1. معرفی
به منظور تشویق اقتصاد محلی و تثبیت هویت و مکان (حس مکان) یک منطقه، خیابان های مختلفی در آمریکا ایجاد شده است. به عنوان مثال، برادوی و وال استریت در شهر نیویورک و بلوار هالیوود در لس آنجلس خیابانهایی با مضمون شناخته شده هستند و به راحتی میتوان آنها را به صورت آنلاین یا در یک سرویس نقشه وب یافت. این نوع خیابانهای مضمون نه تنها مناطقی با ویژگیهای خاص برای یک شهر ارائه میکنند، بلکه مکانی را نیز فراهم میکنند که جامعه بتواند اوقات فراغت خود را در آن سپری کند. همچنین مشخص است که توسعه خیابانهای موضوعی با بلوغ شهر افزایش مییابد [ 1 ].
در حالی که یک خیابان مضمون توسط عموم به رسمیت شناخته می شود، نشان دادن مرز دقیق آن دشوار است زیرا خیابان موضوعی معمولاً به صورت خطوط روی نقشه بیان می شود. از آنجایی که خوشه بندی بر اساس چگالی یا تجمع چند ضلعی ها معمولاً برای ترسیم مرزها به عنوان اشکال منطقه ای روی نقشه ها استفاده می شود، نشان دادن یک منطقه مبتنی بر خط مانند یک خیابان موضوعی محدود است.
در واقع، مردم از طریق جاده ها سفر می کنند و مناطق فعالیت آنها بر اساس جاده ها است. جاده اولین برداشت از یک شهر است. بنابراین، ویژگی های مورد علاقه در امتداد یک جاده به شدت با ویژگی های مورد علاقه شهر مرتبط است [ 2 ]. به عبارت دیگر، تصویر یک منطقه خیابانی که از جاده دیده میشود، میتواند تصوری از شهری که در آن قرار دارد، ایجاد کند. از این منظر، مرز یک فضای خاص باید بر اساس جاده بیان شود تا اطمینان حاصل شود که مردم شهر را به طور شهودی درک می کنند.
برای بیان مکان بر اساس جاده، باید ویژگی های جاده مشخص شود. در بیشتر موارد، ویژگی ها با توجه به نقاط مورد علاقه (POI) در جاده ها شکل می گیرند. با دسته بندی POI ها و انتساب آنها به جاده، می توان انواع مختلفی از تم ها را در جاده ها شناسایی کرد. با این حال، تعداد کمی از مقالات تحقیقاتی بر روی تشخیص موضوعات در جاده ها متمرکز شده اند. حتی تحقیقات مرتبط تنها یک پدیده سنجیده مانند میزان جرم و جنایت در جاده ها را نشان می دهد. با این روش نمی توان چهره شهری را که در آن وقایع مختلف رخ می دهد به تصویر کشید.
بنابراین، این مطالعه از دادههای رفتار افراد و POI بهدستآمده از GPS موبایل و حسگرهای Wi-Fi برای شناسایی خیابانهای مضمون مختلف استفاده کرد. روش خوشه بندی خیابانی مضمون (TSCM) برای این منظور پیشنهاد شده است. برای این مطالعه، دو کلمه ظریف معرفی شده است. “خیابان داغ” و “خیابان مضمون”. اگرچه این دو کلمه می توانند به جای یکدیگر استفاده شوند، اما معنای هر یک هنوز برای این مطالعه تعریف شده است. از آنجایی که یک نقطه داغ یک منطقه خوشهای با مقادیر نسبتاً بالا است، نشاندهنده جادهای است که ارزش بالایی از یک شاخص منحصر به فرد دارد. به عنوان مثال، اگر خیابان محبوب باشد، شاخص محبوبیت یک خیابان بالا است. اما خیابان مضمون، خیابانی است با موقعیت خاص که به دلیل هممکانی نزدیک مکانهای محبوب است. بنابراین، علاوه بر محبوبیت یک خیابان مضمون، برای یک تخصص نیز شناخته شده است.
2. آثار مرتبط
برای تجزیه و تحلیل الگوی زندگی و ویژگیهای افراد با توجه به فضا، پروژه «زندگیها» انجام شد [ 3]. دادههای اعلام حضور (یک کاربر به صورت دستی به برنامه زمانی که در یک مکان خاص است با انتخاب از فهرست مکانهای یک دستگاه هوشمند به برنامه میگوید) همانطور که از سرویس Foursquare و روش خوشهبندی طیفی به دست آمده است، که مشابه را جمعآوری میکند، استفاده شد. داده و خوشه ایجاد می کند. با استفاده از روش، بخشهای خوشهبندی «Livehoods» با محاسبه مقادیر مشابه مکانها و ویژگیها تولید شدند. با این حال، تشخیص مضامین دقیق منطقه برش دشوار بود زیرا داده ها به گونه ای طبقه بندی نشده بودند که این امکان را فراهم کند. به این معنا که «زندگیها» اهمیت بیشتری به تعیین مرزهای جغرافیایی میدهد تا تشخیص موضوعات مرتبط با چنین مرزهایی.
در همین حال، مطالعه ای برای تجزیه و تحلیل نقاط داغ با استفاده از داده های ورود از جیپانگ، یک سرویس رسانه اجتماعی مبتنی بر مکان چینی انجام شد [ 4]. منطقه آزمایش به شبکه های ماهیگیری تقسیم شد و تعداد داده های ورود شمارش شد. هر شبکه بر اساس سطح معنیداری که نقاط داغ ورود را بیان میکند رنگبندی شد. در نتیجه، محققان اصرار داشتند که دادههای ورود به خانه به طور غیرمستقیم جمعیت و اقتصاد منطقه آن را با نشان دادن همبستگی بین سرشماری جمعیت و تعداد دادههای ورود شمارش شده منعکس میکند. در حالی که این مطالعه از نظر تحقیق در مورد مناطق فعال اجتماعی-اقتصادی مرجع خوبی است، نتایج متفاوتی می تواند هنگام تغییر اندازه شبکه ماهیگیری (همچنین به عنوان مشکل واحد منطقه ای قابل اصلاح شناخته می شود) به دست آید. علاوه بر این، این مطالعه تنها منطقهای را که در آن تعداد زیادی چک در آن انجام میشد، تعریف کرد و فقط نقاط داغ ورود را نشان داد. بنابراین، مناطق موضوعی را نمی توان از طریق این نوع تحلیل درک کرد.
مطالعات معرفی شده در بالا ([ 3 ]) دارای محدودیت هایی هستند که به موجب آن نتایج را فقط می توان به صورت اشکال منطقه ای (چند ضلعی) بیان کرد. مشکلات دیگری مانند فقدان معنایی برای تقسیم مناطق به وجود آمد، زیرا مطالعه فقط تعداد دفعات ورود را اندازه گیری می کند. باز هم، با روشهای معرفیشده توسط مطالعات قبلی، شناسایی خیابانهای موضوعی یک چالش است.
در این میان، مطالعاتی بر روی روشهای خوشهبندی مبتنی بر شبکه به منظور تکمیل محدودیتهای روشهای خوشهبندی مبتنی بر منطقه انجام شده است. یکی از محبوبترین و پرکاربردترین روشها برای تجزیه و تحلیل توزیع نقطهای، تخمین چگالی هسته (KDE) است [ 5 ]. با این حال، KDE معمولی در یافتن نقاط داغ در شبکههای جادهای اشکالات زیادی دارد. یکی از ایرادات اصلی این است که ناحیه چگالی نه تنها در شبکهها، بلکه در سایر نواحی نیز شناسایی میشود و این منجر به نتایج کجشده میشود. به همین دلیل، تخمین تراکم هسته شبکه (NKDE) پیشنهاد شد [ 6 ] و برای کاربردهای مختلفی مانند تشخیص احتمال یک نقطه داغ در حوادث خودرو استفاده شده است [ 7]]. نه تنها NKDE، بلکه همچنین تجزیه و تحلیل فضایی و زمانی شبکه جرم (NT-STAC) و آمار اسکن فضایی شبکه (NT-SaTScan) برای کشف وقوع جرم (سرقت، سرقت، معاملات/استفاده از مواد مخدر و غیره) در شبکه های جاده ای معرفی شدند. [ 8 ]. در این مطالعه، محققان اصرار داشتند که استفاده از STAC و SaTScan برای تشخیص نتایج نقاط داغ، خوشههای گردی را در یک فضای دوبعدی تولید میکند و استدلال کردند که این روشها زمانی که فضاهای خطی تحلیل میشوند، محدود هستند. بنابراین، آنها نشان دادند که NT-STAC و NT-SaTScan می توانند با موفقیت مناطق جرم و جنایت را در شبکه های جاده ای در طول تحقیقات خود شناسایی کنند.
در مطالعات تشخیص نقاط داغ بر اساس شبکه های جاده ای، نقاط داغ در فضاهای خطی پیدا شد. با این حال، این مطالعات بیشتر بر روی دادههای خوشهبندی روی شبکههای جادهای متمرکز بودند و خود شبکههای جادهای در نظر گرفته نشدند. یعنی نتایج فقط داده های نقطه ای را به اشکال خطی متصل می کند و اطلاعات قابل توجهی در مورد شبکه های جاده ای ارائه نمی دهد.
برای غلبه بر محدودیت های فوق، لو (2005) پدیده فعالیت های اجتماعی-اقتصادی عمومی محدود شده توسط جاده ها در یک شهر را با گسترش روش خوشه بندی داده های نقطه ای، که نقاط داغ را در فضاهای دو بعدی نشان می دهد، به شبکه های جاده ای توضیح داد [9 ]]. به ویژه، اصطلاح «خیابان داغ»، یک شبکه جادهای که به عنوان نقطه داغ عمل میکند، با انجام آزمایش خوشهبندی دادههای نقطه سرقت خودرو در بخشهای خیابان معرفی شد، که در آن تجزیه و تحلیل اساسی شامل تقسیم واحدها به هر تقاطع بود. در نهایت، خیابان های داغ از نظر آماری معنی دار با استفاده از توزیع پواسون در هر بخش خیابان شناسایی شدند. با این وجود محدودیت های تحقیق را می توان به صورت زیر خلاصه کرد. اول، داده های مورد استفاده در این مطالعه فقط مکان های سرقت وسایل نقلیه را در شبکه های جاده ای نشان می دهد. دوم، توزیع پواسون فقط می تواند داده های گسسته، مانند تعداد داده های نقطه شمارش شده را تجزیه و تحلیل کند. در نهایت، از آنجایی که طول بخش های جاده متفاوت است، موارد حادثه با توجه به طول بخش های جاده نمی تواند عادی شود.
مطالعات منتشر شده قبلی شامل روشهایی برای تشخیص خیابانهای مضمون مختلف حاوی ویژگیهای فراوان نمیشود. علاوه بر این، مشخص شده است که یک تجزیه و تحلیل و تجسم خوشه خیابان مضمون بر اساس بخشهای جاده مورد نیاز است. بنابراین، این مطالعه TSCM را برای رسیدگی به محدودیتهای مطالعات قبلی پیشنهاد کرد.
3. روش خوشه بندی خیابانی مضمون
3.1. داده های LBSM
داده های خام مورد استفاده در این مطالعه با استفاده از GPS تلفن همراه یا سیگنال Wi-Fi ایجاد شده است که می تواند به صورت ( [ خطای پردازش ریاضی ]ایکسپ�تی1، [ خطای پردازش ریاضی ]�پ�تی1). اطلاعات اضافی مانند نظرات کاربران و تاریخچه فعالیت های اوقات فراغت با استفاده از داده ها در رسانه های اجتماعی مبتنی بر مکان (LBSM) مانند Foursquare، یک برنامه تلفن همراه که به کاربر اجازه می دهد تا جایی که بوده است را بررسی کند و نظر بگذارد، اضافه می شود. به ویژه، محل برگزاری Foursquare برای شناسایی خیابان های موضوعی مورد استفاده قرار گرفت. اساساً، مکانها معادل POI هستند که شامل اطلاعات زیادی مانند ردیابی (تعداد ورود)، آدرسها، نمرات و غیره است. مکانها به این دلیل استفاده میشوند که دادهها مستقیماً برداشت افراد از POI و رفتار آنها در POI را ثبت میکنند. به عنوان مثال، اگر مقدار قابل توجهی از داده ها در یک مکان انباشته شده باشد، می توان فرض کرد که محل برگزاری محبوب و شناخته شده است [ 10]]. به عبارت دیگر، با تحلیل ویژگیهای مکانها، میتوان به منافع عمومی در مکانها و دادههای تاریخی دست یافت که با دادههای GIS معمولی ارائه نمیشود. بنابراین، مکان های مورد استفاده برای این مطالعه مناسب ترین راه برای یافتن خیابان های موضوعی مختلف است.
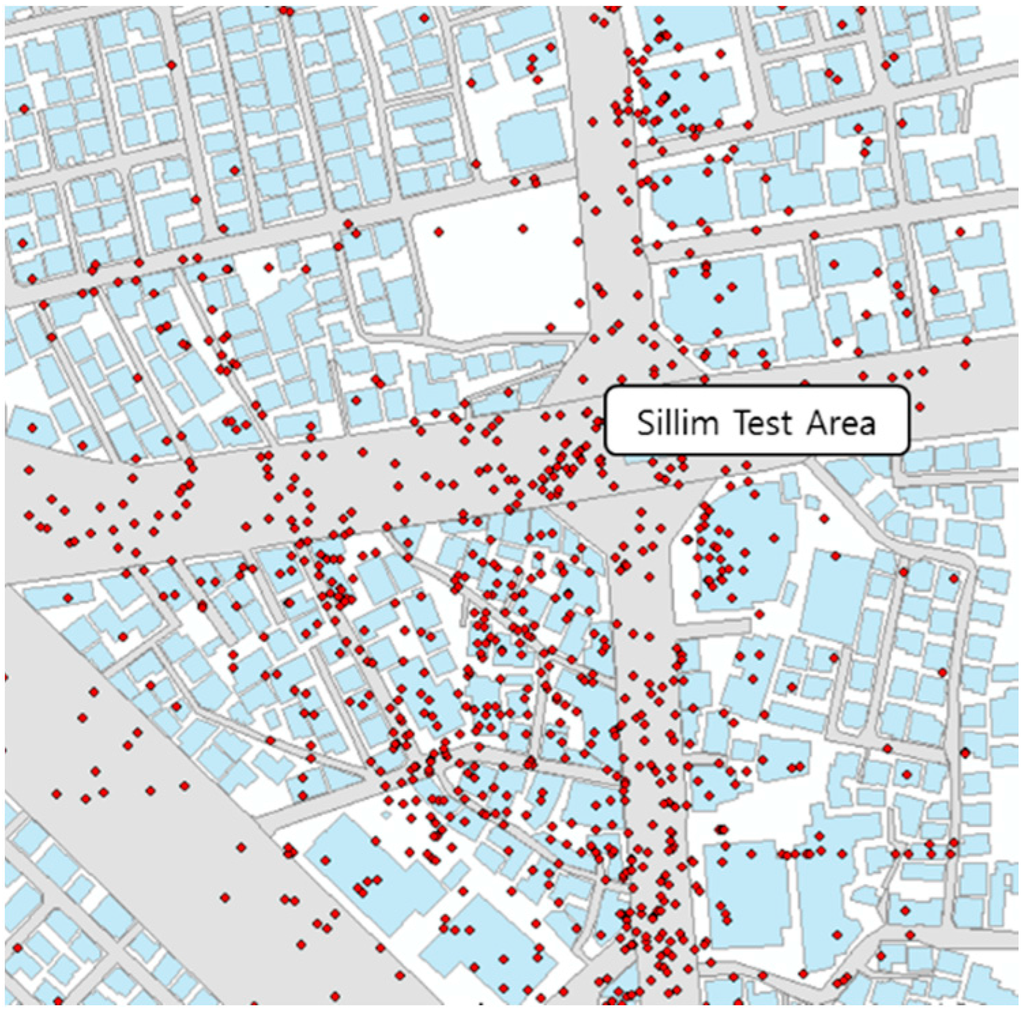
در همین حال، گودچایلد و همکاران. (2012) استدلال کرد که اطلاعات جغرافیایی داوطلبانه (VGI) [ 11 ] می تواند برای ساخت داده های مکانی دقیق و زمان واقعی از لحاظ اقتصادی استفاده شود. با این حال، آنها همچنین به کیفیت و دقت پایین داده های VGI اشاره کردند [ 12 ]. این مطالعه حاضر همچنین کیفیت مکان ها را تأیید می کند. مکان های مورد استفاده در این مطالعه از Foursquare با استفاده از Venues API در شکل 1 نشان داده شده است . همانطور که در زیر نشان داده شده است، مکان ها به وضوح مشخص شده اند. اما برخی از مکان ها در فضاهای خالی و در وسط خیابان ها قرار دارند. تایید شده است که مکان های شناسایی شده دارای دقت مکان پایین هستند، مشابه آنچه توسط Goodchild و همکاران توصیف شده است. (2012).
Sillim، واقع در سئول، کره جنوبی، به عنوان منطقه آزمایشی برای بررسی خطاهای موقعیت مکانها انتخاب شد (SW: 126.928، 37.482؛ NE: 126.931، 37.486). در بین 412 مکان، مختصات 128 نمونه مکان به صورت دستی ثبت شد تا خطای فاصله اقلیدسی بین مختصات ورودی دستی داده های نمونه اندازه گیری شود. [ خطای پردازش ریاضی ]ایکسپ�تی2، [ خطای پردازش ریاضی ]�پ�تی2) و مختصات خام نمونه ها ( [ خطای پردازش ریاضی ]ایکسپ�تی1، [ خطای پردازش ریاضی ]�پ�تی1). همچنین برای بررسی اینکه آیا خطاهای موقعیت جهت خاصی دارند یا خیر، بردار آزیموت خطا اندازه گیری شد. محاسبه خطای فاصله اقلیدسی بین [ خطای پردازش ریاضی ]پ�تی1و [ خطای پردازش ریاضی ]پ�تی2در رابطه (1) و آزیموت بین توضیح داده شده است [ خطای پردازش ریاضی ]پ�تی1و [ خطای پردازش ریاضی ]پ�تی2با استفاده از رابطه (2) اندازه گیری می شود:
از نو، [ خطای پردازش ریاضی ]پ�تی1مختصات خام نمونه ها را نشان می دهد و [ خطای پردازش ریاضی ]پ�تی2مختصات دقیق نمونه ها را به صورت دستی نشان می دهد. با اعمال معادلات برای 128 نمونه، میانگین خطای فاصله اقلیدسی حدود 50 متر بود ( شکل 2 الف) و بردار آزیموت خطا هیچ الگوی خاصی را نشان نمی داد ( شکل 2 ب).
خطای موقعیت توسط سنسورهای موبایل ایجاد می شود. در موارد معمول، هنگامی که کاربران به یک مکان مراجعه می کنند یا یک مکان ایجاد می کنند، تمایل دارند این کار را در داخل ساختمانی که متعلق به محل برگزاری است انجام دهند. در حالی که آنها این کار را انجام می دهند، ممکن است متوجه نشوند که مکان اندازه گیری شده توسط سنسور موبایل در واقع مکان محل برگزاری است، که همیشه درست نیست. مشخص شده است که میانگین خطاهای موقعیت یک سیستم موقعیت یابی با استفاده از GPS موبایل و Wi-Fi به ترتیب 10 متر و 40 متر است [ 13 ]. بنابراین، خطای موقعیت مکان را می توان از محیط های GPS و Wi-Fi یا الگوهای استفاده Foursquare نتیجه گرفت.
برای این مطالعه، مختصات مکان ها به صورت دستی ویرایش شد تا خطای موقعیت تصحیح شود. در نتیجه، 87 درصد از مکانهای استخراجشده از دادههای خام، جغرافیایی کدگذاری شدند. سپس، مکان ها به صورت فضایی با یک لایه چند ضلعی ساختمانی مربوطه به هم متصل شدند.
3.2. بخشهای جاده و تطبیق دادههای مکان پیوسته
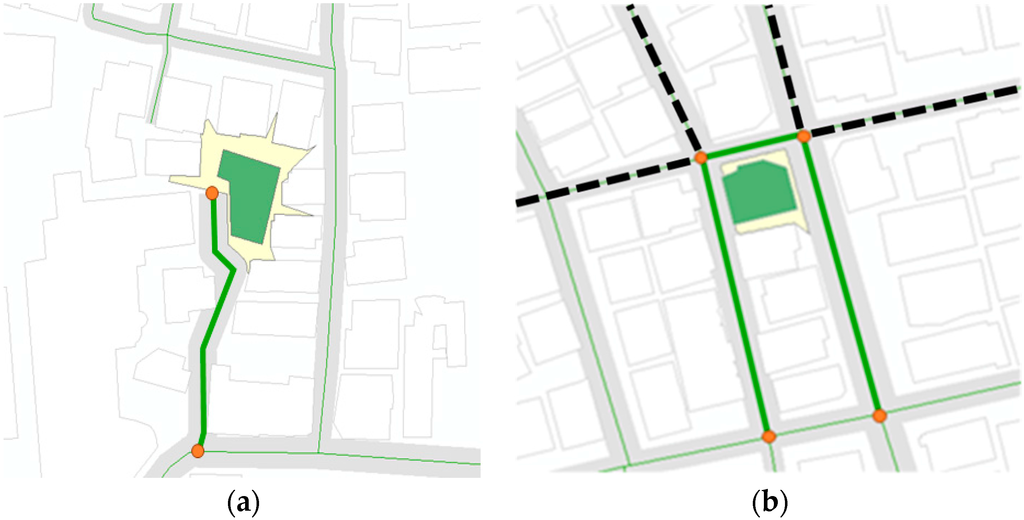
با استفاده از لایه شبکه راه بدون تقسیم آن به مناطق کوچکتر، طول بخش جاده می تواند بیشتر از طول منطقه مورد مطالعه باشد. بخش طولانیتر را میتوان بهعنوان یک خیابان موضوعی تشخیص داد، زیرا میتواند بیشتر تحت تأثیر ساختمانهایی باشد که مکانها به آن تعلق دارند. بنابراین، شبکههای جادهای در هر تقاطع تقسیم میشوند ( شکل 3 )، زیرا این اتصال، شناخت یک فضای پیوسته را قطع میکند و مردم معمولاً هنگام راه رفتن در امتداد جاده در محل اتصال توقف میکنند [ 9 ].
لایه چند ضلعی ساختمان با بخش های جاده تقسیم شده تطبیق داده شد تا اطلاعات محل برگزاری به بخش اختصاص یابد. شرایط تطبیق بین بخشهای جاده و لایه ساختمان به این صورت تعریف میشود که با توجه به فضای جلویی یک ساختمان، ساختمان باید قسمت جاده را لمس کند و جلوی ساختمان باید از جاده دیده شود . با استفاده از Isovist، چند ضلعی های ساختمان با بخش های جاده ای مطابقت داده می شوند که فقط بر هدف تأثیر می گذارند [ 14 ].
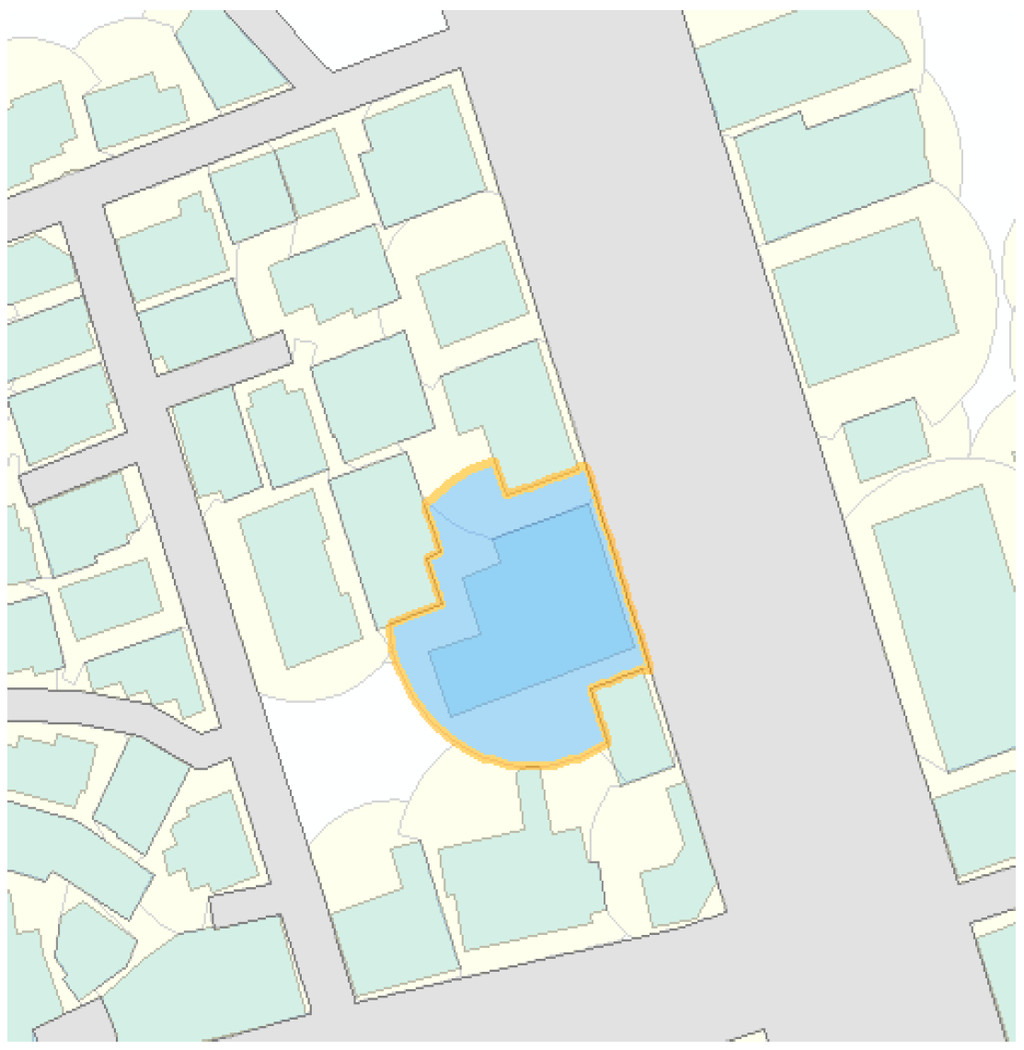
Isovist یک منطقه قابل مشاهده است که می تواند از یک مکان معین (یک نقطه دید) مشاهده شود، به استثنای هر منطقه ای فراتر از موانع اطراف. ایزویست می تواند روند تشخیص تابلوهای راهنما و راه رفتن افراد به سمت ساختمان را به طور مستقیم نشان دهد. علاوه بر این، منطقه ایزویست، که از یک مرکز ساختمان به عنوان نقطه نظر ایجاد شده است، به دلیل ساختمان های مجاور افزایش نمی یابد. این ویژگی بسیار شبیه به دیدگاه مردم در دنیای واقعی است، زیرا بینایی افراد نیز توسط موانع قطع می شود. بنابراین منطقه ایزویست با بخش جاده مناسب مطابقت دارد، حتی اگر ساختمان در داخل سازه های جاده ای پیچیده واقع شده باشد، همانطور که در شکل 4 توضیح داده شده است.آ. علاوه بر این، از لایه جاده به عنوان مانعی برای قطع منطقه در حال رشد ایزویست استفاده شد. با توجه به این اثر، مطابقت نادرست با تمام بخش های جاده در هر تقاطع همانطور که در شکل 4 ب نشان داده شده است، حل شد .
برای استفاده از ایزویست، محدوده خاصی باید بر اساس دیدگاه مردم تنظیم شود. همانطور که در بالا ذکر شد، مرکز هر ساختمان برای مطابقت با این دیدگاه ها تنظیم شده است. اگر محدوده به عنوان فاصله یکسان برای همه ساختمان ها تنظیم شود، یک منطقه ایزویستی می تواند در داخل ساختمان ها ایجاد شود. برای جلوگیری از این نوع مسئله، محدوده ایزویست به شرحی که در رابطه (3) توضیح داده شده است، محاسبه شد:
جایی که [ خطای پردازش ریاضی ]لطول ضلع یک ساختمان است و تمام ساختمان های منطقه مورد مطالعه به صورت مربع در نظر گرفته می شوند. سپس به عرض فضای سردر یک ساختمان و پیاده رو پنج متر اضافه شد. پس از اینکه منطقه ایزویست به یک بخش جاده بریده شد، منطقه ایزویست توسط جاده ها و ساختمان های مجاور محدود می شود ( شکل 5 ).
از آنجایی که مکانها از نظر فضایی به لایههای ساختمانی در فرآیند قبلی متصل شده بودند، و مناطق ایزوویستی از ساختمان ایجاد میشدند، منطقه Isovist نیز دارای ویژگیهای مکان است. بنابراین، نواحی ایزوویستی از نظر فضایی به بخشهای جاده متصل میشوند تا ویژگیهای محل برگزاری را به جادهها اختصاص دهند.
3.3. تشخیص خوشه خیابانی مضمون
3.3.1. ارزش داغ
هر بخش جاده باید دارای ارزشهای منحصربهفرد برای تعیین معیارها باشد، چه بخشهای جاده به عنوان خیابانهای موضوعی در نظر گرفته شوند یا نه. برای این مطالعه، مقدار منحصر به فرد “ارزش داغ” نامیده می شود. [ خطای پردازش ریاضی ]اچمن)” و از رابطه (4) به صورت زیر بدست می آید:
جایی که [ خطای پردازش ریاضی ]اچمن به عنوان مجموع میانگین محبوبیت مکان ها تعریف می شود ( [ خطای پردازش ریاضی ]پمن)، نسبت ساختمان های محل برگزاری ( [ خطای پردازش ریاضی ]آرمنو تراکم ساختمان های محل برگزاری ( [ خطای پردازش ریاضی ]�من). [ خطای پردازش ریاضی ]اچمنمتعاقباً به عنوان مجموعه داده ورودی Getis-Ord استفاده می شود [ خطای پردازش ریاضی ]جیمن*در این صفحه. جزئیات محاسبه هر عامل در ادامه توضیح داده شده است.
[ خطای پردازش ریاضی ]پمنمجموع نظرات تقسیم بر تعداد مکان های موجود در جاده است و با رابطه (5) به صورت زیر بدست می آید:
جایی که [ خطای پردازش ریاضی ]کتعداد کل مکان های برگزاری است [ خطای پردازش ریاضی ]منقطعه جاده ای؛ [ خطای پردازش ریاضی ]نمن،�مقدار عددی کمی شده مانند تعداد اعلام حضورها، نکات، لایکها و موارد دیگر است که اقدامات مثبت افراد را در مکانهای خاص در نظر میگیرد [ 10 ]. را [ خطای پردازش ریاضی ]نمن،�سپس مانند رابطه (6) اندازه گیری می شود:
[ خطای پردازش ریاضی ]نمن،�اشاره به محبوبیت [ خطای پردازش ریاضی ]�محل برگزاری در میان سالن های در [ خطای پردازش ریاضی ]منبخش های جاده ای، زمانی که [ خطای پردازش ریاضی ]�تعدادی از بخش های جاده وجود دارد. به این معنا که، [ خطای پردازش ریاضی ]پمنبه میانگین محبوبیت اشاره دارد [ خطای پردازش ریاضی ]منبخش جاده، زمانی که وجود دارد [ خطای پردازش ریاضی ]�تعداد بخش های جاده
دوم، اگر موضوع مشابهی از مکانها در جادهای با تعداد مکان کافی وجود داشته باشد، جاده تمایل دارد ویژگیهای مکانها را به خود بگیرد. این به مردم کمک می کند تا جاده را به عنوان یک خیابان موضوعی در آن مکان تشخیص دهند. در معادله (7) [ خطای پردازش ریاضی ]آرمنبیانی ریاضی از شناخت مردم و نسبت ساختمان های محل برگزاری است، به شرح زیر:
جایی که [ خطای پردازش ریاضی ]بنمنتعداد ساختمان هایی است که با آن تماس دارند [ خطای پردازش ریاضی ]منقطعه جاده ای؛ [ خطای پردازش ریاضی ]ب�منتعداد ساختمانهایی است که دادههای محل برگزاری متعلق به ساختمانهای همسان را دارند [ خطای پردازش ریاضی ]منقطعه جاده به این معنا که، [ خطای پردازش ریاضی ]آرمننسبت ساختمان های محل برگزاری است [ خطای پردازش ریاضی ]منقطعه جاده بنابراین، همانطور که [ خطای پردازش ریاضی ]آرمنافزایش می یابد، ساختمان های محل برگزاری در بخش جاده هدف متراکم تر می شوند.
در نهایت، به دلیل استفاده از تنها [ خطای پردازش ریاضی ]پمنو [ خطای پردازش ریاضی ]آرمنمی تواند یک خطای آماری ایجاد کند (یعنی یک ساختمان محبوب در بین دو ساختمان و پنج ساختمان محبوب در بین 10 ساختمان می تواند منجر به همان نتیجه شود)، تراکم ساختمان های محل برگزاری در جاده مورد نظر ( [ خطای پردازش ریاضی ]�من) در نهایت به اضافه می شود [ خطای پردازش ریاضی ]اچمن.
[ خطای پردازش ریاضی ]�منتعداد کل ساختمان های محل برگزاری در طول بخش جاده، مانند رابطه (8) است.
جایی که [ خطای پردازش ریاضی ]ب�منتعداد ساختمان های محل برگزاری است [ خطای پردازش ریاضی ]منقطعه جاده ای؛ [ خطای پردازش ریاضی ]له��تیساعتمنطول آن است [ خطای پردازش ریاضی ]منقطعه جاده بر حسب متر؛ و [ خطای پردازش ریاضی ]�منشاخص شهودی است که تراکم ساختمان های محل برگزاری در یک بخش جاده را نشان می دهد. این معادله همچنین برای تشخیص اینکه آیا یک جاده مشابه است یا نه استفاده می شود [ خطای پردازش ریاضی ]پمنو [ خطای پردازش ریاضی ]آرمن.
در نتیجه، [ خطای پردازش ریاضی ]اچمنمقدار داغ از است [ خطای پردازش ریاضی ]منقطعه جاده یک بالاتر [ خطای پردازش ریاضی ]اچمنبه معنی محبوبیت بیشتر مکان ها، نسبت بالاتر ساختمان های محل برگزاری و تراکم بالاتر ساختمان های محل برگزاری است. بنابراین می توان نتیجه گرفت که احتمال بیشتری وجود دارد که بخش های جاده ای با مقدار بالاتر [ خطای پردازش ریاضی ]اچمنبه عنوان خیابان های مضمون شناسایی می شود.
3.3.2. لیزا
در میان روشهای تشخیص خوشه فضایی، این مطالعه استفاده از شاخص محلی ارتباط فضایی (LISA) را در نظر گرفت [ 15 ]. روش تشخیص خوشه فضایی با استفاده از LISA قبلاً در بسیاری از مطالعات استاندارد شده است. LISA خاص را می توان محاسبه کرد، سپس تجمع مهم قابل توجهی را می توان استخراج کرد، و تجمع را می توان به عنوان یک خوشه فضایی (نقطه گرم یا سرد) پس از اهمیت آزمون ارزش نامید [16 ] .
Getis-Ord’s [ خطای پردازش ریاضی ]جیمن*از بین LISA، برای این مطالعه انتخاب شد. مهم ترین مزیت از [ خطای پردازش ریاضی ]جیمن*این است که نقاط گرم و سرد را می توان به طور مستقیم از طریق نتایج آماری شناسایی کرد. Getis-Ord’s [ خطای پردازش ریاضی ]جیمن*همانطور که در رابطه (9) نشان داده شده است اندازه گیری می شود.
جایی که [ خطای پردازش ریاضی ]سانحراف معیار است. [ خطای پردازش ریاضی ]�من�وزن فضایی بین واحد فضایی است [ خطای پردازش ریاضی ]منو [ خطای پردازش ریاضی ]�; و [ خطای پردازش ریاضی ]�تعداد کل داده ها است. اگر واحدها به صورت مجاور تعریف شوند، [ خطای پردازش ریاضی ]�من�=1و 0 در غیر این صورت. از آنجا که [ خطای پردازش ریاضی ]جیمن*به عنوان یک محله در نظر گرفته می شود، [ خطای پردازش ریاضی ]�من�این همچنین به این معنی است که مقادیر قطری ماتریس وزن فضایی 0 نیستند. مقدار انتظاری [ خطای پردازش ریاضی ]جیمن*0 است و واریانس آن 1 است [ 17 ]. بنابراین، آزمون معناداری از [ خطای پردازش ریاضی ]جیمن*تقریباً همانند آزمون توزیع نرمال پردازش می شود [ 16 ].
برای اندازه گیری [ خطای پردازش ریاضی ]جیمن*شاخص، ماتریس وزن فضایی باید برای واحد فضایی این مطالعه، بخشهای جاده اصلاح شود. اگر بخش های جاده به هم متصل هستند، [ خطای پردازش ریاضی ]�من�1 است، در غیر این صورت 0 است. شکل 6 a 9 بخش جاده متصل شده در تقاطع ها را نشان می دهد و ماتریس وزن فضایی بخش های جاده در شکل 6 ب توضیح داده شده است.
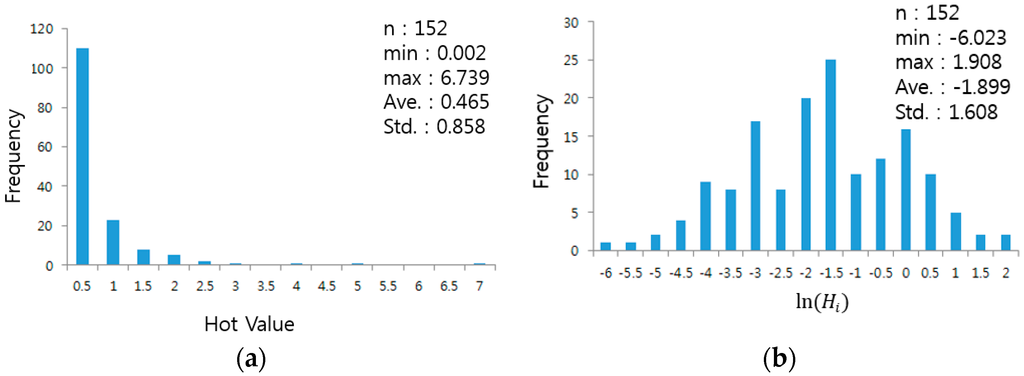
برای دستیابی به نرمال بودن (مقدار انتظار 0 و واریانس 1) Getis-Ord’s [ خطای پردازش ریاضی ]جیمن*، توزیع نرمال داده های مکانی ترجیح داده می شود. به شرطی که تعداد داده های مکانی کافی و تعداد واحدهای فضایی مجاور بیش از 30 واحد باشد، نرمال بودن [ خطای پردازش ریاضی ]جیمن*حتی اگر داده های مکانی دارای توزیع کج باشند، هنوز می توان فرض کرد. از سوی دیگر، اگر تعداد دادههای مکانی کم باشد و تعداد واحدهای فضایی مجاور کمتر از 30 باشد، نرمال بودن [ خطای پردازش ریاضی ]جیمن*نمی توان فرض کرد، مشروط بر اینکه چولگی متوسط باشد [ 18 ].
واحد فضایی این مطالعه در محل اتصالات تقسیم شده است. از این رو تعداد واحدهای فضایی مجاور کم است. همانطور که در بالا ذکر شد، اگر [ خطای پردازش ریاضی ]اچمنتوزیع دارای چولگی متوسط است [ خطای پردازش ریاضی ]جیمن*شاخص را می توان با فرض نرمال بودن آن اندازه گیری کرد. با این حال، همانطور که در شکل 7 الف نشان داده شده است، [ خطای پردازش ریاضی ]اچمنچولگی بسیار مثبتی دارد. بنابراین، مقادیر اریب با استفاده از یک لگاریتم طبیعی برای محاسبه نرمال سازی شدند [ خطای پردازش ریاضی ]جیمن*شاخص ( شکل 7 ب). با این وجود، پیروی دقیق از توزیع نرمال مهم نیست، زیرا Getis و Ord’s [ خطای پردازش ریاضی ]جیمن*معادلات روشنی در مورد محاسبه واریانس و مقدار مورد انتظار ارائه نمی دهد [ 17 ].
در نهایت، [ خطای پردازش ریاضی ]جیمن*شاخص با استفاده از [ خطای پردازش ریاضی ]لوگاریتم(اچمن). برای این مطالعه، فقط مثبت است [ خطای پردازش ریاضی ]جیمن*شاخص (نقطه داغ) به عنوان یک هدف در نظر گرفته شد. با سطح معناداری 05/0، الف [ خطای پردازش ریاضی ]�امتیاز از [ خطای پردازش ریاضی ]جیمن*بیش از 1.96 به عنوان خوشه های خیابانی با موضوع انتخاب شد.
4. نتایج و تجزیه و تحلیل
Sillim و Gangnam، دو منطقه در سئول، برای بررسی نتایج و تطبیق پذیری روش پیشنهادی انتخاب شدند.
تعداد کل داده های محل برگزاری 312 در منطقه آزمایش Sillim است. تأیید شد که تعداد ساختمانهای محل برگزاری و بخشهای جاده منطبق با ساختمانها به ترتیب 154 و 152 است.
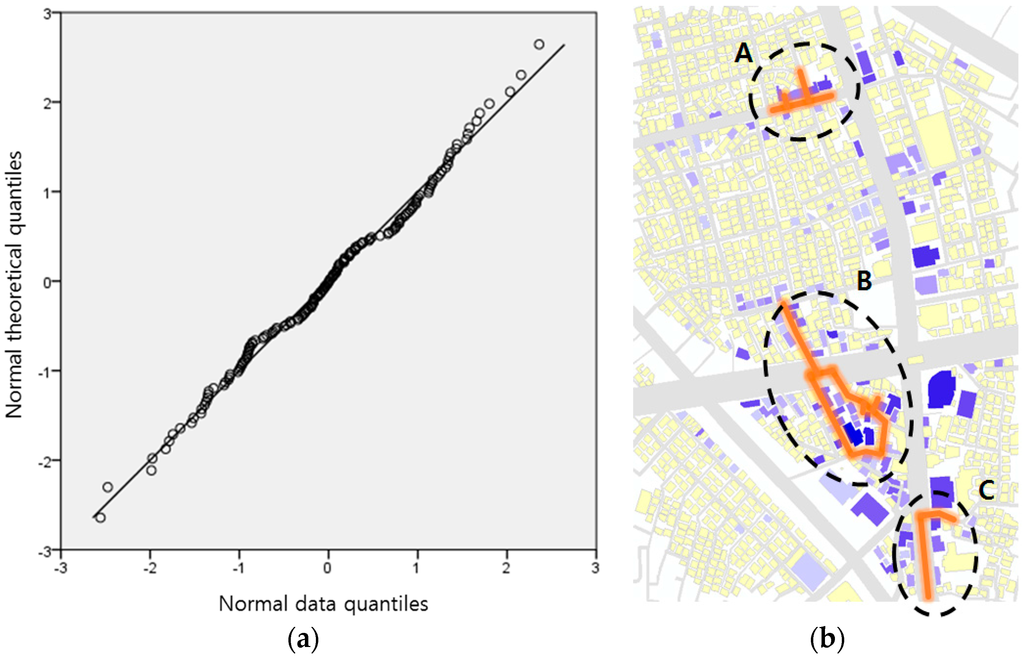
نتایج تجزیه و تحلیل خوشه های خیابانی با موضوع رستوران در منطقه آزمایشی سیلیم در شکل 8 ب نشان داده شده است. خیابان های قرمز رنگ دارای یک [ خطای پردازش ریاضی ]جیمن*مقداری که سطح معنی داری 0.05 را برآورده می کند و به عنوان خیابان های مضمون در نظر گرفته می شود، در حالی که ساختمان های آبی رنگ به مقیاس مکان های محبوب اشاره می کنند. [ خطای پردازش ریاضی ]پمن). برای تأیید عادی بودن [ خطای پردازش ریاضی ]لوگاریتم(اچمن)توزیع موضوع رستوران، یک نمودار QQ عادی ترسیم شد ( شکل 8 a).
منطقه آزمایشی دارای سه خوشه خیابانی بزرگ با موضوع رستوران است. ناحیه A نسبتاً کوچکتر از سایر ولسوالی ها است و در فاصله ای از آنها واقع شده است. منطقه A به عنوان “خیابان مد و فرهنگی” نامگذاری شده است که در ابتدا توسط دولت محلی توسعه یافته است. با این حال، عموم مردم از این توسعه انتقاد کردند و اظهار داشتند که پول مالیات هدر رفت و هدف اولیه توسعه محقق نشد، زیرا اکثر فروشگاههای مرتبط با مد بسته شدهاند و رستورانها اکنون در خیابان هستند [19 ] . منطقه A وضعیت واقعی را مستقیماً با نشان دادن عملکرد خیابان به عنوان یک کوچه غذا منعکس می کند.
مشاهده شد که منطقه B دارای رستوران های زیادی است که 92 مکان رستوران در این منطقه وجود دارد. در این میان، حدود نیمی از آنها مربوط به فروش سوسیسهای کرهای (به کرهای “sundae” نامیده میشود) (44 مکان از 92 مکان، سوسیس کرهای میفروشند). این توزیع غیرعادی رستوران در گزارش تحلیل بازار در Sillim که توسط مرکز توسعه کسب و کار کوچک (SBDC) منتشر شده گزارش شده است. نام این منطقه “Sundae Town” است که اصطلاح کره ای “Sausage Town” است. این گزارش مجدداً از طریق نتیجه آزمایش تأیید شد.
منطقه C دارای رستوران های مختلفی مانند پیتزا هات، مک دونالد، کباب مرغ و غیره به همراه سیلیم رو (خیابان سیلیم) است. ناحیه C، در نزدیکی ناحیه B، در جنوب واقع شده است. با این حال، این دو منطقه به عنوان یک خوشه بزرگ ادغام نشده اند. این نشان می دهد که مکان های رستوران بین مناطق B و C به اندازه کافی مورد توجه قرار نمی گیرند، که B و C را به عنوان مناطق مختلف از هم جدا می کند.
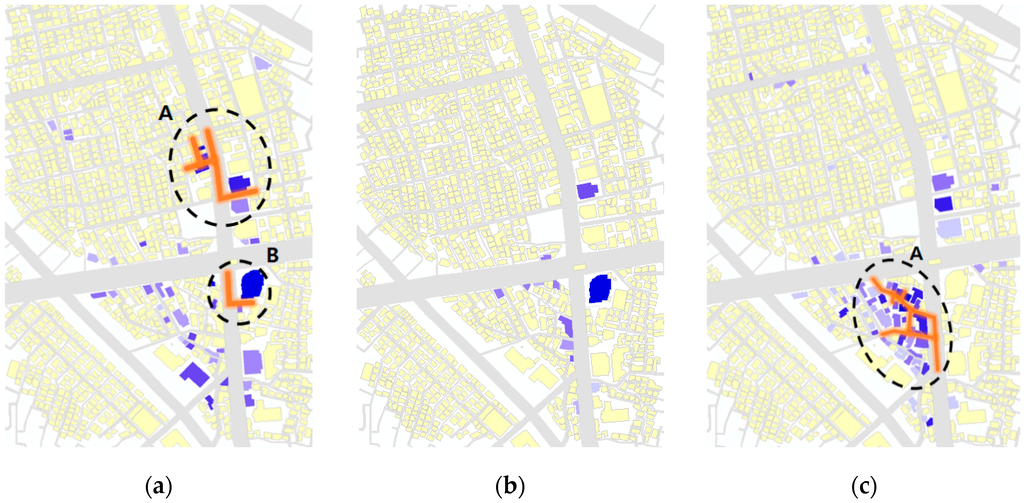
برای استنباط خیابانهای مضمون مختلف، نه تنها رستورانها، بلکه مضامین کافهها ( شکل 9 الف)، فروشگاههای مد ( شکل 9 ب)، و امکانات سرگرمی ( شکل 9 ج) نیز با استفاده از همین روش مورد آزمایش قرار گرفتند. قابل توجه ترین جنبه شکل 9 این است که یک خوشه خیابانی با مضمون مد شناسایی نشد ( شکل 9 ب). هیچ یک از بخش های جاده راضی نمی کند [ خطای پردازش ریاضی ]جیمن*مقدار سطح معنی داری 0.05، اگرچه چند مکان مد در داده ها ظاهر می شود. با این حال، ساختمانی واقع در ضلع جنوب شرقی تقاطع در منطقه آزمایشی بیشترین محبوبیت را نشان می دهد. مشاهده می شود که ورود به فروشگاه های مد محبوب از طریق یک مرکز خرید به جای خیابان ها صورت می گیرد.
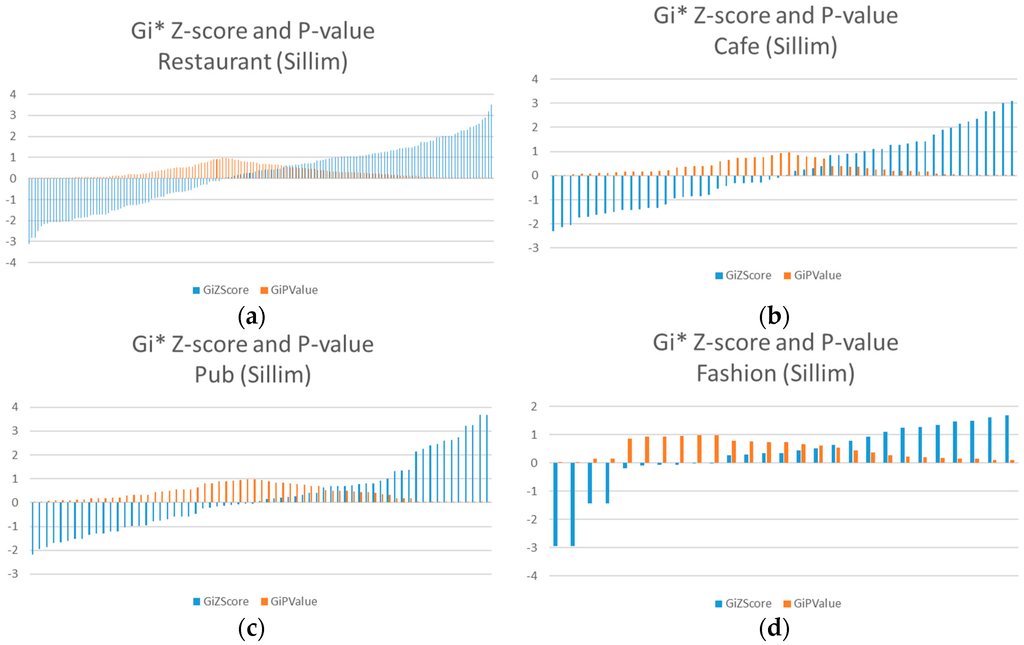
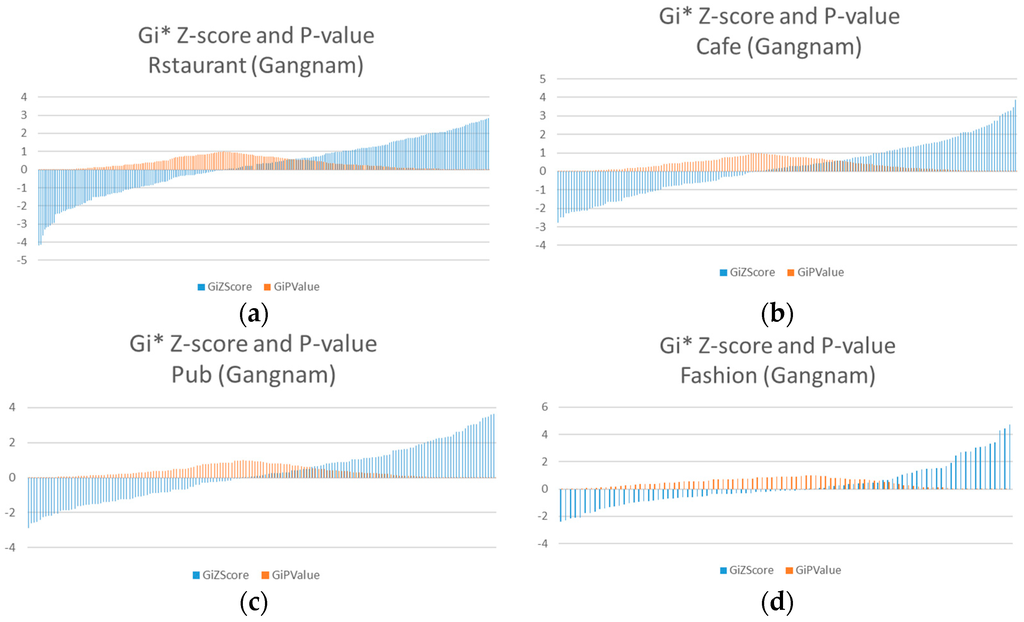
را [ خطای پردازش ریاضی ]جیمن*z-score و p -value هر موضوع ترسیم شده است تا تشخیص کلی خیابان های مضمون قابل مشاهده باشد ( شکل 10 ). مقادیر بر اساس z-score مطابق با p -value مرتب می شوند. توجه داشته باشید که داده ها نشان می دهد [ خطای پردازش ریاضی ]جیمن*محاسبات بخشهای جادهای که حاوی اطلاعات مکان هستند. علاوه بر این، فراوانی هر موضوع متفاوت است زیرا همه بخشهای جاده شامل مکانهای برگزاری نیستند. جاده هایی که هیچ داده ای ندارند نادیده گرفته شدند.
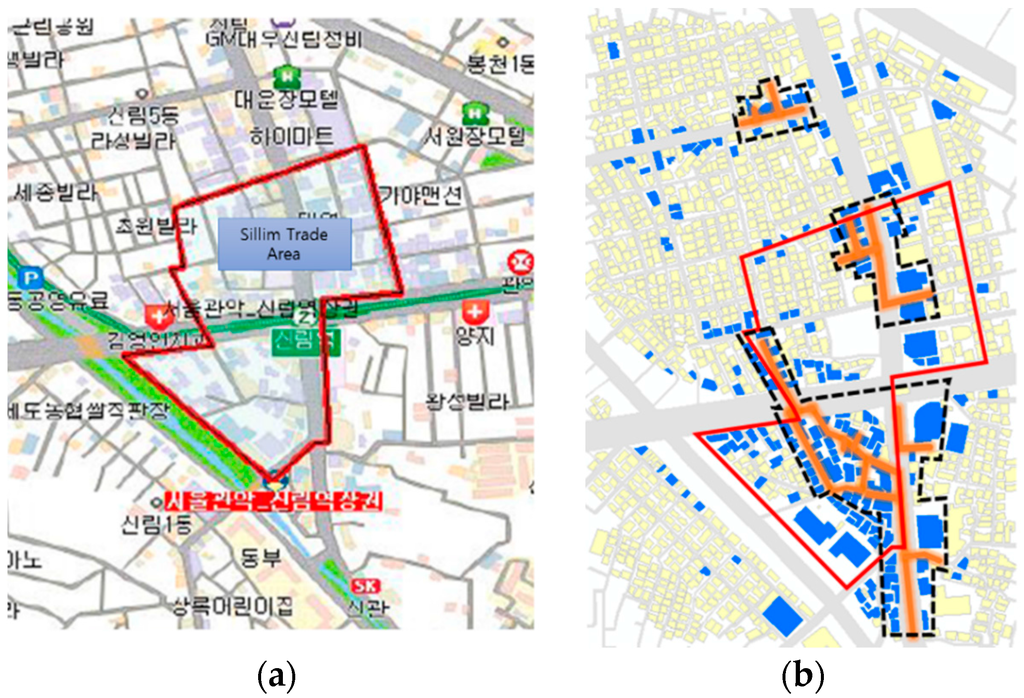
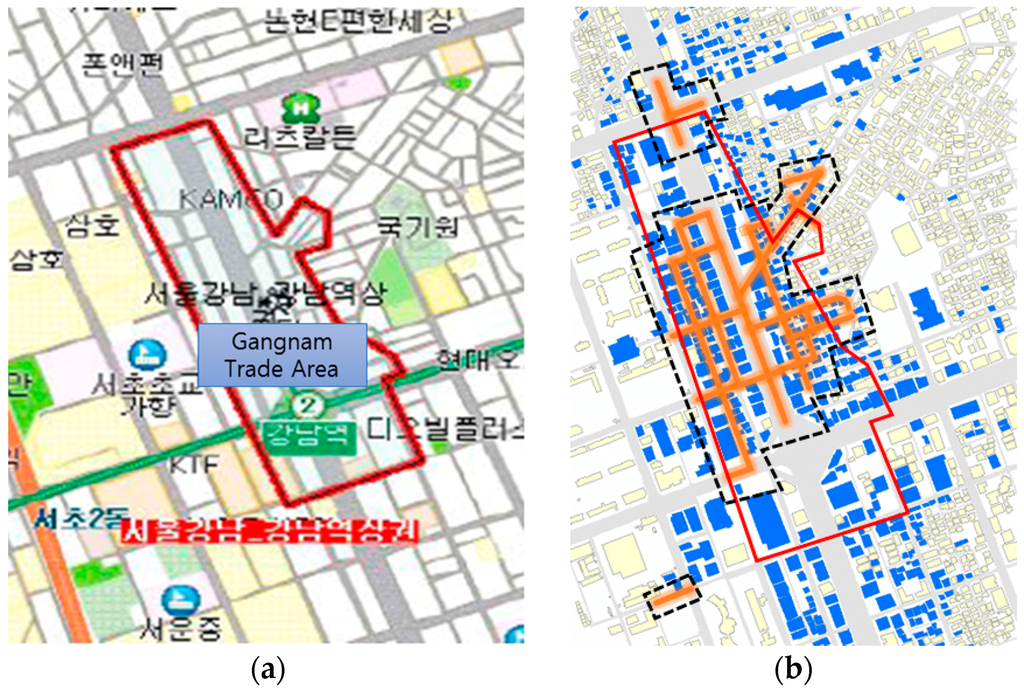
از چهار مکان مختلف برای شناسایی خوشههای خیابانی با مضمون مختلف استفاده شد. در حالی که خیابانهای موضوعی نشاندهنده موقعیت یک منطقه هستند، در شکلگیری منطقه تجاری نیز مهم هستند. بنابراین، مجموع تمام خوشه های خیابانی مضمون ذکر شده در بالا را می توان به عنوان یک منطقه تجاری در نظر گرفت. کل مساحت از نظر بصری با گزارش تحلیل بازار از SBDC کره که در ژوئن 2008 ارائه شد، مقایسه شد.
نقشه ای از منطقه تجاری از گزارش تحلیل بازار ( شکل 11 الف) و خوشه های خیابانی موضوعی همراه با ساختمان ها ( شکل 11 ب) در زیر نشان داده شده است. نتیجه آزمایش نواحی غیرعادی نادرست را نشان نداد و بیشتر نواحی ایجاد شده توسط آزمایش در داخل ناحیه توصیف شده در گزارش SBDC بودند. از این مقایسه بصری می توان دریافت که روش تست قابل اعتماد است. مشاهده شد که گزارش بازار ارائه شده در سال 2008 اطلاعات به روز رسانی را ارائه نکرده است. خوشه های خیابانی مضمون نسبت به گزارش سال 2008 به سمت جنوب گسترش یافته بودند. همچنین خیابان مد و فرهنگی توسط SBDC مورد بررسی قرار نگرفت، بنابراین امکان مقایسه وجود نداشت.
در این میان، تعداد کل مکانها در منطقه آزمایشی گانگنام 1570 و تعداد ساختمانهای محل تایید شده و بخشهای جادهای مطابق با ساختمانها به ترتیب 425 و 242 است. نمودار QQ نرمال نشان می دهد که توزیع [ خطای پردازش ریاضی ]لوگاریتم(اچمن)همانطور که در شکل 12 الف نشان داده شده است، مکان های رستوران در منطقه گانگنام اندکی دارای انحراف منفی هستند (چولگی 0.61-) . همانطور که قبلا ذکر شد، پیروی دقیق از توزیع نرمال از زمان Getis-Ord حیاتی نیست [ خطای پردازش ریاضی ]جیمن*معادلات واضحی برای محاسبه واریانس و مقدار مورد انتظار ارائه نمی دهد [ 17 ]. تشخیص خوشه های خیابانی مضمون از نتایج آزمایش منطقه گانگنام در شکل 12 ب نشان داده شده است.
سه خوشه خیابانی با مضمون رستوران در منطقه گانگنام شناسایی شدند. جنبه خاص منطقه این است که مناطق A و B کوچه پس کوچه های Gangnam-daero (عریض ترین جاده نشان داده شده در شکل 12 ب) را تشکیل می دهند. گزارش شده است که بسیاری از رستوران ها و میخانه ها در کوچه پس کوچه های Gangname-daero قرار دارند [ 20 ]. با توجه به مطالعه، می توان نتیجه گرفت که نتیجه آزمون دارای دقت عینی است. برخلاف مناطق A و B، ناحیه C محدودیتی را در روش آزمون نشان می دهد. در واقع، منطقه C یک خوشه نیست، اما تنها به عنوان یک خیابان داغ (خیابانی که به عنوان یک نقطه داغ عمل می کند) تشخیص داده می شود. تنها یک ساختمان محل برگزاری رستوران به بخش جاده هدف اختصاص داده شد و امتیاز z از آن اختصاص یافت [ خطای پردازش ریاضی ]جیمن*1.98 با سطح معنی داری 0.05 بود که مقادیر آن در محدوده متوسط مناطق مورد مطالعه قرار دارد. با این حال، ارزش محبوبیت [ خطای پردازش ریاضی ](پمن)1045 بود. این مقدار با توجه به میانگین بسیار بالا است [ خطای پردازش ریاضی ]پمندر منطقه Gangnam حدود 80 است. این نشان می دهد که ارزش بسیار بالایی از [ خطای پردازش ریاضی ]پمنمی تواند یک بخش جاده را به عنوان یک خیابان موضوعی ارائه کند.
شبیه به منطقه تست Sillim، مضامین کافه ( شکل 13 الف)، مد ( شکل 13 ب) و میخانه ( شکل 13 ب) آزمایش می شوند.
را [ خطای پردازش ریاضی ]جیمن*z-score و p -value هر تم در شکل 14 رسم شده است .
گزارش تحلیل بازار SBDC گانگنام در می 2008 ارائه شد که در آن همه خوشههای خیابانی مضمون در منطقه گانگنام به صورت بصری با هم مقایسه شدند. شکل 15 نقشه ای از منطقه تجاری را از گزارش تحلیل بازار ( شکل 15 الف) و خوشه های خیابانی موضوعی به همراه ساختمان هایی که داده های محل برگزاری دارند نشان می دهد ( شکل 15 ب). بدون در نظر گرفتن منطقه C در شکل 12 ب، که همانطور که در بالا توضیح داده شد، محدودیت روش آزمایش را نشان می دهد، گزارش تحلیل بازار SBDC نشان می دهد که اکثر خوشه های خیابانی موضوعی در داخل منطقه واقع شده اند. این نشان می دهد که روش آزمون قابلیت اطمینان و تطبیق پذیری دارد.
5. نتیجه گیری ها
TSCM در سراسر این مطالعه برای شناسایی خیابانهای موضوعی پیشنهاد شده است. خیابان های مضمون اقتصاد محلی را تشویق می کند و فضاهای اجتماعی و فرهنگی را فراهم می کند. TSCM صرفاً به شناسایی مناطقی که فروشگاههای مشابه در آنها متراکم هستند محدود نمیشود، بلکه خیابانهای موضوعی مختلف را با استفاده از دادههای LBSM شناسایی میکند و اطلاعات غنی را ارائه میدهد.
با مقایسه مناطق تجاری از گزارش تحلیل بازار تهیه شده از یک بررسی میدانی با نتایج آزمون این مطالعه، پایایی روش تأیید شد.
مهمترین سهم این مطالعه این است که مضامین مختلف با استفاده از TSCM پیشنهادی شناسایی شدند و این روش نتایج ثابتی را تولید کرد. همچنین، از طریق شناسایی خیابانهای موضوعی، دولتهای محلی ممکن است بتوانند پویاییهای اجتماعی مناطق هدف را درک کنند، یا ممکن است در توسعه مجدد برنامهریزی شهری موجود مشارکت کنند [21] .]. با استفاده از این روش، برنامه ریزان می توانند بدون نیاز به بررسی های میدانی یا خطر بررسی ادبیات قدیمی، داده های به روز در مورد کاربری خاص مناطق شهری را دریافت کنند و در نتیجه هزینه های بودجه کاهش می یابد. علاوه بر این، مانند یافتههای این مطالعه که به موجب آن از «خیابان مد و فرهنگی» در منطقه آزمایشی سیلیم برای اهداف مختلف استفاده میشود، برنامهریزان میتوانند نحوه تغییر نتایج برنامهریزی رسمی را شناسایی کنند. با این دیدگاه ها، می توان از فرآیند تصمیم گیری پیشرفته برای توسعه مجدد مناطق شهری استفاده کرد.
علاوه بر این، TSCM بدون توجه به موقعیت منطقه آزمایش، نتایج عینی تولید کرد، زیرا این روش ویژگیهای داده LBSM را به مقادیر ریاضی تبدیل میکند. همچنین، با استفاده از بخشهای جاده بهعنوان واحدهای فضایی پایه برای تجزیه و تحلیل، نتایج آزمون با اجتناب از تشکیل مناطق فضایی مبهم مانند آنهایی که توسط KDE یا مناطق داغ معمولی ایجاد میشوند، بصری و قابل تشخیص بودند. در نهایت، نه تنها تعداد POI و تعداد ورود، بلکه سایر ویژگیها نیز به صورت ریاضی برای یافتن خیابانهای مضمون معنادار اندازهگیری شدند.
با این حال، این مطالعه محدودیت هایی نیز دارد. اول، یک اندازه گیری کمی برای ارزیابی خوشه های خیابانی مضمون انجام نشد. دوم اینکه محدوده سنی افرادی که از سرویس Foursquare استفاده می کنند محدود است. اگرچه این یک مشکل کلی در تجزیه و تحلیل هایی است که داده های LBSM برای آنها استفاده می شود، می توان از داده های اضافی از منابع مختلف برای نشان دادن کل جمعیت استفاده کرد. سوم، خطای انسانی و مشارکت منجر به اشتباهاتی مانند اشتباهات تایپی و نظرات ذهنی از محل برگزاری در هنگام استفاده از LBSM می شود. همچنین، دسترسی به اینترنت و انواع دیگر محدودیتهای فیزیکی میتواند منجر به توزیع غیریکنواخت دادههای LBSM شود. چنین محدودیتهایی باید توسط محققانی که از دادههای LBSM استفاده میکنند، شناخته شوند. در نهایت، تعدادی فروشگاه یا ساختمان (محل برگزاری)، مانند مراکز خرید بزرگ یا رستوران های معروف،
برای غلبه بر محدودیت های فوق الذکر باید یک روش ارزیابی مورد مطالعه قرار گیرد. همچنین باید از خطاهای ناشی از چند مکان اجتناب کرد و با تغییر مقدار داغ به طور مستمر شناسایی و بررسی شود. [ خطای پردازش ریاضی ]اچمن) که نشان دهنده ویژگی های بخش های جاده است.








بدون نظر