1. معرفی
اغلب پدیده های جغرافیایی در مقیاس های مختلف در حوزه زمانی- مکانی ویژگی های متفاوتی دارند. تأثیرات مختلف ناشی از عوامل مختلف متعددی که به طور همزمان در مقیاسها عمل میکنند، دادههای مربوط به پدیدهها را به ترکیبی از سیگنالهای چند مقیاسی هدایت میکنند. ترکیبی از ویژگی های چند مقیاسی بر ویژگی های داده در هر دو حوزه مکانی و زمانی تأثیر می گذارد. در حوزه فضایی، ویژگیهای یک پدیده معین باید با محدوده مکانی یا وضوح مشخصی برای پشتیبانی از تحلیل پیچیده سنجش از راه دور از جمله استخراج شی، تقسیمبندی تصویر، تشخیص تغییر، ردیابی شی، و تحلیل زمینآماری و غیره نشان داده شود . 2]. در حوزه زمانی، ویژگیهای چند مقیاسی دادهها بهعنوان سیگنال دورهای یا شبه تناوبی در فرکانسهایی از ساعت تا چند دهه عمل میکنند. اثرات ویژگی های چند مقیاسی توجه زیادی را به خود جلب کرده است، در بسیاری از رشته های مختلف بحث شده است، و غیره [ 3 ، 4 ، 5 ، 6 ].
داده های سنجش از دور به سرعت به طور مداوم انباشته شده اند. توالیهای سنجش از دور طولانیمدت بیشتری (به عنوان مثال، تصاویر ماهوارهای و هوایی، SAR، و غیره [ 7 ])، که از بازه زمانی بیش از چندین دهه عبور میکنند، ثبت شده و در زمینههای مختلف استفاده میشوند. این مشاهدات داده های بلندمدت اطلاعات ارزشمندی را برای افشای دقیق تکامل فرآیندهای جغرافیایی فراهم می کند [ 8 ]. همراه با کاربرد گسترده دادههای سنجش از دور چند زمانی در بسیاری از زمینههای مختلف، محققان انواع مختلفی از روشهای تحلیل پیشرفته را برای استخراج ویژگی، بخشبندی و غیره پیشنهاد کردهاند [ 9 ].
قبلاً تکنیک هایی برای حل این مشکلات پیشنهاد شده است. مدلسازی دادههای چند بعدی و پایگاههای داده [ 10 ، 11 ] و پایگاههای داده آرایه (به عنوان مثال، rasdaman [ 12 ]، SciDB [ 13 ]) تا حد زیادی عملکرد ذخیرهسازی و پرسوجو از دادههای مکانی-زمانی عظیم چند بعدی را بهبود بخشیدهاند. MOLAP (فرآیند تحلیل خطی چند بعدی)، که معمولاً در انبار داده استفاده می شود، به سرعت برای پرس و جوهای داده های چند بعدی و تجمیع بهبود می یابد [ 14 ]. فنآوریهایی مانند موجکها و خوشهبندی سلسله مراتبی دادهها به MOLAP معرفی میشوند تا تا حدی از محاسبات پشتیبانی کنند [ 15 ، 16]]. با این حال، این تجزیه و تحلیل ها مستلزم دسترسی مستقیم به جزئیات ترین داده ها هستند، زیرا هیچ دانش قبلی برای پرس و جو وجود ندارد. رویکردهای یکپارچه مکانی-زمانی (به عنوان مثال، STIM [ 17 ]، رویکردهای جبر/تنسور کلیفورد [ 18 ، 19 ]) نیز برای تحلیل یکپارچه چنین حجم عظیمی از دادههای مکانی-زمانی پیشنهاد شدهاند. با این حال، این رویکردها هنوز در مراحل اولیه هستند و برای استفاده مستقیم در محیط عملیاتی بسیار پیچیده هستند.
علیرغم پیشرفتهای بزرگی که در توسعه روشهای تحلیل سنجش از دور چند زمانی به دست آمده است، دو مشکل حیاتی هنوز وجود دارد: (1) بیشتر این روشها ابعاد مکانی و زمانی را به طور جداگانه بررسی میکنند. چندین رویکرد می توانند تجزیه و تحلیل چند مقیاسی را در حوزه مکانی یا زمانی انجام دهند (به عنوان مثال، EMD، موجک، و هموارسازی هسته تطبیقی موازی) [ 20 ، 21 ، 22 ]. تعداد کمی از روش ها می توانند از تجزیه و تحلیل دامنه مکانی-زمانی به روش یکپارچه مکانی-زمانی پشتیبانی کنند [ 23 ، 24]. با جداسازی سیگنال مکانی و زمانی در تجزیه و تحلیل داده ها، داده های مکانی-زمانی را فقط می توان به صورت مکانی یا زمانی تجزیه و تحلیل کرد، که منجر به از دست رفتن اطلاعات، ناسازگاری الگوها و مشکلات همگام سازی می شود. (2) به ندرت روش ها اطلاعات چند مقیاسی را در طول تجزیه و تحلیل داده های اکتشافی یکپارچه می کنند. اگرچه چندین روش تجزیه و تحلیل داده های اکتشافی وجود دارد که به خوبی می توانند ویژگی های خاصی را آشکار کنند (به عنوان مثال، توزیع های ارزش، ویژگی های طیف، و تغییرات ویژگی)، توسعه یافته اند، درصد زیادی از این روش ها تنها برای داده های کلی به جای ویژگی های هر مقیاس اعمال می شوند. . آشکار کردن ویژگیهای چند مقیاسی از دیدگاههای مختلف و انجام استخراج ویژگیهای مکانی-زمانی چند مقیاسی اکتشافی هنوز پیچیده است.
خوشهبندی ویژگی، یکی از معمولترین و متداولترین روشهای تحلیل اکتشافی برای دادههای سنجش از راه دور چند زمانی، تا حد زیادی توسط دو مشکل ذکر شده در بالا محدود شده است. ادغام اطلاعات چند مقیاسی در خوشهبندی ویژگی میتواند اطلاعات غنی در مورد فرآیند مکانی-زمانی تولید کند و عملکرد خوشهبندی ویژگی را برای استخراج ویژگی و بررسی فرآیند افزایش دهد. برای مثال، سیگنالهای مختلف، از جمله جریانهای اقیانوسی و جزر و مد، تغییرات فرکانس بالا (مانند نوسان مادن-ژولیان (MJO))، تغییرات بین دههای (مانند ال نینو- نوسان جنوبی (ENSO)) و غیره را میتوان از آن جدا کرد . داده های اقیانوس جهانی با توجه به تفاوت ویژگی های چند مقیاسی آنها [ 25 ، 26]. با خوشه چند مقیاسی در حوزه مکانی-زمانی، ویژگیها و فرآیندهای تکامل مکانی-زمانی سیگنالهای مختلف فوق را میتوان آشکار کرد.
یک روش خوشهبندی ویژگیهای مکانی-زمانی چند مقیاسی با عملکرد خوب باید خواستههای زیر را برآورده کند: (1) از آنجایی که اغلب فرآیندهای جغرافیایی به طور مداوم در حوزه مکانی-زمانی تغییر میکنند، تجزیه و تحلیل باید در حوزه مکانی-زمانی با در نظر گرفتن موارد زیر انجام شود. تداوم داده ها (2) خوشه بندی ویژگی باید برای اجزای مقیاس های مختلف، که دارای توزیع داده های مختلف و سطوح نویز متفاوت هستند، اعمال شود. بنابراین، خوشهبندی ویژگی بهتر است که دادهها سازگار و انعطافپذیر باشد. (3) از آنجایی که حجم داده های داده های سنجش از دور چند زمانی اصلی معمولاً زیاد است و تجزیه چند مقیاسی حجم داده ها را به میزان قابل توجهی افزایش می دهد، خوشه بندی ویژگی باید برای تحلیل عملیاتی در دنیای واقعی کارآمد باشد. برای دستیابی به تمامی الزامات فوق،
این مقاله یک رویکرد یکپارچه برای انجام خوشهبندی ویژگیهای اکتشافی چند مقیاسی مکانی-زمانی ارائه میکند. مقاله به شرح زیر سازماندهی شده است: بخش 2 ایده کلی روش پیشنهادی را ارائه می کند. بخش 3 جزئیات روش را ارائه می دهد. مطالعه موردی با داده های ارتفاع سنج ماهواره ای در بخش 4 نشان داده شده است . اثربخشی فنی و جغرافیایی روش در بخش 5 ارزیابی شده است . بحث و نتیجه گیری به ترتیب در بخش 6 و بخش 7 ارائه شده است .
2. ایده کلی
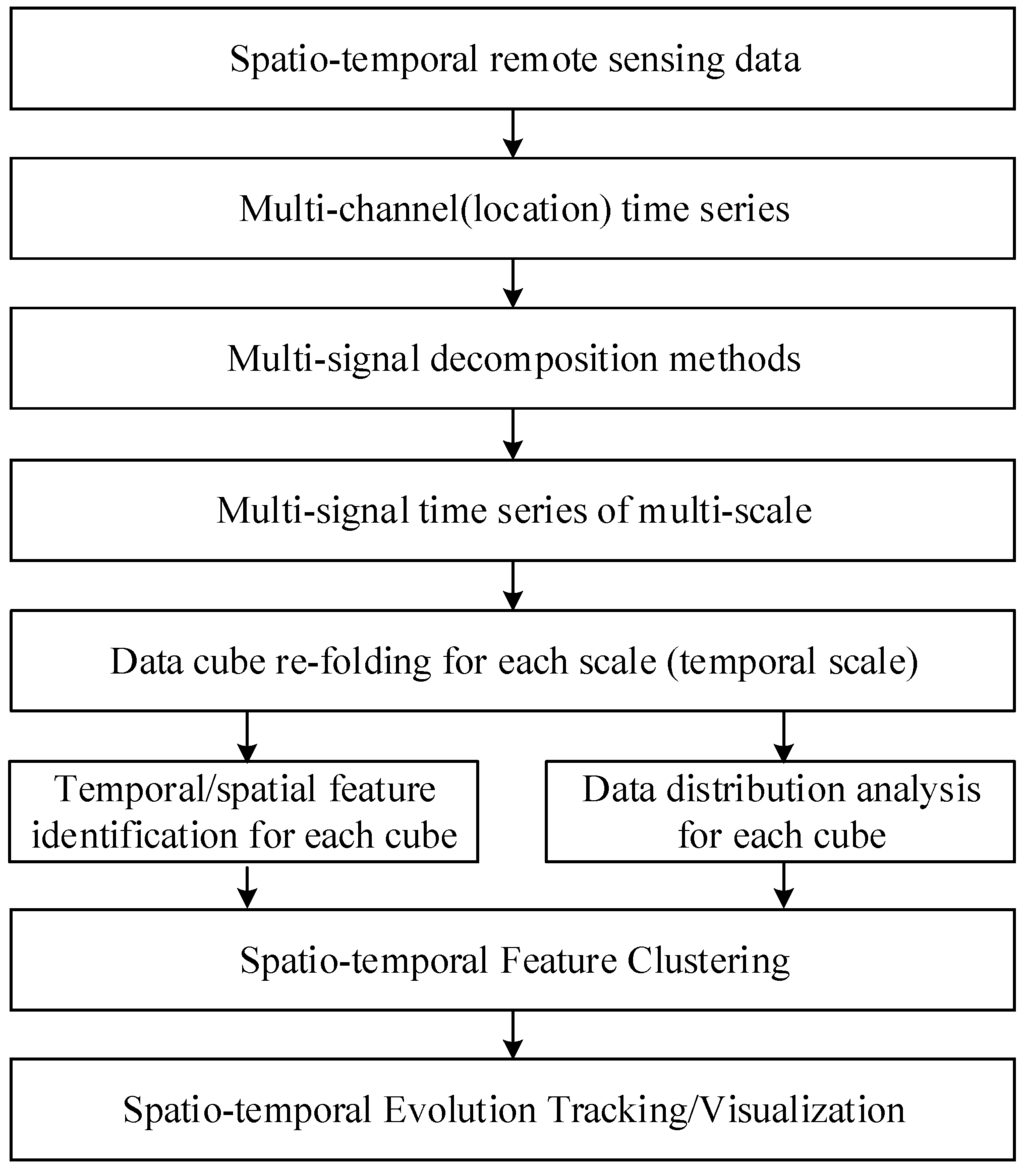
ایده کلی خوشه بندی ویژگی های مکانی-زمانی چند مقیاسی اکتشافی داده های سنجش از دور چند زمانی در شکل 1 نشان داده شده است .
از دیدگاه یکپارچه مکانی-زمانی، داده های سنجش از راه دور چند زمانی اصلی را می توان به عنوان یک مکعب داده های مکانی-زمانی یکپارچه در نظر گرفت. در این مکعب داده، هر مکان (پیکسل هایی با مختصات مکانی یکسان) نمونه ای با سری زمانی است که نوسانات زمانی را در ابعاد زمانی نشان می دهد. به دلیل عدم وجود روشهای تجزیه چند مقیاسی یکپارچه مکانی-زمانی، تجزیه چند مقیاسی مکانی-زمانی فقط در حوزه مکانی یا زمانی قابل انجام است. بنابراین، داده های مکانی-زمانی اصلی، که به عنوان یک مکعب داده های مکانی-زمانی یکپارچه در نظر گرفته می شوند، باید به صورت یک سری زمانی چند کاناله یا سری فضایی باز شوند. تحت این مفهوم، کل داده های سنجش از دور چند زمانی در یک منطقه را می توان به عنوان مجموعه ای از سری های زمانی درک کرد که هر مکان کانالی از سری های زمانی است. بنابراین، کل دادههای مکانی-زمانی را میتوان بهعنوان یک سری زمانی چند سیگنالی منفرد دید که بهطور پیوسته با نرخ نمونهگیری زمانی هماهنگ مشاهده میشود. توزیع فضایی داده ها در روابط کانال به کانال به ارث می رسد.
شکل 1. چارچوب کلی خوشه بندی ویژگی های مکانی-زمانی چند مقیاسی اکتشافی.
روش های تحلیل چندمقیاسی چند متغیره، مانند موجک چند سیگنالی، می تواند در سری های زمانی چند سیگنالی برای استخراج الگوهای تغییرات چند مقیاسی اعمال شود. تجزیه موجک چند سیگنالی الگوی تغییرات چند مقیاسی مشترک همه کانال ها را به طور همزمان با استفاده از اطلاعات کامل داده های مکانی-زمانی تخمین می زند. هم تغییرات مکانی-زمانی جهانی و هم محلی در مقیاس های زمانی- مکانی مختلف را می توان به طور همزمان استخراج کرد [ 27]. با تجزیه موجک چند سیگنالی، داده های سنجش از راه دور چند زمانی اصلی را می توان به چندین جزء چند مقیاسی تجزیه کرد. هر جزء تجزیه شده، که یک سری زمانی چند سیگنالی است که ویژگی خاصی از تغییرات مکانی-زمانی چند مقیاسی را نشان میدهد، میتواند دوباره به یک مکعب داده با همان اندازه دادههای اصلی تا شود. بنابراین، سیگنالهای مفهومی که فقط در مقیاسهای مهم خاص تأثیر میگذارند، قابل استخراج و آشکار هستند.
برای بهبود عملکرد استخراج ویژگی و فیلتر کردن عدم قطعیت ها یا شبه تغییرات احتمالی ناشی از مخلوط مقیاس یا نویز، روش های کلاسیک تجزیه و تحلیل داده های اکتشافی، مانند تجزیه و تحلیل اجزای اصلی، تجزیه و تحلیل طیف توان و هیستوگرام، می تواند برای توصیف ویژگی های مکانی/زمانی استفاده شود. (به عنوان مثال، اشکال فضایی یا شاخص های زمانی) و توزیع ارزش داده های تغییرات چند مقیاسی. این را می توان با مقایسه ویژگی های استخراج شده توسط تجزیه و تحلیل مولفه های اصلی و تجزیه و تحلیل طیف توان با شاخص های جغرافیایی یا الگوهای فضایی موجود برای آشکار کردن معانی جغرافیایی مولفه های چند مقیاسی به دست آورد. برای شناسایی ویژگیهای توزیع مکانی-زمانی پدیدههای جغرافیایی، روشهای خوشهای مانند K-Means، فازی C-Means Cluster (FCM)،و غیره.، می تواند در هیستوگرام های مکانی/زمانی برای دستیابی به خوشه بندی ویژگی های مکانی-زمانی اعمال شود. برای دستیابی به خوشهبندی تطبیقی دادهها برای هر مؤلفه چند مقیاسی تجزیهشده، شاخصهای داده، مانند آنتروپی، میتوانند برای توسعه روش انتخاب شماره خوشه بهینه تطبیقی دادهها استفاده شوند. برای بهبود عملکرد محاسباتی، می توان از هیستوگرام ها برای خوشه بندی ویژگی ها استفاده کرد. خوشه مبتنی بر هیستوگرام از اجزای تجزیه شده به بهبود ویژگی های داده ها کمک می کند که باعث تفکیک بیشتر داده ها می شود. از آنجایی که توزیعهای ارزش دادهها در سطلهای هیستوگرام با مناطق مختلف داده در حوزه مکانی-زمانی مرتبط هستند، دادههای مکانی-زمانی اصلی را میتوان با جدا کردن هیستوگرام با توزیع مقدار مربوط به مناطق مورد نظر خوشهبندی کرد. با ویژگی های خوشه ای،
3. روش ها
با توجه به چارچوب کلی، چندین روش مونتاژ شده و به طور پیوسته در یک گردش کار پردازش یکپارچه می شوند ( شکل 2)). دادههای مکانی-زمانی اصلی ابتدا بهعنوان یک سری زمانی چند سیگنالی سازماندهی میشوند، که سپس با تجزیه موجک چند سیگنالی به چندین مکعب سری ویژگی و یک مکعب نویز تجزیه میشوند. تجزیه و تحلیل تابع متعامد تجربی (EOF) و تجزیه و تحلیل طیف توان برای استخراج ویژگیهای مکانی-زمانی و فرکانس هر جزء تجزیه شده اعمال میشود. تقریب عدد صحیح، که داده ها را گسترش می دهد، برای بهبود ویژگی داده و کاهش هزینه محاسباتی استفاده می شود. با مرتب کردن مجدد داده های تقریب اعداد صحیح هر مکعب سری ویژگی به ترتیب صعودی و تقسیم آنها به چند سطل داده، می توان تقریب هیستوگرام را ساخت. سپس فازی C-Means Cluster (FCM)، با انتخاب تطبیقی اعداد خوشه، بر روی مکعب های ویژگی کشیده اعمال می شود.
3.1. سازماندهی مجدد داده های مکانی-زمانی
در ابتدا، داده های سنجش از راه دور چند زمانی را به عنوان یک مکعب داده چند بعدی یکپارچه سازماندهی می کنیم [ 28 ]. سپس باز شدن روی مکعب داده اعمال می شود تا سری زمانی چند سیگنالی را تشکیل دهد. از آنجایی که معمولاً بیش از یک مختصات در حوزه فضایی وجود دارد، مکعب داده اصلی را در مجموعهای از سریهای زمانی با هر مختصات مکانی یک سری زمانی باز میکنیم ( یعنی، بازگشایی فضایی) داده ها را بسیار ساده تر می کند. بنابراین، دادههای اصلی را بهعنوان یک مکعب زمانی-فضایی یکپارچه سازماندهی میکنیم و سپس بازگشایی مکانی را برای تشکیل سریهای زمانی چند سیگنالی اعمال میکنیم. اگرچه به نظر میرسد که فرآیند بازگشایی دادههای مکانی-زمانی اصلی در سیگنال چند کاناله، ابعاد مکانی و زمانی را از هم جدا میکند، استخراج الگو از طریق توزیع مکانی-زمانی دادهها انجام میشود و مشکلات همگامسازی دادهها به طور طبیعی در طی حل میشوند. تجزیه و تحلیل.
3.2. تجزیه موجک چند سیگنالی
تجزیه موجک چند سیگنالی به سری های زمانی چند سیگنالی بازسازماندهی شده برای بازیابی تغییرات فضایی-زمانی چند مقیاسی اعمال می شود. با فرض اینکه X ( t ) = { x 1 ( t ), x 2 ( t ), …, x M ( t )} سری زمانی چند سیگنالی بعدی M است که از داده های سنجش از راه دور چند زمانی باز شده است، چند سیگنال تجزیه موجک X ( t ) را می توان به صورت زیر فرموله کرد:
که در آن F k ( t ) سیگنال سری مشخصه قطعی است که دارای ویژگی های مقیاس مکانی-زمانی خاصی است، d ( t ) باقیمانده های همبسته فضایی است که می تواند به عنوان نویز دیده شود، و k سطح ویژگی های استخراج شده است.
اجازه دهید نوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontتابع مقیاس باشد. M – 1 توابع موجک (که با j ( i ) ( t ) مشخص شده است) را می توان ساخت. برای هر یک از تابع موجک که مطابق با:
که در آن g ( i ) تابع ضریب فیلتر موجک تابع موجک j ( i ) ( t ) است.
الگوریتم سریع [ 29 ]، که با پارامترسازی موجک مادر و تجزیه سیگنال در فضای ویژگی ساخته میشود، در اینجا برای تجزیه کارآمد استفاده میشود. برای هر کانال سیگنال چندگانه، عناصر نامربوط درگیر در سیگنالها با کاهش دوتایی حذف میشوند، که وضوح اصلی را به نصف طول آن کاهش میدهد. این روش به صورت بازگشتی بر روی ضرایب تقریبی اعمال میشود تا نسخههای روانتر سیگنالهای اصلی تولید شود. بنابراین، ما تجزیه زیر را داریم:
جایی که نوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتضریب تقریب مقیاس اول است، نوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتضرایب تقریبی مقیاس k-ام است، نوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتضریب تفصیلی مقیاس ( k + 1) -ام است و g ( i ) فیلتر بالاگذر تابع مقیاس است. از آنجایی که دادههای اصلی X سیگنالی هستند که مجموع کانالهای M را دارند ، تمام ضرایب تقریبی نوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتیک ماتریس M × p k است، که در آن p k همان طول ضرایب تقریبی DWT در مقیاس k -ام است.
بازسازی تجزیه موجک چند سیگنالی را می توان در سنتز موجک با نمونه برداری و فیلتر معکوس ضرایب تجزیه شده به کار برد. به این معنا که:
طبق رابطه (4)، مولفه تقریب در سطح j را می توان با مولفه های تقریب و جزئیات در سطح j + 1 بازسازی کرد.
از آنجایی که تمام سری های زمانی در یک زمان تجزیه می شوند، آنها در مقیاس های زمانی یکسان هستند. از آنجایی که اجزای تجزیه شده اندازه داده های اصلی را دارند، روش های کاوش مانند مولفه های اصلی، هیستوگرام ها و طیف های توان را می توان مستقیماً برای شناسایی ویژگی ها و معنای جغرافیایی این تغییرات مکانی-زمانی در هر مقیاس به کار برد.
3.3. کشش داده ها
برای بهبود الگوی ویژگی هر جزء تجزیه شده و کاهش هزینه محاسباتی، داده ها به محدوده ای کشیده می شوند که به بهترین وجه ویژگی های آن را نشان می دهد. یک مکانیسم ساده، تقریب عدد صحیح، که داده های نقطه شناور را به یک سری از اعداد صحیح در محدوده معینی پروژه می دهد، استفاده می شود. با توجه به یک سری زمانی چند سیگنالی ایکس( t ) ∈ ( a , b )ایکس(تی)∈(آ، ب)، که دارای محدوده مقدار ( a, b ) است، به عنوان مثال ، ایکس( t ) ∈ ( a , b )ایکس(تی)∈(آ، ب)، که در آن a و b مقادیر شناور هستند. نگاشت سری زمانی چند سیگنالی X ( t ) به تقریب عدد صحیح در محدوده ( m, n ) را می توان به صورت زیر فرموله کرد:
که در آن ℝ مجموعه اعداد واقعی است، R ( X( تی ) )آر(ایکس(تی))محدوده مقدار سری X ( t ) و the است🝕+( m , n )🝕(متر،�)+مجموعه عدد صحیح مثبت با محدوده مقدار ( m, n ) است. یک راه حل معمولی برای نقشه برداری این است:
که در آن ( x ) تابعی است که هدف آن یافتن نزدیکترین عدد صحیح مقدار واقعی x است .
برای هر مکعب سری ویژگی تجزیه شده، میتوانیم معادله (6) را اعمال کنیم تا کل دادهها از محدوده مقدار اصلی ( a , b ) به محدوده مقادیر جدید ( m , n ) با توزیع مکانی و زمانی آنها به ندرت تغییر کند. از آنجایی که هم مقدار مرزی محدوده داده ( m , n ) و هم مقدار سطح i قابل تنظیم هستند، می توانند سیگنال اصلی را با هر دقت مشخصی تقریب بزنند.
3.4. هیستوگرام تقریب داده ها
هیستوگرام برای خلاصه کردن توزیع ارزش داده های تقریبی اعداد صحیح برای کاهش ارزش داده و ابعاد داده استفاده می شود، که همچنین به افزایش ویژگی های داده ها کمک می کند.
اجازه دهید f∈L1(آرn)�∈�1(ℝ�)تقریب عدد صحیح سری زمانی چند سیگنالی X ( t ) است، اپراتور هیستوگرام تجمعی H توسط:
جایی که μ معیار Lebesgue است. H ( f ) تابع واقعی است که هیستوگرام تجمعی را نشان می دهد. با تقریب اعداد صحیح سری چند سیگنالی، هیستوگرام m i تعداد مشاهداتی را که در هر یک از سطلها قرار میگیرند میشمارند و شرایط زیر را دارند: n =∑کi = 1مترمن�=∑من=1کمترمن، که در آن n تعداد کل مشاهدات و k تعداد کل سطل ها است. توزیع ارزش داده ها در سطل های هیستوگرام با مناطق مختلف داده در حوزه مکانی-زمانی به هم مرتبط هستند، خوشه بندی هیستوگرام با توزیع مقادیر مربوط به مناطق مورد نظر می تواند منجر به یک خوشه مکانی-زمانی از داده های اصلی با توجه به توزیع ارزش آنها شود. . از آنجایی که حجم داده های هیستوگرام بسیار کمتر از داده های اصلی است، خوشه هیستوگرام بسیار کارآمدتر از داده های اصلی است.
برای هر سری ویژگی تجزیه شده، می توانیم یک هیستوگرام را با تشخیص مکعب داده به عنوان بردار داده یک بعدی محاسبه کنیم. در هیستوگرام، داده ها به ترتیب صعودی سازماندهی می شوند، بنابراین خوشه بندی بسیار ساده است. تجزیه موجک چند سیگنالی، که می تواند به عنوان یک روش حذف نویز دیده شود، تغییرات ناگهانی در داده ها را تا حد زیادی کاهش می دهد. بنابراین، نمونههای دادهای که فواصل مکانی نزدیک دارند، بسیار امکانپذیر است که در سطلهای یکسان طبقهبندی شوند. این بیشتر منجر به پتانسیل زیادی برای حفظ تداوم فضایی خوشهبندی میشود. عملکرد خوشه ویژگی با کنترل تعداد سطل ها قابل تنظیم است، که باعث می شود خوشه ویژگی برای دستیابی به تعادل بین عملکرد و سطح تقریبی انعطاف پذیر باشد.
3.5. FCM تطبیقی در هیستوگرام برای خوشه بندی ویژگی ها
خوشه بندی مکانی-زمانی اصلی فاصله بین پیکسل ها را در حوزه مکانی-زمانی اندازه گیری می کند. این نوع دامنه مکانی-زمانی محاسباتی فشرده و زمان بر است. هیستوگرام، که یک نمایه مرتب شده مجدد در مورد توزیع ارزش داده های مکانی-زمانی اصلی است، ویژگی های ارزش را در سطل های مختلف انتزاع می کند. از آنجایی که هر bin از هیستوگرام به پیکسل های خاصی در حوزه مکانی-زمانی مربوط می شود، خوشه بندی بن های هیستوگرام بسیار ساده تر است و می تواند توزیع ارزش داده های اصلی را در حوزه مکانی-زمانی بهتر نشان دهد. در رویکرد ما، هیستوگرام مورد استفاده را می توان به عنوان یک پیش فرآیند مشاهده کرد که پیکسل ها را با توجه به داده های مقدارشان به گروه های کمتری جمع آوری می کند. سپس شباهتهای بین سطلهای مختلف خوشهبندی میشوند. به این ترتیب، نه تنها ویژگی ها بهبود می یابند بلکه محاسبات را نیز می توان تا حد زیادی کاهش داد. از آنجایی که برای هر bin، توابع نگاشت دوطرفه برای نگاشت داده ها از حوزه مقدار به حوزه مکانی-زمانی وجود دارد، خوشه بندی بین bin های هیستوگرام در واقع خوشه بندی را در حوزه مکانی-زمانی انجام می دهد. بنابراین، خوشهبندی قطعاً یک خوشهبندی دامنه مکانی-زمانی است که میتواند برای ردیابی تکامل مکانی-زمانی ویژگیها استفاده شود.
برای کاهش تغییرات شکل بین مرزها برای دستیابی به جداسازی هموارتر در حوزه مکانی-زمانی، از فازی C-Means Cluster (FCM) که آستانه های نرمی برای جداسازی داده ها دارد، استفاده می شود. در اینجا، FCM، که نمونهگر داده را با توجه به تابع عضویت فازی به دو یا چند خوشه خوشهبندی میکند، به هیستوگرام اعمال میشود. محاسبه FCM یک روش تکراری است که مراکز خوشه را حرکت میدهد و نقاط داده را به صورت بازگشتی به هر مرکز خوشه اختصاص میدهد تا تقسیمبندی دادهها را طبق یک تابع شی معین بهینه کند [30 ] . تابع هدف [ 31 ] که ما استفاده کردیم این است:
در جایی که m عدد واقعی بزرگتر از 1 است، u ij درجه عضویت xi در خوشه j است ، x i i- مین هیستوگرام بعدی d داده های مشاهده شده است (داده های اصلی یا سری ویژگی های تجزیه شده) ، c j مرکز بعد d خوشه است که در ابتدا به صورت تصادفی انتخاب شده و به صورت بازگشتی به روز می شود. ||*|| هر هنجاری است که شباهت بین هر داده هیستوگرام و مرکز را بیان می کند.
تعیین اعداد خوشه یک مسئله مهم اما در عین حال مهم برای خوشه بندی ویژگی است. از آنجایی که خوشهبندی روی هیستوگرام اعمال میشود، تفاوت بین بنهای هیستوگرام ( یعنی توزیع ارزش) بسیار کوچکتر از تفاوت بین دادههای اصلی است، بسیاری از روشهای سنتی تعیین تعداد خوشه برای چنین کاری کارآمد نیستند. بنابراین عضویت فازی بین بنهای هیستوگرام مختلف، که تنوع نسبی و شباهت بین محدودههای مقادیر مختلف را اندازهگیری میکند، برای نمایهسازی تأثیر اعداد خوشه به کل بخشبندی دادهها و توزیعهای آماری آنها استفاده میشود. آنتروپی طبقه بندی (CE) [ 32]، که فازی بودن پارتیشن خوشه را اندازه گیری می کند، برای تعیین تعداد خوشه تقسیم بندی بهینه به صورت تطبیقی با توجه به توزیع داده ها استفاده می شود. تعریف CE این است:
جایی که تومن جتومن�عضویت نقطه داده j در خوشه i است . طبق تعریف CE ، CE بزرگتر نشان دهنده ابهام زیاد بین خوشه های مختلف است. هنگامی که تعداد خوشه در حال رشد است، مقدار CE کوچکتر می شود، که نشان دهنده توزیع بی نظم داده است. بنابراین، با توجه به ویژگیهای تغییر CE در برابر اعداد خوشهای، ساختارهای تقسیمبندی دادهها در برابر توزیعهای ارزش قابل شناسایی هستند. نقطه تغییر CE نشان می دهد که تغییر قابل توجهی از توزیع خوشه به عنوان مثال، تغییر خصوصیات. بنابراین، تعداد خوشه واقع در نقطه تغییر قابل توجه CE می تواند به عنوان تعداد خوشه بهینه هر جزء تجزیه شده انتخاب شود.
4. مطالعات موردی
4.1. داده های تحقیق و پیکربندی آزمایش
دادههای ماهانه ناهنجاری میانگین سطح دریا با تاخیر زمانی جهانی (MSLA) تولید شده توسط SSAlto/Duacs، AVISO [ 33] به عنوان داده های آزمایش استفاده شد. داده ها با ترکیب ماهواره های T/P، Jason-1، Jason-2 و Envisat تولید شدند. وضوح مکانی داده ها 0.25 درجه است و دوره زمانی داده ها از ژانویه 1993 تا دسامبر 2013 است. کل داده ها 1440 × 721 × 252 است. داده ها بیشتر اقیانوس جهانی را شامل می شود که منطقه بین 81 درجه جنوبی را در بر می گیرد 81 درجه شمالی، قسمت خشکی و اقیانوس در ناحیه قطبی به عنوان مقادیر گمشده نشان داده می شوند. دادههای اصلی در قالب چندین فایل NetCDF به صورت بازگشتی در محیط MATLAB 2011b روی سرور Inspur NP 3560 با دو پردازنده Intel Xeon E5645 (2.4G) و حافظه 48 گیگابایتی DDR-3 ECC خوانده میشوند. سیستم عامل ویندوز سرور 2008 R2 است. تمامی کدهای تست در یک محیط نرم افزاری و سخت افزاری نوشته شده اند. شاخص ENSO چند متغیره (MEI) به عنوان شاخص رویداد ENSO [34 ].
داده های MSLA ابتدا به صورت سری های زمانی چند سیگنالی، با سری های زمانی در هر پیکسل به عنوان یک کانال نمایش داده می شوند. سپس ماتریس چند سیگنالی با موجک چند سیگنالی با موجک تقریبا متقارن “Sym4” به عنوان موجک مادر تجزیه می شود. خانواده موجک Symlet (SymN) یک بازگشت موجک رایج Daubechies است. این یک موجک متعامد و تقریباً متقارن با عرض پشتیبانی 2N-1 و گشتاورهای ناپدید N است. به دلیل خواص تقریباً متقارن آن، میتواند تغییر فاز را در طول بازسازی موجک کاهش دهد [35 ] . مشابه تجزیه و تحلیل فردی DWT، سطح تجزیه در این کار به بزرگترین عدد صحیح موجود در log 2 محدود شد.(n)، که در آن “n” طول سری زمانی است. با توجه به طول داده ها، تجزیه 6 سطحی برای کل مجموعه داده اعمال می شود.
با داده های چند سیگنالی تجزیه شده، حداقل داده ها کم می شود تا همه داده ها مثبت بماند. با توجه به معادلات (5) و (6)، تقریب عدد صحیح داده ها اعمال می شود. پارامترهای محدوده داده ( m , n) با توجه به توزیع ارزش تجزیه داده ها انتخاب می شوند. برای تشخیص بهترین تفاوت بین تمام اجزای تجزیه شده، همه اجزا به مقداری که از 0 تا 160 متغیر است، دوباره عادی می شوند. با تقریب عدد صحیح، توزیع هیستوگرام هر جزء تجزیه شده محاسبه می شود و سپس الگوریتم FCM مبتنی بر هیستوگرام برای هر سری ویژگی تجزیه شده اعمال می شود. خوشه با تعداد خوشه های مختلف شبیه سازی شده و آنتروپی طبقه بندی برای هر شبیه سازی برای تعیین تعداد خوشه بهینه هر جزء تجزیه شده محاسبه می شود. خوشه داده نهایی در هر مقیاس با عدد خوشه بهینه شده برای هر جزء تجزیه شده محاسبه می شود. زمان محاسبات و اشغال حافظه در حال تغییر ثبت و با توجه به اعداد خوشه تجزیه و تحلیل می شوند. سرانجام،تکامل الگوی مکانی-زمانی نیز با ادبیات موجود مقایسه شده است .
4.2. نتیجه تجزیه چند مقیاسی
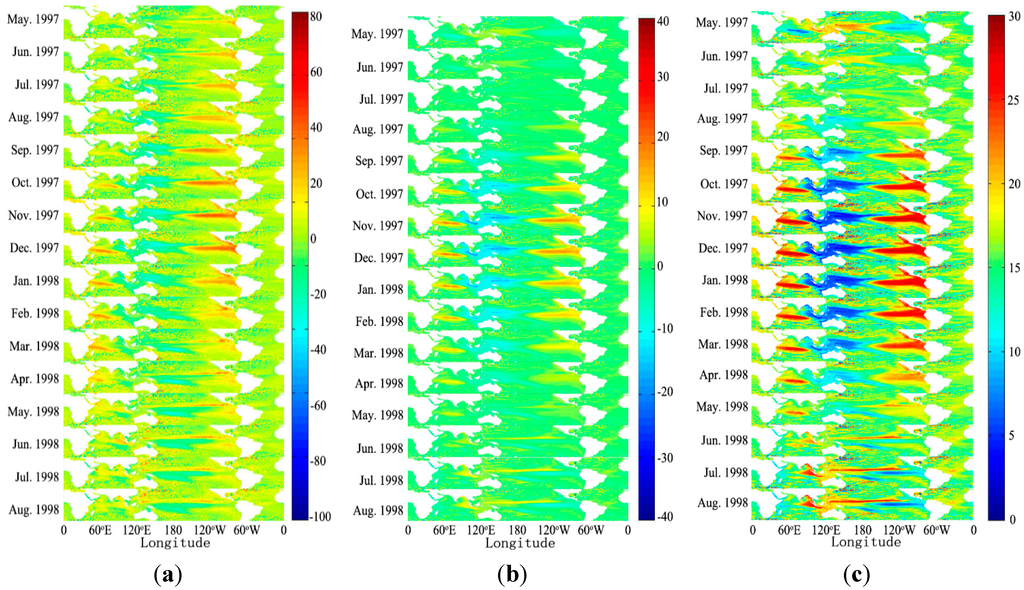
بازسازی اجزای چند مقیاسی داده های ارتفاع سنج ماهواره ای استخراج شده از تجزیه موجک چند سیگنالی در شکل 3 نشان داده شده است . از آنجایی که نمایش کامل همه داده ها غیرممکن است، ما فقط چند برش زمانی ارائه می دهیم. از بعد فضایی، اجزای A6 بسیار روان تر از داده های اصلی هستند. این نشان می دهد که تجزیه موجک چند سیگنالی نه تنها فیلتر چند مقیاسی در حوزه زمانی است، بلکه بر حوزه فضایی نیز تأثیر می گذارد. اگرچه اطلاعات مربوط به مقیاس فضایی تعمیم یافته تجزیه چند مقیاسی هنوز محدود است، در موارد ما، مقیاسهای زمانی بزرگتر نیز منجر به توزیع فضایی صافتر میشود.
برای آشکار کردن توزیع دقیق مکانی-زمانی اجزای تجزیه شده در مقیاسهای مختلف، ما تحلیل تابع متعامد تجربی (EOF) را برای هر جزء تجزیهشده اعمال کردیم. روش EOF می تواند الگوی قابل توجه و رایج داده های مکانی- زمانی را استخراج کند. سهم واریانس و مؤلفههای اصلی (PC)، که سازگاری مؤلفهها در سراسر توزیع فضایی و تغییر زمانی قابلتوجه الگوهای خاص را نشان میدهند، از EOF استخراج میشوند (جدول 1 ) . برای درک بیشتر الگوهای زمانی هر جزء تجزیه شده، طیف توان (PSD) هر کامپیوتر استخراجشده نیز محاسبه میشود. اوج PSD حاکی از دوره قابل توجه PC است. رایانه های شخصی و PSD رایانه های شخصی در شکل 4 نشان داده شده است. برای آشکار کردن مشخصات فرکانس دقیق رایانههای شخصی، بالاترین پیک PSD و فرکانس و دوره مرتبط با آن استخراج و در جدول 2 نشان داده شده است .
شکل 3. نتایج تجزیه موجک چند سیگنالی. چهار برش زمانی از کل مکعب های داده های مکانی-زمانی داده های اصلی و اجزای تجزیه شده بازسازی شده انتخاب شده اند (( الف ) ژانویه 1993؛ ( ب ) ژانویه 1999؛ ( ج ) ژانویه 2005؛ ( د ) ژانویه 2011). نوار رنگی در هر زیرگراف محدوده ناهنجاری داده ها را نشان می دهد. تجزیه موجک چند سیگنالی نه تنها داده ها را در حوزه زمانی فیلتر می کند، بلکه دامنه مکانی را نیز تحت تأثیر قرار می دهد. مقیاسهای زمانی بزرگتر نیز منجر به توزیع فضایی صافتر میشود.
جدول 1. توضیح واریانس از EOF نتیجه تجزیه شده (%).
جدول 2. اوج PSD و فرکانس مربوطه.
از شکل 4، می توانیم متوجه شویم که رایانه های شخصی داده های اصلی که به راحتی جدا نمی شوند، بسیار شبیه هستند. PSD نشان می دهد که اکثر رایانه های شخصی داده های اصلی دارای چرخه سالانه قوی هستند. بیشتر تفاوتهای بین رایانههای شخصی مختلف، اختلاف فاز ناشی از تاخیر توزیع فضایی است. با این حال، رایانه های شخصی و PSD رایانه های شخصی نشان می دهد که اجزای تجزیه شده بسیار قابل تفکیک هستند. دوره های غالب PSD هر جزء به طور قابل توجهی متفاوت است. دوره اصلی مولفه ها از A6 تا D6 از بین دهه ها به دو ماه تغییر می کند. علاوه بر این، PSD هر EOF در هر مقیاس نیز می تواند طبقه بندی شود. این نشان می دهد که الگوهای مختلف فضایی نیز به وضوح استخراج شده است. تجزیه چند مقیاسی به وضوح می تواند طبقه بندی الگوی داده ها را بهبود بخشد.
شکل 4. اجزای اصلی داده های اصلی و هر یک از اجزای تجزیه شده و طیف قدرت آنها. نمودار سه بعدی اجزای اصلی داده های اصلی و هر جزء تجزیه شده ( سمت چپ ). و طیف های توان هر یک داده های هر جزء اصلی داده های اصلی و هر جزء تجزیه شده را تجزیه می کند ( سمت راست ). فرکانس برای تصویر بهتر به دوره تبدیل شده است.
از توضیح واریانس حاصل از EOF نتیجه تجزیه شده، مؤلفههای A6 و D6 بسیار سادهتر از سایر مؤلفهها هستند که مؤلفههای اصلی کمتری دارند. این نشان می دهد که تغییرات در مقیاس بزرگ سازگارتر و روان تر هستند. اگرچه، PSD برای سریهای زمانی که بیش از نیمی از دورههای کل دادهها هستند، چندان دقیق نیستند، تحقیقات ترکیبی از رایانههای شخصی نیز نشان میدهد که هر دو A6 و D6 تغییرات بین دههای هستند. مولفه های A6 دارای یک دوره ده ساله هستند که می توان آن را روند بلند مدت داده ها دانست. در همین حال، اجزای D6 دارای یک دوره شبه 5-7 ساله هستند. تنوع فضایی قوی در اقیانوس آرام استوایی و اقیانوس هند نشان می دهد که D6 ممکن است روابط نزدیکی با تغییرات قابل توجه ENSO داشته باشد. اجزای D5 و D4 نیز تغییراتی بین دههای هستند که توزیع فضایی در سراسر اقیانوسهای جهانی دارند. توزیع فضایی همچنین نشان میدهد که این دو مؤلفه ممکن است روابط نزدیکی با رویدادهای ENSO داشته باشند. مؤلفه D3 که سهم واریانس بسیار بالایی را در رایانه اول دارد، چرخه سالانه قابل توجهی دارد. از آنجایی که دوره سالانه رایج ترین و مهم ترین دوره در سراسر اقیانوس جهانی است، اهمیت چرخه سالانه نیز ثبات EOF را ثابت می کند. اجزای D2 و D1 به ترتیب دارای دوره های نیم ساله و دو تا چهار ماهه هستند. مقداری نویز فرکانس بالا نامنظم نیز در این قطعات وجود دارد. توزیع فضایی همچنین نشان میدهد که این دو مؤلفه ممکن است روابط نزدیکی با رویدادهای ENSO داشته باشند. مؤلفه D3 که سهم واریانس بسیار بالایی را در رایانه اول دارد، چرخه سالانه قابل توجهی دارد. از آنجایی که دوره سالانه رایج ترین و مهم ترین دوره در سراسر اقیانوس جهانی است، اهمیت چرخه سالانه نیز ثبات EOF را ثابت می کند. اجزای D2 و D1 به ترتیب دارای دوره های نیم ساله و دو تا چهار ماهه هستند. مقداری نویز فرکانس بالا نامنظم نیز در این قطعات وجود دارد. توزیع فضایی همچنین نشان میدهد که این دو مؤلفه ممکن است روابط نزدیکی با رویدادهای ENSO داشته باشند. مؤلفه D3 که سهم واریانس بسیار بالایی را در رایانه اول دارد، چرخه سالانه قابل توجهی دارد. از آنجایی که دوره سالانه رایج ترین و مهم ترین دوره در سراسر اقیانوس جهانی است، اهمیت چرخه سالانه نیز ثبات EOF را ثابت می کند. اجزای D2 و D1 به ترتیب دارای دوره های نیم ساله و دو تا چهار ماهه هستند. مقداری نویز فرکانس بالا نامنظم نیز در این قطعات وجود دارد. اجزای D2 و D1 به ترتیب دارای دوره های نیم ساله و دو تا چهار ماهه هستند. مقداری نویز فرکانس بالا نامنظم نیز در این قطعات وجود دارد. اجزای D2 و D1 به ترتیب دارای دوره های نیم ساله و دو تا چهار ماهه هستند. مقداری نویز فرکانس بالا نامنظم نیز در این قطعات وجود دارد.
از بحث بالا، تجزیه موجک چند سیگنالی به خوبی میتواند تغییرات زمانی چند مقیاسی را از دادههای سنجش از راه دور چند زمانی اصلی استخراج کند. تجزیه در حوزه زمانی انجام می شود، اما بر توزیع فضایی نیز تأثیر می گذارد. اجزای تجزیه شده دارای تغییرات زمانی واضح با دوره زمانی قابل توجه هستند. با تجزیه چند مقیاسی، ویژگی های داده های اصلی بسیار قابل تفکیک هستند. بنابراین، برای استخراج ویژگی و تقسیم بندی داده ها در سطوح مختلف مقیاس بسیار مفید و مفید خواهد بود.
4.3. نتیجه خوشه بندی ویژگی ها
تقریب عدد صحیح و نمایش هیستوگرام هر جزء تجزیه شده برای خوشه بندی ویژگی انجام می شود. هیستوگرام داده های اصلی و اجزای چند مقیاسی تجزیه شده در شکل 5 نشان داده شده است. هیستوگرام اصلی فقط یک قله باند وسیع دارد، زیرا ویژگیهای فضایی مختلف با هم ترکیب شدهاند. برای این مورد، طبقه بندی الگوهای مختلف مستقیماً از هیستوگرام اصلی چندان آسان نیست. هیستوگرام اجزای تجزیه شده بسیار قابل تفکیک است. هر هیستوگرام جزء تجزیه شده دارای نوارهای باریک و قله های منفرد شفاف است. مقادیر A6، D6 و D5 کوچکتر از مولفه D4-D1 است. این مربوط به وضعیتی است که در آن دامنه تغییرات چرخه های بین دهه ای کمتر از چرخه های دهه داخلی در بیشتر مناطق است. تقسیم بندی بر اساس هیستوگرام تمام اجزای تجزیه شده از نظر ساختاری بسیار واضح تر از تقسیم بندی بر اساس هیستوگرام داده های اصلی است.
شکل 5. هیستوگرام داده های اصلی و اجزای تجزیه شده.
قبل از خوشه بندی ویژگی نهایی در هر جزء تجزیه شده، تعداد خوشه بهینه شده هر جزء تجزیه شده از شبیه سازی شاخص CE با توجه به عدد خوشه محاسبه می شود. شبیه سازی ها با تغییر تعداد خوشه ها از 10 به 40 ساخته می شوند. برای هر عدد خوشه، CE محاسبه و ثبت می شود. شکل 6نشان می دهد که چگونه CE با توجه به عدد خوشه در هر مقیاس تغییر می کند. برای همه اجزای تجزیه شده، ارزش CE با افزایش تعداد خوشه کمتر می شود. CE داده های اصلی به طور قابل توجهی بالاتر از اجزای تجزیه شده است. و اجزای D1-D4 CE بسیار مشابهی دارند. CE اجزای D5 و D6 نیز بسیار شبیه است و همه آنها دارای مقادیر CE بسیار پایینی هستند. برخلاف سایر اجزا، CE A6 به آرامی تغییر نمی کند، که نشان می دهد درجه پیچیدگی مولفه A6 ممکن است متفاوت باشد. اینها نشان می دهد که پیچیدگی تغییرات بین دهه ای کمتر از تغییرات دهه داخلی است. این تا حدی به این دلیل است که تغییرات بین دههای بسیار نرمتر و آهستهتر تغییر میکنند و تا حدی به این دلیل است که نویزهای کمتری در تغییرات طولانی مدت وجود دارد. متوجه خواهیم شد که در بخش های پایینی D5 و D6 عمدتاً تحت تأثیر رویداد ENSO هستند که یک پدیده نامنظم در هر دو بعد مکانی و زمانی است. بنابراین این نوع بی نظمی در CE نیز ویژگی های سیگنال را نشان می دهد.
بیشتر CE در مقیاس های مختلف پس از بزرگتر شدن عدد خوشه از 30 بسیار آهسته در حال تغییر است. این نشان می دهد که خوشه بندی با عدد خوشه بزرگتر از 30 اطلاعات متفاوت زیادی تولید نمی کند. بنابراین، می توان در نظر گرفت که حداقل تعداد 30 به خوبی توزیع و ویژگی داده های اصلی را نشان می دهد. بنابراین، ما تعداد خوشه بهینه شده 30 را برای تمام اجزای تجزیه شده برای تولید بخش بندی نهایی انتخاب می کنیم. اگرچه، انتخاب تعداد خوشه بهینه متفاوت برای هر سطح بهینه است، ما برای سادگی، تعداد خوشه بهینه شده 30 را برای همه اجزای تجزیه شده طبق CE انتخاب می کنیم.
خوشه بندی ویژگی با خوشه شماره 30 برای هر هیستوگرام اجزای تجزیه شده انجام می شود. توزیع مکانی-زمانی نتیجه تقسیم شده در شکل 7 نشان داده شده است. خوشه داده های اصلی ساختار فضایی قابل توجهی ندارد. تعداد زیادی تکه های کوچک را می توان در نتیجه خوشه ای یافت، که نشان می دهد تقسیم بندی اصلی نمی تواند تغییرات را در مقیاس های زمانی و مکانی مختلف جدا کند. نتیجه خوشه ای اجزای تجزیه شده ساختار فضایی بسیار واضح تری دارد. نتیجه خوشه ای جزء A6 به وضوح دو مرحله قبل و بعد از سال 2003 را نشان می دهد. این با تغییر روند ارتفاع سطح دریا مطابقت دارد. نتیجه خوشهای اجزای D6-D4 در بعد زمانی بسیار مهمتر است. تغییرات عمده تغییرات الگوی فضایی است که از سطح جهانی عبور می کند. از آنجایی که این مؤلفه ها عمدتاً سیگنال ENSO را نشان می دهند، مقایسه دقیق تغییرات مکانی-زمانی در طول رویدادهای ENSO قابل دستیابی است. از تغییرات شاخص خوشه زمانی، روند تکامل، از جمله شروع، رشد، اوج گرفتن، ضعیف شدن و ناپدید شدن، بسیار واضح تر از داده های اصلی است. خوشه بندی اجزای D3-D1 عمدتاً به طور دوره ای در طول زمان تغییر می کند که نشان می دهد خوشه ما می تواند تغییرات مکانی و زمانی داده ها را به خوبی نشان دهد. همه موارد فوق نشان می دهد که رویکرد ما می تواند به عنوان یک ابزار کاوش برای یافتن الگوها در داده های مکانی-زمانی استفاده شود. برخلاف روشهای تانسور، رویکرد ما میتواند از دادههای نامنظم که حاوی دادههای گمشده در هر مکان مکانی است، پشتیبانی کند. خوشه بندی اجزای D3-D1 عمدتاً به طور دوره ای در طول زمان تغییر می کند که نشان می دهد خوشه ما می تواند تغییرات مکانی و زمانی داده ها را به خوبی نشان دهد. همه موارد فوق نشان می دهد که رویکرد ما می تواند به عنوان یک ابزار کاوش برای یافتن الگوها در داده های مکانی-زمانی استفاده شود. برخلاف روشهای تانسور، رویکرد ما میتواند از دادههای نامنظم که حاوی دادههای گمشده در هر مکان مکانی است، پشتیبانی کند. خوشه بندی اجزای D3-D1 عمدتاً به طور دوره ای در طول زمان تغییر می کند که نشان می دهد خوشه ما می تواند تغییرات مکانی و زمانی داده ها را به خوبی نشان دهد. همه موارد فوق نشان می دهد که رویکرد ما می تواند به عنوان یک ابزار کاوش برای یافتن الگوها در داده های مکانی-زمانی استفاده شود. برخلاف روشهای تانسور، رویکرد ما میتواند از دادههای نامنظم که حاوی دادههای گمشده در هر مکان مکانی است، پشتیبانی کند.
شکل 7. نتایج خوشه ای از داده های اصلی و اجزای تجزیه شده: ( الف ) نتیجه خوشه ای از داده های اصلی. و ( b – h ) نتایج خوشه ای از اجزای A6، D6، D5، D4، D3، D2 و D1 به ترتیب. نوار رنگی در هر زیرگراف، شاخص نوع طبقه بندی داده ها را نشان می دهد. با توجه به محدودیت فضا، تنها شش برش زمانی برای نمایش انتخاب شده است.
5. ارزیابی الگوهای مکانی-زمانی ردیابی شده
5.1. ارزیابی با ردیابی تکامل ال نینو 1997-1998
ال نینو 1997-1998 قوی ترین رویداد مشاهده شده ال نینو است که در طول زمان تحقیق رخ داده است. ناهنجاری های سطح دریا تا حد زیادی تحت تأثیر این رویداد ال نینو قرار گرفته است. مطالعات گسترده ای در رابطه با الگوی واکنش سطح دریا به این رویداد ال نینو، به ویژه در منطقه گرمسیری اقیانوس آرام [ 24 ] انجام شده است. بیشتر این الگوهای پاسخ با روشهای استخراج الگوی خاصی (به عنوان مثال، EOF و ICA) مستقیماً از دادههای اصلی انجام میشوند [ 36 ]. با این حال، سیگنال ENSO، که همچنین یک پدیده چند مقیاسی است، اغلب دارای دوره های شبه از دو تا هفت سال است و ممکن است سطح دریا را در مقیاس های مختلف تحت تاثیر قرار دهد، زیرا فعل و انفعالات بین رویدادهای ENSO و سطح دریا پیچیده است [ 24 , 25 ،26 ]. استخراج و ردیابی تکامل مکانی-زمانی با خوشه داده از تجزیه چند مقیاسی برای آشکار کردن مکانیسم های احتمالی در مورد چگونگی تأثیر رویدادهای ENSO بر سطح دریا در دامنه مقیاس مکانی-زمانی مفید خواهد بود.
مرحله اولیه استخراج تعاملات چند مقیاسی بین ENSO و سطح دریا استخراج سیگنال احتمالی ENSO از دادههای اصلی SSHA است. از آنجایی که هیچ شاخص کمی ساده در حوزه مکانی-زمانی وجود ندارد که بتواند به وضوح تکامل ENSO را نشان دهد، ما از شاخص MEI در حوزه زمانی برای شناسایی سیگنالهای ENSO در اجزای مختلف تجزیه شده استفاده میکنیم. MEI با دو مؤلفه اصلی تمام سری های ویژگی تجزیه شده مقایسه شده است ( شکل 8 ). ضرایب همبستگی بین اجزای اصلی و شاخص MEI در جدول 3 ارائه شده است . از شکل 8اولین اجزای اصلی (PC1) D5 و D4 با شاخص MEI به خوبی مطابقت دارد. همبستگی بین PC1های D5 و D4 و MEI به ترتیب -0.534 و -0.571 است. از آنجایی که مولفههای D6-D4 نشاندهنده تغییرات سطح دریا در مقیاسهای زمانی بین دههای است، مطابقت نزدیکی بین مقیاسهای ENSO دارد. در مؤلفههای اصلی دوم، اگرچه مؤلفههای اصلی دادههای اصلی همبستگی بالایی بین MEI دارند و همه مؤلفههای تجزیه شده همبستگی ضعیفی بین MEI دارند. با این حال، از شکل 8 ، PC2 های D5 و D4 نیز مطابقت بالایی با MEI دارند. اجزای دیگر، به عنوان مثال، A6، D3، D2 و D1 فقط همبستگی ضعیفی بین سیگنال های ENSO دارند. بنابراین، میتوان نتیجه گرفت که D5، D4 ممکن است ویژگیهای تکامل چند مقیاسی ENSO را نشان دهد.
جدول 3. زمان و هزینه حافظه رویه خوشه ویژگی.
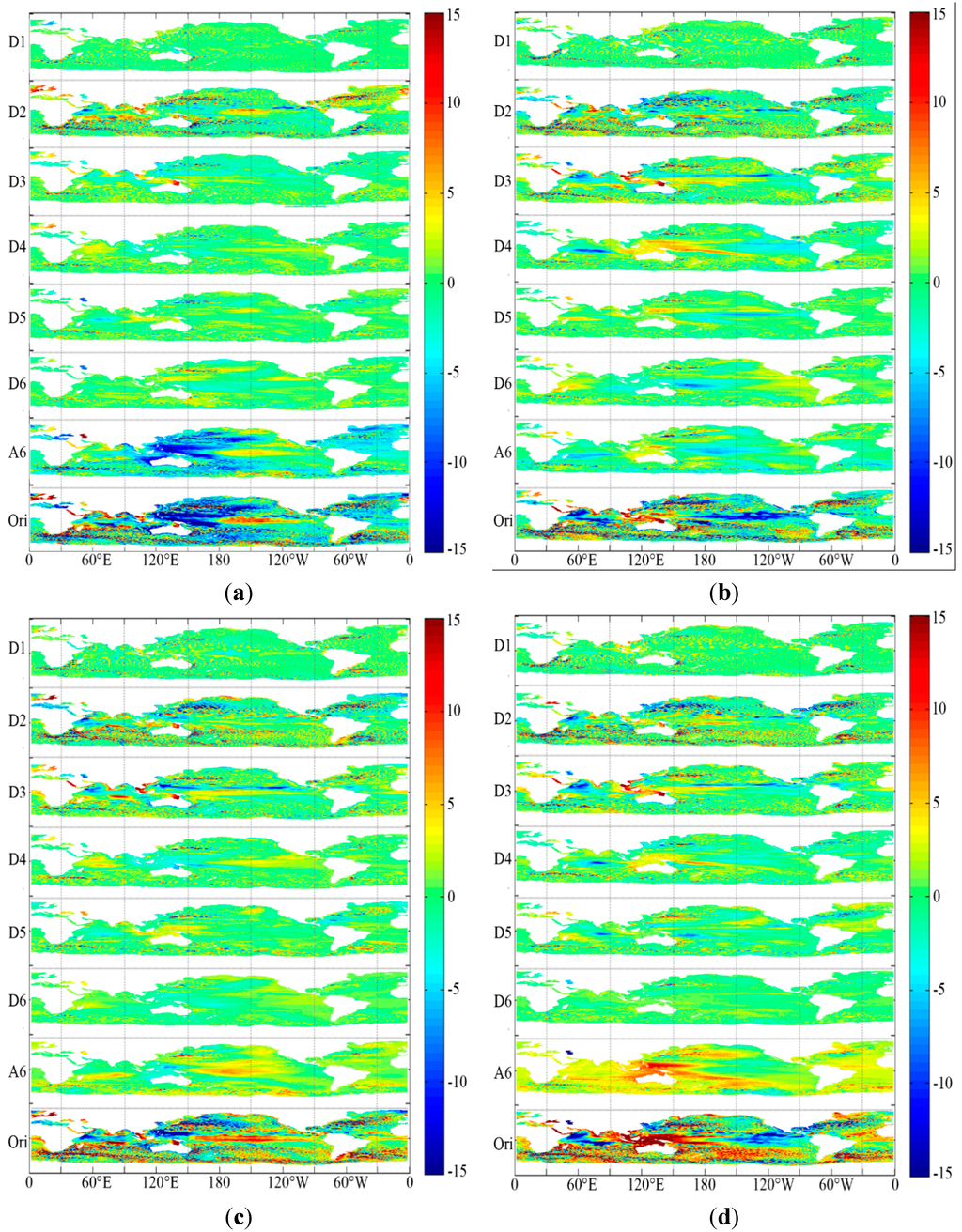
مؤلفههای چندزمانی تجزیهشده D5 و D4 و نتایج خوشهای آنها از مه 1997 تا آگوست 1998، برای تأیید اینکه آیا ویژگی استخراجشده تحت تأثیر رویداد ال نینو در سالهای 1997-1998 قرار گرفته است، انتخاب شدهاند. برای نمایش خوب داده ها، فقط داده های بین 40 درجه شمالی و 40 درجه جنوبی در شکل 9 و شکل 10 نشان داده شده است.. اجزای انتخاب شده دارای چرخه بین دهه ای هستند که حاوی سیگنال ال نینو است و محدوده زمانی انتخاب شده شامل تمام مراحل تکامل از جمله مرحله شروع، رشد، اوج گیری، تضعیف و ناپدید شدن این رویداد ال نینو است. از نتیجه تجزیه شده، هر دو مؤلفه D5 و D4 الگوهای واضحی دارند که می توانند وجود رویداد ال نینو را آشکار کنند. با این حال، ردیابی دقیق این رویداد ال نینو هنوز به طور مستقیم از داده های تجزیه شده دشوار است. بنابراین، خوشهبندی ویژگی با استفاده از FCM بیشتر برای استخراج تکامل فضایی-زمانی چند مقیاسی رویداد ال نینو اعمال میشود.
خوشه اجزای تجزیه شده نشان می دهد که چگونه ال نینو در حوزه مکانی-زمانی بسیار واضح تر از داده های اجزای اصلی تغییر می کند. اجزای D5 یک الگوی قابل توجه ال نینو را از می 1997 تا فوریه 1998 در اقیانوس آرام استوایی نشان می دهد. زبانه سطح دریا از 180 درجه تا 120 درجه غربی در حال حرکت است. پس از مارس 1998، سطح دریاهای آزاد در استوایی اقیانوس آرام ضعیف تر می شود. با این حال، ارتفاعات قله در غرب استوایی اقیانوس هند واقع شده است. مکان ها و مرزها با ادبیات موجود قابل مقایسه هستند [ 37 ، 38 ]. اهمیت تغییرات اقیانوس هند در این رویداد ال نینو که مستقیماً قابل مشاهده و استخراج از اجزای اصلی و تجزیه شده نیست، قبلاً در ادبیات اثبات شده است [39] .]. اجزای D4 کمی با اجزای D5 متفاوت هستند. سطح دریای آزاد به سمت غرب از سپتامبر 1997 شروع می شود و در آوریل 1998 به پایان می رسد. مخلوط دو قله قابل توجه باد تجاری به سمت غرب در مقیاس های مختلف یکی از دلایلی است که چرا این ال نینو به قوی ترین ال نینو تبدیل می شود [40 ، 41 ] .
شکل 8. مقایسه بین اجزای اصلی اجزای تجزیه شده و شاخص MEI: ( الف ) مقایسه بین اولین اجزای اصلی اجزای تجزیه شده و شاخص MEI. و ( ب ) مقایسه بین اجزای اصلی دوم اجزای تجزیه شده و شاخص MEI.
شکل 9. تکامل مکانی-زمانی جزء D5 طی ال نینو 1997-1998: ( الف ) داده های اصلی. ( ب ) اجزای D5. و ( ج ) خوشه مولفه های D5.
شکل 10. تکامل مکانی-زمانی جزء D4 در طول ال نینو 1997-1998: ( الف ) داده های اصلی. ( ب ) اجزای D4. و ( ج ) خوشه اجزای D4.
در بیشتر مطالعات اخیر، دو رویداد متفاوت ال نینو وجود دارد، ال نینوی اقیانوس آرام شرقی (EP) و ال نینوی اقیانوس آرام مرکزی (CP)، که ممکن است بر کل چرخه ENSO تسلط داشته باشد [42 ] . دو نوع مختلف از رویدادهای ال نینو را می توان با محل شروع رویداد در شرق اقیانوس آرام یا اقیانوس آرام مرکزی متمایز کرد. با این حال، دو رویداد مختلف به هم مرتبط هستند و به راحتی نمی توان آنها را به وضوح از هم جدا کرد. تحقیقاتی وجود دارد که نشان می دهد ال نینوی قوی در سال 1997 ناشی از هر دو رویداد متفاوت ال نینو است [ 43 ، 44]]. در نتیجه ما، تفاوت الگوی فضایی بین D4 و D5 تا حدی از چنین نتایجی پشتیبانی می کند. خوشه جزء D5 بالاترین مرکز خود را در اقیانوس آرام مرکزی دارد در حالی که جزء D4 مرکز خود را فقط در شرق اقیانوس آرام دارد. زمان شروع مولفه D4 به خوبی با زمانی که شکوفایی این رویداد ال نینو اتفاق می افتد مطابقت دارد [ 45]. این نشان میدهد که دو سیگنال در حوزه مکانی-زمانی دارای محبتهای متفاوتی هستند، که میتوان با استفاده از خوشهبندی ویژگی اجزای تجزیهشده مکانی-زمانی در مقیاسهای مختلف به وضوح آشکار کرد. از آنجایی که این الگو را نمی توان در داده های اصلی و اجزای تجزیه شده به وضوح مشاهده کرد، خوشه می تواند الگوی چند مقیاسی را از داده های سنجش از راه دور چند زمانی نشان دهد و نمایش را تا حد زیادی افزایش دهد. به عبارت دیگر، روش پیشنهادی میتواند تکامل مکانی-زمانی انواع خاصی از الگوها یا رویدادها را با وضوح بیشتری آشکار کند.
5.2. ارزیابی عملکرد محاسباتی
برای پیچیدگی محاسباتی، هم پیچیدگی محاسباتی نظری و هم نتایج آزمایش محاسبه میشوند. برای روش ما، پیچیدگی محاسباتی نظری از بخشهای زیر تشکیل شده است: پیچیدگی تجزیه چند مقیاسی، نمایش اعداد صحیح، ساخت هیستوگرام، FCM و نگاشت معکوس خوشهای به دادههای اصلی. برای بخش تجزیه چند مقیاسی، پیچیدگی نظری تجزیه موجک چند سیگنالی در حدود kO ( n log( n )) است، که در آن k تعداد سطوح تجزیه شده است. پیچیدگی نمایش اعداد صحیح، ساخت هیستوگرام و نگاشت معکوس همه O ( n) که در آن n تعداد کل داده ها است. پیچیدگی FCM به صورت مجانبی در زمان O ( Nc 2 p ) اجرا می شود، جایی که N تعداد مشاهدات p-بعدی است ( یعنی مجموع تعداد سطل های هیستوگرام هر سطح.) و c تعداد خوشه ها است [46] . بنابراین ، پیچیدگی کلی روش kO ( n log( n ))+ O ( Nc2p ) است. این پیچیدگی محاسباتی بسیار کوچکتر از FCM اصلی است و با توجه به تعداد سطل های هیستوگرام قابل تنظیم است.
کارایی محاسباتی و تداوم فضایی خوشه ویژگی در آزمایشها ارزیابی میشود. زمان محاسباتی و هزینه حافظه رویه خوشه ویژگی داده های اصلی و اجزای تجزیه شده در جدول 3 ثبت شده است . از جدول 3، ما به وضوح می بینیم که هزینه زمان و هزینه حافظه اجزای مختلف بسیار مشابه است، که نشان می دهد عملکرد محاسباتی روش ما پایدار است. زمان محاسبات و هزینه حافظه به ترتیب حدود 1/7 و 1/3 است که کمتر از خوشه K-Means کلاسیک است، زیرا زمان محاسباتی و هزینه حافظه تا حد زیادی تحت تأثیر نمایش هیستوگرام قرار دارند. فناوریهای دقیقتر که میتوانند الگوها را بهبود بخشند و بنهای هیستوگرام را کاهش دهند، میتوانند زمان محاسباتی و هزینه حافظه را حتی بیشتر کاهش دهند. در نتیجه، روش ما برای مقابله با مقدار زیادی از داده های سنجش از راه دور چند زمانی کارآمد است.
6. بحث
در رویکرد ما، تجزیه موجک چند سیگنالی تنها برای تجزیه دادههای سنجش از راه دور چند زمانی در امتداد بعد زمانی برای استخراج تغییرات چند مقیاسی زمانی استفاده شد. با این حال، روابط کانال به کانال (مکان به مکان) در مقیاس های مختلف در طول تجزیه، که همچنین تعامل فضایی و توزیع سیگنال را در مقیاس های زمانی خاص نشان می دهد، به طور کامل مورد مطالعه قرار نگرفته است. آشکار کردن دقیق روابط کانال به کانال در طول تجزیه و ادغام بیشتر آنها در خوشه ویژگی مکانی-زمانی نیز ممکن است بسیار مفید باشد. در نمایش اعداد صحیح، انتخاب تطبیقی bin ها برای ساخت هیستوگرام برای داده هایی که دارای مقدار بسته در یک باند بسیار باریک از عدد صحیح هستند، مهم است. انتخاب آستانه به صورت تطبیقی با توجه به توزیع ارزش داده برای ساخت هیستوگرام می تواند این مشکل را حل کند. معیارهای اطلاعات یا مورفولوژی (به عنوان مثال، آنتروپی) می تواند برای ساخت هیستوگرام تطبیقی استفاده شود. با این حال، برای جلوگیری از حالت شبه که ممکن است توسط اکولایزر ایجاد شود، باید توجه ویژه ای شود. از آنجایی که هم نمایش اعداد صحیح و هم نمایش هیستوگرام، نمایش های بسیار اساسی هستند، تقریب پیشرفته تر در فضای زمان-فرکانس (مثلاً نمایش داده ها با مبنای فوریه یا مبنای موجک) ممکن است نتایج بسیار بهتری ایجاد کند. با تئوری نمایش طیف، ویژگی های داده ها ممکن است با جزئیات بسیار بیشتر با هزینه محاسباتی بسیار کمتر استخراج شوند. g.، آنتروپی) را می توان برای ساخت هیستوگرام تطبیقی استفاده کرد. با این حال، برای جلوگیری از حالت شبه که ممکن است توسط اکولایزر ایجاد شود، باید توجه ویژه ای شود. از آنجایی که هم نمایش اعداد صحیح و هم نمایش هیستوگرام، نمایش های بسیار اساسی هستند، تقریب پیشرفته تر در فضای زمان-فرکانس (مثلاً نمایش داده ها با مبنای فوریه یا مبنای موجک) ممکن است نتایج بسیار بهتری ایجاد کند. با تئوری نمایش طیف، ویژگی های داده ها ممکن است با جزئیات بسیار بیشتر با هزینه محاسباتی بسیار کمتر استخراج شوند. g.، آنتروپی) را می توان برای ساخت هیستوگرام تطبیقی استفاده کرد. با این حال، برای جلوگیری از حالت شبه که ممکن است توسط اکولایزر ایجاد شود، باید توجه ویژه ای شود. از آنجایی که هم نمایش اعداد صحیح و هم نمایش هیستوگرام، نمایش های بسیار اساسی هستند، تقریب پیشرفته تر در فضای زمان-فرکانس (مثلاً نمایش داده ها با مبنای فوریه یا مبنای موجک) ممکن است نتایج بسیار بهتری ایجاد کند. با تئوری نمایش طیف، ویژگی های داده ها ممکن است با جزئیات بسیار بیشتر با هزینه محاسباتی بسیار کمتر استخراج شوند. از آنجایی که هم نمایش اعداد صحیح و هم نمایش هیستوگرام، نمایش های بسیار اساسی هستند، تقریب پیشرفته تر در فضای زمان-فرکانس (مثلاً نمایش داده ها با مبنای فوریه یا مبنای موجک) ممکن است نتایج بسیار بهتری ایجاد کند. با تئوری نمایش طیف، ویژگی های داده ها ممکن است با جزئیات بسیار بیشتر با هزینه محاسباتی بسیار کمتر استخراج شوند. از آنجایی که هم نمایش اعداد صحیح و هم نمایش هیستوگرام، نمایش های بسیار اساسی هستند، تقریب پیشرفته تر در فضای زمان-فرکانس (مثلاً نمایش داده ها با مبنای فوریه یا مبنای موجک) ممکن است نتایج بسیار بهتری ایجاد کند. با تئوری نمایش طیف، ویژگی های داده ها ممکن است با جزئیات بسیار بیشتر با هزینه محاسباتی بسیار کمتر استخراج شوند.
هیستوگرام مقادیر داده های مشابه را در یک سطل هیستوگرام منفرد سازماندهی مجدد می کند، توزیع ارزش و توزیع مکانی-زمانی داده ها را به هم مرتبط می کند. نمایش عدد صحیح، که ساده و کارآمد است، نه تنها الگوی ویژگی را بهبود می بخشد، بلکه پیچیدگی محاسباتی را نیز کاهش می دهد. آستانه نرم نتایج FCM اعمال شده بر روی هیستوگرام می تواند منجر به سازگاری و تداوم بیشتر خوشه ویژگی مکانی-زمانی شود. علاوه بر این، خوشه دادهها را تطبیق میدهد و نیازی به دانش قبلی در مورد تعداد اشیا/ویژگیها و توزیع دادههای اصلی نیست. با این حال، عملکرد خوشه ای روش هنوز هم می تواند از چندین جنبه بهبود یابد. در FCM، انتخاب اعداد خوشه بهینه هنوز آزمایشی است و کارایی روش انتخاب نیز می تواند بهینه شود. در روش نگاشت معکوس از خوشه هیستوگرام به نوع داده اصلی، محدودیت های پیوستگی فضایی را می توان ادغام کرد، که می تواند سطح دقیق جزئیات خوشه را بیشتر کنترل کند.
7. نتیجه گیری
در این مقاله، ما یک رویکرد جدید را پیشنهاد میکنیم که تجزیه زمانی چند مقیاسی را در خوشه ویژگی دادههای سنجش از راه دور چند زمانی ادغام میکند. روشهای تجزیه موجک چند سیگنالی، تقریب عدد صحیح و نمایش هیستوگرام و روشهای FCM برای استخراج بخشهایی از ویژگیهای مهم در مقیاسهای زمانی مختلف ترکیب شدهاند. روش پیشنهادی ما کارآمد و پایدار است و میتواند برای استخراج و ردیابی پدیدههای پیچیده جغرافیایی مانند رویدادهای ال نینو از دادههای سنجش از راه دور پر سر و صدا استفاده شود. نتایج تجربی نشان میدهد که روش ما میتواند به عنوان یک ابزار تحلیل کاوشگر و پایهای برای ساخت روشهایی برای استخراج ویژگیهای مکانی-زمانی کارآمدتر و دقیقتر و خوشه ویژگی سنجش از دور چند زمانی یا سایر دادههای مکانی-زمانی استفاده شود.











بدون نظر