

خلاصه
دادههای فضایی برای تحلیلهای مرزی از جغرافیا، منابع طبیعی، جمعیتشناسی، سیاست، اقتصاد و فرهنگ اساسی هستند. از آنجایی که دادههای مکانی مورد استفاده در تحقیقات مرزی معمولاً مناطق مرزی چندین کشور همسایه را پوشش میدهند، جمعآوری آنها برای هر مؤسسه تحقیقاتی دولتی دشوار است. اطلاعات جغرافیایی داوطلبانه (VGI) یک روش بسیار موفق برای دستیابی به موقع و دقیق داده های مکانی جهانی با هزینه بسیار کم است. بنابراین، VGI منبع معقولی از دادههای فضایی مرزی است. OpenStreetMap (OSM) به عنوان موفق ترین منبع VGI شناخته می شود. با این حال، مدل داده OSM بسیار متفاوت از مدل سنتی اطلاعات جغرافیایی است. بنابراین، داده های OSM باید در مدل داده های سفارشی شده دانشمند تبدیل شوند. زیرا دنیای واقعی به سرعت تغییر می کند، داده های تبدیل شده باید به صورت تدریجی به روز شوند. بنابراین، این مقاله روشی را ارائه میکند که برای ادغام پویا دادههای OSM در پایگاه داده مرزی استفاده میشود. در این روش، با مقایسه سند توصیف ویژگی نقشه OSM و تعاریف مدل مقصد، یک پایه قانون تبدیل اولیه تشکیل میشود. با استفاده از قوانین اولیه می توان ویژگی های اصلی را به صورت خودکار به مدل مقصد تبدیل کرد. یک تغییر مدل تعامل انسان و کامپیوتر و یک مکانیسم قانون/به خاطر سپردن خودکار برای انتقال تعاملی ویژگیهای غیرمعمولی که با قوانین اساسی نمیتوانند به مدل هدف منتقل شوند و قوانین قابل استفاده مجدد را بهطور خودکار به خاطر بسپارند، ایجاد شدهاند. برای به روز نگه داشتن پایگاه داده مرزی، از فایل جهانی تفاوت روزانه OsmChange برای استخراج اطلاعات فقط تغییر برای منطقه تحقیق استفاده می شود. برای استخراج اشیاء تغییر یافته در منطقه مورد مطالعه، رابطه بین شی تغییر یافته و منطقه تحقیقاتی با توجه به تکامل اشیاء درگیر تحلیل میشود. علاوه بر این، پنج قانون برای انتخاب اشیاء و ادغام اشیاء تغییر یافته با نسخه های چندگانه در طول زمان تعیین شده است. تکامل نوع تغییر اشیا مورد تجزیه و تحلیل قرار می گیرد و از هفت قانون برای تعیین نوع تغییر اشیاء تغییر یافته استفاده می شود. بر اساس این قوانین و الگوریتم ها، ما یک سیستم نمونه اولیه (یا نیمه خودکار) یکپارچه سازی و به روز رسانی خودکار را برای پایگاه داده مرزی برنامه ریزی کردیم. سیستم توسعهیافته بهطور فشرده با استفاده از دادههای OSM برای ویتنام و پاکستان به عنوان دادههای تجربی آزمایش شد. رابطه بین شی تغییر یافته و منطقه تحقیقاتی با توجه به تکامل اشیاء درگیر تحلیل میشود. علاوه بر این، پنج قانون برای انتخاب اشیاء و ادغام اشیاء تغییر یافته با نسخه های چندگانه در طول زمان تعیین شده است. تکامل نوع تغییر اشیا مورد تجزیه و تحلیل قرار می گیرد و از هفت قانون برای تعیین نوع تغییر اشیاء تغییر یافته استفاده می شود. بر اساس این قوانین و الگوریتم ها، ما یک سیستم نمونه اولیه (یا نیمه خودکار) یکپارچه سازی و به روز رسانی خودکار را برای پایگاه داده مرزی برنامه ریزی کردیم. سیستم توسعهیافته بهطور فشرده با استفاده از دادههای OSM برای ویتنام و پاکستان به عنوان دادههای تجربی آزمایش شد. رابطه بین شی تغییر یافته و منطقه تحقیقاتی با توجه به تکامل اشیاء درگیر تحلیل میشود. علاوه بر این، پنج قانون برای انتخاب اشیاء و ادغام اشیاء تغییر یافته با نسخه های چندگانه در طول زمان تعیین شده است. تکامل نوع تغییر اشیا مورد تجزیه و تحلیل قرار می گیرد و از هفت قانون برای تعیین نوع تغییر اشیاء تغییر یافته استفاده می شود. بر اساس این قوانین و الگوریتم ها، ما یک سیستم نمونه اولیه (یا نیمه خودکار) یکپارچه سازی و به روز رسانی خودکار را برای پایگاه داده مرزی برنامه ریزی کردیم. سیستم توسعهیافته بهطور فشرده با استفاده از دادههای OSM برای ویتنام و پاکستان به عنوان دادههای تجربی آزمایش شد. تکامل نوع تغییر اشیا مورد تجزیه و تحلیل قرار می گیرد و از هفت قانون برای تعیین نوع تغییر اشیاء تغییر یافته استفاده می شود. بر اساس این قوانین و الگوریتم ها، ما یک سیستم نمونه اولیه (یا نیمه خودکار) یکپارچه سازی و به روز رسانی خودکار را برای پایگاه داده مرزی برنامه ریزی کردیم. سیستم توسعهیافته بهطور فشرده با استفاده از دادههای OSM برای ویتنام و پاکستان به عنوان دادههای تجربی آزمایش شد. تکامل نوع تغییر اشیا مورد تجزیه و تحلیل قرار می گیرد و از هفت قانون برای تعیین نوع تغییر اشیاء تغییر یافته استفاده می شود. بر اساس این قوانین و الگوریتم ها، ما یک سیستم نمونه اولیه (یا نیمه خودکار) یکپارچه سازی و به روز رسانی خودکار را برای پایگاه داده مرزی برنامه ریزی کردیم. سیستم توسعهیافته بهطور فشرده با استفاده از دادههای OSM برای ویتنام و پاکستان به عنوان دادههای تجربی آزمایش شد.
کلید واژه ها:
ادغام _ OSM ; تبدیل مدل ; قاعده ؛ چند نسخه ؛ به روز رسانی تدریجی
1. معرفی
داده های مکانی برای تجزیه و تحلیل های مرزی از جغرافیا، منابع طبیعی، جمعیت شناسی، سیاست، اقتصاد، فرهنگ و غیره اساسی هستند. از آنجا که داده های مکانی مورد استفاده در تحقیقات مرزی معمولاً مناطق مرزی چندین کشور همسایه را پوشش می دهد، برای هر موسسه تحقیقاتی یا دولتی دشوار است. برای جمع آوری طی چند سال گذشته، علاقه به اطلاعات جغرافیایی داوطلبانه (VGI)، که به دادههای جمعسپاری نیز معروف است، به سرعت رشد کرده است. VGI یک روش بسیار موفق برای دستیابی به موقع و دقیق داده های مکانی جهانی با هزینه کم است. بنابراین، VGI یکی از منابع معقول دادههای فضایی مرزی است [ 1]. با این حال، VGI به طور داوطلبانه توسط آماتورها (یا “نئوجغرافیان”) بدون مقررات دقیق یا آموزش رسمی تولید می شود. VGI معمولاً شامل محدودیتهای زیر است: (1) دادههای جعلی یا با کیفیت پایین و (2) بینظمی در کامل بودن آن. این محدودیت ها بر آمادگی VGI برای استفاده تأثیر می گذارد. برای تجزیه و تحلیل مرزی، باید بر این محدودیت ها غلبه کرد. یک روش معقول برای غلبه بر این محدودیتها، ادغام VGI کمهزینه با منبع دیگری از دادههای حرفهای برای بهبود کامل بودن آن، حذف دادههای جعلی یا با کیفیت پایین و بهروزرسانی تدریجی دادهها است. با این حال، مدل داده VGI به طور کلی با مدل سنتی کاربر سیستم اطلاعات جغرافیایی (GIS) متفاوت است. برای مثال، OpenStreetMap (OSM) به عنوان موفق ترین پروژه VGI شناخته می شود. با این حال، اصول هندسی OSM شامل گره، راه، و رابطه به جای نقطه، خط و چند ضلعی، مانند مدل سنتی GIS. همه انواع خیابان ها و مسیرها با یک برچسب مبهم “بزرگراه” مشخص می شوند که بسیار متفاوت از اطلاعات جغرافیایی سنتی و عقل سلیم است. علاوه بر این، از آنجایی که دادههای OSM توسط یک سیستم برچسبگذاری رایگان جمعآوری میشوند، بسیاری از ویژگیهای غیرعادی توسط جغرافیدانان جدید بر اساس عادتهای ارتباطی آنها برچسبگذاری میشوند. برخی از دادههای OSM را میتوان در پایگاههای داده شکلفایل از وبسایتهای شرکت دانلود کرد (مثلاً Geofabrik). با این حال، شکل فایل مشتق شده مجموعه ای از ویژگی ها و ویژگی های داده های OSM اصلی است. بر این اساس، بسیاری از ویژگیهای غیرمعمول در شکل فایل مشتقشده در دسترس نیستند، همه ویژگیهای ناحیه پیچیده وجود ندارند [ که بسیار متفاوت از اطلاعات جغرافیایی سنتی و عقل سلیم است. علاوه بر این، از آنجایی که دادههای OSM توسط یک سیستم برچسبگذاری رایگان جمعآوری میشوند، بسیاری از ویژگیهای غیرعادی توسط جغرافیدانان جدید بر اساس عادتهای ارتباطی آنها برچسبگذاری میشوند. برخی از دادههای OSM را میتوان در پایگاههای داده شکلفایل از وبسایتهای شرکت دانلود کرد (مثلاً Geofabrik). با این حال، شکل فایل مشتق شده مجموعه ای از ویژگی ها و ویژگی های داده های OSM اصلی است. بر این اساس، بسیاری از ویژگیهای غیرمعمول در شکل فایل مشتقشده در دسترس نیستند، همه ویژگیهای ناحیه پیچیده وجود ندارند [ که بسیار متفاوت از اطلاعات جغرافیایی سنتی و عقل سلیم است. علاوه بر این، از آنجایی که دادههای OSM توسط یک سیستم برچسبگذاری رایگان جمعآوری میشوند، بسیاری از ویژگیهای غیرعادی توسط جغرافیدانان جدید بر اساس عادتهای ارتباطی آنها برچسبگذاری میشوند. برخی از دادههای OSM را میتوان در پایگاههای داده شکلفایل از وبسایتهای شرکت دانلود کرد (مثلاً Geofabrik). با این حال، شکل فایل مشتق شده مجموعه ای از ویژگی ها و ویژگی های داده های OSM اصلی است. بر این اساس، بسیاری از ویژگیهای غیرمعمول در شکل فایل مشتقشده در دسترس نیستند، همه ویژگیهای ناحیه پیچیده وجود ندارند [ برخی از دادههای OSM را میتوان در پایگاههای داده شکلفایل از وبسایتهای شرکت دانلود کرد (مثلاً Geofabrik). با این حال، شکل فایل مشتق شده مجموعه ای از ویژگی ها و ویژگی های داده های OSM اصلی است. بر این اساس، بسیاری از ویژگیهای غیرمعمول در شکل فایل مشتقشده در دسترس نیستند، همه ویژگیهای ناحیه پیچیده وجود ندارند [ برخی از دادههای OSM را میتوان در پایگاههای داده شکلفایل از وبسایتهای شرکت دانلود کرد (مثلاً Geofabrik). با این حال، شکل فایل مشتق شده مجموعه ای از ویژگی ها و ویژگی های داده های OSM اصلی است. بر این اساس، بسیاری از ویژگیهای غیرمعمول در شکل فایل مشتقشده در دسترس نیستند، همه ویژگیهای ناحیه پیچیده وجود ندارند [2] و داده های عکس فوری به دست آمده را نمی توان به صورت تدریجی به روز کرد. بنابراین، دادههای OSM اصلی و شکل فایل مشتقشده از دادههای OSM نمیتوانند الزامات برنامه را برای ادغام پویا تحقیقات مرزی برآورده کنند. برای حل این مشکل، ما یک روش یکپارچه سازی پویا برای پایگاه داده مرزی با استفاده از داده های OSM ارائه می کنیم. در این روش، داده های جمع سپاری OSM را به یک مدل داده کاربر منتقل می کنیم. یعنی ویژگی ها را با استفاده از روش مبتنی بر قانون به کلاس های مناسب با کدهای تعریف شده توسط کاربر منتقل می کنیم. برای تبدیل ویژگیهای غیرمعمول به کلاسهای مناسب بهطور خودکار یا نیمه خودکار، یک مکانیسم به خاطر سپردن خودکار برای تخصیص ویژگیهای OSM به کلاسهای کاربر به صورت تعاملی و یادآوری خودکار این دانش منتقل شده به عنوان یک قاعده ارائه شده است. قوانین جدید به خاطر سپرده شده را می توان در تحولات بعدی مورد استفاده مجدد قرار داد. با استفاده از این روش، قوانین تبدیل مدل را می توان به صورت تدریجی افزایش داد. با استفاده از این روش تبدیل مدل داده مبتنی بر قانون، می توان یک عکس فوری از منطقه مرزی تحقیقاتی برای یک زمان خاص به دست آورد. با این حال، برای برنامه های مرزی، نقشه فوری از OSM معمولا کافی نیست و دانشمندان اغلب باید منبع دیگری از داده ها را برای تشکیل یک پایگاه داده مناسب ادغام کنند. با این حال، دنیای واقعی به سرعت در حال تغییر است و لازم است پایگاه داده برای منطقه مرزی تحقیقاتی به صورت تدریجی به روز شود. VGI همچنان یک منبع اطلاعاتی کمهزینه، جهانی و صرفاً تغییر به موقع خواهد بود. با این حال، OSM روش هایی برای دانلود فایل تغییر برای یک منطقه معین در یک دوره خاص ارائه نمی دهد. در عوض، فقط دادههای متفاوت روزانه جهانی را در OsmChange ارائه میکند. بدین ترتیب، روشی توسعه داده شده است که اشیاء تغییر در یک منطقه معین را از دادههای تفاوت روزانه جهانی استخراج میکند، مختصات اشیاء در مناطق را انتخاب میکند و سپس فایلهای تفاوت را در یک فایل اطلاعاتی فقط تغییر با فرمت طراحیشده ادغام میکند. سپس از فایل اطلاعاتی فقط تغییر برای به روز رسانی خودکار پایگاه داده مرزی تحقیق استفاده می شود.
این مقاله در هفت بخش تنظیم شده است. در بخش 2 ، کار مربوط به این مقاله را معرفی می کنیم. ما در مورد استراتژی یکپارچه سازی پویا برای پایگاه داده مرزی در بخش 3 بحث می کنیم. روش تبدیل مدل مبتنی بر قانون در بخش 4 توضیح داده شده است . روش استخراج اطلاعات فقط تغییر در بخش 5 مورد بحث قرار گرفته است . آزمون های تجربی این مطالعه در بخش 6 ارائه شده است. در نهایت، بخش 7 خلاصه ای را ارائه می دهد و بحث را به پایان می رساند.
2. کارهای مرتبط
در سال های اخیر، VGI (یا داده های جمع سپاری) یک موضوع داغ در تحقیقات GIS بوده است. محققان در درجه اول کار خود را بر روی موضوعات زیر متمرکز می کنند: ارزیابی کیفیت داده های جمع سپاری، روش های کنترل کیفیت VGI و کاربرد VGI.
نگرانی اصلی VGI کیفیت داده است. بنابراین، چندین محقق کیفیت VGI را با مقایسه دادههای OSM با دادههای حرفهای مربوطه ارزیابی کردهاند. هاکلی [ 3 ] کیفیت داده ها را برای لندن و انگلیس از طریق مقایسه با مجموعه داده های Ordnance Survey (OS) بررسی کرده است. Zielstra و Zipf [ 4 ] کامل بودن داده های OSM را نسبت به داده های ناوبری مجموعه داده های MultiNet TeleAtlas در آلمان تجزیه و تحلیل کردند. Girres و Touya [ 5 ] یک ارزیابی کیفی دادههای فضایی OSM فرانسه را با استفاده از پایگاه داده مرجع در مقیاس بزرگ (RGE) برای دادههای مرجع و یک روش نمونهگیری با استفاده از مؤلفههای ارزیابی تکمیل کردند .، دقت هندسی، دقت صفت، کامل بودن، ثبات منطقی، دقت معنایی، دقت زمانی، نسب و کاربرد. سیپلوچ و همکاران دقت داده های OSM ایرلند را با نقشه های گوگل و بینگ مپ مقایسه کرد [ 6 ]. Siebritz و Sithole کیفیت داده های OSM را در آفریقای جنوبی با مقایسه آنها با مجموعه داده های مرجع از آژانس های نقشه برداری ملی ارزیابی کردند [ 7 ]. فرقانی و دلاور سازگاری بین مجموعه داده های OSM ایران و مجموعه داده های مکانی مرجع مربوطه را ارزیابی کردند [ 8 ]. جکسون و همکاران کامل بودن و خطای مکانی ویژگی ها (با استفاده از اندازه پردیس مدرسه به عنوان مثال) در ایالات متحده (ایالات متحده) [ 9 ] را ارزیابی کرد. Hechtو همکاران کامل بودن ردپای ساختمان در OSM را با مقایسه داده های OSM با داده های رسمی در آلمان تجزیه و تحلیل کرد [ 10 ]. فن و همکاران کیفیت دادههای ردپای ساختمان OSM را از نظر کامل بودن، معنایی، موقعیت و دقت شکل با استفاده از دادههای ATKIS به عنوان داده مرجع ارزیابی کرد [ 11 ]. کامبر و همکاران قابلیت اطمینان پوشش اراضی داوطلبانه را با استفاده از GLC-2000، GlobCover و MODIS V5 به عنوان داده های کنترلی ارزیابی کرد [ 12 ]. در تجزیه و تحلیل های فوق، تقریباً همه محققان به این نتیجه رسیدند که اگرچه OSM می تواند حجم زیادی از داده های مفید را با پاسخگویی و انعطاف پذیری بالا ارائه دهد، محدودیت اصلی آن بی نظمی کامل بودن داده ها است.
برخلاف دادههای جغرافیایی حرفهای که توسط متخصصان آموزش دیده با استانداردهای تخصصی که قابلیت اطمینان را تضمین میکنند جمعآوری میشوند، VGI توسط کاربران غیرحرفهای و بدون آموزش تخصصی جمعآوری میشود. بر این اساس، VGI می تواند حاوی مقدار زیادی داده جعلی یا با کیفیت پایین باشد. بنابراین، قبل از استفاده از آن در تجزیه و تحلیل علمی، لازم است از برخی معیارهای قابلیت اطمینان برای پاکسازی یا فیلتر کردن داده های جعلی یا با کیفیت پایین استفاده شود. بر اساس این ملاحظات، محققین متعددی روش پایایی یا ارزیابی اعتماد و روش کنترل کیفیت داده VGI را مورد مطالعه قرار دادهاند. برای مثال، بیشر و مانتلاس یک مدل اعتماد و شهرت رسمی با استفاده از زمینه فضایی و مشارکت کاربران ارائه کردند [ 13 ]. ون اکسل و دیاس [ 14] روشی را برای تعیین شهرت و اطلاعات قابل اعتماد کاربر با استفاده از تجربه کاربر، دانش محلی و نسب مشارکت و غیره ارائه کردند. Goodchild و Li [ 15 ] رویکردهای جمع سپاری، اجتماعی و جغرافیایی را برای اطمینان از کیفیت VGI تجزیه و تحلیل کردند.
اطلاعات فراوان و هزینه کم VGI افراد زیادی را به سمت تحقیقات در مناطق مختلف جذب می کند. ندکوف و زلاتانوا با استفاده از دادههای جمعسپاری شده در مورد سلامت زیرساخت، محاسبه کوتاهترین مسیر را انجام دادند [ 16 ]. Roche و Propeck-Zimmermann روش و مسائل مربوط به استفاده از VGI برای حمایت از مدیریت بحران را مورد بحث قرار دادند [ 17 ]، و از VGI برای ساخت و به روز رسانی SDI استفاده کردند [ 18 ، 19 ]. Mooney و Corcoran [ 20 ] پتانسیل استفاده از VGI را در برنامه های کاربردی محاسبات سلامت توصیف کردند. Hagenauer و Helbich از VGI در استخراج الگوی کاربری زمین در اروپا استفاده کردند [ 21 ]. پائودیال و همکاران VGI را در مدیریت حوضه بررسی کرد [ 22]. باکیالله و همکاران نقشه برداری جمعیت را با استفاده از نقاط مورد علاقه OSM انجام داد [ 23 ]. کلارک [ 24 ] از جمع سپاری، VGI و شهروندانی که به عنوان حسگرها در پایداری محیط زیست استرالیا عمل می کنند، استفاده کرد. برنامه های کاربردی فوق در درجه اول بر روی حالت استفاده بالقوه، مزایا و معایب تمرکز داشتند و با هدف توسعه پورتال های جدید در پروژه های فعلی VGI (به عنوان مثال، OSM یا Google Map) برای تسهیل کاربرد آنها در مناطق خاص بودند.
علاوه بر این، از آنجا که OSM موفق ترین پروژه VGI است، چندین محقق پروژه OSM را مورد مطالعه قرار دادند. به عنوان مثال، Neis و Zipf [ 25 ] فعالیت های مشارکت کننده OSM را تجزیه و تحلیل کردند. نیس و همکاران موارد مختلف خرابکاری را تجزیه و تحلیل کرد و یک سیستم تشخیص خرابکاری مبتنی بر قانون را برای OSM توسعه داد [ 26 ]. زیلسترا و همکاران الگوهای ویرایش را در OSM تجزیه و تحلیل کرد [ 27 ]. Fast و Rinner [ 28 ] ارتباط عملی VGI را با استفاده از OSM به عنوان مثالی از علم سیستم ها نشان دادند.
از تجزیه و تحلیل های بالا، ما به این نتیجه رسیدیم که VGI (به ویژه داده های OSM) در بسیاری از مناطق استفاده شده است و می توان دقت و قابلیت اطمینان داده ها را تا سطح معقول (قابل قبول) برای استفاده با توسعه داده های مشارکت کننده بهبود (اطمینان) کرد. حسگر، تصاویر مرجع، و روشهای مدیریت دادهها. با این حال، از آنجایی که کامل بودن داده ها با مشارکت داوطلبان تعیین می شود، بهبود سریع آن آسان نیست. علاوه بر این، کامل بودن محدودیت اصلی خواهد بود که بر تناسب اندام برای استفاده تأثیر می گذارد. بنابراین، برای بسیاری از برنامههای حرفهای، لازم است VGI با چندین منبع داده دیگر ادغام شود تا دادههای از دست رفته را پر کند، دادههای جعلی یا با کیفیت پایین را پاک کند و بهطور دینامیکی دادههای یکپارچه را بهطوریکه برای استفاده خاص مناسب باشد، حفظ کند. بدین ترتیب،
3. استراتژی برای ادغام دینامیک داده های OSM
سه اصل هندسی اولیه (گره، راه و رابطه) برای توصیف اجزای فضایی ویژگیها در مدل داده OSM استفاده میشوند. ویژگیهای OSM به سه کلاس زیر دستهبندی میشوند: ویژگیهای اولیه، مراجع، و ویژگیهای اضافی. ویژگی های اولیه به 18 دسته تقسیم می شوند: «راه هوایی، راه هوایی، امکانات رفاهی، مانع، مرز، ساختمان، صنایع دستی، اضطراری، زمین شناسی، بزرگراه، تاریخی، کاربری زمین، اوقات فراغت، ساخت انسان، نظامی، طبیعی، اداری و مکان». مراجع شامل هشت دسته است: “قدرت، حمل و نقل عمومی، راه آهن، مسیر، فروشگاه، ورزش، گردشگری و آبراه”. ویژگیهای اضافی برای توصیف ویژگیهای توصیفی یک ویژگی، مانند آدرس، نام، کاربر، محدودیتها و غیره استفاده میشوند.بنابراین، ویژگی های اولیه و مرجع عمدتا در ساخت پایگاه داده مرزی استفاده می شود. در این مطالعه، ما عمدتاً ویژگیهای اصلی و مرجع را به یک مدل کاربر سنتی منتقل میکنیم. XML تنها فرمت اصلی است که میتوان آن را از وبسایت رسمی OSM ( http://planet.openstreetmap.org/ ) دانلود کرد و متخصصان تحلیل مرزی به قالب XML عادت ندارند. فایل های Shape به طور گسترده ای در GIS استفاده شده اند و به عنوان داده های مرزی در این مطالعه استفاده می شوند.
بنابراین، ویژگی های اصلی و مرجع در OSM ابتدا از XML به اشیاء نقطه، خط و ناحیه سنتی با استفاده از یک مدل داده میانی تبدیل می شوند. دوم، 18 ویژگی اصلی و هشت ویژگی مرجع می توانند به طور خودکار با توجه به نوع ویژگی و نوع هندسی اولیه به مدل مقصد منتقل شوند. یک مکانیزم به خاطر سپردن خودکار برای تبدیل ویژگیهای غیرمعمول با جفتهای معنیدار «کلید-مقدار» به لایه کاربر مناسب و کد ویژگی استفاده میشود. بنابراین، با استفاده از تبدیل مدل، میتوانیم نقشه شکل-فایل حالت پایه را بدست آوریم.
دنیای واقعی به سرعت در حال تغییر است و پایگاه داده های مرزی باید به روز نگه داشته شوند. همانطور که در بالا ذکر شد، دانشمندان معمولا نیاز به ادغام سایر منابع داده برای تشکیل یک پایگاه داده مناسب برای تجزیه و تحلیل مرزی دارند. بنابراین، تبدیل مستقیم داده های OSM به پایگاه داده مرزی هر روز منطقی نخواهد بود. با این حال، دادههای OSM همچنان یک منبع اطلاعاتی کمهزینه و صرفاً تغییر در سراسر جهان است. بنابراین، یک روش معقول برای حل مشکل، بهروزرسانی تدریجی پایگاه داده مرزی با استفاده از دادههای OSM فقط تغییر است. OsmChange داده های متفاوت روزانه را برای کل جهان برای دانلود فراهم می کند. با این حال، OsmChange روشهایی را برای یکپارچهسازی فایلهای تغییر دانلود شده برای یک منطقه معین در یک دوره معین ارائه نمیکند. از این رو،
بر اساس تحلیل های فوق، ما یک روش یکپارچه سازی پویا را برای پایگاه داده مرزی با استفاده از داده های OSM ارائه می کنیم. در این روش، دادههای OSM با فرمت XML برای یک منطقه مرزی تحقیقاتی دانلود میشوند و ویژگیهای اصلی و مرجع به طور خودکار به مدل دادههای میانی با فرمت فایل شکل (لایههای نقطه، خط و ناحیه) با توجه به ویژگی OSM تبدیل میشوند. تعاریف نوع با مقایسه سند شرح OSM-Map-Feature و فایل تعریف مدل داده های کاربر، یک پایه قانون تبدیل اولیه تشکیل می شود. با استفاده از این قوانین، ویژگی های اصلی مطابق با تعریف OSM-Map-Feature را می توان به طور خودکار به مدل مقصد تبدیل کرد. با این حال، ویژگی های غیر معمول را نمی توان با استفاده از قوانین تبدیل اولیه تبدیل کرد. فرض بر این است که بسیاری از ویژگیهای غیرعادی عمدتاً ناشی از عادتهای ارتباطی مختلف است. در یک منطقه خاص، داوطلبان معمولاً همان عادت ارتباطی را دارند. بنابراین، این ویژگیهای غیرعادی همچنان میتوانند با استفاده از روش مبتنی بر قانون به مدل مقصد تبدیل شوند. اگرچه شکلگیری این قوانین از دانش صریح دشوار است، اما میتوان آنها را با استفاده از مکانیزم به خاطر سپردن خودکار در طول فرآیند تبدیل انسان شکل داد. بنابراین، این مطالعه هم یک مدل تبدیل تعامل انسان-رایانه و هم یک مکانیسم قوانین-ماشین-به خاطر سپردن را توسعه می دهد. اگرچه شکلگیری این قوانین از دانش صریح دشوار است، اما میتوان آنها را با استفاده از مکانیزم به خاطر سپردن خودکار در طول فرآیند تبدیل انسان شکل داد. بنابراین، این مطالعه هم یک مدل تبدیل تعامل انسان-رایانه و هم یک مکانیسم قوانین-ماشین-به خاطر سپردن را توسعه می دهد. اگرچه شکلگیری این قوانین از دانش صریح دشوار است، اما میتوان آنها را با استفاده از مکانیزم به خاطر سپردن خودکار در طول فرآیند تبدیل انسان شکل داد. بنابراین، این مطالعه هم یک مدل تبدیل تعامل انسان-رایانه و هم یک مکانیسم قوانین-ماشین-به خاطر سپردن را توسعه می دهد.
برای به روز نگه داشتن پایگاه داده مرزی، روشی برای استخراج اطلاعات فقط تغییر برای منطقه تحقیقاتی از فایل تفاوت روزانه جهانی OSM و به روز رسانی پایگاه داده مرزی توسعه داده شده است. در این روش فایل دیاف دیاف جهانی به صورت خودکار دانلود می شود و اشیاء تغییر یافته در ناحیه داده شده انتخاب و در یک پایگاه داده ذخیره می شوند. اطلاعات (شامل فضایی، معنایی و نوع تغییر) اشیاء درگیر با نسخه های متعدد در یک نسخه ادغام شده است. در مرحله بعد، پایگاه اطلاعاتی (یا فایل) صرفاً تغییر با استفاده از فرمت طراحی شده تولید می شود و از اطلاعات فقط تغییر برای به روز رسانی خودکار پایگاه داده مرزبانی تحقیق استفاده می شود. استراتژی این مطالعه در شکل 1 نشان داده شده است .
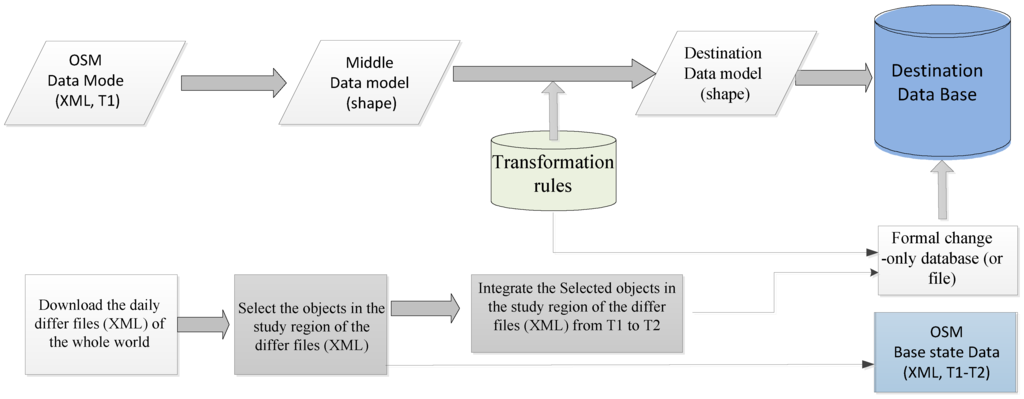
شکل 1. استراتژی یکپارچه سازی پویا پایگاه داده مرزی با استفاده از داده های OSM.
4. روش تبدیل مدل مبتنی بر قانون
همانطور که در بالا ذکر شد، مدل داده OSM معمولا با مدل داده های تحقیقات مرزی متفاوت است. در مدل داده OSM، گره تنها اولیه است که حاوی اطلاعات مختصات است. گره شامل نقاط موجود و نقاط مختصات مسیر و اشیاء رابطه است. گره های دارای برچسب برای نشان دادن ویژگی های نقطه و بقیه برای توصیف مکان راه ها و روابط استفاده می شوند. یک راه یک لیست مرتب شده از گره ها است. راههای ساده (نه نزدیک، نه خود متقاطع) برای توصیف ویژگیهای خطی استفاده میشوند و راههای بسته نشاندهنده ویژگیهای خط ساده ناحیه یا دایره هستند. روابط برای توصیف توپولوژی، محدودیت، و مناطق پیچیده (دارای سوراخ) استفاده می شود. اطلاعات معنایی کلیدی (اطلاعات “آن چیست”) با برچسب گذاری با جفت های کلید-مقدار در OSM XML توصیف می شود. در مدلهای سنتی دادههای GIS (مانند. g.، ISO 14825، 2004، سیستم های حمل و نقل هوشمند – فایل های داده های جغرافیایی، و مدل سیستم اطلاعات جغرافیایی بنیادی ملی چین)، نقاط، خطوط و چند ضلعی ها (شامل چند ضلعی های ساده و پیچیده) به طور مستقیم نشان داده می شوند. اطلاعات معنایی کلیدی (به عنوان مثال ، اطلاعات “چیست”) معمولاً با کدها نشان داده می شود. و اشیا با کدهای مشابه متعلق به یک لایه هستند. در مدل سنتی GIS، روابط پیوندی و مجاور با استفاده از جدول روابط توپولوژیکی نمایش داده می شود. سایر روابط نشان داده شده در OSM (به عنوان مثال، جلو، عقب، e-road_link و غیره ) معمولاً در جدول ویژگی ذخیره می شوند. علاوه بر این، روابط پیوندی و مجاور را می توان به طور خودکار توسط بسیاری از نرم افزارهای GIS تولید کرد. بنابراین، اهداف این مطالعه مربوط به تبدیل مدل بوده و شامل وظایف زیر است:
- (1)
-
استخراج موجودیت های نقطه ای از گره ها و تبدیل آنها به لایه مناسب با کدهایی در مدل مقصد.
- (2)
-
تعیین اینکه آیا روش اشیاء خط ساده، خط دایره یا اشیاء چند ضلعی ساده هستند و با استفاده از کدهای مدل مقصد، آن اشیاء را به لایههای مربوطه اختصاص میدهند.
- (3)
-
استخراج چند ضلعی های پیچیده از روابط و تبدیل آنها به لایه های مناسب با استفاده از کدها.
برای دستیابی به سه هدف فوق، حل دو مشکل زیر ضروری است. اولین مشکل این است که نوع فضایی اشیاء را تعیین کنیم، به عنوان مثال ، خط ساده، خط دایره، چند ضلعی ساده، یا چندضلعی پیچیده. مشکل دوم تبدیل اشیا به لایه های مناسب با استفاده از کد است.
همانطور که در بالا ذکر شد، خطوط ساده، خطوط دایره و چندضلعی های ساده با روش هایی نشان داده می شوند. راه های باز باید خطوط ساده باشند. راه های بسته شامل خطوط دایره و چند ضلعی های ساده است. به عنوان مثال، یک دیوار بسته هنوز یک شی خط است (یک تنه ممکن است به عنوان یک شی راه بسته در داده های OSM نشان داده شود) اما در پایگاه داده کاربران مرزی، دیوار بسته معمولاً به عنوان یک شی خط نشان داده می شود. در این موارد، اطلاعات معنایی نشاندادهشده توسط جفتهای «کلید-مقدار» برای تعیین نوع فضایی راههای بسته استفاده میشود. چند ضلعی های مختلط اشیایی با ak = “نوع” v = “چند چندضلعی” و حداقل یک نقش = عضو “داخلی” و یک نقش = عضو “خارجی” در رابطه هستند. با استفاده از این ویژگی ها می توان چند ضلعی های پیچیده را از سایر روابط تشخیص داد.
هر دو مدل سنتی GIS و مدل OSM این قرارداد را به اشتراک می گذارند که “همه اشیا به یک کلاس و هر شی دقیقاً به یک کلاس تعلق دارد”. بر اساس این قرارداد، می توان مجموعه ای از قوانین تبدیل اولیه را با استفاده از اطلاعات رسمی تعریف OSM-Map-Feature و اطلاعات تعریف مدل داده کاربر ایجاد کرد. با استفاده از این قوانین، اشیاء کلی را می توان به لایه های (کلاس) مناسب در مدل مقصد تبدیل کرد.
با این حال، همانطور که در بخش 3 ذکر شد ، بسیاری از ویژگیهای غیرعادی توسط جغرافیدانان جدید بر اساس عادتهای ارتباطی آنها برچسبگذاری میشوند، به عنوان مثال، ویژگیهای زیادی با جفتهای “کلید-مقدار” وجود دارد که در ویژگیهای نقشه رسمی OSM تعریف نشدهاند. به عنوان مثال، ویژگی هایی که با “k = aeroway v = papi”، “K = waterway، V = spillway”، “papi” و “spillway” برچسب گذاری شده اند را نمی توان در ویژگی های نقشه رسمی OSM یافت. این ویژگیها دارای جفتهای معنیدار «کلید-مقدار» هستند. برخی دیگر از ویژگیها جفتهای «کلید-مقدار» معنیداری ندارند (به عنوان مثال، ویژگیهای با «k = aeroway v = M?cQuy؟»، «k = ساختمان v = بله»، «k = طبیعی v = تهی»، و غیره. ). برای ویژگی نوع اول، یعنی، اشیاء با یک جفت “کلید-مقدار” معنی دار اما تعریف نشده، مقدار “کلید” یا “مقدار” مقدار پیشنهادی تعریف شده در OSM-Map-Features نیست و نمی تواند به طور خودکار به لایه مناسب کاربر تبدیل شود (یا کلاس ها) با استفاده از قوانین اساسی. طبق تحلیل ما، بسیاری از جفتهای کلید-مقدار در یک منطقه خاص در دادههای OSM به اشتراک گذاشته میشوند. این پدیده ممکن است ناشی از عادات ارتباطی مختلف باشد، اما داوطلبان در یک منطقه معمولا عادات ارتباطی یکسانی دارند. بنابراین، تبدیل همچنان می تواند با استفاده از روش مبتنی بر قانون انجام شود. قوانین را می توان با استفاده از یک مکانیسم به خاطر سپردن خودکار در طول یک فرآیند تبدیل انسان شکل داد. به عنوان مثال، هنگامی که ویرایشگر یک مقدار کد مناسب را به یک ویژگی غیر معمول اختصاص می دهد، لایه هدف این شی غیر معمول به طور خودکار تعیین می شود. بدین ترتیب، نه تنها رابطه نگاشت بین جفت های کلید-مقدار OSM و لایه هدف، بلکه کد هدف نیز به عنوان یک قانون جدید که در پایه قانون ذخیره می شود به خاطر سپرده می شود. بر اساس این مشاهدات، استراتژی تبدیل مدل در نشان داده شده استشکل 2 .
روش تبدیل داده OSM به مدل داده مقصد شامل مراحل زیر است:
مرحله 1: با استفاده از قوانین تبدیل نوع فضایی زیر، یعنی قوانین 1، 2، 3 و 4، نوع فضایی اشیاء در داده های OSM را برای مدل داده میانی تعیین کنید .
فرض بر این است که «OSMGeoPrim» نشاندهنده اولیههای هندسی (گره، راه و رابطه) در دادههای OSM است و «OSMtag.k» و «OSMtag.V» جفتهای کلید-مقدار اطلاعات معنایی را در OSM XML نشان میدهند. در GIS سنتی، یک قرارداد وجود دارد که مرز یک شی منطقه بسته است. بنابراین، در دادههای OSM، راههای باز اشیاء خطی هستند (به عنوان مثال، حصار خطی، جاده، دیوار باز، و غیره ) و اشیاء منطقه مربوط به راههای بسته هستند (مانند محوطه دانشگاه، ساختمانها، دریاچهها و غیره ). با این حال، همه راه های بسته در OSM، اشیاء ناحیه نیستند. طبق تجزیه و تحلیل ما، اشیاء زیر معمولاً به عنوان اشیاء خطی در پایگاههای داده فضایی سنتی 1:50000 ارائه میشوند .، OSM دارای مقادیر «دیوار، شینه، حصار، پرچین، میخها، پیوند_تنه، راهآهن، پیادهرو، خیابان زندگی، بزرگراه، مسیر، عابر پیاده، مسیر مسابقه، جاده، درجه سوم، مسیر، موج شکن، و اسکله» است. بنابراین، با استفاده از اصول اولیه هندسی و ویژگیهای معنایی، چهار قانون تبدیل نوع فضایی با استفاده از یک پایگاه داده فضایی 1:50000 به عنوان مثال توسعه داده میشوند.
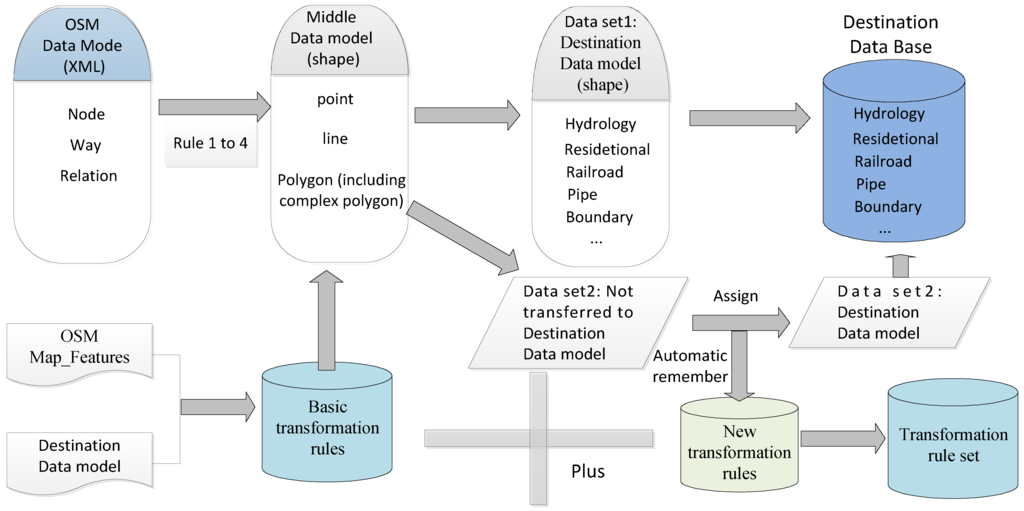
شکل 2. استراتژی تبدیل مدل.
(1) یک گره با جفت های “کلید-مقدار” یک شی نقطه ای است.
قانون 1: اگر OSMGeoPrim = گره && OSMtag.k ≠ Φ&& OSMtag.V ≠ Φ، آنگاه گره یک شی نقطه است.
(2) راه باز یک شی خط است.
قانون 2: اگر OSMGeoPrim = way && Beginnode برابر Endnode = خیر باشد، way یک شی خط است.
(3) یک راه بسته معمولاً یک شی منطقه است، با این تفاوت که شی دارای یک برچسب “ارزش” است که برابر با یکی از موارد زیر است: “دیوار، شینه، حصار، پرچین، میخها، پیوند_تنه، راهآهن، پیادهرو، خیابان_زندگی، بزرگراه، مسیر، عابر پیاده، مسیر مسابقه، جاده، رده سوم، مسیر، موج شکن، یا اسکله».
قانون 3: اگر OSMGeoPrim = way && Beginnode برابر است با Endnode = Yes && (OSMtag.V ≠ دیوار، شینه، حصار، پرچین، میخ ها، trunk_link، راه آهن، پیاده رو، زندگی_خیابان، بزرگراه، مسیر، عابر پیاده، مسیر مسابقه، جاده، سطح سوم، مسیر ، موج شکن، یا اسکله) سپس راه یک شی خط است. در غیر این صورت، راه یک چند ضلعی ساده است.
(4) یک رابطه یک منطقه پیچیده است اگر مقادیر “k = نوع”، “V = چند ضلعی” و حداقل یک چند ضلعی “خارجی” و “داخلی” داشته باشد.
قانون 4: اگر OSMGeoPrim = رابطه && OSMtag.k = نوع && OSMtag.V = چند ضلعی && تعداد عضو “خارجی” ≥ 1 && تعداد عضو “داخلی” ≥ 1، آنگاه رابطه یک منطقه پیچیده است.
بنابراین با استفاده از قوانین فوق می توان نوع فضایی اشیاء OSM را به صورت خودکار تعیین کرد.
مرحله 2: اشیاء کلی که توسط مدل میانی نشان داده شده است را با استفاده از قوانین تبدیل اولیه به لایه های مناسب با کد در مدل مقصد تبدیل کنید.
مرحله 3: به صورت تعاملی ویژگی های غیرعادی باقی مانده در مدل میانی ( یعنی مجموعه داده 2 در شکل 2 ) را با کد مناسب اختصاص دهید و به طور خودکار تعیین کنید که کدام لایه ها برای آنها مناسب است. سپس، با استفاده از مکانیزم یادآوری ماشین، تخصیص به پایگاهداده قوانین بهطور خودکار به خاطر سپرده میشود و قوانین جدید تشکیلدهنده را میتوان بهطور خودکار در سایر تبدیلهای داده استفاده کرد.
فرض بر این است که “Mdl GeoPrim” نشان دهنده اولیه های هندسی در مدل داده میانی و “لایه هدف” و “کد هدف” نشان دهنده کد و لایه در مدل هدف است. برخی از قوانین مثال برای تبدیل اشیاء در مدل داده میانی به مدل مقصد در جدول 1 توضیح داده شده است. قانون اول در جدول 1 را می توان به عنوان قانون 5 تفسیر کرد.
(5) یک نقطه در مدل داده میانی با “k = نقطه طبیعی” و “V = دریا” مربوط به یک نقطه در “لایه نقطه هیدرولوژی” با کد “250000” در مدل دادههای جغرافیایی-اطلاعات بنیادی ملی چین است.
قانون 5: اگر MdlGeoPrim = Point && OSMtag.k = Natural Point && OSMtag.V = دریا، آنگاه TargetLayer = نقطه هیدرولوژیکی، Targetcode = 250000.

جدول 1. قوانین نمونه برای تبدیل اشیاء فضایی در مدل میانی به مدل مقصد کاربر.
با استفاده از قوانین اساسی، ویژگی های اصلی را می توان با موفقیت به مدل مقصد تبدیل کرد. با این حال، از آنجایی که ویژگی های غیر معمول در سند ویژگی نقشه OSM تعریف نشده است، نمی توان آنها را با استفاده از قوانین اساسی منتقل کرد. برای حل این مشکل، یک ابزار نرمافزاری توسعه داده شد تا به صورت تعاملی ویژگیهای غیرعادی را به کلاسهای کاربر با کد اختصاص دهد و بهعنوان یک قاعده بهطور خودکار این انتقال دانش را به خاطر بسپارد. بنابراین، پایه قانون را می توان افزایش داد و قدرت تبدیل را می توان به صورت تدریجی بهبود بخشید. با استفاده از این روش تبدیل مدل مبتنی بر قانون، داده های OSM را می توان به مدل داده مرزی کاربر تبدیل کرد.
5. روشی برای استخراج اطلاعات صرفاً تغییر در یک دوره زمانی
همانطور که در بالا ذکر شد، داده های مرزی باید به صورت تدریجی به روز شوند. دادههای OSM بهعنوان منبع اطلاعاتی کمهزینه و صرفاً تغییر در سراسر جهان باقی خواهند ماند. با این حال، در بسیاری از برنامههای مرزی، اعتبار و کامل بودن دادههای OSM کافی نیست و دانشمندان باید کیفیت دادهها را افزایش داده و سایر منابع داده را برای تشکیل یک مجموعه داده جدید ادغام کنند. معمولا از دو روش برای به روز رسانی پایگاه داده مرزی کاربر استفاده می شود. یک روش این است که داده های OSM جدید را مستقیماً با استفاده از روش تبدیل مدل ذکر شده در بخش 4 تبدیل کنیدو سپس داده های تبدیل شده را با پاکسازی یا فیلتر کردن داده های جعلی یا بی کیفیت و تصحیح خطاهای موجود در آن و ادغام سایر منابع داده در هر بار بررسی کنید. از آنجایی که دادههای OSM توسط کاربران غیرحرفهای و بدون آموزش تخصصی جمعآوری میشوند، حجم زیادی از دادههای جعلی یا با کیفیت پایین وجود دارد و قبل از اعمال دادهها باید حجم زیادی ویرایش انجام شود. انجام این عملیات به صورت خودکار دشوار است (و چنین تعهدی خارج از محدوده این مطالعه است). فرآیندهای تعاملی و ویرایش مکرر هم مستعد خطا و هم کار فشرده هستند. روش دیگر استخراج اطلاعات فقط تغییر از OsmChange و استفاده از آن برای به روز رسانی پایگاه داده مرزی کاربر یکپارچه است. از آنجا که معمولاً مقدار بسیار کمتری از دادههای صرفاً تغییر نسبت به دادههای موجود وجود دارد، اگر فرآیند استخراج و به روز رسانی اطلاعات فقط تغییر به صورت خودکار انجام شود، از حجم زیادی از ویرایش های مکرر جلوگیری می شود و کارایی تا حد زیادی بهبود می یابد. بنابراین، روش دوم به نظر ما معقولتر است.
OsmChange داده های متفاوت روزانه را برای کل جهان فراهم می کند. برخی از شرکت ها (به عنوان مثال، Geofabrik) داده های متفاوت روزانه را برای بسیاری از کشورها، به عنوان مثال، پاکستان، ویتنام و غیره ارائه می دهند.چنین شرکتهایی صرفاً اشیایی را انتخاب میکنند که از کل دنیا به تفاوت روزانه کشور تغییر میکنند و اطلاعات کاملی (مثلاً فضایی، معنایی و نوع تغییر) برای اشیاء تغییریافته یا روشهایی برای ادغام اطلاعات شی تغییریافته به صورت رایگان ارائه نمیکنند. -تعریف منطقه مرزی در یک دوره معین. علاوه بر این، یک شی ممکن است چندین بار ویرایش شود، و چندین نسخه با مقادیر نوع تغییر چندگانه ممکن است در فایلهای متفاوت در یک دوره خاص وجود داشته باشد. برای به روز رسانی، اطلاعات (شامل فضایی، معنایی و نوع تغییر) در نسخه های متعدد باید در یک نسخه ادغام شوند، به خصوص مقدار نوع تغییر که عملیات به روز رسانی را تعیین می کند و مقدار در نسخه نهایی که معمولاً مقدار واقعی نیست. . از این رو،
5.1. استخراج اشیاء در منطقه مورد مطالعه از فایل های Diff
OsmChange یک فایل متفاوت با فرمت XML روزانه برای کل جهان فراهم می کند. از آنجایی که فایل های تفاوت روزانه شامل اطلاعات تغییر برای کل جهان است، اطلاعات اشیاء تغییر یافته در منطقه مورد مطالعه باید از فایل تفاوت روزانه جهان استخراج شود. برای تعیین اینکه آیا شی در منطقه مرزی است یا خیر، هر شیء تغییر یافته باید مختصاتی داشته باشد. اگرچه آنها شبیه به داده های XML حالت پایه OSM هستند، ویژگی های فضایی ویژگی ها به عنوان گره ها، راه ها و روابط در فایل تفاوت OSM توصیف می شوند. در فایلهای OSM diff، سه نوع تغییر وجود دارد: «تغییر»، «حذف» و «ایجاد» (در متن زیر به «تغییر، حذف و ایجاد» به عنوان سه نوع تغییر اشاره میکنیم). همه اشیا به یک بخش تغییر تعلق دارند. این بخش ها با “modify”، “delete” و “create” شروع می شوند و با “/modify” پایان می یابند. «/حذف» و «/create». اطلاعات تغییر اشیا در بخش های نشان داده شده در آن قرار داردشکل 3 .

شکل 3. فرمت فایل متفاوت OSM با استفاده از بخش شیء راه “ایجاد” به عنوان مثال.
در فایلهای تفاوت OSM، گرههای تغییر یافته در بخشهای گره «/create»، «/modify» و «/delete» قرار دارند که اطلاعات مختصات کاملی بهطور مستقیم ارائه میشود. با استفاده از روش تعیین نقطه در چندضلعی می توان گره ها را در منطقه تحقیق استخراج کرد. در تجزیه و تحلیل مرزی، گاهی اوقات نقطه روی مرز منطقه تحقیقاتی یک گره مهم است. برای سادگی، این مقاله با گرههای موجود در مرز منطقه تحقیقاتی مانند گرههایی که در منطقه تحقیقاتی هستند رفتار میکند. بنابراین، تشکیل یک پایگاه داده از گره تغییر یافته در منطقه تحقیق آسان است. این مقاله به این پایگاه داده به عنوان پایگاه داده ChgNodeInReg اشاره می کند.
همانطور که در شکل 3 نشان داده شده است، اشیاء راه و رابطه تغییر یافته فقط شناسه گره های مرجع در بخش های مربوطه دارند .. علاوه بر این، می توان یک شی راه (یا رابطه) جدید با استفاده از گره های جدید یا گره های مرجع اشیاء موجود ایجاد کرد. با این حال، گره های مرجع اشیاء موجود در بخش های گره تغییر یافته ظاهر نمی شوند، حتی اگر آنها گره های شکل اشیاء جدید ایجاد شده باشند. علاوه بر این، گره های مرجع اشیاء موجود در پایگاه داده ChgNodeInReg ظاهر نمی شوند. اگر گره ها اشیاء موجود در منطقه تحقیق باشند، مختصات در پایگاه داده محلی ذخیره شده است. در غیر این صورت مختصات باید از سایت سازمان OSM دانلود شود. بنابراین، چندین روش برای به دست آوردن مختصات و تعیین اینکه آیا آنها در منطقه تحقیق برای اشیاء راه (یا رابطه) تغییر یافته هستند وجود دارد. برای استخراج کامل اشیاء تغییر یافته در منطقه تحقیق،29 ] به عنوان نمونه. اشیاء “حذف” به طور بالقوه در پایگاه داده موجود یا در نسخه های قبلی با مختصات ظاهر می شوند. شناسه یک شی “حذف” می تواند برای تعیین اینکه آیا در منطقه مورد مطالعه قرار دارد یا خیر استفاده می شود. بنابراین، ما عمدتاً در مورد روش استخراج برای “ایجاد” و “تغییر” اشیاء در متن زیر بحث خواهیم کرد.
از منظر توپولوژی، اشیاء در منطقه مورد مطالعه آن دسته از اجرام هستند که منطقه تحقیقاتی را قطع می کنند. بنابراین، ابتدا رابطه بین راه ساده و منطقه تحقیق مورد تجزیه و تحلیل قرار می گیرد. طبق قضیه توپولوژی، هفت رابطه اساسی بین یک خط ساده و یک منطقه ساده وجود دارد، همانطور که در شکل 4 نشان داده شده است. در شکل 4 ، R ناحیه تحقیقاتی است، Cm نشان دهنده اشیاء ایجاد شده، M n نشان دهنده اشیاء اصلاح شده، نقاط قرمز نشان دهنده گره های جدید یا اصلاح شده، نقاط سیاه نشان دهنده گره های موجود، و W i نشان دهنده راه های موجود است. هفت رابطه اصلی “ناهم” هستند، به عنوان مثال، C 2 ، M 2 ، M 3(در این فایل تفاوت، M 3 به R منفک است، اگرچه ممکن است از یک شی موجود که R را قطع می کند یا یک شیء ایجاد شده قبلی در طول روزهای قبلی در دوره، تغییر یابد)، “داخل” (به عنوان مثال، C 1 ، M 1 )، «لمس در نقطه» (مثلاً C 4 )، «لمس در خط» (مثلاً، C 5 )، «روی مرز» (مثلاً، C 7 )، «متقاطع» (به عنوان مثال، C 3 و C 6 ، M 4 )، و “Through” (به عنوان مثال، C 8 ، C 9 ، M 5 ، و M 6 ).
پس از تجزیه و تحلیل گره های مؤلفه راه های تغییر یافته که با منطقه تحقیق تلاقی می کنند، مشخص شد که گره های مؤلفه را می توان به پنج مورد زیر تقسیم کرد:
- (1)
-
گره های جدید یا اصلاح شده در منطقه تحقیقاتی (مانند P1 ، P2 ، P3 ، P8 و P9 ) با ChgNodeInReg مشخص می شوند. مختصات این گره ها را می توان در تفاوت روزانه دانلود شده انتخاب کرد.
- (2)
-
گرههای جدید یا اصلاحشده در ChgNodeInReg نیستند، اما شامل یک گره مرجع از شی است که منطقه تحقیق را قطع میکند (به عنوان مثال، P 4 که با ChgNodeNearReg مشخص میشود). مختصات این گره ها را نیز می توان در تفاوت روزانه دانلود شده انتخاب کرد.
- (3)
-
گره های موجود در ناحیه تحقیق (مثلا P 5 ) هستند که به عنوان ExsNodeInReg نشان داده می شود. مختصات این گره ها را می توان در پایگاه داده محلی موجود انتخاب کرد.
- (4)
-
گرههای موجود در ناحیه تحقیقاتی نیستند، اما شامل یک گره مرجع از شی موجود هستند که ناحیه تحقیقاتی (مثلا P 7 ) را که به عنوان ExsNodeNearReg نشان داده شده است، قطع میکند. مختصات این گره ها را نیز می توان در پایگاه داده محلی موجود انتخاب کرد.
- (5)
-
گره های موجود در ExsNodeInReg و ExsNodeNearReg نیستند، به عنوان مثال، P 6 ، که به عنوان ExsNodeOutReg نشان داده می شود. مختصات این گره های اضافی باید از وب سایت رسمی OSM دانلود شود.
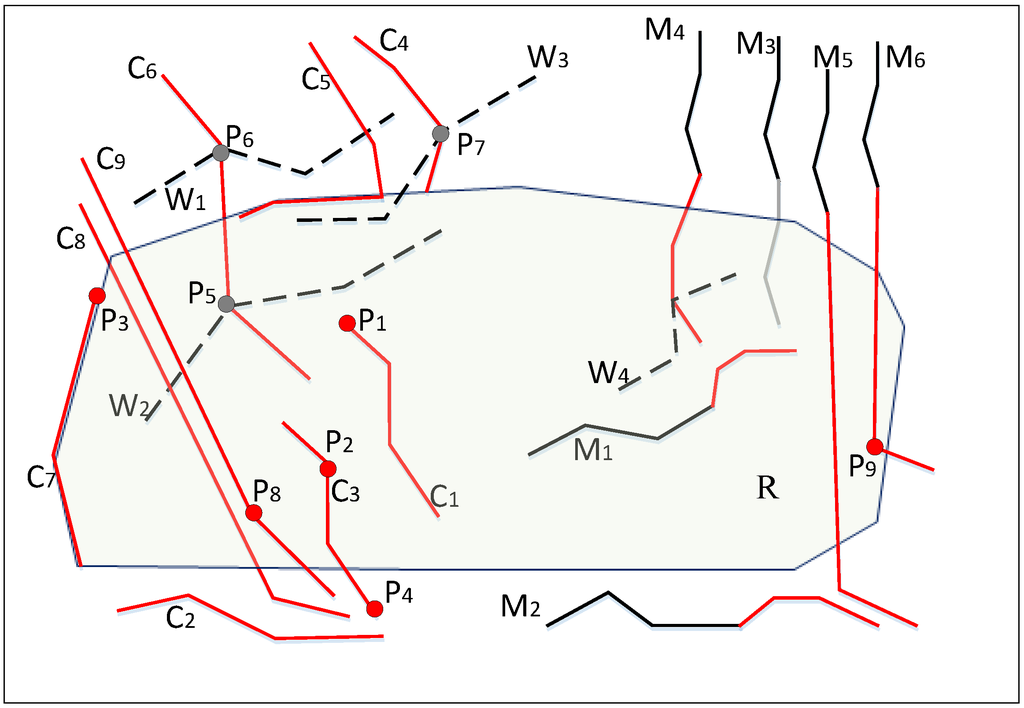
شکل 4. روابط بین راه تغییر یافته و منطقه تحقیقاتی با توجه به تکامل اشیاء.
بنابراین، اطلاعات مکانی ( یعنی مختصات گره های مؤلفه) همه اشیاء موجود در فایل های تفاوت روزانه را می توان به یکی از این پنج راه به دست آورد.
همانطور که در بالا ذکر شد، اشیاء تغییر یافته در منطقه مورد مطالعه، اشیایی هستند که منطقه تحقیق را قطع می کنند، به عنوان مثال، C 1 , C 3 , C 4 , C 5 , C 6 , C 7 , C 8 , C 9 , M 1 , M 4 ، M 5 و M 6 ( شکل 4 ). پس از تجزیه و تحلیل بیشتر، می توان نتیجه گرفت که اشیاء دارای یک یا چند گره در منطقه مورد مطالعه (به عنوان مثال، C 1 , C 3 , C 4 , C 5 , C 6 , C 7 , C9 , M 1 , M 4 , M 6 در شکل 4 ) اشیایی هستند که باید رزرو شوند. همه اشیاء بدون گره در ناحیه مورد مطالعه از ناحیه تحقیق جدا نیستند (مثلاً C 8 و M 5. C 8 و M 5 اشیایی هستند که R را قطع می کنند اما گرهی در R ندارند). علاوه بر این، اشیاء اصلاح شده از ناحیه تحقیق در یک فایل تفاوت روزانه جدا می شوند، و اگر شی دارای یک شی موجود متناظر یا حداقل یک نسخه قبلی است که منطقه مورد مطالعه را قطع می کند (به عنوان مثال، M 3، همچنان رزرو خواهد شد. بنابراین، پنج قانون برای استخراج اشیاء در منطقه مورد مطالعه از فایلهای diff میتوان نتیجه گرفت.
فرض بر این است که “NodeInWay” مجموعه گره های مسیر تغییر یافته را نشان می دهد. “IsWayIntertsectR” تابعی است که برای تعیین اینکه آیا مسیر منطقه مورد مطالعه را قطع می کند یا خیر، استفاده می شود. “WayId” شناسه راه است. “BaseNodeInReg” و “BaseWayInReg” نشان دهنده گره ها (یا راه های) موجود در منطقه مورد مطالعه است. “ChgNodeInReg” و “ChgWayInReg” نشان دهنده گره ها (یا راه های) تغییر یافته در منطقه مورد مطالعه است. و “ChangeType” ChangeType متغیری است که برای ذخیره پرچم شروع بخش (“تغییر”، “حذف”، “ایجاد”) استفاده می شود.
(1) اگر راهی با یک گره در مجموعه گره های روش تغییر یافته در مجموعه گره های موجود یا مجموعه گره های تغییر یافته باشد. راه تغییر یافته در منطقه مورد مطالعه است.
قانون 1 : اگر NodeInWay ∩ (BaseNodeInReg∪ChgNodeInReg) ≠ Φ باشد، راه در ChgWayInReg ذخیره می شود.
(2) اگر راهی در مجموعه گره های موجود یا مجموعه گره های تغییر یافته بدون گره باشد اما مسیری که منطقه تحقیق را قطع می کند، همچنان راه در منطقه مورد مطالعه تغییر یافته است.
قانون 2 : اگر NodeInWay ∩ (BaseNodeInReg∪ChgNodeInReg) = null و IsWayIntertsectR = درست است، آن را در ChgWayInReg ذخیره کنید.
(3) اگر راهی بدون گره در مجموعه گرههای موجود یا مجموعه گرههای تغییر یافته باشد، راه هیچ تلاقی با ناحیه تحقیق ندارد و ChangeType “ایجاد” است، راه تغییر یافته خارج از محدوده مورد مطالعه است. منطقه و می توان آن را دور انداخت
قانون 3 : اگر NodeInWay ∩ (BaseNodeInReg∪ChgNodeInReg) = null، IsWayIntertsectR = false، و “changetype” = “create”، سپس راه را کنار بگذارید.
(4) اگر راهی بدون گره در مجموعه گره های موجود یا مجموعه گره های تغییر یافته باشد و راه با منطقه تحقیق تلاقی نداشته باشد اما ChangeType “modify” باشد و شناسه راه در موجود (یا تغییر یافته) باشد. ) راه ها در منطقه مورد مطالعه، راه حداقل یک نسخه قبلی دارد که منطقه مورد مطالعه را قطع می کند و باید در ChgWayInReg با یک پرچم ذخیره شود تا نشان دهد که از منطقه تحقیقاتی جدا شده است.
قانون 4 : اگر NodeInWay ∩ (BaseNodeInReg∪ChgNodeInReg) = null، IsWayIntertsectR = نادرست، “ChangeType” = “تغییر” و WayId ∩ (BaseWayInReg∪ChgWayInReg) آن را با ChgWayInReg ≠ flaint با ΦWay ذخیره کنید.
(5) اگر راهی بدون گره در مجموعه گره های موجود یا مجموعه گره های تغییر یافته باشد، راه هیچ تلاقی با منطقه تحقیق ندارد، ChangeType “تغییر” است. اگر شناسه راه به روش های موجود (یا تغییر یافته) در منطقه مورد مطالعه نباشد، تمام نسخه های قبلی راه (از جمله خود راه) از منطقه تحقیقاتی جدا شده و باید کنار گذاشته شوند.
قانون 5 : اگر NodeInWay ∩ (BaseNodeInReg∪ChgNodeInReg) = null، IsWayIntertsectR = false، “ChangeType” = “modify” و WayId ∩ (BaseWayInReg∪ChgWayInReg) = تهی، آن را دور بیندازید.
بنابراین با استفاده از روش ها و قوانین فوق می توان گره ها و راه های تغییر یافته در منطقه تحقیق را به صورت خودکار با اطلاعات کامل استخراج کرد. برای چند ضلعی های مختلط در روابط، اگر چند ضلعی بیرونی چند ضلعی است که ناحیه مورد مطالعه را قطع می کند، چند ضلعی مختلط جسمی است که ناحیه تحقیق را قطع می کند و باید ذخیره شود. چند ضلعی بیرونی نیز یک راه ساده است و بنابراین، چند ضلعی های پیچیده در روابط نیز می توانند با استفاده از روش ها و قوانین فوق استخراج شوند.
5.2. ادغام اشیاء تغییر یافته انتخاب شده در یک دوره زمانی
همانطور که در بالا ذکر شد، معمولاً چندین نسخه برای یک شی در مجموعه شی انتخاب شده در یک دوره وجود دارد. هر نسخه دارای نوع تغییر و اطلاعات معنایی با همان شناسه است. اگر آخرین نسخه برای بهروزرسانی دادههای موجود استفاده شود، ممکن است فرآیند بهروزرسانی اشتباه انجام شود. به عنوان مثال، در جایی که یک شی دارای سه نسخه در مجموعه است، انواع تغییرات به ترتیب “ایجاد”، “تغییر” و “حذف” هستند. اگر آخرین نسخه با نوع تغییر “حذف” برای به روز رسانی داده های موجود استفاده شود (به دلیل اینکه این شی در پایگاه داده موجود گنجانده نشده است)، یک اشتباه توسط عامل به روز رسانی گزارش می شود. در واقع، این شی نامعتبر است و نباید در فایل اطلاعاتی فقط تغییر گنجانده شود. بنابراین، روشی برای تعیین نوع تغییر اشیاء چند ویرایشی در طول زمان مورد نیاز است.
از آنجا که اشیاء چند نسخه چندین بار به ترتیب ویرایش شدهاند، فرآیند یکپارچهسازی باید بر اساس ترتیب زمانی انجام شود. پس از تجزیه و تحلیل تکامل اشیاء تغییر یافته شامل فایلهای تفاوت همسایه، شش نوع تکامل نوع تغییر برای اشیاء درگیر بین فایلهای تفاوت همسایه شناسایی میشوند. فرض بر این است که “تفاوت اصلی” یک فایل تفاوت است که برای ذخیره اشیاء تغییر یافته یکپارچه استفاده می شود (اولین فایل اصلی تفاوت برای دوره زمانی، اولین فایل تفاوت روزانه است)، “تفاوت جدید” فایل تفاوت روز بعد است. “تفاوت اصلی” و “تفاوت یکپارچه” فایل تفاوت نتیجه است. تکامل نوع تغییر اجسام در شکل 4 نشان داده شده است .
در شکل 5 ، شش نوع تکامل نوع تغییر به شرح زیر فهرست شده است:
- (1)
-
اگر نوع تغییر شیء در فایل diff اصلی “ایجاد” و در فایل diff جدید “modify” باشد، آنگاه شی یک شی “ایجاد” در فایل diff یکپارچه است.
- (2)
-
اگر نوع تغییر شی “ایجاد” در فایل diff اصلی و “حذف” در فایل diff جدید باشد، در این صورت شی یک شی “نامعتبر” است و در فایل diff یکپارچه گنجانده نخواهد شد.
- (3)
-
اگر نوع تغییر شی “modify” در فایل diff اصلی و “modify” در فایل diff جدید باشد، آنگاه شی یک شی “modify” در فایل diff یکپارچه است.
- (4)
-
اگر نوع تغییر شیء در فایل diff اصلی “modify” و در فایل diff جدید “حذف” باشد، آنگاه شی یک شی “حذف” در فایل diff یکپارچه است.
- (5)
-
اگر شیء تغییر یافته (نوع تغییر شامل “ایجاد”، “تغییر” یا “حذف”) در فایل diff اصلی باشد و در فایل diff جدید ظاهر نشود، آن شی در فایل diff یکپارچه باقی مانده است. همان مقدار تغییر نوع؛
- (6)
-
اگر شی ابتدا در فایل diff جدید ظاهر می شود و نوع تغییر آن “create” است، آنگاه شی یک شی “ایجاد” در فایل diff یکپارچه است.

شکل 5. تکامل نوع تغییر اشیا بین نسخه های همسایه.
بر اساس تجزیه و تحلیل فوق از تغییر نوع تکامل اشیاء بین نسخه های همسایه و فرآیند استخراج شی، به ویژه برای تکامل اشیاء اصلاح شده، هفت قانون برای ادغام اشیاء تغییر یافته تعیین می شود. فرض بر این است که “ChgObjectInReg” پایگاه داده تغییر شی انتخاب شده در طول مدت زمان است، V 1 و V max (حداکثر ≥ 1) اولین و آخرین نسخه یک شی در “ChgObjectInReg” هستند. و ChangeTypeV 1 ، ChangeTypeV max و ChangeTypeO به ترتیب ChangeType V 1 ، V max و شی ادغام شده را نشان می دهند.
(1) اگر شی برای اولین بار در فایل diff جدید ظاهر شد و ChangeType شی ادغام شده با نسخه اول برابر است، معمولاً یک شی “ایجاد” است.
قانون 1: اگر max = 1، سپس ChangeTypeO = ChangeTypeV 1 در ChgObjectInReg ذخیره می شود.
(2) اگر شی در نسخه قبلی ایجاد شده است، در نسخه بعدی اصلاح شده است، و در نسخه نهایی از منطقه تحقیقاتی جدا شده است (با پرچم “ناهم”)، باید دور انداخته شود.
قانون 2: اگر حداکثر ≥ 1، ChangeTypeV 1 = “ایجاد”، و ChangeTypeV max = “تغییر”، و آخرین نسخه با یک پرچم “disjoint” ( بخش 5.1 )، آن را دور بریزید.
(3) اگر یک شی در نسخه قبلی ایجاد شده است، در نسخه بعدی اصلاح شده است، و در نسخه نهایی از منطقه تحقیقاتی (بدون علامت “ناهم”) جدا نشده است، آنگاه شی در طول دوره ایجاد شده است و باید ذخیره شده است.
قانون 3: اگر حداکثر ≥ 1، ChangeTypeV 1 = “ایجاد”، و ChangeTypeV max = “تغییر”، و آخرین نسخه بدون پرچم “disjoint” ( بخش 5.1 )، سپس ChangeTypeO = “ایجاد”، در ChgObjectInReg ذخیره می شود.
(4) اگر یک شی در نسخه قبلی ایجاد شود، و در نسخه بعدی “حذف” ایجاد شود، آن شی “نامعتبر” است و باید دور انداخته شود.
قانون 4: اگر حداکثر ≥ 1، ChangeTypeV 1 = “ایجاد”، و ChangeTypeV max = “حذف”، آن را دور بریزید.
(5) اگر نوع تغییر یک شی در نسخه قبلی “تغییر”، در نسخه بعدی “تغییر” و در نسخه نهایی از منطقه تحقیقاتی (با پرچم “جدا”) جدا باشد، آنگاه شیء منعقد شده تا از منطقه تحقیق جدا شود و باید از فایل diff یکپارچه حذف شود.
قانون 5: اگر حداکثر ≥ 1، ChangeTypeV 1 = “تغییر”، و ChangeTypeV max = “تغییر”، و آخرین نسخه با یک پرچم “دیگر” ( بخش 5.1 )، سپس ChangeTypeO = “حذف”، در ChgObjectInReg ذخیره می شود. با حذف پرچم دلیل “انقباض”.
(6) اگر نوع تغییر یک شی در نسخه قبلی “تغییر”، در نسخه بعدی “تغییر” باشد و در نسخه نهایی از منطقه تحقیق (بدون علامت “جدا”) جدا نباشد، آنگاه شیء در طول دوره اصلاح می شود و باید ذخیره شود.
قانون 6: اگر حداکثر ≥ 1، ChangeTypeV 1 = “تغییر”، و ChangeTypeV max = “تغییر”، و آخرین نسخه بدون پرچم “disjoint” ( بخش 5.1 )، سپس ChangeTypeO = “تغییر”، در ChgObjectInReg ذخیره می شود.
(7) اگر نوع تغییر یک شی در نسخه قبلی “تغییر” و در نسخه بعدی “حذف” باشد، آنگاه شیء در طول دوره یک شی “حذف” است.
قانون 7: اگر حداکثر ≥ 1، ChangeTypeV 1 = “تغییر”، و ChangeTypeV max = “حذف”، سپس ChangeTypeO = “حذف”، در ChgObjectInReg ذخیره می شود.
فرض بر این است که اطلاعات مکانی و موضوعی آخرین نسخه بهترین است و اطلاعات آخرین نسخه به عنوان شی یکپارچه استفاده می شود. بنابراین، با استفاده از قوانین فوق، اشیاء تغییر یافته با نسخه های چندگانه را می توان در یک نسخه ادغام کرد تا یک فایل اطلاعاتی (یا پایگاه داده) فقط تغییر ایجاد کند. با فایل فقط تغییر، هم پایگاه داده مقصد کاربر و هم فایل وضعیت OSM XML منطقه تحقیقاتی را می توان با حذف خودکار اشیاء حذف شده، جایگزینی اشیاء اصلاح شده و ایجاد اشیاء جدید به روز کرد [ 30 ].
6. کاربرد تجربی
بر اساس قوانین و الگوریتم های ذکر شده در بالا، ما یکپارچه سازی خودکار (یا نیمه خودکار) را فعال کردیم و پایگاه داده مرزی را با برنامه نویسی با Visual C# 2010 به روز کردیم. گسترش نام از نام چینی به نام انگلیسی و نام زبان مادری. در این آزمایش، برچسب «HydA» نشاندهنده «منطقه هیدرولوژیکی»، «Hydl» نشاندهنده «خط هیدرولوژیکی»، «HydFacA» نشاندهنده «منطقه تأسیسات هیدرولوژیکی»، «ResiA» نشاندهنده «منطقه مسکونی»، «ResiFacP» نشاندهنده «مسکونی» است. نقاط، “ResiFacA” نشان دهنده “منطقه تسهیلات مسکونی”، “BouP” نشان دهنده “نقطه مرزی”، “VegA” نشان دهنده “منطقه گیاهی” است. “TerP” نشان دهنده “Terrain Point”، “TraP” نشان دهنده “Traffic Point” است.
6.1. آزمایش تبدیل مدل
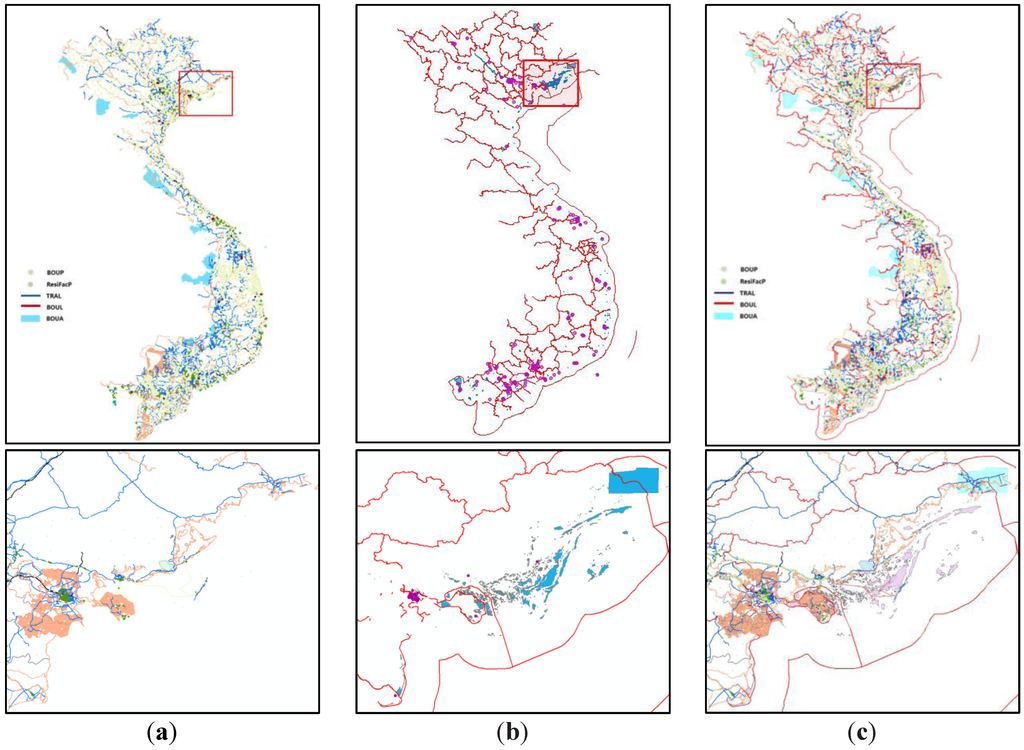
در این آزمایش، دادههای OSM ویتنام از 8 اکتبر 2013 با استفاده از مجموعه قانون 1 (قوانین اساسی 1180) به مدل دادههای بنیادی ملی چین تبدیل میشوند. اشیاء باقی مانده با استفاده از ابزار نرم افزار تعاملی به مدل کاربر تبدیل می شوند و 160 قانون دیگر به طور خودکار ذخیره می شوند تا مجموعه قانون 2 را تشکیل دهند، همانطور که در شکل 6 نشان داده شده است (در شکل 6 ، تصویر پایین جزئیات کادر قرمز در بالا را نشان می دهد. تصویر). دادههای OSM پاکستان از 16 اکتبر 2013 با استفاده از مجموعه قانون 1، که از 1180 قانون اساسی و مجموعه قانون 2 استفاده میکند، به مدل دادههای بنیادی ملی چین تبدیل شده است .، 1180 قانون اساسی به اضافه 160 قانون اضافی ایجاد شده در تکلیف تعاملی در آزمایش ویتنام) به ترتیب. به طور کلی، 109855 ویژگی توسط مجموعه قانون 1 و 1801 شیء اضافی توسط مجموعه قانون 2 منتقل می شوند. با این حال، 398 شی باقی مانده توسط این قوانین قابل انتقال نیستند. با استفاده از ابزار نرم افزار تعاملی، اشیاء باقی مانده به مدل کاربر تبدیل می شوند و 224 قانون دیگر به طور خودکار ذخیره می شوند.

شکل 6. داده های آزمایش تبدیل مدل (ویتنام، 8 اکتبر 2013). ( الف ) داده های منتقل شده توسط قوانین اساسی 1180. ( ب ) اشیاء را نمی توان با استفاده از قوانین اساسی منتقل کرد. ( ج ) داده های کامل را می توان با استفاده از قوانین جهانی منتقل کرد.
اطلاعات دقیق در مورد لایه های اصلی با استفاده از مجموعه قوانین مختلف در جدول 2 نشان داده شده است . برای آزمایش صحت تبدیل مدل، تمام ویژگیهای تبدیلشده اسلامآباد در پاکستان و Qui Nhon در ویتنام برای مقایسه با تصاویر Google مربوطه استفاده میشوند. نتیجه مقایسه در جدول 3 نشان داده شده است .
جدول 2. ویژگی های تبدیل شده توسط مجموعه قوانین مختلف.
جدول 3. مجموع خطای تبدیل مدل.
این آزمایش نشان میدهد که مکانیسم قانون تبدیل-مدل-به خاطر سپردن میتواند پایه قانون را به صورت تدریجی افزایش دهد و به طور موثر قدرت تبدیل مدل را بهبود بخشد. درصد خطای تبدیل کل دو شهر 0.5 درصد است. این نشان می دهد که دقت تبدیل معقول است. پس از تجزیه و تحلیل ویژگیهای تبدیل خطا، متوجه شدیم که دلیل خطای تبدیل عمدتاً ناشی از انواع مختلف نمادهای داوطلبان است.
6.2. به روز رسانی آزمایش
در آزمایش بهروزرسانی، دادههای پاکستان تبدیلشده از OSM برای 30 نوامبر 2014، بهعنوان حالت پایه استفاده میشود، و دادههای متفاوت OSM از 30 نوامبر 2014 تا 30 ژانویه 2015، بهعنوان دادههای منبع اطلاعات فقط تغییر برای پاکستان است. به طور کلی، 10657 شی ایجاد می شود، 7070 شی اصلاح می شود و 587 شی حذف می شود. داده های آزمایشی در شکل 7 نشان داده شده است ، و تصویر زیرین با تصاویر، جزئیات کادر قرمز در تصویر سمت بالا است. توزیع اشیاء در جدول 4 نشان داده شده است .
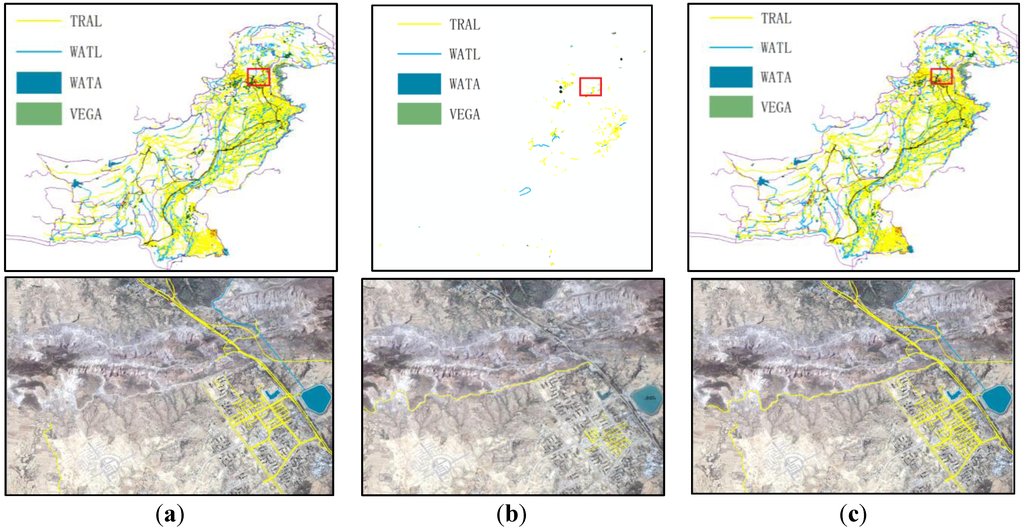
شکل 7. آزمایش به روز رسانی افزایشی با استفاده از داده های OsmChange. ( الف ) داده های پاکستان تبدیل شده از OSM برای 30 نوامبر 2014. ( ب ) دادههای صرفاً تغییر از 30 نوامبر 2014 تا 30 ژانویه 2015؛ ( ج ) داده های به روز شده پاکستان در 30 ژانویه 2015.
جدول 4. توزیع اشیاء در آزمایش به روز رسانی
آزمایش نشان میدهد که دادههای OSM دانلود شده برابر با دادههای بهروزرسانیشده از فایل تفاوت روزانه OsmChange است. بنابراین، استفاده از فایل تفاوت روزانه OsmChange برای ایجاد اطلاعات فقط تغییر منطقه تحقیقاتی، روشی معقول برای بهروزرسانی پایگاه داده مرزی است.
7. نتیجه گیری و بحث
در این مقاله، ما یک روش یکپارچه سازی پویا برای پایگاه های داده مرزی با استفاده از داده های OSM ارائه می کنیم. در این روش، دادههای OSM با فرمت XML برای یک منطقه مرزی تحقیقاتی دانلود میشوند، انواع فضایی اشیاء در دادههای OSM با استفاده از قوانین تبدیل نوع فضایی تعیین میشوند و دادهها به مدل داده میانی تبدیل میشوند. یک پایه قانون تبدیل اولیه با مقایسه سند توصیف ویژگی نقشه OSM و تعاریف مدل مقصد تشکیل می شود. با استفاده از قوانین اساسی، ویژگی های اصلی را می توان به طور خودکار به مدل مقصد تبدیل کرد. یک تغییر مدل تعامل انسان و کامپیوتر و یک مکانیسم خودکار به خاطر سپردن قوانین برای انتقال تعاملی ویژگیهای غیرمعمولی که توسط قوانین اساسی نمیتوانند به لایههای هدف مناسب منتقل شوند و قوانین قابل استفاده مجدد را بهطور خودکار به خاطر بسپارند، ایجاد شدهاند. برای به روز نگه داشتن پایگاه داده مرزی، از فایل جهانی تفاوت روزانه OsmChange برای انتخاب اطلاعات فقط تغییر منطقه تحقیقاتی استفاده می شود. برای انتخاب اشیاء تغییر یافته در منطقه مورد مطالعه، رابطه بین شی تغییر یافته و منطقه تحقیقاتی با توجه به تکامل اشیاء درگیر تجزیه و تحلیل شده، پنج قانون مورد استفاده برای انتخاب اشیا نتیجهگیری میشود. برای ادغام اشیاء تغییر یافته با چند نسخه در یک دوره زمانی معین،
برای آزمایش صحت روشها و الگوریتمهای ارائهشده در این مقاله، یک سیستم نمونه اولیه با برنامهنویسی با Visual C# 2010 توسعه داده شده است. برای ویتنام و پاکستان به عنوان داده های تجربی. آزمایش نشان داد که مکانیسم قانون-به خاطر سپردن هم می تواند پایه قانون را به صورت تدریجی افزایش دهد و هم قدرت تبدیل مدل را به طور موثر بهبود بخشد. علاوه بر این، دقت تبدیل آن معقول است و داده های به روز شده با استفاده از روش به روز رسانی ارائه شده در این مقاله با داده های OSM تازه دانلود شده برابر است.
از تجربه تحقیق فوق، یک روش یکپارچه سازی پویا با استفاده از داده های OSM به دست آمده است. اگرچه این روش برای یکپارچه سازی و به روز رسانی پایگاه داده مرزی با استفاده از داده های OSM توسعه یافته است، روش و الگوریتم ها همچنین می توانند برای یکپارچه سازی و به روز رسانی پایگاه های داده دیگر کاربران استفاده شوند. یک پایگاه قانون تبدیل مدل اولیه از دادههای OSM به مدل دادههای اطلاعات جغرافیایی بنیادی مرزی چینی 1:50000 تشکیل شده است. این پایه قانون دارای 1180 قانون اساسی و 1164 قانون اضافی به خاطر سپردن خودکار است. پایگاه داده اولیه اطلاعات جغرافیایی مرزی چین 1:50000 با هزینه بسیار کم ایجاد شده است. از تجربیات پژوهشی نیز می توان درس هایی گرفت. (1) در تشکیل قوانین تبدیل مدل، این تحقیق تنها از مقادیر برچسب در ستون های کلید و مقدار برای ساخت پایگاه داده قوانین اساسی استفاده می کند. در واقع، بسیاری از ویژگی های اصلاحی که در ستون نظر توضیح داده شده اند، به عنوان مقدار برچسب گذاری در داده های OSM استفاده می شوند. بنابراین، ویژگی های پالایش در نظر می تواند برای ساخت پایگاه داده قوانین تبدیل مدل استفاده شود. (2) در تحقیقات اولیه ما برای استخراج اشیاء تغییر یافته در منطقه مورد مطالعه، روابط کامل بین راه تغییر یافته و منطقه تحقیقاتی مورد تجزیه و تحلیل قرار نگرفته است و تنها راه های دارای گره در منطقه تحقیق استخراج شده است که باعث برخی راه ها شده است. بدون گره در منطقه تحقیقاتی، اما با تقاطع به منطقه تحقیق) از دست داده شود. (3) از آنجایی که ابتدا تغییر نوع تغییر اشیاء بین نسخههای همسایه ذکر نشده بود، برخی از اشیاء با “تغییر” در نسخه قبلی، “تغییر” در نسخه بعدی تغییر نوع میدهند. و جدا از منطقه تحقیقاتی در آخرین نسخه در پایگاه داده به روز شده باقی مانده است. بنابراین، نتیجه با داده های OSM دانلود شده مطابقت ندارد.
لازم به بیان است که برخی از ویژگیها در دادههای OSM فاقد ویژگیهای معتبر «کلید-مقدار» هستند که هنوز نمیتوانند به طور خودکار با استفاده از روش مبتنی بر قانون ارائهشده در این مقاله به مدل مقصد تبدیل شوند. علاوه بر این، این مقاله فرض میکند که اطلاعات مکانی و موضوعی آخرین نسخه بهترین است و اطلاعات موجود در آخرین نسخه به عنوان شی یکپارچه استفاده میشود. اگرچه داده های OSM به طور داوطلبانه توسط آماتورها («نئوجغرافیان») تولید می شود، آخرین نسخه ممکن است بهترین نسخه نباشد. اعتبار داوطلبان بر کیفیت دادههای OSM تأثیر میگذارد و کار آینده بر روی ادغام اشیاء تغییر با نسخههای چندگانه با در نظر گرفتن قابلیت اطمینان شی متمرکز خواهد شد.
منابع
- چن، جی. لی، آر. دونگ، دبلیو. Ge، Y. لیائو، اچ. چنگ، ی. مدل سازی و درک سرزمین های مرزی مبتنی بر GIS: یک چشم انداز. ISPRS Int. J. Geo-Inf. 2015 ، 4 ، 661-676. [ Google Scholar ] [ CrossRef ]
- استخراج داده ها – جزئیات فنی. در دسترس آنلاین: http://download.geofabrik.de/technical.html (در 1 نوامبر 2014 قابل دسترسی است).
- Haklay, M. اطلاعات جغرافیایی داوطلبانه چقدر خوب است؟ مطالعه تطبیقی مجموعه دادههای OpenStreetMap و Ordnance Survey. محیط زیست طرح. B طرح. طراحی 2010 ، 37 ، 682-703. [ Google Scholar ] [ CrossRef ]
- زیلسترا، دی. Zipf، A. مطالعه مقایسه ای داده های جغرافیایی اختصاصی و اطلاعات جغرافیایی داوطلبانه برای آلمان. در مجموعه مقالات سیزدهمین کنفرانس بین المللی AGILE در علم اطلاعات جغرافیایی، گیماراس، پرتغال، 10-14 مه 2010. صص 1-15.
- گیرس، جی اف. Touya, G. ارزیابی کیفیت مجموعه داده OpenStreetMap فرانسه. ترانس. GIS 2010 ، 14 ، 435-459. [ Google Scholar ] [ CrossRef ]
- سیپلوچ، بی. یعقوب، ر. مونی، پی. Winstanley، A. مقایسه دقت OpenStreetMap برای ایرلند با Google Maps و Bing Maps. در مجموعه مقالات نهمین سمپوزیوم بین المللی ارزیابی دقت فضایی در منابع طبیعی و علوم محیطی، لستر، بریتانیا، 20 تا 23 ژوئیه 2010; صص 337-340.
- سیبریتز، ال. سیتول، جی. زلاتانوا، اس. ارزیابی همگنی اطلاعات جغرافیایی داوطلبانه در آفریقای جنوبی. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2012 ، XXXIX-B4 ، 553-558. [ Google Scholar ] [ CrossRef ]
- فرقانی، م. Delavar, MR مطالعه کیفی مجموعه داده OpenStreetMap برای تهران. ISPRS Int. J. Geo-Inf. 2014 ، 3 ، 750-763. [ Google Scholar ] [ CrossRef ]
- جکسون، اس. مولن، دبلیو. آگوریس، پ. کروکس، آ. کرویتورو، آ. استفانیدیس، الف. ارزیابی کامل بودن و خطای مکانی ویژگیها در اطلاعات جغرافیایی داوطلبانه. ISPRS Int. J. Geo-Inf. 2013 ، 2 ، 507-530. [ Google Scholar ] [ CrossRef ]
- هچت، ر. کونز، سی. Hahmann, S. اندازه گیری کامل بودن ردپای ساختمان در OpenStreetMap در مکان و زمان. ISPRS Int. J. Geo-Inf. 2013 ، 2 ، 1066-1091. [ Google Scholar ] [ CrossRef ]
- فن، اچ. Zipf، A.; فو، س. Neis, P. ارزیابی کیفیت برای ایجاد داده های ردپایی در OpenStreetMap. بین المللی جی. جئوگر. Inf. علمی 2014 ، 28 ، 700-719. [ Google Scholar ]
- کامبر، ا. ببینید، L. فریتز، اس. Velde، MVD؛ پرگر، سی. فودی، جی. استفاده از داده های کنترلی برای تعیین قابلیت اطمینان اطلاعات جغرافیایی داوطلبانه در مورد پوشش زمین. بین المللی J. Appl. زمین Obs. Geoinf. 2013 ، 23 ، 37-48. [ Google Scholar ] [ CrossRef ]
- بیشر، م. Mantelas، L. یک مدل اعتماد و شهرت برای فیلتر کردن و طبقه بندی دانش در مورد رشد شهری. جئوژورنال 2008 ، 72 ، 229-237. [ Google Scholar ] [ CrossRef ]
- ون اکسل، ام. دیاس، ای. Fruijtier, S. تاثیر جمع سپاری بر شاخص های کیفیت داده های مکانی. در مجموعه مقالات ششمین کنفرانس بین المللی GiScience در علم اطلاعات جغرافیایی، زوریخ، سوئیس، 14-17 سپتامبر 2010. صص 213-216.
- Goodchild، MF; Li, L. اطمینان از کیفیت اطلاعات جغرافیایی داوطلبانه. تف کردن آمار 2012 ، 1 ، 110-112. [ Google Scholar ] [ CrossRef ]
- ندکوف، اس. زلاتانوا، اس. نقشه های گوگل برای مسیریابی اضطراری جمع سپاری شده. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2012 ، XXXIX-B4 ، 477-482. [ Google Scholar ] [ CrossRef ]
- روشه، اس. پروپک-زیمرمن، ای. Mericskay، B. GeoWeb و مدیریت بحران: مسائل و دیدگاههای اطلاعات جغرافیایی داوطلبانه. جئوژورنال 2013 ، 78 ، 21-40. [ Google Scholar ] [ CrossRef ]
- مک دوگال، ک. Temple-Watts, P. استفاده از LiDAR و اطلاعات جغرافیایی داوطلبانه برای ترسیم گستره سیل و طغیان. ISPRS Ann. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2012 ، I-4 ، 251-256. [ Google Scholar ] [ CrossRef ]
- تیان، دبلیو. زو، ایکس. لیو، ی. مکانیزم به روز رسانی داده های مکانی از پایین به بالا برای به روز رسانی زیرساخت داده های مکانی. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2012 ، XXXIX-B4 ، 445-448. [ Google Scholar ] [ CrossRef ]
- مونی، پی. Corcoran, P. ادغام اطلاعات جغرافیایی داوطلبانه در برنامه های کاربردی محاسبات سلامت فراگیر. در مجموعه مقالات پنجمین کنفرانس بینالمللی فناوریهای محاسباتی فراگیر برای مراقبتهای بهداشتی و کارگاهها، دوبلین، ایرلند، 23 تا 26 مه 2011. صص 93-100.
- هاگناور، جی. Helbich، M. استخراج الگوهای کاربری زمین شهری از اطلاعات جغرافیایی داوطلبانه با استفاده از الگوریتمهای ژنتیک و شبکههای عصبی مصنوعی. بین المللی جی. جئوگر. Inf. علمی 2012 ، 26 ، 963-982. [ Google Scholar ] [ CrossRef ]
- پائودیال، DR. مک دوگال، ک. آپناب، الف. بررسی کاربرد اطلاعات جغرافیایی داوطلبانه در مدیریت حوضه: یک رویکرد پیمایشی. ISPRS Ann. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2012 ، I-4 ، 275-280. [ Google Scholar ] [ CrossRef ]
- باکیالله، م. لیانگ، اس. مبشری، ع. جوکار ارسنجانی، ج. Zipf، A. نگاشت جمعیت با وضوح خوب با استفاده از نقاط مورد علاقه OpenStreetMap. بین المللی جی. جئوگر. Inf. علمی 2014 ، 28 ، 1940-1963. [ Google Scholar ] [ CrossRef ]
- Clark, A. Where 2.0 محیط زیست استرالیا؟ جمع سپاری، اطلاعات جغرافیایی داوطلبانه و شهروندانی که به عنوان حسگرهایی برای پایداری محیطی عمل می کنند. ISPRS Int. J. Geo-Inf. 2014 ، 3 ، 1058-1076. [ Google Scholar ] [ CrossRef ]
- نیس، پ. Zipf، A. تجزیه و تحلیل فعالیت مشارکت کننده یک پروژه داوطلبانه اطلاعات جغرافیایی – مورد OpenStreetMap. ISPRS Int. J. Geo-Inf. 2012 ، 1 ، 146-165. [ Google Scholar ] [ CrossRef ]
- نیس، پ. گوتز، ام. Zipf، A. به سوی شناسایی خودکار خرابکاری در OpenStreetMap. ISPRS Int. J. Geo-Inf. 2012 ، 1 ، 315-332. [ Google Scholar ] [ CrossRef ]
- زیلسترا، دی. هوچمیر، اچ. نیس، پ. تونینی، اف. ترسیم منطقه ای از مناطق خانه از مشارکت و الگوهای ویرایش در OpenStreetMap. ISPRS Int. J. Geo-Inf. 2014 ، 3 ، 1211-1233. [ Google Scholar ] [ CrossRef ]
- سریع، V. Rinner, C. دیدگاه سیستمی در مورد اطلاعات جغرافیایی داوطلبانه. ISPRS Int. J. Geo-Inf. 2014 ، 3 ، 1278-1292. [ Google Scholar ] [ CrossRef ]
- اگنهوفر، ام. Mark, DM مدل سازی همسایگی های مفهومی روابط خط-منطقه توپولوژیکی. بین المللی جی. جئوگر. Inf. علمی 1995 ، 9 ، 555-565. [ Google Scholar ] [ CrossRef ]
- ژو، XG; چن، جی. جیانگ، جی. زو، جی جی. Li، ZL به روز رسانی افزایشی پایگاه داده مکانی-زمانی مبتنی بر رویداد. مجله دانشگاه صنعتی جنوب مرکزی 2004 ، 11 ، 192-198. [ Google Scholar ] [ CrossRef ]
© 2015 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر