

خلاصه
قابلیت همکاری داده ها یک چالش مداوم برای ابتکارات داده باز جهانی است. مشخصات ماشینخوان انواع داده برای مجموعه دادهها به رفع مشکلات قابلیت همکاری کمک میکند. انواع داده ها معمولاً در سطح نحوی مانند عدد صحیح، شناور و رشته و غیره بوده اند.در زبان های برنامه نویسی کار ارائه شده در این مقاله یک طراحی مدل برای مشخصات معنایی انواع داده ها، مانند نقشه توپوگرافی است. این کار در زمینه وب معنایی انجام شد. این مدل نوع داده معنایی را از نوع داده اصلی متمایز می کند. اولی نمونه هایی (به عنوان مثال، نقشه توپوگرافی) از یک کلاس نوع داده خاص است که در مدل توسعه یافته تعریف شده است. دومی کلاس هایی (به عنوان مثال، Image) از انواع منابع در هستی شناسی های موجود هستند. یک منبع داده نمونه ای از یک نوع داده پایه است و با یک یا چند نوع داده خاص برچسب گذاری می شود. پیاده سازی مدل در یک پورتال داده تولیدی موجود ارائه شده است که فرد را قادر می سازد تا انواع داده های خاص را ثبت کرده و از آنها برای حاشیه نویسی منابع داده استفاده کند. کاربران داده می توانند مفروضات توضیحی یا اطلاعات ذاتی یک مجموعه داده را از طریق انواع داده های خاص آن مجموعه داده به دست آورند. اطلاعات قابل خواندن توسط ماشین انواع داده های خاص نیز راه را برای مطالعات بیشتر، مانند توصیه مجموعه داده، هموار می کند.
کلید واژه ها:
معناشناسی ; هستی شناسی ; شناسه دائمی ; داده های پیوندی ؛ مرورگر وجهی
چکیده گرافیکی
1. معرفی
طرحهای دادههای باز جهانی در سالهای اخیر از سوی سازمانهای بخش دولتی و خصوصی حمایت شدهاند. تغییرات را میتوان در سیاستهای دولتی، الزامات آژانس تأمین مالی، دستورالعملهای جامعه، و فناوریها و امکانات مدیریت داده، نگهداری و اشتراکگذاری مشاهده کرد. تلاش بر روی مکانیسم های انتشار داده ها [ 1 ]، فهرست نویسی داده ها [ 2 ]، استناد به داده ها [ 3 ]، و معیارهای جایگزین [ 4 ]] در حال رشد یک سیستم اجتماعی- فنی جدید هستند که هم فرهنگ و هم عملکرد داده های باز را ترویج می کند. در چنین سیستمی، دادهها در سراسر مرزهای کشورها، بخشها، رشتهها، مخازن، و قالبها و همچنین بین سطوح جزئیات به اشتراک گذاشته میشوند و مجددا مورد استفاده قرار میگیرند. قابلیت همکاری داده ها به عنوان یک چالش عمده در آن فعالیت های فرامرزی مطرح می شود که نیازمندی هایی را برای روش ها و فن آوری ها برای ایجاد داده ها قابل کشف، در دسترس، رمزگشایی، قابل فهم و قابل استفاده می کند [5 ] .
انگیزه تحقیق ارائه شده در این مقاله ارتقای رمزگشایی، قابل فهم بودن و قابلیت استفاده داده ها است. سناریوی محققی را در نظر بگیرید که مایل به استفاده از داده های علمی از یک مخزن داده باز است. قبل از بازیابی یک فایل از مخزن داده و استفاده از آن، آنها باید فرمت، ساختار، پارامترها و معنای داده ها و شاید ابزارها و سرویس هایی را که می توان برای پردازش داده ها استفاده کرد، بدانند. در دنیای دادههای باز، محقق اغلب هیچ حمایت یا کمک مستقیمی از تولیدکنندگان داده دریافت نمیکند، که نشان میدهد ابردادههای دادههای بازیابی شده ممکن است تنها منبع برای به دست آوردن اطلاعات مورد نیاز باشد. در میان عناصر مختلف فراداده موجود، مانند عناصر فراداده هسته دوبلین [ 6]] و DataCite Metadata Schema [ 7 ]، عناصری که انواع داده ها را توصیف می کنند، مرتبط ترین عناصر برای ارائه چنین اطلاعاتی هستند.
تایپ داده برای دهه ها موضوع تحقیقاتی در برنامه نویسی رایانه بوده است، به موجب آن یک نوع داده به عنوان مجموعه ای از موجودیت های محاسباتی در نظر گرفته می شود که دارای ویژگی های مشترک هستند. انواع داده ها در زبان های برنامه نویسی از سه کاربرد اصلی پشتیبانی می کنند: (1) نامگذاری و سازماندهی مفاهیم. (2) هماهنگی تفسیر منسجم از توالی بیت در حافظه کامپیوتر. و (3) ارائه اطلاعات در مورد داده ها به کامپایلر [ 8 ، 9]. انواع داده های اولیه (مانند عدد صحیح، شناور، کاراکتر، رشته، و بولی)، انواع داده های ترکیبی (مانند آرایه، اتحادیه، مجموعه و شی)، انواع داده های انتزاعی (مانند صف، پشته، درخت و گراف) وجود دارد. ) و همچنین انواع داده های مشتق شده از انواع فوق، مانند انواع ابزار که به کاربردهای خاص دنیای واقعی می پردازند. دانش این نوع داده ها می تواند بخشی از اطلاعات مورد نیاز محقق را برای کار با داده های بازیابی شده فراهم کند، اما برای پاسخگویی کامل به نیازهای درک داده ها کافی نیست. به عنوان مثال، محققی با خواندن نام جدول، جدولی را بازیابی می کند و می داند که در مورد ترمودینامیک یک ماده شیمیایی است. محقق کلمات و اعداد جدول را می خواند اما نمی تواند معنی آن رکوردها را بفهمد زیرا در عنوان هر ستون فقط یک مخفف وجود دارد، بدون تعاریف بیشتر. علاوه بر این، روابط بین آن ستون ها برای محقق روشن نیست. آیا میتوانیم پوشش محتوایی انواع دادهها را گسترش دهیم تا بتوانند مدلی بدون ابهام و مفید از آنچه که دادهها نشان میدهند ارائه کنند؟ در این محدوده، مشخص کردن انواع دادهها میتواند به محقق کمک کند تا معنای دادهها را در یک زمینه علمی معین درک کند.
هدف این مقاله ارائه کار ما از یک مدل مفهومی برای مشخصات معنایی انواع داده، و همچنین اجرای مدل در یک پورتال داده تولید موجود برای یک برنامه علمی بینالمللی ده ساله است: رصدخانه کربن عمیق [10 ]]. در این کار، ما یک نوع داده را بهعنوان نمایش کیفیت یا ویژگیهای خاصی در نظر میگیریم که گروهی از مجموعههای داده مشترک هستند، مانند ترمودینامیک مواد شیمیایی و مواد معدنی، ترکیب گازهای آتشفشانی، یا زمینههای زمینشناسی. مدل ما به افراد اجازه می دهد تا معانی خاص دامنه را به یک نوع داده اضافه کنند، نوع داده را به عنوان یک شی در یک پورتال داده ثبت کنند، و یک مجموعه داده را با مرتبط کردن آن با یک یا چند نوع داده حاشیه نویسی کنند. هر نوع داده ثبتشده دارای یک شناسه منحصربهفرد است که در وب قابل حل است و اطلاعاتی که انواع دادهها را توصیف میکنند قابل خواندن توسط ماشین هستند و در وب قابل دسترسی هستند. مدل نوع داده ویژگیهای جدیدی را به پورتال داده اضافه میکند و مدیریت بهتر داده و استفاده مجدد کارآمد از دادهها را ممکن میسازد. بقیه مقاله به شرح زیر سازماندهی شده است: بخش 2زمینه این کار ( به عنوان مثال ، وب معنایی) و جزئیات طراحی مدل ما را معرفی می کند. بخش 3 پیاده سازی مدل در یک پورتال داده و توابع جدید ایجاد شده برای پورتال را شرح می دهد. بخش 4 این کار را با مطالعات مربوطه مقایسه می کند و جهت کار آینده را مورد بحث قرار می دهد. در نهایت، در بخش 5 ، بحث پایانی از کار ارائه شده در این مقاله ارائه میکنیم.
2. طراحی مدل
2.1. وب معنایی و داده های باز پیوندی
زمینه این کار، وب معنایی است، که اصول اصلی وب جهانی را گسترش می دهد تا معنای داده ها را برای ماشین قابل خواندن کند [ 11 ]. در جایی که سرویسهای اطلاعاتی در وب اصلی در سطح متن متوقف میشوند و از ساختارهای دانش سازمانیافته برای مفاهیم ذکر شده در متن کوتاه میآیند، وب معنایی با ایجاد امکان توسعه و استفاده از هستیشناسیها، ساختار و معنا را تشویق میکند. هستی شناسی مشخصه رسمی یک مفهوم سازی مشترک از یک دامنه است [ 12]. هر هستی شناسی که در زبان هایی مانند زبان هستی شناسی وب (OWL) کدگذاری شده است، فهرستی از مفاهیم و گروهی از روابط متقابل بین آن مفاهیم را شامل می شود. ساختار داده بنیادی هستی شناسی ها، چارچوب توصیف منبع (RDF) است که از شکل سه گانه «موضوع، محمول، شی» استفاده می کند. به عنوان مثال، “vivo:Dataset rdf:type owl:Class” سه گانه ادعا می کند که vivo:Dataset یک کلاس است. “vivo”، “rdf” و “owl” در اینجا پیشوندهای فضای نام هستی شناسی ها یا طرحواره ها هستند. هر پیشوند مخفف شناسه فضای نام مربوطه است، به عنوان مثال ، یک شناسه منبع یکنواخت (URI). برای مثال، “جغد” نشان دهنده URI واژگان طرحواره OWL 2 [ 13]. هر سه گانه یک ادعای مفصل است که تعریف یک مفهوم یا یک رابطه را اصلاح می کند. هر موضوع، محمول و شی دارای یک URI منحصر به فرد است و هر URI را می توان از طریق پروتکل انتقال ابرمتن (HTTP) در وب جستجو کرد .
هستی شناسی ها ساختار مفهومی را برای داده های رمزگذاری شده و مبادله شده از طریق وب معنایی فراهم می کنند. از آنجا که هستی شناسی ها نیز به شکل سه گانه کدگذاری می شوند، هستی شناسی های مورد استفاده در یک مجموعه داده معین ممکن است در پایگاه داده RDF (یک “ذخیره سه گانه”) بارگذاری شوند که مجموعه داده در آن نگهداری می شود. این ویژگی ها مزایای خاصی از جمله آسان کردن ذاتاً یکپارچه سازی داده ها را فراهم می کند. به عنوان مثال، سه گانه “dco:data_001 rdf:type vivo:Dataset” بیان می کند که dco:data_001 نمونه ای از کلاس vivo:Dataset است. در یک پرس و جو، اگر یک شرط برای یافتن تمام نمونه های vivo:Dataset تعیین کند، dco:data_001 یک رکورد در نتیجه پرس و جو خواهد بود. مشاهده میشود که با پیروی از بهترین روش استفاده مجدد هستیشناسی، دادههای باز آسانتر به اشتراک گذاشته میشوند و در داخل و بین دامنهها مجددا استفاده میشوند. URI ها، HTTP، داده های ساختار یافته مانند آنهایی که در RDF کدگذاری شده اند،14 ، 15 ]. Berners-Lee [ 15 ] بیشتر دادههای باز پیوندی را به عنوان دادههای پیوندی که تحت یک مجوز باز منتشر میشوند، تعریف کرد و یک طرح استقرار پنج ستاره برای دادههای باز پیوند داده شده را متصور شد، به دنبال یک دنباله پنج مرحلهای: (1) در وب. (2) داده های قابل خواندن توسط ماشین؛ (3) فرمت غیر اختصاصی. (4) استانداردهای RDF. و (5) RDF مرتبط.
2.2. رویکرد تحقیق و روش اجرا
مدل مفهومی طراحی شده برای نوع داده در پورتال داده جامعه رصدخانه عمیق کربن (DCO) مستقر شد تا ثبت نوع داده و حاشیه نویسی منابع داده را فعال کند. علم DCO چهار موضوع کلی مرتبط با کربن را پوشش می دهد: فیزیک و شیمی شدید، مخازن و شارها، انرژی عمیق، و حیات عمیق، و این تحقیق توسط شبکه ای متشکل از حدود 1700 دانشمند از بیش از 400 سازمان و 40 کشور انجام می شود. DCO سیاست های داده ای را برای ایجاد چارچوبی برای نظارت بلندمدت داده ها و اطلاعات کربن تأیید کرد [ 16 ]. از آنجایی که مجموعه دادههای DCO از بسیار منظم/مشخص شده تا موارد موردی متغیر است، نیازهای قابل توجهی برای انواع داده های مشخص وجود دارد. علاوه بر این، دانشمندان همچنین علاقه مند به دانستن منشا یا منشأ یک نوع داده هستند و این نمایش منشأ در پورتال داده DCO پیاده سازی می شود. منشأ در وب معنایی اطلاعاتی در مورد موجودیت ها، فعالیت ها و عوامل دخیل در تولید چیزی است [ 17 ]. چنین اطلاعاتی برای ارزیابی کیفیت، قابلیت اطمینان و قابل اعتماد بودن یک منبع مفید است.
در کار قبلیمان، ما قبلا هستیشناسیها را توسعه دادهایم و یک پورتال داده ساختهایم، و آنها را بخشی از دادههای باز پیوندی کردهایم [ 18]]. برای این کار، قصد ما جمع آوری لیست کاملی از انواع داده های خاص برای آن پورتال داده نیست. در عوض، ما میخواهیم سرویسی بسازیم تا کاربران بتوانند انواع دادهها را ثبت کنند و از آنها برای حاشیهنویسی مجموعه دادهها استفاده کنند. مدل مفهومی نوع داده هسته آن سرویس خواهد بود که به نوبه خود بخشی از پورتال داده خواهد بود. بنابراین، ما باید مدل نوع داده را با هستی شناسی های موجود در پورتال داده مطابقت دهیم و همچنین باید مفاهیم را در مدل به اندازه کافی عمومی کنیم تا بتوان از آنها در مکان های دیگر نیز استفاده مجدد کرد. از منظر مدل سازی و رمزگذاری معنایی، می توانیم نوع داده را به عنوان یک موجودیت در نظر بگیریم. باید یک کلاس برای نوع داده و تعدادی ویژگی وجود داشته باشد که ویژگی های هر نمونه نوع داده را توصیف کند.
این مدل توسعه ای برای هستی شناسی های موجود در پورتال داده DCO است و از چند ویژگی و کلاس از آن هستی شناسی ها مجددا استفاده می کند. پیشوندها، نامهای کامل و URIهای فضای نام این هستیشناسیها در جدول 1 فهرست شدهاند . جزئیات مدل توسعه یافته در چند بخش بعدی ارائه خواهد شد.
2.3. مفاهیم انواع پایه و انواع خاص
در میان هستی شناسی های مختلف موجود در وب معنایی، کلاس های تعریف شده ای برای انواع منابع داده وجود دارد. به عنوان مثال، واژگان نوع فراداده هسته دوبلین (DCMI) [ 19] لیستی از انواع، از جمله مجموعه، مجموعه داده، رویداد، تصویر، منبع تعاملی، تصویر متحرک، جسم فیزیکی، سرویس، نرم افزار، صدا، تصویر ثابت و متن را تعریف می کند. هر نوع DCMI به عنوان rdfs:Class تعریف می شود. در هستی شناسی های دیگر نیز کلاس های مشابهی وجود دارد، مانند bibo:Image، vivo:Video و vivo:Dataset. یک منبع در پورتال داده ما می تواند به عنوان نمونه ای از یکی از آن کلاس ها مطرح شود. به عنوان مثال، “dco:data_001 rdf:type vivo:Dataset.” در هستیشناسیهای دیگر، کلاسهای مشابهی برای انواع منابع مانند vivo:Dataset و vivo:Video در هستیشناسی VIVO و bibo:Code در هستیشناسی کتابشناختی وجود دارد (برای پیوندها به این هستیشناسیها به جدول 1 مراجعه کنید ) .
در این مقاله، ما داده ها را به عنوان یک مفهوم کلی در نظر می گیریم که نه تنها نمونه هایی از vivo:Dataset بلکه نمونه هایی از کلاس های دیگر، از جمله موارد تعریف شده در واژگان نوع DCMI و دیگر هستی شناسی ها را پوشش می دهد. ما آن کلاسهای نوع منبع را به عنوان انواع دادههای پایه مینامیم، زیرا هر یک از آنها ماهیت نوع خاصی از منبع را طبقهبندی میکنند. برای مثال منبع داده، میتوانیم نوع داده اصلی آن را با خواندن ثلاث با گزاره rdf:type، مانند مثال بالا “dco:data_001 rdf:type vivo:Dataset” یاد بگیریم. با این وجود، نوع داده پایه تنها اطلاعات محدودی را برای درک معنای یک منبع ارائه می دهد. این بخشی از نیروی محرکه کار بر روی مشخصات معنایی انواع داده است و ما آنها را انواع داده های خاص می نامیم.
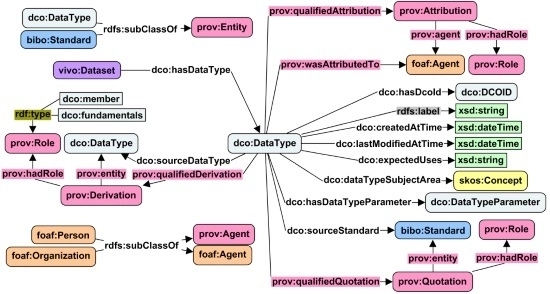
نوع داده خاص اطلاعات بیشتری در مورد یک منبع داده ارائه می دهد. به عنوان مثال، ما می توانیم از سه گانه “dco:data_001 dco:hasDataType dco:volcanicGasComposition” برای حاشیه نویسی یک نوع داده خاص استفاده کنیم. در اینجا، dco:volcanicGasComposition یک کلمه کلیدی یا برچسب نیست. در عوض، نمونه ای از کلاس نوع داده خاص dco:DataType است و گروهی از ویژگی ها آن را توصیف می کنند. شکل 1 ویژگی های مرتبط با کلاس dco:DataType را در مدل طراحی شده ما برای مشخصات نوع داده نشان می دهد. نمودار در شکل نشان می دهد که می توان از انواع داده های خاص برای حاشیه نویسی نمونه هایی از vivo:Dataset استفاده کرد و در عمل می توان از آن برای حاشیه نویسی سایر منابع داده مانند نمونه هایی از dctype:Image، dctype:Sound و غیره استفاده کرد.
2.4. مشخصات و منشأ
ویژگیها و کلاسهای نشاندادهشده در شکل 1 منعکسکننده ملاحظات فعلی ما درباره معنایی انواع دادهها است و دو بخش اصلی را پوشش میدهد: مشخصات یک نوع داده و منشأ آن. ابتدا مقدمهای بر بخش مشخصات ارائه میکنیم که با ویژگی dco:hasDcoId در قسمت سمت راست وسط نمودار در شکل 1 شروع میشود.. با استفاده از dco:hasDcoId، به هر نوع داده یک شناسه منحصربهفرد و پایدار به نام شناسه DCO اختصاص داده میشود که شبیه شناسه دیجیتال شی (DOI) یک مقاله مجله است. با استفاده از ویژگیهای rdfs:label، dco:createdAtTime، و dco:lastModifiedAtTime، یک نوع داده دارای برچسب، تاریخ ایجاد و در صورتی که اصلاح شده باشد، تاریخ اصلاح را دارد. ویژگی dco:expectedUses اجازه می دهد تا محدودیت ها یا پیشنهادهایی در مورد استفاده از نوع داده ثبت شود. یک نوع داده ممکن است از تعدادی پارامتر مانند نام فیلدها در یک صفحه گسترده تشکیل شده باشد. چنین پارامترهایی نمونه هایی از کلاس dco:DataTypeParameter خواهند بود و ویژگی dco:hasDataTypeParameter یک نوع داده را به پارامترهای آن متصل می کند. با استفاده از ویژگی dco:dataTypeSubjectArea، یک نوع داده را می توان با تعدادی از کلمات کلیدی حاشیه نویسی کرد که نمونه هایی از کلاس skos هستند: مفهوم. یک نوع داده می تواند بر اساس یک یا چند استاندارد موجود باشد. ویژگی dco:sourceStandard برای اتصال یک نوع داده به استانداردها استفاده می شود. علاوه بر این، اگر یک نوع داده از یک یا چند نوع داده موجود مشتق شده باشد، می توان از ویژگی dco:sourceDataType استفاده کرد. خالق(های) نوع داده می تواند یک شخص یا یک سازمان باشد که هر دو نمونه هایی از کلاس foaf:Agent هستند. ویژگی prov:wasAttributedTo یک نوع داده را به سازنده(های) آن متصل می کند. که هر دو نمونه ای از کلاس foaf:Agent هستند. ویژگی prov:wasAttributedTo یک نوع داده را به سازنده(های) آن متصل می کند. که هر دو نمونه ای از کلاس foaf:Agent هستند. ویژگی prov:wasAttributedTo یک نوع داده را به سازنده(های) آن متصل می کند.
هنگامی که انواع داده های منبع، استانداردهای منبع، و سازندگان یک نوع داده را در بالا توضیح دادیم، تا حدی در مورد اجزای منشأ صحبت کردیم. مدل داده توسعهیافته به ما امکان میدهد منشأ را در سطوح مختلف جزئیات ثبت کنیم. به عنوان مثال، ما ممکن است فقط از ویژگی prov:wasAttributedTo برای ضبط شخصی که یک نوع داده را ایجاد می کند استفاده کنیم و همچنین می توانیم از سه برابر بیشتر استفاده کنیم، همانطور که در قسمت بالا سمت راست شکل 1 نشان داده شده است .، برای نشان دادن نقش دقیق یک شخص، مانند خالق و مشارکت کننده. به طور مشابه، این مدل همچنین به ما امکان می دهد اطلاعات منشأ دقیق تری را در مورد انواع داده های منبع و استانداردهای منبع جمع آوری کنیم. تمام اطلاعات ثبت شده، از جمله مشخصات و منشأ، قابل خواندن توسط ماشین خواهد بود و در یک فروشگاه سه گانه ذخیره می شود. کاربران نهایی می توانند اطلاعات را از طریق رابط کاربری پورتال داده DCO مرور کنند و همچنین می توانند فروشگاه سه گانه را جستجو کرده و از نتایج بازیابی شده در برنامه های خود استفاده کنند.
3. اجرا و نتایج
پورتال داده DCO، پلتفرم VIVO [ 20 ] را برای مدیریت فراداده و سیستم Handle [ 21 ] را برای تخصیص شناسههای منحصربهفرد ( یعنی شناسه DCO) به همه اشیا تطبیق میدهد. پورتال داده همچنین از Drupal [ 22 ] برای توسعه صفحات وب جلویی کاربرپسند برای ناوبری منابع داده استفاده می کند. قبل از توسعه مدل برای نوع داده، پورتال داده DCO قبلاً از چندین هستی شناسی در هستی شناسی DCO مانند هستی شناسی FOAF و هستی شناسی کتابشناختی استفاده مجدد کرده است ( جدول 1 را ببینید.برای پیوندهایی به آن هستی شناسی ها). به منظور پیوند آنتولوژی ها به بخش های منشأ در مدل طراحی شده برای نوع داده، ما چند کلاس موجود را به عنوان زیر کلاس های کلاس های متناظر در هستی شناسی PROV-O بیان کردیم. به عنوان مثال، ما اظهارات “dco:DataType rdfs:subClassOf prov:Entity” و “foaf:Person rdfs:subClassOf prov:Agent” را اضافه کردیم ( شکل 1 ).
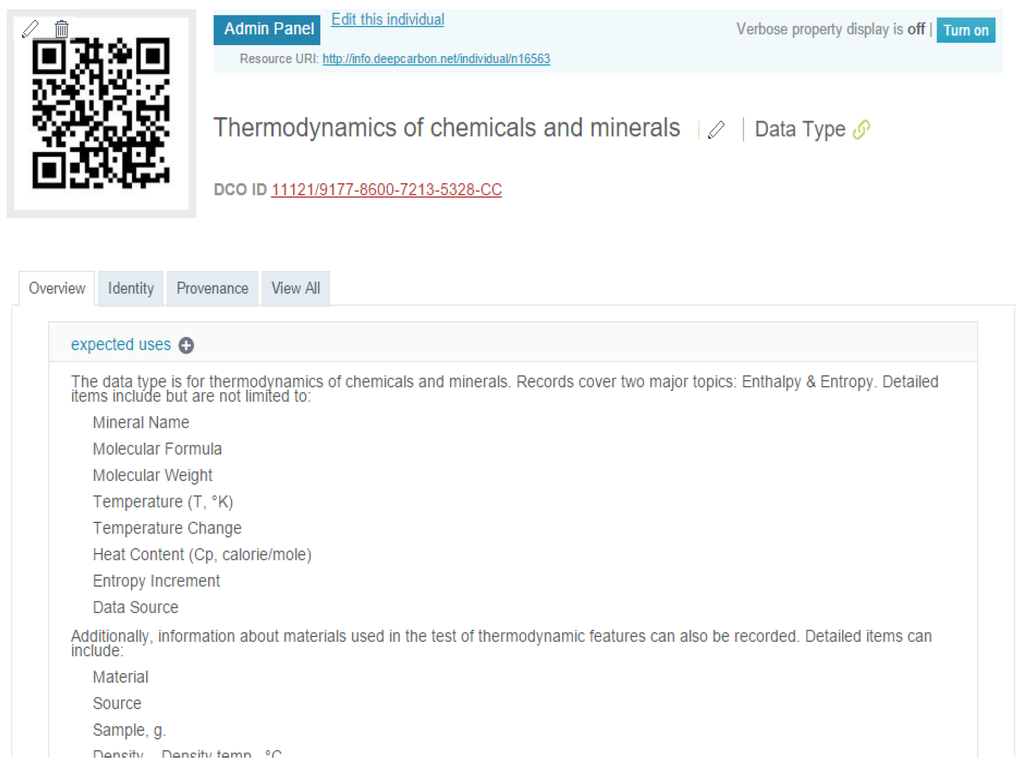
با مدل مفهومی نوع داده، توابع ثبت نوع داده، مرور نوع داده و حاشیه نویسی مجموعه داده را در پورتال داده DCO توسعه دادیم. برای ثبت نوع داده، از رابط کاربری پیشفرض پلتفرم VIVO استفاده کردیم که از روند کلی ایجاد یک نمونه برای هر کلاس پیروی میکند. هنگامی که یک نمونه نوع داده ایجاد می شود، پورتال داده یک شناسه DCO منحصر به فرد را برای آن اختصاص می دهد. سپس، در نمایه VIVO نوع داده، کاربر میتواند رکوردهایی را برای ویژگیهایی که نوع داده و پیوندهایی را که نوع داده را با اشیاء دیگر مرتبط میکنند، پر کند. شکل 2 بخشی از مشخصات نوع داده ثبت شده “ترمودینامیک مواد شیمیایی و کانی ها” را نشان می دهد.
ما همچنین با تطبیق Elasticsearch [ 23 ]، یک مرورگر وجهی برای همه انواع داده های ثبت شده توسعه دادیم. شکل 3 تصویری از مرورگر وجهی با چند نوع داده را نشان می دهد که به عنوان نمونه آزمایشی ثبت کرده ایم. در سمت چپ رابط کاربری لیستی از جنبه ها وجود دارد که مربوط به ویژگی های مربوط به انواع داده های ثبت شده در پورتال است. کاربر می تواند با انتخاب رکوردهایی در آن جنبه ها، در میان انواع داده ها جستجو کند. یکی از ویژگی های مرورگر این است که، هنگامی که رکوردهای انتخاب شده در یک وجه تغییر می کنند، همه رکوردها در سایر جنبه ها و همچنین نتایج نوع داده به ترتیب تغییر می کنند. کاربر میتواند در چندین جنبه انتخاب کند و/یا عبارتهای جستجوی متنی را برای جستجوی یک یا چند نوع داده خاص وارد کند. شکل 3دو نوع داده بهدستآمده را نشان میدهد که «کانیشناسی» را بهعنوان حوزه پژوهشی دارند ( یعنی کلمات کلیدی).
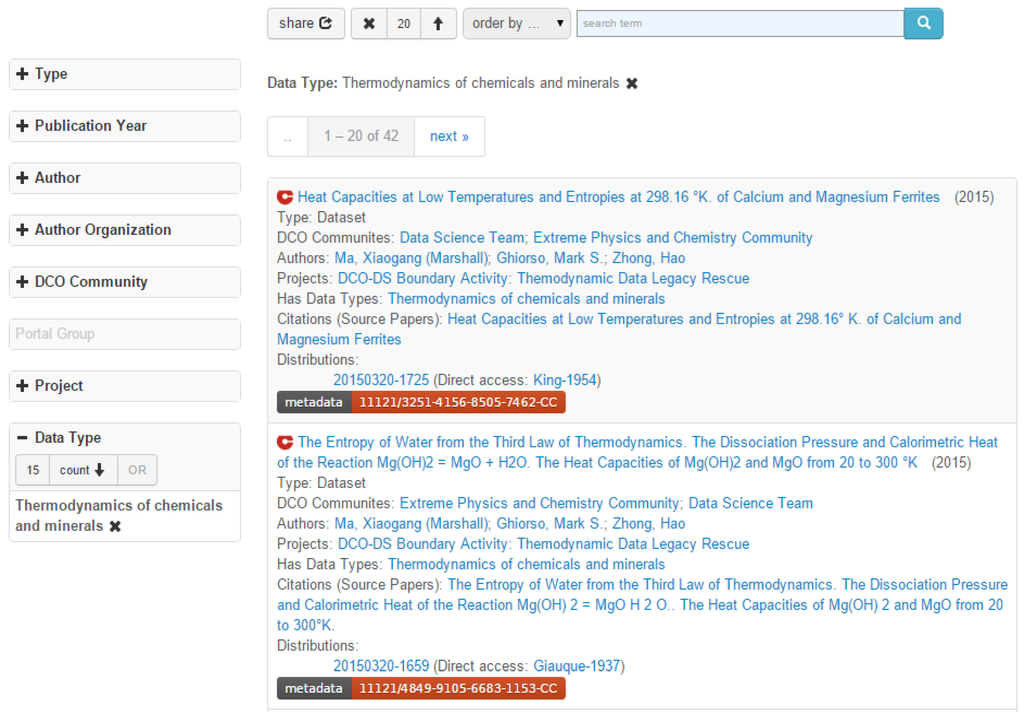
ما می توانیم از انواع داده های ثبت شده برای حاشیه نویسی منابع داده مانند مجموعه داده ها استفاده کنیم. تنها کاری که کاربر باید انجام دهد پر کردن رکوردهای نوع داده برای ویژگی “dco:hasDataType” در نمایه VIVO یک مجموعه داده است. ما همچنین یک مرورگر وجهی برای مجموعههای داده توسعه دادیم و «انواع داده» را به عنوان یک جنبه در آن مرورگر فهرست کردیم. شکل 4 بخشی از مجموعه داده های بازگشتی را نشان می دهد که “ترمودینامیک مواد شیمیایی و کانی ها” در جنبه نوع داده انتخاب شده است.
4. بحث
علم امروزه به طور فزاینده ای توسط داده های باز تسهیل می شود. همانطور که فاکس [ 24 ] تعریف کرد، “علم داده انجام علم با داده های شخص دیگری است.” کار ما بر روی مدل مفهومی نوع داده و پیاده سازی آن در یک پورتال داده، توصیف معنایی مجموعه داده ها را غنی می کند. اطلاعات موجود در چنین توصیفی نه تنها قابل خواندن توسط انسان، بلکه قابل خواندن توسط ماشین نیز هستند، که به افرادی که به مجموعه داده هایی که از دنیای داده های باز بازیابی می شوند دسترسی دارند و از آنها استفاده می کنند کمک ارزشمندی می کند.
کارهای زیادی روی مدلهای ماشینخوان انواع دادهها انجام شده است. در طرحواره RDF (RDFS، URI فضای نام را در جدول 1 برای جزئیات بیشتر دنبال کنید)، یک کلاس rdfs:DataType وجود دارد، و در واژگان مفاهیم RDF، چند نمونه از آن وجود دارد، مانند rdf:HTML، rdf:langString، rdf:PlainLiteral، و rdf:XMLLiteral، که نشان میدهند کار همچنان بر بخش نحوی انواع دادهها متمرکز است. استاندارد ISO/IEC 11179-3:2013(E) [ 25 ] یک نوع داده را به عنوان “مجموعه ای از مقادیر متمایز، مشخص شده با ویژگی های آن مقادیر و با عملیات روی آن مقادیر” تعریف می کند. این تعریف و همچنین تعاریف انواع داده های اولیه و ترکیبی در آن استاندارد، با تعاریف مفاهیم مشابه در زبان های برنامه نویسی سازگار است [ 8] .، 9 ]. در دنیای دادههای باز، یک قرارداد انتشار فراداده همراه با دادهها برای توصیف ساختار و محتوای دادهها است. نمونه هایی را می توان در هدرهای netCDF [ 26 ] و بسته های داده [ 27 ] مشاهده کرد. اخیراً، W3C پیشنهاد واژگان فراداده را برای پشتیبانی از حاشیه نویسی، کشف و نمایش داده های جدولی در وب منتشر کرده است [ 28]]. این توصیه، موارد فوق داده را برای توصیف اشیا در سطوح مختلف جزئیات، مانند گروههایی از جداول، روابط متقابل بین جداول، جداول منفرد و ستونهای جداگانه در یک جدول ارائه میکند. بسیاری از کار در آن توصیه را می توان برای گسترش مدل در این مقاله به مقیاس دقیق تر، به ویژه بخشی که کلاس dco:DataTypeParameter را احاطه کرده است، اتخاذ کرد. کارهای قبلی روی زبانهای نشانهگذاری برای هماهنگ کردن مجموعههای داده ناهمگن، مانند زبان فرادادههای زیستمحیطی [ 29 ]، زبان نشانهگذاری علوم زمین [ 30 ] و GeoSciML [ 31 ] میتوانند به ارائه موارد استفاده از حوزه علم زمین در مورد نحوه نمایش ساختارهای داده در قالب قابل خواندن توسط ماشین
همچنین آثاری وجود داشته است که مجموعه دادهها را با اطلاعات نوع داده خاص دامنه حاشیهنویسی میکنند. به عنوان مثال، پورتال داده EarthChem [ 32 ] یک لیست سلسله مراتبی از انواع داده را پیشنهاد کرد تا برای برچسب گذاری یک مجموعه داده ثبت شده استفاده شود. با این حال، انواع داده ها در EarthChem در سطح متن مشخص می شوند، به عنوان مثال، به عنوان کلمات کلیدی کار ارائه شده در این مقاله با فعال کردن مشخصات معنایی انواع داده ها از طریق یک مدل مفهومی، یک گام از سطح “کلید واژه” فراتر می رود. در حال حاضر، ما فهرست کاملی از انواع دادهها که تمام الزامات جامعه DCO را برآورده میکنند، نداریم و قصد نداریم همه انواع دادهها را فقط به تنهایی ثبت کنیم. در عوض، عملکردی که ما برای ثبت نوع داده ساختهایم برای جامعه DCO باز است و هر کاربر میتواند انواع دادههای مورد علاقه خود را ثبت کند. علاوه بر ثبت نوع داده، ما همچنین می توانیم روابط صریح بین انواع داده های ثبت شده را سازماندهی کنیم، به عنوان مثال، از طریق ویژگی “dco:sourceDataType.” ما همچنین می توانیم روابط ضمنی بین انواع داده را سازماندهی کنیم. به عنوان مثال، کلمات کلیدی مورد استفاده برای توصیف انواع داده ها می توانند سرنخ هایی در مورد دسته ها یا رشته های انواع داده ارائه دهند.
کار ما با پذیرش خروجی گروه کاری رجیستری نوع داده (DTR) اتحاد پژوهش داده ها (RDA) آغاز شد [ 33 ، 34]. هر DTR یک پورتال مستقل برای ثبت و بررسی نوع داده است. فرض بر این است که یک نوع داده ثبت شده برای برخی اطلاعات مفید در مورد آن نوع قابل حل است. با توجه به چشم انداز گروه کاری DTR، موارد متعددی از DTR وجود خواهد داشت و هر کدام توسط پروژه، گروه یا جامعه خود اداره می شوند. همه آن نمونههای DTR از برخی از انواع اولیه رایج استفاده مجدد میکنند که به آنها «اولیه» میگویند. این موارد اولیه در یک ثبت نوع که احتمالاً توسط «Corporation for National Research Initiatives» (CNRI) مدیریت میشود، ثبت خواهند شد. بنابراین ما می توانیم انتظار یک فدراسیون سلسله مراتبی دو سطحی از DTR را داشته باشیم. سطح بالاتر لیستی از موارد اولیه است و سطح پایین تر انواع داده های خاص تعریف شده در یک DTR است.
تمایز ما از انواع داده های پایه و انواع داده های خاص با افکار اولیه و انواع داده های خاص در گروه کاری DTR قابل مقایسه است. با این حال، ما یک رویکرد تکنولوژیکی متفاوت را برای تحقق ثبت نوع داده اتخاذ کردیم. از نقطه نظر مهندسی هستی شناسی، هر دو نوع داده اولیه و خاص در طراحی DTR در سطح نمونه قرار دارند، یعنی هر دو نوع داده ثبت شده هستند. در کار ما، انواع داده های پایه در سطح کلاس هستند، یعنی کلاس هایی در هستی شناسی ها هستند و منابع داده نمونه هایی از آنها هستند. انواع داده های خاص در کار ما در سطح نمونه هستند، به عنوان مثال، همگی نمونه هایی از کلاس dco:DataType هستند. اگر انواع دادههای خاص را در سطح کلاس قرار دهیم، باید هستیشناسی را مرتباً بهروزرسانی کنیم تا کلاسهای نوع داده جدید ایجاد شده را شامل شود. استفاده از یک کلاس dco:DataType و ساخت انواع داده های خاص به عنوان نمونه های آن، به طور قابل توجهی تلاش های مورد نیاز برای به روز رسانی هستی شناسی و حفظ چارچوب پورتال داده را کاهش می دهد.
با تمرکز تنها بر روی مورد پورتال داده DCO، زیرا پورتال توسط هستی شناسی ها پشتیبانی می شود، با ساختن مدل به عنوان بخشی از هستی شناسی DCO، آن را به سرعت و به آرامی در پورتال داده DCO مستقر کردیم. این مزیت مدل مفهومی برای پورتال های داده مبتنی بر فناوری های وب معنایی را نشان می دهد. نگاشت به هستی شناسی PROV-O به اطلاعات نوع داده اجازه می دهد تا با نمودار منشأ گسترده مرتبط شود، مانند دو عنوان مثال “dco:DataType rdfs:subClassOf prov:Entity” و “foaf:Person rdfs:subClassOf prov:Agent” در بخش قبل توضیح داده شد. ما باید توجه داشته باشیم که در این دو ادعای مثال، اولی خوب بود زیرا هستی شناسی DCO توسط خودمان توسعه داده شد و ما می توانیم آن را به روز کنیم. با این حال، برای ادعای اخیر، ما موضوع “ربایی هستی شناسی” را داشتیم [35 ]. یعنی هستی شناسی های جدید توسعه یافته معناشناسی مفاهیم موجود ساکن در هستی شناسی های دیگر را دوباره تعریف می کنند. برای کاهش تأثیر منفی در کارمان، این ادعاهای «ربایی» فقط برای پورتال دادههای DCO کار میکنند و از آنها برای مقاصد دیگر استفاده نکردیم.
کار ما فقط اولین تلاش در به کارگیری فناوری های معنایی برای تقویت معنا و روابط بین انواع داده ها و مجموعه داده ها است. علاوه بر این، ما برخی از کارهای احتمالی آینده را پیشنهاد میکنیم که میتواند معنایی انواع دادهها را بیشتر افزایش دهد. اول، ما میتوانیم مدل مفهومی را گسترش داده و به روز کنیم تا توانایی آن برای نمایش معنای خاص دامنه را بهبود بخشیم. ما میتوانیم این کار را با همکاری با دانشمندان حوزه در جامعه DCO و جامعه گستردهتر علوم زمین، در توسعه موارد استفاده خاص برای حوزههای علمی آنها انجام دهیم. یک کار جالب توجه ویژه گسترش مشخصات کلاس dco:DataTypeParameter و روابط بین نمونه های پارامتر است. چند کار موجود در جامعه وب معنایی (به عنوان مثال، [ 28]) می تواند برای انجام این کار اتخاذ شود. ما حتی میتوانیم به دنبال این فرصت باشیم که مدل را به سطح کلیتری سوق دهیم و یک هستیشناسی نوع داده بسازیم که میتواند در حوزههای مختلف مطالعات خارج از جامعه DCO مورد استفاده قرار گیرد. دوم، جنبه “انواع داده” در مرورگر مجموعه داده را می توان با ویژگی های بیشتری غنی کرد تا به کاربران در یافتن مجموعه داده های مورد علاقه کمک کند. به عنوان مثال، یک ابزار تجسم ممکن است برای نشان دادن روابط متقابل بین انواع داده های ثبت شده اضافه شود. ما می توانیم راهی برای محاسبه شباهت ایجاد کنیم [ 36] بین علایق محقق و انواع داده بر اساس مشخصات محقق در پورتال داده. سپس، پورتال داده میتواند انواع دادههای مورد علاقه را به آن محقق توصیه کند. سوم، هنگامی که تعداد معینی از انواع داده ها ثبت شد، می توان روش هایی را برای استفاده از کلمات کلیدی در توضیحات آنها برای کشف روابط ضمنی بین آن انواع داده توسعه داد. چهارم، برای افزایش ارزش انواع دادهها و رسمیسازی استفاده و استفاده مجدد از آنها، امکان راهاندازی یک رابط برنامه کاربردی که (1) اطلاعات قابل خواندن ماشین در مورد ساختار و محتوای انواع دادههای ثبتشده و (2) ابردادههای ساختیافته را ارائه میدهد. استناد، هر دو از طریق شناسه منحصر به فرد هر نوع داده، ارزش کاوش را دارد. به عبارت دیگر، تلاشی برای ترویج نوع داده به عنوان یک شی درجه یک در دنیای داده های باز است.
5. نتیجه گیری ها
علم در کل توسط داده ها هدایت می شود. داده های باز جهانی فرصت های بزرگی را برای علم ایجاد کرده است، اما چالش هایی را در قابلیت همکاری داده ها ایجاد می کند. شناسایی واضح یک نوع داده معنی دار یک عامل کلیدی در حل قابلیت همکاری داده ها در حوزه های علمی است. به طور معمول، یک نوع داده اغلب در سطح نحوی مانند عدد صحیح، شناور، بولی، رشته و غیره مورد بررسی قرار می گیرد.تعاریف نحوی از انواع داده ها، معنای معنایی دامنه خاص کافی را با انواع داده مرتبط نمی کند. در این کار، ما کاربرد فناوریهای وب معنایی را برای تعیین انواع دادهها شرح میدهیم. با این رویکرد، یک نوع داده می تواند معنای پیچیده ای را منتقل کند، مانند اینکه چه کسی نوع داده را ایجاد می کند، استاندارد منبعی که نوع داده از آن مشتق می شود، عملیاتی که می توان روی مجموعه داده های آن نوع داده انجام داد، حوزه های علمی معمول، برنامه های نرم افزاری و /یا ابزارهایی که از نوع داده استفاده می کنند و موارد دیگر. پیاده سازی مدل ما در یک پورتال داده علمی تولید، تولیدکنندگان داده را قادر می سازد تا انواع داده را ثبت کرده و از آنها برای حاشیه نویسی منابع داده استفاده کنند. اطلاعات نوع داده هم توسط انسان و هم توسط ماشین قابل خواندن است. برای کاربران داده، آنها می توانند مفروضات توضیحی یا اطلاعات ذاتی یک مجموعه داده را از طریق سوابق انواع داده های خاص مرتبط با آن مجموعه داده دریافت کنند. به این ترتیب، آنها می توانند به سرعت جزئیات را در یک مجموعه داده بدون حتی دانلود آن ببینند و درک کنند.
منابع
- کلمپ، جی. برتلمن، آر. بریس، جی. دیپنبروک، ام. گروب، اچ. اومل، CKH؛ لاوتنشلاگر، ام. شیندلر، یو. سنس، من. Wächter, J. انتشار داده در ابتکار دسترسی آزاد. اطلاعات علمی J. 2006 ، 5 ، 79-83. [ Google Scholar ] [ CrossRef ]
- معالی، ف. اریکسون، جی. Archer, P. Data Catalog Vocabulary (DCAT)—توصیه W3C 16 ژانویه 2014. در دسترس آنلاین: http://www.w3.org/TR/vocab-dcat/ (در 11 فوریه 2016 در دسترس است).
- استار، جی. Gastl, A. isCitedBy: یک طرح ابرداده برای DataCite. D-Lib Mag. 2011 , 17 . [ Google Scholar ] [ CrossRef ]
- لین، جی. Fenner, M. Altmetrics in evolution: تعریف و بازتعریف هستی شناسی معیارهای سطح مقاله. Inf. ایستادن. Q. 2013 , 25 , 20-26. [ Google Scholar ]
- ما، ایکس. اش، ک. لاکستون، جی ال. ریچارد، اس ام. آساتو، سی جی; Carranza، EJM; ون در میر، FD; وو، سی. دوکلوکس، جی. Wakita، K. تبادل داده تسهیل شد. نات Geosci. 2011 . [ Google Scholar ] [ CrossRef ]
- سازمان بین المللی استاندارد (ISO). ISO15836: اطلاعات و مستندات – مجموعه عناصر فراداده هسته دوبلین ؛ سازمان بین المللی استاندارد (ISO): ژنو، سوئیس، 2003; پ. 8. [ Google Scholar ]
- گروه کاری فراداده DataCite. طرحواره فراداده DataCite برای انتشار و استناد به داده های تحقیق (نسخه 3.1). در دسترس آنلاین: http://120.52.72.45/schema.datacite.org/c3pr90ntcsf0/meta/kernel-3/doc/DataCite-MetadataKernel_v3.1.pdf (در 11 فوریه 2016 دسترسی پیدا کرد).
- میچل، JC مفاهیم در زبان های برنامه نویسی ; انتشارات دانشگاه کمبریج: کمبریج، انگلستان، 2002; پ. 529. [ Google Scholar ]
- Donahue, J. در مورد معناشناسی “نوع داده”. SIAM J. Comput. 1979 ، 8 ، 546-560. [ Google Scholar ] [ CrossRef ]
- پورتال داده های رصدخانه عمیق کربن. در دسترس آنلاین: https://info.deepcarbon.net (در 11 فوریه 2016 قابل دسترسی است).
- برنرز لی، تی. هندلر، جی. Lassila, O. وب معنایی. علمی صبح. 2001 ، 284 ، 34-43. [ Google Scholar ] [ CrossRef ]
- گروبر، TR به سمت اصولی برای طراحی هستی شناسی های مورد استفاده برای اشتراک دانش. بین المللی جی. هوم. محاسبه کنید. گل میخ. 1995 ، 43 ، 907-928. [ Google Scholar ] [ CrossRef ]
- واژگان طرحواره OWL 2. در دسترس آنلاین: http://www.w3.org/2002/07/owl# (در 11 فوریه 2016 قابل دسترسی است).
- بیزر، سی. هیث، تی. برنرز-لی، تی. داده های مرتبط – داستان تا کنون. بین المللی ج. سمنت. وب اطلاعات سیستم 2009 ، 5 ، 1-22. [ Google Scholar ] [ CrossRef ]
- برنرز لی، تی. داده های پیوندی. در دسترس آنلاین: http://www.w3.org/DesignIssues/LinkedData.html (در 11 فوریه 2016 قابل دسترسی است).
- DCO دسترسی باز و سیاست های داده. در دسترس آنلاین: https://deepcarbon.net/page/dco-open-access-and-da-policies (در 11 فوریه 2016 قابل دسترسی است).
- گروت، پ. Moreau, L. PROV-Overview: مروری بر خانواده اسناد PROV. در دسترس آنلاین: http://www.w3.org/TR/prov-overview/ (در 11 فوریه 2016 قابل دسترسی است).
- ما، ایکس. چن، ی. وانگ، اچ. اریکسون، جی اس. غرب، پ. رصدخانه مجازی فاکس، پی دیپ کربن: یک پلتفرم سایبری فعال برای علوم مرتبط. در مجموعه مقالات SciDataCon2014، دهلی نو، هند، 2 تا 5 نوامبر 2014.
- واژگان نوع DCMI. در دسترس آنلاین: http://dublincore.org/documents/2000/07/11/dcmi-type-vocabulary/ (دسترسی در 10 ژوئن 2015).
- VIVO. در دسترس آنلاین: http://vivoweb.org/ (دسترسی در 10 ژوئن 2015).
- HDL.NET ® خدمات اطلاعاتی. در دسترس آنلاین: http://handle.net/ (دسترسی در 10 ژوئن 2015).
- دروپال. در دسترس آنلاین: https://www.drupal.org/ (دسترسی در 10 ژوئن 2015).
- کشسان. در دسترس آنلاین: https://www.elastic.co/about (دسترسی در 10 ژوئن 2015).
- فاکس، پی. پیشرفت در پلتفرمهای دادههای علمی جهان باز، یکپارچه، شفاف و مشارکتی. ارائه اصلی در کنفرانس ISWC2013، سیدنی. 2013. در دسترس آنلاین: http://tw.rpi.edu/web/doc/ISWC2013_Sydney_Fox20131024a.ppt (در 11 فوریه 2016 قابل دسترسی است).
- سازمان بین المللی استاندارد (ISO). ISO/IEC 11179–3:2013(E) فناوری اطلاعات—رجیسترهای فراداده (MDR)—بخش 3: متامدل رجیستری و ویژگی های اساسی ؛ سازمان بین المللی استاندارد (ISO): ژنو، سوئیس، 2013; پ. 227. [ Google Scholar ]
- ریو، آر. دیویس، جی. NetCDF: رابطی برای دسترسی به داده های علمی. محاسبات IEEE. نمودار. Appl. 1990 ، 10 ، 76-82. [ Google Scholar ] [ CrossRef ]
- پولاک، آر. کیگان، ام. بسته های داده. در دسترس آنلاین: http://dataprotocols.org/data-packages (در 11 فوریه 2016 قابل دسترسی است).
- تنیسون، جی. کلوگ، جی. واژگان فراداده برای داده های جدولی. در دسترس آنلاین: https://www.w3.org/TR/2015/REC-tabular-metadata-20151217 (دسترسی در 11 فوریه 2016).
- میچنر، دبلیو. برانت، جی. هلی، جی. کرشنر، تی. استافورد، S. فراداده های غیر فضایی برای علوم زیست محیطی. Ecol. Appl. 1997 ، 7 ، 330-342. [ Google Scholar ] [ CrossRef ]
- راماچاندران، آر. گریوز، اس. کانور، اچ. Moe, K. Earth Science Markup Language (ESML): راه حلی برای مشکلات علمی کاربردی داده-کاربرد. محاسبه کنید. Geosci. 2004 ، 30 ، 117-124. [ Google Scholar ] [ CrossRef ]
- سن، م. دافی، T. GeoSciML: توسعه زبان نشانه گذاری عمومی علم زمین. محاسبه کنید. Geosci. 2005 ، 31 ، 1095-1103. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- EarthChem. در دسترس آنلاین: http://www.earthchem.org/ (دسترسی در 10 ژوئن 2015).
- برودر، دی. Lannom، L. ثبت نوع داده: یک گروه کاری اتحاد داده های پژوهشی. D-Lib Mag. 2014 ، 20 . [ Google Scholar ] [ CrossRef ]
- اتحاد داده های پژوهشی. در دسترس آنلاین: https://www.rd-alliance.org/groups/data-type-registries-wg.html (دسترسی در 10 ژوئن 2015).
- هوگان، ا. هارث، آ. Polleres، A. SAOR: استدلال معتبر برای وب. در وب معنایی ؛ Domingue, J., Anutariya, C., Eds. Springer: برلین، آلمان، 2008; صص 76-90. [ Google Scholar ]
- ژنگ، جی. فو، ال. ما، ایکس. Fox, P. SEM+: ابزاری برای کشف نقشه مفهومی در حوزه مرتبط با علم زمین. علوم زمین Inf. 2015 ، 8 ، 95-102. [ Google Scholar ] [ CrossRef ]

شکل 1. یک مدل مفهومی برای مشخص کردن انواع داده ها.
شکل 2. تصویری از نمایه یک نوع داده ثبت شده.

شکل 3. یک مرورگر وجهی برای انواع داده های ثبت شده.
شکل 4. یک مرورگر مجموعه داده وجهی با “نوع داده” به عنوان یک جنبه.

جدول 1. هستی شناسی ها و طرحواره های مورد استفاده مجدد در مدل برای مشخصات نوع داده.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons by Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر