

چکیده
محاسبات بیزی ; بیماری مزمن انسدادی ریه ؛ اپیدمیولوژی جغرافیایی ; پیش بینی ؛ اثرات تصادفی ؛ تشخیص خوشه فضایی
1. مقدمه
2. روش ها
2.1. موضوعات مطالعه
2.2. فرآیند وزن دهی
2.3. فرضیه های خاص
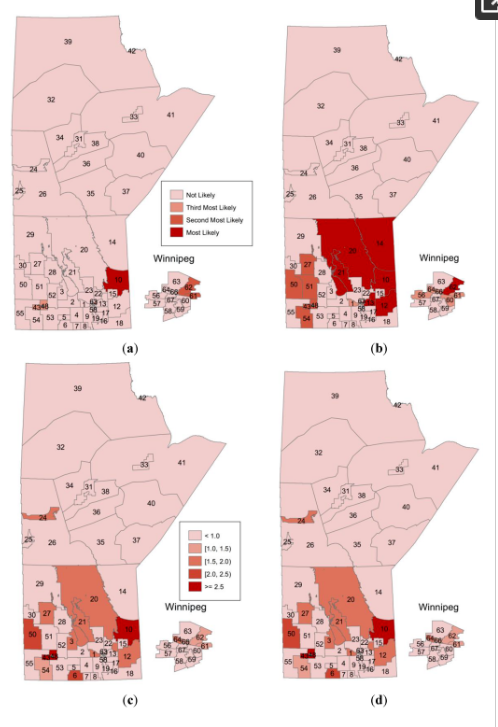
3. نتایج
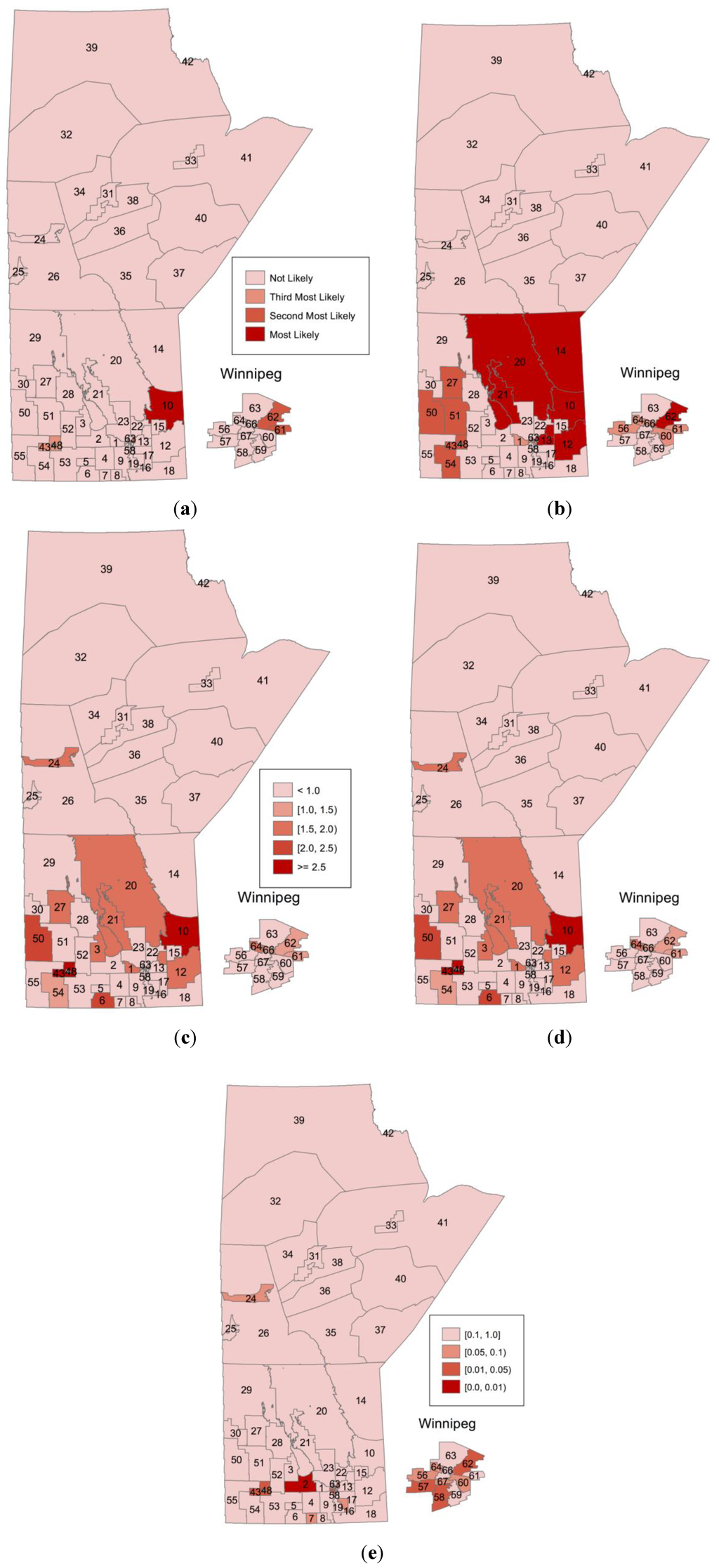
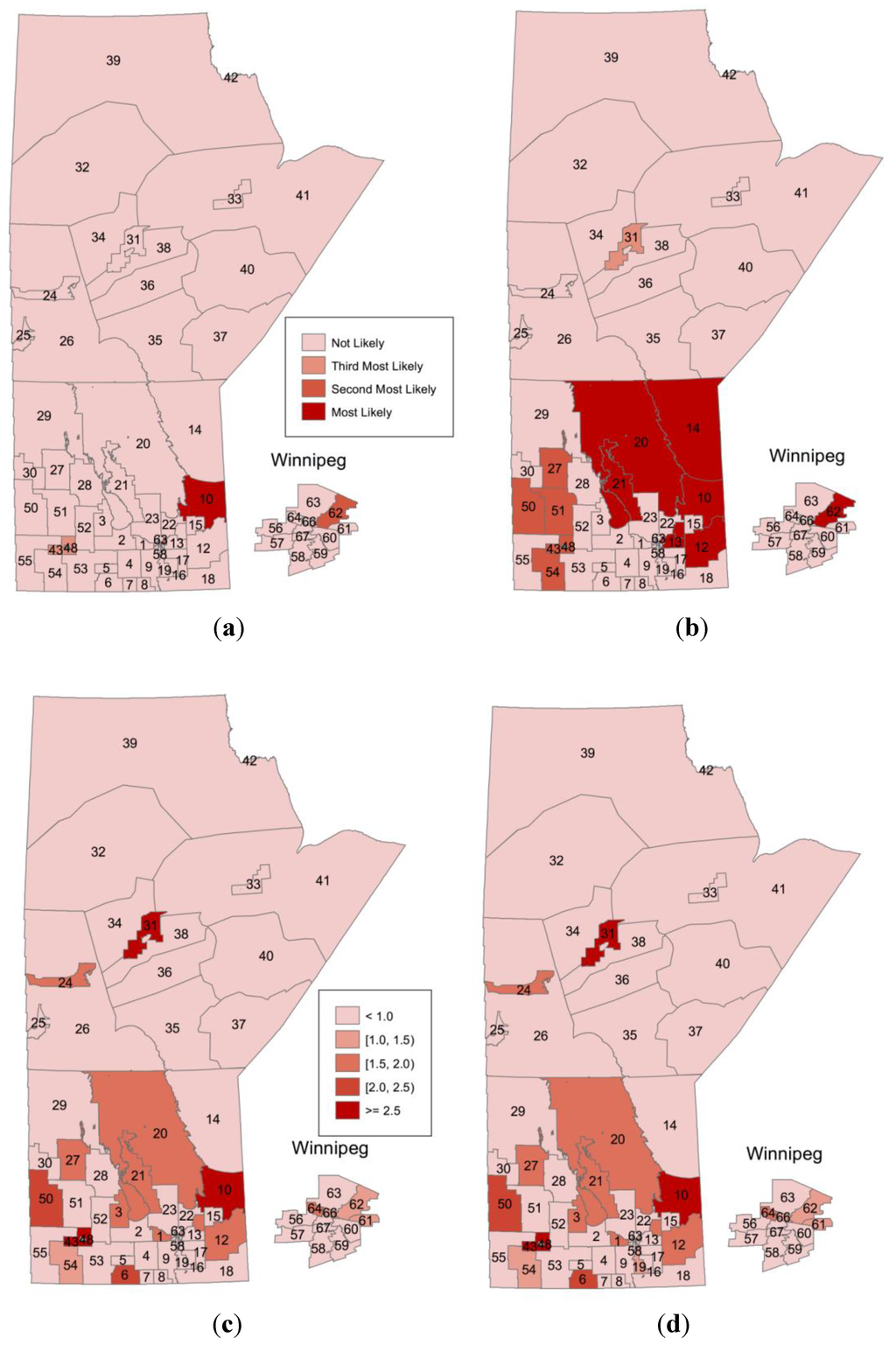



4. بحث و نتیجه گیری
ضمیمه
آمار اسکن فضایی دایره ای (CSS)
جایی که سیمن��تعداد موارد مشاهده شده در یک دایره را نشان می دهد و Eمن��نشان دهنده تعداد مورد انتظار در داخل یک دایره است. همچنین، ( ن– سیمن)(�− ��)و ( ن– Eمن)(�− ��)به ترتیب تعداد موارد مشاهده شده و مورد انتظار خارج از دایره را نشان می دهد. تابع نشانگر من(سیمن > Eمن)�(�� > ��)برابر 1 است وقتی سیمن > Eمن�� > ��و 0 در غیر این صورت. دایره هایی با نسبت احتمال بالا به عنوان خوشه های ممکن شناسایی می شوند [ 17 ].
آمار اسکن فضایی انعطاف پذیر (FSS)
نقشه برداری بیماری بیزی (BYM)
که در آن تعداد موارد مشاهده شده و مورد انتظار در منطقه است من�توسط سیمن��و Eمن،��,به ترتیب. بخش دوم مدل از طریق به دست می آید
جایی که ریسک نسبی ( آر آر��) در منطقه من�از رابطه زیر بدست می آید θمن��، μ�نشان دهنده نسبت میانگین کلی در کل منطقه و ηمن��اثرات تصادفی همبسته فضایی را نشان می دهد. این جلوههای تصادفی فضایی با استفاده از مدل معمولی CAR گرفته میشوند. انواع مدلهای CAR را میتوان با بهدست آوردن مجموعهای از توزیعهای شرطی سازگار با یکدیگر استفاده کرد p (ηمن|η– من) , i = 1 , … , m , �(��|�−�), � = 1,…,�,جایی که η– من = { ηj: j ≠ من ، �−� = {��:� ≠ �, j ∈ δمن}� ∈ ��}و δمن��به مجموعه ای از همسایگان برای منطقه i اشاره می کند [ 14 ]. ما از مدل کلی زیر برای جلوه های فضایی استفاده می کنیم ηمن��:
جایی که پ�هست یک متر × متر � × �ماتریس مورب با عناصر پمن من = 1 / همن��� = 1/��; D�هست یک متر × متر � × �ماتریس با عناصر Dمن ج = (هj/همن)1/2 _ _��� = (��/��)1/2اگر منطقه من�و j�مجاور هستند و Dمن ج = 0 ��� = 0در غیر این صورت؛ همن��تعداد مناطق مجاور منطقه است من�; σ2η��2پارامتر پراکندگی فضایی است. λη��خود همبستگی فضایی را اندازه گیری می کند، λm i n ≤ λη ≤ λm a x���� ≤ �� ≤ ����، جایی که λ– 1m i n����−1و λ– 1m a x����−1کوچکترین و بزرگترین مقادیر ویژه هستند پ− 1/2 _ _Dپ1/2 _ _�−1/2��1/2; و منمتر��ماتریس هویت ابعاد است متر�. برای جزئیات این مدل ماشین مناسب به [ 37 ] مراجعه می کنیم. با استفاده از توزیعهای قبلی مبهم و در چارچوب بیزی (MCMC)، ممکن است پارامترها برای تولید توزیعهای پسینی برای پارامترهای مدل [ 14 ] تخمین زده شوند.
رویکرد مکرر با استفاده از تخمین حداکثر احتمال (MLE)
جایی که توزیع قبلی در فضای پارامتر است π( α )�(�)و اچ(سی( L )) =🔻را{ L ( α , C) }Lπ( α ) دα�(�(�))=∫{�(�,�)}��(�)��ثابت نرمال کننده است. همچنین، { L ( α , C) }L{�(�,�)}�نشان دهنده احتمال برای L�کپی از داده های اصلی همانطور که توسط Lele و همکاران نشان داده شده است. [ 23 ، 24 ]، زمانی که L�به اندازه کافی بزرگ است، πL( α∣∣سی( L ))��(�|�(�))به یک توزیع نرمال چند متغیره با میانگین داده شده توسط MLE پارامترهای مدل و ماتریس واریانس کوواریانس برابر با 1 / L1/�برابر معکوس ماتریس اطلاعات فیشر برای MLE. از این رو، بردار میانگین نمونه اعداد تصادفی تولید شده از معادله (A4) به عنوان تخمینی از MLE و تخمینی از ماتریس واریانس-کوواریانس مجانبی برای MLE عمل می کند. αˆ�̂از رابطه زیر بدست می آید L�برابر ماتریس واریانس-کوواریانس نمونه اعداد تصادفی تولید شده از رابطه (A4). لله و همکاران [ 24 ] همچنین آزمایش های مختلفی را برای تعیین تعداد کافی کلون ها ارائه کرد L�.
پیش بینی ریسک نسبی:
جایی که α1 = μ �1 = �، α2 = ( λη،σ2η) ‘�2 = (��,��2)′، f( ⋅ )�(·)و g( ⋅ )�(·)به ترتیب توزیع پواسون و نرمال هستند و ϕ ( . , ξ ، Σ )�(., �, �)چگالی نرمال چند متغیره را با میانگین نشان می دهد ξ�و واریانس-کوواریانس Σ�. در این مقاله، پیشبینی r�با استفاده از معادله (A5) از طریق نمونه گیری MCMC به دست آمد. خوشه بیماری به عنوان منطقه ای تعریف می شود که در آن خطر نسبی تخمین زده شده (از نظر فاصله پیش بینی کمتر) به طور قابل توجهی بزرگتر از یک است. بسته dclone [ 40 ] در نرم افزار R [ 41 ] به منظور محاسبه مقادیر ریسک نسبی استفاده می شود.
شاخص محلی انجمن فضایی (LISA)
جایی که f�یک تابع است و مقادیر مشاهده شده در جیتی ساعت��ℎهمسایگی منطقه من�توسط yجیمن���. به منظور تعیین اهمیت آماری ارتباط فضایی در منطقه من�، موارد زیر باید رعایت شود
جایی که یک مقدار بحرانی توسط δمن��و αمن��سطح معینی از اهمیت است. یکی دیگر از شرایط یک آمار LISA این است که مجموع تمام آمارهای LISA در یک منطقه باید متناسب با یک شاخص جهانی تداعی فضایی باشد. به عبارت دیگر،
جایی که ΛΛشاخصی از شاخص جهانی با ضریب مقیاس است که توسط γ�. برای آزمایش اینکه آیا ارتباط فضایی آماری معنیداری در تمام مناطق وجود دارد، عبارت زیر باید درست باشد [ 26 ]
یک آمار LISA عمومی ممکن است برای آزمایش فرضیه صفر عدم ارتباط فضایی در برابر فرضیه جایگزین که خوشه بندی فضایی در سراسر یک منطقه وجود دارد استفاده شود. با این حال، یافتن توزیع LISA عمومی ممکن است سخت باشد. به همین دلیل، تصادفی سازی شرطی یا یک رویکرد جایگشت برای یافتن یک توزیع تجربی استفاده می شود. تصادفی سازی با نگه داشتن مقدار مشاهده شده ( yمن�من) در منطقه منمنثابت و مقادیر مشاهده شده باقیمانده در کل منطقه مورد مطالعه به طور تصادفی جابجا می شوند و مقدار Lمن�منمحاسبه می شود. این برای هر منطقه در منطقه مورد مطالعه انجام می شود. نتیجه یک تابع توزیع تجربی است که بیانگر میزانی است که هر مشاهده در مقایسه با سایر مقادیر مشاهده شده افراطی در نظر گرفته می شود [ 26 ].
منابع
- ابتکار جهانی برای بیماری انسداد مزمن ریه (GOLD). استراتژی جهانی برای تشخیص، مدیریت و پیشگیری از COPD. (به روز رسانی 2013). در دسترس آنلاین: http://www.goldcopd.org (در 3 ژوئیه 2013 قابل دسترسی است).
- آیزنر، MD; آنتونیسن، ن. کولتاس، دی. کوئنزلی، ن. پرز-پادیلا، آر. پستما، دی. رومیو، آی. سیلورمن، EK; Balmes, JR بیانیه رسمی سیاست عمومی انجمن قفسه سینه آمریکا: عوامل خطر جدید و بار جهانی بیماری مزمن انسدادی ریه. عامر J. Respir. کریت مراقبت پزشکی. 2010 ، 182 ، 693-718. [ Google Scholar ] [ CrossRef ]
- سزر، اچ. آکورت، آی. گولر، ن. ماراکوغلو، ک. Berk, S. مطالعه مورد-شاهدی در مورد تأثیر قرار گرفتن در معرض مواد مختلف بر ایجاد COPD. ان اپیدمیول. 2006 ، 16 ، 59-62. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- برت، ال. کوربریج، S. تشدید COPD. عامر J. Nurs. 2013 ، 113 ، 34-43. [ Google Scholar ] [ CrossRef ]
- لامپرشت، بی. مک برنی، MA; وولمر، WM; گودموندسون، جی. ولته، تی. Nizankowska-Mogilnicka، E. استودنیکا، م. بیتمن، ای. آنتو، جی.ام. برنی، پی. و همکاران COPD در افراد سیگاری هرگز: نتایج حاصل از بار جمعیتی مطالعه بیماری انسدادی ریه. سینه 2011 ، 139 ، 752-763. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- انجمن توراسیک کانادا بار انسانی و اقتصادی COPD: علت اصلی پذیرش در بیمارستان در کانادا . Canadian Thoracic Society: Ottawa, ON, Canada, 2010. [ Google Scholar ]
- موسسه اطلاعات سلامت کانادا شاخصهای سلامت 2008. در دسترس آنلاین: https://secure.cihi.ca/free_products/HealthIndicators2008_ENGweb.pdf (در 3 ژوئیه 2013 قابل دسترسی است).
- میتمن، ن. کوراموتو، ال. سونگ، اس جی. هادون، جی.ام. بردلی کندی، سی. FitzGerald, JM هزینه تشدید متوسط و شدید COPD برای سیستم مراقبت های بهداشتی کانادا. تنفس پزشکی 2008 ، 102 ، 413-421. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Scheinfeld، MH; مانیاتیس، تی. Gurell، D. COPD؟ عامر جی. مد. 2006 ، 119 ، 839-842. [ Google Scholar ] [ CrossRef ]
- Lawson, AB Statistical Methods in Spatial Epidemiology , 2nd ed.; John Wiley & Sons, Ltd.: London, UK, 2006. [ Google Scholar ]
- جنینگز، جی.ام. کوریرو، اف سی؛ سلنتانو، دی. الن، JM شناسایی جغرافیایی مناطق انتقال سوزاک بالا در بالتیمور، مریلند. عامر J. Epidemiol. 2005 ، 161 ، 73-80. [ Google Scholar ] [ CrossRef ]
- الیوت، پی. بریگز، دی. موریس، اس. د هوگ، سی. صدمه، سی. جنسن، TK; میتلند، آی. ریچاردسون، اس. ویکفیلد، جی. Jarup, L. خطر پیامدهای نامطلوب تولد در جمعیت هایی که در نزدیکی مکان های دفن زباله زندگی می کنند. بریتانیایی پزشکی J. 2001 , 323 , 363-368. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لاوسون، AB; بیگری، ع. ویلیامز، FLR مروری بر رویکردهای مدلسازی در ارزیابی خطر سلامت در اطراف منابع احتمالی. در نقشه برداری بیماری و ارزیابی خطر برای سلامت عمومی ; Lawson, AB, Biggeri, A., Böhning, D., Lesaffre, E., Viel, J., Bertollini, R., Eds.; Wiley: نیویورک، نیویورک، ایالات متحده آمریکا، 1999; صص 231-245. [ Google Scholar ]
- Besag, JE; یورک، جی سی. Mollìe, A. بازیابی تصویر بیزی با دو کاربرد در آمار فضایی (با بحث). ان Inst. آمار ریاضی. 1991 ، 43 ، 1-59. [ Google Scholar ] [ CrossRef ]
- کلیتون، دی. روش های برناردینلی، ال. بیزی برای ترسیم خطر بیماری. در اپیدمیولوژی جغرافیایی و محیطی: روشهایی برای مطالعات مناطق کوچک . Elliott, P., Cuzick, J., English, D., Stern, R., Eds. انتشارات دانشگاه آکسفورد: آکسفورد، انگلستان، 1996; ص 205-220. [ Google Scholar ]
- کلیتون، دی. کالدور، جی. بیز تجربی خطرات نسبی استاندارد شده با سن را برای استفاده در نقشه برداری بیماری تخمین می زند. بیومتریک 1987 ، 43 ، 671-681. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Kulldorff, M. آمار اسکن فضایی. اشتراک. آمار. الف – نظریه. روش. 1997 ، 26 ، 1481-1496. [ Google Scholar ]
- تانگو، تی. تاکاهاشی، ک. یک آمار اسکن فضایی با شکل انعطافپذیر برای تشخیص خوشهها. بین المللی J. Health Geogr. 2005 ، 4 ، 1-15. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Besag, JE; نیول، جی. تشخیص خوشه ها در بیماری های نادر. جی آر استاتی. Soc. سر. A 1991 ، 154 ، 143-155. [ Google Scholar ] [ CrossRef ]
- ترابی، م. Rosychuk، RJ تشخیص خوشه رویداد فضایی با استفاده از توزیع نرمال تقریبی. بین المللی J. Health Geogr. 2008 ، 7 ، 1-22. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Tango, T. آزمونی برای خوشهبندی بیماریهای فضایی که برای آزمایشهای چندگانه تنظیم شده است. آمار پزشکی 2000 ، 19 ، 191-204. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ترابی، م. Rosychuk، RJ بررسی پنج روش خوشهبندی بیماری فضایی برای شناسایی خوشههای سرطان دوران کودکی در آلبرتا، کانادا. تف کردن اپیدمیول فضایی و زمانی 2011 ، 2 ، 321-330. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لله، اس آر. دنیس، بی. Lutscher, F. شبیه سازی داده ها: تخمین حداکثر احتمال آسان برای مدل های پیچیده اکولوژیکی با استفاده از روش های مونت کارلو زنجیره مارکوف بیزی. Ecol. Lett. 2007 ، 10 ، 551-563. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لله، اس آر. ندیم، ک. Schmuland، B. برآورد و احتمال استنتاج برای مدلهای ترکیبی خطی تعمیم یافته با استفاده از شبیهسازی دادهها. مربا. آمار دانشیار 2010 ، 105 ، 1617-1625. [ Google Scholar ] [ CrossRef ]
- ترابی، M. تشخیص خوشه ای بیماری فضایی: کاربرد برای آسم دوران کودکی در مانیتوبا، کانادا. جی بیوم. Biostat. 2012 . [ Google Scholar ] [ CrossRef ]
- Anselin، L. شاخص های محلی ارتباط فضایی-LISA. Geogr. مقعدی 1995 ، 2 ، 93-115. [ Google Scholar ]
- آمار کانادا راهنمای کاربر بررسی سلامت جامعه کانادا (2001–2010) ؛ آمار کانادا: اتاوا، ON، کانادا، 2010. [ Google Scholar ]
- مک کالا، پی. Nelder، JA مدل های خطی تعمیم یافته ، ویرایش دوم. چپمن و هال: لندن، بریتانیا، 1989. [ Google Scholar ]
- ریچاردسون، اس. تامسون، ا. بهترین، ن. الیوت، پی. تفسیر تخمین های خطر خلفی در مطالعات نقشه برداری بیماری. محیط زیست چشم انداز سلامتی 2004 ، 112 ، 1016-1025. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- بانرجی، اس. گلفاند، AE; کارلین، مدلسازی و تحلیل سلسله مراتبی BP برای داده های فضایی . چپمن و هال: لندن، انگلستان، 2004. [ Google Scholar ]
- فرانسو، ر. مارتنز، پی. برلند، ای. تیم نیاز به دانستن . قبل، H.، Burchill، C.، ویرایش. مرکز منیتوبا برای سیاست های بهداشتی، اطلس شاخص های RHA مانیتوبا: وینیپگ، MB، کانادا، 2009. [ Google Scholar ]
- فوکودا، ی. اومزاکی، م. ناکامورا، ک. تاکانو، T. تغییرات در ویژگی های اجتماعی خوشه های بیماری فضایی: نمونه هایی از سرطان روده بزرگ، ریه و پستان در ژاپن. بین المللی J. Health Geogr. 2005 ، 4 ، 1-13. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- کولدورف، ام. رند، ک. ژرمن، جی. ویلیامز، جی. DeFrancesco, D. SaTScan V2.1: نرم افزار برای آمار اسکن مکانی و فضا-زمان . موسسه مرکز ملی: Bethesda، MD، ایالات متحده، 1998. [ Google Scholar ]
- تاکاهاشی، ک. یوکویاما، تی. Tango, T. FleXScan: نرم افزار برای آمار اسکن انعطاف پذیر . موسسه ملی بهداشت عمومی: ناگویا، ژاپن، 2006. [ Google Scholar ]
- برناردینلی، ال. Montomoli، C. بیز تجربی در مقابل تجزیه و تحلیل کاملاً بیزی تنوع جغرافیایی در خطر بیماری. آمار پزشکی 1992 ، 11 ، 983-1007. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Gilks، WR; ریچاردسون، اس. Spielhalter، DJ Markov Chain Monte Carlo در تمرین ; چپمن و هال/CRC: لندن، بریتانیا، 1995. [ Google Scholar ]
- اشپیگلهالتر، دی. توماس، ا. بهترین، ن. راهنمای کاربر Lunn, D. WinBUGS Version 1.4 . واحد آمار زیستی MRC، موسسه بهداشت عمومی: لندن، انگلستان، 2004. [ Google Scholar ]
- آمودت، جی. ساموئلسن، SO; Skrondal, A. مطالعه شبیه سازی شده از سه روش برای تشخیص خوشه های بیماری. بین المللی J. Health Geogr. 2006 ، 5 ، 1-11. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- همیلتون، JD یک خطای استاندارد برای بردار حالت تخمینی مدل فضای حالت. J. Econometrics 1986 ، 33 ، 387-397. [ Google Scholar ] [ CrossRef ]
- Sólymos، P. Dclone: شبیه سازی داده ها در R. R J. 2010 ، 2 ، 29-37. [ Google Scholar ]
- تیم اصلی R. R: زبان و محیطی برای محاسبات آماری . بنیاد R برای محاسبات آماری: وین، اتریش، 2013. [ Google Scholar ]
- Sidák، Z. مناطق اطمینان مستطیلی برای میانگین توزیعهای نرمال چند متغیره. مربا. آمار دانشیار 1967 ، 62 ، 626-633. [ Google Scholar ]
- Bjornstad، ON ncf: توابع کوواریانس ناپارامتری فضایی. بسته R نسخه 1.1-5. 21 نوامبر 2013. در دسترس آنلاین: http://cran.r-project.org/web/packages/ncf/index.html (در 24 ژوئیه 2014 قابل دسترسی است).
© 2014 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/3.0/) توزیع شده است.
بدون نظر