از نگاشت های داخلی سرویس وب استفاده می کنیم تا تشخیص دهیم چگونه عناصر هر مجموعه داده می توانند با یکدیگر تطبیق داده شوند. برای نشان دادن، اجازه دهید دو مجموعه داده، DS1، DS2، و سرویس وب، WS را در نظر بگیریم. فرض کنید DS1 شامل ستون های a1 و b1 است، طرحواره WS شامل ws1، ws2 و ws3 و DS2 حاوی a2 است. با دانستن اینکه ستون ws3 ترکیبی از ws1 و ws2، نقشه a1 و b1 به ترتیب به ws1 و ws2 و نقشه a2 به ws3 است، میتوان نتیجه گرفت که میتوانیم عناصر DS1 را با ویژگی «a1 ترکیب با b1» به عناصر DS2 نگاشت کنیم. معادل a2 است. تصویر کلی در شکل 6 نشان داده شده است .
به طور خلاصه، ایده این است که هر عنصر مجموعه داده را با یک سرویس وب که دارای طرح و قوانین نگاشت درونی شناخته شده است، پرس و جو کنید. سپس از نمونه های به دست آمده برای ایجاد ماتریس های همزمان برای هر مجموعه داده استفاده می کنیم. سپس از ماتریس ها برای تعریف تطابق بین هر مجموعه داده و طرح وب سرویس استفاده می شود تا در نهایت از قوانین نگاشت داخلی سرویس وب برای ایجاد قوانین تطبیق بین مجموعه داده های ورودی استفاده شود.
این فرآیند دو بار برای هر دو مجموعه داده انجام می شود. با استفاده از قوانین تطبیق از D1 به WS و از D2 به WS علاوه بر قوانین نگاشت داخلی WS، فرآیند با نشان دادن تطابق بین D1 و D2 خاتمه می یابد.
4. کشف ارتباطات معنایی بین مجموعه داده های حمل و نقل
کشف اتصالات بین نقاط انتقال انتقال با استفاده از ابزارهای پیوندی موجود امکان پذیر نیست. یک فرآیند تولید اتصال پیچیدهتر برای فعال کردن نمایش اتصال غنیتر و انعطافپذیرتر مورد نیاز است. ما Link++ (نشان داده شده در شکل 7 ) را معرفی می کنیم، سیستمی که کشف اتصال انعطاف پذیر و تعریف خروجی سفارشی شده را با استفاده از الگوهای اتصال، توابع سفارشی و قوانین پیوند امکان پذیر می کند. الگوهای اتصال، الگوهایی برای تولید اتصال هستند که برای تعریف محتوا و قالب خروجی فرآیند پیوند استفاده میشوند.
به طور کلی، رویکرد شامل دو مرحله اصلی است:
-
مرحله تعریف، جایی که کاربران الگوهای اتصال، توابع مورد نیاز و قوانین پیوند را تعریف می کنند.
-
مرحله تولید، که در آن تعاریف گرفته شده و به مجموعه داده ها اعمال می شود. این قانون برای موجودیت ها اعمال می شود و در صورت معتبر بودن، یک اتصال ایجاد و در یک مخزن ذخیره می شود.
در یک تعریف رسمی، یک وظیفه پیوندی T به ورودی زیر برای فرآیند نیاز دارد:
-
منابع داده ورودی د 1�1و د 2�2نشان دهنده مجموعه داده هایی است که باید پیوند داده شوند
-
O الگوی اتصال سفارشی تعریف شده است
-
R قانون پیوند است که تعیین می کند چه زمانی یک اتصال باید ایجاد شود
-
F مجموعه ای از توابع مورد نیاز برای کار پیوند است
-
L مجموعه ای از کتابخانه های از پیش تعریف شده است که وابستگی های F را پیاده سازی می کند
بخشهای زیر به تفصیل وظایف مورد نیاز برای فرآیند پیوند را توضیح میدهند.
4.1. تعیین توابع سفارشی و کتابخانه های خارجی
کاربران میتوانند هر تابعی را بنویسند تا در قوانین پیوند یا محاسبات شباهت استفاده شود. این انعطاف پذیری رویکرد و توانایی پشتیبانی از هر کار مرتبط را تضمین می کند. علاوه بر این، کتابخانه های خارجی پشتیبانی می شوند و می توانند در پیاده سازی توابع استفاده شوند. این توابع ممکن است یک قانون پیوند، یک متریک شباهت، یک عملیات تبدیل/پیش پردازش یا هر تابع دیگری را بر اساس نیازهای کاربران نشان دهند. توابع در یک فایل JAVA همراه با کتابخانه های jar استفاده شده جمع آوری می شوند.
4.2. تعریف قانون پیوند
یک قانون پیوند، شرایط مورد نیاز برای ایجاد ارتباط بین یک جفت موجودیت معین را مشخص می کند. هدف اصلی اعمال این قانون برای هر جفت موجودیت به منظور جستجوی یک تطابق و ایجاد ارتباط مشخص شده است. تعریف یک قانون مستلزم مجموعه ای از توابع (متریک های شباهت و توابع پیش پردازش) است که قبلاً توسط کاربر تعریف شده است. هر قانون با یک گره ریشه تعریف می شود که یا یک عملگر تجمیع یا مقایسه است و گره های فرعی که هر تابع دیگری را به گونه ای زنجیره ای مشخص می کنند که مطابق با وظیفه پیوند باشد.
یک عملگر تجمیع مقادیر عملگرها/مقدارهای مختلف را با اعمال روش تجمیع مشخص شده ترکیب می کند، به عنوان مثال، حداکثر، حداقل، میانگین، و غیره. با یک تابع تجمع و یک آستانه تعریف می شود. هر تابع شامل مجموعه ای از پارامترها است که می تواند از منابع داده داده شده یا مستقیماً توسط کاربر مشخص شود. آستانه تعیین می کند که آیا مقدار عملگر باید به عنوان درست یا نادرست در قانون پیوند ارزیابی شود.
از آنجایی که منابع داده را می توان به روش های مختلف نشان داد، می توانیم از عملگر تبدیل برای تغییر نحوه نمایش مقادیر استفاده کنیم. برای این منظور، تابعی را تعریف می کنیم که پارامترهای خود را از منابع داده یا از ترکیب سایر عملگرهای تبدیل می گیرد، به عنوان مثال، حروف کوچک، بزرگ، الحاق، گرد، سقف و غیره.
در نهایت، عملگر مقایسه برای تعریف شباهت (یا ارتباط) بین دو ویژگی منابع داده داده شده استفاده می شود. مقایسه بین خود عملگرها یا سایر توابع تبدیل معتبر است، و یک آستانه تعیین می کند که آیا این مقدار برای معتبر بودن قانون مورد قبول است یا خیر، به عنوان مثال، فاصله، برابری و غیره.
4.3. پیکربندی یک الگوی اتصال
اتصالات خروجیهای نهایی کار پیوند میانی هستند و دقت در هنگام تعریف الگوی اتصال مهم است. یک الگو فرمت اتصالات تولید شده و اطلاعات مورد نیاز آنها را مشخص می کند. به عبارت دیگر، الگویی را نشان میدهد که با ایجاد یک اتصال پر میشود.
یک الگوی اتصال از مجموعه ای از ویژگی ها تشکیل شده است که در آن هر ویژگی توسط تابعی تعریف می شود که آن را محاسبه می کند. پارامترهای تابع می توانند ورودی از منابع داده یا از پیش تعریف شده توسط سازنده قوانین باشند. یک الگوی اتصال آزادانه توسط کاربر با توجه به وظیفه پیوند و نیازهای پس از پردازش انتخاب می شود. تعریف رسمی یک الگوی اتصال O به شرح زیر است:
تعریف 1 .
فرض کنید D 1 و D 2 دو منبع داده باشند. با توجه به V هر نوع داده و F مجموعهای از توابع سفارشی مورد نیاز برای تولید الگوها ، Pr مجموعهای از ویژگیها است که در آن هر ویژگی با یک نام ویژگی n، یک مقدار v و یک تابع مربوطه نشان داده میشود، که مقدار ویژگی را در طول محاسبه میکند. فرآیند تولید
پr = { ( n ، v ، f) | n ∈ St r i n g، v ∈ Vf∈ F}پ�={(�،�،�)|�∈استی�من��،�∈��∈اف}
یک الگوی اتصال به صورت زیر رسمیت می یابد:
O = (د1،د2، ص ) | _د1∈D1،د2∈D2، p r ⊆ Pr�=(د1،د2،پ�)|د1∈�1،د2∈�2،پ�⊆پ�
ما یک مورد نمایشی با یک سناریوی واقعی از تعریف قانون پیوند و الگوی اتصال در بخش 5 ارائه خواهیم کرد .
هنگامی که مرحله پیکربندی کامل شد، کشف اتصال همانطور که در ادامه توضیح داده شد انجام می شود.
4.4. الگوریتم کشف اتصال
الگوریتم 1 شبه کد فرآیند پیوند اجرا شده را نشان می دهد.
الگوریتم بر روی هر جفت موجودیت در دو منبع داده تکرار میشود و قانون پیوند بین آنها را ارزیابی میکند. بر اساس ارزیابی قانون، الگوریتم تصمیم می گیرد که آیا یک اتصال باید ایجاد شود یا خیر. اگر یک قانون راه اندازی شود، یک اتصال جدید با ارزیابی الگوی اتصال و اعمال تابع مربوط به هر ویژگی ایجاد می شود. مقادیر توسط توابع مشخص شده در الگوی خروجی محاسبه می شوند و پارامترهای آنها از موجودیت های فعلی مقایسه شده پر می شوند. در اینجا، اتصال را نمونه سازی می کنیم و اطلاعات آن را از مقادیر بازگشتی توابع پر می کنیم. اتصال در یک مخزن مشخص ذخیره میشود و الگوریتم بر روی جفتهای باقیمانده تا زمانی که همه درمان شوند ادامه مییابد.
| الگوریتم 1 : الگوریتم کشف اتصال. |
 |
در بدترین موارد، پیچیدگی زمانی الگوریتم O(n * m) است، که در آن n و m اندازه مجموعه داده های ورودی هستند. پیچیدگی ذخیره سازی (از نظر صفحات داده) مانند اتصال حلقه تودرتو در پایگاه داده است که برابر با اندازه کوچکترین مجموعه داده + یک صفحه است که معمولاً در حافظه قرار می گیرد. این پیچیدگی ممکن است با استفاده از برخی تکنیک های پیش فیلتر که سیستم ممکن است در نسخه های بعدی ارائه دهد کاهش یابد. به عنوان مثال، استفاده از یک شاخص فضایی برای جایگزینی حلقه داخلی با جستجو در یک شاخص (که هزینه ورود (n) را کاهش می دهد). سپس قوانین و عملکرد خاص تعریف شده توسط کاربر در مرحله اصلاح به صورت خودکار توسط سیستم اعمال می شود.
هم الگوی اتصال و هم فایلهای قانون پیوند در فایلهای XML توضیح داده شدهاند که با تعریف نوع داده (DTD) مطابقت دارند. توابع سفارشی با استفاده از JAVA نوشته می شوند (کاربران می توانند هر فایل JAVA را بنویسند و از روش های تعریف شده در الگوی اتصال یا قانون خود استفاده کنند)، و خروجی در RDF تولید می شود. نمونه ای با مجموعه داده های پیوند واقعی در بخش ارزیابی ارائه شده است. این فرآیند پیکربندی را نشان میدهد و نمونهای از فایلهای XML (الگوی خروجی و قانون) را نشان میدهد.
ما رویکرد خود را پیادهسازی کردهایم و یک نسخه اجرایی از سیستم را میتوان به صورت آنلاین از طریق پیوند https://github.com/alimasri/link-plus-plus.git پیدا کرد . علاوه بر یک آموزش تصویری در: https://youtu.be/u2gr7Wa4eT4 .
5. ارزشیابی
ما هر دو رویکرد خود را با استفاده از دو مجموعه داده که نماینده شرکتهای حملونقل در منطقه پاریس، SNCF و Autolib، یک شرکت راهآهن و یک سرویس اشتراک خودرو هستند، ارزیابی میکنیم.
ایده اصلی این است که اتصالات گمشده بین ایستگاههای متعلق به حالتهای حملونقل مختلف را فراهم کنیم و ببینیم که چگونه برنامهریزی سفر کاربران را بهبود میبخشد. ابتدا نشان میدهیم که چگونه به طور خودکار ویژگیهای مکانی بین دو مجموعه داده را کشف میکنیم و سپس چگونه میتوانیم از این اطلاعات برای پیوند آنها با استفاده از رویکرد پیوندی پیشنهادی استفاده کنیم.
دادههای ورودی از پورتالهای دادههای باز برای SNCF ( http://gtfs.s3.amazonaws.com/transilien-archiver_20160202_0115.zip ) و Autolib ( http://opendata.paris.fr/explore/dataset/stations_et_espaces_paritropolibene/SNCF ) جمعآوری میشوند ) در نمایش های CSV. تعداد نمونه ها در هر یک از مجموعه داده های SNCF و Autolib به ترتیب 1067 و 869 است. شکل 8 طرح اصلی مجموعه داده ها را نشان می دهد.
5.1. تطبیق خودکار طرحواره
ما فرآیند تشخیص خودکار ویژگیهای مکانی هر دو مجموعه داده را طبق مراحل نشان داده شده در بخش 3 شرح خواهیم داد .
در مرحله پیشپردازش، ستونهای حاوی کاراکترهای خاص (کاما، نیمه ویرگول) را به دو یا چند ستون تقسیم میکنیم که با نام ستون اصلی نامگذاری شدهاند و یک مقدار افزایشیافته به انتهای آن متصل میشود. بنابراین در اینجا ستون Autolib “Cordonnees geo” به دو ستون “Cordonnees geo 0” و “Cordonnees geo 1” تقسیم می شود.
برای انتخاب سرویس وب، ما سرویس وب کدگذاری جغرافیایی Google ( https://developers.google.com/maps/documentation/geocoding ) را با یک تابع در بالا که توسط ما اجرا شده است انتخاب کردیم تا نتایج را در یک طرح ساده که از سه مورد تشکیل شده است فیلتر کنیم. ستونها: آدرس قالببندی شده (نماینده نشانی متنی)، lng (طول جغرافیایی) و عرض (طول عرض جغرافیایی).
فرمولساز پرس و جو از وب سرویس با مقدار هر ستون برای تمام ردیفهای موجود پرس و جو میکند، سپس نتایج را بر اساس نام ستونها گروهبندی کرده و در یک مخزن ذخیره میکند. تعداد کل درخواست های صادر شده 20185 است که به ترتیب برای SNCF و Autolib به 8536 و 11649 تقسیم می شوند.
یک ماتریس همزمانی برای هر ستون ساخته میشود که ستونهایی را که هیچ نتیجهای از وب سرویس ندادهاند نادیده میگیرد. متریک شباهت مورد استفاده فاصله لونشتاین است تا نشان دهد چگونه یک متریک تشابه ساده می تواند نتایج خوبی به ما بدهد. با این حال، معیارهای پیچیده تری را می توان برای افزایش دقت محاسبه شباهت استفاده کرد. سپس یک ماتریس تجمیع با محاسبه مقدار میانگین همه مقادیر ماتریس های همزمان ایجاد می شود. ماتریس های حاصل برای SNCF و Autolib در جدول 2 و جدول 3 نشان داده شده است .
به منظور ایجاد قوانین تطبیق، ما روی هر ردیف تکرار می کنیم، حداکثر مقدار را بدست می آوریم و تطبیقی بین جفت سطر/ستون مربوطه اختصاص می دهیم. با استفاده از جدول 2 و جدول 3، قوانین تطبیق زیر را بین هر یک از آنها و وب سرویس به دست می آوریم. برای SNCF: (stop-id، lng)، (stop-name، formatted-address)، (stop-desc، formatted-address)، (stop-lat، lat) و (stop-lon، lng). برای Autolib: (ID, lat), (Identifiant Autolib’, formatted-address), (Rue, formatted-address), (Ville, formatted-address), (Cordonnees geo-0, lat), (Cordonnees geo-1, lng) و (Autolib’، قالببندی شده-آدرس). زمان اجرا در مجموعه داده های داده شده حدود 3.5 دقیقه طول کشید، از جمله یک ثانیه خنک کردن برای هر ده پرس و جو برای مطابقت با محدودیت های وب سرویس.
با تجزیه و تحلیل نتایج برای SNCF، سیستم ما به درستی تطبیق ویژگی های طول و عرض جغرافیایی را به دست آورد. علاوه بر این، از آنجایی که نام توقف و استاپ-دک معمولاً نامهای ناحیه مربوطه هستند، به عنوان ویژگیهای مکانی نیز شناسایی شدند. با توجه به stop id، این قانون تطبیق مثبت کاذب را می توان با ترکیب نتایج با برخی رویکردهای مبتنی بر محدودیت حل کرد. در مورد Autolib، قوانین تطبیق روابط صحیحی را بین Rue و آدرس قالببندی شده و یکسان برای طول و عرض جغرافیایی با cordonnees geo 0 و 1 شناسایی کردند. (Identifiant Autolib’, formatted-address) و در نهایت (Autolib’, formatted-address). قوانین تطبیق منفی های کاذب را نیز می توان با استفاده از رویکردهای مبتنی بر محدودیت کنار گذاشت.
نتایج دقت 100% و فراخوانی 80% برای SNCF و 100% دقت 42% و فراخوانی برای Autolib را نشان میدهد. نتایج تطبیق را می توان به روش های مختلف بهبود بخشید: (1) انتخاب سرویس های وب غنی تر. (2) پالایش پیش پردازش خروجی. یا (iii) با استفاده از معیارهای مشابه مشابه. با ترکیب هر دو قانون تطبیق، میتوانیم قوانین معتبر زیر را بین SNCF و Autolib استنتاج کنیم: «Cordonnees geo» از نقشههای Autolib تا ترکیب (stop-lat،stop-lon) در SCNF. “Rue” از نقشه های Autolib به “stop-desc” در SNCF.
ما الگوریتم را روی مجموعه داده های دیگر آزمایش کردیم تا اعتبار آن را تأیید کنیم. مجموعه دادههای انتخاب شده، مکانهای بیمارستانی در بریتانیا و نقاط مورد علاقه (POI) در پاریس، علاوه بر ایستگاههای قطار و ماشین قبلی هستند. ایده در اینجا این است که این رویکرد می تواند به بررسی اینکه آیا مجموعه داده ها علاوه بر توانایی شناسایی آنها و ارتباط با سایر مجموعه داده ها حاوی اطلاعات مکانی هستند یا خیر کمک کند. این می تواند در موارد استفاده مانند یافتن نزدیکترین بیمارستان از محل حادثه یا یافتن برخی از POI در نزدیکی یک هتل و غیره استفاده شود. نتایج در جدول 4 نشان داده شده است .
5.2. کشف پیوند
پس از شناسایی ویژگی های مکانی، فرآیند زیر برای یافتن اتصالات حمل و نقل بین هر دو مجموعه داده است. در شبکه های حمل و نقل، اتصال را می توان به عنوان یک مسیر قابل دسترسی از یک نقطه انتقال انتقال به نقطه دیگر توصیف کرد. نقطه انتقال هر توقفی است که به کاربران اجازه می دهد واحد یا حالت حمل و نقل را تغییر دهند. یک اتصال شامل ویژگی هایی است که هر دو توقف خروج و رسیدن را علاوه بر ویژگی های دیگر توصیف می کند. ما یک اتصال حمل و نقل را به عنوان یکی از دو نوع زیر تعریف می کنیم:
-
اتصال جدول زمانی که زمان حرکت و رسیدن مشخصی دارد. این نوع اتصال به عنوان اتصال برنامه ریزی شده نامیده می شود. دارای خواص زیر است: زمان خروج، زمان ورود، توقف توقف و ورود توقف.
-
سایر اتصالات که هیچ اطلاعات برنامه زمانی ندارند و در دسترس بودن آنها با محدودیت های زمانی محدود نشده است. ما از این اتصالات به عنوان اتصالات برنامه ریزی نشده یاد خواهیم کرد. آنها دارای ویژگی های زیر هستند: خروج – توقف، رسیدن – توقف و فاصله.
5.2.1. آماده سازی داده ها
در این مرحله، هدف نمایش اطلاعات جدول زمانی در قالبی سازگار با تعریف ما از اتصال است. به جای طراحی یک شبکه با یک سری توقف یا نمایش های دیگر، می خواهیم آن را با یک سری اتصالات بین ایستگاه ها نشان دهیم. از آنجایی که SNCF یک شرکت حمل و نقل عمومی با داده های شرح داده شده در جدول زمانی است، وظیفه اینجا استخراج اتصالات برنامه ریزی شده از داده های داده شده است. برای این منظور، الگوریتمی را پیشنهاد کردهایم که دادههای جدول زمانی را از فایلهای GTFS به اتصالات زمانبندی شده تبدیل میکند. الگوریتم بر روی اطلاعات جدول زمانی برای هر توقف تکرار میشود و اتصالی ایجاد میکند که از یک توقف حرکت در زمان حرکت شروع میشود و با توقف رسیدن با زمان مشخص شده به پایان میرسد. برای محدود کردن تعداد اتصالات ایجاد شده، این فرآیند تا یک محدوده تاریخ از پیش تعریف شده تکرار می شود.
در مورد Autolib، ما اطلاعات جدول زمانی نداریم، بنابراین به راهی برای کشف ارتباطات بین ایستگاه های آن نیاز داریم. با استفاده از رویکرد ما، میتوانیم مجموعه داده Autolib را با خودش تطبیق دهیم (برای اینکه بدانیم چه زمانی یک ایستگاه Autolib از یک ایستگاه دیگر قابل دسترسی است) تا این اتصالات برنامهریزی نشده بین آنها را کشف کنیم. از آنجایی که وظیفه پیکربندی مشترک و مستقل است، بخش زیر نحوه استفاده از رویکرد ما برای کشف اتصالات برنامه ریزی نشده برای Autolib-Autolib و Autolib-SNCF را توضیح می دهد.
5.2.2. کشف ارتباطات جدید
دو کار مورد نیاز است، یکی برای اتصالات Autolib-Autolib و دیگری برای اتصالات Autolib-SNCF. در این مثال، اتصالات برنامه ریزی نشده به ترتیب اتصالات رانندگی یا پیاده روی بین Autolib-VELIBand Autolib-SNCF هستند. ما از رویکرد خود برای جستجوی اتصالاتی استفاده می کنیم که با معیارهای از پیش تعریف شده مطابقت دارند. از آنجایی که رویکرد ما روی دادههای RDF کار میکند، از پلتفرم DataLift [ 34 ] برای تبدیل هر دو SNCF و فایلهای VELIB CSV به فرمتهای لاکپشت RDF استفاده کردهایم. در ادامه، تمام وظایف مورد نیاز برای رسیدن به هدف را با جزئیات شرح می دهیم.
-
تعریف توابع سفارشی: سیستم ما انعطاف پذیر است زیرا به کاربران اجازه می دهد تا هر تابع سفارشی را برای استفاده در کار پیوند ایجاد کنند. کاربران می توانند از وابستگی های خارجی نیز استفاده کنند. در مثال ما توابع getWalkingDistance، getWalkingTime، getDrivingDistance و getDrivingTime را تعریف می کنیم. در یک سناریوی واقعی، ما این اطلاعات را از یک سرویس وب، مانند API ماتریس فاصله Google ( https://developers.google.com/maps/documentation/distance-matrix/ ) دریافت می کنیم، اما به دلیل محدودیت درخواست، ما انتخاب کرده اند که آنها را با توابع محلی بر اساس محاسبات ریاضی پیاده سازی کنند ( http://www.movable-type.co.uk/scripts/latlong.html ).
-
قوانین پیوند را تعریف کنید: به یاد بیاورید که قانون پیوند شرایطی را توصیف می کند که باعث ایجاد یک اتصال می شود. دو قانون مورد نیاز است، یکی برای Autolib-Autolib و دیگری برای Autolib-SNCF. برای مورد اول، شرط قانون تعریف شده به شرح زیر است: “اگر یک مسیر رانندگی در فاصله 200 کیلومتری (زمان قبل از تخلیه کامل باتری) وجود دارد، یک اتصال ایجاد کنید. برای اتصالات Autolib-SNCF، قانون این است: “اگر یک مسیر پیاده روی از یک ایستگاه به ایستگاه دیگر در یک کیلومتری وجود دارد، یک اتصال ایجاد کنید”. قوانین با فرمت XML نوشته شده اند و توابعی که مسافت و زمان پیاده روی را محاسبه می کنند از فایل توابع سفارشی ارجاع داده می شوند. توجه داریم که پارامترهای “200 کیلومتر” و “1 کیلومتر” توسط کاربری که مسئول پیکربندی است داده می شود.شکل 9 نمونه ای از نحوه تعریف یک قانون را نشان می دهد.
-
تعریف الگوی اتصال: خروجی تولید شده توسط سیستم را در هر قانون معتبر تعریف می کنیم. ما ویژگی های زیر را برای نمایش در یک الگوی اتصال انتخاب کرده ایم: شناسه منبع، شناسه هدف، مسافت راه رفتن/رانندگی و زمان راه رفتن/رانندگی. این الگو برای هر دو کار یکسان است و یک مثال در شکل 10 نشان داده شده است .
اجرای این وظایف با پیکربندی فوق ما را قادر ساخت تا شبکه را با کشف 535966 اتصال داخلی بین ایستگاه های اتومبیل Autolib و 272 اتصال جدید بین دو حالت حمل و نقل مختلف SNCF و Autolib غنی کنیم. در ادامه نحوه استفاده از این اتصالات برای محاسبه زودترین زمان رسیدن (EAT) را توضیح خواهیم داد.
5.2.3. محاسبه مسیرها با استفاده از اتصالات کشف شده
EAT اولین زمانی است که با توجه به توقف حرکت و زمان میتوانیم به تمام ایستگاههای شبکه حملونقل برسیم. ما این رویکرد را انتخاب کردهایم تا دید وسیعی در مورد اینکه چگونه اتصالات تازه معرفی شده میتوانند به طور گسترده بر یک شبکه بزرگ تأثیر بگذارند، داشته باشیم. ما از الگوریتم اسکن اتصال (CSA) استفاده کردهایم [ 48] به عنوان یک پیاده سازی EAT، زیرا با مفهوم ما از اتصال مطابقت دارد. به طور خلاصه، CSA با دریافت جریانی از اتصالات سفارش داده شده بر اساس زمان حرکت کار می کند و سریع ترین راه را برای رسیدن به یک ایستگاه از ایستگاه دیگر انتخاب می کند. با توجه به این واقعیت که اتصالات از قبل مرتب شده اند و می توان یک به یک در یک تکرار به آنها دسترسی داشت، CSA سریعتر و مقیاس پذیرتر از سایر الگوریتم های موجود است. با این حال، در مورد ما محدودیت هایی دارد. اولا، فقط از شبکههای جدول زمانی پشتیبانی میکند، که باعث میشود نتواند سفرها، از جمله سایر خدمات را محاسبه کند. ثانیا، از اتصالات برنامه ریزی نشده پشتیبانی نمی کند. این فقط از یک انتقال مسیر بین دو نقطه انتقال پشتیبانی می کند. بنابراین ترکیب اتصالات برنامه ریزی شده، اتصالات برنامه ریزی نشده و مسیرهای پیاده روی برای ایجاد یک سفر بهینه تر امکان پذیر نیست.
CSA فقط شبکه های حمل و نقل عمومی با مسیرهای پیاده روی را اداره می کند. به منظور پشتیبانی از چندوجهی، ما اتصالات برنامه ریزی نشده را در کنار اتصالات مبتنی بر جدول زمانی معرفی کرده ایم. ما همچنین چندین اتصال برنامه ریزی نشده بین چندین نقطه انتقال را فعال کرده ایم. اتصالات برنامه ریزی نشده زمانی ایجاد می شوند که یک اتصال برقرار شود. برای هر بار تکرار، تمام اتصالات برنامه ریزی نشده موجود از یک ایستگاه رسیدن بررسی می شود تا با تنظیم زمان حرکت برابر با زمان رسیدن به ایستگاه، اتصالات برنامه ریزی شده ایجاد شود. به این حداقل مدت زمان انتقال و زمان رسیدن برای اتصال برنامه ریزی نشده اضافه می شود.
ما الگوریتم جدید خود را با اتصالات برنامه ریزی شده و برنامه ریزی نشده تغذیه کردیم و زمان تخمینی رسیدن را برای هر توقف آزمایش کردیم. برای بررسی تاثیرات معرفی اتصالات ایجاد شده، زمان های تخمینی رسیدن با و بدون آنها را محاسبه کرده و نتایج را با هم مقایسه کرده ایم. شکل 11 نشان دهنده زمان تخمینی رسیدن برای هر توقف است که از ایستگاه خروج SNCF DUA8711617 شروع می شود. شهود این است که هر چه مقدار کمتر باشد، مسافر می تواند زودتر به نقطه ایست برسد که از ایستگاه حرکت شروع می شود.
تجزیه و تحلیل شکل 11 نشان می دهد که استفاده از اتصالات ایجاد شده و ادغام آنها در شبکه حمل و نقل می تواند زمان تخمینی رسیدن را کاهش دهد. بنابراین، معرفی این اتصالات باعث کاهش زمان انتظار مسافران و در نتیجه سفرهای بهینه تر می شود. اکنون میتوانیم انواع جدیدی از تحرک را در نظر بگیریم که قبلاً در نظر گرفته نشدهاند (اشتراکگذاری دوچرخه، اشتراکگذاری خودرو و غیره). این را می توان با ترکیب اتصالات مناسب در حین برنامه ریزی سفرها برای تناسب با پروفایل مسافران استفاده کرد. مسافران میتوانند انواع اتصال، حالتها را تعریف کنند و بهترین نوع سفر را بیابند.
در مقایسه با چارچوبهای کشف پیوند موجود، رویکرد ما در کشف پیوندهایی با نمایشهای غنیتر و ویژگیهای قابل توسعهای که میتوانند برای کارهای متعدد استفاده شوند (EAT در مثال ما) موفق شد.
6. نتیجه گیری
تنوع سیستمها و خدمات حملونقل، نیاز به دیدگاه یکپارچهتر از شبکه حملونقل را افزایش میدهد. این به نوبه خود می تواند چندوجهی را ارائه دهد که تجربه مسافران را با سفرهای بهینه تر و قابل تنظیم تر به میزان زیادی بهبود می بخشد.
در این مقاله، ما رویکردی را برای شناسایی خودکار دادههای مکانی بین منابع داده حملونقل و همچنین راهی برای ارائه ارتباطات معنایی غنی بین موجودیتهای آنها پیشنهاد کردیم. این راه بهتری را برای سیستم های حمل و نقل برای دسترسی به اطلاعات مربوط به خدمات جدید و ادغام آنها با شبکه خود فراهم می کند.
ما رویکرد خود را با سناریوی ادغام یک شرکت اشتراک خودرو و یک شرکت ایستگاه قطار در فرانسه ارزیابی کردیم. نتیجه نشان میدهد که این رویکرد قادر به شناسایی موجودیتهای جغرافیایی و یافتن روابط بین طرحوارههای مجموعه است. علاوه بر این، با استفاده از پیوندهای تولید شده غنی بین مجموعه داده ها، ادغام حالت جدید حمل و نقل، زودترین زمان رسیدن را در هر توقف بهبود بخشید.
در آینده، ما می خواهیم این رویکرد را برای مدیریت پویایی اتصالات تطبیق دهیم. این ما را قادر میسازد تا وضعیت اتصالات موجود را حفظ کنیم و خدمات جدیدی مانند اشتراکگذاری پویا، اشتراکگذاری خودرو و غیره را انجام دهیم. مشکل اینجاست که چگونه تکامل اتصالات را در زمان واقعی ردیابی کنیم. چگونه می توانیم از رویدادهای خارجی که ممکن است استفاده از آنها و غیره را تحت تأثیر قرار دهند، استفاده کنیم؟ علاوه بر این، مقداری بهینه سازی سرعت باید برای هر دو رویکرد تطبیق خودکار و پیوند متقابل در نظر گرفته شود. ما نمونهگیری دادهها را برای کاهش تماسهای سرویس وب و یک فرمولدهنده پرس و جو هوشمندتر برای دریافت مؤثرتر نتایج مرتبط از وب سرویس، هدف قرار خواهیم داد. یکپارچه سازی راه حل های پرس و جوی مکانی نشان داده شده در [ 25] ممکن است به افزایش دقت فرمول پرس کمک کند. استفاده از یک وب سرویس برای پر کردن شکاف بین نمایش داده های مختلف می تواند برای سایر دامنه ها اعمال شود تا زمانی که خدمات وب برای این مجموعه داده ها ارائه شود.
منابع
- Gurstein, MB داده های باز: توانمندسازی استفاده از داده های قدرتمند یا موثر برای همه؟ اولین دوشنبه 2011 . [ Google Scholar ] [ CrossRef ]
- بیزر، سی. هیث، تی. Berners-Lee, T. داده های مرتبط – داستان تاکنون. بین المللی ج. سمنت. وب اطلاعات سیستم 2009 ، 5 ، 1-22. [ Google Scholar ] [ CrossRef ]
- پلو، جی. Scharffe, F. انتشار و پیوند داده های حمل و نقل در وب: نسخه توسعه یافته. در مجموعه مقالات اولین کارگاه بین المللی در مورد داده های باز، نانت، فرانسه، 25 مه 2012; صص 62-69.
- کنسولی، اس. مونگیووی، م. Recupero، DR; پرونی، س. گنگمی، ع. Nuzzolese، AG; Presutti، V. تولید داده های مرتبط برای شهرهای هوشمند: مورد کاتانیا. کلان داده Res. 2016 . [ Google Scholar ] [ CrossRef ]
- Euzenat, J. یک API برای تراز هستی شناسی. در وب معنایی–ISWC 2004 ; Springer: برلین/هایدلبرگ، آلمان، 2004; صص 698-712. [ Google Scholar ]
- یوزنات، ج. شوایکو، پی. تطبیق هستی شناسی ؛ Springer: برلین/هایدلبرگ، آلمان، 2007. [ Google Scholar ]
- شوایکو، پ. Euzenat, J. بررسی رویکردهای تطبیق مبتنی بر طرحواره. در Journal on Data Semantics IV ; Springer: برلین/هایدلبرگ، آلمان، 2005; صص 146-171. [ Google Scholar ]
- سگف، آ. کانتولا، جی. یونگ، سی. لی، جی. تحلیل نوآوری دانش چندزبانه در اختراعات. سیستم خبره Appl. 2013 ، 40 ، 7010-7023. [ Google Scholar ] [ CrossRef ]
- رحم، ای. برنشتاین، PA بررسی رویکردهای تطبیق خودکار طرحواره. VLDB J. 2001 ، 10 ، 334-350. [ Google Scholar ] [ CrossRef ]
- کلفوگلو، ی. Schorlemmer, M. نقشه برداری هستی شناسی: وضعیت هنر. بدانید. مهندس Rev. 2003 , 18 , 1-31. [ Google Scholar ] [ CrossRef ]
- واچه، اچ. ووگل، تی. ویسر، یو. استاکنشمیت، اچ. شوستر، جی. نویمان، اچ. Hübner, S. ادغام اطلاعات مبتنی بر هستی شناسی – بررسی رویکردهای موجود. در کارگاه آموزشی IJCAI-01: هستی شناسی ها و اشتراک گذاری اطلاعات . منبع: پرینستون، نیوجرسی، ایالات متحده آمریکا، 2001; صص 108-117. [ Google Scholar ]
- برنشتاین، PA; مدهاوان، ج. رهم، ای. تطبیق طرحواره عمومی، ده سال بعد. Proc. VLDB Enddow. 2011 ، 4 ، 695-701. [ Google Scholar ]
- شوایکو، پ. Euzenat, J. تطبیق هستی شناسی: وضعیت هنر و چالش های آینده. IEEE Trans. دانستن مهندسی داده 2013 ، 25 ، 158-176. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- داسکالکی، ای. فلوریس، جی. فاندولاکی، آی. Saveta، T. معیارهای تطبیق نمونه در عصر داده های پیوندی. وب سمنت علمی خدمت Agents World Wide Web 2016 ، 39 ، 1-14. [ Google Scholar ] [ CrossRef ]
- زیس، ک. کنراد، اس. Vater، S. معیاری برای آزمایش روش های تطبیق هستی شناسی مبتنی بر نمونه. در مجموعه مقالات هفدهمین کنفرانس بین المللی مهندسی دانش و مدیریت دانش، لیسبون، پرتغال، 11 تا 15 اکتبر 2010.
- دای، بی تی؛ کوداس، ن. سریواستاوا، دی. تونگ، AK; Venkatasubramanian، S. اعتبارسنجی تطابق طرحواره چند ستونی بر اساس نوع. در مجموعه مقالات بیست و چهارمین کنفرانس بین المللی مهندسی داده IEEE 2008، کانکون، مکزیک، 7 تا 12 آوریل 2008.
- وارن، RH; Tompa، FW تطبیق زیر رشته چند ستونی برای ترجمه طرحواره پایگاه داده. در مجموعه مقالات سی و دومین کنفرانس بین المللی پایگاه های داده بسیار بزرگ، سئول، کره، 12 تا 15 سپتامبر 2006.
- بوهانون، پی. النهراوی، ای. فن، دبلیو. Flaster، M. قرار دادن زمینه در تطبیق طرحواره. در مجموعه مقالات سی و دومین کنفرانس بین المللی پایگاه های داده بسیار بزرگ، سئول، کره، 12 تا 15 سپتامبر 2006.
- پارتیکا، جی. پروین، پ. خان، ال. تورایسینگهام، بی. Shekhar, S. تطبیق طرح واره معنایی تایپ شده جغرافیایی پیشرفته. وب سمنت علمی خدمت Agents World Wide Web 2011 ، 9 ، 52-70. [ Google Scholar ] [ CrossRef ]
- لی، WS; Clifton, C. SEMINT: ابزاری برای شناسایی تطابقات ویژگی ها در پایگاه های داده ناهمگن با استفاده از شبکه های عصبی. دانستن داده ها مهندس 2000 ، 33 ، 49-84. [ Google Scholar ] [ CrossRef ]
- امبلی، DW; خو، ال. Ding, Y. نقشه برداری طرحواره مستقیم و غیر مستقیم خودکار: تجربیات و درس های آموخته شده. ACM SIGMOD Rec. 2004 ، 33 ، 14-19. [ Google Scholar ] [ CrossRef ]
- Brauner، DF; اینتراتور، سی. Freitas, JC; Casanova، MA یک رویکرد مبتنی بر نمونه برای تطبیق طرحوارههای صادراتی سرویسهای وب پایگاه داده جغرافیایی. در مجموعه مقالات نهمین سمپوزیوم برزیل در زمینه ژئوانفورماتیک، سائوپائولو، برزیل، 25-28 نوامبر 2007.
- فلیاشیا، ا. آبادیب، ن. حمدیک، اف. تطبیق و تجسم دادههای مرتبط موضوعی: رویکردی مبتنی بر دادههای مرجع جغرافیایی . IOS Press: آمستردام، هلند، 2014. [ Google Scholar ]
- السلمان، ر. دیلا، اف. Fogliaroni، P. تطبیق اطلاعات جغرافیایی فضایی با روابط کیفی فضایی. در مجموعه مقالات اولین کارگاه بین المللی ACM SIGSPATIAL در مورد اطلاعات جغرافیایی جمع سپاری و داوطلبانه، ردوندو بیچ، کالیفرنیا، ایالات متحده آمریکا، 7 تا 9 نوامبر 2012.
- اسمید، م. Kremen, P. OnGIS: Semantic Query Broker for Methods Geospatial Data Sources. J. Semant را باز کنید. وب (OJSW) 2016 ، 3 ، 32–50. [ Google Scholar ]
- لوشر، پی. بورگارد، دی. Weibel, R. تطبیق داده های جاده مقیاس ها با تفاوت قدر. در مجموعه مقالات بیست و سوم کنفرانس بین المللی کارتوگرافی، مسکو، روسیه، 4 تا 10 اوت 2007.
- یی، اس. هوانگ، بی. وانگ، سی. تطبیق الگو برای منابع داده های جغرافیایی ناهمگن با استفاده از نمودار رابطه ای نسبت داده شده و آرامش احتمالی. فتوگرام مهندس Remote Sens. 2007 , 73 , 663-670. [ Google Scholar ] [ CrossRef ]
- لی، جی. وانگ، ز. ژانگ، ایکس. Tang, J. تطبیق نمونه در مقیاس بزرگ از طریق نمایه های متعدد و انتخاب نامزد. سیستم مبتنی بر دانش 2013 ، 50 ، 112-120. [ Google Scholar ] [ CrossRef ]
- جین، پی. هیتزلر، پی. Sheth، AP; ورما، ک. بله، تراز هستی شناسی PZ برای داده های باز پیوند داده شده. در وب معنایی–ISWC 2010 ; Springer: برلین/هایدلبرگ، آلمان، 2010; ص 402-417. [ Google Scholar ]
- فرارا، آ. نیکولوف، آ. نوسنر، جی. Scharffe, F. ارزیابی ابزارهای تطبیق نمونه: تجربه OAEI. وب سمنت علمی خدمت Agents World Wide Web 2013 ، 21 ، 49-60. [ Google Scholar ] [ CrossRef ]
- ایزل، آر. Bizer, C. یادگیری فعال قوانین پیوند بیانی با استفاده از برنامه ریزی ژنتیکی. وب سمنت علمی خدمت Agents World Wide Web 2013 ، 23 ، 2-15. [ Google Scholar ] [ CrossRef ]
- شارف، اف. Euzenat, J. MeLinDa: چارچوبی به هم پیوسته برای وب داده ها. آرتیف. هوشمند 2011 . [ Google Scholar ]
- Le Grange، JJ; لمان، جی. آتاناسیو، اس. گارسیا روخاس، آ. جیانوپولوس، جی. هلادکی، دی. ایزل، آر. Ngomo، ACN; شریف، م. استدلر، سی. و همکاران GeoKnow Generator: مدیریت داده های مکانی در وب داده های پیوندی. در مجموعه مقالات پیوند داده های جغرافیایی، لندن، انگلستان، 5 تا 6 مارس 2014.
- شارف، اف. اتمزینگ، جی. ترونسی، آر. گاندون، اف. ویلاتا، اس. بوچر، بی. حمدی، ف. بیهانیک، ال. کپکلیان، جی. پنبه، اف. و همکاران فعال کردن انتشار داده های مرتبط با پلت فرم Datalift. در مجموعه مقالات کارگاه AAAI در مورد شهرهای معنایی، تورنتو، ON، کانادا، 22 تا 23 ژوئیه 2012.
- حمدی، ف. عبادی، ن. بوچر، بی. Feliachi، A. Geomrdf: یک مبدل داده های جغرافیایی با نمایش ساختاری ریزدانه از هندسه در وب. بین المللی کارگاه ژئوسپات. داده های پیوندی arXiv 2015 . [ Google Scholar ]
- ولز، جی. بیزر، سی. گادکه، م. Kobilarov، G. Silk-A Link Discovery Framework for Web of Data. پیوند داده وب 2009 . [ Google Scholar ] [ CrossRef ]
- Ngomo، ACN; Auer, S. Limes-رویکردی با زمان کارآمد برای کشف لینک در مقیاس بزرگ در وب داده ها. در مجموعه مقالات بیست و دومین کنفرانس بین المللی مشترک هوش مصنوعی، بارسلون، اسپانیا، 16 تا 22 ژوئیه 2011.
- ریموند، ی. ساتن، سی. Sandler, MB پیوند خودکار مجموعه داده های موسیقی در وب معنایی. در مجموعه مقالات داده های پیوندی در وب (LDOW 2008)، پکن، چین، 22 آوریل 2008.
- حسن زاده، ا. لیم، ال. کمنتسیتسیدیس، ا. وانگ، ام. چارچوبی برای کشف پیوند معنایی بر روی داده های رابطه ای. در مجموعه مقالات هجدهمین کنفرانس بین المللی وب جهانی، مادرید، اسپانیا، 20-24 آوریل 2009.
- جعفری، ع. گلیزر، اچ. Millard, I. مدیریت مترادف URI برای فعال کردن مرجع ثابت در وب معنایی. در مجموعه مقالات IRSW2008 – هویت و مرجع در وب معنایی، تنریف، اسپانیا، 2 ژوئن 2008.
- شارف، اف. لیو، ی. ژو، سی. Rdf-ai: معماری برای تطبیق مجموعه داده های rdf، ترکیب و پیوند بین. در مجموعه مقالات کارگاه آموزشی IJCAI 2009 در مورد هویت، مرجع، و بازنمایی دانش (IR-KR)، پاسادنا، کالیفرنیا، ایالات متحده آمریکا، 11 ژوئیه 2009.
- آرنولد، پی. Rahm, E. غنی سازی نگاشت هستی شناسی با روابط معنایی. دانستن داده ها مهندس 2014 ، 93 ، 1-18. [ Google Scholar ] [ CrossRef ]
- آتاناسیو، اس. هلادکی، دی. جیانوپولوس، جی. گارسیا روخاس، آ. Lehmann, J. GeoKnow: تبدیل وب به مکانی اکتشافی برای دانش جغرافیایی. ERCIM News 2014 ، 96 ، 12-13. [ Google Scholar ]
- استدلر، سی. لمان، جی. هافنر، ک. Auer, S. Linkedgeodata: هسته ای برای شبکه ای از داده های فضایی باز. سمنت. وب 2012 ، 3 ، 333-354. [ Google Scholar ]
- باتت، م. هاریسپه، س. رانویز، س. سانچز، دی. Ranwez, V. یک رویکرد نظری اطلاعات برای بهبود ارزیابی شباهت معنایی در سراسر هستی شناسی های متعدد. Inf. علمی 2014 ، 283 ، 197-210. [ Google Scholar ] [ CrossRef ]
- چیتام، ام. Hitzler, P. معیارهای تشابه رشته برای تراز هستی شناسی. در مجموعه مقالات دوازدهمین کنفرانس بین المللی وب معنایی، سیدنی، استرالیا، 21 تا 25 اکتبر 2013.
- لسوت، ام جی. رفقی، م. Benhadda، H. اندازه گیری های مشابه برای داده های باینری و عددی: یک بررسی. بین المللی جی. دانش. مهندس Soft Data Paradig. 2008 ، 1 ، 63-84. [ Google Scholar ] [ CrossRef ]
- دیبلت، جی. پاجور، تی. استراسر، بی. Wagner, D. مسیریابی ساده و سریع ترانزیت جالب توجه. در الگوریتم های تجربی ; Springer: برلین/هایدلبرگ، آلمان، 2013; صص 43-54. [ Google Scholar ]

شکل 1. نمایش آدرس های مختلف.
شکل 2. عملیات تطبیق.
شکل 3. سیستمی برای تشخیص خودکار اطلاعات مکانی.
شکل 4. پرس و جو از خدمات وب برای به دست آوردن نمونه هایی با داده های غنی تر.
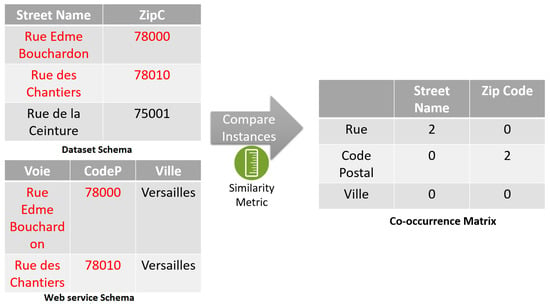
شکل 5. مثالی از محاسبه ماتریس همزمان.
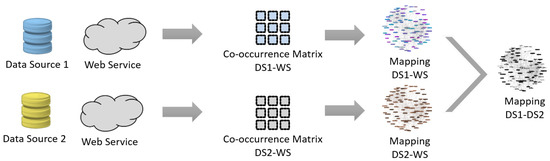
شکل 6. کشف قوانین تطبیق بین مجموعه داده ها با استفاده از یک وب سرویس به عنوان واسطه. DS، مجموعه داده. WS، وب سرویس.

شکل 7. Link++: رویکردی برای تولید اتصالات انعطاف پذیر و قابل تنظیم.

شکل 8. طرحواره های اصلی مجموعه داده های SNCF و Autolib.

شکل 9. مثالی از تعریف قانون در XML.

شکل 10. نمونه ای از الگوی اتصال در XML.
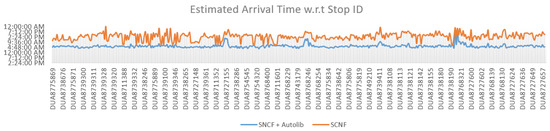
شکل 11. زمان تخمینی رسیدن برای هر توقف با و بدون اتصالات ایجاد شده ما.

جدول 1. ابزارهای پیوندی. CRS، سیستم تفکیک مرجع مشترک.
جدول 2. ماتریس همزمانی SNCF.
جدول 3. ماتریس همزمانی Autolib.
جدول 4. ارزیابی الگوریتم تطبیق.
© 2017 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر