

خلاصه
با استفاده از تکنیک های تجزیه و تحلیل بصری برای داده های ترافیک وسایل نقلیه، ما راهی برای تجسم و مطالعه روابط بین شدت ترافیک و سرعت حرکت در پیوندهای یک شبکه حمل و نقل انتزاعی فضایی پیدا کردیم. ما مشاهده کردیم که شدت و سرعت ترافیک در یک شبکه انتزاعی به همان شکلی که در یک شبکه خیابانی دقیق در سطح بخشهای خیابان هستند به هم مرتبط هستند. ما رابط های بصری تعاملی را توسعه دادیم که از نمایش این وابستگی های متقابل توسط مدل های ریاضی پشتیبانی می کند. برای آزمایش امکان استفاده از آنها برای انجام شبیهسازی ترافیک بر اساس شبکههای حمل و نقل انتزاعی، یک الگوریتم شبیهسازی اولیه را با استفاده از این مدلهای وابستگی ابداع کردیم. این الگوریتم در یک محیط بصری تعاملی برای تعریف سناریوهای ترافیک تعبیه شده است. اجرای شبیهسازیها و بررسی نتایج آنها. تحقیق ما امکان اصلی انجام شبیهسازی ترافیک را بر اساس شبکههای حملونقل انتزاعی فضایی با استفاده از مدلهای وابستگی به دست آمده از دادههای ترافیک واقعی نشان میدهد. این امکان نیاز به بررسی و آزمایش همه جانبه با همکاری متخصصان حوزه حمل و نقل دارد.
کلید واژه ها:
تجزیه و تحلیل بصری ; تحرک ؛ مدل سازی ترافیک ; شبیه سازی ترافیک
چکیده گرافیکی
1. معرفی
دادههای مربوط به ترافیک وسایل نقلیه در شبکههای حمل و نقل به دلیل پیشرفت در فناوریهای سنجش اکنون به مقدار زیادی جمعآوری میشوند. این دادهها فرصتهای جدیدی را برای بهبود درک ویژگیهای ترافیک و افزایش دقت مدلهای توصیف و پیشبینی موقعیتهای ترافیکی و تکامل آنها ارائه میدهند. با این حال، پتانسیل داده های ترافیک واقعی تا حد زیادی مورد بهره برداری قرار نمی گیرد. با استفاده از روشهای تحلیل بصری، ما یک مطالعه سیستماتیک از فرصتهای پنهان انجام دادیم. ما متوجه شدیم که دادههای ترافیکی که یک دوره زمانی به اندازه کافی طولانی را پوشش میدهند تا تغییرات منظم روزانه و هفتگی را منعکس کنند، میتوانند برای استخراج مدلهایی استفاده شوند که قادر به پیشبینی نه تنها جریانهای ترافیکی منظم در زمانهای مختلف، بلکه جریانهای فوقالعاده در موقعیتهای غیرعادی هستند. مانند بسته شدن جاده ها یا تحرکات جمعی ناشی از رویدادهای عمومی یا موارد اضطراری. پیشبینی رفتارهای ترافیکی غیرمعمول بر اساس دادههایی که فقط الگوهای عادی را منعکس میکنند، به دلیل بازسازی وابستگیهای متقابل امکانپذیر میشود.1 ] بین شدت ترافیک (که به عنوان جریان یا شار ترافیک نیز شناخته می شود) و میانگین سرعت حرکت برای پیوندهای مختلف یک شبکه حمل و نقل.
یکی از ویژگیهای متمایز رویکرد ما به تحلیل، مدلسازی و شبیهسازی ترافیک، استفاده از انتزاع فضایی برای نمایش شبکههای حملونقل و ویژگیهای ترافیکی در مقیاسهای فضایی مختلف است. این رویکرد مبتنی بر این یافته کلیدی است که روابط اساسی بین ویژگی های ترافیک در سطوح مختلف انتزاع فضایی یک شبکه حمل و نقل فیزیکی سازگار است.
2. آثار مرتبط
مفهوم مقیاس فضایی یکی از مفاهیم محوری در علوم جغرافیایی است [ 2 ، 3 ، 4 ، 5 ]، جایی که معمولاً تشخیص داده می شود که مقیاس تجزیه و تحلیل باید با مقیاس واقعی پدیده مورد تجزیه و تحلیل مطابقت داشته باشد. از سوی دیگر، مقیاس نیز باید با اهداف تحلیل مطابقت داشته باشد. انتخاب های قابل توجیه آسان نیست. اغلب محققان از رویکردهای آزمایش و خطای تجربی برای شناسایی مقیاس های مناسب برای تجزیه و تحلیل پدیده ها استفاده می کنند. محققان همچنین باید بررسی کنند که چگونه الگوهایی که مشاهده میکنند با مقیاس تغییر میکنند و به طور کلی به مشکل واحد منطقهای قابل تغییر رسیدگی کنند [ 6 ]] که نه تنها به اندازه واحدهای فضایی بلکه به ترسیم مرزهای آنها نیز اشاره دارد. پیشنهاد شد [ 7 ] که رویکردهای تحلیل بصری می تواند به تحلیل گران فضایی در انتخاب مقیاس های مکانی و زمانی مناسب تحلیل و آزمایش حساسیت یافته ها به تغییرات اندازه ها و ترسیم واحدهای مکانی و زمانی کمک کند. این با تحقیق ما نشان داده شده است، که در آن تعبیه بصری تعاملی تکنیکهای انتزاع و تجمیع فضایی [ 8 ] اکتشاف ترافیک وسیله نقلیه را در مقیاسهای فضایی مختلف تسهیل کرد و بنابراین، یافتههای کلیدی ما را فعال کرد که روابط اساسی بین ویژگیهای ترافیک در چندین مورد سازگار است. ترازو ( بخش 3 ).
در تحقیقی که با تجزیه و تحلیل داده های حرکتی سروکار دارد، تنها تعداد کمی از محققین نقش مقیاس را در نظر گرفتند. Laube و Purves [ 9 ] تأثیر تغییر مقیاس زمانی را بر پارامترهای حرکت مشتق شده نشان دادند و سلیمانی و همکاران. [ 10] چارچوبی را برای تحلیل مقیاس متقابل رفتارهای حرکتی با استفاده از روشهای یادگیری ماشین (طبقهبندی) پیشنهاد کرد. با توجه به مقیاس فضایی، ایده استفاده از سه سطح سلسله مراتبی تقسیم فضا، استخراج معیارهای مجموع مختلف برای مناطق تعریف شده، و استفاده از این معیارها به عنوان ویژگیهای یک مدل طبقهبندی است. مقیاسی که در آن بالاترین عملکرد طبقهبندیکننده به دست میآید، مناسبترین مقیاس ارزیابی میشود. به روشی مشابه، یک مقیاس زمانی مناسب انتخاب می شود. هنوز مشخص نیست که چگونه می توان این رویکرد را فراتر از وظیفه طبقه بندی رفتار حرکتی تعمیم داد.
مقیاس همچنین یک مفهوم مرتبط در تحقیقات حمل و نقل است. به طور خاص، مدل های شبیه سازی ترافیک به ماکروسکوپی، مزوسکوپی و میکروسکوپی طبقه بندی می شوند [ 11 ]. مدلهای ماکروسکوپی، ترافیک را در سطح بالایی از تجمع به عنوان جریان بدون در نظر گرفتن وسایل نقلیه فردی توصیف میکنند [ 12 ، 13 ]. در مدل های میکروسکوپی، ترافیک در سطح وسایل نقلیه فردی و تعامل آنها با یکدیگر و با زیرساخت جاده توصیف می شود. دو کلاس اصلی مدلهای مبتنی بر عامل [ 14 ] و مدلهای اتوماتای سلولی [ 15 ] هستند.]. از آنجایی که مدلهای میکروسکوپی کاملاً نیاز به منابع دارند، به طور سنتی برای شبیهسازی محلی در مناطق کوچک استفاده میشوند، اما افزایش قدرت رایانهها و محاسبات موازی، شبیهسازی میکروسکوپی را برای شبکههای بزرگ فعال کرده است. یک نقطه ضعف مدل های میکروسکوپی، تلاش زیاد برای آماده سازی مدل است. مدلهای مزوسکوپی شکاف بین مدلهای ماکروسکوپی و میکروسکوپی را با ترکیب نمایش خودروهای فردی با نمایش کلی دینامیک ترافیک پر میکنند [ 16 ]. وسایل نقلیه منفرد یا بسته های وسایل نقلیه از طریق پیوندهای یک شبکه حمل و نقل بر اساس روابط عمومی سرعت – چگالی تعریف شده در تئوری های جریان ترافیک [ 17 ] یا برگرفته از داده های واقعی [ 18 ] حرکت می کنند.]. پارامترهای این روابط را می توان برای انواع پیوندهای مختلف به طور متفاوت تنظیم کرد [ 16 ]. مدل های ترکیبی مدل های ماکروسکوپی یا مزوسکوپی را با مدل های میکروسکوپی ترکیب می کنند [ 19 ، 20 ]. انواع مدل های مختلف برای بخش های مختلف یک شبکه اعمال می شود. بنابراین، Sewall و همکاران. [ 11 ] شبیه سازی مبتنی بر عامل خودروهای فردی را در مناطق مورد علاقه کاربر انجام می دهد در حالی که یک مدل ماکروسکوپی سریعتر در بقیه شبکه استفاده می شود.
پشتیبانی تجسم برای شبیه سازی ترافیک در حال حاضر تنها توسط آثار Sewall و همکاران نشان داده شده است. [ 11 ، 12 ]، که انیمیشن های سه بعدی واقعی از حرکات شبیه سازی شده وسیله نقلیه تولید می کنند. برای شبیهسازی میکرو ماکرو هیبریدی، آنها ابزار تعاملی طراحی کردند که به صورت خودکار و پویا روش شبیهسازی مناسب را برای بخشهای مختلف شبکه بر اساس نیاز کاربر انتخاب میکند. در کار ما، تجسمها و رابطهای تعاملی نه تنها از شبیهسازی ترافیک، بلکه از تجزیه و تحلیل دادههای ترافیک واقعی و ایجاد مدلهایی پشتیبانی میکنند که متعاقباً برای شبیهسازی اعمال میشوند.
3. انتزاع فضایی یک شبکه حمل و نقل
داده های ترافیک ممکن است به شکل مسیر حرکت اجسام متحرک در دسترس باشند. یک مسیر شامل رکوردهایی است که موقعیتهای (مثلاً مختصات جغرافیایی) اجسام متحرک را در زمانهای مختلف گزارش میکنند. با توجه به مجموعه بزرگی از مسیرها، ما یک روش موجود [ 8 ] را اعمال می کنیم که یک شبکه انتزاعی متشکل از سلول ها (بخش های قلمرو) و پیوندهای بین آنها را مشتق می کند. سلول های کوچکتر یا بزرگتر را می توان با پارامترهای روش متفاوت تولید کرد، بنابراین، امکان تجزیه و تحلیل ترافیک و مدل سازی در مقیاس فضایی انتخابی را فراهم می کند. علاوه بر این، همچنین میتوان مقیاس فضایی را در سراسر قلمرو بسته به تراکم دادهها تغییر داد و بنابراین، سلولهای ظریفتری را در مناطق متراکم داده و سلولهای درشتتر در مناطق پراکنده داده به دست آورد [ 21 ].
گره های یک شبکه ترافیک انتزاعی سلول های چند ضلعی هستند. سلول های همسایه توسط جفت پیوندهای جهت دار به هم متصل می شوند. پس از ساخت یک شبکه، داده های مسیر اصلی به صورت مکانی توسط گره ها و پیوندهای شبکه و به طور موقت با فواصل زمانی جمع می شوند [ 8 ]]. نتیجه تجمیع شامل دو مجموعه سری زمانی برای پیوندها است: شدت ترافیک و میانگین سرعت خودرو (سرعت). شدت ترافیک روی یک پیوند که جریان ترافیک یا شار نیز نامیده می شود، تعداد اشیایی است که در واحد زمان از پیوند عبور می کنند. سرعت متوسط در یک لینک به صورت زیر محاسبه می شود. برای هر جسمی که از سلول A به سلول B منتقل شده است، دو نقطه مسیری که نزدیک ترین نقطه به مراکز این سلول ها هستند انتخاب می شود. تقسیم طول مسیر بین نقاط انتخاب شده بر اختلاف زمانی بین آنها میانگین سرعت این جسم را به دست می دهد. میانگین سرعت کلی پیوند (A,B) در یک بازه زمانی [t 1 ,t 2 ] به عنوان میانگین سرعت تمام اجسامی که از سلول A به سلول B در این بازه زمانی حرکت کرده اند محاسبه می شود.
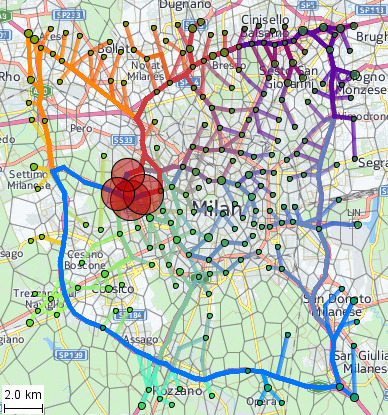
شکل 1 نمونه ای از یک شبکه ترافیک انتزاعی شده از میلان (ایتالیا) را نشان می دهد که از مسیرهای GPS 17241 اتومبیل جمع آوری شده در یک دوره یک هفته از یکشنبه، 1 آوریل، تا شنبه، 7 آوریل، 2007 بازسازی شده است (منبع داده: Octo Telematics SpA) . سوابق اصلی GPS شامل شناسه های وسیله نقلیه ناشناس، مهرهای زمانی و مختصات جغرافیایی است. وضوح زمانی بیشتر 30 ثانیه است در حالی که شکاف های زمانی بزرگتر نیز رخ می دهد. در شکل 1 ، قلمرو میلان به سلول هایی با شعاع تقریبی 1 کیلومتر تقسیم شده است.
شکل 1. انتزاعی از شبکه خیابان میلان (ایتالیا) که با شعاع سلولی ≈ 1 کیلومتر ساخته شده است.
توضیح: سلول ها چند ضلعی های Voronoi هستند که در اطراف “مراکز جرم” خوشه های فضایی نقاط استخراج شده از مسیرها ساخته شده اند. روش خوشهبندی [ 8 ] نقاط را طوری گروهبندی میکند که هر گروه در دایرهای با حداکثر شعاع تعیینشده توسط کاربر (در مثال ما 1 کیلومتر) قرار گیرد، اما شعاع گروه واقعی ممکن است کوچکتر نیز باشد. مدوید هر گروه (به عنوان مثال.، نقطهای که کمترین مجموع فاصلهها را با تمام نقاط دیگر دارد) بهعنوان یک بذر مولد برای تسسل ورونوی در نظر گرفته میشود. توجه داشته باشید که مدوید لزوماً مرکز دایره دور گروه نیست. شکل و اندازه چند ضلعی های حاصل به توزیع فضایی مدویدهای گروهی بستگی دارد. از آنجایی که دومی نامنظم است، شکل و اندازه سلول نیز نامنظم است. وقتی از عبارت “سلول هایی با شعاع تقریبی x ” استفاده می کنیم، در واقع منظور این است که سلول ها بر اساس خوشه های نقطه ای با حداکثر شعاع x ساخته شده اند .
مرزهای سلول در شکل 1 با خطوط خاکستری و پیوندهای بین آنها با خطوط منحنی رنگی نشان داده شده است که در یک قطعه نقشه بزرگ شده در بالا سمت راست بهتر دیده می شود. انحنای خطی که یک پیوند را نشان میدهد به سمت انتهای پیوند [ 22 ] افزایش مییابد که جهات پیوندهای مخالف را بین همان سلولها متمایز میکند. یک روش جایگزین برای نشان دادن پیوندها با نمادهای نیم فلش [ 23 ] است که در سمت راست پایین شکل 1 نشان داده شده است. می توان اشاره کرد که همه جفت سلول های همسایه با پیوند به هم متصل نیستند. عدم وجود پیوند بین دو سلول به معنای عدم وجود حرکات واقعی بین این سلول ها است.
برای بهبود خوانایی نقشه، نمادهای پیوند بر اساس نتایج خوشهبندی مبتنی بر پارتیشن با شباهت سریهای زمانی مربوط به شدت ترافیک و سرعت میانگین رنگآمیزی میشوند، یعنی هر رنگ مربوط به یکی از خوشهها است. رنگها برای خوشهها طوری انتخاب میشوند که خوشههای نزدیک رنگهای مشابه و خوشههای دور رنگهای متفاوت دریافت کنند. این کار با نمایش مراکز خوشه بر روی یک فضای رنگی دو بعدی انجام می شود [ 24]. از این رو، در مثال ما، رنگهای مشابه با خوشههایی از پیوندها با شدت ترافیک و سرعت متوسط مشابه مطابقت دارند. سه خوشه با متمایزترین رنگ ها (قرمز تیره، ارغوانی تیره و بنفش) از پیوندهایی تشکیل شده اند که در امتداد بزرگراه مداری اطراف شهر و بزرگراه های شعاعی قرار دارند. رنگ ها نشان می دهد که این پیوندها با پیوندهای باقی مانده در داخل شهر و حومه های مسکونی تفاوت زیادی دارند.
برای مطالعه و کمی کردن روابط بین شدت ترافیک و میانگین سرعت در پیوندها، داده ها به روش زیر تبدیل می شوند. فرض کنید A و B دو ویژگی وابسته به زمان باشند که با یک شی (به ویژه پیوند) مرتبط و برای مراحل زمانی یکسان تعریف شده اند.
-
محدوده ارزش ویژگی A را به فواصل تقسیم کنید.
-
برای هر بازه مقدار A:
-
تمام مراحل زمانی را که در آن مقادیر A در این بازه قرار می گیرند، پیدا کنید.
-
تمام مقادیر B را که در این مراحل زمانی رخ می دهد، جمع آوری کنید.
-
از مقادیر جمع آوری شده B، آمار خلاصه را محاسبه کنید: میانگین، چارک، دهک نهم ( یعنی صدک 90)، و حداکثر.
-
برای هر معیار آماری ( به عنوان مثال ، میانگین، دهک نهم ، حداکثر، و غیره )، یک دنباله مرتب از مقادیر متناظر با فواصل ارزشی A که به ترتیب صعودی مرتب شده اند، بسازید.
-
به این ترتیب یک خانواده از صفات مشتق می شود: میانگین B، دهک نهم B، حداکثر B و غیره. برای هر یک از ویژگی های مشتق شده، یک دنباله مرتب از مقادیر مربوط به فواصل مقادیر انتخابی ویژگی A وجود دارد. این دنباله شبیه به یک سری زمانی است با این تفاوت که مراحل نه بر اساس زمان، بلکه بر اساس مقادیر ویژگی A است. چنین سری های وابستگی دنباله ای (DS) زیرا وابستگی بین ویژگی های A و B را بیان می کنند. ویژگی A به عنوان متغیر مستقل و B به عنوان متغیر وابسته در نظر گرفته می شود.
برای مطالعه و مدلسازی وابستگیهای متقابل بین میانگین سرعت و شدت ترافیک، دو تبدیل انجام میدهیم. ابتدا، ما شدت ترافیک را به عنوان متغیر مستقل در نظر می گیریم و خانواده ای از ویژگی ها را استخراج می کنیم که وابستگی میانگین سرعت را به شدت ترافیک بیان می کند. دوم، سرعت متوسط را به عنوان متغیر مستقل در نظر می گیریم و خانواده ای از ویژگی ها را استخراج می کنیم که وابستگی شدت ترافیک را به میانگین سرعت بیان می کند. سریهای وابستگی ممکن است با استفاده از شدت ترافیک مطلق یا نسبی استخراج شوند، که دومی به عنوان نسبت یا درصد شدت مطلق به حداکثر شدت بهدستآمده در همان پیوندها محاسبه میشود.
سری های وابستگی که ما برای شبکه حمل و نقل انتزاعی میلان نشان داده شده در شکل 1 به دست آورده ایم به صورت گرافیکی در شکل 2 نشان داده شده است. خطوط در نمودارها با پیوندهای شبکه مطابقت دارند و با توجه به عضویت خوشه پیوندها با استفاده از رنگ های مشابه در شکل 1 رنگ می شوند . نمودار سمت چپ نشان می دهد که چگونه سرعت متوسط به شدت ترافیک نسبی که به عنوان درصد به حداکثر بیان می شود بستگی دارد. محور افقی با شدت ترافیک و محور عمودی با دهک نهم میانگین سرعت مطابقت دارد . ما نهم را گرفته ایمدهک است زیرا این معیار آماری نسبت به مقادیر پرت به عنوان حداکثر حساسیت کمتری دارد. نقاط پرت در میان مقادیر میانگین سرعت اغلب در بازه های زمانی با شدت ترافیک کم، زمانی که یک یا چند وسیله نقلیه از یک لینک عبور می کنند، رخ می دهد. نمودار سمت راست برای هر لینک وابستگی حداکثر شدت ترافیک نسبی به میانگین سرعت را نشان می دهد. محور افقی با میانگین سرعت و محور عمودی با حداکثر شدت نسبی ترافیک مطابقت دارد.
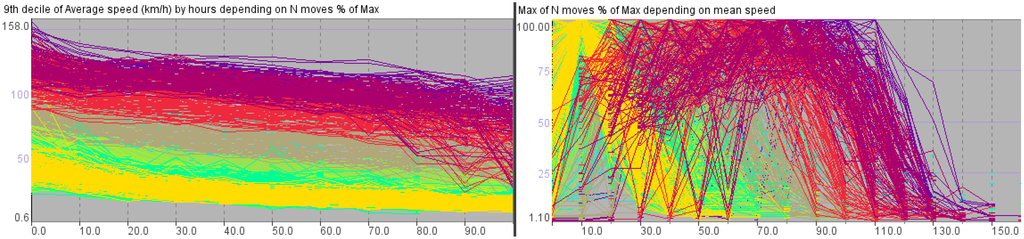
شکل 2. نمودارها وابستگی متقابل بین شدت ترافیک و سرعت متوسط را برای پیوندهای شبکه حمل و نقل انتزاعی میلان نشان داده شده در شکل 1 نشان می دهند.
در سمت چپ شکل 2 ، شکل خطوط نشان می دهد که سرعت متوسط با افزایش شدت ترافیک کاهش می یابد. در سمت راست، خطوط به شکل زنگ یا نماد “⌒” هستند که می توان آن را به صورت زیر تفسیر کرد. وقتی وسایل نقلیه با سرعت متوسط کم حرکت می کنند، فقط تعداد کمی از وسایل نقلیه می توانند از یک پیوند در واحد زمان عبور کنند، به عنوان مثال، شدت ترافیک کم است. وقتی میانگین سرعت افزایش مییابد، شدت نیز افزایش مییابد، اما فقط تا زمانی که به یک مقدار «بهینه» معینی از سرعت متوسط میرسد. پس از این نقطه، حرکت با میانگین سرعت بالاتر تنها زمانی امکان پذیر است که شدت ترافیک کاهش یابد. این مشاهدات با دانش و تجربیات عقل سلیم ما در مورد رفتار ترافیک وسایل نقلیه در جاده ها مطابقت دارد، اما به یک شبکه حمل و نقل انتزاعی و نه فیزیکی اشاره دارد.
شکل 3نشان می دهد که چگونه وابستگی های دو طرفه بین شدت ترافیک و سرعت متوسط را می توان با مدل های رسمی، مانند رگرسیون چند جمله ای نشان داد (انواع دیگر منحنی ها را نیز می توان برازش داد). مدلسازی برای خوشههای پیوندها به جای هر پیوند جداگانه انجام میشود تا از برازش بیش از حد جلوگیری شود و تأثیر نوسانات و نقاط پرت محلی کاهش یابد. شکل نمایانگر تصاویری از ابزار بصری تعاملی است که از ساختمان مدل پشتیبانی می کند. عناصر رابط کاربری زیر نمودارها، بهویژه، برچسب خوشهای را که مدل برای آن ساخته میشود، روش مدلسازی انتخابی (رگرسیون چند جملهای) و ترتیب چند جملهای را نشان میدهد. منحنی های خاکستری در هر نمودار نشان دهنده سری وابستگی برای پیوندهای جداگانه از خوشه انتخابی است، در آبی تیره منحنی خلاصه برای این خوشه است.

شکل 3. وابستگی های دو طرفه بین شدت ترافیک و سرعت متوسط را می توان با مدل های رگرسیون چند جمله ای نشان داد.
شکل منحنیهای برازش شده، که ویژگی وابستگیها را نشان میدهد، شبیه شکل منحنیها در نمودار اساسی جریان ترافیک است که رابطه بین ویژگیهای ترافیک را توصیف میکند [ 1 ]. نمودار اساسی جریان ترافیک شامل سه نمودار است: میانگین سرعت u در مقابل تراکم ترافیک k (تعداد وسایل نقلیه در هر 1 کیلومتر طول جاده)، میانگین سرعت u در برابر شدت ترافیک (یا جریان، یا شار. به عنوان مثال ، تعداد وسایل نقلیه در هر واحد زمان) q و شدت q در مقابل چگالی k . شکل منحنی پایین در شکل 3با شکل منحنی u در مقابل q مطابقت دارد ، با این تفاوت که محور u (سرعت) در نمودار اصلی عمودی و محور q افقی است، یعنی نمودار ما با توجه به نمودار متعارف جابهجا میشود. تصویر بالای ما وابستگی u (سرعت) در مقابل q (شدت) را نشان می دهد. در نمودار اصلی هیچ گراف متناظر مستقیمی وجود ندارد، اما نموداری از u در برابر چگالی k وجود دارد. بر اساس تئوری ترافیک، تراکم ترافیک به صورت k = q / u محاسبه می شود . تبدیل نمودار u در مقابل kبر اساس این فرمول، نموداری از u در مقابل q با شکل منحنی مشابه شکل 3 (بالا) ایجاد می شود.
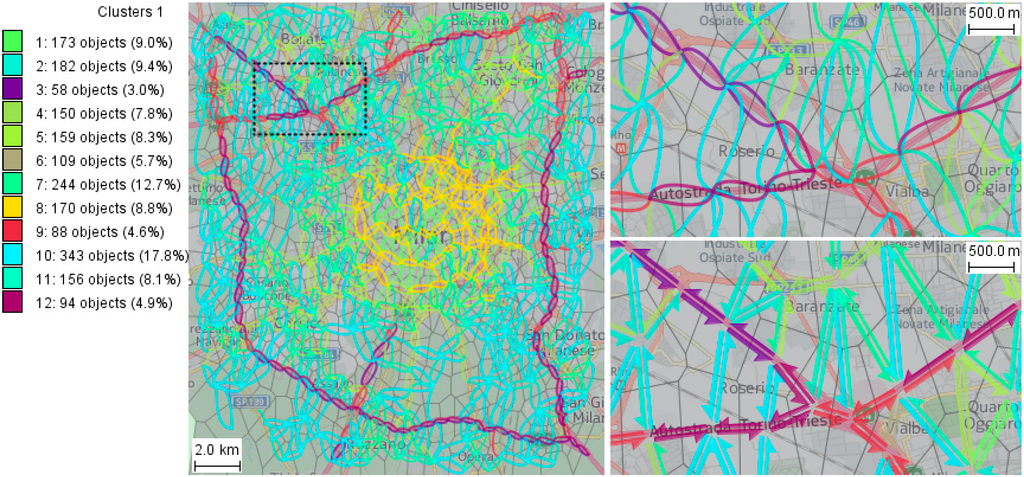
نمودار اساسی به پیوندهای یک شبکه حمل و نقل فیزیکی، به عنوان مثال ، به بخش های خیابان اشاره دارد. پارامترهای دقیق منحنی ها به ویژگی های خیابان مانند عرض، تعداد خطوط و محدودیت سرعت بستگی دارد. می بینیم که همان روابطی که در یک شبکه فیزیکی وجود دارد در یک شبکه انتزاعی فضایی نیز وجود دارد. پارامترهای منحنی ها به ویژگی های پیوندهای انتزاعی بستگی دارد. از آنجایی که هر پیوند انتزاعی مخفف گروهی از پیوندهای فیزیکی است، ویژگی های آن ویژگی های این پیوندهای فیزیکی را در خود گنجانده و خلاصه می کند. علاوه بر این، ما دریافتیم که روابط مطابق با نمودار اصلی ترافیک در سطوح مختلف انتزاع فضایی وجود دارد، همانطور که در شکل 4 نشان داده شده است.
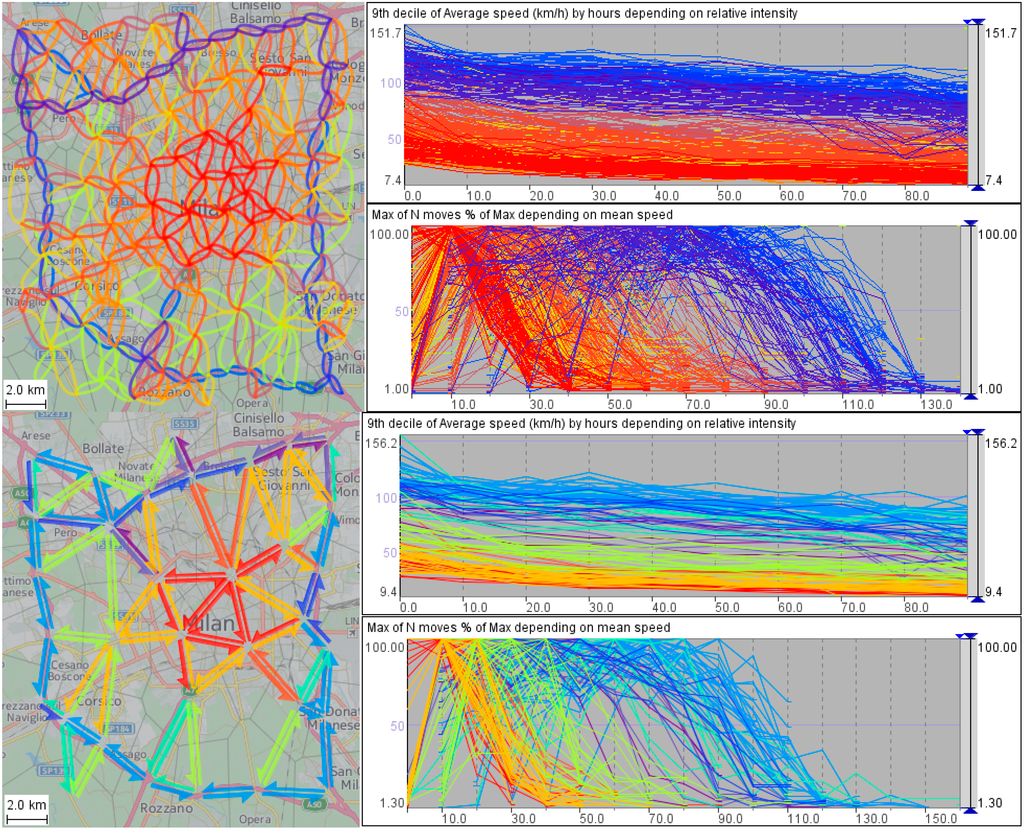
شکل 4. نقشه ها شبکه های حمل و نقل انتزاعی فضایی میلان را نشان می دهند که با شعاع سلولی ≈ 2 کیلومتر (بالا) و 4 کیلومتر (پایین) ساخته شده اند. نمودارهای سمت راست هر نقشه نشان دهنده وابستگی دو طرفه بین شدت ترافیک نسبی و سرعت متوسط در پیوندهای شبکه است.
ما این یافته را با استفاده از یک مجموعه داده بسیار بزرگتر که منطقه جغرافیایی توسکانی (ایتالیا) را پوشش می دهد و یک دوره زمانی یک ماهه بررسی کرده ایم. روابط مشابهی مانند میلان در مقیاس های فضایی متنوع برای جریان ترافیک در داخل و بین شهرهای توسکانی مشاهده شده است.
این یافته کلیدی مبنایی برای رویکرد ما به تحلیل و مدلسازی ترافیک فراهم میکند. روابط اساسی بین ویژگی های جریان ترافیک بیان شده توسط نمودار جریان ترافیک معمولی معمولاً برای پیش بینی و شبیه سازی جریان ترافیک استفاده می شود که معمولاً بر اساس یک شبکه فیزیکی خیابان انجام می شود. وجود روابط مشابه در سطوح بالاتر انتزاع فضایی، انجام مدلسازی، پیشبینی و شبیهسازی را در مقیاسهای مکانی بالاتر در مواردی که جزئیات دقیق ضروری نیست، ممکن میسازد.
4. مزایا و محدودیت های انتزاع فضایی
انتزاع فضایی یک شبکه خیابانی مزایای زیر را ارائه می دهد:
-
تعداد گره ها و پیوندها در یک شبکه انتزاعی می تواند بسیار کمتر از شبکه فیزیکی زیربنایی باشد. از این رو، زمان و تلاش بسیار کمتری برای ساخت مدل و کالیبراسیون مورد نیاز است و همچنین شبیهسازیها در مقایسه با روشهای فعلی بسیار سریعتر انجام میشوند. این امر به ویژه امکان پیشبینی و ارزیابی سریع و تقریبی پویایی ترافیک را در شرایط اضطراری، زمانی که زمان بسیار محدود است، میدهد.
-
انتزاع فضایی کم بودن داده های واقعی را در خیابان هایی با ترافیک کم جبران می کند. ممکن است نقاط مسیر کافی در یک بخش خیابان معین برای بازسازی وابستگی بین میانگین سرعت و شدت ترافیک وجود نداشته باشد، اما تجمیع چندین پیوند فیزیکی در یک پیوند انتزاعی این مشکل را کاهش میدهد.
-
می توان یک شبکه انتزاعی ساخت که در آن سطح انتزاع فضایی در سراسر یک قلمرو با توجه به تنوع چگالی داده ها متفاوت باشد. در مناطق با ترافیک زیاد، پیوندهای انتزاعی ممکن است بسیار نزدیک به پیوندهای فیزیکی (به عنوان مثال ، بخش های خیابان) باشند، در حالی که مناطق با ترافیک کم را می توان با سلول های بزرگ نشان داد. از این رو، می توان سطوح مختلفی از جزئیات را در شبیه سازی ترافیک و پیش بینی در مناطق پر و کم تردد داشت، زمانی که جزئیات دقیق در مناطق کم تردد مهم نیست.
ما ادعا نمی کنیم که مقیاس فضایی (به عنوان مثال ، اندازه سلول ها) را می توان به طور نامحدود افزایش داد، بدون اینکه اشکال منحنی هایی را که نشان دهنده روابط بین شارهای ترافیکی و سرعت هستند، از بین ببرند. به طور کلی، افزایش مقیاس فضایی میزان نویز را افزایش می دهد (به عنوان مثال.، نوسانات) درون منحنی ها. اشکال کلی منحنی ها تا یک سطح انتزاعی مشخص، که در آن نوسانات بسیار زیاد می شوند، قابل تشخیص باقی می مانند. آزمایشهای ما نشان میدهد که حد بالایی برای اندازه سلولها ممکن است به تعداد و تنوع پیوندهای فیزیکی موجود بین سلولها بستگی داشته باشد. بنابراین، برای میلان و مناطق شهری توسکانی، افزایش شعاع سلولی بیش از 4 کیلومتر، منحنی ها را بیش از حد منحرف می کند، در حالی که سلول های بسیار بزرگتر را می توان برای مناطق روستایی توسکانی استفاده کرد. از این رو، هیچ حد بالایی یکنواخت برای سطح انتزاع فضایی وجود ندارد که در همه جا معتبر باشد. سطح مناسب برای یک قلمرو مشخص و داده های موجود را می توان به صورت تجربی با استفاده از تکنیک های تجزیه و تحلیل بصری تعیین کرد.
میتوان استدلال کرد که استفاده از انتزاع فضایی در مدلسازی جریان ترافیک، در مقایسه با مدلسازی بر اساس شبکه دقیق خیابان، واقعیت را بسیار ساده میکند. در واقع، انتزاع مستلزم سادهسازی است، اما هر مدلی نمایشی انتزاعی و سادهشده از واقعیت است. روابط اساسی ترافیک اتخاذ شده در حوزه حمل و نقل، خود انتزاعات نظری هستند. علاوه بر این، استفاده از این روابط برای مدلسازی ترافیک مبتنی بر یک فرض سادهکننده است که پارامترهای معادله در همه جا برای خیابانهایی از همان نوع یکنواخت هستند. از این رو، حتی زمانی که از یک شبکه خیابانی دقیق استفاده می شود، مدل سازی ناگزیر شامل ساده سازی می شود. اما سادهسازی را نباید از ویژگیهای بد و نامطلوب مدلها دانست. در مقابل، این سادهسازی واقعیت است که مدلها را عملاً مفید میسازد. واقعیت آنقدر پیچیده است که حتی اگر بتوان مدلی ساخت که بخشی از آن را با جزئیات کامل نشان میدهد، این مدل غیرقابل حل خواهد بود. در حمل و نقل، هر کلاس از مدل ها (ماکروسکوپی، مزوسکوپی، میکروسکوپی یا ترکیبی) واقعیت را به روش خاص خود ساده می کند. درست نیست که بگوییم برخی از راه ها بهتر از دیگران هستند. بلکه روش های مختلف برای اهداف مختلف مناسب هستند. ما یک رویکرد دیگر برای سادهسازی پیشنهاد میکنیم، که قرار نیست جایگزین هیچ یک از رویکردهای موجود شود، اما میتواند آنها را تکمیل کند. موارد استفاده ممکن برای آن در ابتدای بخش ذکر شده است. ما رویکرد خود را با محققان حمل و نقل از دانشگاه هاسلت (بلژیک) مورد بحث قرار دادیم. با آنها در یک پروژه تحقیقاتی همکاری کردیم. آنها این رویکرد را معقول و امیدوارکننده میدانند در حالی که نیاز به اثبات بیشتر با مطالعات تجربی اضافی دارند.
5. استخراج مدل های ترافیک از داده های واقعی
در مورد بازسازی روابط اساسی بین ویژگی های جریان ترافیک از مسیرهای واقعی وسیله نقلیه باید رزرو انجام شود. معمول است که مسیرهای موجود فقط نمونه ای از وسایل نقلیه را پوشش می دهند که در یک شبکه حرکت می کنند و نه کل جمعیت را. از این رو، شدت ترافیک محاسبه شده از این مسیرها باید به طور مناسب مقیاس بندی شود تا شدت واقعی تقریب شود. این رزرو مختص شبکههای انتزاعی فضایی نیست، بلکه برای شبکههای خیابانی دقیق نیز اعمال میشود. پارامترهای مقیاس بندی مناسب (یا حتی توابع مقیاس بندی که تغییرات روزانه و هفتگی را ثبت می کنند) را می توان با مقایسه تعداد وسایل نقلیه محاسبه شده از داده های مسیر با شمارش های اندازه گیری شده به دست آمده از سنسورهای ترافیک [ 25 ] به دست آورد.
برای اشتقاق مدل، ما یک روش [ 24 ] را اعمال می کنیم] که در آن یک رابط بصری تعاملی با کتابخانه مدلسازی استفاده می شود. این روش برای دادههای حرکت انبوه مرتبط با گرهها و پیوندهای یک شبکه، که ممکن است یک شبکه فیزیکی خیابانی یا یک شبکه انتزاعی فضایی باشد، قابل استفاده است. دادهها باید شامل سریهای زمانی شدت ترافیک باشد، یعنی تعداد اشیایی که از طریق پیوندها بر اساس بازههای زمانی حرکت کردهاند، و سریهای زمانی میانگین سرعت حرکت آنها. طول و وضوح زمانی سری های زمانی باید برای ثبت تغییرات ترافیک مربوط به چرخه های زمانی روزانه و هفتگی مناسب باشد، به این معنی که طول باید حداقل یک هفته باشد (بیشتر بهتر است) و وضوح باید حداکثر یک باشد. ساعت (بهتر است). در حالت ایده آل، شمارش ها باید کل جمعیت اشیایی را که در شبکه جابجا شده اند را نشان دهد.
همانطور که قبلا ذکر شد، مدلها برای دستهای از پیوندها به جای پیوندهای جداگانه ساخته شدهاند تا از تطبیق بیش از حد و کاهش اثرات نویز و نقاط پرت محلی جلوگیری شود. پیوندها بر اساس شباهت سریهای زمانی مرتبط با شدت ترافیک و سرعت میانگین با استفاده از الگوریتم خوشهبندی مبتنی بر پارتیشن، مانند k-means، و ابزارهای بصری تعاملی که امکان اصلاح خوشههای انتخابی را در صورت نیاز فراهم میکنند، خوشهبندی میشوند [ 24 ].]. سه مجموعه از مدل ها ساخته شده اند: (1) مدل های تغییرات زمانی شدت ترافیک. (2) مدلهای وابستگی میانگین سرعت به شدت ترافیک. و (3) مدل های وابستگی شدت ترافیک به سرعت متوسط. برای مجموعه مدل (1)، ما روش هموارسازی نمایی دوگانه (هولت-وینترز) را اعمال میکنیم که شخصیت دورهای تغییرات زمانی را در مورد چرخههای زمانی روزانه و هفتگی نشان میدهد. برای مجموعه های مدل (2) و (3)، ما مدل های رگرسیون چند جمله ای را اعمال می کنیم، همانطور که در شکل 3 نشان داده شده است. فرآیند مدلسازی وابستگیهای دو طرفه بین شدت ترافیک و میانگین سرعت با جزئیات بیشتری در کتابی که اخیراً منتشر شده است [ 21 ] توضیح داده شده است.
از آنجایی که مدل ها برای خوشه های پیوند مشتق شده اند، هر مدل به خودی خود یک پیش بینی مشترک برای همه اعضای خوشه انجام می دهد. با این حال، این پیش بینی به صورت جداگانه برای هر عضو خوشه بر اساس آمار توزیع مقادیر اصلی آن تنظیم می شود [ 24 ].
6. استفاده از مدل ها برای پیش بینی و شبیه سازی ترافیک
مدلهای تغییرات زمانی شدت ترافیک را میتوان برای پیشبینی ترافیک منظم برای بازههای زمانی انتخابشده در آینده، با فرض عدم تغییر ویژگیهای تغییرات زمانی استفاده کرد. هنگامی که داده های ترافیک واقعی به طور منظم جمع آوری می شوند، منطقی است که به طور دوره ای مدل ها را در برابر داده های واقعی بررسی کنید. اگر کیفیت پیش بینی کاهش یابد، مدل ها باید به روز شوند.
مدلهای وابستگی بین شدت ترافیک و میانگین سرعت را میتوان برای شبیهسازی و پیشبینی رفتارهای ترافیکی غیرمعمول استفاده کرد. ایده اصلی به شرح زیر است:
-
برای هر پیوند، تعیین کنید که در دقیقه جاری چند وسیله نقلیه باید از طریق آن حرکت کنند.
-
با استفاده از مدل وابستگی از شدت ترافیک تا میانگین سرعت، میانگین سرعتی را که برای این بار لینک ممکن است تعیین کنید.
-
با استفاده از مدل وابستگی از میانگین سرعت تا شدت ترافیک، تعیین کنید که در این دقیقه چند وسیله نقلیه واقعاً می توانند از طریق پیوند حرکت کنند.
-
این تعداد وسیله نقلیه را به انتهای پیوند ارتقا دهید و وسایل نقلیه باقیمانده را در محل شروع پیوند به حالت تعلیق درآورید.
برای انجام یک شبیه سازی، تحلیلگر باید سناریویی را که قرار است شبیه سازی شود، تعریف کند. این شامل تعریف مجموعه ای از وسایل نقلیه اضافی است که علاوه بر ترافیک معمولی در شبکه در حال حرکت هستند، مبدا و مقصد سفرهایشان، مسیرهایی که دنبال خواهند کرد و زمانی که هر وسیله نقلیه شروع به حرکت می کند. برای پشتیبانی از فرآیند تعریف سناریو، ما یک جادوگر ایجاد کرده ایم که تحلیلگر را از طریق مراحل مورد نیاز راهنمایی می کند و در هر مرحله بازخورد بصری ارائه می دهد. با این حال، توصیف جادوگر و سایر ابزارهای بصری تعاملی مورد استفاده خارج از حوصله این مقاله است که هدف آن ارائه ایده کلیدی و طرح کلی رویکرد مبتنی بر این ایده است. بنابراین، ما فقط یک مثال مختصر از نحوه استفاده از شبیه سازی ارائه می دهیم.
برای میلان، آزمایشهایی را بر روی شبیهسازی حرکت تعداد زیادی ماشین شخصی از ناحیه اطراف استادیوم سن سیرو پس از یک بازی فوتبال انجام دادهایم. برای اینکه بتوانیم این سناریو را شبیه سازی کنیم، باید مشکل مقیاس بندی داده ها را که در انتهای بخش 2 ذکر شد، حل کنیم . دادههایی که ما برای ساخت مدل استفاده کردیم، نشاندهنده همه وسایل نقلیهای نیست که در میلان حرکت میکنند، بلکه تنها حدود 2٪ از خودروهای شخصی را نشان میدهد. ما روش زیر را اعمال می کنیم. اگر بخواهیم حرکات N خودروی شخصی را شبیه سازی کنیم، این عدد را به ۲ درصد N کاهش می دهیم تا با مدل ها سازگار شود. شکل 5 و شکل 6 مسیرهای شبیه سازی شده 250 خودرو را نشان می دهد که با حدود 12500 خودرو در مقیاس واقعی مطابقت دارد.
در شکل 5 ، مسیرها به صورت خطوط در یک مکعب فضا-زمان نشان داده شده اند. برای تشخیص بهتر، خطوط با توجه به مکان مقصدشان رنگ های متفاوتی دارند. نمایشگر مکعبی به ما امکان می دهد مسیرهای دنبال شده و پیشرفت حرکت را در طول زمان ببینیم. ما میتوانیم مکانهایی را که بسیاری از خودروها معلق هستند و منتظر امکان حرکت هستند، تشخیص دهیم. تعلیق ها در مکعب به عنوان بخش های مسیر عمودی ظاهر می شوند، به این معنی که موقعیت مکانی با گذشت زمان تغییر نمی کند.
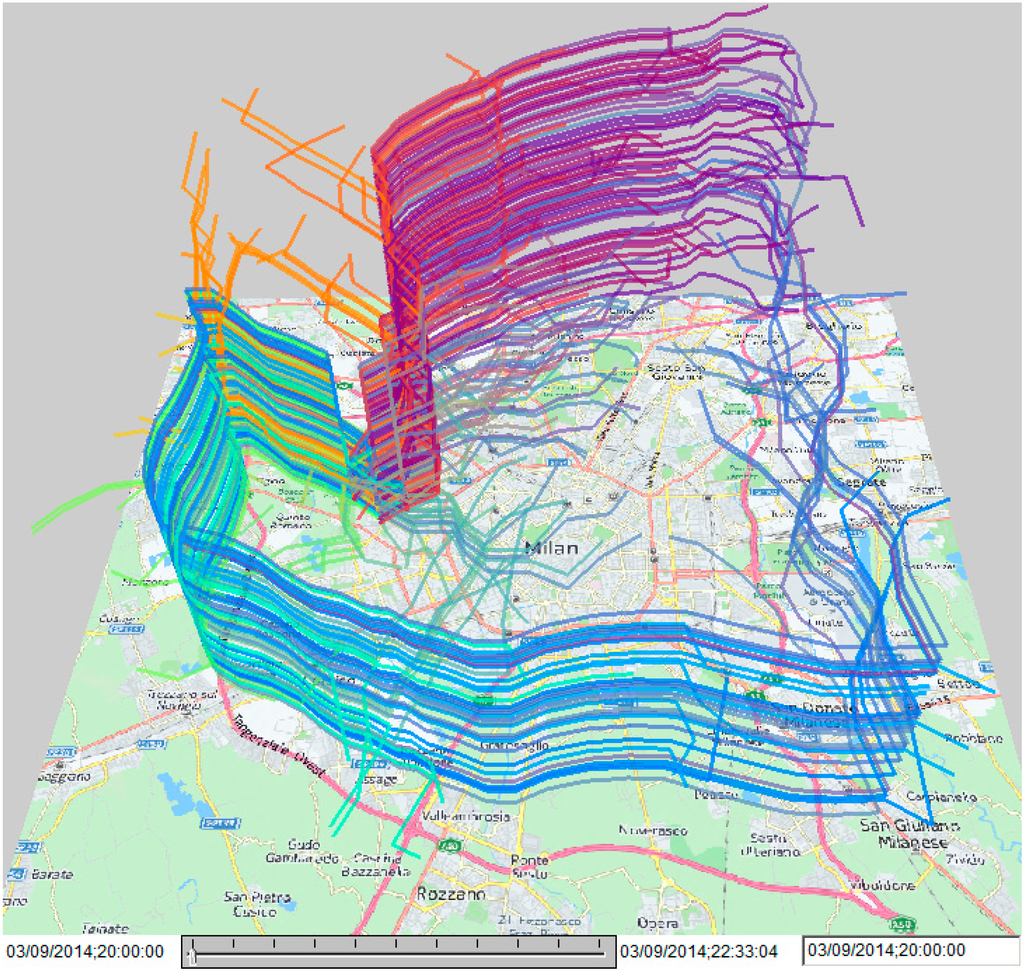
شکل 5. مسیرهای شبیهسازی شده اتومبیلهایی که از مجاورت استادیوم سن سیرو به مکانهای خانگی فرضی پس از یک بازی فوتبال حرکت میکنند در یک مکعب فضا-زمان نشان داده شدهاند.
در شکل 6، خطوط مسیر بر روی نقشه ترسیم می شوند و جزء زمانی را نادیده می گیرند. در این دیدگاه، مسیرها می توانند به شبکه فیزیکی خیابان میلان و شبکه انتزاعی فضایی سلول های مرتبط آسان تر باشند. دایره های قرمز روی نقشه در چهار سلول در اطراف استادیوم سن سیرو ترسیم شده اند که ما آنها را به عنوان مبدا سفرهای شبیه سازی شده با ماشین انتخاب کردیم. دایره های سبز رنگ مقصد سفر را مشخص می کنند. برای انتخاب مقاصد از استدلال زیر استفاده کردیم. پس از پایان بازی، اکثر تماشاگران با ماشین به سمت خانه خود می رفتند. از این رو، احتمال اینکه یک سلول مقصد سفر باشد، متناسب با تعداد افرادی است که در آنجا زندگی می کنند. ما هیچ داده ای در مورد توزیع فضایی جمعیت ساکن میلان در سطحی از جزئیات کافی برای تخمین تعداد ساکنان در هر سلول Voronoi نداریم. با این حال، ما تعداد ساعتی پایان سفر در سلول ها را در نتیجه تجمع داده های مسیر اصلی داریم. می توان انتظار داشت که تعداد سفرهایی که در ساعات عصر و شب به پایان می رسد با تعداد خانه های یک سلول مرتبط باشد، زیرا در عصرها مردم معمولاً به خانه می روند. این انتظار عقل سلیم با نتایج مطالعات تجربی مطابقت دارد [26 ]. از این رو، توزیع سفر در عصر و شب به پایان می رسد می تواند به عنوان نماینده ای برای توزیع جمعیت ساکن عمل کند. بر اساس این استدلال، ما به ابزار اجازه میدهیم مقصدهای سفر را بهطور تصادفی در سراسر قلمرو توزیع کند، به طوری که احتمال انتخاب سلول متناسب با وزن سلول است، که مجموع تعداد ساعتهای پایان سفر در ساعتهای 6 است: 00 بعد از ظهر تا 12:00 صبح
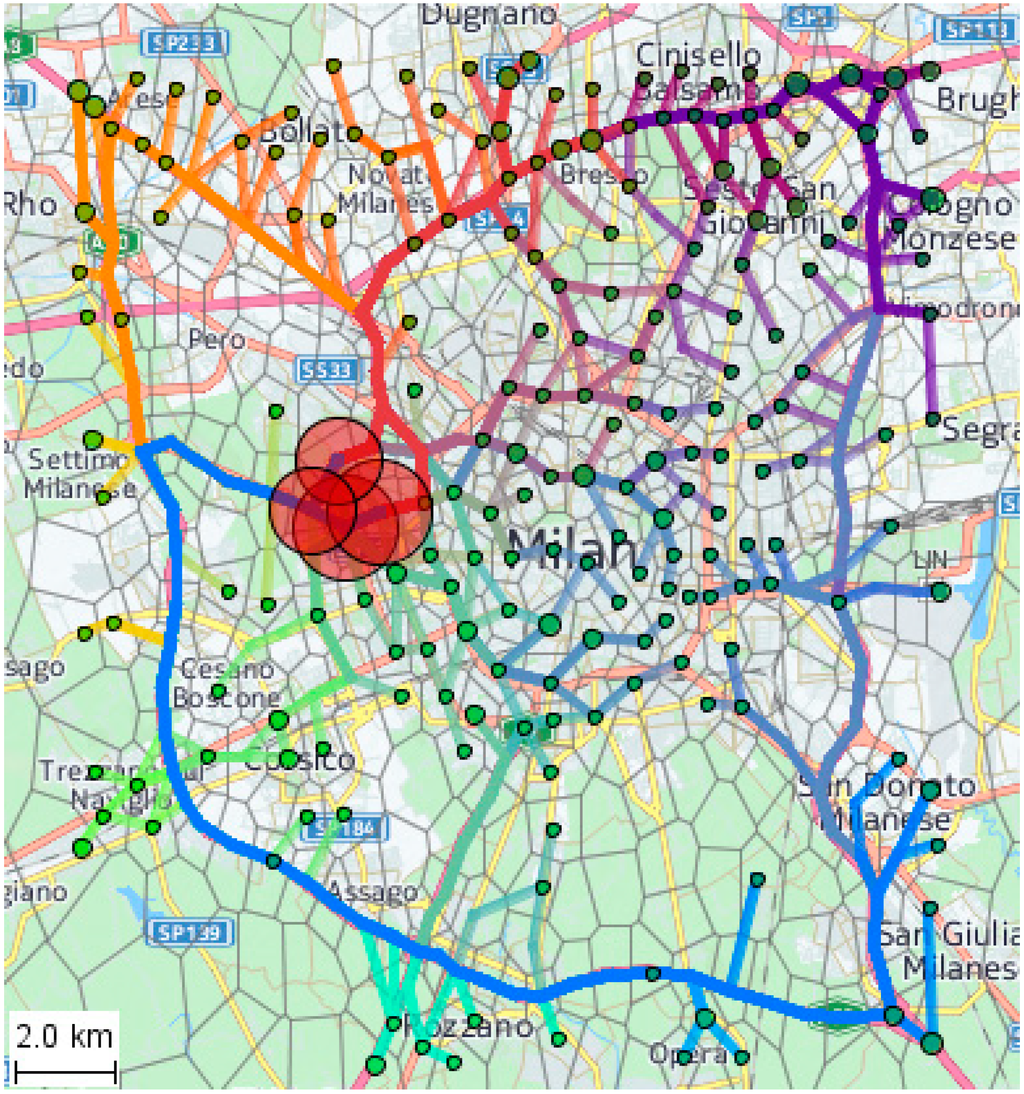
شکل 6. مسیرهای شبیه سازی شده روی نقشه نشان داده شده است. دایره های قرمز و سبز به ترتیب مبدا و مقصد سفر را نشان می دهند.
علاوه بر مشاهده مسیرهای شبیه سازی شده در یک مکعب فضا-زمان و روی نقشه، که ممکن است برای نشان دادن حرکات ماشین در طول زمان متحرک باشد، فرصت های بیشتری برای تجزیه و تحلیل وجود دارد. این ابزار نتایج شبیهسازی را برای سلولها و پیوندها با فواصل زمانی انتخابی کاربر جمعآوری میکند. با استفاده از نمایشگرهای نمودار زمان، میتوانیم بارهای پیوند، سرعتهای متوسط بهدستآمده و تعداد خودروهای معلق در سلولها را تجزیه و تحلیل کنیم. گلوگاه ها در زیرساخت های حمل و نقل را می توان آشکار کرد.
پس از تجزیه و تحلیل توسعه پیشبینیشده وضعیت ترافیک، میتوان تغییراتی را در سناریو ارائه کرد (مثلاً غیرفعال کردن استفاده از برخی پیوندها و/یا تغییر وزن پیوندها برای مدلسازی مسیریابی مجدد ترافیک) و شبیهسازی جدید. از طریق چنین تحلیل “چه می شد اگر”، ممکن است بتوان اقدامات مناسبی برای کاهش تعلیق و ازدحام ترافیک پیدا کرد.
7. ارزیابی نیکویی مدل
ارزیابی چگونگی پیشبینی مدلها جریانهای ترافیکی منظم به روشی ساده و با مقایسه شدت جریان ترافیک پیشبینیشده با شدت واقعی انجام میشود. چالشبرانگیزتر ارزیابی پیشبینی موقعیتهای ترافیکی فوقالعاده زمانی است که هیچ داده واقعی منعکس کننده چنین موقعیتهایی وجود ندارد. ما بدون پرداختن به جزئیات، ایده ای از چگونگی انجام چنین ارزیابی ارائه می کنیم. ایده این است که از تفاوتهای بین دورههای آرام و شلوغ ترافیک معمولی استفاده شود که در دادههای واقعی منعکس میشود. تحلیلگر یک بازه زمانی آرام t q و یک بازه زمانی شلوغ t b را انتخاب می کند و تفاوت ΔN را بین تعداد کل وسایل نقلیه N(t b ) و N(t q پیدا می کند.) که در این دو بازه در شبکه حضور داشتند: ΔN = N(t b ) − N(t q ). سپس تحلیلگر این سناریو را شبیه سازی می کند که گویی ΔN وسایل نقلیه اضافی در شبکه در بازه زمانی t q علاوه بر ترافیک عادی برای t q ظاهر می شوند. وسایل نقلیه اضافی بر روی گره های شبکه به نسبت تفاوت در تعداد وسایل نقلیه بین فواصل t b و t q توزیع می شوند. پس از انجام شبیهسازی، شدت ترافیک پیشبینیشده با ترکیب ترافیک عادی و اضافی با شدت ترافیک واقعی در بازه tb مقایسه میشود . ارزیابی چندین بار برای جفت های مختلف t q و t تکرار می شودب . ما این رویکرد را برای مدلهای ساخته شده برای میلان و توسکانی اعمال کردیم و همبستگی بسیار بالایی بین مقادیر پیشبینیشده و واقعی به دست آوردیم.
8. نتیجه گیری
در سالهای اخیر، تحقیقات ما به شدت بر تجزیه و تحلیل دادههای مربوط به حرکت [ 21 ]، از جمله حرکت محدود به شبکه متمرکز بود. با توسعه و بکارگیری روشهای مختلف تجزیه و تحلیل بصری، ما تلاش کردیم تا فرصتهای بالقوهای را که میتوان با دادههای حرکتی فراهم کرد، کاوش کنیم. برای حرکت محدود به شبکه، ما تغییرات داده را پیدا کردیم که به ما امکان میدهد وابستگی متقابل بین دو جنبه کلیدی حرکت، شدت ترافیک و سرعت را تجسم کنیم. داشتن تصاویر واضح، مانند شکل 2 و شکل 4، متوجه الگوهای رایج شدیم و این ایده را به دست آوردیم که وابستگی های متقابل را می توان کمی سازی کرد و به طور رسمی به روشی یکسان بیان کرد. برای اجرای این ایده، ابزارهای تجزیه و تحلیل بصری اضافی را توسعه دادیم که ما را قادر میسازد وابستگیها را با مدلهای رسمی نشان دهیم. این نشان میدهد که روشهای تحلیل بصری میتوانند به تحلیلگران کمک کنند نه تنها به درک (به عنوان مثال ، یک مدل ذهنی) از یک پدیده نشاندادهشده توسط دادهها، بلکه برای تبدیل این مدل ذهنی به مدلهای رسمی صریح نیز کمک کنند.
ایده بعدی ما این بود که مدلهایی که روابط شدت ترافیک را ثبت میکنند، میتوانند نه تنها حرکات معمولی بلکه حرکات غیرعادی را که در دادههای اصلی نشان داده نشدهاند، پیشبینی کنند. این امکان پذیر است زیرا مدل ها داده ها را تعمیم می دهند و می توانند فراتر از محدوده اصلی داده ها برون یابی کنند. ما یک ابزار شبیهسازی ترافیک را توسعه دادهایم که قادر به استفاده از مدلهای به دست آمده از دادههای ترافیک واقعی و یک زیرساخت تحلیل بصری است که از تعریف سناریوهای ترافیک برای شبیهسازی و تجزیه و تحلیل نتایج شبیهسازی پشتیبانی میکند.
تحقیقات ما امکان اصلی استفاده از دانش بهدستآمده از دادههای حرکت واقعی را برای پیشبینی توسعه موقعیتهای ترافیکی، حتی در شرایط غیرعادی نشان داد. علاوه بر این، یکی از یافتههای ما این بود که وابستگیهای بین شدت ترافیک و سرعت موجود در یک شبکه انتزاعی فضایی شبیه به وابستگیهای شناخته شده موجود در ترافیک جادهای است و در سطح بخشهای جاده مشاهده میشود. این یک فرصت بالقوه برای انجام شبیهسازیهای سریع در مقیاس بزرگ از تحولات وضعیت ترافیک در مناطق بزرگ، زمانی که جزئیات دقیق مورد نیاز نیست، باز میکند. این فرصت نیاز به بررسی و آزمایش همه جانبه با همکاری متخصصان حوزه حمل و نقل دارد.
منابع
- Gazis، DC Traffic Theory ; Kliwer Academic: Boston, MA, USA, 2002. [ Google Scholar ]
- مقیاس هادسون، جی سی در فضا و زمان. در جهان های درونی جغرافیا: مضامین فراگیر در جغرافیای معاصر آمریکا . Abler، RF، Marcus، MG، Olson، JM، Eds. انتشارات دانشگاه راتگرز: نیوبرانزویک، نیوجرسی، ایالات متحده آمریکا، 1992; ص 280-297. [ Google Scholar ]
- Goodchild، MF مدل های مقیاس و مقیاس های مدل سازی. در مقیاس مدلسازی در علم اطلاعات جغرافیایی ; Tate, NJ, Atkinson, PM, Eds. John Wiley & Sons, Ltd.: Chichester, UK, 2001; صص 3-10. [ Google Scholar ]
- Mackaness، WA درک فضای جغرافیایی. در تعمیم اطلاعات جغرافیایی: مدلسازی نقشه برداری و کاربردها ; Mackaness, WA, Ruas, A., Sarjakoski, T., Eds.; الزویر: آکسفورد، انگلستان، 2007; صص 1-10. [ Google Scholar ]
- Lloyd, CD Exploring Spatial Scale in Geography ; Wiley-Blackwell: Chichester، UK، 2014; پ. 253. [ Google Scholar ]
- Openshaw, S. مسئله واحد مساحتی قابل تغییر . Geo Books: Norwich، UK، 1984. [ Google Scholar ]
- آندرینکو، جی. آندرینکو، ن. دمشار، یو. درانش، دی. دایکز، جی. فابریکانت، اس. جرن، ام. کراک، ام.-جی. شومان، اچ. تومینسکی، سی. تحلیل فضا، زمان و بصری. بین المللی جی. جئوگر. Inf. علمی 2010 ، 24 ، 1577-1600. [ Google Scholar ] [ CrossRef ]
- آندرینکو، ن. آندرینکو، جی. تعمیم فضایی و تجمیع داده های حرکت عظیم. IEEE Trans. Vis. محاسبه کنید. گر 2011 ، 17 ، 205-219. [ Google Scholar ] [ CrossRef ]
- لاوب، پی. Purves، R. سرعت یک گاو چقدر است؟ تجزیه و تحلیل مقیاس متقابل داده های حرکت. ترانس. GIS 2011 ، 15 ، 401-418. [ Google Scholar ] [ CrossRef ]
- سلیمانی، ع. کشات، جی. رابینسون، ک. دوج، اس. کالوف، ا. Weibel, R. ادغام تجزیه و تحلیل مقیاس متقابل در حوزه های مکانی و زمانی برای طبقه بندی حرکت رفتاری. جی. اسپات. Inf. علمی 2014 ، 8 ، 1-25. [ Google Scholar ]
- سیوال، جی. ویلکی، دی. شبیه سازی ترکیبی تعاملی Lin, MC از ترافیک در مقیاس بزرگ. ACM Trans. گر 2011 ، 30 . [ Google Scholar ] [ CrossRef ]
- سیوال، جی. ویلکی، دی. مرل، پی. شبیه سازی ترافیک Lin, MC Continuum. محاسبه کنید. گر انجمن 2010 ، 29 ، 439-448. [ Google Scholar ] [ CrossRef ]
- Lighthill، MH; Whitham، GB در امواج سینماتیک. II. تئوری جریان ترافیک در جاده های شلوغ طولانی Proc. R. Soc. لندن. A 1955 , 229 , 317-345. [ Google Scholar ] [ CrossRef ]
- نیوول، جی. اثرات غیرخطی در دینامیک خودروهای زیر. اپراتور Res. 1961 ، 9 ، 209-229. [ Google Scholar ] [ CrossRef ]
- ناگل، ک. Schreckenberg، M. یک مدل خودکار سلولی برای ترافیک آزادراه. J. Phys. I 1992 , 2 , 2221-2229. [ Google Scholar ]
- بورگوت، دبلیو. کوتسوپولوس، HN; Andreasson، I. یک مدل شبیهسازی ترافیک مزوسکوپی رویداد گسسته برای شبیهسازی ترافیک ترکیبی. در مجموعه مقالات کنفرانس سیستم های حمل و نقل هوشمند IEEE 2006 (ITSC’06)، تورنتو، ON، کانادا، 17-20 سپتامبر 2006. صص 1102–1107.
- دل کاستیلو، جی.ام. بنیتز، FG در مورد شکل عملکردی رابطه سرعت – چگالی I: نظریه عمومی. ترانسپ Res. بخش ب: روش. 1995 ، 29 ، 373-389. [ Google Scholar ] [ CrossRef ]
- Helbing، D. استخراج یک نمودار اساسی برای جریان ترافیک شهری. یورو فیزیک J. B 2009 , 70 , 229-241. [ Google Scholar ] [ CrossRef ]
- بورل، ای. لسورت، جی.-بی. ترکیب نمایشهای خرد و کلان جریان ترافیک: یک مدل ترکیبی بر اساس نظریه LWR در مجموعه مقالات هشتاد و دومین نشست سالانه هیئت تحقیقات حمل و نقل، واشنگتن، دی سی، ایالات متحده آمریکا، 12 ژانویه 2003.
- بورگوت، دبلیو. کوتسوپولوس، HN; Andreasson، I. شبیه سازی ترافیک مزوسکوپی-میکروسکوپی هیبریدی. ترانسپ Res. ضبط 2005 ، 1034 ، 218-225. [ Google Scholar ] [ CrossRef ]
- آندرینکو، جی. آندرینکو، ن. باک، پ. کیم، دی. Wrobel, S. Visual Analytics of Movement ; Springer: Heidelberg، آلمان، 2013. [ Google Scholar ]
- وود، جی. Slingsby، A.; دایکز، جی. تجسم پویایی طرح کرایه دوچرخه لندن. Cartographica 2011 ، 46 ، 239-251. [ Google Scholar ] [ CrossRef ]
- Tobler, W. آزمایشهایی در نقشهبرداری مهاجرت توسط کامپیوتر. صبح. کارتوگر. 1987 ، 14 ، 155-163. [ Google Scholar ] [ CrossRef ]
- آندرینکو، ن. آندرینکو، جی. چارچوب تجزیه و تحلیل بصری برای تحلیل و مدلسازی مکانی-زمانی. حداقل داده بدانید. کشف کنید. 2013 ، 27 ، 55-83. [ Google Scholar ]
- پاپالاردو، ال. رینزیویلو، اس. Qu، Z. پدرشی، دی. Giannotti، F. درک الگوهای سفر با ماشین. یورو فیزیک J. Spec. بالا. 2013 ، 215 ، 61-73. [ Google Scholar ] [ CrossRef ]
- جیانوتی، اف. نانی، م. پدرشی، دی. پینلی، اف. رنسو، سی. رینزیویلو، اس. Trasarti، R. پرده برداری از پیچیدگی تحرک انسان با جستجو و استخراج داده های عظیم مسیر. VLDB J. 2011 ، 20 ، 695-719. [ Google Scholar ] [ CrossRef ]
© 2015 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر