1. معرفی
محدود کردن حوزههای تجاری میتواند به کسبوکارها کمک کند تا فرصتهای بازار، توزیع مشتریان و ویژگیهای مشتری را برای طراحی استراتژیهای تجاری رقابتیتر درک کنند. بنابراین، تعیین حدود مناطق تجاری یکی از دغدغه های اصلی شرکت های خرده فروشی و خدماتی است [ 1 ]. به گفته هاف، یک منطقه تجاری “منطقه ای است که از نظر جغرافیایی مشخص شده است که شامل مشتریان بالقوه ای است که احتمال خرید آنها برای طبقه معینی از محصولات یا خدمات ارائه شده برای فروش توسط یک شرکت خاص یا توسط یک مجموعه خاص از شرکت ها بیشتر از صفر است.” [ 2]. بنابراین، یک درک تجربی از مناطق تجاری، پایه و اساس هوش تجاری استراتژیک و مقدمه ای است که در پس انتخاب مکان برای تسهیلات تجاری جدید یا خدمات پذیرایی قرار دارد.
منبع داده سنتی برای تعیین حدود مناطق تجاری اغلب اطلاعات مشتری است که از نظرسنجی ها به دست می آید. این اطلاعات می تواند شامل محل سکونت و دفعات بازدید از امکانات تجاری باشد. اطلاعات پاسخدهندگان جمعآوریشده از پرسشنامهها نسبتاً کامل است و هر پاسخدهنده را میتوان به عنوان یک نمونه در هنگام تعیین محدودههای تجاری در نظر گرفت. مدیران می توانند از این مناطق تجاری محدود شده برای مکان یابی سوپرمارکت های جدید با عدم اطمینان کمتر [ 3 ] و برای برآورد دقیق فروش فروشگاه های فردی استفاده کنند [ 4 ]. نظرسنجی ها متداول ترین روشی هستند که برای به دست آوردن اطلاعات مشتری مورد استفاده قرار می گیرند، اما کار فشرده و زمان بر هستند [ 5 ]. علاوه بر این، نرخ پاسخ و تعداد پاسخ دهندگان نسبتا پایین است [6 ]. بنابراین، دادههای دیگر و روشهای دیگری برای درک و تعیین حدود مناطق تجاری مورد نیاز است. رسانه های اجتماعی ممکن است راه حلی ارائه دهند.
دادههای رسانههای اجتماعی فرصتهای نویدبخشی را برای درک بهتر رفتارهای مصرفکننده و تعیین محدودههای تجاری باز میکنند. این دادهها راحتتر از دادههای نظرسنجی بهدست میآیند و منعکسکننده رفتار تعداد زیادی از کاربران در دورههای نسبتاً طولانی هستند تا رفتارهای نمونه کوچکی از مصرفکنندگان. به عنوان نماینده ای برای جمعیت بزرگتر خدمت می کند. با این حال، داده های رسانه های اجتماعی محدود هستند، زیرا نمی توانند فعالیت های تکمیل شده کاربر را در دنیای واقعی منعکس کنند. ما فقط می توانیم فعالیت هایی را مشاهده کنیم که یک فرد در رسانه های اجتماعی به اشتراک می گذارد [ 7 , 8 , 9 , 10]. در این مقاله، ما بر توسعه راههای جدید برای تعیین حدود مناطق تجاری با استفاده از رسانههای اجتماعی به روشهایی تمرکز میکنیم که بر کیفیتهای جزئی و ناقص این منبع داده غنی غلبه کند.
تحقیقات فزاینده ای در مورد داده های رسانه های اجتماعی که برای تجزیه و تحلیل منطقه تجاری اعمال می شود، وجود دارد. هو و همکاران [ 11 ] آزمایشی را برای استخراج در منطقه تجاری با داده های ورود به سیستم به دست آمده از خدمات رسانه های اجتماعی طراحی کرد. مناطق تجاری استخراج شده به این روش ارتباط زیادی با برنامه ریزی شهری داشتند اما برای تعیین محدوده تجاری یک فروشگاه خاص یا تجمع خرده فروشی مناسب نبودند. کو و همکاران [ 12] هر کاربر فلیکر را به عنوان یک نمونه در نظر گرفت. بر اساس این داده ها، آنها مناطق تجاری را برای انواع مختلف تسهیلات تجاری، بدون ارزیابی تعیین کردند. از آنجایی که دادههای رسانههای اجتماعی فعالیتهای کامل را منعکس نمیکنند، مناسب نیست که هر کاربر فردی را به عنوان یک موضوع نمونه در هنگام تعیین محدودههای تجاری در نظر بگیریم. تا به امروز، هیچ مطالعهای در مورد چگونگی استخراج نمونههایی از دادههای رسانههای اجتماعی که برای تعیین حدود مناطق تجاری مناسب هستند، تحقیق نکرده است. تحقیقات ما به این مشکل می پردازد و راه حلی عملی برای مشاغل به روشی مقرون به صرفه ارائه می دهد.
ما یک روش بهبود یافته را برای تعیین حدود مناطق تجاری با استفاده از داده های رسانه های اجتماعی پیشنهاد می کنیم. در رویکرد ما، خوشهبندی فضایی مبتنی بر چگالی برنامههای کاربردی با الگوریتم خوشهبندی نویز (DBSCAN) برای استخراج مرکز فعالیت برای هر کاربر Sina Weibo اعمال شد. سپس، 10 مجموعه نمونه با انتخاب کاربران بر اساس تعداد مناطق از پیش تعریف شده بازدید شده و تجمیع این مراکز فعالیت کاربر در هر سلول شبکه، گروه بندی شدند. ما ویژگیهای فاصله و فرکانس بازدید را برای هر کاربر و هر سلول شبکه محاسبه کردیم. مقدار فاصله یک سلول شبکه، میانگین فاصله مراکز فعالیت کاربر در این سلول شبکه تا یک تجمع خرده فروشی است. تعداد بازدید از سلول شبکه به میانگین تعداد بازدید از تجمعات خرده فروشی توسط مراکز فعالیت کاربر برای این سلول اشاره دارد. ویژگیهای فاصله و فرکانس بازدید 10 مجموعه نمونه در مدل هاف، یک روش سنتی تعیین حدود منطقه تجاری، وارد شد. ریشه میانگین مربعات خطا (RMSE) و ضریب تعیین (R2 ) برای ارزیابی مناطق تجاری محدود شده استفاده شد. نتایج ما نشان میدهد که استفاده از واحدهای فضایی برای جمعآوری کاربران رسانههای اجتماعی، تعیین حدود مناطق تجاری را بهبود میبخشد. این نتایج همچنین ویژگی های اندازه و شدت مناطق مختلف تجاری را نشان می دهد.
2. پس زمینه
2.1. روش تحدید محدوده تجاری
روش های مختلفی برای تعیین حدود و تجزیه و تحلیل مناطق تجاری وجود دارد. روش های اصلی شامل مدل رینگ، مدل ورونوی، مدل رگرسیون، روش آنالوگ و مدل هاف است. این روش ها از ساده مانند مدل حلقه تا پیچیده و پیچیده مانند مدل هاف را شامل می شود. همه روش ها به مقدار زیادی نمونه نیاز دارند، به جز مدل های Ring و Voronoi.
با تطبیق نظریه مکان مرکزی کریستالر [ 13 ]، یک مدل مورفولوژیکی متحدالمرکز توسط اپلبام و کوهن [ 14 ] برای تعیین محدوده تجاری فروشگاه با کشیدن حلقههایی در اطراف محل فروشگاه، با فروشگاه به عنوان نقطه مرکزی، پیشنهاد شد . یک مشکل با این رویکرد این است که یک منطقه تجاری اغلب از توزیع های غیر همسانگرد مصرف کنندگان ساخته شده است که ممکن است الگوی منطقه تجاری را تحریف کند [ 15 ].
روش های Voronoi یک راه سریع و ساده برای تعریف مناطق تجاری بر اساس مفهوم ریاضی چندضلعی های Thiessen ارائه می دهند. چند ضلعی تیسن تقسیم بندی یک صفحه به مناطق بر اساس فاصله تا نقاط در زیر مجموعه خاصی از صفحه است [ 16 ]. نقطه ضعف این روش این فرض است که هیچ عامل مؤثری بر تحدید محدوده تجاری به جز فاصله اقلیدسی وجود ندارد.
روش رگرسیون به دنبال اندازه گیری یک پارامتر عملکرد با همبستگی آن با متغیرهای مختلف اجتماعی-اقتصادی، محیطی و بازاریابی است [ 17 ]. رگرسیون به طور گسترده ای برای تعیین حدود منطقه تجاری اعمال نمی شود زیرا به مشاهدات زیادی نیاز دارد و متغیرهای توضیحی بیشتری باید گنجانده شوند [ 18 ].
یک روش تجربی رایج بر اساس تجربه قبلی برای تعیین مرزهای مناطق تجاری، روش آنالوگ [ 19 ] است. این روش ابتدا محل سکونت را بر روی نقشه ترسیم می کند. سپس سطوح مختلف حوزه تجارت با توجه به تعداد مشتریان محدود تعریف می شود. نقطه ضعف روش آنالوگ این است که منطقه تجاری محدود نمی تواند روابط رقابتی بین امکانات تجاری مختلف را آشکار کند [ 20 ].
مدل هاف یکی از متداولترین روشهای مورد استفاده برای تعیین حدود منطقه تجاری است [ 15 ]. این مدل فرض می کند که منطقه تجاری توسط دو عامل تعیین می شود: (1) فاصله بین مشتریان و امکانات تجاری مختلف. (2) جذابیت هر یک از امکانات [ 2 ]. مدل هاف را می توان به صورت زیر در نظر گرفت:
که در آن P ij احتمال مشتریانی است که در منطقه من برای بازدید از تأسیسات تجاری یا خرده فروشی j می روم . A j جذابیت تاسیسات یا مجتمع خرده فروشی j است . D ij فاصله بین i و j است و α، λ به ترتیب پارامترهای حساس جذابیت و فاصله هستند. هاف ابتدا α و λ را به صورت پیش فرض 1 و 2 تعریف کرد. گاوتشی [ 21 ] و همچنین اپلی و شیلینگ [ 22]] نشان می دهد که پارامترهای حساس ممکن است در تحقیقات قبلی مدل هاف به طور قابل توجهی اغراق شده باشند. بر این اساس، کالیبراسیون پارامتر در طول اعمال مدل هاف برای تعیین حدود مناطق تجاری بسیار ضروری است. امکانات بازدید، فواصل و جذابیت ویژگی های ضروری هر موضوعی است که ورودی مدل هاف است.
در مقایسه با سایر روشهای منطقه تجاری، عوامل تأثیرگذار در نظر گرفته شده توسط مدل هاف نسبتاً کامل هستند. یک مدل هاف می تواند یک منطقه تجاری را با دقت مشخص کند و رابطه رقابتی بین امکانات را با جزئیات نشان دهد. بنابراین، در این مقاله از مدل هاف برای تعیین حدود مناطق تجاری استفاده کردیم.
2.2. سینا ویبو
Sina Weibo که در سال 2009 تأسیس شد، یکی از بزرگترین خدمات رسانه های اجتماعی در چین است [ 23 ]. از دسامبر 2012، کاربران فعال می توانند روزانه 4.6 میلیون نفر با حدود 100 میلیون پیام ارسال شده در هر روز [ 24 ]. Sina Weibo به کاربران این امکان را میدهد تا محتوای مختصری به نام «میکروبلاگ» را در قالب جملات کوتاه، تصاویر جداگانه، لینکهای صفحه وب یا پیوندهای ویدیویی بهروزرسانی کنند. مشابه پیامهای توییتر به نام «توییت»، کاربران Sina Weibo فقط میتوانند پیامهایی را در محدوده 140 نویسه چینی ارسال کنند. توابع Sina Weibo بسیار شبیه به توییتر هستند، مانند retweets (RTs)، ذکر شده (@)، و هشتگ (#) [ 25 ].
Sina Weibo به کاربران این امکان را می دهد که در نقاط مورد علاقه (POI) چک کنند. این دادههای ورود میتوانند برای تعیین حدود مناطق تجاری در دنیای واقعی استفاده شوند [ 12 ]. داده های اعلام حضور با رفتار خرید مشتریان واقعی متفاوت است، اما راحت تر به دست می آیند و می توانند اطلاعات مفیدی در مورد فعالیت های مشتری ارائه دهند.
3. داده ها و منطقه مطالعه
3.1. جمع آوری داده ها و پیش پردازش
به منظور به دست آوردن دادههای Sina Weibo مربوط به زندگی روزمره مردم، دادههای رسانههای اجتماعی با برچسب جغرافیایی را با Sina API جمعآوری کردیم و نویز را فیلتر کردیم. ما از API با نام “place/nearby_timeline” ارائه شده توسط Sina Weibo برای جمع آوری داده های برچسب گذاری شده جغرافیایی در پکن استفاده کردیم. این API میتواند دادههای Sina Weibo را که در دایرههایی با مراکز و شعاعهای معین قرار دارند، بدست آورد. مرکز را می توان در هر مکانی قرار داد و شعاع را می توان روی هر مقداری از 2 تا 11 کیلومتر تنظیم کرد. مجموعه ای از دایره ها به شعاع 10 کیلومتر برای پوشش منطقه مرکزی پکن تنظیم شده بود. با فیلتر کردن موارد تکراری، در مجموع 16682330 پیام Weibo با برچسب جغرافیایی ارسال شده بین 1 ژانویه 2014 تا 28 فوریه 2015 جمع آوری کردیم. نمونه هایی از داده های Weibo در جدول 1 نشان داده شده است.. هر پیام Weibo دارای چندین ویژگی است: شناسه Weibo، شناسه کاربری، محل ثبت نام، زمان ارسال پست Weibo، متن Weibo، مختصات مکان ارسال، شناسه POI ورود، و نام. در میان این ویژگی ها، محل ثبت نام به شهر یا منطقه ای اطلاق می شود که کاربر در آن زندگی می کند اما محل دقیق سکونت او نیست. بنابراین محل سکونت کاربر باید از داده های Sina Weibo آنها استخراج شود.
نویز در داده های Sina Weibo در طول پیش پردازش فیلتر شد. بر اساس تجربیات یک مطالعه قبلی [ 25 ]، نویز عمدتاً تبلیغاتی بود که در Sina Weibo ارسال شده بود و بیشتر تبلیغات دارای نمادهای خاصی مانند “【】 بودند. پس از فرآیند فیلتر کردن، 16,676,720 پیام Weibo ارسال شده توسط 2,428,705 کاربر برای تجزیه و تحلیل بیشتر حفظ شد.
3.2. منطقه مطالعه
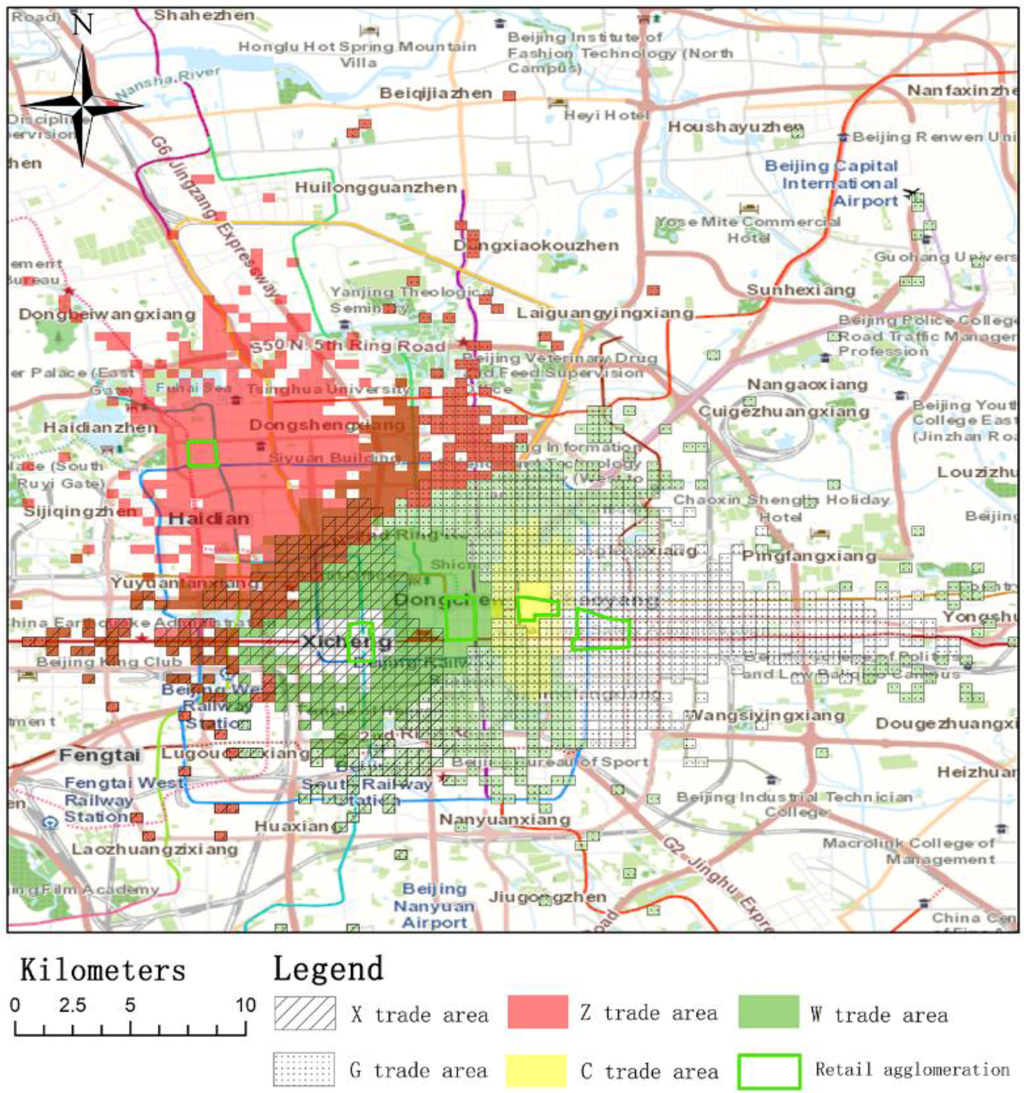
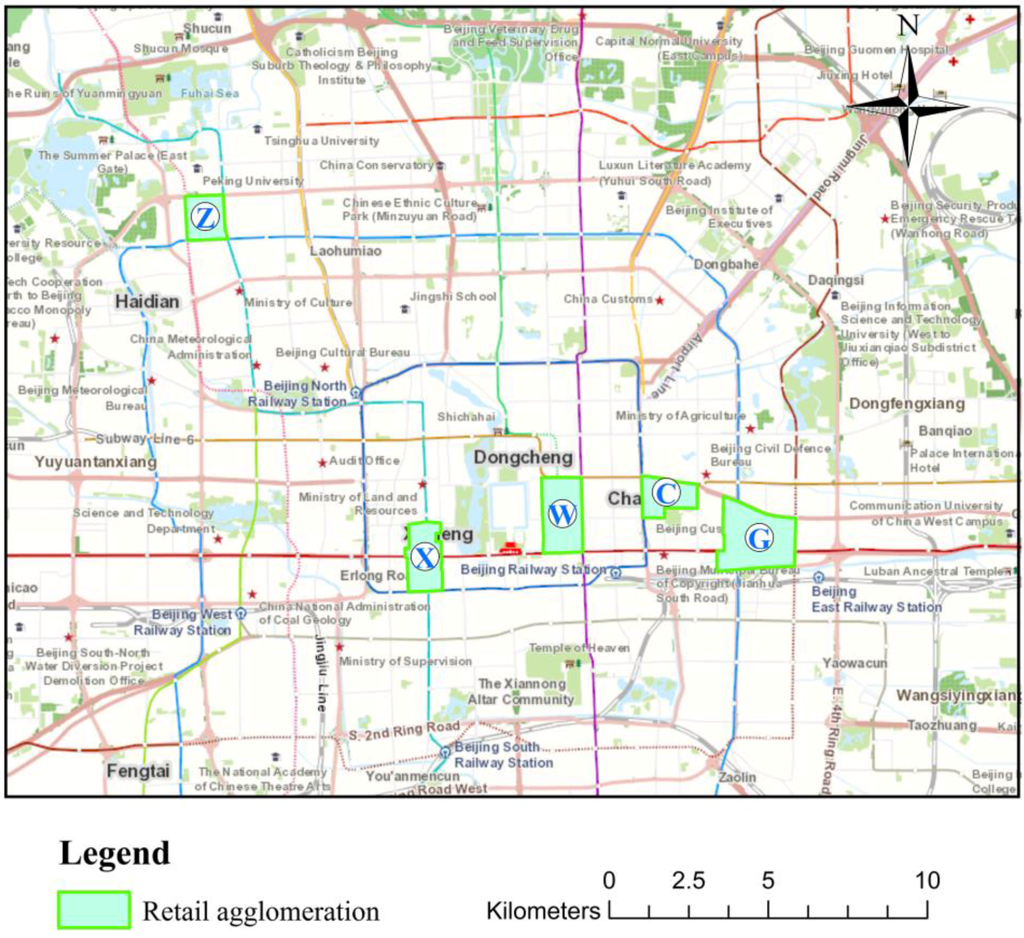
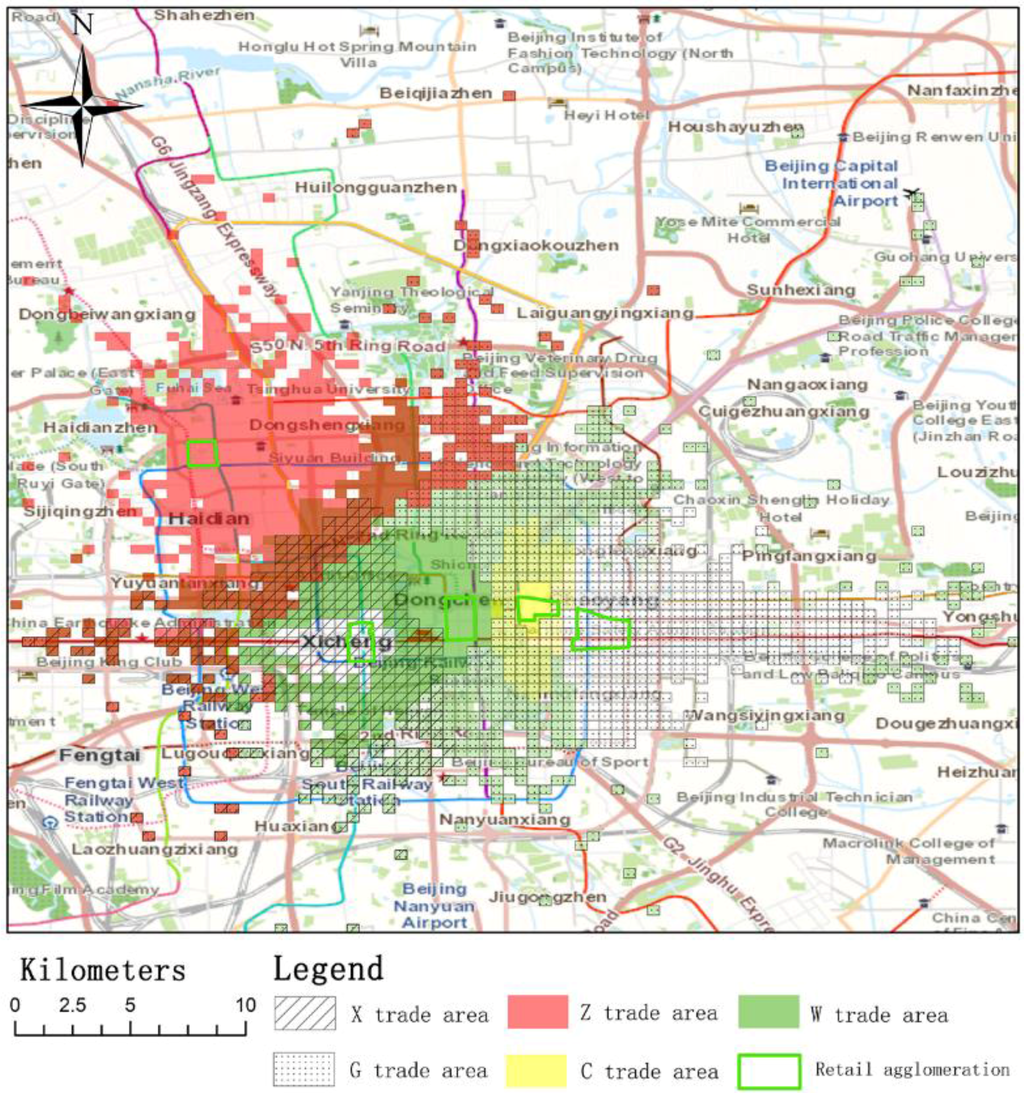
پکن پایتخت چین است و از نظر مساحت پس از شانگهای دومین کلان شهر بزرگ چین است. تجمعات خرده فروشی همگام با توسعه اقتصادی کلی این مناطق شهری شکل گرفتند. در تحقیقات خود، از پنج مجتمع خرده فروشی در پکن به عنوان موارد آزمایشی استفاده کردیم. مکان ها و توزیع این پنج مجتمع خرده فروشی پکن، که در یک بررسی میدانی جمع آوری شده اند، در شکل 1 نشان داده شده است.. مرزهای Zhongguancun (“Z”) خیابان Zhongguangcun، خیابان Suzhou، جاده غربی حلقه چهارم شمالی و جاده جنوبی Haidian است. Xidan (“X”) در جنوب Xirongxian Hutong و شمال Lingjing Hutong با خیابان شمالی Xidan به عنوان محور قرار دارد. Wangfujing (“W”) قدیمی ترین مجتمع خرده فروشی در پکن است. مجتمع خرده فروشی وانگ فوجینگ بر اساس خیابان وانگ فوجینگ، در جنوب خیابان چانگان، شمال دنگشی، شرق جینگیو هوتونگ و غرب خیابان دونگانمنگ قرار دارد. Chaowai (“C”) در غرب حلقه دوم شرقی، شرق جاده حلقه سوم شرقی، با خیابان Chaowai به عنوان محور است. گومائو (“G”) بزرگترین مجتمع خرده فروشی در پکن در حال حاضر است. در تقاطع رینگ سوم شرقی و خیابان جیانگومن واقع شده است. همه مجتمعهای خردهفروشی در بخش شرقی-غربی پکن به جز Zhongguancun هستند.
4. روش ها
در این بخش، بر اساس مدل هاف، روش تور خود را برای استخراج نمونه هایی که می تواند برای تعیین محدوده تجاری از داده های رسانه های اجتماعی مناسب باشد، شرح می دهیم. چارچوب تور در شکل 2 نشان داده شده است . ابتدا، کاربران رسانه های اجتماعی را که توسط هر مجموعه خرده فروشی جذب شده اند، استخراج می کنیم. سپس، الگوریتم خوشهبندی DBSCAN برای استخراج مرکز فعالیت برای هر کاربر اعمال میشود. اصطلاح مرکز فعالیت به میانگین نقطه مرکزی منطقه جغرافیایی اشاره دارد که کاربر اغلب در آن ظاهر می شود [ 26]]. ما تعداد بازدید، مسافت سفر و جذابیت را برای هر مجموعه خرده فروشی محاسبه کردیم. مجموعه های مختلف نمونه با انتخاب کاربر و تجمع فضایی به دست آمد. در مرحله آخر، مناطق تجاری محدود شده را با مجموعه های نمونه مختلف ارزیابی کردیم.
4.1. استخراج کاربران جذب شده
امکانات بزرگ بیشترین سهم را در جذابیت یک مجتمع خرده فروشی دارد [ 27 ]. از آنجایی که اکثر مراکز تجاری از ساعت 9 صبح تا 10 شب باز هستند [ 28 ]، ما کاربرانی را که در این دوره زمانی در این مجتمعهای خردهفروشی حضور داشتند را استخراج کردیم و آنها را به عنوان کاربران جذبشده تعیین کردیم. به طور کلی، 87215 کاربر جذب شده از مجموعه داده های ما استخراج شده اند و 3.6 درصد از کل کاربران را تشکیل می دهند.
4.2. استخراج مراکز فعالیت
در این بخش، نحوه استفاده از الگوریتم خوشهبندی DBSAN برای استخراج مراکز فعالیت از تورهای کاربران جذب شده به منظور جایگزینی محل سکونت در اطلاعات مشتریان سنتی مورد بحث قرار میگیرد.
علاوه بر محل سکونت، مکانهای دیگری که کاربران اغلب در آنها حضور پیدا میکنند شامل کار، سوپرمارکتها و کتابخانهها میشود [ 29 ، 30 ]. اطلاعات Sina Weibo دارای برچسب جغرافیایی از کاربری که اعلام حضور خود را در Sina Weibo به اشتراک گذاشته است به عنوان مثال در شکل 3 نشان داده شده است.. سه منطقه با تراکم نقطه بالا وجود دارد. بیشتر نقاط ورود این کاربر در این مناطق یافت می شود. با تجزیه و تحلیل دستی متون Weibo در مناطق مختلف، اطلاعات معنایی غنی که معنای ذهنی عملی این حوزه های مختلف را به کاربر منتقل می کند می تواند استنباط شود: (1) نقاط زیادی در یک مکان در ناحیه حاوی نقطه A همپوشانی دارند. متن یک Weibo در مکان A “狂追猛跑追上一辆公交车…之后早到单位十分钟!” است (پس از عجله برای گرفتن اتوبوس، 10 دقیقه زودتر به محل کار رسیدم). این نشان می دهد که این منطقه ممکن است یک محل کار باشد. (2) متن در مکان B این است “袜子未免太好看了吧!买了15双…” (جوراب ها خیلی خوش قیافه هستند! من 15 جفت آورده ام…). بنابراین، منطقه حاوی نقطه B ممکن است محل خرید و تفریح کاربر باشد. (3) ناحیه حاوی نقطه C بزرگترین با بیشترین چگالی نقطه است. متن در محل C “6点15出家门上班,9点半终于到家了,晚安。” است (ساعت 6:15 صبح برای کار از خانه خارج شوید و در نهایت ساعت 9:30 شب بخیر به خانه برگردید). . این نشان می دهد که این منطقه ممکن است خانه کاربر باشد.
مطالعات سنتی اغلب از محل سکونت برای تعیین حدود یک منطقه تجاری استفاده می کنند. از طرف دیگر، یک منطقه تجاری مبتنی بر مناطقی که اغلب مشتریان از آنها بازدید می کنند، اغلب برای حمایت از تصمیم گیری توسط آژانس های تجاری و برنامه ریزی شهری استفاده می شود [ 12 ]. مناطق پربازدید استخراج شده برای هر کاربر ممکن است به درک بهتری از رفتارهای مصرف کننده کمک کند و در نتیجه به کسب و کارها کمک کند تا زمانی که در نزدیکی هر یک از مناطق پربازدید قرار دارند، استراتژی هایی برای جذب مشتریان ایجاد کنند.
تحقیقات قبلی از الگوریتم DBSCAN برای شناسایی خوشههای چگالی و استخراج مراکز فعالیت برای افراد از دادههای رسانههای اجتماعی برچسبگذاری شده جغرافیایی استفاده کرده است [ 26 ، 31 ]. بر اساس این تحقیق، ما از DBSCAN برای به دست آوردن مناطق پربازدید هر کاربر استفاده کردیم. برای کاربرانی با کمتر از سه ناحیه، مرکز نقطه تمام مناطق به عنوان مرکز فعالیت در نظر گرفته شد. برای کاربران با بیش از سه ناحیه، مرکز سه ناحیه فعال برتر به عنوان مرکز فعالیت استخراج شد. DBSCAN یک الگوریتم خوشه بندی فضایی است که بر اساس چگالی پیشنهاد شده توسط استر در سال 1996 [ 32]]. Eps (شعاع جستجو) و MinPts (حداقل تعداد نقاط مورد نیاز برای تشکیل یک ناحیه متراکم) دو پارامتر مهم در این الگوریتم هستند. DBSCAN نسبت به بسیاری از الگوریتم های خوشه بندی دیگر مانند K-means دو مزیت دارد: (1) به تعیین تعداد خوشه ها در داده ها از قبل نیاز ندارد، (2) و می تواند خوشه هایی با شکل دلخواه پیدا کند. به دلیل این مزایا، DBSCAN برای استخراج مناطق پربازدید مناسب تر است. ماژول “sklearn.cluster” در بسته Python “scikit-learn” برای نقاط چک در خوشه اعمال شد. بر اساس کار قبلی استفاده از DBSCAN برای خوشهبندی دادههای رسانههای اجتماعی [ 12]، Eps را به طور جداگانه روی یک کیلومتر و MinPts را روی 10 تنظیم کردیم، و دریافتیم که 61.17٪ از کاربران هیچ خوشه ای ندارند. این به این دلیل است که بسیاری از کاربران در یک دوره 14 ماهه نقاط ورود بسیار کمی داشتند و این نقاط یک خوشه تشکیل نمی دادند. کاربران با بیش از یک خوشه 15.36 درصد از کاربرانی را تشکیل می دهند که خوشه داشتند. این نشان می دهد که تعداد زیادی از کاربران بیش از یک منطقه پربازدید داشتند. بر اساس این نتایج خوشهبندی، مراکز فعالیت استخراج شدند.
4.3. محاسبه احتمال بازدید مشاهده شده، مسافت سفر، و جذابیت تراکم خرده فروشی
احتمال بازدید مشاهده شده، مسافت سفر و جذابیت مقادیر ورودی لازم هنگام اعمال مدل هاف هستند. در این بخش به روش های بدست آوردن این سه مقدار می پردازیم. همه مقادیر با استفاده از پایتون محاسبه شدند و سپس برای اجرای مدل هاف در Mathlab بارگذاری شدند.
تعداد نقاط ورود در یک تجمع برای هر کاربر به عنوان دفعات بازدید کاربر توسط تجمع در نظر گرفته شد. احتمال بازدید مشاهده شده P ij کاربر i که به تراکم j می رود به صورت زیر محاسبه شد:
که در آن A ij فرکانس بازدید کاربر i از تراکم j و n تعداد تجمعات است. برخی از کاربران ممکن است در طی یک بازدید از یک مجتمع بارها بررسی کنند. برای مقابله با نفوذ ورودهای تهاجمی بیش از حد، اعلام حضورهای تکراری را در یک مجموعه در همان روز حذف کردیم.
بر اساس مرکز فعالیت و شبکه جادهای بهدستآمده در پکن، ما از الگوریتم Dijkstra برای محاسبه کوتاهترین فاصله شبکه بین کاربران و مراکز تجمعات خردهفروشی به عنوان مسافت سفر استفاده کردیم. الگوریتم Dijkstra الگوریتمی برای یافتن کوتاه ترین مسیرها بین گره ها در یک گراف است [ 33 ]. در دنیای واقعی، مردم فعالیت های اجتماعی و اقتصادی خود را در شبکه های خیابانی واقعی می کنند [ 20 ]. بنابراین، بر خلاف فاصله سنتی اقلیدسی، فاصله شبکه همانطور که با الگوریتم Dijkstra محاسبه می شود، می تواند مسافت واقعی را که افراد هنگام رفتن به یک مکان یا منطقه هدف طی می کنند، منعکس کند [20 ] .
در هر مجتمع خرده فروشی، اکثر مشتریان توسط امکانات تجاری بزرگی که در یک منطقه خرده فروشی مستقر هستند، جذب می شوند. بنابراین، حوزه های تجاری این تسهیلات بزرگ را می توان به عنوان معیاری برای سنجش جذابیت یک مجتمع خرده فروشی به طور کلی در نظر گرفت [ 27 ]. مجموع مساحت تاسیسات با 10000 متر مربع بیشتر بر اساس بررسی میدانی تعیین شد. این مقدار مساحت به عنوان شاخصی از جذابیت پنج مجتمع خرده فروشی استفاده شد. مساحت کل هر توده در جدول 2 نشان داده شده است .
4.4. به دست آوردن مجموعه های مختلف تحدید محدوده تجاری
4.4.1. انتخاب کاربر
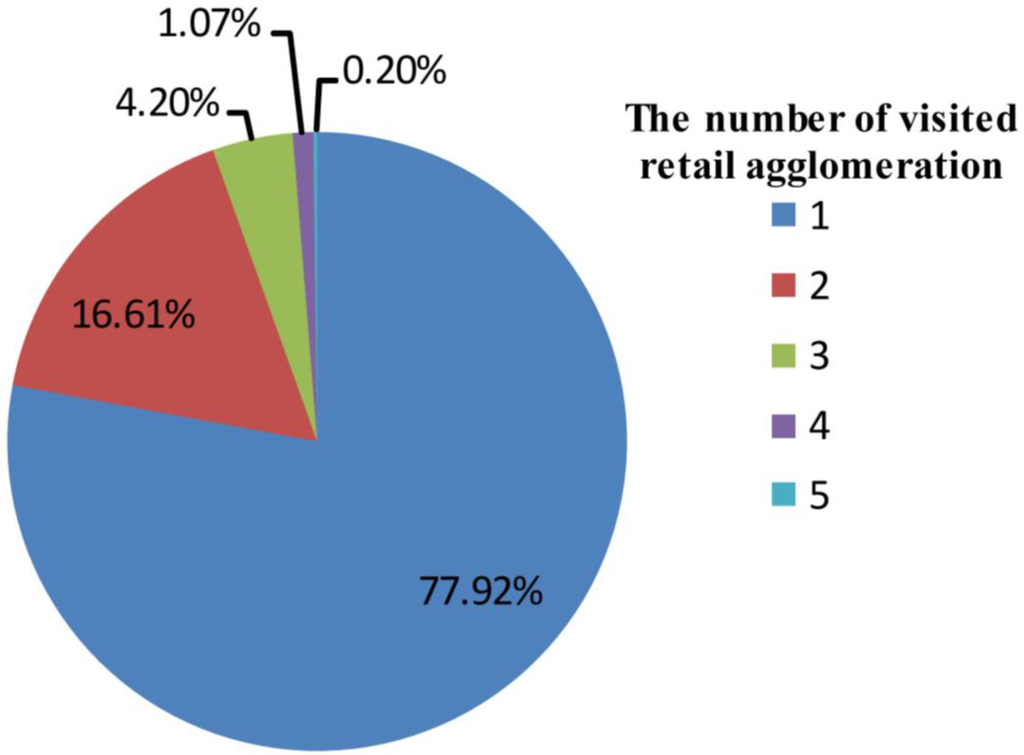
مطالعه قبلی نشان داد که افراد مختلف الگوهای رفتاری متفاوتی دارند [ 34 ]. برای آشکار کردن تفاوتها در رفتار مصرفکننده بین کاربران رسانههای اجتماعی با اسناد متفاوت، کاربران را بر اساس تعداد تجمعهای خردهفروشی که بازدید کردهاند انتخاب کردیم. برای هر کاربر، تعداد تجمعهای بازدید شده، مهمترین انتساب او است. هرچه یک کاربر از تجمعات خرده فروشی کمتر بازدید کند، احتمال بیشتری دارد که این کاربر تجمعات فردی خاص را ترجیح دهد. تعداد تجمعاتی را که آنها بازدید کردند را شمردیم. کاربرانی که از تجمعات 1، 2، 3 و 4 بازدید می کردند، فیلتر شدند. مقادیر ترکیبی برای تجمعات بازدید شده توسط هر کاربر در شکل 4 نشان داده شده است. اکثر کاربران فقط از یک تجمع بازدید کردند. با افزایش تعداد تجمعات بازدید شده، تعداد کاربران کاهش یافت. هر کاربر جذب شده به عنوان یک موضوع نمونه در نظر گرفته شد و همه کاربران به عنوان مجموعه نمونه 1 در نظر گرفته شدند. ما کاربرانی را که از بیش از 1، 2، 3، و 4 تجمع بازدید می کردند، به ترتیب به عنوان مجموعه های 2، 3، 4، و 5 انتخاب کردیم.
4.4.2. تجمع فضایی
ما منطقه مورد مطالعه را به واحدهای فضایی منظم و مراکز فعالیت کاربر را به هر یک از این واحدهای فضایی تقسیم کردیم. احتمال بازدید و مسافت سفر هر واحد فضایی برای کاربرانی که مراکز فعالیتشان در یک واحد است به طور میانگین محاسبه شد. این مقادیر تجمیع شده به عنوان ویژگی های هر واحد [ 35 ] گنجانده شد . نقاط ورود هر کاربر ناقص است. این ناقصی می تواند بر تعیین حدود مناطق تجاری تأثیر بگذارد. مطالعات قبلی بر اساس نظرسنجیهای سنتی نشان میدهد که پاسخدهندگان پرسشنامهها احتمال مشخصی نسبت به احتمالات بازدید تصادفی دارند (مشکل تعداد کم) و علاوه بر این، این احتمالات بر تعیین حدود مناطق تجاری تأثیر دارد [35 ]]. تجمیع فضایی می تواند تأثیر احتمالات تصادفی و فعالیت های ناقص را بر تحدید حدود منطقه تجاری بهبود بخشد.
در این مطالعه، برای جلوگیری از سوگیری ناشی از تقسیمبندیهای اداری، از سلولهای شبکهای منظم 400 × 400 متر برای تقسیم پکن به 18492 واحد به دنبال کار یو یانگ [28] استفاده کردیم . در بسیاری از این واحدها، تعداد کل بازدید از هر مجتمع خرده فروشی نسبتاً کم بود. هرچه تعداد دفعات بازدید از یک واحد کمتر باشد، احتمال بیشتری وجود دارد که این واحد تحت تأثیر احتمالات بازدید تصادفی باشد [ 36]]. بنابراین، سلولهای شبکهای را با فرکانس کل بازدید کمتر از 30 فیلتر کردیم و 1827 سلول شبکه را برای تجزیه و تحلیل بیشتر حفظ کردیم. این سلول های شبکه ای مناطق اصلی و فعال ترین مناطق در پکن را پوشش می دهند. هر سلول شبکه به عنوان یک نمونه در نظر گرفته شد. با تجمیع تمام مراکز فعالیت کاربر در هر سلول شبکه، مجموعهای را بهدست آوردیم که بهعنوان مجموعه نمونه 6 رفتار میشود. مراکز فعالیت کاربرانی را که از بیش از 1، 2، 3، 4 تجمع بازدید میکردند جمعآوری کردیم تا مجموعههایی تولید کنیم که به عنوان مجموعههای 7، 8 در نظر گرفته شدند. ، به ترتیب 9، 10.
4.5. روش ارزشیابی و شاخص ها
بر اساس الگوریتم Levenberg-Marquard در Mathlab، پارامتر حساس به فاصله (λ) و پارامتر حساس به جذابیت (α) را ارزیابی کردیم. الگوریتم لونبرگ-مارکوارد یک روش تکراری برای حل مسائل شبیه سازی مدل است [ 37 ]. ریشه میانگین مربعات خطا (RMSE) و ضریب تعیین ( R2 ) برای آشکار کردن تفاوتهای بین مناطق تجاری تعیینشده با استفاده از مجموعههای نمونه مختلف استفاده شد. RMSE واریانس بین مقادیر برآورد شده و مشاهده شده را برای ارزیابی مدل ها اندازه گیری می کند. RMSE به صورت زیر محاسبه می شود:
که در آن y i و x i احتمال بازدید مشاهده شده و شبیه سازی شده برای هر تجمع هستند، N تعداد افراد نمونه است.
ضریب تعیین R2 مقدار تغییرات متغیر وابسته را توصیف می کند که می تواند با ارتباط آن با متغیر مستقل توضیح داده شود . R 2 به صورت زیر محاسبه می شود:
که در آن y i و x i احتمال بازدید مشاهده شده و شبیه سازی شده برای هر تجمع هستند. N تعداد افراد نمونه است. y¯�¯و ایکس¯ایکس¯به ترتیب میانگین های مقدار مشاهده شده و شبیه سازی شده را نشان می دهد. و σ y و σ x به ترتیب خطاهای استاندارد مقدار مشاهده شده و شبیه سازی شده هستند. مقدار قابل قبول R2 می تواند بسته به نوع مقایسه های انجام شده متفاوت باشد، اما در حالت ایده آل، R2 باید بزرگتر از 0.5 باشد [ 38 ].
5. نتایج و بحث
5.1. مقایسه اثرات مجموعه های مختلف
با مقایسه اثرات مجموعههای مختلف، متوجه شدیم که مجموعه نمونه بهدستآمده با استفاده از نمایش تمام مراکز فعالیت کاربر تجمیع شده در واحدهای فضایی، مناطق تجاری را بهتر از سایر مجموعههای آزمایششده محدود میکند. علاوه بر این، نتایج مقایسهای ما نشان میدهد که اثرات مجموعههای مختلف بر تحدید حدود منطقه تجاری بهطور مشهودی با یکدیگر متفاوت است. اثرات مجموعه های نمونه مختلف در جدول 3 نشان داده شده است . کاربرانی که از بیش از 1، 2، 3، 4 تجمع خرده فروشی بازدید می کردند، به ترتیب به عنوان gt1، 2، 3، 4 در نظر گرفته شدند.
مجموعههای بدون مراکز فعالیت کاربر انبوه برای تعیین حدود منطقه تجاری بیاثر بودند. همانطور که در جدول 3 نشان داده شده است ، از مجموعه 1 تا مجموعه 5، بالاترین مقدار R 2 تنها 0.25 است. این ممکن است به این دلیل باشد که در داده های رسانه های اجتماعی، نقاط ورود کاربر نشان دهنده فعالیت های کامل در دنیای واقعی نیست. با فیلتر کردن مراکز فعالیت کاربر به صورت گام به گام، R2 ، RMSE، پارامتر حساس به فاصله (λ) و پارامتر حساس به جذابیت (α) کاهش یافتند . این نتیجه نشان می دهد که هرچه کاربران بیشتر از تجمعات بازدید کنند، توجه کمتری به مسافت سفر یا جذابیت یک تجمع می کنند.
در مقایسه با مجموعههای بدون تجمیع، مجموعههای بهدستآمده با تجمیع مراکز فعالیت کاربر برای تعیین حدود مناطق تجاری مؤثرتر بودند. همانطور که در جدول 3 نشان داده شده است ، مجموعه نمونه (مجموعه 6) که همه کاربران را جمع می کند دارای بالاترین مقدار R 2 (0.64) است. با فیلتر کردن کاربرانی که از مجتمع های خرده فروشی 1، 2، 3، 4 بازدید می کنند به صورت گام به گام، R 2 کاهش و RMSE افزایش یافت. این نشان میدهد که با حذف کاربرانی که اولویتهای انتخاب نسبتاً قوی دارند، نمیتوان اثر تعیینکننده را بهبود بخشید. مشابه مجموعه های نمونه بدون تجمع، پارامترهای حساس نیز از مجموعه 6 به مجموعه 10 کاهش یافتند.
پارامترهای حساسیت کالیبرهشده برای این 10 مجموعه نمونه با پارامترهای پیشفرض (α = 1، λ = 2) که در مطالعات قبلی استفاده شدهاند، متفاوت است. اثر مجموعه 6 بهترین بود، زیرا R 2 مجموعه 6 بالاترین و RMSE کمترین بود. α و λ کالیبره شده توسط این مجموعه نمونه به ترتیب 1.84 و 1.44 بود. برخلاف پارامترهای پیشفرض مورد استفاده در مطالعات قبلی، پارامتر حساس به جذابیت ما نسبتاً بالاتر و پارامتر فاصله کمتر بود. این ممکن است نشان دهد که بهبود شرایط ترافیک شهری باعث شده است مشتریان نسبت به گذشته نسبت به جذابیت و مسافت کمتر حساس باشند.
5.2. تجزیه و تحلیل منطقه تجاری
ما از پارامترهای مدل هاف کالیبره شده توسط مجموعه 6 برای تعیین محدوده تجاری استفاده کردیم. تفاوت های شدیدی در توزیع و شدت مناطق تجاری برای مجتمع های خرده فروشی مختلف مورد مطالعه وجود دارد. وسعت و جهت منطقه تجارت برای هر مجتمع خرده فروشی در شکل 5 نشان داده شده است در حالی که همپوشانی این مناطق تجاری در شکل 6 نشان داده شده است.. در میان تمام تجمعات، منطقه تجاری برای G بزرگترین است. منطقه تجاری G به سمت شرق در امتداد یک جاده اصلی گسترش می یابد و سمت غربی منطقه تجاری با سایر مناطق تجاری همپوشانی دارد. این نشان می دهد که G فقط با دیگر تجمعات در غرب رقابت می کند. منطقه تجاری Z از دیگر تجمعات دور است، اما بخش جنوب شرقی منطقه تجاری Z با مناطق دیگر همپوشانی دارد. منطقه تجارت C کوچکترین است. این به این دلیل است که جذابیت C نسبتاً کم است و C نزدیک به سایر تجمعات با جذابیت بالاتر است.
6. نتیجه گیری
توسعه فن آوری ارتباطات سیار فرصت های جدیدی را برای بررسی مشکلات در دنیای واقعی از طریق داده های رسانه های اجتماعی فراهم می کند [ 39 , 40 , 41 , 42 , 43]. بر اساس یک مدل هاف، مجموعههای نمونه متفاوتی را برای تعیین حدود مناطق تجاری از دادههای رسانههای اجتماعی بهدست آوردیم. نتایج ما نشان میدهد که مجموعههای بهدستآمده از تجمیع فضایی تمام مراکز فعالیت کاربر برای تعیین محدودههای تجاری مناسبتر هستند و تأثیر بهتری نسبت به مجموعههای بدون تجمع دارند. نتایج همچنین تفاوتها را در توزیع و شدت مناطق تجاری برای مجتمعهای خردهفروشی مختلف نشان میدهد. یافته های ما پیامدهای اجتماعی و اقتصادی بسیار مهمی دارد. بر اساس منطقه تجاری محدود شده، برنامه ریزان شهری می توانند محل تجمع های خرده فروشی جدید را به طور موثرتری مکان یابی کنند. علاوه بر این، کسبوکارها میتوانند از این رویکرد برای تجزیه و تحلیل توزیع مشتریان خود و پیشبینی دقیقتر عملکرد تجاری استفاده کنند.
اگرچه مطالعه اولیه ما یک روش عملی را برای استفاده از داده های رسانه های اجتماعی برای تعیین حدود منطقه تجاری به طور موثر پیشنهاد می کند، ما باید به نحوه استفاده از رسانه های اجتماعی برای تجزیه و تحلیل بیشتر توزیع مناطق تجاری و رفتارهای مشتریان جذب شده توجه بیشتری داشته باشیم. در مطالعات آتی، چالش ها و مشکلات خاص رسانه های اجتماعی مورد توجه قرار خواهند گرفت، مانند:
- (1)
-
ساختار سنی کاربران شبکه های اجتماعی؛ اکثر کاربران رسانه های اجتماعی جوانان هستند و ساختار سنی کاربران با دنیای واقعی متفاوت است [ 24 ]. تیم تحقیقاتی ما تأثیر ساختار سنی را بر تعیین حدود منطقه تجاری بررسی خواهد کرد.
- (2)
-
مسئله واحد منطقه قابل تغییر (MAUP)؛ ما از سلول های شبکه ای 400 متر × 400 متر برای تجمع استفاده کردیم. اندازه های مختلف واحدهای فضایی ممکن است به نتایج متفاوتی منجر شود. در کارهای آینده، هدف ما این است که با آزمایش اندازه ها و اشکال مختلف واحدهای فضایی، بهترین واحد فضایی را به دست آوریم.
- (3)
-
انتخاب کاربر شبکه های اجتماعی؛ کاربران رسانههای اجتماعی ویژگیهای زیادی دارند، مانند جنسیت، محل ثبت نام خانواده، سطوح تحصیلی و تعداد طرفداران Weibo. در تجزیه و تحلیل منطقه تجاری، کاربران را بر اساس این ویژگی های شخصی که ممکن است بر تعیین حدود منطقه تجاری تأثیر بگذارد، دسته بندی می کنیم.
- (4)
-
جذابیت تراکم خرده فروشی؛ حوزه کسب و کار مهمترین عامل تأثیرگذار برای جذابیت است. عوامل دیگری مانند پارکینگ، تاریخچه و سطح قیمت نیز ممکن است بر جذابیت تأثیر بگذارند. به منظور بررسی تأثیر این عوامل دیگر، ما اطلاعات آماری بیشتری را در رابطه با هر تراکم جمع آوری خواهیم کرد.
- (5)
-
اطلاعات متنی؛ داده های رسانه های اجتماعی حاوی مقدار زیادی اطلاعات متنی است. این اطلاعات منعکس کننده افکار عمومی در مورد تأسیسات تجاری و تجمعات است. مطالعات آینده برای کشف این اطلاعات غنی، متنی و معنایی برای درک بهتر تفکر و الگوهای رفتاری مشتری مورد نیاز است.






بدون نظر