1. معرفی
تولید خودکار مدلهای سهبعدی نمای بیرونی ساختمانها مانند نماها یا سقفها در سطح جزئیات 3 (LoD3) طبق CityGML [1] موضوع تحقیقات فشرده [ 2 ، 3 ] بوده است. برای ناوبری داخلی، برای مثال، مدلهای داخلی مانند مدلهای سهبعدی نشاندادهشده در LoD4 CityGML [ 4 ] یا مدلهای بهدستآمده از مدلسازی اطلاعات ساختمان (BIM) مورد نیاز است [ 5 ، 6]]. در مقایسه با مدل های فضای باز، مدل های داخلی هنوز به طور گسترده در دسترس نیستند. مدلهای داخلی، با این حال، زمینههای کاربردی جدیدی را با ارتباط بالا، از جمله ناوبری داخلی، برنامهریزی تخلیه و مدیریت تسهیلات باز میکنند. علاوه بر این، چنین مدل هایی یک پیش نیاز ضروری برای کارهایی مانند راهنمای نابینایان هستند. در حالی که اکثر رویکردهایی که مدلهای داخلی را استخراج میکنند بر دادههای اندازهگیری شده مانند تصاویر یا ابرهای نقطه سه بعدی متکی هستند، ما معتقدیم که این جمعآوری دادههای گسترده از اندازهگیریهای اضافی داخلی ضروری نیست. برای این هدف، ما یک روش جدید برای استخراج مدلهای سه بعدی داخلی از مشاهدات پراکنده بدون نیاز به اندازهگیریهای داخلی اضافی پیشنهاد میکنیم. اگر مدلهای اطلاعاتی ساختمان در دسترس نباشد، رویکردهای قبلی برای مدلسازی داخلی نیاز به اندازهگیری و مدلسازی فضای داخلی دارد که هم گران و هم دشوار است. اندازه گیری ها گران هستند زیرا باید به هر اتاق یک نفره دسترسی داشت. به دلیل پوشاندن دیوارها توسط مبلمان، استخراج مدل ها از اندازه گیری ها دشوار است. برای تمایز بین دیوارها و به عنوان مثال قفسه های کتاب یا کمد، مدل سازی دانش قبلی و منظم سازی را فراهم می کند. در این مقاله، ما نشان میدهیم که دانش قبلی همراه با مدلهای فضای باز، بهویژه ردپاها و اطلاعات در مورد موقعیت پنجرهها و کفها در بسیاری از موارد کافی است اگر دادههای عمومی در دسترس در مورد مناطق اتاق، کاربری عملکردی و شماره اتاقها ارائه شود. برای ساختار و سادهسازی ارائه، با این فرض شروع میکنیم که هم پلانهای طبقه و هم اتاقها مستطیل شکل هستند و در پایان درباره اشکال کلیتر بحث میکنیم. به دلیل پوشاندن دیوارها توسط مبلمان، استخراج مدل ها از اندازه گیری ها دشوار است. برای تمایز بین دیوارها و به عنوان مثال قفسه های کتاب یا کمد، مدل سازی دانش قبلی و منظم سازی را فراهم می کند. در این مقاله، ما نشان میدهیم که دانش قبلی همراه با مدلهای فضای باز، بهویژه ردپاها و اطلاعات در مورد موقعیت پنجرهها و کفها در بسیاری از موارد کافی است اگر دادههای عمومی در دسترس در مورد مناطق اتاق، کاربری عملکردی و شماره اتاقها ارائه شود. برای ساختار و سادهسازی ارائه، با این فرض شروع میکنیم که هم پلانهای طبقه و هم اتاقها مستطیل شکل هستند و در پایان درباره اشکال کلیتر بحث میکنیم. به دلیل پوشاندن دیوارها توسط مبلمان، استخراج مدل ها از اندازه گیری ها دشوار است. برای تمایز بین دیوارها و به عنوان مثال قفسه های کتاب یا کمد، مدل سازی دانش قبلی و منظم سازی را فراهم می کند. در این مقاله، ما نشان میدهیم که دانش قبلی همراه با مدلهای فضای باز، بهویژه ردپاها و اطلاعات در مورد موقعیت پنجرهها و کفها در بسیاری از موارد کافی است اگر دادههای عمومی در دسترس در مورد مناطق اتاق، کاربری عملکردی و شماره اتاقها ارائه شود. برای ساختار و سادهسازی ارائه، با این فرض شروع میکنیم که هم پلانهای طبقه و هم اتاقها مستطیل شکل هستند و در پایان درباره اشکال کلیتر بحث میکنیم. در این مقاله، ما نشان میدهیم که دانش قبلی همراه با مدلهای فضای باز، بهویژه ردپاها و اطلاعات در مورد موقعیت پنجرهها و کفها در بسیاری از موارد کافی است اگر دادههای عمومی در دسترس در مورد مناطق اتاق، کاربری عملکردی و شماره اتاقها ارائه شود. برای ساختار و سادهسازی ارائه، با این فرض شروع میکنیم که هم پلانهای طبقه و هم اتاقها مستطیل شکل هستند و در پایان درباره اشکال کلیتر بحث میکنیم. در این مقاله، ما نشان میدهیم که دانش قبلی همراه با مدلهای فضای باز، بهویژه ردپاها و اطلاعات در مورد موقعیت پنجرهها و کفها در بسیاری از موارد کافی است اگر دادههای عمومی در دسترس در مورد مناطق اتاق، کاربری عملکردی و شماره اتاقها ارائه شود. برای ساختار و سادهسازی ارائه، با این فرض شروع میکنیم که هم پلانهای طبقه و هم اتاقها مستطیل شکل هستند و در پایان درباره اشکال کلیتر بحث میکنیم.
مشکلی که ما به آن می پردازیم با مجموعه ای از N اتاق مستطیلی مشخص می شود که باید در یک ردپای چند ضلعی قرار گیرند. در این زمینه، اتاق با یک نقطه مرجع و عرض و عمق آن تعریف می شود. عرض و عمق اتاق ها با مقادیر بالا و پایین محدود شده و توسط یک محدودیت دوخطی محدود می شود. a r e a = w i dt h * de p t h _����=����ℎ*����ℎ,که در آن منطقه به صورت پیشینی و دو پارامتر شناخته شده است w i dتی ساعت����ℎو دe p t h����ℎناشناخته هستند. در مسئله ای که حل می کنیم، ردپای ساختمان و همچنین مساحت هر اتاق آورده شده است. ما فرض می کنیم که هر اتاق یک شکل مستطیلی دارد. مرزهای پایین و بالایی برای عرض و عمق هر اتاق از توابع چگالی احتمال (PDF) به دست آمده است. نوع تصمیم مشکل ما این است که تصمیم بگیریم آیا ردپای ساختمان را می توان به اتاق هایی تقسیم کرد که مشخصات ما را برآورده می کند یا خیر. در حالت خاصی که ردپای ساختمان یک مستطیل است و برای هر اتاق کران پایین با کران بالایی برابر است، این مشکل مربوط به Perfect Rectangle Packing است. از آنجایی که بسته بندی مستطیلی کامل به عنوان NP-hard شناخته شده است [ 7]، مشکل کلی تر ما نیز NP-hard به نظر می رسد. به همین دلیل، بعید است که در بدترین حالت راه حلی کارآمد پیدا شود. با این حال، ما میدانیم که نمایش مناسب دانش پسزمینه، تعریف حوزهها و محدودیتها در پارامترهای مدل و ترکیبی هوشمندانه از انتشار محدودیت و استدلال تصادفی، راهحلهای بهینه را به روشی نسبتاً کارآمد در اکثر سناریوهای واقعبینانه به دست میدهد. به منظور برآورده کردن این انتظارات، ما روشی را پیشنهاد می کنیم که فضای جستجو را با استدلال گام به گام کاهش می دهد. محدودیتها و قاعدهمندیهای معماری همراه با آرامش اولیه مشکل منجر به یک نتیجه متوسط سریع میشود که در مرحله دوم با یک فرضیه واجد شرایط سازگار میشود. آرامش به این واقعیت کمک می کند که دیوارها در ابتدا مدل سازی نشده اند و اتاق ها مجبور نیستند کل فضا را پر کنند. با این حال، یک محدودیت مهم معماری شامل این واقعیت است که دیوارهای داخلی پنجره ها را قطع نمی کنند. در این مرحله، این محدودیت کاهش می یابد تا اطمینان حاصل شود که مرزهای داخلی اتاق از محدوده پنجره ها عبور نمی کند. اتاقها به روش توپولوژیکی درستی مدلسازی میشوند (غیر همپوشانی، درون ردپایی،…) اما لزوماً در امتداد یک راهرو تراز نیستند. در مفهوم صحت توپولوژیکی دوبعدی، دو اتاق در بافت ما یا از هم جدا هستند یا در دیوارهای مشترک با یکدیگر ملاقات می کنند و از همپوشانی آنها اجتناب می شود. ما از یک مدل فنری مشابه روشی که در [ این محدودیت برای اطمینان از اینکه مرزهای داخلی اتاق از محدوده پنجره عبور نمی کند کاهش می یابد. اتاقها به روش توپولوژیکی درستی مدلسازی میشوند (غیر همپوشانی، درون ردپایی،…) اما لزوماً در امتداد یک راهرو تراز نیستند. در مفهوم صحت توپولوژیکی دوبعدی، دو اتاق در بافت ما یا از هم جدا هستند یا در دیوارهای مشترک با یکدیگر ملاقات می کنند و از همپوشانی آنها اجتناب می شود. ما از یک مدل فنری مشابه روشی که در [ این محدودیت برای اطمینان از اینکه مرزهای داخلی اتاق از محدوده پنجره عبور نمی کند کاهش می یابد. اتاقها به روش توپولوژیکی درستی مدلسازی میشوند (غیر همپوشانی، درون ردپایی،…) اما لزوماً در امتداد یک راهرو تراز نیستند. در مفهوم صحت توپولوژیکی دوبعدی، دو اتاق در بافت ما یا از هم جدا هستند یا در دیوارهای مشترک با یکدیگر ملاقات می کنند و از همپوشانی آنها اجتناب می شود. ما از یک مدل فنری مشابه روشی که در [8 ]. به این ترتیب در مرحله اول عناصر دیوار را در نظر نمی گیریم و بافر ایجاد می کنیم و امکان بهبود نتایج اولیه را در مرحله بعدی فراهم می کنیم.
بر اساس نتیجه میانی، استنتاج تصادفی به منظور ارائه مجموعه ای واجد شرایط از راه حل ها استفاده می شود که از نظر توپولوژیکی معادل هستند اما از نظر هندسی متفاوت هستند. ما از مفهوم هم ارزی توپولوژیکی به معنای استاندارد استفاده می کنیم، یعنی معادل تبدیل های همومورفیک (برای جزئیات، به عنوان مثال، [ 9 ] یا [ 10] را ببینید.]). به طور خاص، هم ارزی توپولوژیکی مجاورت را حفظ می کند. مجموعه راه حل ها با احتمالات به دست آمده از یک تخمین محتمل افزایش می یابد. مکان دقیق اتاق ها – با در نظر گرفتن تراز بین اتاق ها – به همراه عرض و عمق و عرض دیوارها در مرحله بعدی تخمین زده می شود. نکته کلیدی تعیین فرضیه ها به همراه اطلاعات احتمال است که فضای فرضیه ها را ساختار می دهد. در آزمایشهای خود، بیان کردیم که این فضا تحت تسلط یک فرضیه با توجه به دیگران است که یک راهحل مورد انتظار را توصیف میکند.
تجزیه و تحلیل گسترده پارامترهای شکل و مکان مانند عرض و عمق اتاق ها منجر به دانش قبلی می شود که توسط محدودیت های معماری و توابع چگالی احتمال نشان داده می شود. مشابه فرآیند استدلال انجام شده در [ 11]، تخمین پلان طبقات با یک مدل دوخطی مشخص می شود. غیر خطی بودن به این واقعیت نسبت داده می شود که یک منطقه اتاق حاصلضرب عرض و عمق آن است. علاوه بر عدم اجازه عبور دیوارها از پنجره ها، این واقعیت که پنجره ها به عنوان مثال، بخشی از اتاق های اداری یا مسکن هستند، یک محدودیت مهم است که دامنه شکل و پارامترهای مکان اتاق ها را به طور قابل توجهی محدود می کند. بدیهی است که محدودیت اخیر در مورد راهروها یا اتاق های خدمات ضروری نیست. علاوه بر این، برای ساختمانهای اداری با تعداد اتاقهای معمولاً زیاد، تعداد اتاقهای موجود مزیتی است که نباید دست کم گرفته شود، زیرا اتاقهایی با شماره اتاقهای متعاقب با احتمال زیاد مجاور هستند. این دانش قبلی همراه با توابع چگالی احتمال، مشکل مکان یابی اتاق ها در ردپای را امکان پذیر می کند.
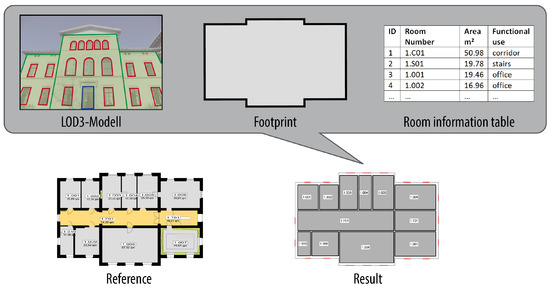
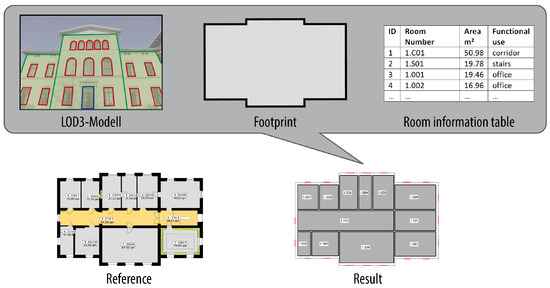
این مقاله یک رویکرد جدید برای پیشبینی و تولید خودکار پلانهای طبقه ساختمان ارائه میکند. بر اساس مشاهدات پراکنده، ما به طور خودکار تعداد محدودی از بهترین فرضیه ها را ایجاد می کنیم و احتمالاتی را برای هر راه حل ارائه می دهیم. فرضیه های به دست آمده بر اساس یک برآورد MAP [ 12] رتبه بندی می شوند]. توابع چگالی احتمال برای هر پارامتر مدل امکان ارزیابی احتمال هر فرضیه و مرتب کردن آن را بر اساس فرضیه های رقابتی فراهم می کند. مشاهدات متراکم مانند ابرهای نقطه سه بعدی مورد نیاز نیست. ما میدانیم که تأیید یا جعل فرضیهها آسانتر از بازسازی مدلها از مشاهدات به روش پایین به بالا و پیروی از یک رویکرد از بالا به پایین مبتنی بر مدل است. در حالی که بیشتر رویکردها انتظار مشاهدات با چگالی کافی را دارند، ویژگی رویکرد ما این است که میتوانیم بهترین فرضیهها را برای پلان طبقات بر اساس اندازهگیریهای ناکافی ایجاد کنیم. ما با اطلاعات هندسی در مورد ردپای ساختمان و همچنین موقعیت و اندازه پنجره ها شروع می کنیم. علاوه بر این، ما از دادههای غیر هندسی در اتاقها از جمله مناطق و کاربری عملکردی بهرهبرداری میکنیم. حداقل تمایز بین اتاق های اداری یا مسکن، راهروها و توالت. این مهم است زیرا برخلاف اتاق های اداری یا مسکونی، راهروها و توالت ها نیازی به پنجره ندارند. همانطور که در نشان داده شده استشکل 1 ، ورودی شامل ردپای ساختمان و اطلاعات موجود در مورد اتاق ها (مساحت اتاق ها، شماره شناسایی هر اتاق و احتمالاً کاربری کاربردی هر اتاق) است. بیشتر این اطلاعات را می توان از خدمات مدیریت ساختمان به دست آورد. مکان پنجرهها را میتوان با استفاده از روشهای موجود برای شناسایی قطعات ساختمان از ابرهای نقطهای یا تصاویری از نماها به دست آورد، مثلاً در [ 13 ] یا [ 14 ] شرح داده شده است. این الگوریتم برای پیشبینی پلانهای طبقاتی مانند آنچه در شکل 1 نشان داده شده است، به هیچ تصویر داخلی یا اسکن لیزری از دیوارها نیاز ندارد.. برای مقایسه، پلان طبقه مرجع مرتبط نشان داده شده است. دادههای اضافی ممکن است منجر به تأیید یا جعل مدلها شود که البته هزینه کمتری نسبت به بازسازی داخلی ساختمان از پایین به بالا بر اساس اندازهگیریها دارد. خروجی روش ما یک مدل داخلی برای طبقه داده شده است که شامل چیدمان اتاق ها، محل درب ها و ارتفاع اتاق ها می شود. توپولوژی سازگار خواهد بود و دقت هندسه بر اساس اطلاعات داده شده به دلیل استنتاج تصادفی دقیق به معنای [ 12 ] بهینه خواهد بود. در موارد آزمایشی ما، دقت پارامترهای مدل را بین 10 تا 20 سانتی متر به دست آوردیم.
با وجود مسئله پیچیده غیر خطی، استدلال ارائه شده استنتاج های دقیقی را انجام می دهد. بنابراین، برنامه نویسی منطقی محدودیت (CLP) با مدل های گرافیکی ترکیب می شود. شکل 2a رویکرد کلی ما را خلاصه میکند: ما با مسئلهای شروع میکنیم که با پارامترهای گسسته و پیوسته و فضای فرضیههای نامحدود مشخص میشود. این به تعداد کمی از نامزدهای امکان پذیر با انتشار محدودیت در مرحله اول محدود می شود. در این فرضیه ها، پارامترهای مدل از نقطه نظر توپولوژی ثابت هستند، اما میانی هستند. آنها در مرحله دوم به یک استدلال تصادفی وارد می شوند. پارامترها با مشاهدات موجود و دانش پسزمینه در قالب توزیعهای احتمال پارامترهای مدل با استفاده از استنتاج مبتنی بر MAP تطبیق داده میشوند. توزیع احتمال پارامترهای مدل مانند عرض اتاق های اداری را می توان به خوبی با تخمین تراکم هسته [ 15 ] یا – برای هدف ما حتی بهتر – مخلوط های گاوسی، همانطور که در شکل 2 نشان داده شده است، نشان داد.ب مشاهده میشود که مخلوط گاوسی تقریبی خوبی برای مدلسازی توزیعهای متقارن یا چندوجهی چوله است و در عین حال امکان استفاده از الگوریتمهای استدلال به خوبی تثبیتشده را میدهد. همانطور که در [ 16 ] بیان شد، هر تابع چگالی احتمال دلخواه را می توان با مدل های مخلوط گاوسی تقریب زد. ما از یک مورد خاص از مدل های گرافیکی استفاده می کنیم که یک مدل گاوسی خطی شرطی است. این امکان انجام یک استنتاج تصادفی دقیق را فراهم می کند.
برخی از نتایج توصیف شده در این مقاله در کارگاه سه بعدی داخلی در چارچوب یازدهمین کنفرانس 3D Geoinfo در آتن ارائه شده است. این مقاله [ 17 ] را در چند جنبه گسترش می دهد:
-
در حالی که [ 17 ] رویکرد کلی را توصیف می کند، این مقاله روش ها و الگوریتم های مربوطه را با عمق بیشتری مورد بحث قرار می دهد.
-
در حالی که [ 17 ] موقعیت اتاقها و پنجرهها را در یک حوزه پیوسته نشان میدهد و استدلال را با نابرابریها در این حوزهها انجام میدهد، در این مقاله، هندسه را در حوزههای گسسته در طول قسمت ترکیبی نشان میدهیم و روشی را برای انتشار محدودیت در حوزههای محدود اعمال میکنیم که به طور قابلتوجهی است. کارآمدتر.
-
این مقاله به درها می پردازد و اندازه و موقعیت آنها را تخمین می زند و بنابراین یک دسترسی برای ناوبری داخلی فراهم می کند.
-
از طرحبندیهای پلان دوبعدی به مدلهای سه بعدی داخلی تعمیم میدهد.
سهم اصلی این مقاله یک رویکرد جدید است که مدلهای داخلی سه بعدی را ارائه میکند و از اندازهگیریهای اضافی در قالب تصاویر یا ابرهای نقطه سهبعدی اجتناب میکند. از نقطه نظر روششناختی، ما استنتاج تصادفی را به معنای مدلهای گرافیکی اعمال میکنیم و استدلال ترکیبی / انتشار محدودیت را در یک مدل دوخطی با استنتاج تصادفی با استفاده از مخلوطهای گاوسی به روشی جدید ترکیب میکنیم. به عنوان بسط انتشار قبلی ما [ 17 ]، این رویکرد در بخشهای بعدی توضیح و تشریح شده است.
2. کارهای مرتبط
در حالی که مدلهای سهبعدی نمای بیرونی ساختمانها به طور گسترده در سطوح مختلف جزئیات در دسترس هستند، مدلهای سه بعدی داخلی ساختمان (LoD4 در CityGML، [ 18 ]) هنوز گسترده نشدهاند. وظایفی مانند مدیریت نجات، ناوبری داخلی و راهنمای نابینایان منجر به افزایش علاقه به طراحی و مدل سازی فضای داخلی ساختمان شده است. در این زمینه، نویسندگان [ 19 ] رویکردی را برای تولید پلان کف ساختمان از دادههای برد لیزری بر اساس مثلثسازی یک نمونهبرداری دوبعدی از موقعیتهای دیوار پیشنهاد کردند. بکر و همکاران از دستور زبانهای شکل در [ 20 ] برای بازسازی مدلهای سه بعدی داخلی از ابرهای نقطه سه بعدی استفاده کرد. در [ 21]، اوچمن و همکاران. یک ابر نقطه ای را به اتاق ها و محوطه بیرونی تقسیم کرد و با حل یک مشکل برچسب گذاری بر اساس کمینه سازی انرژی، صحنه را بازسازی کرد. برای استخراج مدلهای داخلی، همه رویکردهای ذکر شده بر مشاهدات متراکم مانند ابرهای نقطه سهبعدی از لیزر اسکنها یا دوربینهای برد با استفاده از سیستمهای نقشهبرداری متحرک تکیه دارند. اندازه گیری های لازم هم هزینه و هم زمان زیادی دارند. استخراج مشاهدات برای مدلهای داخلی با اندازهگیری مدلهای فضای باز با استفاده از سکوهای هوابرد یا زمینی متفاوت است. هر اتاق یک نفره باید وارد شده و اسکن شود. علاوه بر این، در حالی که شخص به مدل سازی دیوارها، درها، پنجره ها و سقف ها علاقه مند است، آنها توسط انواع مبلمان پنهان می شوند. در هر صورت مفروضات مدل قوی مورد نیاز است. به منظور غلبه بر کسب مشاهدات متراکم به عنوان یک فرآیند زمانبر، حسگرهای کم هزینه در چندین رویکرد به کار گرفته شدهاند. به عنوان مثال، دیاکیته و همکاران. بررسی شده در [22 ] سودمندی تبلت اندرویدی ارزان قیمت از پروژه تانگو گوگل برای دستیابی به محیط های داخلی ساختمان. اطلاعات استخراج شده از مدل های بومی این دستگاه به اندازه کافی غنی نیست تا بتوان مدل های داخلی دقیق را استخراج کرد. در نتیجه، انگیزه اصلی ما پیشبینی زیرساختهای ناشناخته در ساختمانهایی مانند پلانهای طبقات بر اساس فرضیات مدل قوی به معنای دانش پسزمینه است، اما تنها مشاهدات کمی مانند مساحت اتاقها و ردپاها. برای اطلاعات بیشتر در مورد کارهای مدلسازی و نقشه برداری داخلی، به بررسی تحقیقات اخیر در این زمینه مراجعه می کنیم [ 23 ].
یک رویکرد مبتنی بر محدودیت برای تولید پلانهای طبقه قبلاً در سال 1994 طراحی شده است. در [ 24 ]، چارمن یک سیستم مبتنی بر دانش را توصیف میکند که تمام پلانهای طبقه ممکن را تولید میکند که مجموعهای از محدودیتهای هندسی را در اتاقها برآورده میکند (غیر همپوشانی، مجاورت، مساحت حداقل/حداکثر، بعد حداقل/حداکثر و غیره). بنابراین، او قوام قوس نیمه هندسی را به منظور تطبیق تکنیک های سازگاری با مسائل هندسی تعریف می کند. در مقایسه با روش ما، این رویکرد به بازسازی پلان های طبقه برای ساختمان های موجود نمی پردازد و پیکربندی های احتمالی را در نظر نمی گیرد.
انتشار محدودیت یک روش قدرتمند برای حل مسائل ترکیبی است. با این حال، رویکردهایی که این چارچوب را توسط یک جزء تصادفی گسترش میدهند، نسبتاً نادر هستند. نویسندگان [ 25 ] عملگرهای ترکیبی و حاشیهسازی را برای یافتن بهترین راهحلها برای کارهای بهینهسازی در مدلهای گرافیکی تطبیق میدهند. فواصل با توابع توزیع تجمعی در [ 26 ] برای مدل سازی درجه ای از دانش برای داده های نامشخص استفاده می شود. به منظور پرداختن به عدم قطعیت، رویکرد ما انتشار محدودیت کلاسیک را با شبکههای بیزی ترکیب میکند و بنابراین از قدرت هر دو پارادایم بهره میبرد.
3. مدل سازی پلان های طبقه با محدودیت ها
رویکرد ما برای پیشبینی پلانهای طبقات از یک رویکرد از بالا به پایین مبتنی بر مدل پیروی میکند. بنابراین، مسئله بر اساس تحلیل گسترده پلان های واقعی طبقات و همچنین محدودیت های ابعادی بر اساس قوانین و ویژگی های معماری مدل سازی شده است. ما درک می کنیم که اشیاء ساخته شده توسط انسان با تعدادی قانون مشخص می شوند. از یک سو، روابط هندسی مانند موازی و متعامد در ساختمان ها غالب است. در [ 27]، لوچ دهبی و همکاران. قوانین هندسی را که می توان در اشیاء ساخته دست بشر یافت و رویکردی برای استنتاج روابط هندسی در مدل های ساختمانی سه بعدی ارائه کرد. از سوی دیگر، ساختمان ها را می توان با وابستگی های عملکردی و آماری بین پارامترهای مدل توصیف کرد. در این مقاله، ما بر ویژگی های اخیر ساختمان ها تمرکز می کنیم. دانش طراحی معماری و همچنین توزیع های موجود در مورد پارامترهای مدل، امکان تولید فرضیه های خوبی را برای بازسازی ساختمان ها فراهم می کند.
برای یافتن عرض می توان تخمین پلان های طبقات را کاهش داد wمن��و عمق دمن��و همچنین نقطه مرجع (ایکسمن،yمن)(��,��)برای هر تک من تا ساعت��ℎاتاق علاوه بر مدلهای ساختمان در فضای باز در LOD3، ما فقط به دادههایی نیاز داریم که برای هر خانهدار و هر مدیر املاک و مستغلات بدون نیاز به اندازهگیریهای داخلی در دسترس باشد. مساحت اتاق ها علاوه بر ردپای ساختمان مربوطه و احتمالاً کاربری عملکردی و تعداد شناسایی اتاق ها به ما داده می شود. علاوه بر این، ما از پارامترهای مکان (دو بعدی) بهره برداری می کنیم (ایکسw 1،yw 1)(��1,��1)و (ایکسw 2،yw 2)(��2,��2)از پنجره های ناشی از اندازه گیری های بیرونی نما. شکل 3 a یک نمای کلی از مدل دامنه و پارامترهای آن را نشان می دهد. این شکل همچنین نشان میدهد که برای اتاقهای دارای پنجره، حداقل یکی از دیوارهای آنها باید مقدار حداقل یا حداکثر را داشته باشد. ایکسm i n����، ym i n����، ایکسm a x����و ym a x����به ترتیب در ردپای مربوطه.
در مرحله اول، فرض می کنیم که اتاق ها و همچنین ردپای مربوطه دارای شکل مستطیلی هستند. این فرض بعداً برای مدل سازی ساختمان هایی که مستطیل نیستند، اما از فرضیه جهان منهتن پیروی می کنند، راحت تر خواهد شد. بنابراین، اتاقهای مجازی کمکی (مستطیلهای سبز در شکل 3 ب را میتوان اضافه کرد که شکافها را پر میکنند تا یک مستطیل کامل شود. بدون از دست دادن کلیت، فرض میکنیم که طولانیترین ضلع یک ردپای به ترتیب موازی با محور x است. برای استفاده ثابت از عرض و عمق برای اتاق ها. برای ردپاهای مستطیلی، این بر اساس یک اصلاح عمودی پس از تعیین محور اصلی ردپای تضمین شده است.
3.1. محدودیت های سخت و نرم
دانش توپولوژیکی و معماری در مورد ساختمان ها به ویژه اتاق ها برای تعریف محدودیت ها در پارامترهای مدل استفاده می شود. در مقابل توابع، محدودیت ها معمولاً چندین پارامتر ناشناخته دارند که باید تعیین شوند. اولین محدودیت به ناحیه پارامتر داده شده مربوط می شود
من تا ساعتمنتیساعتاتاق با عرض دو مجهول
wمن�منو عمق
دمندمنکه یک محدودیت دوخطی است، یعنی غیر خطی است:
یک محدودیت واضح اما مهم این است که همه اتاق ها باید به شکل (مستطیل شکل) کف باشند
که از ردپای ساختمان گرفته شده است. آن را برای یک آزمایش ساده می کند که آیا
من تا ساعتمنتیساعتاتاق در یک جعبه محدود با نقطه مرجع قرار دارد
(ایکسf،yf)(ایکس�،��)، عرض
wf��و عمق
دf��. شاخص
i مربوط به شناسه اتاق در شناسه ستون از جدول اطلاعات اتاق از شکل 1 است :
یکی دیگر از محدودیت های مهم برای حفظ صحت توپولوژیکی، عدم همپوشانی اتاق ها است. این واقعیت که دو اتاق مجزا
i و
j باید جدا باشند را می توان به صورت زیر مدل کرد:
آگاهی از موقعیت پنجره ها برای دو منظور قابل استفاده است: از یک طرف، مختصات اتاق ها به مختصات پنجره هایی بستگی دارد که روی دیوار مشترک قرار می گیرند. در نتیجه، برای مثال یک پنجره
w که در قسمت جلویی طبقه قرار دارد، مانند پنجره در شکل 3 ، و مطابق با
من تا ساعتمنتیساعتاتاق، مقادیر ممکن مختصات
y این اتاق را به صورت زیر محدود می کند:
جایی که w a lلe x t�������عمق دیوار بیرونی را نشان می دهد. از طرف دیگر، ما از این واقعیت استفاده می کنیم که دیوارهای جداکننده اتاق ها مجبور به عبور از پنجره نیستند. بنابراین، مختصات x – و y – به ترتیب نمی توانند مقادیری را در جایی که پنجره ها قرار می گیرند، بگیرند. برای همان پنجره ای که در سمت جلوی طبقه قرار دارد، محدودیت را می توان به صورت زیر بیان کرد:
برای پنجره های سمت چپ، راست و پشت یک ساختمان محدودیت هایی معادل وجود دارد. توجه داشته باشید که مطابقت یک پنجره w با اتاق i نشان داده شده است wجw= r noمن�ج�=���منبه طور پیشینی شناخته شده نیست و باید در طول فرآیند استدلال مشخص شود. این کار ترکیبی به عنوان یک مسئله برچسبگذاری فرموله شده است. وجود پنجره در اتاق بستگی به کاربری کاربردی این اتاق دارد. برای اتاق های اداری، اختصاص پنجره اجباری است، در حالی که برای راهروها یا اتاق های تاسیساتی این گونه نیست. اگر اتاقی به پنجره اختصاص داده نشود، با روابط ( 4 ) و ( 5 ) محدود نمی شود و بنابراین می توان آن را به عنوان یک اتاق داخلی در نظر گرفت.
علاوه بر محدودیت های سخت توصیف شده که باید برای همه اتاق ها رعایت شود، مدل پلان طبقه شامل دو محدودیت نرم است. آنها در بیشتر موارد صادق هستند اما در موارد استثنا می توان آنها را نقض کرد. با این حال، تعداد تخلفات با اجتناب از مدلهای توپولوژیکی غیرقابل قبول محدود است. یک محدودیت نرم در نظر میگیرد که تعداد اتاق با همسایگی اتاقها بسیار مرتبط است. اگر دو اتاق دارای شماره اتاق متوالی هستند، در صورت امکان باید در مجاورت یکدیگر قرار گیرند. در متن ما، اصطلاح مجاورت به همسایگی اتاق ها اشاره دارد. این با محدودیت زیر بیان می شود – به طور مثال برای یک
من تا ساعتمنتیساعتاتاقی
که گذاشتم به a
j t h�تیساعتاتاق
j :
جایی که w a lلمن n t������تینشان دهنده عمق دیوار داخلی است. نماد “¬” مخفف یک نفی منطقی است. مجاورت راست، بالا و پایین نیز امکان پذیر است و می تواند به روشی معادل تعریف شود. از آنجایی که روابط نسبی بین اتاق ها مشخص نیست، یک انحصاری یا ترکیبی از چهار احتمال برای مجاورت اتاق ها است. این نیز یک کار ترکیبی است که ما آن را حل می کنیم.
از آنجایی که راهرو معمولاً ورودی یک اتاق است، یک محدودیت نرم بیشتر مجاورت یک اتاق با راهروی موجود را توصیف می کند. در این مورد، محدودیت مجاورت مورد استفاده برای محله بالا مشروط به استفاده کاربردی – در این مورد “راهرو” – اتاق ها است.
3.2. توابع چگالی احتمال
علاوه بر محدودیتها، فرآیند استدلال از دانش قبلی آماری سود میبرد که از یک پایگاه داده حقیقت پایه از حدود 1600 اتاق با کاربردهای عملکردی مختلف مشتق شده است. شکل 4 گزیده ای از مدل پایگاه داده زیربنایی را نشان می دهد. مرکز تجزیه و تحلیل ما اتاق رابطه با پارامترهای شکل و مکان هر اتاق و همچنین کاربرد عملکردی آنها و مکان درها و پنجره ها است . اتاقها به ساختمانهای مربوطه خود اشاره میکنند که دسترسی به ردپای موجود را امکانپذیر میسازد. بالاخره محلهاتاق ها به منظور تجزیه و تحلیل مکان های دو طرفه به عنوان مثال، با توجه به استفاده کاربردی اتاق ها حاشیه نویسی شده است. توجه داشته باشید که این دادهها بهعنوان ورودی مستقیم برای فرآیند استدلال عمل نمیکنند، اما مبنایی برای استخراج توزیعهای احتمال و محدودیتها برای مدل پلان طبقه و پیشبینی آن هستند.
همانطور که در محدودیت های قبلی نشان داده شده است، مدل اساساً با پارامترهای پیوسته توصیف می شود:
x ،
y ، عرض و عمق اتاق ها و همچنین عمق دیوارهای بیرونی و داخلی. شکل 2 b تابع چگالی احتمال عرض پارامتر پلان طبقه اتاق های اداری را نشان می دهد که با استفاده از تراکم هسته تخمین زده شده و با مخلوط گاوسی نصب شده آن مقایسه شده است. نشان داده شده است که هر توزیع دلخواه را می توان با یک مخلوط گاوسی تقریب زد ([ 16 ]):
مخلوطهای گاوسی راه مناسبی برای مدلسازی توزیعهای متقارن یا چندوجهی اریب هستند و تکیه بر تعدادی از الگوریتمهای استنتاج به خوبی مطالعه شده در ادبیات موجود را ممکن میسازند. با استفاده از حداکثر کردن انتظار ([ 16 ])، یک مخلوط گاوسی از m اجزا، که هر کدام با احتمال خود وزن میشوند. ωمن�منبرای هر پارامتر پیوسته، برای فرآیند استدلال تخمین زده می شود. از یک طرف، از توابع چگالی احتمال برای استخراج کران های بالا و پایین برای پارامترهای مدل پیوسته در طول انتشار محدودیت استفاده می شود. از سوی دیگر، دانش مهمی برای استنتاج آماری هستند.
4. انتشار محدودیت برای استخراج طرح طبقه توپولوژیکی
در مرحله اول، مدل پلان طبقات با محدودیتهایی بر روی چندین متغیر با حوزههای مرتبط تعریف میشود. محدودیتهایی که در بالا توضیح داده شد، این حوزهها را محدود میکنند تا راهحل نهایی به تعداد کمی از فرضیههای واجد شرایط منجر شود. در نتیجه، مشکل ما می تواند به عنوان یک مشکل رضایت محدودیت (CSP) دیده شود.. علاوه بر مقادیر پارامترهای مدل پیوسته که اتاق ها را تعریف می کنند، ما به پارامترهای گسسته بیشتر علاقه مندیم. در این زمینه، مطابقت پنجره ها با یک اتاق و همچنین روابط دوجانبه بین اتاق ها باید مشخص شود. معلوم می شود که این یک مشکل ترکیبی پیچیده است. ایده رویکرد ما حل مشکل رضایت محدودیت با توجه به مقادیر معتبر است که میتواند بعداً به عنوان نمونههای اولیه برای استدلال آماری استفاده شود. برای حل مشکلات رضایت از محدودیت ترکیبی، برنامه نویسی محدودیت یک چارچوب قدرتمند است.
یک مشکل رضایت از محدودیت با مجموعه ای از محدودیت ها مشخص می شود سی= {سی1، . . . ،سیq}سی={سی1،…،سی�}در دامنه ها D= {D1، . . . ،Dn}�={�1،…،��}از مجموعه ای از متغیرها ایکس= {ایکس1، . . . ،ایکسn}ایکس={ایکس1،…،ایکس�}که می تواند عددی-گسسته و همچنین پیوسته یا نمادین باشد. حاصلضرب دکارتی دامنه ها، به عنوان مثال، D1× _ . . ×Dn�1×…×��، فضای جستجوی اولیه را مشخص می کند. یک محدودیت سیمنسیمنبه عنوان یک رابطه در زیر مجموعه ای از متغیرها تعریف می شود ایکس“⊆ Xایکس”⊆ایکس، یعنی زیر مجموعه ای از D1× _ . . ×Dn�1×…×��. آنها می توانند بولی یا محاسباتی باشند که به وابستگی های خطی و همچنین غیرخطی اجازه می دهند. راه حل یک CSP نمونه ای از متغیرها است، به عنوان مثال، تخصیص مقادیر برای هر متغیر { (ایکس1،α1) ، . . . ، (ایکسn،αn) }{(ایکس1،�1)،…،(ایکس�،��)}با (α1، . . . ،αn) ∈D1× _ . . ×Dn(�1،…،��)∈�1×…×��به طوری که تمام محدودیت ها برآورده می شود. بنابراین، حل کننده محدودیت از اصل “محدود کردن و تولید” پیروی می کند تا فضای جستجو را محدود کند. استنتاج محدودیت قبل از یافتن نمونه های معتبر انجام می شود. در طول استنتاج، محدودیتهای جدید از محدودیتهای موجود استخراج میشوند و محدودیتهای موجود تشدید میشوند. این کار با استفاده از به اصطلاح الگوریتمهای اعمال سازگاری و انتشار محدودیت [ 28 ] انجام میشود.
جستجو از دامنه های شناخته شده پیشینی پارامترها و محدودیت های آنها سود می برد. در زمینه پلان های طبقات، پارامترهای مدل هر اتاق توسط جعبه مرزی تعریف شده توسط ردپای (مستطیل شکل) ساختمان محدود می شود. عرض و عمق اتاق ها به کاربری کاربردی بستگی دارد. به عنوان مثال، توالت ها معمولاً نمی توانند به بزرگی سالن های سخنرانی باشند. کران پایین و بالایی آنها را میتوان از مخلوطهای گاوسی که با استفاده از پایگاهداده حقیقت زمین برای اتاقها تخمین زده میشود، استخراج کرد. موقعیت اتاق ها بیشتر با موقعیت پنجره هایی که قبلاً از اندازه گیری های بیرونی مشخص هستند، محدود می شود. محدودیت های توضیح داده شده در بخش 3برای حذف نمونه های غیرممکن با انتشار محدودیت استفاده می شود. مورد دوم به معنای استنتاج محدودیت های اضافی یا محدود کردن محدودیت های موجود مانند محدود کردن دامنه ها است. به این ترتیب تعداد راه حل های ممکن کاهش می یابد. با این حال، مجموعه راه حل های ممکن می تواند شامل راه حل هایی باشد که با توجه به محدودیت ها سازگار نیستند. ادعا این است که جستجوی بعدی به استثنای ناسازگاریها را در اسرع وقت که منجر به ایجاد دامنههای با ارزش واحد میشود حذف کنید. در این زمینه، فضای جستجو تحت تأثیر سطح سازگاری است. بسیاری از دامنههای محدودیتها را میتوان به محض تغییر دامنه مرتبط با در نظر گرفتن سازگاری قوس بهروزرسانی کرد. یک متغیر ایکسمن∈Dمن, i = 1 . . . nایکسمن∈�من،من=1…�یک محدودیت (دودویی) با توجه به متغیر دیگری با قوس سازگار است ایکسj، j ≠ iایکس�،�≠مناگر، برای هر مقدار از ایکسمنایکسمن، یک نمونه برای وجود دارد ایکسjایکس�عدم نقض محدودیت با این حال، در برخی موارد، به عنوان مثال، محدودیت برابری که ما استفاده میکنیم، یک مفهوم کارآمدتر و به اندازه کافی قدرتمند برای اجرای چنین سازگاری، دستیابی به ثبات مرزها است. یک محدودیت C با n متغیر ایکس1، . . . ،ایکسnایکس1،…،ایکس�اگر برای هر متغیر با کران سازگار استایکسمن∈ [ A , B ] , i = 1 . . . nایکسمن∈[آ،ب]،من=1…�، نمونه هایی برای سایر متغیرها وجود دارد ایکسj، j ≠ i��,�≠�به طوری که C با توجه به نمونه ها راضی کننده است ایکسمن= A��=�و ایکسمن= ب��=�، به ترتیب. A و B کران پایین و بالای دامنه مربوط به متغیر را نشان می دهد ایکسمن��به عنوان یک فاصله نمایش داده می شود. اگر یک کران برای یک متغیر تغییر کند، فواصل جدید برای متغیرهای دیگر توسط قوانین انتشار محاسبه می شود تا فضای جستجو در دامنه ها کاهش یابد. به عنوان مثال، برای محدودیت ایکس= Y* ز�=�*�(به عنوان مثال، a r e a = w i dt h * de p t h����=����ℎ*����ℎ) با ایکس∈ [ A ، B ] ، Y∈ [ سی، د ]�∈[�,�],�∈[�,�]، ز∈ [ E، اف]�∈[�,�]و ایکس، ی، ز> 0�,�,�>0، محدوده بازه های Z را می توان به روز کرد [ A / D ، B / C][�/�,�/�].
جستجوی راه حل ها با پیمایش نمودار جستجو و یافتن مسیر حل به گره های برگ انجام می شود. یک گره یک متغیر را همراه با یک نمونه ممکن نشان می دهد. یک قوس عملگری را نشان میدهد که راهحل فعلی را با تخصیص مقدار به یک متغیر اضافی که با نمونههای قبلی در مورد محدودیتها تضاد ندارد، تقویت میکند. جستجو به طور کلی با بازگشت به عقب مشخص می شود. از یک جستجوی عمقی استفاده میکند و اگر جستجو به بنبست منجر شود، به حالتهای قبلی (گرهها در نمودار جستجو) بازمیگردد. بن بست، ترکی است که با محدودیت ها ناسازگار است، به این معنی که دامنه متغیر مربوطه آن پس از انتشار محدودیت خالی می شود. به منظور انجام جستجو با کمترین شکست ممکن و جلوگیری از عقب نشینی، دو اصل در طول جستجو به صورت پویا دنبال می شود: نگاه به جلو و نگاه به عقب. اولی بهترین انتخاب را برای متغیر بعدی و مقدار آن تعیین می کند، در حالی که دومی به سطحی می پردازد که الگوریتم در صورت بن بست به عقب می پرد. جزئیات بیشتر در مورد پردازش محدودیت را می توان در [28 ، 29 ].
پیاده سازی های مختلفی از حل کننده های محدودیت وجود دارد [ 29 ]. علاوه بر الگوریتم های جبری، نمادین یا مبتنی بر نمودار، یک پیاده سازی برجسته برنامه نویسی منطقی محدودیت است که با استفاده از برنامه نویسی منطقی تحقق می یابد. CLP از ویژگی های اعلامی برنامه های منطقی و استراتژی های جستجوی قدرتمند برنامه های محدودیت به منظور تعریف و حل مشکلات رضایت از محدودیت سود می برد. استراتژی جستجو در برنامه نویسی منطقی با عقبگرد با جستجوی عمقی مشخص می شود. قیود با روابط و محمولات در زبان منطقی مطابقت دارند. حلکنندههای محدودیت (منطقی) همانطور که در پیادهسازی ما استفاده میشود، ابزار قدرتمندی برای رسیدگی به محدودیتهای غیرخطی با بیش از یک ناشناخته هستند.
نقطه قوت CLP حل مسائل ترکیبی به روشی اعلامی است. این امر علاوه بر روابط از پیش تعریف شده امکان تعریف روابط سفارشی شده را به روشی ساده و انعطاف پذیر می دهد. “مشکلات ترکیبی را می توان حل کرد که معمولاً دارای پیچیدگی نمایی هستند” [ 30 ]. در زمینه خود، ما از این واقعیت استفاده می کنیم که دیوارهای جداکننده اتاق ها از پنجره ها عبور نمی کنند. ما این محدودیت را به عنوان یک رابطه منطقی بیان کردیم. قبل از جستجوی راه حل ها، مقادیر ممکن (گسسته) را برای x برشمردیم- مختصات هر اتاق به استثنای اتاق هایی که در محدوده پنجره قرار دارند. با بهرهبرداری از دانش معماری، مجبور نیستیم با فضای جستجوی پیوسته بینهایت پیشینی کنار بیاییم. در عوض، مسئله را به شمارشی از مقادیر جالب منتقل میکنیم تا الگوریتم جستجو، آرایش اتاقها را بسیار سریعتر از رسیدگی به دامنههای پیوسته بینهایت پیدا کند. مهمترین مقدار آن چیزی است که در وسط بین دو پنجره قرار دارد. دلیل این امر این است که بیشتر دیوارها بین پنجره ها قرار دارند. این سطح بالای گسسته به ویژه برای اتاق هایی که دارای پنجره اجباری هستند مانند اتاق های اداری معتبر است. اتاقهای دیگر با کاربردهای مختلف بهعنوان مثال، راهروها حذف شدهاند و حوزههای آنها با فواصل با دقت دسیمتر نشان داده میشوند.
گسسته سازی در امتداد محور x منجر به نمونه سازی آسان تر از پارامترهای دیگر می شود. اگر، برای من تا ساعت��ℎاتاق، ایکسمن��و ایکسm a xمن�����تعیین می شوند، عرض wمن=ایکسm a xمن–ایکسمن��=�����−��می توان متعاقباً مشتق شد (ر.ک. شکل 3 ). به همین ترتیب، تخصیص عمق از تخصیص قبلی عرض با توجه به محدودیت پیروی می کند. a r e a =دمن*wمن����=��*��. با پیروی از این الگو، ما در حال تبدیل محدودیت ها به توابع با تنها یک پارامتر ناشناخته هستیم. مختصات y _ yمن��توسط پنجره مربوطه تعیین می شود، که حداقل است ym i n����یا حداکثر ym a x����به ترتیب، بسته به موقعیت پنجره. اگر پنجره در سمت جلوی زمین قرار دارد، yمن– w a lلe x t��−�������برابر با کران پایین است ym i n����از کف در غیر این صورت، اگر پنجره در طرف مقابل قرار دارد، ym a xمن+ w a lلe x t�����+�������برابر است ym a x����.
ما آگاه هستیم که انتقال از مقادیر پیوسته به مقادیر گسسته تضمینی برای مطابقت با مقادیر مورد انتظار نیست. ما به طور موقت دیوارها را نادیده گرفتیم تا بافرهایی را برای انحرافات رخ داده پس از گسسته سازی مقدار فراهم کنیم. در این زمینه متغیرها w a lلمن n t�������و w a lلe x t�������در این مرحله نباید تعیین شود. در نتیجه، شکاف های نامنظم بین اتاق ها وجود دارد و تراز اتاق ها در امتداد راهرو به طور خودکار مشخص نمی شود. علاوه بر این، اندازهگیریهای نامشخص در طول استدلال ترکیبی در نظر گرفته نشد. شکل 5 در ردیف دوم نتیجه میانی را نشان می دهد که با انتشار محدودیت پیدا می شود. اگر چه نتیجه از نظر توپولوژیکی صحیح است و محدودیت های داده شده را که مدل پلان طبقه را تعریف می کنند برآورده می کند، باید در مرحله بعدی از نظر هندسی تطبیق داده شود. در بخش بعدی به تفصیل توضیح داده خواهد شد.
5. مدل های گاوسی خطی شرطی برای پیش بینی پلان طبقه تصادفی
همانطور که در بخش قبل گفته شد، انتشار محدودیت یک نتیجه متوسط با یک توپولوژی صحیح، اما پارامترهای هندسی کمتر از حد مطلوب به دست میدهد. اتاق های مقدماتی پیش بینی شده کل فضای ردپا را پر نمی کنند. به ویژه، تراز اتاق ها در امتداد یک راهرو تضمین نمی شود. استدلال ترکیبی مقادیر اولیه ای را ارائه می دهد که به روز و اصلاح می شوند. نتیجه از نظر توپولوژیکی معادل می ماند اما از نظر هندسی متفاوت می شود تا با اندازه گیری های ارائه شده مطابقت داشته باشد. پس از پرداختن به کار ترکیبی که منجر به یک راه حل سازگار از نقطه نظر توپولوژیکی می شود، بر بستن شکاف بین اتاق ها تمرکز می کنیم. در این مرحله می توان استنباط دقیقی را برای ارضای این وظیفه انجام داد.
استنتاج در چارچوب یک استدلال تصادفی که دسترسی به الگوریتم های آماری شناخته شده را می دهد تحقق می یابد. مدل عملکردی اساساً توسط دو نوع محدودیت تعریف می شود که ثبات هندسی را تضمین می کند. مهمترین محدودیت، رابطه محلی بین دو اتاق مجاور را توصیف می کند. ما از این واقعیت استفاده می کنیم که مولفه ترکیبی روابط دوجانبه بین اتاق ها را پیدا می کند. به عنوان مثال، اگر
من تا ساعت��ℎاتاق به
j t h��ℎاتاق، سپس مختصات آنها با:
این محدودیت نه تنها مجاورت بین اتاق ها، بلکه تراز اتاق ها در امتداد راهروها را نیز اعمال می کند. این نتیجه اتاق های مستطیلی شکل طبق فرض جهان منهتن است. لازم به ذکر است که محدودیت ( 8 ) بخشی از محدودیت ( 6 ) است زیرا جنبه های توپولوژیکی دیگر لازم نیست در نظر گرفته شوند.
مشابه محدودیت ( 4 )، مکان دقیق نقطه مرجع هر اتاق با استفاده از اطلاعات مربوط به تناظر پنجره ها با اتاق ها از قسمت ترکیبی تصحیح می شود:
باز هم، این محدودیت به طور مثال برای پنجرهها (و اتاقهای مرتبط با آنها) که در سمت جلوی کف قرار دارند، صادق است.
به منظور انجام یک استدلال تصادفی، ما از توابع چگالی احتمال استفاده میکنیم که عدم قطعیت پارامترهای مدل را بررسی میکنند. می توان بیان کرد که دانش قبلی در اصل نه گوسی است و نه تک وجهی. این گفته را می توان در شکل 2 تایید کردb با عرض اتاق به عنوان بخش مهمی از دانش پس زمینه تصادفی ما مثال می زند. توزیعهای غیر گاوسی و چندوجهی برای استدلال کارآمد و دقیق مناسب نیستند. قبلاً اشاره کردیم که با استفاده از مخلوطهای گاوسی بر این مانع غلبه میکنیم. هنگامی که از مدل میانی قسمت ترکیبی به عنوان نقطه شروع برای تخمین تصادفی پارامترهای هندسی استفاده می کنیم، هر پارامتر مدل به یک جزء از مخلوط گاوسی مربوط می شود. با استفاده از این رویکرد، می توانیم با خیال راحت فرض کنیم که پارامترها به طور معمول در موارد زیر توزیع شده اند و دیگر چندوجهی نیستند. ما اکنون در یک زمینه خاص و کاملاً درک شده از استدلال تصادفی با مدلهای گرافیکی احتمالی هستیم.
مدلهای گرافیکی احتمالی امروزه یکی از برجستهترین و قویترین روشها برای استدلال در حوزههای نامشخص هستند. شبکههای بیزی یکی از انواع مدلهای گرافیکی هستند که توسط گرافهای هدایتشده، جایی که هر گره در آن نمایش داده میشود
v ∈ V�∈�مربوط به یک متغیر تصادفی است
ایکسv��و جایی که عدم وجود لبه ها نشان دهنده استقلال بین این پارامترهای مدل است ([ 12 ]). متغیرهای تصادفی با توزیع احتمال شرطی (CPD) مشخص می شوند.
پ(ایکسv∣∣ایکسp a ( v ))�(��|���(�))که احتمالاتی را برای وضعیت هر متغیر وابسته به نمونه سازی گره های والد آن می دهد
p a ( v )��(�)، که پیشینیان بلافصل آن بر اساس نمودار القا شده اند. ساختار نمودار یک نمایش فشرده از یک توزیع مشترک را امکان پذیر می کند و راه را برای یک استنتاج کارآمد به منظور تعیین توزیع پسین با توجه به یک مشاهده هموار می کند. مدل پلان طبقه ارائه شده با محدودیت هایی بر روی متغیرهای گسسته و پیوسته تعریف می شود و بنابراین باید توسط شبکه های ترکیبی که توسط گره های مرتبط با متغیرهای گسسته و پیوسته مشخص می شوند، نمایش داده شود.
ایکس=ایکسΔ∪ایکسΓایکس=ایکسΔ∪ایکسΓ. برخلاف استدلال تقریبی، استنتاج دقیق در شبکه های ترکیبی به طور کلی امکان پذیر نیست. امکان سنجی با مفروضات اضافی حاصل می شود، مانند اینکه پارامتر
X معمولاً با میانگین
μ و واریانس توزیع می شود.
σ2�2:
یک مورد خاص از شبکههای بیزی، شبکه گاوسی خطی شرطی (CLG) است ([ 31 ، 32 ]) که توزیعهای گاوسی را برای پارامترهای پیوسته فرض میکند. همه متغیرهای پیوسته باید توسط CPDهای گاوسی خطی مشروط توصیف شوند و گرههای پیوسته متناظر آنها اجازه ندارند والد یک گره گسسته باشند. یک CPD گاوسی خطی شرطی با
من⊆ایکسΔمن⊆ایکسΔو
ز⊆ایکسΓز⊆ایکسΓبه عنوان … تعریف شده است
جایی که μτ��یک مقدار متوسط برای نمونه τ است ، βτ��بردار ضرایب رگرسیون و στ��واریانس مربوطه
بنابراین توزیع مشترک در یک شبکه هیبریدی را می توان به عنوان یک تعریف کرد
|ایکسΓ||ایکسΓ|توزیع گاوسی بعدی
برای هر نمونه τ از ایکسΔایکسΔ([ 33 ]).
در زمینه مدلسازی پلان طبقه، مشکل ما به خوبی با مفروضات CLG مطابقت دارد. بنابراین، ما از یک شبکه CLG به منظور مدل سازی عدم قطعیت و بهبود نتیجه میانی از CLP استفاده می کنیم. انتخاب اجزای مخلوطهای گاوسی به ما اجازه میدهد از یک شبکه بیزی ساختار یافته استفاده کنیم: یک مدل مشاهده حالت با بردار حالت n بعدی.x∈ _آرnایکس∈آر�نشان دهنده پارامترهای مدل و یک بردار مشاهده m بعدیo ∈آرمتر�∈آرمترکه با نقشه برداری قابل توصیف است o = Mایکس�=مایکسبا ماتریس اندازه گیری م∈آرn × mم∈آر�×متر. برای چنین تخمین حالتی، مرحله تصحیح فیلتر کالمن یک الگوریتم کارآمد برای محاسبه پسین است. فرض میکند که انتقال حالت و اندازهگیری را میتوان به صورت خطی توصیف کرد و باورهای اولیه با توزیعهای گاوسی چند متغیره نشان داده میشوند.
در زمینه ما، توزیعهای گاوسی با
μ و
σ از حلکننده محدودیت استدلالگر منتقل میشوند و به منظور مدلسازی دیوارهای بیرونی و داخلی با دو بعد افزایش مییابند. مدل عملکردی نشان داده شده توسط ماتریس اندازه گیری
M با توجه به معادلات ( 8 ) و ( 9 ) تعریف شده است. لازم به ذکر است که در این مورد نسبت به معادله ( 6) برابری پارامترها به تفریق برابر با صفر تبدیل می شود. به این ترتیب می توان از مدل مشاهده حالت با شبه مشاهده برابر با صفر استفاده کرد. پسین با ضرب های ماتریسی مشابه مرحله تصحیح فیلتر کالمن محاسبه می شود. سود کالمن
برای به روز رسانی استفاده می شود، یعنی برای تنظیم نتیجه میانی جزء ترکیبی و توزیع های گاوسی توسط به روز رسانی می شوند.
جایی که س∈ _آرمتر × مترس∈آرمتر×مترنویز گاوسی مشاهدات و Id ماتریس هویت است.
در نهایت، محتمل ترین تکلیف (تخصیص MAP) برای شواهد ارائه شده E= e�=هبا به حداکثر رساندن احتمال خلفی برای متغیرها پیدا می شود دبلیو= X\ Eدبلیو=ایکس\�: مA P( W| ه ) =ارگحداکثرωپ( ω , e )مآپ(دبلیو|ه)=ارگحداکثر�پ(�،ه). هدف کار ارائه شده یافتن k محتمل ترین توضیح است که با نشان داده شده است مآپک( W| ه ) ،مآپک(دبلیو|ه)،به منظور ارزیابی کیفیت راه حل ها.
استدلال کننده وسایلی را فراهم می کند
μمن∈آر|ایکسΓ|�من∈آر|ایکسΓ|برای پارامترهای مدل پیوسته از
من تا ساعتمنتیساعتفرضیه و مصادیق مرتبط
τمن∈آر|ایکسΔ|�من∈آر|ایکسΔ|برای متغیرهای گسسته فرضیه های نهایی بر اساس احتمالات (غیر عادی) آنها مرتب می شوند
پمنپمنمحاسبه شده بر اساس توزیع های پیشینی شناخته شده:
جایی که p df01jپد��01روشن است [ 0 . . . 1 ][0…1]چگالی مقیاس شده توزیع مربوط به j t h�تیساعتپارامتر مدل ما در نهایت مجموعه ای از فرضیه های محتمل ترین پلان های طبقه را با توجه به مشاهدات زیر بدست می آوریم:
از آنجایی که در این مرحله میتوانیم توزیعهای گاوسی را فرض کنیم، احتمال فرضیهها بر اساس ماتریسهای کوواریانس داده شده و باقیماندهها به روش معمولی محاسبه میشود. توابع چگالی احتمال برای هر پارامتر مدل امکان ارزیابی احتمال هر فرضیه و ترتیب آنها را بر اساس آن فراهم می کند.
6. نتایج و بحث
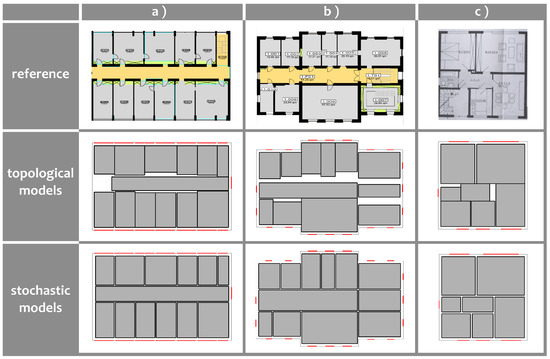
در نتیجه، استدلالگر به طور خودکار محتملترین نقشههای طبقه را در تقریباً همه موارد در یک دستگاه ویندوز 64 بیتی (3.4 گیگاهرتز، 16 گیگابایت رم) در کمتر از یک ثانیه نشان میدهد. ما انحرافات استاندارد را 10 سانتی متر برای مکان پنجره ها در نظر گرفتیم و در موارد آزمایشی خود، دقت پارامترهای مدل را بین 10 تا 20 سانتی متر بدست آوردیم. نتایج در شکل 5 خلاصه شده است. هر پلان طبقه پیش بینی شده در ردیف آخر با بهترین فرضیه رتبه بندی شده توسط رویکرد ما مطابقت دارد. ردیف دوم نتایج میانی ارائه شده توسط انتشار محدودیت را نشان می دهد. برای مقایسه، پلان طبقه مرجع در ردیف اول به تصویر کشیده شده است. کیفیت نتایج بستگی به این دارد که چقدر پلان های طبقات با توجه به توزیع های حاصل از دانش قبلی هنجار را برآورده می کنند.
مشاهده می شود که مؤلفه استدلال در قسمت ترکیبی مطابقت پنجره ها با اتاق ها را تخمین می زند و مکان تقریبی هر اتاق را تعیین می کند. مدل سازی نکردن دیوارهای داخلی بافری را فراهم می کند که از حفظ صحت توپولوژیکی پشتیبانی می کند. همسانی هندسی در مرحله بعدی نیز در نظر گرفته می شود. جزء آماری با تنظیم پارامترهای شکل و مکان و عمق دیوارها شکاف ها را پر می کند. تراز اتاق ها در امتداد راهروهای موجود نیز تضمین می شود. نتایج فهرستشده فرآیند استدلال ما بهطور مثالی نقشههای طبقه پیشبینیشده با توجه به نیازهای مختلف را نشان میدهد. ستون اول یک پلان مستطیل شکل از یک ساختمان اداری را نشان می دهد. بیشتر ساختمان ها با شکل مستطیلی مشخص می شوند. ستون دوم یک پلان طبقه را نشان می دهد که فرض مستطیل بودن را برآورده نمی کند. در این حالت با افزودن چهار اتاق کمکی به شکل مستطیل تطبیق داده می شود. با این وجود، غیر مستطیلی بودن سودمند است و می توان از آن برای تعیین نقاط شبکه برای گسسته سازی استفاده کرد.x – مختصات. در حالی که یک ردپای مستطیلی بدون ساختار ساده هیچ اطلاعاتی در مورد دیوارها ارائه نمی دهد، در این مورد، مرزهای چپ و راست برآمدگی ها نشان دهنده یک دیوار داخلی به عنوان مرزی برای یک اتاق در این موقعیت است. ردیف آخر نتایج استدلال برای پلان طبقه در یک خانه مسکونی را به تصویر می کشد. ویژگی خاص این نوع پلان طبقه این است که اتاق ها معمولاً شماره شناسایی ندارند که بتواند مکان آنها را محدود کند.
چگونگی تأثیر دانش در مورد اعداد اتاق بر پیش بینی در شکل 6 نشان داده شده است . با توجه به محدودیت نرم اتاق های مجاور در مورد شماره اتاق های متعاقب، استدلال کننده ترتیب صحیح اتاق ها را پیدا می کند و بنابراین نقشه طبقه را پیش بینی می کند. از نتیجه سمت چپ استفاده از کران بالایی برای تعداد نقض محدودیت نرم اجتناب می شود، به طوری که تنها اتاق های 1.006 و 1.007 مجاور نیستند. علاوه بر این، دانش یک تناظر واحد از یک اتاق به یک پنجره، روند استدلال را تسریع می کند. این واقعیت به ویژه برای اتاقهایی که پنجرههای مرتبط با آنها به راحتی از بیرون قابل شناسایی هستند، مانند مورد پلهها بسیار مفید است.
اشتقاق یک مدل سه بعدی داخلی از پلان های پیش بینی شده طبقات
تا به حال، ما توضیح دادهایم که چگونه میتوان پلانهای طبقه را بدون هیچ گونه اندازهگیری داخلی تخمین زد. این مدل دوبعدی با اکسترود کردن دیوارهای اتاق ها و قرار دادن پنجره ها و درها به مدل سه بعدی گسترش یافته است. پنجره ها به طور پیشینی از اندازه گیری های فضای باز شناخته می شوند. درها را می توان با توجه به توزیع های موجود مکان درب ها از داده های مشروح پیش بینی کرد. شکل 7 این توزیع ها را نشان می دهد، جایی که مکان های احتمالی یک در به چپ، راست یا وسط تقسیم می شوند. فرضیه ها بسته به اندازه اتاق ها به دست می آیند که بر توزیع تأثیر می گذارد.
ارتفاع دیوارها به نوبه خود از ارتفاع نما و موقعیت پنجره ها حاصل می شود. همانطور که در [ 13 ] توضیح داده شد، ارتفاع هر طبقه را می توان به راحتی توسط تخمین تراکم هسته بر اساس ابرهای نقطه سه بعدی نما بدست آورد. از آنجایی که پنجره ها معمولاً در ارتفاع باسن قرار می گیرند، می توان از دانش برای پیش بینی موقعیت کف در داخل ساختمان استفاده کرد.
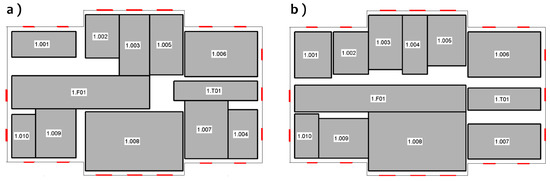
شکل 8 مدل داخلی سه بعدی مربوط به پلان طبقه مشتق شده در شکل 5 ب را نشان می دهد. در اتاق هایی با عرض کمتر از 3 متر، درها بیشتر در وسط دیوار مشترک با راهرو قرار می گیرند. در اتاق های بزرگتر، هیستوگرام نشان می دهد که موقعیت چپ و راست درب محتمل تر است. درها در مدل سه بعدی ما بر اساس این توزیع ها پیش بینی می شوند. قوانین خاصی به منظور مدل سازی ویژگی های معماری معرفی شده است. به عنوان مثال، برای اتاق های سمت راست ساختمان، درها را نمی توان نزدیک به دیوار سمت راست قرار داد، همانطور که با توزیع آموخته شده نشان می دهد، زیرا پله ها از این قرارگیری جلوگیری می کنند (به تصویر مرجع در شکل 5 مراجعه کنید .ب علاوه بر این، در توالتهای کوچک، مانند اتاق 1.010، در وسط قرار نمیگیرد، زیرا باید از فضا برای قرار دادن سینک نزدیک در استفاده شود. اتاق دادگاه در ساختمانهای میراث فرهنگی، مانند مورد اینجا، معمولاً در را روی دیوار قرار میدهد در حالی که سالنهای سخنرانی یا سالنها به دلیل ردیفهای صندلیها و راهرو دسترسی آنها، در را در سمت چپ یا راست قرار میدهند. موارد مثبت کاذب پیشبینی درب ما با خطوط نقطهدار سبز مشخص شدهاند. کار آینده این موضوع را بر اساس یک وظیفه طبقه بندی نظارت شده در نظر خواهد گرفت تا درها را به روشی قوی تر پیش بینی کند.
7. نتیجه گیری
این مقاله یک رویکرد جدید برای پیشبینی پلانهای طبقه بدون نیاز به اندازهگیری داخلی ارائه میکند. الگوریتم دانش قبلی را با توزیع احتمال پارامترهای مدل از یک سو و محدودیتهای خطی و دوخطی از سوی دیگر، با استفاده از تحلیل دادههای گسترده نشان میدهد. این تجزیه و تحلیل بر اساس یک پایگاه داده بزرگ از حدود 1600 ساختمان است که از جمله پارامترهای شکل و مکان اتاق ها را نشان می دهد. توزیعهای پارامتری توسط مخلوطهای گاوسی نشان داده میشوند که از یک سو برای مدلسازی توزیعهای چندوجهی به اندازه کافی انعطافپذیر هستند و از سوی دیگر میتوان در رویکرد ما به توزیعهای گاوسی منفرد کاهش داد که امکان استنتاج تصادفی دقیق را فراهم میکند.
برای اینکه بتوانیم استنتاج تصادفی دقیق را در مدلهای پیچیده اعمال کنیم، پردازش محدودیت را با یک مدل گرافیکی گاوسی خطی شرطی ترکیب میکنیم. مشکل ترکیبی اختصاص دادن هر پنجره به یک اتاق و تعیین روابط دوجانبه بین اتاق ها با انتشار محدودیت حل می شود که منجر به مدل های توپولوژیکی اولیه می شود. این نتیجه میانی توسط یک مؤلفه آماری تنظیم میشود که اتاقها را در امتداد راهروها تا جایی که ممکن است تراز میکند و دیوارهایی را که مدل پلان طبقه را تکمیل میکنند، تخمین میزند.
در ابتدا تصور می کردیم که پلان ها و اتاق ها مستطیل شکل هستند. با این حال، شکل 8 نشان می دهد که چگونه یک پسوند اجازه می دهد تا اشکال کلی تری از پلان های طبقه را فراهم کند. می دانیم که چیدمان اتاق های کلی تری مانند اتاق های L، T یا حتی U شکل وجود دارد. علیرغم اینکه این اشکال اتاق ها به نظر می رسد که فرضیات اساسی در رویکردهای کلی را نقض می کنند، ما معتقدیم که می توان آنها را به عنوان ترکیبی از دو یا چند اتاق مستطیل شکل مدل کرد. در حالی که به نظر می رسد مدل سازی تصادفی امکان پذیر است، مدل سازی و طراحی محدودیت ها برای حل کننده محدودیت موضوع کار آینده خواهد بود.
بر اساس پلان های پیش بینی شده طبقات، یک مدل سه بعدی داخلی با استفاده از نظم های معماری و توزیع احتمال برای پیش بینی درها ساخته می شود. ارتفاع کف از فاصله بین پنجره ها از طبقات بعدی استخراج می شود. مکانهای درب با استفاده از مخلوطهای گاوسی پیشبینی میشوند، در حالی که پارامترهای شکل درها از توابع چگالی احتمال بسته به سبک ساختمان مشتق میشوند.
در این مقاله، نمونه ها به گونه ای انتخاب شده اند که نشان دهنده مدل های مستطیلی هستند که بخش قابل توجهی از اتاق های اداری و همچنین پلان های غیر مستطیلی را پوشش می دهند. ما نه تنها سبک های ساختمانی پس از جنگ را در نظر گرفتیم، بلکه ساختمان هایی را که از ابتدای قرن گذشته نشات گرفته بودند نیز در نظر گرفتیم. این مقاله همچنین به خانه های مسکونی می پردازد. چیدمان اتاق های پیچیده تر در این زمینه موضوع مقاله آینده خواهد بود.
اخیراً ادغام مدل های BIM و فضای باز در قالب CityGML توجه بیشتری را به خود جلب کرده است. BIM یک موضوع داغ در زمینه صنعت ساخت و ساز است و از فرآیند ساخت و ساز و مدیریت تسهیلات پشتیبانی می کند. در حالی که در گذشته نه چندان دور، مدلهایی در زمینه اطلاعات جغرافیایی و CityGML بر سطوح بیرونی ساختمان متمرکز شدهاند، جنبههای سازنده و ساختمانهای داخلی از نقطهنظر BIM اصلیترین نقاط مورد توجه هستند. ما معتقدیم که در مواردی که مدلهای BIM در دسترس نیستند، رویکرد ما که مدلهای داخلی را بدون اندازهگیریهای اضافی پیشبینی میکند، پیوندی بین BIM و CityGML ایجاد میکند.







بدون نظر