

خلاصه
با توسعه روزافزون شهرهای هوشمند، پیش بینی حمل و نقل عمومی توجه قابل توجهی را به خود جلب کرده است. در این مقاله، ما رویکردی برای پیشبینی انتخابهای سوار شدن به مسافران و جریان حمل و نقل عمومی مسافران پیشنهاد میکنیم. مدل پیشبینی ما مبتنی بر کاوی رفتارهای مشترک کاربر برای مسیرهای معنایی و غنیسازی ویژگیها با استفاده از دانش از دادههای جغرافیایی و آب و هوا است. تمام داده های آزمایشی از شرکت اتوبوسرانی Ridge Nantong Limited و پلت فرم علی بابا که برای عموم نیز باز است، به دست می آید. ما رویکرد خود را با استفاده از منابع داده های مختلف، از جمله نقطه مورد علاقه (POI)، وضعیت آب و هوا، و اطلاعات اتوبوس عمومی در گوانگژو ارزیابی می کنیم تا اثربخشی آن را نشان دهیم.
کلید واژه ها:
شبکه های ژئوسنسور ؛ شهر هوشمند ؛ شلوغی ; معناشناسی ; فراگیری ماشین
1. معرفی
در سالهای اخیر، شبکههای حسگر زمین و وب حسگر به سرعت در شهرهای هوشمند گسترش یافتهاند. ژئوسنسورها، مانند پایانههای GPS کارت و اتوبوس، هر روز جریانهای داده عظیمی تولید میکنند. این داده ها از سنجش جمعی [ 1] در برخی زمینه ها دارای ارزش بالایی هستند و می توان برای تولید دانش مفید برای اهداف تصمیم گیری استخراج کرد. با گسترش شهر و افزایش جمعیت آن، سیستم حمل و نقل عمومی شهر فشار قابل توجهی را متحمل می شود. به عنوان مثال، مسافران معمولاً برای رسیدن به محل کار باید با اتوبوس ها یا متروهای شلوغ سر و کار داشته باشند که ناخوشایند و ناخوشایند است. علاوه بر این، هم برای بخش خصوصی و هم برای ارائه دهندگان ترانزیت دولتی، ترتیب دادن مسیرهای معقول و پیش بینی جریان بالقوه مسافران در آینده می تواند دشوار باشد. بنابراین، توانایی پیش بینی نیازهای حمل و نقل عمومی سودمند است.
خوشبختانه، ادارات دولتی به طور فزاینده ای مایل به ارائه دسترسی آزاد به داده های شهر هستند (به عنوان مثال، از طریق data.org)، که برای محققانی که هدفشان مقابله با مشکلات دنیای واقعی است مفید است. دولت استانی گوانگدونگ و شرکت اتوبوسرانی Ridge Nantong Limited مسابقهای را برای پیشبینی انتخابهای سوار شدن به مسافران و جریان در سکوی علیبابا برگزار کردند [ 2]]، که میلیون ها جریان داده رفتار کاربر را در چندین مسیر حمل و نقل عمومی فراهم می کند. پیشبینی انتخابهای سوار شدن مسافران، یک تحلیل رفتار کاربر است که ممکن است خدمات حملونقل عمومی هوشمندتر و زمانبندی بهتر تبلیغات جهتدار را برای ساکنان فراهم کند. علاوه بر این، پیش بینی جریان مسافر در حمل و نقل عمومی برای تصمیم گیری کنترل ترافیک توسط ارائه دهنده حمل و نقل و دولت مفید است.
مسائل مربوط به استخراج الگوهای مکرر در مسیرهای کاربران تلفن همراه که در مطالعات موجود مورد بحث قرار گرفته است، بیشتر ویژگی های جغرافیایی مسیرها را در نظر می گیرد [ 3 ، 4 ]. با این حال، الگوهای مبتنی بر مسیرهای جغرافیایی توسط داده های جغرافیایی محدود می شوند و هنگام در نظر گرفتن مکان های بازدید نشده به خوبی کار نمی کنند. برعکس، مسیرهای معنایی توسط بوگورنی و همکاران پیشنهاد شده است. [ 5]. در عمل، یک مسیر معنایی شامل فهرستی از مکانهای برچسبگذاری شده با برچسبهای معنایی است که ممکن است فعالیتهای انجام شده در این مسیرها را نشان دهد. به عنوان مثال، ما ممکن است مسیرهای کاربر را با برچسب های معنایی مانند <Community, Education, Community> استخراج کنیم که رفتارهای معنایی کاربر را نشان می دهد. با این حال، افراد مختلف شرایط سفر متفاوتی دارند. برای مثال، تقاضای سفت و سخت برای کارمندان اداری برای رفتن به سر کار در صبح و بازگشت به خانه در شب (یعنی در ساعات شلوغی) وجود دارد. در حالی که برای افراد مسن، زمان سفر معمولا نامشخص تر است. علاوه بر این، شرایط آب و هوایی مختلف و عملکردهای منطقه یا محله تأثیرات متفاوتی بر سفر دارند. به عنوان مثال، کارمندان اداری باید در روزهای هفته به سر کار بروند و به خانه برگردند، مهم نیست چقدر هوا بد باشد. با این حال، وقتی آخر هفته هوا بد است، بیرون نمی روند. در مقابل، سالمندان ممکن است در روزهای خوب بیرون بروند، چه در تعطیلات آخر هفته باشد و چه در روزهای هفته. علاوه بر این، عملکرد یک منطقه ممکن است اقدامات مسافران را محدود کند. به عنوان مثال، کارکنان اداری معمولاً صبح ها در نزدیکی منطقه تجاری مرکزی شهر از اتوبوس پیاده می شوند، در حالی که افراد مسن معمولاً به ایستگاهی نزدیک پارک یا سوپرمارکت می رسند.
در این مقاله روشی برای پیش بینی حمل و نقل عمومی در هفته آینده پیشنهاد می کنیم. ما ابتدا دادههای خام را پیش پردازش میکنیم (با استفاده از طرحوارهای که در پیوست نشان داده شده است )، دادههای کثیف را فیلتر میکنیم و آنچه را که باقی میماند گسسته میکنیم. سپس، داده ها را با اطلاعات معنایی حاشیه نویسی می کنیم. ما چندین بردار ویژگی می سازیم و داده ها را با XGBoost [ 6 ] آموزش می دهیم. ما دو مطالعه موردی را ارائه میکنیم: (1) پیشبینی انتخابهای سوار شدن به مسافران، پیشبینی اینکه آیا مسافر سوار اتوبوس میشود یا نه. (2) پیشبینی جریان مسافری حملونقل عمومی، پیشبینی تعداد مسافری که سوار اتوبوس میشوند.
اهم آثار این مقاله به شرح زیر است:
- (1)
-
ما رویکردی برای پیشبینی حمل و نقل عمومی با استفاده از سنجش جمعیت ارائه میکنیم.
- (2)
-
ما دو مطالعه موردی را در مورد پیشبینی انتخابهای سوار شدن به حملونقل عمومی و جریان مسافر ارائه میکنیم.
- (3)
-
ما رویکرد خود را با استفاده از منابع داده های مختلف، از جمله نقطه مورد علاقه (POI)، وضعیت آب و هوا، و اطلاعات اتوبوس عمومی در گوانگژو ارزیابی می کنیم تا اثربخشی آن را نشان دهیم.
ادامه این مقاله به شرح زیر سازماندهی شده است. بخش 1 به طور خلاصه مطالعات موجود در مورد پیش بینی مسیر را مرور می کند. بخش 2 شامل چارچوب، پیش پردازش داده ها، استخراج مسیرهای معنایی و اطلاعات ویژگی است. در بخش 3 ، ما نتایج آزمایش های خود را ارائه می دهیم. در نهایت، بخش 4 یافتههای ما را خلاصه میکند و مقاله را با بحث مختصری در مورد دامنه کار آینده ما به پایان میرساند.
2. کارهای مرتبط
2.1. کاوی رفتار کاربر
دو رویکرد اصلی برای درک رفتار کاوی کاربر وجود دارد که بهعنوان الگوی مکرر و پیادهروی تصادفی شناخته میشوند. اولا، جیانگ و همکاران. [ 7 ] مسیرهای تاکسی را مورد مطالعه قرار داد و دریافت که آنها از پرواز Levy پیروی می کنند (پیاده روی تصادفی که در آن مراحل بر حسب طول پله ها تعریف می شوند که توزیع احتمال خاصی دارند و جهت گام ها همسانگرد و تصادفی است.) رفتار – اخلاق. تیتوس و همکاران [ 8 ] حرکت براونی و پل های براونی را با نقاط پایانی دلخواه بررسی کرد. با این حال، سونگ و همکاران. [ 9 ] فقط آن را یافت 93 درصد93%تحرک کوتاه مدت کاربران را می توان پیش بینی کرد، به این معنی که روش های تصادفی مبتنی بر پیاده روی برای پیش بینی های طولانی مدت به خوبی کار نمی کنند. علاوه بر این، انواع الگوهای مکرر مورد استفاده وجود دارد، مانند الگوهای ترتیبی مکانی-زمانی [ 10 ]، معنایی-جغرافیایی [ 11 ]، و الگوهای متوالی متحرک [ 12 ]. در واقع، بسیاری از رفتارهای کاربر دارای معانی معنایی هستند. آلوارس و همکاران [ 11 ] برای کاوش ویژگی های جغرافیایی و معنایی با استخراج الگوهای مسیر معنایی از تاریخچه مکان کاربران تلفن همراه پیشنهاد شد. یینگ و همکاران [ 13] یک رویکرد پیشبینی مکان مبتنی بر معدن به نام پیشبینی مکان مبتنی بر جغرافیای زمانی- معنایی (GTS-LP) را پیشنهاد کرد، که اهداف جغرافیایی کاربر را در نظر میگیرد. با این حال، بسیاری از عوامل دیگر مانند آب و هوا، زمان و تعطیلات وجود دارد که بر حرکات کاربران تأثیر می گذارد.
2.2. ساختمان مدل پیش بینی
مطالعات موجود که در مورد رفتارهای کاربر پیش بینی می کنند را می توان به سه دسته طبقه بندی کرد: مطالعاتی که از داده های فردی کاربر استفاده می کنند. آنهایی که از داده های تولید شده توسط جمعیت استفاده می کنند. و روش های ترکیبی با استفاده از تمام داده ها. مدل پیشبینی در [ 14 ] مبتنی بر فضای بردار ویژه است که حرکت عادی کاربر را به منظور پیشبینی مکان بعدی کاربر مدلسازی میکند. چنین مدل پیش بینی حرکت کاربر تاریخی را در نظر نمی گیرد که منجر به عملکرد ضعیف می شود. به طور معمول، تنها استفاده از داده های فردی کاربر به خوبی کار نمی کند. در مقابل، مدل پیشبینی در [ 15] بر اساس یک تقریب اجتماعی- فضایی است که از مختصات GPS فعلی دوستان کاربر برای تخمین مختصات GPS کاربر استفاده می کند. با این حال، این روش ها حرکات فعلی کاربر را در نظر نمی گیرند. به عنوان مثال، با وجود اینکه کاربر به طور مکرر از یک باشگاه ورزشی بازدید می کند، احتمال اینکه او پس از بازدید از استخر به باشگاه ورزشی مراجعه کند، باید بسیار کم باشد. مونریال و همکاران [ 16 ] یک روش ترکیبی پیشنهاد کرد که نه تنها داده های خود کاربر را در نظر می گیرد، بلکه از داده های تولید شده توسط جمعیت نیز استفاده می کند. با این حال، این مدلها فقط بر حرکات کاربر با انگیزههای معنایی و جغرافیایی تمرکز میکنند، در حالی که شرایط آب و هوایی مختلف یا عملکردهای منطقه (آموزش/تجارت) ممکن است مقصد نهایی کاربران را تغییر دهد.
روش های پیش بینی زیادی وجود دارد. شبکه عصبی مصنوعی بدیهی است که یک مدل مناسب برای پیش بینی است. با این حال، آموزش و بهینه سازی پارامترهای شبکه های عصبی زمان بر است. XGBoost [ 6] یک روش یادگیری ماشینی در مقیاس بزرگ است که می تواند برای ساخت سیستم های یادگیری مقیاس پذیر استفاده شود. XGBoost توسط یک سری راه حل های کاربردی استفاده شده است که در موقعیت های واقعی به خوبی عمل می کند. این کارایی این روش را که برای محاسبات خارج از هسته سریع و بهینه شده است را اثبات می کند. روش های استفاده از درختان تقویت شده برای مدتی مورد استفاده قرار گرفته است. آنها با درختهای تصمیم با اندازه ثابت بهعنوان یادگیرنده پایه آموزش میبینند که نسبت به موارد پرت مقاوم است. به عنوان یک الگوریتم مبتنی بر درخت، درختهای تصمیم تقویتکننده گرادیان (GBDTs) همچنین میتوانند تعاملات ویژگیهای غیرخطی را مدیریت کنند.
3. رویکرد
3.1. چارچوب
همانطور که شکل 1 نشان می دهد، چارچوب ما از دو بخش تشکیل شده است: مهندسی ویژگی و ساخت مدل. ابتدا داده های خام را پیش پردازش می کنیم تا داده های کثیف را فیلتر کرده و مجموعه داده را گسسته کنیم. سپس، داده ها را با اطلاعات معنایی حاشیه نویسی می کنیم. ما چندین بردار ویژگی می سازیم و با این داده ها آموزش می دهیم.
بیان مشکل : با توجه به مجموعه دادههای رکورد کارت اتوبوس در یک دوره چند ماهه (1 اوت 2014 تا 31 دسامبر 2014)، که هر کدام شامل شناسه کارت اتوبوس، شناسه پایانه (شناسه ایستگاه اتوبوس)، زمان سفر و غیره است، مشکل ما این است. (1) یک طبقه بندی باینری و (2) یک کار رگرسیون. هدف ما این است که برای هفته بعد (1 ژانویه 2015 تا 7 ژانویه 2015) (1) پیش بینی کنیم که آیا یک مسافر خاص با پیش بینی برچسب وجود اتوبوس خاصی را سوار می شود یا خیر. y∈ { 0 , 1 }�∈{0,1}در این رکوردها ( سیa r d_ من د, L i n e _ n a m e����_��,����_����، و (2) شماره مسافر برای یک خط اتوبوس، به عنوان ( L i n e _ n a m e , D e a l _ da t e , D e a l _ h o u r , P a s e n g e r _ c o u n t ( p r e d i c t i o n ) _����_����,����_����,����_ℎ���,Passenger_count(prediction)).
3.2. پیش پردازش داده ها
3.2.1. پیش پردازش داده های کثیف
شکل 2 انواع مختلف داده های کثیف را نشان می دهد که در عمل وجود دارند. مختصات افقی زمان و مختصات عمودی تعداد کل رکوردهای گذرگاه 1 است. وارد کردن این داده های خام در مدل آموزشی نتیجه معقولی ایجاد نمی کند، بنابراین پردازش پیش پردازش داده ها از اهمیت کلیدی برخوردار است. در باره 40 درصد40%از داده های خام یک t e r m i n a l _ i d��������_��که با بیش از دو مطابقت دارد l i n e _ n a m e����_����ارزش های. ما تقسیم می کنیم t e r m i n a l _ i d��������_��به دو دسته: t e r m i n a l _ i d��������_��با یکی l i n e _ n a m e����_����و آنهایی که دو یا چند مقدار دارند l i n e _ n a m e����_����. این روش اهمیت عملی دارد، زیرا مسافران را با خطوط اتوبوس معمولی فیلتر می کند. تمام ویژگی ها به طور جداگانه تولید می شوند. علاوه بر این، برخی از داده ها وجود دارد که برای آنها یکسان است c a r d_ من د����_��بیش از دو رکورد در همان l i n e _ n a m e����_����همزمان. این بسیار غیر طبیعی است و ممکن است ناشی از خرابی تجهیزات پایانه یا انتقال داده باشد. ما اینها را رتبه بندی می کنیم c a r d_ من د����_��رکورد در همان l i n e _ n a m e����_����در همان زمان و تمام رکوردهای تکراری را فیلتر کنید.
3.2.2. پیش پردازش داده های خام
علاوه بر داده های کثیف، بسیاری از انواع داده ها را نمی توان به طور مستقیم برای آموزش استفاده کرد، مانند وضعیت آب و هوا، زمان و غیره. ما باید رکوردهایی را با شرایط یکسان (مثلاً آب و هوا، زمان و …) رکوردها در نظر بگیریم سیa r d_ من د����_��و L i n e _ n a m e����_����و ویژگی ها را بسازید. آب و هوا را به عنوان مثال در نظر بگیرید: باید تعداد رکوردهای یک وضعیت آب و هوایی را در چند ساعت، روزهای گذشته و … محاسبه کنیم که می تواند تفاوت مسافران را در شرایط آب و هوایی مختلف اندازه گیری کند. در بسیاری از وظایف یادگیری ماشین، این ویژگی همیشه یک مقدار پیوسته نیست، اما احتمالاً ارزش طبقه بندی است. به عنوان مثال، کلاس های دما می توانند دما را در شرایط آب و هوایی خاص توصیف کنند در حالی که متغیرهای پیوسته نمی توانند. ما این داده ها را با استفاده از متغیرهای ساختگی برای مدیریت داده ها گسسته می کنیم. به عنوان مثال، دمای روز به عنوان “0001” برای شرایطی که در آن است ثبت می شود t e m p e r a t u rهدیک سال≥��������������≥10 ∘∘سی و t e m p e r a t u rهدیک سال≤��������������≤20 ∘∘C که به طور گسترده در ویژگی های دسته بندی استفاده می شود و دو مزیت دارد: (1) حل مشکل طبقه بندی کننده برای مقابله با داده های ویژگی خوب نیست و (2) تا حدی ویژگی ویژگی ها را گسترش می دهد. بنابراین ما وضعیت آب و هوا و داده های زمان را تغییر می دهیم. دمای روز به (10) تقسیم می شود ∘∘C–20 ∘∘ج)، (20 ∘∘C–30 ∘∘ج)، و (> 30 ∘∘ج) و دمای شب به (0) تقسیم می شود ∘∘C-10 ∘∘ج)، (10 ∘∘C–20 ∘∘ج) و (20 ∘∘C–30 ∘∘ج). داده های زمانی به روزهای هفته، آخر هفته، تعطیلات و ساعت شلوغی تقسیم می شوند.
3.3. استخراج مسیر معنایی
ما یک شهر را به بلوک های از هم گسیخته [ 17 ] تقسیم می کنیم، با این فرض که قرارگیری در بلوک g یکنواخت است. شبکه راه معمولاً از تعدادی جاده اصلی مانند جاده کمربندی تشکیل شده است و شهر به مناطق تقسیم می شود [ 18 ]. ما طرح ریزی شبکه جاده ای مبتنی بر برداری را بر روی یک صفحه ترسیم می کنیم و آن را به یک مدل شطرنجی تبدیل می کنیم [ 19 ]. هر پیکسل از تصویر نقشه پیش بینی شده را می توان به عنوان یک عنصر بلوکی از نقشه شطرنجی مربوطه مشاهده کرد. در نتیجه، شبکه جاده ای به یک تصویر باینری تبدیل می شود. سپس، اسکلت جاده را استخراج می کنیم، در حالی که توپولوژی تصویر دو مقدار اصلی را حفظ می کنیم. در نهایت بلوک های g شهرها را بدست می آوریم.
هر ایستگاه اتوبوس به دلیل محیط اطراف خود، مانند POI و عملکرد محله، معنای معنایی پنهانی دارد. به عنوان مثال، مسافری که در ایستگاهی در یک منطقه مسکونی سوار اتوبوس می شود و هر روز در نزدیکی مدرسه پیاده می شود، ممکن است در ساعت مشخصی به مدرسه برود. ما می توانیم این رکوردها را به صورت <Community, Education> فرموله کنیم. “جامعه” به منطقه ای از محله های مسکونی اطلاق می شود که افراد زیادی در آنجا زندگی می کنند. ما از رویکرد یینگ و همکاران پیروی می کنیم. [ 13 ] برای استخراج الگوهای معنایی از سوابق هر کاربر. اطلاعات مکان معنایی از Baidu Map API برچسب گذاری شده است (شکل داده نشان داده شده در ضمیمه). ما از برخی دسته بندی های کلی مانند نوع POI و تابع همسایگی به عنوان برچسب های معنایی استفاده می کنیم. اگر یک مکان رکورد با یک یا چند ناحیه با برچسب های معنایی همپوشانی داشته باشد، معانی معنایی این مناطق به این رکورد اختصاص داده می شود. شکل 3 نشان می دهد که برچسب معنایی بلوک 253 (Block ID) Education است. ما هر رکورد مسافر را به یک رکورد معنایی تبدیل می کنیم، مانند < سیo m u n i t y _، ایدu c a t i o n���������,���������> رفتارهای کاربر اولیه ممکن است برخی از الگوها را نشان دهند و بنابراین می توان آنها را پیش بینی کرد. به طور رسمی، n دسته (شامل POI و تابع همسایگی) از بلوک ها وجود دارد{ل1،ل2، . . . ،لn}{�1,�2,…,��}، جایی که لمن��مقوله ای مانند آموزش (عملکرد) یا کافی شاپ (POI) است. سوابق اتوبوس مسافران در چنین ترکیباتی نشان داده شده است (231 ترکیب در این مقاله) { (ل1،ل2) ، (ل1،ل3) ، . . . ،لمن،لj، . . . ، (لn – 1،لn) }{(�1,�2),(�1,�3),…,��,��,…,(��−1,��)}. هر ترکیب نشان دهنده رفتار سفر کاربر متفاوت است.
3.4. پیش بینی انتخاب سوار شدن به مسافر
برای این کار، ترکیبی از ویژگی ها را در نظر می گیریم سیa r d_ من د����_��و L i n e _ n a m e����_����، و ارتباط یک کارت اتوبوس خاص با این خط اتوبوس. ویژگی های ما شامل هفت دسته است: (1) مسافر (2) خط اتوبوس (3) زمان (4) آب و هوا (5) مکان صدور کارت اتوبوس (6) کارت اتوبوس و (7) ویژگی های رفتار معنایی پنهان کاربر. به طور خاص، ما این ویژگی ها را برای هر روز محاسبه می کنیم. ما تعداد کل رکوردها را محاسبه می کنیم. تعداد ساعتها، روزها و هفتههایی که رکورد دارند؛ و تعداد دفعاتی که کارت در پایانه های مختلف (ایستگاه اتوبوس) در 1، 3، 7، 28، 70 و 126 روز گذشته برای ترکیبی از سیa r d_ من د����_��و L i n e _ n a m e����_����. روزهای خاص به این دلیل انتخاب می شوند که داده ها دارای تناوب بیش از یک هفته هستند. ویژگی آب و هوا را به عنوان مثال در نظر بگیرید. ما رکوردهایی را با شرایط آب و هوایی یکسان رکوردها در نظر می گیریم سیa r d_ من د����_��و L i n e _ n a m e����_����و ویژگی ها را محاسبه کنید. به طور رسمی، ما داریم:
-
اف= {افp a s s e n ge r،افب تو _،افمن هستم _ _،افw e a t h e r،افمن s u e d _،افc a r d،افs e m a n t i c}�={����������,����,�����,�����ℎ��,�������,�����,���������}
-
افمن= {f1 دیک سال،f3 دیک سال،f7 دیک سال،f28 روزیک سال،f70 روزیک سال،f125 دیک سال}��={�1���,�3���,�7���,�28���,�70���,�125���}
-
fمن= { تیo t a l _ R e c o r dاس ، اچای تو ، د آ ای _ _اس ، دبلیوe e k s ، Tمن هستم _ D i f _ _fe r e n t _ Te r m i n a l s }��={�����_�������,�����,����,�����,�����_���������_���������}
جایی که افمن��با توجه به نوع ویژگی محاسبه می شود. به عنوان مثال، اگر من هستم من هستم _ _����(ما زمان را به چهار دسته تقسیم می کنیم که در بخش 3.2.2 شرح داده شده است )، رکوردهایی را با شرایط زمانی یکسان (مانند ساعت شلوغی، روزهای هفته) به عنوان در نظر می گیریم. سیa r d_ من د����_��و L i n e _ n a m e����_����.
3.5. پیش بینی جریان مسافر
سه روش برای پیشبینی جریان مسافر وجود دارد: (1) جمعآوری مستقیم تمام دادههای پیشبینی انتخاب سوار شدن مسافران برای بدست آوردن تعداد کل مسافران اتوبوس. (2) پیش بینی رگرسیون روزانه با استفاده از تعداد کل مسافران. و (3) طبقه بندی گروه کاربر و جمع آوری داده ها. ما رویکرد سوم را به دلیل تفاوت های فردی بزرگ در سوابق اتوبوس اتخاذ می کنیم. برهم نهی ساده سوابق کاربر نمی تواند بازتاب خوبی از روند کلی داده باشد زیرا دو نوع مسافر وجود دارد، همانطور که در شکل 4 نشان داده شده است.. خط قرمز مسافران گاه به گاه و خط آبی مسافران مکرر را از 1 سپتامبر 2014 تا 7 اکتبر 2014 نشان می دهد. سوابق مسافران مکرر منظم و سوابق مسافران گاه به گاه تصادفی است. ما مدل های مختلفی را برای این نوع مسافران می سازیم. این Yr a n d�����نتیجه پیشبینی مدل تصادفی مسافر است در حالی که Yfr e q�����نتیجه پیشبینی مدل مسافری مکرر است. باید این دو نتیجه را با هم ترکیب کنیم و به نتیجه نهایی برسیم. با این حال، در روزهای مختلف (آخر هفته / تعطیلات و روزهای هفته)، سهم مسافران تصادفی یا مسافران مکرر در کل مسافران متفاوت است. برای تنظیم این انحراف از متغیر α و β استفاده می کنیم. به طور رسمی، ما داریم:
Y= {α ∗Yfr e q+Yr a n dβ∗Yfr e q+Yr a n dمن f Yمن f Y∈ w e e k e n d a n d h o l i dیک سال∈ w e e k dیک سال�=�∗���ه�+��آ�دمن� �∈�ههکه�د آ�د ساعت�لمندآ��∗���ه�+��آ�دمن� �∈�ههکدآ�
ما تعداد کل مسافران را در هر ساعت از هر خط محاسبه میکنیم و کدگذاری یکباره شرایط آب و هوایی و رفتارهای معنایی کاربر را به عنوان ویژگیهایی برای رگرسیون اتخاذ میکنیم.
4. آزمایشات
4.1. برپایی
همه داده های تجربی ما به صورت آنلاین در دسترس هستند. تاریخ های داده های حمل و نقل عمومی از 1 اوت 2014 تا 31 دسامبر 2014 متغیر است. ما از داده های 1 دسامبر 2014 تا 31 دسامبر 2014 به عنوان داده های آموزشی و از 1 ژانویه 2015 تا 7 ژانویه 2015 به عنوان داده های آزمایشی استفاده می کنیم. محدوده داده ها از ساعت 06:00 تا 20:00 هر روز بوده و جزئیات شرح طرح داده در پیوست موجود است . ما داده های POI و تابع ناحیه را از Baidu Map API [ 20 ] به دست می آوریم. ما توضیحات مکان متن آزاد را با استفاده از تجزیه جغرافیایی [ 21 ] برای تبدیل متن به شناسه های جغرافیایی بدون ابهام (مختصات طول و عرض جغرافیایی) بدست می آوریم. ما داده های خود را با XGBoost [ 22 ] آموزش می دهیم و پارامترهای آن را با روش وزنی خطی بهینه می کنیم. تنظیم کردیم α = 1 . 21�=1.21و β= 0 . 95�=0.95. ما عمدتاً پارامترها را تنظیم میکنیم، از جمله حداکثر عمق درخت و انقباض اندازه گام مورد استفاده در بهروزرسانیها، برای جلوگیری از برازش بیش از حد و به حداقل رساندن مجموع وزن نمونه (Hessian) مورد نیاز در یک گره فرزند. در نهایت، ما حداکثر عمق را بر روی 10، اندازه گام را 0.3، و حداقل مجموع وزن نمونه را در آزمایشات خود 2.0 تنظیم کردیم. رگرسیون لجستیک [ 23 ] و رگرسیون خطی به عنوان طبقهبندی ضعیف در آزمایش ما استفاده میشوند.
4.2. معیارهای
ابتدا، ما از مجموعه خطوط مبنا استفاده می کنیم تا ضرورت هر جزء از روش خود را با استفاده نکردن از رفتار کاربر توجیه کنیم. افs e m a n t i cافسهمترآ�تیمنج) یا آب و هوا ( افw e a t h e rاف�هآتیساعته�).
برای پیشبینی انتخاب سوار شدن مسافران، رگرسیون لجستیک [ 23 ]، GBDTs [ 24 ] و جنگلهای تصادفی [ 25 ] را به عنوان خطوط پایه اتخاذ میکنیم . برای پیشبینی جریان مسافر، از میانگین متحرک خودکار (ARMA) [ 26 ]، شبکه عصبی مصنوعی تک لایه (ANN) و رگرسیون خطی به عنوان خطوط پایه استفاده میکنیم.
به طور خاص، ما داریم:
پr e c i s i o n =| ⋂ ( صr e dمن c t i o n Se t ، R e fe r e n c e Se t ) || پr e dمن c t i o n Se t |پ�هجمنسمن��=|⋂(پ�هدمنجتیمن��اسهتی،آره�ه�ه�جهاسهتی)||پ�هدمنجتیمن��اسهتی|
R e c a l l =| ⋂ ( صr e dمن c t i o n Se t ، R e fe r e n c e Se t ) || R e fe r e n c e Se t |آرهجآلل=|⋂(پ�هدمنجتیمن��اسهتی،آره�ه�ه�جهاسهتی)||آره�ه�ه�جهاسهتی|
ما نتیجه نهایی را با امتیازات F1 ارزیابی می کنیم، جایی که اف1 =2 × Pr e c i s i o n × R e c a l lپr e c i s i o n + R e c a l lاف1=2×پ�هجمنسمن��×آرهجآللپ�هجمنسمن��+آرهجآلل، برای پیش بینی انتخاب سوار شدن مسافر.
برای پیشبینی جریان مسافر، از ریشه میانگین مربعات خطا (RMSE) استفاده میکنیم که به صورت تعریف شده است R MاسE=∑nمن(yمن–y^من)2n––––––––√آرماس�=∑من�(�من–�^من)2�، جایی که y^من�^منیک پیش بینی است و yمن�منحقیقت زمینی است
4.3. بینش داده
ما ابتدا سوابق حمل و نقل عمومی فردی را تجزیه و تحلیل می کنیم. همانطور که شکل 5 نشان می دهد، مختصات افقی ساعت (06:00-20:00) سفر و مختصات عمودی نشان دهنده تاریخ سفر (1 تا 31 روز ماه) است. تفاوت های قابل توجهی بین افراد وجود دارد. خط 1 را به عنوان مثال در نظر بگیرید: 19،513،511 مسافر و 6،738،391 رکورد در طول پنج ماه وجود دارد، به این معنی که در این مدت 3.45 مسافر در هر رکورد وجود دارد. این نتیجه نشان می دهد که مسافران زیادی هستند که به ندرت سوار اتوبوس می شوند. سپس آن مسافران را بر فراوانی رکورد سفرشان تقسیم می کنیم. مسافران با بیش از هشت رکورد در هر هفته به عنوان مسافران مکرر رفتار می شوند، در حالی که بقیه مسافران گاه به گاه هستند. همانطور که در شکل 6نشان می دهد، هیستوگرام آبی نشان دهنده جریان مسافران مکرر و مسافران سبز و گاه به گاه است. واضح است که این دو گروه از قوانین متفاوتی در مورد زمان سفر پیروی می کنند. از این رو، ما مدل های مختلف پیش بینی جریان مسافر را برای مسافران مکرر و گاه به گاه ایجاد می کنیم.
4.4. نتایج
4.4.1. پیش بینی انتخاب های سوار شدن به مسافران
شکل 7 الف ضرورت هر یک از اجزای روش ما را برای پیش بینی انتخاب سوار شدن مسافران نشان می دهد. مورد “هیچ” فقط ویژگی های زمانی را می پذیرد و بدترین نتایج را دارد. با افزودن ویژگی های آب و هوا و معنایی، امتیازات F1 به سرعت افزایش می یابد. مورد “همه” از تمام ویژگی های روش ما استفاده می کند و بهترین نتایج را می گیرد. شکل 7 ب نتایج رگرسیون لجستیک، GBDT، Random Forest و XGBoost را نشان می دهد. XGBoost عملکرد خوبی را در مقایسه با روش های دیگر نشان می دهد.
4.4.2. پیش بینی جریان مسافر
شکل 8 الف ضرورت هر جزء از روش ما را برای پیش بینی جریان مسافر نشان می دهد. مورد “هیچ” فقط ویژگی های زمانی را می پذیرد و بدترین نتایج را دارد. با افزودن ویژگی های آب و هوا و معنایی، امتیازات F1 به سرعت افزایش می یابد. مورد “همه” تمام ویژگی های ممکن روش ما را به کار می گیرد و بهترین نتایج را به دست می آورد. شکل 8 ب نتایج رگرسیون خطی، ANN، ARMA و XGBoost را نشان می دهد. XGBoost در مقایسه با روش های دیگر عملکرد بهتری دارد.
4.5. مطالعات موردی: حمل و نقل عمومی در گوانگژو
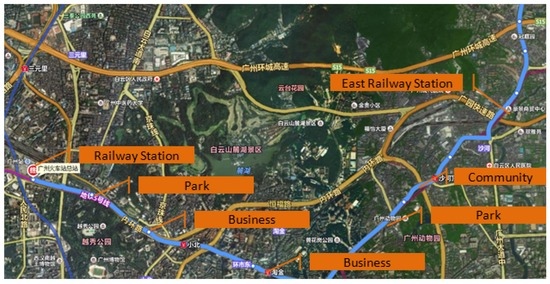
داده های اتوبوس فقط داده های ترافیکی نیستند. می تواند نیازهای بالقوه سفر کاربران را آشکار کند. همانطور که شکل 9 نشان می دهد، مسافرانی که در ایستگاه راه آهن سوار اتوبوس می شوند و در ایستگاه راه آهن شرق پیاده می شوند، ممکن است بخواهند قطار را تغییر دهند. مسافران از شاهه (جامعه) به Xiaobei (تجارت) ممکن است به سر کار بروند، در حالی که کسانی که از شاهه (جامعه) به باغ وحش (پارک) سفر می کنند ممکن است برای اهداف سرگرمی سفر کنند. دفعات و زمان سفرهای حمل و نقل عمومی نیز می تواند دلایل بالقوه سفر را نشان دهد و نبض یک شهر را منعکس کند.
4.6. بحث
راه حل های خوب از درک کامل کسب و کار و تجزیه و تحلیل دقیق داده ها به دست می آیند. امروزه اهمیت اپلیکیشنهای موبایلی مانند Uber و Didi (یک برنامه مشابه اوبر در چین) در ارتباط افراد و ابزارهای سفر نهفته است. با این حال، این مدل اقتصادی مشترک با اقتصادی فاصله زیادی دارد. تصور کنید زمانی که اوبر و دیدی راه اندازی شدند، تعداد مسافرت با ماشین به میزان قابل توجهی افزایش یافت که منجر به کاهش فراوانی استفاده از حمل و نقل عمومی و در نتیجه افزایش تراکم ترافیک و آلودگی محیط زیست شد. حمل و نقل عمومی بسیار اقتصادی تر و دوستدار محیط زیست نسبت به سفر با ماشین شخصی است و هنوز هم تراکم ترافیک شدید و مشکلات زیست محیطی در شهرهای بزرگ وجود دارد. از این رو، توسعه حمل و نقل عمومی بیش از خودروهای شخصی ضروری است. حتی اگر مسافران حمل و نقل عمومی را کمتر راحت و راحت بدانند. بر اساس تجزیه و تحلیل مجموعه دادههای بزرگ، مانند دادههای حملونقل عمومی و شبکه جادهای از شهرهای هوشمند، میتوانیم راحتی، آسایش، سهولت و سرعت سفر از طریق حملونقل عمومی را بهبود بخشیم. علاوه بر این، زمان بندی تبلیغات جهت دار را می توان با تجزیه و تحلیل رفتار مسافر ارائه کرد. در سالهای اخیر، دادههای بیشتری از طریق سرویسهای وب در دسترس قرار گرفتهاند تا ارزش بالقوه آنها استخراج شود. تجزیه و تحلیل این داده ها می تواند کارایی اجتماعی را بهبود بخشد. در سالهای اخیر، دادههای بیشتری از طریق سرویسهای وب در دسترس قرار گرفتهاند تا ارزش بالقوه آنها استخراج شود. تجزیه و تحلیل این داده ها می تواند کارایی اجتماعی را بهبود بخشد. در سالهای اخیر، دادههای بیشتری از طریق سرویسهای وب در دسترس قرار گرفتهاند تا ارزش بالقوه آنها استخراج شود. تجزیه و تحلیل این داده ها می تواند کارایی اجتماعی را بهبود بخشد.
5. نتیجه گیری ها
در این مطالعه، ما رویکردی را برای پیشبینی حملونقل عمومی با استفاده از دادههای سنجش ازدحام پیشنهاد میکنیم که برای شرکتهای حملونقل عمومی و تصمیمگیری دولت مفید است، اما قبلاً بررسی نشده بود. در این چارچوب، ابتدا دادههای خام را پیش پردازش میکنیم تا دادههای کثیف را فیلتر کنیم تا مجموعه داده گسسته شود. در مرحله بعد، داده ها را با اطلاعات معنایی حاشیه نویسی می کنیم، چندین بردار ویژگی می سازیم و با آن داده ها آموزش می دهیم.
محدودیت هایی برای این مطالعه وجود دارد که باید در کارهای آینده به آن پرداخته شود. یکی از محدودیتهای اصلی در عدم دسترسی به دادههای ناقص برخی از کاربران و در دسترس بودن محدود دادههای باز نهفته است. به عنوان مثال، سوابق زیادی وجود دارد که زمان پیاده شدن مسافر از اتوبوس را ثبت نمی کنند (مسافران باید هم برای سوار شدن و هم برای پیاده شدن از اتوبوس/مترو از کارت اتوبوس خود استفاده کنند). ما می خواهیم در آینده رفتارهای مسافران را عمیق تر بررسی کنیم. سازگاری این رویکرد با شرایط دنیای واقعی نیز در کار آینده ما در نظر گرفته خواهد شد. ابتدا، برخی از توابع تجزیه و تحلیل بصری به سیستم نمایش مداوم ما اضافه می شود. از طریق ارائه شرایط تاریخی مشابه یا پیشبینی نتایج با توجه به ویژگیهای مختلف، سیستم قادر خواهد بود اطلاعات بیشتری را برای تصمیمگیری انعطافپذیر فراهم کند.
پیوست A. طرح واره داده های حمل و نقل عمومی

جدول A1. برگه اطلاعات تراکنش کارت اتوبوس.
جدول A2. جدول اطلاعات مسیر اتوبوس
پیوست B. طرح واره داده های مرتبط با ترافیک
جدول B1. اطلاعات آب و هوای گوانگژو
جدول B2. اطلاعات POI گوانگژو.
جدول B3. توابع ناحیه در گوانگژو.
منابع
- جمعیت سنجی. در دسترس آنلاین: http://www.igi-global.com/dictionary/crowdsensing/48313 (در 29 سپتامبر 2016 قابل دسترسی است).
- پلتفرم علی بابا در دسترس آنلاین: https://open.alibaba.com/ (در 29 سپتامبر 2016 قابل دسترسی است).
- مونریال، آ. پینلی، اف. تراسارتی، ر. Giannotti، F. WhereNext: پیشبینیکننده مکان در استخراج الگوی مسیر. در مجموعه مقالات پانزدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، پاریس، فرانسه، 28 ژوئن تا 1 ژوئیه 2009.
- لو، EHC؛ الگوهای متوالی تلفن همراه مبتنی بر خوشه Tseng، VS Mining در محیط های خدمات مبتنی بر مکان. IEEE Trans. دانستن مهندسی داده 2009 . [ Google Scholar ] [ CrossRef ]
- بوگورنی، وی. کویجپرز، بی. Alvares، LO ST-DMQL: یک زبان جستجوی داده کاوی مسیر معنایی. بین المللی جی. جئوگر. Inf. علمی 2009 ، 23 ، 1245-1276. [ Google Scholar ] [ CrossRef ]
- چن، تی. Guestrin, C. XGBoost: یک سیستم تقویت درخت مقیاس پذیر. محاسبه کنید. علمی 2016 . [ Google Scholar ] [ CrossRef ]
- جیانگ، بی. یین، جی. ژائو، اس. مشخص کردن الگوی تحرک انسان در یک شبکه خیابانی بزرگ. فیزیک Rev. E 2009 . [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لوپو، تی. پیتمن، جی. تانگ، دبلیو. تبدیل Vervaat پل های براونی و حرکت براونی. الکترون. جی. پروباب. 2015 . [ Google Scholar ] [ CrossRef ]
- آهنگ، سی. Qu، Z. بلوم، ن. Barabási، AL محدودیت های قابل پیش بینی در تحرک انسان. Science 2010 ، 327 ، 1018-1021. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لی، ز. هان، جی. جی، م. تانگ، لس آنجلس; یو، ی. دینگ، بی. لی، جی جی; Kays, R. Movemine: استخراج داده های جسم متحرک برای کشف الگوهای حرکت حیوانات. ACM Trans. هوشمند سیستم تکنولوژی 2011 . [ Google Scholar ] [ CrossRef ]
- به سوی کشف دانش سیر معنایی. در دسترس آنلاین: https://uhdspace.uhasselt.be/dspace/bitstream/1942/1832/1/towards.pdf (دسترسی در 30 سپتامبر 2016).
- یاواش، جی. کاتساروس، دی. اولوسوی، او. Manolopoulos، Y. یک رویکرد داده کاوی برای پیش بینی مکان در محیط های تلفن همراه. دانستن داده ها مهندس 2005 ، 54 ، 121-146. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یینگ، JJC; لو، EHC؛ لی، WC; Weng، TC; شباهت کاربر Tseng، VS Mining از مسیرهای معنایی. در مجموعه مقالات دومین کارگاه بین المللی ACM SIGSPATIAL درباره شبکه های اجتماعی مبتنی بر مکان، نیویورک، نیویورک، ایالات متحده آمریکا، 2 تا 5 نوامبر 2010.
- عقاب، ن. رفتارهای ویژه پنتلند، AS: شناسایی ساختار در روال. رفتار Ecol. Sociobiol. 2009 ، 63 ، 1057-1066. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بکستروم، ال. سان، ای. مارلو، سی. اگر می توانید مرا بیابید: بهبود پیش بینی جغرافیایی با نزدیکی اجتماعی و فضایی. در مجموعه مقالات نوزدهمین کنفرانس بین المللی وب جهانی، رالی، NC، ایالات متحده، 26-30 آوریل 2010.
- مونریال، آ. پینلی، اف. تراسارتی، ر. Giannotti، F. Wherenext: پیش بینی مکان در استخراج الگوی مسیر. در مجموعه مقالات پانزدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، پاریس، فرانسه، 28 ژوئن تا 1 ژوئیه 2009.
- نقشه های بخش. در دسترس آنلاین: https://github.com/zxlzr/Segment-Maps (در 29 سپتامبر 2016 قابل دسترسی است).
- یوان، نیوجرسی؛ ژنگ، ی. Xie، X. وانگ، ی. ژنگ، ک. Xiong، H. کشف مناطق عملکردی شهری با استفاده از مسیرهای فعالیت نهفته. محاسبات IEEE. Soc. 2014 ، 3 ، 712-725. [ Google Scholar ] [ CrossRef ]
- یوان، جی. ژنگ، ی. Xie, X. کشف مناطق با عملکردهای مختلف در یک شهر با استفاده از تحرک انسان و POI. در مجموعه مقالات هجدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، پکن، چین، 12 تا 16 اوت 2012.
- Baidu Map API. در دسترس آنلاین: http://developer.baidu.com/map/reference/index.php (در 29 سپتامبر 2016 قابل دسترسی است).
- ژئوپارسر. در دسترس آنلاین: https://github.com/ropenscilabs/geoparser (در 29 سپتامبر 2016 قابل دسترسی است).
- Xgboost. در دسترس آنلاین: http://xgboost.readthedocs.io/en/latest/ (در 29 سپتامبر 2016 قابل دسترسی است).
- Hosmer، DW، Jr. Lemeshow, S. رگرسیون لجستیک کاربردی ; جان وایلی و پسران: نیویورک، نیویورک، ایالات متحده آمریکا، 2004. [ Google Scholar ]
- فریدمن، تقویت گرادیان تصادفی JH. محاسبه کنید. آمار داده آنال. 2002 ، 38 ، 367-378. [ Google Scholar ] [ CrossRef ]
- لیاو، ا. وینر، ام. طبقه بندی و رگرسیون توسط جنگل تصادفی. R News 2002 , 2 , 18-22. [ Google Scholar ]
- گفت، SE; آزمایش دیکی، DA برای ریشه های واحد در مدل های میانگین متحرک اتورگرسیو با مرتبه ناشناخته. Biometrika 1984 ، 71 ، 599-607. [ Google Scholar ] [ CrossRef ]
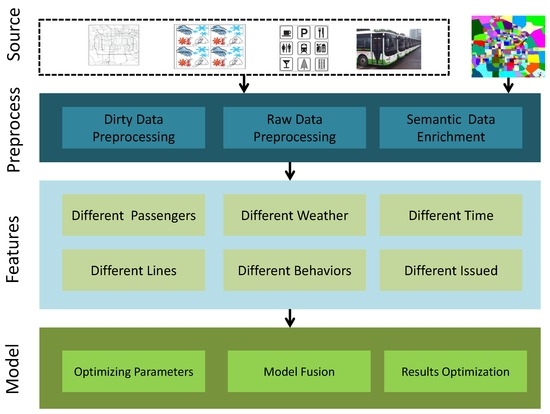
شکل 1. چارچوبی برای پیش بینی حمل و نقل عمومی با استفاده از سنجش جمعیت و استخراج مسیر معنایی.
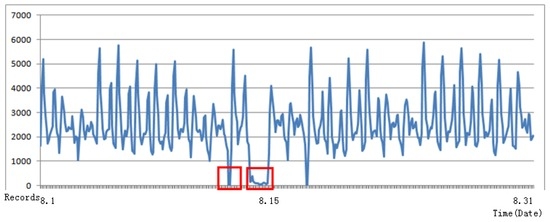
شکل 2. نمونه های داده های کثیف از باس خط 1.
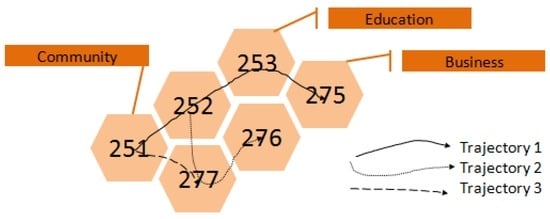
شکل 3. مسیرهای معنایی.

شکل 4. مسافران مکرر و گاه به گاه اتوبوس خط 1.
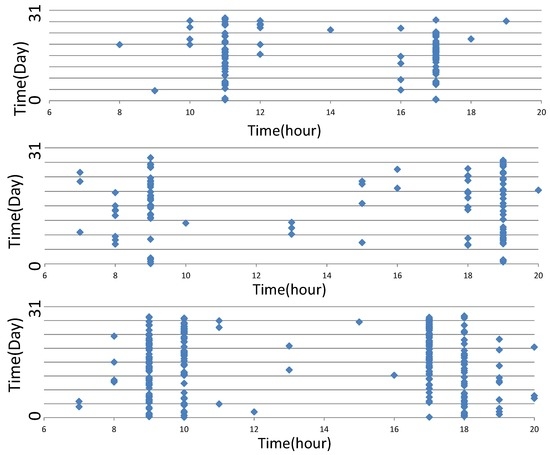
شکل 5. تفاوت داده های فردی در سفرهای اتوبوس خط 1.

شکل 6. جریان مسافران مکرر و موردی اتوبوس خط 1.
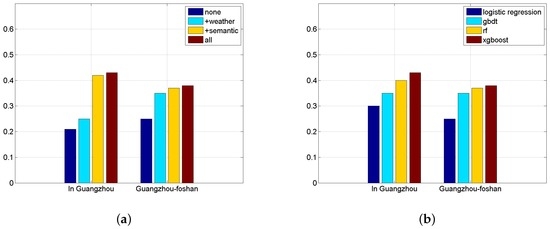
شکل 7. امتیازات F1 پیش بینی انتخاب سوار شدن مسافران. ( الف ) ویژگی ها؛ ( ب ) مدل ها.
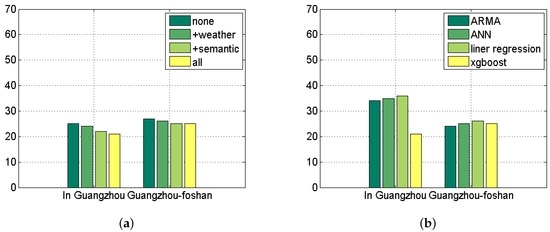
شکل 8. ریشه میانگین مربعات خطا (RMSE) پیش بینی جریان مسافر. ( الف ) ویژگی ها؛ ( ب ) مدل ها.
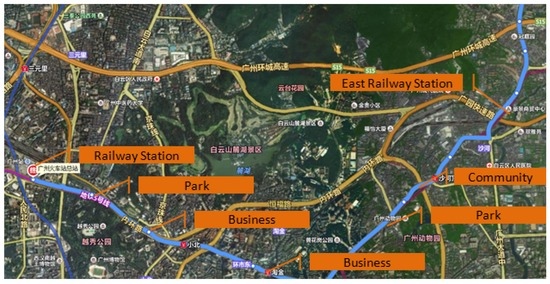
شکل 9. دلایل بالقوه برای سوار شدن به اتوبوس.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر