

چکیده
سلامت انسان بخشی از یک سیستم چند وجهی وابسته به هم است. بیش از هر زمان دیگری، ما به طور فزاینده ای داده های زیادی در مورد بدن، اعم از فضایی و غیر فضایی، سیستم های آن، بیماری ها و محیط اجتماعی و فیزیکی خود داریم. این داده ها دارای یک جزء جغرافیایی هستند. یک دوره جدید هیجان انگیز در حال طلوع است که در آن ما به طور همزمان مجموعه های داده متعددی را برای توصیف بسیاری از جنبه های سلامت، تندرستی، فعالیت های انسانی، محیط زیست و بیماری جمع آوری می کنیم. بینشهای ارزشمند از این مجموعه دادهها را میتوان با استفاده از تکنیکهای محاسباتی چند متغیره، مانند یادگیری ماشین، همراه با تکنیکهای مکانی، استخراج کرد. این ابزارهای محاسباتی به ما کمک میکنند تا توپولوژی دادهها را درک کنیم و بینشهایی را برای کشف علمی، پشتیبانی تصمیمگیری و تدوین خطمشی ارائه کنیم. این مقاله یک پارادایم کل نگر به نام کل نگری 3 را ترسیم می کند. 0 برای تجزیه و تحلیل داده های سلامت با مجموعه ای از مثال ها. Holistics 3.0 مجموعهای از مجموعه دادههای بزرگ را که در زمینه جغرافیایی آنها تنظیم شدهاند، ترکیب میکند که تا حد ممکن حوزههای مشکل را با یادگیری ماشین و علیت توصیف میکند تا هم از دادهها یاد بگیرد و هم ابزارهایی برای تصمیمگیریهای مبتنی بر داده بسازد.
کلید واژه ها:
جغرافیایی ; یادگیری ماشینی ؛ کلان داده ؛ سلامتی ؛ سنجش از دور ؛ کل نگری 3.0 ; تصمیمات مبتنی بر داده
1. مقدمه
برای چندین دهه، متخصصان بهداشت عمومی و علوم اجتماعی تنوع جغرافیایی جمعیت ها را تشخیص داده اند. سلامت توسط عوامل متعددی شکل میگیرد، از جمله مراقبتهای بهداشتی، سیستمهای بهداشت عمومی، رفتارهای فردی (مثلاً سیگار کشیدن) و عوامل خطر (مثلاً چاقی)، عوامل اجتماعی-اقتصادی (مانند درآمد، تحصیلات)، محیط فیزیکی (مثلاً آلودگی هوا)، محیط اجتماعی (به عنوان مثال، حمایت اجتماعی)، سیاست های عمومی و عناصر “کلان ساختاری” جامعه که کل این فهرست را شکل می دهند. پیوند دادن این دادهها برای حل نگرانیهای مربوط به سلامت عمومی نیاز به حسابداری روابط چند متغیره غیرخطی و همچنین بعد فضایی دادهها دارد.
دههها تحقیق همچنین تلاش کرده است تا عوامل خاصی را که بیشترین اهمیت را دارند، نه تنها به عنوان یک تمرین آکادمیک، بلکه برای کمک به سیاستگذاران برای تعیین اولویتها در یک محیط تصمیمگیری با منابع محدود، جدا کنند. به عنوان مثال، در یک جامعه خاص که با نرخ بالای بیماری های مزمن مواجه است، آیا شورای شهر یا هیئت نظارت باید بودجه بیمارستان ها، گسترش مراقبت های اولیه، تصویب قوانین ممنوعیت سیگار در داخل خانه، رسیدگی به بیکاری، تقویت مدارس و غیره را در اولویت قرار دهند؟ همه به وضوح مهم هستند، اما کدام یک یا کدام ترکیب بیشترین اهمیت را دارد و بهترین بازگشت سرمایه را به همراه خواهد داشت؟
با طرح چنین سؤالاتی، دانشمندان معمولاً به تکنیکهای آماری سنتی مانند معادلات رگرسیون متوسل میشوند تا اهمیت نسبی عوامل مختلف را کمی یا مدلسازی کنند. این رویکرد به برخی از عوامل کلیدی بینش داده است، اما محدودیت هایی نیز دارد که دو مورد از آنها در اینجا ذکر می شود. اولاً، این محاسبات اغلب به جای علیت، ارتباط را مورد بررسی قرار میدهند: برای مثال، این واقعیت که افرادی که از دبیرستان فارغالتحصیل نشدهاند، وضعیت سلامت بدتری دارند، به این معنا نیست که با اعطای دیپلم، تفاوتها کاملاً از بین میرود. در عوض، سطح تحصیلات نشان می دهد که یک پروکسی مفید است. دوم، متغیرهایی که محققان در فرمولهای خود وارد میکنند، بر اساس متغیرهایی که دادهها برای آنها در دسترس است و آنهایی که محققان فکر میکنند مهمترین در نظر گرفتن هستند، بهطور انتخابی انتخاب میشوند.
گزینش پیشینی در انتخاب متغیرهایی که باید در نظر گرفته شوند تا حدی میراث روش علمی قدیمی است (ابتدا یک فرضیه مطرح کنید و سپس داده ها را برای حمایت یا رد آن جمع آوری کنید)، اما تا حدی یک ضرورت عملی است، زیرا بررسی همه داده ها قبلاً اغلب یک گزینه غیرقابل دفاع بود، به خصوص که حجم داده های موجود افزایش یافته است. ظهور یادگیری ماشینی مانع دوم را در زمانی از بین می برد که در دسترس بودن «داده های بزرگ» در همه زمینه ها رو به افزایش است [ 1 ، 2 ، 3 ، 4 ، 5 ، 6 ].
1.1. اطلاعات بزرگ
افراد مختلف اصطلاح Big Data را به روش های کمی متفاوت به کار می برند. با این حال، ایده رایج مجموعه داده های بزرگ از نظر حجم داده ها (به عنوان مثال، به دلیل وضوح زمانی یا مکانی و/یا پوشش) و/یا بزرگ بودن از نظر تعداد متغیرهای گنجانده شده است. یکی از تفاوت های اصلی در استفاده از داده های بزرگ معمولاً به این مربوط می شود: دقیقاً چقدر بزرگ است؟
برای مثالهای خاص مورد استفاده در این مقاله، این مجموعه دادهها تغییرات جغرافیایی را نیز توصیف میکنند. تعداد متغیرها از ده ها تا هزاران متغیر متغیر است و تعداد رکوردهای هر متغیر از هزاران تا میلیون ها متغیر است که هم یک عکس فوری در زمان و هم تغییرات روزانه ردیابی شده برای نزدیک به دو دهه را پوشش می دهد. این مقدار داده احتمالاً توسط اکثر محققین به عنوان کلان داده طبقه بندی می شود.
1.2. فراگیری ماشین
یادگیری ماشینی مجموعهای از ابزارهای ارزشمند برای تخمین تجربی و طبقهبندی متغیرهای مورد علاقه است، زمانی که ما توصیف نظری کاملی از یک فرآیند نداریم، اما دادههای مفیدی داریم. علاوه بر این، اغلب مایلیم از این داده ها برای ارائه بینش و/یا کمک به تصمیم گیری استفاده کنیم.
یادگیری ماشینی طیف بسیار گستردهای از الگوریتمها را در بر میگیرد (به عنوان مثال، شبکههای عصبی، ماشینهای بردار پشتیبان، فرآیندهای گاوسی، درختهای تصمیمگیری، جنگلهای تصادفی و غیره ) که میتوانند رگرسیون چند متغیره، غیرخطی، ناپارامتریک یا مبتنی بر طبقهبندی را ارائه دهند. روی یک مجموعه داده آموزشی ( به عنوان مثال ، مجموعه ای از مثال ها برای یادگیری) و بینشی در مورد توپولوژی زیرین داده ها ارائه دهید. این رویکرد به داده ها اجازه می دهد تا خودشان صحبت کنند.
یادگیری ماشینی کاربردهای گسترده و رو به رشدی دارد. چند نمونه از استفاده روزانه آن عبارتند از بررسی اعتبار، استفاده توسط آمازون و سایر فروشگاههای آنلاین برای پیشنهاد سایر محصولات بالقوه مورد علاقه به مصرفکنندگان، پیشنهادات فیلم نتفلیکس، برنامههای سنجش از راه دور، ابزارهای مختلف Google و تصمیمگیریهای موجودی که توسط خردهفروشان بزرگ، مانند Walmart گرفته میشود. [ 7 ، 8 ، 9 ].
یادگیری ماشین هنوز در مقیاس بزرگ وارد سلامت عمومی نشده است، اما داده های بزرگ به طور گسترده در سلامت جمعیت وجود دارد، دریایی از داده هایی که می توان در مراقبت های بهداشتی استخراج کرد (مثلاً پرونده های پزشکی الکترونیکی)، آمار بهداشت عمومی، داده های سرشماری جمعیت. شرایط زندگی، خطرات محیطی و برنامه های عمومی. در سال گذشته، مقالات و موضوعات کلی مجلات پزشکی، توجه را به فرصت های هیجان انگیزی که در به کارگیری یادگیری ماشین در این مجموعه داده ها وجود دارد جلب کرده اند. سازمان ها جوایزی را برای تشویق نوآوری ها در این زمینه راه اندازی کرده اند [ 10]. دولت فدرال میزبان چهار کنفرانس سالانه Health Datapalooza بوده که حاصل تلاشهای دولت اوباما برای «آزادسازی» دادههای بهداشتی است (http://healthdatapalooza.org/about/). بسیاری از این طرحها بر ایجاد ابزارهای پشتیبانی تصمیم برای ردیابی بیماریها، مانند شناسایی زودهنگام شیوع بیماریهای عفونی یا داشبوردهایی برای ردیابی شرایط و هزینههای سلامت تمرکز میکنند، اما استفاده از یادگیری ماشین در این مجموعه دادهها افق بسیار بزرگتری را باز میکند.
1.3. کل نگری 3.0
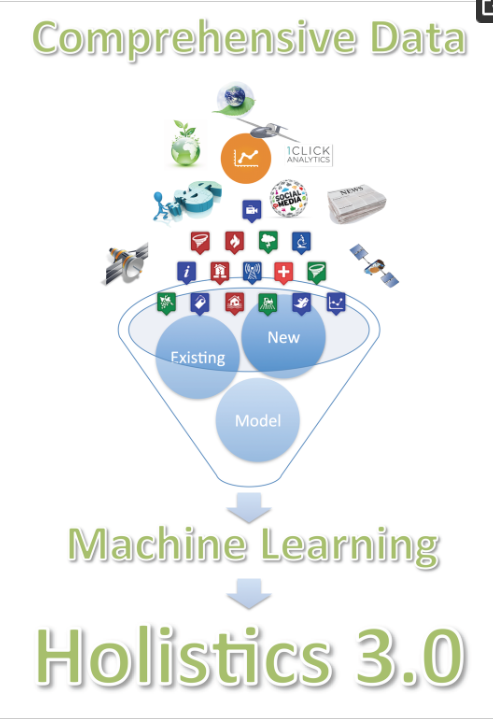
ما Holistics 3.0 را به این صورت تعریف می کنیم که (1) مجموعه داده های متعددی را که تا حد ممکن جنبه های یک مشکل را توصیف می کند، گرد هم می آورد . (2) همراه کردن این توصیف جامع از مشکل با یادگیری ماشین برای ساخت ابزارهای پشتیبانی تصمیم گیری تجربی برای تصمیم گیری های داده محور. و (3) در صورت لزوم، همبستگیها و ارتباطهای مورد بهرهبرداری توسط یادگیری ماشین را برای رسیدگی به موضوع بیشتر علیت تقویت کنید. در مجموع این پارادایم Holistics 3.0 نامیده می شود و به صورت شماتیک در شکل 1 نشان داده شده است.
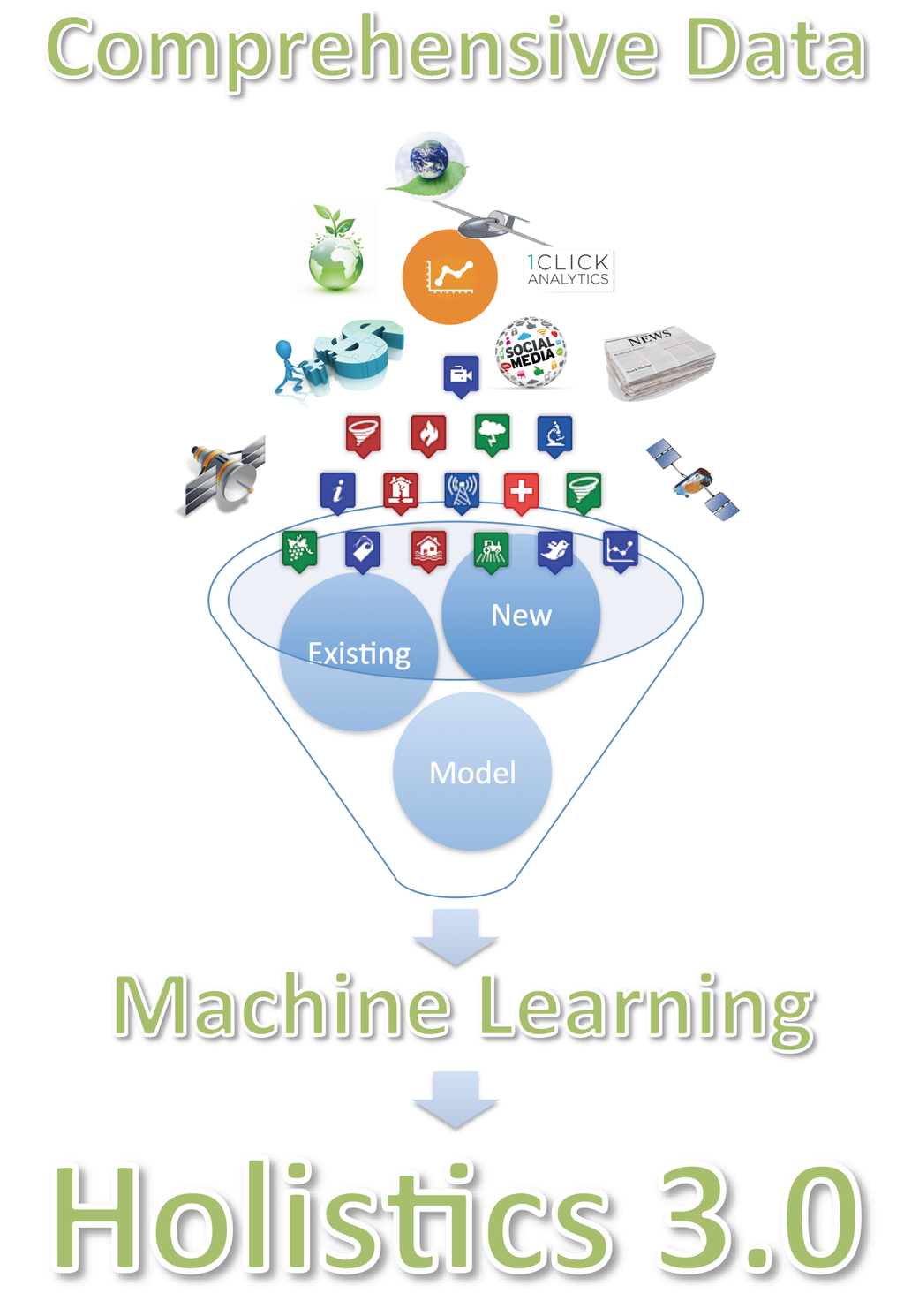
شکل 1. شماتیکی که مؤلفههای کلیدی Holistics 3.0 را نشان میدهد: (1) مجموعه دادههای جغرافیایی چندگانه که بسیاری از جنبههای یک مشکل را به طور کلنگر توصیف میکنند. (2) استفاده از یادگیری ماشین برای ساخت ابزارهای پشتیبانی تصمیم گیری تجربی. و (3) افزایش با استنباط در مورد علیت. در مجموع، این پارادایم Holistics 3.0 نامیده می شود.
2. استخراج معنی از داده ها
آیا راهاندازی یک کامپیوتر قدرتمند برای اسکن ارتباط در میان شبکه گستردهای از متغیرهای بیشمار مفید است؟ تصمیمات مبتنی بر داده می تواند به سیاست گذاران، از پزشکان گرفته تا مقامات منتخب، کمک کند تا عواملی را که به احتمال زیاد باعث بهبود سلامت می شوند، شناسایی کنند. متغیرهایی که قبلاً مورد توجه قرار نگرفتهاند یا حتی به آنها توجه نشدهاند، ممکن است کلید درک محرکهای مهم پیامدهای سلامتی باشند که راهحلهای جدید و درک جدیدی از چگونگی ایجاد عوارض بیماری در وهله اول ارائه میدهند. در بسیاری از مطالعات یادگیری ماشین قبلی ما، متوجه شدیم که در بسیاری از موارد، توصیف دقیق مشکل ما را ملزم میکند که به طور همزمان چندین جنبه از مشکل را توصیف کنیم. گاهی اوقات، این فقط شامل پنج یا شش متغیر است، اما گاهی اوقات چهل یا بیشتر. معمولاً یک متغیر “جادویی” وجود ندارد. نسبتا، ما معمولاً با مشکلات واقعاً چند متغیره روبرو هستیم، که در آن عوامل بسیاری باید به طور همزمان در نظر گرفته شوند، که اغلب غیرخطی نیز هستند. در بسیاری از موارد، شکل عملکردی رابطه را نمی دانیم (به عنوان مثال ، آنها همچنین ناپارامتریک هستند)، و بسیاری از اوقات، متغیرها ممکن است دارای توزیع های غیر گاوسی باشند.
یادگیری ماشینی می تواند فقط به این نوع مشکلات کمک شایانی کند، نه تنها برای شناسایی متغیرهای کلیدی، بلکه در ارائه ابزارهای تجربی، اغلب با وفاداری قابل توجه. اگر مفهوم علیت را همانطور که توسط Judea Pearl [ 11 ] توضیح داده است اضافه کنیم، یک پارادایم بسیار قدرتمند برای تصمیم گیری های داده محور خواهیم داشت. درک کنونی از مسیر علّی بیماری ها بر اساس روش علمی ساخته شده است، که میراث قوی دارد، اما محدودیت اتکا به ذهن انسان برای انتخاب متغیرها (و فرضیه ها) شایسته مطالعه بیشتر است.
یادگیری ماشینی فرصت بیسابقهای را ارائه میدهد تا دادهها بدون پیشفرضهای انسانی صحبت کنند و توجه را به متغیرهای ناشناخته قبلی جلب کنیم که به نظر میرسد ارتباط مهمی با پیامدهای سلامت دارند و مستلزم مطالعه بیشتر تحت روش علمی سنتی برای تأیید/رد این ارتباط هستند. . بنابراین، یادگیری ماشینی میتواند روش علمی را با ارائه رویکردی “با ذهن باز” برای آزمایش فرضیهها و تولید سرنخ علمی که بر دادهها برای جلب توجه به سؤالات جذاب متکی است، تقویت کند. به این ترتیب، استفاده از یادگیری ماشینی بیشتر مبتنی بر شواهد است تا تکیه بر افراد معدودی برای انتخاب و انتخاب متغیرهایی که «فکر میکنند» مهم هستند.
جدای از کشف اهرمهای جدید برای بهبود سلامت، یادگیری ماشینی همچنین این پتانسیل را دارد که اهمیت نسبی اهرمهایی را که قبلاً مهم شناخته شدهاند، کمیت کند. به عنوان مثال، ادعاهایی مبنی بر اینکه مراقبت های بهداشتی 10 درصد از پیامدهای سلامت را به خود اختصاص می دهد عمدتاً بر اساس معادلات رگرسیون خطی است. یادگیری ماشینی میتواند این رویکرد را نه تنها با ارائه یک رگرسیون چند متغیره، غیرخطی و غیر پارامتری، که نیازی به دانش قبلی از فرم عملکردی ندارد، بهبود بخشد، بلکه با ارائه فهرستی عینی از اهمیت نسبی متغیرهای مورد استفاده در رگرسیون
علاوه بر این، دسترسی به چندین مجموعه داده بزرگ مورد نیاز برای انجام یادگیری ماشینی نیز منبع آماده ای را برای سیاستگذارانی فراهم می کند که نیاز به دسترسی سریع به آمار توصیفی یا روندها برای جوامع یا جمعیت های خاص خود دارند. برای مثال، قانون مراقبت مقرون به صرفه (ACA) بیمارستانها را ملزم میکند تا ارزیابیهای نیازهای سلامت جامعه را برای حفظ وضعیت غیرانتفاعی خود با خدمات درآمد داخلی آماده کنند. بیمارستانهای سراسر کشور که تجربه کمی در مطالعه آمار جمعیت دارند، در تلاش هستند تا همکارانی را در سازمانهای بهداشت عمومی یا اجتماعی بیابند که میتوانند برای تهیه این گزارشها با آنها قرارداد ببندند. بینشهای عظیمی که از طریق یادگیری ماشینی در دسترس است، سیستمهای سلامت را قادر میسازد تا جوامع خود را در سطحی از جزئیات که در حال حاضر قابل تصور نیست، نمایه کنند.
سیستمهای بهداشتی بزرگ همچنین سازمانهای مراقبت پاسخگو (ACO) را تشکیل میدهند که تحت ACA، موظف هستند مسئولیت سلامت جمعیتی را که به آنها خدمت میکنند بر عهده بگیرند. انگیزه پشت ACO ها تشویق سیستم های مراقبت های بهداشتی برای شناسایی مدل های جدید مداخله، از جمله مدل هایی که شامل عوامل تعیین کننده سلامت خارج از کلینیک هستند، برای جلوگیری از بیماری، کاهش عوارض و کنترل هزینه ها است. اکثر رهبران ACO در حال حاضر بر حدس های تحصیل کرده تکیه می کنند تا تصمیم بگیرند که چگونه دلارهای خود را برای بهبود سلامت جمعیت سرمایه گذاری کنند [ 12 ]]. ابزارهای پشتیبانی تصمیم مبتنی بر یادگیری ماشینی این پتانسیل را دارند که تصمیمگیرندگان و سیاستگذاران را با اطلاعات دقیقتری در مورد سلامت جمعیت، شیوع و جغرافیای عوامل محلی که سلامت جامعه را شکل میدهند و بیشترین بالقوه بازده سرمایهگذاری را مسلح کنند. اگر تحقیقات تأییدی از پیوند علی پشتیبانی کند، ممکن است دروغ باشد.
3. چند مثال
اجازه دهید اکنون دو مثال بسیار متفاوت مرتبط با سلامت مکانی را بررسی کنیم که این رویکرد را نشان میدهد.

جدول 1. نتایج بهداشتی مرتبط با ذرات معلق (PM) و ذرات بسیار ریز (UFP) (اصلاح شده از [ 13 ]).
3.1. ذرات معلق در هوا
با افزایش آگاهی از تأثیرات فراوان ذرات معلق بر سلامتی ( جدول 1 ) از مرگ و میر عمومی گرفته تا شرایط خاص ریوی، تنفسی، قلبی عروقی، سرطان و تولید مثل، به جز چند مورد، نیاز فزاینده و مبرمی به داشتن جهانی وجود دارد. تخمین روزانه غلظت ذرات معلق هوا در سطح زمین با قطر 2.5 میکرون یا کمتر (PM 2.5 ). پارادایم Holistics 3.0 را می توان در مجموعه داده های سنجش از دور موجود ناسا همراه با تجزیه و تحلیل های هواشناسی، داده های جمعیت شناختی و مشاهدات درجا به کار برد تا به طور موثر این نیاز را برآورده کند. ما قبلاً با موفقیت از یادگیری ماشینی برای تخمین PM 2.5 جهانی روزانه استفاده کرده ایمتمرکز بر اساس معمول این رویکرد از مجموعهای از محصولات سنجش از دور و دادههای هواشناسی و مشاهدات زمینی ذرات در 8329 مکان اندازهگیری در 55 کشور ( شکل 2 ) که از سال 1997 تا کنون انجام شدهاند، برای تخمین توزیع روزانه PM 2.5 استفاده میکند.
بسیاری از اثرات سلامتی PM 2.5 به غلظت هوا در سطح زمین بستگی دارد، جایی که PM 2.5 می تواند استنشاق شود ( جدول 1 ). با این حال، همانطور که در شکل 2 مشاهده می شود ، پوشش فضایی دارای شکاف های زیادی است و در برخی از کشورها، به طور کلی هیچ رصد PM 2.5 وجود ندارد. این تا حد زیادی به دلیل هزینه های مربوط به راه اندازی چنین شبکه حسگر است. مطالعات متعددی به دنبال غلبه بر فقدان مشاهدات مستقیم PM 2.5 با استفاده از سنجش از دور و عمق نوری آئروسل مشتق از ماهواره (AOD) همراه با رگرسیون و/یا مدلهای عددی برای تخمین غلظت PM 2.5 در سطح زمین هستند [ 14 ، 15 ], 16 , 17 , 18 , 19 , 20 , 21 , 22 , 23 , 24 , 25 , 26 , 27 , 28 , 29 , 30 , 31 , 32 ].
بسیاری از مطالعات نشان داده اند که رابطه بین PM 2.5 و AOD تابعی چند متغیره از تعداد زیادی پارامتر از جمله: رطوبت، دما، ارتفاع لایه مرزی، فشار سطح، تراکم جمعیت، توپوگرافی، سرعت باد، نوع سطح، سطح است. بازتاب، فصل، کاربری زمین، واریانس نرمال شده رویدادهای بارندگی، طیف اندازه و فاز ذرات ابر، پوشش ابر، عمق نوری ابر، فشار بالای ابر و نزدیکی به منابع ذرات [ 17 ، 18 ، 20 ، 27 ، 29 ، 33 ، 34 ، 35 ، 36 ، 37 ، 38 ،39 , 40 , 41 , 42 , 43 , 44 , 45 , 46 , 47 , 48 , 49 , 50 , 51 ]. در برخی موارد، مانند سرعت باد، رابطه بسیار غیرخطی است و در بسیاری از موارد به خوبی مشخص نشده است.
این تصویر با سوگیری های موجود در محصولات AOD ماهواره ای [ 52 ، 53 ، 54 ، 55 ، 56 ]، تفاوت در مقیاس های فضایی مشاهدات PM 2.5 نقطه درجا و داده های سنجش از دور (چند کیلومتر در هر پیکسل) پیچیده تر می شود. و در نهایت، شیب شدید PM 2.5 که می تواند در داخل و اطراف شهرها، به ویژه در آسیا وجود داشته باشد.
در مجموع، همه این عوامل به طور طبیعی نشان می دهد که هر رگرسیون موفق باید چند متغیره، غیر خطی و ناپارامتریک باشد. بنابراین انتخاب طبیعی یادگیری ماشین است، رویکردی که در توصیف مسائل چند متغیره، غیرخطی و غیر پارامتری برتری دارد. یادگیری ماشینی در ارائه محصول جدید PM 2.5 کار برجسته ای انجام می دهد . شکل 3 میانگین ماهانه محصول یادگیری ماشینی PM 2.5 ما (μg/m 3 ) را برای آگوست 2001 نشان میدهد. میانگین مشاهدات در یک سایت معین به صورت دایرههای رنگی پوشانده میشوند، زمانی که مشاهدات حداقل برای یک سوم در دسترس بود. روزها. به توافق خوب بین محصول PM 2.5 و مشاهدات توجه کنید (به عنوان مثال، پر رنگ دایره هایی که مشاهدات را به تصویر می کشند با رنگ پس زمینه که محصول جدید یادگیری ماشینی PM 2.5 را نشان می دهد مطابقت دارد.
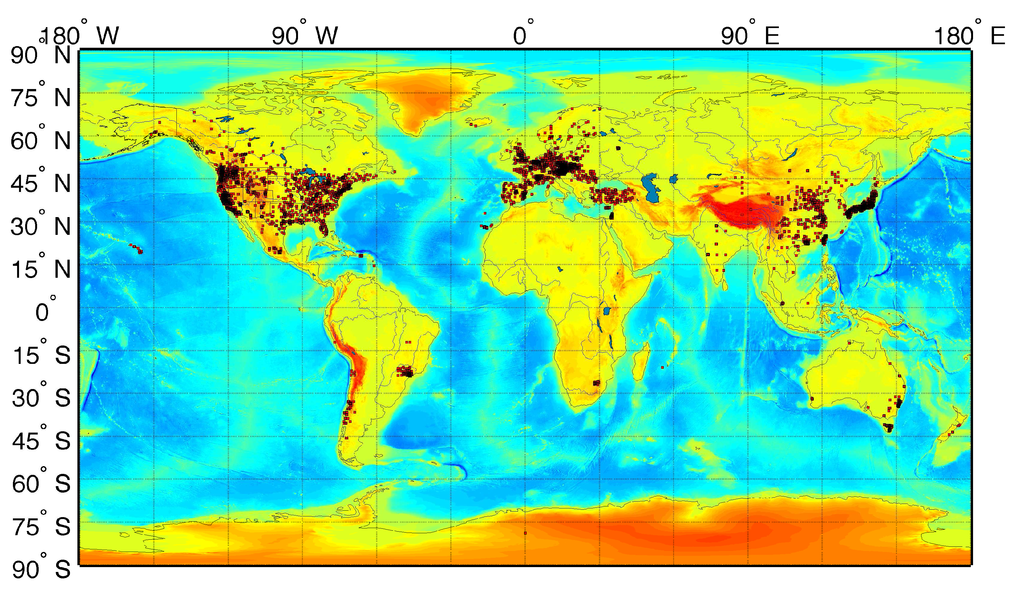
شکل 2. نقشه ای که مکان های سایت اندازه گیری 8329 PM 2.5 را از 55 کشور (مربع های قرمز) نشان می دهد که در دوره 1997 تا کنون استفاده شده است. بیشترین تراکم سایت ها در آمریکای شمالی، اروپا و آسیا است. با این حال، سایت های نیمکره جنوبی در آمریکای جنوبی، آفریقای جنوبی، استرالیا و نیوزیلند نیز وجود دارد. مقیاس رنگ پس زمینه توپوگرافی و عمق سنجی جهانی را نشان می دهد.
همانطور که در اواخر تابستان انتظار می رفت، شرق ایالات متحده غلظت PM 2.5 بسیار بالاتری نسبت به غرب ایالات متحده دارد . شکل 3 b,c تطابق خوب بین محصول و مشاهدات ما را نشان می دهد. شکل 3 d PM 2.5 بالا را با دره مرکزی به شدت کشاورزی در کالیفرنیا، منطقه پرجمعیت شهری لس آنجلس، صحرای Sonoran، یکی از فعال ترین مناطق منبع گرد و غبار در ایالات متحده، نیروگاه های چهار گوشه، برخی از مناطق نشان می دهد. بزرگترین ایستگاه های تولید زغال سنگ در ایالات متحده و صحرای دریاچه نمک بزرگ.
ما در حال ترکیب محصول دادههای ذرات روزانه تولید شده با استفاده از یادگیری ماشین هستیم (نمونهای در شکل 3 نشان داده شده است ) و سایر محصولات دادههای محیطی با سیستم ثبت الکترونیک سلامت (EHR) VA برای تسهیل بینشها و تصمیمگیریهای مبتنی بر دادهها.
3.2. امید به زندگی و داده های اجتماعی و اقتصادی از سرشماری ایالات متحده
در سال 2012، مرکز جامعه و سلامت در دانشگاه مشترک المنافع ویرجینیا، یک مطالعه دو ساله را در مورد عوامل مؤثر بر امید به زندگی در مناطق سرشماری کالیفرنیا با نرخ بالای فقر راهاندازی کرد. آنها امید به زندگی هزاران بخش سرشماری را در کالیفرنیا محاسبه کردند و با آمارهای حیاتی ارائه شده توسط وزارت بهداشت کالیفرنیا کار کردند. محققان از روشهای آماری سنتی، مانند معادلات رگرسیون، برای مطالعه عواملی در این سرشماریها استفاده کردند که ممکن است بر امید به زندگی تأثیر بگذارد، مانند مراقبتهای بهداشتی و سلامت عمومی، محیط فیزیکی و اجتماعی، شرایط اجتماعی-اقتصادی افراد و خانوارها و منابع کلان ساختاری. هدف آنها این بود که ببینند آیا به نظر می رسد این عوامل در سرشماری های پرت با امید به زندگی به طور غیرمنتظره بالا یا پایین با توجه به نرخ فقر آنها متفاوت است یا خیر. هدف کمک به مقامات منتخب و سایر سیاست گذاران برای شناسایی دارایی هایی است که برای کمک به جوامع فقیر در محافظت از اثرات نامطلوب فقر بر سلامتی عمل می کنند. صرفهجویی مورد نیاز برای روشهای سنتی، همانطور که در بالا مورد بحث قرار گرفت، محققین را ملزم میکرد که تعداد محدودی از متغیرها را در هر حوزه انتخاب کنند تا وارد معادله رگرسیونی خود شوند.
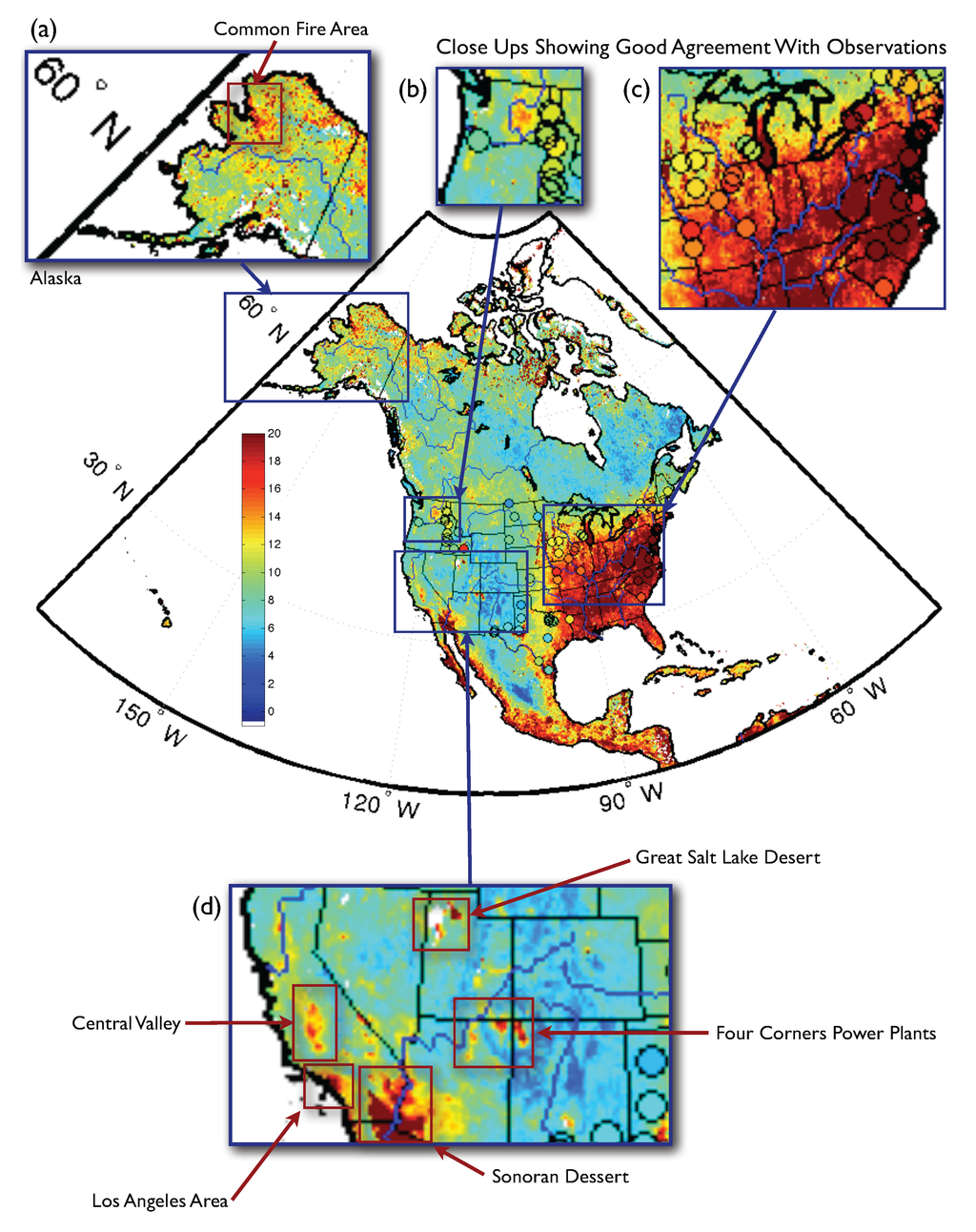
شکل 3. میانگین ماهانه نمونه اولیه محصول یادگیری ماشینی PM 2.5 ما (μg/m 3 ) برای آگوست 2001. میانگین مشاهدات در یک سایت معین زمانی که مشاهدات حداقل برای یک سوم در دسترس بود، به صورت دایرههای پر رنگ پوشانده میشود. روزها. به توافق خوب بین محصول PM 2.5 و مشاهدات توجه کنید. علاوه بر این، همانطور که انتظار می رود، در تابستان، شرق ایالات متحده غلظت PM 2.5 بسیار بالاتری نسبت به غرب ایالات متحده دارد . ( ب ، ج ) توافق خوب بین محصول ما و مشاهدات. ( دPM 2.5 مرتفع با دره مرکزی به شدت کشاورزی در کالیفرنیا، منطقه پرجمعیت مترو لس آنجلس، صحرای Sonoran، یکی از فعال ترین مناطق منبع گرد و غبار در ایالات متحده، نیروگاه های چهار گوشه، برخی از بزرگترین زغال سنگ ها ایستگاه های تولید را در ایالات متحده و صحرای دریاچه نمک بزرگ شلیک کرد.
بر اساس این مطالعه، ما یک پروژه موازی انجام دادیم تا به عنوان نمایشی از قدرت یادگیری ماشین عمل کند. بهعنوان اثبات مفهوم، عمداً به یک منطقه جغرافیایی (ایالت کالیفرنیا) و یک حوزه در مدل محققان محدود شد: شرایط اجتماعی-اقتصادی در افراد و خانوادهها.
نظرسنجی جامعه آمریکایی 2007-2011 اداره سرشماری ایالات متحده یک مجموعه داده غنی در مورد شرایط اجتماعی-اقتصادی برای افراد و خانواده ها ارائه می دهد که برای محققان سنتی بسیار گسترده است که در مجموع آنها را بررسی کنند، اما در سطح سرشماری به شکل قابل دانلودی که ابررایانه ها می توانند ارائه کنند. به راحتی تجزیه و تحلیل کنید تعداد کل متغیرهای موجود در سطح سرشماری گسترده است: در مجموع 21038 متغیر در 113 فایل داده پراکنده شده است. برخی از متغیرها در بیش از یک فایل کپی می شوند و زمانی که این موارد تکراری حذف شوند، 18528 متغیر منحصر به فرد باقی می ماند. برخی از این متغیرها دارای مقادیر گمشده برای مناطق سرشماری خاص هستند. اگر متغیرهایی با مقادیر از دست رفته حذف شوند، 13065 متغیر باقی می ماند. اگرچه این تعداد حیرتانگیز متغیرهایی است که اکثر محققین معمولی حتی سعی نمیکنند آنها را تجزیه و تحلیل کنند، ما به راحتی از یادگیری ماشین برای طراحی یک برازش کاملاً غیرخطی، غیر پارامتری و چند متغیره از همه 13065 متغیر استفاده کردیم. ما اهمیت آماری دو متغیره همبستگی فردی این متغیرها را با امید به زندگی محاسبه کردیم و دریافتیم که 10339 متغیر دارای p-value کمتر از 0.05 بودند. متغیرهای سرشماری متعامد نیستند و جنبههایی از محتوای اطلاعاتی یکسان در بسیاری از متغیرهای سرشماری تکرار میشوند. اگر آستانه p-value به تدریج کاهش یابد، متوجه می شویم که به طور قابل توجهی، هفت متغیر دارای p-value کمتر از 10 هستند. ما اهمیت آماری دو متغیره همبستگی فردی این متغیرها را با امید به زندگی محاسبه کردیم و دریافتیم که 10339 متغیر دارای p-value کمتر از 0.05 بودند. متغیرهای سرشماری متعامد نیستند و جنبههایی از محتوای اطلاعاتی یکسان در بسیاری از متغیرهای سرشماری تکرار میشوند. اگر آستانه p-value به تدریج کاهش یابد، متوجه می شویم که به طور قابل توجهی، هفت متغیر دارای p-value کمتر از 10 هستند. ما اهمیت آماری دو متغیره همبستگی فردی این متغیرها را با امید به زندگی محاسبه کردیم و دریافتیم که 10339 متغیر دارای p-value کمتر از 0.05 بودند. متغیرهای سرشماری متعامد نیستند و جنبههایی از محتوای اطلاعاتی یکسان در بسیاری از متغیرهای سرشماری تکرار میشوند. اگر آستانه p-value به تدریج کاهش یابد، متوجه می شویم که به طور قابل توجهی، هفت متغیر دارای p-value کمتر از 10 هستند.– 240 .
چه از همه 13065 متغیر استفاده کنیم چه از 10339 با p-value کمتر از 0.05 یا فقط از هفت متغیر با p-value کمتر از 10-240 استفاده کنیم ، یادگیری ماشین می تواند کار خوبی برای تخمین امید به زندگی انجام دهد. دو نمونه از برآوردهای کاملاً غیر خطی، غیر پارامتری و چند متغیره از امید به زندگی با استفاده از جنگلهای تصادفی [ 57 ، 58 ] در شکل 4 نشان داده شده است.
چند پیام برداشت واضح پیدا شد.
اول، متغیرهایی که یادگیری ماشینی به عنوان مهمترین مطالعات اپیدمیولوژیک کلاسیک تکراری در برجسته کردن اهمیت عوامل مرتبط با امید به زندگی (سن، جنس، نژاد، قومیت، درآمد/فقر، و تحصیلات) برجسته شدند، اما علاوه بر این، ماشین رویکرد یادگیری برخی از عوامل کلیدی اضافی را شناسایی کرد. در میان 50 نفر برتر، عوامل دیگری را شناسایی کرد که از نظر اهمیت رتبه بسیار بالایی داشتند، از جمله: جابجایی (اول). اشتغال به ویژه در صنایع خاص (سوم، هفتم، هشتم، سیزدهم، پانزدهم، نوزدهم، بیستم، سی و ششم، چهل و دوم، چهل و نهم)؛ مسکن اشغالی (ششم، یازدهم، شانزدهم، هجدهم، بیست و یکم، 31، 50)؛ خانوارهای تک والدی (ششم، دوازدهم)؛ زبان (چهاردهم)؛ پدربزرگ و مادربزرگ که با نوه ها زندگی می کنند (26، 48)؛ و واجد شرایط بودن اسنپ (38th).
دوم، شاید به این دلیل که اطلاعات کلیدی در سرشماری بارها تکرار شده است، برازش تنها با استفاده از هفت متغیر تقریباً به اندازه 13065 متغیر یا 10339 با مقدار p کمتر از 0.05 بود.
سوم، به همان اندازه که تناسب یادگیری ماشین خوب بود، شیب نمودار پراکندگی دقیقاً یک نیست. این امضای داده نشان می دهد که عوامل کلیدی اضافی در نظر گرفته نشده اند. این غیر منتظره نیست. این مطالعه تنها بر بعد اجتماعی-اقتصادی متمرکز بود و نه سایر عوامل تعیین کننده سلامت، مانند عوامل محیطی، مانند کیفیت هوا، یا عادات غذایی و دسترسی به مراقبت های بهداشتی. واضح است که عوامل مهم مرتبط با امید به زندگی که باید به طور همزمان مورد توجه قرار گیرند عبارتند از: مراقبت های بهداشتی، رفتارهای بهداشتی، محیط اجتماعی، محیط فیزیکی (از جمله آلودگی) و هزینه های عمومی برای خدمات اجتماعی و بهداشتی.

شکل 4. دو نمونه از نمودارهای پراکندگی برای برآوردهای کاملاً غیرخطی، غیر پارامتری و چند متغیره از امید به زندگی: (الف) 10339 متغیر در نظرسنجی جامعه آمریکا (اداره سرشماری ایالات متحده) با مقدار p دو متغیره برای زندگی انتظار کمتر از 0.05; (ب) هفت متغیر در نظرسنجی جامعه آمریکا (اداره سرشماری ایالات متحده) با مقدار p دو متغیره برای امید به زندگی کمتر از 10-240 . دایره های آبی داده های آموزشی را به تصویر می کشند. مربعهای قرمز، دادههای اعتبارسنجی کاملاً مستقل و تصادفی انتخاب شده را نشان میدهند که در آموزش استفاده نشده است. خط سبز بهترین خط 1:1 برای تناسب کامل است.
بنابراین، ما دیدهایم که یادگیری ماشین ابزار قدرتمندی برای مقابله با سیستمهای چند متغیره، برای اجازه دادن به دادهها، برجسته کردن محرکهای کلیدی و ارائه ابزارهای عینی است که به ما میگوید چه زمانی باید عوامل اضافی را در نظر گرفت.
3.3. مثبت های کاذب
مهم است که بدانیم همبستگی علیت نیست. علاوه بر این، هنگام استفاده از یادگیری ماشینی با متغیرهای زیاد، همیشه احتمال تداعی نادرست وجود دارد. تحلیل کامل چنین احتمالاتی از حوصله این مقاله خارج است. با این حال، یک راه برای پرداختن به این سوالات نوعی کنترل تجربی در تمرین داده کاوی است، اما روشهای متنوع دیگری نیز پیشنهاد شده است.
4. خلاصه
سلامت انسان بخشی از یک سیستم چند وجهی و وابسته به هم است که جنبههای زیادی از نظر جغرافیایی متفاوت است. پارادایم Holistics 3.0 که دادهها را در بسیاری از جنبههای یک مشکل گرد هم میآورد و آن را با یادگیری ماشین (و در صورت لزوم، علیت) ترکیب میکند، ابزار قدرتمندی برای اطلاعرسانی تصمیمهای مبتنی بر داده است که میتواند تغییرات جغرافیایی را در خود گنجانده و توضیح دهد. کلید این امر اجازه دادن به داده ها برای “گفتن خود” و توانایی پردازش هزاران متغیر به طور همزمان در یک چارچوب کاملاً چند متغیره، غیر خطی، غیر پارامتری و غیر گاوسی است.
منابع
- جاکوبز، آ. آسیب شناسی داده های بزرگ. اشتراک. ACM 2009 ، 52 ، 36-44. [ Google Scholar ] [ CrossRef ]
- گوهانی یوگی، ر. فینلی، AO؛ بانرجی، اس. مدلهای فرآیند پیشبینی گاوسی تطبیقی Gelfand، AE برای مجموعه دادههای فضایی بزرگ. Environmetrics 2011 ، 22 ، 997-1007. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- فینلی، AO؛ بانرجی، اس. Gelfand، مدلسازی پویا بیزی AE برای مجموعه داده های بزرگ فضا-زمان با استفاده از فرآیندهای پیش بینی گاوسی. جی. جئوگر. سیستم 2012 ، 14 ، 29-47. [ Google Scholar ] [ CrossRef ]
- آژانس فضایی اروپا (ESA). داده های بزرگ از فضا ؛ آژانس فضایی اروپا: فراسکاتی، ایتالیا، 2013. [ Google Scholar ]
- هی، اس. جورج، دی. مویس، سی. Brownstein, J. فرصت های داده های بزرگ برای نظارت جهانی بیماری های عفونی. PLoS Med. 2013 ، 10 ، e1001413. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- کریمی، HA (ویرایش) کلان داده: تکنیک ها و فناوری ها در ژئوانفورماتیک ; CRC Press: Boca Raton، FL، USA، 2014; پ. 312.
- بارتون، دی. دادگاه، دی. ایجاد تجزیه و تحلیل پیشرفته برای شما. هارو. اتوبوس. Rev. 2012 , 90 , 78-83. [ Google Scholar ] [ PubMed ]
- داونپورت، تی. پاتیل، دی. دانشمند داده: جذاب ترین شغل قرن بیست و یکم. بررسی کسب و کار هاروارد ، اکتبر 2012. [ Google Scholar ]
- مک آفی، ا. Brynjolfsson، E. داده های بزرگ: انقلاب مدیریت. بررسی کسب و کار هاروارد ، اکتبر 2012. [ Google Scholar ]
- مرداک، تی. Detsky، A. کاربرد اجتناب ناپذیر داده های بزرگ در مراقبت های بهداشتی. جاما 2013 ، 309 ، 1351-1352. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Pearl, J. Causality: Models, Reasoning and Inference ; انتشارات دانشگاه کمبریج: نیویورک، نیویورک، ایالات متحده آمریکا، 2009. [ Google Scholar ]
- نوبل، دی. Casalino, L. آیا سازمان های مراقبت پاسخگو می توانند سلامت جمعیت را بهبود بخشند؟ آیا باید تلاش کنند؟ جاما 2013 ، 11 ، 119-120. [ Google Scholar ]
- راکرل، آر. اشنایدر، آ. برایتنر، اس. ساریس، جی. پیترز، A. اثرات بهداشتی آلودگی هوا ذرات: مروری بر شواهد اپیدمیولوژیک. سم استنشاقی 2011 ، 23 ، 555-592. [ Google Scholar ] [ CrossRef ]
- انگل کاکس، جی. هاف، آر.ام. توصیه های هایمت، ADJ در مورد استفاده از داده های سنجش از دور ماهواره ای برای کیفیت هوای شهری. J. Air Waste Manag. دانشیار 2004 ، 54 ، 1360-1371. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- انگل کاکس، جی. هولومن، CH; Coutant، BW; Hoff، RM ارزیابی کیفی و کمی داده های سنسور ماهواره ای MODIS برای کیفیت هوا در مقیاس منطقه ای و شهری. اتمس. محیط زیست 2004 ، 38 ، 2495-2509. [ Google Scholar ] [ CrossRef ]
- انگل کاکس، جی. هاف، آر.ام. راجرز، آر. دیمیک، اف. راش، AC؛ Szykman، JJ; السعدی، ج. چو، دی. Zell، ER ادغام عمق نوری لیدار و ماهواره با نظارت بر محیط برای شناسایی ذرات سه بعدی. اتمس. محیط زیست 2006 ، 40 ، 8056-8067. [ Google Scholar ] [ CrossRef ]
- لیو، ی. سرنات، ج.ا. کیلارو، ا. جیکوب، دی جی; کوتراکیس، پی. تخمین PM2.5 سطح زمین در شرق ایالات متحده با استفاده از سنجش از دور ماهواره ای. محیط زیست علمی تکنولوژی 2005 ، 39 ، 3269-3278. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لیو، ی. فرانکلین، ام. کان، آر. کوتراکیس، ص. استفاده از ضخامت نوری آئروسل برای پیشبینی غلظت PM2.5 سطح زمین در منطقه سنت لوئیس: مقایسه بین MISR و MODIS. سنسور از راه دور محیط. 2007 ، 107 ، 33-44. [ Google Scholar ] [ CrossRef ]
- لیو، ی. پاچیورک، سی. Koutrakis، P. برآورد قرار گرفتن در معرض روزانه PM2.5 در ماساچوست با دادههای سنجش از راه دور آئروسل ماهوارهای، اطلاعات هواشناسی، و اطلاعات کاربری زمین. اپیدمیولوژی 2008 ، 19 ، S116. [ Google Scholar ]
- ون دونکلار، ا. مارتین، RV; پارک، RJ برآورد PM2.5 سطح زمین با استفاده از عمق نوری آئروسل تعیین شده از سنجش از راه دور ماهواره ای. جی. ژئوفیس. Res. 2006 111 . _ [ Google Scholar ] [ CrossRef ]
- ون دونکلار، ا. مارتین، آر. وردوزکو، سی. بروئر، ام. کان، آر. لوی، آر. Villeneuve, P. یک رویکرد ترکیبی برای پیشبینی پاسخ قرار گرفتن در معرض PM2.5. محیط زیست چشم انداز سلامتی 2010 , 118 . [ Google Scholar ] [ CrossRef ]
- ون دونکلار، ا. مارتین، RV; بروئر، ام. کان، آر. لوی، آر. وردوزکو، سی. Villeneuve, PJ برآوردهای جهانی غلظت ذرات ریز محیط از عمق نوری آئروسل مبتنی بر ماهواره: توسعه و کاربرد. محیط زیست چشم انداز سلامتی 2010 ، 118 ، 847-855. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ون دونکلار، ا. مارتین، RV; لوی، RC; دا سیلوا، AM; کریزانوفسکی، م. چوبارووا، NE; سموتنیکوا، ای. کوهن، تخمینهای ماهوارهای AJ از ذرات ریز سطح زمین در طول رویدادهای شدید: مطالعه موردی آتشسوزیهای مسکو در سال 2010. Atmos. محیط زیست 2011 ، 45 ، 6225-6232. [ Google Scholar ] [ CrossRef ]
- Martin, RV ماهواره سنجش از دور کیفیت هوای سطحی. اتمس. محیط زیست 2008 ، 42 ، 7823-7843. [ Google Scholar ] [ CrossRef ]
- هاف، آر.ام. کریستوفر، SA سنجش از دور آلودگی ذرات از فضا: آیا به سرزمین موعود رسیدهایم؟ J. Air Waste Manag. دانشیار 2009 ، 59 ، 645-675. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- هافمن، بی. موبوس، اس. دراگانو، ن. استنگ، آ. موهلنکامپ، اس. اشمرموند، آ. ممشایمر، ام. بروکر-پریوس، ام. مان، ک. اربل، آر. و همکاران قرار گرفتن در معرض مزمن مسکونی در معرض آلودگی هوا ذرات معلق و نشانگرهای التهابی سیستمیک. محیط زیست چشم انداز سلامتی 2009 ، 117 ، 1302-1308. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ژانگ، اچ. هاف، آر.ام. Engel-Cox، JA رابطه بین عمق نوری آئروسل طیف سنج تصویربرداری با وضوح متوسط (MODIS) و PM2.5 در ایالات متحده: مقایسه جغرافیایی توسط مناطق آژانس حفاظت از محیط زیست ایالات متحده. J. Air Waste Manag. دانشیار 2009 ، 59 ، 1358-1369. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ژانگ، اچ. لیاپوستین، آ. وانگ، ی. کوندراگونتا، اس. لازلو، آی. سیرن، پی. Hoff, RM یک الگوریتم بازیابی عمق نوری آئروسل چند زاویه ای برای داده های ماهواره ای زمین ایستا بر روی ایالات متحده. اتمس. شیمی. فیزیک 2011 ، 11 ، 11977-11991. [ Google Scholar ] [ CrossRef ]
- وبر، SA; انگل کاکس، جی. هاف، آر.ام. پرادوس، هوش مصنوعی؛ Zhang، H. یک روش بهبود یافته برای تخمین غلظت ذرات ریز سطحی با استفاده از عمق نوری آئروسل ماهواره ای تنظیم شده فصلی. J. Air Waste Manag. دانشیار 2010 ، 60 ، 574-585. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- کومار، ن. چو، AD; فاستر، AD; پیترز، تی. ویلیس، R. سنجش از دور ماهوارهای برای توسعه زمان و مکان تخمینهای ذرات محیط را در کلیولند، OH حل کرد. Aerosol Sci. تکنولوژی 2011 ، 45 ، 1090-1108. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لی، اچ جی; لیو، ی. کول، بی. شوارتز، جی. کوتراکیس، P. PM2.5 مدل سازی پیش بینی با استفاده از MODIS AOD و پیامدهای آن برای مطالعات اثرات سلامت. اپیدمیولوژی 2011 ، 22 ، S215. [ Google Scholar ] [ CrossRef ]
- لی، اچ جی; لیو، ی. کول، کارشناسی; شوارتز، جی. کوتراکیس، پی. یک رویکرد کالیبراسیون جدید داده های MODIS AOD برای پیش بینی غلظت PM2.5. اتمس. شیمی. فیزیک 2011 ، 11 ، 7991-8002. [ Google Scholar ] [ CrossRef ]
- چوی، YS; هو، CH; چن، دی. نه، YH; آهنگ، تجزیه و تحلیل طیفی CK تغییرات هفتگی در غلظت جرم PM10 و شرایط هواشناسی در چین. اتمس. محیط زیست 2008 ، 42 ، 655-666. [ Google Scholar ] [ CrossRef ]
- لیو، ی. کوتراکیس، پ. کان، آر. تخمین غلظت اجزای ذرات ریز و توزیع اندازه با استفاده از عمق نوری آئروسل کسری بازیابی شده توسط ماهواره: قسمت 1 – توسعه روش. J. Air Waste Manag. دانشیار 2007 ، 57 ، 1360-1369. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لیو، ی. کوتراکیس، پ. کان، آر. تورکوتی، اس. Yantosca، RM تخمین غلظت اجزای ذرات ریز و توزیع اندازه با استفاده از عمق نوری آئروسل کسری بازیابی شده توسط ماهواره: قسمت 2 – مطالعه موردی. J. Air Waste Manag. دانشیار 2007 ، 57 ، 1360-1369. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لیو، ی. Paciorek، CJ; کوتراکیس، ص. برآورد تنوع مکانی و زمانی منطقه ای غلظت PM2.5 با استفاده از داده های ماهواره ای، هواشناسی و اطلاعات کاربری زمین. محیط زیست چشم انداز سلامتی 2009 ، 117 ، 886-892. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لیو، ی. چن، دی. کان، RA; او، ک. بررسی کاربردهای طیفسنج تصویربرداری چند زاویهای در تحقیقات کیفیت هوا. علمی چین سر. D-Earth Sci. 2009 ، 52 ، 132-144. [ Google Scholar ] [ CrossRef ]
- لیو، ی. کان، RA; چالولاکو، ع. کوتراکیس، ص. تجزیه و تحلیل تأثیر آتشسوزیهای جنگلی در آگوست 2007 بر کیفیت هوای آتن با استفاده از دادههای سنجش از راه دور آئروسل چند سنسوری، هواشناسی و مشاهدات سطحی. اتمس. محیط زیست 2009 ، 43 ، 3310-3318. [ Google Scholar ] [ CrossRef ]
- لیو، YJ; هریسون، RM خواص ذرات درشت در جو انگلستان. اتمس. محیط زیست 2011 ، 45 ، 3267-3276. [ Google Scholar ] [ CrossRef ]
- لیو، ی. او، ک. لی، اس. وانگ، ز. کریستینی، دی سی; کوتراکیس، P. یک مدل آماری برای ارزیابی اثربخشی کنترل انتشار PM2.5 در طول بازیهای المپیک 2008 پکن. محیط زیست بین المللی 2012 ، 44 ، 100-105. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لیامانی، ح. اولمو، اف جی. آلکانترا، ا. آلادوس-آربولداس، L. ذرات معلق در هوا در طول موج گرمای 2003 در جنوب شرقی اسپانیا I: عمق نوری طیفی. اتمس. محیط زیست 2006 ، 40 ، 6453-6464. [ Google Scholar ] [ CrossRef ]
- پلتیه، بی. سانتر، آر. Vidot, J. بازیابی ذرات معلق از اندازه گیری های نوری: یک رویکرد نیمه پارامتریک. جی. ژئوفیس. Res.-Atmos. 2007 112 . _ [ Google Scholar ] [ CrossRef ]
- وانگ، کیو. شائو، ام. لیو، ی. ویلیام، ک. پل، جی. لی، ایکس. لیو، ی. لو، اس. تأثیر سوختن زیست توده بر کیفیت هوای شهری برآورد شده توسط ردیابهای آلی: گوانگژو و پکن به عنوان موارد. اتمس. محیط زیست 2007 ، 41 ، 8380-8390. [ Google Scholar ] [ CrossRef ]
- ناتونن، ا. آرولا، ا. میلونن، تی. هاتونن، جی. کومپولا، م. Lehtinen، KEJ مقایسه چند ساله PM2.5 و AOD برای منطقه هلسینکی. محیط شمالی. Res. 2010 ، 15 ، 544-552. [ Google Scholar ]
- Paciorek، CJ; لیو، ی. مورنو ماسیاس، اچ. Kondragunta، S. ارتباطات فضایی و زمانی بین بازیابی عمق نوری آئروسل GOES و PM2.5 سطح زمین. محیط زیست علمی تکنولوژی 2008 ، 42 ، 5800-5806. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Paciorek، CJ; لیو، ی. محدودیتهای آئروسل سنجش از راه دور به عنوان یک پروکسی فضایی برای ذرات ریز. محیط زیست چشم انداز سلامتی 2009 , 117 . [ Google Scholar ] [ CrossRef ]
- Paciorek، CJ; لیو، ی. ارزیابی و مدلسازی آماری رابطه بین عمق نوری آئروسل سنجش از دور و PM2.5 در شرق ایالات متحده . گزارش تحقیق؛ موسسه اثرات سلامت: بوستون، MA، ایالات متحده آمریکا، 2012. [ Google Scholar ]
- راجیف، ک. پارامسواران، ک. Nair, SK; Meenu، S. شواهد مشاهده ای برای تأثیر تشعشعی دود اندونزی در تعدیل دمای سطح دریا در اقیانوس هند استوایی. جی. ژئوفیس. Res.-Atmos. 2008 , 113 . [ Google Scholar ] [ CrossRef ]
- شاپ، م. آپیتولی، ا. تیمرمنز، RMA; Koelemeijer، RBA; de Leeuw, G. بررسی رابطه بین عمق نوری آئروسل و PM2.5 در Cabauw، هلند. اتمس. شیمی. فیزیک 2009 ، 9 ، 909-925. [ Google Scholar ] [ CrossRef ]
- تیان، دی. وانگ، ی. برگین، م. هو، ی. لیو، ی. تاثیرات راسل، AG کیفیت هوا ناشی از آتشسوزیهای جنگلها تحت شیوههای مختلف مدیریتی. محیط زیست علمی تکنولوژی 2008 ، 42 ، 2767-2772. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ون دو کاستیل، جی. Koelemeijer، RBA; دکرز، ALM؛ شاپ، م. هومن، سی دی; استین، الف. نقشهبرداری آماری غلظت PM10 در اروپای غربی با استفاده از اطلاعات ثانویه از مدلسازی پراکندگی و مشاهدات ماهوارهای MODIS. استوک. محیط زیست Res. ارزیابی ریسک 2006 ، 21 ، 183-194. [ Google Scholar ] [ CrossRef ]
- ژانگ، جی. Reid، JS تجزیه و تحلیل آسمان صاف و سوگیری های متنی با استفاده از یک محصول آئروسل MODIS عملیاتی بر روی اقیانوس. ژئوفیز. Res. Lett. 2009 ، 36 . [ Google Scholar ] [ CrossRef ]
- لری، دی جی; ریمر، لس آنجلس; مک نیل، دی. روسکو، بی. Paradise, S. یادگیری ماشین و تصحیح بایاس عمق نوری آئروسل MODIS. IEEE Geosci. سنسور از راه دور Lett. 2009 ، 6 ، 694-698. [ Google Scholar ] [ CrossRef ]
- هایر، ای جی; رید، JS; Zhang, J. مجموعه ای از داده های عمق نوری آئروسل روی زمین برای جذب داده ها با فیلتر کردن، تصحیح و تجمیع بازیابی عمق نوری MODIS Collection 5. اتمس. Meas. فنی 2011 ، 4 ، 379-408. [ Google Scholar ] [ CrossRef ]
- شی، ی. ژانگ، جی. رید، JS; هایر، ای جی; Hsu، NC ارزیابی انتقادی محصول عمق نوری آئروسل MODIS Deep Blue برای جذب داده در شمال آفریقا. اتمس. Meas. فنی بحث و گفتگو. 2012 ، 5 ، 7815-7865. [ Google Scholar ] [ CrossRef ]
- رید، JS; هایر، ای جی; جانسون، آر اس؛ هولبن، BN; یوکلسون، RJ; ژانگ، جی. کمپبل، جی آر. کریستوفر، SA; جیرولامو، LD; گیگلیو، ال. و همکاران مشاهده و درک سیستم آئروسل جنوب شرقی آسیا با سنجش از دور: بررسی و تحلیل اولیه برای برنامه هفت مطالعه جنوب شرقی آسیا (7SEAS). اتمس. Res. 2013 ، 122 ، 403-468. [ Google Scholar ] [ CrossRef ]
- Ho, TK روش تصادفی زیرفضای برای ساختن جنگل های تصمیم. IEEE Trans. الگوی مقعدی ماخ هوشمند 1998 ، 20 ، 832-844. [ Google Scholar ] [ CrossRef ]
- بریمن، L. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ] [ CrossRef ]
© 2014 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/3.0/) توزیع شده است.
بدون نظر