

خلاصه
ناهنجاریهای جادهای، مانند ترکها، گودالها و گودالها، معمولاً با گزارشهای شهروندان از طریق ایمیل یا تلفن شناسایی شدهاند. با این حال، یافتن این ناهنجاری برای تعمیر برای نهادهای اداری دشوار است. یک راه حل پیشرفته مبتنی بر تلفن هوشمند که گزارش های متنی و/یا تصویری را همراه با اطلاعات موقعیت مکانی ارسال می کند، راه حل طولانی مدتی نیست، زیرا به گزارش فعال افراد بستگی دارد. در این مقاله، ما یک سیستم مبتنی بر حسگر فرصتطلب را نشان میدهیم که از تلفن هوشمند برای تشخیص ناهنجاری جادهها بدون دخالت کاربر فعال استفاده میکند. برای تشخیص ناهنجاریهای جاده، ما بر رفتارهای اجتنابی عابران پیاده تمرکز میکنیم که با تغییر الگوهای آزیموت مشخص میشوند. سه رفتار اجتنابی معمولی تعریف شده است و جنگل تصادفی به عنوان طبقهبندی انتخاب میشود. بیست و نه ویژگی تعریف شده است، که در آن ویژگی های محاسبه شده با تقسیم یک بخش به نیمه اول و نیمه دوم و در نظر گرفتن یکنواختی تغییر در تشخیص موثر هستند. آزمایش ها در یک محیط ایده آل و کنترل شده انجام شد. اعتبارسنجی متقاطع ده برابری عملکرد متوسط طبقه بندی را با اندازه گیری F 0.89 برای شش فعالیت نشان می دهد. ثابت شد که روش تشخیص پیشنهادی در برابر اندازه موانع قوی است و وابستگی به موقعیت ذخیرهسازی گوشی هوشمند را میتوان با یک طبقهبندی کننده مناسب در هر موقعیت ذخیرهسازی کنترل کرد. علاوه بر این، تجزیه و تحلیل نشان می دهد که طبقه بندی داده های یک فرد “ناشناس” را می توان با در نظر گرفتن سازگاری یک طبقه بندی کننده بهبود بخشید. اعتبارسنجی متقاطع ده برابری عملکرد متوسط طبقه بندی را با اندازه گیری F 0.89 برای شش فعالیت نشان می دهد. ثابت شد که روش تشخیص پیشنهادی در برابر اندازه موانع قوی است و وابستگی به موقعیت ذخیرهسازی گوشی هوشمند را میتوان با یک طبقهبندی کننده مناسب در هر موقعیت ذخیرهسازی کنترل کرد. علاوه بر این، تجزیه و تحلیل نشان می دهد که طبقه بندی داده های یک فرد “ناشناس” را می توان با در نظر گرفتن سازگاری یک طبقه بندی کننده بهبود بخشید. اعتبارسنجی متقاطع ده برابری عملکرد متوسط طبقه بندی را با اندازه گیری F 0.89 برای شش فعالیت نشان می دهد. ثابت شد که روش تشخیص پیشنهادی در برابر اندازه موانع قوی است و وابستگی به موقعیت ذخیرهسازی گوشی هوشمند را میتوان با یک طبقهبندی کننده مناسب در هر موقعیت ذخیرهسازی کنترل کرد. علاوه بر این، تجزیه و تحلیل نشان می دهد که طبقه بندی داده های یک فرد “ناشناس” را می توان با در نظر گرفتن سازگاری یک طبقه بندی کننده بهبود بخشید.
کلید واژه ها:
ناهنجاری جاده ؛ اجتناب ; تشخیص رفتار ؛ گوشی هوشمند ؛ حس فرصت طلبی
1. معرفی
ناهنجاریهای جادهای مانند ترکها، گودالها، گودالها و درختان افتاده معمولاً از گزارشهای شهروندان شناسایی میشوند و توسط دستگاههای اجرایی تعمیر میشوند. در اغلب موارد، گزارش ها از طریق تلفن یا ایمیل انجام می شود که تشخیص محل ناهنجاری را برای نهادهای اداری دشوار می کند. برای رسیدگی به این مشکل، نهادهای اداری و اشخاص ثالث در تلاش هستند تا برنامههای مبتنی بر گوشیهای هوشمند را ارائه دهند که گزارشهای متنی و/یا تصویری را با اطلاعات مکان میپذیرند [ 1 ، 2 ]. چنین حسی انسان محور اغلب حس مشارکتی نامیده می شود [ 3]. اگرچه موفقیت این برنامهها به افرادی بستگی دارد که فعالانه وظایف را گزارش میکنند، تعداد بسیار کمی از شهروندانی که این برنامهها را دانلود کردهاند، در واقع موارد ناهنجاری را گزارش کردهاند [ 1 ]. بنابراین، ما روشی را برای تشخیص ناهنجاریهای جاده به طور ضمنی بر اساس سنجش فرصتطلب پیشنهاد میکنیم. سنجش فرصتطلب یکی دیگر از پارادایمهای سنجش انسان محور است که در آن فرآیند جمعآوری دادهها بدون دخالت کاربر خودکار میشود [ 4 ].
برای تشخیص ناهنجاری های جاده، ما بر رفتارهای اجتنابی تمرکز می کنیم. شناخت رفتارهای اجتنابی و تجمیع رویدادها با مکان ها می تواند به تولید گزارش های ناهنجاری خودکار کمک کند. تکنیکهای تشخیص خودکار ناهنجاری جادهای برای اتومبیلها و دوچرخهها قبلاً پیشنهاد شدهاند [ 5 ، 6 ، 7 ، 8 ، 9 ]، اما این موارد با حرکات نسبتاً بزرگ سروکار دارند. در مقابل، ما در نظر میگیریم که رفتارهای اجتنابی عابران پیاده برای قابل قبول کردن انطباق روشهای موجود بسیار ناچیز است. مشارکت های این مقاله به شرح زیر است:
-
یک سیستم تشخیص ناهنجاری جاده مبتنی بر تلفن هوشمند ارائه شده است که در آن رفتارهای اجتناب از مانع به سه کلاس طبقهبندی میشوند. این سه کلاس عبارتند از: (1) بازگشت به همان خط در مجاورت اجتناب از مانع. (2) رفتن مستقیم پس از اجتناب از مانع. و (3) معکوس کردن مسیر خود. که ممکن است نشان دهنده تاثیر مانع بر روی عابران باشد. این سه کلاس ممکن است شدت موانع را نشان دهند، که برای یک نهاد اداری برای برنامه ریزی برنامه تعمیر مفید خواهد بود.
-
بیست و نه ویژگی طبقه بندی بر اساس ویژگی های تغییر آزیموت هر کلاس تعریف شده است. ارتباط ویژگی ها ارزیابی می شود.
-
ما به طور گسترده اثرات عوامل مختلف را بر عملکرد تشخیص تجزیه و تحلیل می کنیم. این شامل افرادی میشود که دادههایی را برای طبقهبندیکنندههای آموزشی و موقعیت حسگرها (یعنی گوشیهای هوشمند) روی بدنشان و همچنین اندازه موانع هدف ارائه میکنند.
تصمیم اولیه در مورد موقعیت و کلاس یک مانع در سمت گوشی هوشمند در مقابل جریانی از داده های حسگر گرفته می شود، در حالی که اطلاعات جمع آوری شده از تعدادی عابران پیاده برای تصمیم گیری نهایی استفاده می شود. عملیات کم مصرف و پردازش سمت سرور خارج از حوصله این مقاله است. علاوه بر این، ما با روشی برای تشخیص رفتار عادی، به عنوان مثال، راه رفتن در امتداد یک جاده منحنی، از رفتار اجتنابی سروکار نداریم. در عوض، ما بر طبقه بندی یک بخش داده از رفتار اجتنابی به یکی از شش کلاس (سه کلاس × چرخش راست و چپ) تمرکز می کنیم.
ادامه این مقاله به شرح زیر سازماندهی شده است. در بخش 2 ، کار مرتبط ارائه شده است. بخش 3 نمای کلی سیستم و به دنبال آن آزمایش های آفلاین در بخش 4 را نشان می دهد . در نهایت، بخش 5 مقاله را به پایان می رساند. توجه داشته باشید که در [ 10 ]، ما ایده اصلی تشخیص ناهنجاری جادهای مبتنی بر گوشیهای هوشمند را پیشنهاد کردیم. این مقاله در موارد زیر دارای پسوند است: بخشی از کار مرتبط به منظور روشن شدن منحصر به فرد بودن اثر اضافه شده است ( بخش 2 ). ایده های کلی سیستم ارائه شده است، از جمله نه تنها پردازش محلی در تلفن هوشمند، بلکه همچنین پردازش سمت سرور برای فیلتر کردن تشخیص اشتباه از سمت تلفن هوشمند (بخش 3.1 )؛ جزئیات تشخیص رفتار اجتنابی (روی تلفن هوشمند) شرح داده شده است، از جمله اینکه چگونه جریان داده های آزیموت خام در رویداد اجتنابی نهایی و تعریف جزئیات ویژگی ها پردازش می شود ( بخش 3.3 ). آزمایشها با شرایط مختلف انجام شد، به عنوان مثال، یک نوع رفتار “مستقیم” حذف شد، زیرا ما در نظر گرفتیم که میتوان آن را در مرحله پیش پردازش انجام داد. و تجزیه و تحلیل های گسترده ای در مورد وابستگی فرد ( بخش 4.4 )، وابستگی به موقعیت ذخیره حسگر ( بخش 4.5 ) و استحکام به اندازه مانع ناشناخته ( بخش 4.6 ) انجام شد.
2. کارهای مرتبط
موتورسیکلت ها و سایر وسایل نقلیه اغلب به عنوان روشی برای تشخیص خودکار ناهنجاری جاده ها و تشخیص رفتار ناایمن استفاده می شوند [ 6 ، 7 ، 8 ، 9 ، 11 ، 12 ، 13 ، 14 ]. Thepvilojanapong و همکاران. [ 14 ] و کامیمورا و همکاران. [ 12 ] روشی را با استفاده از شتابسنج و ژیروسکوپ نصبشده در گوشی هوشمند برای تشخیص فعالیتهای رانندگی، مانند چرخش به چپ یا راست، جلو رفتن یا عبور دوچرخهها و موتورسیکلتها از کنار اتومبیلهای مجاور پیشنهاد کرد. ایوازاکی و همکاران [ 15] روشی را برای تشخیص ویژگی های جاده، مانند تقاطع با دید ضعیف و جاده شلوغ بر اساس رفتار دوچرخه سواری پیشنهاد کرد. علاوه بر این، یک واحد حسگر ویژه که زاویه و سرعت سکان را اندازهگیری میکند برای دوچرخهسواران برای شناسایی مکانهای خطرناک توسعه داده شد [ 8 ]. جابجایی عمودی وسایل نقلیه ای که از روی دست اندازها و چاله ها عبور می کنند اغلب در مورد اتومبیل ها تحت نظارت هستند [ 5 ، 7 ، 9 ، 11 ، 13 ]. در مقابل، چن و همکاران. عوامل رانندگی شناسایی شده که باعث جابجایی افقی می شوند، مانند تغییر خط، جاده منحنی S شکل، پیچش یا جاده منحنی L شکل [ 6 ]. در کار فوق الذکر، همه به جز [ 8] از شتابسنج، ژیروسکوپ و/یا مغناطیسسنج نصبشده روی گوشی هوشمند استفاده کرد. این نشان میدهد که گوشیهای هوشمند بهعنوان حسگرهایی با قابلیت استقرار آسان در ترکیب با تکنیک موقعیتیابی، به عنوان مثال، GPS. علاوه بر این، تجمیع داده ها به دنبال تجزیه و تحلیل مناسب می تواند انواع جدیدی از محتوای اطلاعاتی را برای سیستم های حمل و نقل راحت و ایمن ایجاد کند. کار ما انگیزه های خود را با مطالعات فوق به اشتراک می گذارد. با این حال، ما بر روی ناهنجاری های جاده از دیدگاه عابر پیاده تمرکز می کنیم. علاوه بر این، اگرچه کار فوق در مورد جابجایی افقی [ 6 ، 12 ، 14 ، 15] ممکن است مسیرهای مشابهی از اجسام متحرک پیدا کند، دوچرخهها و اتومبیلها حرکتهای بزرگتر و سریعتری نسبت به عابران پیاده دارند و بنابراین، اعمال روشهای موجود در حوزه ما دشوار خواهد بود.
برای پایش وضعیت جاده مبتنی بر عابر پیاده، جین و همکاران. یک تکنیک سنجش گرادیان زمین مبتنی بر کفش را پیشنهاد کرد [ 16 ]. یک واحد حسگر متشکل از مغناطیسسنج، شتابسنج و ژیروسکوپ روی کفشها نصب شده است که دادههایی را جمعآوری میکند که انتقال بین پیادهروها و خیابانها را از طریق تشخیص شیبهای اختصاصی تشخیص میدهد. انگیزه اولیه آن مطالعات استفاده از داده ها برای هشدار دادن به عابران پیاده ای بود که می خواهند وارد خیابان شوند. تکنیک سنجش شیب همچنین می تواند وضعیت عمودی پیاده روها، به عنوان مثال، دست اندازها را تشخیص دهد. علاوه بر این، کفش ها می توانند چرخش ها و جهت حرکت را تشخیص دهند. این قابلیتها نشان میدهند که کفشهای تقویتشده را میتوان با سیستم ما بهعنوان حسگر ترکیب کرد تا تغییرات رفتاری افقی را تشخیص دهد.
3. شناخت رفتار اجتنابی
3.1. بررسی اجمالی سیستم
شکل 1 مفهوم سیستم پیشنهادی را نشان می دهد. سیستم پیشنهادی برای شناسایی یک ناهنجاری جاده به صورت خودکار طراحی شده است که شامل یک عملکرد تشخیص رفتار اجتنابی با اندازهگیری مکان در سمت گوشی هوشمند و عملکردهای تجمع و فیلتر در سمت سرور است. رفتار اجتنابی با اندازهگیری تغییرات آزیموت جهت راه رفتن توسط شتابسنج و مغناطیسسنج نصبشده روی گوشی هوشمند تشخیص داده میشود. در API اندروید، این دو حسگر به صورت داخلی برای به دست آوردن داده های آزیموت استفاده می شوند. موقعیتی که رویداد اجتنابی در آن رخ می دهد با تکنیک موقعیت یابی مانند GPS اندازه گیری می شود. اطلاعات به یک پایگاه داده در سمت سرور ارسال می شود. در شکل 1 ، آv1��1، آv2��2و آv3��3نامزدهای رویدادهای اجتنابی را نشان می دهد. توجه داشته باشید که مصرف برق یک مسئله اصلی برای موفقیت سنجش فرصت طلبانه از دیدگاه کاربر است. برای به حداقل رساندن ارتباط با یک سرور، پردازش برای تشخیص رویداد اجتنابی در سمت ترمینال انجام می شود و فقط رویدادهای رفتار اجتنابی به سرور ارسال می شود. علاوه بر این، فرض میکنیم گیرنده GPS تنها زمانی فعال میشود که یک رویداد اجتنابی شناسایی شود (فاصله موقعیتی بین زمان تشخیص رویداد و زمان آمادهسازی GPS نیز در نظر گرفته میشود).
اطلاعات جمعآوریشده ممکن است حاوی رویدادهای اشتباهی باشد که به اشتباه بهعنوان رفتارهای اجتنابی شناخته میشوند، مانند عبور یک نفر از کنار دیگری و نگاه کردن به پشت با پایانه تلفن هوشمند در دست، و همچنین اثر خطای موقعیتیابی. بنابراین، فیلتر مکانی-زمانی باید برای استخراج تنها “موانع استاتیک” در جاده اعمال شود (به عنوان مثال، [ 17 ]). در شکل 1 ، آv1��1چنین تشخیص نادرستی است، و سیستم در نهایت یک ناهنجاری جاده را در نزدیکی موقعیت شناسایی می کند آv2��2و آv3��3. محاسبه مرکز موقعیت های رویدادهای رفتار اجتنابی یک راه حل ساده است. علاوه بر این، یک سیستم اطلاعات جغرافیایی (GIS) برای تطبیق نقشه موقعیت یک رویداد در یک جاده می تواند اعمال شود. یک GIS همچنین میتواند برای حذف رویدادی که به اشتباه بهعنوان اجتناب طبقهبندی شده است، که در واقع یک رفتار عادی است، با انعکاس معناشناسی جاده، به عنوان مثال، شناسایی اینکه یک منحنی در موقعیت (x، y) وجود دارد ، استفاده شود . این مقاله بر روی عملکرد تشخیص اجتناب در سمت گوشی هوشمند تمرکز دارد. موقعیت یابی کم مصرف و پردازش سمت سرور فراتر از تمرکز این مقاله است.
3.2. مدل سازی رفتار اجتنابی
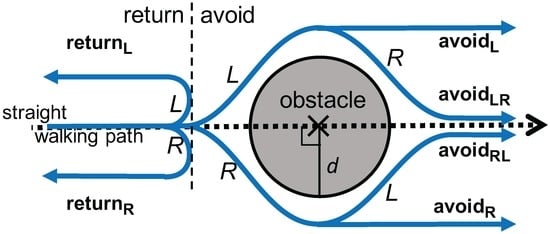
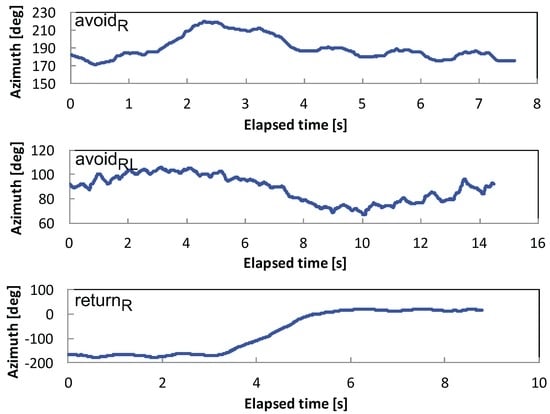
ما بر روی تشخیص ناهنجاریها در سطح جاده، مانند گودالها، ترکها، گودالها، درختان افتاده و رانش زمین تمرکز میکنیم. این ناهنجاری ها باعث می شود عابران پیاده مسیرهای پیاده روی خود را به عنوان یک رفتار دفاعی طبیعی تغییر دهند [ 18 ]. رفتار اجتنابی در طول راه رفتن با ترکیب سه عنصر مدلسازی میشود: (1) اجتناب از جهت (چپ یا راست). (2) عبور از مانع (اجتناب) یا بازگشت (بازگشت). و (3) تغییر جهت پس از اجتناب از مانع. در مجموع، شش نوع رفتار اجتنابی تعریف شده است که در شکل 2 نشان داده شده است : avoidLR�������، avoidL������، avoidRL�������، avoidR������، returnL�������و ” returnآر�������“. در اینجا، پسوند “LR” نشان می دهد که برای مثال، عابر پیاده جهت را به سمت چپ و به دنبال آن تغییر به راست تغییر می دهد، در حالی که پسوند “L” به تنهایی دومین تغییر را پس از اولین تغییر به چپ ندارد. خط نقطه چین افقی در شکل 2 مسیر مستقیم پیاده روی عابر را نشان می دهد. علاوه بر این، d نشان دهنده اندازه یک رفتار اجتنابی است، که در درجه اول با اندازه فیزیکی یک مانع تعیین می شود، به عنوان مثال، اندازه رفتار اجتنابی برابر با اندازه مانع است. اندازه درک شده نیز ممکن است بر رفتار یا به عبارت دیگر بر شدت ناهنجاری تأثیر بگذارد. ما در مجموع d را “اندازه مانع” یا “اندازه مانع” می نامیم. شکل موج معمولی سیگنال های آزیموت خام در شکل 3 نشان داده شده است.
3.3. تشخیص رفتار اجتنابی
همانطور که در شکل 4 نشان داده شده است، سیستم تشخیص بخشی از داده های آزیموت را به عنوان ورودی می گیرد و بخش را به یکی از شش رفتار طبقه بندی می کند. وظیفه تشخیص باید روی داده های حسگر جریانی انجام شود. واریانس لغزشی را می توان بر روی داده های جریانی محاسبه کرد تا بر شروع و پایان تغییر جهت راه رفتن تأکید شود. با این حال، تغییر جهت راه رفتن نیز زمانی اتفاق میافتد که یک عابر پیاده به گوشهای بپیچد یا در امتداد یک جاده منحنی راه برود، که رفتارهای عادی هستند و نباید به عنوان اجتناب از مانع تشخیص داده شوند. بنابراین، برای تشخیص این موقعیت ها از یکدیگر مراقبت ویژه ای لازم است. تقسیمبندی خودکار فراتر از تمرکز این مقاله است، و ما از دادههای بخشبندی شده دستی برای تمرکز بر تشخیص این شش رفتار استفاده میکنیم.
3.3.1. شکل موج
فرآیند شکل دهی شکل موج به عنوان یک پیش فرآیند عمل می کند و از تشخیص تغییر آزیموت و هموارسازی تشکیل شده است. ما مقدار آزیموت را از یک API Android بدست می آوریم. مقداری که از دادههای شتابسنج و مغناطیسسنج محاسبه میشود، از متغیر است 0∘0∘به 359∘359∘. بنابراین، هنگامی که جهت راه رفتن از شمال عبور می کند، یک تغییر غیر پیوسته ظاهر می شود، به عنوان مثال، 0∘0∘همانطور که در B’ از شکل 4 مشاهده شده است . در این حالت، قرار است یک فرد جهت را از نزدیک غرب به شمال غربی تغییر دهد (P = 335 .2∘335.2∘) به نزدیک شرقی-شمال شرقی (Q = 21 .4∘21.4∘). علاوه بر این، مقدار با تبدیل آن از مقدار اول به مقدار نسبی نرمال می شود. سپس، تغییر آزیموت در یک قطعه توسط الگوریتم 1 محاسبه می شود، که در آن خطوط 7 تا 9 یک تغییر غیر پیوسته را کنترل می کنند. سیگنال تبدیل شده در C از شکل 4 نشان داده شده است .
| الگوریتم 1 تغییر آزیموت را نسبت به مقدار اول در یک بخش محاسبه کنید. |
|
علاوه بر این، برای حذف اثر حرکت بدن، به عنوان مثال، صاف کردن، یک میانگین متحرک به عنوان یک فیلتر پایین گذر اعمال می شود، همانطور که در D شکل 4 نشان داده شده است . اندازه پنجره برای میانگین های متحرک 1/6 از بخش داده های آزیموت است، همانطور که در یک آزمایش اولیه تعیین شد.
3.3.2. طبقه بندی رفتار
طبقه بندی رفتار، که شامل محاسبه ویژگی و طبقه بندی نظارت شده است، پس از شکل دادن به شکل موج انجام می شود. در مجموع، ما 29 ویژگی را مشخص کردیم که در جدول 1 خلاصه شده است . این ویژگی ها عمدتاً شامل آمارهای اساسی مانند میانگین، حداکثر، حداقل، محدوده، ربع اول و سوم، محدوده بین چارکی (IQR)، واریانس، انحراف معیار، جمع، جمع مجذورها، ریشه میانگین مربع (RMS) و مقادیر مطلق هستند. . در صفبندی ویژگیها، توجه ویژهای به این نکته داشتیم که مسیرهای avoidRL�������و avoidR������پس از عبور از یک مانع به وضوح از یکدیگر متمایز می شوند ( شکل 5 )، بنابراین یک قطعه را در مرکز قطعه به دو قسمت تقسیم می کنیم. ویژگی های محاسبه شده از بخش نیمه اول و بخش نیمه دوم به ترتیب دارای زیرنویس های FH و SH هستند. در مقابل، ویژگی های یک بخش کامل دارای زیرنویس ALL هستند. توجه داشته باشید که جدول 1 به ترتیب مشارکت در طبقه بندی فهرست شده است. همه اثرات متناظر ویژگیها نمیتوانند مهم باشند یا حتی میتوانند تأثیر منفی داشته باشند، که در بخش 4.3 مورد بحث قرار گرفته است .
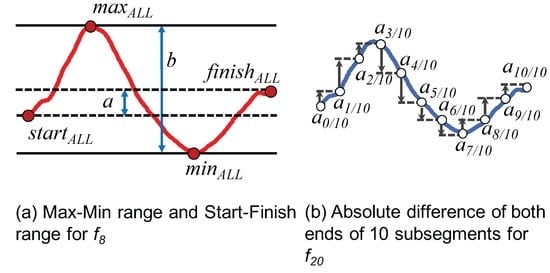
برای محاسبه ویژگی هشتم، ( f8�8) برای نشان دادن یکنواختی تغییر آزیموت در یک قطعه معرفی شده است. همانطور که در شکل 6 a نشان داده شده است و با معادله ( 1 ) نشان داده شده است، این ویژگی به عنوان حداکثر بزرگتر می شود ( maxALL������) و حداقل ( minALL������) ارزش ها به هر دو طرف نزدیک می شوند ( startALL��������و finishALL�����ℎ���). ما در نظر داریم که ” returnR�������” بیشترین مقدار را در بین سه رفتار دارد زیرا تغییر آزیموت ” returnR�������” در حالت ایده آل یک افزایش یا کاهش یکنواخت است ( شکل 5 را ببینید ).
f8=|maxALL−minALLstartALL−finishALL|�8=|������−��������������−�����ℎ���|
برای ویژگی بیستم ( f20�20، یک بخش به طور مساوی به 10 زیربخش تقسیم می شود و اختلاف مطلق بین هر دو انتهای هر زیربخش تا 10 زیربخش جمع می شود. نماد در شکل 6 ب نشان داده شده است و همچنین با معادله ( 2 ) بیان شده است. منطق معرفی این ویژگی این است که رفتاری با تغییر آزیموت زیاد تمایل به تفاوت مطلق بزرگ دارد. همانطور که در شکل 5 نشان داده شده است ، avoidR������دارای ارزش کمتر از avoidRL�������به دلیل عدم تغییر آزیموت در نیمه دوم بخش. در همین حال، returnR�������باید بیشترین تغییر را داشته باشد زیرا جهت راه رفتن به سمت مخالف تغییر می کند.
f20=∑i=09∣∣a(i+1)/10−ai/10∣∣�20=∑�=09|�(�+1)/10−��/10|
با توجه به قابلیت تشخیص (طبقه بندی)، رویکردهای مبتنی بر قانون دست ساز [ 6 ، 12 ]، یک رویکرد یادگیری ماشین آماری (درخت تصمیم J48) [ 8 ] و یک رویکرد احتمالی (مدل مارکوف پنهان (HMM)) [ 14 ] در ادبیات تشخیص جابجایی افقی یک رویکرد مبتنی بر قاعده دست ساز را می توان به عنوان شکلی از درخت تصمیم در نظر گرفت که قوانین «اگر-پس» با استفاده از دانش متخصص تنظیم می شوند. بنابراین، فرآیند تصمیم گیری تفسیری تر از آنچه درخت تصمیم J48 ارائه می دهد است. با این حال، این رویکرد مستلزم طراحی دقیق قانون است، و بنابراین، موردی با تعداد کمی از کلاسهای تشخیص مناسب به نظر میرسد، به عنوان مثال، سه برای [ 6]] و دو برای [ 12 ]. مشکل تشخیص رفتار اجتنابی را می توان به عنوان یک تشخیص الگوی سری زمانی در نظر گرفت، که در آن HMM یکی از موارد زیر است: گفتار رویکرد عمومی [ 19 ]، شخصیت دست نویس [ 20 ] و تشخیص اشاره [ 21 ]. با این حال، سیستم مبتنی بر HMM در نظر گرفته میشود که به مقدار قابلتوجهی آموزش برای دادهها برای عملکرد خوب نیاز دارد [ 22 ، 23 ]. بر اساس این ملاحظات، ما از یک طبقهبندی یادگیری نظارت شده استفاده کردیم. مقایسه بین انواع مختلف طبقه بندی کننده ها در بخش 4.2 ارائه شده است .
4. آزمایش آفلاین
یک آزمایش آفلاین بر روی جنبههای مختلف، مانند ویژگیهای کمککننده و تفاوت در افراد، موقعیتهای ذخیرهسازی و اندازه موانع، علاوه بر عملکرد طبقهبندی اولیه، انجام شد.
4.1. مجموعه داده
جمع آوری داده ها همانطور که در جدول 2 خلاصه شده است انجام شد و شکل 7 صحنه جمع آوری داده ها را نشان می دهد. علامت “صلیب” به عنوان مانع روی زمین قرار گرفت. از آزمودنی ها خواسته شد تا در مسیر مستقیم راه بروند و در عین حال از موانع با انواع رفتارهای اجتنابی جهت دار اجتناب کنند. حدود هفت متر پشت وسط مانع شروع به راه رفتن کردند. زمان شروع و پایان در هر رفتار اجتنابی بر اساس تصمیمات آنها بود، اگرچه از آنها خواسته شد از نقطه ای عبور کنند که نشان دهنده لبه یک مانع است. تقسیم بندی با دست انجام شد.
علاوه بر داده های اصلی، ما سنتز کردیم avoidLR�������، avoidL������و returnL�������بر اساس یافته هایی که رفتارهای اجتنابی دارای تقارن چپ و راست هستند [ 18 ]. همانطور که در رابطه ( 3 ) نشان داده شده است، سنتز با معکوس کردن علامت هر نمونه محقق می شود. اینجا، aL,k��,�و aR,k��,�در دادههای جمعآوریشده و در دادههای سنتز شده به ترتیب k- امین نمونه را نشان میدهند . در نهایت، مشخصات مجموعه داده جمع آوری شده و سنتز شده در جدول 3 خلاصه شده است . توجه داشته باشید که دادههای با اندازههای مانع 0.5 و 1.0 متر فقط در بخش 4.6 برای ارزیابی استحکام طبقهبندی کننده در برابر اندازه ناشناخته موانع استفاده شده است .
aL,k=−aر ، ک��,�=−��,�
توجه داشته باشید که اندازه گیری آزیموت به مغناطیس سنج متکی است که ممکن است تحت تأثیر ساختار معماری، از جمله فلز، جریان ولتاژ بالا و مغناطیس باشد. جمعآوری دادهها در محیطی انجام شد که هیچ ساختمان و ماشینآلاتی در اطراف سوژهها وجود نداشت، که در آن هیچ گونه خواندن ناپایداری از حسگر مشاهده نشدیم. با این حال، برای مشاهده اینکه آیا اختلالی در خواندن سنسور وجود دارد، ما به طور تجربی در نزدیکی واحدهای بیرونی تهویه مطبوع، وسایل نقلیه، ماشینهای فروش خودکار، دیوار بیرونی ساختمانها و غیره قدم زدیم و نموداری از جریان داده را به صورت بصری بررسی کردیم. در نتیجه، در موارد بسیار محدود عبور از یک وسیله نقلیه الکتریکی و عبور از یک گذرگاه باریک که توسط یک دیوار بتونی مسلح احاطه شده بود، اختلال پیدا کردیم. در هر دو مورد، به نظر می رسد داده ها به طور تصادفی و به سرعت در حال تغییر هستند. از این رو، ما در نظر داریم که چنین وضعیتی برای جلوگیری از تشخیص نادرست رفتار اجتنابی قابل تشخیص است. با این حال، برای شناسایی رفتار اجتنابی که در چنین موقعیتی رخ می دهد، مطالعه بیشتری مورد نیاز است.
4.2. عملکرد طبقه بندی پایه
4.2.1. روش
اول از همه، انواع مختلفی از روشهای طبقهبندی، به عنوان مثال، طبقهبندیکنندهها، با استفاده از اعتبارسنجی متقاطع 10 برابری (CV) برای تثبیت یک طبقهبندی برای ارزیابی بعدی، مقایسه میشوند. در اینجا، بیز ساده (رویکرد پایه)، شبکه بیزی (رویکرد مدل گرافیکی)، پرسپترون چند لایه (MLP، رویکرد شبکه عصبی مصنوعی)، بهینهسازی حداقل متوالی (SMO، رویکرد ماشین بردار پشتیبانی)، درخت تصمیم (J48) ) و جنگل تصادفی (رویکرد یادگیری گروهی) استفاده شد. جدول 4 پارامترهای هر طبقه بندی مورد استفاده در ابزار یادگیری ماشین Weka ver را خلاصه می کند. 7.3.13 [ 24 ]، که در آن از مقادیر پیش فرض استفاده شده است. نمادهای پارامتر را می توان به عنوان راهنمای مرجع Weka نام برد.
4.2.2. نتیجه و تجزیه و تحلیل
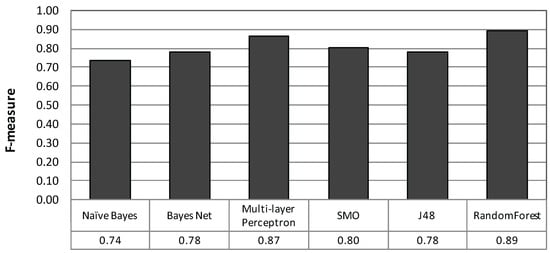
شکل 8 اندازه گیری F هر طبقه بندی کننده را نشان می دهد که در آن جنگل تصادفی به دنبال MLP بهترین عملکرد را داشت. یکی دیگر از مزایای جنگل تصادفی تعداد کم پارامترهای تنظیم است. در پیاده سازی Weka، تعداد پارامترهای اصلی دو است، در حالی که پارامتر MLP پنج است. بنابراین، ما در نظر می گیریم که جنگل تصادفی برای تنظیم آسان است. از این پس از جنگل تصادفی با 100 درخت استفاده می شود.
جدول 5 ماتریس سردرگمی را نشان می دهد که در آن ردیف نشان دهنده کلاس برچسب گذاری شده و ستون نتیجه شناسایی است. جدول 6 نتایج فراخوانی، دقت و اندازه گیری F را خلاصه می کند. توجه داشته باشید که ما نتایج شناسایی را با کمترین تعداد بخش در سراسر این مقاله عادی کردیم زیرا تعداد داده ها بر اساس کلاس متفاوت است، همانطور که در جدول 3 نشان داده شده است . نتیجه یک عملکرد طبقه بندی متوسط با اندازه گیری F 0.89 و دامنه ای از 0.84 تا 1.00 را نشان می دهد.
کلاس ها a v o iدR L�������و a v o iدال آر�������به اشتباه طبقه بندی شدند a v o iدآر������و a v o iدL������، به ترتیب. ما در نظر می گیریم که این اتفاق افتاده است زیرا نیمه دوم بخش این کلاس ها مسطح است که تشخیص کلاس ها از یکدیگر را دشوار می کند. متقابلا، r e t u rnآر�������و r e t u rnL�������کاملا طبقه بندی شدند ما فرض کردیم که شروع و پایان مسیر راه رفتن از a v o i d�����یکسان هستند، در حالی که شروع و پایان r e t u r n������متفاوت هستند، یعنی در طرف مقابل. ما در نظر داریم که ویژگی های r e t u r n������تفاوت های زیادی با آنها داشت a v o i d�����.
تشخیص کلاس ناهنجاری جاده برای اداره راهداری مفید است. با این حال، برای اولویت بندی وظایف تعمیر آنها، اندازه ناهنجاری جاده باید تشخیص داده شود، زیرا یک رفتار اجتنابی بزرگ نشان دهنده اهمیت ناهنجاری است. در حال حاضر، ما یک مجموعه داده با پنج اندازه مانع داریم. تعریف کلاس های جدید برای هر اندازه عملی نیست. بنابراین، ما یک مدل رگرسیون بر اساس برخی ویژگیها و اندازه موانع خواهیم ساخت که پس از طبقهبندی مجموعههای داده در شش کلاس رفتار اجتنابی اعمال خواهد شد.
4.3. ارتباط ویژگی
4.3.1. روش
برای درک ویژگیهای مؤثر برای تشخیص رفتار اجتنابی، ارتباط ویژگیها بر اساس تئوری اطلاعات ارزیابی شد. بهره اطلاعات معمولاً در انتخاب ویژگی استفاده می شود، جایی که سود اطلاعات ارائه شده توسط یک ویژگی خاص با کم کردن یک آنتروپی شرطی با آن ویژگی از آنتروپی تحت یک حدس تصادفی محاسبه می شود [25 ] . ما از InfoGainAttributeEval و Ranker در Weka [ 24 ] به ترتیب به عنوان پیاده سازی برای ارزیابی به دست آوردن اطلاعات و ایجاد رتبه بندی استفاده کردیم.
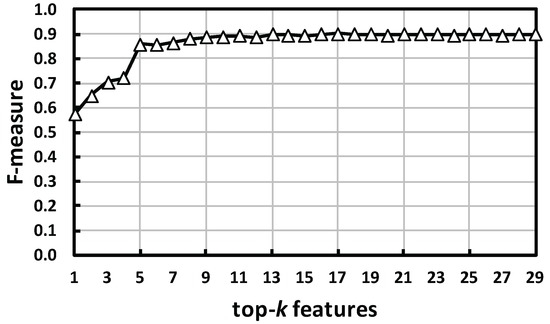
همانطور که در بخش 3.3.2 توضیح داده شد ، جدول 1 قبلاً به ترتیب مشارکت (ارتباط) با پیاده سازی های فوق فهرست شده است. برای مشاهده تغییر عملکرد طبقهبندی در برابر تعداد ویژگیها، یک اعتبارسنجی متقاطع 10 برابری در برابر یک مجموعه داده با ویژگیهای top- k انجام شد و اندازهگیریهای F محاسبه شد. در اینجا، k از یک (بهترین) تا 29 (همه) متغیر است.
4.3.2. نتیجه و تجزیه و تحلیل
همانطور که در شکل 9 نشان داده شده است ، اندازه گیری F برای پنج ویژگی برتر به سرعت افزایش می یابد. از 6 تا 20 ویژگی برتر، F-measure به تدریج با حرکات بسیار خفیف بالا و پایین افزایش می یابد. در نهایت، افزایش تقریباً برای بیش از 20 ویژگی کاهش می یابد. همانطور که در بخش 3.3.2 توضیح داده شد ، یک قطعه را به دو قسمت تقسیم کردیم: نیمه اول (FH) و نیمه دوم (SH) ( شکل 5 را ببینید ). با مشاهده جدول 1، چهار ویژگی اصلی کمک کننده از SH مشتق شده اند. این نشان می دهد که تصمیم برای محاسبه ویژگی ها با تقسیم آنها به FH و SH صحیح بوده است. توجه داشته باشید که تقسیم دو قسمت بر اساس تعداد نمونه ها در یک بخش با این فرض است که مردم با سرعت ثابت راه می روند. با این حال، در عمل، سرعت ممکن است در مجاورت یک مانع تغییر کند. این باعث می شود که دو قسمت تقسیم شده به اندازه آنچه در شکل 5 نشان داده شده است واضح نباشد . تشخیص چنین نقطه تغییری بر تفاوت فعالیت ها با وضوح بیشتری تأکید می کند و عملکرد را بهبود می بخشد.
علاوه بر این، «نسبت دامنهA L Lrange���به ΔSF” ( f8�8) که برای بدست آوردن یکنواختی تغییر اضافه شد، به عنوان هشتمین رتبه بندی ظاهر شد. در دو سوم رتبه بندی، ویژگی هایی یافت می شود که مقادیر منفی را حذف می کند ( f12�12، f14�14، f17�17، f25�25، f26�26و f28�28). این بدان معناست که جزء جهت مهمتر از بزرگی حرکت است. برخلاف انتظار تغییر آزیموت انباشته شرح داده شده در بخش 3.3.2 ، “مجموع تفاوت مطلق هر دو انتهای 10 زیربخش” در رتبه بیستم ظاهر می شود. f20�20). ما آن را در نظر می گیریم f20�20به تبعیض کمک می کند r e t u r n�هتیتو��از جانب a v o i dآ��مندبه دلیل تغییر بزرگ جهت با این حال، تفاوت تغییر انباشته بین a v o iدآرآ��مندآرو a v o iدLآ��مند�به اندازه سایر ویژگی ها بزرگ نیست و کمتر کمک کننده است. علاوه بر این، از آنجا که f20�20نشان دهنده میزان تغییر است، تشخیص آن دشوار است a v o iدR Lآ��مندآر�از جانب a v o iدال آرآ��مند�آر، که نسبت به محور افقی متقارن هستند.
4.4. وابستگی به شخص
4.4.1. روش
عملکرد طبقه بندی نشان داده شده در بخش 4.2 با اعتبارسنجی متقاطع 10 برابری در برابر مجموعه داده از همه افراد به دست آمد. این نشان دهنده میانگین عملکرد روش طبقه بندی است. برای ارزیابی روش در شرایط واقعی، که در آن دادههای کاربر برای آموزش طبقهبندیکننده استفاده نمیشود، اعتبارسنجی متقاطع ترک یک موضوع (LOSO-CV) را انجام دادیم. در LOSO-CV، مجموعه داده های یک موضوع خاص برای اهداف آزمایشی استفاده می شود، در حالی که مجموعه داده های بقیه گروه موضوعی، یعنی هشت موضوع، برای آموزش یک طبقه بندی کننده استفاده می شود. این فرآیند برای همه آزمودنی ها تکرار شد و میانگین محاسبه شد.
پیشبینی اینکه بهترین عملکرد از طریق استفاده از یک طبقهبندیکننده شخصیشده به دست میآید، که در آن طبقهبندیکننده با مجموعه دادههای یک شخص خاص آموزش داده میشود و با مجموعه دادههای همان شخص آزمایش میشود، دشوار نیست (به عنوان مثال، [26] ) . بنابراین، برای مشاهده عملکرد در این بهترین شرایط، اعتبارسنجی متقاطع 10 برابری را با استفاده از طبقهبندیکنندههای شخصیسازی شده انجام دادیم. این ارزیابی به عنوان خود CV نامیده می شود.
4.4.2. نتیجه و تجزیه و تحلیل
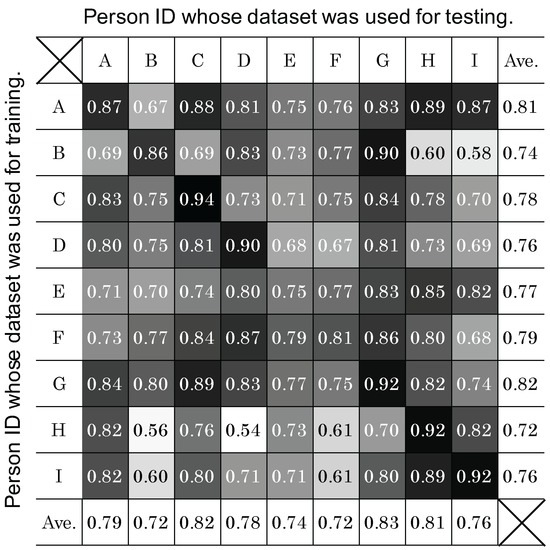
شکل 10 مقایسه تفاوت های فردی (موضوع A تا I) و میانگین ها را برای دو شرایط ارزیابی نشان می دهد. همانطور که در این شکل نشان داده شده است، همه آزمودنی ها عملکرد طبقه بندی برابر یا بهتری با خود CV نسبت به LOSO-CV داشتند. به طور متوسط، self-CV بهتر از LOSO-CV با اختلاف F-measure 0.07 عمل کرد.
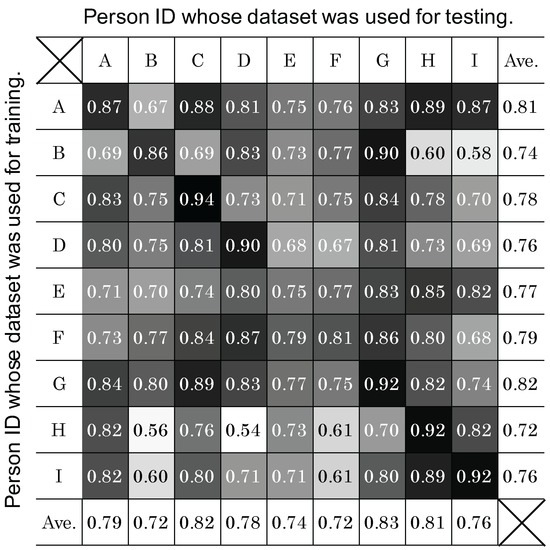
تفاوت بین F-Measure self-CV و LOSO-CV برای افراد B، D و I نسبتاً زیاد است (به ترتیب 0.11، 0.12 و 0.15). برای تجزیه و تحلیل دلایل، یک طبقه بندی برای هر موضوع تنظیم شد. سپس طبقهبندیکنندهها با مجموعه دادههای سایر افراد مورد آزمایش قرار گرفتند. شکل 11 اندازه گیری های F حاصل را خلاصه می کند. در این جدول، سطوح خاکستری به ترتیب بین مقادیر حداقل (0.54) و حداکثر (0.94) به سفید و سیاه نرمال شده است. علاوه بر این، مقادیر روی خط مورب همان شناسههای موضوعی نشاندهنده F-اندازهگیری از خود CV است که در ردیف اول شکل 10 نیز نشان داده شده است.. در نتیجه، ما در نظر می گیریم که داده های “نویز” در LOSO-CV برای موضوعات B، D و I گنجانده شده است. به عبارت دیگر، برخی از داده های آموزشی ممکن است دارای موضوعاتی باشند که داده های آنها با موضوعات B، D و I ناسازگار باشد. در شکل 11به نظر می رسد موضوع H با موضوعات B و D ناسازگار باشد، همانطور که با کمترین مقادیر در هر ستون نشان داده شده است (به ترتیب 0.56 و 0.54). علاوه بر این، به نظر می رسد موضوع B برای موضوع I (0.58) یک موضوع ناسازگار باشد. برای تأیید این افکار، ما طبقهبندیکنندههایی را با مجموعه دادههایی از موضوعات «سازگار» به شرح زیر ساختیم. ابتدا، میانگین F-Measure به استثنای مقدار self-CV برای هر ستون محاسبه می شود. سپس، مجموعه دادههای آزمودنیهایی که طبقهبندیکنندههای شخصیشده آنها بهتر از میانگین عمل میکنند، برای آموزش یک طبقهبندی جدید استفاده میشوند. از این رو، آزمودنیهای C، D، E، F و G بهعنوان آزمودنیهای سازگار برای موضوع B انتخاب شدند، در حالی که آزمودنیهای A، B، E، F و G به عنوان آزمودنیهای سازگار برای موضوع D انتخاب شدند. افراد A، E، G و H انتخاب شدند. در نتیجه آزمایش با این طبقهبندیکنندههای جدید، اندازه گیری F LOSO-CV در برابر افراد B، D و I به ترتیب به 0.80، 0.85 و 0.86 بهبود یافت. این افزایش 0.05، 0.07 و 0.09 نسبت به LOSO-CV اصلی بود. در آینده، روشی را برای یافتن افراد سازگار برای ساخت یک طبقهبندی کننده به صورت سیستماتیک بررسی خواهیم کرد.
F-اندازه گیری های خود رزومه برای افراد E و F نسبتا کم است، به عنوان مثال، 0.75 و 0.81، به ترتیب. این نشان میدهد که ویژگیهای بهدستآمده از آنها نتوانستند ویژگیهای رفتارهای هدف را به دلیل تنوع زیاد درون آزمودنیها به تصویر بکشند. علاوه بر این، میانگین تعداد بخش ها در هر کلاس برای موضوعات E و F به ترتیب 48 و 52 است که از جدول 3 محاسبه شده است . بنابراین، طبقهبندیکنندههای این موضوعات به ترتیب با حدود 44 و 47 بخش (نهدهم تعداد بخشها) آموزش داده میشوند. ما در نظر داریم که این دسته بندی کننده ها به اندازه کافی آموزش ندیده اند.
4.5. اثر موقعیت ذخیره سنسور
4.5.1. روش
همانطور که توسط Ichikawa و همکاران بررسی شده است. [ 27 ]، مردم پایانه های تلفن هوشمند خود را در موقعیت های مختلفی مانند جیب شلوار و جیب سینه حمل می کنند. ما آزمایشی را برای مشاهده تأثیر موقعیت ذخیره سازی بر عملکرد طبقه بندی انجام دادیم. این آزمایش با آموزش یک طبقهبندی کننده با مجموعه داده از یک موقعیت خاص و آزمایش طبقهبندی با مجموعه دادهها از موقعیتهای دیگر انجام شد.
4.5.2. نتیجه و تجزیه و تحلیل
جدول 7 نتایج اندازه گیری F را خلاصه می کند. در این جدول، ردیف موقعیتهای ذخیرهسازی را نشان میدهد که مجموعههای داده برای طبقهبندیکنندههای موقعیت خاص آموزش از آنها به دست آمدهاند، و ستون نشاندهنده مجموعههای داده برای آزمایش است. توجه داشته باشید که مقادیر روی خط مورب در همان موقعیت ها با اعتبارسنجی متقاطع 10 برابری به دست آمده است. این مقادیر عملکرد ایده آل را زمانی که طبقه بندی کننده ها برای موقعیت های اختصاصی تنظیم شده اند نشان می دهد و میانگین آن 0.87 است. جدول نشان می دهد که طبقه بندی کننده های تنظیم شده برای موقعیت های خاص عمدتاً بهترین عملکرد را نداشتند. این مشاهدات به ما امکان می دهد دو رویکرد را برای ساخت مدل های طبقه بندی پیشنهاد کنیم.
اولین رویکرد، رویکردی ساده است که یک طبقهبندی کننده واحد با مجموعه دادهها از همه موقعیتها ایجاد میکند. این موردی است که در بخش 4.2 نشان داده شده استو یک F-Measure 0.89 بدست می آوریم. این بهتر از میانگین رویکرد طبقه بندی کننده تنظیم شده (0.87) است. با این حال، برای تحقق این رویکرد، مجموعه داده ها از همه موقعیت ها باید جمع آوری شوند. رویکرد دوم، اشتراکگذاری طبقهبندیکنندهها با برخی موقعیتها است. در این مورد، یک طبقهبندیکننده تنظیمشده برای موقعیت «دست» با موردی که در آن موقعیت ترمینال بهعنوان «جیب سینه» قضاوت میشود، به اشتراک گذاشته میشود، زیرا عملکرد «جیب سینه» با استفاده از طبقهبندیکننده تنظیمشده برای «دست» است. به اندازه یک طبقه بندی تنظیم شده برای “جیب سینه”. این می تواند جمع آوری داده های آموزشی را برای طبقه بندی کننده “جیب سینه” حذف کند. به طور مشابه، طبقهبندیکنندهای که از مجموعه دادههای «جیب پشت شلوار» ساخته شده است با دادههای بهدستآمده از «جیب جلوی شلوار» به اشتراک گذاشته میشود. همانطور که در [ 26]، جیب های جلو و پشت شلوار اغلب برای یکدیگر اشتباه تشخیص داده می شوند. بنابراین، اشتراکگذاری طبقهبندیکننده بین دو موقعیت میتواند در برابر اشتباه تشخیصدهنده موقعیت ذخیرهسازی زیربنایی قوی شود. در رویکرد دوم، میانگین اندازه گیری F 0.88 است. جدول 8 نتیجه را خلاصه می کند. روش دوم یک اندازه گیری F کمی بدتر دارد. با این حال، فقط باید مجموعه داده را از دو موقعیت “دست” و “جیب پشت شلوار” جمع آوری کند، که ما آن را یک مزیت بزرگ در کاهش هزینه جمع آوری داده ها می دانیم. چنین مدل سازی کم هزینه استقرار سیستم را تسریع می کند. رویکرد اشتراکگذاری ممکن است دقت تشخیص را قربانی کند. با این حال، اگر تعدادی از افراد از سیستم استفاده کنند، می تواند در سمت سرور بهبود یابد.
4.6. استحکام تا اندازه مانع نامشخص
4.6.1. روش
ارزیابیهای عملکرد بالا توسط طبقهبندیکنندههای آموزش دیده توسط مجموعههای داده با اندازههای مانع 0.2، 0.7 و 1.5 متر انجام شد. برای درک استحکام در برابر اندازههای ناشناخته موانع، از مجموعه دادههای اندازه موانع 0.5 و 1.0 متر برای آزمایش استفاده کردیم که در آن از مجموعه دادههای اندازه موانع 0.2، 0.7 و 1.5 متر برای آموزش طبقهبندیکنندهها استفاده شد.
4.6.2. نتیجه و تجزیه و تحلیل
اندازه گیری های F نتایج در جدول 9 نشان داده شده است ، جایی که می توانیم دریابیم که همه مقادیر بهتر از مقادیر موجود در سمت راست ترین ستون در جدول 6 هستند . ما در نظر می گیریم که این به این دلیل است که اندازه مانع استفاده شده برای این آزمون در محدوده مجموعه داده آموزشی است، یعنی 0.2 تا 1.5 متر. بنابراین، ویژگی های به دست آمده از مجموعه داده با اندازه موانع ناشناخته ممکن است در محدوده ویژگی های آموزش دیده قرار گیرند. نتیجه نشان می دهد که یک طبقه بندی کننده می تواند با اندازه محدودی از موانع آموزش داده شود، به عنوان مثال، احتمالاً برای تشخیص اندازه های بالا، متوسط و پایین موانع.
5. نتیجه گیری ها
در این مقاله، ما یک سیستم تشخیص ناهنجاری جادهای را بر اساس سنجش فرصتطلب با استفاده از پایانههای تلفن هوشمند عابران پیاده ارائه کردیم. سنجش فرصتطلبانه نیازی به دخالت صریح کاربر ندارد، که انتظار میرود مانع مشارکت مردم در فعالیت سنجش کاهش یابد. اگرچه روشهای تشخیص خودکار ناهنجاری جاده قبلاً برای اتومبیلها و دوچرخهها پیشنهاد شده است، ما در نظر گرفتیم که رفتارهای اجتنابی عابران پیاده برای انطباق با این روشهای موجود بسیار ناچیز است. پس از نشان دادن مفهوم کلی سیستم، ما بر روی طراحی یک سیستم تشخیص رفتار اجتناب از مانع تمرکز کردیم که در آن شکلدهی شکل موج، استخراج ویژگی و طبقهبندیکنندههای نظارت شده به عنوان اجزای اصلی ارائه شد. پس از جمعآوری دادهها از 9 نفر با 410 کارآزمایی، شش کلاس از رفتارهای اجتنابی برای آزمایش سیستم تشخیص از جنبههای مختلف تعریف شد. نتایج زیر بدست آمده اند:
-
یک CV 10 برابر عملکرد متوسط طبقه بندی با اندازه گیری F 0.89 را برای شش رفتار اجتنابی نشان داد.
-
سیستم تشخیص می تواند اندازه موانع 0.2 تا 1.5 متر را تحمل کند. اندازه های آموزش ندیده اجتناب از مانع نیز با اندازه گیری F 0.94 شناسایی شد.
-
یک طبقهبندی مستقل از کاربر، شش رفتار اجتنابی را با اندازهگیری F 0.81 طبقهبندی کرد. امکان بهبود طبقهبندی مستقل از کاربر با انتخاب طبقهبندیکنندههای آموزش دیده توسط افراد سازگار نشان داده شد.
-
ویژگی های حاصل از (1) تقسیم یک بخش به نیمه اول و نیمه دوم و (2) در نظر گرفتن یکنواختی تغییر به طور مؤثر رفتارهای اجتنابی را تشخیص داد.
-
عملکرد کمی به موقعیت ذخیره سنسور (تلفن هوشمند) روی بدنه بستگی دارد. انتخاب یک طبقه بندی کننده برای یک موقعیت خاص باعث بهبود عملکرد می شود. برای کاهش هزینه جمعآوری دادهها، فقط باید دادههای «دست» و «جیب پشت شلوار» جمعآوری شود.
نتایج تحت یک محیط ایده آل و کنترل شده به دست می آید. با این حال، نتایج نشان میدهد که روش تشخیص پیشنهادی در برابر اندازه موانع قوی است و اینکه وابستگی به موقعیت ذخیرهسازی یک گوشی هوشمند میتواند توسط یک طبقهبندی کننده مناسب در هر موقعیت ذخیرهسازی کنترل شود. علاوه بر این، تجزیه و تحلیل نشان می دهد که طبقه بندی داده ها از یک فرد “ناشناس” می تواند با در نظر گرفتن سازگاری یک طبقه بندی کننده بهبود یابد. گام بعدی به سمت یک سیستم تشخیص ناهنجاری جاده ای همه در یک، بررسی یک روش تقسیم خودکار رویداد اجتنابی است که به صورت دستی در این مقاله انجام شد. چالش اصلی تمایز قائل شدن رفتارهای عادی است که با تغییر جهت پیاده روی همراه است، به عنوان مثال، یک عابر پیاده به گوشه ای بپیچد یا در امتداد یک جاده منحنی راه برود. از اجتناب واقعی از موانع ما از ویژگیهای تفاوت آزیموت و مسافت پیادهروی برای تکمیل تغییر جهت راه رفتن برای تشخیص این موقعیتها استفاده میکنیم. یک آزمایش در دنیای واقعی نیز برای ارزیابی استحکام سیستم پیشنهادی مورد نیاز است. عملیات کم مصرف یک مسئله حیاتی برای سنجش فرصت طلبانه است که توسط مردم پذیرفته شود زیرا موقعیت یابی مبتنی بر GPS عموماً یک رویکرد انرژی بر است.28 ]. برخلاف موقعیتیابی پیوسته، مانند نقشه نویز [ 29 ]، سیستم ما میتواند موقعیتیابی مبتنی بر رویداد را اتخاذ کند، که در آن موقعیتیابی تنها زمانی انجام میشود که یک مانع شناسایی شود. چالش در اینجا خطای موقعیت یابی به دلیل تأخیر فعال کردن گیرنده GPS است، به عنوان مثال، موقعیت واقعی یک رویداد اجتنابی ممکن است از موقعیتی که گیرنده GPS برمیگردد عقب باشد. ما یک روش تصحیح را با استفاده از فناوری محاسبه مرده عابر پیاده (PDR) بررسی خواهیم کرد. در نهایت، تجمع سمت سرور و تکنیک فیلتر برای تحقق سیستم کلی مورد بررسی قرار خواهد گرفت.
منابع
- شهر چیبا آزمایش میدانی Chiba-Repo: گزارش مرور. 2013. موجود به صورت آنلاین: http://www.city.chiba.jp/shimin/shimin/kohokocho/documents/chibarepo-hyoukasho.pdf (دسترسی در 30 سپتامبر 2016).
- mySociety Limited. FixMyStreet. در دسترس آنلاین: http://fixmystreet.org (در 30 سپتامبر 2016 قابل دسترسی است).
- گلدمن، جی. شیلتون، ک. بورک، جی. استرین، دی. هانسن، ام. راماناتان، ن. ردی، اس. سامانتا، وی. سریواستاوا، م. غرب، آر. حس مشارکتی: رویکردی مبتنی بر شهروندی برای روشن کردن الگوهایی که جهان ما را شکل میدهند . پروژه آینده نگری و حکومت داری، کاغذ سفید. مرکز بین المللی وودرو ویلسون برای محققان: واشنگتن، دی سی، ایالات متحده آمریکا، 2009. [ Google Scholar ]
- لین، ND؛ میلوزو، ای. لو، اچ. پیبلز، دی. چودوری، تی. کمپبل، AT بررسی سنجش تلفن همراه. IEEE Commun. Mag. 2010 ، 48 ، 140-150. [ Google Scholar ] [ CrossRef ]
- کاررا، اف. گورین، اس. Thorp، JB توسط مردم، برای مردم: جمع سپاری “STREETBUMP”: یک برنامه خودکار نقشه برداری چاله ها. ISPRS Int. قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2013 ، XL-4/W1 ، 19-23. [ Google Scholar ] [ CrossRef ]
- چن، دی. چو، KT; هان، اس. جین، ز. Shin, KG حس نامرئی فرمان خودرو با گوشی های هوشمند. در مجموعه مقالات سیزدهمین کنفرانس بین المللی سالانه سیستم های تلفن همراه، برنامه ها و خدمات (MobiSys ’15)، فلورانس، ایتالیا، 18-22 مه 2015. صص 1-13.
- اریکسون، جی. جیرود، ال. هال، بی. نیوتن، آر. مدن، اس. Balakrishnan، H. The Pothole Patrol: با استفاده از یک شبکه حسگر موبایل برای نظارت بر سطح جاده. در مجموعه مقالات ششمین کنفرانس بین المللی سیستم های تلفن همراه، برنامه ها و خدمات (MobiSys ’08)، برکنریج، CO، ایالات متحده آمریکا، 17-20 ژوئن 2008. ص 29-39.
- کاندا، س. اسدا، س. یاماموتو، ای. کواچی، ی. تاباتا، Y. یک روش تشخیص خطر برای دوچرخه ها با استفاده از دوچرخه پروب. در مجموعه مقالات سی و هشتمین کنفرانس بین المللی نرم افزار و برنامه های کامپیوتری IEEE (COMPSACW)، وستراس، سوئد، 21 تا 25 ژوئیه 2014. صص 547-551.
- موهان، پ. Padmanabhan، VN; Ramjee, R. Nericell: نظارت غنی بر شرایط جاده و ترافیک با استفاده از تلفن های هوشمند موبایل. در مجموعه مقالات ششمین کنفرانس ACM در مورد سیستم های حسگر شبکه جاسازی شده (SenSys ’08)، رالی، NC، ایالات متحده آمریکا، 4-7 نوامبر 2008. صص 323-336.
- ایشیکاوا، تی. فوجینامی، K. شناسایی رفتار اجتنابی عابر پیاده برای تشخیص ناهنجاری جاده در شهر. در مجموعه مقالات کنفرانس مشترک بین المللی ACM در مورد محاسبات فراگیر و همه جا حاضر و سمپوزیوم بین المللی ACM در مورد رایانه های پوشیدنی (UbiComp/ISWC ’15)، اوزاکا، ژاپن، 7-11 سپتامبر 2015. ص 201-204.
- بوراسکار، ر. وانکاهارا، ن. رامان، بی. Kulkarni، P. Wolverine: برآورد وضعیت ترافیک و جاده با استفاده از حسگرهای تلفن هوشمند. در مجموعه مقالات چهارمین کنفرانس بین المللی IEEE در مورد سیستم ها و شبکه های ارتباطی (COMSNETS)، بنگلور، هند، 3 تا 7 ژانویه 2012. صص 1-6.
- کامیمورا، تی. کیتانی، تی. Kovacs، DL طبقه بندی خودکار داده های سنجش حرکت موتور سیکلت. در مجموعه مقالات کنفرانس بین المللی IEEE در مورد لوازم الکترونیکی مصرفی-تایوان (ICCE-TW)، تایپه، تایوان، 26-28 مه 2014. صص 145-146.
- سراج، ف. ون در زواگ، BJ; دیلو، ا. لوراسی، ت. Havinga، PJM RoADS: یک سیستم نظارت بر روسازی جاده برای تشخیص ناهنجاری با استفاده از تلفن های هوشمند. در مجموعه مقالات اولین کارگاه بین المللی در مورد یادگیری ماشین برای داده های حسگر شهری، SenseML 2014، نانسی، فرانسه، 15 سپتامبر 2014. صص 1-16.
- تپویلوجاناپونگ، ن. سوگو، ک. نامیکی، ی. Tobe، Y. تشخیص حالات دوچرخه سواری با HMM بر اساس داده های شتاب سنج و مغناطیس سنج. در مجموعه مقالات کنفرانس سالانه SICE (SICE)، توکیو، ژاپن، 13 تا 18 سپتامبر 2011. صص 831-832.
- ایوازاکی، جی. یاماموتو، ای. Kaneda، S. سیستم اشتراک گذاری اطلاعات جاده برای کاربران دوچرخه با استفاده از تلفن های هوشمند. در مجموعه مقالات چهارمین کنفرانس جهانی IEEE در مورد لوازم الکترونیکی مصرفی (GCCE)، اوزاکا، ژاپن، 27 تا 30 اکتبر 2015. صص 674-678.
- جین، اس. بورجیاتینو، سی. رن، ی. گروتسر، م. چن، ی. Chiasserini، CF LookUp: فعال کردن خدمات ایمنی عابر پیاده از طریق حسگر کفش. در مجموعه مقالات سیزدهمین کنفرانس بین المللی سالانه سیستم های تلفن همراه، برنامه ها و خدمات (MobiSys ’15)، فلورانس، ایتالیا، 18-22 مه 2015. صص 257-271.
- الساندرونی، جی. کلوپفنشتاین، ال سی. دلپریوری، س. درومداری، م. لوچتی، جی. پائولینی، بی.دی. سراقیتی، ع. لاتانزی، ای. فرشی، وی. کارینی، ا. و همکاران SmartRoadSense: نظارت مشترک بر وضعیت سطح جاده. در مجموعه مقالات هشتمین کنفرانس بین المللی محاسبات همه جا حاضر موبایل، سیستم ها، سرویس ها و فناوری ها، رم، ایتالیا، 24 تا 28 اوت 2014. ص 210-215.
- طاطبه، ک. ناکاجیما، H. رفتار اجتنابی در برابر یک مانع ثابت تحت راه رفتن تک: مطالعه ای در مورد رفتار عابر پیاده در اجتناب از موانع (I). جی آرچیت. طرح. محیط زیست مهندس 1990 ، 418 ، 51-57. [ Google Scholar ]
- Rabiner, LR آموزش مدل های پنهان مارکوف و برنامه های منتخب در تشخیص گفتار. Proc. IEEE 1989 ، 77 ، 257-286. [ Google Scholar ] [ CrossRef ]
- هو، جی. براون، MK; تشخیص دست خط آنلاین مبتنی بر تورین، W. HMM. IEEE Trans. الگوی مقعدی ماخ هوشمند 1996 ، 18 ، 1039-1045. [ Google Scholar ]
- ویلسون، AD; Bobick، مدل های مارکوف پنهان پارامتریک AF برای تشخیص ژست. IEEE trans. الگوی مقعدی ماخ هوشمند 1999 ، 21 ، 884-900. [ Google Scholar ] [ CrossRef ]
- لیو، جی. ژونگا، ال. ویکراماسوریاب، ج. Vasudevanb، V. uWave: تشخیص حرکت شخصی مبتنی بر شتاب سنج، برنامه های کاربردی آن. اوباش فراگیر. محاسبه کنید. 2009 ، 5 ، 657-675. [ Google Scholar ] [ CrossRef ]
- راجکو، س. کیان، جی. اینگالس، تی. James, J. تشخیص حرکات در زمان واقعی با حداقل نیازهای آموزشی و یادگیری آنلاین. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو، مینیاپولیس، MN، ایالات متحده، 17-22 ژوئن 2007. صص 1-8.
- گروه یادگیری ماشین در دانشگاه وایکاتو. Weka 3 — داده کاوی با نرم افزار یادگیری ماشین منبع باز در جاوا. در دسترس آنلاین: http://www.cs.waikato.ac.nz/ml/weka/ (دسترسی در 30 سپتامبر 2016).
- ویتن، آی اچ. فرانک، ای. هال، کارشناسی ارشد داده کاوی: ابزارها و تکنیک های یادگیری ماشین عملی ، ویرایش سوم. Morgan Kaufmann Publishers: San Francisco, CA, USA, 2011. [ Google Scholar ]
- فوجینامی، ک. کوچی، اس. تشخیص موقعیت ذخیره سازی تلفن همراه به عنوان زمینه یک دستگاه و کاربر. در مجموعه مقالات نهمین کنفرانس بین المللی سیار و سیستم های همه جا حاضر: محاسبات، شبکه و خدمات (MobiQuitous)، پکن، چین، 12 تا 14 دسامبر 2012. صص 76-88.
- ایچیکاوا، اف. چیپچیز، جی. گریگنانی، آر. تلفن کجاست؟ بررسی مکان تلفن همراه در فضاهای عمومی در مجموعه مقالات دومین کنفرانس بین المللی فناوری تلفن همراه، برنامه ها و سیستم ها، گوانگژو، چین، 15-17 نوامبر 2005. صص 1-8.
- بن ابدسلم، اف. فیلیپس، ای. هندرسون، تی. در مجموعه مقالات اولین کارگاه ACM در مورد شبکهسازی، سیستمها و برنامههای کاربردی برای موبایلهای دستی (MobiHeld ’09)، بارسلون، اسپانیا، 16 تا 21 اوت 2009. صص 61-62.
- رعنا، ر.ک. Chou، CT; Kanhere, SS; بولوسو، ن. تلفن هو، دبلیو: یک سیستم نقشهبرداری نویز شهری مشارکتی سرتاسر. در مجموعه مقالات نهمین کنفرانس بین المللی ACM/IEEE در مورد پردازش اطلاعات در شبکه های حسگر (IPSN ’10)، استکهلم، سوئد، 12-15 آوریل 2010. صص 105-116.

شکل 1. مفهوم سیستم خودکار گزارش ناهنجاری جاده ها.
شکل 2. تعریف رفتار اجتنابی.
شکل 3. سیگنال های آزیموت خام از avoidRآ��مندآر(بالا)، avoidRLآ��مندآر�(مرکز) و returnR�هتیتو��آر(پایین).

شکل 4. جریان تشخیص رفتار اجتنابی.

شکل 5. تقسیم بندی avoidRLآ��مندآر�و avoidRآ��مندآر.
شکل 6. نشانه گذاری برای f8�8و f20�20.

شکل 7. صحنه جمع آوری داده ها.
شکل 8. مقایسه مدل های مختلف طبقه بندی کننده نظارت شده.
شکل 9. عملکرد طبقه بندی با ویژگی های کمک کننده بالا . ویژگی ها در جدول 1 ارائه شده است .

شکل 10. تفاوت های فردی در اعتبار سنجی متقاطع خود (CV) و اعتبار سنجی متقاطع ترک یک موضوع (LOSO-CV).
شکل 11. کاربرد مدل طبقه بندی وابسته به شخص.

جدول 1. ویژگی ها، به ترتیب سهم از بالا سمت چپ به پایین سمت راست فهرست شده است.
جدول 2. شرایط جمع آوری داده ها.
جدول 3. مشخصات مجموعه داده.
جدول 4. پارامترهای طبقه بندی کننده در Weka.
جدول 5. ماتریس سردرگمی اعتبارسنجی متقاطع 10 برابری (CV) با استفاده از جنگل تصادفی.
جدول 6. یادآوری، دقت و اندازه گیری F با استفاده از جنگل تصادفی.
جدول 7. استحکام در تغییر موقعیت ذخیره سازی.
جدول 8. برخورد با وابستگی به موقعیت.
جدول 9. عملکرد در برابر اندازه مانع ناشناخته.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر