1. مقدمه
تجزیه و تحلیل ویژگی های عملیاتی گیرنده (ROC) به فرد اجازه می دهد تا عملکرد روش های طبقه بندی باینری را با ترتیب رتبه یا مقادیر خروجی پیوسته ارزیابی کند. تجزیه و تحلیل ROC به طور گسترده در بسیاری از حوزه ها استفاده شده است، مانند تشخیص پزشکی [ 1 ]، مالی کمی [ 2 ]، بیوانفورماتیک [ 3 ] و GIS [ 4 ، 5 ، 6 ].
کاربردهای اصلی ROC در مطالعات مبتنی بر GIS به ارزیابی مدلهای دادههای شطرنجی با هدف پیشبینی تغییر کاربری/پوشش زمین، توزیع گونهها، بیماریها و خطرات بلایا و غیره مربوط میشود. تجزیه و تحلیل ROC برای ارزیابی عملکرد مدلهای فضایی که یک نقشه «احتمال» تولید میکنند، استفاده میشود، که دنبالهای را ارائه میدهد که در آن مدل سلولهای شبکه را برای تعیین وقوع یک رویداد خاص، به عنوان مثال، تغییر کاربری زمین، حضور یک گونه، انتخاب میکند. رانش زمین، آتش سوزی و غیرهما از اصطلاح “احتمال” استفاده می کنیم، اگرچه مقدار آن همیشه درست نیست، یک احتمال به معنای آماری بسته به الگوریتم مورد استفاده برای تولید مقدار. این مقدار اغلب به عنوان مناسب بودن، تمایل، پتانسیل انتقال، شاخص، احتمال یا ارزش امتیاز نامیده می شود. اگرچه ادبیات تجزیه و تحلیل ROC چند کلاسه را گزارش می کند [ 7 ]، ROC استاندارد بیشتر برای رویدادهای باینری استفاده می شود، به عنوان مثال، تغییر در مقابل عدم تغییر، حضور در مقابلعدم وجود یک گونه در رویکرد استاندارد ROC، نقشه احتمال پیشبینیکننده با نقشه رویداد باینری واقعی به منظور ارزیابی همزمانی فضایی بین رویداد و مقادیر احتمال مقایسه میشود. مدلی با قدرت پیشبینی بالا نقشهای از احتمال تولید میکند که در آن احتمالات بسیار رتبهبندی شده با رویداد واقعی منطبق هستند. ROC آستانه های مختلفی را برای نقشه احتمال اعمال می کند تا دنباله ای از نقشه های رویداد پیش بینی شده باینری تولید کند ( شکل 1 ) و برای ارزیابی همزمانی بین رویدادهای پیش بینی شده و واقعی همانطور که در جدول 1 خلاصه شده است.
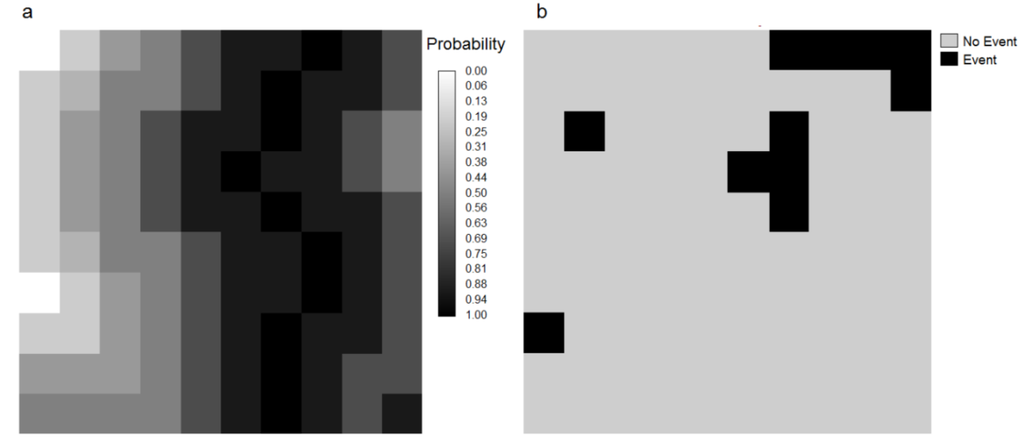
شکل 1. ( الف ) نقشه احتمال و ( ب ) نقشه باینری رویداد، برای 100 سلول شبکه. سلولهای شبکهای با احتمال زیاد تا متوسط (سلولهای سیاه و خاکستری تیره) تمایل دارند با سلولهای شبکه مشکی ۱۱ رویدادی منطبق شوند.
جدول 1. جدول احتمالی مورد استفاده برای محاسبه یک نقطه آستانه در منحنی ROC. Ht ، Ft ، Mt و Ct به ترتیب نسبت سلولهای شبکه مربوط به ضربهها، آلارمهای کاذب، اشتباهات و رد صحیح هستند (اصلاح شده از Pontius و Parmentier [ 6 ] ) .
در منحنی ROC، محور افقی نرخ مثبت کاذب را نشان میدهد (نسبت سلولهای هیچ رویدادی که به عنوان رویداد مدلسازی شده است، یعنی Ft /( Ft + C t ) ) و محور عمودی نرخ مثبت واقعی (نسبت رویداد واقعی) را نشان میدهد. سلولهایی که بهعنوان رویداد مدلسازی میشوند، یعنی Ht / ( Ht + M t)). یک متریک خلاصه محبوب ناحیه زیر منحنی (AUC) است که نقاط به دست آمده توسط آستانه های مختلف را به هم متصل می کند. اگر رویدادهای واقعی کاملاً با احتمالات با رتبه بالاتر منطبق باشند، آنگاه مساحت زیر منحنی (AUC) برابر با یک است زیرا منحنی از نقطه (0,0) شروع می شود و از محور افقی تا نقطه (0,1) بالا می رود. ، و به سمت راست به نقطه (1،1). یک نقشه احتمال تصادفی یک منحنی ROC مورب تولید می کند که در آن نرخ مثبت واقعی برابر با نرخ مثبت کاذب در تمام نقاط آستانه است. هر نقشه احتمالی که دارای منحنی ROC زیر قطر باشد، نسبت به نقشه تصادفی قدرت پیش بینی کمتری دارد. در ادبیات، نرخ های مثبت کاذب و درست نیز به ترتیب به عنوان (1-ویژگی) و حساسیت نامیده می شوند ( شکل 2 ).
شکل 2. منحنی ROC برای نقشه های شکل 1 . نرخ های مثبت درست و غلط برای هر آستانه اعمال شده بر روی نقشه احتمال محاسبه می شود. برای تعریف اولین نقطه در مربع قرمز، مشاهده میکنیم که سطل اول دارای سلولهایی با کد 1 در یک نقشه آستانه است که 10 تاریکترین سلول را با بیشترین احتمال ثبت میکند. چهار مورد از آنها با 11 سلول رویداد منطبق است، بنابراین یک نرخ مثبت واقعی = 4/11 ایجاد می کند. شش سلول دیگر با 89 سلول بدون رویداد منطبق است، بنابراین نرخ مثبت کاذب = 6/89 ایجاد می کند. نقطه بعدی در منحنی ROC با در نظر گرفتن تمام سلول های بالاتر از آستانه احتمال پایین بعدی تعریف می شود.
AUC اغلب برای مقایسه نقشه های احتمال استفاده می شود. هنگامی که داده های مورد استفاده برای ساخت منحنی ROC با نمونه گیری به دست آمد، چنین مقایسه ای باید با تجزیه و تحلیل آماری مناسب انجام شود. در برخی موارد، ارزیابی عملکرد باید بر روی بخش خاصی از منحنی ROC با استفاده از یک AUC جزئی متمرکز شود. بسته های نرم افزاری مختلفی برای تجزیه و تحلیل ROC در حال حاضر وجود دارد. به طور خاص، pROC یک بسته منبع باز برای R و S+ است که شامل تست های آماری متعدد برای مقایسه منحنی های ROC است [ 8 ]]. با این حال، این برنامهها دادههای شطرنجی را بهعنوان ورودی نمیپذیرند و برای مجموعههای داده نسبتاً کوچک، مانند پایگاههای داده پزشکی با صدها یا هزاران مشاهدات، طراحی شدهاند، و بنابراین هنگام پردازش صدها هزار مشاهدات معمولی از مجموعه دادههای شطرنجی، عملکرد پایینی دارند. از سوی دیگر، نرم افزار GIS تست های آماری و ابزارهای تحلیلی کمی برای تجزیه و تحلیل ROC ارائه می دهد.
ابزارهای ارائه شده در این مقاله برای تسهیل تجزیه و تحلیل منحنی ROC برای کاربران GIS با ارائه چندین ابزار برای تجزیه و تحلیل و آزمونهای آماری مناسب برای مقایسه طراحی شدهاند. این ابزارها به کاربران اجازه می دهند منحنی های ROC را تولید کنند، نقاط استراتژیک را شناسایی کنند، AUC های کامل یا جزئی را به همراه فواصل اطمینان خود محاسبه کنند و دو منحنی ROC را از نظر آماری مقایسه کنند. ما این ابزارها را به عنوان مدلها و زیرمدلهای Dinamica EGO، یک پلتفرم نرمافزار رایگان برای مدلسازی محیطی [ 9 ] ( www.csr.ufmg.br/dinamica/ ) پیادهسازی کردیم.
مقاله به شرح زیر سازماندهی شده است: بخش 2 به طور خلاصه دینامیکا EGO را معرفی می کند و بخش 3 اجرای ابزارها را شرح می دهد. بخش 4 استفاده از این ابزارها را برای ارزیابی نقشه های بدست آمده از دو برنامه کاربردی مدل سازی رایج نشان می دهد. در نهایت، بخش 5 نتایج را تفسیر و بحث می کند.
2. دینامیکا ایگو
Dinamica EGO (از این پس Dinamica) بستری برای مدلسازی محیطی است که طراحی از مدلهای فضایی استاتیک ساده تا پیچیده پویا را امکانپذیر میسازد. این مدلها میتوانند شامل تکرارهای تودرتو، بازخوردهای پویا، رویکردهای چند منطقهای و چند مقیاسی، فرآیندهای تصمیمگیری برای انشعاب و پیوستن به خطوط لوله اجرا، دستکاری و ترکیبهای جبری دادهها در قالبهای مختلف، مانند نقشهها، جداول، ماتریسها و ثابتها باشند. مجموعهای از الگوریتمهای فضایی کاربران را قادر میسازد تا شبیهسازیهای فضا-زمان، از جمله تجزیه و تحلیل ساختار چشمانداز، کالیبراسیون مدل، شبیهسازی الگوهای فضایی تغییر و اعتبارسنجی مدل را توسعه دهند. نسخه 64 بیتی این نرمافزار از معماری پردازندههای متعدد بهره میبرد و کتابخانه GDAL آن مجموعههای داده بزرگ را در بسیاری از قالبهای شطرنجی و تقریباً هر طرح نقشهکشی یا مبنا را مدیریت میکند. مدلهایی که میتوانند به عنوان گردشهای کاری تعریف شوند که دنبالهای از عملیات ژئوپردازش را اجرا میکنند، با کشیدن و اتصال تابعهای داده (اپراتورهای داده) در یک نمودار مدل نمایش داده شده در رابط گرافیکی ایجاد میشوند. در نهایت، مدلهای موجود در Dinamica EGO را میتوان بهعنوان مدلهای فرعی ذخیره کرد و بهعنوان تابعهای جدید در کتابخانه تابع ذخیره کرد، بنابراین به کاربران کمک میکند تا مدلها را بهتر سازماندهی، استفاده مجدد و به اشتراک بگذارند.9 ]. در مطالعه حاضر، ما یک کتابخانه جدید به نام “تحلیل ROC” متشکل از هفت مدل فرعی ایجاد کردیم که کاربر را قادر میسازد تا عملیات مختلف مربوط به تجزیه و تحلیل ROC را انجام دهد، به عنوان مثال، محاسبه AUC و AUC جزئی، تخمین اطمینان فاصله AUC، راهاندازی و نمونهبرداری مجدد تصویر. . این کتابخانه برای دانلود در csr.ufmg.br/dinamica و http://www.ciga.unam.mx/ciga/images/proyectos/vigentes/modelos/images/ROC_tools.zip در دسترس است.
3. پیاده سازی تجزیه و تحلیل ROC برای نقشه های شطرنجی
برای ایجاد یک منحنی ROC، کاربر باید یک نقشه احتمال و یک نقشه رویداد ارائه دهد. به عنوان مثال، یک نقشه احتمال جنگل زدایی از یک بازه زمانی و یک نقشه باینری از جنگل زدایی واقعی در همان بازه زمانی. در بستههای نرمافزاری دیگر، یک الگوریتم اسکن خطی مشاهدات (سلولها) را با کاهش احتمال مرتب میکند و سپس به پایین فهرست میرود، هر بار یک مشاهده را پردازش میکند و تعداد موارد مثبت درست و غلط را بهروزرسانی میکند [ 7 ]]. در مورد مجموعه دادههای شطرنجی، تعداد مشاهدات (سلولها) اغلب برای انجام اسکن خطی بسیار زیاد است، بنابراین دادههای ورودی با گروهبندی سلولهایی با احتمالات مشابه در سطلها ساده میشوند. سه روش برای انتخاب آستانه های برش برای تعریف سطل ها وجود دارد. گزینه اول یک روش افزایش احتمال برابر است که در آن افزایش آستانه برش 0.1 که مقدار پیش فرض است، 10 بازه و در نتیجه 10 بن تولید می کند. افزایش آستانه 0.2 پنج فاصله و در نتیجه پنج سطل و غیره ایجاد می کند.این بازهها محدوده احتمال یکسانی دارند، اما لازم نیست تعداد سلولهای یکسانی داشته باشند، زیرا برای مثال، فاصله احتمال از 0.0 تا 0.1 لزوماً شامل 10٪ سلولها نیست. گزینه دوم یک روش افزایش مساحت مساوی است که در آن می توان نقشه را با استفاده از سطل های مساوی طبقه بندی کرد، جایی که هر سطل تقریباً تعداد سلول های مشابهی دارد. مقدار پیشفرض آستانه 10 درصدی، 10 بن را تولید میکند که هر بن 10 درصد سلولها را شامل میشود. برای این گزینههای اول و دوم، افزایش آستانه کوچکتر به سطلهای بیشتر منجر میشود، که اجازه میدهد منحنی ROC دقیقتر و تخمین AUC دقیقتری داشته باشد، اما به زمان رایانه بیشتری نیاز دارد. گزینه سوم استفاده از آستانه های استراتژیک انتخاب شده توسط کاربر است. به عنوان مرحله زیر،
در مورد ارزیابی نقشهها از مدلهای پراکنش گونهها، نقشه رویداد از نقاط وقوع (حضور گونه) استخراج شده و پسزمینه (یا بخشی از آن) به عنوان شبه غیبت در نظر گرفته میشود. پایگاههای اطلاعاتی بیولوژیکی به طور کلی شواهدی از غیبت ارائه نمیدهند، زیرا یک گونه میتواند در یک منطقه مشخص وجود داشته باشد بدون اینکه در طی بررسی میدانی شناسایی شود. علاوه بر این، اطلاعات غیبت برای مدلسازی پراکنش بالقوه کاربرد مشکوکی دارد، زیرا فقدان یک گونه به این معنی نیست که منطقه به عنوان یک زیستگاه بالقوه مناسب نیست [ 10 ]. ابزار Dinamica به کاربران اجازه می دهد منحنی ROC را با یک محور افقی جایگزین پیشنهاد شده توسط [ 10 ] بسازند.]، که پیشنهاد می کنند که محور افقی به جای نرخ مثبت کاذب، نسبت مساحت مطالعه پیش بینی شده موجود در محور افقی ( Ht + F t ) را نشان می دهد. در واقع، این تغییر محور افقی باعث ایجاد تغییر زیادی در منحنی ROC نمیشود، زمانی که تعداد ضربهها بسیار کمتر از تعداد آلارمهای کاذب ( Ht << F t ) و تعداد سلولهای حضور (نقاط وقوع) باشد. بسیار کوچکتر از تعداد شبه غیبت است ( H t + M t << F t + C t، اما محور افقی جایگزین می تواند به بینش های بیشتری در مورد منحنی ROC منجر شود.
3.1. تخمین AUC و pAUC
AUC ها با ذوزنقه ها محاسبه می شوند. به منظور محاسبه یک AUC جزئی (pAUC)، که با مساحت AEFD در شکل 3 نشان داده شده است، کاربران محدوده ای از منحنی ROC را برای تجزیه و تحلیل بر روی محور افقی (نرخ هشدارهای نادرست) یا محور عمودی (نرخ مثبت واقعی) تعریف می کنند ( شکل ). 3). ذوزنقه های خارج از محدوده جزئی نادیده گرفته می شوند. اگر محدوده جزئی با نقاط آستانه منطبق نباشد، ذوزنقههای جدیدی با استفاده از درونیابی خطی از طریق نقاط روی منحنی ROC کامل به منحنی اضافه میشوند. ابزار Dinamica به گزینه ای اجازه می دهد تا یک pAUC را محاسبه کند که با استفاده از رابطه (1) استاندارد شده است تا تفسیر مشابه AUC را ارائه دهد، به این معنی AUC = 0.5 برای یک منحنی ROC غیر متمایز که از نقشه احتمال تصادفی مشتق شده است، و AUC = 1.0 برای یک منحنی ROC کامل [ 8 ، 11 ].
که در آن pAUCs pAUC استاندارد شده است، تصادفی AUC pAUC است که توسط مدل تصادفی (مساحت ABCD) در همان محدوده منحنی ROC به دست میآید، و perfectAUC pAUC در همان محدوده منحنی ROC کامل (منطقه AGHD) است.
شکل 3. ناحیه جزئی زیر منحنی (AUC) برای محدوده ای در محور افقی. pAUC مربوط به منطقه AEFD است. مقدار آن با استفاده از pAUC یک مدل تصادفی (ناحیه ABCD) و یک مدل کامل (منطقه AGHD) استاندارد شده است.
در طول آستانهسازی نقشه احتمال، یک سطل منفرد ممکن است حاوی سلولهایی با احتمالات مختلف باشد. رویکرد ذوزنقه ای تغییرات درون یک سطل را نادیده می گیرد، زیرا رویکرد ذوزنقه ای از یک پاره خط مستقیم برای اتصال دو نقطه متوالی منحنی ROC استفاده می کند. آستانههای اضافی که سطلهای کوچکتر را تعریف میکنند، میتوانند منحنی ROC را اصلاح کنند، از لحاظ نظری تا جایی که هر سلول در یک سطل است. با این حال، این معمولا به دلیل محدودیت های محاسباتی امکان پذیر نیست. اگر تعداد bin ها بسیار کمتر از تعداد مقادیر احتمال یکتا باشد، در این صورت عدم قطعیت در مورد منحنی ROC و در نتیجه AUC وجود دارد که از نحوه تعریف بن ها ناشی می شود. برای این وضعیت، [ 6] دو ارزیابی اضافی از ROC به نامهای ROClower و ROCupper را پیشنهاد کرد که بر اساس منحنیهای شکل پلکانی هستند که به ترتیب در زیر و بالای منحنی ذوزنقهای ROC قرار دارند. از این دو منحنی اضافی، دو مقدار AUC به ترتیب به نامهای AUClower و AUCupper استخراج میشوند. مقادیر آنها برای ارزیابی عدم قطعیت مربوط به انتخاب آستانه برای نقشه احتمال مفید است.
3.2. فاصله اطمینان
هنگامی که AUC یا pAUC از یک نمونه مشتق می شود، فواصل اطمینان (CIs) را می توان با نمونه گیری مجدد طبقه بندی شده بوت استرپ تخمین زد. نقشههای تکراری جدید احتمال با نمونهگیری مجدد با جایگزینی از نقشه احتمال اولیه تولید میشوند. ابزار Dinamica از طبقهبندی استفاده میکند تا اطمینان حاصل کند که هر نمونه همان نسبت سلولهای رویداد را در دادههای اصلی دارد. تجزیه و تحلیل ROC بر روی هر نقشه تکرار شده برای محاسبه AUC یا pAUC انجام می شود. سپس CI ها با استفاده از دو رویکرد برآورد می شوند. اولین مورد بر اساس یک فرض توزیع نرمال است و مرزهای CI را با استفاده از انحراف استاندارد AUCهای تکرار شده و یک جدول نرمال استاندارد برای به دست آوردن احتمال مشاهده AUC در زیر، بالاتر یا بین مقادیر معین تخمین می زند. روش دوم روش فاصله صدک بوت استرپ است،
برای انجام بوت استرپینگ، احتمال Pk برای سلولی که k بار در یک تکرار بوت استرپ انتخاب شود با رابطه (2) محاسبه می شود :
که در آن Pk احتمال انتخاب یک سلول k بار در یک نسخه بوت استرپ است که در آن n تعداد سلولهای لایهای است که سلول به آن تعلق دارد .
به منظور جلوگیری از سرریز محاسباتی، فرمول سرریز قوی برای محاسبه ضرایب دو جمله ای ارائه شده توسط [ 12 ] اصلاح شد، بنابراین معادلات (3a) و (3b) تولید شد:
3.3. مقایسه دو منحنی ROC
معمولاً مقایسه مقادیر AUC یا pAUC بین منحنیهای ROC جفت شده مفید است. این جفت ها ممکن است از مفاهیم مختلفی ناشی شوند. به عنوان مثال، یک مجموعه واحد از داده ها می تواند دو نقشه احتمال متفاوت را به دلیل دو روش تحلیل متفاوت تولید کند. وقتی منحنیهای ROC از یک نمونه استخراج میشوند، ارزیابی اینکه آیا تفاوت از نظر آماری معنیدار است یا اینکه آیا این تفاوت را میتوان به تغییرپذیری ناشی از نمونهگیری نسبت داد، مهم است. برای این وضعیت، یک آزمون بوت استرپ بر اساس روش هانلی و مک نیل اصلاح شده توسط [ 8 ] بر اساس محاسبه Z با استفاده از رابطه (4) اجرا شد:
که در آن AUC 1 و AUC 2 دو AUC هستند و sd (AUC 2 – AUC 1 ) انحراف استاندارد تفاوت بین دو AUC با تکرارهای متعدد است. از آنجایی که Z تقریباً یک توزیع نرمال را نشان می دهد، مقادیر p یک یا دو دنباله به ترتیب برای انجام تست های یک یا دو دنباله محاسبه می شوند. همین مفاهیم در مورد AUC های جزئی نیز صدق می کند.
با در نظر گرفتن تغییرات ناشی از تخصیص مکان تصادفی در نقشه تصادفی، آزمایش اینکه آیا یک نقشه تناسب جمعیت کامل AUC متفاوتی نسبت به نقشه تصادفی ایجاد می کند یا خیر، می تواند مفید باشد. بنابراین، شبیهسازی مونت کارلو را میتوان توسط دینامیکا انجام داد تا آزمایش کند که آیا مدل مکانهایی را به طور قابلتوجهی متفاوت از تصادفی اختصاص میدهد [ 13 ]. در این مورد از همان آماره Z استفاده می شود.
3.4. بهبود در استفاده و تفسیر منحنی های ROC
بهبودهای استفاده از ROC و AUC آن که توسط [ 6 ] پیشنهاد شده بود در مجموعه ابزارها اجرا شد. این پیشرفتها انتقاداتی را مطرح میکنند که AUC نباید به عنوان تنها شاخص عملکرد مدل استفاده شود، زیرا AUC یک معیار بالقوه گمراهکننده است [ 10 ، 14 ]. ما یک مدل دینامیکا را برای تولید تابع توزیع تجمعی (CDF) طراحی کردیم، که یک هیستوگرام تجمعی از فرکانس سلول ها به عنوان تابعی از احتمال است. محققان میتوانند از CDF برای انتخاب آستانههای مهمی برای منحنی ROC استفاده کنند، مانند آستانههایی که چارک اول، میانه، چارک سوم منطقه مورد مطالعه و آستانهای که در آن Ht + M t را در بر میگیرد.برابر H t + F t است. به منظور برجسته کردن نقاط آستانه مهم در منحنی ROC، ابزاری برای نشان دادن احتمال متناظر آستانه و نسبت منطقه مورد مطالعه که احتمال زیر آستانه دارد طراحی شد. در نهایت، چگالی وقوع رویداد در هر سطل منحنی ROC به عنوان نسبت بین سلولهای وقوع و سلولهای کاندید یک سطل معین محاسبه شد (معادله (5)). نتیجه را می توان با نمودار میله ای یا نقشه نشان داد.
که در آن D t تراکم سلول های رخداد در bin t است، Ht و Ht + 1 به ترتیب در آستانه t و t + 1 و M t و M t + 1 به ترتیب در آستانه t و t + 1 رد می شوند.
3.5. کاهش زمان محاسبات
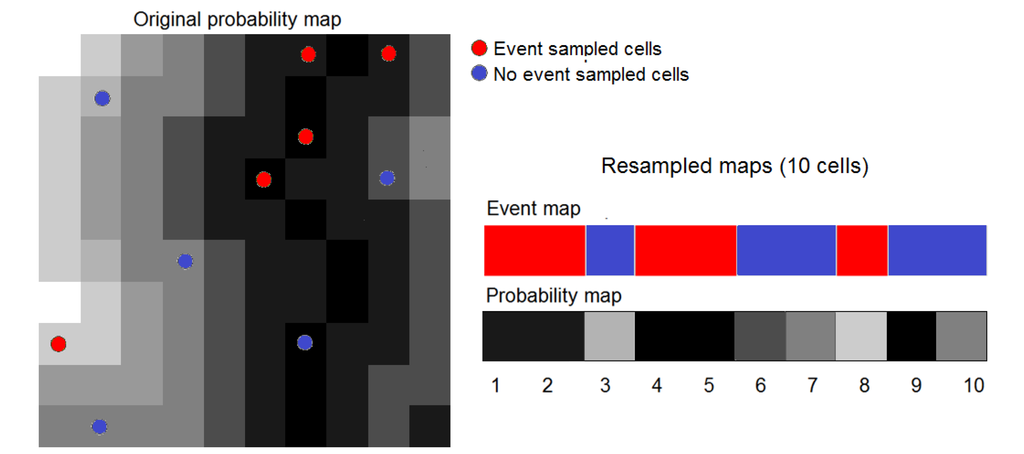
روش های مونت کارلو و بوت استرپ شامل تعداد زیادی تکرار است. هر تکرار به چندین عملیات جبر نقشه از کل نقشه ها نیاز دارد، بنابراین نیاز به زمان محاسباتی قابل توجهی دارد. به منظور سرعت بخشیدن به پردازش، ابزاری ایجاد کردیم که به صورت تصادفی از تصاویر احتمال و وقوع نمونه برداری می کند تا از داده های کمتری هنگام محاسبه شاخص ها بر اساس این فرآیندهای تکراری استفاده شود. نمونه برداری به منظور کنترل نسبت نمونه برداری برای سلول های رویدادی و بدون رویداد طبقه بندی می شود. به عنوان مثال، در مدل سازی طاقچه، تعداد سلول های شبه غیبت به طور کلی بسیار بیشتر از سلول های حضور است، بنابراین باید تنها داده های شبه عدم حضور را کاهش داد. در نتیجه، نقشههای جدید حاوی تعداد کمتری سلول از سلولهای نمونهبرداری شده برای فرآیندهای بعدی تولید میشوند. ساختار فضایی نقشه های اصلی حفظ نشده است. با این حال،شکل 4 روش نمونه گیری مجدد را با استفاده از داده های شکل 1 نشان می دهد. از نمونهگیری طبقهای تصادفی برای انتخاب پنج سلول به ترتیب برای دستههای رویداد و بدون رویداد استفاده میشود. سپس با استفاده از اطلاعات این ده سلول انتخابی، نقشههای رویداد و احتمال «کاهششده» جدید (1 × 10 سلول) ساخته میشوند. فرآیندهای تکراری شامل تعداد زیادی تکرار با استفاده از این تصاویر “کاهش یافته” انجام می شود. ما تأثیر روش نمونهگیری مجدد را بر دقت AUC در بخش 4.2 بررسی میکنیم.
شکل 4. روش نمونه گیری. تصویر اصلی خط به خط خوانده می شود و سلول های انتخاب شده در یک نقشه نمونه برداری مجدد یک خطی مرتب می شوند.
4. برنامه های کاربردی
ما مجموعه ای از ابزارها را در دو تمرین مدل سازی اعمال کردیم. اولین مورد شامل یک مدل تغییر کاربری و پوشش زمین (LUCC) در آمازون برزیل است که با استفاده از Dinamica EGO اجرا شده است. دومی مدلی از توزیع تنبل سه انگشتی گلو قهوه ای ( Bradypus variegatus ) است که با استفاده از MaxEnt [ 15 ] و Dinamica EGO [ 16 ] پیاده سازی شده است.
4.1. مدل تغییر کاربری/پوشش (LUCC).
داده های مطالعه موردی با بسته نصبی Dinamica EGO ارائه می شود. هدف آن مدل سازی الگوهای فضایی جنگل زدایی در شمال ماتو گروسو، مرز کشاورزی در آمازون برزیل است. مدل جنگل زدایی از وزن شواهد (WofE) برای تهیه نقشه احتمال جنگل زدایی پس از سال 1994 ( شکل 5 ) با استفاده از لایه های داده زیر استفاده کرد: پوشش جنگلی 1991، پوشش جنگلی 1994، فاصله تا جاده ها، فاصله. به جنگل و شیب [ 17]. در بسیاری از مدلهای LUCC، از این نوع نقشه احتمالی برای تهیه نقشههای پوشش زمین با تخصیص جنگلزدایی در آینده استفاده میشود. روش شبیه سازی معمولاً تغییرات را در مناطقی که احتمال انتقال بالاتری را نشان می دهند اختصاص می دهد. به منظور ارزیابی قدرت پیش بینی نقشه احتمال، نقشه احتمال جنگل زدایی را از طریق تحلیل ROC با جنگل زدایی واقعی بین سال های 1994 و 1999 مقایسه کردیم ( شکل 6 ).
شکل 5. ( الف ) نقشه تغییر پوشش جنگلی مشاهده شده طی سال های 1994-1999 و ( ب ) احتمال جنگل زدایی پس از سال 1994. مناطق سفید غیر جنگلی در سال 1994 از تجزیه و تحلیل حذف شدند.
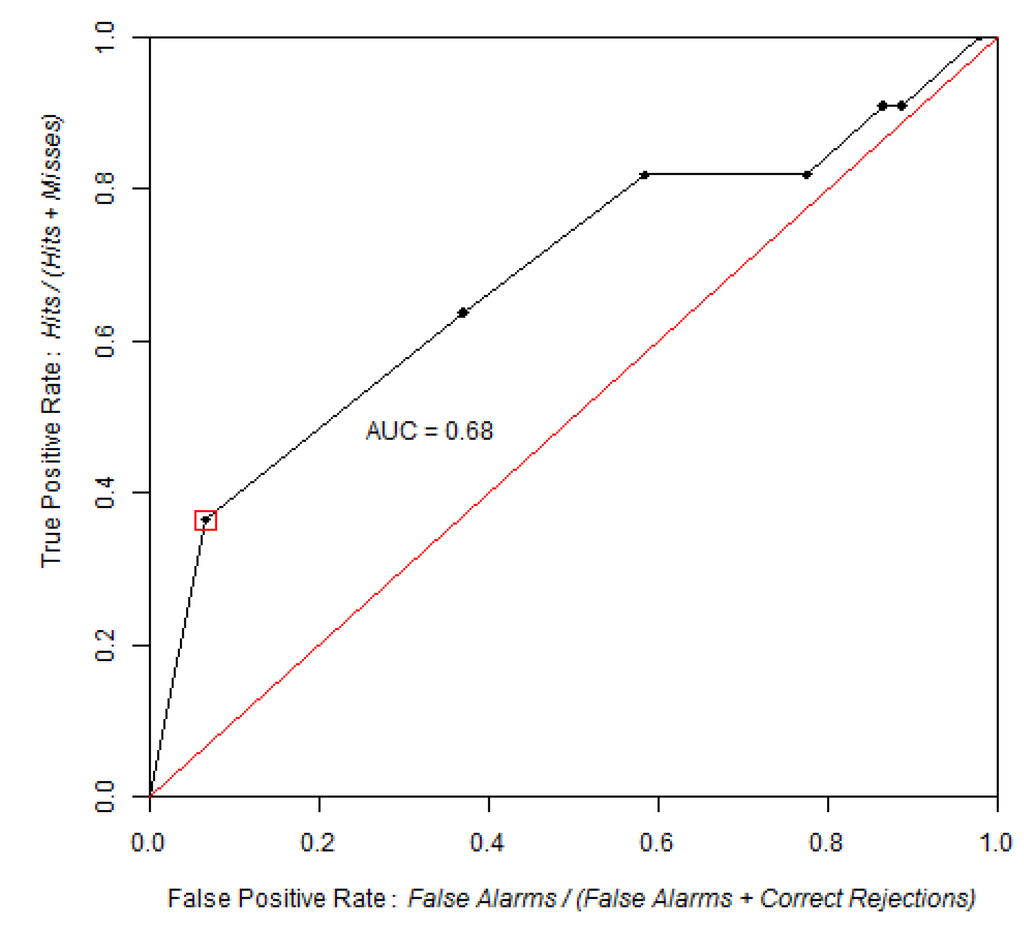
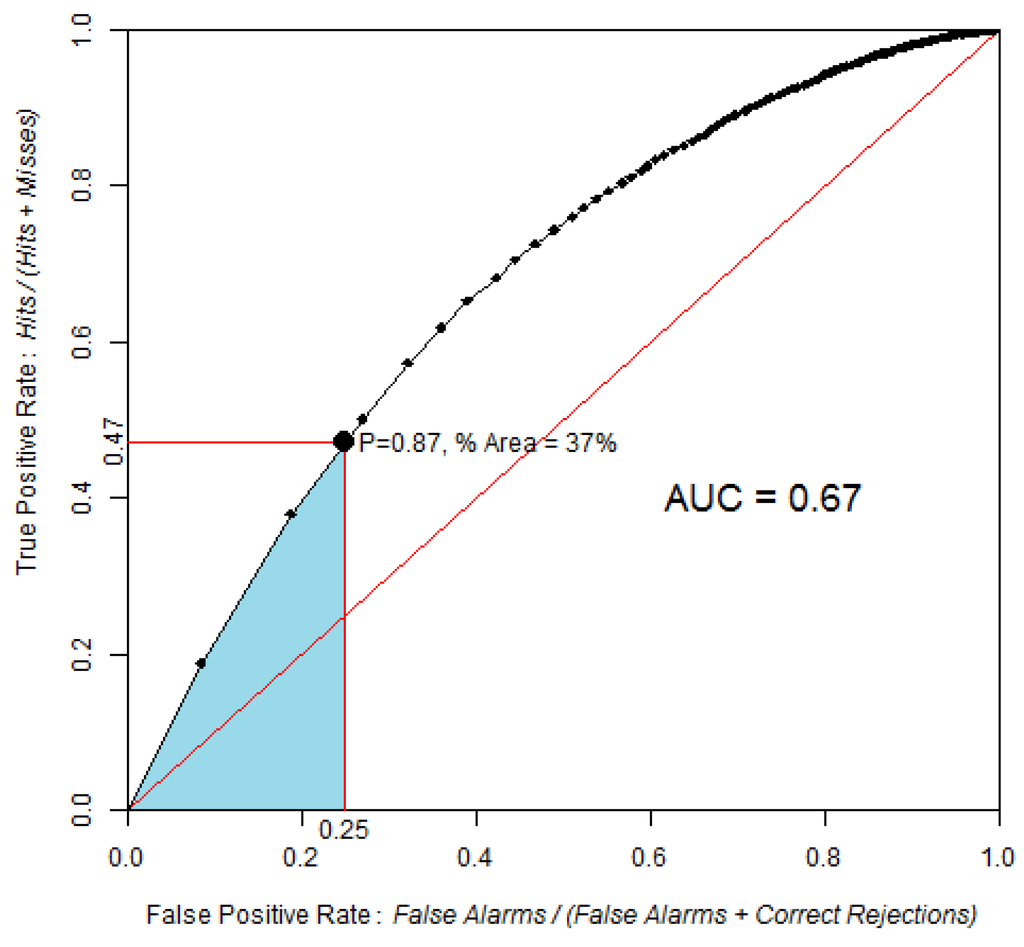
شکل 6. منحنی ROC با مقایسه احتمال نقشه جنگل زدایی پس از سال 1994 با جنگل زدایی مشاهده شده بین سال های 1994 و 1999، با استفاده از 100 سطل و روش افزایش احتمال برابر به دست آمد. نقطه شناسایی شده در منحنی ROC مربوط به منطقه ای است که انتظار می رود در طول سال های 1994-1999 جنگل زدایی شود، با فرض اینکه روندهای قبل از 1994 پس از سال 1994 ادامه یابد. در محور نرخ مثبت کاذب.
AUC 0.67 است که تفاوت قابل توجهی با یک مدل تصادفی دارد. آزمون Z با 2000 تکرار مونت کارلو Z = 118، p-value = 5 × 10-89 بود.
بر اساس برون یابی خطی نرخ جنگل زدایی مشاهده شده در بازه کالیبراسیون 1991-1994 (14100 هکتار در سال)، انتظار می رود که حدود 37٪ از مساحت جنگل 1994 طی سال های 1994-1999 پاکسازی شود که معادل 70500 هکتار از 1906000 است. هکتار از جنگل 1994. بنابراین، یک آستانه استراتژیک مربوط به 37 درصد از مساحت جنگلی در سال 1994 است. این نقطه با احتمال 0.87 مطابقت دارد و در مختصات (0.25، 0.47) روی منحنی ROC قرار دارد. اگر pAUC را به بازه 0-0.25 در محور نرخ مثبت کاذب محدود کنیم، آنگاه pAUC روی قسمتی از منحنی متمرکز خواهد شد که نقشه احتمال بالاترین مقادیر خود را دارد. pAUC نرمال شده 0.602 برای این بخش از منحنی ROC پیدا شد. مدلهای تصادفی، مانند Dinamica، برخی از تغییرات شبیهسازی شده را در سلولهای با احتمال کم تخصیص میدهند.18 ]، از این رو عملکرد مدل به بخش وسیع تری از منحنی ROC بستگی دارد.
ارزیابی مدلهای LUCC از طریق تجزیه و تحلیل ROC بر اساس همزمانی تغییرات مشاهدهشده و نقشه احتمال تغییر تولید شده توسط مدل، بدون توجه به تخصیص فضایی ضربهها، خطاها، آلارمهای کاذب و رد صحیح است. جنبه های فضایی اضافی را می توان در نظر گرفت مانند واقع گرایی الگوهای مناظر شبیه سازی شده [ 18 ] و تطابق تغییرات در یک محله جستجو [ 19 ]. از این نظر، یک سری از معیارهای مقایسه نقشه موجود در دینامیکا می تواند ارزیابی ROC [ 9 ] را تکمیل کند.
4.2. مدل های توزیع گونه ها
ما نقشههای توزیع بالقوه Bradypus variegatus را با استفاده از دادههای (موجود در http://www.cs.princeton.edu/~schapire/maxent/ ) [ 15 ] با استفاده از بسته برنامه MaxEnt (رویکرد حداکثر آنتروپی، [ 15 ]) تولید کردیم. ) و روش Weights of Evidence (WofE) که در Dinamica EGO موجود است. داده های وقوع به طور تصادفی به دو زیر مجموعه تقسیم شدند. ما مدلهایی را با استفاده از زیرمجموعه اول، متشکل از 81 رخداد به اضافه 699719 سلول شبه غیبت، آموزش دادیم. سپس تجزیه و تحلیل ROC را با استفاده از زیرمجموعه دوم انجام دادیم که شامل 34 رخداد به علاوه 651316 سلول شبه عدم وجود است. تجزیه و تحلیل ROC نیز پس از نمونه برداری مجدد از داده های زیرمجموعه دوم با استفاده از روشی که در بخش 3.5 توضیح داده شده است، انجام شد.. ما از 100 درصد دادههای وقوع (34 سلول) و تقریباً 10 درصد از دادههای شبه غیبت (حدود 65000 سلول تصادفی) استفاده کردیم. در نتیجه، نمونهبرداری مجدد ما را قادر میسازد تا نقشههایی را با 65034 سلول به جای نقشههای اصلی با 1929504 (1592 × 1212) سلول پردازش کنیم. این ما را قادر می سازد تا بوت استرپ را با 2000 تکرار در زمان معقول انجام دهیم، به ویژه 6 ساعت و 35 دقیقه با استفاده از یک رایانه رومیزی با پردازنده i7-3770k 3.50 گیگاهرتز و 24 گیگابایت رم.
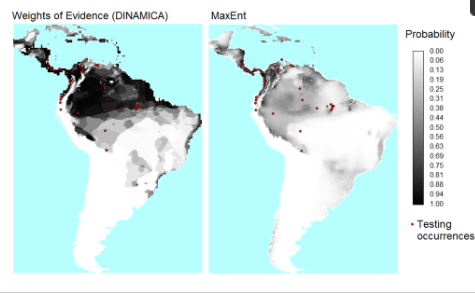
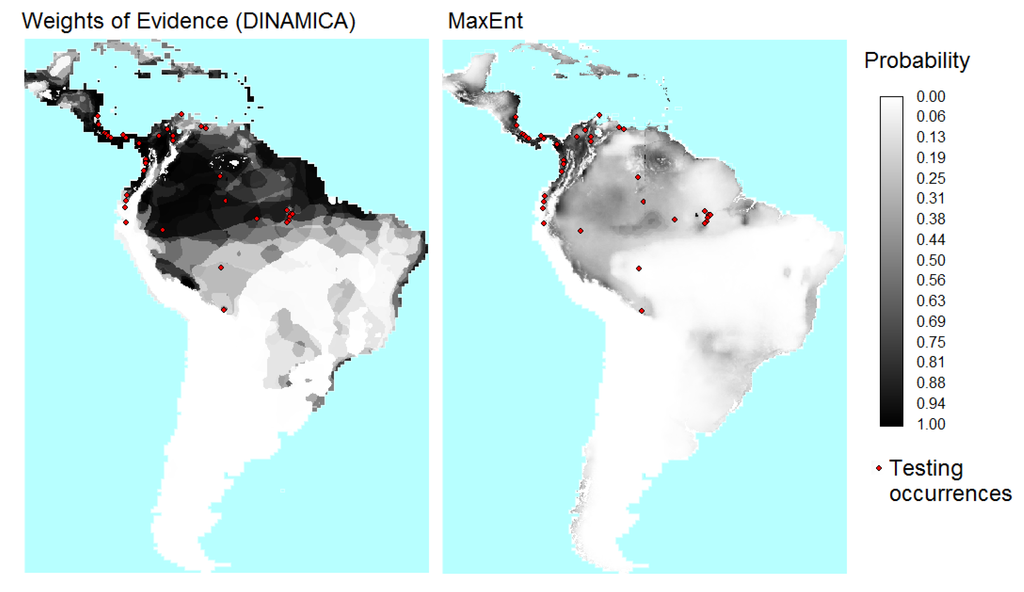
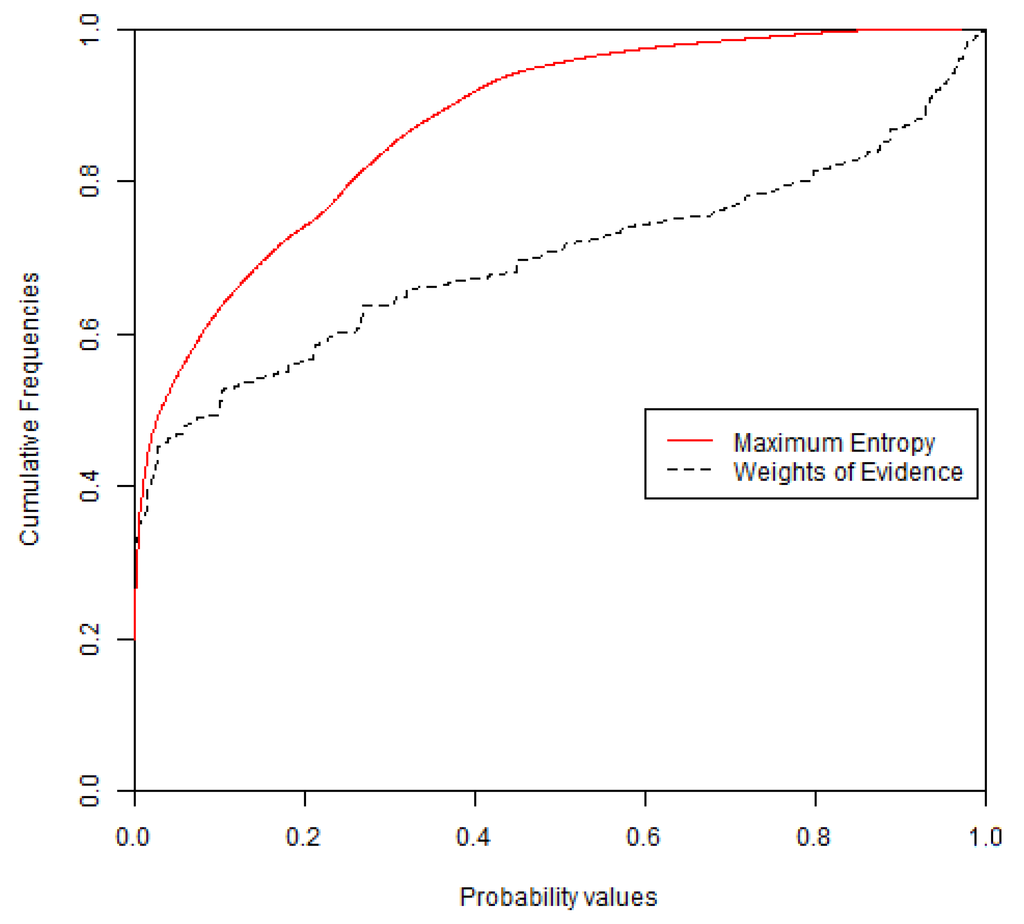
شکل 7 ، شکل 8 نقشه های احتمال و توابع توزیع تجمعی (CDF) به دست آمده از WofE و MaxEnt را نشان می دهد. نقشه احتمال به دست آمده با روش WofE دارای مقادیر پیوسته کمتری است زیرا در این روش از نقشه های طبقه بندی شده به دست آمده از طبقه بندی مجدد متغیرهای توضیحی پیوسته استفاده می شود. حدود 97 درصد از سلولهای MaxEnt دارای مقادیر احتمالی زیر 0.6 هستند، در حالی که 74 درصد از سلولهای WofE دارای مقادیر احتمالی زیر 0.6 هستند.
شکل 7. نقشههای احتمال حضور B. variegatus بهدستآمده با روشهای Weights of Evidence (WofE) و MaxEnt.
شکل 8. توابع توزیع تجمعی (CDF) برای نقشه های احتمال از WofE و MaxEnt. محور عمودی نسبتی از ناحیه کاندید است که مقادیر احتمالی آن کمتر یا مساوی با مقدار روی محور افقی است.
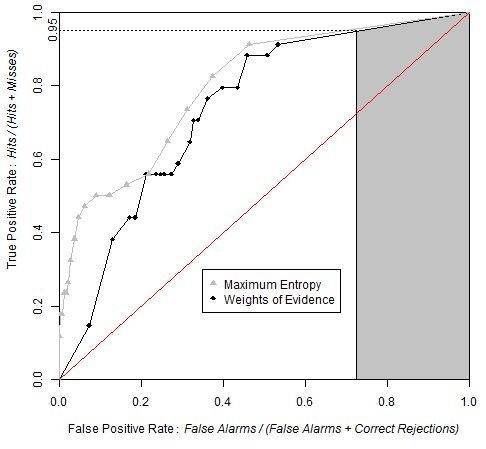
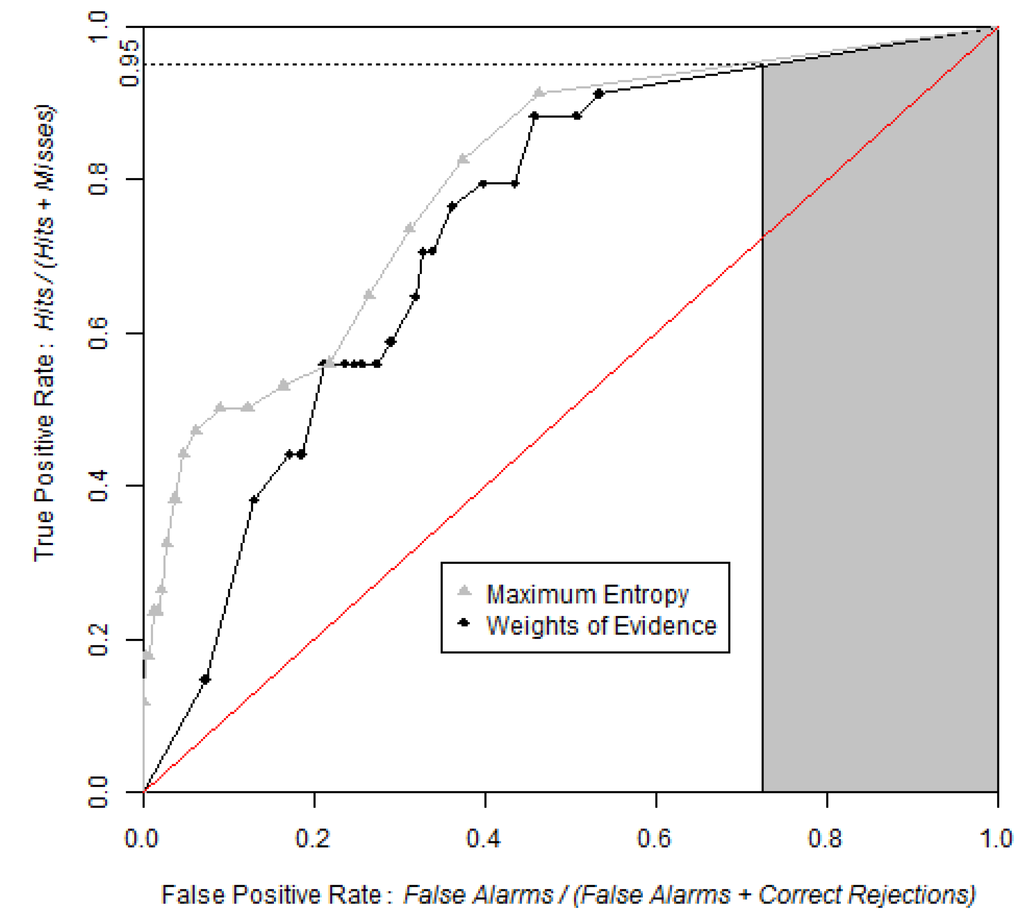
شکل 9 نشان می دهد که منحنی ROC از MaxEnt ناگهانی تر از WofE افزایش می یابد. شکل منحنی نزدیک به مبدأ نشان میدهد که مناطق با احتمال بالا از MaxEnt سلولهای حضور بیشتری را نسبت به مناطق با احتمال بالا بهدستآمده از WofE میگیرند. هر دو منحنی بسیار نزدیک به سمت راست بالای منحنی ROC هستند، که نشان می دهد که احتمالات کم مربوط به مناطقی است که گونه وجود ندارد.
مقدار دقیق AUC به دست آمده از دو روش با استفاده از بسته pROC [ 8 ] که از الگوریتم اسکن خطی شرح داده شده توسط [ 7 ] استفاده می کند، محاسبه شد. AUC برای WofE و MaxEnt به ترتیب 0.7478 و 0.8110 محاسبه شد. جدول 2مقادیر AUC محاسبه شده با استفاده از چهار افزایش آستانه برای روش افزایش احتمال برابر و برای روش افزایش مساحت مساوی به همراه تفاوت بین این مقادیر و مقدار دقیق AUC (در درصد مقدار دقیق) را نشان می دهد. نتایج بهدستآمده با استفاده از سطلهای 100 و 20 دارای اختلاف کمتر از 2 درصد (افزایش احتمال برابر) هستند، در حالی که نتایج مبتنی بر 10 و 5 بنها تخمینهای دقیقتری ندارند (خطای بین 2 تا 10 درصد برای افزایش احتمال مساوی). استفاده از دادههای نمونهگیری مجدد تأثیر مهمی بر تخمینهای AUC ندارد. روشی که برای آستانه گذاری نقشه احتمال استفاده می شود تأثیر بیشتری نسبت به تعداد bin ها دارد. هر دو رویکرد منجر به دست کمگرفتن سیستماتیک AUC شدند، در حالی که برای روشی که از افزایش مساحت مساوی استفاده میکند، برای مطالعه موردی ما، کمتر برآورد شدیدتر است (خطای بین 0.3٪ و 9.3٪ و بین 5).
شکل 9. منحنی های ROC به دست آمده با روش WofE و MaxEnt. ناحیه سایه دار خاکستری نشان دهنده AUC جزئی مدل WofE بین 0.95 و 1 در محور نرخ مثبت واقعی است. pAUCها برای WofE و MaxEnt مشابه هستند، که نشان میدهد نقشههای احتمال در مورد جایی که احتمالات نسبتاً پایینتر تخصیص داده میشوند مشابه هستند.
جدول 2. مقادیر AUC به دست آمده با استفاده از افزایش آستانه های مختلف و روش های برش بر روی داده های کل و نمونه برداری مجدد. مقادیر دقیق AUC برای WofE و MaxEnt به ترتیب 0.7478 و 0.8110 است. عدد بین پرانتز خطای تخمینی است که به صورت تفاوت نسبی بین مقدار و مقدار دقیق (در درصد مقدار دقیق) بیان میشود.
جدول 3 AUClower و AUCupper را نشان می دهد که با چهار افزایش احتمال برابر متفاوت (0.01، 0.05، 0.10 و 0.20) محاسبه شده اند، که دلالت بر چهار اندازه سطل مختلف (100، 20، 10 و 5) دارد. ما از کل منطقه مورد مطالعه و نقشه احتمال WofE استفاده کردیم. همانطور که انتظار می رود، در افزایش برش درشت، عدم قطعیت تخمین AUC بزرگ است (0.5952-0.8218 برای 5 سطل) و با استفاده از فواصل باریک تر (0.7299-0.7617 برای 100 سطل) به طور قابل توجهی کاهش می یابد. اثر فواصل مورد استفاده برای برش تصویر احتمال را می توان در شکل 10 درک کرد .
ما AUC جزئی را برای محدوده بین 0.95 و 1 در محور نرخ مثبت واقعی (عمودی) همانطور که توسط [ 10 ] پیشنهاد شده است محاسبه کردیم. در نهایت، ما فواصل اطمینان را برای AUC و pAUC از طریق روش فاصله صدک راهاندازی با 2000 تکرار محاسبه کردیم و سپس تفاوت مقادیر AUC و pAUC بین دو مدل را آزمایش کردیم ( جدول 4 ).
جدول 3. مقادیر AUC بالایی، ذوزنقه ای و پایینی در تعداد سطل های مختلف برای روش افزایش احتمال برابر.
شکل 10. منحنی های ذوزنقه ای، پایین و بالایی ROC از همان نقشه احتمال با افزایش 0.05 ( چپ ) و 0.2 ( راست ) افزایش می یابد. وقتی افزایش آستانه 0.2 باشد، تعداد بن ها 5 است. وقتی افزایش آستانه 0.05 باشد، تعداد بن ها 20 است.
جدول 4. مقادیر AUC و AUC جزئی به همراه فاصله اطمینان آنها با استفاده از آلفا = 0.05 به دست آمده با استفاده از WofE و MaxEnt. AUC جزئی بین 0.95 و یک در محور نرخ مثبت واقعی (عمودی) محاسبه شد، مقادیر گزارش شده نرمال می شوند.
آزمون مورد استفاده برای مقایسه AUC و pAUC بهدستآمده از هر دو مدل نشان داد که AUC بهدستآمده از MaxEnt بهطور قابلتوجهی با AUC بهدستآمده از WofE متفاوت است (Z = 1.73، دو دنباله p-value = 0.084). با این حال تفاوت معنی داری بین دو pAUC وجود ندارد (Z = 0.00، دو دنباله p-value = 0.999). این نشان میدهد که اگر نقشههای توزیع پتانسیل با اعمال آستانهای در نقشههای احتمال با احتمالی مطابق با نرخ مثبت واقعی 0.95 به دست آیند، آنگاه MaxEnt و WofE هر دو نقشههای توزیع بالقوه را تولید خواهند کرد که مناطق و تعداد نقاط وقوع مشابه را ثبت میکنند.
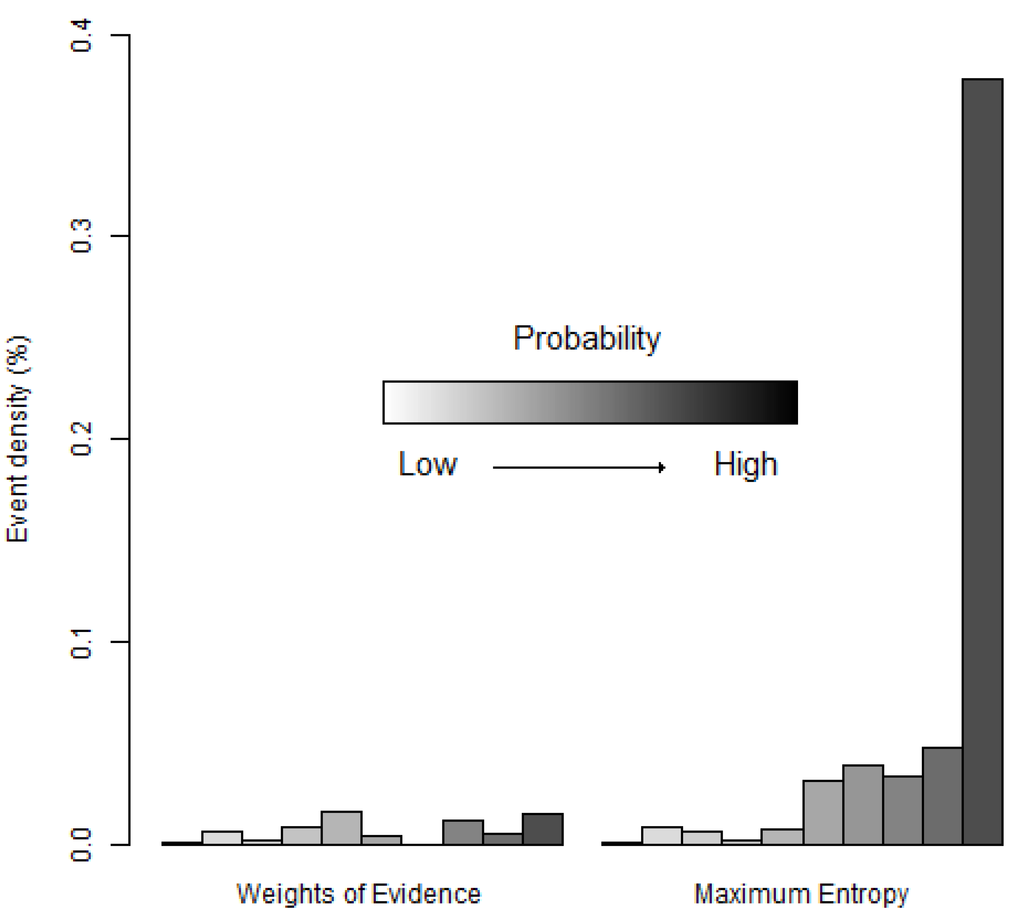
روش دیگر برای مقایسه دو نقشه احتمال، ارزیابی چگالی نقاط وقوع در هر سطل است ( شکل 11 ). شکل 11 نشان می دهد که سطل های احتمال زیاد MaxEnt دارای تراکم نقاط وقوع بیشتری نسبت به سطل های احتمال بالا WofE هستند. این با منحنی ROC MaxEnt که به طور ناگهانی در نزدیکی مبدا فضای ROC نسبت به منحنی ROC WofE افزایش می یابد مطابقت دارد ( شکل 9 ).
شکل 11. تراکم وقوع گونه ها به صورت نسبت (%) در هر سطل بیان شده است (معادله (5)). سطل ها با احتمال کمتر در سمت چپ و احتمال بیشتر در سمت راست با استفاده از روش افزایش احتمال برابر مرتب می شوند.
5. بحث
برای مجموعه داده های بزرگ، تعداد مشاهدات (سلول ها) برای اجرای الگوریتم اسکن خطی [ 7 ] بسیار زیاد می شود. بنابراین، ابزار ما نقشه احتمال را با گروه بندی مجدد سلول ها در سطل ها ساده می کند. علاوه بر این، نقشههای ورودی مجدداً نمونهبرداری شدند تا ابعاد آنها کاهش یابد. همانطور که در جدول 2 نشان داده شده است ، برخی از این عملیات می تواند منجر به تغییرات تخمین AUC شود. در مطالعه موردی ما، انتخاب بین مساحت مساوی در مقابلروش فاصله برابر تأثیر بیشتری بر AUC نسبت به تعداد سطلها و نمونهگیری مجدد داشت، زیرا رویکرد مساحت مساوی AUC را به طور سیستماتیک دستکم گرفت. با استفاده از روش احتمال برابر، تعداد افزایشها در صورت کافی (0.01 و 0.05 معادل 100 و 20 بن به ترتیب) و نمونهبرداری مجدد (10% عدم وقوع) منجر به خطای تخمین AUC کمتر از 2% میشود. این نتایج به مطالعه موردی خاص وابسته است و نمی توان آن را به عنوان قوانین کلی تفسیر کرد. به عنوان مثال، تاثیر روش برش به توزیع مقادیر احتمال بستگی دارد که توسط CDF نشان داده شده است ( شکل 8)). محاسبه AUClower و AUCupper به فرد امکان می دهد عدم قطعیت را به دلیل آستانه بودن تصویر احتمال ارزیابی کند. علاوه بر این، برآورد AUC می تواند تحت تأثیر عوامل دیگری غیر از محاسبات باشد. به عنوان مثال، در مدل های طاقچه، داده های وقوع اندک است، که اغلب از یک نمونه مغرضانه به دست می آیند و می توانند خطاهایی داشته باشند که بر محل نقاط مشاهده یا شناسایی گونه تأثیر بگذارد. در مدلسازی LUCC، دادهها را میتوان تحت تأثیر خطاهای طبقهبندی در تصاویر مورد استفاده برای نظارت بر تغییرات قرار داد.
محاسبه فاصله اطمینان AUC توسط بوت استرپ به فرد اجازه می دهد تا تأثیر اندازه نمونه را بر دقت AUC ارزیابی کند. با این حال، فواصل اطمینان، سوگیری احتمالی نمونه را در نظر نمی گیرند. برای مثال، اگر دادههای حضور یک گونه بهدلیل دسترسی آسانتر، بهطور سیستماتیک به سمت ارتفاع کم سوگیری شود، آنگاه مجموعه دادههایی که برای آموزش و آزمایش نقشه توزیع استفاده میشوند، این تعصب را به ارث خواهند برد. در نتیجه، AUC محاسبهشده و فاصله اطمینان آن میتواند AUCهای بزرگتری نسبت به یک تخمین بیطرف داشته باشد، زیرا هم دادههای آموزشی و هم ارزیابی حضور گونهها را در مناطق مرتفعتر دستکم میگیرند. در نتیجه، زمانی که نمونه گیری نماینده کل جامعه نیست، کاربران باید با این شاخص ها محتاط باشند.
با وجود افزایش کارایی محاسباتی رویکرد ما در مقایسه با الگوریتم اسکن خطی، برخی از الگوریتمهای ما هنوز میتوانند به زمانهای محاسباتی طولانی نیاز داشته باشند. به عنوان مثال، بوت استرپ باید همه داده ها را دوباره ترکیب کند و سپس مقادیر AUC را هنگام استفاده از روش فاصله صدک راه انداز مرتب کند. این آخرین عملیات با استفاده از یک الگوریتم مرتبسازی حبابی انجام میشود که یک روش مرتبسازی مستقیم اما آهسته است. بنابراین، اگر زمانهای محاسباتی بیش از حد طولانی باشد، کاربران میتوانند نسبتهای نمونهگیری و افزایش آستانه را که پردازش را سرعت میبخشد، شناسایی کنند. برای مثال، در مطالعه موردی ما با استفاده از راهاندازی، AUC با استفاده از برش دادههای نمونهگیری مجدد با افزایش احتمال مساوی 0.05 محاسبه شد، بنابراین 20 bin تولید شد.
6. نتیجه گیری
مجموعه ابزارهای ارائه شده در این مقاله امکان تجزیه و تحلیل و مقایسه منحنی های ROC را با استفاده از داده های شطرنجی فراهم می کند. همانطور که برای دو مطالعه موردی نشان داده شد، مجموعه اجازه ایجاد منحنی ROC، مشخص کردن نقاط مرتبط در این منحنی، محاسبه AUC و pAUC، دو نوع فاصله اطمینان، محاسبه AUClower و AUCupper، مقایسه دو منحنی ROC جفتی و محاسبه چگالی رویداد در هر سطل احتمال. ما معتقدیم که این مجموعه ابزارهای مناسبی را برای تفسیر خروجی از مدلهای فضایی مختلف در اختیار محققان، بهویژه در جامعه GIS قرار میدهد. با توجه به اینکه دینامیکا به کاربران اجازه می دهد ابزارهای خود را بسازند، کاربران همچنین می توانند این ابزارهای ROC موجود را بهبود بخشند یا آنها را با ابزارهای جدید تکمیل کنند.



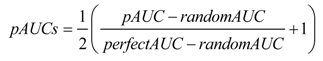

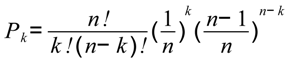
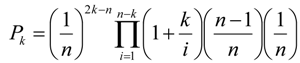
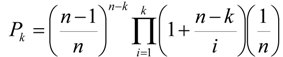
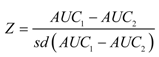
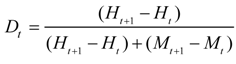


بدون نظر