

خلاصه
با پیچیده تر شدن موضوعات تحقیقاتی، پروژه های تحقیقاتی بین رشته ای در مقیاس بزرگ معمولاً برای تقویت همکاری های بین رشته ای و استفاده از هم افزایی های بالقوه ایجاد می شوند. در مورد مرکز تحقیقات مشارکتی (CRC) 1026، 19 پروژه فردی از رشته های مختلف گرد هم آمده اند تا دیدگاه ها و راه حل های تولید پایدار را بررسی کنند. این گونه پروژه های بین رشته ای علاوه بر هزینه های سربار در زمینه هماهنگی فعالیت ها و ارتباطات، با چالش هایی نیز در زمینه مدیریت داده ها روبرو هستند. برای تبادل و ترکیب نتایج تحقیق، دادههای پروژههای فردی باید بهطور سیستماتیک، طبقهبندی و بر اساس روابط منطقی حوزههای دانش انضباطی مرتبط ذخیره شوند. در CRC 1026، پروژه زیرساخت اطلاعاتی شیوه های همکاری را مشاهده و تجزیه و تحلیل کرد و راه حل های پشتیبانی شده از فناوری اطلاعات را برای تسهیل و تقویت همکاری تحقیقاتی توسعه داد. اقدامات مدیریت داده در این دوره عمدتاً بر ایجاد یک چارچوب مفهومی مشترک و سازماندهی داده های مربوط به وظیفه متمرکز بود. برای جنبه قبلی، یک رویکرد مبتنی بر هستی شناسی توسعه داده شد و به طور نمونه اولیه اجرا شد. برای جنبه دوم، یک سیستم مدیریت وظیفه یکپارچه تابلو پیام توسعه داده شد و اعمال شد. یک رویکرد مبتنی بر هستی شناسی توسعه داده شد و به طور نمونه اولیه اجرا شد. برای جنبه دوم، یک سیستم مدیریت وظیفه یکپارچه تابلو پیام توسعه داده شد و اعمال شد. یک رویکرد مبتنی بر هستی شناسی توسعه داده شد و به طور نمونه اولیه اجرا شد. برای جنبه دوم، یک سیستم مدیریت وظیفه یکپارچه تابلو پیام توسعه داده شد و اعمال شد.
کلید واژه ها:
تحقیق مشارکتی ؛ تحقیق میان رشته ای ; مدیریت داده ها ؛ هستی شناسی ; تطبیق معنایی
1. معرفی
علم مدرن با زمینههای تحقیقاتی پیچیدهتر مشخص میشود که به ترکیب دانش از رشتههای مختلف نیاز دارد [ 1 ]. به عنوان مثال، تحقیق در مورد تولید پایدار به ادغام مفهومی در حوزههایی مانند توسعه محصول، فناوریهای تولید، مهندسی پایداری، ریاضیات، آموزش و اقتصاد بستگی دارد. در نتیجه، پروژههای تحقیقاتی بینرشتهای در مقیاس بزرگ به ابزاری منظم برای دانشگاهها و آژانسهای تأمین مالی برای پرداختن به موضوعات تحقیقاتی پیچیده تبدیل شدهاند [ 2 ، 3]]. به عنوان مثال، در آلمان، بنیاد علم آلمان (DFG) به مراکز تحقیقاتی مشترک (CRC) کمک مالی می کند تا مؤسسات متعددی با پیشینه های رشته های مختلف برای تحقیقات مشترک مشارکت دهند.
در میان سیاست گذاران و آژانس های تامین مالی، به طور گسترده فرض می شود که همکاری های تحقیقاتی بین رشته ای پتانسیل های زیادی برای بارورسازی بین رشته ای به همراه دارد و امکان بهره برداری از هم افزایی ها را فراهم می کند. از این رو، انتظار می رود که راه حل های نوآورانه تری نسبت به تحقیقات انضباطی کلاسیک ایجاد کند. پیچیدگی فرآیند همکاری و هزینههای سربار ناشی از آن اغلب توسط تضاد [ 4 ] دست کم گرفته میشود. ادغام دیدگاه های مختلف رشته ای نیازمند یک فرآیند یادگیری شدید برای غلبه بر فاصله های شناختی بین رشته های مختلف است [ 5 ]. این فرآیند معمولاً زمان بر است و نیازمند میانجیگری و هماهنگی گسترده توسط پرسنل مجرب است [ 6]. در ابتدا باید یک چشم انداز مشترک ایجاد شود که دیدگاه های مختلف را در خود جای دهد و سهم آنها را برای رسیدن به یک هدف مشترک تعیین کند. بر اساس چنین چارچوب موضوعی، دانش را می توان به طور هدفمند مبادله، ترکیب و بازسازی کرد تا یک چارچوب مفهومی یکپارچه را تشکیل دهد که حوزه تحقیق مشارکتی را تعریف می کند. چارچوب مفهومی به نوبه خود دستورالعمل هایی را برای فعالیت های پژوهشی فردی و مشارکتی ارائه می دهد [ 5 ]. هزینه های اضافی برای همکاری های بین رشته ای می تواند از نظر زمان، مسائل مالی، یا تلاش های مدیریتی ناشی از پدیده های مرتبط با همکاری در سطوح سازمانی، فرهنگی و فردی رخ دهد [ 4 ، 7]]. در سطح سازمانی، فواصل جغرافیایی ممکن است مانع همکاری شود، زیرا باید برای سفر از یک مکان به مکان دیگر زمان صرف شود. ساختار سازمانی سازمانی میتواند بر استقلال تیمها و توانایی آنها برای همکاری به شیوهای کارآمد و تعیینکننده تأثیر بگذارد. فرهنگ کار – به عنوان مجموعه ای مشترک از نگرش ها، ارزش ها و باورها – ممکن است بر رفتار محققان از نظر باز بودن در ارتباطات یا تمایل به اشتراک گذاری دانش تأثیر بگذارد. در سطح فردی، شخصیت و پیشینه فرهنگی ممکن است انگیزه شخصی برای همکاری را تعیین کند و بر درک و ارزیابی مشوق های همکاری تأثیر بگذارد. شرایط محیطی مانند طرحهای تأمین مالی و سیستمهای پاداش نیز ممکن است با تمایل مؤسسات و افراد برای مشارکت در فعالیتهای تحقیقاتی مشترک تداخل داشته باشد. بدین ترتیب،5 ، 8 ، 9 ].
یکی از جنبه هایی که در زمینه همکاری های پژوهشی بین رشته ای اهمیت پیدا می کند، مدیریت داده های پژوهشی است. این توسعه تا حدی مرهون چالش های ناشی از پیچیدگی تحقیقات بین رشته ای و تا حدودی به دلیل افزایش سریع حجم داده های تحقیقاتی است [ 10 ]. به دلیل تفاوت های انضباطی، هیچ درک ثابتی از آنچه که می توان به عنوان داده های تحقیق در نظر گرفت وجود ندارد [ 11 ]. پس از تعریف DFG، دادههای تحقیق میتواند هر نوع «دادههای دیجیتالی و الکترونیکی باشد که در طول یک تلاش علمی تولید میشوند، به عنوان مثال، از طریق بررسی ادبیات، آزمایش، اندازهگیری، نظرسنجی یا مصاحبه». این تعریف شامل داده های اولیه می شوددادههایی که مستقیماً از یک فعالیت جمعآوری دادهها (مثلاً پروتکلهای اندازهگیری مصرف انرژی یک ماشین خاص) به دست میآیند – و همچنین دادههای ثانویه که از آنها مشتق میشوند (مثلاً رتبهبندیهای بازده ماشین بر اساس پروتکلهای اندازهگیری).
هدف مدیریت داده های تحقیق جمع آوری و آرشیو سیستماتیک داده ها به منظور در دسترس قرار دادن آنها برای استفاده بیشتر است [ 12 ]. از دیدگاه سنتی، مدیریت داده به عنوان فعالیتی تلقی میشد که تنها در مراحل بسیار پایانی یک فرآیند خلاقانه مرتبط میشود. در نتیجه، بر روی مصنوعات نهایی تر مانند گزارش های تحقیقاتی و انتشارات متمرکز است. این مفهوم از مدیریت داده ها منجر به اقدامات ناقصی برای حفظ داده هایی شد که در جریان فعالیت های تحقیقاتی تولید و پردازش می شوند و حتی به از دست دادن داده های اولیه [13 ]]. با این حال، آگاهی فزاینده ای در مورد اهمیت داده های اولیه برای اطمینان از قابلیت استفاده مجدد و ردیابی نتایج تحقیقات وجود دارد، به طوری که مدیریت داده های تحقیق به موضوع مهمی در جوامع تحقیقاتی ملی و بین المللی تبدیل شده است [10 ] .
مدیریت داده ها در زمینه همکاری پژوهشی بین رشته ای با چالش های مشابهی مانند خود فرآیند همکاری مواجه است. علیرغم نیاز روزافزون محققان برای دسترسی به دادههای سایر رشتهها، مدیریت دادهها هنوز عمدتاً به صورت انضباطی مشخص میشود [ 10 ]. هر رشته دارای مجموعه ابرداده های خاص خود است. موسسات انضباطی ممکن است سیستم های سازمانی و فنی خود را داشته باشند، و حتی درک خود را از آنچه در واقع “داده های تحقیق” هستند [ 14]]. الزامات مربوط به مدیریت داده ها عمدتاً منحصر به راه اندازی همکاری است و در مراحل مختلف پروژه تکامل می یابد. در مرحله اولیه پروژههای میان رشتهای، ارائه ابزارها و روشهای رسمی کمتری که امکان اشتراکگذاری آسان دادهها و تحریک تبادل دانش داخلی را فراهم میکند، مهمتر است. در مراحل بعدی، زمانی که اهداف مشترک تعریف شده اند و شیوه های همکاری ایجاد شده اند، ابزارهایی برای یکپارچه سازی و ساختار استاندارد داده های تولید شده مورد نیاز است (به عنوان مثال، طرح استاندارد ابرداده). دادههای مربوط و حاصل از فرآیند همکاری نه تنها باید بهطور سیستماتیک ذخیره و توزیع شوند، بلکه باید براساس روابط معنایی حوزههای دانش رشتهای درگیر طبقهبندی و مرتبط شوند [15 ]]. از این رو، مدیریت داده ها در همکاری های بین رشته ای به معنای غلبه بر مرزهای خاص حوزه در سطوح مختلف، و افزایش مستمر الزامات و ارائه اقدامات مناسب برای حمایت از محقق در تمام مراحل فرآیند همکاری است. برای رسیدگی به چالشهای مربوط به مدیریت دادههای تحقیقاتی و فعالیتهای تحقیقاتی توزیعشده، آژانسهای تأمین مالی انواع مختلفی از مکانیسمها را در سیاستهای تأمین مالی خود گنجاندهاند [ 10 ، 12 ]. در داخل CRCها، DFG پروژههای خدمات اختصاصی برای زیرساختهای اطلاعاتی (INF) را برای توسعه راهحلهای پشتیبانیشده از فناوری اطلاعات برای تسهیل همکاریهای تحقیقاتی و انجام وظایف مدیریت دادهها تأمین مالی میکند [ 12 ].
در این مقاله، تجربیات و نتایج مربوط به فعالیتهای پروژه INF CRC 1026-Sustainable Manufacturing با بودجه DFG ارائه و مورد بحث قرار خواهد گرفت. در طول اولین دوره تامین مالی CRC 1026 (از 2012 تا 2015) پروژه INF رویکردهای روششناختی و ابزارهای فناوری اطلاعات را برای برآوردن الزامات خاص CRC 1026 توسعه داد. در طول این دوره مالی، INF شیوههای همکاری را به طور مداوم مشاهده و تجزیه و تحلیل کرد. انطباق راه حل ها با الزامات در حال تحول یک زمینه تحقیقاتی نوپا. در بخش دوم، ویژگیهای CRC 1026 و الزامات و چالشهای خاص آن معرفی میشود و الزامات مربوطه برای پشتیبانی از فناوری اطلاعات استخراج میشود. در بخش سوم، نتایج و یافته های منتخب پروژه INF ارائه خواهد شد. در بخش چهارم، نتایج و یافته ها مورد بحث قرار خواهد گرفت.
2. ویژگی های CRC 1026 — تولید پایدار
2.1. ماموریت و ساختار CRC 1026
ماموریت اصلی CRC 1026 توسعه راه حل هایی برای ایجاد ارزش جهانی پایدار با ترکیب دانش از رشته های مختلف است. تولید پایدار اهرم بزرگی برای تحقق توسعه پایدارتر صنعت در آینده فراهم می کند و به موضوعی اصلی در جامعه و سیاست تبدیل شده است. یکی از دلایلی که چرا بخش تولید در زمینه توسعه پایدار جالب توجه است، نقش آن به عنوان یک بخش اساسی از بخش صنعت است که به نوبه خود یکی از سهامداران اصلی در بسیاری از زمینههای زندگی انسانی است. به عنوان مثال، در سطح اروپا، بخش صنعت 17 درصد نیروی کار را استخدام می کند [ 16 ]، 26 درصد از مصرف نهایی انرژی را نشان می دهد [ 17 ]، و 28.5 درصد از گازهای گلخانه ای (GHG) را منتشر می کند [ 18] .]. تولید نه تنها از طریق تأثیرات مستقیم خود بر جنبه های پایداری تأثیر می گذارد (به عنوان مثال، مصرف منابع، شرایط کار، انتشار گازهای گلخانه ای، و غیره )، بلکه به طور غیرمستقیم با تعیین مصرف منابع محصولات در کل چرخه عمر آنها [ 19 ، 20 ]. علاوه بر این، تولید نیز یک بخش حیاتی برای کشورهای در حال توسعه است [ 21 ].
پیچیدگی این زمینه تحقیقاتی از این واقعیت ناشی می شود که جنبه های توسعه پایدار و تولید باید با هم ترکیب شوند. از یک سو مفهوم توسعه پایدار وجود دارد. معنای آن همانطور که توسط کمیسیون برونتلند در سال 1987 تعریف شد، از آن زمان توسط سازمانهای ملی و بینالمللی مختلف تغییر یافته است تا با تغییرات شرایط محیطی یا اهداف خاص تنظیم شود [ 22 ، 23 ]. با این حال، بیشتر تعاریف کنونی توسعه پایدار متضمن تأثیر متقابل سه بعد اقتصاد، محیط زیست و جامعه و همچنین پیامدهای ناشی از آن در طول زمان است [ 24] .]. از سوی دیگر، تولید شامل طراحی و عملیات فرآیندهای فیزیکی (مثلاً ماشینکاری)، و همچنین فرآیندهای سربار مربوطه (مثلاً تولید منابع عملیاتی) و فرآیند سازمانی در کل چرخه عمر محصول (به عنوان مثال، توسعه محصول، توزیع، استفاده از محصول و پایان عمر). از این رو، در نظر گرفتن توسعه پایدار در زمینه تولید به معنای درگیر شدن در فرآیندهای ارزش آفرینی در امتداد شبکه های بسیار پیچیده با توجه به جنبه های اقتصادی، زیست محیطی و اجتماعی و تغییرات پویا در طول زمان است.
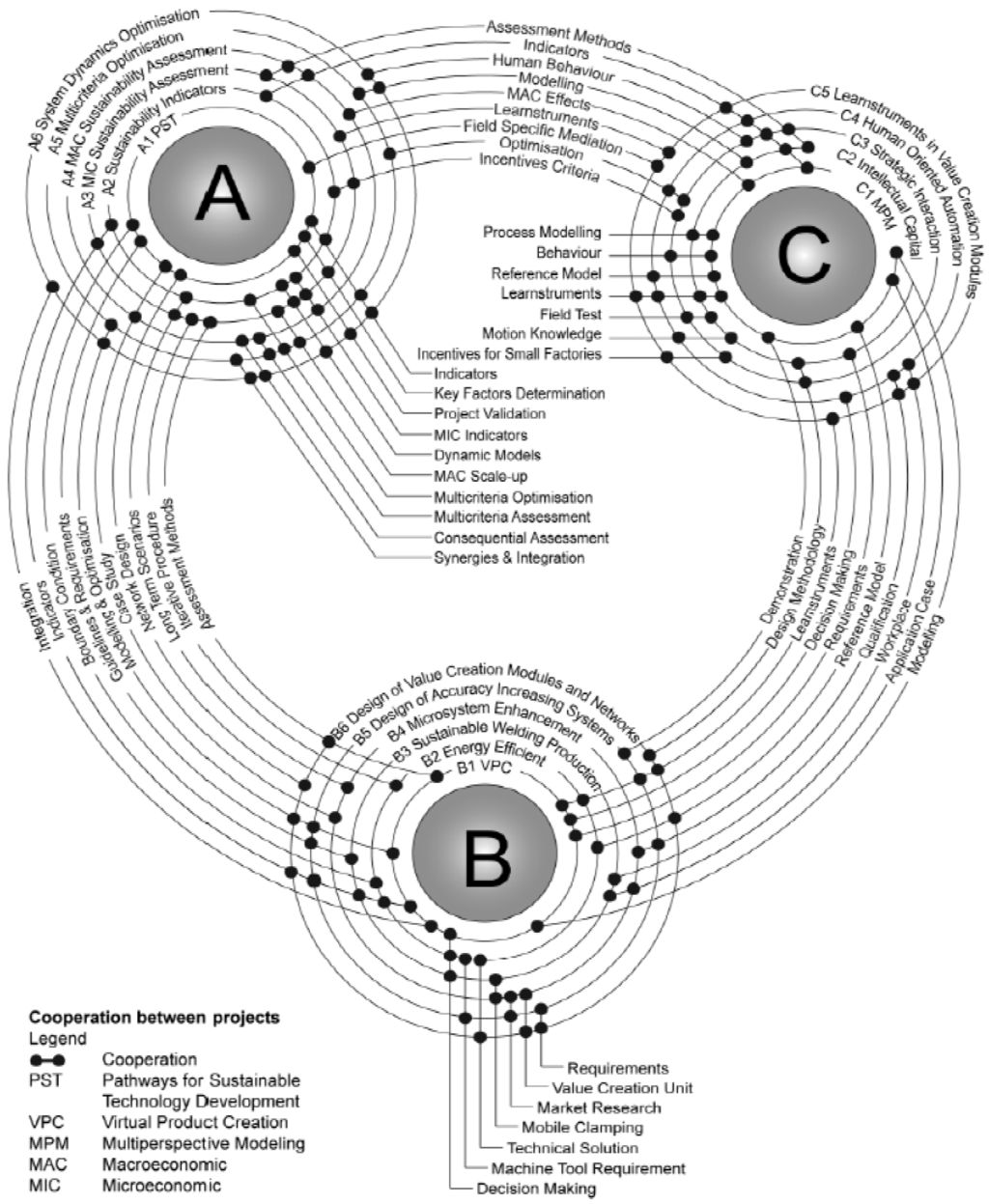
از دیدگاه CRC1026، تولید پایدار بهعنوان ایجاد محصولات تولیدی تعریف میشود که در انجام عملکرد خود در کل چرخه عمر خود، ضمن ارائه ارزش اقتصادی، تأثیر پایداری بر محیطزیست (طبیعت و انسان) داشته باشند. محققان درگیر از چهار رشته اصلی تولید، مهندسی محیط زیست، ریاضیات و اقتصاد در 17 پروژه جداگانه و سه حوزه پروژه (A، B و C) سازماندهی شدهاند. منطقه پروژه A جنبه های استراتژیک تولید پایدار را بررسی می کند تا یک چارچوب مرجع سیستمی گسترده برای اجرای موثر استراتژی های ایجاد ارزش پایدار ارائه دهد. منطقه پروژه B مبتنی بر فناوری است، و بر تحقیق ساخت و توسعه یک روش مناسب برای ادغام عناصر فناوری تولید در مفاهیم ارزش آفرینی پایدار تمرکز دارد. در منطقه پروژه C، دو دیدگاه حوزه پروژه A و B با هم ادغام می شوند. هدف اصلی تحقیق توسعه روش ها و ابزارهای یادگیری و آموزش و در نتیجه افزایش بهره وری در انتقال چالش پایداری به مخاطبان جهانی است. علاوه بر این، دو پروژه مقطعی—یعنی INF و آگاهی عمومی (PA)— از فعالیت های تحقیقاتی از نظر ارائه زیرساخت های اطلاعاتی و وسیله ای برای ارتباط عمومی و انتقال دانش تولید شده در CRC 1026 پشتیبانی می کند.
2.2. نتایج مورد انتظار و فرمت های داده
بر اساس راهاندازی CRC، فرض بر این بود که فعالیتهای تحقیقاتی در پروژههای منفرد و در سراسر آنها به نتایج ناهمگونی مانند ابزارهای نرمافزاری، روشها، مدلها، الگوریتمها و دادههای خام منجر میشود. علاوه بر انتشار این نتایج در مقالات علمی، اشکال دیگری از مستندسازی و ارائه مانند پروتکلهای اندازهگیری، جداول دادهها، بستههای کد یا انواع مدلهای متنوع (مانند مدلهای تجاری، مدلهای سهبعدی، روش اجزای محدود) باید در نظر گرفته میشد. مدلهای شبیهسازی FEM) بر اساس زبانهای مدلسازی مختلف (مانند زبان مدلسازی یکپارچه (UML)، مدل فرآیند کسبوکار و نمادگذاری (BPMN)) و تولید شده توسط انواع مختلف ابزار (مانند طراحی به کمک رایانه (CAD)، مدلساز فرآیند). برای ارزیابی گرایش های کلی نتایج آینده نگر و قالب های مربوطه آنها، INF مصاحبه های کوتاهی با محققان دوازده پروژه منفرد در آغاز CRC در سال 2012 انجام داد. این مصاحبه ها بر اساس یک پرسشنامه ساختاریافته متشکل از چهار سؤال باز بود که در آن از محققان خواسته شد تا نتایج مورد انتظار خود را شرح دهند و به چه روشی انجام خواهند داد. در دسترس باش. پاسخ های متعدد مجاز بود.
در منطقه پروژه A، نتایج عمدتاً در قالب گزارشها، جداول و پایگاههای اطلاعاتی بهعنوان سناریوهای میدانی اطراف، مجموعههای شاخص پایداری، روشهای ارزیابی چرخه عمر، مدلهای علی اقتصاد کلان و ریاضی بررسی میشوند. در مورد پروژه های مرتبط با ریاضی، الگوریتم های بهینه سازی و نرم افزارهای مربوطه نیز به عنوان نتیجه مورد انتظار بود. در منطقه پروژه متمرکز بر فناوری B، دادههای خام از اندازهگیری فرآیندهای ماشینکاری (به عنوان مثال، حفاری، جوشکاری) و دادههای شبیهسازی (به عنوان مثال، از شبیهسازیهای FEM) و همچنین روشها و ابزارهای فناوری اطلاعات که از طراحی محصول پایدار پشتیبانی میکنند، پیشبینی میشد. علاوه بر این، محققین مورد مصاحبه همچنین انتظار داشتند که مدلهای دیجیتال (مثلاً مدلهای CAD) ماشینها و قطعات ماشین در آن منطقه پروژه تولید شود. و همچنین نمونه های اولیه فیزیکی (به عنوان مثال، اجزای ماشین). در منطقه پروژه C، نتایج حاصل از آزمایشهای نظری بازی، ارزیابیهای تجاری، و مطالعات موردی در مورد عملکرد پایداری شرکت، پردازش و در گزارشها و مقالات مستندسازی میشوند. علاوه بر این، ابزارهای نرم افزاری برای ردیابی، تجزیه و تحلیل و ارزیابی ارگونومی فرآیندهای کاری با نمایشگرهای فیزیکی همراه باید توسعه یابد. در این راستا، داده های بصری (به عنوان مثال، توالی های ویدئویی) از ابزارهای ردیابی و ضبط حرکت نیز پیش بینی شده بود. تجزیه و تحلیل و ارزیابی ارگونومی فرآیندهای کاری با نمایشگرهای فیزیکی همراه باید توسعه یابد. در این راستا، داده های بصری (به عنوان مثال، توالی های ویدئویی) از ابزارهای ردیابی و ضبط حرکت نیز پیش بینی شده بود. تجزیه و تحلیل و ارزیابی ارگونومی فرآیندهای کاری با نمایشگرهای فیزیکی همراه باید توسعه یابد. در این راستا، داده های بصری (به عنوان مثال، توالی های ویدئویی) از ابزارهای ردیابی و ضبط حرکت نیز پیش بینی شده بود.
با توجه به فرمتهای مورد انتظار نتایج، شکل 1 نشان میدهد که اکثر محققان قصد داشتند نتایج خود را در قالب انتشارات مستند کنند، در حالی که دادههای خام یا اولیه فقط دو بار ذکر شده است. حتی در منطقه B مبتنی بر فناوری، تنها یک پروژه ذکر کرد که دادههای اندازهگیری وجود دارد که به عنوان یک نتیجه تحقیقاتی در نظر گرفته میشود.
2.3. تعریف الزامات کاربر برای پشتیبانی فناوری اطلاعات
برای ایجاد راهحلهای جدید برای تولید پایدار، نتایج تحقیقات باید در داخل و در بین پروژههای جداگانه در هر سه حوزه پروژه مبادله شود و دانش باید ترکیب و بازسازی شود. برای تعریف الزامات برای پشتیبانی مناسب فناوری اطلاعات برای چنین همکاریهایی، گفتگوهای اکتشافی و مصاحبههای شخصی در سال 2010، در مرحله آمادهسازی CRC 1026 انجام شد. گفتگوهای اکتشافی بین محققان پروژههای فردی در کارگاههای مشترک هدایت شد و در درجه اول هدف قرار گرفت. در شناسایی اولین مجموعه از زمینه ها و رابط های همکاری بالقوه ( شکل 2 را ببینید). بر اساس این رابط های آینده نگر، الزامات اساسی برای پشتیبانی IT مربوطه می تواند مشتق شود. به عنوان مثال، توانایی مدیریت انواع مدلها ضروری است زیرا پروژههای متعددی در حال برنامهریزی برای مشارکت در فرآیندهای مدلسازی مشترک هستند. علاوه بر این، یک سیستم مدیریت محتوای مبتنی بر وب برای فعال کردن تبادل داده ها برای فعالیت های مشترک شرکای تحقیقاتی توزیع شده جغرافیایی مورد نیاز است. پس از آن، INF مجموعه ای از 40 ویژگی متمایز را برای حمایت از تحقیقات مشترک آماده کرد. پس از گفتگوهای اکتشافی، مصاحبه های شخصی نیمه ساختاریافته با 16 رهبر پروژه تعیین شده در آگوست 2010 برای جمع آوری نیازهای کاربر خاص برای توسعه ابزارهای IT مناسب انجام شد. علاوه بر این مصاحبه ها، از رهبران پروژه خواسته شد تا یک نظرسنجی آنلاین را برای ارزیابی و اولویت بندی لیست ویژگی های شناسایی شده توسط INF پر کنند. برای این نظرسنجی از یک سیستم LimeSurvey با میزبانی شخصی (limesurvey.org) استفاده شد. در پرسشنامه از شرکت کنندگان خواسته شد تا ارتباط 40 ویژگی شناسایی شده را در یک مقیاس چهار درجه ای ارزیابی کنند، که در آن “4” مساوی “بسیار مهم” و “1” برابر است با “اصلا مهم نیست”. گزینهای برای «نمیدانم» نیز موجود بود و با مقدار عددی «0» به آن اختصاص داده شد. ده نفر از 16 رهبر پروژه احتمالی در این نظرسنجی شرکت کردند و ویژگیها با توجه به میانگین رتبهبندیهایشان اولویتبندی شدند (نگاه کنید به در پرسشنامه از شرکت کنندگان خواسته شد تا ارتباط 40 ویژگی شناسایی شده را در یک مقیاس چهار درجه ای ارزیابی کنند، که در آن “4” مساوی “بسیار مهم” و “1” برابر است با “اصلا مهم نیست”. گزینهای برای «نمیدانم» نیز موجود بود و با مقدار عددی «0» به آن اختصاص داده شد. ده نفر از 16 رهبر پروژه احتمالی در این نظرسنجی شرکت کردند و ویژگیها با توجه به میانگین رتبهبندیهایشان اولویتبندی شدند (نگاه کنید به در پرسشنامه از شرکت کنندگان خواسته شد تا ارتباط 40 ویژگی شناسایی شده را در یک مقیاس چهار درجه ای ارزیابی کنند، که در آن “4” مساوی “بسیار مهم” و “1” برابر است با “اصلا مهم نیست”. گزینهای برای «نمیدانم» نیز موجود بود و با مقدار عددی «0» به آن اختصاص داده شد. ده نفر از 16 رهبر پروژه احتمالی در این نظرسنجی شرکت کردند و ویژگیها با توجه به میانگین رتبهبندیهایشان اولویتبندی شدند (نگاه کنید بهجدول 1 ).
از نتایج ترکیبی گفتگوها و مصاحبههای اکتشافی، چهار مورد استفاده اصلی به دست آمد که هر کدام مجموعهای از نیازهای خاص را در رابطه با یک جنبه از فعالیتهای تحقیقاتی مشترک خوشهبندی میکنند و به عنوان چارچوبی برای توسعه و ترکیب پلت فرم همکاری پیشبینیشده CRC عمل میکنند.
مدیریت نیازمندی هابه توانمندسازی محققان برای گفتگو با یکدیگر در مورد فرآیندهای همکاری و دستیابی به توافقات متقابل در مورد تبادل نتایج تحقیقات اشاره دارد. برای این مورد، باید از فناوریهای فناوری اطلاعات برای مدیریت محتوای وب، توزیع ایمیل، چت، مدیریت اسناد و نظرسنجیهای آنلاین استفاده شود. یک پلت فرم همکاری مشترک باید به محققان اجازه دهد تا با استفاده از فناوری مدیریت محتوای وب، الزامات خود را در مورد نتایج تحقیقات درخواستی از پروژههای دیگر تعریف کنند. در صورت تغییر الزامات یا انجام کارهای دیگر، فهرستهای توزیع ایمیل، نمایندگی را قادر میسازد تا اعلان خودکار را بازیابی کند. مدیریت اسناد به منظور ذخیره و تبادل داده ها و ردیابی تکامل آنها استفاده خواهد شد. برای جمع آوری نیازمندی ها باید از نظرسنجی های آنلاین یا نظرسنجی های ساده استفاده کرد. علاوه بر این،
همکاری الزامات کلی را که باید برای حمایت از فعالیت های تحقیقاتی هماهنگ انجام شود، توصیف می کند. ارتباطات داخلی باید با برنامه های پیام رسانی یکپارچه و کاملاً یکپارچه (چت صوتی، تصویری و متنی) و با آگاهی از موقعیت مکانی پشتیبانی شود. لیست های تماس، صفحات وب پروژه و اطلاعات متنی باید از روند هماهنگی پشتیبانی کند و به افراد در یافتن همتایان مناسب و برقراری ارتباط با آنها کمک کند. به منظور ذخیره داده ها و همگام سازی آنها با محیط کاری شخصی، یک برنامه مدیریت اسناد مبتنی بر وب باید پیاده سازی شود که ویژگی هایی مانند کنترل نسخه و آپلود و دانلود محتوا را ارائه می دهد. برای فعال کردن همکاری زنده (به عنوان مثال، برای بررسی های طراحی توزیع شده)، یک راه حل اشتراک گذاری دسکتاپ باید معرفی شود.
کنترل پیشرفت پروژهبه نیازهای خاص مدیریت CRC و محققین اصلی (PI) برای ردیابی پیشرفت کل CRC و همچنین پروژه های فردی می پردازد. داشبوردهای مدیریتی باید ایجاد شوند که شاخصهای مربوط به پیشرفت کل CRC، فعالیتهای همکاری خاص (مثلاً تظاهرکنندگان)، یا پروژههای فردی را خلاصه و نمایش دهند. یک سیستم مدیریت وظیفه باید برای پشتیبانی از هماهنگی بسته های کاری و پیگیری پیشرفت آنها اعمال شود. فناوری مدیریت محتوای وب باید امکان پیوند محتوای مرتبط (مثلاً موضوعات بحث یا اسناد) را به کار خاص و از پیش تعریف فضاهای بارگذاری نتایج را فراهم کند. توزیع ایمیل و RSS باید امکان اطلاع رسانی خودکار در مورد تغییرات در وضعیت یک کار یا نظرات تکلیف کنندگان را فراهم کند.
عوامل پیرامون مدیریت داده به طور مستقیم توسط کشف محتوای مورد استفاده در نظر گرفته شد . این نیاز به روشها و ابزارهای مناسب را برطرف میکند تا اطمینان حاصل شود که هر محتوای خاصی را میتوان ذخیره کرد و به راحتی توسط همه محققین یافت. این مورد استفاده نیز اهمیت فزاینده ای در نظر گرفته شد زیرا مقدار محتوا ( به عنوان مثال ، نتایج تحقیق مانند متن، شکل ها، تصاویر، داده های اندازه گیری شده و غیره ) به طور مداوم در طول دوره CRC رشد می کند. ویژگیهای مدیریت اسناد باید برای ذخیره سیستماتیک محتوا در پایگاههای اطلاعاتی اسناد استفاده شوند تا امکان جستجوی محتوا نه تنها با نام فایل یا مکان آن در ساختار پوشه، بلکه بر اساس ابردادههای آن (مانند موضوع، نویسنده، پروژه، تاریخ ایجاد) فراهم شود. و غیره). برچسب گذاری اجتماعی باید به منظور طبقه بندی محتوا و ایجاد یک جمله بندی مشترک برای موضوعات، انواع نتایج تحقیق و روابط آنها با یکدیگر استفاده شود. یک جستجوی محتوای معقول کلمه کلیدی، نوع محتوا و زمینه که با فناوری های نمایه سازی تکمیل می شود، باید محقق شود. به منظور اطلاع کاربران در مورد تغییرات در محتوا، آنها می توانند از طریق ایمیل یا RSS Feeds مشترک به روز رسانی شوند. برای کنترل حقوق دسترسی، یک سیستم کنترل دسترسی اجباری باید ارائه شود که همچنین اطمینان می دهد که محتوا فقط برای نقش های تعریف شده، کاربران خاص یا گروه های کاربری قابل مشاهده است.
در نهایت، این موارد استفاده و فهرست اولیه از 40 ویژگی اولویتبندی شده، معیاری را برای درخواست نرمافزار ارائه کردند.
3. نتایج پیاده سازی در CRC 1026
در آغاز یک پروژه تحقیقاتی مشترک جدید، مانند CRC 1026، ایجاد یک چارچوب مفهومی مشترک و ایجاد یک پایگاه دانش مشترک به منظور فعال کردن همکاری های بین رشته ای بسیار مهم است [5 ]]. در طول این فرآیندها، شیوه های همکاری در سطح سازمانی و فردی باید تکامل یافته و تثبیت شوند. بنابراین، پروژه INF بر توسعه پشتیبانی روششناختی و فناوری از فعالیتهای ارتباطی و هماهنگی در CRC برای تسهیل این مرحله از اکتشاف متمرکز شد. مدیریت داده ها در این زمینه به ویژه نیازمند فراهم کردن فضاهای کاری مشترک برای تبادل داده، مدیریت داده های مربوط به کار، و همچنین ایجاد یک پایه معنایی در سطح گسترده پروژه است که امکان پیوند داده های انضباطی را فراهم می کند. در طول دوره CRC INF به طور مداوم آمار استفاده از ابزارهای پیادهسازی شده را نظارت میکرد و نیازهای کاربر را از طریق کانالهای مختلف (مثلاً گفتگوهای شخصی، کارگاههای کاربر، و نظرسنجیهای آنلاین) ارزیابی میکرد تا فعالیتهای توسعه خود را تطبیق دهد. علاوه بر این،و غیره ) برای مشاهده و تجزیه و تحلیل شیوه های همکاری واقعی.
3.1. بنیاد زیرساخت اطلاعات – بستر همکاری CRC
ستون فقرات زیرساخت اطلاعاتی CRC یک پلت فرم همکاری مبتنی بر راه حل پورتال منبع باز “Liferay” (liferay.org) است. این چارچوب مبتنی بر جاوا شامل مجموعه گستردهای از برنامههای داخلی به نام «پورتلت» است که مجموعهای غنی از ویژگیهای اساسی همکاری را ارائه میکند. به عنوان مثال، ویژگی مدیریت اسناد مبتنی بر وب، با کنترل نسخه یکپارچه و تنظیمات فراداده گسترده، امکان تبادل ساده داده ها را بین پروژه های فردی فراهم می کند. یک سیستم کنترل دسترسی مبتنی بر نقش، امتیازات دسترسی را برای محققان با توجه به نقش آنها در پروژه تعریف می کند ( به عنوان مثال، محقق اصلی، محقق، محقق خارجی، یا دستیار دانشجو) و تکالیف ویژه آنها (مثلاً مدیر عامل). ابزارهای هماهنگی، مانند فهرستهای تماس مشترک و تابلوهای بحث، اطلاعات تماس و کانالهای ارتباطی را برای تبادل فردی فراهم میکنند. ویکی زمینه مشترکی برای به اشتراک گذاشتن دانش انضباطی و ایجاد درک مشترک از مفاهیم اساسی فراهم می کند.
برای تطبیق این ویژگیهای پیشفرض با موارد استفاده شناساییشده، تغییراتی باید در سطوح مختلف انجام میشد. به عنوان مثال، در مورد تقویم مشترک، تنظیمات بسیار ساده بودند زیرا فقط یک رابط کاربری بازسازی شده و یک رابط Outlook توسعه و اعمال شد. در موارد دیگر، مانند سیستم مدیریت وظایف شرح داده شده در بخش 3.2، منطق عملکردی سیستم Liferay باید با پورتلت توسعه یافته خود اصلاح می شد. مثال دیگری برای سفارشیسازی پیچیدهتر، فضای کاری مشترک در پلتفرم همکاری است که به آن بخش «اسناد و رسانه» نیز میگویند. برای تسهیل استفاده از این فضای کاری مشترک، دوباره طراحی شد تا شبیه یک ساختار پوشه سنتی باشد. علاوه بر پوشههای مشترک، که برای همه اعضای CRC باز است، باید پوشههای خصوصی با دسترسی محدود برای هر پروژه و برای بدنههای مدیریتی نیز وجود داشته باشد. علاوه بر این، کاربران باید بتوانند پوشههای همکاری اختصاصی را بر حسب تقاضا ایجاد کنند و امتیازات دسترسی را برای آنها به صورت دلخواه تنظیم کنند. برای اینکه کاربران بتوانند امتیازات دسترسی را تا این حد تغییر دهند، منطق کنترل دسترسی پیشفرض Liferay باید اصلاح میشد و پورتلت مدیریت اسناد جدیدی ایجاد میشد.شکل 3 ). اولی به طور برجسته در بخش بالایی رابط نمایش داده می شود، در حالی که دومی در بخش پایین نمایش داده می شود، زیرا فرض بر این است که دخالت مستقیم به علاقه بالاتر برای کاربر مربوط می شود. این تمایز بر اساس نقش های دسترسی اعمال شده در پوشه های مربوطه انجام می شود.
برای تطبیق بیشتر کارنامه عملکردی Liferay برای برآورده کردن الزامات CRC، ابزارهای منبع باز تکمیلی برای برآورده کردن الزامات عملکردی و ارائه خدمات کمکی ادغام شدند. برای میزبانی برنامه های کاربردی وب، Apache™ Tomcat و Apache™ HTTP سرور استفاده می شود (apache.org). MySQL (mysql.com) به عنوان سیستم مدیریت پایگاه داده استفاده می شود. با افزودن یک موتور جستجوی سفارشی مبتنی بر Apache Lucene™ (apache.org)، INF به کاربران امکان داد تا در میان محتویات ذخیره شده بر اساس نوع، نام و متن خود جستجو کنند. ابزار تجزیه و تحلیل وب Piwik (piwik.org) برای ردیابی فعالیتها در وبسایت و فعال کردن تجزیه و تحلیل ترافیک صفحه، از جمله: کشور مبدا، میانگین زمان صرف شده در وبسایت، نرخ پرش، و دانلودها پیادهسازی شده است. سرور ایمیل رایگان hMailServer (hmailserver. com) به سیستم Liferay اجازه می دهد تا ایمیل ها را پردازش کند و اعلان های خودکار توسط سیستم را فعال می کند. برای کنفرانس وب سیستم منبع باز، BigBlueButton (bigbluebutton.org) پیاده سازی شد. برای استفاده از تمام قابلیتهای BigBlueButton، ابزارهای خدمات تکمیلی مانند: Red5 (red5.org) سرور جریان رسانه، FreeSwitch (freeswitch.org) اتصال صوتی برای صدا از طریق IP (VoIP) و Redis (redis.io) پیادهسازی شدند. ذخیره ارزش کلیدی برای مدیریت پیکربندی علاوه بر این، Libre Office (libreoffice.org) برای پردازش اسناد پیاده سازی شد. در نهایت، Limesurvey (limesurvey.org) برای ارائه قابلیت های نظرسنجی آنلاین مورد استفاده قرار گرفت. برای متعادل کردن بار زیرساخت، اجزا بین دو ماشین مجازی توزیع می شوند برای کنفرانس وب سیستم منبع باز، BigBlueButton (bigbluebutton.org) پیاده سازی شد. برای استفاده از تمام قابلیتهای BigBlueButton، ابزارهای خدمات تکمیلی مانند: Red5 (red5.org) سرور جریان رسانه، FreeSwitch (freeswitch.org) اتصال صوتی برای صدا از طریق IP (VoIP) و Redis (redis.io) پیادهسازی شدند. ذخیره ارزش کلیدی برای مدیریت پیکربندی علاوه بر این، Libre Office (libreoffice.org) برای پردازش اسناد پیاده سازی شد. در نهایت، Limesurvey (limesurvey.org) برای ارائه قابلیت های نظرسنجی آنلاین مورد استفاده قرار گرفت. برای متعادل کردن بار زیرساخت، اجزا بین دو ماشین مجازی توزیع می شوند برای کنفرانس وب سیستم منبع باز، BigBlueButton (bigbluebutton.org) پیاده سازی شد. برای استفاده از تمام قابلیتهای BigBlueButton، ابزارهای خدمات تکمیلی مانند: Red5 (red5.org) سرور جریان رسانه، FreeSwitch (freeswitch.org) اتصال صوتی برای صدا از طریق IP (VoIP) و Redis (redis.io) پیادهسازی شدند. ذخیره ارزش کلیدی برای مدیریت پیکربندی علاوه بر این، Libre Office (libreoffice.org) برای پردازش اسناد پیاده سازی شد. در نهایت، Limesurvey (limesurvey.org) برای ارائه قابلیت های نظرسنجی آنلاین مورد استفاده قرار گرفت. برای متعادل کردن بار زیرساخت، اجزا بین دو ماشین مجازی توزیع می شوند org) سرور جریان رسانه، رابط صوتی FreeSwitch (freeswitch.org) برای صدا از طریق IP (VoIP) و ذخیره ارزش کلید Redis (redis.io) برای مدیریت پیکربندی. علاوه بر این، Libre Office (libreoffice.org) برای پردازش اسناد پیاده سازی شد. در نهایت، Limesurvey (limesurvey.org) برای ارائه قابلیت های نظرسنجی آنلاین مورد استفاده قرار گرفت. برای متعادل کردن بار زیرساخت، اجزا بین دو ماشین مجازی توزیع می شوند org) سرور جریان رسانه، رابط صوتی FreeSwitch (freeswitch.org) برای صدا از طریق IP (VoIP) و ذخیره ارزش کلید Redis (redis.io) برای مدیریت پیکربندی. علاوه بر این، Libre Office (libreoffice.org) برای پردازش اسناد پیاده سازی شد. در نهایت، Limesurvey (limesurvey.org) برای ارائه قابلیت های نظرسنجی آنلاین مورد استفاده قرار گرفت. برای متعادل کردن بار زیرساخت، اجزا بین دو ماشین مجازی توزیع می شوند
تا سپتامبر 2015، پلتفرم همکاری حدود 20 گیگابایت داده، 5000 مورد (اسناد، فایل های رسانه ای و غیره )، 52 تابلوی پیام با حدود 250 پست و 99 صفحه ویکی داشت. حجم متوسط داده ها عمدتاً از این واقعیت ناشی می شود که بسته های بزرگ داده مانند نتایج ضبط حرکت در آنجا ذخیره نمی شدند، بلکه به صورت محلی در زیرساخت محقق مربوطه ذخیره می شدند. برای همکاری بین پروژههای منفرد، تنها جنبههای مرتبط این دادهها از طریق پلتفرم همکاری (مثلاً به عنوان جداول، گزارشها، انتشارات و غیره ) استخراج و مبادله شدند.
از دسامبر 2013، استفاده از منطقه همکاری داخلی به طور اختصاصی با استفاده از متغیرهای خاص اعضا در ابزار تجزیه و تحلیل وب پیگیری شد. دادههای ترافیکی ثبتشده از دسامبر 2013 تا دسامبر 2015، رشد جزئی اما ثابتی را در فعالیتهای پلتفرم با اوجهای دقیق و همزمان با رویدادهایی مانند جلسات عمومی یا کنفرانسهای آتی نشان میدهد. به طور متوسط، 17 بازدید منحصر به فرد در هفته از منطقه همکاری داخلی وجود داشت ( شکل 4 را ببینید ). یک بازدید منحصر به فرد در این زمینه به این معنی است که هر کاربر متمایز فقط یک بار برای بازدید از صفحه در 24 ساعت شمارش می شود.
3.2. مدیریت داده های مربوط به وظایف در گروه های بزرگ
در طول دوره CRC، تشکیل گروههای کاری و گروههای ضربت به شکل معمول همکاری تبدیل شد. مدیریت وظایف و داده های مربوط به وظایف در چنین صورت فلکی گاهی دشوار است، زیرا پردازش آنها مستلزم تغییر گروهی از افراد است. شفاف نگه داشتن مبدأ و تحول وظایف برای هماهنگی فعالیت های مشترک ضروری است. اسناد در مکاتبات ایمیلی یا صورتجلسات مجزای جلسات اغلب منجر به تلاشهای بیشتر هماهنگی میشود، برای مثال، اگر تغییراتی در پرسنل رخ دهد. از این رو، INF یک سیستم مدیریت وظیفه را طراحی کرد که عمیقاً با ویژگی ارتباطی گروه مرکزی پلت فرم همکاری – تابلوهای پیام – یکپارچه شده است. هر کار باید به یک رشته تابلوی پیام مرتبط باشد که در آن زمینه آن شرح و مستند شده است. همین رشته فضای مشترکی را برای بحث در مورد کار فراهم می کند و توافقات نهایی را در مورد پردازش آن شفاف می کند. اسناد مربوطه مانند صورتجلسه جلسه یا داده ها و مدل های استفاده شده را می توان با آن مرتبط کرد. برخلاف ارتباطات مبتنی بر ایمیل، ساختار رشتههای تابلوی پیام حتی برای کاربرانی که در حالت بعدی به گروه ملحق میشوند، قابل درک است. این رویکرد هم جنبه ساختن جامعه و هم شفافیت فعالیت های همکاری در CRC را تقویت می کند. با درخواست دادههای مربوط به وظیفه که از طریق پلتفرم همکاری مبادله شوند، خطر گم شدن دادهها در فرآیند مشارکتی کاهش مییابد. در دسترس بودن و یافتن داده های مربوطه بهبود می یابد زیرا آنها باید در یک محیط مشترک ذخیره شوند و از افراد مجرد (یا به ترتیب صندوق پست الکترونیکی آنها) مستقل هستند. عملکرد کنترل نسخه ارائه شده پلت فرم همکاری، خطر ناسازگاری ناشی از ذخیره سازی اضافی داده را کاهش می دهد (به عنوان مثال، اگر چندین محقق روی یک مقاله کار می کنند). علاوه بر این، به داده های مرتبط با موضوعات بحث، زمینه و هدف خاصی داده می شود و از این رو، با معنای معنایی غنی می شود.
3.3. مفهوم و نمونه اولیه مدیریت داده مبتنی بر هستی شناسی
برای رسیدن به هدف کلی CRC، فعالیت های تحقیقاتی باید هماهنگ و نتایج با هم ترکیب شوند. از این رو، ایجاد یک درک مشترک نیز یکی از وظایف اساسی INF است. برای انجام این وظیفه باید یک هستی شناسی CRC مشترک ایجاد شود. هستی شناسی ها بازنمایی رسمی از درک مشترک برخی از حوزه های مورد علاقه هستند. یک هستی شناسی لزوماً نوعی جهان بینی از یک حوزه را در بر می گیرد و می تواند به عنوان یک چارچوب متحد کننده برای حل مشکلات مربوط به ارتباط بین افراد و/یا سازمان ها (مثلاً با ارائه یک مدل هنجاری)، قابلیت همکاری (مثلاً با فعال کردن استفاده مجدد و به اشتراک گذاری داده ها/اطلاعات/مدل ها بین سیستم های IT) و مهندسی سیستم ها (مثلا با تسهیل تعریف نیازمندی ها) [ 25]. در CRC1026، یک گروه کاری هستی شناسی برای تعریف فرآیند توسعه مشترک و هماهنگ کردن فعالیت های توسعه ایجاد شد. در حال حاضر، هستی شناسی CRC از ده زیرهستی شناسی تشکیل شده است که هر کدام مفاهیمی را در رابطه با جنبه های خاصی از تولید پایدار که توسط پروژه های جداگانه پوشش داده می شوند، خوشه بندی می کند ( شکل 5 را ببینید ).
این هستیشناسیها با استفاده از چارچوبهای مدلسازی داده استاندارد شده، یعنی طرح چارچوب توصیفی منابع (RDF-S) و زبان هستیشناسی وب (OWL) مدلسازی میشوند، که هر دو مکانیسمهایی را برای توصیف رسمی هستیشناسیها (به عنوان مثال، گروههایی از مفاهیم/منابع مرتبط و روابط) ارائه میکنند . بین این مفاهیم/منابع). ابزار مدلسازی Protégé 4.3 (protege.stanford.edu) استفاده می شود. تا کنون، هستیشناسیها فقط به زبان انگلیسی مدلسازی شدهاند، زیرا زبان رسمی CRC 1026 است. زبانهای دیگر به دلایل ظرفیت در نظر گرفته نشدند.
از دیدگاه مدیریت داده، هستیشناسیها میتوانند تبادل (اتوماتیک) داده و یکپارچهسازی دادهها را در میان سیستمها، مؤسسات و رشتههای فناوری اطلاعات ناهمگن با خدمت به عنوان زبان بینالمللی تسهیل کنند [26 ، 27 ]]. در زمینه CRC، جنبه حمایت از کشف و سازماندهی داده با فناوریهای معنایی در نیمه دوم دوره پروژه، زمانی که همکاریها شدیدتر شد و مقدار دادههای ذخیره شده در پلتفرم به طور مداوم افزایش یافت، به طور فزایندهای مرتبط شد. در کارگاههای اختصاصی با کاربران پلتفرم (که در آن INF محققانی از پروژههای دیگر را برای ارزیابی توسعه ابزارهای پلتفرم درگیر میکرد)، بحث شد که در یک زمینه بینرشتهای، گاهی اوقات ویژگیهای جستجو برای یافتن محتوا کافی نیست. در برخی موارد، کاربران ممکن است حتی ندانند که دقیقاً به دنبال چه چیزی بوده اند که قصد دارند پلتفرم همکاری را برای داده های “مفید” مرور کنند. در این راستا، سازماندهی داده ها در یک ساختار پوشه سلسله مراتبی کلاسیک برای همکاری در مقیاس بزرگ نامناسب دیده می شود. چنین ساختارهایی در طول یک پروژه به طور فزاینده ای گیج می شوند زیرا پوشه ها و زیرپوشه ها بر اساس عادات شخصی و منطق سازمانی ایجاد و نامگذاری می شوند. از این رو، یک مفهوم مبتنی بر هستی شناسی برای پشتیبانی از مدیریت داده های بین رشته ای در پلت فرم همکاری از این کارگاه های کاربر برخاسته است.
ایده پشت این رویکرد این است که یک واژگان مشترک با روابط معنایی تعریف شده بین اصطلاحات محصور شده، همانطور که توسط هستی شناسی CRC نشان داده شده است، می تواند به عنوان چارچوبی برای سازماندهی داده های ذخیره شده در یک محیط مشترک استفاده شود. تطبیق واژگان با اشیاء داده (مانند فایلها، اسناد، یا صفحات ویکی) و/یا ابردادههای آنها (مثلاً نویسنده، عنوان، نوع داده) به آنها اجازه میدهد که نه تنها با ویژگیهای فیزیکی (مثلاً مکان در ساختار پوشه) سازماندهی شوند. ) بلکه با روابط معنایی آنها در محیط. علاوه بر این، ادغام روابط معنایی بین اشیاء داده می تواند اتصالاتی را که در غیر این صورت ممکن است مورد توجه قرار نگیرد را آشکار کند.
اجرای نمونه اولیه بر روی پلت فرم همکاری باید به محققان اجازه دهد تا به دنبال مفاهیم خاص باشند و ارتباطات را با مفاهیم دیگر در CRC از دامنه پروژه خود کشف کنند. هنگام کاوش در شبکه مفاهیم، اشیاء داده مربوط به آن مفاهیم نمایش داده می شوند. از این رو، این رویکرد از شبکهسازی دانش انضباطی با تسهیل کشف رابطها و محتوای مرتبط پشتیبانی میکند. برای نمونه اولیه، فقط فایلها، صفحات ویکی، و رشتههای تابلوی پیام در پلتفرم در نظر گرفته شدند، زیرا اکثر داراییهای موجود را نشان میدهند. سایر داراییها مانند وظایف، رویدادهای تقویم، و ورودیهای وبلاگ را میتوان در مرحله بعد گنجاند. برای تطبیق مفاهیم از الگوریتم تطبیق معنایی استفاده شد.28 ]. پاراگراف های زیر ساختار اصلی الگوریتم و کاربرد عملی آن در پلتفرم همکاری را شرح می دهند.
ایده اصلی الگوریتم تطبیق معنایی، شناسایی تطابق بین مفاهیم از یک هستی شناسی موجود با عناصر در مقادیر زیادی از اشیاء داده بر اساس مقایسه متن است. برای نمونه اولیه، به این معنی است که تطابق بین مفاهیم از هستی شناسی های CRC با متون از دارایی های پلت فرم باید کشف و نمایش داده شود. این امر مستلزم آن است که مفاهیم هستیشناختی مدلهای هستیشناسی به زبان طبیعی قابل دسترسی باشند. بنابراین، هر مفهوم در مدل های هستی شناسی CRC با یک نام زبان طبیعی با استفاده از ویژگی “rdfs:label” از نحو استاندارد RDF-S حاشیه نویسی شد.
علاوه بر این، دارایی ها همچنین باید حاوی متن زبان طبیعی باشند که در آن مفاهیم را بتوان با الگوریتم شناسایی کرد. این متن میتواند بخشی از عنوان (مثلاً نام فایل)، محتوای واقعی (مثلاً محتوای صفحه ویکی)، یا کلمات کلیدی (مثلاً برچسبها) باشد. متن نیازی به در برگیرنده نوعی اصطلاحات از پیش تعریف شده ندارد، اما به طور کلی باید در یک حوزه دانش مشابه با هستی شناسی مربوطه تخصیص داده شود.
الگوریتم را می توان به طور کلی به سه بخش اصلی ساختار داد. بخش اول، رخدادهای فردی مفاهیم را در این دارایی ها کشف می کند. این امر با مقایسه رشته ای ساده که برچسب های زبان طبیعی مفاهیم فوق را در اجزای متن دارایی ها شناسایی می کند، محقق می شود. به منظور تسهیل بیشتر شناسایی مفهوم، هم متون دارایی و هم برچسب های مفهومی به صورت لماتیزه می شوند. اگر برچسب مفهومی در جایی از متن دارایی مشخص شود، به آن “رویداد فردی” مفهوم می گویند. از آنجایی که یک برچسب به طور بالقوه می تواند در بخش های مختلف دارایی شناسایی شود، می توان یک مفهوم را مشاهده کرد که به صورت جداگانه چندین بار در هر دارایی رخ می دهد.
بخش دوم الگوریتم این رخدادهای فردی را در امتیازات کلی برای هر ترکیبی از مفهوم و دارایی جمع می کند. در نتیجه، مفهومی که اغلب در یک دارایی اتفاق میافتد، امتیاز بالایی میگیرد، در حالی که مفهومی بدون وقوع، نمره صفر دریافت میکند. به منظور محاسبه این نمرات، روشهای بازیابی اطلاعات رایج مورد استفاده برای هدف تطبیق معنایی اقتباس شدهاند. به طور خاص، استفاده از مقیاس بندی زیرخطی، و همچنین یک نسخه اصلاح شده از نرمال سازی فرکانس حداکثر مدت، محاسبه امتیازهای قابل مقایسه بین صفر و یک را امکان پذیر می کند. از آنجایی که این محاسبات تاکنون فقط از اطلاعات نحوی استفاده میکنند، این بخش به عنوان امتیاز نحوی نیز نامیده میشود و به همین ترتیب نمرات نحوی تولید میکند. علاوه بر این،
بخش سوم الگوریتم، اطلاعات معنایی هستیشناسی را مدیریت میکند و امتیازهایی را برای انسجام معنایی بین مفهوم و دارایی تعیین میکند. برای محاسبه چنین امتیاز معنایی برای یک مفهوم، وجود مفاهیم هستیشناختی مرتبط، که از این پس به عنوان شرکای معنایی نامیده میشوند، در نظر گرفته میشوند. با الهام از روشهای دیگر جستجوی معنایی و محاسبه شباهت مفهومی [ 29 ، 30 ، 31 ، 32 ، 33 ، 34 ، 35 ]، این شرکا عبارتند از:
-
کودکان معنایی: مفاهیم فرعی مفهوم ارزیابی شده
-
خواهر و برادر معنایی: مفاهیم فرعی یک ابرمفهوم از مفهوم ارزیابی شده
-
همسایگان معنایی: مفاهیمی با هر ارتباط معنایی مستقیم دیگری با مفهوم ارزیابی شده
بر اساس نمرات نحوی انباشته شده این شرکای معنایی و مربوط به حضور حداکثری بالقوه آنها، امتیاز معنایی نشان دهنده درجه انسجام معنایی است. از صفر، بدون هیچ شریک معنایی، تا یک، برای همه شرکای معنایی ممکن با حداکثر امتیاز نحوی متغیر است. در نتیجه، امکان محاسبه امتیازهای معنایی برای مفاهیم مستقل از رخدادهای فردی این مفاهیم در یک دارایی مشخص وجود دارد. بنابراین نمره معنایی را می توان به عنوان اندازه گیری وقوع مفهوم ضمنی در نظر گرفت. نمرات معنایی و نحوی در نهایت در قسمت های مساوی ترکیب می شوند تا یک امتیاز کلی برای همه ترکیبی از دارایی ها و مفاهیم اطلاعاتی ایجاد شود.
این پیادهسازی نمونهای از مکانیزم تطبیق معنایی، ناوبری در سراسر مفاهیم و داراییها را بر اساس اتصالات آنها (تطابق) امکانپذیر میسازد. برای هر دارایی، مفاهیم موجود فهرست شده و می توان آنها را انتخاب کرد، در حالی که برای هر مفهوم، تمام دارایی های حاوی این مفهوم نمایش داده می شوند. با توسعه بیشتر این رویکرد تطبیق معنایی، کاربردهای مختلف اضافی قابل تامل است. برای گسترش نمونه اولیه به منظور شامل سایر حوزههای پلتفرم همکاری و انواع دیگر داراییها، تطابق مفهومی شناسایی شده میتواند به سادگی مانند برچسبها یا کلمات کلیدی مورد استفاده قرار گیرد. به عنوان مثال، یک ابر برچسب مبتنی بر هستی شناسی، رویکردی بصری را برای کاوش روابط معنایی دارایی ها در اختیار کاربران قرار می دهد، در حالی که به طور همزمان یک نمای کلی از ارتباطات و روندهای اطلاعاتی اصلی پلت فرم ارائه می دهد. علاوه بر این،30 ، 31 ، 33 ، 35 ، 36]، میتوان الگوریتم جستجوی پلتفرم را گسترش داد و بهبود داد، با استفاده از اطلاعات معنایی تطابق مفهوم/دارایی برای بهینهسازی یادآوری یا دقت. از یک سو، یادآوری را میتوان با گسترش خودکار پرسشهای جستجو با اطلاعات هستیشناختی و تطبیق آن با تطابق مفهومی و امتیازها برای بازیابی داراییهایی که با روشهای بازیابی اطلاعات سنتی یافت نمیشوند، افزایش داد. از سوی دیگر، نمرات مفهومی را می توان برای اصلاح امتیازات مربوط به کار برد، بنابراین نتایج جستجوی مرتبط تری را ارائه داد و دقت کلی را بهبود بخشید. آخرین اما نه کماهمیت، برنامه نمونه اولیه را میتوان با عملکردهای بیشتر و ارائه بهبودیافته تقویت کرد، بنابراین کاربران را قادر میسازد تا به صورت پویا در میان شبکه مفاهیم و داراییها حرکت کنند.37 ]، و حتی هستی شناسی زیربنایی و نتایج تطبیق را با نظرات و حاشیه نویسی های فردی غنی کنید.
4. بحث در مورد استقرار راه حل
پروژههای بینرشتهای در مقیاس بزرگ، بهویژه در ابتدای کار، نیازمندیهای زیادی برای هماهنگی و ارتباط دارند. ایجاد شرایطی که بتوان اطلاعات و دانش را به روشی خودسازمانده تولید کرد، یک وظیفه مدیریتی تعیین کننده در پروژه های بین رشته ای است [ 38 ]. موفقیت آن تا حد زیادی به شناسایی و اعمال اقدامات مناسب برای تحریک همکاری و ایجاد هویت گروهی و اعتماد متقابل بستگی دارد [ 5 ، 39 ، 40 ].
در اولین دوره تامین مالی CRC 1026، پروژه INF راه حل هایی را توسعه داد که از مدیریت داده های مرتبط با وظایف و شبکه معنایی حوزه های انضباطی پشتیبانی می کرد. سیستم مدیریت وظیفه ارائه شده، جمع آوری و قابلیت ردیابی داده های مربوط به وظایف را بهبود می بخشد، و به ویژه در طول آماده سازی پیشنهاد برای دوره دوم بودجه، که در آن وظایف و تحویل های متعدد باید به طور همزمان بین تمام پروژه های فردی هماهنگ می شد، مفید بود. از سوی دیگر، باید این احتیاط را قائل شد که مخصوصاً برای کارهای ساده، تلاش برای انجام مراحل واجب برای ایجاد تکلیف، گاه از منافع محقق فراتر می رود. بنابراین، موفقیت چنین سیستم مدیریت وظیفه ای به شدت به تعهد نهادهای درگیر و انگیزه محققان بستگی دارد. در حالت اول، ویژگیهای مؤسسات واحد، مانند قراردادهای نامگذاری، باید برای بهرهمندی از سیستم کنترل نسخهسازی منطبق و متحد شوند. نگرانی های فردی (مثلاً در مورد ایمنی و استحکام سیستم اعمال شده) باید با اقدامات مطابق (مثلاً پشتیبان گیری منظم از داده ها) و مشارکت دادن کاربران در آزمایش های گسترده قبل از راه اندازی برطرف شود. این جنبه اخیر را می توان با بهبود قابلیت استفاده در سطح فنی، و با ارائه مشوق ها در سطح سازمانی (به عنوان مثال، با ادغام سیستم های غیر سنتی ارزش گذاری مشارکت) مقابله کرد. در مورد ایمنی و استحکام سیستم اعمال شده) باید با اقدامات مطابق (مثلاً پشتیبان گیری منظم از داده ها) و درگیر کردن کاربران در آزمایش های گسترده قبل از راه اندازی کاهش یابد. این جنبه اخیر را می توان با بهبود قابلیت استفاده در سطح فنی، و با ارائه مشوق ها در سطح سازمانی (به عنوان مثال، با ادغام سیستم های غیر سنتی ارزش گذاری مشارکت) مقابله کرد. در مورد ایمنی و استحکام سیستم اعمال شده) باید با اقدامات مطابق (مثلاً پشتیبان گیری منظم از داده ها) و درگیر کردن کاربران در آزمایش های گسترده قبل از راه اندازی کاهش یابد. این جنبه اخیر را می توان با بهبود قابلیت استفاده در سطح فنی، و با ارائه مشوق ها در سطح سازمانی (به عنوان مثال، با ادغام سیستم های غیر سنتی ارزش گذاری مشارکت) مقابله کرد.39 ].
رویکرد مدیریت داده مبتنی بر هستیشناسی با توجه به مدیریت دادههای میان رشتهای امیدوارکننده بود. این یک مبنای مفهومی برای همکاری و طبقه بندی داده ها با نمایش روابط متقابل منطقی بین پروژه های فردی فراهم می کند. علاوه بر این، کاربرد فنآوریهای معنایی و هستیشناسی به طور فزایندهای به مدیریت دادههای تحقیق مرتبط میشود [ 26 ، 41 ، 42 ]. از این رو، برنامه های کاربردی مدیریت داده های عمومی تر مشابه نمونه اولیه شرح داده شده در بخش 3.3 استقابل تصور هستند، مشروط بر اینکه داده ها به طور مناسب حاشیه نویسی شده و توسط ابرداده توصیف شوند. به عنوان مثال، الگوریتم تطبیق معنایی را می توان برای هر نوع داده ای اعمال کرد – درست مانند فایل های پلت فرم همکاری – با توجه به اینکه عنوان، کلمات کلیدی و شرح داده های مربوطه به زبان طبیعی وجود دارد. بنابراین، افزایش برچسب، گسترش جستجوی معنایی، یا ناوبری شبکه (همانطور که در بالا و در بخش 3.3 توضیح داده شد.) در سایر ساختارهای مدیریت داده نیز امکان پذیر خواهد بود. با در نظر گرفتن مدیریت چرخه عمر داده ها، این می تواند هنگام حفظ داده ها اعمال شود (به عنوان مثال، نه تنها با ایجاد ابرداده و اسناد، بلکه متعاقباً تعیین تطابق مفهومی و روابط متقابل معنایی). سپس قابلیت دسترسی و استفاده مجدد را می توان با تقویت الگوریتم های جستجوی متناظر و ارائه امکانات ناوبری پیشرفته برای تسهیل شبکه ارتباطات معنایی بهبود بخشید. اگر تطبیق معنایی علاوه بر این به اسناد و انتشارات حاصل از تجزیه و تحلیل داده ها اعمال شود، شباهت های معنایی می تواند بین داده ها و اسنادی تعیین شود که در غیر این صورت هیچ ارتباطی ندارند. با این حال، ما بر این باوریم که تطبیق معنایی میتواند روش اساسی را فراهم کند که قابلیتهای بیشتر را بر اساس آن قادر میسازد.
با این حال، فرآیند توسعه زمانبر خود هستیشناسی و الگوریتم تطبیق تنها امکان استقرار بسیار دیرهنگام ابزار را فراهم میآورد. از این رو، آزمایش های گسترده کاربر نمی تواند انجام شود.
از منظر استقرار، مراحل بعدی برای توسعه نمونه اولیه تطبیق معنایی شامل طراحی یک رابط کاربری جامع با فرم تجسم مناسب برای روابط متقابل معنایی و تعریف بیشتر سناریوهای استفاده خواهد بود. در حال حاضر، دو سناریو کلی شناسایی شده است. سناریوی “جستجوی هدفمند” بر مواردی تمرکز دارد که محققان به طور هدفمند به دنبال داده های خاص در بستر همکاری CRC هستند. سناریوی دوم موارد اکتشافی بیشتری را در نظر میگیرد که در آن محققان فقط به دنبال ارتباط با سایر پروژههای فردی هستند. هر دو سناریو نیازمند مکانیسمها و ویژگیهای خاصی هستند که باید در ابزار تطبیق معنایی ادغام شوند. از جنبه نظری،www.plcs.org ) و زمینه عمومی (به عنوان مثال، DBpedia). در زمینه در نظر گرفتن حوزه تولید پایدار، یک چارچوب فراداده منسجم مانند چارچوب CERA2 برای داده های تحقیقات آب و هوایی مورد نیاز است.
5. نتیجه گیری ها
تجربیات CRC 1026 نشان میدهد که ادغام مدیریت دادهها در پروژههای بین رشتهای هنوز یک جنبه چالش برانگیز است. علیرغم آگاهی روزافزون برای مدیریت داده ها، هنوز یک برداشت عمدتا سنتی از مدیریت داده به عنوان یک فعالیت نهایی تلاش های تحقیقاتی در بسیاری از حوزه های علمی وجود دارد. در نتیجه، مدیریت داده ها هنوز هم اغلب مترادف مدیریت انتشار تلقی می شود. تعداد گیجکنندهای از مدلهای کپیرایت، بندهای تحریم و مدلهای مجوز اعمال شده توسط ناشران مختلف به نوبه خود باعث میشود که محققان از استفاده از سیستمهای مدیریت انتشارات متمرکز یا مخازن سازمانی خودداری کنند زیرا از مواجهه با مسائل مربوط به حق نسخهبرداری میترسند. یکی دیگر از موانع مدیریت داده ها عدم تمایل به ارائه داده های خام تولید شده در جریان فعالیت های تحقیقاتی است. این امر تا حدی ناشی از نگرانیهای مربوط به محرمانگی است (به عنوان مثال، زمانی که دادهها مربوط به درخواستهای ثبت اختراع در حال انتظار هستند یا در پایاننامه دکتری فعلی استفاده میشوند). در موارد دیگر، دادههای جمعآوریشده بهعنوان «بیش از حد خاص پروژه» برای استفاده برای سایر پروژههای تحقیقاتی رتبهبندی شدند. در نهایت، وظایف مربوط به جمعآوری سیستماتیک و ارائه دادهها گاهی اوقات بهعنوان سربار تلقی میشوند، که به پیشرفت حرفهای فرد کمک نمیکنند – یا حداقل مستقیماً – به پیشرفت حرفهای فرد کمک نمیکنند و پاداشی دریافت نمیکنند (مثلاً با شهرت). داده های جمع آوری شده به عنوان “بیش از حد خاص پروژه” برای استفاده برای سایر پروژه های تحقیقاتی رتبه بندی شدند. در نهایت، وظایف مربوط به جمعآوری سیستماتیک و ارائه دادهها گاهی اوقات بهعنوان سربار تلقی میشوند، که به پیشرفت حرفهای فرد کمک نمیکنند – یا حداقل مستقیماً – به پیشرفت حرفهای فرد کمک نمیکنند و پاداشی دریافت نمیکنند (مثلاً با شهرت). داده های جمع آوری شده به عنوان “بیش از حد خاص پروژه” برای استفاده برای سایر پروژه های تحقیقاتی رتبه بندی شدند. در نهایت، وظایف مربوط به جمعآوری سیستماتیک و ارائه دادهها گاهی اوقات بهعنوان سربار تلقی میشوند، که به پیشرفت حرفهای فرد کمک نمیکنند – یا حداقل مستقیماً – به پیشرفت حرفهای فرد کمک نمیکنند و پاداشی دریافت نمیکنند (مثلاً با شهرت).
برای رویارویی با این چالش ها، محققان باید نسبت به جنبه های مدیریت داده ها و مزایای آنها حساس باشند. بهویژه در آغاز پروژههای میان رشتهای، باید دستورالعملهای مشترکی در مورد اینکه «دادههای تحقیق» چیست و چگونه باید در یک محیط مشارکتی به کار گرفته شوند، ایجاد شود. علاوه بر این، محققان باید با مثال های عملی از مزایای تلاش های مدیریت داده آگاه شوند. به عنوان مثال، می توان نشان داد که با ارائه داده های اولیه در مورد انتشارات خود، محققان نه تنها از پیشرفت علمی حوزه مربوطه خود حمایت می کنند، بلکه اعتبار علمی کار خود را تقویت می کنند و در نتیجه کیفیت آن را بهبود می بخشند. این به نوبه خود بر شهرت آنها می افزاید. برای پروژه های INF، یکی از وظایف اساسی در حمایت از مدیریت داده ها باید توسعه و ارائه خدمات تسهیل کننده فرآیند مدیریت داده باشد. از یک طرف، این را می توان با ابزارهای فناوری اطلاعات که، برای مثال، امکان استخراج ابرداده از موارد ذخیره شده در محیط های مشترک در قالب های استاندارد شده (مثلا BibTex) را فراهم می کند، محقق شود. از سوی دیگر، پروژه های INF می توانند خدمات مقدماتی (به عنوان مثال، پیش پردازش داده های جمع آوری شده و آموزش های مربوط به استفاده از خدمات مخزن موجود) را ارائه دهند. در این راستا باید از خدمات تخصصی و اطلاعاتی کتابخانه های دانشگاهی یا کارشناسان مدیریت داده های خارجی نیز استفاده شود. می تواند امکان استخراج ابرداده را از موارد ذخیره شده در محیط های مشترک در قالب های استاندارد (مانند BibTex) فراهم کند. از سوی دیگر، پروژه های INF می توانند خدمات مقدماتی (به عنوان مثال، پیش پردازش داده های جمع آوری شده و آموزش های مربوط به استفاده از خدمات مخزن موجود) را ارائه دهند. در این راستا باید از خدمات تخصصی و اطلاعاتی کتابخانه های دانشگاهی یا کارشناسان مدیریت داده های خارجی نیز استفاده شود. می تواند امکان استخراج ابرداده را از موارد ذخیره شده در محیط های مشترک در قالب های استاندارد (مانند BibTex) فراهم کند. از سوی دیگر، پروژه های INF می توانند خدمات مقدماتی (به عنوان مثال، پیش پردازش داده های جمع آوری شده و آموزش های مربوط به استفاده از خدمات مخزن موجود) را ارائه دهند. در این راستا باید از خدمات تخصصی و اطلاعاتی کتابخانه های دانشگاهی یا کارشناسان مدیریت داده های خارجی نیز استفاده شود.
زیرساخت اطلاعاتی توسعه یافته توسط INF برای جمع آوری و ذخیره داده ها در طول دوره CRC مناسب است. با این حال، برای اطمینان از حفظ طولانی مدت و در دسترس بودن داده های پژوهشی، باید از زیرساخت های پایدارتر مانند خدمات مخزن نهادی از کتابخانه های دانشگاهی استفاده شود. در مورد CRC 1026، سرویس مخزن، “DepositOnce” برای حفظ نتایج تحقیق استفاده خواهد شد. این مخزن توسط مرکز خدمات پژوهشی داده ها و انتشارات (SZF) TU برلین توسعه و نگهداری می شود. هر مجموعه داده ذخیره شده در “DepositOnce” با یک شناسه شی دیجیتال (DOI) ارائه می شود تا بتوان به آن در کارهای تحقیقاتی و انتشارات بیشتر اشاره کرد. از آنجایی که SZF یک مرکز خدمات مشترک از کتابخانه دانشگاه، مرکز خدمات فناوری اطلاعات مرکزی و بخش تحقیقات TU برلین است،
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| CRC |
مرکز تحقیقات مشارکتی
|
| DFG |
Deutsche Forschungsgemeinschaft (بنیاد علم آلمان)
|
| INF |
پروژه خدمات برای زیرساخت اطلاعات
|
| گازهای گلخانه ای |
گاز گلخانه ای
|
| RDF-S |
طرح چارچوب شرح منبع
|
| جغد |
زبان هستی شناسی وب
|
| SZF |
Servicezentrum für Forschungsdaten und –publikationen (مرکز خدمات داده های پژوهشی و انتشارات)
|
منابع
- Haythornthwaite، C. شبکه های یادگیری و دانش در همکاری های بین رشته ای. مربا. Soc. Inf. علمی تکنولوژی 2006 . [ Google Scholar ] [ CrossRef ]
- راش، سی. لی، وی. اسپات، اس. هرستات، سی. ظهور و سقوط تحقیقات بین رشته ای: مورد نوآوری منبع باز. Res. سیاست 2013 . [ Google Scholar ] [ CrossRef ]
- کورلی، EA; بردمن، کامپیوتر; بوزمن، بی. طراحی و مدیریت همکاری های تحقیقاتی چند نهادی: مفاهیم نظری از دو مطالعه موردی. Res. سیاست 2006 . [ Google Scholar ] [ CrossRef ]
- کاتز، جی اس. مارتین، BR همکاری پژوهشی چیست؟ Res. سیاست 1997 ، 26 ، 1-18. [ Google Scholar ] [ CrossRef ]
- پنینگتون، همکاری و یادگیری متقابل رشتهای DD. در دسترس آنلاین: http://www.ecologyandsociety.org/vol13/iss2/art8/ (دسترسی در 6 ژانویه 2016).
- ویلیامز، پی. آچار مرزی شایسته. عمومی Adm. 2002 . [ Google Scholar ] [ CrossRef ]
- پاتل، اچ. پتیت، ام. ویلسون، جی آر عوامل کار مشترک: چارچوبی برای یک مدل همکاری. Appl. ارگون. 2012 . [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ون راینسوور، اف جی; هسلز، LK عوامل مرتبط با همکاری پژوهشی رشته ای و بین رشته ای. Res. سیاست 2011 . [ Google Scholar ] [ CrossRef ]
- Nooteboom، B. یادگیری از طریق تعامل: ظرفیت جذب، فاصله شناختی و حاکمیت. جی. مناگ. دولت 2000 . [ Google Scholar ] [ CrossRef ]
- بوتنر، اس. هوبوهم، اچ. مولر، ال. مدیریت داده های پژوهشی. در Handbuch Forschungsdatenmanagement ; Büttner, S., Hobohm, H., Eds. Bock + Herchen: Bad Honnef، آلمان، 2011; صص 13-24. [ Google Scholar ]
- Dallmeier-Tiessen, S. Strategien bei der Veröffentlichung von Forschungsdaten. در Handbuch Forschungsdatenmanagement ; Büttner, S., Hobohm, H., Eds. Bock + Herchen: Bad Honnef، آلمان، 2011; صص 169-190. [ Google Scholar ]
- افرتز، ای. دیدگاه سرمایه گذار: مدیریت داده ها در برنامه های هماهنگ بنیاد تحقیقات آلمان (DFG). در مجموعه مقالات کارگاه مدیریت داده ها، کلن، آلمان، 29 تا 30 اکتبر 2009.
- رومپل، S. Der Lebenszyklus von Forschungsdaten. در Handbuch Forschungsdatenmanagement ; Büttner, S., Hobohm, H., Eds. Bock + Herchen: Bad Honnef، آلمان، 2011; صص 25-34. [ Google Scholar ]
- هوشکا، دی. اولرز، سی. Ott, N. Datenmanagement und Data Sharing: Erfahrungen in den Sozial- und Wirtschaftswissenschaften. در Handbuch Forschungsdatenmanagement ; Büttner, S., Hobohm, H., Eds. Bock + Herchen: Bad Honnef، آلمان، 2011; صص 35-48. [ Google Scholar ]
- ولتر، ال. وانگ، WM; Rainer, S. سیستم های اطلاعاتی برای حمایت از همکاری در پروژه های تحقیقاتی بزرگ. IJMO 2014 . [ Google Scholar ] [ CrossRef ]
- والد- تیریون، A.; ورمایلن، جی. ون هوتن، جی. Lyly-Yrjänäinen، M.; بیلتا، آی. کابریتا، جی. پنجمین بررسی شرایط کاری اروپا. در دسترس آنلاین: http://www.eurofound.europa.eu/surveys/2010/fifth-european-working-conditions-survey-2010 (در 8 ژانویه 2016 قابل دسترسی است).
- Lapillonnee، B. پولیر، ک. Samci, N. روندهای بهره وری انرژی در اتحادیه اروپا – درسهایی از پروژه ODYSSEE MURE. در دسترس آنلاین: http://www.odyssee-mure.eu/publications/br/synthesis-energy-efficiency-trends-policies.pdf (دسترسی در 14 ژانویه 2016).
- کمیسیون اروپا – اداره کل انرژی (op. 2013): انرژی اتحادیه اروپا در ارقام. دفترچه جیبی آماری 2013. لوکزامبورگ. در دسترس آنلاین: https://ec.europa.eu/energy/sites/ener/files/documents/2013_pocketbook.pdf (در 18 ژانویه 2016 قابل دسترسی است).
- دوفلو، جی آر. ساترلند، جی دبلیو. دورنفلد، دی. هرمان، سی. جسویت، جی. کارا، اس. هاوشیلد، ام. کلنز، ک. به سوی تولید کارآمد انرژی و منابع: رویکرد فرآیندها و سیستم ها. CIRP Ann. Manuf. تکنولوژی 2012 . [ Google Scholar ] [ CrossRef ]
- دیالو، ی. اتین، آ. مهران، ف. روند جهانی کار کودکان 2008 تا 2012 ; ILO: ژنو، سوئیس، 2013. [ Google Scholar ]
- استکل، جی سی. ادنهوفر، او. Jakob, M. رانندگان برای رنسانس زغال سنگ. Proc. Natl. آکادمی علمی ایالات متحده آمریکا 2015 . [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Edmund, AS Geschichte der Nachhaltigkeit: Vom Werden und Wirken Eines Beliebten BEGRIFFES. 2012. در دسترس آنلاین: http://www.nachhaltigkeit.info/media/1326279587phpeJPyvC.pdf (در 21 آوریل 2014 قابل دسترسی است).
- Wissenschaftliche Dienste des Deutschen Bundestages. Nachhaltigkeit: Wissenschaftliche Dienste des Deutschen Bundestages. 2004. در دسترس آنلاین: http://webarchiv.bundestag.de/archive/2008/0506/wissen/analysen/2004/2004_04_06.pdf (در 21 آوریل 2014 قابل دسترسی است).
- گیدینگز، بی. هاپ وود، بی. O’Brien، G. محیط زیست، اقتصاد و جامعه: تطبیق آنها با یکدیگر در توسعه پایدار. حفظ کنید. توسعه دهنده 2002 . [ Google Scholar ] [ CrossRef ]
- Uschold، M. گرونینگر، ام. هستی شناسی ها: اصول، روش ها و کاربردها. بدانید. مهندس Rev. 1996 , 11 , 93-136. [ Google Scholar ] [ CrossRef ]
- نهر، جی. Ritschel, B. Semantische Vernetzung von Forschungsdaten. در Handbuch Forschungsdatenmanagement ; Büttner, S., Hobohm, H., Eds. Bock + Herchen: Bad Honnef، آلمان، 2011; صص 169-190. [ Google Scholar ]
- وانگ، WM; Pförtner، A.; لیندو، ک. هایکا، اچ. استارک، آر. استفاده از هستی شناسی برای حمایت از همکاری علمی میان رشته ای در پروژه های مشترک تحقیقاتی پایداری. در مجموعه مقالات یازدهمین کنفرانس جهانی در زمینه تولید پایدار: راه حل های نوآورانه، برلین، آلمان، 23 تا 15 سپتامبر 2013. صص 612-617.
- Göpfert، T. تطبیق مفاهیم هستیشناختی با اسناد: یک رویکرد تطبیق معنایی در زمینه تشخیص جامعه کتابسنجی. پایان نامه Mater’s, Humboldt–Universität zu Berlin, 2016. [ Google Scholar ]
- Giunchiglia، F. خارکویچ، یو. Zaihrayeu, I. Concept Search. لکت. یادداشت ها محاسبه. علمی 2009 ، 5554 ، 429-444. [ Google Scholar ]
- ناویگلی، آر. Velardi, P. An Analysis of Ontology-based Query Expansion Strategies. Cavtat-Dubrovnik. در مجموعه مقالات کنفرانس یادگیری ماشین (ECML 2003)، دوبرونیک، کرواسی، 22-26 سپتامبر 2003.
- خان، ال. مک لئود، دی. Hovy، E. اثربخشی بازیابی یک مدل مبتنی بر هستی شناسی برای انتخاب اطلاعات. VLDB J. 2004 ، 13 ، 71-85. [ Google Scholar ] [ CrossRef ]
- آنیانوو، ک. Sheth, A. ρ-Queries: Enableing Querying for Semantic Associations on Semantic Web. در مجموعه مقالات دوازدهمین کنفرانس بین المللی وب جهانی، بوداپست، مجارستان، 20-24 مه 2003.
- ژو، Q. وانگ، سی. شیونگ، ام. وانگ، اچ. Yu, Y. SPARK: تطبیق پرس و جو کلیدواژه با جستجوی معنایی. لکت. یادداشت ها محاسبه. علمی 2007 ، 4825 ، 694-707. [ Google Scholar ]
- روشا، سی. شوابه، دی. د آراگائو، MP یک رویکرد ترکیبی برای جستجو در وب معنایی. در مجموعه مقالات سیزدهمین کنفرانس بین المللی وب جهانی، نیویورک، نیویورک، ایالات متحده آمریکا، 17 تا 22 مه 2004.
- چنگ، جی. Ge، W. Qu, Y. Falcons: جستجو و مرور موجودات در وب معنایی. در مجموعه مقالات هفدهمین کنفرانس بین المللی وب جهانی، پکن، چین، 21 تا 25 آوریل 2008.
- فرناندز، م. لوپز، وی. صبو، م. اورن، وی. والت، دی. موتا، ای. Castells, P. Semantic Search Meets the Web. در مجموعه مقالات کنفرانس بین المللی IEEE 2008 در محاسبات معنایی، سانتا کلارا، کالیفرنیا، ایالات متحده آمریکا، 4 تا 7 اوت 2008. صص 253-260.
- وانگ، WM; ولتر، ال. لیندو، ک. استارک، آر. تجسم گرافیکی جنبههای تولید پایدار برای انتقال دانش به مخاطبان عمومی. اقدام کرد. CIRP 2015 . [ Google Scholar ] [ CrossRef ]
- فوکس کیتوفسکی، ک. هاینریش، LJ; رولف، ا. در Wirtschaftsinformatik und Wissenschaftstheorie ; Springer: برلین، آلمان، 1999; صص 329-361. [ Google Scholar ]
- ونگر، اتحادیه اروپا؛ اسنایدر، WM جوامع عمل: مرز سازمانی. هارو. اتوبوس. Rev. 2000 , 78 , 139-146. [ Google Scholar ]
- پیکت، ST; Burch، WR، Jr. Grove، JM تحقیقات میان رشته ای: حفظ انگیزه سازنده در فرهنگ انتقاد. اکوسیستم ها 1999 ، 2 ، 302-307. [ Google Scholar ] [ CrossRef ]
- کاکس، ای. Milsted، AJ; گاتریج، سیجی فناوری دادههای پیوندی که کشف خودکار دادهها را به واقعیت تبدیل میکند. در مجموعه مقالات دومین کارگاه مدیریت داده، کلن، آلمان، 28-29 نوامبر 2014.
- دکر، بی. Politze، M. مدیریت داده های معنایی مبتنی بر هستی شناسی برای پروژه های تحقیقاتی پاندیسیپلیناری. در مجموعه مقالات دومین کارگاه مدیریت داده، کلن، آلمان، 28-29 نوامبر 2014.
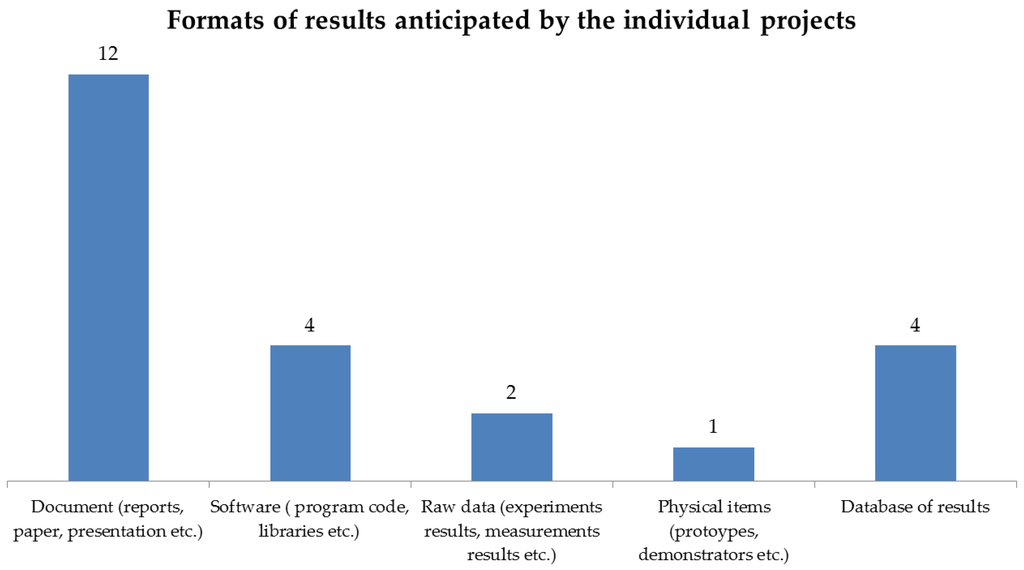
شکل 1. گزیده ای از نتایج نظرسنجی: اکثر نتایج برای انتشار به عنوان مقالات علمی برنامه ریزی شده بود.
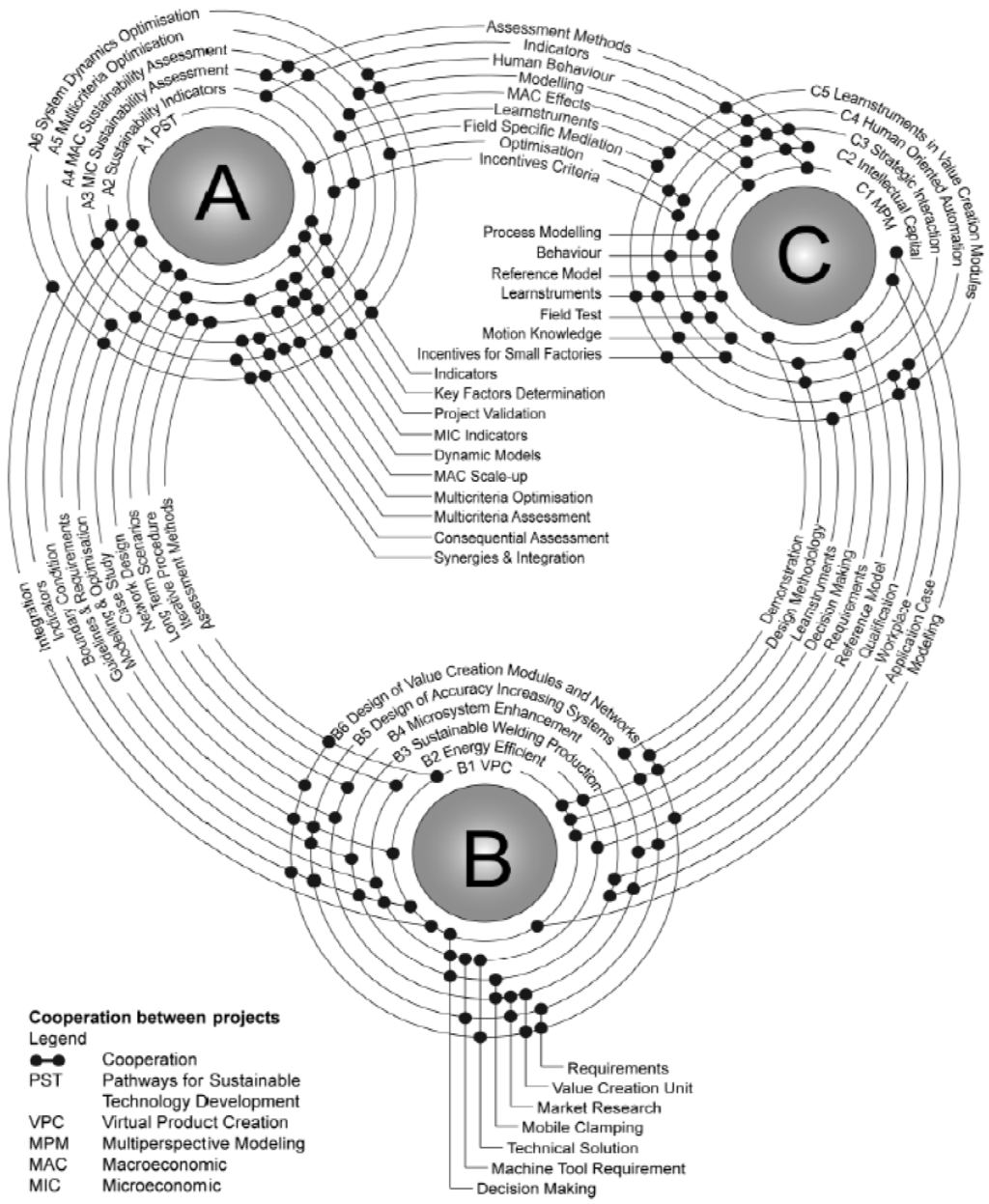
شکل 2. رابط های بالقوه بین پروژه های فردی CRC 102.

شکل 3. رابط کاربری بخش “اسناد و رسانه” پلت فرم همکاری.
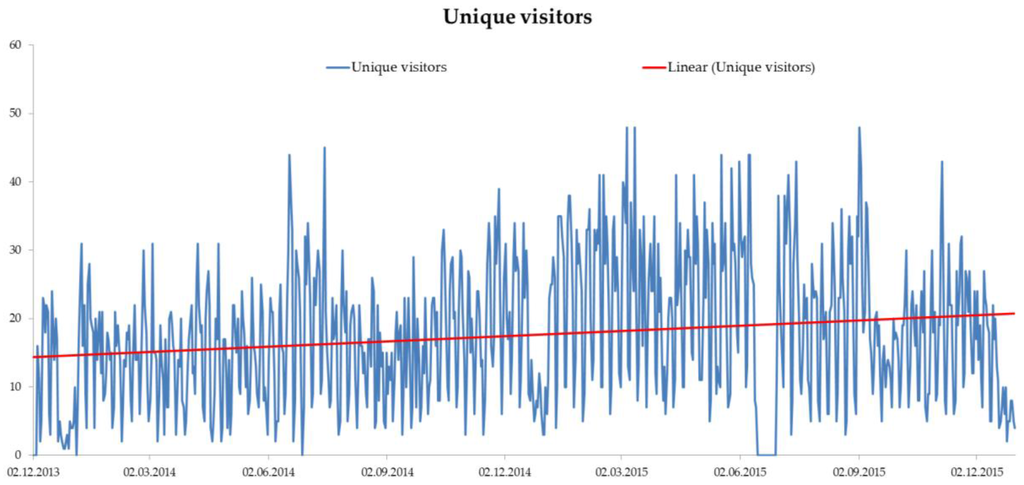
شکل 4. آمار استفاده از منطقه همکاری داخلی از دسامبر 2013 تا دسامبر 2015.

شکل 5. مروری بر زیر هستی شناسی های توسعه یافته.

جدول 1. ویژگی های عملکردی شناسایی شده توسط INF و رتبه بندی بر اساس بازخورد کاربر.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons by Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر