

خلاصه
ماسکهای جغرافیایی گروهی از روشهای حفاظت از موقعیت مکانی برای انتشار و انتشار اطلاعات محرمانه و حساس مانند دادههای مرتبط با سلامت و جرم و جنایت هستند. استفاده از چنین ماسک هایی تضمین می کند که حریم خصوصی افراد درگیر در مجموعه داده ها محافظت می شود. با این وجود، فرآیند حفاظت خطای مکانی را به مجموعه داده پوشانده شده معرفی می کند. این مطالعه با استفاده از دو رویکرد، خطای فضایی مجموعههای داده پوشانده شده را کمیسازی میکند. ابتدا، یک نظرسنجی ادراکی به کار گرفته شد که در آن شرکتکنندگان شباهت یک نمونه متنوع از نقشههای ماسکدار و اصلی را رتبهبندی کردند. دوم، یک تحلیل آماری فضایی انجام شد که نتایج کمی را برای همان جفت نقشه ارائه کرد. شباهت آماری فضایی با سه شاخص واگرایی محاسبه میشود که از روشهای مختلف خوشهبندی فضایی استفاده میکنند. همه شاخص ها به طور معنی داری با شباهت ادراکی همبستگی دارند. در نهایت، از نتایج تحلیل فضایی به عنوان متغیر توضیحی برای برآورد شباهت ادراکی استفاده می شود. سه مدل پیشبینی ایجاد میشوند که مرزهای بالایی را برای نتایج آماری فضایی نشان میدهند که براساس آن دادههای پوشانده شده متفاوت از دادههای اصلی درک میشوند. هدف از نتایج این مطالعه کمک به «نقابگیران» بالقوه برای تعیین کمیت و ارزیابی خطای تجسمهای پوشانده شده محرمانه است. سه مدل پیشبینی ایجاد میشوند که مرزهای بالایی را برای نتایج آماری فضایی نشان میدهند که براساس آن دادههای پوشانده شده متفاوت از دادههای اصلی درک میشوند. هدف از نتایج این مطالعه کمک به «نقابگیران» بالقوه برای تعیین کمیت و ارزیابی خطای تجسمهای پوشانده شده محرمانه است. سه مدل پیشبینی ایجاد میشوند که مرزهای بالایی را برای نتایج آماری فضایی نشان میدهند که براساس آن دادههای پوشانده شده متفاوت از دادههای اصلی درک میشوند. هدف از نتایج این مطالعه کمک به «نقابگیران» بالقوه برای تعیین کمیت و ارزیابی خطای تجسمهای پوشانده شده محرمانه است.
کلید واژه ها:
حریم خصوصی مکان ؛ ماسک های جغرافیایی ; داده های جرم ؛ خطای مکانی ؛ شباهت درک شده
1. معرفی
نقشه های موضوعی توزیع نقطه در مطالعات تحقیقاتی برای کمک به تجسم تجزیه و تحلیل در سطح خرد، در انتشارات رسانه ای و در پلت فرم های نقشه برداری آنلاین برای ارائه اطلاعات به عموم ظاهر می شود. در عین حال، تعداد انتشارات علمی که حاوی نقشه های اطلاعات محرمانه هستند اخیرا افزایش یافته است [ 1]. همین امر را می توان در پلتفرم های عمومی نیز انتظار داشت، زیرا فناوری اطلاعات جغرافیایی ابزار مؤثری برای ارائه اطلاعات دقیق برای اهداف جامعه است. انواع محرمانه یا حساس اطلاعات مکان معمولاً برای محافظت از حریم خصوصی افراد به شکل مبهم ظاهر می شوند. فرآیند مبهم سازی در مقایسه با داده های اصلی منجر به تجسم هایی با خطای مکانی می شود. هدف این مقاله محاسبه میزان خطای مکانی است که میتواند به تجسم مبهم بدون تغییر اطلاعات ضروری که دادههای واقعی به تصویر میکشند، معرفی شود.
ضرورت محاسبه خطای تجسم های مبهم به این دلیل است که اطلاعات محرمانه، حساس و خصوصی به طور مداوم از طریق نقشه های نقطه ای توسط سه منبع اصلی مشاهده می شود: (1) انتشار روزنامه ها. (2) انتشارات علمی؛ و (3) وب سایت های نقشه برداری جرم.
1.1. نمونه هایی از نقشه های نقطه مبهم برای حفاظت از حریم خصوصی
در برخی موارد، تکنیک های پوشش جغرافیایی برای محافظت از موضوع محرمانه تجسمی استفاده می شود. ماسکهای جغرافیایی گروهی از روشهای حفاظت از مکان هستند که برای اولین بار توسط آرمسترانگ و همکاران معرفی شدند . [ 2 ] به عنوان رویکردهایی برای پوشاندن مکانهای محرمانه خاص افراد. تا کنون، آنها در انواع انتشارات علمی برای محافظت از مکان های مربوط به سلامت، جرم یا اطلاعات مربوط به حریم خصوصی استفاده شده اند [ 1 ]. روشهای حفاظت از مکان فقط به ماسکهای جغرافیایی محدود نمیشوند [ 3 ، 4 ]، اما به نظر میرسد این نوع روشها برای حفاظت از دادههای نقطه گسسته ترجیح داده میشوند. ویلر در زمینه اپیدمیولوژی [ 5] به طور تصادفی موارد لوسمی دوران کودکی را از محل واقعی خود برای حفظ محرمانه بودن اطلاعات جابجا کرد. آلمانزا و همکاران [ 6 ] از رویکرد مشابهی برای ترسیم سطح فعالیت بدنی کودک در مکانهای مختلف استفاده کرد. علاوه بر این، ویرا و همکاران . [ 7 ] یک جابجایی تصادفی در 1.2 کیلومتر مربع را برای ارائه مکان های سکونتگاه های سرطان پستان در کیپ کد، ماساچوست به کار گرفت. مخاطبان این انتشارات ممکن است در درجه اول جامعه علمی (متخصصان موضوع) و در مرحله بعد، عموم باشند.
علاوه بر این، سازمانهای خاصی که مسئول انتشار اطلاعات به عموم هستند، دادههای محافظت شده را منتشر میکنند. نمونهای از این روش، وبسایت Police.uk است که دادههای جرم را در سطح ملی در بریتانیا منتشر میکند. برای محافظت از هویت و حریم خصوصی قربانیان، همه دادههای جرم با استفاده از یک تکنیک خاص «ناشناسسازی مکان» پنهان میشوند [ 8 ]. به نظر میرسد تکنیک «ناشناسسازی مکان» مطابق با دستورالعملهایی باشد که در گزارش آییننامه عملی از نهاد عمومی غیردپارتمانی «دفتر کمیسر اطلاعات» [ 9 ] و گزارش وزارت دادگستری ایالات متحده در مورد انتشار داده های جرم مکانی [ 10]. علاوه بر این، ابتکارات پلیسی، مانند نقشه برداری جرم، ادراک مردم از محله خود و پلیس محلی را بهبود می بخشد و به عنوان آموزنده و قابل اعتماد درک می شود [ 11 ]. از سوی دیگر، چینی و تامپسون [ 12 ] استدلال میکنند که کیفیت و تجسم نقشهکشی اطلاعات منتشر شده باید بهبود یابد و رسانههای اجتماعی باید برای امکان گفتوگو در مورد مسائل جرم و جنایت درگیر شوند. با توجه به خطر نقض حریم خصوصی ناشی از شناسایی مجدد، شرکت کنندگان در نظرسنجی که در لندن، انگلستان انجام شد، ترجیح دادند روش حفاظتی با خطر متوسط (از هشت تا 20 آدرس) که نشان دهنده نیاز به حفاظت در سطح خیابان است. قطعنامه ها، مانند ماسک های جغرافیایی [ 13 ].
1.2. نمونه هایی از نقشه های نقطه ای که در آن یک موضوع محرمانه مبهم نیست
تعداد قابل توجهی از نشریات مکانهای محرمانه را بدون نقاب ارائه کردند (مکانهای واقعی در نقشههای نقطهای). یک نمونه بارز نقشه تعاملی است که مکان صاحبان اسلحه را در دو شهرستان حومه نیویورک مشخص می کند که در دسامبر 2012 توسط “ژورنال نیوز” منتشر شد [ 14 ، 15 ]. ساکنان با انتشار اطلاعات خود مخالفت کردند و ادعا کردند که نقشه باعث سرقت می شود، زیرا سارقان اکنون از محل یافتن اسلحه آگاه هستند [ 16 ]. سارق سابق والتر تی شاو تأیید کرد که چنین اطلاعاتی برای سارقان و اجتناب از چنین اقامتی یا یافتن سلاح های موجود بسیار مفید است [ 17 ]]. مثال دیگر نقشه ای است که مکان دقیق مرگ و میر ناشی از طوفان کاترینا را نشان می دهد که در یک روزنامه محلی در باتون روژ، لس آنجلس، ایالات متحده آمریکا منتشر شد [ 18 ]. در آخر، کونادی و لایتنر [ 1 ] 41 مقاله علمی پیدا کردند که اطلاعات محرمانه، حساس یا خصوصی واقعی را بر روی نقشه ها نمایش می دادند.
خطر شناسایی مجدد زمانی که اطلاعات محرمانه مسکونی فاش میشود و نقاب آن آشکار میشود ممکن است برای عموم ناشناخته باشد، اما محققان تلاش کردهاند تا آگاهی را در مورد آن افزایش دهند. فرآیند به دست آوردن اطلاعات بیشتر در مورد افراد از نقشه هایی که مکان های محرمانه دقیقی را ارائه می دهند توسط کونادی و همکاران به عنوان “سناریوی متجاوز” توصیف شده است . [ 19 ]. علاوه بر این، لایتنر، میلز و کورتیس [ 20 ] دقت فرآیند مهندسی معکوس را که فرآیند استخراج مختصات جغرافیایی از توزیع نقطه ای بر روی نقشه دیجیتال است، بررسی کردند. از منظر مسیرهای مکان (به عنوان مثال، داده های GPS)، Krumm [ 21] نشان داد که چگونه می توان نام و شماره تلفن افراد را از چنین داده هایی بازیابی کرد. نمونههایی از انتشار بدون نقاب دادههای محرمانه و یافتههای حاصل از مطالعات شناسایی مجدد، ضرورت استفاده از ماسکهای جغرافیایی برای تجسم را نشان میدهد.
1.3. محاسبه خطای مکان های مبهم
عیب ماسکهای جغرافیایی این است که با تغییر مکانهای اصلی، مکانهای نقابدار به نوعی با مکانهای اصلی متفاوت میشوند. حتی بیشتر، متولیان داده های پوشانده شده، خطای مکانی تجسم های خود را ارزیابی و گزارش نمی کنند. شکست در تجزیه و تحلیل و ارزیابی این خطا ممکن است منجر به تجسم نادرست و تصورات نادرست در مورد ویژگی الگوهای اصلی شود.
البته، محققانی که در مورد ماسکهای جغرافیایی منتشر کردهاند، از دست دادن اطلاعات مکانی دادههای پوشانده شده را با استفاده از معیارها و رویکردهای مختلف بررسی کردهاند. آرمسترانگ و همکاران [ 2 ] بررسی کرد که آیا چندین ماسک جغرافیایی ویژگیهای فضایی الگوی اصلی را حفظ میکنند (به عنوان مثال ، روابط زوجی، روابط رویداد-جغرافی، روندها، ناهمسانگردیها، وجود خوشهها، مکانهای واقعی خوشهها و مکانهای نسبی خوشهها). در حالی که این رویکرد برای درک اثراتی که استفاده از ماسک های جغرافیایی مختلف بر الگوی نقطه اصلی خواهد داشت مفید است، امکان کمی کردن این اثر را نمی دهد. به عنوان مثال، ماسک “اختلال تصادفی” ( به عنوان مثال،معرفی یک خطای تصادفی در فاصله و جهت نقطه اصلی) تقریباً مکان های واقعی خوشه ها را حفظ می کند. با این حال، نمی توان به این سوال پاسخ داد: یک ماسک جغرافیایی چقدر مکان های اصلی خود را حفظ می کند؟ از سوی دیگر، کوان و همکاران . [ 22] اثرات geomasking را بر روی الگوی فضایی اصلی با انجام روشهای تحلیل الگوی نقطهای برای هر دو مجموعه داده اصلی و ماسکدار تعیین کرد و سپس نتایج را مقایسه کرد. روشهایی که آنها استفاده کردند شامل تجسم الگوهای نقطهای، تجسم سطوح چگالی دو بعدی و سه بعدی، بررسی نقشههای تفاوت چگالی و تحلیل تابع متقاطع K بود. علاوه بر این، سایر محققان از آمار فضایی برای تعیین کمیت اثرات و به ویژه شاخصهای خوشهای مانند حساسیت، ویژگی، نرخ تشخیص، دقت و مهمترین خوشه استفاده کردند [ 23 ، 24 ، 25 ، 26 ].
بیشتر تکنیکهای تشخیص اثرات، عملکرد ماسکهای مختلف را با مجموعه دادههای مشابه مقایسه میکنند تا ماسکی را شناسایی کنند که کمترین خطای مکانی را برای مجموعه داده پوشانده شده دارد. مطالعه کونادی و لایتنر [ 27] همین هدف را داشت و از دو «شاخص واگرایی» استفاده کرد. “واگرایی” اعوجاج یا تفاوت یک الگوی نقطه ماسکدار با یک الگوی نقطه اصلی را با استفاده از آمار فضایی توصیف میکند. علاوه بر این، از نتایج شاخصهای واگرایی میتوان برای مقایسه خطاها با سایر مجموعههای داده پوشانده شده یا تجسمها استفاده کرد. شاخص های واگرایی از دو شاخص ترکیبی تشکیل شده است. اینها عبارتند از: (1) «شاخص واگرایی جهانی» (GDi) که واگرایی نتایج تحلیلی مرکز نگاری نقاط نقاب دار را از نتایج تحلیلی مرکز نگاری نقاط اصلی محاسبه می کند. و (2) شاخص واگرایی محلی (LDi) که واگرایی نتایج تحلیلی نقاط حساس نقاط پوشانده شده را از نتایج تحلیلی نقاط داغ نقاط اصلی محاسبه می کند. Hotspot ها مناطق یا نقاطی هستند که تراکم بالایی از حوادث دارند. تا این حد، نقاط مهم از نظر آماری مناطق مهمی هستند که از روشهای خوشهبندی فضایی حاصل میشوند که ویژگیهای محلی یک الگوی نقطهای را اندازهگیری میکنند. برای ماسک های بررسی شده و پارامترهای آنها، داده های پوشانده شده به طور قابل توجهی ویژگی های محلی داده های اصلی را تغییر دادند. از سوی دیگر، ماسک ها خطاهای جزئی را به ویژگی های جهانی داده های اصلی معرفی کردند.
سرانجام، لایتنر و کورتیس [ 28] یک عامل مهم به روش خود برای بررسی خطای فضایی ماسک ها، یعنی نمایشگر نقشه اضافه کرد. نویسندگان میخواستند بفهمند تأثیر بصری ماسکها بر توزیع الگوی نقطه و شناسایی نقاط داغ در مقایسه با توزیع اصلی و نقاط داغ چیست. به طور خاص، آنها از یک نظرسنجی استفاده کردند که در آن شرکتکنندگان مشاهدات بصری انجام دادند و شباهتهای الگوهای نقطهای نقابدار و اصلی را رتبهبندی کردند. علاوه بر این، شرکتکنندگان نقاط داغ را به الگوی نقطه اصلی یا نقابدار ترسیم کردند، که به نویسندگان اجازه میداد تفاوتهای نقاشیهای نقاط داغ را به صورت بصری مقایسه کنند. این یک رویکرد مهم است، زیرا افراد (متخصص یا غیرمتخصص) کسانی هستند که در نهایت در معرض نقشه های ماسک شده قرار می گیرند. در نتیجه، زمانی که اطلاعات مکانی محرمانه منتشر می شود،
1.4. هدف مطالعه
دو مطالعه اخیر خطای مجموعه داده های پوشانده شده را برای تحلیل های فضایی خاص بررسی کردند. اولین مطالعه توسط Heydrich، Burgert و Emch [ 29 ] جابجایی مکانها از خوشههای بررسی جمعیتی و سلامت (DHS) را بررسی کرد (خوشهها مکانهایی هستند) که با استفاده از یک ماسک اختلال تصادفی خاص جابجا شدهاند. خوشه های پوشانده شده توسط سازمان برای تحلیل فضایی در اختیار محققان قرار می گیرد. مطالعه دوم توسط تامپسون و همکاران . [ 30] تفکیک فضایی را بررسی کرد که برای تجزیه و تحلیل کافی است در صورتی که دادههای جنایت پنهانی که از وبسایت Police.uk در دسترس است برای تحقیق استفاده شود. هر دو مطالعه دستورالعمل هایی را در مورد استفاده مناسب از این مجموعه داده های پوشانده شده با چشم انداز تحقیقات بیشتر ارائه کردند. دستورالعمل ها مختص این مجموعه داده های پوشانده شده است و نمی توانند برای سایر مجموعه داده ها یا ماسک های جغرافیایی اعمال شوند.
از سوی دیگر، خطای تجسم دادههای پوشانده شده هنوز مورد توجه قرار نگرفته است، حتی اگر به نظر میرسد تجسم خالص و انتشار اطلاعات استفاده اصلی از مجموعه دادههای پوشانده شده باشد. آنچه در ادبیات کنونی وجود ندارد، یک رویکرد کلی کاربردی است که نه تنها از دست دادن اطلاعات مکانی داده های پوشانده شده را محاسبه می کند، بلکه یک مقدار آستانه را نیز تعیین می کند که تا آن حد خطای مکانی نمی تواند ویژگی های الگوی اصلی را به طور معناداری تغییر دهد. فرم تجسم نهایی از این رو، نیاز به تعریف حداکثر سطح قابل قبول خطای مکانی وجود دارد که در زیر آن خطای مکانی به صورت بصری قابل مشاهده نباشد. هدف این مطالعه پیشنهاد روشی برای «نقابگذاران» بالقوه برای تعیین کمیت خطای فضایی و بر اساس این خطا، ارزیابی کیفیت تجسمهای پوشانده شده محرمانه آنهاست. برای پرداختن به این موضوع، فرض می کنیم که مشاهدات بصری به شدت با نتایج آماری مرتبط هستند. به عبارت دیگر، شباهت درک شده توسط عموم از الگوهای نقطهای را میتوان با شباهت آماری بین الگوهای نقطهای مشابه مرتبط دانست. این فرضیه اصلی این تحقیق است. این بدان معناست که هرچه خطای مکانی دادههای پوشانده شده در مقایسه با دادههای اصلی بیشتر باشد، احتمال کمتری وجود دارد که افراد الگوی نقطه ماسکشده را شبیه به الگوی اصلی درک کنند. اگر این فرضیه تایید شود، شباهت درک شده از تجسم های آینده را می توان با محاسبه خطای مکانی داده های پوشانده شده تخمین زد. شباهت ادراک شده عموم از الگوهای نقطه ای را می توان با شباهت آماری بین الگوهای نقطه ای مشابه مرتبط دانست. این فرضیه اصلی این تحقیق است. این بدان معناست که هرچه خطای مکانی دادههای پوشانده شده در مقایسه با دادههای اصلی بیشتر باشد، احتمال کمتری وجود دارد که افراد الگوی نقطه ماسکشده را شبیه به الگوی اصلی درک کنند. اگر این فرضیه تایید شود، شباهت درک شده از تجسم های آینده را می توان با محاسبه خطای مکانی داده های پوشانده شده تخمین زد. شباهت ادراک شده عموم از الگوهای نقطه ای را می توان با شباهت آماری بین الگوهای نقطه ای مشابه مرتبط دانست. این فرضیه اصلی این تحقیق است. این بدان معناست که هرچه خطای مکانی دادههای پوشانده شده در مقایسه با دادههای اصلی بیشتر باشد، احتمال کمتری وجود دارد که افراد الگوی نقطه ماسکشده را شبیه به الگوی اصلی درک کنند. اگر این فرضیه تایید شود، شباهت درک شده از تجسم های آینده را می توان با محاسبه خطای مکانی داده های پوشانده شده تخمین زد. کمتر احتمال دارد که مردم الگوی نقطه ماسک شده را شبیه به الگوی اصلی درک کنند. اگر این فرضیه تایید شود، شباهت درک شده از تجسم های آینده را می توان با محاسبه خطای مکانی داده های پوشانده شده تخمین زد. کمتر احتمال دارد که مردم الگوی نقطه ماسک شده را شبیه به الگوی اصلی درک کنند. اگر این فرضیه تایید شود، شباهت درک شده از تجسم های آینده را می توان با محاسبه خطای مکانی داده های پوشانده شده تخمین زد.
2. استراتژی تحلیلی
برای تعریف یک مقدار آستانه برای حداکثر خطای مکانی دادههای پوشانده شده، ما از یک استراتژی استفاده کردیم که شامل سه مرحله است. در مرحله اول یک بررسی ادراکی انجام شد. در مرحله دوم، تجزیه و تحلیل آماری مکانی انجام شد. آخرین مرحله شامل مقایسه نتایج آماری و ادراکی با استفاده از تحلیل رگرسیون لجستیک بود.
به عنوان بخشی از مرحله اول، ما مجبور شدیم شرکتکنندگانی را که به یکی از این دو گروه تعلق دارند، استخدام کنیم: (1) کارشناسان، یعنی افرادی که معمولاً با دادههای مکانی کار میکنند. و (2) افراد غیر متخصص در رسیدگی به داده های مکانی. از آنجایی که کارشناسان داده های مکانی زیر گروه بسیار کوچکی از جمعیت هستند، ما از روش گلوله برفی برای به دست آوردن یک نمونه به اندازه کافی بزرگ استفاده کردیم. نمونه گیری گلوله برفی یک روش نمونه گیری غیراحتمالی است که در آن شرکت کنندگان شرکت کنندگان بیشتری را از میان آشنایان خود استخدام می کنند [ 31 ]]. برای شناسایی افراد بالقوه در مطالعاتی که نمونه برداری از افراد با استفاده از روش های نمونه گیری تصادفی رایج دشوار است، استفاده می شود. در مطالعه ما، پرسشنامههای آنلاین از طریق فهرستهای پست الکترونیکی بین دوستان، همکاران و همچنین در پستهایی در گروههای فیسبوک مرتبط با گروههای دانشگاه GIS یا GIS توزیع شد. سپس، شرکتکنندگانی که به آنها نزدیک شده بود میتوانستند پیوند نظرسنجی را بین افراد دیگر توزیع کنند. توزیع مجدد بدون محدودیت مجاز بود، زیرا هر دو “متخصص” و “غیر متخصص” مورد نیاز بودند. وظیفه شرکت کنندگان رتبه بندی شباهت جفت نقشه ها بود. برای هر جفت، یک نقشه وجود داشت که توزیع اصلی نقاط را نشان می داد و یک نقشه که توزیع ماسک شده را نشان می داد. شرکت کنندگان شباهت نقشه ها را با انتخاب یکی از پاسخ های مرتب شده زیر رتبه بندی کردند: “بسیار مشابه”، “مشابه”، “کمی شبیه”، “متفاوت” و “بسیار متفاوت”. سطح شباهت به صورت قالب مقیاس لیکرت طراحی شد [32 ]. این دسته بندی های ترتیبی پس از آزمایش طرح نظرسنجی با تعدادی از همکاران ما تصمیم گیری شد. به شرکت کنندگان تاکید شد که هیچ پاسخ صحیح یا غلطی در مورد درک فرد از شباهت وجود ندارد. در نهایت، برای اطمینان از اینکه پاسخ دهندگان فقط بر مقایسه الگوهای نقطه تمرکز می کنند و هیچ عامل دیگری بر قضاوت آنها تأثیر نمی گذارد، همه نقشه ها دارای نمادشناسی و طراحی نقشه برداری یکسان بودند. علاوه بر آن، اطلاعاتی در مورد منطقه و موضوع توزیع داده نشد.
برای هر جفت نقشه، خطای فضایی توزیع پوشانده شده با استفاده از رویکرد “واگرایی اطلاعات مکانی” توسط کونادی و لایتنر [ 27 ] محاسبه شد. به گفته نویسندگان، برخی از مزایای این رویکرد این است که میزان اعوجاج ارزش اصلی یک آمار فضایی را به مقدار پوشانده شده نشان میدهد و امکان مقایسه در مورد اعوجاج بین مناطق و مجموعه دادههای مختلف را فراهم میکند. به دلایلی که در مقدمه ذکر شد، فقط «شاخص واگرایی محلی (LDi)» استفاده شد، یعنی واگرایی نقاط داغ ماسکدار (نقاط داغ نقاط ماسکدار) به اصلیها (نقاط داغ نقاط اصلی) و میتواند با استفاده از فرمول زیر محاسبه شود:
L o c a l d i v e r g e n c e = اسym m e t r i c d من ffe r e n c e o f A a n d ب A + B × 100��جآل دمن�ه��ه�جه= اس�مترمترهتی�منج دمن��ه�ه�جه �� آ آ�د ب آ+ب ×100
که در آن A = منطقه هات اسپات اصلی و B = منطقه هات اسپات های پوشانده شده است.
شاخص واگرایی محلی از صفر تا 100 است. حداکثر واگرایی برابر با 100 است که نقاط داغ اصلی و پوشانده شده کاملاً از هم جدا شوند. از سوی دیگر، واگرایی برابر با صفر است که نقاط اصلی و ماسک شده یکسان باشند. در مجموع، ما سه شاخص واگرایی محلی را محاسبه کردیم: (1) Nnh.di، شاخص واگرایی مناطق کانونی با استفاده از خوشهبندی فضایی سلسله مراتبی نزدیکترین همسایه. (2) Gi*.di، شاخص واگرایی مناطق داغ با استفاده از آمار Getis-Ord Gi*. و (3) Ans.di، شاخص واگرایی مناطق داغ با استفاده از آماره موران محلی Anselin [ 33 ، 34 ، 35]. از این رو، برای یک نقشه از هر جفت نقشه، شاخص واگرایی محلی سه بار با استفاده از یک روش خوشهبندی در هر زمان محاسبه شد.
در آخرین مرحله، ما فرضیه خود را با استفاده از تحلیل رگرسیون لجستیک که یک مدل مهم و مفید برای دادههای پاسخ طبقهای در نظر گرفته میشود، آزمایش کردیم [ 36 ]]. ما واگرایی هات اسپات را به عنوان متغیر مستقلی تعریف کردیم که می تواند شباهت درک شده را پیش بینی کند، زیرا این متغیر وابسته بود. با این حال، تغییرات در قابلیت پیشبینی هر روش خوشهبندی (خوشهبندی فضایی سلسله مراتبی نزدیکترین همسایه، Getis-Ord Gi*، Anselin Local Moran’s I)، و همچنین در پاسخهای بین دو گروه نمونه (“متخصصان” و “غیر متخصصان” ”) ممکن است وجود داشته باشد. از این رو، نه ترکیب زیر مورد آزمایش قرار گرفتند: (1) پاسخهای شباهت “متخصصان” با نتایج یکی از سه روش خوشهبندی (سه ترکیب). (2) پاسخهای شباهت «غیر متخصصان» با نتایج یکی از سه روش خوشهبندی (سه ترکیب). و (3) پاسخ شباهت همه شرکت کنندگان با نتایج یکی از سه روش خوشه بندی (سه ترکیب).
تهیه نقشه های اصلی و ماسک شده
دادههای مکانی که در این مطالعه استفاده میشود، سرقتهای خودرو در وین، اتریش، از ژانویه 2007 تا ژوئن 2007 است. دادهها توسط سرویس اطلاعات جنایی اتریش ارائه شده است. مجموعه داده به دو دلیل برای این مطالعه مناسب است. دزدی های وسیله نقلیه معمولاً به صورت مکانی شبیه به سایر داده های محرمانه (مثلاً مکان بیماران برای یک بیماری خاص) یا داده های حساس (مثلاً مکان سرقت های مسکونی) دسته بندی می شوند. از سوی دیگر، سرقت های خودرو نه محرمانه هستند و نه حساس، زیرا اکثر مکان های آنها را نمی توان با آدرس افراد مرتبط کرد. استثناها شامل سرقت هایی است که در آن وسیله نقلیه از گاراژ یا پارکینگ مرتبط با یک خانه خانوادگی به سرقت رفته است. با این وجود، این نوع حادثه از سایر موارد در مجموعه داده متمایز نیست. علاوه بر این، دادهها در حال حاضر هفت سال از عمرشان میگذرد، بنابراین اطلاعات دیگر واقعاً مرتبط نیستند و برای کسی که سعی میکند آدرسها را معکوس کند، مکانها را برای شناسایی مجدد افرادی که در آن آدرس زندگی میکنند، تطبیق دهد، کاربرد چندانی ندارد. بنابراین، چنین نقشه هایی را می توان با خیال راحت برای اهداف مطالعه بدون افشای اطلاعات خصوصی منتشر کرد.
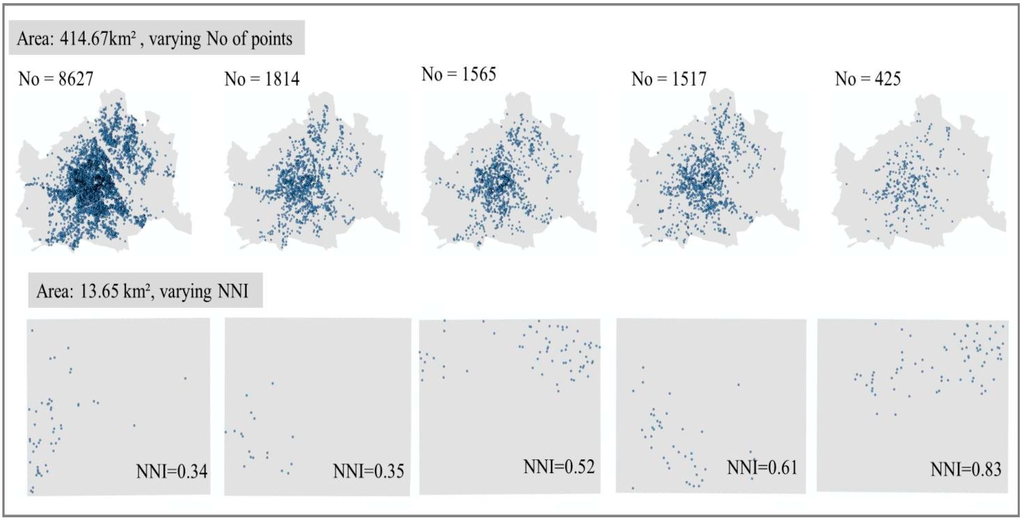
برای ایجاد نقشهها، نقشههای مختلفی را هدف قرار دادیم که سناریوهای مختلفی از الگوهای نقطهای را نشان میدهند که بیننده ممکن است با آنها برخورد کند. ابتدا، ما زیر مجموعههای زیر را از مجموعه داده اصلی استخراج کردیم: یک مجموعه در ماه (در مجموع شش عدد)، یک مجموعه در هفته (در مجموع 24) و یک مجموعه برای کل دوره. علاوه بر این، ما یک شبکه 7 × 7 را روی منطقه مورد مطالعه (شهر وین) قرار دادیم و سلول هایی را که حاوی 50 یا بیشتر سرقت بودند (22 سلول / زیر مجموعه) استخراج کردیم. از مجموعه 52 زیرمجموعه، ده زیرمجموعه را انتخاب کردیم که در سه ویژگی فضایی متفاوت هستند: (1) تراکم مکانها. (2) درجه خوشه بندی مکان ها. و (3) روند توزیع. ده مجموعه پایانی به روش های زیر متفاوت است: (1) تراکم نقاط از 50 حادثه تا 8627 حادثه متغیر است. (2) درجه خوشه بندی محاسبه شده توسط شاخص نزدیکترین همسایه (NNI) از 0.34 تا 0.83 متغیر است. و (3) الگوهای نقطه ای دارای شش روند مختلف هستند (پنج ناحیه شبکه و شهر وین). از ده مجموعه، ده نقشه اصلی ایجاد کردیم که با نقشه های ماسک شده آنها مقایسه می شود. ده نقشه اصلی نهایی در ارائه شده استشکل 1 .

شکل 1. نقشه های اصلی. پنج نقشه در بالا کل شهر وین (414.67 کیلومتر مربع) را پوشش می دهد و از نظر تراکم نقاط متفاوت است. پنج نقشه در پایین، مناطق مربعی در وین هستند، هر کدام 13.65 کیلومتر مربع بزرگ ، و از نظر توزیع نقاط و درجه خوشه بندی (NNI، شاخص نزدیکترین همسایه) متفاوت هستند.
“ماسک دایره ای” برای ایجاد مجموعه های نقاب دار استفاده شد [ 22 ]. این روش پوشش جغرافیایی نقاط اصلی را در یک فاصله از پیش تعریف شده ثابت (شعاع) و در جهت تصادفی (0 تا 360 درجه) در محیط دایره جابجا می کند. روش به دلیل اجرای ساده آن انتخاب شد. با این حال، هر روش دیگری می توانست به جای آن استفاده شود. پارامتری از ماسک های جغرافیایی که میزان خطای فضایی وارد شده به داده ها را تعیین می کند، “درجه پوشش” نامیده می شود. برای “ماسک دایره ای”، درجه پوشش اندازه شعاع است. یافتههای قبلی نشان داد که با افزایش درجه پوشش، الگوی نقطه ماسکدار از نظر فضایی بیشتر از الگوی نقطه اصلی متفاوت است [ 22 ، 23 ،37 ]. از آنجا که نقشه های اصلی دارای دو مقیاس متفاوت (پنج نقشه که کل شهر وین را با مساحت 414.67 کیلومتر مربع نشان می دهد و پنج نقشه در مقیاس بزرگتر، که بخشی از وین را با مساحت 13.65 کیلومتر مربع نشان می دهد ) ، همان درجه پوشاندن است. بر روی نقشه های مقیاس بزرگتر بیشتر از نقشه های مقیاس کوچکتر تاثیر می گذارد. علاوه بر این، استفاده از ماسک باید طیف گسترده ای از نتایج “واگرایی محلی” را به همراه داشته باشد (0-100). به عبارت دیگر، ترکیبی از نقشه های پوشانده شده با یک خطای کوچک که می تواند از دیدگاه شرکت کنندگان مشابه در نظر گرفته شود، و همچنین نقشه های پوشانده شده با خطای بزرگ که ممکن است متفاوت تلقی شود. برای اطمینان از نتایج متنوع، مجموعه دادههای اصلی را با استفاده از سه شعاع پنهان کردیم.

شکل 2. سه جفت نقشه اصلی در مقابل ماسک شده با درجات مختلف پوشش.

شکل 3. استراتژی تحلیلی مطالعه.
برای انتخاب اندازههای مناسب برای شعاعها، ما از تخمینهای خطاهای فضایی درجات مختلف پوششی که در مطالعات قبلی پیشنهاد شده بود، استفاده کردیم [ 7 ، 22 ، 37 ، 38 ]. بر اساس این مطالعات، ما یک شعاع را انتخاب کردیم که فرض میشود تأثیر کمی بر الگوی نقطه ماسکدار (200 متر)، شعاع با تأثیر بزرگ (1000 متر) و یکی در وسط (600 متر) دارد. روش پوشش دهی منجر به 30 نقشه پوشانده شد که با 10 نقشه اصلی مقایسه شده است. شکل 2 بالا سه جفت از 30 جفتی را که در تجزیه و تحلیل استفاده شده است نشان می دهد. در نهایت، شکل 3خلاصه ای از استراتژی تحلیلی را در پنج مرحله نشان می دهد. هر مرحله ورودی، خروجی و فرآیندهایی را که درگیر بوده اند، توصیف می کند.
3. نتایج
این بخش در سه بخش سازماندهی شده است. ابتدا، نتایج نظرسنجی را با توجه به شرکت کنندگان تجزیه و تحلیل می کنیم. دوم، ما نتایج آماری (LDi) را با نتایج ادراکی (پاسخ های نظرسنجی در مورد شباهت درک شده) مقایسه می کنیم تا روش خوشه بندی را شناسایی کنیم که می تواند شباهت درک شده را به بهترین نحو تخمین بزند. در نهایت، با استفاده از روش خوشهبندی بهینه، مدلهایی را برای پیشبینی شباهت درک شده توسعه میدهیم.
3.1. نتایج نظرسنجی و شرکت کنندگان
این نظرسنجی طی دو هفته از 14 تا 26 جولای 2014 انجام شد.در مجموع 398 پاسخ پرسشنامه جمع آوری شد. طراحی پرسشنامه در ابتدا توسط گروه منتخبی از همکاران نویسندگان مورد آزمون قرار گرفت. پیشنهاد شد که تعداد جفت نقشه ها باید به 15 در هر پرسشنامه محدود شود تا کار طاقت فرسا رتبه بندی مکرر شباهت جفت تصاویری که قالب مشابهی دارند تسهیل شود. از این رو، 30 جفت نقشه که 30 سؤال را تشکیل می دادند به دو پرسشنامه آنلاین 15 سؤالی تقسیم شدند. جفت نقشه ها به صورت تصادفی انتخاب و در قالب پرسشنامه ها مرتب شدند. علاوه بر سؤالات اصلی (رتبه بندی شباهت)، چهار سؤال دیگر نیز در خصوص ویژگی های شرکت کنندگان مطرح شد. اینها عبارت بودند از: جنسیت، سن، ملیت و حرفه. سؤال حرفه ای به شرح زیر تنظیم شد: آیا در دانشگاه کار می کنید؟ صنعت یا بخش دولتی مرتبط با ژئودزی، ژئوماتیک، ژئوانفورماتیک، جغرافیا، برنامه ریزی شهری یا محیط زیست (بله/خیر)؟ هدف این سؤالات اولاً جداسازی گروه «متخصصان» از گروه «غیر متخصص» و ثانیاً بررسی تنوع پاسخها با توجه به جنبههای جمعیت شناختی نمونه ما بود.
ویژگی های نمونه نظرسنجی در جدول 1 خلاصه شده است. گروه حرفه ای با 210 شرکت کننده مرتبط با علوم فضایی (“متخصصان”) و 148 شرکت کننده غیر مرتبط با علوم فضایی نشان داده شده است. علاوه بر این، اکثر شرکت کنندگان بین 20 تا 39 سال (76.1٪) بودند و ملیت آنها یونانی، اتریشی، آلمانی یا کرواتی بود (59.5٪؛ در مجموع، 42 ملیت نمایندگی داشتند). همچنین از 398 شرکتکننده، 40 نفر به سؤالات «حرفه»، «جنس» و «گروه سنی» و 57 نفر از 398 شرکتکننده به سؤال «ملیت» پاسخ ندادند.
علاوه بر این، آزمونهای آماری با دستههای گروهها برای بررسی تغییرات آماری معنیدار در شباهتهای درک شده انجام شد. آزمون هایی که مورد استفاده قرار گرفتند، آزمون جفت همسان ویلکاکسون برای گروه های دو دسته و آزمون فریدمن برای گروه های سه دسته بودند [ 39 ، 40 ].]. هر دسته به عنوان یک نمونه زوجی در نظر گرفته میشود و برای تشخیص همخوانی رتبهبندی دستهها با یکدیگر مورد بررسی قرار گرفت (به عنوان مثال، آیا رتبهبندی زنان متفاوت از مردان است؟). برای گروههای سنی و ملیتی، دستههایی را که بیش از 30 شرکتکننده داشتیم، بررسی کردیم. برای هر دسته و جفت نقشه، شباهت درک شده حالت را محاسبه کردیم که به صورت زیر کدگذاری شد: 1 = بسیار شبیه، 2 = مشابه، 3 = کمی شبیه، 4 = متفاوت، 5 = بسیار متفاوت. جدول 2میانگین تمام جفت حالتهای نقشه و اهمیت آماری آزمونها را بر اساس دستهبندی نشان میدهد. به غیر از ملیت، سایر گروهها از نظر آماری پاسخهای متفاوتی در بین دستههای خود دادند. شباهت درک شده شرکت کنندگانی که متعلق به دستههای «متخصص»، مرد و گروه سنی «21 تا 29» هستند، از نظر آماری کمتر از گروههای «غیر متخصص»، زن و گروههای سنی «30 تا 39» است. و “40-49”. بیشترین تفاوت در گروه حرفه مشاهده می شود و بنابراین منطق ایجاد مدل های جداگانه را توجیه می کند.

جدول 1. ویژگی های شرکت کنندگان (No = 398). a ملیتها در بریتانیا به تابعیت «بریتانیایی» تجمیع میشوند، زیرا شرکتکنندگان از عبارات مختلفی برای توصیف ملیت خود استفاده میکردند. b ملیت با کمتر از 10 شرکت کننده در هر ملیت (در مجموع 36 ملیت).
جدول 2. اهمیت تفاوت در ادراک شباهت بین دسته های هر گروه. a دسته بندی گروه ها از نظر آماری در سطح معنی داری 0.05 متفاوت است.
3.2. مقایسه درک شده با شباهت آماری
نتایج خلاصه شده شباهت درک شده و شاخص های واگرایی محلی بر اساس اندازه سطح و درجه پوشش در جدول 3 نشان داده شده است. نتایج واگرایی میانگین مقدار را برای هر روش خوشهبندی نشان میدهد و نتایج شباهت شباهت درک شده از حالت را نشان میدهد. برای محاسبه خوشههای هر روش، از پارامترهای زیر استفاده کردیم: (1) برای خوشهبندی فضایی سلسله مراتبی نزدیکترین همسایه: دو بیضی انحرافی استاندارد برای طرح کلی خوشهها، حداقل پنج نقطه در هر خوشه، فقط خوشههای مرتبه اول و یک شعاع جستجو بر اساس فاصله تصادفی نزدیکترین همسایه. و (2) برای آمار Getis-Ord Gi* و Anselin Local Moran’s I: استخراج سلول هایی که z > 1.65 ( p-مقدار <0.1) مربع شبکه ای 150 متری. همه مجموعههای اصلی با الگوهای نقطهای مشخص میشوند که بیشتر خوشهای هستند تا پراکنده (NNI از 0.34 تا 0.83 متغیر است). پارامترها به گونهای انتخاب شدند که همه مجموعهها خوشههای فضایی معنیدار آماری را برگردانند. پارامترهای محافظه کارانه تر ( به عنوان مثال ، حداقل 20 نقطه در هر خوشه برای خوشه بندی فضایی سلسله مراتبی نزدیکترین همسایه) مجموعه هایی از تعداد کم نقاط و مقادیر NNI بالاتر را از ایجاد خوشه های قابل توجه باز می دارد، حتی اگر آنها از نظر آماری خوشه بندی شده باشند. پارامترهای دیگری نیز می توانست استفاده شود. با این حال، این پارامترها امکان تکرارپذیری این مطالعه را در مناطق مختلف از محلههای کوچک تا سطوح شهر فراهم میکند.
در بخش قبل توضیح داده شد که درجه پوشش و مقیاس چگونه بر بزرگی خطای مکانی در مجموعه داده پوشانده شده تأثیر می گذارد. نتایج جدول 3 با این توضیح هم برای واگرایی های محلی و هم برای شباهت های درک شده مطابقت دارد. برای همه روشهای خوشهبندی، واگرایی برای درجات پوشش بزرگتر همان ناحیه بیشتر و برای اندازههای ناحیه بزرگتر با همان درجه پوشش کمتر است. علاوه بر این، به طور متوسط، یک منطقه کوچکتر واگرایی بیشتری دارد (اندازه منطقه: 13.65 کیلومتر مربع ؛ محدوده واگرایی: 65.56-83.29) نسبت به یک منطقه بزرگتر (اندازه منطقه: 414.67 کیلومتر مربع) .; محدوده واگرایی: 52.21-71.75). مشاهدات مشابهی را می توان برای شباهت درک شده انجام داد. تنها استثنا این است که با کاهش درجه پوشش از 1000 متر به 600 متر از همان منطقه، درک شباهت به سمت نظر “مشابه” تر تغییر نمی کند.
جدول 3. شباهت درک شده و واگرایی های محلی بر اساس اندازه منطقه و درجه پوشش. ادراک شباهت با نتایج به دست آمده از سه روش خوشه بندی فضایی مقایسه می شود. Nnh.di شاخص واگرایی نواحی هات اسپات با استفاده از خوشه بندی فضایی سلسله مراتبی نزدیکترین همسایه است. Gi*.di شاخص واگرایی نواحی هات اسپات با استفاده از آمار Getis-Ord Gi* است. در نهایت، Ans.di شاخص واگرایی نواحی هات اسپات با استفاده از آماره موران محلی Anselin است. هرچه این واگرایی بیشتر باشد، تفاوت بین نقاط داغ اصلی و ماسک دار بیشتر است.
یافتههای تاکنون نشان میدهد که شباهت درک شده یک نقشه اصلی در مقابل یک نقشه ماسکدار به نوعی با اعوجاج نقاط داغ (LDi) نقشههای ماسکدار مرتبط است. یعنی هرچه خطای بیشتری به داده ها وارد شود، نقشه ماسک شده مشابه کمتری نسبت به نقشه اصلی درک می شود. برای بررسی آماری ارتباط متغیر مرتب شده «شباهت درک شده» با شاخصهای واگرایی محلی، آزمونهای tau b کندال و اسپیرمن را انجام دادیم [ 41 ، 42 ].]. برای اعمال این روشهای ناپارامتریک زمانی که یک متغیر ترتیبی و دیگری مقیاس نسبت است، متغیر دوم نیز باید در مقیاس ترتیبی باشد. این بدان معنی است که اطلاعات واگرایی محلی باید به مقیاس ترتیبی اندازه گیری کاهش یابد. در نتیجه، متغیر واگرایی محلی به صورت زیر مرتب شد: 1 = 0-25، 2 = 26-50، 3 = 51-75، 4 = 76-100. برای هر جفت نقشه، حالت شباهت درک شده و دسته مرتب شده واگرایی محلی محاسبه شد. از نتایج جدول 4 ، فرضیه صفر استقلال متقابل بین متغیرها را برای همه آزمونها رد میکنیم. علاوه بر این، برای همه گروه های جدول 4(کلیه شرکت کنندگان، غیر متخصصان و خبرگان)، Nnh.di بیشترین همبستگی را دارد و سپس Gi*.di قرار دارد. Ans.di کمترین همبستگی را در بین هر سه شاخص واگرایی و در بین همه گروه ها دارد.
جدول 4. همبستگی بین شباهت درک شده و شاخص های واگرایی محلی. یک همبستگی در سطح 0.05 (2 دنباله) معنی دار است. همه همبستگی های دیگر در سطح 0.01 (2 دنباله) معنی دار هستند.
3.3. مدل های برآورد شباهت درک شده
با توجه به اینکه تحلیل های ارائه شده در بالا نشان می دهد که شاخص های واگرایی محلی احتمالاً می توانند شباهت درک شده را تخمین بزنند، ما از مدل های رگرسیون لجستیک ترتیبی برای بررسی قابلیت پیش بینی آنها استفاده می کنیم. ما یک مدل برای هر گروه (همه شرکت کنندگان، کارشناسان، غیر متخصصان) ایجاد کردیم. به جای تجزیه و تحلیل نتایج برای همه متغیرهای مستقل (شاخصهای واگرایی محلی)، Nnh.di را تحلیل میکنیم که قویترین همبستگی را با متغیر وابسته مورد بررسی (شباهت درک شده) دارد. مشابه قبل، برای هر جفت نقشه، شباهت درک شده حالت محاسبه شد. nnh.di به عنوان یک متغیر توضیحی، مدل های پیش بینی قابل توجهی را برای دسته های زیر ایجاد کرد: 1 = بسیار مشابه یا مشابه، 2 = کمی مشابه و 3 = متفاوت یا بسیار متفاوت. دسته اول “بسیار مشابه یا مشابه” مرز بالایی نتایج Nnh.di و طیفی از نتایج بهینه یا قابل قبول را تعریف می کند. دسته دوم “کمی مشابه” طیفی از نتایج Nnh.di را نشان می دهد که ممکن است برای تجسم قابل قبول نباشد. با این حال، آنها تجسم متفاوت ادراک شده را به عنوان تجسم های دسته آخر “متفاوت یا بسیار متفاوت” نشان نمی دهند. نتایج آزمون های تشخیصی و ضرایب تحلیل رگرسیون لجستیک ترتیبی درجدول 5 .
جدول 5. نتایج تشخیص و ضریب برای هر مدل رگرسیون لجستیک ترتیبی.

شکل 4. درصدهای تجمعی Nnh.di بر اساس طبقه بندی شباهت درک شده (بسیار مشابه/مشابه، کمی مشابه و متفاوت/بسیار متفاوت) برای هر گروه (همه شرکت کنندگان، غیر متخصصان، کارشناسان).
به طور کلی، مدلها نشان میدهند که Nnh.di یک پیشبینیکننده مهم برای شباهت درک شده نقشههای نقطهای ماسکدار و اصلی است. ابتدا، آزمونهای مجذور کای نشان میدهند که با گنجاندن متغیر مستقل، مدلها به طور قابلتوجهی بهبود مییابند ( p< 0.01). دوم، آمار کای دو پیرسون از مدل ها ناچیز است، به این معنی که داده های مشاهده شده با مدل برازش همخوانی دارند و داده ها و پیش بینی های مدل مشابه هستند. مقادیر Nagelkerke (شبه R-squared) نشان می دهد که هر سه مدل کار خوبی در پیش بینی متغیر پاسخ انجام می دهند، با توجه به اینکه یک مدل مناسب برای این آمار مقدار یک را برمی گرداند. مدل «همه شرکتکنندگان» شامل تمام پاسخهای «متخصصان»، «غیر متخصصان» و همچنین شرکتکنندگانی است که به سؤال مربوطه پاسخ ندادهاند (در مجموع، 398 نفر). در نهایت، آزمونهای خطوط موازی، که فرض میکنند متغیر با دستههای ترتیبی متناسب است، بیاهمیت هستند. این بدان معناست که مدل رگرسیون نوع ترتیبی نسبت به مدل کلی برازش بهتری برای متغیر وابسته دارد.شکل 4 درصدهای تجمعی Nnh.di را بر اساس طبقه بندی شباهت درک شده نشان می دهد. مطابق با آزمونهای نتایج خطوط موازی، مقولههای شباهت نه تنها در محدودههای مختلف مقادیر Nnh.di به خوبی از هم جدا شدهاند، بلکه به نظر میرسد به طور مساوی از یکدیگر فاصله دارند. با این حال، در نمودار غیرمتخصص شکل 4 ، دسته “کمی مشابه” به دسته “بسیار مشابه یا مشابه” نزدیکتر از دسته “متفاوت یا بسیار متفاوت” است. این توضیح می دهد که چرا این گروه کمترین مقدار ناچیز را برای آزمایش خطوط موازی نسبت به دو خط دیگر دارد (0.116). با این حال، مدل رگرسیون لجستیک ترتیبی از نظر آماری مناسبترین مدل برای دادههای ما است.

شکل 5. نتایج Nnh.di و احتمال تشابه درک شده در سه دسته مرتب شده (بسیار مشابه/مشابه، کمی مشابه و متفاوت/بسیار متفاوت) برای هر گروه (( الف ) همه شرکت کنندگان؛ ( ب ) غیر متخصصان؛ ( ج ) ) کارشناسان).
قسمت پایین جدول 5 تخمین ضریب Nnh.di را نشان می دهد. همه آنها در فاصله اطمینان 99 درصد از نظر آماری معنادار هستند و با شباهت درک شده رابطه مثبت دارند. به عبارت دیگر، هر چه مقدار Nnh.di بالاتر باشد، احتمال اینکه شباهت درک شده در یک دسته بالاتر باشد (1 = بسیار شبیه یا مشابه، 2 = کمی شبیه و 3 = متفاوت یا بسیار متفاوت) بیشتر است. شکل 5احتمال تشابه درک شده برای مقادیر مختلف نتایج Nnh.di توسط هر مدل را نشان می دهد. روند برای همه مدل ها یکسان است. با افزایش Nnh.di، احتمال پاسخهای «بسیار مشابه یا مشابه» کاهش مییابد. برعکس، با افزایش Nnh.di، احتمال پاسخهای «متفاوت یا بسیار متفاوت» افزایش مییابد. پاسخ های “کمی مشابه” برای مقادیر متوسط در محدوده نتایج Nnh.di محتمل تر است. با این حال، محدودیتهای Nnh.di که احتمال بین کلاسها بیشتر است در بین مدلها متفاوت است. مقدار بحرانی که زیر آن نقشه پوشانده شده به احتمال زیاد به عنوان “بسیار مشابه یا مشابه” درک می شود، برای مدل “غیر متخصصان” 51، برای مدل “متخصصان” 63 و برای مدل “همه شرکت کنندگان” 56 است.
4. بحث
برای تعیین مقدار آستانه برای خطای مکانی دادههای پوشانده شده، ما از یک مطالعه ادراکی با استفاده از یک پرسشنامه آنلاین استفاده کردیم و نتایج کیفی آن را با نتایج کمی تحلیل آماری فضایی مقایسه کردیم. یافتههای ما نشان میدهد که میزان خطا در مکانهای کانونهای پوشانده شده با افرادی که توزیع را شبیه به توزیع اصلی میدانند، ارتباط زیادی دارد. در نتیجه، شباهت درک شده نقابدار در مقابلیک نقشه اصلی را می توان با محاسبه واگرایی نقاط حساس ماسک شده به نقاط اصلی (LDi) تخمین زد. این به ما این امکان را می دهد که یک مرز بالایی برای مقدار خطا تعیین کنیم که تضمین می کند که نقشه مبهم نهایی متفاوت از نقشه اصلی درک نمی شود. “مرز بالایی” یک مقدار بحرانی LDi است که در زیر آن یک نقشه پوشانده شده به احتمال زیاد به عنوان “بسیار مشابه یا مشابه” با نقشه اصلی درک می شود. سه مرز بالایی با سه مدل پیشبینی شناسایی میشوند. مدل پیشبینی اول شامل پاسخهای کارشناسان – افرادی که معمولاً با دادههای مکانی کار میکنند – است و مقدار LDi بحرانی برای این مدل 63 است. مدل پیشبینی دوم شامل پاسخهای افراد غیر متخصص در مدیریت دادههای مکانی و LDi بحرانی است. مقدار برای این مدل 51 است. مدل سوم پیش بینی شامل تمام پاسخ ها است،
پرسشنامه آنلاین در مورد درک شباهت الگوی نقطه ای توجه زیادی را به خود جلب کرد و ما 398 پاسخ از شرکت کنندگان از 42 ملیت جمع آوری کردیم. از آنجا که درک شباهت فضایی هنوز موضوعی ناشناخته است، علاوه بر هدف این مطالعه، ما این فرصت را داشتیم که نتایج را توسط گروههایی از پاسخدهندگان تجزیه و تحلیل کنیم. گروه های سن، جنس و حرفه از نظر آماری پاسخ های متفاوتی دادند. به عنوان مثال، افراد جوان (21 تا 29 سال) به طور قابل توجهی پاسخ های مشابه بیشتری نسبت به افراد مسن (40 تا 49 سال) دادند. میانگین رتبهها برای همه گروههای سنی از 2.90 تا 3.17 است که با همان پاسخ “کمی مشابه” مطابقت دارد. از این رو، تفاوت ها از نظر آماری معنی دار است، اما فقط کمی متفاوت است. این بدان معنی است که حتی اگر در پاسخ ها تغییراتی وجود داشته باشد، هنوز همبستگی بالایی بین تمام پاسخ ها و نتایج LDi وجود دارد. مورد دوم با تشخیص مدل پیشبینی «همه شرکتکنندگان» ثابت میشود (جدول 5 نشان می دهد که مدل برازش خوبی با متغیر پاسخ (شباهت ادراکی) دارد.
نتایج این مطالعه را می توان در اکثر سناریوهایی که نیاز به روش پوشاندن است استفاده کرد. با این حال، باید به چهار جنبه از فرآیند پوشاندن توجه شود: (1) K-ناشناس بودن مجموعه داده های محرمانه. (2) روش پوشش جغرافیایی؛ (3) محاسبه LDi. و (4) تفسیر نمودارهای تشابه درک شده.
این مقاله یک مقدار آستانه افشا برای حفاظت از حریم خصوصی (K-anonymity) را مورد بحث قرار نمی دهد. K-nonymity تعداد مواردی است که در میان آنها یک مورد خاص را نمی توان دوباره شناسایی کرد [ 23 ]. ناشناس بودن K میتواند به خانوادهها، افراد یا حتی آدرسها اشاره داشته باشد و ممکن است بسته به مقررات مربوط به نوع خاصی از مجموعه داده مکان متفاوت باشد. “پوششدهنده” باید مقررات مربوط به نوع اطلاعاتی که در شرف پوشاندن است را در نظر بگیرد و از روش پوشش جغرافیایی با خطای مورد نیاز برای اطمینان از محافظت مناسب استفاده کند.
انتخاب روش پوشش جغرافیایی برای استفاده مجدد از نتایج مدل مهم است. هر ایزو ماسک جغرافیایی به غیر از تبدیل های وابسته [ 2 ] یا چرخاندن [ 28 ] می تواند استفاده شود. این به این دلیل است که LDi نسبت به چرخش، مقیاس بندی یا ترجمه ثابت نیست. به عنوان مثال، LDi مکان های پوشانده شده از یک ماسک دایره ای ممکن است با LDi مکان های پوشانده شده از چرخش افین (چرخش هر نقطه با یک زاویه ثابت از یک نقطه محوری) یکسان باشد، اما الگوی متفاوت به نظر می رسد. با این وجود، بسیاری از تکنیکهای اغتشاش تصادفی و تجمع نقطهای در ادبیات وجود دارد که میتوان از آنها استفاده کرد. علاوه بر این، چرخش، مقیاسبندی، ترجمه و ورق زدن توسط دانشمندان یا سازمانها ترجیح داده نمیشود. طبق یافته های کونادی و لایتنر [1 و روش ناشناس سازی به کار گرفته شده توسط وب سایت Police.uk [ 8 ]، تجمع نقطه و اغتشاش تصادفی بیشتر مورد استفاده قرار می گیرند.
علاوه بر این، محاسبه LDi باید الزاماً پارامترهایی را که در این مطالعه استفاده شده است ( بخش نتایج ) اتخاذ کند. به طور واضح تر، برای ارزیابی خطای مکانی داده های پوشانده شده، باید شاخص واگرایی محلی را با استفاده از خوشه بندی فضایی سلسله مراتبی نزدیکترین همسایه با پارامترهایی که در اینجا استفاده کردیم محاسبه کرد. تغییر پارامترهای روش، تفسیر شباهت درک شده را به روشی پیش بینی نشده تغییر می دهد. به عنوان مثال، با افزایش تعداد نقاط از پنج به 10 در هر خوشه، شاخص واگرایی محلی نیز افزایش می یابد، زیرا این به معنای درخواست خوشه های محافظه کارتر است. مشاوره با نتایج مدل ما ( شکل 5) در این حالت ممکن است منجر به تخمین شباهت درک شده به عنوان “متفاوت” شود، اگرچه اگر از پارامترهای اصلی استفاده می شد، شباهت درک شده می توانست به عنوان “مشابه” تخمین زده شود. علاوه بر این، این رویکرد بهترین کاربرد را برای مناطقی با اندازه مشابه با موارد این مطالعه (از 414.67 کیلومتر مربع تا 13.65 کیلومتر مربع ) دارد. این یک نمایش تقریبی از مناطقی است که از سطح شهر تا محله را شامل می شود. اگرچه تجسم توزیع حوادث جرم در این مقیاس ها معمول است، اما ممکن است از مقیاس های کوچکتر یا بزرگتر نیز استفاده شود. به عنوان مثال، نقشه تعاملی وب سایت Police.uk در سطح خیابان به وضوح می رسد. بنابراین، تحقیقات بیشتری برای ارزیابی دقیق خطاهای فضایی در این وضوح مورد نیاز است.
در نهایت، نمودارهای شکل 5 مقادیر بحرانی نتایج LDi را برای ارزیابی خطا مشخص می کنند. نمودار کارشناسان نشان میدهد که افرادی که با دادههای مکانی کار میکنند، تمایل دارند جفتهای الگوهای نقطهای مکانی را در مقایسه با عموم مردم کمی شبیهتر ببینند. این نشان می دهد که مقدار آستانه خطای مکانی را می توان با توجه به مخاطب مورد نظر تنظیم کرد. به عنوان مثال، برای تجسم های پوشانده شده در نشریات علمی یا کنفرانس ها، حداکثر مقدار LDi 63 می تواند خطای قابل قبولی باشد. از سوی دیگر، زمانی که تجسم های پوشانده شده در معرض دید عموم هستند، کمترین مقدار بحرانی (51) نمودار غیر متخصص باید به عنوان حداکثر خطای قابل قبول در نظر گرفته شود.
منابع
- کوندی، ا. لایتنر، ام. چرا حریم خصوصی جغرافیایی اهمیت دارد؟ انتشار علمی داده های محرمانه ارائه شده بر روی نقشه ها. جی امپایر. Res. هوم Res. اخلاق 2014 ، 9 ، 34-45. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- آرمسترانگ، نماینده مجلس؛ راشتون، جی. Zimmerman، DL از نظر جغرافیایی داده های بهداشتی را برای حفظ محرمانگی پنهان می کند. پزشکی آمار 1999 ، 18 ، 497-525. [ Google Scholar ] [ CrossRef ]
- Cottrill، CD حریم خصوصی مکان: چه کسی محافظت می کند؟ URISA J.-Urban Reg. Inf. سیستم انجمن 2011 ، 23 ، 49-59. [ Google Scholar ]
- Bridwell, SA ابعاد حریم خصوصی مکان. Soc. دسترسی فوری عصر شهرها 2007 ، 88 ، 209-225. [ Google Scholar ]
- Wheeler، DC مقایسه خوشهبندی فضایی و تکنیکهای تشخیص خوشه برای بروز لوسمی دوران کودکی در اوهایو، 1996-2003. بین المللی J. Health Geogr. 2007 ، 6 . [ Google Scholar ] [ CrossRef ]
- آلمانزا، ای. جرت، ام. دانتون، جی. ستو، ای. Pentz, MA مطالعه ای درباره طراحی جامعه، سبز بودن و فعالیت بدنی در کودکان با استفاده از ماهواره، GPS و داده های شتاب سنج. Health Place 2012 ، 18 ، 46-54. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ویرا، VM؛ وبستر، TF; واینبرگ، جی.ام. Aschengrau، A. تجزیه و تحلیل مکانی-زمانی سرطان پستان در کیپ کاد فوقانی، ماساچوست. بین المللی J. Health Geogr. 2008 ، 7 . [ Google Scholar ] [ CrossRef ]
- Data.police.uk. در دسترس آنلاین: http://data.police.uk/about/#location-anonymisation (در 23 مارس 2015 قابل دسترسی است).
- گراهام، سی. ناشناس سازی: آیین نامه اجرایی ریسک حفاظت از داده ها . دفتر کمیسر اطلاعات: Cheshire، انگلستان، 2012. [ Google Scholar ]
- وارتل، جی. McEwen، JT Privacy در عصر اطلاعات: راهنمای به اشتراک گذاری نقشه های جرم و سری داده های مکانی: گزارش پژوهشی . موسسه حقوق و عدالت: واشنگتن، دی سی، ایالات متحده آمریکا، 2001. [ Google Scholar ]
- Quinton, P. تأثیر اطلاعات در مورد جرم و جنایت و پلیس بر ادراک عمومی: نتایج یک کارآزمایی تصادفی کنترل شده . آژانس بهبود پلیس ملی: لندن، بریتانیا، 2011. [ Google Scholar ]
- چینی، اس. تامپسون، ال. تعامل، توانمندسازی و شفافیت: انتشار آمار جرم و جنایت با استفاده از نقشه برداری جرایم آنلاین. سیاسی J. سیاست سیاست. 2012 . [ Google Scholar ] [ CrossRef ]
- کوندی، ا. باورز، ک. لایتنر، ام. نقشه برداری جرایم به صورت آنلاین: درک عمومی از مسائل حریم خصوصی. یورو جی. جنایت. نتیجه سیاست 2014 . [ Google Scholar ] [ CrossRef ]
- ژورنال نیوز. در دسترس آنلاین: http://archive.lohud.com/interactive/article/20121223/NEWS01/121221011/Map-Where-gun-permits-your-neighborhood-?nclick_check=1 (در 23 مارس 2015 قابل دسترسی است).
- مجله نیویورک تایمز. در دسترس آنلاین: http://www.nytimes.com/2013/01/07/nyregion/after-pinpointing-gun-owners-journal-news-is-a-target.html (در 23 مارس 2015 قابل دسترسی است).
- CNN. در دسترس آنلاین: http://edition.cnn.com/2012/12/25/us/new-york-gun-permit-map/ (در 23 مارس 2015 قابل دسترسی است).
- اخبار فاکس. در دسترس آنلاین: http://www.foxnews.com/us/2013/01/04/ex-burglars-say-newspapers-gun-map-wouldve-made-job-easier-safer/ (دسترسی در 12 فوریه 2015) .
- کرتیس، ای جی؛ Mills, JW; لایتنر، M. محرمانگی فضایی و GIS: مهندسی مجدد مکان های مرگ و میر از نقشه های منتشر شده در مورد طوفان کاترینا. بین المللی J. Health Geogr. 2006 , 5 , 44. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- کوندی، ا. Lampoltshammer، TJ; لایتنر، ام. Heistracher, T. جنبههای دقت و حریم خصوصی در خدمات رمزگذاری معکوس آنلاین رایگان. کارتوگر. Geogr. Inf. علمی 2013 ، 40 ، 140-153. [ Google Scholar ] [ CrossRef ]
- لایتنر، ام. Mills, JW; کورتیس، ای. کارتوگر. Nachr.(Cartographic News) 2007 , 57 , 78-84. [ Google Scholar ]
- حملات Krumm, J. Inference به مسیرهای مکان. در محاسبات فراگیر ; LaMarca, A., Langheinrich, M., Truong, K., Eds.; Springer: برلین هایدلبرگ، آلمان، 2007; جلد 4480، ص 127–143. [ Google Scholar ]
- کوان، نماینده مجلس؛ کاساس، آی. اشمیتز، BC حفاظت از حریم خصوصی جغرافیایی و دقت اطلاعات مکانی: ماسک های جغرافیایی چقدر موثر هستند؟ کارتوگر. اینتر جی. جئوگر. Inf. جئوویس. 2004 ، 39 ، 15-28. [ Google Scholar ]
- کاسا، کالیفرنیا؛ گرانیس، اس جی. Overhage, JM; Mandl، KD رویکرد حساس به زمینه برای ناشناس کردن دادههای نظارت فضایی: تأثیر بر تشخیص شیوع. مربا. پزشکی آگاه کردن. دانشیار 2006 ، 13 ، 160-165. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- اولسون، KL; گرانیس، اس جی. Mandl، KD حفاظت از حریم خصوصی در مقابل تشخیص خوشه در اپیدمیولوژی فضایی. صبح. J. بهداشت عمومی 2006 ، 96 ، 2002-2008. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- همپتون، KH; Fitch، MK; آل هاوس، WB; دوهرتی، IA; Gesink، DC; لئون، PA; Serre, ML; Miller, WC Mapping Data Health: حفاظت از حریم خصوصی بهبود یافته با استفاده از geomasking به روش دونات. صبح. J. Epidemiol. 2010 ، 172 ، 1062-1069. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ویلند، SC; کاسا، کالیفرنیا؛ ماندل، KD; برگر، ب. افشای توزیع فضایی یک بیماری با حفظ حریم خصوصی. Proc. Natl. آکادمی علمی ایالات متحده آمریکا 2008 ، 105 ، 17608-17613. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- کوندی، ا. لایتنر، ام. واگرایی اطلاعات فضایی: استفاده از شاخص های جهانی و محلی برای مقایسه نقاب های جغرافیایی اعمال شده بر داده های جرم. ترانس. GIS 2014 . [ Google Scholar ] [ CrossRef ]
- لایتنر، ام. کورتیس، A. دستورالعمل های نقشه برداری برای پوشاندن جغرافیایی مکان های داده های نقطه ای محرمانه. کارتوگر. چشم انداز 2004 ، 49 ، 22-39. [ Google Scholar ] [ CrossRef ]
- پرز-هایدریش، سی. وارن، جی ال. برگرت، CR; Emch, M. Guidelines on Use of DHS GPS Data ; آژانس توسعه بین المللی ایالات متحده (USAID): Calverton, MD, USA, 2013.
- تامپسون، ال. جانسون، اس. اشبی، م. پرکینز، سی. Edwards, P. UK داده های جرم منبع باز: دقت و امکانات برای تحقیق. کارتوگر. Geogr. Inf. علمی 2015 ، 42 ، 97-111. [ Google Scholar ] [ CrossRef ]
- نمونه گیری گودمن، LA Snowball. ان ریاضی. آمار 1961 ، 32 ، 148-170. [ Google Scholar ] [ CrossRef ]
- لیکرت، آر. تکنیکی برای سنجش نگرش ها. قوس. روانی 1932 ، 22 ، 140. [ Google Scholar ]
- Everett, B. تجزیه و تحلیل خوشه ای ; Heinemann Educational Books Ltd.: لندن، بریتانیا، 1974. [ Google Scholar ]
- Anselin، L. شاخص های محلی ارتباط فضایی-LISA. Geogr. مقعدی 1995 ، 27 ، 93-115. [ Google Scholar ] [ CrossRef ]
- گتیس، ع. Ord، JK آمار فضایی محلی: یک مرور کلی. در تجزیه و تحلیل فضایی: مدل سازی در یک محیط GIS ; Longley, PA, Batty, M., Eds. Geolnformation International: کمبریج، انگلستان، 1996; ص 261-277. [ Google Scholar ]
- Agresti، A. رگرسیون لجستیک. در تجزیه و تحلیل داده های طبقه بندی شده، ویرایش دوم. جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2002; پ. 165. [ Google Scholar ]
- لایتنر، ام. کورتیس، A. اولین گام به سمت چارچوبی برای ارائه مکان داده های نقطه محرمانه بر روی نقشه ها – نتایج یک مطالعه ادراکی تجربی. بین المللی جی. جئوگر. Inf. علمی 2006 ، 20 ، 813-822. [ Google Scholar ] [ CrossRef ]
- شی، ایکس. آلفورد-تیستر، جی. تخمین چگالی هسته Onega، T. با نقاط پوشانده شده جغرافیایی. در مجموعه مقالات هفدهمین کنفرانس بین المللی ژئوانفورماتیک، فیرفکس، VA، ایالات متحده آمریکا، 12-14 اوت 2009; جلد 1 و 2، ص 1153–1156.
- فریدمن، ام. استفاده از رتبه ها برای اجتناب از فرض نرمال بودن ضمنی در تحلیل واریانس. مربا. آمار دانشیار 1937 ، 32 ، 675-701. [ Google Scholar ] [ CrossRef ]
- Wilcoxon, F. مقایسه های فردی با روش های رتبه بندی. بیوم. گاو نر 1945 ، 1 ، 80-83. [ Google Scholar ] [ CrossRef ]
- کندال، ام جی اندازه گیری جدید همبستگی رتبه. Biometrika 1938 ، 30 ، 81-93. [ Google Scholar ] [ CrossRef ]
- Spearman, C. اثبات و اندازه گیری ارتباط بین دو چیز. صبح. جی روانی. 1904 ، 15 ، 72-101. [ Google Scholar ] [ CrossRef ]
© 2015 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر