

خلاصه
جریان های اطلاعاتی در پلتفرم های رسانه های اجتماعی می توانند گرایش ها و علایق کاربران و همچنین ارتباطات بین کاربران را نشان دهند. در این مقاله، روشی برای تجزیه و تحلیل شبکههای مرتبط با شهر در پلتفرم رسانه اجتماعی توییتر بر اساس محتوای کاربر ارائه میکنیم. چهل میلیون توییت از طریق دانلود شده استREST API توییتر (رابط برنامه نویسی برنامه) و API استریم توییتر. این تحقیق بر دو جنبه متمرکز است: اولاً، تشخیص روند برای تجزیه و تحلیل 31 شهر اطلاعاتی جهان، با توجه به فعالیت کاربر، محبوبیت وبسایتهای اشتراکگذاری شده و موضوعات تعریف شده توسط هشتگ انجام شده است. ثانیاً، با ایجاد یک شبکه خوشهبندی شده بر اساس تعداد اتصالات بین جفتهای شهر مختلف، اشارهای به ارتباط شهرهای اطلاعاتی به یکدیگر داده میشود. توکیو، نیویورک، لندن و پاریس به وضوح در رتبه بندی فعال ترین شهرها در مقایسه با تعداد کل توییت ها پیشرو هستند. بررسی ها نشان می دهد که توییتر اغلب برای به اشتراک گذاری محتوا از سرویس های دیگر مانند اینستاگرام یا یوتیوب استفاده می شود. محبوب ترین موضوعات در توییت ها تفاوت های زیادی را بین شهرها نشان می دهد. در نتیجه، تحقیقات نشان میدهد که سرویسهای رسانههای اجتماعی مانند توییتر نیز میتوانند آینهای از جامعهای باشند که در آن استفاده میشوند و جریانهای اطلاعاتی شهرهای متصل را در یک شبکه جهانی آشکار کنند. روش ارائه شده را می توان در تحقیقات بیشتر برای تجزیه و تحلیل جریان اطلاعات در مورد موضوعات خاص و/یا مکان های جغرافیایی به کار برد.
کلید واژه ها:
رسانه های اجتماعی ؛ میکروبلاگینگ ; توییتر ؛ شهر اطلاعاتی ; کلان داده ؛ تجزیه و تحلیل شبکه
چکیده گرافیکی
1. معرفی
شبکه های اجتماعی به یک موضوع اصلی در جامعه امروزی تبدیل شده است. زندگی روزمره بسیاری از مردم و همچنین خود اینترنت را تغییر داد. پلتفرم های آنلاین مانند فیس بوک یا توییتر به یک جنبه مهم در علم اطلاعات تبدیل شده اند زیرا فرصت های جدیدی برای تولید و به اشتراک گذاری اطلاعات ایجاد می شود. رسانه های اجتماعی نه تنها یک پدیده منطقه ای هستند بلکه بر نحوه ارتباط در جهان و جامعه تأثیر می گذارند. طبق نظر کاستلز [ 1 ] ما به “جامعه شبکه ای” اشاره می کنیم که عمدتاً در به اصطلاح “شهرهای اطلاعاتی” نشان داده شده است [ 2 ، 3 ، 4 ].
منطق فضایی جدید، مشخصه شهر اطلاعاتی، با برتری فضای جریان ها بر فضای مکان ها تعیین می شود. با فضای جریان، من به سیستم مبادله اطلاعات، سرمایه و قدرت اشاره میکنم که فرآیندهای اساسی جوامع، اقتصادها و دولتها را بین مکانهای مختلف، بدون توجه به محلیسازی، ساختار میدهد .((ص 136)، [ 5 ])
علاوه بر این، جریان اطلاعات اغلب نقشی را در تحلیل های شهر جهانی ایفا می کند [ 6 ]. شهرهای جهان با اتصالات خود بر فاصله ها غلبه می کنند. این ارتباطات می تواند فیزیکی باشد، مانند فرودگاه هایی که پروازها را از و به همه مقصدهای شهردار در جهان ارائه می دهند، یا دیجیتال، مانند ایمیل یا مکاتبات تلفنی. با مراجعه به سهام [ 3 ]، امروزه ممکن است «شهرهای اطلاعاتی» را پیدا کنیم که در سلسله مراتب شهر جهانی نقشی جهانی دارند. آن شهرها در یک شبکه جهانی [ 2 ] با توجه به فضای جریان خود، هاب هستند. به گفته ماینکا و همکاران. [ 7]، آن شهرها را «شهرهای جهان اطلاعاتی» می نامیم. تعریف آنها از “شهرهای جهان اطلاعاتی” و 31 شهری که آنها شناسایی کردند، اساس این مقاله را تشکیل می دهد.
این سوال مطرح می شود که چگونه می توان جریان اطلاعات را اندازه گیری کرد. در سطح شهر، میتوانیم ارتباطی را که بین بازیگران مستقر در شهرهای مختلف رخ میدهد، اندازهگیری کنیم. جریان اطلاعات از طریق ارتباطات الکترونیکی بین کارکنان در شرکت ها منبع در دسترس محققان نیست [ 8]، اما، از طریق ارتباطات جمعی در کانال های رسانه های اجتماعی، ما قادر به تجزیه و تحلیل ارتباطات بین کاربران مستقر در شهرها یا انتشار اطلاعات در مورد شهرها هستیم. ما کاربران را در سطوح سلسله مراتبی، به عنوان مثال، افراد مشهور و کاربران معمولی از هم جدا نمی کنیم، بلکه ارتباطات بین آنها را عمودی می دانیم. برای تجزیه و تحلیل اتصالات عمودی، از رویکرد علم سنجی استفاده خواهیم کرد. در اینجا، جریان اطلاعات به عنوان مثال، با انتشارات علمی و شهرت یا نویسندگی مشترک آنها اندازه گیری می شود [ 9 ]. این جریان ها را می توان در سطح کشور یا شهر نیز اندازه گیری کرد. به عنوان مثال، هاستین و همکاران. [ 10] میزان استناد و همکاری بین محققان منطقه آسیا و اقیانوسیه را در سطح کشور مورد مطالعه قرار داد. بنابراین، می توان دید که اطلاعات از کجا می آید، به عنوان مثال، یک جریان اطلاعاتی از چین به اندونزی ارائه می شود که محققی از اندونزی به یک مقاله تحقیقاتی که توسط یک محقق چینی نوشته شده است استناد می کند. علاوه بر این، در صورتی نزدیکی هر دو محقق توسط محقق ثالث ذکر شده باشد. ما ایده این مطالعه را با توجه به بررسی اطلاعاتی از اتصال میکروبلاگینگ 31 شهر اطلاعاتی جهان در توییتر تطبیق خواهیم داد. با توجه به این موضوع، یک جریان اطلاعات در توییتر در سطح ابرداده ارائه میشود، (1) زمانی که یک کاربر واقع در شهر A به یک توییت از یک کاربر واقع در شهر B پاسخ میدهد، یا (2) محتوای یک توییت به موارد بیشتری اشاره میکند. بیش از یک شهر11 ]. اصطلاح گسترده تری که همه این روش های اندازه گیری را ترکیب می کند هنوز اطلاعاتی است [ 12 ]. بنابراین، ما اندازه گیری می کنیم که آیا جریان اطلاعات از طریق شهرها وجود دارد یا خیر و آیا شهرها در حوزه Twitter به هم متصل هستند یا خیر. Twittersphere شامل تمام پستها ( به عنوان مثال ، توییتها) است که در توییتر ایجاد میشود و بنابراین فقط به کاربران این میکروبلاگ اشاره میکند. از این رو، اینها محدودیت های این تحلیل است. توییتر در همه شهرهای جهان به یک اندازه پخش نشده است. علاوه بر این، توییتر در چین مسدود شده است [ 13 ] و بنابراین فقط بازدیدکنندگان یا شهروندانی که می دانند چگونه از این مانع عبور کنند در این تحلیل گنجانده شده است.
توییتر که در سال 2006 با تعداد کل حدود یک میلیارد کاربر ثبت نام شده و 241 میلیون کاربر فعال ماهانه راه اندازی شد که تا 3 اکتبر 2013 300 میلیارد توییت ایجاد کردند و روزانه 500 میلیون توییت جدید ارسال کردند [14]، توییتر یکی از بزرگترین شبکه های اجتماعی و میکروبلاگینگ است . خدمات موجود توییتر نمونهای از پلتفرم میکروبلاگینگ است که مبتنی بر تولید بهروزرسانیهای بلادرنگ است [ 15]. هر پست به 140 کاراکتر محدود شده است. کاربران را می توان با ذکر نام های کاربر (به عنوان مثال، @ladygaga) و توییت ها را می توان با استفاده از هشتگ ها (به عنوان مثال، #tweetsandthecity) در دسته بندی ها فهرست کرد. علاوه بر این، شرکتهای سهامی عام با استفاده از علامت دلار درست قبل از نماد سهام خود برجسته میشوند (مثلاً $SI برای زیمنس). از این رو، ما با مجموعه داده های عظیمی که به سرعت در حال تغییر هستند سر و کار داریم که با روش های کلاسیک پردازش داده ها، به اصطلاح Big Data، قابل تحلیل نیستند. بنابراین، توییتر هدف بزرگی از تحقیقات علمی و رویکردهای استخراج در مورد بسیاری از موضوعات مختلف مانند استفاده توسط باشگاه های ورزشی [ 16 ، 17 ]، تجزیه و تحلیل احساسات سیاسی [ 18 ]، انتشار و توصیه اخبار [ 19 ، 20] است.] بلایای طبیعی و رویدادها [ 21 ، 22 ، 23 ] فقط به چند مورد اشاره می کنیم. ولر و همکاران [ 24 ] مجموعه بزرگی از کارهای مهم اخیر را در انتشارات خود «توئیتر و جامعه» با گردآوری کار محققان بینالمللی پیشرو توئیتر در یک نشریه ارائه میکنند. اهمیت و تنوع تحقیقات توییتر را نشان می دهد و تعامل ما را برای بررسی شهرهای جهان اطلاعاتی در توییتر تقویت می کند.
تحقیقاتی که به طور کلی شهرها یا مکانها را در توییتر بررسی میکنند، قبلاً برای اهداف مختلفی انجام شدهاند. Heverin و Zach [ 25 ] فعالیت های توییتر را در 60 شهر ایالات متحده با جمعیت بیش از 300000 مورد بررسی کردند که 30 بخش پلیس دارای حساب های توییتر فعال هستند. آنها مشاهده کردند که بیشتر توییتهای ارسال شده توسط این حسابها حاوی اطلاعات جنایت یا رویداد است. تشخیص موضوع همچنین می تواند برای شناسایی موقعیت جغرافیایی کاربران رسانه های اجتماعی استفاده شود. هان و کوک [ 26 ] (ص. 452) فرض می کنند که برخی از موضوعات مانند “Piccadilly” و “Tube” بیشتر در توییت های افرادی که در لندن هستند استفاده می شود تا در شهر دیگری.
Weidemann [ 27 ] نشان داد که تنها 6٪ از تمام کاربران توییتر موقعیت جغرافیایی خود را به اشتراک می گذارند. تحقیقاتی در مورد فعالیتهای عمومی توییتر در لندن، پاریس و شهر نیویورک قبلاً توسط عدنان و لانگلی [ 28 ] انجام شده است. آنها اسامی، قومیت های احتمالی و جنسیت کاربران توییتر را در این شهرها مقایسه کردند. بر اساس یافته های آنها، اکثر کاربران توییتر مرد و انگلیسی زبان هستند، علاوه بر این، کاربران در برخی مناطق فعال تر از سایرین هستند. به عنوان مثال، کوئینز در مقایسه با منهتن، فعالیت توییتر نسبتاً پایینی را نشان می دهد.
Mossberger، Wu و Crawford [ 29 ] یک “امتیاز تعامل” برای 75 شهر بزرگ ایالات متحده ایجاد کردند که تعامل بین دولت ها و شهروندان در شبکه های اجتماعی مانند توییتر را تعیین می کند. آنها به این نتیجه می رسند که استفاده از توییتر توسط دولت ها در این شهرها از 25 درصد (2009) به 87 درصد (2011) افزایش یافته است. در رتبه بندی خود، نیویورک، لس آنجلس و شیکاگو در 10 شهر برتر تعاملی ترین شهرها قرار دارند. سانفرانسیسکو (#18) و بوستون (#26) در رتبه های پایین تری قرار دارند. ماینکا و همکاران [ 30] مطالعه مشابهی را برای 31 شهر جهان اطلاعاتی انجام داد. آنها به این نتیجه رسیدند که توییتر فعال ترین پلتفرم رسانه اجتماعی برای استفاده دولتی و کتابخانه ای است. این ظن ما را تأیید می کند که فعالیت های توییتر این شهرها ارزش بررسی دارد. بنابراین، بررسی ما از 31 شهر در حوزه توییتر، سؤالات تحقیق زیر را تجزیه و تحلیل خواهد کرد:
- (1)
-
شهرهای مورد تجزیه و تحلیل چند کاربر توییتر دارند؟
- (2)
-
کدام وبسایتها در جریان اطلاعات شهرهای تحلیلشده در حوزه توییتر غالب هستند؟
- (3)
-
کدام محتوا در جریان اطلاعات شهرهای تحلیل شده در حوزه توییتر غالب است؟
- (4)
-
آیا می توان ارتباط بین شهرها را از طریق تجزیه و تحلیل محتوای توییتر اندازه گیری کرد؟
این چهار سوال بر روی یکدیگر بنا می شوند. در ابتدا، ما می خواهیم بدانیم که کاربران در 31 شهر چقدر فعال هستند. برای دقیقتر بودن، میخواهیم بدانیم که در هر یک از شهرها چند توییت تولید میشود تا نشانهای از مرتبط بودن نتایج عمیقتر را به دست آوریم. پاسخ به سوالات 2 و 3 نمای کلی خوبی از محتوای تولید شده در هر شهر می دهد. با این نتایج، میتوان در نهایت سعی کرد توضیحاتی مبتنی بر محتوا برای ارتباط بین شهرها پیدا کرد. در نتیجه، سه سوال اول به تجزیه و تحلیل نتایج سوال 4 کمک می کند. جریان اطلاعات توسط فراداده های جغرافیایی و تحلیل محتوا اندازه گیری می شود. در نهایت، یافتههای این تحقیق یک تحقیق کوتاهمدت را نشان میدهد و گزیدهای کوچک از حوزه توییتر را نشان میدهد. تا آن جایی که می دانیم،
2. جمع آوری مطالب مرتبط با شهر در توییتر
از آنجایی که توییتر پارامترهای متنوعی را ارائه میکند که میتوان از آنها برای یافتن توییتها استفاده کرد، میتوان دو معیار را تعریف کرد که یک توییت برای ارتباط با یک شهر باید رعایت کند [ 31 ].
- (1)
-
نام شهر در توییت به عنوان یک هشتگ یا به عنوان یک اصطلاح معمولی ذکر شده است.
- (2)
-
این توییت با یک مکان جغرافیایی که در محدوده شهر قرار دارد برچسب گذاری شده است.
برای این منظور، توییتر دو API مختلف (رابط برنامه نویسی برنامه) ارائه می دهد: REST API و Streaming API. مورد اول از منابع متعددی مانند کاربران، جدول زمانی، دوستان و فالوورها ناشی می شود. برای یافتن توییتهایی که با جستارهای کاربر مطابقت دارند، به ترتیب از منبع جستجو – Search API – استفاده میکنیم. توییت هایی که توسط یک مکان جغرافیایی مشخص برچسب گذاری شده اند، بدون در نظر گرفتن محتوا، می توانند با استفاده از Streaming API شناسایی شوند. برای جستجوی توییتها، از نام شهرهای 31 شهر اطلاعاتی جهان با املای متنوع استفاده میکنیم. به منظور بازیابی یک مجموعه تا حد امکان جامع، همه شهرها به زبان ملی مربوطه و در نه زبان رایج با استفاده از الفبای لاتین جستجو میشوند: اسپانیایی، انگلیسی، پرتغالی، آلمانی، فرانسوی، ایتالیایی، لهستانی، رومانیایی و هلندی. 32]. برای پایین نگه داشتن نرخ خطا تا حد امکان، پرس و جوهایی که حاوی نویسه های غیر لاتین هستند به دو یا چند پرس و جو تقسیم می شوند. به عنوان مثال پرس و جوها برای پکن به صورت زیر تقسیم می شوند:
- (1)
-
Beijing OR #Beijing OR Běijing OR #Běijing OR Pechino OR #Pechino OR Pekin OR #Pekin OR Peking OR #Peking OR Pekin OR #Pekín OR Pequim OR #Pequim OR Pékin OR #Pékin
- (2)
-
北京 OR #北京
برای پرس و جوهایی که حاوی هیچ کاراکتر غیر لاتین نیستند، کافی است فقط از یک پرس و جو استفاده کنید.
محدودیت به زبان های مبتنی بر الفبای لاتین برای خواندن و ترجمه آسان تر زبان ها انتخاب شده است. با توجه به اینکه در کشورهایی که زبانهای مبتنی بر الفبای لاتین ندارند، بسیاری از توییتها به هر حال به زبان انگلیسی هستند – طبق Semiocast [ 33] حدود 40 درصد از همه توییتها به زبان انگلیسی نوشته میشوند—تعداد توییتهایی که جمعآوری نمیشوند، حتی اگر حاوی نام یکی از شهرها باشند، باید در محدوده قابل قبولی باشد. علاوه بر این، برخی از اختصارات محبوب مانند #la برای لس آنجلس و #nyc برای شهر نیویورک در جستوجوها گنجانده شدهاند، در صورتی که مخفف معروفی وجود داشته باشد. تصمیم گرفتیم عباراتی را که به شدت به شهرهایی مانند «میدان تایمز» (نیویورک) یا «پیکادلی» (لندن) مرتبط هستند را کنار بگذاریم تا اولین بار در مورد نحوه نمایش شهرها در توییتها و اینکه آیا نام شهرها کافی است، دریافت کنیم. شاخص برای اندازه گیری فراوانی توییت های مربوط به شهر.
هنگام استفاده از Streaming API توییتر برای یافتن توییت هایی که در یک منطقه خاص برچسب گذاری شده اند، یک کادر محدود باید مشخص شود. یک جعبه مرزی با گوشه های جنوب غربی و شمال شرقی آن مشخص می شود که به نوبه خود به صورت جفت طول و عرض جغرافیایی تعریف می شوند. در نتیجه، یک مستطیل در حال شکل گیری است که ناحیه ای را که باید نظارت شود، مشخص می کند. اندازه مستطیل ها بر اساس اندازه های رسمی مناطق شهر در صورت ارائه اظهارنامه رسمی است. در غیر این صورت، ما از تعریف نقشه های گوگل از منطقه شهر استفاده کردیم که با استفاده از Google Maps API v3 می توان به آن دست یافت (این وب سایت با استفاده از Google Maps API v3 کادرهای محدود کننده را نشان می دهد مانند: http://www.mapdevelopers.com/geocode_bounding_box.php ).
2.1. پایگاه داده و فرآیند جمع آوری
توییتها بین 2 دسامبر 2013 و 16 دسامبر 2013 جمعآوری شدند. در نتیجه، مجموعه دادههای ما حاوی دو هفته دادههای توییتر است که به نظر میرسد یک بازه زمانی کوتاه باشد. هدف ما دریافت نشانه هایی از نحوه تجزیه و تحلیل این مجموعه داده ها برای ایجاد روش بهینه برای تعیین ویژگی های جریان اطلاعات و ارتباط بین شهرهای جهان اطلاعاتی است. علاوه بر این، از آنجایی که یک توییت فقط برای یک ساعت «زندگی» میکند، دو هفته میتواند تأثیر خوبی در مورد جریانهایی که در توییتر اتفاق میافتد ایجاد کند. به منظور رسیدگی به شرایط مختلف REST و Streaming API توییتر، دو ربات مختلف (برنامه های خودکار برای جمع آوری داده ها) با استفاده از زبان برنامه نویسی PHP (نسخه 5.4.4) ایجاد شده است: ربات جستجو و ربات جریان. هر دو ربات با یک صف از پرس و جوها کار می کنند که در MySQL (نسخه 5) ذخیره می شود. 6) پایگاه داده تفاوت بین Stream Bot و Search Bot در این است که Search Bot به صورت دوره ای پرس و جوی بعدی را از پایگاه داده واکشی می کند، درخواست HTTP را به REST API ارسال می کند و پرس و جو را به روز می کند تا در انتهای صف پرس و جو قرار گیرد. در عوض، ربات Stream تنها یک بار درخواستها را زمانی که مقداردهی اولیه میشود، واکشی میکند و یک اتصال HTTP دائمی به Streaming API را باز نگه میدارد تا زمانی که ربات توسط کاربر متوقف شود. پس از اینکه هر یک از دو ربات دادههای توییت جدید را از یکی از دو API بازیابی کرد، پاسخ JSON (JavaScript Object Notation) در جدول کش ذخیره میشود. یک فرآیند دائماً در حال اجرا، این جدول را برای دادههای درج شده جدید بررسی میکند و آن را به اسکریپتهایی که دادهها را به فرمت تعریفشده توسط مدل پایگاه داده تجزیه و عادی میکنند و در نهایت دادهها را به آن وارد میکنند، تفویض میکند.34 ]، که فقط از API استریم توییتر برای جمع آوری توییت ها استفاده می کند. فرآیند کامل در شکل 1 نشان داده شده است .
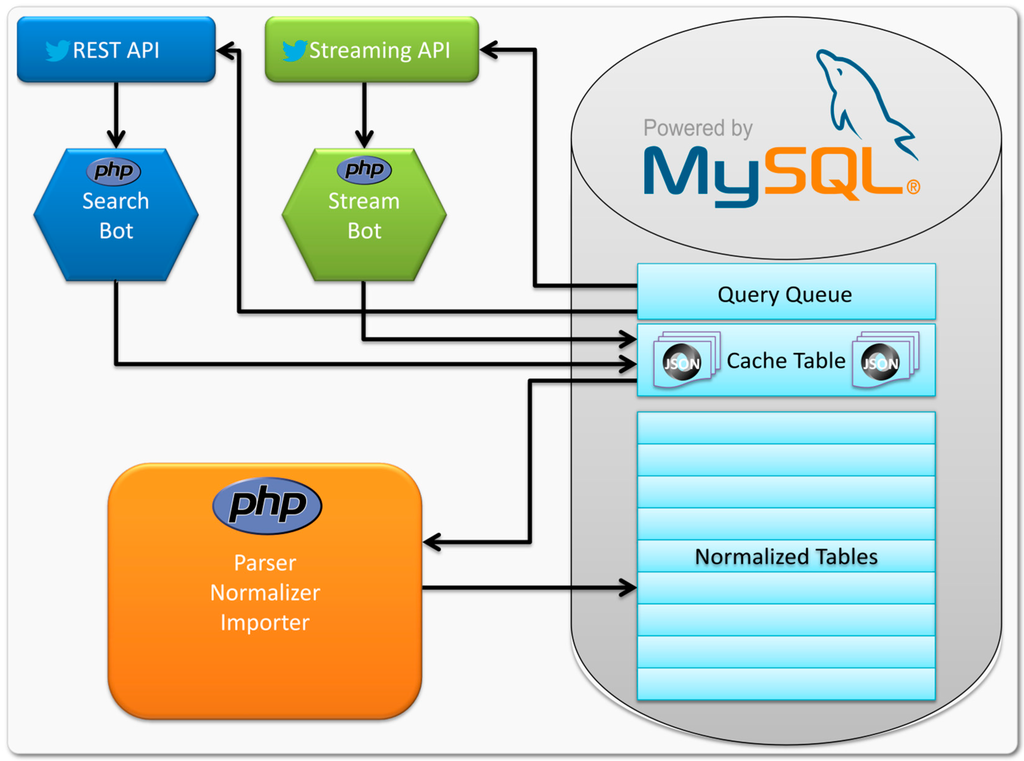
شکل 1. فرآیند جمع آوری.
2.2. مجموعه داده
پایگاه داده حاوی 40 میلیون توییت است که با استفاده از پرس و جوهای مختلف برای دو API ذکر شده در بالا پیدا شده است و بنابراین دارای موارد تکراری است. به عنوان مثال، هنگام استفاده از REST API توییتر، یک توییت از طریق پیدا می شودعبارت جستجوی «نیویورک» اگر حاوی رشته «نیویورک سیتی» باشد. اگر این توییت با شناسه منحصربهفرد ارائه شده توسط توییتر در پایگاه داده وجود نداشته باشد، یک رکورد جدید ذخیره میشود و کوئری که مطابقت دارد با آن مرتبط میشود. اگر توییت دوباره پیدا شود زیرا علاوه بر این حاوی #paris است، فقط ارتباط بین کوئری پاریس و توییت در پایگاه داده ذخیره میشود و رکورد حاوی دادههای توییت، دو بار ذخیره نمیشود. علاوه بر این، ممکن است توییت قبلی دارای اطلاعات جغرافیایی باشد و مختصات آن در مستطیل برلین قرار گرفته باشد. بنابراین، این توییت برای سومین بار اما این بار از طریق یافت می شودStreaming API و یک اتصال جدید بین توییت و پرس و جو ذخیره خواهد شد. از این رو، بین شمارش تعداد دفعات یافتن توییت با استفاده از هر یک از APIها و شمارش توییت های منحصر به فرد ذخیره شده در پایگاه داده تفاوت وجود دارد. شکل 2 تعداد توییتهایی را نشان میدهد که مجموعه شامل دو دسته با سه زیر شاخه است. زیرشاخه REST API نشان دهنده تمام توییت هایی است که فقط با استفاده از REST API توییتر یافت می شوند. اگر توییت نمونه ما با استفاده از عبارت “نیویورک” و بار دوم با استفاده از عبارت “پاریس” یافت شود، در این دسته قرار می گیرد. در نتیجه، تعداد توییتهای منحصربهفرد یافت شده از طریق افزایش مییابدREST API یک و تعداد تمام توییتهای حاوی موارد تکراری دو نفر است زیرا با استفاده از جستجوهای نیویورک و پاریس پیدا شده است. با این حال، از آنجایی که توییت مثال ما دو بار با استفاده از REST API و یک بار با استفاده از Streaming API پیدا شده است، ما فقط یک توییت منحصر به فرد اما سه بازدید برای دسته همه توییتهای حاوی موارد تکراری داریم که در هر دو API یافت شده است. همانطور که در شکل 2نشان می دهد، تفاوت 1,019,548 توییت بین توییت های منحصر به فرد و تکراری وجود دارد. مقادیر توییتهای منحصربهفرد و تکراری یافت شده توسط Streaming API یکسان هستند، زیرا یک توییت نمیتواند با دو مکان جغرافیایی مختلف برچسبگذاری شود. با مقایسه دو روش جستجوی مورد استفاده برای ایجاد پیکره، واضح است که توییتهای بیشتری با استفاده از عبارات جستجو نسبت به استفاده از مکانهای جغرافیایی پیدا شده است، که به دلیل عدم مشخص کردن مکان توسط کاربران است. حدود 68 درصد از همه توییتها (غیر منحصر به فرد) با استفاده از REST API، 31 درصد با استفاده از Streaming API و 1 درصد با استفاده از هر دو یافت شدند.
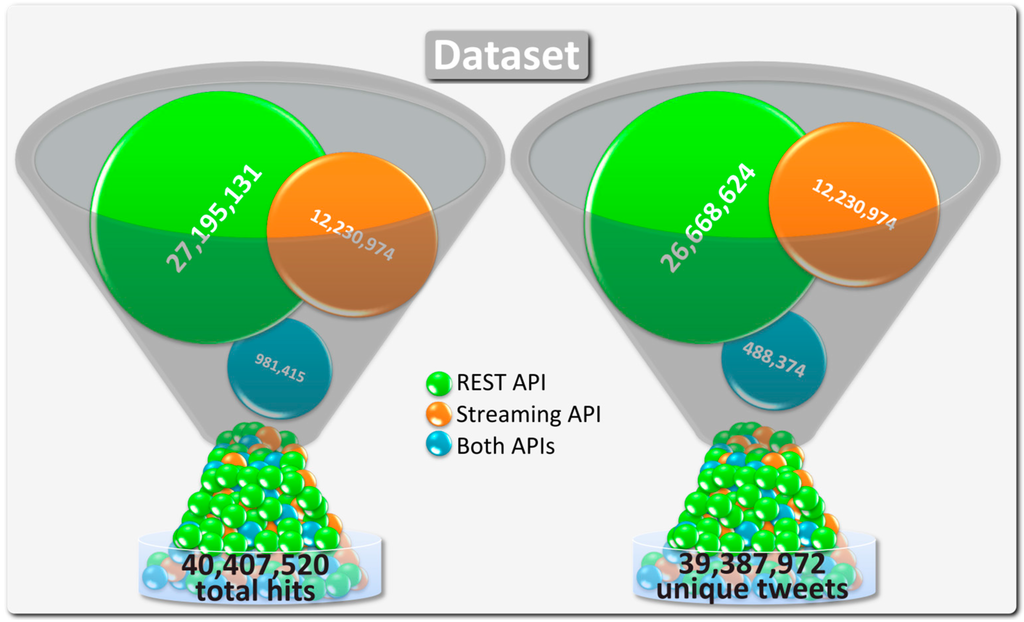
شکل 2. مجموعه داده.
2.3. تشخیص موضوع
بزرگترین بخش تجزیه و تحلیل با استفاده از ویژگی های MySQL مانند جستجوی متن کامل یا توابع جمع انجام شده است. علاوه بر این، اسکریپتهای خودکار PHP (زبان برنامهنویسی سمت سرور) که برای هدف ما نوشته شدهاند، در مورد محدودیتهای MySQL کار میکنند. برای تجزیه و تحلیل محتوا، روش های تجزیه و تحلیل متن MySQL کافی نیست. بنابراین، دادههای توییت علاوه بر این در یک Apache Lucene Index که برای مدیریت دادههای بزرگ طراحی شده بود، فهرستبندی شدهاند و یک موتور جستجوی متن کامل با ویژگیهای مناسبتر را ارائه میدهد. هر توییت به عنوان یک سند واحد با داده ها و ابرداده های زیر نمایه شده است:
-
شناسه توییت،
-
متن،
-
تاریخ ایجاد،
-
شهرهای مرتبط (Geo یا Query)،
-
شناسه مکالمه شامل در صورت وجود،
-
ریتوییت می شود،
-
اسپم است،
-
تعداد مورد علاقه،
-
تعداد بازتوییت،
-
زبان ارائه شده توسط توییتر.
بنابراین، امکان جستجوی پیکره در تمام ترکیبات قابل تصور این ویژگی ها وجود دارد. اکنون می توان پرس و جوهایی مانند “دریافت همه توییت هایی که به مونیخ مرتبط هستند و بیش از 1000 مورد علاقه دارند” را به عنوان مثال فرموله کرد.
برای هر شهر، ما اکنون دو لیست از 100 هشتگ برتر استفاده شده در مجموعه خود ایجاد کرده ایم. ما از شمارش ساده توییتها بهعنوان مقدار وزن استفاده کردیم و اعداد را جمع کردیم تا فهرستی مرتب از بیشترین موضوعات اختصاص داده شده به هشتگها و در نتیجه توییتهای مجموعه داده به دست آوریم. موضوعات به صورت دستی از طریق تجزیه و تحلیل محتوا تعریف شده اند و همه هشتگ ها با استفاده از یک طرح کدگذاری مشخص اضافه شده اند. مجدداً از دو لیست هشتگ برای تعیین موضوعات نشان داده شده توسط هشتگ ها استفاده کردیم. یک لیست برای توییت های دارای برچسب جغرافیایی و دیگری برای توییت هایی است که از طریق عبارات جستجو یافت می شوند. بر خلاف اصطلاح لیست، لیست هشتگ ها هر کدام از 25 هشتگ پرکاربرد تشکیل شده است. به عنوان مثال، هشتگ #music و هشتگ #آهنگ به موضوع “عکس، فیلم و موسیقی” اختصاص داده شده است. هشتگ ذکر شده اول در 500 توییت و هشتگ دوم در 350 توییت یافت شده است. در نتیجه، تعداد کل توییتها 850 توییت برای موضوع «عکسها، فیلمها و موسیقی» است.
2.4. تشخیص هرزنامه
ما از یک الگوریتم تشخیص هرزنامه با برخی جنبههای دستی استفاده کردیم تا بیشتر توییتهای هرزنامه را لغو کنیم. در مرحله اول، ما 100 کاربر برتر را در کل مجموعه داده طبقه بندی شده بر اساس تعداد توییت شناسایی کردیم. ثانیاً برای همه این کاربران یک درخواست از کاربران/نمایش منبع REST API توییتر انجام شده است. اگر پاسخ API حاوی اطلاعاتی باشد که حساب توسط توییتر به حالت تعلیق درآمده است، همه توییتهای این حساب بهعنوان هرزنامه علامتگذاری شدهاند. ثالثاً، ما به صورت دستی همه حسابهای باقیمانده را بررسی کردیم که آیا توییتهایی با محتوای مرتبط تولید میکنند یا خیر. حسابهایی که فقط برای هشتگ یا موضوع خاصی مانند «Toronto Retweeter» (@toronto_rt) یا «Vancouver Retweeter» (@vancouver_rt) ریتوییت میکنند، به عنوان ارسالکننده هرزنامه طبقهبندی میشوند زیرا محتوای مرتبطی برای این تحلیل تولید نمیکنند. اکثر این حساب ها حاوی اطلاعات “من یک ربات هستم” در توضیحات حساب خود هستند. در نهایت، برخی از حسابهای اسپم که قبلاً شناسایی شدهاند، توییتهایی تولید میکنند که میتوان آنها را بهعنوان هرزنامه با محتوایشان شناسایی کرد. برای یک کاربر، واضح است که توییت فقط با خواندن متن توییت یک توییت اسپم است. برای مثالی از این نوع توییت، نگاه کنیدشکل 3 .
برای شناسایی سایر توییتهای مشابه و علامتگذاری آنها بهعنوان هرزنامه، از نمایه Lucene سؤال کردیم ( http://lucene.apache.org/) برای همه توییتهای هرزنامه و همه نشانههای منحصربهفرد مجموعه نتایج اسناد شامل میشود. تمام عباراتی که کلمات هرزنامه بالقوه نیستند به صورت دستی با لیستی از 580 کلمه هرزنامه احتمالی فیلتر شده اند. برای یافتن توییتهای هرزنامه اضافی، از پایگاه داده برای توییتهایی پرس و جو کردیم که حداقل دو مورد از این کلمات هرزنامه را داشته باشند، زیرا توییتی که حاوی عبارت mature باشد، لزوما توییت اسپم نیست. توییتی که حاوی بزرگسالان و پورن است به احتمال زیاد یک توییت اسپم است. برای پایین نگه داشتن نرخ مثبت کاذب تا حد امکان، همه توییتهای یافت شده را به صورت دستی بررسی کردیم و آنهایی را که نمیتوان بهعنوان هرزنامه علامتگذاری کرد حذف کردیم. انتخاب توییت ها با در نظر گرفتن سوالات زیر انجام شد:
-
آیا این توییت از یک کاربر واقعی می آید؟
-
آیا توییت نه تنها حاوی هشتگ است؟
-
آیا توییت دیگری با محتوای مشابه ( یعنی ایجاد شده توسط ربات های بازتوییت و غیره ) در مجموعه داده وجود ندارد ؟
اگر بتوان به یکی از سوالات مربوط به یک توییت با “خیر” پاسخ داد، در بیشتر موارد توییت می تواند به عنوان یک توییت اسپم علامت گذاری شود. این توییتهای هرزنامه در تمام تحقیقاتی که ممکن است نتایج را تحریف کنند، فیلتر میشوند.

شکل 3. مثالی از یک توییت اسپم.
3. نتایج و بحث
جدول 1 تعداد توییتهای یافت شده برای هر شهر را نشان میدهد، یا از طریق جستجوی اصطلاحات و API REST توییتر یا از طریق مکان جغرافیایی ارائه شده و API جریانی توییتر که بر اساس تعداد کل توییتها رتبهبندی شدهاند. واضح است که ما یک رهبر روشن داریم: توکیو. با تقریباً 4.5 میلیون توییت یافت شده از طریق عبارات جستجو، توکیو از سایر شهرها با فاصله قابل توجهی از جایگاه دوم که در اختیار شهر نیویورک با حدود سه میلیون توییت است، فاصله دارد. جالب است که از پاریس تا بارسلونا شکاف مهم دیگری رخ می دهد و از آن نقطه به بعد، تعداد توییت ها به طور مداوم کاهش می یابد. به طور خلاصه، چهار شهر معادل 45 درصد از توییتهایی است که با استفاده از عبارات جستجو برای 31 شهر پیدا شدهاند. این پدیده را می توان با این واقعیت توضیح داد که این چهار شهر دارای نرخ بالایی از گردشگری شهری هستند [ 31]. نیویورک (بیش از 10 میلیون بازدید کننده)، لندن (بیش از 15 میلیون بازدید کننده)، و پاریس (بیش از 8 میلیون بازدید کننده) متعلق به شهرهای مجموعه ما هستند که بیشترین بازدید کننده بین المللی را در سال 2011 داشتند [35 ] . توکیو تنها حدود 2.7 میلیون بازدید کننده بین المللی داشته است، اما همیشه گردشگری داخلی قوی داشته است (430 میلیون بازدید کننده داخلی در سال 2008).
با در نظر گرفتن اعدادی که تعداد توییتها در هر شهر را نشان میدهند و از طریق مکانهای جغرافیایی پیدا شدهاند، میتوانیم دو پیشتاز پاریس و سائوپائولو را با تعداد تقریباً مساوی توییت (حدود 1.8 میلیون) شناسایی کنیم. نیویورک سیتی و لندن پس از فاصله حدود 470 هزار توییت کمتر از سائوپائولو و سپس سومین جفت شهر، لس آنجلس و کوالالامپور، با حدود 1.4 تا 1.7 میلیون توییت، به عنوان جفت بعدی (هر دو حدود 1.3 میلیون توییت) دنبال میشوند. ، نشان دهنده آخرین گروهی است که قبل از کاهش مداوم تعداد توییت ها برجسته است. به عنوان یک نتیجه نسبتا منطقی، اگر نگاهی به توییتهایی بیندازیم که منشأ هر یک از این شهرها دارند، میتوانیم سه شهر چین – پکن، شانگهای و شنژن – را که در رتبههای 29-31 قرار دارند، بیابیم.36 ].
در تجزیه و تحلیل کمی قبلی خود [ 31 ]، ما قبلاً برخی از عوامل تأثیرگذار را نقل کردیم که می توانند تفاوت های عظیم بین اعدادی را که از مجموعه داده خود محاسبه کرده ایم توضیح دهند. برای مثال، تعداد زیادی توییت را مشاهده میکنیم که از طریق مکانهای جغرافیایی برای سائوپائولو و کوالالامپور یافت میشوند، اما تعداد نسبتا کمی از توییتهایی که نام این دو شهر را ذکر میکنند. شهرهای آلمان برلین، فرانکفورت و مونیخ تصویری برعکس را نشان می دهند. برای این شهرها، تعداد کمی توییت با برچسب جغرافیایی پیدا کردیم. ما فرض می کنیم که سطح بالای آگاهی از حفاظت از حریم خصوصی داده ها در آلمان [ 37] می تواند عاملی برای تعداد کمی توییت های دارای برچسب جغرافیایی باشد. بنابراین، کاربران آلمانی موقعیت مکانی خود را مانند کاربران برزیل یا مالزی به اشتراک نمی گذارند. ما همچنین متوجه شدیم که نرخ نفوذ گوشیهای هوشمند، که آشکارا بر میزان توئیتهای دارای برچسب جغرافیایی به دلیل ماژولهای GPS داخلی تأثیر میگذارد، به نظر میرسد بر تعداد آنها تأثیر بگذارد. Rowinski [ 38 ] 70 میلیون کاربر تلفن هوشمند در برزیل و تنها 32 میلیون کاربر در آلمان دارد. با این حال، فرانسه نیز تنها 33 میلیون کاربر تلفن هوشمند دارد که منجر به این فرض می شود که این عامل قابل تعمیم نیست.

جدول 1. توییتها به ازای هر شهر رتبهبندی شده بر اساس تعداد کل توییتهای جمعآوریشده بین 2 دسامبر 2013 تا 16 دسامبر 2013.
3.1. توییتر به عنوان یک سرویس اشتراک گذاری برای سایر خدمات رسانه های اجتماعی
استخراج لینک های برتر به اشتراک گذاشته شده در توییت های مربوط به شهرهای جهان اطلاعات نشان می دهد که سایر خدمات رسانه های اجتماعی تقریباً در هر شهر رتبه بندی را دارند. شکل 4، 5 سرویس رایج مشترک را نشان می دهد. مقادیر معکوس شده اند. رتبه یک 100 امتیاز، رتبه دو 90 امتیاز، رتبه سه 80 امتیاز و غیره. اگر وبسایتی به 10 لینک برتر در توییتهای مربوط به یک شهر خاص راه پیدا نکند، در نهایت امتیاز صفر میشود.
بزرگترین برنده این محاسبه اینستاگرام است. تقریباً تمام رتبه بندی وب سایت هایی که بیشترین اشتراک گذاری را دارند، امتیاز 70 تا 100 را برای اینستاگرام به دست می آورند. در اینجا فقط مونیخ یک استثنا است. اینستاگرام تنها در توییت های مربوط به مونیخ به امتیاز 40 می رسد. پدیده مشابهی را می توان با نگاه کردن به مقادیر دومین وب سایت رتبه بندی شده Foursquare مشاهده کرد که حتی به 10 سایت برتر مرتبط با مونیخ راه پیدا نمی کند. با این حال، مونیخ این وجه مشترک با بارسلونا دارد. بدیهی است که مردم این شهرها علاقه چندانی به اشتراک گذاری مکان فعلی خود از طریق آن ندارندFoursquare یا آنها فقط حساب Foursquare خود را به حساب توییتر خود متصل نکردند. به نظر می رسد کاربران توکیو، فرانکفورت، کوالالامپور و سائوپائولو بیشتر از این ویژگی استفاده می کنند، اما Foursquare بهترین گلزن این شهرها است. یوتیوب و فیس بوک تقریباً اهمیت مشابهی را هنگام نگاه کردن به توییت هایی که به وب سایت های دیگر پیوند می دهند نشان می دهند. یوتیوب به امتیاز کلی 2040 و فیس بوک به امتیاز 1980 رسیده است. فیس بوک در لندن صد امتیاز و یوتیوب در سئول نیز صد امتیاز کسب می کند. در تمام شهرهای دیگر، این دو سرویس می توانند در خط هافبک قرار بگیرند. Tumblr با امتیاز 400 نیز جزو پنج سرویس برتر رسانه های اجتماعی است که از طریق آن به اشتراک گذاشته شده است.توییتر. همه سرویسهای دیگر، مانند Pinterest، Flickr یا LinkedIn، فقط در این تحقیق علاقهمند هستند و بنابراین در تجسم ما گنجانده نشدهاند. به عنوان مثال، سرویس میکروبلاگینگ چینی Weibo، فقط در شهرهای چین مهم است، اما در هیچ یک از شهرها به ده نفر برتر نمی رسد.
3.2. موضوعات اصلی در توییت ها
از آنجایی که ما نه تنها به نتایج کمی علاقه مندیم، بلکه می خواهیم با تعیین موضوعات اصلی در توییت ها، رویکرد کیفی تری را دنبال کنیم. کدام محتوا در جریان اطلاعات بین شهرها در حوزه توییتر غالب است؟ داده های تجزیه و تحلیل شده نشان می دهد که ذکر شهرها یا مکان های جغرافیایی دیگر در توییت هایی که مربوط به شهرهای جهان اطلاعاتی است بسیار محبوب است. از آنجایی که قبلاً Foursquare را به عنوان یکی از وب سایت های به اشتراک گذاشته شده در مجموعه داده خود شناسایی کرده بودیم و اشتراک گذاری مکان ها مدل کسب و کار این سرویس است، این تعجب آور نیست.
توییتر همچنین اغلب برای پیشنهادهای شغلی، چه توسط آژانس های کاریابی یا خود شرکت ها، استفاده می شود. در نتیجه، مقوله موضوعی «اقتصاد، صنعت، امور مالی و مشاغل» حتی بیشتر از «رویدادها و تاریخها» وجود دارد که ما همچنین انتظار داریم که به دلیل ماهیت رویداد محور یک سرویس میکروبلاگینگ مانند توییتر یکی از موضوعات برتر باشد. . به دلیل شهرهایی مانند بارسلونا یا مونیخ با تیمهای معروف فوتبالشان، اما شهرهایی مانند شیکاگو یا لسآنجلس با تیمهای معروف آمریکایی فوتبال، بسکتبال یا بیسبال، «ورزش» را نیز میتوان در میان محبوبترین موضوعات یافت. این همچنین بر تعداد مکالمات بین کاربران از شهرهای مختلف جهان اطلاعاتی تأثیر می گذارد که در فصل بعدی نشان خواهیم داد.

شکل 4. پنج سرویس مشترک برتر در توییتر.
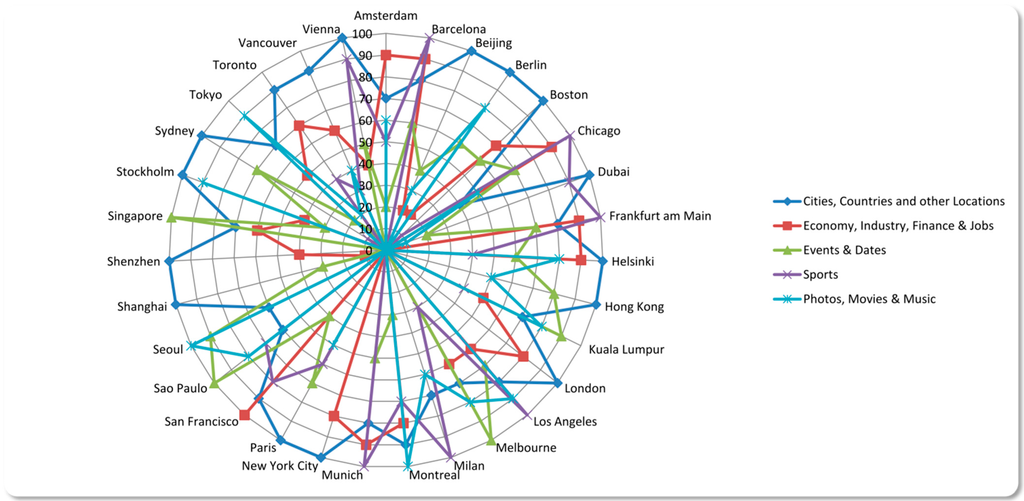
شکل 5. مهمترین موضوعات در توییت I.
با توجه به امکان اشتراکگذاری محتوای چندرسانهای یا لینکهایی به محتوای چندرسانهای، تعداد بسیار زیادی توییت در مجموعه داده ما وجود دارد که میتوانیم آنها را به دسته «عکسها، فیلمها و موسیقی» اختصاص دهیم. علاوه بر این، بسیاری از ایستگاههای رادیویی شهرستانها حساب کاربری خود را دارند و توییتهایی درباره موسیقی در حال پخش (#در حال پخش) به اشتراک میگذارند.

شکل 6. مهمترین موضوعات در توییت ها II.
علاوه بر موضوعات ذکر شده، توییتر همچنین برای صحبت در مورد افراد مشهور، به اشتراک گذاری اخبار از سرویس های خبری آنلاین مانند وب سایت روزنامه ها یا صحبت در مورد سیاست استفاده می شود. در طول دوره جمع آوری ما، یک ماجرای سیاسی در تورنتو در مورد شهردار راب فورد رخ داد. ویدئویی فاش شده است که او را در حال کشیدن کراک نشان می دهد [ 39 ]. در نتیجه، «سیاست و جامعه» یکی از مهمترین مقولههای موضوعی در آن دوران بود.
آخرین دستهای که باید به آن اشاره کنیم «رسانههای اجتماعی و ارتباطات» میگوییم. به تمام توییت هایی اطلاق می شود که حاوی محتوایی است که معمولاً در توییتر برای برقراری ارتباط یا شرکت در رویدادهای خاص استفاده می شود. یک مثال می تواند هشتگ #ff یا #followfriday یا هشتگ #tbt (“پنجشنبه بازگشت”) باشد. 9 موضوع مهم در شکل 5 و شکل 6 نشان داده شده است که توسط محاسبات معکوس ما در مقیاس 0 تا 100 رتبه بندی شده اند.
3.3. نزدیکی بین شهرهای جهان اطلاعاتی
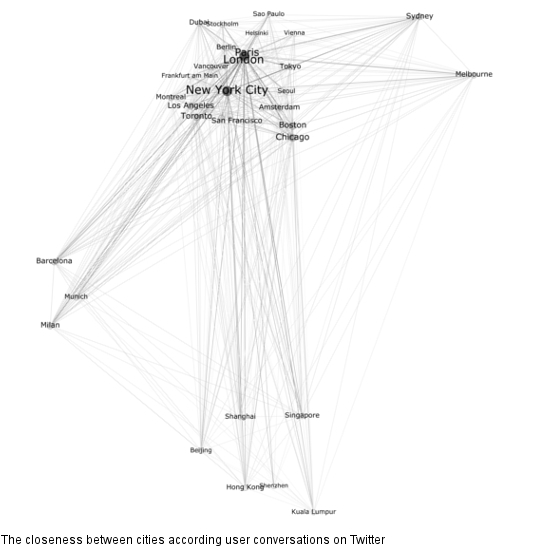
یکی از جنبههای جالب پژوهش شهر اطلاعاتی، تعیین نزدیکی شهرها به یکدیگر است. نزدیکی را می توان از طریق اتصالات در شبکه ای از هاب ها تجزیه و تحلیل کرد. داده های ارائه شده توسط توییتر دارای پتانسیل استخراج مکالمات توسط شناسه مکالمه در فراداده است. بنابراین، ما تمام مکالمات موجود در مجموعه داده خود را استخراج کردیم و شهرهایی را که ذکر شده یا با کدهای جغرافیایی برچسب گذاری شده اند، تجزیه و تحلیل کردیم. شهرها گره های این شبکه را تشکیل می دهند. در نتیجه، ما یک نمودار خوشهای ساختیم که شامل تمام شهرهایی است که از طریق تعداد مکالمات به هم متصل شدهاند. به عنوان مثال، 1438 مکالمه را می توان به طور همزمان به شیکاگو و نیویورک اختصاص داد، بنابراین این عدد میزان “ارتباط” بین این دو شهر را به ما نشان می دهد. با استفاده از الگوریتم OpenOrd در Gephi،شکل 7 ). اندازه نوع نشان دهنده اهمیت یک گره است که یک شهر را نشان می دهد. هرچه بتوان در مجموع مکالمات بیشتری را به یک شهر اختصاص داد، گره در نمودار اهمیت بیشتری پیدا می کند. از این رو، شبکه مورد بررسی فقط یک عکس فوری است که یک بازه زمانی معین را نشان می دهد. روابطی که در اینجا می بینیم، ممکن است از طریق رویدادهای خاص تحت تأثیر قرار گیرند، به عنوان مثال، فرمول یک در یک شهر اتفاق می افتد، که توجه جهانی را به خود جلب می کند و همچنین بر مکالمات در توییتر تأثیر می گذارد و در نتیجه منجر به گره بزرگتری از این شهر می شود.
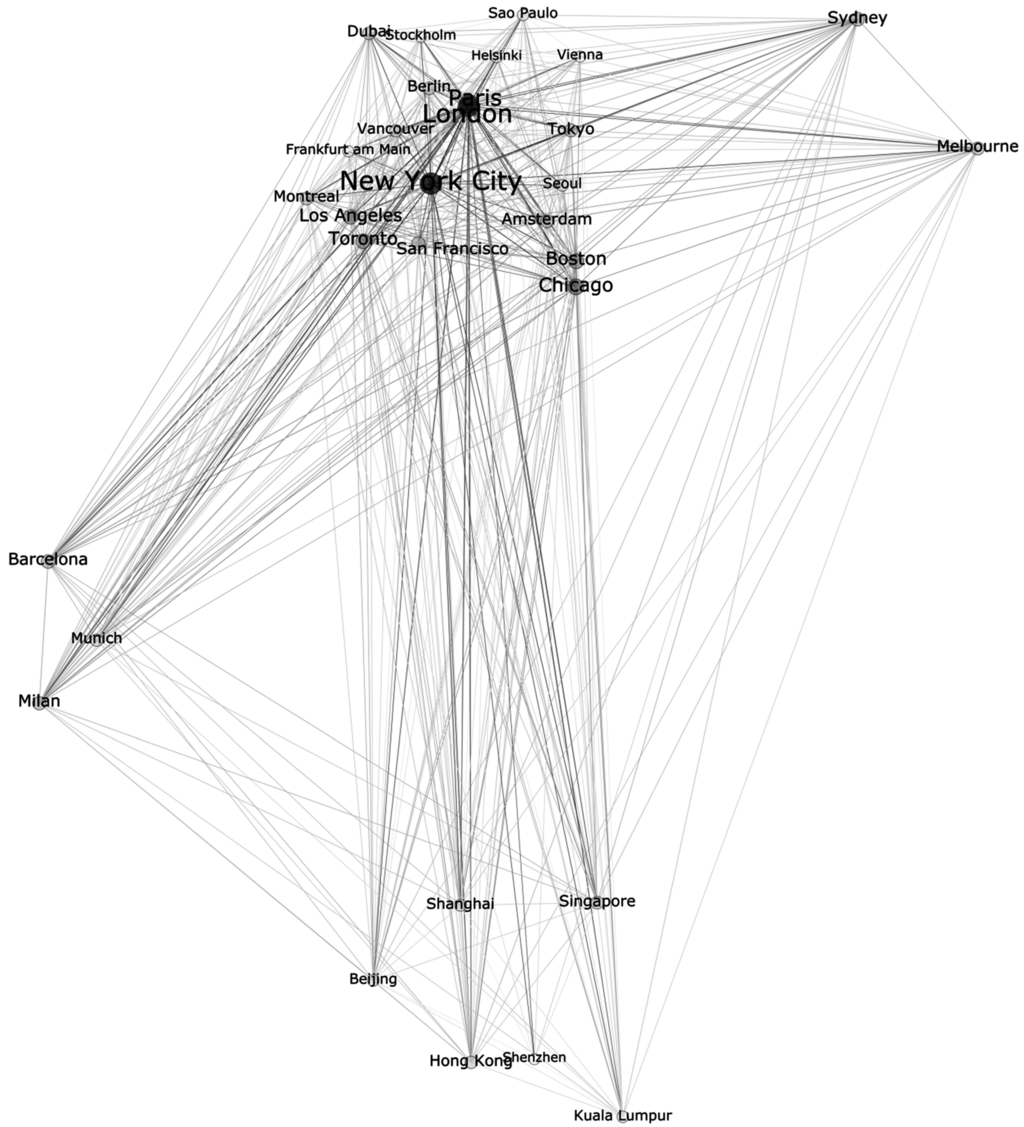
شکل 7. نزدیکی بین شهرها بر اساس مکالمات کاربر.
واضح ترین پدیده در نمودار توزیع چهار خوشه با اندازه های مختلف است. ما یک خوشه استرالیایی متشکل از ملبورن و سیدنی و یک خوشه آسیای جنوب شرقی متشکل از پکن، شانگهای، سنگاپور، هنگ کنگ، شنژن و کوالالامپور پیدا کردیم. علاوه بر این دو خوشه که عمدتاً شامل شهرهایی می شود که در دنیای واقعی از نظر جغرافیایی نیز به هم نزدیک هستند، دو خوشه دیگر ظاهر شدند که این ویژگی را برآورده نمی کنند. خوشه ای که شامل بارسلونا، مونیخ و میلان است، ما به آن “خوشه فوتبال” می گوییم. از آنجایی که موضوعات برتر در توییتهای مربوط به هر یک از این شهرها در مجموعه داده ما به وضوح تحت سلطه ورزش یا به طور دقیقتر فوتبال است، بنابراین میتوان فرض کرد که محتوای توییتها بر جایی که کاربران از طریق مستقیم ارتباط برقرار میکنند نیز تأثیر دارد. گفتگواز طریق توییتر یا در مورد کدام شهرها صحبت می کنند. با تجزیه و تحلیل مکالمات اختصاص داده شده به سه شهر، متوجه شدیم که اکثر آنها با تیم های برتر فوتبالی سر و کار دارند که منشا این شهرها هستند: اف سی بارسلونا، آث میلان و اف سی بایرن مونیخ. می توان فکر کرد که این امر به این دلیل رخ می دهد که نام باشگاه های ورزشی شامل نام شهر می شود، اما سایر خوشه ها غالب نیستند، به عنوان مثال، دانشگاه آمستردام یک خوشه با دانشگاه های دیگر ایجاد نمی کند. در نتیجه، به نظر می رسد علایق مشترک افرادی که در شهرهای جهان اطلاعات زندگی می کنند، منجر به ارتباطات بین شهری بیشتر می شود. شکل 8 نمونه ای از مکالمه مربوط به هر سه شهر را نشان می دهد.
آخرین خوشه نشان داده شده در نمودار نیز بزرگترین خوشه است. این شامل تمام شهرهای آمریکای شمالی و جنوبی است که بخشی از تحقیقات ما هستند و به جز بارسلونا، میلان و مونیخ، تمام شهرهای اروپایی نیز وجود دارد. با توکیو، ما همچنین میتوانیم تنها شهری از جنوب شرق آسیا را پیدا کنیم که به شهرهای دیگر این خوشه نزدیک است اما به شهرهای دیگر منطقه خودش نزدیک نیست. در نتیجه، به نظر میرسد توکیو قویتر از شهرهای جنوب شرقی آسیا با سایر شهرهای جهان اطلاعاتی مرتبط است.
بزرگترین خوشه همچنین شامل بزرگترین گره های پاریس، لندن و نیویورک است. همانطور که در شکل نشان داده شده است، گره های پاریس و لندن تقریباً روی هم قرار دارند. این پدیده از این واقعیت ناشی می شود که با ارزش 1833، این شهرها بیشترین تعداد مکالمات رایج را در مجموعه داده ما نشان دادند. با این حال، شهر نیویورک بیشترین میزان مکالمه را نشان می دهد، در مجموع شهرهای دیگر به تعداد 9230 مکالمه می رسند که به حداقل یکی از سی شهر دیگر نیز متصل هستند. برای مقایسه، لندن به 8300 مکالمه و پاریس به 6335 مکالمه می رسد. بدون هیچ تعجبی، شنژن نشان دهنده کوچکترین گره در نمودار است (در مجموع 79 مکالمه).

شکل 8. نمونه گفتگوی مربوط به میلان، بارسلونا و مونیخ.
4. شهرهای جهان اطلاعاتی در حوزه توییتر
نتایج ما به شدت به تحقیقات فعلی شهر اطلاعاتی جهان کمک می کند. اگر میخواهیم بدانیم یک شهر چقدر «اطلاعاتی» است، باید رفتار رسانههای اجتماعی کاربرانی را که محتوای مرتبط با شهر تولید میکنند، تحلیل کنیم. با تجزیه و تحلیل مکالمات، نکاتی از ارتباط برخی شهرها با یکدیگر را دیده ایم. یک ارتباط بر اساس محتوا (به عنوان مثال، فوتبال) و یک ارتباط بر اساس موقعیت جغرافیایی وجود دارد. این به ما اشاره می کند که شهرهایی که در توییتر “نزدیک” به یکدیگر هستند به دلیل عوامل دیگر نیز به یکدیگر نزدیک هستند. در نتیجه، میتوانیم فرض کنیم که خدمات رسانههای اجتماعی میتواند آینهای از جامعهای باشد که در آن استفاده میشود. همسایهها با همسایهها و درباره آنها صحبت میکنند و طرفداران فوتبال بدون توجه به جایی که در آن قرار دارند، با دیگر طرفداران فوتبال صحبت میکنند.
مهمترین موضوعات در توییتهای مربوط به شهر میتواند به ما اشارهای از کیفیت محتوای تولید شده در پلتفرمهای رسانههای اجتماعی در شهرهای جهان اطلاعاتی و در مورد آنها بدهد. بررسی های طولانی مدت می تواند نشان دهد که آیا توییتر عمدتاً برای اشتراک گذاری (به طور خودکار) مکان ها استفاده می شود یا برای بحث در مورد موضوعات با کیفیت بالاتر نیز استفاده می شود. مشابه موضوعات، ما همچنین می توانیم از پیوندها برای ایجاد فرضیاتی در مورد کیفیت محتوا استفاده کنیم. تسلط سایر خدمات رسانههای اجتماعی در فهرست برتر وبسایتهای اشتراکگذاری شده نشان میدهد که حجم عظیمی از محتوا نیز وجود دارد که تنها اشارهای به محتوا و خدمات دیگر است.
تحلیل ما زیربنای چند محدودیت است. اولین محدودیتی که باید به آن اشاره کرد، API های توییتر و محدودیت های فنی آنهاست. برای تحقیقات خود، ما مجبور شدیم به دادههایی تکیه کنیم که توییتر به کاربران اجازه دسترسی به فایرهوس توییتر را نمیدهد. مطالعات نشان داد که کاربران می توانند از 1٪ تا 40٪ توییت های عمومی را از Streaming API دریافت کنند [ 40 ]. علاوه بر این، خرابی سرور یا پایگاه داده ممکن است منجر به از دست رفتن موقت دادههای کوتاه مدت شود، اگرچه ما هیچ یک از این مشکلات را در طول دوره جمعآوری خود ردیابی نکردیم.
به دلیل چندزبانگی قوی در مجموعه داده ما که توسط 59 زبان ارائه شده است، ما از الگوریتم تشخیص زبان توییتر، از جمله زبان های غیر معمول مانند چروکی دریافت کردیم، با چالش های متعددی مواجه شدیم. برخی از سیستمهای نوشتاری (مثلاً چینی) وجود دارند که لزوماً کلمات را با فاصلههای سفید جدا نمیکنند و در نتیجه باید با استفاده از فرهنگهای لغت که ما به آنها دسترسی نداشتیم تجزیه و تحلیل شوند. از آنجایی که ما قادر به ترجمه همه زبانهای موجود در مجموعه نبودیم، مجبور شدیم به ابزارهای ترجمه خودکار ( به عنوان مثال ، Google Translate، Bing Translator) یا چندین فرهنگ لغت آنلاین ( به عنوان مثال) تکیه کنیم., dict.cc, leo.org, Wiktionary) برای شناسایی موضوعات در توییت ها. بنابراین، تشخیص موضوع در این تحقیق بهترین تلاش است و ممکن است زیربنای چند نادرستی باشد، مانند بسیاری از بررسیهای خودکار یا نیمه خودکار در بدنهها که بر اساس زبان طبیعی هستند.
نتایج ما نشان میدهد که هنوز مشکلاتی در مورد همنامی وجود دارد، اگرچه ما شدیدترین مشکلات ( به عنوان مثال ، “پاریس هیلتون”) را فیلتر کردیم. فیلتر کردن توییتهایی که نام شهری مشابه شهری مورد نظر ما را ذکر میکنند و علاوه بر این، برچسب جغرافیایی ندارند، دشوار است. اگر توییتی حاوی متن “من در سیدنی هستم” باشد، چگونه متوجه شویم که منظور کاربر شهر استرالیا است یا سیدنی، MT، ایالات متحده آمریکا؟ به نظر می رسد هنگام جستجوی توییت ها از طریق، باید درصد مشخصی از موارد مثبت کاذب در مجموعه داده را بپذیریمREST API توییتر. حداقل، جستجوی مکانهای جغرافیایی فقط توییتهایی را از شهر مورد نظر ما ارائه میکند. با این حال، سایر مشکلات همنامی را می توان به صورت دستی حل کرد. به عنوان مثال، توییتهایی که به دلیل ذکر نام کاربری حاوی نام شهر پیدا میشوند، میتوانند به راحتی با بررسی دستی همه توییتها فیلتر شوند، اگرچه در مجموعه دادهای به بزرگی مجموعهای که برای بررسی خود استفاده کردهایم، مدتی طول میکشد.
5. نتیجه گیری و کار آینده
تحلیل ما گام بزرگی به جلو در تحقیق شهرهای جهان اطلاعاتی است که در رسانه های اجتماعی ارائه شده است. به ما نشانه های زیادی داده شده است که چگونه یک شهر جهانی اطلاعاتی را می توان در رابطه با فعالیت های توییتر طبقه بندی کرد. در واقع، تحقیقات در این زمینه به اینجا ختم نمی شود. همانطور که دیدیم، محدودیتهای متعددی زیربنای این تحقیق است که در صورت امکان، باید در تحقیقات آینده برطرف شود. برای این کار، ایجاد و جمعآوری اکتشافاتی ضروری است که اکثر مشکلات مربوط به همنامی را از بین ببرد. علاوه بر این، یک الگوریتم فیلتر اسپم کاملاً توسعه یافته باید ایجاد یا استفاده شود تا از اکثریت قریب به اتفاق توییتهای هرزنامه جلوگیری شود. نتایج مقاله ارائه شده را فقط می توان با بررسی های بعدی با مجموعه داده های جدید تأیید کرد. برای این منظور می توان از یک دوره زمانی دیگر برای جمع آوری توییت ها استفاده کرد.
به غیر از تحقیقات بیشتر در مورد جنبه ها، که در مقاله داده شده بررسی کردیم، جنبه های دیگری نیز مورد توجه ما است. تجزیه و تحلیل احساسات توییتها و موضوعات توییتها میتواند نتیجهگیری بیشتری در مورد رفتار کاربران در شهرهای جهان اطلاعات ارائه کند. علاوه بر این، توییتر ارقام کلیدی دیگری مانند تعداد فالوورها، ریتوییت ها یا تعداد علاقه مندی ها و موارد دیگر را ارائه می دهد. از این ارقام کلیدی نیز می توان برای طبقه بندی کیفیت محتوای تولید شده استفاده کرد که می تواند به یکی از شهرها مرتبط باشد.
در مجموع، با استفاده از توییتر به عنوان مثال نشان دادیم که تحقیقات رسانه های اجتماعی را نمی توان هنگام بررسی شهرهای نمونه اولیه جامعه دانش نادیده گرفت، زیرا رسانه های اجتماعی به عنوان بخش مهمی از آن شناخته شده است.
منابع
- Castells, M. The Rise of the Network Society: The Information Age, Economy, Society, and Culture , ویرایش دوم. John Wiley & Sons ناشر: Chichester، UK، 2010. [ Google Scholar ]
- کاستلز، ام. شهر اطلاعاتی: فناوری اطلاعات، بازسازی اقتصادی، و فرآیند شهری-منطقه ای . باسیل بلکول: آکسفورد، بریتانیا، 1989. [ Google Scholar ]
- سهام، WG شهرهای اطلاعاتی: تحلیل و ساخت شهرها در جامعه دانش. مربا. Soc. Inf. علمی تکنولوژی 2011 ، 62 ، 963-986. [ Google Scholar ] [ CrossRef ]
- Yigitcanlar، T. شهر اطلاعاتی. در دایره المعارف مطالعات شهری ; هاچینسون، آر.، اد. Sage: نیویورک، نیویورک، ایالات متحده آمریکا، 2010; جلد 1، ص 392–395. [ Google Scholar ]
- کاستلز، ام سیتس، جامعه اطلاعاتی و اقتصاد جهانی. در جهانی شهرهای ریدر ، ویرایش دوم. Neil, B., Roger, K., Eds. Routledge: لندن، انگلستان/نیویورک، نیویورک، ایالات متحده آمریکا، 2006; صص 135-136. [ Google Scholar ]
- فریدمن، جی. جایی که ما ایستادهایم: یک دهه تحقیقات جهانی شهر. در شهرهای جهان در یک سیستم جهانی ؛ Paul, LK, Peter, JT, Eds. انتشارات دانشگاه کمبریج: کمبریج، انگلستان، 1995; ص 21-47. [ Google Scholar ]
- ماینکا، ا. هارتمن، اس. اورسولوک، ال. پیترز، آی. استالمن، ا. استوک، WG کتابخانه های عمومی در جامعه دانش: خدمات اصلی کتابخانه ها در شهرهای جهان اطلاعاتی. Libri 2013 ، 63 ، 295-319. [ Google Scholar ] [ CrossRef ]
- تیلور، پی جی مدل شبکه درهم تنیده. در کتاب راهنمای بین المللی جهانی شدن و شهرهای جهان ; Derudder, B., Hoyler, M., Taylor, PJ, Witlox, F., Eds. انتشارات ادوارد الگار: چلتنهام، UK/Northampton، UK، 2012; صص 51-63. [ Google Scholar ]
- Haustein, S. Multidimensional Journal Evaluation: Analysing Scientific Periodical فراتر از ضریب تاثیر . Walter de Gruyter: برلین، آلمان، 2012. [ Google Scholar ]
- هاستاین، اس. تونگر، دی. هاینریش، جی. Baelz, G. دلایل و پیشرفتها در همکاری علمی بینالمللی: آیا منطقه تحقیقاتی آسیا-اقیانوسیه از دیدگاه کتابسنجی وجود دارد؟ Scientometrics 2010 ، 86 ، 727-746. [ Google Scholar ] [ CrossRef ]
- Prime, J. Altmetrics. در فراتر از کتاب سنجی: مهار شاخص های چند بعدی تأثیر علمی . Cronin, B., Sugimoto, CR, Eds. مطبوعات MIT: لندن، انگلستان، 2014; ص 263-287. [ Google Scholar ]
- Tague-Sutcliffe, J. مقدمه ای بر انفورمتریکس. Inf. روند. مدیریت 1992 ، 28 ، 1-4. [ Google Scholar ] [ CrossRef ]
- ژانگ، Q. دی فرانزو، دی. هندلر، JD شبکه های اجتماعی در شبکه جهانی وب. در دایره المعارف تحلیل و کاوی شبکه های اجتماعی ; الحاج، ر.، رکنه، ج.، ویرایش. Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2014; صفحات 1879-1892. [ Google Scholar ]
- توسط The Numbers: 138 آمار شگفت انگیز توییتر. در دسترس آنلاین: http://expandedramblings.com/index.php/march-2013-by-the-numbers-a-few-amazing-twitter-stats/#.UzKoTfnWUqJ (در 12 دسامبر 2014 قابل دسترسی است).
- کیتزمن، ج.اچ. هرمکنس، ک. مک کارتی، IP; Silvestre، BS رسانه های اجتماعی؟ جدی باش! درک اجزای سازنده عملکردی رسانه های اجتماعی. اتوبوس. هوریز. 2011 ، 54 ، 241-251. [ Google Scholar ]
- ولر، ک. Bruns, A. Das Spiel dauert 140 Zeichen-Wie deutsche Fußballvereine Twitter für Marketing und Fan-Kommunikation entdecken. In Proceedings of des 8. Hildesheimer Evaluierungs-und Retrieval Workshop, Hildesheim, Germany, 25-16 آوریل 2013.
- هاچینز، بی. شتاب فرهنگ ورزش رسانه ای: توییتر، حضور از راه دور و پیام رسانی آنلاین. Inf. اشتراک. Soc. 2011 ، 14 ، 237-257. [ Google Scholar ] [ CrossRef ]
- توماسجان، ع. اسپرنگر، TO; سندنر، پی.جی. Welpe، IM پیش بینی انتخابات با توییتر: آنچه 140 شخصیت در مورد احساسات سیاسی آشکار می کنند. ICWSM 2010 ، 10 ، 178-185. [ Google Scholar ]
- لرمن، ک. Ghosh, R. Information contagion: یک مطالعه تجربی از انتشار اخبار در شبکه های اجتماعی Digg و Twitter. ICWSM 2010 ، 10 ، 90-97. [ Google Scholar ]
- فیلان، او. مک کارتی، ک. اسمایث، ب. استفاده از توییتر برای توصیه اخبار موضوعی بلادرنگ. در مجموعه مقالات سومین کنفرانس ACM در مورد سیستم های توصیه کننده، نیویورک، نیویورک، ایالات متحده آمریکا، 23 تا 25 اکتبر 2009.
- ساکاکی، ت. اوکازاکی، م. Matsuo, Y. زلزله کاربران توییتر را می لرزاند: تشخیص رویداد در زمان واقعی توسط حسگرهای اجتماعی. در مجموعه مقالات نوزدهمین کنفرانس بین المللی وب جهانی، رالی، NC، ایالات متحده، 26-30 آوریل 2010.
- آکار، ا. موراکی، ی. توییتر برای ارتباطات بحران: درسهایی از فاجعه سونامی ژاپن. بین المللی J. انجمن مبتنی بر وب. 2011 ، 7 ، 392-402. [ Google Scholar ] [ CrossRef ]
- Vieweg، S. هیوز، آل. استاربرد، ک. Palen, L. میکروبلاگینگ در طول دو رویداد مخاطره طبیعی: آنچه توییتر ممکن است به آگاهی موقعیتی کمک کند. در مجموعه مقالات کنفرانس SIGCHI در مورد عوامل انسانی در سیستم های محاسباتی، پاریس، فرانسه، 27 آوریل تا 2 مه 2013.
- ولر، ک. برونز، آ. برگس، جی. ماهرت، م. پوشمن، سی. توییتر و جامعه ; پیتر لانگ: نیویورک، نیویورک، ایالات متحده آمریکا، 2014. [ Google Scholar ]
- هیورین، تی. Zach, L. Twitter برای به اشتراک گذاری اطلاعات اداره پلیس شهر. در مجموعه مقالات جامعه آمریکا برای علوم و فناوری اطلاعات، پیتسبورگ، PA، ایالات متحده آمریکا، 22 تا 27 اکتبر 2010.
- هان، بی. Cook, P. پیشبینی موقعیت جغرافیایی کاربر توییتر مبتنی بر متن. جی آرتیف. هوشمند Res. 2014 ، 49 ، 451-500. [ Google Scholar ]
- Weidemann, C. اطلاعات موقعیت مکانی رسانه های اجتماعی: نبرد حریم خصوصی بعدی – افزودنی ArcGIS و تجزیه و تحلیل داده های مکانی جمع آوری شده از Twitter.com. بین المللی J. Geoinform. 2013 ، 9 ، 21-27. [ Google Scholar ]
- عدنان، م. Longley، P. تجزیه و تحلیل استفاده از توییتر در لندن، پاریس، و شهر نیویورک . AGILE: لوون، بلژیک، 2013. [ Google Scholar ]
- موسبرگر، ک. وو، ی. کرافورد، جی. ارتباط شهروندان و دولت های محلی؟ رسانه های اجتماعی و تعامل در شهرهای بزرگ ایالات متحده. فرمانداری Inf. Q. 2013 , 30 , 351-358. [ Google Scholar ]
- ماینکا، ا. هارتمن، اس. سهام، WG; پیترز، آی. دولت و رسانه های اجتماعی: مطالعه موردی 31 شهر اطلاعاتی جهان. در مجموعه مقالات چهل و هفتمین کنفرانس بین المللی هاوایی در علوم سیستم، Waikoloa، HI، ایالات متحده، 6-9 ژانویه 2014.
- فورستر، تی. لامرز، ال. ماینکا، ا. پیترز، آی. توییت و شهر: مقایسه فعالیتهای توییتر در شهرهای جهان اطلاعاتی. در مجموعه مقالات کنفرانس 2014: Informationsqualität und Wissensgenerierung، فرانکفورت آم ماین، آلمان، 8-9 مه 2014.
- Lewis, MP Ethnologue: Languages of the World , ed. 16; SIL International: دالاس، تگزاس، ایالات متحده آمریکا، 2009. [ Google Scholar ]
- عربی بالاترین رشد در توییتر. در دسترس آنلاین: http://semiocast.com/publications/2011_11_24_Arabic_highest_growth_on_Twitter (در 23 اوت 2013 قابل دسترسی است).
- اوسلاح، م. بات، اف. چالیس، ک. Schnier, T. معماری نرم افزاری برای مجموعه توییتر، جستجو و خدمات موقعیت جغرافیایی. سیستم مبتنی بر دانش 2013 ، 37 ، 105-120. [ Google Scholar ] [ CrossRef ]
- رتبه بندی 100 شهر برتر مقصد. در دسترس آنلاین: http://blog.euromonitor.com/2013/01/top-100-cities-destination-ranking.html (در 23 اوت 2013 قابل دسترسی است).
- Eichstädt، B. Wei, C. Im social web der mitte. در شبکه های اجتماعی ؛ Leinemann, R., Ed. Springer: برلین، آلمان، 2013; صص 107-110. [ Google Scholar ]
- شاخص امنیتی Unisys در دسترس آنلاین: http://www.unisyssecurityindex.com/usi/germany (در 23 اوت 2013 قابل دسترسی است).
- فکر می کنید موبایل اکنون بزرگ است؟ در اینجا دلیلی وجود دارد که نشان می دهد تازه شروع شده است. در دسترس آنلاین: http://readwrite.com/2013/05/29/huge-potential-only-15-of-global-internet-traffic-is-mobile#awesm=~ofKwdMIxymYk5E (در 29 مه 2013 قابل دسترسی است).
- راب فورد: “بله، من کراک کوکائین کشیده ام”. در دسترس آنلاین: http://www.thestar.com/opinion/editorials/2013/08/04/toronto_mayor_rob_ford_remains_shadowed_by_crack_video_scandal_editorial.html (در 18 آوریل 2014 دسترسی پیدا کرد).
- Twitter Firehose در مقابل Twitter API: تفاوت چیست و چرا باید به آن اهمیت دهید. در دسترس آنلاین: http://www.brightplanet.com/2013/06/twitter-firehose-vs-twitter-api-whats-the-difference-and-why-should-you-care/ (در 2 مارس 2013 دسترسی پیدا کرد) .
© 2015 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر