

خلاصه
از آنجایی که سرمایهگذاران مهم ملی و بینالمللی پروژههای تحقیقاتی نیاز به اظهاراتی در مورد دسترسی بلندمدت به نتایج تحقیقات دارند، راهحلهای جدید بسیاری برای برآورده کردن این خواستهها ظاهر شد. راه حل ها در حوزه های مختلف، از راه حل های خاص برای یک گروه تحقیقاتی تا راه حل هایی با تمرکز ملی ( به عنوان مثال، پروژه رادار). در حالی که پورتالهایی برای دادههای پژوهشی استاندارد شده در سطح جهانی (مثلاً دادههای آب و هوا) در دسترس هستند، در حال حاضر هیچ پیشبینی برای حجم زیادی از دادههای حاصل از تحقیقات تخصصی در کانونهای تحقیقاتی فردی، به اصطلاح دم دراز علوم، وجود ندارد. در این مقاله ما ملاحظات مربوط به اجرای یک مخزن داده های تحقیقاتی محلی برای مرکز تحقیقات مشترک (CRC) 840 را شرح می دهیم. تمرکز اصلی بر بررسی الزامات و دستور کار اجرای فنی احتمالی خواهد بود. الزامات از بررسی نظری بیشتر پروژههای مشابه و ادبیات مرتبط، بحثهای متنوع با محققان و رهبران پروژه، با تجزیه و تحلیل دادههای انتشارات موجود، و در نهایت اجرای نمونه اولیه با تکرارهای اصلاحشده به دست آمد. به ویژه، بحث با محققان منجر به ویژگی های جدیدی می شود که فراتر از چالش های صرفاً حفظ طولانی مدت داده های تحقیقاتی است. علاوه بر نیاز به زیرساختی که امکان حفظ و بازیابی طولانی مدت داده های تحقیقاتی را فراهم می کند، سیستم ما امکان بازسازی منشأ کامل نتایج تحقیقات منتشر شده را فراهم می کند. این نیاز یک تنوع جدی برای مشکل است، زیرا نیاز به واجد شرایط بودن دادههای تبدیل اضافی را ایجاد میکند و فرآیند تبدیل از دادههای تحقیقات اولیه به نتایج تحقیقات را توصیف میکند. سیستم ما امکان بازسازی منشأ کامل نتایج تحقیقات منتشر شده را می دهد. این نیاز یک تنوع جدی برای مشکل است، زیرا نیاز به واجد شرایط بودن دادههای تبدیل اضافی را ایجاد میکند و فرآیند تبدیل از دادههای تحقیقات اولیه به نتایج تحقیقات را توصیف میکند. سیستم ما امکان بازسازی منشأ کامل نتایج تحقیقات منتشر شده را می دهد. این نیاز یک تنوع جدی برای مشکل است، زیرا نیاز به واجد شرایط بودن دادههای تبدیل اضافی را ایجاد میکند و فرآیند تبدیل از دادههای تحقیقات اولیه به نتایج تحقیقات را توصیف میکند.
کلید واژه ها:
مدیریت داده های تحقیق ; انتشارات ; نگهداری طولانی مدت ؛ ابرداده
1. مقدمه و انگیزه
اهمیت دسترسی بلندمدت و دسترسی عمومی به دادههای تحقیقاتی با انتشار «اصول و دستورالعملهای OECD برای دسترسی به دادههای تحقیقاتی از بودجه عمومی» در سال 2007 به طور قابل توجهی افزایش یافت [1 ] . ایده اصلی دستورالعمل ها تشویق انتشار داده های تحقیقاتی با حقوق دسترسی آزاد است تا امکان استفاده مجدد از نتایج توسط سایر گروه های تحقیقاتی فراهم شود. بنابراین، فرآیندهای تحقیق به طور کلی می تواند با اجتناب از کارهای تکراری تسریع شود. در همان زمان، مجلات مهمی (به عنوان مثال، Nature) شروع به درخواست دسترسی به داده های تحقیقاتی مورد استفاده در انتشارات کردند. نتایج منتشر شده باید برای داوران و خوانندگان قابل تکرار باشد. این ایده های اساسی توسط سرمایه گذاران اصلی (مثلاً در آلمان توسط Deutsche Forschungsgemeinschaft – DFG) پذیرفته شد.2 ]. بنابراین، توصیف دسترسی بلندمدت به دادههای پژوهشی باید بخشی از پیشنهادات پژوهشی باشد و امروزه پیششرطی برای تأمین مالی پروژههای بزرگ است.
اگرچه تقاضا برای نگهداری طولانی مدت داده های تحقیقاتی برای مدتی وجود داشته است، اما زیرساخت های ذخیره سازی داده های تحقیقاتی به کندی توسعه یافته است، به ویژه در مناطقی که داده های تحقیق در درجه اول فردی هستند. مخازن در دسترس جهانی برای حفظ و استفاده مجدد از نتایج تحقیقات تنها در چند حوزه تحقیقاتی ایجاد شده است. دلیل اصلی فقدان مخازن فرامنطقه ای این است که جمع آوری مشترک داده های تحقیق و تضمین کیفیت فقط برای داده های بسیار استاندارد شده امکان پذیر است. نمونه های خوبی که در آن استانداردسازی به دست آمد، پروژه ژنوم انسانی (HGP) [ 3 ، 4 ]، تحقیقات آب و هوا، یا تنوع زیستی (GRBIO) [ 5] است.]. در بیشتر زمینه های تحقیقاتی، آزمایش ها بسیار تخصصی و گاه حتی تکی هستند. توصیف کلی این آزمایشها، محاسبات یا شبیهسازیهای بسیار خاص و نتایج آنها بسیار زمانبر است و محققان اغلب از صرف وقت برای شرح دقیق کار خود اجتناب میکنند. راهحلهای موجود برای ذخیرهسازی طولانیمدت دادهها از این نوع، تخصصی هستند و معمولاً برای استفاده عمومی و حتی کمتر برای استفاده مجدد طراحی نشدهاند.
وضعیت در دانشگاه ها در واقع هنوز متنوع است. پشتیبانی از حفظ داده های تحقیقاتی عمدتاً به ارائه فضای ذخیره سازی دیسک با در دسترس بالا و راه حل های پشتیبان مناسب محدود می شود. همکاری در بسیاری از موارد به استفاده از پوشه های مشترک محدود می شود. ابزارها یا پورتال هایی برای پشتیبانی از جستجوی فراداده بسیار نادر هستند. مؤسساتی که میتوانند نقش مهمی ایفا کنند، مانند کتابخانهها یا مراکز فناوری اطلاعات، در ایجاد راهحل تردید دارند، زیرا سیاستهایی برای درمان نتایج تحقیقات هنوز توسط دولت نصب نشده است. بنابراین، فعالیتها معمولاً از پروژههای منفرد منتج به تعدادی مخزن مستقل و ناسازگار میشوند. این راه حل های بسیار تخصصی به گونه ای طراحی نشده اند که بسط داده شوند تا در مراکز تحقیقاتی دیگر مورد استفاده قرار گیرند و بنابراین تعداد مخازن در حال افزایش است.
یک رویکرد جالب از نصب به اصطلاح “Fachinformationsdienste (FIDs)” در کتابخانه های آلمان [ 6 ] ناشی می شود. در پاسخ به ارزیابی انتظارات محققان که در سالهای 2010-2011 انجام شد، DFG سیستم مجموعههای موضوعی ویژه سراسری را بازسازی کرد. تمرکز اصلی برای FID های نصب شده جدید، تامین داده ها و اطلاعات لازم در مورد نیازهای ویژه هر حوزه تحقیقاتی خواهد بود. برخی از کتابخانههایی که برای چنین FIDهایی درخواست دادهاند تا راهحلهایی را برای حفظ طولانیمدت دادههای تحقیقاتی در پورتالهای گروههای ذینفع خاص قرار دهند [ 7 ].
در حالی که سرمایهگذاران و ناشران عموماً خواستار دسترسی طولانیمدت و دسترسی آزاد به دادههای تحقیقاتی هستند [ 8]، بحث و گفتگو با محققان نشان می دهد که آنها دیدگاه های متفاوتی در مورد آن موضوع دارند. به طور کلی از بهبود دسترسی بلندمدت و همکاری با سایر گروههای تحقیقاتی استقبال میشود. با این حال، موضع آنها در مورد دسترسی به داده های پژوهشی این است که در طول فرآیند تحقیق باید به شدت به افراد خاصی محدود شود. حتی پس از انتشار نتایج، دسترسی آزاد به دادههای تحقیقات اولیه مورد نیاز نیست، زیرا اعتقاد بر این است که استفاده مجدد از دادهها باید حداقل برای مدتی محدود به گروه تحقیقاتی اصلی باشد. با در نظر گرفتن این موضوع، حتی دسترسی بازبینان به داده ها نیز با شک و تردید دیده می شود. بنابراین، هر راهحلی برای مدیریت دادههای پژوهشی باید یک سیستم مدیریت حقوق بسیار پیچیده را پیادهسازی کند، که با تقاضای محافظت از دادهها از دسترسی غیرمجاز از یک طرف مقابله کند.
در مورد ویژه مرکز تحقیقات مشارکتی (CRC) 840، هماهنگکنندگان پروژههای فرعی به عنوان سهامداران مهم دیگری به آن ملحق شدند. آنها خواستار راهی آسان برای درک منشأ نتایج تحقیق شده اند. به طور دقیق تر، آنها می خواهند در صورت لزوم اطلاعاتی در مورد منشاء، تبدیل و تفسیر داده های تحقیق به دست آورند. این سوال از این واقعیت ناشی می شود که محققان ممکن است CRC را در طول دوره تامین مالی ترک کنند. هنگامی که سؤالاتی در مورد نتایج تحقیق مطرح می شود، بازتولید نتایج فقط از روی داده های اولیه یا نتایج بسیار دشوار خواهد بود. بنابراین، نه تنها نتایج و داده های تحقیقات اولیه باید ذخیره شود، بلکه کل فرآیند تبدیل از داده های اولیه به نتایج تحقیق باید ذخیره شود. چالشهای ناشی از این تقاضا بعداً به تفصیل مورد بحث قرار خواهند گرفت.
با توجه به این خواسته های ناهمگون، تصمیم گرفتیم الزامات یک مخزن مدیریت داده را در چندین سطح ارزیابی کنیم. اول از همه، ما پروژه های موجود، الزامات آنها و پیشرفت اجرای آنها را مطالعه می کنیم. پس از آن، برخی مصاحبهها و بحثهای مفصل با محققان در CRC منجر به اولین مفهوم برای یک مخزن شد که متعاقباً به عنوان نمونه اولیه پیادهسازی شد. این اولین پیاده سازی در برخی از مراحل تکراری اصلاح شد تا پیشنهادات محققان را در بر گیرد. این تلاش بر روی پردازش داده های تحقیقات اولیه متمرکز بود. برای تکمیل مفهوم در رابطه با نمایش تبدیل داده ها، در ابتدا سعی کردیم ایده ای از نوع و مقدار داده ای که باید با آن سر و کار داشته باشیم به دست آوریم. به آن دلیل،
به طور خلاصه، تمرکز اصلی این دستنوشته، شرح فرآیند ایجاد نیازمندیها برای مخزن دادههای تحقیقاتی برای CRC 840، خود نیازمندیها و مفهوم پیادهسازی ناشی از آن است.
2. الزامات ناشی از پیشینه نظری
با توجه به تفسیر گسترده داده های تحقیق و مدیریت داده های تحقیق، به طور کلی، و خواسته های ناهمگون از سوی ذینفعان درگیر، طیف گسترده ای از موضوعات مرتبط باید در نظر گرفته شود. برای اینکه راه خود را گم نکنیم، ابتدا سه سوال اصلی را به عنوان یک جهت گیری از طریق انتشارات مختلف اعلام کردیم:
- (1)
-
به طور کلی داده های تحقیق چیست و چگونه این اصطلاح را در مورد CRC 840 تعریف کنیم؟
- (2)
-
حفظ طولانی مدت و مدیریت داده ها به چه معناست؟
- (3)
-
چه چیزی می توانیم از رویکردهای امیدوارکننده در پروژه های موجود بیاموزیم؟
برای شروع، نگاهی به دیدگاه آکادمیک نگهداری طولانی مدت، مدیریت داده ها، و الزامات ناشی از آن برای یک مفهوم مناسب برای نگهداری، حفظ و انتشار داده انداختیم. در ارتباط با تعریف ابرداده مفید و استفاده از طرحواره های متادیتا معقول، می توان کانون های تحقیقاتی مختلفی را یافت. در ابتدا، یک جنبه مربوط به اطلاعات ساختاری و معنایی بر روی داده های منتشر شده است، و دوم، انتشارات تقویت شده بر اساس این اطلاعات و در نهایت، زیرساخت ها یا مفاهیم حمایت کننده از رویکردهای پژوهش الکترونیکی. سه پروژه مورد ارزیابی قرار گرفت که نشان دهنده سه کانون مختلف در مورد زیرساخت مدیریت داده است. پروژه “رادار” به عنوان اجرای یک مخزن داده های تحقیقاتی کلی ارائه شده است. پروژه های “Prospect” و “Driver I + II” در نظر گرفته شدند،
2.1. مفاهیم بنیادی
2.1.1. حفظ بلند مدت و مدیریت داده ها به طور کلی
لودویگ و انکه [ 9 ] اهداف حفظ طولانی مدت داده ها را به عنوان ترکیب حفظ جریان بیت و امکان استفاده بعدی در محتوا و همچنین در اهداف فنی توصیف می کنند. برای تضمین استفاده مجدد از نتایج تحقیق، لازم است پیشینه و دانش زمینه ای در مورد منشأ آنها جمع آوری شود. برای جمعآوری اطلاعات ترجیحاً کامل در مورد دادههای تحقیق، لودویگ و انکه [ 9 ] چک لیستی را بر اساس یک مدل چرخه حیات و «پیوسته Curation» برای برنامهریزی مدیریت دادههای پژوهشی مفید ایجاد کردند. «پیوسته تنظیم داده ها» [ 10] شامل این واقعیت است که دادههای تحقیق در حوزههای مختلف (تحقیق، همکاری و عمومی) تولید، تبدیل و منتشر میشوند، جایی که ذینفعان مختلف درگیر هستند، ابردادههای متفاوتی مورد نیاز است، و حقوق دسترسی و سطح کنترل متفاوتی صورت میگیرد.
داده های تحقیق از حوزه تحقیقات خصوصی، از طریق حوزه تحقیقات مشترک گروه داخلی، به حوزه عمومی پس از انتشار نتایج می رسد. از این رو، ویژگیهای دادههای تحقیق در حین پردازش این چرخه حیات، بین نقطه شروع و پایان یک زنجیره است. در نتیجه، نمی توان اطلاعات ویژه ای را برای هر دامنه شناسایی کرد، اما همان اطلاعات را با تمرکز متفاوت شناسایی کرد. به عنوان مثال، اطلاعات عینی در مورد اندازه گیری زمینه، یک واقعیت بسیار مهم برای محققی است که واقعاً اندازه گیری و ارزیابی را انجام می دهد. این اطلاعات در حوزه چیزی مانند CRC (دامنه مشترک) در جایگاه دوم قرار می گیرد. در اینجا، اطلاعاتی در مورد اینکه چه کسی آزمایش را انجام می دهد، چه زمانی انجام شد و کدام سخت افزار و نرم افزار درگیر بود، بیشتر مورد توجه است. در مقایسه،
از آنجایی که رویکرد مدیریت داده ما از تمام مراحل چرخه عمر داده پشتیبانی میکند، لازم است پیوستار مدیریت داده (مثلاً برای ایجاد طرحوارههای فراداده کافی) در نظر گرفته شود.
2.1.2. اطلاعات معنایی – “بسته های انتشارات علمی (SPPs)”
با توجه به تعریف دادههای تحقیق در معنای وسیعتر، دادهها باید با ابردادههای مفید ( به عنوان مثال ، اطلاعاتی که ایجاد، تبدیل، و/یا زمینه استفاده از آن را توصیف میکند) مرتبط باشد. علاوه بر این، افزایش همکاری محققان در سالهای اخیر، تقاضا برای به اشتراک گذاشتن دادههای تحقیقات اولیه و همچنین اطلاعات مربوط به تبدیل از دادههای خام به نتایج تحقیقات منتشر شده را برانگیخته است. اطلاعات مورد نیاز برای این امر فراتر از اطلاعات ساختاری خالص است و ممکن است به عنوان اطلاعات معنایی تعریف شود که داده ها را با زمینه علمی غنی می کند.
هانتر [ 11 ] روشی را برای کپسوله کردن داده های تحقیقاتی، فراداده ها، و پیدایش آن در به اصطلاح «بسته های انتشار علمی» (SPPs) توصیف می کند. این بستهها حاوی اطلاعات ساختاری و معنایی کامل در مورد دادههای تحقیق فردی، ارتباط آن با سایر دادهها، پیدایش نتایج تحقیق از دادههای اولیه، انتشارات مرتبط، «و فرادادههای زمینهای، منشأ و اداری مرتبط» است. این تجمیع تمام اطلاعات و داده های مرتبط این فرصت را ایجاد می کند تا اجزای پیچیده را به عنوان یک شی دیجیتال واحد در نظر بگیریم. تا اینجا، SPP ها امکان انتشار، اشتراک گذاری و ارائه آسان داده های تحقیقاتی پیچیده را فراهم می کنند.
رویکرد SPPها امکان غنیسازی دادهها با اطلاعات مفید را فراهم میکند، و بنابراین سزاوار توجه بیشتر است، حتی اگر در حال حاضر فقط در مرحله مفهومی باشد. کاستی اصلی آن فقدان سناریوی اجرای واقعی در حال حاضر است. بنابراین، ما قادر به استفاده از SPP در مخزن خود برای غنیسازی اشیاء تحقیقاتی نبودیم، اما تشویق میشویم نگاهی دقیقتر به نحوه یافتن یک راه استاندارد برای افزایش اشیاء داده داشته باشیم.
2.2. پروژه های جامع
2.2.1. یک مخزن کلی داده های تحقیقاتی – پروژه “رادار” [ 12 ]
هدف اصلی پروژه “رادار” [ 13 ] که توسط DFG تامین می شود، اجرای یک مخزن داده های تحقیقاتی کلی به عنوان یک سرویس برای موسسات تحقیقاتی است. با کمک آن، محققان قادر خواهند بود داده های تحقیق را حفظ و منتشر کنند [ 14 ]. این پروژه بر اساس ایدههای «پیوسته تنظیم دادهها» یک فرآیند دو مرحلهای را ارائه میکند [ 15 ]. از یک طرف، مخزن با ارائه حفاظت خالص از داده ها از یک رویکرد چند رشته ای پشتیبانی می کند. از سوی دیگر، یک پیشنهاد پیشرفته برای حفظ و انتشار داده های تحقیقاتی وجود خواهد داشت.
با نگاهی دقیقتر، سیستم حاصل به اصطلاح رشتههای دم بلند بدون طرحهای متادیتا استاندارد شده با تعریف یک طرحواره ابرداده برای همه، هدف قرار میدهد.
هدف این طرح (…) افزایش قابلیت ردیابی و قابلیت استفاده از داده های تحقیقاتی با حفظ یک ویژگی علمی-آشنایی است و به طور همزمان اجازه می دهد تا توصیفی از داده های رشته خاص را ارائه دهد. طرحواره فراداده رادار (…) شامل نه فیلد اجباری است که نشان دهنده هسته کلی طرح است. (…). علاوه بر این، 12 پارامتر فراداده اختیاری به منظور توصیف دادههای رشته خاص عمل میکنند. [ 16 ] (ص 6).
دادههای مربوط به رشته به عنوان دادههای تحقیقاتی اضافی مرتبط با دادههای اصلی در نظر گرفته میشوند که در فرآیند جستجوی فراداده در نظر گرفته نمیشوند. بر این اساس، راهحل RADAR یک مخزن برای ذخیرهسازی طولانیمدت دادههای تحقیقاتی با تمرکز بسیار کمی بر در نظر گرفتن ابردادههای فردی برای کانونهای تحقیقاتی مختلف پیادهسازی میکند. این واقعیت نشان می دهد که یک راه حل کلی مدیریت داده با پشتیبانی فردی برای رشته های تحقیقاتی مختلف باید مدولار باشد و شامل تنظیمات دستی (پیکربندی) باشد. از آنجایی که ما آن را برای CRC مهم میدانیم که اطلاعات فراداده قابل تنظیم دستی را پیادهسازی کند، از الزام یک طرح ابرداده استاندارد شده خودداری کردیم. بنابراین رادار در وضعیت فعلی راه حل مناسبی برای CRC نیست.
2.2.2. اطلاعات ساختاری – پروژه “چشم انداز”
هر نشریه دارای اجزای ساختاری مانند نوع معنایی، نوع رسانه، قالب رسانه، مکان شبکه، و داده های مرتبط، مانند اطلاعات اضافی یا سایر انتشارات مرتبط است [ 17]]. علاوه بر ویرایش دستی چنین اطلاعاتی توسط نویسنده، جمع آوری خودکار این اطلاعات در حین انتشار نتایج تحقیق بسیار راحت و در نتیجه مطلوب است. از نقطه نظر فنی، استخراج اطلاعات در مورد اندازه، تعداد، قالب و ساختار سلسله مراتبی اشیاء داده به راحتی امکان پذیر است. برعکس، جمع آوری خودکار اشیاء داده مرتبط پیچیده تر است. یک ایده برای مقابله با این چالش، تقویت انتشارات با کمک زبان نشانه گذاری (به عنوان مثال، با استفاده از XML) است. نویسندگان باید تمام عبارات مرتبط را در انتشارات خود برچسب گذاری کنند تا داده های مشابه یا مناسب پس از آن پیوند داده شوند.
در حال حاضر، زبان های نشانه گذاری مختلفی برای حوزه های تحقیقاتی خاص مانند زبان نشانه گذاری شیمیایی، زبان نشانه گذاری ریاضیات یا زبان نشانه گذاری زیست شناسی وجود دارد.
پروژه “Prospect” [ 18 ]، که توسط انجمن سلطنتی شیمی آغاز شده است، یک ویژگی اصطلاحات هستی شناسی را ارائه می دهد که در صورت استفاده از عبارت موجود از زبان نشانه گذاری مرتبط، جعبه های کشویی را ارائه می دهد. اصطلاحات در هستی شناسی ژن، هستی شناسی توالی یا هستی شناسی سلولی جستجو می شوند. علاوه بر این، پیکربندی برجسته سازی اصطلاحات مختلف در یک نشریه امکان پذیر است. بنابراین، خواننده به راحتی می تواند متن را ارزیابی کند.
هم پیاده سازی در پروژه فوق الذکر و هم سایر مفاهیم نشانه گذاری فاقد سطح انتزاع لازم هستند. یک زبان نشانه گذاری فردی فقط در یک رشته دانشگاهی خاص مفید است. بنابراین، این مفهوم فقط برای مخازن موضوعی خاص مفید است.
2.2.3. انتشارات پیشرفته—پروژههای «درایور»/«راننده دوم»
ووترسن-ویندوور و برندسما [ 17] (ص. 79) این تعریف را ارائه می دهد که “انتشار پیشرفته انتشاراتی است که با داده های تحقیق به عنوان شواهد تحقیق، مطالب اضافی برای نشان دادن یا شفاف سازی یا داده های پس از انتشار مانند تفسیرها و رتبه بندی تقویت شده است.” پروژه های درایور به افزایش نتایج تحقیقاتی با اطلاعات اضافی و مفید قبل یا در حین انتشار مربوط می شود. برای این کار استانداردها، زیرساخت ها و مفاهیم موجود مورد ارزیابی قرار گرفت. درایور با نتایج تحقیقات در قالب انتشارات سروکار دارد، نه با داده های تولید شده در کل فرآیند تحقیق. با این حال، ایده به دست آوردن اطلاعات هنگام آپلود داده ها به هر شکلی را می توان به لیست الزامات ما اضافه کرد، زیرا جستجوی خودکار اطلاعات برای کاربر بسیار مفید خواهد بود.
2.3 درس های آموخته شده و الزامات حاصل
برای جمعبندی ارزیابی کار مرتبط، میتوان این واقعیت را بیان کرد که «بهترین شیوه» برای حمایت از مدیریت دادههای پژوهشی بدون در نظر گرفتن فنی و علمی اهداف وجود ندارد. هر مفهوم یا راه حلی پیامدهای خاص خود را برای پیاده سازی یا استفاده از مخزن مدیریت داده دارد. با این اوصاف باید از ابتدا اولین تلاش ها برای پاسخگویی به سوالات مربوطه را ارائه و تعریف می کردیم.
- (1)
-
داده های تحقیق، به طور کلی، داده هایی هستند که برای تأیید یک فرض علمی تولید، مشاهده یا اندازه گیری شده اند [ 19]]. این بدان معنی است که آنها از نظر مقدار و ساختار بسیار ناهمگن هستند و به حوزه تحقیق فردی بستگی دارند. دادههای تحقیق در معنای وسیعتر با اطلاعات اضافی در مورد زمینه ایجاد و تغییر دادهها و ساختار مرتبط هستند، به این معنی که این نوع اطلاعات نیز باید در نظر گرفته شوند. بنابراین، تعریف داده های تحقیق در مورد خاص CRC 840 باید با همکاری حوزه های تحقیقاتی مرتبط و محققان آنها انجام شود. خواستههای ملموس برای حمایت از دادههای پژوهشی متنوع و طرحهای فراداده با مصاحبه با برخی از محققان شرکتکننده بهدست آمد و بعداً شرح داده میشود. با این وجود، میتوانستیم تقاضای ذخیرهسازی داده/فراداده انعطافپذیر و قابل تنظیم را ببینیم.
- (2)
-
این ما را به سؤال بعدی در مورد حفظ و مدیریت طولانی مدت داده های موجود برد. حفظ طولانی مدت در معنای کلاسیک تر به معنای حفظ جریان بیت است و هدف آن استفاده بعدی از داده ها در محتوا و همچنین در اهداف فنی است. تحقق فنی توسط استاندارد سیستم اطلاعات بایگانی باز (OAIS) تعیین می شود. این مدل مرجع با ارائه طرحهای حفاظتی که حتی امکان تبدیل فرمتهای داده را فراهم میکند، فراتر از سیستمهای ذخیرهسازی و پشتیبانگیری بسیار در دسترس است. اگرچه اجرای این مدل نسبتاً پیچیده است، اما استاندارد در سطح بین المللی به عنوان مرجع پذیرفته شده است. بنابراین، راه حلی برای حفظ طولانی مدت داده های تحقیقاتی باید با OAIS مطابقت داشته باشد.دومین جنبه مهم ذخیره سازی طولانی مدت دسترسی به این داده ها است. برای اعطای دسترسی متمایز به داده های تحقیق، باید یک شناسه منحصر به فرد اختصاص داده شود. یک سیستم مناسب برای شناسایی اشیاء دیجیتال، سیستم شناسه شی دیجیتال (DOI) است. طبق DOI ها، سازمان غیرانتفاعی DataCite اطلاعات مربوط به داده های تحقیقاتی را با هدف ایجاد دسترسی آسان به داده ها و قابل مشاهده تر کردن داده ها جمع آوری می کند.
جنبه اصلی ما از ارزیابی رویکردهای موجود این واقعیت بود که استانداردسازی بیشتر ساختار داده و طرحهای فراداده منجر به فردیسازی کمتر میشود. بنابراین باید تصمیم میگرفتیم که آیا یک مخزن را با یک یا دو فرآیند مدیریت داده استاندارد شده پیادهسازی کنیم، یا به سیستم قابل تنظیمی اجازه دهیم که از ایجاد طرحهای فراداده متنوع متناسب با خواستههای فردی، با اشکال نیاز بیشتر به پیکربندی پشتیبانی کند.
3. چالش ها، الزامات و مفاهیم در CRC-Subproject INF Z2
در مرحله بعد، خواستههای «مشترک» مدیریت دادههای تحقیقاتی، و خواستههای فردی رهبران پروژه و محققان برای اجرای یک مخزن دادههای تحقیقاتی کافی در CRC 840 باید در نظر گرفته میشد. اجرای موفقیت آمیز در زیر شرح داده شده است.
3.1. شرح CRC 840 و پروژه فرعی INF Z2
CRC 840 “از نانوسیستم های ذره ای تا مزوتکنولوژی” به دنبال اتصال واحدهای ساختمانی در مقیاس نانو مولکولی یا ذرات به بلوک های ساختمانی پیچیده با اثرات قابل استفاده از نظر ماکروسکوپی است. ایجاد این رابط ضروری بین اجسام در اندازه نانو و سیستم های ماکروسکوپی یکی از چالش های بزرگی است که امروزه جامعه فناوری نانو با آن مواجه است و از آن به عنوان مزوتکنولوژی یاد می شود. [ 20 ].
پروژه فرعی “INF Z2″، به عنوان بخشی از CRC 840، به زیرساخت های اطلاعاتی می پردازد. همانطور که در [ 2 ] ذکر شد، هدف برای این نوع ماژول تامین مالی دوگانه است. اول از همه، نیاز به پشتیبان گیری و حفظ داده های تحقیقاتی خاص در CRC ویژه وجود دارد. ثانیا، همکاری سازنده محققان در داخل و خارج از CRC نیاز به حمایت زیرساختی مناسب دارد. بنابراین، این پروژه باید در خدمت تمام یا بیشتر پروژه های علمی باشد. باید استانداردهای موجود را در نظر بگیرد و به مخازن موجود، پایگاه داده یا موارد مشابه متصل شود. همچنین لازم است از داده ها با همکاری یک کتابخانه محلی یا مرکز محاسباتی در یک سیستم پایدار، دائمی و پایدار نگهداری، مدیریت، مستندسازی و پشتیبان گیری شود. [ 2] (ص 36).
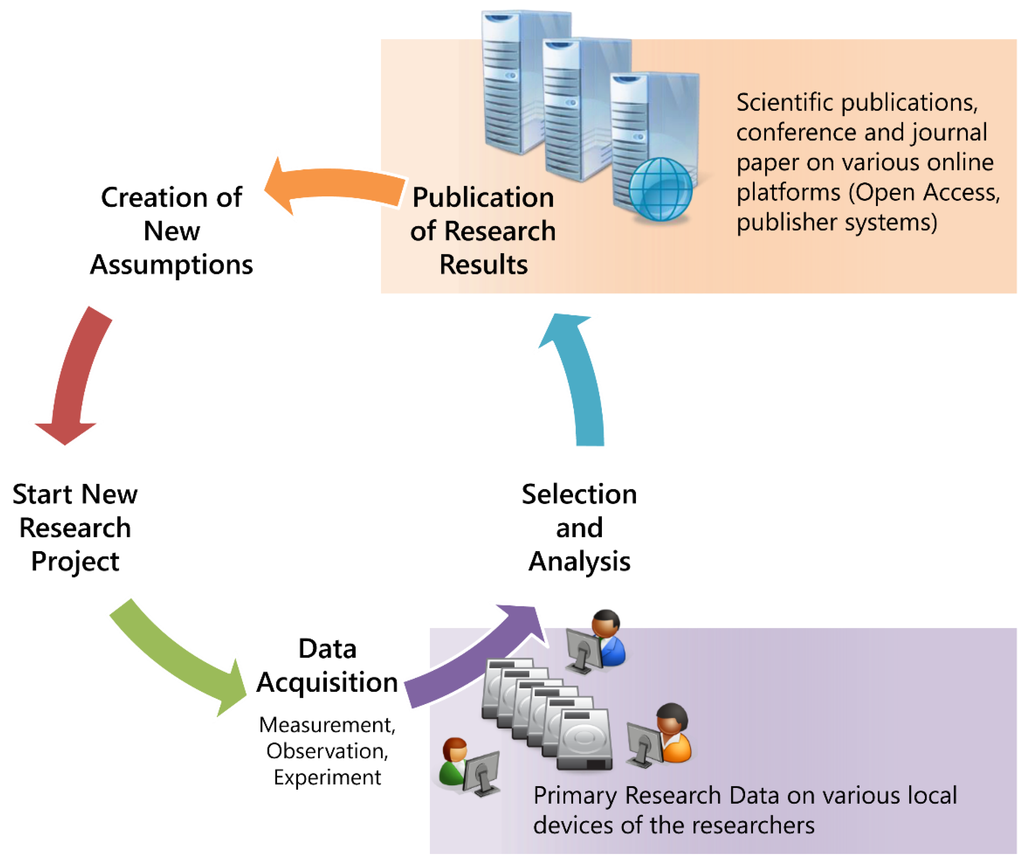
هنگامی که پروژه فرعی “INF Z2” شروع شد، داده های تحقیق در دستگاه های محلی یا سیستم های ذخیره سازی شبکه موسسات ذخیره می شد. بنابراین، دسترسی به افراد مجرد یا گروه های کوچک محدود می شد. توصیف داده ها به روش های سنتی انجام شد. چرخه حیات دادههای تحقیقاتی اجازه دسترسی گسترده از خارج را تنها به انتشارات میداد، در حالی که دادههای تحقیق در سیستمهای ذخیرهسازی محلی پنهان بودند، همانطور که در شکل 1 نشان داده شده است .
محققان نگران مشکلات بسیار خاصی هستند و در نتیجه فقط تعداد بسیار کمی از اشیاء داده کاندید ذخیره در مخازن جهانی هستند. بنابراین، یک راه حل محلی باید طراحی شود که نیازهای مختلف را برآورده کند. با توجه به تلاشهای فنی فراوان انجام شده، از مرکز خدمات فناوری اطلاعات (ITS) خواسته شد تا مسئولیت پروژه و اجرای مخزن داده را بر عهده بگیرد. تخصیص در یک نهاد مرکزی دانشگاه امکان طراحی کلی تری از سیستم و در نتیجه استفاده آینده را فراتر از زمینه های تحقیقاتی CRC می دهد.
3.2. چالش ها
در [ 8 ] DFG تغییر انتظارات محققان را در مورد همکاری و انتشار داده های تحقیقاتی و دانش علمی و تحقیقات توزیع شده مشخص می کند. ایجاد محیطهای دیجیتالی یکپارچه در سازمانهای تحقیقاتی و سیاستهای مربوطه در سراسر کشور، مسائل اساسی آینده است که باید با مفاهیم و پیادهسازیهای مناسب مدیریت داده برآورده شود. علاوه بر این، دسترسی آزاد به تمام نتایج تحقیقات منتشر شده باید تضمین شود.
علاوه بر چالشهایی که توسط مطالعه میز مفاهیم نظری و الزامات DFG ایجاد میشود، خواستههای فردی ناشی از ساختار علمی CRC 840 وجود دارد. به همین دلیل است که از رهبران و محققان پروژه در طول مصاحبههای ساختاریافته سؤال شد. رویکرد کار فعلی، برنامه های آینده و آرزوهای آنها. پرسشنامه بر اساس چک لیست در لودویگ و انکه [ 9 ] بود. در مجموع شامل 27 سوال باز بود که بر اساس موضوع گروه بندی شده بودند.
- (1)
-
منشأ داده های تحقیقاین بخش سؤالاتی را در مورد منشاء، نوع اندازه گیری، ساختار و نوع داده های تولید شده و فرآیندهای رایج در مورد چگونگی ایجاد و تبدیل داده ها در نظر گرفته است.
- (2)
-
بازیابی اطلاعات برای داده های تحقیقجنبه اول مربوط به محدودیت های مربوط به استفاده از داده های تحقیقاتی مانند حریم خصوصی داده ها، حق چاپ یا حمایت قانونی است.علاوه بر این، این بخش شامل سوالاتی در مورد چگونگی به دست آوردن اطلاعات در مورد محققان، پروژه های مرتبط یا گروه های پروژه است.در نهایت، این بخش حاوی سوالاتی با هدف اطلاعاتی است که باید جمع آوری شود تا فرصت استفاده بعدی کافی از داده های تحقیق در همان تیم یا برای محققان خارجی فراهم شود. آیا طرح های ابرداده ای وجود دارد که باید در نظر گرفته شود؟
- (3)
-
استفاده متداول از داده های تحقیقاین بخش به مدیریت رایج استفاده از داده می پردازد. چگونه داده ها پس از ایجاد استفاده یا تبدیل می شوند؟ کدام رویکردهای استفاده مجدد قابل تصور است و کدام داده برای استفاده مجدد رایگان خواهد بود؟ در نهایت، در مورد داده های “قدیمی” چطور؟
- (4)
-
ذخیره سازی طولانی مدت / انتشار داده های تحقیقاتیاز یک سو، این بخش بر فرآیندهای پیشفرض برای ذخیرهسازی و انتشار دادههای تحقیقاتی در CRC 840 تمرکز داشت. از سوی دیگر، سؤالاتی در مورد اهداف ذخیرهسازی بلندمدت، اختیار تصمیمگیری و انتخاب دادههای ارزشمند باید پاسخ داده می شد
- (5)
-
آرزوهای اضافیدر بخش آخر، محققان این فرصت را داشتند که خواستههای اضافی برای مدیریت داده، حفظ طولانیمدت و بازیابی متا اطلاعات در CRC 840 را شرح دهند.
مفهوم پرسشنامه دو جنبه دارد. ابتدا، به عنوان مبنایی برای مصاحبه های ساختاریافته با رهبران و محققان پروژه عمل کرد. ثانیا، در پیکربندی زمینه های تحقیقاتی اضافی (اشیاء داده) در آینده کمک خواهد کرد.
3.2.1. تنوع
دامنه حوزه های تحقیقاتی شرکت کننده در CRC 840 بسیار گسترده است. در نتیجه، داده های تحقیقاتی انباشته شده در پروژه های فرعی دارای ویژگی های متفاوتی هستند. از یک طرف، داده ها از دستگاه های فنی مانند طیف سنج ها یا میکروسکوپ های مختلف سرچشمه می گیرند و معمولاً در قالب های داده خاص فروشنده ذخیره می شوند. از سوی دیگر، داده ها توسط برنامه های کامپیوتری تولید می شوند که اغلب توسط خود محققین برنامه ریزی می شوند و فرمت های داده دلخواه را تولید می کنند. معمولاً هیچ مخزن فرامنطقه ای برای جمع آوری داده ها از این زمینه های تحقیقاتی بسیار تخصصی وجود ندارد. سطح بالایی از انتزاع در توصیف داده های تحقیق از طریق ابرداده ترجیحاً عمومی و نیاز به ذخیره انواع فرمت های داده الزامات اساسی برای زیرساخت محلی است. از این رو، گسترش پورتال های مورد استفاده برای توزیع نشریات نمی تواند به عنوان یک راه حل پایدار در نظر گرفته شود. نیاز به یک راه حل تخصصی به زودی مشخص شد. علاوه بر این، بحث با محققان نشان داد که تصحیح دادهها پیشنیاز برای حفظ معقول طولانیمدت است. از آنجایی که محققان تجربه ای در برخورد با قالب های مختلف داده ندارند، باید در انتخاب بهترین قالب داده و داده های توصیفی مناسب از آنها پشتیبانی شود. بنابراین، کتابخانه به دلیل تجربه فراوان در توصیف اشیاء مختلف با داده های توصیفی، شریک پروژه شد. اگر محققی بخواهد دادهها را وارد کند، اولین قدم آن است که قالب دادهها را با کمک کتابداران تجزیه و تحلیل کند. هدف تعیین بهترین قالب برای ذخیره سازی بلندمدت و داده های توصیفی حیاتی است. سپس این اطلاعات به مرکز کامپیوتر منتقل میشود، جایی که مجموعه دادههای دادههای توصیفی به صورت فنی پیادهسازی میشوند و در صورت امکان استخراج خودکار دادههای توصیفی از دادههای اولیه اجرا میشود. بدیهی است که این رویکرد بسیار وقت گیر است و باید تلاش زیادی برای یافتن توصیفات کلی برای انواع داده های مشابه صورت گیرد. علاوه بر این، روشهایی برای پیادهسازی خودکار دادههای توصیفی بررسی میشوند.
3.2.2. تکرارپذیری
در ابتدای پروژه، ما رویکرد ساخت یک مخزن برای داده های تحقیقات اولیه را دنبال کردیم. بر اساس بحث با رهبران پروژه، مجموعه گسترده ای از الزامات شناسایی شد. علاوه بر خود داده های تحقیق اولیه، نتایج منتشر شده و منشأ کامل آنها باید حفظ شود. از دیدگاه یک تیم یا رهبر پروژه، پورتال باید ابزاری باشد که امکان بازسازی هر نتیجه منتشر شده را فراهم کند، حتی زمانی که محققی که نتیجه را تولید کرده است، تیم را ترک کرده است. بنابراین، معماری باید به گونه ای انتخاب شود که هر مرحله از فرآیند تحقیق تا نتایج منتشر شده قابل توصیف باشد. نتایج منتشر شده با یک DOI منحصر به فرد ارائه شده است. بر اساس DOI، پیدایش کامل نتایج ممکن است بازسازی شود. این رویکرد نیاز به پردازش داده ها را به شدت گسترش می دهد، زیرا برای هر مرحله پردازش باید مجموعه ای از داده های توصیفی پیدا و در سیستم پیاده سازی شود. این باید با همکاری نزدیک با محقق انجام شود، زیرا بینش عمیق در فرآیندهای علمی ضروری است. علاوه بر این، ممکن است نیاز به ذخیره برنامه هایی باشد که در پردازش داده ها استفاده می شوند. این منجر به ساختار بسیار پیچیده ای از اجزای مرتبط موجود در سیستم می شود.
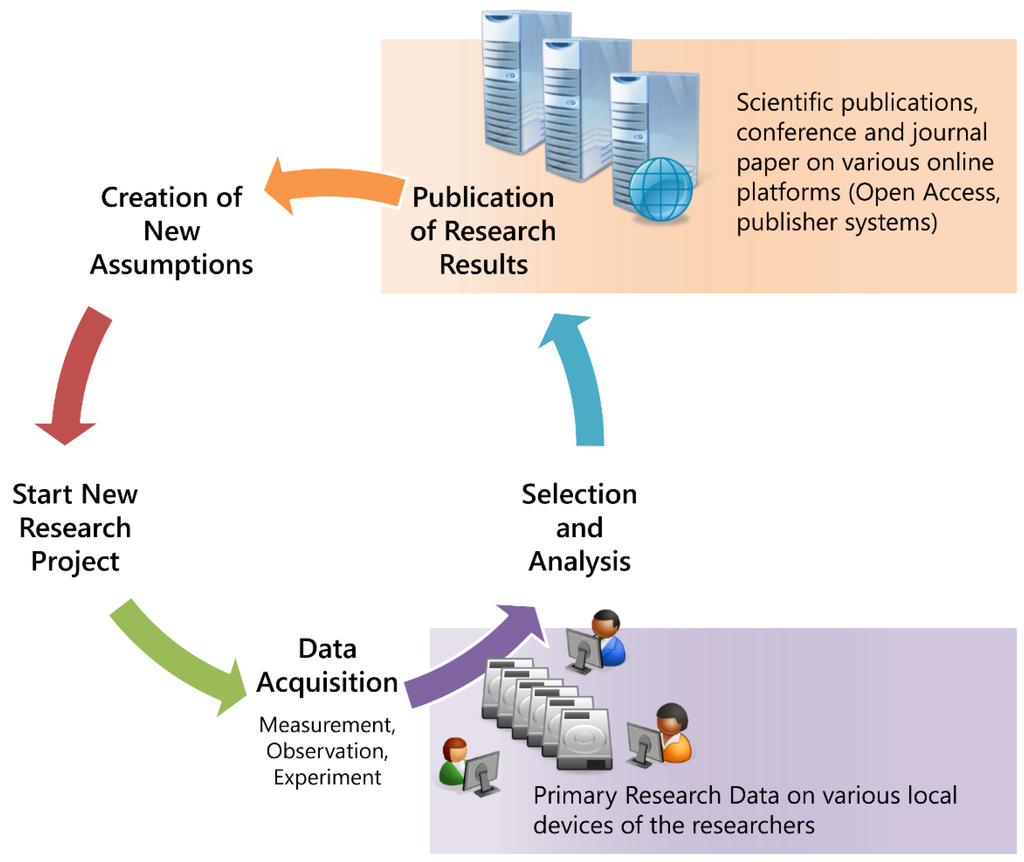
این روش به این معناست که وارد حوزه تحقیقات الکترونیکی می شویم. فراتر از ارائه یک فروشگاه داده برای ذخیره سازی دائمی داده های تحقیقاتی، ما ابزاری را برای مدیریت داده های تحقیق منشأ اجرا می کنیم. همانطور که در شکل 2 نشان داده شده است، اکنون بخشی از چرخه حیات داده های تحقیق هستیم . از این تصویر، می توان به گسترش در جهت پیدایش داده ها ( یعنی اجرای یک مجله آزمایشگاهی الکترونیکی) فکر کرد. ایده های مختلف دیگری برای حمایت از محققان ممکن است از این ملاحظات ناشی شود.
3.2.3. نگهداری طولانی مدت
به منظور ارائه در دسترس بودن قابل اعتماد و استفاده پایدار از داده ها، ذخیره سازی باید هنجارهای حفظ طولانی مدت را برآورده کند. در حال حاضر مهمترین استاندارد، مدل مرجع سیستم اطلاعات آرشیو باز (OAIS) است. مدل OAIS مشخص می کند که چگونه دارایی های دیجیتال را می توان از طریق استراتژی های حفظ بعدی حفظ کرد. این یک مدل مرجع سطح بالا است و بنابراین به فناوری خاصی وابسته نیست. اگرچه این مدل پیچیده است، اما سیستمهای ذخیرهسازی بلندمدت دادههای دیجیتال باید الزامات را برآورده کنند.
3.2.4. مجوز و قابلیت استفاده
دسترسی به داده ها باید توسط یک مجوز منعطف کنترل شود تا از استفاده غیرقانونی جلوگیری شود و در عین حال امکان همکاری معقول وجود داشته باشد. ذخیره سازی داده های تحقیق در یک مخزن اغلب با دسترسی آزاد به داده ها ترکیب می شود. این تا حدی فقط برای نتایج منتشر شده صادق است. اگر مخزن به عنوان ابزاری در نظر گرفته شود که محقق را در مدیریت داده های تحقیق و تکرارپذیری نتایج پشتیبانی می کند، تنها بخشی از داده های موجود در مخزن در دسترس باز خواهد بود. بقیه داده ها باید محافظت شوند و فقط محقق یا یک گروه تحقیقاتی باید اجازه دسترسی به آن را داشته باشند. برای اجازه دادن به همکاری بین محققان، مجوز باید به روشی بسیار دقیق سازماندهی شود.
در نهایت، راه حل ها باید به راحتی قابل استفاده باشند و برای محقق مزایایی به همراه داشته باشند. فرآیند گردآوری داده ها نیازمند احتیاط بیشتری در مدیریت داده های تحقیق است. این تلاش باید از نظر خدمات اضافی، مانند جستجوی راحت داده ها، همکاری یا ابزارهای تجزیه و تحلیل، مزایای قابل توجهی را برای محقق فراهم کند. علاوه بر این، درج داده ها باید راحت باشد و مدیریت حقوق دسترسی باید آسان باشد.
4. اجرای نمونه اولیه
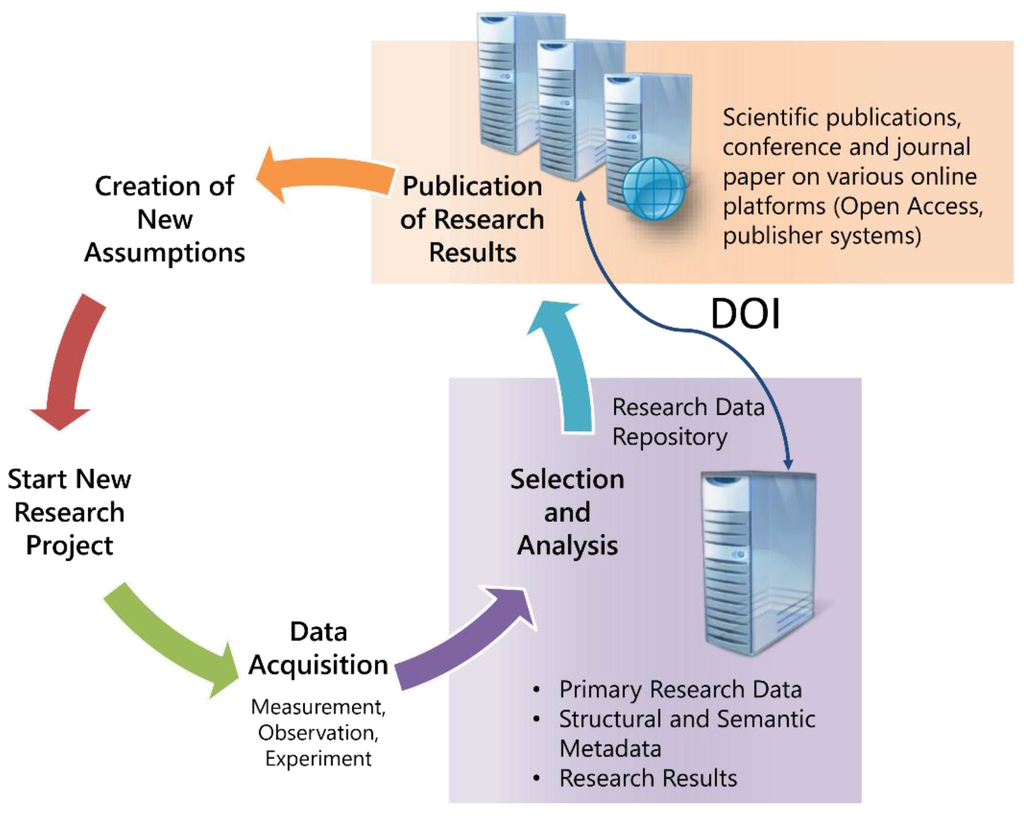
به طور عمده بر اساس چالش های ذکر شده، یک زیرساخت تحقیقاتی در رابطه با داده های علمی در CRC 840، همانطور که در شکل 3 نشان داده شده است، برنامه ریزی و اجرا شد . علاوه بر این الزامات، برخی خواسته های بیشتر، یعنی در قالب برخی شرایط مرزی عملی که به وجود آمد، باید در نظر گرفته می شد.
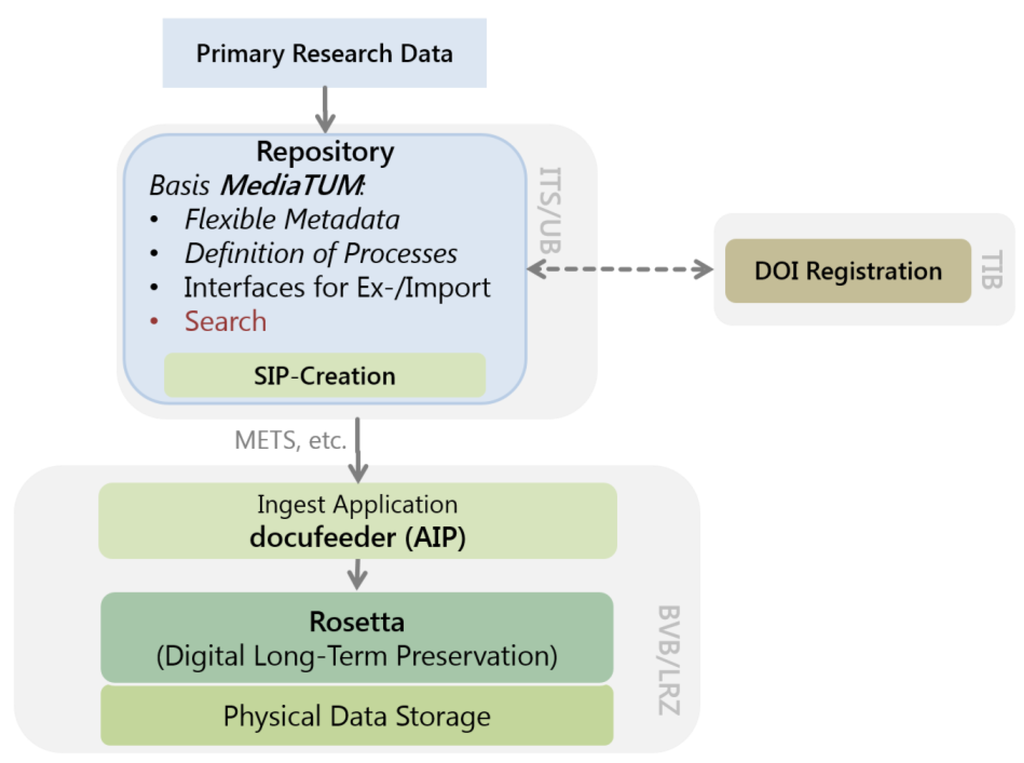
مشارکت. پیاده سازی اساساً بر اساس راه حل های موجود ساخته شده است. بنابراین، تمرکز بر همکاری بین شرکای مختلف است. با توجه به استراتژیهای انتقال دادهها به ذخیرهسازی بلندمدت و گزینههای بازیابی برای ابرداده، تماسهایی با TU Munich (استفاده از جزء آنها MediaTUM) و ETH Zurich (کاربرد نرمافزار Docuteam) برقرار شد. با توجه به حفظ طولانی مدت، توافق نامه ای با کتابخانه ایالتی باواریا (BSB) وجود دارد که اجازه استفاده مشترک از نصب نرم افزار Rosetta توسط ExLibris را می دهد.
پورتال داده های پژوهشی رویکرد فعلی تمام مراحل پردازش از داده های اولیه تا نتایج منتشر شده را به عنوان گره هایی با داده ها و ابرداده های خاص پیوست شده توصیف می کند. چارچوب MediaTUM برای این منظور مناسب است زیرا امکان تعریف انعطاف پذیری از طرحواره های ابرداده را فراهم می کند. منشأ نتایج تحقیق (تصاویر، گرافیکها، جداول و دادههای مختلف) باید بر اساس دادههای اولیه تجزیه و تحلیل شود و هر مرحله از فرآیند باید تا حد امکان انتزاع شود و به عنوان یک گره ترسیم شود. طرحواره ابرداده مرتبط و فرآیند آپلود داده باید برای هر گره تعریف و اجرا شود.
بازیابی طولانی مدت. برای هر گره از یک نتیجه منتشر شده، یک DOI توسط Technische Informationsbibliothek (TIB) Hannover اختصاص داده می شود، بنابراین دیده شدن جهانی نتایج تحقیقات از طریق DataCite را تضمین می کند. تمام گرههایی که برای بازسازی نتیجه ضروری هستند، بهطور خودکار در روزتا در طول تخصیص یک DOI ذخیره میشوند و از در دسترس بودن نتیجه و منشأ آن در طولانیمدت اطمینان حاصل میکنند.
حفاظت از داده ها. محافظت در برابر دسترسی غیرمجاز به داده ها توسط مدل مجوز MediaTUM تضمین شده است که امکان کنترل دسترسی متفاوت برای هر گره را فراهم می کند. علاوه بر ورود به سیستم از طریق پروتکل دسترسی دایرکتوری سبک (LDAP) در مدیریت هویت محلی (IdM)، کاربران ممکن است در خود سیستم راه اندازی شوند. ممکن است یک کاربر به گروههای انعطافپذیر اختصاص داده شود که امکان نقشهبرداری از همکاری بین دانشمندان را فراهم میکند.
4.1. وضع موجود
مطالبات خاص مربوط به فرآیند تحقیق با مصاحبه ساختاریافته و پرسشنامه ارزیابی شد و پاسخ ها با توجه به شباهت ها و تفاوت ها مورد تجزیه و تحلیل قرار گرفت. به دلیل گستره وسیعی از حوزه های تحقیقاتی شرکت کننده در CRC، هیچ فرآیند پژوهشی یکسانی وجود ندارد. برعکس، محققان برای جمعآوری نتایج تحقیقاتی گامهای متفاوتی برمیدارند و عادتهای مختلفی در خصوص حفظ و اظهارنظر دادههای تولید شده، حتی در همان حوزه پژوهشی دارند. به همین دلیل، ما در وهله اول در حال توسعه یک نمونه اولیه از مخزن داده برای CRC 840 بر اساس پلتفرم MediaTUM هستیم. روند فعلی اجرای این نمونه اولیه شامل مراحل زیر است:
- (1)
-
تجزیه و تحلیل انتشارات موجود
- (2)
-
تعریف و پیاده سازی انواع شی مورد نیاز
- (3)
-
تعریف و پیاده سازی طرحواره های ابرداده مرتبط
- (4)
-
آزمایش آپلود برای انواع شی تعریف شده
4.1.1. تجزیه و تحلیل انتشارات موجود
در مرحله اول، نتایج در نشریات باید مکان یابی و طبقه بندی شوند (داده، تصویر، جدول، متن و … ). سپس، منشأ آنها را باید به منبع ردیابی کرد – مجموعه داده های تحقیقات اولیه مرتبط. شکل 4 نمای کلی از تجزیه و تحلیل یک نشریه از علوم شیمی را نشان می دهد.
جزئیات در شکل 5 و شکل 6 پیدایش و روابط برخی از گرافیک های مورد استفاده در نشریه را نشان می دهد. بر اساس اندازهگیری ساختار کریستالی یک ماده خاص با اصطلاح «Einkristalldiffraktometer STOE IPDS»، محقق تجزیه و تحلیل دادهها را با کمک برنامه «SHEIXTL 5.1» آغاز کرد و یک فایل CIF حاوی تمام اطلاعات آنالیز به دست آورد.
متعاقباً، برنامه «Diamond v3» با کمک اطلاعات CIF-File، گرافیک های مربوطه را تولید کرد. در نهایت، این گرافیک ها باید با یک ابزار گرافیکی ویرایش می شدند و بر حسب مورد، برای برآورده کردن نیازهای نشریه ترکیب می شدند.
برای اجرای نمونه اولیه، سه نشریه به این روش برای درک بهتر پیدایش نتایج تحقیقات در حوزههای تحقیقاتی مرتبط تجزیه و تحلیل خواهند شد. از آنجایی که این روش بسیار وقت گیر است، باید در یک محیط تولیدی استاندارد شود. بنابراین، تحلیل خود نشریات باید تا حد امکان انتزاع شود.
4.1.2. تعریف و پیاده سازی انواع اشیاء مورد نیاز
تجزیه و تحلیل یک نشریه همه گره های مرتبط را نشان می دهد، که متعاقباً باید در مخزن داده ذخیره شوند. به همین دلیل، گره ها (داده های اولیه، داده های تبدیل، داده های حاصل و غیره ) به انواع گسسته با ویژگی های یکسان یا مشابه طبقه بندی می شوند. بر اساس این طبقه بندی، انواع شی جدید در مخزن داده پیاده سازی می شوند. ساختار انعطاف پذیر MediaTUM امکان ایجاد بسیار آسان انواع شی جدید را فراهم می کند. ایجاد شامل تعریف ویژگیهای شی استاندارد شده، ارائه نوع شی، نوع نوع (محتوا، ظرف)، و دوره عمل در هنگام آپلود دادهها برای این نوع شی است.
شکل 7 ، به عنوان مثال، ارائه دادهها را برای نوع شیء “Panalytical” به عنوان یک لیست در حالت پیشنمایش کوچک نشان میدهد. حالت ارائه در طول ایجاد نوع شی تعریف شده است و شامل یک پیشنمایش بصری از دادههای طیفی (ایجاد شده در هنگام بارگذاری دادههای اندازهگیری در مخزن)، اطلاعات فراداده انتخابی و اطلاعات مربوط به محقق مسئول است.
4.1.3. تعریف و اجرای طرحواره های فراداده مرتبط
یک طرحواره ابرداده به عنوان ماسکی برای نمایش مقادیر فراداده انتخاب شده از یک نوع شی خاص تحقق می یابد. در حالی که اطلاعات فراداده واقعی همیشه به طور کامل در پایگاه داده ذخیره می شود، ارائه ابرداده را می توان با موارد استفاده فردی تطبیق داد. برای مثال، نیازی به نمایش تمام ابرداده ها در یک نمای کلی نیست. با این حال، هنگام ویرایش اطلاعات، لازم است تمام فیلدهای ابرداده قابل ویرایش را مشاهده کنید. بنابراین، هر نوع شی دارای طرحواره های فراداده مختلفی است که با موارد استفاده متفاوت مرتبط است. حتی تغییر بعدی طرحواره ابرداده بر داده های موجود برای نوع شی خاص تأثیر می گذارد.
پس از تعریف انواع شی جدید، طرحواره ابرداده مورد نظر باید به صورت زیر ایجاد شود:
- (1)
-
تعریف تمام فیلدهای فراداده لازم
- (2)
-
ایجاد طرحواره های فراداده دلخواه
- (3)
-
اختصاص فیلدهای فراداده به طرحواره خاص
- (4)
-
تعریف قوانین دسترسی / حقوق دسترسی برای گروه ها و / یا کاربر
شکل 8 نمای کلی اطلاعات فراداده را برای نوع شی “Panalytical” در ناحیه مدیریت مخزن داده نشان می دهد. در صورت داشتن حقوق صحیح، امکان مشاهده و ویرایش اطلاعات فراداده شی داده فعلی وجود دارد.
4.1.4. تخصیص DOI
یکی از الزامات اصلی پروژه فرعی “INF Z2” این است که داده ها را قابل استناد و قابل استفاده مجدد با ایجاد دسترسی عمومی به داده های تعریف شده است. این امر با تنظیم یک DOI برای هر شیء داده ای که شایسته استناد است، اتفاق می افتد. با این شناسه پایدار، اشیاء داده به صورت غیر مبهم ارجاع می شوند. مسئولیت صدور DOI به عهده محقق است و باید به ویژه در نظر گرفتن شرایط کیفی DOI و قرارداد TIB DOI انجام شود. در نتیجه، شی داده پس از آن از مخزن حذف نمیشود و از نوشتن محافظت میشود، در حالی که DOI موجود است. تغییرات لازم متعاقباً فقط برای کاربران اداری مجاز خواهد بود. فرآیند تخصیص DOI باید به صورت دستی توسط کاربر سیستم شروع شود. این یک فرآیند خودکار برای هر شی داده آپلود شده در مخزن نیست، در حالی که به روز رسانی متا اطلاعات تغییر یافته برای یک DOI خودکار خواهد بود. برای تضمین رعایت شرایط طرحواره ابرداده DataCite برای هر طرح ابرداده شی داده، تطبیقی بین فیلدهای فراداده شی داده و طرحواره ابرداده DataCite وجود خواهد داشت. همانطور که در فصل پیاده سازی توضیح داده شد، طرح های ابرداده برای اشیاء داده جدید و فرآیند آپلود اختصاص داده شده باید به صورت دستی پیکربندی شوند. بنابراین، ما قابلیت استفاده انعطاف پذیر را برای زمینه های تحقیقاتی مختلف در آینده با اشکالاتی از پیکربندی دستی تضمین می کنیم. مزیت، فردی شدن و سازگاری بالا است. برای تضمین رعایت شرایط طرحواره ابرداده DataCite برای هر طرح ابرداده شی داده، تطبیقی بین فیلدهای فراداده شی داده و طرحواره ابرداده DataCite وجود خواهد داشت. همانطور که در فصل پیاده سازی توضیح داده شد، طرح های ابرداده برای اشیاء داده جدید و فرآیند آپلود اختصاص داده شده باید به صورت دستی پیکربندی شوند. بنابراین، ما قابلیت استفاده انعطاف پذیر را برای زمینه های تحقیقاتی مختلف در آینده با اشکالاتی از پیکربندی دستی تضمین می کنیم. مزیت، فردی شدن و سازگاری بالا است. برای تضمین رعایت شرایط طرحواره ابرداده DataCite برای هر طرح ابرداده شی داده، تطبیقی بین فیلدهای فراداده شی داده و طرحواره ابرداده DataCite وجود خواهد داشت. همانطور که در فصل پیاده سازی توضیح داده شد، طرح های ابرداده برای اشیاء داده جدید و فرآیند آپلود اختصاص داده شده باید به صورت دستی پیکربندی شوند. بنابراین، ما قابلیت استفاده انعطاف پذیر را برای زمینه های تحقیقاتی مختلف در آینده با اشکالاتی از پیکربندی دستی تضمین می کنیم. مزیت، فردی شدن و سازگاری بالا است. طرح های ابرداده برای اشیاء داده جدید و فرآیند آپلود اختصاص داده شده باید به صورت دستی پیکربندی شوند. بنابراین، ما قابلیت استفاده انعطاف پذیر را برای زمینه های تحقیقاتی مختلف در آینده با اشکالاتی از پیکربندی دستی تضمین می کنیم. مزیت، فردی شدن و سازگاری بالا است. طرح های ابرداده برای اشیاء داده جدید و فرآیند آپلود اختصاص داده شده باید به صورت دستی پیکربندی شوند. بنابراین، ما قابلیت استفاده انعطاف پذیر را برای زمینه های تحقیقاتی مختلف در آینده با اشکالاتی از پیکربندی دستی تضمین می کنیم. مزیت، فردی شدن و سازگاری بالا است.
DOI از دو بخش تشکیل شده است: پیشوند یکسان برای کل مرکز داده، و پسوند جداگانه برای شی داده صریح. این پسوند فردی توسط وب سرویس تولید می شود و در سراسر مرکز داده بدون ابهام است.
اجرای توابع درخواستی به عنوان یک برنامه وب سرویس رخ می دهد که در صورت لزوم می تواند توسط مخزن داده های تحقیق مورد استفاده قرار گیرد. این رابط برای درخواست DOI های جدید، به روز رسانی DOI ها، ابرداده ها یا رسانه ها و حذف DOI ها ارائه می دهد. در پس زمینه، وب سرویس از DataCite RESTful API برای مراکز داده استفاده می کند [ 21 ].
4.2. اثرات هم افزایی
علاوه بر حفظ طولانی مدت داده های تحقیق، نیاز به ذخیره داده های دیجیتالی (مانند اسلایدهای اسکن شده، تصاویر، سوابق صوتی یا تصویری، یا نسخه های اصلی دیجیتالی) از آرشیوها و کتابخانه ها وجود دارد. با توجه به توانایی ایجاد انواع شی منعطف و طرحواره های ابرداده مرتبط، رویکرد ما به راحتی می تواند به عنوان مخزن داده های دیجیتالی شده استفاده شود. به عنوان یک اثر جانبی، ما در راه پیادهسازی پلتفرمی برای اسلایدهای گیاهی دیجیتالی هستیم.
علاوه بر این، مزایای اضافی ناشی از پروژه توصیف شده در مورد تخصیص DOI ها وجود دارد. دسترسی به وب سرویس پیاده سازی شده برای درخواست DOI در سراسر دانشگاه قابل ارائه است و می تواند توسط سایر پروژه های تحقیقاتی یا خدمات فناوری اطلاعات مورد استفاده قرار گیرد.
5. چشم انداز
مفهوم سنتی حفظ بلندمدت دادههای تحقیق عمدتاً ذخیرهسازی فیزیکی دادههای اولیه یا انتشارات کامل را که بهصورت جداگانه توسط اطلاعات توصیفی افزایش مییابد، پوشش میدهد. در نتیجه، مفاهیم مدلها و زیرساختهای پشتیبان با توجه به این دو دیدگاه تقسیم میشوند.
در مقابل، رویکرد ما فراتر از این تقسیمبندیها است و یک سیستم یکپارچه ایجاد میکند. فرآیند کامل تحقیق در رابطه با حفظ داده ها و اطلاعات پشتیبانی خواهد شد. در اینجا، مخزن دادههای ما ذخیرهسازی دادههای اولیه، حفظ فعالیتهای تبدیلکننده، انتشار نتایج تحقیقات، و بهبود همه اشیاء داده با توصیف اطلاعات را ارائه میدهد. بنابراین، منشأ نتایج تحقیقات قابل ردیابی است و بنابراین می توان از کیفیت تحقیق اطمینان داشت.
چالش بعدی در کار فعلی ما پیاده سازی روابط بین اشیاء داده های مختلف است. علاوه بر این، راه های مناسب برای نمایش این روابط باید در رابط کاربری پیاده سازی شود. متأسفانه به دلیل طراحی سیستم زیربنایی (MediaTUM) محدودیت هایی در نمایش و نمایش روابط مختلف گره ها وجود دارد. بنابراین، چالش بعدی بررسی راههای کافی برای ادغام برنامههای خارجی با رابط کاربری مخزن خواهد بود.
منابع
- OECD: اصول و رهنمودهای OECD برای دسترسی به داده های تحقیقاتی از بودجه عمومی. در دسترس آنلاین: http://www.oecd.org/science/sci-tech/38500813.pdf (در 27 اکتبر 2014 قابل دسترسی است).
- افرتز، ای. دیدگاه سرمایه گذار: مدیریت داده ها در برنامه های هماهنگ بنیاد تحقیقات آلمان (DFG). در مجموعه مقالات کارگاه مدیریت داده ; Curdt, C., Bareth, G., Eds. دانشگاه کلن: کلن، آلمان; صص 35-38.
- HGP: پروژه ژنوم انسان. در دسترس آنلاین: http://www.genome.gov/10001772 (در 27 اکتبر 2014 قابل دسترسی است).
- پروژه ژنوم انسان (اطلاعات آرشیو شده). در دسترس آنلاین: http://web.ornl.gov/sci/techresources/Human_Genome/index.shtml (در 31 مارس 2016 قابل دسترسی است).
- GRBIO: ثبت جهانی مخازن زیستی. در دسترس آنلاین: http://grbio.org (در 27 اکتبر 2014 قابل دسترسی است).
- Kümmel, C. Nach den Sondersammelgebieten: Fachinformationen als forschungsnaher Service. Z. Bibl. Bibliogr. 2013 ، 60 ، 5-15. [ Google Scholar ] [ CrossRef ]
- میتلر، ای. کتاب مقدس فورش. پراکسیس 2014 ، 3 ، 344-364. [ Google Scholar ] [ CrossRef ]
- Deutsche Forschungsgemeinschaft (DFG). خدمات کتابخانههای علمی و سیستمهای اطلاعات — اولویتهای تأمین مالی تا سال 2015. در دسترس آنلاین: http://dfg.de/download/pdf/foerderung/programme/lis/pos_papier_funding_priorities_2015_en.pdf (در 28 اکتبر 2014 قابل دسترسی است).
- لودویگ، جی. Enke, H. (Eds.) Leitfaden zum Forschungsdaten-Management-Handreichungen aus dem WissGrid-Projekt ; Verlag Werner Hülsbusch: Glückstadt، آلمان، 2013.
- ترلوار، ا. هاربو-ری، سی. مدیریت داده ها و پیوستگی مدیریت: چگونه تجربه موناش روابط مخزن را اطلاع رسانی می کند. در دسترس آنلاین: http://valaconf.org.au/vala2008/papers2008/111_Treloar_Final.pdf (در 20 اوت 2014 قابل دسترسی است).
- هانتر، جی. بسته های انتشارات علمی – رویکردی انتخابی برای ارتباط و بایگانی خروجی های علمی. بین المللی جی دیجیت. Curation 2006 , 1 , 33-52. [ Google Scholar ] [ CrossRef ]
- رادار – مخزن داده های تحقیق. در دسترس آنلاین: https://www.radar-projekt.org/display/RE/Home (در 31 مارس 2016 قابل دسترسی است).
- رادار – مخزن داده های تحقیق. DFG-Antrag. در دسترس آنلاین: http://www.radar-projekt.org/display/RD/Projektantrag (در 29 اکتبر 2014 قابل دسترسی است).
- رزم، م. Neumann, J. Das RADAR Projekt: Datenarchivierung und -publikation als Dienstleistung—disziplinübergreifend, nachhaltig, kostendeckend. نسخه Dtsch. کتاب مقدس (VDB) 2014 ، 1 ، 30-44. [ Google Scholar ]
- پوتوف، جی. ون وزل، جی. رزم، م. Walk, M. Anforderungen eines Nachhaltigen, Disziplinübergreifenden Forschungsdaten-Repositoriums. در دسترس به صورت آنلاین: https://www.dfn.de/fileadmin/3Beratung/DFN-Forum7/konferenzband/02-Anforderungen_eines_nachhaltigen__disziplinuebergreifenden_Forschungsdaten-Repositoriums.pdf (دسترسی در 5 اوت 20).
- کرافت، A. رادار – مخزنی برای داده های دم بلند. در دسترس آنلاین: http://docs.lib.purdue.edu/iatul/2015/mrd/1 (در 31 مارس 2016 قابل دسترسی است).
- ووترسن-ویندوور، اس. Brandsma, R. Enhanced Publications, State of Art. در Enhanced Publications — Linking Publications and Research Data in Digital Repositories ; Vernooy-Gerritsen، M.، Ed. انتشارات دانشگاه آمستردام: آمستردام، هلند، 2009; ص 19-91. [ Google Scholar ]
- انجمن سلطنتی شیمی. پروژه “چشم انداز” – پیوند ترکیبات و مفاهیم در مقالات. در دسترس آنلاین: http://www.rsc.org/Publishing/Journals/ProjectProspect/index.asp (در 29 اکتبر 2014 قابل دسترسی است).
- بوتنر، اس. هوبوهم، اچ.-سی. مولر، ال. مدیریت داده های پژوهشی. در Handbuch Forschungsdatenmanagement ; Büttner, S., Hobohm, H.-C., Müller, L., Eds.; BOCK + HERCHEN Verlag: Bad Honnef، آلمان، 2011; صص 13-25. [ Google Scholar ]
- مرکز تحقیقات مشارکتی 840: «از نانوسیستمهای ذرهای تا مزوتکنولوژی»: تمرکز و رویکرد مرکز تحقیقات مشارکتی SFB 840. موجود آنلاین: http://www.sfb840.uni-bayreuth.de/en/index.html (دسترسی در 23 نوامبر 2015).
- DataCite. DataCite API v2 for Datacentres، API Documentation. در دسترس آنلاین: https://mds.datacite.org/static/apidoc (دسترسی در 31 مارس 2016).
شکل 1. چرخه زندگی سنتی داده های تحقیق.
شکل 2. چرخه حیات مطلوب داده های تحقیق در CRC 840.
شکل 3. اجرای حفظ بلندمدت داده های تحقیقاتی در CRC 840.
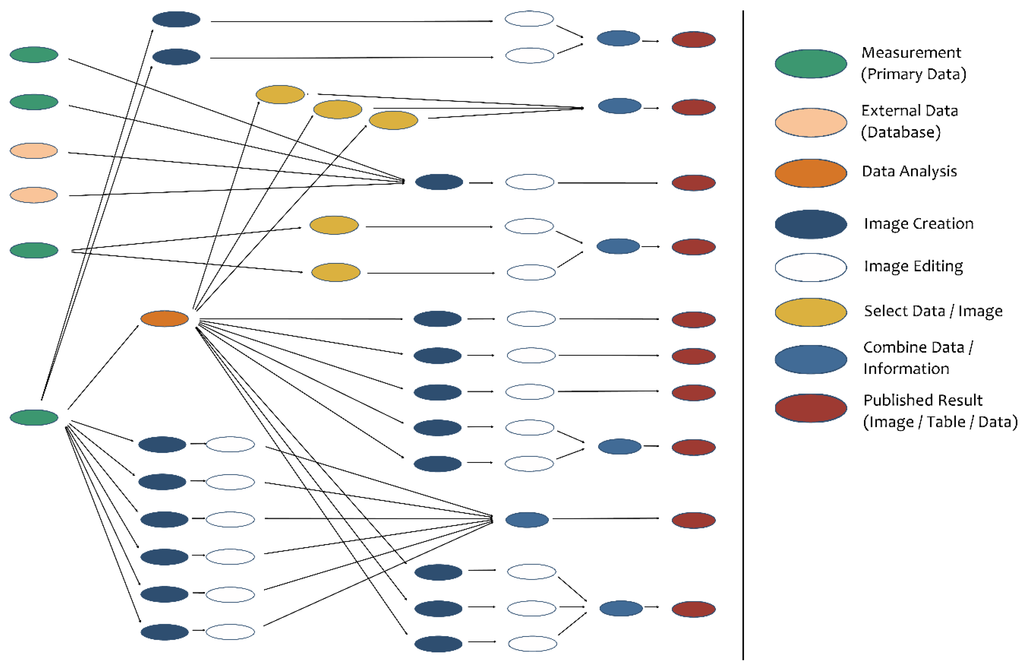
شکل 4. منشأ داده های تحقیق منتشر شده برای انتشار تعریف شده (نمای کلی شماتیک، می توانید نسخه کامل را در مکمل مشاهده کنید ).
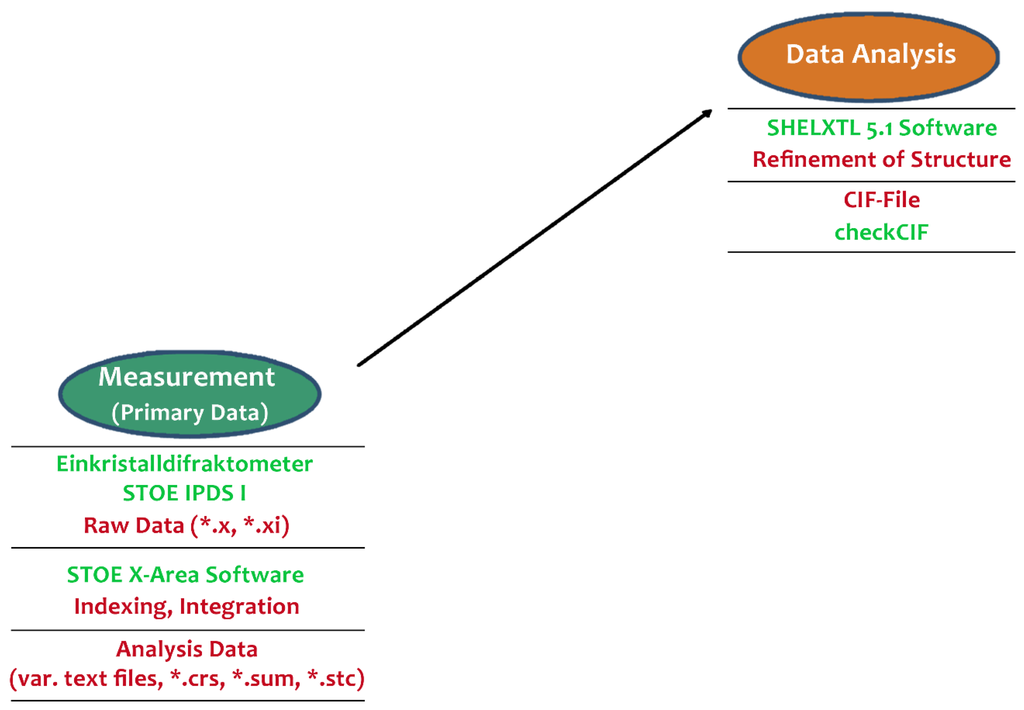
شکل 5. منشأ داده های پژوهشی منتشر شده برای انتشار تعریف شده (جزئیات: مرحله 1).
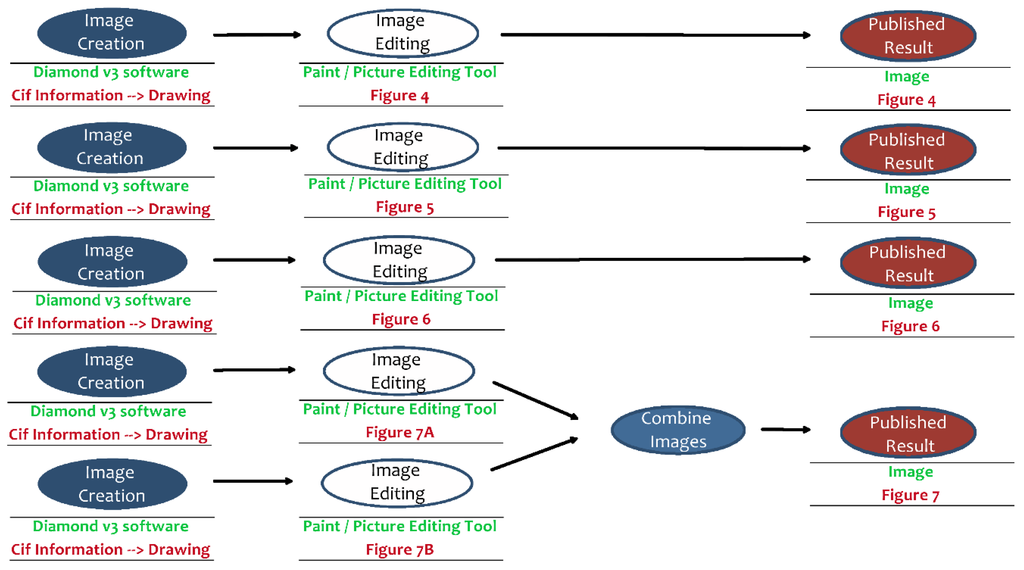
شکل 6. منشأ داده های تحقیقاتی منتشر شده برای انتشار تعریف شده (جزئیات: مرحله 2-5).
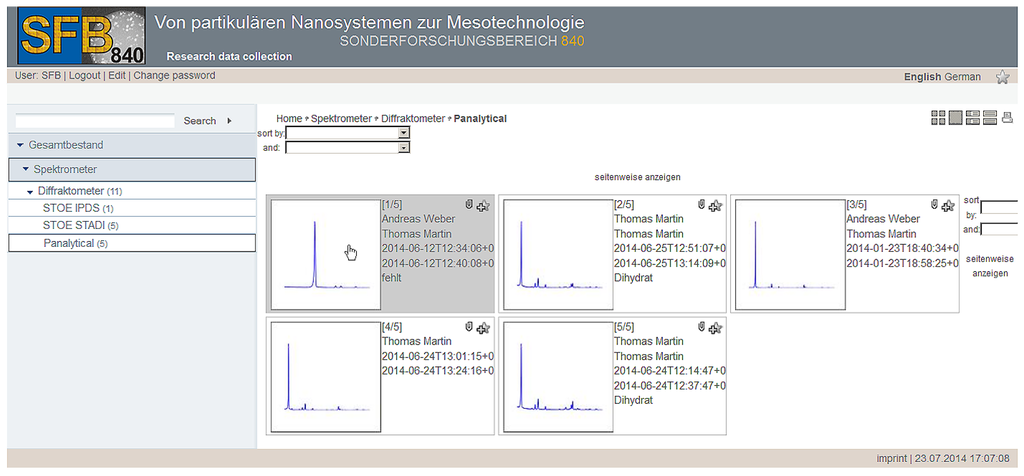
شکل 7. ارائه نوع شی “Panalytical” در مخزن داده.
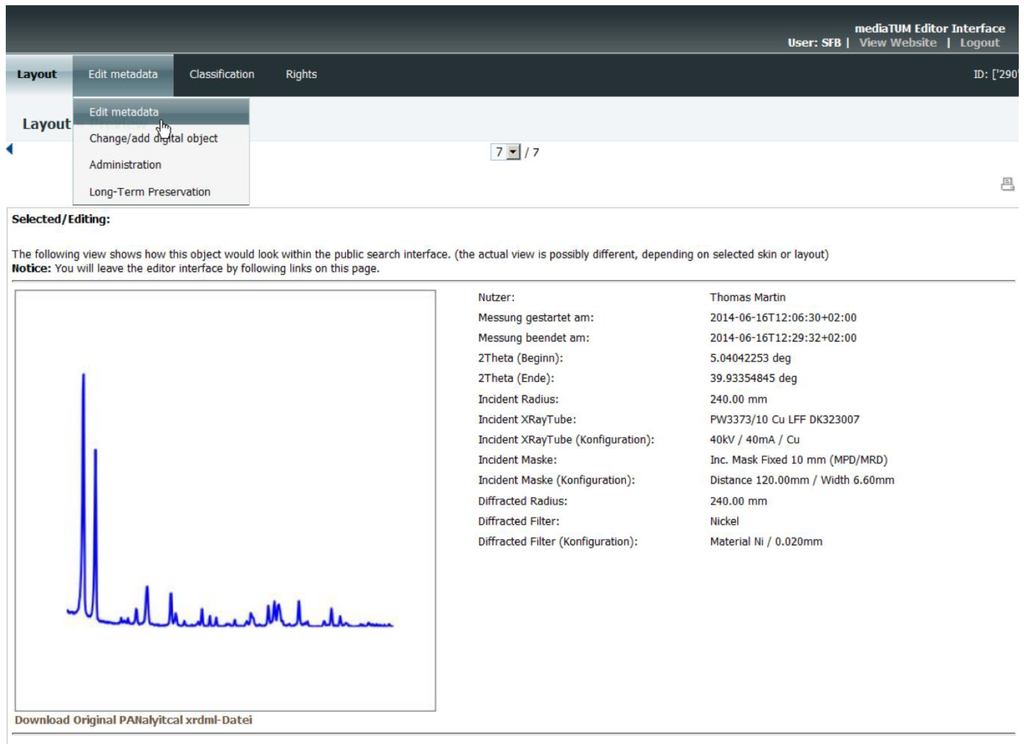
شکل 8. متادیتا را در مخزن داده مشاهده و ویرایش کنید.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons by Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر