1. مقدمه
فناوریهای موقعیتیابی فراگیر شامل سیستمهای ناوبری ماهوارهای جهانی (GNSS) مانند سیستم موقعیتیابی جهانی آمریکا (GPS)، شبکههای تلفن همراه و Wi-Fi، شناسایی فرکانس رادیویی (RFID)، باند فوقالعاده (UWB)، ZigBee است، اما محدود به آن نیست. ، و ادغام آنها. در میان این فناوریهای موقعیتیابی، شبکههای Wi-Fi با استاندارد ارتباطی بدون مجوز IEEE 802.11 به سرعت در بسیاری از شهرهای بزرگ مانند استرالیا، هنگ کنگ SAR چین و تایوان توسعه یافتهاند. عملکرد اساسی شبکه های وای فای فراهم کردن بستری کم هزینه و موثر برای ارتباطات چندرسانه ای است. علاوه بر این، انتشار سیگنالهای Wi-Fi، در صورت مدلسازی مناسب، میتواند اطلاعات موقعیت مکانی دستگاههای تلفن همراه را در هر دو محیط داخلی و خارجی ارائه دهد. رویکردهای مختلف موقعیت یابی Wi-Fi شامل شناسایی سلولی (Cell-ID)، سه لایه و انگشت نگاری است. توضیح تفصیلی این رویکردها را می توان به عنوان مثال در [1 ، 2 ].
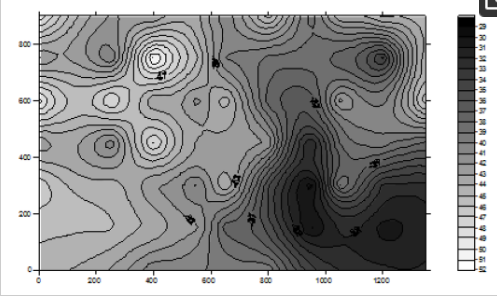
Cell-Identification سادهترین روش برای سیستمهای موقعیتیابی مبتنی بر قدرت سیگنال مانند شبکه تلفن همراه و موقعیتیابی Wi-Fi است. با این حال، تنها نتایج موقعیت یابی بسیار خام را می توان به دست آورد. در موقعیت یک دستگاه تلفن همراه ناشناخته که در آن قدرت سیگنال از m تعداد نقاط دسترسی نزدیک (Aps) قابل شناسایی است، موقعیت AP با قویترین RSS شناساییشده برای تقریبی موقعیت دستگاه تلفن همراه استفاده میشود. به عنوان مثال، اگر RSS 2 از AP 2 در بین RSS i از AP i قوی ترین باشد، برای i = 1، 2، …، m ، پس (X 2 ، Y 2) برای تقریب موقعیت دستگاه تلفن همراه استفاده خواهد شد. با این رویکرد، دقت به فاصله انتشار موثر سیگنال و همچنین چگالی و توزیع APهای نصب شده بستگی دارد. این رویکرد به عنوان مثال، بوسیله محلی سازی وزنی مرکز (WCL) پیشنهاد شده توسط [ 3 ] بیشتر بهبود یافت.]. برای رویکرد سه لایه، موقعیت دستگاه تلفن همراه، معمولاً در دو بعد، با استفاده از مجموعهای از فواصل اندازهگیری شده از APهای شناخته شده نزدیک تعیین میشود. راه حل حداقل مربعات معمولاً زمانی اعمال می شود که بیش از دو فاصله مشاهده شود. لازم به ذکر است که تکنیک های نقشه برداری زمینی فاصله اندازه گیری شده را به عنوان مشاهدات خام اتخاذ می کنند، در حالی که برای تکنیک های مبتنی بر Wi-Fi، داده های خام RSS هستند، بنابراین یک روش تبدیل RSS به فاصله باید اعمال شود و APهای شناخته شده موقعیت ها به عنوان نقاط کنترل تلقی خواهند شد. رویکرد تبدیل کلی RSS به فاصله با برازش منحنی با به عنوان مثال، رگرسیون سهموی یا لگاریتمی، بر اساس مدل انتشار فضای آزاد [ 4 ] است.]. با در نظر گرفتن بیشتر شرایط پیچیده سایت واقعی مانند از دست دادن مسیر سیگنال به دلیل تضعیف، انعکاس و شکست، و همچنین اثرات هندسی بر برداشت طول، الگوریتمهای مختلف تبدیل RSS به فاصله مانند رگرسیون فرآیند گاوسی [ 5 ] و برآورد پارامتر تلفات مسیر آماری [ 6 ] پیشنهاد شد. با توجه به روش انگشت نگاری که برای محیط های داخلی مناسب تر است، این مزیت را دارد که مختصات AP در فرآیند تعیین موقعیت مورد نیاز نیست. با این حال، به تلاش های اولیه برای توسعه پایگاه داده نیاز دارد. پایگاه داده که نقشه رادیویی نیز نامیده می شود ( شکل 1)، شامل مجموعه ای از نقاط کالیبراسیون در مکان های مختلف در منطقه ای است که قرار است موقعیت یابی Wi-Fi انجام شود. فرآیند توسعه پایگاه داده معمولاً در صورتی انجام می شود که عوامل مهمی وجود نداشته باشد که به طور جدی بر الگوهای RSS به دلیل جابجایی اشیاء بزرگ و حذف یا اضافه کردن ساختارهای ثابت در منطقه موقعیت یابی Wi-Fi تأثیر جدی بگذارد.
شکل 1. نمونه ای از نقشه رادیویی تولید شده از پایگاه داده قدرت سیگنال Wi-Fi.
در موقعیت یابی بلادرنگ، RSS های جمع آوری شده در یک موقعیت ناشناخته با الگوی نقشه رادیویی مقایسه می شوند. الگوریتم های مقایسه الگو را می توان به طور کلی به رویکردهای قطعی و آماری طبقه بندی کرد که شامل تطبیق نقطه، احتمال مبتنی بر ناحیه و شبکه بیزی [ 7 ] است. خروجی های تحقیقاتی اخیر در مورد روش های آماری شامل، اما نه محدود به، به عنوان مثال، الگوریتم انتظار-بیشینه سازی (EM) [ 8 ]، تخمین منطقه پوشش [ 9 ]، و الگوریتم های تعیین طبقه برای موقعیت یابی Wi-Fi در ساختمان های چند طبقه پیشنهاد شده است. توسط [ 10 ، 11 ].
در این مقاله، الگوریتم شبکه عصبی پیشنهادی ما با رویکرد تطبیق نقطه بر اساس اصل حداقل هنجار که در زیر توضیح داده شده است، مقایسه میشود.
روش تطبیق حداقل هنجار را می توان به صورت ریاضی به صورت زیر بیان کرد:
که در آن SS RM ( i , j ) مقدار RSS سیگنال ارسال شده از نقطه دسترسی ( i ) در نقطه نقشه رادیویی ( j ) است و SS MEAS ( i ) RSS اندازه گیری شده سیگنال ارسال شده از نقطه دسترسی ( i ) است. . نقطه نقشه رادیویی ( j) داشتن حداقل هنجار محتمل ترین موقعیت در نظر گرفته می شود. از آنجایی که در فرآیند موقعیتیابی بلادرنگ، حسگر Wi-Fi میتواند در هر جهتی باشد، یک رویکرد عملی در فرآیند توسعه پایگاه داده این است که در هر نقطه نمونهبرداری، دادههای RSS ابتدا در یک مرجع 0 درجه و سپس 90 درجه جمعآوری میشوند. جهات 180 درجه و 270 درجه و میانگین مقدار RSS داده های جمع آوری شده در این چهار جهت در محاسبات استفاده می شود. از رابطه (1) واضح است که دقت موقعیتیابی به وضوح نقاط کالیبراسیون بستگی دارد و نتایج موقعیتیابی همیشه به موقعیت نقاط گسسته میچسبند. بنابراین، هرچه نقاط کالیبراسیون با وضوح بالاتری انجام شود، نتیجه دقیق تر است. با این حال، همانطور که در شکل 1 نشان داده شده است، انتشار سیگنال از هر AP موجود یک سطح غیر خطی پیوسته است. بنابراین، مدلی که بتواند سطح انتشار سیگنال همه AP ها را به بهترین شکل توصیف کند، به بهبود دقت موقعیت یابی کمک خواهد کرد. به دلیل انعکاس امواج توسط موانع و سایر تداخل ها، ساختار توابع فوق می تواند نسبتاً پیچیده باشد. روشهای آماری سنتی مبتنی بر برخی تقریبهای هموارسازی ممکن است نتوانند ویژگیهای بسیار نوسان این الگوهای موجی را ثبت کنند.
از زمان پیدایش، شبکه عصبی انواع و ساختارهای مختلف به طور موثر در تعدادی از فرآیندهای شناختی استفاده شده است. نشان داده شده است که آنها قادر به تشخیص برخی تغییرات بسیار ظریف در الگوهای داده های قابل مشاهده هستند. توابع فعالسازی (یا انتقال) که یک لایه از نورونها را به لایه بعدی متصل میکنند، به جای توابع جبری معمولی، سیگموئید هستند که آن را به شدت به هرگونه تغییر ناگهانی در دادههای ورودی پاسخ میدهد. در واقع با [ 12 ] ثابت شدشبکههای عصبی پیشخور با یک لایه ورودی، یک لایه خروجی و یک لایه پنهان منفرد با توابع فعالسازی سیگموید قادرند هر تابع قابل اندازهگیری بورل (شامل آن توابع شرحدادهشده با الگوهای بالا) را با هر درجه دقت مطلوبی تقریب دهند. ، به شرطی که تعداد زیادی واحد عصبی پنهان در دسترس باشد. بر اساس این یافته، [ 13 ] یک شبکه عصبی بازگشتی 3 لایه با یک الگوریتم یادگیری کارآمد که قادر به انجام پیشبینی دقیق نرخ ارز است، معرفی کرد. در ادامه، مدلسازی شبکه عصبی برای رویکرد انگشت نگاری و آزمایشهای تجربی برای اعتبارسنجی الگوریتم پیشنهادی مورد بحث قرار میگیرد.
2. مدل سازی شبکه های عصبی
از مقدمه بالا رویکرد موقعیت یابی اثر انگشت، می توان مختصات (( x , y ) در حالت 2 بعدی) یک نقطه را به عنوان تابعی از قدرت سیگنال از چندین نقطه دسترسی در نظر گرفت { s i }، i = 1، 2، …، m، که در آن، x = f ( s 1 ، s 2 ، …، s m ) و y = g ( s 1 ، s 2 ، …، s m). اگر نمونه ای از توزیع یکنواخت (یا تصادفی) نقاط با موقعیت های شناخته شده و قدرت سیگنال از آن نقاط دسترسی را بتوان به دقت اندازه گیری کرد، حداقل نرم افزار همانطور که در رابطه (1) نشان داده شده است یا برخی از روش های آماری شناخته شده می تواند گاهی اوقات نتایج نسبتاً خوبی ارائه دهد. تقریب موقعیت هر نقطه دیگر در این منطقه بر اساس قدرت سیگنال اندازه گیری شده در این موقعیت. همانطور که در بخش قبل توضیح داده شد، روشهای آماری سنتی مبتنی بر برخی تقریبهای هموارسازی ممکن است نتوانند ویژگیهای نوسانی گسترده این الگوهای موج تولید شده توسط آن نقاط دسترسی را نشان دهند. این خطاهای زیاد در موقعیت یابی Wi-Fi در داخل ساختمان های خاص را توضیح می دهد [ 1 ].
با دلیل فوق، یک شبکه عصبی پیشخور سه لایه ساده به عنوان یک الگوریتم یادگیری کارآمد برای تعیین موقعیت دقیقتر با استفاده از شبکههای Wi-Fi در نظر گرفته میشود و این مدل شبکه عصبی در زیر توضیح داده شده است.
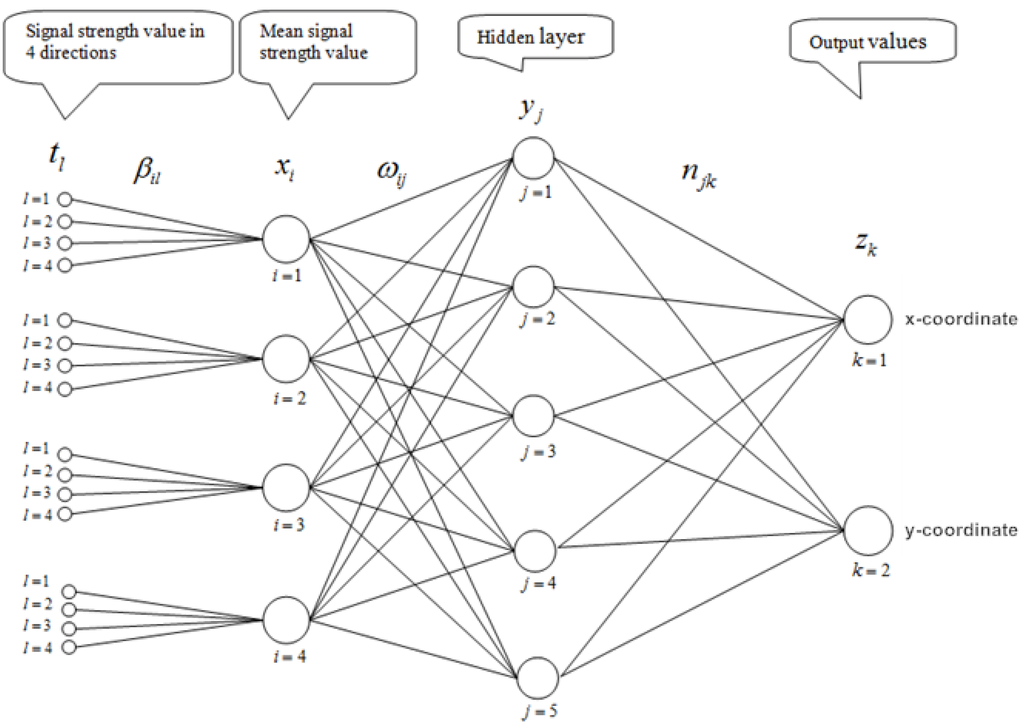
فرض کنید x i ورودی میانگین قدرت سیگنال اندازه گیری شده از نقطه دسترسی i در موقعیت P باشد، جایی که، i = 1, 2, …, m .
خروجی نورون j در لایه پنهان به وسیله داده می شود
که در آن θ j پارامتر آستانه است، و j = 1، 2، …، n ، و مختصات خروجی ( z 1، z 2 ) توسط
که در آن φ k پارامتر آستانه است.
با ترکیب معادلات (2) و (3)، داریم،
از رابطه (4)، می بینیم که با توجه به مجموعه ای از میانگین وزنی سیگنال از مجموعه ای از نقاط دسترسی m ، با وزن ω ij ‘s، مختصات ( z 1، z 2 ) به عنوان خروجی از شبکه مطابقت دارد. در نظر گرفتن
که در آن β i,l پارامترهایی هستند که باید در فرآیند یادگیری ما گنجانده شوند
برای ارائه بهترین تقریب
پیکربندی شبکه عصبی پیشنهادی ما در شکل 2 نشان داده شده است . لازم به ذکر است که قدرت سیگنال xi در یک نقطه P از نقطه دسترسی i در ابتدا میانگین حسابی سطوح سیگنال p ( p = 3 یا 4) است که در جهتهای مناسب انتخاب شده p اندازهگیری میشود . فرآیند یادگیری ما شامل تعیین پارامترهای { η jk }، { ω ij }، { θ j }، { ϕ k } و { β i,l است.} به طوری که اختلاف مختصات خروجی و مختصات واقعی در مجموعه ای از نقاط انتخاب شده حداقل باشد. دقیق تر؛ مختصات واقعی ( 1 , 2 ) یک نقطه معین در مجموعه آموزشی ما مربوط به خروجی ( z 1 , z 2 ) است . و پارامترهای فوق باید با شرطی تعیین شوند که مجموع مجذورات اختلاف آنها به حداقل برسد. یعنی به حداقل رساندن بیان
شکل 2. یک شبکه عصبی پیشخور سه لایه برای موقعیت یابی Wi-Fi.
در اینجا جمع بندی کل مجموعه آموزشی گرفته شده است. خواهیم دید که موفقیت فرآیند یادگیری ما به این بستگی دارد که آیا بتوانیم کوچکترین مقدار ممکن را برای مجموع مجذورهای تفاوت آنها بدست آوریم یا به عبارت دیگر بهترین سطح یادگیری را که الگوی RSS واقعی تولید شده توسط همه دسترسی ها را توصیف می کند. نقاطی که کل منطقه را در بر می گیرد.
الگوریتم کمینه سازی از [ 14 ] اقتباس و اصلاح شد که نشان داده شده است برای حل تعدادی از مسائل بسیار دشوار در کمینه سازی حداقل مربعات بسیار کارآمد است. از آنجایی که تابع هدف غیرخطی است، از یک روش بهینه سازی اکتشافی ساده اما موثر که توسط [ 14 ] معرفی شده است استفاده می شود. نشان داده شده است که در تعدادی از مشکلات کمینه سازی حداقل مربعات پیچیده از جمله آموزش شبکه عصبی مکرر کارآمد است. این روش شامل سه مرحله اساسی است:
- (من)
-
اکتشاف کامل محلی
- (II)
-
حرکت محلی جزئی و
- (iii)
-
حرکات اکتشافی
هر مرحله به طور خلاصه به شرح زیر توضیح داده شده است.
(i) اکتشاف کامل محلی
فرض کنید x (k) k امین تقریب به نقطه ای باشد که حداقل رخ می دهد و h طول پله باشد. تابع هدف در دو مجموعه از نقاط در مورد x (k) تعریف شده در معادلات (8) و (9) ارزیابی می شود.
که در آن e j = (0، …، 1، 0، …، 0) بردار واحدی است که مختصات j آن یک و مختصات باقیمانده صفر است.
در نظر بگیرید که اولین مجموعه نقاط به طور یکنواخت روی کره ای به شعاع h قرار دارد، در حالی که مجموعه دوم S 2 روی کره ای به شعاع h قرار دارد که مرکز آن x (k) با گرفتن طول های مربوطه x (k+1) به دست می آید. در معادلات (8) و (9) تعریف شده است. این بدان معنی است که تعداد کل ارزیابی های تابع 2n(n-1) + 2n = 2n2 است . می توان نشان داد که حداقل جهانی، اگر وجود داشته باشد، به احتمال زیاد در داخل این محله به دام می افتد. 
جهت جستجو را می توان به شرح زیر بیشتر اصلاح کرد:
اگر f ( x (k + 1) ) ≤ f ( x (k) ) برای برخی از گزینه های i و j، آنگاه مقادیر تابع در مجموعه اضافی 2 (n – 1) نقطه در مورد x (k + 1) خواهد بود. قبل از انجام کاوش محلی جزئی به منظور تنظیم دقیق جهت جستجو، ارزیابی شود، یعنی تنظیم شود:
برای برخی از مقادیر t عدد صحیح متعلق به مجموعه {1, 2, …, n} که بهترین مقدار تابع را می دهد.
(2) جنبش محلی جزئی
این روش به ما کمک میکند تا تصمیم بگیریم چه زمانی باید حرکت تهاجمیتری انجام دهیم تا از راه دور به حد مطلوب برسیم یا چه زمانی رویکردی با احتیاط آهستهتر داشته باشیم، زمانی که بهینه واقعی نزدیک است. روش اصلی در زیر آورده شده است:
فرض کنید b = x (k+1) − x (k) . ما f را در مجموعه نقاط زیر در مورد x (k + 1) ارزیابی می کنیم :
برای i = 1، 2، …، n، و ε i = 1 یا -1 با توجه به علامت مختصات b . در غیر این صورت، مجموعه x s = x (k+1) ± b − h e i و e i در امتداد جهت b حذف می شود.
حال، اگر f ( x s ) ≤ f ( x (k+1) ) برای برخی از انتخاب های i , آنگاه x s − x (k+1) قطعا جهت نزول بهتری را نشان می دهد و می توانیم حرکت های اکتشافی انجام دهیم، همانطور که توضیح داده شد. در (iii) زیر، در امتداد این جهت. در غیر این صورت، باید طول گام را با D کاهش دهیم و کاوش کامل را دوباره در x (k + 1) شروع کنیم. لازم به ذکر است که ترتیب تکرار نسبت به n خطی است.
(iii) جنبش اکتشافی
حرکت اکتشافی کلاسیک در اکتشافی “جستجوی الگو” یا “روش گرادیان” متناظر، هرگز نمیتواند بهطور کامل مورد استفاده قرار گیرد، اگر مسیر جابهجایی را نتوان با ادامه حرکت تغییر داد. با تنظیم صحیح جهت هنگام حرکت از نقطهای به نقطه دیگر، میتوانیم به هدایت جستجوی خود بسیار سریعتر به سمت بهینه واقعی کمک کنیم. این می تواند به صورت زیر انجام شود:
m = x s − x (k) را فرض کنید و f را در نقاط زیر ارزیابی کنید:
و e i در امتداد جهت b مستثنی است.
توجه داشته باشید که حداکثر 2n + 1 ارزیابی عملکرد باید انجام شود.
(IV) اثر نسبت انقباض و طول مرحله اولیه
نسبت انقباض D = 4 می تواند مناسب ترین انتخاب باشد. زیرا، در موارد ابعاد پایین تر ( یعنی تعداد متغیرها یا پارامترها خیلی زیاد نیست)، اگر حداقل واقعی خارج از مکعب کاهش یافته در اطراف موقعیت جستجو قرار گیرد، می توان در چند مرحله به آن رسید. با این حال، اگر حداقل در داخل مکعب کاهش یافته باشد، اندازه فضای جستجو در مقایسه با نسبت انقباض D = 2 قابل توجه است. دقت محاسباتی در موردی که D = 4 باشد، طول منقبض شده یک چهارم اندازه گام اصلی است. اگر حداقل نقطه x (k) باشدباز هم می توان مطمئن بود که حداقل نقطه واقعی در این حوزه های قراردادی قرار دارد. حال، اگر مقدار حداقل در یکی از نقاط کره منقبض S’ 1 باشد ، ( یعنی x (k + 1) = x (k) ± (h/4) e i برای برخی i ) یا یکی از نقاط روی کره منقبض S’ 2 ، ( یعنی x (k + 1) = x (k) ± (h/4) e i ± (h/4) e j برای برخی i و j)، دوباره فقط یک کاوش کامل در اطراف این نقطه با طول گام h/4 مورد نیاز است تا مشخص شود که حداقل واقعی احتمالاً در حوزه های منقبض قرار دارد. در غیر این صورت، یک حرکت جزئی اضافی جستجو را به خارج از این منطقه هدایت می کند. از سوی دیگر، اگر حداقل نقطه واقعی بین کره خارجی منقبض S’ 2 و کره خارجی اصلی S 2 قرار گیرد، به راحتی می توان دریافت که برای رسیدن به آن بیش از چهار حرکت ترکیبی محلی یا اکتشافی لازم نیست. در همه موارد، ترتیب پیچیدگی جستجو n 2 است، مشابه مواردی که نسبت انقباض کمتری دارند. توسط [ 14 ، 15 پیدا شد] که برای آزمایش بیشتر نمونههای تست معیار، بهترین نسبتهای انقباض D = 4 و به دنبال آن D = 5 بودند. هیچ سودی در افزایش بیشتر نسبت انقباض وجود نداشت، مگر در موارد نادر.
(V) ضوابط خاتمه
اگر اندازه گام به کمتر از سطح تحمل تجویز شده کاهش یابد، جستجو را خاتمه دهید. باید مراقب بود که تلرانس خیلی پایین تنظیم نشود، در غیر این صورت، نتایج ضعیف تری حتی با هزینه طولانی تر کامپیوتر بدست می آید. در فرآیند یادگیری خود، از آزمایش دریافتیم که بهترین تحمل 1e- 7 است.
طول مرحله اولیه بر میزان همگرایی تأثیر می گذارد. در آزمایشهای ما، طول گام اولیه 0.25 نتایج رضایتبخشی را در بیشتر نمونههای تست معیار ارائه داد. به جز در مواردی که تابع هدف به شدت در بخشی از منطقه جستجو نوسان می کند، طول گام کوتاه تر یا تغییر مقیاس تابع هدف ممکن است به همگرایی رضایت بخش تری کمک کند. اغلب، اینکه آیا طول گام اولیه مناسب است یا نه، در چند تکرار اول قابل تشخیص است.
برای به دست آوردن بهترین نتیجه یادگیری، فرآیند بهینه سازی باید یک یا دو بار دیگر با یک نقطه شروع مجدد جدید در هر بار اجرا شود و بهترین راه حل ( یعنی راه حلی که کمترین مجموع مربع خطا را می دهد) انتخاب شود. این نقاط شروع مجدد را می توان به طور تصادفی انتخاب کرد، اما در فاصله خوبی از موقعیت های شروع قبلی یا با پیروی از روشی که در [ 15 ] توضیح داده شده است.
3. اعتبار سنجی الگوریتم
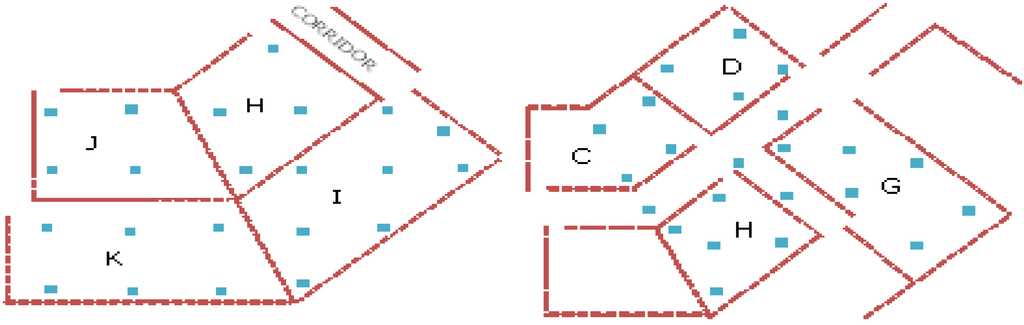
الگوریتم فوق با استفاده از داده های جمع آوری شده در داخل ساختمان پردیس دانشگاه پلی تکنیک هنگ کنگ (HKPolyU)، با توزیع APها که در شکل 3 نشان داده شده است، اعتبارسنجی شد .
شکل 3. پلان طبقه که توزیع نقاط دسترسی را در محل آزمایش نشان می دهد.
14 شماره AP بر اساس شماره منطقه از A تا N به ترتیب برچسب گذاری شدند. در تحقیق ما، دادههای قدرت سیگنال از 3 و 4 عدد AP برای آموزش توسط شبکه عصبی استفاده شد. همانطور که در شکل 4 نشان داده شده است ، هر منطقه شامل 4 تا 5 نقطه تمرینی است که بسته به شکل و اندازه منطقه بین 3 تا 4 متر از هم جدا شده اند. دادههای جمعآوریشده در نقاط دیگر، بهعنوان مثال نشاندادهشده در شکل 5 ، سپس برای تأیید دستیابی به دقت با سطح انتشار قدرت سیگنال آموزشدیده استفاده شد. تمام مکان های نشان داده شده در شکل 4 ، شکل 5قادر به دریافت سیگنال های AP از اتاق های مجاور و همچنین از اتاق های دیگر در شعاع حدود 30 متری بودند. با این حال، در فرآیند اعتبارسنجی ما، فقط سیگنالهای نزدیکترین AP استفاده شد. از آنجایی که کارت وای فای استاندارد IEEE 802.11 b/g برای جمع آوری داده ها استفاده می شد، سیگنال های دریافتی در همان فرکانس 2.4 گیگاهرتز بودند.
شکل 4. نمونه ای از نقاط انتخاب شده برای آموزش توسط شبکه عصبی.
شکل 5. نقاط با موقعیت شناخته شده برای تأیید صحت دستیابی به نتایج شبکه عصبی استفاده شد.
جدول 1 نتایج پردازش شده را با استفاده از ترکیب های مختلف چهار AP نشان می دهد. به عنوان مثال، G_D_E_F آزمایشی را نشان می دهد که با داده های جمع آوری شده در اتاق های G، D، E و F با داده های RSS ارسال شده از APs G، D، E و F تأیید شده است (به شکل 3 مراجعه کنید ). جدول میزان موفقیت را در سطوح مختلف دقت نشان میدهد، میانگین مربعات خطا (MSE) نشاندهنده میانگین حداقلسازی نتایج در فرآیند آموزش شبکه عصبی و تعداد کل نقاط مورد استفاده برای تأیید است. MSE با فرمول محاسبه می شود ، که در آن N نشان دهنده تعداد کل نقاط استفاده شده برای آموزش است.
جدول 1. دستیابی به دقت بر اساس دریافت سیگنال از چهار نقطه دسترسی (APs).
به همین ترتیب، نتایج پردازش شده با استفاده از ترکیب های مختلف سه AP در جدول 2 نشان داده شده است. لازم به ذکر است که نتایج نشان داده شده در جدول 1 ، جدول 2 تنها با یک مجموعه از پارامترهای اولیه پذیرفته شده به طور کلی پردازش می شوند. در زیر نشان داده می شود که تخصیص های مختلف توالی ورودی قدرت سیگنال و پارامترهای اولیه منجر به تغییر جهت و مقیاس بردار ورودی می شود و از این رو سطوح آموزش دیده متفاوتی برای تخمین موقعیت ایجاد می شود و MSE می تواند مورد استفاده قرار گیرد. به طور موثر بررسی کنید که کدام انتساب بردار ورودی به احتمال زیاد بهترین راه حل موقعیت یابی را ارائه می دهد.
جدول 2. دستیابی به دقت بر اساس دریافت سیگنال از سه AP.
از جدول 1 ، جدول 2 می توان دریافت که ترکیبات مختلف AP دستیابی به دقت متفاوتی را به همراه خواهد داشت. قابل درک است که مسیرهای انتشار سیگنال متفاوت است و در نتیجه تداخل سیگنال متفاوت است. علاوه بر این، با بررسی میزان موفقیت 0-4 متر و ستونهای MSE، یک روند آشکار میتوان یافت این است که هرچه MSE کمتر باشد، درصد موفقیت بالاتر است. به منظور بررسی بیشتر این روند، از تمام نتایج پردازش شده برای رسم نمودار درصد دقت در برابر MSE استفاده شد. در شکل 6 به وضوح نشان داده شده استکه، علاوه بر همبستگی منفی آشکار بین دو مؤلفه، اکثر نتایج با MSE کمتر از 5، نرخ موفقیت 80٪ تا 100٪ را به همراه خواهند داشت. این تجزیه و تحلیل اولیه نشان می دهد که برخی از نتایج نشان داده شده در جدول 1 ، جدول 2 ، به ویژه آنهایی که دارای MSE بالا هستند، بر اساس بهترین برازش سطح آموزش دیده شبکه عصبی تعیین نشده اند. با این وجود، برای تأیید اعتبار الگوریتم، داده های ترکیبات 3-AP با MSE کمتر از 5 در جدول 2 نشان داده شده است.در مقایسه با روش تطبیق حداقل نقطه، با داده های آموزشی شبکه عصبی به عنوان نقاط کالیبراسیون ذخیره شده در پایگاه داده نقشه رادیویی، استخراج شد. از آنجایی که دادههای نقشه رادیویی تا حد زیادی در یک شبکه 3 متری توزیع میشوند، روش تطبیق نقطه مزیت این را دارد که نقاط آزمایش را به نقاط شبکه مجاور متصل میکند، بنابراین میزان موفقیت بالای 2 متر یا بهتر، و بسیار بالا 4 متر است. یا دستاوردهای دقت بهتری انتظار می رود. از این رو نتایج تطبیق نقطه می تواند یک پایه مقایسه خوب به عنوان بالاترین راه حل ممکن برای تأیید اثربخشی الگوریتم شبکه عصبی تشکیل دهد. مقایسه آنها در جدول 3 خلاصه شده است.
شکل 6. رابطه بین میانگین مربعات خطا و دقت.
جدول 3. مقایسه دستیابی به دقت بین شبکه عصبی و روش های تطبیق حداقل نقطه.
مشاهده می شود که میزان موفقیت این دو رویکرد به طور کلی بسیار مشابه هستند به جز ترکیب K_J_M که دقت 0-2 متر برای روش تطبیق نقطه به طور قابل توجهی بهتر است. لازم به ذکر است که تنها از مجموعه ای از پارامترهای اولیه سازی ثابت در فرآیند آموزش شبکه عصبی استفاده شده است. این مجموعه از پارامترها ممکن است بهترین سطح آموزش دیده را برای تعیین موقعیت ایجاد نکند. در واقع، برخی از راهحلهای بهدستآمده ممکن است به دلیل پیچیدگی بالای مشکل ما، حداقلهای محلی باشند. بنابراین اجرای واقعی 3 مرحله پیشنهاد شده در بخش 2 برای ایجاد سطح بهینه RSS برای موقعیت یابی Wi-Fi باید بیشتر بررسی و تأیید شود. توجه کنید که ترکیب 3-AP از I_J_K که در جدول 2 نشان داده شده استدارای MSE 8.9 و دقت 0-4 متر پایین 64.7٪ است. این ترکیب برای نشان دادن تحقیقات ما استفاده می شود.
اولین بررسی اثر سطح آموزش دیده با تغییر پارامترهای اولیه است. پارامترهای β ij = 0.25، θj = 300 و φ k = 1 به عنوان تنظیمات قابل قبول در نظر گرفته شدند ، آنها در بررسی ما به منظور بهبود کارایی تمرین ثابت شدند. پارامترهای ω ij و η jk بین دامنهها و افزایشهای زیر متفاوت بودند.
جدول 4 نتایج پردازش شده I_J_K را با استفاده از سه مجموعه مختلف از پارامترهای اولیه نشان می دهد. مشاهده میشود که مجموعه دوم پارامترها کمترین MSE برابر با 2/4 را در بین سه مورد به دست میدهد و دقت 4 متر یا بهتر از 0/31 درصد به 4/91 درصد افزایش یافته است. با مقایسه نتایج مجموعه 2 با نتایج تطبیق نقطه، در جدول 5 مشاهده می شود که میزان موفقیت کلی (4 متر یا بهتر) روش شبکه عصبی بهتر از روش تطبیق نقطه است.
جدول 4. نتایج پارامترهای مقداردهی اولیه برای ترکیب 3-AP I_J_K.
جدول 5. مقایسه شبکه عصبی و روش تطبیق نقطه با استفاده از کمترین MSE از ترکیب I_J_K.
بررسی دوم تغییر ترتیب ورودی قدرت سیگنال از سه AP با مجموعه ای از تنظیمات پارامتر ثابت است. یک مجموعه معمولی از نتایج در جدول 6 نشان داده شده است . مشاهده می شود که تغییر ترتیب ورودی AP ها به طور قابل توجهی MSE و همچنین دستیابی به دقت را تغییر می دهد. (توجه داشته باشید که دو ترتیب ورودی در ردیفهای میانی جدول میانگین مربعات خطا را تقریباً 20٪ کاهش میدهند، در حالی که نسبت دقت 0-4 متر را حداقل 4.5٪ نسبت به چهار تنظیم باقیمانده افزایش میدهند).
جدول 6. نتایج مرتبه های مختلف سه AP مورد استفاده برای آموزش شبکه عصبی.
آزمایشها و مطالعات مقایسهای بالا، کارایی الگوریتم پیشنهادی ما را تأیید کردهاند. بر اساس تجربه ما، روش بهینه سازی اکتشافی 3 مرحله ای را می توان به طور موثر با تغییر پارامترهای ω ij (0.1 تا 0.5) و ηjk ( 0.1 تا 0.9) و تغییر ترتیب ورودی ترکیب AP برای به دست آوردن بهترین سطح آموزش دیده پیاده سازی کرد. .
4. نتیجه گیری
از تحقیقات ما، موقعیتیابی Wi-Fi به طور کلی میتواند به دقت 1 تا 4 متر در یک منطقه شبکه Wi-Fi دلخواه با استفاده از رویکرد شبکه عصبی دست یابد. با این حال، فرآیند آموزش و انتخاب پارامتر شبکه عصبی کلید دستیابی به بالاترین دقت ممکن در نتایج موقعیتیابی Wi-Fi است. نتایج تجربی ما نشان میدهد که شبکه عصبی پیشنهادی با بهبود الگوهای انتشار سیگنال Wi-Fi غیرخطی و بسیار پیچیده، دقت موقعیتیابی را به طور قابلتوجهی بهبود میبخشد. برای جلوگیری از گیر افتادن در حداقل محلی، آموزش باید با تنظیمات پارامترهای اولیه متفاوت و ترتیب متفاوت ورودی داده های AP مجدداً امتحان شود، به طوری که بهترین مجموعه از پارامترها (به عنوان مثال، موردی که کمترین مقدار هدف را می دهد) را می توان یافت. این دقت کلی را بهبود می بخشد. ما نشان دادهایم که بین میانگین مقدار مربع خطای بهدستآمده در فرآیند آموزش و درصد دقت در موقعیتیابی ما رابطه منفی وجود دارد. این بدان معنی است که بر اساس نمودار در شکل 6 ، می توان فرآیند آموزش را همانطور که در بالا توضیح داد تکرار کرد تا به بالاترین دقت ممکن دست یافت.
موارد زیر به طور خلاصه مزایای الگوریتم پیشنهادی ما را نشان می دهد:
-
این الگوریتم مبتنی بر رویکرد انگشت نگاری Wi-Fi است که مختصات Wi-Fi AP در فرآیند تعیین موقعیت مورد نیاز نیست. برای ایجاد یک سیستم موقعیت یابی مبتنی بر Wi-Fi در مناطقی مانند داخل مراکز خرید که تعیین موقعیت APها دشوار است یا امکان تعیین دقیق آن وجود ندارد، مناسب است.
-
این رویکرد کاملاً کلی و منعطف است. هر زمان که تغییراتی در شبکه Wi-Fi موجود وجود دارد (مثلاً اضافه کردن، حذف یا تغییر مکان نقاط دسترسی)، تنها کاری که باید انجام دهیم این است که شبکه عصبی خود را به درستی آموزش دهیم.
-
هیچ محدودیتی برای نزدیک بودن تقریب شبکه عصبی ما به الگوی دادههای رادیویی واقعی (یا سطح فوقالعاده) وجود ندارد، تا زمانی که تعداد نورونهای کافی در لایه پنهان شبکه عصبی سه لایه ساده خود داشته باشیم. با این حال، باید توجه داشت که تعداد بیش از حد نورونها در لایه میانی ممکن است فرآیند یادگیری را کمتر قابل تحملتر کند و خطای کوتاهسازی را بیشتر کند. این به این دلیل است که ساختار پیچیدهتر تابعی که باید به حداقل برسد ممکن است برخی از دقت بهبود یافته آن را جبران کند.
-
از آنجایی که درصد دقت بهتر از چهار متر از نظر گرافیکی با میانگین مربع خطا در فرآیند آموزشی ما نسبت معکوس دارد، میتوان آن را با به حداقل رساندن بیشتر به هر نسبت مطلوبی ارتقا داد. نشان داده شده است که می توان با آموزش مجدد شبکه عصبی با تنظیمات پارامترهای اولیه مختلف به حداقل مربع خطای واقعی نزدیک شد، الگوریتم بهینه سازی ما ساده و موثر است و می تواند با یک الگوریتم قدرتمندتر دیگر که اساساً هیچ ندارد، بیشتر بهبود یابد یا جایگزین شود. تغییر در ساختار مدل ما
در بررسی ما، تنها روش تطبیق نقطه هنجار حداقل با الگوریتم پیشنهادی ما مقایسه شده است. همانطور که در بخش مقدمه به آن اشاره شد، اخیراً بسیاری از الگوریتمهای موثر موقعیتیابی Wi-Fi پیشنهاد شدهاند. بررسی بیشتر نقاط قوت هر رویکرد تحت شرایط هندسی مختلف، در دسترس بودن و توزیع نقطه دسترسی، و شرایط تأثیرگذاری، برای توسعه یک سیستم موقعیت یابی قابل اطمینان همه جا حاضر با بهترین دقت قابل دستیابی، و همچنین پشتیبانی از سیستم های ناوبری ماهواره ای جهانی (GNSS) در این زمینه ارزشمند است. موقعیتیابی ماهوارهای موردی در محیطهای بیرونی با انسداد بسیار ناموفق است.



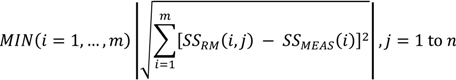

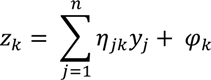





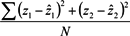


بدون نظر