1. معرفی
استنتاج خودکار نقشه راه یک ابزار مهم در زمینه سیستم های حمل و نقل هوشمند (ITS) است: این امکان را می دهد که مناطق جغرافیایی ناشناخته (مثلاً در کشورهای در حال توسعه) به سرعت نقشه برداری شوند [1 ، 2 ، 3 ، 4 ] . می تواند نقشه های موجود را به روز کند [ 5 ، 6 ]. و همچنین اطلاعاتی در مورد تراکم ترافیک [ 7 ] ارائه می دهد که می تواند در ناوبری [ 8 ] و برای برنامه ریزی شهری استفاده شود [ 9 ، 10 ].
نقشههای راه قبلاً از طریق نقشهبرداری جغرافیایی کار فشرده با استفاده از تلسکوپها، سکستانتها و سایر دستگاهها ساخته میشدند. امروزه این روش ها با وسایل نقلیه نقشه برداری سیار جایگزین شده اند که می توانند کل شهرها را با دقت بالا ترسیم کنند [ 11 ]. با این حال، کمپین های نقشه برداری موبایل گران هستند، و در نتیجه، داده ها به ندرت به روز می شوند. علاوه بر این، نقشهبرداری موبایل اطلاعات مرتبط با ترافیک، مانند تراکم ترافیک به عنوان تابعی از زمان، مسیرهای ترجیحی مسافران و تأخیرهای ناشی از ترافیک را ارائه نمیکند.
به لطف استفاده همه جانبه از دستگاههای سیستم موقعیتیابی جهانی (GPS)، نقشههای جاده دیجیتال اکنون میتوانند از مسیرهای GPS کاربران مختلف جاده استخراج شوند [ 12 ، 13 ]. از آنجایی که دستگاههای جیپیاس دستی در دهه گذشته به طور فزایندهای محبوب شدهاند، دادههای جغرافیایی نه تنها از خودروها، تاکسیها و کامیونها، بلکه از دوچرخهسواران و عابران پیاده نیز به راحتی قابل دستیابی هستند. این فراوانی دادههای جغرافیایی مشتقشده از GPS، توسعه هر دو پروژه نقشهبرداری با منبع جمعی [ 14 ، 15 ] و همچنین محصولات تجاری را تحریک کرده است. تحقیق در مورد تجزیه و تحلیل ردیابی GPS بر ساختن نقشه های راه [ 16 ] و یادگیری حالت های تحرک افراد [ 17] متمرکز شده است.]. تحقیقات دیگر بر محاسبه بهترین مسیر بین دو مکان [ 9 ، 18 ، 19 ] یا یافتن کارآمدترین مسیر برای کامیون زباله [ 8 ] متمرکز است.
شبکههای جادهای یک جنبه حیاتی برای بهینهسازی مسیر و برنامهریزی مسیر هستند. در این مقاله، ما یک روش جدید برای استنتاج ساختار شبکه جادهای از ردیابیهای مختلف GPS، از جمله شناسایی تقاطعها، اتصال بین تقاطعها و جادههای هدایتشده پیشنهاد میکنیم. ما با محاسبه جهت حرکت کاربران در هر نقطه از ردیابی GPS شروع می کنیم. سپس تقاطعها با خوشهبندی «نقاط عطف» پیدا میشوند، که ما آنها را بهعنوان مکانهای جغرافیایی خاصی که در آن کاربران تغییر جهت میدهند، تعریف میکنیم. اتصال بین هر جفت تقاطع سپس از ردیابی خام GPS استنتاج می شود، که به مسیرهای مربوط به بخش های جاده بین هر جفت تقاطع متصل تقسیم می شود. سرانجام، مسیرهای هر بخش جاده با استفاده از روشی مبتنی بر تابخوردگی زمانی دینامیکی (DTW) تراز میشوند و سپس میانگینگیری میشوند تا به طور دقیق بخش جاده را محلیسازی کنند. بر اساس تراز مسیر، میانگین سرعت و واریانس سرعت در طول هر بخش جاده قابل تجزیه و تحلیل است.
این مقاله توسعهای از کار است که در ابتدا در کنفرانس سیستمهای حملونقل هوشمند IEEE در سال 2014 منتشر شد [ 20 ]. در این مقاله، روشهای تشخیص تقاطع و تراز چند مسیر را با عمق بیشتری شرح میدهیم. ما همچنین روش تشخیص تقاطع خود را با حذف تقاطعهای جعلی ناشی از پیچهای جاده که در کار قبلی ما وجود داشت، بهبود میبخشیم. ما پیچ ها را از تقاطع ها با استفاده از این شهود متمایز می کنیم که کاربران جاده می توانند جهت را در تقاطع ها به روش های مختلف تغییر دهند، اما همیشه در پیچ های جاده در یک جهت حرکت می کنند. سپس دقت شبکه جادهای استخراجشده را از نظر توپولوژیکی و جغرافیایی با استفاده از متریک F-score [ 21] ارزیابی میکنیم.]، که هم دقت و هم یادآوری را در نظر می گیرد. علاوه بر این، ما آمار ترافیک زمانی را برای هر بخش جاده با استفاده از مسیرهای GPS مرتبط آن محاسبه میکنیم. به عنوان مثال، ما می توانیم سرعت متوسط و تغییرات سرعت را تعیین کنیم که برای تجزیه و تحلیل ترافیک مفید است.
ادامه مقاله به شرح زیر تدوین شده است. در بخش بعدی، کار مرتبط با استنتاج نقشه راه را معرفی می کنیم. در بخش 3 ، نحوه استخراج تقاطع ها از نقاط عطف، نحوه کاوش اتصال آنها و در نهایت، نحوه تراز کردن چندین مسیر غیرخطی در زمان با استفاده از استراتژی “کشش و سپس فشرده سازی” را توضیح می دهیم. در بخش 4 ، ما دقت توپولوژیکی و جغرافیایی یک شبکه جاده را که با استفاده از روش ما استنباط شده است، ارزیابی می کنیم. در نهایت، در بخش 5 ، نتایج تجربی خود را نشان میدهیم.
2. کارهای مرتبط
هدف از استنتاج شبکه جاده ای این است که به طور خودکار یک نمودار هدایت شده از ردیابی خام GPS تولید کند که هندسه و توپولوژی جاده ها را نشان می دهد. بسته به نحوه پردازش ردیابی های GPS، روش های استنتاج شبکه جاده ای را می توان به طور کلی به دو گروه طبقه بندی کرد:
-
روشهای عمل بر روی یک تصویر باینری ایجاد شده از ردیابی GPS: این روشها ابتدا منطقه جغرافیایی تحت پوشش ردیابی GPS را به شبکهای دو بعدی از سلولها تقسیم میکنند و تراکم هسته (KD) نقاط داده ردیابی را برای هر سلول تخمین میزنند [ 1 , 3 ، 5 ، 22 ]. سپس یک نمایش دودویی از تمام آهنگها با اعمال یک آستانه در تخمین KD تولید میشود. این روش ها در نحوه استخراج خطوط مرکزی جاده از تصویر باینری حاصل متفاوت است. دیویس و همکارانبرای استخراج مجموعهای از چند ضلعیهای بسته که طرح کلی مناطق جادهها را توصیف میکنند، یک دنبالهروی کانتور را روی تصویر دودویی اعمال کنید و سپس خطوط مرکزی جاده را با تولید یک نمودار Voronoi از خطوط که لبههای جاده را توصیف میکند، محاسبه کنید [3 ] . چن و همکاران از یک رویکرد پردازش تصویر برای استخراج نقشه راه از تصویر باینری استفاده کنید [ 22 ]. ابتدا، عملیات اتساع مورفولوژیکی و بستن برای ادغام نقاط داده گسسته ردیابی GPS استفاده می شود. سپس از عملیات نازکسازی برای تولید اسکلت در امتداد خطوط مرکزی جاده استفاده میشود. شی و همکاران روشی بسیار مشابه با رویکرد چن [ 22 ] پیشنهاد می کنند، اما آنها سعی می کنند گذرگاه ها را از اسکلت شبکه راه ها استخراج کنند [ 5]]. Biagioni و Eriksson با اعمال یک آستانه ساده در KDE یک تصویر نقشه باینری تولید نمی کنند، زیرا یک آستانه نمی تواند هم دقت بالا و هم پوشش بالای نقشه راه را بدست آورد. برای حل این مشکل، آنها از تکنیک اسکلت سازی در مقیاس خاکستری برای استخراج یک اسکلت بدون آستانه از KDE استفاده می کنند [ 16 ].
-
روشهای مبتنی بر KDE از آستانهگذاری رنج میبرند، زیرا یک آستانه بالاتر لبههای جعلی تولید میکند. با این حال، یک آستانه پایین تر، مسیرها را در مناطق پراکنده به عنوان سر و صدا نادیده می گیرد، که منجر به شناسایی ناموفق جاده هایی می شود که اغلب از آنها عبور نمی شود. اگرچه هندسه شبکه جادهها با استفاده از مکانهای جغرافیایی در امتداد خطوط مرکزی جاده ساخته شده است، توپولوژی شبکه جادهای که توسط اتصالات بین جادهها شکل میگیرد، به طور کامل در تجزیه و تحلیل جاده مبتنی بر تصویر باینری که قبلا ذکر شد، تجزیه و تحلیل نمیشود. توپولوژی شبکه راه برای بهینه سازی مسیر و برنامه ریزی مسیر ضروری است. در این مقاله، ما بر روی مسیرها (موقعیت های فضایی به عنوان تابعی از زمان) به طور مستقیم به منظور استخراج تقاطع های جاده ها و تجزیه و تحلیل اتصال آنها با استفاده از ردیابی GPS عمل می کنیم.
-
روشهای کار بر روی نقاط داده ردیابی GPS: اکثر محققان ردیابیهای GPS را به قطعات مسیر برای هر بخش جاده تقسیم میکنند و نمایش هر بخش جاده را از قطعات مسیر مطابق با آن استنباط میکنند. در این روشها، تقاطعها قبل از تولید بخش جاده شناسایی میشوند و اتصال بین تقاطعها برای تقسیم ردیابی GPS در هر بخش جاده مفید است. با توجه به مجموعهای از قطعات مسیر، روشهای متنوعی، از برازش منحنی گرفته تا تقسیمبندی نمودار، برای استخراج یک بخش راهنما از قطعات مسیر مربوطه آن پیشنهاد شدهاند. این رویکردها را می توان بر اساس مبانی الگوریتمی به سه دسته تقسیم کرد.
- –
-
روشهای برازش منحنی: Edelkamp و Schroedl از یک الگوریتم K-means برای خوشهبندی نقاط داده آثار GPS خام هر دو بخش جادهها و تقاطعها بر اساس اندازهگیری فاصله استفاده میکنند. خطوط مرکزی جاده با استفاده از یک رویکرد برازش اسپلاین برای هر بخش جاده از نقاط داده GPS مربوط به آن تولید میشوند [ 2 ، 18 ].
- –
-
روش های توپولوژیکی: موریس و همکاران. [ 23 ] یک نمودار توپولوژیکی برای نمایش شبکه فیزیکی ردیابی های GPS بسازید. یک نمودار اولیه از نقاط تعامل و خطوط اتصال بین تمام مسیرها ایجاد می شود. این خطوط اتصال برای استخراج یک نمایش واحد برای هر بخش جاده با استفاده از یک الگوریتم نمودار، مانند کاهش موازی، کاهش چهره، کاهش سریال و انقباض لبه کاهش مییابد.
- –
-
روشهای ادغام ردیابی: Karagiorgou و Pfoser تقاطعها را با خوشهبندی پیچها بر اساس مکانشان تشخیص میدهند و نوع پیچ و مسیرهای بین تقاطعها را دستهبندی میکنند تا آنها را در بخشهای جاده ادغام کنند [24 ] .
محققان دیگر ترجیح میدهند که یک ردیابی GPS را در یک زمان پردازش کنند تا آن را به شبکه جادهای اضافه کنند، به جای پردازش چند قطعه مسیر برای یک بخش جاده. Cao و Krumm [ 4 ] پیشنهاد میکنند که ردیابی GPS را با استفاده از شبیهسازی نیروهای فیزیکی در میان ردیابیها، که اثرات نویز GPS را کاهش میدهد، و ردیابیهای GPS تمیز شده را با حریصانه در یک نمودار ادغام میکنند. لبههای هر ردیابی GPS خام به نمودار اضافه میشوند، مگر اینکه لبهای با موقعیت و یاتاقان مشابه از قبل در نمودار در حال ساخت وجود داشته باشد. سپس تقاطع ها از نمودار تولید شده شناسایی می شوند. روش بسیار مشابهی توسط Niehoefer و همکاران استفاده شده است. ، که هر اثر جدید را با یک نقشه موجود ادغام می کند و موقعیت جاده های موجود را به روز می کند [ 10]. همه روشهای ذکر شده در بالا از تولید لبههای جادهای جعلی از ردیابی GPS با خطای بالا رنج میبرند.
ما روشی را برای استنباط توپولوژی شبکه جاده از طریق شناسایی تقاطع پیشنهاد می کنیم و به استخراج نمایش هندسی هر بخش جاده با تراز مسیر ادامه می دهیم. اولین مشارکت ما تشخیص تقاطع ها با خوشه بندی نقاط عطف در ردیابی GPS و استفاده از این تقاطع های شناسایی شده برای تقسیم ردیابی GPS به قطعات مربوط به بخش های جاده است. ما همچنین یک استراتژی “کشش و سپس فشرده سازی” برای DTW ارائه می دهیم تا همه مسیرها را برای هر بخش جاده تراز کند. مسیرهای پیچ و تاب تولید شده در طول تراز برای استخراج یک مسیر متوسط استفاده می شود تا به عنوان یک نمایش هندسی برای هر بخش جاده عمل کند. این مسیرهای پیچ و تاب همچنین می توانند برای تجزیه و تحلیل زمانی مسیرها، مانند واریانس سرعت، استفاده شوند.
به طور خلاصه، مشارکت های اصلی ما دو برابر است. ابتدا، ما روشی را برای تشخیص تقاطع ها با خوشه بندی نقاط عطف در داده های مسیر پیشنهاد می کنیم. دوم، ما یک استراتژی “کشش و سپس فشرده سازی” را برای تراز کردن تمام مسیرها برای هر بخش جاده با استفاده از DTW معرفی می کنیم، و مسیرهای پیچ و تاب تولید شده برای استنتاج هندسه بخش جاده استفاده می شود. نتایج ما عملکرد بهتری را با حذف بسیاری از جادههای جعلی و همچنین مکانهای جغرافیایی دقیقتر برای جادههای شناساییشده نشان میدهد. Biagioni به طور مقایسه ای برخی از روش های موجود برای استنتاج شبکه راه را ارزیابی کرد [ 16 ]. ما روش خود را با کار Biagioni بر روی همان مجموعه داده GPS در این مقاله مقایسه می کنیم.
3. استنباط شبکه راه
عناصر اصلی یک شبکه حمل و نقل عمومی تر شامل تقاطع ها، جاده ها، راه آهن، بزرگراه ها، خطوط وسایل نقلیه موتوری، خطوط دوچرخه و عابر پیاده است. با این حال، ما فقط زیرمجموعه ای از این عناصر را در قالب یک شبکه جاده ای بررسی خواهیم کرد، که سیستمی است که راه های متصل به هم واقع در یک منطقه معین را نشان می دهد. به منظور روشن شدن دامنه کار خود در این مقاله، سه عنصری که یک شبکه جاده را تعریف میکنند را در زیر ارائه میکنیم.
-
تقاطع ها: تقاطع های جاده ای با موقعیت جغرافیایی آنها نشان داده می شوند q =( x ، y)تیq=(�,�)�، که در آن x و y مختصاتی در طول و عرض جغرافیایی هستند. تقاطع را می توان به عنوان مکانی تعریف کرد که در آن کاربران می توانند مسیرها را به روش های مختلف تغییر دهند، بدون توجه به تعداد بخش های جاده ای که در یک تقاطع خاص ملاقات می کنند. تقاطع ها از پیچ ها در جاده ها منحصر به فرد هستند، که فقط به کاربران اجازه می دهد یک تغییر جهت را ایجاد کنند.
-
نمودار اتصال: اگر یک جفت تقاطع مستقیماً توسط یک بخش جاده که شامل هیچ تقاطع دیگری نباشد، به هم متصل شوند، نمودارهای اتصال جاده کدگذاری میکنند. این نمودارها با یک باینری نمایش داده می شوند م× م�×�ماتریس اتصال C ، با M تعداد تقاطع ها. طبق تعریف، سیمن ، ج= 1��,�=1اگر تقاطعهای i و j مستقیماً توسط یک بخش جاده به هم متصل شوند. در مقاله ما، C نامتقارن است، به عنوان مثال ، سیمن ، ج��,�می تواند متفاوت باشد سیj ، iسی�،منبه دلیل ترافیک یک طرفه علاوه بر این، فرض میکنیم که عناصر مورب اصلی C صفر هستند، یعنی یک تقاطع به خودش متصل نیست.
-
بخش های جاده: بخش های جاده هدایت شده R جفت تقاطع ها را به هم متصل می کنند. هندسه هر بخش جاده با استفاده از یک توالی از مکان های جغرافیایی نشان داده شده است. در این مقاله، میانگین سرعت و واریانس سرعت در طول هر بخش جاده با استفاده از ردیابی GPS تجزیه و تحلیل خواهد شد. با این حال، نوع جاده و تعداد خطوط جاده مورد تجزیه و تحلیل قرار نخواهد گرفت.
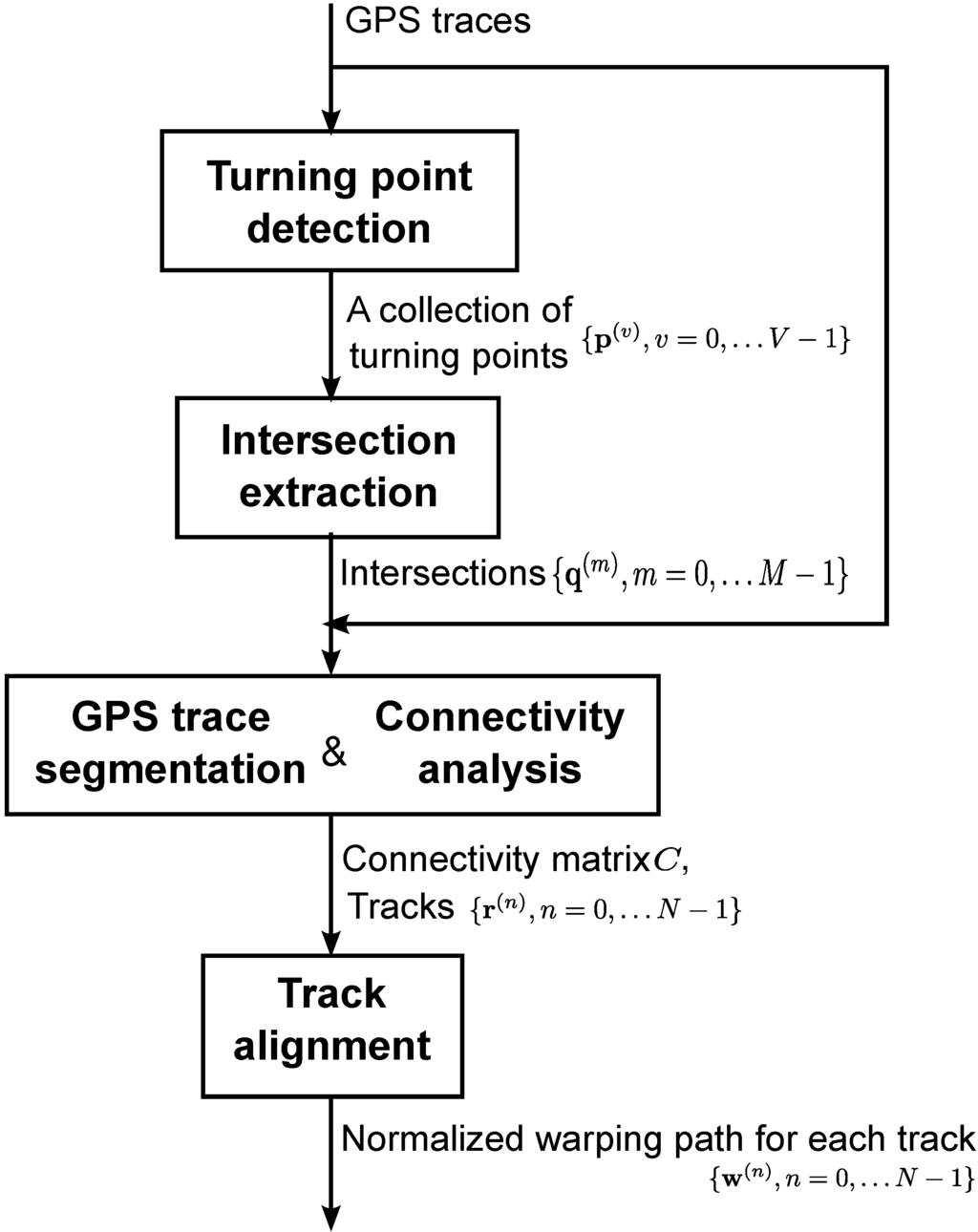
شکل 1 یک نمای کلی از روش ما را نشان می دهد. ابتدا، با استفاده از روش خوشهبندی خود، بدون استفاده از دانش قبلی از تعداد تقاطعها، نقاط عطف آثار منفرد را به تقاطعها گروهبندی میکنیم.
دوم، ما تمام ردیابی های GPS را بر اساس تقاطع های شناسایی شده تقسیم بندی می کنیم. کاربران دستگاههای GPS اغلب مسیرهای مختلفی را به سمت یک مقصد دنبال میکنند و ردیابیهای GPS متفاوتی با سرعتها و مکانهای متغیر ایجاد میکنند. با این حال، همه ردیابی ها بخش های مشترک مربوط به بخش های جاده را به اشتراک خواهند گذاشت.
در نهایت، ما تمام مسیرها را برای هر بخش جاده، نقطه به نقطه، با استفاده از DTW با استراتژی “کشش و سپس فشرده سازی” تراز می کنیم. مسیرهای تراز شده به طور میانگین برای تشکیل یک نمایش برای هر بخش جاده محاسبه می شوند. تراز مسیر از روش های موجود در تولید شبکه های جاده ای تمیزتر بدون لبه های جعلی بهتر عمل می کند. همچنین امکان تجزیه و تحلیل آماری واریانس سرعت ترافیک نشان داده شده توسط مسیرهایی که هر بخش جاده را تشکیل می دهند را می دهد.
3.1. تشخیص نقطه عطف
شهود پشت تشخیص نقطه عطف ما این است که در حالی که برخی از کاربران جاده ممکن است مستقیماً از میان تقاطع ها حرکت کنند، حداقل برخی از آنها در تقاطع ها به جاده های دیگر می روند. این رفتار چرخشی منحصر به تقاطع ها نیست، زیرا کاربران جاده ممکن است به نظر برسند که در پیچ های جاده ها پیچ می زنند، که ما آنها را تقاطع در نظر نمی گیریم. بنابراین، هنگامی که مکانهای مکانی را شناسایی میکنیم که در آن بسیاری از مسیرها نقاط عطف را نشان میدهند، همچنین یک تجزیه و تحلیل اضافی برای تشخیص خمها در جادهها از جادههای متقاطع واقعی انجام میدهیم که در بخش 3.2 توضیح داده شده است .
شکل 1. مروری بر روش پیشنهادی.
هنگامی که کاربران جاده در تقاطع ها پیچ می خورند، تغییر جهت حرکت آنها در مدت زمان ثابت بسته به سرعت آنها متفاوت است. بنابراین، انتخاب یک آستانه واحد برای تشخیص تغییر جهت برای تشخیص پیچ ها دشوار است. برای اینکه رویکرد در برابر اختلاف سرعت قوی باشد، تغییر جهت حرکت را در یک فاصله ثابت محاسبه می کنیم. اگر فاصله ثابت خیلی کم باشد، تغییر جهت در تقاطع ها را نمی توان از نوسانات در جهت حرکت تشخیص داد. بر اساس تجربه ما، تغییر جهت بیش از حداقل 2 متر در تقاطع را می توان به اندازه کافی از نوسانات متمایز کرد. با این حال، بسته به میزان نمونه برداری از واحدهای GPS و سرعت کاربران جاده،
بنابراین، جهت حرکت کاربر در (ایکسآ،yآ)(ایکسآ،�آ)به صورت زیر محاسبه می شود:
با توجه به یک نقطه در ردیابی GPS، (ایکسآ،yآ)(ایکسآ،�آ)، نقطه دوم را انتخاب می کنیم، (ایکسب،yب)(ایکسب،�ب)، یعنی 2 متر جلوتر در همان مسیر. اگر چنین نقطه ای وجود نداشته باشد، نقطه مجاور بعدی را انتخاب می کنیم. جهت حرکت کاربر در (ایکسآ،yآ)(ایکسآ،�آ)به صورت زیر محاسبه می شود:
جایی که θآ∈ [ – π، π]��∈[−�,�]( – π–�غرب است، رادیان در خلاف جهت عقربه های ساعت).
جهت حرکت کاربر، θب�ب، در نقطه (ایکسب،yب)(ایکسب،�ب)به طور مشابه با استفاده از نقطه بعدی در ردیابی GPS که در فاصله ثابتی قرار دارد محاسبه می شود. اگر جهت تغییر کند Δθب=θب–θآΔ�ب=�ب–�آبین نقاط (ایکسآ،yآ)(ایکسآ،�آ)و (ایکسب،yب)(ایکسب،�ب)از یک آستانه از پیش تعریف شده فراتر می رود، سپس به عنوان یک نقطه عطف در نظر گرفته می شود.
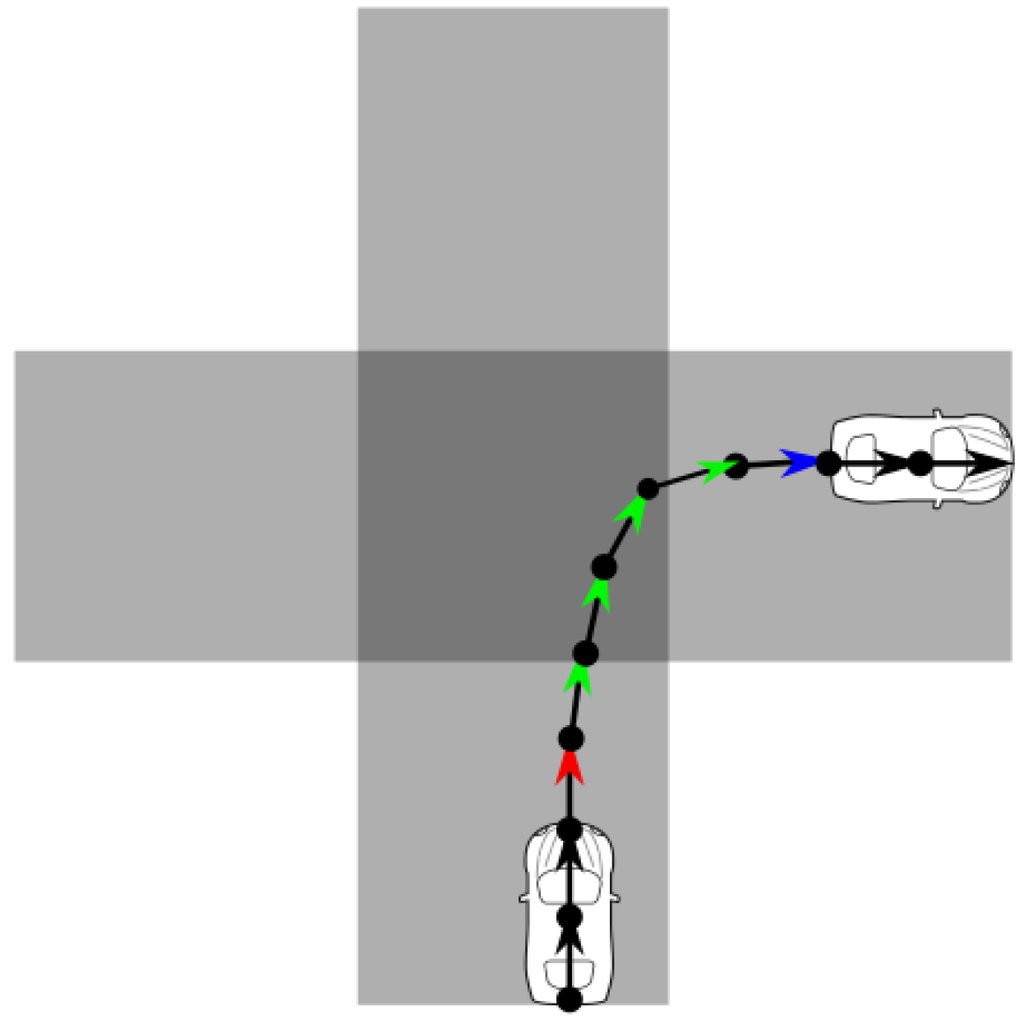
از آنجایی که تقاطع ها معمولاً بسیار بزرگتر از آستانه فاصله تشخیص پیچ دو متری ما هستند، بسیاری از نقاط GPS با تغییر جهت را می توان در داخل همان تقاطع شناسایی کرد. ما تمام نقاط داده مجاور با تغییرات جهت شناسایی شده از ردیابی GPS را به عنوان نقاط عطف در نظر می گیریم. ما اولین و آخرین نقطه را در دنباله ای از تغییرات جهت حرکت دنبال می کنیم، که می تواند نشان دهنده ورود و خروج کاربر از تقاطع باشد، که بعداً برای تشخیص پیچ ها در جاده ها از تقاطع های واقعی استفاده می شود. نمونه ای از چرخش در شکل 2 نشان داده شده است، همانطور که وسیله نقلیه در تقاطع به راست می پیچد. جهت حرکت نقاط عطف با فلش های رنگی نشان داده شده است، جایی که قرمز نشان دهنده اولین نقطه عطف، آبی نشان دهنده آخرین نقطه عطف و سبز برای سایر نقاط عطف است. جهت حرکت سایر نقاط بدون تغییر جهت به صورت یک فلش سیاه نشان داده می شود.
شکل 2. نمونه ای از چرخش. بخشی از ردیابی GPS در اطراف یک تقاطع با یک خط سیاه با دایره هایی که موقعیت ضبط داده ها را نشان می دهد و فلش هایی که جهت حرکت را در هر نقطه نشان می دهد نشان داده می شود.
خروجی این مرحله مجموعه ای از نقاط عطف است {پ( v ), v = 0 , … V− 1 }{پ(�)،�=0،…�–1}، که با بررسی تغییر جهت حرکت در هر نقطه در امتداد تمام ردیابی های GPS به همراه نشانگرهای باینری از ورود کاربر به تقاطع شناسایی می شوند. {هv1, v = 0 , … V− 1 }{ه1�،�=0،…�–1}یا از تقاطع خارج می شود {ه( v )2, v = 0 , … V− 1 }{ه2(�)،�=0،…�–1}در یک نقطه عطف خاص، جایی که ه( v )1∈ [ 0 , 1 ]ه1(�)∈[0،1]و ه( v )2∈ [ 0 , 1 ]ه2(�)∈[0،1]. ه( v )1= 1�1(�)=1نشان می دهد که کاربر در نقطه عطف v وارد یک تقاطع می شود و صفر نشان دهنده عدم ورود است. در بخش بعدی توضیح میدهیم که چگونه این نقاط عطف در تقاطعها دستهبندی میشوند.
3.2. استخراج تقاطع
در کار خود، ما یک تکنیک خوشه بندی را برای گروه بندی مجموعه نقاط عطف P به تقاطع ها بر اساس فاصله اقلیدسی پیشنهاد می کنیم. همانطور که در الگوریتم 1 نشان داده شده است، اگر فاصله متوسط آنها تا نقاط فعلی در خوشه به اندازه کافی کوچک باشد، یک خوشه اولیه از یک نقطه بذر با اضافه کردن مکرر نقاط به خوشه رشد می کند. سپس این روش روی نقاطی که هنوز خوشهبندی نشدهاند تکرار میشود. خروجی این مرحله مجموعه ای از خوشه ها است پمن= {پ( n )من��={p�(�)، n = 0 … |پمن| − 1 }�=0…|��|−1}، با |پمن||��|به عنوان تعداد نقاط عطف در هر خوشه. به عنوان یک مرحله پس از پردازش، ما همچنین خوشه هایی را که دارای نقاط عطف بسیار کمی هستند، کنار می گذاریم. این ممکن است ناشی از نویز GPS یا نمونه برداری ناکافی از یک تقاطع باشد.
| الگوریتم 1 نقاط عطف خوشه. |
| ورودی: {پ( v ){p(�)، v = 0 … V− 1 }�=0…�−1} |
| خروجی: {پمن: |پمن| >تیدقیقه{پمن:|پمن|>تیدقیقه i = 0 … I− 1 }من=0…من–1} |
| 1: مقداردهی اولیه پu n← {پ( v )پتو�←{پ(�)، v = 0 … V− 1 }�=0…�–1} من ← 0من←0 |
| 2: برای هر کدام p ∈پu nپ∈پتو� انجام دادن |
| 3: پo u t= ∅����=∅، پمن= { p }��={p}، |
| 4: برای هر کدام پ“≠ p ∈پu np′≠p∈��� انجام دادن |
| 5: اگر 1|پمن|∑پ“∈پمند(پ“،پ“) ≤دتی ه ر ای1|پمن|∑پ“∈پمندپ“،پ“≤دتیساعت�ه سپس دتی ه ر ایدتیساعت�هآستانه از پیش تعریف شده برای میانگین فاصله اقلیدسی است. |
| 6: پمن←پمن∪ {پ“}پمن←پمن∪{پ“} |
| 7: پایان اگر |
| 8: پایان برای |
| 9: پu n=پu n\پمنپتو�=پتو�\پمن |
| 10: پایان برای |
برای حذف پیچهای جادهای که اشتباهاً شناسایی شدهاند از خوشهها، جایی که کاربران جاده ممکن است جهت حرکت خود را نیز تغییر دهند، باید نوع پیچهای هر خوشه را با استفاده از ورودی بررسی کنیم (با ه( v )1= 1ه1(�)=1) و نقاط عطف خروجی (با ه( v )2= 1ه2(�)=1) همانطور که در مرحله قبل توضیح داده شد. همانطور که در شکل 3 نشان داده شده است، نقاط عطف ورودی و خروجی را انتخاب کرده و جهت آنها را به طور جداگانه برای هر خوشه از نقاط عطف خوشه بندی می کنیم. اگر جهت ورود و خروج ثابت بماند (برای یک قطعه جاده یک طرفه) یا مخالف باشد (برای یک قطعه جاده دو طرفه)، این خوشه حذف خواهد شد، زیرا نقاط عطف در این خوشه در یک خم قرار دارند. یک تقاطع
در نهایت، مکان های فضایی qمترqمترخوشه ها با میانگین گیری نقاط عطف در هر خوشه به دست می آیند. نتیجه مجموعه ای از تقاطع ها است Q = {qمتر, m = 0 , … , M− 1 }�={q�,�=0,…,�−1}.
3.3. تجزیه و تحلیل اتصال و تقسیم بندی ردیابی GPS
اتصال تقاطع ها با تعیین اینکه آیا ردیابی GPS وجود دارد که مستقیماً از یک تقاطع به تقاطع دیگر می رود، تجزیه و تحلیل می شود. ما ابتدا با محاسبه فاصله هر نقطه در ردیابی با موقعیت مکانی تا تقاطع های شناسایی شده تعیین می کنیم که آیا یک ردیابی GPS معین حاوی هر تقاطع است یا خیر. اگر فاصله بین یک نقطه در یک ردیابی و یک تقاطع در یک آستانه از پیش تعیین شده باشد، نتیجه می گیریم که ردیابی GPS از یک تقاطع عبور می کند. در حالت ایدهآل، اگر ردی وجود داشته باشد که مستقیماً از هر دو تقاطع عبور کند، بدون برخورد با تقاطع، مستقیماً به هم متصل میشوند. با این حال، اگر یک تقاطع در امتداد یک ردیابی شناسایی نشود، خطاهای GPS می توانند به اتصالات تقاطع مثبت کاذب کمک کنند. به عنوان مثال، فرض کنید یک کاربر از سه تقاطع در یک رد عبور می کند، اما فقط اولین و آخرین مورد توسط آستانه فاصله ما شناسایی می شوند. مورد دوم به دلیل نویز GPS از دست رفته است. این منجر به اتصال مثبت کاذب بین تقاطع اول و سوم می شود.
شکل 3. تشخیص خم. خمیدگی ها با بررسی مسیرهای ورود و خروج شناسایی می شوند.
در این مقاله، تعداد ردیابی هایی که بین دو تقاطع مجاور حرکت می کنند برای تصمیم گیری در مورد اتصال مستقیم آنها استفاده می شود. پس از تعیین اتصال، همه ردیابیهای GPS را به بخشهای مسیر بین هر جفت تقاطع متصل مستقیم تقسیم میکنیم. خروجی این مرحله ماتریس اتصال C و بخش های مسیر مرتبط با هر بخش جاده بین تقاطع ها است. از نمادهای زیر استفاده خواهیم کرد. برای یک قطعه جاده R ، N مسیر وجود دارد{r( n )n = 0 , … , N _− 1 }{r(�),�=0,…,�−1}، با آهنگ n متشکل از Ln��نکته ها r( n )= (r( n )( 0) ، … _r(n )(Ln– 1 ) )r(�)=(r(�)(0),…,r(�)(��−1)). به طور مشخص، r( ن)( من ) = (ایکس( n )( من ) ،y( n )( من ) )r(�)(�)=(�(�)(�),�(�)(�))از طول و عرض جغرافیایی نقطه i در مسیر n تشکیل شده است .
3.4. تراز مسیر
برای همان بخش جاده، مسیرهای GPS از همان دو تقاطع شروع و پایان مییابند. اگرچه مسافت جغرافیایی که هر مسیر طی می کند مشابه طول بخش جاده است، تراکم نقطه GPS مکانی مسیرها متفاوت است زیرا وسایل نقلیه می توانند با سرعت های مختلف حرکت کنند. اگر کاربر با سرعت بیشتر در جاده ها حرکت کند، نقاط GPS کمتری ثبت می شود و بالعکس. وظیفه اصلی این بخش یافتن تناظرهای نقطه ای بین تمام مسیرها و میانگین گیری آنها برای تشکیل یک نمایش واحد از بخش جاده است. با این حال، به دلیل سرعتهای متفاوت در هر مسیر، تشخیص دقیق نقاط مربوطه دشوار است. برخی از روشهای سادهلوحانه میتوانند مطابقتهای زمانی ناسازگار ایجاد کنند. در این مقاله برای حل این مشکل از زمان تابش پویا (DTW) استفاده می کنیم. ما با توضیح اصل DTW برای استفاده با تراز دو مسیر شروع می کنیم و سپس با استفاده از استراتژی “کشش و سپس فشرده سازی” خود برای تراز چند مسیر، رویکرد را تعمیم می دهیم. میانگین مسیر با استفاده از ترازهای مسیرها محاسبه خواهد شد.
3.4.1. تراز دو مسیر با استفاده از DTW
DTW یک الگوریتم هم ترازی سری زمانی است که در اصل برای تشخیص گفتار توسعه یافته است [ 25 ]. سعی میکند یک همترازی زمانی بین دو سیگنال پیدا کند که اندازهگیری شباهت بین نمونههای دو سیگنال را با تاب برداشتن محور زمانی آنها به حداکثر میرساند.
با توجه به دو آهنگ از نقاط (r( 0 )( 0 ) ، … _r( 0 )(L0– 1 )(r(0)(0),…,r(0)(�0−1)و (r( 1 )( 0 ) ، … _r( 1 )(L1– 1 )(r(1)(0),…,r(1)(�1−1)و اندازه گیری فاصله بین جفت نقطه، مشکل یافتن بهترین هم ترازی را می توان به عنوان یافتن یک ارتباط توصیف کرد. (ل0( 0 ) ، … _ل0(ک0– 1 ) )(�0(0),…,�0(�0−1))و (ل1( 0 ) ، … _ل1(ک0– 1 ) )(�1(0),…,�1(�0−1))که فاصله کل را به حداقل می رساند.
جایی که ل0(ک0)ل0(ک0)و ل0(ک0)�0(�0)موارد زمانی مربوطه را مرتبط کنید ل0�0از آهنگ اول و ل1�1از آهنگ دوم همه این گونه انجمن ها مجاز نیستند. به طور خاص، ما فقط مسیرهای پیچ و تاب را در نظر می گیریم که به زیرمجموعه Γ از همه انجمن های ممکن تعلق دارند و محدودیت های زیر را برآورده می کنند:
-
شرایط مرزی: مسیر Warp باید از ابتدای هر سری زمانی شروع شود و در پایان هر سری زمانی پایان یابد: ل0( 0 ) = 0�0(0)=0، ل0(ک0− 1 ) =L0– 1�0(�0−1)=�0−1، ل1( 0 ) = 0�1(0)=0و ل1(ک0− 1 ) =L0– 1�1(�0−1)=�0−1.
-
یکنواختی: مسیر تاب باید در هر دو محور زمانی به صورت یکنواخت بدون کاهش باشد: ل0(ک0) ≤ل0(ک0+ 1 )�0(�0)≤�0(�0+1)و ل1(ک0) ≤ل1(ک0+ 1 )�1(�0)≤�1(�0+1).
-
تداوم: هر دو مرحله مجاور مسیرهای پیچ و تاب دنبال می شوند (ل0(ک0) –ل0(ک0– 1 ) ،ل1(ک0) –ل1(ک0− 1 ) ∈ { ( 0 , 1 ) , ( 1 , 0 ) , ( 1 , 1 ) } _(ل0(ک0)–ل0(ک0–1)،ل1(ک0)–ل1(ک0–1))∈{(0،1)،(1،0)،(1،1)}. با این محدودیت، مسیر تار برای هر مسیر حداکثر یک نقطه در یک زمان حرکت می کند.
پس از محاسبه توابع ل0(ک0)�0(ک0)و ل1(ک0)ل1(ک0)، آهنگ ها r( 0 )r(0)و r( 1 )r(1)اکنون به این معنا تراز شدهاند که در همان شاخص k به موقعیتهای مکانی نزدیک میرسند و در نتیجه مسیرهای تابدار جدید با ک0�0نکته ها r( 0 )1= (r( 0 )1( 0 ) ، … _r( 0 )1(ک0– 1 ) )r1(0)=(r1(0)(0)،…،r1(0)(ک0–1))و r( 1 )1= (r( 1 )1( 0 ) ، … _r( 1 )1(ک0– 1 ) )r1(1)=(r1(1)(0)،…،r1(1)(ک0–1))، جایی که r( 0 )1(ک0) =r( 0 )(ل0(ک0) )r1(0)(ک0)=r(0)(ل0(ک0))و r( 1 )1(ک0) =r( 1 )(ل1(ک0) )r1(1)(ک0)=r(1)(ل1(ک0)). برای به دست آوردن یک تراز بهینه، این احتمال وجود دارد که این مسیرهای تابدار دارای نقاط تکراری باشند.
برای تراز کردن دو مسیر با استفاده از DTW، ابتدا ماتریس فاصله را محاسبه می کنیم D( 1 )L0×L1��0×�1(1)برای هر جفت نقطه GPS در هر دو مسیر، جایی که عنصر د( 1 )(ل0،ل1)د(1)(ل0،ل1)در ل0ل0ردیف -امین و ل1ل1– ستون از D( 1 )L0×L1�(1)�0×�1نشان دهنده فاصله بین (ل0)(ل0)نقطه -ام در آهنگ r( 0 )r(0)و (ل1)(ل1)نقطه -ام در آهنگ r( 1 )r(1). سپس ماتریس فاصله انباشته شده را محاسبه می کنیم D( 2 )L0×L1��0×�1(2)از ماتریس فاصله D( 1 )L0×L1��0×�1(1)، جایی که عنصر د( 2 )(ل0،ل1)د(2)(ل0،ل1)در (ل0،ل1)(ل0،ل1)که در D( 2 )L0×L1��0×�1(2)با افزودن مقدار محاسبه می شود د( 1 )(ل0،ل1)�(1)(�0,�1)همراه با حداقل مقدار {د( 2 )(ل0− 1 ،ل1) ،د( 2 )(ل0،ل1– 1 ) ،د( 2 )(ل0− 1 ،ل1− 1 ) }�(2)(�0−1,�1),�(2)(�0,�1−1),�(2)(�0−1,�1−1).
سپس مسیرهای پیچ و تاب از ماتریس انباشته جستجو می شوند D( 2 )�(2)به ترتیب نزولی، با شروع در د( 2 )(L0،L1)�(2)(�0,�1)و به پایان می رسد د( 2 )( 1 , 1 )�(2)(1,1)تحت شرایط مرزی مرحله قبل (w( 0 )(ک0– 1 ) ،w( 1 )(ک0– 1 )(w(0)(�0−1),w(1)(�0−1)) در مسیرها از موقعیت عنصر با کمترین مقدار از عناصر مجاور با شاخص های کاهشی یک مرحله ای انتخاب می شود. {د( 2 )(ل0− 1 ،ل1) ،د( 2 )(ل0،ل1– 1 ) ،د( 2 )(ل0− 1 ،ل1− 1 ) }�(2)(�0−1,�1),�(2)(�0,�1−1),�(2)(�0−1,�1−1). این تضمین می کند که روند جستجو شرایط تداوم و یکنواخت را برآورده می کند.
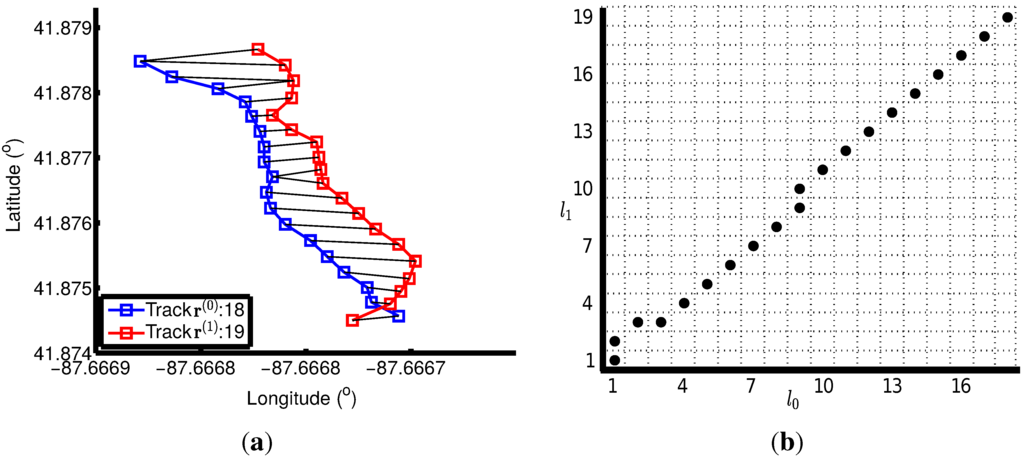
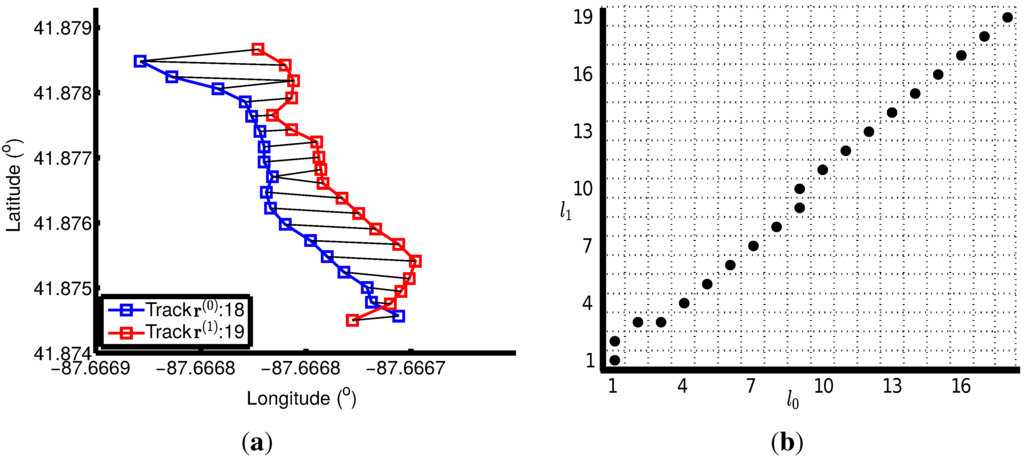
نمونه ای از تراز کردن دو مسیر در شکل 4 نشان داده شده است . 18 امتیاز در مسیر وجود دارد r( 0 )r(0)، که با یک خط آبی با مربع نشان می دهد که موقعیت نقاط داده را نشان می دهد. مسیر r( 1 )r(1)به عنوان یک خط قرمز با مربع نشان دهنده موقعیت 19 نقطه آن به تصویر کشیده شده است. جفت تطبیق این دو آهنگ با پیوند دادن نقاط با استفاده از یک خط سیاه نشان داده می شود. در شکل 4 ب، محور افقی این نقشه شبکه، محور زمانی Track است r( 0 )r(0)و عمودی برای Track است r( 1 )r(1). بهترین تراز آهنگ r( 0 )r(0)و r( 1 )r(1)را می توان به عنوان یافتن مسیری از طریق شبکه از شبکه پایین سمت چپ توصیف کرد ( 1 , 1 )(1,1)به شبکه سمت راست ( 18 و 19 )(18,19)با کمترین فاصله کلی بین تمام جفت نقاط. بهترین مسیر پیچ و تاب در این حالت در دایره های گرد ثابت نشان داده شده است. با توجه به مسیر تاب بهینه، هر دو مسیر تا 20 عنصر گسترش مییابند.
شکل 4. نمونه ای از تراز دو مسیر. ( الف ) عناصر در دو مسیر با استفاده از DTW با فاصله بین این عناصر به عنوان ویژگی جفت می شوند. ( ب ) مسیر پیچ و تاب با محور افقی و عمودی نشان دهنده شاخص زمانی مسیر است r( 0 )r(0)و آهنگ r( 1 )r(1)بصورت جداگانه.
به دلیل خطاهای GPS یا از دست دادن داده ها، برخی از مسیرها در امتداد “جاده” فیزیکی قرار نمی گیرند، اگرچه نقطه شروع و پایان یکسانی دارند. فاصله مکانی یک مسیر r( n )r(�)به تمام مسیرهای دیگر متعلق به همان بخش جاده به عنوان محاسبه می شود ∑m =نمن– 1m ≠ n ، m = 0اس(r( n )،r( متر ))∑�≠�,�=0�=��−1�(r(�),r(�))، در حالی که اس(r( n )،r( متر ))�(r(�),r(�))میانگین فاصله فضایی بین دو مسیر است.
که در آن K طول مسیرهای تاب آنها است.
اگر میانگین فاصله مکانی یک مسیر تا مسیرهای دیگر از مقدار از پیش تعریف شده بیشتر شود، برای انجام تراز مسیر برای این جاده استفاده نمی شود. با این کار مسیرهایی با خطاهای GPS زیاد و از دست دادن داده های زیاد حذف می شوند.
3.4.2. استراتژی “کشش و سپس فشرده سازی”.
رویه DTW فقط امکان تراز کردن دو مسیر را می دهد. برای جفت مسیرهای مختلف، مسیرهای پیچ و تاب آنها و طول مسیرهای تابدار می تواند متفاوت باشد. بنابراین، یافتن یک مسیر نرمال شده برای تراز کردن همه جفتهای ممکن از مسیرها با هم دشوار است. ما اکنون یک استراتژی “کشش و سپس فشرده سازی” را برای فعال کردن تراز چند مسیر همه مسیرها پیشنهاد می کنیم. این استراتژی از دو عملیات مختلف تشکیل شده است، یک (1) عملیات کشش و سپس یک (2) عملیات فشرده سازی، همانطور که در زیر توضیح داده شده است.
(1) کشش: مسیر r( 0 )r(0)با L0�0امتیاز و آهنگ r( 1 )r(1)با L1�1نقاط به دنبال تاب (r( 0 )(ل0( 0 ) ) ،…،r( 0 )(ل0(ک0− 1 ) ) )(r(0)(�0(0)),…,r(0)(�0(�0−1)))و آهنگ (r( 1 )(ل1( 0 ) ) ،…،r( 1 )(ل1(ک0− 1 ) ) )(r(1)(�1(0)),…,r(1)(�1(�0−1)))به طور جداگانه با استفاده از DTW برای کشش هر دو مسیر برای مهار ک0�0نکته ها. برخی از نقاط یک مسیر با مکان های مشابه با همان نقطه در مسیر دیگر مطابقت دارند. بنابراین، نقاط در مسیرهای تاب خورده، تکرار نقاط در مسیرهای اصلی هستند. مسیر تاب خورده کوتاهتر از هر دو آهنگ اصلی نیست، به عنوان مثال ، ک0⩾L0a n dک0⩾L1�0⩾�0����0⩾�1که به آن “کشش” می گویند.
(2) فشرده سازی: برخی از نقاط یک مسیر با همان نقطه در مسیر دیگر مطابقت دارند، که منجر به تناظر چند به یک بین نقاط داده در مسیرهای کشیده می شود. ما مسیرهای کشیده شده را با کوچک کردن نقاط داده آنها فشرده می کنیم، که از همان نقطه داده در مسیر اصلی منحرف شده اند. ما فقط نقطه ای را با کمترین فاصله تا نقطه مربوطه در مسیر کشیده دیگر نگه می داریم. به این ترتیب، آهنگ های کشیده شده است (r( 0 )(ل0( 0 ) ) ،…،r( 0 )(ل0(ک0− 1 ) ) )(r(0)(�0(0)),…,r(0)(�0(�0−1)))و (r( 1 )(ل1( 0 ) ) ،…،r( 1 )(ل1(ک0− 1 ) ) )(r(1)(�1(0)),…,r(1)(�1(�0−1)))به Track فشرده می شوند r( 0 )جr�(0)و r( 1 )جrج(1)با جی0جی0نقاط، ایجاد مسیرهای فشرده سازی w( 0 )جwج(0)و w( 1 )جwج(1)، جایی که r( 0 )ج(j0) =r( 0 )(ل0(ک0(j0)) ) )rج(0)(�0)=r(0)(ل0(ک0(�0)))، r( 1 )ج(j0) =r( 1 )(ل1(ک0(j0)) ) )rج(1)(�0)=r(1)(ل1(ک0(�0)))، w( 0 )ج(j0) =ل0(ک0(j0) )wج(0)(�0)=ل0(ک0(�0))و w( 1 )ج(j0) =ل1(ک0(j0) )wج(1)(�0)=ل1(ک0(�0)). ل0(ک0(j0) )ل0(ک0(�0))شاخص موقعیت مکانی است j0�0-مین نقطه از مسیر فشرده r( 0 )جrج(0)در آهنگ اصلی r( 0 )r(0)و شاخص موقعیت مکانی است j0�0-مین نقطه از مسیر فشرده r( 1 )جrج(1)در آهنگ اصلی r( 1 )r(1). نقطه داده یک آهنگ فشرده تنها با یک نقطه داده از یک آهنگ فشرده دیگر در شاخص همزمان مطابقت دارد که به آن تناظر یک به یک می گویند. با فشرده سازی آهنگ ها، آنها کوتاه تر از آهنگ های اصلی هستند، به عنوان مثال ، جی0⩽L0a n dجی0⩽L1جی0⩽�0آ�دجی0⩽�1.
3.4.3. تراز چند آهنگ
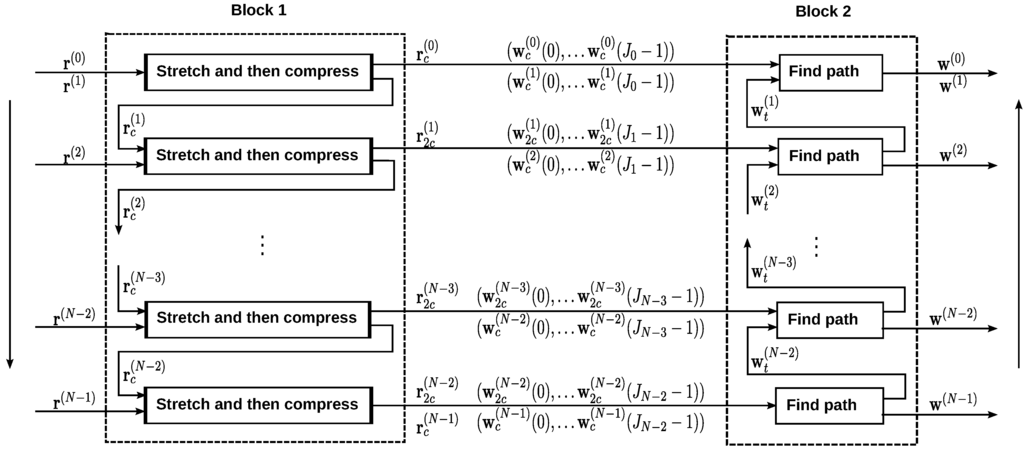
ما با استفاده از استراتژی «کشش و سپس فشردهسازی» چندین مسیر را تراز میکنیم تا همه آهنگها را یکی یکی از اولین تا آخرین آهنگ بهطور متوالی پردازش کنیم.
بلوک 1 در شکل 5 روش ارائه شده در زیر را نشان می دهد:
(الف) آهنگ r( 0 )r(0)با L0�0امتیاز و آهنگ r( 1 )r(1)با L1�1نقاط ورودی به ماژول “کشش و سپس فشرده سازی” هستند تا آهنگ های یک بار فشرده شده را بدست آورید. r( 0 )جrج(0)و r( 1 )جrج(1). مسیرهای فشرده سازی w( 0 )جwج(0)و w( 1 )جwج(1)شاخص های مکان Track را شرح دهید r( 0 )جrج(0)و آهنگ r( 1 )جrج(1)در آهنگ های اصلی، r( 0 )r(0)و r( 1 )r(1)، به طور جداگانه، که در آن c به معنای یک بار فشرده سازی در اینجا است.
(ب) آهنگ یک بار فشرده r( 1 )جrج(1)و آهنگ r( 2 )r(2)ورودی های ماژول “کشش و سپس فشرده سازی” هستند که منجر به دوبار فشرده شدن آهنگ می شود r( 1 )2 جr2ج(1)و آهنگ یکبار فشرده شده r( 2 )جrج(2)، جایی که 2 ج2جیعنی اینجا دوبار فشرده شده. مسیرهای فشرده سازی w( 1 )2 جw2ج(1)شاخص های زمانی مسیر دوبار فشرده شده را ذخیره کنید r( 1 )2 جr2ج(1)در مسیر یکبار فشرده شده r( 1 )جrج(1)و w( 2 )جwج(2)برای شاخص های زمانی مسیری که یک بار فشرده شده است r( 2 )جrج(2)در آهنگ اصلی r( 2 )r(2).
(C) آهنگ یک بار فشرده r( n )جrج(�)و آهنگ جدید r( n + 1 )r(�+1)، به ماژول “کشش و سپس فشرده سازی” تا آخرین آهنگ وارد می شوند r( ن– 1 )r(ن–1)پردازش می شود.
خروجی های بلوک 1 تراک های یک بار فشرده شده برای اولین و آخرین تراک هستند r( 0 )جrج(0)و r( ن– 1 )جrج(ن–1)، آهنگ های دوبار فشرده شده برای آهنگ های دیگر {r( n )2 ج, n = 1 , … , N− 2 }{r2ج(�)،�=1،…،ن–2}، مسیرهای فشرده سازی {w( n )ج، n =0 ، … ، N− 1 }{wج(�)،�=0،…،ن–1}، که شاخص های زمانی تراک های یک بار فشرده شده را در مسیرهای اصلی و مسیرهای فشرده نگه می دارد. {w( n )2 ج, n = 1 , … , N− 2 }{w2ج(�)،�=1،…،ن–2}برای نمایههای مکان آهنگهای دوبار فشردهشده در مسیرهای یکبار فشردهشده.
شکل 5. تراز چند مسیر. در بلوک 1، مسیرها یک به یک به ترتیب تصادفی با استفاده از “کشش و سپس فشرده سازی” تراز می شوند و مسیرهای میانی را تولید می کنند. بلوک 2 نحوه یافتن مسیرهای نرمال شده را نشان می دهد که برای تراز کردن همه مسیرها با مطابقت یک به یک در بین نقاط با استفاده از مسیرهای میانی تولید شده در بلوک 1 استفاده می شود.
فشرده سازی در بلوک 1 ضروری است، زیرا هر نقطه در یک مسیر فشرده دارای یک نقطه متناظر منحصر به فرد در مسیرهای فشرده دیگر است. با مکاتبات یک به یک، نقاط موجود در مسیرهای دیگر مربوط به نقاط r( n )2 جr2ج(�)را می توان به راحتی مکان یابی کرد. بدون مرحله فشردهسازی، مسیرها با مکاتبات چند به یک طولانیتر و طولانیتر میشوند، زیرا مسیرهای جدید با استفاده از DTW تاب میخورند که منجر به افزایش هزینههای محاسباتی میشود.
بلوک 2 نحوه یافتن مسیرهای نرمال شده را نشان می دهد {w( n )، n = 0 ، … _ N− 1 }{w(�)،�=0،…،ن–1}که با استفاده از مسیرهای میانی، تمام مسیرها را با تناظر یک به یک در میان نقاط تراز می کند {w( n )تی، n = N− 2 , … , 1 }{wتی(�)،�=ن–2،…،1}، و در نتیجه آهنگ های عادی شده است {g( n ), n = 0 , … N− 1 }{�(�)،�=0،…ن–1}با همان طول مسیر نرمال شده w( n )w(�)اطلاعات مکان نقاط مسیر نرمال شده را حفظ می کند g( n )�(�)در آهنگ اصلی r( n )r(�).
در میان آهنگ های خروجی از بلوک 1، آخرین آهنگ یک بار فشرده شده r( ن– 1 )جrج(ن–1)با جین– 2جین–2امتیاز کوتاه ترین مسیر است، از آن زمان جیnجی�همیشه کوتاهتر از جیn – 1جی�–1. در روش ما، r( ن– 1 )جrج(ن–1)به عنوان مسیر عادی گرفته می شود g( ن– 1 )�(ن–1)برای آهنگ r( ن– 1 )r(ن–1). برای آهنگ های دیگر، نقاط داده ای که مطابقت دارند g( ن– 1 )�(ن–1)ابتدا از مسیرهای دوبار فشرده شده انتخاب می شوند. شاخص های زمانی نقاط داده از g( n )�(�)که در r( n )جrج(�)با استفاده از یک مسیر میانی ایندکس می شوند w( n )تیwتی(�)، جایی که t به یک مسیر میانی موقت اشاره دارد. شاخص های زمانی نقاط داده از g( n )�(�)در مسیر ورودی اصلی r( n )r(�)را می توان با استفاده از مسیر میانی پیدا کرد w( n )تیwتی(�)و مسیر پیچ و تاب w( n )جwج(�):
مسیر عادی شده g( n )�(�)با انتخاب به دست می آید ک=جین– 2ک=جین–2امتیاز از r( n )r(�)با توجه به مسیر تاب نرمال شده آن w( n )w(�)، یعنی _ g( n )=r( n )(w( n ))�(�)=r(�)(w(�)).
شکل 6. مثالی از تراز چهار مسیر. ( الف ) نقاط داده آهنگ ها را در طول زمان نشان می دهد. در شکل 2، آهنگ ها r( 0 )r(0)و r( 1 )r(1)کشیده و فشرده می شوند و در نتیجه r( 0 )جrج(0)و r( 1 )جrج(1)، با خطوط سیاه نشان دهنده ارتباط آنها است. یک آهنگ یکبار فشرده شده و یک آهنگ جدید به ماژول “کشش و سپس فشرده سازی” وارد می شوند تا مطابقت یک به یک بین آهنگ های زیرشکل های 3 و 4 را بیابند. شکل فرعی 5 نحوه انجام مسیر نرمال شده را توسط خطوط اتصال پیدا کنید. ( ب ) نشان می دهد که چگونه نقاط داده مسیرهای نرمال شده از مسیرهای اصلی در طول مسیر نرمال شده انتخاب شده و با استفاده از خطوط سیاه به هم متصل می شوند.
نمونه ای از تراز چهار مسیر در شکل 6 نشان داده شده است . نقاط هر مسیر در امتداد محور زمان به صورت دایره هایی با رنگ های مختلف نشان داده شده است. اگر نقطه ای از مسیر با روش “فشرده سازی” حذف شود، با استفاده از یک ضربدر نشان داده می شود. در شکل فرعی اول شکل 6 الف، تمام نقاط داده به صورت دایره ای نشان داده شده اند، زیرا تراز مسیر شروع نشده است. در شکل فرعی دوم خود، r( 0 )r(0)و r( 1 )r(1)ورودی های ماژول “کشش و سپس فشرده سازی” هستند که منجر به r( 0 )جrج(0)و r( 1 )جrج(1)که به صورت دایره ای نشان داده شده اند و با خطوط مشکی به هم متصل می شوند. پنج امتیاز در r( 0 )r(0)و یکی در r( 1 )r(1)حذف می شوند. شکل فرعی بعدی نتایج Tracks را نشان می دهد r( 1 )جrج(1)و r( 2 )r(2)تراز به عنوان خطوط متصل از r( 1 )2 جr2ج(1)به r( 2 )جrج(2). در شکل فرعی چهارم، r( 2 )2 جr2ج(2)و r( 3 )جrج(3)کشیده و فشرده می شوند r( 2 )جrج(2)و r( 3 )r(3)بصورت جداگانه. نقاط داده سایر آهنگ ها که مطابقت دارند r( 3 )جrج(3)می توان با دنبال کردن خطوط اتصال، یعنی مسیرهای فشرده سازی، از پایین به بالا قرار گرفت. شکل 6 ب مکان فیزیکی نقاط برای هر مسیر را نشان می دهد. در این چهار مسیر به ترتیب 16، 13، 14 و 10 امتیاز وجود دارد. پس از تراز، 9 نقطه داده در هر آهنگ نگهداری می شود که با یکدیگر مرتبط هستند.
3.5. تحلیل آماری
در این مقاله از میانگین تمام مسیرها به عنوان نمایش هندسی یک بخش جاده استفاده می کنیم. از آنجایی که مسیرها دارای طول های متفاوتی هستند، میانگین گیری مستقیم آنها در شاخص های زمانی منجر به نتایج نادرست می شود. با آهنگ های عادی {g( n )n = 0 , … , N _− 1 }{�(�)،�=0،…،ن–1}با طول K یکسان ، که طبق مسیرهای تاب نرمال شده تاب میخورند {w( n )n = 0 , … , N _− 1 }{w(�)،�=0،…،ن–1}، آهنگ متوسط g = ( g ( 0 ) , … , g ( K– 1 ) )�=(�(0)،…،�(ک–1))می توان از مسیرهای نرمال شده در امتداد مسیرهای پیچ و تاب استخراج کرد.
با توجه به سرعت در هر نقطه از مسیر نرمال شده (س( n )( 0 ) ، … _س( n )( ک– 1 )(س(�)(0)،…،س(�)(ک–1)، جایی که n = 0 ، … ، N− 1 }�=0،…،ن–1}، سرعت متوسط، μ ( k )�(ک)و واریانس سرعت، δ( ک )�(ک)، در امتداد مسیر میانگین به صورت زیر محاسبه می شود:
جایی که k = 0 ، … ، K– 1ک=0،…،ک–1.
4. ارزیابی عملکرد الگوریتم
به منظور ارزیابی عملکرد الگوریتم پیشنهادی ما، باید دقت شبکه جادهای تولید شده را که متشکل از تقاطعها، اتصال آنها و نمایشهای بخش جاده است، محاسبه کنیم. شبکه جاده تولید شده باید هم از نظر توپولوژیکی و هم از نظر هندسی با توجه به نقشه حقیقت زمینی دقیق باشد. دقت توپولوژیکی شبکه راه ها تعداد تقاطع های استخراج شده در شبکه راه ها و اتصال آنها را توصیف می کند. به عنوان مثال، اینکه آیا هر جفت تقاطع به یکدیگر متصل هستند یا خیر، و در این صورت، آیا اتصال یک طرفه است یا دو طرفه. دقت هندسی به میزان دقت مکانهای جغرافیایی موجود در شبکه جادهای در مقایسه با نقشه حقیقت زمینی اشاره دارد.
4.1. محاسبه دقت توپولوژیکی
تقاطع های ما از ردیابی GPS استخراج شده است. به دلیل دقت و نقاط پرت محدود در ردیابی های GPS، هم ممکن است تقاطع های «جعلی» را که در نقشه حقیقت زمینی وجود ندارند شناسایی کنیم، و هم ممکن است نتوانیم برخی از تقاطع های واقعی را شناسایی کنیم (به عنوان مثال، که در نقشه حقیقت زمین وجود دارد . ). دقت تقاطع ها به سه جنبه اصلی بستگی دارد: تعداد تقاطع های “همسان” که با موفقیت شناسایی می شوند، تعداد تقاطع های “جعلی” و تعداد تقاطع های “مفقود شده”.
در این مقاله از دو پارامتر برای تعیین کمیت دقت تقاطع ها استفاده می کنیم: منسمنس، نسبت تقاطع های “جعلی” و منمترمنمتر، نسبت تقاطع های “فقدان” [ 16 ]; هر دو در زیر تعریف شده اند.
جایی که منسمنستعداد تقاطع های جعلی است، منجمنجتعداد تقاطع هایی که به درستی تطبیق داده شده اند و منمترمنمترتعداد تقاطع های غیر همسان، به عنوان مثال ، از دست رفته.
امتیاز F شناخته شده ، بر اساس ترکیبی از دقت و یادآوری، به عنوان نمره کیفیت کلی استفاده می شود:
مقادیر بالاتر از افمنافمن-score نشان می دهد که تشخیص تقاطع دقیق تر است [ 21 ].
مشابه شاخص های کیفیت تقاطع، ما همچنین شاخص های کیفیت را برای اتصال بین تقاطع ها تعریف می کنیم: rس�سنسبت بخشهای جادهای است که بهطور جعلی شناسایی شدهاند که در نقشه حقیقت زمینی وجود ندارند، rمتر�مترنسبت بخشهای جادهای «مفقودشده» که در نقشه حقیقت زمینی وجود دارد، اما شناسایی نمیشوند، و افrاف�امتیاز F مربوطه
4.2. ارزیابی دقت جغرافیایی
اندازه گیری دقت جاده های تولید شده نسبت به نقشه حقیقت زمینی مربوط به مبحث تطبیق نقشه می باشد. به عنوان اولین گام، این نیاز به تطبیق بخشهای جاده از نتایج تجربی با موارد موجود در نقشه حقیقت زمینی دارد. برای حل این مشکل می توان از الگوریتم های مختلفی استفاده کرد [ 26 ]، برای مثال فیلتر کالمن، منطق فازی و بسیاری دیگر. در مورد ما، بخش جاده را می توان با یافتن تقاطع های مربوطه از طریق بررسی فاصله بین نقاط داده روی نقشه حقیقت زمین و تقاطع ها به راحتی شناسایی کرد، زیرا در این مجموعه داده، حداکثر یک بخش جاده جهت دار بین هر جفت تقاطع وجود دارد. .
برای قضاوت در مورد تفاوت بین یک بخش جاده استنباط شده (همانطور که توسط الگوریتم در بخش 3.4.3 تولید شده است.و بخش جاده مربوطه در نقشه حقیقت زمینی، میتوانیم سادهلوحانه اندازهگیری را بر اساس فاصله بین نقاط در هر دو بخش جاده محاسبه کنیم. با این حال، این برخی از پیچیدگیها را به همراه دارد، زیرا بخشهای جاده استنباطشده در مقاله ما بهعنوان دنبالهای از نقاط داده (میانگین نقاط مسیرهای همسو با زمان) نشان داده میشوند. بخش های جاده حقیقت زمینی موجود نیز به عنوان یک سری زمانی از نقاط داده نشان داده می شوند. با این حال، تعداد کل نقاط در هر بخش جاده و توزیع آن در طول زمان می تواند به طور قابل توجهی بین داده های حقیقت استنباط شده و زمینی و از یک بخش جاده به دیگری متفاوت باشد. بنابراین، هر معیار کیفی بر اساس فواصل بین نقاط در حقیقت زمین و بخش های جاده استنباط شده تحت تأثیر این تغییرپذیری قرار می گیرد.
یک راه حل جزئی می تواند اعمال DTW برای تراز کردن سری های دو نقطه و تاب برداشتن آنها به سری های جدید با طول یکسان، سپس محاسبه معیار کیفیت در آن بخش های مسیر تاب خورده باشد. با این حال، این مشکل را به طور کامل حل نمی کند، زیرا سری های تاب خورده فقط می توانند حاوی نقاط تکرار شونده باشند، اما هرگز نمی توانند داده های از دست رفته را “پر کنند”. بنابراین، شکافهای زمانی بزرگ در حقیقت زمین یا دادههای استنباطشده میتواند منجر به فواصل مکانی بزرگ بین حقیقت زمین و دادههای استنتاج شده شود، حتی اگر بخشهای مسیر در غیر این صورت بسیار مشابه باشند. به عنوان مثال، نقاط اول و دوم جاده تولید شده در شکل 7a با استفاده از DTW با اولین نقطه روی حقیقت زمین تطبیق داده می شود، زیرا هیچ نقطه نزدیکتری روی حقیقت زمین یافت نمی شود. فاصله بین این نقاط جفت شده در واقع بزرگتر از فاصله واقعی بین بخش جاده تولید شده و حقیقت زمینی آن است [ 27 ].
شکل 7. نمونه ای از یک جاده. ( الف ) یک قطعه جاده تولید شده و حقیقت زمین آن را به عنوان مثال نشان می دهد. ( ب ) آنها را پس از درونیابی نشان می دهد تا خطای فاصله آنها ناشی از توزیع ناهموار نقاط داده در جاده را کاهش دهد.
در این مقاله، ما با درون یابی نقاط داده هر دو بخش جاده حقیقت استنباط شده و زمینی به این مشکل نزدیک می شویم. درونیابی فاصله مکانی بین نقاط متوالی در همان بخش جاده را به یک متر محدود می کند، همانطور که در شکل 7 ب نشان داده شده است، و سپس، میانگین فاصله بین نقاط داده درون یابی جفت شده را از طریق DTW به عنوان فاصله بین بخش جاده تولید شده محاسبه می کنیم. و حقیقت پایه آن از طریق درون یابی، نقاط داده متراکم تر و به طور مساوی توزیع می شوند و خطای اندازه گیری فاصله را کاهش می دهند.
5. آزمایشات
یک مجموعه داده از 889 GPS ردیابی در طول 118 ساعت از شاتل های دانشگاه ایلینویز برای آزمایش الگوریتم پیشنهادی استفاده می شود. این مجموعه داده را می توان به صورت عمومی در وب سایت آزمایشگاه BITS آنها [ 28]. دادههای GPS توسط رانندگان شاتل دانشگاه جمعآوری میشوند که یک آیفون دارند که برنامه ردیابی آزمایشگاه BITS را اجرا میکند. اگرچه برنامه آیفون آنها هر ثانیه موقعیت مکانی GPS خود را به سرور خود ارسال می کند، سرور گاهی اوقات داده های GPS را دریافت نمی کند که منجر به فاصله نمونه گیری متفاوتی از 1 ثانیه تا 29 ثانیه می شود (میانگین: 3.61 ثانیه؛ انحراف استاندارد: 3.67 ثانیه). اگرچه ضبطهای GPS آنها از یک دستگاه است، روش ما به نرخ نمونهگیری یکسانی نیاز ندارد. شاتل های شرکت کننده از هر دو منطقه با ساختمان های کم ارتفاع و سایر مناطق با خطای GPS قابل توجه به دلیل ساختمان های بلند حرکت می کنند. ردیابی خام GPS با خطوط سیاه در شکل 8 نشان داده شده است .
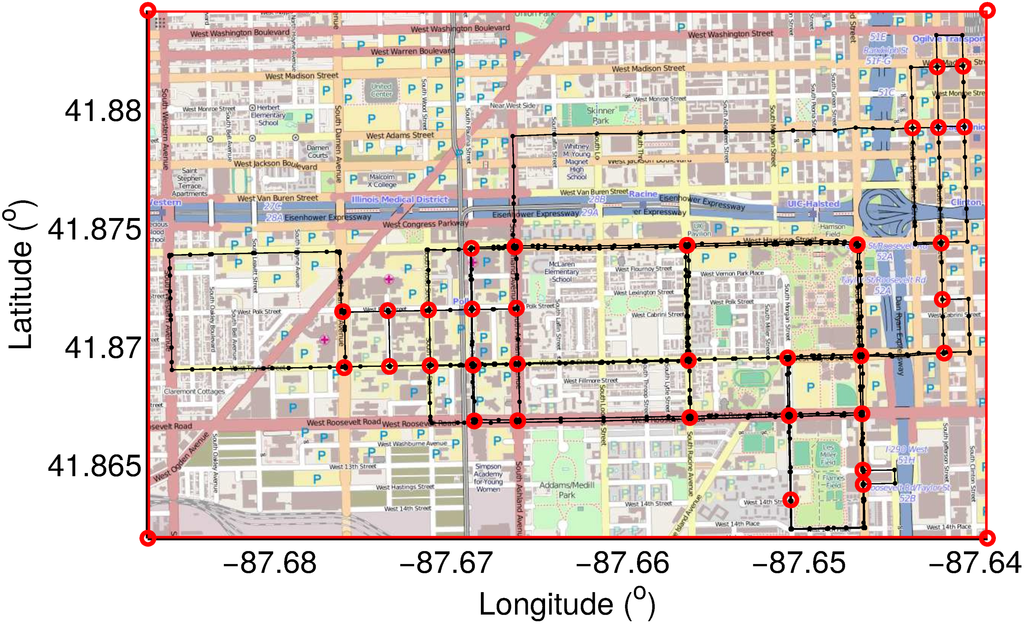
برای اندازهگیری دقت شبکه جادهای که از ردیابی شاتل ایجاد میشود، OpenStreetMap را به عنوان نقشه حقیقت زمینی انتخاب میکنیم. اگرچه خطای موقعیتی ردیابی GPS در OpenStreetMap تقریباً 10 تا 20 متر است، اما به دلیل دسترسی منبع باز و پوشش وسیع، همچنان به عنوان حقیقت اصلی برای تحقیقات در تولید شبکه جاده ای استفاده می شود. از آنجایی که شاتل ها همه خیابان ها را در OpenStreetMap کاوش نکردند [ 29 ]، شبکه جاده ای تولید شده تنها جایی که شاتل ها رفتند را پوشش می دهد. نقشه حقیقت زمینی به صورت دستی به خیابان هایی کاهش می یابد که در واقع توسط شاتل ها عبور کرده اند. شکل 9 نقشه حقیقت زمین را با دایره های قرمز برای تقاطع ها و خطوط سیاه با دایره های سیاه و سفید برای بخش های جاده نشان می دهد.
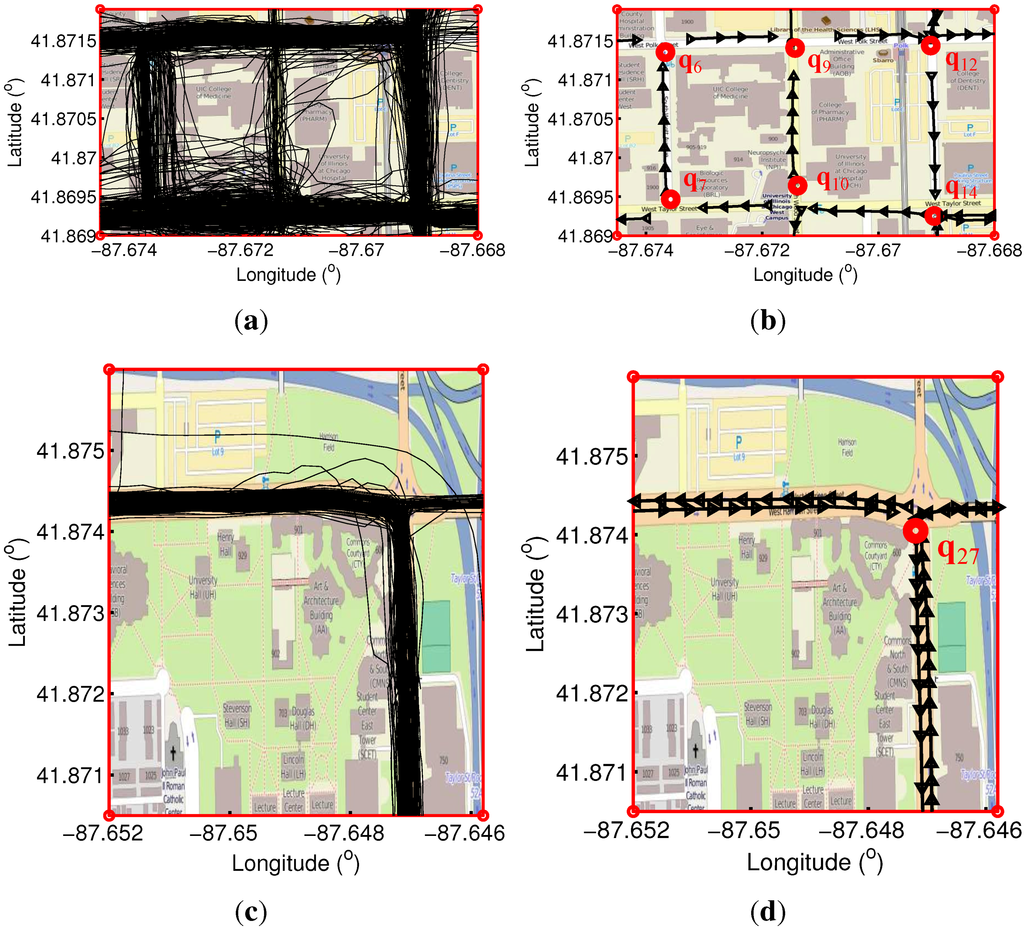
شکل 8. استخراج تقاطع. تقاطع ها در دایره های قرمز از نقاط عطف در نقاط سبز تشخیص داده می شوند، جایی که شاتل ها جهت حرکت خود را تغییر می دهند.
شکل 9. نقشه حقیقت زمین. نقشه حقیقت زمینی هدایت شده به صورت دستی از طریق کاهش نقشه خیابان باز این منطقه به خیابان هایی که شاتل ها از آن عبور می کنند ساخته شده است.
5.1. نتایج با استفاده از روش ما
5.1.1. نقاط عطف و تقاطع استنباط شده
در شکل 8 ، نقاط عطف استخراج شده از همه 889 ردیابی GPS به صورت نقاط قرمز نشان داده شده است. مکان هایی که بسیاری از نقاط عطف جمع می شوند و به عنوان تقاطع تشخیص داده می شوند، در شکل 8 با نقاط سبز نشان داده شده اند . گاهی اوقات، نقاط عطف جدا شده به دلیل خطاهای GPS یا پوشش ناکافی از شاتل شناسایی می شوند. این نقاط عطف جدا شده به عنوان تقاطع در الگوریتم ما در نظر گرفته نمی شوند. شکل 8 تقاطعی را نشان می دهد که ظاهراً بین آن وجود دارد q14q14و q15q15. با این حال، با استفاده از روش ما، هیچ تقاطعی در آنجا شناسایی نمیشود، زیرا تنها چند نقطه عطف مجزا وجود دارد.
در این مکان، شاتل همیشه بدون تغییر جهت حرکت می کند، احتمالاً به دلیل وجود یک پل. علاوه بر این، دو تقاطع در نقشه حقیقت زمین در اطراف محل تقاطع استخراج شده وجود دارد q26q26با استفاده از روش ما ما متوجه شدیم که نقاط عطف در یک گروه قرار دارند q26q26، زیرا آنها بیش از حد به یکدیگر نزدیک هستند. پیچ هایی که کاربران جاده همیشه در یک جهت می چرخند به عنوان تقاطع شناخته نمی شوند. به عنوان مثال، دو خم در لبه سمت چپ نقشه از تقاطع ها حذف می شوند. در مجموع، 36 تقاطع، که به صورت دایره های قرمز در شکل 8 نشان داده شده اند، از نقاط عطف تشخیص داده می شوند، در حالی که در واقع 33 تقاطع بر روی نقشه حقیقت زمین، همانطور که در شکل 9 نشان داده شده است، وجود دارد . تقاطع های بیشتری با استفاده از روش ما به دلیل نویز GPS شناسایی می شوند.
در نقشه حقیقت زمین، هر تقاطع در مرکز تقاطع بین بخشهای جاده قرار دارد. با این حال، تقاطع هایی که با استفاده از روش ما شناسایی می شوند، بسته به نوع چرخش هایی که شاتل در یک اتصال خاص انجام می دهد، گاهی اوقات از مرکز منحرف می شوند. به عنوان مثال، تقاطع q22q22چهار بخش جاده را به هم متصل می کند، اما شاتل فقط از سه تای آنها بازدید کرد. علاوه بر این، شاتل فقط یک نوع چرخش را در آنجا انجام داد: از آنجا می آمد q18q18، چرخش به راست در q22q22به q24q24. بنابراین، تقاطع شناسایی شده است q22q22به سمت جهت حرکت کرد q24q24. میانگین فاصله بین تقاطع های شناسایی شده و حقیقت زمین آنها است 22 . 6922.69متر
شکل 10 a مسیرها را به صورت خطوط سرخابی نشان میدهد، برای جادههایی که از تقاطعهای شاخص پایینتر شروع میشوند و به تقاطعهایی با شاخص بالاتر ختم میشوند. شکل 10 ب جاده های تولید شده از این مسیرها را با فلش هایی نشان می دهد که جهت جاده ها را نشان می دهد. در حالی که مسیرهای نشان داده شده با خطوط آبی در شکل 10 ج برای جاده ها از تقاطع های شاخص بالاتر به تقاطع های شاخص پایین تر و شکل 10 d برای جاده های هدایت شده تولید شده از این مسیرها هستند. در مجموع 38 جاده در شکل 10 ب و 39 در شکل 10 د استخراج شده است که به این معنی است که 77 جفت تقاطع به طور مستقیم به یکدیگر متصل می شوند. از شکل 10، همچنین می دانیم که برخی از جاده ها یک طرفه هستند، به عنوان مثال بخش جاده بین تقاطع اول و سوم. شاتل ها همیشه از q1q1به q3q3و هرگز جهت مخالف را انتخاب نکنید. در مورد دیگر، شاتل ها بین تقاطع حرکت می کنند q22q22و q29q29در هر دو جهت با توجه به ردیابی GPS آنها. با این حال، همانطور که در شکل 9 نشان داده شده است، هیچ بخش جاده ای بین آنها در نقشه حقیقت زمینی وجود ندارد . این می تواند ناشی از ساخت و ساز موقت جاده باشد. مجموعه داده شیکاگو در آوریل 2011 ثبت شد، اما OpenStreetMap در آگوست 2014 مشاهده شد. با بررسی این بخش جاده در نمای خیابان Google در نزدیکترین تاریخها به تاریخ دسترسی، جاده بین تقاطع q22q22و q29q29در می 2011 قابل دسترسی بود، اما به دلیل ساخت و ساز جاده در اکتبر 2014 مسدود شد.
شکل 10. جاده های هدایت شده. ( الف ) بخشی از مسیرها را نشان میدهد که برای تولید جادههای هدایتشده در ( ب ) میانگین میشوند. ( ج ) قسمت دیگر مسیرها را نشان میدهد که برای تولید جادههای هدایتشده در ( d ) میانگین میشوند.
5.1.2. جاده های استنباط شده
شکل 10 جاده های هدایت شده را در هر جهت به طور جداگانه نشان می دهد.
برای هر بخش جاده، سرعت متوسط و تغییرات سرعت در امتداد نقاط داده میانگین مسیر محاسبه شده در بخش 3.5 در شکل 11 نشان داده شده است . رنگ نقاط نشان دهنده نقاط قوت سرعت است و عرض باند در اطراف مسیر متوسط نشان دهنده تغییر سرعت است.
5.1.3. ارزیابی نتایج
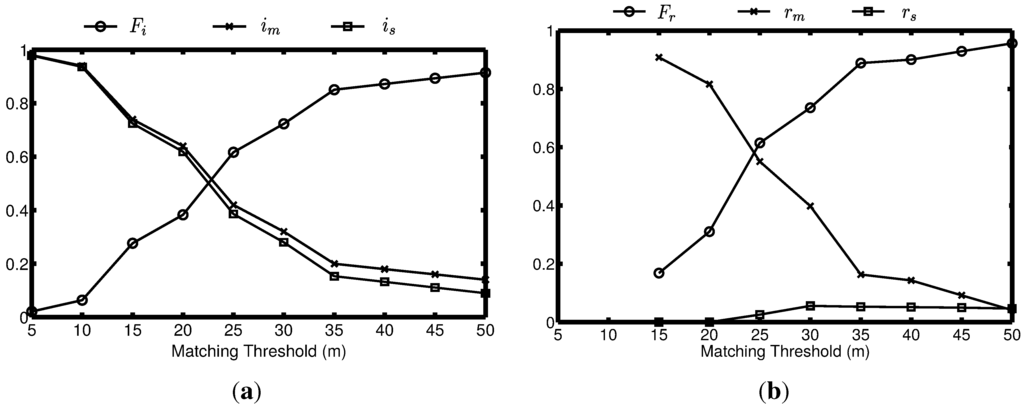
شکل 12 دقت توپولوژیکی شبکه جاده تولید شده را نشان می دهد، شکل 12 a دقت تقاطع ها و شکل 12 b دقت اتصال را نشان می دهد. آستانه تطبیق به عنوان فاصله مجاز بین تقاطع ها و موقعیت آنها در نقشه حقیقت زمین تعریف می شود. ما می توانیم ببینیم که با کمترین آستانه تطبیق 5 متری نشان داده شده در شکل 12الف، هیچ تقاطع منطبقی شناسایی نشد. در این حالت، تمام تقاطع های موجود در شبکه راه های تولید شده به عنوان تقاطع های جعلی و تمام تقاطع های موجود در نقشه حقیقت زمینی به عنوان تقاطع های گمشده طبقه بندی می شوند. همانطور که آستانه تطبیق بزرگتر می شود، تقاطع های بیشتری شناسایی شده و با حقیقت زمین مطابقت داده می شود و در نتیجه کاهش می یابد. منسمنسو منمترمنمترو بالاتر افمنافمن. شکل 12 ب دقت اتصال بین تقاطع های شناسایی شده را نشان می دهد. در شبکه جاده های تولید شده ما، هیچ لبه کاذب وجود ندارد، اگرچه گاهی اوقات، تقاطع ها به اشتباه متصل می شوند. چنین خطاهایی بر روی افrاف�عدد. با آستانه تطبیق 5 و 10 متری، تنها چند تقاطع در شبکه جاده تولید شده و نقشه حقیقت زمینی مطابقت داده شده است. با این حال، این تقاطع ها به یکدیگر متصل نیستند، بنابراین هیچ نتیجه کمی در این دو آستانه در شکل 12 ب نشان داده نشده است.
شکل 11. تجزیه و تحلیل آماری. سرعت و تغییرات سرعت در امتداد بخش جاده از تقاطع q3q3به q1q1به تصویر کشیده می شوند.
شکل 12. ارزیابی دقت توپولوژیکی. ( الف ) دقت تقاطع های ایجاد شده را نشان می دهد. ( ب ) دقت اتصال بین تقاطع ها را نشان می دهد. با فواصل تطبیق متفاوت بین تقاطع های ایجاد شده و حقیقت زمینی آنها. هرچه امتیاز F بزرگتر باشد، دقیق تر است.
با 50 متر به عنوان آستانه تطبیق برای تقاطع ها، 77 جاده هدایت شده در مقاله ما شناسایی شده است. میانگین فاصله بین تمام جاده های تولید شده و حقیقت زمینی آنها برای توصیف دقت جغرافیایی شبکه جاده تولید شده استفاده می شود که به صورت محاسبه می شود. 7 . 357.35متر
5.1.4. بحث در مورد اینکه ترتیب همسویی چگونه بر نتایج تأثیر می گذارد
از آنجایی که ما مسیرها را یک به یک کشیده و فشرده می کنیم، تراک هایی که ورودی بلوک 1 قبل از آن هستند باید تأثیر بیشتری بر نتایج داشته باشند. به خصوص اگر نقاط داده GPS یک مسیر در مرحله فشرده سازی حذف شوند، نقاط داده در مسیرهای دیگر که بعداً با این نقاط حذف شده مطابقت دارند نیز با استفاده از الگوریتم ما حذف می شوند که منجر به تأثیر نامتعادل می شود. با این حال، مسیرهایی که برای استخراج بخش جاده استفاده می شود کاملاً شبیه به یکدیگر هستند. علاوه بر این، آهنگهای پرت با امتیاز شباهت پایینتر حذف میشوند و برای انجام همترازی مسیر استفاده نمیشوند. در این صورت ترتیب تراز کردن مسیرها تاثیر زیادی روی نتایج نخواهد داشت.
نتایج نشان داده شده در شکل 10 با استفاده از ترتیبی بر اساس امتیاز شباهت آنها به مسیرهای دیگر که به عنوان مجموع امتیاز شباهت آنها به هر آهنگ دیگر محاسبه می شود، از مسیرها استخراج می شود. برای ارزیابی کمی تأثیر، ما همچنین آهنگ ها را با تراز کردن آنها در 50 ترتیب تصادفی دیگر، میانگین گرفتیم. میانگین فاصله بین قطعه جاده تولید شده و حقیقت زمین آن با 50 مرتبه مختلف محاسبه شده و در شکل 13 نشان داده شده است . محور افقی و عمودی به ترتیب شاخص ترتیب تراز و فاصله را نشان می دهد. مهم نیست که کدام ترتیب برای تراز کردن مسیرها انتخاب شده است، فاصله از بخش جاده تولید شده تا حقیقت زمین همیشه در اطراف است. 7 . 387.38m با حداکثر مقدار 7 . 857.85متر و حداقل مقدار 6 . 816.81m، که به این معنی است که ترتیب تراز تأثیر قابل توجهی در میانگین گیری مسیرها ندارد.
شکل 13. تأثیر ترتیب تراز. مهم نیست که مسیرها به چه ترتیبی در یک راستا قرار دارند، میانگین فاصله بین تمام جاده های تولید شده و حقیقت زمینی آنها در اطراف است. 7 . 377.37m پایدار است، به این معنی که ترتیب تراز به طور قابل توجهی بر تراز مسیر تأثیر نمی گذارد.
5.2. مقایسه با سایر روش ها
نتایج ما با روشهای موجود به شرح زیر مقایسه میشوند: روش برازش منحنی پیشنهاد شده توسط Schroedl [ 2 ]، روش مبتنی بر KDE توسط Davies [ 3 ] و همچنین روش ادغام ردیابی پیشنهاد شده توسط Cao [ 4 ]. از آنجایی که ارزیابیهای کمی و کیفی این سه الگوریتم موجود در Biagioni و Eriksson در [ 16 ] با استفاده از همان مجموعه دادههای شاتل پردیس شیکاگو مانند ما انجام شده است ، میتوانیم نتایج الگوریتمهای آنها را مستقیماً با الگوریتم خود مقایسه کنیم.
شکل 14 نتایج همان دو مثالی را نشان می دهد که بیاجیونی در مقاله خود استفاده کرده است [ 16 ]، یک مثال با ردیابی GPS با خطای بالا، در حالی که دیگری با ردیابی GPS با خطای پایین. هم Schroedl و هم Cao با استفاده از ردیابی GPS با خطای بالا در شکل 14 a لبه های جاده های جعلی تولید کردند، در حالی که الگوریتم ما، بر اساس تشخیص تقاطع، توپولوژی جاده را با موفقیت بدون افزودن لبه های اضافی استخراج کرد. اگرچه دیویس جادههای تمیزی را نیز تولید کرد، روش ما همچنان بهتر از روش اوست، زیرا جادههای تولید شده ما هدایتشده هستند، در حالی که او فقط جادههای هدایت نشده را استخراج میکرد.
شکل 14 الف بخشی از مسیرها را نشان می دهد که برای تولید جاده های هدایت شده در شکل 14 ب به طور متوسط محاسبه شده اند. شکل 14 ج بخش دیگری از مسیرها را نشان می دهد که برای تولید جاده های هدایت شده در شکل 14 د.
شکل 14. مقایسه با روش های دیگر. ( الف ) برخی از ردیابی های GPS با خطای بالا را نشان می دهد که برای استخراج جاده های هدایت شده در ( b ) استفاده می شود. ردیابی در ( c ) خطای نسبتاً کمی دارد و در نتیجه جادههای جهتدار در ( d ) میشوند.
علاوه بر این، 83 درصد از جادهها در فاصله 10 متری از حقیقت زمین شناسایی میشوند که از همه روشهای ذکر شده در بالا که امتیاز F کمتر از آن است، بهتر عمل میکند. 0 . 70.7با آستانه تطبیق 15 متری، همانطور که در شکل 6 در [ 16 ] نشان داده شده است.
6. نتیجه گیری و کار آینده
ما یک رویکرد جدید برای استنباط یک شبکه جادهای با استخراج تقاطعها، استنباط توپولوژی آنها و بخشبندی بخشهای جاده بین تقاطعها با استفاده از ردیابی GPS ارائه کردهایم. ما همچنین با استفاده از استراتژی «کشش و سپس فشردهسازی»، نمایشهای هندسی هر بخش جاده را با تراز کردن و میانگینگیری مسیرها برای هر بخش جاده تشکیل میدهیم. مسیرها، نقطه به نقطه، از طریق عملیات “کشش” ما در بعد زمانی با استفاده از DTW تراز می شوند، و نقاط اضافی با استفاده از عملیات “فشرده سازی” ما حذف می شوند، که منجر به مطابقت یک به یک بین نقاط در تمام نقاط می شود. آهنگ های. تراز مسیر همچنین برای تجزیه و تحلیل آماری بیشتر مسیرها، مانند تجزیه و تحلیل سرعت و دینامیک زمان سفر در مکان های خاص، مفید است.
اگرچه الگوریتم ما از سایر روشهای موجود بهتر عمل میکند، استراتژی «فشردهسازی» ما نقاط داده کمتری را بهعنوان نمایش جاده تولید میکند، اگر در هر مسیری از دست دادن دادههای GPS کوچک وجود داشته باشد یا فرکانس نمونهگیری برخی از مسیرها کمتر از سایرین باشد. این امر به این دلیل است که مسیرهایی با از دست دادن داده های GPS زیاد یا با فرکانس نمونه برداری فوق العاده کم به عنوان نقاط پرت دسته بندی می شوند و با سایر مسیرها تراز نمی شوند. بنابراین، در آینده، ما بر تراز کردن مسیرها بدون استراتژی “فشرده سازی” و بنابراین، حفظ تناظر چند به یک در بین نقاط در همه مسیرها تمرکز خواهیم کرد. علاوه بر این، به جای منطق دو ارزشی در روش فعلی، روی استنباط آماری وجود و پوشش تقاطع ها و بخش های جاده با استفاده از روش احتمالی کار خواهیم کرد.









بدون نظر