

خلاصه
نوع دادههایی که یک مشارکتکننده فردی به OpenStreetMap (OSM) اضافه میکند بسته به منطقه متفاوت است. دانش محلی یک مشارکتکننده داده، امکان جمعآوری و ویرایش ویژگیهای دقیق مانند مسیرهای کوچک، نیمکتهای پارک یا شیر آتش نشانی، و همچنین افزودن اطلاعات ویژگیهایی را فراهم میکند که فقط به صورت محلی قابل دسترسی هستند. برخلاف این، تصاویر ماهوارهای که بهعنوان تصاویر پسزمینه در ویرایشگرهای داده OSM، مانند ID، Potlatch یا JOSM ارائه میشوند، مشارکت دادههای با جزئیات کمتر را از طریق دیجیتالسازی روی صفحه تسهیل میکنند، اغلب برای مناطقی که مشارکتکننده با آنها کمتر آشنا هستند. بنابراین دانستن اینکه آیا یک منطقه بخشی از منطقه اصلی یک مشارکت کننده است یا خیر، می تواند یک پیش بینی مفید برای کیفیت داده های OSM برای یک منطقه جغرافیایی باشد. این تحقیق تاریخچه ویرایش گرهها و راههای 13 عضو OSM بسیار فعال را در یک فرآیند خوشهبندی دو لایه بررسی میکند تا منطقه خانه یک نقشهبردار را از مناطق نقشهبرداری از راه دور مشخص کند. یافتهها در برابر آنهایی که با روشی که قبلاً معرفی شده بود، ارزیابی میشوند که منطقه اصلی مشارکتکننده را تنها بر اساس خوشهبندی فضایی گرههای ایجاد شده تعیین میکند. مقایسه نشان میدهد که هر دو روش میتوانند مناطق خانه مشابه را برای 13 مشارکتکننده با تفاوتهایی مشخص کنند.
کلید واژه ها:
اطلاعات جغرافیایی داوطلبانه (VGI) ; OpenStreetMap ; ترسیم منطقه ای ; الگوهای مشارکت خوشه بندی
چکیده گرافیکی
1. معرفی
تکامل دادههای جغرافیایی جمعآوریشده داوطلبانه و توزیع آن در اینترنت منجر به افزایش قابل توجهی در تحقیقات در مورد اطلاعات جغرافیایی داوطلبانه (VGI) شده است [ 1 ]] در سالهای اخیر. طیف منابع داده VGI از وبسایتهای اشتراکگذاری تصویر مانند Flickr یا Panoramio، از طریق پلتفرمهای رسانههای اجتماعی مانند Twitter و Foursquare تا پورتالهای نقشهبرداری پیچیدهتر مانند OpenStreetMap (OSM) میرسد. با این حال، نوع اطلاعات جمعآوریشده که میتوان از پلتفرمهای جداگانه بازیابی کرد، از نظر پیچیدگی و هدف متفاوت است. بیشتر منابع ذکر شده به سفر فردی و تجربه شخصی مرتبط با یک مکان مربوط می شود. از چنین اطلاعاتی می توان برای تحلیل الگوهای سفر مکانی-زمانی افراد و درک آنها از فضا استفاده کرد. مثالها عبارتند از استخراج مسیر حرکت مردم [ 2 ، 3 ]، رویدادها [ 4 ]، مکانهای محبوب [ 5 ]، و مناطق بومی [2].6 ] از وب سایت های تصویر مشترک Panoramio و Flickr. علاوه بر این، توییتها برای استخراج دانش در مورد مکانهای شخصی مهم در زندگی روزمره مردم [ 7 ]، الگوهای فعالیت افراد [ 8 ، 9 ]، احساسات سواران حملونقل در مورد خدمات حملونقل [ 10 ] و شادی مردم [ 11 ] استفاده شدهاند. اطلاعات ورود از وب سایت شبکه اجتماعی مبتنی بر مکان Foursquare برای شناسایی الگوهای حرکتی در محیط های مختلف شهری استفاده شد [ 12]. با این حال، OSM، به دلیل هدف خود برای ایجاد یک نقشه جامع از جهان، بر نقشه برداری از مکان های سفر فرد تمرکز نمی کند و همچنین از اظهارات ذهنی اجتناب می کند. استثناها در مورد دوم برای مثال موقعیت هایی هستند که در آن اختلاف بر سر مکان یا نام ویژگی منجر به ویرایش گسترده ویژگی می شود [ 13 ]. OSM از ساختارهای فضایی پیچیده تری مانند ویژگی های نقطه، خط و چند ضلعی مربوط به ویژگی های فیزیکی و واحدهای اداری در مقایسه با سایر منابع داده VGI استفاده می کند.
تجزیه و تحلیل الگوهای مشارکت OSM اخیراً در جامعه تحقیقاتی زمین فضایی مورد توجه قرار گرفته است زیرا این الگوها ارتباط نزدیکی با کیفیت داده های OSM دارند [ 14 ، 15 ، 16 ]. تجزیه و تحلیل مشارکت OSM شامل طبقه بندی مشارکت کنندگان بر اساس سطح فعالیت آنها [ 17 ، 18 ]، مقایسه فعالیت های OSM بین مناطق مختلف جهان [ 17 ]، ارزیابی تأثیر مشارکت اعضا بر کیفیت ویژگی OSM [ 13 ، 15 ] است. ]، تجزیه و تحلیل الگوهای مشارکتی در ویرایش های ویژگی OSM [ 19 ]، و ارزیابی تغییر الگوهای ویرایش در یک منطقه جغرافیایی در طول زمان [20 ، 21 ]. با این حال، تحقیقات محدودی تاکنون بر روی تجزیه و تحلیل الگوهای مشارکت فضایی یک مشارکت کننده انجام شده است، به عنوان مثال ، تنوع مشارکت بین مناطق مختلف. یکی از ویژگی های اصلی که منابع داده VGI را از مجموعه داده های دولتی و تجاری سنتی متمایز می کند، رویکرد “شهروندان به عنوان حسگرهای داوطلبانه” است [ 1 ].]. از طریق حضور فیزیکی در یک مکان و دانش محلی، مشارکتکنندگان فردی میتوانند اطلاعات جغرافیایی را جمعآوری کنند که از بالا قابل مشاهده نیستند و بنابراین نمیتوانند از تصاویر ماهوارهای استخراج شوند. ما فرض میکنیم که این اصل مشارکت دادههای محلی به فرآیند جمعآوری دادههای OSM ترجمه میشود، جایی که یک مشارکتکننده میتواند اطلاعات دقیقتری را اضافه کند و مراحل تصحیح دادههای دقیقتری را برای منطقهای که مشارکتکننده با آن آشنا است (مثلاً یک منطقه خانگی) ارائه دهد. مناطق دور افتاده تر و کمتر مسافرت شده است. برخلاف این، مناطق دورافتاده اغلب تنها از طریق ردیابی تصاویر ماهواره ای نقشه برداری می شوند، که به احتمال زیاد منجر به انواع مختلفی از مشارکت داده ها یا ویرایش ویژگی ها در مقایسه با منطقه اصلی مشارکت کننده می شود.17 ]، تا کنون هیچ روشی از اطلاعات اضافی در مورد نوع ویرایش های انجام شده در داده های OSM برای شناسایی منطقه اصلی مشارکت کننده استفاده نکرده است. ما فرض می کنیم که چنین اطلاعات ویرایشی می تواند برای شناسایی منطقه اصلی یک مشارکت کننده نیز ارزشمند باشد.
برای آزمایش این فرض ما از یک رویکرد خوشهبندی دو لایه استفاده میکنیم که الگوهای ویرایش گرهها و راههای 13 مشارکتکننده فعال OSM را تحلیل میکند. این روش تلاشهای جمعآوری دادههای مشارکتکننده را در یک منطقه خانگی و مناطقی که احتمالاً مشارکتکننده با آنها آشنا نیست (از اینجا به بعد منطقه خارجی نامیده میشود) ترسیم میکند. ما از چندین روش برای تأیید معقول بودن نتایج ترسیم منطقه استفاده میکنیم، به عنوان مثال، با مقایسه تعداد روزهایی که یک نقشهبردار در خانه و منطقه خارجی فعال بوده است، یا با مقایسه تعداد انواع ویژگیهای مختلف نقشهبرداری شده در خانه و منطقه خارجی به ترتیب. این بینشی در مورد تفاوت در سطح تنوع و فعالیت رفتار نقشه برداری بین مناطق داخلی و خارجی می دهد.
ساختار باقیمانده این مقاله به شرح زیر است: بخش بعدی یافتههای قبلی الگوهای مشارکتکننده OSM را مرور میکند، که با بخشی در بازیابی دادهها و تجزیه و تحلیل ویرایش، و بخشی در ارزیابی مدل دنبال میشود. بخش آخر خلاصه ای از یافته ها را ارائه می دهد.
2. الگوهای مشارکت در OSM
تعدادی از مطالعات تحقیقاتی اخیر OSM بر جنبه های کیفیت داده ها مانند کامل بودن، دقت موقعیتی و به موقع بودن تمرکز داشتند. کیفیت داده VGI ذاتاً به الگوهای مشارکت و رفتار بستگی دارد. هیپکه [ 18] بیان می کند که افرادی که به طور جمعی یک پروژه نقشه برداری را انجام می دهند، بیش از رفتارهای صرفاً نقشه برداری را به اشتراک می گذارند و بنابراین یک گروه مرتبط اجتماعی را تشکیل می دهند. این مقاله طبقهبندی نقشهبرداران جمعسپاری را بر اساس انگیزه و تعامل آنها با یکدیگر ارائه میکند. این طبقهبندی شامل نقشهبرداران معمولی (مثلاً کوهنوردان)، کارشناسان (مشارکتکنندگان برجسته نقشه در سازمانهایی مانند نجات کوهستان)، نقشهبرداران رسانهای (گروههای بالقوه بزرگ، که بهطور پراکنده توسط کمپینهای رسانهای فعال میشوند) و نقشهبرداران غیرفعال (شامل جمعآوری دادههای غیرفعال در مورد موقعیت افراد است). به عنوان مثال، از طریق تلفن های همراه). Neis و Zipf [ 17 ] مشارکتکنندگان OSM را بر اساس تعداد گرههایی که مشارکت میکنند، به نقشهبرداران ارشد، نگاشتکنندگان جوان، نگاشتکنندگان غیرتکرارکننده و اعضایی که هیچ مشارکتی در گره نداشتند، طبقهبندی میکنند. ررل و همکاران[ 21 ] و گروچنگ [ 22] ویرایش های داده های OSM را به عملیات، اقدامات و فعالیت ها طبقه بندی می کند. عملیات تغییرات یک ویژگی OSM واحد را از طریق هر یک از سه عملیات اصلی: ایجاد، تغییر و حذف توصیف می کند. به عنوان مثال می توان به ایجاد یک گره جدید با شناسه ویژگی جدید (ایجاد)، به روز رسانی مختصات یک گره (اصلاح) یا حذف یک راه (حذف) اشاره کرد. ایجاد، تغییر و حذف را میتوان روی گرهها، راهها و روابط اعمال کرد و از تاریخچه کامل OSM استخراج کرد. یک اقدام VGI به دنباله ای از عملیات متوالی توسط یک مشارکت کننده داوطلبانه در یک بازه زمانی محدود، مانند ایجاد یک راه، که شامل عملیات ایجاد یک ویژگی راه جدید، اضافه کردن گره ها، و افزودن یک برچسب اولیه است، اشاره می کند. فعالیت VGI مجموعه ای از اقدامات توسط یک مشارکت کننده داوطلبانه یا گروهی از مشارکت کنندگان داوطلبانه است که معمولاً از انگیزه خاصی پیروی می کند. مانند بهبود دقت موقعیت. استینمنو همکاران [ 23 ] توسعه زمانی عملیات ویرایش OSM را برای آلمان، اتریش و سوئیس بین سالهای 2005 تا 2011 تجزیه و تحلیل کرد و دریافت که عملیات «ایجاد» در سالهای اولیه برجستهترین است، در حالی که نسبت عملیات «اصلاح» و «حذف» وجود دارد. پس از ترسیم اولیه یک منطقه، در طول سال ها افزایش می یابد. استینمن و همکاران [ 24 ] نمایههای ویرایشی را از طریق خوشهبندی k-means ایجاد کرد که برای کنشها و انواع ویژگیهای تحت تأثیر این کنشها اعمال میشود. نمایههای حاصل شامل 10 گروه مشارکتکننده برای اقدامات، مانند ایجادکننده اصلی، بهروزرسانیکننده، یا همهجانبه اولیه، و 10 گروه مشارکتکننده برای انواع ویژگیها، از جمله نقشهبردار بزرگراه، نقشهبردار ساختمان، یا نقشهبردار امکانات رفاهی است.
کامل بودن و دقت موقعیتی داده های جاده OSM در مقایسه با مجموعه داده های دولتی یا اختصاصی برای کشورهای مختلف در مطالعات متعدد مورد بررسی قرار گرفته است [ 25 ، 26 ، 27 ]. نتایج، ناهمگونی کیفیت دادههای OSM را در هر کشور نشان میدهد، با یک الگوی واضح از مشارکت بالاتر اعضای OSM در مناطق شهری در مقایسه با مناطق روستایی. مشارکت کنندگان OSM تمایل دارند اطلاعات دقیق تری را برای عابر پیاده نسبت به ارائه دهندگان تجاری و دولتی در مناطق شهری اضافه کنند [ 28 ] که همچنین می تواند منجر به برآورد واقعی تر از دسترسی عابر پیاده به ایستگاه های حمل و نقل شود [ 29 ]. یک مطالعه اخیر کامل بودن ویژگی های دوچرخه را ارزیابی کرد، خطوط دوچرخه در خیابان و مسیرهای خارج از جاده، بین مناطق شهری انتخاب شده در ایالات متحده [ 30 ]. نتایج نشان داد که مسیرهای خارج از جاده به طور کامل تر از خطوط دوچرخه سواری در خیابان ترسیم شده است. توضیح احتمالی برای دومی این است که مسیرها به غیر از جاده ها هندسه خاص خود را دارند، در حالی که خط دوچرخه به عنوان یک ویژگی جاده بدون هندسه خاص خود کدگذاری می شود. بنابراین، ویژگیهای مسیرهای جدید نقشهبرداری شده از نظر بصری متمایزتر از خطوط نقشهبرداری شده هستند، که ممکن است انگیزه بیشتری را برای نقشهبردار OSM ایجاد کند تا مسیرهای دوچرخه را به جای مسیرهای دوچرخه در خیابان اضافه کند.
مطالعات دیگری که بر کاربرد VGI متمرکز شدهاند نیز پتانسیل OSM را در طول تلاشهای امدادرسانی در بلایا نشان میدهند [ 31 ] یا هنگام تصمیمگیری در مورد اینکه آیا VGI یا اطلاعات جغرافیایی حرفهای (PGI) به عنوان منبع داده بهتری هنگام برنامهریزی فعالیتهای خارج از منزل عمل میکند [ 32 ]. اهمیت منابع داده VGI و PGI برای اهداف طراحی نقشه و درک کاربران از اطلاعات نیز با جزئیات بیشتری مورد بررسی قرار گرفت [ 33 ، 34 ]. نتایج نشان داد که طراحان GIS میتوانند بر سطحی از جزئیات در VGI در مناطق انتخاب شده تکیه کنند که بعید است از طریق PGI ایجاد شود.
بر اساس نتایج یک تجزیه و تحلیل کیفیت گسترده از مجموعه داده OpenStreetMap فرانسه، Girres و Touya [ 35 ] پیشنهاد می کنند که به دلیل فقدان معیارهای کیفیت در OSM باید تعادلی یافت شود که رویکرد رایگان به مشارکت داده ها را حفظ کند، اما به برخی موارد نیز احترام بگذارد . مشخصات داده ها برای بهبود کیفیت داده ها به طور مشابه، Mooney و Corcoran [ 36 ] دریافتند که فقدان یک مکانیسم دقیق برای ارزیابی اینکه آیا کلیدها و مقادیر کمک شده به واژگان کنترل شده OSM پایبند هستند یا خیر، باعث خطاهای املایی و در نتیجه کاهش کیفیت داده های OSM می شود. این فرض که تعداد مشارکت کنندگان کیفیت را افزایش می دهد در جامعه منبع باز به عنوان “قانون لینوس” شناخته می شود. هاکلی و همکاران [ 25] دریافت که قانون به طور کلی در مورد دقت موقعیت OSM اعمال می شود. با این حال، قانون لینوس را نمی توان در زمینه ویژگی های جاده در مطالعه دیگری که اشیاء به شدت ویرایش شده در OSM را تجزیه و تحلیل کرد تأیید کرد. هیچ رابطه قوی بین تعداد مشارکت کنندگانی که یک شی معین را ویرایش می کنند و مقدار اطلاعات ویژگی اختصاص داده شده به آن پیدا نکرد [ 13 ]. در تلاش برای درک اینکه آیا همکاری بین مشارکتکنندگان OSM که در مناطق انتخابی وجود دارد میتواند به طور بالقوه منجر به افزایش کیفیت دادهها شود، مطالعه دیگری نشان داد که بسیاری از مشارکتکنندگان اصلی OSM ترجیح میدهند به تنهایی کار کنند و در عین حال، ویژگیهایی را که اضافه شده است را ویرایش کنند. مشارکت کنندگان کمتر فعال [ 20 ]. کسلر و همکاران [ 37 ، 38] اهمیت اعتماد را به عنوان معیاری برای تخمین کیفیت VGI برجسته کرد. نتایج تجزیه و تحلیل از این فرضیه پشتیبانی می کند که کیفیت داده های VGI سطح ویژگی را می توان با استفاده از یک مدل اعتماد بر اساس منشأ داده ارزیابی کرد.
همه مشارکتهای OSM را نمیتوان به فعالیت اعضا تأیید کرد، اما ممکن است نتیجه واردات داده از ارائهدهندگان داده شخص ثالث باشد. یکی از نمونههای بارز چنین بارگذاری انبوه، واردات مجموعه دادههای دولتی TIGER/Line ایالات متحده به OSM است. یک مطالعه طولی که تأثیر واردات مجموعه داده TIGER/Line 2005 را بر کیفیت داده OSM تجزیه و تحلیل کرد، نشان داد که بسیاری از خطاها با مجموعه دادههای قدیمی و اشتباه جاده TIGER/Line 2005 برای ترافیک موتوری مرتبط است که تاکنون توسط جامعه اصلاح نشده است. 39]. برخلاف این، سهم قابل توجهی در داده های شبکه مربوط به عابر پیاده در OSM در مقایسه با داده های TIGER/Line وارد شده اولیه مشاهده می شود. در مطالعه دیگری برای فلوریدا مشخص شد که نقاط مورد علاقه (POI) که از پایگاه داده سیستم اطلاعات نامهای جغرافیایی (GNIS) به OSM وارد شده بودند، متعاقباً توسط جامعه OSM بهروزرسانی شدند [ 40 ].
الگوی مشارکت جامعه OSM تا حد زیادی بین شهرهای مختلف جهان متفاوت است [ 19 ]. برخی از این شهرها برای بهبود کیفیت داده ها در مناطق منتخب از طریق گردهمایی داوطلبان، بر مفهوم به اصطلاح احزاب نقشه برداری تکیه می کنند [ 41 ]. با این حال، اگرچه شهرهای اروپایی تمایل دارند از طریق مقادیر بیشتری از دادههای VGI از تعداد بیشتری از مشارکتکنندگان نقشهبرداری شوند، همچنین نشان داده شد که شهرهای خاصی مانند استانبول، به شدت به دادههای اعضای خارجی که حوزه فعالیت اصلی آنها نزدیک نیست، متکی هستند. به شهر [ 19]. برای آن مطالعه، ناحیه اصلی هر مشارکتکننده از طریق مثلثسازی Delaunay برای همه گرههای ایجاد شده توسط یک عضو منفرد، یا نقاط مرکزی مجموعههای تغییرات، به ترتیب تعیین شد، که متعاقباً تمام یالهای مثلث و نقاط آنها حذف میشوند، اگر طول یالها باشد. بیش از 1 کیلومتر [ 17 ]. یک توسعه برای این رویکرد این است که فقط شبکه مثلثی را که بیشترین تعداد مرکز تغییرات را در بر می گیرد به عنوان یک منطقه خانه واحد در صورت وجود چندین نمودار قطع شده، حفظ می کند. این رویکرد در http://hdyc.neis-one.org پیاده سازی شد . در مطالعه ما، ما مناطق اصلی حاصل از آن وب سایت را با چند ضلعی های منطقه اصلی شناسایی شده در رویکرد ترسیم منطقه دو لایه پیشنهادی مقایسه می کنیم.
3. تعیین منطقه ای اطلاعات مشارکت کننده OSM
3.1. آماده سازی داده ها و انتخاب مشارکت کننده
از آگوست 2014، پروژه OSM دارای بیش از 1.7 میلیون عضو ثبت شده است که تنها درصد کمی به طور منظم در مجموعه داده مشارکت فعال دارند [ 17 ]]. برای آزمایش رویکرد پیشنهادی برای ترسیم منطقه داخلی و خارجی، ما 13 عضو OSM بسیار فعال را انتخاب کردیم که نشان دهنده حجم نمونه کافی برای انجام یک تحلیل کیفی و امکان ارزیابی امکانسنجی روش پیشنهادی است. هر یک از اعضای منتخب اطلاعاتی را در سه یا چند کشور جمع آوری کردند و بیش از 50 درصد از روزهایی که از زمان ثبت نام خود در پروژه می گذرد، به طور فعال در پروژه مشارکت داشته اند. علاوه بر این، برای حذف کاربرانی که ویرایشهایی از رباتها، اسکریپتهای خودکار یا واردات داشتند، تعداد گرههای ایجاد شده و اصلاحشده را با تعداد مجموعههای تغییرات برای هر عضو باقیمانده مقایسه کردیم و مشارکتکنندگانی را که تعداد گرههای مشارکتشده یا تغییر یافته در هر مجموعه تغییرات بیش از یک تغییر است، حذف کردیم. ارزش 4000 که برای ویرایش دستی غیر منطقی به نظر می رسید. مجموعه تغییرات تمام تغییرات دادهها را که توسط یک مشارکتکننده در طول یک جلسه انجام میشود را ذخیره میکند و وسعت آن شامل تمام تغییرات ایجاد شده در پایگاه داده OSM در آن جلسه خاص است. از این فهرست 141 کاربر، 13 نفر به طور تصادفی انتخاب شدند و داده های مشارکت آنها برای تجزیه و تحلیل بیشتر مورد استفاده قرار گرفت. ما تعداد کاربران تجزیه و تحلیل شده را به 13 محدود کردیم زیرا تمرکز این مطالعه تعیین امکانسنجی روش خوشهای پیشنهادی بود، که نیازمند آزمایش رویکردهای مختلف خوشهای و مراحل ارزیابی دستی بود. بنابراین، این مطالعه ماهیت اکتشافی دارد و روشی که نتایج اولیه آن برای 13 کاربر منتخب تجزیه و تحلیل میشود، میتواند در آینده برای تجزیه و تحلیل کمی دقیقتر خودکار شود. ما تعداد کاربران تجزیه و تحلیل شده را به 13 محدود کردیم زیرا تمرکز این مطالعه تعیین امکانسنجی روش خوشهای پیشنهادی بود، که نیازمند آزمایش رویکردهای مختلف خوشهای و مراحل ارزیابی دستی بود. بنابراین، این مطالعه ماهیت اکتشافی دارد و روشی که نتایج اولیه آن برای 13 کاربر منتخب تجزیه و تحلیل میشود، میتواند در آینده برای تجزیه و تحلیل کمی دقیقتر خودکار شود. ما تعداد کاربران تجزیه و تحلیل شده را به 13 محدود کردیم زیرا تمرکز این مطالعه تعیین امکانسنجی روش خوشهای پیشنهادی بود، که نیازمند آزمایش رویکردهای مختلف خوشهای و مراحل ارزیابی دستی بود. بنابراین، این مطالعه ماهیت اکتشافی دارد و روشی که نتایج اولیه آن برای 13 کاربر منتخب تجزیه و تحلیل میشود، میتواند در آینده برای تجزیه و تحلیل کمی دقیقتر خودکار شود.جدول 1 تلاشهای جمعآوری دادهها را برای 13 مشارکتکننده منتخب که از فایل رونوشت تاریخچه کامل OSM در تاریخ 2 اوت 2013 استخراج شدهاند، خلاصه میکند.

جدول 1. مشارکت کنندگان منتخب OpenStreetMaps (OSM) با آمار فعالیت آنها.
پس از پردازش فایل dump تاریخچه کامل، داده ها برای تجزیه و تحلیل بیشتر به عنوان جدولی که شامل تمام ویژگی ها با نسخه های آنها است، به پایگاه داده PostgreSQL وارد شد. شکل 1گردش کار پردازش داده، ترسیم منطقه ای و تجزیه و تحلیل خوشه سلسله مراتبی پروفایل های ویرایش را به دنبال انتخاب 13 مشارکت کننده فعال OSM و وارد کردن داده های خام OSM به پایگاه داده نشان می دهد. یک ابزار جاوا برای استخراج عملیات روی ویژگی های نقطه یا خط برای هر مشارکت کننده انتخاب شده استفاده شد. برای این منظور، تمام نسخههای مجاور هر ویژگی ایجاد شده توسط هر یک از اعضای OSM با توجه به هر نوع ویرایش بین آنها مقایسه و ارزیابی شدند. سپس ویرایشهای دادههای انجامشده توسط مشارکتکننده مورد علاقه بهعنوان تعدادی عملیات برای هر ویژگی خلاصه شد. در کدگذاری OSM، ویژگی ها (گره ها، راه ها و روابط) از طریق برچسب ها توصیف می شوند. هر تگ از یک کلید و یک مقدار تشکیل شده و به صورت key = value نوشته می شود. یک کلید به طور کلی یک عنصر (به عنوان مثال، یک بزرگراه) یا ویژگی مرتبط با یک عنصر (مانند محدودیت سرعت) را توصیف می کند. و مقدار به طور خاص کلید همراه آن را توصیف می کند. OSM در مجموع از 26 کلید ویژگی اصلی پیشنهادی از جمله ساختمان، بزرگراه یا کاربری زمین استفاده می کند.
اولین مجموعه عملیاتی که برای ترسیم منطقه در نظر گرفته شد شامل کارهای ویرایشی رایج برای گره ها و راه ها می شود، مانند افزودن یک جفت کلید-مقدار اولیه به یک نقطه (مثلاً راحتی = مدرسه) یا افزودن یک گره به ویژگی راه. این مجموعه از عملیات از این پس به عنوان ویرایش های اصلی نامیده می شود. جدول 2 لیستی از عملیات برای گره ها و راه ها برای ویرایش های اصلی در نظر گرفته شده است. سه عملیات اول (خط اول) به ویرایش کلیدها یا مقادیر روی هر تگ (به جز کلید اصلی یا ارزش یا برچسب منبع) اشاره دارد و سه عملیات بعدی فقط به عملیات روی برچسب های کلید-مقدار اولیه اشاره دارد. به دنبال آن دو عملیات هندسه و عملیات خاص دو طرفه انجام می شود.
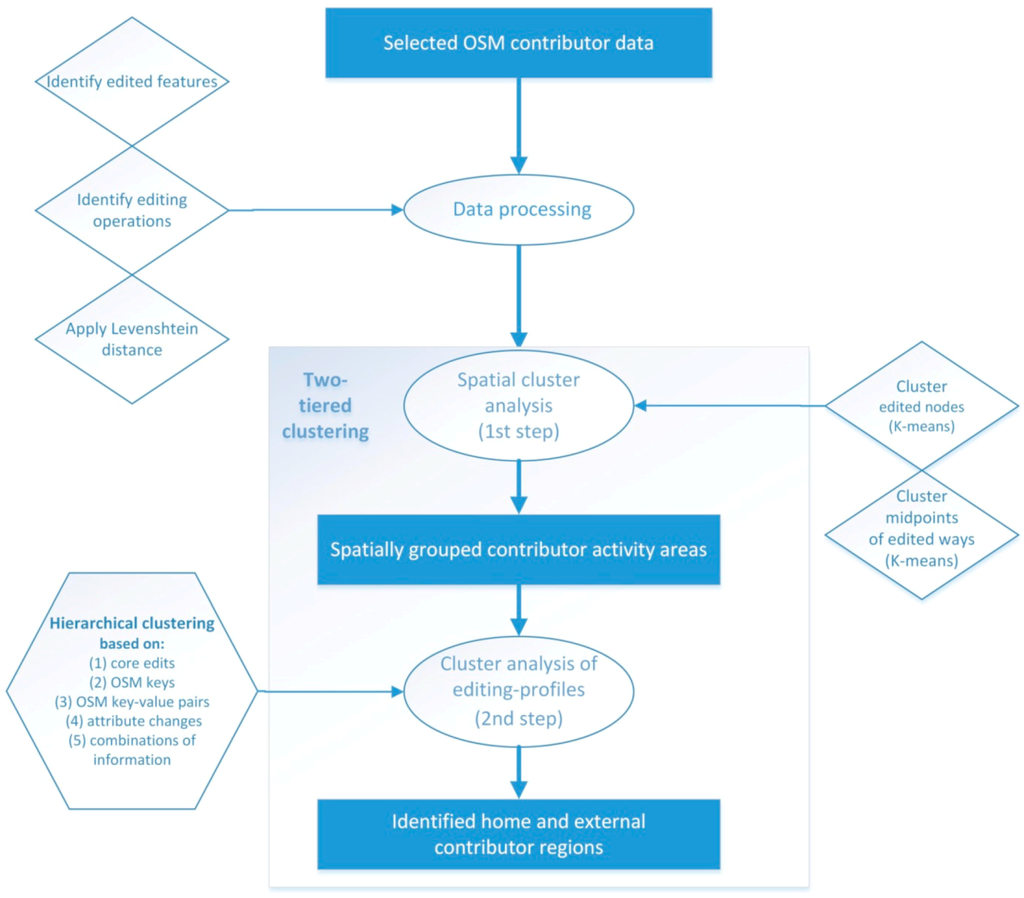
شکل 1. نمودار جریان تجزیه و تحلیل داده ها.
داده ها همچنین به طور خاص برای عملیات بر روی ویژگی های ویژگی که احتمالاً به دانش محلی نیاز دارند و نمی توانند بر اساس اطلاعات تصاویر هوایی انجام شوند، مورد بررسی قرار گرفتند. اگرچه برخی از این اطلاعات، مانند نام خیابان و آدرس را می توان از منابع جایگزین جستجو کرد، ما معتقدیم که اکثر مشارکت کنندگان داده OSM متعهد به جمع آوری داده ها به تنهایی و ارائه اطلاعات دست اول به پروژه OSM هستند. ویژگی های ویژگی مورد بررسی در قسمت پایین جدول 2 فهرست شده است. برخی از این ویژگیها دارای یک کلید متناظر در مستندات ویژگی OSM مانند نام یا سطح هستند، در حالی که سایر ویژگیها در جدول چندین تگ OSM را به طور همزمان برای مقایسه و تشخیص تغییر در ویژگیها در نظر میگیرند. به عنوان مثال، محدودیتهای کلی برای یک جاده (آخرین ردیف در جدول 2 ) شامل کلیدهای حداکثر (حداکثر ارتفاع)، حداکثر سرعت (حداکثر سرعت)، یا حداکثر عرض (حداکثر عرض) است. تغییر در هر یک از این مقادیر بهعنوان بهروزرسانی برای این ویژگی محسوب میشود.
جدول 2. عملیات در نظر گرفته شده برای شناسایی خانه و منطقه خارجی.
برای حذف ویرایشهای جزئی در اطلاعات ارزش ویژگی از شمارش، مانند تغییر حروف بزرگ در نام خیابان بین دو نسخه از یک ویژگی (که نیازی به دانش محلی ندارد)، فقط تغییرات ویژگی در نظر گرفته شد که فاصله لونشتاین بزرگتر از سه بین آنها تشخیص داده شد. هر دو مقادیر رشته ای یک ویژگی را با هم مقایسه کردند.
3.2. خوشه بندی مرحله 1: ترسیم فضایی مناطق فعالیت از طریق خوشه بندی k-Means
ایده اساسی رویکرد ترسیم منطقه ای پیشنهادی برای منطقه داخلی و خارجی این است که الگوهای ویرایش یک مشارکت کننده فردی بین این مناطق متفاوت است، جایی که الگوهای ویرایش را می توان به طور جداگانه برای ویژگی های گره یا راه تجزیه و تحلیل کرد. ویرایش های یک ویژگی می تواند در امتداد هر یک از عملیات فهرست شده در جدول 2 رخ دهد و برای ویژگی به عنوان یک بردار n بعدی حاوی مقادیر 0 و 1 ذخیره شود، جایی که n تعداد عملیات در نظر گرفته شده است. به طور مشابه، میتوان تحلیل کرد که کدام کلیدها یا جفتهای کلید-مقدار ویژگیهای ویرایششده تحت تأثیر ویرایشها قرار میگیرند. بنابراین، بردار n بعدی را میتوان با تعداد دستههای کلیدی یا ارزشی در صورت در نظر گرفتن افزایش داد. چنین بردار نمایانگر یک نمایه ویرایش برای یک ویژگی فردی است.
ما انتظار داریم که خوشهبندی ویژگیها بر اساس نمایههای ویرایش مرتبط، جدایی بین ویژگیهای واقع در خانه و منطقه خارجی را آشکار کند. اگرچه برخی از ویرایشها عمدتاً در مناطق اصلی یافت میشوند، مانند افزودن برچسب محدودیت سرعت به یک جاده، این تعداد ویرایش در مقایسه با همه ویرایشهایی که در هر منطقه انجام میشود، کم خواهد بود. بنابراین، همانطور که برخی آزمایشها با مجموعه دادههای موجود نشان دادند، خوشهبندی در سطح ویژگی اعمال شد، به عنوان مثال، با استفاده از الگوریتم خوشهبندی TwoStep [ 42]، منجر به الگوهای متمایز بین مناطق نشد، بلکه ظاهری درهم از مناطق داخلی و خارجی داشت. گرفتن ویژگیهای ویرایشهای ویژگی در مناطق از پیش تعریفشده از طریق خلاصه کردن ویرایشهای مربوط به ویژگیها در این مناطق (مرحله اول)، که نمایه ویرایش انبوهی را برای هر منطقه ارائه میدهد، آموزندهتر است. در مرحله بعد، می توان مناطق از پیش تعریف شده را بر اساس شباهت بین نمایه های ویرایش انبوه تنها با استفاده از ویژگی های غیر مکانی (مرحله دوم) خوشه بندی کرد. بنابراین، اولین مرحله شامل خوشهبندی فضایی گرههای ویرایش شده (به ترتیب یا نقاط میانی ویژگیهای راه) با استفاده از مختصات شرقی و شمالی ویژگیها است. اگرچه روشهای خوشهبندی پیشرفتهتری مانند خوشهبندی طیفی وجود دارد، اما ما از خوشهبندی k-means استفاده کردیم که روش پیشنهادی را به طور گستردهتری قابل اجرا میکند. همچنین،این نباید برای این نوع تجزیه و تحلیل هنگام انتخاب k به اندازه کافی بزرگ برای پوشش مناطق با اندازه شهر یا کوچکتر مشکلی ایجاد کند، زیرا می توان انتظار داشت که مناطق خانگی که معمولاً در مناطق شهری یافت می شوند دارای شکل محدب باشند. یعنی حتی اگر یک مشارکتکننده داده فعالیتهای روزانه را در مکانهای مختلف یک شهر انجام دهد، به عنوان مثال، خانه، محل کار، خرید یا اوقات فراغت، و دادههای مرتبط با این مکانها را جمعآوری کند، مناطق نقشهبرداری شده را میتوان از طریق یک چندضلعی محدب محدود کرد.
برای آماده سازی داده ها، هندسه خط راه ها با نقاط میانی آنها جایگزین شد. علاوه بر این، هر ویژگی فقط یک بار نقشه برداری شد، حتی اگر چندین نسخه در فایل dump تاریخ داشته باشد. ما مقادیر k متفاوتی (به عنوان مثال ، خوشههای فضایی) را برای گرهها و روشهای هر یک از 13 مشارکتکننده امتحان کردیم، و با k-مقدارهای نسبتاً کوچک (در محدوده 5 تا 10) شروع کردیم که به نظر میرسید به صورت بصری یک گروهبندی فضایی معنادار ارائه میکرد. از گره ها بعداً، در ترکیب با مرحله 2 از رویکرد خوشهبندی، ما مقادیر k را افزایش دادیم تا بتوانیم ترسیم فضایی دقیقتری از منطقه اصلی به دست آوریم. شکل 2 مناطق ایجاد شده از طریق خوشه بندی k-means در گره های (a) و نقاط میانی راه (b) را برای یکی از 13 مشارکت کننده انتخاب شده نشان می دهد.
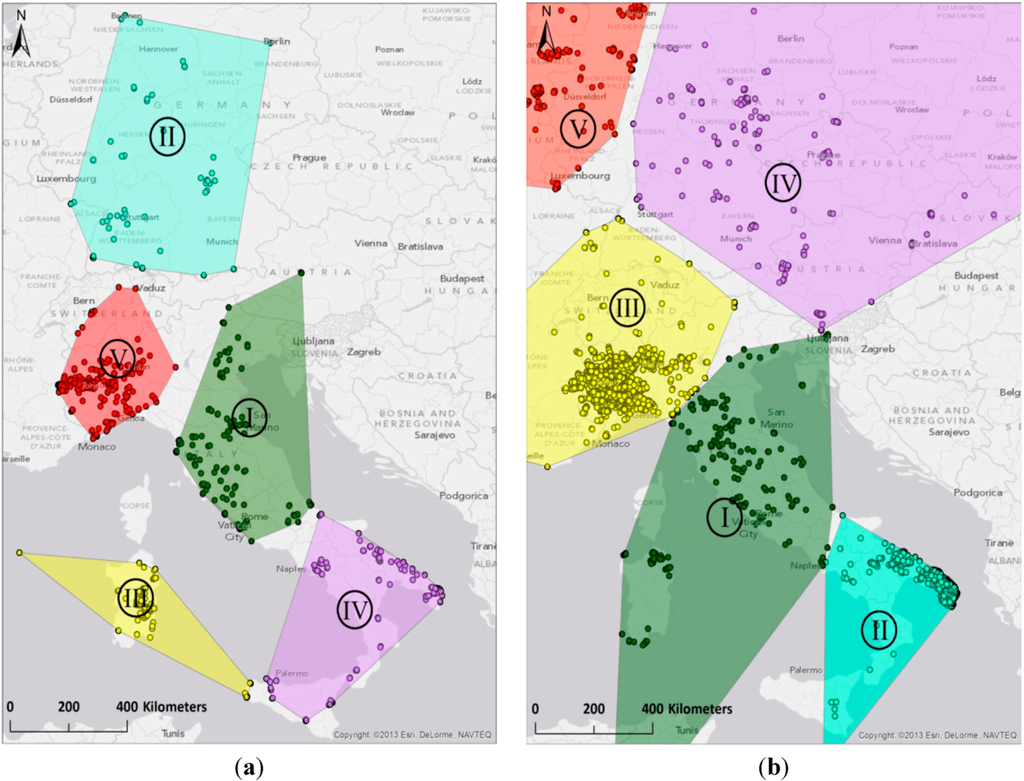
شکل 2. خوشههای k-means برای ( a ) گرهها (5 گروه) و ( b ) راهها (هفت گروه – فقط پنج گروه در وسعت قابل مشاهده نشان داده شدهاند) برای یک مشارکتکننده انتخابشده OSM ایجاد شده است.
خلاصه کردن تعداد ویرایش برای هر خوشه k-means یک کاربر به k بردار نمایه ویرایش انبوه می دهد، به عنوان مثال ، یک نمایه برای هر ناحیه از پیش تعریف شده. بنابراین، هر بردار نمایه تجمیع شده یک ردیف با n ستون است که n تعداد عملیات، کلید و دستههای کلید-مقدار مورد بررسی است. مقادیر عددی در یک ردیف بهعنوان تعداد کل ویرایشها برای خوشهای که در دسته ویرایش مورد بررسی قرار میگیرد، محاسبه شد و به دنبال آن بر تعداد ردیفهای ویرایش در آن خوشه k-means تقسیم شد. این برای همه گروههای k تکرار شد تا ماتریسی از بردارهای نمایه جمعآوری شود. جدول 3بخشی از چنین ماتریسی از ویرایش گره ها را برای یک مشارکت کننده OSM نشان می دهد. در این مثال، ترسیم فضایی به پنج گروه k-means منجر شد. مقدار 0.012، به عنوان مثال، در ردیف اول در زیر ستون «AddTag» یافت میشود، نشان میدهد که در خوشه k-means #1، 1.2 درصد از ویرایشها شامل افزودن یک برچسب کلید غیراصولی است.
جدول 3. نمونه ویرایش نمایه برای یک مشارکت کننده انتخاب شده.
3.3. مرحله 2 خوشه بندی: شناسایی منطقه داخلی و خارجی از طریق خوشه بندی سلسله مراتبی پروفایل های ویرایش مبتنی بر منطقه
سپس، یک تحلیل خوشهای سلسله مراتبی برای k خوشهها (مورد نامیده میشود) با نمایههای ویرایش انبوه آنها اعمال شد، جایی که انتظار میرود دو خوشه آخر در جدول تجمع، منطقه اصلی (در حالت ایدهآل شامل تنها یک مورد) و خارجی را نشان دهند. منطقه (خوشه با موارد باقیمانده). ما زیر مجموعه های مختلف عملیات را آزمایش کردیم ( جدول 2 را ببینید) و اطلاعات کلید-مقدار برای استفاده به عنوان اطلاعات در نمایه های ویرایش انبوه در فرآیند خوشه بندی سلسله مراتبی، که (1) ویرایش های اصلی هستند. (2) کلیدها؛ (3) جفت کلید-مقدار. (4) تغییرات ویژگی. و (5) ترکیبی از این اطلاعات. در حالی که تغییرات ویژگی منجر به یک الگوی خوشهای بهم ریخته از مناطق از پیش تعریف شده با توجه به جداسازی منطقه داخلی و خارجی شد، روشهای (1) تا (3) و ترکیب آنها به طور کلی نتایج بهتری ارائه کردند که بیشتر آنها با موارد قبلی همسو بودند. رویکردهای ترسیم منطقه خانه [ 17 ]. چندین روش خوشهبندی سلسله مراتبی مانند روش وارد یا میانگین پیوند بین گروهها به کار گرفته شد، اما هیچ تأثیری بر ترتیب خوشهبندی در برنامه تجمع مشاهده نشد.
شکل 3 خوشههای نقطهای و دندروگرامها را در نتیجه فرآیند خوشهبندی سلسله مراتبی ویرایشهای گره برای یک مشارکتکننده انتخاب شده، با استفاده از ویرایشهای اصلی (a)، کلیدهای (b) و جفتهای کلید-مقدار (c) نشان میدهد. ما آن موارد از دندروگرام را به عنوان منطقه اصلی در نظر گرفتیم که بخشی از دو خوشه نهایی در برنامه تجمع و در خوشه حاوی تعداد کمتری از موارد بودند. در این مثال، اطلاعات ویرایش اصلی دو خوشه کوچکتر را به عنوان مناطق اصلی شناسایی کرد که شامل یک خوشه تا حدی پراکنده در شرق اتریش است ( شکل 3).الف) (خوشه شماره 3، 8 امتیاز) و یکی در ایالات متحده (خوشه شماره 6، 1 امتیاز). بعید به نظر می رسید که این یک منطقه خانگی باشد هم بر اساس فاصله فضایی بین دو خوشه و هم به دلیل تعداد کم گره ها در هر دو خوشه. این مثال یک محدودیت در رویکرد خوشهبندی پیشنهادی را نشان میدهد، که این است که گروههای k-means متشکل از اعداد بسیار کوچک ممکن است به دلیل چند ویرایش که در فرآیند خوشه سلسله مراتبی به عنوان منطقه اصلی شناسایی میشوند، نمایه مجزایی داشته باشند. بنابراین، قبل از تجزیه و تحلیل خوشه سلسله مراتبی، باید حداقل تعداد نقاط را در هر ناحیه k-means نگه داشت.

شکل 3. نتایج تجزیه و تحلیل خوشه سلسله مراتبی با استفاده از ویرایش های اصلی ( a ) (فقط خوشه شماره 3 نشان داده شده در وسعت قابل مشاهده)، کلید ( b ) و اطلاعات کلید-مقدار ( c ) گره های ویرایش شده.
روش دیگر برای جلوگیری از این مشکل، حذف نقاط جدا شده از نظر فضایی قبل از تجزیه و تحلیل خوشهای است، زیرا یک منطقه خانگی از بیش از چند نقطه تشکیل شده است.
اطلاعات کلیدی ویژگی های ویرایش شده به ترسیم دو خوشه از پیش تعریف شده در منطقه بزرگ کوفشتاین (اتریش) ( شکل 3 ب) به عنوان منطقه اصلی (خوشه شماره 2 و 7) کمک کرد. سپس، با استفاده از ترکیب کلید-مقدار به عنوان ویژگی در فرآیند خوشهبندی سلسله مراتبی، منطقه خانه بالقوه تنها به یک منطقه، یعنی نزدیکی کوفشتاین (خوشه شماره 2 در شکل 3 ج) محدود میشود.
جدول 4 توضیح می دهد که در نتیجه خوشه بندی سلسله مراتبی اعمال شده برای ویرایش گره ها و نقاط میانی راه، چند مورد ( یعنی مناطق k-means از پیش تعریف شده) بخشی از کوچکتر از دو خوشه نهایی در دندروگرام ها (نشان دهنده منطقه اصلی) هستند. . خط تیره (-) نشان می دهد که هیچ منطقه خانگی قابل قبولی را نمی توان بر اساس فرآیند خوشه سلسله مراتبی شناسایی کرد، که یا مناطق قطع شده یا مناطق دورافتاده با تنها چند نقطه بودند. نمونه ای که هر دو این اثرات را نشان می دهد در شکل 3 ارائه شده استآ. اگر فقط به دلیل چند نقطه مجزا ایجاد نشود، مناطق جدا شده که به عنوان موارد در خوشه نهایی ظاهر می شوند به طور کلی نشان می دهد که هیچ منطقه جغرافیایی واحدی وجود ندارد بلکه کاربر در حال سفر است و ویرایش های داده و مشارکت های مشابهی را در بخش های مختلف مناطق نقشه برداری انجام می دهد. . برای مثال، اگر کاربر پس از پیوستن به جامعه OSM جابهجا شود و به مشارکت و ویرایش دادهها ادامه دهد، ممکن است چنین وضعیتی رخ دهد. با این حال، در جدول 4 ، مناطق قطع شده در ستونهای ویرایشهای اصلی و کلیدها زمانی که بهعنوان یک خط تیره علامتگذاری شدهاند، نتیجه اطلاعات ناکافی برای ترسیم یک خوشه فعالیت اولیه، هم برای گرهها و هم برای راهها، بر خلاف نتایج خوشهبندی بهدستآمده از در نظر گرفتن کلیدها یا ستون های کلید-مقدار.
جدول 4. تعداد گروه های خوشه ای k-means شناسایی شده در مناطق اصلی.
نتایج حاصل از 13 مشارکتکننده آزمایششده همچنین نشان داد که ویرایشهای اصلی گرهها اطلاعات بیشتری را برای تمایز بین مناطق داخلی و خارجی نسبت به روشها دارند، در حالی که این تفاوت در هنگام استفاده از کلیدها یا کلید-مقدارها قابل مشاهده نیست.
4. ارزیابی
4.1. مقایسه روش های خوشه ای
از آنجایی که هنگام ثبت نام برای یک حساب کاربری OSM نیازی به ارائه منطقه خانه نیست، هیچ مجموعه داده مرجعی در دسترس نیست که منطقه خانه خود تعریف شده توسط مشارکت کننده را فراهم کند. بنابراین، رویکرد ترسیم منطقه ای ارائه شده با مقایسه وسعت مناطق خانه شناسایی شده با مناطق استخراج شده از روش معرفی شده قبلی بر اساس مثلث سازی دلونی که از مرکز همه تغییرات ایجاد شده توسط مشارکت کننده مورد بررسی استفاده می کند، ارزیابی شد [ 17 ].
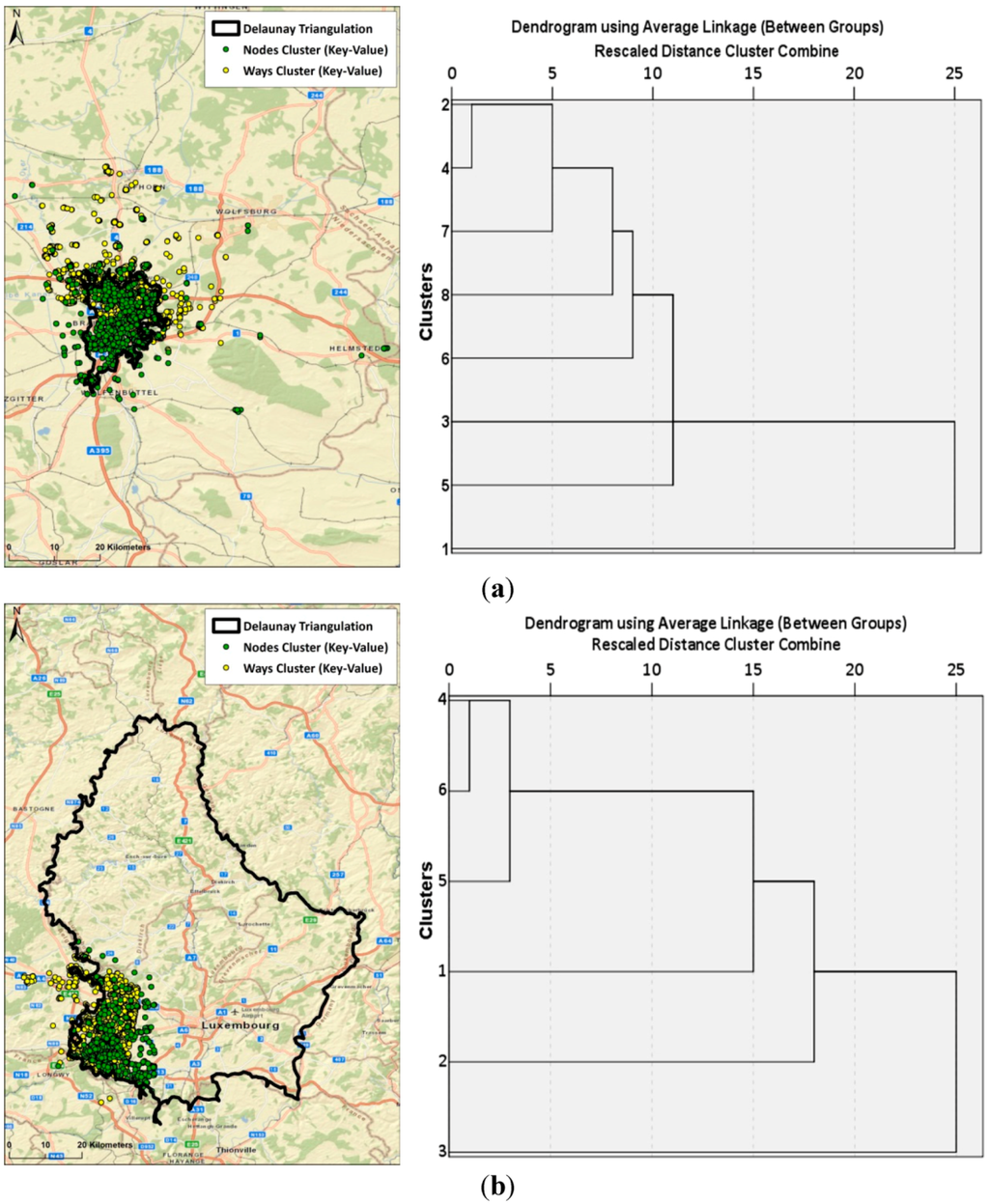
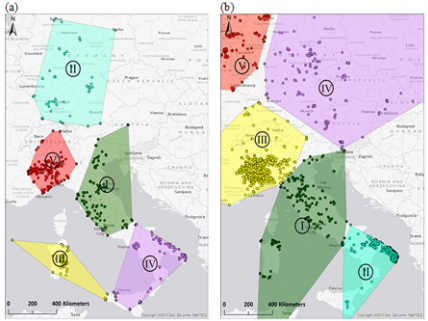
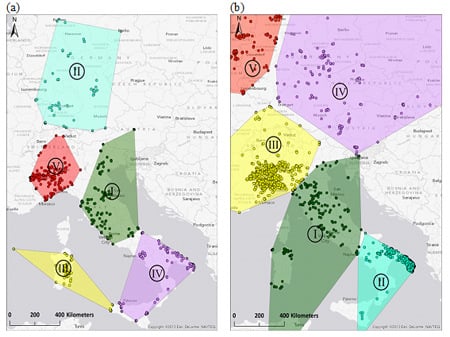
شکل 4. نتایج روش دو سطحی k-means/ خوشه بندی سلسله مراتبی و روش مثلث بندی Delaunay برای دو مشارکت کننده انتخاب شده OSM که همپوشانی بزرگ ( a ) و تفاوت های واضح ( b ) بین نتایج هر دو روش را نشان می دهد.
علاوه بر این، با تمام 13 مشارکت کننده به صورت جداگانه از طریق سیستم پیام OSM تماس گرفته شد که به اعضای OSM اجازه می دهد تا زمانی که هر دو شرکت کننده در پروژه ثبت نام کرده اند، پیام تبادل کنند. از مشارکت کنندگان خواسته شد تا منطقه اصلی را که با «چگونه در OpenStreetMap مشارکت کردید؟» تجسم شده را تأیید یا رد کنند. وب سایت ( http://hdyc.neis-one.org/ )، که از روش مثلث سازی Delaunay ذکر شده برای تعیین منطقه اصلی یک مشارکت کننده استفاده می کند. هفت نفر از 13 مشارکت کننده به پیام ارسال شده اولیه پاسخ دادند و شرحی از منطقه اصلی خود ارائه کردند.
شکل 4 نتایج ترسیم هر دو روش را برای دو نفر از 13 عضو OSM انتخاب شده پوشش می دهد. ابرهای نقطه، ویژگیها (گرهها یا نقاط میانی راه) را در منطقه محلی نشان میدهند که از طریق رویکرد خوشهبندی سلسله مراتبی با استفاده از اطلاعات کلید-مقدار شناسایی شدهاند. چند ضلعی های با طرح کلی مشکی، ناحیه فعالیت خانه را نشان می دهد که از مثلث سازی دلونای حاصل می شود. شکل 4a موردی را نشان می دهد که در آن دو روش منجر به یک منطقه اصلی یکسان می شوند (براونشوایگ، آلمان). با این حال، رویکرد خوشهبندی 2 لایه، به دلیل مناطق k-means از پیش تعریفشده بزرگتر، منطقه بزرگتری را پوشش میدهد. این مثال همچنین تطابق خوبی بین مناطق اصلی بر اساس ویرایشهای گره (سبز) و روش (زرد) در رویکرد خوشهبندی 2 لایه نشان میدهد. دندروگرام سمت راست برای خوشه های گره نشان داده شده است، و نقاط خوشه شماره 1 به سمت چپ نگاشت می شوند. شکل 4b نشان میدهد که چگونه استفاده از اطلاعات کلید-مقدار میتواند به تعیین یک منطقه خانه تصفیهشدهتر در مقایسه با مثلث Delaunay در برخی موارد کمک کند. در حالی که چند ضلعی مثلثی ناحیهای را پوشش میدهد که تقریباً با لوکزامبورگ یکسان است، ابر نقطهای برای گرهها نشاندهنده منطقه کوچکتر اصلی مشارکتکننده در منطقه جنوب غربی لوکزامبورگ است که کمی به بلژیک و فرانسه میرسد. منطقه اخیر بیشتر با آنچه که مشارکت کننده این منطقه به عنوان یکی از مناطق اصلی نقشه برداری خود در پاسخ خود تعریف کرده بود، مطابقت داشت.
4.2. حساسیت طبقه بندی
یک همپوشانی فضایی کامل بین روش خوشهای دو لایه و روش مثلثبندی به دلیل انتخاب دلخواه مناطق خوشهای k-means در مرحله اول، که وضوح فضایی مرحله خوشهبندی سلسله مراتبی را تعیین میکند، به دست نمیآید. به عنوان مثال، در شکل 5 a، خوشه اصلی شناسایی شده برای گره ها (سبز) بر اساس یک مقدار k پایین 9، وین (اتریش) و اطراف آن (خوشه شماره 4) را پوشش می دهد، در حالی که شکل 5 b با یک مقدار k بزرگتر از 30 منطقه اصلی را به چند منطقه شهری محدود می کند (خوشه شماره 27)، با اطلاعات ارائه شده توسط مشارکت کننده در طول تبادل ایمیل بیشتر مطابقت دارد.
در حالی که هر دو دندروگرام در این مورد خاص یک الگوی متمایز را با یک خوشه منفرد به عنوان منطقه اصلی نشان میدهند، انتخاب عدد خوشه k-means باید دو هدف متضاد را متعادل کند، که هدف آن تفکیک فضایی بالای منطقه خانه است (به عنوان مثال ، یک k-value بالا)، در حالی که در همان زمان یک نمایه ویرایش انبوه نماینده برای هر خوشه k-means برای خوشهبندی سلسله مراتبی موفق پس از آن به دست میآید ( به عنوان مثال ، با انتخاب یک مقدار k نسبتاً کم از خوشههایی که حاوی نقاط بسیار کمی هستند اجتناب کنید).
برخی از مشارکتکنندگان OSM تلاشهای جمعآوری دادههای دقیق خود را به یک منطقه محدود نمیکنند، در این صورت مشخصکردن منطقهای یک منطقه خانگی مشکلساز است. شکل 6 b,c برای عضو OSM 11 ( جدول 4 را مقایسه کنید ) نشان می دهد که چگونه ناحیه اصلی هنگام افزایش مقدار k تغییر می کند. با استفاده از k = 6، دندروگرام ( شکل 6 ب) نشان می دهد که منطقه بزرگتر سنت پترزبورگ (روسیه) (خوشه شماره 4) منطقه اصلی مشارکت کننده را نشان می دهد ( شکل 6 a، نقاط سبز). پس از افزایش مقدار k به 50 برای شناسایی یک منطقه کوچکتر و متمایزتر از خانه، منطقه شناسایی شده به قسمت شرقی قبرس تغییر می کند ( شکل 6 د)، مطابق با مورد #45 در دندروگرام ( شکل 6).ج). دندروگرام بریده شده 13 خوشه از 50 خوشه را در پایان برنامه تجمع نشان می دهد که هشت تای آنها در منطقه سن پترزبورگ قرار دارند و به طور بالقوه می توانند در یک منطقه خانگی بزرگتر ادغام شوند. با این حال، 13 مورد آخر همچنین شامل خوشه هایی برای تنریف و مسکو، علاوه بر قبرس است، که هیچ منطقه جغرافیایی متمایز از محل زندگی خود را نشان نمی دهد.

شکل 5. بهبود ترسیم منطقه خانه از طریق افزایش مقدار k از 9 ( a ) به 30 ( b ).
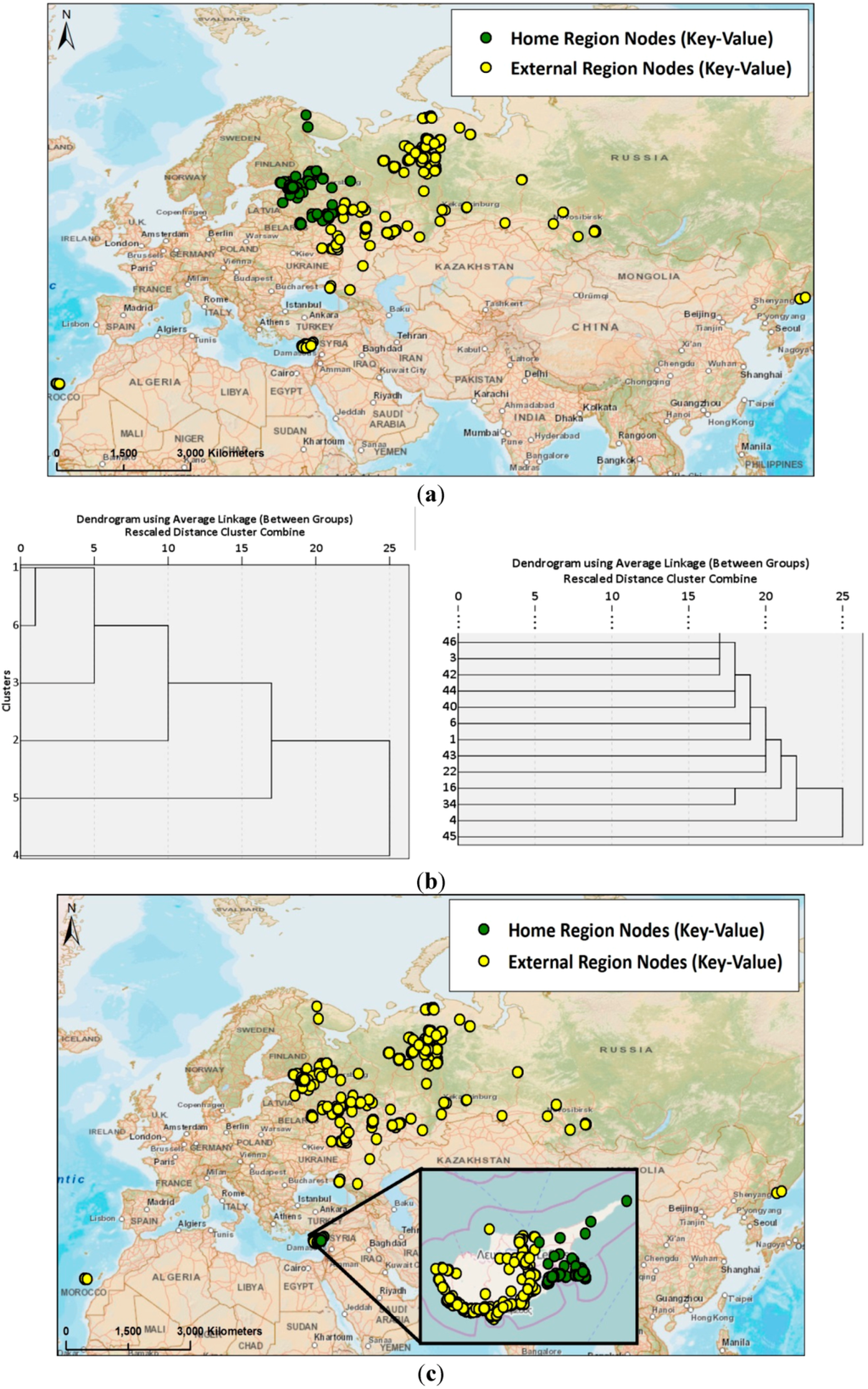
شکل 6. ترسیم چندین منطقه خانه از طریق افزایش مقدار k.
نتایج بهدستآمده توسط مشارکتکننده تأیید شد، او اظهار داشت که ترسیم یک منطقه خانه واحد در مورد خاص او مشکلساز خواهد بود. سفرهای گسترده در سالهای اخیر و تلاشهای نقشهبرداری دقیق مشابه در همه مناطق بازدید شده، تعیین یک منطقه خانگی را دشوار میکند. ما انتظار داریم نوع مشابهی از نتایج خوشهای را نیز از مشارکتکنندگانی که بهطور موقت کشور خود را ترک میکنند تا دادههای OSM را در خارج از کشور جمعآوری کنند، به عنوان مثال، برای کار NGO یا برای تیم انساندوستانه OpenStreetMap (HOT) [ 44 ]]، جایی که آنها پس از آن به محلیهای «عملی» تبدیل میشوند و رفتار نقشهبرداری مشابهی را در منطقه قبلی خود نشان میدهند. سپس تجزیه و تحلیل خوشهبندی سلسله مراتبی، مناطق مختلف خانه را بر اساس مقدار k انتخاب شده نشان میدهد، که نشان میدهد هیچ منطقه خانه واحدی برای آن کاربر وجود ندارد.
بنابراین، در مقایسه با روش مثلثسازی Delaunay کاملاً مبتنی بر فضایی، ادغام ویرایش اطلاعات در ترکیب با خوشهبندی k-means ابزار اضافی برای درک اینکه آیا یک مشارکتکننده OSM دارای یک منطقه اصلی منسجم است یا یک منطقه فعالیت متشکل از بخشهای جدا شده، فراهم میکند. به طور خاص، تغییر مقادیر k و بررسی بعدی ساختار دندروگرام حاصل میتواند به تمایز بین هر دو موقعیت کمک کند. به این معنا که اگر بین مناطقی که بهعنوان مناطق اصلی شناسایی شدهاند بر اساس یک مقدار k کوچک اما همچنین بر اساس یک مقدار بزرگ همپوشانی وجود داشته باشد، این نشاندهنده یک منطقه منفرد است. یک مثال وضعیتی است که در شکل 5 نشان داده شده است، جایی که منطقه اصلی از طریق یک مقدار k افزایش یافته 30 پالایش می شود و منطقه تصفیه شده هنوز در ناحیه درشت تر است که در ابتدا به عنوان منطقه اصلی با مقدار اولیه k پایین تر 9 شناسایی شده است. ما انتظار داریم این نوع الگوی ترسیم متوالی نیز برای کاربران وجود داشته باشد. که دارای منطقه منسجمی هستند اما در آن احزاب نقشهبرداری که مشارکتکنندگان از خارج از کشور بر روی مناطق مورد توافق تمرکز میکنند و ویژگیهای تصاویر ماهوارهای را دیجیتالی میکنند، مشارکت میکنند [ 45 ]. ویرایشهای انجامشده در این مهمانیهای نقشهبرداری از ترکیبی مشابه با سایر مناطق خارجی که توسط کاربر نقشهبرداری میشود، خواهد بود و بنابراین کاربران را «دفاکتو» محلی نمیکند.
بر خلاف این، مناطق جغرافیایی مجزا از فعالیت های نقشه برداری با مقادیر k تغییر یافته، همانطور که در رابطه با شکل 6 نشان داده شده است، نشان می دهد که هیچ منطقه خانه واحدی وجود ندارد. برای همین وضعیت، مثلث دلاوی سن پترزبورگ را به عنوان یک منطقه محلی گزارش میکند، که تنها تا حدی درست است زیرا سایر بخشها نیز باید به عنوان مناطق اصلی در نظر گرفته شوند. این یکی از مزایای رویکرد خوشهبندی دو لایه پیشنهادی را نشان میدهد.
4.3. تنوع و فعالیت
پس از ترسیم منطقه ای از خانه و مناطق خارجی، آنالیز شد که چند نوع ویژگی مختلف ویرایش شده و در چند روز ویرایش در خانه و منطقه خارجی برای هر مشارکت کننده انجام شده است. تنوع بیشتر ویژگی ها به این معنی است که مشارکت کننده جزئیات بیشتری را برای یک حوزه خاص مورد علاقه جمع آوری می کند، که نشان دهنده دانش محلی است که بسیاری از علاقه مندان VGI آن را به عنوان یکی از مزایای اصلی پروژه OSM در نظر می گیرند. لازم به ذکر است که تنوع نوع ویژگی به طور مساوی بین مناطق مختلف جغرافیایی توزیع نشده است. به طور خاص، تنوع ویژگی ها، به عنوان مثال، اندازه گیری شده با انواع امکانات رفاهی، در محیط های شهری بزرگتر از مناطق روستایی کم جمعیت است. بدین ترتیب، یک مشارکتکننده OSM که تنوع بیشتری از ویژگیهای نقشهبرداری شده را در یک منطقه خانگی که در یک محیط شهری واقع شده است در مقایسه با مناطق خارجی که منحصراً در مناطق روستایی واقع شدهاند، نشاندهنده جزئیات سطح بالاتری از تلاش جمعآوری دادهها در منطقه خانگی نیست، اما محصول توزیع طبیعی تنوع ویژگی. با این حال، هر یک از 13 نقشه نگار منتخب، از آنجایی که بسیار فعال بودند، داده ها را در چندین منطقه پرجمعیت مجزا ارائه کردند. بنابراین، تنوع بیشتری از ویژگیهای نقشهبرداری شده در منطقه اصلی (که معمولاً فقط یک شهر یا منطقه شهری را شامل میشود)، در واقع نشاندهنده تلاش نقشهبرداری دقیقتر نسبت به مناطق خارجی است، که در موارد مورد تجزیه و تحلیل ما، مناطق شهری (سایر) را نیز شامل میشود. . از آنجایی که بسیار فعال بود، داده ها را در چندین منطقه پرجمعیت مجزا ارائه کرد. بنابراین، تنوع بیشتری از ویژگیهای نقشهبرداری شده در منطقه اصلی (که معمولاً فقط یک شهر یا منطقه شهری را شامل میشود)، در واقع نشاندهنده تلاش نقشهبرداری دقیقتر نسبت به مناطق خارجی است، که در موارد مورد تجزیه و تحلیل ما، مناطق شهری (سایر) را نیز شامل میشود. . از آنجایی که بسیار فعال بود، داده ها را در چندین منطقه پرجمعیت مجزا ارائه کرد. بنابراین، تنوع بیشتری از ویژگیهای نقشهبرداری شده در منطقه اصلی (که معمولاً فقط یک شهر یا منطقه شهری را شامل میشود)، در واقع نشاندهنده تلاش نقشهبرداری دقیقتر نسبت به مناطق خارجی است، که در موارد مورد تجزیه و تحلیل ما، مناطق شهری (سایر) را نیز شامل میشود. .
برای 12 تلاش موفقیت آمیز ترسیم منطقه بر اساس حاشیه نویسی های کلیدی-مقدار برای گره ها (مقایسه کنید جدول 4 )، تجزیه و تحلیل نشان داد که تقریباً در بین تمام مشارکت کنندگان، مناطق خانگی دارای تنوع بیشتری از ویژگی ها نسبت به مناطق خارجی بودند ( شکل 7 )، اگرچه وسعت فضایی مناطق خانگی کوچکتر از مناطق خارجی است. لازم به ذکر است که با افزایش مقدار k در داخل خوشه بندی k-means و در نتیجه منطقه خانگی کوچکتر در مقایسه با مناطق خارجی، می توان انتظار داشت که تنوع ویژگی برای منطقه اصلی کاهش یابد. بنابراین، نتایج در شکل 7با مقادیر k که برای نقشهنگارهای مختلف در این تحلیل انتخاب شدهاند، ارتباط نزدیکی دارند. تنوع ویژگی های کوچکتر در مناطق خارجی را احتمالاً می توان به روش نقشه برداری نسبت داد، به عنوان مثال ، دیجیتالی کردن جاده ها، ساختمان ها، یا اطلاعات کاربری زمین از تصاویر ماهواره ای، که بیشتر برای مناطق دورافتاده یا مناطق ناشناخته برای مشارکت کننده استفاده می شود. یک آزمون رتبهبندی با جفتهای همسان ویلکاکسون تأیید کرد که تعداد انواع ویژگیهای نگاشتشده در مناطق اصلی به طور قابلتوجهی بیشتر از آنهایی است که در مناطق خارجی نگاشت شده است (z = -2.045، p .= 0.019، 1 دنباله). علیرغم تنوع بیشتر ویژگیهای آماری در مناطق خانگی نسبت به منطقه خارجی در میان مجموعه دادههای تحلیلشده، نتایج برای پنج مشارکتکننده سمت راست تصویر کمتر واضحتری ارائه میدهد. نرخهای تنوع مشابه بین مناطق خانگی و خارجی را میتوان با این واقعیت توضیح داد که برای این مشارکتکنندگان، مناطق خانگی شناساییشده در محیطهای شهری قرار داشتند، جایی که مناطق خارجی در مجاورت ویژگیهای مشابهی را برای نقشهبرداری ارائه میدهند. این نشان میدهد که روش خوشهای ارائهشده در شناسایی مرزهای واضح مناطق خانگی که در داخل یک محیط شهری قرار دارند که در آن انتقال بین یک خانه و مناطق خارجی ممکن است تدریجی باشد، غیرقابل اعتماد است.
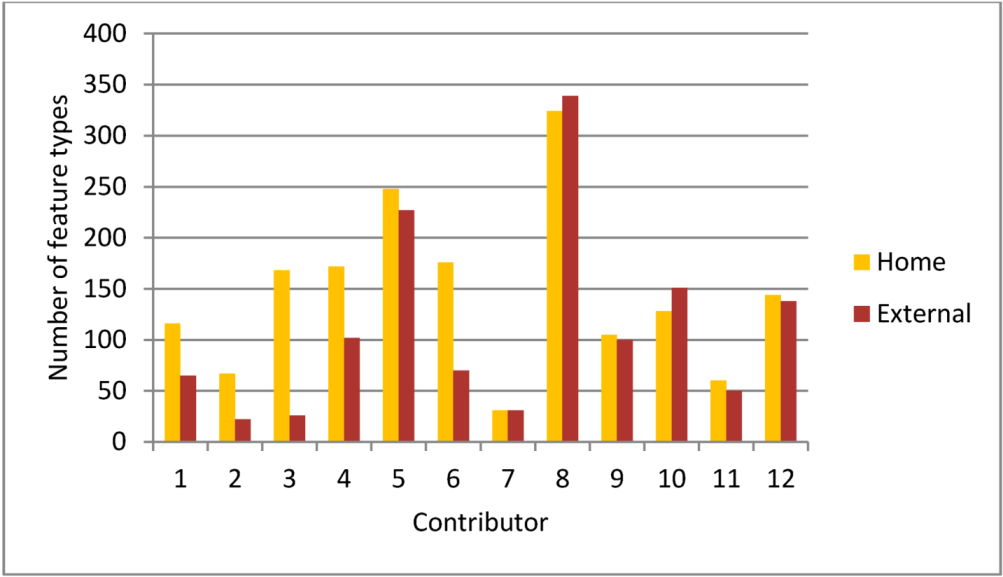
شکل 7. تنوع تلاش های نقشه برداری در مناطق داخلی و خارجی.
مشابه تنوع ویژگیها، فرض میکنیم که منطقه با بیشترین تعداد روز اختصاص داده شده به فعالیتهای نقشهبرداری، منطقه اصلی مورد علاقه مشارکتکننده را در سطح زمانی مشخص میکند. برای تحلیل زمانی تلاشهای نقشهبرداری میتوان یک الگوی مشابه را مشاهده کرد ( شکل 8 ). به استثنای دو مشارکتکننده، همه اعضای OSM روزهای بیشتری را به نقشهبرداری ویژگیها در منطقه خانگی خود نسبت به منطقه خارجی اختصاص دادند. یک آزمون رتبهبندی با جفتهای همسان ویلکاکسون تأیید کرد که تعداد روزهای با فعالیتهای نقشهبرداری در مناطق خانگی به طور قابلتوجهی بیشتر از مناطق خارجی بود (z = -1.961، p .= 0.025، 1 دنباله). دو مشارکت کننده که از این روند پیروی نکردند، به دلیل نزدیکی نزدیک به مناطق داخلی و خارجی، به عنوان مثال مرکز شهر وین (منطقه اصلی) و حومه وین (منطقه خارجی) مقدار قابل توجهی بالاتری را برای روزهای نقشه برداری در منطقه خارجی نشان دادند.
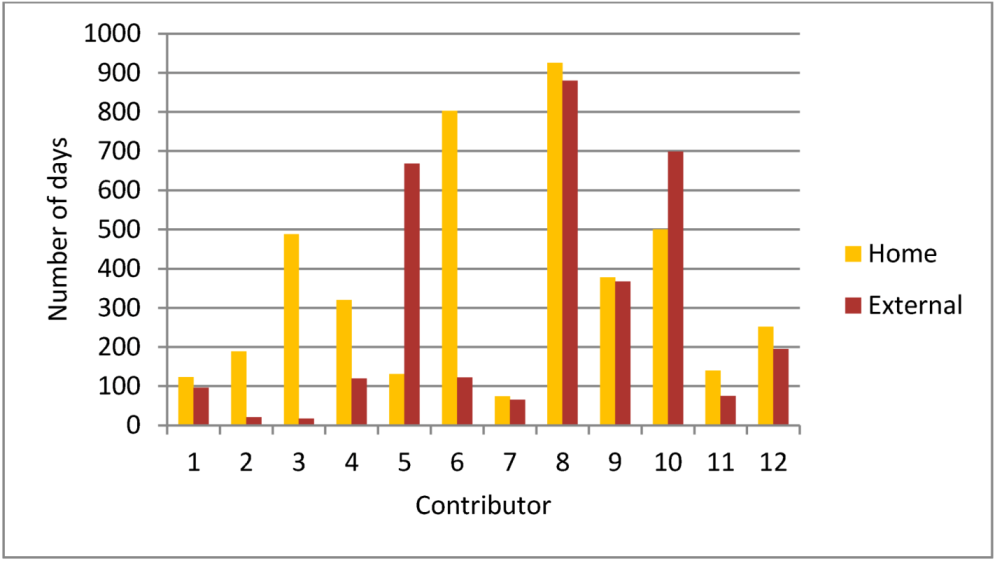
شکل 8. طیف زمانی تلاش های نقشه برداری در مناطق داخلی و خارجی.
تجزیه و تحلیل ارائه شده در رابطه با شکل 7 و شکل 8 نشان می دهد که چرا تعیین منطقه اصلی مشارکت کنندگان OSM مهم است: این نشان دهنده بهبود کیفیت داده در یک منطقه از طریق افزایش فعالیت (تعداد روزهای نقشه برداری) و تنوع بیشتر ویرایش های ویژگی است. توسط یک مشارکت کننده داده فردی کیفیت داده، البته، به تعداد مشارکتکنندگان دادههای مختلف که در یک منطقه خانگی مشترک هستند نیز بستگی دارد. میتوان انتظار داشت که تعداد بیشتری از مشارکتکنندگان در همان منطقه منجر به کیفیت دادههای بهتری نسبت به این موضوع شود که فقط در مورد یک مشارکتکننده وجود دارد. این در مطالعه فعلی آزمایش نشده است، اما می تواند به عنوان بخشی از کار آینده در نظر گرفته شود.
5. خلاصه و نتیجه گیری
الگوهای مشارکت کننده OSM می تواند به طور قابل توجهی بین مناطق نقشه برداری شده یک مشارکت کننده متفاوت باشد. روش خوشهبندی دو لایه پیشنهاد شده در این مقاله از ویرایش اطلاعات اشیاء OSM برای ترسیم منطقه داخلی و خارجی یک مشارکتکننده استفاده میکند. این روش جایگزینی برای روشهای ترسیم موجود ارائه میکند که یک منطقه خانگی را تنها بر اساس اطلاعات موقعیتی ویرایشهای ویژگی شناسایی میکند و بینش بیشتری در مورد تمایز بین خوشههای منفرد در مقابل مناطق خانه پراکنده ارائه میکند.
تجزیه و تحلیل تنوع ویژگیهای گره در مناطق خانگی و خارجی نشان داد که بیشتر مشارکتکنندگان تنوع بیشتری از ویژگیها را در مناطق خانگی نسبت به مناطق خارجی ویرایش میکنند. این الگو از مفهوم دانش محلی پشتیبانی می کند که بسیاری ادعا می کنند یکی از مزایای اصلی پروژه های VGI، مانند OSM است. دانش محلی را می توان از حضور در محل به دست آورد که امکان جمع آوری اطلاعات دقیق تری را نسبت به نقشه برداری از تصاویر ماهواره ای فراهم می کند. به طور مشابه، تجزیه و تحلیل زمانی، با تمرکز بر تعداد روزهایی که یک مشارکتکننده به تلاشهای نقشهبرداری در هر منطقه اختصاص داده است، ارزش بیشتری را برای مناطق داخلی نسبت به مناطق خارجی برای تقریباً همه مشارکتکنندگان نشان داد.
در این مطالعه، تجزیه و تحلیل خوشهای دو لایه پیشنهادی به صورت دستی بر روی مجموعه کوچکی از کاربران فعال برای ارزیابی پتانسیل، نقاط قوت و ضعف آن انجام شد. حجم نمونه 13 کاربر تجزیه و تحلیل شده به وضوح برای ارزیابی کمی تحلیل خوشهای دو لایه پیشنهادی یا مقایسه کیفی بین هر دو روش خوشهای مورد بحث بسیار کوچک است. بنابراین، یک کار آینده، خودکار کردن فرآیند خوشهبندی دو لایه است تا آن را برای مجموعه دادههای کاربر بزرگتر، شبیه به رویکرد مثلثسازی دلونای که در [ 17 ] استفاده میشود، قابل اجرا کند. این همچنین مستلزم تمایز خودکار بین یک خوشه منفرد در مقابل.منطقه خانه پراکنده، که در مطالعه ارائه شده با کاوش دستی دندروگرام ها و نقشه ها با تغییر k در گام خوشه ای k-means انجام شد. برای کار آینده، میتوان رویکردهای خوشهای مکانی-زمانی را به جای خوشهبندی k-means برای شناسایی مناطق نقشهبرداری که از نظر مکانی و زمانی متفاوت هستند، در نظر گرفت و سپس میتواند برای خوشهبندی سلسله مراتبی استفاده شود. علاوه بر این، جابجایی بالقوه یک نقشهبردار و تغییر متناظر منطقه اصلی میتواند در آینده نزدیک با جزئیات بیشتری مورد بررسی قرار گیرد.
برای 13 کاربر تجزیه و تحلیل شده، مقایسه بین نتایج روش خوشهبندی دو لایه پیشنهادی و رویکرد مثلثسازی Delaunay که قبلاً معرفی شده بود، به طور کلی تطابق خوبی بین مناطق خانه شناسایی شده نشان داد. در حالی که روش مثلثسازی تنها از هندسهها به عنوان منبع استفاده میکند، روش خوشهبندی به دلیل اطلاعات اضافی در نظر گرفته شده، مانند نوع ویرایش یا حاشیهنویسیهای مقدار کلید، امکان تحلیل عمیقتر را فراهم میکند. در مواردی که خوشههای خانه k-means بیش از حد درشت هستند، نشان داده شد که یک مقدار k افزایش یافته میتواند به شناسایی منطقه اصلی کمک کند. با این حال، شناسایی مناطق اصلی هنوز هم برای مشارکت کنندگان با منطقه نقشه برداری مجزا که در آن تلاش های نقشه برداری دقیق انجام شده است، مانند در طول تعطیلات یا فعالیت های دیگر، مشکل ساز است. روش دو لایه پیشنهادی برای نقشهبرداران فعال که در آن ویرایشهای متعدد در نواحی مشخص شده فضایی نمایههای ویرایش مجزای مجزا ایجاد میکنند، به خوبی کار میکند. برخلاف این، ویرایشهای بسیار کم یا مقادیر k بسیار بالا به ترتیب میتوانند به طور تصادفی به نمایههای ویرایش مجزا منجر شوند، بنابراین منطقه اصلی اصلی مشارکتکننده را منعکس نمیکنند. با این حال، یک هدف تحقیقاتی باقیمانده برای آینده ارزیابی این است که آیا روش پیشنهادی برای نقشهبرداران کمتر فعال نیز کار میکند یا خیر. بر اساس مثالهای آزمایششده، انتخاب یک مقدار k که منجر به اندازههای k-means خوشهای میشود که تقریباً یک شهر یا برخی مناطق شهر را پوشش میدهد، به نظر میرسد نتایج معنیداری ارائه میدهد، بنابراین از مشکل اعداد بسیار کوچک در خوشهبندی نمایه جلوگیری میکند. همچنین می توان نتایج خوشه ای را از هر دو روش مقایسه کرد، به عنوان مثال، مثلث بندی Delaunay و روش خوشه دو لایه پیشنهادی، برای به دست آوردن اعتماد به نفس در تشخیص منطقه اصلی. هر دو روش به تشخیص خانه از مناطق مشارکتکننده خارجی کمک میکنند، که پایهای را برای تحقیقات آینده ایجاد میکند که بر رابطه متقابل بین رفتار مشارکتکننده و ارزیابی کیفیت تمرکز دارد.
منابع
- Goodchild، MF Citizens به عنوان حسگرهای داوطلبانه: زیرساخت داده های مکانی در دنیای وب 2.0. بین المللی جی. اسپات. زیرساخت داده Res. (IJSDIR) 2007 ، 2 ، 24-32. [ Google Scholar ]
- ژیراردین، اف. بلات، جی. کالابرز، اف. Fiore، FD; راتی، سی. ردپای دیجیتال: کشف گردشگران با محتوای تولید شده توسط کاربر. محاسبات فراگیر 2008 ، 7 ، 36-43. [ Google Scholar ] [ CrossRef ]
- آندرینکو، جی. آندرینکو، ن. باک، پ. کیسیلویچ، اس. کیم، دی. تجزیه و تحلیل دادههای ارجاعشده به فضا و زمان مشارکتشده توسط جامعه (مثالی از عکسهای فلیکر و پانورامیو). در مجموعه مقالات سمپوزیوم IEEE در علم و فناوری تجزیه و تحلیل بصری، آتلانتیک سیتی، نیوجرسی، ایالات متحده، 12 تا 13 اکتبر 2009. صص 213-214.
- چن، ال. روی، A. تشخیص رویداد از داده های فلیکر از طریق تجزیه و تحلیل فضایی مبتنی بر موجک. در مجموعه مقالات هجدهمین کنفرانس ACM در مدیریت اطلاعات و دانش، هنگ کنگ، چین، 2 تا 6 نوامبر 2009. ACM: نیویورک، نیویورک، ایالات متحده آمریکا؛ صص 523-532.
- شلیدر، سی. ماتیاس، سی. عکاسی از یک شهر: تحلیلی از مفاهیم مکان بر اساس انتخاب های فضایی. تف کردن شناخت. محاسبه کنید. 2009 ، 9 ، 212-228. [ Google Scholar ]
- هولنشتاین، ال. Purves، RS کاوش مکان از طریق محتوای تولید شده توسط کاربر: استفاده از flickr برای توصیف هسته های شهر. جی. اسپات. Inf. علمی 2010 ، 1 ، 21-48. [ Google Scholar ]
- آندرینکو، جی. آندرینکو، ن. بوش، اچ. ارتل، تی. فوکس، جی. یانکوفسکی، پ. تام، دی. الگوهای موضوعی در توییتهای جغرافیایی ارجاعشده از طریق تحلیل بصری فضا-زمان. محاسبه کنید. علمی مهندس 2013 ، 15 ، 72-82. [ Google Scholar ] [ CrossRef ]
- کروم، جی. کاروانا، آر. شمارش، S. یادگیری مکان های احتمالی. در مدل سازی کاربر، سازگاری و شخصی سازی ؛ Carberry, S., Weibelzahl, S., Micarelli, A., Semeraro, G., Eds. Springer: برلین، آلمان؛ صص 64-76.
- لی، ی. شان، جی. درک الگوی مکانی-زمانی توییت ها. فتوگرام مهندس Remote Sens. 2013 ، 79 ، 769-773. [ Google Scholar ] [ CrossRef ]
- کالینز، سی. حسن، س. Ukkusuri، SV یک معیار جدید رضایت سواره حمل و نقل: احساسات سوار که از داده های رسانه های اجتماعی آنلاین اندازه گیری می شود. J. Public Transp. 2013 ، 16 ، 21-45. [ Google Scholar ]
- میچل، ال. فرانک، ام آر. هریس، KD; Dodds، PS; دانفورث، سی ام. PLoS One 2013 ، 8 ، e64417. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- نولاس، ا. اسکلاتو، اس. ماسکولو، سی. پونتیل، ام. مطالعه تجربی الگوهای فعالیت کاربر جغرافیایی در چهار مربع. در مجموعه مقالات پنجمین کنفرانس بین المللی AAAI در وبلاگ ها و رسانه های اجتماعی، منلو پارک، کالیفرنیا، ایالات متحده آمریکا، 19 تا 21 ژوئیه 2011; Adamic, L., Baeza-Yates, R., Counts, S., Eds.; مطبوعات AAAI: پالو آلتو، کالیفرنیا، ایالات متحده؛ صص 570-573.
- مونی، پی. Corcoran, P. خصوصیات اشیاء به شدت ویرایش شده در OpenStreetMap. اینترنت آینده 2012 ، 4 ، 285-305. [ Google Scholar ] [ CrossRef ]
- ارسنجانی، ج. بارون، سی. باکیالله، م. Helbich، M. ارزیابی کیفیت مشارکت کنندگان OpenStreetMap همراه با مشارکت آنها. در مجموعه مقالات AGILE 2013، لوون، بلژیک، 5 تا 9 اوت 2013.
- هاکلی، م. بسیوکا، اس. آنتونیو، وی. Ather، A. برای نقشه برداری خوب یک منطقه به چند داوطلب نیاز است؟ اعتبار قانون لینوس برای اطلاعات جغرافیایی داوطلبانه کارتوگر. J. 2010 , 47 , 315-322. [ Google Scholar ] [ CrossRef ]
- نیس، پ. زیلسترا، دی. Zipf، A. مقایسه مشارکت داوطلبانه اطلاعات جغرافیایی و توسعه جامعه برای مناطق منتخب جهان. اینترنت آینده 2013 ، 5 ، 282-300. [ Google Scholar ] [ CrossRef ]
- نیس، پ. Zipf، A. تجزیه و تحلیل فعالیت مشارکت کننده یک پروژه داوطلبانه اطلاعات جغرافیایی – مورد OpenStreetMap. ISPRS Int. جی. ژئو. Inf. 2012 ، 1 ، 146-165. [ Google Scholar ] [ CrossRef ]
- هیپک، سی. دادههای جغرافیایی جمعسپاری. ISPRS J. Photogramm. Remote Sens. 2010 , 65 , 550-557. [ Google Scholar ] [ CrossRef ]
- مونی، پی. Corcoran، P. تجزیه و تحلیل الگوهای تعامل و ویرایش مشترک در میان مشارکت کنندگان OpenStreetMap. ترانس. GIS 2013 ، 18 ، 633-659. [ Google Scholar ] [ CrossRef ]
- گروچنیگ، اس. بروناور، آر. رهرل، ک. برآورد کامل بودن مجموعه داده های VGI با تجزیه و تحلیل فعالیت جامعه در طول دوره های زمانی. در اتصال اروپای دیجیتال از طریق مکان و مکان ؛ Huerta, J., Schade, S., Granell, C., Eds. Springer: برلین، آلمان، 2014; صص 3-18. [ Google Scholar ]
- ررل، ک. گروچنیگ، اس. Hochmair، HH; لاتینگر، اس. استاینمن، آر. واگنر، الف. یک مدل مفهومی برای تحلیل الگوهای مشارکت در زمینه VGI. در حال پیشرفت در خدمات مبتنی بر مکان ; Krisp، JM، Ed. Springer: برلین، آلمان، 2013; صص 373-388. [ Google Scholar ]
- Gröchenig، S. استفاده از الگوهای ویرایش مکانی و زمانی برای ارزیابی داده های نقشه خیابان باز. پایان نامه کارشناسی ارشد، دانشگاه علوم کاربردی کارینتیا، ویلاخ، کارینتیا، اتریش، 2012. [ Google Scholar ]
- استاینمن، آر. بروناور، آر. گروچنیگ، اس. Rehrl، K. Wie aktiv sind freiwillige Mapper؟ Ein Vergleich der OpenStreetMap-Aktivitäten in den Jahren 2005–2012 در Beispiel der DACH-Region. در Angewandte Geoinformatik ; Strobl, J., Blaschke, T., Griesebner, G., Zagel, B., Eds. Wichmann: برلین، آلمان، 2013; صص 173-182. [ Google Scholar ]
- استاینمن، آر. گروچنیگ، اس. ررل، ک. Brunauer, R. نمایه های مشارکت نقشه برداران داوطلب در OpenStreetMap. در کارگاه آموزشی مجموعه مقالات اقدام و تعامل در اطلاعات جغرافیایی داوطلبانه (ACTIVITY) در AGILE 2013، لوون، بلژیک، 14 مه 2013.
- Haklay, M. اطلاعات جغرافیایی داوطلبانه چقدر خوب است؟ مطالعه تطبیقی مجموعه دادههای OpenStreetMap و Ordnance Survey. محیط زیست طرح. B طرح. دس 2010 ، 37 ، 682-703. [ Google Scholar ]
- زیلسترا، دی. Zipf، A. OpenStreetMap تحقیق کیفیت داده در آلمان. در مجموعه مقالات ششمین کنفرانس بین المللی علم اطلاعات جغرافیایی (GIScience)، زوریخ، سوئیس، 14 تا 17 سپتامبر 2010.
- نیس، پ. زیلسترا، دی. Zipf، A. تکامل شبکه خیابانی نقشههای crowdsourced: OpenStreetMap در آلمان 2007-2011. اینترنت آینده 2012 ، 4 ، 1-21. [ Google Scholar ]
- زیلسترا، دی. Hochmair، HH استفاده از دادههای رایگان و اختصاصی برای مقایسه طولهای کوتاهترین مسیر برای مسیریابی مؤثر عابر پیاده در شبکههای خیابانی. ترانسپ Res. رکورد 2012 ، 2299 ، 41-47. [ Google Scholar ] [ CrossRef ]
- زیلسترا، دی. Hochmair، HH مطالعه مقایسه ای دسترسی عابر پیاده به ایستگاه های حمل و نقل با استفاده از داده های شبکه رایگان و اختصاصی. ترانسپ Res. رکورد 2011 ، 2217 ، 145-152. [ Google Scholar ] [ CrossRef ]
- Hochmair، HH; زیلسترا، دی. Neis، P. ارزیابی کامل بودن مسیر دوچرخه و ویژگی های خط تعیین شده در OpenStreetMap برای ایالات متحده. ترانس. GIS 2014 ، در دست چاپ. [ Google Scholar ]
- Zook، MA; گراهام، ام. شلتون، تی. Gorman, S. داوطلبانه اطلاعات جغرافیایی و جمع سپاری امداد رسانی به بلایا: مطالعه موردی زلزله هائیتی. پزشکی جهانی سیاست سلامت 2010 ، 2 ، 7-33. [ Google Scholar ] [ CrossRef ]
- پارکر، سی جی; می، ای جی. میچل، وی. نقش VGI و PGI در حمایت از فعالیت های فضای باز. Appl. ارگون. 2012 ، 44 ، 886-894. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- پارکر، سی جی; می، ای جی. میچل، وی. طراحی کاربر محور نئوجغرافی: تأثیر اطلاعات جغرافیایی داوطلبانه بر اعتماد نقشه های آنلاین “ماشاپ”. ارگونومی 2014 ، 57 ، 987-997. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- پارکر، سی جی; می، ای جی. میچل، وی. درک طراحی با VGI با استفاده از چارچوب ارتباط اطلاعات. ترانس. GIS 2012 ، 16 ، 545-560. [ Google Scholar ] [ CrossRef ]
- گیرس، جی اف. Touya, G. ارزیابی کیفیت مجموعه داده OpenStreetMap فرانسه. ترانس. GIS 2010 ، 14 ، 435-459. [ Google Scholar ] [ CrossRef ]
- مونی، پی. Corcoran, P. فرآیند حاشیه نویسی در OpenStreetMap. ترانس. GIS 2012 ، 16 ، 561-579. [ Google Scholar ] [ CrossRef ]
- کسلر، سی. de Groot، R. Trust به عنوان یک معیار پراکسی برای کیفیت اطلاعات جغرافیایی داوطلبانه در مورد OpenStreetMap. در علم اطلاعات جغرافیایی در قلب اروپا ; Vandenbroucke, D., Bucher, B., Crompvoets, J., Eds. Springer: هایدلبرگ، آلمان، 2013; ص 21-37. [ Google Scholar ]
- کسلر، سی. ترام، جی. Kauppinen، T. منشأ و اعتماد به اطلاعات جغرافیایی داوطلبانه: مورد OpenStreetMap. در مجموعه مقالات کنفرانس تئوری اطلاعات فضایی: COSIT’11، بلفاست، ME، ایالات متحده آمریکا، 12-16 سپتامبر 2011; صص 1-3.
- زیلسترا، دی. Hochmair، HH; Neis، P. ارزیابی تأثیر واردات داده بر کامل بودن نقشه خیابان باز – مطالعه موردی ایالات متحده. ترانس. GIS 2013 ، 17 ، 315-334. [ Google Scholar ] [ CrossRef ]
- Hochmair، HH; Zielstra، D. توسعه و کامل بودن نقاط مورد علاقه در مجموعه داده های رایگان و اختصاصی: مطالعه موردی فلوریدا. در مجموعه مقالات GI_Forum 2013، ایجاد GISociety، سالزبورگ، اتریش، 2 تا 5 ژوئیه 2013. Jekel, T., Car, A., Strobl, J., Griesebner, G., Eds. Wichmann: برلین، آلمان؛ صص 39-48.
- پرکینز، سی. Dodge, M. پتانسیل نقشه برداری توسط کاربر: مطالعه موردی پروژه OpenStreetMap و حزب نقشه برداری Mapchester. جئوگر شمال غرب 2008 ، 8 ، 19-32. [ Google Scholar ]
- باچر، جی. ونزیگ، ک. ووگلر، ام. خوشه دو استپ: یک ارزیابی اول. 2004. در دسترس آنلاین: http://www.opus.ub.uni-erlangen.de/opus/volltexte/2004/81/pdf/a_04-02.pdf (در 16 اوت 2014 قابل دسترسی است).
- ابوبکر، م. آشور، دبلیو. الگوریتمهای خوشهبندی دادههای کارآمد: پیشرفتها نسبت به Kmeans. بین المللی جی. اینتل. سیستم Appl. 2013 ، 5 ، 37-49. [ Google Scholar ]
- تیم OpenStreetMap بشردوستانه [HOT]. در دسترس آنلاین: http://hot.openstreetmap.org/projects (در 16 اوت 2014 قابل دسترسی است).
- OpenStreetMap عملیات کابوی. در دسترس آنلاین: http://wiki.openstreetmap.org/wiki/Operation_Cowboy (در 16 اوت 2014 قابل دسترسی است).
© 2014 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر