

خلاصه
این مقاله به نحوه مدیریت دادههای فضایی مسطح با استفاده از MongoDB، یک پایگاه داده محبوب NoSQL میپردازد که بهعنوان یک زبان پرس و جوی مبتنی بر سند، غنی و در دسترس بودن بالا مشخص میشود. ایده اصلی این است که یک ساختار R-tree سلسله مراتبی را به یک مجموعه MongoDB جدولی تبدیل کنیم، که طی آن گره های درخت R به عنوان اسناد مجموعه و اشاره گرهای درخت R به عنوان شناسه سند بیان می شوند. با پیروی از این استراتژی، یک طرح ذخیرهسازی برای پشتیبانی از عملیات ایجاد، خواندن، بهروزرسانی و حذف (CRUD) مبتنی بر درخت R طراحی شده و یک ماژول برای مدیریت دادههای فضایی مسطح با مصرف و حفظ ساختار درخت R مسطح توسعه مییابد. سپس ماژول R-tree به طور یکپارچه در MongoDB ادغام میشود، به طوری که کاربران میتوانند دادههای فضایی مسطح را با رابطهای دستوری موجود که به دادههای مکانی ژئودتیکی گرایش دارند، دستکاری کنند. ارزیابی تجربی، با استفاده از مجموعه دادههای دنیای واقعی با پوشش، انواع و اندازههای متنوع، نشان میدهد که دادههای فضایی مسطح را میتوان بهطور مؤثری توسط MongoDB با درخت R مسطح ما مدیریت کرد و بنابراین، وسعت کاربرد MongoDB بسیار بزرگتر خواهد شد. کار ما منجر به یک شاخه MongoDB با پشتیبانی R-tree شد که برای دسترسی آزاد در GitHub منتشر شده است.
کلید واژه ها:
NoSQL ; MongoDB _ 2dsphere ; داده های فضایی مسطح ; درخت R پهن شده
1. معرفی
فناوریهای سنجش و اطلاعات ما را وارد عصر به اصطلاح «دادههای بزرگ» کرده است [ 1 ، 2 ]. پایگاه های داده سنتی رابطه ای، محدود به تقاضای عادی سازی [ 3 ] و ضمانت اتمی، سازگاری، جداسازی و دوام (ACID) [ 4 ]، عملکرد ضعیفی در رویارویی با نیازهای مبرم برنامه های «داده های بزرگ»، مانند ذخیره سازی انبوه داده، بالا دسترسی همزمان، مقیاسپذیری افقی راحت، و غیره اخیراً پایگاههای اطلاعاتی NoSQL (نه فقط SQL) بیشتری [ 5 ، 6 ] برای به چالش کشیدن «دادههای بزرگ» مانند BigTable [ 7 ]، Dynamo [ 8 ]، Cassandra [ 9 ] توسعه یافتهاند. و MongoDB [ 10]. در میان آنها، MongoDB یک پایگاه داده منبع باز سند محور با طرحواره پویا، زبان جستجوی غنی و در دسترس بودن بالا است که صنایع بیشتری را برای تجربه قدرت خود جذب می کند. به عنوان مثال، Adobe از MongoDB برای ذخیره پتابایت داده در مخازن محتوای بزرگ که زیربنای Experience Manager هستند استفاده می کند. eBay از MongoDB در پیشنهاد جستجو و Hub داخلی Cloud Manager State استفاده می کند. علاوه بر این، MongoDB شروع به ایفای نقش مهمی برای محققان برای ذخیره داده های علمی خود می کند. به عنوان مثال، جیانگ و همکاران. یک سیستم ذخیره سازی خوشه بندی مبتنی بر MongoDB برای داده های بدون ساختار ایجاد کرد [ 11 ]. لانگ و همکاران از MongoDB برای مدیریت اجزای مدلسازی ساختمان و ابرداده آنها استفاده کرد [ 12 ].
در میان «دادههای بزرگ»، بخش بزرگی به طور صریح یا ضمنی با مکانهای مکانی مانند دادههای مشاهده زمین، دادههای شی متحرک، دادههای OD رفتوآمد و غیره مرتبط است. به منظور دستکاری دادههای مکان، MongoDB استاندارد GeoJSON را اتخاذ میکند [13] .] برای رمزگذاری ساختارهای داده های جغرافیایی و علاوه بر این، شاخص 2dsphere را برای تسریع پردازش پرس و جو فضایی فراهم می کند. از یک طرف، ویژگی های جغرافیایی مختلف، از جمله نقاط، رشته های خط، چند ضلعی و ترکیب آنها، در MongoDB موجود است. از سوی دیگر، پرس و جوهای متنوعی مانند مکان یابی نقطه، محدوده و جستجوی نزدیک توسط MongoDB پشتیبانی می شوند. در نتیجه، تعداد فزایندهای از مطالعات بر روی MongoDB برای توسعه کاربردهای فضایی متمرکز شدهاند. Foursquare، ارائهدهنده خدمات مبتنی بر مکان (LBS) محبوب، دادههای خود را به MongoDB منتقل کرده است تا از اشتراکگذاری خودکار داخلی و شاخص 2dsphere استفاده کند. Zhang و غیره از MongoDB برای انجام تجزیه، ذخیره سازی و پرس و جو از داده های مکانی عظیم GIS با فرمت شکل استفاده کردند [ 14]؛ لوتز و همکاران به استفاده از MongoDB برای ارائه داده های انبوه اندازه گیری و پردازش شده جمع آوری شده توسط ابزار سنجش از راه دور GLORIA [ 15 ] پرداخت. بوهم و همکاران MongoDB را امتحان کرد تا فایلهای بزرگ LiDAR را ذخیره کند و پرسوجوهای فضایی را در کادر محدود کاشیهای LiDAR مجاز کرد [ 16 ].
شاخص 2dsphere MongoDB در واقع قدرت شبکههای جهانی گسسته [ 17 ] و ساختارهای B + -tree [ 18 ] را ترکیب میکند، که ابتدا سطح زمین را به سلولهایی در سطوح وضوح چندگانه تقسیم میکند و سپس B + را اعمال میکند.درخت برای نمایه سازی ویژگی های جغرافیایی که به صورت یک یا چند سلول تقریبی شده اند. این بدان معناست که شاخص 2dsphere محدود به پذیرش دادههای مکانی سیستم مختصات ژئودتیکی (یعنی طول و عرض جغرافیایی) و محاسبه هندسه روی سطح زمین است (توجه داشته باشید که شاخص 2d که تنها از دادههای نقطهای یک سیستم مختصات دکارتی پشتیبانی میکند، دیگر مورد حمایت قرار نمیگیرد. MongoDB). با این حال، تعداد زیادی کاربرد، به ویژه در مقیاس شهر/کشور، وجود دارد که هنوز برای اعمال مختصات دکارتی مسطح برای اندازهگیری دادههای مکانی به دلیل اکتساب راحت و محاسبه ساده استفاده میشوند. دادههای فضایی مسطح جمعآوریشده توسط این برنامهها، مانند دادههای کاربری زمین، دادههای شبکه جاده، و دادههای تقسیم اداری، معمولاً در پایگاههای داده رابطهای شی، مانند Oracle و PostgreSQL ذخیره میشوند. ممکن است کسی استدلال کند که امکان تبدیل داده های فضایی مسطح تحت یک سیستم مختصات ژئودتیکی و سپس وارد کردن آن به MongoDB وجود دارد. با این حال، چنین تبدیلی برای دادههای مکانی در مقیاسهای کوچک نه ضروری است و نه مناسب، زیرا مکانیابی موقعیت و محاسبه هندسه تحت یک سیستم مختصات دکارتی دقیقتر است، و علاوه بر این، محاسبات دکارتی سادهتر و کارآمدتر از محاسبات کروی است.
به خوبی شناخته شده است که R-tree [ 19] یک ساختار شاخص دوبعدی پرکاربرد برای مدیریت داده های فضایی مسطح است و در حال حاضر به یک پیکربندی ضروری و ضروری در پایگاه داده های فضایی مدرن تبدیل شده است. علاوه بر این، R-tree حجم زیادی از کار تحقیقاتی را در زمینههای دانشگاهی مرتبط به خود جلب میکند، که در نتیجه انواع کمی از R-tree ایجاد میشود. تا آنجا که ما می دانیم، کار کمی در جهان NoSQL وجود دارد که به پردازش داده های مکانی که توسط R-tree ارائه می شود، می پردازد. در واقع، اکثر محصولات NoSQL به مسائلی مانند مقیاس پذیری و در دسترس بودن توجه زیادی دارند، با توجه به ارائه انواع داده های مکانی، چه رسد به پشتیبانی از پردازش پرس و جو فضایی، ترک فضای ذخیره سازی، و پردازش یک کار نسبتاً دشوار توسعه برنامه. اگرچه MongoDB استاندارد GeoJSON را برای پذیرش داده های مکانی و در نتیجه فعال کردن توابع فضایی اعمال می کند.
به منظور استفاده از MongoDB و R-tree، این مقاله چگونگی ادغام موثر شاخص های R-tree را در MongoDB و بنابراین، توانایی مدیریت داده های فضایی مسطح را بررسی می کند. ایده اصلی این است که ساختار سلسله مراتبی R-tree را در مجموعه MongoDB جدولی قرار دهیم، که در آن گره های درخت R به عنوان اسناد مجموعه و نشانگرهای درخت R بین گره ها به عنوان شناسه سند برای ارجاع خارجی بیان می شوند. در ابتدا، یک طرح داده در مورد داده های فضایی مسطح و یک درخت R مسطح طراحی شده است. پس از آن، ماژولی که دادههای فضایی مسطح را با مصرف و حفظ درخت R مسطح مدیریت میکند، توسعه مییابد، که سپس به طور یکپارچه به گرههای مسیریابی MongoDB متصل میشود. با این طراحی، نه تنها داده های فضایی مسطح، بلکه درختان R هموار، میتوان بین گرههای ذخیرهسازی MongoDB توزیع کرد و علاوه بر این، دادههای فضایی مسطح را میتوان با رابطهای موجود برای دادههای مکانی زمینشناسی بارگذاری و پرس و جو کرد. ارزیابی تجربی، با استفاده از مجموعه دادههای دنیای واقعی با پوشش، انواع و اندازههای متنوع، نشان میدهد که دادههای فضایی مسطح را میتوان بهطور مؤثری توسط MongoDB با درخت R مسطح ما مدیریت کرد و بنابراین، وسعت کاربرد MongoDB بسیار بزرگتر خواهد شد. پیاده سازی ما بر اساس MongoDB 3.2.0 منتشر شده است وسعت کاربرد MongoDB بسیار بزرگتر خواهد شد. پیاده سازی ما بر اساس MongoDB 3.2.0 منتشر شده است وسعت کاربرد MongoDB بسیار بزرگتر خواهد شد. پیاده سازی ما بر اساس MongoDB 3.2.0 منتشر شده استhttps://github.com/lmars-gis/mongo/tree/v3.2.0/rtree برای دسترسی آزاد، با هدف بهره مندی بیشتر افراد در زمینه GIS.
ساختار باقیمانده این مقاله به شرح زیر است. بخش 2 برخی از دانش پیش زمینه لازم را معرفی می کند و بخش 3 ایده جدیدی را برای صاف کردن ساختار درخت R در مجموعه MongoDB ارائه می دهد. در بخش 4 ، چارچوب ادغام یک ماژول R-tree در MongoDB توضیح داده شده و برخی از مسائل کلیدی یکپارچه سازی مورد بحث قرار گرفته است. در بخش 5 ، مدیریت داده های مکانی با درخت R مسطح، شامل عملیات ایجاد، خواندن، به روز رسانی و حذف (CRUD) مورد بررسی قرار گرفته است. بخش 6 ارزیابی تجربی را با مقایسه درخت R مسطح و 2dsphere داخلی گزارش می کند و در نهایت بخش 7 نتیجه گیری های ما را گزارش می کند.
2. پس زمینه
2.1. NoSQL و MongoDB
NoSQL که توسط درخواستهای شرکتهای Web 2.0 مانند فیسبوک و آمازون آغاز شده است، به وجود آمده است تا مکانیزمی برای ذخیرهسازی و بازیابی دادهها فراهم کند که به روشهایی غیر از روابط جدولی مورد استفاده در پایگاههای داده رابطهای مدلسازی میشوند. یک پایگاه داده NoSQL دارای یک معماری توزیع شده و مقاوم در برابر خطا است که از SQL به عنوان زبان پرس و جو استفاده نمی کند و ممکن است تضمین کامل ACID را ارائه نکند. با توجه به نحوه ذخیره داده ها، پایگاه های داده NoSQL را می توان به چهار دسته طبقه بندی کرد: پایگاه داده های Key-value مانند Dynamo، پایگاه داده ستون محور مانند BigTable، پایگاه داده های سند گرا مانند MongoDB، و پایگاه داده های Graph مانند Neo4j [20 ] .
پایگاه داده های مختلف NoSQL مزایای متفاوتی را برای برنامه های مختلف ارائه می دهند. MongoDB در مقایسه با سایر پایگاه های داده NoSQL، توابع پرس و جو پیچیده تری را در برابر یک مدل داده مدار مدار ارائه می دهد. این یک سیستم خوشه بندی توزیع شده معمولی است که از سه جزء کلیدی، یعنی سرور خرد، سرور پیکربندی و سرور مسیر تشکیل شده است. برنامهها MongoDB را از طریق هر یک از گرههای سرور روتر آدرسدهی میکنند، که سپس عملیات را به گرههای مناسب سرور خرد ارسال میکند. داده ها در تمام گره های سرور خرد توزیع می شود، در حالی که ابرداده در مورد توزیع در سرور پیکربندی حداکثر سه گره ذخیره می شود. MongoDB قادر به ارائه قابلیت توزیع خودکار است که به معنای تعادل بار ورودی/خروجی خودکار در میان چندین گره سرور خردهای است.
یک پایگاه داده MongoDB از مجموعه ها، یک واحد منطقی مانند جداول در یک پایگاه داده رابطه ای برای سازماندهی داده های مرتبط تشکیل شده است. برخلاف جدولی که از ردیف هایی با ساختار ثابت تشکیل شده است، یک مجموعه شامل اسنادی است که ممکن است ساختارهای مختلفی را ارائه دهند. یک سند در قالب BSON (JSON باینری) کدگذاری میشود که بنابراین، میتواند برای نمایش ساختار پیچیدهتری مانند اشیاء جغرافیایی تودرتو باشد. برای هر سند ذخیره شده در MongoDB، یک شناسه منحصر به فرد 12 بایتی به نام “_id” اختصاص داده می شود. از نظر فنی، یک مجموعه ترجیح داده می شود که در “_id” توسط B + داخلی ایندکس شود-tree که پرس و جوی مجموعه را از طریق “_id” بسیار کارآمد می کند. به منظور پشتیبانی از داده های مکانی، MongoDB از فرمت GeoJSON برای کدگذاری انواع ساختارهای داده جغرافیایی استفاده می کند که سپس توسط نمایه داخلی 2dsphere ایندکس می شوند. این بدان معنی است که اگر مجموعه ای برای ذخیره اشیاء جغرافیایی تنظیم شده باشد، همه اسناد درج شده باید یک فیلد از ساختار GeoJSON را به اشتراک بگذارند. همانطور که گفته شد، 2dsphere هندسهها را بر روی یک سطح زمین مانند محاسبه میکند که آن را به دادههای فضایی سیستم مختصات ژئودتیکی محدود میکند.
2.2. R-Tree و انواع آن
به منظور ارائه عملکرد بالا برای پرس و جوهای فضایی، ساختارهای شاخص فضایی مختلفی مانند Quadtree [ 21 ]، kd-tree [ 22 ]، R-tree، BSP-tree [ 23 ] و غیره توسعه یافته اند. در میان آنها، درخت R محبوب ترین است و به طور گسترده در هر دو زمینه نظری و کاربردی استفاده می شود. می توان آن را به عنوان یک پسوند چند بعدی از B + مشاهده کرددرخت، که در آن ایده کلیدی تقریب اشیاء فضایی با حداقل مستطیل های مرزی آنها (MBRs) و سپس گروه بندی بازگشتی MBR های مجاور در یک ساختار درختی سلسله مراتبی است. با استفاده از جعبه مرزی، R-tree از پرس و جوهای کارآمد نقطه، محدوده و نزدیک در برابر اشیاء فضایی تحت یک فضای چند بعدی مسطح، مانند نقاط دو بعدی، خطوط، مناطق یا ساختمان های سه بعدی پشتیبانی می کند. مانند B + -tree، R-tree نیز صفحهگرا است، به این معنی که اندازه یک گره دقیقاً برابر با صفحه دیسک است. به منظور جلوگیری از تقسیم مکرر گره، R-tree حداکثر تعداد ورودی را برای هر گره اختصاص می دهد. R-tree همچنین حداقل پر شدن را برای همه گره ها، به جز ریشه، تضمین می کند تا استفاده از فضا را بهبود بخشد.
در طول اعصار، R-tree به موفقیت های بزرگی دست یافته است، که نه تنها توسط غول های پایگاه داده فضایی مانند Oracle و PostgreSQL به خوبی پشتیبانی می شود، بلکه مطالعات زیادی را برای بهبود R-tree جذب می کند، که منجر به بسیاری از گونه های R-tree می شود. R*-tree [ 24 ] عملکرد پرس و جوی R-tree را با اعمال قوانین هرس قدرتمندتر برای کاهش پوشش و همپوشانی گره ها بهبود می بخشد. TPR-Tree [ 25 ] R-tree را گسترش می دهد تا اشیایی را که در حال حرکت هستند، به عنوان مثال، مکان آنها را به طور مداوم تغییر دهد و بنابراین می تواند مکان های آینده اشیاء را پیش بینی کند. MV3R-tree [ 26 ] یک درخت R چند نسخه ای و یک درخت R 3 بعدی کمکی کوچک را ترکیب می کند و از پرس و جوهای زمانی- مکانی کارآمد پشتیبانی می کند. SD-Rtree [ 27] با تعمیم درخت R به یک درخت باینری توزیع شده و متعادل، ساختار R-tree را به محیط های مقیاس پذیر و توزیع شده می آورد.
تا آنجا که به داده های مکانی مربوط می شود، کاراکترها و کاربردها، و همچنین مزایا و معایب MongoDB و R-tree در جدول 1 خلاصه شده است . سهم اصلی این مقاله دقیقاً ترکیب قدرت MongoDB و R-tree و بنابراین توسعه یک مدیریت مبتنی بر MongoDB از دادههای فضایی مسطح با R-tree است.
3. صاف کردن درختان R با مجموعه های MongoDB
3.1. یک استراتژی مسطح
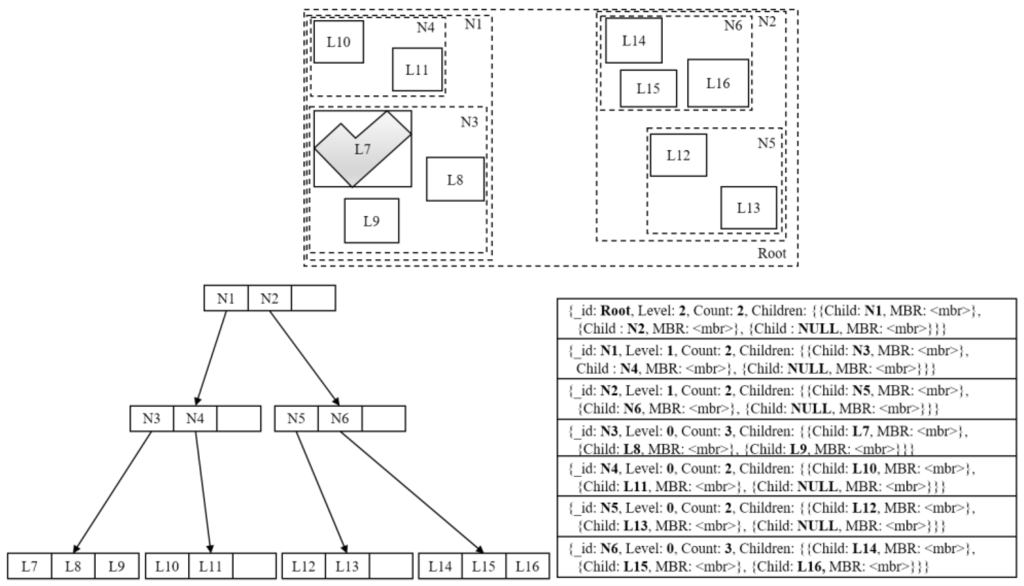
از یک طرف، گرههای درخت R، اعم از گرههای برگ یا گرههای درونی، از ساختارهای تودرتو هستند و اشارهگرهای درخت R از والدین به فرزندان در واقع آدرسهایی هستند که هر یک مکان دیسک منحصر به فرد را نشان میدهند. از سوی دیگر، اسناد MongoDB که با فرمت BSON کدگذاری شدهاند، از مکانیزم قدرتمندی برای مدلسازی اشیاء با ساختارهای پیچیده پشتیبانی میکنند و هر سند MongoDB با یک شناسه منحصربهفرد، یعنی «_id» اختصاص داده میشود. این به ما انگیزه میدهد تا R-trees را با مجموعههای MongoDB شبیهسازی کنیم و بنابراین، MongoDB را قادر میسازد تا دادههای فضایی مسطح را مدیریت کند. به طور خاص، یک ساختار R-tree به عنوان یک مجموعه MongoDB ارائه می شود، که در آن گره ها به عنوان اسناد بیان می شوند و نشانگرها با شناسه های سند جایگزین می شوند. با چنین شبیه سازی، یک درخت R از ساختار سلسله مراتبی به یک مجموعه MongoDB از ارائه جدولی مسطح می شود. در نتیجه،شکل 1 نمونه ای از R-tree پهن شده با مجموعه MongoDB را نشان می دهد، که در آن درخت R پایین سمت چپ 10 شی فضایی (یعنی L7-L16) نشان داده شده در بالا را نشان می دهد و مجموعه پایین سمت راست نتیجه مسطح شده است.
می توان دید که هر سند مجموعه ای که دقیقاً یک گره R-tree را ارائه می کند به گونه ای طراحی شده است که شامل چهار جفت کلید-مقدار باشد. اولین مورد نشان دهنده شناسه گره است که از شناسه سند داخلی استفاده می کند، یعنی “_id”. مورد دوم نشان دهنده سطح شمارش گره از برگ تا ریشه است. مورد سوم دلالت بر تعداد ورودی های شاخص در یک گره دارد. آخرین مورد اطلاعات ورودی را مشخص می کند، که در آن جزء مقدار به عنوان آرایه ای از ورودی های شاخص اعلام می شود. برای هر ورودی شاخص I ، شامل دو جفت کلید-مقدار ثابت است: «فرزند» برای ارجاع به سند استفاده میشود در حالی که «MBR» مقداری از نوع MBR را ذخیره میکند. اگر گره Iیک برگ است، “Child” به یک شی فضایی واقعی که به عنوان سند در مجموعه دیگری ذخیره شده است اشاره می کند و “MBR” MBR این شی را ثبت می کند، در غیر این صورت، “Child” به سند مربوط به گره فرزند I و “MBR” اشاره می کند . MBR را برای همه اشیاء فضایی در شاخه I محاسبه می کند . به عنوان مثال، ورودی شاخص سوم سند اول دارای مقدار “NULL” برای کلید “Child” اعلام شده است، به این معنی که این ورودی هنوز استفاده نشده است و بنابراین، شاخه مربوطه در حال حاضر خالی است.
اگرچه MongoDB از ذخیرهسازی دادههای بدون طرحواره پشتیبانی میکند، ما هنوز یک ساختار ثابت برای اسناد در مجموعه R-tree را بررسی میکنیم، زیرا پیشتخصیص فضا میتواند از جابجایی دائمی دادهها روی دیسک سخت در طول گسترش گره و کوچکشدن جلوگیری کند [28 ] . به عبارت دیگر، تمام اسناد با حداکثر تعداد ورودی های شاخص «فرزندان» ایجاد می شوند، اگرچه تعداد ورودی های شاخص واقعی معمولا کمتر از آن است. علاوه بر این، یک MBR برای هر ورودی فهرست استفاده شده در یک سند گره نگه داشته می شود، به طوری که ورودی های نامربوط را می توان به سرعت بدون نیاز به دسترسی به فرزندان در هنگام انجام پرس و جوها فیلتر کرد. در نهایت، “Count” که به عنوان یک جفت میانبر اضافی عمل می کند، می تواند از اسکن مکرر از طریق “Children” در طول مرحله تعادل مجدد درخت R جلوگیری کند.
3.2. طرحواره مرتبط با درخت R
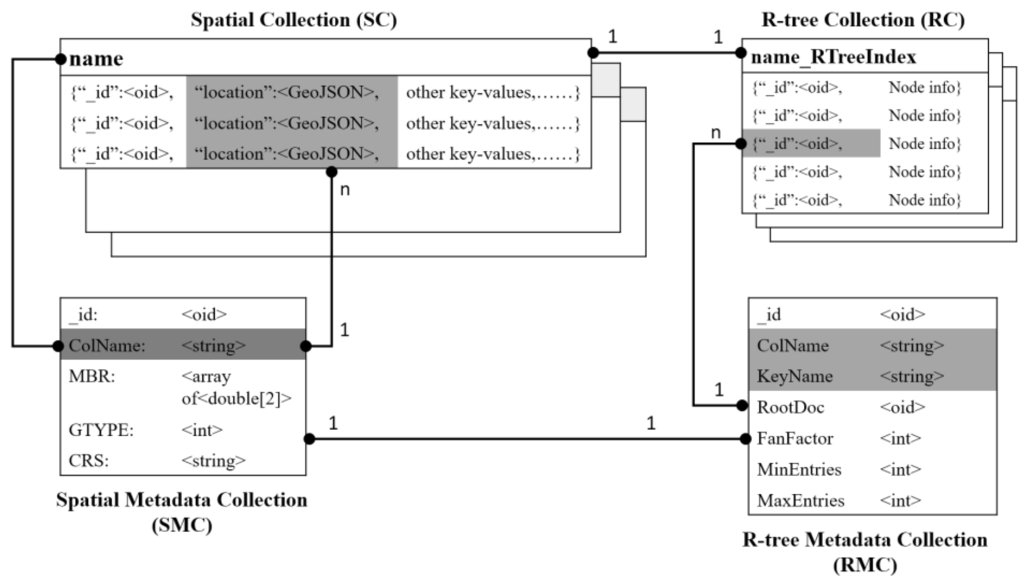
همانطور که در شکل 2 نشان داده شده است، چهار نوع مجموعه وجود دارد که در مدیریت داده های فضایی مسطح نقش دارند . آنها مجموعه فضایی (SC)، مجموعه درخت R (RC)، مجموعه ابرداده مکانی (SMC) و مجموعه ابرداده درخت R (RMC) هستند. با دو مورد اخیر، هر یک مجاز است یک نمونه در سیستم داشته باشد، در حالی که با دو مورد اول، هر یک می تواند چندین نمونه داشته باشد. علاوه بر این، SC و RC یک رابطه 1:1 را تشکیل می دهند، به عنوان مثال، یک مجموعه فضایی با یک مجموعه R-tree پیکربندی شده است.
SC یک مجموعه معمولی با یک جفت کلید-مقدار برای ذخیره داده های فضایی کدگذاری شده در قالب GeoJSON، همراه با سایر جفت های کلید-مقدار برای توصیف ویژگی های غیر مکانی است. RC یک مجموعه کمکی با ساختاری خاص برای صاف کردن درختان R است که در بخش بالا ارائه شده است. اگر یک مجموعه فضایی به گونهای تنظیم شده است که با R-tree نمایه شود، یک مجموعه R-tree باید ایجاد و با اضافه کردن پسوند “_RTree” به نام مجموعه فضایی، نامگذاری شود. تحت این قانون نامگذاری، می توان به راحتی مجموعه R-tree را برای هر مجموعه فضایی مشخص شناسایی و به کار برد. با توجه به یک مجموعه داده فضایی مسطح، ابرداده آن در SMC ذخیره می شود و اگر توسط درخت R نمایه شود، پارامترهای آن در RMC ثبت می شود.
با SMC، کاربران میتوانند بگویند که چند مجموعه داده فضایی مسطح، که هر کدام مربوط به یک SC است، در سیستم مدیریت میشوند، و همچنین فرادادهای را برای یک مجموعه داده ثبتشده، مانند نوع هندسه، جعبه مرزی، سیستم مختصات و غیره به دست آورند. از آنجایی که RMC حاوی یک کلید خارجی به نام “ColName” است که به SMC ارجاع می دهد، کاربران می توانند ردیابی کنند که آیا یک مجموعه فضایی توسط یک عملگر پیوستن به درخت R فهرست شده است یا نه. از این رو، ابرداده درخت R، مانند کلید هدف (که درخت R بر روی آن ساخته شده است)، سند ریشه و فاکتور انشعاب نیز در دسترس کاربران است. توجه داشته باشید که در SMC: کلید “MBR” یک کادر محدود چند بعدی است و فقط به یک فضای دو بعدی محدود نمی شود، کلید “GTYPE” باید یکی از هفت نوع هندسه بومی باشد که توسط GeoJSON پشتیبانی می شود و کلید “CRS” دارای یک اعتبار معتبر است. شناسه سیستم مرجع فضایی تحت چارچوب EPSG (گروه بررسی نفت اروپا).
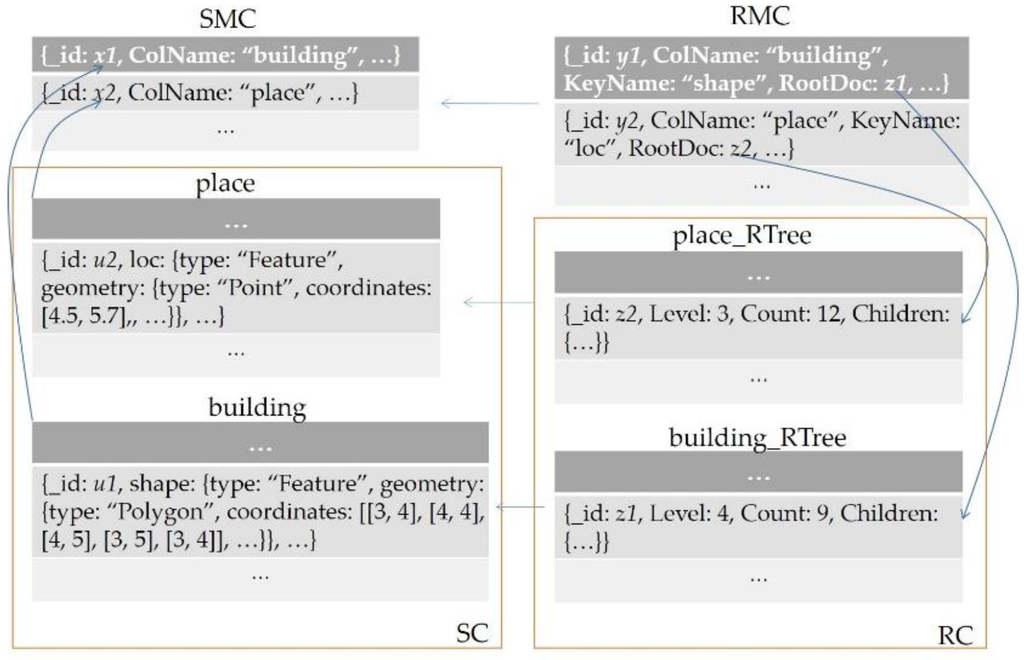
به منظور نشان دادن طرح ذخیره سازی مرتبط با درخت R، یک مورد کاربر در مورد داده های مکانی در یک شهر در شکل 3 ارائه شده است . می توان دید که دو مجموعه داده فضایی به عنوان دو مجموعه (“مکان” و “ساختمان”) در فضای نام SC در پایگاه داده بارگذاری شده و در SMC به عنوان دو سند (x 1 و x 2) ثبت شده است . علاوه بر این، درختان R برای دو مجموعه داده در فضای نام RC، یعنی “place_Rtree” و “building_RTree” ایجاد شده اند و ابرداده های آنها در RMC، یعنی y 1 و y ذخیره شده است.2. با این مورد کاربر، می توان به راحتی از SMC دریافت که دو مجموعه داده فضایی در پایگاه داده موجود است. علاوه بر این، می توان از RMC تأیید کرد که هر یک از آنها با یک درخت R همراه هستند.
4. ادغام R-Tree در MongoDB
4.1. چارچوب و گردش کار
دو استراتژی برای MongoDB برای ادغام درخت R مسطح وجود دارد: یک آژانس برای محافظت از MongoDB و یک ماژول برای اتصال به MongoDB. اولی بهعنوان یک میانافزار بین کلاینت و پایگاهداده عمل میکند و بنابراین پیادهسازی آن نسبتاً آسان است، با این حال، هزینه یادگیری کاربران نهایی را که ممکن است مجبور باشند با یک ابزار جدید آشنا باشند و به یک زبان اسکریپت جدید تسلط داشته باشند، افزایش میدهد. از این رو، ما دومین گزینه یکپارچهسازی را انتخاب کردیم که به کاربران اجازه میدهد از درخت R مسطح تقریباً به روشی مشابه 2dsphere داخلی استفاده کنند.
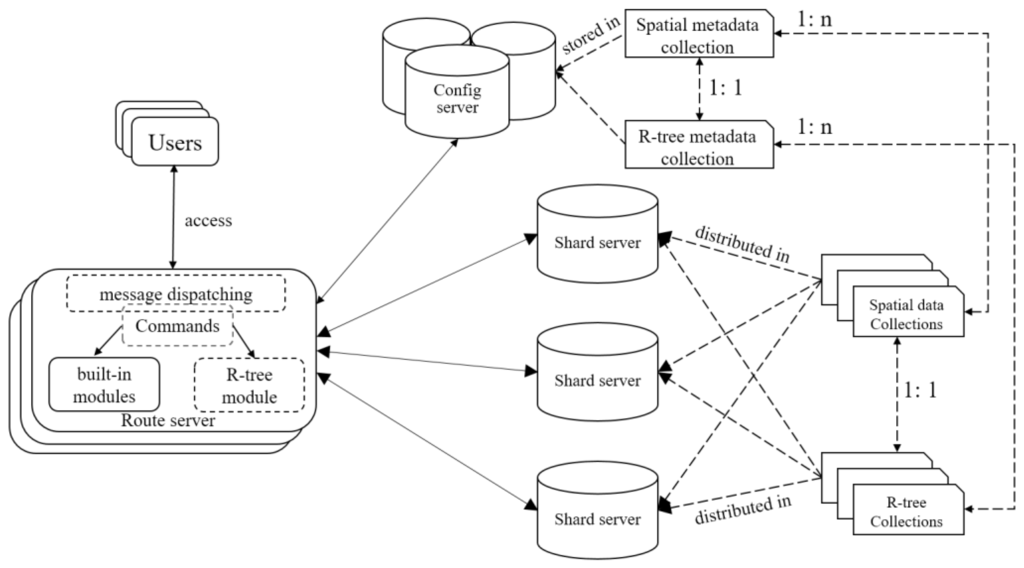
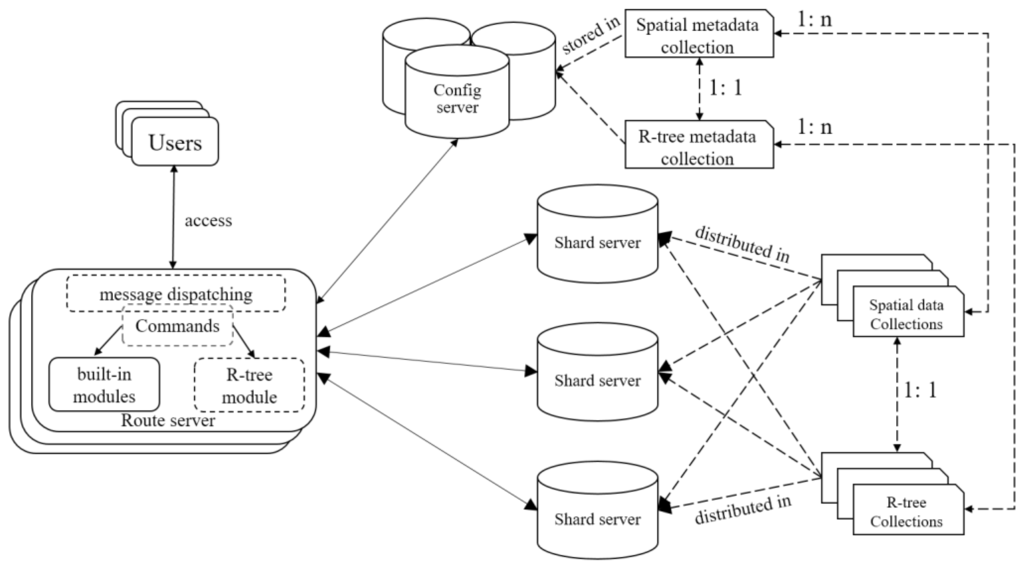
چارچوب ادغام R-tree مبتنی بر MongoDB در شکل 4 ارائه شده است . قسمت سمت راست پیکربندی طرحواره ذخیره سازی R-tree را نشان می دهد و قسمت سمت چپ نشان می دهد که چگونه R-tree در MongoDB تعبیه شده است. می توان مشاهده کرد که SMC و RMC که به عنوان ابرداده عمل می کنند، در سرور پیکربندی ذخیره می شوند، در حالی که SC و RC ممکن است با فعال کردن عملکرد اشتراک گذاری در شناسه های سند در تمام گره های سرور خرد توزیع شوند. این بدان معناست که یک درخت R مسطح، در صورت لزوم، میتواند گرههای خود را بین گرههای ذخیرهسازی مختلف توزیع کند و بنابراین، بازده ورودی/خروجی دسترسی R-tree به اشتراک گذاشته میشود، که بدیهی است که پردازش پرس و جو، بهویژه برای پرسوجوهای همزمان، مفید خواهد بود.
ماژول R-tree در سرور روتر پیاده سازی و مستقر می شود که از عملیات CRUD با دستکاری SMC و RMC در سرور پیکربندی و همچنین SC و RC در سرور خرد پشتیبانی می کند. همانند 2dsphere، عملیات CRUD پشتیبانی شده از درخت R در دستوراتی کپسوله میشوند که از فرمان سیستم ریشه به ارث میبرند. کاربران می توانند دستوری را در قالب GeoJSON صادر کنند که سپس به عنوان یک پیام شبکه از ساختار باینری بسته بندی شده و در نهایت به سرور روتر ارسال می شود. در ورودی سرور روتر، عملکرد مدیریت پیام بازنویسی می شود که ابتدا پیام دریافتی را تجزیه می کند، دستور مربوطه را دوباره ساخته و سپس آن را به ماژول R-tree یا ماژول های داخلی برای اجرا ارسال می کند. به طور خاص، اگر دستوری برای داده های فضایی مسطح هدف قرار گیرد، به ماژول R-tree می رود تا یک دستور تازه مشتق شده را فراخوانی کند، در غیر این صورت به ماژول های داخلی می رود تا برخی از دستورات بومی را اجرا کند. فرض کنید دستور {$geoIntersects: {$geometry: {type: “Polygon”, مختصات: [[100, 100], [150, 100], [120, 140], [100, 100]]}}} در مقابل صادر شده است “city.place.loc”، که در آن “city” یک پایگاه داده را نشان می دهد، “place” مجموعه ای در “city” و “loc” یک فیلد فضایی در “place” است. بدیهی است که این دستور عملیات خواندن جستجوی همپوشانی را در بر می گیرد، که اگر درخت R بر روی فیلد “loc” مجموعه “place” در پایگاه داده “city” ساخته شده باشد، توسط ماژول R-tree اجرا می شود. 100]]}}} در برابر “city.place.loc” صادر می شود، که در آن “city” نشان دهنده پایگاه داده، “place” مجموعه ای در “city” و “loc” یک فیلد فضایی در “place” است. بدیهی است که این دستور عملیات خواندن جستجوی همپوشانی را در بر می گیرد، که اگر درخت R بر روی فیلد “loc” مجموعه “place” در پایگاه داده “city” ساخته شده باشد، توسط ماژول R-tree اجرا می شود. 100]]}}} در برابر “city.place.loc” صادر می شود، که در آن “city” نشان دهنده پایگاه داده، “place” مجموعه ای در “city” و “loc” یک فیلد فضایی در “place” است. بدیهی است که این دستور عملیات خواندن جستجوی همپوشانی را در بر می گیرد که اگر درخت R بر روی فیلد “loc” مجموعه “place” در پایگاه داده “city” ساخته شده باشد، توسط ماژول R-tree اجرا می شود.
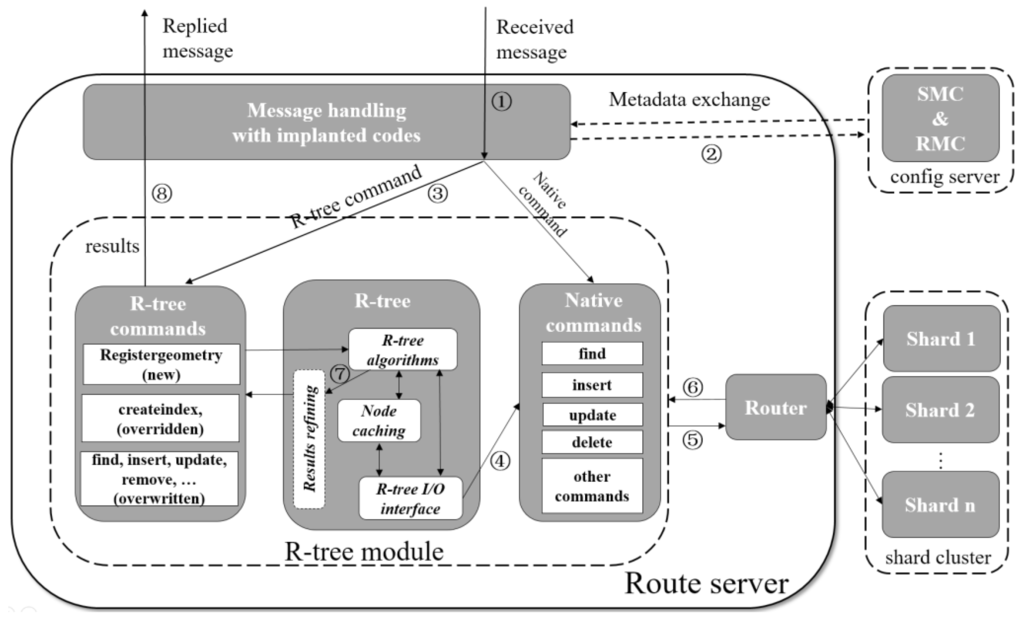
شکل 5یک گردش کار معمولی را برای عملیات های پشتیبانی شده از درخت R ارائه می دهد که در آن مراحل درگیر با اعداد دایره ای نشان داده می شوند. پس از اینکه سرور مسیر یک پیام شبکه را دریافت کرد و سپس آن را تجزیه کرد (مرحله 1)، کدهای ما در مدیریت پیام با سرور پیکربندی مشورت خواهند کرد تا بررسی کنند که آیا درخت R مسطح برای مجموعه هدف ایجاد شده است (مرحله 2)، و در در صورت بله، یک فرمان مناسب ارائه شده توسط ماژول R-tree مشخص شده است (مرحله 3). سپس، SC و RC مربوطه با تشکیل یک سری دستورات بومی (مرحله 4) و ارسال آنها به سرور شارد (مرحله 5) پرس و جو و/یا نگهداری می شود. سپس سرور shard دستورات را به صورت محلی اجرا می کند و به ماژول R-tree با نتایج پاسخ می دهد (مرحله 6). در صورت لزوم، نتایج بازگردانده شده از سرور مسیر پالایش خواهد شد (مرحله 7). سرانجام،
4.2. دو موضوع کلیدی
- (1)
-
طراحی جداشده ورودی/خروجی R-tree
همانطور که در شکل 4 نشان داده شده است، درخت R مسطح به گونه ای طراحی شده است که از دو سطح از اجزای با اتصال شل تشکیل شده است.. سطح زمین یک رابط ورودی/خروجی بر اساس واحد سند فراهم میکند و مسئولیت عملیات چهار نوع مجموعه را بر عهده میگیرد. سطح سقف از الگوریتمهای درخت R مختلف، یعنی جستجو، درج، حذف، و بهروزرسانی پشتیبانی میکند، و همچنین عملکردهایی را برای کارکردن دو مجموعه ابرداده و بنابراین، به عهده گرفتن مسئولیت جستجو/نگهداری درخت R مسطح شده ارائه میکند. در نتیجه، سطح سقف مستقل از ذخیره سازی می شود، با تمرکز بر منطق درخت R، در حالی که سطح زمین بر تبادل داده متمرکز است. اگرچه این درخت R جدا شده از ورودی/خروجی برای پایگاه داده MongoDB سند گرا توسعه داده شده است، اما می توان آن را به راحتی با رونویسی رابط I/O به حافظه های دیگر مانند سیستم های فایل منتقل کرد.
به منظور بهبود بیشتر بازده ورودی/خروجی، ماژول R-tree با یک کش پیکربندی شده است تا اسناد گره پرکاربرد را در حافظه نگه دارد. در اینجا، ما روش LRU را به عنوان استراتژی جایگزینی برای دور انداختن گرههای درخت R که اخیراً استفاده شدهاند، اتخاذ میکنیم. از آنجایی که گرههای R-tree توسط اسناد MongoDB شبیهسازی میشوند که اندازه ثابتی دارند و هر یک از آنها دارای یک شناسه منحصربهفرد هستند، این کش مبتنی بر گره از نظر ساختار ساده است، به راحتی قابل دستکاری است و در نتیجه، میزان واکشی سند از طریق I است. رابط /O را می توان به طور قابل توجهی کاهش داد.
- (2)
-
استفاده مجدد و گسترش دستورات سیستم
شبیه به 2dsphere، ماژول R-tree با عملکرد مدیریت پیام از طریق دستورات به ارث رسیده از دستور root در سیستم فرمان سرور روتر ارتباط برقرار می کند. علاوه بر این، دستوراتی که 2dsphere را اجرا می کنند، تا آنجا که ممکن است مجدداً در درخت R استفاده می شوند تا کمترین دستورات جدید را معرفی کنند. جدول 2دستورات اصلی پشتیبانی شده توسط ماژول R-tree را خلاصه می کند. توجه داشته باشید که دستوری به نام “registerGeomtry” برای شناسایی مجموعههای مورد استفاده برای ذخیره دادههای فضایی مسطح و ابردادههای آنها اضافه میشود و در نتیجه، مفهوم لایه مشترک برای مدیریت دادههای فضایی مسطح به MongoDB آورده میشود. علاوه بر این، “createIndex” یک دستور لغو شده است زیرا R-tree پارامترهای متفاوت از 2dsphere را درخواست می کند، در حالی که بقیه همه دستورات روی دستورهای اصلی خود بازنویسی می شوند. این به این معنی است که یک فرمان بازنویسی شده، به عنوان مثال، find، اعلان یکسانی از نام و آرگومانها را با دستور اصلی خود به اشتراک میگذارد، اما اجرای آن بر روی ساختار درخت R مسطح شده است. با طراحی دستور ما، دادههای فضایی مسطح را میتوان توسط درخت R مسطح شده از طریق تقریباً مجموعهای از دستورات مانند دادههای مکانی زمینشناسی با 2dsphere دستکاری کرد.
همانطور که در بخش فرعی آخر ذکر شد، مجموعه ای از دستورات بومی هنگام اجرای یک دستور R-tree درگیر خواهند شد که جزئیات آن در جدول 2 ارائه شده است . به عنوان مثال، “registerGeometry” ابتدا “find” را فراخوانی می کند تا بررسی کند که آیا سندی با همین نام در SMC وجود دارد یا خیر، و سپس در هیچ موردی، “insert” را برای نوشتن یک سند در SMC فراخوانی می کند. با تبدیل یک دستور R-tree به یک سری دستورات بومی، ماژول R-tree به انجام عملیات منطقی مختلف بدون نیاز به دانستن نحوه پیکربندی و توزیع داده ها و ابرداده ها در بین خوشه بندی MongoDB دست می یابد.
5. مدیریت داده های فضایی مسطح با R-Trees پهن شده
5.1. عملیات CRUD
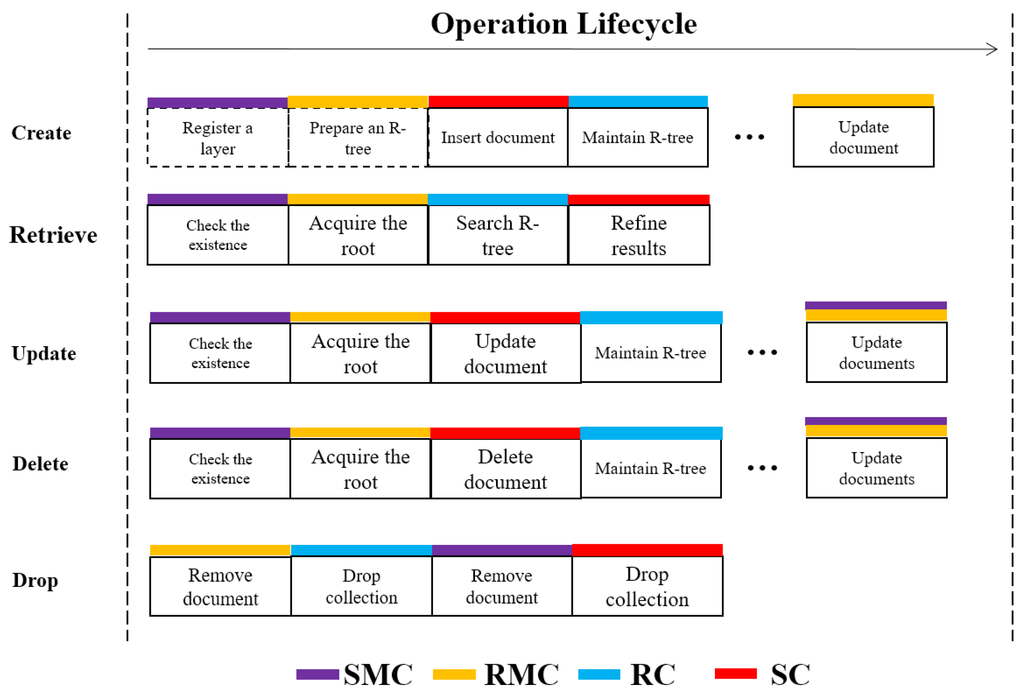
عملیات CRUD، از جمله ایجاد، خواندن، به روز رسانی و حذف، توابع اساسی هستند که یک پایگاه داده یا یک لایه پایدار باید پشتیبانی کند. در شکل 6 ، منطق اجرا با درخت R مسطح برای عملیات CRUD و همچنین برای عملیات drop ارائه شده است. توجه داشته باشید که هر عملیات توسط یک سری دستورات، یا یک دستور درخت R یا یک دستور بومی انجام می شود.
با توجه به یک مجموعه داده فضایی مسطح، وظیفه اولویت بارگذاری آن در MongoDB به عنوان یک لایه با عملیات ایجاد است که شامل سه دستور درخت R متوالی است. ابتدا، “registerGeometry” برای ثبت یک لایه فضایی در SMC فراخوانی می شود، سپس “createIndex” برای ثبت یک درخت R در RMC و در نهایت، “insert” چندین بار فراخوانی می شود تا هندسه ها را در SC پر کند و یک R مسطح ایجاد کند. درخت در RC. آخرین فرمان برای هر بار فراخوانی “insert” تا حدودی پیچیده است. یک سند را در SC می نویسد، یک ورودی را به RC اضافه می کند، ساختار RC را حفظ می کند و اگر یک سند ریشه جدید ایجاد شود، سند مربوطه را در RMC به روز می کند. برای محافظت بهتر از داده ها در برابر حوادث غیرقابل مشاهده، مانند خرابی سیستم، مهم است که اطمینان حاصل شود که نوشتن SC باید قبل از به روز رسانی RC انجام شود.
عملیات بازیابی به سادگی فرمان R-tree را “یافتن” می نامد، که طی آن یک استراتژی سه مرحله ای بررسی می شود. اولین مرحله بررسی وجود لایه فضایی هدف و درخت R مسطح به ترتیب در SMC و RMC است و در صورت وجود، شناسه سند گره ریشه از RMC به دست می آید. مرحله دوم فیلتر کردن است که درخت R مسطح شده را از سند ریشه به اسناد برگ هدایت می کند و شاخه هایی را که MBR های آنها با محدوده ورودی قطع نمی شود حذف می کند. در نتیجه مجموعه ای از مدارک نامزد به دست می آید که مرحله نهایی یعنی پالایش با هندسه دقیق را طی می کند. پس از آن، نتیجه نهایی برگردانده می شود. توجه داشته باشید که مرحله پالایش از محاسبات دکارتی استفاده می کند که توسط GEOS [ 28]، یک کتابخانه هندسه منبع باز شناخته شده است.
عملیات حذف را می توان فقط با فراخوانی فرمان درخت R “remove” به پایان رساند که شامل حذف SC و به روز رسانی RC است. برخلاف “insert”، “remove” ابتدا بهروزرسانی RC را برای حفظ درخت R اجرا میکند و سپس حذف SC را برای حذف اسناد انجام میدهد، بنابراین از ورودیهای ارجاع شده خالی در اسناد برگ جلوگیری میکند. علاوه بر این، اگر عملیات حذف باعث ایجاد یک گره ریشه جدید یا یک لایه کوچک شده MBR شود، دستور بومی “update” برای به روز رسانی RMC یا SMC فراخوانی می شود. به طور مشابه، عملیات به روز رسانی را می توان پیاده سازی کرد. به منظور حفظ درخت R مسطح تحت “به روز رسانی”، یک استراتژی درج مجدد متداول استفاده می شود [ 19] به تصویب رسید. در نهایت، یک عملیات drop برای رها کردن یک لایه داده فضایی مسطح، شامل داده ها و ابرداده های آن استفاده می شود. بنابراین، ابتدا یک سند را از RMC با “حذف” بومی حذف می کند، سپس RC را با “قطع” بومی حذف می کند و در نهایت SMC و SC را به روشی مشابه پردازش می کند.
5.2. پردازش پرس و جو با مکان نما
در این بخش فرعی، پردازش پرس و جو با مکان نما بر اساس ساختار درخت R مسطح، شامل محدوده و پرس و جوهای نزدیک، با جزئیات مورد بحث قرار می گیرد. درخواستی را در نظر بگیرید که دارای تعداد زیادی رکورد است، پردازش با مکان نما اجازه می دهد تا نتیجه به صورت دسته ای برگردانده شود و بنابراین، کاربران می توانند رکوردهای واجد شرایط را در سریع ترین زمان ممکن مرور و تجزیه و تحلیل کنند، بدون اینکه نیازی به انتظار طولانی مدت باشد. کل نتیجه به همین دلیل، مکان نما به یک پیکربندی ضروری برای پاسخگویی به پرسش ها در سیستم های پایگاه داده مدرن و برنامه های کاربردی مرتبط با داده تبدیل شده است. به منظور افزودن پشتیبانی مکان نما برای جستارهای محدوده، RC با یک پیمایش در عمق جستجو می شود: هر بار که یک ورودی برگ اسکن می شود و سپس به عنوان یک مورد واجد شرایط اعتبار می یابد، سندی که leنقاط به در یک صف با تعداد ثابتی از ورودی ها قرار می گیرند. هنگامی که صف پر است، به عنوان یک نتیجه جزئی به کاربر برگردانده می شود و در این بین، جستجوی RC به حالت تعلیق در می آید. سپس، کاربر میتواند مکاننمای مرتبط با پرس و جو را برای راهاندازی دور بعدی واکشی، که ابتدا یک صف خالی آماده میکند و سپس روند جستجو را از سر میگیرد، به جلو حرکت دهد.
پرس و جوهای نزدیک، در مقایسه با پرس و جوهای محدوده، بسیار پیچیده تر هستند. تا آنجا که به اشیاء فضایی ایستا مربوط می شود، قوی ترین روش برای جست و جوی k-نزدیکترین همسایه، تا آنجا که ما می دانیم، الگوریتم نزدیکترین همسایه افزایشی است [ 29 ]. توجه داشته باشید که درختهای R مسطح در MongoDB قرار دارند که با دستور زیر کوئریهای نزدیک صادر میکنند: {$near: {$geometry: {type: “Point”, مختصات: [< طول جغرافیایی >، < طول جغرافیایی >]}، $ maxDistance : < distance >, $minDistance: < فاصله >}}. بدیهی است که پرس و جوهای نزدیک پشتیبانی شده توسط MongoDB سعی می کنند به دنبال اشیاء فضایی مرتب شده با فاصله تا نقطه پرس و جو در [ minDistance ،حداکثر فاصله ]. با قرار دادن یک محدودیت فاصله و آزمایش آن در طول جستجو، الگوریتم افزایشی می تواند با محیط MongoDB سازگار شود. با این حال، چنین اصلاحی، اگرچه ساده است، اما ناکارآمد است، به طوری که یک نوع کارآمدتر با پشتیبانی مکان نما بر اساس ساختار درخت R مسطح ایجاد شده است که شبه کد آن در شکل 7 ارائه شده است .
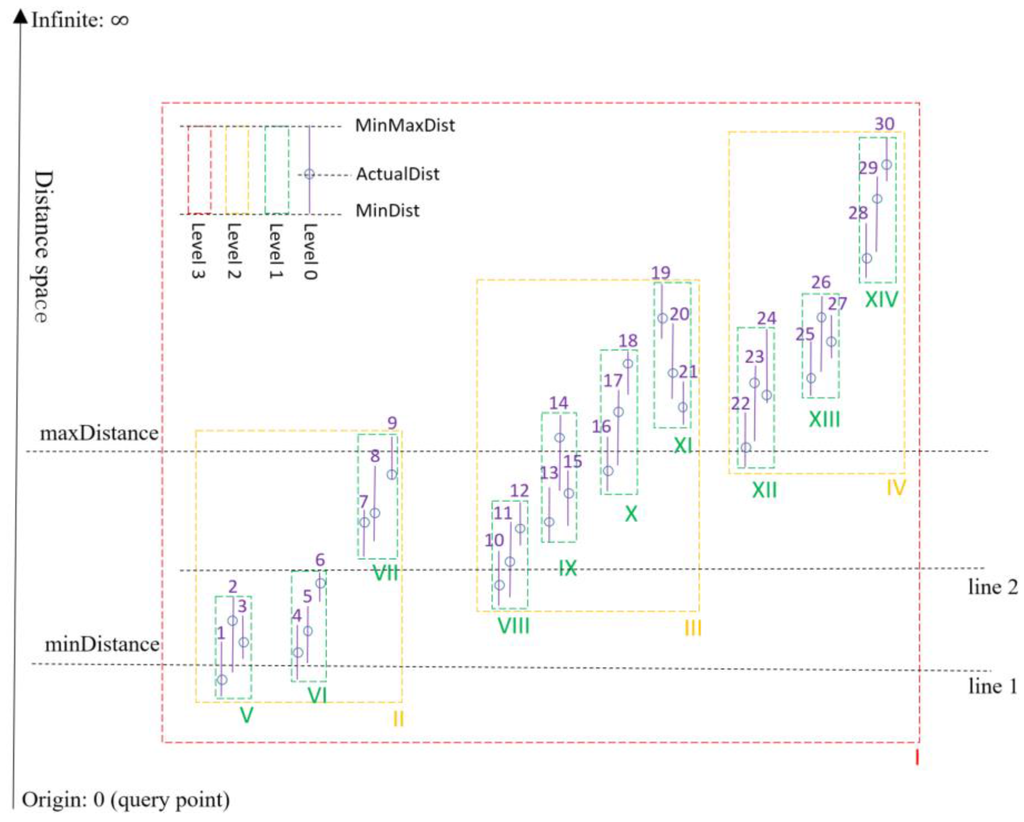
شکل 8 نمودار توزیع یک درخت R مثال را در فضای فاصله با توجه به یک نقطه پرس و جو نشان می دهد، که برای نشان دادن نحوه رسیدگی به یک پرس و جو نزدیک با الگوریتم بالا بررسی خواهد شد. برای دور اول اسکن (با فرض اینکه el در خط 1 باشد)، گره های V و VI در مرحله 2 تعیین می شوند، el2 واقع در خط 2 در مرحله 3 مشتق شده است، و گره VIII به S در مرحله 4 متصل می شود . سه گره برگ درگیر به بهترین شکل گسترش خواهند یافت [ 29 ]، و در نتیجه، اشیاء 4، 3، 5، 2، 10 و 6 به Q رانده خواهند شد.به تدریج آخرین مرحله این است که خط همسانی را به سمت خط 2 جلو ببریم، که دور بعدی اسکن را می توان از آنجا انجام داد. ایده اصلی پشت الگوریتم شکل 6 این است که خط فاصله را از minDistance به maxDistance جلو ببریم که طی آن گره ها و ورودی های مرتبط به تدریج اسکن و پردازش می شوند. در مقایسه با اصلاح ساده، نوع ما تا حد امکان تعداد کمتری از اسناد گره را می خواند و بررسی می کند تا نتیجه را به صورت دسته ای برگرداند و بنابراین، به روشی کارآمدتر به پرس و جوهای MongoDB نزدیک می شود.
6. ارزیابی های تجربی
در میان عملیات CRUD، ایجاد و خواندن، در مقایسه با به روز رسانی و حذف، بسیار بیشتر مورد استفاده قرار می گیرند و در زمینه کاربردهای فضایی حساس به عملکرد هستند، به طوری که در این بخش، ارزیابی ماژول R-tree طراحی و بحث شده است. دو دیدگاه: ساخت سازه و پردازش پرس و جو. سه مجموعه داده با پوشش، انواع و اندازههای متنوع برای آزمایش عملکرد پیادهسازی MongoDB R-tree ما وارد شدند. این مجموعه دادهها از وبسایت OSM (نقشه خیابان باز، www.openstreetmap.org ) دانلود شدند و سپس تحت یک سیستم مختصات دکارتی پیشبینی شدند. در نتیجه، هر مجموعه داده دارای دو نسخه است: یکی ژئودتیک و دیگری پیش بینی شده است. جدول 3 جزئیات سه مجموعه داده را نشان می دهد، در حالی که شکل 9تصاویر کوچک از سه مجموعه داده را نشان می دهد.
نسخه MongoDB انتخاب شده برای ادغام درخت R پهن شده 3.2.0 است. همه آزمایشها بر روی رایانهای با ویندوز 10 با پردازنده Intel Core i5-4200H با فرکانس 2.8 گیگاهرتز و 16 گیگابایت رم انجام شده است، که در آن سادهترین کلاستر MongoDB متشکل از یک نمونه خرد، یک نمونه پیکربندی و یک نمونه مسیر (شامل R-است). ماژول درختی) پیکربندی شد. برنامه آزمایشی که دستورات افشا شده توسط ماژول R-tree را صادر می کند، روی همان ماشین اجرا می شود.
6.1. ساخت درختان R-Flattened
هدف این آزمایش ارزیابی کارایی ساخت درخت R است که طی آن پنج درخت R مسطح با فاکتورهای انشعاب متفاوت برای هر مجموعه داده پیشبینیشده ساخته شد. نتایج، اندازه گیری تعداد اسناد درج شده در ثانیه، در شکل 10 ارائه شده است. از نقطه نظر افقی، سه منحنی عملکرد هم در شکل و هم در روند ظاهری بسیار مشابه دارند. از یک طرف، با افزایش ضریب انشعاب از 8 به 256، سرعت درج در ابتدا افزایش می یابد، اما پس از رسیدن به حداکثر در ضریب انشعاب 96، کاهش می یابد، زیرا اندازه یک گره درخت R با 96 ورودی بیشتر نزدیک است. به صفحه دیسک (یعنی 4096 بایت). از سوی دیگر، نوسان کلی به دلیل دو سطح ذخیره سازی، یعنی کش ساختار داخلی در سرور خرده و ذخیره سازی گره توسعه یافته در ماژول R-tree، نسبتاً کم است.
از نقطه نظر عمودی، سرعت درج مجموعه داده سوم به طور قابل توجهی کندتر از دو مجموعه داده دیگر است، زیرا مجموعه داده سوم دارای تراکم بالاتری در توزیع شی است و بنابراین، به احتمال زیاد باعث سرریز گره در طول R می شود. -درخت سازی علاوه بر این، اولین مجموعه داده به دلیل نوع هندسی نقطه، به بالاترین سرعت درج دست می یابد.
در نهایت، ما همچنین یک شاخص 2dsphere بر روی نسخه ژئودتیکی مجموعه داده سوم ساختیم و زمان اجرا ضبط شده حدود 230 ثانیه است، که به این معنی است که سرعت درج حدود 755 سند در ثانیه است. به طور قابل توجهی بالاتر از درختان R مسطح است، فقط به این دلیل که 2dsphere در واقع نوعی B + -tree با ساختار بسیار سادهتر در مقایسه با R-tree است و بنابراین، به زمان کمتری برای ساختن نیاز دارد.
6.2. پردازش پرس و جو با R-Tree پهن شده
به منظور استخراج عملکرد پردازش پرس و جو با درخت R مسطح، هر مجموعه داده با سه گزاره مختلف پشتیبانی شده توسط MongoDB، یعنی $geoWithin، $geoIntersects و $near مورد آزمایش قرار گرفت. گزاره $geoWithin اشیایی را بازیابی می کند که به طور کامل در یک پنجره پرس و جو قرار دارند. گزاره $geoIntersects اشیایی را بازیابی می کند که با یک پنجره پرس و جو همپوشانی دارند. گزاره $near first اشیایی را که در یک فاصله زمانی مشخص با توجه به یک نقطه پرس و جو قرار می گیرند واکشی می کند و سپس آنها را به ترتیب از نزدیکترین به دورترین خروجی می دهد. قبل از آزمایش، گروهی از پنجرههای مربعی با موقعیتهای مرکزی تصادفی و طول ضلعهای مختلف برای $geoWithin و $geoIntersects تهیه شد و گروهی از دایرهها با شعاعهای مختلف، اما در مرکز یک نقطه ثابت، برای $near ایجاد شد.
در طول هر آزمون، درخت R مسطح با ضریب انشعاب 96 برای تسریع پردازش پرس و جو انتخاب شد. نتایج در شکل 11 ارائه شده است، که در آن هر مجموعه داده از دو منظر اندازه گیری می شود، یکی زمان پردازش و دیگری سرعت بازیابی. از نظر گزارهها، $geoWithin و $geoIntersects بر روی سه مجموعه داده نه تنها در زمان پردازش، بلکه بر روی توان عملیاتی سند نیز بسیار مشابه عمل میکنند. با بزرگ شدن پنجره پرس و جو، زمان پاسخ به طور چشمگیری افزایش می یابد، در حالی که توان عملیاتی در ابتدا افزایش می یابد، سپس تمایل به تثبیت دارد. به عنوان مثال، سرعت بازیابی مجموعه داده سوم از حدود 1000 سند در ثانیه شروع می شود، سپس افزایش می یابد، اما در نهایت در حدود 2500 سند بر ثانیه تثبیت می شود. در مقایسه، پردازش $near با درخت R مسطح کارایی کمتری دارد، اما با بزرگ شدن پنجره پرس و جو، شکاف به طور مداوم کاهش می یابد. دلیل آن این است که $near جستجو و همچنین رتبه بندی را انجام می دهد: با یک پنجره کوئری کوچک، رتبه بندی سهم بالایی از زمان اجرا را به خود اختصاص می دهد. در حالی که یک پنجره پرس و جو بزرگ را وارد می کنید، جستجو، به دلیل درگیر شدن مقدار قابل توجهی از I/O، بر زمان اجرا غالب است. علاوه بر این، توان عملیاتی اسناد نزدیک به دلار همچنان در حال افزایش است، اگرچه رشد تمایل به کاهش دارد.
از نظر مجموعه داده ها، هر سه گزاره نسبت به مجموعه داده سوم در زمان پردازش و سرعت بازیابی بسیار بهتر عمل می کنند. به عنوان مثال، سرعت بازیابی دو مجموعه داده اول کمتر از 2000 سند بر ثانیه است، در حالی که این سرعت به حدود 2500 سند بر ثانیه در مجموعه داده سوم می رسد. این به این دلیل است که مجموعه داده اول در واقع یک شبکه جاده ای با هندسه نوع خط است که منجر به همپوشانی با درجه بالایی از MBR در درخت R آن می شود، در حالی که مجموعه داده دوم دارای توزیع ناهمواری از اشیا است که منجر به درجه بالایی از فضای مرده می شود. در درخت R آن در مقایسه، توزیع اشیاء در مجموعه داده سوم به طور قابل ملاحظه ای یکنواخت است، یک موقعیت ایده آل برای R-tree برای پردازش پرس و جوها.
6.3. مقایسه با 2dsphere در پردازش پرس و جو
در نهایت، پردازش پرس و جو درخت R مسطح با پردازش 2dsphere مقایسه شد. گروهی از پنجره های پرس و جو با مقیاس بندی از 0.5٪ تا 5٪ در کل ناحیه ورودی برای هر مجموعه داده، شامل هر دو نسخه ژئودتیک و پیش بینی شده، ایجاد شد و سپس مخلوطی از $geoWithin و $geoIntersects برای هر پنجره پرس و جو تهیه شد. زمان اجرا میانگین گرفت. نتایج در شکل 12 a-c ارائه شده است.
بدیهی است که 2dsphere نسبت به درخت R مسطح در سه مجموعه داده بسیار بهتر عمل می کند و با افزایش اندازه پنجره، شکاف بزرگتر و بزرگتر می شود. دلیل آن دو مورد است: (1) محاسبات و ذخیره سازی در دو نمونه MongoDB مختلف (و ممکن است در گره های فیزیکی مختلف توزیع شوند) برای درخت R مسطح از هم جدا می شوند در حالی که آنها در یک نمونه MongoDB برای 2dsphere با هم جفت می شوند. یعنی 2dsphere در دسترسی به داده کارآمدتر است. و (2) بیشتر اشیاء در سه مجموعه داده اندازه کوچکی دارند (توجه داشته باشید: جادههای موجود در مجموعه دادههای خیابان پکن در واقع بخشهایی هستند که تقاطعها را به هم پیوند میدهند)، به این معنی که هر شی میتواند با یک یا چند سلول تقریب یابد، بنابراین که نه تنها 2dsphere حاصل از نظر ساختار نسبتاً ساده است، بلکه محاسبه هندسه روی اجسام نیز کارآمد می شود. ممکن است مشاهده شود که مزیت 2dsphere در برابر درخت R مسطح در مجموعه داده پاریس POI قابل توجه تر است، زیرا این مجموعه داده دارای هندسه نوع نقطه ای است و بنابراین، همه اشیا دقیقاً توسط سلول های منفرد تقریب می شوند.
علاوه بر این، این آزمایش بر روی مجموعه داده دریاچه ووهان، چین که شامل 4260 شی چند ضلعی است، تکرار شد و نتایج در شکل 12 d ارائه شده است. با افزایش اندازه پنجره، درخت R مسطح ما در ابتدا از 2dsphere داخلی بهتر عمل می کند اما در نهایت به آن می رسد. دلیل آن این است که اشیاء در این مجموعه داده از نظر شکل پیچیده هستند و از نظر دامنه متفاوت هستند (از هزاران متر مربع تا ده ها کیلومتر مربع) و بنابراین، محاسبه هندسه، به ویژه برای 2dsphere، کمک زیادی به زمان پردازش هنگام پرس و جو می کند. پنجره کوچک یا متوسط است، در حالی که واکشی داده ها با بزرگ شدن پنجره پرس و جو شروع به تسلط بر زمان اجرا می کند.
7. نتیجه گیری
این مقاله به چگونگی کاوش MongoDB، یک محصول NoSQL محبوب که به عنوان یک زبان پرس و جوی مبتنی بر سند، غنی و بسیار در دسترس است، برای مدیریت دادههای فضایی مسطح که هنوز به طور گسترده در کاربردهای فضایی در مقیاس شهر استفاده میشوند، میپردازد. ایده اصلی این است که ساختار سلسله مراتبی R-tree را به یک مجموعه MongoDB جدولی تبدیل کنیم، که طی آن گره های درخت R به عنوان اسناد مجموعه نمایش داده می شوند و نشانگرهای درخت R با شناسه اسناد جایگزین می شوند. با این ایده، یک ماژول R-tree برای مدیریت داده های فضایی مسطح توسعه یافته و به طور یکپارچه در MongoDB یکپارچه شده است. عملیات CRUD مبتنی بر درخت R در سرور روتر انجام می شود، در حالی که ابرداده در سرور پیکربندی ذخیره می شود و داده ها در سرور خرد توزیع می شوند. با در دست گرفتن مدیریت پیام و بازنویسی دستورات بومی، ماژول R-tree به دستکاری داده های فضایی مسطح با دستورات سیستم موجود علاوه بر یک فرمان جدید دست می یابد. علاوه بر این، یک الگوریتم جدید مبتنی بر درخت R مسطح برای MongoDB در نزدیکی پرسوجوها توسعه داده شده است تا از واکشی نتایج با مکاننما پشتیبانی کند. ارزیابی تجربی با مجموعه دادههای دنیای واقعی که بر اساس پوشش، نوع و اندازه متفاوت است، نشان میدهد که درخت R مسطح مبتنی بر MongoDB در مدیریت دادههای فضایی مسطح موفق بوده و در پردازش پرس و جو، بهویژه برای اشیاء فضایی پیچیده و بزرگ، به خوبی عمل میکند.
پیاده سازی فعلی ما بر اساس MongoDB 3.2.0 در https://github.com/lmars-gis/mongo/tree/v3.2.0/rtree برای دسترسی آزاد منتشر شده است. در آینده نزدیک، علاوه بر ادامه کاوش استراتژیها و الگوریتمها برای ارائه سازگاری و بازیابی در صورت خرابیهای غیرقابل پیشبینی، ما اپراتورهای فضایی پیشرفته مانند بافر و پیوستن را بررسی خواهیم کرد و در نهایت یک ماژول فضایی برای MongoDB توسعه خواهیم داد تا فناوریهای NoSQL را فعال کند. داده های فضایی. ما همچنین نحوه فشار دادن درختهای R مسطح به یک سرور خردهای را برای تطبیق محاسبات و ذخیرهسازی درخت R مسطح با هم در نظر خواهیم گرفت، که در آن بزرگترین چالش این است که چگونه دادههای مکانی را به طور کارآمد نقشهبرداری کنیم و نتایج را در گرههای ذخیرهسازی جمع کنیم.
منابع
- رایشمن، OJ; جونز، مگابایت؛ Schildhauer، MP چالش ها و فرصت های داده های باز در محیط زیست. Science 2011 ، 331 ، 703-705. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- اسنایدرز، سی. ماتزات، یو. ریپس، U.-D. داده های بزرگ: شکاف های بزرگ دانش در زمینه اینترنت. بین المللی J. Internet Sci. 2012 ، 7 ، 1-5. [ Google Scholar ]
- Codd, EF یک مدل رابطه ای از داده ها برای بانک های داده مشترک بزرگ. اشتراک. ACM 1970 , 13 , 377-387. [ Google Scholar ] [ CrossRef ]
- گری، جی. مفهوم معامله: فضایل و محدودیت ها. در مجموعه مقالات هفتمین کنفرانس بین المللی پایگاه های داده بسیار بزرگ، کن، فرانسه، 9 تا 11 سپتامبر 1981.
- Sadalage, PJ; Fowler, M. NoSQL Distilled : A Brief Guide to the Emerging World of Polyglot Persistence Addison-Wesley: Boston, MA, USA, 2012. [ Google Scholar ]
- موهان، سی. تاریخچه خود را تکرار می کند: جنبه های معقول و بی معنی SQL حلقه NoSQL. در مجموعه مقالات شانزدهمین کنفرانس بین المللی گسترش فناوری پایگاه داده، جنوا، ایتالیا، 18 تا 22 مارس 2013.
- چانگ، اف. دیم، جی. قماوت، س. هسیه، دبلیو. والاک، دی. باروز، ام. چاندرا، تی. فیکس، ا. Gruber، RE Bigtable: یک سیستم ذخیره سازی توزیع شده برای داده های ساخت یافته. ACM Trans. محاسبه کنید. سیستم 2008 ، 26 ، 1-26. [ Google Scholar ] [ CrossRef ]
- دکاندیا، جی. هسترون، د. Jampani، M. Dynamo: فروشگاه بسیار در دسترس آمازون با ارزش کلیدی. در مجموعه مقالات بیست و یکمین سمپوزیوم ACM SIGOPS در مورد اصول سیستم عامل، استیونسون، WA، ایالات متحده آمریکا، 14-17 اکتبر 2007.
- لاکشمن، ا. Malik, P. Cassandra: سیستم ذخیره سازی ساختاریافته در یک شبکه p2p. در مجموعه مقالات بیست و هشتمین سمپوزیوم ACM در اصول محاسبات توزیع شده، کلگری، AB، کانادا، 10 تا 12 اوت 2009.
- چودوروف، ک. Dirolf, M. MongoDB: The Definitive Guide , 1st ed.; رسانه O’Reilly: سباستوپل، کالیفرنیا، ایالات متحده آمریکا، 2010. [ Google Scholar ]
- جیانگ، دبلیو. ژانگ، ال. لیائو، ایکس. جین، اچ. Peng, Y. یک سیستم ذخیره سازی مبتنی بر MongoDB خوشه ای جدید برای داده های بدون ساختار با در دسترس بودن بالا. محاسبات 2014 ، 96 ، 455-478. [ Google Scholar ] [ CrossRef ]
- لانگ، ن. فلمینگ، ک. براکنی، LB یک پایگاه داده شی گرا برای مدیریت اجزای مدل سازی ساختمان و ابرداده ها. در مجموعه مقالات دوازدهمین کنفرانس انجمن بین المللی شبیه سازی عملکرد ساختمان، سیدنی، NSW، استرالیا، 14-16 نوامبر 2011.
- مشخصات فرمت GeoJSON. در دسترس آنلاین: http://geojson.org/geojson-spec.html (دسترسی در 10 آوریل 2016).
- ژانگ، ایکس. آهنگ، دبلیو. لیو، ال. یک رویکرد پیاده سازی برای ذخیره داده های مکانی GIS در پایگاه داده NoSQL. در مجموعه مقالات بیست و دومین کنفرانس بین المللی ژئوانفورماتیک، کائوسیونگ، تایوان، 25 تا 27 ژوئن 2014.
- لوتز، آر. عامری، پ. لاتزکو، تی. Meyer, J. مدیریت داده های جرم هواشناسی با MongoDB. در مجموعه مقالات بیست و هشتمین کنفرانس EnviroInfo، اولدنبورگ، آلمان، 10 تا 12 سپتامبر 2014.
- بوهم، جی. Liu, K. NoSQL برای ذخیره سازی و بازیابی مجموعه های بزرگ داده LiDAR. در مجموعه مقالات آرشیو بین المللی فتوگرامتری، سنجش از دور و علوم اطلاعات مکانی، La Grande Motte، فرانسه، 28 سپتامبر تا 3 اکتبر 2015.
- کوین، اس. دنیس، دبلیو. سیستم های شبکه جهانی گسسته Kimerling، AJ Geodesic. کارتوگر. Geogr. Inf. علمی 2003 ، 30 ، 121-134. [ Google Scholar ]
- الماسری، ا. Navathe، SB Fundamentals of Database Systems , 6th ed.; Pearson: Upper Saddle River، نیوجرسی، ایالات متحده آمریکا، 2010. [ Google Scholar ]
- گاتمن، A. R-Tree: ساختار شاخص پویا برای جستجوی فضایی. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 1984 در مدیریت داده ها، بوستون، MA، ایالات متحده آمریکا، 18 تا 21 ژوئن 1984.
- Neo4j. در دسترس آنلاین: http://en.wikipedia.org/wiki/Neo4j (دسترسی در 14 آوریل 2016).
- صامت، ح. وببر، RE ذخیره مجموعه ای از چند ضلعی ها با استفاده از چهار درخت. ACM Trans. گر 1985 ، 4 ، 182-222. [ Google Scholar ] [ CrossRef ]
- بنتلی، JL درخت های جستجوی دوتایی چند بعدی که برای جستجوی انجمنی استفاده می شوند. اشتراک. ACM 1975 ، 18 ، 509-517. [ Google Scholar ] [ CrossRef ]
- هایدر، آر. ریکاردو، ال. مارتین، وی. بروس، N. نمایش درخت پارتیشن بندی فضای دودویی تصاویر. J. Vis. اشتراک. تصویر نشان می دهد. 1991 ، 2 ، 201-221. [ Google Scholar ]
- بکمن، ن. کریگل، اچ پی؛ اشنایدر، آر. Seeger, B. R*-tree: یک روش دسترسی کارآمد و قوی برای نقطه و مستطیل. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 1990 در مدیریت داده ها، آتلانتیک سیتی، نیوجرسی، ایالات متحده آمریکا، 23-25 مه 1990.
- سالتنیس، اس. جنسن، سی. لوتنگر، ST; لوپز، MA نمایه سازی موقعیت اجسام متحرک پیوسته. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 2000 در مدیریت داده ها، دالاس، تگزاس، ایالات متحده آمریکا، 16-18 می 2000.
- تائو، ی. Papdias, D. درخت MV3R: یک روش دسترسی مکانی-زمانی برای پرس و جوهای مهر زمانی و بازه زمانی. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی پایگاه های داده بسیار بزرگ، رم، ایتالیا، 11-14 سپتامبر 2001.
- موزا، سی. لیتوین، دبلیو. Rigaux، P. نمایه سازی در مقیاس بزرگ داده های مکانی در مخازن توزیع شده: SD-Rtree. VLDB J. 2009 ، 18 ، 933-958. [ Google Scholar ] [ CrossRef ]
- GEOS. در دسترس آنلاین: http://trac.osgeo.org/geos (دسترسی در 10 فوریه 2016).
- Hjaltason، GR; Samet, H. مرور از راه دور در پایگاه داده فضایی. ACM Trans. سیستم پایگاه داده 1999 ، 24 ، 265-318. [ Google Scholar ] [ CrossRef ]
شکل 1. صاف کردن درخت R در مجموعه اسناد MongoDB.
شکل 2. طرح ذخیره سازی مربوط به درخت R.
شکل 3. نمونه ای از طرح ذخیره سازی مرتبط با درخت R.
شکل 4. چارچوب ادغام R-tree مبتنی بر MongoDB.
شکل 5. یک گردش کار معمولی برای عملیات پشتیبانی شده توسط درخت R.
شکل 6. منطق اجرای عملیات مربوط به درخت R.

شکل 7. پردازش یک MongoDB در نزدیکی پرس و جو با یک درخت R پهن شده.
شکل 8. نمودار توزیع فاصله یک درخت R با توجه به یک نقطه پرس و جو.
شکل 9. تصاویر بند انگشتی از سه مجموعه داده تجربی. ( الف ) پاریس POI; ( ب ) خیابان های پکن؛ و ( ج ) ساختمانهای DC.
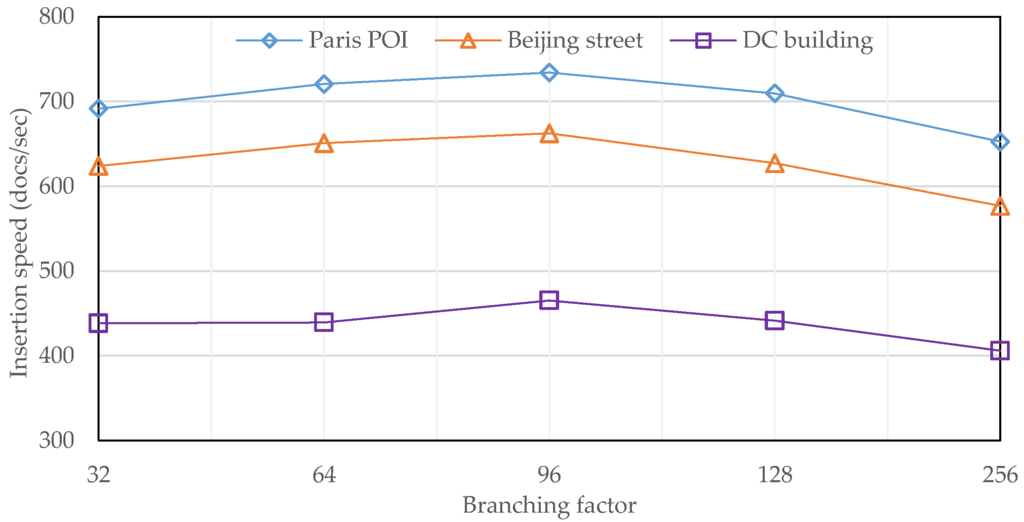
شکل 10. ارزیابی ساخت و ساز با عوامل انشعاب متفاوت.
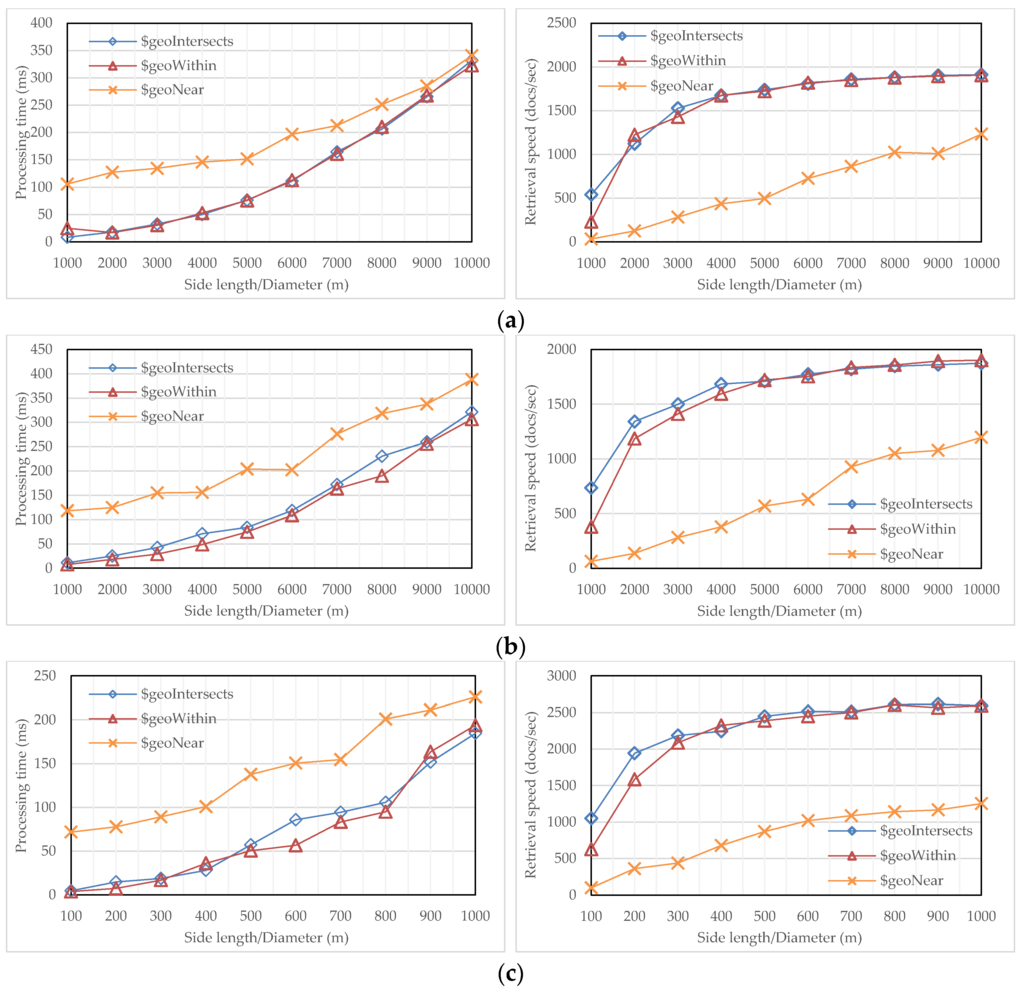
شکل 11. ارزیابی پردازش پرس و جو با مجموعه داده های مختلف. ( الف ) داده های POI پاریس؛ ( ب ) داده های خیابان پکن؛ و ( ج ) داده های ساختمان واشنگتن دی سی.

شکل 12. مقایسه درخت R مسطح با 2dsphere در پردازش پرس و جو. ( الف ) داده های ساختمان واشنگتن دی سی. ( ب ) داده های خیابان پکن؛ ( ج ) داده های POI پاریس. و ( د ) داده های دریاچه ووهان.

جدول 1. مقایسه MongoDB و R-tree.
جدول 2. دستورات اصلی پشتیبانی شده توسط ماژول R-tree.
جدول 3. سه مجموعه داده تجربی.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر