

خلاصه
OpenStreetMap (OSM) یک منبع اطلاعات جغرافیایی بیسابقه، رایگان و بیسابقه است که میلیونها نفر به آن کمک کردهاند، که منجر به ایجاد پایگاه دادهای با حجم و ناهمگونی زیاد میشود. در این مطالعه، ما ناهمگونی کل پایگاه داده OSM و آرشیو تاریخی را در زمینه داده های بزرگ مشخص می کنیم. ما همه کاربران، عناصر جغرافیایی و مشارکتهای کاربر را از یک آرشیو دادههای هشت ساله با حجم 692 گیگابایت در نظر میگیریم. ما به برخی از روشهای غیرخطی مانند آمار قانون توان و شکستهای سر/دم برای کشف و نشان دادن ویژگیهای مقیاسبندی اساسی تکیه میکنیم. هر سه جنبه (کاربران، عناصر و مشارکت ها) قوانین قابل توجه قدرت یا توزیع های سنگین را نشان می دهند. توزیعهای سنگین نشان میدهند که عناصر کوچک بسیار بیشتر از عناصر بزرگ، کاربران غیرفعال بسیار بیشتر از عناصر فعال وجود دارد. و عناصر ویرایش شده بسیار کمتر از موارد ویرایش شده سنگین. علاوه بر این، حدود 500 کاربر در گروه اصلی OSM از نظر همکاری بسیار شبکه ای هستند.
کلید واژه ها:
OpenStreetMap ; کلان داده ؛ قوانین قدرت ؛ شکستگی سر/دم ؛ ht-index
1. معرفی
جامعه قرن بیست و یکم به طور قابل توجهی از دو نیرویی که با سر و دم یک توزیع دم بلند مشخص می شوند، سود می برد و به طور فزاینده ای توسط آن هدایت می شود [ 1 ]. به عنوان مثال، در حالی که صنعت تلفن تحت سلطه مخابرات ملی مانند AT&T بود، اکنون خدماتی مانند اسکایپ داریم. دایره المعارف بریتانیکا بسیار محبوب بود، اما ما اکنون همتای رایگان و محبوب تری در ویکی پدیا داریم. اطلاعات توسط دولت ها و رسانه های جمعی غول پیکر مانند CNN کنترل می شد، اما WikiLeaks یا OpenLeaks اخیراً با به اشتراک گذاری آزادانه اطلاعات تاریخ ساز شدند. در همین راستا، اطلاعات جغرافیایی داوطلبانه (VGI) [ 2] به عنوان همتای اطلاعات جغرافیایی که به طور متعارف توسط آژانس های نقشه برداری ملی جمع آوری و نگهداری می شود ظهور کرد. به عنوان بخشی از محتوای تولید شده توسط کاربر در عصر وب 2.0، VGI به طور منحصربهفردی اطلاعات مکان مرجع جغرافیایی را ارائه میکند. OpenStreetMap موفق ترین و شناخته شده ترین پروژه VGI است که علاقه قابل توجه و پایداری را در آکادمی، صنعت و سازمان های دولتی به خود جلب کرده است.
در این مقاله، ما تمام دادههای OSM جمعآوریشده در دهه گذشته را که توسط حدود 1 میلیون کاربر ثبتشده تا فوریه 2013 ارسال شده بود، مطالعه میکنیم. مطالعات قبلی نشان داد که دادهها و جامعه کاربران بسیار ناهمگن هستند. برای مثال، تنها درصد کمی از کاربران تقریباً همه مشارکتها، از جمله ایجاد و ویرایش را انجام میدهند [ 3 ، 4 ، 5 ]. از نظر تمرکز و دقت دادهها، دادههای OSM بهطور چشمگیری از شهری به مناطق روستایی یا از کشوری به کشور دیگر متفاوت است [ 6 ، 7 ].]. با این حال، این مطالعات قبلی بیشتر در سطح کشور و شهر انجام شده است. آنها فاقد شاخص های کمی در مورد ناهمگنی یا تنوع هستند. در مقابل، ما تمام دادههای OSM و تاریخچه آن را بررسی کردیم تا تصویری جامع از OSM بر اساس آمار قانون قدرت و شاخص ht ناشی از شکستگی سر/دم ارائه کنیم. به طور خاص، ناهمگونی اساسی عناصر OSM، کاربران، و مشارکت آنها را از طریق مجموعهای از معیارهای کمی مانند α، p value و ht-index نشان میدهیم و کمیت میکنیم.
آمار قانون قدرت بر اساس برآورد قوی حداکثر درستنمایی است که با تخمین حداقل مربعات مرسوم [ 8 ] متفاوت است ( برای جزئیات بیشتر به بخش 3 مراجعه کنید). برآورد حداکثر درستنمایی دو معیار را ارائه می دهد: α (درجه ناهمگنی)، و مقدار p (خوبی برازش). از سوی دیگر، شکستگی سر/دم [ 9 ] یک طرح طبقه بندی جدید توسعه یافته برای داده ها با توزیع دم سنگین است. همچنین یک ابزار تجسم کارآمد و مؤثر برای داده های بزرگ است [ 10]. سر/دم کل را حول یک اندازه متوسط به بسیاری از چیزهای کوچک تقسیم میکند که در دم اکثریت هستند و چند مورد بزرگ در سر که اقلیت هستند. این پارتیشن به صورت بازگشتی برای هد (چیزهای بزرگ) ادامه می یابد تا زمانی که مفهوم چیزهای کوچک بسیار بیشتر از چیزهای بزرگ نقض شود. در نهایت، تعداد دفعاتی که چیزهای بسیار کوچکتر تکرار میشوند، بهعنوان شاخص ht [ 11 ] برای توصیف پیچیدگی یا سطوح سلسله مراتبی کل تعریف میشود.
سهم این مقاله سه برابر است. ما مطالعه را در زمینه داده های بزرگ قرار دادیم و اطلاعات تاریخی و ویژگی های مرتبط را از کل پایگاه داده های OSM و آرشیو تاریخی کاربران استخراج کردیم. بر اساس استخراج، ما ناهمگونی پایگاههای داده OSM را مشخص کردیم و الگوهای مقیاسبندی بسیار قابل توجهی را هم برای کاربران و هم برای دادهها کشف کردیم. ما شبکههای مشارکتی را در بازه زمانی هشت ساله داده ایجاد کردیم و ویژگیهای غیرخطی اساسی شبکههای همکاری کاربر OSM را پیدا کردیم.
ادامه مقاله به شرح زیر تدوین شده است. بخش 2 داده های تاریخچه OSM و روش کار پردازش مجموعه داده عظیم را ارائه می دهد. بخش 3 به طور خلاصه روش انجام تجزیه و تحلیل مقیاس بندی، از جمله آمار قانون قدرت و تشخیص و شکستگی سر/دم را معرفی می کند. بخش 4 نتایج آماری الگوهای مقیاس بندی و سایر نتایج را نشان می دهد. بخش 5 بیشتر مفاهیم این مطالعه را مورد بحث قرار می دهد. در نهایت، بخش 6 نتیجه گیری می کند و به کارهای آینده اشاره می کند.
2. داده ها و پردازش داده ها
در جولای 2004 و با انگیزه موفقیت بزرگ ویکیپدیا، OSM با هدف ارائه نقشههای قابل ویرایش رایگان برای کل جهان [ 12 ] آغاز شد.]. تعداد زیادی از داوطلبان برای جمع آوری داده های مسیر GPS به گیرنده های GPS متکی بودند و با استفاده از ابزارهای ویرایش آنلاین آن را به داده های نقشه تبدیل کردند. فرآیندهای نقشه برداری زمان بر و خسته کننده هستند. در سال 2006، Yahoo! تصاویر دیجیتال را به صورت رایگان به جامعه OSM اهدا کرد، به طوری که نقشه برداری می تواند مستقیماً از تصاویر انجام شود. بعداً، OSM مجموعههای داده رایگان را از شرکتها و کشورها بهدست آورد، مانند مجموعه دادههای جادهای کامل هلند که توسط Automotive Navigation Data اهدا شده بود، و تبدیل مجموعه دادههای جاده سرشماری TIGER ایالات متحده. در طول دهه گذشته، OSM با حدود 1.8 میلیون کاربر و میلیاردها عنصر جغرافیایی به یکی از بزرگترین منابع داده های جغرافیایی و معروف ترین پلت فرم VGI تبدیل شده است.
داده های OSM به صورت آزاد در اینترنت و با تعدادی از فرمت های پشتیبانی شده مانند XML و فایل های شکل قابل دسترسی هستند. این مطالعه از اطلاعات کامل تاریخچه داده های OSM استفاده می کند که می تواند از طریق [ 13 ] دانلود شود]. این کمپرسی بسیار بزرگ است، در 692 گیگابایت که از 9 آوریل 2005 تا 5 فوریه 2013 در قالب XML جمع آوری شده است. این عمدتا شامل و به صورت متوالی توسط سه نوع اصلی از عناصر جغرافیایی داده های OSM ساخته شده است: گره، راه و رابطه. گره ها به عنوان ویژگی های نقطه ای که اطلاعات مکان مختصات طول و عرض جغرافیایی را ذخیره می کنند. راه ها چند خط و چند ضلعی هستند که شامل مجموعه ای از گره های مرتب شده هستند. روابط بیانگر روابط جغرافیایی بین سه نوع عنصر است. هر عنصر حاوی اطلاعات مختلفی مانند شناسه، مُهر زمانی ایجاد یا ویرایشها، شناسه کاربر و کاربر مشارکت، شماره نسخه و انواع مختلف برچسبها است. اطلاعات تاریخی بر اساس شماره نسخه با ویژگی نام نسخه سازماندهی می شود که هر بار که نسخه جدیدی از این عنصر وجود دارد، 1 افزایش می یابد.
کار با چنین فایل بزرگی دشوار است، زیرا اجرای ساده آن در یک کامپیوتر رومیزی پیشرفته چندین ساعت طول می کشد. بنابراین ما یک رویه کاری ایجاد کردیم ( شکل 1) برای استخراج اطلاعات تاریخی و ویژگی برای هر عنصر از کل پایگاه داده برای تجزیه و تحلیل بیشتر. برای اطلاعات تاریخی، شناسه عنصر، مهر زمانی، شناسه کاربر مشارکت کننده و شماره نسخه را در هر نسخه جمع آوری کردیم. اطلاعات ویژگی هر عنصر با توجه به آخرین نسخه بود. برای هر عنصر گره، جفت مختصات آن (طول و عرض جغرافیایی) و برای هر عنصر راه و رابطه، شناسه اعضای آنها را جمع آوری کردیم. کل فرآیند سه روز بر روی یک پردازنده هشت هسته ای 3.4 گیگاهرتزی و دسکتاپ حافظه 32 گیگابایتی به طول انجامید. استخراج به عنوان یک جدول بزرگ سازماندهی شد و به صورت یک فایل txt با حجم حدود 150 گیگابایت، شامل تقریباً 2.1 میلیارد عنصر متشکل از 1.9 میلیارد گره، 0.2 میلیارد راه و 2 میلیون رابطه فرمت شد. برای تجزیه و تحلیل بیشتر، تعداد کاربران، ویرایشها،بخش 4 ). استخراج به عنوان یک نسخه کوچک شده از داده ها، کارایی را به شدت بهبود می بخشد، زیرا فقط نیم ساعت طول می کشد تا فایل را طی کنید و کمتر از یک ثانیه برای بازگشت نتایج پرس و جو با استفاده از جستجوی باینری بر اساس شناسه عنصر مرتب شده، طول می کشد.
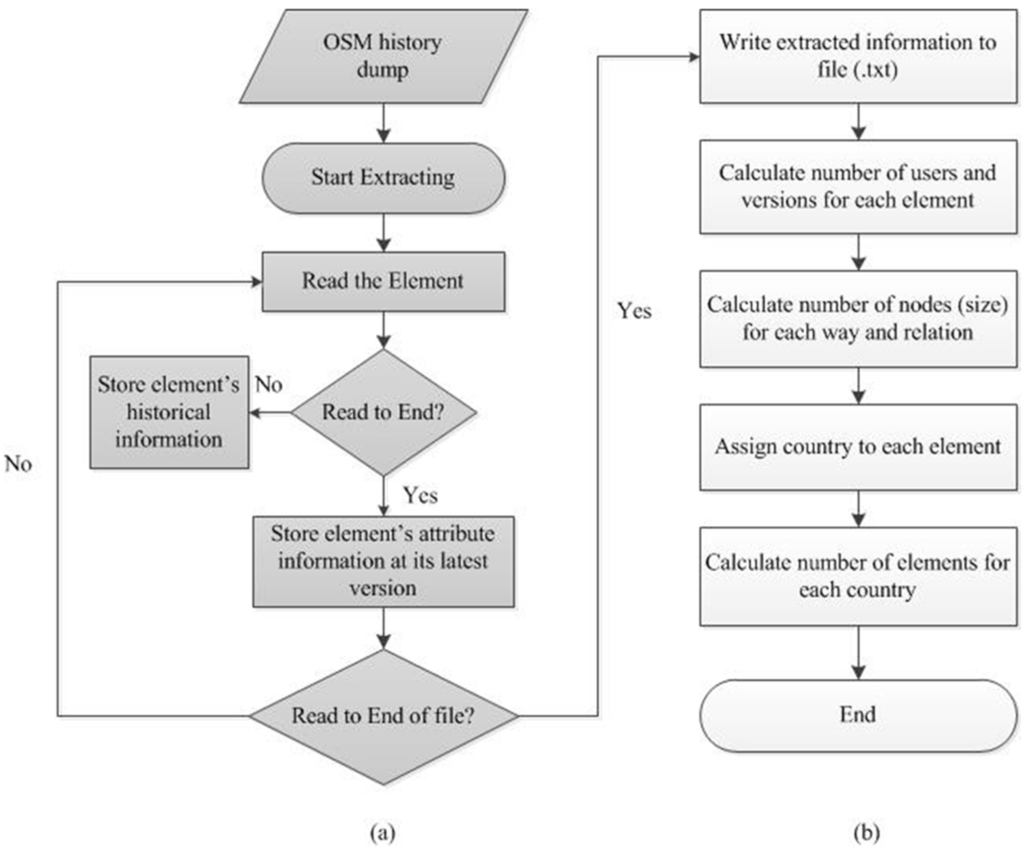
شکل 1. نمودار جریان برای پردازش داده ها برای استخراج اطلاعات ضروری برای تجزیه و تحلیل بیشتر. توجه داشته باشید که ( a ) پردازش داده و ( b ) نتایج است
3. روش شناسی
این مطالعه مجموعهای از روشهای غیرخطی اتخاذ شده را نشان میدهد، از جمله تشخیص قدرت-قانون بر اساس تخمین حداکثر احتمال [ 8 ] و شکستگیهای سر/دم به عنوان یک طرح طبقهبندی برای دادهها با توزیع دم سنگین [ 9 ]. ما به این دو روش برای تجزیه و تحلیل مقیاس بندی تکیه می کنیم زیرا (1) تشخیص قانون توان احتمالا قوی ترین و قابل اعتمادترین روش برای تخمین قانون توان است. و (2) شکستن سر/دم می تواند هم به عنوان یک طرح طبقه بندی و هم به عنوان ابزار تجسم عمل کند [ 10]. این دو روش تا حد زیادی یکدیگر را تکمیل می کنند تا ویژگی های مقیاس بندی داده های OSM را آشکار و تجسم کنند. به طور خاص، تشخیص قدرت-قانون مربوط به این است که چگونه یک مجموعه داده بهتر از هر گزینه دیگری مانند lognormal، نماها و انواع آنها منطبق می شود، در حالی که هدف breaks head/tail نشان دادن سطوح سلسله مراتبی ذاتی یا شکست سر / دم القا شده ht است. -شاخص [ 11 ]. مهمتر از همه، شکستن سر/دم می تواند به طور موثر و موثر داده های اضافی را به عنوان یک ابزار تجسم قدرتمند برای داده های بزرگ فیلتر کند.
3.1. تشخیص قانون قدرت
داده های دارای ویژگی مقیاس بندی از توزیع قانون توان پیروی می کنند، به این معنی که بسامد هر مقدار با توان رتبه آن نسبت معکوس دارد. به عبارت دیگر، داده ها حاوی مقادیر بسیار کوچک تر و در عین حال مقادیر بسیار کمی هستند. معروف ترین مثال قانون قدرت در رخدادهای کلمه، اندازه شهرها و توزیع ثروت یافت می شود [ 14 ]. به طور کلی قانون قدرت به صورت زیر مشخص می شود:
y = kایکس– αy=��−�
که در آن k یک ثابت است و α توان قانون توان است.
ساده ترین راه برای تشخیص قانون توان، گرفتن مقیاس لگاریتمی در هر دو محور برای دیدن اینکه آیا منحنی توزیع یک خط مستقیم است، بر اساس:
ln ( y) = – α ln ( x ) + ln ( k ) لوگاریتم(�)= –�لوگاریتم(ایکس)+لوگاریتم(ک)
با این حال، این روش از دم آشفته در انتهای توزیع رنج می برد. از این رو، Clauset و همکاران. [ 8 ] یک آزمون آماری دقیق بر اساس حداکثر احتمال و آزمون کولموگروف-اسمیرنوف (KS) برای تشخیص قانون توان معرفی کردهاند. دو پارامتر وجود دارد: یک توان تخمینی α و شاخص یک p خوبی برازش . آنها به عنوان شاخصی برای تناسب قدرت-قانون و خوبی برازش استفاده می شوند. این روش به طور گسترده ای مورد استفاده قرار گرفته است و ثابت شده است که برای تشخیص توزیع های قانون قدرت با طیف گسترده ای از سیستم های پیچیده قوی است [ 15 ، 16 ، 17 ].
به بیان ساده، توان تخمینی α برای شکل دادن به توزیع قانون توان استفاده می شود و محدوده پذیرش از 1 تا 3 است، که به صورت زیر ارائه می شود:
α = 1 + n⎡⎣∑i = 0nلوگاریتمایکس1ایکسm i n⎤⎦– 1α=1+n[∑من=0�لوگاریتمایکس1ایکسمترمن�]–1
که در آن α نشان دهنده توان تخمینی است و x min کوچکترین مقداری است که برازش قانون توان بالاتر از آن برقرار است.
ما یک آزمون KS اصلاحشده را برای ارزیابی اینکه چگونه دادهها با توزیع قانون قدرت (خوبی برازش) منطبق میشوند، اتخاذ کردیم. این بر اساس این ایده است که حداکثر فاصله (D) بین توابع چگالی تجمعی (CDF) داده ها و مدل برازش شده است:
D =| f( x ) – g( x ) |x ≥ایکسm i nm a x�=|�(ایکس)–�(ایکس)|ایکس≥ایکسمترمن�مترآایکس
که در آن f ( x ) CDF دادهها برای مشاهدات با مقدار حداقل x min است و g ( x ) CDF برای مدل قانون قدرت است که به بهترین وجه با دادههایی مطابقت دارد. x ≥ایکسm i nایکس≥ایکسمترمن�.
معمولاً 1000 مجموعه داده مصنوعی سپس با مدل برازش شده g ( x ) تولید میشود که حاوی دادههایی است که مقادیر آنها بالاتر از xmin کاملاً از توزیع قانون توان پیروی میکند. برعکس، مقادیر کمتر از xmin با قانون قدرت توزیع نمیشوند . حداکثر اختلاف D بین مدل برازش شده و هر مجموعه داده مصنوعی دوباره محاسبه می شود. شاخص تناسب p به عنوان کسری از تعداد D i که مقادیر آن بزرگتر از D است نشان داده می شود.به 1000. هر چه مقدار p بالاتر باشد، با قانون توان سازگارتر است. هرچه مقدار p به 1 نزدیکتر شود، داده ها برای توزیع قانون توان پذیرفته می شوند. آستانه قابل قبول به عنوان حسن تناسب 0.05 در نظر گرفته شده است.
تشخیص قدرت-قانون احتمالاً سختترین تخمین آماری برای متمایز کردن قوانین توان از گزینههای دیگر مانند لگ نرمال، نمایی و دیگر انواع است. برخلاف تشخیص دقیق قانون قدرت، شکستن سر/دم راه حل ساده ای برای آشکار کردن پوسته پوسته شدن زیرین ارائه می دهد و انواع توزیع های دم سنگین را اعمال می کند، تا زمانی که الگوی پوسته پوسته شدن چیزهای کوچک بسیار بیشتر از موارد بزرگ تکرار شود. چندین بار.
3.2. سر / دم می شکند
شکستگی سر/دم اساساً از ویژگی اصلی توزیع های دم سنگین ناشی می شود. با توجه به دادههایی با توزیع دم سنگین، میانگین حسابی یا میانگین میتواند تمام مقادیر دادهها را به دو بخش نامتعادل تقسیم کند: اقلیتی از مقادیر بزرگ بالاتر از میانگین، به نام head . و اکثر مقادیر کوچک زیر میانگین، به نام دم . این فرآیند به صورت بازگشتی برای هد ادامه می یابد تا زمانی که مفهوم مقادیر بسیار کوچکتر از مقادیر بزرگ نقض شود. تابع بازگشتی زیر یعنی شکستن سر/دم را ببینید. درصد تقسیم داده ها به سر و دم 40 درصد تعیین شده است. این بدان معناست که درصد دم 60 درصد است. تعداد دفعاتی که داده ها را می توان به اضافه 1 تقسیم کرد، ht-index [ 11 ] است]. این نشان می دهد که چند برابر الگوی مقیاس بندی چیزهای بسیار کوچکتر از چیزهای بزرگ در داده ها تکرار می شود. مشخصه مقیاس بندی داده ها را کمی می کند. هر چه ht-index بالاتر باشد، سطح سلسله مراتبی در داده ها بیشتر می شود.
عملکرد بازگشتی شکست های سر/دم : داده های ورودی (در حدود میانگین یا متوسط) را به سر و دم تقسیم کنید. // سر برای مقادیر داده بالاتر از میانگین // دم برای مقادیر داده زیر میانگین در حالی که (سر <= 40%) : شکستگی سر/دم (سر); تابع پایان
برخی از داده های این مطالعه، مانند 2 میلیارد عنصر، برای تشخیص قوانین قدرت بسیار بزرگ بودند. در این زمینه، شکستن سر/دم راه حل خوبی ارائه می دهد. به جای گرفتن همه عناصر، قسمت سر را برای تشخیص قدرت-قانون گرفتیم. اگر قسمت سر هنوز خیلی بزرگ بود، قسمت بعدی سر را برداشتیم، تا زمانی که قسمت سر به اندازه کافی برای تشخیص قدرت-قانون کوچک شد. دلیل اینکه ما به صورت بازگشتی هد را می گیریم، صرفاً به این دلیل است که هد خود شبیه به کل مجموعه داده است. این همچنین استدلال اساسی برای شکست های سر/دم به عنوان یک ابزار تجسم کارآمد و موثر برای داده های بزرگ است [ 10 ]. بنابراین، تشخیص قانون قدرت و شکستگیهای سر/دم مکمل یکدیگر هستند و ابزارهای قدرتمندی برای آشکار کردن مقیاسبندی یا ناهمگونی دادههای OSM فراهم میکنند.
4. ویژگی های مقیاس دهی داده های OSM
این بخش نتایج تجزیه و تحلیل مقیاس را بر روی انواع ویژگی ها بر اساس سه جنبه در زمینه کلان داده شامل 1 میلیون کاربر، 2.1 میلیارد عنصر و 2.7 میلیارد مشارکت ارائه می دهد ( شکل 2 ). این سه بخش تصویری به هم پیوسته از داده ها و جامعه OSM را تشکیل می دهند. کاربران به عناصر کمک می کنند، که منجر به افزایش زیادی در حجم و پیچیدگی عناصر و جامعه کاربر می شود. از طریق مشارکت ها، کاربران یک شبکه همکاری بهم پیوسته را تشکیل دادند. تجزیه و تحلیل مقیاس بندی مبتنی بر تشخیص قدرت-قانون و شکستگی سر/دم در این سه جنبه اعمال شد تا بررسی شود که تا چه حد الگوی مقیاس بندی چیزهای بسیار کوچکتر از موارد بزرگ برای داده های OSM صادق است.

شکل 2. سه جنبه از مطالعه در زمینه داده های بزرگ.
4.1. در مورد کاربران و عناصر
ما ابتدا کاربران را بر اساس تعداد مشارکت آنها بررسی کردیم. این بررسی بر این اساس بود که یک کاربر میتواند در چه تعداد شناسه عنصر منحصربهفرد مشارکت داشته باشد. این مشارکت ها شامل ایجاد و ویرایش می شود. در مجموع 268227 کاربر مشارکت داشتند. تعداد مشارکتهای هر کاربر توزیع قانون قدرت را با α پذیرفتهشده 2.24 و p مقدار 0.26 نشان میدهد ( شکل 3 a). با اعمال شکست های سر/دم، سلسله مراتب مقیاس بندی این اعداد را استخراج می کنیم که با شاخص ht 7 و درصدهای بسیار پایین برای هر سر (<30٪) نشان داده شده است. این به این معنی است که الگوی مقیاس بندی قابل توجه 6 برابر این داده ها تکرار می شود ( جدول 1). این الگوی مقیاسبندی آشکار نشان میدهد که تنها تعداد بسیار کمی از کاربران اکثر عناصر OSM را مشارکت دادهاند. به عبارت دیگر، تعداد کاربران غیرفعال به مراتب بیشتر از کاربران فعال است.

جدول 1. آمار شکست های سر/دم برای مشارکت های کاربر (توجه: # = عدد، % = درصد).
در مرحله دوم، ما به ویژگی های مختلف عناصر نگاه کردیم. هر عنصر به ترتیب با تعداد کاربران، ویرایش ها و اندازه مشخص می شود. به طور خاص، تعداد کاربران برای هر عنصر نشان می دهد که تعداد کاربرانی که در آن مشارکت دارند، با تعداد شناسه های کاربری منحصر به فرد این عنصر ارائه می شود. توجه داشته باشید که مشارکت شامل ایجاد و ویرایش می شود. تعداد ویرایشها را میتوان مستقیماً با حداکثر تعداد نسخه این عنصر به دست آورد، زیرا برابر با حداکثر نسخه منهای یک است. تعداد اندازه به تعداد شناسه گره منحصر به فرد آن اشاره دارد. اندازه هر عنصر گره همیشه 1 است. اندازه هر عنصر راه برابر با تعداد نقاط متشکل منحصر به فرد آن است. اندازه هر عنصر رابطه با تعداد نقاط منحصر به فردی که عضو آن دارد تعیین می شود: گره، راه یا رابطه (این سه عضو همیشه به طور همزمان در یک رابطه وجود ندارند). از آنجایی که برخی از عناصر رابطه می توانند عنصر(های) رابطه دیگری را به عنوان عضو(های) خود داشته باشند، محاسبه اندازه آن عناصر رابطه زمانی که آنها متقابلاً یکدیگر را به عنوان عضو(های) خود دارند، دشوار است. 4356 عنصر رابطه به دلیل چنین ساختارهای پیچیده حذف شدند. با در نظر گرفتن عناصر 2.1 میلیارد مورد مطالعه، ما معتقدیم که 4356 حذف شده تاثیر زیادی بر نتایج ما نخواهد داشت.
در مرحله بعد، شکستگی های سر/دم را به سه جنبه فوق اعمال کردیم. هر سه شاخص ht مشتق شده بسیار بالا بودند (> 10)، و بیشتر درصدهای سر کوچک بودند (<30 درصد؛ نتایج تفصیلی را در ضمیمه ببینید). این نشان می دهد که عناصر کوچک بسیار بیشتر از عناصر بزرگ هستند. تشخیص قدرت-قانون بیشتر بر روی داده های سطوح سلسله مراتبی بالای هر دسته اعمال شد ( جدول 2 ). داده های “فیلتر شده” پروکسی کل بود زیرا الگوی مقیاس بندی در هر سطح باقی می ماند. فقط تعداد اندازه عنصر از آزمون قانون توان عبور کرد ( شکل 3 د). همانطور که در شکل 3 مشاهده میشود، تعداد کاربران و ویرایشهای عنصر همچنان میتواند بهعنوان توزیعشده سنگین در نظر گرفته شود .b و 3c که هر نمودار در مقیاسهای لگاریتمی به یک خط مستقیم نزدیک است، بنابراین فکر میکنیم که کل مجموعه دادههای سه جنبه دارای خاصیت مقیاسبندی قوی هستند. ما همچنین تکامل داده ها را به صورت سالانه بررسی کردیم و دریافتیم که ناهمگونی با کل داده ها تفاوتی ندارد. به عبارت دیگر، دادههای سالهای گذشته همگی توزیع شدهاند، اما با شاخصهای مختلف ht متفاوت هستند.
جدول 2. آمار خلاصه شده در عناصر OpenStreetMap (OSM) در سلسله مراتب بالا در سه دسته.
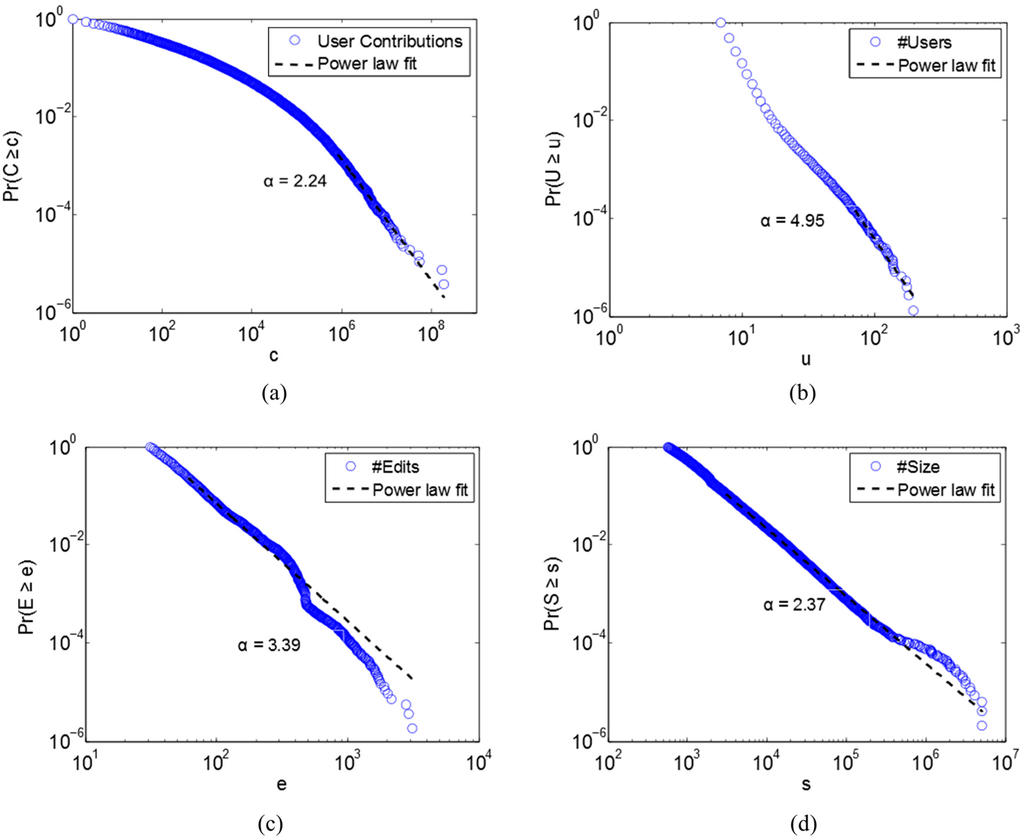
شکل 3. توزیع قانون قدرت مشارکت های کاربر: ( الف ) تعداد کاربران. ( ب ) تعداد ویرایشها؛ و ( ج ) تعداد اندازه ( d ) هر عنصر. داده های (b)، (c) و (d) از سلسله مراتب بالای همه عناصر انتخاب می شوند. (b) و (c) توزیع شده با قانون قدرت نیستند زیرا هر دو مقدار α بزرگتر از 3 هستند، اما دم سنگین هستند، که با شاخص ht بالا نشان داده شده در ضمیمه نشان داده شده است.
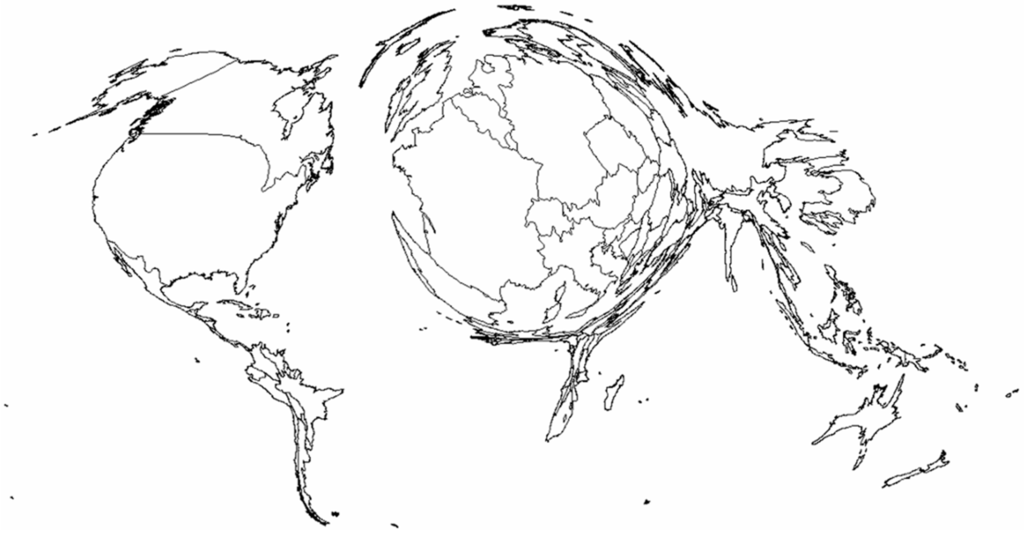
ما بیشتر توزیع فضایی عناصر را بررسی کردیم، به عنوان مثال ، چند عنصر در هر کشور قرار دارند. ما تعداد عناصر و مقادیر مشخصه انبوه هر جنبه را محاسبه و به هر کشور اختصاص دادیم. در نتیجه، دادههای هر سه جنبه بسیار توزیع شده با قانون قدرت است ( جدول 3 )، که نشان میدهد کشورهای کوچک بسیار بیشتر از کشورهای بزرگ در سرتاسر جهان از نظر عناصر، کاربران و مشارکتها وجود دارد و این نشان میدهد که که تنوع بالای کیفیت و کامل بودن پایگاه داده OSM از کشوری به کشور دیگر از طریق غلظت عناصر مختلف. کارتوگرام اندازه های کشور حاصل را نشان می دهد ( شکل 4) که 5 کشور برتر آمریکا، فرانسه، کانادا، آلمان و روسیه هستند. این کشورها همچنین از نظر تعداد کل کاربران، ویرایشها و اندازه، 5 کشور برتر هستند، اما با رتبهبندی کمی متفاوت (کانادا و آلمان موقعیتهای خود را تغییر میدهند).
جدول 3. آمار خلاصه عناصر در سطح کشور.
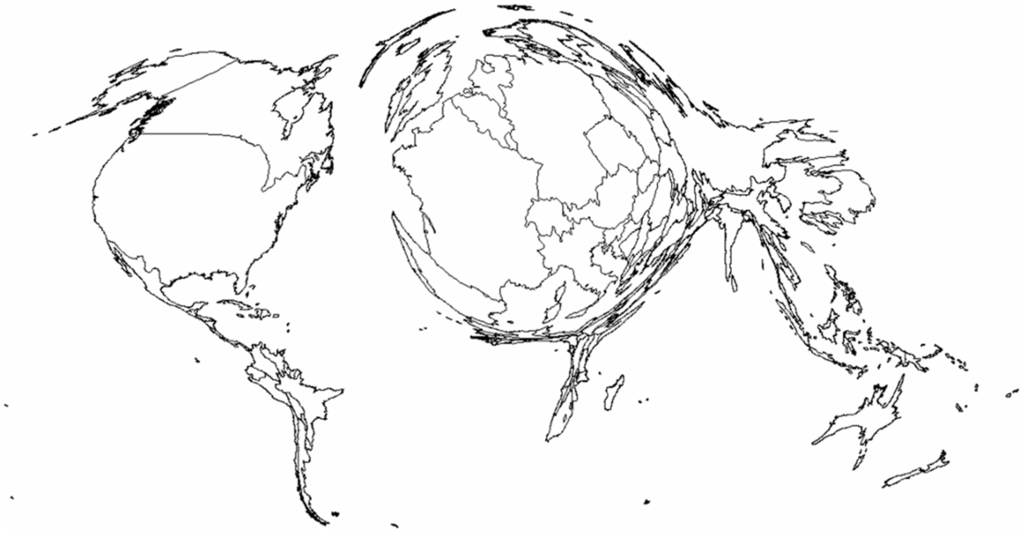
شکل 4. کارتوگرام توزیع فضایی عناصر OSM جهانی را در سطح کشور نشان می دهد.
4.2. در شبکه مشارکت
پس از بررسی کاربران و عناصر، ما متعاقباً الگوی مقیاسبندی را در شبکه همکاری کاربران OSM مطالعه کردیم. رابطه اجتماعی مورد استفاده در این تحقیق رابطه مشارکتی است زیرا رابطه دوستانه مانند سایر پلتفرم های اجتماعی (مثلاً فیس بوک) در تاریخچه OSM مستند نیست. رابطه همکاری یا مشارکت زمانی در آرشیو داده های OSM ایجاد می شود که بیش از یک کاربر در یک عنصر مشارکت داشته باشند. به عبارت دیگر، ما در نظر گرفتیم که کاربر اگر همان عنصر را ایجاد یا ویرایش کند، چنین رابطه ای با دیگران دارد. این رویکرد با رویکرد تعریف شده توسط مونی و کورکوران [ 4 ، 18 ] متفاوت است] که فقط تعامل ویرایش و همچنین توالی ویرایش ها را در نظر می گیرند. در این راستا، ما به جای شبکه ویرایش مشترک، یک “شبکه مشارکت” ایجاد می کنیم. همانطور که شکل 5 الف نشان می دهد، با فرض اینکه کاربر 1، 3 و 4 در عنصر b مشارکت می کنند، روابط مشارکتی بین هر دو مورد وجود دارد، به طوری که شبکه حاصل ( شکل 5 ب) را می توان به دست آورد. توجه داشته باشید که این مقاله فقط شبکه دودویی را در نظر می گیرد که از لبه های غیر جهت دار و وزنی تشکیل شده است.
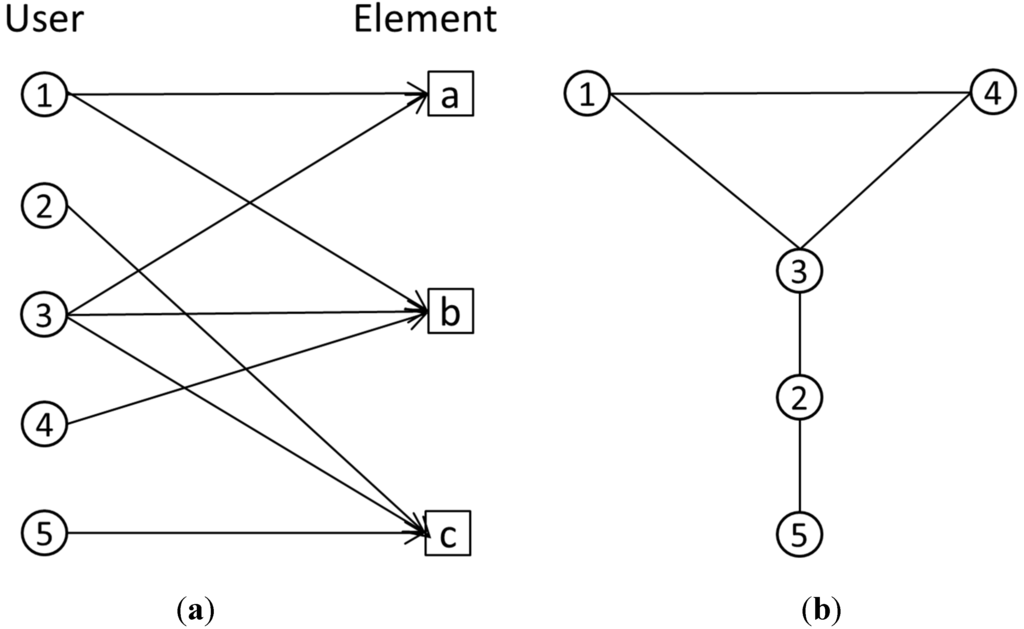
شکل 5. تصویر رابطه مشارکتی. مشارکت کاربران در عناصر به صورت یک نمودار دو بخشی ( a ) نشان داده می شود که به یک شبکه مشارکتی ( b ) تبدیل می شود.
با پیروی از قاعده رابطه مشارکت، ما شبکه را بر اساس کل تاریخچه همه عناصر ایجاد کردیم تا تعامل در جامعه OSM را بهتر نشان دهیم [ 19 ]. نمودار اجتماعی حاصل از 248070 گره و 6446086 یال تشکیل شده است. درجه گره این شبکه توزیع شده با قانون قدرت است و دارای ht-index 10 است ( جدول 4 ) که نشان می دهد شبکه فوق العاده بدون مقیاس است. شکل 6شبکه “فیلتر شده” شامل 477 گره از 5 سلسله مراتب برتر را به عنوان نماینده کل شبکه نشان می دهد که الگوی مقیاس بندی زیربنایی به وضوح آشکار می شود. ما شبکههای سالهای گذشته را از سال 2005 بیشتر بررسی میکنیم تا ببینیم آیا الگوی مقیاسبندی در طول تکامل جامعه OSM از نظر مشارکت، همیشه ادامه دارد یا خیر. به عنوان نتایج، به جز عدم وجود چنین شبکه ای بین سال های 2005 و 2006، تکامل شبکه های مشارکتی با رشد غیرخطی گره ها و یال ها از سال 2007 به بعد بوده و به طور فزاینده ای مقیاس پذیر می شود که توسط قانون قدرت نشان داده می شود. معیارهای برازش و به طور کلی ht-index بزرگ هر سال ( جدول 5 ).
جدول 4. آمار شکست سر/دم برای درجه گره شبکه مشارکتی در سال 2013.
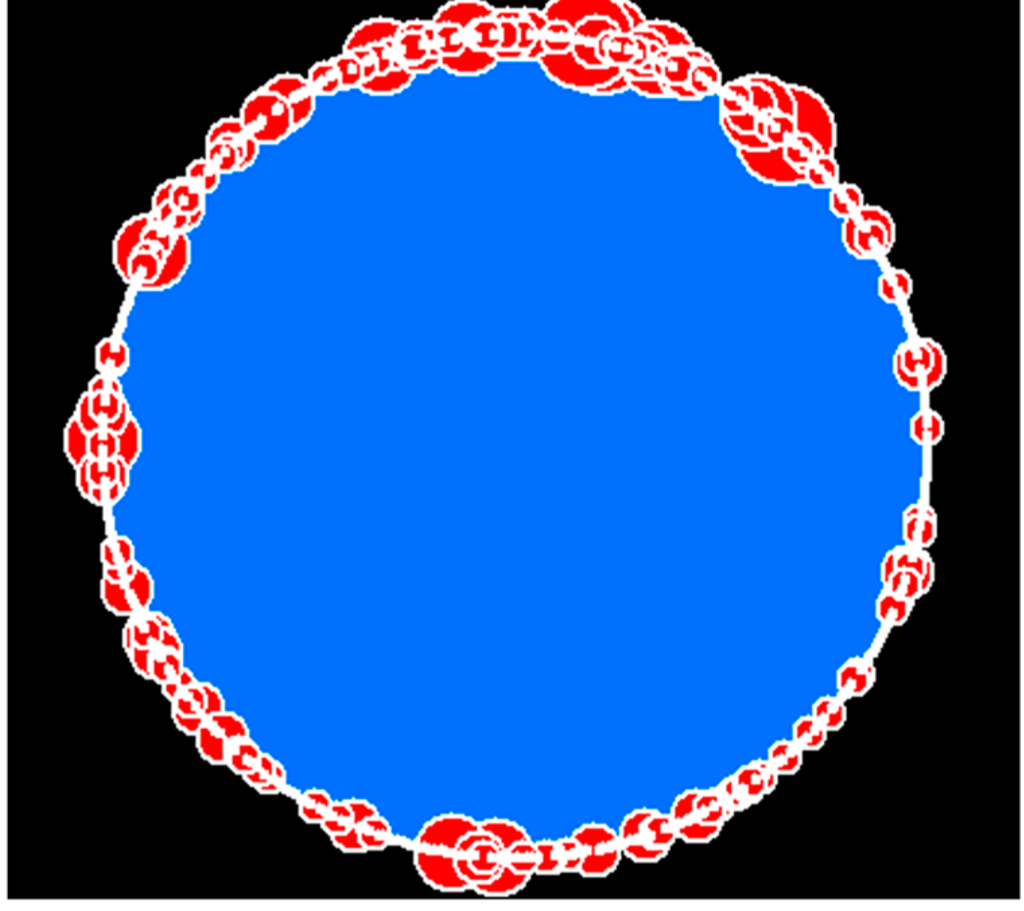
شکل 6. شبکه مشارکت برای پنج سطح سلسله مراتبی بالا شامل 477 گره و 80957 یال. سلسله مراتب مقیاس گره های بسیار کوچکتر از گره های بزرگتر با اندازه نقاط قرمز نشان داده می شود.
جدول 5. نتایج تحلیل مقیاس شبکه های مشارکتی از سال 2007 تا 2013.
ما همچنین بینش هایی را در مورد جامعه OSM از نظر همکاری کاربر از شبکه مشارکت مشتق شده ایجاد کردیم. در مقایسه با شبکه همکاری ویکیپدیای انگلیسی [ 20 ، 21 ، 22 ]، الگوی مقیاسبندی یکسانی از کاربران غیرفعال به مراتب بیشتر از کاربران فعال دارد. علاوه بر این، شبکه همچنین دارای برخی از غلظتهای چگالی بالا، به ویژه در میان کاربران بسیار فعال است. به طور خاص، هر کاربر به طور متوسط با حدود 52 کاربر دیگر در کل شبکه همکاری می کند و آن کاربران درجه بالا حتی تقریباً با همه دیگر همکاری دارند. ما همچنین دو شبکه اجتماعی مبتنی بر مکان جهانی (Gowalla و Brightkite) را برای مقایسه انتخاب می کنیم (داده ها در [ 23 موجود است]) و دریافتند که شبکه مشارکتی بسیار متراکم تر از آنها در مورد شبکه کل و نمونه (گره های سلسله مراتب بالا) است.
5. بحث های بیشتر در مورد مطالعه
از نتایج ارائهشده در بخش 4 ، میتوانیم به ناهمگونی بزرگ دادههای OSM و جامعه از عناصر تا مشارکتهای کاربر، و بیشتر به شبکههای مشارکت سالانه اشاره کنیم. همه آنها را می توان به خوبی با الگوهای مقیاس بندی قابل توجه مشخص کرد، که با برخی از معیارهای آمار قانون قدرت و سلسله مراتب زیربنایی و آمار اضافی از شکستگی سر/دم نشان داده شده است. این بخش بیشتر برخی از مفاهیم نتایج و مطالعه را به طور کلی مورد بحث قرار می دهد.
در این مطالعه، ما کل دادههای OSM و آرشیو جامعه را از دیدگاهی جامع شامل عناصر، کاربران و شبکههای همکاری آنها که در دهه گذشته تکامل یافتهاند، پردازش و تحلیل کردهایم. بیش از صدها گیگابایت از داده ها پردازش و محاسبه می شود تا بینش جدیدی در مورد داده ها و جامعه ایجاد شود. یافته های این مطالعه با تحقیقات قبلی در مورد کاربران و عناصر همخوانی دارد [ 3 ، 4 ، 5 ، 24 .] که اقلیتی از کاربران/عناصر اکثر مشارکت ها/ویرایش ها را تشکیل می دهند. تفاوت عمده بین کار ما و مطالعات قبلی این است که ما یک تجزیه و تحلیل کمی عمیق بر روی همه کاربران و عناصر در مقیاس جهانی انجام دادیم. این ما را قادر می سازد چیزی را ببینیم که در کارهای قبلی به تصویر کشیده نشده است. با بهترین دانش ما، الگوهای مقیاس بندی هرگز برای مجموعه داده های OSM در چنین سطح عظیمی مورد بررسی قرار نگرفته است. در این رابطه، ما معتقدیم که این مطالعه را می توان به سایر محتوای تولید شده توسط کاربر مانند ویکی پدیا [ 21 ] تعمیم داد.
این مقاله تجزیه و تحلیل مقیاس بندی را برای توصیف ناهمگونی پایگاه داده جهانی OSM اعمال می کند. جدای از بررسی آمار قانون توان برای تشخیص الگوهای پوستهگذاری، سایر توزیعهای دم سنگین مشاهده و با شاخص ht اندازهگیری میشوند. به طور گسترده ای شناخته شده است که داده های تشکیل شده از پدیده های دنیای واقعی به احتمال زیاد مانند داده های OSM به صورت سنگین توزیع می شوند، زیرا داده ها به طور طبیعی تکامل یافته و از افراد از پایین به بالا انباشته می شوند به جای تحمیل توسط مقامات بالا به پایین در نتیجه، دادههای همه جنبهها از قوانین قدرت یا توزیعهای دنباله دار به طور کلی پیروی میکنند. بنابراین، روشهای خطی مرسوم مانند آمار گاوسی، نارساییهایی را در توصیف این نوع ناهمگونی نشان میدهند. به سادگی هیچ میانگین یا مقیاس معمولی برای توصیف ناهمگونی وجود ندارد. در عوض، مقیاس بندی در تمام مقیاس ها می تواند برای مشخص کردن تنوع یا ناهمگنی استفاده شود. مطالعه ما به این استدلال اشاره می کند که در عصر داده های بزرگ، تجزیه و تحلیل جغرافیایی نیاز به روش جدیدی از تفکر دارد – تفکر پارتی [25 ] برای درک بهتر اشکال و فرآیندهای جغرافیایی.
داده های بزرگ، به دلیل تنوع و ناهمگونی آن، احتمالاً الگوی مقیاس بندی چیزهای کوچک بسیار بیشتری را نسبت به چیزهای بزرگ نشان می دهد. چیزهای بزرگ و کوچک به ترتیب سر و دم یک توزیع دم بلند را تشکیل می دهند. جالب توجه است که الگوی پوستهگذاری چندین بار تکرار میشود، که به این معنی است که اشیاء در سر، الگوی پوستهگذاری چیزهای کوچکتر را نسبت به چیزهای بزرگ، بارها و بارها نشان میدهند. این الگوی پوستهگذاری مکرر چیزی است که اساس طرح طبقهبندی جدید به نام شکستگی سر/دم [ 9 ] است.]. سر/دم اشیاء را به طور متوسط به چند چیز بزرگ در سر و بسیاری از چیزهای کوچک در دم تقسیم میکند و به صورت بازگشتی برای فرآیند تقسیم سر تا زمانی که مفهوم چیزهای بسیار کوچکتر از چیزهای بزرگ نقض شود ادامه مییابد. شکستگی های سر/دم می توانند به طور موثر و موثر داده ها را فیلتر کنند در حالی که داده ها خیلی بزرگ هستند که نمی توان آنها را مدیریت کرد. این تابع فیلتر همچنین چیزی است که زیربنای عملکرد تجسم شکستگیهای سر/دم است [ 10 ]. ما معتقدیم که تفکر سر/دم پشت سر/دم شکستهها برای کلان دادهها و تحلیلهای آن بسیار امیدوارکننده است.
6. نتیجه گیری
داده های OSM اساساً در مقیاس محلی یا جهانی بسیار ناهمگن هستند. این به این دلیل است که فضای جغرافیایی یا سطح زمین بسیار ناهمگن است – هیچ موقعیت متوسطی در سطح زمین وجود ندارد. در این مقاله، کل دادههای OSM را مطالعه میکنیم و متوجه میشویم که این ناهمگونی را میتوان به طور عادلانه از عنصر، کاربران و همکاریهای آنها نشان داد و اندازهگیری کرد. برای کاربران، هم مشارکت آنها و هم درجه شبکه های مشارکتی، توزیع قانون قدرت واضحی را نشان می دهد، به این معنی که تعداد کاربران غیرفعال بسیار بیشتر از کاربران فعال است. برای عناصر، عناصر کوچک بسیار بیشتری نسبت به عناصر بزرگ وجود دارد، زیرا مقادیر ویژگی آنها در سه دسته (تعداد کاربران، ویرایشها و اندازه) در دم سنگین توزیع شده است. علاوه بر این، عناصر اختصاص داده شده به کشورها، قانون قدرت قابل توجهی را نشان می دهد. علاوه بر این، چنین الگوی در سطح کشور در مورد توزیع فضایی همه عناصر نیز باقی می ماند. شکستن سر/دم را می توان به عنوان یک ابزار کارآمد و موثر برای تجزیه و تحلیل و تجسم داده های بزرگ در گرفتن سلسله مراتب مقیاس بندی زیربنایی و تکمیل تشخیص قانون قدرت ریاضی استفاده کرد. به طور خلاصه، ویژگی مقیاسبندی به وضوح با دادههای OSM نشان داده میشود و میتواند این ناهمگونی بزرگ را از طریق معیارهای برازش قانون قدرت و زیربنای سطوح سلسله مراتبی مقیاسبندی به خوبی مشخص کند. شکستن سر/دم را می توان به عنوان یک ابزار کارآمد و موثر برای تجزیه و تحلیل و تجسم داده های بزرگ در گرفتن سلسله مراتب مقیاس بندی زیربنایی و تکمیل تشخیص قانون قدرت ریاضی استفاده کرد. به طور خلاصه، ویژگی مقیاسبندی به وضوح با دادههای OSM نشان داده میشود و میتواند این ناهمگونی بزرگ را از طریق معیارهای برازش قانون قدرت و زیربنای سطوح سلسله مراتبی مقیاسبندی به خوبی مشخص کند. شکستن سر/دم را می توان به عنوان یک ابزار کارآمد و موثر برای تجزیه و تحلیل و تجسم داده های بزرگ در گرفتن سلسله مراتب مقیاس بندی زیربنایی و تکمیل تشخیص قانون قدرت ریاضی استفاده کرد. به طور خلاصه، ویژگی مقیاسبندی به وضوح با دادههای OSM نشان داده میشود و میتواند این ناهمگونی بزرگ را از طریق معیارهای برازش قانون قدرت و زیربنای سطوح سلسله مراتبی مقیاسبندی به خوبی مشخص کند.
این مطالعه از دیدگاه کلان داده انجام شده است، که بر کل مجموعه داده و محاسبات فشرده داده تمرکز دارد [ 26 ]. بنابراین، ما یک تصویر جامع از ناهمگونی دادههای OSM ایجاد کردهایم و یک مجموعه داده ارزشمند با توجه به اطلاعات تاریخی و ویژگیهای همه عناصر در یک زمان خاص به دست آوردهایم. محققان علاقه مند همیشه می توانند برای اطلاعات دقیق بیشتر در مورد پردازش داده ها با ما تماس بگیرند. در مورد کارهای آینده، دو کار باید انجام شود. اولین مورد، در نظر گرفتن اطلاعات برچسب هر عنصر و انجام تجزیه و تحلیل مقیاس بر روی آنها است. دوم مطالعه دینامیک غیرخطی اطلاعات فضایی و ویژگی های هر عنصر در دانه بندی های زمانی مختلف (به عنوان مثال، سال، ماه، هفتهو غیره ) مکانیسم اساسی تکامل جامعه OSM و فعالیت های نقشه برداری کاربر را پیدا کنید.
مشارکت های نویسنده
دینگ ما، متس سندبرگ و بن جیانگ این مطالعه را طراحی کردند و مقاله را با هم نوشتند. دینگ ما برنامه نویسی را روی پردازش داده انجام داد و معیارها را محاسبه کرد. بن جیانگ و متس سندبرگ مسئول بازبینی نسخه خطی بودند.
پیوست: آمار شکستهای سر/دم برای کاربران، ویرایشها، اندازهها
برای تکمیل شرح نتایج ارائه شده در بخش 4.1 ، این ضمیمه شامل آمار دقیق در مورد فرآیند شکستن سر/دم برای سه جنبه است: کاربران، ویرایشها و اندازهها. همانطور که می بینیم، همه داده ها بیش از 12 سطح سلسله مراتبی دارند که در ستون سطح نشان داده شده است، و میانگین درصد سر در هر سه جنبه کمتر از 30٪ است که به مراتب کمتر از آستانه پیش فرض 40٪ است. توجه داشته باشید که برای نتایج اندازه هر عنصر ( جدول A3 )، 4356 عنصر از محاسبه حذف شده است، بنابراین تعداد عناصر 2,138,154,220 – 4356 = 2,138,149,864 است.
جدول A1. سر/دم آمار تعداد کاربران هر عنصر را می شکند.
جدول A2. سر/دم آمار تعداد ویرایشهای هر عنصر را میشکند.
جدول A3. سر/دم آمار را برای هر اندازه عنصر تجزیه می کند.
منابع
- Anderson, C. The Long Tail: چرا آینده کسب و کار فروش کمتر و بیشتر است . Hyperion: نیویورک، نیویورک، ایالات متحده آمریکا، 2006. [ Google Scholar ]
- Goodchild، MF Citizens به عنوان حسگر: دنیای جغرافیای داوطلبانه. Geo J. 2007 , 69 , 211-221. [ Google Scholar ]
- نیس، پ. Zipf، A. تجزیه و تحلیل فعالیت مشارکت کننده یک پروژه داوطلبانه اطلاعات جغرافیایی – مورد OpenStreetMap. ISPRS Int. J. Geo-Inf. 2012 ، 1 ، 1-23. [ Google Scholar ]
- مونی، پی. Corcoran, P. OpenStreetMap چقدر اجتماعی است؟ در مجموعه مقالات پانزدهمین کنفرانس بین المللی AGILE در علم اطلاعات جغرافیایی، آوینیون، فرانسه، 27 آوریل 2012; صص 514-518.
- مونی، پی. Corcoran, P. خصوصیات اشیاء به شدت ویرایش شده در OpenStreetMap. اینترنت آینده 2012 ، 4 ، 285-305. [ Google Scholar ]
- نیس، پ. زیلسترا، دی. Zipf، A. تکامل شبکه خیابانی نقشههای crowdsourced: OpenStreetMap در آلمان 2007-2011. اینترنت آینده 2011 ، 41 ، 1-21. [ Google Scholar ]
- نیس، پ. Zielstra، D. تحولات اخیر و روندهای آینده در تحقیقات داوطلبانه اطلاعات جغرافیایی: مورد OpenStreetMap. اینترنت آینده 2014 ، 61 ، 76-106. [ Google Scholar ]
- کلاوزت، ا. شالیزی، CR; نیومن، توزیعهای قانون قدرت MEJ در دادههای تجربی. SIAM Rev. 2009 , 51 , 661-703. [ Google Scholar ]
- Jiang, B. Head/tail breaks: یک طرح طبقه بندی جدید برای داده ها با توزیع دم سنگین. پروفسور Geogr. 2013 ، 65 ، 482-494. [ Google Scholar ]
- جیانگ، بی. شکستن سر/دم برای تجسم ساختار و پویایی شهر. شهرها 2015 ، 43 ، 69-77. [ Google Scholar ]
- جیانگ، بی. یین، J. شاخص Ht برای کمی کردن ساختار فراکتال یا مقیاس بندی ویژگی های جغرافیایی. ان دانشیار صبح. Geogr. 2014 ، 104 ، 530-541. [ Google Scholar ]
- Bennett, J. OpenStreetMap: نقشهبردار خود باشید . PCKT Publishing: بیرمنگام، بریتانیا، 2010. [ Google Scholar ]
- سیاره OSM. در دسترس آنلاین: http://planet.openstreetmap.org/planet/full-history/ (در 25 ژوئن 2014 قابل دسترسی است).
- Zipf، GK Human Behavior and the Principles of Last Effort ; ادیسون وسلی: کمبریج، MA، ایالات متحده آمریکا، 1949. [ Google Scholar ]
- مارتا، سی جی; سزار، ق. Barabási، AL درک الگوهای تحرک فردی انسان. طبیعت 2008 ، 453 ، 779-782. [ Google Scholar ]
- جیانگ، بی. یین، جی. ژائو، اس. مشخص کردن الگوهای تحرک انسان در یک شبکه خیابانی بزرگ. فیزیک Rev. E 2009 , 80 , 021136. [ Google Scholar ]
- جیانگ، بی. جیا، قانون T. Zipf برای همه شهرهای طبیعی در ایالات متحده: یک دیدگاه جغرافیایی. بین المللی جی. جئوگر. Inf. علمی 2011 ، 25 ، 1269-1281. [ Google Scholar ]
- مونی، پی. Corcoran، P. تجزیه و تحلیل الگوهای تعامل و ویرایش مشترک در میان مشارکت کنندگان OpenStreetMap. ترانس. GIS 2013 ، 18 ، 633-659. [ Google Scholar ]
- هریستوا، دی. مشهدی، ع. کواترون، جی. Capra, L. نقشهبرداری تعامل جامعه با جمعسپاری شهری. در مجموعه مقالات کارگاه آموزشی وقتی شهر با شهروند ملاقات می کند (WCMCW)، در ارتباط با ICWSM، دوبلین، ایرلند، 7 ژوئن 2012.
- لانیادو، دی. تاسو، آر. نویسندگی مشترک 2.0: الگوهای همکاری در ویکی پدیا. در مجموعه مقالات بیست و دومین کنفرانس ACM در مورد فرامتن و ابررسانه ها، آیندهوون، هلند، 9 ژوئن 2011; ص 201-210.
- ووس، جی. اندازه گیری ویکی پدیا. در مجموعه مقالات ISSI 2005 — دهمین کنفرانس بین المللی انجمن بین المللی علم سنجی و انفورمتریکس، استکهلم، سوئد، 28 ژوئیه 2005.
- هیرت، م. لهردر، اف. Oberste-Vorth، S. هاسفلد، تی. Tran-Gia، P. Wikipedia و شبکه نویسندگان آن از دیدگاه شبکه اجتماعی. در مجموعه مقالات چهارمین کنفرانس بین المللی ارتباطات و الکترونیک 2012 (ICCE)، 3 اوت 2012; صص 119-124.
- مجموعه داده شبکه بزرگ استانفورد. در دسترس آنلاین: http://snap.stanford.edu/data/ (دسترسی در 15 نوامبر 2014).
- نیس، پ. زیلسترا، دی. Zipf، A. مقایسه مشارکت داوطلبانه اطلاعات جغرافیایی و توسعه جامعه برای مناطق منتخب جهان. اینترنت آینده 2013 ، 5 ، 282-300. [ Google Scholar ]
- جیانگ، ب. تجزیه و تحلیل جغرافیایی نیاز به روش متفاوتی از تفکر دارد: مشکل ناهمگونی فضایی. Geo J. 2015 ، 80 ، 1-13. [ Google Scholar ]
- هی، تی. تانسلی، اس. Tolle, K. پارادایم چهارم: کشف علمی فشرده داده . تحقیقات مایکروسافت: ردموند، دی سی، ایالات متحده آمریکا، 2009. [ Google Scholar ]
© 2015 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر