

خلاصه
سادهسازی مسیر به یک کانون تحقیقاتی تبدیل شده است زیرا نقش مهمی در پیشپردازش دادهها، ذخیرهسازی و تجسم بسیاری از برنامههای کاربردی آنلاین و آفلاین، مانند نقشههای آنلاین، برنامههای سلامت تلفن همراه، و خدمات مبتنی بر مکان دارد. الگوریتمهای مبتنی بر اکتشافی سنتی از استراتژی حریصانه برای کاهش هزینه زمان استفاده میکنند که منجر به خطای تقریب بالا میشود. یک الگوریتم ساده سازی مسیر بهینه بر اساس مدل نمودار (OPTTS) برای به دست آوردن راه حل بهینه در این مقاله پیشنهاد شده است. هر دو مسایل min-# و min-ε با ساخت و بازسازی درخت پوشا با عرض اول و جستجوی کوتاهترین مسیر بر اساس نمودار غیر چرخه جهت دار (DAG) حل می شوند. اگرچه الگوریتم OPTTS پیشنهادی می تواند نتایج ساده سازی بهینه را به دست آورد، استفاده از آن در خدمات بلادرنگ به دلیل هزینه بالای آن دشوار است. بنابراین، یک الگوریتم ساده سازی مسیر آنلاین جدید بر اساس گراف غیر چرخه ای جهت دار (OLTS) برای مقابله با جریان مسیر پیشنهاد شده است. الگوریتم به صورت پویا درخت پوشا در عرض اول را می سازد و به دنبال آن خطای تقریب و خروجی بلادرنگ را به حداقل می رساند. نتایج تجربی نشان میدهد که OPTTS خطای تقریب کلی را 82 درصد در مقایسه با روشهای اکتشافی کلاسیک کاهش میدهد، در حالی که OLTS خطا را تا 77 درصد کاهش میدهد و 32 درصد سریعتر از الگوریتم آنلاین سنتی است. هر دو OPTTS و OLTS برتری پیشرو و عملکرد پایدار در مجموعه داده های مختلف دارند. الگوریتم به صورت پویا درخت پوشا در عرض اول را می سازد و به دنبال آن خطای تقریب و خروجی بلادرنگ را به حداقل می رساند. نتایج تجربی نشان میدهد که OPTTS خطای تقریب کلی را 82 درصد در مقایسه با روشهای اکتشافی کلاسیک کاهش میدهد، در حالی که OLTS خطا را تا 77 درصد کاهش میدهد و 32 درصد سریعتر از الگوریتم آنلاین سنتی است. هر دو OPTTS و OLTS برتری پیشرو و عملکرد پایدار در مجموعه داده های مختلف دارند. الگوریتم به صورت پویا درخت پوشا در عرض اول را می سازد و به دنبال آن خطای تقریب و خروجی بلادرنگ را به حداقل می رساند. نتایج تجربی نشان میدهد که OPTTS خطای تقریب کلی را 82 درصد در مقایسه با روشهای اکتشافی کلاسیک کاهش میدهد، در حالی که OLTS خطا را تا 77 درصد کاهش میدهد و 32 درصد سریعتر از الگوریتم آنلاین سنتی است. هر دو OPTTS و OLTS برتری پیشرو و عملکرد پایدار در مجموعه داده های مختلف دارند.
کلید واژه ها:
ساده سازی مسیر ; درخت پوشا در عرض اول ; جستجوی کوتاه ترین مسیر ; گراف غیر چرخه ای جهت دار
چکیده گرافیکی
1. معرفی
با رشد سریع فناوریهای مدرن برای پیمایش مکانهای جغرافیایی اشیا، دستگاههای تلفن همراه موقعیتیابی جغرافیایی حجم عظیمی از دادههای مسیر را جمعآوری کردهاند. دانش بهره برداری نشده پشت داده های مسیر توجه و علاقه بسیاری از محققان را به خود جلب کرده است. علاوه بر این، دامنههای مختلف همگی از دادههای مسیر در برنامههای کاربردی خود مانند برنامههای ناوبری، آژانسهای حفاظت از حیوانات و بخش کنترل ترافیک هوایی استفاده کردهاند [ 1] .]. با توسعه فناوری حسگر، تجهیزات مکان یابی می توانند اطلاعات نقطه ای را با دقت بیشتری به دست آورند، همچنین در فرکانس بالاتر، که منجر به دقت قوی تر در ردیابی مسیر می شود. با این حال، جمع آوری نقاط گاهی اوقات می تواند مشکلاتی را در ذخیره سازی، انتقال، تجسم و کشف الگو ایجاد کند. دادههای مسیر عظیم میتوانند حجم زیادی از فضای ذخیرهسازی را اشغال کنند، بنابراین هزینههای انتقال دادهها به شدت افزایش مییابد [ 2 ] و سیستم تجسم را به تأخیر یا حتی فروپاشی سوق میدهد. بنابراین، نگرانی فزاینده ای برای موضوع ساده سازی مسیر (TS) مطرح شده است.
یک مسیر از یک سری نقاط مسیر تشکیل شده است که به صورت بیان شده است تی= {پمن| i = 1 ، 2 ، 3 ، … ، N}�={��|�=1,2,3,…,�}، که در آن N تعداد نقاط مسیر است. وقتی ورودی یک جریان داده است، ن→ ∞�→∞. هر نقطه مسیر از اطلاعات مکانی و مهر زمانی تشکیل شده است که به صورت بیان شده است پمن= (ایکسمن،yمن،تیمن)��=(��,��,��). هدف الگوریتم TS انتخاب و حفظ نقاط M از N نقطه مسیر اصلی ( M <N ) است. با ساده سازی، مسیر را می توان به صورت بیان کرد تی“= {پک1،پک2, … ,پکم}�′={��1,��2,…,���}، جایی که 1 ≡ک1<ک2< … <کم≡ N1≡�1<�2<…<��≡�. نقطه شروع و پایان معمولاً در مسیر فشرده قرار دارند. شکل 1 تصویر مسیر اصلی و ساده شده را نشان می دهد.
ساده سازی بهینه حفظ کوچکترین تعداد امتیاز و دستیابی به حداقل خطای تقریب است. با این حال، افزایش خطای تقریب یا تعداد نقاط باقی مانده ممکن است منجر به کاهش عامل دیگر شود. با توجه به محدودیتهای خاص، TS را میتوان به دو روش بررسی کرد:
-
مسئله حداقل نقطه (min-#): با توجه به آستانه خطای تقریبی ε , مسیر T برای دستیابی به حداقل تعداد نقاط، M فشرده می شود .
-
مسئله خطای حداقل تقریب (min-ε): با توجه به حداکثر تعداد نقاط M ، مسیر T برای رسیدن به حداقل خطای تقریب فشرده می شود.
تعداد زیادی الگوریتم TS پیشنهاد شده است که بیشتر آنها مبتنی بر اکتشاف هستند. الگوریتم های اکتشافی از استراتژی حریصانه برای حذف نقاط مسیر با حداقل خطا استفاده می کنند که منجر به پیچیدگی زمانی کم می شود. با این حال، انتخاب نامناسب شرایط بهینهسازی محلی میتواند منجر به خطای تقریب بالایی شود. برخی از الگوریتمهای TS مبتنی بر بهینه برای کاهش خطای فشردهسازی پیشنهاد شدهاند، اما نمیتوانند راهحل بهینه را در شرایط فعلی بدست آورند. علاوه بر این، به دلیل تقاضای فوری خدمات بلادرنگ، الگوریتمهای TS آنلاین برای مقابله با جریان مسیر توسعه داده شدهاند. با این حال، روشهای آنلاین فعلی معمولاً از روشهای اکتشافی استفاده میکنند که نمیتوانند راهحل بهینه را به دست آورند.
در این مقاله، یک الگوریتم ساده سازی مسیر بهینه بر اساس مدل نمودار (OPTTS) برای دستیابی به جواب بهینه پیشنهاد شده است. ابتدا، مشکل min-# با ساختن یک درخت پوشا با عرض اول حل می شود. سپس بازسازی درخت پوشا و جستجوی کوتاه ترین مسیر بر اساس نمودار غیر چرخه ای جهت دار (DAG) برای حل مشکل min-ε انجام می شود. OPTTS در حالت دسته ای کار می کند و نتیجه بهینه را به دست می آورد. علاوه بر این، یک الگوریتم سادهسازی مسیر آنلاین جدید بر اساس گراف غیر چرخهای جهتیافته (OLTS) برای اعمال در خدمات آنلاین پیشنهاد شدهاست. OLTS چارچوب OPTTS را به ارث می برد و گسترش می دهد، که از ساخت دینامیکی درخت پوشا در عرض اول با معیار توقف استفاده می کند، به دنبال آن حداقل سازی بلادرنگ خطای تقریب، و دستیابی به خروجی بلادرنگ.
2. کارهای مرتبط
2.1. معیار ارزیابی
هدف الگوریتم TS حفظ کمترین تعداد نقاط و شبیه سازی مسیر ساده شده تا حد امکان به مسیر اصلی خود است. بنابراین، معیارهای خطای مناسب و معیارهای عملکرد معیارهای ارزیابی کلیدی برای الگوریتمهای TS هستند.
2.1.1. اندازه گیری خطا
خطای تقریب برای تعیین کمیت از دست دادن دقت مسیر ساده شده مورد نیاز است. معیارهای خطای متعددی در زمینه ساده سازی منحنی وجود دارد، مانند فاصله عمودی، ناحیه تحمل، نوار موازی، حداقل ارتفاع و حداقل عرض [ 3 ، 4 ، 5 ]. پرکاربردترین متریک در الگوریتم های TS، فاصله اقلیدسی سنکرون (SED) [ 2 ] است.
اگرچه SED به خوبی خطای تقریب را نشان می دهد، جمع آوری SED های متوالی از بخش خط دشوار است. پمنپj¯¯¯¯¯¯����¯به سرعت. در مقابل، فاصله اقلیدسی همگام مربع انتگرال محلی ( LISSED ) و فاصله اقلیدسی همگام مربع انتگرال (ISSED)، پیشنهاد شده در [ 6 ]، می تواند به طور موثر در داخل محاسبه شود. O ( 1 )�(1)زمان پس از محاسبه از پیش تمام شرایط انباشته. LISSED به معنای تجمع SED برای هر امتیاز استپک��بین پمن��و پj��:
L IاساسEد (تیjمن) =∑i < k < jاسED2(پک،پک“)������(���)=∑�<�<����2(��,��′)
ISSED مجموع تمام LISSED های مسیر ساده شده استتی“�′:
مناساسED =∑پکمن∈تی“L IاساسEد (تیکمن + 1کمن)�����=∑���∈�′������(�����+1)
در بخشهای بعدی، از LISSED و ISSED برای تقریب سادهسازی مسیر و برای ارزیابی انحراف بین مسیر فشرده و اصلی استفاده میشود.
2.1.2. معیارهای عملکرد
علاوه بر معیارهای خطا، به منظور دستیابی به ارزیابی جامع تر و موثرتر از عملکرد الگوریتم های TS، شاخص های زیر نیز تعریف شده است.
نسبت تراکم. برای الگوریتم های آفلاین TS، نسبت فشرده سازی است λ =نم�=��، که در آن N تعداد نقاط اصلی و M تعداد نقاط فشرده شده است. برای برنامه های آنلاین، تعداد کل امتیازها را نمی توان از قبل به دست آورد، نسبت فشرده سازی در این وضعیت به این معنی است که برای هر λ�نقاط ورودی، یک نقطه خروجی وجود خواهد داشت.
زمان فشرده سازی هزینه زمان با پیچیدگی زمانی الگوریتم تعیین می شود. در بیشتر کاربردها، زمان فشرده سازی باید تا حد امکان کم باشد.
تاخیر و شکاف. خدمات آنلاین انتظار دارند که الگوریتم های TS به طور مداوم خروجی بدهند. بنابراین، تاخیر و شکاف در این مقاله برای ارزیابی به موقع بودن یک الگوریتم TS آنلاین مطرح شده است. فرض کن که {آمن| 1 ≤ i ≤ M}{��|1≤�≤�}به معنی شاخص های نقاط ورودی است پآمن( 1≤ _آمن≤ N)���(1≤��≤�)، که خروجی دارند پبمن���، و {بمن| 1 ≤ i ≤ M}{��|1≤�≤�}نشان دهنده شاخص های نقاط خروجی است. دe l ayمن=آمن–آمن – 1������=��−��−1به عنوان فاصله بین دو نقطه ورودی که دارای خروجی هستند و gآپمن=آمن–بمن����=��−��فاصله یک نقطه ورودی و خروجی آن را نشان می دهد. هر چه تاخیر و شکاف کمتر باشد، به موقع بودن الگوریتم بیشتر می شود.
2.2. الگوریتم های موجود
الگوریتم های TS موجود دارای دو دسته اصلی هستند، یعنی ساده سازی منحنی و مسیر. هر یک از آنها را می توان با توجه به ایده های مختلف الگوریتم به اکتشافی و بهینه تقسیم کرد. با توجه به سناریوهای برنامه، می توان آن را به فشرده سازی آفلاین و آنلاین نیز تقسیم کرد. طبقه بندی دقیق الگوریتم های TS در جدول 1 ارائه شده است .
2.2.1. الگوریتم های ساده سازی منحنی
الگوریتمهای سادهسازی منحنی را میتوان برای مرجع استفاده کرد اگر ویژگیهای توپولوژیکی و اطلاعات فضایی دادههای مسیر تنها عواملی باشند که باید در نظر گرفته شوند. اکثر الگوریتمهای سادهسازی منحنی مبتنی بر استراتژی اکتشافی هستند که میتوان آنها را به دو دسته تقسیم و ادغام تقسیم کرد. الگوریتم کلاسیک داگلاس-پوکر [ 7 ] ابتدا نقطه با حداکثر خطای انحراف کل منحنی را پیدا کرده و آن را به مجموعه ساده شده منتقل می کند. سپس منحنی به دو قسمت تقسیم می شود، برای هر قسمت عملیات تکرار می شود تا جایی که هیچ نقطه ای خطایی از آستانه داده شده بیشتر نشود. میانگین پیچیدگی زمانی الگوریتم است O ( Nl o gن)�(�����)، در حالی که ای (ن2)�(�2)در بدترین حالت به دست می آید. پیکاز و همکاران [ 8 ] یک الگوریتم ادغام با O ( Nl o gن)�(�����)پیچیدگی زمانی، که از استراتژی حریصانه برای ترکیب جفت بخش ها با حداقل انحراف استفاده می کند. این روشهای اکتشافی پیچیدگی زمانی کمی دارند، اما ممکن است زمانی که شرایط بهینهسازی محلی به درستی انتخاب نشده باشند، منجر به خطای تقریب بالایی شوند.
الگوریتم های ساده سازی منحنی بهینه عمدتاً با ساخت یک نمودار [ 5 ] پیاده سازی می شوند و از محدودیت هزینه محاسباتی رنج می برند. ای (ن2)�(�2). آگاروال [ 9 ] یک الگوریتم تقسیم و غلبه را با استفاده از یک نقشه تکراری پیشنهاد کرد و به بهترین پیچیدگی زمانی رسید. ای (ن43+ δ)�(�43+�)، جایی که δ یک ثابت دلخواه کوچک است. بعدها، چارچوب الگوریتم گراف توسط Daescu و همکاران سازماندهی و بهبود یافت. [ 10 ]. دو صف اولویت پویا برای کاهش تعداد تست های لبه استفاده می شود. الگوریتم های بهینه می توانند به نتایج فشرده سازی مطلوبی دست یابند اما هزینه زمانی بالایی دارند.
کولسنیکوف یک روش ترکیبی را برای کاهش پیچیدگی زمانی پیشنهاد کرد که برنامهنویسی پویا جستجوی کاهش یافته نام داشت [ 11 ]. این الگوریتم منحنی مرجع را با محدود کردن راهرو تولید می کند و به دنبال آن جستجوی مسیر حداقل هزینه برای به دست آوردن منحنی فشرده انجام می شود. با این حال، الگوریتمهای سادهسازی منحنی شاخصهای مهم مسیر، مانند ویژگیهای توپولوژیکی و جغرافیایی، سرعت، جهتگیری و اطلاعات زمان را نادیده میگیرند.
2.2.2. الگوریتم های ساده سازی مسیر
الگوریتم های آفلاین و مبتنی بر اکتشافی TS به طور گسترده استفاده می شود. الگوریتم آستانه پیشنهاد شده توسط پوتامیاس و همکاران. [ 12 ] سعی می کند منطقه ای را پیش بینی کند که یک نقطه مسیر ممکن است با توجه به موقعیت تاریخی، سرعت و جهت ظاهر شود. مراتنیا و همکاران [ 2 ] الگوریتم داگلاس-پوکر را با جایگزینی تابع فاصله با همگام سازی فاصله اقلیدسی (SED) به ساده سازی مسیر گسترش داد. الگوریتمهای TS آفلاین مبتنی بر اکتشافی قادر به دستیابی به حداقل خطای تقریب جهانی نیستند.
رویکردهای مبتنی بر بهینه قادر به بدست آوردن خطای تقریب کم هستند، اما ممکن است منجر به هزینه محاسباتی بالا شوند. چن و همکاران یک الگوریتم ترکیبی به نام MRPA [ 6 ] پیشنهاد کرد. این الگوریتم از یک صف اولویت و شرط توقف برای کاهش محاسبه ساخت گراف استفاده می کند و سپس نمودار را برای به دست آوردن حداقل خطای تقریب تنظیم می کند. MRPA پیچیدگی زمانی کمی دارد، اما نمی تواند بهینه جهانی را به دست آورد. با این حال، الگوریتمهای آفلاین TS باید قبل از سادهسازی، کل مسیر را جمعآوری کنند، که در خدمات بلادرنگ غیرعملی هستند.
بیشتر الگوریتم های آنلاین مبتنی بر اکتشافی هستند. ساده ترین الگوریتم TS آنلاین، نمونه برداری یکنواخت [ 13 ] است که در آن جریان مسیر با یک بازه از پیش تعریف شده یا تصادفی نمونه برداری می شود. الگوریتم مبتنی بر پنجره باز (OPW) پیشنهاد شده توسط Keogh [ 14 ] نقاط را به طور مداوم در یک پنجره اضافه می کند تا زمانی که خطای تقریب از آستانه از پیش تعریف شده فراتر رود. آخرین نقطه با خطای قانونی خروجی و به عنوان نقطه شروع پنجره جدید انتخاب می شود. با این حال، نتیجه OPW به اندازه پنجره و آستانه خطا حساس است. الگوریتم ST-Trace پیشنهاد شده توسط Potamias و همکاران. [ 12 ] با استفاده از یک استراتژی از پایین به بالا پیاده سازی می شود که خطای SED در هر مرحله به حداقل می رسد. SQUISH-E، پیشنهاد شده توسط Muckell و همکاران. [ 15]، از پنجره ای استفاده می کند که توسط نرخ فشرده سازی تعیین می شود و یک صف اولویت را حفظ می کند، که افزایش خطای SED ناشی از کاهش نقاط را حفظ می کند. هنگامی که یک نقطه جدید اضافه شده از اندازه پنجره بیشتر شود، نقطه در صف اولویت با حداقل مقدار کاهش می یابد. الگوریتمهای TS آنلاین مبتنی بر اکتشاف ممکن است از خطای تقریب بالایی رنج ببرند.
به طور خلاصه، الگوریتمهای TS آفلاین موجود که بر روی یک روش مبتنی بر اکتشافی متمرکز شدهاند، ویژگیهای پیادهسازی آسان و کارایی بالا را دارند، اما شرایط بهینه محلی ممکن است منجر به خطای بزرگ در مسیر کلی شود. بنابراین یک الگوریتم ساده سازی مسیر بهینه بر اساس مدل نمودار (OPTTS) در این مقاله پیشنهاد شده است که می تواند طرح فشرده سازی بهینه را با حداقل خطای تقریب جهانی به دست آورد. OPTTS در حالت آفلاین کار می کند، که برای خدمات بلادرنگ مناسب نیست. اکثر الگوریتمهای TS آنلاین نیز مبتنی بر اکتشاف هستند و از همان مشکل الگوریتمهای آفلاین رنج میبرند. بنابراین، این مقاله یک الگوریتم ساده سازی مسیر آنلاین جدید بر اساس گراف غیر چرخشی جهت دار (OLTS) پیشنهاد می کند. الگوریتم مبتنی بر OPTTS است و با خدمات آنلاین سازگار است،
3. الگوریتم ساده سازی مسیر بهینه بر اساس مدل نمودار
3.1. راه حل بهینه
هدف اصلی الگوریتم TS یافتن مسیر ساده شده با حداقل تعداد نقاط فشرده شده است، در شرایطی که خطای SED کمتر از آستانه داده شده باشد. در عین حال، خطای تقریب جهانی را به حداقل می رساند:
{تی“= ارگدقیقهتی“ م و ارگدقیقهتی“ مناساسEDاسEد (پک،پک“) ≤εth{�′=argmin�′ � and argmin�′ ��������(��,��′)≤��ℎ
سپس عبارت ISSED را با معادله (6) جایگزین کنید:
تی“= ارگدقیقهتی“ مناساسED= ارگدقیقهتی“∑پکمن∈تی“L IاساسEد (تیکمن + 1کمن)= ارگدقیقهتی“∑پکمن∈تی“∑کمن< k <کمن + 1اسED2(پک،پک“)�′=argmin�′ �����=argmin�′∑���∈�′������(�����+1)=argmin�′∑���∈�′∑��<�<��+1���2(��,��′)
حل معادله (7) با انتخاب تعیین می شود پکمن���، جایی که کمن��نشانگر نقطه ساده شده است. برای یافتن تمامی گزینه های ممکن می توان از روش شمارش استفاده کرد پکمن���. اگر مسیر فشرده شده حاوی m نقاط باشد، m -2 نقطه در بین N -2 نقطه (به استثنای نقاط سر و انتهای) حفظ می شود.سیm – 2ن– 2��−2�−2طرح های فشرده سازی با برشمردن تمام مقادیر ممکن m ، تعداد کل تمام طرح های فشرده سازی می شود ∑2 ≤ m ≤ Nسیm – 2ن– 2=2ن– 2∑2≤�≤���−2�−2=2�−2. رابطه بین تعداد نقاط ساده شده m و خطای ISSED در شکل 2 الف نشان داده شده است.
در میان آن ها 2ن– 22�−2طرحواره های فشرده سازی، راه حل بهینه را می توان با فرآیند زیر به دست آورد. اول، تعداد نقاط فشرده شده زیر آستانه خطا را به حداقل می رساند، که مشکل min-# است. داده شده اسEد (پک،پک‘ ) ≤εth���(��,��′)≤��ℎ، مناساسED ≤ M⋅( ε t h )2�����≤�·(��ℎ)2می تواند مشتق شود. به طور شهودی، کران بالای ISSED به عنوان خط قرمز افقی در شکل 2 ب ترسیم شده است. طرح های فشرده سازی زیادی در زیر آن خط وجود دارد، در حالی که min-# برای یافتن حداقل M است . سپس، راهحل بهینه، راهحلی است که حداقل خطای ISSED را در بین طرحوارههایی با نقاط فشرده M داشته باشد ، که مسئله min-ε است. در شکل 2 ب، راه حل بهینه با دایره قرمز مشخص شده است.
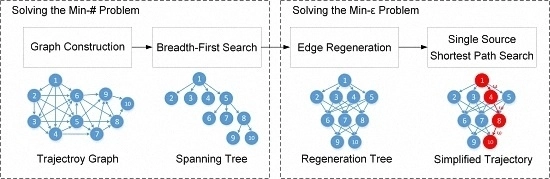
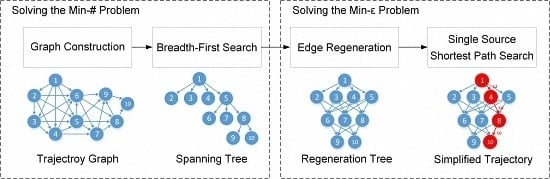
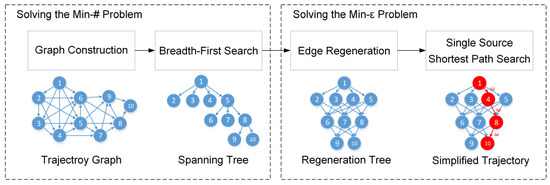
برای حل مشکل min-#، OPTTS ابتدا مسیر را به مدل نمودار زیر آستانه داده شده تبدیل میکند، سپس از یک جستجوی گسترده برای به دست آوردن درخت پوشا حاوی مسیر با حداقل تعداد نقاط استفاده میکند (بخش 3.2 ) . برای حل مشکل min-ε، بازسازی لبه بر روی درخت پوشا برای به دست آوردن درخت بازسازی انجام می شود. در نهایت، از جستجوی کوتاهترین مسیر تک منبعی برای یافتن مسیری با حداقل خطای تقریب استفاده می شود ( بخش 3.3 ). نمودار جریان OPTTS در شکل 3 نشان داده شده است .
3.2. حل مسئله Min-# بر اساس درخت پوشای عرض اول
3.2.1. ساخت نمودار
نقاط در مسیر بر اساس مهر زمانی مرتب می شوند، بنابراین نمودار مسیر جهت دهی می شود، به این معنی که فقط از نقطه شاخص کوچک به نقطه شاخص بزرگ ارتباط وجود دارد. در همین حال، خطاهای تقریبی از پمن�منو هر نقطه پشت آن پj( i < j ≤ N)��(�<�≤�)باید محاسبه شود. فقط یال هایی که کمتر از آستانه خطای تقریبی داده شده، εth هستند ، می توانند به نمودار اضافه شوند. این فرآیند همانطور که در شکل 4 نشان داده شده است، تست لبه نامیده می شود . تابع وزن را برای هر یال به صورت تعریف کنید ω : E→ آر�:�→�، که نشان دهنده خطای تقریب بین است پمن��و پj��، برای مثال ω (پمن،پj) =LIاساسEد (پمن،پj)�(��,��)=������(��,��). در نهایت، نمودار مسیر می تواند به صورت نمایش داده شود G ( T, ε t h ) = { V، ای}G(�,��ℎ)={�,�}، جایی که V= {پمن∈ تی| 1 ≤ i ≤ N}�={��∈�|1≤�≤�}و E= { (پمن،پj) | i<jand ω (پمن،پj) <εth}�={(پمن،پ�)|من<� آ�د �(پمن،پ�)<�تیساعت}.
3.2.2. جستجوی عرض-اول
مشکل min-# کشف مسیری است که دارای کمترین تعداد رئوس از نمودار است. کوتاهترین فاصله مسیر را به عنوان تعریف کنید L (پ1،پn)�(پ1،پ�)برای نشان دادن حداقل تعداد نقاط در مسیر از پ1پ1به پnپ�. اگر مسیری بین آن وجود نداشته باشد پ1پ1و پnپ�، سپس L (پ1،پn) = ∞�(پ1،پ�)=∞.
L (پ1،پn) = {m i n { l ( p a t h (پمن) ):پ1–→––p a t h (پمن)پمن}∞من f t h e r e is a p a t h f _ r o m پ1 t o پمنo t h e r w i s e�(پ1،پ�)={مترمن�{ل(پآتیساعت(پمن)):پ1→پآتیساعت(پمن)پمن}من� تیساعته�ه منس آ پآتیساعت ���متر پ1 تی� پمن∞�تیساعته��منسه
الگوریتم جستجوی پهنای اول [ 16 ] می تواند حداقل تعداد یال ها را محاسبه کند پ1پ1به هر گره قابل دسترسی در طول اولین جستجوی عرض، برای هر گره قابل دسترسی پمنپمناز پ1پ1، گره قبلی آن پمن. πپمن.�نگهداری می شود و پمن. لپمن.لحداقل فاصله را از پ1پ1به پمنپمن. همانطور که در شکل 5 نشان داده شده است، پس از جستجوی عرض اول، یک درخت پوشا به عرض اول تولید می شود . کوتاه ترین مسیر از پ1پ1به پمنپمندر نمودار مربوط به مسیر ساده از پ1پ1به پمنپمندر درخت پوشا و طول مسیر برابر با ارتفاع درخت است. جزئیات جستجوی پهنا-اول و صحت BFS برای حل کوتاه ترین مسیر طول را می توان در [ 16 ] یافت.
3.3. حل مسئله Min-ε بر اساس جستجوی کوتاهترین مسیر منبع تک
3.3.1. بازسازی لبه
درخت پهنا اول محاسبه شده توسط BFS ممکن است بسته به ترتیب در لیست های مجاورت متفاوت باشد. همانطور که در شکل 6 الف نشان داده شده است، اگر پ5پ5مقدم است پ6پ6که در A dj [پ1]آد�[پ1]، درخت عرض اول در شکل 5 ب را می توان تولید کرد. با این حال، اگر پ6پ6مقدم است پ5پ5که در A dj [پ1]آد�[پ1]، و پ8پ8مقدم است پ7پ7که در A dj [پ6]آد�[پ6]درخت در شکل 6 ب را می توان به دست آورد. با این حال، ارتفاع هر گره در درخت پوشا ثابت است.
قضیه 1:
ارزش پمن. لپمن.لبه یک راس اختصاص داده شده است پمنپمنمستقل از ترتیب ظاهر شدن رئوس در هر لیست مجاورت است.
اثبات قضیه 1:
اثبات صحت برای الگوریتم BFS در [ 16 ] نشان می دهد که پمن. l = L (پ1،پمن)پمن.ل=�(پ1،پمن)، و الگوریتم فرض نمی کند که لیست های مجاورت به ترتیب خاصی هستند.
طبق قضیه 1، گره ها در هر لایه از درخت بدون تغییر باقی می مانند. منحصر به فرد نبودن درخت پوشا با عرض اول مربوط به اتصالات مختلف بین نقاط در دو لایه مجاور است. هر اتصال نشان دهنده یک طرح فشرده سازی است. هدف مسئله min-ε یافتن طرح فشرده سازی با حداقل خطای تقریب جهانی است. بنابراین، تمام اتصالات ممکن درخت پوشا در عرض اول باید ایجاد شود که به آن بازسازی لبه می گویند.
مجموعه گره ها را در لایه k درخت پوشا با عرض اول به صورت تعریف کنید Vک= {پمن|پمن. l = k }�ک={پمن|پمن.ل=ک}. گره ها در لایه k + 1 می توانند به صورت نمایش داده شوند Vk + 1= {پj|پj. l = k + 1 }�ک+1={پ�|پ�.ل=ک+1}. بازسازی لبه نقاط را به هم متصل می کند Vک�کو Vk + 1�ک+1اگر خطای تقریبی برآورده شود ω (پمن،پj) <εth�(پمن،پ�)<�تیساعت. در نهایت، درخت بازسازی را می توان به دست آورد که به عنوان ثبت می شود جیتیr e e= ( V،Eتیr e e)جیتی�هه=(�،�تی�هه)همانطور که در شکل 7 نشان داده شده است . مشکل min-ε پیدا کردن مسیر از پ1پ1به پنپندر درخت بازسازی که کمترین خطای تقریب را دارد.
3.3.2. کوتاهترین مسیر تک منبعی در DAG
کل خطای تقریب مسیر را تعریف کنید {پ1،پ2, … ,پک}{پ1،پ2،…،پک}مانند ω ( p a t h ) =∑کi = 1ω (پمن – 1،پمن)�(پآتیساعت)=∑من=1ک�(پمن–1،پمن). حداقل خطای تقریب مسیر از پ1پ1به پمنپمندر درخت بازسازی به صورت زیر تعریف می شود:
δ(پ1،پمن) = {m i n { ω ( p a t h ) :پ1–→p a t hپمن}∞من f t h e r e is a p a t h f _ r o m پ1 t o پمنo t h e r w i s e�(پ1،پمن)={مترمن�{�(پآتیساعت):پ1→پآتیساعتپمن}من� تیساعته�ه منس آ پآتیساعت ���متر پ1 تی� پمن∞�تیساعته��منسه
الگوریتم Dijkstra [ 17 ] مسئله کوتاهترین مسیر تک منبعی را بر روی یک نمودار وزن دار و جهت دار حل می کند. الگوریتم یک صف اولویت را برای ثبت حداقل وزن از گره منبع به گره فعلی حفظ می کند. موکل و همکاران [ 15 ] و چن و همکاران. [ 6 ] از ایده صف اولویت در روش های خود برای به حداقل رساندن خطای تقریب استفاده می کنند. با این حال، پیچیدگی زمانی الگوریتم Dijkstra است ای (ن2+ E)�(ن2+�). در این مقاله، الگوریتم جستجوی کوتاهترین مسیر مبتنی بر گراف غیر چرخهای جهتدار پیشنهاد شده توسط لاولر [ 16 ] برای کاهش پیچیدگی زمانی مورد استفاده قرار میگیرد.
تعريف كردن پمن. دپمن.دبه عنوان کوتاه ترین مسیر برآورد از پ1پ1به پمنپمن. حیاتی ترین مرحله در جستجوی کوتاه ترین مسیر، آرامش است . پمن. دپمن.دبا وزن لبه بین اضافه می شود پمنپمنو پjپ�، و در مقایسه با پj. دپ�.د. اگر اولی کوچکتر است، پس پj. πپ�.�و پj. دپ�.دبه روز می شوند. کد شبه Relaxation در تابع 1 فهرست شده است.
| تابع 1 آرEL A X(پمن،پj، ω )آر��آایکس(پمن،پ�،�) |
| 1. مناف پj. د>پمن. د+ ω (پمن،پj)مناف پ�.د>پمن.د+�(پمن،پ�) |
| 2. پj. د=پمن. د+ ω (پمن،پj)پ�.د=پمن.د+�(پمن،پ�) |
| 3. پj. π=پمنپ�.�=پمن |
اثبات اینکه نمودار مسیر یک گراف غیر چرخه جهت دار (DAG) است آسان است. در همین حال، هر لبه در درخت بازسازی با اتصال از نقطه شاخص کوچک به نقطه شاخص بزرگ تشکیل می شود، بنابراین درخت بازسازی از نظر توپولوژیکی مرتب می شود. بنابراین، برای حل حداقل وزن مسیر، شل کردن تمام لبهها از هر گره مطابق با ترتیب مرتبسازی توپولوژیکی است. در نهایت، مسیری با حداقل خطای تقریب کل از درخت بازسازی به دست می آید که راه حل فشرده سازی بهینه است. شبه کد فرآیند در تابع 2 نشان داده شده است.
| تابع 2 D A G _ Sاچای آرتیEاستی_ پA Tاچاس( G , ω )�آجی_اساچ�آرتی�استی_پآتیاچاس(جی،�) |
| 1. افای آر پمن منن جیاف�آر پمن منن جی |
| 2. افای آر پj منن جی . A dj [پمن]اف�آر پ� منن جی.آد�[پمن] |
| 3. R EL A X(پمن،پj، ω )آر��آایکس(پمن،پ�،�) |
3.4. تحلیل پیچیدگی
OPTTS راه حل بهینه را از طریق چهار مرحله حل می کند، یعنی ساخت نمودار، جستجوی وسعت اول، بازسازی درخت پوشا و جستجوی کوتاه ترین مسیر مبتنی بر DAG. بیشترین زمان مصرف در ساخت نمودار، تست لبه است. ن( ن− 1 ) /2ن(ن–1)/2خطاهای تقریب برای هر جفت رئوس محاسبه می شود و بنابراین پیچیدگی زمانی است ای (ن2)�(ن2). همانطور که در [ 16 ] نشان داده شد، پیچیدگی زمانی BFS است O ( N+ E)�(ن+�). در مرحله بازسازی، هر نقطه در Vک�کبررسی می شود تا ببینیم آیا ارتباطی با نقاط داخل دارد یا خیر Vk + 1�ک+1. بنابراین، پیچیدگی زمانی است O ( N)�(ن). طبق [ 16 ]، جستجوی کوتاهترین مسیر مبتنی بر DAG دارای پیچیدگی زمانی است O ( N+ E)�(ن+�). از آنجایی که تمام مراحل به طور مستقل انجام می شوند، پیچیدگی کلی زمان OPTTS است ای (ن2+ 3 N+ 2 E)�(ن2+3ن+2�). در نمودار مسیر، هر نقطه به چندین نقطه پشت خود متصل است، بنابراین عدد یال E خطی به N است . بنابراین، پیچیدگی زمانی مشابه است ای (ن2)�(ن2).
4. الگوریتم ساده سازی مسیر آنلاین بر اساس گراف غیر چرخه ای جهت دار
4.1. مشکلات پذیرش OPTTS برای خدمات آنلاین
OPTTS در حالت آفلاین طراحی شده است و به دلایل زیر برای خدمات آنلاین نامناسب است. اول، ساخت نمودار مسیر و جستجوی عرض اول برای عبور از تمام نقاط مسیر مورد نیاز است، در حالی که خدمات آنلاین نمی توانند کل مسیر را از قبل بدست آورند. ثانیا، جستجوی کوتاه ترین مسیر تنها پس از بازسازی درخت پوشا انجام می شود. چنین فرآیندی همچنین به کل مسیر نیاز دارد، بنابراین برای خدمات آنلاین مناسب نیست. در نهایت، خدمات آنلاین باید به طور پیوسته نقاط فشرده شده را به عنوان ورودی جریان مسیر خروجی دهند، در حالی که OPTTS پس از وارد شدن کل مسیر تنها یک خروجی دارد.
به منظور مقابله با جریان مسیر در خدمات آنلاین، بهبودهایی برای رفع مشکل بالا انجام شده است. یک الگوریتم ساده سازی مسیر آنلاین جدید بر اساس گراف غیر چرخه ای جهت دار (OLTS) در این بخش پیشنهاد شده است. روش کلی OLTS در شکل 8 نشان داده شده است . اول از همه، ساخت دینامیکی درخت پوشا با عرض اول و معیار توقف برای مقابله با جریان مسیر مطرح می شود ( بخش 4.2 ). با ادغام جستجوی پهنای اول در ساخت گراف، به محض اینکه به الگوریتم متصل شد، یک نقطه به درخت پوشا اختصاص داده می شود. سپس، هنگامی که ساخت هر لایه در درخت پوشا به پایان رسید، خطای تقریب کمینهسازی بلادرنگ برای حل مسئله min-ε انجام میشود.بخش 4.3 ). در نهایت، خروجی بلادرنگ برای پاسخگویی به تقاضای خدمات آنلاین مورد استفاده قرار می گیرد ( بخش 4.4 ).
4.2. ساخت دینامیک درخت پوشاننده عرض اول
4.2.1. ساخت لایه پویا
ساخت نمودار مسیر و جستجوی عرض اول ترکیب شده اند. درخت پوشا مستقیماً به عنوان ورودی جریان مسیر ساخته می شود. تعريف كردن Vک�کهمانطور که گره ها در سطح k درخت پوشا تنظیم می شوند، یعنی Vک= {پمن|پمن. L = k }�ک={پمن|پمن.�=ک}. فرض کنید که Vک�کساخته شده است در حال حاضر، ساخت و ساز از Vk + 1�ک+1به شرح زیر تعیین می شود: هنگامی که یک نقطه جدید پjپ�ورودی سیستم است، آزمایش لبه باید برای آن انجام شود پjپ�و هر نقطه در Vک�ک. اگر ω (پمن،پj) <εth�(پمن،پ�)<�تیساعت، سپس پjپ�به اضافه می شود Vk + 1�ک+1، و پj. L =پمن. L + 1پ�.�=پمن.�+1، پj. π=پمنپ�.�=پمن، پj. د=پمن. د+ ω (پمن،پj)پ�.د=پمن.د+�(پمن،پ�). همانطور که در شکل 9 نشان داده شده است ، فرض کنید پآ،پب∈Vکپآ،پب∈�کو a < بآ<بچه زمانی پjپ�در حال آمدن است، اگر ω (پآ،پj) <εth�(پآ،پ�)<�تیساعت، تنظیم پjپ�به عنوان فرزند پآپآو به طور مداوم یک نقطه دیگر را وارد کنید. یک بار پjپ�به درخت، تست های لبه اضافه می شود پjپ�با سایر نکات در Vک�کو Vk + 1�ک+1را می توان اجتناب کرد، که به طور قابل توجهی هزینه زمان را کاهش می دهد.
یک آرایه Visited[] را برای بازیابی اینکه آیا یک نقطه یال آزمایش شده است یا خیر، تعریف کنید. اگر پjپ�لبه با تمام گره ها در تست شده است Vک�کاما هنوز به درخت پوشا اضافه نشده است، سپس Visited[] = true . اگر ω (پمن،پj) >εth�(پمن،پ�)>�تیساعت، پیوستن پjپ�به صف موقت ستیستیمنتظر تست لبه در لایه بعدی باشید و Visited[] = true را علامت بزنید .
4.2.2. معیار توقف برای ساخت لایه درخت پوشا
ساخت لایه در درخت پوشا باید در زمان مناسب خاتمه یابد. مطالعات متعددی در مورد استراتژی های توقف انجام شده است. D. Chen و همکاران. [ 18 ] یک معیار منطقه تحمل توسط دو مخروط متقاطع پیشنهاد کرد. Kolesnikov [ 19 ] ادعا کرد که آزمون لبه باید زمانی خاتمه یابد که خطای تقریب بزرگتر از آستانه داده شده باشد. این مقاله معیار توقف را به روشی مشابه تعریف می کند. برای یک نقطه تازه وارد شده پjپ�، اگر خطای تقریب بین پjپ�و تمام نکات در Vک�کراضی می کند ω (پمن،پj) >2⋅εth�(پمن،پ�)>2·�تیساعت، ساخت k + 1 انجام شده است.
یک عدد صحیح را تعریف کنید که به عنوان شمارنده خاتمه یافته است . اگر نکته ای در آن وجود دارد Vک�ککه خطای تقریب با پjپ�ملاقات می کند ω (پمن،پj) >2⋅εth�(پمن،پ�)>2·�تیساعت، شمارنده یک افزایش می یابد. اگر numTerminated برابر است با تعداد امتیازهای موجود Vک�ک، ساخت لایه k + 1 خاتمه می یابد. این فرآیند در شکل 10 نشان داده شده است .
استفاده از معیار توقف می تواند به طور قابل توجهی هزینه زمانی در ساخت درخت پوشا را کاهش دهد، اما بهینه بودن تضمین نمی شود. با این حال، تنها با استفاده از معیار توقف می توان آن را با خدمات آنلاین تطبیق داد. بنابراین، ارزش آن را دارد که بهینه سازی خاصی را برای افزایش بیشتر در کارایی قربانی کنیم. شبه کد فرآیند در الگوریتم 1 نشان داده شده است.
| الگوریتم 1. ساخت درخت پوشا با عرض پویا (تکرار k ) |
| ورودی: ورودی فعلی پjپ�، مجموعه امتیاز VکVک، صف موقت ستیستیو آستانه خطا ε th�هفتم. |
| 1. EنQ UEUE (ستی،پj) ؛�نس���� (ستی،پ�); |
| 2. دبلیواچمنL E ستی≠ ∅دبلیواچمن�� ستی≠∅ |
| 3. پj= D EQ UEUE(ستی) ؛ n u m T e r m i n a t e d= 0 ;پ�=��س����(ستی); �تومترتیه�مترمن�آتیهد=0; |
| 4. مناف v i s i t e d[ j ] = = FA L SEمناف �منسمنتیهد[�]==افآ�اس� |
| 5. v i s i t e d[ j ] = t r u e ;�منسمنتیهد[�]=تی�توه; |
| 6. افای آر پمن من n Vکاف�آر پمن من� �ک |
| 7. مناف ω (پمن،پj) <εthمناف �(پمن،پ�)<�تیساعت |
| 8. پj. L e n gt h =پمن. L e n gt h + 1 ;پ�.�ه��تیساعت=پمن.�ه��تیساعت+1; |
| 9. پj. π=پمن;پ�.�=پمن; |
| 10. پj. د=پمن. د+ ω ( پمن،پj) ؛پ�.د=پمن.د+ �(پمن،پ�); |
| 11. v i s i t e d[ j ] = t r u e ;�منسمنتیهد[�]=تی�توه; |
| 12. Vk + 1. A PپEند (پj)�ک+1.آپپ�ن�(پ�); |
| 13. B R EA K افای آربآر�آک اف�آر |
| 14. Eال اسE مناف ω (پمن،پj) >2⋅εth��اس� مناف �(پمن،پ�)>2·�تیساعت |
| 15. n u m Te r m i n a t e d+ + _�تومترتیه�مترمن�آتیهد++; |
| 16. مناف پj مناس نO T منناسEآر تیEDمناف پ� مناس ن�تی منناس�آرتی�� |
| 17. EنQ UEUE(ستی،پj)�نس����(ستی،پ�) |
| 18. مناف n u m Te r m i n a t e d= =Vک. c o u n tمناف �تومترتیه�مترمن�آتیهد==�ک.ج�تو�تی |
| 19. ممننمنممنزE مناساسED a c c o r d من n g t o S e c t i o n 4.3 ; ممننمنممنز� مناساس�� آجج��دمن�� تی� اسهجتیمن�� 4.3; |
| 20. Vک=Vk + 1;�ک=�ک+1; |
| 21. v i s i t e d[ j i n ستی] = fa l s e ;�منسمنتیهد[� من� ستی]=�آلسه; |
| 22. O UتیپUتی a c c o r dمن n g t o S e c t i o n 4.4 ; ��تیپ�تی آجج��دمن�� تی� اسهجتیمن�� 4.4; |
| 23. مننپUتی نEایکستی پای مننتیمننپ�تی ن�ایکستی پ�مننتی |
4.3. زمان واقعی به حداقل رساندن خطای تقریب
هنگامی که ساخت لایه k + 1 به پایان رسید، لبه ها بین لایه k و لایه k + 1 دوباره به هم وصل می شوند تا حداقل خطای تقریب حاصل شود. این فرآیند در واقع ترکیبی از بازسازی لبه و جستجوی کوتاهترین مسیر مبتنی بر داگ است که در بخش 3 توضیح داده شده است . هر گره پمنپمنکه در Vک�کبا نودها تست لبه خواهد شد پjپ�که در Vk + 1�ک+1. اگر ω (پمن،پj) <εth�(پمن،پ�)<�تیساعت، اجرای عملیات آرام سازی: اگر پj. د>پمن. د+ ω (پمن،پj)پ�.د>پمن.د+�(پمن،پ�)، سپس پj. د=پمن. د+ ω (پمن،پj)پ�.د=پمن.د+�(پمن،پ�)، و پj. π=پمنپ�.�=پمن. شبه کد خطای تقریب کمینه سازی بلادرنگ در الگوریتم 2 نشان داده شده است.
| الگوریتم 2. خطای تقریب به حداقل رساندن زمان واقعی (تکرار k ) |
| ورودی: مجموعه امتیازها VکVکو Vk + 1Vک+1، آستانه خطا ε th�هفتم. |
| 1. افای آر پj منن Vk + 1اف�آر پ� منن �ک+1 |
| 2. m i n D i s t a n c e =پj. د; m i n P a r e n t =پj. π;مترمن��منستیآ�جه=پ�.د; مترمن�پآ�ه�تی=پ�.�; |
| 3. افای آر پمن منن Vکاف�آر پمن منن �ک |
| 4. مناف ω (پمن،پj) <εthAN D پمن. د+ ω (پمن،پj) <minDistanceمناف �(پمن،پ�)<�تیساعت آن� پمن.د+�(پمن،پ�)<مترمن��منستیآ�جه |
| 5. m i n D i s t a n c e =پمن. د+ ω (پمن،پj) ؛مترمن��منستیآ�جه=پمن.د+�(پمن،پ�); |
| 6. m i n Pa r e n t =پمن;مترمن�پآ�ه�تی=پمن; |
| 7. پj. د= m i n D i s t a n c e ; پj. π= m i n Pa r e n t ;پ�.د=مترمن��منستیآ�جه; پ�.�=مترمن�پآ�ه�تی; |
4.4. خروجی زمان واقعی
پس از فرآیند به حداقل رساندن خطای تقریب، خروجی بلادرنگ انجام می شود تا تصمیم گیری شود که کدام نقطه خروجی باشد. کوتاه ترین مسیر وزن از پ1پ1به پjپ�ممکن است تغییر کند زیرا پjپ�ممکن است فرزند هر گره در لایه بالایی آن باشد. همانطور که در شکل 11 نشان داده شده است ، چهار لایه اول ساخته شده است. از آنجا که پ12پ12ممکن است فرزند هر چهار گره در آن باشد V4�4، ممکنه که پ8~پ12پ8~پ12تبدیل شدن به نقطه ای در مسیر اگر پ12پ12متصل است پ8پ8یا پ9پ9، پ6پ6در مسیر ظاهر خواهد شد. اگر پ12پ12متصل است پ10پ10یا پ11پ11، پس آن است پ7پ7که در مسیر خواهد بود. با این حال، هیچ گره فرزندی وجود ندارد پ5پ5که در V4�4، بنابراین امکان پذیر نیست پ5پ5بخشی از مسیر بودن نقطه ای که ممکن است در مسیر وجود داشته باشد، گره فعال نامیده می شود که با یک دایره جامد در شکل 11 نشان داده شده است. نشان داده شده است . نقطه ای که نمی تواند در مسیر باشد به عنوان یک گره غیرفعال تعریف می شود که به صورت یک دایره توخالی نشان داده می شود. وقتی هیچ فرزندی در لایه بعدی وجود نداشته باشد، گره فعال غیرفعال می شود.
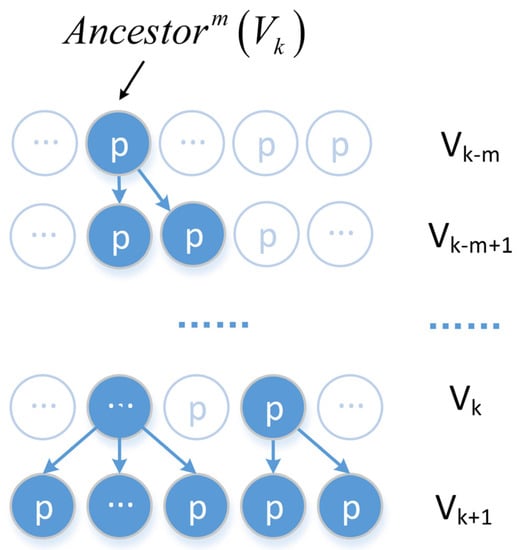
اگر پمنپمندر مسیر گره ریشه قرار دارد پ1پ1به پjپ�، سپس پمنپمنجد از استپjپ�. والدین همه گره ها در Vک�کبه عنوان اجداد نسل اول تعریف می شوند، یعنی A n c e s t or1(Vک) = { p . π| ∀ p ∈Vک}آ�جهستی��1(�ک)={پ.�|∀پ∈�ک}. نسل m از اجداد هستند A n c e s t orمتر(Vک) = A n c e s t or1( A n c e s t orm – 1(Vک) )آ�جهستی��متر(�ک)=آ�جهستی��1(آ�جهستی��متر–1(�ک))، که تمام گرههای لایه k تا m را نشان میدهد که هنوز دارای فرزندان در لایه k هستند که به عنوان یک گره فعال تعریف میشود. همانطور که در شکل 12 نشان داده شده است، سایر گره های این لایه گره های غیر فعال نامیده می شوند .
d را به عنوان لایه ای که نقطه خروجی قبلی است تعریف کنید. هنگامی که لایه k + 1 ساخته می شود و خطای تقریبی به حداقل می رسد، وضعیت فعال هر نقطه از لایه d به لایه k به روز می شود. اگر نقطه از اجداد آخرین نقطه باشد، به عنوان یک گره فعال تنظیم می شود، در غیر این صورت یک گره غیرفعال است. اگر لایه m تنها یک گره فعال دارد، این گره را خروجی بگیرید. شبه کد فرآیند در الگوریتم 3 نشان داده شده است.
| الگوریتم 3. خروجی بلادرنگ (تکرار k ) |
| ورودی: شاخص لایه d، مجموعه نقاط VدVدبه Vk + 1Vک+1. |
| 1. افO R m = k : − 1 : d اف�آر متر=ک:–1:د |
| 2. افای آر پj من n Vm + 1 a n d پj من a c t i v e _ اف�آر پ� من� �متر+1 آ�د پ� منس آجتیمن�ه |
| 3. اسe t P a r e n t (پj) asactive; اسهتی پآ�ه�تی(پ�) آس آجتیمن�ه; |
| 4. m = d;متر=د; |
| 5. دبلیواچمنL E m ≤ k A N D Vمتر h a s 1 a c t i v e v e r t e x پm ∗دبلیواچمن�� متر≤ک آن� �متر ساعتآس 1 آجتیمن�ه �ه�تیهایکس پمتر∗ |
| 6. O u t p u t پm ∗ t o T ‘ ;�توتیپتوتی پمتر∗ تی� تی‘; |
| 7. m = m + 1 ;متر=متر+1; |
| 8. د= m _د=متر; |
4.5. تحلیل پیچیدگی
هر نقطه وارد شده به OLTS از طریق یک پردازش سه مرحلهای، یعنی ساخت دینامیک درخت پهنا، خطای تقریب کمینهسازی بلادرنگ، و خروجی بلادرنگ انجام میشود. در طول ساخت درخت پوشا، آزمایش های لبه بین نقطه فعلی و هر نقطه در لایه بالایی انجام می شود. در هر لایه به طور متوسط نقاط N/M وجود دارد ، بنابراین پیچیدگی زمانی آن است O ( N/ م)�(ن/م). پس از ساخت یک لایه، به لایه های مجاور اشاره کنید Vک�کو Vk + 1�ک+1برای به حداقل رساندن خطای تقریب آرام می شوند. ای (ن2/م2)�(ن2/م2)زمان استراحت مورد نیاز است. در نهایت، در مرحله خروجی، گره ها از لایه های k تا d به روز می شوند. خواهد بود ( k – d) N/ م(ک–د)ن/مگره ها در همه بنابراین پیچیدگی زمانی خطی است O ( N/ م)�(ن/م). در برخورد با جریان مسیر با N نقطه، فرض کنید M نقطه خروجی وجود دارد ، کل پیچیدگی زمانی برابر است با
O ( N/ م⋅ ن+ (ن2/م2+ ن/ م) ×م)= O ( 2ن2/ م+ ن)= O ( ( 2 γ+ 1 ) ×N)�(ن/م⋅ن+(ن2/م2+ن/م)×م)=�(2ن2/م+ن)=�((2�+1)×ن)
در معادله (10) γ�نشان دهنده نسبت تراکم است. بنابراین، پیچیدگی OLTS به تعداد نقاط خطی است.
5. آزمایشات
این بخش ابتدا سه مجموعه داده رایج و سه الگوریتم را برای مقایسه توصیف میکند، سپس سه جنبه، یعنی معیارهای خطا، هزینه زمانی و تجزیه و تحلیل تاخیر/فاصله را ارزیابی میکند. در نهایت، نتایج مورد بحث قرار گرفته و عملکرد الگوریتم های پیشنهادی خلاصه می شود.
5.1. آماده سازی تجربی
5.1.1. مجموعه داده ها
الگوریتم ها ممکن است در مجموعه داده های مختلف رفتار متفاوتی داشته باشند. برای اعتبارسنجی حساسیت الگوریتمها، سه مجموعه داده، یعنی Mopsi [ 20 ]، Geolife [ 21 ] و Movebank [ 22]] در این آزمایش استفاده می شود. مجموعه داده Mopsi شامل 344 مسیر فعالیت های ورزشی انسانی است که در سال 2011 در فنلاند ایجاد شده است. Geolife حرکات 182 کاربر در پکن چین را در مدت پنج سال در فضای باز ثبت می کند و شامل 14638 مسیر و 18 میلیون نقطه است. Movebank یک پایگاه داده عمومی و آنلاین است که توسط بیش از 11000 کاربر نگهداری می شود و حاوی داده های حرکت حیوانات است که در مناطق محلی حرکت می کند و در سراسر کشورها مهاجرت می کند. استحکام الگوریتمهای TS ممکن است تحت تأثیر ویژگیهای مختلف مجموعه دادهها، مانند نرخ نمونهبرداری، دامنه حرکت، سرعت حرکت، و غیره قرار گیرد. بنابراین، سه مسیر معرف با ویژگیهای متمایز از هر مجموعه داده انتخاب میشوند. ارائه های گرافیکی سه مسیر مثال در شکل 13 نشان داده شده است .
جدول 2 ویژگی های سه مسیر معرف را خلاصه می کند. هر مسیر به ترتیب شامل 3747، 3273 و 12380 نقطه است که در مقایسه با میانگین نقاط مسیر در دنیای واقعی بسیار بزرگ است. به عنوان مثال، هر مسیر در مجموعه داده Geolife به طور متوسط شامل 1234 نقطه است. مسیر از مجموعه داده Movebank دارای بیشترین فاصله بین دو نقطه و بزرگترین نرخ نمونه برداری است. مسیر از مجموعه داده Geolife دارای بالاترین میانگین سرعت و بیشترین تغییرات در سرعت است. در مقابل، مسیر از مجموعه داده Mopsi ویژگیهای متوسطتری نسبت به سایرین دارد.
5.1.2. انتخاب الگوریتم های مقایسه شده
ما از سه الگوریتم برای مقایسه استفاده کردیم، یعنی الگوریتم داگلاس-پیکر (DP)، الگوریتم مبتنی بر پنجره باز (OPW)، و الگوریتم تقریب چند ضلعی با وضوح چندگانه (MRPA). ویژگی های سه الگوریتم مقایسه شده و دو روش پیشنهادی در جدول 3 خلاصه شده است . OPTTS در حالت آفلاین کار می کند، بنابراین دو الگوریتم آفلاین دیگر برای مقایسه انتخاب می شوند. DP به دلیل اجرای آسان و راندمان بالا به طور گسترده در جوامع صنعتی مورد استفاده قرار می گیرد. MRPA یک الگوریتم پیشرفته است که ادعا می کند به خطای تقریب بهتری دست می یابد. تفاوت ها در این است که OPTTS یک الگوریتم مبتنی بر بهینه است، در حالی که DP مبتنی بر اکتشافی است و MRPA از استراتژی ترکیبی استفاده می کند. OLTS در حالت آنلاین کار می کند، بنابراین الگوریتم آنلاین کلاسیک OPW انتخاب شده است.
5.2. ارزیابی بر اساس معیارهای خطا
معیارهای خطا، اثربخشی فشرده سازی را اندازه گیری می کند. به طور کلی، یک خطای تقریبی کوچکتر نشان دهنده نتیجه فشرده سازی بهتر است. این بخش پنج الگوریتم را در چندین معیار از جمله میانگین SED ، حداکثر SED ، SED میانه و میانگین ISSED مقایسه میکند . فرمول اختصاری و محاسبه چهار نوع معیار خطا در جدول 4 فهرست شده است .
تنظیمات آزمایش یک مسیر 3747 نقطه در موپسی انتخاب شده است. معیارهای خطا تحت نرخ های فشرده سازی مختلف اندازه گیری می شوند. ده نرخ فشرده سازی با تعیین آستانه های فاصله متفاوت انتخاب می شود.
میانگین SED _ به طور کلی، میانگین کوچکتر خطای SED نشان دهنده نتایج فشرده سازی بهتر است. همانطور که در شکل 14 الف نشان داده شده است، میانگین خطای SED با افزایش نرخ تراکم افزایش می یابد. OPTTS کمترین خطا را در هر نرخ فشرده سازی دارد و به دنبال آن OLTS قرار دارد. میانگین خطای SED OLTS 40.8٪ کاهش می یابد، در حالی که خطای SED OPTTS 45.6٪ کاهش می یابد.
حداکثر SED _ برای ارزیابی پایداری الگوریتم های TS از خطای Max SED استفاده می شود. هرچه روند صعودی منحنی ملایم تر باشد، الگوریتم پایدارتر است. شکل 14 ب نشان می دهد که OPTTS و OLTS در نرخ های فشرده سازی مختلف عملکرد پایداری دارند. حداکثر مقدار 3 تا 4 برابر مقدار متوسط است. با این حال، OPW، DP و MRPA با افزایش نرخ تراکم، نوسانات زیادی دارند. حداکثر مقادیر دارای یک افزایش ناگهانی به 6 تا 8 برابر مقادیر متوسط هستند.
SED میانه _ مقدار زیاد غیرعادی SED ممکن است مقدار متوسط را افزایش دهد، بنابراین اندازه گیری عملکرد تنها با میانگین خطای SED کافی نیست . میانه خطای SED به عنوان شرط کمکی میانگین SED انتخاب می شود . همانطور که در شکل 14 ج نشان داده شده است، وضعیت مقادیر میانه مشابه مقادیر میانگین است. OPTTS همچنان کوچکترین خطا را دارد و به دنبال آن OLTS قرار دارد.
میانگین ISSED _ میانگین ISSED خطای تقریب کلی مسیر فشرده را اندازه گیری می کند که هدف بهینه سازی نیز هست. شکل 14 d نشان می دهد که OPTTS کمترین میانگین خطای LISSED را دارد و به دنبال آن OLTS قرار دارد. OPTTS خطای LISSED را در مقایسه با الگوریتم های سنتی 82.2 درصد کاهش می دهد، در حالی که OLTS خطا را 77.1 درصد کاهش می دهد.
میانگین SED در مجموعه داده های مختلف. میانگین خطای SED برای ارزیابی استحکام الگوریتم ها در مجموعه داده های مختلف استفاده می شود. سه خط سیر نماینده به ترتیب از مجموعه داده های Geolife، Mopsi و Movebank انتخاب شده اند. میانگین خطای SED با نسبت فشرده سازی ثابت محاسبه می شود γ= 10�=10. برای مقایسه بهتر، نرمال سازی حداکثر حداقل برای یکسان سازی مجموعه داده های مختلف در یک سیستم مرجع استفاده می شود. شکل 14 e نشان می دهد که OPTTS و OLTS روی همه مجموعه داده ها نسبتاً پایدار عمل می کنند، در حالی که OPW، DP و MRPA نوسان زیادی را نشان می دهند.
تجسم نتیجه فشرده سازی خطای تقریب نشان دهنده انحراف بین مسیر فشرده و اصلی است. به طور شهودی از نمایش گرافیکی مسیرها می توان فهمید که تفاوت چقدر زیاد است. شکل 15 تجسم مسیرهای فشرده شده و اصلی را توسط الگوریتم های مختلف نشان می دهد. همان خط سیر در ارزیابی معیارهای خطا انتخاب شده و نسبت فشرده سازی روی 100 تنظیم شده است. در شکل 15 a-d، خط آبی همیشه نشان دهنده مسیر اصلی و خط قرمز نشان دهنده نتیجه OPTTS است. خطوط سبز به ترتیب نتایج OLTS، MRPA، OPW و DP را نشان می دهند. از آن قابل مشاهده استاز شکل 15d که مسیر فشرده DP دارای بیشترین انحراف است و نتیجه OPTTS دقیق ترین نمایش مسیر اصلی است.
تنظیمات آزمایش هزینه زمان از دو جنبه اندازه گیری می شود، یعنی تعداد نقاط و نرخ تراکم. ابتدا یک مسیر از Geolife انتخاب شده و فشرده سازی هر 5000 نقطه از 5000 تا 40000 با نرخ ثابت انجام می شود. γ= 10�=10. هنگام بررسی رابطه با نرخ تراکم، یک مسیر از Mopsi انتخاب شده و ساده سازی در 10 نرخ فشرده سازی مختلف با تعداد نقاط ثابت انجام می شود. همه الگوریتمها در C++ پیادهسازی شدند و بر روی پلتفرم ویندوز (64 بیتی) با پردازنده i7 2.50 گیگاهرتز و 8 گیگابایت رم اجرا شدند.
تاثیر تعداد امتیازات همانطور که در شکل 16 الف نشان داده شده است، هزینه های زمانی همه الگوریتم ها روند افزایشی را با رشد نقاط نشان می دهد. OLTS 32.2٪ سریعتر از الگوریتم آنلاین سنتی OPW است، حتی 40.3٪ سریعتر از الگوریتم آفلاین MRPA. در حالی که OPTTS در مقایسه با سایر الگوریتم ها کندتر است.
تاثیر نرخ تراکم. همانطور که در شکل 16 نشان داده شده است، هزینه های زمانی DP، OPW و OPTTS با نسبت تراکم تغییر نمی کند، در حالی که MRPA و OLTS روند صعودی را نشان می دهند. وقتی نسبت تراکم کمتر از 20 باشد، OLTS جلوتر از DP، OPW و OPTTS اجرا می شود. وقتی نسبت تراکم بالاتر از 20 باشد OLTS سریعتر از MRPA است.
5.3. ارزیابی بر اساس تحلیل تاخیر/شکاف
تجسم تاخیر و شکاف. تاخیر و شکاف از ویژگی های مهم OLTS هستند. سه مسیر از Mopsi، Geolife، و Movebank با 3273 امتیاز با نرخ فشرده سازی ثابت ساده شده است. γ= 10�=10. رابطه بین شاخص ورودی و شاخص خروجی در شکل 17 الف نشان داده شده است. مجموعه داده Movebank (خط قرمز) بیشترین تاخیر و شکاف را دارد. هنگامی که نقطه 2181 وارد می شود، OLTS نقطه 2078 را خروجی می کند. از نقطه 2182 تا 2457 هیچ خروجی الگوریتم وجود ندارد. تا ورودی نقطه 2458، نقطه 2160 خروجی است. بنابراین، تاخیر = 2458 – 2181 و شکاف = 2458 – 2160.
تاخیر متوسط رابطه بین تاخیر و نرخ تراکم در شکل 17 ب نشان داده شده است. میانگین تأخیر تقریباً برابر با نرخ فشرده سازی در همه مجموعه داده ها است. بنابراین، OLTS می تواند تاخیر پایدار در مجموعه داده های مختلف را تضمین کند.
فاصله متوسط ارتباط بین نرخ تراکم و میانگین شکاف در شکل 17 ج نشان داده شده است. به طور کلی، شکاف OLTS با افزایش نرخ تراکم بزرگتر می شود. میانگین شکاف مجموعه داده Movebank بزرگترین است و پس از آن Geolife و Mopsi قرار دارند.
5.4. بحث
تحلیل اثربخشی اول، OPTTS کمترین نتیجه را در بین تمام معیارهای خطا به دست آورده است. OPTTS از درخت بازآفرینی-بازسازی از عرض اول و جستجوی کوتاه ترین مسیر برای حل مسائل min-# و min-ε استفاده می کند و در نتیجه به راه حل بهینه دست می یابد. خطای تقریب OLTS کمی بیشتر از OPTTS است. از آنجایی که OLTS چارچوب اصلی OPTTS را گسترش می دهد و از یک معیار توقف برای سرعت بخشیدن به ساخت درخت پوشا استفاده می کند که منجر به نتیجه تقریباً بهینه می شود. با این حال، DP، OPW و MRPA از استراتژی حریصانه برای بهبود کارایی استفاده میکنند، اما خطای فشردهسازی بزرگ است. همانطور که در نشان داده شده است شکل 15 نشان داده شده استd، خط سبز نشان دهنده نتیجه DP دارای انحراف زیادی از مسیر اصلی است. عملکرد DP ممکن است برای برخی از کاربردها که در آن مسیر باید تا حد امکان دقیق فشرده شود، غیرقابل قبول باشد. به عنوان مثال، در برخی از برنامه های ناوبری، اگر مسیرهای کاربر فشرده شده توسط DP دارای یک خطای تقریبی بزرگ باشد، ممکن است منجر به انحراف از نقشه راه شود که گمراه کننده است. ثانیا، OPTTS و OLTS دارای حداکثر خطای SED پایدار هستند زیرا از روشهای بهینه جهانی استفاده میکنند. با این حال، DP، OPW و MRPA دارای حداکثر غیرعادی بزرگ هستند SED غیرطبیعی زیادی دارنددر برخی از قسمت های مسیر، به دلیل انتخاب نامناسب شرایط بهینه سازی محلی. در نهایت، OPTTS و OLTS می توانند به عملکرد پایدار در تمام مجموعه داده ها دست یابند. تأثیر ویژگی های مختلف سه مجموعه داده با انتخاب یک روش بهینه کاهش می یابد.
تحلیل پیچیدگی زمانی پیچیدگی زمانی حاصل از اشتقاق نظری در جدول 5 خلاصه شده است . در ارزیابی کارایی، DP در بین پنج الگوریتم سریعترین است و پس از آن OLTS و MRPA هستند. DP مبتنی بر اکتشافی است و از پیچیدگی بالایی رنج نمیبرد، در حالی که OPTTS از روش بهینهسازی در طول ساخت یک درخت بازسازی گسترده استفاده میکند که زمانبر است. با این حال، هزینه زمانی OPTTS هنوز برای اکثر برنامه های آفلاین قابل قبول است، جایی که هزینه زمان به اندازه عملکرد فشرده سازی مهم در نظر گرفته نمی شود. همانطور که در نشان داده شده است شکل 15 نشان داده شده استالف، هزینه زمانی OPTTS تا یک مسیر 1200 نقطه ای حدود 100 میلی ثانیه است. می توان محاسبه کرد که کل هزینه زمانی برای فشرده سازی تمام 14638 مسیر در Geolife حدود 24 دقیقه است که قابل تحمل است. بنابراین، بهبود اثر فشرده سازی OPTTS از دست دادن راندمان محاسباتی را تحت تأثیر قرار می دهد. علاوه بر این، پیچیدگی زمانی OLTS و MRPA با N/M همبستگی مثبت دارد ، بنابراین هزینه زمان با افزایش نرخ تراکم افزایش مییابد. در حالی که OPTTS، OPW و DP فقط به تعداد نقاط مربوط می شوند.
تحلیل تاخیر و شکاف OLTS پیشنهادی دارای تاخیر و شکاف نامشخصی است که با ساخت تدریجی درخت پوشا با عرض اول و خروجی بلادرنگ معرفی شده است. شکاف با فاصله بین همبستگی دارد Vد�دو Vک�ک، و تاخیر نشان دهنده تعداد گره ها در هر لایه درخت پوشا است، یعنی γ= ن/ م�=ن/م. اولاً، تأخیر و شکاف محلی ممکن است تحت تأثیر وضعیت حرکت جسم باشد. همانطور که در شکل 17 الف نشان داده شده است، تاخیر و شکاف مقادیر غیرعادی زیادی در برخی از قسمت های مسیر دارند. این به این دلیل است که ماهیماهی ممکن است وضعیت پرواز مستقیم را برای مدت طولانی حفظ کند. ثانیا، متوسط تاخیر تقریبا برابر با نرخ فشرده سازی است. زیرا تاخیر در OLTS نشان دهنده تعداد گره ها در هر لایه درخت پوشا است که برابر با نرخ فشرده سازی است. در نهایت، همانطور که در شکل 17 ج نشان داده شده است، شکاف 3 تا 5 برابر نرخ تراکم است، زیرا شکاف مربوط به فاصله بین Vد�دو Vک�ک، که محدود شده است O ( l o gن/ م)O(ل��ن/م). بنابراین، فاصله باید متناسب با l o gγل���در تئوری.
6. نتیجه گیری
به منظور حل این مشکل که الگوریتمهای مبتنی بر اکتشاف ممکن است باعث خطای تقریب بالا شوند، این مقاله یک الگوریتم سادهسازی مسیر بهینه بر اساس مدل نمودار (OPTTS) ارائه میکند. ابتدا راه حل بهینه به عنوان طرح فشرده سازی با حداقل تعداد نقاط و همچنین حداقل خطای ISSED تعریف می شود. سپس یک الگوریتم سه مرحله ای برای حل جواب بهینه پیشنهاد می شود. با انتقال مسیر به یک مدل گراف، از جستجوی عرض اول برای حل مسئله min-# استفاده میشود و پس از آن از جستجوی کوتاهترین مسیر منفرد برای حل مسئله min-ε استفاده میشود. مطالعه تجربی نشان داده است که OPTTS خطای تقریب را تا 82 درصد در مقایسه با روشهای سنتی کاهش میدهد. OPTTS در حالت دسته ای کار می کند و پیچیدگی زمانی دارد ای (ن2)O(ن2).
برای گسترش OPTTS به برنامه آنلاین، یک الگوریتم ساده سازی مسیر آنلاین جدید بر اساس گراف غیر چرخه ای جهت دار (OLTS) پیشنهاد شده است که از ساختار OPTTS پیروی می کند. در برخورد با جریان مسیر، OLTS به صورت پویا درخت پوشا با عرض اول را با معیار توقف برای پایان دادن به ساخت هر لایه میسازد. سپس خطای تقریب لایه فعلی به حداقل می رسد و به دنبال آن خروجی بلادرنگ. OLTS به یک راه حل تقریبا بهینه دست می یابد که خطای تقریب را تا 77 درصد کاهش می دهد. در همین حال، OLTS 32٪ سریعتر از الگوریتم آنلاین کلاسیک است. هر دو OPTTS و OLTS دارای اثربخشی و هزینه زمانی پایدار در مجموعه داده های مختلف هستند.
چندین پسوند بالقوه برای این مقاله وجود دارد. اولاً، نقاط ماندن در مسیر از اهمیت زیادی در شناسایی الگوی نقطه مورد علاقه و فعالیت استخراج برخوردار است. [ 23 ، 24 ]. با این حال، الگوریتمهای سنتی TS تمام نقاط ماندن را کاهش میدهند. ساخت اولین درخت در OPTTS و OLTS برای رزرو نقطه اقامت بهبود خواهد یافت. علاوه بر این، نمایش مسیر با وضوح چندگانه در بسیاری از برنامه های ناوبری مورد نیاز است. حجم عظیمی از داده های مسیر در وضوح درشت ممکن است باعث توقف و از کار افتادن برنامه شود [ 25 ، 26 ]. الگوریتم های TS چند وضوحی موجود اغلب در حالت دسته ای کار می کنند. یک هدف کلیدی کار آینده ما کشف یک روش آنلاین جدید TS با وضوح چندگانه است.
منابع
- ژنگ، ی. ژو، X. محاسبات با مسیرهای فضایی . Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2011. [ Google Scholar ]
- مراتنیا، ن. de By، تکنیک های فشرده سازی فضایی-زمانی RA برای حرکت اجسام نقطه ای. در مجموعه مقالات نهمین کنفرانس بین المللی گسترش فناوری پایگاه داده، هراکلیون، یونان، 14 تا 18 مارس 2004. صص 765-782.
- ملکمن، ا. O’Rourke, J. در مورد تقریب زنجیره چند ضلعی. در مورفولوژی محاسباتی ; Elsevier Science: آمستردام، هلند، 1988; صص 87-95. [ Google Scholar ]
- سالوتی، ام. تقریب چند ضلعی بهینه منحنی های دیجیتالی شده با استفاده از معیار مجموع انحرافات مربع. تشخیص الگو 2002 ، 35 ، 435-443. [ Google Scholar ] [ CrossRef ]
- ایمای، اچ. Iri, M. تقریب های چند ضلعی یک منحنی-فرمول بندی ها و الگوریتم ها. در مورفولوژی محاسباتی ; Elsevier Science: آمستردام، هلند، 1988; صص 71-86. [ Google Scholar ]
- چن، ام. خو، ام. Fränti، P. یک الگوریتم تقریب چند ضلعی چند ضلعی سریع برای ساده سازی مسیر GPS. IEEE Trans. فرآیند تصویر 2012 ، 21 ، 2770-2785. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- داگلاس، دی اچ. الگوریتم های Peucker، TK برای کاهش تعداد نقاط مورد نیاز برای نمایش یک خط دیجیتالی یا کاریکاتور آن. کارتوگر. بین المللی جی. جئوگر. Inf. جئوویس. 1973 ، 10 ، 112-122. [ Google Scholar ] [ CrossRef ]
- پیکاز، الف. الگوریتمی برای تقریب چند ضلعی بر اساس حذف نقطه تکراری. تشخیص الگو Lett. 1995 ، 16 ، 557-563. [ Google Scholar ] [ CrossRef ]
- آگاروال، پی کی; Varadarajan، KR الگوریتم های کارآمد برای تقریب زنجیره های چند ضلعی. گسسته. محاسبه کنید. Geom. 2000 ، 23 ، 273-291. [ Google Scholar ] [ CrossRef ]
- داسکو، او. Mi، N. تقریب زنجیره چند ضلعی: یک رویکرد مبتنی بر پرس و جو. محاسبه کنید. Geom. تئوری کاربردی 2005 ، 30 ، 41-58. [ Google Scholar ] [ CrossRef ]
- کولسنیکوف، آ. Fränti, P. برنامه نویسی پویا با جستجوی کاهش یافته برای تقریب منحنی های چند ضلعی. تشخیص الگو Lett. 2003 ، 24 ، 2243-2254. [ Google Scholar ] [ CrossRef ]
- پوتامیاس، م. پاترومپاس، ک. Sellis, T. در نمونهبرداری از جریانهای مسیری با معیارهای مکانی-زمانی. در مجموعه مقالات هجدهمین کنفرانس بین المللی مدیریت پایگاه داده های علمی و آماری، وین، اتریش، 3 تا 5 ژوئیه 2006. ص 275-284.
- ویتر، JS نمونهبرداری تصادفی با یک مخزن. ACM Trans. ریاضی. نرم افزار 1985 ، 11 ، 37-57. [ Google Scholar ] [ CrossRef ]
- کیوگ، ای. چو، اس. Pazzani, M. الگوریتم آنلاین برای تقسیم بندی سری های زمانی. در مجموعه مقالات کنفرانس بین المللی IEEE در سال 2001 در مورد داده کاوی، سان خوزه، کالیفرنیا، ایالات متحده آمریکا، 29 نوامبر تا 2 دسامبر 2001. ص 289-296.
- ماکل، جی. اولسن، PW; هوانگ، جی اچ. لاوسون، سی تی. راوی، SS فشرده سازی داده های مسیر: ارزیابی جامع و رویکرد جدید. Geoinformatica 2014 ، 18 ، 435-460. [ Google Scholar ] [ CrossRef ]
- لاولر، EL بهینه سازی ترکیبی: شبکه ها و ماتروئیدها. گاو نر صبح. ریاضی. Soc. 2001 ، 84 ، 461-463. [ Google Scholar ]
- Dijkstra، EW یادداشتی در مورد دو مشکل در ارتباط با نمودارها. عدد. ریاضی. 1959 ، 1 ، 269-271. [ Google Scholar ] [ CrossRef ]
- چن، DZ; Daescu، O. الگوریتم های فضای کارآمد برای تقریب منحنی های چند ضلعی در فضای دو بعدی. بین المللی جی. کامپیوتر. Geom. Appl. 2003 ، 13 ، 135-142. [ Google Scholar ] [ CrossRef ]
- کولسنیکوف، آ. Fränti، P. تقریب چند ضلعی منحنی های دیجیتالی شده سریع و نزدیک به بهینه. در مجموعه مقالات کنفرانس بین المللی IASTED در اتوماسیون، کنترل و فناوری اطلاعات-ACIT’02، نووسیبیرسک، روسیه، 10-13 ژوئن 2002. صص 418-422.
- پروژه موپسی در دسترس آنلاین: http://cs.joensuu.fi/mopsi/ (دسترسی در 3 اکتبر 2016).
- ژنگ، ی. Xie، X. Ma، WY Geolife: یک سرویس شبکه اجتماعی مشترک بین کاربر، مکان و مسیر. IEEE Data Eng. گاو نر 2010 ، 33 ، 32-39. [ Google Scholar ]
- Movebank. در دسترس آنلاین: http://www.movebank.org (در 3 اکتبر 2016 قابل دسترسی است).
- شیانگ، ال. گائو، ام. وو، تی. استخراج توقف از مسیرهای پر سر و صدا: رویکرد خوشهبندی توالی گرا. ISPRS Int. J. Geo-Inf. 2016 ، 5 ، 29. [ Google Scholar ] [ CrossRef ]
- فو، ز. تیان، ز. خو، ی. Qiao, C. یک رویکرد خوشهبندی دو مرحلهای برای استخراج مکانها از دادههای مسیر GPS فردی. ISPRS Int. J. Geo-Inf. 2016 ، 5 ، 166. [ Google Scholar ] [ CrossRef ]
- کولسنیکوف، آ. فرانتی، پ. Wu، X. تقریب چند ضلعی چند ضلعی منحنی های دیجیتال. در مجموعه مقالات هفدهمین کنفرانس بین المللی تشخیص الگو، ICPR 2004، کمبریج، انگلستان، 23 تا 26 اوت 2004. جلد 2، ص 855–858.
- مارتو، پی اف. Nier, G. سرعت بخشیدن به ساده سازی منحنی های چند ضلعی با استفاده از تقریب های تو در تو. الگوی مقعدی Appl. 2009 ، 12 ، 367-375. [ Google Scholar ] [ CrossRef ]
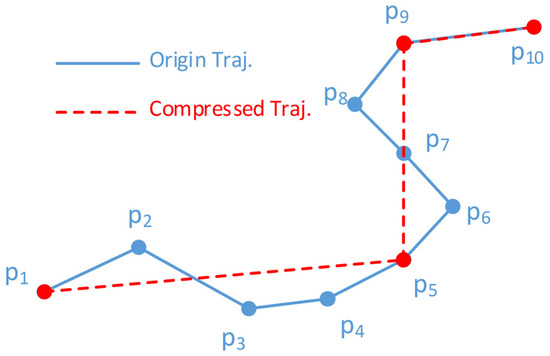
شکل 1. تصویر ساده سازی مسیر. مسیر اصلی شامل ده نقطه و مسیر ساده شده شامل چهار نقطه است {پ1،پ5،پ9،پ10}{پ1،پ5،پ9،پ10}.

شکل 2. ( الف ) شمارش تمام طرحواره های فشرده سازی یک مسیر که شامل 16 نقطه است. هر نقطه در نمودار یک مسیر ساده شده با نقاط M را نشان می دهد و محور Y خطای ISSED را نشان می دهد . ( ب ) مشکل Min-# یافتن حداقل مقدار M زیر آستانه خطا است که چهار زیر خط قرمز افقی است. مشکل Min-ε یافتن حداقل ISSED در زیر آستانه M است که پایین ترین نقطه در امتداد خط قرمز عمودی است.
شکل 3. نمودار جریان OPTTS.
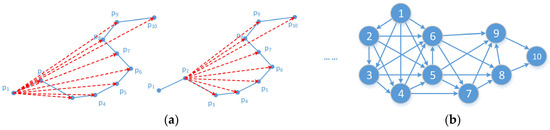
شکل 4. ( الف ) فرآیند تست لبه. ( ب ) نمودار مسیر.

شکل 5. ( الف ) فرآیند جستجوی وسعت-اول. ( ب ) درخت پوشا با عرض اول.

شکل 6. ( الف ) فرآیند جستجوی وسعت-اول. ( ب ) درخت پوشا با عرض اول.
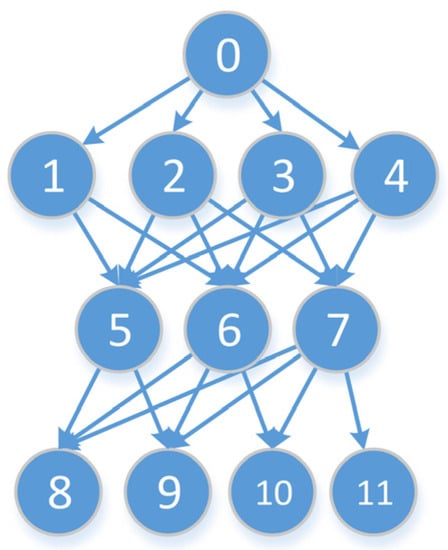
شکل 7. درخت بازسازی.

شکل 8. نمودار جریان OLTS.
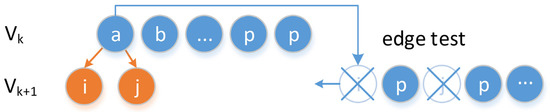
شکل 9. ساختار دینامیکی درخت پوشا.

شکل 10. مثال در حال اجرا از معیار توقف.
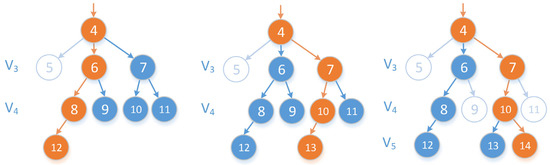
شکل 11. مثال در حال اجرا از فرآیند خروجی.
شکل 12. نسل m از اجداد Vک�ک.
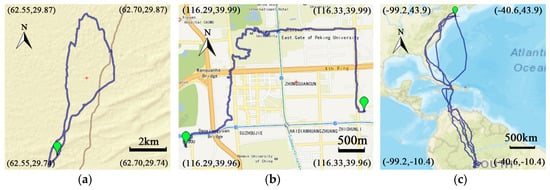
شکل 13. ( الف ) موپسی: یک مسیر دویدن در پارکی در هلسینکی، فنلاند. ( ب ) Geolife: آهنگ یک دانش آموز در حال سفر از خانه به مدرسه در پکن، چین. ( ج ) Movebank: یک مسیر سه ساله (ژانویه 2006 تا دسامبر 2008) از یک ماهیماهی که از ایالات متحده به برزیل مهاجرت میکند.
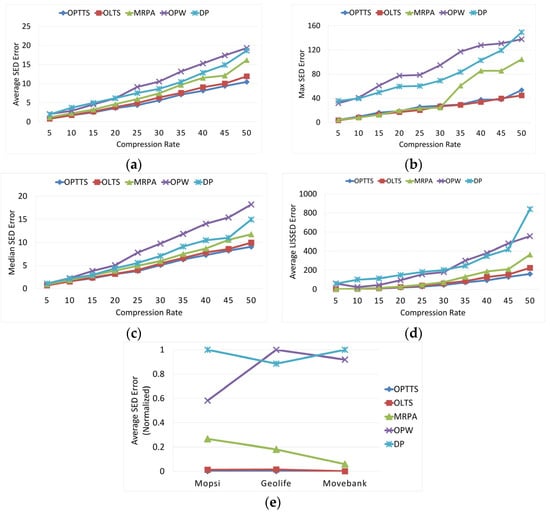
شکل 14. ( الف ) میانگین خطای SED . ( ب ) حداکثر خطای SED . ( ج ) میانه خطای SED . ( د ) میانگین خطای ISSED . ( ه ) میانگین خطاهای SED در مجموعه داده های مختلف.

شکل 15. تجسم مسیرهای فشرده شده توسط الگوریتم های مختلف. ( الف ) OPTTS در مقابل OLTS. ( ب ) OPTTS در مقابل MRPA. ( ج ) OPTTS در مقابل OPW. ( د ) OPTTS در مقابل DP.5.3. ارزیابی بر اساس هزینه زمانی
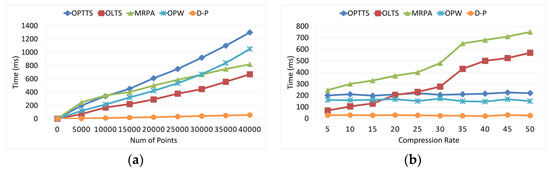
شکل 16. ( الف ) هزینه زمانی تعداد نقاط مختلف. ( ب ) هزینه زمانی نرخ های مختلف فشرده سازی.

شکل 17. ( الف ) تجسم تاخیر و شکاف. ( ب ) تاخیر متوسط. ( ج ) فاصله متوسط.

جدول 1. طبقه بندی الگوریتم های TS.
جدول 2. آمار سه مسیر مثال.
جدول 3. ویژگی های الگوریتم های مقایسه شده.
جدول 4. فرمول اختصاری و محاسبه معیارهای خطای مختلف.
جدول 5. پیچیدگی زمانی پنج الگوریتم.
© 2017 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر