

خلاصه
تحلیل ورزش هایی مانند فوتبال نه تنها برای خود تیم ورزشی، بلکه برای عموم و رسانه ها نیز جالب است. هر دو متوجه شدهاند که استفاده از تحلیلهای دقیقتر از رفتار تیمها، جذابیت و همچنین عملکرد آنها را افزایش میدهد. به همین دلیل، بازی ها و تک تک بازیکنان با استفاده از سیستم های ردیابی توسعه یافته ویژه ضبط می شوند. راه حل ردیابی معمولاً با نرم افزار تجزیه و تحلیل ابتدایی ارائه می شود که امکان استخراج اطلاعات آماری اولیه را فراهم می کند. فراتر رفتن از این آمارهای ساده یک کار چالش برانگیز است. با این حال، زمانی ارزشمند است که دید بهتری نسبت به تاکتیک های تیمی یا حرکات معمولی یک بازیکن انفرادی ارائه دهد. در این مقاله رویکردی برای شناخت الگوهای حرکتی به عنوان یک روش تحلیل پیشرفته ارائه شده است. که از مسیرهای بازیکنان به عنوان داده ورودی استفاده می کند. علاوه بر الگوهای حرکتی فردی، همچنین قادر به تشخیص الگوهای مربوط به حرکات گروهی است. شرح مفصل با بحثی در مورد رویکرد دنبال میشود، که در آن آزمایشهای مختلف بر روی مجموعه دادههای مسیر واقعی، حتی از زمینههای دیگر به جز فوتبال، مزایا و ویژگیهای روش را نشان میدهند.
کلید واژه ها:
تجزیه و تحلیل مکانی – زمانی ; تشخیص الگو ؛ خط سیر ; تحلیل فوتبال
1. معرفی
درست مانند اهمیت روزافزون فوتبال در رسانه ها و رشد سریع بازار مربوطه، تحلیل بازی های فوتبال نیز روز به روز اهمیت بیشتری پیدا می کند. در حوزه های مختلف با اهداف مختلف استفاده می شود. به عنوان مثال، پخشکنندههای تلویزیونی در نتایج تجزیه و تحلیل از طریق همپوشانی یا تقسیم صفحه نمایش محو میشوند.
با این حال، تنها رسانه ها نیستند که به چنین حقایق و آماری علاقه دارند. باشگاه های فوتبال نیز می خواهند عملکرد تیم را در طول مسابقات یا تمرینات بررسی کنند. موارد استفاده بیشتر می تواند تجزیه و تحلیل خودکار تیم خود در طول تمرین یا حریف بعدی برای کشف تاکتیک ها، نقاط قوت یا ضعف آن باشد. در حال حاضر، دومی به صورت دستی از طریق بازرسی ویدیویی انجام می شود. اغلب، برخی از جزئیات، مانند سرعت در حین دوی سرعت، تشخیص الگوهای حرکتی نامحسوس یا توالی پاس های تکراری، نمی توانند تعیین شوند یا حتی توسط یک تیم بزرگ مربی قابل توجه نیستند، زیرا تشخیص آنها با چشم غیرمسلح دشوار است. برای این منظور، چندین سیستم برای تجزیه و تحلیل مسابقات فوتبال در زمان واقعی توسعه یافته است. این سیستم ها از یک جزء سخت افزاری (ردیابی اشیا) تشکیل شده اند،
ارزیابی معمولاً شامل تجزیه و تحلیل های مختلفی است که اطلاعاتی در مورد عملکرد بازیکنان یا تیم ها ارائه می دهد. آنها دانش در مورد رفتار بازیکنان یا تیم ها را در طول بازی افزایش می دهند. این دانش مهم است زیرا بینش عمیقی را در مورد رفتار مشخصه بازیکنان یا تاکتیک های تیمی امکان پذیر می کند. مقدار دانش به دست آمده از یک عدد منفرد، که برای مثال، پارامتری از عملکرد دویدن را توصیف می کند، تا الگوهای حرکتی پیچیده، که حاوی اطلاعات دقیق در مورد حرکات تکراری یا مشخصه یک بازیکن یا کل تیم است، متغیر است. طیف گسترده ای از تحلیل های مختلف وجود دارد که از نظر دانش به دست آمده و پیچیدگی الگوریتمی متفاوت است.
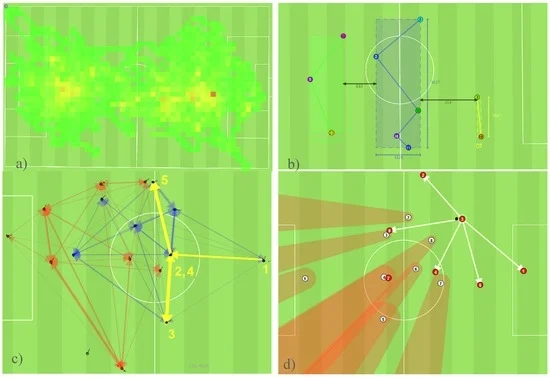
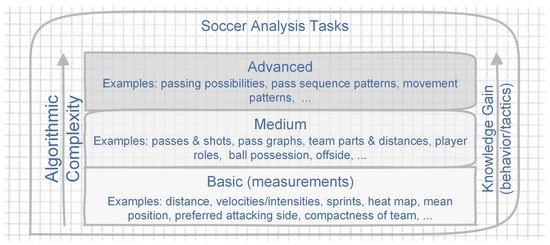
طرح در شکل 1 سطوح مختلف پیچیدگی را نشان می دهد که در آن وظایف رایج آنالیز فوتبال را می توان طبقه بندی کرد. آنها به ترتیب صعودی از “پایه” به “پیشرفته” مرتب شده اند. کسب دانش نیز افزایش می یابد. آنالیزهای “پایه” کمترین پیچیدگی را دارند، اما کمترین دانش را در مورد رفتار یا تاکتیک های حرکتی بازیکنان نیز ارائه می دهند. آنها عمدتاً از اندازه گیری های خالص یا تجمعات ساده تشکیل شده اند. نمونه های محبوب برای این کارها نقشه های حرارتی هستند ( شکل 2الف)، که یک نمای کلی از ترجیحات و محدوده های مکانی واقعی بازیکنان در طول بازی و مسافت تحت پوشش ارائه می دهد. مورد دوم ممکن است نشان دهنده سطح آمادگی بازیکن مورد ارزیابی باشد، حتی اگر عملکرد بالا در دویدن همیشه به معنای عملکرد کلی خوب نباشد. کسب دانش رفتاری یا تاکتیکی نسبتاً کم است. سطح “متوسط” شامل تحلیل هایی است که به چیزی بیش از الگوریتم های تجمیع ساده نیاز دارند. نماینده این گروه تشخیص خودکار قطعات تیم و فواصل بین آنها است ( شکل 2ب). مربی را قادر می سازد تا رفتار تیم را با توجه به قوانین تاکتیکی پیشینی ارزیابی کند. پیچیده ترین تحلیل ها با بالاترین خروجی دانش در سطح “پیشرفته” قرار دارند. حل آن کارها به الگوریتم های پیچیده ای نیاز دارد که به عنوان مثال، قادر به یافتن الگوهای توالی عبور ( شکل 2 ج)، تعیین احتمالات عبور ( شکل 2 د) یا تشخیص الگوهای حرکت هستند.
اکثر رویکردهای تحلیل فعلی در سطوح پیچیدگی پایینتر قرار دارند و بنابراین عمدتاً شامل جمعآوری دادههای آماری یا انجام تحلیلهای حرکت متوسط میشوند. ما قصد داریم رویکردی را ارائه کنیم که تجزیه و تحلیل حرکت پیشرفته را از نظر شناخت الگوهای حرکتی امکان پذیر می کند. یک کار پیشرفته شامل یافتن رفتار حرکتی تکراری و پیشینی ناشناخته افراد یا گروههای متحرک است. به عنوان مثال، مسیرهای معمولی بازیکن یا رفتارهای یک تیم در موقعیت های بازی خاص است. این الگوها ممکن است بینش عمیقی از رفتار حرکتی بازیکنان به صورت جداگانه و همچنین حرکات تاکتیکی کل تیم ارائه دهد. از آنها می توان برای مشخص کردن یک بازیکن با حرکات معمولی یا پیش بینی حرکات استفاده کرد.
با این حال، تشخیص آن الگوها یک کار چالش برانگیز است، زیرا ما نمی دانیم که آنها چگونه به نظر می رسند یا چه چیزی را جستجو کنیم. برخلاف الگوهای شناخته شده قبلی، به عنوان مثال، مسیرهای هندسی از پیش تعریف شده مانند دایره ها یا الگوهای گروهی مانند گله، ما نمی توانیم از هیچ استراتژی تطبیقی برای شناسایی نمونه های الگو در داده ها استفاده کنیم. رویکرد brute force هنوز ممکن است، اما پیچیدگی محاسباتی همراه با اندازه مجموعه دادهها به یک راهحل معقول منجر نمیشود. به منظور شناسایی آنها، ما رویکردی را پیشنهاد می کنیم که مبتنی بر تبدیل یک مسئله تشخیص الگوی مسیر به یک مسئله کاوی دنباله است. برای این منظور، ما مسیرها را به دنبالهای از حرکات تبدیل میکنیم، که بعداً برای دنبالههای تکراری که الگوهای درخواستی را تشکیل میدهند، جستجو میشوند. علاوه بر این،
مقاله به شرح زیر سازماندهی شده است: در بخش بعدی مروری بر کارهای مرتبط ارائه شده است. در بخش 3 رویکرد ما به طور مفصل توضیح داده شده است. بخش 4 شامل توصیفی از آزمایشهای مختلف است که در آن این رویکرد برای دادههای مسیر واقعی از بازیهای فوتبال و ترافیک ماشین اعمال میشود. در آنجا الگوهای حرکتی استخراج شده نشان داده و ارزیابی می شوند. در نهایت، ما این مقاله را با جمعبندی دستاوردهای اصلی و ارائه یک نمای کلی از توسعههای احتمالی و وظایف آینده به پایان میبریم.
2. کارهای مرتبط
2.1. سیستم های آنالیز فوتبال تجاری
چندین شرکت وجود دارند که سیستم های آنالیز فوتبال متشکل از سخت افزار ردیابی و نرم افزار آنالیز مربوطه را توسعه داده اند. در حالی که تحقیقات زیادی در مورد مؤلفه تولید داده وجود دارد، مؤلفه تجزیه و تحلیل پتانسیل بهبود را نشان می دهد. برای دید بهتر ما روی منجنیق [ 1 ]، Deltatre AG [ 2 ]، Prozone Sports Ltd [ 3 ] و Chyronhego [ 4 ] تمرکز می کنیم.]. در حالی که سه اول بر روی فوتبال متمرکز هستند، Chyronhego همچنین راه حل هایی را برای انواع دیگر ورزش ها ارائه می دهد. همه آنها حرکات بازیکن و توپ را تجزیه و تحلیل می کنند و آمار بازیکنان و تیم را ایجاد می کنند. آنها نتایج را با استفاده از جداول، نمودارها و نقشه های حرارتی به عنوان ابزار تجسم ارائه می کنند. Deltatre همچنین تجزیه و تحلیل هایی مانند نوارهای مرزی تیم، خط آفساید و خطوط اتصال بازیکن را ارائه می دهد که به تجسم حرکات نسبی اعضای تیم کمک می کند. آنها همچنین یک فناوری خط هدف را توسعه داده اند که مبتنی بر یک سیستم ردیابی میدان مغناطیسی اضافی است و به موازات سیستم ردیابی بازیکن عمل می کند. به این ترتیب آنها هنگام تعیین اینکه آیا توپ پشت خط است یا خیر، به دقت بالایی دست می یابند. Prozone چندین برنامه کاربردی را ارائه می دهد که اهداف تحلیلی متفاوتی دارند. علاوه بر ابزار تجزیه و تحلیل پایگاه داده، آنها برنامه هایی را برای تجزیه و تحلیل بازی فعلی، داور و همچنین تیم مقابل بعدی بر اساس آخرین مسابقات ثبت شده ارائه می دهند. از آنجایی که آنها توپ را نیز ردیابی می کنند، می توانند آنالیزهای مربوط به توپ را انجام دهند، به عنوان مثال، برای پاس ها یا ضربات گل. هر یک از این ابزارها، انواع مختلفی از تحلیلهای مربوط به حرکت و توپ را ارائه میدهند. تا آنجا که ما می دانیم، تجزیه و تحلیل های پیچیده تری مانند تشخیص الگوی حرکت یا تجزیه و تحلیل توالی، که به سطح “پیشرفته” طبقه بندی وظایف ارائه شده درشکل 1 ارائه نشده است.
وقتی به ورزش های فردی مانند دویدن یا تناسب اندام به طور کلی نگاه می کنیم، شرکت هایی مانند آدیداس (micoach) [ 5 ]، نایک (nike+) [ 6 ] یا Garmin [ 7 ] و پلتفرم هایی مانند runtastic [ 8 ] راه حل هایی برای ارزیابی فعالیت های ورزشی ارائه می دهند. در اغلب موارد داده های حرکتی جمع آوری شده با شتاب سنج ها یا گیرنده های GPS ارزیابی می شوند. آمار مسافت تحت پوشش، سرعت ها و شتاب ها، احتمالا با امکان بازرسی و تجزیه و تحلیل بصری، و همچنین طرحی از مسیرها بر روی نقشه ایجاد می شود. تجزیه و تحلیل دقیق تر در مورد مسیرها پشتیبانی نمی شود.
2.2. تشخیص الگوی حرکت
علاوه بر این ابزارهای حرفه ای، برخی رویکردهای علمی برای تجزیه و تحلیل فوتبال و به ویژه شناخت الگوهای حرکتی وجود دارد. آنها در زمینه تحلیل نقاط متحرک توسعه یافته اند و هم از منظر هندسه محاسباتی و هم از نقطه نظر محاسبات غیرمتمرکز مورد بررسی قرار گرفته اند. علاوه بر این، ما بین تشخیص الگوهای شناخته شده و ناشناخته پیشینی تمایز قائل می شویم. هنگامی که الگوها شناخته شده باشند، شناسایی شبیه به یک کار تطبیق الگو است، در حالی که جستجوی الگوهای ناشناخته بیشتر یک فرآیند استخراج است.
در رابطه با تطبیق الگو، رویکردهای زیادی برای شناسایی الگوهای حرکت گروهی تعریف شده وجود دارد، به عنوان مثال، گله، رهبری یا الگوهای برخورد (به عنوان مثال، [ 9 ، 10 ، 11 ]). آن الگوها به وضوح در [ 12 ] توضیح داده شده است. الگوریتم دیگری که قادر به تشخیص الگوهای گروهی و همچنین الگوهای حرکتی فردی است توسط [ 13 ] پیشنهاد شده است. آنها حرکات گسسته و نسبی ( REMO ) اجسام مشاهده شده را تجزیه و تحلیل می کنند. برای این منظور، آنها یک نمایش ماتریسی (ردیفها: اشیاء، ستونها: مراحل زمانی) ایجاد میکنند که سپس با استفاده از عبارات منظم گسترشیافته فضایی، الگوها را جستجو میکنند.
همچنین کارهای مرتبطی در مورد الگوبرداری وجود دارد. در زمینه تحلیل فوتبال، رویکردهای مختلفی برای شناخت الگوها وجود دارد. یک مطالعه قبلی [ 14 ] یک جعبه ابزار جامع ایجاد کرد که ابزارهایی برای تجزیه و تحلیل مسیرها و پاس های بازیکن ارائه می دهد. هنگام تجزیه و تحلیل حرکات، آنها به دنبال خوشه های زیر خطی مانند حرکات تکراری بازیکن می گردند. به منظور یافتن آن خوشه ها، از تکنیک های خوشه بندی پیشنهاد شده توسط [ 15 ] استفاده می کنند. تجزیه و تحلیل پاس همچنین شامل نوعی تشخیص الگو از نظر توالی پاس های مکرر است. آنها با عبور از هر شاخه از درخت پسوند تولید شده استخراج می شوند. چندین رویکرد مستقل با هدف استخراج یا طبقه بندی الگوهای حرکتی (یا تاکتیکی) وجود دارد. در [ 16، 17 ]، حملات بر اساس مکان شروع و یک طرح تعریف شده قبلی طبقه بندی می شوند. چندین رویکرد به طور کلی با استخراج الگوهای حرکت تیمی یا گروهی سروکار دارند. در [ 18 ] یک “مدل نیروی محرکه مکانی- زمانی” آموخته شده برای توصیف الگوهای حرکت گروهی استفاده شده است. در [ 19 ] چارچوبی با استفاده از مدل ویژگی و ویژگیهای مورفولوژیکی ویژگیها برای تجزیه و تحلیل تاکتیکهای فوتبال معرفی شده است. مرجع [ 20 ] از معماری سلسله مراتبی شبکه های عصبی مصنوعی برای یافتن الگوهای تاکتیکی استفاده می کند. مرجع [ 21] روشی را برای پیدا نکردن حرکت، بلکه الگوهای عبور توصیف می کند. آنها یک روش تطبیق چند مقیاسی را بر اساس مقایسه کانتور اعمال کردند. برای استخراج الگوهای حرکت توپ، که ممکن است در طول توالی پاسها رخ دهد، [ 22 ] یک روش استخراج گامبهگام را پیشنهاد میکند که از معیارهای شباهت مختلف برای مقایسه مسیر توپ استفاده میکند و با ترجمه، مقیاسگذاری و تغییرناپذیری چرخش مواجه میشود.
با نگاهی به تجزیه و تحلیل فوتبال، رویکردهای بیشتری را می توان در حوزه های دیگر یافت، به عنوان مثال، ترافیک یا حرکت حیوانات. آن ها نیز می توانند به بافت ما منتقل شوند. چند روش (به عنوان مثال، [ 23 ، 24 ، 25 ، 26 ، 27 ]) از الگوریتم های خوشه بندی در ترکیب با اندازه گیری فاصله، به عنوان مثال، ویرایش فواصل، تاب خوردگی زمان پویا، یا طولانی ترین دنباله متداول، برای شناسایی مسیرهای مشابه و استخراج شی معمولی استفاده می کنند. حرکات یک روش مرتبط بر اساس تبدیل مسیرها به دنباله ای از نمادهای کلاس توسط [ 28 ارائه شده است.]). سپس از این نمایش نمادین برای مقایسه توالی ها با کمک فاصله ویرایش وزنی نرمال شده به عنوان اندازه گیری فاصله استفاده می شود. در [ 29 ] الگوریتمی توضیح داده شده است که تشخیص الگوها را بر حسب گروه های شی که رفتار حرکتی یکسانی دارند، امکان پذیر می سازد. آنها از یک الگوریتم استخراج برای تشخیص الگوهای حرکت محلی استفاده می کنند که پس از آن با استفاده از یک معیار تشابه برای شناسایی روابط گروهی خوشه بندی می شوند. علاوه بر این، گروهی از رویکردها وجود دارد که الگوهای تناوبی را در توالی های نمادین یک بعدی استخراج می کنند. چالش اصلی آنها تبدیل داده های حرکتی دو بعدی به داده های توالی 1 بعدی است. برای این منظور، آنها دنباله هایی از مستطیل شکل [ 30 ]، اغلب بازدید شده [ 31 ] یا مناطق از پیش تعریف شده [ 32] تولید می کنند.] که توسط مسیرها بازدید می شود. به این ترتیب، آنها به طور همزمان ابعاد داده ها و تعداد بالای نقاط مسیر را به تجمع های معنی دار تری کاهش می دهند. سپس الگوها با استفاده از روشهای تحلیل توالی موجود استخراج میشوند.
به طور خلاصه، رویکردهای پیچیده زیادی برای استخراج الگوها در داده های حرکتی وجود دارد. با این حال، آنها واقعاً با مورد استفاده ما مطابقت ندارند. از یک طرف، ما نمی خواهیم با الگوهای از پیش تعریف شده مطابقت داشته باشیم، زیرا الگوهایی که به دنبال آن هستیم ناشناخته هستند. از سوی دیگر، روشهایی که الگوهای ناشناخته را نیز استخراج میکنند، اغلب بر روی کل مسیرها یا بر روی بخشها کار میکنند و بنابراین به نوعی تقسیمبندی به عنوان پیش پردازش نیاز دارند. از آنجایی که فرض میکنیم الگوهای مورد استفاده ما فقط در برخی از بخشهای یک مسیر گسترش مییابند، نمیتوانیم روی کل مسیرها کار کنیم. با این حال، ما عمداً از تقسیم بندی اجتناب می کنیم، زیرا قادر به شناسایی قسمت های مسیر مربوطه از قبل نیستیم و نمی خواهیم الگوهای احتمالی را برش دهیم. علاوه بر آن، تقسیم منطقی و غیر دلخواه مسیرهای یک بازی فوتبال بدون هیچ گونه اطلاعات اضافی، به عنوان مثال، مالکیت توپ، موقعیت های بازی، وقفه در بازی، یک کار کاملا چالش برانگیز است. محتملترین روشهای برازش، رویکردهایی هستند که مبتنی بر کاوی توالی هستند. با این حال، تعیین مناطق فضایی، که آیتم های دنباله ای هستند، در این زمینه قابل اجرا نیست زیرا ما با حرکات بازیکن بدون محدودیت سروکار داریم.
3. رویکرد تشخیص الگوی حرکت
در این کار ما یک روش تجزیه و تحلیل ارائه می کنیم که به ترتیب الگوهای حرکتی بازیکنان یا تیم را تشخیص می دهد. فرآیند الگوریتم ما شامل سه مرحله است و به صورت شماتیک در شکل 3 ارائه شده است . با یک ورودی شروع می شود، که داده های مسیر ارائه شده توسط برخی راه حل های ردیابی است. پیش پردازش زیر، مسیرها را برای تجزیه و تحلیل آماده می کند. در مرحله تشخیص الگوی مبتنی بر توالی، الگوهای حرکتی استخراج می شوند. در بخش های بعدی هر یک از این مراحل به تفصیل توضیح داده شده است.
3.1. ورودی
تجزیه و تحلیل ما بر اساس مسیرهای حرکتی برای هر بازیکن است. می توان آن را با یک راه حل ردیابی مبتنی بر ویدئو، رادیو یا GPS تولید کرد. این سیستم ها موقعیت ها را در مراحل زمانی گسسته به دست می آورند. فاصله نمونه برداری از چند نانوثانیه تا چند ثانیه متغیر است. دقت هندسی به سیستم مورد استفاده بستگی دارد: در حالی که ردیابی ویدئویی و رادیویی دقت را در چند سانتی متر فراهم می کند، ردیابی GPS به سنسورهای مورد استفاده بستگی دارد و به طور کلی در چند متر، مطلقا و در عرض یک متر، نسبتاً است. علاوه بر سیستم های ردیابی حرفه ای بسیار گران قیمت ارائه شده توسط Deltatre AG، Prozone Sports Ltd یا Chyronhego، که داده های حرکتی با کیفیت بالا را ارائه می دهند، یک رویکرد جدید توسط [ 33] ردیابی مبتنی بر GPS و ویدیو را فیوز می کند تا از مزایای فردی آنها استفاده کند. هدف آن ترکیب قابلیت اطمینان ردیابی GPS با دقت هندسی بالای تشخیص دوربین است. به این ترتیب، سیستمهایی که ممکن است متشکل از یک گوشی هوشمند (که به عنوان دوربین کار میکند) و مجموعهای از دستگاههای GPS (که توسط بازیکنان حمل میشود) تشکیل شده باشند، میتوانند برای به دست آوردن دادههای مسیر با کیفیتی مشابه استفاده شوند. در ترکیب با چنین سیستم کمهزینهای، تحلیل خودکار فوتبال نیز ممکن است برای کاربران ضعیفتر از نظر مالی جذاب شود.
3.2. پیش پردازش
بسته به راه حل ردیابی مورد استفاده، مسیرهای ورودی حاوی خطاهای سیستماتیک و تصادفی هستند. خطاهای سیستماتیک ناشی از کالیبراسیون های نادرست یا شرایط اندازه گیری بد است، به عنوان مثال دوربین های کالیبره نشده یا زاویه دید بد در طول ردیابی ویدیو. آنها در طول مشاهده قابل پیش بینی و ثابت هستند و به عنوان مثال می توان آنها را با تبدیل داده ها حذف کرد. خطاهای تصادفی غیر قابل پیش بینی و ثابت هستند. روشهای میانگینگیری میتواند از مشاهدات متعدد برای کاهش آنها استفاده کند.
در رویکرد ما از داده های مسیر از GPS و ردیابی ویدیو استفاده می کنیم. در حالی که مسیرهای GPS خطاهای معمولی GPS را نشان می دهند، ردیابی ویدیو حاوی خطاهای تصادفی بیشتری است. این موارد اغلب به دلیل انسداد بازیکن یا تشخیص اشتباه جعبه محدود کننده ایجاد می شود که منجر به خطاهای مکان بازیکن می شود ( شکل 4 ). ما از تبدیل ها برای اصلاح نادرستی های سیستماتیک استفاده می کنیم. برای کاهش خطاهای تصادفی از یک تکنیک فیلترینگ استفاده می کنیم. علاوه بر فیلتر کالمن، که مطمئناً اغلب انتخاب خوبی برای این کار است، یک فیلتر متوسط ساده تر (مرکز) نیز نتایج به اندازه کافی خوب ارائه می دهد ( شکل 4 ، سمت راست). سپس مسیرهای فیلتر شده برای مرحله بعدی الگوریتم ما وارد می شوند.
3.3. تشخیص الگوی مبتنی بر توالی
رویکرد تشخیص الگو در [ 34 ] معرفی شده است. در اصل، این یک روش عمومی برای تشخیص الگوهای حرکتی گروه های شی با اندازه گروه ثابت بود. در این کار ما آن را با سناریوی فوتبال تطبیق می دهیم و یک نسخه تعمیم یافته ایجاد می کنیم که همچنین قادر به تجزیه و تحلیل الگوهای حرکتی فردی است. همانطور که در شکل 5 نشان داده شده است ، الگوریتم شامل مراحل پردازش متوالی است که در این بخش به تفصیل توضیح داده شده است. سمت راست این طرح قبلاً در یک مقاله اصلی بررسی شده است.
3.3.1. ورودی الگوریتم
به طور کلی، رویکرد تشخیص الگوی ما از مسیرهای فیلتر شده به عنوان ورودی استفاده می کند. بسته به مورد استفاده، که در آن الگوهای حرکت فردی یا تیمی جستجو میشوند، ورودی الگوریتم متفاوت است. ورودی برای تجزیه و تحلیل فردی، مسیر منفرد بازیکن مشاهده شده است. تعلیق آن برای شناسایی الگوهای تیم، مسیر همه اعضای تیم را به طور همزمان در نظر می گیرد. برای این منظور از صورت فلکی اجرام استفاده می شود که موقعیت اجسام را نسبت به یکدیگر با روابط موقعیت توصیف می کند، به عنوان مثال، مختصات، فواصل، زوایا، و غیره. بسته به انتخاب، وجود دارد. (n2)(n2)روابط موقعیت ذخیره شده در یک صورت فلکی، که در آن n تعداد اجرام مشاهده شده است. در مورد ما یک صورت فلکی نشان دهنده تشکیل یک تیم در یک نقطه خاص از زمان است. با توجه به این واقعیت که ما همچنین می خواهیم الگوهای تبدیل شده (ترجمه شده یا چرخش شده) را شناسایی کنیم، باید روابط موقعیت مناسب را برای ذخیره در یک صورت فلکی انتخاب کنیم. صورت های فلکی با بردار این مقادیر رابطه توصیف می شوند. استفاده از فواصل بین موقعیت ها باعث می شود که یک صورت فلکی در مورد چرخش و انتقال تغییر نکند. شکل 6 یک مثال صورت فلکی و الزامات مربوط به تغییر ناپذیری تبدیل را به تصویر می کشد. بسته به کاربرد، سه سناریو برابر در نظر گرفته می شوند.
3.3.2. نسل دنباله حرکت
رویکرد ما مبتنی بر تبدیل کل دادههای مسیر به دنبالهای از حرکات S tot است که میتواند به روشهای کاوی توالی برای استخراج الگوهای حرکتی وارد شود. این دنباله کل دوره مشاهده را به طول می انجامد و از عناصر دنباله I i تشکیل شده است که حاوی اطلاعاتی در مورد حرکات جسم در هر مرحله زمانی است.
اسt o t= {من0،من1، .. ، منnt o t}استی�تی={من0،من1، ..، من�تی�تی}
برای موردی که در آن حرکات تک شی را تحلیل میکنیم و به هیچ وجه نمیخواهیم الگوها ثابت باشند، عناصر موقعیت بازیکن در x و y هستند (برای حالت دو بعدی). اگر به دنبال الگوهای حرکت تیم هستیم، هر عنصر یک صورت فلکی خواهد بود که اطلاعاتی در مورد مکان بازیکنان در یک نقطه از زمان می دهد. اگر اجازه دهیم دنباله های بعدی الگو ترجمه شوند، باید محتوای عناصر دنباله را به بردارهای حرکتی برای تحلیل فردی و به بردارهایی که حاوی فواصل x و y بین هر جفت بازیکن برای تجزیه و تحلیل تیمی هستند تغییر دهیم. در جدول 1 سناریوهای احتمالی دیگر فهرست شده است.
نرخ نمونه برداری، که طول مراحل زمانی را تعیین می کند، باید به طور منطقی انتخاب شود و تا حد زیادی به مورد استفاده بستگی دارد. به عنوان مثال، هنگام تجزیه و تحلیل مسیر بازیکنان در طول یک بازی فوتبال، ما باید با حرکات بدون محدودیت از جمله تعداد زیادی از تغییرات در جهت و سرعت مقابله کنیم. به منظور حفظ جزئیات حرکات، باید نرخ نمونه برداری بالایی را انتخاب کنیم. به طور کلی، این بدان معناست که نرخ نمونهبرداری بالاتر، ضبط دقیقتری از حرکات بازیکن را ممکن میسازد و الگوهای دقیقتری را به دست میآورد. با این حال، باعث توالی طولانیتری از حرکات میشود و بنابراین نیاز به تلاش محاسباتی بیشتری دارد.
3.3.3. تعیین شباهت
از آنجایی که زمین فوتبال یک فضای حرکتی اقلیدسی [ 35 ] با محدودیت های کمی در حرکت است، باید با حرکت آزاد و پیوسته بازیکنان سر و کار داشته باشیم. همچنین باید ابهامات مربوط به عناصر توالی حرکت را در نظر بگیریم، که ناشی از عدم دقت ذاتی دستگاه های اندازه گیری است (به بخش 3.2 مراجعه کنید ). به همین دلیل، ما انتظار نداریم که دقیقاً دنبالههای مشابهی از حرکات را در یک بازه زمانی مشاهده محدود پیدا کنیم. بنابراین، دنباله ای از عناصر حاوی مقادیر گسسته را از S tot استخراج می کنیمبا گسسته سازی و خوشه بندی حرکات. به این ترتیب ما به جای اینکه عناصر مشابه را بخواهیم یکسان باشند جستجو می کنیم. معیار تشابه، که به مورد استفاده نیز بستگی دارد، فاصله محاسبه شده در فضا است که توسط بردارهای ذخیره شده در عناصر دنباله تنظیم می شود. عناصر توالی مشابه به همان خوشه اختصاص داده می شوند. برای این منظور، ما دو احتمال داریم: از یک طرف میتوانیم از ویژگیهای ویژگی از پیش تعریفشده استفاده کنیم، به عنوان مثال، جهت حرکت مانند شمال، جنوب، غرب، شرق برای حرکات فردی و ترجمه ثابت. از سوی دیگر میتوانیم از یک خوشهبندی مبتنی بر چگالی، مانند DBSCAN [ 36 ]، یا یک روش خوشهبندی مبتنی بر مرکز، مانند k-means [ 37] استفاده کنیم.]، اگر بخواهیم خوشه های ناشناخته پیشینی را شناسایی کنیم. برای کنترل درجه تشابه مورد نیاز برای تخصیص عناصر دنباله به یک خوشه، میتوانیم از پارامترهای خوشهبندی مورد نیاز استفاده کنیم، به عنوان مثال، الگوریتم k-means به تعداد خوشهها نیاز دارد. هر چه تعداد خوشه های حاصل یا از پیش تعریف شده بیشتر باشد، شباهت عناصر همسان خوشه ای بیشتر خواهد بود. نتیجه این مرحله دنباله ای از عناصر S tot,cluster با نام های خوشه مربوطه است و به عنوان ورودی برای مرحله بعدی استفاده می شود.
3.3.4. شناخت الگوهای مکرر
از آنجایی که ما به الگوهای تکراری علاقه مندیم، یک الگوی P را حداقل suppc min (حداقل تعداد پشتیبانی) بار تکرار دنباله بعدی S i با حداقل طول l دقیقه در کل دنباله S tot، خوشه فرض می کنیم :
پ= {اس0،اس1، .. ،اسs u p p c}پ={اس0،اس1،..،اسستوپپج}
s u p p c ( P) ≥ s u p pجm i nستوپپج(پ)≥ستوپپجمترمن�
ل ( P) =لm i nل(پ)=لمترمن�
با پیروی از این فرض، میتوانیم یک روش کاوی الگوی مکرر موجود را اعمال کنیم. این روشها معمولاً به عنوان پارامترهای ورودی حداقل طول زیر دنباله l min و حداقل تعداد پشتیبانی suppc min را نیاز دارند . اگر انحرافات جزئی را در زیر دنباله های مکرر اجازه دهیم و بنابراین یک توالی کاوی تقریبی را اعمال کنیم، به پارامتر دیگری d نیاز داریم.که انحراف مجاز را کمیت می کند. روشهای استخراج تقریبی از معیارهای فاصله معینی برای تعیین انحراف بین دو دنباله استفاده میکنند. فواصل ویرایش رایج هستند، مانند فاصله Levenshtein، که حداقل تعداد ویرایش های تک عنصری مورد نیاز (یعنی جایگزینی، درج یا حذف) را برای تبدیل یک دنباله به دنباله دیگر فراهم می کند. بسته به اینکه دنبال دنباله های مکرر دقیق یا تقریبی را جستجو کنیم، باید یک الگوریتم استخراج مربوطه را اعمال کنیم. در حالی که برای روش های موردی دقیق مانند Apriori [ 38 ] یا الگوریتم FP-Growth [ 39 ] مناسب است، برای موارد تقریبی الگوریتم Baeza-Yates-Gonnet [ 40]]، از جمله، امکان پذیر است. در هر دو مورد، تمام دنباله های مکرر تعیین می شوند که الزامات ارائه شده توسط مجموعه پارامترهای مربوطه را برآورده می کنند. هر یک از آن دنبالههای فرعی مکرر که شامل تمام رخدادهای آن هستند، یک الگو را در توالی خوشهای تشکیل میدهند.
3.3.5. نقشه برداری مجدد به داده های مسیر
از آنجایی که ما نه تنها به خود الگو، بلکه به نمونههای آنها در دادهها نیز علاقهمندیم، باید الگوهای خوشهای پیدا شده را به ترتیب به دنبالههای حرکت اصلی در S tot و به مسیرها بازنگری کنیم تا الگوهای حرکت واقعی را بدست آوریم. برای این منظور، ما از یک ساختار داده مناسب استفاده می کنیم که در [ 34 ] توضیح داده شده است و عناصر دنباله مربوطه S tot، خوشه و S tot را به هم پیوند می دهد و بنابراین امکان نگاشت در هر دو جهت را فراهم می کند. نقشه برداری از عنصر در دنباله حرکت به حرکت واقعی شی از طریق timestamp و object-id انجام می شود.
4. آزمایش و بحث
4.1. مجموعه داده ها
به منظور ارزیابی رویکرد تشخیص الگوی توسعهیافته خود، آن را در سه مجموعه داده با ویژگیهای مختلف اعمال کردیم. در حالی که دو مجموعه داده اول شامل اطلاعات حرکت بازیکنان در طول مسابقات فوتبال است، سومی شامل مسیرهای ماشین است و بنابراین از یک زمینه کاملاً متفاوت است.
در آزمایش اول ما یک مجموعه داده فوتبال موجود را پردازش کردیم که در FraunhoferIIS [ 41 ] تولید شد و شامل یک بازی فوتبال کوچک با یک داور و 8 بازیکن در هر تیم است ( شکل 7 ، سمت چپ). با سیستم مکان یابی بلادرنگ خودشان ضبط شد. در یک مسابقه 60 دقیقه ای، بازیکنان و داور به دو سنسور نزدیک به پای خود مجهز شدند. توپ ها مجهز به حسگر بودند. برای این آزمایش ما هر دو مسیر پا را با هم ادغام کردیم تا یک خط سیر بازیکن نماینده به دست آوریم. موقعیت اشیاء با نرخ نمونه برداری در حدود 200 هرتز (توپ ها حتی در 2000 هرتز) با دقت چند سانتی متر ثبت شد، بنابراین یک مجموعه داده بسیار دقیق و زمانی بسیار حل شده است.
برای آزمایش دوم از مجموعه داده فوتبالی بزرگی از مسیرهای GPS استفاده می کنیم. این شامل اطلاعات حرکت یک تیم کامل (11-14 بازیکن) در بیش از 20 بازی کامل است. دستگاههای GPS که برای ثبت مسیرها استفاده شدهاند دادههایی را با نرخ نمونهبرداری 5 هرتز با دقت حدود 5 متر به طور متوسط ارائه میکنند. بنابراین، ما باید حدود 27 هزار امتیاز مسیر برای هر بازیکن در هر بازی پردازش کنیم (در مجموع حدود 7 میلیون امتیاز). برخلاف مورد قبلی، این مجموعه داده حاوی اطلاعات حرکتی بسیار بیشتری است اگرچه دقت مکانی و وضوح زمانی کمتر است.
سومین و آخرین مجموعه داده حاوی داده هایی از زمینه ترافیک است. در داده های شیکاگو از [ 42 ]، مسیرها از طریق GPS با نرخ نمونه برداری متوسط حدود 4 هرتز ثبت شده است. مجموعه داده شامل 889 مسیر با در مجموع حدود 118 هزار نقطه است. در این سناریو، اشیاء مشاهده شده در یک فضای شبکه حرکت می کنند [ 35 ] که منجر به درجات آزادی کمتری در حرکت و در نتیجه تراکم بالای مسیرها می شود، اگرچه فضای مشاهده بسیار بزرگتر از هر دو آزمایش قبلی است. ما فرض میکنیم که این چگالی بالا شانس یافتن الگوها را حتی اگر هیچ تغییری مجاز نباشد، بیشتر میکند. در شکل 7 سمت راست مجموعه داده کامل نشان داده شده است.
در جدول 2 مروری بر مجموعه داده های مورد استفاده، ویژگی های آنها و عدم تغییر در نظر گرفته شده است.
4.2. تأیید نتایج و جالب بودن الگو
راستیآزمایی تحلیلهای حرکتی اساسی هنگام داشتن دادههای حقیقت زمین یا استفاده از روشهای جایگزین برای مقایسه آسان است. با این حال، تأیید الگوهای حرکتی بسیار چالش برانگیز است، زیرا به طور کلی هیچ داده ای از حقیقت زمینی وجود ندارد. مقایسه با نتایج روشهای الگوکاوی، که مبتنی بر خوشهبندی بخشهای مسیر هستند، امکانپذیر است. با این حال، به دلیل روش بسیار متفاوت برخورد با مشکل، انتظار نداریم الگوهای قابل مقایسه ای پیدا کنیم. با مقایسه عناصر تک تک توالیها، میتوانیم صحت الگوهای بهدستآمده را ارزیابی کنیم، که البته با استفاده از یک الگوریتم کاوش دنباله آزمایش شده و درست کار میکند. ما نمی توانیم کامل بودن نتایج را ارزیابی کنیم، زیرا هیچ داده صحت زمینی برای آزمایش های ما در دسترس نیست.
به همین دلیل، ما جذابیت الگو را به عنوان یک متریک معرفی میکنیم که نتایج را قابل مقایسه میکند و همچنین اطلاعاتی را که الگوها میتوانند ارائه کنند، که هدف اصلی ماست، توصیف میکند. به دست آوردن اطلاعات به شدت به سناریوی برنامه ها بستگی دارد. در سناریوهای رایج، که در آن از الگوهای حرکتی استفاده میشود، یعنی پیشبینی حرکت و مشخصهسازی، سود با میزان الگو و شباهت دنبالههای فرعی موجود تعیین میشود. به عنوان مثال، هرچه الگوهای حرکت طولانی تر و شبیه تر باشند، بهتر می توان حرکت یک جسم را پیش بینی کرد. وسعت الگو با تعداد قطعات مسیر suppc و طول آنها l ( P ) تعیین می شود. هنگام تجزیه و تحلیل حرکات فردی،l ( P ) میانگین فاصله مکانی s است که بازیکن در دنباله های موجود طی کرده است (معادله (5)). در مورد تجزیه و تحلیل حرکات گروهی، s ( Si ) میانگین تمام فواصل بازیکنان درگیر D j است ((معادله (6)) .
ل ( P) =منظور داشتن1 ≤ i ≤ s u p p cس (اسمن) ،ل(پ)=منظور داشتن1≤من≤ستوپپجس(اسمن)،
س (اسمن) =منظور داشتن1 ≤ j ≤ n Dj،س(اسمن)=منظور داشتن1≤�≤� ��،
سیم شباهت ( P ) توسط
s i m ( P) = 1 / ( 1 +حداکثر1 ≤ i , j ≤ s u p p cد(اسمن،اسj) )سمنمتر(پ)=1/(1+حداکثر1≤من،�≤ستوپپجد(اسمن،اس�))
برای تعیین فاصله بین دو دنباله د(اسمن،اسj)د(اسمن،اس�)ما فاصله بین مسیرهای متناظر آنها را با استفاده از متریک Fréchet محاسبه می کنیم. برای هر مورد، ما به سادگی هر ترکیبی از دنباله ها را در نظر می گیریم. با این حال، از آنجایی که برای هر سکانس برای حرکات گروهی یک مسیر برای هر بازیکن وجود دارد، قبل از اینکه بتوانیم فواصل دنباله را محاسبه کنیم، ابتدا باید مسیرهای متناظر در سراسر دنباله ها را تعیین کنیم. بنابراین، جالب بودن I یک الگو است
من( ص) = s u p p c ( P) ⋅ l ( ص ) ⋅ s i m ( ص ) .من(پ)=ستوپپج(پ)· ل(پ)· سمنمتر(پ).
این امتیاز استفاده از الگوریتم ما را در زمینه تحلیل بصری امکان پذیر می کند، زیرا کاربر را به سمت الگوهای جالب راهنمایی می کند. تفسیر نهایی الگوها باید توسط خود کاربر انجام شود. شکل 8 برخی از الگوهای به دست آمده را نشان می دهد که بر اساس امتیاز جالب بودن آنها مرتب شده اند. لطفا توجه داشته باشید که امتیاز از چپ به راست افزایش می یابد. در بخش بعدی، از این معیار برای ارزیابی نتایج رویکرد خود استفاده خواهیم کرد. ما بیشتر به صورت بصری الگوهای مربوط به معقول بودن آنها را بر اساس تخصص کافی فوتبال خود بررسی می کنیم.
4.3. نتایج تشخیص الگوی حرکت
4.3.1. آزمایش 1
از آنجایی که رویکرد ما به مجموعهای از پارامترها در طول مراحل مختلف نیاز دارد، ابتدا یک مطالعه پارامتری انجام دادیم تا معقولترین تنظیم را برای هر نوع از عدم تغییری که در جدول 1 ارائه شده است، پیدا کنیم . پارامترها تعداد خوشههای k ( k -means) و ورودی suppc min و l min به الگوریتم استخراج Apriori بود. برای هر دو مورد آخر ما مقادیر ثابت را در نظر گرفتیم، یعنی s u p pجm i n= 2ستوپپجمترمن�=2به عنوان حداقل تعداد پشتیبانی ممکن و لm i n= 10 متر لمترمن�=10 متربرای الگوهای به اندازه کافی بلند
به این ترتیب، تأثیر تعداد خوشهها را که میزان شباهت را کنترل میکنند، بر روی الگوهای حاصل بررسی کردیم. ما هر تنظیمات را با جمعبندی نمرات جذابیت به دست آمده برای به دست آوردن جذابیت کلی ارزیابی کردیم ( جدول 3 ).
مطالعه پارامتر روندهای زیر را نشان می دهد: هنگامی که تعداد خوشه ها افزایش می یابد، میانگین شباهت نیز افزایش می یابد، در حالی که تعداد الگوهای حاصل، تعداد پشتیبانی متوسط و طول الگو کاهش می یابد. جذابیت کل دارای حداکثر است زیرا به همه عوامل بستگی دارد. به این ترتیب، مطالعه امیدوارکنندهترین تنظیمات پارامتر را برای تجزیه و تحلیل فردی و گروهی (نقاط برجسته قرمز/زرد در جدول 3 ) ارائه میکند که در آزمایش زیر استفاده خواهد شد. علاوه بر این، تنها با نگاه کردن به حداکثر مقادیر برای هر ترکیب بیتغییر، تعداد الگوهای حاصل با هر بیتغییر اضافی افزایش مییابد (افراد: 983، 1895، 5609 الگو، گروه: 188، 207، 243 الگو). در شکل 9ما در ادامه چند نمونه الگو را نشان میدهیم که با آن تنظیمات شناسایی شدهاند.
در همان مجموعه داده، 207 الگوی حرکت تیمی با روش استخراج ما (همان الگوریتمهای قبلی) هنگامی که از تنظیم پارامتر (k-means: k = 128 خوشه ) ارائه شده توسط مطالعه ( جدول 3 ) برای عدم تغییر ترجمه استفاده میکنیم، پیدا شد. شکل 10یک الگوی حرکت گروهی (صورت های فلکی 408-413) را نشان می دهد که 6 ثانیه طول می کشد و متشکل از دنباله ای از 3 نوع صورت فلکی مختلف (2 سبز، 2 آبی تیره، 2 خوشه آبی) است. این نشان می دهد که چگونه پنج بازیکن (محصور قرمز) در گروه از بالا به پایین حرکت می کنند. در طول زمان مشاهده دو بار اتفاق می افتد (یعنی همچنین در توالی خوشه ای 831-836). این الگو یک رفتار دفاعی معمولی را نشان می دهد، که در آن تیم از زمین راست به چپ (بازیکن راست تنها، دروازه بان تیم است) جابجا می شود تا بر بازیکنان صاحب توپ تیم مقابل فشار بیاورد.
4.3.2. آزمایش 2
برخلاف آزمایش اول، که در آن مجموعه داده ای را پردازش کردیم که فقط یک بازی فوتبال را شامل می شد، از مجموعه داده دوم حاوی چندین بازی و بنابراین اطلاعات حرکتی بسیار بیشتری برای هر بازیکن برای این آزمایش استفاده کردیم. به همین دلیل ما میتوانیم هر بازیکن را به صورت جداگانه پردازش کنیم تا الگوهای خاص بازیکن را به دست آوریم، که همچنین حاوی دانش خاص بازیکن بیشتری است. بنابراین، در این آزمایش، بازیکنانی با نقشهای مختلف انتخاب کردیم تا بررسی کنیم که آیا الگوهای خاصی وجود دارد یا خیر. ما یک هافبک میانی و یک بازیکن کناری را با هم مقایسه می کنیم که نقشه های حرارتی آنها ( شکل 11).) موقعیت های معمول خود را در طول بازی ها نشان می دهد. اگر بخواهیم که الگوها نه تبدیل و نه چرخش ثابت باشند، توزیع الگوها با نقشه های حرارتی مطابقت دارد. علاوه بر این، جهت گیری الگوها برای هر دو بازیکن متفاوت خواهد بود: الگوهای بازیکن وینگر عمدتاً جهت افقی خواهد بود، در حالی که الگوهای هافبک مرکزی هم به صورت افقی و هم به صورت عمودی است.
در این آزمایش ما اجازه می دهیم الگوها ترجمه شوند. علاوه بر این، از الگوریتم k-means و Apriori استفاده کردیم. تنظیم پارامتر همان بود که در آزمایش قبلی شناسایی کردیم. 12 بازی را ارزیابی کردیم که هر دو بازیکن در آن حضور داشتند. در شکل 12 برخی از الگوها را برای هر دو بازیکن نشان می دهیم. با استفاده از این تنظیم میتوانیم همان رفتار جهتگیری الگوها را مشاهده کنیم. علاوه بر این، تفاوت در شکل الگوها وجود دارد. الگوهای بازیکن بال ( شکل 12سمت راست) عمدتاً مسیرهای مستقیم با تغییر جهت اندک هستند. برخلاف آن، الگوهای هافبک مرکزی (چپ) دارای چرخش های قابل توجهی بیشتری است. این نیز با رفتار معمول هر دو نقش بازیکن مطابقت دارد. در حالی که هافبک به طور کلی در اکثر موقعیت های بازی آزادی حرکت بیشتری دارد، وینگر باید در بیشتر مواقع به موقعیت/کنار خود بچسبد. همچنین می توان از نظر تاکتیکی به نتایج نگاه کرد که مطمئناً برای مربیان یا پیشاهنگان جالب است. به عنوان مثال، می توان رفتارهای متفاوت بازیکن کناری را در هر دو دوره مسابقه مشاهده کرد. لطفاً توجه داشته باشید که سه الگوی پایین (آبی، زرد، صورتی) از اول و سه الگوی بالایی (فیروزهای، قرمز، سبز) از نیمه دوم مسابقه میآیند. به خصوص، الگوهای رنگی فیروزه ای و آبی رفتارهای حرکتی متفاوتی را نشان می دهند. در حالی که در نیمه اول (الگوی آبی) بازیکن مدت بیشتری روی بال می ماند و بنابراین مستقیماً در امتداد خط بیرونی حرکت می کرد، در نیمه دوم (الگوی فیروزه ای) خیلی زود (چند متر قبل از خط مرکزی) موقعیت خود را ترک کرد و مستقیماً به سمت حرکت کرد. گل حریف دلیل تغییر رفتار او را نمی توان با این تحلیل پیدا کرد. با این وجود، این یک اطلاعات مهم است که می تواند توسط مربیان بازیکن برای قضاوت در مورد عملکرد او و یا توسط مربیان حریف برای آماده سازی تیم های خود استفاده شود. دلیل تغییر رفتار او را نمی توان با این تحلیل پیدا کرد. با این وجود، این یک اطلاعات مهم است که می تواند توسط مربیان بازیکن برای قضاوت در مورد عملکرد او و یا توسط مربیان حریف برای آماده سازی تیم های خود استفاده شود. دلیل تغییر رفتار او را نمی توان با این تحلیل پیدا کرد. با این وجود، این یک اطلاعات مهم است که می تواند توسط مربیان بازیکن برای قضاوت در مورد عملکرد او و یا توسط مربیان حریف برای آماده سازی تیم های خود استفاده شود.
4.3.3. آزمایش 3
با این آزمایش میخواستیم قابلیت حمل و نقل رویکرد خود را به سایر دادهها و زمینهها ثابت کنیم. با این حال، ما باید ویژگی های مجموعه داده مورد استفاده را در نظر می گرفتیم. از آنجایی که حرکات اجسام به شدت تحت تأثیر شبکه خیابانی زیرین قرار داشت و ما به ساختارهای شبکه تکراری علاقه نداشتیم، بلکه به حرکات تکراری علاقه مند بودیم، این بار نیاز داشتیم که الگوها نه ترجمه شوند و نه چرخانده شوند. ما همچنین از 64 خوشه (k-means) برای تعیین شباهت حرکات استفاده کردیم. به منظور استخراج الگوها، ما دوباره از الگوریتم Apriori با تنظیمات پارامتر مشابه در هر دو آزمایش قبلی استفاده کردیم. ما فقط به دنبال الگوهای افراد گشتیم و از تجزیه و تحلیل الگوی گروهی صرف نظر کردیم زیرا مجموعه داده حاوی هیچ اطلاعاتی در مورد گروههای معنیدار ماشینها، به عنوان مثال، کاروانها،
در مجموع 350 الگو پیدا شد. در مقایسه با مطالعه پارامتر قبلی ( جدول 3 )، میانگین تعداد پشتیبانی (2.04) و شباهت (0.08 1/m) کمی کمتر است. با این حال، میانگین طول یک الگو (406.21 متر) و نمره کل جذابیت (23203) بسیار بالاتر است، که می تواند با درجه آزادی کمتر در حرکت در این فضای حرکتی توضیح داده شود. لطفاً توجه داشته باشید که استفاده از امتیاز جذابیت برای این سناریو نیز معتبر است، زیرا هیچ عامل وابسته به زمینه در معادله (8) وجود ندارد. در شکل 13برخی از جالب ترین الگوها، با توجه به امتیاز جذابیت ما، و شبکه خیابانی زیرین (رنگ خاکستری) نشان داده شده است. الگوهای ارائه شده (هر الگوی رنگ مخصوص به خود را دارد) از دو یا چند بخش مسیر همپوشانی تشکیل شده است و نشان دهنده مسیرهای متداول در شهر است. این مسیرها اغلب به ترتیب در جاده های اصلی و جاده های تغذیه کننده هستند. با این حال، الگوها همچنین میتوانند مسیرهای پرکاربرد یا میانبرهایی را نشان دهند که مسیرهای محبوب میتوانند برای زمینههای مختلف استفاده شوند: برنامهریزی یا مدیریت شهری میتواند از این اطلاعات برای بهینهسازی طراحی شبکه خیابانها و همچنین مدیریت ترافیک استفاده کند. سیستمهای ناوبری میتوانند از این اطلاعات برای پیشبینی مسیر بعدی کاربر و به روشی مشترک، زمانی که اطلاعات بین کاربران جاده به اشتراک گذاشته میشود، برای پیشبینی ترافیک در منطقه مربوطه استفاده کنند.
5. نتیجه گیری و چشم انداز
5.1. خلاصه
5.1.1. انگیزه و رویکرد
هدف این کار فراتر رفتن از وظایف رایج آنالیز فوتبال بود تا دانش معنیدارتری در مورد رفتار حرکتی بازیکنان و همچنین تاکتیکهای کل تیمها نشان دهد. برای این منظور، ما الگوهای حرکتی را به عنوان تامین کننده مهم آن نوع دانش شناسایی کرده ایم. ما رویکردی برای تشخیص الگوهای ناشناخته پیشینی در حرکات فردی و گروهی بر اساس دادههای مسیر ارائه کردهایم.
این رویکرد شامل یک پیش پردازش است که در آن خطاها در داده های حرکت کاهش می یابد و یک تشخیص الگوی مبتنی بر توالی. دومی از گسستهسازی دادههای مسیر برای توالیبندی دادهها استفاده میکند، که سپس با روشهای کاوی توالی برای شناسایی دنبالههای تکراری تحلیل میشوند. در نهایت، آن دنبالهها به دادههای مسیر اصلی تبدیل میشوند تا بخشهای مسیر را که بخشی از یک الگو هستند، بدست آورند.
ما این رویکرد را در سه آزمایش مختلف برای دادههای مسیر بازیهای فوتبال و همچنین از یک سناریوی ترافیک اعمال کردیم. در هر یک از آن آزمایشها، ما توانستیم الگوهای حرکتی اجسام مشاهده شده را شناسایی کنیم. این الگوها معمولاً دانش بیشتری در مورد رفتار حرکتی بازیکنان، یا به طور کلی اشیاء، نسبت به سایر روشهای تحلیل پایه یا متوسط ( شکل 1 ) که اغلب بر اساس آمار پایه هستند، ارائه میکنند.
5.1.2. ویژگی های رویکرد
ساختار کل رویکرد ما مدولار است، بنابراین میتوان روشهای پیشنهادی را در مراحل مختلف مبادله کرد تا زمانی که جایگزینها بتوانند نتایج یک ساختار را ارائه دهند. به عنوان مثال، ما قبلاً روشهای مختلف خوشهبندی جایگزین را برای تولید روشهای S tot، خوشهای یا استخراج برای شناسایی دنبالههای مکرر پیشنهاد کردهایم.
در وضعیت فعلی این رویکرد، الگوها را نمی توان در زمان واقعی استخراج کرد. خوشه بندی پیشنهادی به دلیل پیچیدگی های محاسباتی بالا (DBSCAN: O ( n log n )�(�ورود به سیستم�)، k به معنی: O ( nkdi )�(nkdi)) و توالی کاوی (تولید نامزد در Apriori: ای (2د)�(2د)، FP-Growth: ای (n2)�(�2)) روش ها امکان تجزیه و تحلیل بلادرنگ را ندارند. به منظور شناسایی الگوها در زمان اجرا، رویکرد ما باید به گونهای سفارشی شود که الگوریتمهای کار فزاینده برای خوشهبندی، به عنوان مثال، IncrementalDBSCAN [ 43 ] یا Ik-means ([ 44 ]، یا استخراج توالی، به عنوان مثال، IncSpan ([ 45 ]، با این حال، به دلیل ساختار مدولار، این تبادل زیربخش های الگوریتم کلی پشتیبانی می شود.
رویکرد ما علاوه بر انعطافپذیری درونی، برای سایر سناریوهای تحلیلی به جای تحلیل فوتبال کاربرد دارد. از آنجایی که الزامات بیشتری ندارد، برای مسیرهای هر نوع اجسام نقطه متحرک از حوزه های تحقیقاتی مختلف، به عنوان مثال، تجزیه و تحلیل رفتار حیوانات، مدیریت ترافیک، نظارت و غیره قابل استفاده است. به عنوان مثال، این مورد در آخرین آزمایش این کار شرح داده شده است. و در کار قبلی [ 34 ]، که در آن آزمایشی بر روی حرکت حیوانات (مرغ دریایی) انجام شد. مجموعه ای از پارامترها برای روش های مختلف که در این رویکرد استفاده می شود و همچنین امکان تعریف درجات آزادی الگوها که در بی تغییری های مختلف نشان داده می شوند ( جدول 1)) آن را برای سایر موارد استفاده قابل حمل می کند که با آزمایش سوم بخش تجربی ثابت شده است.
5.2. چشم انداز
5.2.1. گسترش رویکرد
چندین امکان برای گسترش کار ارائه شده در آینده وجود دارد. همانطور که قبلاً ذکر شد، یک مورد باقیمانده فعال کردن قابلیت بلادرنگ است که برای برنامههای خاص مفید است، با وسایل داده شده.
علاوه بر این، اطلاعات زمینه های مختلف را می توان برای شناسایی الگوهای معنی دار تر و همچنین برای سرعت بخشیدن به الگوریتم برای پرداختن به پردازش زمان واقعی گنجاند. در حال حاضر فقط حرکت بازیکنان مشاهده شده در نظر گرفته می شود. به عنوان مثال، استفاده از نقش بازیکن (به عنوان مثال، بازیکن چپ یا راست، جلو و غیره) به عنوان اطلاعات قبلی می تواند به کاهش فضای جستجوی الگو کمک کند. برای انجام این کار، احتمالات حرکتی که برای موقعیت مربوطه بسیار بعید است، در طول فرآیند تشخیص در نظر گرفته نمی شود زیرا شانس تشخیص الگو در این حرکات نیز بسیار کم است. علاوه بر این، از آنجایی که این حرکت اغلب تحت تأثیر موقعیت های حریفان و اعضای تیم و همچنین موقعیت توپ قرار می گیرد، می توان مسیر حرکت آنها را نیز در نظر گرفت.S tot، خوشه .
علاوه بر این، موقعیت های مختلف بازی را می توان به طور جداگانه تجزیه و تحلیل کرد تا به عنوان مثال، الگوهای حمله و دفاع بازیکنان فردی یا کل تیم ها را به دست آورد. همین امر برای اجرای موقعیت های استاندارد مانند کرنر یا ضربات آزاد نیز صدق می کند. حتی در آنجا، حرکات معمولی تمرین شده بازیکن یا تیم را می توان شناسایی کرد. برای این منظور، ابتدا باید دورههای زمانی که شامل آن موقعیتهای بازی است، تعیین شوند، مثلاً با استفاده از روشهای یادگیری نظارت شده. به این ترتیب فضای جستجو تنها به بخش های مسیر مرتبط کاهش می یابد. این کاهش منجر به شناسایی الگوهای کمتر اما معنادارتر می شود.
5.2.2. استفاده از الگوهای حرکتی
یکی دیگر از موارد باز، استفاده از الگوهای به دست آمده است. در [ 46] دو کاربرد معمولی نامگذاری شده است: خصوصیات و پیش بینی. از نظر شخصیت پردازی، الگوهای شناسایی شده به ترتیب برای توصیف بازیکنان یا تیم های مشاهده شده استفاده می شود. این توضیحات می تواند به عنوان کسب اطلاعات ساده برای مربیان یا بینندگان یا برای شناسایی بازیکنان صرفاً بر اساس حرکات آنها استفاده شود. مورد دوم زمانی مفید است که این اطلاعات بازیکن اضافی به سیستم ردیابی داده شود تا عملکرد آن با تخصیص مجدد خودکار بازیکنان از دست رفته در صحنه های پیچیده بهبود یابد. اولین قدم به سمت شخصیت پردازی بازیکنان در آزمایش دوم انجام می شود، جایی که الگوهای دو بازیکن مختلف با نقش های متفاوت را با هم مقایسه می کنیم. سپس می توان از این دانش همانطور که در بالا توضیح داده شد استفاده کرد.
این پیش بینی اطلاعاتی در مورد حرکات آینده بازیکنان ارائه می دهد. در شکل 14، دو نمونه، یکی برای فوتبال و دیگری برای سناریوی ترافیک، نشان داده شده است که در آن الگوهای حرکتی احتمالات متفاوتی از آنچه که مسیر آینده ممکن است به نظر برسد را توصیف می کند، با فرض اینکه جسم (سبز) در ابتدای آن الگوها قرار دارد. برای این منظور باید الگوی حرکتی فعلی یک بازیکن را شناسایی کنیم. با کمک این الگو میتوانیم در مورد مسیرهای آینده پیشبینی کنیم. بنابراین، ما به تعداد کافی الگو برای هر بازیکن نیاز داریم تا بتوانیم موقعیتهای زیادی را پوشش دهیم و دقیقتر شویم. در زمینه ترافیک، به اصطلاح سیستمهای ناوبری آگاه از کاربر، که به طور خودکار مقاصد معمول کاربر را پیشبینی میکنند، به عنوان مثال، مسیر روزانه به محل کار و بازگشت به خانه یا مسیر فعالیتهای اوقات فراغت مرتباً بازدید شده، میتوانند از الگوهای استخراجشده استفاده کنند. . دانش پیشبینیها را میتوان از مسیر طی شده فعلی و تاریخچه مسیر کاربر بازیابی کرد. این تاریخچه برای الگوهایی استخراج میشود که سپس با مسیر فعلی مطابقت داده میشوند تا مقصد ممکن را بدست آورند.
منابع
- منجنیق استرالیا | فناوری پوشیدنی برای ورزش های نخبه. در دسترس آنلاین: http://www.catapultsports.com/au/ (در 8 سپتامبر 2016 قابل دسترسی است).
- Digitale Medien، TV-Übertragung، Backend-Services für den Sport. در دسترس آنلاین: http://www.deltatre.com/de/ (در 8 سپتامبر 2016 قابل دسترسی است).
- نرم افزار نظارت بر ورزشکاران، نرم افزار تجزیه و تحلیل عملکرد. در دسترس آنلاین: http://prozonesports.stats.com/ (در 8 سپتامبر 2016 قابل دسترسی است).
- ChyronHego. در دسترس آنلاین: http://chyronhego.com/ (در 8 سپتامبر 2016 قابل دسترسی است).
- Fitter, Schneller, Stärker | Wachs über dich hinaus | آدیداس miCoach. در دسترس آنلاین: http://www.adidas.de/micoach (در 8 سپتامبر 2016 قابل دسترسی است).
- برنامهها و خدمات NIKE+. در دسترس آنلاین: http://www.nike.com/us/en_us/c/nike-plus (در 8 سپتامبر 2016 در دسترس است).
- ورزش | گارمین | دویچلند در دسترس آنلاین: http://www.garmin.com/de-DE/explore/intosports (در 8 سپتامبر 2016 قابل دسترسی است).
- Runtastic: Laufen، Radfahren و Fitness GPS-Tracker. در دسترس آنلاین: https://www.runtastic.com/de/ (در 8 سپتامبر 2016 قابل دسترسی است).
- لاوب، پی. داکهام، ام. Wolle، T. تشخیص الگوی حرکت غیرمتمرکز در میان گرههای ژئوسنسور متحرک. در علم اطلاعات جغرافیایی ; Cova، TJ، Miller، HJ، Beard، K.، Frank، AU، Goodchild، MF، Eds. Springer: برلین/هایدلبرگ، آلمان، 2008; صص 199-216. [ Google Scholar ]
- گودموندسون، جی. ون کرولد، ام. Speckmann, B. تشخیص کارآمد الگوها در مسیرهای دوبعدی نقاط متحرک. GeoInformatica 2007 ، 11 ، 195-215. [ Google Scholar ] [ CrossRef ]
- بنکرت، ام. گودموندسون، جی. هوبنر، اف. Wolle, T. گزارش الگوهای گله. محاسبه کنید. Geom. 2008 ، 41 ، 111-125. [ Google Scholar ] [ CrossRef ]
- دوج، اس. ویبل، آر. Lautenschütz، AK به سوی طبقه بندی الگوهای حرکت. Inf. Vis. 2008 ، 7 ، 240-252. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لاوب، پی. ون کرولد، م. ایمفلد، اس. یافتن REMO-تشخیص الگوهای حرکتی نسبی در خطوط حیاتی جغرافیایی. در تحولات در مدیریت داده های مکانی ; Springer: برلین/هایدلبرگ، آلمان، 2005; ص 201-215. [ Google Scholar ]
- گودموندسون، جی. تحلیل وول، تی فوتبال با استفاده از ابزارهای مکانی-زمانی. محاسبه کنید. محیط زیست سیستم شهری 2014 ، 47 ، 16-27. [ Google Scholar ] [ CrossRef ]
- بوچین، ک. بوچین، م. ون کرولد، ام. لو، جی. یافتن بخش های طولانی و مشابه مسیرها. محاسبه کنید. Geom. 2011 ، 44 ، 465-476. [ Google Scholar ] [ CrossRef ]
- نیو، ز. گائو، ایکس. تیان، کیو. تحلیل تاکتیکی بر اساس مسیر توپ در دنیای واقعی در ویدیوی فوتبال. تشخیص الگو 2012 ، 45 ، 1937-1947. [ Google Scholar ] [ CrossRef ]
- زو، جی. هوانگ، Q. خو، سی. روی، ی. جیانگ، اس. گائو، دبلیو. یائو، اچ. تحلیل تاکتیکهای رویداد مبتنی بر مسیر در پخش ویدئوهای ورزشی. در مجموعه مقالات پانزدهمین کنفرانس بین المللی ACM در چند رسانه ای، باواریا، آلمان، 23-28 سپتامبر 2007.
- لی، آر. Chellappa، R. بخشبندی حرکت گروهی با استفاده از مدل نیروی محرکه مکانی-زمانی. در مجموعه مقالات کنفرانس IEEE 2010 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 13 تا 18 ژوئن 2010.
- کیم، اچ سی; کوون، او. لی، کی جی تحلیل فضایی و مکانی-زمانی فوتبال. در مجموعه مقالات نوزدهمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، نیویورک، نیویورک، ایالات متحده آمریکا، 1 تا 4 نوامبر 2011.
- گرونز، ا. ممرت، دی. Perl, J. تشخیص الگوی تاکتیکی در بازی های فوتبال با استفاده از نقشه های خودسازماندهی ویژه. هوم حرکت علمی 2012 ، 31 ، 334-343. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- هیرانو، اس. Tsumoto, S. پیدا کردن الگوهای پاس جالب از سوابق بازی های فوتبال. در کنفرانس اروپایی اصول داده کاوی و کشف دانش ; Springer: برلین، آلمان، 2004; ص 209-218. [ Google Scholar ]
- موچلر، سی. کوکای، جی. Edelhäusser, T. جریان داده کاوی آنلاین در مسیرهای تعاملی در بازی های فوتبال. IEEE Trans. هوشمند ترانسپ سیستم 2015 . [ Google Scholar ] [ CrossRef ]
- پلکیس، ن. کوپاناکیس، آی. کوتسیفاکوس، EE; فرنتزوس، ای. تئودوریدیس، ی. خوشهبندی مسیرهای اجسام متحرک در دنیایی نامشخص. در مجموعه مقالات ICDM’09، پیزا، ایتالیا، 15-19 دسامبر 2009.
- لانگ، ج.ا. نلسون، TA اندازه گیری تعامل دینامیکی در داده های حرکتی. ترانس. GIS 2013 ، 17 ، 62-77. [ Google Scholar ] [ CrossRef ]
- نانی، م. Pedreschi، D. خوشه بندی زمان محور از مسیر حرکت اجسام متحرک. جی. اینتل. Inf. سیستم 2006 ، 27 ، 267-289. [ Google Scholar ] [ CrossRef ]
- موریس، بی. تریودی، ام. الگوهای مسیر یادگیری با خوشه بندی: مطالعات تجربی و ارزیابی تطبیقی. در مجموعه مقالات CVPR 2009، میامی، FL، ایالات متحده آمریکا، 22-24 ژوئن 2009.
- لی، جی جی; هان، جی. لی، ایکس. Gonzalez, H. TraClass: طبقه بندی مسیر با استفاده از خوشه بندی مبتنی بر منطقه سلسله مراتبی و مبتنی بر مسیر. Proc VLDB Enddow. 2008 ، 1 ، 1081-1094. [ Google Scholar ] [ CrossRef ]
- دوج، اس. لاوب، پی. ارزیابی تشابه حرکت با استفاده از نمایش نمادین مسیرها. بین المللی جی. جئوگر. Inf. علمی 2012 ، 26 ، 1563-1588. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تسای، اچ پی؛ یانگ، DN; الگوهای حرکتی گروه چن، ام اس ماینینگ برای ردیابی موثر اجسام متحرک. IEEE Trans. بدانید. مهندسی داده 2011 ، 23 ، 266-281. [ Google Scholar ] [ CrossRef ]
- کائو، اچ. مامولیس، ن. Cheung، DW ماینینگ الگوهای متوالی مکانی-زمانی مکرر. در مجموعه مقالات پنجمین کنفرانس بین المللی IEEE در مورد داده کاوی، هیوستون، TX، ایالات متحده، 27-30 نوامبر 2005.
- جیانوتی، اف. نانی، م. پینلی، اف. Pedreschi، D. استخراج الگوی مسیر. در مجموعه مقالات سیزدهمین کنفرانس بین المللی کشف دانش و داده کاوی، نیویورک، نیویورک، ایالات متحده آمریکا، 12 تا 15 اوت 2007.
- مامولیس، ن. کائو، اچ. کولیوس، جی. حاجی الفتریو، م. تائو، ی. Cheung، DW Mining، نمایه سازی، و پرس و جو از داده های مکانی و زمانی تاریخی. در مجموعه مقالات دهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، سیاتل، WA، ایالات متحده آمریکا، 22-25 اوت 2004.
- فوئرهاک، یو. برنر، سی. Sester, M. ردیابی ویدئویی به کمک GPS. ISPRS Int. J. Geo-Inf. 2015 ، 4 ، 1317–1335. [ Google Scholar ] [ CrossRef ]
- فوئرهاک، یو. سستر، ام. الگوهای حرکت گروه معدن. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، اورلاندو، فلوریدا، ایالات متحده آمریکا، 5 تا 8 نوامبر 2013.
- گودموندسون، جی. لاوب، پی. Wolle, T. تحلیل حرکت محاسباتی. در کتاب راهنمای اطلاعات جغرافیایی Springer ; Springer: برلین، آلمان، 2012; ص 423-438. [ Google Scholar ]
- استر، ام. کریگل، اچ پی؛ ساندر، جی. Xu, X. یک الگوریتم مبتنی بر چگالی برای کشف خوشه ها در پایگاه داده های فضایی بزرگ با نویز. در مجموعه مقالات دومین کنفرانس بین المللی کشف دانش و داده کاوی، پورتلند، OR، ایالات متحده آمریکا، 2 تا 4 اوت 1996.
- مک کوئین، جی. برخی روشها برای طبقهبندی و تحلیل مشاهدات چند متغیره. در مجموعه مقالات پنجمین سمپوزیوم برکلی در مورد آمار و احتمالات ریاضی، اوکلند، کالیفرنیا، ایالات متحده آمریکا، 1 تا 24 ژوئیه 1967.
- آگراوال، آر. Srikant، R. الگوهای متوالی معدن. در مجموعه مقالات یازدهمین کنفرانس بین المللی مهندسی داده، تایپه، تایوان، 6 تا 10 مارس 1995.
- هان، جی. پی، جی. یین، ی. الگوهای مکرر استخراج بدون تولید نامزد. بدانید. دیس 2004 . [ Google Scholar ] [ CrossRef ]
- بازا-یتس، آر. Gonnet, GH یک رویکرد جدید برای جستجوی متن. اشتراک. ACM 1992 ، 35 ، 74-82. [ Google Scholar ] [ CrossRef ]
- DEBS 2013. در دسترس آنلاین: http://www.orgs.ttu.edu/debs2013/index.php?goto=cfchallengedetails (در 7 نوامبر 2016 قابل دسترسی است).
- ساخت نقشه. در دسترس آنلاین: http://www.mapconstruction.org (در 8 ژانویه 2016 قابل دسترسی است).
- استر، ام. کریگل، اچ پی؛ ساندر، جی. ویمر، ام. Xu, X. خوشه بندی افزایشی برای استخراج در یک محیط انبار داده. VLDB 1998 ، 98 ، 323-333. [ Google Scholar ]
- لین، جی. ولاچوس، م. کیوگ، ای. Gunopulos، D. خوشهبندی افزایشی تکراری سریهای زمانی. در کنفرانس بین المللی گسترش فناوری پایگاه داده ; Springer: برلین، آلمان، 2004; صص 106-122. [ Google Scholar ]
- چنگ، اچ. یان، ایکس. Han, J. IncSpan: کاوی افزایشی الگوهای متوالی در پایگاه داده بزرگ. در مجموعه مقالات دهم ACM SIGKDD، نیویورک، نیویورک، ایالات متحده آمریکا، 22 تا 25 اوت 2004.
- هان، جی. کمبر، م. پی، جی. داده کاوی: مفاهیم و تکنیک ها . الزویر: آمستردام، هلند، 2011. [ Google Scholar ]
شکل 1. وظایف آنالیز معمولی فوتبال که در سه سطح پیچیدگی مرتب شده اند.
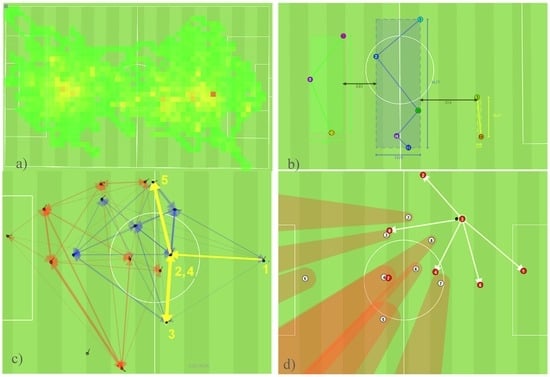
شکل 2. چهار کار تجزیه و تحلیل از سطوح مختلف پیچیدگی: ( الف ) نقشه حرارتی بازیکن. ( ب ) قطعات تیم و فواصل بین آنها. ( ج ) الگوهای توالی پاس (اعداد زرد نشان دهنده ترتیب بازیکنان پاس می باشد) و ( د ) امکان پاس دادن بازیکن صاحب توپ (نقطه سیاه توپ است، پاس های احتمالی با فلش های سفید مشخص می شوند).
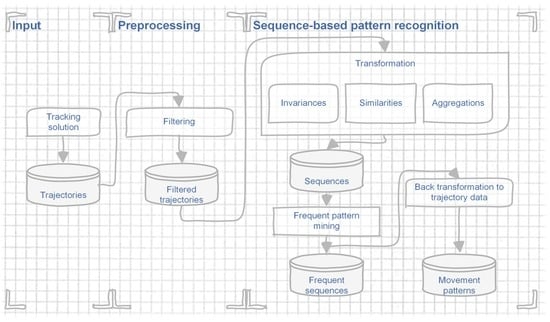
شکل 3. طرح رویکرد تشخیص الگوی ما.

شکل 4. عدم دقت در مسیرها به دلیل تشخیص اشتباه جعبه مرزبندی. ( سمت چپ ) کادر محدود محاسبه شده دقیقاً با شی مطابقت ندارد. ( سمت راست ) مسیر خام حاصل (خط قرمز) با عدم دقت قابل توجهی مواجه است که پس از اعمال تکنیک فیلترینگ (خط آبی) کاهش می یابد.

شکل 5. یک طرح دقیق از فرآیند تشخیص برای الگوهای حرکتی فردی و تیمی، همانطور که به عنوان “تشخیص الگوی مبتنی بر توالی” – مرحله در شکل 3 آمده است .

شکل 6. بسته به تغییر ناپذیری مورد نظر در مورد انتقال T ( b ) و علاوه بر آن چرخش T + R ( c )، صورت های فلکی نشان داده شده برابر با ( a ) در نظر گرفته می شوند.
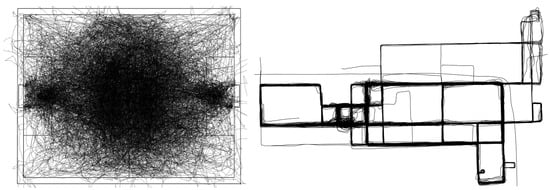
شکل 7. سمت چپ : مسیرهای با دقت بالا موجود در مجموعه داده فوتبال آزمایش اول. سمت راست : مسیرهای ماشین پردازش شده در آزمایش سوم.

شکل 8. تصویر امتیاز جالب بودن بر اساس الگوهای حرکتی فردی: از چپ به راست افزایش می یابد. رنگهای مختلف نشاندهنده انتسابهای خوشهای مختلف از هر عنصر حرکت/توالی است.

شکل 9. برخی از الگوهای حرکتی حاصل: ( بالا سمت چپ ) بدون تغییر: مسیرهای همپوشانی فضایی یافت می شوند. ( بالا سمت راست ) تغییر ناپذیری ترجمه و چرخش: مسیرهای متعلق به یک الگو جابجا شده و می چرخند. ( پایین ) تغییر ناپذیری ترجمه: در این مورد فقط جابجایی مجاز است. رنگ ها نماد تخصیص های مختلف خوشه ای از هر عنصر تک حرکت / دنباله هستند.

شکل 10. الگوی حرکت کل تیم که دو بار در طول بازی رخ می دهد.
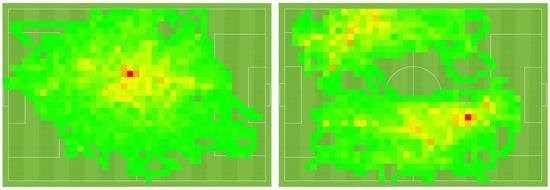
شکل 11. نقشه های حرارتی معمولی هافبک مرکزی ( چپ ) و بازیکن کناری ( راست ) در طول بازی ها.

شکل 12. مقایسه الگوهای حرکتی بازیکنان با نقش های مختلف. چپ : هافبک میانی سمت راست : بازیکن وینگر

شکل 13. برخی از جالب ترین الگوهای حرکتی استخراج شده از مجموعه داده های ترافیک. هر رنگ نشان دهنده یک الگو است.

شکل 14. الگوهای حرکتی را می توان برای پیش بینی حرکات شی در آینده استفاده کرد. در هر دو مورد ( چپ : فوتبال، راست : ترافیک) دو الگو (قرمز و آبی) مسیرهای ممکن آینده جسم سبز (بازیکن/ماشین) را توصیف می کنند.

جدول 1. الزامات مختلف برای تغییر ناپذیری الگوها منجر به محتویات مختلف عناصر دنباله می شود (x, y: مختصات؛ φ: عنوان؛ r: طول بردار حرکت).
جدول 2. مروری بر مجموعه داده های مختلف مورد استفاده برای آزمایش های این بخش.
جدول 3. تأثیر تعداد خوشه ها بر الگوهای حاصله (انفرادی/گروهی). حداکثر مقادیر جالب برای افراد با رنگ قرمز و برای گروه ها با زرد مشخص شده است.
© 2016 توسط نویسنده; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر