

خلاصه
ماشین بردار ارتباط (RVM) ; مناطق مسکونی ؛ تطبیق موجودیت ; شباهت ; ادغام شی
1. معرفی
2. روش ها
2.1. روابط تطبیق مناطق مسکونی چند مقیاسی
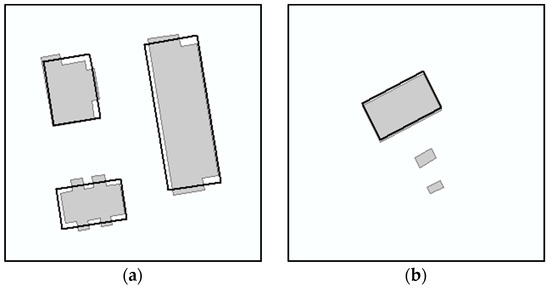
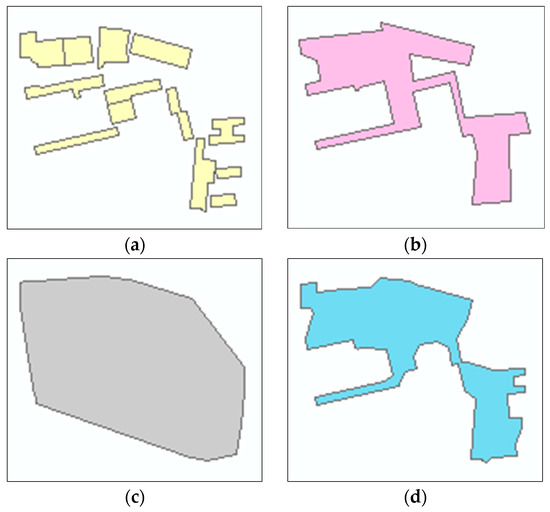
تطبیق دادههای چند مقیاسی جغرافیایی به دلیل تأثیر جامع نقشهبرداری، خطاهای ایجاد شده در طول تولید دادهها و تغییر خود نهادهای جغرافیایی دشوار است. در زیر مقدمه ای بر روابط تطبیق موجودیت های فضایی در مقیاس های مختلف پس از تعمیم نقشه کشی ارائه شده است. برای شروع، فرض میکنیم که موجودیتهای فضایی چند مقیاسی مختصات فضایی یکسانی دارند و نقشههای مقیاس کوچک، تعمیمهایی از نقشههای مقیاس بزرگ هستند. بنابراین، تفاوت هایی در بیان فضایی موجودیت های مقیاس بندی شده مختلف وجود دارد. برای مناطق مسکونی مسطح، روابط تطبیق مقیاس های بزرگ و کوچک را می توان به صورت زیر طبقه بندی کرد:
-
1:1 ( شکل 1 الف) – در هر دو مقیاس بزرگ و کوچک، موجودیتهای همنام دارای یک رابطه تطبیقی 1:1 هستند.
-
1:0 ( شکل 1 ب) – جایی که برخی از موجودیت ها در نقشه های مقیاس بزرگ رخ می دهند، اما در نقشه های مقیاس کوچک نامرئی هستند زیرا در طول تعمیم نقشه، برخی از موجودیت های کوچک حذف می شوند.
-
m :1 ( شکل 1 ج) – یک رابطه چند به یک برای موجودیتها بین نقشههای مقیاس بزرگ و نقشههای مقیاس کوچک، که در فرآیند تعمیم نقشه، اشیاء مقیاس بزرگ برای تشکیل اشیاء مقیاس کوچک ترکیب میشوند.
-
m : n ( m > n ) ( شکل 1 d) – یک رابطه چند به چند برای موجودیت ها بین نقشه های مقیاس بزرگ و نقشه های مقیاس کوچک، که در طی فرآیند تعمیم نقشه، یک عملیات سبک سازی برای منعکس کردن اشکال و ویژگی های توزیع فضایی مناطق مسکونی
2.2. طراحی کلی
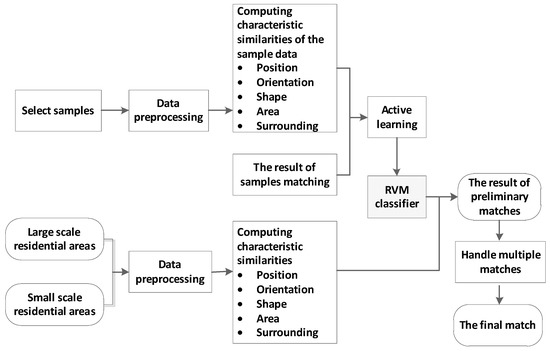
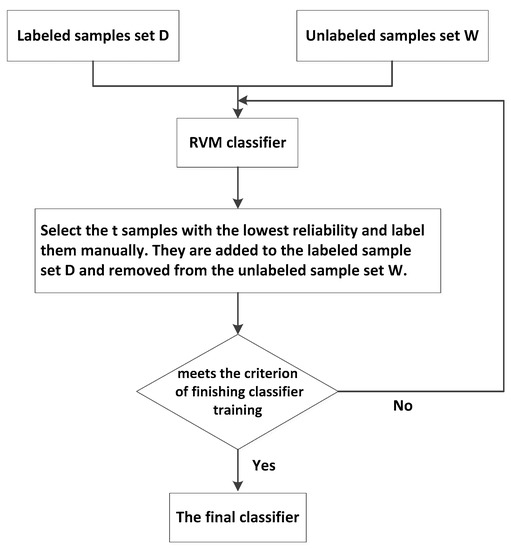
هدف مطالعه حاضر ایجاد یک روش تطبیق مناطق مسکونی چند مقیاسی سازگار با ویژگیهای دادهها، با معرفی مفهوم طبقهبندی از تشخیص الگو است. علاوه بر این، این مطالعه با هدف قرار دادن نمونههای انتخاب شده در مدلهای طبقهبندی توسط یادگیری ماشینی طراحی شده برای کاربرد با شیء تطبیق در سناریوهای یکسان طراحی شده است. چارچوب کلی در شکل 2 نشان داده شده است و به شرح زیر است:
- (من)
-
انتخاب نمونه های آموزشی از اشیاء همسان و غیر همتا از طریق همکاری انسان و ماشین.
- (II)
-
برای اشیاء تطبیق نامزد، تبدیل روابط تطبیقی که یک به یک مطابقت ندارند به روابط یک به یک برای راحتی محاسبه شباهت با پردازش داده ها.
- (iii)
-
محاسبه شباهت های مشخصه داده های نمونه.
- (IV)
-
استفاده از الگوریتم ماشین بردار ربط (RVM) برای شباهت های مشخصه و تطبیق نتایج برای تولید طبقه بندی کننده ها.
- (v)
-
وارد کردن دادههای مسکونی در مقیاسهای مختلف پس از پردازش دادهها در طبقهبندیکنندههای (iv) برای به دست آوردن نتایج طبقهبندی.
- (vi)
-
برای به دست آوردن نتایج تطبیق نهایی، داده های تطبیق چندگانه به عنوان همسان طبقه بندی می شوند.
2.3. ادغام اشیا
هدف ما حفظ کانتور بیرونی مناطق مسکونی در طول ادغام است زیرا چندین روش ادغام برای اشیاء با مقیاس بزرگ به دلیل انواع روشهای تعمیم نقشهکشی امکانپذیر است. مناطق مسکونی که با یکدیگر ملاقات می کنند با حذف لبه های متصل ادغام می شوند، در حالی که مناطق مسکونی گسسته از یکدیگر با تولید و پردازش مثلث دلون [ 27 ] ادغام می شوند، همانطور که در شکل 3 نشان داده شده است . رویکرد دقیق به شرح زیر است:
- (من)
-
برای انجام رمزگذاری گره با قرار دادن گره ها در خطوط عناصر مناطق مسکونی، و برای ساخت مثلث Delaunay، بنابراین طبقه بندی مثلث های خارج و داخل عناصر مناطق مسکونی به مثلث های خارجی و داخلی.
- (II)
-
برای تولید بدنه محدب از مناطق مسکونی پیش از ادغام و حذف سه نوع مثلث خارجی زیر که دارای لبه های متصل با بدنه محدب هستند: (1) هر سه راس در داخل یک منطقه مسکونی یکسان قرار دارند. (2) رئوس در دو منطقه مسکونی با یک زاویه داخلی بیشتر از θ (θ مبهم است) و یک یال با هر یک از دو منطقه مسکونی دارای لبه یکسانی قرار دارند. و (3) رئوس در دو منطقه مسکونی با یک لبه همپوشانی با خطوط مناطق مسکونی قرار دارد و ارتفاع این لبه بزرگتر از آستانه است. این قانون در اندازه گیری فاصله بین مناطق مسکونی اعمال می شود.
- (iii)
-
اعمال یک الگوریتم بازگشتی برای جستجوی دیگر مثلث های خارجی که دارای لبه های به هم پیوسته با مثلث های حذف شده هستند و اعمال قانون (2) و (3) در مرحله قبل برای حذف مثلث های مناسب.
- (IV)
-
برای ادغام مثلث های باقی مانده با حذف لبه های متصل.
2.4. محاسبه شباهت
2.4.1. شاخص تشابه موقعیت
نزدیکی موجودات فضایی نشان دهنده شباهت زیاد موقعیت است. برای یک موجود منطقه جغرافیایی، مرکز ممکن است به بهترین وجه ویژگی های مکان آن را منعکس کند. مطالعه حاضر معادله (1) زیر را برای اندازهگیری شباهت موقعیت با محاسبه نسبت فاصله اقلیدسی مرکز دو گروه مسکونی و حداکثر فاصله D اعمال میکند . در معادله (1)، ( x 1 , y 1 ) و ( x 2 , y 2 ) مختصات مرکز دو موجود هستند که باید مطابقت داده شوند. حداکثر فاصله Dاز موجودیت های همسان با تجزیه و تحلیل آماری فاصله مرکز نمونه های تطبیق مثبت و منفی تعیین می شود. در این مطالعه، مقدار D دو برابر فاصله مرکز نمونههای همسان است.
2.4.2. شاخص تشابه ناحیه
مساحت یک ویژگی مهم است که اندازه یک موجود جغرافیایی را نشان می دهد. اگرچه به دلیل تعمیم نقشه ها و سایر عوامل، تفاوت در مساحت در موجودیت های منطقه در مقیاس های مختلف وجود دارد، حفظ ویژگی های اندازه یک موجود جغرافیایی یکی از اصول تعمیم نقشه است. مناطق مسکونی که دارای روابط منطبق هستند از نظر مساحت شباهت هایی دارند. این مطالعه معادله (2) زیر را برای اندازهگیری شباهت مساحت مناطق مسکونی با محاسبه نسبت مساحت مناطق مسکونی که باید مطابقت داده شوند، اعمال میکند، که در آن A و B به مناطق مسکونی مورد تطبیق اشاره دارد.
2.4.3. شاخص تشابه شکل
توصیف کمی شکل یک معما در زمینه GIS و کامپیوتر است [ 28 ]. با در نظر گرفتن اشکال واحدهای مسکونی، مطالعه حاضر از شاخص شکل (فشردگی) پیشنهاد شده توسط پیتر برای اندازه گیری آن استفاده می کند [ 29 ]. فشردگی تحت تأثیر اندازه و مرز جسم [ 30 ] قرار می گیرد و همانطور که در رابطه (3) نشان داده شده است، محاسبه می شود، جایی که p نشان دهنده موجودیت منطقه است. روش محاسبه شباهت شکل در رابطه (4) پیشنهاد شده است، که در آن A و B به ترتیب نشان دهنده اشیایی هستند که باید در مقیاس های بزرگ و کوچک مطابقت داده شوند.
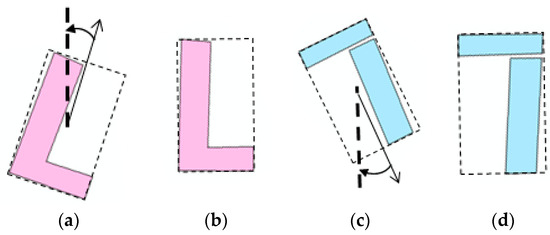
2.4.4. شاخص تشابه جهت گیری
شباهت جهت مناطق مسکونی به جهت کلی گسترش اشاره دارد. روش های رایج مورد استفاده شامل روش ضلع طولانی، روش آماری مبتنی بر دیوار، و روش کوچکترین مستطیل مرزی (SMBR) [ 30 ] است. روش SMBR از جهت محور طولانی SMBR موجودیت ها برای تطبیق به عنوان جهت مناطق مسکونی استفاده می کند. تفاوت زاویه جهت محور بلند، اختلاف زاویه دو موجودیت منطقه است. این روش نمی تواند جهت دو نهاد ناحیه ای را که جهت های خود را 180 درجه می چرخانند تشخیص دهد. مطالعه حاضر روش بهبود یافته ای را برای روش SMBR پیشنهاد می کند. اگر مناطق مسکونی مورد تطبیق A و B باشند، شباهت جهت مناطق مسکونی با توجه به رابطه (5) محاسبه می شود، که در آن θ A و θ B به ترتیب زوایای محورهای بلند SMBR A و B و محور y هستند . فواصل مقدار [0، π�/2]؛ و F تابع بولی است که تعیین می کند مناطق مسکونی 180 درجه بچرخند.
روش های تشخیص جهت از طریق هیستوگرام به شرح زیر است: (1) هیستوگرام ها را با استفاده از رابطه (6) با روش درون یابی صاف کنید، که در آن x در معادله ( 6 ) مقدار مختصات افقی هیستوگرام است، f( x ) مقدار مختصات عمودی، گام طول گام و Z مقدار هیستوگرام پس از هموارسازی است. جهت محور x هیستوگرام ناحیه بعد از هموارسازی دارای h واحد است و جهت محور y هیستوگرام ناحیه دارای j است.واحدها (2) مقادیر میانگین هیستوگرام ها و هر مقدار واحد را مقایسه کنید، به استثنای هیستوگرام هایی که کمترین اختلاف مقدار واحد را دارد. هیستوگرام یک مستطیل را نشان می دهد که نیازی به مقایسه ندارد. مقدار F برابر است با 1. (3) واحد i یک هیستوگرام را با (hi)امین یک هیستوگرام دیگر مقایسه کنید. هنگامی که اختلاف آنها کوچکتر از مقدار آستانه داده شده باشد، این دو مقدار یکسان در نظر گرفته می شوند. پس از مقایسه گروههای h، تعداد واحدهای مشابه به u میرسد (در اینجا u/h > 0.9)، یعنی دو هیستوگرام مخالف یکدیگر هستند. (4) هنگامی که هیستوگرام متناظر مخالف وجود دارد، مقدار F در رابطه (5) 0 است. در غیر این صورت 1 است.
2.4.5. شاخص شباهت محیطی
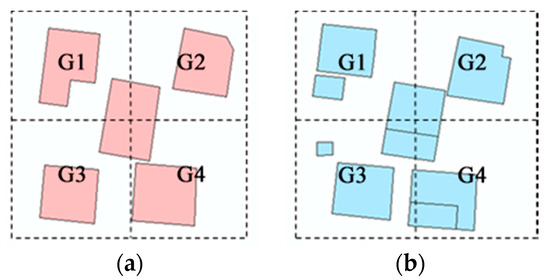
معمولاً در یک نقشه در مقیاس بزرگ، ساخت و سازها در همان منطقه شکل یکسانی دارند و اگر فقط از موقعیت و مشخصه هندسی برای تطبیق استفاده شود، اشتباه می شود. با توجه به عادت شناخت فضایی، تطبیق مصنوعی اطلاعات در مناطق اطراف اغلب برای شناسایی موجودیت ها ترکیب می شود. ما اندازهگیری شباهت محیط اطراف را با اندازهگیری ویژگیهای موجودات اطراف در مناطق مسکونی تعیین میکنیم، همانطور که در شکل 6 نشان داده شده است، مرکز جرم موجودیتی که باید مطابقت داده شود به عنوان نقطه مرکزی برای ساخت یک شبکه مربع 2 × 2 استفاده میشود. موازی با محور مختصات طول ضلع شبکه دو برابر طول ضلع بلند عنصر SMBR در مناطق مسکونی در مقیاس کوچک که باید مطابقت داده شود تنظیم شده است. جی1 ، G 2 ، G 3 و G 4 به ترتیب نمایانگر سمت چپ بالا، سمت راست بالا، پایین سمت چپ و پایین سمت راست شبکه هستند که در شکل 6 نشان داده شده است . شباهت محیطی هر ناحیه شبکه با توجه به رابطه (7) محاسبه می شود، که در آن مساحت ( SM i ) و مساحت ( LA i ) مناطق مسکونی اطراف هستند که در ناحیه شبکه در داده های مقیاس کوچک و بزرگ قرار دارند. ، به ترتیب. وقتی مقدار Area ( SM i ) و مقدار Area ( LA i ) 0 نباشد، مقدارسیم (G i ) نسبت مساحت خواهد بود. وقتی مقدار Area ( SM i ) و مقدار Area ( LA i ) 0 باشد، مقدار شبکه S ( G i ) 1 خواهد بود. مناطق مسکونی کوچک در مقیاس کوچک که در داده های مقیاس بزرگ ارائه می شوند ممکن است مشاهده نشوند. وقتی مقدار Area ( SM i ) 0 و مقدار Area ( LA i ) یک عدد کوچک (کمتر از آستانه) باشد. ε�، مقدار شبکه S ( Gi ) 1 خواهد بود. وقتی مقدار Area ( SM i ) 0 نباشد و مقدار Area ( LA i ) 0 باشد، مقدار شبکه S ( Gi ) خواهد بود. 0. مجموع شباهت محیط اطراف طبق رابطه (8) محاسبه می شود.
2.5. رویکرد تطبیق
2.5.1. ماشین وکتور مربوط
در مطالعه حاضر، بردار ورودی RVM به صورت پنج بعدی، شامل شباهتهای پنج ویژگی (یعنی موقعیت، مساحت، شکل، جهتگیری و محیط) تعریف شده است. طبقه بندی به عنوان “تطابق” یا “عدم تطابق” تعریف می شود. خروجی RVM می تواند به عنوان ارزیابی قابلیت اطمینان نتایج طبقه بندی مورد استفاده قرار گیرد. تابع خروجی RVM در معادله (9) [ 32 ] نشان داده شده است، جایی که y∈ [ 0 , 1 ]�∈[0,1].
مقدار z در معادله (9) همانطور که در رابطه (10) نشان داده شده محاسبه می شود، که در آن Q( x , xn ) تابع هسته است و wn��وزن مدل است.
تخمین مجموعه داده به دست آمده از تخمینگر احتمال به صورت معادله (11) نشان داده شده است، که در آن t =(تی1⋯تین)تی�=(�1⋯��)تیو دبلیو=(w0⋯wن)تی�=(�0⋯��)�.
در چارچوب بیزی، اوزان دبلیو�در رابطه (11) را می توان با روش برآورد حداکثر درستنمایی به دست آورد. با این حال، برای جلوگیری از یادگیری بیش از حد، RVM یک توزیع احتمال قبلی گاوسی را برای هر وزن تعریف می کند تا پارامترها را محدود کند (معادله (12))، که در آن α�در رابطه (12) یک پارامتر فوق العاده N + 1 بعدی است. اگرچه احتمال عقبی وزن ها را نمی توان محاسبه کرد، می توان آن را با تئوری لاپلاسی تقریب زد. حداکثر وزن ممکن دبلیومپ���برای ثابت فعلی محاسبه می شود α�ارزش. زیرا p ( w | t , α ) ∝ p ( t | w ) p ( w | α )�(�|�,�)∝�(�|�)�(�|�)، می توان آن را به حداکثر معادله (13) ترجمه کرد.
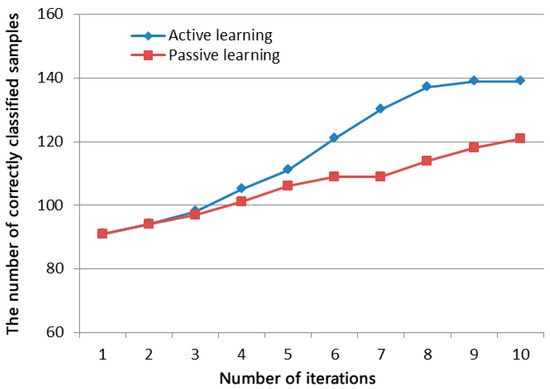
2.5.2. یادگیری فعال
هنگام استفاده از فرآیند یادگیری ماشینی، انتخاب نمونه زمانبر است. انتخاب نمونه های منطبق از داده های مسکونی نیاز به شناسایی مصنوعی دارد. برای کاهش تعداد نمونه های آموزشی و بهبود کارایی تطبیق، مطالعه حاضر رویکرد یادگیری فعال [ 33 ] را اتخاذ می کند. ایده اصلی پشت این رویکرد این است که با نمونهگیری چندگانه، نمونههایی که برای بهبود عملکرد طبقهبندی مفید هستند انتخاب میشوند و با آموزش نمونه برچسبدار در مقیاس کوچک، عملکرد یادگیری که میتوان با نمونههای برچسبدار در مقیاس بزرگ به دست آورد، به دست میآید. مراحل یادگیری به شرح زیر است:
- (من)
-
N نمونه از مجموعه نمونه کاندید U انتخاب شده است. طبقه بندی آنها به صورت دستی برچسب گذاری می شوند تا مجموعه نمونه آموزشی اولیه D را تشکیل دهند. هر طبقه بندی باید حداقل یک نمونه در D داشته باشد.
- (II)
-
نمونه ها در D آموزش داده می شوند و طبقه بندی کننده اولیه F ایجاد می شود.
- (iii)
-
طبقه بندی F برای طبقه بندی نمونه های بدون برچسب استفاده می شود و نتایج طبقه بندی ضریب اطمینان پایین پس از برچسب گذاری دستی آنها اضافه می شود.
- (IV)
-
Classifier برای یک زمان دیگر آموزش داده می شود تا زمانی که معیار اتمام آموزش طبقه بندی کننده را برآورده کند. معیار این است که تعداد حلقه ها به مقدار از پیش تعیین شده برسد یا تعداد نمونه های برچسب گذاری شده به مقدار مورد انتظار برسد.
2.5.3. تطبیق استراتژی
در زیر برخی از مراحل مهم در استراتژی تطبیق آورده شده است.
-
پیش پردازش داده ها: اولین مرحله پیش پردازش داده ها، شناسایی عناصر نامزد برای تطبیق است. یک منطقه حائل از مناطق مسکونی در مقیاس کوچک تولید میشود و ویژگیهای مقیاس بزرگی که با این منطقه بافر تلاقی میکنند به عنوان ویژگیهای نامزد شناسایی میشوند. دوم، عناصر نامزد با شناسایی جفت روابط تطبیق چندگانه و با استفاده از جستجوی دو طرفه تعیین می شوند. سوم، پس از به دست آوردن ویژگی های کاندید، زیرا تعداد زیادی 1: n یا m : n وجود داردروابط تطبیق در مناطق مسکونی چند مقیاسی، جایگشت و ترکیب برای تولید ترکیبی از اشیاء منطبق برای تشخیص رابطه تطبیق استفاده میشوند. از آنجایی که ترکیب اشیاء منطبق بر نامزد با توجه به تعداد عناصر تعیین می شود، ما اشیایی را که مطابق با انواع مناطق مسکونی چند مقیاسی غیرممکن است، به عنوان ناهماهنگ تنظیم می کنیم (به عنوان مثال، شیئی که رابطه کمی بین شی مقیاس بزرگ و شی مقیاس کوچک 1: n یا m : n ( m < n )) است و این اشیاء را از اشیاء تطبیق نامزد حذف کرد. برای سهولت اندازه گیری شباهت، از روش ادغام موجودیت شرح داده شده در بخش 2.3 استفاده می کنیم.برای ترکیب چندین موجودیت در یک موجودیت واحد.
-
انتخاب نمونه: برای نمونه های آموزشی، ما روش همکاری انسان-رایانه را اتخاذ می کنیم و یک ناحیه بافر را با استفاده از اشیاء مبدأ برای جستجوی اشیاء منطبق با نامزد ایجاد می کنیم. کار دستی برای شناسایی و برچسب گذاری مطابقت یا عدم تطابق بین عناصر نامزد و عناصر منبع استفاده می شود. نمونه های بدون برچسب با جستجوی اشیاء منطبق با نامزد در ناحیه بافر تولید شده از عناصر منبع به دست می آیند.
-
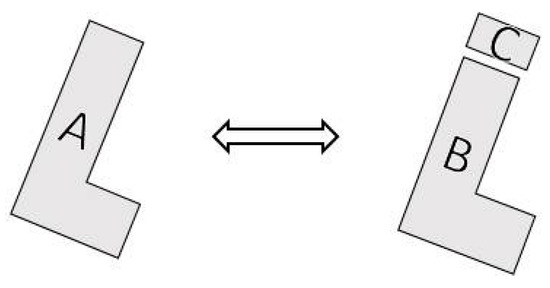
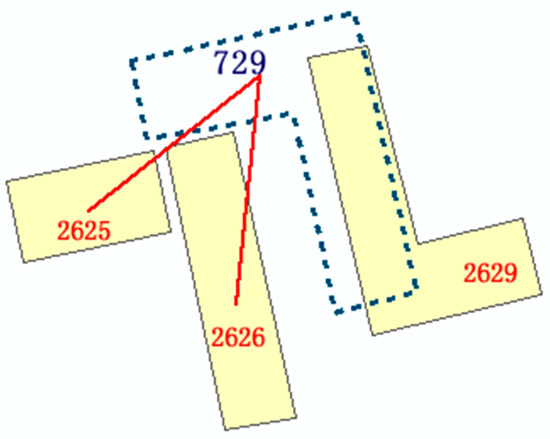
پردازش روابط تطبیق چندگانه: ممکن است مواردی از تطابق چندگانه بر اساس خروجی طبقهبندیکننده وجود داشته باشد، همانطور که شکل 8 نشان میدهد. موجودیت های A و B و A و BC همه به عنوان منطبق طبقه بندی می شوند. با این حال، تعیین رابطه تطبیق نهایی به خروجی قابلیت اطمینان RVM بستگی دارد. برای مشخص بودن، جفتهای منطبق حاوی عناصر مشابه را در دستهبندی مسابقه، پس از انتخاب توسط طبقهبندیکننده تعیین میکنیم. با استفاده از معادله (14)، مجموعه ای با حداکثر قابلیت اطمینان به عنوان نتیجه مسابقه نهایی انتخاب می شود.
R = Mیک x (r1،r2،r3، . . . ،rn)�=���(�1,�2,�3,…,��)
2.6. طراحی تجربی
ارزیابی نتایج تجربی با مقایسه نتایج تطبیق دستی توسط نقشهبرداران حرفهای با نتایج تطبیق خودکار انجام میشود. اشیایی که با تطبیق دستی و تطبیق خودکار برچسب مطابقت دارند TP هستند . آنهایی که با تطبیق دستی مطابقت دارند در حالی که با تطبیق خودکار شناسایی نمی شوند NP هستند . و آنهایی که با تطبیق خودکار مطابقت دارند اما با تطبیق دستی شناسایی نمی شوند FP هستند . شاخص های ارزیابی دقت و میزان فراخوانی هستند. از معادله (15) برای محاسبه دقت و از رابطه (16) برای به دست آوردن نرخ فراخوان استفاده می شود. پارامتر Fمقدار 1 برای اندازه گیری میانگین هارمونیک دقت و یادآوری با معادله (17) برای محاسبه F1 معرفی شد.
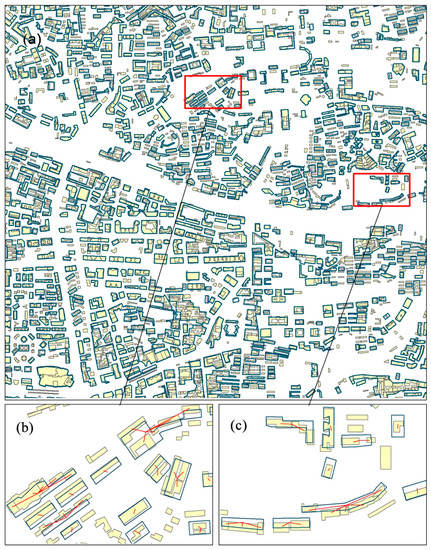
3. نتایج و بحث
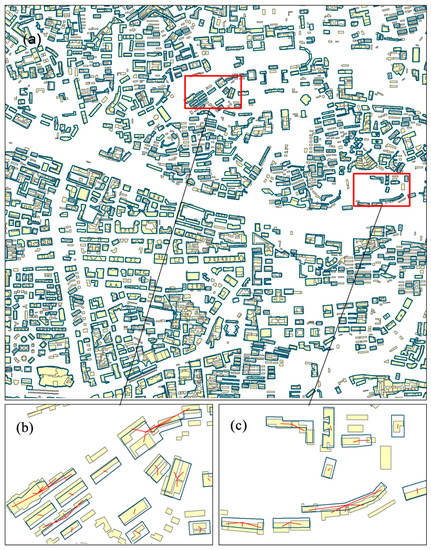
3.1. ادغام مناطق مسکونی
3.2. اندازه گیری تشابه ویژگی
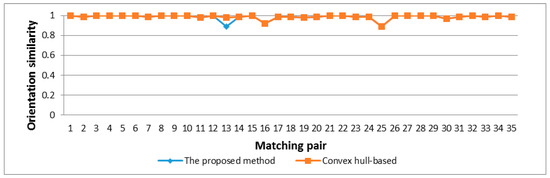
3.3. مقایسه نتایج روشهای تطبیق
4. نتیجه گیری
اختصارات
| GIS | سیستم اطلاعات جغرافیایی |
| RVM | ماشین بردار ربط |
| SVM | ماشین بردار پشتیبانی |
| SMBR | کوچکترین حداقل مستطیل مرزی |
منابع
- کوپر، الف. مفاهیم به روز رسانی و نسخه سازی افزایشی. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی کارتوگرافی، دوربان، آفریقای جنوبی، 10-16 اوت 2003.
- ژانگ، ایکس. گوا، تی. هوانگ، جی. Xin، Q. انتشار بهروزرسانیهای مناطق مسکونی در پایگاههای داده چند بازنمایی با استفاده از مثلثسازیهای محدود شده Delaunay. ISPRS Int. J. Geo-Inf. 2016 ، 5 ، 80. [ Google Scholar ] [ CrossRef ]
- Haunert، JH; Sester, M. انتشار به روز رسانی بین مجموعه داده های مرتبط با مقیاس های مختلف. در مجموعه مقالات XXII کنفرانس بین المللی کارتوگرافی، A Coruña، اسپانیا، 9-16 ژوئیه 2005.
- Qi، HB; Li، ZL; Chen, J. تشخیص تغییر خودکار برای بهروزرسانی سکونتگاهها در نقشههای مقیاس کوچکتر از نقشههای بهروزشده در مقیاس بزرگتر. جی. اسپات. علمی 2010 ، 55 ، 133-146. [ Google Scholar ] [ CrossRef ]
- یینگ، اس. ون، دبلیو. وان، ی. Duan, X. مدلسازی تکامل فضایی اشیاء نقشه توسط عوامل نقشه. Geocarto Int. 2016 ، 31 ، 408-427. [ Google Scholar ] [ CrossRef ]
- سمال، ع. ست، اس. Cueto1، K. یک رویکرد مبتنی بر ویژگی برای ترکیب منابع جغرافیایی. بین المللی جی. جئوگر. Inf. علمی 2004 ، 18 ، 459-489. [ Google Scholar ] [ CrossRef ]
- ووگلین، اف. علی، ABH تطبیق هندسی سطوح چند ضلعی در GIS. در مجموعه مقالات نشست سالانه ASPRS، تامپا، FL، ایالات متحده آمریکا، 30 مارس تا 3 آوریل 1998.
- گوسلن، جی. Sester, M. تغییر تشخیص و ادغام به روز رسانی های توپوگرافی از ATKIS به مجموعه داده های زمین شناسی. در اطلاعات جغرافیایی نسل بعدی ; CRC Press: Boca Raton، FL، USA، 2005; صص 85-100. [ Google Scholar ]
- Min، D. ژیلین، ال. Xiaoyong، C. فاصله Hausdorff طولانی برای اشیاء فضایی در GIS. بین المللی جی. جئوگر. Inf. علمی 2007 ، 21 ، 459-475. [ Google Scholar ] [ CrossRef ]
- تانگ، ایکس. لیانگ، دی. Jin, Y. روش تطبیق شی جاده خطی برای ادغام بر اساس بهینه سازی و رگرسیون لجستیک. بین المللی جی. جئوگر. Inf. علمی 2014 ، 28 ، 824-846. [ Google Scholar ] [ CrossRef ]
- آی، تی. چنگ، ایکس. لیو، پی. یانگ، ام. تحلیل شکل و تطبیق الگوی ویژگیهای ساختمان با روش تبدیل فوریه. محاسبه کنید. محیط زیست سیستم شهری 2013 ، 41 ، 219-233. [ Google Scholar ] [ CrossRef ]
- An، X. سان، س. شیائو، کیو. Yan, W. روش توصیف چندسطحی شکل و کاربرد در اندازهگیری شباهت هندسی دادههای فضایی چند مقیاسی. Acta Geod. کارتوگر. گناه 2011 ، 40 ، 495-501. [ Google Scholar ]
- فو، ز. Lu, Y. ایجاد مدل جامع برای تشابه موجودیت چند ضلعی با استفاده از تابع پیچیده شعاع خمشی. Acta Geod. کارتوگر. گناه 2013 ، 42 ، 145-151. [ Google Scholar ]
- هاستینگز، JT ترکیب خودکار داده های روزنامه دیجیتال. بین المللی جی. جئوگر. Inf. علمی 2008 ، 22 ، 1109-1127. [ Google Scholar ] [ CrossRef ]
- Shao, S. Researehes and Applications on Polygon Entity Matching برای داده های برداری چند مقیاسی بر اساس ویژگی های هندسی . دانشگاه ووهان: ووهان، چین، 2011. [ Google Scholar ]
- لو، جی. ژانگ، ایکس. چی، ال. Guo, T. روش تطبیق موقعیت سریع و ترکیب بهینه شیء بردار تغییر. Acta Geod. کارتوگر. گناه 2014 ، 43 ، 1285-1291. [ Google Scholar ]
- ها، ی. یو، ک. Heo, J. تشخیص جفت نقطه مزدوج برای تراز نقشه بین دو مجموعه داده چند ضلعی. محاسبه کنید. محیط زیست سیستم شهری 2011 ، 35 ، 250-262. [ Google Scholar ] [ CrossRef ]
- کیلر، بی. هوانگ، دبلیو. Haunert، JH; جیانگ، جی. تطبیق مجموعه دادههای رودخانه در مقیاسهای مختلف. در پیشرفت در GIScience ; Springer: برلین/هایدلبرگ، آلمان، 2009; صص 135-154. [ Google Scholar ]
- کیم، جو. یو، ک. هیو، جی. Lee, WH یک روش جدید برای تطبیق اشیاء در دو مجموعه داده جغرافیایی مختلف بر اساس زمینه جغرافیایی. محاسبه کنید. Geosci. 2010 ، 36 ، 1115-1122. [ Google Scholar ] [ CrossRef ]
- ژانگ، ایکس. آی، تی. استوتر، جی. ژائو، ایکس. تطبیق دادههای چند ضلعیهای ساختمانی در مقیاسهای چندگانه نقشه با اطلاعات متنی و آرامش بهبود یافته است. ISPRS J. Photogramm. Remote Sens. 2014 ، 92 ، 147-163. [ Google Scholar ] [ CrossRef ]
- والتر، وی. Fritsch، D. تطبیق مجموعه داده های مکانی: یک رویکرد آماری. بین المللی جی. جئوگر. Inf. علمی 1999 ، 13 ، 445-473. [ Google Scholar ] [ CrossRef ]
- تانگ، ایکس. شی، دبلیو. دنگ، اس. روش تطبیق ویژگی چند اندازه گیری مبتنی بر احتمال در ترکیب نقشه. بین المللی J. Remote Sens. 2009 ، 30 ، 5453-5472. [ Google Scholar ] [ CrossRef ]
- صفرا، ای. کانزا، ی. ساگیو، ی. بیری، سی. Doytsher, Y. الگوریتمهای مبتنی بر مکان برای یافتن مجموعههایی از اشیاء متناظر بر روی چندین مجموعه دادههای جغرافیایی-مکانی. بین المللی جی. جئوگر. Inf. علمی 2010 ، 24 ، 69-106. [ Google Scholar ] [ CrossRef ]
- لیو، پی. ژانگ، ی. Gong، J. Root میانگین مربعات خطا و رویکرد تطبیق رابطه همسایه برای ویژگی منطقه چند مقیاسی. Acta Geod. کارتوگر. گناه 2014 ، 43 ، 419-425. [ Google Scholar ]
- ژانگ، ایکس. ژائو، ایکس. مولنار، م. استوتر، جی. کراک، ام جی. Ai، T. رویکردهای طبقهبندی الگو برای تطبیق چند ضلعیهای ساختمانی در مقیاسهای چندگانه. در ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences ; XXII کنگره ISPRS; انجمن بین المللی فتوگرامتری و سنجش از دور: Tempe، AZ، ایالات متحده آمریکا، 2012; جلد I-2، صص 19-24. [ Google Scholar ]
- وانگ، ی. چن، دی. ژائو، ز. رن، اف. Du, Q. یک رویکرد مبتنی بر شبکه عصبی پس انتشار برای تطبیق ویژگی های چندگانه در انتشار به روز رسانی. ترانس. GIS 2015 ، 19 ، 964-993. [ Google Scholar ] [ CrossRef ]
- فیشر، جی. تجسم ارتباط میان بدنه محدب، نمودار ورونوی و مثلث سازی دلون. در مجموعه مقالات سی و هفتمین سمپوزیوم آموزش و محاسبات غرب میانه، مینیاپولیس، MN، ایالات متحده، 16-17 آوریل 2004.
- لی، دبلیو. Goodchild، MF; چرچ، R. یک اندازه گیری کارآمد از فشردگی برای اشکال دو بعدی و کاربرد آن در مسائل منطقه بندی. بین المللی جی. جئوگر. Inf. علمی 2013 ، 27 ، 1227-1250. [ Google Scholar ] [ CrossRef ]
- پیتر، بی. Weibel, R. استفاده از تکنیک های بردار و شطرنجی در تعمیم نقشه طبقه بندی شده. در مجموعه مقالات سومین کارگاه ICA در مورد پیشرفت در تعمیم خودکار نقشه، اتاوا، ON، کانادا، 12-14 اوت 1999.
- ژانگ، ایکس. شیائو، پی. آهنگ، X. She, J. روش تقسیم بندی چند مقیاسی محدود با مرز برای تصاویر سنجش از دور. ISPRS J. Photogramm. Remote Sens. 2013 ، 78 ، 15-25. [ Google Scholar ] [ CrossRef ]
- رول، پی. آنتوان، ب. تطبیق خودکار ویژگیهای ساختمان با سطوح مختلف جزئیات: مطالعه موردی. در مجموعه مقالات بیست و چهارمین کنفرانس بین المللی کارتوگرافی، سانتیاگو، شیلی، 15 تا 19 نوامبر 2009.
- انعام، یادگیری بیزی پراکنده ME و ماشین بردار مربوط. جی. ماخ. فرا گرفتن. Res. 2001 ، 1 ، 211-244. [ Google Scholar ]
- وو، ی. کوزینتسف، آی. Bouguet, JY; Dulong، C. استراتژیهای نمونهگیری برای یادگیری فعال در بازیابی عکس شخصی. در مجموعه مقالات کنفرانس بین المللی IEEE در سال 2006 در چند رسانه ای و نمایشگاه، تورنتو، ON، کانادا، 9 تا 12 ژوئیه 2006. صص 529-532.










© 2017 توسط نویسندگان. دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC BY) ( http://creativecommons.org/licenses/by/4.0/ ) توزیع شده است.
بدون نظر