

خلاصه
در زمینههای سیستمهای اطلاعات جغرافیایی (GIS) و سنجش از دور (RS)، الگوریتم خوشهبندی بهطور گستردهای برای تقسیمبندی تصویر، تشخیص الگو و تعمیم نقشهبرداری استفاده شده است. اگرچه تجزیه و تحلیل خوشهبندی نقش کلیدی در مدلسازی مکانی ایفا میکند، روشهای خوشهبندی سنتی به دلیل پیچیدگی محاسباتی، توانایی مقاوم در برابر نویز و استحکام محدود هستند. علاوه بر این، روشهای سنتی بیشتر بر زمینه فضایی مجاور متمرکز شدهاند، که استفاده از روشهای خوشهبندی را برای اشیاء گسسته چند چگالی سخت میکند. در این مقاله، یک روش جدید، خوشه بندی سلسله مراتبی تقسیم سلولی (CDHC)، بر اساس عقب نشینی بدنه محدب پیشنهاد شده است. مراحل اصلی به شرح زیر است. اول، یک ساختار بدنه محدب برای توصیف زمینه فضایی جهانی اشیاء مکانی ساخته شده است. سپس، ساختار عقب نشینی هر خط مرزی به ترتیب با تنظیم پارامتر اولیه ایجاد می شود. اگر ساختار جمع شونده با خطوط مرزی تقاطع پیدا کند، اشیاء به دو خوشه تقسیم می شوند (یعنی «خوشه های فرعی»). در نهایت، خوشه ها به طور مکرر تقسیم می شوند و پارامتر اولیه تا زمانی که شرط پایان برآورده شود، به روز می شود. نتایج تجربی نشان میدهد که CDHC اجسام چند چگالی را به اندازه کافی از نویز جدا میکند و همچنین پیچیدگی را در مقایسه با الگوریتم خوشهبندی سلسله مراتبی تجمعی سنتی کاهش میدهد. خوشه ها به طور مکرر تقسیم می شوند و پارامتر اولیه تا زمانی که شرط پایان برآورده شود به روز می شود. نتایج تجربی نشان میدهد که CDHC اجسام چند چگالی را به اندازه کافی از نویز جدا میکند و همچنین پیچیدگی را در مقایسه با الگوریتم خوشهبندی سلسله مراتبی تجمعی سنتی کاهش میدهد. خوشه ها به طور مکرر تقسیم می شوند و پارامتر اولیه تا زمانی که شرط پایان برآورده شود به روز می شود. نتایج تجربی نشان میدهد که CDHC اجسام چند چگالی را به اندازه کافی از نویز جدا میکند و همچنین پیچیدگی را در مقایسه با الگوریتم خوشهبندی سلسله مراتبی تجمعی سنتی کاهش میدهد.
کلید واژه ها:
خوشه بندی فضایی ; انقباض بدنه محدب ; خوشه نقطه چند چگالی ; CDHC
1. معرفی
تجزیه و تحلیل خوشه بندی وظیفه گروه بندی مجموعه ای از اشیاء است به گونه ای که اشیاء موجود در یک گروه (که خوشه نامیده می شود) بیشتر به یکدیگر شباهت داشته باشند تا در گروه های دیگر (خوشه). خوشه بندی اشیاء مکانی کاربردهای گسترده ای در زمینه تقسیم بندی تصویر، تشخیص الگو و تعمیم نقشه برداری پیدا کرده است [ 1 ، 2 ، 3 ، 4 ، 5 ]. یکی از کاربردهای اصلی خوشه بندی در سنجش از دور فراطیفی کاهش ابعاد است [ 6 ، 7 ، 8 ]. تجزیه و تحلیل خوشه بندی را می توان در تعمیم و بردار سازی نقشه استفاده کرد [ 9 ، 10] و برخی از الگوریتمهای خوشهبندی جدید برای تقسیمبندی نویز و سیگنالها در سناریوهای متغیر زمانی اعمال میشوند [ 11 ]. با این حال، در واقعیت، تجزیه و تحلیل خوشهبندی یک الگوریتم خاص نیست، بلکه وظیفهای است که باید حل شود، که میتوان با الگوریتمهای مختلفی که در تعاریف اجزای خوشهای و کارایی در یافتن آنها تفاوت قابلتوجهی دارند، به دست آمد [12 ] . مفهوم رایج خوشهبندی در اطلاعات جغرافیایی، طبقهبندی اشیاء مکانی با فواصل کم بین خوشهها است که به آن خوشهبندی فضایی میگویند.
به طور کلی، خوشه بندی فضایی اشیاء را بر اساس ویژگی های توپولوژیکی، هندسی یا جغرافیایی طبقه بندی می کند. چهار نوع روش سنتی خوشه بندی فضایی وجود دارد: روش خوشه بندی سلسله مراتبی، روش خوشه بندی پارتیشن بندی، روش خوشه بندی چگالی شبکه و روش خوشه بندی بر اساس اطلاعات ترجیحی [ 13 ]. انتخاب یک روش خوشه بندی مناسب به مجموعه داده های فردی و استفاده مورد نظر از نتایج بستگی دارد. ژو [ 14 ] یک استراتژی هرس N-بهترین را برای به حداقل رساندن فضای جستجو در جریان کاری روش خوشهبندی سلسله مراتبی پیشنهاد کرد. گلبارد [ 15 ] از روش باینری مثبت برای ترکیب اطلاعات ویژگی در ساختار سلسله مراتبی استفاده کرد. علاوه بر این، چن [ 16] آشکارسازی اطلاعات مکانی نهفته را با استفاده از خوشه بندی فضایی نقاط در جهت پیشنهاد کرد. بسیاری از روش های ذکر شده در بالا، فرآیندهای خودکار نیستند. در عوض، آنها توسط دانش قبلی کاربران محدود شده و نسبتاً نسبت به نویز حساس هستند. در نتیجه، توجه کمی به شناسایی اجسام زمین فضایی با چگالی چندگانه و نویز می شود.
رویکرد خوشه بندی چند چگالی به طور گسترده در تحقیقات داده کاوی فضایی مورد بحث قرار گرفته است. الگوریتم سنتی خوشهبندی فضایی برنامههای کاربردی با نویز (DBSCAN) برای خوشهبندی دادههای چند چگالی، مانند کشف دانش و خوشهبندی داده (KDDClus) و یک خوشهبندی افزایشی بر اساس تخمین Eps خودکار، بهبود یافت [17 ، 1 ] . تفاوت بین اجسام چند چگالی و نویز عمدتاً در زمینه فضایی تجسم یافته است. طلا [ 19] بافت فضایی را به عنوان “وسعت” یک موجودیت، شامل اشیاء، شبکه ها و سطوح مجزا تعریف کرد، در حالی که وسعت معمولاً به مجاورت متریک بین اشیاء مجاور در فضای مدل اشاره دارد. در این مقاله، بافت فضایی را می توان تنها به عنوان بافت فضایی محلی تفسیر کرد. برای تمایز اجسام چند چگالی از نویز، لازم است از بافت فضایی جهانی اشیاء جغرافیایی استفاده شود. روش خوشهبندی سلسله مراتبی فرآیندی است برای تجمیع یا تقسیم با ایجاد یک سلسله مراتب [ 20]]. به طور کلی، استراتژی های خوشه بندی سلسله مراتبی به دو دسته تقسیم می شوند: خوشه بندی سلسله مراتبی تجمعی (AHC) و خوشه بندی سلسله مراتبی تقسیمی (DHC). DHC یک رویکرد “بالا به پایین” است، یعنی تمام اشیاء مکانی در یک خوشه شروع می شوند و توسط سلسله مراتب به دو زیر خوشه تقسیم می شوند. اشیاء جغرافیایی قبل از تقسیم خوشه به صورت کلی دیده می شوند. استراتژی خوشه بندی بسیار نزدیک به زمینه فضایی جهانی اشیاء مکانی است.
در این مقاله، یک الگوریتم خوشهبندی بدون نظارت برای مدیریت اشیاء مکانی پیشنهاد شده است که ویژگیهای زمینه جهانی را در نظر میگیرد، کمتر به دانش قبلی وابسته است و از مزیت بزرگی در شناسایی اشیاء با چگالی چندگانه و نویز برخوردار است.
عمده ترین کمک های این مقاله عبارتند از:
(1) معرفی زمینه فضایی جهانی اشیاء جغرافیایی برای تمایز بین نقاط نویز و نقاط چند چگالی.
(2) یک الگوریتم خوشهبندی سلسله مراتبی جدید برای مدیریت اشیاء گسسته با چگالی چندگانه، طراحی ساختار پسکشی مرزی برای پیادهسازی کل تقسیمشده به دو خوشه فرعی پیشنهاد شده است.
(3) مقایسه ای بین الگوریتم خوشه بندی سلسله مراتبی انبوه سنتی و الگوریتم خوشه بندی سلسله مراتبی تقسیم در این مقاله ارائه شده است.
در بخش 2 ، نمودار جریان الگوریتم خوشه بندی جدید را شرح خواهیم داد. پس از آن، مرحله کلیدی الگوریتم، پسکشی مرز، توضیح داده میشود که برای یافتن مرز خوشههای مختلف استفاده میشود. سپس، پردازش تقسیم نقاط گسسته ارائه می شود و خوشه بندی اشیاء گسسته چند چگالی بر اساس دانش کمتر قبلی حاصل می شود. بخش 3 مجموعهای از آزمایشها را شرح میدهد، از جمله مقایسه با الگوریتمهای خوشهبندی، خوشهبندی اشیاء چند چگالی و تحلیل فضایی در حلقه تجاری ووهان. موضوع هر آزمایش متفاوت است. بخش 4 مقاله را با خلاصه و چشم انداز به پایان می رساند.
2. روش ها
Wu [ 21 ] یک روش ساختاری جهانی برای تقریب ویژگی های تجمع خوشه نقطه با استفاده از ساختار سلسله مراتبی بدنه محدب پیشنهاد کرد. ساختار جهانی نقاط جغرافیایی با نادیده گرفتن تفاوت های فردی با هدف آشکار کردن ویژگی های نقاط است. در این بخش ابتدا ایده طراحی و اصل الگوریتم خوشه بندی را در بخش 2.1 معرفی می کنیم . سپس ما یک روش خوشهبندی سلسله مراتبی را بر اساس تحلیل ساختار کلی با ایجاد ساختار پسکشی مرزی در بخش 2.2 پیشنهاد میکنیم و خوشهبندی تقسیمبندی اجسام جغرافیایی با چگالی چندگانه را در بخش 2.3 پیادهسازی میکنیم .
2.1. مفهوم و اصل طراحی
در مقایسه با الگوریتمهای AHC، الگوریتمهای DHC از بالا با همه اشیا در یک خوشه شروع میشوند. این خوشه بر اساس تجزیه و تحلیل ساختار جهانی اشیاء جغرافیایی تقسیم شده است. در فرآیند خوشه بندی اشیاء مکانی، از بدنه محدب برای توصیف ساختار جهانی با در نظر گرفتن اجسام به عنوان یک “ارگانیسم” استفاده می شود. با توجه به اینکه ویژگیهای تمایز فضایی «ارگانیسم» عمدتاً بین خوشههای متصل مجاور تجسم مییابد، استراتژیهای زیر به منظور کشف تفاوتهای اساسی خوشههای فضایی و تقسیم «ارگانیسم» با شرایط انتهایی مناسب اتخاذ میشوند. در ابتدا ساختار جمع شونده اجسام جغرافیایی بر اساس خط مرزی بدنه محدب ساخته می شود. سپس، مشابه فرآیند تقسیم سلولی،
2.2. عقب نشینی مرز
ژو [ 22 ] میانگین فاصله اجسام جغرافیایی را به عنوان محدودیت برای عقب نشینی مرز بدنه محدب در نظر گرفت. با این حال، ساختن یک ساختار جمع شونده از اجسام چند چگالی با استفاده از پارامترهای ثابت دشوار است. در این مقاله، روش انقباض بدنه محدب مبتنی بر سهمی پیشنهاد شده است، که یک روش تطبیقی برای به دست آوردن مرز خوشهای برای اجسام جغرافیایی چند چگالی است.
لی [ 23 ] از یک قوس به عنوان مرز برای ایجاد یک ناحیه انقباض استفاده کرد. مفهوم دقت عقب نشینی (RA) برای محدود کردن دقت مرز خوشه بندی معرفی شده است. بنابراین، دقت جمع شدن یک مجموعه نقطه گسسته P به صورت زیر به دست می آید:
- (آ)
-
بدنه محدب Pc خوشه نقطه گسسته P ساخته شده است .
- (ب)
-
یک قوس با رادیان α به سمت داخل بدنه محدب از طریق دو نقطه متوالی Pm و Pn در بدنه محدب Pc کشیده شده است ( شکل 1 ) .
- (ج)
-
دقت جمع شدن α از قوس و خط ساخته شده است پمترپn¯¯¯¯¯¯¯¯پمترپ�¯و عمق جمع شدن h است .
با توجه به روش جمع شده با قوس محدود، در هنگام تشخیص مرز گسسته، دامنه دقت جمع شدن در [0، π] و عمق جمع شدن برابر است. h ≤|پمترپn|2ساعت≤|پمترپ�|2. عمق جمع شدن با طول خطوط مرزی کاهش می یابد. بنابراین، با استفاده از روش جمع شده با قوس محدود، تلاقی خطوط مرزی دشوار است.
در این مطالعه، ما محدوده دقت جمع شدن را در [0، 2π] اصلاح کردیم. در همان زمان، ما روش مبتنی بر قوس را با روش جدید پسکشی بدنه محدب مبتنی بر سهمی مقایسه کردیم.
محاسبه دقت جمع شدن در روش انقباض بدنه محدب مبتنی بر سهمی مشابه روش انقباض بدنه محدب مبتنی بر قوس است. روند کار به صورت زیر است:
- (آ)
-
بدنه محدب Pc خوشه نقطه گسسته P را بسازید .
- (ب)
-
یک سهمی را به سمت داخل بدنه محدب از طریق دو نقطه متوالی P m و Pn در بدنه محدب Pc بکشید ( شکل 2 ). نقطه میانی از پمترپn¯¯¯¯¯¯¯¯پمترپ�¯مبدأ سهمی است و تابع سهمی با معادله (1) مطابقت دارد.2 ( h – y) = γ⋅ایکس2( | x | ≤|پمترپn|2)2(ساعت–�)=�⋅ایکس2(|ایکس|≤|پمترپ�|2)
- (ج)
-
دقت جمع شدن را از مرز جمع شده بدست آورید پمترپn¯¯¯¯¯¯¯¯پمترپ�¯و سهمی پمترپnپمترپ�، ارزش آن است γ�، و عمق جمع شده h است .
حتی با دقت جمع شدن یکسان برای مرز، ناحیه جمع شدن متفاوت خواهد بود زیرا عمق جمع شدن مرز متفاوت است. بنابراین، میتوانیم ناحیه جمع شدن را با توجه به تراکم اجسام در اطراف مرز هنگام مدیریت اشیاء جغرافیایی گسسته چند چگالی تنظیم کنیم.
شکل 3 ساختار انقباض قوس و سهمی را در شرایط محدود کننده مختلف نشان می دهد. با توجه به مقایسه می توان نتیجه زیر را گرفت. با همان عمق جمع شدن، ناحیه انقباض بر اساس ساختار انقباض قوس بزرگتر از آن بر اساس ساختار جمع شدن سهمی است. 10 نقطه وجود دارد که باید بر اساس ساختار انقباض قوس در ناحیه انقباض مورد بازرسی قرار گیرند، اما تنها چهار نقطه بر اساس ساختار عقب نشینی سهمی باید بازرسی شود. بنابراین، ساختار انقباض سهمی جدید کارایی تشخیص بالاتری نسبت به ساختار پسکشی قوس دارد. علاوه بر این، نقطه انتخاب شده برای پس کشیدن خط مرزی خوشه با استفاده از این دو روش متفاوت است. در شکل 3نقطه انتخاب شده با استفاده از ساختار انقباض قوس به سمت راست اطراف خط مرزی خیلی نزدیک است و مرز جمع شده پیچش بزرگی را تشکیل می دهد. در مقایسه با ساختار انقباض قوس، نقطه انتخاب شده برای جمع کردن مرز در ناحیه سهمی معقول تر است.
علل این تفاوت را می توان به صورت زیر خلاصه کرد. زاویه خط مرزی و مماس نقاط در سهمی کوچکتر از 90 درجه است و ساختار انقباض قوس در فضای جغرافیایی واگراتر است. در نتیجه، از ساختار عقب نشینی سهمی برای تشکیل ناحیه انقباض و اجرای روش خوشه بندی استفاده می شود.
2.3. پردازش خوشه ای
پس از ساخت بدنه محدب نقاط جغرافیایی و تعیین مقدار دقت جمع شدن γ�، برای هر خط مرزی بدنه محدب ناحیه انقباض سهمی را تعیین می کنیم. برای طول خط مرزی طولانی تر، تقسیم خوشه بین نقاط جغرافیایی خط مرزی آسان تر است. می توان به طور مداوم بخش های خط را که در آن دو زیر خوشه مختلف به یکدیگر متصل می شوند، جمع کرد. عقب نشینی مرزی تا زمانی که خوشه تقسیم نشود متوقف نخواهد شد. در شکل 4 ، نمودار جریان الگوریتم خوشه بندی سلسله مراتبی تقسیمی را بر اساس عقب نشینی بدنه محدب نشان می دهد.
در زیر مراحل کامل الگوریتم آمده است:
مرحله 1 : ساخت حداقل بدنه محدب نقاط جغرافیایی.
مرحله 2 : ساختار عقب نشینی مرزی را به ترتیب با عبور از نقاط جغرافیایی که از طولانی ترین خط مرزی در بدنه محدب شروع می شود، بسازید.
مرحله 3 : مقدار پارامتر اولیه α را تعیین کنید.
ارزش دقت عقب نشینی γ�با توجه به تراکم نقطه نزدیک خطوط مرزی بدنه محدب تعیین می شود. روش تخمین چگالی نقطه به صورت معادله (2) نشان داده شده است:
ρ¯=اسن–––√،�¯=اسن،
جایی که ρ¯�¯چگالی نقطه تخمین زده شده در بدنه محدب، S مساحت بدنه محدب، و N تعداد نقاط داخل بدنه محدب است. محاسبه دقت جمع شدن مرز به صورت معادله (3) نشان داده شده است:
γ=αρ¯�=��¯
پس از تنظیم مقدار اولیه پارامتر α�، در الگوریتم خوشه بندی اعمال خواهد شد. هر بار که یک زیر خوشه جدید به دست می آید، ناحیه بدنه محدب و کمیت اجرام جغرافیایی در زیر خوشه تغییر می کند. فرآیند خوشهبندی توزیع شی را در فضای جغرافیایی یکسان میکند و دقت عقبنشینی را تضمین میکند. γ�با تغییر همگرا می شود ρ¯�¯. بهترین نتایج خوشه بندی زمانی ظاهر می شود که مقدار اولیه پارامتر α بر اساس تعداد زیادی آزمایش بین [ 1 ، 2 ] قرار گیرد.
مرحله 4 : جمع کردن خطوط مرزی
دو هدف برای ساختن ساختار جمع شونده سهمی وجود دارد. یکی محدود کردن منطقه جستجو برای بهبود کارایی، و دیگری تعریف آن به عنوان یک شرط خاتمه خوشه بندی تقسیم شده است. ساختار عقب نشینی را به ترتیب با توجه به طول خطوط مرزی بدنه محدب می سازیم. این روش در شکل 5 نشان داده شده است . ابتدا، ساختار جمعشده طولانیترین خط مرزی بدنه محدب را میسازیم. دوم، همه نقاط را در داخل ناحیه جمع شونده پیدا می کنیم و نقطه ای را که نزدیکترین نقطه به مرز است را به عنوان نقطه جمع می کنیم. اگر اشیاء در منطقه خالی باشند، خط مرزی به عنوان “0” مشخص می شود. شکل 5روند کامل جمع شدن مرزی و تقسیم خوشه را نشان می دهد. اگر نزدیکترین نقطه در داخل ناحیه جمع شونده به نقطه مرزی تعلق داشته باشد، همانطور که در شکل 5 ج نشان داده شده است، خوشه به دو خوشه فرعی تقسیم می شود. شکل 5 d نتیجه تقسیم را نشان می دهد. ما میتوانیم متوجه شویم که دو زیر خوشه پس از تقسیم یک نقطه مشترک دارند. میتوانیم بر اساس فاصله نقطه تا نزدیکترین نقطه آن، تعیین کنیم که نقطه مشترک به کدام زیر خوشه تعلق دارد.
مرحله 5 : پارتیشن های زیر خوشه ای
خوشه فرعی حاصل از تقسیم امتیاز را می توان به عنوان یک خوشه مستقل در نظر گرفت. سپس مراحل 2 تا 4 را تکرار می کنیم تا تمام خطوط مرزی زیر خوشه ها به صورت “0” مشخص شوند. اگر در یک خوشه بیش از سه نقطه وجود نداشته باشد و قادر به ساخت بدنه محدب نباشد، نقاط به عنوان نویز در نظر گرفته می شوند.
فرآیند خوشهبندی فوق مشابه فرآیند تقسیم سلولی در زیستشناسی است. بنابراین، ما الگوریتم خوشه بندی را تقسیم سلولی سلسله مراتبی (به اختصار CDHC) نام گذاری می کنیم.
3. آزمایش ها و نتایج
مجموعهای از آزمایشها برای اعتبارسنجی کارایی الگوریتم CDHC در مقایسه با الگوریتم سنتی AHC و الگوریتم خوشهبندی مثلثی Delaunay انجام میشود. ما همچنین برتری الگوریتم CDHC را در برخورد با اجسام چند چگالی تأیید میکنیم.
3.1. آزمایش 1-مقایسه الگوریتم های خوشه بندی
این آزمایش برای آزمایش اثربخشی از طریق مقایسه نتایج محاسبات مختلف طراحی شده است. مجموعه ای از نقاط با نویز لبه، همانطور که در شکل 6 الف نشان داده شده است، به عنوان داده های تجربی انتخاب می شوند. واضح است که دو خوشه نقطه وجود دارد که توسط نقاط پر سر و صدا احاطه شده است. الگوریتم CDHC برای خوشه بندی داده های تجربی با پارامتر اولیه α = 1.45 استفاده می شود و نتیجه خوشه بندی در شکل 6 ب نشان داده شده است.
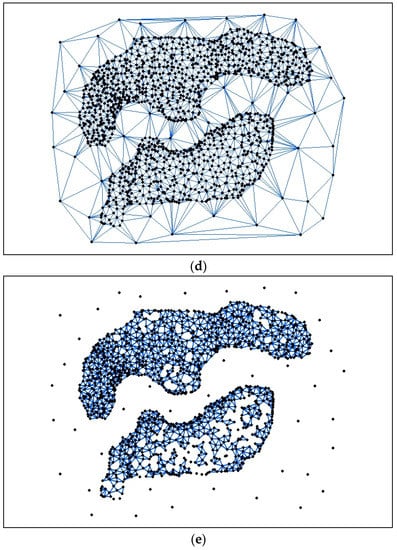
الگوریتم سنتی AHC هر شی را به عنوان یک کلاس مستقل می گیرد. برای یک مجموعه معین از N شیء ( N = 0، 1، 2، …، n )، N کلاس وجود دارد و هر کلاس شامل یک شی در ابتدا است. بنابراین می توان یک ماتریس فاصله N × N بدست آورد. فاصله بین دو کلاس به عنوان فاصله بین اشیاء در دو کلاس محاسبه می شود. نزدیکترین دو کلاس با هم ادغام می شوند و فاصله بین کلاس جدید و کلاس های اصلی دوباره محاسبه می شود. باقیمانده به همین ترتیب انجام می شود تا زمانی که تمام کلاس ها در یک کلاس ادغام شوند یا فاصله بین دو کلاس به یک آستانه معین برسد. شکل 6c نتیجه خوشه بندی را با استفاده از الگوریتم سنتی AHC با 5.0 به عنوان آستانه نشان می دهد.
لی [ 24 ] الگوریتم خوشه بندی را بر اساس مثلث سازی دلونی (CBDT) پیشنهاد کرد. خوشه بندی داده های تجربی با استفاده از الگوریتم CBDT در سه مرحله انجام می شود. ابتدا مثلث دلونی برای مجموعه نقطه ساخته می شود. دوم، همه مثلث ها بر اساس نسبت مساحت مثلث به طول ضلع به سه دسته تقسیم می شوند، یعنی مثلث های کوچک، مثلث های بلند- باریک و مثلث های بزرگ. در نهایت، نتیجه خوشهبندی با حذف مثلثهای بلند-باریک و مثلثهای بزرگ ایجاد میشود. شکل 6 d، مثلث بندی دلونی داده های تجربی را نشان می دهد. شکل 6 e نتیجه خوشه بندی را با استفاده از الگوریتم CBDT با K = 2.5 ( K نشان می دهد.نسبت طولانی ترین ضلع به کوتاه ترین ضلع مثلث است).
از طریق مقایسه نتایج خوشه بندی با استفاده از الگوریتم CDHC، الگوریتم CBDT و الگوریتم سنتی AHC، می توان استنباط کرد که الگوریتم CDHC می تواند تجزیه و تحلیل خوشه بندی داده های مکانی را به خوبی انجام دهد و قادر به مقاومت در برابر نویز است.
برای محاسبه یک ماتریس فاصله N × N ، پیچیدگی زمانی با استفاده از الگوریتم AHC O ( n2 ) و پیچیدگی زمانی با استفاده از الگوریتم CDHC O ( Kn ) است، که در آن K تعداد خوشهها و K < n است . یک رایانه شخصی با سیستم عامل ویندوز 32 بیتی، پردازنده 2.6 گیگاهرتز و رم فیزیکی 1G به عنوان پلتفرم آزمایشی عمل می کند. نتیجه مقایسه ای پیچیدگی زمانی بین الگوریتم های CDHC و AHC در جدول 1 نشان داده شده است .
طبق جدول 1 ، الگوریتم CDHC نسبت به الگوریتم سنتی AHC در برخورد با تعداد زیادی از نقاط جغرافیایی برتری دارد. با این حال، نقاط نویز به عنوان یک خوشه زمانی که الگوریتم CDHC اتخاذ می شود، پردازش می شوند. بنابراین، کارایی الگوریتم CDHC به دلیل نقاط نویز کاهش می یابد.
خوشهبندی فضایی با استفاده از الگوریتم CBDT بر اساس شناسایی شکل مثلث پس از مثلثسازی Delaunay است. نتیجه خوشه بندی به نقاط نویز بین دو زیر خوشه حساس است. علاوه بر این، K نامناسب منجر به ترکیب دو زیر خوشه یا جداسازی یک زیر خوشه می شود. برای جلوگیری از ادغام دو خوشه فرعی، یک K کوچک در شکل 6 e استفاده شده است. به نظر می رسد که برخی از نقاط در همان زیر خوشه به عنوان نویز طبقه بندی می شوند.
3.2. آزمایش 2- خوشه بندی اجسام چند چگالی
هدف از این آزمایش برجسته کردن مزایای الگوریتم CDHC پیشنهادی است. اولین مجموعه دادهها، نقاط چند چگالی بدون نویز، با استفاده از الگوریتم CDHC خوشهبندی میشوند و دو مجموعه داده اضافی با نویز با استفاده از روشهای مختلف خوشهبندی به روش زیر پردازش میشوند.
ما اجسام چند چگالی با نویز را با استفاده از الگوریتم CDHC در آزمایش 2 مدیریت میکنیم. اولین دادههای تجربی، اشیاء با چگالی چندگانه بدون نویز هستند، همانطور که در شکل 7 الف نشان داده شده است، و سه مجموعه نقطه جغرافیایی با چگالی متفاوت وجود دارد. الگوریتم CDHC برای پردازش نقاط چند چگالی با پارامتر اولیه α = 1.75 استفاده می شود. نتیجه خوشه بندی در شکل 7 ب نشان داده شده است.
همانطور که نشان داده شده است، الگوریتم CDHC اجسام چند چگالی را به خوبی شناسایی می کند. برای روشن شدن بیشتر این نکته، دو آزمایش دیگر با استفاده از الگوریتم CDHC انجام شد، در حالی که الگوریتم CBDT، الگوریتم DBSCAN و الگوریتم خوشهبندی رایج دیگر، K-means، به عنوان مقایسه در نظر گرفته شد. برای اجسام با چگالی چندگانه و نویز، این الگوریتمها ویژگیهای زیادی دارند. بنابراین، این دو آزمایش برای آزمایش جداسازی کافی اجسام چند چگالی از نویز هستند. در یکی از داده های آزمایشی دو خوشه با نویز فراوان در شکل 8 الف وجود دارد و داده های تجربی دیگر اجسام چند چگالی با کمی نویز هستند، همانطور که در شکل 9 نشان داده شده است.آ. تجزیه و تحلیل خوشه ای با استفاده از الگوریتم های CDHC، CBDT، DBSCAN و K-means بر روی داده های تجربی اعمال شده است.
از طریق مقایسه نتایج خوشهبندی، الگوریتمهای CDHC، CBDT و DBSCAN میتوانند در مقابل نویز مقاومت کنند در حالی که دادههای تجربی عمومی را علیرغم نویز مدیریت میکنند. این سه روش دارای مزیت توانایی ضد نویز خوب با نرخ تشخیص 95% در شکل 8 b-d هستند. با این حال، روش سنتی خوشهبندی، الگوریتم K-means، توانایی شناسایی دادهها و نویز مؤثر را ندارد، همانطور که در شکل 8 e نشان داده شده است. سپس این سه الگوریتم بر روی اجسام چند چگالی با کمی نویز اعمال می شود. نتایج نشان می دهد که سه خوشه با اجسام با چگالی متفاوت را می توان از روی نویز در شکل 9 شناسایی کرد.ب الگوریتم CDHC از متغیر دقت جمع شدن استفاده می کند و از مزیت قوی در برخورد با نقاط جغرافیایی چند چگالی برخوردار است. با این حال، به کارگیری الگوریتم CBDT برای خوشهبندی نقاط چند چگالی بر اساس شکل مثلث در شکل 9 ج دشوار است و نرخ تشخیص تا 70 درصد کاهش مییابد، به این دلیل که این روش در شناسایی داخلی به خوبی عمل میکند. ساختار خوشه ها از طریق تقسیم مثلثی و نادیده گرفتن بافت فضایی جهانی اشیاء مکانی. در مقایسه با نتیجه خوشه بندی با استفاده از الگوریتم CDHC، متوجه شدیم که یک نقطه نویز در دایره چین به درستی با استفاده از الگوریتم DBSCAN در شکل 9 شناسایی نشده است.د DBSCAN میتواند خوشههای غیرخطی قابل تفکیک و حتی اشکال پیچیدهتر را پیدا کند، اما نمیتواند مجموعههای داده را با تفاوتهای زیاد در چگالی به خوبی خوشهبندی کند. اگر فاصله بین نقاط خوشه سمت راست بزرگ شود، نتایج رضایت بخشی مانند نتیجه خوشه بندی بالا به دست نمی آید. الگوریتم K-means یک روش خوشه بندی عمومی برای یافتن مراکز خوشه ای است که واریانس درون کلاسی را به حداقل می رساند. اگرچه مراکز خوشه را می توان به طور دقیق شناسایی کرد، اما اجرام زمین فضایی با چگالی چندگانه چالش برانگیز هستند و به خوشه اشتباه تقسیم می شوند. همانطور که در شکل 9 e نشان داده شده است، نتیجه خوشه بندی با هدف مورد انتظار فاصله زیادی دارد.
3.3. آزمایش 3 – کاربرد الگوریتم CDHC برای تجزیه و تحلیل فضایی
این آزمایش با هدف انجام تحلیل فضایی تراکم خرده فروشی در محافل تجاری در ووهان چین با استفاده از الگوریتم CDHC انجام شده است. کارکرد اصلی یک حلقه تجاری متقاعد کردن مشتریان برای خرید است. جهت گیری دایره تجاری هر چه باشد، صنعت خدمات غذایی به طور کلی می تواند نشان دهنده رونق تجاری در شهرها و شهرهای چین باشد. از این رو، رستورانهای منطقه مرکزی ووهان به عنوان دادههای تجربی انتخاب شدهاند (همانطور که در شکل 10 نشان داده شده است)، که به پنج نوع تقسیم میشوند: رستوران چینی، رستوران غربی، رستوران داغ، فست فود و سوپرمارکت. توزیع فضایی این رستوران ها نشان دهنده طیف گسترده ای از فعالیت های مصرفی است.
ووهان که در تقاطع بخش میانی رودخانه یانگ تسه و رودخانه هان قرار دارد، به سه ناحیه یعنی ووچانگ، هانکو و هانیانگ تقسیم میشود و پر از دریاچههای زیادی در ناحیه مرکزی است. می توان مشاهده کرد که بسیاری از رستوران ها بر اساس شرایط توپوگرافی طبیعی و سیستم های آبی تقسیم یا جمع شده اند. در ابتدا، تحلیل خوشهبندی فضایی پنج نوع رستوران با استفاده از الگوریتم CDHC انجام میشود. سپس، نتیجه خوشه بندی مشمول تجزیه و تحلیل همپوشانی می شود، که منجر به یک نقشه موضوعی می شود که در شکل 11 الف نشان داده شده است.
در نقشه، 0 تا 5 به ترتیب نشان دهنده تعداد لایه های پوشش داده شده است. به عنوان مثال، مناطقی که تعداد لایه های پوشاننده 5 است در تصویر ماهواره ای ووهان در شکل 11 نشان داده شده است.ب با مراجعه به نقشه، دو منطقه اصلی وجود دارد: منطقه سمت چپ (I) در نزدیکی رودخانه یانگ تسه و رودخانه هان در هانکو و سمت راست (II) در مرکز ووچانگ قرار دارد. نتایج با برنامه ریزی و توسعه حلقه های تجاری مقایسه شده است. متوجه شدیم که حلقههای تجاری WuGuang و Jianghan Road در منطقه I قرار دارند و منطقه II شامل حلقههای تجاری Xudong، Zhongnan و Jiedaokou است. این دو منطقه در مناطق توسعه یافته اقتصادی در ووهان قرار دارند و نتایج این آزمایش به خوبی با وضعیت توسعه تجاری فعلی در ووهان مطابقت دارد.
4. بحث و نتیجه گیری
الگوریتمهای خوشهبندی فضایی برای گروهبندی مجموعهای از اشیاء به گونهای توسعه داده میشوند که اشیاء مجزا در همان گروه، که نزدیک به یکدیگر هستند، از آنهایی که در گروههای دیگر هستند، جدا باشند. با این حال، شباهت ساختار فضایی بین اجسام چند چگالی و داده های نویز وجود دارد. بنابراین، تمایز بین این دو در زمینه فضایی محلی دشوارتر می شود. پرداختن به اشیاء گسسته چند چگالی بر اساس ساختار فضایی جهانی ضروری است. در این مقاله، یک ساختار بدنه محدب اصلاح شده برای توصیف زمینه فضایی جهانی اشیاء گسسته ارائه شده است. یک پسکشی مرزی برای استخراج ناهمگونی طبقهبندیشده فضایی بین خوشهها در روش خوشهبندی ما استفاده میشود. سپس، ساختار مرزی هر زیر خوشه، زمینه فضایی جهانی زیرمجموعه جدید را توصیف می کند.
کارایی الگوریتمی از دیرباز یکی از موضوعاتی است که در تجزیه و تحلیل خوشهبندی هنگام برخورد با حجم زیادی از دادهها مطرح میشود. بسیاری از الگوریتم های خوشه بندی در پردازش مقدار کمی داده به خوبی کار می کنند، اما عملکرد الگوریتم با افزایش حجم داده بدتر می شود. پس از مقایسه با دو الگوریتم خوشهبندی سلسله مراتبی در آزمایش 1، متوجه میشویم که الگوریتم CDHC مزایایی در برخورد با مقدار زیادی از اشیاء فضایی دارد. الگوریتم CDHC یک خوشه بندی سلسله مراتبی تقسیمی است که از رویکرد “بالا به پایین” استفاده می کند: همه اشیاء فضایی در یک خوشه شروع می شوند و توسط سلسله مراتب به دو زیر خوشه تقسیم می شوند. این از محاسبه موقعیت هر شی در هر تکرار جلوگیری می کند، بنابراین الگوریتم CDHC می تواند به طور قابل توجهی کارایی تجزیه و تحلیل خوشه بندی را بهبود بخشد.
این مقاله یک الگوریتم خوشهبندی فضایی جدید را پیشنهاد میکند: خوشهبندی سلسله مراتبی تقسیم سلولی (CDHC)، که نقاط جغرافیایی با چگالی چندگانه را مدیریت میکند. الگوریتم CDHC می تواند زمینه فضایی جهانی نقاط جغرافیایی را با ایجاد حداقل ساختار بدنه محدب توصیف کند. پس از اینکه یک خوشه به دلیل عقب نشینی مرز به دو خوشه فرعی تقسیم شد، هر زیر خوشه دوباره به همان روش تقسیم می شود. بنابراین می توان دریافت که نقاط جغرافیایی را می توان بر اساس ساختار جهانی در همه زمان ها طبقه بندی کرد. سپس، الگوریتم از یک روش جمع شده با محدود سهموی برای تقسیم نقاط، و دستیابی به الزامات خوشهبندی سلسله مراتبی استفاده میکند.
نتایج تجربی نشان می دهد که نقاط نویز و مجموعه نقاط چند چگالی به خوبی با استفاده از الگوریتم CDHC شناسایی می شوند. علاوه بر این، الگوریتم CDHC میتواند نظم تمایز داخلی یک خوشه اشیاء جغرافیایی را با استفاده از یک استراتژی پارامتر متغیر با توجه به ویژگیهای خوشههای فضایی استخراج کند. الگوریتم CDHC از عدم قطعیت ناشی از پارامترهای قطعی و همچنین پیچیدگی محاسباتی بالا مورد نیاز الگوریتمهای خوشهبندی سلسله مراتبی سنتی جلوگیری میکند. اگرچه الگوریتم CDHC توانایی شناسایی نقاط در مرزها را دارد، اما قادر به آدرس دهی خوشه های موجود در یک خوشه دیگر نیست. روشهای بهبود یافته DBSCAN قادر به مقابله با این چالش هستند، اگرچه هنوز مشکلات و محدودیتهایی وجود دارد. کار آینده تحقیقات در این زمینه را ادامه خواهد داد،
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| RA |
دقت عقب نشینی
|
| AHC |
خوشه بندی سلسله مراتبی تجمعی
|
| DHC |
خوشه بندی سلسله مراتبی
|
| CDHC |
خوشه بندی سلسله مراتبی تقسیم سلولی
|
| CBDT |
الگوریتم خوشه بندی بر اساس مثلث سازی دلونی
|
| DBSCAN |
خوشه بندی فضایی مبتنی بر چگالی برنامه های کاربردی با نویز
|
منابع
- کریس، سی. گروتزر، ام. هنگارتنر، اچ. دانیل، SB خوشه بندی فضا-زمان سرطان های دوران کودکی در سوئیس: یک مطالعه سراسری. بین المللی J. Cancer 2016 ، 138 ، 2127-2135. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- غفاریان، س. Ghaffarian, S. C-means فازی مبتنی بر هیستوگرام خودکار برای تصاویر سنجش از دور. ISPRS J. Photogramm. Remote Sens. 2014 ، 97 ، 46-57. [ Google Scholar ] [ CrossRef ]
- ژنگ، ن. ژانگ، اچ. فن، جی. Guan، H. یک الگوریتم مبتنی بر جاذبه محله محلی فازی c-means الگوریتم خوشهبندی برای طبقهبندی تصاویر با وضوح فضایی بسیار بالا. سنسور از راه دور Lett. 2014 ، 5 ، 843-852. [ Google Scholar ] [ CrossRef ]
- آی، تی. استخراج الگوی خوشه ای چندضلعی Guo، R. بر اساس اصول گشتالت. Acta Geod. کارتوگر. گناه 2007 ، 36 ، 302-308. [ Google Scholar ]
- Mao, Z. مطالعه استخراج اطلاعات ساختار یک الگوی نقطه فضایی خوشه ای. Acta Geod. کارتوگر. گناه 2007 ، 36 ، 181-186. [ Google Scholar ]
- جیا، اس. تانگ، جی. ژو، جی. لی، کیو. رویکرد خوشهبندی جدید مبتنی بر رتبهبندی برای انتخاب باند ابرطیفی. IEEE Trans. Geosci. Remote Sens. 2016 ، 54 ، 88-102. [ Google Scholar ] [ CrossRef ]
- سان، ایکس. یانگ، ال. گائو، ال. ژانگ، بی. لی، اس. Li, J. روش خوشهبندی تصویر فراطیفی بر اساس الگوریتم کلونی زنبورهای مصنوعی و میدانهای تصادفی مارکوف. J. Appl. Remote Sens. 2015 ، 9 ، 1-19. [ Google Scholar ] [ CrossRef ]
- ما، ا. ژونگ، ی. Zhang، L. خوشه بندی طیفی- فضایی با روش تعیین پارامتر وزن محلی برای تصاویر سنجش از دور. Remote Sens. 2016 , 8 , 124. [ Google Scholar ] [ CrossRef ]
- عامری، ف. محمد، جی. بردارسازی جاده از تصاویر با وضوح بالا بر اساس خوشهبندی پویا با استفاده از بهینهسازی ازدحام ذرات. Photogramm. ضبط 2015 ، 30 ، 363-386. [ Google Scholar ] [ CrossRef ]
- گوا، کیو. ژنگ، سی. روش خوشه بندی سلسله مراتبی گروه نقاط بر اساس نمودار همسایگی. Acta Geod. کارتوگر. گناه 2008 ، 37 ، 256-261. [ Google Scholar ]
- Chacon-Murguia، MI; رامیرز-کوئینتانا، جی. Urias-Zavala، D. بخشبندی مناطق پسزمینه ویدیو بر اساس رویکرد خوشهبندی DTCNN. فرآیند ویدئو تصویر سیگنال. 2015 ، 9 ، 135-144. [ Google Scholar ] [ CrossRef ]
- ویکیپدیا. تجزیه و تحلیل خوشه بندی. در دسترس آنلاین: https://en.wikipedia.org/wiki/Cluster_analysis (دسترسی در 1 مه 2016).
- سان، ج. لیو، جی. ژائو، ال. تحقیق الگوریتم های خوشه بندی. چانه. جی. سافتو. 2008 ، 19 ، 48-61. [ Google Scholar ] [ CrossRef ]
- ژو، ایکس. یائو، پی. Xin, W. استقرار منابع فرماندهی و کنترل بر اساس روش خوشهبندی سلسله مراتبی بهبود یافته. جی. سیست. مهندس الکترون. 2012 ، 34 ، 523-528. [ Google Scholar ]
- گلبارد، آر. گلدمن، او. بررسی تنوع روش های خوشه بندی: مقایسه تجربی. دانستن داده ها مهندس 2007 ، 63 ، 155-166. [ Google Scholar ] [ CrossRef ]
- چن، ی. تحقیق خوشه بندی فضایی نقاط گسسته در جهت. محاسبه کنید. مهندس Appl. 2012 ، 48 ، 7-10. [ Google Scholar ]
- پرادیپ، ال. Sowjanya، AM خوشه بندی افزایشی بر اساس چند چگالی. بین المللی جی. کامپیوتر. Appl. 2015 ، 116 ، 6-9. [ Google Scholar ] [ CrossRef ]
- میترا، س. Nandy، J. KDDClus: یک روش ساده برای خوشه بندی چند چگالی. در مجموعه مقالات کارگاه بین المللی کاربردهای محاسبات نرم و کشف دانش (SCAKD 2011)، مسکو، روسیه، 25 ژوئن 2011; صص 72-76.
- طلا، ج. جاسازی فضایی و زمینه فضایی. در کیفیت متن ; Springer: اشتوتگارت، آلمان، 2009; صص 53-64. [ Google Scholar ]
- Marques de Sá، JP Data Clustering. در مفاهیم، روش ها و کاربردهای تشخیص الگو ؛ Springer: برلین/هایدلبرگ، آلمان، 2001; صص 53-78. [ Google Scholar ]
- وو، اچ. اصل بدنه محدب و کاربردهای آن در تعمیم اشیاء نقطه گروه بندی شده. مهندس Surv. نقشه 1997 ، 1 ، 1-6. [ Google Scholar ]
- ژو، Q. وانگ، ی. Ma, J. تحقیق در مورد الگوریتم تولید مرز برای مدل TIN. گاو نر Surv. نقشه 2005 ، 5 ، 30-32. [ Google Scholar ]
- لی، دبلیو. لی، اس. کیو، جی. ژو، T. تشخیص مرزی خوشه نقطه چند چگالی با استفاده از روش جمع شدن بدنه محدب. علمی Surv. نقشه 2014 ، 39 ، 126-129. [ Google Scholar ]
- لی، جی. چن، ال. چنگ، اچ. Nie, Y. مطالعه الگوریتم خوشه بندی فضایی بر اساس مثلث دهی. محاسبه کنید. تکنولوژی توسعه دهنده 2009 ، 19 ، 21-24، 28. (به زبان چینی) [ Google Scholar ]
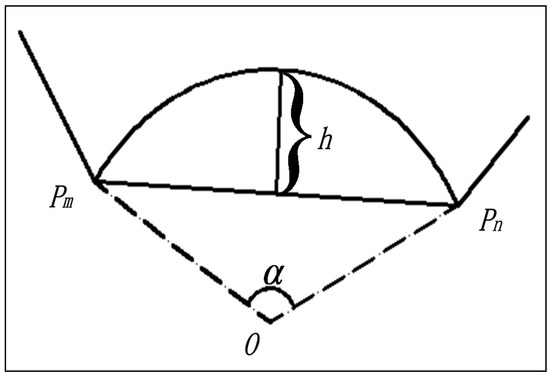
شکل 1. ساختار جمع شده با قوس محدود با دقت جمع شوندگی α، با پمترپn¯¯¯¯¯¯¯¯پمترپ�¯به عنوان یکی از خطوط مرزی بدنه محدب، O مرکز و h عمق جمع شدن است.
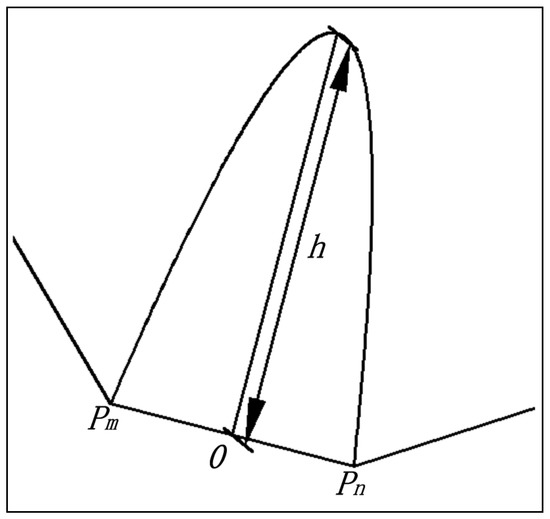
شکل 2. ساختار جمع شده با سهمی محدود که در آن مرز جمع شده است پمترپn¯¯¯¯¯¯¯¯پمترپ�¯یکی از خطوط مرزی بدنه محدب است و h عمق جمع شدنی است.
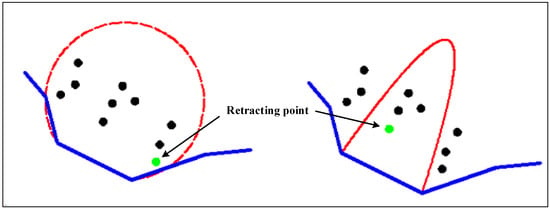
شکل 3. همان عمق جمع شدن در شرایط محدود کننده متفاوت.

شکل 4. روش الگوریتم خوشه بندی سلسله مراتبی تقسیمی بر اساس عقب نشینی بدنه محدب.

شکل 5. ترسیم نقشه خطوط مرزی عقب نشینی. ( الف ) ساختار عقب نشینی سهمی. ( ب ) خطوط مرزی برای اولین بار باز می گردند. ج ) خطوط مرزی متقاطع . ( د ) تقسیم خوشه ای.


شکل 6. نتایج تجربی. ( الف ) داده های تجربی. ( ب ) نتیجه خوشهبندی با استفاده از الگوریتم خوشهبندی سلسله مراتبی تقسیم سلولی (CDHC). ( ج ) نتیجه خوشهبندی با استفاده از الگوریتم سنتی خوشهبندی سلسله مراتبی تجمعی (AHC). ( د ) مثلث بندی دلونی داده های تجربی. ( ه ) نتایج خوشهبندی با استفاده از الگوریتم خوشهبندی مبتنی بر مثلثسازی دلونی (CBDT).

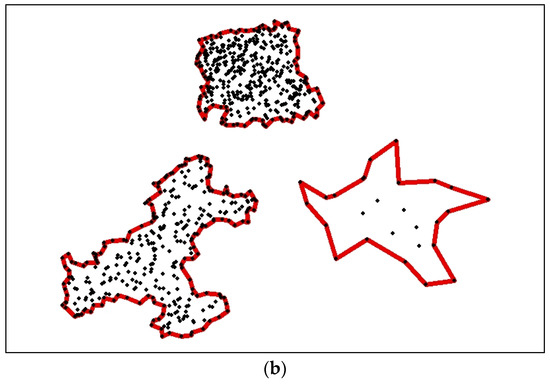
شکل 7. نتایج تجربی. ( الف ) داده های تجربی. ( ب ) نتیجه خوشه بندی با استفاده از الگوریتم CDHC.
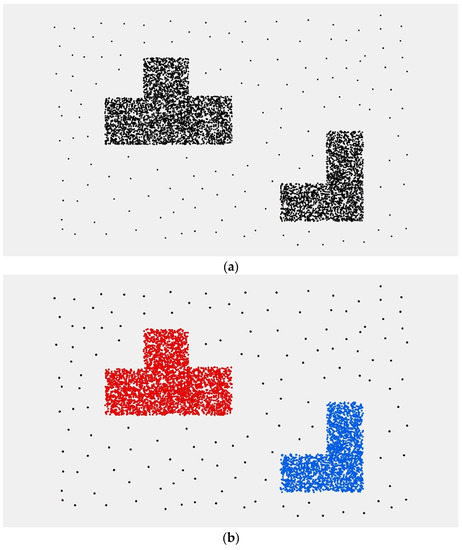
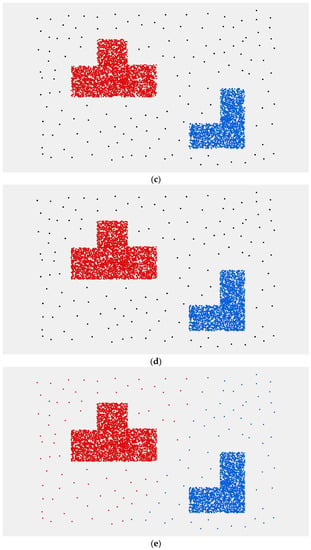
شکل 8. نتایج تجربی. ( الف ) داده های تجربی. ( ب ) نتیجه خوشه بندی با استفاده از الگوریتم CDHC. ( ج ) نتیجه خوشهبندی با استفاده از الگوریتم CBDT. ( د ) نتیجه خوشه بندی با استفاده از الگوریتم DBSCAN. ( ه ) نتیجه خوشه بندی با استفاده از الگوریتم K-means. ( و ) افسانه.

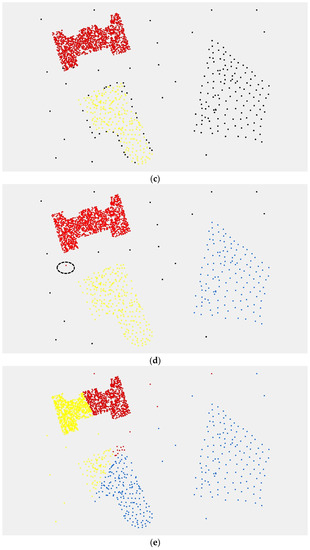

شکل 9. نتایج تجربی. ( الف ) داده های تجربی. ( ب ) نتیجه خوشه بندی با استفاده از الگوریتم CDHC. ( ج ) نتیجه خوشهبندی با استفاده از الگوریتم CBDT. ( د ) نتیجه خوشه بندی با استفاده از الگوریتم DBSCAN. ( ه ) نتیجه خوشه بندی با استفاده از الگوریتم K-means. ( و ) افسانه.
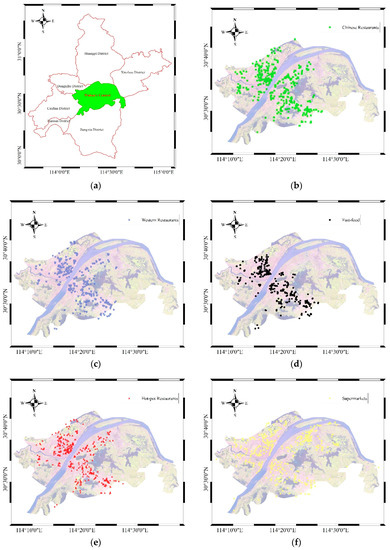
شکل 10. توزیع فضایی رستوران ها در ووهان. ( الف ) ناحیه مرکزی ووهان؛ ( ب ) رستوران چینی؛ ( ج ) رستوران غربی؛ د ) فست فود؛ ( ه ) رستوران هات پات؛ ( و ) سوپرمارکت.
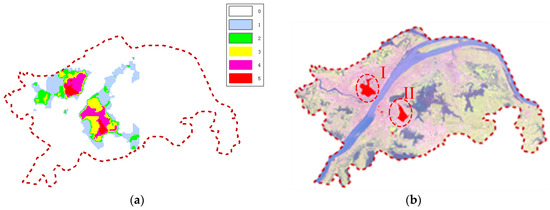
شکل 11. نتایج خوشه بندی رستوران ها و مکان آنها در ناحیه مرکزی ووهان. ( الف ) نقشه موضوعی با تحلیل همپوشانی. ( ب ) مناطقی با بزرگترین لایه های پوششی در ووهان.

جدول 1. مقایسه پیچیدگی زمانی بین الگوریتم های CDHC و AHC.
© 2017 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر