

چکیده
محلیسازی بلادرنگ کاربر در محیطهای داخلی یک مسئله مهم در زندگی با کمک محیط (AAL) است. در این زمینه، بومیسازی بر اساس قدرت سیگنال دریافتی (RSS) به دلیل هزینه کم و مصرف انرژی و در دسترس بودن آن بر روی تمام سختافزارهای ارتباط بیسیم، در ادبیات اخیر مورد توجه قابل توجهی قرار گرفته است. از سوی دیگر، محلی سازی مبتنی بر RSS با خطای بیشتری نسبت به سایر فناوری ها مشخص می شود. با محدود کردن مشکل به محلیسازی کاربران AAL در محیطهای داخلی، نشان میدهیم که پیشبینی با کمی پیشروی حرکت کاربر (به عنوان مثال، زمانی که کاربر میخواهد اتاقی را ترک کند) مزایای قابلتوجهی برای دقت سیستمهای محلیسازی مبتنی بر RSS فراهم میکند. به طور مشخص،
زندگی با کمک محیط ; سیستم های محلی سازی ; قدرت سیگنال دریافتی ؛ پیش بینی حرکت ؛ شبکه های دولتی پژواک ؛ شبکه های حسگر بی سیم
1. مقدمه
شبکههای حسگر بیسیم (WSN) منبع مهمی از اطلاعات زمینه هستند که کاربردهای مهمی را در محیطهای هوشمند و زندگی با کمک محیط (AAL) پیدا میکنند [ 1 ]. در این برنامه ها، WSN ها می توانند پارامترهای مختلف کاربر و خانه او، از جمله پارامترهای فیزیولوژیکی، حرکات و فعالیت ها را نظارت کنند [ 2 ]. در میان تمام پارامترهای مورد علاقه برای AAL، محلیسازی کاربر و ردیابی برخی از مهمترین آنها هستند (ارائه خدمات AAL در مکان مناسب ضروری است). متأسفانه، این امر توسط سیستم های موقعیت یاب جهانی مبتنی بر ماهواره به طور گسترده قابل دستیابی نیست، زیرا آنها دقت لازم را در محیط های داخلی، جایی که برنامه های کاربردی AAL معمولاً در آن کار می کنند، به دست نمی آورند. به همین دلیل، اکثر سیستم های محلی سازی برای AAL به WSN [3 ].
راه حل های مبتنی بر WSN با استقرار مجموعه ای از حسگرهای ثابت (به نام لنگر) در محیط کاربر و یک حسگر روی خود کاربر (به نام موبایل) ساخته می شوند و مکان (ناشناخته) موبایل را با توجه به لنگرها تخمین می زنند. ، که موقعیت آن مشخص است. این تخمین از اندازهگیریهای مقادیر فیزیکی مربوط به بستههای بیکن رد و بدل شده بین موبایل و لنگرها استفاده میکند. اندازه گیری سیگنال رادیویی معمولاً قدرت سیگنال دریافتی (RSS)، زاویه ورود (AOA)، زمان رسیدن (TOA) و اختلاف زمانی رسیدن (TDOA) است. اگرچه AOA یا TDOA می توانند دقت محلی سازی بالایی را تضمین کنند، اما به سخت افزار خاص و پیچیده ای نیاز دارند. این یک اشکال بزرگ به ویژه در برنامه های AAL است که عمیقاً با نظارت کاربر درگیر هستند و بنابراین ممکن است از سخت افزار پیچیده و بیش از حد تهاجمی رنج ببرند. در این کار، بومی سازی مبتنی بر RSS را در نظر می گیریم، زیرا به سخت افزار خاصی نیاز ندارد و در اکثر دستگاه های بی سیم استاندارد موجود است. علاوه بر این، اندازهگیری RSS تقریباً تأثیر صفر بر مصرف انرژی، اندازه سنسور و هزینه دارد و به همین دلایل، در ادبیات اخیر مورد توجه قابل توجهی قرار گرفته است.4 ].
اگرچه ساده است، اما الگوریتمهای محلیسازی داخلی مبتنی بر RSS به خودی خود کافی نیستند، زیرا اندازهگیریهای RSS تحت تأثیر نویز قرار میگیرند، که اطلاعات محلیسازی را نادقیق میکند. این مشکل هم به دلیل تاثیرات چند مسیره محیط های داخلی و هم به این دلیل است که بدن کاربر با الگوهای نامنظم بر انتشار سیگنال رادیویی بسته به جهت کاربر، جهت آنتن و غیره تاثیر می گذارد .
یک رویکرد برای بهبود دقت محلیسازی مبتنی بر RSS شامل بهرهبرداری از اطلاعات زمینهای است که ممکن است توسط سنسورهای دیگر برنامههای AAL تولید شود. به عنوان مثال، اگر کاربر چراغ را روشن کند، سیستم AAL موقعیت کاربر را بسیار دقیق (البته برای مدت کوتاه) شناسایی می کند و این اطلاعات می تواند برای بازخورد به سیستم محلی سازی به منظور تنظیم پارامترهای آن و بهبود بیشتر استفاده شود. اندازه گیری ها [ 4 ]. با این حال، این بهبود فقط فرصت طلبانه است، زیرا اطلاعات مورد استفاده برای بازخورد به سیستم محلی سازی فقط به صورت پراکنده و در حضور سنسورهای مناسب در برنامه ها (مثلاً روی درها، کلیدهای چراغ و غیره ) در دسترس است.
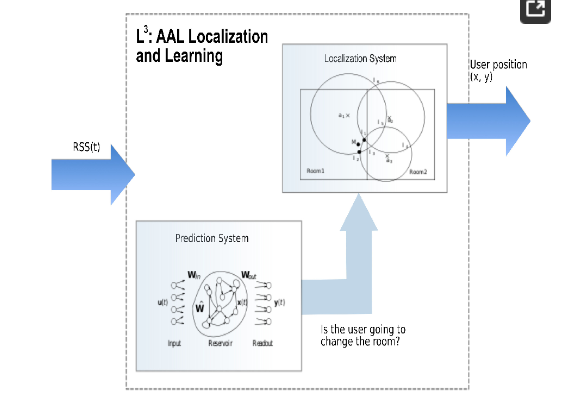
در این کار، مدلهای یادگیری ماشین را برای پیشبینی برخی از فعالیتهای کاربر که مستلزم موقعیت خاصی از کاربر در محیط هستند، در نظر میگیریم و از این اطلاعات برای بازخورد به سیستم محلیسازی استفاده میکنیم. به طور خاص، ما از شبکههای عصبی بازگشتی (RNNs) [ 5 ] برای پردازش اطلاعات RSS به منظور پیشبینی اینکه آیا کاربر اتاق فعلی را ترک میکند یا خیر، با فرض اینکه چنین تصمیمی به الگوی حرکت کاربر بستگی دارد، بهرهبرداری میکنیم. سپس این اطلاعات به الگوریتم محلیسازی داده میشود که با استفاده از آن، دقت محلیسازی را بهبود میبخشد ( شکل 1 ).
ما نتایج مجموعهای از آزمایشها را در یک محیط داخلی واقعی با هدف تولید یک مجموعه داده به اندازه کافی بزرگ برای استفاده برای آموزش یک RNN ارائه میکنیم و دقت آن را در یک طبقهبندی پیشبینیکننده الگوهای حرکت کاربر و هزینه ارزیابی میکنیم. به طور خاص، ما هزینه را بر حسب تعداد لنگرهایی که برای دستیابی به دقت مطلوب در پیشبینی لازم است و از نظر میزان استقلال این پیشبینیها از خطا در استقرار واقعی لنگرها ارزیابی میکنیم که دارای یک مستقیم است. تاثیر بر هزینه های استقرار در آزمایشهایمان، نشان میدهیم که رویکرد ما دقت بهینه را با چهار لنگر ارائه میکند، اما میتواند دقت خوبی را حتی با یک لنگر واحد ارائه دهد.
بعداً، ما نتایج آزمایشهایی را ارائه میکنیم که سیستم پیشبینی پیشنهادی را همراه با یک الگوریتم محلیسازی RSS مورد استفاده قرار میدهند، که نشان میدهد چگونه ترکیب این دو عنصر دقت کلی محلیسازی مبتنی بر RSS را افزایش میدهد.
2. آثار مرتبط
به منظور افزایش دقت، تکنیکهای محلیسازی مبتنی بر RSS از اطلاعاتی که از محیط اطراف میآید بهرهبرداری میکنند. در [ 6 ]، نویسندگان یک روش بومی سازی مبتنی بر RSS فرصت طلبانه را توصیف می کنند. ایده اصلی شامل اجازه دادن به کاربران تلفن همراه برای تبادل فرصتطلبانه اطلاعات مکان زمانی که اتفاقاً در محدوده رادیویی قرار دارند و از این اطلاعات به منظور بهبود دقت مکانیابی خود استفاده کنند. نویسندگان نشان میدهند که پارادایم محلیسازی فرصتطلب در افزایش دقت محلیسازی گره در محیطهای داخلی مؤثر است، حتی اگر افزایش عملکرد به شدت به الگوهای تحرک گره، ناهمگونی گرههای فرصتطلب و دقت محدوده وابسته است.
رویکرد دیگری به نام COAL (محلی سازی آگاه از زمینه) [ 7 ]، از نوع متفاوتی از اطلاعات زمینه بهره برداری می کند. به طور خاص، COAL از برنامه های کاربر (مانند یک رویداد در حال انجام، برنامه سمینار یا دستور کار شخصی) برای تسهیل محلی سازی کاربر استفاده می کند. با استفاده از این اطلاعات زمینه، نویسندگان به طور قابل توجهی فرکانس محلی سازی را کاهش می دهند، بنابراین مصرف انرژی را کاهش می دهند، در حالی که درجه بالایی از دقت را حفظ می کنند.
روشهای دیگر از دادههای حسی اضافی، مانند صدا و نور، برای شناسایی مکان استفاده میکنند [ 8 ]. تکنیک های یادگیری اغلب برای آموزش سیستم و افزایش دقت استفاده می شود. به عنوان مثال می توان به EEMSS [ 9 ] و CenceMe [ 10 ] اشاره کرد. CenceMe استنباط حضور تلفنهای همراه با استفاده از تلفنهای همراه دارای حسگر را با اطلاعات به اشتراک گذاشته شده از طریق برنامههای شبکههای اجتماعی مانند فیسبوک و مای اسپیس ترکیب میکند.
در [ 4 ]، نویسندگان از اطلاعات زمینه تولید شده توسط دستگاه هایی که فعالیت های کاربر را به عنوان بخشی از برنامه های AAL نظارت می کنند، بهره برداری می کنند. چنین دستگاه هایی اطلاعاتی را در مورد باز و بسته شدن یخچال، درها یا کلیدهای چراغ ارائه می دهند.
برخلاف کارهای فوق، در رویکرد خود، از منابع اطلاعات اضافی استفاده نمی کنیم، بلکه صرفاً به همان اطلاعات RSS که برای بومی سازی استفاده می شود، تکیه می کنیم تا توسط یک RNN اطلاعات اضافی مرتبط با بومی سازی استنباط کنیم و از این اطلاعات استفاده کنیم. بازخورد به سیستم محلی سازی.
3. L 3 – بومی سازی و یادگیری AAL
سیستم پیشنهادی L 3 از دو زیرسیستم به نامهای زیرسیستم پیشبینی و زیرسیستم محلیسازی تشکیل شده است. زیرسیستم پیش بینی (شرح شده در بخش 3.1) بر اساس الگوی محاسباتی مخزن است، در حالی که زیرسیستم محلی سازی (شرح شده در بخش 3.2) از یک الگوریتم سه لایه بندی معروف بهره برداری می کند. در عمل، ایده کلیدی پیشبینی حرکات کاربر است تا دانش مربوط به اتاقی که کاربر در آن وارد میشود به الگوریتم محلیسازی ارائه شود. این دانش توسط سیستم محلی سازی به عنوان ورودی اضافی مورد استفاده قرار می گیرد.
3.1. زیرسیستم پیش بینی
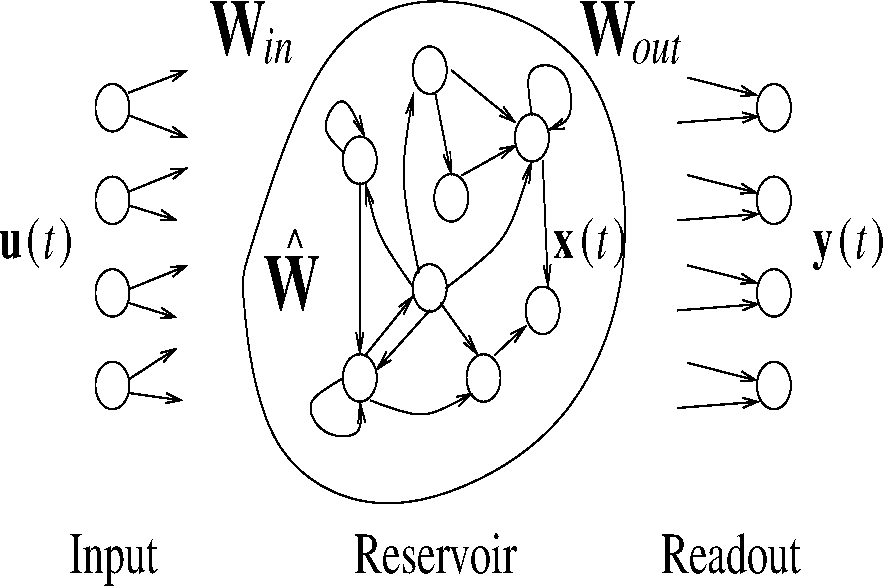
محاسبات مخزن (RC) یک الگوی محاسباتی است که چندین مدل در خانواده شبکه عصبی بازگشتی (RNN) را پوشش میدهد که با حضور یک لایه مخزن مخفی بزرگ و پراکنده از واحدهای غیرخطی تکراری مشخص میشوند که با استفاده از برخی مکانیسم خواندن، به عنوان مثال، معمولاً ترکیبی خطی از خروجی های مخزن است. با توجه به آموزش سنتی RNN، که در آن همه وزنهها تطبیق داده میشوند، RC یادگیری را عمدتاً بر روی وزنههای خروجی انجام میدهد و آنهایی را که در مخزن هستند آموزش ندیدهاند. همانند سایر RNNها، مدلهای RC برای مدلسازی سیستمهای دینامیکی و بهویژه برای پردازش دادههای زمانی مناسب هستند. از آنجایی که مشکل پیشبینی حرکت مورد بحث در این مقاله، از منظر یادگیری ماشین، یک کار پیشبینی سری زمانی است، ما طبیعتاً علاقهمندیم تا اثربخشی الگوی RC را در چنین سناریویی تحلیل و بحث کنیم. به طور خاص، ما بر روی شبکههای حالت پژواک محاسباتی کارآمد (ESNs) [11-13] تمرکز میکنیم که یکی از شناختهشدهترین مدلهای RC هستند که با یک لایه ورودی N مشخص میشوند.واحدهای U ، یک لایه مخزن پنهان ازواحدهای غیرخطی بازگشتی آموزش ندیده NR و یک لایه بازخوانی از واحدهای خطی پیشخور N Y ( شکل 2 را ببینید ). در یک کار پیشبینی سری زمانی، مخزن آموزشدیده بهعنوان یک تابع بسط موقت غیرخطی ثابت عمل میکند و یک فرآیند رمزگذاری دنباله ورودی را در فضای حالتی پیادهسازی میکند که در آن بازخوانی خطی آموزشدیده اعمال میشود. مخازن استاندارد ESN از واحدهای افزودنی ساده با یک تابع فعال سازی سیگموئید ساخته شده اند که، با این حال، نشان داده شده است که به طور ضعیفی تکامل زمانی سیستم های دینامیکی آهسته را مدل می کند [ 14 ]. به طور خاص، [ 5 ] نشان داده اند که حرکات کاربر در داخل خانه را می توان به بهترین شکل توسط a مدل کردنوع یکپارچه ساز نشتی شبکه RC (LI-ESNs) [ 14 ]. با توجه به یک دنباله ورودی s = [ u (1)، …، u ( n )] در فضای ورودی، آرنUℝن�، در هر مرحله زمانی t = 1, …, n , مخزن LI-ESN انتقال حالت زیر را محاسبه می کند:
جایی که x ( t ) ∈ آرنآرℝنآرنشان دهنده وضعیت مخزن ( یعنی خروجی واحدهای مخزن) در مرحله زمانی t ، W در ∈ است.آرنآر×نUℝنآر×ن�ماتریس وزن ورودی به مخزن است (احتمالاً شامل یک اصطلاح بایاس)، Ŵ ∈ آرنآر×نآرℝنآر×نآرماتریس وزن مخزن بازگشتی (پراکنده) است و f تابع فعال سازی اعمال شده از نظر اجزای واحدهای مخزن است (ما از f ≡ tanh استفاده می کنیم ). بازگشت زمانی در معادله (1) بر اساس یک حالت اولیه صفر است، یعنی x ( 0 ) = 0 ∈ آرنآرℝنآر. اصطلاح، a ∈ [0، 1]، یک پارامتر نرخ نشتی است که برای کنترل سرعت دینامیک مخزن استفاده می شود، با مقادیر کوچک یک مخازن منجر به مخازنی می شود که به آرامی به ورودی واکنش نشان می دهند [ 13 ، 14 ]. در مقایسه با مدل استاندارد ESN، LI-ESN یک میانگین متحرک نمایی را به مقادیر حالت تولید شده توسط واحدهای مخزن اعمال میکند ( یعنی x ( t ) )، و در نتیجه یک فیلتر پایینگذر از فعالسازیهای مخزن ایجاد میکند که به شبکه اجازه میدهد تا بهتر عمل کند. کنترل سیگنال های ورودی که به آرامی نسبت به فرکانس نمونه گیری تغییر می کنند. دینامیک حالت LI-ESN بنابراین برای نمایش تاریخچه سیگنال های ورودی مناسب تر است.
برای یک کار طبقهبندی باینری روی دادههای متوالی، بازخوانی خطی تنها پس از پایان فرآیند رمزگذاری محاسبهشده توسط مخزن، با استفاده از موارد زیر اعمال میشود:
که در آن sgn یک تابع آستانه علامت است که +1 را برای آرگومان های غیر منفی و −1 برمی گرداند، در غیر این صورت، y (s) ∈ { − 1 , + 1 }نY{–1،+1}ن�طبقه بندی خروجی است که برای دنباله ورودی، s و W out ∈ محاسبه می شودآرنY×نآرℝن�×نآرماتریس وزن مخزن به خروجی (احتمالاً شامل یک اصطلاح بایاس) است.
مخزن برای ارضای به اصطلاح Echo State Property (ESP) مقداردهی اولیه شده است [ 11 ]. ESP ادعا می کند که وضعیت مخزن یک ESN که توسط یک دنباله ورودی طولانی هدایت می شود فقط به خود توالی ورودی بستگی دارد. وابستگی به حالت های اولیه به تدریج پس از یک گذرا اولیه فراموش می شود (مخزن پژواک سیگنال ورودی را ارائه می دهد). یک شرط کافی و ضروری برای مقداردهی اولیه مخزن در [ 11 ] آورده شده است. معمولاً فقط شرط لازم برای مقداردهی اولیه مخزن استفاده می شود، در حالی که شرط کافی اغلب بسیار محدود کننده است [ 11 ]. شرط لازم برای ESP این است که سیستم حاکم بر دینامیک مخزن معادله (1)به طور محلی به صورت مجانبی در اطراف حالت صفر، 0 ∈ پایدار است آرنآرℝنآر. با تنظیم دبلیو˜دبلیو˜= (1 −a ) I + a دبلیو˜دبلیو˜، در جایی که a پارامتر نرخ نشت است، هر زمان که محدودیت زیر برقرار باشد، شرط لازم برآورده می شود:
جایی که ρ (دبلیو˜)�(دبلیو˜)شعاع طیفی است دبلیو˜دبلیو˜. ماتریس های W در و دبلیو˜دبلیو˜بنابراین به طور تصادفی از یک توزیع یکنواخت مقداردهی اولیه می شوند و دبلیو˜دبلیو˜به طور متوالی مقیاس بندی می شود، به طوری که معادله (3) برقرار است. در عمل، مقادیر ρ نزدیک به یک معمولاً مورد استفاده قرار میگیرند، که منجر به دینامیک مخزن نزدیک به لبه آشوب میشود، که اغلب منجر به بهترین عملکرد در کاربردها میشود (به عنوان مثال، [ 11 ]).
در وظایف طبقهبندی دنبالهای، هر دنباله آموزشی برای تعدادی N بار متوالی گذرا به مخزن ارائه میشود تا گذرای اولیه را محاسبه کند. حالتهای مخزن نهایی مربوط به توالیهای آموزشی در ستونهای ماتریس X جمعآوری میشوند ، در حالی که بردار، y هدف ، شامل طبقهبندیهای هدف مربوطه (در پایان هر دنباله) است. بنابراین بازخوانی خطی برای حل مسئله رگرسیون خطی حداقل مربعات آموزش داده شده است:
معمولاً از وارونگی شبه مور-پنروز ماتریس X یا رگرسیون خطی برای آموزش خواندن استفاده می شود [ 13 ].
3.2. زیرسیستم محلی سازی
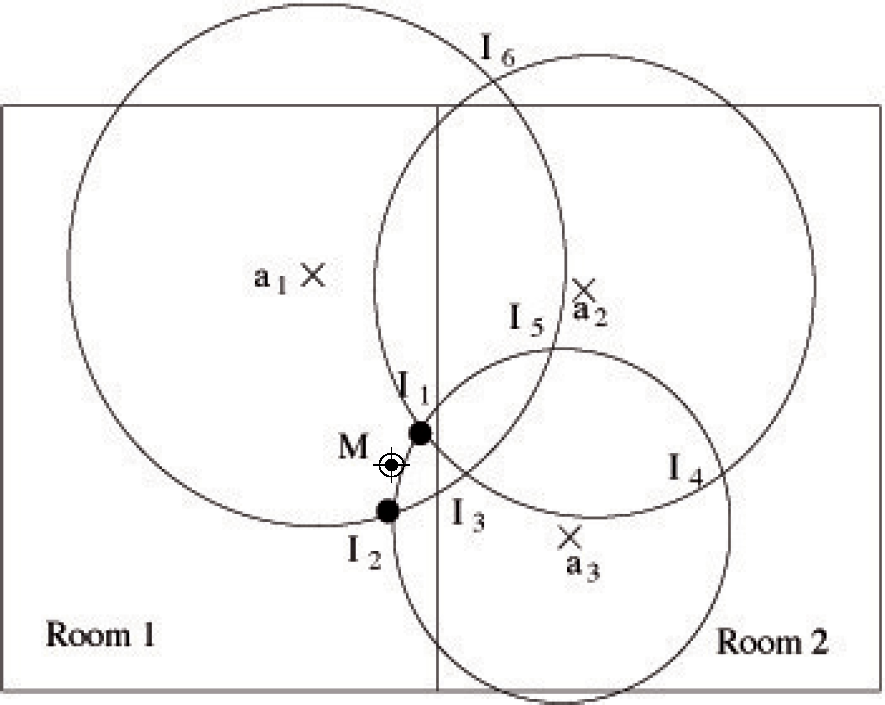
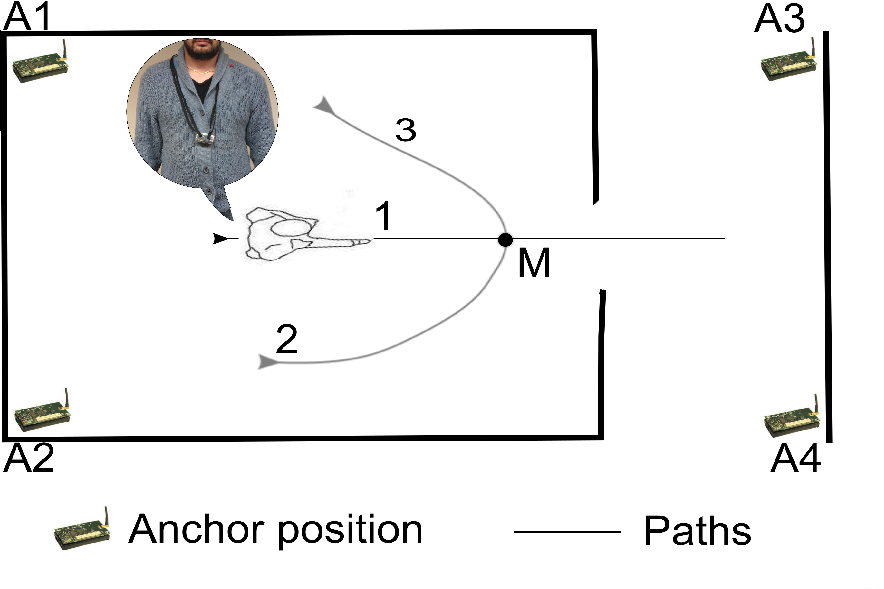
به منظور در نظر گرفتن دانش حاصل از زیرسیستم پیشبینی درباره اتاقی که کاربر در آن قرار دارد یا در حال ورود است، دو الگوریتم محلیسازی را در نظر میگیریم، یکی بر اساس چندلایه و دیگری بر اساس اثر انگشت، که از حداقل میانگین استفاده میکند. مربع (LMS در زیر). هر یک از این الگوریتم ها ممکن است با اطلاعات زمینه افزوده شوند. الگوریتمهای اصلاحشده از خروجی زیرسیستم پیشبینی برای ایجاد اتاقی که کاربر در حال حاضر در آن است، در هر لحظه استفاده میکند. نمونه ای از نحوه عملکرد الگوریتم چند بعدی در شکل 3 نشان داده شده است (به منظور سادگی، این شکل بدون توجه به اثر تضعیف دیوار نشان داده شده است). سه لنگر، a 1 ، a 2 و a3 ، با RSS بزرگتر انتخاب میشوند و تنها دو نقطه از شش نقطه تقاطع ( I 1 و I 2 ) در نظر گرفته میشوند، زیرا آنها در اتاقی هستند که توسط زیرسیستم پیشبینی نشان داده شده است. نقاط تقاطع به عنوان جرم نقطه در نظر گرفته می شوند و سپس موقعیت متحرک M تخمین زده می شود و مرکز همه جرم ها را ارزیابی می کند. البته این احتمال وجود دارد که تمام نقاط تقاطع خارج از اتاق باشند (با این حال، این هرگز در همه آزمایشهای ما اتفاق نیفتاده است). در این مورد، داده های ورودی سازگار نیستند و بسته به نیازهای سیستم محلی سازی، جایگزین های ممکن متفاوتی وجود دارد. به عنوان مثال، سیستم ممکن است یک ناسازگاری را برگرداند یا ممکن است آخرین موقعیت شناخته شده را برگرداند و غیره .
از سوی دیگر، الگوریتم LMS از یک نقشه RSS از محیط استفاده می کند که در طول استقرار سیستم محلی سازی محاسبه می شود. این نقشه فهرستی از جفتهای <مختصات، RSS تاپل> است که برای یک نقطه معین از مختصات ( x, y ) در محیط، یک N-تبلی از اندازهگیریهای RSS را در بین هر یک از N لنگرها، a i و موبایل در آن نقطه به طور معمول، این لیست در گره های یک شبکه معمولی در محیط محاسبه می شود و دانه بندی آن به دقت مورد نیاز بومی سازی بستگی دارد. در زمان اجرا، الگوریتم LMS N-tup RSS اندازه گیری شده < r 1 , r 2 , …, r N را می گیرد.>، و در لیست تاپل RSS را پیدا می کند که میانگین مربعات خطای بین دو تاپل را به حداقل می رساند. سپس، جفت مختصات مربوطه ( x, y ) را خروجی می دهد. در الگوریتم LMS، فقط از جفتهای <coordinate, RSS tuple> محاسبه شده در اتاقی که توسط زیرسیستم Prediction نشان داده شده است استفاده میشود.
4. سناریو
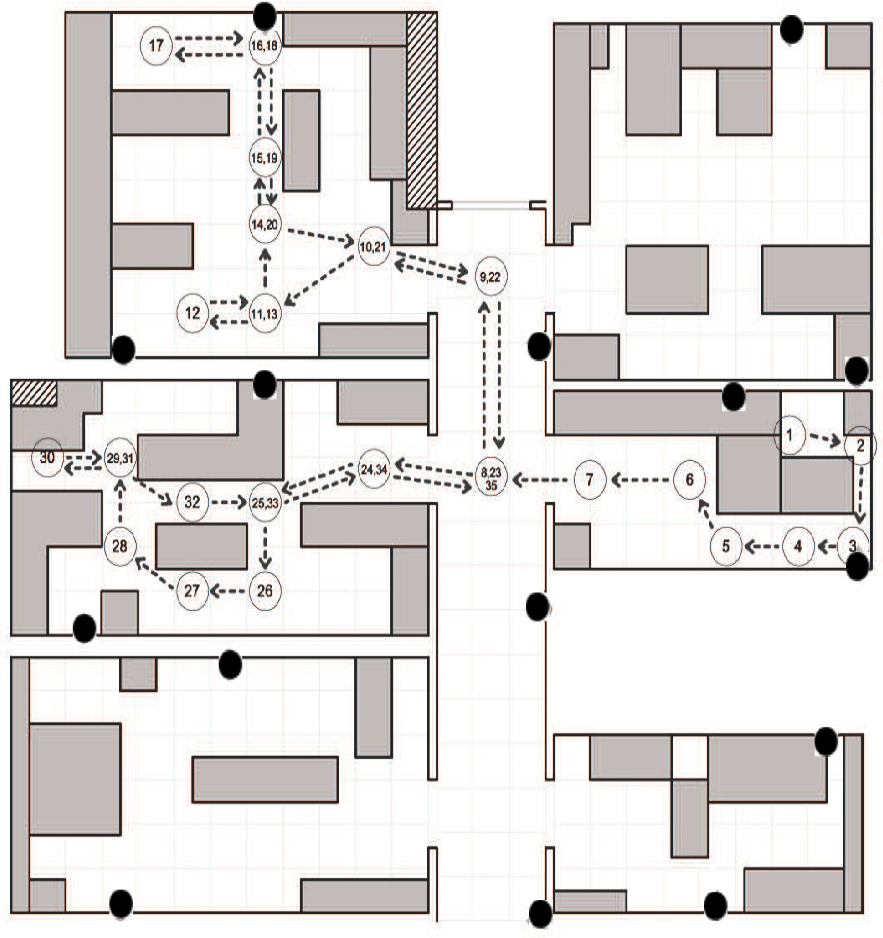
یک کمپین اندازه گیری در طبقه اول موسسه ISTI از CNRin منطقه تحقیقاتی پیزا، در ایتالیا انجام شده است. سناریو یک محیط اداری معمولی است که شامل شش اتاق با هندسه های مختلف است، همانطور که در شکل 4 نشان داده شده است. اتاق ها دارای مبلمان اداری معمولی هستند: میز، صندلی، کابینت و مانیتور. از نقطه نظر ارتباطات بی سیم، این یک محیط خشن است که به دلیل بازتاب های چند مسیره ناشی از دیوارها و تداخل تولید شده توسط دستگاه های الکترونیکی است. اندازه گیری های تجربی توسط یک شبکه حسگر متشکل از 15 گره IRIS انجام شده است که یک زیرسیستم رادیویی Chipcon AT86RF230 را تعبیه کرده است که استاندارد IEEE 802.15.4 [ 15 ] را پیاده سازی می کند. پانزده حسگر، در لنگرهای زیر، در موقعیتهای ثابتی در محیط قرار دارند (همانطور که درشکل 4 ) و یک حسگر بر روی کاربر قرار می گیرد که از این پس موبایل نامیده می شود. ارتفاع لنگرها از سطح زمین 1.5 متر تعیین شده است و موبایل بر روی سینه کاربر بسته شده است. کاربر در مسیرهای آزاد حرکت می کند تا با سرعت ثابت حدود 1 متر بر ثانیه تسهیل کند. کمپین اندازه گیری شامل آزمایش هایی بر روی شش اتاق مختلف با سطح کلی حدود 100 متر مربع است . آزمایشها شامل اندازهگیری RSS بین لنگرها و موبایل برای دو مسیر انتخاب شده است که در اینجا به عنوان مسیر اول و دوم نامیده میشود. شکل 4 و 5موقعیت و جهت لنگرهای مستقر در محیط و همچنین مسیر اجرای مسیر اول و دوم را به ترتیب نشان می دهد. ما نمونههای RSS را با ارسال یک بسته بیکن از لنگرها به موبایل در فواصل زمانی منظم، هشت بار در ثانیه، با استفاده از قدرت انتقال کامل گرههای IRIS، جمعآوری کردیم.
5. نتایج تجربی
این بخش نتایج آزمایش های انجام شده در سناریوهای ترسیم شده در بخش قبل را شرح می دهد.
در طول آزمایشها، ما اندازهگیریهای خاصی را برای ارزیابی عملکرد زیرسیستم پیشبینی، هم از نظر دقت طبقهبندی پیشبینیکننده و هم از نظر هزینه انجام دادیم. در مجموعه دوم آزمایشها، عملکرد را از نظر دقت محلیسازی سیستم محلیسازی L3 برای دو مسیر انتخابشده سناریوها ارزیابی کردیم. علاوه بر این، ما چگونگی افزایش دقت کلی سیستم پیشبینی را با توجه به روشهای سهلایهبندی و اثرانگشت تعیین کردیم.
5.1. دقت پیش بینی موقعیت مکانی
به منظور ارزیابی عملکرد از نظر دقت پیشبینی، آزمایشهایی شامل اندازهگیری RSS بین مجموعهای از چهار لنگر و موبایل برای مجموعهای از حرکات مکرر کاربر انجام دادیم. کمپین اندازهگیری شامل آزمایشهایی بر روی شش اتاق مختلف است که در اینجا به مجموعه دادههای 1، 2، 3، 4، 5 و 6 گفته میشود . 3). مسیر مستقیم (با برچسب 1) از داخل اتاق به بیرون می رفت و منجر به تغییر در بافت فضایی کاربر ( یعنی به خروجی اتاق) می شد. مسیرهای منحنی (که در شکل 2 و 3 نشان داده شده اند) زمینه فضایی را حفظ می کنند ( یعنی در همان اتاق هستند). میز 1تعداد آزمایشها را برای شش اتاق مختلف (مرتبط با مجموعه دادههای 1-6) و برای هر مسیر خلاصه میکند. توجه داشته باشید که به دلیل محدودیت های فیزیکی، مجموعه داده 1 دارای مسیر منحنی در اتاق نیست که به عنوان مسیر 3 نشان داده شده است. تعداد مسیرهای منتهی به خروجی اتاق، با توجه به مسیرهایی که بافت فضایی را حفظ می کنند، در جدول 1 آورده شده است. با برچسب T ot. خروج و T ot. به ترتیب بدون تغییر. هر مسیر ردی از اندازهگیریهای RSS ایجاد میکند که وقتی کاربر به نقطهای میرسد مشخص میشود (در شکل 6 با M مشخص شده است.) در 0.6 متری درب واقع شده است. به طور کلی، آزمایش حدود 5000 نمونه RSS از هر یک از چهار لنگر و برای هر مجموعه داده تولید کرد. نشانگر M برای همه حرکات یکسان است. بنابراین، مسیرهای مختلف را نمی توان تنها بر اساس مقادیر RSS جمع آوری شده در M تشخیص داد.
سناریوی تجربی و معیارهای RSS جمعآوریشده برای تغذیه یک کار طبقهبندی باینری در سریهای زمانی برای پیشبینی حرکت استفاده میشوند. مقادیر RSS از چهار لنگر به دنباله هایی با طول های مختلف سازماندهی می شوند ( جدول 1 را ببینید ) که مربوط به اندازه گیری های مسیر از نقطه شروع تا نشانگر M است. یک برچسب طبقه بندی هدف با هر دنباله ورودی مرتبط است تا نشان دهد آیا کاربر در شرف خروج است یا خیر. اتاق یا نه به طور خاص، کلاس +1 هدف با حرکات تغییر مکان مرتبط است (به عنوان مثال ، مسیر 1 در شکل 6 )، در حالی که برچسب -1 برای نشان دادن مسیرهای حفظ مکان استفاده می شود ( یعنی مسیرهای 2 و 3 در شکل 6 ).
در [ 5 ]، عملکرد پایه مدلهای مختلف ESN در پیشبینی حرکت کاربر با یک مجموعه داده کوچک دو اتاقه تحلیل شده است. چنین تحلیلی نشان میدهد که مدل LI-ESN که در بخش 3.1 توضیح داده شده است، برای مقابله با سریهای زمانی RSS که به آرامی تغییر میکنند مناسبتر است. بنابراین، در بقیه بخش، ما تجزیه و تحلیل خود را به ارزیابی یک مدل یکپارچه با نشت، با متا پارامترهایی که در [ 5 ] انتخاب شده اند، محدود می کنیم. به طور خاص، ما LI-ESN ها را شامل مخازن N R = 500 واحد و 10٪ از اتصالات تصادفی تولید شده، شعاع طیفی ρ = 0.99، وزن ورودی در [-1، 1] و نرخ نشت a در نظر می گیریم.= 0.1. نتایج به میانگین 10 مخزن مستقل و به طور تصادفی حدس زده شده اشاره دارد. بازخوانی ( N Y = 1) با استفاده از وارونگی کاذب و رگرسیون پشته با پارامتر منظمسازی λ ∈ {10 -i |i = 1، 3، 5، 7} آموزش داده میشود.
دادههای ورودی شامل سریهای زمانی اندازهگیریهای RSS چهار بعدی ( NU = 4) است که مربوط به چهار لنگر در شکل 6 است که بهطور مستقل در محدوده [-1، 1] برای هر مجموعه داده نرمال شده است. توالی های RSS نرمال شده فقط تا زمانی که سیگنال نشانگر، M به شبکه LI-ESN داده می شود.
ما از دادههای جمعآوریشده در آزمایش برای آموزش یک RC برای پیشبینی اینکه آیا کاربر با رسیدن به نقطه M از اتاق خارج میشود یا خیر استفاده کردیم. بهویژه، برای آزمایش توانایی RC برای تعمیم پیشبینی خود به محیطهای داخلی نادیده، ما یک تعریف میکنیم. تنظیم ارزیابی تجربی، که در آن آموزش RC بر روی اندازهگیریهای RSS مربوط به تنها دو اتاق از سناریوها انجام میشود، در حالی که آزمایشها در اتاقهای باقیمانده برای آزمایش قابلیت تعمیم مدل RC استفاده میشوند. به طور خاص، ما دو تنظیمات آزمایشی (ESs) را تعریف کردهایم که برای ارزیابی عملکرد پیشبینیکننده LI-ESN ها در زمانی که دادههای آموزش/آزمون از هر دو پیکربندی محیطی یکنواخت (ES1) و قبلاً دیده نشده (ES2) میآیند، در نظر گرفته شده است .، ارائه یک مجموعه تست خارجی. تنظیم ES1 شامل مجموعه دادههای 1، 2، 3 و 4 میشود تا یک مجموعه داده منفرد از 210 دنباله را تشکیل دهد. این منجر به یک مجموعه آموزشی با اندازه 168 و یک مجموعه آزمایشی با اندازه 42، با طبقه بندی در انواع مسیر می شود. پارامتر تنظیم بازخوانی ES1 بر روی یک مجموعه اعتبارسنجی (33%) استخراج شده از نمونه های آموزشی، روی λ = 10-1 تنظیم شده است. در تنظیم ES2، از LI-ESN با تنظیم بازخوانی انتخاب شده در ES1 استفاده می کنیم. ما آن را بر روی اتحاد مجموعه دادههای 1، 2، 3 و 4 ( یعنی چهار اتاق) آموزش میدهیم، و از مجموعه دادههای 5 و 6 به عنوان یک مجموعه آزمایش خارجی (با اندازهگیری از دو محیط ناشناخته) استفاده میکنیم. جدول 2میانگین دقت آزمون را برای هر دو ES گزارش می کند. یک عملکرد پیش بینی عالی برای ES1 به دست می آید که با نتایج گزارش شده در [ 5 ] منسجم است. به نظر میرسد این نشان میدهد که رویکرد LI-ESN، از یک سو، مقیاسپذیری خوبی دارد و تعداد محیطهای آموزشی افزایش مییابد، در حالی که، از سوی دیگر، برای تغییرات در تنظیمات اتاق تمرین قوی است. توجه داشته باشید که مسیرهای RSS برای اتاقهای مختلف، معمولاً به طور مداوم متفاوت است، و به این ترتیب، افزودن اتاقهای جدید به شدت حافظه کوتاهمدت مخازن و توانایی آنها برای رمزگذاری سیگنالهای دینامیکی پیچیده را اعمال میکند.
نتیجه در تنظیمات ES2 معنیدارتر است، زیرا نشان میدهد که عملکرد مدل LI-ESN را میتوان به محیطهای ناشناخته تعمیم داد. به طور خاص، مدل به دقت پیشبینی حدود 90 درصد در آزمایش خارجی که شامل پیکربندیهای محیطی غیرقابل مشاهده است میرسد. جدول 3 ماتریس سردرگمی مجموعه آزمایش خارجی در ES2 را توصیف میکند که بر اساس حدسهای مخزن میانگین گرفته شده و به صورت درصد بر تعداد نمونههای آزمایشی بیان میشود. این اجازه می دهد تا تعادل عملکرد پیش بینی را ارزیابی کنیم، که دارای مقادیر قابل مقایسه برای هر دو کلاس است. توجه داشته باشید که دقت کل به صورت مجموع روی قطر به دست می آید، در حالی که خطا از مجموع عناصر خارج از مورب محاسبه می شود.
5.2. نتایج بومی سازی
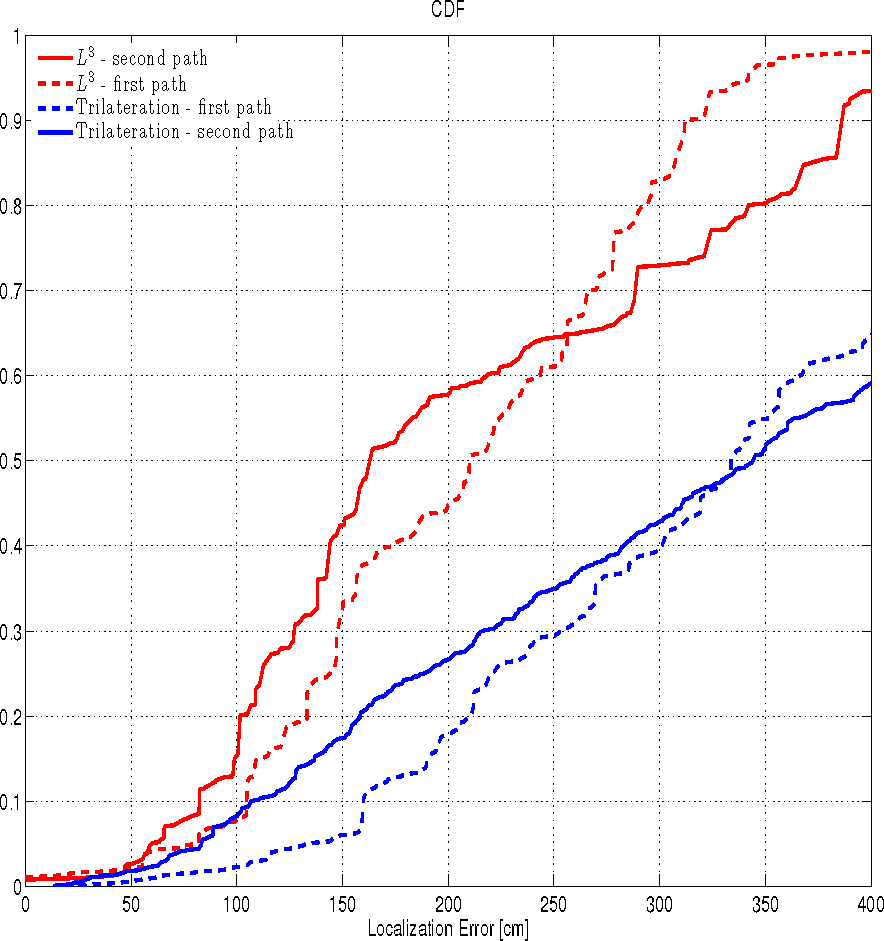
با استفاده از سیستم پیشبینی آموزشدیده با کمپین اندازهگیری موقت قبلی (ES2)، ما دقت سیستم محلیسازی پیشنهادی L 3 را با استفاده از الگوریتمهای سه لایه و LMS ارزیابی میکنیم. عملکرد محلی سازی بر حسب خطای محلی سازی ϵ ارزیابی می شود ، که فاصله بین نقطه ای که موبایل در واقع در آن قرار دارد و نقطه شناسایی شده توسط الگوریتم محلی سازی است. این معیاری است که بیشتر در ادبیات استفاده می شود: در حالی که لزوماً برای کاربردهای عملی مهم ترین نیست، اما امکان مقایسه آسان بین روش های مختلف در محیط های مختلف را فراهم می کند. اجازه دهید تابع توزیع تجمعی (CDF) ϵاحتمال اینکه خطای محلی سازی مقدار کمتر یا مساوی x متر به خود بگیرد باشد. شکلهای 7 و 8 CDF خطای محلیسازی ϵ را با استفاده از هر دو الگوریتم L 3 و trilateration یا LMS به ترتیب با یا بدون سیستم پیشبینی نشان میدهند.
5.2.1. نتایج سه لایه
یکی از عوامل موثر بر مقادیر RSS، فاصله بین لنگر (امیتر) و موبایل (گیرنده) است، زیرا این فاصله باعث کاهش مقادیر RSS می شود. بنابراین، تعیین وابستگی بین مقادیر RSS و فاصله بین امیتر و گیرنده الزامی است. این تضعیف که در اثر فاصله بین امیتر و گیرنده ایجاد می شود، به عنوان افت مسیر شناخته می شود، و به طور کلی به گونه ای مدل می شود که با فاصله بین امیتر و گیرنده افزایش یافته تا یک توان مشخص، که به عنوان توان از دست دادن مسیر شناخته می شود، نسبت عکس دارد. [ 16 ] یا گرادیان از دست دادن مسیر [ 17]. عوامل دیگری که بر مقادیر RSS تأثیر می گذارند ضریب تضعیف دیوار و تضعیف در فاصله مرجع است. از دست دادن مسیر در دسی بل بین یک لنگر داده شده و یک موبایل مشخص را می توان به صورت زیر بیان کرد:
که در آن l 0 تلفات مسیر در فاصله مرجع، α توان افت مسیر و lw تضعیف ایجاد شده توسط هر یک از دیواره های W است که توسط سیگنال عبور می کند. یک تخمین از مقدار RSS، r ، دریافت شده از لنگر در تلفن همراه به این صورت است:
جایی که r 0 ، نشان دهنده RSS در فاصله مرجع 1 متری است، اصطلاحی است که به عوامل مختلفی بستگی دارد، مانند متوسط محو شدن سریع و آهسته، افزایش آنتن و توان ارسالی. در عمل، مقدار r 0 را می توان از قبل دانست [ 16 ].
هدف کالیبراسیون انطباق مدل انتشار نظری ( معادله (6) ) با محیطی است که در آن واقعاً استفاده می شود. پارامترهای مدل انتشار ( معادله (6) ) عبارتند از: r 0 (RSS اندازه گیری شده در 1 متر)، α (شار از دست دادن مسیر) و lw (ضریب تضعیف دیوار، w ) . r 0 باید در یک محیط عمومی مشابه با محیطی که قرار است مکان را در آن انجام دهیم، تخمین زده شود، زیرا تنها به ویژگی های فیزیکی سخت افزار دستگاه بستگی دارد. سایر پارامترها با استفاده از روش کالیبراسیون مجازی خودکار شرح داده شده در [ 4 ] برآورد شده اند] که نیازی به دخالت انسان ندارد. این روش از ارتباطات بین لنگرها (که موقعیت آنها از قبل مشخص است ) برای ارزیابی پارامترهای معادله (6) استفاده می کند.
پس از کالیبراسیون، عملکرد هر دو الگوریتم L3 و سه لایه، با یا بدون سیستم پیش بینی در دو مسیر ( شکل 4 و 5 ) ارزیابی شده است. همانطور که در شکل 7 مشخص شده است، می بینیم که در 50٪ موارد، خطای محلی سازی ϵ L 3 در دو مسیر زیر 2.2 متر و 1.6 متر است، در حالی که بدون بهره برداری از سیستم پیش بینی، ϵ زیر 3.4 و 3.5 اینچ است. 50 درصد موارد بنابراین، استفاده از سیستم پیش بینی دقت محلی سازی را تا حدود 47 درصد بهبود می بخشد. دقت محلی سازی در هر دو مسیر افزایش می یابد، به ویژه، خطای محلی سازی میانه مسیر 1 به میزان 1.9 متر کاهش می یابد، در حالی کهϵ از مسیر 2 1.2 متر کاهش یافته است. اگر از نقطه نظر کاربردپذیری به شکل 7 نگاه کنیم ، در این تنظیم و با خطای محلی سازی هدف 2 متر، تکنیک رایج سه لایه بندی بدون سیستم پیش بینی عملاً غیرقابل استفاده است، زیرا در کمتر از 25 درصد نتایج صحیح می دهد. موارد از سوی دیگر، با همان خطای هدف، L 3 به سختی بیش از نیمی از مواقع به هدف می رسد. برای الزامات دقت محدودتر، به عنوان مثال، ϵ < 1.5 متر، می توانیم ببینیم که استفاده از سیستم پیش بینی به طور قابل توجهی دقت کلی محلی سازی را بهبود می بخشد (در حد 75٪)، اما برای قابل استفاده کردن سیستم محلی سازی کافی نیست. ، زیرا خطا همیشه در بیش از 50 درصد موارد بیشتر از 1.5 متر است.
5.2.2. نتایج LMS
کالیبراسیون الگوریتم LMS شامل مجموعه ای از اقدامات بین یک لنگر و یک نقطه از یک شبکه با ضلع حدود 1 متر بود ( شکل 9 ). این معیارها برای ایجاد نقشه RSS <مختصات، RSS تاپل> محیط به خاطر سپرده شده اند که برای یک نقطه معین از مختصات (x,y) در محیط، یک N-tup از اندازه گیری های RSS را در بین هر لنگر و موبایل در آن نقطه هر اندازه گیری حدود 1000 اندازه گیری RSS را جمع آوری کرد که در آن هر اندازه گیری RSS میانگین 32 نمونه دریافتی متوالی بود. نمونه ها با ارسال یک بسته بیکن از لنگر به موبایل در فواصل زمانی معین، 32 بار در ثانیه به دست آمد.
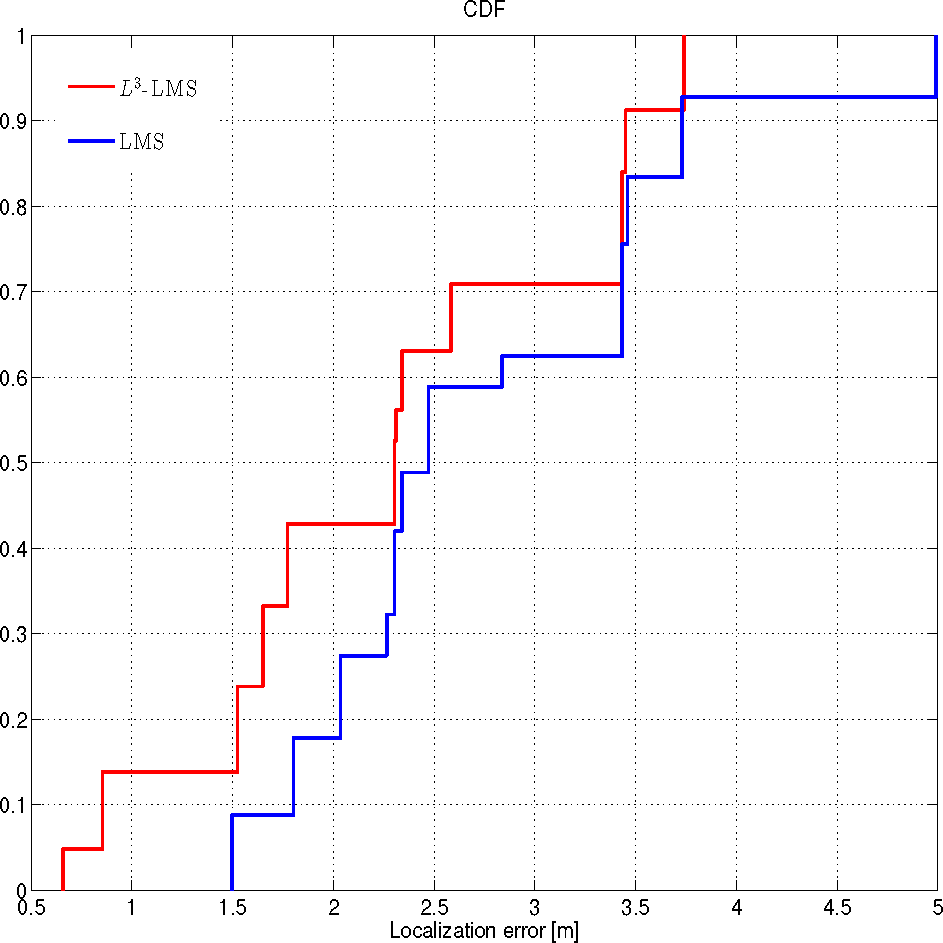
به منظور ارزیابی اینکه چگونه سیستم پیشبینی دقت محلیسازی سیستمهای محلیسازی مبتنی بر RSS را بهبود میبخشد، عملکرد الگوریتم LMS برای یک هدف ثابت ارزیابی شده است، یعنی کاربران حداقل برای 30 ثانیه در همان موقعیت باقی میمانند. همانطور که در شکل 8 مشخص شده است، می بینیم که در 50٪ موارد، خطای محلی سازی ϵ L 3 زیر 2.2 متر است، در حالی که بدون بهره برداری از سیستم پیش بینی، ϵ در 50٪ موارد زیر 2.3 است. بنابراین، استفاده از سیستم پیش بینی دقت محلی سازی را حدود 10 درصد بهبود می بخشد.
اگر از نقطه نظر کاربردپذیری به شکل 8 نگاه کنیم ، در این تنظیمات و با خطای محلی سازی هدف 2 متر، تکنیک LMS بدون سیستم پیش بینی عملاً غیرقابل استفاده است، زیرا در کمتر از 20 درصد نتایج صحیح می دهد. موارد از سوی دیگر، با همان خطای هدف، L 3 به سختی بیش از نیمی از موارد ( یعنی 43٪ موارد) به هدف می رسد. در این مورد، سیستم پیشبینی دقت محلیسازی را حدود 20 درصد بهبود میبخشد. علاوه بر این، حداکثر خطای ما حدود 3.7 متر بود که L 3 در برابر 5 متر بدون سیستم پیش بینی استفاده شد.
5.3. سربار کالیبراسیون
تنظیم سیستم ما برای یک محیط خاص به دو فعالیت اصلی نیاز دارد: کالیبراسیون زیر سیستم محلی سازی و کالیبراسیون زیر سیستم پیش بینی.
در آزمایشهای ما، کالیبراسیون زیرسیستم محلیسازی مستلزم جمعآوری نمونههای RSS در شبکهای از نقاط قرار گرفته در فاصله 1 متری از یکدیگر بود تا فضایی حدود 50 متر مربع را پوشش دهد . بنابراین، تعداد کل نقاط در شبکه حدود 50 بود. برای هر نقطه، با تبادل داده بین لنگرها و موبایل به مدت 3 دقیقه، اندازهگیری RSS را انجام دادیم. فقط برای اندازه گیری ها، زمان کالیبراسیون 2.5 ساعت بود. با این حال، این شامل زمان مورد نیاز برای تعویض دستگاه تلفن همراه در هر نقطه، راه اندازی مجدد اندازه گیری ها و اجرای کالیبراسیون نمی شود.
کالیبراسیون زیرسیستم پیش بینی در عوض حدود 6 ساعت کار به طول انجامید که عمدتاً صرف شبیه سازی حرکات کاربر در طول مسیرهای مختلف می شود. این زمان آخر کالیبراسیون بسیار مهم است، زیرا این هزینه اضافی مورد نیاز برای بهبود دقت محلی سازی روش انگشت نگاری است. علاوه بر این، زمان مشابهی را می توان برای بهبود زیرسیستم محلی سازی با روش های مرسوم تر، با افزایش وضوح شبکه نقاط (به عنوان مثال ، استفاده از نقاط مرجع بیشتر برای انگشت نگاری) صرف کرد.
با این حال، مشاهده میکنیم که کالیبراسیون انگشت نگاری باید در مرحله استقرار اجرا شود، قبل از اینکه کاربر بتواند واقعاً از سیستم استفاده کند، در حالی که کالیبراسیون زیرسیستم پیشبینی این الزام را ندارد، زیرا میتواند با یک دوره همپوشانی داشته باشد. استفاده واقعی کاربر از سیستم (در این مدت، سیستم بومی سازی مبتنی بر انگشت نگاری به تنهایی و با کاهش کارایی کار می کند).
به طور خاص، کالیبراسیون زیرسیستم پیشبینی به ردپایی از اندازهگیریهای RSS نیاز دارد که قبل از رویدادی که کاربر از اتاق/محیط خارج میشود، باشد. تشخیص دقیق وقوع چنین رویدادی را می توان به روش های مختلف به دست آورد. به عنوان مثال، می توان آن را در هر مکانیزم ارتباطی میدان نزدیک (مبتنی بر RFID یا موارد دیگر)، با قرار دادن خواننده در نزدیکی درها و تاگون کاربر استفاده کرد. هر زمان که خواننده برچسب را تشخیص دهد، به عنوان نشانه ای از یک رویداد “خروج” در نظر گرفته می شود. در نتیجه، چند ثانیه قبلی اندازهگیری RSS (در آزمایشهای ما 6 ثانیه) به عنوان نمونهای از یک رویداد «خروج» گرفته میشود. هر دنباله دیگری از اندازه گیری های RSS را می توان به عنوان یک رویداد “خروج” منفی در نظر گرفت. چنین روش خودکار جمعآوری دادهها دارای این اشکال بود که به یک زیرسیستم اضافی نیاز دارد که با این حال،
از این رو، در این پیکربندی، زمان مورد نیاز برای کالیبراسیون مناسب زیرسیستم پیشبینی برای کاربر تقریباً شفاف است (او فقط باید یک برچسب RFID یا یک دستگاه مشابه را برای مدت زمان محدودی بپوشد). از سوی دیگر، زمان مورد نیاز برای انجام انگشت نگاری عمیق تر از محیط، تأثیر قوی تری بر کاربر دارد، زیرا زمان غیرفعال بودن سیستم است و به دلیل انجام اپراتورهای انسانی نیاز به مداخله تهاجمی در محیط کاربر دارد. انگشت نگاری
6. نتیجه گیری و بحث
ما یک رویکرد RC برای پیشبینی حرکت کاربر در محیطهای داخلی، بر اساس ردیابیهای RSS جمعآوریشده توسط دستگاههای WSN کمهزینه ارائه کردهایم. ما از توانایی LI-ESN در گرفتن دینامیک زمانی اندازهگیریهای RSS پر سر و صدای آهسته در حال تغییر برای پیشبینیهای بسیار دقیق بافت فضایی کاربر بهرهبرداری میکنیم. عملکرد مدل پیشنهادی بر روی داده های چالش برانگیز دنیای واقعی شامل اطلاعات RSS جمع آوری شده در محیط های واقعی آزمایش شده است.
ما نشان دادهایم که رویکرد LI-ESN قادر است عملکرد پیشبینیکننده خود را به اطلاعات آموزشی مربوط به تنظیمات متعدد تعمیم دهد. مهمتر از آن، می تواند به طور موثر پیش بینی حرکت را به محیط هایی که قبلا دیده نشده بود تعمیم دهد، همانطور که توسط ارزیابی مجموعه تست خارجی نشان داده شده است. چنین انعطافپذیری برای توسعه راهحلهای عملی خانههای هوشمند از اهمیت بالایی برخوردار است، زیرا به فرد اجازه میدهد تا به طور مداوم هزینههای نصب و راهاندازی را کاهش دهد. به عنوان مثال، ما سناریویی را در نظر می گیریم که در آن یک سیستم محلی سازی مبتنی بر ESN به صورت آفلاین (مثلاً در آزمایشگاه/کارخانه) بر روی اندازه گیری های RSS که در مجموعه ای (کوچک) از اتاق های نمونه گرفته شده است، آموزش داده می شود. سپس، سیستم مستقر شده و در محیط هدف خود به بهره برداری می رسد و نیاز به یک فاز تنظیم دقیق گران قیمت را کاهش می دهد.
به منظور ارزیابی اینکه چگونه سیستم پیشبینی عملکرد یک سیستم محلیسازی مبتنی بر RSS را افزایش میدهد، اندازهگیریهایی را در یک محیط اداری معمولی متشکل از شش اتاق مجاور با مبلمان انجام دادهایم.
ما یک سهلایهبندی رایج و یک الگوریتم محلیسازی اثر انگشت را در نظر گرفتیم و آنها را با و بدون سیستم پیشبینی آموزشدیده قبلی ارزیابی کردیم. اطلاعات مورد استفاده توسط سیستم محلی سازی شامل دانستن اینکه آیا کاربر از اتاق فعلی خارج می شود یا خیر. اندازهگیریها نشان میدهند که الگوریتم سهلایهبندی، همراه با این اطلاعات، عملکرد قابلاستفادهتری را ارائه میدهد، به این صورت که در حدود ۸۰ درصد مواقع برای خطای محلیسازی هدف ۳ متری، نتیجه صحیح را ارائه میدهد. علاوه بر این، L 3 پیشنهادیسیستم محلیسازی که حرکات پیشبینی را اعمال میکند، دقت را با توجه به یک سیستم محلیسازی سه لایه مبتنی بر RSS که از آن بهرهبرداری نمیکند، حدود 47 درصد بهبود میبخشد. سپس عملکرد یک الگوریتم محلیسازی اثر انگشت را با و بدون سیستم پیشبینی ارزیابی کردیم. برای اینکه واقعاً نشان دهیم که چگونه سیستم پیشبینی دقت محلیسازی یک سیستم محلیسازی مبتنی بر RSS را بهبود میبخشد، عملکرد برای یک هدف ثابت ارزیابی شده است، یعنی کاربران حداقل برای 30 ثانیه در همان موقعیت باقی میمانند. حتی اگر این مورد مناسب تری برای الگوریتم های محلی سازی مبتنی بر RSS باشد، دقت حدود 10 درصد افزایش می یابد.
در حالی که، هزینه محاسباتی یک جزئیات جزئی است، از آنجایی که ما یک سرور اختصاصی را در نظر می گیریم که تمام این اطلاعات و این الگوریتم ها را توضیح می دهد، تجزیه و تحلیل هزینه کالیبراسیون مورد نیاز است. معمولاً الگوریتم های محلی سازی مبتنی بر RSS باید کالیبره شوند. در این مقاله، ما از کالیبراسیون مجازی خودکار برای سیستم محلیسازی سه لایه (بنابراین، بدون هزینه کالیبراسیون) [ 4 ] استفاده کردیم و سیستم محلیسازی اثر انگشت را با ایجاد یک نقشه RSS از حدود 50 ورودی کالیبره کردیم. علیرغم کالیبراسیون سیستم های محلی سازی مبتنی بر RSS که به تکنیک های مورد استفاده بستگی دارد، L 3 پیشنهادیسیستم باید بیشتر کالیبره شود. در واقع، سیستم پیش بینی با حدود 100 مسیر مستقیم و 100 مسیر منحنی آموزش داده شده است. حتی اگر فاز کالیبراسیون زمان بر باشد، سیستم های محلی سازی مبتنی بر RSS (هر دو تکنیک سه لایه و انگشت نگاری) را قابل استفاده می کند.
تضاد منافع
نویسندگان هیچ تضاد منافع را اعلام نمی کنند.
منابع
- ون دن بروک، جی. کاوالو، اف. Wehrmann, C. AALIANCE Ambient Assisted Living Map ; IOS Press: آمستردام، هلند، 2010. [ Google Scholar ]
- Barsocchi, P. شناسایی موقعیت برای حمایت از پیشگیری از زخم بستر. IEEE J. Biomed. اطلاعات سلامت 2013 ، 17 ، 53-59. [ Google Scholar ]
- آلوارز-گارسیا، جی. بارسوچی، پی. چسا، اس. سالوی، دی. ارزیابی سیستمهای تشخیص محلی و فعالیت برای زندگی با کمک محیط: تجربه مسابقه EvAAL 2012. JAISE 2013 ، 5 ، 119-132. [ Google Scholar ]
- بارسوچی، پی. لنزی، اس. چسا، اس. Furfari، F. کالیبراسیون مجازی خودکار سیستم های محلی سازی داخلی مبتنی بر محدوده. سیم. اشتراک. اوباش محاسبه کنید. 2012 ، 12 ، 1546-1557. [ Google Scholar ]
- گالیکیو، سی. میشلی، ع. بارسوچی، پی. Chessa, S. پیش بینی حرکات کاربر توسط محاسبات مخزن با استفاده از جریان سیگنال تولید شده توسط سنسورهای کلاس حرکتی. در MOBILIGHT ؛ Ser, JD, Jorswieck, EA, Miguez, J., Matinmikko, M., Palomar, DP, Salcedo-Sanz, S., Gil-Lopez, S., Eds.; Springer: برلین/هایدلبرگ، آلمان، 2011; جلد 81، صص 151–168. [ Google Scholar ]
- زورزی، ف. Zanella، A. محلی سازی فرصت طلب: مدل سازی و تجزیه و تحلیل، مجموعه مقالات شصت و نهمین کنفرانس فناوری وسایل نقلیه IEEE، بارسلون، اسپانیا، 26-29 آوریل 2009.
- لیو، ی. لو، اس. Liu, Y. COAL: Context Aware Localization برای بهره وری انرژی بالا در شبکه های بی سیم، مجموعه مقالات کنفرانس ارتباطات و شبکه بی سیم IEEE (WCNC)، کانکون، کوینتانا رو، مکزیک، 28-31 مارس 2011. صفحات 2030–2035.
- عزیزیان، م. Constandache، I. Roy Choudhury, R. SurroundSense: محلیسازی تلفن همراه از طریق اثرانگشت محیطی، مجموعه مقالات پانزدهمین کنفرانس بینالمللی سالانه محاسبات و شبکهسازی موبایل (MobiCom ’09)، پکن، چین، 20-25 سپتامبر 2009. ACM: نیویورک، نیویورک، ایالات متحده آمریکا؛ صص 261-272.
- وانگ، ی. جیکوبسون، QA; لین، جی. هانگ، جی. اناورام، م. کریشناماچاری، بی. Sadeh, N. A Framework of Energy Efficient Mobile Sensing for Automatic State User Recognition، مجموعه مقالات کنفرانس بین المللی سیستم های تلفن همراه، برنامه ها و خدمات (MobiSys)، کراکوف، لهستان، 22-25 ژوئن 2009.
- میلوزو، ای. لین، ND؛ فودور، ک. پترسون، آر. لو، اچ. موصلی، م. آیزنمن، اس بی. ژنگ، ایکس. کمپبل، AT Sensing با شبکه های اجتماعی موبایل ملاقات می کند: طراحی، پیاده سازی و ارزیابی برنامه CenceMe، مجموعه مقالات ششمین کنفرانس ACM در مورد سیستم های حسگر شبکه جاسازی شده (SenSys ’08)، رالی، کارولینای شمالی، ایالات متحده، 5-7 نوامبر 2008. ACM: نیویورک، نیویورک، ایالات متحده آمریکا؛ صص 337–350.
- Jaeger, H. رویکرد “حالت پژواک” به تجزیه و تحلیل و آموزش شبکههای عصبی مکرر . گزارش فنی؛ GMD—موسسه تحقیقات ملی آلمان برای علوم کامپیوتر: دارمشتات، آلمان، 2001. [ Google Scholar ]
- جیگر، اچ. هاس، اچ. مهار غیرخطی: پیش بینی سیستم های آشفته و صرفه جویی در انرژی در ارتباطات بی سیم. Science 2004 ، 304 ، 78-80. [ Google Scholar ]
- لوکوسوویسیوس، م. Jaeger, H. Reservoir Computing رویکردهای آموزش شبکه عصبی مکرر. محاسبه کنید. علمی Rev. 2009 , 3 , 127-149. [ Google Scholar ]
- جیگر، اچ. لوکوسوویسیوس، م. پوپوویچی، دی. Siewert، U. بهینهسازی و کاربردهای شبکههای حالت پژواک با نورونهای نشتکننده-انتگرالگر. شبکه عصبی 2007 ، 20 ، 335-352. [ Google Scholar ]
- Crossbow Technology Inc ، موجود در: http://www.xbow.com قابل دسترسی در 10 اکتبر 2013.
- پهلوان، ک. Levesque, AH شبکه های اطلاعات بی سیم ; Wiley: نیویورک، نیویورک، ایالات متحده آمریکا، 1995. [ Google Scholar ]
- Li، X. برآورد مکان مبتنی بر RSS با مدل ناشناخته ناشناخته. IEEE Trans. سیم. کمون 2006 ، 5 ، 3626-3633 . [ Google Scholar ]



© 2013 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/3.0/) توزیع شده است.
بدون نظر