

خلاصه
:رگرسیون لجستیک یک مدل خطی کلاسیک برای احتمالات شرطی تبدیل شده با لاجیت متغیر هدف باینری است. اگر توزیع مشترک پیشبینیکنندهها و هدف به شکل لگ خطی باشد، احتمالات شرطی واقعی را بازیابی میکند. وزن شواهد یک رگرسیون لجستیک معمولی با پارامترهای برابر با تفاوت وزن شواهد است در صورتی که همه متغیرهای پیش بینی با توجه به متغیر هدف گسسته و به طور مشروط مستقل باشند. فرضیه استقلال شرطی را می توان از نظر مدل های لگ خطی آزمایش کرد. اگر فرض استقلال مشروط نقض شود، اعمال اوزان شواهد نه تنها احتمالات شرطی پیش بینی شده را خراب می کند، بلکه تبدیل رتبه آنها را نیز خراب می کند. مدلهای رگرسیون لجستیک، از جمله شرایط تعامل، می تواند دلیل عدم استقلال مشروط باشد، شرایط تعامل مناسب دقیقاً برای نقض استقلال مشروط جبران می کند. شبکههای عصبی مصنوعی چندلایه ممکن است بهعنوان مدلهای رگرسیون مانند تودرتو، با برخی عملکرد فعالسازی سیگموئیدی دیده شوند. اغلب، تابع لجستیک به عنوان تابع فعال سازی استفاده می شود. اگر توپولوژی خالص،به عنوان مثال ، کنترل آن به اندازه کافی همه کاره است تا از اصطلاحات تعامل تقلید کند، شبکه های عصبی مصنوعی می توانند نقض استقلال شرطی را محاسبه کنند و نتایج بسیار مشابهی به دست آورند. وزن شواهد نمی تواند به طور منطقی شامل شرایط تعامل باشد. اصلاحات بعدی اوزان، همانطور که اغلب پیشنهاد میشود، نمیتواند اثر شرایط تعامل را تقلید کند.
مدل سازی آینده نگر ; مدل سازی بالقوه استقلال مشروط مدل بیز ساده لوح ; عوامل بیز ؛ وزن شواهد شبکه های عصبی مصنوعی ; مجموعه داده های نامتعادل ؛ متعادل کردن
1. معرفی
هدف از مدلسازی یا هدفگیری بالقوه [ 1 ] شناسایی مکانهایی است، به عنوان مثال ، پیکسلها یا وکسلها، که احتمال وقوع یک رویداد به این شکل بهطور مکانی ارجاع داده میشود، به عنوان مثال ، یک نوع کاملاً تعریف شده از کانیسازی سنگ معدن، نسبتاً حداکثر است. ، بزرگتر از پیکسل ها یا وکسل های همسایه است. پیش نیاز اصلی چنین پیشبینیهایی، درک کافی از علل هدفی است که باید پیشبینی شود. مدل های مفهومی ذخایر سنگ معدن توسط [ 2 ] گردآوری شده است]. آنها ممکن است به عنوان مدل های عاملی خوانده شوند (در مفهوم آمار ریاضی)، و یک مدل عامل مناسب ممکن است به یک مدل از نوع رگرسیون تبدیل شود در هنگام استفاده از عوامل به عنوان پیش بینی کننده های مرجع فضایی، که برای رویداد هدف مطلوب یا منع می کنند. . بنابراین، ما میتوانیم وابستگیهای لازم یا کافی را بین هدف باینری T( x ) که نشاندهنده وجود یا عدم حضور هدف در یک مکان منطقهای یا حجمی است ، تشخیص دهیم. پیش بینی کننده ها (B 0 ( x )، B 1 ( x )، …، B m ( x )) T = B (x ) که ممکن است باینری، گسسته یا پیوسته باشد. سپس، مدلهای ریاضی و تحقق عددی آنها برای تبدیل مدلهای توصیفی به مدلهای سازنده، یعنی به مدلهای پیشبینی کمی، مورد نیاز است. به طور کلی، یک مدل پیشبینیکننده B ( x ) را با B 0 ( x ) ≡ 1 برای تمام x ⊂ D در نظر میگیرد و یک پارامتر ( θ 0 ,…, θ m ) T = θ را به آنها اختصاص میدهد که با ابزار کمیت میکند. از یک تابع پیوند نوع گره ناشناخته: فونتنوع گره ناشناخته: فونت، میزان وابستگی احتمال شرطی P (T( x ) = 1| B ( x )) به پیش بینی کننده ها، به عنوان مثال ،
از آنجایی که هدف T(x)، و همچنین پیشبینیکننده B (x) به مکانهای مساحتی یا حجمی x ⊂ D اشاره دارد، ممکن است به یک تصویر نقشه دیجیتالی دو بعدی از پیکسلها یا یک ژئومدل دیجیتال سهبعدی از وکسلها فکر کنیم. پیکسل ها یا وکسل ها در ابتدا پشتیبانی فیزیکی پیش بینی کننده ها و هدف را فراهم می کنند و سپس به ترتیب احتمال شرطی پیش بینی شده و خطاهای تخمین مربوطه را به آنها اختصاص می دهند. سپس، نتایج عددی هدفگیری به اندازه اشیا، پیکسلها یا وکسلها، یعنی به وضوح فضایی آنها بستگی دارد. اگر مرجع مکانی واقعی هدف (یا پیش بینی کننده ها) نسبتاً نقطه ای باشد، به عنوان مثال، اگر پشتیبانی فیزیکی آنها نسبتاً صفر باشد، وابستگی به وضوح فضایی را نباید نادیده گرفت، زیرا قبلاً برآورد نوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتشانس بی قید و شرط تا حد زیادی تحت تأثیر قرار می گیرد، زیرا تعداد کل پیکسل ها یا وکسل ها به وضوح فضایی بستگی دارد، در حالی که تعداد کل رخدادهای نقطه ای ثابت است. اگر وضوح فضایی ارائه شده توسط پیکسل ها یا وکسل ها نسبت به مساحت یا حجم پشتیبانی فیزیکی واقعی پیش بینی کننده ها یا هدف ضعیف باشد، نتایج عددی هر نوع روش ریاضی هدف گیری بیشتر مصنوع از فضای نامناسب است. وضوح.
برای تخمین پارامترهای مدل θ ، دادههای درون یک منطقه آموزشی مورد نیاز است. فرض مدلسازی ریاضی مرتبط با مجموعه داده آموزشی دانش کامل است، به عنوان مثال ، به طور خاص، ما فرض میکنیم که همه رخدادهای متغیر هدف T = 1 را میدانیم. با این حال، بر خلاف آمارهای زمینآمار [ 3 ]، مدلسازی بالقوه از نظر فضایی در نظر گرفته نمیشود. وابستگی های القا شده بین پیش بینی کننده ها و هدف. در واقع، مدلسازی پتانسیل از فرض متغیرهای تصادفی به طور یکسان توزیع شده استفاده میکند. توزیع آنها به مکان بستگی ندارد. بنابراین، هر مرجع مکانی را می توان حذف کرد، و مدل های فرم:
در نظر گرفته می شوند، تنها.
2. مدل های ریاضی
2.1. فرض مدلسازی استقلال مشروط
متغیرهای تصادفی B1 ،…، Bm با توجه به متغیر هدف تصادفی T به صورت شرطی مستقل هستند، اگر احتمال مشروط مشترک در احتمالات شرطی منفرد فاکتور شود:
به طور معادل، اما آموزنده تر از نظر بی ربط بودن، متغیرهای تصادفی B1 ،…، Bm با توجه به متغیر تصادفی T مشروط مستقل هستند، اگر دانستن T همه Bj های دیگر را به جز B i برای پیش بینی B i نامربوط کند ، به عنوان مثال ،
از نظر احتمالات مشروط
تاکید می شود که استقلال به معنای استقلال مشروط نیست و بالعکس. همبستگی معنی دار متغیرهای پیش بینی کننده به معنای مستقل نبودن آنها به صورت شرطی نیست. برعکس، متغیرهای B 1 و B 2 ممکن است با توجه به متغیر T به طور قابل توجهی همبستگی و به طور مشروط مستقل باشند، به ویژه زمانی که T را بتوان به عنوان یک علت مشترک برای B1 و B2 تفسیر کرد ، رجوع کنید به . مثال گویا [ 4]. به این ترتیب، استقلال شرطی یک رویکرد احتمالی به علیت است، در حالی که همبستگی چنین نیست. برای کاهش این فرض محدود کننده که همه متغیرهای پیش بینی مستقل هستند با توجه به متغیر هدف، فرض استقلال شرطی زیرمجموعه های متغیرهای پیش بینی، که به عنوان شبکه باور بیزی نامیده می شود، مدل های میانی را ارائه می دهد که کمتر محدود کننده هستند، اما قابل حمل تر از مدل های عمومی هستند. [ 5 ]. یک انتخاب مناسب از زیرمجموعهها، دستههای مدل گرافیکی [ 6 ] هستند که متغیرها و روابط استقلال شرطی آنها را نشان میدهند که منجر به شرایط تعامل در مدلهای رگرسیون لجستیک میشود [ 7 ].
2.2. رگرسیون لجستیک
یک گزارش مدرن از رگرسیون لجستیک توسط [ 8 ] ارائه شده است. انتظار شرطی از یک متغیر هدف تصادفی شاخص T با توجه به متغیر پیش بینی تصادفی متغیر ( m + 1) برابر با احتمال شرطی آن است، یعنی برای B = (B 0 , B 1 ,…, B m ) T با B 0 ≡ 1
با حذف عبارت خطای توزیع شده دو جمله ای ([ 8 ])، همانطور که اغلب انجام می شود، مدل رگرسیون لجستیک معمولی بدون شرایط تعامل برای احتمال شرطی قابل پیش بینی می تواند به صورت [ 8 ] نوشته شود:
- از نظر یک لاجیت:
آن را ثبت کنید P( T = 1 | B ) =βتیB =β0+∑ℓβℓبℓورود به سیستمآی تیپ(تی=1|ب)=�تیب=�0+∑ℓ�ℓبℓ
- از نظر احتمال:
پ( T = 1 | B ) = Λ (βتیب ) = Λ (β0+∑ℓβℓبℓ)پ(تی=1|ب)=Λ(�تیب)=Λ(�0+∑ℓ�ℓبℓ)
- با تابع لجستیک:
Λ ( z) =11 – exp ( – z)Λ(�)=11–انقضا(–�)
مدل رگرسیون لجستیک معمولی بهینه است، یعنی با احتمال شرطی واقعی مطابقت دارد، اگر متغیرهای پیش بینی با توجه به متغیر هدف گسسته و به طور مشروط مستقل باشند [ 7 ]. در اینجا، متغیرهای پیشبینیکننده گسسته فرض میشوند تا اطمینان حاصل شود که احتمال مشترک B و T نمایشی بهعنوان یک مدل لگ خطی دارد، که سپس طبق قضیه همرسلی-کلیفورد [ 7 ] مشمول عاملسازی میشود.
مدل رگرسیون لجستیک را می توان تعمیم داد تا هر گونه شرایط تعاملی فرم را شامل شود بℓمن* … *بℓjبℓمن*…*بℓ�، به عنوان مثال ، هر شرایط محصول پیش بینی کننده ها:
عدم استقلال شرطی را می توان دقیقاً با شرایط تعامل متناظر موجود در مدل رگرسیون لجستیک جبران کرد و مدل رگرسیون لجستیک حاصل با شرایط تعامل برای متغیرهای پیش بینی پیوسته بهینه است اگر توزیع مشترک متغیر هدف و متغیرهای پیش بینی یک لاگ باشد. -فرم خطی اگر متغیرهای پیش بینی گسسته باشند، یک فرم ورود به سیستم خطی تضمین می شود. بنابراین، برای متغیرهای پیش بینی گسسته، مدل رگرسیون لجستیک، از جمله شرایط تعامل مناسب، بهینه است [ 7 ].
با توجه به m ≥ 2 متغیر پیش بینی بℓ≡1بℓ≡1, ℓ = 1,…, m , مجموع وجود دارد ∑مترℓ = 2(مترℓ) =2متر− ( m + 1 )∑ℓ=2متر(مترℓ)=2متر–(متر+1)شرایط تعامل احتمالی برای اینکه یک مدل عملی باشد، تعداد کل 2 متر از تمام اصطلاحات ممکن باید به طور معقولی کوچکتر از اندازه نمونه n باشد. با این حال، اصطلاح تعامل بℓ1⊗ … ⊗بℓکبℓ1⊗…⊗بℓک، k ≤ m ، در واقع مورد نیاز است اگر بℓ1, … ,بℓکبℓ1،…،بℓکبا توجه به T به طور مشروط مستقل نیستند.
پارامترهای رگرسیون لجستیک را می توان با توجه به لجیت ها به طور مشابه به پارامترهای مدل رگرسیون خطی تفسیر کرد، به عنوان مثال، β ℓ نشان دهنده افزایش لاجیت P (T = 1| B ) است اگر B ℓℓ یک واحد افزایش یابد [ 8 ]. تفاسیر درگیر بیشتری در آینده وجود دارد، ر.ک. ضمیمه B.
با توجه به نمونه bℓ ,i , t i , i = 1,…, n, ℓ = 1,…, m , پارامترهای مدل رگرسیون لجستیک با روش حداکثر درستنمایی که به صورت عددی در الگوریتم امتیاز دهی فیشر تحقق یافته است (فرمی) تخمین زده می شود. نیوتن-رافسون، یک مورد خاص از یک الگوریتم حداقل مربعات با وزن مجدد تکراری) و در هر بسته نرم افزاری آماری اصلی کدگذاری شده است.
2.3. اوزان شواهد
مدل وزن شواهد مورد خاص یک مدل رگرسیون لجستیک بدون شرایط تعامل است، اگر همه متغیرهای پیش بینی با توجه به متغیر هدف باینری و به صورت شرطی مستقل باشند [ 9 ]. به عنوان مثال، بر حسب احتمال مشروط قابل پیشبینی میخواند:
جایی که:
با کنتراست های C ℓ که به صورت زیر تعریف می شوند:
با اوزان شواهد:
و با:
به شرطی که:
از آنجایی که مدل وزن شواهد [ 10-14 ] بر اساس رویکرد بیزی ساده لوح [ 5 ، 14-17 ] با فرض استقلال شرطی B با توجه به T است، می توان آن را به صورت ابتدایی از قضیه بیز برای تصادفی شاخص استخراج کرد . متغیرهای B 0 , B 1 , …, B m :
با:
که در آن شانس (شرطی) O یک رویداد به عنوان نسبت احتمالات (شرطی) یک رویداد و مکمل آن تعریف می شود. حال، فرض ساده بیز مبنی بر استقلال شرطی همه متغیرهای پیش بینی کننده B با توجه به متغیر هدف T منجر به کارآمدترین ساده سازی می شود:
و به نوبه خود به وزن شواهد بر حسب شانس:
بهعنوان مثال ، بهروزرسانی شانس «قبلی» غیرشرطی O(T = 1) با ضرب متوالی با «ضریب بیز» P (B ℓ | T = 1) / P (B ℓ | T = 0) تا به «پسین» شرطی نهایی منجر شود. شانس O(T = 1 | B ) [ 13 ]; برای استنتاج کامل به پیوست 1 مراجعه کنید .
با توجه به فرض سادهکننده استقلال شرطی و برخلاف رگرسیون لجستیک عمومی، نسبتهای احتمالات مشروط درگیر در تعریف وزن شواهد، معادله (4) را میتوان با شمارش صرف تخمین زد. علاوه بر این، وزن شواهد را می توان به راحتی به متغیرهای تصادفی گسسته تعمیم داد، زیرا یک متغیر گسسته با حالت های مختلف می تواند به ( s -1) متغیرهای تصادفی باینری مختلف تقسیم شود تا در مدل های رگرسیونی استفاده شود.
2.4. تست استقلال مشروط
یک آزمون مستقیم استقلال مشروط از رابطه وزن شواهد و مدلهای لاگ خطی استفاده میکند. اگر متغیرهای پیش بینی با توجه به متغیر هدف گسسته و به طور مشروط مستقل باشند، پس به موجب قضیه همرسلی-کلیفورد، یک مدل لاگ خطی ساده فاکتوریزه شده بدون عبارات برهمکنش به اندازه کافی بزرگ است که توزیع مشترک را نشان دهد [ 7 ، 9 ]. بنابراین، اگر آزمون نسبت احتمال این فرضیه صفر با توجه به یک مدل لاگ خطی مناسب منجر به رد منطقی آن شود، فرض استقلال شرطی را نیز می توان رد کرد. این آزمون بر هیچ فرضی که شامل توزیع نرمال باشد، تکیه نمی کند، همانطور که آزمون های omnibus [ 18 ، 19 ] انجام می دهند.
این تستهای omnibus از انحرافات یک ویژگی یک مدل برازش شده استفاده میکنند اف(θ˜|بمن،تیمن, i = 1 , … , n )اف(�˜|بمن،تیمن،من=1،…،�)از ویژگی های مدل ریاضی افℱ( θ | B ) از احتمالات و آمار ریاضی برای تداخل در اعتبار فرض مدلسازی استقلال شرطی شناخته شده است. آزمونهای omnibus میانگین احتمالات مشروط را روی همه اشیا، به عنوان مثال ، پیکسلها یا وکسلها، در مجموعه داده آموزشی با اندازه نمونه n به عنوان مشخصه میگیرند .
بنابراین، برای یک مدل مناسب (“درست”)، میانگین از پˆ( T = 1 | B =بمن) ،پ^(تی=1|ب=بمن)، i = 1,…, n , (تقریباً) برابر است پˆ( T = 1 )پ^(تی=1)، با فراوانی نسبی T = 1 در مجموعه داده آموزشی تخمین زده می شود. انحراف از میانگین از پˆ( T = 1 )پ^(تی=1)نشان می دهد که مدل ممکن است درست نباشد. برای یک مدل وزن شواهد، انحرافات می تواند ناشی از عدم استقلال مشروط باشد، در حالی که برای یک مدل رگرسیون لجستیک، 1n∑ni = 1پˆ( T = 1 | B =بمن) =پˆ( T = 1 )1�∑من=1�پ^(تی=1|ب=بمن)=پ^(تی=1)همیشه راضی است (تا دقت عددی). بر اساس معادله (7) ، [ 19 ] آزمون omnibus و [ 18 ] آزمون omnibus جدید را توسعه داد.
یک آزمون آماری پیچیدهتر برای متغیرهای پیشبینیکننده واقعی اخیراً توسط [ 20 ] پیشنهاد شده است.
2.5. وزن شواهد در مقابل رگرسیون لجستیک
پارامترهای رگرسیون لجستیک معمولی برابر با کنتراست اوزان است، در صورتی که همه متغیرهای پیش بینی کننده شاخص و به طور مشروط مستقل با توجه به متغیر هدف باشند. بنابراین، وزن شواهد مورد خاص رگرسیون لجستیک معمولی است اگر پیشبینیکنندههای B متغیرهای شاخص و مستقل از شرط T باشند. برعکس، رگرسیون لجستیک تعمیم متعارف وزنهای شواهد است [ 14 ، 17 ] . توجه داشته باشید که مدل وزن شواهد را نمی توان بزرگ کرد تا شامل اصطلاحات تعامل باشد.
به طور کلی، به عنوان مثال ، بدون فرض استقلال مشروط، رابطه پارامترهای رگرسیون لجستیک معمولی و تضاد وزن شواهد به وضوح غیر خطی است [ 21 ، 22 ]. برای اشتقاق صریح به پیوست 2 مراجعه کنید .
چه زمانی پˆ( T = 1 | B =بمن)پ^(تی=1|ب=بمن), i = 1, …, n , با حداکثر احتمال اعمال شده برای مدل رگرسیون لجستیک معمولی تخمین زده می شود، معادله (7) همیشه برقرار است، زیرا بخشی از سیستم های حداکثر درستنمایی معادلات است. با تشخیص وزن شواهد به عنوان یک مورد خاص از رگرسیون لجستیک، زمانی که پیش بینی کننده ها متغیرهای شاخص هستند و با توجه به متغیر هدف به طور مشروط مستقل هستند، مقایسه فوق اکنون ممکن است به عنوان بررسی آمار مدل های مختلف دیده شود. به طور مشابه، تضادهای برآورد شده سیˆℓسی^ℓوزن شواهد را می توان با ضرایب رگرسیون لجستیک برآورد شده مقایسه کرد βˆℓ�^ℓ. سپس، هرگونه انحراف بین آنها نشان دهنده نقض فرض مدلسازی استقلال مشروط است.
2.6. وزن شواهد در مقابل مدل τ- یا ν
فرض مدلسازی با توجه به عوامل معادله (6) مدل τ [ 23-25 ] عبارت است از:
سپس وزن های اصلاح شده به صورت زیر تعریف می شوند:
و:
با دبلیو˜( 0 )= ∑مترℓ = 1τ( 0 )ℓدبلیو( 0 )ℓدبلیو˜(0)=∑ℓ=1متر�ℓ(0)دبلیوℓ(0).
فرض مدلسازی با توجه به عوامل معادله (6) مدل ν [ 26 ، 27 ] است:
سپس وزن های اصلاح شده به صورت زیر تعریف می شوند:
و:
با دبلیو˜˜( 0 )= ∑مترℓ = 1( lnν( 0 )ℓ+دبلیو( 0 )ℓ)دبلیو˜˜(0)=∑ℓ=1متر(لوگاریتم�ℓ(0)+دبلیوℓ(0)).
با این نکته، ممکن است نتیجه بگیریم که هیچ راهی برای تقلید اثر شرایط تعامل مدل های رگرسیون لجستیک با دستکاری وزن شواهد یا تضاد آنها وجود ندارد.
2.7. شبکه های عصبی مصنوعی
مدل های رگرسیون عمومی را می توان با رویکردهای مختلف یادگیری آماری، از جمله شبکه های عصبی مصنوعی [ 15 ] مقابله کرد. با توجه به شبکه های عصبی مصنوعی و یادگیری آماری [ 5 ، 15 ، 16 ، 28 ]، مدل رگرسیون لجستیک، معادله (1) ،
شبکه عصبی مصنوعی پرسپترون تک لایه یا شبکه عصبی مصنوعی تک لایه نامیده می شود. به حداقل رساندن مجموع مجذور باقیمانده به عنوان آموزش نامیده می شود. روشهای گرادیان برای حل پارامترهای مدل به عنوان قانون آموزش پرسپترون خطی نامیده میشوند. اندازه گام در امتداد گرادیان منفی را نرخ یادگیری و غیره می گویند.به نظر نمی رسد مفهوم متغیرهای تصادفی، استقلال شرطی، تخمین و خطای تخمین و اهمیت پارامترهای مدل در قلمرو شبکه های عصبی مصنوعی، حتی تحت برچسب های جدید وجود داشته باشد. با این وجود، شبکههای عصبی مصنوعی ممکن است به عنوان یک تعمیم برای بزرگتر کردن مدل رگرسیون لجستیک از طریق تودرتو کردن مدلهای رگرسیون لجستیک با یا بدون عبارات تعاملی دیده شوند. یک تعمیم اضافی جزئی جایگزینی تابع لجستیک Λ با توابع سیگموئیدی دیگر و مدل کردن احتمال شرطی یک متغیر مقوله ای T (بیش از دو دسته) با توجه به متغیرهای پیش بینی کننده B است.
مدل اصلی شبکه عصبی چند لایه را می توان به عنوان دنباله ای از تبدیل های عملکردی [ 15 ، 29-31 ] توصیف کرد، که اغلب به عنوان یک نمودار نشان داده می شود:
- ورودی: متغیرهای پیش بینی کننده B ;
- لایه اول: ترکیبات خطی آ( 1 )jآ�(1)j = 1، …، J ، از متغیرهای پیشبینیکننده B ، که به عنوان واحدهای ورودی یا فعالسازی نامیده میشوند:
آ( 1 )j=∑ℓ = 0مترβ( 1 )j ℓبℓj = 1 , … , J _آ�(1)=∑ℓ=0متر��ℓ(1)بℓ،�=1،…،جی
یا:
آ( 1 )j=∑ℓ = 0مترβ( 1 )j ℓبℓ+∑ℓمن, … ,ℓمن“β( 1 )j (ℓمن, … ,ℓمن“)بℓمن⊗ … ⊗بℓمنj = 1 , … , J _آ�(1)=∑ℓ=0متر��ℓ(1)بℓ+∑ℓمن،…،ℓمن“��(ℓمن،…،ℓمن“)(1)بℓمن⊗…⊗بℓمن،�=1،…،جیبرای تقلید از اصطلاحات تعامل:
- لایه پنهان: هر یک از آنها با اعمال یک تابع فعال سازی غیرخطی متمایزپذیر h معمولاً به شکل سیگموئیدی که به عنوان واحدهای پنهان شناخته می شود، تحت یک تبدیل قرار می گیرند:
زj= ساعت (آ( 1 )j) ,j=1,…,Jز�=ساعت(آ�(1))،�=1،…،جی
- لایه دوم: ترکیبات خطی آ( 2 )jآ�(2)، k = 1، …، K از واحدهای پنهان، به عنوان فعال سازی واحد خروجی نامیده می شود:
آ( 2 )ک=∑j = 0جیβ( 2 )k jزj, k = 1 , … , Kآک(2)=∑�=0جی�ک�(2)ز�،ک=1،…،ک
- خروجی: هر یک از فعال سازی های واحد خروجی تابع یک تابع فعال سازی S است، به عنوان مثال، تابع لجستیک:
πک= S(آ( 2 )ک) ،k=1،…،K�ک=اس(آک(2))،ک=1،…،ک
سپس:
πک( B ) = P( T =تیک| ب ) ) = S⎛⎝⎜⎜⎜⎜⎜∑j = 0جیβ( 2 )k jساعت(∑ℓ = 0مترβ( 1 )j ℓبℓ)لایه پنهان⎞⎠⎟⎟⎟⎟⎟, k = 1 , … , K�ک(ب)=پ(تی=تیک|ب))=اس(∑�=0جی�ک�(2)ساعت(∑ℓ=0متر��ℓ(1)بℓ)︸لایه پنهان)،ک=1،…،ک
اگر K = 1 و S = Λ، h = id، J = 0، آنگاه به رگرسیون لجستیک معمولی، معادله (1) برمی گردیم . از سوی دیگر، در معادله (10) ، ترکیب خطی پیشبینیکنندهها، همانطور که در رابطه (8) به دست میآید ، میتواند به راحتی با ترکیب بزرگشده، از جمله عبارتهای تعامل، که در رابطه (9) ارائه شده است، جایگزین شود.، جایی که در نظر گرفتن اصطلاحات برهمکنش ها به توپولوژی خالص همه کاره تری نیاز دارد. فقدان مفهوم پارامترهای قابل توجه و به نوبه خود، مدل های قابل توجه، مانع از ساخت متوالی مدل های مناسب است. در عوض، همه متغیرها و یک توپولوژی خالص به اندازه کافی همه کاره وصل شده اند و ضرایب برای همه متغیرها به صورت عددی با روش گرادیان تعیین می شود. به نظر می رسد این روش با ایده مدل های صرفه جویی مطابقت ندارد.
2.8. متعادل کردن
اگر شانس O(T=1) خیلی کوچک باشد، روشهای یادگیری آماری مستعد شکست هستند. [ 32-37 ] . _ متعادلسازی ساده نمونهبرداری ترجیحی را تقلید میکند، به عنوان مثال ، یک مجموعه داده متعادل جدید با وزن دادن به همه اشیا با T = 1 با وزن 1 < μ∈ ℝ ساخته میشود. این نوع تعادل بلافاصله منجر به موارد زیر می شود:
و سپس در:
علاوه بر این، اگر:
یک مدل مناسب (“درست”) برای نمونه متعادل است، سپس:
یک مدل مناسب از لاجیت P (T = 1| B ) با توجه به نمونه اولیه است و:
مدل های مناسب هر چه باشد به عنوان مثال، اگر رگرسیون لجستیک معمولی بدون شرایط تعامل، به عنوان مثال ، با فرض استقلال مشروط،
یک مدل مناسب برای نمونه متعادل است، پس:
یک مدل مناسب برای نمونه اولیه است. بنابراین، تعادل با وزن دادن به اشیا، پیکسل ها یا وکسل ها، پشتیبانی از T = 1 با μ > 1، دقیقاً همان کاری را انجام می دهد که برای آن طراحی شده است: شانس O(T = 1) را با ضریب μ افزایش می دهد و مدل های مناسب را حفظ می کند، به عنوان مثال ، پارامترهای آنها، در غیر این صورت.
تاکید می شود که معادله (11) برای مدل های ریاضی در صورت مناسب بودن صادق است. سپس، معادله (11) را می توان به عنوان تبدیل معکوس تعادل با وزن دادن به اجسام با T = 1 با وزن μ خواند . ممکن است برای مدل های برازش مناسب نباشد، به عنوان مثال ، تخمین پارامترهای یک مدل ضعیف ممکن است معادله را خراب کند. سپس، اف(θˆ| ب ) ≠F(θˆ|ببال) –lnμℱ(�^|ب)≠ℱ(�^|ببال)–لوگاریتم�. توجه داشته باشید که وزن شواهد همه تحت تأثیر این نوع تعادل قرار نمی گیرند.
2.9. پیچیدگی عددی رگرسیون لجستیک
مدلسازی بالقوه با رگرسیون لجستیک با استفاده از مجموعه دادههای آموزشی سهبعدی از n وکسل و ( m + 1) متغیرهای پیشبینیکننده برای برازش پارامترهای رگرسیون نیاز به حل یک سیستم معادلات غیر خطی ( m + 1) دارد. معمولاً تعداد کل متغیرهای پیش بینی بسیار کمتر از تعداد کل وکسل ها است. روش عددی انتخابی آماردانان حداقل مربعات وزنگذاری مجدد تکراری است. پیچیدگی عددی یک مرحله تکرار از مرتبه 2 n ( m + 1) 2 است.فلاپ; به طور کلی نمی توان تعداد کل تکرارها را تخمین زد. در نظر گرفتن اندازه مسئله برای ژئومدلهای سه بعدی با وضوح فضایی مناسب به وضوح نشان میدهد که راهحل عددی آن نیازمند مدیریت داده بسیار کارآمد ژئومدلهای سه بعدی در حالت وکسل و اعداد بسیار سریع بر اساس پردازش موازی انبوه است.
3. مثال ها
هر دو مجموعه داده برای خدمت به اهداف خاصی ساخته شده اند. فرض ریاضی مرتبط با مجموعه داده آموزشی دانش کامل است، به عنوان مثالبه طور خاص، ما فرض می کنیم که همه رخدادهای متغیر هدف T = 1 را می دانیم. در غیر این صورت، حتی شانس یا لجیت T = 1 را نمی توان به درستی تخمین زد. بنابراین، رخدادهای ناشناخته قبلی یا احتمالات آنها را نمی توان با توجه به مجموعه داده آموزشی پیش بینی کرد. مقایسه احتمالات شرطی تخمین زده شده با فرکانس های مشروط شمارش شده، بررسی مناسب بودن مدل اعمال شده را فراهم می کند. یک بررسی قوی تر، استفاده از تنها بخشی از داده های خارج از مجموعه داده آموزشی برای تخمین پارامترهای یک مدل و سپس اعتبارسنجی مدل با داده های باقی مانده است که قبلاً استفاده نشده اند. تمامی محاسبات با نرم افزار آماری رایگان، R [ 38 ] انجام شد.
3.1. مجموعه داده RANKIT بازبینی شد
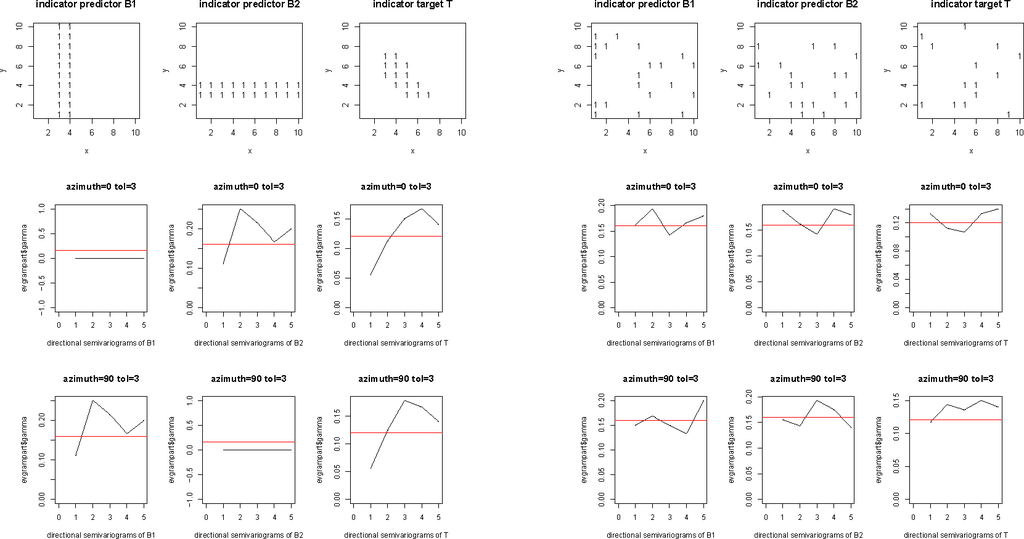
اولین ارائه و بحث از رتبه بندی مجموعه داده ها ( شکل 1 ) در [ 9 ] ارائه شده است. مجموعه داده رتبهبندی شامل دو متغیر پیشبینیکننده B1 ، B2 و یک متغیر هدف T است که به پیکسلهای یک تصویر نقشه دیجیتال اشاره دارد. متغیرهای پیشبینیکننده B1 ، B2 با توجه به متغیر هدف T، همبستگی ندارند و به صورت شرطی مستقل نیستند.
در اینجا، مثال با در نظر گرفتن یک مجموعه دادههای رتبهبندی بهطور تصادفی بازآرایی شده تکمیل میشود ( شکل 1 )، که از رتبهبندی مجموعه دادهها با مرتبسازی مجدد مراجع پیکسلی ( i , j ) از سهقلوها ( bk1 , bk2 , tk ) نشات میگیرد . = 1، …، n ، تحقق B 1 ، B 2 و T در مجموعه داده به صورت تصادفی. واریوگرام های تک جهتی شکل 1 به وضوح نشان می دهد که دو مجموعه داده در آمار فضایی متفاوت هستند.
با این حال، مجموعههای داده رتبهبندی و rankitmix دارای آمارهای معمولی یکسانی مانند جداول احتمالی، جداول 1 و 2 ، یا یک ماتریس همبستگی، جدول 3 ، مشترک هستند.
متغیرهای پیشبینیکننده شاخص B1 و B2 به نظر همبستگی ندارند، در حالی که B1 و T، و B2 و T، به ترتیب ، بهترتیب برای تمام سطوح معنیداری α > 0.002213 و α > 0.02101 همبستگی دارند. رجوع کنید به جدول 3 .
بنابراین، برای هر دو مجموعه داده rankit و rankitmix ، به ترتیب، مدلهای وزن شواهد، رگرسیون لجستیک معمولی بدون عبارت تعامل و رگرسیون لجستیک بزرگ با عبارت تعامل به صراحت خوانده میشوند:
از آنجایی که فرض مدلسازی ریاضی استقلال شرطی نقض میشود، تنها رگرسیون لجستیک با شرایط تعامل یک مدل مناسب را به دست میدهد و احتمالات شرطی را تقریباً دقیقاً پیشبینی میکند.
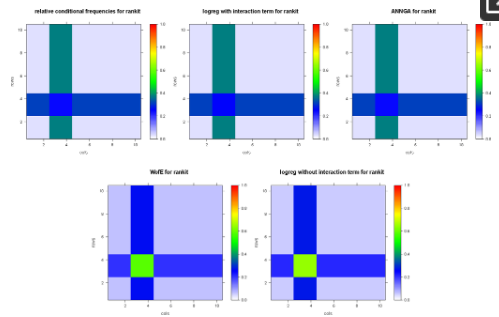
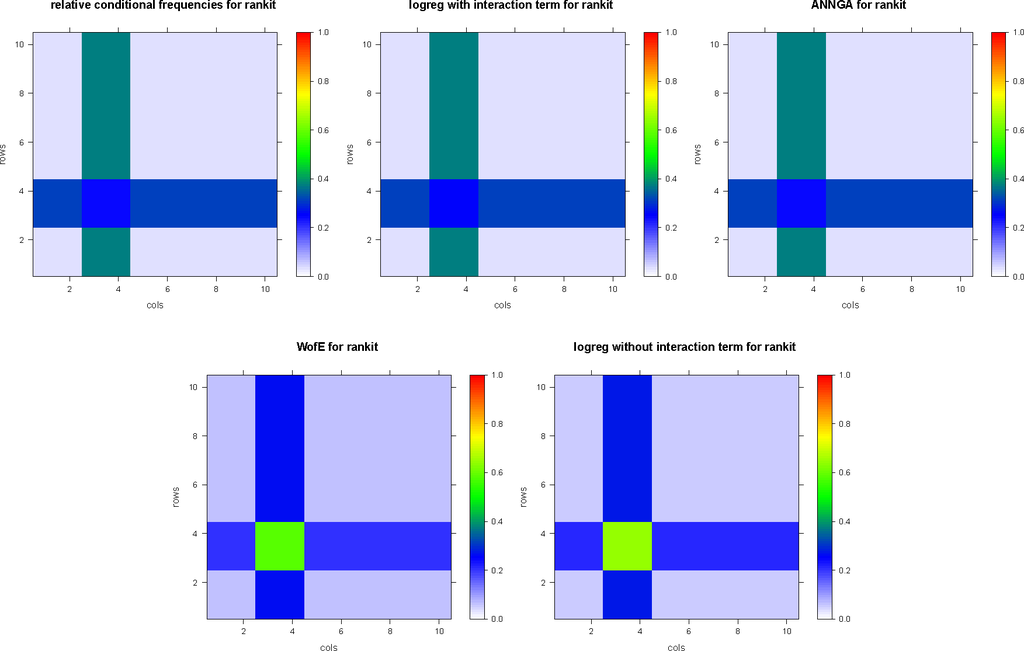
نتایج وزن شواهد، رگرسیون لجستیک با یا بدون عبارات تعامل و شبکه عصبی مصنوعی اعمال شده به رتبه بندی مجموعه داده های ساخته شده و مجموعه داده های rankitmix ، به ترتیب در جدول 4 خلاصه شده است. شکل 2 نتایج رتبه بندی مجموعه داده ها را نشان می دهد و شکل 3 نتایج رتبه بندی مجموعه داده ها را نشان می دهد .
بدیهی است که تصاویر نقشه دیجیتال شکلهای 2 و 3 با بازآرایی مشابهی با رتبهبندی مجموعه دادهها و ترکیب رتبهبندی ردیف بالای شکل 1 به یکدیگر مرتبط هستند . این رابطه را می توان مانند یک نمودار جابجایی ( شکل 4 ) نشان داد، به عنوان مثال با توجه به رگرسیون لجستیک، از جمله شرایط تعامل.
برای بیان صریح آن، هر یک از روشهای هدفیابی که در اینجا در نظر گرفته میشود، با هر گونه بازآرایی تصادفی که به طور همزمان بر روی تمام تصاویر نقشه دیجیتال درگیر یا ناشی از هدفگیری اعمال میشود، جابجا میشود. بنابراین، هدف گذاری و مدل سازی بالقوه، به عبارت دیگر، روش های فضایی نیستند. آنها از وابستگی های ناشی از فضایی استفاده نمی کنند، که با نگاه کردن به نیمه متغیرهای مجموعه داده ها نشان داده شده است که متفاوت هستند. شکل 1 .
پس از تعادل با m = 10، مدل های وزن شواهد و رگرسیون لجستیک بزرگ شده با شرایط تعامل به صراحت می خوانند:
به ترتیب با – 0.423 – ln(10) = – 0.423 – 2.302 = – 2.726 و – 1.132 – 2.302 = – 3.434، بنابراین معادله (11) را تأیید می کند. با این حال، مدل رگرسیون لجستیک معمولی بدون شرایط تعامل می گوید:
با – 0.960 – 2.302 = – 3.263 ≠ – 2.831 و پارامترهای مختلف βبال1�1بالو βبال2�2بالاز آنجایی که مدل رگرسیون لجستیک معمولی به دلیل نقض فرض مدلسازی استقلال شرطی، مدل مناسبی نیست.
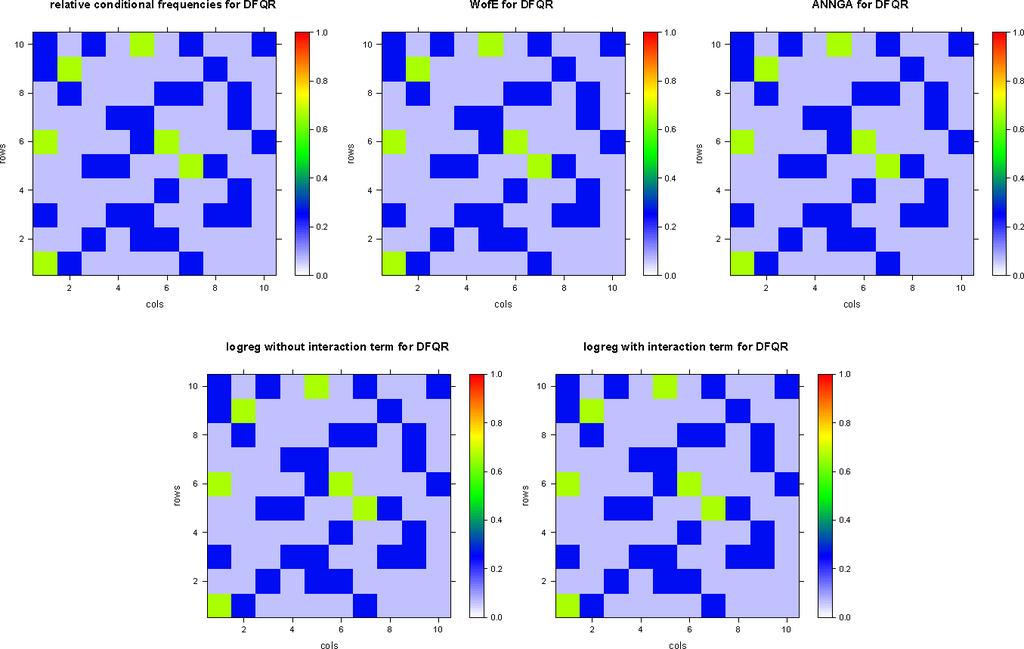
3.2. مجموعه داده DFQR
مجموعه داده DFQR به عنوان یک تصویر نقشه دیجیتال در شکل 5 تجسم شده است .
موارد احتمالی در جداول 5 و 6 آورده شده است.
ماتریس همبستگی ( جدول 7 ) نشان میدهد که B1 و B2 همبستگی ندارند، و به طور قابلتوجهی با T برای تمام سطوح معنیداری α > 0.001652 همبستگی دارند .
آزمون استقلال شرطی با اشاره به مدلهای log-linear ( جدول 8 ) نشان میدهد که فرضیه صفر استقلال شرطی B1 و B2 با توجه به T را نمیتوان به طور منطقی رد کرد.
فرکانسهای نسبی مشروط مربوطه تقریباً دقیقاً فاکتور میشوند، به عنوان مثال ،
ولی:
و:
با Oˆ( T = 1 ) = 0.1904 ، آن را وارد کنیدپˆ( T = 1 ) = – 1.6582O^(تی=1)=0.1904،ورود به سیستمآی تیپ^(تی=1)=–1.6582، مدل وزن شواهد به صراحت می گوید:
مدل رگرسیون لجستیک معمولی بدون شرایط تعامل به صراحت می گوید:
جایی که:
- β 0 برای همه α > 1.12 e – 08 معنی دار است و
- β1 ، β2 برای همه α > 0.00651 معنی دار هستند .
این دو مدل تقریباً یکسان هستند. انحرافات کوچک پارامترهای آنها ناشی از نقض کوچک استقلال مشروط است. در حالی که آزمون با p = 0.999950 نشان می دهد که فرضیه صفر استقلال شرطی را نمی توان معقولانه رد کرد، فرکانس های نسبی شرطی به طور کامل فاکتورسازی نمی شوند، بلکه فقط تقریباً می شوند. احتمالات مشروط برآورد شده با وزن شواهد یا رگرسیون لجستیک معمولی تقریباً دقیقاً احتمالات مشروط تخمین زده شده را با شمارش فرکانس های شرطی برای مجموعه داده آموزشی DFQR بازیابی می کند. رجوع کنید به جدول 9 .
مدل رگرسیون لجستیک با اصطلاحات تعاملی به صراحت می گوید:
جایی که:
- β 0 برای همه α > 1.57 e -07 معنی دار است،
- β1 ، β2 برای همه α > 0.0295 معنی دار هستند و
- β 12 به هیچ وجه معنی دار نیست به عنوان p = 0.9949.
احتمالات مشروط تخمین زده شده با رگرسیون لجستیک، از جمله شرایط تعامل، دقیقاً احتمالات شرطی تخمین زده شده اولیه را با شمارش فرکانس های شرطی برای مجموعه داده آموزشی DFQR بازیابی می کنند، که فقط تأیید عددی است، که مدل لاگ خطی با شرایط تعامل یک مدل کامل است. برای مجموعه داده آموزشی DFQR؛ رجوع کنید به جدول 9 و شکل 6 .
پس از تعادل با m = 10، مدل های مجموعه داده متعادل عبارتند از:
تائید معادله (11) ، زیرا فرض استقلال مشروط رد نشد.
4. نتیجه گیری
مدلسازی هدف یا بالقوه از مدلهای رگرسیون یا رگرسیون مانند برای تخمین احتمال شرطی یک متغیر هدف با توجه به متغیرهای پیشبینیکننده استفاده میکند. تمام مدل های در نظر گرفته شده در اینجا:
- به ترتیب متغیرهای پیشبینیکننده تصادفی توزیعشده و متغیرهای هدف بهطور مستقل یکسان را فرض کنید ، بهعنوان مثال ، همه مدلها غیرمکانی هستند و وابستگیهای ناشی از فضای مکانی را در نظر نمیگیرند، بهعنوان مثال، زمینآمار. بنابراین، تنظیم مجدد مجموعه داده به صورت تصادفی منجر به تصاویر نقشه تصادفی یا مدلهای جغرافیایی میشود، اما مدلهای برازش را تغییر نمیدهد.
- نکته ای نیستند؛ آنها شامل متغیرهای تصادفی هستند که به مکان های داده شده از نظر پیکسل های منطقه ای تصاویر نقشه دیجیتال دو بعدی یا وکسل های حجمی ژئومدل های سه بعدی اشاره می کنند. بنابراین، نتایج آنها به ترتیب به وضوح فضایی تصویر نقشه یا ژئومدل بستگی دارد.
- نیاز به یک منطقه آموزشی برای تناسب با پارامترهای مدل. به این معنا که فرض مدلسازی ریاضی مرتبط با منطقه آموزشی این است که “حقیقت زمینی” را ارائه می دهد.
سپس، مدلها را میتوان در یک سلسله مراتب قرار داد، که با مدل بیزی سادهلوح وزن شواهد بسته به فرض مدلسازی استقلال شرطی همه متغیرهای پیشبین با توجه به متغیر هدف شروع میشود. اگر متغیرهای پیش بینی کننده (i) متغیرهای تصادفی شاخص یا گسسته باشند و (ii) با توجه به متغیر هدف، به صورت شرطی مستقل باشند، مورد خاص مدل رگرسیون لجستیک است. در این مورد، تضادهای وزن شواهد با ضرایب رگرسیون لجستیک یکسان است. در غیر این صورت، هیچ رابطه خطی بین وزن شواهد و پارامترهای رگرسیون لجستیک وجود ندارد.
تعمیم متعارف مدل بیزی ساده لوح که دارای وزن شواهد در مورد عدم استقلال شرطی است، رگرسیون لجستیک، از جمله شرایط تعامل است. اگر عبارات تعاملی برای مطابقت با نقض استقلال مشروط انتخاب شوند، اگر متغیرهای پیشبین گسسته باشند، دقیقاً این تخلفات را جبران میکنند. برای متغیرهای پیشبینیکننده پیوسته، آنها دقیقاً فقط در صورتی جبران میکنند که احتمال مشترک لگ خطی باشد. در غیر این صورت، آنها ممکن است تقریبا جبران کنند. بنابراین، در مورد متغیرهای پیش بینی گسسته، مدل رگرسیون لجستیک بهینه است.
اعمال وزن شواهد با وجود نداشتن استقلال شرطی، هم احتمالات شرطی پیشبینیشده و هم تغییر رتبهشان را خراب میکند. آنها راهی برای تقلید اثر اصطلاحات تعاملی با “اصلاح” وزن شواهد متعاقباً، به عنوان مثال، با توان یا ضرب در برخی ضرایب τ – یا ν – نیستند.
برای بزرگنمایی بیشتر مدلها، تودرتو کردن مدلهای رگرسیونمانند لجستیک یک گزینه است. صرف نظر از واژگان، لانه سازی که باعث ایجاد “لایه های پنهان” می شود، هسته سخت شبکه های عصبی مصنوعی است. اگر پیکربندی توپولوژی شبکه به اندازه کافی همه کاره باشد، مدلهای شبکه عصبی مصنوعی میتوانند فقدان استقلال شرطی را جبران کنند، دقیقاً مانند مدلهای رگرسیون لجستیک، از جمله شرایط تعامل. هنگامی که شانس هدف خیلی کوچک است، ممکن است مقداری “تعادل” مورد نیاز باشد. یک روش متعادل سازی ساده نشان داده شد تا پارامترهای مدل را بدون تغییر باقی بگذارد، اگر خود مدل مناسب باشد.
امکان گنجاندن اصطلاحات تعاملی در مدلهای رگرسیون لجستیک یا سایر مدلهای منشأ یادگیری آماری، مسیر امیدوارکنندهای را به سوی وسیلهای مؤثر برای کنار گذاشتن فرضیه مدلسازی شدید استقلال شرطی و مقابله با فقدان استقلال شرطی در عمل باز میکند.
چشم انداز آینده امیدوارکننده، حسابداری رگرسیون برای وابستگی های فضایی برای خلاص شدن از (i) منطقه آموزشی تقسیم بندی شده در پیکسل یا وکسل و وابستگی به وضوح فضایی است که آنها ارائه می کنند. و (ب) فرض مدلسازی متغیرهای تصادفی توزیع شده مستقل و یکسان.
الف. ضمیمه
الف.1. اشتقاق اوزان شواهد در اصطلاحات ابتدایی
اگر T، B متغیرهای تصادفی شاخص با P (T = j ) > 0، P (B = i ) > 0، i، j = 0، 1 باشند، آنگاه قضیه بیز بیان می کند:
سپس، نسبت احتمالات شرطی T = 1 و T = 0، به ترتیب، با توجه به B، به عنوان شکل لگ خطی قضیه بیز نامیده می شود،
مستقل از احتمال شرط B است. قضیه بیز برای چندین متغیر تصادفی شاخص B 0 , B 1 , …, B m به:
با:
حال، فرض ساده بیز مبنی بر استقلال شرطی همه متغیرهای پیش بینی کننده B با توجه به متغیر هدف T منجر به کارآمدترین ساده سازی می شود:
و به وزن شواهد بر حسب شانس منجر می شود:
با:
به شرطی که P (B ℓ = i | T = j ) ≠ 0, i, j = 0, 1 برقرار باشد. سپس، مدل وزنهای شواهد چنین میخواند:
- از نظر یک لاجیت (“شکل خطی ورود به فرمول بیز”):
لاجیت پی( T = 1 | B ) = logit P( T = 1 ) +∑ℓ :بℓ= 1دبلیو( 1 )ℓ+∑ℓ :بℓ= 0دبلیو( 0 )ℓلوجیتپ(تی=1|ب)=لوجیتپ(تی=1)+∑ℓ:بℓ=1دبلیوℓ(1)+∑ℓ:بℓ=0دبلیوℓ(0)
و:
- از نظر احتمال:
پ( T = 1 | B ) = Λ ( logit P( T = 1 ) +∑ℓ :بℓ= 1دبلیو( 1 )ℓ+∑ℓ :بℓ= 0دبلیو( 0 )ℓ)پ(تی=1|ب)=Λ(لوجیتپ(تی=1)+∑ℓ:بℓ=1دبلیوℓ(1)+∑ℓ:بℓ=0دبلیوℓ(0))
با دبلیو( 1 )ℓ= lnاسℓدبلیوℓ(1)=لوگاریتماسℓ، دبلیو( 0 )ℓ= lnنℓدبلیوℓ(0)=لوگاریتمنℓ، اگر معادله (5) برقرار باشد. سپس، مدل وزن شواهد بر حسب تضاد، معادله (2) از نمایش اولیه آن بر حسب وزن به صورت زیر مشتق شده است:
پ( T = 1 | B ) = Λ ( logit P( T = 1 ) +∑ℓ :بℓ= 1دبلیو( 1 )ℓ+∑ℓ :بℓ= 0دبلیو( 0 )ℓ)= Λ ( logit P( T = 1 ) +∑ℓ = 1متر(دبلیو( 1 )ℓبℓ+دبلیو( 0 )ℓ( 1- _بℓ) )) )= Λ ( logit P( T = 1 ) +دبلیو( 0 )+∑ℓ = 1مترسیℓبℓ)= Λ ( logit P( T = 1 ) +دبلیو( 0 )+∑ℓ :بℓ= 1سیℓ)پ(تی=1|ب)=Λ(لوجیتپ(تی=1)+∑ℓ:بℓ=1دبلیوℓ(1)+∑ℓ:بℓ=0دبلیوℓ(0))=Λ(لوجیتپ(تی=1)+∑ℓ=1متر(دبلیوℓ(1)بℓ+دبلیوℓ(0)(1–بℓ)))=Λ(لوجیتپ(تی=1)+دبلیو(0)+∑ℓ=1مترسیℓبℓ)=Λ(لوجیتپ(تی=1)+دبلیو(0)+∑ℓ:بℓ=1سیℓ)
برای اجتناب از شرایط محدود کننده، معادله (5) مدل وزن شواهد بر حسب شانس، معادله (12) به صورت زیر بازنویسی شده است:
برای تشخیص موارد مختلف، تنظیم می کنیم مℳ= {1،…، m }، m ∈ ℕ، و سپس:
منجر به:
و پس از گرفتن لگاریتم به:
در نهایت، مدل بیز ساده لوح از نظر لجیت چنین می گوید:
بنابراین، برای معادله (15) کمی عمومیتر از معادله (13) ، معادله مطابقت اولیه (3) کمی بیشتر درگیر می شود، به عنوان مثال ، با نماد معادله (14) :
الف.2. اشتقاق صریح رابطه عموما غیر خطی ضرایب رگرسیون لجستیک و وزن شواهد
برای متغیرهای پیش بینی کننده شاخص (B 0 ,… B m ) T = B با تحقق ( b 0 ,…, b m ) T = b با b 0 =1, b ℓ = 0, 1, برای ℓ = 1,…, m ، مدل رگرسیون لجستیک معمولی به صراحت می گوید:
با:
2 متر تحقق متفاوت وجود دارد. از این رو، 2 متر لجیت مختلف وجود دارد. حال، ثابت نگه داشتن تمام Bj = b j ، به جز B ℓ ، معادله (16) نشان می دهد که نسبت شانس لگاریتمی:
برای همه B j ، j = 1، …، m، j ≠ ℓ ، ثابت، ر.ک. [ 8 ]. با استفاده از فرمول بیز و فرض استقلال شرطی B با توجه به T، سمت چپ معادله (17) به کنتراست C ℓ وزنهای دبلیو( 1 )ℓدبلیوℓ(1)و دبلیو( 0 )ℓدبلیوℓ(0). به این ترتیب معادله (17) تفسیر مشترکی از پارامترهای رگرسیون لجستیک معمولی و وزن شواهد و تضادهای مرتبط با آنها در مورد استقلال شرطی ارائه میکند.
با توجه به مدل رگرسیون لجستیک معمولی، شانس لگاریتم حاشیه 2 متری cℓk توسط:
برای ℓ = 1، …، m و i = 0، 1 و جایی که b′ یک کپی از b است. مجموع همه b با b ℓ = 1 گرفته می شود. سپس، متضادهای m عبارتند از:
معادله (18) رابطه غیر خطی کنتراست ها و پارامترهای رگرسیون را ایجاد می کند. مورد بی اهمیت m = 1 بلافاصله به C 1 = β 1 منتهی می شود . برای m = 2، معادله (18) به صورت زیر ساده می شود:
اشتباه گرفتن تبدیل لاجیت به عنوان خطی منجر به رابطه خطی اشتباه کنتراست ها و پارامترهای رگرسیون لجستیک می شود که توسط دنگ (2009) ارائه شده است. رجوع کنید به [ 22 ].
منابع
- هرونسکی، JMA; Groves، DI Science of targeting: تعریف، استراتژی ها، هدف گیری و اندازه گیری عملکرد. اوست J. Earth Sci. 2008 ، 55 ، 3-12. [ Google Scholar ]
- کاکس، DP; Singer, DA Mineral Deposit Models ; بولتن سازمان زمین شناسی ایالات متحده 1693; دفتر چاپ دولت ایالات متحده: واشنگتن، دی سی، ایالات متحده آمریکا، 1986. [ Google Scholar ]
- Chilès، J.-P. دلفینر، ص. زمین آمار- مدلسازی عدم قطعیت فضایی ، ویرایش دوم. جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2012. [ Google Scholar ]
- Independence and Conditional Independence ، در دسترس آنلاین: http://www.eecs.qmul.ac.uk/norman/BBNs/Independence_and_conditional_independence.htm در 10 اکتبر 2014 قابل دسترسی است.
- میچل، TM یادگیری ماشین ; McGraw-Hill: نیویورک، نیویورک، ایالات متحده آمریکا، 1997. [ Google Scholar ]
- هویسگارد، اس. ادواردز، دی. Lauritzen, S. Graphical Models with R. Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2012. [ Google Scholar ]
- Schaeben, H. دیدگاهی ریاضی از وزن شواهد، استقلال شرطی، و رگرسیون لجستیک از نظر میدانهای تصادفی مارکوف. ریاضی. Geosci. 2014 ، 46 ، 691-709. [ Google Scholar ]
- Hosmer، DW; Lemeshow, S. Applied Logistic Regression , 2nd ed.; Wiley: نیویورک، نیویورک، ایالات متحده آمریکا، 2000. [ Google Scholar ]
- شایبن، اچ. مدلسازی بالقوه: استقلال شرطی اهمیت دارد. بین المللی J. Geomath. 2014 ، 5 ، 99-116. [ Google Scholar ]
- آگتربرگ، FP; بونهام-کارتر، GF; رایت، DF ادغام الگوی آماری برای اکتشاف مواد معدنی. در برنامه های کامپیوتری در برآورد منابع پیش بینی و ارزیابی برای فلزات و نفت ; Gaal, G., Merriam, DF, Eds.; چاپ پرگامون: آکسفورد، نیویورک، ایالات متحده آمریکا، 1990; ص 1-21. [ Google Scholar ]
- بونهام-کارتر، GF; آگتربرگ، FP کاربرد یک سیستم اطلاعات جغرافیایی مبتنی بر میکرو کامپیوتر برای نقشه برداری پتانسیل معدنی. در برنامه های کاربردی مبتنی بر میکرو کامپیوتر در زمین شناسی II، نفت ; Hanley, JT, Merriam, DF, Eds. چاپ پرگامون: نیویورک، نیویورک، ایالات متحده آمریکا، 1990; صص 49-74. [ Google Scholar ]
- خوب، احتمال IJ و وزن شواهد ؛ گریفین: لندن، بریتانیا، 1950. [ Google Scholar ]
- خوب، IJ برآورد احتمالات: مقاله ای در مورد روش های مدرن بیزی . رساله پژوهشی شماره 30; انتشارات MIT: کمبریج، MA، ایالات متحده آمریکا، 1968. [ Google Scholar ]
- دست، دی جی; یو، کی. احمق – بالاخره خیلی احمقانه نیست؟ بین المللی آمار Rev. 2001 , 69 , 385-398. [ Google Scholar ]
- هستی، تی. طبشیرانی، ر. فریدمن، جی . عناصر یادگیری آماری . Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2001. [ Google Scholar ]
- اسمولا، ای جی; Vishwanathan، SVN مقدمه ای بر یادگیری ماشینی ؛ انتشارات دانشگاه کمبریج: کمبریج، انگلستان، 2008. [ Google Scholar ]
- ساتن، سی. McCallum، A. مقدمه ای بر زمینه های تصادفی شرطی برای یادگیری رابطه ای. در مقدمه ای بر یادگیری رابطه ای آماری ; Getoor, L., Taskar, B., Eds. انتشارات MIT: لندن، انگلستان، 2007; صص 93-127. [ Google Scholar ]
- آگتربرگ، FP; چنگ، Q. آزمون استقلال شرطی برای مدلسازی وزن شواهد. نات. منبع. Res. 2002 ، 11 ، 249-255. [ Google Scholar ]
- بونهام-کارتر، سیستم های اطلاعات جغرافیایی GF برای دانشمندان زمین شناسی ؛ چاپ پرگامون: آکسفورد، نیویورک، ایالات متحده آمریکا، 1994. [ Google Scholar ]
- ژانگ، ک. پیترز، جی. جانزینگ، دی. Schölkopf، B. آزمون استقلال شرطی مبتنی بر هسته و کاربرد در کشف علی، مجموعه مقالات بیست و هفتمین کنفرانس عدم قطعیت در هوش مصنوعی (UAI 2011)، بارسلونا، اسپانیا، 14-17 ژوئیه 2011. Cozman, FG, Pfeffer, A., Eds. AUAI Press: Corvallis, OR, USA, 2011; صص 804-813.
- Schaeben, H. مقایسه روش های ریاضی مدل سازی پتانسیل. ریاضی. Geosci. 2012 ، 44 ، 101-129. [ Google Scholar ]
- شایبن، اچ. ون دن بوگارت، KG نظر در مورد “یک وابستگی شرطی وزن های مدل شواهد تنظیم شده” توسط Minfeng Deng در تحقیقات منابع طبیعی 18 (2009)، 249-258. نات. منبع. Res. 2011 ، 29 ، 401-406. [ Google Scholar ]
- Journel، AG ترکیب دانش از منابع مختلف: جایگزینی برای فرضیههای سنتی استقلال دادهها. ریاضی. جئول 2002 ، 34 ، 573-596. [ Google Scholar ]
- کریشنان، اس. بوچر، ا. Journel, AG ارزیابی افزونگی اطلاعات از طریق مدل τ . در Geostatistics Banff 2004 ; Leuangthong, O., Deutsch, CV, Eds.; Springer: Dordrecht، هلند، 2005; صص 1037–1046. [ Google Scholar ]
- کریشنان، اس. مدل τ برای افزونگی داده ها و ترکیب اطلاعات در علوم زمین: نظریه و کاربرد. ریاضی. Geosci. 2008 ، 40 ، 705-727. [ Google Scholar ]
- پولیاکوا، EI؛ Journel, AG مدل ν برای ادغام داده های احتمالی، IAMG’2006، مجموعه مقالات کنگره بین المللی XI انجمن بین المللی زمین شناسی ریاضی: زمین شناسی کمی از منابع متعدد، لیژ، بلژیک، 3-8 سپتامبر 2006.
- پولیاکوا، EI؛ Journel, AG بیان ν برای ادغام داده های احتمالی. ریاضی. جئول 2007 ، 39 ، 715-733. [ Google Scholar ]
- Vapnik، VN ماهیت نظریه یادگیری آماری ، ویرایش دوم. Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2000. [ Google Scholar ]
- Bishop، CM Pattern Recognition and Machine Learning ; Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2006. [ Google Scholar ]
- راسل، اس. Norvig, P. Artificial Intelligence, A Modern Approach , 2nd ed.; Prentice Hall: Upper Saddle River، نیوجرسی، ایالات متحده آمریکا، 2003. [ Google Scholar ]
- Skabar, A. مدل سازی توزیع فضایی ذخایر معدنی با استفاده از شبکه های عصبی. نات. منبع. مدل. 2007 ، 20 ، 435-450. [ Google Scholar ]
- آدم، ا. ابراهیم، ز. شاپیایی، MI; جویدن، LC; Jau، LW; خالد، م. Watada، J. یک شبکه عصبی مصنوعی یادگیری با نظارت دو stwp برای مشکلات مجموعه داده نامتعادل. بین المللی J. Innov. محاسبه کنید. Inf. کنترل. 2012 ، 8 ، 3163-3172. [ Google Scholar ]
- آدم، ا. شاپیایی، MI; ابراهیم، ز. خالد، م. Jau، LW توسعه یک شبکه عصبی مصنوعی ترکیبی – طبقهبندی کننده ساده و بی تکلف برای مشکل طبقهبندی باینری مجموعه دادههای نامتعادل. ICIC Express Lett. 2011 ، 5 ، 3171-3175. [ Google Scholar ]
- باتیستا، GEAPA؛ پراتی، آرسی Monard، MC مطالعه رفتار چندین روش برای متعادل کردن دادههای آموزش یادگیری ماشین. SIGKDD کاوش. مشخصات Issue Learn. مجموعه داده های نامتعادل 2004 ، 6 ، 20-29. [ Google Scholar ]
- Chawla، NV; بویر، KW; هال، لو. Kegelmeyer, WP Smote: روش نمونه برداری بیش از حد اقلیت مصنوعی. جی آرتیف. هوشمند Res. 2002 ، 16 ، 321-357. [ Google Scholar ]
- کوتسیانتیس، س. کانلوپولوس، دی. Pintelas، P. مدیریت مجموعه داده های نامتعادل: یک بررسی. GESTS Int. ترانس. محاسبه کنید. علمی مهندس 2006 ، 30 ، 25-36. [ Google Scholar ]
- ژائو، Z.-Q. یک شبکه عصبی مدولار جدید برای مسائل طبقه بندی نامتعادل تشخیص الگو Lett. 2008 ، 30 ، 783-788. [ Google Scholar ]
- تیم اصلی توسعه R. R-A زبان و محیط برای محاسبات آماری ; R Foundation for Statistical Computing: وین، اتریش، 2013. موجود به صورت آنلاین: http://www.R-project.org/ قابل دسترسی در 10 اکتبر 2014.



© 2014 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر