

خلاصه
:
دسترسی روزافزون به دادههای مکانی باز مرتبط، منبع بیسابقهای از اطلاعات جغرافیایی برای توصیف محیطهای شهری است. این انبوه داده باید به دانش عملی تبدیل شود: برای مثال، داده های باز می تواند به عنوان یک پروکسی یا جایگزین اطلاعات بسته یا گران قیمت استفاده شود. استفاده موفق از داده های مکانی باز مرتبط می تواند راه را برای راه حل های نوآورانه برای مشکلات شهر هوشمند هموار کند. در این مقاله، مجموعهای از آزمایشها را نشان میدهیم که با شروع از دادههای مکانی باز مرتبط، فرآیند کشف دانش را برای پیشبینی معناشناسی شهری اجرا میکنند. به طور خاص، ما از اطلاعات جغرافیایی در مورد نقاط مورد علاقه به عنوان ورودی در یک مدل طبقهبندی استفاده از زمین با وضوح فضایی متوسط (250 متر) در مناطق وسیع شهری در اروپا استفاده میکنیم. ما آزمایشهای خود را در شهرهای مختلف اروپایی – میلانو، مونیخ، بارسلونا و بروکسل – تکرار میکنیم تا از تکرارپذیری و عمومیت رویکرد خود اطمینان حاصل کنیم، و شرایط آزمایشی و همچنین مجموعه دادههای به کار رفته را برای تضمین تکرارپذیری توضیح میدهیم. ما به طور گسترده در مورد نتایج ارزیابی کمی و کیفی، برای قضاوت در مورد اعتبار، و همچنین محدودیت های رویکرد پیشنهادی خود، گزارش می دهیم.
کلید واژه ها:
کاربری اراضی شهری ; داده های جغرافیایی-مکانی باز مرتبط ؛ نقاط مورد علاقه ؛ شهرهای هوشمند
چکیده گرافیکی
1. معرفی
دیجیتالی شدن فضای شهری، ناشی از فراگیر شدن روزافزون فناوری های اطلاعات و ارتباطات، به اکوسیستم غنی از تولیدکنندگان اطلاعات و مصرف کنندگان اطلاعات منجر شده است [ 1 ]. با این حال، این انبوه داده، ارزش افزوده پنهانی را که مدیریت هوشمند چنین اطلاعاتی می تواند برای شهرها به ارمغان بیاورد، مخاطره می کند. سوال باز این است که “اطلاعات مرتبط برای رسیدن به هدف من چیست؟”: مصرف کنندگان اطلاعات ممکن است بدون حل وظایف خود در داده های بزرگ غرق شوند و گم شوند. در این تصویر، دادههای مکانی باز مرتبط میتوانند نقش مهمی را ایفا کنند و اطلاعات جغرافیایی معنایی غنی مرتبط با محیطهای شهری را ارائه دهند. همانطور که در زمینه های دیگر اتفاق می افتد، تبدیل اطلاعات خام به دانش عملی چالش کلیدی است [ 2].
علاوه بر این، ظهور اقتصاد به اصطلاح داده محور نشان می دهد که مالکیت و انتقال داده ها به چندین ملاحظات حقوقی و مالی منجر می شود [ 3 ]. علاوه بر این، در زمینه دادههای شهری، منابع مختلف با هزینههای متفاوتی به دست میآیند: در حالی که برخی از اطلاعات تقریباً بهطور رایگان ایجاد و بهروزرسانی میشوند، در نتیجه فعالیتهای دیگر (به عنوان مثال، تحرک وسیله نقلیه ردیابی GPS ایجاد میکند، فعالیت تلفن همراه مکان افراد را در طول زمان جمعآوری میکند. [ 4])، سایر مجموعههای داده همچنان برای تولید و نگهداری بسیار پرهزینه باقی میمانند، مانند آنهایی که نیاز به مداخله دستی دارند (مثلاً دادههای جمعیتی، که به فعالیت سرشماری مبتنی بر انسان نیاز دارد) یا پردازش نیمه خودکار. هزینه های مجموعه داده ها به کل زنجیره ارزش مبتنی بر داده، از تولید تا توزیع، از پردازش تا مصرف مربوط می شود [ 5 ].
آیا می توان از یک یا چند مجموعه داده ارزان قیمت به عنوان «پراکسی» برای منابع داده گرانتر استفاده کرد؟ به عبارت دیگر، آیا بر اساس محتوای سایر منابع اطلاعاتی بهروز، میتوان بهطور (نیمه) خودکار یک مجموعه داده قدیمی را که در غیر این صورت مستلزم کار پرهزینه انسانی است، تولید یا اصلاح کرد؟ این چالشی است که امروزه جامعه مدیریت داده با آن مواجه است. هدف تحقیق ما پاسخگویی به سوالات فوق در زمینه آمایش سرزمین است.
برنامهریزی شهری رشتهای است که با ایجاد مکانهای راحتتر، پایدارتر و جذابتر به بهبود رفاه مردم و جوامع میپردازد. برنامهریزی شهری زمانی که برای کاربری زمین به کار میرود، به مدیریت و تغییرات محیطی توجه میکند و معمولاً با هدف تنظیم انواع فعالیتهای مجاز در مناطق خاص است. در بافت شهرها، نظارت بر تغییرات کاربری زمین برای هدایت و حمایت از فرآیند شهرنشینی پایدار از اهمیت بالایی برخوردار است [ 6 ].
شناسایی و گزارش تغییرات کاربری اراضی به دور از این است که یک کار بی اهمیت باشد. در واقع، معمولاً برای جمعآوری، ادغام و درک اطلاعات شهری برای استخراج دانش مفید برای پشتیبانی از فعالیتهای برنامهریزی، به یک فرآیند گران قیمت و تا حدی دستی نیاز دارد. در اروپا، ابتکار CORINE ( ر.ک. http://www.eea.europa.eu/publications/COR0-landcover ) یک طبقهبندی و رویه مشترک برای حمایت از شرکتهای محلی و منطقهای که بهطور دورهای نقشههای کاربری زمین را تولید یا بهروزرسانی میکنند، ارائه کرد . از تصاویر سنجش از دور
هدف این مقاله آزمایش این است که آیا دادههای مکانی آزاد مرتبط با محیطهای شهری میتوانند به عنوان یک «نماینده» برای منابع اطلاعات جغرافیایی گران قیمت استفاده از زمین با معنایی که در بالا توضیح داده شد، مشابه آنچه [7، 8، 9] استفاده شود ، آزمایش شود . ، 10 ] با استفاده از رسانه های اجتماعی، داده های تلفن همراه یا ردیابی GPS انجام داد.
در ادامه راه حل ابتکاری خود را برای استخراج کاربری اراضی شهری و پشتیبانی از فعالیت های برنامه ریزی شهرهای هوشمند ارائه می دهیم. ما مجموعهای از آزمایشهای طبقهبندی را برای پیشبینی استفاده از زمین CORINE نشان میدهیم که از اطلاعات جغرافیایی نقطهنظر شهرها (POI) مشتقشده از OpenStreetMap، مشابه [ 11 ، 12 ]، اما با وضوح فضایی دقیقتر، استفاده میکند.
به منظور اطمینان از تکرارپذیری و عمومیت رویکردمان، آزمایشهای خود را در شهرهای مختلف اروپایی تکرار میکنیم. از آنجایی که نقشه های CORINE برای کل اروپا در دسترس است، ما چهار شهر را انتخاب می کنیم که ویژگی های مشابهی را از نظر تعداد ساکنان و اندازه منطقه شهری نشان می دهند. ما میلان را در ایتالیا، مونیخ در آلمان، بارسلونا در اسپانیا و بروکسل در بلژیک را انتخاب می کنیم.
ابتکار CORINE که توسط آژانس محیط زیست اروپا ( رجوع کنید به http://www.eea.europa.eu/ ) اتحادیه اروپا هماهنگ شده است، یک طبقه بندی چند سطحی (به نام “نامگذاری پوشش زمین”، آخرین به روز رسانی در سال 2006) ارائه می دهد. طبقه بندی کاربری زمین در دسته های مختلف (آب در مقابل زمین، زمین با پوشش گیاهی در مقابل زمین بدون پوشش گیاهی و غیره )؛ سپس از این طبقهبندی برای توصیف کاربری واقعی زمین در قلمرو اروپا استفاده میشود و نقشههای موضوعی را با وضوح کاملاً دقیق (100 متر) ایجاد میکند. تولید و به روز رسانی نقشه های CORINE یک فرآیند طولانی و پرهزینه است [ 13]: تصاویر به دست آمده توسط سنجش از دور به عنوان منبع اصلی برای استخراج اطلاعات پوشش زمین، از طریق یک سری فعالیتهای تفسیر عکس، تصحیح عمودی و انواع فعالیتهای تضمین کیفیت استفاده میشوند. نقشه های CORINE به عنوان داده های شطرنجی در دسترس هستند. برای مثال، بهروزرسانی دسامبر 2013 بهصورت آنلاین برای دانلود در دسترس است ( ر.ک. http://www.eea.europa.eu/data-and-maps/data/corine-land-cover-2006-raster-3 ) . رویههای استاندارد شده و پیشنهاد شده توسط CORINE سپس در سطح محلی و منطقهای نیز با فرکانس بهروزرسانی بسیار متفاوت اجرا میشوند که اغلب نه تنها به استراتژی برنامهریزی شهری محلی، بلکه به در دسترس بودن منابع انسانی و اقتصادی برای تکمیل فرآیند بستگی دارد. .
به دلیل این هزینهها، یافتن راهحلهای «ارزان» جایگزین یا اضافی برای فرآیند بهروزرسانی و طبقهبندی کاربری زمین سودمند خواهد بود. به عبارت دیگر، ما می خواهیم امکان بهره برداری از مجموعه داده هایی را که باز و/یا رایگان هستند و از تولید یا به روز رسانی مجموعه داده های گران قیمت دیگر مانند نقشه های موضوعی CORINE پشتیبانی می کنند را بررسی کنیم. در این مقاله، ما به صورت تجربی فرضیه خود را با استخراج کاربری زمین شهری از دادههای مکانی باز مرتبط، آزمایش میکنیم.
محبوبترین و جامعترین منبع در به اصطلاح وب جغرافیایی، احتمالاً OpenStreetMap (OSM؛ رجوع کنید به http://www.openstreetmap.org/ )، مجموعه دادههای فضایی رایگان، قابل ویرایش و تولید شده توسط کاربر است که به نامهای دیگر نیز شناخته میشود. ویکی پدیای نقشه ها OpenStreetMap شامل یک پایگاه دانش فضایی بزرگ است که به طور فزاینده ای از طریق تلاش های داوطلبانه اطلاعات جغرافیایی (VGI [ 14 ]) جمع آوری و مدیریت می شود، به عنوان مثال ، از طریق تلاش های مشارکتی که از یک شهروند دانشمند یا رویکرد جمع سپاری [ 15] پیروی می کند.]. این شامل یک توصیف بسیار غنی از زمین از نظر ویژگیهای فضایی (نقاط و چندضلعیها) است، که بیشتر توسط مجموعهای از جفتهای نیمه کنترل شده ارزش کلید (به عنوان مثال، امکانات رفاهی: رستوران یا اوقات فراغت: پارک ) توصیف میشوند . جامعه وب معنایی، با تجزیه و تحلیل استفاده از آن جفت های کلید-مقدار، LinkedGeoData (LGD [ 16 ]) را با نگاشت خصوصیات OSM در یک هستی شناسی و انتشار مجدد مجموعه داده OSM به عنوان داده های پیوندی ایجاد کرد [ 17 ].
ادامه مقاله به شرح زیر است: بخش 2 آماده سازی و پیش پردازش داده ها را نشان می دهد. بخش 3 روش شناسی دنبال شده در آزمایش ها را شرح می دهد. بخش 4 ، بخش 5 و بخش 6 نتایج تجربی ما را با یک بحث مفصل در بخش 7 ارائه می کند . هدف بخش 8 مقایسه یافته های ما با رویکردهای پیشرفته است. در نهایت، در بخش 9 ، ما برخی از نتایج را بیان می کنیم.
2. آماده سازی داده ها
در این بخش، ترکیبی از انتخابهای دستی و رویکردهای خودکار را که در آزمایشهای خود انجام میدهیم، نشان میدهیم. ما انتخاب و خصوصیات فضایی چهار منطقه شهری را توضیح میدهیم، و سپس، برای درک بهتر بخشهای زیر، جزئیاتی در مورد متغیرهای ورودی و خروجی آزمایشهای طبقهبندی خود ارائه میدهیم.
2.1. تفکیک فضایی مناطق منتخب شهری
تفکیک فضایی و همچنین توصیف فضایی مناطق شهری چهار شهر منتخب باید یکسان باشد تا کلیت رویکرد ما آزمایش شود. برای ارائه یک وضوح فضایی معقول و یکنواخت، ما یک شبکه منظم از سلولهای مربعی را برای تقسیم هر فضای شهری اتخاذ میکنیم.
برای داشتن وسعت زمین قابل مقایسه در شهرهای مختلف، مساحتی معادل 625 کیلومتر مربع را برای هر شهر انتخاب می کنیم. بنابراین شبکه از 10000 سلول مربع 250 متری تشکیل شده است. این منطقه هم کل کلان شهر و هم روستاها و اراضی اطراف را شامل می شود. همانطور که در ادامه توضیح داده شد، آن شبکههای شهری در آزمایشهای ما به عنوان یک مرجع و توصیف فضایی یکنواخت برای مجموعه دادههای ورودی و خروجی استفاده میشوند. به عبارت دیگر، هر شهر 10000 نمونه برای آموزش و آزمایش طبقهبندی کاربری اراضی شهری ارائه میکند.
2.2. پیش پردازش داده های CORINE
اطلاعات CORINE به عنوان داده های شطرنجی برای کل قلمرو اروپا ارائه می شود. بنابراین، ما باید (1) روی شهرهای انتخاب شده تمرکز کنیم و (2) اطلاعات CORINE را بر روی شبکه های شهر ارائه دهیم. هر دو فعالیت را می توان از طریق استفاده از یک GIS مانند QGIS پیاده سازی کرد.
فعالیت قبلی با استخراج بخش جغرافیایی از تصویر شطرنجی CORINE در سراسر اروپا، با استفاده از جعبه مرزی شبکههای شهر تحقق مییابد. فعالیت دوم یک عملیات تقاطع بین لایه CORINE و شبکه شهری را اعمال می کند. نتیجه یک لایه برداری است که برای هر سلول شبکه ای شهر، ترکیب آن را با توجه به طبقه بندی CORINE مشخص می کند. به عنوان مثال، یک سلول می تواند ترکیبی از 60٪ منطقه مسکونی متراکم (رده 111، بافت شهری پیوسته)، 15٪ خیابان ها (رده 122، شبکه های جاده ای و ریلی و زمین های مرتبط) و 25٪ پارک (رده 141، مناطق سبز شهری باشد. ). به دلیل مقیاس نسبتاً کوچک شبکه سلولی، ما اطلاعات کاربری زمین را با در نظر گرفتن استفاده از زمین غالب برای هر سلول شبکه ساده می کنیم .، دسته CORINE که بیشترین سهم از مساحت سلول را پوشش می دهد (در مثال بالا، آن سلول دارای رده 111 به عنوان کاربری غالب زمین است، زیرا 60٪ از سطح سلول را نشان می دهد).
مقولههای کاربری زمین CORINE با یک طبقهبندی چند سطحی کاملاً دقیق شامل بیش از 40 کلاس در عمیقترین سطح سلسله مراتب توصیف میشوند [ 13 ]. با این حال، برای هدف آزمایشهای طبقهبندی ما، ترجیح میدهیم تعداد کلاسهای خروجی مورد انتظار را با توجه به دستههای اصلی بیش از 40 CORINE کاهش دهیم. در واقع، معمولاً الگوریتمهای طبقهبندی، مسئله چند طبقهای را بهعنوان مسائل طبقهبندی باینری متعدد مدیریت میکنند: با استفاده از رویکرد یک در برابر یک، k ( k – 1 ) / 2ک(ک–1)/2طبقهبندیکنندههای باینری آموزش داده میشوند، که k تعداد کلاسها است ( برای طبقهبندی چند کلاسه SVM رجوع کنید به [ 18 ]). انتخاب دسته بندی کاربری مناسب به شرح زیر انجام می شود.
با توجه به اینکه هر سلول با بردار درصدهای متعلق به هر کاربری توصیف میشود، ما خوشهبندی K-means [ 19 ] را روی این بردارها انجام میدهیم تا بفهمیم چگونه این مقادیر به طور طبیعی با هم گروهبندی میشوند و بنابراین، کدام نوع کاربریها میتوانند کنار هم قرار گیرد. ما خوشهبندی را در همه شهرها تکرار میکنیم و نتایج قابل مقایسه را هم از نظر تعداد خوشه (همگرایی در k = 5) و هم از نظر ترکیب خوشه به دست میآوریم. بنابراین میتوان این خوشهبندی را قوی، کلی و مناسب برای توصیف محیط شهری دانست.
با تجزیه و تحلیل ترکیب خوشههای حاصل از نظر کاربریها، متوجه میشویم که هر خوشه با مجموعهای از کاربریهای زمین مشخص میشود، که میتوانیم توضیح معناداری در مورد آن ارائه دهیم: خوشه 1 مناطق مسکونی متراکم را شناسایی میکند (مطابق با CORINE رده 111)، خوشه 2 مناطق مسکونی پراکنده (رده 112)، خوشه 3 مناطق صنعتی و تجاری (رده های 12x و 13x)، خوشه 4 مناطق کشاورزی (رده های 2xx) و خوشه 5 پارک ها و مناطق طبیعی (رده ها) 14x، 3xx، 4xx و 5xx).
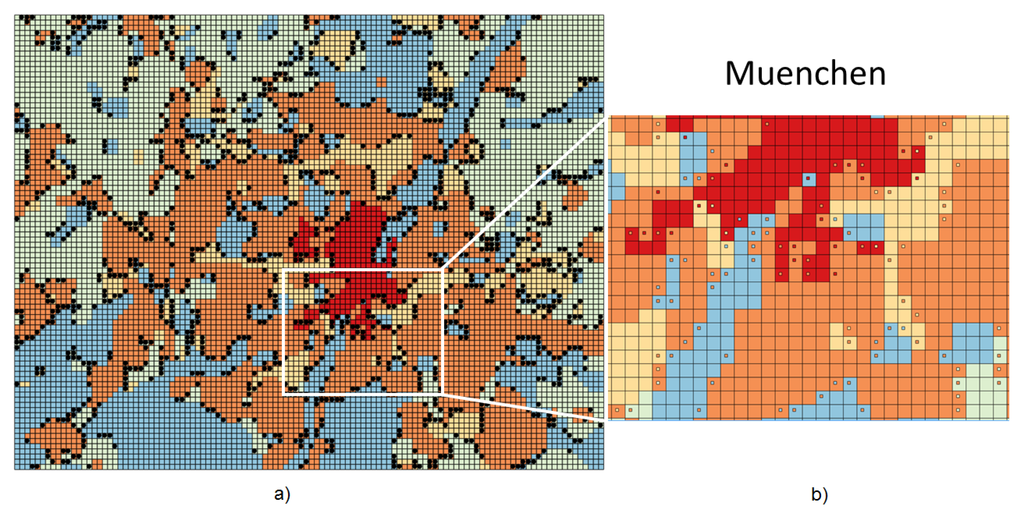
در نتیجه این مرحله، تصمیم میگیریم دستههای CORINE را که مشخصه خوشهها هستند به عنوان طبقهبندی خروجی خود گروه بندی کنیم. سلول های شبکه شهرهای انتخاب شده با در نظر گرفتن کاربری غالب آنها (همانطور که در بالا توضیح داده شد) به آن پنج طبقه نگاشت می شوند. توزیع سلول در پنج کلاس برای میلان، بروکسل، مونیخ و بارسلونا در شکل 1 نشان داده شده است .
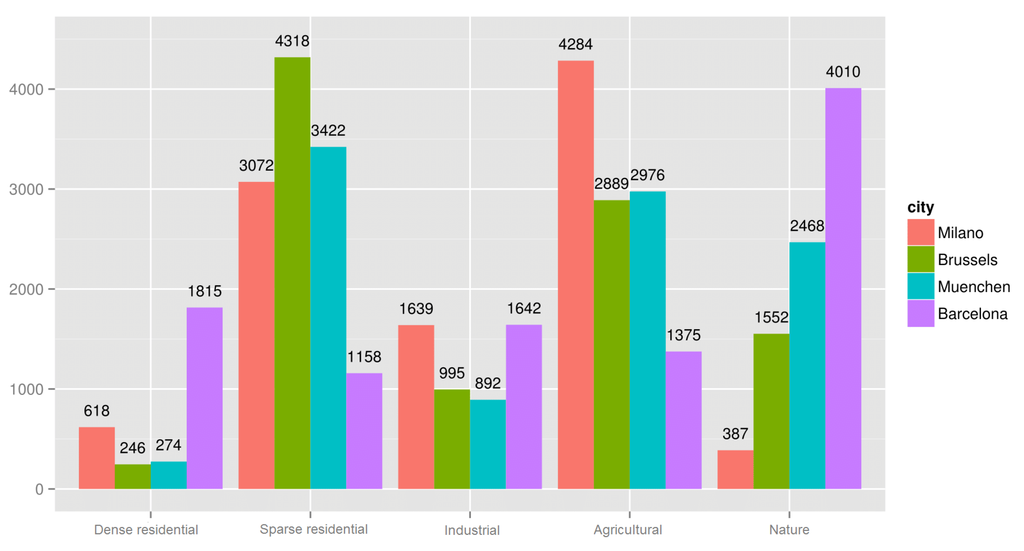
شکل 1. توزیع سلولی در شهرهای انتخاب شده (2013).
در حالی که ما سعی کردیم طبقات را تا حد امکان متعادل از نظر کاردینالیته تعریف کنیم، با مشاهده شکل 1 ، مشهود است که شهرهای ما تفاوت های واضحی را نشان می دهند. این نشان دهنده ساختار و ماهیت ذاتی یک شهر و اطراف آن است: به عنوان مثال، منطقه بارسلون دارای زمین های طبیعی زیادی است (طبقه “طبیعت”)، در حالی که منطقه میلان فاقد این طبقه است و سرشار از زمین های زراعی و مزارع برنج است (” کشاورزی»).
2.3. پیش پردازش داده های مکانی باز پیوند داده شده
به دلیل پوشش جغرافیایی بسیار گسترده، و همچنین وضوح فضایی متوسط، ما OpenStreetMap/LinkedGeoData را به عنوان منبع متغیرهای اطلاعات جغرافیایی خود انتخاب می کنیم تا به عنوان پیش بینی کننده در آزمایش های طبقه بندی استفاده شوند.
به منظور مشخص کردن سلولهای شبکه فضایی با دادههای OSM/LGD، اطلاعات کیفی و مکانی را به مجموعهای از متغیرهای کمی تبدیل میکنیم. برای این منظور، ابتدا مجموعه ای از 50 دسته POI را انتخاب می کنیم که می توانند منظر شهری را مشخص کنند. فهرست 1 فهرست کاملی از مفاهیم هستی شناسی LGD انتخاب شده مورد استفاده در آزمایشات ما را گزارش می دهد. سپس، برای هر دسته POI، یک متغیر عددی ایجاد می کنیم که شبکه های سلولی را توصیف می کند.
ما باید هر سلول شبکه را از نظر محیط اطرافش توصیف کنیم. در ابتدا، ما فکر کردیم که از چگالی POI به عنوان یک معیار کمی استفاده کنیم، اما به دلیل وضوح فضایی بسیار متوسط، این یک بعد نامناسب بود. بنابراین، ما یک روش متداول از تفکر و تحلیل فضای شهری را اتخاذ کردیم، به عنوان مثال در تجارت املاک: هنگام انتخاب محل خرید یا اجاره خانه، معمولاً فاصله تا نزدیکترین مغازه ها، حمل و نقل عمومی، مدرسه و غیره را ارزیابی می کنیم .
فهرست 1. دستههای نقطه مورد علاقه (POI) از LinkedGeoData مورد استفاده در آزمایشهای ما. پیشوند lgdo: فضای نام هستی شناسی LinkedGeoData را مخفف می کند.
| lgdo: اثر هنری | lgdo: پزشکان | lgdo: بیمارستان | lgdo: پارکینگ | lgdo: رستوران |
| lgdo: جاذبه | lgdo: آب آشامیدنی | lgdo: هتل | lgdo: داروخانه | lgdo: مدرسه |
| lgdo: بانک | lgdo: EmergencyThing | lgdo: مهدکودک | lgdo: مکان عبادت | lgdo: SportThing |
| lgdo: بار | lgdo: مزرعه | lgdo: کیوسک | lgdo: پلیس | lgdo: سوپرمارکت |
| lgdo: پارکینگ دوچرخه | lgdo: فست فود | lgdo: کتابخانه | lgdo: PostOffice | lgdo: استخر شنا |
| lgdo: کتابفروشی | lgdo: چشمه | lgdo: بازار | lgdo: PowerThing | lgdo: تاکسی |
| lgdo: BusStop | lgdo: FuelStation | lgdo: موزه | lgdo: میخانه | lgdo: تئاتر |
| lgdo: سینما | lgdo: مبلمان | lgdo: روزنامه فروشی | lgdo: PublicBuilding | lgdo: اطلاعات گردشگری |
| lgdo: لباس | lgdo: ورزشگاه | lgdo: کلوپ شبانه | lgdo: Public TransportThing | lgdo: دانشگاه |
| lgdo: فروشگاه بزرگ | lgdo: HistoricThing | lgdo: پارک | lgdo: ایستگاه راه آهن | lgdo: WaterwayThing |
فهرست 2. الگویی برای جستارهای GeoSPARQL از طریق LinkedGeoData برای بدست آوردن فاصله از یک سلول شبکه تا نزدیکترین نقطه نقطه از یک دسته معین.
PREFIX lgdm: < http://linkedgeodata.org/meta/ > پیشوند geom: < http://geovocab.org/geometry# > PREFIX ogc: < http://www.opengis.net/ont/geosparql# > SELECT ?mydistance # نزدیکترین فاصله را انتخاب کنید جایی که { ?poi a @@ POI_CATEGORY@ @, lgdm:Node ; # POI های متعلق به یک دسته خاص را دریافت کنید geom:geometry [ ogc:asWKT ?wkt ]. # نمایش فضایی POI را دریافت کنید BIND ( bif:st_point(@@ LONGITUDE@ @, @@ LATITUDE@ @) AS ?mypoint ) # مرکز سلول شبکه یک نقطه با مختصات است BIND ( bif:st_distance(?wkt, ?mypoint) AS ?mydistance ) # فاصله بین POI و سلول شبکه را محاسبه کنید FILTER ( ?فاصله من < @@ MAX_DISTANCE@ @ ) # فقط POI را در یک محدوده معین دریافت کنید (مثلاً حداکثر 25 کیلومتر) } ORDER BY ASC(?mydistance) # نتیجه سفارش بر اساس مسافت LIMIT 1 # اولین (نزدیکترین) را بگیرید |
در نتیجه، هر سلول با 50 بعد کمی توصیف میشود، یکی برای هر دسته POI، که نشاندهنده فاصله مرکز سلول تا نزدیکترین POI یک دسته معین است. برای محاسبه این ابعاد، بهجای جستجو در OpenStreetMap، از نسخه حاشیهنویسی معنایی LinkedGeoData استفاده کردیم که به طور خودکار جفتهای کلید-مقدار مختلف OSM را در مفاهیم LGD فهرست 1 ترسیم میکند . پرس و جو برای LinkedGeoData از الگوی پرس و جو GeoSPARQL [ 20 ] نشان داده شده در فهرست 2 پیروی می کند . با 50 دسته POI و چهار شهر اروپایی، که هر کدام با 10000 سلول، در مجموع، دو میلیون پرس و جو را برای استخراج پیش بینی کننده های طبقه بندی اجرا می کنیم.
3. آزمایش های مقدماتی طبقه بندی کاربری زمین
آزمایشهای ما برای آموزش مدلهای پیشبینی طراحی شدهاند که با در نظر گرفتن متغیرهای پیشبینی ورودی مشتقشده از مجموعه داده POI LinkedGeoData، قادر به پیشبینی کاربری زمین شهری هستند. به طور خاص، از آنجایی که CORINE یک طبقه بندی است، ما با یک مشکل طبقه بندی مواجه هستیم، به این معنا که می خواهیم محیط شهری را بر اساس کاربری زمین آن طبقه بندی کنیم.
چندین الگوریتم طبقهبندی وجود دارد، و ما تعدادی از آنها را آزمایش کردیم – طبقهبندیکنندههای آماری خطی، درجه دوم و لجستیک [ 21 ] و جنگلهای تصادفی، شبکههای عصبی و ماشین بردار پشتیبان (SVM) تکنیکهای یادگیری ماشین نظارت شده [ 22 ] – برای درک بهترین تناسب ممکن. برای حل مشکل ما، مشابه [ 23 ] برای پیش بینی ویژگی تصاویر سنجش از دور. با این حال، برخلاف آن کار، در مورد ما، مشاهده کردیم که عملکرد طبقهبندیکنندههای آماری ساده با تکنیکهای پیچیدهتر یادگیری ماشین نظارتشده قابل مقایسه نیست و بهویژه، SVM [24] بهترین نتایج را به دست آورد.
در بخش های بعدی، ما فقط نتایج به دست آمده با استفاده از SVM را نشان می دهیم. طبقهبندیکنندهها با اعتبارسنجی متقاطع 10 برابری آموزش داده شدند و پارامترهای آن با اصطلاح بهینهسازی جستجوی شبکه تنظیم شدند [ 25 ]. بهینه سازی تلاش می کند تا حساسیت هر کلاس را به حداکثر برساند و تفاوت بین کلاس ها را به حداقل برساند. ارزیابی آزمایشهای ما ( ر.ک. بخش 4 ، بخش 5 و بخش 6 ) از نظر دقت طبقهبندی کلی، حساسیت و ویژگی کلاسهای خروجی مختلف، ماتریس سردرگمی و نقشههای خطا ارائه شده است .
آزمایشهای ما بهصورت مجموعهای از مراحل متوالی به شرح زیر طراحی شدهاند: ابتدا، کاربری هر شهر را بهطور جداگانه طبقهبندی میکنیم، مدلی را برای هر شهر آموزش میدهیم و دادههای دیده نشده همان شهر را پیشبینی میکنیم (انتخاب مدل خاص شهر). سپس، روششناسی خود را با ایجاد یک مدل واحد مناسب برای پیشبینی چندین شهر تعمیم میدهیم و با استفاده از دانش قبلی در مورد همه شهرهای درگیر آموزش میدهیم (انتخاب مدل بین شهری با دانش پیشزمینه). در نهایت، با پیشبینی یک شهر با استفاده از مدلهایی که با استفاده از چندین شهر مختلف آموزش داده شدهاند، مدل خود را حتی عمومیتر میکنیم، یعنی بدون هیچ دانش قبلی در مورد شهری که باید پیشبینی شود (انتخاب مدل بین شهری بدون دانش پسزمینه).
تمام مطالب مربوط به پروتکل آزمایشی ما (مجموعه داده ها، پرس و جوها، اسکریپت ها، تجسم ها) در وب سایت همراه این مقاله به آدرس http://swa.cefriel.it/geo/ijgi.html در دسترس است .
4. انتخاب مدل خاص شهر
با فرض اینکه هر منطقه شهری ویژگی های متمایز خود را دارد، ما تصمیم گرفتیم آزمایش های خود را با تجزیه و تحلیل هر شهر به طور جداگانه آغاز کنیم تا مدلی بسازیم که بتواند هر الگوی شهری خاص را توصیف کند.
ما با استفاده از الگوریتم SVM که با بهترین پارامترهای کشف شده در مرحله بهینه سازی جستجوی شبکه ای (همانطور که در بخش 3 توضیح داده شده است ) با اعتبار دهی متقاطع 10 برابری تنظیم شده است، مدلی را برای هر یک از شهرهای انتخابی خود (میلانو، مونیخ، بارسلونا، بروکسل) آموزش دادیم. .
متداولترین و شهودیترین معیاری که برای ارزیابی عملکرد یک طبقهبندیکننده استفاده میشود، بدون شک دقت کلی است، که تعداد موارد طبقهبندی صحیح را بر تعداد کل موارد اندازهگیری میکند. مقادیر دقت کلی در جدول 1 نشان می دهد که SVM یک طبقه بندی قوی است، زیرا در هر چهار آزمایش مختلف بسیار خوب عمل می کند (مقادیر مشابه برای چهار شهر و همه دقت های بیشتر از 0.80). ضریب کاپا کوهن آمار دیگری است که برای اندازهگیری توافق بین ارزیابها برای اقلام طبقهبندی شده استفاده میشود، که عموماً یک معیار کاملاً قوی است، زیرا توافق تصادفی را در نظر میگیرد. ضرایب کاپا در جدول 1نشان می دهد که توافق قابل توجهی بین پیش بینی SVM و کاربری های واقعی زمین (مقادیر بیشتر از 0.74) وجود دارد.
بررسی عمیقتر نحوه رفتار طبقهبندیکنندهها در کلاسهای مختلف نیز میتواند با تجزیه و تحلیل شاخصهای حساسیت و ویژگی که در جدول 1 فهرست شده است انجام شود . این جدول وجود تفاوتهای بین طبقاتی را نشان میدهد که بیشتر در شاخص حساسیت مشهود است، که تنوع بالایی را با مقادیری از حداقل 0.75 تا حداکثر 0.90 نشان میدهد. در مقابل، ویژگی همیشه بسیار بالا و بیشتر از 0.90 است. این بدان معناست که از یک طرف، طبقهبندیکننده ما بهطور متوسط قادر است برخی از کلاسها را بهتر از سایرین پیشبینی کند، و از سوی دیگر، سلولهایی را که به یک کلاس معین تعلق ندارند، به درستی شناسایی میکند.
با نگاه کردن به جدول 1 از منظر بین شهری، اولاً مشاهده می کنیم که مقادیر حساسیت یک طبقه کاملاً با یکدیگر متفاوت است (به جز کلاس “مسکونی متراکم”) و ثانیاً بدترین پیش بینی شده کلاس همیشه یکسان نیست (کلاس «طبیعت» برای میلانو، کلاس «صنعتی» برای مونیخ و کلاسهای «مسکونی پراکنده» و «کشاورزی» برای بارسلونا). اگر به شکل 1 برگردیم، می توانیم یک مطابقت بین کاردینالیته پایین کلاس و مقدار کم حساسیت را مشاهده کنیم (برای مثال کلاس “Nature” در میلانو فقط 387 نمونه و حساسیت 0.75 دارد). اگرچه به نظر می رسد SVM یک الگوریتم بسیار قوی است، این رفتار به ما نشان می دهد که داشتن یک مجموعه داده نامتعادل می تواند تأثیر قابل توجهی بر قدرت پیش بینی مدل داشته باشد.

جدول 1. دقت کلی، ضریب کاپا، حساسیت و ویژگی پنج کلاس (مسکونی متراکم، مسکونی پراکنده، صنعتی، کشاورزی، طبیعت).
برای تجزیه و تحلیل بهتر این نتایج، ما تحقیقات خود را در مورد هر شهر عمیق می کنیم. به دلایل فضایی، از این پس، ما فقط ملاحظات خود را در مورد مونیخ، که شهری است که به طور متوسط، طبقه بندی کننده ما در آن بهتر عمل می کند (87٪ دقت کلی و بالاترین مقادیر حساسیت) و بروکسل، که شهری است، گزارش می کنیم. کمترین دقت کلی (82%). دو شهر دیگر رفتار بسیار مشابهی از خود نشان می دهند و خوانندگان علاقه مند می توانند تمام ماتریس های سردرگمی و نقشه های خطای چهار شهر را در وب سایت همراه بیابند.
با نگاهی به ماتریس های سردرگمی (نرمال شده) (به جدول 2 مراجعه کنید )، می توانیم نحوه انتشار خطاهای پیش بینی در تمام کلاس ها را تجزیه و تحلیل کنیم. به عنوان مثال، اگر به کلاس پیشبینیشده «مسکونی متراکم» در جدول 2 a نگاه کنیم، میبینیم که 88 درصد سلولها به درستی پیشبینی شدهاند و سلولهای باقیمانده عمدتاً بهصورت نادرست بهعنوان کلاس «مسکونی پراکنده» (7 درصد) برچسبگذاری شدهاند. ; این منطقی است، زیرا هر دو مناطق مسکونی را توصیف می کنند. پیشبینی کلاس «صنعتی» سختترین است، زیرا میزان صحت آن چندان بالا نیست (78%)، و خطا به طور مساوی بین سه کلاس دیگر پخش میشود (10 درصد کلاس «مسکونی پراکنده»، 6 درصد طبقه کشاورزی» و 5 درصد کلاس «طبیعت»).
بدترین شهر، بروکسل (جدول 2b)، رفتار مشابهی را نشان می دهد، به جز طبقات «مسکونی پراکنده» و «کشاورزی» که به ترتیب 11 درصد و 17 درصد بالاترین میزان طبقه بندی غلط را دارند.
علاوه بر این تجزیه و تحلیل کمی، ما یک بازرسی کیفی از خطاهای طبقهبندی را با رسم سلولهای طبقهبندی اشتباه مونیخ روی نقشه انجام دادیم. هدف ما شناسایی الگوهای ممکن در توزیع فضایی خطاها است. ما تأیید کردیم که همه شهرها رفتار یکسانی از خود نشان میدهند، هم از نظر جابجایی فضایی خطاها و هم از نظر نوع طبقهبندی اشتباه.
جدول 2. ماتریس سردرگمی مونیخ و بروکسل با پنج طبقه (مسکونی متراکم، مسکونی پراکنده، صنعتی، کشاورزی، طبیعت). مدل مخصوص شهر با 50 پیش بینی و همه مشاهدات. ( الف ) بهترین شهر: مونیخ. ( ب ) بدترین شهر: بروکسل.
( الف )
( ب )
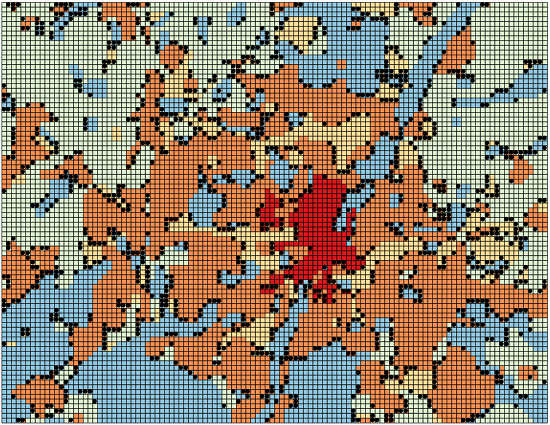
شکل 2 توزیع فضایی سلول های طبقه بندی نادرست در مونش را نشان می دهد. در شکل 2a ، خطاها به صورت سلول های سیاه رنگ در کل منطقه مونیخ نشان داده شده اند، که در غیر این صورت با توجه به کلاس های کاربری زمین به درستی پیش بینی شده رنگ می شوند. بدیهی است که تمام خطاها در “مرز” بین مناطق با کاربری همگن قرار دارند. شکل 2b در بخشی از نقشه بزرگنمایی می کند تا انواع خطاها را بهتر تجسم کند: رنگ مربع کوچک در مرکز هر سلول طبقه بندی اشتباه به صورت بصری کلاس پیش بینی شده (مناسب) را نشان می دهد و بنابراین می تواند با رنگ پس زمینه که نشان دهنده کلاس صحیح است مقایسه شود. .
متوجه می شویم که طبقه بندی کننده همیشه کلاس یک سلول را با کلاس یکی از سلول های مجاور خود اشتباه می کند. این در واقع معقول است: سلولهای موجود در آن «مرزها» به احتمال زیاد از کاربریهای مخلوط تشکیل شدهاند، در حالی که در تحلیل ما، ما فقط کاربری غالب زمین را در نظر گرفتیم (به بخش 2 مراجعه کنید ) . علاوه بر این، هر چه مناطق همگن کوچکتر و “کروی شکل” تر باشند، خطاها بیشتر می شود.

شکل 2. توزیع فضایی سلول های طبقه بندی نادرست در مونش. “مسکونی متراکم” = قرمز؛ “Sparse Residential” = نارنجی; “صنعتی” = زرد؛ «کشاورزی» = سبز؛ و “طبیعت” = آبی. ( الف ) سلول های طبقه بندی شده اشتباه (نقاط سیاه) در کل منطقه مونشن؛ ( ب ) انواع خطا در ناحیه بزرگنمایی شده.
5. انتخاب مدل بین شهری با مقداری دانش پیش زمینه
از آنجایی که ما نتایج رضایت بخشی را در پیش بینی کاربری اراضی یک شهر از نظر دقت کلی، ضریب کاپا کوهن و حساسیت به دست آوردیم، تحقیقات خود را ادامه می دهیم تا بررسی کنیم که آیا امکان ساخت یک مدل بین شهری واحد با استفاده از دانش پیشینه وجود دارد یا خیر. از هر شهر در نظر گرفته شده در تحلیل.
منطقی استفاده از دانش پیشینه این است که آن مدلهای طبقهبندی میتوانند برای بهروزرسانی نقشههای کاربری زمین، به عنوان مثال، برای شناسایی مناطق خاصی که کاربری زمین در آنها تغییر کرده باشد، برای تمرکز بر نگهداری دستی گران قیمت نقشههای کاربری زمین، تنها در جایی که در آن قرار دارد، استفاده شود. در واقع مورد نیاز است.
برای بررسی اینکه آیا مدل بین شهری قادر به پیشبینی طبقهبندی کاربری زمین سلولهای ناشناخته است، ما زیر مجموعههای مختلفی از مجموعه دادههای اصلی خود را ایجاد میکنیم: مجموعهای آموزشی از هر چهار شهر، که مدل با اعتبارسنجی متقاطع 10 برابری بر روی آن ساخته شده است. و یک مجموعه تست برای هر شهر برای بررسی دقت الگوریتم.
ما از دو استراتژی نمونه برداری برای بررسی میزان اطلاعات مورد نیاز در مرحله آموزش استفاده می کنیم: از یک طرف، ما 200 سلول برای هر کلاس و برای هر شهر نگه می داریم، مجموعه آموزشی از 4000 مشاهده (1000 مشاهده برای هر شهر) و سه تست را به دست می آوریم. مجموعههای 9000 واحدی هر کدام، یعنی تفاوت بین 10000 سلول هر شهر و 1000 سلول مورد استفاده در آموزش (متعادل در شهرها، متعادل بر اساس کلاسها (BCi.BCl)). از سوی دیگر، ما از یک سوم از 40000 سلول اصلی به عنوان مجموعه آموزشی استفاده می کنیم، با توجه به نسبت اصلی پنج کلاس در سراسر شهرها، و سلول های باقی مانده را به عنوان مجموعه آزمایشی (طبقه بندی شده در شهرها، طبقه بندی شده بر روی کلاس ها (SCi.SCl) ).
به طور طبیعی، منطقی است که انتظار داشته باشیم هرچه تعداد سلول های مورد استفاده در تمرین بیشتر باشد، مدل پیش بینی در سلول های ناشناخته قابل اعتمادتر است. انتظارات ما با نگاه کردن به جدول 3 تأیید می شود، که دقت کلی پیش بینی و ضریب کاپا کوهن را برای هر شهر و برای هر استراتژی نمونه گیری نشان می دهد: آنها همیشه در آزمایش SCi.SCl بالاتر هستند.
جدول 3. دقت کلی و ضرایب کاپا به دست آمده از یک مدل بین شهری با آموزش دانش پس زمینه (با استفاده از همه 50 پیش بینی کننده). BCi.BCl، متوازن بر شهرها، متوازن بر طبقات. SCi.SCl، طبقه بندی شده در شهرها، طبقه بندی شده بر روی طبقات.
علاوه بر این، در این مجموعه دوم از آزمایشها، طبقهبندی بهترین عملکرد را در مونیخ به دست میآورد، بنابراین ما با تجزیه و تحلیل ماتریس سردرگمی در جدول 4 a که دقت پیشبینی مدل را در همه موارد نشان میدهد، ملاحظات عمیقی را در مورد این شهر ارائه میکنیم. کلاس ها
جدول 4. ماتریس سردرگمی مونیخ و میلانو با پنج طبقه (مسکونی متراکم، مسکونی پراکنده، صنعتی، کشاورزی، طبیعت). نتیجه به دست آمده با یک مدل بین شهری با دانش پس زمینه نمونه برداری شده با SCi.SCl و 50 پیش بینی کننده. ( الف ) بهترین شهر: مونیخ. ( ب ) بدترین شهر: میلانو.
( الف )
( ب )
با نگاه کردن به عناصر مورب، که نشان دهنده درصد سلول های طبقه بندی شده به درستی هستند، می بینیم که مدل به خوبی مناطق کشاورزی را پیش بینی می کند (85%)، در حالی که در طبقه بندی سلول های متعلق به کلاس “مسکونی متراکم” دقت کمتری دارد. (71%). ما میتوانیم این نتیجه بدتر را با تجزیه و تحلیل نحوه انتشار خطاهای این کلاس در کلاسهای دیگر توجیه کنیم: 21٪ از سلولهایی که بهطور اشتباه به عنوان کلاس «مسکونی متراکم» پیشبینی شدهاند، متعلق به کلاس «مسکونی پراکنده» هستند، و باز هم، این معقول است.
علاوه بر این، جدول 4 b نتایج دقیق میلانو، شهری با کمترین دقت جهانی (75%) را نشان می دهد. نتایج مشابه هستند، با مقادیر در مورب کمی کمتر.
6. انتخاب مدل بین شهری بدون هیچ گونه دانش پیش زمینه
با توجه به نتایج رضایتبخش بهدستآمده در پیشبینی کاربری یک شهر با استفاده از مدلی که شامل برخی اطلاعات پیشزمینه در مورد خود شهر است، تصمیم میگیریم تکرارپذیری و عمومیت رویکرد خود را با پیشبینی شهری بدون دانش قبلی، یعنی بدون داده های مربوط به آن شهر در مرحله آموزش مورد استفاده قرار گرفت.
بنابراین، ما یک طبقهبندیکننده را با سه شهر از چهار شهر موجود آموزش میدهیم، و چهارمی را پیشبینی میکنیم، که در مرحله مدلسازی کاملاً کنار گذاشته میشود ( یعنی مونیخ را با استفاده از مدل آموزشدیده در میلان، بارسلونا و بروکسل پیشبینی میکنیم).
6.1. طبقه بندی با پنج سطح
ابتدا، ما یک مدل SVM را با استفاده از همه پیشبینیکنندهها (50 فاصله POI) و همه مشاهدات (30000 سلول، 10000 برای هر شهر مورد استفاده در آموزش) آموزش میدهیم. همانطور که در ادامه به تفصیل خواهیم دید، مقادیر دقت کلی، به دست آمده از پیش بینی تمام 10000 سلول شهر چهارم، بسیار پایین است و از 14٪ تا 40٪ متغیر است. این بدان معناست که طبقهبندیکننده قدرت پیشبینی ضعیفی دارد و میتوانست بیش از حد برازش داشته باشد (مدل به خوبی در مجموعه آزمایش تعمیم نمییابد).
برای پرداختن به این موضوع، آزمایشهای بیشتری را طراحی میکنیم که تعداد متغیرهای پیشبینیکننده و نمونههای آموزشی را کاهش میدهد.
با توجه به تعداد مشاهدات، ما سه استراتژی زیر نمونه برداری را اتخاذ می کنیم: (1) داده های خود را به روشی متعادل نمونه برداری می کنیم، به طور تصادفی 200 مشاهده را برای هر طبقه کاربری زمین و برای هر شهر انتخاب می کنیم (متوازن بر اساس شهرها و متوازن بر طبقات (BCi) BCl))، بنابراین با استفاده از 3000 مشاهدات از مجموعه اصلی. (2) ما یک سوم از 30000 مشاهدات اصلی را به روش طبقه بندی شده بر اساس طبقات کاربری زمین و شهرها (طبقه بندی شده در شهرها و طبقه بندی شده بر روی طبقات (SCi.SCl)) انتخاب می کنیم. (3) ما یک راه حل ترکیبی را اتخاذ می کنیم، یک سوم از 30000 مشاهدات اصلی را به روش طبقه بندی شده بر اساس طبقات و به روشی متعادل با توجه به شهرها (متوازن بر روی شهرها و طبقه بندی شده بر اساس طبقات (BCi.SCl)) نمونه برداری می کنیم. ما آن راه حل های مختلف را آزمایش می کنیم تا با مسائل شناسایی شده در آزمایش شهر واحد روبرو شویم (cf . بخش 4 ) در مورد تأثیر کاردینالیته کلاس های مورد استفاده در مجموعه آموزشی بر نتایج ارزیابی (هرچه کاردینالیته کمتر باشد، شاخص های عملکرد کمتر است).
با توجه به انتخاب متغیر، ما همه پیشبینیکنندهها را بر حسب به دست آوردن اطلاعاتشان، که بر اساس آنتروپی شانون [ 26 ] محاسبه میشود، رتبهبندی میکنیم، که ناهمگونی دادهها را با توجه به طبقات کاربری زمین اندازهگیری میکند. سپس، پنج متغیر برتر و ۱۱ متغیر برتر را بر اساس ناپیوستگیهای آشکار در مقادیر کسب اطلاعات انتخاب میکنیم. هدف این روش تنها انتخاب آموزندهترین پیشبینیکنندهها، اجتناب از برازش بیش از حد مدل است.
متغیرهای انتخابی که در فهرست 3 فهرست شدهاند، نشاندهنده فواصل تا نزدیکترین POI دستههای زیر هستند: امکانات عمومی (مدرسهها، داروخانهها و بانکها)، حملونقل (ایستگاههای اتوبوس، راهآهن و جایگاههای سوخت) و امکانات رفاهی (رستورانها، سینماها و مغازهها) .
شکل 3 توزیع پنج متغیر برتر را برای هر شهر نشان می دهد: در واقع، به نظر می رسد که آن فواصل خاص POI تفاوت مربوطه را بین چهار شهر نشان نمی دهد. این شباهت می تواند نشان دهد که یک مدل بین شهری ساخته شده بر روی این پنج پیش بینی کننده می تواند الگوهای شهرهای مختلف را به طور مناسب تری توصیف کند.
فهرست 3. رتبه بندی پیش بینی کننده ها با توجه به به دست آوردن اطلاعات. پیشوند lgdo: فضای نام هستی شناسی LinkedGeoData را مخفف می کند.
| 1. lgdo: داروخانه | 7. lgdo: رستوران |
| 2. lgdo: بانک | 8. lgdo: مدرسه |
| 3. lgdo: BusStop | 9. lgdo: FuelStation |
| 4. lgdo: Railway Station} | 10. lgdo: BookShop} |
| 5. lgdo: سوپرمارکت} | 11. lgdo: سینما} |
| 6. lgdo: PublicTransportThing} |
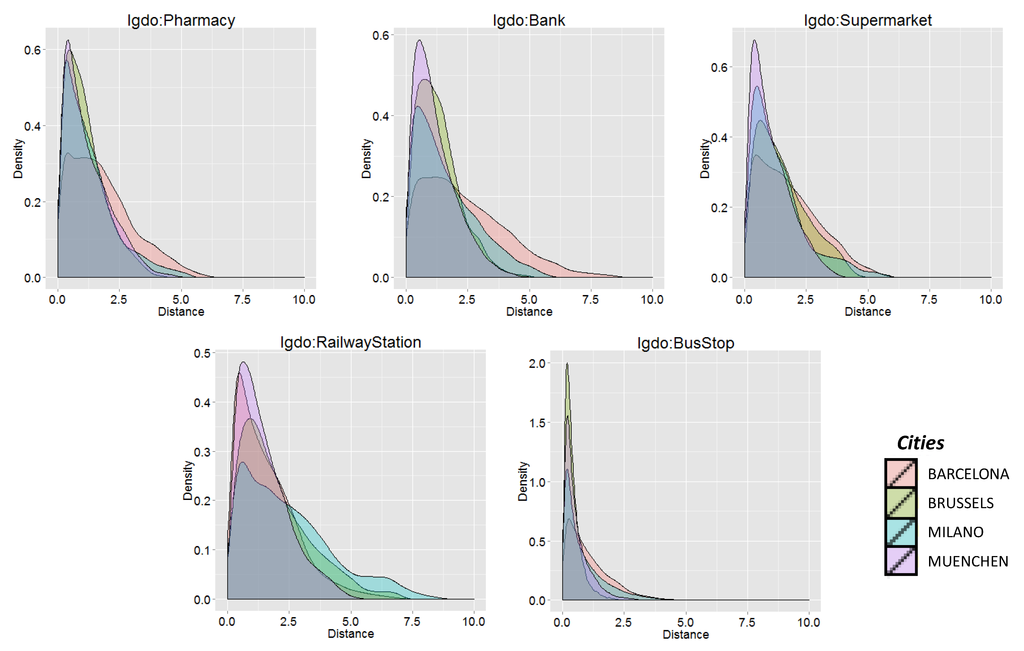
شکل 3. توزیع در چهار شهر از پنج پیش بینی رتبه برتر، با توجه به کسب اطلاعات آنها.
جدول 5. دقت کلی به دست آمده توسط چندین مدل آموزش دیده با تعداد متفاوت پیش بینی کننده ها و مشاهدات.
همه آزمونهای انجامشده، با تغییر تعداد پیشبینیکنندهها و روشهای نمونهگیری، در جدول 5 نشان داده شدهاند . به طور کلی، مقادیر دقت کلی چندان هیجان انگیز نیستند (هیچ مقادیر بالاتر از 50٪) و تمایل کلی این است که هرچه تعداد پیش بینی ها کمتر باشد، دقت کلی بالاتر است. ضرایب کاپا کوهن نیز از همین گرایش پیروی می کند.
بهترین نتایج بهطور متوسط با استفاده از روشهای نمونهگیری طبقهای (BCi.SCl و SCi.SCl) با پنج پیشبینیکننده به دست میآید. با نگاهی به جدول از منظر بین شهری، میتوان مشاهده کرد که یک بار دیگر، شهر با بهترین نتایج مونیخ است (50 درصد دقت با پنج پیشبینیکننده و نمونهبرداری SCi.SCl)، و شهری با بدترین نتایج، شهر مونیخ است. بارسلونا که به حداکثر دقت 39 درصد می رسد.
ماتریس سردرگمی برای مونیخ ( جدول 6 را ببینیدالف) حاصل از طبقهبندیکننده آموزشدیده با پنج پیشبینیکننده و با نمونهگیری طبقهبندیشده در هر دو کلاس و شهرها (SCi.SCl) ملاحظاتی را که قبلاً در آزمایشهای قبلی مورد بحث قرار گرفت، تقویت میکند. خطای طبقهبندی اشتباه بین کلاس «مسکونی متراکم» و کلاس «مسکونی پراکنده» حتی واضحتر است (۲۰ درصد سلولها بهدرستی بهعنوان کلاس «مسکونی متراکم» طبقهبندی شدهاند و ۶۴ درصد به اشتباه بهعنوان کلاس «مسکونی پراکنده» برچسبگذاری شدهاند)، و همچنین مشکلات در پیشبینی طبقه «مسکونی صنعتی» (خطاهای بالاتر بین طبقات «مسکونی پراکنده»، «کشاورزی» و «طبیعت» پخش میشود). ماتریس سردرگمی همچنین خطاهای طبقهبندی اشتباه مربوطه را بین کلاسهای «کشاورزی» و «طبیعت» برجسته میکند. با این حال، این معقول است.
در مورد بارسلونا (نگاه کنید به جدول 6 ب)، “مسکونی متراکم” و “طبیعت” بهترین طبقات پیش بینی شده هستند، در حالی که تمایز بین سه طبقه دیگر به درستی مدل سازی نشده است، که مشکلات را در تشخیص این نوع کاربری ها نشان می دهد.
از این نتایج، بدیهی است که آموزش طبقهبندیکننده برای پیشبینی کاربری اراضی شهری، بدون دانش قبلی در مورد خود شهر، دشوار است. در واقع، نتایج نشان داده شده در بخش 5(مدل آموزش داده شده با داده های دریافتی از همه شهرها) بسیار بهتر هستند، حتی اگر اطلاعات پیش زمینه کمی به مرحله آموزش داده شود. این می تواند این فرضیه را تقویت کند که هر شهر ویژگی های خاص و الگوهای ذاتی خود را دارد. بنابراین، یک مدل واحد نمی تواند به اندازه کافی کلی برای پیش بینی سایر محیط های شهری ناشناخته باشد. ما این ایده را با انجام یک آزمون فرضیه (“آزمون Z دو نسبت”) بیشتر بررسی می کنیم تا ارزیابی کنیم که آیا چهار شهر انتخاب شده احتمالاً معیارهای مشابهی را در پنج کلاس دریافت می کنند یا خیر. هدف ما این است که بررسی کنیم آیا تفاوت در مقادیر حساسیت و ویژگی بین شهرها از نظر آماری معنیدار است یا خیر.
جدول 6. ماتریس سردرگمی مونیخ و بارسلونا با پنج طبقه (مسکونی متراکم، مسکونی پراکنده، صنعتی، کشاورزی، طبیعت). نتیجه به دست آمده با یک مدل بین شهری با دانش پس زمینه نمونه برداری شده با SCi.SCl و 50 پیش بینی کننده. ( الف ) بهترین شهر: مونیخ. ( ب ) بدترین شهر: بارسلون.
( الف )
( ب )
جدول 7 مقادیر p آزمون فرضیه را ارائه می دهد که برای معیارهای حساسیت و ویژگی محاسبه شده است ( جدول 1 ) ، برای هر زوج شهر و برای هر طبقه. سلول های رنگی نتایجی را برجسته می کنند که از نظر آماری در سطح معنی داری 5 درصد معنی دار نیستند، بنابراین مواردی که فرضیه صفر را نمی توان رد کرد.
نتایج جدول 7 ثابت میکند که در اکثر موارد، تفاوت بین شهرها از نظر آماری معنیدار است (اکثر گلبولهای سفید در جدول)، به جز طبقه «مسکونی متراکم» که در آن تفاوت تقریباً همیشه از نظر آماری معنیدار نیست. از آنجایی که کلاس “مسکونی متراکم” با رده CORINE 111 “بافت شهری پیوسته” مطابقت دارد، همچنین، این نتیجه منطقی به نظر می رسد: آزمایش های ما بر مناطق شهری متمرکز شده اند، و در واقع، این نوع کاربری زمین برای شهرها معمولی تر است.
به طور خلاصه، دلیل محدودیت مدل آموزش داده شده بدون هیچ دانش قبلی احتمالاً در ویژگی های ذاتی هر شهر نهفته است، که آنقدر در مدل طبقه بندی منعکس می شود که نمی توان آنها را در مکان دیگری اعمال کرد، و در پیش بینی های موجود. ، که از مکانی به مکان دیگر قابلیت اطمینان متفاوتی دارند.
جدول 7. p- مقادیر آزمون های فرضیه در مورد تفاوت در حساسیت و ویژگی بین شهرها (“آزمون Z دو نسبت”). طبقه بندی پنج طبقه (مسکونی متراکم، مسکونی پراکنده، صنعتی، کشاورزی، طبیعت)؛ خاکستری تیره: در سطح معنی داری 5 درصد معنی دار نیست. خاکستری روشن: در سطح 10% معنی دار است اما در سطح معنی داری 5% نه.
6.2. طبقه بندی با دو سطح
با در نظر گرفتن نتایج بهدستآمده در طبقهبندی با پنج کلاس و در آزمون فرضیه جدول 7 ، در نهایت بررسی میکنیم که آیا میتوانیم با ساخت یک مدل طبقهبندی تک شهری تنها برای گونهشناسی کاربری اراضی مسکونی، نتایج بهتری به دست آوریم یا خیر. به عبارت دیگر، ما آزمایش می کنیم که آیا شباهت قوی تری بین شهرها را می توان با تغییر سطح دانه بندی طبقه بندی کاربری زمین پیدا کرد. به همین دلیل است که با ادغام کلاسهای «مسکونی متراکم» و «مسکونی پراکنده» و از سوی دیگر، طبقات باقیمانده (صنعتی/تجاری، کشاورزی و مناطق طبیعی)، یک طبقهبندی دو جملهای ایجاد میکنیم.
ما یک طبقهبندی کننده را با استفاده از استراتژی نمونهگیری SCi.SCl که در بخش قبل نشان داده شده است و پنج پیشبینیکننده برتر آموزش میدهیم. ما مقادیر بالایی از دقت کلی را برای همه شهرها به دست می آوریم (از 71٪ بروکسل تا 83٪ از مونیخ). جدول 8 ماتریس سردرگمی به دست آمده برای مونیخ را نشان می دهد. درصد سلولهایی که به درستی طبقهبندی شدهاند در هر دو کلاس بسیار بالا است (76٪ برای مسکونی و 88٪ برای غیر مسکونی).
جدول 8. ماتریس سردرگمی München با یک مدل دوجمله ای نمونه برداری شده با SCi.SCl و 5 پیش بینی کننده به دست آمده است.
اگر به شکل 4 نیز نگاه کنیم ، که توزیع فضایی سلولهای طبقهبندیشده اشتباه را نشان میدهد، میتوانیم متوجه شویم که بیشتر خطاها دوباره در “مرزهای” بین مناطق مسکونی (به رنگ خاکستری تیره) و مناطق طبیعی (به رنگ سفید) قرار دارند. سلول های آبی نشان دهنده سلول هایی هستند که به اشتباه به عنوان مناطق مسکونی طبقه بندی شده اند (24٪ در جدول 8 )، در حالی که سلول های سبز سلول های غیرمسکونی اشتباه پیش بینی شده هستند.
برای جمعبندی این سومین و آخرین مجموعه آزمایشها، با دو کلاس، با توجه به طبقهبندی پنج کلاس، پیشرفت زیادی به دست میآوریم. بنابراین این نتایج نکات ارائه شده توسط آزمون فرضیه و ملاحظات قبلی ما در مورد آن نتایج را تأیید می کند.
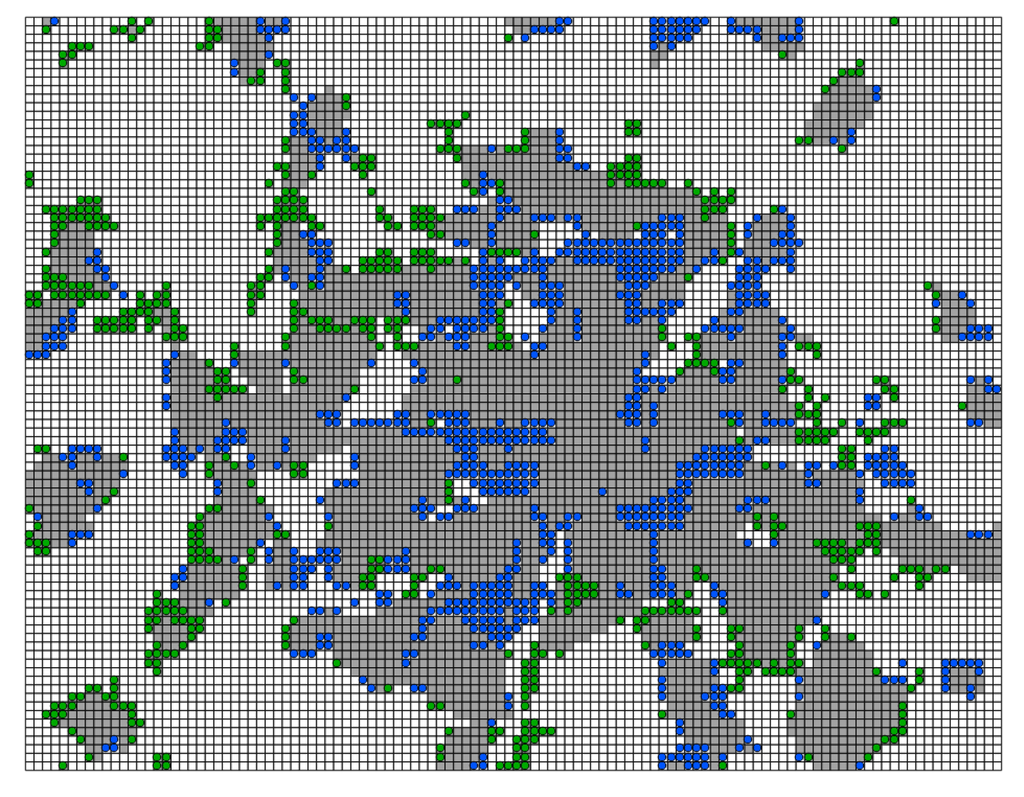
شکل 4. خطاهای طبقه بندی دوجمله ای در München (نمونه برداری با SCi.SCl و پنج پیش بینی کننده). خاکستری تیره نشان دهنده مناطق مسکونی است. نقاط آبی سلول هایی هستند که به اشتباه به عنوان مسکونی طبقه بندی می شوند. نقاط سبز سلول هایی هستند که به اشتباه به عنوان غیر مسکونی طبقه بندی می شوند.
7. بحث
آزمایشهای ما نتایج بسیار خوبی (دقت کلی همیشه بالاتر از 75٪) در پیشبینی کاربری اراضی یک شهر هنگام استفاده از طبقهبندیکنندهای که برخی از دانش پیشزمینه خود شهر را در مرحله آموزش آن در نظر میگیرد، نشان داد. بنابراین، ارزیابیهای کمی و کیفی ارائهشده در مقاله از فرضیه ما حمایت میکنند که دادههای مکانی باز مرتبط میتوانند با موفقیت در پشتیبانی از تولید یا بهروزرسانی منابع داده مکانی گران قیمت، مانند مجموعه داده کاربری زمین CORINE [13] استفاده شوند .]. کاربرد در چهار شهر مختلف اروپایی تکرارپذیری و اعتبار کلی روش شناسی ما را نشان داد، مشروط بر اینکه برخی اطلاعات پس زمینه از محیط شهری ارائه شود. میتوان ثابت کرد که راهحل ما برای نظارت و تشخیص تغییرات کاربری زمین مفید است: برای مثال، اگر مدلهای پیشبینی ما که پس از مدتی در همان منطقه شهری اعمال میشوند، پیشبینیهای کاربری متفاوتی را در مناطق محدود نشان میدهند، نقشههای CORINE. تجدید نظر فقط می تواند بر آن مناطق متمرکز شود. به این ترتیب، فرآیند به روز رسانی اطلاعات کاربری زمین می تواند به روشی کم هزینه تر و متناسب تر انجام شود.
نتایج پایینتر بهدستآمده در پیشبینی کاربری زمین شهری بدون هیچ گونه دانش پیشزمینهای از خود شهر، محدودیتهای روششناسی فعلی ما را نشان میدهد، حداقل هنگام استفاده از طبقهبندی پنج سطحی با تنظیمات تجربی نشاندادهشده. در واقع، ما هنگام استفاده از یک طبقهبندی کاربری دو سطحی سادهتر، با تمرکز بر پیشبینی مسکونی در مقابل، نتایج بهتری به دست آوردیم.. مناطق غیر مسکونی علاوه بر این، حرکت از یک طبقهبندی با سطوح انگشت شمار به طبقهبندی کامل CORINE (که شامل سلسله مراتبی بیش از 40 کلاس است) به بررسی بیشتر نیاز دارد. اولین آزمایش ما در آموزش مدلی از تمام کلاسهای CORINE در منطقه میلانو (که در این مقاله گزارش نشده است) منجر به حساسیتهای بالاتر از 70٪ فقط در دو کلاس مربوط به دستههایی با بالاترین کاردینالیته و در حساسیتهای نزدیک به 0٪ در منطقه شد. طبقات اقلیت، که در تعداد بسیار محدودی از سلول های شبکه غالب بودند.
این به این معنی است که برای نتیجهگیری در مورد امکانسنجی پیشبینی طبقهبندی کامل CORINE، مطالعات آینده باید شامل نمونههای بزرگتر و جامعتر باشد.
به نظر ما، دلیل محدودیتهای طرحشده مدلهای بدون دانش پیشزمینه، از یک سو، در ویژگیهای ذاتی هر شهر نهفته است: ویژگیهای خاص شهرهای مورد استفاده در مرحله آموزش به شدت در طبقهبندیکننده منعکس میشوند. که مدل پیش بینی می تواند برای استفاده در مکان دیگری نامناسب شود. از سوی دیگر، دلیل تفاوت مدلها را میتوان به اطلاعات جغرافیایی که ما به عنوان پیشبینیکننده استفاده میکردیم، یعنی فاصلهها تا نزدیکترین نقطه نقطه از دستههای خاص جستجو کرد. این فواصل بر روی دادههای مکانی باز مرتبط که در نهایت از OpenStreetMap میآیند، محاسبه شدند. زیرا دومی یک VGI است [ 14] ابتکار، تنوع در نتایج ما همچنین می تواند ناشی از ناهمگونی ذاتی تلاش های نقشه برداری داوطلبان OpenStreetMap در شهرهای انتخاب شده باشد. به عبارت دیگر، سطوح مختلف کامل بودن داده ها و قابلیت اطمینان از مکانی به مکان دیگر در OpenStreetMap می تواند در واقع علت اصلی تفاوت های شدید بین شهرها باشد که در طبقه بندی کننده های آموزش دیده منعکس شده است. معیارهای متعددی در ادبیات برای تجزیه و تحلیل “کیفیت” OpenStreetMap [ 27 ، 28 ] پیشنهاد شده است، و ما قصد داریم این اقدامات را در توسعه های آینده رویکرد ارائه شده در نظر بگیریم.
از جنبه مثبت، با توجه به تکامل اطلاعات کاربری زمین در طول زمان، OpenStreetMap در انعکاس پویایی واقعی یک مکان، هم در مکانهای شهری عمومی [29] و به ویژه در پاسخ به موقعیتهای اضطراری [ 30 ] موثر ثابت شده است. در واقع، انگیزههای نقشهبرداران برای مشارکت بلندمدت نشان میدهد که OpenStreetMap بهعنوان منبع اطلاعات جغرافیایی مرجع باقی میماند [ 31]]. علاوه بر این، در این مطالعه، ما به صورت دستی تنها زیرمجموعهای از دستههای POI موجود را برای ساخت متغیرهای پیشبینی کننده طبقهبندی خود انتخاب کردیم. این انتخاب میتواند مشکوک باشد و ما روی بهبود انتخاب POI کار خواهیم کرد تا بهترین پوشش ممکن را از همه انواع کاربریهای زمین داشته باشیم. به عنوان مثال، ما احتمالاً نیاز به انتخاب POI های اضافی خواهیم داشت که مناطق صنعتی/تجاری، کشاورزی و طبیعی یا سایر کاربری های خاص تر زمین را بهتر مشخص کنند.
در نهایت، کار آینده ما بر گسترش آزمایشهایمان برای مؤثرتر و قویتر کردن راهحل حاصل تمرکز خواهد کرد. یکی از گزینههای دستور کار تحقیقاتی ما ترکیب و تکمیل اطلاعات جغرافیایی از OpenStreetMap با منابع ناهمگون دیگر، مانند دادههای فعالیت تلفن است که اغلب به عنوان پیشبینیکننده کاربری زمین استفاده میشود.
8. مقایسه با رویکردهای پیشرفته
طبقه بندی کاربری زمین به دلیل تأثیرات آن در زندگی روزمره ما، به ویژه در زمینه طراحی محیط های شهری، موضوعی است که به طور گسترده در برنامه ریزی شهری، مهندسی محیط زیست و علوم زمین به طور کلی مورد بررسی قرار گرفته است. برای مثال، به خوبی شناخته شده است که چندین جنبه مختلف بر استفاده از زمین و تغییر آن در طول زمان تأثیر میگذارند، مانند عوامل اجتماعی-اقتصادی [ 32 ]، رفتارهای سفر [ 33 ] یا تعاملات با ذینفعان شهری [ 34 ].
هنگام پرداختن به چالشهای تحلیل تغییر کاربری زمین [ 35 ]، همچنین ارزش تمایز بین پوشش زمین، پوشش فیزیکی سطح زمین و کاربری زمین را دارد که انسانها از زمین برای چه استفاده میکنند. در واقع، بیشتر رویکردهای خودکار و نیمه خودکار که بر روی اطلاعات سنجش از دور کار میکنند، مانند تصاویر ماهوارهای، با هدف تعیین معیارهای منظر [ 36 ] و طبقهبندی پوشش زمین [ 37 ] هستند، زیرا آن منابع داده میتوانند تنها به تشخیص بصری کمک کنند. -تغییرات قابل مشاهده این مورد برای طبقهبندی CORINE اروپا [ 13 ] نیز صادق است که تحت یک پردازش طولانی، پیچیده و فقط تا حدی خودکار دادههای سنجش از دور قرار میگیرد.
از سوی دیگر، مردم نقش مرتبط فزایندهای با توجه به اطلاعات جغرافیایی به طور کلی بازی میکنند [ 14 ، 15 ]، به دلیل ظهور به اصطلاح وب جغرافیایی در دهه گذشته: پایگاه کاربر بزرگی در این مجموعه درگیر است. و مدیریت ابرداده های مکانی، به ویژه شبکه های جاده ای و POI، از جمله اطلاعات مربوط به برنامه ریزی شهری. به عنوان مثال، همچنین در زمینه پوشش زمین، ابتکاراتی مانند Geo-Wiki [ 38 ] از تلاشهای جمعسپاری و/یا علوم شهروندی برای بهبود دانش محیطی استفاده میکند.
همچنین به همین دلیل است که تعدادی از روشها، رویکردها و آزمایشها بر بهرهبرداری از منابع اطلاعاتی ناهمگن برای طبقهبندی کاربری اراضی متمرکز شدهاند. در بیشتر موارد، این منابع یا توسط انسان تولید میشوند یا از فعالیتهای روزمره آنها ناشی میشوند. نمونههای قابل توجه عبارتند از اطلاعات کاربری زمین مشتق شده از رسانههای اجتماعی (به عنوان مثال، توییتهای دارای برچسب جغرافیایی مانند [ 7 ])، فعالیت تلفن همراه (مانند الگوهای تماس خوشهای در [ 39 ]، خوشههای مکان برگرفته از الگوهای فعالیت در [ 8 ] و زمان جمعآوری شده است. سری هایی که هم الگوهای زمانی و هم حجم تماس را در [ 9 ] در نظر می گیرند، داده های انتقال و تحرک (به عنوان مثال، مجموعه داده های مسیر GPS، مانند [ 10 ]، یا داده های کارت هوشمند اتوبوس، مانند [ 40]])، و همچنین ترکیبی از منابع مختلف داده باز و سازمانی (مانند کار قبلی ما [ 41 ]).
آخرین، اما نه کم اهمیت، رویکرد ارائه شده در این مقاله اولین رویکردی نیست که از اطلاعات POI از OpenStreetMap استفاده می کند، که همچنین توسط [11] برای استخراج الگوهای کاربری زمین و توسط [ 12 ] برای شناسایی قطعات شهری استفاده می شود. با توجه به آن آثار، سهم اصلی ما در توصیف فضا با فاصله تا نزدیکترین نقطه نقطه از یک نوع معین، تکرارپذیری آزمایشها و وضوح فضایی کاملاً متوسط محیطهای شهری (در حد 250 متر) است. ) از جمله مناطق اطراف شهرها که کاربری های مخلوطی از زمین را نشان می دهند.
9. نتیجه گیری
در چند سال گذشته، افزایش دسترسی به دادههای مکانی باز مرتبط، راه را برای راهحلهای نوآورانه در حوزه شهر هوشمند هموار کرده است. در زمینه برنامه ریزی و نظارت شهری، انبوه داده های موجود امروز فرصتی برای معرفی نوآوری های افزایشی یا مخرب در فرآیندهای مدیریت داده های شهری است.
مطالعه ارائه شده در این مقاله در همین چارچوب است. پژوهش ما بر بهرهبرداری از منابع دادههای متنوع و ناهمگن برای نظارت بر کاربری زمین متمرکز است. به طور خاص، ما نشان دادیم که دادههای فضایی باز در واقع استفاده از قلمرو را منعکس میکند و بنابراین، میتواند اطلاعات ورودی اضافی و مرتبطی باشد که در برنامهریزی شهری مورد استفاده قرار میگیرد. به طور خاص، در این مقاله، ما یک رویکرد کشف دانش برای استخراج کاربری زمین شهری از دادههای باز مرتبط با ماهیت جغرافیایی پیشنهاد کردیم: مدلهای پیشبینیکننده آموزشدیده با اطلاعات جغرافیایی مرتبط با POIهای شهری برای طبقهبندی کاربری شهری بر اساس پنج مورد استفاده شدند. طبقه بندی سطح برگرفته از طبقه بندی CORINE اروپا.
منحصربهفرد بودن روش پیشنهادی ما در تکرار آزمایشهای ما در چهار شهر مختلف اروپایی است، بنابراین تکرارپذیری و عمومیت راهحل پیشنهادی را تضمین میکند. علاوه بر این، مطالعه ما تکرارپذیری را نیز تضمین میکند، زیرا ما با جزئیات آزمایشهای انجامشده و همچنین مجموعه دادههای بکار گرفته شده را که بهصورت آنلاین در دسترس هستند، توضیح دادیم.
یک مشارکت اصلی، بررسی سطح دانش پیشینه مورد نیاز به عنوان ورودی است. ما نشان دادیم که برای به دست آوردن نتایج طبقه بندی بهتر، ضروری است که در مدل اطلاعاتی در مورد شهر پیش بینی شود گنجانده شود. در واقع ما بهترین نتایج را با یک مدل خاص شهر به دست آوردیم که به 87٪ از دقت کلی رسید (آموزش الگوریتم در شهر برای پیش بینی) و با یک مدل بین شهری با دانش پس زمینه که منجر به دقت کلی تا 80٪ می شود. به طور کلی، ما مقادیر حساسیت متعادلی را در بین طبقات به دست آوردیم که قابل مقایسه و در بیشتر موارد بهتر از ادبیات قبلی هستند. با این حال، تحقیقات بیشتری مورد نیاز است تا روششناسی ما برای هر محیط شهری قابل اجرا باشد و آزمایشهای بیشتری برای کشف کاربریهای خاصتر زمین مورد نیاز است.
در حالی که ما ادعا نمی کنیم که روش های پیش بینی پیشنهادی می توانند برای تولید نقشه های کاربری دقیق زمین مورد استفاده قرار گیرند، ما معتقدیم که معرفی اطلاعات آشکارا در دسترس می تواند پشتیبانی معتبری را برای نظارت و به روز رسانی اطلاعات برنامه ریزی شهری، مانند نقشه های CORINE اروپا، ارائه دهد. در واقع، نظارت بر زمین در اروپا با ابتکار EAGLE در حال تجربه یک تجدید نظر اساسی در فرآیندها از نظر روشها و طبقهبندی است [ 6 ]. در این زمینه، راهحلهای نوآورانهای مانند راهحل ما، مبتنی بر استفاده از منابع مختلف اطلاعات جغرافیایی، میتواند کمک ارزشمندی ارائه دهد.
منابع
- سلینو، آی. کوتولاس، S. شهرهای هوشمند. IEEE Internet Compu. 2013 ، 17 ، 8-11. [ Google Scholar ] [ CrossRef ]
- یانوویچ، ک. شیدر، اس. پهله، ت. هارت، جی. معناشناسی جغرافیایی و دادههای مکانی-زمانی مرتبط – گذشته، حال و آینده. سمنت. وب 2012 ، 3 ، 321-332. [ Google Scholar ]
- همرلی، ج. ملاحظات سیاست عمومی برای نوآوری مبتنی بر داده. کامپیوتر 2013 ، 46 ، 25-31. [ Google Scholar ] [ CrossRef ]
- Talbot, D. داده های بزرگ از تلفن های ارزان قیمت. فناوری MIT Rev. 2013 , 116 , 50-54. [ Google Scholar ]
- مندل، ام. فراتر از کالاها و خدمات: افزایش (بدون اندازه گیری) اقتصاد مبتنی بر داده. پیش رفتن. موسسه سیاست گذاری 2012 ، 10 ، 1-14. [ Google Scholar ]
- آرنولد، اس. کوزترا، بی. بانکو، جی. اسمیت، جی. هازو، جی. بوک، ام. والکارسل سانز، ن. مفهوم EAGLE – چشم انداز یک چارچوب نظارت بر زمین اروپا در آینده. در مجموعه مقالات سی و سومین سمپوزیوم EARseL “به سوی افق 2020″، ماترا، ایتالیا، 3 تا 6 ژوئن 2013.
- فریاس مارتینز، وی. سوتو، وی. هوهوالد، اچ. Frias-Martinez، E. مشخص کردن مناظر شهری با استفاده از توییتهای جغرافیایی. در مجموعه مقالات کنفرانس بین المللی محاسبات اجتماعی 2012 (SocialCom) (حریم خصوصی، امنیت، ریسک و اعتماد (PASSAT))، آمستردام، هلند، 3 تا 5 سپتامبر 2012.
- Toole، JL; اولم، ام. گونزالس، ام سی؛ بائر، دی. استنباط کاربری زمین از فعالیت تلفن همراه. در مجموعه مقالات کارگاه بین المللی ACM SIGKDD در محاسبات شهری (UrbComp 2012)، پکن، چین، 12 اوت 2012.
- پی، تی. سوبولفسکی، اس. راتی، سی. شاو، اس ال. لی، تی. ژو، سی. بینشی جدید در طبقه بندی کاربری زمین بر اساس داده های تلفن همراه جمع آوری شده است. بین المللی جی. جئوگر. آگاه کردن. علمی 2014 ، 28 ، 1988-2007. [ Google Scholar ] [ CrossRef ]
- یوان، جی. ژنگ، ی. Xie, X. کشف مناطق با عملکردهای مختلف در یک شهر با استفاده از تحرک انسان و POI. در مجموعه مقالات هجدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، پکن، چین، 12 تا 16 اوت 2012.
- جوکار ارسنجانی، ج. هلبیچ، ام. باکیالله، م. هاگناور، جی. Zipf، A. به سمت نقشه برداری الگوهای کاربری زمین از اطلاعات جغرافیایی داوطلبانه. بین المللی جی. جئوگر. آگاه کردن. علمی 2013 ، 27 ، 2264-2278. [ Google Scholar ] [ CrossRef ]
- لانگ، ی. لیو، ایکس. شناسایی خودکار و مشخص کردن بسته ها (AICP) با نقشه خیابان باز و نقاط مورد علاقه. 2013. موجود به صورت آنلاین: http://arxiv.org/abs/1311.6165 (دسترسی در 25 ژوئن 2015).
- بوتنر، جی. کوزترا، بی. ماوچا، جی. Pataki, R. پیاده سازی و دستاوردهای CLC2006 ; گزارش فنی برای آژانس محیط زیست اروپا (EEA): کپنهاگ، دانمارک، 2012. [ Google Scholar ]
- Goodchild، MF Citizens به عنوان حسگر: دنیای جغرافیای داوطلبانه. ژئوژورنال 2007 ، 69 ، 211-221. [ Google Scholar ] [ CrossRef ]
- Goodchild، MF Spatial accuracy 2.0. در مجموعه مقالات هشتمین سمپوزیوم بین المللی ارزیابی دقت فضایی در منابع طبیعی و علوم محیطی، شانگهای، چین، 25-27 ژوئن 2008.
- استدلر، سی. لمان، جی. هافنر، ک. Auer, S. LinkedGeoData: هسته ای برای شبکه ای از داده های فضایی باز. سمنت. وب J. 2012 ، 3 ، 333-354. [ Google Scholar ]
- بیزر، سی. هیث، تی. برنرز-لی، تی. داده های مرتبط – داستان تا کنون. بین المللی ج. سمنت. وب اطلاعات سیستم 2009 ، 5 ، 1-22. [ Google Scholar ] [ CrossRef ]
- Duan، KB; Keerthi، S. بهترین روش SVM چند کلاسه کدام است؟ یک مطالعه تجربی. در سیستم های طبقه بندی کننده چندگانه ؛ Oza, N., Polikar, R., Kittler, J., Roli, F., Eds. یادداشت های سخنرانی در علوم کامپیوتر; Springer: برلین، آلمان، 2005; جلد 3541، ص 278–285. [ Google Scholar ]
- مک کوئین، جی. برخی روشها برای طبقهبندی و تحلیل مشاهدات چند متغیره. در مجموعه مقالات پنجمین سمپوزیوم برکلی در مورد آمار و احتمالات ریاضی، برکلی، کالیفرنیا، ایالات متحده آمریکا، 21 ژوئن تا 18 ژوئیه 1965.
- پری، م. Herring, J. OGC GeoSPARQL—یک زبان پرس و جوی جغرافیایی برای داده های RDF . گزارش فنی برای کنسرسیوم فضایی باز: Wayland، MA، ایالات متحده آمریکا، 2011. [ Google Scholar ]
- هستی، تی. طبشیرانی، ر. فریدمن، جی. عناصر یادگیری آماری . Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2009. [ Google Scholar ]
- Kotsiantis، SB; زهارکیس، آی. پینتلاس، پی. یادگیری ماشینی نظارت شده: مروری بر تکنیک های طبقه بندی. در کاربردهای نوظهور هوش مصنوعی در مهندسی کامپیوتر ; Maglogiannis, I., Karpouzis, K., Wallace, M., Soldatos, J., Eds. IOS Press: آمستردام، هلند، 2007; صص 3-24. [ Google Scholar ]
- وتساوایی، ر.ر. برایت، ای. وارون، سی. بودندرا، بی. چریادات، ع. Grasser، J. رویکردهای یادگیری ماشین برای طبقه بندی پوشش زمین شهری با وضوح بالا: یک مطالعه مقایسه ای. در مجموعه مقالات دومین کنفرانس بین المللی محاسبات برای تحقیقات و کاربردهای جغرافیایی، واشنگتن، دی سی، ایالات متحده آمریکا، 23 تا 25 مه 2011.
- Boser، BE; Guyon، IM; Vapnik، VN یک الگوریتم آموزشی برای طبقهبندیکننده حاشیه بهینه. در مجموعه مقالات پنجمین کارگاه سالانه نظریه یادگیری محاسباتی، پیتسبورگ، پنسیلوانیا، ایالات متحده آمریکا، 27-29 ژوئیه 1992.
- Hsu، CW; چانگ، سی سی; Lin, CJ راهنمای عملی برای پشتیبانی از طبقه بندی برداری . دانشگاه ملی تایوان: تایپه، تایوان، 2010. [ Google Scholar ]
- شانون، سی تئوری ریاضی ارتباطات. SIGMOBILE Mob. محاسبه کنید. اشتراک. Rev. 2001 , 5 , 3-55. [ Google Scholar ] [ CrossRef ]
- مونی، پی. کورکوران، پ. Winstanley، AC به سمت معیارهای کیفیت برای OpenStreetMap. در مجموعه مقالات هجدهمین کنفرانس بین المللی SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سن خوزه، کالیفرنیا، ایالات متحده آمریکا، 2 تا 5 نوامبر 2010.
- کسلر، سی. de Groot، RTA Trust به عنوان معیاری برای کیفیت اطلاعات جغرافیایی داوطلبانه در مورد OpenStreetMap. در علم اطلاعات جغرافیایی در قلب اروپا ; انتشارات بین المللی Springer: چم، سوئیس، 2013; ص 21-37. [ Google Scholar ]
- هریستوا، دی. کواترون، جی. مشهدی، عج. Capra, L. زندگی مهمانی: تأثیر نقشه برداری اجتماعی در OpenStreetMap. در مجموعه مقالات هفتمین کنفرانس بین المللی AAAI در وبلاگ ها و رسانه های اجتماعی، کمبریج، MA، ایالات متحده آمریکا، 8 تا 11 ژوئیه 2013.
- پالن، ال. سودن، آر. اندرسون، تی جی; Barrenechea، M. موفقیت و مقیاس در یک سازمان تولید کننده داده: تکامل اجتماعی و فنی OpenStreetMap در پاسخ به رویدادهای بشردوستانه. در مجموعه مقالات سی و سومین کنفرانس سالانه ACM در مورد عوامل انسانی در سیستم های محاسباتی، سئول، جمهوری کره، 18 تا 23 آوریل 2015.
- بوداتوکی، NR; Haythornthwaite، C. انگیزه برای همکاری باز جمعیت و مدل های جامعه و مورد OpenStreetMap. صبح. رفتار علمی 2013 ، 57 ، 548-575. [ Google Scholar ] [ CrossRef ]
- استد، D. روابط بین کاربری زمین، عوامل اجتماعی-اقتصادی، و الگوهای سفر در بریتانیا. محیط زیست طرح. B 2001 , 28 , 499-528. [ Google Scholar ] [ CrossRef ]
- ماات، ک. ون وی، بی. استد، د. استفاده از زمین و رفتار سفر: اثرات مورد انتظار از دیدگاه نظریه مطلوبیت و نظریه های مبتنی بر فعالیت. محیط زیست طرح. ب: برنامه ریزی کنید. دس 2005 ، 32 ، 33-46. [ Google Scholar ] [ CrossRef ]
- جومبا، ا. Dragićević، S. مدل سازی تغییر کاربری زمین شهری با وضوح بالا: رویکرد iCity عامل. Appl. مقعد فضایی. سیاست 2012 ، 5 ، 291-315. [ Google Scholar ] [ CrossRef ]
- اریکسون، ا. راجرز، ال. هورویتز، پی. هریس، جی. چالش ها و راه حل ها برای تجزیه و تحلیل تغییر کاربری زمین منطقه ای. در مجموعه مقالات کنفرانس بین المللی کاربران ESRI، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 8 تا 12 ژوئیه 2013.
- هرولد، ام. اسکپن، جی. Clarke، KC استفاده از سنجش از دور و معیارهای چشم انداز برای توصیف ساختارها و تغییرات در کاربری های شهری. محیط زیست طرح. A 2002 , 34 , 1443-1458. [ Google Scholar ] [ CrossRef ]
- جیانگ، دی. هوانگ، ی. ژوانگ، دی. زو، ی. خو، X. رن، اچ. یک رویکرد نیمه خودکار ساده برای طبقه بندی پوشش زمین از تصاویر سنجش از دور چند طیفی. PloS one 2012 , 7 , e45889. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- فریتز، اس. مک کالوم، آی. شیل، سی. پرگر، سی. ببینید، L. شپاچنکو، دی. ون در ولده، م. کراکسنر، اف. Obersteiner, M. Geo-Wiki: یک پلت فرم آنلاین برای بهبود پوشش جهانی زمین. محیط زیست مدل نرم افزار 2012 ، 31 ، 110-123. [ Google Scholar ] [ CrossRef ]
- سوتو، وی. Frías-Martínez، E. شناسایی خودکار کاربری زمین با استفاده از سوابق تلفن همراه. در مجموعه مقالات سومین کارگاه بین المللی ACM در MobiArch، Bethesda، MD، ایالات متحده آمریکا، 28 ژوئن تا 1 ژوئیه 2011.
- هان، اچ. یو، ایکس. لانگ، ی. کشف مناطق عملکردی با استفاده از داده های کارت هوشمند اتوبوس و نقاط مورد علاقه در پکن. 2015. در دسترس آنلاین: http://arxiv.org/abs/1503.03131 (در 25 ژوئن 2015 قابل دسترسی است).
- ری کالگاری، جی. Celino، I. پشتیبانی از برنامه ریزی شهری هوشمند از طریق علم داده های وب در داده های باز و سازمانی. در مجموعه مقالات بیست و چهارمین کنفرانس بین المللی در مورد همنشین وب جهانی، فلورانس، ایتالیا، 18 تا 22 مه 2015.
© 2015 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر