

خلاصه
:
دستبندهای مچ پا (خلخال) که توسط قانون برای ردیابی افراد محکوم اعمال شده است در بسیاری از کشورها به عنوان جایگزینی برای زندان های پر بار استفاده می شود. سیستمهای مختلفی برای نظارت بر افرادی وجود دارد که از چنین دستگاههایی استفاده میکنند، و این سیستمهای نظارت الکترونیکی خلخال معمولاً نقض مناطق گردش خون مجاز به دارندگان را تشخیص میدهند. علیرغم اینکه قادر به نظارت بر بومی سازی فردی هستند، چنین سیستم هایی فعالیت های گروه بندی افراد تحت نظارت را شناسایی نمی کنند، اگرچه این نوع رویداد می تواند خطر واقعی جرایم برنامه ریزی شده توسط آن افراد را نشان دهد. به منظور پرداختن به چنین مشکلی و کمک به سیستمهای نظارتی برای داشتن یک رویکرد فعال، این مقاله الگوریتمهای همجوشی دادههای حسگر را پیشنهاد میکند که قادر به شناسایی چنین گروههایی بر اساس دادههای ارائه شده توسط دستگاههای موقعیتیابی خلخال هستند. نتایج حاصل از الگوریتم های پیشنهادی را می توان برای حمایت از ارزیابی ریسک در زمینه سیستم های نظارت به کار برد. پردازش با استفاده از نقاط جغرافیایی جمعآوریشده توسط یک مرکز نظارت انجام میشود و در نتیجه، تاریخچه گروهها با اعضای آنها، مهرهای زمانی، مکانها و دفعات جلسات را تولید میکند. الگوریتم های پیشنهادی در سناریوهای محاسباتی سری و موازی مختلف اعتبارسنجی می شوند و نتایج مربوطه ارائه و مورد بحث قرار می گیرند. اطلاعات تولید شده توسط الگوریتمهای پیشنهادی به توصیف بهتر افراد تحت نظارت منجر میشود و میتواند برای حمایت از سیستمهای تصمیمگیری مورد استفاده توسط مقاماتی که مسئول برنامهریزی تصمیمگیریها در مورد اقدامات مؤثر بر امنیت عمومی هستند، سازگار شود. پردازش با استفاده از نقاط جغرافیایی جمعآوریشده توسط یک مرکز نظارت انجام میشود و در نتیجه، تاریخچه گروهها با اعضای آنها، مهرهای زمانی، مکانها و دفعات جلسات را تولید میکند. الگوریتم های پیشنهادی در سناریوهای محاسباتی سری و موازی مختلف اعتبارسنجی می شوند و نتایج مربوطه ارائه و مورد بحث قرار می گیرند. اطلاعات تولید شده توسط الگوریتمهای پیشنهادی به توصیف بهتر افراد تحت نظارت منجر میشود و میتواند برای حمایت از سیستمهای تصمیمگیری مورد استفاده توسط مقاماتی که مسئول برنامهریزی تصمیمگیریها در مورد اقدامات مؤثر بر امنیت عمومی هستند، سازگار شود. پردازش با استفاده از نقاط جغرافیایی جمعآوریشده توسط یک مرکز نظارت انجام میشود و در نتیجه، تاریخچه گروهها با اعضای آنها، مهرهای زمانی، مکانها و دفعات جلسات را تولید میکند. الگوریتم های پیشنهادی در سناریوهای محاسباتی سری و موازی مختلف اعتبارسنجی می شوند و نتایج مربوطه ارائه و مورد بحث قرار می گیرند. اطلاعات تولید شده توسط الگوریتمهای پیشنهادی به توصیف بهتر افراد تحت نظارت منجر میشود و میتواند برای حمایت از سیستمهای تصمیمگیری مورد استفاده توسط مقاماتی که مسئول برنامهریزی تصمیمگیریها در مورد اقدامات مؤثر بر امنیت عمومی هستند، سازگار شود. الگوریتم های پیشنهادی در سناریوهای محاسباتی سری و موازی مختلف اعتبارسنجی می شوند و نتایج مربوطه ارائه و مورد بحث قرار می گیرند. اطلاعات تولید شده توسط الگوریتمهای پیشنهادی به توصیف بهتر افراد تحت نظارت منجر میشود و میتواند برای حمایت از سیستمهای تصمیمگیری مورد استفاده توسط مقاماتی که مسئول برنامهریزی تصمیمگیریها در مورد اقدامات مؤثر بر امنیت عمومی هستند، سازگار شود. الگوریتم های پیشنهادی در سناریوهای محاسباتی سری و موازی مختلف اعتبارسنجی می شوند و نتایج مربوطه ارائه و مورد بحث قرار می گیرند. اطلاعات تولید شده توسط الگوریتمهای پیشنهادی به توصیف بهتر افراد تحت نظارت منجر میشود و میتواند برای حمایت از سیستمهای تصمیمگیری مورد استفاده توسط مقاماتی که مسئول برنامهریزی تصمیمگیریها در مورد اقدامات مؤثر بر امنیت عمومی هستند، سازگار شود.
کلید واژه ها:
نظارت و ردیابی قوزک پا ; الگوریتم های تشخیص ; ژئوپردازش ; سیستم های مخابراتی مجری قانون (LETS) ; ادغام داده های حسگر
1. معرفی
استفاده از خلخال های الکترونیکی توسط افراد تحت بازجویی و محکومیت توسط مقامات اجرایی برزیل برای کاهش حبس دسته جمعی در این کشور اعمال شده است. بر اساس داده های دسامبر 2013 از اداره ملی مجازات (DEPEN – Departamento Penitenciário Nacional) وزارت دادگستری، برزیل با 581507 زندانی یکی از بزرگترین جمعیت زندان های جهان را دارد [1 ] . تعداد افراد زندانی در دوره 2005-2013 52 درصد افزایش یافته است. در عین حال، کسری رو به رشد ظرفیت زندان وجود دارد ( شکل 1 ) که منجر به بارگیری بیش از حد زندان ها می شود. در شکل 1، اطلاعات ارائه شده از سیستم یکپارچه اطلاعات کیفری (INFOPEN – Sistema Integrado de Informação Penitenciária) از DEPEN استخراج شده است که آخرین بار در جولای 2014 به روز شده است.
اثربخشی اجرای احکام در زندانهای پربار کنونی مورد تاکید تلقینگران قرار گرفته است، که ادعا میکنند چنین زندانهایی همراه با روشهای مدیریتی خود، به عنوان ابزاری برای بازپروری مجرمان ناموفق هستند. علاوه بر این، این تلقینگران استدلال میکنند که این نهاد برای بازپروری رفتار اثبات نشده است، بلکه برعکس بهعنوان «مکتب واقعی برای مجرمان» عمل میکند.
در اصل، اجرای مجازات حبس در برزیل باید از پارامترهای کاملاً تعریف شده در رابطه با احترام و حیثیت زندانی پیروی کند که یک الزام کل جامعه زندان است، بنابراین محدودیتهای ناشی از مجازات و همچنین اجتماعی، اقتصادی و فرهنگی رعایت شود. حقوق. بنابراین امکان بازیابی کرامت محکوم از طریق تعامل اجتماعی یکی از اهدافی است که تمامی طرح های اجرای مجازات و در نتیجه اجرای قانون را هدایت می کند. به نظر می رسد راه حلی که به بازپروری کمک می کند، اجتماعی کردن مجدد یک محکوم است و از دولت می خواهد که نظارت دقیق بر این روند را انجام دهد.
از این نظر، استفاده از نظارت بر محکومان به وسیله ابزارهای تلهماتیک به عنوان یک جایگزین مناسب برای نظارت بر اجرای محکومیت ثابت شده است، بنابراین منجر به توسعه نوآوریهایی در کنترل افرادی میشود که قوانین کیفری را نقض میکنند. یکی از این گزینهها، نظارت بر محکومانی است که ملزم به پوشیدن خلخالهای الکترونیکی با حسگرهای GPS هستند، نوعی نظارت که هم در ایالات متحده و هم در اروپا مؤثر بود [2 ] . بنابراین، سیستمهای عدالت کیفری از دستگاههای GPS برای نظارت بر مجرمان استفاده میکنند، افرادی که خارج از زندان هستند، اما طبق قانون مجبور به پوشیدن خلخالهایی میشوند که مکان آنها را به آژانسهای نظارتی گزارش میدهند [3 ]]. این نظارت الکترونیکی بر محکومان ممکن است ابزار مؤثری برای ادغام مجدد اجتماعی در نظر گرفته شود، که می تواند تدریجی باشد زیرا نظارت فردی می تواند با رژیم های مختلف اجرای مجازات، مانند رژیم های بسته، نیمه باز و باز در سیستم حقوقی برزیل، سازگار شود.
استفاده از نظارت الکترونیکی پیشرفتی را در سیستم اجرای کیفری به ارمغان می آورد. اولاً، از نقطه نظر اجتماعی، ادغام مجدد بهتری را برای محکوم بازپروری در جامعه ای فراهم می کند که در غیر این صورت آمادگی گفت و گو را ندارد و بسیار کمتر مستعد کمک به افراد محکوم در فرآیند ادغام مجدد اجتماعی است. علاوه بر این، نظارت الکترونیکی به مسئله حریم خصوصی زندگی شخصی افراد تحت نظارت و خانواده های آنها پاسخ می دهد. با در نظر گرفتن اینکه در حال حاضر «35 درصد از جمعیت زندانی در برزیل را زندانیان پیش از محاکمه تشکیل می دهند و 30 درصد از زندانیان به دلیل ارتکاب جرایم بدون خشونت یا تهدید جدی محکوم شده اند» [4]، نظارت الکترونیکی به عنوان کلیدی برای تحول نظام ندامتگاهی
مزیت دیگر این است که نظارت الکترونیکی باعث صرفه جویی در هزینه های مالی عمومی در مورد سیستم زندان می شود، به ویژه با توجه به موضوع تلاش عملیاتی و هزینه نظارت. یک سیستم نظارت بر محکومان می تواند تا حد زیادی تعداد مراحل تدریجی آزادی را که در حال حاضر در پیشرفت رژیم زندان به کار می رود، از جمله مرخصی های موقت، کاهش دهد. صرفه جویی مشابهی را می توان از سایر برنامه های کاربردی برای نظارت بر محکومان بدون نظارت مستقیم به دست آورد.
معماریهای مورد استفاده در سیستمهای مانیتورینگ با خلبانهای الکترونیکی بهطور کلی از جریان کار زیر پیروی میکنند: مختصات ژئودزیکی جمعآوریشده توسط دستگاههای خلبان از طریق یک شبکه انتقال داده GSM/General Packet Radio Service (GPRS) از طریق اپراتورهای شبکه تلفن همراه ارسال میشود، بنابراین دادهها را فشار میدهند. به مرکز نظارت این دومی دادههای جغرافیایی را از خلخالها پردازش میکند و گزارشها و هشدارهایی را برای مقامات مربوطه صادر میکند تا مطابق با سیاستهای هر ایالت اقدام کنند. رایج ترین خروجی اطلاعات نظارتی، نشانه ورود مجرم ردیابی شده به مناطق ممنوعه جغرافیایی است.
در ادامه، به طور خلاصه عناصر اصلی را که بخشی از ساختار مورد استفاده برای یک سیستم نظارت بر خلخال هستند، توضیح میدهیم، زیرا این عناصر برای درک عملکرد سیستم و جریان داده مربوط به آن ضروری هستند:
-
GPS:سامانههای ماهوارهای ناوبری جهانی (GNSS) مجموعهای از ماهوارهها را تشکیل میدهند که با ارسال سیگنالها به گیرنده، تعیین مختصات آن را ممکن میسازند. این سیگنالها که در فرکانسهای خاص ارسال میشوند، دارای ویژگیهای عجیبی هستند که امکان شناسایی آنها توسط گیرندهها را فراهم میکند و آنچه را که GNSS مشاهدهپذیر نامیده میشود مشخص میکند [ 5] .]. GNSS اتخاذ شده برای این ارائه مقاله، سیستم موقعیت یابی جهانی آمریکای شمالی (GPS) است. از طریق این سیستم، دستگاه های الکترونیکی به طور مداوم سیگنال های ماهواره ها را دریافت می کنند و با محاسبه زمان سپری شده برای دریافت سیگنال و سرعت آنها، فاصله آنها را از این ماهواره ها مشخص می کنند. با توجه به فواصل بین دستگاه ها و ماهواره ها، دستگاه موقعیت نسبی خود را بر روی کره زمین محاسبه می کند و یک جفت اعداد را تولید می کند که مکان (مختصات) آن را مشخص می کند، با مشاهده یک سیستم جغرافیایی ارجاع خاص.
-
GSM/GPRS:استاندارد سیستم جهانی برای موبایل (GSM) یک سیستم ارتباطات دیجیتالی است که امکان جابجایی داده ها به صورت همزمان و ناهمزمان را فراهم می کند و همچنین سرویس پیام کوتاه GSM (SMS) موجود در سیستم های قبلی را حفظ می کند [6 ]]. سرویس رادیویی بسته عمومی (GPRS) یک واسطه بین شبکه های سلولی GSM و 3G در نظر گرفته می شود و انتقال داده را از طریق یک شبکه GSM در محدوده 9.6 کیلوبیت تا 115 کیلوبیت ارائه می دهد. علاوه بر این، فناوری GPRS از تماسهای تلفنی و انتقال دادهها به طور همزمان پشتیبانی میکند، بنابراین برای مثال به کاربر تلفن همراه GPRS اجازه میدهد همزمان تماس بگیرد و پیامهای ایمیل را دریافت کند. GPRS منابع رادیویی را تنها زمانی ذخیره می کند که داده هایی برای ارسال وجود داشته باشد و اتکا به عناصر شبکه سوئیچ مدار سنتی را کاهش می دهد، سپس انتقال داده پروتکل IP را از طریق GSM فعال می کند [ 6 ].
-
دستگاه تحت نظارت:این دستگاه شامل یک جعبه با یک مدار الکترونیکی مجهز به یک ماژول GPS برای تعیین موقعیت جغرافیایی است. همچنین دارای اسلات برای یک یا چند سیم کارت اتصال شبکه تلفن همراه برای انتقال داده از طریق GSM/GPRS است. به منظور حفظ عملکرد مداوم، دستگاه دارای یک باتری داخلی است که کاربر باید به صورت دوره ای از طریق شارژر ارائه شده به همراه تجهیزات شارژ شود. نظرسنجی انجام شده در بین تامین کنندگان خلخال الکترونیکی نشان می دهد که اکثر دستگاه ها دارای ویژگی های زیر هستند: چهار باند GSM/GPRS 850/900/1800/1900 مگاهرتز، دریافت سیگنال GPS از حداقل 20 ماهواره، توانایی کار با یک یا چند موبایل. اپراتورها (چند شیار سیم کارت)، حافظه کافی برای انباشت حداقل 24 ساعت گذشته مسیر در صورت ارتباطات آفلاین، حداقل 24 ساعت عمر باتری،
-
سیستم مرکزی نظارت:رایج ترین اطلاعات خروجی از یک سیستم نظارت بر خلخال، نشانه ورود مجرم ردیابی شده به مناطق ممنوعه است. بنابراین، سیستم مرکزی آن باید منابع ذخیرهسازی و محاسباتی را مستقر کند که قادر به جمعآوری دادهها از شبکه نظارت، سازماندهی این دادهها، انجام محاسبات در نقشهها، ثبت مناطق ممنوعه برای افراد و پشتیبانی از عملکردهای احراز هویت، مجوز و ممیزی باشد.
علاوه بر این، این مقاله این امکان را در نظر میگیرد که مرکز نظارت میتواند خدمات اضافی مربوط به دادههای مربوط به تشکیل گروههایی از افراد تحت نظارت را بر اساس تشخیص مجاورت با توجه به مختصات ارائه شده توسط خلخالها ارائه دهد. علاوه بر نشان دادن گروه ها و مکان آنها، همچنین می توان اطلاعات مربوط به زمان سپری شده که طی آن هر گروه در کنار هم باقی می ماند، تعداد افراد و همچنین دفعات و زمان جلسات ادغام کرد. چنین اطلاعاتی پتانسیل کمک به تجزیه و تحلیل ریسک را دارد که شامل اقدامات پیشگیرانه توسط سازمان های مجری قانون می شود.
سیستمهای مخابراتی مجری قانون (LETS) باید ریسک واقعی ناشی از گروههای خاص را با در نظر گرفتن عواملی مانند سطح خطر ناشی از عناصر آنها و انواع جرایم ارتکابی توسط هر یک از آنها و سایر عوامل در نظر بگیرند [7 ] . . بنابراین، طراحی الگوریتمهایی که دادهها را به منظور تأیید ارزیابی ریسک و تصمیمگیری در این زمینه ارائه میدهند، مهم است. هدف این است که از این طریق هشدارهایی را در مورد احتمال وقوع شورش، آمادگی برای فعالیت های مجرمانه، در میان سایر فعالیت های مشکوک صادر کنیم.
سهم اصلی این مقاله طراحی مجموعه ای از الگوریتم های مفصلی است که یک مدل سیستمی را ارائه می دهد که قادر به پردازش داده ها از شبکه نظارت به منظور: (1) بررسی نزدیکی ها (تشخیص جفت ها) است. (2) دستگاه هایی را که در مجاورت یکدیگر قرار دارند به خوشه ها گروه بندی کنید (تشخیص گروه ها). و (3) ثبت مدت زمان گروه بندی و تعداد متوسط عناصر گروه بندی شده (تشخیص خطرات). مشارکت های اضافی در مورد جنبه های پیاده سازی و عملکرد این الگوریتم ها شرح داده شده است. جالب است بدانیم که چنین الگوریتمهایی در موقعیتهای دیگر، به عنوان مثال، نظارت بر گروهبندی حیوانات در جنگلها، قابل استفاده هستند.
بقیه این مقاله به شرح زیر سازماندهی شده است: بخش 2 به بحث درباره مقالات مرتبط می پردازد. بخش 3 مشکل تشخیص گروه بندی را شرح می دهد و مدل سیستمیک راه حل پیشنهادی را معرفی می کند. بخش 4 تحلیلی از مدل سیستمیک و نتایج حاصل از الگوریتمها در یک محیط شبیهسازی شده ارائه میکند. بخش 5 این مقاله را به پایان می رساند و تحقیقات احتمالی بیشتر را ارائه می دهد.
2. آثار مرتبط
این موضوع مقاله به حوزه کلی ترکیب داده های چند حسگر ([ 8 ، 9 ]) مربوط می شود، اما به طور خاص به کارهای ارائه شده در زیر مربوط می شود.
مقالاتی که به پردازش نقاط جغرافیایی و شناسایی خوشه می پردازند، عموماً بر اساس جستجوی تمرکز نقاط با تجزیه و تحلیل توزیع آنها هستند. با این حال، آنها نیاز خاص به شناسایی افراد جمع آوری شده در نقاطی را که در حداقل فاصله هستند، که مشخصه یک جلسه است، در نظر نمی گیرند. بدون چنین ملاحظاتی، یک غلظت احتمالاً شناسایی شده از نقاط می تواند به نقاطی اشاره کند که با فاصله به ترتیب کیلومتر و نه فقط چند متر از هم جدا شده اند، که با مفهوم جلسه یا جمع آوری افراد تحت نظارت مغایر است.
لیو و همکاران [ 10 ] به الگوریتمهایی میپردازد که خوشههایی از اشیاء طبقهبندیشده در دستهها را با در نظر گرفتن جنبههای صرفاً جغرافیایی یا سایر ویژگیهای مرتبط شناسایی میکنند. این عمدتاً الگوریتم «خوشهبندی فضایی مبتنی بر چگالی» (DBSC) را مورد بحث قرار میدهد که خوشهها را با استفاده از مجاورت فضایی و شباهت ویژگیها شناسایی میکند. DBSC شامل ایجاد روابط مجاورت بین نقاط به دست آمده از طریق مثلث سازی دلونی است [ 11]. برای به دست آوردن مثلث های تشکیل شده توسط نقاط در مجاورت مورد نیاز الگوریتم، فاصله بین نقاط باید قبلا محاسبه شود، اما بدون در نظر گرفتن محدودیت زمانی که در مقاله حاضر در نظر می گیریم. مقاله مورد استناد فرض می کند که نقاط جغرافیایی ایستا هستند و هیچ گونه جابجایی و دگرگونی خوشه ها را در طول زمان در نظر نمی گیرند، ویژگی هایی که در دیدگاه ما از گروه ها نیز در نظر گرفته می شوند.
کارلینو [ 12] در مورد تأثیر نزدیکی فیزیکی آزمایشگاههای تحقیق و توسعه (R&D) بر تأثیر دانش در منطقه تمرکز آنها بحث میکند. برای این اثر، مکان آزمایشگاه ها در قلمرو ایالات متحده را با ثبت اختراعات در همان منطقه مقایسه می کند و ارتباط آنها را نشان می دهد. سپس، به روشی برای اندازهگیری میزان تمرکز فضایی فعالیتهای آزمایشگاهها نزدیک میشود و خوشهای را که توسط آزمایشگاههای همسایه تشکیل شده است، با در نظر گرفتن دایرهای در اطراف هر نقطه با شعاع اولیه یک چهارم مایل تعریف میکند. سپس تعداد نقاط داخل دایره را فهرست می کند. در نتیجه، بسیاری از دایره ها با هم همپوشانی دارند و در نتیجه خوشه ای را تشکیل می دهند که باید با ثبت اختراعات مورد تجزیه و تحلیل و مقایسه قرار گیرد. همچنین نقاط ایستا را در رابطه با آدرس آزمایشگاه ها در نظر می گیرد. در مشکل ارائه شده، نیازی به تحلیل تغییر در خوشه در طول زمان نیست. علاوه بر این، منطقه خوشه با تحدید دوایر در فضای جغرافیایی اعمال شده به همه نقاط به دست میآید که در مقاله بدون چشمانداز رشد تقریباً روی 1000 ثابت شده است.
الگوریتم DBSCAN پیشنهاد شده توسط لوهیچی و همکاران. [ 13 ] به دنبال شناسایی خوشه ها با انواع مختلف اشیاء جغرافیایی (نقاط، چندضلعی، خطوط و غیره) است. هر گروه مجاور در یک شعاع معین باید حداقل دارای حداقل تعداد نقاط باشد، یعنی چگالی آن از یک آستانه معین فراتر رود، که روشن می کند که پردازش نقطه به نقطه با استفاده از رابطه فاصله بین نقاط مشابه مقاله حاضر انجام می شود. مقاله ذکر شده تخمین مقدار فاصله را به منظور تشخیص ایده تمرکز نقاط از ایده نقاط پراکنده خارج از غلظت (نویز) پیشنهاد می کند. با این حال، در مقاله حاضر ما، این مقدار ضروری نیست زیرا ما از دقت (دقت) GPS استفاده می کنیم.
مقالات فوق در زمینه LETS نیستند و الزامات مسئله مطرح شده در مقاله حاضر را برآورده نمی کنند، یعنی: (1) با شناسایی مدت زمان تمرکز نقاط، تکامل گروه در طول زمان را در نظر نمی گیرند. و اندازه (تعداد امتیازات) گروه؛ (2) آستانه پردازش و شناسایی خوشه ای ندارند. و (3) برخی از الگوریتم ها حداقل فاصله بین نقاط در خوشه ها را تحمیل نمی کنند.
موریل [ 14] طرحی را برای حسگر اطلاعات شبکه بیسیم و سیستم شناسایی (WINS Id) پیشنهاد میکند که در آن حجم زیادی از دادههای زمانی حسگر توزیعشده جغرافیایی جمعآوری، ذخیره و در زمان واقعی ارائه میشود. این مقاله نتایج پردازش بلادرنگ را با نتایج قبلی که تا حدودی تکامل را برای تجزیه و تحلیل نشان میدهند، مقایسه نمیکند. تفاوت اساسی بین معماری مانیتورینگ برای خلبانهای الکترونیکی و معماری شبکه حسگر در این واقعیت است که در حالت اول، هیچ زنجیرهای زنجیرهای یا تمرکز گرههای ترافیک داده در شبکه وجود ندارد، زیرا در مانیتورینگ خلخال، دادهها مستقیماً ارسال میشوند. به مرکز نظارت مسئول پردازش داده ها به عنوان یک کل. این طراحی با سادگی دستگاه های خلخال طراحی شده برای اتصال از طریق شبکه های GSM/GPRS مطابقت دارد.
یکی دیگر از زمینههای مرتبط برای این مقاله، مطالعه تکنیکهای دادهکاوی بر روی دادههای جمعآوریشده و ذخیرهشده تا کشف دانش است، مانند Zhu [ 15] .]. در این مورد، تغییرات در تعداد گروههای شناساییشده، تعداد عناصر گروه، فرکانس و غیره را میتوان با تکنیک DTW برای پرورش افراد با رفتار غیرعادی نظارت شده بهعنوان یک کل پردازش کرد. این سیستم یک سیستم واحد را برای ثبت رویدادهای مجرم با تمرکز بر دستگاه های تلفن همراه پیشنهاد می کند که در آن مکان فعلی دستگاه برای شناسایی منطقه جغرافیایی محل وقوع رویداد استفاده می شود. مختصات جغرافیایی از دستگاههایی مانند تلفنهای هوشمند یا تبلتها جمعآوری میشود، در حالی که در مقاله حاضر به خلخالهای الکترونیکی با قدرت پردازش کمتر اشاره میکنیم. مقاله ذکر شده بهعنوان کار آینده، استفاده از تکنیکهای دادهکاوی روی سوابق را به منظور ایجاد اقدامات پیشگیرانه در برابر جرایم پیشنهاد میکند. در این معنا، ما در نظر می گیریم که یکپارچه سازی یک سیستم همانطور که توسط Jakkhupan و Klaypaksee پیشنهاد شده است [ 16]] با نظارت با خلخال می تواند در شرایط خاص با شناسایی مظنونینی که در زمان وقوع جرم در منطقه جرم حضور داشتند، تشخیص رفتار نادرست را تسریع بخشد.
با استفاده از تکنیک های داده کاوی، Sathyadevan [ 17] رویکردی برای پیش بینی جرایم بر اساس مناطق جغرافیایی پیشنهاد می کند. جریان پردازش شامل جمع آوری داده ها، طبقه بندی، شناسایی الگو، پیش بینی و تجسم است. در میان منابع داده، این مقاله به «وبسایتها، سایتهای خبری، وبلاگها، رسانههای اجتماعی، فیدهای RSS و غیره» اشاره میکند و دادههای بدون ساختار در MongoDB ذخیره میشوند. سوابق و گروههای ساختاریافته شناساییشده با تکنیک ما که در مقاله حاضر مورد بحث قرار گرفتهاند، میتوانند برای غنیسازی تحلیل پیشبینیکننده وقوع جرایم اضافه شوند. مقاله ذکر شده توسعه یک برنامه تلفن همراه برای سوابق پرونده های جنایی را نشان می دهد، که نیاز شهروندان را برای مراجعه به آژانس پلیس برای پر کردن فرم های بوروکراتیک حذف می کند. بنابراین، علاوه بر افزایش تعداد حوادث ثبت شده (بسیاری از آنها به دلیل بوروکراسی ثبت نمی شوند)، خطاهای احتمالی در پر کردن را نیز کاهش می دهد.
تلاقی داده ها از خلخال های الکترونیکی، همانطور که توسط پیشنهاد در مقاله حاضر ارائه شده است، با سوابق رخدادهای پیشنهاد شده توسط Oduor [ 18 ] می تواند پشتیبانی بهتری برای تحقیقات آن موارد ارائه دهد. این یک معماری نظارتی برای خلخال های الکترونیکی با توپولوژی پیشنهاد می کند که عوامل مستقل موقت بین دستگاه ها و یک مرکز را در نظر می گیرد. عامل ها اجزای نرم افزاری پویا هستند که خدمات عملیات مشترک را ارائه می دهند. با استفاده از این عوامل، سیستم می تواند تصمیمات غیرمتمرکز بگیرد و فرآیند هشدار را ساده تر کند. پارک [ 19] به عنوان مثال سطوح مختلف هشدارها در مورد نزدیکی مجرمان جنسی و کودکان تحت نظارت را ذکر می کند. با این حال، این کار جزئیاتی در مورد زیرساخت و مکان این عوامل و نحوه اتصال به دستگاه ها و کنترل پنل ارائه نمی دهد.
از سوی دیگر، Urbano و Dettki [ 20 ] به مسائل مربوط به ایجاد و نگهداری پایگاه داده در PostgreSQL با پسوند PostGIS می پردازند که داده های جغرافیایی ارسال شده توسط حسگرهای واقع در ایتالیا را ذخیره می کند. مراحل ایجاد پایگاه داده و جداول لازم برای نمایش و ذخیره داده های جغرافیایی را شرح می دهد. مقاله حاضر چنین تحلیلی را با جزئیات بیشتر در مورد پایگاه داده و الزامات پیاده سازی تکمیل می کند تا الگوریتم های ارائه شده در آینده را اعتبار سنجی کند.
با توجه به نیاز به پردازش نقاط جغرافیایی در یک پنجره زمانی خاص، حتی با مقدار زیادی مختصات جغرافیایی در نمونه جمعآوریشده، اتخاذ الگوریتمهایی که میتوانند موازی شوند، به ویژه در مورد شناسایی جفت نقاط در مجاورت، مرتبط میشود. بنابراین، استناد به دینگ و دنشم [ 21 ] جالب است که برخی از گزینهها را در مورد تقسیم احتمالی یک فضای جغرافیایی برای پردازش موازیسازی ارائه میکنند.
3. شرح مسئله و مدل سیستمی
سیستمهای ردیابی دستگاه مبتنی بر ماهواره شامل چندین فناوری یکپارچه برای ردیابی محکومان بازپروری در رژیمهای خدمت باز و نیمه باز و تحت بازداشت خانگی هستند. این سیستمها در ارتباط با اقدامات مشترک پلیس ملکی و نظامی، اجرای کارآمد قانون را از طریق یک مرکز نظارتی امکانپذیر میسازند که هشدارها را به نزدیکترین ایستگاههای پلیس به محلی که در آن یک رویداد نامنظم توسط دستگاههای نظارتی شناسایی میشود، مخابره میکند.
چندین شرکت راه حل های نظارت الکترونیکی را از طریق خلخال در برزیل و جهان ارائه می دهند. به عنوان یک عملکرد اساسی؛ آنها از تجهیزات مکان یابی GPS استفاده می کنند و داده های موقعیت مکانی را از طریق شبکه های تلفن همراه ارسال می کنند و تخلفات منطقه را به صورت شامل (مناطقی که محکوم تحت نظارت نمی تواند ترک کند) یا حذف (مناطقی که محکوم تحت نظارت نمی تواند وارد شود) شناسایی می کند. مرکز نظارت وظیفه رسیدگی به نقاط مکان یابی و ارسال هشدار به مراجع ذیربط در صورت وقوع این گونه تخلفات را بر عهده دارد.
3.1. مشکل
از منظر نظارت نیروی انتظامی، تمرکز دستگاه های تحت نظارت در یک محدوده جغرافیایی لزوماً نشان دهنده گروه بندی افراد در یک جلسه نیست. به عنوان مثال، با در نظر گرفتن غلظت نقاط نظارت شده در یک منطقه فضای جغرافیایی که در آن کوتاه ترین فاصله یافت شده بین نقاط مشاهده شده 1 کیلومتر است، نمی توان فوراً نتیجه گرفت که سوژه های نظارت شده در واقع در یک جلسه هستند، اگرچه غلظت مشاهده شده حتی به صورت بصری در یک مکان مشاهده می شود. نقشه در واقع، برای اینکه دو یا چند فرد تحت نظارت با هم در یک گروه در نظر گرفته شوند، فاصله بین نقاط نشان دهنده این افراد باید کمتر از یک آستانه مجاورت معین باشد. دقت در مفهوم مجاورت بعداً در بخش 3.1.1 آورده شده است .
الگوریتمهای پیشنهادی در این مقاله برای انجام پردازش نقاط جغرافیایی برای شناسایی گروهبندی افراد تحت نظارت با در نظر گرفتن چنین فاصله آستانه، علاوه بر بهروزرسانی پایگاه داده با دادههای اضافی، مانند مدت زمان تشکیل گروه و تعداد عناصر آن، مورد نیاز است.
علاوه بر این، مراحل الگوریتمها باید در یک دوره زمانی انجام شوند که به دلیل الزامات اجرای قانون در مورد تازگی اطلاعات نظارت شده، از یک پنجره پردازش تعیینشده فراتر نرود. این پنجره بدون هیچ گونه لطمه ای به نتایج به دست آمده پارامتر شده و به صورت دلخواه در یک دقیقه تنظیم می شود. علاوه بر این، جالب است که این مقدار یک آستانه عملکرد برای الگوریتمهای ما نیز باشد، زیرا در صورت تجاوز از این پنجره زمانی، خطر انباشته شدن پردازش پنجرههای واقعی سازی متوالی، احتمالاً بارگذاری بیش از حد زیر سیستم پردازش و ذخیرهسازی وجود دارد. منجر به از دست دادن اطلاعات
مسئله مهم دیگر این است که برای سیستمی برای نظارت بر بازپروری مجرمان، که دلالت بر نگرانی های امنیت عمومی دارد، محاسبه خطر واقعی ناشی از یک گروه شامل عوامل بسیار بیشتری از جمله سطح خطر افراد گروه بندی شده و انواع جرایمی است که قبلاً مرتکب شده اند. توسط هر یک از آنها، از جمله عوامل دیگر. بنابراین، الگوریتمهای پردازش ما باید دادههایی را برای پشتیبانی از تجزیه و تحلیل ریسک ارائه دهند، نه اینکه در نهایت مسئول خود تجزیه و تحلیل باشند. این یک ملاحظه مهم قبل از پرداختن به مفهوم مجاورت است که در ادامه این مقاله اتخاذ شده است.
3.1.1. تعریف مجاورت
برای اینکه دو یا چند فرد تحت نظارت با هم در یک گروه در نظر گرفته شوند، باید حداقل فاصله ای بین نقاط نشان دهنده آنها وجود داشته باشد. الگوریتمهای پیشنهادی در این مقاله از نظر عملکردی برای در نظر گرفتن این فاصله برای پردازش نقاط جغرافیایی به منظور شناسایی گروهبندی محکومان تحت نظارت مشخص شدهاند.
حداقل فاصله ای که یک جلسه را مشخص می کند، که به عنوان آستانه در پردازش استفاده می شود، باید حاشیه خطا ( ε ) ذاتی تجهیزات GPS را در نظر بگیرد ( شکل 2 ).
با توجه به تیم ملی آزمایش ماهواره ای تخت / سیستم تقویت منطقه وسیع (NSTB/WAAS) T&E [ 22 ]، دقت دستگاه های GPS کمی کمتر از 10 متر است. بنابراین، با در نظر گرفتن این حاشیه خطا، معادله ( 1 ) برای تنظیم آستانه فاصله ملاقات ( l rل�). به عبارت دیگر، در عمل، برای اهداف محاسباتی، هر دو نقطه ای که با فاصله کمتر از 20 متر از هم جدا شوند، سوژه های نظارت شده در مجاورت در نظر گرفته می شوند.
l r = 2 ⋅ |εm i n|ل�=2·|�مترمن�|
3.1.2. مدت زمان یک گروه احتمالاً شناسایی شده
تشخیص گروه ها نه تنها با در نظر گرفتن گروه بندی نقاط در فضا در یک لحظه معین، بلکه با توجه به تکامل این گروه در طول زمان انجام می شود. بنابراین، شاخصهایی مانند مدت زمان گروه و میانگین تعداد عناصر، اطلاعاتی هستند که میتوان با مقایسه و شناسایی گروهها در هر نقطه نمونه ارسال شده توسط دستگاهها، تولید کرد. سپس الگوریتم های پیشنهادی ما باید پردازش این اطلاعات را فراهم کنند.
با حفظ پایگاهی از گروههای فعال و غیرفعال که در هر پردازش نمونه بهروز میشوند، میتوان به راحتی اطلاعات دیگری مانند دفعات و زمان ملاقات هر گروه را استخراج کرد. این اطلاعات تکمیل کننده تجزیه و تحلیلی است که هرگونه خطر واقعی اقدام مجرمانه قریب الوقوع یا ادامه رابطه مجرمانه را نشان می دهد.
شکل 3 a,b اندازه گیری مدت زمان گروه را به ترتیب در موقعیت هایی که افراد ایستاده یا حرکت می کنند نشان می دهد. در طول بازه محاسبه مجاورت نقاط، t 0تی0زمان خاصی است که نزدیکی کافی بین نقاط وجود ندارد تا بتوان آنها را به عنوان گروه بندی در نظر گرفت. در زمان t 1تی1با نزدیک شدن نقاط به یکدیگر جزء گروهی تلقی می شوند که حداقل دارای دو امتیاز باشد. در طول زمان های پردازش زیر ( t 2تی2و t 3تی3، همان نقاط همچنان در محدوده مجاورت باقی می مانند. در زمان t 4تی4، دو نقطه از یکدیگر جدا می شوند. سیستم محاسبه خواهد کرد t 1تی1به عنوان تاریخ و ساعت شروع جلسه گروه و t 3تی3پایان این جلسه چنین داده هایی شامل مدت زمان وجود گروه است. همین استدلال باید برای نقاط ثابت ( شکل 3 الف) و متحرک ( شکل 3 ب) در مجاورت اعمال شود.
هنگامی که دو فرد تحت نظارت در مکانی، به عنوان مثال در یک خیابان، با هم تلاقی می کنند، نزدیکی فیزیکی آنها ممکن است با این محاسبات تشخیص داده شود، اما لزوماً به معنای گروه بندی افراد تحت نظارت نیست. برای جلوگیری از چنین موقعیت هایی که به عنوان “مثبت کاذب” تعریف می شوند، گروه هایی که مدت زمان آنها کمتر از یک مقدار از پیش تعیین شده است باید کنار گذاشته شوند. در ابتدا، این متغیر روی حداقل 5 دقیقه تنظیم می شود. به عبارت دیگر، با در نظر گرفتن نمونه های دقیقه به دقیقه، هنگامی که همان گروه در پردازش پنج نمونه متوالی شناسایی می شود، آن نقاط مجاور به عنوان یک گروه به طور موثر تشخیص داده می شوند.
3.1.3. تعداد عناصر در یک گروه شناسایی شده
تعداد عناصری که بخشی از یک گروه بندی هستند بر ارزیابی ریسک تأثیر می گذارد. برای مثال، گروههای پنجگانه میتوانند خطر بیشتری نسبت به گروههای دو عنصری داشته باشند، زیرا این وضعیت ممکن است از طریق تقسیم فعالیتها بین اعضای گروه، جرم شدیدتر و سازمانیافتهتری را نشان دهد. از این رو، ارائه تعداد افراد در یک گروه در پایان پردازش برای حمایت از تصمیم گیری مهم است.
همچنین باید در نظر داشته باشیم که در طول وجود یک گروه، تعداد افراد آن ممکن است افزایش یا کاهش یابد، تغییراتی که با محاسبه مجاورت آنها قابل تشخیص است. این تغییرات باعث رد صلاحیت گروه نمی شود. بنابراین، ما مقدار متوسط تعداد افراد در گروه را در طول وجود آن در نظر می گیریم، شاخصی که به ما امکان می دهد تناسب را در مقایسه های احتمالی بین گروه ها در نظر بگیریم.
با این حال، تغییر در تعداد اعضای یک گروه میتواند بر مقایسه این گروه با گروههای شناسایی شده قبلی تأثیر بگذارد. این سؤال را به وجود می آورد که چگونه می توان به طور دقیق ثابت کرد که یک گروه قبلاً شناسایی شده که مثلاً 10 نفر داشته است در اکثر موارد مشابه گروهی است که اکنون دارای 12 عنصر است: چند عضو مشترک این دو گروه به این نتیجه می رسد که یک گروه در واقع تجسم کاهش یافته یا گسترش یافته دیگری است. برای در نظر گرفتن این نوع عود یک گروه، در روال انجام مقایسه گروه ها متغیری به نام “مشترک” را وارد می کنیم که مربوط به تعداد افراد مشترک در هر دو گروه (فعالی و سابق) تقسیم بر مقدار کل است. عناصر گروه قبلی، به صورت درصد بیان شده است. اگر اشتراک بین دو گروه برابر یا بیشتر از یک آستانه اشتراک باشد که در ابتدا 50 درصد تعیین شده است، در نظر می گیریم که آنها یک گروه هستند و در این حالت، یک ویژگی حاوی میانگین مقدار این اعضای گروه به درستی است. به روز شد. در غیر این صورت، گروه مورد تجزیه و تحلیل، گروه جدیدی در نظر گرفته می شود که باید به خاطر بسپارید.
3.1.4. محدودیت های زمانی برای اجرای الگوریتم ها
دستگاههای خلخال طوری پیکربندی شدهاند که بطور دورهای مختصات یا نقاط جغرافیایی خود را ارسال کنند، معمولاً تقریباً هر 1 دقیقه، اگرچه این زمان معمولاً قابل تنظیم است. بنابراین، الگوریتمهای شناسایی گروهها و جمعآوری دادههای مرتبط باید در زمان کمتری نسبت به مرز کل دوره اجرا شوند، یعنی قبل از رسیدن مجموعه بعدی مختصات برای محاسبه جدید. علاوه بر این، این حد یک آستانه عملکرد است، زیرا در صورت تجاوز از این حد، خطر انباشته شدن وظایف، یا محاسبات رشتهها با پردازش مجموعه قبلی، یا بارگذاری بیش از حد تجهیزات مسئول پردازش یا از دست دادن اطلاعات وجود دارد. بنابراین، کل الگوریتم باید در یک پنجره زمانی اجرا شود که از مجموعه دوره رسیدن مختصات تجاوز نکند که در این مقاله روی 1 دقیقه تنظیم شده است.
الگوریتم برای مقابله با یک مشکل پیچیدگی محاسباتی مربوط به تعداد جفت نقاط مورد نیاز است، زیرا ما باید فاصله هر یک از این جفت ها را محاسبه کنیم، همانطور که در شکل 4 نشان داده شده است . فاصله از یک نقطه به نقطه دیگر در یک جفت نقطه امکان ارزیابی اینکه آیا دو نقطه در مجاورت هم قرار دارند یا خیر، میدهد، شرطی که برای تأیید بعدی نقاطی که در گروهها مرتبط هستند لازم است. با افزایش تعداد نقاط متعلق به یک گروه جمع آوری شده، تعداد مقایسه های لازم برای شناسایی این نقاط گروه بندی شده نیز افزایش می یابد.
تعداد مقایسهها برای تأیید مجاورت با فرمول ترکیبی ساده (معادله ( 2 )) ارائه میشود که n تعداد آیتمهای یک مجموعه و p تعداد عناصر در هر ترکیب است، بنابراین نتیجه سیn ، pسی�،پبه ترکیبی از n چیز که k در یک زمان بدون تکرار گرفته می شود اشاره دارد. در محاسبات ما، p روی دو تنظیم میشود، زیرا ما به جفتهایی از نقاط در نمونه مختصاتی اشاره میکنیم که باید هر بار مورد بررسی قرار گیرند.
سیn ، p=n !p ! ( n − p ) !=n _ ( n – 1 ) . ( n − 2 ) !2 . ( n – 2 )=n _ ( n – 1 )2سی�،پ=�!پ!(�–پ)!=�.(�–1).(�–2)!2.(�–2)=�.(�–1)2
به عنوان مثال، در یک نمونه از 10000 نقطه، تقریباً 50 میلیون محاسبه فاصله وجود دارد. این تعداد محاسبات و پنجره زمانی پردازش مورد نیاز، عوامل حیاتی برای اجرای موفقیت آمیز هستند. علاوه بر این، کنترل این عوامل مهم است، زیرا با توجه به نرخ رشد جمعیت زندان، همانطور که در شکل 1 نشان داده شده است، میزان افراد تحت نظارت می توانند با تکامل استفاده از سیستم نظارتی مبتنی بر قوزک رشد کنند .
مشکل تا حدی با تقسیم فضای مختصات کل به زیر ناحیهها حل میشود، که امکان شکستن نمونههای پردازش را، همانطور که در بخش 3.1.5 توضیح داده شد، میدهد . راه حل پیشنهادی را می توان با همکاری گره های محاسباتی موازی تکمیل کرد. در واقع، برای جلوگیری از به خطر انداختن تعداد افراد تحت نظارت از پردازش در یک پنجره زمانی تعریف شده، پیشنهاد جایگزین الگوریتمی است که زیر ناحیههای فضای مختصات را به صورت موازی پردازش میکند. در این حالت، با افزایش تعداد نقاط پردازش، می توان گره های موازی بیشتری را برای تکمیل پردازش در یک پنجره زمانی مورد نیاز به سیستم اضافه کرد.
3.1.5. تقسیم فضای مختصات به زیرمناطق برای اجازه دادن به موازی سازی پردازش
مشکل اجرای تعدادی از محاسبات مربوط به مجاورت در یک پنجره زمانی پردازش مورد نیاز راه حلی را می طلبد که در آن هنگام افزایش تعداد افراد تحت نظارت یا کاهش در پنجره زمان پردازش، توان محاسباتی بیشتری به سیستم اضافه شود. بنابراین، تقسیم ناحیه مختصات به مناطق کوچکتر در اینجا پیشنهاد شده است تا پردازش را بتوان به چندین واحد پردازش تقسیم کرد.
با اشاره به شکل 5 ، یک منطقه اولیه محاسبه شده از دورترین نقاط در یک نمونه دوره ای گزارش شده توسط دستگاه های نظارت شده را در نظر می گیریم. این انتزاع یک منطقه جغرافیایی مربع شامل تمام نقاط نمونه را تشکیل می دهد. سپس، یک تقسیمبندی بازگشتی از این ناحیه انجام میشود که توسط یک استراتژی تقسیم کن به شرح زیر هدایت میشود، که توسط کار دینگ و دنشم [ 21 ] نیز پشتیبانی میشود.
ابتدا ناحیه انتزاع شده به چهار ناحیه کوچکتر با اندازه مساوی (ربع) تقسیم می شود و تعداد نقاط هر ربع شمارش می شود. اگر مشاهده شود که یک ربع دارای امتیاز بیشتری نسبت به آستانه جمعیت ربع است، این ربع بیشتر تقسیم می شود به طوری که تقسیمات ربع بازگشتی منجر به تعدادی ربع می شود که هر یک شامل تعدادی نقطه است که نشان دهنده مشکل پردازش عملکرد نیست. در مورد محاسبات مجاورت در پنجره زمانی محدود. آستانه جمعیت ربع، یعنی حداکثر امتیازی که یک ربع می تواند داشته باشد، به طور دلخواه در این مقاله ثابت شده است، اما از آنجایی که این آستانه به ظرفیت پردازش موجود محدود است، باید به عنوان متغیری در نظر گرفته شود که رفتار آن مربوط به آینده است. مطالعه. علاوه بر این،
این تقسیمبندی بازگشتی از فضای اصلی شبیه به آنچه توسط Xia و همکاران ارائه شده است. [ 23 ] با استفاده از ساختار چهاردرختی. با این حال، این مطالعه ارتباط سلسله مراتبی بین زیر حوزه ها را در نظر نمی گیرد. علاقه اصلی این است که هر یک از این مناطق می توانند به طور مستقل از مناطق دیگر پردازش شوند، که موازی سازی پردازش را امکان پذیر می کند. در یک دیدگاه جایگزین دیگر، محاسبات فاصله فقط در داخل ربعهایی که نقاط در آن قرار دارند انجام میشود، بنابراین تلاش پردازش کاهش مییابد. با این حال، اگرچه ما دیگر نقاطی را که از ربع های دور هستند مقایسه نمی کنیم و در نتیجه تعداد محاسبات فاصله را کاهش می دهیم، شرایطی وجود خواهد داشت که دو نقطه در ربع مجاور در مجاورت یکدیگر باشند و احتمال شکست شناسایی برای آن جفت وجود دارد. با اشاره به دینگ و دنشم [21 ]، ما یک جایگزین برای حل این مشکل داریم، با گسترش مساحت یک ربع تازه ایجاد شده ( شکل 5 ) با افزودن حاشیه ای معادل حداقل فاصله برای شناسایی نقاط مجاور به آن ( شکل 6 ).
با در نظر گرفتن این حاشیه اضافه، هر ناحیه با مناطق مجاور همپوشانی دارد و امکان محاسبه مجاورت نقاطی را که به نقاطی در مرزهای ربع مجاور نزدیک هستند، می دهد. از آنجایی که محاسبات برای یک ربع مستقل از محاسبات برای یک ربع دیگر است، می توان پاسخ های تکراری را برای همان جفت نقطه در مجاورت (AB و BA) به دست آورد. چنین تکراری مشکلی ایجاد نمی کند زیرا موارد تکراری توسط الگوریتم تشخیص گروه که در بخش 3.2.4 توضیح داده شده است حذف می شوند و به عنوان مرحله 3 از مدل سیستمیک نشان داده شده است ( شکل 7 ).
3.2. مدل سیستمی و الگوریتم های مرتبط
شکل 7 مدل سیستمیک ارائه شده در این مقاله را نشان می دهد که پردازش را به سه مرحله تقسیم می کند: (1) تشخیص جفت: دریافت مجموعه ای از نقاط ارسال شده توسط دستگاه ها از طریق شبکه و محاسبه نقاط مجاور. (2) تشخیص گروه ها: نقاط مجاور را در خوشه ها گروه بندی کنید. و (3) تشخیص شاخص های خطر: اضافه کردن داده ها در مورد مدت زمان گروه و تعداد شرکت کنندگان.
مرحله اول مجموعه ای از نقاط جمع آوری شده در یک لحظه معین (نقاط جمع آوری شده) را به عنوان ورودی دریافت می کند که ساختار آنها در جدول 1 توضیح داده شده است . نقاط جمعآوریشده در مرحله دوم با الگوریتم تشخیص جفتها، که فهرستی از نقاط مجاور را ایجاد میکند، درمان میشوند ( جدول 1 ). متعاقباً، الگوریتم تشخیص گروهها در مرحله 2 فهرست جفتها را بررسی میکند و فهرستی از گروههای شناساییشده را تولید میکند که ویژگیهای ریسک آنها سپس در مرحله 3 محاسبه میشوند، و در نتیجه ساختار خروجی نهایی مطابق جدول 2 مشخص شده است .
3.2.1. الگوریتم 1: تشخیص جفت
با مراجعه به شکل 8 ، که مرحله 1 شکل 7 را به تفصیل شرح می دهد، نقاط مختصات با یکدیگر مقایسه می شوند و جفت هایی که فاصله آنها کمتر یا مساوی است. l rل�(معادله ( 1 )) به عنوان جفت نقاط در مجاورت شناسایی می شوند و به لیستی اضافه می شوند که بخشی از خروجی الگوریتم خواهد بود. در این مورد، شایان ذکر است که فاصله در نظر گرفته شده برای این رویکرد 20 متر است به دلیل خطاهای دقیقی که در سیستم های GPS رخ می دهد که در [ 22 ] شرح داده شده است. ورودی آن لیستی از نقاط جمع آوری شده با ساختاری است که در جدول 1 به تفصیل آمده است و مراحل آن در جدول 3 به تفصیل آمده است .
این مرحله از نظر محاسباتی پرهزینه ترین است، زیرا مستلزم مقایسه بین تمام نقاط نمونه برای شناسایی نقاط مجاورت است ( شکل 4 ).
3.2.2. الگوریتم 1.1: تقسیم بازگشتی فضای اصلی به زیرمنطقه ها
با توجه به مفاهیم ارائه شده در مورد تعریف مجاورت و ایده تقسیم فضا به ربع های کوچکتر به عنوان تابعی از تعداد نقاط مورد بررسی، الگوریتم نشان داده شده در شکل 9 را ابداع کرده ایم که وظیفه دریافت نقاط جمع آوری شده را بر عهده دارد . سپس ربع های کافی را تعریف کنید و نقاطی را که در داخل این ربع ها قرار دارند فهرست کنید ( شکل 5 ).
دو تابع اول یک ناحیه اولیه را تعریف می کنند که تمام نقاط جمع آوری شده را پوشش می دهد و همه نقاط را به این ناحیه اولیه پیوند می دهد. این برای اینکه تابع 3 بتواند به صورت بازگشتی کار کند ضروری است. تابع 3 همیشه یک ناحیه را با نقاط آن دریافت می کند و سپس تصمیم می گیرد که آیا لازم است این ناحیه را به ربع کوچکتر تقسیم کند یا خیر. معیار تصمیم گیری تصریح می کند که اگر تعداد نقاط داخل منطقه از آستانه جمعیت ربع فراتر رود، این ناحیه باید به مناطق کوچکتر تقسیم شود که به صورت بازگشتی به تابع 3 ارسال می شود. جزئیات این الگوریتم در جدول 4 مشخص شده است .
تابع بازگشتی نشان داده شده در شکل 9 الگوریتم خود را در شکل 10 نشان داده است ، در حالی که جدول 5 مراحل این تابع بازگشتی را توضیح می دهد.
هر مجموعه زیرحوزه ای از نقاط را می توان برای پردازش در گره های محاسباتی مختلف تخصیص داد، که اجازه می دهد کار موازی شود. در حالی که از یک طرف، اطمینان حاصل می کنیم که هر زیرمنطقه دارای تعدادی امتیاز کوچکتر از یک آستانه تعیین شده است، از طرف دیگر، ممکن است زیرمنطقه هایی با تعداد امتیازات کم داشته باشیم. این ممکن است نشان دهنده اتلاف بالقوه منابع محاسباتی و حافظه باشد زیرا پردازش با توجه به تعداد نقاط در زیر ناحیه متفاوت است. با این حال، یک فرآیند زمانبندی در این کار به کار گرفته شد که به ترتیب زیر ناحیهها را در رشتههای موجود توزیع میکند و تفاوتهای احتمالی را در کل زمان پردازش در گرهها به حداقل میرساند.
الگوریتم 1.1 لیستی از نقاط را با زیرحوزه های مربوطه ایجاد می کند تا به صورت موازی توسط الگوریتم 1.2 پردازش شوند. چنین ساختاری در جدول 6 به تفصیل آمده است .
3.2.3. الگوریتم 1.2: تشخیص جفت ها در زیر ناحیه ها
الگوریتم برای تشخیص جفت ها در زیر ناحیه ها همان است که در شکل 8 توضیح داده شده است و فقط در لیست نقاطی که باید پردازش شوند متفاوت است. خروجی این الگوریتم لیستی است شامل جفت نقاط مجاور که ساختار آنها در جدول 7 به تفصیل آمده است .
3.2.4. الگوریتم 2: تشخیص گروه ها
این الگوریتم، شماره 2 از شکل 7 ، جفت نقاط در نظر گرفته شده در مجاورت توسط الگوریتم 1.2 را می گیرد و سپس نقاطی را می یابد که با جستجوی همسایگان یک همسایه گروه بندی می شوند، یعنی در موقعیت هایی که نقطه A نزدیک به B و نقطه B است. نزدیک به C؛ از این رو، A، B و C گروهی از افراد تحت نظارت را تشکیل می دهند. این الگوریتم تشخیص گروه ها در شکل 11 ارائه شده است ، در حالی که جزئیات آن در جدول 8 و خروجی آن در جدول 9 با لیستی از گروه ها، هر یک دارای یک شناسه، یک مهر زمانی برای لحظه جمع آوری امتیازات و لیستی از گروه ها مشخص شده است. دستگاه های تشکیل دهنده گروه
3.2.5. الگوریتم 3: محاسبه شاخص های ریسک
تشخیص خطرات، که مطابق با الگوریتم 3 در شکل 7 است، برای گروهی از افراد تحت نظارت، داده های اضافی را در رابطه با مدت زمان گروه و میانگین تعداد عناصر محاسبه می کند، شاخص هایی که به عنوان نمونه های جدید به روز می شوند از دستگاه های نظارت شده جمع آوری می شوند. از نقطه نظر پایش قوزک، این دادهها در مورد گروهها ممکن است به تجزیه و تحلیل ریسک که متعاقباً برای اجرای الگوریتمهای مشخص شده انجام میشود کمک کند. راهحل پیشنهادی در این مقاله فقط شاخصهای ریسک مرتبط با گروههای شناساییشده را محاسبه میکند و این دادهها را برای یک فعالیت تحلیل ریسک که خارج از سیستم نظارت انجام میشود، ذخیره میکند.
در طول اجرای خود ( شکل 12 و جدول 10 )، الگوریتم 3 داده های زیر را جمع آوری می کند: (i) مدت زمان گروه: این شاخص از این تصور ناشی می شود که گروه هایی که بیشتر دوام می آورند ممکن است نشان دهنده خطر بیشتر باشد و حتی گروه هایی با مدت زمان بسیار کوتاه. ممکن است دور انداخته شود؛ (2) میانگین تعداد عناصر در هر گروه: گروههایی که تعداد عناصر بیشتری دارند میتوانند موارد نقض در مقیاس بزرگتر را نشان دهند، برای مثال جنایت سازمانیافته یا توطئه.
برای نشان دادن مدت یا ماندگاری یک گروه، الگوریتم باید این گروه شناسایی شده قبلی را با داده های مربوط به مدت زمان (تاریخ شروع/پایان/زمان) به روز کند. هنگامی که مشخصه تاریخ/زمان پایان پر نمی شود، نشان می دهد که گروه هنوز فعال است، یعنی تا آخرین اجرای ترکیب داده ها به طور مداوم حفظ شده است. تاریخ/ساعتهای ثبتشده برای گروه، لحظه دقیق شروع یا پایان این گروه را نشان نمیدهند، زیرا تحت تأثیر زمانهای انتظار و سرویس در طول جمعآوری دادههای حسگر و اجرای خود الگوریتمها هستند.
همانطور که قبلاً بحث شد، خروجی الگوریتم 3 در جدول 2 مشخص شده است . ساختار حاصل برای تجزیه و تحلیل ریسک و برای نوبت های پردازش آتی در دسترس است.
4. سناریوهای اعتبار سنجی و نتایج
به منظور اعتبارسنجی الگوریتم های ارائه شده در این مقاله، یک پایگاه داده شبیه سازی شده با تقریباً 10000 دستگاه استفاده شد. شبیه سازی گروه ها با ایجاد تغییرات مجموعه ای از مسیرهای به دست آمده از تجهیزات واقعی GPS انجام شد. مسیرهای جدید شبیهسازی شده با استفاده از جابجایی افقی و عمودی نقاط مختصات دستگاه اصلی در فضای جغرافیایی و همچنین افزایش تعداد نقاط مختصات در نمونه تشکیل شدهاند. علاوه بر این، مسیرهای جدیدی با معکوس کردن طول و عرض جغرافیایی و نسبت دادن آنها به نقاط شبیه سازی شده جدید ایجاد شد. در نتیجه، سه ست با 10000 امتیاز ایجاد شد. این نمونهها با سه مجموعه متوالی از نقاط از خلخالهای شبیهسازی شده در یک برنامه زمانی شبیهسازی شده، به ترتیب مربوط به تاریخ 25 مه 2015 در برچسبهای زمانی هستند: (i) 12:00، (ii) 12: 01 و (iii) 12:02. که درجدول 11 ، نمونه ای از رکوردها به صورت تصادفی از پایگاه داده شبیه سازی شده استخراج شده است.
به عنوان نمونه ای از یک منطقه تحت پوشش، 10000 امتیاز مربوط به نمونه برداری از مهر زمانی 25 مه 2015 ساعت 12:00:00-03 در یک منطقه جغرافیایی پراکنده شده است که در شکل 13 نشان داده شده است .
پیکربندی محاسباتی مورد استفاده برای اعتبارسنجی اجرای الگوریتم های پیشنهادی در جدول 12 ارائه شده است .
الگوریتم های پیشنهادی در پنج سناریو پیاده سازی و ارزیابی می شوند. اولین مورد یک پیاده سازی سریال در یک زبان پرس و جو پایگاه داده رابطه ای (سناریو) است. این سناریوی کلاسیک برای توسعه برنامه به عنوان یک خط پایه برای مقایسه نتایج در این مقاله در نظر گرفته شده است زیرا هیچ سهم عملکرد خاصی را به کار نمیگیرد، اگرچه عملکرد صحیح کامل پیشنهاد شده در این مقاله را ارائه میکند. سناریوهای دیگر به تدریج مشارکت های موازی (سناریو 2) و زبان برنامه نویسی (سناریوهای 3 و 4) را برای الگوریتم های پیشنهادی ارائه می دهند و عملکرد یکسانی را حفظ می کنند. سناریوی پردازش توزیع شده ممکن در بحث نتایج تحلیل می شود.
به طور خاص، برای اهداف اصلاحی، در تمام سناریوهای ارزیابی شده، تعداد رکوردهای حاصل از اجرای هر الگوریتم اعمال شده بر روی داده های شبیه سازی شده در جدول 13 آورده شده است .
در ارائه نتایج هر سناریو از این پس، مقادیر اندازه گیری میانگین 10 اجرای مکرر است.
4.1. سناریو 1: پردازش سریال در PL/pgSQL
در این سناریو، الگوریتم های توصیف شده 1-3 به طور کامل در پردازش سریال اجرا می شوند و عملکرد هر یک اندازه گیری می شود. هر یک از سه الگوریتم به طور جداگانه اندازه گیری شده و سپس، زمان پاسخ مجموع آنها ارائه می شود. این روش برای امکان مقایسه منطقی با نتایج سناریوهای بعدی، زمانی که بخشهایی از آن الگوریتمها با ماژولهایی در پردازش موازی یا به زبان C یا در پردازش توزیع شده جایگزین میشوند، انتخاب شده است.
4.1.1. الگوریتم 1: تشخیص جفت
پیاده سازی یک الگوریتم ساده است که تمام نقاط مختصات را با به دست آوردن لیستی از جفت نقاط مجاور تولید شده از طریق یک دستور SQL که یک خود پیوستگی را در جدول نقاط انجام می دهد، مقایسه می کند. در این دستور SQL، یک فیلتر در عبارت Where تنها نقاطی را انتخاب می کند که فاصله محاسبه شده آنها کمتر از آستانه مجاورت باشد. این آستانه همانطور که در بخش 3.1.1 بیان شد در 20 متر تعریف شد. علاوه بر این، در این بند جایی، فیلتری اضافه می شود که فقط نقاطی را در نظر می گیرد که شناسه نقطه A کوچکتر از شناسه نقطه B است. این فیلتر از محاسبه دو برابر فاصله بین یک جفت، یعنی فاصله از یک جفت جلوگیری می کند. A به B و از B به A، بنابراین تلاش پردازش کاهش می یابد. به عنوان خروجی، جدولی از جفت ها تولید می شود. به عنوان مثال، جدول خروجی، مربوط به نمونه ما با برچسب 25 مه 2015 ساعت 12:00، دارای تعداد تقریبی 9103 رکورد (جفت نقطه در مجاورت) است.
این الگوریتم با فاصله 10، 20 و 40 متر به عنوان آستانه آزمایش شد. اگرچه در میزان جفت های شناسایی شده به دلیل متغیر فاصله تفاوت وجود داشت، زمان پاسخ تقریبی باقی ماند. علاوه بر این، 20 متر در دقت خطا قابل قبول است [ 22 ].
4.1.2. الگوریتم 2: تشخیص گروه ها
به منظور شناسایی گروه هایی از نقاط مجاور، کد PL/pgSQL توسعه یافته مشخص شده در شکل 11 جدولی از گروه ها با 1673 گروه شناسایی شده ایجاد می کند.
4.1.3. الگوریتم 3: محاسبه شاخص های ریسک
این الگوریتم مطابق شکل 12 یک ماژول PL/pgSQL است . با این حال، زبان پیادهسازی با اعمال بهروزرسانی در مجموعه رکوردهایی که با فیلتر مطابقت دارند به جای بررسی هر گروه بهدستآمده در پردازش اخیر در برابر هر یک از گروههای شناساییشده قبلی، امکان بهبود کد را فراهم میکند.
4.1.4. نتایج زمان پاسخگویی
قابل ذکر است، الگوریتمی که جفت نقاط را در مجاورت تشخیص می دهد، زمان پردازش بسیار بالاتری نسبت به الگوریتم های 2 و 3 ارائه می دهد و به میانگین زمان 280 ثانیه می رسد ( شکل 14 ). هنگام در نظر گرفتن آستانه عملکرد کلی مورد نیاز (بر روی یک پنجره پردازش 1 دقیقه ای ثابت شده است)، مجموع زمان های سه الگوریتم پردازش از این مقدار فراتر می رود، که از غیرعملی بودن آنها هشدار می دهد. با این حال، مقادیر اندازه گیری شده به عنوان پایه ای برای سناریوهای اعتبارسنجی بعدی جالب هستند.
نتایج سناریوی 1 مسئله زمان پاسخ را هنگام شناسایی نقاط مختصات در مجاورت بدون استفاده از پردازش موازی، که سناریوی بعدی را توجیه میکند، نشان میدهد.
4.2. سناریوی 2: پردازش PL/pgSQL با چند نمونه موازی
در سناریوی 1، الگوریتم 1 برای تشخیص جفت ها، که زمان بسیار بیشتری نسبت به دو الگوریتم دیگر نیاز دارد، کاندیدای قابل مشاهده برای بهبود است، بنابراین در سناریوی 2 با افزودن یک الگوریتم داخلی برای توزیع نقاط در زیر ناحیه ها، فرمول بندی مجدد می شود (الگوریتم 1.1). ) که اجازه می دهد تا شناسایی جفت ها (الگوریتم 1.2) در چندین نمونه موازی اجرا شود. از آنجایی که الگوریتم های 2 و 3 از سناریو 1 اصلاح نشده اند، در سناریو 2 ارائه نشده اند.
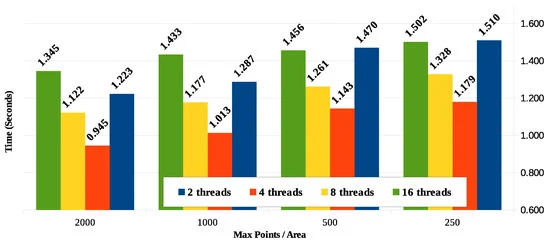
تقسیم کل فضای مختصات به ربع کوچکتر به معنای تقسیم متناظر تعداد نقاط مختصات مورد مقایسه در هر پردازش ربع است. اکنون، یک مبادله در مورد تعداد نقاطی که به عنوان معیار تصمیم گیری برای تقسیمات فرعی بازگشتی ربع ها استفاده می شود، وجود دارد. با توجه به اینکه هر چه این عدد کوچکتر باشد، تعداد زیرمنطقه ها بیشتر می شود، باید حداکثر امتیاز را برای هر زیرمنطقه ربع تعیین کرد.
با توجه به اینکه ما پایگاه داده ای از 10000 نقطه مختصات را برای تمام سناریوهای اعتبار سنجی ایجاد کرده ایم، چهار مورد را برای حداکثر تعداد نقاط در زیر ناحیه (به ترتیب 250، 500، 1000 و 2000) تعریف کرده و ارقام زمان پاسخ را برای این موارد به دست می آوریم.
4.2.1. الگوریتم 1.1: توزیع امتیاز در هر زیرمنطقه
این الگوریتم که در PL/pgSQL مطابق جریان های شکل 9 و شکل 10 پیاده سازی شده است ، بر اساس 10 اجرای مکرر، میانگین نتایج زمان پاسخ نشان داده شده در شکل 15 را برای هر یک از حداکثر مقادیر نقاط در زیر ناحیه نشان می دهد.
داده های مربوط به تقسیمات فرعی ناحیه مختصات در جدول 14 ارائه شده است . همانطور که انتظار می رود، هر چه حداکثر تعداد نقاط در هر منطقه بزرگتر باشد، اندازه متوسط ناحیه مورد پردازش کمتر است. اندازه بزرگترین منطقه همیشه یکسان است زیرا با اولین تقسیم بندی کل مساحت مربوط به 146.56 کیلومتر مطابقت دارد. 22.
هرچه حداکثر امتیاز در هر زیرمنطقه کمتر باشد، میانگین اندازه زیرمنطقه ها کوچکتر است. اندازه کوچکترین ناحیه حاصل از بازگشتی ترین تقسیم به ربع نیز با تعداد نقاط در هر منطقه کاهش می یابد. در کوچکترین موارد، زیر مساحت حاصل تقریباً 150 متر مربع عرض دارد.
4.2.2. الگوریتم 1.2: تشخیص جفت ها با چند نمونه موازی
الگوریتم تشخیص جفت از سناریو 1 برای اجرای موازی تنظیم شده است. از آنجایی که PostgreSQL از توسعه روتین ها در PL/pgSQL پشتیبانی نمی کند، ما از یک اسکریپت پوسته ای استفاده می کنیم که تحت یک سیستم عامل اوبونتو اجرا می شود که به طور همزمان نمونه های مختلفی از یک روال را ارسال می کند تا هر نمونه گروهی از مناطق مجزا را در نظر بگیرد.
4.2.3. نتایج زمان پاسخگویی
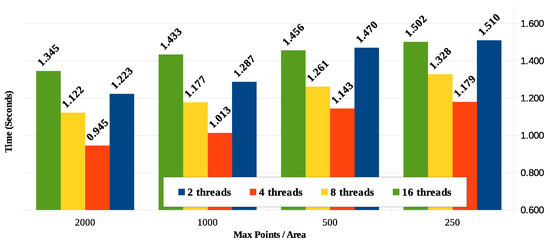
شکل 16 نتایج زمان پاسخ مقایسه ای را برای پردازش موازی با در نظر گرفتن چهار مقدار برای حداکثر نقاط در زیر ناحیه مختصات (250، 500، 1000 و 2000) و تعداد رشته های پردازش استفاده شده (2، 4، 8 و 16) نشان می دهد. .
مقدار زیرمنطقهها معمولاً بیشتر از تعداد گرههای محاسباتی (یا هستههای) موجود برای رسیدگی به آنها خواهد بود. علیرغم اینکه می دانیم این بهترین تکنیک به دلیل تغییر در مقدار نقاط در زیر ناحیه (صفر تا حداکثر نقاط در هر منطقه) نیست، در این مقاله فرض می کنیم که توزیع زیر ناحیه ها در بین گره های محاسباتی در مراحل مشابه اعمال می شود. به یک الگوریتم دورگرد. این می تواند منجر به اضافه بار گره های خاص شود در حالی که سایر گره ها بیکار می شوند. یک تکنیک پردازش توزیع بهتر بین گره ها موضوعی برای کار بیشتر است.
شکل 16 نشان می دهد که با کاهش حداکثر تعداد نقاط در هر منطقه، زمان پردازش مربوطه نیز به دلیل تعداد کمتر مقایسه بین نقاط لازم برای پردازش و محاسبه فاصله کاهش می یابد. برای نمونه مورد استفاده در این کار و با در نظر گرفتن نتایج در سناریوی 1، کاهش زمان پاسخ قابل توجه است و با کاهش نقاط در زیر ناحیه، تمایل به صاف شدن دارد.
تجهیزات مورد استفاده دارای پردازنده هایی با دو هسته و فناوری Hyper-threading است که چهار هسته منطقی را شبیه سازی می کند. انتظار می رفت که بهترین زمان پاسخگویی با چهار رشته باشد. با این حال، برای مناطق با تعداد امتیاز بیشتر (1000 و 2000)، موارد با هشت و 16 نخ نتایج بهتری را نشان دادند. برای مناطقی که با نقاط کمتر تعریف شده اند، تفاوت در تعداد نخ ها کمتر است. باید در نظر گرفت که از آنجایی که پردازش برخی از عملیات خواندن و نوشتن دیسک را انجام می دهد، به نظر می رسد زمان انتظار I/O نتیجه، زمان پاسخگویی بهتر را هنگام پردازش با رشته های بیشتر توضیح می دهد.
4.3. سناریوی 3: الگوریتم 1.2 به زبان C بدون پردازش موازی
در این سناریو، برای مقایسه، یک روال با استفاده از زبان C برای پیاده سازی الگوریتم تشخیص جفت ها ( شکل 9 ) بدون پردازش موازی توسعه داده شد. همه نقاط با سایر نقاط مقایسه می شوند و با محاسبه فاصله مربوطه، کسانی که در مجاورت هستند شناسایی می شوند. در این حالت هیچ تقسیم بندی نقاط به زیرمنطقه ها وجود ندارد و کل فرآیند به صورت سریال انجام می شود. روال 10000 نقطه را از یک فایل در یک سیستم فایل می خواند و نتیجه را به صورت یک فایل متنی در همان سیستم فایل می نویسد.
زمان پاسخ پردازش ( شکل 17 ) برای الگوریتم 1.2 در زبان C تقریباً 20 برابر سریعتر از همان روال در PL/pgSQL بود (14.66 ثانیه در سناریوی 3، در حالی که در سناریوی 1 280 ثانیه بود). البته این برتری از نظر کارایی مورد انتظار است و به این ترتیب نشان می دهد که کدام زبان برای این کلاس کاربرد مناسب تر است.
4.4. سناریوی 4: الگوریتم 1.2 در زبان C با چند نمونه موازی
با توجه به اینکه روال در زبان C که در سناریوی قبلی توسعه یافته بود اکنون در چندین نمونه از هم جدا شده توسط زیر ناحیه مختصات اجرا می شود و چنین نمونه هایی را با 2، 4، 8 و 16 رشته اجرا می کند، نتایج زمان پاسخ در شکل 18 نشان داده شده است .
نتایج بهدستآمده برای اجرای موازی روال در زبان C، در هر مورد زیر ۲ ثانیه، عموماً بسیار کمتر از نتایج بهدستآمده در PL/pgSQL است. یک مشاهدات قابل توجه این است که، بر خلاف نتایج بهدستآمده در پردازش با PL/pgSQL، تفاوتها در مورد تعداد رشتههای در حال اجرا قابل توجه است و بهترین عملکرد هنگام اجرا با چهار رشته به دست میآید. زمان پاسخ کمتری که با چهار رشته به دست میآید به دلیل معماری پردازنده تجهیزات مورد استفاده در آزمایش است که دارای چهار هسته منطقی با فناوری Hyper-threading (دو هسته فیزیکی) است.
4.5. بحث
الگوریتم های پیشنهادی بر روی سه مجموعه نقطه برای بررسی نتایج و زمان پاسخ آنها در سناریوهای مختلف اعمال شدند. در سناریوی اول، به کاربرد الگوریتمها مستقیماً در پایگاه داده PostgreSQL با استفاده از PL/pgSQL و پسوند PostGIS میپردازیم.
در سناریوی دوم، پردازش به دو مرحله تقسیم شد که به دنبال کاهش زمان اجرای کلی الگوریتمها بود. در این سناریو، راهحل پیشنهادی توزیع نقاط مختصات به زیر ناحیههای ناحیه اصلی است که امکان موازیسازی پردازش را برای این زیرحوزهها فراهم میکند.
در سناریوی سوم، بدون پردازش موازی، کار کندتر در زبان C پیادهسازی شد، اما مشخص شد که حتی در یک زبان با عملکرد بالاتر، زمان پاسخ همچنان قابل افزایش است.
در نتیجه، در سناریوی چهارم، الگوریتم شناسایی جفت پیادهسازی شده در زبان C در چندین نمونه موازی اجرا شد و جای خود را به نتایج زمان پاسخ بهتر داد.
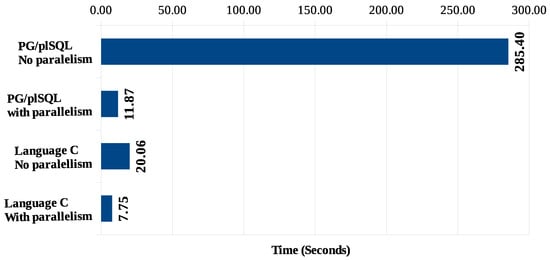
هنگام مقایسه کمترین زمان پردازش ممکن برای هر سناریو (شامل مجموعه الگوریتمها برای شناسایی جفت نقاط مجاور، گروهبندی این جفتها و شناسایی شاخصهای ریسک)، نمودار نشان داده شده در شکل 19 را به دست میآوریم . سناریوهای 1 و 3، مربوط به پردازش بدون موازی در PG/pgSQL و در C، به ترتیب، یک نتیجه نهایی با زمان پاسخ بالاتر دارند. سناریوهای 2 و 4 زمان پاسخ بهتری را نشان دادند که به دلیل استفاده از پردازش موازی برای شناسایی مجاورت بین جفتهای مختصات ممکن شد.
در تمام سناریوها، پردازش الگوریتمهای 2 و 3 (تشخیص گروهها و محاسبه شاخصهای ریسک) با ماژولهای زبان PL/pgSQL انجام میشود، به دلیل زمان پاسخدهی خوب بهدستآمده با این زبان برنامهنویسی، که اجازه میدهد حداقل زمان کل باقی بماند. 7.75 ثانیه (سناریو 4). اجرای آینده با همه الگوریتمها در زبان C، کوتاهترین زمان اجرای کل فرآیند را بیشتر کاهش میدهد.
این مقاله به یکپارچهسازی روتینها در زبان C که توسط فراخوانیهای توابع PL/pgSQL فعال میشوند، نمیپردازد، ویژگیای که توسط PostgreSQL 9 پشتیبانی میشود. با این حال، تخمین زده میشود که زمانهای اجرای روالها در این موقعیت بسیار نزدیک به آن هستند. در سناریوهای ارائه شده ما اندازه گیری شد.
4.6. در مورد امکان سنجی استفاده از پردازش توزیع شده
از آنجایی که پردازش موازی با رشته های متعدد در مقایسه با رشته واحد، هم در PL/pgSQL و هم در زبان C بهتر عمل می کند، بنابراین طبیعی است که به آزمایشی در یک محیط پردازش توزیع شده در یک معماری داده محور بزرگ فکر کنیم. در این زمینه، یکی از پرکاربردترین پلتفرم ها Hadoop است. با این حال، برخی از ویژگی های این نوع پردازش باید در نظر گرفته شود:
- (آ)
-
دادههای بزرگ حجم عظیمی از دادهها را برای پردازش فرض میکنند. به نظر می رسد که این موردی نیست که در این مقاله توضیح داده شده است. اگرچه پردازش با کارایی بالا بر اساس الزامات برنامه دلالت دارد، اما میزان داده های پردازش شده در یک زمان (به عنوان مثال، 10000 نقطه پیشنهاد شده در اینجا) حجم داده قابل توجهی نیست. در نتیجه، بدون هیچ گونه پیکربندی خاصی، بارگذاری این داده ها در یک محیط گره چندگانه همانطور که در یک محیط کلان داده انتظار می رود، این حجم از داده ها تمایل دارد روی یک گره بارگذاری شود، بنابراین امکان پردازش توزیع شده از بین می رود. همانطور که توسط داونپورت [ 24]، اصطلاح کلان داده اساساً بر حسب حجم، تنوع و سرعت تعریف می شود، ویژگی هایی که اجرای پلت فرم های کلان داده را هدایت می کنند. اولین مشخصه (حجم) قبلاً در مورد استفاده ما به خطر افتاده است.
- (ب)
-
برای پردازش در یک محیط پردازش توزیع شده، کل فرآیند چند ثانیه (در برخی موارد، حتی چند دقیقه) طول می کشد تا برای پردازش آماده شود. این زمان اولیه ضروری میتواند برآوردن نیاز اولیه توصیفشده در مشکل ما را غیرممکن کند، که یک پنجره زمانی ۱ دقیقهای را برای انجام پردازش نمونههای داده فرض میکند، در مورد ما با ۱۰۰۰۰ نقطه مختصات شبیهسازیشده برای اعتبارسنجی ما.
به نظر میرسد کاربرد الگوریتمهای ارائهشده برای پردازش توزیعشده با پلتفرم هدوپ کلان داده، اگرچه در صورت گسترش نظارت بر قوزک به جمعیتهای بزرگتر میتواند مفید باشد، اما همچنان موضوعی قابل بررسی است، زیرا اگرچه ظرفیت پردازش ارائه شده نسبتاً بالاتر است. ، مقدار داده هایی که باید پردازش شوند کم است، اما نیاز به تلاش آماده سازی مهمی دارد که باعث می شود داده های بزرگ در حال حاضر به عنوان یک راه حل جایگزین برای مشکل نامناسب باشند.
5. نتیجه گیری ها
روند نظارت بر محکومان با استفاده از خلخال های الکترونیکی را می توان با تولید داده های اضافی برای پشتیبانی از تجزیه و تحلیل خطر برای تصمیم گیری بهبود بخشید. در این مقاله چالش شناسایی گروههایی از محکومان تحت نظارت، زمان ماندگاری این گروهها و تعداد اعضای آنها با افزودن محدودیت زمانی رسیدگی مطرح شد. نشان داده شد که استفاده از الگوریتم های سریال به دلیل زمان پاسخ بیش از حد پردازش آنها یک مشکل است. مشاهده شد که طولانی ترین زمان پردازش مربوط به محاسبه جفت مختصات دستگاه با توجه به مجاورت آنها بود.
راه حل پیشنهادی برای افزایش عملکرد، تقسیم کل منطقه جغرافیایی شامل تمام نقاط مختصات به مناطق کوچکتر (ربع) است به طوری که هر منطقه می تواند به طور مستقل پردازش شود، بنابراین امکان پردازش موازی در هنگام شناسایی نقاط مجاورت فراهم می شود. تقسیم کل مساحت به مناطق کوچکتر شامل رسیدگی به وضعیتی بود که نقاط مجاور در زیرمناطق مجاور بودند که با گسترش هر منطقه توسط ضریب دقت GPS (10 متر) در همه جهات و حذف موارد تکراری در گروه بندی حل شد. نقاط در مجاورت
اتخاذ روال هایی با استفاده از PL/pgSQL برای پیاده سازی الگوریتم ها به تنهایی پنجره زمانی مورد نیاز را برآورده نمی کند. با این حال، هنگام استفاده از یک زبان سطح پایین، مانند C، برای پیادهسازی الگوریتمهای مشابه، زمان پاسخ کلی کاهش قابلتوجهی را تجربه میکند.
با این حال، این کاهش زمان پاسخ، کنار گذاشتن موازیسازی در پردازش پیشنهادی را توجیه نمیکند، زیرا حتی زمان معمول در زبان C بدون استفاده از موازیسازی (که مربوط به تقریباً 1/4 از حد پنجره تعریفشده است) میتواند الزامات عملکرد را به خطر بیاندازد. به عنوان مثال، افزایش خطی در تعداد نقاطی که باید پردازش شوند، تعداد مقایسههایی را که برای محاسبه فاصله باید انجام شود، بهطور تصاعدی افزایش میدهد، که مستقیماً بر زمان پاسخ تأثیر میگذارد. در این مورد، حتی با استفاده از زبان C برای پیاده سازی روال های مربوط به الگوریتم های پیشنهادی، استفاده از راه حل پردازش موازی مناسب است.
محاسبات با واحدهای پردازش گرافیکی (GPU) در موارد روتین های کوتاه و موازی مناسب است، همانطور که در مورد تشخیص نقاط نزدیک با محاسبه و مقایسه فاصله ها مناسب است. اگرچه محدود به سخت افزار خاص است، اما به وفور در بازار موجود است، این جایگزین باید در مورد نیاز به کاهش حتی بیشتر در زمان پاسخ برای الگوریتم های مطرح شده در این مقاله در نظر گرفته شود. در حالی که به دلیل ویژگیهای پردازش شدید و موازی یا الگوریتم تشخیص جفت، باید محاسبات با شتاب GPU را در کارهای آینده در نظر گرفت، سایر پلتفرمهای کلان داده، مانند Hadoop، میتوانند بیشتر مورد مطالعه و آزمایش قرار گیرند تا به روشی ساده برای دستیابی به آن دست یابند. الزامات عملکرد فرآیند
بر خلاف سایر الگوریتمها، راهحل پیشنهادی در این مقاله شامل نظارت بر گروههای تشکیلشده در طول زمان، بهروزرسانی دورهای دادههای هر گروه است، بنابراین از تحلیل بر اساس مدت زمان گروه (فاصله زمانی که گروه در آن جمع میماند) و به طور میانگین پشتیبانی میکند. تعداد عناصر گروه در طول عمر آن علاوه بر این، هنگام در نظر گرفتن گروههای غیرفعال (آنهایی که در گذشته شناسایی شدهاند و اکنون به پایان رسیدهاند)، میتوان از دفعات و زمانی که معمولاً گروههای خاصی با هم ملاقات میکنند، مطلع شد.
ما تأکید می کنیم که این مقاله به مسائل مربوط به محاسبات مجاورت و عملکرد آنها اختصاص دارد، اگرچه می دانیم که چندین موضوع دیگر نیز وجود دارد که به همان اندازه مهم هستند که باید مورد بررسی قرار گیرند، مانند جنبه های همجوشی مربوط به تاریخ که توسط خالقی [9] که موارد مرتبط را طبقه بندی کرده است، پرداخته است . مسائلی مانند نقص، همبستگی، ناسازگاری و ناهمگونی. بنابراین، دادههای مورد استفاده در شبیهسازیهای ما میتوانند اصلاح و تکمیل شوند تا موقعیتهای مستعد این مشکلات را نشان دهند. سپس، برای اینکه الگوریتمهای ما نسبت به این مشکلات کیفیت دادهها مدارا کنند، باید فیلترهایی را با توجه به ویژگیهای دادهها، مانند تاریخهای نامعتبر، در نهایت نقاط از دست رفته، جمعآوری نقاط مکرر یا تأخیر، و غیره داشته باشند.
سایر مسائل مربوط به تحرک گروه ها به دلیل پیچیدگی شناسایی و درمان آنها در کارهای آینده مورد بررسی قرار خواهد گرفت. چنین مشکلاتی رخ می دهد، به عنوان مثال، زمانی که یک دستگاه ردیابی شده در یک جلسه وجود دارد و این دستگاه نمی تواند مختصات را ارسال کند، در نتیجه باعث می شود که پوشنده خارج از گروه در پردازش دوره ای مربوطه در نظر گرفته شود. در واقع، گروههایی که شناسایی و ردیابی میشوند، ثابت یا در حال حرکت هستند، در الگوریتمهای پیشنهادی به روش مشابهی رفتار میشوند، اگرچه هر یک از این موقعیتها ممکن است خطرات متفاوتی داشته باشند.
ادغام دادههای تولید شده در این کار با سایر پایگاههای داده تکمیلی، مانند موارد ثبت جرایم رخ داده در همان زمان و محل ملاقاتهای کشفشده، و ثبت خطرات فردی برای افزایش و بهبود اطلاعات در دسترس تحقیقات مهم هستند. تیم ها چنین ادغامی باید به عنوان کار آینده مورد توجه قرار گیرد.
منابع
- DEPEN، Levantamento Nacional de Informações Penitenciárias. در دسترس آنلاین: http://dados.mj.gov.br/dataset/infopen-levantamento-nacional-de-informacoes-penitenciarias (دسترسی در 27 مارس 2016).
- Barbosa، RM O Monitoramento Eletrônico Para Presos de Baixa Periculosidade ; Universidade Católica de Brasília: Brasília، برزیل، 2010. (به پرتغالی) [ Google Scholar ]
- داوبال، م. فاجینمی، ا. جانگارد، ال. سیمونسون، ن. یاسوتاکه، بی. نیول، جی. Ali, M. Safe step: یک سیستم ردیابی و تجزیه و تحلیل GPS در زمان واقعی برای فعالیت های مجرمانه با استفاده از دستبند مچ پا. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، اورلاندو، فلوریدا، ایالات متحده آمریکا، 5 تا 8 نوامبر 2013. پ. 515.
- فدراسیون اتومبیل رانی اسپانیا. Congresso Nacional de Execução de Penas e Medidas Alternativas ; Federación Española de Empresarios de Automocion: Manaus، برزیل، 2008. (به پرتغالی) [ Google Scholar ]
- وانی، ب. مونیکو، جی اف جی؛ Shimabukuro, MH Fundamentos e Aspectos Computacionais Para Posicionamento Por Ponto GP ; Revista Brasileira de Geomática: Apucarana، برزیل، 2013. (به پرتغالی) [ Google Scholar ]
- ناتان، PMC Wireless Communications ; PHI Learning Pvt. Ltd.: دهلی، هند، 2010. [ Google Scholar ]
- ماس، ام ال. Townsend، AM چگونه سیستم های مخابراتی فضاهای شهری را تغییر می دهند. در شهرهای عصر ارتباطات از راه دور: گسست جغرافیاها . Routledge: نیویورک، نیویورک، ایالات متحده آمریکا، 2000. [ Google Scholar ]
- هال، DL; Llinas، J. مقدمه ای بر ترکیب داده های چندحسگر. Proc. IEEE 1997 ، 81 ، 6-23. [ Google Scholar ] [ CrossRef ]
- خالقی، ب. خمیس، ع. Karray، FO; ادغام داده های چندحسگر رضوی، SN: مروری بر آخرین هنر. Inf. فیوژن 2013 ، 14 ، 28-44. [ Google Scholar ] [ CrossRef ]
- لیو، کیو. دنگ، م. شی، ی. Wang, J. یک الگوریتم خوشهبندی فضایی مبتنی بر چگالی که هم مجاورت فضایی و هم شباهت ویژگیها را در نظر میگیرد. محاسبه کنید. Geosci. 2012 ، 46 ، 296-309. [ Google Scholar ] [ CrossRef ]
- جویدن، LP مثلث delaunay محدود. الگوریتمیکا 1989 ، 4 ، 97-108. [ Google Scholar ] [ CrossRef ]
- کارلینو، GA; Carr، JK Clusters of Knowledge: R&D Proximity and the Spillover Effect . بررسی کسب و کار؛ بانک فدرال رزرو فیلادلفیا: فیلادلفیا، PA، ایالات متحده آمریکا، 2013. [ Google Scholar ]
- لوهیچی، س. گذرا، م. بن عبدالله، اچ. الگوریتمی مبتنی بر چگالی برای کشف خوشههایی با چگالی متفاوت. در مجموعه مقالات کنگره جهانی 2014 در برنامه های کاربردی کامپیوتری و سیستم های اطلاعاتی (WCCAIS)، Hammamet، تونس، 17-19 ژانویه 2014.
- موریل، پی. Suleski, R. طراحی سیستم و تجزیه و تحلیل یک برنامه کاربردی مبتنی بر وب برای یکپارچه سازی داده های شبکه حسگر و ارائه بلادرنگ. در مجموعه مقالات سومین کنفرانس سالانه سیستم های بین المللی IEEE، ونکوور، BC، کانادا، 23 تا 26 مارس 2009.
- زو، اس. کنگ، ال. چن، ال. داده کاوی سری های زمانی نظارت بر حسگر و کشف دانش. در مجموعه مقالات دومین کنفرانس بین المللی 2011 در زمینه هوش مصنوعی، علوم مدیریت و تجارت الکترونیک (AIMSEC)، دنگ فنگ، چین، 8 تا 10 اوت 2011.
- جاخوپان، دبلیو. Klaypaksee، P. یک سیستم پرونده کیفری مبتنی بر وب با استفاده از دستگاه تلفن همراه: مطالعه موردی شهرداری هات یای. در مجموعه مقالات کنفرانس IEEE آسیا و اقیانوسیه 2014 در مورد بی سیم و موبایل، بالی، اندونزی، 28 تا 30 اوت 2014. ص 243-246.
- ساتیادوان، س. دوان، ام اس; Gangadharan، تجزیه و تحلیل و پیشبینی جرم SS با استفاده از داده کاوی. در مجموعه مقالات اولین کنفرانس بین المللی شبکه ها و محاسبات نرم 2014 (ICNSC2014)، گونتور، آندرا پرادش، هند، 19 تا 20 اوت 2014. ص 406-412.
- عود، سی. آکوستا، اف. ماخانو، ای. پذیرش فناوری موبایل به عنوان ابزاری برای پیشگیری از وقوع جرم در کنیا. در مجموعه مقالات کنفرانس IST-Africa 2014، Le Meridien Ile Maurice، Pointe Aux Piments، موریس، 7-9 مه 2014.
- پارک، کی. Youn, HY Crime Prevention System بر اساس آگاهی از زمینه. در مجموعه مقالات سومین کارگاه بین المللی 2011 در مورد سیستم ها و برنامه های هوشمند، ووهان، چین، 28-29 مه 2011.
- اوربانو، اف. Dettki، H. ذخیره داده های ردیابی در یک پلت فرم پایگاه داده پیشرفته. در پایگاه داده مکانی برای داده های ردیابی حیات وحش GPS ; Springer: برلین/هایدلبرگ، آلمان، 2014; ص 9-24. [ Google Scholar ]
- دینگ، ی. دنشم، PJ استراتژیهای فضایی برای مدلسازی فضایی موازی. بین المللی جی. جئوگر. Inf. سیستم 1996 ، 10 ، 669-698. [ Google Scholar ] [ CrossRef ]
- تیم NSTB/WAAS T&E. گزارش تجزیه و تحلیل عملکرد سیستم موقعیت یابی جهانی (GPS) سرویس موقعیت یابی استاندارد (SPS) ; اداره هوانوردی فدرال (FAA): واشنگتن، دی سی، ایالات متحده آمریکا، 2014.
- شیا، ی. لیو، ی. بله، ز. وو، دبلیو. Zhu، M. تجزیه دامنه مبتنی بر Quadtree برای تطبیق نقشه موازی بر روی داده های GPS. در مجموعه مقالات پانزدهمین کنفرانس بین المللی IEEE در سال 2012 در مورد سیستم های حمل و نقل هوشمند، Anchorage، AK، ایالات متحده، 16-19 سپتامبر 2012. ص 808-813.
- داونپورت، تی. داده های بزرگ در کار: رد اسطوره ها، کشف فرصت ها . انتشارات بازنگری هاوارد: واترتاون، MA، ایالات متحده آمریکا، 2014. [ Google Scholar ]
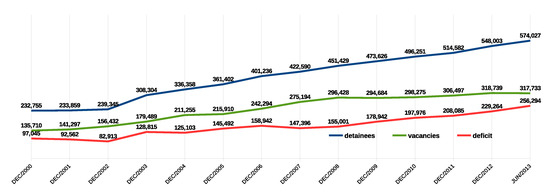
شکل 1. تکامل جمعیت زندانی برزیل. منبع: نویسندگان اقتباس شده از [ 1 ].
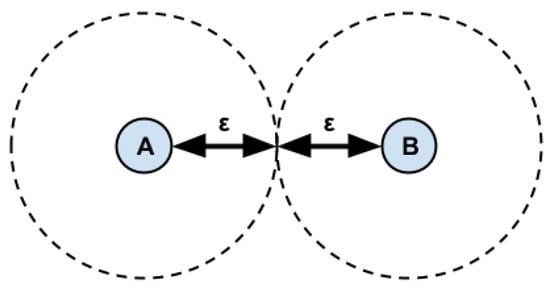
شکل 2. حداقل فاصله بین دو نقطه برای مشخص کردن مجاورت. منبع: نویسندگان
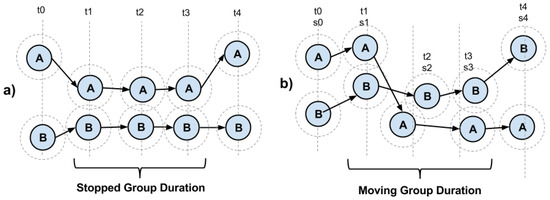
شکل 3. ( الف ) سیستم نظارت بر قوزک با تشخیص گروه متوقف شده. ( ب ) سیستم نظارت بر خلخال با تشخیص گروه متحرک. منبع: نویسندگان
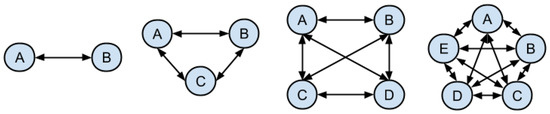
شکل 4. افزایش محاسبات به دلیل افزایش تعداد نقاط. منبع: نویسندگان

شکل 5. تقسیم کل مساحت به زیرمناطق. منبع: نویسندگان
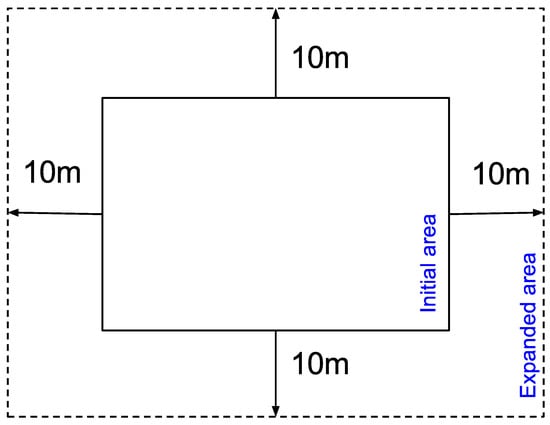
شکل 6. گسترش منطقه برای در نظر گرفتن نزدیکی نقاط در مناطق مجاور. منبع: نویسندگان

شکل 7. مراحل پردازش. منبع: نویسندگان
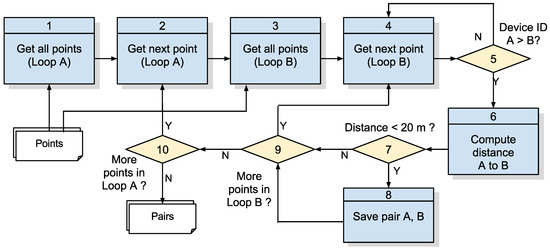
شکل 8. الگوریتم 1: تشخیص جفت. منبع: نویسندگان

شکل 9. الگوریتم 1.1: توزیع نقاط به زیر ناحیه ها. منبع: نویسندگان
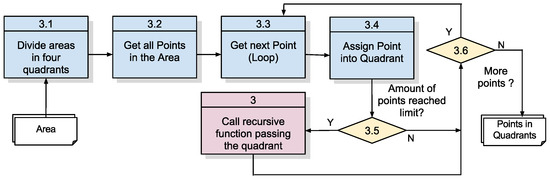
شکل 10. جریان تابع تقسیم فضای بازگشتی در الگوریتم 1.1. منبع: نویسندگان
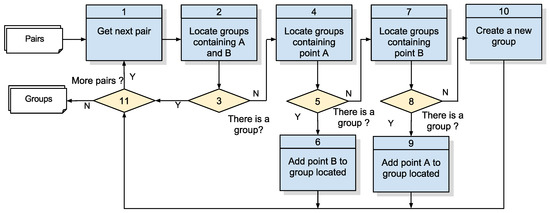
شکل 11. الگوریتم 2: تشخیص گروه ها. منبع: نویسندگان
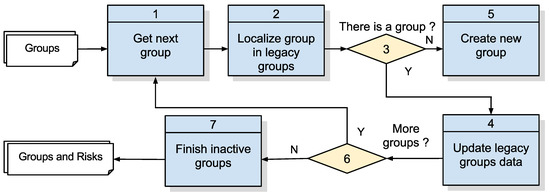
شکل 12. الگوریتم 3: محاسبه شاخص های ریسک. منبع: نویسندگان

شکل 13. نقاط نمونه برداری در 25 مه 2015 ساعت 12:00:00-03. منبع: نویسندگان
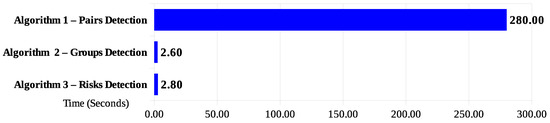
شکل 14. زمان پاسخگویی توسط الگوریتم ها. منبع: نویسندگان
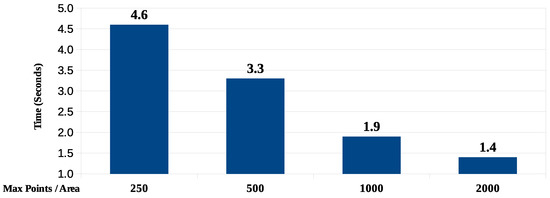
شکل 15. زمان پاسخگویی با حداکثر امتیاز بر حسب منطقه. منبع: نویسندگان

شکل 16. زمان های پاسخ با استفاده از زبان PL/pgSQL. منبع: نویسندگان

شکل 17. زمان پاسخ به زبان.
شکل 18. زمان پاسخ الگوریتم تشخیص زوج در زبان C.
شکل 19. کمترین زمان پردازش بر اساس سناریو.

جدول 1. نقاط جمع آوری شده: الگوریتم 1 (تشخیص جفت) ورودی.
جدول 2. گروه ها و ریسک ها: خروجی الگوریتم 3 (تشخیص ریسک ها).
جدول 3. مراحل تفصیلی الگوریتم 1 (تشخیص جفت ها).
جدول 4. مراحل تفصیلی الگوریتم 1.1: تقسیم به زیر ناحیه ها.
جدول 5. مراحل تابع تقسیم فضای بازگشتی در الگوریتم 1.1.
جدول 6. گروه ها و ریسک ها: خروجی الگوریتم 3 (تشخیص ریسک ها).
جدول 7. الگوریتم 1.2 ساختار خروجی (تشخیص جفت مجاورت).
جدول 8. مراحل تفصیلی الگوریتم 1 (تشخیص جفت ها).
جدول 9. ساختار خروجی الگوریتم 2 (تشخیص گروه ها).
جدول 10. مشخصات الگوریتم 3 (شاخص های ریسک گروهی).
جدول 11. نمونه برداری از پایگاه داده شبیه سازی شده.
جدول 12. تجهیزات مورد استفاده در آزمایشات.
جدول 13. نتایج پردازش الگوریتم ها.
جدول 14. حداکثر امتیاز در هر منطقه و اندازه منطقه.
© 2017 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر