

خلاصه
شیوع چاقی در دهه های اخیر به طور چشمگیری افزایش یافته است. این یک موضوع مهم بهداشت عمومی است زیرا باعث بسیاری از بیماری های مزمن دیگر مانند فشار خون بالا، بیماری های قلبی عروقی و دیابت نوع دوم می شود. چاقی بر امید به زندگی و حتی کیفیت زندگی تاثیر می گذارد. در نهایت، به دلیل افزایش هزینه های مراقبت های بهداشتی و غیبت در محل کار، هزینه های اجتماعی را از بسیاری جهات افزایش می دهد. استفاده از الگوهای فضایی شیوع چاقی به عنوان مثال. ما نشان میدهیم که چگونه واحدهای جغرافیایی مختلف میتوانند درجات مختلفی از جزئیات را در نتایج تحلیل آشکار کنند. ما از هر دو بخش سرشماری و گروه های بلوک سرشماری به عنوان واحدهای تحلیل جغرافیایی استفاده کردیم. علاوه بر این؛ برای نشان دادن اینکه چگونه مقیاس های جغرافیایی مختلف ممکن است بر نتایج تحلیلی تأثیر بگذارد. ما از رگرسیون وزندار جغرافیایی برای مدلسازی روابط بین میزان چاقی (متغیر وابسته) و سه متغیر مستقل استفاده کردیم. از جمله دستیابی به تحصیلات؛ نرخ بیکاری؛ و درآمد متوسط خانواده اگرچه فهرست جامعی از متغیرهای توضیحی را شامل نمی شود. این مدل رگرسیون مثالی برای آشکار کردن تأثیر مقیاسهای جغرافیایی بر تحلیل دادههای سلامت ارائه میکند. با داده های چاقی بر اساس قد و وزن گزارش شده در گواهینامه های رانندگی در شهرستان سامیت، اوهایو، نشان دادیم که رگرسیون وزنی جغرافیایی روندهای مکانی متفاوتی را بین متغیرهای وابسته و مستقل نشان می دهد که مدل های رگرسیون معمولی مانند رگرسیون حداقل مربعات معمولی نمی توانند. مهمتر از همه، تجزیه و تحلیل های انجام شده با مقیاس های جغرافیایی مختلف نتایج بسیار متفاوتی را نشان می دهد. با این یافته ها،
کلید واژه ها:
شیوع چاقی ; مقیاس های جغرافیایی ; رگرسیون وزنی جغرافیایی
1. مقدمه و بیان مسئله
تجزیه و تحلیل جغرافیایی داده های بهداشتی اغلب با استفاده از راه های سرشماری به عنوان واحد جغرافیایی تجزیه و تحلیل انجام می شود. این ممکن است تا حد زیادی به دو دلیل باشد. اولاً، دادههای بهداشتی به دلیل محرمانه بودن دادههای بیمار، تنها در سطوح انبوه منتشر میشد. ثانیاً، دادههای اجتماعی-اقتصادی از منابع دولتی در سطح جزییات بیشتری نسبت به بخشهای سرشماری مانند بلوکهای سرشماری در دسترس نیست. در نتیجه، به نظر میرسد که سرشماریها به واحد تحلیل بالفعل برای اکثر مطالعات در جغرافیای سلامت تبدیل شدهاند.
با گسترش اینترنت، داده های بهداشتی در دسترس تر شده اند و اکنون در حجم بیشتری نسبت به قبل تولید می شوند. این منجر به نیاز به ارزیابی می شود که آیا تجزیه و تحلیل داده های بهداشتی در مقیاس سرشماری کافی است یا خیر و آیا چنین واحد تجزیه و تحلیلی نمی تواند جزئیات جغرافیایی را که باید به آن توجه می کردیم نشان دهد. برای این منظور، ما در این مقاله تجزیه و تحلیل خود را از شیوع چاقی در شهرستان سامیت، اوهایو، با استفاده از دستگاههای سرشماری و گروههای بلوک سرشماری به عنوان واحدهای تجزیه و تحلیل گزارش میکنیم. ما نشان میدهیم که اغلب تعمیم بیش از حد در هنگام استفاده از دستگاههای سرشماری وجود دارد و گروههای بلوک سرشماری انتخاب بهتری برای بررسی تفاوتهای جغرافیایی در شیوع چاقی بودهاند.
به عنوان مثالی برای بررسی تأثیر مقیاسهای جغرافیایی مختلف بر مطالعات بهداشتی، بررسی موضوع نابرابری جغرافیایی شیوع چاقی را انتخاب کردیم. مدلهای رگرسیون وزندار جغرافیایی با استفاده از شیوع چاقی به عنوان متغیر وابسته ساخته شدند. ترکیب نژادی، درآمد، تحصیلات و اشتغال به عنوان متغیرهای توضیحی در نظر گرفته شد. فهرست متغیرهای توضیحی از ادبیات چاقی تعیین شده است و به هیچ وجه فهرستی جامع نیست.
داده های شیوع چاقی از محاسبه شاخص توده بدنی (BMI kg/m 2 ) که قد و وزن خود گزارش شده را در تمام داده های گواهینامه رانندگی به دست آمده از اداره وسایل نقلیه موتوری اوهایو برای سال های 2008 تا 2012 گنجانده است. اشاره کرد که قدها و وزن های خود گزارش شده در گواهینامه رانندگی با گذشت زمان منسوخ می شوند. اکثر دارندگان مجوز به سادگی مجوزهای خود را بدون به روز رسانی قد و وزن خود تمدید می کنند. به همین دلیل، ما تصمیم گرفتیم که فقط دادههای مربوط به دارندگان مجوز را که در هنگام صدور مجوز برای اولین بار بین 16 تا 21 سال سن داشتند، لحاظ کنیم.
داده های متغیرهای توضیحی از American Community Survey 2011 از اداره سرشماری ایالات متحده گرفته شده است. ما تصدیق میکنیم که این دادهها ممکن است بهترین داده برای استفاده نباشند، اما به منظور مقایسه نتایج تحلیلی بین نتایج استفاده از سرشماری و کسانی که از گروههای بلوک سرشماری استفاده میکنند، باید به خوبی به این هدف عمل کنند. ما از مدلهای رگرسیون برای بررسی روابط بین ویژگیهای اجتماعی-اقتصادی واحدهای جغرافیایی کوچک و تفاوتهای جغرافیایی در شیوع چاقی استفاده میکنیم. این روش مجدداً برای تسهیل مقایسه بین استفاده از دستگاههای سرشماری و استفاده از گروههای بلوک سرشماری به عنوان واحدهای تجزیه و تحلیل استفاده میشود و به عنوان بهترین مدل برای توضیح تغییرات شیوع چاقی پیشنهاد نمیشود. سرانجام،1 به روشی مشابه، مسائل استفاده از داده های از پیش انباشته شده برای تجزیه و تحلیل جغرافیای سلامت در Cockings و Martin [ 2 ] مورد بحث قرار گرفته است.
لازم به ذکر است که در حالی که شهرستان سامیت، اوهایو، در اینجا به عنوان مطالعه موردی استفاده می شود. نتایج حاصل از مقایسهها احتمالاً برای بسیاری از مکانهای دیگر در ایالات متحده قابل استفاده است زیرا مشخصات جمعیتی و مشخصات اجتماعی-اقتصادی در منطقه مورد مطالعه بسیار نزدیک به میانگینهای ملی است.
شیوع چاقی در بین بزرگسالان و کودکان در ایالات متحده در دهه های اخیر به طور چشمگیری افزایش یافته است (به عنوان مثال، [ 3 ، 4 ، 5 ، 6 ، 7 ، 8 ]). چاقی یک مسئله بهداشت عمومی است زیرا اغلب باعث بسیاری از بیماری های مزمن دیگر مانند فشار خون بالا، بیماری قلبی عروقی و دیابت نوع II می شود (به عنوان مثال، [ 4 ، 9 ، 10 ، 11 ، 12 ، 13 ]]). چاقی بر امید به زندگی، کیفیت زندگی تأثیر می گذارد و در نهایت به دلیل افزایش هزینه های مراقبت های بهداشتی و غیبت در محل کار یا حضور در محل کار، هزینه های اجتماعی را از بسیاری جهات افزایش می دهد.
علت اصلی چاقی عدم تعادل بین مقدار انرژی دریافت شده از طریق خوردن و آشامیدن و مقدار انرژی مصرف شده از طریق متابولیسم و فعالیت بدنی است [ 14 ، 15 ، 16 ، 17 ، 18 ، 19 ]. برای جبران انرژی دریافتی بیش از حد، افزایش فعالیت بدنی به عنوان راهی برای حفظ تعادل انرژی تشویق می شود. با این حال، به نظر می رسد عدم تعادل انرژی توسط ویژگی های محیط های فیزیکی، اجتماعی و اقتصادی تسهیل می شود.
همانطور که در Sobal و Stunkard [ 20 ] بررسی شد، یک رابطه معکوس قوی بین جغرافیای وضعیت اجتماعی-اقتصادی و توزیع چاقی وجود دارد، اگرچه تغییرات جزئی بین جوامع در حال توسعه و توسعه یافته مشاهده شد. این روند توسط Zhang و Wang [ 21 ] از مطالعه آنها در مورد روند ارتباط بین چاقی و وضعیت اجتماعی-اقتصادی در بزرگسالان ایالات متحده از سال 1971 تا 2000 تأیید شد. مک لارن [ 22 ] همچنین از بررسی 333 مطالعه منتشر شده به این نتیجه رسید که چاقی یک مربوط به پرکاربردترین متغیرهای SES، مانند تحصیلات، شغل و درآمد.
2. داده ها
به منظور بررسی اینکه چگونه توزیع جمعیت چاق ممکن است با ویژگی های اجتماعی-اقتصادی خاص منطقه مرتبط باشد، پایگاه داده خود را از تعدادی منبع جمع آوری کردیم:
-
دادههای BMI مشتقشده – دادههای یک چرخه پنج ساله همه دارندگان گواهینامه رانندگی در شهرستان سامیت، اوهایو از اداره وسایل نقلیه موتوری اوهایو (OBMV) برای اهداف سلامت عمومی در سالهای 2008-2012 به دست آمد. رانندگان در اوهایو باید هر پنج سال یک بار گواهینامه خود را تمدید کنند. با گنجاندن دادهها (سن، قد، وزن، و آدرس منزل) همه بزرگسالان (16 سال و بالاتر) در یک چرخه پنج ساله، اساساً همه افرادی را که گواهینامه رانندگی در شهرستان در طول دوره مطالعه داشتند، جمعآوری کردیم. لازم به ذکر است که این مجموعه داده شامل BMI مشتق شده برای جمعیت 15 سال و کمتر یا افرادی که گواهینامه رانندگی ندارند، نمی شود. بیش از 480000 آدرس و داده های مرتبط با مختصات طول و عرض جغرافیایی کدگذاری شدند. BMI برای هر رکورد محاسبه شد. آن دسته از سوابق با BMI برابر و بیش از 30 انتخاب شده و در مجموعه داده های جمعیت چاق گنجانده شده اند زیرا این مطالعه فقط بر توزیع جمعیت چاق تمرکز دارد. از آنجایی که ارتفاعهای گزارششده توسط خود معمولاً به سمت بالا (≈1 اینچ) سوگیری میکنند در حالی که وزنهای گزارششده توسط خود به سمت پایین (10 پوند) در نظرسنجیهای بزرگ مانند آنچه که توسط Ossiander گزارش شده است.و همکاران [ 23 ]، BMI از داده های OBMV ممکن است شیوع واقعی چاقی را در شهرستان سامیت دست کم بگیرد. با این حال، ما هیچ دلیلی نداریم که انتظار داشته باشیم که سوگیری زیاد باشد یا به شدت با وضعیت اجتماعی-اقتصادی (SES) مرتبط باشد. به همین دلیل، ما در این مطالعه تنها سوابق دارندگان مجوز را که در زمان صدور مجوز برای اولین بار بین 16 تا 21 سال سن داشتند، وارد کردیم. البته این همچنان فرض میکند که وزنها و ارتفاعهای گزارششده توسط خود همچنان در معرض همان سوگیری بالقوهای هستند که قبلاً گفته شد.
-
دادههای اقتصادی-اجتماعی – دادههای پنج ساله (2007-2011) را از نظرسنجی جامعه آمریکا استخراج کردیم تا مجموعه دادهای را تشکیل دهیم که شامل دادههای گروه سرشماری و بلوک سرشماری، از جمله شمارش جمعیت، شمارش جمعیت با تحصیلات دانشگاهی یا تحصیلات عالی است. ، متوسط درآمد خانواده، بیکاری و درصد جمعیت سفیدپوست.
-
فایلهای مرزی گروه سرشماری و بلوک سرشماری از فایلهای TIGER/Line 2010 توسط اداره سرشماری ایالات متحده.
3. تجزیه و تحلیل و نتایج
3.1. توزیع فضایی جمعیت چاق و مقیاس های جغرافیایی
پس از اینکه آدرسهای مسکونی جمعیت بزرگسال چاق کدگذاری جغرافیایی شد (به عنوان مثال ، BMI ≥ 30)، از آنها برای محاسبه نرخ چاقی استفاده شد، که به عنوان تعداد افراد چاق در هر 1000 جمعیت، توسط گروههای بلوک سرشماری و توسط دستگاههای سرشماری تعریف میشود. دو نقشه در شکل 1یک نمای کلی از جغرافیای چاقی در شهرستان سامیت، اوهایو ارائه دهید. الگوهای کلی هر دو نقشه نشان میدهند که سطح شیوع چاقی بالاتر در شهر آکرون و اطراف آن، شهریشدهترین بخش شهرستان در بخش مرکزی شهرستان، مشاهده میشود. با این حال، باید توجه داشت که توزیع فضایی نسبتهای چاقی توسط گروههای بلوک سرشماری، سطح بسیار بالاتری از جزئیات جغرافیایی را ارائه میدهد و تفاوت در نتایج بین دو سطح مقیاس جغرافیایی به وضوح قابل تشخیص است.
همانطور که در شکل 1 الف، ب نشان داده شده است، در بخشهای متعددی از شهرستان، گروههای بلوک با سطوح شیوع چاقی بسیار متفاوت، زمانی که گروههای بلوک مجاور در بخشها جمع شدند، تعمیم داده شدند. به عنوان مثال، در قسمت شمالی شهرستان، واضح است که جزئیات بیشتری از سطوح مختلف شیوع چاقی توسط گروههای بلوک نشان داده میشود، اما به یک الگوی با جزئیات کمتر تعمیم داده میشود. تعمیم مشابهی را می توان در سایر نقاط شهرستان مشاهده کرد.
هر دو مقیاس در نشان دادن اینکه مرکز شهر دارای نرخ های بسیار پایینی است، سازگار هستند. نرخ های پایین در هر دو مقیاس به این واقعیت مربوط می شود که مرکز شهر جوان ترین جمعیت را دارد. این مرکز توسط مناطقی با نرخ چاقی نسبتاً بالا احاطه شده بود، به ویژه در شرق و غرب آن، و تا حدودی در جنوب. اگرچه بسیاری از گروههای بلوک دارای نرخهای نسبتاً بالایی بودند، اما مناطق اطراف مرکز را به طور مداوم پر نکردند تا تکههای پیوسته را تشکیل دهند، و برخی از گروههای بلوک با نرخ بالا نسبتاً در خارج پراکنده بودند، از جمله برخی در گوشه جنوب غربی شهرستان. با این حال، در سطح دستگاه، دستگاههایی با نرخهای بالا نسبتاً به هم پیوسته بودند، عمدتاً به این دلیل که نرخهای گروه بلوک در مناطق بزرگتر (دستگاهها) به طور متوسط یا هموار میشدند. بدین ترتیب،به عنوان مثال ، خود همبستگی فضایی مثبت بزرگتر). این فرآیند هموارسازی فضایی با جزئیات زیاد در Wong [ 1 ] توضیح داده شد.
شکل 1. نرخ چاقی در شهرستان سامیت، اوهایو. ( الف ) تراکتهای سرشماری؛ ( ب ) گروه های بلوک سرشماری.
3.2. روابط فضایی بین جمعیت چاق و ویژگی های SES
برای بررسی نابرابریهای اجتماعی-اقتصادی و جغرافیایی جمعیت چاق، ما روابط فضایی بین نسبتهای چاقی و مجموعهای از ویژگیهای اجتماعی-اقتصادی (SES) را که با دقت انتخاب شده بودند، با استفاده از دستگاههای سرشماری و گروههای بلوک سرشماری تحلیل کردیم. همانطور که در Geographies of Obesity [ 24 ] پیشنهاد شده است، ویژگی های اجتماعی-اقتصادی که ممکن است بر نسبت چاقی تأثیر بگذارد عبارتند از تراکم جمعیت، ترکیب نژادی، میزان تحصیلات، سطح درآمد، سطح اشتغال و عوامل دیگر. بر این اساس، ما دادههایی را از نظرسنجی جامعه آمریکا در سال 2011 (اداره سرشماری ایالات متحده) برای هر دو بخش سرشماری و گروههای بلوک سرشماری با متغیرهای زیر برای تحلیل خود جمعآوری کردهایم:
-
تراکم جمعیت (POPDEN)
-
درصد جمعیت سفید پوست (RWHITE)
-
متوسط درآمد خانواده (MEDINC)
-
درصد با مدرک لیسانس یا بالاتر (RGEBA)
-
درصد بیکار (RUNEMP)
با استفاده از این ویژگیهای منطقهای بهعنوان متغیرهای توضیحی (یا مستقل) و نرخ چاقی به عنوان متغیر وابسته، ابتدا بررسی کردیم که تغییرات در میزان چاقی در هر دو سطح گروههای بلوک (BGs) و tracts (TRs) تا چه میزان میتواند توسط هر یک از آنها توضیح داده شود. متغیرهای مستقل. نتایج نشان داد که تنها سه متغیر در تبیین تغییرات میزان چاقی در هر دو سطح جغرافیایی از نظر آماری معنادار هستند. این متغیرها تحصیلات (RGEBA)، درآمد (MEDINC) و بیکاری (RUNEMP) هستند، همانطور که در جدول 1 نشان داده شده است. به نظر می رسد که سطح تحصیلات پایین تر، سطح درآمد پایین تر و نسبت های بیکاری بالاتر در تأثیرگذاری بر الگوهای جغرافیایی شیوع چاقی مهم هستند. همچنین شایان ذکر است که متغیر نژاد معنی دار نبود. تنظیم شده – R2 مقدار فهرست شده در جدول 1 نشان می دهد که این مدل های رگرسیون نسبتا ضعیف هستند. با این حال، به نظر می رسد که این متغیرهای SES می توانند تغییرات نرخ چاقی را بهتر در سطح دستگاه نسبت به سطح گروه بلوک توضیح دهند.

جدول 1. مدل های رگرسیون با بالاترین مقادیر تنظیم شده R 2 .
ضرایب همبستگی بالاتر برای واحدهای منطقه ای بزرگتر (TRs در مقابل BGs) انتظار می رود، زیرا این بخشی از اثر مقیاس تحت MAUP است، و به خوبی مستند و توضیح داده شده است [ 25 ]. به طور خلاصه، داده های انباشته بیشتر دارای تنوع کمتر و واریانس کمتر (و انحراف معیار) هستند. واریانس کمتر (و انحراف معیار) تا حدی باعث افزایش همبستگی می شود. حتی در سطح TRs، R 2ارزش ها قوی نیستند یکی از دلایل احتمالی قدرت توضیحی پایین یک مدل رگرسیون وجود ناهمگونی فضایی است. در حالی که مدل ممکن است متغیرهای مربوطه را برای توضیح نتایج بدست آورده باشد، روابط بین پیامد و متغیرهای توضیحی ممکن است در مشاهدات مختلف متفاوت باشد. چنین تنوعی اغلب از الگوهای جغرافیایی خاصی پیروی می کند. برای پرداختن به این موضوع، ما از رگرسیون وزندار جغرافیایی (GWR) [ 26 ، 27 ] با سه متغیر توضیحی در هر دو سطح گروههای بلوک و تراکت استفاده کردیم. نتایج به همراه نتایج حاصل از مدلهای رگرسیون حداقل مربعات معمولی (OLS) با متغیرهای وابسته و مستقل یکسان در جدول 2 فهرست شدهاند. ما از ArcGIS 10.1 [ 28 ] استفاده کردیم] برای انجام محاسبات برای مدل های GWR.
جدول 2. خروجی خلاصه از رگرسیون وزنی جغرافیایی (GWR) و رگرسیون حداقل مربعات معمولی (OLS).
از جدول 2 ، مشاهده می شود که مقدار کلی تنظیم شده R 2 در سطح تراکت ها بیشتر از سطح گروه های بلوک است (9/1 برابر). باز هم، مقدار R2 بزرگتر در سطح دستگاه به دلیل اثر مقیاس مانند رگرسیون های معمولی انتظار می رود. علاوه بر این، مقادیر AICc در سطح تراکت ها کمتر از سطح گروه های بلوکی است. این برای هر دو GWR و OLS صادق است، تنها با تفاوت های جزئی در تنظیم R2و در AICc. آمار عملکرد این دو مدل نشان میدهد که مدل OLS در مقایسه با مدل محلی با استفاده از GWR به طور معقولی مناسب است زیرا مقادیر AICc مدل OLS کوچکتر از مدل GWR است. با این حال، ما در زیر نشان خواهیم داد که علیرغم راهنمایی این آمار مدل به نفع مدل جهانی OLS، مدل محلی دارای ارزش های فوق العاده ای در آشکار کردن روابط مربوطه است که مدل های OLS آشکار نمی کنند.
GWR اساساً از یک تابع از پیش تعریف شده برای تعیین سطح تأثیر واحدهای همسایه بر هر واحد جغرافیایی در مدل رگرسیون استفاده می کند. به عنوان مثال، برای گروه بلوک سرشماری، b i ، یک تابع از پیش تعریف شده ممکن است بر اساس مفهوم فروپاشی فاصله باشد، به طوری که گروههای بلوک که دورتر از b i قرار دارند، وزن کمتری در نتایج رگرسیون نسبت به گروههای بلوک همسایه فوری b i دارند. . تابع از پیش تعریف شده را می توان برای انعکاس پدیده های خاص بر اساس الگوهای فضایی آنها تنظیم کرد.
به طور معمول، تابع از پیش تعریف شده برای همه واحدهای جغرافیایی اعمال می شود. هنگامی که این مورد است، گفته می شود که از یک هسته ثابت استفاده می کند. یک گزینه در استفاده از GWR برای تجزیه و تحلیل روابط فضایی، تغییر تابع از پیش تعریف شده با توجه به تراکم نقاط داده به صورت محلی است. در مناطقی که دادهها از نظر مکانی متراکمتر هستند، کاهش فاصله میتواند به گونهای ساختاردهی شود که در مناطقی که دادهها از نظر مکانی چگالی کمتری دارند، منعکس شود. هنگام استفاده از توابع فاصله متغیر، گفته می شود که از هسته های تطبیقی استفاده می شود. در این مطالعه، ما از رویکرد هسته تطبیقی در مدلهای GWR خود برای منعکس کردن توزیع جغرافیایی ناهموار متغیرهای مدل استفاده کردیم.
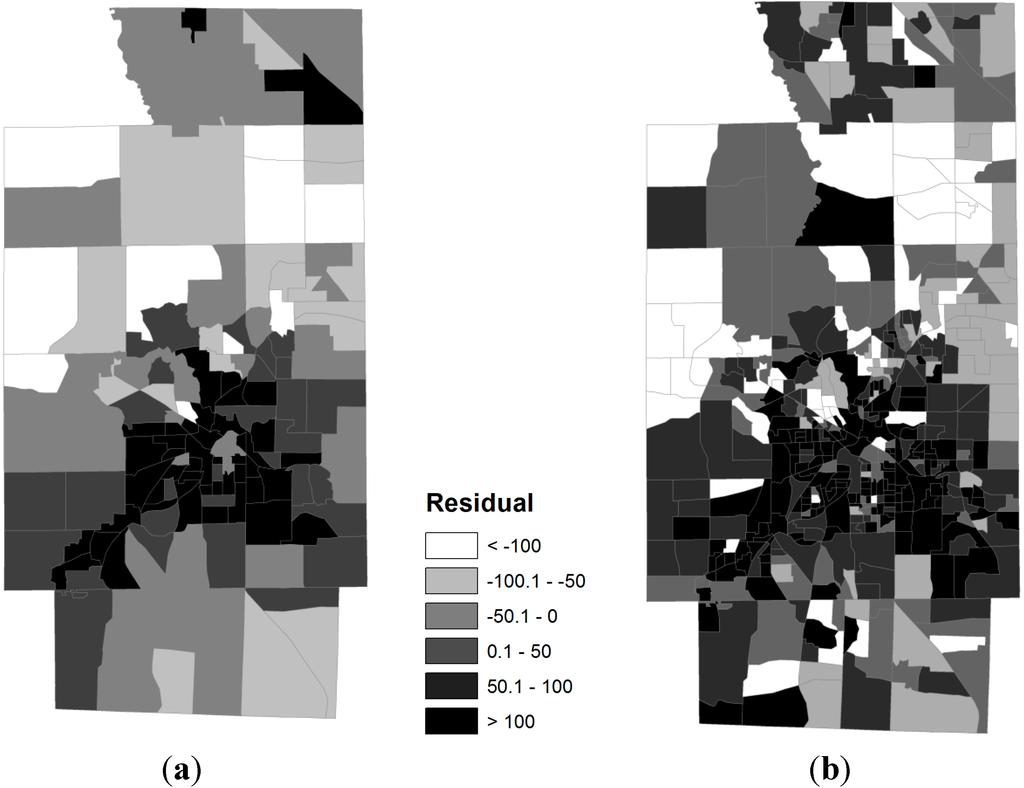
در شکل 2 زیر ، توزیع باقیماندهها، یعنی تفاوت بین نرخ چاقی واقعی و نرخ چاقی پیشبینیشده توسط مدلهای GWR، هیچ همبستگی مکانی را در TRs یا BGs نشان نمیدهد. مقادیر شاخص موران جهانی، یک شاخص پرکاربرد برای اندازهگیری خودهمبستگی فضایی، 0.016- است ( Z-score = 0.3737-، Prob = 0.7086) برای TRs و 0.004 است (Z-score = – 0.1667 Gs7، B برای هر دو = 0.1667، Bs7 = 5). در α = از نظر آماری معنی دار نیستندسطح 0.025 نقشه بر اساس تراکت های سرشماری الگوی تعمیم یافته تری را نسبت به گروه های بلوک سرشماری نشان می دهد. بر روی نقشه توسط گروه های بلوک، ما به راحتی می توانیم مناطقی را که چنین باقیمانده هایی بزرگتر یا کوچکتر هستند با جزئیات بسیار شناسایی کنیم. سطوح مختلف جزئیات که توسط بخشها و گروههای بلوک نشان داده میشود نشان میدهد که واحدهای جغرافیایی کوچکتر ممکن است برای مدلسازی SES و نابرابریهای منطقه در سلامت بهتر باشند. برخی از مناطق کوچک نگران کننده ممکن است در سطح دستگاه پنهان باشند، اما در سطح گروه بلوک آشکار می شوند.
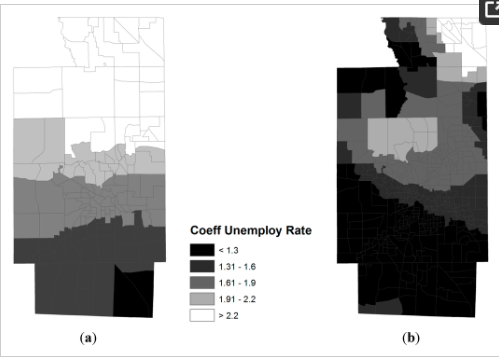
از مدل رگرسیون وزندار جغرافیایی، میتوان مشاهده کرد که چگونه یک متغیر توضیحی خاص بر میزان چاقی کم و بیش در منطقه مورد مطالعه تأثیر میگذارد. این کار با نگاشت ضرایب رگرسیون متغیرهای توضیحی انجام می شود. شکل 3توزیع مقادیر ضرایب نسبت های بیکاری را در مدل نشان می دهد. به نظر میرسد که بخشهای شمالی شهرستان با افزایش نسبتهای بیکاری، افزایش نرخ چاقی را تجربه کردهاند، جایی که بخشهای جنوبی و جنوب شرقی شهرستان روند معکوس را نشان میدهند. باز هم، نتایج حاصل از استفاده از گروههای بلوک، جزئیات فضایی بیشتری را نسبت به آنچه که مسیرها نشان میدهند، نشان میدهند. با این حال، یکی از جنبههای مهم این نتایج این است که سطوح بیکاری و چاقی در بخشهای مختلف منطقه روابط متضادی دارند (ضریب از 0.2- تا 0.4 متغیر است)، وضعیتی که توضیح آن دشوار است، اما نمیتوان آن را با رگرسیون جهانی آشکار کرد. مدل.
همچنین با نشان دادن الگوهای فضایی مقادیر ضرایب، شکل 4 نشان می دهد که پیشرفت تحصیلی (درصد جمعیت با مدرک لیسانس یا بالاتر) تأثیر قوی تری بر کاهش نرخ چاقی در مناطق شمالی نسبت به سایر نقاط شهرستان دارد. این روند با گروه های بلوکی بهتر از تراکت های سرشماری توصیف می شود زیرا در بخش ها بسیار تعمیم یافته است. در شهر آکرون، میزان تحصیلات تأثیر کمتری بر میزان چاقی نسبت به بخش شمالی این شهرستان دارد.
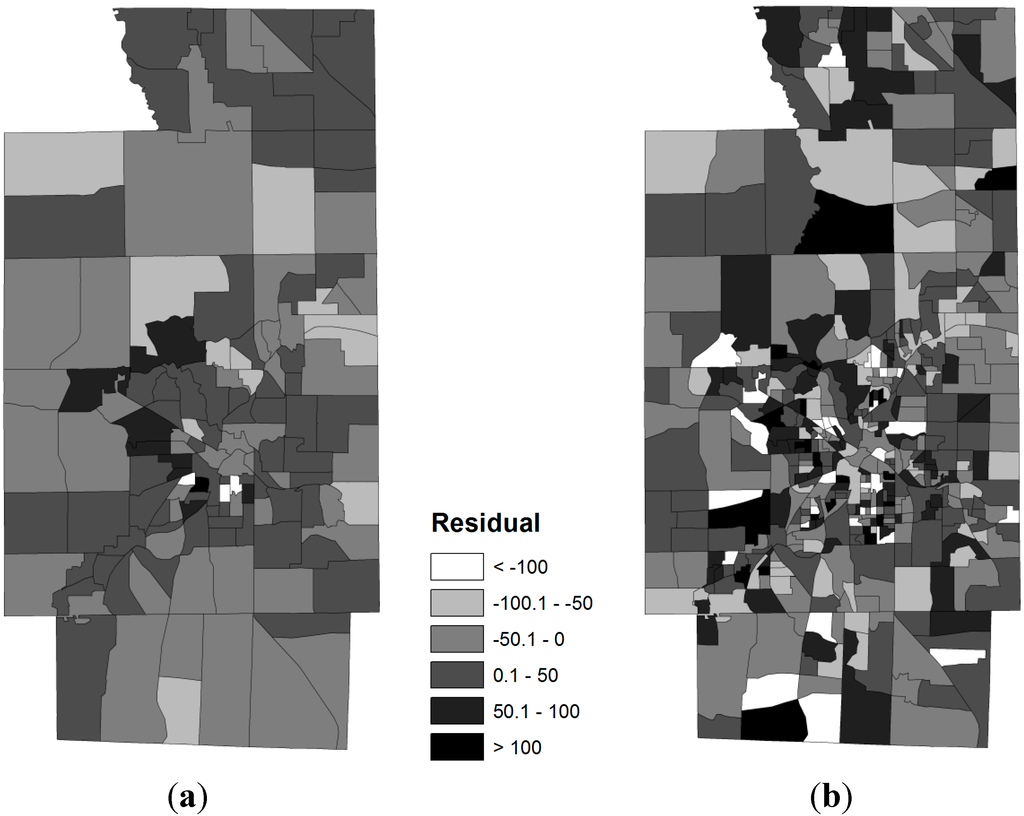
شکل 2. الگوهای فضایی باقیمانده از مدلهای رگرسیون وزندار جغرافیایی، ObRates = تابع (RGEBA، MEDINC، RUNEMP). ( الف ) تراکتهای سرشماری، ( ب ) گروههای بلوک سرشماری.
شکل 3. الگوهای فضایی ضرایب رگرسیون برای نسبت های بیکاری. ( الف ) تراکتهای سرشماری؛ ( ب ) گروه های بلوک سرشماری.
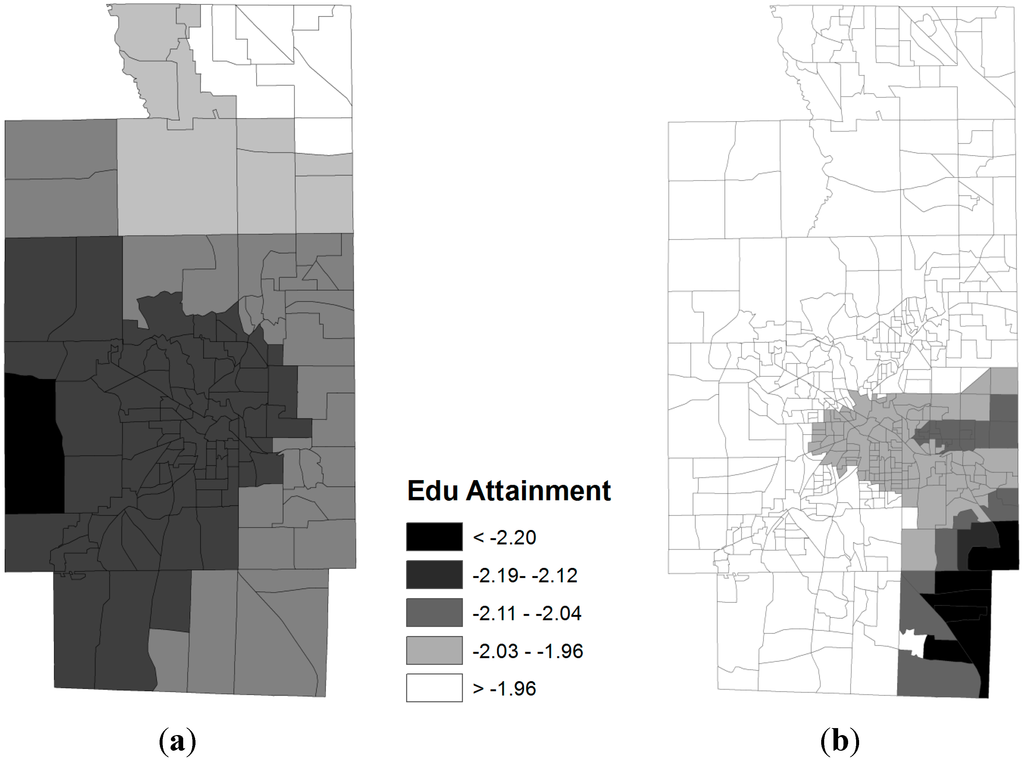
شکل 4. الگوهای فضایی ضرایب رگرسیون برای پیشرفت تحصیلی. ( الف ) تراکتهای سرشماری؛ ( ب ) گروه های بلوک سرشماری.
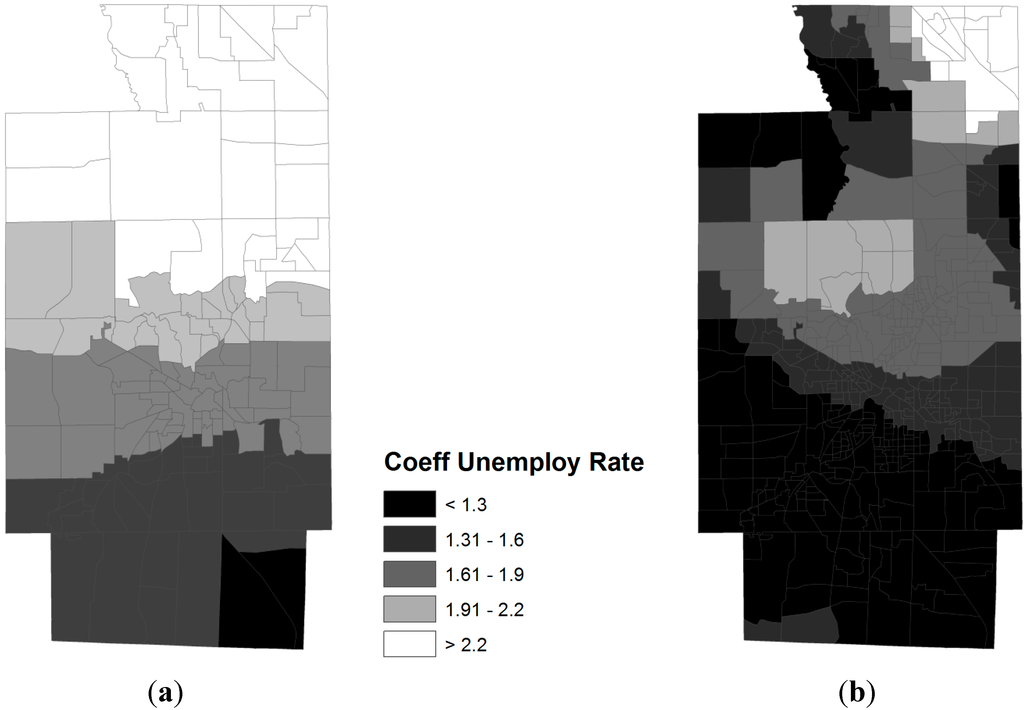
دوباره در شکل 5که ضرایب رگرسیون را برای درآمد متوسط خانواده در مدل GWR نشان میدهد، خطوط همچنین الگوی فضایی را تعمیم میدهند که چگونه درآمد متوسط خانواده بر نرخ چاقی در شهرستان سامیت تأثیر میگذارد. با گروههای بلوکی، سطوح مختلف تأثیرات بر میزان چاقی بر اساس درآمد متوسط خانواده با حلقههای مدور در شهر آکرون نشان داده میشود – از تأثیر مثبت افزایش درآمد متوسط خانواده که باعث افزایش جزئی نرخ چاقی میشود تا تأثیر منفی افزایش آن. درآمد متوسط خانواده باعث کاهش نرخ چاقی می شود. با مقایسه آنچه توسط بخشها و گروههای بلوکی نشان داده شده است، تأثیرات درآمد متوسط خانواده بر میزان چاقی، الگوهای متفاوتی را در بخشهای غربی شهرستان نشان میدهد. علاوه بر این، مشابه متغیر بیکاری، مقدار ضریب از – متغیر است0.2 تا 0.1، نشان می دهد که جهت رابطه در سراسر منطقه یکنواخت نیست. به عبارت دیگر، پایین بودن سطح درآمد مربوط به کاهش درصد چاقی در برخی مناطق (مرکز و شرق) است، اما با نرخ چاقی بیشتر در مناطق دیگر (شمال و غرب) مرتبط است.
به طور کلی، تجزیه و تحلیل ما نشان داد که نرخ چاقی در واقع تحت تأثیر میزان تحصیلات، سطح درآمد و سطح بیکاری است. در حالی که چنین روابطی همه از نظر آماری برای سه متغیر SES موجود در مدلهای GWR معنیدار هستند، مهم است که جزئیات فضایی بیشتری را مورد بررسی قرار دهیم تا درک کنیم که در داخل شهرستان میتوان انتظار داشت چنین روابطی قویتر یا ضعیفتر باشند. بنابراین، هنگام اتخاذ سیاستهایی در مورد چگونگی ارتقای سلامت و نحوه تخصیص بودجه به مناطق مختلف شهرستان، به عنوان مثال، در سطح همسایگی، میتوان نابرابریهای جغرافیایی در سلامت را برای نتایج مؤثرتر گنجاند.

شکل 5. الگوهای فضایی ضرایب رگرسیون برای درآمد متوسط خانواده (1000 دلار). ( الف ) تراکتهای سرشماری؛ ( ب ) گروه های بلوک سرشماری
4. بحث و نتیجه گیری
ما در این مقاله تحلیل خود را از میزان چاقی از نظر الگوهای فضایی و روابط آنها با مجموعه ای از متغیرهای اجتماعی-اقتصادی انتخاب شده ارائه کرده ایم. رویههای تحلیلی مشابهی برای بخشهای سرشماری و گروههای بلوک سرشماری تکرار شد تا نشان دهد که قطعنامههای جغرافیایی واقعاً در چنین تحلیلهایی اهمیت دارند.
در حالی که سوابق فردی بزرگسالان 16 و 21 ساله در شهرستان سامیت، اوهایو، همانطور که از دفتر وسایل نقلیه موتوری اوهایو به دست آمده، در مطالعه ما استفاده شد، باید توجه داشت که این پوشش 100٪ از کل جمعیت بزرگسال در شهرستان سامیت نیست. این مجموعه داده شامل کسانی نمی شود که گواهینامه رانندگی را دریافت نکرده اند و کسانی که موفق به تمدید گواهینامه نشده اند. علاوه بر این، ممکن است قد و وزن به دست آمده از خود گزارش دهی از طریق ثبت گواهینامه رانندگی دقیق نباشد. به عنوان مثال، قد و وزن یک فرد در سن 16 سالگی در هنگام دریافت گواهینامه رانندگی ممکن است قبل از تمدید گواهینامه در سن 20 سالگی کمتر از قد و وزن او باشد. این یک پدیده کاملاً مستند است (برای مثال، [ 23]). با این حال، داده های BMI که از قد و وزن گزارش شده به اداره وسایل نقلیه موتوری به دست می آید، احتمالا بهترین و کامل ترین داده هایی است که می توانیم به دست آوریم. اگر تجزیه و تحلیل دقیق تری لازم است، باید تنظیماتی برای تصحیح چنین سوگیری های گزارش نشده انجام شود.
وضوح جغرافیایی تفاوت ایجاد می کند. به طور کلی، هرچه وضوح بالاتر باشد، جزئیات بیشتری در نتایج تجزیه و تحلیل آشکار می شود. تجزیه و تحلیل با دادههایی با وضوح جغرافیایی پایینتر ممکن است با خطر پنهان کردن فرآیندهای بالقوه معنیدار و آموزنده که تنها در مقیاس دقیقتر عملیاتی هستند، مواجه شود. برای این منظور، لطفاً لام [ 29] برای بحث در مورد انواع مختلف مقیاس و اثرات آنها بر مطالعات جغرافیایی. به عنوان یک قانون کلی، تجزیه و تحلیل با وضوح بالاتر ترجیح داده می شود. متأسفانه، وضوح جغرافیایی تجزیه و تحلیل اغلب به دلیل در دسترس بودن داده های پشتیبانی تعیین می شود. اگرچه در این مطالعه دادههایی در سطح گروه بلوکی موجود و مورد استفاده قرار گرفت و این دادهها وضوح بالاتری نسبت به دادههای سرشماری مربوطه دارند، باید علاوه بر سطوح مطلوب مقیاس، کیفیت دادهها را نیز در نظر بگیریم. یا وضوح اگر دادههایی با وضوح جغرافیایی مختلف کیفیت مشابهی دارند، ترجیح داده میشود از دادههایی با جزئیات جغرافیایی بیشتر استفاده شود. همچنین در اینجا باید به این نکته توجه داشت که به عنوان داده های خرد بیشتر (مثلاً آدرس های فردی یا مختصات GPS و غیره ).) به طور فزاینده ای در دسترس هستند، ما استدلال می کنیم که تجزیه و تحلیل ها باید در بالاترین وضوح جغرافیایی هر زمان ممکن و زمانی که داده های پشتیبانی اجازه می دهد انجام شود.
در مورد خاص ما، و احتمالاً وضعیت ما برای بسیاری از مطالعات در علوم اجتماعی و بهداشت عمومی نیز قابل استفاده است، ما باید از داده های ACS، تنها منبع اصلی داده در ایالات متحده پس از سرشماری سال 2000 استفاده کنیم تا بتوانیم اطلاعات SES را در زمینه اجتماعی به دست آوریم. محیطی که آزمودنی ها در آن زندگی می کردند. یکی از جنبههای مهم دادههای ACS ماهیت پیمایشی است به طوری که تخمینها، بهویژه برای واحدهای جغرافیایی کوچکتر، غیرقابل اعتماد هستند، اغلب با حاشیه خطای نسبتاً زیادی [ 30 ].
از آنجایی که ما ترجیح میدهیم تجزیه و تحلیل را با دادههایی با وضوح جغرافیایی بالاتر انجام دهیم، و بنابراین استفاده از دادههای گروه بلوک برای آشکار کردن الگوهای جغرافیایی دقیق ترجیح داده میشود، دادههای ACS در سطح گروه بلوک دارای خطای قابلتوجهی نسبت به دادههای سطح دستگاه مربوطه خود هستند. فقط متغیر متوسط درآمد خانواده را به عنوان مثال در نظر بگیرید، حداقل، حداکثر و میانگین ضریب تغییرات ( CV ) متغیر در جدول 3 گزارش شده است.زیر واضح است که تخمین های ACS در سطح دستگاه بسیار قابل اعتمادتر از برآوردهای موجود در سطح گروه بلوک هستند. در واقع، برخی از برآوردها در سطح گروه بلوک دارای حاشیه خطای 90 درصدی بزرگتر از برآوردها هستند. از سوی دیگر، کیفیت برآورد سطح تراکت ایده آل نیست. با این وجود، این تخمین های تراکت قابل اعتمادتر هستند. بنابراین، از منظر کیفیت داده ها، تجزیه و تحلیل سطح دستگاهی که ما در اینجا انجام دادیم و گزارش کردیم احتمالاً نتایجی با سطح اطمینان بالاتری ارائه می دهد. این سطح اطمینان بالاتر، متأسفانه، باید با وضوح جغرافیایی پایینتر در نتایج تحلیل جایگزین شود.
جدول 3. خلاصه آمار ضریب تغییرات (CV) برای متغیر درآمد متوسط خانواده از ACS در سطح گروه ها و مناطق بلوک سرشماری.
بسیاری از مطالعات چاقی، سرشماری را به عنوان واحد جغرافیایی واقعی تجزیه و تحلیل پذیرفته اند. این ممکن است به دلیل دلایل واضح در دسترس بودن داده ها و محدودیت های منابع محاسباتی باشد. ما استدلال می کنیم که مسیرهای سرشماری ممکن است الگوهای فضایی را بیش از حد تعمیم دهند و گروه های بلوک سرشماری یا واحدهای جغرافیایی کوچکتر باید در صورت امکان استفاده شوند. با فرض برابری کیفیت دادهها، تجزیه و تحلیل جغرافیای چاقی در مقیاس جغرافیایی دقیقتر، تصمیمات بهتری را در هنگام تدوین سیاستهایی برای ارتقای سلامت برای مناطق دارای نابرابریهای بهداشتی ممکن میسازد.
استفاده از GWR همچنین جزئیات جدیدی را از نظر روندهای فضایی نشان می دهد که چگونه متغیرهای مستقل با متغیرهای وابسته مرتبط هستند. این روندهای فضایی را نمی توان با مدل های رگرسیون جهانی مرسوم، مانند رگرسیون حداقل مربعات معمولی که فقط روندهای جهانی روابط بین متغیرهای وابسته و مستقل را ارائه می دهد، کشف کرد. به عنوان مثال، روندهای فضایی متفاوت در مورد اینکه چگونه نسبت های بیکاری بر شیوع چاقی تأثیر می گذارد، همانطور که در شکل 3 نشان داده شده است ، هرگز تنها با استفاده از روش های مدل سازی رگرسیون مرسوم کشف نمی شوند.
منابع
- Wong, D. مسئله واحد منطقه ای قابل اصلاح (MAUP). در SAGE Handbook of Spatial Analysis ; Fotheringham, AS, Rogerson, PA, Eds. Sage: لندن، انگلستان، 2009; صص 105-123. [ Google Scholar ]
- کاکینگ، اس. طراحی مارتین، دی. برای مطالعات محیطی و بهداشتی با استفاده از داده های از پیش انباشته شده. Soc. علمی پزشکی 2005 ، 60 ، 2729-2742. [ Google Scholar ] [ PubMed ]
- اندرسون، بی. رافرتی، AP; لیون-کالو، اس. فوسمن، سی. Imes، G. مصرف فست فود و چاقی در میان بزرگسالان میشیگان. قبلی دیس مزمن 2011 ، 8 ، A71. [ Google Scholar ] [ PubMed ]
- خوب، LJ; فیلوژن، GS; گراملینگ، آر. کودتا، EJ; Sinha, S. شیوع چندین عامل خطر بیماری مزمن: 2001 مصاحبه ملی سلامت. صبح. J. قبلی پزشکی 2004 ، 27 ، 18-24. [ Google Scholar ] [ PubMed ]
- فلگال، KM; کارول، MD; اوگدن، سی. جانسون، شیوع CL و تمایل به چاقی در بین بزرگسالان ایالات متحده، 1999-2000. مربا. پزشکی دانشیار 2002 ، 288 ، 1723-1727. [ Google Scholar ]
- هدلی، AA; اوگدن، CL; جانسون، CL; کارول، MD; کرتین، ال آر. Flegal، KM شیوع اضافه وزن و چاقی در میان کودکان، نوجوانان و بزرگسالان ایالات متحده، 1999-2002. مربا. پزشکی دانشیار 2004 ، 291 ، 2847-2850. [ Google Scholar ]
- اوگدن، CL; فلگال، KM; کارول، MD; جانسون، شیوع CL و روند اضافه وزن در میان کودکان و نوجوانان ایالات متحده، 1999-2000. مربا. پزشکی دانشیار 2002 ، 288 ، 1728-1732. [ Google Scholar ]
- اوگدن، CL; کارول، MD; کیت، BK; Flegal، KM شیوع چاقی و روند شاخص توده بدنی در میان کودکان و نوجوانان ایالات متحده، 1999-2010. مربا. پزشکی دانشیار 2012 ، 307 ، 483-490. [ Google Scholar ] [ CrossRef ]
- فلین، مت. مک نیل، دی. مالف، بی. موتاسینوا، دی. وو، ام. فورد، سی. سخت، SC کاهش چاقی و خطر بیماری مزمن مرتبط در کودکان و جوانان: ترکیبی از شواهد با توصیه های “بهترین عملکرد”. چاق ها Rev. 2006 , 7 , 7-66. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- باید، الف. اسپادانو، جی. کوکلی، ای اچ. فیلد، AE; کولدیتز، جی. Dietz، WH بار بیماری مرتبط با اضافه وزن و چاقی. مربا. پزشکی دانشیار 1999 ، 282 ، 1523-1529. [ Google Scholar ]
- ریپ، جی.ام. کراسلی، اس. رینگر، آر. چاقی به عنوان یک بیماری مزمن: مدیریت پزشکی و شیوه زندگی مدرن. مربا. رژیم غذایی. دانشیار 1998 ، 98 ، S9–S15. [ Google Scholar ] [ PubMed ]
- وانگ، ی. می، جی. شان، X.-Y.; وانگ، QJ; Ge، K.-Y. آیا چین با اپیدمی چاقی و عواقب آن مواجه است؟ روند چاقی و بیماری مزمن در چین بین المللی جی. اوبز. 2007 ، 31 ، 177-188. [ Google Scholar ]
- سازمان بهداشت جهانی. چاقی: پیشگیری و مدیریت اپیدمی جهانی در دسترس آنلاین: http://libdoc.who.int/trs/WHO_TRS_984.pdf (در 24 نوامبر 2013 قابل دسترسی است).
- Eckel، RH; کراوس، RM انجمن قلب آمریکا دعوت به اقدام: چاقی به عنوان یک عامل خطر اصلی برای بیماری عروق کرونر قلب. تیراژ 1998 ، 98 ، 2099-2100. [ Google Scholar ] [ PubMed ]
- مارتینز، JA تنظیم وزن بدن: علل چاقی. Proc. Nutr. Soc. 2000 ، 59 ، 337-345. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- چاقی، CW علل چاقی. در چاقی و مدیریت وزن در مراقبت های اولیه ; وین، سی، اد. Blackwell Science: Oxford, UK, 2008; پ. 118. [ Google Scholar ]
- سونیا، AG؛ منسینگر، جی. هوانگ، SH. Kumanyika، SK; Stettler، N. بازاریابی فست فود و مصرف فست فود کودکان: بررسی تأثیرات والدین در یک نمونه قومی متنوع. J. Public Policy Mark. 2007 ، 26 ، 221-235. [ Google Scholar ]
- Wilding, J. علل چاقی. تمرین کنید. Diabetes Int. 2001 ، 18 . [ Google Scholar ] [ CrossRef ]
- رایت، اس ام. Aronne, LJ علل چاقی. شکم. تصویربرداری 2012 ، 37 ، 730-732. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- سوبال، ج. Stunkard، AJ وضعیت اجتماعی و اقتصادی و چاقی: مروری بر ادبیات. روانی گاو نر 1989 ، 105 ، 260-275. [ Google Scholar ] [ PubMed ]
- ژانگ، Q. وانگ، Y. روند در ارتباط بین چاقی و وضعیت اجتماعی-اقتصادی در بزرگسالان ایالات متحده: 1971-2000. چاق ها Res. 2004 ، 12 ، 1622-1632. [ Google Scholar ] [ PubMed ]
- مک لارن، ال. وضعیت اجتماعی و اقتصادی و چاقی. اپیدمیول. Rev. 2007 , 29 , 29-48. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- اوسیاندر، EM; امانوئل، آی. اوبرایان، دبلیو. مالون، K. گواهینامه رانندگی به عنوان منبع داده در مورد قد و وزن. اقتصاد هوم Biol. 2004 ، 2 ، 219-227. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- پیرس، جی. Witten, K. Geographies of Obesity: Environmental Understands of Obesity Epidemic ; Ashgate Publishing Ltd.: Burlinton, VT, USA, 2010; پ. 331. [ Google Scholar ]
- Fotheringham، AS; Wong، DWS مسئله واحد سطحی قابل اصلاح در تحلیل آماری چند متغیره. محیط زیست طرح. A 1991 , 23 , 1025-1044. [ Google Scholar ] [ CrossRef ]
- براندون، سی. Fotheringham، AS; چارلتون، ام. رگرسیون وزنی جغرافیایی. JR Stat. Soc. سر. D 1998 , 47 , 431-443. [ Google Scholar ] [ CrossRef ]
- Fotheringham، AS; براندون، سی. چارلتون، ام. رگرسیون وزندار جغرافیایی: تحلیل روابط متغیر فضایی . Wiley & Sons: نیویورک، نیویورک، ایالات متحده آمریکا، 2002. [ Google Scholar ]
- ESRI. در دسترس آنلاین: http://www.esri.com (دسترسی در 10 اکتبر 2014).
- لام، NS-N. فراکتال ها و مقیاس در ارزیابی و پایش محیطی. در مقیاس و جغرافی پرس و جو: طبیعت، جامعه و روش . Sheppard, E., McMaster, RB, Eds. جان وایلی و پسران: نیویورک، نیویورک، ایالات متحده آمریکا، 2008; ص 23-40. [ Google Scholar ]
- سان، م. Wong، DWS ترکیب اطلاعات کیفیت داده در نقشه برداری داده های نظرسنجی جامعه آمریکا. کارتوگر. Geogr. Inf. علمی 2010 ، 37 ، 285-300. [ Google Scholar ]
© 2014 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر