1. مقدمه و انگیزه
این مقاله یک زیر کلاس خاص و کاربردی از میدانهای تصادفی دوبعدی گاوسی همگن (2D) را شناسایی میکند و یک روش ساده، سریع و متوالی را برای ایجاد تحققهای گسسته در یک pxq ارائه میکند.شبکه (افقی) به منظور تحلیل های مبتنی بر شبیه سازی مونت کارلو. اجازه دهید برای اختصار توضیح بیشتر، این روش را شبیه سازی متوالی سریع (FSS) بگذاریم. FSS را می توان توسعه ای از نسل متوالی یک فرآیند مرتبه اول گاوس-مارکوف از یک تابع 1 بعدی زمان به یک تابع دو بعدی از فضای افقی در نظر گرفت. اگرچه FSS به طور مستقل مشتق شده است، اما یک مورد خاص از شبیه سازی گاوسی متوالی نیز نشان داده شده است که معمولاً در جامعه زمین آمار استفاده می شود. به طور خاص، FSS یک شبیهسازی بدون قید و شرط با سادگی و سرعت به دلیل همبستگی نمایی در جهتهای مکانی و تولید منظم در شبکهای با فاصله مساوی از مکانهای افقی است. اگرچه سایر کاربردهای شبیه سازی گاوسی متوالی عمومی تر هستند (نقاط مشروط یا بدون قید و شرط با فاصله نامنظم،و غیره )، بسیاری از برنامه ها به این کلیات نیاز ندارند، اما نیاز به سرعت، ترجیحا با اجرای ساده و مستقیم دارند.
این مقاله ابتدا به فیلدهای تصادفی اسکالر می پردازد، به عنوان مثال ، z ( k، l ) که در آن z معمولاً یک خطای اسکالر یا اغتشاش را در محل شبکه ( k، l ) نشان می دهد. واریانس مورد نظر و همبستگی های فضایی برای z ( k، l ) با FSS قابل تعیین هستند و ماتریس کوواریانس نقطه چند شبکه ای مشتق شده است. سپس این مقاله FSS را به تولید میدانهای تصادفی دوبعدی گاوسی چند متغیره تعمیم میدهد، به عنوان مثال ، X ( k، l )، که در آن X بردار بعد دلخواه n است.. در نهایت، این مقاله نتایج FSS را حتی بیشتر به میدانهای تصادفی دو بعدی گاوسی غیرهمگن تعمیم میدهد، که در آن واریانس و همبستگیهای فضایی تابعی از مکان شبکه ( k، l ) هستند. برخی از تکنیکهای عملی ارائه شده برای تولید متوالی میدانهای تصادفی چند متغیره و غیرهمگن جدید و تا حدودی نوآورانه هستند.
نمونههایی از میدانهای تصادفی اسکالر، چند متغیره، همگن و غیرهمگن در سراسر مقاله ارائه شدهاند، همچنین ویژگیهای نظری، بینشها و اثباتهای مختلفی که مورد دوم در ضمیمهها موجود است، ارائه شدهاند. FSS همچنین با روش های معادل بر اساس (1) تجزیه Cholesky یک ماتریس کوواریانس پیشینی از پیش محاسبه شده مقایسه می شود. و (2) شبیه سازی گاوسی متوالی همانطور که در بسته های آماری مختلف پیاده سازی شده است. نشان داده شده است که FSS بسیار سریعتر از همه این روش های تولید دیگر است و همچنین پیاده سازی ساده تری است.
توانایی شبیهسازی خطاها در سراسر یک شبکه افقی با مقادیر مورد انتظار مشخص (واریانس) و روابط متقابل (همبستگی) یک قابلیت مهم در پشتیبانی از علوم جغرافیایی است و با روش FSS ارائهشده در این مقاله پشتیبانی میشود. به عنوان مثال، خطاها می توانند خطاهای ارتفاع در یک پایگاه داده Digital Elevation، خطاهای افقی در محل رئوس در یک پایگاه داده GIS، خطاهای افقی و عمودی در مکان های نقاط کنترل در یک پایگاه داده نقطه کنترل و غیره را نشان دهند. همه این خطاها عبارتند از اساسا تابعی از مکان افقی است، به عنوان مثال ، قابل نمایش به عنوان یک میدان تصادفی دو بعدی.
این خطاهای شبیه سازی شده را می توان برای اصلاح داده های “حقیقت” مربوطه در یک محیط شبیه سازی استفاده کرد. سپس عملکرد بعدی برنامه های مختلف پایین دستی را می توان به طور معناداری ارزیابی کرد، از جمله اصلاح (تنظیم) الگوریتم های آنها برای عملکرد بهینه و قابل اعتماد. متناوباً، در یک محیط عملیاتی، خود برنامهها میتوانند قابلیت شبیهسازی تعبیهشده را داشته باشند تا اثرات خطاها را در دادههای ورودی خود با ویژگیهای پیشینی شناخته شده (قابل مشخص) نشان دهند. اثر نسبت به محصول خروجی برنامه است و معمولاً به صورت گرافیکی نشان داده می شود. شبیه سازی ده ها میلیون خطا در عرض چند ثانیه و صدها میلیون خطا در عرض 30 ثانیه در رایانه لپ تاپ مورد نظر است.
پیش از این، خطاهای مربوطه گاهی اوقات به عنوان خطاهای همگن تنها به عنوان یک فرض برای کاهش پیچیدگی و/یا افزایش سرعت شبیه سازی می شدند. با این حال، بسیاری از برنامه های کاربردی واقع بینانه با داده هایی با ویژگی های خطای غیر همگن مطابقت دارند. به عنوان مثال، مجموعه دادههایی که قبلاً با سایر مجموعههای داده با ویژگیهای خطا (دقت) متفاوت ترکیب شدهاند. این مقاله به هر دو نوع خطا می پردازد. تکنیکهای غیرهمگن ارائهشده در این مقاله اساساً سرعت مرتبط با تکنیک ارائهشده برای حالت همگن را حفظ میکنند، و معمولاً سرعت را تنها دو یا سه ضریب کاهش میدهند. ویژگی های غیر همگن مربوطه کاملاً عمومی نیستند، اما هنوز برای بسیاری از کاربردها کافی هستند.
در نهایت، یک موضوع مشترک در سراسر این مقاله، محاسبات عملی و نیاز به یک ماتریس کوواریانس نقطه چند شبکه ای مربوط به z ( k، l ) یا X ( k، l ) در مکان های نقطه شبکه چندگانه است. توسط برنامه های مختلف برای پیش بینی دقت داده های ورودی و وزن مناسب آن در الگوریتم های مختلف خود استفاده می شود.
نویسندگان [ 1 ، 2 ، 3 ، 4 ، 5 ] زمینه های تصادفی را به طور کلی مورد بحث قرار می دهند، از جمله تولید یا شبیه سازی آنها. تکنیکهای تولید شامل تکنیکهای مبتنی بر تجزیه کولسکی و شبیهسازی گاوسی متوالی است. علاوه بر این، این منابع در مورد درونیابی تحقق یک میدان تصادفی بر اساس کریجینگ بحث می کنند. این مراجع در جامعه زمین آمار نسبتاً استاندارد هستند. آنها، همراه با سایر مراجع از این جامعه، در طول باقیمانده این مقاله، از جمله ضمیمه ها، برای هر موضوع خاص ارجاع داده می شوند.
همانطور که بعداً توضیح داده شد، FSS مستقل از شبیهسازی متوالی گاوسی استخراج شد، اما در شرایط مشخص معادل است. FSS همچنین مستقیماً با ماتریس های کوواریانس نقطه چندشبکه تعمیم یافته [ 6 ] و توابع همبستگی قطعی کاملاً مثبت [ 7 ] مرتبط است که در جامعه جغرافیایی کاربرد دارند. کاربردهای اخیر FSS شامل ارزیابی روش های ادغام [ 8 ] و الگوریتم های مختلف جغرافیایی [ 9 ] است.
نقشه راه
بخش 1 ، بخش 2 ، بخش 3 و بخش 4 این مقاله، میدان تصادفی دوبعدی گاوسی همگن اسکالر، الگوریتم تولید متوالی سریع FSS، و جنبه های عملی مرتبط را تعریف می کند. بخش 5 FSS را با روشهای تولید معمولیتر مانند روشهای مبتنی بر تجزیه Cholesky یا شبیهسازی متوالی گاوسی، بهویژه با توجه به زمانبندی یا توان، مقایسه میکند. بخش 6 سپس تکنیک FSS را به یک میدان تصادفی 2 بعدی گاوسی همگن چند متغیره و بخش 7 را به یک میدان تصادفی دو بعدی گاوسی غیر همگن گسترش می دهد.
2. یک میدان تصادفی 2 بعدی گاوسی اسکالر و تولید متوالی آن
در این بخش از مقاله، ما یک میدان تصادفی دوبعدی (2D) اسکالر، همگن و گاوسی را تعریف میکنیم که معمولاً مربوط به اختلالات یا خطاها است. ما همچنین FSS، الگوریتمی برای تولید سریع و متوالی یک تحقق گسسته و خاص از این میدان تصادفی را ارائه میکنیم که میتواند برای تحلیلهای مختلف مبتنی بر شبیهسازی مونت کارلو استفاده شود.
فرض می کنیم که فیلد تصادفی با z -error برای ویژگی مطابقت دارد. شاخصهای k و l با یک شبکه دو بعدی در صفحه افقی y – x مطابقت دارند: k در جهت « y » است و اولین شاخص شبکه است، l در جهت « x » است و شاخص شبکه دوم است. به طور خاص، z ( k، l ) با z -error در متر در نقطه شبکه ( k ، l ) مطابقت دارد .
2.1. ویژگی های آماری
z ( k, l ) به طور معمول (گاوسی) توزیع شده است و دارای مقدار میانگین صفر و یک سیگما قابل تعیین σ z است، یعنی به طور معمول N (0, σ z ) برای همه مکانهای شبکه توزیع میشود ( k, l ) . همبستگی فضایی آن در سراسر شبکه قابل تفکیک است، یعنی دارای تابع همبستگی (نرمال شده) ρ ( Δk, ∆l ) است، که در آن ∆k و ∆l مقادیر مطلق تفاوتهای مؤلفهای در ( k, l) هستند. ) محل دو نقطه شبکه دلخواه. این تابع به صورت زیر نمایش داده می شود:
که در آن Ty و Tx ثابت های فاصله همبستگی فضایی قابل تعیین (متر) و δy و δ x فاصله شبکه مشخص ( متر ) به ترتیب در جهت y و x در صفحه افقی هستند. توجه داشته باشید که ∆y = ∆k δ y و ∆x = ∆l δ x
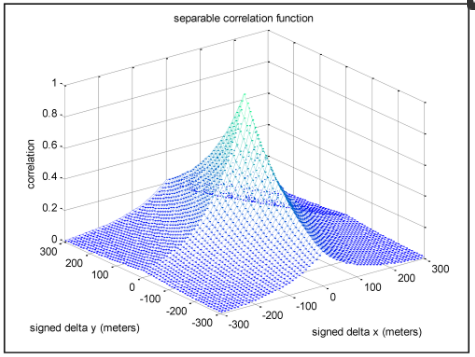
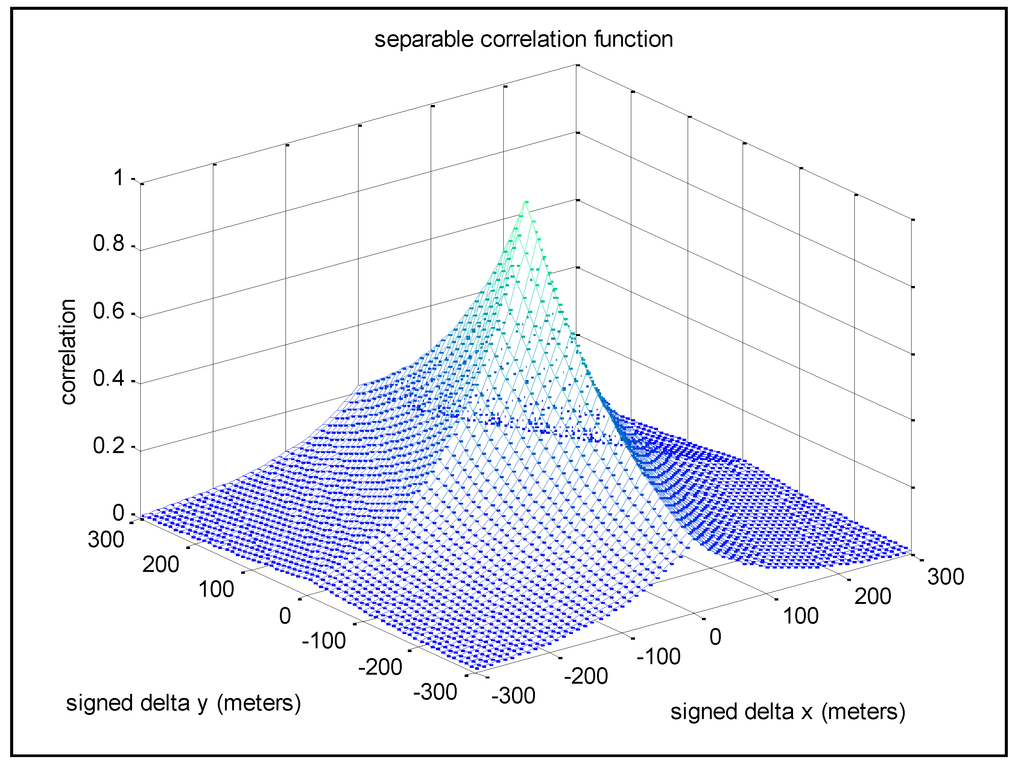
شکل 1 مثالی از ρ ( Δy, ∆x ) را با Ty = 200 m، T x = 100 m، و δy = δ x = 10 m نشان میدهد. همبستگی فضایی ρ ( Δy، ∆x ) برای هر جفت نقطه شبکه در کل شبکه که با ∆y متر در جهت y و ∆x متر در جهت x از هم جدا شده اند، قابل اعمال است . استفاده از دو ثابت فاصله همبستگی فضایی مختلف اجازه می دهد تا ویژگی های همبستگی مختلف در هر یک از جهت های افقی مشخص شود.
شکل 1. نمونه ای از تابع همبستگی فضایی قابل تفکیک. در نمودار ρ ( Δy، ∆x )، ∆y و ∆x دارای مقادیر علامت دار هستند.
با توجه به آمار پیشینی z ( k, l ) به صورت رسمی تر:
در یک مکان دلخواه ( k، l ) در شبکه.
توجه داشته باشید که E {} عملگر انتظار است، و ∆k ≥ 0، ∆l ≥ 0، T y > 0، T x > 0، δ y > 0، δ x > 0، | ρ ( ∆k, ∆l )| ˂ 1 اگر ∆k ≠ 0 یا ∆l ≠ 0، و ρ ( Δk, ∆l ) = 1 وقتی ∆k = ∆l = 0. بخش 3.0 این مقاله همچنین ماتریس کوواریانس مرتبط با دو یا چند z را ارائه میکند. k، lهر کدام با یک نقطه شبکه متفاوت ( k,l ) مرتبط است.
2.2. معادله شبکه اصلی-تولید
معادله (3) معادله اصلی تولید شبکه برای FSS است:
اعداد صحیح k و l مربوط به نقاطی در شبکه هستند، s = e -δy/Ty و r = e -δx/Tx . u(k, l) یک نمونه تصادفی از نویز سفید گاوسی است و به طور معمول N (0, σu ) توزیع می شود که در آن . یعنی با توجه به s ، r و σ z دلخواه، مقدار متناظر σ u به ازای موارد فوق محاسبه می شود. 
s همبستگی فضایی خطای اسکالر z بین نقاط شبکه مجاور در جهت k (یا y ) است (0 ≤ s ≤ 1، واحد کمتر)، و r همبستگی فضایی خطای اسکالر بین نقاط شبکه مجاور در جهت l (یا x ) (0 ≤ r ≤ 1، بدون واحد) بنابراین، ما همچنین میتوانیم تابع همبستگی فضایی ρ ( Δk, ∆l ) را فقط به عنوان تابعی از واحدهای شبکه بنویسیم:
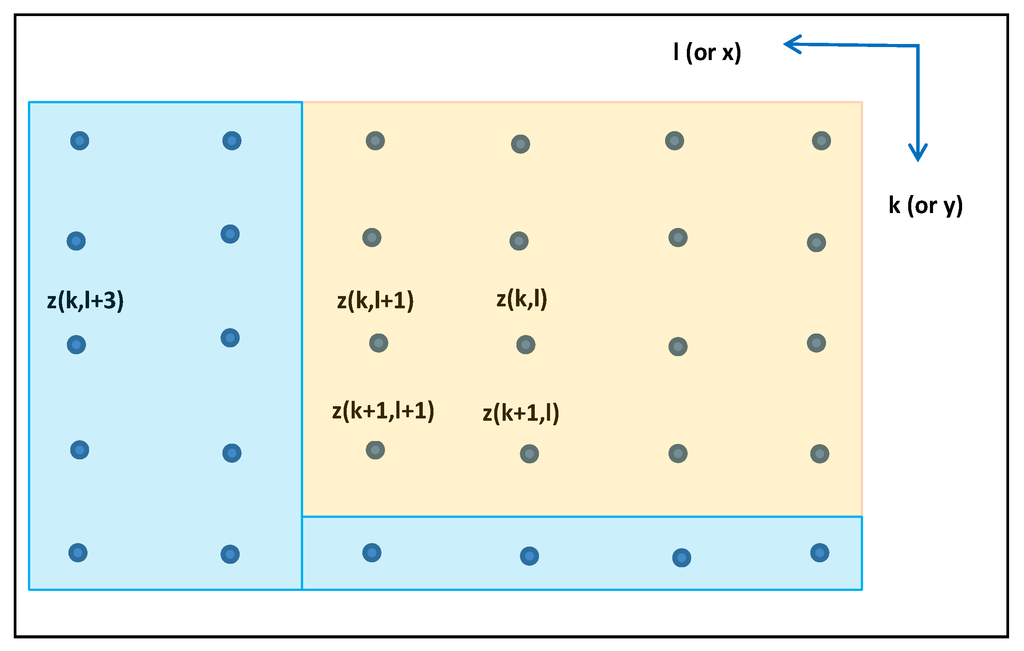
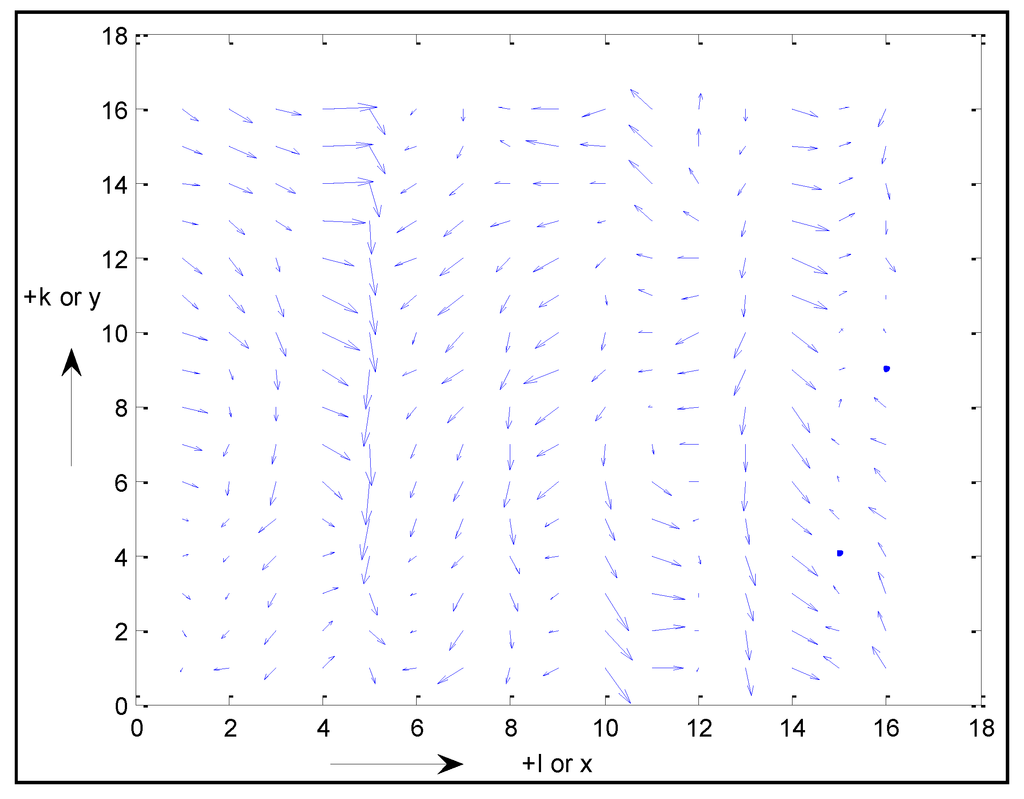
شکل 2 شبکه خطاهای z ( k, l ) ایجاد شده بر اساس رابطه (3) و مربوط به تحقق خاصی از میدان تصادفی اسکالر، همگن و دو بعدی را نشان می دهد.
شکل 2. شبکه افقی خطاهای z .
تمام خطاها در ناحیه نارنجی روشن روی خطای z ( k + 1, l + 1) تأثیر میگذارند و خطاهای ناحیه آبی روشن تأثیری ندارند. همچنین، بر اساس الگوریتم تولید شبکه متوالی خاص ارائه شده در بخش 2.3 ، یک خطا در ناحیه آبی روشن (به عنوان مثال، z ( k ، l + 3)) ممکن است قبل از z ( k + 1، l + 1) حتی ایجاد شود. هر چند تاثیری بر آن ندارد.
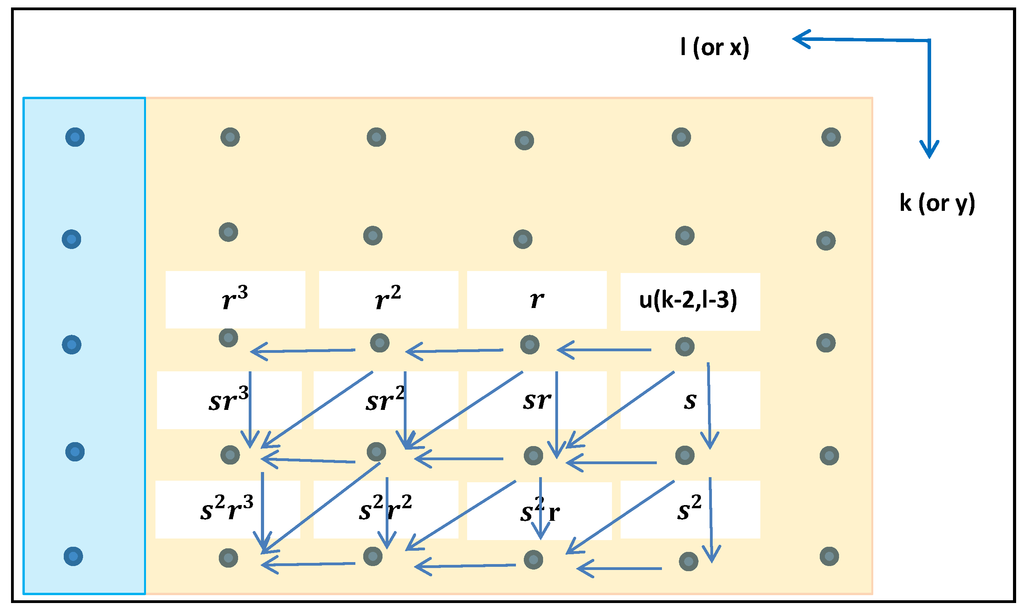
2.3. الگوریتم تولید متوالی برای تحقق روی یک شبکه pxq
در زیر یک الگوریتم FSS خاص برای تحقق گسسته z ( k, l ) بر روی یک شبکه pxq بر اساس رابطه (3) ارائه میشود:
-
z (1,1) = تصادفی _ N (0, σ z );
-
z (2,1) = sz (1,1) + تصادفی _ N (0, σ u );
-
z (1,2) = rz (1,1) + تصادفی _ N (0, σ u );
-
z (2,2) = rz (2,1) + sz (1,2) – rsz (1,1) + تصادفی _ N (0, σ u );
-
z (1, q ) = rz (1, q -1) + تصادفی _ N (0, σ u );
-
z (2, q ) = rz (2, q -1) + sz (1, q ) − r s z (1, q -1) + تصادفی _ N (0, σ u );
موارد فوق ردیف های 1 و 2 را تکمیل می کند. ردیف 3 را به صورت زیر ایجاد کنید:
-
z (3,1) = sz (2,1) + تصادفی _ N (0, σ u );
-
z (3,2) = rz (3,1) + sz (2,2) – rsz (2,1) + تصادفی _ N (0, σ u );
-
z (3, q ) = rz (3, q – 1) + sz (2, q ) – rsz (2, q – 1) + تصادفی _ N (0, σ u );
پردازش ردیف 3 را برای ردیف های 4 تا p تکرار کنید .
توجه داشته باشید که، به طور کلی، ” تصادفی _ N (0, σ a )” مربوط به یک عدد تصادفی (تحقق) از توزیع احتمال N (0, σu ) است. به عنوان مثال، در matlab این به صورت ” sigma_a * randn (1،1)” پیاده سازی می شود.
ضمیمه A این مقاله اثبات مستقیمی را ارائه می دهد که الگوریتم FSS فوق، تحقق یک میدان تصادفی دو بعدی با ویژگی های آماری مشخص ارائه شده در بخش 2.1 را ایجاد می کند. ضمیمه Bهمچنین معادل ریاضی آن را با رویکرد شبیه سازی متوالی گاوسی برای کامل بودن نشان می دهد. دومی باید همبستگی نمایی قابل تفکیک در جهات فضایی و یک شبکه ثابت با یک مسیر منظم خاص در سراسر آن برای تولید تحقق مشخص کند. همچنین، بسته به نحوه اجرای آن، ممکن است از نیاز به استفاده از تحقق تنها در سه نقطه شبکه تولید شده قبلی برای تولید در نقطه شبکه فعلی استفاده کند یا نکند، مانند FSS. اگر با استفاده از وزنهای کریجینگ از پیش محاسبهشده و سربار کمی به دلیل انعطافپذیری و پیچیدگی به شیوهای کارآمد عمل کند، سرعت آن میتواند به سرعت FSS نزدیک شود.
2.3.1. فاصله شبکه
معادله (3) و الگوریتم فوق معمولاً باید فاصله شبکهای δ y و δ x معادل تقریباً یک نهم یا کمتر از ثابت فاصله همبستگی فضایی مربوطه خود را در خود جای دهند و حداقل همبستگی 0.9 را با یک نقطه شبکه مجاور تضمین کنند ، یعنی s = e – δ y / T y ≥ e -1/9 ≅ 0.9 و r = e – δ x / T x ≥ e -1/9 ≅ 0.9، یا به طور معادل، δ y ≤ Ty /9 m و δ x ≤ T x /9 m. البته، این “قاعده سرانگشتی” وابسته به کاربرد است. به عنوان مثال، اگر همبستگی فضایی بسیار بالا بین نقاط شبکه مجاور مورد توجه باشد، فاصله باید نزدیکتر باشد.
2.3.2. بافر شبکه
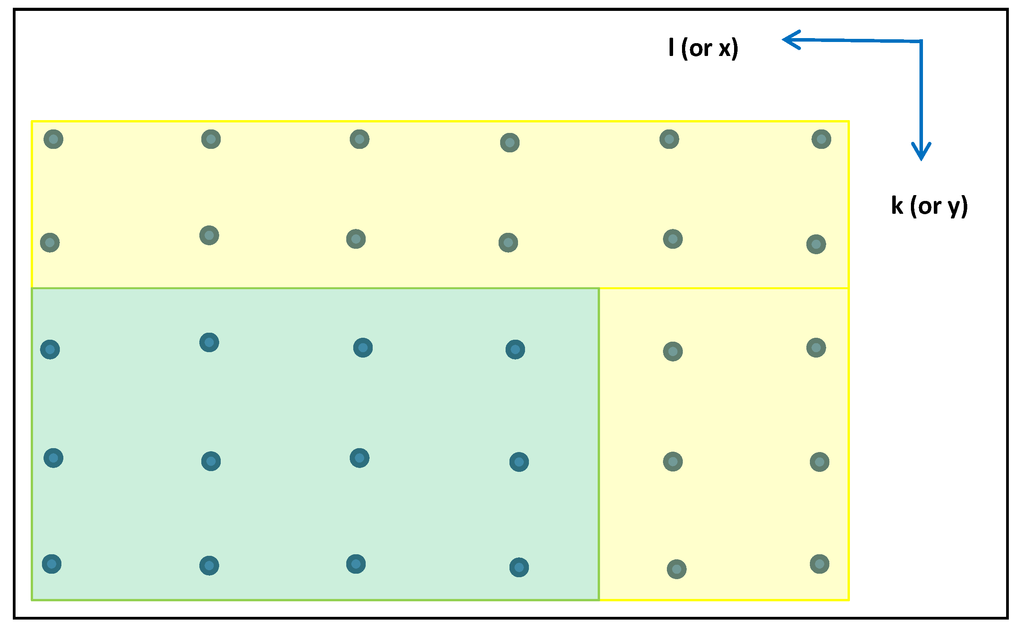
همانطور که در ضمیمه A این مقاله نشان داده شده است، ویژگی های آماری z ( k، l ) بر اساس ویژگی های حالت پایدار بر روی یک شبکه افقی بی نهایت فرض شده است. بنابراین، برای یک کاربرد واقعی (تحقق) که لزوماً از یک شبکه محدود استفاده میکند، شبکه «نهایی» باید یک «بافر» در دو لبه شبکه محاسبهشده داشته باشد تا اطمینان حاصل شود که اساساً به حالت پایدار رسیده است. این در شکل 3 نشان داده شده است ، جایی که بافر زرد و شبکه نهایی سبز است.
شکل 3. بافر شبکه (زرد)، شبکه محاسبه شده (زرد + سبز)، شبکه نهایی (سبز).
قرار دادن بافر مربوط به الگوریتم تولید شبکه متوالی خاصی است که قبلا ارائه شده بود که از بالای شبکه شروع می شود و همیشه از راست به چپ ادامه می یابد. عرض بافر بالایی باید معادل تقریباً دو برابر ثابت فاصله همبستگی فضایی در جهت y باشد و عرض بافر جانبی باید معادل تقریباً دو برابر ثابت فاصله همبستگی فضایی در x مطابقت داشته باشد. -جهت.
به طور خاص، عرض بافر بالا (# ردیف شبکه ) = و عرض بافر جانبی (# ستون شبکه ) = 2 T x / δ x . یا به طور معادل، اگر s و r برابر با 0.9 باشد، 19 ردیف شبکه و 19 ستون شبکه. این امر باعث ایجاد خطا در سراسر شبکه نهایی با ویژگی های آماری مورد نظر می شود.
2.4. نمونه تحقق: پلات های سطحی
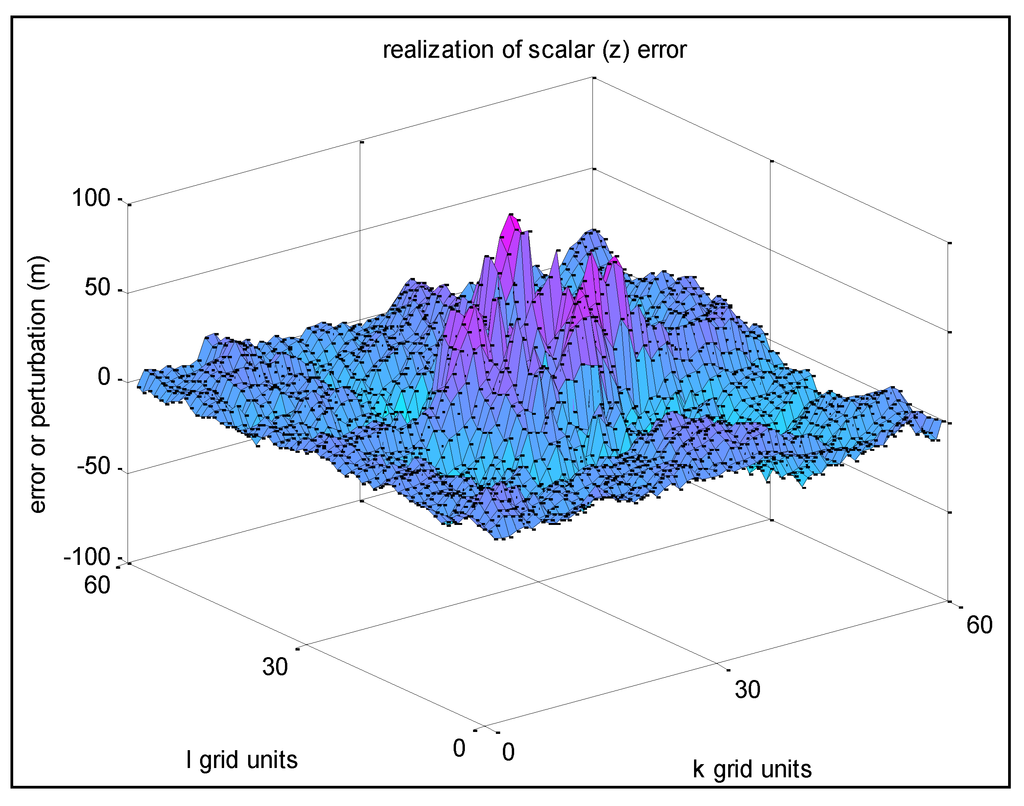
این بخش نمودارهای سطحی خطای z را بر روی زیرمجموعه ای از یک شبکه نهایی دوبعدی تولید شده با استفاده از الگوریتم ترتیبی بخش 2.3 ارائه می دهد. مثال 1 مربوط به مشخص شده σ z = 10 m، و مشخص شده s = r = 0.95 (بنابراین σu = 0.975 m) است. با فرض فاصله شبکه در هر دو جهت y و x 1 متر ( δ y = δ x = 1)، این مربوط به ثابت های فاصله فضایی برابر با Ty = T x = 19.5 متر است.
در این مورد خاص، ثابت های فاصله فضایی Ty و Tx از s و r مشخص شده به دست آمدند ، با توجه به فاصله شبکه فرضی δy و δx نه برعکس . ثابت فاصله مکانی فقط برای اطلاعات محاسبه شد. یعنی دو رویکرد اساسی اما معادل برای مشخصات، کاربرد و تفسیر همبستگی فضایی وجود دارد، رویکرد خاصی که بر اساس راحتی انتخاب شده است:
رویکرد 1- همبستگی فضایی را با مقادیر s و r (بدون واحد) به طور مستقیم مشخص کنید، معادله (3) را اجرا کنید، و سپس نتایج وابسته به مکان را بر حسب واحدهای شبکه تفسیر کنید. با توجه به فاصله شبکه فرضی δ y و δ x (متر)، ثابت های فاصله مکانی Ty و Tx ( متر ) را می توان فقط برای اهداف اطلاعاتی به دست آورد.
رویکرد 2- همبستگی فضایی را با مقادیر Ty و Tx (متر) و فاصله شبکه δy و δx (متر) مشخص کنید ، s و r را محاسبه کنید ، معادله ( 3 ) را اجرا کنید ، و سپس نتایج وابسته به مکان را بر حسب تفسیر کنید. فضای افقی yx بر حسب متر. این رویکرد زمانی به خوبی کار میکند که میدان تصادفی تولید شده با آمار پیشینی و وضوح فضایی یک کاربرد خاص مورد علاقه در علوم زمین فضایی مطابقت داشته باشد.
شکل 4 نتایج تحقق مثال 1 را بر اساس رویکرد 1 نشان می دهد. توجه داشته باشید که نمونه های تحقق باقی مانده در این مقاله از رویکرد 1 نیز استفاده می کنند، زیرا راحت ترین است.
شکل 4. مثال 1-تحقق خطای z با همبستگی فضایی بالا بین نقاط شبکه مجاور.
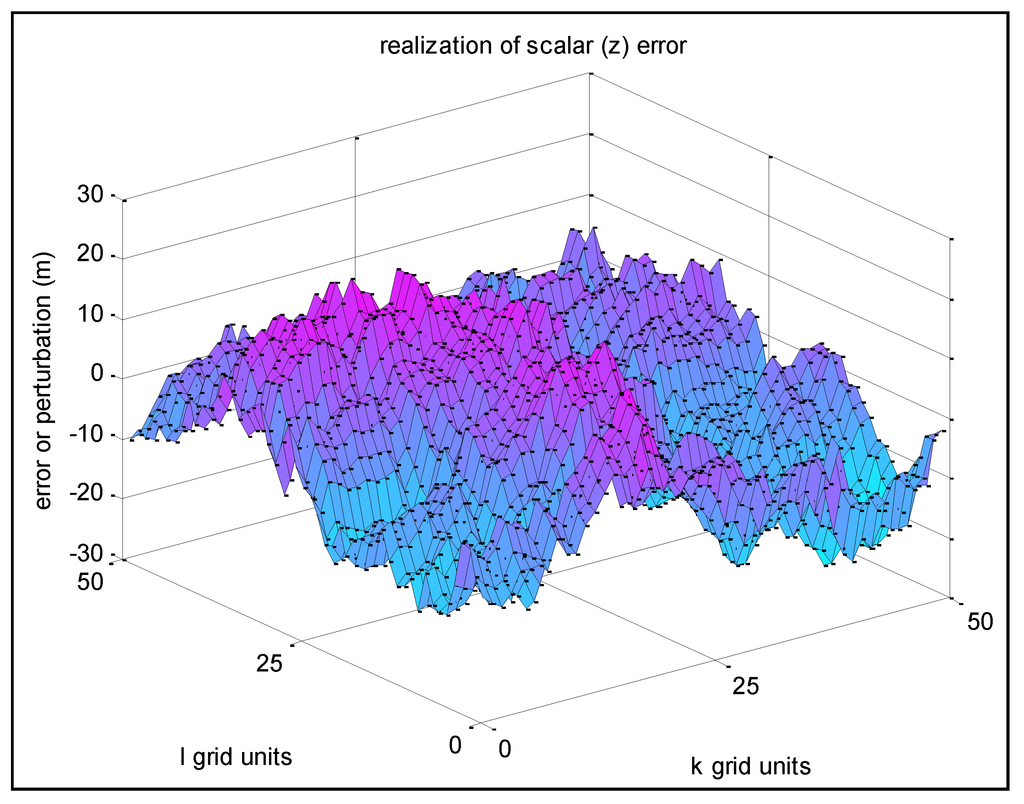
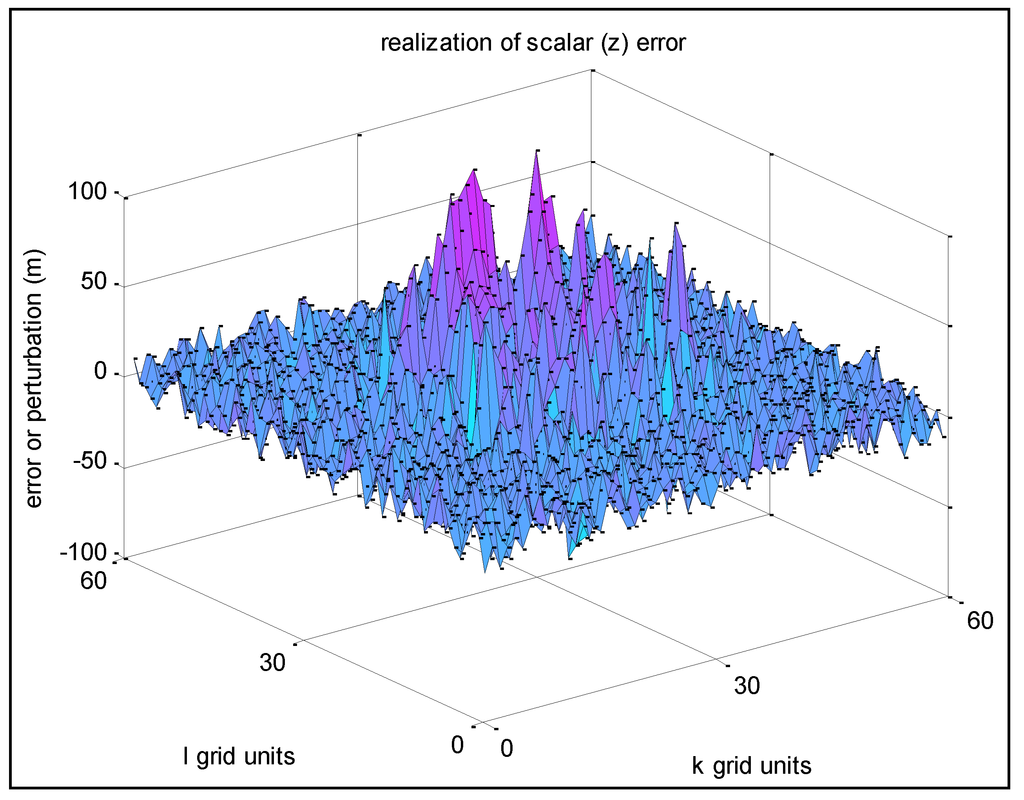
شکل 5 مربوط به مثال 2 است، یک تحقق جدید با همان σ z = 10 m، اما با s = r = 0.1 (بنابراین σu = 9.9 m).
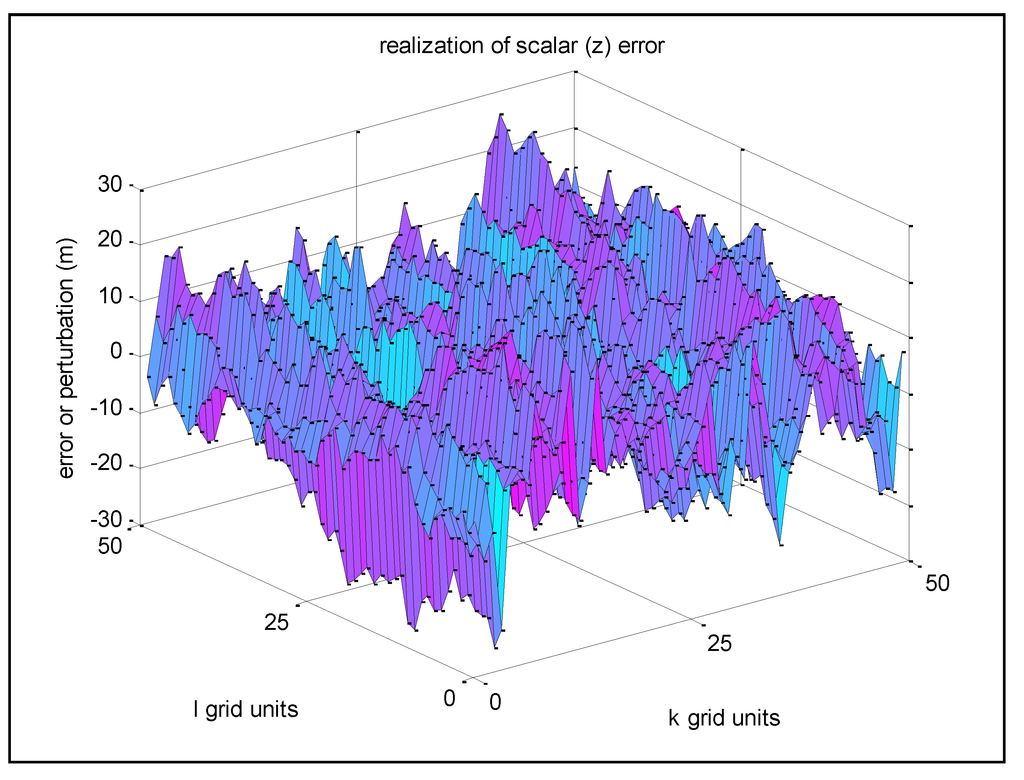
شکل 6 مربوط به مثال 3 است، یک تحقق جدید با همان σ z = 10 m، اما با s = r = 0.999 (بنابراین σu = 0.02 m).
همانطور که انتظار می رود، تحقق های فوق در بخش هایی از شبکه دارای میانگین z- خطای صفر و یا انحراف استاندارد در مورد میانگین 10 متر نیستند. با این حال، هنگامی که آمار نمونه بر روی تحقق های متعدد محاسبه می شود، میانگین و انحراف استاندارد مربوطه به ترتیب برابر با 0 متر و 10 متر است که با آمارهای پیشینی رایج مورد استفاده برای تولید تحقق ها مطابقت دارد.
در نهایت، شکل 7 زیر مثال 4 را نشان میدهد، تحقق جدیدی با همان σ z = 10 m، اما با s = 0.1 و r = 0.95 (بنابراین، σu = 3.107 )، یعنی همبستگیهای فضایی متفاوت در دو جهت.
شکل 5. مثال 2-تحقق خطای z با همبستگی فضایی کم بین نقاط شبکه مجاور.
شکل 6. مثال 3-تحقق خطای z با همبستگی فضایی بسیار بالا بین نقاط شبکه مجاور.
2.5. نمونه تحقق: آمار نمونه
توابع همبستگی یا همبستگی نمونه برای دو تحقق مستقل در یک شبکه z نهایی با اندازه 1000 × 1000 محاسبه شد. آمار پیشینی با مقدار میانگین ثابت 0 و انحراف استاندارد در مورد میانگین σ z = 10 متر مشخص شد. اولین تحقق مطابق با همبستگی های پیشینی است که با r = 0.95 و s = 0.75 نشان داده شده است، و در شکل 8 ارائه شده است . توابع همبستگی به عنوان تابعی از فاصله افقی در جهت x و فاصله افقی در جهت y ترسیم شدند و همانطور که انتظار می رود در مقادیر r و s متفاوت هستند.
شکل 7. مثال 4-تحقق خطای z با همبستگی های فضایی مختلف.
شکل 8. آمار نمونه مربوط به شبکه 1000 × 1000 با همبستگی های پیشینی متفاوت.
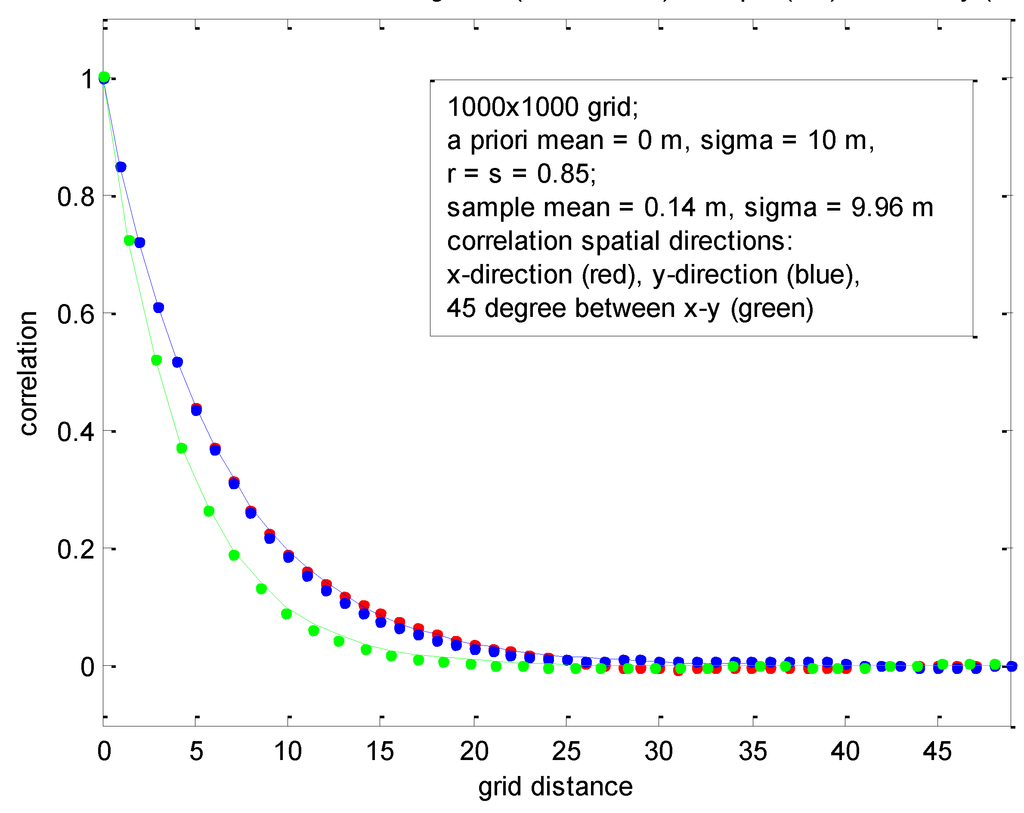
تحقق دوم با r = s = 0.85 مطابقت دارد و در شکل 9 ارائه شده است . سه جهت افقی مختلف مورد ارزیابی قرار گرفت: x، y، و 45 درجه بین. توجه داشته باشید که نتایج برای دومی متفاوت است حتی اگر r = s زیرا مدل همبستگی FSS همسانگرد نیست. (توجه داشته باشید که 45 درجه جهت را با حداکثر اختلاف نشان می دهد.) به طور کلی، هر دو نمودار نتایج تقریباً یکسانی را بین توابع همبستگی واقعی و نمونه نشان می دهند – غیرمنتظره نیست زیرا FSS تقریبا هیچ تقریبی ندارد و به دلیل اینکه میدان تصادفی ارگودیک و تعداد نمونه است. در یک تحقق بزرگ.
شکل 9. آمار نمونه مربوط به شبکه 1000 × 1000 با همبستگی های پیشینی یکسان برای جهت های x و y، در سه جهت مختلف ارزیابی شده است .
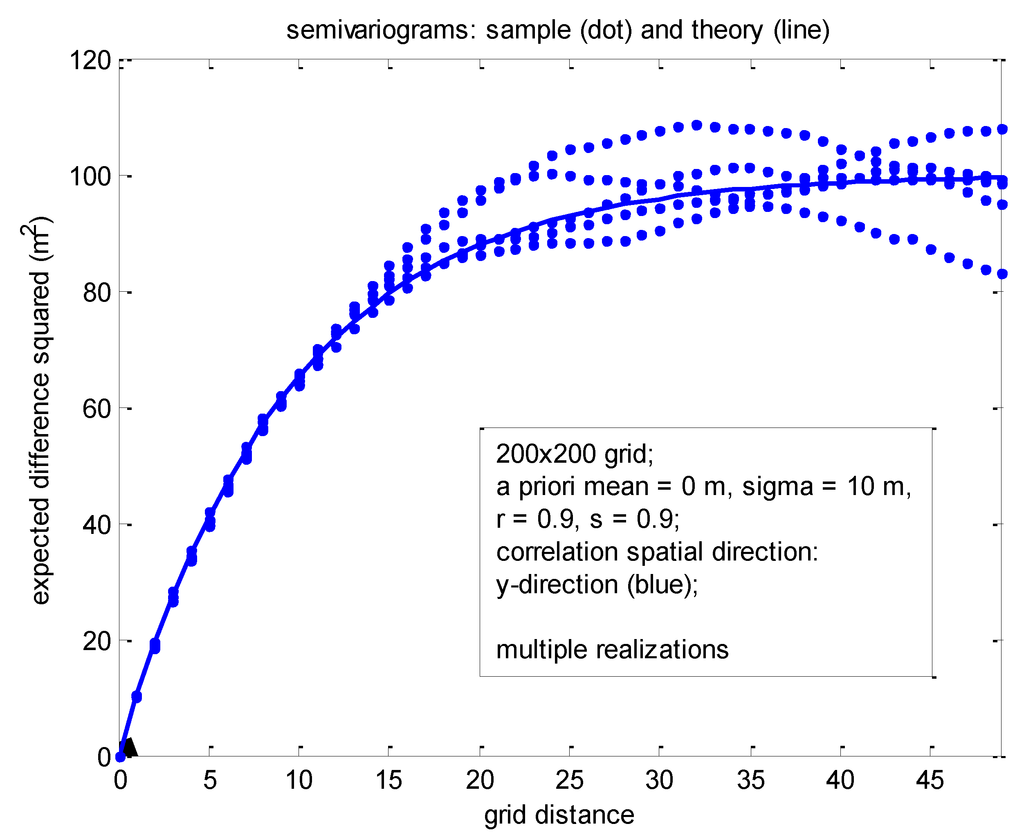
شکل 10. نیم متغیره های مربوط به شبکه 200 × 200 با همبستگی های پیشینی یکسان برای جهت های x و y، که در سراسر جهت y برای پنج تحقق مختلف ارزیابی شده اند.
شکل 10 مربوط به مجموعه ای از پنج تحقق مستقل است، این بار در یک شبکه بسیار کوچکتر 200 × 200. آمارهای پیشینی مشابه با آمار مربوط به شکل 9 بود به جز اینکه r = s = 0.9. همچنین، نمونه و آمار نظری محاسبهشده با نیمواریوگرام، معمولاً مورد علاقه جامعه زمینآمار، که در جهت y در سراسر شبکه افقی محاسبه میشود، مطابقت دارد. (به عنوان مثال، به تعاریف همبستگی و نیمه متغیریگرام به [ 5 ] مراجعه کنید.) به تغییرپذیری معقول نیمواریوگرامهای نمونه مربوط به هر یک از پنج تحقق در مورد نیمه متغیر نظری رایج توجه کنید.
3. ماتریس کوواریانس نقطه چند شبکه ای
اگر m خطاهای اسکالر خاص z ( k, l ) مربوط به m شبکه دلخواه و مکان های مختلف شبکه ( k, l ) وجود داشته باشد، ماتریس کوواریانس m × n (مشترک) آنها متقارن و قطعی مثبت (معتبر) است. خطاهای نقطه شبکه دارای واریانس یکسانی هستند و دارای همبستگی بین نقطه ای بین جفت های مربوط به یک تابع همبستگی قطعی کاملاً مثبت نرمال شده (spdcf) ρ ( Δk, ∆l ) = ρ ( ∆y, ∆x ) = e -∆lδy / تی y e -∆kδ x / T x ،عنوان مثال، ماتریس کوواریانس نقطه چند شبکه ای برابر است:
که در آن Z یک بردار mx 1 است به طوری که Z T = [ z 1 , …, z m ] و z i = z ( k i , l i ), i = 1,…, m به لیست مرتب شده ای از m مکان های نقطه شبکه. همچنین ∆y ij = ∆y ji و ∆x ij = ∆x ji فاصلههای y و x بر حسب متر در صفحه افقی بین نقاط مرتب شده i, j هستند.∈ {1,…, m }; مستقیماً هر عنصر ماتریس mxm را ضرب می کند. (به طور متناوب، تابع همبستگی فضایی و فواصل را میتوان بر اساس واحدهای شبکه نوشت.)
توجه داشته باشید که موارد فوق یک ماتریس کوواریانس پیشینی مربوط به z های مختلف ( k, l ) است که به عنوان متغیرهای تصادفی در نظر گرفته می شوند، نه تحقق های خاص. مرجع [ 7 ] را در رابطه با ویژگیهای یک spdcf ببینید به طوری که mxm P فوق یک ماتریس کوواریانس معتبر (متقارن و قطعی مثبت) بدون توجه به اندازه m تضمین میکند. به طور کلی، فقط به این دلیل که مقدار مطلق همبستگی بین دو مکان نقطه شبکه دلخواه کمتر از 1.0 است، این به خودی خود ماتریس کوواریانس چند شبکه ای معتبر برای m > 2 را تضمین نمی کند.
تولید FSS از تحقق z ( k, l ) روی یک شبکه دو بعدی همانطور که در بخش 2.3 ارائه شده است.نیازی به استفاده از ماتریس کوواریانس نقطه چند شبکه ای صریح در فرآیند تولید نداشت. بنابراین، چرا محاسبه این ماتریس کوواریانس از نظر کاربردهای خاص خطاها یا اغتشاشات ایجاد شده مورد توجه است؟ دلیل اصلی به شرح زیر است: یک “ماژول تحلیل” ممکن است شبکه شبیه سازی شده خطاها را ایجاد کند و یک زیرمجموعه را به “داده های حقیقت” اعمال کند و سپس داده های ترکیبی را به یک برنامه کاربردی “پایین جریان” ارسال کند تا عملکرد آن را بتوان در آن ارزیابی کرد. وجود خطاها بسیاری از این کاربردها همچنین به دانش ماتریس کوواریانس نقطه چند شبکه ای مربوط به داده های مرکب به منظور وزن دهی مناسب داده های ترکیبی در روش های تخمین مختلف (فیلتر کالمن و برآوردگرهای حداقل مربعات وزنی) برای پارامترها (بردارهای حالت) مورد علاقه نیاز دارند. به برنامه [ 6]. البته، این برنامه ها را می توان به سادگی همراه با داده های ترکیبی، متناظر و پارامترهایی که ρ ( ∆k, ∆l ) = ρ ( ∆y, ∆x ) = e -∆lδy / T y e – را تعریف می کنند، ارسال کرد. ∆lδ x / T x ، به طوری که برنامههای کاربردی میتوانند خودشان ماتریس کوواریانس نقطه چند شبکهای مناسب بسازند.
همگنی و چگالی احتمال مشترک گاوسی
خطاهای اسکالر z ( k، l ) ایجاد شده با استفاده از تکنیک تولید متوالی FSS، توزیع گاوسی هستند زیرا آنها ترکیبی خطی از u ( k، l ) هستند، که طبق تعریف گاوسی توزیع شده اند. (ترکیب خطی به صراحت در ضمیمه A نشان داده شده است.) همچنین، شبکه متناظر خطاهای z با یک میدان تصادفی همگن با حس گسترده مطابقت دارد زیرا واریانس و همبستگی خطاها در مکان(های) شبکه مطلق خاص ثابت هستند. علاوه بر این، از آنجایی که خطاها توزیع گاوسی هستند، یک میدان تصادفی همگن با حس گسترده معادل یک میدان تصادفی همگن است [ 2 ].
هر مجموعه محدودی از z ( k، l ) در مکانهای شبکه مختلف ( k، l ) موجود در بردار mx 1 Z دارای تابع چگالی احتمال مشترک گاوسی است که به صورت زیر تعریف میشود:
که در آن P ماتریس کوواریانس نقطه چند شبکه ای است و det تعیین کننده ماتریس است. بنابراین، احتمالات را می توان به روشی ساده به هر فاصله اطمینان مطلق یا نسبی مورد علاقه نسبت داد.
در نهایت، شایان ذکر است که همه ماتریسهای کوواریانس نقطهای چندشبکهای که در این مقاله محاسبه شدهاند، بدون توجه به توزیع احتمالی اساسی خطاها معتبر هستند. این هم برای خطای اسکالر بخش 1 ، بخش 2 ، بخش 3 ، بخش 4 و بخش 5 ، خطاهای چند متغیره بخش 6 و خطاهای غیر همگن بخش 7 صادق است . این در منابع [ 6 ، 7 ] مورد بحث قرار گرفته است، که همچنین استفاده از هر خانواده معتبر spdcf را مجاز میکند. علاوه بر این، نویسندگان [ 6] اهمیت چنین ماتریسهای کوواریانس، روشهای تولید دیگر برای چنین ماتریسهای کوواریانس، و چگونگی تولید بیضیهای خطای احتمال مربوطه را مورد بحث قرار میدهد. توجه داشته باشید که در مرجع [ 6 ]، این ماتریسهای کوواریانس به طور کلی «ماتریس کوواریانس خطای بردار چند حالته» نامیده میشوند.
4. درون یابی در شبکه
تکنیک FSS همانطور که در بخش 1 و بخش 2 این مقاله توضیح داده شده است، تحقق یک میدان تصادفی را فقط در مکانهای نقطه شبکه ایجاد میکند. این برای بسیاری از کاربردها کاملاً کافی است زیرا شبکه می تواند بسیار بزرگ و متراکم باشد. با این حال، اگر خطاهای اسکالر بین مکان های نقطه شبکه مورد نظر باشد، درون یابی z ( k, l)) در چهار مکان نقطه شبکه محصور ممکن است انجام شود. همچنین، کوواریانس نقطه چند شبکه ای (معادله (5)) را می توان به راحتی برای مجموعه متناظری از نقاط درون یابی اصلاح کرد. به سادگی فاصله بین نقاط شبکه را به فاصله متناظر بین مکان نقاط درونیابی تغییر دهید. این فواصل ممکن است در واحدهای غیرصحیح فاصله شبکه یا فواصل مربوط به y و x بر حسب متر در صفحه افقی نمایش داده شوند.
5. مقایسه با روش های تولید جایگزین
این مقاله FSS، یک روش متوالی سریع و کارآمد برای تولید یک شبکه دو بعدی از خطاها یا اغتشاشات را ارائه میکند. همچنین یک ماتریس کوواریانس نقطه ای چند شبکه ای ضمنی وجود دارد (به عنوان مثال، معادله (5))، اما این ماتریس کوواریانس در فرآیند تولید مورد نیاز نیست. از سوی دیگر، همبستگی مکانی خطاها با این روش تولید محدود به یک خانواده spdcf خاص از توابع همبستگی فضایی است، یعنی ρ ( ∆k , ∆l ) = ρ ( ∆y, ∆x ) = e -∆kδ. y / T y e -∆lδ x / T x. (البته، از این نظر که ثابت های فاصله Ty و Tx قابل تعیین هستند ، نسبتاً کلی است ) .
دو رویکرد کلی دیگر برای تولید (شبیهسازی) از طریق یک شبکه دو بعدی وجود دارد: (1) ریشههای مربع ماتریس. و (2) شبیه سازی گاوسی متوالی. مورد دوم متوالی است و همانطور که قبلاً ذکر شد کلی تر از FSS است. اولی نیز کلی تر است، اما متوالی نیست. آنها با جزئیات بیشتر در زیر بخش بعدی توضیح داده شده اند.
5.1. مقایسه زمان بندی در میان تکنیک های شبیه سازی
شکل 12 مقایسه زمان CPU را در بین پنج تکنیک مختلف برای شبیه سازی اغتشاشات برای یک شبکه مربع با تغییر تعداد نقاط n نشان می دهد . تعداد نقاط در امتداد یک طرف شبکه کجاست . زمانهای محاسباتی با یک لپتاپ PC با پردازندههای Intel i5 دو هستهای 2.3 گیگاهرتز و 8 گیگابایت حافظه اندازهگیری شد.
هدف اندازه گیری عملکرد CPU محاسبات اصلی (بدون راه اندازی سربار) برای هر روش بود. تلاش برای تطبیق پارامترهای مدلسازی در بین همه روشها تا حد امکان انجام شد. آزمایش فقط مدلهای بدون قید و شرط، همگن و همسانگرد را در نظر گرفت (در واقع، برای FSS مدل تقریباً همسانگرد بود، به عنوان Tx = Ty ) . در زیر توضیح میدهد که چه محاسباتی اصلی در هر یک از پنج روش زمانبندی شدهاند و به ترتیب صعودی افزایش سرعت محاسباتی مطابق شکل 12 فهرست شدهاند .
(1) ریشه مربع ماتریس اصلی (با استفاده از تابع Matlab SQRTM)
n x n ماتریس اصلی ج z کجاست . r یک تحقق برداری n × 1 از n متغیر تصادفی توزیع شده مستقل N (0،1) است و ε z بردار n × 1 آشفتگی مربوط به متغیر تصادفی z یا z ( k, l ) در شبکه است. Σ z به عنوان یک ماتریس قطعی کامل و مثبت، یعنی پیشینی در نظر گرفته شد ماتریس کوواریانس مربوط به میدان تصادفی در n نقطه مختلف در شبکه. Matlab از تکنیک تجزیه Schur برای محاسبه SQRTM برای یک ماتریس مربع کلی استفاده می کند که می تواند برای ماتریس های متقارن و واقعی سرعت بیشتری داشته باشد.
شکل 12. مقایسه زمانی بین روشهای شبیهسازی بدون قید و شرط یک میدان تصادفی اسکالر z ( k, l ) روی یک شبکه مربع دو بعدی (توجه داشته باشید که FSS به دلیل رسیدن به حد حافظه سیستم در 15 ثانیه قطع میشود).
(2) تجزیه Cholesky (با استفاده از تابع Matlab CHOL)
که در آن L ماتریس nxn مثلثی پایینی از تجزیه Cholesky است، Σ z = LL * ، که در آن L * انتقال مزدوج L است . r یک تحقق برداری n × 1 از n متغیر تصادفی توزیع شده مستقل N (0,1) است و ε z بردار n × 1 اختلالات مربوط به متغیر تصادفی z یا z ( k, l ) در شبکه است. Σ zیک ماتریس قطعی کامل و مثبت در نظر گرفته شد.
(3) PREDICT.GSTAT (نسخه 1.0، 19 آوریل 2014) [ 10 ] الگوریتم مبتنی بر Pebesma [ 11 ] است که در بسته آماری “R” (نسخه 3.0.2، 64 بیت) پیاده سازی و آزمایش شده است. اسکریپت R زیر نمونهای از پارامترهایی است که برای زمانبندی شبیهسازی بدون قید و شرط بر روی یک شبکه 100×100 استفاده میشوند. توجه داشته باشید که فقط اجرای تابع PREDICT زمان بندی شده بود.
(4) VISIM در mGstat [ 12 ] یک کد شبیهسازی متوالی مبتنی بر GSLIB (کتابخانه نرمافزار زمینآماری، مرکز پیشبینی مخزن استنفورد، دانشگاه استنفورد) [ 13 ] برای شبیهسازی متوالی گاوسی و مستقیم است. mGstat یک جعبه ابزار زمین آماری Matlab است که به عنوان منبع باز موجود است که امکان دسترسی به VISIM (در میان الگوریتم های دیگر) را از طریق رابط Matlab فراهم می کند. فایل پارامتر مورد استفاده برای اندازه گیری عملکرد VISIM را می توان در پیوست C یافت .
(5) شبیه سازی سریع ترتیبی (FSS) تکنیکی است که در این مقاله توضیح داده شده است و به عنوان یک تابع Matlab کدگذاری و زمان بندی شده است. پارامترهای اصلی مورد نیاز عبارت بودند از فاصله شبکه ( δ = 1)، انحراف استاندارد برای متغیر تصادفی ( σ z = 1)، و ثابت های همبستگی فاصله مکانی ( T x = Ty = 10)، همانطور که همه در بخش 2.3 و توضیح داده شد. بخش 2.4 این مقاله.
5.2. بحث در مورد نتایج زمان بندی
روشهای ریشه مربع ماتریس اصلی (SQRTM) و تجزیه Cholesky (CHOL) به عنوان یک معیار شروع ارائه شدند. در حالی که آنها کمترین کاربرد را برای n بزرگ دارند، مزیت اصلی آنها ارائه یک راه حل دقیق برای هر توزیع فضایی نقاط و هر آمار فضایی پیشینی (ماتریس کوواریانس معتبر) است. شکل 12 نشان می دهد که Cholesky تقریباً نصف مرتبه افزایش سرعت نسبت به SQRTM را ارائه می دهد.
PREDICT.GSTAT و VISIM پیاده سازی تکنیک های زمین آماری استاندارد را برای شبیه سازی گاوسی متوالی ارائه می کنند. شکل 12 نشان می دهد که آنها عملکرد سرعت قابل مقایسه ای را ارائه می دهند و 1-2 مرتبه بزرگتر از SQRTM و Cholesky هستند. مزیت اصلی آنها ارائه انعطاف پذیری گسترده برای مدل سازی با هدف عمومی در بین شبیه سازی های مشروط و بدون قید و شرط است. علاوه بر این، راندمان سرعت اضافی را می توان هنگام شبیه سازی تحقق های متعدد با یک مجموعه پارامتر ثابت، که در شکل 12 نشان داده نشده است، به دست آورد. به عنوان مثال، با دنبال کردن یک مسیر تصادفی واحد از طریق مکانها، PREDICT.GSTAT از نتایج برای هر یک از شبیهسازیهای بعدی استفاده مجدد میکند [ 10 ].
FSS تکنیک پیشنهاد شده در این مقاله است. دو مزیت اصلی FSS عبارتند از (1) افزایش سرعت، به عنوان مثال، سه مرتبه قدر سریعتر از سریعترین تکنیک بعدی همانطور که در شکل 12 نشان داده شده است . و (2) سادگی عملیات، به عنوان مثال، نیاز به تنها سه پارامتر اصلی. توجه داشته باشید که منحنی FSS در شکل 12 بر روی 15 ثانیه است که به دلیل رسیدن به حد حافظه برای اندازه شبکه ( n > 2 × 10 8 امتیاز) است. با این حال، این محدودیت را می توان به راحتی با انجام محاسبات با یک پنجره متحرک محلی در مقابل غلبه کردذخیره کل شبکه در حافظه سیستم افزایش سرعت FSS شبیهسازی شبکههای بسیار متراکمتر را در مقایسه با روشهای دیگر کاربردیتر میکند. با این قابلیت، حدس ما این است که برای آن دسته از کاربردهایی که نیاز به درون یابی دارند، درون یابی دوخطی یا نزدیکترین همسایه ارزانتر می تواند برای شبکه های بسیار متراکم در مقابل کریجینگ گران تر در شبکه های درشت تر کافی باشد. مدل واریوگرام (همبستگی) به یک تابع نمایی با FSS محدود میشود، که آن را نسبت به روشهای GSTAT (شبیهسازی گاوسی متوالی) انعطافپذیرتر میکند. با این حال، معاوضه در افزایش سرعت و سادگی اجرا، مزایای عملی و مفیدی را برای ایجاد انگیزه در جامعه بالقوه گستردهتری از کاربران ارائه میدهد.
6. گسترش FSS به یک میدان تصادفی 2 بعدی گاوسی چند متغیره
معادله تولید شبکه هسته FSS، معادله (3)، را می توان از یک خطای اسکالر z به یک بردار خطای n × 1 (چند متغیری) X بر روی یک شبکه دو بعدی به روشی ساده گسترش داد. حالت کلیتر مستقیماً در زیر ارائه شده است، با موارد فرعی خاص اما کاربردی در بخشهای فرعی بعدی که شامل نمادگذاری سادهتر است، ارائه شده است.
که در آن مورب ، 0 < r i < 1، i = 1،..، n ; مورب ، 0 < s i < 1، i = 1،..، n ;
E { X ( k ، l ) X ( k ، l ) T = P X ، ماتریس کوواریانس n × n .
E { X ( k , l ) X ( k + ∆k , l + ∆l ) T } = P X S ∆k R ∆l , { X ( k , l ) X ( k ∆k , l + ∆l ) T } = S ∆k P X R ∆l ،
E { X ( k , l ) X ( k + ∆k , l − ∆l ) T } = R ∆l P X S ∆k , E { X ( k , l ) X ( k − ∆k , l − ∆ l ) T } = S ∆k R ∆l P X ، برای ∆k ≥ 0 و ∆ l≥ 0;
و P U = E { U ( k , l ) U ( k , l ) T باید یک ماتریس کوواریانس معتبر (متقارن و قطعی مثبت) باشد که موارد زیر را برآورده کند:
P U = H * P X ، حاصل ضرب هادامارد (محصول ترم به مدت) دو ماتریس nxn ، که در آن
و i , j با سطر ماتریس i , ستون j مطابقت دارد .
توجه داشته باشید که قید بالا مبنی بر اینکه PU یک ماتریس قطعی مثبت است برای همه ترکیبات ممکن از si, r i و کوواریانس خطای حالت پایدار مورد نظر (معتبر) P X برآورده نمی شود ، در این صورت معادله ( 9 ) و آمار آن عبارتند از دیگر معتبر نیست
استخراج متناظر از آمار پیشینی برای میدان تصادفی دوبعدی گاوسی همگن چند متغیره فوق، از جمله محدودیت برای PU ، تا حدودی پیچیده است و در پیوست D ارائه شده است.
الگوریتم تولید شبکه واقعی مرتبط با معادله (9) همانطور که قبلاً در بخش 2.3 این مقاله در رابطه با معادله (3) توضیح داده شده است، با این تفاوت که تصادفی _ N (0, σ z ) با , و تصادفی _ N (0, σ u ) جایگزین می شود ، که در آن بالانویس 1/2 مربوط به ماتریس اصلی ریشه مربع است و تصادفی _ v تحقق یک بردار تصادفی مستقل nx 1 با هر جزء یک تحقق مستقل از یک متغیر تصادفی اسکالر است که N توزیع شده است (0) . ، 1). البته، S جایگزین s ، R جایگزین r و X نیز جایگزین z می شود.
در نهایت، به دلایلی مشابه موارد ارائه شده در بخش 3.1 برای میدان تصادفی اسکالر، خطاهای فوق X ( k ، l ) گاوسی چند متغیره توزیع شده و مربوط به یک میدان تصادفی همگن هستند. مجدداً به مرجع [ 1 ] مراجعه کنید.
6.1. زیرمورد همبستگی فضایی مشترک
زیر یک مورد خاص، اما کاربردی از معادله (9) است که در آن محدودیت PU همیشه برآورده می شود :
جایی که R = r I nxn , S = s I nxn , P U = (1 − s 2 )(1 − r 2 ) P X .
این به نوبه خود منجر به شکل ساده ای برای کوواریانس متقاطع و spdcf فضایی متناظر می شود: E { X ( k , l ) X ( k + یا – ∆k , l + یا – ∆l ) T } = ρ ( ∆k , ∆l ) P X ; یعنی تمام n جزء X ( k , l ) دارای همبستگی بین شبکه ای (مکانی) مشترک از طریق spdcf ρ ( Δk, ∆l ) مشترک (اسکالری) هستند.) = s ∆k r ∆l = e -∆kδ y / T y e -∆lδ x / T x
توجه داشته باشید که معادله (10) یک ماتریس کوواریانس کامل nxn P X را اجازه می دهد ، به عنوان مثال ، می تواند همبستگی های درون مولفه ای غیر صفر بین اجزای X ( k ، l ) وجود داشته باشد. برای مثال، فرض کنید n = 3 و X T = [ x y z ] از اجزای خطای x ، y و z تشکیل شده است. علاوه بر این، در یک مکان نقطه شبکه دلخواه ( k , l ) مولفه z- خطا 0.10+ با y همبستگی دارد.– مؤلفه خطا و همان x – مؤلفه خطا 0.60- با مؤلفه z -خطا همبستگی دارد . البته، همه n -choose-2 (مقدار 3 برای مورد n = 3) ترکیبات همبستگی بین اجزای خطا باید با یک P X قطعی متقارن و مثبت مطابقت داشته باشد .
ماتریس کوواریانس نقطه چند شبکه ای
برای مورد خاص همبستگی فضایی مشترک، ماتریس کوواریانس نقطه چندشبکه ای متناظر mn × mn برای مجموعه ای از X ( k , l ) در m نقاط شبکه دلخواه ( k , l ) یک نمایش مناسب و معتبر دارد:
جایی که Λ یک بردار mn × 1 است به طوری که و X i = X ( k i , l i ), i = 1,…, m با لیست مرتب شده ای از مکان های نقطه شبکه مطابقت دارد . n × n اصطلاح کوواریانس متقاطع ρ ( Δy ij , ∆x ij ) P X شامل هر عنصر P X ضرب در مقدار اسکالر ρ ( Δy ij , ∆x ij ) است. i، j = 1،…، m .
6.2. زیرمورد کوواریانس قطری
یکی دیگر از موارد خاص، اما کاربردی، معادله (9) زمانی است که P X مشخص شده یک ماتریس مورب باشد. این اجازه می دهد تا برای هر مقدار 0 < s i < 1 و 0 < r i < 1، به عنوان مثال ، همبستگی های فضایی مختلف مشخص برای هر یک از دو جهت برای هر یک از n جزء خطا. علاوه بر این، البته، این اجازه می دهد تا واریانس های مختلف مشخص شده در امتداد عناصر مورب P X . همچنین، محدودیت PU همیشه برآورده می شود . توجه داشته باشید که این حالت خاص به سادگی معادل حالت اسکالر برای هر یک از n استاجزا به طور مستقل اعمال می شوند.
سیستم معادلات حاصل با معادله (9) یکسان است با این تفاوت که ماتریس های مورب زیر را داریم:
جایی که
توجه داشته باشید که هر جزء از X ( k ، l ) تابع همبستگی فضایی خود را با ثابت های فاصله مشخص دارد.
6.2.1. نمونه تحقق ها
این بخش نمودارهای خطای چند متغیره را بر روی زیرمجموعه ای از یک شبکه نهایی دوبعدی ارائه می کند که با استفاده از الگوریتم ترتیبی که در بخش 6 بحث شد . خطای چند متغیره مربوط به یک بردار دو بعدی است ( n =2). ماتریس کوواریانس مربوطه مورب با یک واریانس مشترک برای دو مؤلفه خطا برای راحتی است ، یعنی . به طور مشابه، همبستگی های فضایی مربوط به یک جهت فضایی خاص برای راحتی رایج است، به عنوان مثال ، s 1 = s 2 و r 1 = r 2 . شکل 13 (مقیاس خودکار) مربوط به σ 1 = σ 2 = 10 متر و s 1 = s 2 = 0.95 و r 1 = r 2 = 0.95 است. شکل 14 (مقیاس خودکار) مربوط به σ 1 = σ 2 = 10 متر و s 1 = s 2 = 0.95 و r 1 = r 2 = 0 است. 5.
6.2.2. ماتریس کوواریانس نقطه چند شبکه ای
برای مورد خاص یک ماتریس کوواریانس مورب PX، ماتریس کوواریانس mn × mn مربوط به مجموعه ای از X ( k ، l ) در m نقاط شبکه دلخواه ( k ، l ) یک نمایش مناسب و معتبر دارد:
که در آن Λ یک بردار mn x 1 است به طوری که و X i = X ( k i , l i ), i = 1,…, m , با لیست مرتب شده ای از مکان های نقطه شبکه مطابقت دارد . همچنین، * مربوط به محصول ماتریس هادامارد (عنصر به عنصر)، ماتریس مورب nxn ، و ρ v ( Δy ij ، ∆x ij ) مربوط به تابع همبستگی فضایی مرتبط با جزء v = 1،…، m است. از X ( k ، l ).
6.3. مورد عمومی با اعمال محدودیت
با مراجعه به حالت کلی بخش 6 ، در ادامه دو مثال برای n = 2 ارائه شده است. فرض کنید که دو جزء خطا با x -error و y -error برای ویژگی مطابقت دارند. از معادله (9)، s 1 , s 2 , r 1 , r 2 می تواند هر ترکیبی از مقادیر را داشته باشد به طوری که هر کدام در بازه مثبت (0,1) و PU ، تابعی از P X و s مورد نظر باشد . 1 ، s 2 ، r 1 ، r 2، یک ماتریس قطعی متقارن و مثبت است.
شکل 13. تحقق خطاهای چند متغیره دو بعدی در یک شبکه دو بعدی: همبستگی فضایی بالا در جهت k یا y شبکه و همبستگی فضایی بالا در جهت l یا x شبکه.
زیرمورد 1: فرض کنید s 1 = s 2 = s و r 1 = r 2 = r , برای محدود کردن ترکیبات ممکن. از این رو،
که همیشه برای هر s و r قطعی مثبت است.
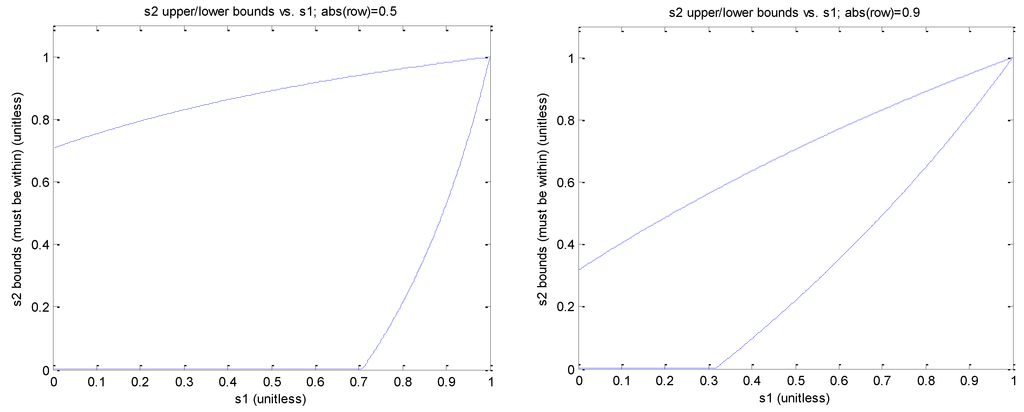
حالت فرعی 2: فرض کنید s 1 = r 1 و s 2 = r 2 .
که مثبت است قطعی اگر
قسمت سمت چپ شکل 15 کرانهای بالا و پایین را برای s 2 با توجه به مقدار مورد نظر s 1 ترسیم می کند و با فرض اینکه | ρ | = 0.5; سمت راست با فرض اینکه | ρ | = 0.9.
شکل 14. تحقق خطاهای چند متغیره دو بعدی در یک شبکه دو بعدی: همبستگی فضایی بالا در جهت k یا y شبکه و همبستگی فضایی پایین در جهت l یا x شبکه.
شکل 15. کاهش جریان محدودیت ها به مرزهای همبستگی فضایی.
همانطور که از مطالب بالا مشاهده می شود، هر چه قدر مطلق همبستگی ρ بین مولفه های خطای x و y بزرگتر باشد، s 2 = r 2 باید به s 1 = r 1 نزدیکتر باشد.
توجه داشته باشید که هر ماتریس کوواریانس نقطه ای چندشبکه ای برای این حالت کلی باید “ترم به ترم” با استفاده از آمارهای پیشینی ارائه شده در معادله (9) جمع آوری شود، به عنوان مثال ، هیچ فرم عملکردی مناسبی برای کوواریانس های متقابل وجود ندارد. ماتریس کوواریانس نقطهای چند شبکهای شبیه به مواردی که برای مورد خاص همبستگی فضایی مشترک بین اجزای X ( k ، l ) و مورد خاص یک ماتریس کوواریانس مورب PX ارائه شده است، ارائه شده است.
7. گسترش FSS به یک میدان تصادفی 2 بعدی غیر همگن
این بخش از مقاله FSS یک میدان تصادفی دوبعدی گاوسی همگن اسکالر را به یک میدان تصادفی گاوسی غیرهمگن اسکالر گسترش میدهد. به طور خاص، مقادیر مشخص شده برای σz ، s ، و r (پارامترهای واریانس و همبستگی فضایی) مربوط به z ( k ، l ) به طور صریح یا ضمنی تابعی از محل شبکه ( k ، l ) هستند. هیچ “راه درستی” برای انجام پسوند وجود ندارد.
دو روش کلی در زیر ارائه شده است که هر کدام عملی اما با ویژگیهای متفاوت در رابطه با شکل عدم همگنی نشان داده شده است. هر روش همچنین می تواند یک ماتریس کوواریانس نقطه چند شبکه ای متناظر را محاسبه کند، که برای بسیاری از کاربردها همانطور که قبلاً در بخش 3 بحث شد ضروری است. برای یک روش، این ماتریس کوواریانس دقیق و برای روش دیگر، تقریبی است. بهترین روش، زمانی که هم ویژگیهای غیر همگن و هم تقریبهای ماتریس کوواریانس نقطه چند شبکهای ممکن در نظر گرفته شوند، وابسته به کاربرد است. (روشهای ارائهشده در زیر را میتوان به شیوهای ساده برای ایجاد میدانهای تصادفی دوبعدی گاوسی غیرهمگن توسعه داد.)
7.1. روش 1: ترکیب محدب
معادله تولید شبکه اصلی و الگوریتم ترتیبی متناظر برای خطاهای اسکالر ( بخش 2.2 و بخش 2.3 ) به سادگی در زمانهای مختلف اعمال میشود ، یا بهطور متوالی با نتایج ذخیرهشده موقت یا بهطور موازی به منظور صرفهجویی در ذخیرهسازی. (البته، اندازه شبکه و فاصله هر بار ثابت می ماند.) تعداد دفعات معمولاً دو است، یعنی n = 2. هر کدام از مجموعه متفاوتی از σ z ، s و r استفاده می کنند. بنابراین، پس از انجام موارد فوق، n شبکه وجود دارد که هر یک همگن و مطابق با σ z , s هستند.و r برای استفاده با آن شبکه خاص مشخص شده است. هر شبکه با شبکه های دیگر همبستگی ندارد.
n شبکه z ( k ، l )، که z i ( k ، l ) برای i = 1،…، n مشخص شده است، سپس بر اساس یک ترکیب محدب در یک شبکه نهایی z ( k ، l ) ترکیب می شوند. یعنی در هر مکان ( k , l ) در شبکه p × q :
مشخصات مقادیر w i ( k , l ) که همچنین برای راحتی به عنوان wi kl نمادین می شود، می تواند به همان اندازه ساده یا به همان اندازه پیچیده باشد که در مکان های سراسر شبکه p × q باشد. با این حال، مقادیر توصیه شده آنها مطابق با موارد زیر است:
فرض کنید z ( k ، l ) منحصراً مقدار z i ( k ، l ) در سراسر ( k ، l ) مختلف در ناحیه i شبکه pxq باشد. از این رو، در این منطقه، همه wi kl = 1. علاوه بر این، اجازه دهید منطقه i–j را به عنوان یک «منطقه بافر» از منطقه i به منطقه j تعریف کنیم. در این ناحیه بافر، wi kl به صورت خطی از 1-0 مربوط به ( k , l) متفاوت است.) به ترتیب در ابتدا تا انتهای منطقه بافر. علاوه بر این، البته، wj kl = 1 – wi kl در سراسر منطقه i–j . در نهایت، wi kl = 0 برای همه مکانها ( k ، l ) در منطقه j . شکل 16 را به عنوان مثال برای n = 2 ببینید.
توجه داشته باشید که عرض منطقه بافر منطقه i-j باید حداقل دو برابر حداکثر ثابت فاصله مکانی مربوط به z i ( k ، l ) و zj ( k ، l ) باشد ، که در واحد شبکه بیان می شود. این امر همبستگی فضایی منطقی را در سراسر منطقه بافر تضمین می کند. اگر منطقه بافری وجود نداشت، همبستگی فضایی بین دو نقطه، یکی در هر نقطه در منطقه i و دیگری در هر نقطه در منطقه j ، 0 خواهد بود، یعنی یک تغییر ناگهانی ناخواسته در سراسر مرز دو منطقه وجود خواهد داشت.
شکل 16. مثالی از چیدمان منطقه بر روی یک شبکه p × q .
7.1.1. ماتریس کوواریانس نقطه چند شبکه ای
فرض کنید که m اسکالرهای مختلف z ( k , l ) در شبکه (نهایی) در رابطه با ماتریس کوواریانس نقطه چند شبکه ای متناظر مورد توجه هستند. هر یک از این z ( k ، l ) مربوط به مکان منحصر به فرد خود ( k ، l ) در شبکه است، و به شکل شناخته شده ای به ترتیب برای j = 1،…، m مرتب شده و در یک بردار mx 1 قرار می گیرند. Z ، که در آن Z T = [ z 1 … z m]. چنین بردار را میتوان برای مکانهای مرتب شده مشابه برای هر یک از تحققهای مختلف بهعنوان Z i ، = 1،…، n تعریف کرد. بنابراین، بر اساس رابطه (17) داریم:
که در آن W i یک ماتریس مورب mxm برای i = 1،…، n با مقادیر مناسب قطر پایین آن است.
به عنوان مثال، اگر اولین جزء Z با محل شبکه ( k , l ) = (10,20) مطابقت داشته باشد، اولین مؤلفه مورب W i برابر است.
اجازه دهید ماتریس کوواریانس نقطه چندشبکه ای متناظر mxm را برای Z i به صورت P i نشان دهیم . (به بخش 3 برای نحوه محاسبه این ماتریس با توجه به σ z ، s و r مربوطه مراجعه کنید .) ماتریس کوواریانس نقطه چند شبکه ای mxm برای Z به صورت زیر محاسبه می شود:
یکی از ویژگی های خوب روش 1 این است که نمایش فوق برای ماتریس کوواریانس نقطه چند شبکه ای P دقیق است. P نیز با موارد زیر مطابقت دارد:
که در آن Z یک بردار mx 1 است به طوری که Z T = [ z 1 … z m ] و z i = z ( k i , l i ), i = 1,…, m با لیست مرتب شده مطابقت دارد m مکان های نقطه شبکه. ρj 1 j 2 مربوط به همبستگی صریح بین دو نقطه است. ورودی های ماتریس “_” نشان دهنده تقارن است.
7.1.2. آمارهای معمولی
آمار پیشینی برای یک نقطه و یک جفت نقطه در شبکه z نهایی ( k ، l ) به آسانی توسط ورودی های مناسب یک ماتریس کوواریانس نقطه چند شبکه ای که در آن دو نقطه ارجاع داده شده اند، تعیین می شود. برای راحتی، نتایج برای یک مورد معمولی به شرح زیر خلاصه می شود:
مجموعا دو ناحیه و مقادیر معمولی را برای w 1 kl در منطقه 1 ( w 1 kl = 1 ) ، در منطقه 2 ( w 1 kl = 0 ) و w 1 kl در منطقه 1-2 ( w 1 kl = ) فرض کنید 1 → 0). اجازه دهید توابع یک سیگما و همبستگی پیشینی را برای z 1 همگن ( k , l ) و z 2 ( k , l ) در سراسر شبکه تعیین کنیم.σ z 1 و ρ 1 ( Δk، ∆l )، و σ z 2 و ρ 2 ( Δk، ∆l )، به ترتیب، برای راحتی. ما آمارهای وابسته به مکان زیر را برای z ترکیبی نهایی داریم ( k ، l ):
مقدار تک سیگما σ z : نقطه ای در منطقه 1, σ z 1 ; یک نقطه در منطقه 2, σ z 2 ; یک نقطه در منطقه 1-2، .
مقدار تابع همبستگی فضایی ρ ( Δk، ∆l ) برای یک جفت نقطه: هر دو در منطقه 1 ، ρ1 ( Δk، ∆l ). هر دو در منطقه 2، ρ 2 ( Δk، ∆l )، یکی در منطقه 1 و یکی در منطقه 2، 0. یکی در منطقه 1 و دیگری در منطقه 1-2، و غیره.
7.1.3. نمونه تحقق ها
تحقق ناهمگن زیر دو تحقق همگن را با { r 1 = s 1 = 0.9، σ z1 = 10 m} و { r 2 = s 2 = 0.9، σ z ترکیب می کند.به ترتیب 2 = 30 متر}. منطقه 1 از بخش نمایش داده شده از شبکه نهایی شامل k = 1-10، منطقه 1-2 k = 11-30، و منطقه 2 k = 31-60 است. (برای هر منطقه، l = 1-60 مربوطه.) استفاده از طرح انتساب معمولی برای مقادیر w 1 kl (و w 2 kl = 1 – w 1 kl ) استفاده شد. شکل 17 زیر نتایج را نشان می دهد.
شکل 17. انتقال آرام از منطقه 1 به منطقه 2 ، که هر کدام دارای آمارهای پیشینی مشخص شده خود هستند .
همان آزمایش انجام شد (اما تحقق متفاوت) با این تفاوت که هیچ منطقه 1-2 وجود نداشت ، یعنی یک طرح غیر معمولی. شکل 18 در زیر نتایج را نشان می دهد.
7.2. روش 2: تغییرات عملکردی یک آمار قبلی
با روش دوم، معادله تولید شبکه اصلی و الگوریتم ترتیبی مربوط به خطاهای اسکالر ( بخش 2.2 و بخش 2.3 ) تنها یک بار اجرا می شود، اما به شرح زیر اصلاح می شود:
که در آن u ( k ، l ) یک نمونه تصادفی از نویز سفید گاوسی توزیع شده N است (0، σu (k ، l ) ) ، و در کجا . همچنین s ( k , l ) = e −δ y / T y ( k , l ) , و r ( k , l ) = e −δ x / T x ( k,l ) , یعنی ثابت های فاصله مکانی را می توان تابعی از ( k , l ) نیز همینطور.
شکل 18. انتقال ناگهانی بین منطقه 1 و منطقه 2 ، که هر کدام دارای آمارهای پیشینی مشخص شده خود هستند .
همانطور که در بالا نشان داده شد، مقادیر σ z ، s ، و r ، و از این رو σu ، تابعی از محل شبکه ( k ، l ) هستند. علاوه بر این، برای روش 2، آنها با درون یابی دوخطی چنین مقادیر مشخص شده روی یک شبکه با چگالی کمتر که روی شبکه خطاهایی که باید ایجاد می شود، تعیین می شوند. به عنوان مثال، اگر شبکه 2 بعدی pxq از خطاهایی که باید ایجاد شود 900 × 1000 باشد، شبکه برای درونیابی ممکن است یک شبکه پارامتری 4×3 با فاصله مساوی روی شبکه متراکم تر باشد. هر یک از 12 نقطه شبکه پارامتر مربوطه حاوی مقادیر مشخص شده برای σ z ، s و r است.برای منطقه محلی مربوطه در اطراف نقطه شبکه پارامتر. توجه داشته باشید که σ u تابعی از مقادیر درونیابی σ z ، s و r است. بنابراین، در معادله (21) برای هر مکان شبکه ( k ، l ) مجدداً محاسبه می شود. برای نمایش گرافیکی شبکه پارامتر درونیابی، شکل 19 را ببینید . هر مکان شبکه پارامتر درون یابی شامل مجموعه ای منحصربفرد از مقادیر برای σ z ، s و r است.
همچنین، فاصله بین نقاط شبکه پارامتر درون یابی باید حداقل دو برابر حداکثر ثابت های فاصله مکانی مربوط به آن نقطه شبکه و سایر نقاط شبکه پارامتر درون یابی بلافاصله در اطراف آن باشد که در واحد شبکه بیان می شود. این تضمین می کند که هم تقریب مورد نظر و هم تقریب محاسبه شده از آمار پیشینی مربوط به z ( k ، l ) در سراسر شبکه متراکم تقریباً برآورده شده و به طور معقولی قابل اعتماد هستند (به ترتیب به بخش 7.2.2 مراجعه کنید ). (این همچنین فرض می کند که بافر مناسب نسبت به شبکه “نهایی” نیز گنجانده شده است – بخش 2.3.2 را ببینید )
پس از تعریف مناسب، معادله (21) سپس از طریق یک همتای مستقیم برای الگوریتم شرح داده شده در بخش 2.3 پیاده سازی می شود . دومی به سادگی از مقادیر σ u ، s و r مناسب استفاده می کند که با مکان ( k ، l ) تغییر می کند.
شکل 19. نمونه ای از شبکه پارامتر درون یابی.
7.2.1. نمونه تحقق ها
مثالهای زیر مربوط به یک شبکه درونیابی 7 × 7 پارامتری است که یک شبکه دو بعدی 90 × 90 را پوشانده است. نتایج مربوط به بخش نمایش داده شده 60 × 60 از شبکه نهایی ارائه شده است.
همه 49 مجموعه از پارامترهای { s,r,σ z } یکسان بودند به جز چهار مجموعه مربوط به یک مستطیل داخلی در نزدیکی مرکز شبکه نهایی. اجازه دهید 45 مجموعه رایج را به عنوان گروه 1 و چهار مجموعه رایج دیگر را به عنوان گروه 2 نامگذاری کنیم. در شکل 20 زیر، مجموعه گروه 1 حاوی مقادیر σ z = 10 m، s = r = 0.9 است. مجموعه های گروه 2 حاوی مقادیر σ z = 50 m، s = r = 0.9 هستند.
در شکل 21 زیر، مجموعه های گروه 1 حاوی σ z = 10 m، s = r = 0.1 هستند. مجموعه های گروه 2 شامل σ z = 50 m، r = 0.95 است
7.2.2. آمار و ماتریس کوواریانس نقطه چند شبکه ای
آمار پیشینی متناظر دیگر برای این روش ساده نیست، اما می توان آن را تقریبی کرد. به طور خاص، σ z مربوط به یک مکان خاص ( k ، l ) مقدار درونیابی دوخطی مربوطه است. تابع همبستگی فضایی مربوط به m مکانهای مختلف ( k ، l ) میانگین m توابع همبستگی فضایی است که هر کدام مربوط به مقادیر درونیابی دوخطی برای و r برای آن مکان است. البته این آمار منعکس کننده عدم همگنی است، یعنی تابعی از ( k ,ل ) مکان های مورد علاقه. تقریب mxm مربوطه برای ماتریس کوواریانس نقطه چند شبکه ای مربوط به خطاهای اسکالر در m مکان های شبکه مختلف به صورت زیر نمایش داده می شود:
که در آن Z یک بردار mx 1 است به طوری که Z T = [ z 1 … z m ] و z i = z ( k i , l i ), i = 1,…, m با یک لیست مرتب مطابقت دارد از مکان های نقطه شبکه m .
شکل 20. تحقق اسکالر غیر همگن – واریانس های مختلف.
شکل 21. تحقق اسکالر غیر همگن – واریانس های مختلف و همبستگی های فضایی.
و توابع همبستگی فضایی فردی با مقادیر درون یابی مربوطه آنها برای s و r تعریف می شوند.
از آنجا که میانگین مجموعه ای از توابع همبستگی قطعی کاملاً مثبت (spdcfs) خود یک spdcf است، ماتریس کوواریانس بالا بدون توجه به این واقعیت که σ z i مختلف می توانند در مقدار متفاوت باشند تضمین می شود (مرجع [ 7 ]).
توجه داشته باشید که اگر m نقاط شبکه شامل زیرگروههایی از نقاط با فاصله زیاد باشد، به طوری که خطای اسکالر در هر نقطه شبکه در یک زیرگروه همبستگی (تقریبی) کم (به عنوان مثال، کمتر از 0.1) با خطای اسکالر در هر نقطه شبکه در هر زیرگروه دیگر داشته باشد. در زیر گروه، یک نمایش وفاداری بالاتر برای ماتریس کوواریانس نقطه چند شبکه ای به شرح زیر بدست می آید: از نمایش در رابطه (22) برای محاسبه یک “ماتریس کوواریانس نقطه چند شبکه ای” برای هر زیر گروه از نقاط شبکه استفاده کنید و سپس آنها را با قرار دادن (به ترتیب) هر ماتریس کوواریانس نقطه چند شبکه ای در پایین مورب بلوک با مقادیر صفر برای همه بلوک های خارج از مورب (کوواریانس متقاطع) در ماتریس کوواریانس نقطه چند شبکه ای (نهایی) ترکیب کنید.
در نهایت، برای ایجاد یک ماتریس کوواریانس نقطه ای چندشبکه ای برای یک X چند متغیره غیرهمگن X ( k , l ) به جای ماتریس اسکالر غیرهمگن z ( k , l )، همان روش کلی ارائه شده در این بخش را می توان گسترش داد. به روشی ساده با استفاده از روش های شرح داده شده در مراجع [ 6 ، 7 ].
8. خلاصه و نتیجه گیری
روشهای عملی برای تولید متوالی میدانهای تصادفی دو بعدی ارائه شد و ماتریسهای کوواریانس چند متغیره مربوط به آنها به دست آمد. روشهای مربوطه بر اساس FSS بود که با شبیهسازی گاوسی متوالی و سایر رویکردها نیز مقایسه شد. اگرچه کمتر عمومیت دارد، FSS از نظر سرعت و سادگی به وضوح برتر است، در درجه اول به دلیل همبستگی فضایی نمایی قابل تفکیک و تولید منظم ساده در یک شبکه با فاصله یکنواخت. روشهای FSS ارائهشده در این مقاله برای ارزیابی عملکرد و تنظیم برنامههای مکانی در یک محیط شبیهسازی، و همچنین نمایش زمان واقعی تأثیر خطاها بر برنامهها توسط خود برنامهها قابل استفاده هستند.








 y e -∆kδ x / T x ،عنوان مثال، ماتریس کوواریانس نقطه چند شبکه ای برابر است:
y e -∆kδ x / T x ،عنوان مثال، ماتریس کوواریانس نقطه چند شبکه ای برابر است:




 ماتریس کوواریانس مربوط به میدان تصادفی در n نقطه مختلف در شبکه. Matlab از تکنیک تجزیه Schur برای محاسبه SQRTM برای یک ماتریس مربع کلی استفاده می کند که می تواند برای ماتریس های متقارن و واقعی سرعت بیشتری داشته باشد.
ماتریس کوواریانس مربوط به میدان تصادفی در n نقطه مختلف در شبکه. Matlab از تکنیک تجزیه Schur برای محاسبه SQRTM برای یک ماتریس مربع کلی استفاده می کند که می تواند برای ماتریس های متقارن و واقعی سرعت بیشتری داشته باشد.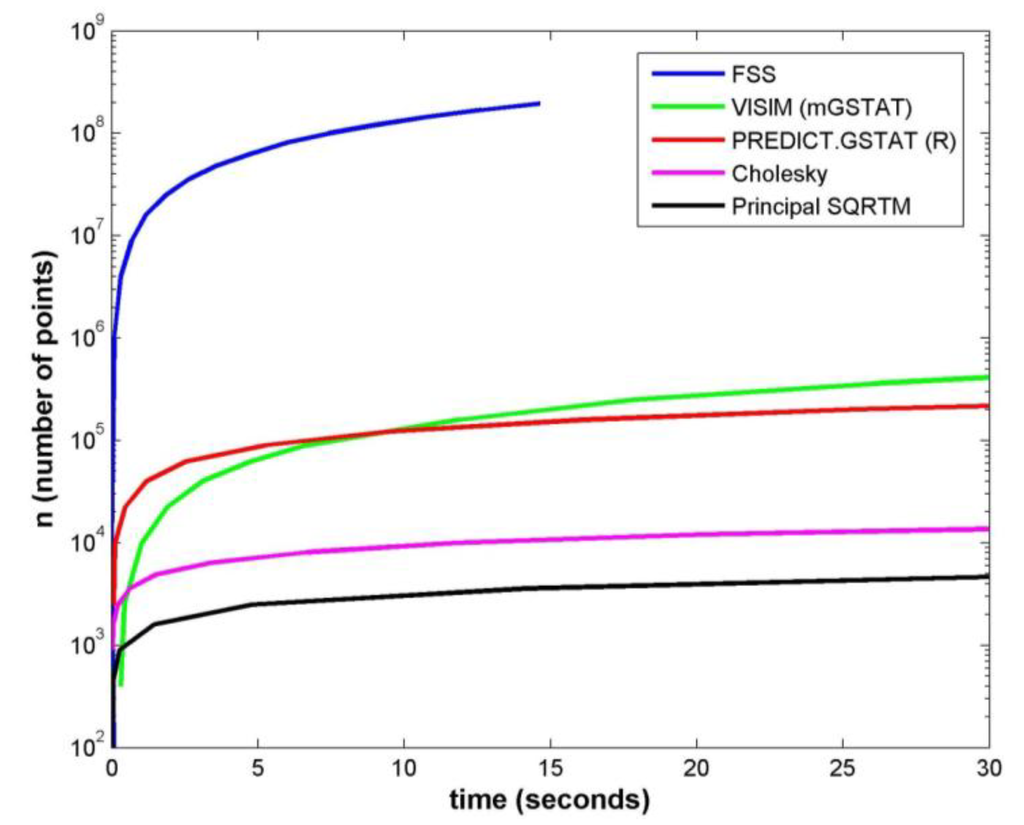




 و i , j با سطر ماتریس i , ستون j مطابقت دارد .
و i , j با سطر ماتریس i , ستون j مطابقت دارد .
 S جایگزین s ، R جایگزین r و X نیز جایگزین z می شود.
S جایگزین s ، R جایگزین r و X نیز جایگزین z می شود.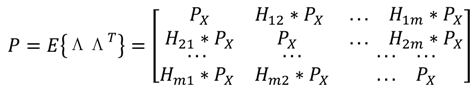
 i، j = 1،…، m .
i، j = 1،…، m .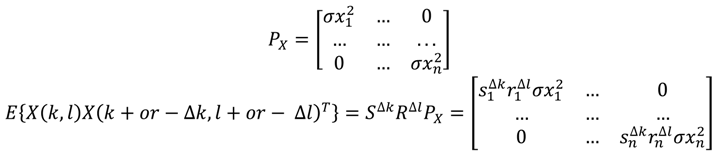

 (مقیاس خودکار) مربوط به σ 1 = σ 2 = 10 متر و s 1 = s 2 = 0.95 و r 1 = r 2 = 0.95 است. شکل 14 (مقیاس خودکار) مربوط به σ 1 = σ 2 = 10 متر و s 1 = s 2 = 0.95 و r 1 = r 2 = 0 است. 5.
(مقیاس خودکار) مربوط به σ 1 = σ 2 = 10 متر و s 1 = s 2 = 0.95 و r 1 = r 2 = 0.95 است. شکل 14 (مقیاس خودکار) مربوط به σ 1 = σ 2 = 10 متر و s 1 = s 2 = 0.95 و r 1 = r 2 = 0 است. 5.
 k ، l ).
k ، l ).


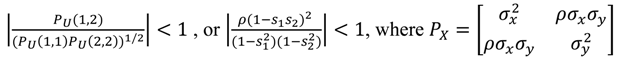






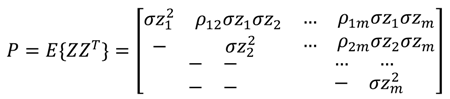



 k , l ) نیز همینطور.
k , l ) نیز همینطور.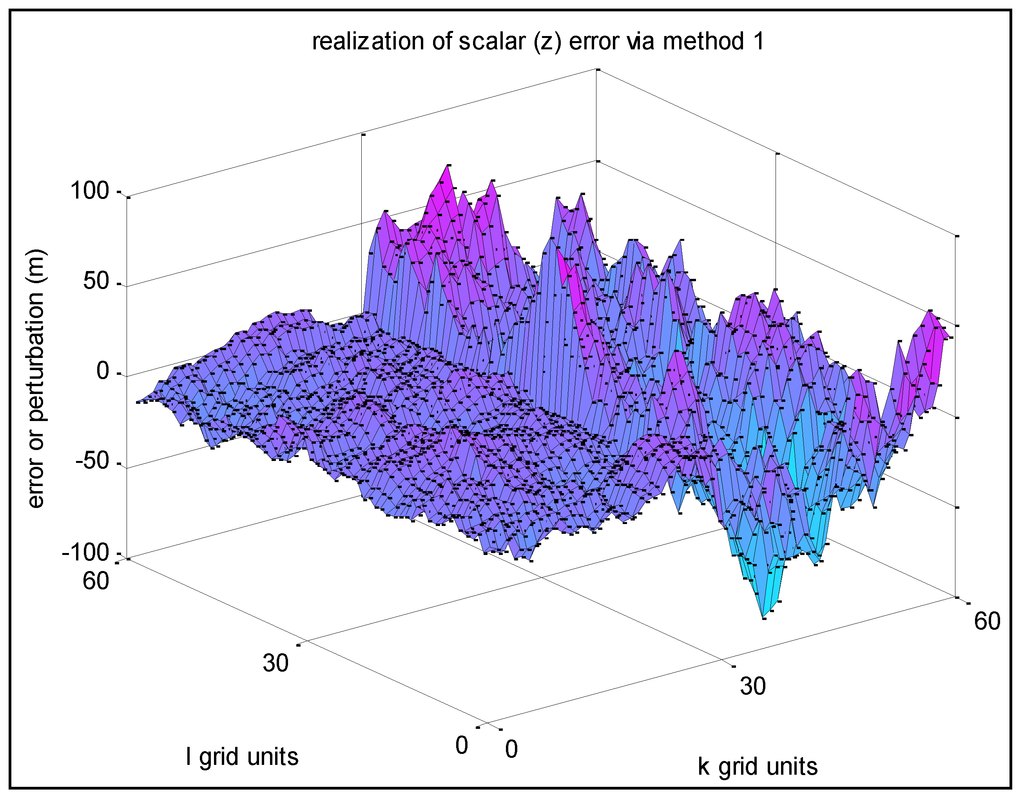

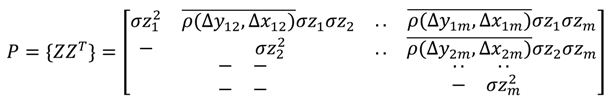
 و توابع همبستگی فضایی فردی با مقادیر درون یابی مربوطه آنها برای s و r تعریف می شوند.
و توابع همبستگی فضایی فردی با مقادیر درون یابی مربوطه آنها برای s و r تعریف می شوند.

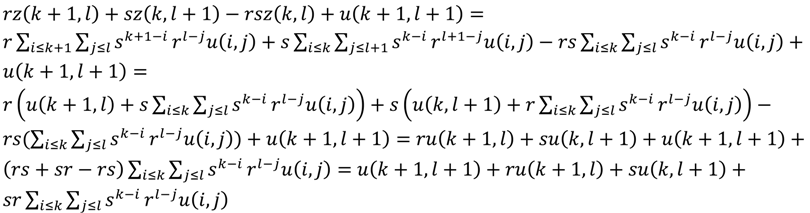
 یا به طور کلی تر، E { z ( k ، l ) z ( k + یا – ∆k ، l + یا – ∆l )} = .
یا به طور کلی تر، E { z ( k ، l ) z ( k + یا – ∆k ، l + یا – ∆l )} = . 
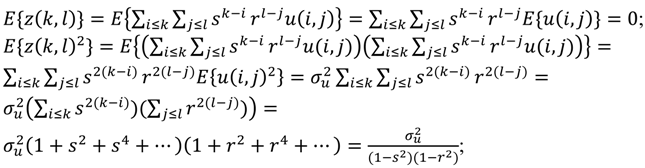

 a = r 2 = e – 2δ x / T x < 1 در بالا.
a = r 2 = e – 2δ x / T x < 1 در بالا.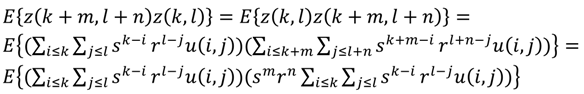

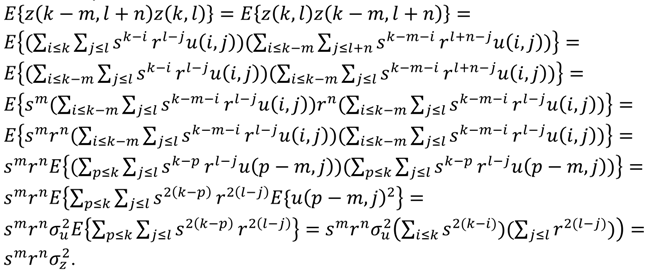





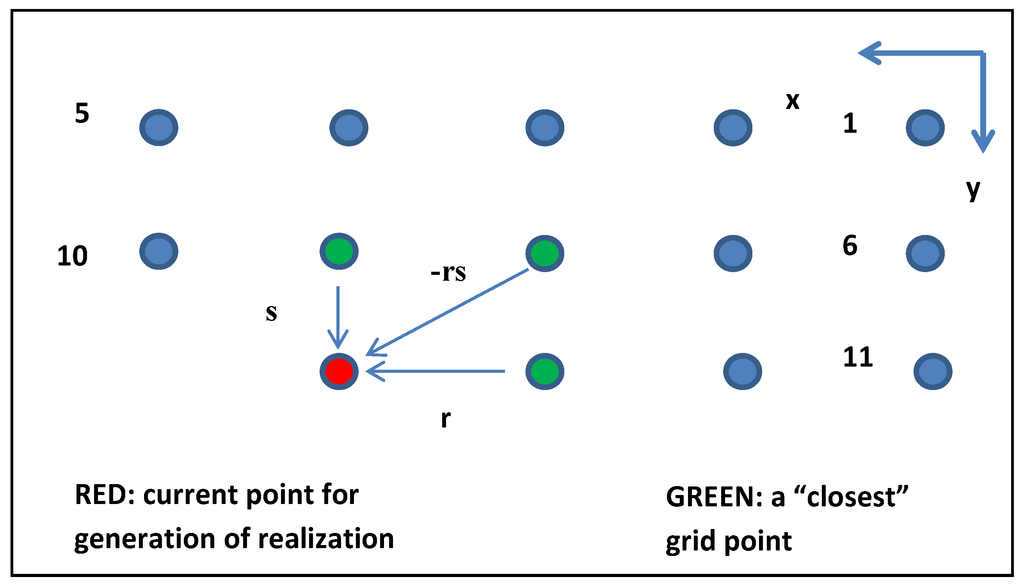

 = 1.31. (همچنین با استفاده از نماد شناسی معادله (3)، X 2 با z ( k + 1، l + 1) و u به u ( k + 1، l + 1) مطابقت دارد.)
= 1.31. (همچنین با استفاده از نماد شناسی معادله (3)، X 2 با z ( k + 1، l + 1) و u به u ( k + 1، l + 1) مطابقت دارد.)
 = 1.31، که برابر با σ u است. این معادلها و استفاده از تنها نزدیکترین سه نقطه شبکه به دلیل همبستگی فضایی نمایی قابل تفکیک و شبکه منظم تحققهایی که بهصورت ساده و منظم تولید میشوند، فعال شدند. (بنابراین، برای مثال، اگر نقطه شبکه شماره 8 به + 0.5 واحد شبکه در جهت y منتقل شود، به جای 3 وزن اسکالر غیر صفر، 7 وجود خواهد داشت.)
= 1.31، که برابر با σ u است. این معادلها و استفاده از تنها نزدیکترین سه نقطه شبکه به دلیل همبستگی فضایی نمایی قابل تفکیک و شبکه منظم تحققهایی که بهصورت ساده و منظم تولید میشوند، فعال شدند. (بنابراین، برای مثال، اگر نقطه شبکه شماره 8 به + 0.5 واحد شبکه در جهت y منتقل شود، به جای 3 وزن اسکالر غیر صفر، 7 وجود خواهد داشت.)






بدون نظر