1. معرفی
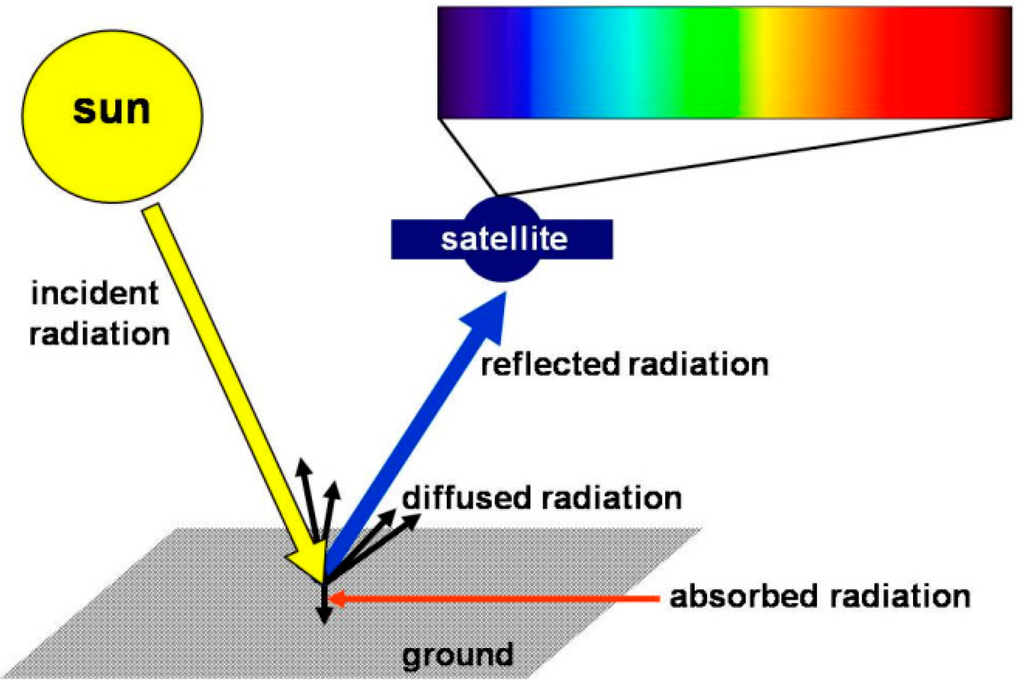
مفهوم جهانی شدن، یکپارچگی تکنولوژیکی جهان است که منجر به جامعه اطلاعاتی جهانی می شود. چنین فرآیندهایی مستلزم چندین مرحله مانند طراحی و توسعه زیرساختهای سازمانیافته قادر به حل مشکلات جهانی و منطقهای است .]. برای این کار نیاز به اطلاعات و ارجاع جغرافیایی دانش جهان است. این وظیفه پروژه “زمین دیجیتال” است. در این چارچوب، فناوریهای سنجش از راه دور و رصد زمین کمک قابل توجهی به پیشرفت زمین دیجیتال میکنند. از جمله وظایف و اهداف مختلف علوم سنجش از دور، پایش خصوصیات، فرسودگی و کاربری خاک (مثلاً کشت یا شهرنشینی) است. تخریب خاک و بیابان زایی پدیده ای است که بسیاری از کشورها به ویژه کشورهای دارای مناطق خشک و نیمه خشک را تحت تاثیر قرار می دهد. فرآیندهای تخریب رایج شامل تنش آبی، شوری خاک، آتش سوزی جنگل ها، چرای بیش از حد و فرسایش آبی و غیره است.چنین فرآیندهایی اغلب با استفاده از رویکردهای مبتنی بر شاخص های مختلف بیوفیزیکی و اجتماعی-اقتصادی پایش می شوند. ارزیابی چنین شاخص هایی اخیرا گزارش شده است [ 2 ]. روشهای دیگر بر اساس تخمین کسر پوشش گیاهی و/یا کلاس خاک با سنجش از دور با استفاده از دادههای تصاویر ماهوارهای (معمولاً طیف بازتابی) است. طرح روش اکتساب داده های بازتابی با استفاده از یک ماهواره در شکل 1 آورده شده است.
شکل 1. طرح اصل سنجش از دور. کسری از نور خورشید منعکس شده یا پراکنده شده توسط خاک در طول موج های انتخاب شده توسط ماهواره تشخیص داده می شود.
تخمین سنجش از دور طبقه خاک و کاربری/پوشش زمین یک فرآیند پیچیده است که شامل چندین مرحله است. ابتدا تصویر منطقه مورد مطالعه توسط ماهواره ثبت می شود. کیفیت تصویر ماهواره ای با پارامترهایی مانند تفکیک مکانی، طیفی، رادیومتری و زمانی مشخص می شود. وضوح فضایی مربوط به ابعاد پیکسل ها در یک تصویر شطرنجی است. پیکسل معمولاً مربوط به منطقه ای با ابعاد بین 1 تا 1000 متر است. وضوح طیفی به عرض طول موج باندهای فرکانسی شناسایی شده اشاره دارد. وضوح رادیومتریک توانایی یک سیستم تصویربرداری را در تشخیص تفاوت های جزئی در انرژی تشعشع شناسایی شده نشان می دهد. وضوح زمانی از فرکانس پرواز توسط ماهواره جمع آوری می شود.
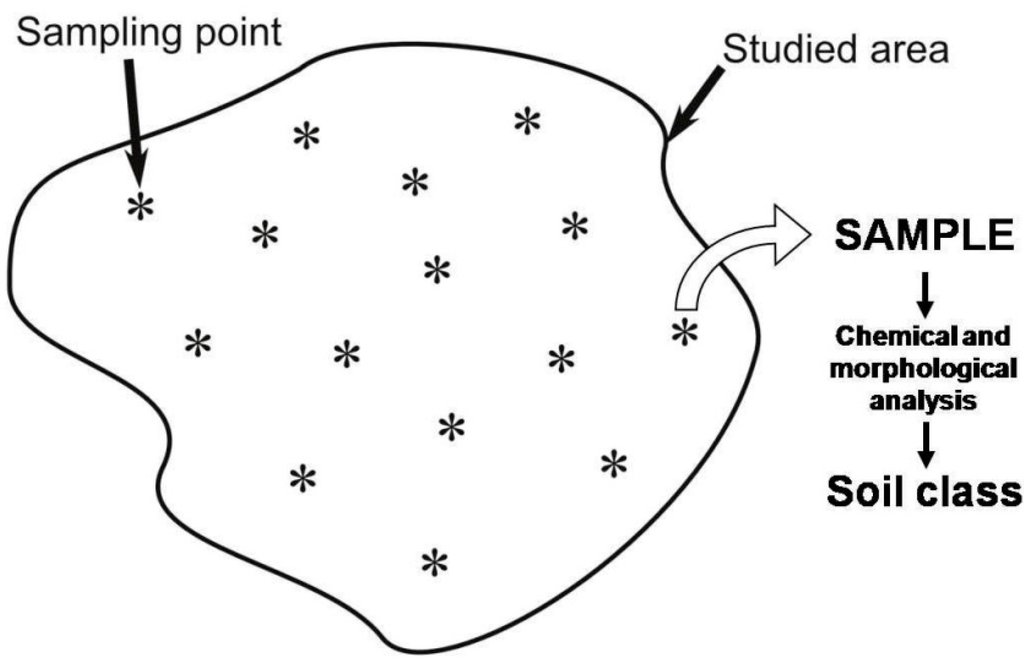
در منطقه مورد مطالعه، m نقاط نمونه برداری به صورت تصادفی یا با استفاده از یک شبکه انتخاب می شوند. سپس نمونه های خاک از نقاط نمونه برداری جمع آوری شده و بر اساس نتایج آنالیزهای شیمیایی و مورفولوژیکی طبقه بندی می شوند ( شکل 2 ).
شکل 2. نمونه ای از توزیع تصادفی 15 نقطه نمونه برداری در منطقه مورد مطالعه. از هر نقطه نمونه برداری، یک نمونه خاک جمع آوری می شود. کلاس نمونه های خاک جمع آوری شده با استفاده از تجزیه و تحلیل شیمیایی و مورفولوژیکی تعیین می شود.
جدول طیف بازتاب نمونههای خاک جمعآوریشده و کلاس مربوط به آنها «پایگاه داده» را تشکیل میدهد. طیف بازتاب یک نمونه خاک بیشتر به ترکیب شیمیایی خاک بستگی دارد. بنابراین انتظار میرود که طیف بازتابی خاکهای متعلق به طبقات مختلف متفاوت باشد. متأسفانه، قانون ریاضی بیانگر رابطه بین طیف بازتاب و ترکیب شیمیایی خاک شناخته شده نیست. با این حال، دادههای پایگاه داده حاوی اطلاعاتی هستند که میتوان از آنها برای ساخت یک مدل تجربی از رابطه طیف-خاک استفاده کرد. فرآیندی که منجر به دستیابی به چنین رابطه تجربی می شود « مدل سازی » نامیده می شود“. این مدل امکان پیشبینی کلاس خاک را با استفاده از دادههای بازتابی برای پیکسلهای دلخواه تصویر ماهوارهای در مکانهایی که هیچ نمونهبرداری و آنالیز شیمیایی انجام نشده است، میدهد. به این ترتیب نقشه ای نشان دهنده توزیع طبقات مختلف خاک در منطقه مورد مطالعه به دست می آید.
روش های ریاضی مختلفی برای مدل سازی موجود است. انتخاب روش به پیچیدگی داده هایی که باید مدل سازی شوند بستگی دارد. روشهای غیر خطی انعطافپذیری لازم برای مدلسازی ساختارهای داده پیچیده را ارائه میکنند. روشهای مبتنی بر شبکههای عصبی مصنوعی از قویترین و گستردهترین روشها هستند [ 3 ، 4 ]. کاربرد شبکههای عصبی مصنوعی در علم و فناوری در شاخههای مختلف شیمی، فیزیک، زیستشناسی، علوم اجتماعی و اقتصاد بسیار گسترده است و اهداف طبقهبندی، مدلسازی، تشخیص الگو و غیره را پوشش میدهد. برای مثال، شبکههای عصبی مصنوعی در سینتیک شیمیایی استفاده میشوند [ 5 ]. ]، پیش بینی رفتار راکتورهای صنعتی [ 6 ]، مدل سازی سینتیک انتشار دارو [6]7 ، پیشبینی ترکیب بهینه مخلوطهای چند دارویی [ 8 ]، بهینهسازی روشهای الکتروفورتیک [ 9 ]، طبقهبندی محصولات کشاورزی مانند انواع پیاز [ 10 ] و حتی تعیین گونههای حشرات [ 11 ، 12 ]. کاربرد ANN در تشخیص پزشکی اخیراً مورد بررسی قرار گرفته است [ 13 ]. به طور کلی، دادههای بسیار متنوعی مانند طبقهبندی اشیاء بیولوژیکی، دادههای جنبشی شیمیایی یا حتی پارامترهای بالینی را میتوان اساساً به روشی مشابه مدیریت کرد. نمونه های منتخب از کاربردهای ANN در سنجش از دور عبارتند از: پایش کیفیت آب [ 14 ]، تخمین تبخیر و تعرق [ 15 ]]، اشتقاق محصولات رنگی اقیانوس [ 16 ]، نقشه برداری کسری پوشش برف [ 17 ]، پیش بینی مواد آلی خاک [ 18 ]، ارزیابی فضایی دمای هوا [ 19 ]، نقشه برداری شیوه های خاکورزی متضاد [ 20 ]، طبقه بندی بافت خاک [20] 21 ] پیشبینی مکانهای فسیلی مولد [ 22 ]، نگاشت زیر پیکسل و شارپ کردن پیکسلهای فرعی [ 23 ]، و غیره .
هدف این کار ارائه فلسفه کلی و مراحل روششناختی اساسی است که باید دنبال شود، یعنی در ارزیابی دادههای طیفی ماهوارهای با استفاده از شبکههای عصبی مصنوعی برای اهداف طبقهبندی خاک. به طور خاص، اهمیت استفاده از اکتشاف داده های اولیه (غربالگری داده ها) توسط تجزیه و تحلیل مقادیر ویژه (EA) و تجزیه و تحلیل اجزای اصلی (PCA) تاکید شده است. روش پیشنهادی برای ارزیابی داده های ماهواره ای مربوط به منطقه الفیوم در مصر نمونه است و نتایج هر مرحله در مورد آن توضیح داده می شود.
2. منطقه مطالعه
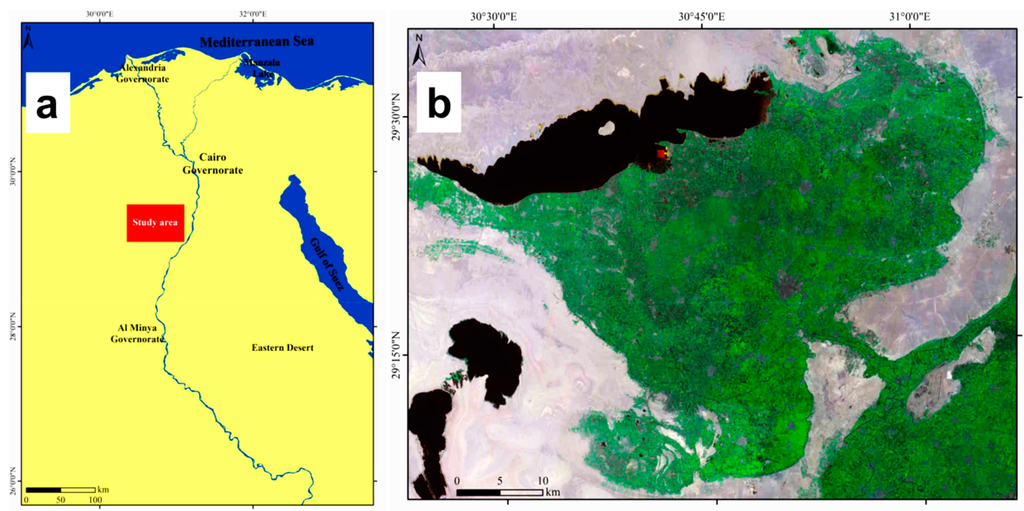
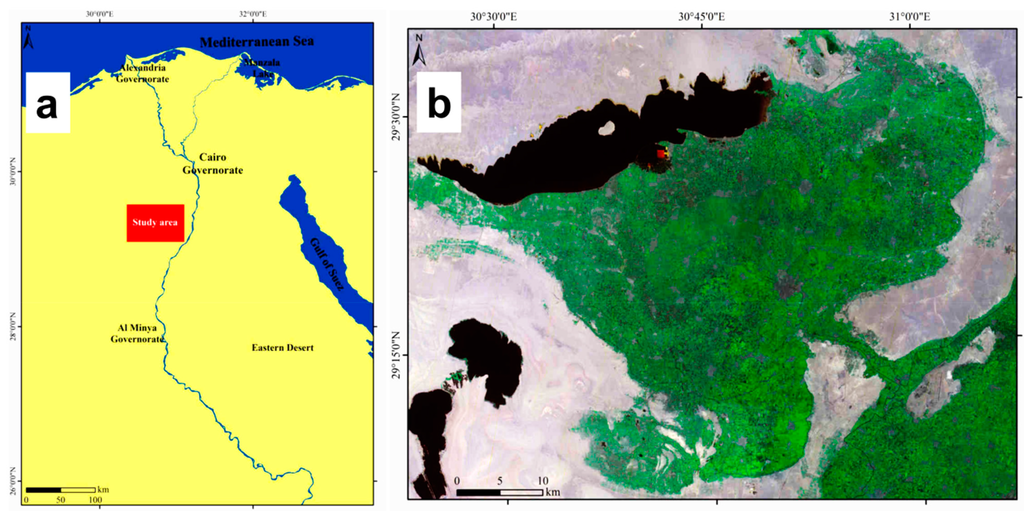
فرورفتگی الفیوم یک استان واقع در 90 کیلومتری جنوب غربی قاهره است ( شکل 3 ) و با شرایط آب و هوایی معتدل مشخص می شود. مساحت کل فرورفتگی 6068.70 کیلومتر مربع است . کاربری زمین در این منطقه تنها 1849.64 کیلومتر مربع ( یعنی 30.48 درصد از کل مساحت) را شامل می شود. زمین کشاورزی در فرورفتگی 1609.34 کیلومتر مربع است . الفیوم توسط منطقه هوارا به دره نیل متصل می شود، جایی که کانالی به نام بحر یوسف آب نیل را منتقل می کند. این افسردگی به دلیل تاریخ طولانی خود متمایز است که به میلیون ها سال قبل می رسد و در دوران ظهور مصر باستان، یونان، روم، قبطی و اسلامی اهمیت دارد. این تنها استان مصر است که در آن دریاچه نمک (یعنی دریاچه قارون)، پوشش گیاهی و کویر با ویژگی های متنوع و ترکیب منحصر به فرد خود وجود دارد. داده های اقلیمی منطقه الفیوم نشان می دهد که کل بارندگی از 7.2 میلی متر در سال تجاوز نمی کند و میانگین حداقل و حداکثر دمای سالانه به ترتیب 14.5 و 31.0 درجه سانتی گراد است. نرخ تبخیر همزمان با دما است، جایی که کمترین میزان تبخیر (1.9 میلی متر در روز) در ژانویه و بالاترین (7.3 میلی متر در روز) در ژوئن ثبت شد [ 24 ]. با توجه به کلاس های شاخص خشکی [ 25 ]، فرورفتگی به عنوان قلمرو تحت شرایط آب و هوایی خشک طبقه بندی می شود.
افسردگی ماهیت خاصی دارد و با مصر علیا و مناطق دلتا و واحه نیز متفاوت است. تفاوت ها به کشاورزی محدود نمی شود. آنها به ویژگی های جغرافیایی و توپوگرافی گسترش می یابند، زیرا محیط بین مناطق کشاورزی، بیابانی و ساحلی متفاوت است. فرورفتگی الفیوم در نتیجه فرونشست حوضه، نسبت به رودخانه نیل شکل گرفته است که به آن اجازه می دهد از آن عبور کند و منطقه را سیل کند. این منجر به تشکیل یک آبرفت ضخیم حاصلخیز شد [ 26 ]. لندفرم های اصلی شناسایی شده در فرورفتگی الفیوم عبارتند از بادبزن ها، تراس های دریاچه اخیر و قدیمی، فرورفتگی ها، دشت ها و حوضه ها [ 27 ].]. با رژیم فعلی جاری شدن سیلاب و بالا آمدن سطح آب در دریاچه قارون، زمین های زراعی اطراف در خطر شور شدن و قطع شدن آب قرار خواهند گرفت.
شکل 3. نقشه موقعیت ( الف ) فرورفتگی الفیوم و ( ب ) تصویر ماهواره ای (Landsat ETM 2011).
3. داده های ماهواره ای
در این مطالعه، مقادیر عدد دیجیتال ماهواره ای (DN) پیکسل های نشان دهنده محل های نمونه برداری خاک از باندهای طیفی مختلف که شامل هفت تصویر LANDSAT (باندهای 1-5، 7) و سه تصویر SPOT (باندهای 1، 2 و 3) استفاده شد. ). طول موج و وضوح فضایی باندهای طیفی مختلف در جدول 1 نشان داده شده است.
جدول 1. طول موج و وضوح فضایی باندهای طیفی ماهواره ای استفاده شده.
4. نرم افزار و محاسبات
تمام محاسبات بر روی یک کامپیوتر x86 استاندارد که مایکروسافت Windows XP Home Edition را به عنوان سیستم عامل اجرا می کند، انجام شد. پردازش و تجزیه و تحلیل داده های آماری با استفاده از STATISTICA 10 (StatSoft. Inc. 1984-2011، Tulsa، USA) انجام شد. محاسبات ANN با استفاده از شبیه ساز شبکه عصبی Trajan، Release 3.0 D (Trajan Software Ltd. 1996-1998, Durham, UK) انجام شد.
5. تجزیه و تحلیل داده های اولیه
همانطور که در مقدمه ذکر شد، پایگاه داده برای ساخت یک مدل تجربی استفاده می شود که توسط آن می توان کلاس خاک را به درستی از روی داده های بازتاب پیش بینی کرد. این تنها در صورتی قابل دستیابی است که داده های پایگاه داده حاوی اطلاعاتی باشد که قادر به تشخیص نمونه های متعلق به کلاس های مختلف خاک باشد. تجزیه و تحلیل داده های اولیه توسط EA به محققان اجازه می دهد تا تعداد طبقات خاک قابل تشخیص را تخمین بزنند در حالی که PCA فشرده سازی و تجسم داده ها را امکان پذیر می کند.
5.1. سازماندهی داده های تجربی
برای هر یک از m نمونه خاک جمع آوری شده در منطقه مورد مطالعه، مقدار شدت بازتاب در n طول موج توسط ماهواره ثبت می شود. داده ها در یک ماتریس X با ابعاد m × n سازماندهی شده اند . بنابراین، عناصر ردیف i- امین ماتریس X نشان دهنده طیف بازتابی I- امین نمونه خاک است. بحث بیشتر مربوط به تجزیه و تحلیل داده ها در ماتریس X است.
5.2. پیش پردازش داده ها
پیش پردازش داده ها در ماتریس X شامل موارد زیر است: ( i ) بازرسی داده ها برای جستجوی مقادیر از دست رفته و ( ii ) تبدیل ریاضی داده ها. روشهای مختلفی مانند هموارسازی دادهها [ 28 ] یا الگوریتمهای تکراری [ 29 ، 30 ] برای جایگزینی مقادیر گمشده با برآوردهای مناسب در دسترس هستند. تبدیل داده های رایج شامل مرکزیت ستون یا استانداردسازی یا عادی سازی است [ 31 ، 32 ]. در این کار، دادهها به صورت خودکار مقیاسبندی شدند (به عنوان مثال ، در محور میانگین ستون و با انحراف استاندارد ستون مقیاسبندی شدند).
5.3. تجزیه و تحلیل مقادیر ویژه
اجازه دهید ماتریس X را با m ردیف و n ستون حاوی داده های بدون خطا در نظر بگیریم. ماتریس استاندارد شده ستون Z به صورت زیر محاسبه می شود:
که در آن 1 متر بردار طول m با تمام عناصر برابر با یک است، ایکس¯¯¯تیn�¯�Tانتقال بردار است ایکس¯¯¯n�¯�کدام عناصر مقادیر میانگین ستون X و اس– 1n��−1ماتریس مورب با ابعاد n × n است که در آن عناصر مورب اصلی برابر با انحراف استاندارد ستون داده ها در ماتریس X است. ماتریس Z برای محاسبه ماتریس واریانس کوواریانس D به صورت زیر استفاده می شود:
ماتریس D متقارن و با ابعاد m×m است. جبر خطی تضمین می کند که ماتریس واریانس-کوواریانس نیز نیمه معین مثبت است و این نشان می دهد که تمام مقادیر ویژه آن غیر منفی هستند. اولین گام در تجزیه و تحلیل ماتریس D ، محاسبه مقادیر ویژه آن λi است ( i = 1,…, m ) . این را می توان با استفاده از رویکردهای مختلف [ 32 ] انجام داد. در مورب اصلی ماتریس D ، واریانس ستون ماتریس اصلی Z قرار دارد. بنابراین، ردیابی D برابر است با کل واریانس ستون Z :
یک ویژگی ماتریس واریانس کوواریانس و مقادیر ویژه آن این است که:
و با در نظر گرفتن رابطه (3):
بنابراین، درصد کل واریانس “توضیح داده شده” با مقدار ویژه i به صورت زیر بیان می شود:
به تعداد مقادیر ویژه غیر صفر یک ماتریس “رتبه” r می گویند . به طور کلی، در نظر گرفتن ماتریسی با ابعاد m × n :
برای ماتریس D ، مقادیر ویژه غیر صفر فقط r اول هستند ، در حالی که بقیه مقادیر همگی برابر با صفر هستند. رتبه D برابر است با رتبه ماتریس X.
تعداد مقادیر ویژه غیر صفر (یا رتبه) به عنوان تعداد “عوامل” مسئول واریانس در داده ها تفسیر می شود. در مورد داده های بازتاب خاک، رتبه r ماتریس داده X را می توان به عنوان تعداد طبقات خاک “قابل تشخیص” تفسیر کرد.
تا به حال، ماتریس X با داده های بدون خطا در نظر گرفته شده است. با این حال، هر کمیت اندازه گیری شده (مانند مقادیر بازتاب) در معرض خطاهای اندازه گیری است. نتیجه این است که خطاها به واریانس کلی در داده ها کمک می کنند (σ2 ) . بنابراین، همه مقادیر ویژه ماتریس D غیر صفر هستند و رتبه “ظاهری” آن برابر با m است. مقادیر ویژه mr نشان دهنده واریانس ناشی از خطاهای اندازه گیری است. هدف از تجزیه و تحلیل مقادیر ویژه تخمین رتبه واقعی r ماتریس D است. چندین معیار برای این منظور در دسترس است [ 32 ، 33]. یک روش ساده برای تخمین رتبه واقعی ماتریس D که در این کار توصیه می شود، استفاده از به اصطلاح scree-plot [ 31 ] است. اول از همه، n مقدار ویژه λ i ماتریس D محاسبه و بر اساس بزرگی آنها مرتب می شوند. نمودار صفحه با ترسیم بزرگی مقادیر ویژه λ i در برابر مقدار متناظر i به دست می آید . همانطور که مقدار i افزایش می یابد، واریانس توضیح داده شده توسط مقدار ویژه i متناظر کاهش می یابد. به دنبال آن، مماس بر دو شاخه پلات اسکریپ رسم شده و مقدار rبه عنوان عدد صحیح نزدیکترین عدد به مختصات نقطه تقاطع در محور x یافت میشود ( بخش 7 « نمونهها »). دانش مقدار r برای کاربرد بعدی تکنیکهای مدلسازی (مانند ANN) اهمیت اساسی دارد.
5.4. تجزیه و تحلیل اجزای اصلی
PCA یک تکنیک تحلیل اکتشافی و کاهش ابعاد داده های چند متغیره است. بردارهای ویژه و مقادیر ویژه مربوط به X با فاکتورسازی ماتریسی به دست می آیند.
یک بردار ویژه با هر مقدار ویژه مرتبط است که با درصد کل واریانس توضیح داده شده توسط آن مقدار ویژه مرتبط است. بردارهای ویژه “مولفه های اصلی” (PC) نامیده می شوند و جهت های متعامد متعامد حداکثر واریانس در داده ها را نشان می دهند. بنابراین، بردارهای ویژه یک سیستم مختصات جدید (فضای عامل اصلی) را تعریف می کنند که در آن هم متغیرها و هم نمونه ها می توانند نمایش داده شوند. با استفاده از اسکری پلات یا روش مناسب دیگر [ 32 ]، رتبه r ماتریس D برآورد می شود. سپس، دادهها را میتوان در یک فضای عاملی با ابعاد r کاهش یافته نشان داد.
به طور کلی، ماتریس داده X را می توان با چندین روش به مقادیر ویژه و بردارهای ویژه تجزیه کرد. در این میان، تجزیه ارزش منفرد (SVD) یکی از قویتر و دقیقتر است. SVD منجر به فاکتورسازی ماتریس X به صورت زیر می شود:
که در آن U ماتریس امتیازهای هنجار است، W ماتریس مورب مقادیر ویژه ریشه مربع، و V ماتریس بارگذاری ها است [ 31 ، 32 ].
ماتریس E = W 2 ماتریس مورب مقادیر ویژه است. ردیابی E نشان دهنده واریانس کل در داده ها است. اهمیت k- امین مولفه اصلی به عنوان درصد واریانس توضیح داده شده (% var k ) با استفاده از k- امین مقدار ویژه (λk ) بیان می شود :
عناصر ستون k- امین ماتریس VT مختصات متغیرها (باندهای طیفی ماهواره) را روی k- امین مؤلفه اصلی ( بارگذاری ) نشان می دهند. به طور مشابه، عناصر j- امین ستون ماتریس U مختصات نمونه های خاک را بر روی j- امین مولفه اصلی ( نمرات ) نشان می دهد. با رسم ستونهای U ، توزیع متغیرها در فضای عامل اصلی کاهشیافته r بعدی به تصویر کشیده میشود ( نقشه بارگذاری). به همین ترتیب، توزیع نمونه ها در فضای ضریب کاهش یافته با رسم ستون های ماتریس VT ( نمرات نمودار ) به دست می آید . از چنین نموداری، خوشه هایی از نمونه های “مشابه” را می توان مشاهده کرد.
6. شبکه های عصبی مصنوعی
ANN ها ابزارهای ریاضی هستند که ساختار و عملکرد مغز انسان را تقلید می کنند. آنها قادر به انجام وظایف « یادگیری »، « تعمیم » و « پیشبینی » هستند. به همین دلیل، شبکههای عصبی مصنوعی به اصطلاح روشهای هوش مصنوعی (AI) تعلق دارند. شبکه از یک سری « نمونهها » که « پایگاه آموزشی » را تشکیل میدهند، « یاد میگیرد ». یک ” مثال ” توسط یک بردار داده می شود ایکسمن ، ص= (ایکسمن 1، ایکسمن 2, … , ایکسمن ص)ایکسمن،پ=(ایکسمن1، ایکسمن2، …، ایکسمنپ)از ورودی ها و یک بردار Yمن ، q= (yمن 1، yمن 2, … , yمن ق)�من،�=(�من1، �من2، …، �من�)از خروجی ها در مورد طبقهبندی خاک از دادههای ماهوارهای، بردارهای Xi و Yi به ترتیب شامل شدت بازتاب و کلاس i- امین نمونه هستند. هدف از ” یادگیری ” مدل سازی رابطه مجهول f بین بردارهای Xi ,p و Y i,q است (معادله (10)) :
به دلیل ماهیت غیر خطی ذاتی خود، شبکه های عصبی مصنوعی قادر به مدل سازی روابط پیچیده بین داده ها هستند. با این حال، PCA برای تجسم ساختار زیربنایی داده ها و به دست آوردن ایده ای از نتایج احتمالی ANN، اساسی است. علاوه بر استفاده گسترده از شبکههای عصبی چندلایه پیشخور، چندین شبکه دیگر از جمله شبکههای بیزی، تصادفی، بازگشتی یا فازی در دسترس هستند. مروری بر طبقات مختلف شبکه های عصبی را می توان در جاهای دیگر یافت [ 34 ، 35 ].
6.1. پیشینه ریاضی شبکه های عصبی مصنوعی
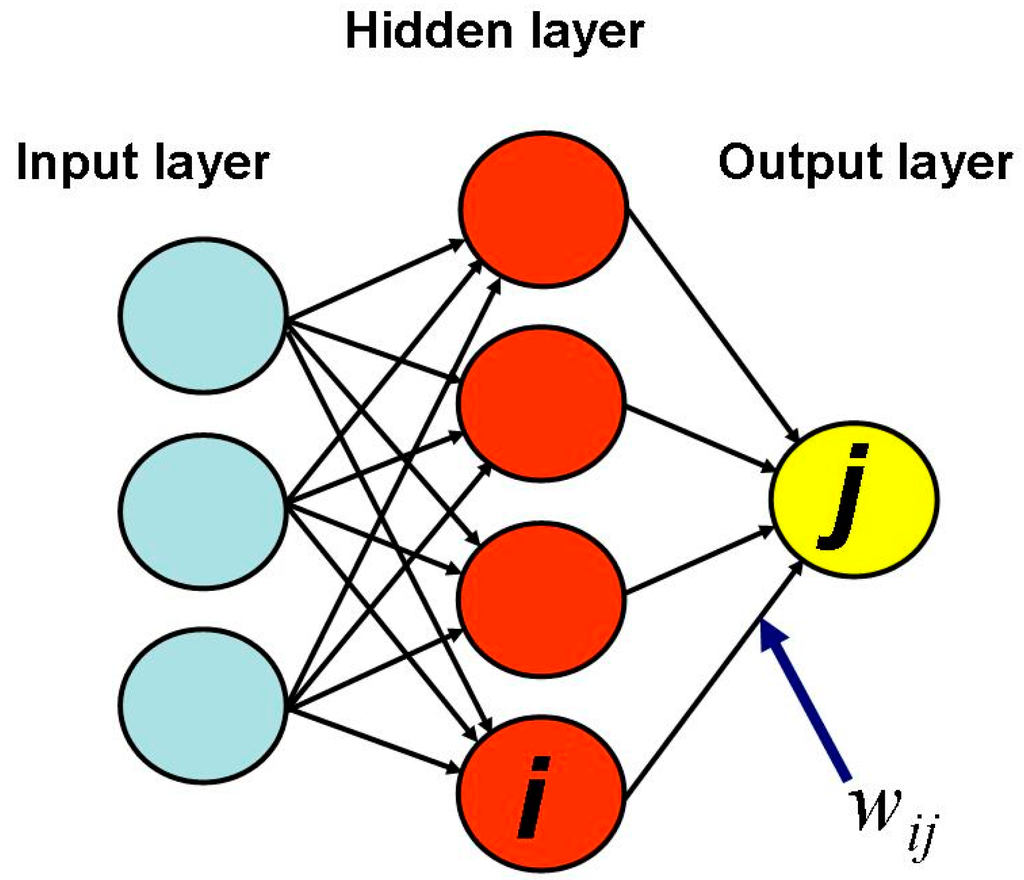
واحد پردازش اصلی یک شبکه عصبی ” نرون ” (یا ” گره “) نامیده می شود. نورون ها در لایه ها سازماندهی می شوند و هر نورون در یک لایه از طریق یک اتصال وزنی به هر نورون در لایه بعدی متصل می شود. مقدار وزن w ij نشان دهنده قدرت اتصال بین نورون i و j ام است. یک شبکه عصبی توسط لایه ” ورودی “، یک یا چند لایه ” مخفی ” و لایه ” خروجی ” تشکیل می شود. تعداد لایه های پنهان و نورون های موجود در آن ( z ) به پیچیدگی رابطه f بستگی دارد.مدل سازی شود (معادله (10)). بنابراین در گام اول باید معماری شبکه بهینه شود. طرح کلی یک معماری ANN سه لایه معمولی در شکل 4 آورده شده است.
شکل 4. نمونه ای از معماری ANN سه لایه با یک لایه پنهان. نماد w ij نشان دهنده وزن ارتباط بین نورون i- امین و j- امین است.
دادههای ( xi ) دریافتشده توسط لایه ورودی به نورونها در اولین لایه پنهان منتقل میشوند، جایی که با محاسبه مجموع وزنی آنها و اضافه کردن یک عبارت «بایاس» (θj) مطابق با رابطه (11) به صورت ریاضی پردازش میشوند :
که در آن p و q همانطور که در بالا ذکر شد تعریف می شوند. مقدار خالص j با استفاده از یک تابع ریاضی مناسب ( تابع انتقال ) تبدیل شده و در لایه بعدی به نورون ها منتقل می شود. توابع انتقال مختلفی در دسترس هستند [ 35 ] اما متداولترین آنها سیگموئید است (معادله (12)):
در ابتدا، مقادیر تصادفی در بازه [-1،1] به تمام وزن های اتصال w ij اختصاص داده می شود . ” یادگیری ” با تغییر تکراری مقادیر وزن اتصال ( w ij ) طبق یک قانون ریاضی داده شده ( الگوریتم آموزشی ) به دست می آید. الگوریتم های مختلفی در دسترس هستند [ 35 ، 36 ]. متداولترین الگوریتم آموزشی، انتشار پسانداز (BP) است که مقادیر وزنهای w ij را جستجو میکند که مجموع مجذور باقیمانده ( E ) را بهصورت زیر محاسبه میکند:
که در آن y ij و y ij * خروجی واقعی و شبکه j -امین را نشان می دهد.
تغییر وزن در دوره k بر روی نورون ها در یک لایه مشخص به صورت زیر محاسبه می شود:
که در آن η ثابت مثبتی به نام « نرخ یادگیری » است، μ عبارت « تکانه » است، و Δ w ij k -1 تغییر وزن w ij از ( k− 1) – دوره است. نرخ یادگیری سرعت یادگیری را کنترل میکند در حالی که مدت حرکت، فرآیند را تثبیت میکند و از حداقلهای محلی اجتناب میکند. جزئیات را می توان در تک نگاری ها [ 35 ] یافت. یک مقدمه خوب و مفصل برای ANN ها را می توان در جای دیگری یافت [ 37 ].
6.2. بهینه سازی معماری شبکه
معماری شبکه بهینه شده را می توان با استفاده از تابع داده شده در رابطه (13) به عنوان معیار به دست آورد. یک رویکرد پرکاربرد ترسیم مقدار E (معادله (13)) به عنوان تابعی از تعداد z گره ها در لایه پنهان است ( بخش 7 ” مثال ها “). مقدار E با افزایش مقدار z کاهش می یابد. با این حال، پس از مقدار بهینه z ، تغییر در مقدار E نسبتا ضعیف می شود.
معمولاً مقدار بهینه z از مختصات نقطه تقاطع مماس ها به دو شاخه نمودار پیدا می شود. قبل از اقدام به بهینه سازی معماری ANN، توصیه می شود داده ها را در ماتریس X برای وجود نقاط پرت احتمالی با استفاده از آزمون های آماری مناسب بررسی کنید [ 31 ]. اثر نقاط پرت بر عملکرد ANN در جاهای دیگر گزارش شده است [ 38 ]. روشهای تشخیص پرت با استفاده از شبکههای عصبی مصنوعی نیز شرح داده شده است [ 39 ].
6.3. تایید شبکه
فرآیند آموزش با استفاده از معماری شبکه بهینه یافت شده تا رسیدن به حداقل مقدار مناسب E انجام می شود. توانایی ” تعمیم ” شبکه در روش به اصطلاح ” تأیید ” با استفاده از داده هایی که در آموزش استفاده نشده است بررسی می شود. یک رویکرد رایج استفاده از تأیید متقاطع با انتخاب تصادفی یک یا چند ردیف از ماتریس X برای تأیید و استفاده از بقیه ردیفها برای آموزش است. این روند تا هر ردیف X تکرار می شودحداقل یک بار برای تأیید استفاده شده است. نرم افزار مدرن ANN به کاربران امکان می دهد آموزش و تأیید را به طور همزمان انجام دهند. پس از آموزش و تأیید موفقیت آمیز، می توان از شبکه برای طبقه بندی نمونه های جدید استفاده کرد.
6.4. ساختار پایگاه آموزشی
همانطور که در بالا گفته شد، یک پایگاه داده آموزشی مناسب برای انجام آموزش ANN استفاده می شود. چنین پایگاه داده ای جدول (یا ماتریس ) از داده های مربوط به نمونه هایی از خاک است که کلاس برای آنها شناخته شده است. هر ردیف از ماتریس به یک نمونه خاک اشاره دارد. n عنصر اول ردیف داده های ماهواره ای هستند در حالی که آخرین عنصر خروجی ( کلاس خاک ) است. شبکه های عصبی مصنوعی به تعداد «کافی» نمونه برای هر کلاس نیاز دارند، با این حال، این تعداد به پیچیدگی مسئله بستگی دارد و قانون کلی در دسترس نیست.
6.5. پیش پردازش داده ها قبل از تجزیه و تحلیل ANN
پیش پردازش داده یک مرحله توصیه شده قبل از استفاده از ANN است. چنین مرحله ای شامل تبدیل داده های ریاضی است. معمولاً داده ها در بازه [0،1] مقیاس بندی می شوند. هنگامی که ماتریس X حاوی داده های از دست رفته است، روش های مختلفی را می توان اعمال کرد، مانند جایگزینی با هموارسازی داده ها [ 28 ] یا حذف سطر و ستون مربوطه.
7. مثال ها
داده های بازتاب ماهواره مربوط به 100 مکان که به طور تصادفی در منطقه الفیوم انتخاب شده بودند ( شکل 5 ) در 9 طول موج ثبت شد. دو مثال اول مربوط به استفاده از داده های بازتاب برای برآورد کاربری/پوشش زمین است. برای این منظور، مکانها به کلاسهای « پوشش گیاهی » (V)، « دریاچه » (L) و « شهری » (U) گروهبندی شدند . مثال سوم به استفاده از داده های بازتاب برای طبقه بندی نوع خاک مربوط می شود.
شکل 5. توزیع 100 مکان در منطقه الفیوم (مصر) که داده های بازتاب ماهواره برای آنها ثبت شده است.
7.1. تمایز طبقات “گیاهی” و “دریاچه”.
در این مثال، دادههای بازتاب فقط مربوط به: کلاسهای ” گیاهی ” (V) و ” دریاچه ” (L) استفاده شد. داده ها در یک ماتریس X با 76 ردیف و 9 ستون سازماندهی شدند.
مقادیر ویژه ماتریس X محاسبه شد و تعداد مقادیر ویژه غیر صفر (که به آنها مقادیر ویژه ساختاری نیز گفته می شود ) از روی نمودار مطابق شکل 6 برآورد شد . همانطور که مشاهده می شود، دو مقدار ویژه 87.54 درصد از واریانس داده ها را توضیح می دهند.
7.1.1. تجزیه و تحلیل اجزای اصلی
بردارهای ویژه و مقادیر ویژه مربوط به ماتریس X توسط SVD محاسبه شدند. توزیع متغیرها و نمونه ها در فضای عامل اصلی دوبعدی به ترتیب توسط نمودارهای بارگذاری و امتیازدهی داده می شود. در نمودار بارگذاری ( شکل 7 )، دو گروه از متغیرها به صورت بیضی برجسته شده اند. هر چه فاصله بین متغیرها در نمودار بارگذاری کمتر باشد، همبستگی آنها بیشتر است. به عنوان مثال، فاصله کم بین متغیرهای SPOT (B2) و LANDSAT (B4) در شکل 7به این معناست که همبستگی بالایی دارند. بنابراین، باندهای طیفی SPOT (B2) و LANDSAT (B4) برای تمایز کلاس های V و L “معادل” هستند. نمودار بارگذاری وسیله ای برای تجسم میزان همبستگی بین متغیرها است.
شکل 6. نمودار صفحه به دست آمده برای داده های بازتاب مربوط به 76 مکان انتخاب شده در منطقه الفیوم مصر. روش مماس ها دو مقدار ویژه ساختاری می دهد. درصد واریانس در داده ها که توسط هر مقدار ویژه توضیح داده شده است، داده شده است.
شکل 7. نمایش باندهای طیفی ماهواره ای (متغیرها) در فضای عامل اصلی دو بعدی کاهش یافته. نوارهای طیفی بسیار همبسته در بیضی ها برجسته می شوند.
توزیع نمونه ها در فضای عامل اصلی دو بعدی کاهش یافته در نمودار امتیازها نشان داده شده است ( شکل 8 ). به وضوح، دو خوشه از نمونه ها به خوبی از هم جدا شده اند. این نتیجه با یافته EA مطابقت دارد (دو ارزش ویژه ساختاری پیدا شد).
شکل 8. نمایش نمونه ها در فضای عامل اصلی دو بعدی کاهش یافته. نمونه های متعلق به کلاس V به خوبی از نمونه های متعلق به کلاس V (بیضی نقطه چین) جدا می شوند.
7.1.2. طبقه بندی با استفاده از شبکه های عصبی مصنوعی
از ماتریس X ، ماتریس موسوم به ” کامل ” F با اضافه کردن یک ستون دیگر حاوی کلاس (V یا L) هر نمونه به X به دست آمد. ماتریس F به عنوان پایگاه آموزشی استفاده شد. در مرحله اول، داده ها با مقیاس خودکار (استانداردسازی تا صفر میانگین و انحراف استاندارد واحد) پیش پردازش شدند. در مرحله دوم، معماری شبکه عصبی بهینه جستجو شد. شبکه ای با تنها یک نورون در لایه پنهان یافت شد که می توانست نمونه ها را به درستی طبقه بندی کند. این نتیجه به دلیل این واقعیت است که خوشه های شکل 8را می توان با یک خط مستقیم از هم جدا کرد. بنابراین، شبکه یک تبعیض خطی ساده را انجام می دهد. توانایی تعمیم شبکه با انتخاب تصادفی شش یا چند نمونه در یک زمان برای انجام تأیید متقاطع بررسی شد. مشخص شد که شبکه آموزش دیده همیشه قادر است کلاس نمونه را به درستی پیش بینی کند (100% طبقه بندی صحیح).
7.2. تمایز طبقات “گیاهی”، “دریاچه” و “شهری”.
این مثال توسعهای از نمونه قبلی است که شامل کلاس شهر (U) در کنار کلاسهای V و L میشود. دادهها در یک ماتریس X با ابعاد 100 × 9 سازماندهی شدند. ماتریس کامل F با اضافه کردن یک ماتریس بیشتر به دست آمد. ستون تا X شامل کلاس (V، L یا U) هر نمونه.
7.2.1. تجزیه و تحلیل مقادیر ویژه
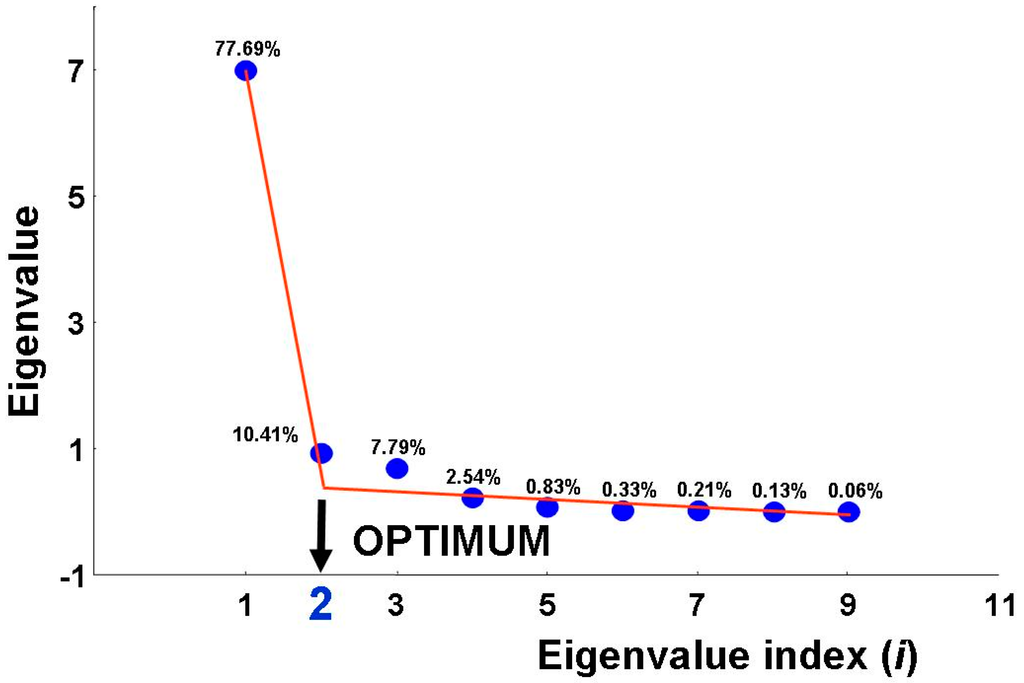
در مرحله اول، مقادیر ویژه X محاسبه شد. همانطور که در شکل 9 نشان داده شده است، تعداد مقادیر ویژه ساختاری از روی پلات صفحه برآورد شد . در این مورد، تعیین تعداد مقادیر ویژه ساختاری مانند مورد قبلی ساده نیست. می دانیم که داده ها برای سه کلاس خاک جمع آوری شده است. با این حال، اگرچه دو مقدار ویژه اول کاملاً با یکدیگر متفاوت هستند، تفاوت بین ارزش ویژه دوم و سوم بسیار کم است. این نشان می دهد که احتمالاً دو طبقه از سه طبقه خاک به سختی قابل تشخیص هستند.
شکل 9. نمودار به دست آمده از داده های بازتاب مربوط به طبقات “پوشش گیاهی”، “دریاچه” و “شهری” (منطقه الفیوم مصر). تعداد مقادیر ویژه ساختاری به احتمال زیاد برابر با دو است.
7.2.2. تجزیه و تحلیل اجزای اصلی
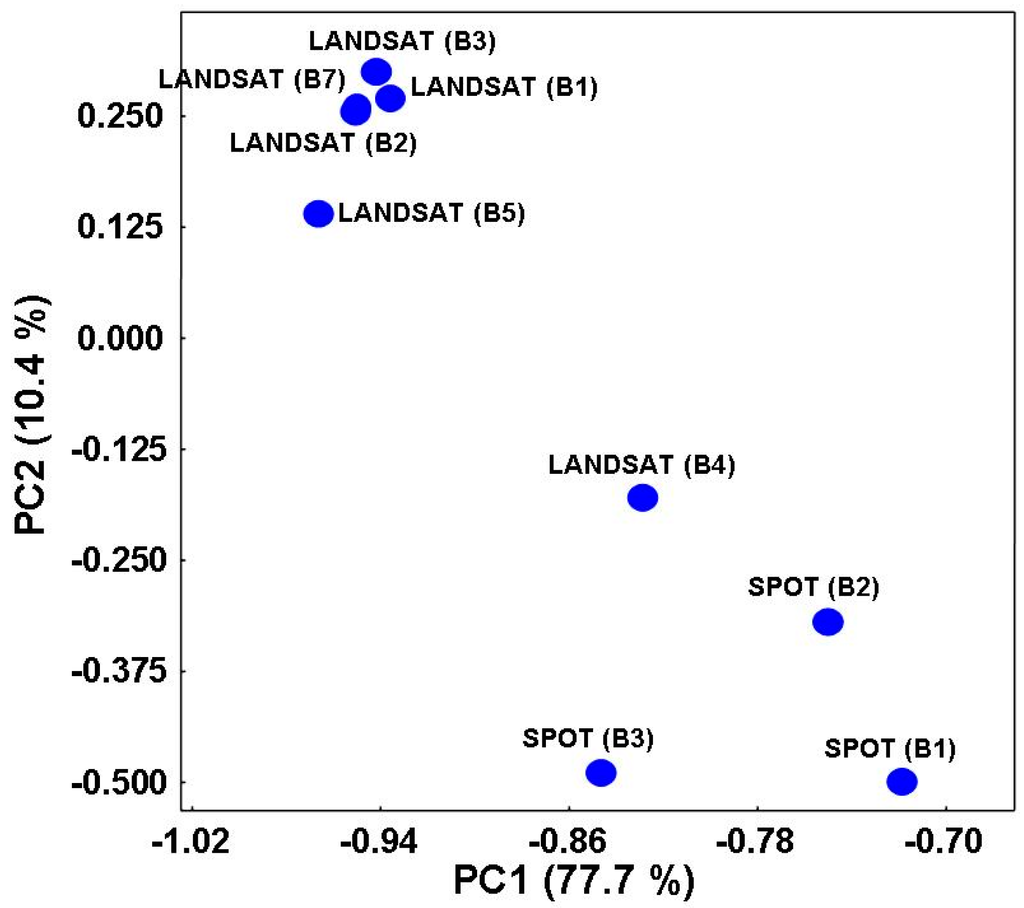
ماتریس X با استفاده از الگوریتم SVD تجزیه شد. نمودار بارگذاری ( شکل 10 ) توزیع باندهای طیفی مورد استفاده در فضای عامل اصلی دو بعدی کاهش یافته را نشان می دهد. باندهای طیفی LANDSAT (B1-5، 7) همبستگی بالایی دارند.
شکل 10. نمودار بارگذاری نشان دهنده توزیع باندهای طیفی ماهواره ای (متغیرها) در فضای عامل اصلی دو بعدی کاهش یافته است. PC1 و PC2 به ترتیب اولین و دومین جزء اصلی هستند.
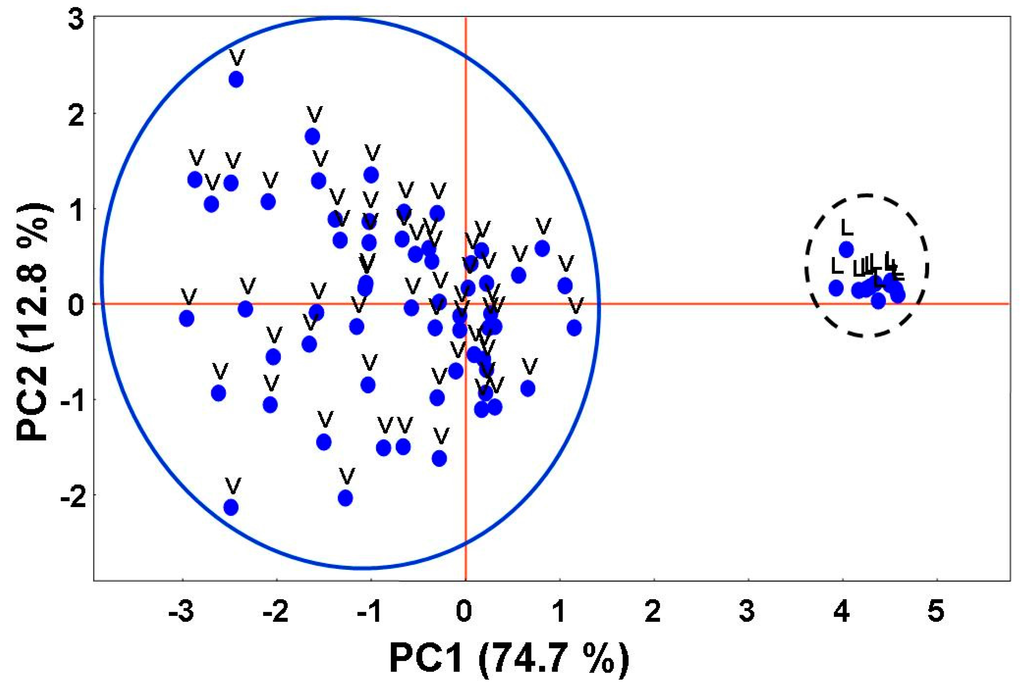
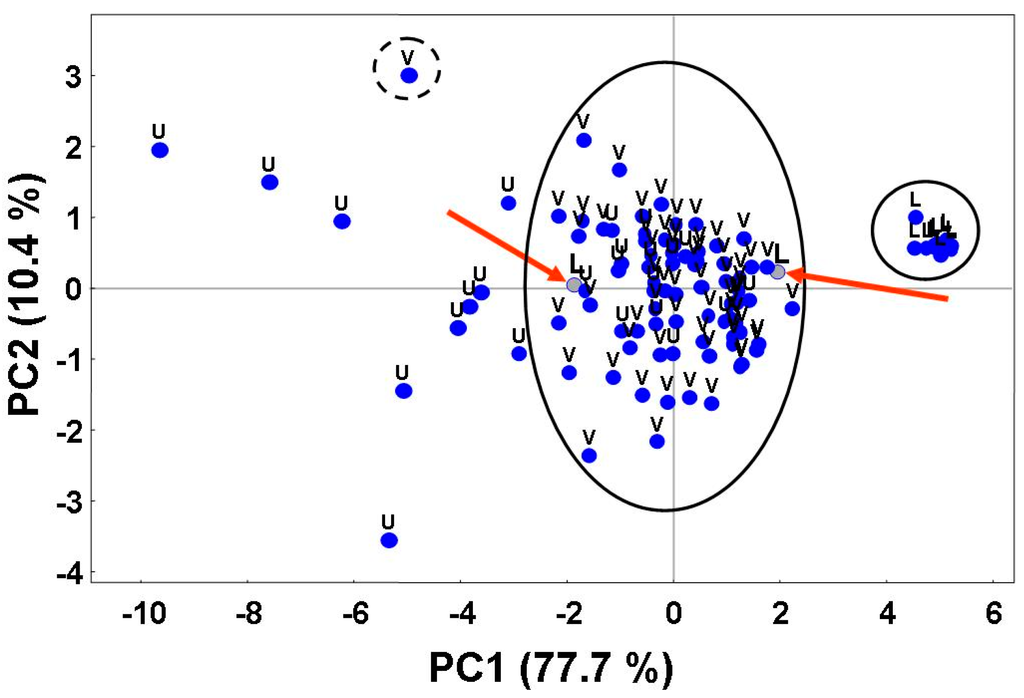
نمودار امتیازات در شکل 11 نشان داده شده است . فقط نمونه های متعلق به کلاس L را می توان به وضوح از سایرین متمایز کرد. این یافته با نتایج EA مطابقت دارد. همانطور که مشاهده می شود، یک همپوشانی جزئی از خوشه ها برای کلاس های U و V وجود دارد (که با بیضی در شکل 11 مشخص شده است). این ممکن است به این معنی باشد که چندین نمونه نشان دهنده مناطق شهری “سبز” است. به همین ترتیب، نمونههای متعلق به کلاس L که با فلشهای قرمز در شکل 11 مشخص شدهاند، ممکن است «نقاط پرت» یا نمونههایی باشند که مناطق «دریاچه» را نشان میدهند که در آن پوشش گیاهی فراوان است. نمونه ای که با دایره نقطه چین در شکل 11 مشخص شده استبسیار دور از نمونه های دیگر متعلق به کلاس V است. با این حال، این لزوماً به این معنی نیست که نمونه در دایره نقطهدار یک نقطه پرت را نشان میدهد. موقعیت آن در نمودار امتیاز نشان می دهد که ممکن است منطقه شهری را نشان دهد که در آن پوشش گیاهی نیز وجود دارد (به عنوان مثال، یک پارک در یک شهر).
شکل 11. توزیع نمونه ها در فضای عامل دو بعدی کاهش یافته توسط مولفه های اصلی اول و دوم (به ترتیب PC1 و PC2). همپوشانی جزئی خوشهها برای نمونههای متعلق به کلاس U با نمونههای متعلق به کلاس V با بیضی سیاه برجسته میشود. فلش ها نقاط پرت احتمالی را نشان می دهند. مورد مشکوک با یک دایره نقطهدار برجسته میشود.
از نتایج PCA، واضح است که دادههای بازتاب استفاده شده حاوی اطلاعات کافی برای تمایز واضح کلاس “دریاچه” از هر دو “شهری” و “پوشش گیاهی” است. با این حال، داده ها امکان تمایز کامل مناطق شهری خالص و شهری “سبز” توسط PCA را نمی دهد. بنابراین، میتوان انتظار داشت که پس از حذف نقاط پرت از پایگاه داده، شبکههای عصبی مصنوعی بتوانند نمونههای کلاس L را از نمونههای متعلق به کلاسهای U یا V تشخیص دهند.
7.2.3. طبقه بندی با استفاده از شبکه های عصبی مصنوعی
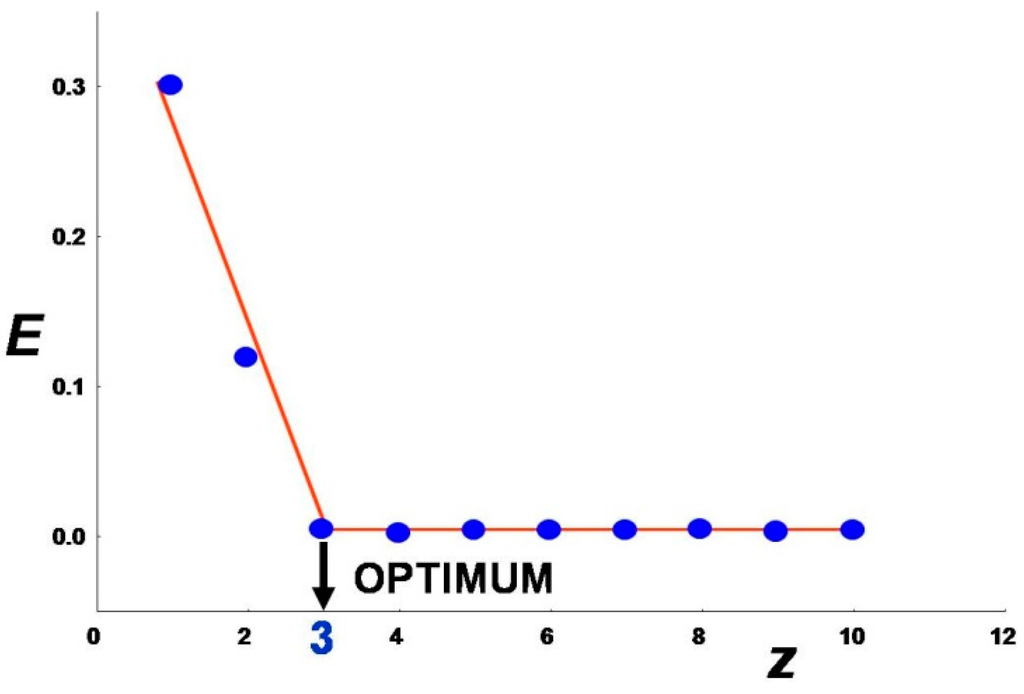
پایگاه داده آموزشی از هفت نقطه پرت همانطور که در بخش 6.2 توضیح داده شد ( “بهینه سازی معماری شبکه” ) پاک شد. نمودار E در برابر تعداد نورون ها در اولین لایه پنهان ( z ) در شکل 12 نشان داده شده است . مختصات نقاط تقاطع دو مماس روی محور x نشان می دهد که حداقل تعداد نورون های لایه پنهان برای مدل سازی داده ها برابر با سه است. در اینجا از شبکه ای با چهار نورون در اولین لایه پنهان استفاده شد.
توانایی ” تعمیم ” شبکه آموزش دیده با تایید متقابل با استفاده از یک نمونه در یک زمان بررسی شد. چنین فرآیندی تا زمانی که همه نمونه ها حداقل یک بار استفاده شوند تکرار شد. اگرچه PCA قادر به تشخیص واضح کلاسهای U و V نبود، درصد نمونههای طبقهبندی صحیح با استفاده از ANN عبارتند از: 100٪ (کلاس L)، 92٪ (کلاس V) و 84٪ (U).
شکل 12. نمودار مجموع باقیمانده های مربع ( E ) به عنوان تابعی از عدد z نورون ها در اولین لایه پنهان شبکه. مقدار بهینه z برابر با سه است.
7.3. تمایز خاک ها بر اساس طبقه بندی آنها
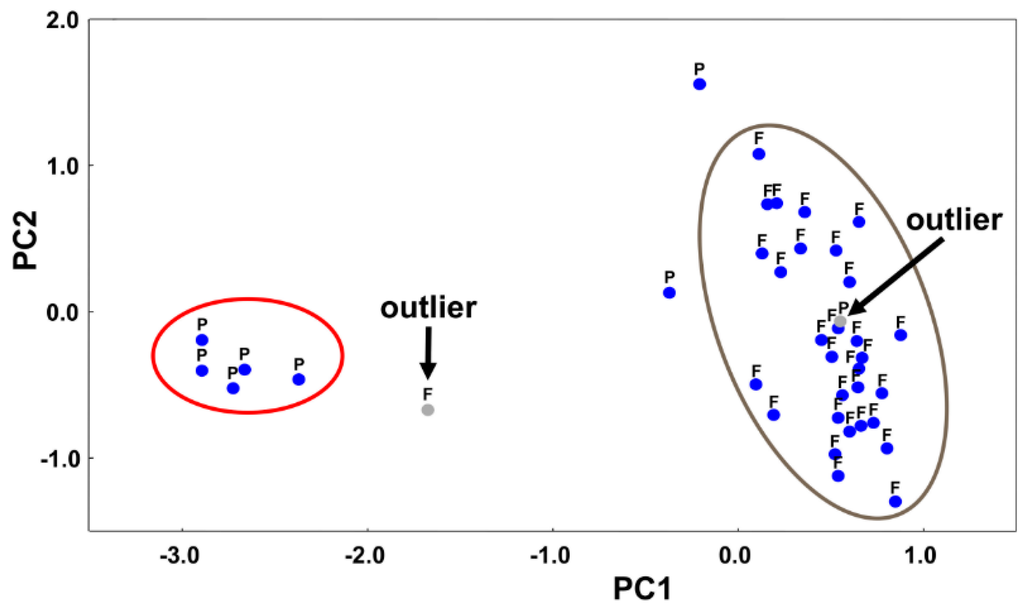
تجزیه و تحلیل شیمیایی و مورفولوژیکی 71 نمونه خاک جمعآوریشده در منطقه فرورفتگی الفیوم انجام شد و خاکها بر اساس طبقهبندی خاک USDA به زیرگروههای زیر دستهبندی شدند: هاپلوکالسیدهای تیپیک، هاپلوکالسیدهای لیتیک، کوارتزیپسامنتهای تیپیک، توریپسامنتهای تیپیک، پتروپیپسهای تیپیک. torriorthens، typic haplosalids، vertic torrifluvents، typic torrifluvents، و petrogypsic gypsiorthids. داده های انعکاس مربوط به 71 نمونه خاک در یک ماتریس X با ابعاد 71 × 9 سازماندهی شدند و همانطور که قبلاً توضیح داده شد از قبل پردازش شدند. تعداد ویژههای ساختاری X برابر دو (94.60 درصد از کل واریانس) به دست آمد. این بدان معنی است که داده های بازتاب در Xبه محققان این امکان را می دهد که فقط دو “گروه” خاک را تشخیص دهند. بنابراین، نمونههای خاک با توجه به طبقهبندی آنها با طبقهبندی خاک USDA مجدداً طبقهبندی شدند. طبقات جدید به دست آمده عبارتند از: فلوونت ها، کلسیم ها، سالیدها و پسامنت ها (به ترتیب با برچسب F، C، S و P). با این حال، نشان داده شده است که حتی این چهار طبقه نیز قابل تبعیض نیستند. مشخص شد که واقعاً فقط کلاس های “F” و “P” قابل تمایز هستند (نمرات نمرات در شکل 13 ارائه شده است). این نتایج قدرت غربالگری داده ها را نشان می دهد. در واقع، تجزیه و تحلیل مقادیر ویژه ثابت می کند که داده های بازتابی موجود حاوی اطلاعات کافی برای تمایز هر چهار زیر ردیف خاک نیستند. برای دستیابی به قابلیت تشخیص بالاتر، باندهای طیفی بیشتری مورد نیاز است.
دادههای بازتاب مربوط به نمونههای متعلق به کلاسهای “F” و “P” در مرحله طبقهبندی ANN استفاده شد. پس از حذف دو نقطه پرت که در شکل 13 مشخص شده است، شبکه های عصبی با دو نورون در لایه پنهان به 100٪ طبقه بندی صحیح نمونه های خاک دست یافتند.
شکل 13. توزیع نمونه ها در فضای عامل دو بعدی کاهش یافته توسط مولفه های اصلی اول و دوم (به ترتیب PC1 و PC2). برچسب های “F” و “P” به ترتیب به کلاس های خاک “fluvent” و “psamment” اشاره دارند. فلش ها نقاط پرت احتمالی را نشان می دهند.
8. نتیجه گیری
سنجش از دور با استفاده از داده های طیفی ماهواره ای، نظارت کارآمد بر کیفیت خاک را تا حد زیادی امکان پذیر می کند. ANN ها ابزارهای قدرتمندی برای تخمین طبقات خاک هستند و ارزیابی مناسب بودن داده های طیفی ماهواره ای یک گام اساسی است.
بر اساس دادههای طیفی ماهوارهای واقعی، روششناسی برای اهداف طبقهبندی خاک و تخمین کاربری/پوشش زمین توسط شبکههای عصبی مصنوعی با اشاره به مسائل اصلی که اغلب نادیده گرفته میشوند، توسعه داده شد. آنالیز مقادیر ویژه و تجزیه و تحلیل مولفه های اصلی به عنوان ابزاری قدرتمند برای ارزیابی در پیشبرد تعداد طبقات خاک قابل تشخیص و مناسب بودن باندهای طیفی برای طبقه بندی خاک به اثبات رسید. غربالگری داده ها یک پیش نیاز مهم برای بهبود تجزیه و تحلیل داده های سنجش از دور با استفاده از شبکه های عصبی مصنوعی نشان داده شد.
در نتیجه، روش توسعهیافته برای غربالگری دادههای سنجش از دور و تجزیه و تحلیل متعاقب آنها ANN نتایج مقرونبهصرفهای را ارائه میدهد که به اهداف زمین دیجیتال کمک میکند.






بدون نظر