

خلاصه
: برای بهبود تصمیم گیری، تراکم جمعیت در زمان واقعی باید شناخته شود. با این حال، محاسبه چگالی نقطه یک مجموعه داده عظیم در زمان واقعی از نظر زمان پردازش غیر عملی است. بر این اساس، یک الگوریتم سریع برای تخمین توزیع چگالی نقاط متحرک پیشنهاد شده است. این الگوریتم که مبتنی بر تخمین بیزی متغیر است، یک رویکرد پارامتری برای سرعت بخشیدن به فرآیند تخمین اتخاذ می کند. اگرچه رویکرد پارامتریک دارای یک اشکال است، یعنی فرآیندهایی که باید روی سرور انجام شوند بسیار کند هستند، الگوریتم پیشنهادی با استفاده از نتیجه تخمین توزیع چگالی گذشته مجاور بر این اشکال غلبه میکند.
تخمین بیزی متغیر ; تخمین چگالی ; ویژگی های متحرک ؛ اطلاعات بزرگ
1. معرفی
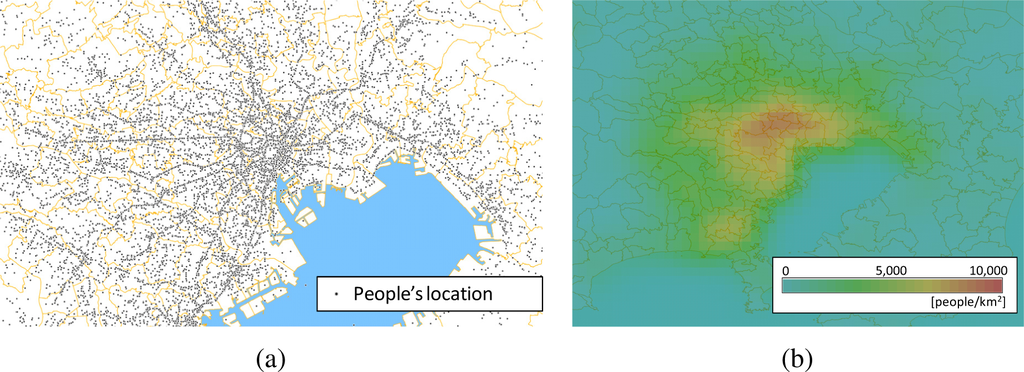
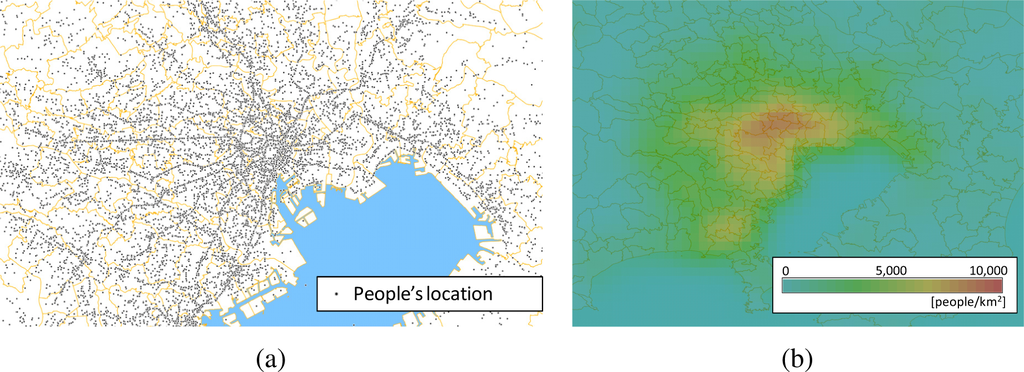
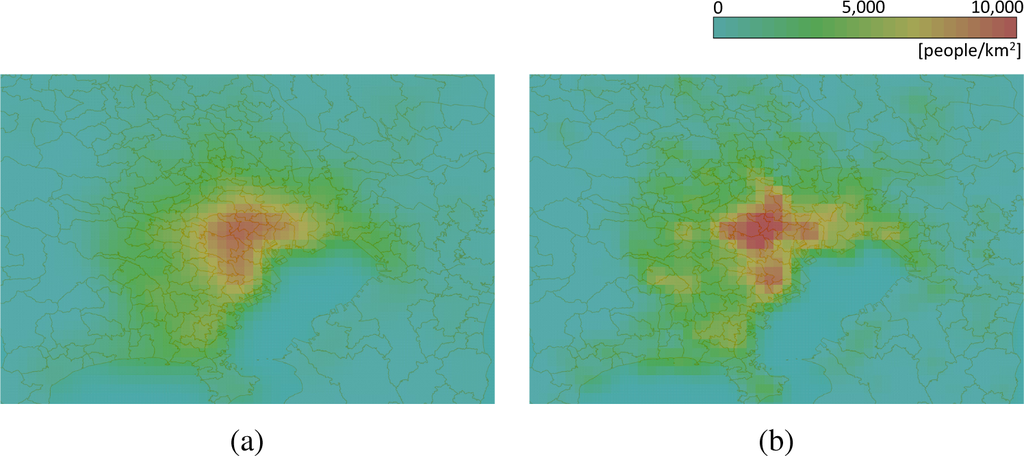
تراکم جمعیت، یعنی تعداد افراد در واحد سطح، یکی از مؤثرترین عوامل در تصمیمگیری درگیر در وظایفی مانند مدیریت زیرساخت، برنامهریزی توسعه شهر و تجارت است [ 1 ]. به عنوان مثال، افسران پلیس می توانند گشت زنی خود را در یک شهر بر اساس مکان های پرتراکم جمعیت بهینه کنند، زیرا تصادفات اغلب در آن مکان ها در شهرها رخ می دهد. مجموعهای از موقعیتهای افراد، متشکل از «نقاط متحرک»، به عنوان مثال در شکل 1a ، میتواند برای محاسبه تراکم جمعیت استفاده شود. شکل 1a با رسم نتایج پرسشنامه های مربوط به سفرهای افراد (یعنی جفت داده ها متشکل از جفت مبدا و مقصد سفر) در طول یک روز کامل بر روی نقشه پایه ترسیم شد [ 2 ].]. بنابراین این نقاشی نشان دهنده موقعیت افراد در لحظه گذشته است. در مقابل، موقعیتهای افراد در زمان واقعی از طریق تلفنهای همراه با عملکردهای موقعیتیابی مشابه GPS اندازهگیری میشوند [ 3 ، 4 ]، حرکات افراد را منعکس میکنند. در این صورت، موقعیت افراد در زمان واقعی به عنوان نقاط متحرک ثبت می شود. چنین داده های انبوهی در مورد موقعیت های افراد باید به طور معمول مورد استفاده قرار گیرد، زیرا آنها باید برای بسیاری از تصمیم گیری ها، مانند طراحی طرح های گشت زنی برای افسران پلیس، مورد توجه قرار گیرند. OGC (کنسرسیوم فضایی باز [ 5])، که یک سازمان استاندارد بین المللی است که با سیستم های اطلاعات مکانی مرتبط است، مشخصات استاندارد قابل اجرا برای چنین داده هایی را منتشر می کند. استانداردی برای رمزگذاری دادههای نقطه متحرک عظیم بهعنوان «رمزگذاری ویژگیهای متحرک OGC» [ 6 ] تعریف میشود که برای تبادل آسان مقادیر عظیم دادههای نقطه متحرک تعریف شده است.
همانطور که در بالا ذکر شد، داده های لحظه حرکت برای بسیاری از برنامه ها مفید هستند. به ویژه، تابع توزیع چگالی نقاط متحرک (از این پس “چگالی نقطه”)، که به عنوان تابعی از موقعیت ( x ، y ) و زمان t بیان می شود، موثرترین ویژگی برای توصیف گرایش نقاط متحرک است. با این حال، مدیریت یک مجموعه داده عظیم نقطه به خودی خود چندان آسان نیست، حتی اگر قابل مبادله باشد. بنابراین، تبدیل از دادههای نقطه متحرک عظیم به دادههای قابل کنترل آسان مورد نیاز است.
«دادههای پوشش»، که چگالی نقطه را توصیف میکند، یکی از آسانترین انواع دادهها هستند که قابل کنترل هستند. پوشش را می توان با استانداردهای رمزگذاری مختلف، مانند OGC NetCDF [ 7 ] و GML [ 8 ] کدگذاری کرد. شکل 1b توزیع تراکم جمعیت را نشان می دهد که از نقاط نشان داده شده در (الف) نشان داده شده است. چنین تصویر قابل فهمی که بر اساس چگالی رنگ شده است، که اغلب “نقشه حرارتی” نامیده می شود، می تواند به طور خودکار تولید شود ( شکل 1b توسط یک تخمینگر تراکم هسته درجه دوم که در بخش 2 نشان داده شده است تولید می شود.) پس از تجسم، نقشه های حرارتی را می توان با فرمت های تصویر عمومی کدگذاری کرد. مانند PNG و JPG. برای توزیع چنین تصاویری، یک OGC WMS (سرویس نقشه وب) [ 9رابط ] معمولا استفاده می شود. بر این اساس، تبدیل از داده های نقطه ای به پوشش به قابلیت همکاری سیستم کمک می کند.
شمارش تعداد نقاط سادهترین روش برای تخمین چگالی نقاط ثابت است. یعنی فضایی که در آن نقاط وجود دارد به سلولهای کوچکی تقسیم میشود و تعداد نقاط هر سلول شمارش میشود. چنین روشی روش هیستوگرام [ 10 ] نامیده می شود. با این حال، روش هیستوگرام مشکلات متعددی دارد. یکی از مشکلات، مبادله بین اندازه سلول (“اندازه سلول”) و تعداد داده ها است. اندازه سلول را می توان در موردی تنظیم کرد که ساختار سلسله مراتبی سلول، مانند یک “چهاردرخت” [ 11 ]]، اقتباس شده است. اگر لازم است چگالی نقطه ریزتر باشد، باید کوچکتر باشد. با این حال، پراکندگی آماری نتایج تخمین اگر سلولها کوچک باشند، بیشتر میشود، زیرا سلولهای کوچکتر نقاط کمتری دارند. بنابراین برای تخمین چگالی نقطه ریزتر، به مجموعه داده عظیمی نیاز است. به همین دلیل، چندین الگوریتم مرسوم برای تخمین دقیق چگالی نقطه، حتی با سلول های کوچک، پیشنهاد شده است. متقابل اندازه سلول “رزولوشن” نامیده می شود. یعنی وضوح یک چگالی نقطه ای با استفاده از سلول های کوچک “بالا” است.
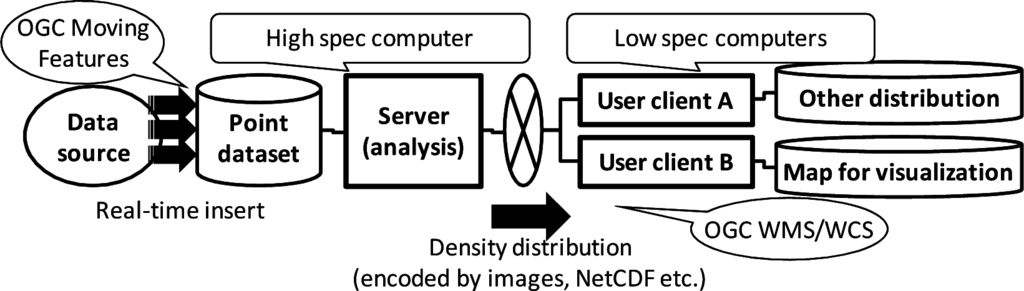
یکی دیگر از مشکلات هیستوگرام ها در سیستم های ارائه دهنده داده عملی به وجود می آید. نمونه ای از یک سیستم مشتری-سرور با استفاده از چگالی نقطه ای در شکل 2 نشان داده شده است . منبع داده به صورت دوره ای یک مجموعه داده نقطه واقعی را به سرور تجزیه و تحلیل ارائه می دهد. سرور چگالی نقطه را تخمین زده و آن را به سیستم های کاربر-مشتری A و B ارسال می کند. مشتریان کاربر از چگالی نقطه با مرتبط کردن آن با اطلاعات دیگر، مانند توزیع دما و تصاویر نقشه استفاده می کنند. در این مورد، سرور اساساً یک رایانه با مشخصات بالا است. در مقابل، کلاینتهای کاربر عموماً رایانههایی با مشخصات پایین هستند. برای چنین سیستم هایی، استانداردهای OGC در دسترس هستند. یعنی OGC WMS [ 9 ] یک رابط سرویس برای توزیع تصاویر نقشه است و OGC WCS (سرویس پوشش وب) [ 12 ]] یک رابط سرویس برای توزیع داده های پوشش است. آنها APIهای وب را برای ارسال داده های چگالی نقطه ارائه می کنند. دادههای درخواست WMS ارسال شده از سیستمهای کاربر مشتری شامل مرز منطقه نقشه مورد نیاز و اندازه تصویر نقشه است که وضوح تصویر را تعیین میکند. وضوح مورد نیاز کاربر-مشتری A ممکن است با وضوح مورد نیاز کاربر-کلینت B متفاوت باشد. علاوه بر این، وضوح مورد نیاز به صورت پویا با توجه به نیاز کاربر تغییر می کند. بنابراین چگالی نقطه باید به صورت دینامیکی محاسبه شود.
قدرت محاسباتی سیستم مشتری کاربر به طور کلی ضعیف تر از سرور است. علاوه بر این، خود مجموعه داده نقطه ای ممکن است توزیع نشود، زیرا مقدار داده ارائه شده توسط سرور باید به اندازه کافی کم باشد تا از طریق شبکه ای با توان عملیاتی پایین ارسال شود. بنابراین بسیاری از محاسبات چگالی نقطه با وضوح های مختلف باید در زمان واقعی بر روی سرور انجام شود. بر این اساس، یک الگوریتم آنلاین سریع برای محاسبه چگالی نقطه مورد نیاز است.
برای برآوردن الزامات ذکر شده در بالا، در این کار، یک “الگوریتم تخمین چگالی نقطه” برای مدیریت مجموعه داده های نقطه متحرک (توضیح داده شده با ویژگی های متحرک OGC) پیشنهاد شده است. الگوریتم پیشنهادی، که بر اساس تخمین بیزی است، می تواند چگالی نقطه (توزیع شده با OGC WMS یا WCS) را تنها با استفاده از یک مجموعه داده جزئی تخمین بزند. در نتیجه، سریعتر از الگوریتم های معمولی کار می کند.
2. آثار و مشارکت های مرتبط
2.1. تحلیل مسیر و برآوردگرهای چگالی
تجزیه و تحلیل مسیرهای نقاط متحرک “تحلیل مسیر” نامیده می شود، یعنی هموارسازی مسیر [ 13 ] (برای کاهش خطاها در موقعیت یابی)، خوشه بندی مسیر [14-17 ] (برای بازیابی مسیرهای مشابه از پایگاه داده)، پیش بینی حرکت [ 18 ] . ، 19 ]، استخراج مسیر نماینده [ 15 ، 17 ، 20-22 ] و الگوریتمی برای برچسب گذاری داده های موقعیت یابی [ 23 ] .
این تحلیل های مسیر برای استخراج اطلاعات از مسیرهای ذخیره شده، نه از نقاط، توسعه یافته اند. اساساً چگالی نقاط متحرک به حرکت نقاط بستگی ندارد. یعنی چگالی را می توان تنها با استفاده از یک عکس فوری از نقاط متحرک محاسبه کرد. با این حال، با الگوریتم پیشنهادی، تخمین چگالی با استفاده از “توزیع چگالی گذشته مجاور” که بر اساس شباهت بین چگالی نقطه فعلی و جدیدترین است، تسریع مییابد.
برآوردگرهای چگالی هسته [ 24 ، 25 ] روشهای محبوبی برای تخمین چگالی نقطه هستند. چگالی محاسبهشده توسط تخمینگر چگالی هسته، مجموع توزیعهای اطراف نقاط است. تخمینگر چگالی هسته گاوسی، که عمومیترین نوع است، چگالیهای نقطهای را به عنوان مجموع گاوسیها تخمین میزند. چگالی P (x) به صورت زیر داده می شود:
که در آن N نقطه با { x n } نشان داده می شود و h با شعاع هر گاوسی مطابقت دارد. یک برآوردگر درجه دوم چگالی هسته، که چگالی نقاط را به عنوان مجموع توابع درجه دوم به صورت زیر تخمین می زند:
اغلب استفاده می شود. تخمینگر هسته درجه دوم سریعتر از تخمینگر هسته گاوسی کار میکند. از سوی دیگر، دقت تخمینگر هسته درجه دوم معمولاً کمتر از تخمینگر هسته گاوسی است. بر این اساس، یک تخمینگر هسته درجه دوم اغلب برای تجسم چگالی در قالب یک نقشه حرارتی استفاده میشود. چندین برآوردگر چگالی هسته برای خلاصه کردن تمایل نقاط متحرک پیشنهاد شده است. به عنوان مثال، تخمینگر چگالی هسته دوگانه [ 26 ] برای نشان دادن تفاوتهای بین دو چگالی نقطهای مختلف طراحی شده است. و تخمینگر تراکم هسته جهتی [ 27 ] تمایل خود حرکت را تجسم میکند. این برآوردگرهای چگالی هسته از تمام نقاط برای تخمین چگالی نقطه استفاده می کنند. بنابراین، محاسبه P ( x) در تخمین چگالی به نسبت تعداد نقاط پیچیده تر می شود. در نتیجه، انجام محاسبه در زمان واقعی دشوار است. این نوع تخمینگر «ناپارامتریک» نامیده میشود، زیرا پارامترهای مورد استفاده در مدل توسط فرآیند تخمین تعیین نمیشوند.
رویکرد دیگری به نام “پارامتری” بر اساس یک فرمول عملکردی خاص است. پارامترهای فرمول عملکردی بهینه شده اند تا با مجموعه داده سازگار شوند. زمان محاسبه که توسط رویکرد پارامتری انجام می شود با پیچیدگی تابع متناسب است. بنابراین، حتی اگر تعداد نقاط زیاد باشد، تخمین چگالی زمان زیادی نمی برد. با این حال، بهینه سازی پارامترها زمان بسیار زیادی می برد. به عنوان مثال، یک تخمین بیزی متغیر استاندارد، که بر اساس یک مدل مخلوط گاوسی (GMM) است، اغلب به عنوان توزیع احتمال مجموعه داده نقطه ای استفاده می شود. در مورد یک تخمین بیزی متغیر، مدلسازی توزیع یک همگرایی است که پارامترها را با تمام دادههای نقطهای سازگار میکند. یعنی محاسبات تکرار می شوند.
2.2. مشارکت ها
اگرچه الگوریتم پیشنهادی یک رویکرد پارامتری دارد، بهینهسازی پارامتر آن بسیار سریع است، زیرا چگالی نقطه با بهروزرسانی چگالی نقطه گذشته مجاور تولید میشود. اندازهگیری با توابع موقعیتیابی شبیه به GPS عموماً دورهای است، بنابراین الگوریتم پیشنهادی زمان گسسته را کنترل میکند (دورهای از آن برابر با واحد گسستهسازی زمان است). شاخص های زمان های گسسته با اعداد صحیح ··· t ، t +1، ··· نشان داده می شوند. با این فرض که چگالی نقطه ای در زمان t به صورت مجموع مولفه های گاوسی بیان می شود، چگالی نقطه ای در t + 1 به عنوان مجموع مولفه های گاوسی مشابه مولفه های گاوسی در زمان t در نظر گرفته می شود. تفاوت بین چگالی نقطه در t و آن در t+ 1 قابل پیش بینی است حتی اگر مجموعه داده نقطه ای تا حدی استفاده شود.
الگوریتم پیشنهادی بر اساس بهروزرسانی مؤلفههای گاوسی با استفاده از مجموعه داده نقطهای جزئی است. به عنوان مکانیزم به روز رسانی مولفه های گاوسی، تخمین بیزی اعمال می شود. در مورد تخمین بیزی، یک تابع توزیع احتمال به صورت پیشینی فرض شده و با استفاده از مجموعه داده نقطه ای تجدید نظر می شود. بنابراین تخمین بیزی برای به روز رسانی تابع توزیع احتمال قابل استفاده به نظر می رسد. با این حال، برای اعمال تخمین بیزی، ترفندی برای تعیین پارامترهای استفاده شده توسط تابع احتمال-توزیع مفروض مورد نیاز است. در قسمت زیر ترفندی با عنوان کاهش مسئولیت شرح داده شده است.
3. الگوریتم پیشنهادی
3.1. تخمین بیزی متغیر
تخمین بیزی متغیر اغلب برای تخمین یک تابع احتمال-توزیع چند متغیره استفاده می شود. یک آرگومان تابع احتمال-توزیع چند متغیره با یک جفت مقادیر مختصات یک نقطه به عنوان ( x , y ) جایگزین می شود. چگالی نقاط N که از توزیع احتمال نقطه ای P ( x , y ) به دست می آید، به صورت NP ( x , y ) محاسبه می شود.
توزیع احتمال پارامترهای مورد استفاده در تابع توزیع احتمال در تخمین بیزی متغیر تعریف شده است. تابع توزیع احتمال مجموعه پارامترها “تابع احتمال-توزیع قبلی” (“قبلی”) نامیده می شود. نقاط مشاهده شده قبلی و اضافی (“مشاهده”) تخمینی “توزیع احتمال پسین” (“پسین”) را در تخمین بیزی متغیر به دست می آورند. تابع توزیع احتمال GMM با:
که در آن x بردار متشکل از مقادیر مختصات یک مشاهده است ( یعنی ( x ، y ))، ن( x | Λ , μ )ن(ایکس|Λ،�)یک تابع گاوسی دو بعدی با ماتریس همبستگی است که با Λ k و میانگین آن با μk نشان داده شده است، و π k نسبت اختلاط مولفه k -ام به مجموع همه اجزا است. سپس پیشین برای {π k }، {(μ k } و {Λ k } به صورت زیر تعریف می شود:
در اینجا α 0 , W 0 , υ 0 و β 0 پارامترهایی هستند که “هیپرپارامترهای” قبلی نامیده می شوند. دبلیو( ⋅ | دبلیو. v )دبلیو(⋅|دبلیو.�)توزیع Wishart با انحراف W و درجه آزادی υ است و Dir(·|cα) توزیع دیریکله با پارامتر α است. قبلی مزدوج با مخلوط گاوسی است. یعنی فرمول خلفی که توسط مشاهدات به روز می شود مانند فرمول قبلی است. بنابراین تخمین خلفی به عنوان به روز رسانی هایپرپارامترهای α 0 , β 0 , m 0 و W 0 با استفاده از مشاهدات { x n } به صورت زیر اجرا می شود:
N k ، x k و S k به ترتیب به صورت زیر محاسبه می شوند:
r n , k , “مسئولیت” به صورت زیر محاسبه می شود:
که در آن ψ (•) یک تابع دیگاما است. با توجه به رابطه (9) r n ، k به عنوان سهمی که از مشاهدات n به هر جزء برچسب گذاری شده با k تعبیر می شود.
محاسبه مسئولیت به فراپارامترها نیاز دارد. با این حال، برآورد فراپارامترها نیز نیاز به مسئولیت دارد. بر این اساس، برای بهینه سازی هایپرپارامترها، فرآیندهای توصیف شده در بالا تکرار می شوند. اول، هایپرپارامترها به طور تصادفی مقداردهی اولیه می شوند. دوم، مسئولیت ها با فراپارامترهای اولیه محاسبه می شوند. سوم، هایپرپارامترها با مسئولیت محاسبه شده به روز می شوند. پس از تکرار محاسبات، فراپارامترهای بهینه شده به دست می آیند.
3.2. واگرایی KL به عنوان معیاری برای همگرایی
در تخمین بیزی متغیر، فراپارامترهای اولیه α 0 ، β 0 ، m 0 و W 0 α پیشینی داده می شوند .به عبارت دیگر، فراپارامترهای اولیه که پیشین را مشخص میکنند، میتوانند برای همگرایی نتایج تخمین زودتر تعیین شوند. اگر پیشین بر روی تابعی مشابه با پسین تنظیم شود، بیشتر فرآیندهای تخمین چگالی نقطه غیر ضروری هستند. بر این اساس، بیشتر مجموعه داده نقطه ای تأثیر کمی بر تراکم نقطه دارد. یعنی بیشتر مجموعه داده نقطه ای را می توان نادیده گرفت. علاوه بر این، قبلی به طور دقیق به عنوان گذشته مجاور پسین قابل پیش بینی است که در تکرار قبلی تخمین زده شد، زیرا چگالی نقطه ای نقاط متحرک در یک دوره کوتاه چندان تغییر نمی کند. بنابراین، پیشین باید روی همان تابع گذشته مجاور پسین تنظیم شود تا تخمین چگالی نقطه زودتر متوقف شود.
واگرایی Kullback–Leibler (KL)، که مانند فاصله بین توابع توزیع رفتار می کند، به عنوان معیاری برای قضاوت در مورد اینکه آیا محاسبه می تواند متوقف شود یا خیر، قابل استفاده است.
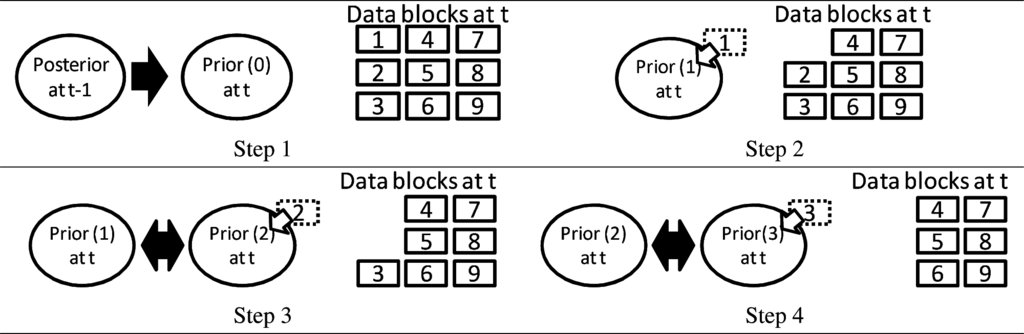
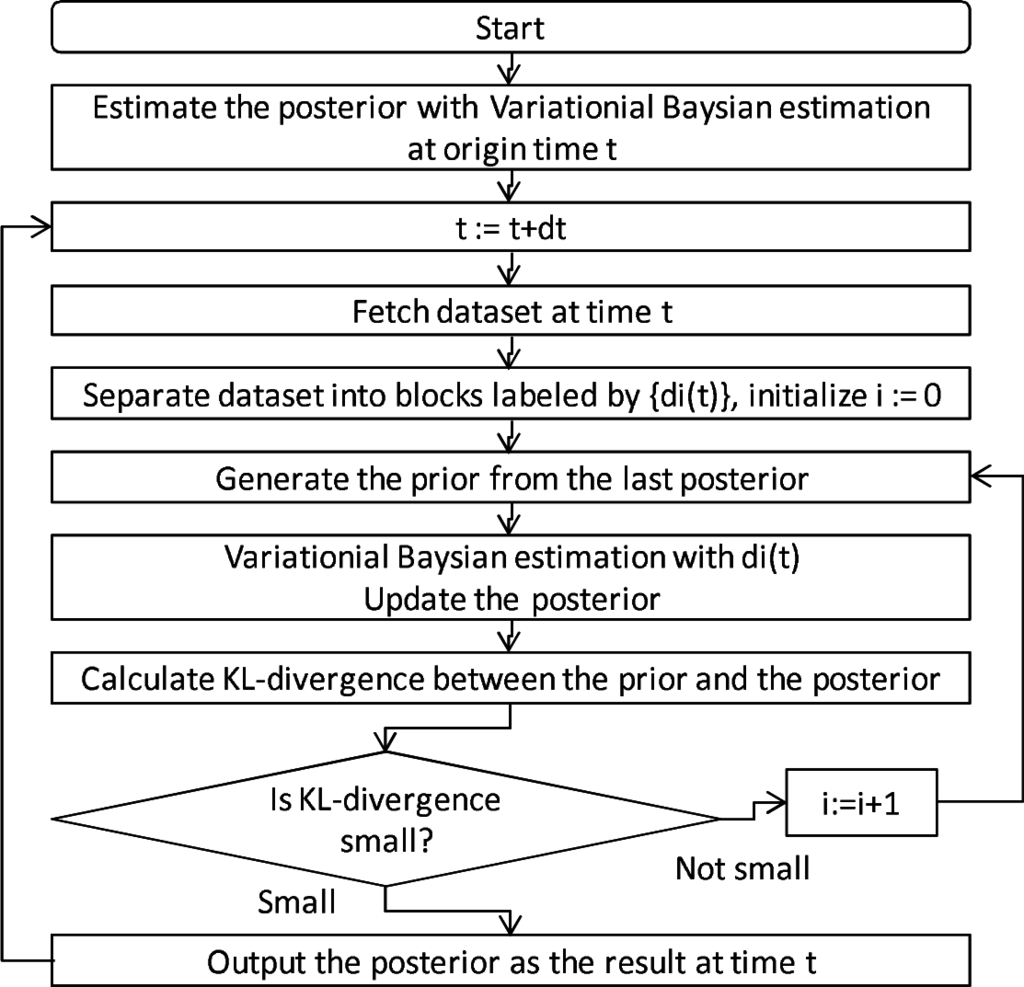
شکل 3چنین فرآیند قضاوتی را نشان می دهد. مجموعه داده نقطه ای از قبل به بلوک های کوچک جدا می شود، جایی که اندازه بلوک یک پارامتر ثابت در طول فرآیند است. توجه داشته باشید که اندازه بلوک باید به اندازه کافی بزرگ باشد تا اهمیت آماری را تشخیص دهد. در مرحله 1، پیشین از پسین گذشته مجاور تولید می شود. در مرحله 2، برای تخمین قسمت بعدی، یکی از بلوک های کوچک (با برچسب “1”) به قسمت قبلی وارد می شود. در مرحله 3، پیشین بعدی، که توسط پسین تخمین زده شده در مرحله 2 ایجاد می شود، با بلوک با برچسب “2” به روز می شود. در این مرحله واگرایی KL از خلفی ایجاد شده در مرحله 2 به خلفی ایجاد شده در مرحله 3 محاسبه می شود. اگر واگرایی KL به اندازه کافی کوچک باشد، بلوک های اضافی غیر ضروری ارزیابی می شوند. اگر نه، پسین به طور مشابه محاسبه می شود، و غیره. در ارزیابی واگرایی KL، تعداد داده های ورودی کنترل می شود. یعنی زمانی که چگالی نقطه کمی تغییر می کند از داده های کمی استفاده می شود، اما زمانی که چگالی نقطه به شدت تغییر می کند از داده های زیادی استفاده می شود.
واگرایی KL از p (x) به q (x) KL ( p ( x )|| q ( x )) به صورت زیر تعریف می شود:
الگوریتم پیشنهادی به واگرایی KL از قبل به پسین نیاز دارد. به این معنا که،
که در آن {θ i } = {{π k }، {Λ k }، {(μ k }}، و { x n } m m -امین بلوک داده است. اگر K به اندازه کافی کوچک باشد، نتیجه برآورد در نظر گرفته می شود. همگرا باشد. p ({θ i }|{ x n } m ) را می توان با q ({θ i }|{ x n } m ) = q ({π k , Λ k , μ k }|{α k } جایگزین کرد , β k , mk , υ k , W k })، زیرا نتیجه تخمین بیزی متغیر است. بنابراین K به زیر تبدیل می شود:
که در آن {α k , β k , m k , υ k , W k }) مجموعه ای از فراپارامترهای به روز شده توسط { xn } m و { α“ک،β“ک،متر“ک،υک،دبلیو“ک��′,β�′,m�′,��,��′} مجموعه ای از هایپرپارامترهای به روز شده توسط است {ایکس“n}m + 1{x�′}�+1. در اینجا، B (•) به صورت زیر تعریف می شود:
3.3. کاهش مسئولیت
با روش پیشنهادی، ترفندی به نام «کاهش مسئولیت» برای تعیین فراپارامترها اعمال میشود. به عنوان مثال، همانطور که در معادله (5) نشان داده شده است ، β t,k = β 0 + N t,k ، که در آن N t,k مجموع مسئولیتهایی است که توسط مؤلفه k- امین زمان t GMMat ایجاد میشود . . بنابراین، N t,k مربوط به تعداد نقاط متعلق به مؤلفه k -ام است، زیرا مسئولیت r n,k نشاندهنده «تعلق» نقطه i به مؤلفه k -ام است. سپس، β t،kبا N t+1,k به عنوان β t +1 , k = β 0 + N t,k + N t+ 1, k به روز می شود که β t +1, k یک فراپارامتر خلفی در t + 1 است. به طور مشابه. ،
بنابراین اگر n بزرگتر شود ، ابرپارامتر در زمان t + n بزرگتر می شود. در نتیجه، سهم جدیدترین مجموعه داده نقطه، N t+n ، k ، نسبتا کوچکتر از سهم قبلی، β 0 است، زیرا قبلی شامل مجموع تمام مسئولیت های گذشته است. با این حال، سهم جدیدترین مجموعه داده نقطه ای باید بیشتر از بقیه باشد.
مشکل توضیح داده شده در پاراگراف قبل از سردرگمی بین مجموعه داده های نقطه ای ناشی می شود. چگالی نقطه جدید با چگالی نقطه گذشته متفاوت است. بنابراین نباید از نکات گذشته و جدید به یک اندازه استفاده کرد. بر این اساس، پیشین باید از پسین گذشته تولید شود، اما پیشین نباید با پسین برابر باشد. بنابراین اثرات نقاط گذشته بر روی فراپارامترها باید حذف شوند. اگر اثرات ابرپارامترها با اثرات تولید شده توسط نقاط جدید برابر باشد، اثرات نقاط در هایپرپارامترها ثابت نگه داشته می شود. مجموعه داده در زمان t به بلوک های M که حاوی نقاط کافی برای ورودی متوالی هستند، که در آن تعداد نقاط بلوک ها با نشان داده می شود، جدا می شود.n( 1 )تی،n( 2 )تی، ⋯ ،n( من )تی، ⋯ ،n( م)تی��(1),��(2),⋯,��(�),⋯,��(�)این بلوک ها به صورت متوالی برای به روز رسانی قسمت های پسین وارد می شوند. هنگامی که بلوک j- امین ورودی است، نسبت تعداد نقاط ورودی به تعداد کل نقاط به صورت محاسبه می شود. ∑jمنn( من )تی∑ممنn( من )تی∑����(�)∑����(�). سپس نرخ کاهش مسئولیت γ ( j ) ( t ) به صورت زیر تعریف می شود:
مجموع مسئولیت گذشته N t,k در نرخ کاهش ضرب می شود. با این فرآیند، تعداد کل نقاط کمک کننده به هایپرپارامترها تنظیم شده و ثابت نگه داشته می شود.
مکانیسم بهروزرسانی بهطور مجازی بهعنوان «دیگ تبخیر» در شکل 4 ترسیم شده است. در مرحله (الف)، دیگ با مایعی پر می شود که برچسب t را نشان می دهد. سپس محتویات قابلمه تبخیر می شود تا نیمی از ظرفیت آن باقی بماند. سپس یک مایع جدید با برچسب t + 1 در قابلمه ریخته می شود. حجم مایع ریخته شده نصف ظرفیت قابلمه است. در مرحله (ب) دوباره محتویات قابلمه تا نصف ظرفیت تبخیر می شود. مایع با برچسب t و مایع با برچسب t + 1 به طور مساوی به نصف حجم اولیه خود کاهش می یابد. یعنی حجم مایعات با برچسب t و t + 1 به 1/4 ظرفیت دیگ تبدیل می شود. سپس، به طور مکرر، یک مایع جدید، با برچسبt + 2 در قابلمه ای که تا نیمه پر از مایع است ریخته می شود. پس از تکرار فرآیند، همانطور که در مراحل (ج) و (د) نشان داده شده است، مواد موجود در قابلمه مخلوطی از مایعات با برچسب t، t + 1، … است. بنابراین حجم مایع با برچسب t ‘ است (12)تی“– t + 1(12)�′−�+1 V ، که در آن V ظرفیت قابلمه است. بنابراین حجم مایع به صورت تصاعدی کاهش می یابد.
مایع در شکل 4 با مجموع مسئولیت ها مطابقت دارد. به عبارت دیگر، تبخیر با ضرب در مجموع مسئولیت ها در نرخ کاهش مطابقت دارد. بر این اساس، سهم از مجموعه داده قدیمی به صورت تصاعدی با ضرب آن در نرخ کاهش کاهش می یابد، در حالی که مجموع همه مسئولیت ها ثابت نگه داشته می شود. با ضرب، فراپارامترهای قبلی در زمان t + 1 داده شده توسط خلفی در زمان t به صورت زیر مشتق می شوند.
اینجا، N t،k ، ایکس¯t ، kایکس¯تی،کو S t,k در زمان t با رابطه (9) به دست می آیند . هایپرپارامترها در قسمت خلفی در زمان t + 1 توسط:
جایی که:
ایکس( 0 )t ، nx�,�(0)و r( 0 )t ، n ، k��,�,�(0)به ترتیب نقاط بلوک n و وظایف آنها هستند.
اگر واگرایی KL بین قسمتهای خلفی زیاد باشد، بلوک دیگری از مجموعه داده نقطهای جدید ورودی است. قبلی با فرمول های زیر با بلوک i- ام به روز می شود:
برای بدست آوردن فرمول بازگشتی، هر ضلع فرمول i + 1 به صورت زیر از هر طرف فرمول i کم می شود.
علاوه بر این، β( من )ک=β( من )0+n( من )کβ�(�)=β0(�)+��(�)، بنابراین:
به طور مشابه، فرمول های زیر مشتق شده است.
بنابراین i + 1-th قبل از آن قابل محاسبه است α( من )t ، k،β( من )0 ، t + 1،متر( من )t + 1 ، k،دبلیو− 1 ( i )t ، k،υ( من )t ، k،γ( من + 1 )تیαتی،ک(من)،β0،تی+1(من)،مترتی+1،ک(من)،دبلیوتی،ک–1(من)،�تی،ک(من)،γتی(من+1)و γ( من )تیγتی(من). پس از تکرار این محاسبات بهروزرسانی تا زمانی که واگرایی KL به اندازه کافی کوچک شود، فراپارامترهای تخمینی در زمان t + 1 به دست میآیند. وقتی واگرایی KL در i = l همگرا شود ، هایپرپارامترهای قبلی بعدی به صورت زیر نوشته می شوند:
توسط نt + 1 ، k،ایکس¯t + 1 ، kنتی+1،ک،ایکس¯تی+1،کو S t+ 1 ,k که به صورت زیر تعریف می شوند:
فرمول به روز شده در t + 2 به طور مشابه مشتق شده است. توجه داشته باشید که نt + 1 ، k،ایکس¯t + 1 ، k،اسt + 1 ، kنتی+1،ک،ایکس¯تی+1،ک،استی+1،کرا می توان به فرمول های زیر تبدیل کرد.
δW به صورت زیر تعریف می شود:
در مقایسه با معادله (9) ، فرمول های N و ایکس¯ایکس¯طبیعی هستند؛ یعنی پشته مشارکت های داده های گذشته کاهش یافته و به سهم فعلی اضافه می شود. با این حال، S شبیه به سایر فراپارامترها به نظر می رسد، به جز δ W. δ W نشان دهنده خطای ناشی از تخمین متوالی است، بنابراین اگر N و n به اندازه کافی بزرگ باشند ، اثر δW بر دقت تخمین بسیار کم است. بر این اساس، در مورد الگوریتم پیشنهادی، δ W نادیده گرفته می شود.
الگوریتم پیشنهادی در شکل 5 نشان داده شده است . ابتدا یک تخمین بیزی متغیر عادی انجام می شود. پسین تخمین زده شده در زمان t برای تولید قبلی در زمان بعدی t+ 1 استفاده میشود. هر مجموعه داده به بلوکهای زیادی جدا میشود و بلوکها بهطور متوالی وارد میشوند تا قبلی تولید شده توسط آخرین تخمین قبلی بهروزرسانی شود. ورود بلوک زمانی متوقف می شود که واگرایی KL بین قبلی و خلفی به اندازه کافی کوچک باشد. هنگامی که آن شرط برآورده شد، تخمین چگالی نقطه در زمان t به پایان می رسد. پس از تخمین، زمان t افزایش یافته به t+ 1 افزایش مییابد، و تخمین چگالی نقطه در زمان t+ 1 شروع شد. این فرآیندها به صورت تکراری برای تخمین چگالی نقطه انجام می شوند.
پارامترهای مورد استفاده برای این الگوریتم، فراپارامترهایی هستند که توسط تخمین بیزی متغیر و تعداد بلوک ها استفاده می شوند. آنها به صورت دستی و به همان روشی که یک تخمین کلی تغییر بیزی تعیین می شود. توجه داشته باشید که تعداد بلوک ها باید بسیار کوچکتر از اندازه کل مجموعه داده باشد تا بلوک هایی به اندازه کافی بزرگ برای تشخیص اهمیت آماری بدست آید. برآورده کردن این شرایط به طور کلی آسان است زیرا کل اندازه داده بسیار بزرگ است.
4. آزمایشات
4.1. تنظیمات و معیارهای آزمایشی
الگوریتم پیشنهادی به صورت تجربی مورد ارزیابی قرار گرفت. ویژگی های مجموعه داده نقطه ای مورد استفاده برای این ارزیابی در جدول 1 فهرست شده است. مجموعه دادههای نقطهای با نام «دادههای جریان افراد» [ 28]، موقعیت افراد را در طول یک روز توصیف کنید. مجموعه دادههای نقطهای از نتیجه پرسشنامههای مربوط به سفرهای افراد در طول یک روز، یعنی جفت دادههای مبدا و مقصد سفرها ایجاد شدهاند. درون یابی بین مبدا و مقصد به منظور تولید مجموعه داده های نقطه ای در هر دقیقه انجام شد. بنابراین، نقاط درونیابی در همان زمان به عنوان یک مجموعه داده جمع آوری شد. چگالی نقطه از ساعت 0:00 صبح تا 12:00 صبح توسط الگوریتم پیشنهادی و توسط دو تخمینگر چگالی هسته معمولی برآورد شد. نقاطی که به صورت مختصات طول و عرض جغرافیایی بیان می شوند، به یک سیستم مختصات متعامد تبدیل شدند که مبدا آن مرکز نقاط در ساعت 0:00 صبح است. علاوه بر این،
مجموعه داده به دو بلوک تفکیک شد. یک بلوک برای تخمین چگالی نقطه استفاده شد. دیگری برای ارزیابی معیارهای دقت استفاده شد. این به طور کلی “تأیید اعتبار موقت” نامیده می شود. پنج هزار امتیاز موجود در بلوک دوم در واقع استفاده شد، زیرا در صورت استفاده از تمام امتیازات بلوک ارزیابی، زمان زیادی برای انجام ارزیابی نیاز است.
دو معیار دقت و زمان پردازش ارزیابی شد. به عنوان معیار دقت، Ev بر اساس احتمال لگاریتمی، به صورت زیر تعریف شده است:
استفاده شد. در اینجا N تعداد نقاطی است که با x n نشان داده می شود . Ev تکرارپذیری چگالی نقطه کل مجموعه داده را نشان می دهد. به عنوان معیار زمان پردازش، زمان تولید یک تصویر نقشه حرارتی 150 پیکسل × 100 پیکسل استفاده شد. یعنی محاسبه 15000 بار انجام شده است. برای ارزیابی دقیق معیارها، اندازه گیری Ev و زمان پردازش سه بار انجام شد و میانگین نتایج به عنوان معیار استفاده شد.
به عنوان پارامترهای مورد استفاده توسط الگوریتم پیشنهادی، تعداد توزیعهای گاوسی مختلط روی 200 تنظیم شد. اندازه بلوک برای ورود متوالی 1500 بود. فراپارامترهای اولیه α 0 = 2.1 و β 0 = 1.0 بودند. اجزای مورب W 0 روی 1.5 تنظیم شدند. و اجزای غیر مورب روی 0.0 و υ 0 = 2.2 تنظیم شدند. علاوه بر این، 200 نقطه به صورت تصادفی از مجموعه داده های نقطه اولیه به عنوان m 0 انتخاب شدند. این پارامترها به صورت دستی تعیین شدند تا بالاترین Ev.
به عنوان روش های مرسوم، روش هسته گاوسی و روش هسته درجه دوم به طور مشابه مورد ارزیابی قرار گرفتند. انحراف استاندارد h برای روش هسته گاوسی روی 0.2 تنظیم شد. شعاع h برای روش هسته درجه دوم روی 3.0 تنظیم شد تا از P ( xn ) = 0 اجتناب شود (که Ev = – ∞ را می دهد).
اتفاقاً برنامه مورد استفاده برای ارزیابی ها با جاوا روی رایانه ای با Intel Core i7-3980K 3.2 گیگاهرتز و 32.0 گیگابایت رم پیاده سازی شد.
4.2. نتایج
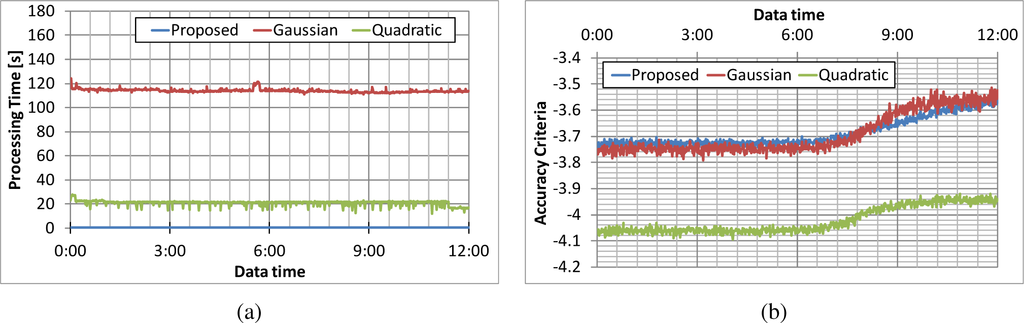
زمان های پردازش برای هر روش در شکل 6a نشان داده شده است. موقعیت افراد در زمانی که با “زمان مجموعه داده” در محور افقی نشان داده شده است در مجموعه داده مورد استفاده برای ارزیابی گنجانده شده است. از این پس، زمان «مجموعه داده» به همین معنا استفاده می شود. زمان پردازش برای الگوریتم پیشنهادی کمتر از 1.0 ثانیه، برای روش هسته گاوسی حدود 250 ثانیه و برای روش هسته درجه دوم 80 ثانیه بود. بنابراین الگوریتم پیشنهادی سریعترین الگوریتم از سه روش است. معیار دقت برای هر روش در شکل 6b نشان داده شده است. معیار دقت برای الگوریتم پیشنهادی به تخمینگر چگالی هسته گاوسی نزدیک است و تخمینگر چگالی هسته درجه دوم کمترین است. این نتایج نشان می دهد که الگوریتم پیشنهادی سریع ترین و به اندازه کافی دقیق است.
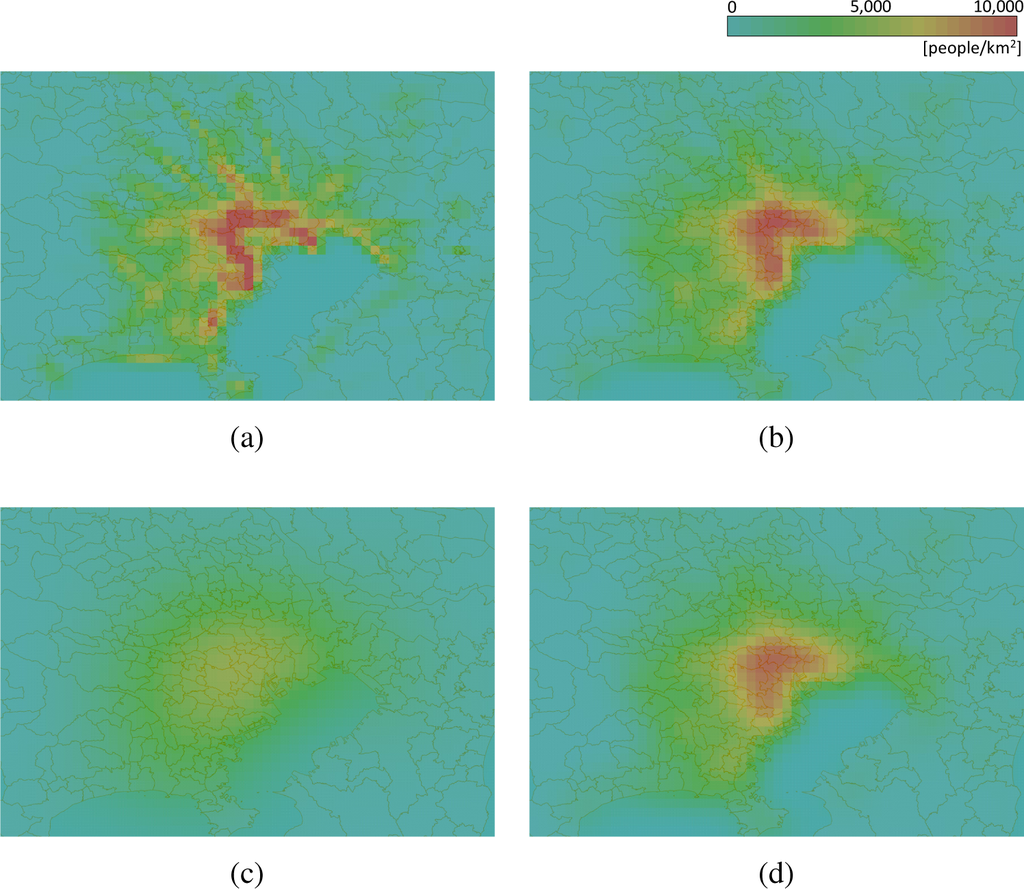
توزیع های به دست آمده با سه روش در شکل 7 مقایسه شده است. نواحی قرمز رنگ در تصاویر مناطق پر تراکم، نواحی زرد با تراکم متوسط و مناطق سبز مناطق پراکنده را نشان می دهد. تصویر (a)، که توزیع چگالی ارائه شده توسط الگوریتم پیشنهادی را نشان میدهد، مشابه تصویری است که توسط تخمینگر هسته گاوسی، یعنی تصویر (b) ارائه شده است، اما کمی پراکنده است. تصویر (c)، که نتیجه تخمین هسته درجه دوم را نشان میدهد، برای توصیف چگالی نقطه بیش از حد منتشر شده است. این انتشار ناشی از h بزرگ است. بنابراین، تصویر تولید شده با نتیجه هسته درجه دوم با h = 1.0 مشابه تصاویر (a) و (b) است، همانطور که در تصویر (d) نشان داده شده است. با این حال، معیارهای دقت برای روش هسته دوم با h= 1.0 −∞ است. یعنی توزیع اصلا دقیق نیست. بر این اساس، الگوریتم پیشنهادی بدون تارترین نقشه حرارتی دقیق را در این سه الگوریتم ایجاد میکند.
4.3. بحث
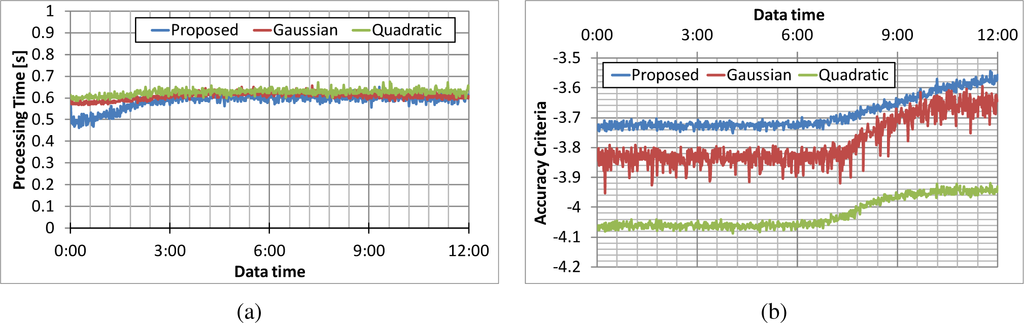
نمونه گیری فرعی یکی از محبوب ترین روش ها برای سرعت بخشیدن به فرآیندهای تخمین چگالی است. بر این اساس، یک مجموعه داده زیر نمونه نیز مورد ارزیابی قرار گرفت. شکل 8a یک سری زمان پردازش را پس از اینکه مجموعه داده نقطه ای به طور تصادفی زیر نمونه برداری شد تا 2300 نقطه برای تخمینگر هسته گاوسی ( h = 3.0) و 17000 امتیاز برای تخمینگر هسته درجه دوم ترسیم کرد. هر دو تخمینگر هسته گاوسی و تخمینگر هسته دوم 0.6 ثانیه در این شرایط طول می کشند. این زمانها با الگوریتم پیشنهادی قابل مقایسه هستند. با این حال، همانطور که در شکل 8b نشان داده شده است، دقت دو برآوردگر قبلی کمتر است . بنابراین نتیجه گیری می شود که الگوریتم پیشنهادی حتی زمانی که زمان پردازش کاهش یافته است، دقت بالایی را حفظ می کند.
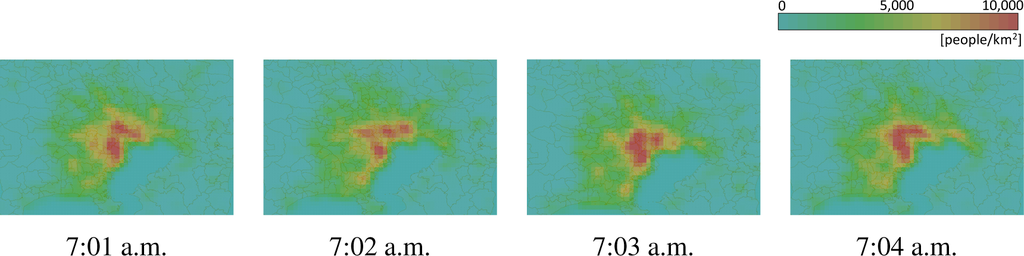
نقشه های حرارتی تولید شده از مجموعه داده های نمونه فرعی در شکل 9a,b نشان داده شده است. نقشه حرارتی ارائه شده توسط تخمینگر هسته درجه دوم ( شکل 9a ) بسیار شبیه به نقشه حرارتی به دست آمده بدون نمونه گیری فرعی است که در شکل 7c نشان داده شده است ، زیرا مجموعه داده های نمونه فرعی به اندازه کافی بزرگ است. با این حال، نقشه حرارتی ارائه شده توسط برآوردگر هسته گاوسی ( شکل 9b ) کاملاً متفاوت از شکل 7b است. این نشان میدهد که مجموعه دادههای نمونهگیری فرعی که توسط تخمینگر هسته گاوسی استفاده میشود، برای ایجاد یک نقشه حرارتی بسیار کوچک است. همانطور که در شکل 10 نشان داده شده استبرای مقایسه نقشه های حرارتی در 7:01 صبح، 7:02 صبح، 7:03 صبح و 7:04 صبح، یک نقشه حرارتی ایجاد شده به نقاطی بستگی دارد که به طور تصادفی انتخاب شده اند، یعنی نقشه حرارتی به طور تصادفی تغییر می کند. از آنجایی که تخمینگر هسته گاوسی کندتر از تخمینگر هسته درجه دوم است، از نقاط کمتری استفاده شد. این بدان معناست که برآوردگر هسته درجه دوم برای تولید سریع نقشه های حرارتی نسبت به تخمینگر هسته گاوسی امکان پذیرتر است. با این حال، همانطور که در شکل 8 نشان داده شده است ، الگوریتم پیشنهادی می تواند نقشه های حرارتی دقیق تری نسبت به آنچه که توسط تخمینگر هسته درجه دوم ایجاد می شود، ایجاد کند.
برای اطمینان از این نتایج، Ev از تخمینگر هسته گاوسی و تخمینگر هسته درجه دوم تحت h های مختلف با 10000 امتیاز در ساعت 0:00 صبح محاسبه می شود. در مورد برآوردگر هسته گاوسی، Ev = -∞ در h = 0.05، Ev = -4.00 در h = 0.1، Ev = -4.11 در h = 0.2، Ev = -4.28 در h = 0.5 و Ev = 4.41 در h = 1.0. به طور مشابه، در مورد هسته درجه دوم، Ev = -∞ در h = 1.0، Ev = -∞ در h = 2.0، Ev = -4.40 در h = 3.0، Ev = -4.47 در h = 4.0 و Ev = -∞ در h = 2.0. 4.53 در h = 5.0. Ev نشان داده شده در شکل 9bقابل مقایسه با این Ev. علاوه بر این، الگوریتم پیشنهادی به Ev = -3.79 رسید که با Ev نیز قابل مقایسه است که در شکل 9b نشان داده شده است. این بدان معناست که تنظیمات ارزیابی مانند h و تعداد داده های نقطه برای ارزیابی دقت مهم نیستند.
با توجه به نتایج آزمایشی که در بالا توضیح داده شد، الگوریتم پیشنهادی نسبت به دو الگوریتم موجود، یعنی یک تخمینگر چگالی هسته درجه دوم و یک تخمینگر چگالی هسته گاوسی، به عملکرد سریعتری دست یافت. علاوه بر این، با نمونه برداری فرعی، برآوردگرهای چگالی هسته را می توان تا سرعت های قابل مقایسه با الگوریتم پیشنهادی شتاب داد. با این حال، آنها دقت کمتری را نشان می دهند. بنابراین، تایید میشود که الگوریتم پیشنهادی نسبت به برآوردگرهای چگالی هسته موجود برتری دارد.
5. نکات پایانی
روشی برای تخمین چگالی نقاط متحرک، بر اساس یک تخمین بیزی متغیر، پیشنهاد شد. قبلی در برآورد از پسین ارائه شده توسط تخمین قبلی ایجاد می شود. مسئولیت های استفاده شده در فرمول پسین باید به منظور ایجاد قبلی کاهش یابد. از این رو ترفندی به نام «کاهش مسئولیت» معرفی شد. علاوه بر این، زمان پردازش و دقت تخمین الگوریتم پیشنهادی به صورت تجربی مورد ارزیابی قرار گرفت. الگوریتم پیشنهادی سریعتر از دو روش مرسوم بود. علاوه بر این، دقت تخمین الگوریتم پیشنهادی با روشهای مرسوم قابل مقایسه است. این نتایج نشان می دهد که الگوریتم پیشنهادی سریع و بدون از دست دادن دقت است. بنابراین، نتیجه گیری می شود که یک مجموعه داده نقطه حرکت عظیم،
به عنوان کار آینده، الگوریتم پیشنهادی برای رسیدگی به توزیعهای غیر GMM گسترش خواهد یافت. کاهش مسئولیت برای سایر توزیع ها اعمال می شود. بنابراین الگوریتم توسعه یافته برای سرعت بخشیدن به تخمین چگالی نقطه توسعه می یابد.
منابع
- Ryosuke، S. OGC استاندارد برای ویژگی های متحرک. الزامات (12-117r1) ، در دسترس آنلاین: https://portal.opengeospatial.org/files/?artifact_id=51623 در 26 فوریه 2015 مشاهده شد.
- سازمان اطلاعات مکانی ژاپن Data Geospatial Fundamental 1:25000 ، موجود آنلاین: http://www.gsi.go.jp/kiban/index.html در 26 فوریه 2015 در دسترس است. به زبان ژاپنی.
- مناندار، د. کاواگوچی، اس. اوچیدا، م. ایشی، م. Tomohiro، H. IMES برای کاربران تلفن همراه. پیاده سازی اجتماعی و آزمایشات مبتنی بر تلفن های همراه موجود برای موقعیت یابی بدون درز. مجموعه مقالات سمپوزیوم بین المللی GPS/GNSS 2008، توکیو، ژاپن، 11-14 نوامبر 2008.
- حلقه. Loopt® ، در دسترس آنلاین: http://www.loopt.com/ در 1 دسامبر 2012 قابل دسترسی است.
- کنسرسیوم فضایی باز ، موجود به صورت آنلاین: http://www.opengeospatial.org/ قابل دسترسی در 26 فوریه 2015.
- کنسرسیوم فضایی باز OGC(R) Moving Features ، در دسترس آنلاین: http://www.opengeospatial.org/standards/movingfeatures در 26 فوریه 2015 قابل دسترسی است.
- کنسرسیوم فضایی باز OGC Network Common Data Form (NetCDF) Core Encoding Standard نسخه 1.0 (10-090r3) ، در دسترس آنلاین: http://www.opengeospatial.org/standards/netcdf در 26 فوریه 2015 قابل دسترسی است.
- کنسرسیوم فضایی باز OGC(R) GML Application Schema—Coverages (1.0.1) (09-146r2) ، در دسترس آنلاین: http://www.opengeospatial.org/standards/gml در 26 فوریه 2015 قابل دسترسی است.
- کنسرسیوم فضایی باز مشخصات اجرایی OpenGIS Web Map Service (WMS) 1.3.0 (06-042) ، در دسترس آنلاین: http://www.opengeospatial.org/standards/wms در تاریخ 26 فوریه 2015 قابل دسترسی است.
- Bishop، CM Pattern Recognition and Machine Learning. Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2006. [ Google Scholar ]
- سامت، اچ. چهار درخت و ساختارهای داده سلسله مراتبی مرتبط. کامپیوتر ACM. Surv. (CSUR) 1984 ، 16 ، 187-260. [ Google Scholar ]
- کنسرسیوم فضایی باز OGC(R) WCS 2.0 Interface Standard—Core، نسخه 2.0.1 (09-110r4) ، در دسترس آنلاین: http://www.opengeospatial.org/standards/wcs در 26 فوریه 2015 قابل دسترسی است.
- شزل، ف. چن، دی. گیباس، ال. جیانگ، ایکس. سامر، سی. هموارسازی مسیر مبتنی بر داده. مجموعه مقالات نوزدهمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی (GIS ’11)، شیکاگو، IL، ایالات متحده آمریکا، 1–4 نوامبر 2011. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2011; صص 251-260. [ Google Scholar ]
- لی، سی. Tamer, OM; وینسنت، او. جستجوی شباهت قوی و سریع برای مسیرهای جسم متحرک. مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 2005 در مدیریت داده ها، بالتیمور، MD، ایالات متحده، 13-17 ژوئن 2005. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2005; صص 491-502. [ Google Scholar ]
- چودوا، دی. گافنی، اس. Mjolsness، E. اسمایث، پی. مدلهای ترکیبی تغییرناپذیر ترجمه برای خوشهبندی منحنی. مجموعه مقالات نهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، واشنگتن، دی سی، ایالات متحده آمریکا، 24-27 اوت 2003. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2003; صص 79-88. [ Google Scholar ]
- الیاس، اف. کوستاس، جی. Yannis, T. شبیه ترین جستجوی مسیر مبتنی بر شاخص. مجموعه مقالات بیست و سومین کنفرانس بین المللی IEEE در زمینه مهندسی داده، استانبول، ترکیه، 15-20 آوریل 2007. صص 816-825.
- ترایچفسکی، جی. دینگ، اچ. شوئرمن، پی. تاماسیا، ر. Vaccaro، D. تشابه علم دینامیک مسیر اجسام متحرک. مجموعه مقالات پانزدهمین سمپوزیوم سالانه بین المللی ACM در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سیاتل، واشنگتن، دی سی، ایالات متحده آمریکا، 7-9 نوامبر 2007. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2007; صص 1-8. [ Google Scholar ]
- آساهارا، ا. مارویاما، ک. ساتو، ا. Seto، K. پیش بینی حرکت عابر پیاده بر اساس مدل ترکیبی زنجیره مارکوف. مجموعه مقالات نوزدهمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی (GIS ’11)، شیکاگو، IL، ایالات متحده آمریکا، 1–4 نوامبر 2011. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2011; صص 25-33. [ Google Scholar ]
- آساهارا، ا. مارویاما، ک. شیباساکی، آر. یک مدل زنجیره پنهان مارکوف اتورگرسیو مختلط که برای جنبش های مردم اعمال می شود. مجموعه مقالات بیستمین کنفرانس بین المللی پیشرفت در سیستم های اطلاعات جغرافیایی (SIGSPATIAL ’12)، ردوندو بیچ، کالیفرنیا، ایالات متحده آمریکا، 7 تا 9 نوامبر 2012. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2012; صص 414-417. [ Google Scholar ]
- لی، جی جی; هان، جی. Whang، KY خوشهبندی مسیر: یک چارچوب پارتیشن و گروهی. مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 2007 در مدیریت داده ها، پکن، چین، 11-14 ژوئن 2007. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2007; صص 593-604. [ Google Scholar ]
- نیروانا، م. Rolf، ADB تجمع و مقایسه مسیرها. مجموعه مقالات دهمین سمپوزیوم بینالمللی ACM در زمینه پیشرفتها در سیستمهای اطلاعات جغرافیایی، مکلین، ویرجینیا، ایالات متحده آمریکا، 8 تا 9 نوامبر 2002. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2002; ص 49-54. [ Google Scholar ]
- ون کرولد، ام. Wiratma، L. مسیرهای میانه با استفاده از مناطق پر بازدید و کوتاه ترین مسیرها. مجموعه مقالات نوزدهمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی (GIS ’11)، شیکاگو، IL، ایالات متحده آمریکا، 1–4 نوامبر 2011. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2011; ص 241-250. [ Google Scholar ]
- آساکورا، ی. هاتو، ای. بررسی ردیابی رفتار سفر فردی با استفاده از ابزارهای ارتباطی سیار. ترانسپ Res. سی ظهور. تکنول 2004 ، 12 ، 273-291. [ Google Scholar ]
- سیلورمن، تخمین چگالی BW برای آمار و تجزیه و تحلیل داده ها . چپمن و هال/CRC: لندن، بریتانیا، 1986. [ Google Scholar ]
- Simonoff، JS Smoothing Methods in Statistics ; Springer: برلین، آلمان، 1996. [ Google Scholar ]
- یانسنبرگر، EM; Staufer-Steinnocher، P. تخمین چگالی هسته دوگانه به عنوان روشی برای توصیف تغییرات مکانی-زمانی در بازار خردهفروشی مواد غذایی اتریش فوقانی. مجموعه مقالات هفتمین کنفرانس AGILE در علم اطلاعات جغرافیایی، هراکلیون، یونان، 29 آوریل تا 1 مه 2004. 29، ص 551-558.
- کریسپ، جی.ام. پیترز، اس. برآورد تراکم هسته (DKDE) برای تجسم سری های زمانی. ان GIS 2011 ، 17 ، 155-162. [ Google Scholar ]
- مرکز علوم اطلاعات فضایی، دانشگاه توکیو. پروژه جریان مردم (PFLOW)، تحقیقات مشترک: «پلتفورم اطلاعات فضای شهری قادر به جذب دادههای پویا» ، در دسترس آنلاین: http://pflow.csis.u-tokyo.ac.jp/ در تاریخ 1 اوت 2014 قابل دسترسی است.


© 2015 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر